Embed Size (px)
Citation preview

2/74
はじめに
I このスライドの LuaLATEXのソースコードはhttps://github.com/pecorarista/documentsにあります.
I 教科書とは若干異なる表記をしている場合があります.
I 10.4.1と 10.7は間に合いませんでした.

3/74
潜在変数とパラメータ
今までモデルの中で観測値 (observed variable)と隠れ変数 (hiddenvariable)を区別してきた.これからは更に以下のような区別を導入する.
I 潜在変数 (latent variable) Z観測値集合の大きさに従って数が増える(外延的変数)例:ガウス混合モデルのインジケータ変数 zkn
I パラメータ (parameter) θ観測値集合の大きさに関わらず数が固定(内包的変数)例:ガウス混合モデルの平均 µk,精度 Λk,混合比 πk

4/74
指数型分布族
独立に同分布に従うデータの集合X := {x1, . . . , xN}とそれに対応する潜在変数の集合 Z := {z1, . . . , zN}があるとする.これらの同時分布が自然パラメータ ηを使った以下の指数型分布族で表せるとする.
p (X, Z|η) =N∏
n=1h (xn, zn) g (η) exp (η′u (xn, zn)) . (10.113)
また ηは共役事前分布
p (η|ν0, χ0) = f (ν0, χ0) g (η)ν0 exp (ν0η′χ0)
に従うものとする.

5/74
指数型分布族について復習
第 2.4節で指数型分布族とその共役事前分布について学んだ.次のような形をした指数型確率分布
p (x|η) = h (x) g (η) exp (η′u (x)) (2.194)
について
p (η|χ, ν) = f (χ, ν) g (η)ν exp (νη′χ) (2.229)
という形の共役事前分布が存在する.データ X = {x1, . . . , xn}が与えられたとき,尤度は
p (X|η) =(
N∏n=1
h (xn))
g (η)N exp(
η′N∑
n=1u (xn)
)(2.227)
となる.

6/74
指数型分布族について復習
事後分布は
p (η|X, χ, ν) ∝ p (X|η) p (η|χ, ν)
∝ g (η)ν+N exp(
η′
(N∑
n=1u (xn) + νχ
))(2.230)
と計算できる.この式から,事前分布のパラメータ ν は,有効な事前の仮想観測値の数と解釈できる.ただし,仮想観測値では,十分統計量u (x)の代わりに,χが与えられる.

7/74
指数型分布族の変分近似
指数型分布族を変分分布近似することを考える.これまでと同様に,周辺分布の対数 log p (X)を
log p (X) = L (q) + KL (q‖p) ,
L (q) =∫
q (Z, η) log(
p (X, Z|η) p (η)q (Z, η)
)(dηdZ) ,
KL (q‖p) = −∫
q (Z, η) log(
p (Z|X, η) p (η)q (Z, η)
)(dηdZ)
と分解し,Lを qについて最大化する.

8/74
KLタイバージェンスの最小化
f と gを確率密度関数とする.区間 (0,∞)において log x ≤ x− 1が成り立つ.ここで x := f/gとすると f log g − f log f ≤ g − f となる.積分の線型性と単調性から∫
X
f log gdµ−∫
X
f log fdµ ≤∫
X
gdµ−∫
X
fdµ
が成り立つ.確率密度関数の性質から∫
Xfdµ =
∫X
gdµ = 1なので∫X
f log gdµ ≤∫
X
f log fdµ
を得る.ほとんど確実に f = gのとき上式の等号が成り立つ.また等号が成り立つのはそのときに限る.

9/74
KLタイバージェンスの最小化の補足[0,∞]値M-可測関数 f について
∫X
f (x) µ (dx) = 0が成り立つならば,µ ({x ∈ X ; f (x) 6= 0}) = 0が成り立つ.
証明 En := {x ∈ X ; f (x) ≥ 1/n}とおくと∞⋃
n=1En = {x ∈ X ; f (x) > 0}
である.仮定∫
Xf (x) µ (dx) = 0と f (x) ≥ 0から,任意の nについて
0 =∫
X
f (x) µ (dx) ≥∫
En
f (x) µ (dx) ≥ 1n
µ (En) ≥ 0
となる.すなわち各 nで µ (En) = 0が成り立つ.ゆえに測度の性質から
µ
( ∞⋃n=1
En
)≤
∞∑n=1
µ (En) = 0
であることが分かる.

10/74
指数型分布族の変分近似
Lの最大化に戻る.
計算を進めるため,変分分布が潜在変数とパラメータで分けられる,すなわち q (Z, η) = q (Z) q (η)と分解できると仮定する.
L (q) =∫
q (Z, η) log (p (X, Z|η) p (η)) (dηdZ)
−∫
q (Z, η) log q (Z, η) (dηdZ)
=∫
q (Z)(∫
q (η) log p (X, Z|η) dη
)dZ
−∫
q (Z) log q (Z) dZ
−∫
q (η) (log q (η)− log p (η)) dη

11/74
指数型分布族の変分近似
したがって最適な q (Z)は
log q? (Z) =∫
q (η) log p (X, Z|η) dη + const.
= Eη [log p (X, Z|η)] + const.
=N∑
n=1(log h (xn, zn) + E [η′] u (xn, zn)) + const. (10.115)
を満たさなければならない.この式の右辺に注目すると,各 nごとに独立な項の和に分解できるので q? (Z) =
∏Nn=1 q? (zn) となる.よって指
数をとって
q? (zn) = h (xn, zn) g (E [η]) exp (E [η′] u (xn, zn)) (10.116)
を得る.ただし g (E [η])は正則化のため,指数型分布族の標準的な形に合わせて付加したものである.

12/74
指数型分布族の変分近似
次に q (η)について最大化する.Lは
L (q) =∫
q (η)(∫
q (Z) log p (X, Z|η) dZ
)dη
−∫
q (Z) log q (Z) dZ
−∫
q (η) (log q (η)− log p (η)) dη
と表せるので
log q? (η) = log p (η|ν0, χ0) + EZ [log p (X, Z|η)] + const. (10.117)= ν0 log g (η) + ν0η′χ0
+N∑
n=1(log g (η) + η′Ezn [u (xn, zn)]) + const. (10.118)
となる.

13/74
指数型分布族の変分近似
指数をとって
q? (η) = f (νN , χN ) g (η)νN exp (νN η′χN ) (10.119)
を得る.ただし,
νN = ν0 + N (10.120)
νN χN = ν0χ0 +N∑
n=1Ezn
[u (xn, zn)] (10.121)
とした.

14/74
指数型分布族の変分近似q? (zn)と q? (η)の解には相互に依存関係があるので,二段階の繰り返しで解く.
変分 Eステップ
q (zn)← h (xn, zn) g (E [η]) exp (E [η′] u (xn, zn))
q (η)← f (νN , χN ) g (η)νN exp (νN η′χN )
where
µn ← Ezn[u (xn, zn)] =
∫q (zn) u (xn, zn) dzn
νN χN ← ν0χ0 +N∑
n=1µn
変分Mステップ
η ← E [η] =∫
q (η) ηdη
15/74
局所的変分推論
10.1節や 10.2節では,事後分布の近似を直接求めた.
10.5節と 10.6節では各変数の上からあるいは下から近似を使う方法を学ぶ.
16/74
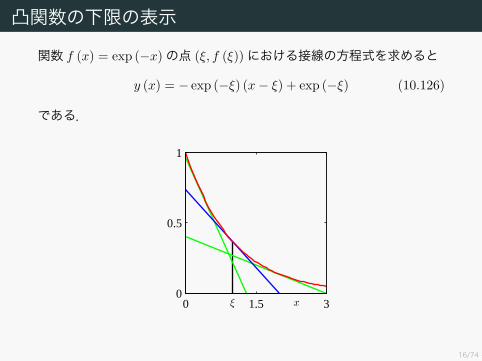
凸関数の下限の表示
関数 f (x) = exp (−x)の点 (ξ, f (ξ))における接線の方程式を求めると
y (x) = − exp (−ξ) (x− ξ) + exp (−ξ) (10.126)
である.
xξ0 1.5 30
0.5
1

17/74
凸関数の下限の表示
ここで η := − exp (−ξ)とすると ξ = − log (−η)なので
y (x, η) = ηx− η + η log (−η) (10.127)
である.凸関数の性質から,f の接線はグラフの下にくるので 1,
f (x) = maxη{ηx− η + η log (−η)} (10.128)
と表せる.
1 任意の λ ∈ (0, 1) をとると
f (λx + (1 − λ) ξ) ≤ λf (x) + (1 − λ) f (ξ)
f (λx + (1 − λ) ξ) − f (ξ)λ
≤ f (x) − f (ξ)
が成り立つ.よって λ → +0 として
∇f (x) · (x − ξ) ≤ f (x) − f (ξ)
を得る.
18/74
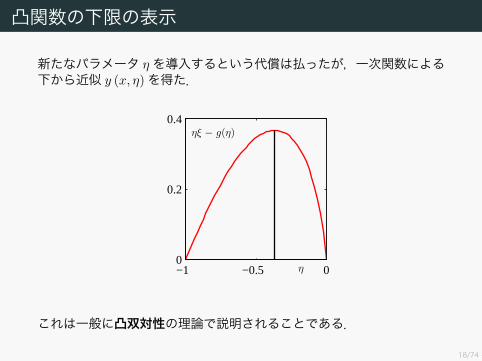
凸関数の下限の表示
新たなパラメータ ηを導入するという代償は払ったが,一次関数による下から近似 y (x, η)を得た.
η
ηξ − g(η)
−1 −0.5 00
0.2
0.4
これは一般に凸双対性の理論で説明されることである.

19/74
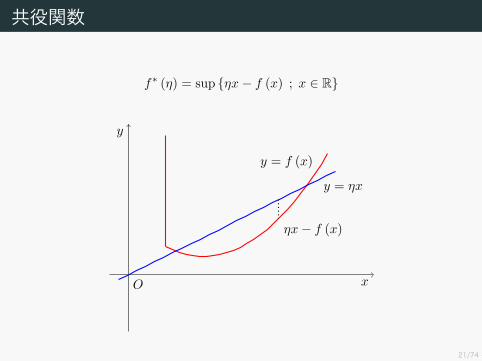
共役関数
X を Banach空間とし,X∗ をX の共役空間 2 とする.このとき関数f : X → [−∞, +∞]に対し,f∗ : X∗ → [−∞, +∞]を
f∗ (φ) := sup {φ (x)− f (x) ; x ∈ X}
で定め,f の共役関数 (conjugate function)や Fenchel双対(Fenchel conjugate)3 などと呼ばれる.
また f の双共役関数 (biconjugate function) f∗∗ : X → [−∞, +∞]を
f∗∗ (x) := sup {φ(x)− f∗ (φ) ; φ ∈ X∗}
と呼ぶ.
2 X 上の有界線型汎関数全体が作る線型空間.3 Werner Fenchel /(de) ˈvɛʀnɐ ˈfɛnçəl/ (1905 - 1988)

20/74
共役関数
共役関数は非凸関数についても考えることができるが,多くの場合はproper4 な凸関数の共役関数を考える.
凹関数については共役関数の定義において supを inf に置き換えた凹共役関数 (concave conjugate function)を考える.
f∗ (φ) := inf {φ (x)− f (x) ; x ∈ X} .
凹双共役関数 (concave biconjugate function)も同様に考えられる.
f∗∗ (x) := inf {φ (x)− f∗ (φ) ; φ ∈ X∗} .
4 関数 f : X → ( −∞, ∞] が proper であるとは dom f = {x ∈ X ; f (x) < ∞} が空でないということである.つまり∞ にべったり張り付かないということ.
21/74
共役関数
f∗ (η) = sup {ηx− f (x) ; x ∈ R}
O x
y
y = f (x)
y = ηx
ηx− f (x)
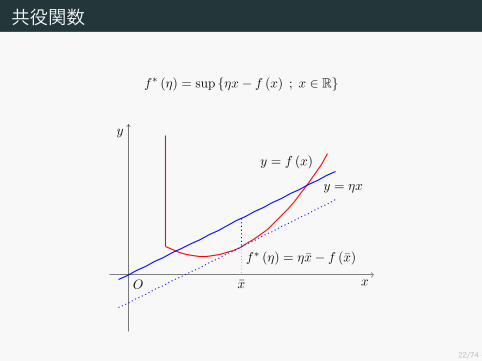
22/74
共役関数
f∗ (η) = sup {ηx− f (x) ; x ∈ R}
O x
y
y = f (x)
y = ηx
f∗ (η) = ηx− f (x)
x
23/74
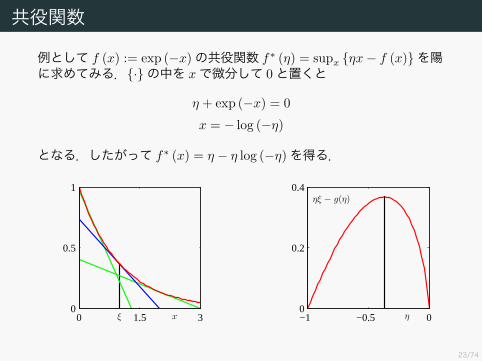
共役関数
例として f (x) := exp (−x)の共役関数 f∗ (η) = supx {ηx− f (x)}を陽に求めてみる.{·}の中を xで微分して 0と置くと
η + exp (−x) = 0x = − log (−η)
となる.したがって f∗ (x) = η − η log (−η)を得る.
xξ0 1.5 30
0.5
1
η
ηξ − g(η)
−1 −0.5 00
0.2
0.4

24/74
共役関数次に双共役関数 f∗∗ (x) = supη {ηx− f∗ (η)}を陽に求めてみる.{·}の中を ηで微分して 0と置くと
d
dη(ηx− η + η log (−η)) = 0
x− 1 + log (−η) + 1 = 0η = − exp (−x)
となる.ゆえに
f∗∗ (x) = − exp (−x) x + exp (−x) + exp (−x) (−x)= exp (−x)= f (x)
を得る.つまり f = f∗∗ が成り立つ.これは Fenchel変換によって情報が失われていないということである.
一般に f を properで下半連続な凸関数とすると f = f∗∗ が成り立つ.

25/74
ロジスティックシグモイド関数
次にパターン認識でよく現れるロジスティックシグモイドの共役関数を求める.
σ (x) = 11 + exp (−x) (10.134)
これは凸でも凹でもないが,対数をとると凹になる.u(x) := log σ (x)とする.
u (x) = − log(1 + e−x
)d
dxu (x) = − −e−x
1 + e−x= 1
ex + 1 > 0
d2
dx2 u (x) = − ex
(ex + 1)2 < 0
26/74
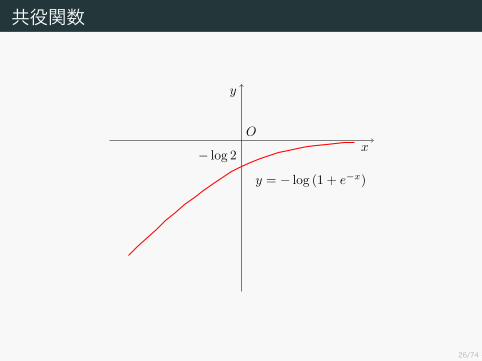
共役関数
Ox
y
y = − log (1 + e−x)
− log 2

27/74
ロジスティックシグモイド関数の上からの評価
関数 uは凹なので,凹共役 u∗ (η) = infx {ηx− u (x)}を考える.{·}の中を xで微分して 0と置くと
η = 1ex + 1
x = log (1− η)− log η
となる.したがって
u∗ (η) = η log (1− η)− η log η + log(
1 + η
1− η
)= −η log η − (1− η) log (1− η)
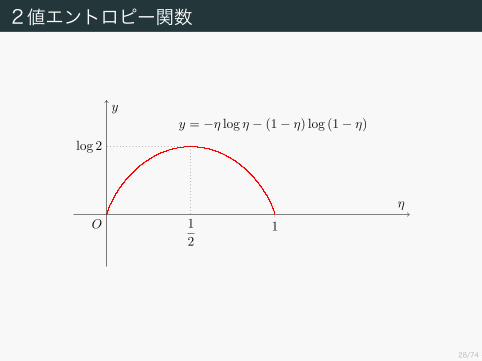
を得る.これは 2値エントロピー関数になっている.
28/74
2値エントロピー関数
1O 12
log 2y = −η log η − (1− η) log (1− η)
η
y

29/74
ロジスティックシグモイド関数の上からの評価
凹共役 u∗ (η)を使えば u (x) = log σ (x)を
log σ (x) ≤ ηx− u∗ (η) (10.136)
と上から抑えられる.指数をとって
σ (x) ≤ exp (ηx− u∗ (η)) (10.136)
となる.
30/74
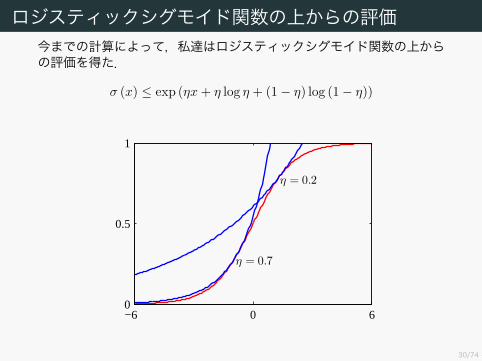
ロジスティックシグモイド関数の上からの評価今までの計算によって,私達はロジスティックシグモイド関数の上からの評価を得た.
σ (x) ≤ exp (ηx + η log η + (1− η) log (1− η))
η = 0.2
η = 0.7
−6 0 60
0.5
1

31/74
ロジスティックシグモイド関数の下からの評価
下からの評価を得るため,まず uを少し変形しておく.
u (x) = − log(1 + e−x
)= − log
(e−x/2
(ex/2 + e−x/2
))= x
2 − log(
2 cosh x
2
)右辺の第 2項に着目する.ここで v := x2,f (v) := − log (2 cosh (
√v/2))と置いて解析を進める.

32/74
ロジスティックシグモイド関数の下からの評価
いま定義した f (v) = − log (2 cosh (√
v/2))は凸関数である.
df
dv(v) = − 2 sinh (
√v/2)
2 cosh (√
v/2)1
4√
v
= − 14√
vtanh
√v
2
d2f
dv2 (v) = − 18v√
vtanh
√v
2 + 14√
v
1cosh2 (
√v/2)
14√
v
= 116v√
v cosh2 (√
v/2)
(2 sinh
√v
2 cosh√
v
2 −√
v
)= sinh
√v −√
v
16v√
v cosh2 (√
v/2)≥ 0
33/74
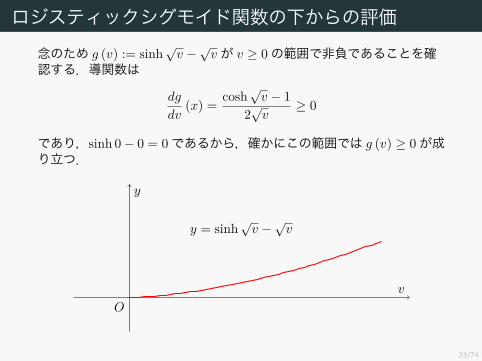
ロジスティックシグモイド関数の下からの評価念のため g (v) := sinh
√v −√
vが v ≥ 0の範囲で非負であることを確認する.導関数は
dg
dv(x) = cosh
√v − 1
2√
v≥ 0
であり,sinh 0− 0 = 0であるから,確かにこの範囲では g (v) ≥ 0が成り立つ.
O
y = sinh√
v −√
v
v
y

34/74
ロジスティックシグモイド関数の下からの評価凸関数の性質から接線がグラフの下にくるので
f (v) ≥ f(ξ2)+ df
dv
(ξ2) (v − ξ2)
f(x2)− f
(ξ2) ≥ − 1
4ξtanh ξ
2(x2 − ξ2)
が成り立つ.教科書に合わせて λ (ξ) := (4ξ)−1 tanh (ξ/2)と置く.上式を使うと
log σ (x)− log σ (ξ) = x
2 + f(x2)− (ξ
2 + f(ξ2))
≥ x− ξ
2 − λ (ξ)(x2 − ξ2)
であり,両辺の指数をとって以下を得る.
σ (x) ≥ σ (ξ) exp(
x− ξ
2 − λ (ξ)(x2 − ξ2)) . (10.144)
35/74
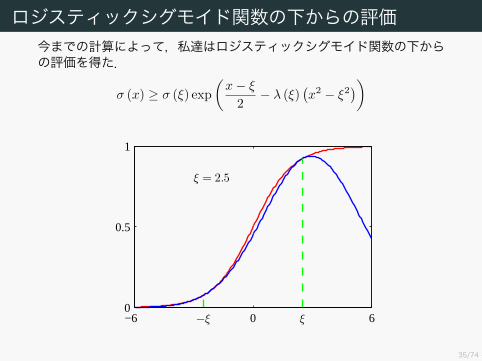
ロジスティックシグモイド関数の下からの評価今までの計算によって,私達はロジスティックシグモイド関数の下からの評価を得た.
σ (x) ≥ σ (ξ) exp(
x− ξ
2 − λ (ξ)(x2 − ξ2))
ξ = 2.5
−ξ ξ−6 0 60
0.5
1
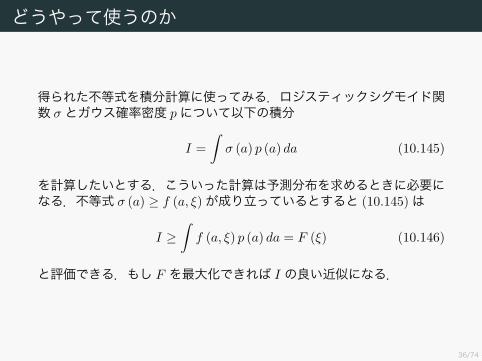
36/74
どうやって使うのか
得られた不等式を積分計算に使ってみる.ロジスティックシグモイド関数 σとガウス確率密度 pについて以下の積分
I =∫
σ (a) p (a) da (10.145)
を計算したいとする.こういった計算は予測分布を求めるときに必要になる.不等式 σ (a) ≥ f (a, ξ)が成り立っているとすると (10.145)は
I ≥∫
f (a, ξ) p (a) da = F (ξ) (10.146)
と評価できる.もし F を最大化できれば I の良い近似になる.

37/74
変分事後分布
ロジスティック回帰モデルに変分近似を使ってみる.目的変数はt ∈ {0, 1}とし,表記を簡単にするため a = w′φとする.このとき尤度は
p (t|w) = σ (a)t (1− σ (a))1−t
=(
11 + e−a
)t(1− 1
1 + e−a
)1−t
=(
11+e−a
1− 11+e−a
)t(1− 1
1 + e−a
)
= eat e−a
1 + e−a= eatσ (−a) (10.148)
となる.

38/74
変分事後分布
前の節で計算した下限を使って評価する.(10.144)により
p (t|w) = eatσ (−a)
≥ eatσ (ξ) exp(−a + ξ
2 − λ (ξ)(a2 − ξ2)) (10.151)
となる.

39/74
変分事後分布
したがって観測値の系列 tが得られたとき
p (t, w) = p (t|w) p (w)
= p (w)N∏
n=1p (tn|w)
≥ p (w) h (w, ξ) , (10.152)
ただし
h (w, ξ) :=N∏
n=1σ (ξn) exp
(w′φntn −
w′φn + ξn
2
− λ (ξn)(
(w′φn)2 − ξ2n
))(10.153)
となる.

40/74
変分事後分布
(10.153)の対数をとると
log (p (t|w) p (w)) ≥ log p (w) + log h (w, ξ)
= log p (w) +N∑
n=1
(log σ (ξn) + w′φntn
−w′φn + ξn
2 − λ (ξn)(
(w′φn)2 − ξ2n
))(10.154)
となる.右辺に事前分布 p (w) = N (w|m0, S0)を代入すると
− (w −m0)′S−1
0 (w −m0)
+N∑
n=1
(w′φn
(tn −
12
)− λ (ξn) w′ (φnφ′
n) w
)+ const. (10.155)
となる.

41/74
変分事後分布
(10.155)の形から,変分事後分布 q (w)5 は適当なガウス分布N (w|mN , SN )で表せることが分かる.2次の項に着目すると精度は
S−1N = S−1
0 + 2N∑
n=1λ (ξn) φnφ′
n
と分かる.1次の項に着目すると平均mN は
mN = SN
(S−1
0 m0 +N∑
n=1
(tn −
12
)φn
)
である.つまり q (w) = N (w|mN , SN )である.
こうして私達はラプラス近似のように事後分布のガウス分布近似を得た.今回はさらに変分パラメータ {ξn}nが加わって柔軟になっているため,より高い精度が期待できる.
5 q (w)は同時確率 p (t, w) = p (t|w) p (w)を近似するもので,結果として事後分布 p (w|t)を近似するものになるのだった.

42/74
変分パラメータの最適化
変分事後分布が q (w) = N (w|mN , SN )となることは分かった.平均mN と分散 SN はどちらも ξに依存しているので,ξの最適化を考えなければならない.いつも通り周辺尤度の下からの近似を考えよう.
log p (t) = log∫
p (t|w) p (w) dw
≥ log∫
h (w, ξ) p (w) dw = L (ξ) (10.159)
この後の方法には二通りある.1. wを潜在変数とみなして EMアルゴリズムを使う.2. wに対する積分を計算し,ξを直接最大化する.
まずは一つ目の EMアルゴリズムを使う方法から見ていく.

43/74
変分パラメータの最適化(EMアルゴリズム)
Mステップの導出については次ページ以降で説明する.
Eステップ
q (w)← N (w|mN , SN )where
S−1N ← S−1
0 + 2N∑
n=1λ (ξn) φnφ′
n
mN ← SN
(S−1
0 m0 +N∑
n=1
(tn −
12
)φn
)
Mステップ
ξ2n ← φ′
nE [ww′] φn = φ′n (SN + mN m′
N ) φn

44/74
変分パラメータの最適化(EMアルゴリズム)
Mステップでは ξの新しい値を求めるため,Eステップで計算した事後分布 q (w)を使って
Q(ξ, ξold) := E [log (h (w, ξ) p (w))]
=∫
q (w) log (h (w, ξ) p (w)) dw
を計算する.ξn に依存する項のみに着目すると
Q(ξ, ξold) =
N∑n=1
(log σ (ξn)− ξn
2 − λ (ξn)(φ′
nE [ww′] φn − ξ2n
))+ const. (10.161)
となる.

45/74
変分パラメータの最適化(EMアルゴリズム)
以下を計算する.
d
dξn
(log σ (ξn)− ξn
2 − λ (ξn)(φ′
nE [ww′] φn − ξ2n
)).
ロジスティックシグモイド関数の微分の公式
dσ
da= σ (1− σ) (4.88)
を使うと
d
dξlog (σ (ξ)) = σ (ξ) (1− σ (ξ))
σ (ξ) = 1− σ (ξ)
が成り立つ.

46/74
変分パラメータの最適化(EMアルゴリズム)
また λ (ξ)については以下のように変形できる.
λ (ξ) = 14ξ
tanh ξ
2
= 14ξ
eξ/2 − e−ξ/2
eξ/2 + e−ξ/2
= 14ξ
1− e−ξ
1 + e−ξ
= 24ξ
(1
1 + e−ξ− 1/2 + e−ξ/2
1 + e−ξ
)= 1
2ξ
(σ (ξ)− 1
2
). (10.150)

47/74
変分パラメータの最適化(EMアルゴリズム)
よって
d
dξn
(log σ (ξn)− ξn
2 − λ (ξn)(φ′
nE [ww′] φn − ξ2n
))= 1− σ (ξn)− 1
2 + dλ
dξn(ξn)
(φ′
nE [ww′] φn − ξ2n
)+ σ (ξn)− 1
2
= dλ
dξn(ξn)
(φ′
nE [ww′] φn − ξ2n
)となる.停留条件を求めたいので
dλ
dξn(ξn)
(φ′
nE [ww′] φn − ξ2n
)= 0 (10.162)
とする.
48/74
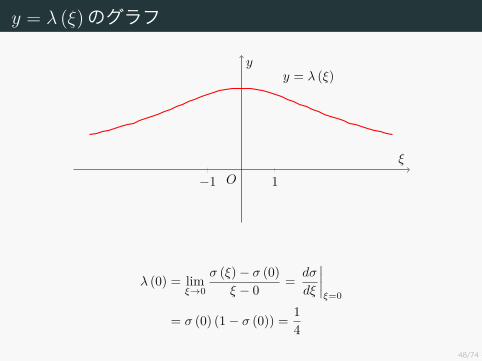
y = λ (ξ)のグラフ
−1 1O
y = λ (ξ)
ξ
y
λ (0) = limξ→0
σ (ξ)− σ (0)ξ − 0 = dσ
dξ
∣∣∣∣ξ=0
= σ (0) (1− σ (0)) = 14
49/74
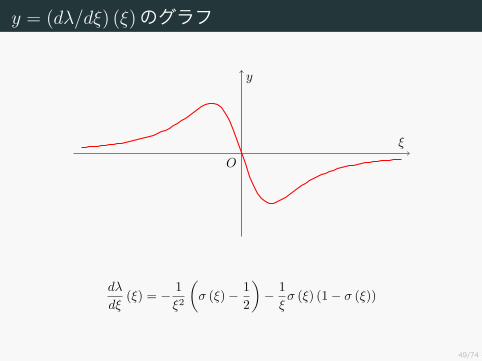
y = (dλ/dξ) (ξ)のグラフ
O
y = λ (ξ)
ξ
y
dλ
dξ(ξ) = − 1
ξ2
(σ (ξ)− 1
2
)− 1
ξσ (ξ) (1− σ (ξ))

50/74
変分パラメータの最適化(EMアルゴリズム)
ξ 6= 0の範囲では (dλ/dξ) (ξ) 6= 0なので
(ξnewn )2 = φ′
nE [ww′] φn
となる.分散の定義,期待値の性質と q (w) = N (w|mN , SN )より
SN = E[(w −mN ) (w −mN )′]
= E [ww′]−mNE [w]′ − E [w] m′N + mN m′
N
= E [ww′]−mN m′N
であるから
(ξnewn )2 = φ′
n (SN + mN m′N ) φn (10.163)
を得る.

51/74
変分パラメータの最適化(直接計算)
二つ目の方法は,L (ξ)を計算する方法である.計算で求められた Lの式を ξで微分することにより,Lを最大化するような ξを求めるのである.
L (ξ) =N∑
n=1
(log σ (ξn)− ξn
2 + λ (ξn) ξ2n
)
+ log∫
dw
(2π)m√|S0|
exp(−1
2 (w −m0)′S−1
0 (w −m0))
exp(
w′
(N∑
n=1
(tn −
12
)φn
)− w′
(N∑
n=1λ (ξn) φnφ′
n
)w
)

52/74
変分パラメータの最適化(直接計算)
積分記号の中の指数関数の引数に着目すると
− 12w′S−1
0 w + w′
(m0S−1
0 +N∑
n=1
(tn −
12
)φn
)
− 12m0S−1
0 m0 − w′
(N∑
n=1λ (ξn) φnφ′
n
)w
= −12w′S−1
0 w + w′S−1N mN −
12m′
0S−10 m0 −
12w′ (S−1
N − S−10)
w
= −12 (w −mN )′
S−1N (w −mN ) + 1
2m′N S−1
N mN −12m′
0S−10 m0

53/74
変分パラメータの最適化(直接計算)
L (ξ) =N∑
n=1
(log σ (ξn)− ξn
2 + λ (ξn) ξ2n
)
+ log∫ √
|SN ||S0|
1√|SN |
exp(−1
2 (w −mN )′S−1
N (w −mN ))
exp(
12m′
N S−1N mN −
12m′
0S−10 m0
)dw
= 12 log |SN |
|S0|+ 1
2m′N S−1
N mN −12m′
0S−10 m0
+N∑
n=1
(log σ (ξn)− ξn
2 + λ (ξn) ξ2n
)(10.164)

54/74
変分パラメータの最適化(直接計算)
(10.164)の各項の ξn についての導関数を計算しておこう.まずlog |SN |を ξn で微分することを考える.公式(d/dt) |A (t)| = tr
(A−1 (t) A (t)
)を使う.
∂
∂ξnlog |SN | = −
∂
∂ξnlog∣∣S−1
N
∣∣= − tr
(SN
∂S−1N
∂ξn
)= − tr
(SN
(2 dλ
dξn(ξn) φnφ′
))対称行列の跡に関する公式 x′Ax = tr (Axx′)を使って次を得る.
∂
∂ξnlog |SN | = −2 dλ
dξn(ξn) φ′
nSN φn.
公式の導出に関しては,このスライドの補足 1と補足 2を参照.

55/74
変分パラメータの最適化(直接計算)
次にm′N S−1
N mN を ξn で微分する.mN = SN vN と置く.(C.21)の公式 ∂A−1/∂x = −A−1(∂A/∂x)A−1 などを使って
∂
∂ξn
(m′
N S−1N mN
)= ∂
∂ξn
(v′
N S′N S−1
N SN vN
)= v′
N
(∂SN
∂ξn
)′
vN
= −v′N S′
N
∂S−1N
∂ξnSN vN
= −2 dλ
dξn(ξn) m′
N (φnφ′n) mN
= −2 dλ
dξn(ξn) φ′
nmN m′N φn
を得る.

56/74
変分パラメータの最適化(直接計算)
最後に総和記号の中を ξn で微分する.
d
dξn
(log σ (ξn)− ξn
2 + λ (ξn) ξ2n
)= 1− σ (ξn)− 1
2 + dλ
dξn(ξn) ξ2
n + 2λ (ξn) ξn
= 12 − σ (ξn) + dλ
dξn(ξn) ξ2
n +(
σ (ξn)− 12
)= dλ
dξn(ξn) ξ2
n

57/74
変分パラメータの最適化(直接計算)
以上の結果から ∂L/∂ξn = 0と置くと
dλ
dξn(ξn)
(ξ2
n − φ′nSN φn − φ′
nmN m′N φn
)= 0
dλ
dξn(ξn)
(ξ2
n − φ′n (SN + mN m′
N ) φn
)= 0
となり,EMアルゴリズムと全く同じ結果になる.

58/74
超パラメータの推論
ベイズロジスティック回帰モデルにおいて今まで wを定める超パラメータ αは既知の定数としてきたが,αもデータから推測できたらうれしい.以下でその方法を説明する.
wの事前分布として,以下の等方ガウス分布を仮定する 6.
p (w|α) = N(w∣∣0, α−1I
)(10.165)
= 1(2π)M/2 |α−1I|1/2 exp
(−α
2 w′w)
=( α
2π
)M/2exp
(−α
2 w′w)
6 w の次元がM であるという記述が見つけられなかったけど多分それであってるはず.

59/74
超パラメータの推論
共役超事前分布 p (α)はガンマ分布
p (α) = Gamma (α|a0, b0) (10.166)
= 1Γ (a0)ba0
0 αa0−1e−b0α
とする.
このモデルの周辺尤度は
p (t) =∫∫
p (w, α, t) dwdα (10.167)
である.ただし
p (w, α, t) = p (t|w) p (w|α) p (α) (10.168)
である.

60/74
超パラメータの推論
いつも通り周辺尤度の対数 log p (t)を以下のように分解する.
log p (t) = L (q) + KL (q‖p) . (10.169)
ここで
L (q) =∫∫
q (w, α) log(
p (w, α, t)q (w, α)
)dwdα (10.170)
KL (q‖p) = −∫∫
q (w, α) log(
p (w, α|t)q (w, α)
)dwdα (10.171)
である.このままでは Lの最大化の計算が進められないので,またいつものように下から近似する.
log p (t) ≥ L (q) ≥ L (q, ξ)
=∫∫
q (w, α) log(
h (w, ξ) p (w|α) p (α)q (w, α)
)dwdα (10.172)

61/74
超パラメータの推論
変分分布がパラメータと超パラメータに分解できると仮定しよう.
q (w, α) = q (w) q (α) (10.173)
これで Lの最大化に取り組むことができる.
L (q) =∫∫
q (w) q (α) log (h (w, ξ) p (w|α) p (α)) dαdw
−∫
q (w)(∫
q (α) log (q (w) q (α)) dα
)dw
=∫
q (w)(∫
q (α) log (h (w, ξ) p (w|α) p (α)) dα
)dw
−∫
q (w) log q (w) dw −∫
q (α) log q (α) dα

62/74
超パラメータの推論
KLダイバージェンスの最小化条件を使って
log q (w) =∫
q (α) log (h (w, ξ) p (w|α) p (α)) dα + const.
= log h (w, ξ) + Eα [log p (w|α)] + const.
となる.log h (w, ξ)に (10.153)を,log p (w|α)に (10.165)を代入して次式を得る.
log q (w) = −E [α]2 w′w
+N∑
n=1
((tn −
12
)w′φn − λ (ξn) w′φnφ′w
)+ const.
これは wの二次関数なので q (w)はガウス分布であることが分かる.

63/74
超パラメータの推論
したがって q (w) = N (w|µN , ΣN )とすれば
Σ−1N = E [α] I + 2
N∑n=1
λ (ξn) φnφ′n, (10.176)
Σ−1N µN =
N∑n=1
(tn −
12φn
)(10.175)
が成り立つ.

64/74
超パラメータの推論
次に αの変分分布について計算する.Lは以下のように変形できる.
L (q) =∫
q (α)(
log p (α) +∫
q (w) log p (w|α) dw
)dα
−∫
q (α) log q (α) dα + const.
よって KLダイバージェンスの最小化条件を使って
log q (α) = Ew [log p (w|α)] + log p (α) + const.
となる.

65/74
超パラメータの推論log p (w|α)に (10.165)を,log p (α)に (10.166)を代入して
log q (α) = M
2 log α− α
2E [w′w] + (a0 − 1) log α− b0α + const.
=(
M
2 + a0 − 1)
log α−(
b0 + 12E [w′w]
)α + const.
を得る.これはガンマ分布の対数の形になっているので
aN := a0 + M
2 , (10.178)
bN := b0 + 12E [w′w] (10.179)
と置くと
q (α) = Gamma (α|aN , bN ) = 1Γ (aN )abN
N αaN −1e−bN α (10.177)
となる.

66/74
超パラメータの推論
最後に ξの推定を行う方法を考える.L (q, ξ)の ξに関連する項に着目すると
L (q) =∫∫
q (w) q (α) log h (w, ξ) dαdw + const.
=∫∫
q (w) log h (w, ξ) dw + const.
となる.これはと同じ形なので前の結果から
(ξnewn )2 = φ′
n (ΣN + µN µ′N ) φn (10.181)
以上で q (w) , q (α) , ξを再推定する方程式が得られた.

67/74
行列式の微分
行列式の微分の公式を導く.Aを n次正則行列とし,その各行をai (i = 1, . . . , n)と表す.
d
dt|A (t)|
= limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t + h)a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣
= limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t + h)a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣+
∣∣∣∣∣∣∣∣∣a1 (t)
a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣

68/74
行列式の微分
= limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t + h)− a1 (t)a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣
+ limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣
=
∣∣∣∣∣∣∣∣∣a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣+ limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣

69/74
行列式の微分
=
∣∣∣∣∣∣∣∣∣a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣+ limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t + h)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t + h)
∣∣∣∣∣∣∣∣∣
+ limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣
=
∣∣∣∣∣∣∣∣∣a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣+
∣∣∣∣∣∣∣∣∣a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣+ limt→0
1t
∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t + h)
∣∣∣∣∣∣∣∣∣−∣∣∣∣∣∣∣∣∣
a1 (t)a2 (t)...
an (t)
∣∣∣∣∣∣∣∣∣

70/74
行列式の微分
上記の計算を繰り返すことで以下の公式を得る.
d
dt|A (t)| =
n∑i=1
∣∣∣∣∣∣∣∣∣∣∣∣
a1 (t)...
ai (t)...
an (t)
∣∣∣∣∣∣∣∣∣∣∣∣=
n∑i=1
n∑k=1
aik∆ik
これを使いさらに簡潔な表現を得ることができる.次頁で説明する.

71/74
行列式の微分
Aを n次正則行列 Aとし,その (i, j)成分の余因子を∆ij := (−1)i+j |Aij |,余因子行列を A = (∆ji)ij と表す.このとき第 i
行に関する余因子展開を行えば
d
dt|A (t)| =
n∑i=1
∣∣∣∣∣∣∣∣∣∣∣∣
a1 (t)...
ai (t)...
an (t)
∣∣∣∣∣∣∣∣∣∣∣∣=
n∑i=1
n∑k=1
aik∆ik
となる.
tr(
A (t) A (t))
= tr
( n∑k=1
∆kiakj
)ij
=n∑
i=1
n∑k=1
∆kiaki
なので (d/dt) |A (t)| = tr(
A (t) A (t))を得る.

72/74
行列式の対数の微分
正則行列について A/ |A| = A−1 が成り立つことと,いま導いた(d/dt) |A (t)| = tr
(A (t) A (t)
)を使うと
d
dtlog |A (t)| = 1
|A (t)|d
dt|A (t)|
= 1|A (t)| tr
(A (t) A (t)
)= 1|A (t)| tr
(A (t) A (t)
)= tr
(A−1 (t) A (t)
)を得る.

73/74
跡と二次形式
公式 tr (Axx′) = x′Axを示す.そのために,まずはtr (AB′) = tr (A′B)を示す.
tr (AB′) =n∑
i=1
n∑k=1
aikbik
=n∑
i=1
n∑k=1
akibki
= tr (A′B)
したがって Aが対称行列ならば
tr (Axx′) = tr(
(x′A)′x′)
= tr (x′Ax)= x′Ax
が成り立つ.

74/74
参考文献
Bogachev, V. I. (2007). Measure theory, volume 1. SpringerScience & Business Media.
Borwein, J. M. and Lewis, A. S. (2010). Convex analysis andnonlinear optimization: theory and examples. SpringerScience & Business Media.
Golberg, M. (1972). The derivative of a determinant.American Mathematical Monthly, pages 1124-1126.
ビショップ, C. M. (2008). パターン認識と機械学習 上. シュプリンガージャパン.






























