
Acta Psychologica 141 (2012) 304–315
Contents lists available at SciVerse ScienceDirect
Acta Psychologica
j ourna l homepage: www.e lsev ie r .com/ locate /actpsy
Determinants of structural choice in visually situated sentence production☆
Andriy Myachykov ⁎, Simon Garrod, Christoph ScheepersInstitute of Neuroscience and Psychology, University of Glasgow, United Kingdom
☆ This researchwas supported by Economic and Social R27-1579 (awarded to Andriy Myachykov) and RES-062-2Scheepers).⁎ Corresponding author at: Institute of Neuroscience
Glasgow, Glasgow, G12 8QB, United Kingdom. Tel.: +4330 46 06.
E-mail address: [email protected] (A
0001-6918/$ – see front matter © 2012 Elsevier B.V. Allhttp://dx.doi.org/10.1016/j.actpsy.2012.09.006
a b s t r a c t
a r t i c l e i n f oArticle history:Received 15 March 2012Received in revised form 3 September 2012Accepted 6 September 2012Available online 17 October 2012
PsychINFO classification:23462720
Keywords:Visual attentionSyntaxSentence productionEnglish
Three experiments investigated how perceptual, structural, and lexical cues affect structural choices duringEnglish transitive sentence production. Participants described transitive events under combinations of visualcueing of attention (toward either agent or patient) and structural priming with and without semantic matchbetween the notional verb in the prime and the target event. Speakers had a stronger preference forpassive-voice sentences (1) when their attention was directed to the patient, (2) upon reading a passive-voiceprime, and (3) when the verb in the prime matched the target event. The verb-match effect was theby-product of an interaction between visual cueing and verb match: the increase in the proportion ofpassive-voice responses with matching verbs was limited to the agent-cued condition. Persistence of visualcueing effects in the presence of both structural and lexical cues suggests a strong coupling betweenreferent-directed visual attention and Subject assignment in a spoken sentence.
© 2012 Elsevier B.V. All rights reserved.
1. Perceptual and linguistic determinants of structural choice
Speaking about visual events involves making linguistic choicesbased on the availability of both non-linguistic and linguistic informa-tion pertaining to the described event. There are a number of suchchoices necessarily made by the speaker when generating a sentence.For example, one can often select between different names in order torefer to the same entity and one can almost always select among differ-ent structural alternatives when describing the same event. The choiceof words and the choice of structural configurations organize the exactcontent and the form of individual sentences. In this paper, we investi-gate how perceptual, verbal, and structural cues available to speakersinteract in jointly predicting their choices between available structuralalternatives.
We generally assume that the choice between structural alternativesis not at all arbitrary in that it reflects an integrative sum of bothnon-linguistic and linguistic biases the speaker has prior to the overtgeneration of an utterance. Some of these biases are deeply rooted inthe overall correspondences between the referential properties ofinteracting protagonists (e.g., animacy) and the related likelihood toperform certain linguistic functions (e.g., Subject) (e.g., Prat-Sala &Branigan, 2000). Other biases may be more local and transient; that is,
esearch Council grants PTA-026-3-2009 (awarded to Christoph
and Psychology, University of4 141 330 61 65; fax: +44 141
. Myachykov).
rights reserved.
they may be established here and now and their influence on thespeaker's linguistic choices may therefore be short-lived. One suchshort-lived effect relates to speakers' tendency to consistently mapthe referent currently in their attentional focus onto the position ofthe sentential Subject (Gleitman, January, Nappa, & Trueswell, 2007;Myachykov, Thompson, Garrod, & Scheepers, 2012; Tomlin, 1995).Here, we will primarily focus on the latter type.
First of all, real-life sentence production is typically situatedmeaningthat individual sentences need to convey the specific context in whichthey are formed and used. Situated sentence production is also typicallygoal-driven in that its details may reflect conscious cognitive biasesincluding the speaker's intention to “manipulate” the discussed contentby highlighting certain referents at the expense of others (e.g., Clark,1996). More relevant to this paper is the fact that situated speakersare often sensitive to more transient and rather implicit informationalbiases. These biases (also cues or primes) can be either top-down(stemming from memory) or bottom-up (stemming from immediatecontext), and they can reflect both non-linguistic and linguisticinformation about the event and its referents. Some specific examplesinclude the tendency to promote recently encountered referents(Myachykov et al., 2012) as well as words (Givon, 1992) and wholenoun phrases (Cleland & Pickering, 2003) to prominent sentential posi-tions (e.g., Subject). One premise of this paper is that although existingresearch has documented abundant evidence about the individualeffects of non-linguistic and linguistic cues on the speaker's structuralchoice, there is very little knowledge about whether and how thesecues interact in their ability to influence the speaker's real-time struc-tural decisions. Here, we report three experiments that represent animportant initial step in this direction.

Fig. 1. Transitive event.
305A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
Throughout this paper, we will distinguish between the terms cues(cueing) and primes (priming). Although conceptually related, the twoterms are rooted in two different research paradigms, both of whichwill be employed in this paper: Visual cueing (Posner, 1980) andstructural priming (Bock, 1986). Visual cueing reflects facilitatedtarget detection in one of two locations previously marked by a visualcue (e.g., a pointer). As such, cueing relates to the facilitation of thechoice between two response alternatives. Priming, on the otherhand, generally refers to increased sensitivity to certain stimuli dueto prior exposure and is viewed by many as a form of implicitmemory (e.g., Tulving & Schacter, 1990). Compared to visual cueing,priming does not have to rely upon response selection, as its mainemphasis is on facilitated retrieval of the primed information regard-less of whether an alternative response exists. In psycholinguisticexperiments, however, priming is often used as a way of cueing par-ticipants to choose one linguistic alternative over another. Structuralpriming is a classic example. In sentence production, structural prim-ing refers to the speakers' tendency to select a recently encountered(therefore primed) structural configuration over generally availablestructural alternatives; for example, after being exposed to a passivevoice sentence, speakers are more likely to produce a passive voicesentence (and less likely to produce an active voice sentence) thanafter being exposed to an active voice sentence (Bock, 1986). Becausestructural priming usually affects structural choice (i.e., the choicebetween at least two alternative linguistic forms), it can, in principle,be understood as a specific form of cueing (at least in the context oflanguage production). We believe it may be useful to keep this logicin mind.
Nevertheless, we will continue to use both terms in the way theyhave been traditionally used in the literature. Hence, we will refer tomanipulations of visual attention by means of spatial cues as visualcueing and we will refer to the repetition of previously encounteredstructural forms in novel utterances as structural priming.
There is now enough evidence pointing to the fact that thespeaker's choice of syntactic structure depends on the transientaccessibility of both non-linguistic and linguistic information aboutthe described event. We will discuss this evidence and emphasizethe need for an integrative approach. The motivation for such anapproach is simple. While it is important to understand howperceptual and linguistic cues motivate speakers' choices in isolation,it is clear that in “realistic” production scenarios, speakers haveperceptual and linguistic information more or less simultaneouslyavailable to them. Therefore, it is quite possible that the productionsystem accommodates the corresponding biases in an interactivemanner. This logic motivates the two main questions underlyingour research. The first question is whether non-linguistic andlinguistic cues provide independent or interacting biases toward theresulting structural choice. The second question addresses the issueof exactly how these biases are integrated.
Before we attempt to answer these questions, we will review therelevant background evidence. First, we discuss how referent-relatedperceptual information can influence structural choice. A typical findingis that visually cueing a referent biases the speaker's decision to assignthis referent as sentential Subject, often resulting in the selection of astructural alternative, in which the cued referent can operate as theSubject.Wewill then discuss how structural and lexical priming, specif-ically, repetition of verbs, can also drive structural choice through re-useof corresponding structural frames. Proper understanding of howperceptual, lexical, and structural cues influence structural choice insentence production will set stage for our presentation of the resultsof our experiments. In all three studies, participants had to describevisually presented transitive target events, each comprising of two ani-mate referents (cf. Fig. 1).Visual cueingwas established via presentationof a spatial location cue (Posner, 1980) in place of one of the referents ofthe subsequently presented target event (cf. Gleitman et al., 2007). Toinduce the verb match effect, we presented participants with a verb
that corresponded to the target event (see details below). Finally,structural priming was operationalized via presentation of an active ora passive voice sentence prior to the presentation of the target event.In Experiment 1, we used all three priming manipulations. We thendecomposed this three-factorial setting into distinct pairings of primingmanipulations: Experiment 2 combined visual cueing with verb match,and Experiment 3 combined visual cueing with structural priming. Thefinal section discusses the experimental results from the point of viewof an integrative sentence production account.
1.1. Visual cueing of structural choice
Psycholinguistic studies using variants of the visual cueingparadigm (Posner, 1980) have investigated the speaker's linguisticbehavior as a function of the distribution of visual attention amongthe elements of the described scene (Myachykov, Thompson,Garrod, & Scheepers, 2011 for a recent review). In a typical experi-ment, the participant's attention is directed to one of the interactingreferents or their corresponding locations by means of an indepen-dent pointer—a visual cue. The participant then describes this eventby choosing between available structural alternatives. One generalfinding is that the shift of attention to the cued referent's locationpredicts assignment of a prominent grammatical role (e.g., Subject)to the referent's name or referring expression (e.g., Tomlin, 1995) ortheir early placement in a spoken sentence (Myachykov & Tomlin,2008), thereby triggering the choice between available structures. Inone of the earliest such studies, Tomlin (1995) instructed Englishspeakers to describe an animation film that portrayed one fisheating the other. An explicit (i.e., consciously perceived) visual cue(an arrow pointer) was presented above either the patient or theagent fish to ensure that the participant's visual focus was directedto one of the two referents. Analysis of the descriptions of the eatingevent revealed that when the cue was on the agent, English speakingparticipants described the event in active voice (e.g., The blue fish atethe red fish). When the cue was on the patient, speakers producedpassive voice descriptions (e.g., The red fish was eaten by the bluefish). From this, Tomlin concluded that the referent currently infocus of the speaker's attention corresponds to the grammaticalSubject in an English transitive sentence.
Bock, Irwin, and Davidson (2004) critically assessed Tomlin'smethod by noting that presenting the same event repeatedly mayinvoke strategic behavior as well as structural priming (see below).Moreover, co-presentation of the cue and the target combined withthe instruction to only look at the cued referent may induce an unnat-urally strong perceptual bias. Studies reported in Gleitman et al.(2007) and in Myachykov (2007) tried to avoid these methodologicalproblems by (1) separating the presentation of the cue from thepresentation of the target, (2) using a greater variety of target events,(3) using an implicit visual cue (a pointer flashed for under 75 ms), and

306 A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
(4) monitoring attention through eye-tracking (see also Myachykovet al., 2012 for an explicit-cue version). The reported visual cueing effectswere smaller in magnitude but generally replicated Tomlin's findings:Directing speakers' visual attention to a referent's location predictedthe assignment of the Subject and the resulting structural choice.
One common limitation of these studies is that visual cueingmanipulations were used in the absence of any linguistic context,understood here as the availability of valid linguistic cues competingfor the same response selection (e.g., Bock et al., 2004; Kuchinsky &Bock, 2010). In more “realistic” scenarios, speakers have available tothem both perceptual and linguistic information prior to generatingthe target sentence. In the view of Bock and colleagues, the perceptu-al status of the visual referents is encoded during Subject assignmentonly when there is no linguistic information available. This meansthat linguistic context as given by lexical or syntactic primingmanipulations (discussed in the next section) should attenuate oreven eliminate visual cueing effects. Hence, visual cueing effectson structural choice should only occur in highly circumscribedunnatural situations. Myachykov, Posner, and Tomlin (2007) suggestan alternative view: The assignment of the sentential Subject followsa multi-factorial mapping mechanism that takes into account bothnon-linguistic and linguistic information. In their view, a referent'sperceptual salience is one but not the only factor that predictsSubject assignment. Importantly, the production model discussed inMyachykov et al. (2007) predicts that, although linguistic factorsmay turn out to influence Subject assignment to a stronger degree,perceptual salience will also play a role. Therefore, referential salienceshould still influence structural choice when linguistic predictors areavailable to the speaker. The data presented below provide strongevidence in favor of this hypothesis.
1.2. Lexical and structural priming of structural choice
Lexical and structural priming manipulations can also equip thespeaker with cues that can bias structural choice. Lexical priminggenerally relates to the ease of retrieval of names for referents andevents. For example, the speaker's recent encounter of a noun thatrefers to a referent will increase the likelihood of making this referentthe subject or the starting point of the next sentence. Many authorsargue that lexical priming makes the referent given or presupposed.Although the two notions are terminologically distinct (e.g., Collins,1991), they are closely related in that both present information asknown to the speaker. Similarly to visually salient referents, givenreferents tend to appear earlier in a sentence, and they tend tobecome Subjects (Bates & Devescovi, 1989; Bock & Irwin, 1980;Ferreira & Yoshita, 2003; Flores d'Arcais, 1975; Osgood & Bock,1977; Prat-Sala & Branigan, 2000).
Less is known about the effects of verb priming on structuralchoice. Consider the event in Fig. 1.
If verbs carry both lexical-semantic and grammatical properties,then priming the verb punch before the presentation of a pictureportraying this event may lead not only to a greater chance of usingthe verb punch (as opposed to, say, hit) when the event is described.It will also lead to pre-activation of a typical associated thematic map(e.g., presence of an agent acting upon a patient). More importantly,it will also result in pre-activation of associated structural alternatives(e.g., an active frame and a passive frame). This assumption issupported by findings from Melinger and Dobel (2005) showing thatexposure to an isolated verb can potentiate both structural frames asso-ciated with it in subsequent sentence production. In Melinger andDobel's study, German participants first read a ditransitive verb that ei-ther permitted a PO object frame only (i.e., adressieren/to address) or aDO frame only (i.e., entziehen/to deprive). Then, they described a visualevent semantically unrelated to either of the prime verbs. Importantly,the verbs necessary to describe the target event encouraged the use onan alternating di-transitive verb (permitting both structural frames).
The frame associated with the isolated prime verb influenced speakers'structural choices in the target descriptions such that participants weremore likely to produce a PO alternative after a PO biasing verb primeand a DO alternative—after a DO biasing prime.
This is an intriguing finding as it suggests that isolated verbs canact as individual structural cues implicitly projecting their associatedconfigurations onto newly generated sentences independent ofexplicit structural framing of sentences in which they appear. Unfor-tunately, there is very little further evidence that would supportthe idea that verbs in general can prime structural choice outside ofthe much better studied tendency of speakers to repeat recently pro-duced or encountered structures (but see also Salamoura & Williams,2006). The latter effect is known as structural priming. It generallyrefers to a tendency of speakers to repeat previously encountered orproduced syntactic configurations (Bock, 1986). Numerous recentreviews provide comprehensive accounts of the phenomenon(Branigan, 2007; Ferreira & Bock, 2006; Pickering & Ferreira, 2008).Structural priming is ubiquitous in language production and it isfound with a variety of structures (e.g. Bock, 1986; Cleland &Pickering, 2003; Ferreira, 2003; Hartsuiker & Westenberg, 2000;Scheepers, 2003). There are several theoretical accounts of structuralpriming. Some view the phenomenon as related to short-termactivation and decay of structural representations in workingmemory (e.g. Pickering & Branigan, 1998; Pickering et al., 2000) whileothers propose that it is based on implicit learning (e.g. Chang, Dell, &Bock, 2006). Finally, some suggest that structural priming results fromalignment and routinization in discourse (Pickering & Garrod, 2004).In this paper, we will not address such potential mechanisms behindstructural priming in detail. Rather, we will treat structural primes ascues predicting structural choice alongside perceptual and lexicalcues.
Although structural priming occurs independent of repeating ofeither conceptual or lexical information (e.g. Bock & Loebell, 1990;Bock, Loebell, & Morey, 1992; Desmet & Declercq, 2006; Scheepers,2003), its magnitude increases as a function of both lexical overlap(e.g. Branigan, Pickering, & Cleland, 2000; Cleland & Pickering,2003; Corley & Scheepers, 2002; Hartsuiker, Bernolet, Schoonbaert,Speybroeck, & Vanderelst, 2008; Pickering & Branigan, 1998) andconceptual overlap (e.g. Cleland & Pickering, 2003; Griffin & Weinstein-Tull, 2003) between primes and targets. Specifically, Pickering andBranigan (1998) demonstrated reliably stronger PO/DO priming effectswhen primes and targets employ the same verbs (see also Branigan etal., 2000; Corley & Scheepers, 2002; Hartsuiker et al., 2008).Myachykov(2007) demonstrated a similar verb repetition effect for the priming ofactive versus passive sentences in English sentence production. Thisfinding is important as it shows that the typically rather strongpreference for the active-voice structural frame in English (up to 95% oftransitive sentences in corpora, e.g., Svartvik, 1966) can be modulatedby structural priming (e.g., Bock, 1986), which in turn can be furtherenhanced by verb repetition.
The contribution of conceptual information to structural priminghas received much less attention. However, one relevant study(Bock et al., 1992) showed that while manipulating the accessibilityof conceptual information about the referents at the conceptuallevel had an impact on the speaker's choice of structure, this effectdid not interact with structural priming. Specifically, Bock andcolleagues systematically varied the animacy of agent and patientNPs in active/passive prime sentences (e.g., the boat carried fivepeople/five people were carried by the boat vs. five people carried theboat/the boat was carried by five people). Participants repeated thosesentences, which were read to them by the experimenter, andthen described pictures of unrelated transitive events. In half of thetarget pictures, an animate agent was paired with an inanimatepatient (e.g. a girl picking a flower); in the other half, the patientwas animate and the agent was inanimate (e.g. an alarm clockawakening a boy). The results showed a structural priming effect

307A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
(more passive voice descriptions after passive rather than active voiceprimes) irrespective of whether animacy assignments were congru-ent between primes and targets. However, independently of structur-al priming, speakers were also more likely to assign the(sentence-initial) Subjects to animate referents than to inanimatereferents (more passive descriptions when the target showed ananimate patient and more active descriptions when the targetshowed an animate agent). These results suggest that structural andconceptual-level priming provide independent cues to choosing onestructure over another.
The research discussed so far suggests that perceptual, lexical, andstructural cues may separately, and sometimes jointly, bias thespeaker's structural choices. What remains unknown is how simulta-neously available cues together produce such a bias. More specifically,while visual cueing has been shown to affect structural choice, it isuncertain to what degree this effect is constrained by the simulta-neous availability of linguistic cues. The detailed patterns of interac-tion between the individual priming effects also remain largelyuncertain. In the experiments that follow, we attempt at answeringthis question by providing speakers with combinations of perceptualand linguistic cues to structural choice.
2. Experiment 1
2.1. Design
Three factors were independently manipulated in Experiment 1:Visual Cue (agent/patient), Structural Prime (active/passive), and Verbmatch (match/mismatch). The manipulations were all within-subjectsand between-items. Visual cue was manipulated by means of a brieflypresented visual cue in the location of one of the subsequentlypresented visual referents (agent or patient). Structural Prime
Table 1Structural priming materials.
Verb match
1. The stranger is chasing the barman.2. The stewardess is kicking the pilot.3. The student is punching the driver.4. The plumber is pushing the secretary.5. The fisherman is pulling the nurse.6. The partisan is shooting the barber.7. The tourist is scolding the child.8. The baby is touching the manager.9. Cinderella is chasing the prince.
10. The driver is kicking the tourist.11. The wrestler is punching the gymnast.12. The builder is pushing the foreman.13. The acrobat is pulling the manager.14. The terrorist is shooting the captain.15. The teacher is scolding the principle.16. The professor is touching the shop-assistant.17. The cannibal is being chased by the gangster.18. The officer is being kicked by the girl.19. The nurse is being punched by the patient.20. The visitor is being pushed by the foreman.21. The traveller is being pulled by the old lady.22. The worker is being shot by the fireguard.23. Then astronaut is being scolded by his mother.24. The bartender is being touched by the client.25. The refugee is being chased by the drug-dealer.26. The singer is being kicked by the pianist.27. The librarian is being punched by the policeman.28. The child is being pushed by the teenager.29. The writer is being pulled by the milkmaid.30. The janitor is being shot by the pianist.31. The shopper is being scolded by the manager.32. The engineer is being touched by the pilot.
comprised a sentence in either active or passive voice thatparticipants had to read aloud before describing the targetevent (cf. Bock, 1986). The referents' names used in the primingsentences never corresponded in any way to the referents used in thesubsequent target picture. However, the sentential verb matched thetarget event semantically in 50% of the structural priming materials.This established the Verb Match factor, which consisted of the levelsMatch and Mismatch. The relative frequency of producing an activevoice target description was taken as the main dependent variable.
2.2. Materials
The target pictures consisted of 64 cartoon-like black-and-whitedrawings showing simple transitive events (see example in Fig. 1) andemployed eight different event types (chase, kick, pull, punch, push,scold, shoot, and touch). There were 17 human referents used in thetarget stimuli. We prepared the pictorial materials in such a way thateach referent appeared in both the agent and the patient role onequal number of trials. The materials were also counterbalanced forleft-right orientation: half of the pictures showed the agent to the leftof the patient, and vice versa for the other half. Since it was importantthat the visual referents were easily recognisable and distinguishablefrom one another, it was difficult to match them for familiarity. Tocompensate for this, we provided a practice session at the beginningof each experiment which familiarized participants with all the charac-ters and events they would encounter (see procedure).
In addition, we constructed a set of 64 sentences for reading(see Table 1). They were either in active or in passive voice (structuralpriming) and contained a verb that either denoted the same or adifferent event to that shown in the subsequent target picture(verb match). The passive voice primes always included an agentiveby-phrase.
Mismatch
1. The contortionist is admiring the gymnast.2. The child is tickling the teenager.3. The drummer is buying the slave.4. Then orphan is robbing the hooligan.5. The thief is chasing the burglar.6. The actor is pulling the engineer.7. The witness is saving the robber.8. The secretary is washing the driver.9. The manager is robbing the bystander.
10. The soldier is killing the officer.11. The peasant is riding the explorer.12. The janitor is inviting the butcher.13. The nurse is saving the fireguard.14. The wrestler is catching the dentist.15. The bartender is carrying the drunkard.16. The student is stealing the baby.17. The warden is being robbed by schoolchildren.18. The patient is being sedated by the visitor.19. The presenter is being followed by the professor.20. The spinster is being educated by the gentleman.21. The savage is being killed by the sailor.22. The footballer is being chased by the referee.23. The pirate is being eaten by the captain.24. The man is being beaten by the athlete.25. The TV-star is being buried by the magician.26. The librarian is being killed by the politician.27. The spy is being accused by the victim.28. The climber is being shot by the terrorist.29. The president is being strangled by the native.30. The acrobat is being attacked by the apprentice.31. Pinocchio is being robbed by hooligans.32. The orphan is being hugged by the boy-scout.

308 A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
Each participant was given the same set of 64 stimuli, comprisingeight items per Visual Cue×Structural Prime×Verb Match condition.Finally, we included 130 filler pictures showing various arrangementsof geometrical shapes presented in different regions of the screen(e.g., a square diagonally above and right of a heart); participantshad to describe those visual arrangements in the filler trials by pro-ducing a locative sentence describing the shapes and the relationshipbetween them. Randomization was constrained so that there werealways four fillers at the beginning of each session and that eachprime-target pair was preceded by at least two filler trials.
2.3. Apparatus
The experiment was implemented in SR-Research ExperimentBuilder. An EyeLink II head-mounted eye tracker monitored partici-pants' eye movements in order to ensure the efficiency of thevisual cueing manipulation. Other than that, we will not report anyeye-movement data since the focus of this paper is on how the experi-mental manipulations affect speakers' structural choices. The experi-mental materials were presented on a 17′ CRT monitor of a DELLOptiplex GX 270 desktop computer running at a display refresh rate of75 Hertz. Also connected to the PC was a pair of stereo speakers. ASONY DAT recorder was used for speech recording. The audio clipswere later uploaded onto a PC and analyzed with the help of AdobeAudition 2.0. The eye-tracking data were extracted and filtered usingSR-Research Data Viewer.
2.4. Participants
Twenty-four native English speakers (Glasgow Universityundergraduates; 12 female; average age: 19.7 years) with normalor corrected-to-normal vision took part. They either receivedcourse credits or £6 subject payment.
2.5. Procedure
Participants were positioned approximately 60 cm from the dis-play. Viewing was binocular, but only the participant's right eye wastracked. Before the main experimental session, each participant wasrun through a practice session during which they saw the pictures
+
Experimenter defined
Begin
Gaze-contingent offset The driver is being
punched/kissed by the artist
+fixation
fixation
prime
Structural Prime (active/passive) + Verb Match (match/mismatch) t = 7000 msec.
Fig. 2. Experiment 1. Exp
of the referent characters that would later be presented in the targettrials. The referents appeared one at a time in the center of the screen.The referent names (e.g., boxer) were presented with the pictures,and participants were instructed to read out those names and toremember them for the following tasks. Also, each participant hadto describe eight sample event pictures (one for each event type)during the practice session. The pictures of the events were presentedin the middle of the screen. No specific instruction as to how todescribe these event pictures was given to participants, except thatparticipants should always make reference to the event and bothinteracting characters.
The instruction for the experiment proper was to read out the sen-tence that appears on the screen, press the space bar when finishedreading, and then describe a picture extemporaneously and in a singlesentence. Participants were unaware of the nature of experimentalmanipulations, any difference between target and filler trials, andthe exact purpose of the study. They were told that the study wasconcerned with speaking about what they see on the computerscreen. Fig. 2 illustrates a typical target trial sequence. Each targettrial began with the presentation of the central fixation point. Shortlyafter the participant fixated this point, a priming sentence appearedon the screen. Note that both the structural priming and the verbmatch manipulations occurred before the visual cue was displayed.Priming sentences were presented in Arial 16-point font in the mid-dle of the screen and in direct view of the participant. The participantread the priming sentence aloud as soon as it appeared on the screenand pressed the space bar when finished reading. Then, a dislocatedfixation mark appeared on the screen. This ensured that participantswould not be looking at the center of the screen when the cue waspresented and that they would always have to make a saccade tothe cued area of the screen or, if the cue was overlooked, to anotherarea in the target picture once it appeared on the screen. Thedislocated fixation mark was equally distant from the cued locations.The presentation of the cue (was contingent on fixating the dislocatedfixation mark: Participants had to look at the dislocated fixation markfor a minimum of 200 ms before the cue was displayed. The cue itselfwas a red circle (1 cm in diameter) which appeared in the approxi-mate center of the to-be-primed referent (agent or patient) for500 ms. There was no specific instruction as to how to treat the cue.After the cue disappeared, the target picture appeared in the center
Visual Cue( agent/patient) t = 500 msec.
Target (400 x 400 pixels) t = 7700 msec. Offset – Space Bar
+
prime
target
Experimenter defined
End
fixation
erimental sequence.

Table 2Mean percentages of producing an active voice target description in Experiment 1 as afunction of Visual Cue (agent or patient), Structural Prime (active or passive), and VerbMatch (match or mismatch).
Structural Prime
Active Voice Passive Voice
Verb Match
Mismatch Match Mismatch MatchVisual Cue
Agent 94% 84% 84% 64%Patient 67% 71% 60% 51%
Table 3Results from logit binomial GEE analyses (by subjects) modelling proportions of activevoice descriptions as a function of Visual Cue (VC), Verb Match (VM) and StructuralPrime (SP) in Experiment 1. The first three rows refer to main effects, the next threerows to two-way interactions, and the last row to the three-way interaction. PartitionsI and II refer to the two random partitions of items for analysis (see text). GSχ2 meansGeneralized Score Chi-Square.
Partition I Partition II
Effect GSχ2(1) p GSχ2(1) p
Visual Cue 5.66 .02 10.36 .001Verb Match 12.70 .001 5.27 .03
309A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
of the screen. Participants were instructed to extemporaneouslydescribe the target picture in a single sentence, and to press thespace bar to move on to the next trial when finished. In case theparticipant did not respond, the picture disappeared from the screenafter 7700 ms timeout.
2.6. Results
2.6.1. Cueing efficiencyIn order to analyze initial fixations on perceptually primed versus
non-primed referents, the pictures were pre-coded to include separateareas of interest: one for each referent (agent, patient) and one for thebackground. The referent areas included the referent itself plus a sur-rounding area of about two degrees of visual angle. The cue was foundto be highly effective in biasing participants' initial visual attention dur-ing picture viewing. Perceptually primed agent referents were initiallyfixated 94% of the time, and perceptually primed patient referents 93%of the time. There were no detectable effects involving structural orlexical priming on cueing efficiency.
2.6.2. Target structureParticipants' verbal responses were coded as one of Active Voice,
Passive Voice, or Other. To be coded as Active Voice, the descriptionhad to employ a transitive verb referring to the depicted event, a subjectNP referring to the agent, and a direct object NP referring to the patient(e.g. The cowboy is punching the boxer). To be coded as Passive Voice, thedescription had to employ a passivized transitive verb referring to thedepicted event, a subject NP referring to the patient, and a by-phrasereferring to the agent (e.g. The boxer is [being] punched by the cowboy).Note that truncated passives (not including a by-phrase) were hardlyever produced since they were explicitly discouraged in the practicesession. All remaining responses (including missing responses) werecoded as Other. The latter accounted for less than 1% of the data andwill not be considered further. Table 2 summarizes the relative frequen-cies of producing an Active Voice target description separately for eachVisual cue×Structural Prime×Verb match combination.
Statistical analyses in all three studies were performed in SPSS/PASW 18 using Generalized Estimating Equations (GEE, e.g. Hardin &Hilbe, 2003). Unlike ANOVA, GEE allows for specifying distributionand link functions that are appropriate for analysing categoricalfrequencies.1 Here, we used a binomial distribution and logit link func-tion (cf. Jaeger, 2008) to model proportions of active voice descriptionsas a function of Visual Cue (agent or patient), Verb Match (match ormismatch) and Structural Prime (active or passive voice). The threepredictors were entered as within-subjects variables assuming acompound symmetry covariance structure for repeatedmeasurements.Potential item-dependencies of effects could not be estimated directly(all manipulations were between-items). To assess generalizability
1 In this respect, GEE is equivalent to mixed effect logistic regression. However, wedid not opt for the latter because mixed effects models on binary data often fail to con-verge, especially with complex factorial designs and appropriate maximal random ef-fect structures for hypothesis testing.
across items, we therefore employed an analysis strategy comparableto computing split-half reliability in psychometrics. We randomlypartitioned the full set of 64 items into two equal halves of 32 items(each comprising four items per condition), referred to as Partition Iand II, respectively. All within-subjects analyses were then performedon each of the two random halves of items. Consistently significant re-sults across the two random item-partitions are therefore generalizableacross subjects as well as across items (Table 3).
As can be seen, there were significant main effects of Visual Cueand Verb Match, and an at least marginal main effect of StructuralPrime. Ninety-five per cent confidence intervals for pooled condi-tion differences (derived from the GEE model parameters) indi-cated that speakers were more likely to produce active voicedescriptions in the agent- rather than patient-cued condition(.19±.13 and .25±.11 for Partitions I and II, respectively). Activevoice descriptions were also more likely to occur when the primeverb mismatched the target event (.12±.05 and .10±.08, respec-tively). Finally, active voice was more likely to be chosen in theactive- rather than passive-voice Structural Prime condition(.14±.14 and .16±.10, respectively).
Therewas also a significant Visual Cue byVerbMatch interaction: Asillustrated in Fig. 3, the effect of the Visual Cue manipulation wasstronger in theMismatch condition (.21±.12 and .32±.13, respectively)than in the Match condition (.13±.14 and .14±.11, respectively).
2.7. Discussion
Experiment 1 employed a three-factorial designwhere visual cueing,structural priming, and verb matching were orthogonally manipulated.Analyses of the resulting structural choices in describing the targetpictures indicated the following.
There was a main effect of Visual Cue (more passive voice/feweractive voice descriptions when the location of the patient referent wascued prior to picture presentation) consistent with previous findings(e.g., Gleitman et al., 2007; Myachykov et al., 2012; Tomlin, 1995).
The main effect of Verb Match (more non-canonical passive voicedescriptions when the prime verb matched the target event) has nodirect equivalent with earlier findings. It interacted reliably with thevisual cueing effect. Importantly, the visual cueing effect was reliableeven in the context of simultaneous lexical and structural priming,counter to the predictions from Kuchinsky and Bock (2010) whosuggested that visual cueing effects should be diminished (or evenabsent) in the presence of linguistic priming. In other words, therewas a clear tendency to produce more passive-voice sentences inthe patient-cued trials regardless of the presence of structurallybiasing linguistic primes.
As far as the contribution of Verb Match to structural choice isconcerned, 95% confidence intervals confirmed that there was astronger tendency to produce a passive-voice sentence (respectively,
Structural Prime 3.21 .07 7.20 .01VC×VM 6.31 .01 9.65 .002VC×SP 1.34 .25 2.38 .12VM×SP 0.14 .71 0.71 .40VC×VM×SP 2.21 .14 0.05 .82
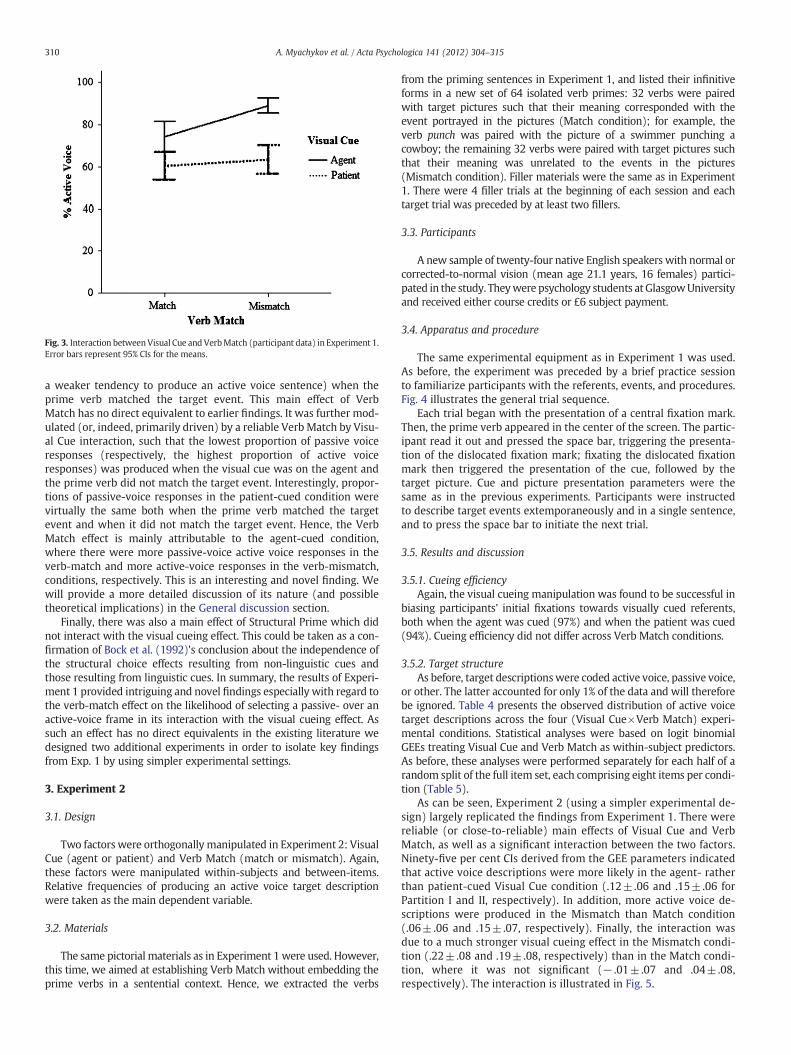
Fig. 3. Interaction betweenVisual Cue and VerbMatch (participant data) in Experiment 1.Error bars represent 95% CIs for the means.
310 A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
a weaker tendency to produce an active voice sentence) when theprime verb matched the target event. This main effect of VerbMatch has no direct equivalent to earlier findings. It was further mod-ulated (or, indeed, primarily driven) by a reliable Verb Match by Visu-al Cue interaction, such that the lowest proportion of passive voiceresponses (respectively, the highest proportion of active voiceresponses) was produced when the visual cue was on the agent andthe prime verb did not match the target event. Interestingly, propor-tions of passive-voice responses in the patient-cued condition werevirtually the same both when the prime verb matched the targetevent and when it did not match the target event. Hence, the VerbMatch effect is mainly attributable to the agent-cued condition,where there were more passive-voice active voice responses in theverb-match and more active-voice responses in the verb-mismatch,conditions, respectively. This is an interesting and novel finding. Wewill provide a more detailed discussion of its nature (and possibletheoretical implications) in the General discussion section.
Finally, there was also a main effect of Structural Prime which didnot interact with the visual cueing effect. This could be taken as a con-firmation of Bock et al. (1992)'s conclusion about the independence ofthe structural choice effects resulting from non-linguistic cues andthose resulting from linguistic cues. In summary, the results of Experi-ment 1 provided intriguing and novel findings especially with regard tothe verb-match effect on the likelihood of selecting a passive- over anactive-voice frame in its interaction with the visual cueing effect. Assuch an effect has no direct equivalents in the existing literature wedesigned two additional experiments in order to isolate key findingsfrom Exp. 1 by using simpler experimental settings.
3. Experiment 2
3.1. Design
Two factors were orthogonally manipulated in Experiment 2: VisualCue (agent or patient) and Verb Match (match or mismatch). Again,these factors were manipulated within-subjects and between-items.Relative frequencies of producing an active voice target descriptionwere taken as the main dependent variable.
3.2. Materials
The same pictorial materials as in Experiment 1 were used. However,this time, we aimed at establishing Verb Match without embedding theprime verbs in a sentential context. Hence, we extracted the verbs
from the priming sentences in Experiment 1, and listed their infinitiveforms in a new set of 64 isolated verb primes: 32 verbs were pairedwith target pictures such that their meaning corresponded with theevent portrayed in the pictures (Match condition); for example, theverb punch was paired with the picture of a swimmer punching acowboy; the remaining 32 verbs were paired with target pictures suchthat their meaning was unrelated to the events in the pictures(Mismatch condition). Filler materials were the same as in Experiment1. There were 4 filler trials at the beginning of each session and eachtarget trial was preceded by at least two fillers.
3.3. Participants
A new sample of twenty-four native English speakers with normal orcorrected-to-normal vision (mean age 21.1 years, 16 females) partici-pated in the study. Theywere psychology students at GlasgowUniversityand received either course credits or £6 subject payment.
3.4. Apparatus and procedure
The same experimental equipment as in Experiment 1 was used.As before, the experiment was preceded by a brief practice sessionto familiarize participants with the referents, events, and procedures.Fig. 4 illustrates the general trial sequence.
Each trial began with the presentation of a central fixation mark.Then, the prime verb appeared in the center of the screen. The partic-ipant read it out and pressed the space bar, triggering the presenta-tion of the dislocated fixation mark; fixating the dislocated fixationmark then triggered the presentation of the cue, followed by thetarget picture. Cue and picture presentation parameters were thesame as in the previous experiments. Participants were instructedto describe target events extemporaneously and in a single sentence,and to press the space bar to initiate the next trial.
3.5. Results and discussion
3.5.1. Cueing efficiencyAgain, the visual cueing manipulation was found to be successful in
biasing participants' initial fixations towards visually cued referents,both when the agent was cued (97%) and when the patient was cued(94%). Cueing efficiency did not differ across Verb Match conditions.
3.5.2. Target structureAs before, target descriptionswere coded active voice, passive voice,
or other. The latter accounted for only 1% of the data and will thereforebe ignored. Table 4 presents the observed distribution of active voicetarget descriptions across the four (Visual Cue×Verb Match) experi-mental conditions. Statistical analyses were based on logit binomialGEEs treating Visual Cue and Verb Match as within-subject predictors.As before, these analyses were performed separately for each half of arandom split of the full item set, each comprising eight items per condi-tion (Table 5).
As can be seen, Experiment 2 (using a simpler experimental de-sign) largely replicated the findings from Experiment 1. There werereliable (or close-to-reliable) main effects of Visual Cue and VerbMatch, as well as a significant interaction between the two factors.Ninety-five per cent CIs derived from the GEE parameters indicatedthat active voice descriptions were more likely in the agent- ratherthan patient-cued Visual Cue condition (.12±.06 and .15±.06 forPartition I and II, respectively). In addition, more active voice de-scriptions were produced in the Mismatch than Match condition(.06±.06 and .15±.07, respectively). Finally, the interaction wasdue to a much stronger visual cueing effect in the Mismatch condi-tion (.22±.08 and .19±.08, respectively) than in the Match condi-tion, where it was not significant (− .01±.07 and .04±.08,respectively). The interaction is illustrated in Fig. 5.

+
Visual cue (agent/patient) t = 500 msec.
Target (400 x 400 pixels) t = 7700 msec. Offset – Space bar
Begin
Verb Match (match/mismatch) t = 7000 msec.
Gaze-contingent offset
punch/kiss
+
+
fixation
fixation
prime
target
prime
fixation
Experimenter defined
End
Fig. 4. Experiment 2. Experimental sequence.
311A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
The results from Experiments 1 and 2 revealed that visual cueingand verb matching are both reliable and partly interwoven predictorsof speakers' structural choices. An intriguing finding from Experiment1, replicated in Experiment 2, was the interaction between visualcueing and verb match, with virtually the same pattern. The 95%confidence intervals indicated that the significantly the highestproportion of actives (and the lowest proportion of passives) wasproduced in the agent-cued Verb Mismatch condition while the pro-portion of passives stayed the same across both levels of the VerbMatch manipulation when the visual cue was on the patient. Experi-ment 3 was designed to isolate key findings from Experiment 1 withregard to visual cueing and structural priming, i.e. in the absence of averb match manipulation.
4. Experiment 3
4.1. Design
Two factorswere independentlymanipulated in Experiment 3: VisualCue (agent or patient) and Structural Prime (active or passive). Themanipulations therefore resulted in a 2×2 within-subjects/between-items design.
4.2. Materials
The same pictorial materials (including fillers) as in Experiment 1were used. The prime sentences from Experiment 1 were paired withthe target pictures in such a way that there was no lexical or semanticcorrespondence between them. The verbs in the prime sentenceswere therefore always unrelated to the target events. Thirty-twotarget pictures were paired with active voice prime sentences andanother 32 with passive voice prime sentences.
Table 4Mean percentages of producing an active voice target description in Experiment 2 as afunction of Visual Cue (agent or patient), and Verb Match (mismatch or match).
Verb Match
Mismatch MatchVisual Cue
Agent 90% 72%Patient 69% 72%
4.3. Participants
A new sample of twenty-four native English speakers (mean age19.4 years, 16 females) was recruited for this study. All were under-graduate psychology students at Glasgow University. They weregiven course credits or £6 subject payment.
4.4. Apparatus and procedure
The experimental apparatuswas the same as in the previous studies.As before, participants went through a brief practice session before theexperiment proper began. Fig. 6 illustrates the general procedure foreach experimental trial.
Once the central fixation mark was successfully fixated, a primesentence appeared on the screen. The prime sentence appeared in a16-point Arial font in the center of the screen. After the participanthad read out the prime sentence, they pressed the space bar to con-tinue. Then, the dislocated fixation mark appeared on the screen,followed by the cue (contingent on fixating the dislocated fixationmark), and finally, the target picture. Presentation parameters wereidentical to those in the previous experiments. Participants wereinstructed to describe each picture extemporaneously, using a singlesentence. The experiment started with four filler trials. Each experi-mental trial was preceded by at least two filler trials.
4.5. Results and discussion
4.5.1. Cueing efficiencyThe visual cueing manipulation successfully biased participants'
initial fixations on the target pictures. Cued agent referents were
Table 5Results from logit binomial GEE analyses (by subjects) modelling proportions of activevoice descriptions as a function of Visual Cue (VC) and Verb Match (VM) in Experiment2. Partitions I and II refer to the two random partitions of items for analysis (see text).GSχ2 means Generalized Score Chi-Square.
Partition I Partition II
Effect GSχ2(1) p GSχ2(1) p
Visual Cue 9.69 .002 10.86 .001Verb Match 3.47 .06 12.78 .001VC×VM 12.45 .001 8.87 .003
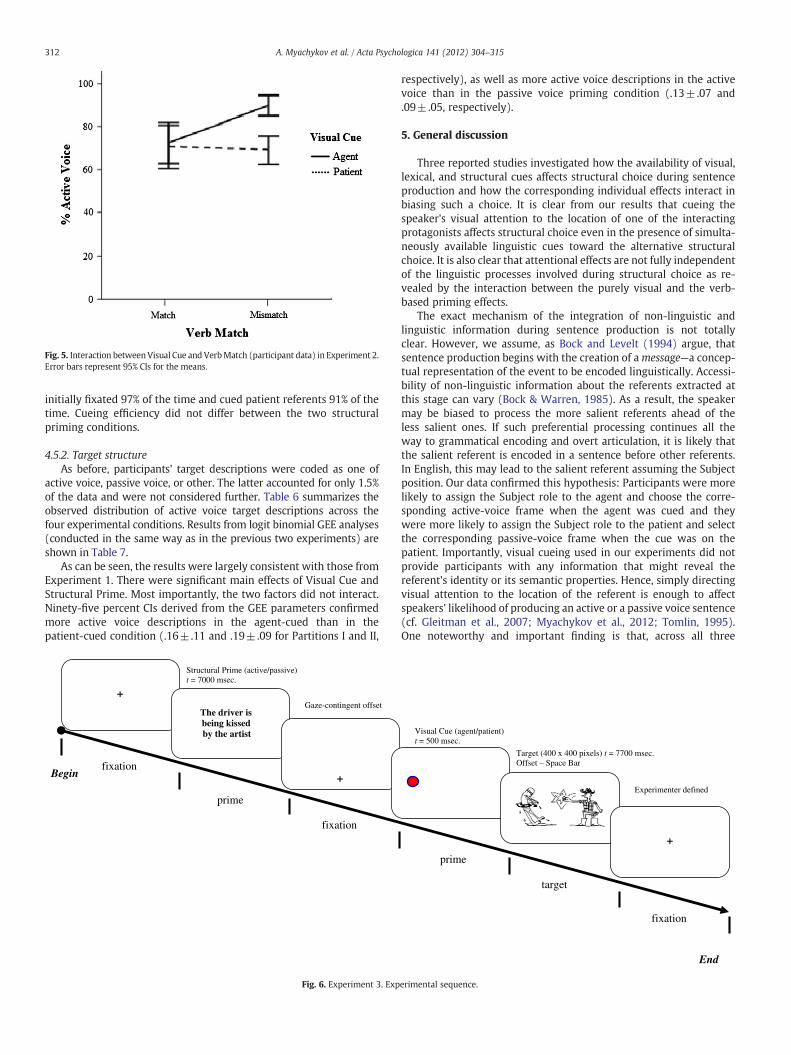
Fig. 5. Interaction betweenVisual Cue and VerbMatch (participant data) in Experiment 2.Error bars represent 95% CIs for the means.
312 A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
initially fixated 97% of the time and cued patient referents 91% of thetime. Cueing efficiency did not differ between the two structuralpriming conditions.
4.5.2. Target structureAs before, participants' target descriptions were coded as one of
active voice, passive voice, or other. The latter accounted for only 1.5%of the data and were not considered further. Table 6 summarizes theobserved distribution of active voice target descriptions across thefour experimental conditions. Results from logit binomial GEE analyses(conducted in the same way as in the previous two experiments) areshown in Table 7.
As can be seen, the results were largely consistent with those fromExperiment 1. There were significant main effects of Visual Cue andStructural Prime. Most importantly, the two factors did not interact.Ninety-five percent CIs derived from the GEE parameters confirmedmore active voice descriptions in the agent-cued than in thepatient-cued condition (.16±.11 and .19±.09 for Partitions I and II,
+
Begin
Structural Prime (active/passive) t = 7000 msec.
Gaze-contingent offset The driver is being kissed by the artist
+fixation
fixation
prime
Fig. 6. Experiment 3. Exp
respectively), as well as more active voice descriptions in the activevoice than in the passive voice priming condition (.13±.07 and.09±.05, respectively).
5. General discussion
Three reported studies investigated how the availability of visual,lexical, and structural cues affects structural choice during sentenceproduction and how the corresponding individual effects interact inbiasing such a choice. It is clear from our results that cueing thespeaker's visual attention to the location of one of the interactingprotagonists affects structural choice even in the presence of simulta-neously available linguistic cues toward the alternative structuralchoice. It is also clear that attentional effects are not fully independentof the linguistic processes involved during structural choice as re-vealed by the interaction between the purely visual and the verb-based priming effects.
The exact mechanism of the integration of non-linguistic andlinguistic information during sentence production is not totallyclear. However, we assume, as Bock and Levelt (1994) argue, thatsentence production begins with the creation of amessage—a concep-tual representation of the event to be encoded linguistically. Accessi-bility of non-linguistic information about the referents extracted atthis stage can vary (Bock & Warren, 1985). As a result, the speakermay be biased to process the more salient referents ahead of theless salient ones. If such preferential processing continues all theway to grammatical encoding and overt articulation, it is likely thatthe salient referent is encoded in a sentence before other referents.In English, this may lead to the salient referent assuming the Subjectposition. Our data confirmed this hypothesis: Participants were morelikely to assign the Subject role to the agent and choose the corre-sponding active-voice frame when the agent was cued and theywere more likely to assign the Subject role to the patient and selectthe corresponding passive-voice frame when the cue was on thepatient. Importantly, visual cueing used in our experiments did notprovide participants with any information that might reveal thereferent's identity or its semantic properties. Hence, simply directingvisual attention to the location of the referent is enough to affectspeakers' likelihood of producing an active or a passive voice sentence(cf. Gleitman et al., 2007; Myachykov et al., 2012; Tomlin, 1995).One noteworthy and important finding is that, across all three
Visual Cue (agent/patient) t = 500 msec.
Target (400 x 400 pixels) t = 7700 msec. Offset – Space Bar
+
prime
target
fixation
Experimenter defined
End
erimental sequence.

Table 6Mean percentages of producing an active voice target description in Experiment 3 as afunction of Visual Cue (agent or patient) and Structural Priming (active or passive).
Structural Prime
Active Voice Passive VoiceVisual Cue
Agent 91% 81%Patient 74% 64%
313A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
experiments, there were clear and robust visual cueing effects even inthe presence of concurrent structural priming and/or verb matchmanipulations. This finding speaks against the claim that visualcueing effects are only detectable in the absence of simultaneouslyavailable linguistic context (Bock et al., 2004; Kuchinsky & Bock,2010). On the contrary, it provides further evidence that perceptualinformation about the referents (e.g., referential salience) plays anintegral and self-sufficient role during the assignment of structuralroles alongside available lexical and structural information.
Alongside a strong visual cueing effect, our data showed ubiqui-tous structural priming effects: Speakers were more likely to describethe target event with a passive voice sentence after reading anunrelated passive-voice prime than after reading an active voiceprime. This is a reassuring though not really surprising finding. Of agreater interest is the observation that the effect of visual cueing onstructural choice was no more subtle than the structural primingeffect and that the structural priming effect did not interact withvisual cueing. The latter is in line with earlier findings by Bock et al.(1992). It suggests that interactions between priming effects areconstrained by what we shall call a neighborhood principle: Onlyimmediately neighboring processing stages (e.g. message andlemma; lemma and syntax) can interact with one another in deter-mining structural choice, while non-neighboring stages (messageand syntax) cannot. The ubiquitous presence and comparablemagnitude of the perceptual and the structural priming effects hintat the existence of a dual-path mapping mechanism akin to Chang(2002). According to dual-path mapping, non-linguistic effects(such as perceptual salience) and linguistic effects (such as structuraland lexical accessibility) can affect Subject assignment independentlyand in parallel, each producing its individual biases.
5.1. Verb match effects
Our experiments also consistently revealed the presence of a verbmatch effect. That is, whether or not the verb in the prime matchedthe one necessary to describe the target event had an overall influ-ence on structural choice. The prime verbs were always transitive,and either presented as part of a whole-sentence prime (Experiment1) or in isolation (Experiment 2). A crucial point to note is that, inboth Experiments 1 and 2, the verb match main effect never occurred‘on its own’, but was always modulated by a reliable interactionbetween visual cueing and verb match. It is also important to notethat the Verb Match contrast was only observed in the agent-cuedcondition. Such an effect has never been reported (let alone
Table 7Results from logit binomial GEE analyses (by subjects) modelling proportions of activevoice descriptions as a function of Visual Cue (VC) and Structural Prime (SP) in Exper-iment 3. Partitions I and II refer to two random partitions of items for analysis. GSχ2
means Generalized Score Chi-Square.
Partition I Partition II
Effect GSχ2(1) p GSχ2(1) p
Visual Cue 5.87 .02 9.72 .002Structural Prime 7.32 .01 7.95 .005VC×SP 0.41 .52 2.42 .12
predicted) before, and as such warrants closer examination. Assuggested earlier, the observed interaction can be characterized intwo ways (see also Figs. 3 and 5).
The first scenario may be characterized as suppression of verbmatch effects via visual cueing of the patient. The key observation un-derlying this scenario is the visual cueing effect (the increase in theproportion of passive-voice responses in the patient-cued condition)remained relatively unaffected by the verb match manipulation.This may indicate that speakers have a general tendency to use salientpatients as Subjects of their sentences (and correspondingly select apassive-voice frame) regardless of the co-presence of linguistic cuescompeting for the same choice. The verb match effect in this scenariowould result from a relatively higher activation of the otherwisedispreferred passive voice frame when the prime verb matches thetarget event (cf. Melinger & Dobel, 2005, who found that isolatedverbs can indeed prime syntactic frames). Importantly, this passive-promoting verb match effect was only observed when the visual cuewas on the agent or in the situation when the visual cue did notsimultaneously compete for the choice of passive. One possibility isthat matching prime verbs can only make the passive-voice alterna-tive to the canonical active more available in absence of a visualcue competing for the same choice: In the agent-cued condition(supporting active voice), the verb cue is informative as it providesa cue toward the alternative (passive voice); in the patient-cued con-dition (supporting passive voice), the verb cue is uninformative as itsupports the same response as the patient-cue itself. If this interpre-tation is correct, then it follows that lexical information (whetherthe prime verb matches the target event or not) is considered onlyafter perceptual information (visual cueing) has already been integrat-ed into the grammatical encoding process. Thus perceptual informationwould take priority over lexical information (at least in the current ex-perimental setup where the visual cue was always delivered most re-cently, i.e. immediately before the target event).
This theoretical scenario entails an interesting prediction, namely,that it should be possible to register an independent transitiveverb-match effect (more passive voice target descriptions afterpresenting a matching prime verb) in the absence of any visual cuesto either agent or patient.
The diametrically opposed second scenario for the verb match byvisual cueing interaction may be characterized as suppression ofagent-cueing effects via matching verbs. This explanation takes theperspective that, when the agent was cued, there was a substantialincrease in active-voice descriptions compared to the patient cueingcondition, but only when the verb in the prime did notmatch the targetevent. In other words, matching verbs suppressed the effectiveness ofagent-cueing in its ability to promote active-voice descriptions, therebyreducing the proportion of active voice descriptions in general.2
One very important implication following from both scenarios isthat they point to the existence of a general executive control mech-anism regulating selection between exogenous cues (related to visualsalience) and endogenous cues (related to linguistic knowledge). Assoon as speakers realize that they have both linguistic andnon-linguistic cues competing for the same structural choice, theyneed to select one of these cues at the expense of the other. The
2 Note the two scenarios outlined here effectively hypothesise different “baseline”proportions of active versus passive voice target descriptions when no visual cuesare present. In the first scenario, the highest observed proportion of active voice targetdescriptions (agent-cued, mismatching verb condition) would constitute the “base-line” relative to which patient-cueing and/or matching verbs take effect by increasingthe number of passive voice target descriptions. The second scenario assumes the de-creased proportion of active voice target descriptions in the baseline (patient-cued,mismatching verb condition), such that agent-cueing increases the number of activevoice target descriptions. The lack of an explicit baseline condition in our experimentsmakes it difficult to decide which of the two scenarios is more plausible. Future re-search in this area would certainly benefit from the inclusion of additional baselineconditions without visual cueing.

314 A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
difference between the two scenarios is that the first one assumesthe 6dominance of the visual cues over the linguistic ones in regulat-ing the response selection mechanism while the second scenario sug-gests the opposite—that presence of linguistic cues generallyoverrides the potential effect of the simultaneously present visualcues. Importantly, as a relative weight of an endogenous linguistic cueincreases (verb match), speakers become more biased to entertain al-ternatives such as passive voice in their structural choices but onlywhen there is no exogenous visual cues simultaneously competing forthe same response (cue to the patient). At the very least, the interactionbetween verbmatch and visual cueing (as repeatedly established in ourexperiments) suggests that structural choice is affected by a general ex-ecutive control mechanism responsible for selecting between partiallycompeting linguistic and non-linguistic constraints in line with ac-counts that viewgeneral attention as an integrative concept in cognitiveoperations including language (e.g., Posner & Rothbart, 2007). Furtherresearch is necessary to provide further details about the exact proper-ties of this control mechanism (see also Footnote 2).
5.2. Verb match and structural priming
Another somewhat surprising result in relation to previous find-ings is that we found no reliable boost to structural priming fromour verb match manipulation in Experiment 1 (but note that therewere descriptive trends in support of such a lexical boost effect, seeTable 2). It is possible that matching the structural prime verb tothe semantics of a depicted target event (as in our Experiment 1)results in a weaker lexical boost effect than directly matching actualverbs between prime and target trials. Indeed, recent data from ourown lab (Raffray, Myachykov, & Scheepers, 2009) support the latterpart of this conclusion. In a series of sentence production experiments(where participants had to generate sentences from random arrays ofcontent words after being primed by a sentence containing the sameor a different verb), we found evidence for a verb-based lexical boosteffect in active/passive priming comparable to that in di-transitivestructure priming (e.g., Pickering & Branigan, 1998). The descriptivesuggestion of stronger structural priming with matching verbs in Ex-periment 1 is generally in line with this finding. However, the rele-vant interaction failed to reach significance presumably because ofthe weaker ‘semantic’ verb match manipulation (no explicit repeti-tion of verbs between prime and target).
6. Conclusion
Together, our data provide insights into how availability ofnon-linguistic and linguistic cues predicts speakers' structural choiceduring visually situated sentence production. At the same time, ourresearch poses new questions. One question is whether multiple cuesestablished within the same stage interact. For example, does visual sa-lience interact with animacy, since both relate to the message level?Other questions follow from the neighborhoodprinciple outlined earlier.For example, if the stage of phonological encoding were included in thepriming environment, our theoretical view would predict that phono-logical priming should interact with structural priming but not, say,with visual cueing. One earlier report (Cleland & Pickering, 2003)examined whether phonological similarities between nouns in primeand target sentences (e.g., ship and sheep) affect the magnitude of thestructural priming effect, but failed to register the existence of such a“phonological boost”. However, more recent research suggests that abetter phonological match between nouns, such as in homonymic(Santesteban, Pickering, & McLean, 2008) or rhyming (Branigan,ongoing research) pairs, indeed leads to the establishment of a strongerstructural priming effect.
Another interesting future direction relates to the decay functionsfor the individual priming effects. There is evidence that the structuralpriming effects are characterized with considerable persistence (Bock
& Griffin, 2000) and that they tend to outlast the lexical boost effect(Hartsuiker et al., 2008). At the same time, little is known about(1) how persistent perceptual and/or conceptual priming effects areand (2) how the decay of the message-related priming is affected byother priming effects (e.g., lexical and/or structural) established inparallel.
References
Bates, E., & Devescovi, A. (1989). Competition and sentence production. In B. MacWhinney,& E. Bates (Eds.), The crosslinguistic study of sentence processing (pp. 225–256).New York: Cambridge University Press.
Bock, J. K. (1986). Syntactic persistence in language production. Cognitive Psychology,18, 355–387.
Bock, J. K., & Griffin, Z. M. (2000). The persistence of structural priming: Transientactivation or implicit learning? Journal of Experimental Psychology. General, 129,177–192.
Bock, J. K., & Irwin, D. E. (1980). Structural effects of information availability insentence production. Journal of Verbal Learning and Verbal Behavior, 19, 467–484.
Bock, J. K., Irwin, D. E., & Davidson, D. J. (2004). Putting first things first. In J. Henderson,& F. Ferreira (Eds.), The integration of language, vision, and action: Eye movementsand the visual world (pp. 249–278). New York: Psychology Press.
Bock, J. K., & Levelt, W. J. M. (1994). Language production: Grammatical encoding. InM. Gernsbacher (Ed.), Handbook of psycholinguistics (pp. 945–984). New York:Academic Press.
Bock, J. K., & Loebell, H. (1990). Framing sentences. Cognition, 35, 1–39.Bock, J. K., Loebell, H., & Morey, R. (1992). From conceptual roles to structural relations:
Bridging the structural cleft. Psychological Review, 99, 150–171.Bock, J. K., & Warren, R. K. (1985). Conceptual accessibility and structural structure in
sentence formulation. Cognition, 21, 47–67.Branigan, H. P. (2007). Structural priming. Language and Linguistics Compass, 1(1–2),
1–16.Branigan, H. P., Pickering, M. J., & Cleland, A. A. (2000). Structural co-ordination in
dialogue. Cognition, 75(2), B13–B25.Chang, F. (2002). Symbolically speaking: A connectionist model of sentence production.
Cognitive Science, 26, 609–651.Chang, F., Dell, G. S., & Bock, J. K. (2006). Becoming structural. Psychological Review,
113(2), 234–272.Clark, H. (1996). Using language. New York: Cambridge University Press.Cleland, A. A., & Pickering, M. J. (2003). The use of lexical and structural information in
language production: Evidence from the priming of noun phrase structure. Journalof Memory and Language, 49, 214–230.
Collins, P. C. (1991). Cleft and pseudo-cleft constructions in English. NY: Routledge.Corley, M., & Scheepers, C. (2002). Syntactic priming in English sentence production:
Categorical and latency evidence from an internet-based study. Psychonomic Bulletin& Review, 9(1), 126–131.
Desmet, T., & Declercq, M. (2006). Cross-linguistic priming of structural hierarchicalconfiguration information. Journal of Memory and Language, 54, 610–632.
Ferreira, V. S. (2003). The persistence of optional complementizer production: Whysaying “that” is not saying “that” at all. Journal of Memory and Language, 48,379–398.
Ferreira, V. S., & Bock, K. (2006). The functions of structural priming. Language & CognitiveProcesses, 21(7–8), 1011–1029.
Ferreira, V. S., & Yoshita, H. (2003). Given-new ordering effects on the production ofscrambled sentences in Japanese. Journal of Psycholinguistic Research, 32(6),669–692.
Flores d'Arcais, G. B. (1975). Some perceptual determinants of sentence construction.In G. Flores d'Arcais (Ed.), Studies in perception. Festschrift for Fabio Metelli(pp. 344–373). Milan, Italy: Martello- Guinti.
Givon, T. (1992). The grammar of referential coherence as mental processing instruc-tions. Linguistics, 30, 5–55.
Gleitman, L., January, D., Nappa, R., & Trueswell, J. (2007). On the give-and-takebetween event apprehension and utterance formulation. Journal of Memory andLanguage, 57, 544–569.
Griffin, Z. M., & Weinstein-Tull, J. (2003). Conceptual structure modulates structuralpriming in the production of complex sentences. Journal of Memory and Language,49, 537–555.
Hardin, J., & Hilbe, J. (2003). Generalized estimating equations. London: Chapman andHall/CRC.
Hartsuiker, R. J., Bernolet, S., Schoonbaert, S., Speybroeck, S., & Vanderelst, D. (2008).Structural priming persists while the lexical boost decays: Evidence from writtenand spoken dialogue. Journal of Memory and Language, 58(2), 214–238.
Hartsuiker, R. J., & Westenberg, C. (2000). Persistence of word order in written andspoken sentence production. Cognition, 75, B27–B39.
Jaeger, F. T. (2008). Categorical data analysis: Away from ANOVAs (transformation ornot) and towards logit mixed models. Journal of Memory and Language, 59(4),434–446.
Kuchinsky, S., & Bock, K. (2010). From seeing to saying: Perceiving, planning, producing.The talk presented at 23d CUNY Sentence Processing Conference.
Melinger, A., & Dobel, C. (2005). Lexically-driven structural priming. Cognition, 98,B11–B20.
Myachykov, A. (2007). Integrating perceptual, semantic, and syntactic information insentence production. PhD manuscript. University of Glasgow.

315A. Myachykov et al. / Acta Psychologica 141 (2012) 304–315
Myachykov, A., Posner, M. I., & Tomlin, R. S. (2007). A parallel interface for language andcognition in sentence production: Theory, method, and experimental evidence. TheLinguistic Review, 24, 457–475.
Myachykov, A., Thompson, D., Garrod, S., & Scheepers, C. (2011). Visual attention andstructural choice in language production across languages. Language and LinguisticCompass, 5(2), 95–107.
Myachykov, A., Thompson, D., Garrod, S., & Scheepers, C. (2012). Referential and visualcues to structural choice in sentence production. Frontiers in Psychology, 2, 396,http://dx.doi.org/10.3389/fpsyg.2011.00396.
Myachykov, A., & Tomlin, R. S. (2008). Visual cueing and structural choice in Russiansentence production. Journal of Cognitive Science, 9(1), 31–48.
Osgood, C. E., & Bock, J. K. (1977). Salience and sentencing: Some production principles.In S. Rosenberg (Ed.), Sentence production: Developments in research and theory(pp. 89–140). Hillsdale, N.J.: Erlbaum.
Pickering, M. J., & Branigan, H. P. (1998). The representation of verbs: Evidence fromstructural persistence in language production. Journal of Memory and Language,39, 633–651.
Pickering, M. J., Branigan, H. P., Cleland, A. A., & Stewart, A. J. (2000). Activation of syn-tactic information during language production. Journal of Psycholinguistic Research,29(2), 205–216.
Pickering, M. J., & Ferreira, V. S. (2008). Structural priming: A critical review. PsychologicalBulletin, 134(3), 427–459.
Pickering, M. J., & Garrod, S. (2004). Toward a mechanistic psychology of dialogue. TheBehavioral and Brain Sciences, 27, 169–225.
Posner, M. I. (1980). Orienting of attention. Quarterly Journal of Experimental Psychology,32, 3–25.
Posner, M. I., & Rothbart, M. K. (2007). Research on attention networks as a model forthe integration of psychological science. Annual Review of Psychology, 58, 1–23.
Prat-Sala, M., & Branigan, H. P. (2000). Discourse constraints on structural processing inlanguage production: A cross-linguistic study in English & Spanish. Journal of Memoryand Language, 42, 168–182.
Raffray, C. N., Myachykov, A., & Scheepers, C. (2009). The lexical boost effect in di-tran-sitive structure priming: A special role of the verb? Barcelona: Poster, AMLaP.
Salamoura, A., & Williams, J. N. (2006). Lexical activation of cross-language structuralpriming. Bilinguialism: Language and Cognition, 9(3), 299–307.
Santesteban, M., Pickering, M. J., & McLean, J. F. (2008). Does phonological alignmentenhance structural alignment during dialogue? Evidence from homophones. Posterpresented at 21st CUNY Conference on Human Sentence Processing.
Scheepers, C. (2003). Structural priming of relative clause attachments: Persistence ofstructural configuration in sentence production. Cognition, 89, 179–205.
Svartvik, J. (1966). On Voice in the English Verb. The Hague: Mouton.Tomlin, R. S. (1995). Focal attention, voice, and word order. In P. Dowing, & M. Noonan
(Eds.), Word order in discourse (pp. 517–552). Amsterdam: John Benjamins.Tulving, E., & Schacter, D. L. (1990). Priming and human memory systems. Science, 247,
301–306.
Recommended

















