Embed Size (px)
Citation preview

ACADGILDACADGILD
Let us learn how to run a Spark application in Windows.
In this post, we will execute the traditional Spark Scala Word Count program.
•For this, you need to have extracted the Spark tar file and Scala Eclipse IDE.
•Here we have used the spark-1.5.2-bin-hadoop-2.6.0 version (you can usethe later version as well).
•Download the spark tar file from the link given below:
https://drive.google.com/open?id=0ByJLBTmJojjzV0FnajhHekJGY1E
•After downloading, extract the file.
•You will see a spark-1.5.2-bin-hadoop-2.6.0 folder.
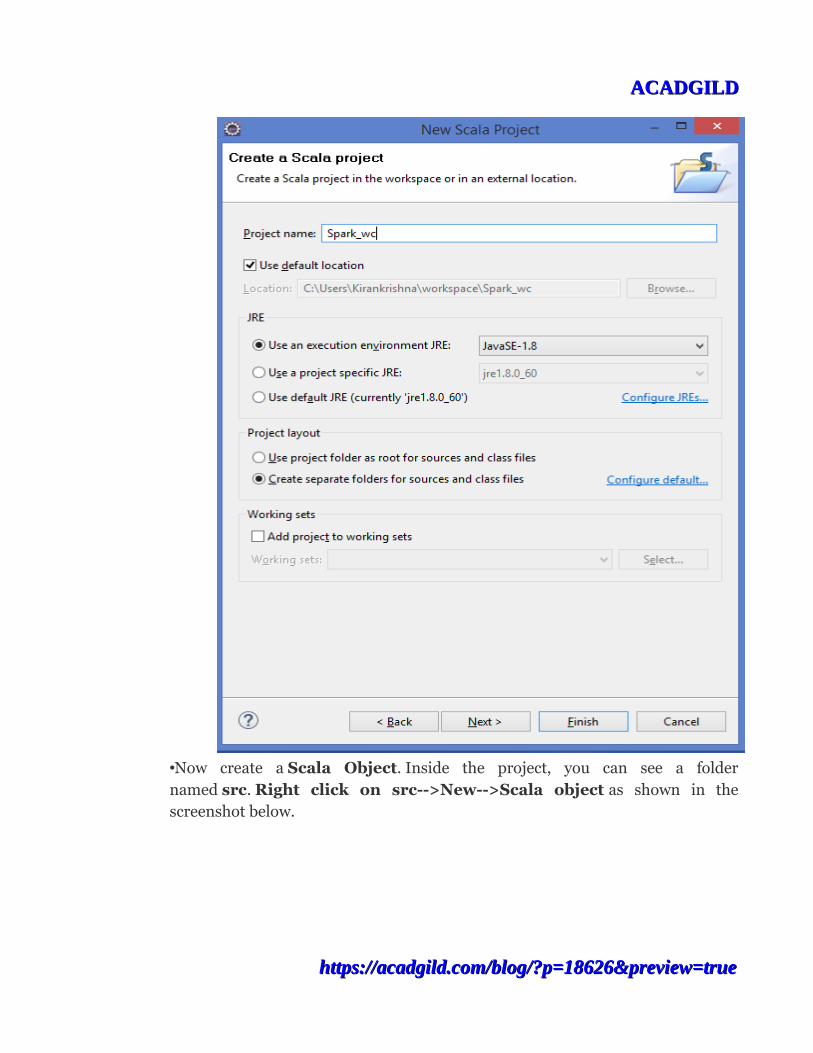
•Now open your Eclipse Scala IDE and create one Scala project as shown in the givenbelow screenshot.
For creating a Scala project, go to:
File-->New-->other-->Scala wizards-->Scala project
•Now you will get a prompt to provide the project name as shown in the givenbelow screen shot.
•We have named the project, "Spark_wc" you can give the project name of your choice
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true
ACADGILDACADGILD
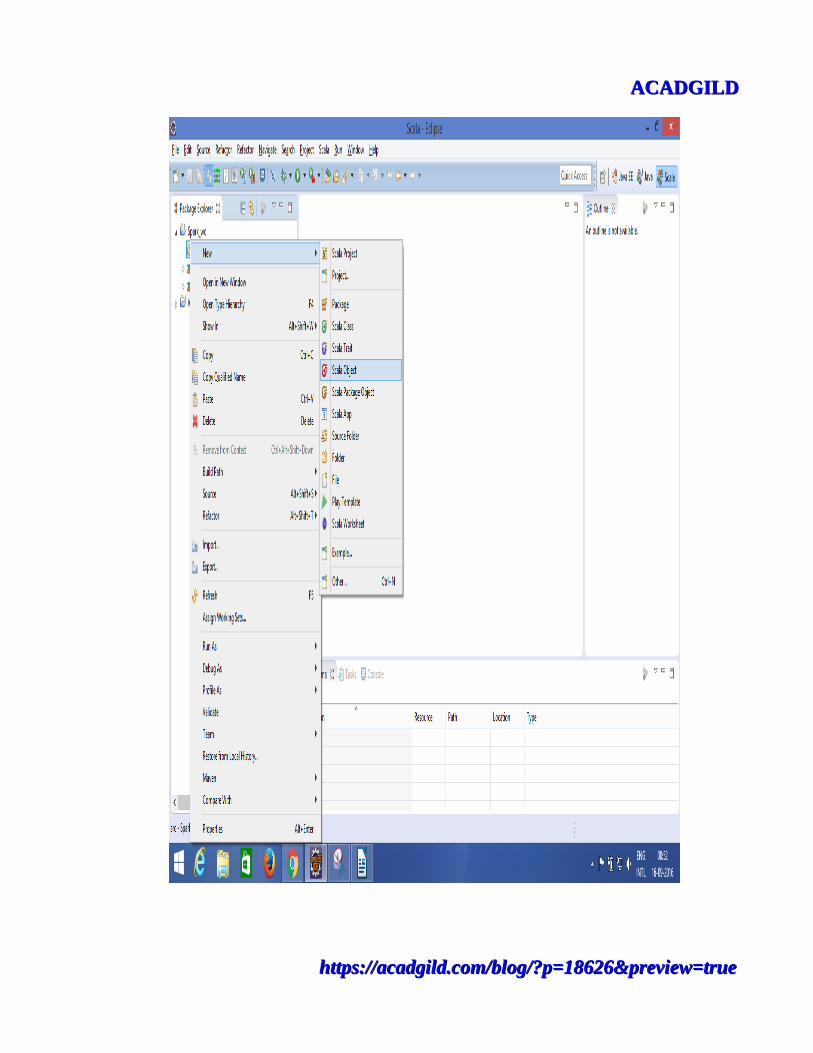
•Now create a Scala Object. Inside the project, you can see a foldernamed src. Right click on src-->New-->Scala object as shown in thescreenshot below.
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true
ACADGILDACADGILD
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true
ACADGILDACADGILD
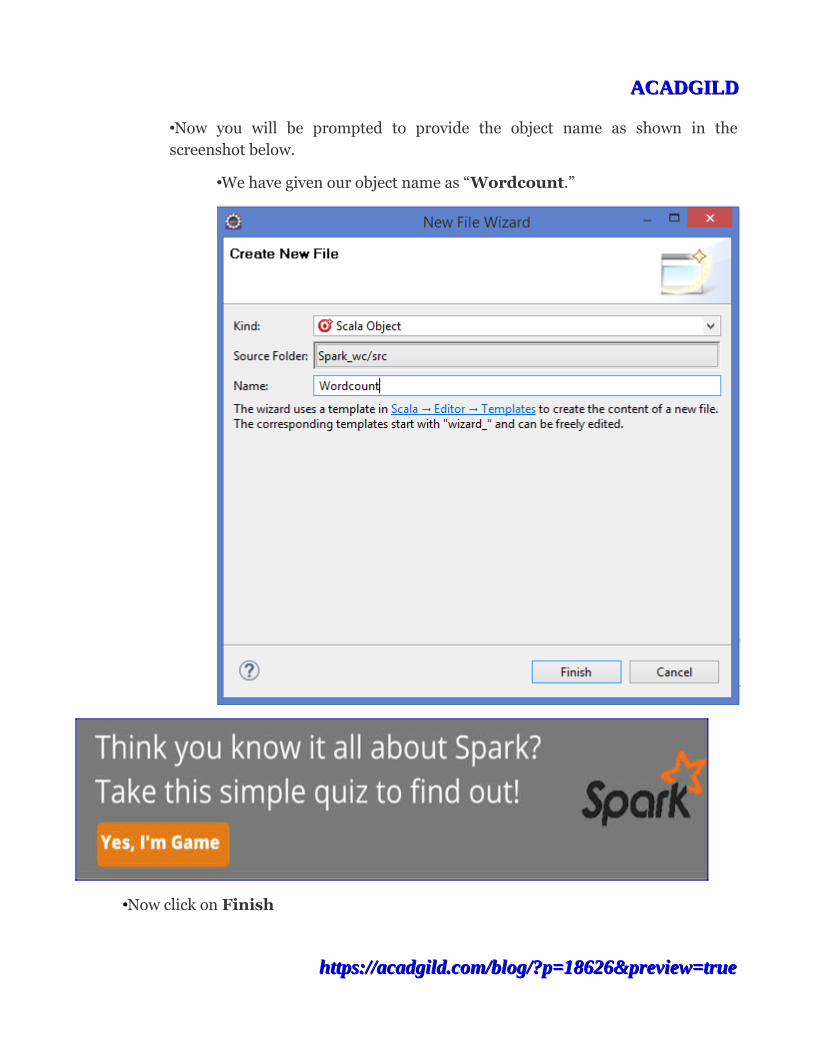
•Now you will be prompted to provide the object name as shown in thescreenshot below.
•We have given our object name as “Wordcount.”
•Now click on Finish
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true

ACADGILDACADGILD
•You can see that a Scala object has been created in the src folder.
import org.apache.spark.SparkConfimport org.apache.spark.SparkContextimport org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object Wordcount { def main(args: Array[String]) = {
//Start the Spark context val conf = new SparkConf() .setAppName("WordCount") .setMaster("local") val sc = new SparkContext(conf)
//Read some example file to a test RDD val test = sc.textFile("inp") //need to provide the input path of the file
test.flatMap { line => //for each line line.split(" ") //split the line in word by word. } .map { word => //for each word (word, 1) //Return a key/value tuple, with the word as key and 1 as value } .reduceByKey(_ + _) //Sum all of the value with same key .saveAsTextFile("output") //Save to a text file
//Stop the Spark context sc.stop }}
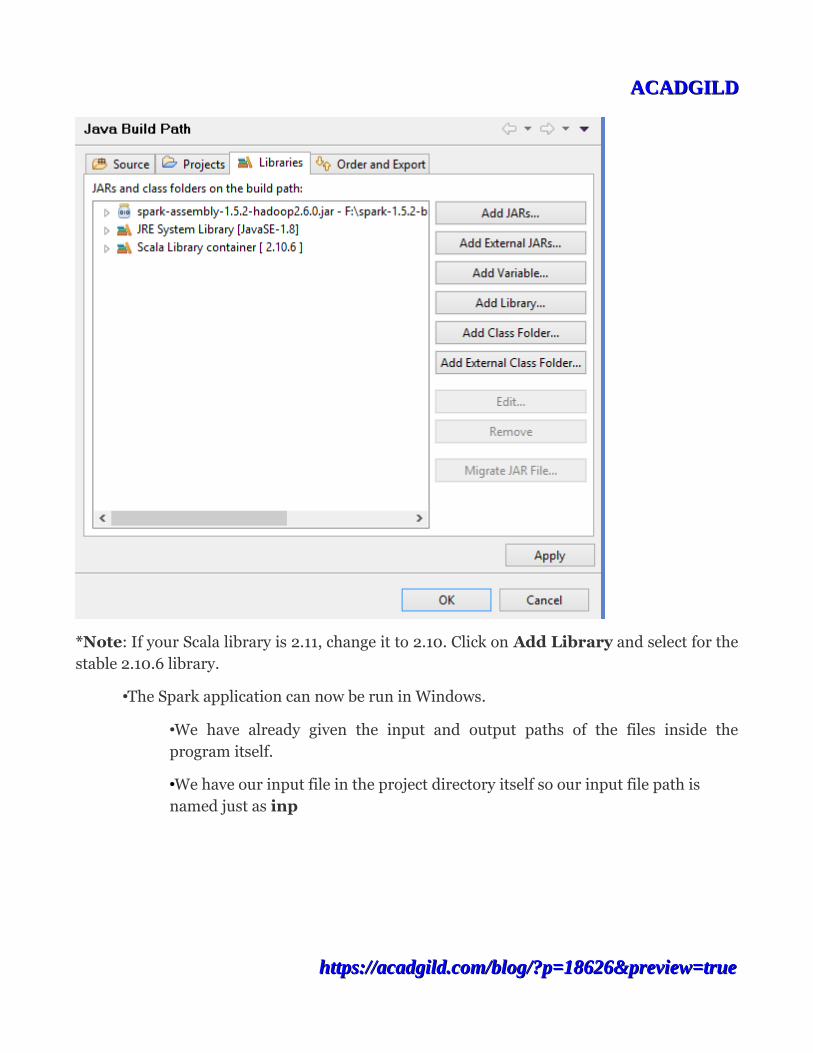
•Now you need to add the spark-assembly JAR file to import the Spark packages.
•Right click on src-->Build Path-->Configure build path-->Libraries-->Add External libraries-->Browse the spark-1.5.2-bin-hadoop-2.6.0folder
•Go to spark-1.5.2-bin-hadoop-2.6.0/lib/ and add the spark-assembly-1.5.2-hadoop-2.6.0.jar file.
•Click on Apply as shown in the screenshot below.
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true
ACADGILDACADGILD
*Note: If your Scala library is 2.11, change it to 2.10. Click on Add Library and select for thestable 2.10.6 library.
•The Spark application can now be run in Windows.
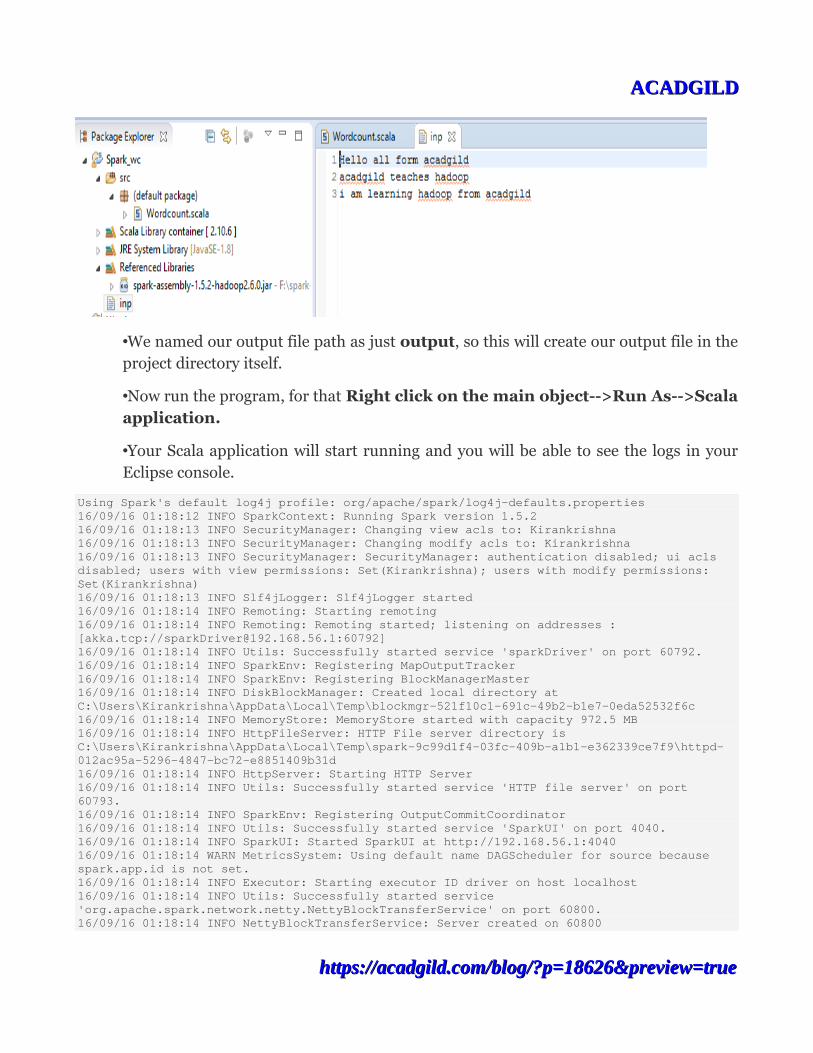
•We have already given the input and output paths of the files inside theprogram itself.
•We have our input file in the project directory itself so our input file path is named just as inp
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true
ACADGILDACADGILD
•We named our output file path as just output, so this will create our output file in theproject directory itself.
•Now run the program, for that Right click on the main object-->Run As-->Scalaapplication.
•Your Scala application will start running and you will be able to see the logs in yourEclipse console.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties16/09/16 01:18:12 INFO SparkContext: Running Spark version 1.5.216/09/16 01:18:13 INFO SecurityManager: Changing view acls to: Kirankrishna16/09/16 01:18:13 INFO SecurityManager: Changing modify acls to: Kirankrishna16/09/16 01:18:13 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Kirankrishna); users with modify permissions: Set(Kirankrishna)16/09/16 01:18:13 INFO Slf4jLogger: Slf4jLogger started16/09/16 01:18:14 INFO Remoting: Starting remoting16/09/16 01:18:14 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:60792]16/09/16 01:18:14 INFO Utils: Successfully started service 'sparkDriver' on port 60792.16/09/16 01:18:14 INFO SparkEnv: Registering MapOutputTracker16/09/16 01:18:14 INFO SparkEnv: Registering BlockManagerMaster16/09/16 01:18:14 INFO DiskBlockManager: Created local directory at C:\Users\Kirankrishna\AppData\Local\Temp\blockmgr-521f10c1-691c-49b2-b1e7-0eda52532f6c16/09/16 01:18:14 INFO MemoryStore: MemoryStore started with capacity 972.5 MB16/09/16 01:18:14 INFO HttpFileServer: HTTP File server directory is C:\Users\Kirankrishna\AppData\Local\Temp\spark-9c99d1f4-03fc-409b-a1b1-e362339ce7f9\httpd-012ac95a-5296-4847-bc72-e8851409b31d16/09/16 01:18:14 INFO HttpServer: Starting HTTP Server16/09/16 01:18:14 INFO Utils: Successfully started service 'HTTP file server' on port 60793.16/09/16 01:18:14 INFO SparkEnv: Registering OutputCommitCoordinator16/09/16 01:18:14 INFO Utils: Successfully started service 'SparkUI' on port 4040.16/09/16 01:18:14 INFO SparkUI: Started SparkUI at http://192.168.56.1:404016/09/16 01:18:14 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.16/09/16 01:18:14 INFO Executor: Starting executor ID driver on host localhost16/09/16 01:18:14 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 60800.16/09/16 01:18:14 INFO NettyBlockTransferService: Server created on 60800
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true

ACADGILDACADGILD
16/09/16 01:18:14 INFO BlockManagerMaster: Trying to register BlockManager16/09/16 01:18:14 INFO BlockManagerMasterEndpoint: Registering block manager localhost:60800 with 972.5 MB RAM, BlockManagerId(driver, localhost, 60800)16/09/16 01:18:14 INFO BlockManagerMaster: Registered BlockManager16/09/16 01:18:15 INFO MemoryStore: ensureFreeSpace(130448) called with curMem=0, maxMem=101978210316/09/16 01:18:15 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimatedsize 127.4 KB, free 972.4 MB)16/09/16 01:18:15 INFO MemoryStore: ensureFreeSpace(14276) called with curMem=130448, maxMem=101978210316/09/16 01:18:15 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 972.4 MB)16/09/16 01:18:15 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:60800 (size: 13.9 KB, free: 972.5 MB)16/09/16 01:18:15 INFO SparkContext: Created broadcast 0 from textFile at Wordcount.scala:1516/09/16 01:18:16 WARN : Your hostname, ACD-KIRAN resolves to a loopback/non-reachable address: fe80:0:0:0:0:5efe:c0a8:ae3%net5, but we couldn't find any external IP address!16/09/16 01:18:17 INFO FileInputFormat: Total input paths to process : 116/09/16 01:18:17 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id16/09/16 01:18:17 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id16/09/16 01:18:17 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap16/09/16 01:18:17 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition16/09/16 01:18:17 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id16/09/16 01:18:17 INFO SparkContext: Starting job: saveAsTextFile at Wordcount.scala:2416/09/16 01:18:17 INFO DAGScheduler: Registering RDD 3 (map at Wordcount.scala:20)16/09/16 01:18:17 INFO DAGScheduler: Got job 0 (saveAsTextFile at Wordcount.scala:24) with 1 output partitions16/09/16 01:18:17 INFO DAGScheduler: Final stage: ResultStage 1(saveAsTextFile at Wordcount.scala:24)16/09/16 01:18:17 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)16/09/16 01:18:17 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)16/09/16 01:18:17 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at Wordcount.scala:20), which has no missing parents16/09/16 01:18:17 INFO MemoryStore: ensureFreeSpace(4008) called with curMem=144724, maxMem=101978210316/09/16 01:18:17 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimatedsize 3.9 KB, free 972.4 MB)16/09/16 01:18:17 INFO MemoryStore: ensureFreeSpace(2281) called with curMem=148732, maxMem=101978210316/09/16 01:18:17 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.2 KB, free 972.4 MB)16/09/16 01:18:17 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:60800 (size: 2.2 KB, free: 972.5 MB)16/09/16 01:18:17 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:86116/09/16 01:18:17 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at Wordcount.scala:20)16/09/16 01:18:17 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks16/09/16 01:18:17 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 2148 bytes)16/09/16 01:18:17 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)16/09/16 01:18:17 INFO HadoopRDD: Input split: file:/C:/Users/Kirankrishna/workspace/Spark_wc/inp:0+84
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true

ACADGILDACADGILD
16/09/16 01:18:17 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver16/09/16 01:18:17 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 107 ms on localhost (1/1)16/09/16 01:18:17 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool16/09/16 01:18:17 INFO DAGScheduler: ShuffleMapStage 0 (map at Wordcount.scala:20) finishedin 0.118 s16/09/16 01:18:17 INFO DAGScheduler: looking for newly runnable stages16/09/16 01:18:17 INFO DAGScheduler: running: Set()16/09/16 01:18:17 INFO DAGScheduler: waiting: Set(ResultStage 1)16/09/16 01:18:17 INFO DAGScheduler: failed: Set()16/09/16 01:18:17 INFO DAGScheduler: Missing parents for ResultStage 1: List()16/09/16 01:18:17 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at Wordcount.scala:24), which is now runnable16/09/16 01:18:18 INFO MemoryStore: ensureFreeSpace(127704) called with curMem=151013, maxMem=101978210316/09/16 01:18:18 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimatedsize 124.7 KB, free 972.3 MB)16/09/16 01:18:18 INFO MemoryStore: ensureFreeSpace(42757) called with curMem=278717, maxMem=101978210316/09/16 01:18:18 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 41.8 KB, free 972.2 MB)16/09/16 01:18:18 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:60800 (size: 41.8 KB, free: 972.5 MB)16/09/16 01:18:18 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:86116/09/16 01:18:18 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at Wordcount.scala:24)16/09/16 01:18:18 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks16/09/16 01:18:18 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1901 bytes)16/09/16 01:18:18 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)16/09/16 01:18:18 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks16/09/16 01:18:18 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 3 ms16/09/16 01:18:18 INFO FileOutputCommitter: Saved output of task 'attempt_201609160118_0001_m_000000_1' to file:/C:/Users/Kirankrishna/workspace/Spark_wc/output/_temporary/0/task_201609160118_0001_m_00000016/09/16 01:18:18 INFO SparkHadoopMapRedUtil: attempt_201609160118_0001_m_000000_1: Committed16/09/16 01:18:18 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 2080 bytes result sent to driver16/09/16 01:18:18 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at Wordcount.scala:24) finished in 0.168 s16/09/16 01:18:18 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 168 ms on localhost (1/1)16/09/16 01:18:18 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool16/09/16 01:18:18 INFO DAGScheduler: Job 0 finished: saveAsTextFile at Wordcount.scala:24, took 0.431022 s16/09/16 01:18:18 INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:404016/09/16 01:18:18 INFO DAGScheduler: Stopping DAGScheduler16/09/16 01:18:18 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!16/09/16 01:18:18 INFO MemoryStore: MemoryStore cleared16/09/16 01:18:18 INFO BlockManager: BlockManager stopped16/09/16 01:18:18 INFO BlockManagerMaster: BlockManagerMaster stopped
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true
ACADGILDACADGILD
16/09/16 01:18:18 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!16/09/16 01:18:18 INFO SparkContext: Successfully stopped SparkContext16/09/16 01:18:18 INFO ShutdownHookManager: Shutdown hook called16/09/16 01:18:18 INFO ShutdownHookManager: Deleting directory C:\Users\Kirankrishna\AppData\Local\Temp\spark-9c99d1f4-03fc-409b-a1b1-e362339ce7f916/09/16 01:18:18 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
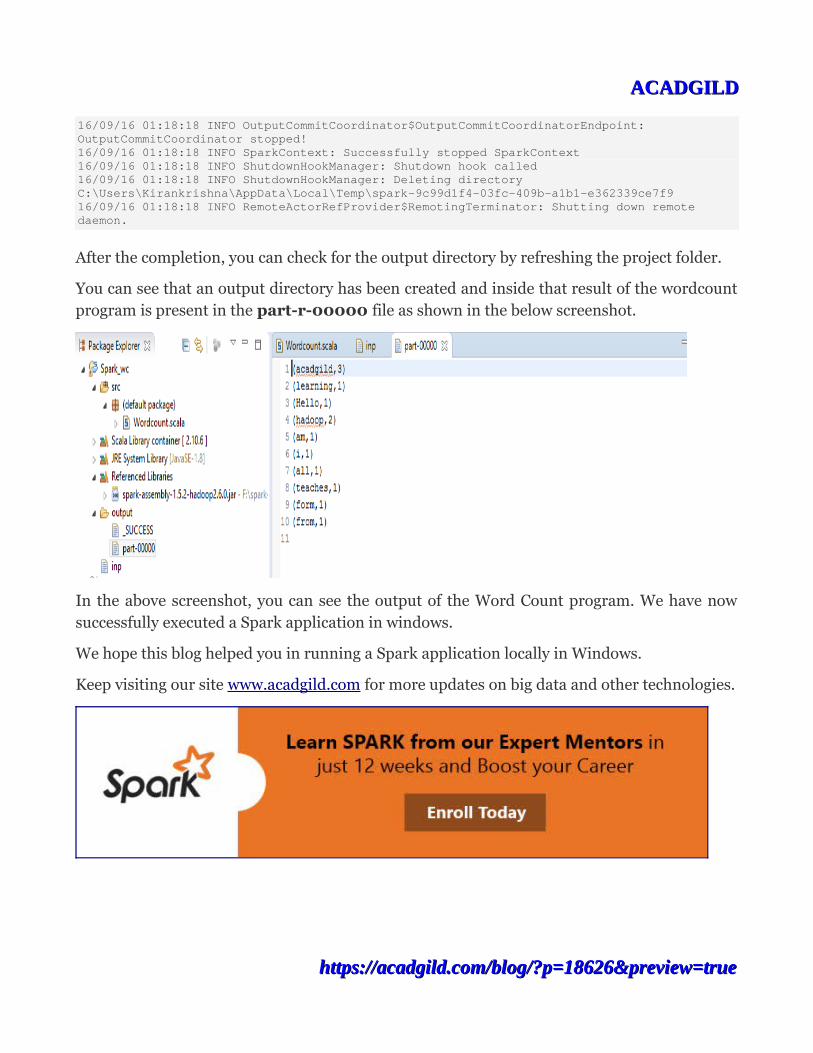
After the completion, you can check for the output directory by refreshing the project folder.
You can see that an output directory has been created and inside that result of the wordcountprogram is present in the part-r-00000 file as shown in the below screenshot.
In the above screenshot, you can see the output of the Word Count program. We have nowsuccessfully executed a Spark application in windows.
We hope this blog helped you in running a Spark application locally in Windows.
Keep visiting our site www.acadgild.com for more updates on big data and other technologies.
https://acadgild.com/blog/?p=18626&preview=truehttps://acadgild.com/blog/?p=18626&preview=true







![Free Spark Cloud Offering - Packt Publishing · [1 ] Free Spark Cloud Offering So far, we have worked with Spark on your machine only. Since Spark was designed with a build locally](https://img.pdfslide.net/doc/110x75/5b80fbb57f8b9a466b8b4cc5/free-spark-cloud-offering-packt-publishing-1-free-spark-cloud-offering.jpg)





















