
Self-Improving Computer Chips – Warp Processing
Contributing Ph.D. StudentsRoman Lysecky (Ph.D. 2005, now Asst. Prof. at
Univ. of ArizonaGreg Stitt (Ph.D. 2007, now Asst. Prof. at Univ. of
Florida, GainesvilleScotty Sirowy (current)David Sheldon (current)
This research was supported in part by the National Science Foundation, the Semiconductor Research
Corporation, Intel, Freescale, IBM, and Xilinx
Frank VahidDept. of CS&E
University of California, Riverside
Associate Director, Center for Embedded Computer Systems, UC Irvine
5/52Frank Vahid, UC Riverside
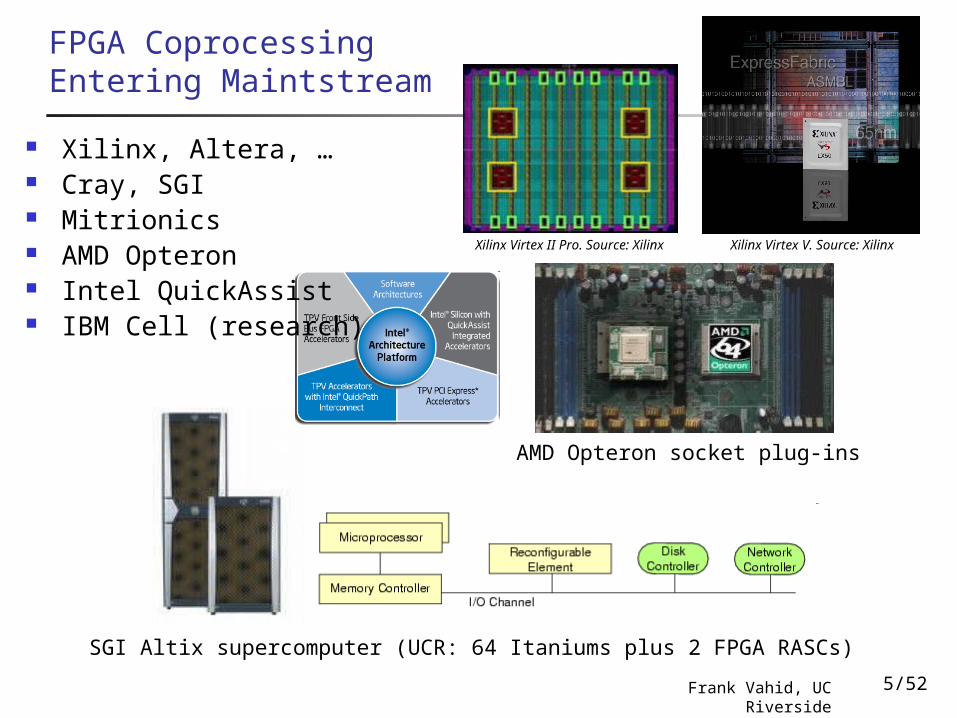
FPGA Coprocessing Entering Maintstream
Xilinx Virtex II Pro. Source: Xilinx
SGI Altix supercomputer (UCR: 64 Itaniums plus 2 FPGA RASCs)
Xilinx Virtex V. Source: Xilinx
AMD Opteron socket plug-ins
Xilinx, Altera, … Cray, SGI Mitrionics AMD Opteron Intel QuickAssist IBM Cell (research)
9/52Frank Vahid, UC Riverside
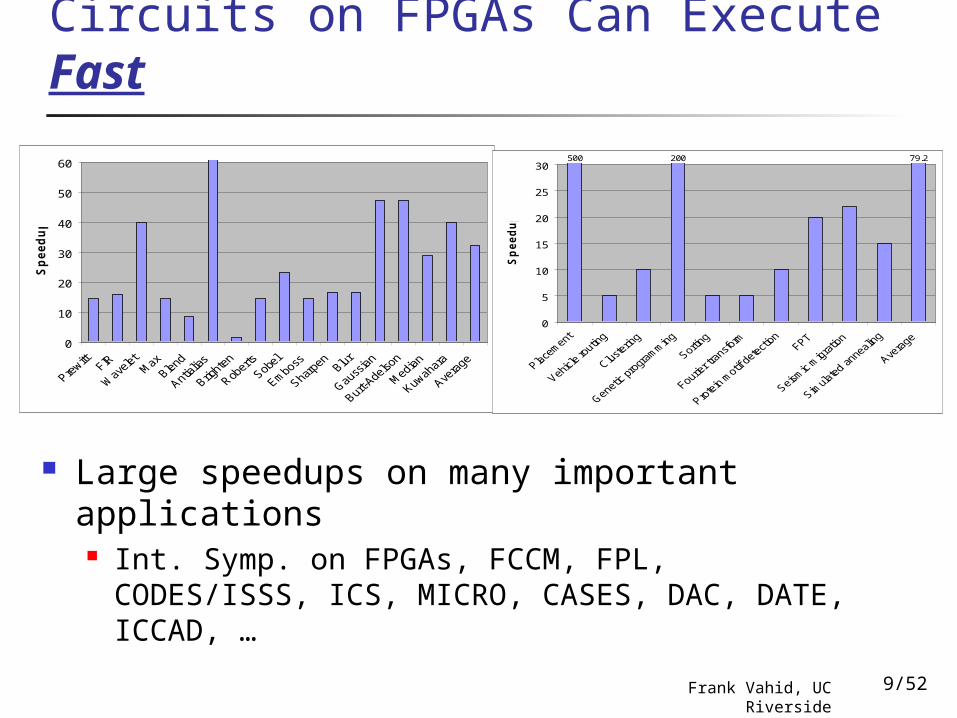
Circuits on FPGAs Can Execute Fast
Large speedups on many important applications Int. Symp. on FPGAs, FCCM, FPL, CODES/ISSS,
ICS, MICRO, CASES, DAC, DATE, ICCAD, …
0
10
20
30
40
50
60
Sp
ee
du
p
79.2200500
0
5
10
15
20
25
30
Sp
ee
du
p
10/52Frank Vahid, UC Riverside
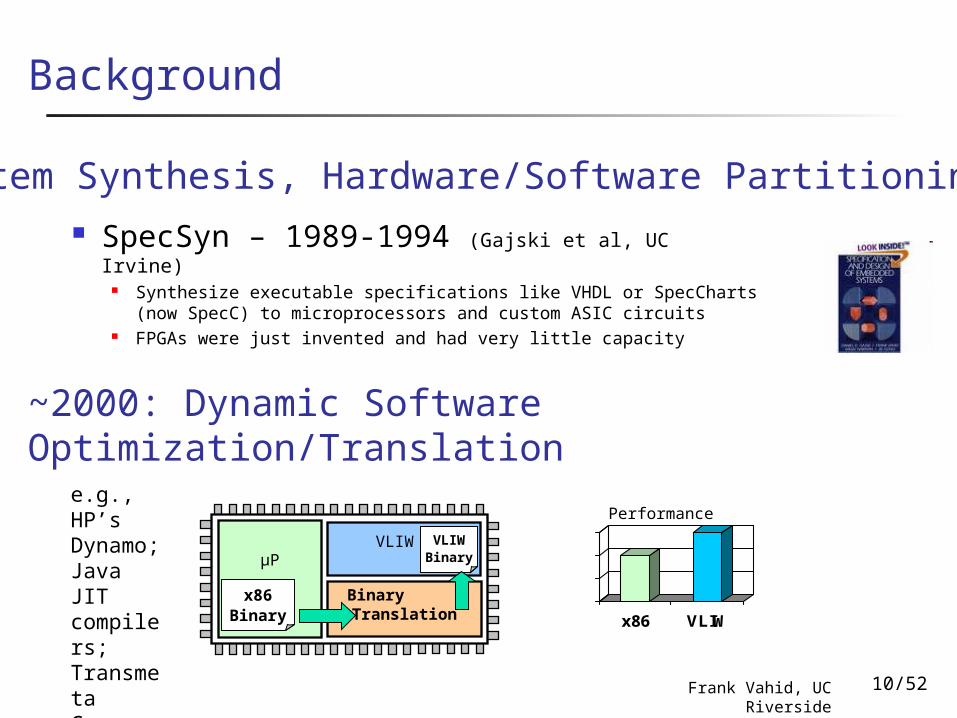
Background
SpecSyn – 1989-1994 (Gajski et al, UC Irvine) Synthesize executable specifications like VHDL or SpecCharts
(now SpecC) to microprocessors and custom ASIC circuits FPGAs were just invented and had very little capacity
Binary Translation
VLIWµP
x86Binary x86 VLIW
VLIWBinary
Performancee.g., HP’s Dynamo; Java JIT compilers; Transmeta Crusoe “code morphing”
~2000: Dynamic Software Optimization/Translation
System Synthesis, Hardware/Software Partitioning

11/52Frank Vahid, UC Riverside
Circuits on FPGAs are Software
Processor Processor
001010010……
001010010……
0010…
Bits loaded into program memory
Microprocessor Binaries (Instructions)
001010010……
01110100...
Bits loaded into LUTs and SMs
FPGA "Binaries“ (Circuits)
Processor FPGA0111
…
More commonly known as "bitstream"
"Software"
"Hardware"

12/52Frank Vahid, UC Riverside
Circuits on FPGAs are Software
“Circuits” often called “hardware” Previously same
1958 article – “Today the “software” comprising the carefully planned interpretive routines, compilers, and other aspects of automative programming are at least as important to the modern electronic calculator as its “hardware” of tubes, transistors, wires, tapes, and the like.”
“Software” does not equal “instructions” Software is simply the “bits”
Bits may represents instructions, circuits, …

13/52Frank Vahid, UC Riverside
Circuits on FPGAs are Software
Sep 2007 IEEE Computer
15/52Frank Vahid, UC Riverside
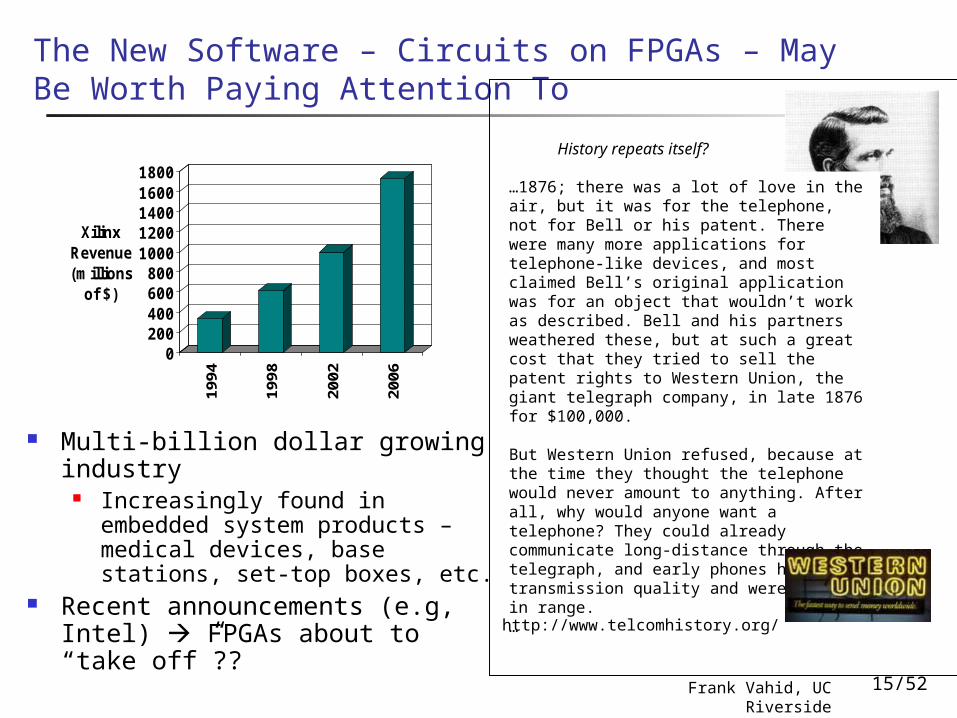
The New Software – Circuits on FPGAs – May Be Worth Paying Attention To
Multi-billion dollar growing industry
Increasingly found in embedded system products – medical devices, base stations, set-top boxes, etc.
Recent announcements (e.g, Intel) FPGAs about to “take off”??
0200400600800
10001200140016001800
Xilinx Revenue (millions
of $)
1994
1998
2002
2006
…1876; there was a lot of love in the air, but it was for the telephone, not for Bell or his patent. There were many more applications for telephone-like devices, and most claimed Bell’s original application was for an object that wouldn’t work as described. Bell and his partners weathered these, but at such a great cost that they tried to sell the patent rights to Western Union, the giant telegraph company, in late 1876 for $100,000.
But Western Union refused, because at the time they thought the telephone would never amount to anything. After all, why would anyone want a telephone? They could already communicate long-distance through the telegraph, and early phones had poor transmission quality and were limited in range. …
http://www.telcomhistory.org/
History repeats itself?
16/52Frank Vahid, UC Riverside
Binary Translation
VLIWµP
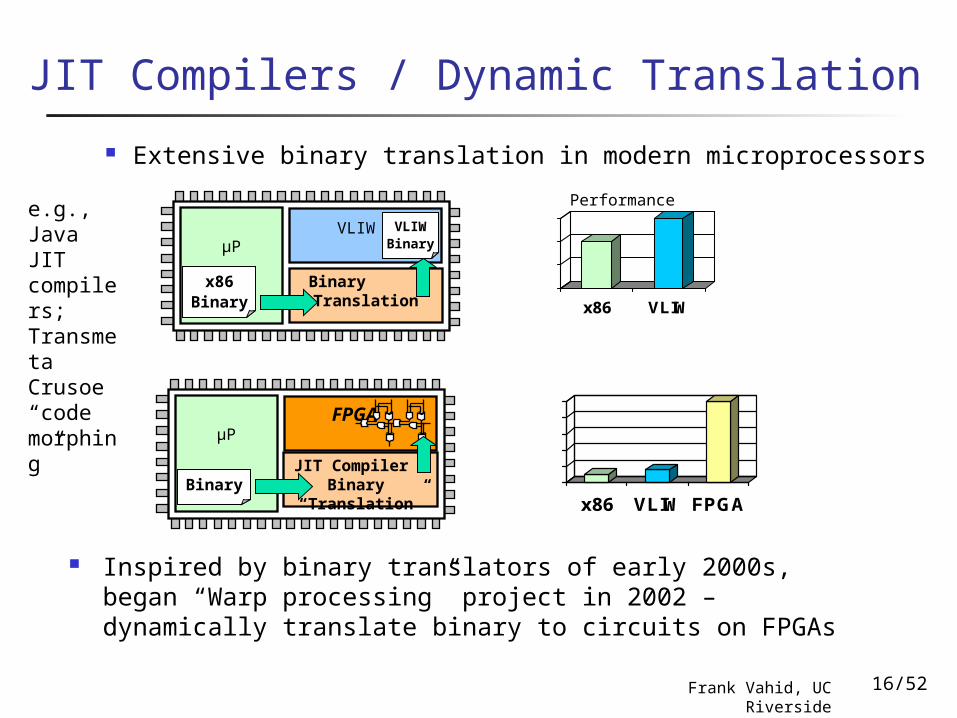
JIT Compilers / Dynamic Translation
Extensive binary translation in modern microprocessors
x86Binary x86 VLIW
x86 VLIW FPGA
VLIWBinary
FPGAµP
Binary
Inspired by binary translators of early 2000s, began “Warp processing” project in 2002 – dynamically translate binary to circuits on FPGAs
Performancee.g., Java JIT compilers; Transmeta Crusoe “code morphing”
JIT Compiler / Binary “Translation”
17/52Frank Vahid, UC Riverside
µP
FPGAOn-chip CAD
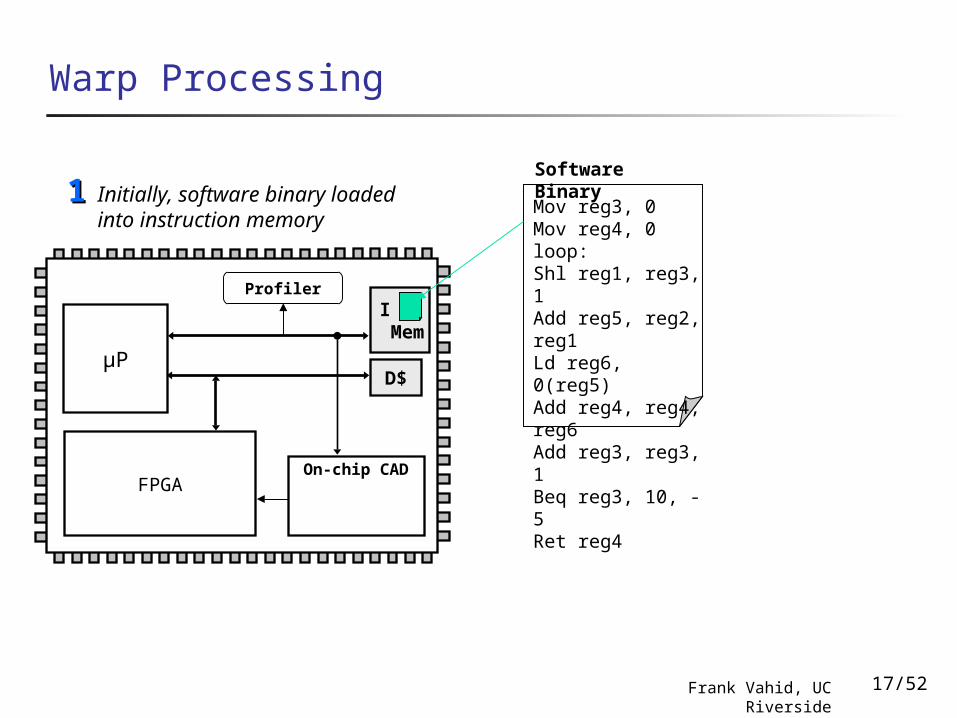
Warp Processing
Profiler
Initially, software binary loaded into instruction memory
11
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary
18/52Frank Vahid, UC Riverside
µP
FPGAOn-chip CAD
Warp Processing
ProfilerI Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
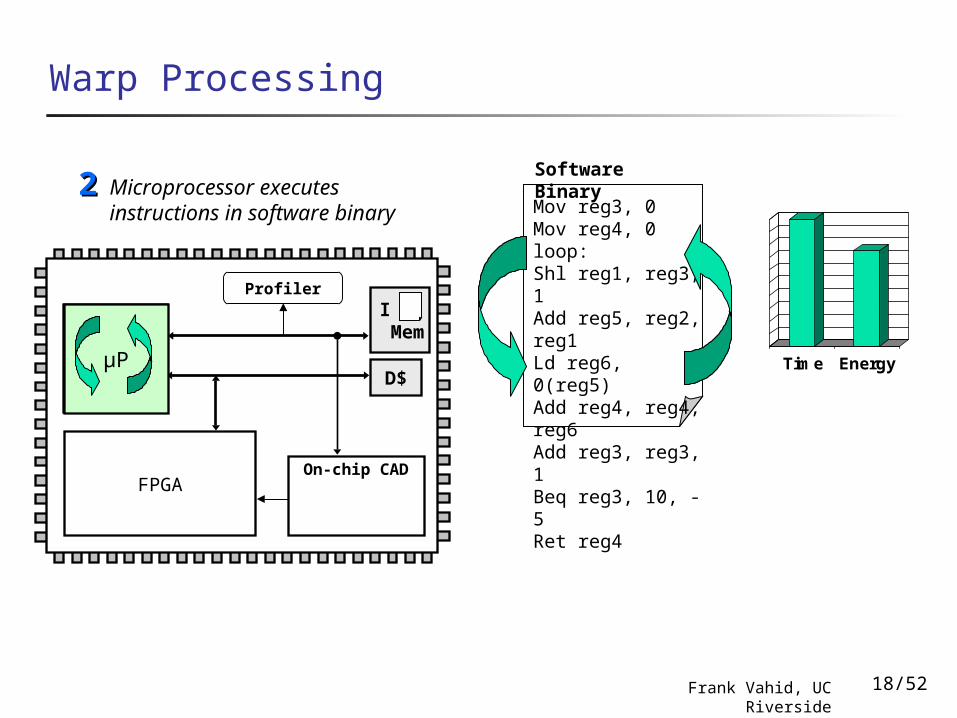
Software BinaryMicroprocessor executes
instructions in software binary
22
Time EnergyµP

19/52Frank Vahid, UC Riverside
µP
FPGAOn-chip CAD
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryProfiler monitors instructions
and detects critical regions in binary
33
Time Energy
Profiler
add
add
add
add
add
add
add
add
add
add
beq
beq
beq
beq
beq
beq
beq
beq
beq
beq
Critical Loop Detected
20/52Frank Vahid, UC Riverside
µP
FPGAOn-chip CAD
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
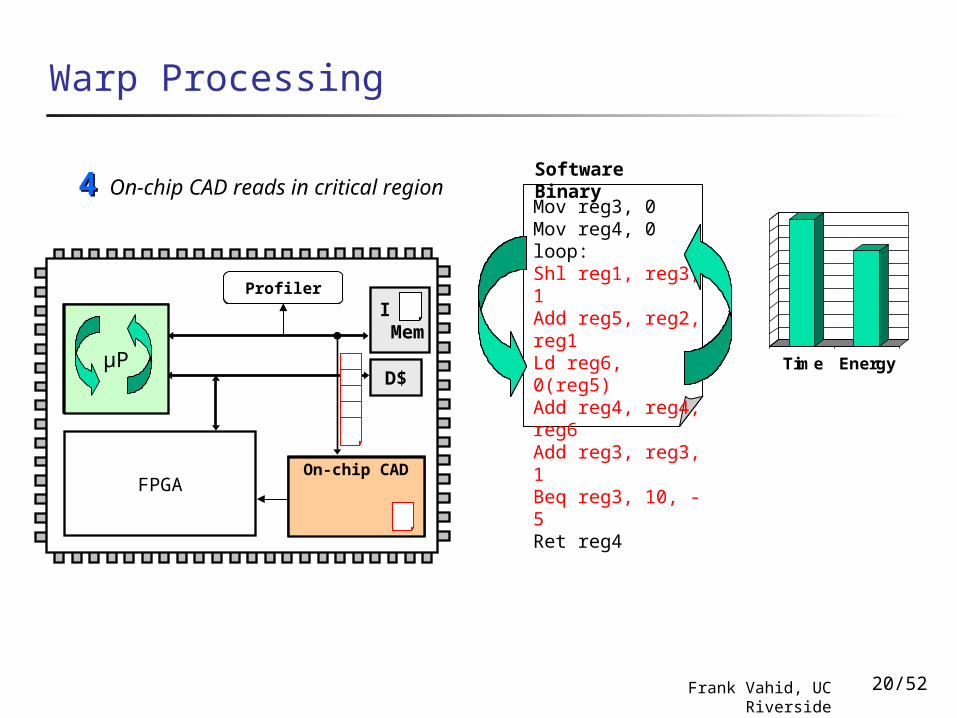
Software BinaryOn-chip CAD reads in critical
region44
Time Energy
Profiler
On-chip CAD
21/52Frank Vahid, UC Riverside
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
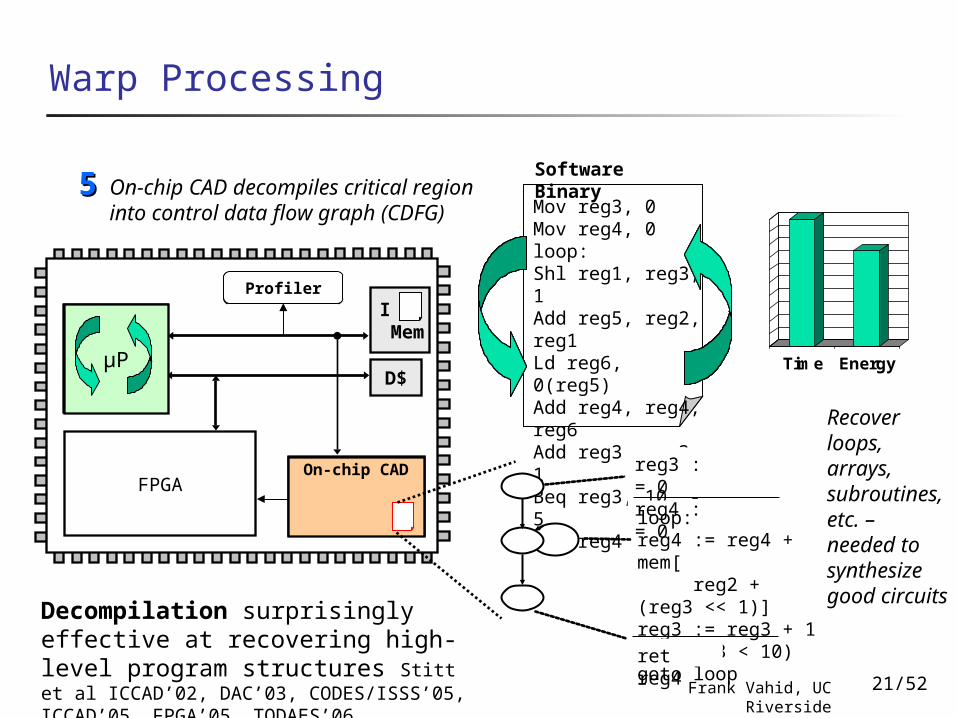
Software BinaryOn-chip CAD decompiles critical
region into control data flow graph (CDFG)
55
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Decompilation surprisingly effective at recovering high-level program structures Stitt et al ICCAD’02, DAC’03, CODES/ISSS’05, ICCAD’05, FPGA’05, TODAES’06, TODAES’07
Recover loops, arrays, subroutines, etc. – needed to synthesize good circuits

22/52Frank Vahid, UC Riverside
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryOn-chip CAD synthesizes
decompiled CDFG to a custom (parallel) circuit
66
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
23/52Frank Vahid, UC Riverside
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
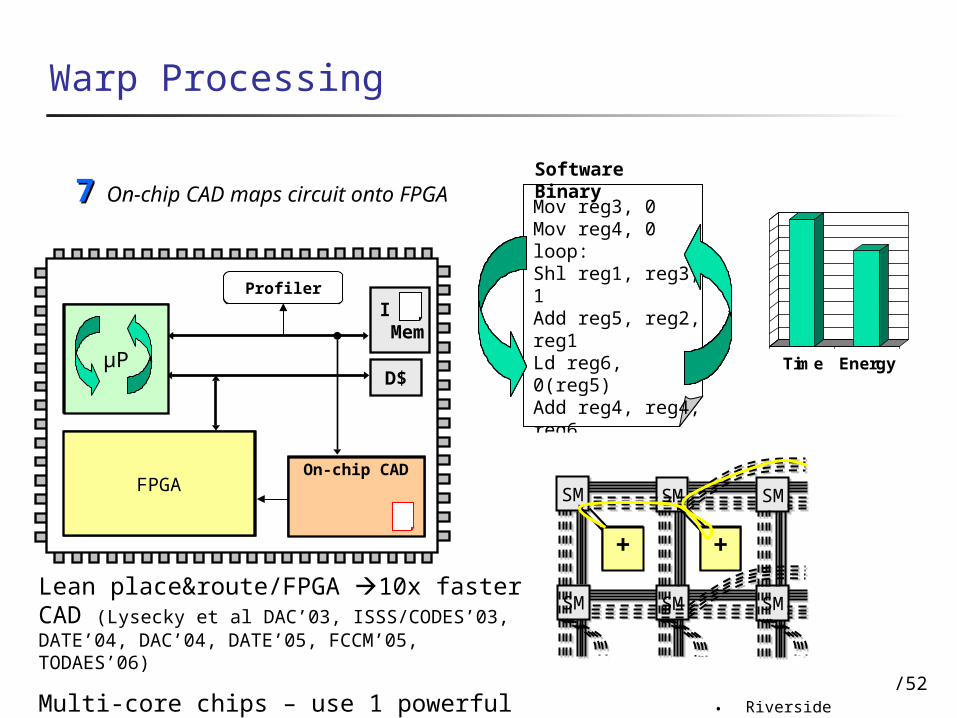
Software BinaryOn-chip CAD maps circuit onto
FPGA77
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++
FPGA
Lean place&route/FPGA 10x faster CAD (Lysecky et al DAC’03, ISSS/CODES’03, DATE’04, DAC’04, DATE’05, FCCM’05, TODAES’06)
Multi-core chips – use 1 powerful core for CAD
24/52Frank Vahid, UC Riverside
µP
FPGADynamic Part. Module (DPM)
Warp Processing
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary88
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++
FPGA
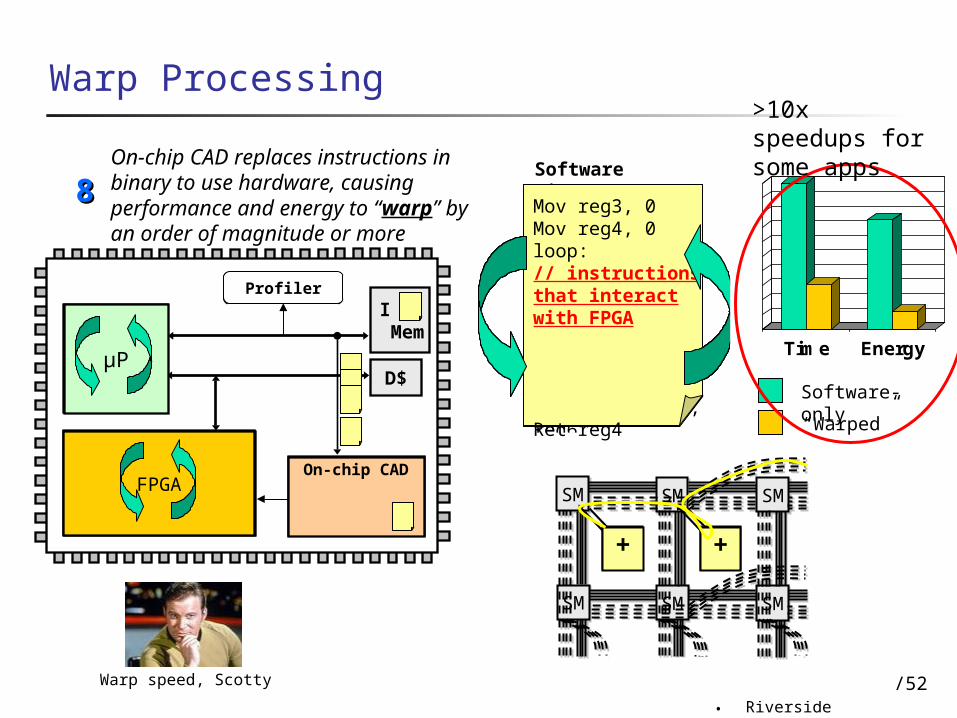
On-chip CAD replaces instructions in binary to use hardware, causing performance and energy to “warp” by an order of magnitude or more
Mov reg3, 0Mov reg4, 0loop:// instructions that interact with FPGA
Ret reg4
FPGA
Time Energy
Software-only“Warped”
>10x speedups for some apps
Warp speed, Scotty

25/52Frank Vahid, UC Riverside
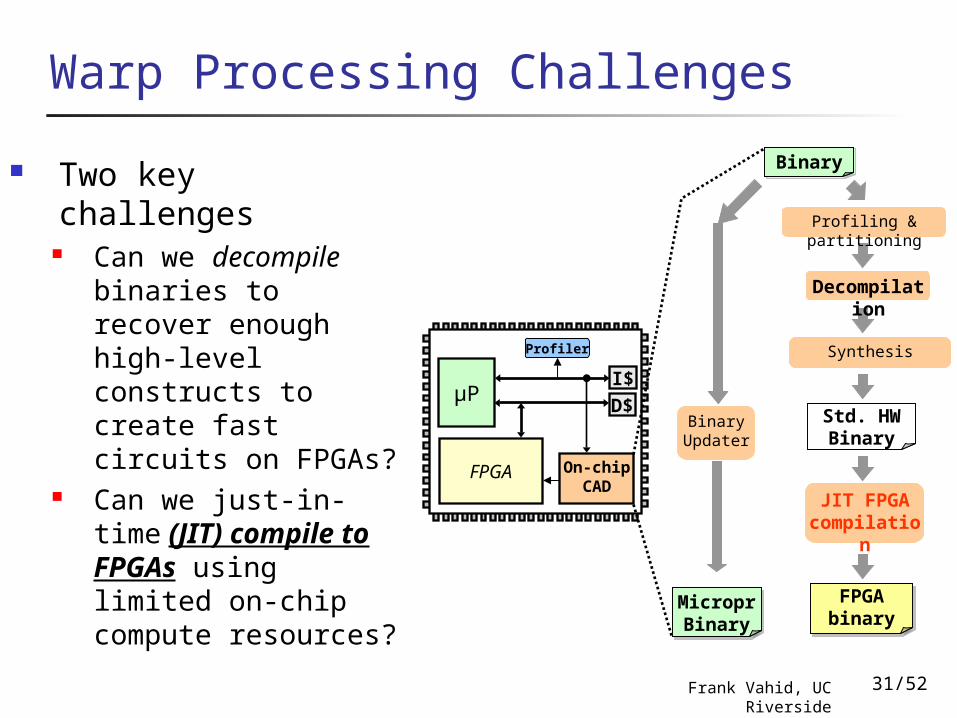
Warp Processing Challenges
Two key challenges Can we decompile
binaries to recover enough high-level constructs to create fast circuits on FPGAs?
Can we just-in-time (JIT) compile to FPGAs using limited on-chip compute resources?
µPI$
D$
FPGA
Profiler
On-chip CAD
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr Binary
Std. Ckt. Binary
JIT FPGA compilation

27/52Frank Vahid, UC Riverside
Decompilation
Solution – Recover high-level information from binary (branches, loops, arrays, subroutines, …): Decompilation
Adapted extensive previous work (for different purposes) Developed new methods (e.g., “reroll” loops) Ph.D. work of Greg Stitt (Ph.D. UCR 2007, now Asst. Prof. at UF Gainesville) Numerous publications: http://www.cs.ucr.edu/~vahid/pubs
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
long f( short a[10] ) { long accum; for (int i=0; i < 10; i++) { accum += a[i]; } return accum;}
loop:reg1 := reg3 << 1reg5 := reg2 + reg1reg6 := mem[reg5 + 0]reg4 := reg4 + reg6reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Control/Data Flow Graph CreationOriginal C Code
Corresponding Assembly
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Data Flow Analysis
long f( long reg2 ) { int reg3 = 0; int reg4 = 0; loop: reg4 = reg4 + mem[reg2 + reg3 << 1)]; reg3 = reg3 + 1; if (reg3 < 10) goto loop; return reg4;}
Function Recovery
long f( long reg2 ) { long reg4 = 0; for (long reg3 = 0; reg3 < 10; reg3++) { reg4 += mem[reg2 + (reg3 << 1)]; } return reg4;}
Control Structure Recovery
long f( short array[10] ) { long reg4 = 0; for (long reg3 = 0; reg3 < 10; reg3++) { reg4 += array[reg3]; } return reg4; }
Array Recovery
Almost Identical Representations
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr. Binary
Std. HW Binary
JIT FPGA compilation
28/52Frank Vahid, UC Riverside
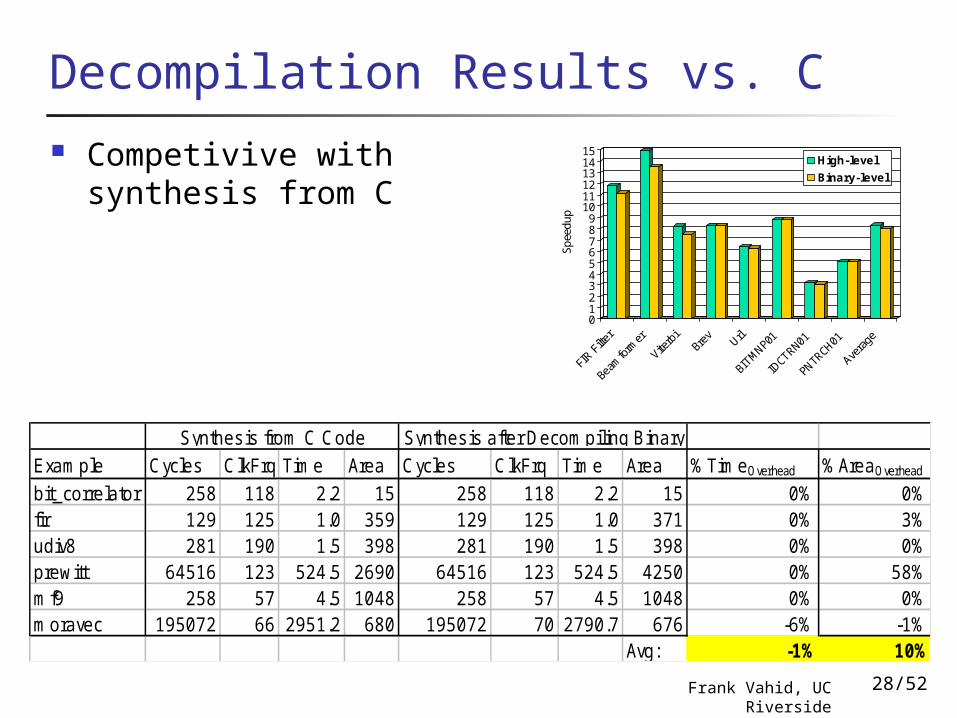
Decompilation Results vs. C Competivive with
synthesis from C
Exam ple Cycles ClkFrq Tim e Area Cycles ClkFrq Tim e Area %Tim eOverhead %AreaOverhead
bit_correlator 258 118 2.2 15 258 118 2.2 15 0% 0%fir 129 125 1.0 359 129 125 1.0 371 0% 3%udiv8 281 190 1.5 398 281 190 1.5 398 0% 0%prewitt 64516 123 524.5 2690 64516 123 524.5 4250 0% 58%m f9 258 57 4.5 1048 258 57 4.5 1048 0% 0%m oravec 195072 66 2951.2 680 195072 70 2790.7 676 -6% -1%
Avg: -1% 10%
Synthes is from C Code Synthes is after Decom piling Binary
0123456789
101112131415
Spee
dup
FIR
Filter
Beam
former
Viterbi
Brev Url
BITM
NP01
IDCT
RN01
PNTR
CH01
Averag
e
High-level
Binary-level

29/52Frank Vahid, UC Riverside
Decompilation Results on Optimized H.264In-depth Study with Freescale
Again, competitive with synthesis from C
Function Name Instr %TimeCumulative SpeedupMotionComp_00 33 6.8% 1.1InvTransform4x4 63 12.5% 1.1FindHorizontalBS 47 16.7% 1.2GetBits 51 20.8% 1.3FindVerticalBS 44 24.7% 1.3MotionCompChromaFullXFullY24 28.6% 1.4FilterHorizontalLuma 557 32.5% 1.5FilterVerticalLuma 481 35.8% 1.6FilterHorizontalChroma133 39.0% 1.6CombineCoefsZerosInvQuantScan69 42.0% 1.7memset 20 44.9% 1.8MotionCompensate 167 47.7% 1.9FilterVerticalChroma 121 50.3% 2.0MotionCompChromaFracXFracY48 53.0% 2.1ReadLeadingZerosAndOne56 55.6% 2.3DecodeCoeffTokenNormal93 57.5% 2.4DeblockingFilterLumaRow272 59.4% 2.5DecodeZeros 79 61.3% 2.6MotionComp_23 279 63.0% 2.7DecodeBlockCoefLevels56 64.6% 2.8MotionComp_21 281 66.2% 3.0FindBoundaryStrengthPMB44 67.7% 3.1
0
1
23
4
5
6
78
9
10
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51
# of Functions on FPGAS
pee
du
p
Ideal
Optimized C
Optimized binary

30/52Frank Vahid, UC Riverside
Decompilation is Effective Even with High Compiler-Optimization Levels
Average Speedup of 10 Examples
0
5
10
15
20
25
30
Do compiler optimizations generate binaries harder to effectively decompile?
(Surprisingly) found opposite – optimized code even better
31/52Frank Vahid, UC Riverside
Warp Processing Challenges
Two key challenges Can we decompile
binaries to recover enough high-level constructs to create fast circuits on FPGAs?
Can we just-in-time (JIT) compile to FPGAs using limited on-chip compute resources?
µPI$
D$
FPGA
Profiler
On-chip CAD
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr Binary
Std. HW Binary
JIT FPGA compilation
32/52Frank Vahid, UC Riverside
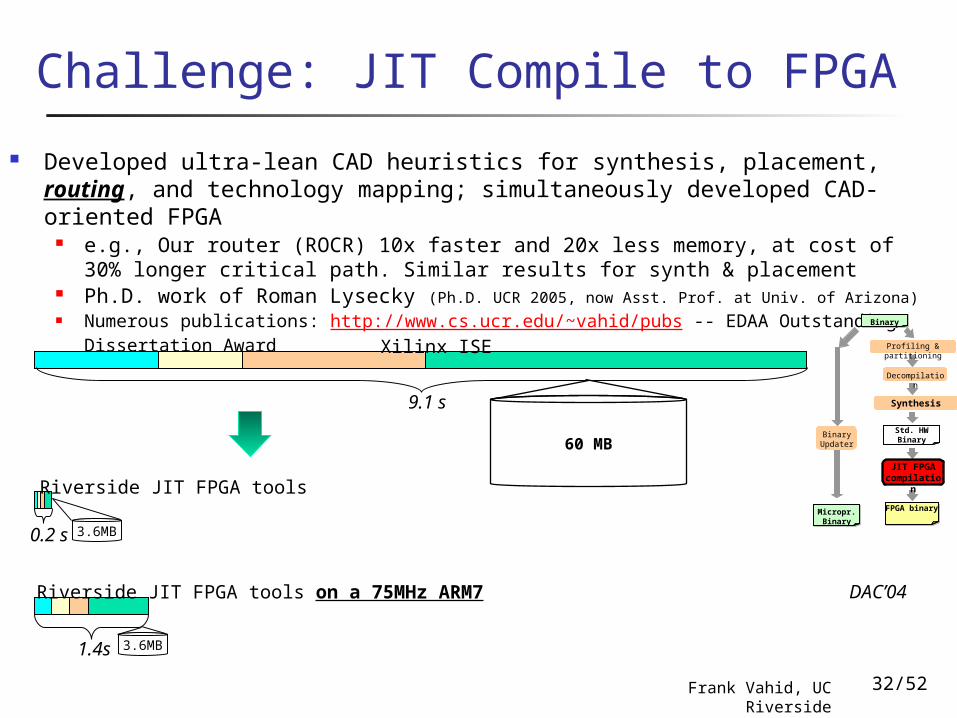
Developed ultra-lean CAD heuristics for synthesis, placement, routing, and technology mapping; simultaneously developed CAD-oriented FPGA
e.g., Our router (ROCR) 10x faster and 20x less memory, at cost of 30% longer critical path. Similar results for synth & placement
Ph.D. work of Roman Lysecky (Ph.D. UCR 2005, now Asst. Prof. at Univ. of Arizona) Numerous publications: http://www.cs.ucr.edu/~vahid/pubs -- EDAA Outstanding
Dissertation Award
Challenge: JIT Compile to FPGA
DAC’04
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr. Binary
Std. HW Binary
JIT FPGA compilation
60 MB
9.1 s
Xilinx ISE
3.6MB1.4s
Riverside JIT FPGA tools on a 75MHz ARM7
3.6MB0.2 s
Riverside JIT FPGA tools
33/52Frank Vahid, UC Riverside
191 130
0
10
20
30
40
50
60
70
80
Spee
dup
Warp Proc.
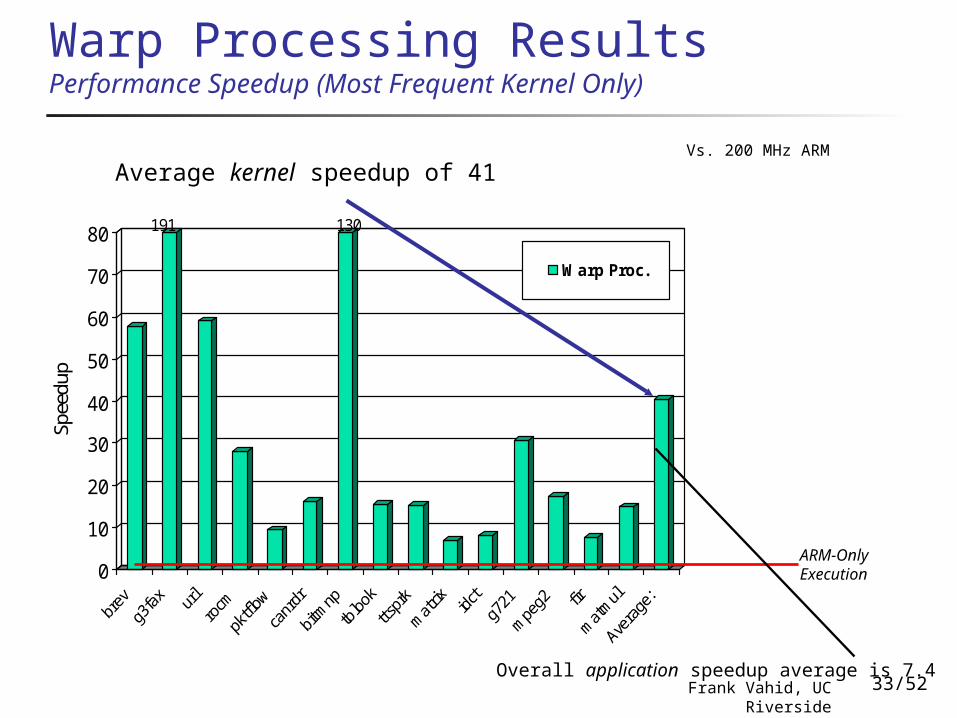
Warp Processing ResultsPerformance Speedup (Most Frequent Kernel Only)
Average kernel speedup of 41
ARM-Only Execution
Overall application speedup average is 7.4
Vs. 200 MHz ARM

34/52Frank Vahid, UC Riverside
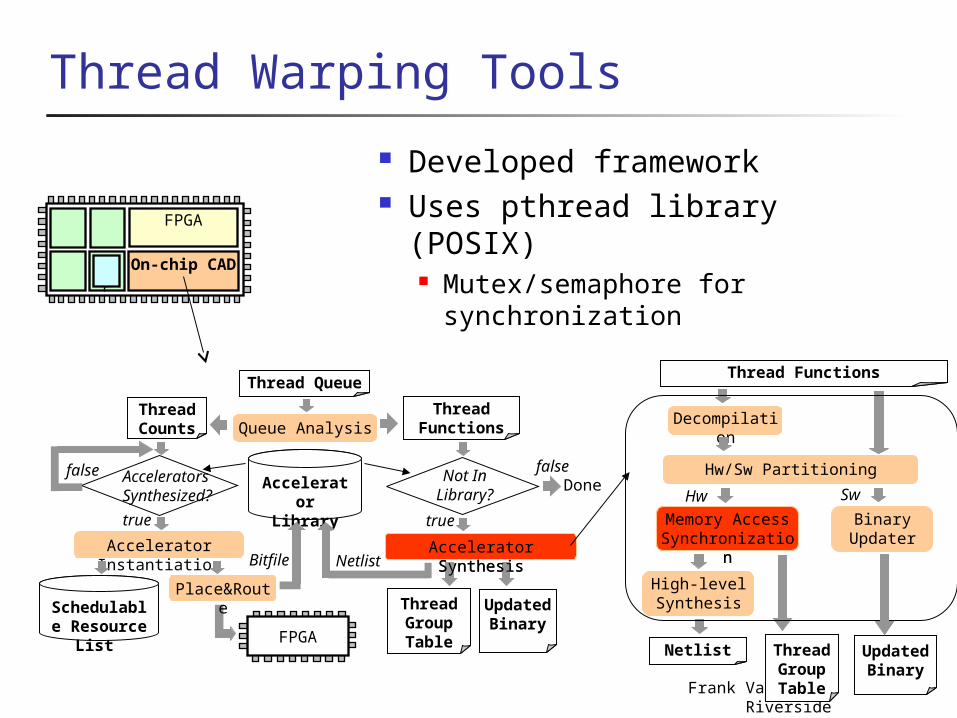
µP
Recent Work: Thread Warping (CODES/ISSS Oct 07 Austria, Best Paper Nom.)
FPGAµPµP
µP
OS
µP
f()
f()f()
Compiler
Binary
for (i = 0; i < 10; i++) {
thread_create( f, i );
}
f()
µP
On-chip CAD
Acc. Lib
f() f()
OS schedules threads onto available µPs
Remaining threads added to queue
OS invokes on-chip CAD tools to create accelerators for f()
OS schedules threads onto accelerators (possibly dozens), in addition to µPs
Thread warping: use one core to create accelerator for waiting threads
Very large speedups possible – parallelism at bit, arithmetic, and now thread level too
uP Warp
PerformanceMulti-core platforms multi-threaded apps
35/52Frank Vahid, UC Riverside
Decompilation
Memory Access Synchronization
High-level Synthesis
Thread Functions
Netlist
Binary Updater
Updated Binary
Hw/Sw Partitioning
Hw Sw
Thread Group Table
Thread Warping Tools
Developed framework Uses pthread library (POSIX)
Mutex/semaphore for synchronization
Accelerator Instantiation
Thread Queue
Thread Functions
Thread Counts
Accelerator Synthesis
Accelerator Library
FPGA
Not In Library?
DoneAccelerators Synthesized?
Queue Analysis
falsefalse
true true
Updated Binary
Schedulable Resource List
Place&RouteThread Group Table
NetlistBitfile
On-chip CAD
FPGA
µP
Accelerator Synthesis
Memory Access Synchronization

36/52Frank Vahid, UC Riverside
Must deal with widely known memory bottleneck problem FPGAs great, but often can’t get data to them fast enough
void f( int a[], int val ){ int result; for (i = 0; i < 10; i++) { result += a[i] * val; } . . . . }
Memory Access Synchronization (MAS)
Same array
FPGA b()a()
RAMData for dozens of threads can create bottleneck
for (i = 0; i < 10; i++) {
thread_create( thread_function, a, i );
}DMA
Threaded programs exhibit unique feature: Multiple threads often access same data
Solution: Fetch data once, broadcast to multiple threads (MAS)
….

37/52Frank Vahid, UC Riverside
Memory Access Synchronization (MAS)
1) Identify thread groups – loops that create threads
for (i = 0; i < 100; i++) { thread_create( f, a, i );}
void f( int a[], int val ){ int result; for (i = 0; i < 10; i++) { result += a[i] * val; } . . . . }
Thread Group
Def-Use: a is constant for all threads
Addresses of a[0-9] are constant for thread group
f() f() ……………… f()
DMA RAMA[0-9]
A[0-9] A[0-9] A[0-9]
Before MAS: 1000 memory accesses
After MAS: 100 memory accesses
Data fetched once, delivered to entire group
2) Identify constant memory addresses in thread function Def-use analysis of parameters to thread function
3) Synthesis creates a “combined” memory access Execution synchronized by OS
enable (from OS)

38/52Frank Vahid, UC Riverside
Memory Access Synchronization (MAS)
Also detects overlapping memory regions – “windows”
void f( int a[], int i ){ int result; result += a[i]+a[i+1]+a[i+2]+a[i+3]; . . . . }
for (i = 0; i < 100; i++) { thread_create( thread_function, a, i );}
a[0] a[1] a[2] a[3] a[4] a[5] ………
f() f() ……………… f()
DMA RAMA[0-103]
A[0-3] A[1-4] A[6-9]
Data streamed to “smart buffer”
Smart Buffer
Buffer delivers window to each thread
W/O smart buffer: 400 memory accessesWith smart buffer: 104 memory accesses
Synthesis creates extended “smart buffer” [Guo/Najjar FPGA04] Caches reused data, delivers windows to threads
Each thread accesses different addresses – but addresses may overlap
enable
39/52Frank Vahid, UC Riverside
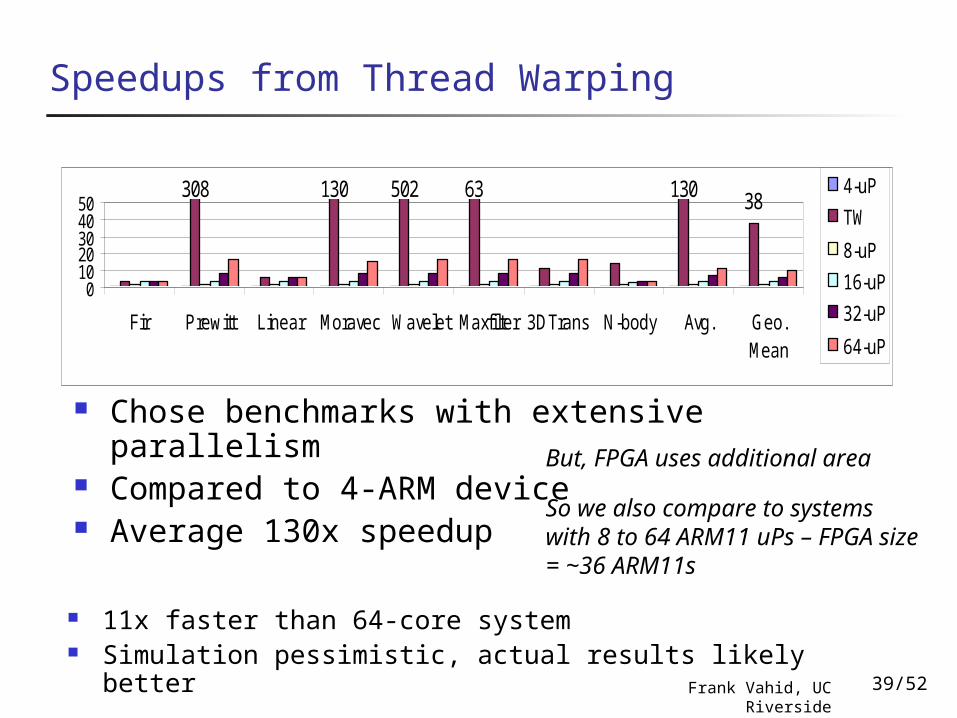
Speedups from Thread Warping
Chose benchmarks with extensive parallelism Compared to 4-ARM device Average 130x speedup
130 502 63 130 38308
01020304050
Fir Prewitt Linear Moravec Wavelet Maxfilter 3DTrans N-body Avg. Geo.Mean
4-uP
TW
8-uP
16-uP
32-uP
64-uP
11x faster than 64-core system Simulation pessimistic, actual results likely better
But, FPGA uses additional area
So we also compare to systems with 8 to 64 ARM11 uPs – FPGA size = ~36 ARM11s
40/52Frank Vahid, UC Riverside
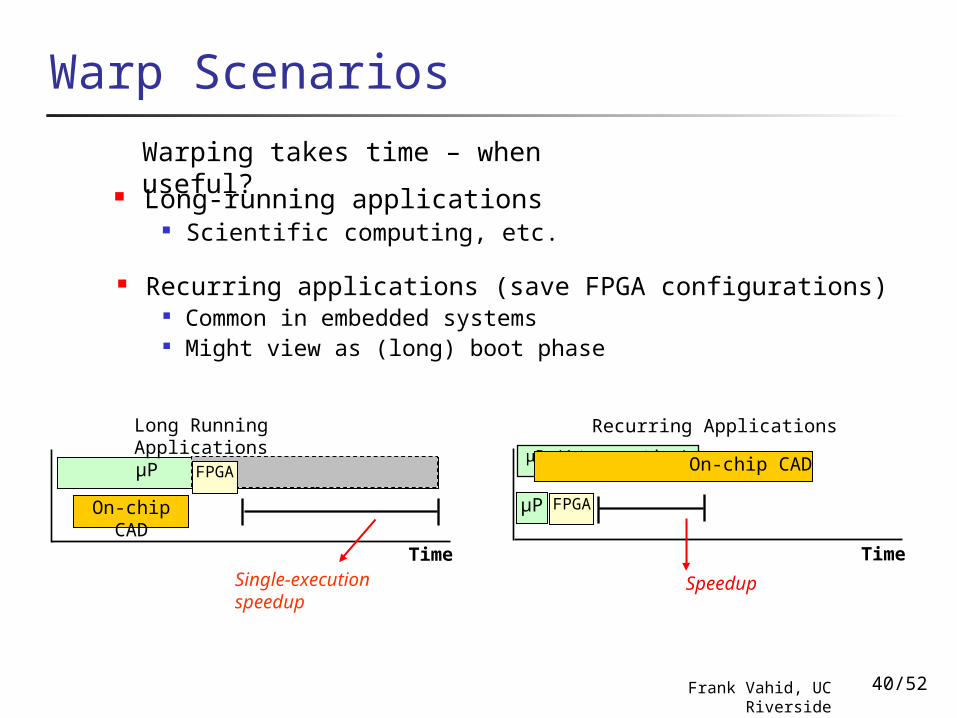
Warp Scenarios
µP
Time
µP (1st execution)
Time
On-chip CAD
µP FPGA
Speedup
Long Running Applications Recurring Applications
Long-running applications Scientific computing, etc.
Recurring applications (save FPGA configurations) Common in embedded systems Might view as (long) boot phase
On-chip CAD
Single-execution speedup
FPGA
Warping takes time – when useful?

41/52Frank Vahid, UC Riverside
Why Dynamic? Static good, but hiding FPGA opens technique to all sw platforms
Standard languages/tools/binaries
On-chip CAD
FPGA
µP
Any Compiler
FPGA
µP
Specialized Compiler
Binary Netlist Binary
Specialized Language Any Language
Static Compiling to FPGAs Dynamic Compiling to FPGAs
Can adapt to changing workloads Smaller & more accelerators, fewer & large accelerators, …
Can add FPGA without changing binaries – like expanding memory, or adding processors to multiprocessor
Custom interconnections, tuned processors, …
42/52Frank Vahid, UC Riverside
µP
Cache
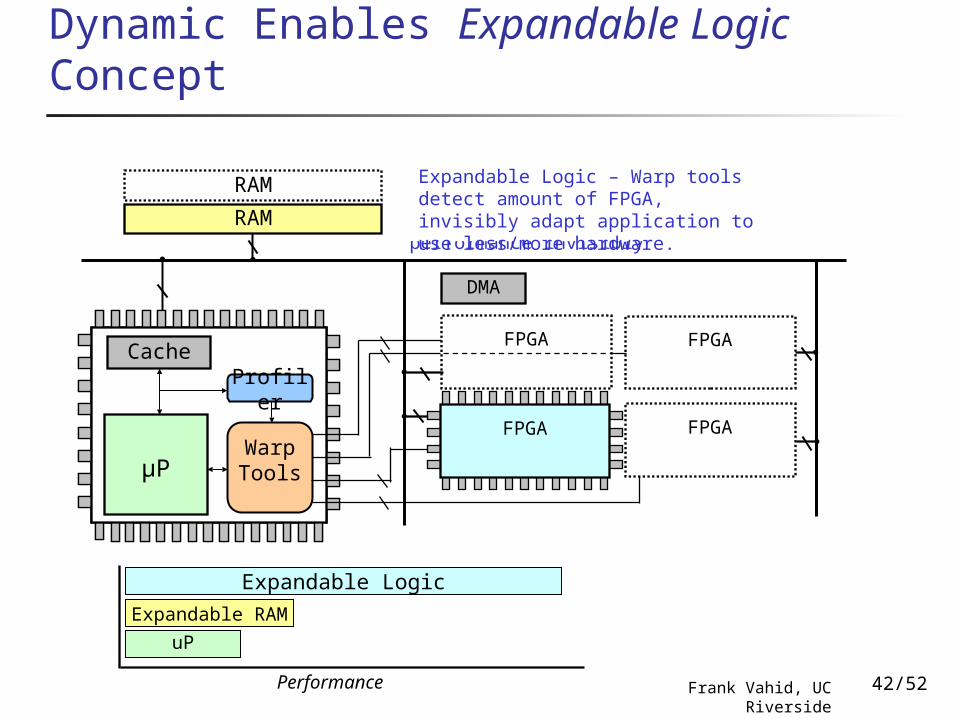
Dynamic Enables Expandable Logic Concept
RAM
Expandable RAM
uP
Performance
Profiler
µP
Cache
Warp Tools
DMA
FPGAFPGA
FPGA FPGA
RAM Expandable RAM – System detects RAM during start, improves performance invisibly
Expandable Logic – Warp tools detect amount of FPGA, invisibly adapt application to use less/more hardware.
Expandable Logic

43/52Frank Vahid, UC Riverside
Dynamic Enables Expandable Logic
Large speedups – 14x to 400x (on scientific apps)
Different apps require different amounts of FPGA
Expandable logic allows customization of single platform
User selects required amount of FPGA
No need to recompile/synthesize
0
100
200
300
400
500
N-Body 3DTrans Prew itt Wavelet
Spee
dup
Softw are1 FPGA2 FPGAs3 FPGAs4 FPGAs 0
2468
10
Sp
ee
du
p
Loaded
Not Loaded
Recent (Spring 2008) results vs. 3.2 GHz Intel Xeon – 2x-8x speedups
Nallatech H101-PCIXM FPGA accelerator board w/ Virtex IV LX100 FPGA. FPGA I/O mems are 8 MB SRAMs. Board connects to host processor over PCI-X bus
44/52Frank Vahid, UC Riverside 44/19
Run
tim
e on
CP
U a
lone
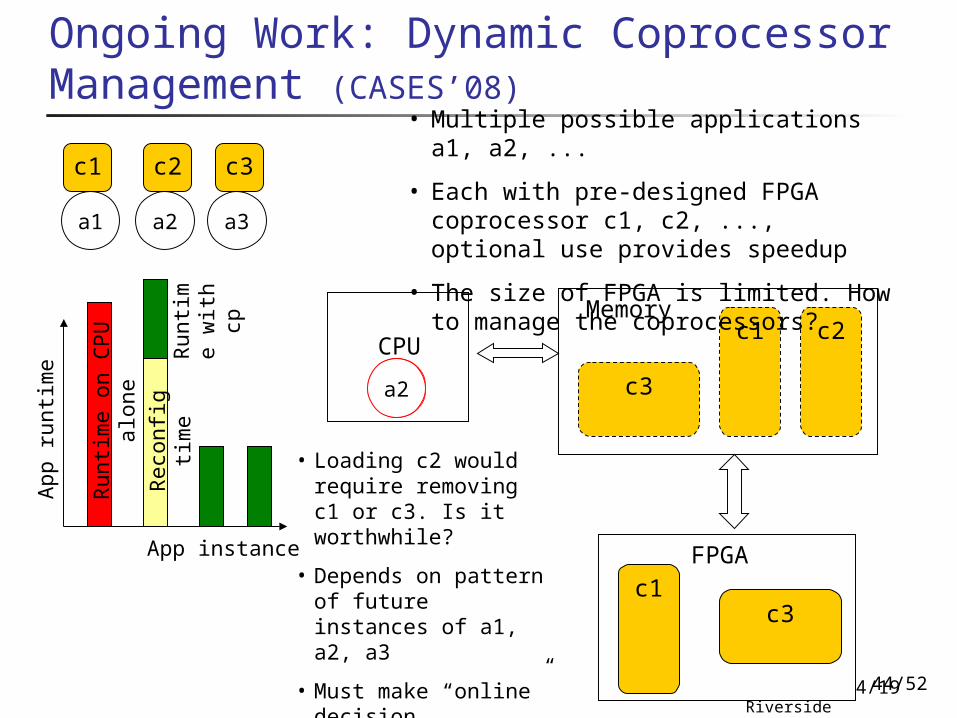
Ongoing Work: Dynamic Coprocessor Management (CASES’08)
CPU
Memory
FPGA
c1 c2
c3
c1c3
• Multiple possible applications a1, a2, ...
• Each with pre-designed FPGA coprocessor c1, c2, ..., optional use provides speedup
• The size of FPGA is limited. How to manage the coprocessors?
a1 a2 a3
c1 c2 c3
a1
App
run
tim
e
Rec
onfi
g ti
me
Run
tim
e w
ith
cp
a2
• Loading c2 would require removing c1 or c3. Is it worthwhile?
• Depends on pattern of future instances of a1, a2, a3
• Must make “online” decision
App instance

45/52Frank Vahid, UC Riverside
The Ski-Rental Problem
Greedy: Always load Doesn’t consider past apps, which
may predict future Solution idea for “ski rental
problem” (popular online technique)
Ski-Rental Problem You decide to take up skiing Should you rent skis each trip, or buy? Popular online algorithm solution – Rent until
cumulative rental cost equals cost of buying, then buy
Guarantee never to pay >2x cost of buying

46/52Frank Vahid, UC Riverside
Cumulative Benefit Heuristic
Maintain cumulative time benefit for each coprocessor
Benefit of coprocessor i: tpi - tci cbenefit(i) = cbenefit(i) + (tpi –
tci) Time that coprocessor i would
have saved up to this point had it always been used for app i
Only consider loading coproc i if cbenefit(i) > loading_time(i)
Resists loading coprocs that are infrequent or with little speedup
Q = <a1, a1, a3, a2, a2, a1, a3>
a1 a2 a3
tpi 200 100 50
tci 10 20 25
Benefit: tpi-tci 190 80 25
c1: 190
380
570 c2: 80
c3: 25
160 50 C
umul
ativ
e be
nefi
t tab
le
Assume loading time for all coprocessors is
200
Loads = <--, c1
380>200
190!>200
--, 25!>200
--, --, --, --> (already loaded)
47/52Frank Vahid, UC Riverside
Cumulative Benefit Heuristic
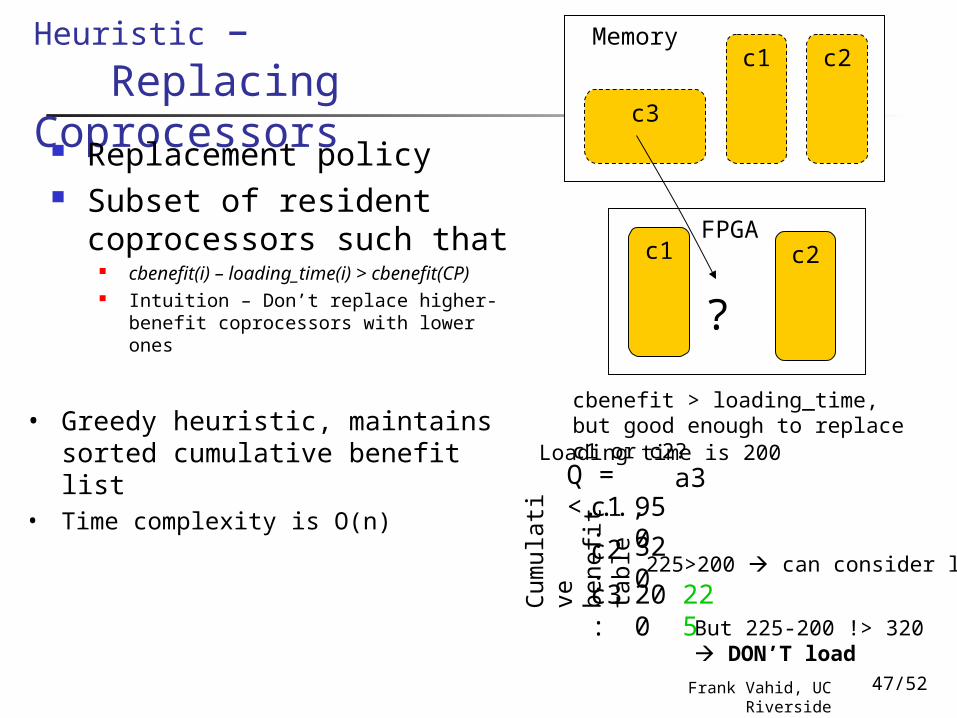
– Replacing Coprocessors Replacement policy
Subset of resident coprocessors such that
cbenefit(i) – loading_time(i) > cbenefit(CP)
Intuition – Don’t replace higher-benefit coprocessors with lower ones
FPGAc1
Memoryc1 c2
c3
c2
?
cbenefit > loading_time, but good enough to replace c1 or c2?
c1: 950 c2:
c3:
320
Cum
ulat
ive
bene
fit t
able
225
Q = <..., a3
200
Loading time is 200
225>200 can consider load
But 225-200 !> 320 DON’T load
• Greedy heuristic, maintains sorted cumulative benefit list
• Time complexity is O(n)

48/52Frank Vahid, UC Riverside
Adjustment for temporal locality
Real application sequences exhibit temporal locality
Extend heuristic to “fade” cumulative benefit values
Multiply by “f” at each step, 0<=f<=1
Define f proportional to reconfiguration time
Small reconfig time – reconfig more freely, less attention to past, small f
Q = <a1,a1,...,a1,a1,a2,a3,a3,a2,a2,a3...>
c1: 950 c2:
c3:
320
Cum
ulat
ive
bene
fit t
able
200
760 128 160
+80
e.g., f = 0.8
...249
...224
...100
a1 a2 a3
tpi 200 100 50
tci 10 20 25
Benefit: tpi-tci 190 80 25
49/52Frank Vahid, UC Riverside
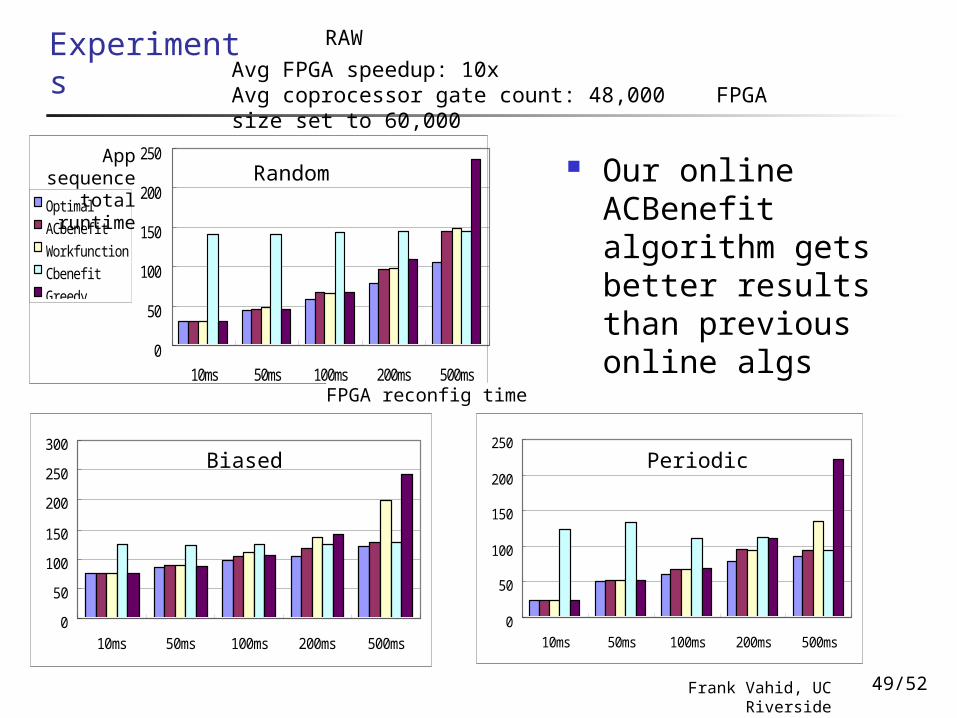
Experiments
Our online ACBenefit algorithm gets better results than previous online algs
0
50
100
150
200
250
10ms 50ms 100ms 200ms 500ms
Opt i malACbenefi tWorkf unct i onCbenefi tGreedy
0
50
100
150
200
250
300
10ms 50ms 100ms 200ms 500ms0
50
100
150
200
250
10ms 50ms 100ms 200ms 500ms
RAW
Random
Biased Periodic
Avg FPGA speedup: 10xAvg coprocessor gate count: 48,000 FPGA size set to 60,000
FPGA reconfig time
App sequence total runtime

50/52Frank Vahid, UC Riverside
More Dynamic Configuration: Configurable Cache Example
W1
Four Way Set Associative
Base Cache
W2 W3 W4
W1
Two Way Set Associative
W2 W3 W4
W1
Direct mapped cache
W2 W3 W4
W1
Shut down two ways
W2 W3 W4
Gnd
Vdd BitlineBitline
Gated-VddControl
Way Concatenation Way Shutdown
Counterbus
W116 bytes
4 physical lines filled when line size is 32 bytes
Off Chip Memory
Line Concatenation
[Zhang/Vahid/Najjar, ISCA 2003, ISVLSI 2003, TECS 2005]
One physical cache, can be dynamically reconfigured to
18 different caches
127% 620% 126%
0%
20%
40%
60%
80%
100%
120%
padp
cm crc
auto
2
bcnt bilv
binar
y blit
brev
g3fa
x fir
pjepg
ucbq
sort v4
2
adpc
m epic
g721
pegw
it
mpe
g
jpeg art
mcf
pars
er vpr
Ave
Norm
alize
d En
ergy
)cnv8K4W32B cnv8K1W32B cfg8Kwcwslc
40% avg savings

51/52Frank Vahid, UC Riverside
Highly-Configurable Platforms
Dynamic tuning of configurable components also
Micro-processor
L1 cache
L2 cache
Micro-processor
L1 cache
Voltage/freqRF size
Branch pred.
Total sizeAssociativity
Line size
Total sizeAssociativity
Line size
Memory
Encoding schemes
Encoding schemes
Application1Application2
Dynamically tuning the configurable components to match the currently executing application can significantly reduce power (and even improve performance)

52/52Frank Vahid, UC Riverside
Software is no longer just "instructions" The sw elephant has a (new) tail – FPGA circuits
Warp processing potentially brings massive FPGA speedups to all of computing (desktop, embedded, scientific, …)
Patent granted Oct 2007, licensed by Intel, IBM, Freescale (via SRC) Extensive future work
Online CAD algorithms, online architectures and algorithms, ...
Microprocessor instructions
FPGA circuits
Summary

53/52Frank Vahid, UC Riverside
Warp ProcessorsCAD-Oriented FPGA
BinaryBinary
Decompilation
BinaryHW Bitstream
RT Synthesis
PartitioningBinary Updater
BinaryUpdated Binary
BinaryStd. HW Binary
JIT FPGA Compilation
µPI$
D$
WCLA
Profiler
DPM
Solution: Develop a custom CAD-oriented FPGA
Careful simultaneous design of FPGA and CAD FPGA features evaluated for impact on CAD Add architecture features for SW kernels
Enables development of fast, lean JIT FPGA compilation tools1s <1s
.5 MB
1 MB
<1s
1 MB
10s
3.6 MB
WCLA
54/52Frank Vahid, UC Riverside
ARMI$
D$
WCLA
Profiler
DPM
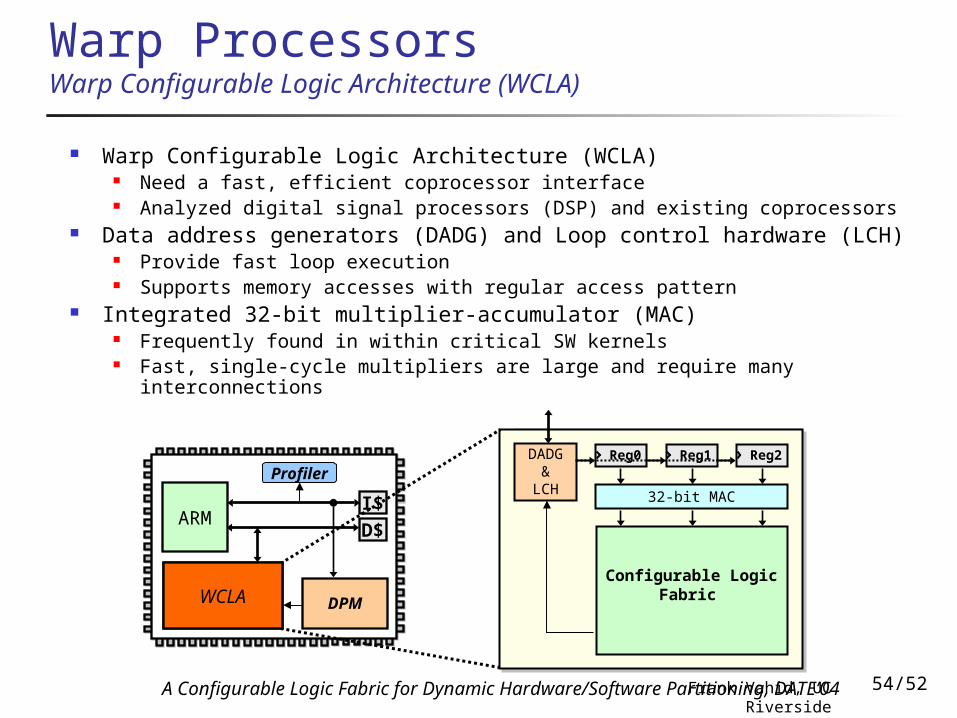
Warp ProcessorsWarp Configurable Logic Architecture (WCLA)
Warp Configurable Logic Architecture (WCLA) Need a fast, efficient coprocessor interface Analyzed digital signal processors (DSP) and existing coprocessors
Data address generators (DADG) and Loop control hardware (LCH) Provide fast loop execution Supports memory accesses with regular access pattern
Integrated 32-bit multiplier-accumulator (MAC) Frequently found in within critical SW kernels Fast, single-cycle multipliers are large and require many
interconnections
ARMI$
D$
WCLA
Profiler
DPM
DADG &
LCH
Configurable Logic Fabric
Reg0
32-bit MAC
Reg1 Reg2
WCLA
A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04

55/52Frank Vahid, UC Riverside
DADGLCH
Configurable Logic Fabric
32-bit MAC
Warp Processors - WCLA Configurable Logic Fabric
SM
CLB
SM
SM
SM
SM
SM
CLB
SM
CLB
SM
SM
SM
SM
SM
CLB
Configurable Logic Fabric (CLF) Hundreds of existing commercial and research FPGA fabrics
Most designed to balance circuit density and speed Analyzed FPGA’s features to determine their impact of CAD
Designed our CLF in conjunction with JIT FPGA compilation tools Array of configurable logic blocks (CLBs) surrounded by switch matrices
(SMs) CLB is directly connected to a SM
Along with SM design, allows for design of lean JIT routing
µPI$
D$
FPGA DPM
µPI$
D$
WCLA DPMWCLA
A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04
56/52Frank Vahid, UC Riverside
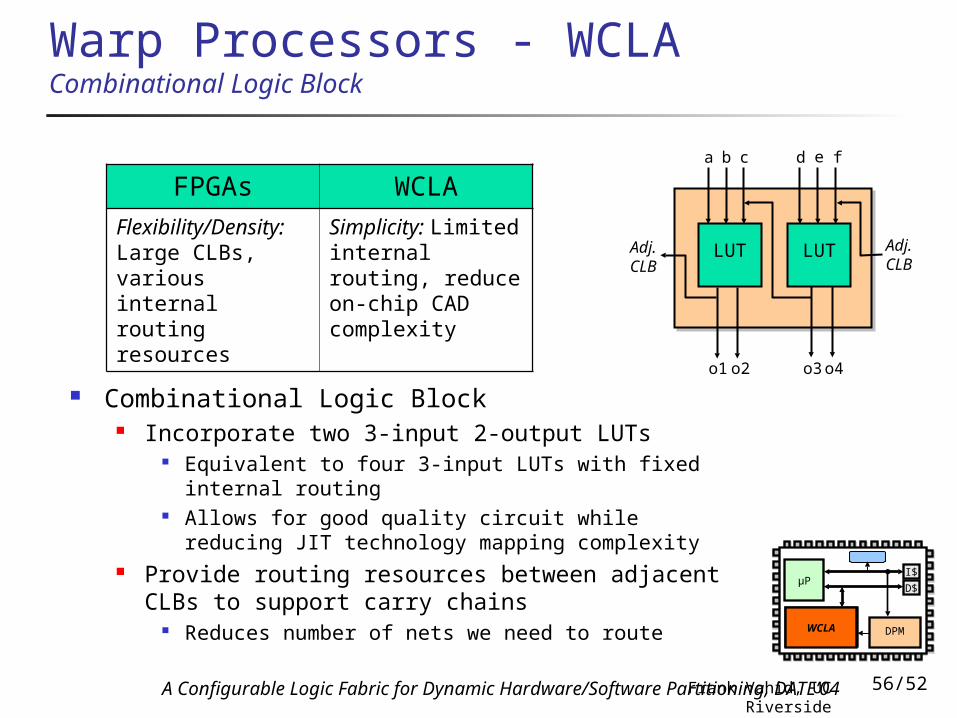
Warp Processors - WCLA Combinational Logic Block
Combinational Logic Block Incorporate two 3-input 2-output LUTs
Equivalent to four 3-input LUTs with fixed internal routing
Allows for good quality circuit while reducing JIT technology mapping complexity
Provide routing resources between adjacent CLBs to support carry chains
Reduces number of nets we need to route
FPGAs WCLAFlexibility/Density: Large CLBs, various internal routing resources
Simplicity: Limited internal routing, reduce on-chip CAD complexity
LUTLUT
a b c d e f
o1 o2 o3o4
Adj.CLB
Adj.CLB
µPI$
D$
FPGA DPM
µPI$
D$
WCLA DPMWCLA
A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04
57/52Frank Vahid, UC Riverside
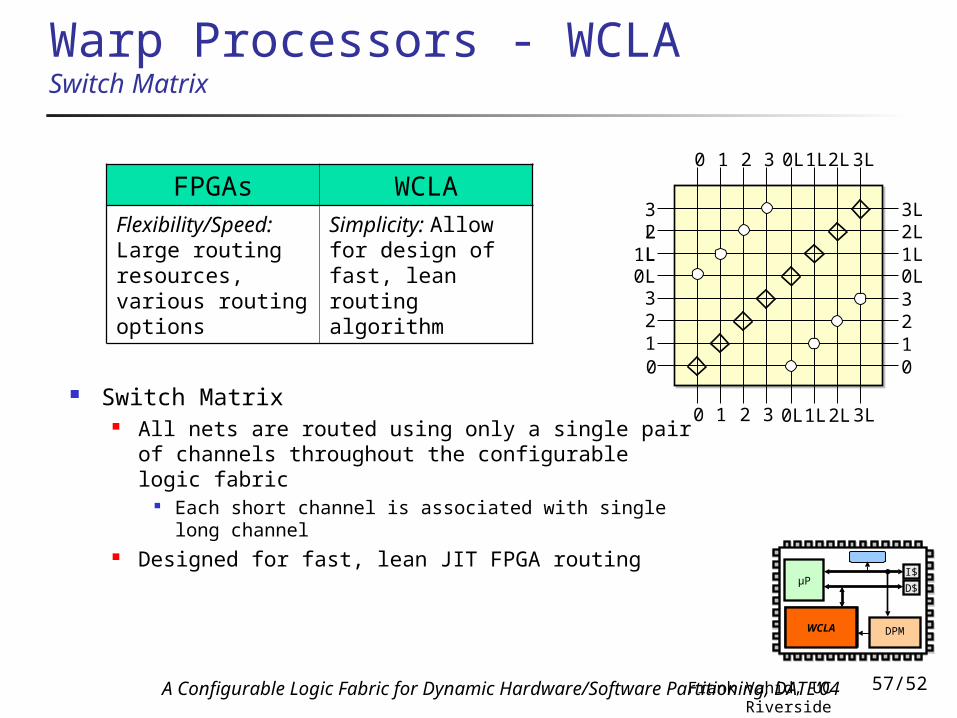
Warp Processors - WCLA Switch Matrix
0
0L
1
1L2L
2
3L
3
0123
0L1L2L
3L
0123
0L1L2L3L
0 1 2 3 0L1L2L3L Switch Matrix
All nets are routed using only a single pair of channels throughout the configurable logic fabric
Each short channel is associated with single long channel
Designed for fast, lean JIT FPGA routing
FPGAs WCLAFlexibility/Speed: Large routing resources, various routing options
Simplicity: Allow for design of fast, lean routing algorithm
µPI$
D$
FPGA DPM
µPI$
D$
WCLA DPMWCLA
A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04
58/52Frank Vahid, UC Riverside
µPI$
D$
WCLA
Profiler
DPM(CAD)
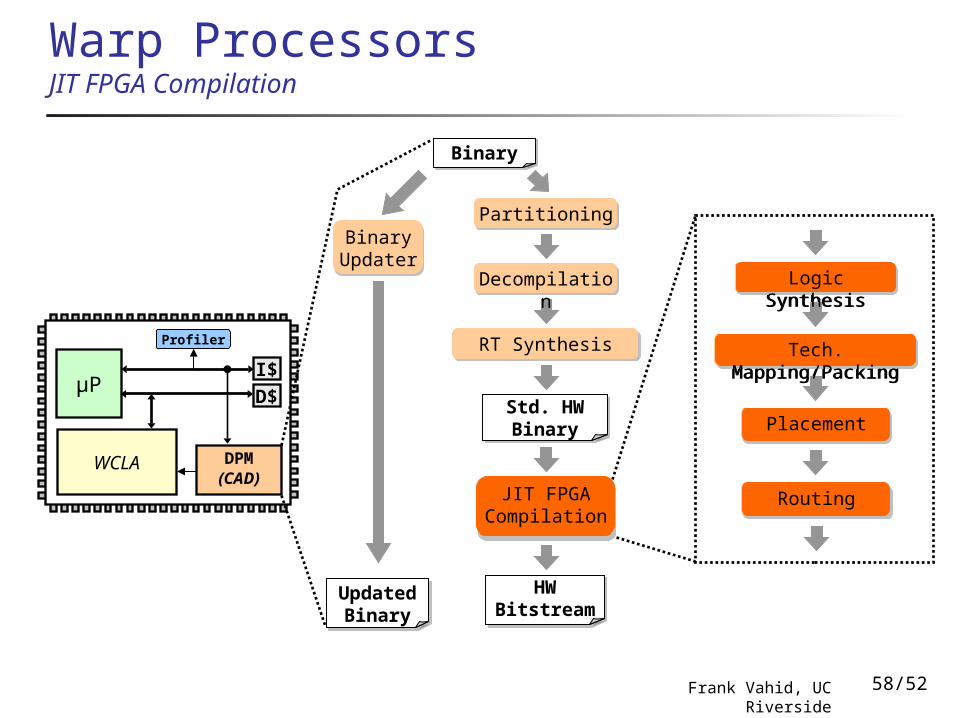
Warp ProcessorsJIT FPGA Compilation
BinaryBinary
Decompilation
BinaryHW Bitstream
RT Synthesis
PartitioningBinary Updater
BinaryUpdated Binary
BinaryStd. HW Binary
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
RoutingJIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing
59/52Frank Vahid, UC Riverside
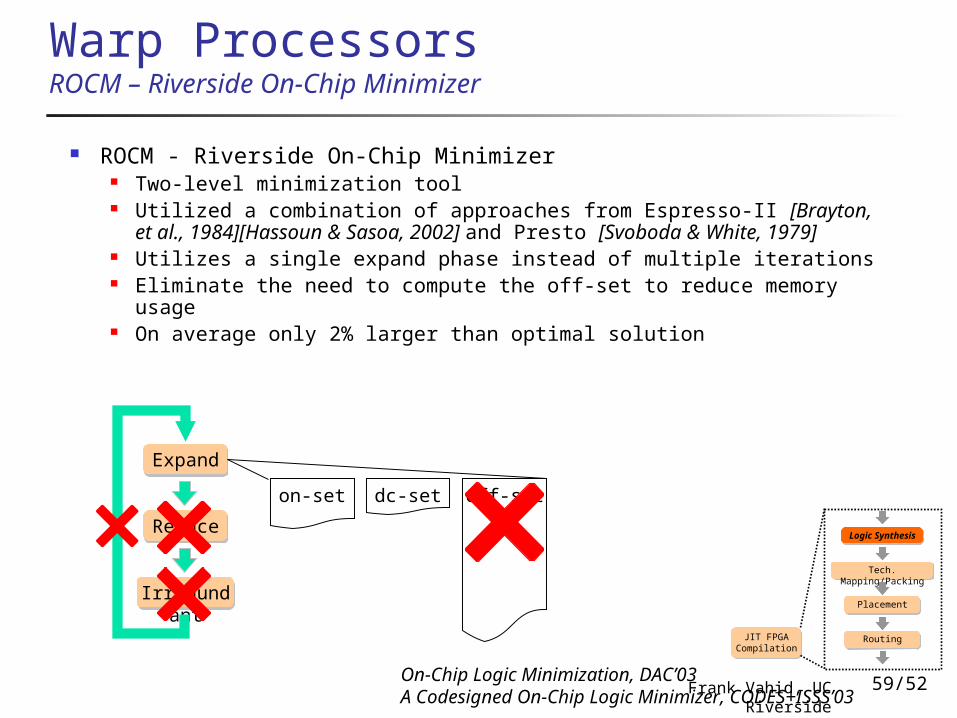
Warp ProcessorsROCM – Riverside On-Chip Minimizer
ROCM - Riverside On-Chip Minimizer Two-level minimization tool Utilized a combination of approaches from Espresso-II [Brayton,
et al., 1984][Hassoun & Sasoa, 2002] and Presto [Svoboda & White, 1979]
Utilizes a single expand phase instead of multiple iterations Eliminate the need to compute the off-set to reduce memory
usage On average only 2% larger than optimal solution
On-Chip Logic Minimization, DAC’03A Codesigned On-Chip Logic Minimizer, CODES+ISSS’03
Expand
Reduce
Irredundant
dc-seton-set off-set
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing
60/52Frank Vahid, UC Riverside
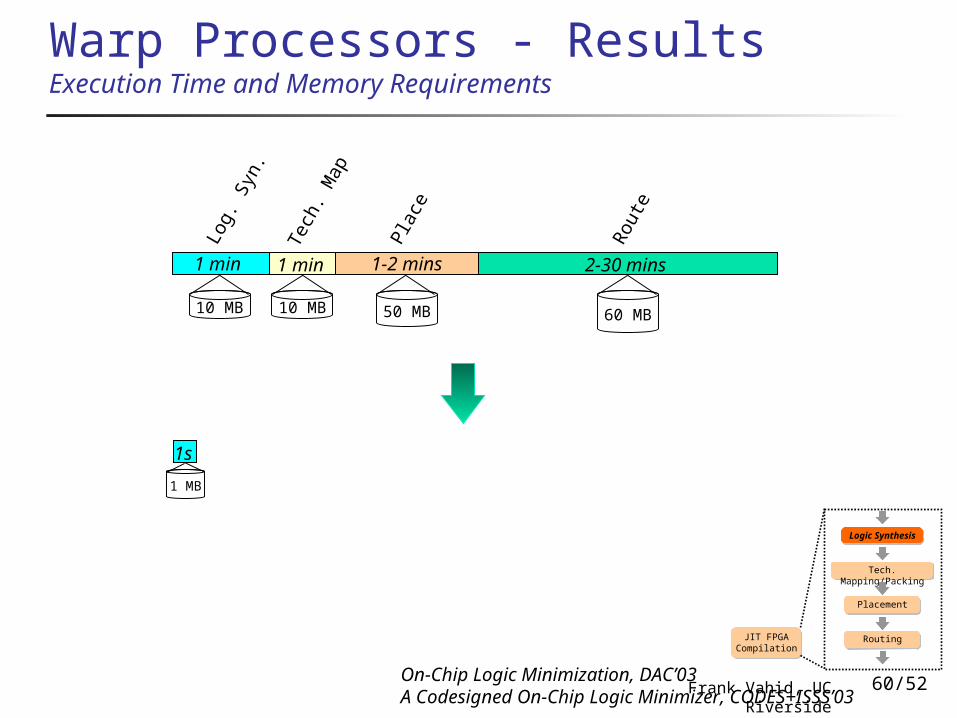
Warp Processors - ResultsExecution Time and Memory Requirements
1 MB
1s
50 MB 60 MB10 MB
1 min
Log.
Syn
.1 min
Tech
. Map
1-2 mins
Plac
e
2-30 mins
Rou
te
10 MB
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing
On-Chip Logic Minimization, DAC’03A Codesigned On-Chip Logic Minimizer, CODES+ISSS’03
61/52Frank Vahid, UC Riverside
Warp ProcessorsROCTM – Riverside On-Chip Technology Mapper
Dynamic Hardware/Software Partitioning: A First Approach, DAC’03A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04
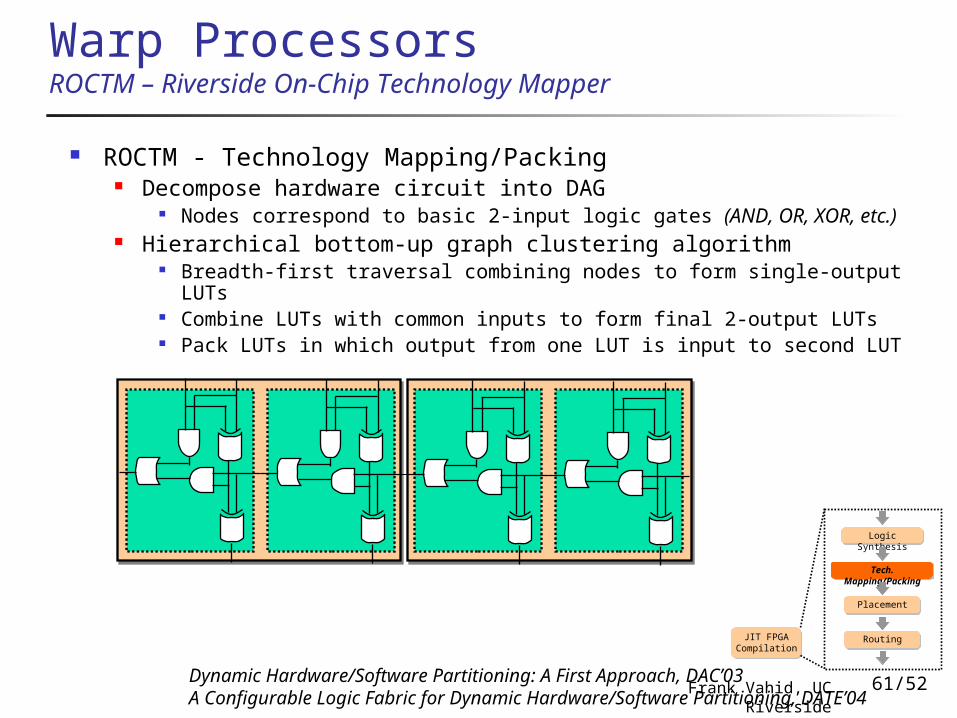
ROCTM - Technology Mapping/Packing Decompose hardware circuit into DAG
Nodes correspond to basic 2-input logic gates (AND, OR, XOR, etc.) Hierarchical bottom-up graph clustering algorithm
Breadth-first traversal combining nodes to form single-output LUTs Combine LUTs with common inputs to form final 2-output LUTs Pack LUTs in which output from one LUT is input to second LUT
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing
62/52Frank Vahid, UC Riverside
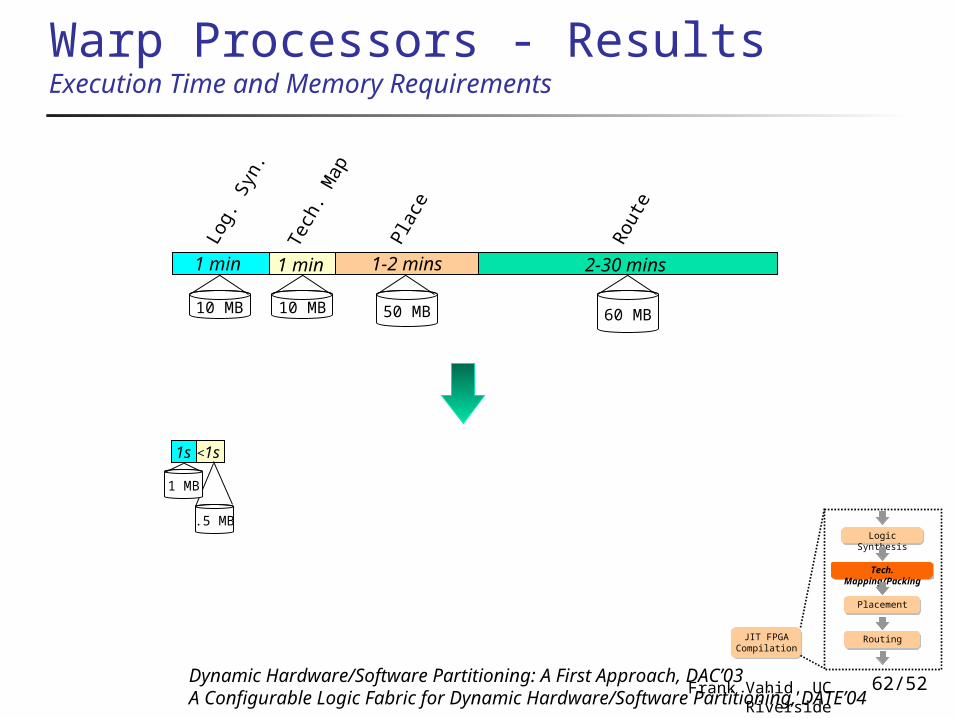
Warp Processors - ResultsExecution Time and Memory Requirements
1s <1s
.5 MB
1 MB
50 MB 60 MB10 MB
1 min
Log.
Syn
.1 min
Tech
. Map
1-2 mins
Plac
e
2-30 mins
Rou
te
10 MB
Dynamic Hardware/Software Partitioning: A First Approach, DAC’03A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing

63/52Frank Vahid, UC Riverside
Warp ProcessorsROCPLACE – Riverside On-Chip Placer
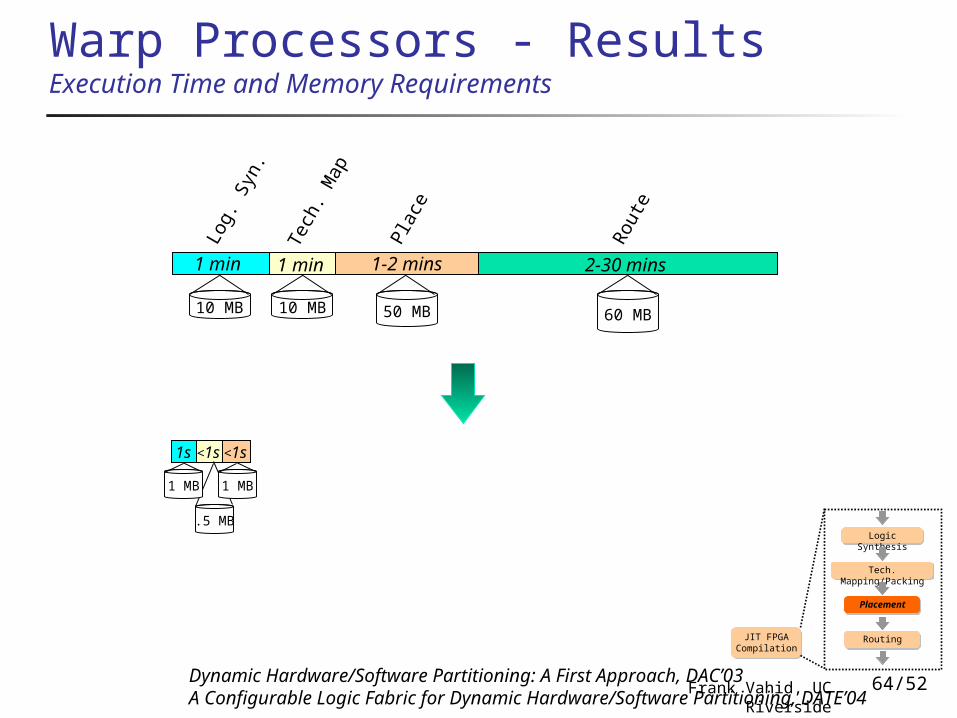
ROCPLACE - Placement Dependency-based positional placement algorithm
Identify critical path, placing critical nodes in center of CLF Use dependencies between remaining CLBs to determine placement Attempt to use adjacent CLB routing whenever possible
CLB CLB CLB CLB
CLB CLB CLB CLB
CLB CLB CLB CLB
CLB CLB CLB CLB
CLB CLB
CLB
Dynamic Hardware/Software Partitioning: A First Approach, DAC’03A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing
64/52Frank Vahid, UC Riverside
Warp Processors - ResultsExecution Time and Memory Requirements
1s <1s
.5 MB
1 MB
<1s
1 MB
50 MB 60 MB10 MB
1 min
Log.
Syn
.1 min
Tech
. Map
1-2 mins
Plac
e
2-30 mins
Rou
te
10 MB
Dynamic Hardware/Software Partitioning: A First Approach, DAC’03A Configurable Logic Fabric for Dynamic Hardware/Software Partitioning, DATE’04
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing
65/52Frank Vahid, UC Riverside
Warp ProcessorsRouting
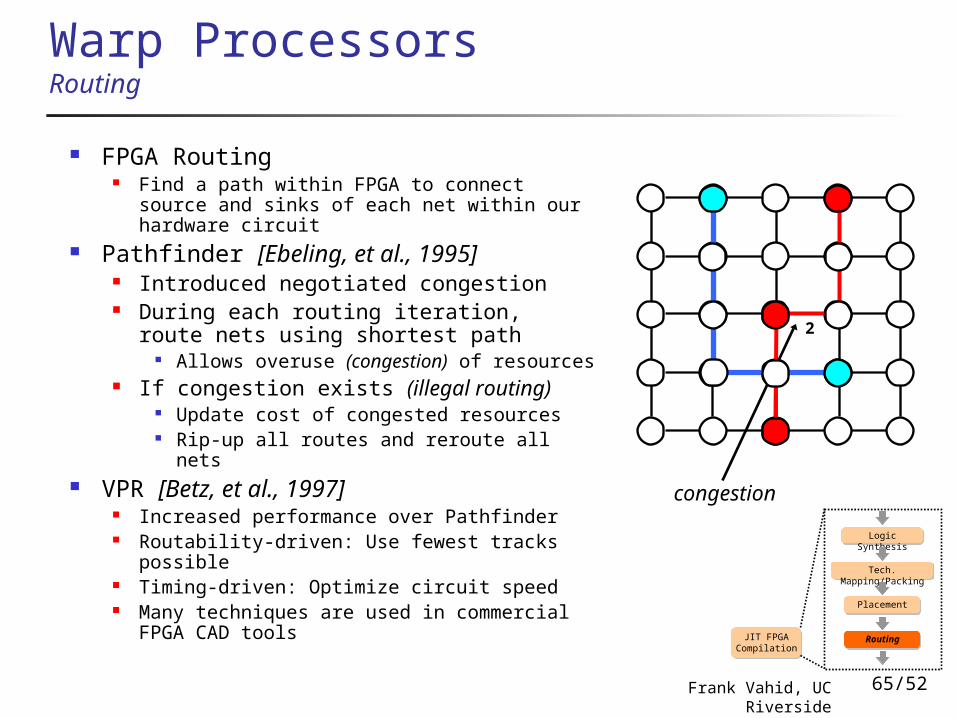
FPGA Routing Find a path within FPGA to connect source
and sinks of each net within our hardware circuit
Pathfinder [Ebeling, et al., 1995] Introduced negotiated congestion During each routing iteration, route
nets using shortest path Allows overuse (congestion) of resources
If congestion exists (illegal routing) Update cost of congested resources Rip-up all routes and reroute all nets
VPR [Betz, et al., 1997] Increased performance over Pathfinder Routability-driven: Use fewest tracks
possible Timing-driven: Optimize circuit speed Many techniques are used in commercial
FPGA CAD tools
1
1
1
1
1
1
11
12
congestion
2
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing

66/52Frank Vahid, UC Riverside
SM
CLB
SM
SM
SM
SM
CLB
SM SMSM
SM
CLB CLB
Routing Resource Graph
0/4
0/4
0/4
0/4
0/4
0/4
0/4
0/4
0/4 0/4
0/4 0/4 0/4
0/4 0/4 0/4
0/4
0/4
SM SM
SM
SM
SM
SM SMSM
SM
Resource Graph
ROCR - Riverside On-Chip Router Resource Graph
Nodes correspond to SMs Edges correspond to channels between SMs Capacity of edge equal to the number of wires within the channel
Requires much less memory than VPR as resource graph is smaller
Produces circuits with critical path 10% shorter than VPR (RD)
Warp ProcessorsROCR – Riverside On-chip Router
JIT FPGA Compilation
Tech. Mapping/Packing
Placement
Logic Synthesis
Routing
Route
Rip-up
Done!
illegal?
noyes
Dynamic FPGA Routing for Just-in-Time FPGA Compilation, DAC’04
Recommended















![Hugh Stitt [1] & Peter Jackson [2]](https://img.pdfslide.net/doc/110x75/56815ce5550346895dcae863/hugh-stitt-1-peter-jackson-2-56bb3f0e271e2.jpg)

