Embed Size (px)
Citation preview

Institut des algorithmes d’apprentissage
de Montréal
Progress on the road to end-to-end speech synthesis
Aaron CourvilleMILA, Université de Montréal SANE - October 19th, 2017
Joint work with: Jose Sotelo, Soroush Mehri, Kundan Kumar, Ishaan Gulrajani, Junyoung Chung, Kyle Kastner, Joao Felipe Santos, Rithesh Kumar Yoshua Bengio

Speech synthesis: a challenging task
• Audio data is very challenging
• Complex structure with very long term dependencies
Image credits: Wavenet blog post (https://deepmind.com/blog/wavenet-generative-model-raw-audio/)

SampleRNN: Model Architecture

Samples: long range structure

Samples: long range structure
PianoSpeech

Samples: long range structure
PianoSpeech

Samples: short range structure
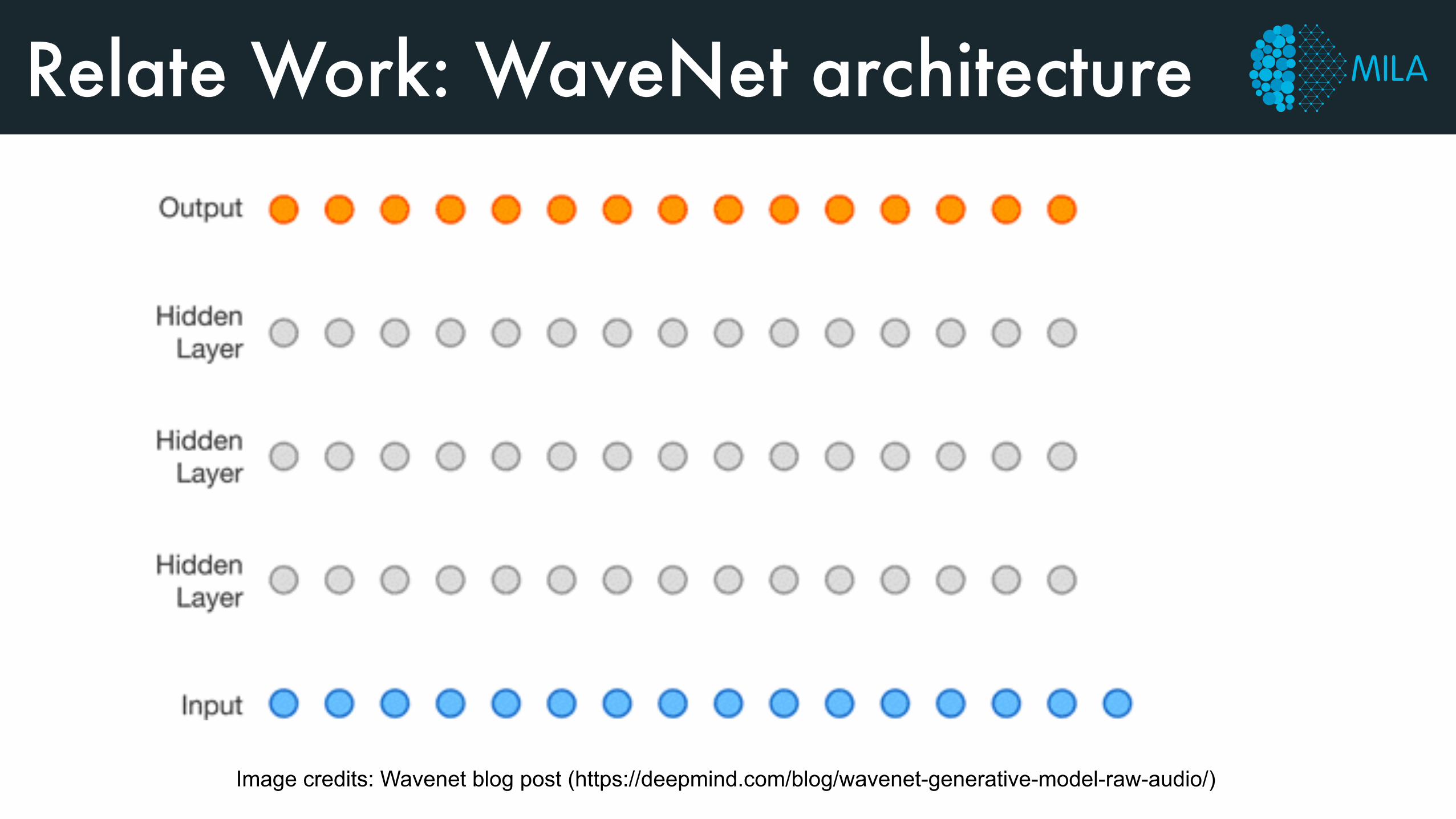
Relate Work: WaveNet architecture
Image credits: Wavenet blog post (https://deepmind.com/blog/wavenet-generative-model-raw-audio/)

SampleRNN -vs- WaveNet
SampleRNN WaveNet
• Different tiers run at different time scale
• All tiers run at full temporal resolution.
• Can keep and use information from arbitrary past
• Can only deal with information from its limited receptive field
• Training cannot be parallelized much (since RNN is the building blocks and require context from previous training step)
• Training is fully parallelizable since model is fully convolutional.
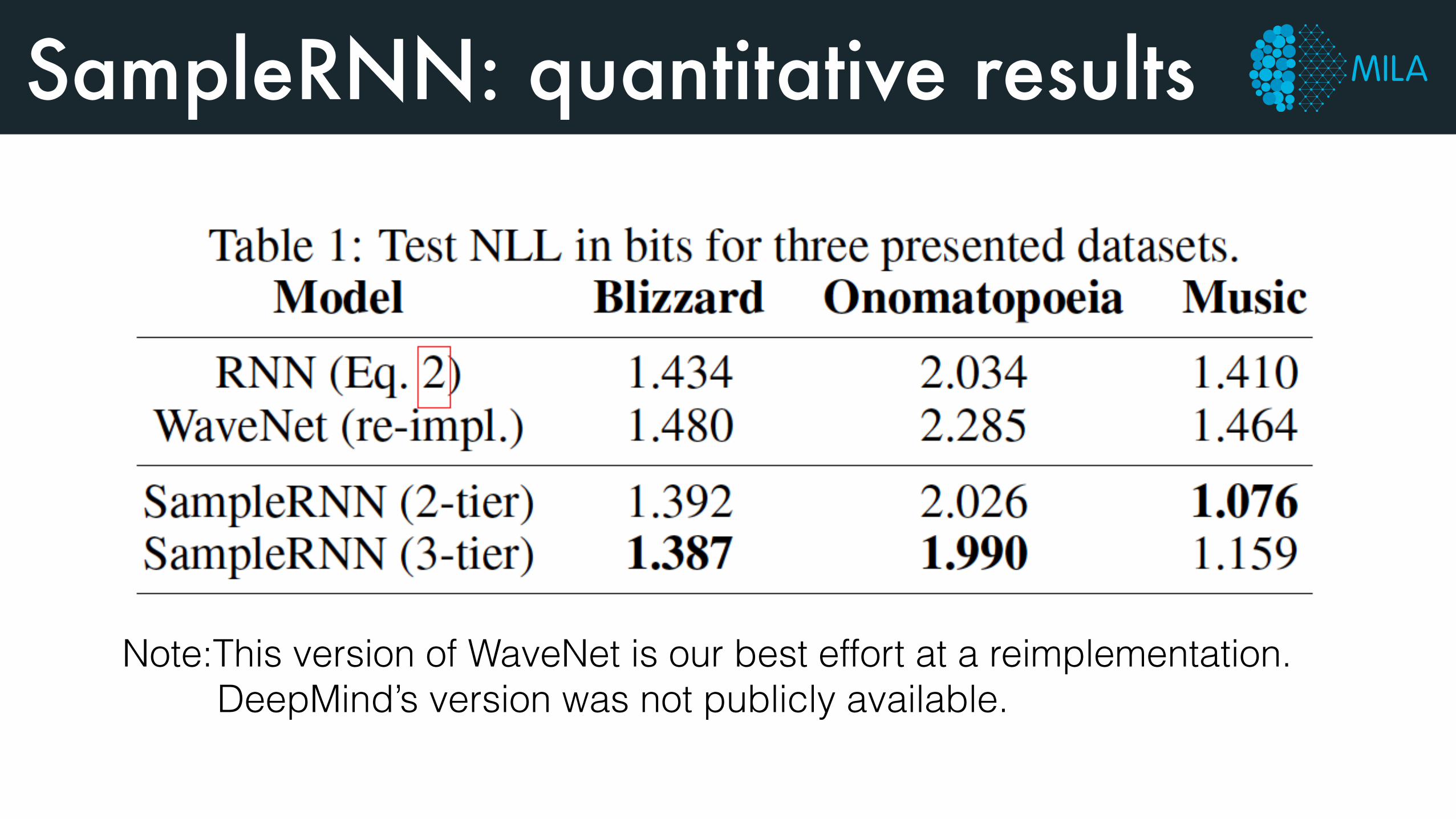
SampleRNN: quantitative results
Note:This version of WaveNet is our best effort at a reimplementation. DeepMind’s version was not publicly available.
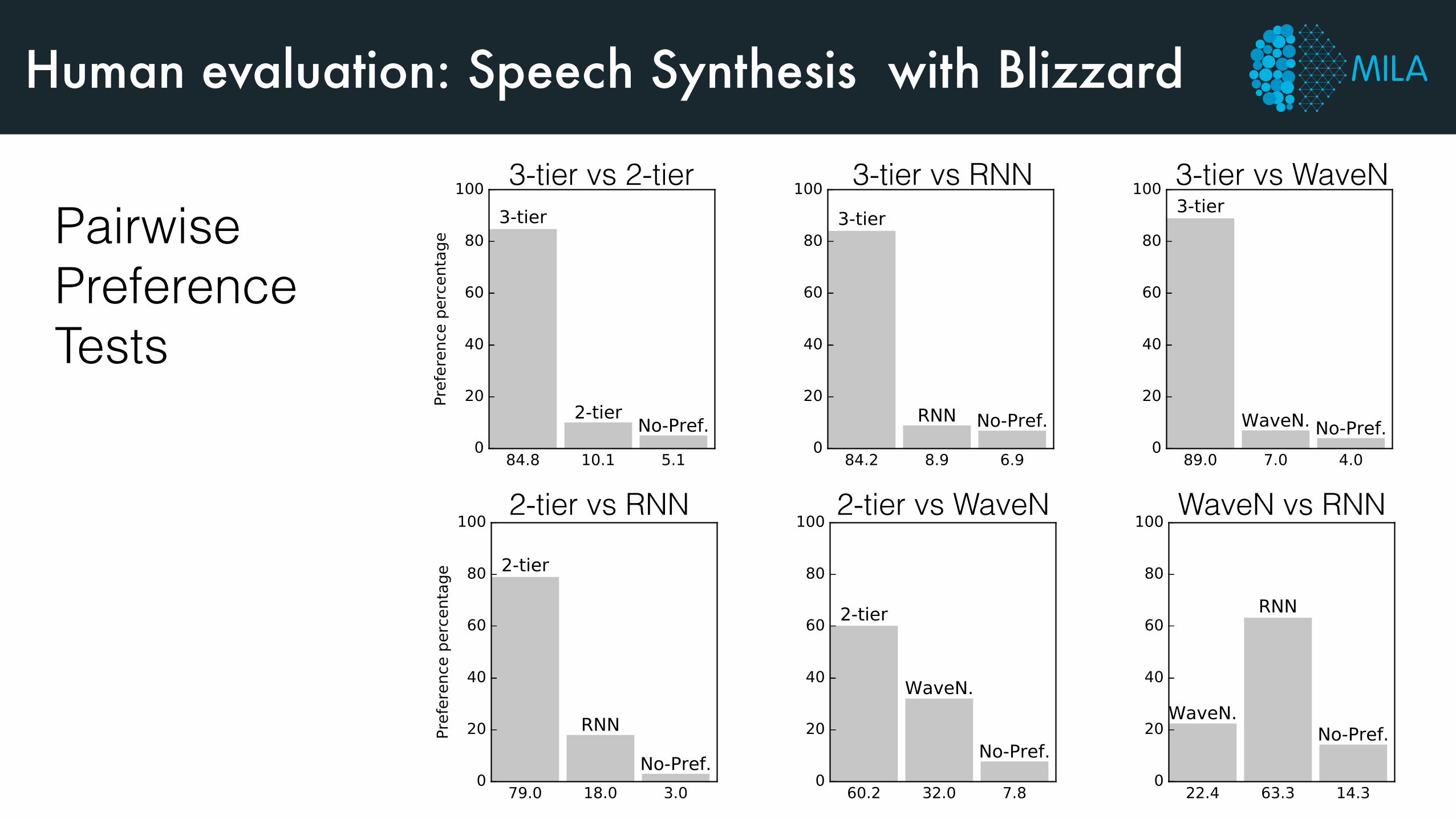
Human evaluation: Speech Synthesis with Blizzard
3-tier vs 2-tier 3-tier vs RNN 3-tier vs WaveN
2-tier vs WaveN2-tier vs RNN WaveN vs RNN
Pairwise Preference Tests

Human evaluation: Music Generation
Pairwise Preference Tests 3-tier vs 2-tier 3-tier vs RNN 2-tier vs RNN

SampleRNN: Key components …
… without which generations sound terrible
• Quantized output i.e. the raw signal is quantized into 256 bins following linear (or mu-law quantization).
• Model output is a multinomial distribution over the integers in range 0 to 255.
• Adding more tiers help more than adding RNN layers within a tier.
• Auto-regressiveness at sample-level is crucial
• Using “embedding” in the input at sample-level improves result
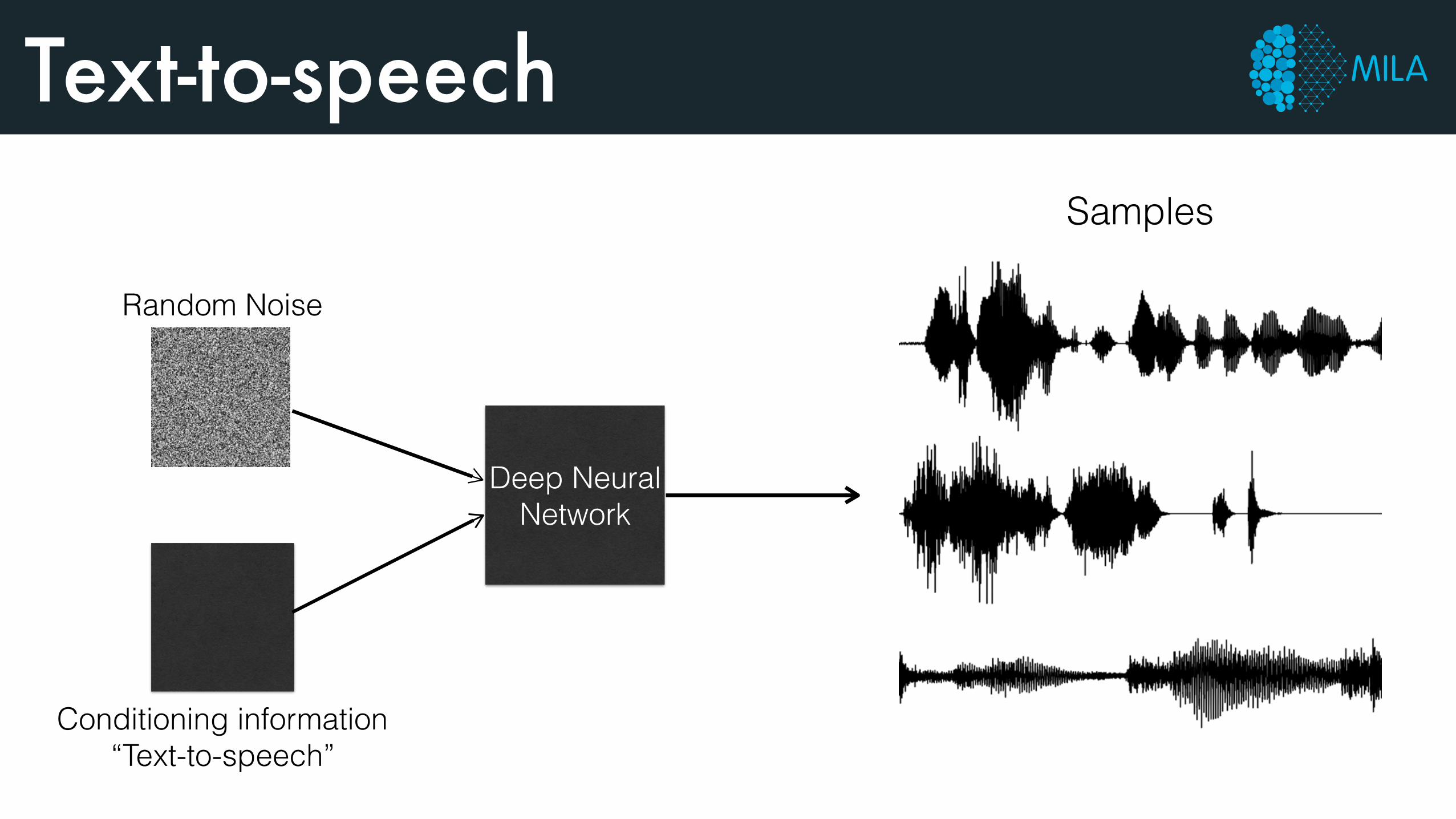
Text-to-speech
Deep Neural Network
Random Noise
Samples
Conditioning information “Text-to-speech”

Char2Wav: Architecture
• Combination of a Reader Network and the Neural Vocoder. - Reader: Maps text to vocoder frames. - Neural Vocoder: Maps vocoder frames to audio
waveforms.
• Reader uses attention (in the decoder) to align characters to vocoder features.
• Neural Vocoder is the SampleRNN.
h e l l o
Encoder
Bidir. RNN
Reader
RNN withattention
Vocoderfeatures
Neuralvocoder
SampleRNN
Audiowaveform
Text
Decoder
…
…
…

Reader: Attention model• Attention mechanism similar to Alex Graves’s
model for hand-writing generation.
h e l l o
Encoder
Bidir. RNN
Reader
RNN withattention
Vocoderfeatures
Neuralvocoder
SampleRNN
Audiowaveform
Text
Decoder
…
…
…
Char2Wav: End-to-End Speech Synthesis
different timescales and lengths making direct end-to-endhard.
In Char2Wav, we leverage vocoder features as an interme-diate representation and split the training procedure intotwo stages. First, we pretrain the reader to map from a se-quence of characters to the vocoder representation. Then,we train a neural vocoder to map from the vocoder repre-sentation generated by the reader to audio samples whilekeeping the reader parameters fixed. Finally, we fine-tuneboth models end-to-end.
While the approach presented here is specific to speech sig-nals, it can be applied to other domains with huge gapsbetween the timescales or sequence lengths of the inputsand outputs to the model are present. For example, in ahigh-resolution image synthesis model, one could imaginetraining a reader to go from an image caption to a represen-tation that encodes which objects are in the scene and theirlayout, and the other part of the model could convert thatrepresentation to a sequence of pixels.
2.1. Attention-based Recurrent Sequence Generator
We adopt the notation of Chorowski et al. (2015). Anattention-based recurrent sequence generator (ARSG) is arecurrent neural network that generates a sequence Y =
(y1, . . . , yT ) conditioned on an input sequence X . X ispreprocessed by an encoder that outputs a sequence h =
(h1, . . . , hL). In this work, the output Y is a sequence ofacoustic features and X is the text to be generated, format-ted as a character or phoneme sequence. Furthermore, theencoder is a bidirectional recurrent network.
At the i-th step the ARSG focuses on h and generates yi:
↵i = Attend(si�1,↵i�1, h) (1)
gi =LX
j=1
↵i,jhj (2)
yi ⇠ Generate(si�1, gi) (3)si = RNN(si�1, gi, yi) (4)
where si�1 is the (i�1)-th state of the generator recurrentneural network and ↵i 2 RL are the attention weights oralignment.
2.2. Reader
We use the location-based attention mechanism developedby Graves (2013). We have ↵i = Attend(si�1,↵i�1) and
given a length L conditioning sequence h, we have:
�(i, l) =KX
k=1
⇢ki exp(��ki (
ki � l)2) (5)
↵i =
LX
l=1
�(i, l) (6)
where i, �i, and ⇢i represent the location, width and im-portance of the window respectively.
Finally, to complete the specification of the Attend func-tion we have:
(⇢̂i, ˆ�i, ̂i) = Wsi�1 (7)⇢̃i = exp(⇢̂i) (8)
�i = exp(
ˆ�i) (9)i = i�1 + exp(̂i) (10)
We made two changes to the attention mechanism thatmakes the conditioning attention training more stable.First, we normalize the window mixture (⇢i) with:
⇢ki =
⇢̃kiPKk=1 ⇢̃
ki
(11)
Second, we add a constant v to Equation 10:
i = i�1 + v exp(̂i) (12)
v helps control the speed at which the model sees the text.This is important in a context of speech synthesis sincethe length of the sequences are of different orders of mag-nitude. In our experiments, v ranged from 0.02 to 0.08,derived from the average length between text and vocoderfeatures over the training set.
For all the models that we trained, we embedded the textor phoneme sequence into a vector of size 128. After that,the encoder was a 1-layer bidirectional RNN using GatedRecurrent Units (GRU) (Cho et al., 2014) with 128 hiddenunits in each direction. Finally, the generator was a 3-layerGRU RNN with 1024 hidden units.
2.2.1. SPEAKER CONDITIONING
Another key feature of having a generative model forspeech is the potential for choosing different voices in gen-eration. We incorporate global speaker identification di-rectly into the model, and find that a single model is ableto perform multi-speaker synthesis. In order to incorpo-rate this speaker information, we add additional (fixed)information about each speaker into the model at eachtimestep of the reader. Our new conditioning input to themodel is a one-hot representation of the speaker sj , where
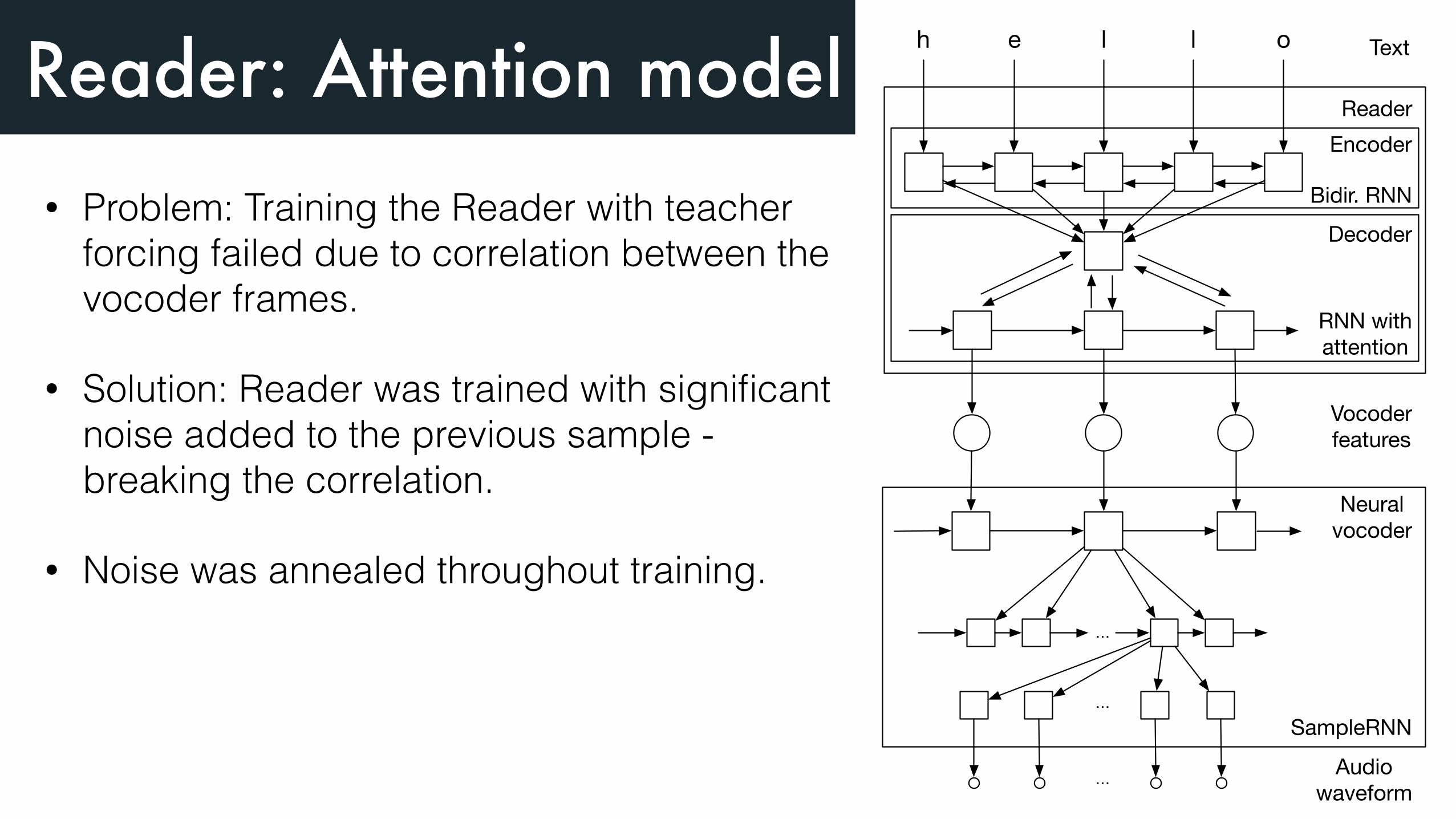
Reader: Attention model• Problem: Training the Reader with teacher
forcing failed due to correlation between the vocoder frames.
• Solution: Reader was trained with significant noise added to the previous sample - breaking the correlation.
• Noise was annealed throughout training.
h e l l o
Encoder
Bidir. RNN
Reader
RNN withattention
Vocoderfeatures
Neuralvocoder
SampleRNN
Audiowaveform
Text
Decoder
…
…
…

Char2Wav Training• Step 1: Train the Reader - Text (or
phonemes) to Vocoder
• Step 2: Train the Neural vocoder - vocoder to raw audio output.
• Step 3: fine-tune the whole process end-to-end.
h e l l o
Encoder
Bidir. RNN
Reader
RNN withattention
Vocoderfeatures
Neuralvocoder
SampleRNN
Audiowaveform
Text
Decoder
…
…
…

English synthesis from TextAdvantages: • No hand-crafted linguistic features • Easy to change the language
Disadvantage: • Limited by the quality of vocoder

English synthesis from phonemes• It is a challenge to use attention to learn the
alignment when conditioning on english text.
• Problem: the mapping between english text and english phonemes is complicated and hard for our model to learn.
• Solution: add a bit of linguistic knowledge. We use a pronounciation dictionary to convert words to phonemes and run on

Spanish synthesis from Text• Spanish: mapping from characters to
phonemes is much more regular than it is in english.
• For Spanish we can use end-to-end mapping from characters to audio output.

Human evaluation: Preference• Vocoder output is preferred
over the SampleRNN-based Neural Vocoder.
• The difference? • Vocoded voice is more robotic. • SampleRNN voice is noisier. • When asked, people seem to
prefer robotic.
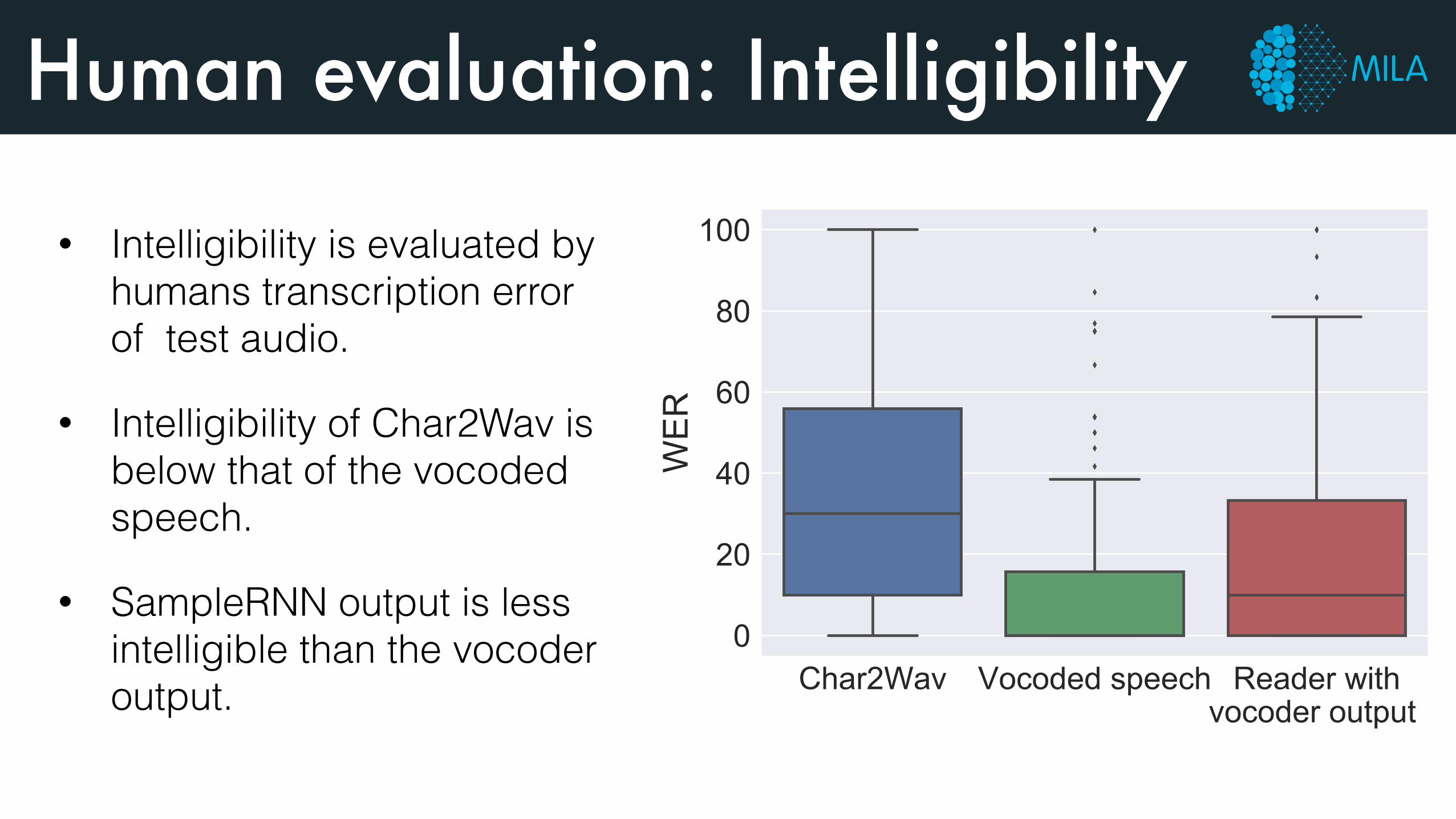
Human evaluation: Intelligibility
• Intelligibility is evaluated by humans transcription error of test audio.
• Intelligibility of Char2Wav is below that of the vocoded speech.
• SampleRNN output is less intelligible than the vocoder output.
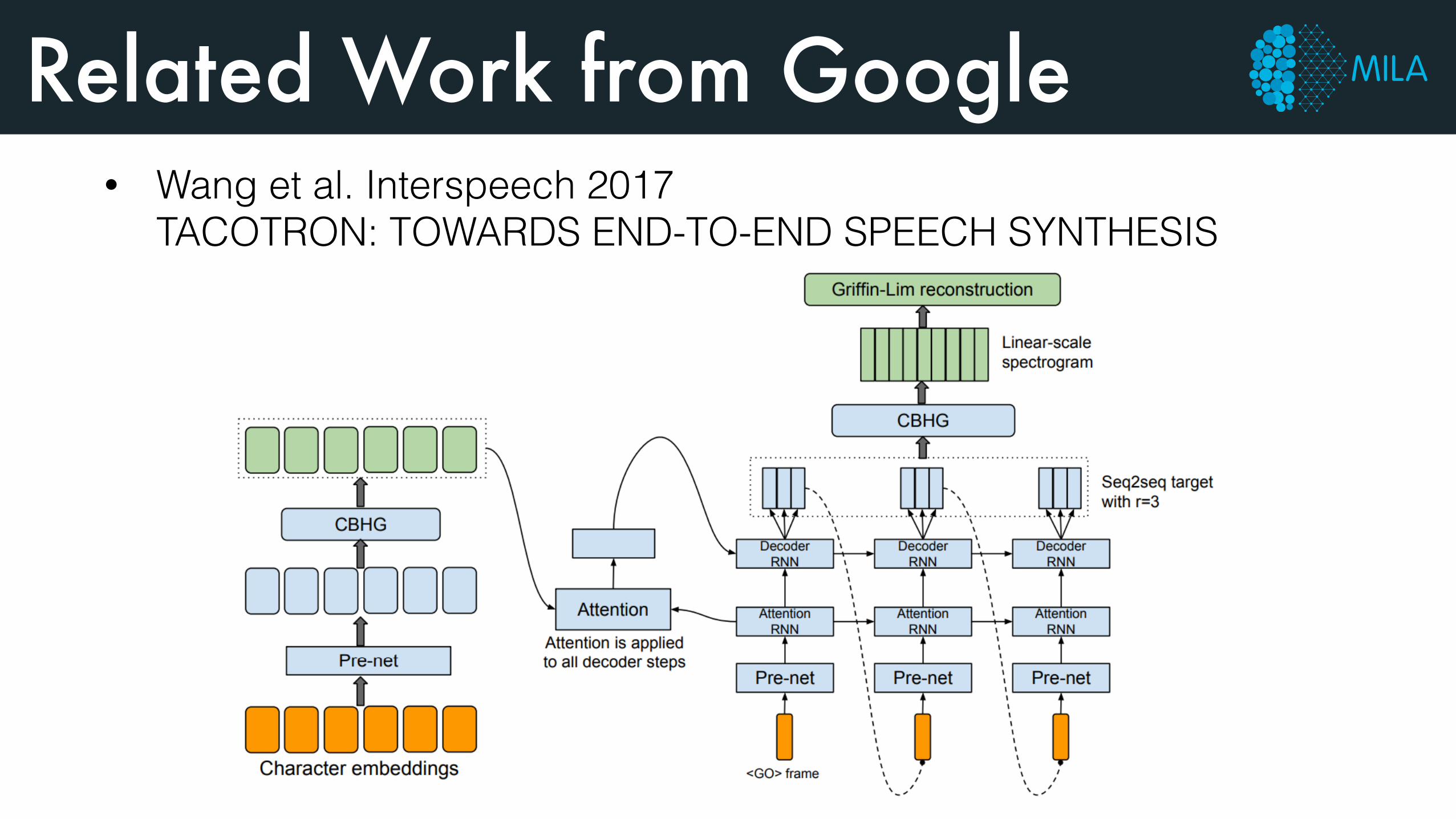
Related Work from Google• Wang et al. Interspeech 2017
TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS

Discovering latent factors
Z
text
speech Generation
Inference
Generations with different latent variablesGround Truth
Lyrebird

Lyrebird

Lyrebird: Samples with Video

Lyrebird: fun with samples
Others, like IBM, are getting into this space

Next Steps: Overcoming challenges• Can we lose the dependence on aligned text-audio?
Really we want to train jointly but somehow with appropriate training at each level.
• GANs: Generative Adversarial Networks might help.
• cycleGAN: learn transformations across domains with unpaired data.
Image credits: Jun-Yan Zhu*, Taesung Park*, Phillip Isola, and Alexei A. Efros. "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks", in IEEE International Conference on Computer Vision (ICCV), 2017.

CycleGAN for unpaired data
Image credits: Jun-Yan Zhu*, Taesung Park*, Phillip Isola, and Alexei A. Efros. "Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks", in IEEE International Conference on Computer Vision (ICCV), 2017.

Conditioned instance normalizationDumoulin et al.A Learned Representation For Artistic Style.ICLR 2017.

Visual resoning: CLEVR DatasetQ: What number of cylinders are small purple things or yellow rubber things? A: ?2

Previous Work on CLEVR: Strong Priors
Johnson et al. Inferring and Executing Programs for Visual Reasoning. arXiv 2017.

FiLM-Based Visual Reasoning
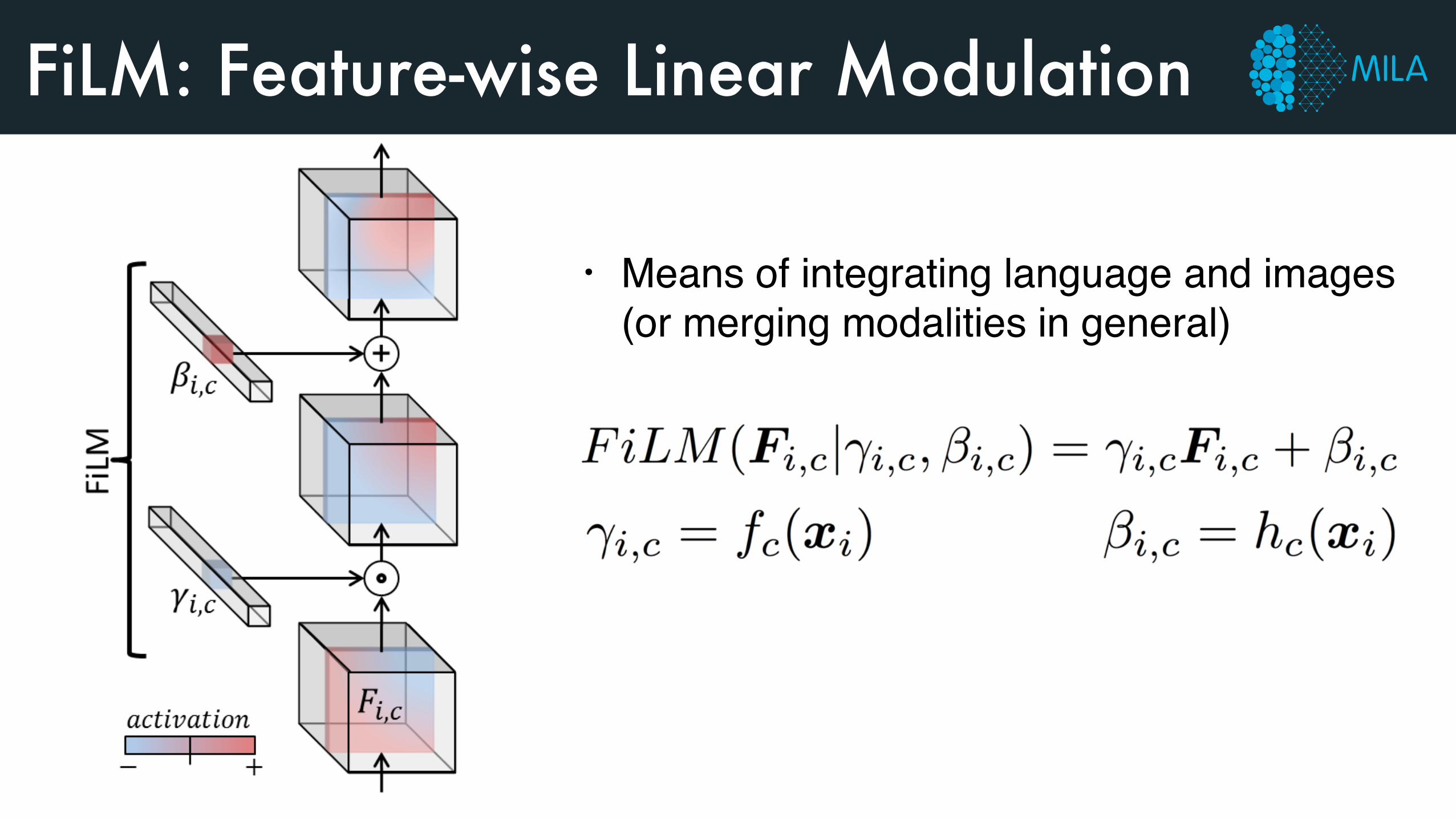
FiLM: Feature-wise Linear Modulation
• Means of integrating language and images (or merging modalities in general)
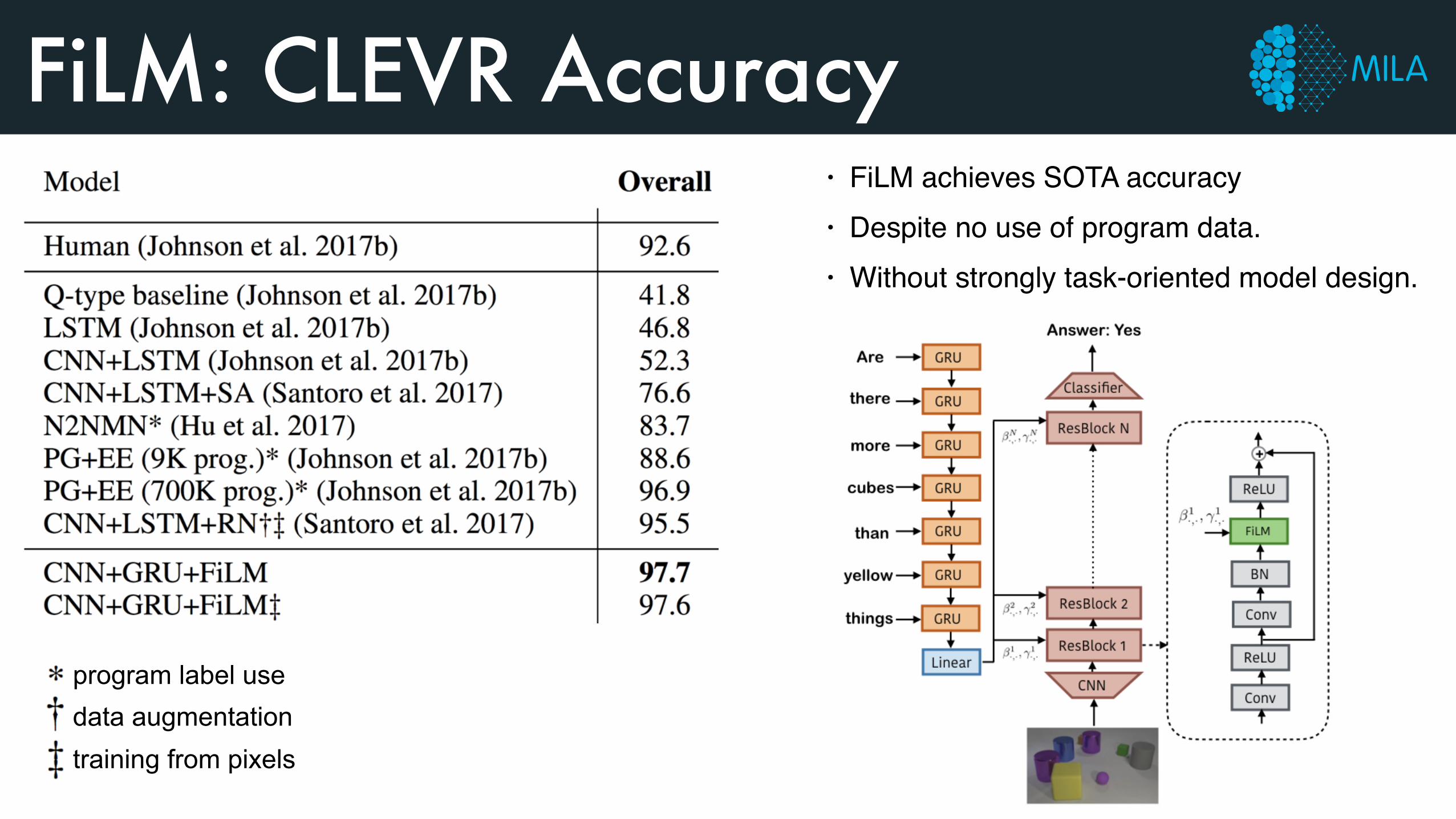
FiLM: CLEVR Accuracy• FiLM achieves SOTA accuracy• Despite no use of program data.• Without strongly task-oriented model design.
program label use data augmentation training from pixels
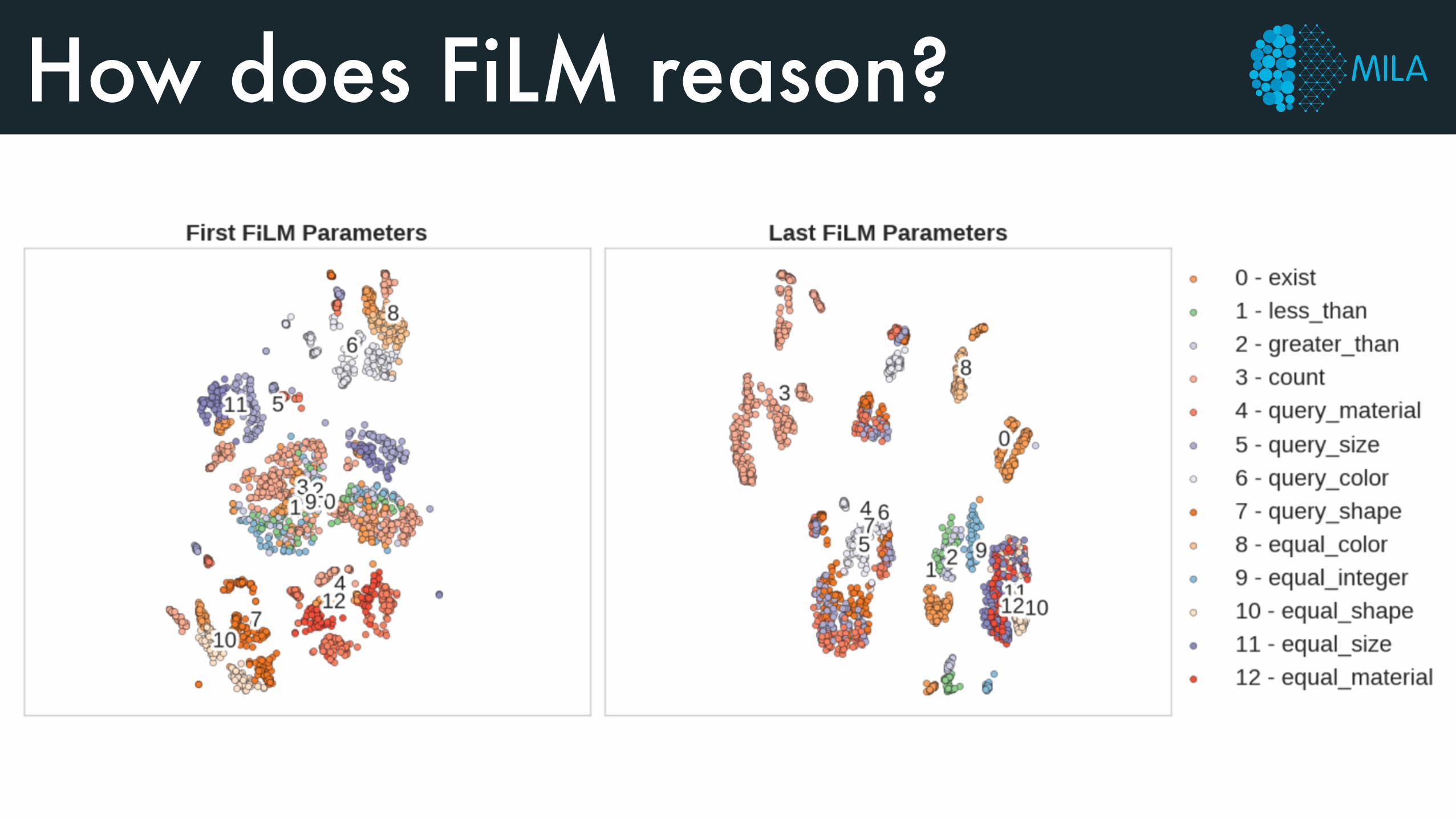
How does FiLM reason?

How does FiLM reason?

Generalizing to Human QuestionsCLEVR-Humans Task:• Human-posed questions
- Free-form - More complex - New vocab (underlined)
• Small: 18K training samples

FiLM for speech recognition
Taesup Kim, Inchul Song, Yoshua Bengio. Interspeech 2017. Dynamic Layer Normalization for Adaptive Neural Acoustic Modeling in Speech Recognition.
• Uses a FiLM-like architectural feature to adapt a neural acoustic model to individual speakers.
• Unlike our use of FiLM that modulates a processing pipeline using side information, they use input-modulation.

Summary• Char2Wav is a our first attempt as an end-to-end speech synthesis,
it currently relies on prior linguistic information.
• Current performance is limited by the challenges of training with nonaligned text and speech.
• Overcoming long-range dependencies in mapping from text to speech is an ongoing challenge for us.
• Innovations such as cycleGAN might point to promising solutions.
• Recent architectural innovations might show a promising path to either cross-modal or perhaps speaker information into the speech synthesis pipeline.





























