Embed Size (px)
Citation preview

Paraphrasing 4 Microblog Normalization長岡技術科学大学 自然言語処理研究室
高橋寛治Ling, W., Dyer, C., Black, A. W., & Trancoso, I. (2013).Paraphrasing 4 Microblog Normalization. Proceedings of the2013 Conference on Empirical Methods in Natural LanguageProcessing, (October), 73–84.
文献紹介 2016年7月8日

概要•マイクロブログのテキストは崩れており解析しずらい•対訳コーパスから換言対を取得する要領で、表記・語彙を正規化する規則を獲得•英中翻訳において、正規化した英語により翻訳の向上
Paraphrasing4MicroblogNormalization2016/7/8

はじめに•Twitter, Weibo, Facebookなどマイクロブログを対象とした研究が増えている•既存の解析器は崩れた言語に対応しない•社会言語学など表記に着目する研究を行わない限りテキスト正規化は必須•対訳コーパスからのピポッド法による換言対抽出を利用する
Paraphrasing4MicroblogNormalization2016/7/8

なぜ正規化に取り組むか?
•見ての通り、砕けた文を取り扱えない•略語
Øyea, inkw -> yes, I knowØimma -> I am going to (伊马(yi ma)と認識される)
Paraphrasing4MicroblogNormalization2016/7/8

アイデア•教師有り学習問題として扱いたい•しかし手製のコーパス作成は大変だから自動で
•μtopia parallel corpus(対訳が含まれる投稿から作成したコーパス)を翻訳することで、正規化候補を獲得
Paraphrasing4MicroblogNormalization2016/7/8

アイデア
Paraphrasing4MicroblogNormalization
Microtopiaコーパス
機械翻訳の結果
2016/7/8

機械翻訳の傾向•機械翻訳の傾向
Ø<e, f>: eが異表記を含んでいても、fは正規形になりやすい
•表記ゆれ以外Ø言語依存Ø英語だとiknw, imma
Paraphrasing4MicroblogNormalization2016/7/8
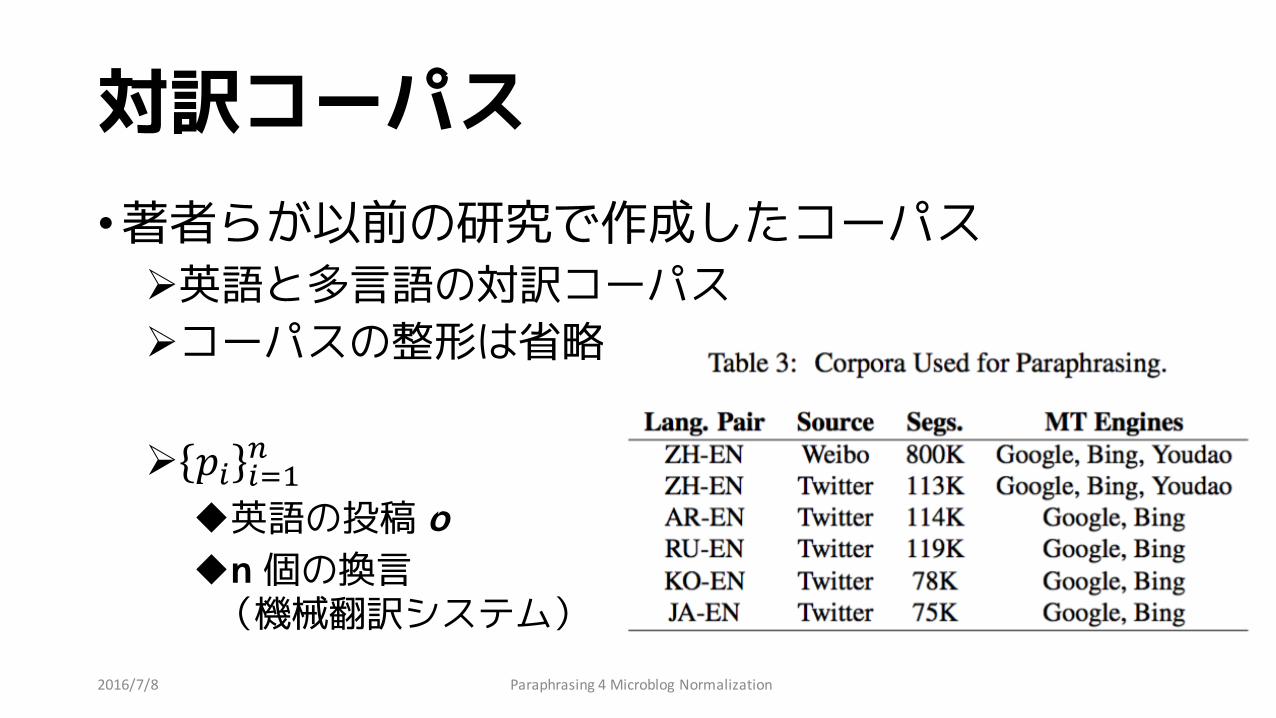
対訳コーパス•著者らが以前の研究で作成したコーパス
Ø英語と多言語の対訳コーパスØコーパスの整形は省略
Ø 𝑝" "#$%
u英語の投稿 oun 個の換言
(機械翻訳システム)Paraphrasing4MicroblogNormalization2016/7/8

正規化のモデル•文から句へ•アラインメント(Dyer et al.,2013のfast alignment)
Ø点線は翻訳、実線は正規化•句のテンプレートによる抽出
Øgo 4, go for
Paraphrasing4MicroblogNormalization2016/7/8

句の抽出
•句の素性Ø句のペア<o,n>
Ø𝑓 𝑛|𝑜 = + %,-+ -
ØC(n,o)はoが正規化された回数ØC(o)はoが抽出された句のペアに出現する回数
Paraphrasing4MicroblogNormalization2016/7/8

句から文字•cat, catt, kat, caaat•句単位で処理
Ø<start>と<end>Ø文字はスペース区切り
•ルールでもいくつか処理
Paraphrasing4MicroblogNormalization2016/7/8
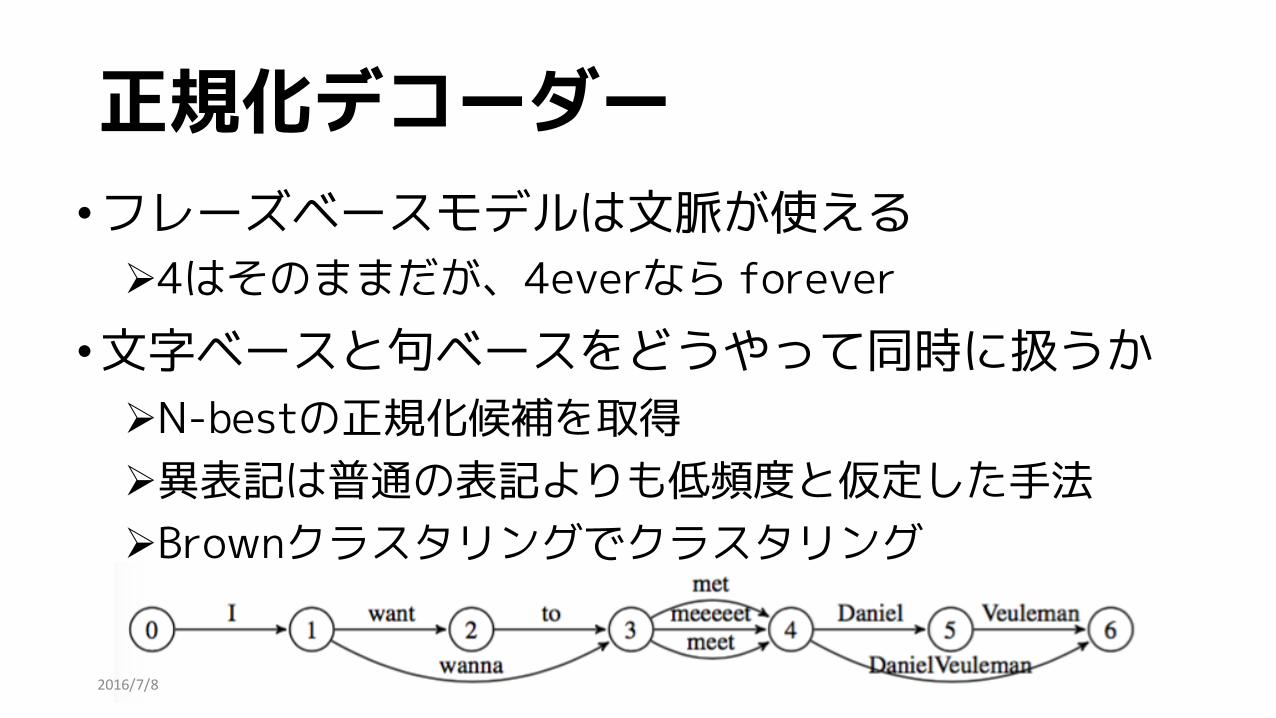
正規化デコーダー•フレーズベースモデルは文脈が使える
Ø4はそのままだが、4everなら forever•文字ベースと句ベースをどうやって同時に扱うか
ØN-bestの正規化候補を取得Ø異表記は普通の表記よりも低頻度と仮定した手法ØBrownクラスタリングでクラスタリング
Paraphrasing4MicroblogNormalization2016/7/8
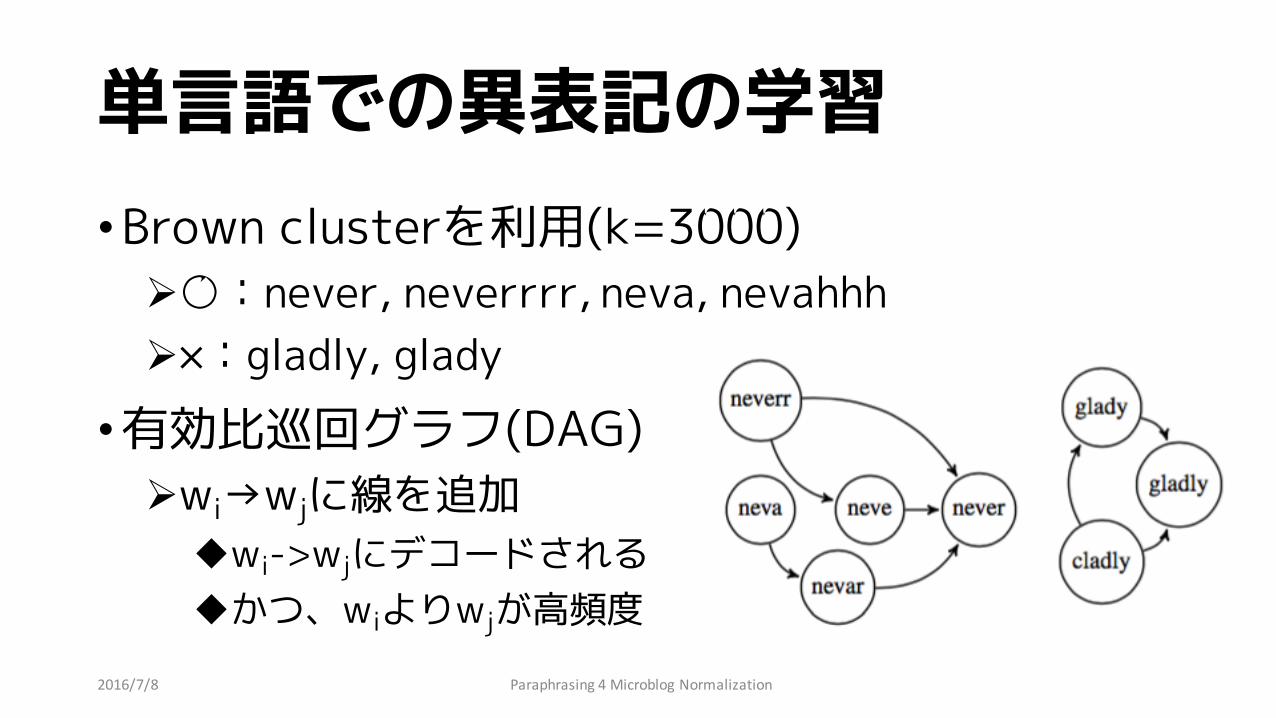
単言語での異表記の学習•Brown clusterを利用(k=3000)
Ø○:never, neverrrr, neva, nevahhhØ×:gladly, glady
•有効比巡回グラフ(DAG)Øwi→wjに線を追加
uwi->wjにデコードされるuかつ、wiよりwjが高頻度
Paraphrasing4MicroblogNormalization2016/7/8

実験•英中マイクロブログ•各正規化を比較•Mosesで訓練
Ø並び替えはMSD reordering modelØ言語モデルは5-gramØMERTでチューニング
• BLEU-4で評価Øいくつかの翻訳機でも評価
Paraphrasing4MicroblogNormalization2016/7/8
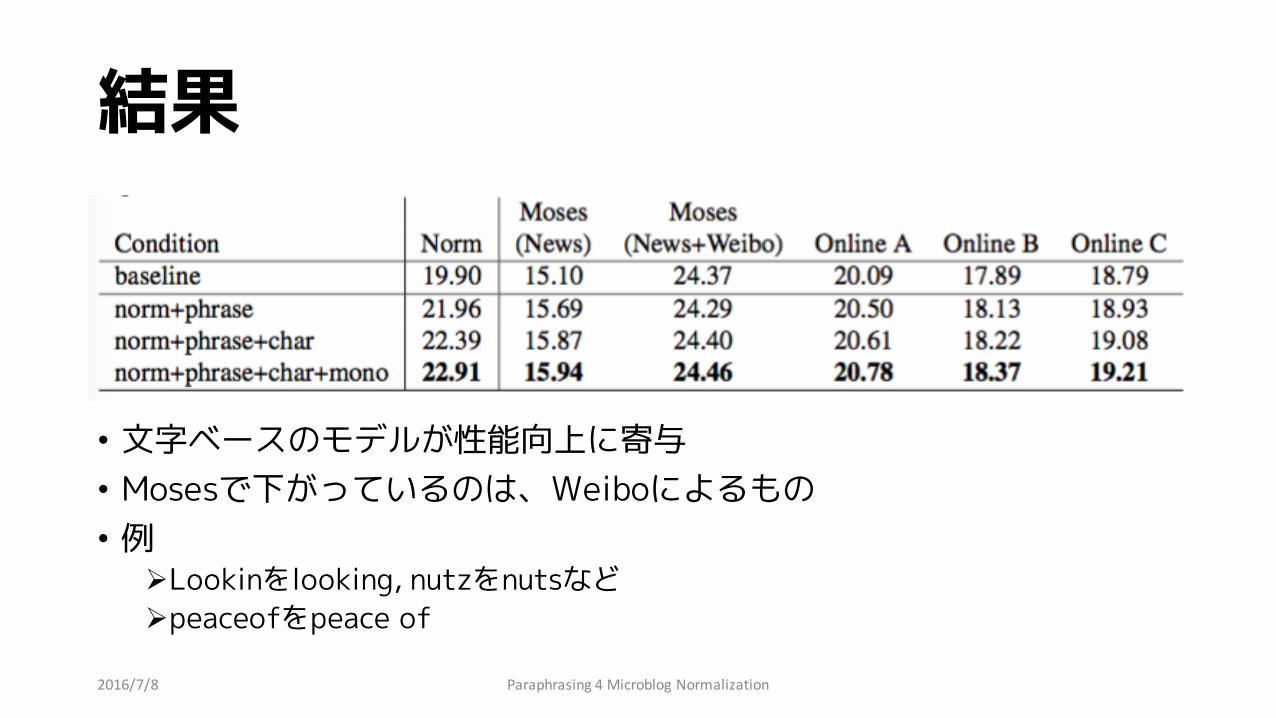
結果
• 文字ベースのモデルが性能向上に寄与• Mosesで下がっているのは、Weiboによるもの• 例
ØLookinをlooking, nutzをnutsなどØpeaceofをpeace of
Paraphrasing4MicroblogNormalization2016/7/8

まとめ•対訳コーパスを元にした換言によるマイクロブログの正規化•フレーズレベルと文字レベルでモデルを学習•結果、様々な翻訳システムで性能が向上
Paraphrasing4MicroblogNormalization2016/7/8