
STAT 254 -lecture1An overview
• Cell biology, microarray, statistics• Bioinformatics and Statistics• Topics to cover• Keep a skeptical eye on everything you read or hear• Keep an eye on bigger picture; while working on
specifics• The shaping of bioinformatics falls on your shoulders• What to take home : not just microarray, or high
throughput data analysis methods, but a set of skills, ways of thinking about quantitative biology

Exploratory data analysis multivariate
high dimensional
20 min

Study of Gene Expression:Statistics, Biology, and Microarrays
Ker-Chau Li
Statistics Department
UCLA
IMS ENAR ConferenceTime : March 31, 2003Place:Tampa, FL

Outline
• Review of cell biology Microarray gene expression data collection• Cell-cycle gene expression (Main Data set)• PCA/Nested regression; SIR (Dim. red.)• Similarity analysis - clustering (Why Popular?)• Liquid association• Closing remarks New statistical
concept, fueled by Stein’s lemma
Justification for IMS

PART I. Cellular Biology
Macromolecules: DNA, mRNA, protein

Why Biology hot?Because of

Human Genome Project
Begun in 1990, the U.S. Human Genome Project is a 13-year effort coordinated by the U.S. Department of Energy and the National Institutes of Health. The project originally was planned to last
15 years, but effective resource and technological advances have accelerated the expected completion date to 2003. Project goals are to
Human Genome Program, U.S. Department of Energy, Genomics and Its Impact on Medicine and Society: A 2001 Primer, 2001
Recent Milestones:
■ June 2000 completion of a working draft of the entire human genome ■ February 2001 analyses of the working draft are published
■ identify all the approximate 30,000 genes in human DNA, ■ determine the sequences of the 3 billion chemical base pairs that make up human DNA, ■ store this information in databases, ■ improve tools for data analysis, ■ transfer related technologies to the private sector, and ■ address the ethical, legal, and social issues (ELSI) that may arise from the project.

• Gene number, exact locations, and functions • DNA sequence organization• Chromosomal structure and organization • Noncoding DNA types, amount, distribution, information content, and functions• Interaction of proteins in complex molecular machines• Evolutionary conservation among organisms• Protein conservation (structure and function)• Proteomes (total protein content and function) in organisms• Correlation of SNPs (single-base DNA variations among individuals) with health and disease• Disease-susceptibility prediction based on gene sequence variation• Genes involved in complex traits and multigene diseases• Complex systems biology including microbial consortia useful for environmental restoration
• Developmental genetics, genomics
Future Challenges: What We Still Don’t Know
Human Genome Program, U.S. Department of Energy, Genomics and Its Impact on Medicine and Society: A 2001 Primer, 2001
• Predicted vs experimentally determined gene function {1}
•Gene regulation {2} (upstream regulatory region)
• Coordination of gene expression, protein synthesis, and post-translational events {3}

Medicine and the New Genomics
• Gene Testing
• Gene Therapy
Human Genome Program, U.S. Department of Energy, Genomics and Its Impact on Medicine and Society: A 2001 Primer, 2001
•improved diagnosis of disease •earlier detection of genetic predispositions to disease •rational drug design •gene therapy and control systems for drugs
Anticipated Benefits
•Pharmacogenomics
•personalized, custom drugs

Agriculture, Livestock Breeding, and Bioprocessing
• disease-, insect-, and drought-resistant crops
• healthier, more productive, disease-resistant farm animals• more nutritious produce• biopesticides• edible vaccines incorporated into food products
• new environmental cleanup uses for plants like tobacco
Human Genome Program, U.S. Department of Energy, Genomics and Its Impact on Medicine and Society: A 2001 Primer, 2001
Anticipated Benefits

How does the cell work?
The guiding principle is the so-called

Medicine and the New Genomics
• Gene Testing
• Gene Therapy
Human Genome Program, U.S. Department of Energy, Genomics and Its Impact on Medicine and Society: A 2001 Primer, 2001
•improved diagnosis of disease •earlier detection of genetic predispositions to disease •rational drug design •gene therapy and control systems for drugs
Anticipated Benefits
•Pharmacogenomics
•personalized, custom drugs

Agriculture, Livestock Breeding, and Bioprocessing
• disease-, insect-, and drought-resistant crops
• healthier, more productive, disease-resistant farm animals• more nutritious produce• biopesticides• edible vaccines incorporated into food products
• new environmental cleanup uses for plants like tobacco
Human Genome Program, U.S. Department of Energy, Genomics and Its Impact on Medicine and Society: A 2001 Primer, 2001
Anticipated Benefits

How does the cell work?
The guiding principle is the so-called


Human Genome Program, U.S. Department of Energy, Genomics and Its Impact on Medicine and Society: A 2001 Primer, 2001

Gene to protein
4 Nucleotides and 20 amino acids
Protein is synthesized from amino acids by ribosome

Gene to Protein
TranscriptionTranslation

Transcription and translation

PART II. Microarray
Genome-wide expression profiling

Exploring the Metabolic and Genetic Control ofGene Expression on a Genomic Scale
Joseph L. DeRisi, Vishwanath R. Iyer, Patrick O. Brown*

Microarray

MicroArray• Allows measuring the mRNA level of thousands
of genes in one experiment -- system level response
• The data generation can be fully automated by robots
• Common experimental themes:
–Time Course (when)–Tissue Type (where)–Response (under what conditions)–Perturbation: Mutation/Knockout, Knock-in Over-expression

MicroArray Technique:
Synthesize GeneSpecific DNA Oligos
Attach oligo toSolid Support
Tissue or Cell
extract mRNA
Amplificationand Labeling
Hybridize
Scan and Quantitate
Reverse-transcriptionColor : cy3, cy5 green, red

Example 1
Comparative expression
Normal versus cancer cells
ALL versus AML
5 min
E.Lander’s group at MIT

PART III. Statistics
Low-level analysis
Comparative expression
Feature extraction
Clustering/classification
Pearson correlation
Liquid association

Issues related to image qualities
• Convert an image into a number representing the ratio of the levels of expression between red and green channels
• Color bias
• Spatial, tip, spot effects
• Background noises
• cDNA, oligonucleotide arrays,
(not to be covered)

Genome-wide expression profileA basic structure
cond1 cond2 …….. condpx11 x12 …….. x1p
x21 x22 …….. x2p
… … ...
… … ...
xn1 xn2 …….. xnp
Gene1Gene2
Genen

Cond1, cond2, …, condp denote various environmental conditions, time points, cell types, etc. under which mRNA samples are taken
Note : numerous cells are involved Data quality issues : 1. chip (manufacturer) 2. mRNA sample (user)It is important to have a homogeneous sample so that cellular signals can be amplified
Yeast Cell Cycle data : ideally all cells are engaged in the same activities- synchronization
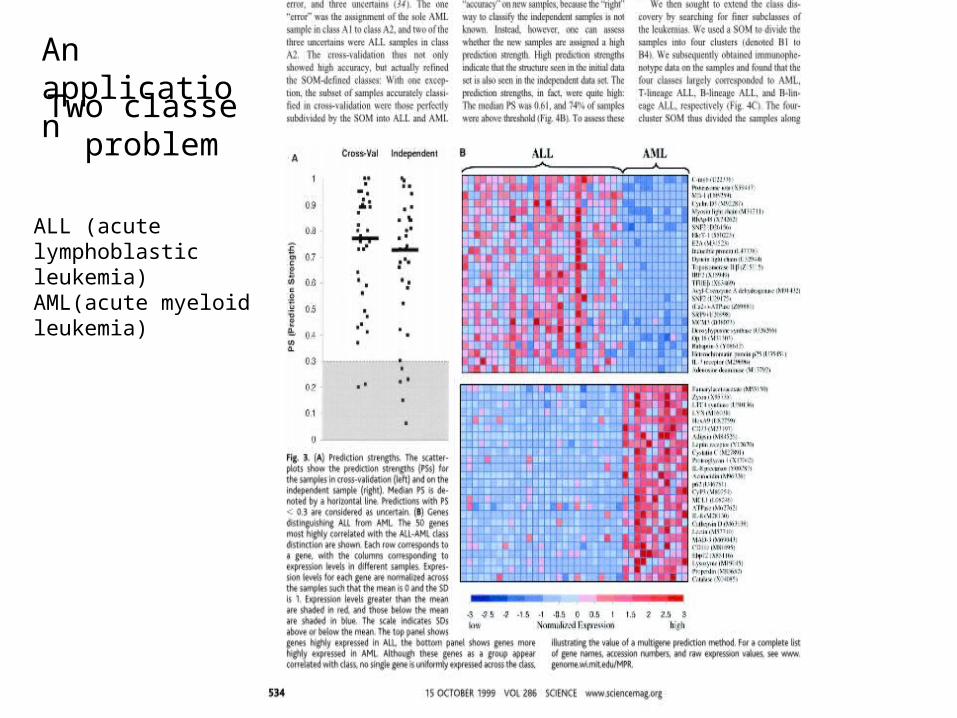
Two classes problem
ALL (acute lymphoblastic leukemia)AML(acute myeloid leukemia)
An application

Which Genes to select? • For each gene (row) compute a score defined by
sample mean of X - sample mean of Y
divided by
standard deviation of X + standard deviation of Y
• X=ALL, Y=AML
• Genes (rows) with highest scores are selected.
Seems to work ! Improvement?
•34 new leukemia samples•29 are predicated with 100% accuracy; 5 weak predication cases
That seems to work well.
They have a method

Study of cell-cycle regulated genes
• Rate of cell growth and division varies• Yeast(120 min), insect egg(15-30 min); nerve
cell(no);fibroblast(healing wounds)• Regulation : irregular growth causes cancer• Goal : find what genes are expressed at each state
of cell cycle• Yeast cells; Spellman et al (2000) • Fourier analysis: cyclic pattern
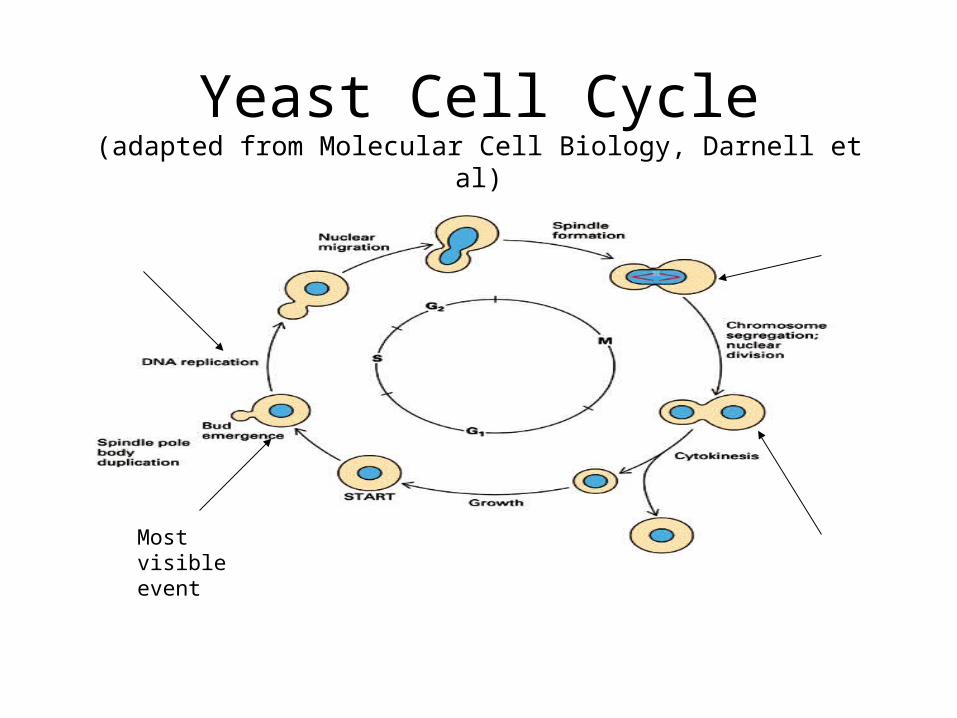
Yeast Cell Cycle(adapted from Molecular Cell Biology, Darnell et al)
Most visible event

Example of the time curve:
Histone Genes: (HTT2)ORF: YNL031CTime course:
50 250100 150 200
Histone

EBP2: YKL172W
TSM1: YCR042C
YOR263C


Why clustering make sense biologically?
Profile similarity implies functional association
The rationale is
Genes with high degree of expression similarity are likely to be functionally related and may participate in common pathways.
They may be co-regulated by common upstream regulatory factors.
Simply put,
Rationale behind massive gene expression analysis:

Some protein complexesProtein rarely works as a single unit

• Pearson's correlation coefficient, a simple way of describing the strength of linear association between a pair of random variables, has become the most popular measure of gene expression similarity.
•1.Cluster analysis: average linkage, self-organizing map, K-mean, ...
2.Classification: nearest neighbor,linear discriminant analysis, support vector machine,…
3.Dimension reduction methods: PCA ( SVD)
Gene profiles and correlation

CC has been used by Gauss, Bravais, Edgeworth … Sweeping impact in data analysis is due to
Galton(1822-1911)
“Typical laws of heridity in man”
Karl Pearson modifies and popularizes the use.
A building block in multivariate analysis, of whichclustering, classification, dim. reduct. are recurrent themes
As a statistician, how can you ignore the time order ?(Isn’t it true that the use of sample correlation relies on the assumption that data are I.I.D. ???)

Other methods forFinding Gene clusters
• Bayesian clustering : normal mixture, (hidden) indicator
• PCA plot, projection pursuit, grand tour
• Multi-Dimension Scaling( bi-plot for categorical responses, showing both cases (genes) and variables(different clustering methods), displaying results from many different clustering procedures)
• Generalized association plot (Chen 2001, Statistica Sinica)
• PLAID model ( Statistica Sinica 2002, Lazzeroni, Owen)

453041448928241665714951missing valuescompletenon-compliancecomplianceinsignificantcycle comonentsSignificant cyclle componentsSmoothNon-smoothFor the non-compliance group, visual examination of each curve pattern is done .*** of these 41 have visible cycle patterns. l 61781648

0 205 10 15 0 205 10 15
0 205 10 15 0 205 10 15
1st PCA direction 2nd PCA direction
3rd PCA direction Eigenvalues
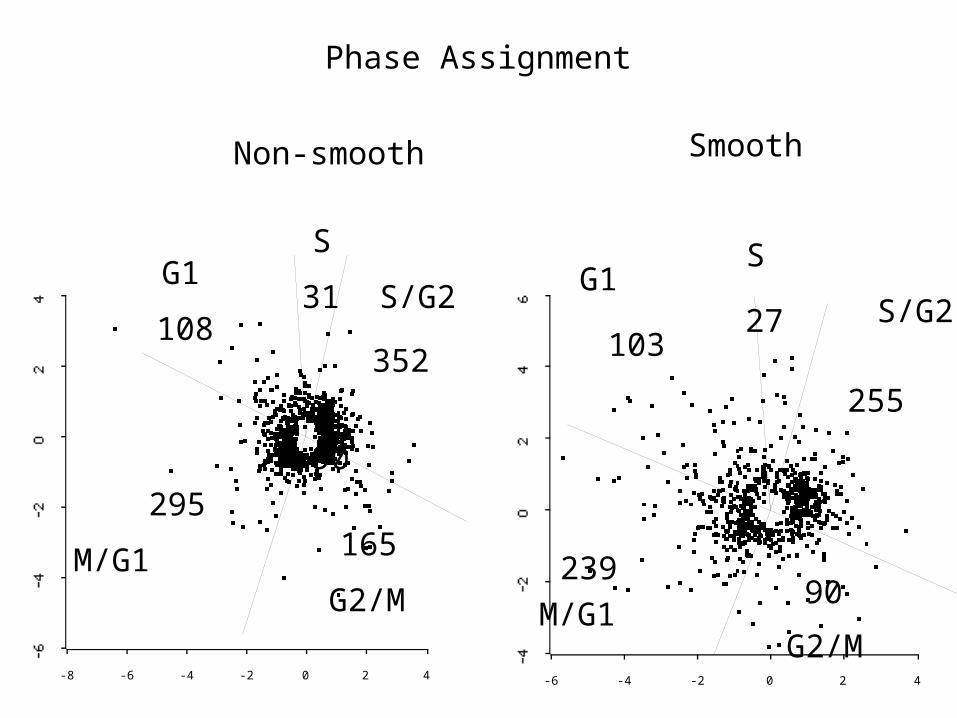
Smooth
-8 4-6 -4 -2 0 2
10831
352
90
295
SG1
S/G2
G2/MM/G1
-6 4-4 -2 0 2
10327
255
239
SG1
S/G2
G2/MM/G1
90
165
Non-smooth
Phase Assignment

ARG1
ARG2
Book a flight from LA to KEGG, JAPAN in less than 10 seconds
Glutamate

ARG1
ornithine
L-arginino-succinate
citrulline arginine
ARG3
ARG4
CAR1
ARG2
CPA2
CPA1
carbamoyl phosphate
N-acetyl-glutamate
Glutamate
Glutamine
CAR2
Proline
L-glutamate-5-semialdehyde
urea
fumarateaspartate
Figure 2 . The four genes in the urea cycle are coded by ARG3, ARG1, ARG4, and CAR1 in S. Cerevisiae.ARG2 enocodes acetyl-glutamate synthase, which catalyzes the first step of ornithine biosynthesis. CPA1 and CPA2 enocode small and large units of carbamoylphosphate synthetase. CAR2 encodes ornithine aminotransferase. This chart is adapted from KEGG.
ARG1
Adapted from KEGG
X
Y
Compute LA(X,Y|Z) for all Z
Rank and find leading genes
8th place negative

Coverage of bioinformaticsby areas | topics
Sequence analysis
Microarray Linkage, pedigree
DNA
RNA
Protein
EST
Drug
Evolution
Promoter
3-D structure
Functional prediction
Pathway discovery
System modeling
SNP Alternative splicing
Motif DomainDrug -gene -proteinProtein-protein
TRANSFAC Protein -gene

Coverage of Bioinformatics by expertise (hat, not person)Biologist Computer
scientistStatistician/mathematician
(huge data volume)(raw data provider)
Literature searching
Make researcher’s life easier (pipeline)
Data cleaning Data mining
(Bio-information distilling/Bio-data refining) Web page
browsing
Pattern searching
/comparison
Physical/Math/prob/stat models, computer optimization
Gene Ontology
Data base/ visualization
Oil-refining(Crude oil)
Generalization/inference
(Noise, garbage, or ignorance?)

Current NextmRNA
mRNA
protein kinase
Nutrients- carbon, nitrogen sourcesTemperatureWater
ATP, GTP, cAMP, etc
localization
DNA methylation, chromatin structure
Math. Modeling : a nightmare
FITNESS
FUNCTION
mRNA
CytoplasmNucleusMitochondriaVacuolar
Observed
hidden
Statistical methods become useful

Bioinformatics(knowledge integration center)
• When• Where• Who• What• Why• Cell level• Organ level• Organism level• Species level• Ecology system level

Special issue on bioinformaticsStatistica Sinica
2002 January
My paper on liquid association : PNAS 2002, 99, 16875-16880
Want to get a quick start ?
Genome-wide co-expression dynamics: theory and application
Classification: Biological Science, Genetics; Physical Science, Statistics

END

Cautionary Notes for Seriation and row-column sorting• Hierarchical clustering is popular, but
• Sharp boundaries may be artifacts due to “clever” permutation
• how to fine-tune user-specified parameters-need some theoretical guidance
• What is a cluster ? Criteria needed

Popular methods for clustering/data mining
• Linkage : Eisen et al , Alon et al
• K-mean : Tavazoein et al
• Self-organizing map : Tamayo et al
• SVD : Holter et al; Alter, Brown, Botstein

Can statisticians take the lead?
• Difficult
• But not impossible
• The key :
• Willingness to learn more biologyFebruary 2002, Talk at UCLA Biochemistry, feedback from David Eisenberg;
March 2002, David gave an inspiring review talk about several of his works (Nature, similarity)
Recommended

















