Embed Size (px)
Citation preview

Bayesian Nonparametric Motor-skill Representationsfor Efficient Learning of Robotic Clothing Assistance
Workshop on Practical Bayesian Nonparametrics, NIPS 2016
Nishanth Koganti1,2, Tomoya Tamei1, Kazushi Ikeda1, Tomohiro Shibata2
1Nara Institute of Science and Technology, Ikoma, Japan2Kyushu Institute of Technology, Kitakyushu, Japan
February 11, 2017
0 / 15
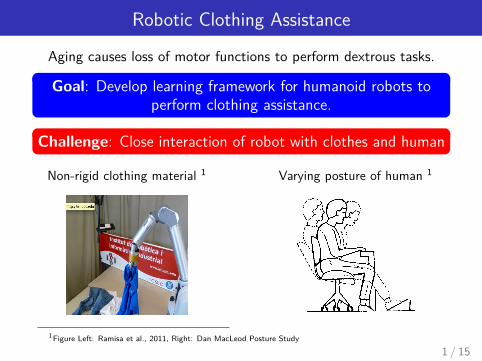
Robotic Clothing Assistance
Aging causes loss of motor functions to perform dextrous tasks.
Goal: Develop learning framework for humanoid robots toperform clothing assistance.
Challenge: Close interaction of robot with clothes and human
Non-rigid clothing material 1 Varying posture of human 1
1Figure Left: Ramisa et al., 2011, Right: Dan MacLeod Posture Study
1 / 15
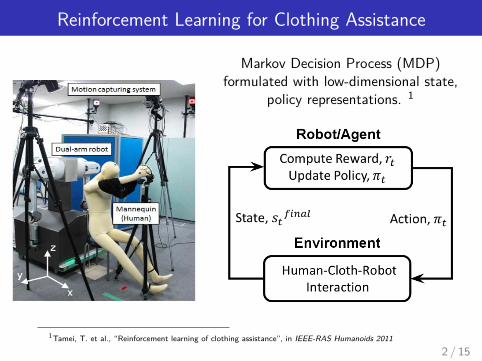
Reinforcement Learning for Clothing Assistance
Markov Decision Process (MDP)formulated with low-dimensional state,
policy representations. 1
1Tamei, T. et al., “Reinforcement learning of clothing assistance”, in IEEE-RAS Humanoids 2011
2 / 15

Clothing Assistance Framework 1: Outline
1Tamei, T. et al., “Reinforcement learning of clothing assistance”, in IEEE-RAS Humanoids 2011
2 / 15
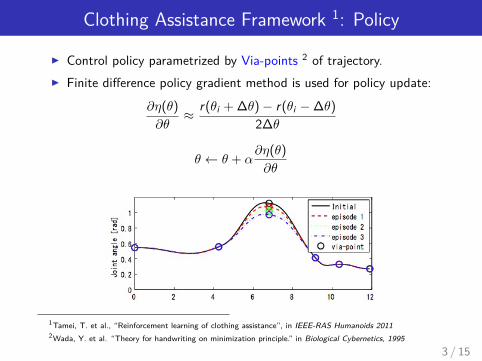
Clothing Assistance Framework 1: Policy
I Control policy parametrized by Via-points 2 of trajectory.I Finite difference policy gradient method is used for policy update:
∂η(θ)
∂θ≈ r(θi + ∆θ)− r(θi −∆θ)
2∆θ
θ ← θ + α∂η(θ)
∂θ
1Tamei, T. et al., “Reinforcement learning of clothing assistance”, in IEEE-RAS Humanoids 20112Wada, Y. et al. “Theory for handwriting on minimization principle.” in Biological Cybernetics, 1995
3 / 15

Problem: Adaptive Learning of Clothing Skills
Design of robust motor-skills learning framework is crucial forreal-world implementation on low-cost robots.
I Tight coupling with cloth and close proximity to Human.I Optimal policy varies with initial conditions.
Non-rigid clothing material Varying posture of human
1Figure Left: Ramisa et al., 2011, Right: Dan MacLeod Posture Study
4 / 15
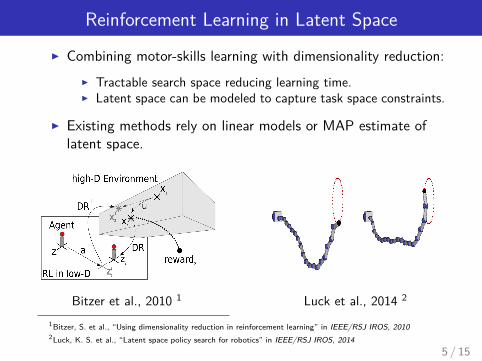
Reinforcement Learning in Latent Space
I Combining motor-skills learning with dimensionality reduction:I Tractable search space reducing learning time.I Latent space can be modeled to capture task space constraints.
I Existing methods rely on linear models or MAP estimate oflatent space.
Bitzer et al., 2010 1 Luck et al., 2014 2
1Bitzer, S. et al., “Using dimensionality reduction in reinforcement learning” in IEEE/RSJ IROS, 20102Luck, K. S. et al., “Latent space policy search for robotics” in IEEE/RSJ IROS, 2014
5 / 15

Motor-skill Learning in Latent Spaces
Use Bayesian nonparametric nonlinear dimensionality reduction forefficient learning of clothing skills 1.
1Nishanth, K. et al., “Bayesian Nonparametric Motor-skill Representations for Efficient Learning of ClothingAssistance” in Workshop on Practical Bayesian Nonparametrics, NIPS, 2016
6 / 15
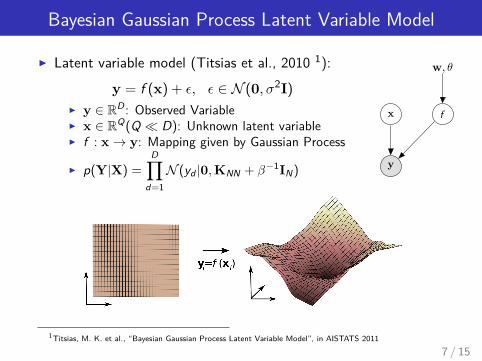
Bayesian Gaussian Process Latent Variable Model
I Latent variable model (Titsias et al., 2010 1):
y = f (x) + ε, ε ∈ N (0, σ2I)
I y ∈ RD : Observed VariableI x ∈ RQ(Q � D): Unknown latent variableI f : x→ y: Mapping given by Gaussian Process
I p(Y|X) =D∏
d=1N (yd |0,KNN + β−1IN)
x f
w, θ
y
1Titsias, M. K. et al., “Bayesian Gaussian Process Latent Variable Model”, in AISTATS 2011
7 / 15

BGPLVM: Manifold Learning
I Bayesian Inference: Posterior distribution on the latentspace.
p(Y) =
∫X
p(Y|X)p(X)dX
I Marginalization made tractable using variational inference:
q(X) =N∏
n=1N (xn|µn,Sn)
log(p(Y)) ≥∫
q(X)p(Y|X)dX−∫
q(X) log q(X)
p(X)dX
I Automatic dimensionality reduction possible using ARD kernel:
k(x , x ′) = σ2f exp
−12
Q∑q=1
wq(xq − x ′q)2
1Titsias, M. K. et al., “Bayesian Gaussian Process Latent Variable Model”, in AISTATS 2011
8 / 15
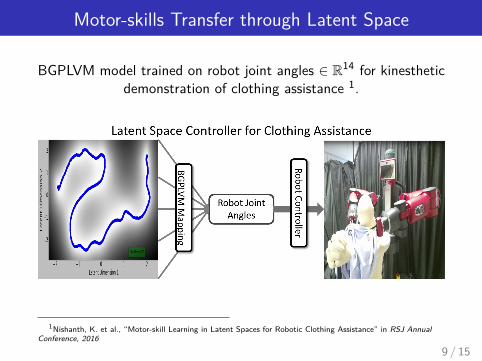
Motor-skills Transfer through Latent Space
BGPLVM model trained on robot joint angles ∈ R14 for kinestheticdemonstration of clothing assistance 1.
1Nishanth, K. et al., “Motor-skill Learning in Latent Spaces for Robotic Clothing Assistance” in RSJ AnnualConference, 2016
9 / 15
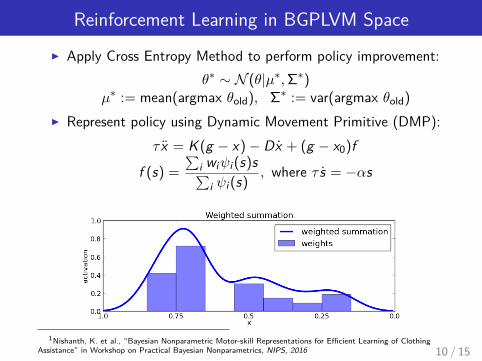
Reinforcement Learning in BGPLVM Space
I Apply Cross Entropy Method to perform policy improvement:θ∗ ∼ N (θ|µ∗,Σ∗)
µ∗ := mean(argmax θold), Σ∗ := var(argmax θold)
I Represent policy using Dynamic Movement Primitive (DMP):τ x = K (g − x)− Dx + (g − x0)f
f (s) =
∑i wiψi (s)s∑
i ψi (s), where τ s = −αs
1Nishanth, K. et al., “Bayesian Nonparametric Motor-skill Representations for Efficient Learning of ClothingAssistance” in Workshop on Practical Bayesian Nonparametrics, NIPS, 2016 10 / 15
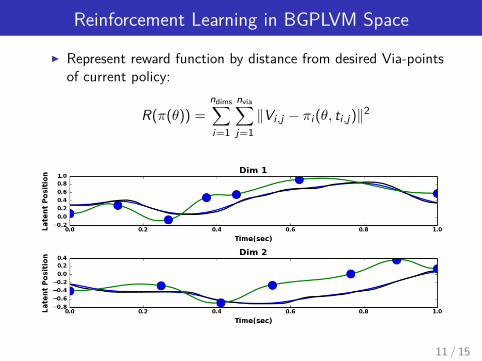
Reinforcement Learning in BGPLVM Space
I Represent reward function by distance from desired Via-pointsof current policy:
R(π(θ)) =ndims∑i=1
nvia∑j=1‖Vi ,j − πi (θ, ti ,j)‖2
11 / 15

Latent Space Controller for Clothing Tasks 1
1Nishanth, K. et al., “Motor-skill Learning in Latent Spaces for Robotic Clothing Assistance” in RSJ AnnualConference, 2016
12 / 15
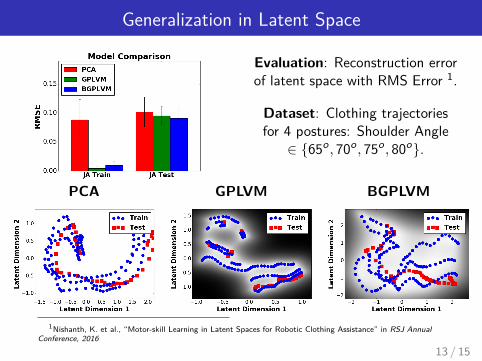
Generalization in Latent Space
Evaluation: Reconstruction errorof latent space with RMS Error 1.
Dataset: Clothing trajectoriesfor 4 postures: Shoulder Angle∈ {65o, 70o, 75o, 80o}.
PCA GPLVM BGPLVM
1Nishanth, K. et al., “Motor-skill Learning in Latent Spaces for Robotic Clothing Assistance” in RSJ AnnualConference, 2016
13 / 15
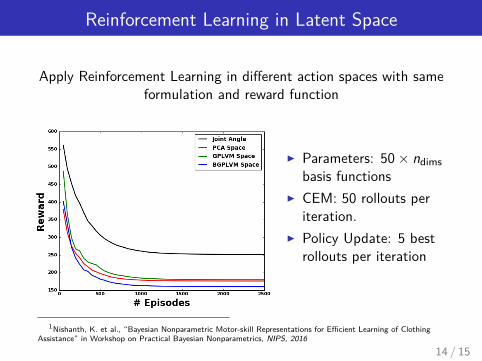
Reinforcement Learning in Latent Space
Apply Reinforcement Learning in different action spaces with sameformulation and reward function
I Parameters: 50× ndimsbasis functions
I CEM: 50 rollouts periteration.
I Policy Update: 5 bestrollouts per iteration
1Nishanth, K. et al., “Bayesian Nonparametric Motor-skill Representations for Efficient Learning of ClothingAssistance” in Workshop on Practical Bayesian Nonparametrics, NIPS, 2016
14 / 15
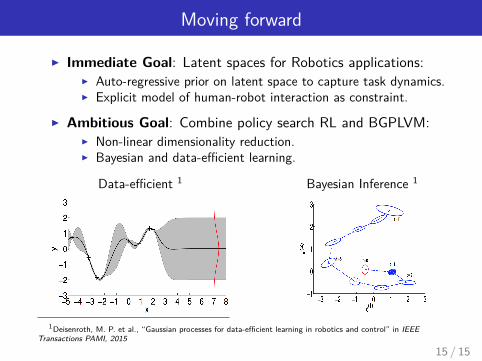
Moving forward
I Immediate Goal: Latent spaces for Robotics applications:I Auto-regressive prior on latent space to capture task dynamics.I Explicit model of human-robot interaction as constraint.
I Ambitious Goal: Combine policy search RL and BGPLVM:I Non-linear dimensionality reduction.I Bayesian and data-efficient learning.
Data-efficient 1 Bayesian Inference 1
1Deisenroth, M. P. et al., “Gaussian processes for data-efficient learning in robotics and control” in IEEETransactions PAMI, 2015
15 / 15

Appendix
15 / 15

Topology Coordinates
I To approximate Markov Decision Process, the relationship betweencloth and subject needs to be observed as much as possible.
I Low dimensional representations need to be used for a fast learningtime.
I Topological Coordinates introduced to address both requirements.Concept proposed by Edmond et. al(2009) 1.
Given 2 line segments, the amount of twist(writhe) between them isgiven by the Guassian Linking Integral(GLI):
w = GLI(γ1, γ2) =1
4π
∫γ1
∫γ2
dγ1 × dγ2 · (γ1 − γ2)
‖γ1 − γ2‖3 (1)
1Motion Synthesis using Topology Coordinates, Edmond et. al., Eurographics 2009
15 / 15
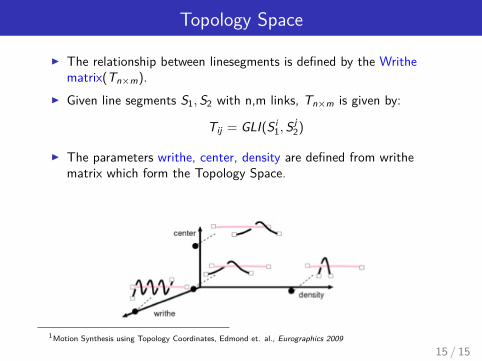
Topology Space
I The relationship between linesegments is defined by the Writhematrix(Tn×m).
I Given line segments S1,S2 with n,m links, Tn×m is given by:
Tij = GLI(S i1,S
j2)
I The parameters writhe, center, density are defined from writhematrix which form the Topology Space.
1Motion Synthesis using Topology Coordinates, Edmond et. al., Eurographics 2009
15 / 15

Clothing Assistance Framework 1: State and Reward
I Low-dimensional representation using Topology Coordinates 2.I Reward given by distance between final state and target state:
ri = −‖stargeti − si‖ (i = 1, 2, 3), r(s) =
3∑i=1
ri − µiσi
1Tamei, T. et al., “Reinforcement learning of clothing assistance”, in IEEE-RAS Humanoids 20112Ho, E. S., et al., “Character synthesis by topology coordinates”, in Computer Graphics Forum 2009
15 / 15

Combining DR and RL
I Policy representation:
a = W(ZT Φ) + MΦ + EΦ
I Expectation Step: Posterior distribution over Latent Variables
pθold (ZTΦ|a) = N (CWT(a −MΦ),Cσ2tr(ΦΦT)),
C = (σ2I + WTW)
I Maximization: Compute gradients with respect to Policyparameters
∂lnp(a)Qtπ
∂M ,∂lnp(a)Qt
π
∂W ,∂lnp(a)Qt
π
∂σ2
1Luck, K. S. et al., “Latent space policy search for robotics” in IEEE/RSJ IROS, 2014
15 / 15
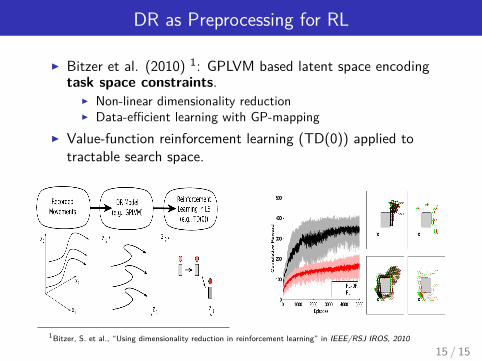
DR as Preprocessing for RL
I Bitzer et al. (2010) 1: GPLVM based latent space encodingtask space constraints.
I Non-linear dimensionality reductionI Data-efficient learning with GP-mapping
I Value-function reinforcement learning (TD(0)) applied totractable search space.
1Bitzer, S. et al., “Using dimensionality reduction in reinforcement learning” in IEEE/RSJ IROS, 2010
15 / 15
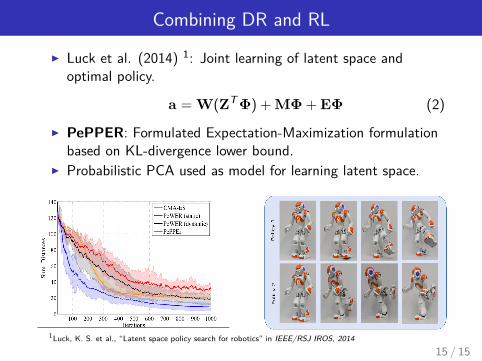
Combining DR and RL
I Luck et al. (2014) 1: Joint learning of latent space andoptimal policy.
a = W(ZT Φ) + MΦ + EΦ (2)
I PePPER: Formulated Expectation-Maximization formulationbased on KL-divergence lower bound.
I Probabilistic PCA used as model for learning latent space.
1Luck, K. S. et al., “Latent space policy search for robotics” in IEEE/RSJ IROS, 2014
15 / 15
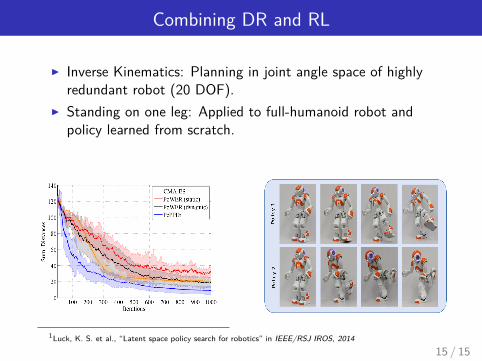
Combining DR and RL
I Inverse Kinematics: Planning in joint angle space of highlyredundant robot (20 DOF).
I Standing on one leg: Applied to full-humanoid robot andpolicy learned from scratch.
1Luck, K. S. et al., “Latent space policy search for robotics” in IEEE/RSJ IROS, 2014
15 / 15

DiscussionI Robotic Clothing Assistance involves several problems.I Propose use of DR with RL for efficient motor-skills learning.
Future WorkI Implement Latent Space RL framework for Clothing
Assistance framework.I Combine real-time state estimation with motor-skills learning
framework.
15 / 15

References
I Tamei, Tomoya, et al. “Reinforcement learning of clothing assistance with adual-arm robot.” Humanoid Robots (Humanoids), 2011 11th IEEE-RASInternational Conference on. IEEE, 2011.
I Ho, Edmond SL, and Taku Komura. “Character motion synthesis by topologycoordinates.” Computer Graphics Forum. Vol. 28. No. 2. Blackwell PublishingLtd, 2009.
I Pohl, William F. “The self-linking number of a closed space curve(Gauss integralformula treated for disjoint closed space curves linking number).” Journal ofMathematics and Mechanics 17 (1968): 975-985.
I Miyamoto, Hiroyuki, et al. “A kendama learning robot based on bi-directionaltheory.” Neural networks 9.8 (1996): 1281-1302.
I Koganti, Nishanth, et al. “Cloth dynamics modeling in latent spaces and itsapplication to robotic clothing assistance.” Intelligent Robots and Systems(IROS), 2015 IEEE/RSJ International Conference on. IEEE, 2015.
I Deisenroth, Marc Peter, Dieter Fox, and Carl Edward Rasmussen. “Gaussianprocesses for data-efficient learning in robotics and control.” Pattern Analysisand Machine Intelligence, IEEE Transactions on 37.2 (2015): 408-423.
I Levine, Sergey, et al. “End-to-end training of deep visuomotor policies.” arXivpreprint arXiv:1504.00702 (2015).
15 / 15





























