Embed Size (px)
Citation preview

Muga Nishizawa (西澤 無我)
Using Embulk at Treasure Data

Today’s talk
> What’s Embulk?
> Why our customers use Embulk? > Embulk > Data Connector
> Data Connector > The architecture > The use case
> with MapReduce Executor > How we configure MapReduce Executor?
2

What’s Embulk?
> An open-source parallel bulk data loader > loads records from “A” to “B”
> using plugins > for various kinds of “A” and “B”
> to make data integration easy. > which was very painful…
3
Storage, RDBMS, NoSQL, Cloud Service,
etc.
broken records,transactions (idempotency),
performance, …

HDFS
MySQL
Amazon S3
Embulk
CSV Files
SequenceFile
Salesforce.com
Elasticsearch
Cassandra
Hive
Redis
✓ Parallel execution ✓ Data validation ✓ Error recovery ✓ Deterministic behavior ✓ Resuming
Plugins Plugins
bulk load

Why our customers use Embulk?
> Upload various types of their data to TD with Embulk > Various file formats
> CSV, TSV, JSON, XML,.. > Various data source
> Local disk, RDBMS, SFTP,.. > Various network environments
> embulk-output-td > https://github.com/treasure-data/embulk-output-td
5

Out of scope for Embulk
> They develop scripts for > generating Embulk configs
> changing schema on a regular basis > logic to select some files but not others
> managing cron settings > e.g. some users want to upload yesterday’s dataas daily batch
> Embulk is just “bulk loader”
6

Best practice to manage Embulk!!
7http://www.slideshare.net/GONNakaTaka/embulk5

Yes, yes,..
8
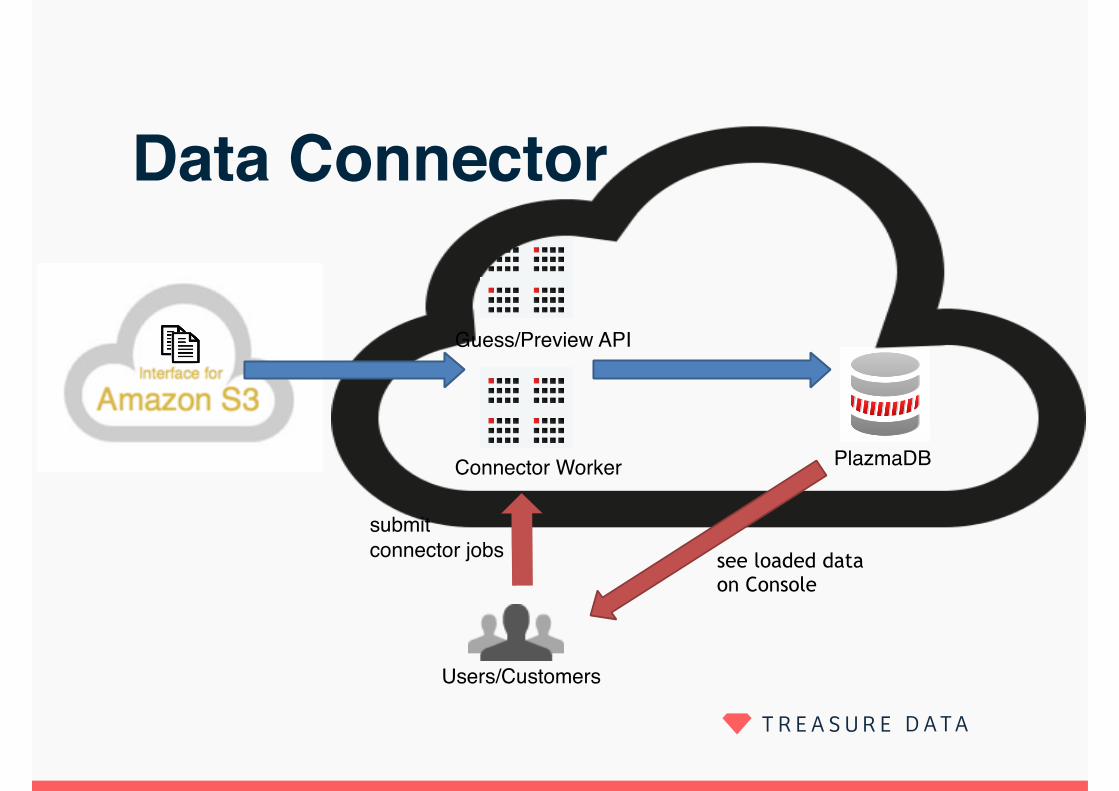
Data Connector
Users/Customers
PlazmaDBConnector Worker
submit connector jobs see loaded data
on Console
Guess/Preview API
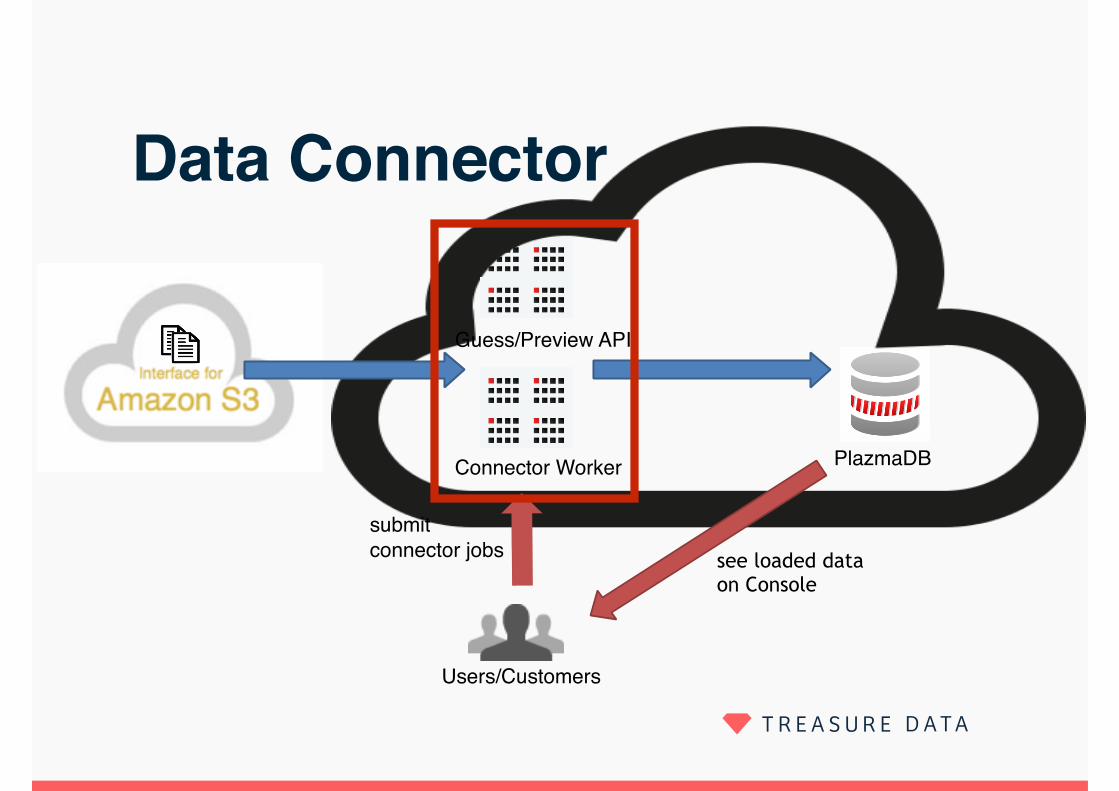
Data Connector
Users/Customers
PlazmaDBConnector Worker
submit connector jobs see loaded data
on Console
Guess/Preview API
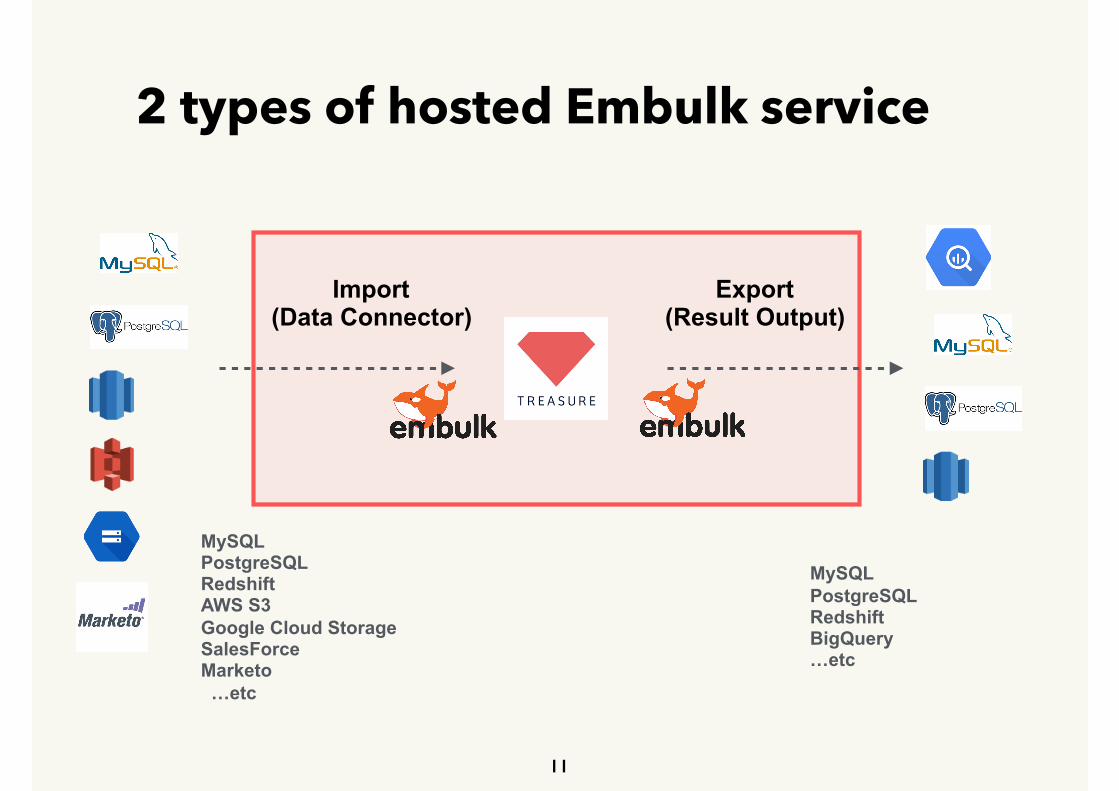
2 types of hosted Embulk service
11
Import (Data Connector)
Export (Result Output)
MySQL PostgreSQL Redshift AWS S3 Google Cloud Storage SalesForce Marketo …etc
MySQL PostgreSQL Redshift BigQuery …etc

Guess/Preview API
Users/Customers
PlazmaDBConnector Worker
submit connector jobs see loaded data
on Console
Guess/Preview API

Guess/Preview API
> Guesses Embulk config based on sample data > Creates parser config
> Adds schema, escape char, quote char, etc.. > Creates rename filter config
> TD requires uncapitalized column names
> Preview data before uploading
> Ensures quick response
> Embulk performs this functionality running on our web application servers
13
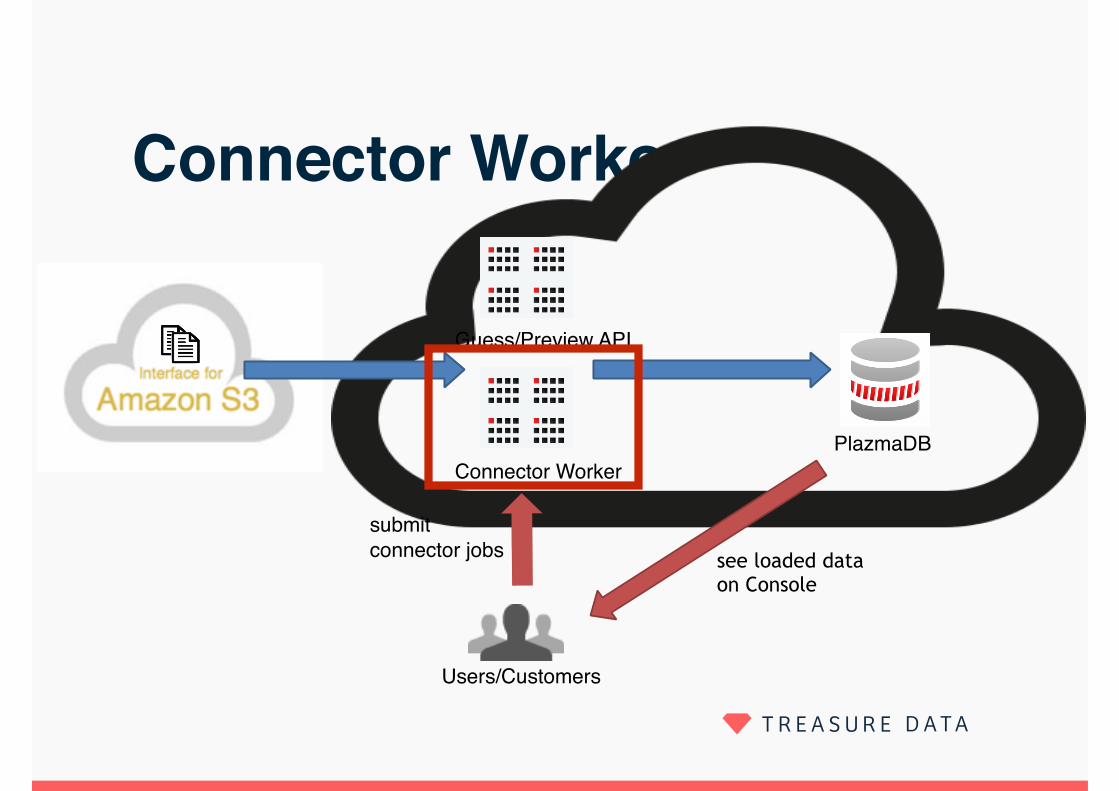
Connector Worker
Users/Customers
PlazmaDBConnector Worker
submit connector jobs see loaded data
on Console
Guess/Preview API

Connector Worker
> Generates Embulk config and executes Embulk > Uses private output plugin instead of embulk-output-td to upload users’ data to PlazmaDB directly
> Appropriate retry mechanism
> Embulk runs on our Job Queue clients
15

Timestamp parsing
Users/Customers
PlazmaDBConnector Worker
submit connector jobs see loaded data
on Console
Guess/Preview API

Timestamp parsing
> Implement strptime in Java > Ported from CRuby implementation > Can precompile the format
> Faster than JRuby’s strptime > Has been maintained in Embulk repo obscurely..
> It will be merged into JRuby
17

How we use Data Connector at TD
> a. Monitoring our S3 buckets access > e.g. “IAM users who accessed our S3 buckets?”“Access frequency” > {in: {type: s3}} and {parser: {type: csv}}
> b. Measuring KPIs for development process > e.g. “phases that we took a long time on the process” > {in: {type: jira}}
> c. Measuring Business & Support Performance > {in: {type: Salesforce, Marketo, ZenDesk, …}}
18

Scaling Embulk
> Requests for massive data loading from users > e.g. “Upload 150GB data by hourly batch”“Start PoC and upload 500GB data today”
> Local Executor can not handle this scale > MapReduce Executor enables us to scale
19
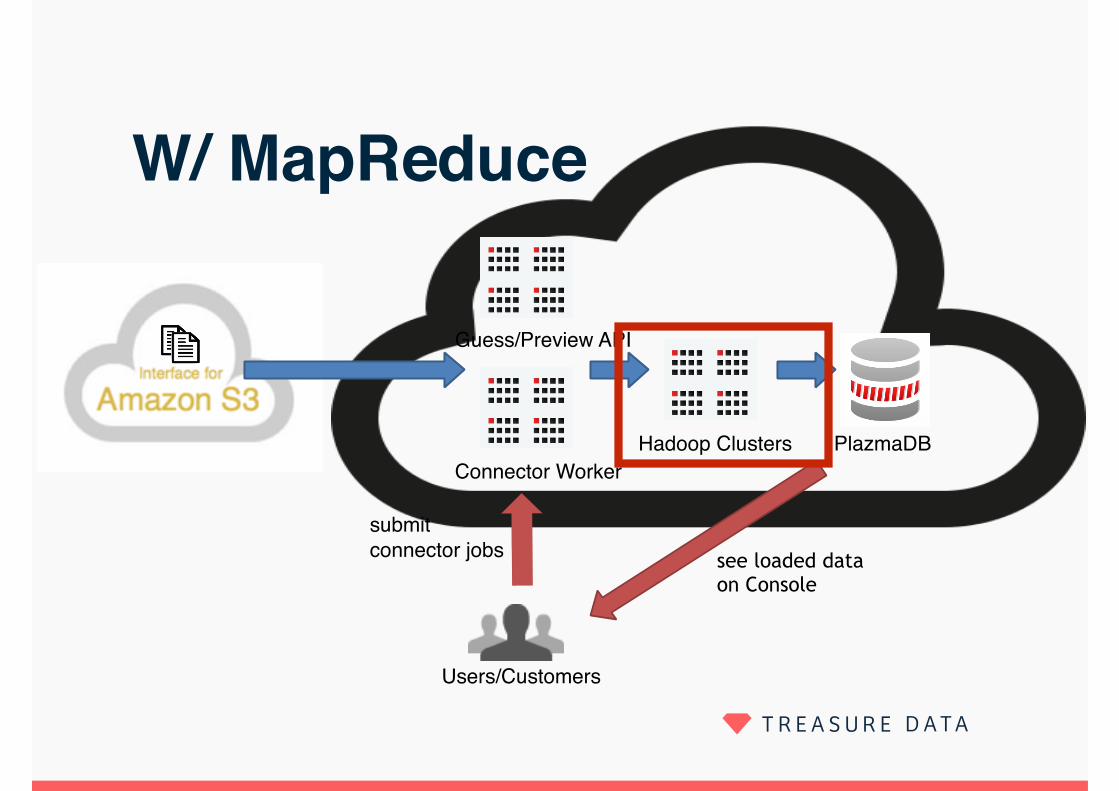
W/ MapReduce
Users/Customers
PlazmaDBConnector Worker
submit connector jobs see loaded data
on Console
Guess/Preview API
Hadoop Clusters
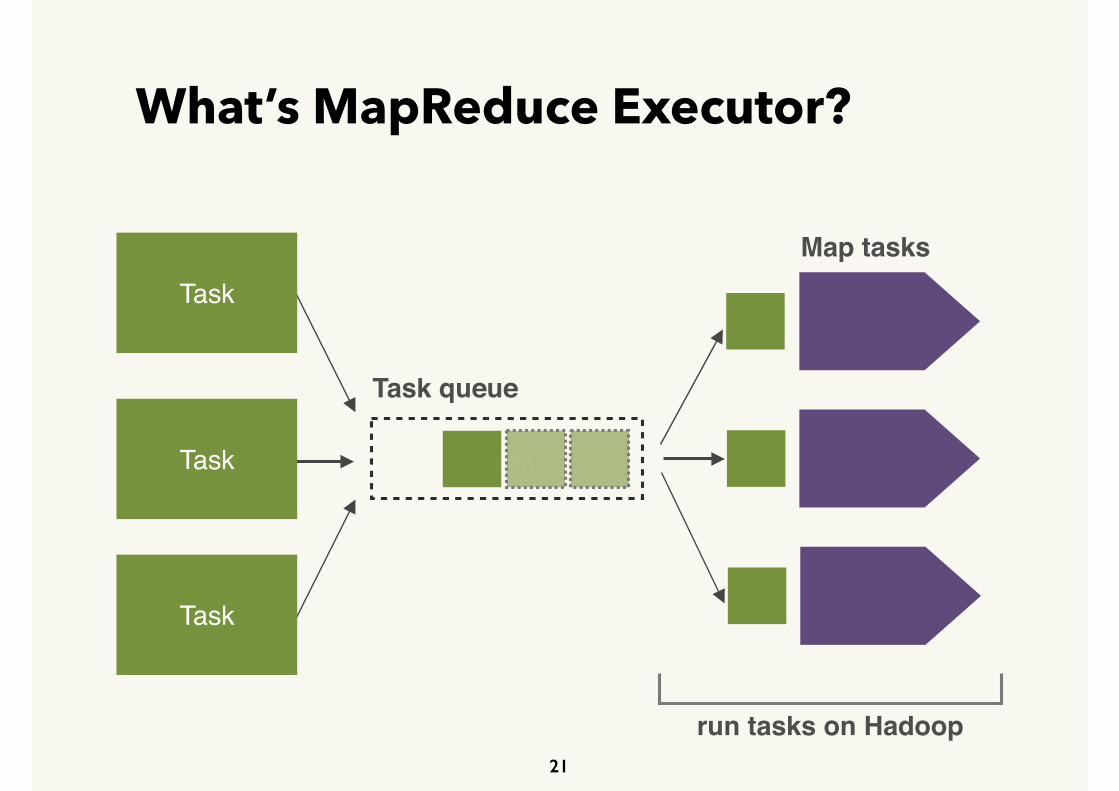
What’s MapReduce Executor?
21
Task
Task
Task
Task
Map tasks
Task queue
run tasks on Hadoop

MapReduce Executor with TimestampPartitioning
22
Task
Map tasks
Task queue
run tasks on Hadoop
Reduce tasksShuffle

built Embulk configs
23
exec: type: mapreduce job_name: embulk.100000 config_files: - /etc/hadoop/conf/core-site.xml - /etc/hadoop/conf/hdfs-site.xml - /etc/hadoop/conf/mapred-site.xml config: fs.defaultFS: “hdfs://my-hdfs.example.net:8020” yarn.resourcemanager.hostname: "my-yarn.example.net" dfs.replication: 1 mapreduce.client.submit.file.replication: 1 state_path: /mnt/xxx/embulk/ partitioning: type: timestamp unit: hour column: time unix_timestamp_unit: hour map_side_partition_split: 3 reducers: 3in: ...
Connector Workers (single-machine workers) are still able to generate config

Different sized files
24
Map tasks Reduce tasksShuffle
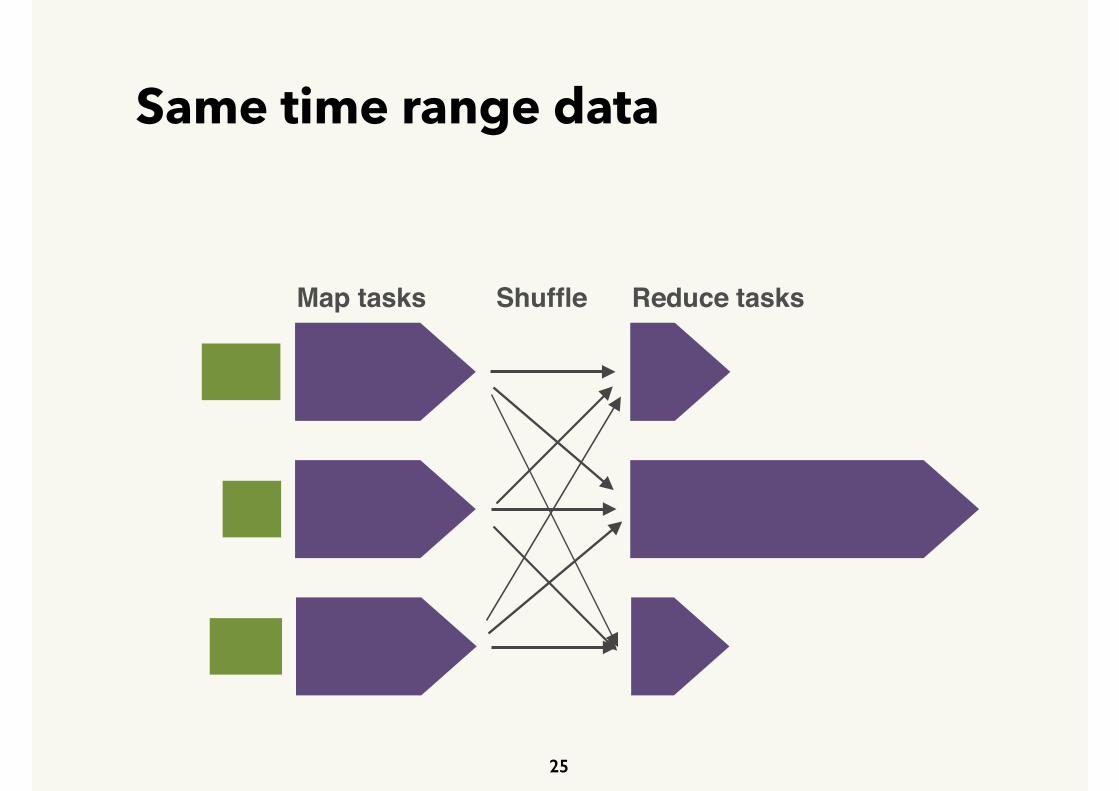
Same time range data
25
Map tasks Reduce tasksShuffle

Grouping input files - {in: {min_task_size}}
26
Map tasks Reduce tasksShuffle
Task
Task
Task
It also can reduce mapper’s launch cost.
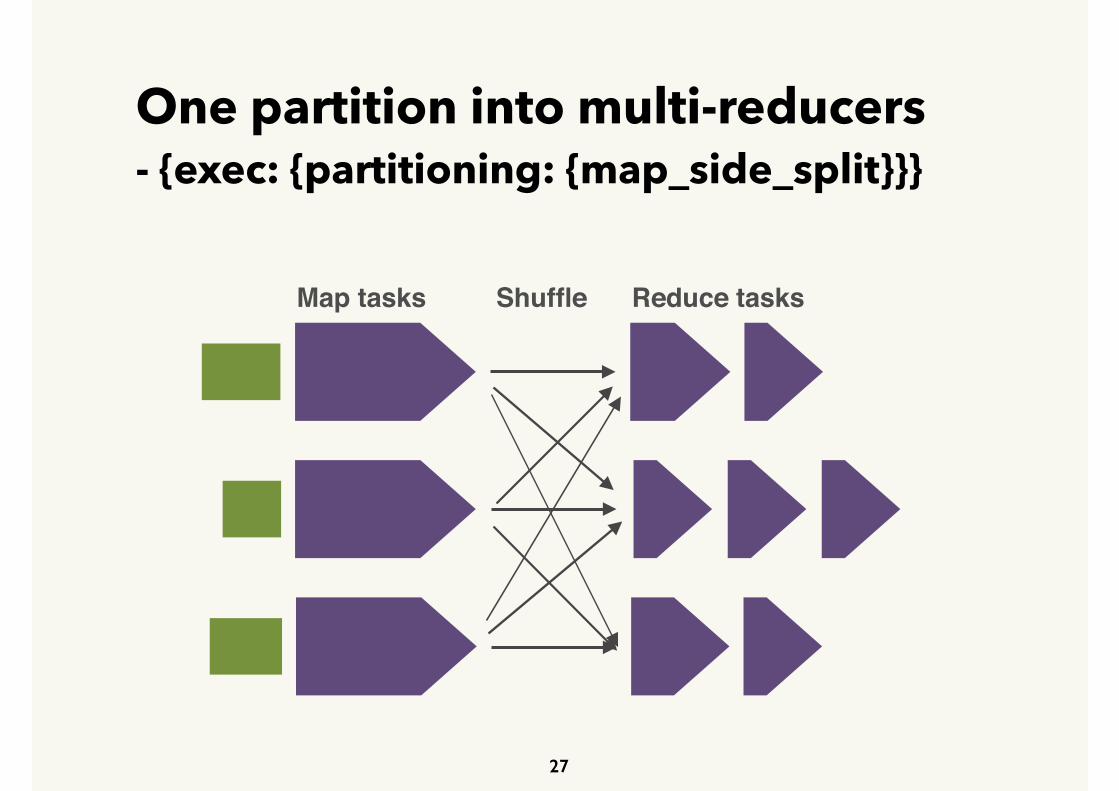
One partition into multi-reducers - {exec: {partitioning: {map_side_split}}}
27
Map tasks Reduce tasksShuffle

Conclusion
> What’s Embulk?
> Why we use Embulk? > Embulk > Data Connector
> Data Connector > The architecture of Data Connector > The use case
> with MapReduce Executor
28

29





























