Embed Size (px)
Citation preview
BỘ LAO ĐỘNG - THƯƠNG BINH VÀ XÃ HỘI
TỔNG CỤC DẠY NGHỀ
GIÁO TRÌNHMô đun : Chuyên đề (Kỹ thuật lập trình)
NGHỀ: QUẢN TRỊ MẠNGTRÌNH ĐỘ: CAO ĐẲNG
( Ban hành kèm theo Quyết định số:120/QĐ-TCDN ngày 25 tháng 02 năm 2013 của Tổng cục trưởng Tổng cục dạy nghề)
Hà Nội, năm 2013

TUYÊN BỐ BẢN QUYỀN:
Tài liệu này thuộc loại sách giáo trình nên các nguồn thông tin có thể được phép dùng nguyên bản hoặc trích dùng cho các mục đích về đào tạo và tham khảo.
Mọi mục đích khác mang tính lệch lạc hoặc sử dụng với mục đích kinh doanh thiếu lành mạnh sẽ bị nghiêm cấm.

LỜI GIỚI THIỆU
Kiến thức môn học Kỹ thuật lập trình là một trong những nền tản cơ bản của những người muốn tìm hiểu sâu về Công nghệ thông tin đặt biệt đối với việc lập trình để giải quyết các bài toán trên máy tính điện tử. Nắm vững các kỹ thuật lập trình là cơ sở để sinh viên tiếp cận với việc thiết kế và xây dựng phần mềm cũng như sử dụng các công cụ lập trình hiện đại.
Mặc dầu có rất nhiều cố gắng, nhưng không tránh khỏi những khiếm khuyết, rất mong nhận được sự đóng góp ý kiến của độc giả để giáo trình được hoàn thiện hơn.
Hà Nội, ngày 20 tháng 1 năm 2013
Chủ biên Hồ Viết Hà

MỤC LỤC TRANG
LỜI GIỚI THIỆU..................................................................................................3BÀI 1: GIỚI THIỆU TỔNG QUAN VỀ NGÔN NGỮ LẬP TRÌNH..................5
1. Lịch sử phát triển của ngôn ngữ lập trình.................................................52. Sự ra đời và thúc đẩy của ngôn ngữ lập trình............................................53. Phân loại các ngôn ngữ lập trình...............................................................74. Vai trò và ảnh hưởng của phần cứng đối với ngôn ngữ lập trình..............95. Các thuộc tính của ngôn ngữ lập trình tốt...............................................106. Các lĩnh vực ứng dụng của ngôn ngữ lập trình.......................................127. Chuẩn hoá ngôn ngữ lập trình.................................................................178. Các vấn đề nảy sinh từ sử dụng ngôn ngữ lập trình................................17
BÀI 2:CÁC LOẠI DỮ LIỆU CẤU TRÚC.........................................................201. Các kiểu dữ liệu cơ sở............................................................................202. Kiểu mảng..............................................................................................233. Xâu kí tự..................................................................................................304. Kiểu cấu trúc...........................................................................................385. Kiểu hợp..................................................................................................476. Kiểu tập tin (file)....................................................................................497. Các kiểu dữ liệu khác..............................................................................56
BÀI 3 :HÀM THỦ TỤC.....................................................................................601. Khái niệm chương trình con....................................................................602. Xây dựng hàm và thủ tục........................................................................613. Cơ chế hoạt động của chương trình con..................................................634. Biến toàn cục và biến cục bộ...................................................................645. Cơ chế truyền tham số.............................................................................666. Tính ưu việt của chương trình con..........................................................71
BÀI 4: ĐẶC TRƯNG CÚ PHÁP VÀ NGỮ NGHĨA CHƯƠNG TRÌNH..........731. Khái niệm ngôn ngữ................................................................................732. Cây phân tích cú pháp (parsing tree).......................................................753. Các vấn đề cú pháp..................................................................................754. Phân tích cú pháp....................................................................................785. Ngữ nghĩa hình thức................................................................................806. Ngữ nghĩa tiên đề...................................................................................80
Bài 5: LẬP TRÌNH THỦ TỤC...........................................................................841. Biến và hằng............................................................................................842. Lập trình cấu trúc....................................................................................84
BÀI 6 : LẬP TRÌNH HƯỚNG ĐỐI TƯỢNG....................................................941. Trừu tượng hóa (Abstraction).................................................................942. Đối tượng (object)...................................................................................95

3. Lớp (Class)..............................................................................................964. Thuộc tính (Attribute).............................................................................975. Phương thức (Method)............................................................................986. Thông điệp (Message).............................................................................987. Tính bao gói (Encapsulation)..................................................................998. Tính thừa kế (Inheritance).......................................................................999.Tính đa hình (Polymorphism)................................................................100
BÀI 7:LẬP TRÌNH LOGIC VÀ LẬP TRÌNH HÀM.......................................1021. Giới thiệu lập trình logic.......................................................................1022. Ngữ nghĩa các kí hiệu............................................................................1033. Logic trong Prolog................................................................................1094. Giới thiệu lập trình hàm........................................................................1095. Ngôn ngữ hàm Scheme.........................................................................110
BÀI 8 : LẬP TRÌNH SONG SONG.................................................................1161. Một số khái niệm...................................................................................1162. Xử lý ngoại lệ........................................................................................1163. Ðề xuất một ngoại lệ.............................................................................1164. Lan truyền một ngoại lệ (Propagating an exception)............................1175. Sau khi một ngoại lệ được xử lý...........................................................117
BÀI 9: CÁC PHƯƠNG PHÁP NGÔN NGỮ LẬP TRÌNH KHÁC.................118BÀI 10: PHÂN TÍCH CÚ PHÁP VÀ CHƯƠNG TRÌNH DỊCH.....................123
1. Chương trình dịch là gì..........................................................................1232. Mô hình phân tích - tổng hợp của một trình biên dịch..........................1243. Môi trường của trình biên dịch..............................................................1244. Các giai đoạn dịch.................................................................................1255. Quản lý bảng ký hiệu............................................................................1266. Xử lý lỗi.................................................................................................1277. Phân tích từ vựng..................................................................................1278. Phân tích cú pháp..................................................................................127
YÊU CẦU VỀ ĐÁNH GIÁ MÔĐUN..............................................................139TÀI LIỆU THAM KHẢO.................................................................................140

MÔ ĐUN CHUYÊN ĐỀ(KỸ THUẬT LẬP TRÌNH)
Mã mô đun: MĐ 39
* VỊ TRÍ, TÍNH CHẤT, Ý NGHĨA VÀ VAI TRÒ CỦA MÔĐUN
- Vị trí: Là mô đun được bố trí trong học kỳ cuối của năm 2.
- Tính chất: Là mô đun để thực hiện một trong những chuyên đề đã nêu.
- Ý nghĩa và vai trò: Đây là môn học cơ sở ngành của các ngành liên quan đến công nghệ thông tin, cung cấp cho sinh viên các kiến thức cơ bản về kỹ thậut lập trình để làm nền tản cho việc lập trình giải quyết các vấn đề cần thiết.
* MỤC TIÊU MÔĐUN:
- Lựa chọn một chủ đề nghiên cứu và thưc hành riêng cho chuyên ngành học .
- Xác định yêu cầu của đề tài, các điều kiện về kỹ thuật, tài chính, hạn chế - Biết lập kế hoach thực hiện đề tài.- Sử dụng được các kỹ thuật đã học để thực hiện đề tài.- Viết được báo cáo đề tài.- Bố trí làm việc khoa học đảm bảo an toàn cho người và phương tiện học
tập* NỘI DUNG CỦA MÔĐUN:
Tiêu đề/Tiểu tiêu đềThời gian (giờ)
T.Số LT TH KT*1. Giới thiệu tổng quan về ngôn ngữ lập trình 1 1
2. Các loại dữ liệu cấu trúc 5 2 33. Hàm thủ tục 4 1 34. Các đặc trưng cú pháp và ngữ nghĩa chương trình 5 2 3
5. Lập trình thủ tục 12 2 106. Lập trình hướng đối tượng 6 1 57. Lập trình Logic và lập trình hàm 12 2 108. Lập trình song song 6 1 59. Các phương pháp ngôn ngữ lập trình khác 3 1 2
10. Phân tích cú pháp và chương trình dịch 4 2 2
* Kiểm tra 2 2Tổng cộng 60 15 43 2
4
BÀI 1: GIỚI THIỆU TỔNG QUAN VỀ NGÔN NGỮ LẬP TRÌNHMã bài : MĐ39-01
Giới thiệuTrong lĩnh vực công nghệ thông tin, không thể không nói đến các ngôn ngữ lập
trình. Bởi vì, chúng là công cụ cần thiết giúp cho chúng ta làm việc và giao tiếp với máy tính điện tử. Vì vậy, việc nắm được các khái niệm cơ bản của các ngôn ngữ lập trình là rất cần thiết đối với những ai làm việc trong lĩnh vực công nghệ thông tin hoặc các lĩnh vực có ứng dụng công nghệ thông tin.
Mục tiêu - Nắm được các khái niệm cơ bản về ngôn ngữ lập trình- Hiểu được lịch sử phát triển của ngôn ngữ lập trình- Đánh giá sơ bộ về một ngôn ngữ lập trình- Xác định lĩnh vực ứng dụng của ngôn ngữ lập trình
Nội dung chínhGiới thiệu lịch sử phát triến của ngôn ngữ lập trình và các khái niệm của chúng.
Chỉ ra các yếu tố ảnh hưởng đến sự phát triển của ngôn ngữ lập trình và các lĩnh vực ứng dụng của ngôn ngữ lập trình.
1. Lịch sử phát triển của ngôn ngữ lập trình
Mục tiêu: Trình bày lịch sử phát triển của ngôn ngữ lập trình, các kỹ thuật lập trình
Những ngôn ngữ lập trình (programming language) đầu tiên trên máy tính điện tử là ngôn ngữ máy (machine language), tổ hợp của các con số hệ nhị phân, hay các bit (binary digit) 0 và 1. Ngôn ngữ máy phụ thuộc vào hoàn toàn kiến trúc phần cứng của máy tính và các quy ước khắt khe của nhà chế tạo. Để giải các bài toán, những người lậ trình phải sử dụng một tập hợp các lệnh điều khiển rất sơ cấp mà mỗi lệnh là tổ hợp các bit nhị phân nên gặp rất nhiều khó khăn, mệt nhọc, rất dễ gặp phải sai sót, nhưng rất khó sửa lỗi.
Từ những năm 1950, để giảm nhẹ việc lập trình, người ta đưa vào kỹ thuật chương trình con (sub-program hay sub-routine) và xây dựng các thư viện chương trình (library) đẻ khi cần thì gọi đến hoặc dùng lại các đoạn chương trình đã viết.
Như thế, chúng ta nhận thấy ở vào giai đoạn sơ khai ban đầu của máy tính điện tử, việc sử dụng máy tính là rất khó khăn, vì ngôn ngữ lập trình là phương tiện giao tiếp lại quá phức tạp đối với người sử dụng. Người sử dụng máy tính vào giai đoạn này chỉ là các chuyên gia về tin học. Như thế, ứng dụng của máy tính điện tử vẫn còn rất hạn chế.
2. Sự ra đời và thúc đẩy của ngôn ngữ lập trình
Cũng từ những năm 1950, ngôn ngữ hợp dịch, hay hợp ngữ (assembly) ra đời. Trong hợp ngữ, các mã lệnh và địa chỉ các toán hạng được thay thế bằng các từ gợi nhớ, như ADD, SUB, JUMP, … tương ứng với các phép toán số học +, -, lệnh chuyển điều khiển, …
5
Do máy tính chỉ hiểu ngôn ngữ máy, các chương trình viết bằng hợp ngữ không thể chạy ngay được mà phải qua giai đoạn hợp dịch (assembler) thành ngôn ngữ máy. Tuy nhiên, hợp ngữ vẫn còn phụ thuộc nhiều vào phần cứng và xa lạ với ngôn ngữ tự nhiên, người lập trình vẫn gặp nhiều khó khăn khi giải các bài toán trên máy tính, đặc biệt là các bài toán tương đối lớn.
Năm 1957, hãng IBM đưa ra ngôn ngữ FORTRAN (FORmula TRANslator). Đây là ngôn ngữ lập trình đầu tiên gần gũi với ngôn ngữ tự nhiên với cách diễn đạt toán học. FORTRAN cho phép giải quyết nhiều loại bài toán khoa học, kỹ thuật và sau đó được nhanh chóng ứng dụng rất rộng rãi cho đến ngày nay với kho tàng thư viện thuật toán rất đồ sộ và tiện dụng.
Tiếp theo là sự ra đời của các ngôn ngữ ALGOL 60 (ALGOrithmic Language) vào năm 1960, COBOL (Common Business Oriented Language) vào năm 1964, Simula vào năm 1964, …
Theo sự phát triển của máy tính điện tử, các ngôn ngữ lập trình không ngừng được cải tiến và hoàn thiện đẻ ngày càng đáp ứng nhu cầu của người sử dụng và làm giảm nhẹ công việc lập trình. Sự phát triển của ngôn ngữ lập trình đã làm xích gần lại “khoảng cách” giữa người sử dụng và máy tính, nghĩa là máy tính không còn chỉ được sử dụng bởi các chuyên gia tin học mà có thể được sử dụng bởi rất nhiều người trong nhiều lĩnh vực khác nhau.
Rất nhiều ngôn ngữ lập trình đã được ra đời trên nền tảng lý thuyết tính toán và hình thành nên hai loại ngôn ngữ lập trình: ngôn ngữ bậc thấp và ngôn ngữ bậc cao.Các ngôn ngữ bậc thấp (low-level language) gồm hợp ngữ và ngôn ngữ máy, thường được dùng để viết các chương trình điều khiển và kiểm tra thiết bị, …Các ngôn ngữ bậc cao (high-level language) là phương tiện giúp người làm tin học giải quyết các vấn đề thực tế đồng thời cũng là nơi mà những thành tựu mới nhất của khoa học máy tính được đưa vào.
Lĩnh vực nghiên cứu các ngôn ngữ lập trình vừa có tính truyền thống vừa có tính hiện đại. Ngày nay, với các tiến bộ của khoa học công nghệ, người ta đã có thể sử dụng các công cụ hình thức cho phép giảm nhẹ công việc xây dựng các hệ thống chương trình từ phân tích, thiết kế cho đến sử dụng ngôn ngữ lập trình.
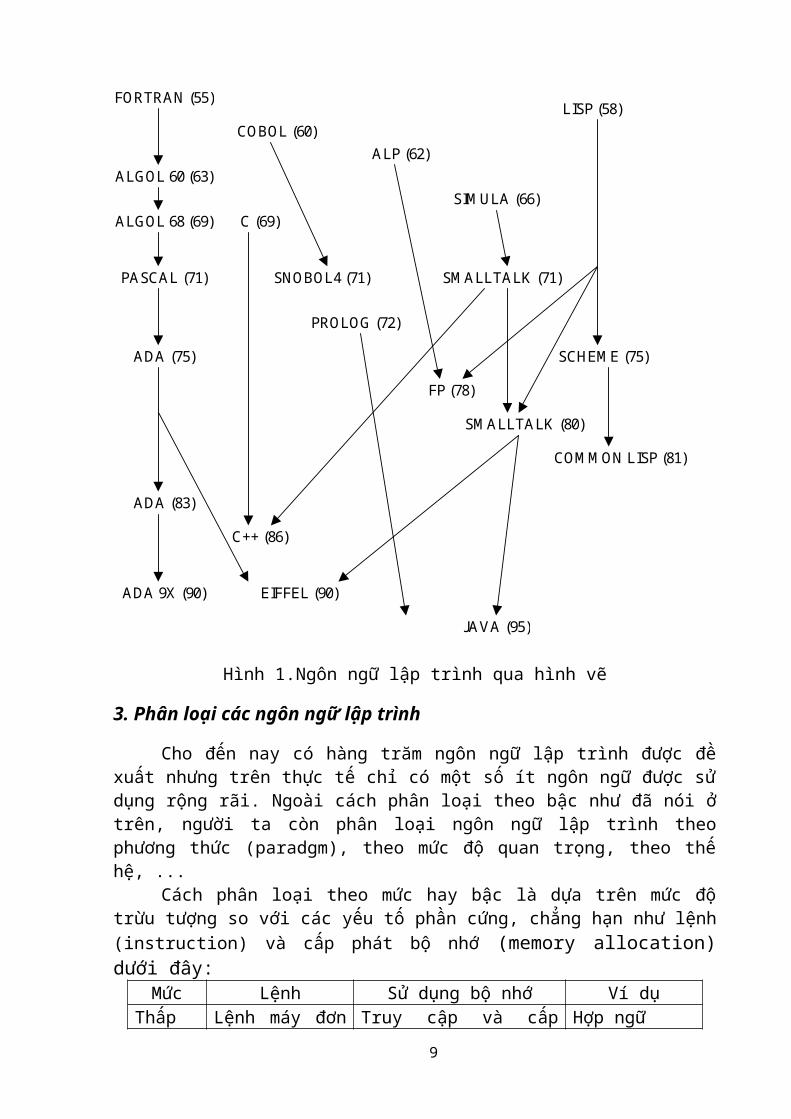
Chúng ta có thể có cài nhìn toàn cảnh hơn về lích sử của các ngôn ngữ lập trình qua hình vẽ dưới đây:
6

FORTRAN (55)
ALGOL 60 (63)
COBOL (60) ALP (62)
LISP (58)
ALGOL 68 (69)
PASCAL (71)
ADA (75)
ADA (83)
ADA 9X (90) EIFFEL (90)
C (69)
C++ (86)
SNOBOL4 (71)
PROLOG (72)
FP (78)
SCHEME (75)
COMMON LISP (81)
JAVA (95)
SIMULA (66)
SMALLTALK (71)
SMALLTALK (80)
Hình 1.Ngôn ngữ lập trình qua hình vẽ
3. Phân loại các ngôn ngữ lập trình
Cho đến nay có hàng trăm ngôn ngữ lập trình được đề xuất nhưng trên thực tế chỉ có một số ít ngôn ngữ được sử dụng rộng rãi. Ngoài cách phân loại theo bậc như đã nói ở trên, người ta còn phân loại ngôn ngữ lập trình theo phương thức (paradgm), theo mức độ quan trọng, theo thế hệ, ...
Cách phân loại theo mức hay bậc là dựa trên mức độ trừu tượng so với các yếu tố phần cứng, chẳng hạn như lệnh (instruction) và cấp phát bộ nhớ (memory allocation) dưới đây:
Mức Lệnh Sử dụng bộ nhớ Ví dụThấp Lệnh máy đơn
giảnTruy cập và cấp phát trực tiếp
Hợp ngữ
Cao Biểu thức và điều kiện tương minh
Truy cập và cấp phát nhờ các phép gán
C, Pascal, Ada
Rất cao Máy trừu tượng Truy cập ẩn và tự động cấp phát
Prolog, Miranda
7

Những năm gần đây, ngôn ngữ lập trình phát triển theo phương thức lập trình (còn được gọi là phong cách hay kiểu lập trình). Một phương thức lập trình có thể được hiểu là một tập hợp các tính năng trừu tượng đặc trưng cho một lớp ngôn ngữ mà có nhiều người lập trình thường xuyên sử dụng chúng. Sau đây là sơ đồ minh họa sự phân cấp các phương thức lập trình:
Sau đây là một số ngôn ngữ lập trình quen thuộc liệt kê theo phương thức: Các ngôn ngữ thủ tục (procedural language) có Fortran (1957), Cobol
(1959), Basic (1965), Pascal (1971), C (1969), Ada (1975), … Các ngôn ngữ hướng đối tượng (object-oriented language) có Smalltalk
(1971), C++ (1985), Eiffel (1990), Java (1995), C# (2000), … Các ngôn ngữ hàm (functional language) có Lisp (1958), ML (1973),
Scheme (1975), Caml (1987), Miranda (1982), … Các ngôn ngữ dựa logic (logic-based language) chủ yếu là ngôn ngữ Prolog
(1972). Các ngôn ngữ thao tác cơ sở dữ liệu SQL (1980),… Các ngôn ngữ xử lý song song như Ada, Occam (1982), C-Linda, …
Ngoài ra còn có một số phương thức lập trình đang được phát triển ứng dụng như: Lập trình phân bổ (distributed programming). Lập trình ràng buộc (constraint programming). Lập trình hướng truy cập (access-oriented programming). Lập trình theo luồng dữ liệu (dataflow programming).
Việc phân loại các ngôn ngữ lập trình theo mức độ quan trọng là dựa trên cái gì (what) sẽ thao tác được, hay tính được, so với cách thao tác như thế nào (how). Một ngôn ngữ thể hiện cái gì sẽ thao tác được mà không chỉ ra cách thao tác như thế nào được gọi là ngôn ngữ định nghĩa (definitional) hay ngôn ngữ khai báo (declarative). Một ngôn ngữ thể hiện cách thao tác như thế nào mà không chỉ ra cái gì sẽ thao tác được gọi là ngôn ngữ thao tác (operational) hay không khai báo (non-declarative), đó là các ngôn ngữ mệnh lệnh.
Ngoài ra, các ngôn ngữ lập trình cũng được phân chia theo thế hệ như sau: Thế hệ 1: ngôn ngữ máy Thế hệ 2: hợp ngữ Thế hệ 3: ngôn ngữ thủ tục Thế hệ 4: ngôn ngữ áp dụng hay hàm Thế hệ 5: ngôn ngữ suy diễn hay dựa logic
8
Phương thức lập trình
Mệnh lệnh Khai báo
Thủ tục Hướng đối
tượng
Xử lý song
song
Logic Hàm Cơ sở dữ
liệu

Thế hệ 6: mạng nơ-ron (neural networks)
4. Vai trò và ảnh hưởng của phần cứng đối với ngôn ngữ lập trình
Ngôn ngữ lập trình liên quan chặt chẽ đến kiến trúc máy tính (phần cứng) mà nó chạy trên đó. Chương trình viết bằng một ngôn ngữ, dù là ngôn ngữ đó thế nào đi nữa thì cũng phải chuyển sang mã máy để thực thi. Ngôn ngữ máy gắn chặt vào kiến trúc máy tính, vì vậy hiểu quả thực thi của ngôn ngữ cũng phụ thuộc rất nhiều vào kiến trúc máy tính.
Một kiến trúc máy tính xử lý tuần tự không thể thực hiện song song thật sự nhiều phát biểu trong chương trình, dù cho dạng đặc tả trong ngôn ngữ là xử lý song song. Một kiến trúc máy tính chỉ cho phép đọc/ghi mỗi lần một từ nhớ không thể bảo đảm việc xử lý đồng thời cả một đối tượng dữ liệu, dù rằng dạng đặc tả của hầu như tấct cả các ngôn ngữ lập trình hiện nay là thao tác trên cả một đối tượng dữ liệu.
Kiến trúc may tính cũng ràng buộc quá trình thiết kế ngôn ngữ chạy trên máy tính đó. Ngôn ngữ lập trình càng xa ngôn ngữ máy bao nhiêu thì càng khó thực hiện bấy nhiêu. Trong trường hợp đó chương trình dich sẽ phức tạp và đòi hỏi mô phỏng nhiều. Quá trình dịch cũng sẽ sinh ra những đaọn mã máy thừa, và do đó khó đạt được hiệu quả cao trong việc sử dụng phần cứng máy tính.
Kiến trúc của hầu hết máy tính hiện nay là kiến trúc Von Neumann. Kiến trúc Von Neumann có hai đặc điểm đáng chú ý sau:
Các lệnh được xử lý tuần tựtheo thứ tự sắp xếp trong bộ nhớ. Đặc điểm này thể hiện rõ ở các ngôn ngữ lập trình thủ tục, trong đó các phát biểu được thực hiện theo thứ tự sắp xếp trong chương trình. Các quá trình mang bản chất xử lý song song không thể được thực hiện một cách hiệu quả trên kiến trúc Von Neumann.
Chỉ cho phép đọc/ghi mỗi lần một từ nhớ. Kết quả là đối tượng dữ liệu phải bị phân nhỏ ra trước khi đọc/ghi đối tượng dữ liệu đó. Quá trình xử lý dữ liệu do vậy bị chậm đi gây nên sự tắc nghẽn trong ”giao thông” các đối tượng dữ liệu.
Giả sử s là một biến chuỗi, phép gán s:= ‘abc’ không làm thay đổi tức thời đối tượng mà thông qua việc cắt từng kí tự của chuỗi ở vế phải vào s.
Các đối tượng dữ liệu kiểu bản ghi, như trong ngôn ngữ Pascal, không được xuất hiện như sự xuất hiện của nó với tư cách là một thực thể hoàn chỉnh trong chương trình. Chẳng hạn, phép gán x := y, với x và y là hai biến cùng một kiểu bản ghi, được thực hiện bằng cách đọc từng thành phần của y và chi vào thành phần tương ứng của x. Bản thân mỗi thành phần x và y lại tiếp tục bị phân rã trong quá trình đọc/ghi.
Ngay cả việc đọc/ghi đối tượng dữ liệu đơn giản như số nguyên dài hai từ nhớ (longint) cũng phải được thực hiện hai lần.
Các phương thức lập trình mới như lập trình hàm, lập trình hướng đối tượng, lập trình logic đang từ bỏ dần dần kiến trúc Von Neumann. Lisp là ngôn ngữ điển hình của họ lập trình hàm, tuy nhiên các đặc tính hàm ban đàu của Lisp cũng đã bị sửa đổi để có thể cài đặt hiệu quả trên kiến trúc máy tính cổ điển. Prolog đại diện cho họ ngôn ngữ lập trình logic, là một công cụ đặc tả vấn đề tốt, nhưng hiệu quả của nó chưa được như mong muốn do cách giải quyêt vấn đề trên đặc tả của ngôn ngữ bị hạn chế bởi cơ chế điều khiển của kiến trúc máy tính hiện thời.
9
Tóm lại, vì sự ảnh hưởng đáng kể của phần cứng như vừa trình bày đối với ngôn ngữ lập trình, bước nhảy vọt thật sự trong ngôn ngữ lập trình, với một ngôn ngữ mới thay đổi tận gốc, chỉ có khi có một kiến trúc máy tính mới bảo đảm cho sự cài đặt hiệu quả của ngônngữ mới trên đó.
5. Các thuộc tính của ngôn ngữ lập trình tốt
Một ngôn ngữ lập trình tốt cần phải thỏa mãn một số yêu cầu cơ bản sau đây: dễ viết, dễ đọc và tin cậy.5.1. Tính dễ viết (writability)
Với tư cách là công cụ để viết chương trình, ngôn ngữ lập trình phải dễ sử dụng, tức là dễ viết.
Ngôn ngữ phải có tính diễn đạt cao. Trường hợp lý tưởng là có ánh xạ từ những suy nghĩ của người lập trình về vấn đề cần giải quyết và chiến lược giải quyết vấn đề vào ngôn ngữ. Nó liên quan đến khả năng trừu tượng hóa dữ liệu và điều khiển của ngôn ngữ. Chẳng hạn, các khiếm khuyết của ngôn ngữ Pascal như không có phát biểu nhập xuất cho kiểu liệt kê hay hàm không thể trả về kết quả kiểu dãy hoặc kiểu bản ghi cũng gây trở ngại cho người lập trình trong một số trường hợp.
Một ví dụ khác là khai niệm đệ quy. Đệ quy không chỉ là một kỹ thuật để lập trình mà còn là công cụ để tư duy. Có những vấn đề mà người lập trình không nghĩ ra một cách giải quyết nào khác ngoài cách sử dụng đệ quy. Vì vậy, ngôn ngữ cần cho phép gọi đệ quy các chương trình con. Tuy nhiên, các ngôn ngữ bậc cao đầu tiên như Fortran, Cobol không cho phép gọi đệ quy. Muốn thực hiện lời giải đệ quy trên các ngôn ngữ này phải gỡ đệ quy, tức là chuyển lời giải đệ quy thành lời giải lặp.
Ngôn ngữ phải đơn giản, để dễ học, dễ nhớ và dễ nắm vững. Ngôn ngữ không nên đưa ra quá nhiều khái niệm làm cho người sử dụng thấy rối rắm. Chẳng hạn, như ngôn ngữ C có quá nhiều toán tử. Nếu như trong Pascal các toán tử Not, And và Ỏ được dùng chung cho kiểu dữ liệu logic và kiểu dữ liệu số học thì trong C lại có sự phân biệt: các toán tử !, &&, || dùng cho kiểu logic còn các toán tử ~, & và | dùng cho kiểu dữ liệu số học. Số lượng toán tử nhiều, các kí hiệu lại gần giống nhau và không gợi nhớ đã làm tăng tính phức tạp của ngôn ngữ C.
Ngôn ngữ phải linh hoạt, không nên quá gò bó vào một nguyên tắc nào đó. Chẳng hạn một trong những nguyên tắc của ngôn ngữ Pascal là: mỗi cấu trúc điều khiển chỉ có một ngõ vào và một ngõ ra. Nó ngăn cấm sự kết thúc bất thường từ bên trong vòng lặp For và các vòng lặp có điều kiện như While và Repeat, cũng như không cho nhiều điểm trở về trong chương trình con. Nguyên tắc này nhằm đảm bảo tính cấu trúc của chương trình nhưng đôi khi cũng gây trở ngại cho người lập trình. Ngôn ngữ C linh hoạt hơn với các phát biểu Break và Return. Ví dụ, trong trường hợp sau, phát biểu Return của C tránh được các phát biểu if lồng nhau:Bằng C:
p (){
<phát biểu 1>;if (<điều kiện 1>) return;<phát biểu 2>;if (<điều kiện 2>) return;<phát biểu 3>;
10
return;}
Bằng Pascal:Procedure p;Begin
<phát biểu 1>;if not(<điều kiện 1>) then begin
<phát biểu 2>;if not(<điều kiện 2>) then begin
<phát biểu 3>; end;
end;End;
5.2. Tính dễ đọc (readability)Yêu cầu về tính dễ đọc của ngôn ngữ xuất phát từ yêu cầu về tính dễ đọc của
chương trình. Chương trình cần phải dễ đọc vì đọc chương trình là công việc thường xuyên trong khi viết, bảo trì và phát triển chương trình. Tính dễ đọc càng có ý nghĩa khi người đọc không phải là tác giả của chương trình. Nói một cách lý tưởng, chương trình được gọi là dễ đọc khi một người bình thường không biết gì về ngôn ngữ dùng để viết chương trình, đọc mà vẫn hiểu được chương trình làm gì.
Ngôn ngữ cần đảm bảo cho cấu trúc chương trình phản ánh được cấu trúc của vấn đề cần giải quyết. Chương trình cũng như các bộ phận của chương trình cần thể hiện được chúng làm những gì, trước khi người đọc cần biết những điều đó được thực hiện như thế nào.
Các cấu trúc điều khiển của ngôn ngữ chỉ nên có một ngõ vào và một ngõ ra để người đọc có thể theo dõi dễ dàng từng bộ phận của chương trình từ trên xuống dưới. Cũng do vây ngôn ngữ cần có các cấu trúc điều khiển để thay thế phát biểu goto. Phát biểu goto làm chương trình trở nên khó đọc, vì người đọc không thể đọc chương trình một mạch từ trên xuống, mà luôn phải dò theo các đích của goto.
Việc cho phép dấu gạch ngang dưới trong danh hiệu sẽ làm cho danh hiệu dễ đọc hơn.
Các từ khóa của ngôn ngữ cũng cần phải gợi nhớ.Ngoài ra, các chú thích trong chương trình là cách thức hữu hiệu để nâng cao
tính dễ đọc của chương trình.Với các ngôn ngữ lập trình hiện nay, tính dễ đọc của chương trình còn tùy thuộc
vào việc người đọc có quen thuộc với ngôn ngữ dùng để viét chương trình hay không, cũng như phong cách và phương pháp lập trình của người viết chương trình.5.3 Tính tin cậy (reliability)
Tính tin cậy của ngôn ngữ lập trình được đánh giá trên khả năng mà ngôn ngữ có thể bảo đảm được cho tính tin cậy của chương trình viết bằng ngôn ngữ đó. Không có một định nghĩa rõ ràng cho tính tin cậy của chương trình. Một cách không hình thức, chương trình được xem là tin cậy nếu xác xuất chạy đúng của nó cao trong quá trình sử dụng.
11

Nói chúng để chương trình có độ tin cậy cao, ngôn ngữ cần hạn chế sự xuất hiện của các lỗi không thể ngờ được. Lỗi đó có thể sinh ra do một cấu trúc ngữ pháp nhiều ngữ nghĩa. Ví dụ phát biểu sau đây trong Fortran:
Sum (i, j) = i + jCó hai nghĩa: (1) đó là định nghĩa hàm tổng của hai đối số nguyên, (2) hoặc đó
là phép gán một biểu thức vào dãy biến. Nếu người lập trình quên khai báo biến dãy Sum thì phát biểu trên sẽ được hiểu theo nghĩa thư nhất, chứ không phải là nghĩa thứ hai như mong muốn (việc quên khai báo biến trong Fortran là bình thường vì Fortran cho phép sử dụng biến mà không cần khai báo).
Hiệu ứng lề cũng là nguồn gây ra lỗi. Hiệu ứng lề, theo nghĩa rộng là hiệu ứng phụ xuất hiện thường ngoài ý muốn, khi sử dụng một cấu trúc ngôn ngữ nào đó của ngôn ngữ. Ví dụ, trong Pascal hiệu ứng lề nảy sinh do sự thay đổi trị của biến không cục bộ trong các chương trình con mà biến có ý nghĩa.
Ngôn ngữ cần kiểm tra chặt chẽ sự tương hợp kiểu của các biến trong biểu thức và phép gán, sự tương hợp của danh sách thông số của chương trình con ở nơi gọi và nơi định nghĩa. Lấy ví dụ đơn giản là phép gán một giá trị thực vào biến nguyên. Nếu không có sự kiểm tra kiểu và báo lỗi, mà tự động đổi kiểu thì kết quả sau đó sẽ bị sai lệch đi vì giá trị thực đã bị cắt hoặc làm tròn phần lẽ để thành giá trị nguyên.
Các bộ phận của chương trình cần có tính độc lập đối với nhau cao, cho phép kiểm tra riêng rẽ tính đúng đắn từng bộ phận của chương trình. Tính dễ sửa đổi cũng liên quan với tính tin cậy, vì trong quá trình sửa đổi tính tin cậy vần phải được duy trì. Sự độc lập của các bộ phận của chương trính sẽ làm cho việc sửa đổi dễ dàng hơn; việc sửa đổi ở một bộ phận sẽ không ảnh hưởng đến các bộ phận còn lại cảu chương trình.
Tính tin cậy đôi khi lại có thể bị ảnh hưởng bởi tính dễ viết của chương trình. Bởi vì ngôn ngữ quá linh hoạt dễ viết thì có thể khó làm chủ bởi người viết chương trình, có nghĩa là chương trình dễ xảy ra lỗi hơn.
Cuối cùng, tính tin cậy của ngôn ngữ còn phụ thuộc vào sự cài đặt ngôn ngữ ấy, tức là phụ thuộc vào chất lượng của chương trình dịch.
6. Các lĩnh vực ứng dụng của ngôn ngữ lập trình
Vào những năm 1950, khi máy tính điện tử mới ra đời, ngôn ngữ lập trình chỉ là ngôn ngữ máy hoặc cao hơn là hợp ngữ. Cho nên, việc xây dựng các ứng dụng tin học là rất phức tạp và khó khăn. Vì thế, vào giai đoạn này ứng dụng của ngôn ngữ lập trình là rất hạn chế.
Đi đôi với sự phát triển của phần cứng và sự ra đời của rất nhiều ngôn ngữ lập trình khác nhau, khả năng và lĩnh vực ứng dụng của ngôn ngữ lập trình trở nên rất phong phú.
Dưới đây là một số ngôn ngữ lập trình và lĩnh vực ứng dụng của chúng: Xây dựng các hệ thống thông tin quản lý trong các lĩnh vực sản xuất, xã
hội, kinh tế, ...: Delphi, Visual Basic, Access, SQL, ... Xây dựng các hệ thống phân tán: Java, Corba, C++, ... Xử lý ảnh và mô hình hóa hình học: C++, Matlab, ... Xây dựng các hệ chuyên gia: Prolog Giải quyết các bài toán trong lĩnh vực trí tuệ nhân tạo: Lisp, Scheme,
Prolog, ...
12

Xây dựng các hệ thống thời gian thực: C, Ada Xây dựng các hệ thống nhúng, điều khiển thiết bị: C, Assembly, ...
Hiện nay, số người quen với máy tính, với việc lập trình ngày một nhiều, PC đã trở nên phổ biến. Nhu cầu được giao tiếp với thế giới bên trong máy tính không chỉ là một sở thích, hay công việc riêng tư của những người làm tin học nữa. Chỉ với vốn tiếng Anh tương đối, một chút trợ giúp là bạn đã có thể trở thành một nhà lập trình rồi, thế nhưng đó chỉ là các điều kiện cần mà chưa đủ. Số lượng trình biên dịch, chủng loại, tính năng ngày một phong phú, để chọn cho mình một ngôn ngữ lập trình, một trình biên dịch phù hợp với công việc chuyên môn cũng như nhu cầu học tập, nghiên cứu, bạn không thể không khỏi có những đắn đo. Những gì sau đây có thể giúp ích cho bạn ?
Để có cho mình một công cụ lập trình phù hợp về cả trình độ lẫn nhu cầu, bạn cần xác định xem bạn sẽ dùng nó để làm gì; tìm hiểu thế giới bên trong máy tính, chỉ để học thêm một ngôn ngữ lập trình mới nhằm phục vụ cho quá trình học tập, hay đó là một lựa chọn cho một hướng phát triển phần mềm chuyên nghiệp ? Hơn thế nữa bạn còn cần phải định hướng rõ ràng; môi trường thực hiện sẽ là môi trường phân tán hay môi trường cục bộ ? Có thể là hơi rắc rối nhưng những suy tính ban đầu này sẽ có ảnh hưởng rất nhiều tới các bước đi sau này.
Những người có ham muốn tìm hiểu sâu thế giới bên trong máy tính thường lấy hợp ngữ (Assembly) làm công cụ, có thể nói đây là thứ ngôn ngữ đầu tiên tương đối độc lập đối với các quá trình thực xảy ra trong các bộ vi xử lý. Qua một tập hữu hạn các lệnh được nhận biết nhờ các từ gợi nhớ sơ đẳng, người lập trình có thể trực tiếp can thiệp vào quá trình di chuyển dữ liệu, sửa đổi dữ liệu, điều khiển thiết bị... Công việc còn lại của trình dịch Assembler rất ít, phần lớn nhiệm vụ của nó là ánh xạ các lệnh gợi nhớ trong chương trình nguồn tới một tập cố định các lệnh của bộ vi xử lý, một số thao tác xử lý macro.
Để có được một chương trình hoàn chỉnh, người lập trình sẽ phải tìm hiểu thấu đáo tập lệnh, vì số lệnh, các chi tiết kỹ thuật cho tập lệnh có thể rất khác nhau giữa các bộ vi xử lý; định hình rõ ràng trình tự các thao tác; khả năng mà trình dịch có thể làm được; và nhất là xác định mức độ cần thiết của các thủ thuật lập trình. Chẳng hạn, trong khi các bộ vi xử lý dòng Intel (x86 phổ dụng trong các máy PC) thường có khoảng 8 thanh ghi đa năng, 6 thanh ghi đoạn, một thanh ghi con trỏ lệnh, cờ... thì các bộ vi xử lý dòng Motorola (MC680x0 phổ dụng trong các máy MacIntosh, các máy trạm của Sun, trong các hệ thống máy tính nhiều bộ vi xử lý, và trong rất nhiều máy PC) thì lại có tới khoảng 8 thanh ghi dữ liệu 80 bit, khoảng ngần ấy số thanh ghi địa chỉ cùng hàng tá thanh ghi với rất nhiều công dụng khác nhau, chế độ làm việc khác nhau.
Chính vì tính chỉ định phần cứng cao như vậy mà hiệu quả làm việc của một người thông qua hợp ngữ phụ thuộc rất nhiều vào kinh nghiệm làm việc, theo đó các chương trình này rất khó bảo trì, khó kiểm soát khi số thao tác của chương trình tăng, và đôi khi còn khó hiểu đối với chính người viết ra nó nếu không có các văn bản bảo trì được ghi chép cẩn thận. Nhưng bù lại, các chương trình thực hiện bằng hợp ngữ nói chung thường có kích thước rất khiêm tốn, chạy nhanh nhất tính trên cùng một trình tự thao tác cụ thể so với các ngôn ngữ khác.
13

Basic vốn là một ngôn ngữ phi cấu trúc, nó được phát triển để giúp người lập trình đỡ phần vất vả khi làm việc trên các bộ vi xử lý khác nhau. Với nó, người lập trình không phải lo lắng nhiều về sự khác nhau trong chi tiết kỹ thuật của từng bộ vi xử lý cụ thể, họ chỉ cần bận tâm tới việc cấu trúc sao cho chương trình của họ được tối ưu. Để có được tính khả chuyển trên nhiều loại vi xử lý, các chương trình Basic cần có một chương trình thông dịch để kích hoạt, trình thông dịch này có nhiệm vụ ánh xạ mã đầu ra của trình dịch Basic vào tập lệnh cụ thể của bộ vi xử lý khi chạy chương trình. Người ta đã từng đưa trình thông dịch này vào trong phần cứng, lưu trữ lâu dài trong các bộ nhớ chỉ đọc (ROM), và cung cấp các khả năng tương tác tương đối thuận tiện, giúp người lập trình thiết kế và gỡ rối nhanh chóng các chương trình Basic.
Ngày nay, Basic đã được cải tiến nhiều, về cả trình dịch lẫn bản thân ngôn ngữ, các ứng dụng của Microsoft thường dùng Basic như một công cụ để người sử dụng tuỳ biến chúng theo nhu cầu. Vì chạy thông dịch cho nên các ứng dụng viết bằng Basic chạy không nhanh, nhưng vì tính phổ cập, rất nhiều nhà phát triển công cụ vẫn hỗ trợ nó. Sản phẩm hỗ trợ Basic ở mức cao được nói đến ở đây là Visual Basic của Microsoft. Đây là một công cụ phát triển được Công ty này rất ưu ái, hiện nó đang được ưu chuộng trong lĩnh vực phát triển ứng dụng trên Windows. Visual Basic được hỗ trợ rất nhiều khả năng về cơ sở dữ liệu, các kỹ thuật phát triển phần mềm mới như OLE, COM, DCOM...
Nếu như bạn chưa có ý định trở thành nhà phát triển phần mềm ứng dụng thì cũng nên biết tới Basic, bởi vì hầu hết các ứng dụng lớn ngày này như Notes, bao gồm cả các phần mềm xử lý bảng tính, văn bản của Mirosoft đều có sử dụng macro lệnh được thiết kế dựa trên Basic, cho phép người sử dụng sửa đổi, bổ sung các tính năng mới theo nhu cầu.
Ngoài ra còn phải nói tới Pascal, có thể nói đây là thứ ngôn ngữ vỡ lòng cho hầu hết những người bắt đầu tiếp xúc với máy tính. Nó được biết tới không chỉ vì là một trong số các ngôn ngữ cấu trúc ra đời đầu tiên trên thế giới, mà còn là vì tính dễ đọc, dễ tiếp cận của nó. Nếu bạn biết tiếng Anh, không nhất thiết phải biết về tin học, khi đọc một chương trình viết trong ngôn ngữ này bạn sẽ thấy ngay về cơ bản nó đang nói về một quá trình làm việc nào đó.
Với thứ ngôn ngữ này, người lập trình khỏi phải đau đầu vì phải tổ chức lấy chương trình, thay vào đó họ sẽ dùng các câu lệnh tiếng Anh rất dễ nhớ, dễ sử dụng. Việc xây dựng một chương trình rất giống với việc mô phỏng một quá trình hoạt động, có đầu ra đầu vào, mã nguồn của một chương trình như thế rất dễ đọc, dễ sửa đổi. Tất nhiên, trình dịch sẽ phải làm việc vất vả hơn bởi nó phải phân giải cả một dãy lệnh vốn chỉ dễ hiểu đối với con người nhưng lại... không thể hiểu nổi đối với các bộ vi xử lý. Hầu hết các ngôn ngữ lập trình cấu trúc (tất nhiên trong đó có Pascal) đều lấy việc dịch sang hợp ngữ làm một bước trung gian, theo đó các cấu trúc lệnh if...then, case...of, v.v. được chuyển thành các khối mã nguồn Assembly. Tóm lại, việc cấu trúc chi tiết cho một chương trình cụ thể được thực hiện tự động bởi trình dịch, lúc này các thủ thuật lập trình Assembly của người lập trình không còn có thể áp dụng vào đây, đôi khi nó còn máy móc làm phình to mã cho dù đã sử dụng tới cả chục thuật toán tối ưu.
14

Hầu hết các công cụ phát triển có hỗ trợ Pascal ngày nay đều đưa ra các khả năng kết nối mới cho nó, mã trình có thể được viết riêng rẽ trên nhiều tệp rồi kết nối, hoặc được nạp từ thư viện động... nhưng nói chung, đây là ngôn ngữ chỉ phù hợp với các ứng dụng nhỏ và trung bình, phổ dụng trong lĩnh vực đào tạo. Nếu bạn là người mới tiếp xúc với máy tính, muốn tìm hiểu cách hoạt động của một chương trình thì bạn hãy chọn ngôn ngữ này.
Delphi của Borland chỉ là một công cụ phát triển ứng dụng, nó được xây dựng bằng lõi Pascal. Với công cụ này, sau một vài tiếng đồng hồ đọc help, nhất là có ai đó hướng dẫn đôi chút, bạn hoàn toàn có thể tự viết cho mình các ứng dụng đơn giản như trình xem tệp .AVI, nghe nhạc, các thao tác tính toán, lưu trữ đơn giản... Nó tỏ ra rất thích hợp với những bạn thích khám phá nhưng không muốn tốn quá nhiều thời gian nghiền ngẫm.
Ngôn ngữ C là ngôn ngữ lập trình cấu trúc như Pascal và là thứ công cụ mạnh đã từng được sử dụng để thiết kế hầu hết các hệ điều hành trên thế giới. Các hệ điều hành như UNIX, AMOEBA... đều thực thi bằng C, và nói chung đây là thứ ngôn ngữ có tính khả chuyển tương đối cao cho nên các hệ điều hành này có thể chạy trên rất nhiều phần cứng khác nhau, ngay cả với WINDOWS cũng vậy, rất nhiều module của nó cũng được xây dựng bằng C.
C++ là một bước phát triển tiếp theo của C trong xu thế 'đối tượng hoá' ngôn ngữ, nói như vậy là bởi hầu hết các trình dịch C++ đều lấy C làm nền cho tất cả các định hướng nhằm tận dụng các ưu thế mà mô hình thiết kế hướng đối tượng mang lại. Vốn dĩ C vẫn chưa được chuẩn hoá mặc cho rất nhiều cố gắng đã được đưa ra, các trình dịch C++ lại càng khó tìm được tiếng nói chung. Các nhà cung cấp trình dịch C đều muốn rằng sản phẩm của họ được các nhà phát triển công cụ ưa dùng, thế nhưng các nhà cung cấp công cụ phát triển lại muốn các trình dịch hướng theo mô hình thiết kế vốn muôn hình muôn vẻ mà họ đưa ra. Cứ như thế, C++ phát triển trong sự thiếu nhất quán, hệ thống từ khoá không được hỗ trợ đầy đủ, đôi khi không thống nhất, cách cấu trúc chương trình cũng không giống nhau mặc dù chúng giống nhau về mô hình.
Ngày nay, hầu hết các công cụ phát triển hệ thống mạnh như Visual C++, C++Builder, Visual Age... đều hỗ trợ song song cả C lẫn C++. Nói chung đây là các công cụ mạnh, thể hiện được ưu thế của chúng trong từng môi trường phát triển cụ thể; ví dụ Visual C++ thích hợp với những người muốn phát triển các ứng dụng nhất là các ứng dụng gắn với Windows, C++Builder thân thiện ngay cả với những người không nhiều kinh nghiệm trong lĩnh vực lập trình, ... Để tìm cho mình một trình dịch C++ phù hợp hãy lựa chọn; chẳng hạn, nếu bạn cần hướng theo việc xây dựng các ứng dụng phục vụ, có liên quan tới các dịch vụ chuẩn của Windows, không nhất thiết phải có màn hình giao tiếp phức tạp, hoặc cần có các ứng dụng can thiệp sâu vào hệ thống... bạn hãy lựa chọn Visual C++. Công cụ này đưa ra khá nhiều mẫu (wizard), theo khung định sẵn đó bạn chỉ cần thực thi các chi tiết là đã có một ứng dụng hoàn chỉnh rồi. Còn nếu bạn không đủ thời gian cần thiết để nghiền ngẫm cả đống các văn bản công bố từ Microsoft, mà lại muốn có các ứng dụng mang tính bề mặt, nhanh, đầy tính tương tác, bạn hãy sử dụng C++Builder hay một số sản phẩm tương tự từ IBM, Symantec...
15

Java là ngôn ngữ thế hệ mới, thế hệ năm, nó kế thừa hầu hết những 'tư chất' tốt đẹp của các bậc tiền bối, hướng đối tượng từ mô hình thiết kế tới mô hình thực thi, hỗ trợ đa luồng một cách rất tinh tế, độ tin cậy cao, tính khả chuyển tuyệt vời... Java nay không còn là một cơn sốt bình thường, nó là một xu thế song song tồn tại với các mô hình lập trình hiện có, ngày càng nhiều lĩnh vực mà nó có mặt. Ban đầu, mục tiêu của các nhà thiết kế của ngôn ngữ này là "Web đi tới đâu, Java đi tới đó", nay thì sao, nó đang len lỏi vào cả các hệ thống đầy tính thương mại như các hệ quản trị dữ liệu của ORACLE, rồi cả các hệ thống phục vụ cực lớn... Với phiên bản 2, từ tên ấn bản JDK được đổi thành SDK, Sun dần lộ rõ những ham muốn rất lớn lao trong việc đưa Java vào đời sống tin học của mọi người trên thế giới.
Java là ngôn ngữ mạnh, về cả mô hình thiết kế lẫn tính năng. Nếu bạn muốn thiết kế các trang Web sống động, bạn hãy chọn nó, một khối mã .CLASS vài KB có thể làm được nhiều điều hơn cả 100KB ảnh, nó là giải pháp cho một đường truyền tốc độ thấp. Nếu bạn muốn thiết kế các chương trình phân tán, Java là một lựa chọn tốt, nó có một lượng thư viện mạng được tổ chức hợp lý, thân thiện với người lập trình. Với nó bạn có thể tự thiết kế lấy các giao thức (ngay cả các giao thức lạ lẫm chưa từng được nhắc tới trong RFC), các ứng dụng phục vụ, và các ứng dụng sử dụng dịch vụ... mà không đòi hỏi mất quá nhiều thời gian tìm hiểu hệ thống, tìm kiếm các công bố kỹ thuật. Nếu bạn cần viết các ứng dụng mà mã của chúng có thể được sử dụng lại một cách linh hoạt, trên nhiều loại phần cứng, tốn ít thời gian bảo trì...và hợp 'thời' nhất, bạn cũng nên chọn Java. Với các ngôn ngữ khác, việc sử dụng lại mã rất khó, ví dụ bạn đã có một tệp .dll, cùng với hàng tá chi tiết kỹ thuật kèm theo bạn cũng rất khó sử dụng lượng thư viện có trong đó, đấy là chưa tính tới việc mã thư viện động này chỉ có thể sử dụng được trên các hệ thống Windows. Với Java thì lại khác, mô hình thiết kế của nó cho phép mã của mỗi lớp được gói trong một tệp .CLASS riêng, được kiểm soát trong không gian tên bởi hệ thống chạy Java, và được nạp một cách tường minh mỗi khi chương trình cần tới các hành vi của chúng. Có thể xem môi trường chạy Java lúc này là một cái giỏ táo, mỗi quả táo là một đối tượng, vết kích hoạt của một chương trình Java rất giống như lối của các con sâu, đục xuyên từ quả này sang quả khác... ứng với một con sâu, chương trình có một luồng kích hoạt, nhiều con sâu ứng với một chương trình Java đa luồng (multithread).
Môi trường kích hoạt Java có xu hướng phân tán, các đối tượng kích hoạt có thể không cùng nằm trên một máy duy nhất, theo đó nó có thể nằm rảI rác đâu đó trên mạng, chúng 'liên kết' với nhau để hình thành một chương trình thông qua mạng... Thế nhưng, khi các ưu thế trên không có trong định hướng của bạn về một công cụ lập trình, bạn đừng nên sử dụng nó. Thứ nhất, Java chạy thông dịch, tốc độ chậm dù đã được cải thiện nhờ cơ chế dịch JIT (một cơ chế nhận biết để ánh xạ một cách thông minh khối mã đầu vào cần thông dịch và khối mã đầu ra cần kích hoạt nhằm tiết kiệm thời gian dịch), và dù có mong đợi thế nào thì Java vẫn sẽ chạy thông dịch. Thứ hai, bản thân ngôn ngữ này đang trong thời gian hoàn thiện; hoàn thiện về hệ thống từ khoá, hoàn thiện về cách tổ chức máy ảo, hoàn thiện về thư viện... Có rất nhiều loại ngôn ngữ lập trình :Java,C#,VB.Net,PHP,ASP....Java thì lập trình cho các thiết bị di động nhiều hơn.
16

Lập trình web thì có thể dùng Java hoặc PHPBạn có thể thiết kế web bằng ASP.NET, viết bằng ngôn ngữ C#, hoặc VB.NETNgoài ra còn có công nghệ .NET của Microsoft, hỗ trợ rất nhiều ngôn ngữVề lập trình phần mềm thì có rất nhiều ngôn ngữ thông dụng tùy theo loại phần mềm nào :
- Phần mềm quản lý chạy trên windows : Visual Basic 6.0, Visual Basic.NET , Visual C#...- Web : ASP, ASP.NET, PHP, JSP, CGI, Perl...- Phần mềm mạng : Java, Visual C++- Lập trình hệ thống : C/C++- Trí tuệ nhân tạo : PrologNgoài ra còn nhiều ngôn ngữ khác nữa phục vụ cho nhiều mục đích khác nhau...
7. Chuẩn hoá ngôn ngữ lập trình
Là việc chọn lọc một ngôn ngữ theo một chuẩn ngôn ngữ nhất định nào đó phù hợp để có thể phát triển và ứng dụng rộng rãi trong các công việc
Khi việc chuẩn hoá ngôn ngữ hoàn thành thì nó sẽ trở thành một ngôn ngữ tiêu chuẩn trên toàn thế giới với các mức khác nhau của tiêu chuẩn
8. Các vấn đề nảy sinh từ sử dụng ngôn ngữ lập trình
Mỗi ngôn ngữ, do hạn chế của môi trường và bản thân ngôn ngữ cũng như do mục tiêu sử dụng, có thể có một số luật cấm mà người lập trình không thể vi phạm. Những luật cấm này có thể có những cách xử lý khác nhau như là:
Nhiều ngôn ngữ cho phép dùng các câu lệnh đặc biệt để lập trình viên có toàn quyền xử lý lỗi và thường được gọi là ngoại lệ (hay exception). Những ngoại lệ này nếu không xử lý đúng mức sẽ có thể gây ra những sai sót trong thời gian thi hành hay ngay cả trong thời gian dịch. Dĩ nhiên, người viết mã có thể tùy theo tình huống mà viết các câu lệnh rẽ nhánh tránh không để cho mã vi phạm các lỗi. Hay là dùng các câu lệnh xử lý các ngoại lệ này.
Một số ngôn ngữ không cung cấp khả năng xử lý ngoại lệ thì người viết mã buộc phải tự mình phán đoán hết các tình huống có thể vi phạm lỗi và dùng câu lệnh điều kiện để loại trừ.
Các loại lỗi về ngôn ngữ khi lập trình thường xảy ra là :Lỗi cú phápVi phạm khi đặt hay gọi tên biến và hàm: Lỗi loại này thường rất dễ tìm ra
trong lúc phát triển mã. Thường người ta có thể đọc lại các bảng tham chiếu về ngôn ngữ để tránh sai cú pháp mẫu (prototype) của hàm hay tránh dùng các ký tự đặc biệt bị cấm không cho dùng trong khi đặt tên. Trong không ít trường hợp người lập trình có thể đã định nghĩa cùng một tên cho nhiều hơn một đối tượng khác nhau và lại có giá trị toàn cục. Trong nhiều trường hợp chúng tạo thành lỗi ý nghĩa.
17

Lỗi chính tả: người viết mã có thể viết hay gọi sai tên hàm, tên biến. Trong nhiều ngôn ngữ có kiểu tĩnh thì các lỗi này sẽ rất dễ bị phát hiện. Còn đối với ngôn ngữ có kiểu động hay có kiểu yếu thì nó có thể dẫn đến sai sót nghiêm trọng vì bản thân phần mềm dịch không hề phát hiện ra.
Vượt quá khả năng tính toán: Bản thân máy tính và hệ điều hành cũng có rất nhiều giới hạn về phần cứng, phần mềm và các đặc diểm chuyên biệt. Khi người lập trình yêu cầu máy làm quá khả năng sẽ gây ra các lỗi mà đôi khi không xác định được như :
Lỗi thời gian (timing error) thường thấy trong các hệ thống đa luồng hay đa nhiệm.
Lỗi chia cho 0: Bản thân phần cứng máy tính sẽ ở trạng thái bất định khi thực hiện phép chia cho 0; trong nhiều trường hợp, mã sau khi dịch mới phát hiện ra trong lúc thi hành và được đặt tên là lỗi division by 0.
Dùng hay gọi tới các địa chỉ hay các thiết bị mà bản thân máy hay hệ điều hành đang thực thi lại không có hay không thể đạt tới. Đây là trường hợp rất khó lường. Bởi vì thường ngưòi lập trình có thể viết mã trên một máy nhưng lại cho thi hành trong các máy khác và các máy này lại không thỏa mãn các yêu cầu. Để giảm trừ các lỗi loại này thường người lập trình nên xác định trước các điều kiện mà phần mềm làm ra sẽ hỗ trợ.
Thí dụ: trong nhiều phần mềm ngày nay ở trong vỏ hộp đều được ghi rõ các yêu cầu về vận tốc, bộ nhớ tối thiểu, và quan trọng là hệ điều hành nào mà phần mềm đó hỗ trợ.
Gán sai dữ liệu: Tức là dùng một dữ liệu có kiểu khác với kiểu của biến để gán cho biến đó một cách không chủ ý. Đối với các ngôn ngữ tĩnh hay có kiểu mạnh thì lỗi này dể tìm thấy hơn. Còn những ngôn ngữ động hay ngôn ngữ có kiểu yếu thì lỗi tạo ra sẽ có thể khó phát hiện và thường xảy ra lúc thi hành.
Các lỗi biên: Lỗi biên thường xảy ra khi người viết mã không chú ý đến các giá trị ở biên của các biến, các hàm. Những lỗi để thấy có thể là:
Gán giá trị của một số (hay một chuỗi) lên một biến mà nó vượt ngoài sự cho phép của định nghĩa.
Thí dụ: Gán một giá trị lớn hơn 255 cho một biến có kiểu là short trong ngôn ngữ C
Tạo nên các lỗi khi biến chạy trong vòng lặp đạt giá trị ở biên.Thí dụ: đoạn mã C/C++ sau đây sẽ gây ra lỗi biên -- Chia cho 0
for (m=10; m >= 0, m--) { x= 8+ 2/m; }
Lỗi ý nghĩaLỗi về quản lý bộ nhớ. Trong nhiều loại ngôn ngữ người lập trình có thể xin đăng ký một lượng nào đó của bộ nhớ để dùng làm chỗ chứa giá trị cho một biến (một hàm hay một đối tượng). Thường thì sau khi dùng xong người viết mã phải có phần lệnh trả về các phần bộ nhớ mà nó đã đăng ký dùng. Nếu không, sự trả về này chỉ xảy ra ở giai đoạn kết thúc việc thi hành. Trong nhiều trường hợp, số lượng bộ nhớ xin đăng ký quá
18

nhiều và không được dùng đúng chỗ có thể làm cho máy kiệt quệ về mặt tài nguyên bộ nhớ và gây ra treo máy. Điển hình nhất là việc xin đăng ký các phần của bộ nhớ trong các vòng lặp lớn để gán cho các đối tượng bên trong vòng lặp nhưng không trả về sau khi xử dụng. Người ta thường gọi lỗi kiểu này là lỗi rò rỉ bộ nhớ (memory leaking).
Sai sót trong thuật toán: Trước khi viết một chương trình, để giảm thiểu sai sót về mặt lập luận thì người ta có nhiều biện pháp để làm giảm lỗi trong đó có các phương pháp vẽ lưu đồ, vẽ sơ đồ khối, hay viết mã giả. Những biện pháp này nhằm tạo nên các thuật toán để giải quyết vấn đề. Tuy nhiên, một thuật toán không chặt chẽ, xử lý không rốt ráo mọi trường hợp có thể xảy ra, không dự đoán được sự thay đổi trong lúc thi hành thì có thể tạo nên các lỗi và các lỗi này thường khó thấy bởi vì nó chỉ xảy ra ở những chỗ, những thời điểm mà người lập trình không ngờ trước. Một trong những phương pháp đơn giản làm giảm thiểu lỗi thuật toán là phải chú ý xử lý mọi tình huống khi dùng câu lệnh điều kiện (hay chẻ nhánh) mặc dù có thể có các trường hợp tưởng như hiển nhiên.
Lỗi về lập luận: Đây có thể xem là trường hợp đặc biệt của sai sót trong thuật toán. Trong các biểu thức tính giá trị, đôi khi không quen dùng đại số Bool (nhất là khi dùng luật De Morgan để phủ định một biểu thức phức tạp) nên người lập trình có thể tính toán sai, hay định nghĩa sai các phép toán. Do đó, giá trị trả về của các biểu thức logic hay biểu thức nhị phân sẽ bị sai trong một vài trường hợp hay toàn bộ biểu thức. Trong những tình huống như vậy phần mềm dịch sẽ không thể nào phát hiện ra cho đến khi chương trình được thi hành và lọt vào tình huống tính sai của người lập trình.
19

BÀI 2:CÁC LOẠI DỮ LIỆU CẤU TRÚCMã bài: MĐ39-02
Giới thiệu :Trong khi lập trình tạo ra sản phẩm, người lập trình cần phải hiểu được các kiến
thức liên quan đến các kiểu dữ liệu có cấu trúc đơn giản của công cụ (ngôn ngữ lập trình) đang sử dụng để phát triển chương trình. Mặt khác, tất cả các kiễu dữ liệu có cấu trúc phức tạp đều được hình thành bởi các thành phần chứa các cấu trúc cơ bản. Để đi sâu hơn về các vấn đề được đề cập đến trong bài học này cũng nhưng trong những bài học tiếp theo, chúng ta cần phải hiểu ngôn ngữ lập trình C/C++ đồng thời cần phải nghiên cứu lại các bài học đã học trong chương trình Lập trình căn bản.Mục tiêu thực hiện:
- Hiểu và nắm được các kiểu dữ liệu cơ bản: kiểu số nguyên, số thực, ký tự, chuỗi, mảng.
- Nắm được cách thức tổ chức bộ nhớ để lưu trữ các kiểu dữ liệu cơ bản- Áp dụng giải một số bài toán.
Nội dung chính:
1. Các kiểu dữ liệu cơ sở
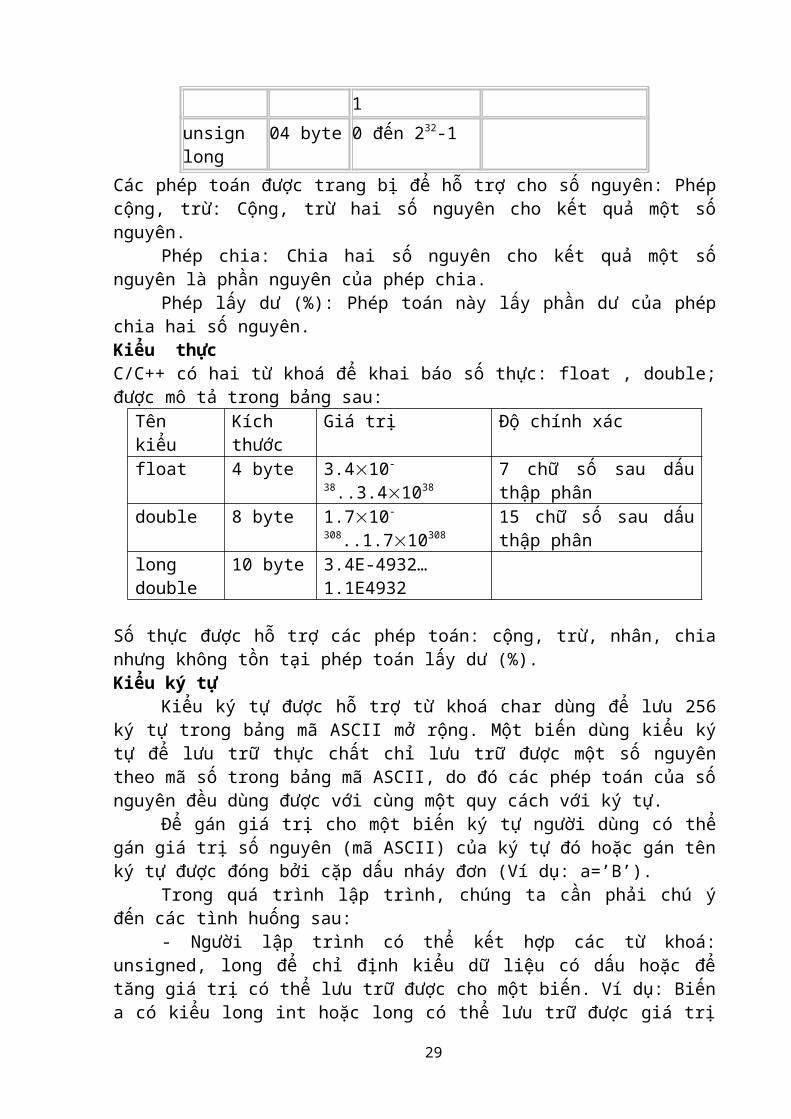
Các kiểu dữ liệu cơ sở là các kiểu dữ liệu do ngôn ngữ lập trình dựng sẵn, ở đây chúng ta xét ngôn ngữ lập trình C++ với công cụ lập trình Borland C++ 3.0.Kiểu nguyênKiểu số nguyên được khai báo với từ khoá int (short) có kích thước 2 byte, với miền giá trị -32768..32767.
Tên kiểu Kích thước Miền giá trị Chú thíchint 02 byte -32738 đến 32767 unsign int 02 byte 0 đến 65335 Có thể gọi tắt là unsignlong 04 byte -232 đến 231 -1 unsign long 04 byte 0 đến 232-1
Các phép toán được trang bị để hỗ trợ cho số nguyên: Phép cộng, trừ: Cộng, trừ hai số nguyên cho kết quả một số nguyên.
Phép chia: Chia hai số nguyên cho kết quả một số nguyên là phần nguyên của phép chia.
Phép lấy dư (%): Phép toán này lấy phần dư của phép chia hai số nguyên.Kiểu thựcC/C++ có hai từ khoá để khai báo số thực: float , double; được mô tả trong bảng sau:
Tên kiểu Kích thước Giá trị Độ chính xácfloat 4 byte 3.410-38..3.41038 7 chữ số sau dấu thập phândouble 8 byte 1.710-308..1.710308 15 chữ số sau dấu thập phânlong double 10 byte 3.4E-4932… 1.1E4932
20

Số thực được hỗ trợ các phép toán: cộng, trừ, nhân, chia nhưng không tồn tại phép toán lấy dư (%).Kiểu ký tự
Kiểu ký tự được hỗ trợ từ khoá char dùng để lưu 256 ký tự trong bảng mã ASCII mở rộng. Một biến dùng kiểu ký tự để lưu trữ thực chất chỉ lưu trữ được một số nguyên theo mã số trong bảng mã ASCII, do đó các phép toán của số nguyên đều dùng được với cùng một quy cách với ký tự.
Để gán giá trị cho một biến ký tự người dùng có thể gán giá trị số nguyên (mã ASCII) của ký tự đó hoặc gán tên ký tự được đóng bởi cặp dấu nháy đơn (Ví dụ: a=’B’).
Trong quá trình lập trình, chúng ta cần phải chú ý đến các tình huống sau:- Người lập trình có thể kết hợp các từ khoá: unsigned, long để chỉ định kiểu dữ
liệu có dấu hoặc để tăng giá trị có thể lưu trữ được cho một biến. Ví dụ: Biến a có kiểu long int hoặc long có thể lưu trữ được giá trị số nguyên có dấu giá trị khoảng 2 tỷ; biến b có kiểu unsigned int có thể lưu trữ được giá trị số nguyên có độ lớn từ 0..65535; biến c có kiểu unsigned long int có thể lưu trữ được số nguyên không dấu giá trị khoảng 4,2 tỷ.
Kiểu logicBorland C++ 3.0 trở lên có cung cấp một kiểu dữ liệu logic mang tên kiểu bool.
Kiểu dữ liệu này chứa một trong hai giá trị TRUE (đúng), FALSE (sai). Tuy nhiên, trong C/C++, khi sử dụng giá trị bằng 0 được hiểu là FALSE, sử dụng giá trị khác 0 được hiểu là FALSE.
- Từ khoá long không dùng được với kiểu char.- Ngoài các các phép toán chuẩn, người sử dụng phải còn có thể sử dụng các
hàm dựng sẵn được cung cấp bởi các thư viện trong C/C++ để xử lý đối với từng kiểu dữ liệu được yêu cầu của từng hàm.
- Kiểu trả về của một biểu thức số có kiểu dữ liệu là kiểu dữ liệu cao nhất trong các phần tử trong biểu thức.
Ví dụ: Biểu thức 1/n với n là số nguyên sẽ trả về một giá trị nguyên. Chẳng hạn, 1/5 sẽ trả về giá trị 0.
- Trong trường hợp muốn biểu thức cho ra một kết quả theo kiểu dữ liệu nào đó, chúng ta phải thực hiện phép toán ép kiểu.Ví dụ 1: Viết chương trình thực hiện nhập vào một số nguyên dương n, sau đó in kết
quả của biểu thức 1 1 11 ...2 3Sn
#include <conio.h>#include <iostream.h>void main(){ float s; int n; int i; clrscr(); cout<<"Nhap n nguyen duong:";cin>>n; s=0; for (i=1;i<=n;i++)
21

s+=float(1)/float(i); cout<<"Tong s="<<s; getch();}Trong quá trình lập trình, việc sử dụng dữ liệu và cấu trúc dữ liệu phù hợp đóng vai trò cực kỳ quan trọng. Xét ví dụ, tính n! sau:Ví dụ 2: Tính n! sử dụng biến lưu trữ là số nguyên long.#include <stdio.h>#include <conio.h>#include <iostream.h>long giaithua(long n){ if (n == 0) return(1); else return(n * giaithua(n-1));}void main(){ int n; char c; clrscr(); printf("Chuong trinh tinh giai thua.\n"); do { printf("\nNhap n: "); scanf("%d", &n); printf("Giai thua cua %d la %ld\n", n, giaithua(n)); printf("\nTiep tuc khong? (c/k): "); c = getche(); } while(c == 'c' || c == 'C');}Chương trình trên chỉ tính chính xác 12!, 13! trở lên chương trình trên tính không chính xác nữa. Vì lý do, số nguyên long chỉ chứa được giá trị của 12! mà không chứa được giá trị của 13! hay lớn hơn. Để khắc phục hiện tượng này, chúng ta sử dụng giá trị long double thay cho long. Chương trình được viết lại như sau:Ví dụ 3: Tính n! sử dụng biến lưu trữ là số thực long double.#include <stdio.h>#include <conio.h>#include <iostream.h>long double giaithua(long double n){ return(n == 0.0 ? 1.0 : n * giaithua(n-1));}
void main(){
22

long double n; char c; clrscr(); printf("Chuong trinh tinh giai thua.\n"); do { cout<<"Nhap n: "; cin>>n; cout<<"Giai thua cua "<<n<<" la " << giaithua(n); printf("\nTiep tuc khong? (c/k): "); c = getche(); } while(c == 'c' || c == 'C');}
Phiên bản này xử lý số liệu lớn hơn và đã tính được giá trị lớn hơn hơn 13!.
2. Kiểu mảng
Kiểu dữ liệu mảng là một tập hợp có thứ tự chứa các phần tử có cùng kiểu dữ liệu được lưu trữ liên tiếp nhau trong bộ nhớ. Mảng có thể một chiều hay nhiều chiều.
Mảng một chiều được khai báo như sau: <tên kiểu dữ liệu> tênbiến[<kích thước>]Ví dụ 4: Để khai báo một biến a là một mảng nguyên một chiều có 100 phần tử, chúng ta phải khai báo như sau: int a[100]; Để truy xuất đến các phần tử,chúng ta phải chỉ định tên và chỉ số phần tử cần truy xuất. Chẳng hạn: a[0] - Truy xuất đến phần tử đầu tiên. a[11] – Truy xuất đến phần tử thứ 12 (có chỉ số 11) a[99] – Truy xuất đến phần tử thứ 100 (có chỉ số 99), là phần tử cuối cùng ở mảng trên.Chúng ta cũng có thể vừa khai báo vừa gán giá trị cho một mảng như sau: int a [5] = { 16, 2, 77, 40, 12071 };Tương tự, chúng ta có thể khai báo một mảng 2 hay nhiều chiều theo cú pháp sau: <tên kiểu dữ liệu> tênbiến[<kích thước1>][<kích thước 2>][…];Chẳng hạn, chúng ta khai báo khai báo mảng nguyên 2 chiều như sau: int a[100][20];Ví dụ 1: Nhập một mảng 1 chiều có tối đa 100 phần tử, số phần tử được nhập từ bàn phím. Hãy in tổng các phần tử không chia hết cho 2 và các phần tử chia hết cho 2.#include <conio.h>#include <iostream.h>void main(){ int a[100]; //toi da 100 phan tu int n,i; long tongle,tongchan; clrscr(); cout<<"Nhap vao so phan tu:";cin>>n;
23

for (i=0;i<=n-1;i++) { cout<<"Nhap gia tri phan tu thu "<<i<<": "; cin>>a[i]; } tongle=0;tongchan=0; for (i=0;i<=n-1;i++) if (a[i]%2==0) tongchan+=a[i]; else tongle+=a[i]; cout<<"Tong cac phan tu khong chia het cho 2:"<<tongle<<endl; cout<<"Tong cac phan tu chia chet cho 2:"<<tongchan; getch();}Ví dụ 5: Nhập vào hai ma trận ,m n m nA B với m,n được nhập từ bàn phím. Sau đó in ra ma trận C là ma trận có được khi cộng ma trận A cho B.#include <conio.h>#include <iostream.h>void main(){ int a[100][100],b[100][100]; int c[100][100]; int n,m,i,j; clrscr(); cout<<"Nhap m=";cin>>m; cout<<"Nhap n=";cin>>n; cout<<"Nhap cac phan tu cho ma tran A"<<endl; for (i=0;i<m;i++) for (j=0;j<n;j++) { cout<<"a["<<i<<"]["<<j<<"]="; cin>>a[i][j]; } cout<<"Nhap cac phan tu cho ma tran B"<<endl; for (i=0;i<m;i++) for (j=0;j<n;j++) { cout<<"b["<<i<<"]["<<j<<"]="; cin>>b[i][j]; } //tinh ma tran C for (i=0;i<m;i++) for (j=0;j<n;j++) c[i][j]=a[i][j]+b[i][j]; cout<<"cac phan tu trong ma tran C:"<<endl; for (i=0;i<m;i++)
24

for(j=0;j<n;j++) cout<<"c["<<i<<"]["<<j<<"]="<<c[i][j]<<endl; getch();}
Mảng được xử lý rất uyển chuyển nhờ phép toán truy cập trực tiếp dữ liệu thông qua chỉ số phần tử, do đó, mảng thường được dùng để lưu trữ các dữ liệu trong những chương trình mà khả năng lưu trữ dữ liệu không lớn. Đồng thời, mảng vẫn là cấu trúc dữ liệu hay được dùng trong các giải pháp xử lý đệ quy-quay lui, hay xử lý tham lam, ... Chúng ta tiến hành nghiên cứu việc ứng dụng mảng trong một số phương pháp.Ví dụ 6: Bài toán tám quân hậu: Tìm cách đặt các quân hậu lên bàn cờ vua sao cho không quân nào có thể ăn được quân nào. Quy luật khống chế ô cờ của quân hậu được thể hiện theo hướng mũi tên sau:
Hình 2.1 Quy luật khống chế ô cờ của quân HậuThuật toán xây dựng dựa trên việc đặt quân hậu lần lượt trên từng dòng. Chúng
ta phải tìm cột thích hợp để đặt quân hậu lên dòng thứ i, tại cột j nào? - Giá trị cột đã bị quân hậu khống chế rất dễ dàng xác định bằng cách xem có
quân hậu nào nằm trên cột đó hay không? - Các đường chéo xuôi được xác định dễ dàng vì lấy chỉ số cột trừ chỉ số dòng
trên một đường chéo luôn luôn là một hằng số.- Cac đường chéo ngược được xác định dễ dàng vì lấy chỉ số dòng cộng chỉ số
cột trên một đường chéo luôn luôn là một hằng số.Bảng chỉ số i+j của đường chéo xuôi.
Hậu
25

Hinh 2.2 Bảng chỉ số i+j của đường chéo xuôi.
Bài toán này chúng ta xử lý bằng cách dùng một mảng để lưu lời giải (mảng loigiai). Hai mảng dùng để lưu đường chéo của bàn cờ (cheoxuoitrong, cheonguoctrong), một mảng lưu trữ các cột trống#include <stdio.h>#include <stdlib.h>#include <conio.h>#include <iostream.h>
#define KICHTHUOC 8 // Kich thuoc cua ban co#define SODUONGCHEO (2*KICHTHUOC-1) // So duong cheo cua ban co#define SOGIA (KICHTHUOC-1) // so gia#define TRUE 1#define FALSE 0// prototypesvoid hoanghau(int);void inloigiai(int loigiai[]);
I+j01234567891011121314
26

int cottrong[KICHTHUOC]; // mang cac cot co the dat hoang hauint cheoxuoitrong[SODUONGCHEO]; // mang cac duong cheo xuoi co the dat hhauint cheonguoctrong[SODUONGCHEO]; // mang cac duong cheo nguoc co the dat hhau
int loigiai[KICHTHUOC]; /* mang loigiai cho biet cot dat cac hoang hau tren ban co. Vi du cac phan tu cua mang la: 7 3 0 2 5 1 6 4 cho biet hoanghau0 dat o cot 7, hoanghau1 dat o cot 3, ..., hoanghau7 o cot 4 */
int SoLoiGiai = 0;
void main(void){ int i;
/* Khoi dong tat ca cac cot duong cheo xuoi, duong cheo nguoc deu co the dat hoang hau */ for(i = 0; i < KICHTHUOC; i++) cottrong[i] = TRUE; for(i = 0; i < SODUONGCHEO; i++) {
cheoxuoitrong[i] = TRUE; cheonguoctrong[i] = TRUE; }
// Goi ham de qui de bat dau dat HoangHau0 (hoang hau o hang 0) hoanghau(0);}
// Ham hoanghau giup dat hoang hau i (i tu 0 den KICHTHUOC-1) tren hang ivoid hoanghau(int i){ int j; for(j = 0; j < KICHTHUOC; j++) if(cottrong[j] && cheoxuoitrong[i-j+SOGIA] && cheonguoctrong[i+j]) {
// Dat hoang hau vao o (i, j) tren ban co loigiai[i] = j; cottrong[j] = FALSE; cheoxuoitrong[i-j+SOGIA] = FALSE; cheonguoctrong[i+j] = FALSE;
if(i == KICHTHUOC-1) // Dkien dung, dat duoc con hoang hau cuoi
27

inloigiai(loigiai); else // Buoc de qui, goi dat hoang hau i+1 hoanghau(i + 1);
// lan nguoc cottrong[j] = TRUE; cheoxuoitrong[i-j+SOGIA] = TRUE; cheonguoctrong[i+j] = TRUE;
}}
void inloigiai(int loigiai[]){ int j; SoLoiGiai++; cout<<”Loi giai thu “<<SoLoiGiai;
for (j=0;j<n;j++) cout<<”Hoang hau “<< j << “dat co cot “ << loigiai[j] <<” dong “ <<j <<endl;
clrscr(); }
Tương tự, bài toán mã đi tuần sau cũng sử dụng cấu trúc mảng để giải quyết một cách dễ dàng.Ví dụ 7: Bài toán mã đi tuần: Đặt 1 quân mã vào bàn cờ vua, hãy tìm đường đi để quân mã đi hết bàn cờ mà không đi lại bất cứ ô nào.
#include <stdio.h>#include <stdlib.h>#include <conio.h>
#define KICHTHUOC 5 // Kich thuoc cua ban co
void nuocdi(int, int, int);void innuocdi();
// To chuc ban co la mang hai chieuint BanCo[KICHTHUOC][KICHTHUOC];
// 8 cach di cua con maint a[8] = {2, 2, 1, -1, -2, -2, -1, 1};int b[8] = {1, -1, -2, -2, -1, 1, 2, 2};
int SoLoiGiai = 0;
int main(void)
28

{ int i, j, m, n;
clrscr(); for(i = 0; i < KICHTHUOC; i++) for(j = 0; j < KICHTHUOC; j++) {
// Khoi dong tat ca cac o tren ban co deu chua di for(m = 0; m < KICHTHUOC; m++) for(n = 0; n < KICHTHUOC; n++) BanCo[m][n] = 0;
// Chon nuoc di dau tien va goi ham de qui de di nuoc thu hai BanCo[i][j] = 1; nuocdi(2, i, j);
} return 0;}
// Ham NuocDi giup di nuoc thu n xuat phat tu o(x, y)void nuocdi(int n, int x, int y){ int i; char c; for(i = 0; i < 8; i++) { if(x+a[i] >= 0 && x+a[i] < KICHTHUOC
&& y+b[i] >= 0 && y+b[i] < KICHTHUOC &&BanCo[x+a[i]][y+b[i]] == 0) {
// Di nuoc thu n BanCo[x+a[i]][y+b[i]] = n;
if(n == KICHTHUOC*KICHTHUOC) // Dkien dung, di duoc nuoc cuoi { innuocdi();
} else // Buoc de qui, goi di nuoc n+1 nuocdi(n+1, x+a[i], y+b[i]);
// lan nguoc BanCo[x+a[i]][y+b[i]] = 0;
} }}void inloigiai()
29
{ int i,j; cout<<”Loi giai”; for (i=0;i<8;i++) { for (j=0;j<8;j++) printf(“%3d”,BanCo[i][j]);}
3. Xâu kí tự
Trong C++ không có kiểu dữ liệu cơ bản để lưu các xâu kí tự. Để có thể thỏa mãn nhu cầu này, người chúng ta sử dụng mảng có kiểu char. Hãy nhớ rằng kiểu dữ liệu này (char) chỉ có thể lưu trữ một kí tự đơn, bởi vậy nó được dùng để tạo ra xâu của các kí tự đơn. Ví dụ, mảng sau (hay là xâu kí tự): char alpha [20];có thể lưu một xâu kí tự với độ dài cực đại là 20 kí tự. Bạn có thể tưởng tượng tương tự như sau:
Kích thước cực đại này không cần phải luôn luôn dùng đến.Chẳng hạn, alpha có thể lưu xâu "Hello" hay "Merry christmas". Vì các mảng kí
tự có thể lưu các xâu kí tự ngắn hơn độ dài của nó, trong C++ đã có một quy ước để kết thúc một nội dung của một xâu kí tự bằng một kí tự null, có thể được viết là '\0'.
Chúng ta có thể biểu diễn alpha (một mảng có 20 phần tử kiểu char) khi lưu trữ xâu kí tự "Hello" và "Happy New Year" theo cách sau:
Hình 2.3 Biểu diễn alpha xâu kí tự HELLO và HAPPY NEW YEARChú ý rằng sau nội dung của xâu, một kí tự null ('\0') được dùng để báo hiệu kết
thúc xâu. Những ô màu xám biểu diễn những giá trị không xác định. Khởi tạo các xâu kí tự.
Vì những xâu kí tự là những mảng bình thường nên chúng cũng như các mảng khác. Chẳng hạn, nếu chúng ta muốn khởi tạo một xâu kí tự với những giá trị xác định chúng ta có thể làm điều đó tương tự như với các mảng khác: char mystring[] = { 'H', 'e', 'l', 'l', 'o', '\0' };
Tuy nhiên, chúng ta có thể khởi tạo giá trị cho một xâu kí tự bằng cách khác: sử dụng các hằng xâu kí tự.
alpha
Helllo\0
HappyNewYear\0
30

Trong các biểu thức chúng ta đã sử dụng trong các ví dụ trong các chương trước các hằng xâu kí tự để xuất hiện vài lần. Chúng được biểu diễn trong cặp ngoặc kép ("), ví dụ:"the result is: " là một hằng xâu kí tự chúng ta sử dụng ở một số chỗ.
Không giống như dấu nháy đơn (') cho phép biểu diễn hằng kí tự, cặp ngoặc kép (") là hằng biểu diễn một chuỗi kí tự liên tiếp, và ở cuối chuỗi một kí tự null ('\0') luôn được tự động thêm vào.
Chúng ta có thể khởi tạo xâu mystring theo một trong hai cách sau đây: char mystring [] = { 'H', 'e', 'l', 'l', 'o', '\0' };char mystring [] = "Hello";
Trong cả hai trường hợp mảng (hay xâu kí tự) mystring được khai báo với kích thước 6 kí tự: 5 kí tự biểu diễn Hello cộng với một kí tự null. Trước khi tiếp tục, tôi cần phải nhắc nhở bạn rằng việc gán nhiều hằng như việc sử dụng dấu ngoặc kép (") chỉ hợp lệ khi khởi tạo mảng, tức là lúc khai báo mảng. Các biểu thức trong chương trình như: mystring = "Hello";mystring[] = "Hello";là không hợp lệ, cả câu lệnh dưới đây cũng vậy: mystring = { 'H', 'e', 'l', 'l', 'o', '\0' };
Vậy hãy nhớ: Chúng ta chỉ có thể "gán" nhiều hằng cho một mảng vào lúc khởi tạo nó. Nguyên nhân là một thao tác gán (=) không thể nhận vế trái là cả một mảng mà chỉ có thể nhận một trong những phần tử của nó. Vào thời điểm khởi tạo mảng là một trường hợp đặc biệt, vì nó không thực sự là một lệnh gán mặc dù nó sử dụng dấu bằng (=). Gán giá trị cho xâu kí tự
Vế trái của một lệnh gán chỉ có thể là một phần tử của mảng chứ không thể là cả mảng, chúng ta có thể gán một xâu kí tự cho một mảng kiểu char sử dụng một phương pháp như sau: mystring[0] = 'H';mystring[1] = 'e';mystring[2] = 'l';mystring[3] = 'l';mystring[4] = 'o';mystring[5] = '\0';
Nhưng rõ ràng đây không phải là một phương pháp thực tế. Để gán giá trị cho một xâu kí tự, chúng ta có thể sử dụng loạt hàm kiểu strcpy (string copy), hàm này được định nghĩa trong string.h và có thể được gọi như sau: strcpy (string1, string2);
Lệnh này copy nội dung của string2 sang string1. string2 có thể là một mảng, con trỏ hay một hằng xâu kí tự, bởi vậy lệnh sau đây là một cách đúng để gán xâu hằng "Hello" cho mystring: strcpy (mystring, "Hello");Ví dụ 8: #include <iostream.h>#include <string.h>
J. Soulie
31

int main (){ char szMyName [20]; strcpy (szMyName,"J. Soulie"); cout << szMyName; return 0;}
Để ý rằng chúng ta phải include file <string.h> để có thể sử dụng hàm strcpy. Mặc dù chúng ta luôn có thể viết một hàm đơn giản như hàm setstring dưới đây để thực hiện một thao tác giống như strcpy:Ví dụ 9:// setting value to string#include <iostream.h>
void setstring (char szOut [], char szIn []){ int n=0; do { szOut[n] = szIn[n]; n++; } while (szIn[n] != 0);}
int main (){ char szMyName [20]; setstring (szMyName,"J. Soulie"); cout << szMyName; return 0;}
J. Soulie
Một phương thức thường dùng khác để gán giá trị cho một mảng là sử dụng trực tiếp dòng nhập dữ liệu (cin). Trong trường hợp này giá trị của xâu kí tự được gán bởi người dùng trong quá trình chương trình thực hiện.
Khi cin được sử dụng với các xâu kí tự nó thường được dùng với phương thức getline của nó, phương thức này có thể được gọi như sau:
cin.getline ( char buffer[], int length, char delimiter = ' \n');trong đó buffer (bộ đệm) là địa chỉ nơi sẽ lưu trữ dữ liệu vào (như là một mảng
chẳng hạn), length là độ dài cực đại của bộ đệm (kích thước của mảng) và delimiter là kí tự được dùng để kết thúc việc nhập, mặc định - nếu chúng ta không dùng tham số này - sẽ là kí tự xuống dòng ('\n').
Ví dụ sau đây lặp lại tất cả những gì bạn gõ trên bàn phím. Nó rất đơn giản nhưng là một ví dụ cho thấy bạn có thể sử dụng cin.getline với các xâu kí tự như thế nào:Ví dụ 10:
32

#include <iostream.h>
int main (){ char mybuffer [100]; cout << "What's your name? "; cin.getline (mybuffer,100); cout << "Hello " << mybuffer << ".\n"; cout << "Which is your favourite team? "; cin.getline (mybuffer,100); cout << "I like " << mybuffer << " too.\n"; return 0;}
What's your name? JuanHello Juan.Which is your favourite team? Inter MilanI like Inter Milan too.
Chú ý trong cả hai lời gọi cin.getline chúng ta sử dụng cùng một biến xâu (mybuffer). Những gì chương trình làm trong lời gọi thứ hai đơn giản là thay thế nội dung của buffer trong lời gọi cũ bằng nội dung mới.
Nếu bạn còn nhớ phần nói về giao tiếp với, bạn sẽ nhớ rằng chúng ta đã sử dụng toán tử >> để nhận dữ liệu trực tiếp từ đầu vào chuẩn. Phương thức này có thể được dùng với các xâu kí tự thay cho cin.getline. Ví dụ, trong chươn trình của chúng ta, khi chúng ta muốn nhận dữ liệu từ người dùng chúng ta có thể viết: cin >> mybuffer;
lệnh này sẽ làm việc như nó có những hạn chế sau mà cin.getline không có: Nó chỉ có thể nhận những từ đơn (không nhận được cả câu) vì phương thức này
sử dụng kí tự trống(bao gồm cả dấu cách, dấu tab và dấu xuống dòng) làm dấu hiệu kết thúc..
Nó không cho phép chỉ định kích thước cho bộ đệm. Chương trình của bạn có thể chạy không ổn định nếu dữ liệu vào lớn hơn kích cỡ của mảng chứa nó.Vì những nguyên nhân trên, khi muốn nhập vào các xâu kí tự bạn nên sử dụng cin.getline thay vì cin >>. Chuyển đổi xâu kí tự sang các kiểu khác.
Vì một xâu kí tự có thể biểu diễn nhiều kiểu dữ liệu khác như dạng số nên việc chuyển đổi nội dung như vậy sang dạng số là rất hữu ích. Ví dụ, một xâu có thể mang giá trị "1977"nhưng đó là một chuỗi gồm 5 kí tự (kể cả kí tự null) và không dễ gì chuyển thành một số nguyên. Vì vậy thư viện cstdlib (stdlib.h) đã cung cấp 3 macro/hàm hữu ích sau: atoi: chuyển xâu thành kiểu int. atol: chuyển xâu thành kiểu long. atof: chuyển xâu thành kiểu float.Tất cả các hàm này nhận một tham số và trả về giá trị số (int, long hoặc float). Các hàm này khi kết hợp với phương thức getline của cin là một cách đáng tin cậy hơn phương thức cin>> cổ điển khi yêu cầu người sử dụng nhập vào một số.Ví dụ 11:
#include <iostream.h> Enter price: 2.75
33

#include <stdlib.h>
int main (){ char mybuffer [100]; float price; int quantity; cout << "Enter price: "; cin.getline (mybuffer,100); price = atof (mybuffer); cout << "Enter quantity: "; cin.getline (mybuffer,100); quantity = atoi (mybuffer); cout << "Total price: " << price*quantity; return 0;}
Enter quantity: 21Total price: 57.75
Các hàm để thao tác trên chuỗiThư viện cstring (string.h) không chỉ có hàm strcpy mà còn có nhiều hàm khác
để thao tác trên chuỗi. Dưới đây là giới thiệu lướt qua của các hàm thông dụng nhất: strcat: char* strcat (char* dest, const char* src); Gắn thêm chuỗi src vào phía cuối của dest. Trả về dest. strcmp: int strcmp (const char* string1, const char* string2); So sánh hai xâu string1 và string2. Trả về 0 nếu hai xâu là bằng nhau. strcpy: char* strcpy (char* dest, const char* src); Copy nội dung của src cho dest. Trả về dest. strlen: size_t strlen (const char* string); Trả về độ dài của string.Chú ý: char* hoàn toàn tương đương với char[]Ví dụ 12: Chương trình sau sẽ hiển thị một dòng chữ chạy trên màn hình.#include <stdio.h>
void main(){ char qcao[81], i=0, len;
textattr(0x1e); printf("\nNhap vao dong quang cao : "); gets(qcao); len = strlen(qcao); while (!kbhit()) { movetext(2, 1, 80, 1, 1, 1); gotoxy(80, 1); cprintf("%c", qcao[i++]); delay(100);
34

i %= len; } getch();}Ví dụ 13: Chương trình sau dùng các hàm dựng sẵn của C++ để chuyển sang các dạng ký tự khác nhau.#include"stdio.h"#include"alloc.h"#include"string.h"#include"conio.h"char *thaythe(unsigned char kytu,size_t lan)
{char *inkytu;inkytu=calloc(lan,sizeof(char)+1);memset(inkytu,kytu,lan);return(inkytu);
}main()
{char *s, *t;s=calloc(60,sizeof(char));t=calloc(60,sizeof(char));clrscr();textcolor(YELLOW);cprintf(" - Nhap chuoi thu nhat (chu thuong)= ");gets(s);textcolor(LIGHTRED);cprintf(" - Nhap chuoi thu hai (chu thuong) = ");gets(t);cprintf("\n %s",thaythe(205,60));textcolor(LIGHTCYAN);cprintf("\n\r %10c DOI RA CHU HOA",' ');cprintf("\n\n\r");puts(strupr(s));cprintf("\r");puts(strupr(t));cprintf("\n %s",thaythe(205,60));textcolor(LIGHTMAGENTA);cprintf("\n\r %10c DOI TRO LAI CHU THUONG",' ');cprintf("\n\n\r");puts(strlwr(s));cprintf("\r");puts(strlwr(t));cprintf("\n %s",thaythe(205,60));textcolor(LIGHTGREEN);cprintf("\n\r %10c DAO NGUOC CHU",' ');cprintf("\n\n\r");
35

puts(strrev(s));cprintf("\r");puts(strrev(t));cprintf("\n %s",thaythe(205,60));getch();
}Ví dụ 14:Chương trình sau thực hiện xóa một số ký tự#include"conio.h"#include"alloc.h"void xoa(char *nguon, char vitri, char so)
{char k;for (k=vitri-1;nguon[k+so];k++)
nguon[k]=nguon[k+so];nguon[k]='\0';
}void main()
{int m,n;char *s;s=calloc(100,sizeof(char));clrscr();textcolor(YELLOW);cprintf("\n - Nhap vao mot chuoi :");gets(s);textcolor(LIGHTRED);cprintf("\r - Muon xoa tu vi tri nao : ");scanf("%d",&m);textcolor(LIGHTMAGENTA);cprintf("\r- Muon xoa bao nhieu ky tu : ");scanf("%d",&n);textcolor(LIGHTRED);cprintf("\n\r**********************************");textcolor(YELLOW);cprintf("\n\n\r + Chuoi nguon la :");textcolor(LIGHTCYAN);cprintf("\n\r %s",s);textcolor(LIGHTGREEN);cprintf("\n\r + Chuoi nguon dai :%d ky tu",strlen(s));textcolor(LIGHTRED);cprintf("\n\r + Sau khi xoa con lai chuoi : ");xoa(s,m,n);textcolor(LIGHTMAGENTA);cprintf("\n\r %s",s);textcolor(LIGHTGREEN);cprintf("\n\r + Chieu dai la : %d ky tu",strlen(s));textcolor(LIGHTCYAN);
36

cprintf("\n\n\r * Bam phim bat ky de ket thuc");getch();
}Ví dụ 15: Chương trình sau thực hiện đảo chuỗi ký tự.#include"conio.h"#include"stdio.h"#include"string.h"#include"alloc.h"void main()
{char *chuoi;chuoi=calloc(80,sizeof(char));clrscr();cprintf("\n- Nhap vao 1 chuoi : ");gets(chuoi);cprintf("\n\r- Chuoi nay co : %d ky tu ke ca ky tu trong \
n",strlen(chuoi));cprintf("\n\r- Dao nguoc chuoi nay thanh \n ");cprintf("\n\r %s ",strrev(chuoi));cprintf("\n\n\r * Bam phim bat ky de ket thuc");getch();
}Ví dụ 16: Chương trình sau minh họa hàm cộng chuỗi.#include"string.h"#include"stdio.h"void main()
{char mot[100]="Que huong la chum khe ngot";char hai[100]=" Cho con treo hai moi ngay";char ba[100]="Que huong la duong di hoc";char bon[100]=" Con ve rop buom vang bay";
clrscr();printf("\nCau \" %s\". Co chieu dai :%d ky tu ",mot,strlen(mot));printf("\nCau \" %s\". Co chieu dai :%d ky tu ",hai,strlen(hai));printf("\nCau \" %s\". Co chieu dai :%d ky tu ",ba,strlen(ba));printf("\nCau \" %s\". Co chieu dai :%d ky tu ",bon,strlen(bon));strcat(mot,hai);strcat(ba,bon);printf("\n");printf("\n PHEP CONG CHUOI KY TU \n");printf("\n + Dem cau 1 + cau 2");printf("\nHai cau %s",mot);printf("\n - Co chieu dai: %d ky tu :",strlen(mot));printf("\n");printf("\n + Dem cau 3 + cau 4");printf("\nHai cau %s",ba);
37

printf("\n - Co chieu dai : %d ky tu",strlen(ba));getch();
}
4. Kiểu cấu trúc
Cấu trúc là một kiểu dữ liệu được người dùng tự định nghĩa, kiểu dữ liệu này chứa trong nó các phần tử mà mỗi phần tử có thể có kiểu dữ liệu khác nhau. Kiểu cấu trúc cho phép mô tả các đối tượng có cấu trúc phức tạp.Khai báo tổng quát của kiểu cấu trúc (struct) như sau:struct <tên kiểu cấu trúc>{ <kiểu dữ liệu 1> <thành phần 1>; <kiểu dữ liệu 2> <thành phần 2>; <kiểu dữ liệu 3> <thành phần 3>; ……………………………………… <kiểu dữ liệu n> <thành phần n>};Ví dụ 17: Để mô tả các thông tin về một con người, chúng ta có thể khai báo một kiểu dữ liệu và khai báo một cấu trúc như sau:struct nguoi{ char hoten[35]; int namsinh; char noisinh[60]; int gioitinh; {0- nu;1:nam} char diachi[79];}Kiểu cấu trúc được tổ chức trong bộ nhớ với một cấu trúc liên tục, không chồng lấp lên nhau:
35 bytes 2 bytes 60 bytes 2 bytes 79bytesHoten namsinh Noisinh gioitinh diachi
Kiểu cấu trúc bổ sung những hạn chế của kiểu mảng, giúp chúng ta có khả năng thể hiện các đối tượng đa dạng của thế giới thực vào trong máy tính một cách dễ dàng và chính xác hơn.Khi khai báo biến có kiểu dữ liệu cấu trúc, chúng ta truy xuất đến các thành phần con bên trong bằng dấu chấm (.).Ví dụ 18: Nhập danh sách các học sinh có kiểu dữ liệu nguoi như trên. In ra màn hình thông tin của các học sinh có năm sinh bé hơn 1985.#include <iostream.h>#include <conio.h>#include <stdio.h>void main(){ struct nguoi {
38

char hoten[35]; int namsinh; char noisinh[60]; int gioitinh; char diachi[79]; }; nguoi ds[100]; int n,i; clrscr(); cout<<"Nhap vao so hoc sinh:";cin>>n; cout<<"Nhap thong tin cho tung hoc sinh:"<<endl; for (i=0;i<=n-1;i++) { cout<<"Nhap thong tin cho hoc sinh thu "<<i+1<<endl; cout<<"Ho ten:";gets(ds[i].hoten);//scanf("%s",L[i].hoten); cout<<"Nam sinh:";cin>>ds[i].namsinh; cout<<"Noi sinh:";gets(ds[i].noisinh); cout<<"Gioi tinh(1-Nam;0-Nu):";cin>>ds[i].gioitinh; cout<<"Dia chi:";gets(ds[i].diachi); } cout<<"Thong tin ve cac hoc sinh co nam sinh be hon 1985"<<endl; for (i=0;i<=n-1;i++) if (ds[i].namsinh<1985) { cout<<"Thong tin:"<<endl; cout<<"Ho ten:"<<ds[i].hoten<<endl; cout<<"nam sinh:"<<ds[i].namsinh<<endl; cout<<"Noi sinh:"<<ds[i].noisinh<<endl; cout<<"Gioi tinh:"<<ds[i].gioitinh<<endl; cout<<"Dia chi:"<<ds[i].diachi<<endl; } getch();}Ví dụ 19: Nhập danh sách có tối đa 100 nhân viên gồm 2 thông tin: họ tên và tuổi. Tính tuổi trung bình của các nhân viên trong công ty và in ra danh sách các nhân viên có tuổi lớn hơn tuổi trung bình.#include <conio.h>#include <stdio.h>#include <iostream.h>void main(){ struct nv { char hoten[35]; int tuoi; }; nv nhanvien[100];
39

float tuoitrungbinh=0; int n,i; clrscr(); cout<<"Nhap so nhan vien:";cin>>n; for (i=0;i<=n-1;i++) { cout<<"Nhap thong tin cho nhan vien thu "<<i+1<<endl; cout<<"Ho ten:";gets(nhanvien[i].hoten); cout<<"Tuoi:";cin>>nhanvien[i].tuoi; } for (i=0;i<=n-1;i++) tuoitrungbinh+=float(nhanvien[i].tuoi)/float(n); cout<<"Tuoi trung binh cua cong ty:"<<tuoitrungbinh<<endl; cout<<"Danh sach cac nhan vien co tuoi lon hon tuoi trung binh:"<<endl; for (i=0;i<=n-1;i++) if (nhanvien[i].tuoi>tuoitrungbinh) { cout<<"Thong tin"<<endl; cout<<nhanvien[i].hoten<<endl; cout<<nhanvien[i].tuoi<<endl; } getch();
}Ví dụ 20: Chương trình quản lý sinh viên cài đặt trên danh sách dùng mảng các phần tử có kiểu cấu trúc. Số lượng các phần tử tối đa là 100. Đây là hình ảnh của một danh sách.#include <stdio.h>#include <conio.h>#include <iostream.h>#define MAXLIST 100#define TRUE 1#define FALSE 0
struct sinhvien{ int mssv; char hoten[20];};
struct list{
int numnodes;sinhvien nodes[MAXLIST];
};list L;void initialize(list &L)
40

{L.numnodes = 0; //khởi động danh sách
}
// Xác định số phần tửint listsize(list &L){
return(L.numnodes);}
//Kiểm tra xem danh sách rỗng hay khôngint empty(list L){
return((L.numnodes == 0) ? TRUE : FALSE);}
// Kiểm tra xem danh sách có đầy không?int full(list L){
return((L.numnodes == MAXLIST) ? TRUE : FALSE);}
//chèn một phần tử vào vị trí posvoid insert(list &L, int pos, sinhvien x){
int i;if(pos < 0 || pos > listsize(L)){
printf("Vi tri chen khong phu hop.");return;
}else
if(full(L)){
printf("Danh sach bi day.");return;
}else{
for(i = listsize(L)-1; i >= pos; i--)L.nodes[i+1] = L.nodes[i];
L.nodes[pos] = x;L.numnodes++;
}}
//xoá một nút tại pos
41

sinhvien remove(list &L, int pos){
int i; sinhvien x;
if(pos < 0 || pos >= listsize(L))printf("Vi tri xoa khong phu hop.");
elseif(empty(L))
printf("Danh sach khong co sinh vien.");else{
x = L.nodes[pos];for(i = pos; i <= listsize(L)-1; i++)
L.nodes[i] = L.nodes[i+1];L.numnodes--;return(x);
}}
//xoá các phần tử trong danh sáchvoid clearlist(list &L){
L.numnodes = 0;}
//sửa nội dung tại vị trí posvoid replace(list &L, int pos, sinhvien x){
if(pos < 0 || pos >= listsize(L)){
printf("Vi tri hieu chinh khong phu hop.");return;
}else
if(empty(L)){
printf("Danh sach khong co sinh vien.");return;
}else
L.nodes[pos] = x;}//duyệt danh sáchvoid traverse(list L){
int i;if(L.numnodes == 0)
42

{printf("\n Danh sach khong co sinh vien");return;
}for(i = 0; i < L.numnodes; i++)
printf("\n%7d%7d%16s", i, L.nodes[i].mssv, L.nodes[i].hoten);}//sắp xếp danh sách sinh viênvoid selectionsort(list &L){
int i, j, vitrimin; sinhvien svmin;
for(i = 0; i < L.numnodes-1; i++){
svmin = L.nodes[i];vitrimin = i;for(j = i+1; j < L.numnodes; j++)
if(svmin.mssv > L.nodes[j].mssv){
svmin = L.nodes[j];vitrimin = j;
}// hoan doiL.nodes[vitrimin] = L.nodes[i];L.nodes[i] = svmin;
}}//tìm kiếm một sinh viênint linearsearch(list &L, int mssv){
int vitri = 0;while(L.nodes[vitri].mssv != mssv && vitri < L.numnodes)
vitri++;if(vitri == L.numnodes) // khong tim thay
return(-1);return(vitri); // tim thay
}
void main(){ sinhvien sv;
int chucnang, vitri;char c;
clrscr();initialize(L);
43

do{
// menu chinh cua chuong trinhprintf("\n\nCHUONG TRINH QUAN LY DANH SACH SINH VIEN:\
n");printf("Cac chuc nang cua chuong trinh:\n");printf(" 1: Xem danh sach sinh vien\n");printf(" 2: Them mot sinh vien vao danh sach\n");printf(" 3: Xoa mot sinh vien trong danh sach\n");printf(" 4: Hieu chinh sinh vien\n");printf(" 5: Sap xep danh sach theo MSSV\n");printf(" 6: Tim kiem sinh vien theo MSSV\n");printf(" 7: Xoa toan bo danh sach\n");printf(" 0: Ket thuc chuong trinh\n");printf("Chuc nang ban chon: ");scanf("%d", &chucnang);switch(chucnang){
case 1:{
printf("\nDanh sach sinh vien: ");printf("\n STT MSSV HO TEN");traverse(L);break;
}case 2:{
printf("\nVi tri them (0, 1, 2, ...): ");scanf("%d", &vitri);printf("Ma so sinh vien: ");scanf("%d", &sv.mssv);printf("Ho ten sinh vien: ");scanf("%s", &sv.hoten);insert(L, vitri, sv);break;
}case 3:{
printf("\nVi tri xoa (0, 1, 2, ...): ");scanf("%d", &vitri);remove(L, vitri);break;
}case 4:{
printf("\nVi tri hieu chinh (0, 1, 2, ...): ");scanf("%d", &vitri);
44

printf("\nSTT:%d MSSV:%d HOTEN:%s", vitri, ds.nodes[vitri].mssv, ds.nodes[vitri].hoten);
printf("\nMa so sv moi: ");scanf("%d", &sv.mssv);printf("Ho ten sv moi: ");scanf("%s", &sv.hoten);replace(L, vitri, sv);break;
}case 5:{
printf("\nBan co chac khong (c/k): ");c = getche();if(c == 'c' || c == 'C')
selectionsort(L);break;
}case 6:{
printf("\nMa so sinh vien can tim: ");scanf("%d", &sv.mssv);vitri = linearsearch(L, sv.mssv);if(vitri == -1)
printf("Khong co sinh vien co MSSV %d trong danh sach", sv.mssv);
elseprintf("Tim thay o vi tri %d trong danh sach", vitri);
break;}case 7:{
printf("\nBan co chac khong (c/k): ");c = getche();if(c == 'c' || c == 'C')
clearlist(L);break;
}}
} while(chucnang != 0);}Ví dụ 21: Viết chương trình tạo một mảng các điểm ngẫu nhiên (dùng cấu trúc điểm). Kiểm tra xem các điểm phát sinh này có thỏa mãn 2x+4y>20. Nhập r là bán kính của một đường tròn tâm 0. Kiểm tra xem các điểm phát sinh ở trên có nằm trên đường tròn này hay không? In kết quả lên màn hình.#include"stdio.h"#include"stdlib.h"#define Max 100
45

typedef struct{
int x,y;}toa_do;
toa_do M[Max];unsigned char k;int r;char tim_thay;void khoi_tao()
{randomize();for (k=0; k<Max; k++)
{M[k].x = random(20)-10;M[k].y = random(20)-10;
}}
void tim_kiem1(){
tim_thay=0;puts("Cac diem tren mat phang thoa 2x + 4y > 20 :");for (k=0; k<Max; k++)
if (2*M[k].x + 4 * M[k].y > 20){
tim_thay = 1;printf("( %2d\, %2d )",M[k].x, M[k].y);
}if (tim_thay)
puts("\n..la cac diem thoa x + 2y > 3");else
puts("\nKhong co diem nao nhu vay");}
void tim_kiem2(){
tim_thay=0;printf("-Nhap ban kinh R= ");scanf("%d",&r);printf("Cac diem tren vong tron tam O ban kinh %d :\n",r);for (k=0; k<Max; k++);
if (M[k].x * M[k].x + M[k].y * M[k].y == r*r){
tim_thay=1;printf("( %2d\, %2d )",M[k].x, M[k].y);
}if (tim_thay)
printf("\n..la cac diem tren vong tron tam O ban kinh %d",r);
46

elseputs("\nKhong co diem nao nhu vay");
}void main()
{khoi_tao();tim_kiem1();tim_kiem2();printf("\n\t Bam phim bat ky de ket thuc");getch();
}
5. Kiểu hợp
Kiểu hợp khá giống kiểu cấu trúc. Tuy nhiên, tất cả các thành phần được lưu trữ trên cùng một địa chỉ bộ nhớ. Ví dụ:union viduhop{ long lonnhat; int thap;};
Biến a có kiểu dữ liệu viduhop và thực hiện phép gán: a.lonnhat bểu diễn trong bộ nhớ như sau:
a.lonnhat=5020104162bytes 2bytes11101111011000001001000110000a.thap
Một trong những công dụng của union là dùng để kết hợp một kiểu dữ liêu cơ bản với một mảng hay các cấu trúc gồm các phần tử nhỏ hơn. Ví dụ: union mix_t{ long l; struct { short hi; short lo; } s; char c[4];} mix;
định nghĩa ba phần tử cho phép chúng ta truy xuất đến cùng một nhóm 4 byte: mix.l, mix.s và mix.c mà chúng ta có thể sử dụng tuỳ theo việc chúng ta muốn truy xuất đến nhóm 4 byte này như thế nào. Tôi dùng nhiều kiểu dữ liệu khác nhau, mảng và cấu trúc trong union để bạn có thể thấy các cách khác nhau mà chúng ta có thể truy xuất dữ liệu.
47

Kiểu hợp khá thuận tiện trong việc xử lý các chương trình tính theo byte trong một luồng dữ liệu nhiều byte nhận được, chẳng hạn, xử lý các dữ liệu từ các cổng điều khiển.
Ngoài ra, kiểu hợp còn rất thuận lợi trong việc xử lý số liệu đến bit, byte hay xử lý các giá trị ở mức độ hệ thống.Ví dụ 22: Chương trình sau hiển thị giá trị byte thấp và byte cao của một số nguyên int.#include <stdio.h>#include <iostream.h>
union kieu_hop {int i;char ch[2];
};kieu_hop uni;void main()
{uni.i=0X2040;hien_thi(uni);
}void hien_thi(kieuhop so)
{clrscr();cout<<"\n\n CHUONG TRINH MINH HOA SU DUNG UNION\n";printf("-Hien thi tri 16 (thap luc) cua Byte thap : %X\n",so.ch[0]);printf("-Hien thi tri 16 (thap luc) cua Byte cao : %X\n",so.ch[1]);printf("\n Bam phim bat ky de ket thuc");getch();
}Ví dụ 23: Hiển thị bảng mã ASCII theo hai kiểu mã: thập phân và nhị phân.#include"stdio.h"typedef struct
{unsigned a: 1;unsigned b: 1;unsigned c: 1;unsigned d: 1;unsigned e: 1;unsigned f: 1;unsigned g: 1;unsigned h: 1;
48

}kytu;union
{char ch;kytu b;
}ma;void hien_thi(char c)
{ma u;u.ch = c;printf("\n %c %3d %u %u %u %u %u %u %u %u ",
u.ch,u.ch,u.b.h,u.b.g,u.b.f,u.b.e,u.b.d,u.b.c,u.b.b,u.b.a);}
void main(){
char c;clrscr();printf("\n B A N G M A A S C I I");
cout<<”In theo khung dang: Ky tu Thap phan Nhi phan”<<endl;for (c=1; c<7; hien_thi(c++));
for (c='A'; c<'K'; hien_thi(c++));printf("\n
****************************************************");printf("\n Bam phim bat ky de ket thuc");getch();
}
6. Kiểu tập tin (file)
Kiểu tập tin là kiểu dữ liệu được lưu trữ trên đĩa với một tên tập tin xác định.- File có 2 loại :
+ Text file ( file văn bản ).+ Binary ( nhị phân : dbf, doc, bitmap,...).
- File văn bản chỉ khác binary khi xử lý ký tự chuyển dòng (LF) ( mã 10 ) được chuyển thành 2 ký tự CR (mã 13) và LF ( mã 10) và khi đọc 2 ký tự liên tiếp CR và LF trên file cho chúng ta một ký tự LF.
- Các thao tác trên file thực hiện thông qua con trỏ kiểu FILE. Mỗi biến FILE có 1 con trỏ lúc đầu sẽ trỏ vào phần tử đầu tiên của file. Sau mỗi thao tác đọc hay ghi dữ liệu con trỏ tự động dời xuống mẫu tin kế tiếp. Làm việc trên kiểu File thường có 3 công đoạn : mở file, nhập xuất thông trên file và đóng file.* Một số hàm thông dụng thao tác trên file ( tập tin/tệp tin ) :
+ Mở file : FILE *fopen ( char *filename, char *mode); Nếu có lỗi fp sẽ trỏ đến NULL.
+ Các chế độ mở file : " r" " rt " / " rb " : mở file để đọc theo kiểu văn bản / nhị phân - file phải tồn tại trước nếu không sẽ có lỗi.
49

"w" "wt" / " wb " : mở ( tạo ) file mới để ghi theo kiểu văn bản/nhị phân - nếu file đã có nó sẽ bị xóa (ghi đè )( luôn luôn tạo mới )."a" "at"/ "ab" : mở file để ghi bổ sung (append) thêm theo kiểu văn bản hoặc nhị phân( chưa có thì tạo mới ).+ Ðóng file : int fclose ( file + biến file ) ;Ví dụ 24: Minh họa mở tập tin. void main ( ) { FILE *fp ; fp = fopen ("c:\\THUCTAP\\Data.txt", "wt" ); if (fp = NULL ) printf ( " không mở được file c:\Thuctap\data.txt"); else { < xử lý file > } fclose (fp) ; /* đóng file */}+ Đóng tất cả các tập đang mở : int fcloseall(void) ; nếu thành công trả về số nguyên bằng tổng số các file đóng được, ngược lại trả về EOF.+ Hàm xóa tập : remove (const + char*ten tập ) ; nếu thành công cho giá trị 0, ngược lại EOF.+ Hàm kiểm tra cuối tập : int feof(FILE*fp) : !=0 : nếu cuối tập= 0 : chưa cuối tập.+ Hàm int putc ( int ch, FILE*fp); Hàm int fputc( int ch, FILE*fp);Công dụng của hai hàm này :ghi một ký tự lên tập fp theo khuôn dạng được xác định trong chuỗi điều khiển dk. Chuỗi dk và danh sách đối tương tự hàm printf( ).+ Hàm int fscanf ( FILE *fp, const char *dk, ...);Công dụng : đọc dữ liệu từ tập tin fp theo khuôn dạng ( đặc tả) làm việc giống scanf( ).
Ví dụ 25: Giả sử có file c:\data.txt lưu 10 số nguyên 1 5 7 9 8 0 4 3 15 20 . Hãy đọc các số nguyên thêm vào một mãng sau đó sắp xếp tăng dần rồi ghi vào file datasx.txt.#include <stdio.h>#include<conio.h>#include<stdlib.h>#define n 10void main ( ){ FILE *fp ; int i, j, t, a[n]; clrscr ( ) ; fp = fopen (" c :\\data.txt ", "rt" ); /* mở file để đọc vào mãng */ if (fp = NULL) { printf ("không mở được file "); exit (1);
50

}while (1){ fscanf (fp,"%d",&a[i] ; i++; if (foef(fp) ) break ;
/* Sắp xếp mảng */ for ( i=0 ; i<n-1 ; i++) for (j=i+1; j<n ; j++) if (a[i]<a[j] ) { t = a[i] ; a[i]=a[j] ; a[j] = t ; } fclose (fp);/* mở file datasx.txt để ghi sau khi sắp xếp */ fp = fopen ("c:\\datasx.txt ", "wt"); for ( i=0 ; i<n;i++) printf (fp,"%2d", a[i] ); fclose (fp); i = 0 ;while (1){ fscanf (fp,"%d",&a[i] ; i++; if (foef(fp) ) break ;
}- Hàm int fputs ( const char *s, file *fp )Công dụng : ghi chuỗi s lên tập tin fp ( dấu "\0" ghi lên tập) nếu có lỗi hàm cho eof.- Hàm char fgets ( char *s, int n , FILE *fp);Công dụng : đọc 1 chuỗi ký tự từ tập tin fp chứa vào vùng nhớ s. Việc đọc kết thúc khi : hoặc đã đọc n-1 ký tự hoặc gặp dấu xuống dòng( cắpmã 13 10). khi đó mã 10 được đưa vào chuỗi kết quả.- Hàm int fwrite (void *p, int size , int n , FILE*fp);p : là con trỏ trỏ tới vùng nhớ chứa dữ liệu cần ghi.size : là kích thước của mẫu tin theo byte.n số mẫu tin cần ghi.fp là con trỏ tập.chẳng hạn, fwrite(&tam) size of(tam),1,fv); /* tam là 1 mẫu tin(record) nào đó*/Công dụng : ghi một mẫu tin (record) kích thước sizebyte ( size of (tam)) từ vùng nhớ p(&tam) lên tập fp. Hàm sẽ trả về một giá trị = số mẫu tin thực sự ghi được.+ Hàm int fread (void*p), int size , int n, FILE *fp);p : là con trỏ trỏ tới vùng nhớ chứa dữ liệu đọc được.size là kích thước của mẫu tin theo byten : là số mẫu tin cần đọc, fp là con trỏ tập tin.Chẳng hạn, fread (&tam, size of(KIEUHS) , 1, 4 )>0)Công dụng : đọc n(1) mẫu tin kích thước sizebyte (size of(tam)) từ tập tin fp chứa vào vùng nhớ p(&tam). Hàm trả về một giá trị bằng số mẫu tin thực sự đọc được.
51

Ví dụ 26 : Nhập vào danh sách lớp gồm n học viên ("nhập vào). Thông tin về mỗi học viên gồm Họ tên, phái , điểm, kết quả. Xét kết quả theo điều kiện sau : nếu Ðiểm>= 5 ( đậu ), điểm <5 : rớt. Sau đó sắp xếp theo điểm và ghi vào tập tin c:\lop.txt. Ðọc lại tập tin c:\lop.txt và xét lại kết quả nếu điểm =4 và phái là nữ sẽ đậu và chép sang tập tin c:\ketqua.txt.#include<stdio.h>#include<conio.h>#include<stdlib.h>#include<string.h>struct{ char ten[20] ; char phai[4] ; int diem ; char kq[4] ; } KieuHV;KieuHV lop[100] , tam;/* Hàm nhập danh sách n học viên */void nhapds ( int n, KieuHV lop[ ] ){ int i , diem ; for ( i=0; i<n ; i++ ){ printf (" nhập họ và tên người thứ %d : " , i + 1) ; gets ( lop[i].ten);printf ("phái (nam/nữ ) : ") ; gets (lop[i].phai );printf ("nhập điểm = ") ; scanf ("%d%c*c", &diem); lop[i].diem=diem;if (diem>5)strcpy (lop[i].kq,"Ðậu");else strcpy (lop[i].kq, "rớt " ) ;}/* Hàm sắp xếp */void sapxep ( int n , KieuHV lop[ ] ){ int i , j ; KieuHV tam;for ( i=0 ; i<n-1; i++)for ( j=i+1 ; j<0; j++)if (lop[i].diem< lop[j]diem ){ tam = lop[i] ; lop[i] = lop[j] ; lop [i] = tam ;}}/* Hàm in danh sách */void inds ( int n, KieuHS lop[ ] ){ int i ;for ( i=0 ; i<n ; i++)printf ("\n %20s %5s%5d%5s, lop[i].ten, lop[i].phai, lop[i].diem, LOP[I].kq );
void main ( ){ int i , j, n, t, diem ; FILE *fp, *fr ; printf ("\n nhập sĩ số : ") ; scanf("%d%*c",&n); lop = (KieuHV*) malloc (n*size of (KieuHV)); nhapds(n, lop) ; sapxep ( n, lop ); inds( n, lop); getch( );fp = fopen ( "c :\\lop.txt ", "wb");
52

for ( i = 0; i<n ; i++)fwrite (&lop[ i], size of (KieuHV), 1, fp); fclose(fp);printf ("\n ghi dữ liệu xong ");printf("\n in file sau khi sắp xếp và xét kết quả lại ");fr = fopen ("c:\\ketqua.txt", "wb");while ( fread (&tam, size of ( KieuHV), 1, fp ) > 0){ printf ("\n %s %s%d%s", tam.ten, tam.phai, tam.diem, tam.kq);if (tam.diem = = 4 &&strcmp(tam.phai,"nữ")= =0 ) strcpy(&tam.kq, "đậu");fwrite(&tam,size of(tam),1, fr);}fclose (fp); fclose(fr);printf ("\n in file ketqua.txt sau khi xét lại kết qủa ");fp = fopen ("c:\\ketqua.txt", "rb");while (fread(&tam, size of (KieuHV) , 1, fp) > 0) printf("\n %s%s%d%s",tam.ten,tam.phai, tam.diem,tam.kq); fclose (fp); getch( );}Các hàm xuất nhập ngẫu nhiên- Khi mở tệp tin để đọc hay ghi, con trỏ chỉ vị luôn luôn ở đầu tập tin (byte 0) nếu mở mode "a" (append) chuyển con trỏ chỉ vị trí cuối tập tin.+ Hàm void rewind (FILE*fp) : chuyển con trỏ chỉ vị của tập fp về đầu tập tin.+ Hàm int fseek (FILE*fp, long số byte, int xp)fp : là con trỏ tập tin; số byte : là số byte cần di chuyển.xp " cho biết vị trí xuất phát mà việc dịch chuyển được bắt đầu từ đó.xp = SEEK - SET hay 0 xuất phát từ đầu tập.xp = SEEK - CUR hay 1 : xuất phát từ vị trí hiện tại của con trỏ.xp= SEEK - END HAY 2 : xuất phát từ vị trí cuối tập của con trỏ.+ Công dụng : hàm di chuyển con trỏ chỉ vị của tập fp từ vị trí xác định bởi xp qua một số byte bằng giá trị tuyệt đối của số byte. Nếu số byte > 0 : chuyển về hướng cuối tập ngược lại chuyển về hướng đầu tập. Nếu thành công trả về trị 0. Nếu có lỗi trả khác 0.+ Chú ý : không nên dùng fseep trên kiểu văn bản, vì sự chuyển đổi ký tự( mã 10) sẽ làm cho việc định vị thiếu chính xác.+ Hàm long ftell(FILE*fp) ; : cho biết vị trí hiện tại của con trỏ chỉ vị (byte thứ mấy trên tập fp) nếu không thành công trả về trị -1L.Ví dụ 27: giả sử chúng ta có tập tin c:\lop.txt chứa danh sách các học viên. Hãy đọc danh sách và sắp xếp giảm dần theo điểm sau đó ghi lại file c:\lop.txt ( nối điểm)#include <stdio.h>#include<conio.h>#include<string.h>#define N 100struct{ char ten[20] ; int tuoi; float diem ; } KieuHV ;void main( )
53

{ KieuHV hv[N] ; t;FILE*fp ; int i, , n ;fp = fopen ("c:\\lop.txt ", "rat");if (fp = =NULL) { printf ("không mở được file "); exit(1); } n = 0 ; i = 0 ; while (!feof (fp)) { fread (&hv[i], size of (KieuHV), 1,fp); i++; n++ ; /* sắp xếp giảm dần theo điểm */ for (i=0, i <n-1, i++) for (j=i+1; j<n, j++) if (hv[i].diem <hv[j].diem) { t =hv[i] ; hv[i] = hv[j] ; hv[j] = t }/* ghi lên đĩa */fseek (fp, 0, SEEK-END);for ( i=0; i<n ; i++)fwrite(&hv[i], size of (KieuHV), 1, fp);} Ví dụ 28: Hiển thị từng ký tự có trong tập tin văn bản ra màn hình.Phiên bản 1: Dùng biến ký tựTên tập tin: typex.cpp#include <stdio.h>
void main(int argc, char *argv[]){ FILE *fp; char c;
if (argc <= 1) printf("\nCach su dung : \n typex <ten tap tin>"); else if ((fp = fopen(argv[1], "r")) == NULL) printf("\nKhong the mo tap tin %s", argv[1]); else { while ((c = fgetc(fp)) != EOF) putc(c, stdout); } getch();}Phiên bản 2: Dùng mảng ký tựTên tập tin: typex.cpp#include <stdio.h>#include <string.h>
void main(int argc, char *argv[])
54

{ FILE *fp; char s[255];
if (argc <= 1) printf("\nCach su dung : \n typex <ten tap tin>"); else if ((fp = fopen(argv[1], "r")) == NULL) printf("\nKhong the mo tap tin %s", argv[1]); else
while (fgets(s, 255, fp)) { s[strlen(s) - 1] = 0; if (strlen(s)) puts(s); } getch();}Ví dụ 29: Chương trình sau đọc hai tập tin và nối 2 tập tin thành tập thứ 3.#include <stdio.h>void main(){ FILE *fp1, *fp2, *fpout; char sf1[50], sf2[50], sfout[50]; int c;
printf("\nNhap ten tap tin thu nhat : "); scanf("%s", &sf1); printf("\nNhap ten tap tin thu hai : "); scanf("%s", &sf2); printf("\nNhap ten tap tin ket qua : "); scanf("%s", &sfout); if ((fp1 = fopen(sf1, "r")) == NULL) fprintf(stderr, "Khong the mo tap tin %s\n", sf1); if ((fp2 = fopen(sf2, "r")) == NULL) fprintf(stderr, "Khong the mo tap tin %s\n", sf2); if ((fpout = fopen(sfout, "w")) == NULL) fprintf(stderr, "Khong the mo tap tin %s\n", sfout);
while ((c = getc(fp1)) != EOF) putc(c, fpout); while ((c = getc(fp2)) != EOF) putc(c, fpout); fclose(fp1); fclose(fp2); fclose(fpout);
55

printf("\nHoan tat! Nhan phim bat ky de ket thuc."); getch();}Ví dụ 30: Chương trình sẽ mã hóa từng ký tự trong tập tin với một ký tự nhập vào theo phép toán XOR.#include <stdio.h>
void main(){ char c, filein[50], fileout[50], key; FILE *fpin, *fpout;
printf("\nCho biet ten tap tin nguon : "); gets(filein); printf("\nCho biet ten tap tin dich : "); gets(fileout); printf("\nCho biet khoa : "); scanf("%c", &key); if ((fpin = fopen(filein, "r")) == NULL) printf("Khong tim thay tap tin %s", filein); else if ((fpout = fopen(fileout, "w+")) == NULL) { printf("Khong the tao tap tin %s", fileout); fclose(fpin); } else { do { c = fgetc(fpin); if (c != EOF) fputc(c ^ key, fpout); //XOR } while (c != EOF); fclose(fpin); fclose(fpout); printf("\nĐã mã hóa xong"); } getch();}
7. Các kiểu dữ liệu khác
Kiểu tự định nghĩa typedefC++ cho phép chúng ta định nghĩa các kiểu dữ liệu của riêng mình dựa trên các
kiểu dữ liệu đã có. Để có thể làm việc đó chúng ta sẽ sử dụng từ khoá typedef, dạng thức như sau:
56

typedef kiểu_dữ_liệu_đã_có kiểu_dữ_liệu_mới; trong đó kiểu_dữ_liệu_đã_có là một kiểu dữ liệu cơ bản hay bất kì một kiểu dữ
liệu đã định nghĩa và kiểu_dữ_liệu_mới là tên của kiểu dữ liệu mới. Ví dụ typedef char C;typedef unsigned int WORD;typedef char * string_t;typedef char field [50];
Trong trường hợp này chúng ta đã định nghĩa bốn kiểu dữ liệu mới: C, WORD, string_t và field kiểu char, unsigned int, char* kiểu char[50], chúng ta hoàn toàn có thể sử dụng chúng như là các kiểu dữ liệu hợp lệ:
achar, anotherchar, *ptchar1;WORD myword;string_t ptchar2;field name;
typedef có thể hữu dụng khi bạn muốn định nghĩa một kiểu dữ liệu được dùng lặp đi lặp lại trong chương trình hoặc kiểu dữ liệu bạn muốn dùng có tên quá dài và bạn muốn nó có tên ngắn hơn. Kiểu liệt kê (enum)
Kiểu dữ liệu liệt kê dùng để tạo ra các kiểu dữ liệu chứa một cái gì đó hơi đặc biệt một chút, không phải kiểu số hay kiểu kí tự hoặc các hằng true và false. Dạng thức của nó như sau: enum model_name { value1, value2, value3, . .} object_name;
Chẳng hạn, chúng ta có thể tạo ra một kiểu dữ liệu mới có tên color để lưu trữ các màu với phần khai báo như sau: enum colors_t {black, blue, green, cyan, red, purple, yellow, white};
Chú ý rằng chúng ta không sử dụng bất kì một kiểu dữ liệu cơ bản nào trong phần khai báo. Chúng ta đã tạo ra một kiểu dữ liệu mới mà không dựa trên bất kì kiểu dữ liệu nào có sẵn: kiểu color_t, những giá trị có thể của kiểu color_t được viết trong cặp ngoặc nhọn {}. Ví dụ, sau khi khai báo kiểu liệt kê, biểu thức sau sẽ là hợp lệ: colors_t mycolor;mycolor = blue;if (mycolor == green) mycolor = red;
Trên thực tế kiểu dữ liệu liệt kê được dịch là một số nguyên và các giá trị của nó là các hằng số nguyên được chỉ định. Nếu điều này không đựoc chỉ định, giá trị nguyên tương đương với phần tử đầu tiên là 0 và các giá trị tiếp theo cứ thế tăng lên 1, Vì vậy, trong kiểu dữ liệu colors_t mà chúng ta định nghĩa ở trên, white tương đương với 0, blue tương đương với 1, green tương đương với 2 và cứ tiếp tục như thế.
Nếu chúng ta chỉ định một giá trị nguyên cho một giá trị nào đó của kiểu dữ liệu liệt kê (trong ví dụ này là phần tử đầu tiên) các giá trị tiếp theo sẽ là các giá trị nguyên tiếp theo, chẳng hạn: enum months_t { january=1, february, march, april,
57

may, june, july, august, september, october, november, december} y2k;trong trường hợp này, biến y2k có kiểu dữ liệu liệt kê months_t có thể chứa một trong 12 giá trị từ january đến december và tương đương với các giá trị nguyên từ 1 đến 12, không phải 0 đến 11 vì chúng ta đã đặt january bằng 1.Ví dụ 31: Chương trình sau kết hợp giữa kiểu liệt kê và kiểu cấu trúc để tính lương cho một tuần làm việc. Chủ nhật được tính giờ gấp đôi, thứ năm được tính 1,25 giờ cho một giờ làm. Giá tiền trả cho một giờ lương là 1,1 USD.#include"stdio.h"enum luong_tuan {Thu_Hai,Thu_Ba,Thu_tu,Thu_Nam,Thu_Sau,Thu_Bay,Chu_Nhat};char *thu[]={"Thu Hai","Thu Ba","Thu Tu","Thu Nam","Thu Sau","Thu Bay","Chu Nhat"};void main()
{enum luong_tuan ngay;char ten[8];float luong=0;int gio;clrscr();printf("\nCho biet ten : ");scanf("%s",&ten);for (ngay=Thu_Hai; ngay <=Chu_Nhat;ngay++)
{printf("\n- Gio lam viec trong ngay: %s la=
",thu[(int)ngay]);scanf("%d",&gio);switch (ngay)
{case Thu_Nam: luong+=1.25*gio; break;case Chu_Nhat: luong+=2*gio; break;default : luong+=1.1*gio; break;
}}
printf("\n Ong ( Ba ) : %s ",ten);printf("\n-Se nhan duoc tien luong trong tuan la = ");printf("%d dollars va %0.2f cents",(int)luong,luong-(int)luong);getch();
}
BÀI TẬPBài tập 1: Hãy viết chương trình nhập vào một dãy các số nguyên. Lưu dãy số nguyên này vào file.Bài tập 2: Tìm kiếm một số nguyên trong dãy các số nguyên có trong file ở bài tập 1.
58

Bài tập 3: Viết chương trình giải hệ phương trình dùng phương pháp Gauss-Jordan.Bài tập 4: Viết chương trình quản lý sách trong thư viện.Bài tập 5: Viết chương trình đọc hai ma trận vuông từ hai tập tin. Thực hiện các phép toán:
a) Nhân hai ma trận.b) Cộng hai ma trận.c) Tính đa thức ma trận.d) Trừ hai ma trậne) Tính AT
Bài tập 6: Vẽ sơ đồ các kiểu dữ liệu đã học trong bài.Bài tập 7: Viết chương trình với hai tập tin, một tập tin dùng để mã hóa, một tập tin chứa dữ liệu. Thực hiện, đọc tập tin dữ liệu và đọc tập tin mã hóa, sau đó dùng phép toán XOR để mã hóa từng ký tự đọc được lưu lại vào tập tin thứ 3.
59

BÀI 3 :HÀM THỦ TỤCMã bài: MĐ39-03
Giới thiệuKhái niệm chương trình con (sub-program hay sub-routine) ra đời từ rất sớm
vào những năm 1950. Mà sau đó chương trình con dạng hàm hay thủ tục đã được sử dụng rộng rãi trong các ngôn ngữ lập trình, đặc biệt là các ngôn ngữ lập trình mệnh lệnh. Cho đến ngày nay, khi mà các ngôn ngữ lập trình rất pgong phú đa dạng thì khái niệm này vẫn tồn dưới nhiều hình thức khác nhau.
Mục tiêu thực hiện- Hiểu rõ cơ chế thực hiện của chương trình con dạng hàm và thủ tục- Phân biệt và sử dụng đúng các dạng tham số- Nắm cấu trúc chuẩn của một chương trình con- Hiểu được tính ưu việt của các chương trình con- Nắm được cách xây dựng và sử dụng chương trình con trong ngôn ngữ lập
trình Pascal- Nắm được khái niệm đệ quy
Nội dung chínhTrình bày hai khái niệm hàm và thủ tục. Nêu bật ưu điểm của hàm và thủ tục. Trình bày cách xây dựng hàm và thủ tục trong ngôn ngữ lập trình Pascal.
1. Khái niệm chương trình con
Khái niệm chương trình con (sub-program hay sub-routine) được ra đời từ rất sớm vào những năm 1950, khi mà ngôn ngữ để lập trình mới chỉ là ngôn ngữ máy. Do việc, viết chương trình bằng các bit nhị phân là rất phức tạp, khó khăn, người ta đã nghĩ đến việc xây dựng sẵn các đoạn chương trình thường hay sử dụng. Các đoạn chương trình này chính là tiền thân cho khái niệm chương trình con.Chương trình con thực ra là những đoạn chương trình (dãy các câu lệnh) thường được hay sử dụng lặp đi lặp lại trong khi lập trình. Để giảm bớt thời gian lập trình, người ta xây dựng sẵn các thư viện chứa các chương trình con mà sau đó các chương trình con này có thể được sử dụng nhiều lần.
Ví dụ, tính cos hay sin là các công việc thường hay gặp trong toán học. Thế thì thay vì mỗi lần cần đến ta phải thực hiện tính toán, ta có thể xây dựng sẵn các chương trình con cho phép thực hiện công việc tính toán này và sau đó chỉ việc sử dụng. Trong thực tế, trong hầu hết tất cả các ngôn ngữ lập trình các công việc thường được lặp đi lặp lại như thế này đều được xây dựng sẵn thành các chương trình con chứa trong các thư viện dành cho người sử dụng. Ngoài ra trong quá trình lập trình, người lập trình có thể tự xây dựng cho mình các chương trình con được sử dụng nhiều lần trong một chương trình.
Khái niệm chương trình con có hầu hết trong các ngôn ngữ lập trình, mà có thể tên gọi của nó bị thay đổi đi chút ít, như: hàm, thủ tục, thao tác, phương thức, ... Đặc biệt trong các ngôn ngữ lập trình mệnh lệnh (như Pascal) thì chương trình con được chia làm hai loại: hàm (function) và thủ tục (procedure).
60

Trong bài học này chúng ta sẽ tìm hiểu về hai loại chương trình con này thông qua ngôn ngữ lập trình Pascal, là một ngôn ngữ mang tính sư phạm cao và thể hiện rất rõ hai khái niệm này.
2. Xây dựng hàm và thủ tục
Trước hết hàm hay thủ tục đều là những đoạn chương trình thường được sử dụng lặp đi lặp lại. Thế sự khác nhau giữa hai khái niệm này là gì?
Hàm sau khi thực hiện xong công việc thì tra về một giá trị thông qua tên hàm, trong khi thủ tục không trả về giá trị nào cả.
Ví dụ, hàm binhphương tính giá trị bình phương của một số nguyên sẽ trả về giá trị đó qua tên hàm. Trong khi thủ tục xuatmanhinh thực hiện việc in ra màn hình một kết quả tính toán nào đó thì nó không trả về một giá trị nào cả.
Trong ngôn ngữ Pascal, các chương trình con phải được khai báo và viết bên trên thân chương trình, sau đó được sử dụng trong thân chương trình.
Cú pháp tổng quát để viết một hàm trong Pascal như sau:
Function tên_hàm (khai báo các tham số hình thức) : kiểu_trả_về_của_hàm;(* Các khai báo hằng, biến cục bộ *)Begin
(*thân hàm*)tên_hàm := biểu_thức; (* gán giá trị trả về *)
End;Khi khai báo một hàm, nếu hàm đó có sử dụng các hằng hay biến cục bộ thì
phải khai báo sau khi khai báo hàm. Ở đây chúng ta thấy xuất hiện khái niệm biến cục bộ (local variable) là các biến được khai báo bên trong một hàm (hay thủ tục). Trong thân hàm luôn phải có phép gán giá trị trả về cho tên hàm.
Ví dụ, viết hàm tính tổng của 3 số thực:Function tong3so (x, y, z : real) : real;
Begintong3so := x + y + z;
End;Đây là hàm rất đơn giản, nhận 3 giá trị số thực và trả về tổng của chúng. Đối
với hàm này không có các khai báo thêm hằng, biến cục bộ. Hàm được bắt đầu bởi từ khóa Function, sau đó là tên hàm tong3so. Hàm nhận 3 tham số hình thức là x, y, z có kiểu real và trả về giá trị kiểu real. Thân hàm gồm các câu lệnh được đặt giữa hai từ khóa Begin và End. Giá trị tổng 3 số thực được gán trực tiếp cho tên hàm trong thân hàm.
Dưới đây là một ví dụ khác, chương trình có chứa hàm tính giá trị lớn nhất của hai số thực. Hàm được sử dụng trong thân chương trình để tính giá trị lớn nhất của các biểu thức a+b và a-b.
Program vi_du_max;Var
a, b, s : real;(*Khai báo hàm max2so*)Function max2so(x, y : real) : real;
Var
61

r : real; (* khai báo biến cục bộ *)Begin
if x > y then r := xelse r := y;max2so = r;
End;(*Thân chương trình chính*)Begin
a := 11.45b := -42.7s := max2so(a+b, a-b); (* gọi chương trình hàm *)Writeln(‘Max = ’, s:5:1);
End.Như thế, chúng ta nhận thấy hàm luôn trả về một giá trị trong tên hàm. Trong
khi định nghĩa hàm thì phải gán tên hàm cho giá trị trả về. Ngược lại, thủ tục không trả về giá trị. Cú pháp tổng quát để viết một thủ tục trong Pascal là như sau:Procedure tên_thủ_tục (khai báo các tham số hình thức);
(* Các khai báo hằng, biến cục bộ*)Begin
(*thân thủ tục*)End;Bây giờ chúng ta viết lại chương trình tính giá trị lớn nhất hai số thực sử dụng
chương trình con là thủ tục như sau:Program vi_du_max;Var
a, b : real;(*Khai báo thủ tục max2so*)Procedure max2so(x, y : real);
Varr : real; (* khai báo biến cục bộ *)
Beginif x > y then r := xelse r := y;Writeln(‘Max = ’, r:5:1);
End;
(*Thân chương trình chính*)Begin
a := 11.45b := -42.7max2so(a+b, a-b); (* gọi chương trình thủ tục *)
End.Trong ngôn ngữ Pascal, còn cho phép viết các chương trình con bên trong thân một chương trình con khác. Chẳng hạn, chúng ta xem xét ví dụ thủ tục M sau:
62

(* khai báo thủ tục M*)Procedure M (x, y : real);
Vars : real; (* biến cục bộ của thủ tục M*)
(* khai báo hàm M1 bên trong thân thủ thủ tục M*)Function M1 (m, n : real) : real; Var
r : real; (* biến cục bộ của thủ tục M1*) Begin
if m > n then r := melse r := n;M1 := r;
End;
(* khai báo thủ tục M2 bên trong thân thủ tục M*)Procedure M2 (a : real); Begin
Writeln(‘In ket qua : ’, a:5:1); End;
(* thân của thủ tục M *)Begin
s := M1(x, y); (* gọi hàm M1*)M2(s); (* gọi thủ tục M2*)
End;Trong ví dụ này, bên trong thân của thủ tục M chứa hai chương trình con khác
là hàm M1 và thủ tục M2. Sau đó, trong thân của thủ tục M sử dụng hai chương trình con này.
Lưu ý là không phải ngôn ngữ lập trình nào cũng cho phép khai báo các chương trình con bên trong chương trình con khác, chẳng hạn như ngôn ngữ C không cho phép điều này.
3. Cơ chế hoạt động của chương trình con
Liên quan đến chương trình con (hàm và thủ tục ở trên), chúng ta có một số khái niệm sau:
- Biến cục bộ: là biến được khai báo và chỉ sử dụng bên trong thân một chương trình con, là biến r trong ví dụ trên.
- Biến toàn cục: là biến được khai báo ở đầu chương trình và có thể được sử dụng bất cứ đâu trong chương trình, là các biến a và b trong ví dụ trên.
- Tham số hình thức (hay còn được gọi là đối): là các biến được khai báo sau tên của chương trình con (chúng ta sẽ được giới thiệu chi tiết hơn về tham số hình thức trong các phần tiếp theo), là các tham số x và y trong ví dụ trên.
63

- Tham số thực: là các giá trị truyền cho các tham số hình thức tương ứng khi gọi các chương trình con. Chẳng hạn, trong ví dụ trên là các giá trị của biểu thức a+b và a-b.
Cơ chế hoạt động của một chương trình con là như sau: chương trình được batứ đầu từ câu lệnh đầu tiên và kết thúc khi thực hiện xong câu lệnh cuối cùng trong thân chương trình, nếu chương trình gặp một lời gọi chương trình con (thủ tục hay hàm) thì máy sẽ thực hiện:
- cấp phát bộ nhớ cho các biến cục bộ của chương trình con,- truyền giá trị của các tham số thực cho các tham số hình thức tương ứng,- thực hiện lần lượt các câu lệnh trong thân chương trình con,- giải phóng các biến cục bộ và trở về nơi gọi nó, nếu chương trình con là hàm
thì khi trở về mang theo một giá trị.Quay trở lại chương trình chứa thủ tục max2so trên, hoạt động của nó là như sau:
- gán giá trị 11.45 cho biến a và –42.7 cho biến b,- gặp lời gọi thủ tục max2so, thực hiện thủ tục max2so:
o cấp phát bộ nhớ cho biến cục bộ r và các tham số hình thức x và y,o giá trị của biểu thức a+b và a-b được truyền cho các tham số hình thức x
và y,o thực hiện các câu lệnh trong thân thủ tục để tính giá trị lớn nhất chứa
trong biến r,o gọi thủ tục Writeln để in ra kết quả,o giải phóng các biến cục bộ r và tham số hình thức x, y,o máy thoát ra khỏi thủ tục để trở về chương trình chính,
- kết thúc chương trình chính.
4. Biến toàn cục và biến cục bộ
Ở trên chúng ta đã nhắc đến hai khái niệm biến cục bộ và biến toàn cục, trong phần này chúng ta sẽ xem xét một cách chi tiết hơn.Biến toàn cục (global variable) là những biến được khai báo ở đầu chương trình, chúng tồn tại trong suốt thời gian làm việc của chương trình. Biến toàn cục được sử dụng bất kì đâu ở trong chuơnưg trình, nghĩa là trong thân chương trình chính hoặc trong các thân chương trình con.
Biến cục bộ (local variable) là biến được khai báo ở đầu một chương trình con. Biến cục bộ được cấp phát bộ nhớ khi chương trình con được gọi tới và bị giải phóng khỏi bộ nhớ khi máy ra khỏi chương trình con. Biến cục bộ chỉ được sử dụng bên trong thân của chương trình con khai báo nó cũng như các chương trình con khác nằm bên trong thân của chương trình con khai báo nó.
Để phân biệt rỏ sự khác nhau của biến cục bộ và biến toàn cục, chúng ta quan sát ví dụ sau:
Program cac_loai_bien;Var
x : integer; (* x là biến toàn cục *)(* Khai báo thủ tục M *)Procedure M;
64

Vara, b : integer; (* a và b là biến cục bộ trong M *)
(* Khai báo thủ tục M1 *) Procedure M1;
Var n : inetger; (* n là biến cục bộ trong M1 *)Begin
x := x + 1; (* sử dụng biến toàn cục x *)n := a + b;Writeln(‘n = ’, n);a := a + 1;b := b + 1;
End; (* Thân thủ tục M *) Begin
a := 1;b := 5;Writeln(‘a = ’, a);Writeln(‘b = ’, b);M1; (* gọi thủ tục M1 *)Writeln(‘a = ’, a);Writeln(‘b = ’, b);
End;(* Thân chương trình chính *)Begin
x := 10;Writeln(‘x = ’, x);M; (* gọi thủ tục M *)Writeln(‘x = ’, x);
End.Trong ví dụ này, chương trình chính chứa thủ tục M, thủ tục M lại chứa thủ tục
M1. x là biến toàn cục được khai báo ở đầu chương trình chính, x có thể được sử dụng bất kỳ đâu trong chương trình. a và b là các biến cục bộ khai báo đầu thủ tục M, nên a và b chỉ có thể được sử dụng trong thân thủ tục M và thủ tục M1. n là biến cục bộ khái báo trong thủ tục M1, nên m chỉ có thể được sử dụng trong thân thủ tục M1.Hoạt động của chương trình này là như sau:
- bắt đầu chương trình chính, biến x được gán giá trị 10, - in x ra màn hình, - gọi thủ tục M, thực hiện các câu lệnh trong thân thủ tục M,
o gán biến a bằng 1 và biến b bằng 5,o in ra màn hình giá trị các biến a và b,o gọi thủ tục M1, thực hiện các câu lệnh trong thân thủ tục M1,
biến toàn cục x được tăng lên một đơn vị, gán biến cục bộ n bằng giá trị biểu thức a+b,
65

in n ra màn hình, tăng mỗi biến cục bộ a và b của thủ tục M lên một đơn vị, kết thúc thủ tục M1, quay trở về thủ tục M,
o in ra giá trị của các biến cục bộ a và b,o kết thúc thủ tục M, quay trở về chương trình chính,
- in ra giá trị của biến cục bộ x và kết thúc chương trình.Kết quả của chương trình trên là:
x = 10a = 1b = 5n = 6a = 2b = 6x = 11
Nhận xét: - Biến cục bộ và tham số hình thức có cơ chế hoạt động giống nhau, chúng chỉ
tồn tại trong thời gian chương trình con hoạt động.- Biến toàn cục có thể bị thay đổi giá trị bất cứ đâu trong chương trình, điều này
dẫn đến việc sử dung tùy tiện các biến toàn cục sẽ làm cho chương trình rất phức tạp, khó gỡ rối khi có lỗi xảy ra. Vì vậy, nên hạn chế sử dụng biến toàn cục.
5. Cơ chế truyền tham số
Ở trong các phần trên, chúng ta đã được giới thiệu cách xây dựng các chương trình con. Sau đó, chúng ta có thể sử dụng (lời gọi chương trình con) chương trình con. Mỗi khi sử dụng chương trình con, thông thường đều phải truyền dữ liệu cho nó. Có các cách truyền dữ liệu cho chương trình con khác nhau sau:
- truyền tham số dạng biến toàn cục,- truyền tham số dạng tham trị,- truyền tham số dạng tham biến.
Truyền tham số dạng biến toàn cụcDo phạm vi sử dụng của biến toàn cục là bất kỳ mọi nơi trong chương trình nen
ta có thể sử dụng chúng đẻ truyền dữ liệu cho các chương trình con cũng như nhận kết quả tính được từ các chương trình con.
Ví dụ chương trình giải phương trình bậc hai (ax2 + bx + c = 0) dưới đây truyền tham số bằng biến toàn cục. Trong ví dụ này, để giảm bớt phức tạp, chúng ta không xét đến các trường hợp suy biến của phương trình bậc 2.
Program Phuong_trinh_bac_2;Var
a, b, c, x1, x2, delta : real;Procedure gptb2;
Var r : real;Begin
delta := b*b – 4*a*c;
66

if delta >= 0 then Begin
r := sqrt(delta);x1 := (-b-r)/(2*a);x2 := (-b+r)/(2*a);
End;End;
(* Thân chương trình *)Begin
Write(‘a = ’); readln(a);Write(‘b = ’); readln(b);Write(‘c = ’); readln(c);gptb2; (* gọi thủ tục gptb2 *)if (delta < 0) then
Writeln(‘Phương trình vô nghiệm’);if (delta = 0) then
Writeln(‘Phương trình có nghiệm kép: ’, x1:5:2);if (delta > 0) then
Writeln(‘Phương trình có hai nghiệm: x1 = ’, x1:5:2, ‘x2 = ’, x2:5:2);End.
Trong ví dụ trên, thủ tục gptb2 sử dụng 6 biến toàn cục của chương trình chính , các biến a, b, c truyền dữ liệu cho thủ tục, còn các biến x1, x2, delta nhận giá trị từ thủ tục.
Nhận xét: Cách truyền tham số dùng biến toàn cục rất là đơn giản, tuy nhiên phương pháp này có nhược điểm rất lớn: vì chương trình con sử dụng biến toàn cục nên khi viết chương trình con phải luôn luôn nhớ toiư các biến này, nếu có sự thay đổi biến toàn cục trong chương trình chính thì phải thay đổi tương ứng trong chương trình con. Ngoài ra, cách sử dụng biến toàn cục như thế này rất khó để kiểm soát giá trị của chúng nên điều này thường dẫn đến sai sót.
Do những nhược điểm như vây, nên người ta khuyến khích người lập trình không sử dụng phương pháp truyền tham số bằng biến toàn cục. Phương pháp dưới đây sẽ khắc phục nhược điểm trên.
Truyền tham số dạng tham trịChúng ta cần nhắc lại rằng, đối với chương trình con có hai loại tham số. Tham
số hình thức là các biến khai báo sau tên chương trình con, tham số thực là các giá trị hay biến truyền cho các tham số hình thức tương ứng khi gọi chương trình con.
Tham số hình thức được chia làm hai dạng: tham trị và tham biến. Trước hết chúng ta sẽ xét đến dạng tham trị.
Các tham số hình thức dạng tham trị được khai báo sau tên chương trình con giữa hai dấu ngoặc theo mẫu sau:danh_sách_tham_số : kiểu; danh_sách_tham_số : kiểu; ...Ví dụ:
Function ham (x, y : real; a, b : real) : real;Procedure thutuc (x : real; a, b, c : real);
67

Khi có lời gọi chương trình con, các tham số thực sẽ được truyền cho các tham số hình thức. Các tham số thực phải là một biểu thức cùng kiểu với tham số hình thức tương ứng. Chẳng hạn, nếu tham số hình thức có kiểu nguyên thì tham số thực phải là một biểu thức kiểu nguyên.
Bây giờ chúng ta viết lại chương trình giải phương trình bậc 2 sử dụng tham số dạng tham trị như sau:
Program Phuong_trinh_bac_2;Var x, y, z : real;Procedure gptb2(a, b, c : real);
Varx1, x2, delta, r : real;Begin
delta := b*b – 4*a*c;if delta < 0 then
Writeln(”Phương trình vô nghiệm”);else Begin
r := sqrt(delta);x1 := (-b-r)/(2*a);x2 := (-b+r)/(2*a);if (delta = 0) then
Writeln(‘PT có nghiệm kép: ’, x1:5:2);if (delta > 0) then
Writeln(‘PT có hai nghiệm: x1 = ’, x1:5:2, ‘x2 = ’, x2:5:2); End;
End;(* Thân chương trình chính *)Begin
Write(‘x = ’); readln(x);Write(‘y = ’); readln(y);Write(‘z = ’); readln(z);gptb2(x, y, z); (* gọi thủ tục gptb2 *)
End.Cơ chế hoạt động của một chương trình sử dụng tham số dạng tham trị là như
sau: khi chương trình gặp một lời gọi tới chương trình con, máy sẽ:- cấp phát bộ nhớ cho biến cục bộ và các tham số hình thức dạng tham trị của
chương trình con, trong ví dụ trên là cấp phát cho các biến x1, x2, delta, r và các tham số hình thức a, b, c,
- truyền giá trị của các tham số thực cho các tham số dạng tham trị tương ứng, các giá trị x, y, z, được truyền vào tương ứng cho a, b, c,
- thực hiện các câu lệnh trong chương trình con,- kết thúc chương trình con, máy sẽ giải phóng các biến cục bộ và các tham số
hình thức, như thế các giá trị đặt trong các biến cục bộ và các tham số hình thức không thể đưa về để sử dụng trong một chương trình khác.
68

Nhận xét: các tham số hình thức dạng tham trị chỉ được sử dụng trong chương trình con khai báo chúng.
Truyền tham số dạng tham biếnTrong ví dụ trên, các nghiệm của phương trình được in ra ngay trong thủ tục. Tuy nhiên, nếu chúng ta muốn chương trình phải trả về nghiệm của phương trình và việc in sẽ được thực hiện trong chương trình chính thì cách sử dụng tham số dạng tham trị không giải quyết được. Trong trường hợp này, chúng ta sử dụng tham số dạng tham biến, tức là giá trị của tham số vẫn được sử dụng sau khi ra khỏi chương trình con.Các tham số dạng tham biến được khai báo sau tên chương trình con giữa hai dấu ngoặc theo mẫu sau (với từ khóa Var):Var danh_sách_tham_số : kiểu; Var danh_sách_tham_số : kiểu; ...Ví dụ:
Function (x,y : real; Var a : real; Var p,q : real) : real;Khi có lời gọi chương trình con, các tham số thực sẽ được truyền cho các tham
số hình thức. Các tham số thực phải là một biến hay phần tử mảng có cùng kiểu với tham số hình thức tương ứng. Chẳng hạn, nếu tham số hình thức có kiểu nguyên thì tham số thực phải là một biến kiểu nguyên.
Chúng ta viết lại chương trình giải phương trình bậc 2, trong đó thủ tục gptb2 nhận 3 tham số dạng tham trị là a, b, c, trả về ba giá trị bởi tham biến là delta, x1, x2.
Program Phuong_trinh_bac_2;Var x, y, z, d, n1, n2 : real;Procedure gptb2(a, b, c : real; Var delta, x1, x2 : real);
Var r : real;Begin
delta := b*b – 4*a*c;if delta >= 0 then Begin
r := sqrt(delta);x1 := (-b-r)/(2*a);x2 := (-b+r)/(2*a);
End; End;(* Thân chương trình chính *)Begin
Write(‘x = ’); readln(x);Write(‘y = ’); readln(y);Write(‘z = ’); readln(z);gptb2(x, y, z, d, n1, n2); (* gọi thủ tục gptb2 *)if (d < 0) then
Writeln(‘Phương trình vô nghiệm’);if (d = 0) then
Writeln(‘Phương trình có nghiệm kép: ’, n1:5:2);if (d > 0) then
Writeln(‘Phương trình có hai nghiệm: x1 = ’, n1:5:2, ‘x2 = ’, n2:5:2);End.
69

Đối với chương trình con sử dụng tham số dạng tham biến, thì khi gặp lời gọi chương trình con, máy sẽ:
- cấp phát bộ nhớ cho các biến cục bộ và các tham số dạng tham trị và tham biến,
- truyền giá trị của tham số thực cho các tham số dạng tham trị tương ứng,- truyền địa chỉ của các biến tham số thực cho các tham số dạng tham biến,- thực hiện các câu lệnh trong thâm chương trình con
Như thế, đối với các tham số dạng tham biến, thay vì truyền giá trị của tham số thực thì phải truyền địa chỉ của biến tham số thực. Vì vậy, mọi sự thay đổi giá trị của tham biến trong chương trình con sẽ kéo theo sự thay đổi của biến tham số thực. Trong ví dụ trên, mọi thay đổi giá trị trên các biến d, n1, n2 trong chuơng trình con cũng sẽ có hiệu lực sau khi đã thoát ra khỏi chương trình con.
Đệ quyMột chương trình con được gọi là đệ quy (recursivity) nếu trong thân chương
trình con đó có lời gọi đến chính nó. Nhiều ngôn ngữ lập trình cho phép xây dựng các chương trình con đệ quy.Chúng ta lấy ví dụ tính giai thừa của một số nguyên n. Giai thừa n được định nghĩa như sau:
n! = 1.2.3...(n-1).nhoặc
1 nếu n = 0n! =
n.(n-1)! nếu n1Trong cách định nghĩa sau, cách tính n! phụ thuộc vào (n-1)!. Với định nghĩa
này chúng ta xây dựng hàm đệ quy tính n! bằng ngôn ngữ Pascal như sau:Function giai_thua1(n : longint) : longint;
Beginif n = 0 then giai_thua1 := 1;else giai_thua1 := n * giai_thua1(n-1);
End;Như thế, chúng ta nhận thấy hàm giai_thua1 được gọi trong khi định nghĩa
chính nó. Mỗi lời gọi đệ quy cũng như lời gọi chương trình con, máy phải cấp phát bộ nhớ cho các biến cục bộ, và sau khi kết thúc thì phải giải phóng chúng. Với một chương trình con đệ quy thì có thể có nhiều lần gọi, vì vậy có bao nhiêu lần gọi thì cũng có bấy nhiêu lần cấp phát và giải phóng các biến cục bộ. Quá trình giải phóng các biến cục bộ được thực hiện theo thứ tự ngược lại quá trình cấp phát chúng: các biến cục bộ được tạo ra trước sẽ được giải phóng sau.Như thế, đối với một chương trình con đệ quy thì sẽ cần rất nhiều bộ nhớ cho các biến cục bộ. Thậm chí nếu chương trình con đệ quy thực hiện lời gọi đệ quy không dừng thì sẽ dẫn đến tình trạng tràn bộ nhớ. Chẳng hạn, nếu người sử dụng gọi hàm giai_thua1 trên như sau:
n = giai_thua1(-1);thì sẽ bị lỗi tràn bộ nhớ.Tuy nhiên, chúng ta có thể dễ dàng nhận thấy rằng để tính n! chúng ta có thể sử dụng vòng lặp thay vì đệ quy như sau:
Function giai_thua2(n : longint) : longint;
70

Var i, gt : longint;Begin
gt := 1;if n > 0 then
for i : = 1 to n do gt := gt * i;giai_thua2 := gt;
End;Bây giờ nếu, chúng ta phân tích hai lời gọi chương trình con sau:
n = giai_thua1(100);n = giai_thua2(100);
Với lời gọi thứ nhất, hàm giai_thua1 được gọi đệ quy đến 100 lần, và mỗi lần gọi cần cấp phát 4 byte cho tham số n kiểu longint, như thế cần 400 byte bộ nhớ. Trong khi với lời gọi thứ hai, hàm giai_thua2 chỉ được gọi 1 lần, chỉ cần cấp phát 12 byte bộ nhớ cho tham số n và hai biến cục bộ i, gt kiểu longint.Một ví dụ thứ hai minh họa chương trình con đệ quy. Ước số chung lớn nhất của hai số nguyên a và b được xác định theo công thức:
- nếu x = y thì usc(x, y) = x- nếu x > y thì usc(x, y) = usc(x-y, y)- nếu x < y thì usc(x, y) = usc(x, y-x)
Hàm đệ quy usc được viết như sau:Function usc(a, b : int) : int;
Beginif x = y then usc := x;else if x > y then usc := usc(x – y, y);else usc := usc(x, y - x);
End;Nhận xét: Phương pháp đệ quy cho phép viết chương trình ngắn gọn đơn giản, nhưng lại không hiệu quả về mặt sử dụng tài nguyên bộ nhớ.
6. Tính ưu việt của chương trình con
Hầu hết tất cả các ngôn ngữ lập trình đều sử dụng khái niệm chương trình con. Chương trình con chỉ định nghĩa một lần nhưng sao đó được sử dụng nhiều lần. Việc viết chương trình sử dụng chương trình con chúng ta nhận thấy có các ưu điểm sau:
- giảm bớt số dòng lệnh của một chương trình,- giảm thời gian lập trình,- giảm độ phức tạp của chương trình,- chương trình được tổ chức theo dạng tập hợp các chương trình con, nên dễ
quản lý hơn,- dễ sữa đổi chương trình khi cần thiết,- dễ kiểm tra lỗi.
Bài tập1. Hai khái niệm hàm và thủ tục khác nhau chổ nào?2. Tại sao không nên sử dụng biến toàn cục?
71

3. Viết thủ tục giải phương trình trùng phương ax4 + bx2 + c = 0.4. Viết hàm tính giá trị lớn nhất (nhỏ nhất) của một dãy số.5. Viết hàm hay thủ tục giải hệ phương trình bậc nhất:
ax + by = pcx + dy = q
6. Viết hàm đệ quy tính:P(n) = 1 + 22 + 32 + ... + n2
7. Viết chương trình sử dụng hàm đệ quy đẻ tạo ra dãy số Fibonacci F1, F2, ... Fn được định nghĩa như sau:
F1 = 1, F2 = 1Fn = Fn-1 + Fn-2
Ví dụ: 1, 1, 2, 3, 5, 8, 13, 21, ...8. Hãy viết lại hàm tính ước số chung lớn nhất của hai số nguyên sử dụng vòng
lặp.
72

BÀI 4: ĐẶC TRƯNG CÚ PHÁP VÀ NGỮ NGHĨA CHƯƠNG TRÌNHMã bài:MĐ39-04
Giới thiệuBài học sẽ trình bày tổng quan các vấn đề liên quan đến ngôn ngữ lập trình.
Chẳng hạn, một ngôn ngữ lập trình được xây dựng như thế nào, làm sao để máy tính có thể hiểu được một chương trình nào đó, … Như thế, việc hiểu được bản chất của ngôn ngữ lập trình sẽ giúp cho người lập trình viết các chương trình hữu hiệu hơn.
Mục tiêu thực hiện- Hiểu được cú pháp của các ngôn ngữ
- Nắm các đặc trưng mang tính ngữ nghĩa của chương trình
- Nắm các tiền đề cho sự phát triển của chương trình qua ngữ pháp và ngữ nghĩa
- Viết chương trình có khả năng thân thiện hơn
Nội dung chínhTrình bày ngắn gọn cách định nghĩa, xây dựng một ngôn ngữ lập trình, cách phân tích một chương trình, các thành phần cần thiết để phân tích một chương trình.
1. Khái niệm ngôn ngữ
Một ngôn ngữ dù là ngôn ngữ tự nhiên như tiếng Việt hay là ngôn ngữ lập trình như Pascal, cũng đều có thể xem là một tập hợp các câu có cấu trúc quy định nào đó. Cấu trúc câu được quy định ra sao thì đó là vấn đề cách biểu diễn ngôn ngữ. Chúng ta có thể nhận xét thấy rằng, một câu của ngôn ngữ, dù là câu tiếng Việt “bạn đi học” hay cả một văb bản chương trình từ chữ “Program” cho đến dấu chấm “.” kết thúc chương trình, thì cũng đều chẳng qua là một dãy các xâu/từ có sẵn như “bạn”, “đi”, “học”, hay “Program”, … được liệt kê trong một bảng chữ nào đó, mà ta có thể xem là các kí hiệu cơ bản của ngôn ngữ.Từ nhận xét trên đây, chúng ta đi đến một số khái niệm hình thức về ngôn ngữ như dưới đây.Bảng chữ (alphabet) là một tập hợp các kí hiệu. Ví dụ:
{a, b, c, .., z} : bảng chữ cái Latin{0,1, 2, .., 9} : bảng chữ số thập phân{0,1} : bảng chữ số nhị phân
Xâu (string) là một dãy hữu hạn các kí hiệu từ bảng chữ cái.Ví dụ, với bảng chữ {0, 1} thì các xâu là 0, 1, 00, 01, 11, 001, 000, …
Một cách không hình thức, ngôn ngữ (language) là một tập hợp các xâu trên một bảng chữ cái.Ví dụ, với bảng chữ {0, 1} thì ngôn ngữ trên bảng chữ này là tập hợp {0, 1, 00, 01, 11, 001, 000, …}.
Cụ thể, ngôn ngữ lập trình là một hệ thống gồm các kí hiệu và các quy tắc kết hợp các kí hiệu thành một cấu trúc có ý nghĩa. Phần cú pháp (syntax) qui định sự kết hợp các kí hiệu, còn phần ngữ nghĩa qui định ý nghĩa của mỗi sự kết hợp đó.Sau đây là một ví dụ về các khía cạnh cú pháp và ngữ nghĩa trong ngôn ngữ lập trình. Chúng ta có các biểu thức sau:
bt1 = 2
73

bt2 = 1 + 1bt3 = 1 * 2
Cả ba biểu thức trên có cùng giá trị, tức giống nhau về mặt ngữ nghĩa, tuy nhiên chúng khác nhau về mặt cú pháp.
1.1. Định nghĩa cú phápTrước hết, phần này sẽ trình bày chi tiết hơn về khai niệm cú pháp, văn phạm là
cơ chế để mô tả ngôn ngữ.1.2 Văn phạm phi ngữ cảnhÐể xác định cú pháp của một ngôn ngữ, người ta dùng văn phạm phi ngữ cảnh CFG (Context Free Grammar).Văn phạm phi ngữ cảnh bao gồm bốn thành phần:
1. Một tập hợp các token , gọi là các ký hiệu kết thúc (terminal symbols). Ví dụ: Các từ khóa, các chuỗi, dấu ngoặc đơn, ...
2. Một tập hợp các ký hiệu chưa kết thúc (nonterminal symbols), còn gọi là các biến (variables)
Ví dụ: Câu lệnh, biểu thức, ...3. Một tập hợp các luật sinh (productions) trong đó mỗi luật sinh bao gồm một
ký hiệu chưa kết thúc - gọi là vế trái, một mũi tên và một chuỗi các token và / hoặc các ký hiệu chưa kết thúc gọi là vế phải.
4. Một trong các ký hiệu chưa kết thúc được dùng làm ký hiệu bắt đầu của văn phạm. Chúng ta qui ước: - Mô tả văn phạm bằng cách liệt kê các luật sinh.- Luật sinh chứa ký hiệu bắt đầu sẽ được liệt kê đầu tiên.- Nếu có nhiều luật sinh có cùng vế trái thì nhóm lại thành một luật sinh duy nhất, trong đó các vế phải cách nhau bởi ký hiệu “ | “ đọc là “hoặc”.Ví dụ 4.1: Xem biểu thức là một danh sách của các số phân biệt nhau bởi dấu + và dấu -. Ta có, văn phạm với các luật sinh sau sẽ xác định cú pháp của biểu thức.list list + digitlist list – digitlist digit digit 0 | 1 | 2 | ...| 9Như vậy văn phạm phi ngữ cảnh ở đây là:- Tập hợp các ký hiệu kết thúc: 0, 1, 2, ..., 9, +, -- Tập hợp các ký hiệu chưa kết thúc: list, digit.- Các luật sinh đã nêu trên.- Ký hiệu chưa kết thúc bắt đầu: list. Ví dụ 4.2Từ ví dụ 2.1 ta thấy: 9 - 5 + 2 là một list vì: 9 là một list vì nó là một digit. 9 - 5 là một list vì 9 là một list và 5 là một digit. 9 - 5 + 2 là một list vì 9 - 5 là một list và 2 là một digit.
Ví dụ 4.3:
Một list là một chuỗi các lệnh, phân cách bởi dấu ; của khối begin - end trong Pascal. Một danh sách rỗng các lệnh có thể có giữa begin và end.
74

Chúng ta xây dựng văn phạm bởi các luật sinh sau: block begin opt_stmts end opt_stmts stmt_list | stmt_list stmt_list ; stmt | stmtTrong đó opt_stmts (optional statements) là một danh sách các lệnh hoặc không có lệnh nào ().Luật sinh cho stmt_list giống như luật sinh cho list trong ví dụ 2.1, bằng cách thay thế +, - bởi ; và stmt thay cho digit.
2. Cây phân tích cú pháp (parsing tree)
Cây phân tích cú pháp minh họa ký hiệu ban đầu của một văn phạm dẫn đến một chuỗi trong ngôn ngữ.Nếu ký hiệu chưa kết thúc A có luật sinh A XYZ thì cây phân tích cú pháp có thể có một nút trong có nhãn A và có 3 nút con có nhãn tương ứng từ trái qua phải là X, Y, Z.
Hình 4.1 Cây phân tích cú pháp nhãn A
Một cách hình thức, cho một văn phạm phi ngữ cảnh thì cây phân tích cú pháp là một cây có các tính chất sau đây:1. Nút gốc có nhãn là ký hiệu bắt đầu.2. Mỗi một lá có nhãn là một ký hiệu kết thúc hoặc một .3. Mỗi nút trong có nhãn là một ký hiệu chưa kết thúc.4. Nếu A là một ký hiệu chưa kết thúc được dùng làm nhãn cho một nút trong nào đó và X1 ... Xn là nhãn của các con của nó theo thứ tự từ trái sang phải thì A X1X2 ... Xn là một luật sinh. Ở đây X1, ..., Xn có thể là ký hiệu kết thúc hoặc chưa kết thúc. Ðặc biệt, nếu A thì nút có nhãn A có thể có một con có nhãn .
3. Các vấn đề cú pháp
a. Sự nhập nhằng của văn phạmMột văn phạm có thể sinh ra nhiều hơn một cây phân tích cú pháp cho cùng một chuỗi nhập thì gọi là văn phạm nhập nhằng.
Ví dụ 4.4: Giả sử chúng ta không phân biệt một list với một digit, xem chúng đều là một string ta có văn phạm:
string string + string | string - string | 0 | 1 | ... | 9. Với văn phạm này thì chuỗi biểu thức 9 - 5 + 2 có đến hai cây phân tích cú pháp như sau :
75

Hình 4.2 Hai cây phân tích cú pháp
Tương tự với cách đặt dấu ngoặc vào biểu thức như sau : (9 - 5) + 2 9 - ( 5 + 2)Bởi vì một chuỗi với nhiều cây phân tích cú pháp thường sẽ có nhiều nghĩa, do đó khi biên dịch các chương trình ứng dụng, chúng ta cần thiết kế các văn phạm không có sự nhập nhằng hoặc cần bổ sung thêm các qui tắc cần thiết để giải quyết sự nhập nhằng cho văn phạm.
b. Sự kết hợp của các toán tử Thông thường, theo quy ước ta có biểu thức 9 + 5 + 2 tương đương (9 + 5) + 2 và 9 - 5 - 2 tương đương với (9 - 5) - 2. Khi một toán hạng như 5 có hai toán tử ở trái và phải thì nó phải chọn một trong hai để xử lý trước. Nếu toán tử bên trái được thực hiện trước ta gọi là kết hợp trái. Ngược lại là kết hợp phải. Thường thì bốn phép toán số học: +, -, *, / có tính kết hợp trái. Các phép toán như số mũ, phép gán bằng (=) có tính kết hợp phải.
Ví dụ 4.5 : Trong ngôn ngữ C, biểu thức a = b = c tương đương a = ( b = c) vì chuỗi a = b = c với toán tử kết hợp phải được sinh ra bởi văn phạm:
right letter = right | letter letter a | b | ... | zTa có cây phân tích cú pháp có dạng như sau (chú ý hướng của cây nghiêng về bên phải trong khi cây cho các phép toán có kết hợp trái thường nghiêng về trái):
76

c) Thứ tự ưu tiên của các toán tử Xét biểu thức 9 + 5 * 2. Có 2 cách để diễn giải biểu thức này, đó là 9 + (5 * 2) hoặc ( 9 + 5) * 2. Tính kết hợp của phép + và * không giải quyết được sự mơ hồ này, vì vậy cần phải quy định một thứ tự ưu tiên giữa các loại toán tử khác nhau. Thông thường trong toán học, các toán tử * và / có độ ưu tiên cao hơn + và -.
d) Cú pháp cho biểu thức Văn phạm cho các biểu thức số học có thể xây dựng từ bảng kết hợp và ưu tiên của các toán tử. Chúng ta có thể bắt đầu với bốn phép tính số học theo thứ bậc sau : Kết hợp trái +, - Thứ tự ưu tiên Kết hợp trái *, / từ thấp đến cao
Chúng ta tạo hai ký hiệu chưa kết thúc expr và term cho hai mức ưu tiên và một ký hiệu chưa kết thúc factor làm đơn vị phát sinh cơ sở của biểu thức. Ta có đơn vị cơ bản trong biểu thức là số hoặc biểu thức trong dấu ngoặc.
factor digit | (expr) Phép nhân và chia có thứ tự ưu tiên cao hơn đồng thời chúng kết hợp trái nên luật
sinh cho term tương tự như cho list : term term * factor | term / factor | factorTương tự, ta có luật sinh cho expr : expr expr + term | expr - term | termVậy, cuối cùng ta thu được văn phạm cho biểu thức như sau : expr expr + term | expr - term | term term term * factor | term / factor | factor factor digit | (expr)Như vậy: Văn phạm này xem biểu thức như là một danh sách các term được phân
cách nhau bởi dấu + hoặc -. Term là một list các factor phân cách nhau bởi * hoặc /. Chú ý rằng bất kỳ một biểu thức nào trong ngoặc đều là factor, vì thế với các dấu ngoặc chúng ta có thể xây dựng các biểu thức lồng sâu nhiều cấp tuỳ ý.
e) Cú pháp các câu lệnh Từ khóa (keyword) cho phép chúng ta nhận ra câu lệnh trong hầu hết các ngôn
ngữ. Ví dụ trong Pascal, hầu hết các lệnh đều bắt đầu bởi một từ khóa ngoại trừ lệnh gán. Một số lệnh Pascal được định nghĩa bởi văn phạm (nhập nhằng) sau, trong đó id chỉ một danh biểu (tên biến).
stmt id := expr | if expr then stmt | if expr then stmt else stmt | while expr do stmt | begin opt_stmts end
Ký hiệu chưa kết thúc opt_stmts sinh ra một danh sách có thể rỗng các lệnh, phân cách nhau bởi dấu chấm phẩy (;).
f) Dạng chuẩn Backus-NaurThông thường để mô tả cú pháp của các ngôn ngữ lập trình người ta sử dụng dạng chuẩn Backus-Naur (Backus-Naur Form, viết tắt là BNF).
Một văn phạm được định nghĩa bởi BNF gồm một dãy các quy tắc. Mỗi quy tắc gồm vế trái, dấu định nghĩa ::= (đọc được định nghĩa bởi) và vế phải. Vế trái là một kí hiệu phải được định nghĩa, còn vế phải là một dãy các kí hiệu, hợac được thừa nhận hoặc đã
77

được định nghĩa từ trước đó, tuân theo một quy ước nào đó. BNF dùng các kí tự quy ước như sau:
Kí hiệu Ý nghĩa::=, hoặc , hoặc = được định nghĩa là{ } chuỗi của 0 hoặc nhiều mục liệt kê tùy chọn[ ] hoặc 0 hoặc 1 mục liệt kê tùy chọn< > mục liệt kê phải được thay thế| hoặc (theo nghĩa loịa trừ)
Các quy tắc BNF định nghĩa tên trong Pascal:<tên> ::= <chữ> { <chữ> | <số> }<chữ> ::= ‘A’ | … | ‘Z’ | ‘a’ | … | ‘z’<số> ::= ‘)’ | … | ‘9’
Ví dụ văn phạm của một ngôn ngữ lập trình đơn giản dang BNF như sau:<program> ::= program <statement> end<statement> ::= <identifier> := <expression>;<loop> ::= while <expression> do <statement> done<expression> ::=
<value> | <value> + <value> | <value> <= <value><value> ::= <identifier> | <number><identifier> ::=
<letter> | <identifier><letter> | <identifier><digit><number> ::= <digit> | <number><digit><letter> ::= ‘A’ | … | ‘Z’ | ‘a’ | … | ‘z’<digit> ::= ‘)’ | … | ‘9’
Một xâu, tức là một chương trình đơn giản, viết trong văn phạn được định nghĩa ở trên như sau:
programi := 1;while i <= 10 do i := i + 1 done
end
4. Phân tích cú pháp
Một ngôn ngữ lập trình, như trình bày ở phần trên, được thường định nghĩa bởi cú pháp hay văn phạm của nó bởi dạng chuẩn BNF. Sau đó, khi người lập trình sử dụng ngôn ngữ để viết chương trình, người lập trình phải tuân theo văn phạm đã được định nghĩa. Để kiểm tra xem một chương trình có đúng cú pháp hay không thì cần phải thực hiện phân tích cú pháp.
Phân tích cú pháp là quá trình xác định xem một xâu/câu có thể được sinh ra từ một văn phạm cho trước không. Cụ thể, phân tích cú pháp của một chương trình là xác định xem từng câu lệnh của chương trình có được sinh ra bởi cú pháp của ngôn ngữ lập trình đó không.
Trong phần này, chúng ta chỉ giới thiệu sơ bộ về quá trình phân tích cú pháp. Vấn đề này sẽ được trình bày đầy đủ hơn trong bài cuối cùng của môn học.
78

Có nhiều phương pháp phân tích cú pháp khác nhau. Tuy nhiên, các phương pháp này đều nằm trong hai lớp: từ trên xuống (top down) và từ dưới lên (bttom-up).
Để xác định xem một chương trình nguồn có được sinh ra từ một văn phạm hay không, các phương pháp phân tích cú pháp thường xây dựng cây phân tích của chương trình nguồn dựa trên văn phạm. Nếu tồn tại cây phân tích thì ta nói chương trình được sinh ra bởi văn phạm hay chương trình đúng cú pháp, ngược lại thì chương trình nguồn là không đúng cú pháp.
Để xây dựng cây phân tích cho một chương trình nguồn, chúng ta có thể tiến hành hai cách cơ bản tương ứng với hai lớp các phương pháp phân tích cú pháp. Phương pháp phân tích từ trên xuống sẽ bắt đầu xây dựng cây phân tích từ các lá đi đến đỉnh của một câu hay chương trình cho trước. Ngược lại, phương pháp phân tích từ dưới lên sẽ bắt đầu xây dựng cây phân tích từ đỉnh đến các lá của một câu hay chương trình cho trước.
Đối với mỗi lớp phương pháp phân tích cú pháp, có nhiều phương pháp khác nhau:
- Phân tích cú pháp từ trên xuống gồm:o Phân tích đệ quy đi xuống: phương pháp này thực hiện việc xây dựng
cây phân tích từ gốc đến lá và có khả năng quay lui (backtracking).o Phân tích cú pháp đoán nhận trước: phương này phân tích từ trên xuống
nhưng không bị quay lui.o Phân tích cú pháp đoán nhận trước không đệ quy: phương này sử dụng
ngăn xếp (stack) thay vì quay lui.- Phân tích cú pháp từ dưới lên gồm:
o Phân tích cú pháp thứ tự yếuo Phân tích cú pháp LR
Dưới đây là một ví dụ đơn giản minh họa phân tích cú pháp. Chúng có văn phạm G định nghĩa ngôn ngữ sau:
<exp> <exp> + <term><exp> <exp> - <term><exp> <term><term> 0…<term> 9
Chương trình nguồn là biểu thức: 9 – 5 + 3.Thực hiện việc phân tích cú pháp sẽ tạo được cây phân tích như sau: exp
exp
exp
term
term
term
9
5
2 -
+
79

Như thế, chương trình nguồn 9 – 5 + 3 là đúng đắn về mặt cú pháp.
5. Ngữ nghĩa hình thức
Căn cứ vào cú pháp của ngôn ngữ lập trình, người lập trình viết chương trình gồm các câu lệnh theo trình tự cho phép để giải quyết bài toán đặt ra. Để đạt được mục đích đó, mỗi câu lệnh viết ra không những chỉ đúng đắn về mặt cú pháp mà còn phải đúng đắn về mặt ngữ nhĩa (semantic) hay ý nghĩa logic câu lệnh. Tính đúng đắn về mặt ngữ nghĩa cho phép giải quyết được bài toán, chương trình chạy luôn dừng, ổn định và cho kết quả phù hợp với yêu cầu đặt ra.
Ngữ nghĩa không chỉ là cơ sở cho việc chứng minh tính đúng đắn của chương trình mà còn có ích cho quá trình thiết kế và cài đặt ngôn ngữ lập trình.Trong bài học này sẽ giới thiệu hai loại ngữ nghĩa hình thức: ngữ nghĩa tiên đề (axiomatic semantics) và ngữ nghĩa biểu thị (denotationnal semantics).
6. Ngữ nghĩa tiên đề
a) Ngữ nghĩa của phát biểuNgữ nghĩa của phát biểu đượcđặc tả bởi biểu thức sau:{ P } S { Q }trong đó P là điều kiện về trị các biến trước khi thực thi S, gọi là điều kiện trước (precondition) của S; Q là điều kiện về trị các biến sau khi thực thi S, gọi là hậu điều kiện (postcondition) của S.Diễn dịch đặc tả trên: nếu P đúng thì sau khi S được thực hiện xong ta có Q đúng.Nếu với điều kiện sau bất kỳ của S, ta biết được những điều kiện trước sao cho khi S được thực hiện xong điều kiện sau trên được thỏa mãn, thì ta nói biết được ngữ nghĩa của S.Điều kiện P2 gọi là yếu hơn P1 nếu P1 P2. Điều kiện trước ở đặc tả của phát biểu càng yếu, ngữ nghĩa của phát biểu càng rõ. Với điều kiện sau Q của S, chúng ta kí hiệu p (S, Q) là điều kiện trước yếu nhất bảo đảm Q đúng sau khi được thực hiện xong. Hàm p (S, Q) với Q là biến số có thể xem là ngữ nghĩa chính xác của S.Ví dụ: p (n := n +1, n > 0) = n 0 (n nguyên).Với mọi điều kiện trước P về n thỏa mãn đặc tả:
{ P } n : = n + 1 { n > 0 }ta đều có P n 0.
b) Hệ luật HoareNgữ nghĩa tiên đề được phát triển dựa trên hệ luật Hoare. Hệ luật Hoare gồm các tiên đề và luật suy dẫn về ngữ nghĩa của phát biểu theo đặc tả vừa được trình bày ở trên.Trong hệ luật Hoare, các kí hiệu , , lần lượt tương ứng với các phép toán logic NOT, AND, OR. Kí hiệu được sử dụng làm kí hiệu định nghĩa.
Luật L1: Nếu ( {P} S {Q}) (Q R)thì {P} S {R}
Luật L2: Nếu ( {P} S {Q}) (R P)thì {R} S {Q}
Luật L3: (tiên đề về phép gán)
80

{ Px->E} x := E {P}ở đây E là biểu thức và Px->E là P trong đó x được thay bằng E.
Ví dụ 4.6, chứng minh tính đúng đắn của đặc tả:{ f = i!} i := i +1 {f * i = i!}
trong ví dụ này ta có:P f * i = i!E i + 1Pi->E f * (i + 1) = (i + 1)!
Theo L3 chúng ta có:{f * (i + 1) = (i + 1) !} i := i + 1 {f * i = i!}
Vì f = i! f * (i + 1) = (i + 1)! nên theo L2 chúng ta có điều phải chứng minh.Ví dụ 4.7, chứng minh tính đúng đắn của đặc tả:
{ f * i = i!} f := f * i {f = i!}ở đây:
P f = i!E f * iPi->E f * i = i!
Luật L3 cho chúng ta điều phải chứng minh.
Luật L4: (luật về câu lệnh ghép)Nếu ({P} S1 {Q}) ({Q} S2 {R})thì {P} S1 ; S2 {R}
Ví dụ 4.8, chứng minh tính đúng đắn của đặc tả:{f = i!} i := i + 1; f = f * i {f = i!}
Theo ví dụ 4.6 và 4.7chúng ta có:{ f = i!} i := i +1 {f * i = i!} { f * i = i!} f := f * i {f = i!}
Áp dụng L4 cho chúng ta điều phải chứng minh.
Luật L5: (luật về phát biểu IF)Nếu ({P B} S1 {Q}) ({P B} S2 {Q})thì {P} if B then S1 else S2 {Q}
Luật L6: (luật về phát biểu IF không có thành phần ELSE)Nếu ({P B} S1 {Q}) ({P B} Q)thì {P} if B then S1 {Q}
Ví dụ 4.9, chứng minh tính đúng đắn của đặc tả:{x.y < 0} if x > y then max := x else max := y {max > 0}
Áp dụng L3 ta có:{ x > 0 } max := x {max > 0}
Vì (x.y < 0) (x > y) x > 0 nên theo L2 ta có:{(x.y < 0) (x > y)} max := x {max > 0} (*)
Tương tự theo L3 và L2 ta có:{(x.y < 0) (x y)} max := y {max > 0} (**)
Áp dụng L5 cho (*) và (**) với:P x.y < 0B x > yQ max > 0S1 max := x
81

S2 max := ychúng ta có điều phải chứng minh.
Luật L7: (luật về vòng lặp WHILE)Nếu {P B} S {Q}thì {P} while B do S {P B}P được gọi là bất biến của vòng lặp.
Ví dụ 4.10: chứng minh tính đúng đắn của đặc tả:{f = i!} while i n do begin i := i + 1, f := f*i {f = n!}
Theo ví dụ 4.8 ta có:{f = i!} i = i +1; f := f*i {f = i!}
Vì (f = i!) (i n) f = i! Nên theo L2 ta có:{(f = i!) (i n)} i = i +1; f := f*i {f = i!}
Áp dụng L7 với:P f = i!B (i n)S i := i + 1, f := f*i
ta có:{f = i!} while i n do begin i := i + 1, f := f*i {(f = i!) (i = n)}
mà:(f = i!) (i = n) f = n!
nên theo L1 chúng ta suy ra được điều phải chứng minh.
Ngữ nghĩa biểu thịỞ ngữ nghĩa biểu thị, ngữ nghĩa của mỗi cấu trúc cú pháp được đặc tả bằng một
ánh xạ, gọi là hàm ngữ nghĩa (semantic function), từ miền cú pháp (semantic domain) vào miền ngữ nghĩa (semantic domain).
Như thế, chúng ta nhận thấy, ngữ nghĩa biểu thị chỉ ra ngữ nghĩa của mỗi cấu trúc cú pháp, tưca là mỗi cấu trúc cú pháp có một ngữ nghĩa nhất định.Chúng ta sẽ lấy một ví dụ đơn giản: mô tả hình thức ngữ nghĩa của ngôn ngữ gồm các số nhị phân bằng ngữ nghĩa biểu thị.
Ngôn ngữ số nhị phân là ngôn ngữ chỉ gồm các số nhị phân ‘0’ và ‘1’. Ngữ nghĩa của của số nhị phân chính là giá trị thập phân của số nhị phân đó. Như thế, miền cú pháp là tập hợp các số nhị phân, còn miền ngữ nghĩa là tập hợp các số tự nhiên (giá trị của các số nhị phân).Cú pháp và ngữ nghĩa của ngôn ngữ số nhị phân được định nghĩa như sau:Cú pháp:
N Nml số nhị phânN ::= 0 | 1 | N0 | N1
Miền ngữ nghĩa:N = {0, 1, 2, ...} số tự nhiên
Hàm ngữ nghĩa: : Nml N
[[ 0 ]] = 0[[ 1 ]] = 1[[ N 0 ]] = 2 * [[N]]
82

[[ N 0 ]] = 2 * [[N]] + 1Trong đó, tập hợp các số nhị phân Nml là miền cú pháp, tập hợp các số tự nhiên N
là miền ngữ nghĩa và là hàm ngữ nghĩa của số nhị phân.
Bài tập:
Câu 1: Trình bày định nghĩa cú pháp
Câu 2:Hãy nêu các vấn đề cú phápCâu 3: Hãy nêu các phương pháp phân tích cú pháp Câu 4: Hãy nêu các loại ngữ nghĩa hình thức
83

Bài 5: LẬP TRÌNH THỦ TỤCMã bài: MĐ39-05
Mục tiêu:
- Lập trình thực hiện một số các lệnh cơ bản : Gán, rẽ nhánh, lặp
- Khai báo các đại lượng sử dụng trong chương trình
- Sử dụng kỹ thuật lập trình có cấu trúc
- Sử dụng các biến bí danh
Nội dung: - Biến và hằng
- Lập trình cấu trúc
1. Biến và hằng
1.1 BiếnBiến là một ÐTDL được người lập trình định nghĩa và đặt tên một cách tường
minh trong chương trình. Giá trị của biến có thể bị thay đổi trong thời gian tồn tại của nó. Tên biến được dùng để xác định và tham khảo tới biến. Trong các NNLT, tên biến thường được quy định dưới dạng một dãy các chữ cái, dấu gạch dưới và các chữ số, bắt đầu bằng một chữ cái và có chiều dài hữu hạn.1.2 Hằng
Hằng là một ÐTDL có tên và giá trị của hằng không thay đổi trong thời gian tồn tại của nó.
Hằng trực kiện (literal constant) là một hằng mà tên của nó là sự mô tả giá trị của nó (chẳng hạn "27" là sự mô tả số thập phân của ÐTDL giá trị 27). Chú ý sự khác biệt giữa 2 giá trị 27. Một cái là một số nguyên được biểu diễn thành một dãy các bit trong bộ nhớ trong quá trình thực hiện chương trình và cái tên "27" là một chuỗi 2 ký tự "2" và "7" mô tả một số nguyên như nó được viết trong chương trình.
2. Lập trình cấu trúc
Lệnh đơn là một sự tính toán được kết thúc bằng dấu chấm phẩy. Các định nghĩa biến và các biểu thức được kết thúc bằng dấu chấm phẩy như trong ví dụ sau:
int i; // lệnh khai báo ++i; // lệnh này có một tác động chính yếu double d = 10.5; // lệnh khai báo d + 5; // lệnh không hữu dụng Ví dụ cuối trình bày một lệnh không hữu dụng bởi vì nó không có tác động
chính yếu (d được cộng với 5 và kết quả bị vứt bỏ). Lệnh đơn giản nhất là lệnh rỗng chỉ gồm dấu chấm phẩy mà thôi. ; // lệnh rỗng Mặc dầu lệnh rỗng không có tác động chính yếu nhưng nó có một vài việc dùng
xác thật. Nhiều lệnh đơn có thể kết nối lại thành một lệnh phức bằng cách rào chúng bên
trong các dấu ngoặc xoắn. Ví dụ:
84

{ int min, i = 10, j = 20; min = (i < j ? i : j); cout << min << '\n'; } Bởi vì một lệnh phức có thể chứa các định nghĩa biến và định nghĩa một phạm
vi cho chúng, nó cũng được gọi một khối. Phạm vi của một biến C++ được giới hạn bên trong khối trực tiếp chứa nó. Các khối và các luật phạm vi sẽ được mô tả chi tiết hơn khi chúng ta thảo luận về hàm trong chương kế. Lệnh if
Đôi khi chúng ta muốn làm cho sự thực thi một lệnh phụ thuộc vào một điều kiện nào đó cần được thỏa. Lệnh if cung cấp cách để thực hiện công việc này, hình thức chung của lệnh này là:
if (biểu thức) lệnh; Trước tiên biểu thức được ước lượng. Nếu kết quả khác 0 (đúng) thì sau đó lệnh
được thực thi. Ngược lại, không làm gì cả. Ví dụ, khi chia hai giá trị chúng ta muốn kiểm tra rằng mẫu số có khác 0 hay
không. if (count != 0) average = sum / count; Để làm cho nhiều lệnh phụ thuộc trên cùng điều kiện chúng ta có thể sử dụng
lệnh phức: if (balance > 0) { interest = balance * creditRate; balance += interest; }
Một hình thức khác của lệnh if cho phép chúng ta chọn một trong hai lệnh: một lệnh được thực thi nếu như điều kiện được thỏa và lệnh còn lại được thực hiện nếu như điều kiện không thỏa. Hình thức này được gọi là lệnh if-else và có hình thức chung là: if (biểu thức ) lệnh 1; else lệnh 2; Trước tiên biểu thức được ước lượng. Nếu kết quả khác 0 thì lệnh 1 được thực thi. Ngược lại, lệnh 2 được thực thi. Ví dụ:
if (balance > 0) { interest = balance * creditRate; balance += interest; } else { interest = balance * debitRate; balance += interest; }
Trong cả hai phần có sự giống nhau ở lệnh balance += interest vì thế toàn bộ câu lệnh có thể viết lại như sau:
if (balance > 0)
85

interest = balance * creditRate; else interest = balance * debitRate; balance += interest;
Hoặc đơn giản hơn bằng việc sử dụng biểu thức điều kiện: interest = balance * (balance > 0 ? creditRate : debitRate); balance += interest;
Hoặc chỉ là: balance += balance * (balance > 0 ? creditRate : debitRate);
Các lệnh if có thể được lồng nhau bằng cách để cho một lệnh if xuất hiện bên trong một lệnh if khác. Ví dụ:
if (callHour > 6) { if (callDuration <= 5) charge = callDuration * tarrif1; else charge = 5 * tarrif1 + (callDuration - 5) * tarrif2; } else charge = flatFee;
Một hình thức được sử dụng thường xuyên của những lệnh if lồng nhau liên quan đến phần else gồm có một lệnh if-else khác. Ví dụ:
if (ch >= '0' && ch <= '9') kind = digit; else { if (ch >= 'A' && ch <= 'Z') kind = upperLetter; else { if (ch >= 'a' && ch <= 'z') kind = lowerLetter; else kind = special; } }
Để cho dễ đọc có thể sử dụng hình thức sau: if (ch >= '0' && ch <= '9') kind = digit; else if (ch >= 'A' && ch <= 'Z') kind = capitalLetter; else if (ch >= 'a' && ch <= 'z') kind = smallLetter; else kind = special;
Lệnh switch Lệnh switch cung cấp phương thức lựa chọn giữa một tập các khả năng dựa trên giá trị của biểu thức. Hình thức chung của câu lệnh switch là: switch (biểu thức) { case hằng : 1 các lệnh;
86

... case hằng : n các lệnh; default : các lệnh; } Biểu thức (gọi là thẻ switch) được ước lượng trước tiên và kết quả được so sánh với mỗi hằng số (gọi là các nhãn) theo thứ tự chúng xuất hiện cho đến khi một so khớp được tìm thấy. Lệnh ngay sau khi so khớp được thực hiện
sau đó. Chú ý số nhiều: mỗi case có thể được theo sau bởi không hay nhiều lệnh (không chỉ là một lệnh). Việc thực thi tiếp tục cho tới khi hoặc là bắt gặp một lệnh break hoặc tất cả các lệnh xen vào đến cuối lệnh switch được thực hiện.Trường hợp default ở cuối cùng là một tùy chọn và được thực hiện nếu như tất cả các case trước đó không được so khớp.
Ví dụ, chúng ta phải phân tích cú pháp một phép toán toán học nhị hạng thành ba thành phần của nó và phải lưu trữ chúng vào các biến operator , operand1 , và operand2 . Lệnh switch sau thực hiện phép toán và lưu trữ kết quả vào result .
switch (operator) { case '+': result = operand1 + operand2; break; case '-': result = operand1 - operand2; break; case '*': result = operand1 * operand2; break; case '/': result = operand1 / operand2; break; default: cout << "unknown operator: " << operator << '\n'; break; } Như đã được minh họa trong ví dụ, chúng ta cần thiết chèn một lệnh break ở
cuối mỗi case. Lệnh break ngắt câu lệnh switch bằng cách nhảy đến điểm kết thúc của lệnh này. Ví dụ, nếu chúng ta mở rộng lệnh trên để cho phép x cũng có thể được sử dụng như là toán tử nhân, chúng ta sẽ có:
switch (operator) { case '+': result = operand1 + operand2; break; case '-': result = operand1 - operand2; break; case 'x': case '*': result = operand1 * operand2; break; case '/': result = operand1 / operand2; break; default: cout << "unknown operator: " << operator << '\n'; break; }
87

Bởi vì case 'x' không có lệnh break nên khi case này được thỏa thì sự thực thi tiếp tục thực hiện các lệnh trong case kế tiếp và phép nhân được thi hành.
Chúng ta có thể quan sát rằng bất kỳ lệnh switch nào cũng có thể được viết như nhiều câu lệnh if-else. Ví dụ, lệnh trên có thể được viết như sau:
if (operator == '+') result = operand1 + operand2; else if (operator == '-') result = operand1 - operand2; else if (operator == 'x' || operator == '*') result = operand1 * operand2; else if (operator == '/') result = operand1 / operand2; else cout << "unknown operator: " << ch << '\n';
người ta có thể cho rằng phiên bản switch là rõ ràng hơn trong trường hợp này. Tiếp cận if-else nên được dành riêng cho tình huống mà trong đó switch không thể làm được công việc (ví dụ, khi các điều kiện là phức tạp không thể đơn giản thành các đẳng thức toán học hay khi các nhãn cho các case không là các hằng số).
Lệnh while Lệnh while (cũng được gọi là vòng lặp while) cung cấp phương thức lặp một lệnh cho tới khi một điều kiện được thỏa. Hình thức chung của lệnh lặp là: while ( biểu thức) lệnh; Biểu thức (cũng được gọi là điều kiện lặp) được ước lượng trước tiên. Nếu kết quả khác 0 thì sau đó lệnh (cũng được gọi là thân vòng lặp) được thực hiện và toàn bộ quá trình được lặp lại. Ngược lại, vòng lặp được kết thúc. Ví dụ, chúng ta muốn tính tổng của tất cả các số nguyên từ 1 tới n. Điều này có thể được diễn giải như sau:
i = 1; sum = 0; while (i <= n){ sum += i; i++; }
Trường hợp n là 5, Bảng 3.1 cung cấp bảng phát họa vòng lặp bằng cách liệt kê các giá trị của các biến có liên quan và điều kiện lặp.
Bảng 3.1 Vết của vòng lặp while.Vòng lặp i n i <= n sum += i++Một 1 5 1 1Hai 2 5 1 3Ba 3 5 1 6Bốn 4 5 1 10Năm 5 5 1 15Sáu 6 5 0
88

Đôi khi chúng ta có thể gặp vòng lặp while có thân rỗng (nghĩa là một câu lệnh null). Ví dụ vòng lặp sau đặt n tới thừa số lẻ lớn nhất của nó.
while (n % 2 == 0 && n /= 2) ; Ở đây điều kiện lặp cung cấp tất cả các tính toán cần thiết vì thế không thật sự
cần một thân cho vòng lặp. Điều kiện vòng lặp không những kiểm tra n là chẵn hay không mà nó còn chia n cho 2 và chắc chắn rằng vòng lặp sẽ dừng. Lệnh do - while
Lệnh do (cũng được gọi là vòng lặp do) thì tương tự như lệnh while ngoại trừ thân của nó được thực thi trước tiên và sau đó điều kiện vòng lặp mới được kiểm tra. Hình thức chung của lệnh do là:
do lệnh; while ( biểu thức) ;
Lệnh được thực thi trước tiên và sau đó biểu thức được ước lượng. Nếu kết quả của biểu thức khác 0 thì sau đó toàn bộ quá trình được lặp lại. Ngược lại thì vòng lặp kết thúc.
Vòng lặp do ít được sử dụng thường xuyên hơn vòng lặp while. Nó hữu dụng trong những trường hợp khi chúng ta cần thân vòng lặp thực hiện ít nhất một lần mà không quan tâm đến điều kiện lặp. Ví dụ, giả sử chúng ta muốn thực hiện lặp đi lặp lại công việc đọc một giá trị và in bình phương của nó, và dừng khi giá trị là 0. Điều này có thể được diễn giải trong vòng lặp sau đây:
do { cin >> n; cout << n * n << '\n'; } while (n != 0);
Không giống như vòng lặp while, vòng lặp do ít khi được sử dụng trong những tình huống mà nó có một thân rỗng. Mặc dù vòng lặp do với thân rỗng có thể là tương đương với một vòng lặp while tương tự nhưng vòng lặp while thì luôn dễ đọc hơn. Lệnh for
Lệnh for (cũng được gọi là vòng lặp for) thì tương tự như vòng lặp while nhưng có hai thành phần thêm vào: một biểu thức được ước lượng chỉ một lần trước hết và một biểu thức được ước lượng mỗi lần ở cuối mỗi lần lặp. Hình thức tổng quát của lệnh for là:
for ( biểu thức1; biểu thức2; biểu thức3) lệnh; Biểu thức1 (thường được gọi là biểu thức khởi tạo) được ước lượng trước tiên.
Mỗi vòng lặp biểu thức2 được ước lượng. Nếu kết quả không là 0 (đúng) thì sau đó lệnh được thực thi và biểu thức3 được ước lượng. Ngược lại, vòng lặp kết thúc. Vòng lặp for tổng quát thì tương đương với vòng lặp while sau:
biểu thức1; while ( biểu thức 2) { lệnh; biểu thức 3; } Vòng lặp for thường được sử dụng trong các trường hợp mà có một biến được
tăng hay giảm ở mỗi lần lặp. Ví dụ, vòng lặp for sau tính toán tổng của tất cả các số nguyên từ 1 tới n.
89

sum = 0; for (i = 1; i <= n; ++i) sum += i; Điều này được ưa chuộng hơn phiên bản của vòng lặp while mà chúng ta thấy
trước đó. Trong ví dụ này i thường được gọi là biến lặp. C++ cho phép biểu thức đầu tiên trong vòng lặp for là một định nghĩa biến. Ví
dụ trong vòng lặp trên thì i có thể được định nghĩa bên trong vòng lặp: for (int i = 1; i <= n; ++i)
sum += i; Trái với sự xuất hiện, phạm vi của i không ở trong thân của vòng lặp mà là
chính vòng lặp. Xét trên phạm vi thì ở trên tương đương với: int i; for (i = 1; i <= n; ++i)
sum += i; Bất kỳ biểu thức nào trong 3 biểu thức của vòng lặp for có thể rỗng. Ví dụ, xóa
biểu thức đầu và biểu thức cuối cho chúng ta dạng giống như vòng lặp while: for (; i != 0;) // tương đương với: while (i != 0)
something; // something; Xóa tất cả các biểu thức cho chúng ta một vòng lặp vô hạn. Điều kiện của vòng
lặp này được giả sử luôn luôn là đúng. for (;;) // vòng lặp vô hạn something;
Trường hợp vòng lặp với nhiều biến lặp thì hiếm dùng. Trong những trường hợp như thế, toán tử phẩy (,) được sử dụng để phân cách các biểu thức của chúng:
for (i = 0, j = 0; i + j < n; ++i, ++j) something;
Bởi vì các vòng lặp là các lệnh nên chúng có thể xuất hiện bên trong các vòng lặp khác. Nói các khác, các vòng lặp có thể lồng nhau. Ví dụ, for (int i = 1; i <= 3; ++i) for (int j = 1; j <= 3; ++j) cout << '(' << i << ',' << j << ")\n"; cho tích số của tập hợp {1,2,3} với chính nó, kết quả như sau:
(1,1) (1,2) (1,3) (2,1) (2,2) (2,3) (3,1) (3,2) (3,3)
Lệnh continue Lệnh continue dừng lần lặp hiện tại của một vòng lặp và nhảy tới lần lặp kế
tiếp. Nó áp dụng tức thì cho vòng lặp gần với lệnh continue. Sử dụng lệnh continue bên ngoài vòng lặp là lỗi.
Trong vòng lặp while và vòng lặp do-while, vòng lặp kế tiếp mở đầu từ điều kiện lặp. Trong vòng lặp for, lần lặp kế tiếp khởi đầu từ biểu thức thứ ba của vòng lặp.
90

Ví dụ, một vòng lặp thực hiện đọc một số, xử lý nó nhưng bỏ qua những số âm, và dừng khi số là 0, có thể diễn giải như sau:
do { cin >> num; if (num < 0) continue; // xử lý số ở đây … } while (num != 0);
Điều này tương đương với: do { cin >> num; if (num >= 0) { // xử lý số ở đây … } } while (num != 0);
Một biến thể của vòng lặp này để đọc chính xác một số n lần (hơn là cho tới khi số đó là 0) có thể được diễn giải như sau:
for (i = 0; i < n; ++i) { cin >> num; if (num < 0) continue; // làm cho nhảy tới: ++i // xử lý số ở đây … }
Khi lệnh continue xuất hiện bên trong vòng lặp được lồng vào thì nó áp dụng trực tiếp lên vòng lặp gần nó chứ không áp dụng cho vòng lặp bên ngoài. Ví dụ, trong một tập các vòng lặp được lồng nhau sau đây, lệnh continue áp dụng cho vòng lặp for và không áp dụng cho vòng lặp while:
while (more) { for (i = 0; i < n; ++i) { cin >> num; if (num < 0) continue; // làm cho nhảy tới: ++i // process num here... } //etc... }
Lệnh break Lệnh break có thể xuất hiện bên trong vòng lặp (while, do, hay for) hoặc một
lệnh switch. Nó gây ra bước nhảy ra bên ngoài những lệnh này và vì thế kết thúc chúng. Giống như lệnh continue, lệnh break chỉ áp dụng cho vòng lặp hoặc lệnh switch gần nó. Sử dụng lệnh break bên ngoài vòng lặp hay lệnh switch là lỗi.
Ví dụ, chúng ta đọc vào một mật khẩu người dùng nhưng không cho phép một số hữu hạn lần thử:
for (i = 0; i < attempts; ++i) { cout << "Please enter your password: "; cin >> password; if (Verify(password)) // kiểm tra mật khẩu đúng hay sai break; // thoát khỏi vòng lặp cout << "Incorrect!\n"; }
91

Ở đây chúng ta phải giả sử rằng có một hàm được gọi Verify để kiểm tra một mật khẩu và trả về true nếu như mật khẩu đúng và ngược lại là false.
Chúng ta có thể viết lại vòng lặp mà không cần lệnh break bằng cách sử dụng một biến luận lý được thêm vào (verified ) và thêm nó vào điều kiện vòng lặp:
verified = 0; for (i = 0; i < attempts && !verified; ++i) {
cout << "Please enter your password: "; cin >> password; verified = Verify(password)); if (!verified) cout << "Incorrect!\n"; }
Người ta cho rằng phiên bản của break thì đơn giản hơn nên thường được ưa chuộng hơn.
Lệnh goto Lệnh goto cung cấp mức thấp nhất cho việc nhảy. Nó có hình thức chung là:
goto nhãn; trong đó nhãn là một định danh được dùng để đánh dấu đích cần nhảy tới. Nhãn
cần được theo sau bởi một dấu hai chấm (:) và xuất hiện trước một lệnh bên trong hàm như chính lệnh goto.
Ví dụ, vai trò của lệnh break trong vòng lặp for trong phần trước có thể viết lại bởi một lệnh goto.
for (i = 0; i < attempts; ++i) { cout << "Please enter your password: "; cin >> password; if (Verify(password)) // check password for correctness goto out; // drop out of the loop cout << "Incorrect!\n"; } out: //etc... Bởi vì lệnh goto cung cấp một hình thức nhảy tự do không có cấu trúc (không
giống như lệnh break và continue) nên dễ làm gãy đổ chương trình. Phần lớn các lập trình viên ngày nay tránh sử dụng nó để làm cho chương trình rõ ràng. Tuy nhiên, goto có một vài (dù cho hiếm) sử dụng chính đáng. Vì sự phức tạp của những trường hợp như thế mà việc cung cấp những ví dụ được trình bày ở những phần sau. Lệnh return
Lệnh return cho phép một hàm trả về một giá trị cho thành phần gọi nó. Nó có hình thức tổng quát:
return biểu thức; trong đó biểu thức chỉ rõ giá trị được trả về bởi hàm. Kiểu của giá trị này nên
hợp với kiểu của hàm. Trường hợp kiểu trả về của hàm là void , biểu thức nên rỗng: return;
Hàm mà được chúng ta thảo luận đến thời điểm này chỉ có hàm main , kiểu trả về của nó là kiểu int . Giá trị trả về của hàm main là những gì mà chương trình trả về cho hệ điều hành khi nó hoàn tất việc thực thi. Chẳng hạn dưới UNIX qui ước là trả về
92

0 từ hàm main khi chương trình thực thi không có lỗi. Ngược lại, một mã lỗi khác 0 được trả về. Ví dụ:
int main (void) { cout << "Hello World\n"; return 0; }
Khi một hàm có giá trị trả về không là void (như trong ví dụ trên), nếu không trả về một giá trị sẽ mang lại một cảnh báo trình biên dịch. Giá trị trả về thực sự sẽ không được định nghĩa trong trường hợp này (nghĩa là, nó sẽ là bất cứ giá trị nào được giữ trong vị trí bộ nhớ tương ứng của nó tại thời điểm đó). Bài tập 3.1 Viết chương trình nhập vào chiều cao (theo centimet) và trọng lượng (theo
kilogram) của một người và xuất một trong những thông điệp: underweight , normal , hoặc overweight , sử dụng điều kiện: Underweight: weight < height/2.5 Normal: height/2.5 <= weight <= height/2.3 Overweight: height/2.3 < weight
3.2 Giả sử rằng n là 20, đoạn mã sau sẽ xuất ra cái gì khi nó được thực thi? if (n >= 0) if (n < 10) cout << "n is small\n"; else cout << "n is negative\n";
3.3 Viết chương trình nhập một ngày theo định dạng dd/mm/yy và xuất nó theo định dạng month dd, year. Ví dụ, 25/12/61 trở thành:
Thang muoi hai 25, 1961 3.4 Viết chương trình nhập vào một giá trị số nguyên, kiểm tra nó là dương hay không
và xuất ra giai thừa của nó, sử dụng công thức: Chương 3: Lệnh 41
giaithua (0) = 1 giaithua (n) = n × giaithua (n-1)
3.5 Viết chương trình nhập vào một số cơ số 8 và xuất ra số thập phân tương đương. Ví dụ sau minh họa các công việc thực hiện của chương trình theo mong đợi:
Nhap vao so bat phan: 214 BatPhan(214) = ThapPhan(140)
3.6 Viết chương trình cung cấp một bảng cửu chương đơn giản của định dạng sau cho các số nguyên từ 1 tới 9:
1 x 1 = 1 1 x 2 = 2 ... 9 x 9 =
93

BÀI 6 : LẬP TRÌNH HƯỚNG ĐỐI TƯỢNG Mã bài : MĐ39-06
Giới thiệu Hướng đối tượng (object orientation) cung cấp một kiểu mới để xây dựng
phần mềm. Trong kiểu mới này, các đối tượng (object) và các lớp (class) là những khối xây dựng trong khi các phương thức (method), thông điệp (message), và sự thừa kế (inheritance) cung cấp các cơ chế chủ yếu.
Lập trình hướng đối tượng (OOP- Object-Oriented Programming) là một cách tư duy mới, tiếp cận hướng đối tượng để giải quyết vấn đề bằng máy tính. Thuật ngữ OOP ngày càng trở nên thông dụng trong lĩnh vực công nghệ thông tin.
Nếu bạn chưa bao giờ sử dụng một ngôn ngữ OOP thì trước tiên bạn nên nắm vững các khái niệm của OOP hơn là viết các chương trình. Bạn cần hiểu được đối tượng (object) là gì, lớp (class) là gì, chúng có quan hệ với nhau như thế nào, và làm thế nào để các đối tượng trao đổi thông điệp (message) với nhau, vâng vâng.
OOP là tập hợp các kỹ thuật quan trọng mà có thể dùng để làm cho việc triển khai chương trình hiệu quả hơn. Quá trình tiến hóa của OOP như sau: Lập trình tuyến tính Lập trình có cấu trúc Sự trừu tượng hóa dữ liệu Lập trình hướng đối tượng
Lập trình hướng đối tượng (OOP) là một phương pháp thiết kế và phát triển phần mềm dựa trên kiến trúc lớp và đối tượng.
1. Trừu tượng hóa (Abstraction)
Trừu tượng hóa là một kỹ thuật chỉ trình bày những các đặc điểm cần thiết của vấn đề mà không trình bày những chi tiết cụ thể hay những lời giải thích phức tạp của vấn đề đó. Hay nói khác hơn nó là một kỹ thuật tập trung vào thứ cần thiết và phớt lờ đi những thứ không cần thiết.
Ví dụ những thông tin sau đây là các đặc tính gắn kết với con người: Tên Tuổi Địa chỉ Chiều cao Màu tóc Giả sử ta cần phát triển ứng dụng khách hàng mua sắm hàng hóa thì những chi tiết thiết yếu là tên, địa chỉ còn những chi tiết khác (tuổi, chiều cao, màu tóc, ..) là không quan trọng đối với ứng dụng. Tuy nhiên, nếu chúng ta phát triển một ứng dụng hỗ trợ cho việc điều tra tội phạm thì những thông tin như chiều cao và màu tóc là thiết yếu.
Sự trừu tượng hóa đã không ngừng phát triển trong các ngôn ngữ lập trình, nhưng chỉ ở mức dữ liệu và thủ tục. Trong OOP, việc này được nâng lên ở mức cao
94

hơn – mức đối tượng. Sự trừu tượng hóa được phân thành sự trừu tượng hóa dữ liệu và trừu tượng hóa chương trình.
2. Đối tượng (object)
Các đối tượng là chìa khóa để hiểu được kỹ thuật hướng đối tượng. Bạn có thể nhìn xung quanh và thấy được nhiều đối tượng trong thế giới thực như: con chó, cái bàn, quyển vở, cây viết, tivi, xe hơi ...Trong một hệ thống hướng đối tượng, mọi thứ đều là đối tượng. Một bảng tính, một ô trong bảng tính, một biểu đồ, một bảng báo cáo, một con số hay một số điện thoại, một tập tin, một thư mục, một máy in, một câu hoặc một từ, thậm chí một ký tự, tất cả chúng là những ví dụ của một đối tượng. Rõ ràng chúng ta viết một chương trình hướng đối tượng cũng có nghĩa là chúng ta đang xây dựng một mô hình
Trừu tượng hóa dữ liệu (data abstraction) là tiến trình xác định và nhóm các thuộc tính và các hành động liên quan đến một thực thể đặc thù trong ứng dụng đang phát triển.
Trừu tượng hóa chương trình (program abstraction) là một sự trừu tượng hóa dữ liệu mà làm cho các dịch vụ thay đổi theo dữ liệu. của một vài bộ phận trong thế giới thực. Tuy nhiên các đối tượng này có thể được biểu diễn hay mô hình trên máy tính.
Một đối tượng thế giới thực là một thực thể cụ thể mà thông thường bạn có thể sờ, nhìn thấy hay cảm nhận được. Tất cả các đối tượng trong thế giới thực đều có trạng thái (state) và hành động (behaviour). Ví dụ:
Trạng thái Hành động
Con chó
Tên Màu Giống Vui sướng
Sủa Vẫy tai Chạy Ăn
Xe đạp Bánh răng Bàn đạp Dây xích Bánh xe
Tăng tốc Giảm tốc Chuyển bánh răng
Hình 6.1 Ví dụ về trạng thái và hành động
Các đối tượng phần mềm (software object) có thể được dùng để biểu diễn các đối tượng thế giới thực. Chúng được mô hình sau khi các đối tượng thế giới thực có cả trạng thái và hành động. Giống như các đối tượng thế giới thực, các đối tượng phần mềm cũng có thể có trạng thái và hành động. Một đối tượng phần mềm có biến (variable) hay trạng thái (state) mà thường được gọi là thuộc tính (attribute; property) để duy trì trạng thái của nó và phương thức (method) để thực hiện các hành động của nó. Thuộc tính là một hạng mục dữ liệu được đặt tên bởi một định danh (identifier) trong khi phương thức là một chức năng được kết hợp với đối tượng chứa nó.
95

OOP thường sử dụng hai thuật ngữ mà sau này Java cũng sử dụng là thuộc tính (attribute) và phương thức (method) để đặc tả tương ứng cho trạng thái (state) hay biến (variable) và hành động (behavior). Tuy nhiên C++ lại sử dụng hai thuật ngữ dữ liệu thành viên (member data) và hàm thành viên (member function) thay cho các thuật ngữ này.
Xét một cách đặc biệt, chỉ một đối tượng riêng rẽ thì chính nó không hữu dụng. Một chương trình hướng đối tượng thường gồm có hai hay nhiều hơn các đối tượng phần mềm tương tác lẫn nhau như là sự tương tác của các đối tượng trong trong thế giới thực. Khái niệm 6.3
Kể từ đây, trong giáo trình này chúng ta sử dụng thuật ngữ đối tượng (object) để chỉ một đối tượng phần mềm. Hình 6.1 là một minh họa của một đối tượng phần mềm:
Đối tượng (object) là một thực thể phần mềm bao bọc các thuộc tính và các phương thức liên quan.
Mọi thứ mà đối tượng phần mềm biết (trạng thái) và có thể làm (hành động) được thể hiện qua các thuộc tính và các phương thức. Một đối tượng phần mềm mô phỏng cho chiếc xe đạp sẽ có các thuộc tính để xác định các trạng thái của chiếc xe đạp như: tốc độ của nó là 10 km trên giờ, nhịp bàn đạp là 90 vòng trên phút, và bánh răng hiện tại là bánh răng thứ 5. Các thuộc tính này thông thường được xem như thuộc tính thể hiện (instance attribute) bởi vì chúng chứa đựng các trạng thái cho một đối tượng xe đạp cụ thể. Trong kỹ thuật hướng đối tượng thì một đối tượng cụ thể được gọi là một thể hiện (instance).
Khái niệm 6.4 Hình 6.2 minh họa một xe đạp được mô hình như một đối tượng phần mềm:
Đối tượng xe đạp phần mềm cũng có các phương thức để thắng lại, tăng nhịp đạp hay là chuyển đổi bánh răng. Nó không có phương thức để thay đổi tốc độ vì tốc độ của xe đạp có thể tình ra từ hai yếu tố số vòng quay và bánh răng hiện tại. Những phương thức này thông thường được biết như là các phương thước thể hiện (instance method) bởi vì chúng tác động hay thay đổi trạng thái của một đối tượng cụ thể.
Một đối tượng cụ thể được gọi là một thể hiện (instance).
3. Lớp (Class)
Trong thế giới thực thông thường có nhiều loại đối tượng cùng loại. Chẳng hạn chiếc xe đạp của bạn chỉ là một trong hàng tỉ chiếc xe đạp trên thế giới. Tương tự, trong một chương trình hướng đối tượng có thể có nhiều đối tượng cùng loại và chia sẻ những đặc điểm chung. Sử dụng thuật ngữ hướng đối tượng, chúng ta có thể nói rằng chiếc xe đạp của bạn là một thể hiện của lớp xe đạp. Các xe đạp có một vài trạng thái chung (bánh răng hiện tại, số vòng quay hiện tại, hai bánh xe) và các hành động (chuyển bánh răng, giảm tốc). Tuy nhiên, trạng thái của mỗi xe đạp là độc lập và có thể khác với các trạng thái của các xe đạp khác. Trước khi tạo ra các xe đạp, các nhà sản xuất thường thiết lập một bảng thiết kế (blueprint) mô tả các đặc điểm và các yếu tố cơ bản của xe đạp. Sau đó hàng loạt xe đạp sẽ được tạo ra từ bản thiết kế này. Không hiệu quả nếu như tạo ra một bản thiết kế mới cho mỗi xe đạp được sản xuất.
96

Trong phần mềm hướng đối tượng cũng có thể có nhiều đối tượng cùng loại chia sẻ những đặc điểm chung như là: các hình chữ nhật, các mẫu tin nhân viên, các đoạn phim, … Giống như là các nhà sản xuất xe đạp, bạn có thể tạo ra một bảng thiết kế cho các đối tượng này. Một bảng thiết kế phần mềm cho các đối tượng được gọi là lớp (class).
Khái niệm 6.5 Trở lại ví dụ về xe đạp chúng ta thấy rằng một lớp Xedap là một bảng thiết kế
cho hàng loạt các đối tượng xe đạp được tạo ra. Mỗi đối tượng xe đạp là một thể hiện của lớp Xedap và trạng thái của nó có thể khác với các đối tượng xe đạp khác. Ví dụ một xe đạp hiện tại có thể là ở bánh răng thứ 5 trong khi một chiếc khác có thể là ở bánh răng thứ 3.
Lớp Xedap sẽ khai báo các thuộc tính thể hiện cần thiết để chứa đựng bánh răng hiện tại, số vòng quay hiện tại, .. cho mỗi đối tượng xe đạp. Lớp Xedap cũng khai báo và cung cấp những thi công cho các phương thức thể hiện để cho phép người đi xe đạp chuyển đổi bánh răng, phanh lại, chuyển đổi số vòng quay, .. như Hình 6.3.
Lớp (class) là một thiết kế (blueprint) hay một mẫu ban đầu (prototype) định nghĩa các thuộc tính và các phương thức chung cho tất cả các đối tượng của cùng một loại nào đó.
Một đối tượng là một thể hiện cụ thể của một lớp. Sau khi bạn đã tạo ra lớp xe đạp, bạn có thể tạo ra bất kỳ đối tượng xe đạp nào
từ lớp này. Khi bạn tạo ra một thể hiện của lớp, hệ thống cấp phát đủ bộ nhớ cho đối tượng và tất cả các thuộc tính thể hiện của nó. Mỗi thể hiện sẽ có vùng nhớ riêng cho các thuộc tính thể hiện của nó. Hình 6.4 minh họa hai đối tượng xe đạp khác nhau được tạo ra từ cùng lớp Xedap:
Ngoài các thuộc tính thể hiện, các lớp có thể định nghĩa các thuộc tính lớp (class attribute). Một thuộc tính lớp chứa đựng các thông tin mà được chia sẻ bởi tất cả các thể hiện của lớp. Ví dụ, tất cả xe đạp có cùng số lượng bánh răng. Trong trường hợp này, định nghĩa một thuộc tính thể hiện để giữ số lượng bánh răng là không hiệu quả bởi vì tất cả các vùng nhớ của các thuộc tính thể hiện này đều giữ cùng một giá trị. Trong những trường hợp như thế bạn có thể định nghĩa một thuộc tính lớp để chứa đựng số lượng bánh răng của xe đạp.Tất cả các thể hiện của lớp Xedap sẽ chia thuộc tính này. Một lớp cũng có thể khai báo các phương thức lớp (class methods). Bạn có thể triệu gọi một phương thức lớp trực tiếp từ lớp nhưng ngược lại bạn phải triệu gọi các phương thức thể hiện từ một thể hiện cụ thể nào đó.
4. Thuộc tính (Attribute)
Các thuộc tính trình bày trạng thái của đối tượng. Các thuộc tính nắm giữ các giá trị dữ liệu trong một đối tượng, chúng định nghĩa một đối tượng đặc thù.
Khái niệm 6.7 Một thuộc tính có thể được gán một giá trị chỉ sau khi một đối tượng dựa trên
lớp ấy được tạo ra. Một khi các thuộc tính được gán giá trị chúng mô tả một đối tượng. Mọi đối tượng của một lớp phải có cùng các thuộc tính nhưng giá trị của các thuộc
97

tính thì có thể khác nhau. Một thuộc tính của đối tượng có thể nhận các giá trị khác nhau tại những thời điểm khác nhau.
Thuộc tính lớp(class attribute) là một hạng mục dữ liệu liên kết với một lớp cụ thể mà không liên kết với các thể hiện của lớp. Nó được định nghĩa bên trong định nghĩa lớp và được chia sẻ bởi tất cả các thể hiện của p.
Phương thức lớp (class method) là một phương thức được triệu gọi mà không tham khảo tới bất kỳ một đối tượng nào. Tất cả các phương thức lớp ảnh hưởng đến toàn bộ lớp chứ không ảnh hưởng đến một lớp riêng rẽ nào.
Thuộc tính (attribute) là dữ liệu trình bày các đặc điểm về một đối tượng. Chương 6: Lập trình hướng đối tượng 82
5. Phương thức (Method)
Các phương thức thực thi các hoạt động của đối tượng. Các phương thức là nhân tố làm thay đổi các thuộc tính của đối tượng.
Khái niệm 6.8 Các phương thức xác định cách thức hoạt động của một đối tượng và được thực
thi khi đối tượng cụ thể được tạo ra.Ví dụ, các hoạt động chung của một đối tượng thuộc lớp Chó là sủa, vẫy tai, chạy, và ăn. Tuy nhiên, chỉ khi một đối tượng cụ thể thuộc lớp Chó được tạo ra thì các phương thức sủa, vẫy tai, chạy, và ăn mới được thực thi.
Các phương thức mang lại một cách nhìn khác về đối tượng. Khi bạn nhìn vào đối tượng Cửa ra vào bên trong môi trường của bạn (môi trường thế giới thực), một cách đơn giản bạn có thể thấy nó là một đối tượng bất động không có khả năng suy nghỉ. Trong tiếp cận hướng đối tượng cho phát triển hệ thống, Cửa ra vào có thể được liên kết tới phương thức được giả sử là có thể được thực hiện. Ví dụ, Cửa ra vào có thể mở, nó có thể đóng, nó có thể khóa, hoặc nó có thể mở khóa. Tất cả các phương thức này gắn kết với đối tượng Cửa ra vào và được thực hiện bởi Cửa ra vào chứ không phải một đối tượng nào khác.
6. Thông điệp (Message)
Một chương trình hay ứng dụng lớn thường chứa nhiều đối tượng khác nhau. Các đối tượng phần mềm tương tác và giao tiếp với nhau bằng cách gởi các thông điệp (message). Khi đối tượng A muốn đối tượng B thực hiện các phương thức của đối tượng B thì đối tượng A gởi một thông điệp tới đối tượng B.
Ví dụ đối tượng người đi xe đạp muốn đối tượng xe đạp thực hiện phương thức chuyển đổi bánh răng của nó thì đối tượng người đi xe đạp cần phải gởi một thông điệp tới đối tượng xe đạp.
Đôi khi đối tượng nhận cần thông tin nhiều hơn để biết chính xác thực hiện công việc gì. Ví dụ khi bạn chuyển bánh răng trên chiếc xe đạp của bạn thì bạn phải chỉ rõ bánh răng nào mà bạn muốn chuyển. Các thông tin này được truyền kèm theo thông điệp và được gọi là các tham số (parameter).
Phương thức (method) có liên quan tới những thứ mà đối tượng có thể làm. Một phương thức đáp ứng một chức năng tác động lên dữ liệu của đối tượng (thuộc tính).
98

Một thông điệp gồm có: Đối tượng nhận thông điệp Tên của phương thức thực hiện Các tham số mà phương thức cần
Khái niệm 6.9 Khi một đối tượng nhận được một thông điệp, nó thực hiện một phương thức
tương ứng. Ví dụ đối tượng xe đạp nhận được thông điệp là chuyển đổi bánh răng nó sẽ thực hiện việc tìm kiếm phương thức chuyển đổi bánh răng tương ứng và thực hiện theo yêu cầu của thông điệp mà nó nhận được.
7. Tính bao gói (Encapsulation)
Trong đối tượng xe đạp, giá trị của các thuộc tính được chuyển đổi bởi các phương thức. Phương thức changeGear() chuyển đổi giá trị của thuộc tính currentGear. Thuộc tính speed được chuyển đổi bởi phương thức changeGear() hoặc changRpm().
Trong OOP thì các thuộc tính là trung tâm, là hạt nhân của đối tượng. Các phương thức bao quanh và che giấu đi hạt nhân của đối tượng từ các đối tượng khác trong chương trình.Việc bao gói các thuộc tính của một đối tượng bên trong sự che chở của các phương thức của nó được gọi là sự đóng gói (encapsulation) hay là đóng gói dữ liệu.
Đặc tính đóng gói dữ liệu là ý tưởng của các nhà thiết các hệ thống hướng đối tượng. Tuy nhiên, việc áp dụng trong thực tế thì có thể không hoàn toàn như thế. Vì những lý do thực tế mà các đối tượng đôi khi cần phải phơi bày ra một vài thuộc tính này và che giấu đi một vài phương thức kia. Tùy thuộc vào các ngôn ngữ lập trình hướng đối tượng khác nhau, chúng ta có các điều khiển các truy xuất dữ liệu khác nhau.
Một đối tượng có một giao diện chung cho các đối tượng khác sử dụng để giao tiếp với nó. Do đặc tính đóng gói mà các chi tiết như: các trạng thái
Một thông điệp (message) là một lời yêu cầu một hoạt động. Một thông điệp được truyền khi một đối tượng triệu gọi một hay nhiều phương
thức của đối tượng khác để yêu cầu thông tin. Đóng gói (encapsulation) là tiến trình che giấu việc thực thi chi tiết của một đối
tượng. được lưu trữ như thế nào hay các hành động được thi công ra sao có thể được che giấu đi từ các đối tượng khác. Điều này có nghĩa là các chi tiết riêng của đối tượng có thể được chuyển đổi mà hoàn toàn không ảnh hưởng tới các đối tượng khác có liên hệ với nó. Ví dụ, một người đi xe đạp không cần biết chính xác cơ chế chuyển bánh răng trên xe đạp thực sự làm việc như thế nào nhưng vẫn có thể sử dụng nó. Điều này được gọi là che giấu thông tin.
8. Tính thừa kế (Inheritance)
Hệ thống hướng đối tượng cho phép các lớp được định nghĩa kế thừa từ các lớp khác. Ví dụ, lớp xe đạp leo núi và xe đạp đua là những lớp con (subclass) của lớp xe đạp. Như vậy ta có thể nói lớp xe đạp là lớp cha (superclass) của lớp xe đạp leo núi và xe đạp đua.
99

Các lớp con thừa kế thuộc tính và hành động từ lớp cha của chúng. Ví dụ, một xe đạp leo núi không những có bánh răng, số vòng quay trên phút và tốc độ giống như mọi xe đạp khác mà còn có thêm một vài loại bánh răng vì thế mà nó cần thêm một thuộc tính là gearRange (loại bánh răng).
Các lớp con có thể định nghĩa lại các phương thức được thừa kế để cung cấp các thi công riêng biệt cho các phương thức này. Ví dụ, một xe đạp leo núi sẽ cần một phương thức đặc biệt để chuyển đổi bánh răng.
Che giấu thông tin (information hiding) là việc ẩn đi các chi tiết của thiết kế hay thi công từ các đối tượng khác.
Thừa kế (inheritance) nghĩa là các hành động (phương thức) và các thuộc tính được định nghĩa trong một lớp có thể được thừa kế hoặc được sử dụng lại bởi lớp khác.
Lớp cha (superclass) là lớp có các thuộc tính hay hành động được thừa hưởng bởi một hay nhiều lớp khác.
Lớp con (subclass) là lớp thừa hưởng một vài đặc tính chung của lớp cha và thêm vào những đặc tính riêng khác.
Các lớp con cung cấp các phiên bản đặc biệt của các lớp cha mà không cần phải định nghĩa lại các lớp mới hoàn toàn. Ở đây, mã lớp cha có thể được sử dụng lại nhiều lần.
9.Tính đa hình (Polymorphism)
Một khái niệm quan trọng khác có liên quan mật thiết với truyền thông điệp là đa hình (polymorphism). Với đa hình, nếu cùng một hành động (phương thức) ứng dụng cho các đối tượng thuộc các lớp khác nhau thì có thể đưa đến những kết quả khác nhau.
Khái niệm 6.14 Chúng ta hãy xem xét các đối tượng Cửa Sổ và Cửa Cái. Cả hai đối tượng có
một hành động chung có thể thực hiện là đóng. Nhưng một đối tượng Cửa Cái thực hiện hành động đó có thể khác với cách mà một đối tượng Cửa Sổ thực hiện hành động đó. Cửa Cái khép cánh cửa lại trong khi Cửa Sổ hạ các thanh cửa xuống. Thật vậy, hành động đóng có thể thực hiện một trong hai hình thức khác nhau. Một ví dụ khác là hành động hiển thị. Tùy thuộc vào đối tượng tác động, hành động ấy có thể hiển thị một chuỗi, hoặc vẽ một đường thẳng, hoặc là hiển thị một hình.
Đa hình có sự liên quan tới việc truyền thông điệp. Đối tượng yêu cầu cần biết hành động nào để yêu cầu và yêu cầu từ đối tượng nào. Tuy nhiên đối tượng yêu cầu không cần lo lắng về một hành động được hoàn thành như thế nào. Bài tập
1 Trình bày các định nghĩa của các thuật ngữ: Lập trình hướng đối tượng Trừu tượng hóa Đối tượng Lớp Thuộc tính Phương thức Thông điệp
Đa hình (polymorphism) nghĩa là “nhiều hình thức”, hành động cùng tên có thể được thực hiện khác nhau đối với các đối tượng/các lớp khác nhau.
100

2. Phân biệt sự khác nhau giữa lớp và đối tượng, giữa thuộc tính và giá trị, giữa thông điệp và truyền thông điệp.
3. Trình bày các đặc điểm của OOP. 4. Những lợi ích có được thông qua thừa kế và bao gói. 5. Những thuộc tính và phương thức cơ bản của một cái máy giặt. 6. Những thuộc tính và phương thức cơ bản của một chiếc xe hơi. 7. Những thuộc tính và phương thức cơ bản của một hình tròn. 8. Chỉ ra các đối tượng trong hệ thống rút tiền tự động ATM. 9. Chỉ ra các lớp có thể kế thừa từ lớp điện thoại, xe hơi, và động vật.
101

BÀI 7:LẬP TRÌNH LOGIC VÀ LẬP TRÌNH HÀMMã bài : MĐ39-07
Giới thiệuTrong các họ ngôn ngữ lập trình, lập trình hàm và lập trình logic là hai họ ngôn
ngữ lập trình ít phổ dụng hơn, do nét đặc trưng trong ứng dụng của nó. Tuy nhiên, trong lĩnh vực công nghệ thông tin, để giải quyết một số bài toán thực tế liên quan đến hệ chuyên gia, cơ sở tri thức hay trí tuệ nhân tạo thì việc sử dụng các họ ngôn ngữ lập trình này là rất phù hợp và mang lại hiệu quả cao.
Mục tiêu thực hiện- Hiểu rõ lập trình logic và sự khác biệt với lập trình mệnh lệnh- Các thành phần ngôn ngữ lập trình logic- Xác định ngữ nghĩa của các ký hiệu- Nắm được thành phần cơ bản của ngôn ngữ Prolog- Viết được các chương trình cỡ nhỏ và vừa bằng Prolog- Hiểu cơ chế lập trình hàm- Thực hiện các phép biến đổi hàm và ngữ nghĩa hàm
Nội dung chínhBài học này trình bày hai phương pháp: lập trình logic và lập trình hàm. Đồng
thời cũng giới thiệu hai ngôn ngữ cụ thể là lập trình logic Prolog và lập trình hàm Scheme.
1. Giới thiệu lập trình logic
Lập trình logic được sử dụng phổ biến trong lĩnh vực trí tuệ nhân tạo và hệ chuyên gia. Các ngôn ngữ lập trình logic rất thích hợp để giải quyết các bài toán liên quan đến các đối tượng (object) và mối quan hệ (relation) giữa chúng. Nguyên lý lập trình logic dựa trên các mệnh đề Horn (Horn clauses). Một mệnh đề Horn biểu diễn một sự kiện hay sự việc nào nào đó là đúng hoặc không đúng, xảy ra hoặc không xảy ra (có hoặc không có, …). Ví dụ sau đây là một số mệnh đề Horn:
1. Nếu một người An cha của Lộc và Lộc là cha của Dương thì An là ông của Dương.
2. Hùng là cha của Tuyết.3. Nếu một học viên chịu khó và học hỏi thì học viên đó có kết quả tốt.4. Học viên Linh có kết quả tốt.5. Tất cả mọi người đều phải chết
(Hoặc Nếu ai đó là người, thì ai đó phải chết).6. Socrat là người.
Trong các mệnh đề Horn ở trên, các mệnh đề 1, 3, 5 được gọi là các luật (rule), các mệnh đề còn lại được gọi là các sự kiện (fact). Một chưưng trình logic có thể được xem như là một cơ sở dữ liệu gồm các mệnh đề Horn, hoặc dạng luật hoặc dạng sự kiện, chảng hạn như tất cả các sự kiện và luật từ 1 đến 6 ở trên. Ngưới sử dụng gọi chạy một chương trình logic bằng cách đặt các câu hỏi (question) truy vấn trên cơ sở dũ liệu này, chẳng hạn câu hỏi:

Socrat có chết không (tương đương với khẳng định “Socrat chết” là đúng hay sai)?Một hệ thống logic sẽ thực hiện chương trình theo cách suy luận – tìm kiếm dựa trên vốn tri thức (knowledge) đã có là chương trình – cơ sở dữ liệu, để chứng minh câu hỏi là một khẳng định đúng (Yes) hoặc sai (No). Với câu hỏi trên, hệ thống tìm kiếm trong cơ sở dữ liệu khẳng định Socrat chết bằng cách tìm xem ai đó là Socrat và tìm thấy luật 5 thỏa mãn (vế thì). Vận dụng luật 5, hệ thống nhận được Socrat là người (vế nếu) chính là sự kiện 6. Từ đó câu trả lời sẽ là:
YesCó nghĩa là sự kiện Socrat chết là đúng.Trong họ các ngôn ngữ logic thì Prolog (nghĩa là Programing in Logic) là ngôn ngữ lập trình được sử dụng rộng rãi nhất. Ngôn ngữ này ra đời năm 1970 do một nhóm nghiên cứu người Pháp đề xuất, sau đó Prolog nhanh chóng được áp dụng rộng rãi ở châu Âu và nhiều nước trên thế giới.Từ năm 1980, Prolog được công nhận như là một ngôn ngữ phát triển trong lĩnh vực Trí tuệ Nhân tạo. Và gần đây, Prolog còn được ứng dụng trong lập trình bởi các ràng buộc.
2. Ngữ nghĩa các kí hiệu
2.1 Một số khái niệmMột chương trình Prolog là một cơ sở dữ liệu gồm các mệnh đề (clause). Mỗi
mệnh đề được xây dựng từ các vị từ (predicat). Một vị từ là một phát biểu nào đó về các đối tượng có giá trị chân lý đúng (true) hoặc sai (false). Một vị từ có thể có các đối là các nguyên tử (logic atom).
Mỗi nguyên tử biểu diễn một quan hệ giữa các hạng (term). Như vậy, hạng và quan hệ giữa các hạng tạo thành mệnh đề. Hạng được xem là những đối tượng dữ liệu trong một chương trình Prolog. Hạng có thể là hạng sơ cấp (elementary term) gồm hằng (constant) hay trực kiện (literal), biến (variable) và các hạng phức hợp (compound term).
Các hạng phức hợp biểu diễn các đối tượng phức tạp của bài toán cần giải quyếtthuộc lĩnh vực đang xét. Hạng phức hợp là một hàm tử (functor) có chứa các đối (argument), có dạng:
Tên_hàm_tử (đối_1, đối_2, …)Tên hàm tử là một chuỗi chữ cái hoặc chữ số được batư đầu bởi chữ cái. Các
đối có thể là các biến, hạng sơ cấp, hoặc hạng phức hợp.Ví dụ các hàm tử:
a(x, y, 5).Person(Hùng, 1980, địachỉ(15, Pasteur, ĐàNẵng)).
Sau mỗi mệnh đề, Prolog quy ước kết thúc bởi một dấu chấm.Mệnh đề có thể là một sự kiện, một luật hay một câu hỏi. Mỗi mệnh đề được
viết như sau:- Sự kiện: < … >.- Luật: < … > :- < … >.- Câu hỏi: ?- < … >.
1.2 Các kiểu dữ liệu Prolog

Hình 7.1 sau biểu diễn phân lớp các kiểu dữ liệu trong Prolog.Hình 7.1 Các kiểu dữ liệu trong Prolog
Như thế, các kiểu dữ liệu gồm các kiểu sơ cấp và các kiểu phức hợp. Các kiểu sơ cấp gồm các kiểu hằng và biến.
Kiểu hằng số gồm số nguyên và số thực. Cú pháp số nguyên và số thực rất đơn giản, ví dụ: 10 1111 546.67 -123.05
Các số thực rất ít được sử dụng trong Prolog, bởi vì Prolog là một ngôn ngữ lập trình kí hiệu, phi số.
Kiểu hằng logic có giá trị true và fail.Kiểu hằng chuỗi kí tự được đặt giữa hai dấu nháy kép. Ví dụ:“Chuoi @ ki tu #” Chuỗi kí tự tùy ý“” Chuỗi rỗng
Kiểu hằng nguyên tử là một chuỗi kí tự ở một trong 3 dạng sau:1. Chuỗi gồm chữ cái, chữ số và kí tự _ luôn được bắt đầu bởi một chữ cái in
thường, ví dụ:ok studentalain_smith x232. Chuỗi các kí hiệu đặc biệt::::=== <---->3. Chuỗi đặt giữa hai dấu nháy đơn được bắt đầu bởi kí tự in hoa:‘Alain Smith’ ‘No thing’
Biến là một chuỗi kí tự gồm chữ cái, chữ số, được bắt đầu bởi chữ in hoa hoặc dấu _:X, Y, ZProg, Array_Of_Nat,_X, _A320
Kiểu dữ liệu phức hợp là các kiểu dữ liệu có cấu trúc (cây, danh sách, …), tương tự cấu trúc bản ghi, là đối tượng nhiều thành phần, mỗi thành phần lại có thể là một cấu trúc. Ví dụ:
triangle(point(1, 4), point(6, 4), point(5, 8))Chú thích
Trong chương trình Prolog, chú thích (comment) được đặt giữa hai cặp ký hiệu /* và */. Ví dụ:/******************************//** Đây là chú thích trong Prolog **//******************************/
kiểu dữ liệu
kiểu sơ cấp
kiểu phức hợp
hằng biến
số chuỗi kí tự
nguyên tử

Trong trường hợp muốn đặt một chú thích ngắn sau mỗi phần khai báo Prolog cho đến hết dòng thì có thể đặt trước kí hiệu %.
Thực nghiệm ngôn ngữ lập trình PrologNhư chúng ta đã biết, một chương trình Prolog là một cơ sở dữ liệu gồm các
mệnh đề. Mỗi mệnh đề hoặc là sự kiện hoặc là luật.Xây dựng sự kiệnMột sự kiện khẳng định một thực thể có một vài tính chất nào đó.Để xây dựng các sự kiện chúng ta lấy ví dụ về cây gia hệ
Hình 7.2.Ví dụ về cây gia hệTrong cây gia hệ, các nút chỉ người, các mũ tên chỉ quan hệ cha (hay mẹ) của
(parent of). Sự kiện anna là cha (hay mẹ) của luc được viết thành vị từ như sau:parent(anna, luc).
Vị từ parent có hai đối là anna và luc.Từ cây gia hệ trên chúng ta có thể viết các vị từ sau:
parent(anna, luc).parent(jerry, luc).parent(jerry, dam).parent(luc, toto).parent(luc, sam).parent(toto, jan).
Sau khi hệ thống nhận được chương trình này mà thực ra là một cơ sở dữ liệu thì người sử dụng có thể đặt ra các câu hỏi liên quan đến quan hệ parent. Chẳng hạn, câu hỏi luc có phải là cha (hay mẹ) của toto không được chuyển thành câu hỏi trong hệ thống đối thoại của Prolog như sau (dấu nhắc ?-):
?- parent(luc, toto).Sau khi tìm thấy sự kiện này, Prolog trả lời:
YesTiếp tục đặt câu hỏi khác:
?- parent(luc, jan).No
Bởi vì Prolog không tìm thấy sự kiện Luc là mẹ của Jan.
anna
jerrry
luc
toto
sam
dam
jan

Hơn nữa, chúng ta có thể đặt ra các câu hỏi khác. Chẳng hạn, ai là cha (hay mẹ) của của luc?
?- parent(X, luc).anna ;jerryYes
Với câu hỏi này Prolog sẽ có hai câu trả lời. Để biết câu trả lời tiếp theo, trong hầu hết các trình cài đặt Prolog, người sử dụng phải gõ vào dấu chấm phẩy (;) như trong ví dụ trên. Lưu ý, nếu đã hết phương án trả lời mà vẫn tiếp tục yêu cầu (;) thì Prolog trả lời No ngược lại trả lời Yes.Chúng ta có thể đặt các câu hỏi tổng quát hơn, như ai là cha (hay mẹ) của ai? Nói cách khác cần tìm tất cả X và Y sao cho X là cha (hay mẹ) của Y. Ta đặt câu hỏi như sau:
?- parent(X, Y).Sau khi nhận được câu hỏi trên, Prolog sẽ lân lượt tìm tất cả các cặp cha (hay mẹ) - conm thỏa mãn yêu cầu:
X = annaY = luc ;X = jerryY = luc ;X = jerryY = dam ;X = lucY = toto ;X = lucY = sam ;X = totoY = jan Yes
Tùy theo trình cài đặt Prolog chúng ta có thể gõ vào một dấu chấm (.) hoặc Enter để chấm dứt giữa chừng luồng trả lời.
Ngoài ra, chúng ta còn có thể đưa ra các câu hỏi phức tạp hơn, chẳng hạn ai là cháu của jerry. Thực tế, thì quan hệ cháu chưa được định nghĩa tuy nhiên chúng ta có thể tách câu hỏi thành hai thành phần sơ cấp:Ai là con của jerry? Giả sử có tên là X.Ai là con của X? Giả sử có tên là Y.
Như vậy Y sẽ là cháu của jerry. Quan hệ cháu được thiết lập từ quan hệ cha (hay mẹ) (hay ngược lại là quan hệ con).
Câu hỏi có thể được đặt ra như sau:?- parent(jerry, X), parent(X, Y).
Prolog trả lời:X = lucY = toto ;X = lucY = sam Yes

Như thế, Prolog đưa ra hai trả lời là toto và sam.Mỗi câu hỏi trong Prolog được gọi là một đích (goal) cần phải được thỏa mãn.
Nếu câu trả lời là Yes thì đích được thỏa mãn hay thành công, ngược lại câu trả lời là No thì đích là không được thỏa mãn hay thất bại.
Xây dựng luậtTừ chương trình Prolog trên, chúng ta có thể thêm vào các sự kiện về giới tính
như sau:man(luc).man(jerry).man(dam).man(sam).woman(anna).woman(toto).woman(jan).
Trong ví dụ trên chúng ta đã nói đến quan hệ con, nhưng thực ra chúng ta vẫn chưa định nghĩa chúng mà chỉ coi là hệ quả của quan hệ cha (hay mẹ). Thật vây, jerry là cha (hay mẹ) của luc thì đương nhiên luc là con của jerry. Chúng ta có thể đưa vào quan hệ mới child như sau:
child(luc, jerry).Thay vì định nghĩa từng sự kiện như thế này cho quan hệ cha (hay mẹ) - con, ta
định nghĩa luật như sau:child(Y, X) :- parent(X, Y).
Luật trên được hiểu là: với mọi X và Y, Y là con của X, nếu X là cha (hay mẹ) của của Y.
Như thế, một luật bao gồm hai phần:- phần bên phải chỉ điều kiện, còn được gọi là thân (body) của luật;- phần bên trái chỉ kết luận, còn được gọi là đầu (head) của luật.
Có sự khác nhau giữa sự kiện và luật. Một sự kiện luôn đúng, khong chịu bất cứ ràng buộc nào cả. Trong khi một luật chỉ đúng khi một số thuộc tính nào đó phải được thỏa mãn.
Thật vậy, nếu parent(X, Y) là đúng thì child(Y, X) cũng phải đúng là kết quả logic của phép suy luận.
Ngoài ra chúng ta có thể định nghĩa các luật (dấu phẩy (,) chỉ phép và logic (and)) để bổ sung thêm các quan hệ mới, như quan hệ mẹ/cha (mother/father) và quan hệ ông bà (grandparent).
mother(X, Y) :- parent(X, Y), woman(X).father(X, Y) :- parent(X, Y), man(X).grandparent(X, Z) :- parent(X, Y), parent(Y, Z).Chẳng hạn quan hệ mẹ được hiểu là: với mọi X và Y, nếu X là cha (hay mẹ)
của Y và X là phụ nữ thì X là mẹ của Y.Bây giờ chúng ta xem cách Prolog sử dụng các luật như thế nào. Giả sử ta đặt
câu hỏi: luc có phải là con của anna không.
?- child(luc, anna).Trong chương trình không có sự kiện nào liên quan đến con, như thế phải tìm
các luật. Luật trên áp dụng đối với đối tưuợng tổng quát bất kỳ mà ta lại quan tâm đến các đối tượng cụ thể luc và anna. Prolog sẽ sử dụng phép thế (substitution) bằng cách

gán giá trị luc cho biến Y và anna cho biến X. Ta nói rằng X và Y đã được ràng buộc (bound):
X = anna và Y = luc
Lúc này phần điều kiện có giá trị parent(anna, luc) trở thành đích con (sub-goal) để Prolog thay thế cho đích child(luc, anna). Tuy nhiên, đích này chính là sự kiện đã có, nên câu trả lời sẽ là:
Yes
Ngoài ra, Prolog còn cung cấp chúng ta cách định nghĩa luật đệ quy (recursive rule). Bây giờ chúng ta muốn thêm quan hệ tổ tiên (ancestor). Ta phân biệt ra hai loại quan hệ: tổ tiên trực tiếp và tổ tiên gián tiếp.
Tổ tiên trực tiếp được định nghĩa như sau: với mọi X và Z, X là tổ tiên trực tiếp của Z nếu X là cha hay mẹ của Z.
ancestor(X, Z):- parent(X, Z).Tổ tiên gián tiếp được định nghĩa phức tạp hơn, nếu càng mở rộng lớp hậu duệ.
Chẳng hạn:ancestor(X, Z):- % tổ tiên là ông bà
parent(X, Y),parent(Y, Z).
ancestor(X, Z):- % tổ tiên là cố ông cố bàparent(X, Y1),parent(Y1, Y2),parent(Y2, Z).
…Tuy nhiên nhờ phép đệ quy, tổ tiên gián tiếp được định nghĩa một cách đơn
giản hơn như sau: với mọi X và Z, X là tổ tiên của Z nếu tồn tại Y sao cho X là cha hay mẹ của Y và Y là tổ tiên của Z.
ancestor(X, Z):- parent(X, Z).
ancestor(X, Z):- parent(X, Y),ancestor(Y, Z).
Nếu ta đặt câu hỏi: anna là tổ tiên của ai??- ancestor(anna, X).
Câu trả lời sẽ là:X = luc ;X = toto ;X = sam ;X = jan Yes
Trong Prolog, hầu hết các chương trình phức tạp đều sử dụng đệ quy, đệ quy là một khả năng mạnh của Prolog.
Sử dụng biến trong Prolog

Các biến xuất hiện trong các mệnh đề gọi là biến tự do. Người ta giải thiết rằng các biến là được lượng tử toàn thể và được đọc là “với mọi”. Tuy nhiên, có nhiều cách giải thích khác nhau trong trường hợp các biến chỉ xuất hiện trong phần bên phải của luật. Ví dụ:
haveachild(X) :- parent(X, Y).có thể được đọc như sau:
(a) Với mọi X và Y, nếu X là cha (hay mẹ) của Y thì X có một người con.(b) Với mọi X, X có một người con nếu tồn tại một Y sao cho X là cha (hay mẹ)
của Y.Ngoài ra, khi một biến chỉ xuất hiện một lần trong các mệnh đề thì không cần
đặt tên cho nó. Trong trường hợp này, Prolog cho phép sử dụng biến vô danh (anonymous variable) là các biến có tên chỉ là một dấu gạch dưới (_).Quay trở lại với ví dụ trên, ta nhận thấy trong luật trên đích haveachild không phụ thuộc gì vào Y, nên ta có thể dùng biến vô danh như sau:
haveachild(X) :- parent(X, _).Nghĩa là, X có một người con nếu X là cha (hay mẹ) của ai đó.Phạm vi sử dụng (lexical scope) của một biến trong một mệnh đề không vượt ra khỏi mệnh đề đó. Có nghĩa là, nếu một biến X xuất hiện trong hai mệnh đề khác nhau, thì sẽ tương ứng với hai biến phân biệt nhau.
3. Logic trong Prolog
Prolog có cú pháp là những công thức logic vị từ bậc một (first order predicate logic), được viết dưới dạng các mệnh đề (các lượng tử và xuất hiện không tường minh), nhưng hạn chế chỉ đơn thuần là các mênh đề Horn, là các mệnh đề được khẳng định là đúng.
Prolog diễn giải chương trình là theo kiểu toán học: các sự kiện và các luật là các tiên đề, câu hỏi của người sử dụng như là một định lý cần khẳng định. Prolog sẽ tìm cách chứng minh định lý này, nghĩa là chỉ ra rằng định lý có thể được suy diễn một cách logic từ các tiên đề.
Về mặt thủ tục, Prolog sử dụng phương pháp suy diễn quay lui (back-tracking) để hợp giải (resolution) bài toán, được gọi là chiến lược hợp giải. Có thể tóm tắt như sau:
Để chứng minh P(a), người ta tìm sự kiện P(t) hoặc một luật P(t) :- L1, L2, …, Ln sao cho a có thể hợp nhất được (unifiable) với t nhờ so khớp. Nếu tìm được sự kiện P(a) như vậy việc chứng minh là kết thúc. Còn nếu tìm được P(t) là luật, cần lần lượt chứng minh vế phải của L1, L2, …, Ln nó.
Trong Prolog, mỗi câu hỏi luôn là một dãy nhiều đích. Prolog trả lời câu hỏi là tìm cách làm thỏa mãn tất cả các đích hay còn gọi là xóa các đích. Nói cách khác, xóa một đích có nghĩa là đích này được suy ra một cách logic bởi các sự kiện và luật chứa trong chương trình. Nếu tất cả các đích của câu hỏi được xóa, câu trả lời là Yes, ngược lại là No.
4. Giới thiệu lập trình hàm
Ngôn ngữ lập trình hàm (functional programing language) là ngôn ngữ lập trình bậc cao, mang tính trừu tượng cao hơn so với ngôn ngữ mệnh lệnh.

Khi lập trình với các ngôn ngữ hàm, người lập trình phải định nghĩa các hàm toán học dễ suy luận, dễ hiểu mà không cần quan tấm đến chúng được cài đặt thế nào trong máy.
Ngôn ngữ hàm dựa trên việc tính giá trị của biểu thức được xây dựng từ bên ngoài lời gọi hàm. Ở đây, hàm là một hàm toán học thuần túy: là ánh xạ nhận các giá trị lấy từ một miền xác định để trả về giá trị thuộc một miền khác.
Một hàm có thể có hoặc không có, các tham đối (arguments hay parameters) để sau khi tính toán, hàm trả về một giá trị nào đó. Chẳng hạn, có thể xem biểu thức 2 * 4 là một hàm tính nhân của hai tham đối là 2 và 4.
Trong ngôn ngữ hàm, các biến toàn cục và phép gán bị loại bỏ, giá trị được tính bởi một hàm chỉ phụ thuộc vào các tham đối.
Ngôn ngữ hàm thường được ứng dụng trong các lĩnh vực trí tuệ nhân tạo, giao tiếp hệ thống, xử lí kí hiệu, tính toán hình thức, ...
5. Ngôn ngữ hàm Scheme
5.1 Giới thiệu SchemeScheme là ngôn ngữ hàm thuộc học Lisp và mang tính sư phạm cao. Sheme có cú pháp đơn giản, dễ lập trình. Các cấu trúc dữ liệu cơ sở của Scheme là danh sách và cây, dựa trên khái niệm về kiểu dữ liệu trừu tượng.Một chương trình Scheme là một dãy các định nghĩa hàm (function) góp lại để định nghĩa một hoặc nhiều hàm phức tạp hơn. Hoạt động cơ bản trong lập trình Scheme là tính toán các biểu thức. Scheme làm việc theo chế độ tương tác với người sử dụng:
- Người sử dụng gõ vào một biểu thức, sau mỗi dòng nhấn enter.- Hệ thống in kết quả (hoặc báo lỗi) và qua dòng mới.- Hệ thống đưa ra dấu nhắc và chờ người sử dụng nhập biểu thức tiếp theo.
Để tiện theo dõi, chúng ta có các kí hiệu sau:- Kết quả tính toán được ghi sau dấu mũi tên (-->)- Các thông báo lỗi sai được đặt trước bởi ba dấu sao (***).
Chú thích trong Scheme được bắt đầu bởi một dấu chấm phẩy (;), viết trên một dòng bất kỳ, hoặc đầu dòng haợc cuối dòng. Ví dụ:
; đây là chú thích(= 1 1 1 1) ; so sánh 4 số
5.2 Các kiểu dữ liệu của SchemeTrong scheme có hai loại kiểu dữ liệu: kiểu đơn gián và kiểu phức hợp. Trong
phạm vi bài học này chúng ta chi xét các kiểu dữ liệu đơn giản bao gồm: kiểu số (number), kiểu logic (boolean), kiểu kí tự (character) và kiểu kí hiệu (symbol).
Kiểu số Kiểu số của Scheme có thể là số nguyên, số thực, số hữu tỷ và số phức
như sau:Kiểu số Ví dụSố nguyên 10, 9999Số thực 102.5, 1.7Số hữu tỷ 6/7, 11/4Số phức 2+5i, 4

Scheme không phân biệt số nguyên hay số thực. Các số không hạn chế về độ lớn miễn là bộ nhớ hiện tại cho phép.
Với kiểu số, Scheme cũng sử dụng các phép toán số học thông dụng: +, -, *, /, sqrt, ... và các phép toán quan hệ: =, <, >, >=, <=, ... với cú pháp như sau:
(+ x1 x2 ... xn): tính tổng x1 + x2 + ... + xn(- x1 x2): tính x1 - x2(* x1 x2 ... xn): tính tích x1 * x2 * ... * xn(/ x1 x2): tính x1/x2(quotient x1 x2): tính phần nguyên của x1/x2, lấy dấu x1(remainder x1 x2): tính phần nguyên của x1/x2, lấy dấu x2Các phép so sánh sau đây trả về #t (đúng) nếu kết quả so sánh lần lượt các giá
trị x1, x2, .., xn được thỏa mãn, ngược lại trả về #f (sai):(= x1 x2 ... xn)(> x1 x2 ... xn)(< x1 x2 ... xn)(>= x1 x2 ... xn)(<= x1 x2 ... xn)
Ví dụ:(+ 1 2 3 4 5 6)--> 21(= 1 2 3 4 5)--> #f(< 1 2 3 4 5)--> #t(* 2/3 1/2)--> 2/6
Kí tựTrong của kí tự Scheme có dạng #\<char>. Ví dụ:
#\a ; kí tự a thường--> #\a #\A ; kí tự a hoa--> #\A
Chuỗi Chuỗi là dãy kí tự tùy ý đặt giữa hai dấu nháy kép. Ví dụ:
”Chào các bạn !”--> ” Chào các bạn ! ”
Tên Tên được tạo thành từ các chữ cái, chữ số và dấu đặc biệt trừ # ( ) [] và dấu
cách. Tên trong Scheme không phân biệt chữ in hoa hay in thường. Ví dụ các tên hợp lệ:
pi ; không phân biệt với PI hay Pixlambda
Kiểu logic Kiểu logic (boolean) trong Scheme là các hằng được định nghĩa sẵn: #t (true) và
#f (false).

Vị từVị từ (predicate) là một hàm luôn trả về giá trị logic. Theo quy ước tên của các
vị từ được kết thúc bởi dấu chấm hỏi (?). Thư viện Scheme có sẵn nhiều vị từ. Sau đây là một số vị từ dùng để kiểm tra
kiểu giá trị của một biểu thức:(number? s) --> #t nếu s là số thực, #f nếu không(integer? s) --> #t nếu s là số nguyên, #f nếu không(string? s) --> #t nếu s là một chuỗi, #f nếu không(boolean? s) --> #t nếu s là một logic, #f nếu không
Ví dụ:(number? 111)--> #t(string? 111)--> #f(string? ”111”)--> #t
Kí hiệuScheme xử lý kí hiệu (symbol) nhờ phép trích dẫn. Giá trị kí hiệu của Scheme
là một tên (giống tên biến) mà không gắn với một giá trị nào khác.Để chỉ cho Scheme một giá trị kí hiệu ta sử dụng phép trích dẫn (quote operator). Ví dụ, kí hiệu sam:
‘sam--> sam
Kí tự ‘ là cách viết tắt của hàm quote: ‘<exp> tương đươg (quote <exp>)Để kiểm tra xem một biểu thức có phải là một kí hiệu hay không người ta sử
dụng vị từ symbol? như sau:(symbol? ‘hello)--> #t(symbol? ”hello”)--> #f
Ví dụ này chỉ rằng không nên nhầm lẫn kí hiệu với chuỗi.Khái niệm về biểu thức tiền tố
Có nhiều cách để biểu diễn biểu thức, Scheme sử dụng dạng ngoặc tiền tố: nguyên tắc là viết các phép toán rồi mới đến các toán hạng và đặt tất cả trong dấu ngoặc.Ví dụ, biểu thức số học 2 + 3 được viết thành (+ 2 3). Một cách tổng quát, nếu op chỉ định một phép toán hai ngôi, một biểu thức số học có dạng:exp1 op exp2sẽ được viết dưới dạng:(op ~exp1 ~exp2)trong đó ~exp1 và ~exp2 cũng là các biểu thức dạng tiền tố.Ví dụ biểu thức số học 1 + 2 + 3 được viết thành (+ 1 2 3).Ngoài ra, chíng ta có thể trộn lẫn các phép toán: 2*3 + 4*5*6 được viết thành (+ (* 2 3) (* 4 5 6)).Ví dụ, một biểu thức toán học phức tạp:(cos(a) + sin(a))/(a2 + b2) được viêt thành: (/ (+ (cos a) (cos b)) (+ (* a a) (* b b)))
Các định nghĩa trong Scheme

Định nghĩa biếnScheme sử dụng từ khóa define để định nghĩa biến (variable). Ví dụ, định nghĩa
biến x có giá trị 1000:(define x 1000)
Dạng tổng quát của định nghĩa biến như sau:(define var expr)Sau khi định nghĩa, biến var sẽ nhận giá trị của biểu thức expr.
Định nghĩa hàmKhi cần đặt tên cho các biểu thức chứa tham biến, ta đi đến khái niệm hàm. Ví
dụ ta định nghĩa hàm tính diện tích hình tròn (circleSurface) sử dụng từ khóa define như sau:
(define (circleSurface r)(* 3.14159 r r))
Trong đó r là một tham biến. Một cách tổng quát, định nghĩa hàm có dạng:
(define (function-name x1 x2 ... xn)body)Trong đó, các x1, x2, ..., xn được gọi là các tham biến (parameters), function-
name là tên hàm được định nghĩa, body là phần thân hàm. Trong Scheme các tham biến và giá trị trả về của hàm không cần phải định nghĩa kiểu.
Gọi hàmSau khi định nghĩa hàm, người sử dụng có thể gọi hàm để sử dụng. Lời gọi hàm
có dạng như sau:(function-name arg1 arg1 ... argn)
trong đó, function-name là tên hàm được gọi, các arg1 arg1 ... argn được gọi là các tham đối thực sự. Sau khi gọi hàm, các tham đối agri được tính giá trị đẻ gán cho mỗi tham biến xi tương ứng. Tiếp theo, thân hàm (body) được tính giá trị trong một môi trường cục bộ.Ví dụ, lời gọi hàm circleSurface vừa định nghĩa:
(circleSurface (+ 3 4))thì r được nhận giá trị từ biểu thức (+ 3 4) là 7 rồi sau đó thực hiên thân hàm và cho kết quả là:
--> 153.93791Cấu trúc điều khiển
Dạng điều kiện ifCấu trúc điều kiện cơ bản nhất của Scheme là if có cú pháp như sau:(if e s-then s-else)
Nếu giá trị biểu thức e là #t (có giá trị true), dạng if trả về giá trị của biểu thức s-then, nếu không (có giá trị false) trả về giá trị của biểu thức s-else.
Ví dụ:(define (abs-value n)
(if (<= 0 n) n (- n)))Có thể sử dụng các dạng if lồng nhau:
(define (sign n)(if (> n 0)

1(if (= n 0) 0 –1 )))
Dạng điều kiện condThay vì sử dụng các dạng if lồng nhau, Scheme có dạng điều kiện cond rất
thuận tiện có cú pháp như sau:(cond (e1 s1)
…(en sn)[(else sn+1)] )
Các biểu thức e1, …, en được tính liên tiếp nhau cho đến khi gặp giá trị đúng, giả sử ei khi đó giá trị trả về của cond là biểu thức si tương ứng.Ví dụ, hàm sau đây trả vè kết quae xếp loại của một học viên:
(define (xeploai diem)(cond ((>= diem 8) “Gioi”)
((>= diem 7) “Kha”)((>= diem 5) “Trung Binh”)(else “Kem”)))
Các phép toán logic and và orCác phép toán logic dùng để tổ hợp các biểu thức. Giá trị của:
(and e1 e2 .. en)nhận được bằng cách tính lần lượt dãy các biểu thức e1, …, en và dừng lại khi gặp một giá trị #f và trả về kết quả là #f, nếu không trả về giá trị của biểu thức cuối sn.Ví dụ, kiển tra xem a và b có phải là kiểu số không mới tiến hành so sánh:
(and (number? a) (number? b) (> a b))Một cách tương tự, giá trị của:
(or e1 e2 .. en)nhận được bằng cách tính lần lượt dãy các biểu thức e1, …, en và dừng lại khi gặp một giá trị #t và trả về kết quả là giá trị biểu thức đó, nếu không trả về giá trị #f.
(or (= 2 4) (> 5 3) 100 (string? “abc”))--> 100 ; vì 100 là giá trị dầu tiên khác #f
Hàm đệ quyHàm đệ quy (recursive function) là hàm khi định nghĩa có lời gọi chính hàm đó.
Scheme cũng cho phép định nghĩa các hàm đệ quy, chẳng hạn như định nghĩa hàm tính tổng 12 + 22 + ... n2:
(define (sum n)(if (= n 1))
1(+ (sum (– n 1)) (* n n))))
Sử dụng hàm sum:(sum 4)--> 10
Tính toán LambdaPhép tính lambda là một hệ thống quy tắc nhưng có khả năng biểu diễn, cho
phép mã hóa tất cả các hàm đệ quy. Ở đây, trong phạm vi bài học này chúng ta không đi sâu vào lý thuyết của tính toán lambda mà chỉ nêu ứng dụng trong Scheme.

Trong Scheme, để biểu diễn theo cú pháp lambda một hàm có hai tham số:(x, y) x2 + y2
người ta viết như sau:(lambda (x y) (+ (* x x) (* y y)))
Một cách tổng quát, cú pháp sử dụng phép tính lambda như sau: (lambda arg-list body) trong đó body là một biểu thức (thân hàm), còn arg-list là một danh sách các tham đối.
Trong nhiều trường hợp định nghĩa một hàm có thể nhờ lambda. Chẳng hạn người lập trình cần định nghĩa những hàm bổ trợ trung gian, mà tên gọi của nó không cần ghi nhớ (bởi vì nó chỉ được sử dụng đúng một lần duy nhất). Ví dụ:
(lambda (x) (* x x)) cho phép tính bình phương của giá trị x.Khi gọi cần cung cấp tham đối ((lambda (x) (* x x)) 10) --> 100
Khi sử dụng define để gán một biểu thức lambda cho một tên biến:(define binhphuong (lambda (x) (* x x)))
thì binhphuong có giá trị một hàm, bình phương có thể được gọi với các tham số:(binhphuong 10) --> 100
Cú pháp để định nghĩa một hàm nhờ lambda là như sau:(define function-name
(lambda (x1, ..., xn)(body))
Bài tậpPhần lập trình logic
1. Cho quan hệ parent được định nghĩa trong phần lý thuyết, hãy cho biết kết quả của các câu hỏi sau:a. ?- parent(anna, X).b. ?- parent(jerry, X), parent(X, sam).c. ?- parent(X, anna).
2. Viết các mệnh đề Prolog diễn tả các câu hỏi liên quan đến quan hệ parent:a. Ai là cha (hay mẹ) của dam?b. Sam có con không?c. Ai là ông bà của Dam?
3. Định nghĩa quan hệ cháu (grandchild) bằng cách sử dụng quan hệ parent.Phần lập trình hàm
1. Giải thích các biểu thức sau đây:a. (- (+ (/ 4 2) (* 3 4 5) (- 9 2)) 10)b. (and (= a b) (= c d))c. (and (>= a b) (>= a c))d. (+ 1 (if (> a b) (- a b) (- b a)))
2. Viết dạng ngoặc tiền tố của các biểu thức sau:a. (a + b)(b + c)(c + d) – (e * f)b. (sin(x) + cos(y))2 + (x + y)/2
3. Viết biểu thức tìm giá trị lớn nhất của 3 số a, b và c.4. Viết hàm tính nghiệm phương trình bậc hai: ax2 + bx + c = 0. 5. Viêt hàm đệ quy tính gia thừa của n (n!).


BÀI 8 : LẬP TRÌNH SONG SONGMã bài: MĐ39-08
1. Một số khái niệm
Trong quá trình thực hiện chương trình thường xẩy ra một số sự kiện đặc biệt hoặc các lỗi như sự tràn số, truy xuất đến chỉ số mảng nằm ngoài tập chỉ số, thực hiện lệnh đọc một phần tử cuối tập tin... Các sự kiện đó được gọi là ngoại lệ (exception). Thay vì tiếp tục thực hiện chương trình bình thường, một chương trình con sẽ được gọi đểthực hiện một vài xử lý đặc biệt nào đó gọi là xử lý ngoại lệ. Hành động chú ý đếnngoại lệ, ngắt sự thực hiện chương trình và chuyển điều khiển đến xử lý ngoại lệ đượcgọi là đề xuất ngoại lệ (raising the exception)
2. Xử lý ngoại lệ
Thông thường các ngoại lệ đã được định nghĩa trước bởi ngôn ngữ, chẳng hạn nhưZERO_DIVIDE chỉ sự kiện chia cho một số không, END_OF_FILE: hết tập tin ,OVERFLOW: tràn số, hay tràn stack ... Xử lý ngoại lệ là một hành vi xử lý tương ứngkhi một ngoại lệ có thể diễn ra. Ví dụvoid example () {79......average = sum/total;...return ;when zero_divide {average = 0;printf(“ error: cannot compute average, total is zero\n”);}......} /** function example **/
3. Ðề xuất một ngoại lệ
Một ngoại lệ có thể bị đề xuất bằng phép toán nguyên thuỷ được định nghĩa bởi ngôn ngữ chẳng hạn phép cộng, phép nhân có thể đề xuất ngoại lệ OVERFLOW. Ngoài ra, một ngoại lệ có thể bị đề xuất một cách tường minh bởi người lập trình bằng cáchdùng một lệnh được cung cấp cho mục đích đó. Chẳng hạn trong Ada: raise BAD_DATA_VALUE;
Lệnh này có thể được thực hiện trong một chương trình con sau khi xác định một biến riêng hoặc tập tin nhập chứa giá trị không đúng.

4. Lan truyền một ngoại lệ (Propagating an exception)
Thông thường, khi xây dựng chương trình thì vị trí mà một ngoại lệ xuất hiện không phải là vị trí tốt nhất để xử lý nó. Khi một ngoại lệ được xử lý trong một chương trình con khác chứ không phải trong chương trình con mà nó được đề xuất thì ngoại lệ đó được gọi là được truyền (propagated) từ điểm mà tại đó nó được đề xuất đến điểm mànó được xử lý. Quy tắc để xác định việc xử lý một ngoại lệ đặc thù thường được gọi là chuỗi động (dynamic chain) của các kích hoạt chương trình con hướng tới chương trình con mà nó đề xuất ngoại lệ. Khi một ngoại lệ P được đề xuất trong chương trình con C, thì P được xử lý bởi một xử lý được định nghĩa trong C nếu có một cái xử lý như thế. Nếu không có thì C kết thúc. Nếu chương trình con B gọi C thì ngoại lệ được truyền đến B và một lần nữa được đề xuất tại điểm trong B nơi mà B gọi C. Nếu B không cung cấp một xử lý cho P thì B bị kết thúc và ngoại lệ lại được truyền tới chương trình gọi B vân vân... Nếu các chương trình con và bản thân chương trình chính không có xử lý cho P thì toàn bộ chương trình kết thúc và xử lý chuẩn được định nghĩa bởi ngôn ngữ sẽ được gọi tới.
Một hiệu quả quan trọng của quy tắc này đối với việc truyền các ngoại lệ là nó cho phép một chương trình con kế thừa (remain) như là một phép toán trừu tượng đượcđịnh nghĩa bởi người lập trình ngay cả trong việc xử lý ngoại lệ. Một phép toán nguyên thuỷ có thể bất ngờ ngắt quá trình bình thường của nó và đề xuất một ngoại lệ. Tương tự, thông qua việc thực hiện lệnh RAISE, một chương trình con có thể bất ngờ ngắt quá trình bình thường của nó và đề xuất một ngoại lệ. Ðến chương trình gọi thì hiệu quả của đề xuất ngoại lệ của chương trình con cũng giống như hiệu quả đề xuất của phép toán nguyên thủy, nếu chương trình con tự nó không có một xử lý ngoại lệ.
Nếu ngoại lệ được xử lý trong chương trình con thì chương trình con trở về một cách bình thường và chương trình gọi nó không bao giờ biết được rằng một ngoại lệ đã được đề xuất.
5. Sau khi một ngoại lệ được xử lý
Sau khi một xử lý đã hoàn thành việc xử lý một ngoại lệ và xử lý đó đã kết thúc thì có một vấn đề đặt ra là quyền điều khiển được chuyển tới chỗ nào? Ðiều khiển nên được chuyển tới chỗ mà ngoại lệ được đề xuất? Ðiều khiển nên chuyển về lệnh trong chương trình con chứa xử lý nơi mà ngoại lệ được đề xuất sau khi được truyền tới? Chương trình con chứa xử lý tự kết thúc một cách bình thường và nó xuất hiện tại chương trình gọi như là không có gì xẩy ra. Ðây là những lựa chọn khi thiết kế ngôn ngữ.
CÂU HỎI ÔN TẬP1. Thế nào là điều khiển tuần tự?2. Xét về mặt cấu trúc thì có những loại điều khiển tuần tự nào?3. Xét về mặt thiết kế ngôn ngữ thì có những loại điều khiển tuần tự nào?4. Trong biểu diễn trung tố một biểu thức, để khắc phục tình trạng một biểu thứccó thể có nhiều cây biểu thức (tình trạng mập mờ), người ta thường sử dụng cácquy tắc gì?


BÀI 9: CÁC PHƯƠNG PHÁP NGÔN NGỮ LẬP TRÌNH KHÁC
Mã bài: MĐ39-09Mục tiêu:
Phân loại các loại ngôn ngữ khác nhau
Phân loại các kiểu lệnh trong ngôn ngữ
Phân biệt các ngôn ngữ thủ tục và phi thủ tục
Nắm được cách chuyển đổi từ ngôn ngữ tự nhiên sang ngôn ngữ lập trình
Các loại ngôn ngữ
Đây là danh sách các NNLT, từ những NN đã có cách đây hàng chục năm đến những NN mới xuất hiện gần đây, chủ yếu là các NN tổng quát. Các NN được nhóm theo các tính năng tương đồng. Vì giá trị lịch sử, có một số NN “chết” hay ít được sử dụng hiện diện trong danh sách.
NGÔN NGỮ MÁY dùng các số 0 và 1 để “ra lệnh” cho bộ xử lý. Tập lệnh chỉ tương thích trong cùng họ CPU và rất khó lập trình.
NGÔN NGỮ ASSEMBLY gần giống như NN máy nhưng có ưu điểm là tập lệnh dễ đọc . Nói chung mỗi lệnh trong Assembly (như MOV A,B) tương ứng với một lệnh mã máy (như 11001001). Chương trình Assembly được biên dịch trước khi thực thi. Nếu cần tốc độ và kích thước chương trình thật nhỏ, Assembly là giải pháp.
C đạt được sự thỏa hiệp giữa việc viết code hiệu quả của Assembly và sự tiện lợi và khả năng chạy trên nhiền nền tảng của NNLT cấp cao có cấu trúc. NN hơn 20 năm tuổi này hiện vẫn được tin dùng trong lĩnh vực lập trình hệ thống. Có các công cụ thương mại và miễn phí cho gần như mọi HĐH.
C++ là NN được dùng nhiều nhất hiện nay, đa số phần mềm thương mại được viết bằng C++. Tên của NN có lý do: C++ bao gồm tất cả ưu điểm của C và bổ sung thêm các tính năng hướng đối tượng. Có các công cụ thương mại và miễn phí cho gần như mọi HĐH.
C# [phát âm ‘C sharp“] là lời đáp của Microsoft đối với Java. Do không đạt được thỏa thuận với Sun về vấn đề bản quyền, Microsoft đã tạo ra NN với các tính năng tương tự nhưng chỉ chạy trên nền Windows.
JAVA là phiên bản C++ được thiết kế lại hợp lý hơn, có khả năng chạy trên nhiều nền tảng; tuy nhiên tốc độ không nhanh bằng C++. Có các công cụ miễn phí và thương mại hỗ trợ cho hầu hết các HĐH hiện nay. Tuy Microsoft đã gỡ bỏ hỗ trợ Java khỏi cài đặt mặc định của các phiên bản Windows mới, nhưng việc bổ sung rất dễ dàng.
PASCAL được thiết kế chủ yếu dùng để dạy lập trình, tuy nhiên nó đã trở nên phổ biến bên ngoài lớp học. Pascal yêu cầu tính cấu trúc khá nghiêm ngặt. Có các công cụ thương mại và miễn phí cho DOS, Windows, Mac, OS/2 và các HĐH họ Unix. Trình soạn thảo website BBEdit được viết bằng Pascal.

DELPHI là phiên bản hướng đối tượng của Pascal được hãng Borland phát triển cho công cụ phát triển ứng dụng nhanh có cùng tên. Môi trường Delphi được thiết kế để cạnh tranh với Visual Basic của Microsoft, hỗ trợ xây dựng giao diện nhanh bằng cách kéo thả các đối tượng và gắn các hàm chức năng. Khả năng thao tác CSDL là một ưu điểm khác của NN. Borland, có các công cụ thương mại cho Windows và Linux.
BASIC [’Beginner’s All-purpose Symbolic Instruction Code“] là NNLT đầu tiên dùng cho máy vi tính thời kỳ đầu. Các phiên bản hiện đại của BASIC có tính cấu trúc hơn. Có các công cụ thương mại và miễn phí cho DOS, Windows, Mac và các HĐH họ Unix.
VISUAL BASIC [phiên bản của Basic cho môi trường đồ hoạ] là NN đa năng của Microsoft. Nó bao gồm BASIC, NN macro của Microsoft Office (VBA – Visual Basic for Application), và công cụ phát triển ứng dụng nhanh. Tiếc là ứng dụng VB chỉ có thể chạy trên Windows và bạn bị lệ thuộc vào những chính sách thay đổi của Microsoft. (Chương trình viết bằng VB 6 hay các phiên bản trước sẽ không hoàn toàn tương thích với VB.NET)
ADA phần lớn dựa trên Pascal, đây là một dự án của Bộ Quốc Phòng Mỹ. ADA có nhiều điểm mạnh, như cơ chế kiểm soát lỗi, dễ bảo trì và sửa đổi chương trình. Phiên bản hiện thời có cả các tính năng hướng đối tượng.
ICON là NN thủ tục cấp cao. Xử lý văn bản là một trong những điểm mạnh của nó. Có các phiên bản cho Windows, HĐH họ Unix và các môi trường Java; các phiên bản cũ hơn hỗ trợ các HĐH khác.
SMALLTALK môi trường phát triển hướng đối tượng và đồ hoạ của Smalltalk chính là nguồn cảm hứng cho Steve Jobs và Bill Gates ‘phát minh“ giao diện Mac OS và Windows.
RUBY hợp một số tính năng tốt nhất của nhiều NN khác. Đây là NN hướng đối tượng thuần túy như Smalltalk, nhưng có cú pháp trong sáng hơn. Nó có khả năng xử lý văn bản mạnh tương tự như Perl nhưng có tính cấu trúc hơn và ổn định hơn.
PERL thường được xem đồng nghĩa với “CGI Scripting”. Thực tế, Perl “lớn tuổi” hơn web. Nó ’dính“ vào công việc lập trình web do khả năng xử lý văn bản mạnh, rất linh động, khả năng chạy trên nhiều nền tảng và miễn phí.
TCL (phát âm ‘tickle“) có thể tương tác tốt với các công cụ dùng văn bản như trình soạn thảo, trình biên dịch… dùng trên các HĐH họ Unix, và với phần mở rộng TK nó có thể truy cập tới các giao diện đồ hoạ như Windows, Mac OS và X-Windows, đóng vai trò kết dính các thành phần lại với nhau để hoàn thành các công việc phức tạp. Phương pháp mô-đun này là nền tảng của Unix
PYTHON là NN nguồn mở, hướng đối tượng, tương tác và miễn phí. Ban đầu được phát triển cho Unix, sau đó ‘bành trướng“ sang mọi HĐH từ DOS đến Mac OS, OS/2, Windows và các HĐH họ Unix. Trong danh sách người dùng của nó có NASA và RedHat Linux.
PIKE cũng là NN nguồn mở, miễn phí được phát triển cho nhu cầu cá nhân, và hiện được công ty Roxen Internet Software của Thuỵ Điển phát triển dùng cho máy chủ web trên nền Roxen. Đây là NN hướng đối tượng đầy đủ, có cú pháp tương tự C, và có thể mở rộng để tận dụng các mô-đun và thư viện C đã biên dịch để tăng tốc độ. Nó có thể dùng cho các HĐH họ Unix và Windows.

PHP (Hypertext Pre-Processor) là NN mới nổi lên được cộng đồng nguồn mở ưa chuộng và là mô-đun phổ biến nhất trên các hệ thống Apache (web server). Giống như CFML, mã lệnh nằm ngay trong trang web. Nó có thể dễ dàng truy cập tới các tài nguyên hệ thống và nhiều CSDL. Nó miễn phí và tính khả chuyển đối với các HĐH họ Unix và Windows.
MACROMEDIA COLDFUSION có mã lệnh CFML (Cold Fusion Markup Language) được nhúng trong trang web rất giống với thẻ lệnh HTML chuẩn. Rất mạnh, có các công cụ để truy cập nhiều CSDL và rất dễ học. Hạn chế chính của nó là giá cả, tuy nhiên có phiên bản rút gọn miễn phí. Chạy trên Windows và các HĐH họ Unix.
ACTIVE SERVER PAGES (ASP) được hỗ trợ miễn phí với máy chủ web của Microsoft (IIS). Thực sự nó không là NNLT, mà được gọi, theo Microsoft, là ‘môi trường lập kịch bản phía máy chủ“.Nó dùng VBScript hay JScript để lập trình. Chỉ chạy trên Windows NT/2K. Microsoft đã thay NN này bằng ASP.NET, tuy có tên tương tự nhưng không phải là bản nâng cấp.
JAVASERVER PAGES (JSP) là NN đầy hứa hẹn. Nó dùng Java, có phần mềm máy chủ nguồn mở và miễn phí (Tomcat). Có thể chạy trên hầu hết các máy chủ web, gồm Apache, iPlanet và cả Microsoft IIS.
LISP [’LISt Processing“] là NNLT ‘có thể lập trình“, được xây dựng dựa trên khái niệm đệ quy và có khả năng thích ứng cao với các đặc tả không tường minh. Nó có khả năng giải quyết những vấn đề mà các NN khác không thể, đó là lý do NN hơn 40 năm tuổi này vẫn tồn tại. Yahoo Store dùng Lisp.
PROLOG [“PROgramming in Logic”] được thiết kế cho các bài toán luận lý, ví dụ như “A bao hàm B, A đúng, suy ra B đúng” – một công việc khá khó khăn đối với một NN thủ tục.
COBOL [“Common Business-Oriented Language”] có tuổi đời bằng với điện toán thương mại, bị buộc tội không đúng về vụ Y2K, và dù thường được dự đoán đến hồi cáo chung nhưng nó vẫn tồn tại nhờ tính hữu dụng trong các ứng dụng xử lý dữ liệu và lập báo cáo kinh doanh truyền thống. Hiện có phiên bản với các tính năng hướng đối tượng và môi trường phát triển tích hợp cho Linux và Windows.
FORTRAN [“FORmula TRANslation”] là NN xưa nhất vẫn còn dùng. Nó xuất sắc trong công việc đầu tiên mà máy tính được tin cậy: xử lý các con số. Theo đúng nghĩa đen, đây là NN đưa con người lên mặt trăng (dùng trong các dự án không gian), một số tính năng của NN đã được các NN khác hiện đại hơn “mượn”.
dBase [“DataBASE”] là NN lệnh cho chương trình quản lý CSDL mang tính đột phá của Ashton-Tate. Khi chương trình phát triển, NN cũng phát triển và nó trở thành công cụ phát triển. Tới thời kỳ xuất hiện nhiều công cụ và trình biên dịch cạnh tranh, nó chuyển thành chuẩn.
Foxpro là một nhánh phát triển của dBase dưới sự “bảo hộ” của Microsoft. Thực ra nó là công cụ phát triển hơn là NN. Tuy có lời đồn đại về sự cáo chung, nhưng NN vẫn phát triển. Hiện Foxpro có tính đối tượng đầy đủ và có công cụ phát triển mạnh (Visual Foxpro).
Erlang [“Ericsson LNAGuage”] thoạt đầu được hãng điện tử Ericsson phát triển để dùng riêng nhưng sau đó đưa ra bên ngoài như là phần mềm nguồn mở. Là NN cấp

thấp xét theo việc nó cho phép lập trình điều khiển những thứ mà thường do HĐH kiểm soát, như quản lý bộ nhớ, xử lý đồng thời, nạp những thay đổi vào chương trình khi đang chạy… rất hữu ích trong việc lập trình các thiết bị di động. Erlang được dùng trong nhiều hệ thống viễn thông lớn của Ericsson.
HASKELL là NN chức năng, nó được dùng để mô tả vấn đề cần tính toán chứ không phải cách thức tính toán.
Microsoft Visual Studio làm cho mọi thứ trở nên dễ dàng miễn là bạn phát triển ứng dụng trên HĐH của Microsoft và sử dụng các NN cũng của Microsoft!
Borland cung cấp các công cụ phát triển tích hợp đầu tiên với tên “Turbo” và nhiều năm nay “lăng xê” một loạt các công cụ có thể chạy trên nhiều nền tảng. C++ Builder và Delphi là các công cụ mạnh để phát triển nhanh các ứng dụng Windows với C++ và Object Pasccal. Kylix đem các công cụ này sang Linux. JBuilder cung cấp các công cụ tương tự để làm việc với Java (có các phiên bản cho Windows, Mac OS, Linux và Solaris).
Metrowerks CodeWarrior hỗ trợ nhiều nền tảng hơn bất kỳ công cụ phát triển nào (có thể kể một số như Windows, Mac OS, Linux, Solaris, Netware, PalmOS, PlayStation, Nintendo…). Công cụ có thể làm việc với nhiều NN: C, C++, Java và Assembly.
Macromedia Studio MX cung cấp mọi thứ cần thiết để tạo các ứng dụng internet và đa phương tiện, được xem như là giải pháp thay thế cho các công cụ lập trình truyền thống. Bộ công cụ kết hợp Dreamweaver và Flash, với các công cụ đồ hoạ Fireworks và Freehand, và máy chủ ColdFusion. Dreamweaver có thể dùng một mình, cho phép phát triển website có CSDL, lập trình với JSP, PHP, Cold Fusion và ASP. Flash cũng là môi trường lập trình mạnh, dùng để tạo ứng dụng đồ hoạ tương tác. Gần như các công cụ chính đều chạy trên Windows và Mac OS.
IBM VisualAge bành trướng gần như mọi hệ thống, từ máy tính lớn đến máy tính để bàn và thiết bị cầm tay. Các NN bao gồm, C++, Java, Smalltalk, Cobol, PL/I và PRG. VisualAge for Java là một trong các công cụ phát triển Java phổ biến nhất.
NetBeans là môi trường phát triển mô-đun, nguồn mở cho Java, được viết bằng Java. Điều này có nghĩa nó có thể dùng trên bất kỳ hệ thống nào có hỗ trợ Java (hầu hết các HĐH). Nó là cơ sở đề Sun xây dựng Sun One Studio, BEA dùng nó cho một phần của WebLogic.
Sun có các công cụ phát triển hiệu quả trong lĩnh vực của mình. Sun ONE Studio cho Java với cả bản thương mại và miễn phí. Sun ONE Studio Compiler Collection cho các nhà phát triển Unix, dùng C/C++. Với tính toán tốc độ cao, hãng có Forte for Fortran và High-Performance Computing.
Oracle JDeveloper thuộc bộ công cụ Internet Developer Suite. Nó chủ yếu dùng để phát triển các thành phần như servlet cho các ứng dụng web, và kết hợp tốt với CSDL Oracle.
WebGain VisualCafé chuyên hỗ trợ phát triển các ứng dụng phía server dùng Java. Công cụ gồm 2 phần: expert (cho ứng dụng phía client), và enteprise (cho ứng dụng server). Cả hai đều dùng Macromedia Dreamweaver Ultradev để xây dựng khung ứng dụng.

GNU Compiler Collection (GCC) là bộ công cụ miễn phí dùng để biên dịch chương trình chạy trên HĐH bất kỳ thuộc họ Unix. Hỗ trợ các NN: C, C++, Objective C, C, Fortran, Java và Ada. Một số công cụ đã được đưa sang DOS, Windows và PalmOS. Đây là các công cụ được lựa chọn của hầu hết các dự án nguồn mở và bản thân chúng cũng là nguồn mở. GCC không có môi trường phát triển ứng dụng tích hợp.
KDevelop là công cụ phát triển nguồn mở dùng để xây dựng các ứng dụng Linux dùng C++. Mặc dù có tên như vậy nhưng nó hỗ trợ giao diện GNOME cũng như KDE, ngoài các ứng dụng dùng Qt hay không có thành phần đồ họa.
Black Adder là công cụ phát triển mạnh cho các NN Python và Ruby. Có thể chạy trên Linux và Windows. Nó sinh mã để dùng các thành phần đồ họa Qt.
Intel/KAI cung cấp các công cụ phát triển nhắm đến các hệ thống đa xử lý và các HĐH họ Unix, dùng C/C++ và Fortran. Công cụ KAP cho phép chuyển các ứng dụng xử lý đơn sang kiến trúc đa xử lý.
Bài tập :Câu 1 :Hãy nêu phân loại các loại ngôn ngữ khác nhau
Câu 2 : Hãy phân loại các kiểu lệnh trong ngôn ngữ
Câu 3 : Phân biệt các ngôn ngữ thủ tục và phi thủ tục

BÀI 10: PHÂN TÍCH CÚ PHÁP VÀ CHƯƠNG TRÌNH DỊCHMã bài : MĐ39-10
Giới thiệuSau khi đã nắm được nhiều khái niệm về ngôn ngữ cũng như cách sử dụng
ngôn ngữ lập trình, việc đào sâu vào hiểu cơ chế làm việc của một ngôn ngữ lập trình trên máy tính như thế nào cũng rất quan trọng: đó là khái niệm chương trình dịch. Nó giúp cho người lập trình làm chủ tốt hơn ngôn ngữ và đặc biệt là sử dụng ngôn ngữ một cách tối ưu nhất.
Mục tiêu thực hiện- Hiểu được các khái niệm cơ bản về chương trình dịch- Nắm được các giai đoạn của một chương trình dịch- Nắm đươc các quy tắc về phân tích cú pháp, phân tích từ vựng của ngôn ngữ
lập trình- Vấn đề quản lý bảng kí hiệu
Nội dung chínhTrình bày sơ lược cơ chế của một chương trình dịch.
1. Chương trình dịch là gì
Chương trình được viết trong một ngôn ngữ lập trình bậc cao, hoặc bằng hợp ngữ, đều được gọi là chương trình nguồn (source program).
Bản thân máy tính không hiểu được các câu lệnh trong một chương trình nguồn. Chương trình nguồn phải được dịch thành một chương trình đích (target program) trong ngôn ngữ máy (là các dãy số 0 và 1), máy mới có thể “đọc hiểu” và thực hiện được. Chương trình đích còn được gọi là chương trình thực hiện (executable program).Chương trình làm nhiệm vụ trung gian đảm nhận việc dịch gọi là chương trình dịch (compiler).
Nói một cách đơn giản, chương trình dịch là một chương trình làm nhiệm vụ đọc một chương trình được viết bằng một ngôn ngữ - ngôn ngữ nguồn (source language) - rồi dịch nó thành một chương trình tương đương ở một ngôn ngữ khác - ngôn ngữ đích (target languague). Một phần quan trọng trong quá trình dịch là ghi nhận lại các lỗi có trong chương trình nguồn để thông báo lại cho người viết chương trình.
Việc thiết kế chương trình dịch cho một ngôn ngữ lập trình đã cho là một việc rất khó khăn và phức tạp. Chương trình dịch về nguyên tắc phải được viết trên ngôn ngữ máy để giải quyết vấn đề xử lý ngôn ngữ và tính vạn năng của các chương trình nguồn. Tuy nhiên, người ta thường sử dụng hợp ngữ để viết chương trình dịch. Hiện

nay, người ta lại thường viết chương trình dịch bằng chính các ngôn ngữ bậc cao hoặc các công cụ chuyên dụng.
Thông thường có hai loại chương trình dịch: trình biên dịch và trình thông dịch, hoạt đọng như sau:
- Trình biên dịch (compiler): dịch toàn bộ chương trình nguồn thành chương trình đích rồi mới tiến thực hiện chương trình đích.
- Trình thông dịch (interpreter): dịch lần lượt từng câu lệnh của chương trình nguồn rồi tiến hành thực hiện luôn câu lệnh đã dịch đó, cho tới khi thực hiện xong toàn bộ chương trình.
2. Mô hình phân tích - tổng hợp của một trình biên dịch
Chương trình dịch thường bao gồm hai quá trình : phân tích và tổng hợp- Phân tích đặc tả trung gian- Tổng hợp chương trình đích
Hình 10.1 Mô hình phân tích- tổng hợp của một trình biên dịch
3. Môi trường của trình biên dịch
Ngoài trình biên dịch, chúng ta có thể dùng nhiều chương trình khác nữa để có thể tạo ra một chương trình đích có thể thực thi được (executable). Một chương trình nguồn có thể được phân thành các module và được lưu trong các tập tin riêng rẽ. Công việc tập hợp lại các tập tin này thường được giao cho một chương trình riêng biệt gọi là bộ tiền xử lý (preprocessor). Bộ tiền xử lý có thể "bung" các ký hiệu tắt được gọi là các macro thành các câu lệnh của ngôn ngữ nguồn.
Ngoài ra, chương trình đích được tạo ra bởi trình biên dịch có thể cần phải được xử lý thêm trước khi chúng có thể chạy được. Thông thường, trình biên dịch chỉ tạo ra mã lệnh hợp ngữ (assembly code) để trình dịch hợp ngữ (assembler) dịch thành dạng mã máy rồi được liên kết với một số thủ tục trong thư viện hệ thống thành các mã thực thi được trên máy.
Hình sau trình bày một quá trình biên dịch điển hình :

Hình 10.2 Một quá trình biên dịch điển hình
4. Các giai đoạn dịch
Ðể dễ hình dung, một trình biên dịch được chia thành các giai đoạn, mỗi giai đoạn chuyển chương trình nguồn từ một dạng biểu diễn này sang một dạng biểu diễn khác. Một cách phân rã điển hình trình biên dịch được trình bày trong hình sau.

Hình 10.3 Một phân rã điển hình trình biên dịch
Việc quản lý bảng ký hiệu và xử lý lỗi được thực hiện xuyên suốt qua tất cả các giai đoạn.
5. Quản lý bảng ký hiệu
Một nhiệm vụ quan trọng của trình biên dịch là ghi lại các định danh được sử dụng trong chương trình nguồn và thu thập các thông tin về các thuộc tính khác nhau của mỗi định danh. Những thuộc tính này có thể cung cấp thông tin về vị trí lưu trữ được cấp phát cho một định danh, kiểu và tầm vực của định danh, và nếu định danh là tên của một thủ tục thì thuộc tính là các thông tin về số lượng và kiểu của các đối số, phương pháp truyền đối số và kiểu trả về của thủ tục nếu có.
Bảng ký hiệu (symbol table) là một cấu trúc dữ liệu mà mỗi phần tử là một mẩu tin dùng để lưu trữ một định danh, bao gồm các trường lưu giữ ký hiệu và các thuộc tính của nó. Cấu trúc này cho phép tìm kiếm, truy xuất danh biểu một cách nhanh chóng.
Trong quá trình phân tích từ vựng, danh biểu được tìm thấy và nó được đưa vào bảng ký hiệu nhưng nói chung các thuộc tính của nó có thể chưa xác định được trong giai đoạn này.

6. Xử lý lỗi
Mỗi giai đoạn có thể gặp nhiều lỗi, tuy nhiên sau khi phát hiện ra lỗi, tùy thuộc vào trình biên dịch mà có các cách xử lý lỗi khác nhau, chẳng hạn :
- Dừng và thông báo lỗi khi gặp lỗi đầu tiên (Pascal).- Ghi nhận lỗi và tiếp tục quá trình dịch (C).Giai đoạn phân tích từ vựng thường gặp lỗi khi các ký tự không thể ghép thành một
token. Giai đoạn phân tích cú pháp gặp lỗi khi các token không thể kết hợp với nhau theo
đúng cấu trúc ngôn ngữ.Giai đoạn phân tích ngữ nghĩa báo lỗi khi các toán hạng có kiểu không đúng yêu
cầu của phép toán hay các kết cấu không có nghĩa đối với thao tác thực hiện mặc dù chúng hoàn toàn đúng về mặt cú pháp.
7. Phân tích từ vựng
Ðọc từng ký tự gộp lại thành token, token có thể là một danh biểu, từ khóa, một ký hiệu,...Chuỗi ký tự tạo thành một token gọi là lexeme - trị từ vựng của token đó.
7.1. Phân tích cú pháp và phân tích ngữ nghĩa Xây dựng cấu trúc phân cấp cho chuỗi các token, biểu diễn bởi cây cú pháp và
kiểm tra ngôn ngữ theo cú pháp.
7.2. Sinh mã trung gian Sau khi phân tích ngữ nghĩa, một số trình biên dịch sẽ tạo ra một dạng biểu diễn
trung gian của chương trình nguồn. Chúng ta có thể xem dạng biểu diễn này như một chương trình dành cho một máy trừu tượng. Chúng có 2 đặc tính quan trọng : dễ sinh và dễ dịch thành chương trình đích.
7.3. Tối ưu mã Giai đoạn tối ưu mã cố gắng cải thiện mã trung gian để có thể có mã máy thực hiện
nhanh hơn. Một số phương pháp tối ưu hóa hoàn toàn bình thường.
7.4. Sinh mã Giai đoạn cuối cùng của biên dịch là sinh mã đích, thường là mã máy hoặc mã hợp
ngữ. Các vị trí vùng nhớ được chọn lựa cho mỗi biến được chương trình sử dụng. Sau đó, các chỉ thị trung gian được dịch lần lượt thành chuỗi các chỉ thị mã máy. Vấn đề quyết định là việc gán các biến cho các thanh ghi.
8. Phân tích cú pháp
Phân tích cú pháp là quá trình xác định xem liệu một chuỗi ký hiệu kết thúc (token) có thể được sinh ra từ một văn phạm hay không ? Khi nói về vấn đề này, chúng ta xem như đang xây dựng một cây phân tích cú pháp, mặc dù một trình biên dịch có thể không xây dựng một cây như thế. Tuy nhiên, quá trình phân tích cú pháp (parse) phải có khả năng xây dựng nó, nếu không thì việc phiên dịch sẽ không bảo đảm được tính đúng đắn.

Phần lớn các phương pháp phân tích cú pháp đều rơi vào một trong 2 lớp: phương pháp phân tích từ trên xuống và phương pháp phân tích từ dưới lên. Những thuật ngữ này muốn đề cập đến thứ tự xây dựng các nút trong cây phân tích cú pháp. Trong phương pháp đầu, quá trình xây dựng bắt đầu từ gốc tiến hành hướng xuống các nút lá, còn trong phương pháp sau thì thực hiện từ các nút lá hướng về gốc. Phương pháp phân tích từ trên xuống thông dụng hơn nhờ vào tính hiệu quả của nó khi xây dựng theo lối thủ công. Ngược lại, phương pháp phân tích từ dưới lên lại có thể xử lý được một lớp văn phạm và lược đồ dịch phong phú hơn. Vì vậy, đa số các công cụ phần mềm giúp xây dựng thể phân tích cú pháp một cách trực tiếp từ văn phạm đều có xu hướng sử dụng phương pháp từ dưới lên.8.1. Phân tích cú pháp từ trên xuống (Top - down Parsing)
Xét văn phạm sinh ra một tập con các kiểu dữ liệu của Pascal type simple | id | array [simple] of type simple integer | char | num .. num Phân tích trên xuống bắt đầu bởi nút gốc, nhãn là ký hiệu chưa kết thúc bắt đầu và
lặp lại việc thực hiện hai bước sau đây: 1. Tại nút n, nhãn là ký hiệu chưa kết thúc A, chọn một trong những luật sinh của A
và xây dựng các con của n cho các ký hiệu trong vế phải của luật sinh.2. Tìm nút kế tiếp mà tại đó một cây con sẽ được xây dựng. Ðối với một số văn
phạm, các bước trên được cài đặt bằng một phép quét (scan) dòng nhập từ trái qua phải.
Ví dụ 10.1 : Với các luật sinh của văn phạm trên, ta xây dựng cây cú pháp cho dòng nhập: array [num .. num] of integer
Mở đầu ta xây dựng nút gốc với nhãn type. Ðể xây dựng các nút con của type ta chọn luật sinh type array [simple] of type. Các ký hiệu nằm bên phải của luật sinh này là array, [, simple, ], of, type do đó nút gốc type có 6 con có nhãn tương ứng (áp dụng bước 1)
Trong các nút con của type, từ trái qua thì nút con có nhãn simple (một ký hiệu chưa kết thúc) do đó có thể xây dựng một cây con tại nút simple (bước 2)
Trong các luật sinh có vế trái là simple, ta chọn luật sinh simple num .. num để xây dựng. Nói chung, việc chọn một luật sinh có thể được xem như một quá trình thử và sai (trial - and - error). Nghĩa là một luật sinh được chọn để thử và sau đó quay lại để thử một luật sinh khác nếu luật sinh ban đầu không phù hợp. Một luật sinh là không phù hợp nếu sau khi sử dụng luật sinh này chúng ta không thể xây dựng một cây hợp với dòng nhập. Ðể tránh việc lần ngược, người ta đưa ra một phương pháp gọi là phương pháp phân tích cú pháp dự đoán.

Hình 10.4 Minh họa quá trình phân tích cú pháp từ trên xuống8.2 . Phân tích cú pháp dự đoán (Predictive parsing) Phương pháp phân tích cú pháp đệ qui xuống (recursive-descent parsing) là một phương pháp phân tích trên xuống, trong đó chúng ta thực hiện một loạt thủ tục đệ qui để xử lý chuỗi nhập. Mỗi một thủ tục kết hợp với một ký hiệu chưa kết thúc của văn phạm. Ở đây chúng ta xét một trường hợp đặc biệt của phương pháp đệ qui xuống là phương pháp phân tích dự đoán trong đó ký hiệu dò tìm sẽ xác định thủ tục được chọn đối với ký hiệu chưa kết thúc. Chuỗi các thủ tục được gọi trong quá trình xử lý chuỗi nhập sẽ tạo ra cây phân tích cú pháp.
Ví dụ 10.2 : Xét văn phạm như trên, ta viết các thủ tục type và simple tương ứng với các ký hiệu chưa kết thúc type và simple trong văn phạm. Ta còn đưa thêm thủ tục match để đơn giản hóa đoạn mã cho hai thủ tục trên, nó sẽ dịch tới ký hiệu kế tiếp nếu tham số t của nó so khớp với ký hiệu dò tìm tại đầu đọc (lookahead).
procedure match (t: token); begin if lookahead = t then lookahead := nexttoken else error end; procedure type; begin if lookahead in [integer, char, num] then simple else if lookahead = ‘‘ then begin match (‘‘); match(id); end else if lookahead = array then begin match(array); match(‘[‘); simple; match(‘]’); match(of); type end else error; end;

procedure simple; begin if lookahead = integer then match(integer) else if lookahead = char then match(char) else if lookahead = num then begin match(num); match(dotdot); match(num); end else error end;
Phân tích cú pháp bắt đầu bằng lời gọi tới thủ tục cho ký hiệu bắt đầu type. Với dòng nhập array [num .. num] of integer thì đầu đọc lookahead bắt đầu sẽ đọc token array. Thủ tục type sau đó sẽ thực hiện chuỗi lệnh: match(array); match(‘[‘); simple; match(‘]’); match(of); type. Sau khi đã đọc được array và [ thì ký hiệu hiện tại là num. Tại điểm này thì thủ tục simple và các lệnh match(num); match(dotdot); match(num) được thực hiện. Xét luật sinh type simple. Luật sinh này có thể được dùng khi ký hiệu dò tìm sinh ra bởi simple, chẳng hạn ký hiệu dò tìm là integer mặc dù trong văn phạm không có luật sinh type integer, nhưng có luật sinh simple integer, do đó luật sinh type simple được dùng bằng cách trong type gọi simple. Phân tích dự đoán dựa vào thông tin về các ký hiệu đầu sinh ra bởi vế phải của một luật sinh. Nói chính xác hơn, giả sử ta có luật sinh A , ta định nghĩa tập hợp :
FIRST() = { token | xuất hiện như các ký hiệu đầu của một hoặc nhiều chuỗi sinh ra bởi }. Nếu là hoặc có thể sinh ra thì FIRST().Ví dụ 7.8: Xét văn phạm như trên, ta dễ dàng xác định :
FIRST( simple) = { integer, char, num } FIRST(id) = { } FIRST( array [simple] of type ) = { array }Nếu ta có A và A , phân tích đệ qui xuống sẽ không phải quay lui nếu
FIRST() FIRST() = . Nếu ký hiệu dò tìm thuộc FIRST() thì A được dùng. Ngược lại, nếu ký hiệu dò tìm thuộc FIRST() thì A được dùng.8.3 . Thiết kế bộ phân tích cú pháp dự đoán
Bộ phân tích dự đoán là một chương trình bao gồm các thủ tục tương ứng với các ký hiệu chưa kết thúc. Mỗi thủ tục sẽ thực hiện hai công việc sau: 1. Luật sinh mà vế phải của nó sẽ được dùng nếu ký hiệu dò tìm thuộc FIRST(). Nếu có một sự đụng độ giữa hai vế phải đối với bất kỳ một ký hiệu dò tìm nào thì không thể dùng phương pháp này. Một luật sinh với nằm bên vế phải được dùng nếu ký hiệu dò tìm không thuộc tập hợp FIRST của bất kỳ vế phải nào khác.2. Một ký hiệu chưa kết thúc tương ứng lời gọi thủ tục, một token phải phù hợp với ký hiệu dò tìm. Nếu token không phù hợp với ký hiệu dò tìm thì có lỗi.8.4 Loại bỏ đệ qui trái
Một bộ phân tích cú pháp đệ quy xuống có thể sẽ dẫn đến một vòng lặp vô tận nếu gặp một luật sinh đệ qui trái dạng E E + T bởi vì ký hiệu trái nhất bên vế phải cũng giống như ký hiệu chưa kết thúc bên vế trái của luật sinh.

Ðể giải quyết được vấn đề này chúng ta phải loại bỏ đệ qui trái bằng cách thêm vào một ký hiệu chưa kết thúc mới. Chẳng hạn với luật sinh dạng A A | (.Ta thêm vào một ký hiệu chưa kết thúc R để viết lại thành tập luật sinh như sau : A R R R | Ví dụ 10.3: Xét luật sinh đệ quy trái : E E + T | T
Sử dụng quy tắc khử đệ quy trái nói trên với : A E, + T, T .Luật sinh trên có thể biến đổi tương đương thành tập luật sinh :
E T R R + T R | 8.5. Phân tích từ vựng
Bây giờ chúng ta thêm vào phần trước trình biên dịch một bộ phân tích từ vựng để đọc và biến đổi dòng nhập thành một chuỗi các từ tố (token) mà bộ phân tích cú pháp có thể sử dụng được. Nhắc lại rằng một chuỗi các ký tự hợp thành một token gọi là trị từ vựng (lexeme) của token đó.Trước hết ta trình bày một số chức năng cần thiết của bộ phân tích từ vựng.8.6 Loại bỏ các khoảng trắng và các dòng chú thíchQuá trình dịch sẽ xem xét tất cả các ký tự trong dòng nhập nên những ký tự không có nghĩa (như khoảng trắng bao gồm ký tự trống (blanks), ký tự tabs, ký tự newlines) hoặc các dòng chú thích (comment) phải bị bỏ qua. Khi bộ phân tích từ vựng đã bỏ qua các khoảng trắng này thì bộ phân tích cú pháp không bao giờ xem xét đến chúng nữa. Chọn lựa cách sửa đổi văn phạm để đưa cả khỏang trắng vào trong cú pháp thì hầu như rất khó cài đặt.8.7 Xử lý các hằng Bất cứ khi nào một ký tự số xuất hiện trong biểu thức thì nó được xem như là một hằng số. Bởi vì một hằng số nguyên là một dãy các chữ số nên nó có thể được cho bởi luật sinh văn phạm hoặc tạo ra một token cho hằng số đó. Bộ phân tích từ vựng có nhiệm vụ ghép các chữ số để được một số và sử dụng nó như một đơn vị trong suốt quá trình dịch. Ðặt num là một token biểu diễn cho một số nguyên. Khi một chuỗi các chữ số xuất hiện trong dòng nhập thì bộ phân tích từ vựng sẽ gửi num cho bộ phân tích cú pháp. Giá trị của số nguyên được chuyển cho bộ phân tích cú pháp như là một thuộc tính của token num. Về mặt logic, bộ phân tích từ vựng sẽ chuyển cả token và các thuộc tính cho bộ phân tích cú pháp. Nếu ta viết một token và thuộc tính thành một bộ nằm giữa < > thì dòng nhập 31 + 28 + 59 sẽ được chuyển thành một dãy các bộ :<num, 31>, < +, >, <num, 28>, < +, >, <num, 59>. Bộ <+, > cho thấy thuộc tính của + không có vai trò gì trong khi phân tích cú pháp nhưng nó cần thiết dùng đến trong quá trình dịch. 8.8 Nhận dạng các danh biểu và từ khóa Ngôn ngữ dùng các danh biểu (identifier) như là tên biến, mảng, hàm và văn phạm xử lý các danh biểu này như là một token. Người ta dùng token id cho các danh biểu khác nhau do đó nếu ta có dòng nhập count = count + increment; thì bộ phân tích từ vựng sẽ chuyển cho bộ phân tích cú pháp chuỗi token: id = id + id (cần phân biệt token và trị từ vựng lexeme của nó: token id nhưng trị từ vựng (lexeme) có thể là count hoặc increment). Khi một lexeme thể hiện cho một danh biểu được tìm thấy trong dòng nhập cần phải có một cơ chế để xác định xem lexeme này đã được thấy trước đó chưa? Công việc này được thực hiện nhờ sự lưu trữ trợ giúp của bảng ký hiệu

(symbol table) đã nêu ở chương trước. Trị từ vựng được lưu trong bảng ký hiệuvà một con trỏ chỉ đến mục ghi trong bảng trở thành một thuộc tính của token id. Nhiều ngôn ngữ cũng sử dụng các chuỗi ký tự cố định như begin, end, if, ... để xác định một số kết cấu. Các chuỗi ký tự này được gọi là từ khóa (keyword). Các từ khóa cũng thỏa mãn qui luật hình thành danh biểu, do vậy cần qui ước rằng một chuỗi ký tự được xác định là một danh biểu khi nó không phải là từ khóa. Một vấn đề nữa cần quan tâm là vấn đề tách ra một token trong trường hợp một ký tự có thể xuất hiện trong trị từ vựng của nhiều token. Ví dụ một số các token là các toán tử quan hệ trong Pascal như : <, < =, < >.8.9 Giao diện của bộ phân tích từ vựng
Bộ phân tích từ vựng được đặt xen giữa dòng nhập và bộ phân tích cú pháp nên giao diện với hai bộ này như sau:
Hình 10.5 Giao diện bộ phân tích từ vựng
Bộ phân tích từ vựng đọc từng ký tự từ dòng nhập, nhóm chúng lại thành các trị từ vựng và chuyển các token xác định bởi trị từ vựng này cùng với các thuộc tính của nó đến những giai đọan sau của trình biên dịch. Trong một vài tình huống, bộ phân tích từ vựng phải đọc vượt trước một số ký tự mới xác định được một token để chuyển cho bộ phân tích cú pháp. Ví dụ, trong Pascal khi gặp ký tự >, phải đọc thêm một ký tự sau đó nữa; nếu ký tự sau là = thì token được xác định là “lớn hơn hoặc bằng”, ngược lại thì token là “lớn hơn” và do đó một ký tự đã bị đọc quá. Trong trường hợp đó thì ký tự đọc quá này phải được đẩy trả về (push back) cho dòng nhập vì nó có thể là ký tự bắt đầu cho một trị từ vựng mới.
Bộ phân tích từ vựng và bộ phân tích cú pháp tạo thành một cặp "nhà sản xuất - người tiêu dùng" (producer - consumer). Bộ phân tích từ vựng sản sinh ra các token và bộ phân tích cú pháp tiêu thụ chúng. Các token được sản xuất bởi bộ phân tích từ vựng sẽ được lưu trong một bộ đệm (buffer) cho đến khi chúng được tiêu thụ bởi bộ phân tích cú pháp. Bộ phân tích từ vựng không thể hoạt động tiếp nếu buffer bị đầy và bộ phân tích cú pháp không thể hoạt động nữa nếu buffer rỗng. Thông thường, buffer chỉ lưu giữ một token. Ðể cài đặt tương tác dễ dàng, người ta tạo ra một thủ tục phân tích từ vựng được gọi từ trong thủ tục phân tích cú pháp, mỗi lần gọi trả về một token.
Việc đọc và quay lui ký tự cũng được cài đặt bằng cách dùng một bộ đệm nhập. Một khối các ký tự được đọc vào trong buffer nhập tại một thời điểm nào đó, một con trỏ sẽ giữ vị trí đã được phân tích. Quay lui ký tự được thực hiện bằng cách lùi con trỏ trở về. Các ký tự trong dòng nhập cũng có thể cần được lưu lại cho công việc ghi nhận lỗi bởi vì cần phải chỉ ra vị trí lỗi trong đoạn chương trình.
Ðể tránh việc phải quay lui, một số trình biên dịch sử dụng cơ chế đọc trước một ký tự rồi mới gọi đến bộ phân tích từ vựng. Bộ phân tích từ vựng sẽ đọc tiếp các ký tự cho đến khi đọc tới ký tự mở đầu cho một token khác. Trị từ vựng của token

trước đó sẽ bao gồm các ký tự từ ký tự đọc trước đến ký tự vừa ngay ký tự vừa đọc được. Ký tự vừa đọc được sẽ là ký tự mở đầu cho trị từ vựng của token sau. Với cơ chế này thì mỗi ký tự chỉ được đọc duy nhất một lần.
Quản lý bảng danh hiệuMột cấu trúc dữ liệu gọi là bảng ký hiệu (symbol table) thường được dùng để
lưu giữ thông tin về các cấu trúc của ngôn ngữ nguồn. Các thông tin này được tập hợp từ các giai đoạn phân tích của trình biên dịch và được sử dụng bởi giai đoạn tổng hợp để sinh mã đích. Ví dụ trong quá trình phân tích từ vựng, các chuỗi ký tự tạo ra một token (trị từ vựng của token) sẽ được lưu vào một mục ghi trong bảng danh biểu. Các giai đọan sau đó có thể bổ sung thêm các thông tin về kiểu của danh biểu, cách sử dụng nó và vị trí lưu trữ. Giai đoạn sinh mã sẽ dùng thông tin này để tạo ra mã phù hợp, cho phép lưu trữ và truy xuất biến đó.
Giao diện của bảng ký hiệu Các thủ tục trên bảng ký hiệu chủ yếu liên quan đến việc lưu trữ và truy xuất các trị từ vựng. Khi một trị từ vựng được lưu trữ thì token kết hợp với nó cũng được lưu. Hai thao tác sau được thực hiện trên bảng ký hiệu:
Insert (s, t): Trả về chỉ mục của một ô mới cho chuỗi s, token t.Lookup (s): Trả về chỉ mục của ô cho chuỗi s hoặc 0 nếu chuỗi s không tồn tại.
Bộ phân tích từ vựng sử dụng thao tác tìm kiếm lookup để xác định xem một ô
cho một trị từ vựng của một token nào đó đã tồn tại trong bảng ký hiệu hay chưa? Nếu chưa thì dùng thao tác xen vào insert để tạo ra một ô mới cho nó.
Xử lý từ khóa dành riêngTa cũng có thể sử dụng bảng ký hiệu nói trên để xử lý các từ khóa dành riêng
(reserved keyword). Ví dụ với hai token div và mod vớiï hai trị từ vựng tương ứng là div và mod. Chúng ta có thể khởi tạo bảng ký hiệu bởi lời gọi: insert (“div”, div); insert (“mod”, mod); Sau đó lời gọi lookup (“div”) sẽ trả về token div, do đó “div” không thể được dùng làm danh biểu.
Với phương pháp vừa trình bày thì tập các từ khóa được lưu trữ trong bảng ký hiệu trước khi việc phân tích từ vựng diễn ra. Ta cũng có thể lưu trữ các từ khóa bên ngoài bảng ký hiệu như là một danh sách có thứ tự của các từ khóa. Trong quá trình phân tích từ vựng, khi một trị từ vựng được xác định thì ta phải tìm (nhị phân) trong danh sách các từ khóa xem có trị từ vựng này không. Nếu có, thì trị từ vựng đó là một từ khóa, ngược lại, đó là một danh biểu và sẽ được đưa vào bảng ký hiệu.
Cài đặt bảng ký hiệuCấu trúc dữ liệu cụ thể dùng cài đặt cho một bảng ký hiệu được trình bày
trong hình dưới đây. Chúng ta không muốn dùng một lượng không gian nhớ nhất định để lưu các trị từ vựng tạo ra một danh biểu bởi vì một lượng không gian cố định có thể không đủ lớn để lưu các danh biểu rất dài và cũng rất lãng phí khi gặp một danh biểu ngắn.
Thông thường, một bảng ký hiệu gồm hai mảng :

1. Mảng lexemes (trị từ vựng) dùng để lưu trữ các chuỗi ký tự tạo ra một danh biểu, các chuỗi này ngăn cách nhau bởi các ký tự EOS (end - of - string).
2. Mảng symtable với mỗi phần tử là một mẩu tin (record) bao gồm hai trường, trường con trỏ lexptr trỏ tới đầu trị từ vựng và trường token. Cũng có thể dùng thêm các trường khác để lưu trữ giá trị các thuộc tính.
Mục ghi thứ zero trong mảng symtable phải được để trống bởi vì giá trị trả về của hàm lookup trong trường hợp không tìm thấy ô tương ứng cho chuỗi ký hiệu.
Bảng ký hiệu và mảng để lưu các chuỗi được minh họa như sau:
Hình 10.6 Bảng ký hiệu và mảng để lưu các chuỗiTrong hình trên, ô thứ nhất và thứ hai trong bảng ký hiệu dành cho các từ khóa
div và mod. Ô thứ ba và thứ tư dành cho các danh biểu count và i. Ðoạn mã (ngôn ngữ giả) cho bộ phân tích từ vựng được dùng để xử lý các danh biểu như sau: Function lexan: integer; var lexbuf: array[0..100] of char; c: char begin loop begin đọc một ký tự vào c; if c là một ký tự trống blank hoặc ký tự tab then không thực hiện điều gì ; else if c là ký tự newline then lineno = lineno + 1 else if c là một ký tự số then begin đặt tokenval là giá trị của ký số này và các ký số theo sau; return NUM; end else if c là một chữ cái then

begin đặt c và các ký tự, ký số theo sau vào lexbuf; p := lookup (lexbuf); if p = 0 then p := insert (lexbuf, id); tokenval := p; return trường token của ô có chỉ mục p; end else begin /* token là một ký tự đơn */ đặt tokenval là NONE; /* không có thuộc tính */ return số nguyên mã hóa của ký tự c; end; end; end;
Nó xử lý khoảng trắng và hằng số nguyên cũng giống như thủ tục đã nói ở phần trước. Khi bộ phân tích từ vựng đọc vào một chữ cái, nó bắt đầu lưu các chữ cái và chữ số vào trong vùng đệm lexbuf. Chuỗi được tập hợp trong lexbuf sau đó được tìm trong mảng symtable của bảng ký hiệu bằng cách dùng hàm lookup. Bởi vì bảng ký hiệu đã được khởi tạo với 2 ô cho div và mod (hình 2.14) nên nó sẽ tìm thấy trị từ vựng này nếu lexbuf có chứa div hay mod, ngược lại nếu không có ô cho chuỗi đang chứa trong lexbuf thì hàm lookup sẽ trả về 0 và do đó hàm insert được gọi để tạo ra một ô mới trong symtable và p là chỉ số của ô trong bảng ký hiệu của chuỗi trong lexbuf. Chỉ số này được truyền tới bộ phân tích cú pháp bằng cách đặt tokenval := p và token nằm trong trường token được trả về. Kết quả mặc nhiên là trả về số nguyên mã hóa cho ký tự dùng làm token.

THUẬT NGỮ CHUYÊN NGÀNH
programming language: ngôn ngữ lập trình machine language:ngôn ngữ máy sub-program hay sub-routine:kỹ thuật chương trình con library:thư viện chương trình assembly:hợp ngữ assembler:giai đoạn hợp dịch FORmula TRANslator:ngôn ngữ FORTRAN ALGOrithmic Language:ngôn ngữ ALGOL 60 Common Business Oriented Language:ngôn ngữ COBOLlow-level language:ngôn ngữ bậc thấp high-level language:ngôn ngữ bậc cao paradgm:phương thức instruction:lệnhmemory allocation:cấp phát bộ nhớ procedural language: ngôn ngữ thủ tục object-oriented language:ngôn ngữ hướng đối tượng functional language:ngôn ngữ hàm logic-based language:ngôn ngữ dựa logic distributed programming:lập trình phân bổ constraint programming:lập trình ràng buộc access-oriented programming:lập trình hướng truy cập dataflow programming:lập trình theo luồng dữ liệu operational:ngôn ngữ thao tác non-declarative:không khai báo neural networks:mạng nơ-ron longint:số nguyên dài hai từ nhớ writability:Tính dễ viết readability:Tính dễ đọc reliability:Tính tin cậy mybuffer:biến xâu function: hàm procedure:thủ tục global variable:biến toàn cục local variable:biến cục bộ recursivity:đệ quy syntax:cú pháp terminal symbols:các ký hiệu kết thúc nonterminal symbols:các ký hiệu chưa kết thúc variable: biến production:luật sinh parsing tree:cây phân tích cú pháp Backus-Naur Form:chuẩn Backus-Naur top down:trên xuống bottom-up:dưới lên backtracking:khả năng quay lui

stack:ngăn xếp semantic:mặt ngữ nhĩa axiomatic semantics:ngữ nghĩa tiên đề denotationnal semantics:ngữ nghĩa biểu thị semantic function:hàm ngữ nghĩa semantic domain:miền cú pháp literal constant:Hằng trực kiện object orientation:hướng đối tượng object:đối tượng message: thông điệp method:phương thức Object-Oriented Programming:Lập trình hướng đối tượng Abstraction:Trừu tượng hóa software object:đối tượng phần mềm state:trạng thái behavior:hành động member function:hàm thành viên instance:thể hiện blueprint:bảng thiết kế prototype:mẫu ban đầu blueprint:thiết kế class attribute:thuộc tính lớp class methods:phương thức lớp parameter:tham số Encapsulation:Tính bao gói Inheritance:Tính thừa kế Subclass:lớp con Superclass:lớp cha information hiding:che giấu thông tin Polymorphism:Tính đa hình Relation:mối quan hệ Horn clause:mệnh đề Horn Rule:luậtFact:sự kiện Question:câu hỏi Knowledge: tri thứcPredicat:vị từ logic atom:nguyên tử elementary term:hạng sơ cấp constant:hằng literal:trực kiện compound term:hạng phức hợp comment:chú thích substitution :sử dụng phép thế bound :ràng buộc recursive rule :luật đệ quy ancesto :quan hệ tổ tiên

anonymous variable:biến vô danh irst order predicate logic:công thức logic vị từ bậc một resolution:hợp giải functional programing language:ngôn ngữ lập trình hàm arguments hay parameters:tham đối boolean:kiểu logic exception :ngoại lệ raising the exception:đề xuất ngoại lệ Propagating an exception:Lan truyền một ngoại lệ Propagated:được truyền dynamic chain:chuỗi độngremain:kế thừa source program:chương trình nguồn executable program;chương trình thực hiện source language:ngôn ngữ nguồn compiler:Trình biên dịch interprete:Trình thông dịch preprocessor:bộ tiền xử lý executable:thực thi được assembly code:mã lệnh hợp ngữ assembler:trình dịch hợp ngữ symbol table:Bảng ký hiệu parse:cú pháp Predictive parsing:Phân tích cú pháp dự đoán Token: từ tố Lexeme:trị từ vựng Keyword:từ khóa producer – consumer:nhà sản xuất - người tiêu dùngbuffer:bộ đệm

YÊU CẦU VỀ ĐÁNH GIÁ MÔĐUNKỹ năng:- Sử dụng thành thạo phần mềm hỗ trợ thiết kế, hiểu được các ngôn ngữ lập trình- Lập tài liệu phân tích thiết kế- Hiểu được các kiểu dữ liệu và các loại ngôn ngữ lập trìnhThái độ:- Cẩn thận lắng nghe ý kiến và thảo luận trong nhóm thiết kế- Học viên cần tuân thủ các bài tập thực hành theo thứ tự các chương, từ dễ đến khó.
Đánh giá thông qua kiểm tra trắc nghiệm:- Dùng phần mềm thi trắc nghiệm.- Kiểm tra trắc nghiệm có thể trên giấy hoặc trên máy tính.- Xây dựng ngân hàng câu hỏi, học viên sẽ nhận được một bộ để phát sinh ngẫu
nhiên và chất lượng các đề như nhau (trung bình, khá, giỏi, xuất sắc).- Thời gian làm bài tuỳ theo số lượng các câu trong đề.- Thang điểm 10 chia đều cho các câu.- Kết quả đánh giá dựa vào bài làm theo điểm đạt được.
Thực hành: Đánh giá thông qua khả năng giải hoàn thành chương trình (đề kiểm tra) đề ra.
Thang điểm: (đánh giá câu hỏi trắc nghiệm)
0-49 : Không đạt
50-69 : Đạt trung bình
70-85 : Đạt khá 86-100 : Đạt Giỏi

TÀI LIỆU THAM KHẢO
[1] Terrence W. Pratt, Marvin V. Zelkowitz; Programming Languages: Design and Implementation; Prentice-Hall, 2000.
[2] Doris Appleby, Julius J. VandeKopple; Programming Languages; McGraw- Hill; 1997.
[3] Ryan Stensifer; The Study of Programming Languages; Prentice Hall, 1995.
[4] Maryse CONDILLAC; Prolog fondements et applications; BORDAS, Paris1986.
[5] Website về XLISP
http://webmaker.web.cern.ch/WebMak e r/examples/xlisp/www/cldoc_1.html
[6] Website về Turbo Prolog
http://www.csupo m ona.edu/%7Ejrfisher / www/p r olog_ t utorial/con t ents.html



![[] Chuyen de He Phuong Trinh](https://img.pdfslide.net/doc/110x75/55cf9d7a550346d033adca6f/wwwtoanphothongtk-chuyen-de-he-phuong-trinh.jpg)









![Hai Ngo (PVNi) Chuyen de bonus - Nghe thuat thuyet trinh goi von [slideshare]](https://img.pdfslide.net/doc/110x75/58ea5dad1a28abb8208b60c9/hai-ngo-pvni-chuyen-de-bonus-nghe-thuat-thuyet-trinh-goi-von-slideshare.jpg)















