Embed Size (px)
Citation preview

New technologies, new management challenges for reference assemblies
Valerie Schneider, Ph.D.@dnadiver
NCBI13 February 2017

• Reference assembly management
• Challenges of changing technologies, new resources
• De novo assembly assessment
Evolution of Human Reference Assembly Management

Why do we need data managementand assembly infrastructure?
Reference Assembly Management
Reference Assembly Management
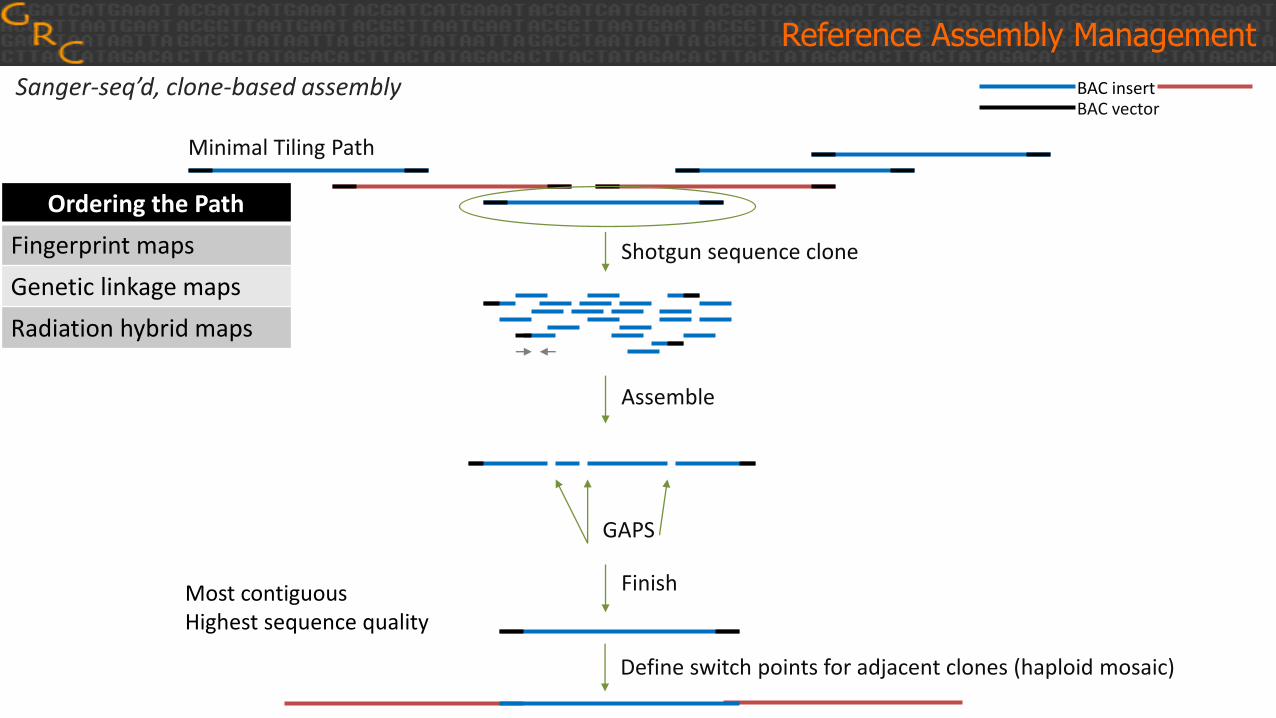
Sanger-seq’d, clone-based assembly BAC insertBAC vector
Shotgun sequence clone
Assemble
GAPS
Finish
Minimal Tiling Path
Define switch points for adjacent clones (haploid mosaic)
Most contiguousHighest sequence quality
Ordering the Path
Fingerprint maps
Genetic linkage maps
Radiation hybrid maps
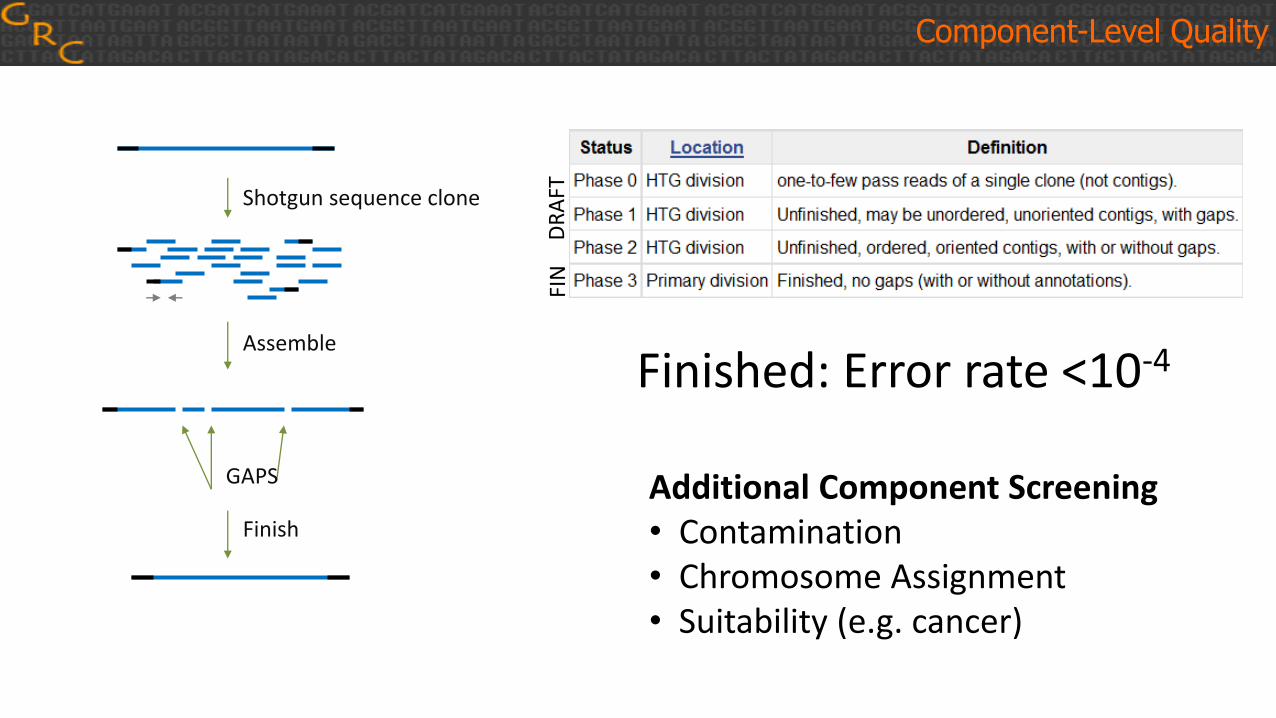
Component-Level Quality
Shotgun sequence clone
Assemble
GAPS
Finish
Finished: Error rate <10-4
Additional Component Screening• Contamination• Chromosome Assignment• Suitability (e.g. cancer)
DR
AFT
FIN
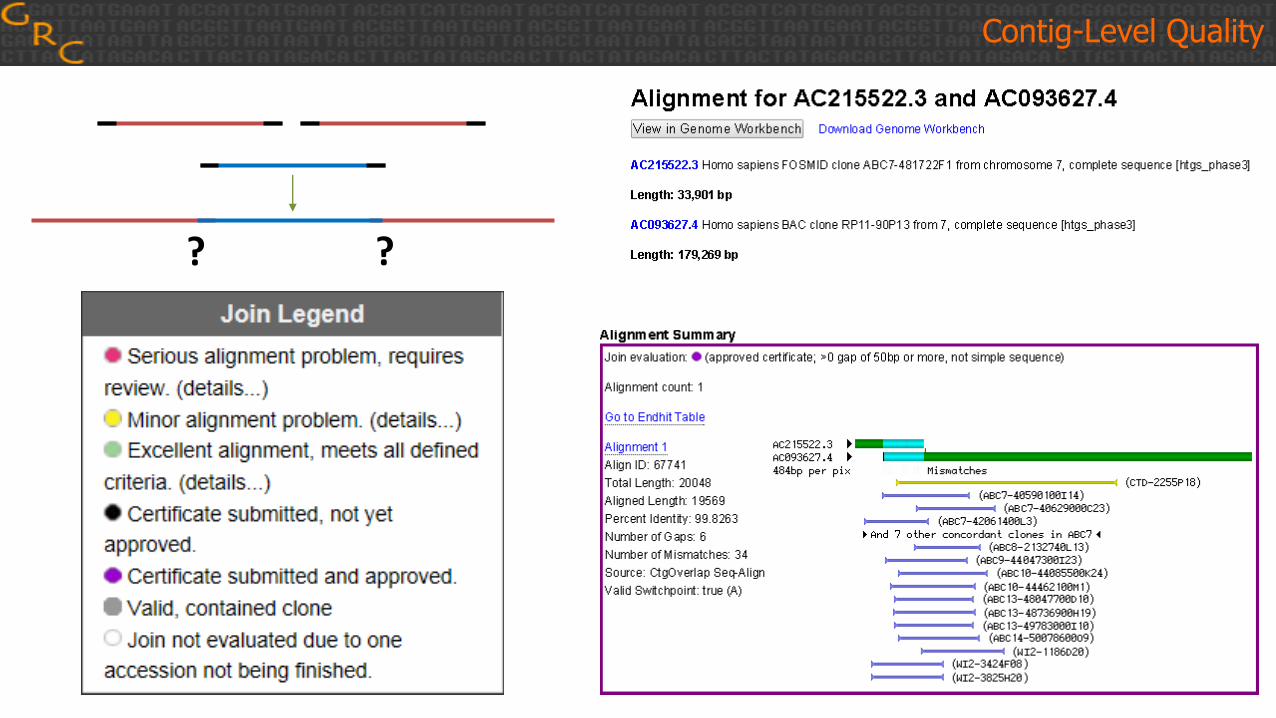
Contig-Level Quality
? ?

• Reference assembly management
• Challenges of changing technologies, new resources
• De novo assembly assessment
Evolution of Human Reference Assembly Management

Changing Technologies, New Resources
Declining clone usage
New technologiesNew public WGS genomes
CostTimeQuality?
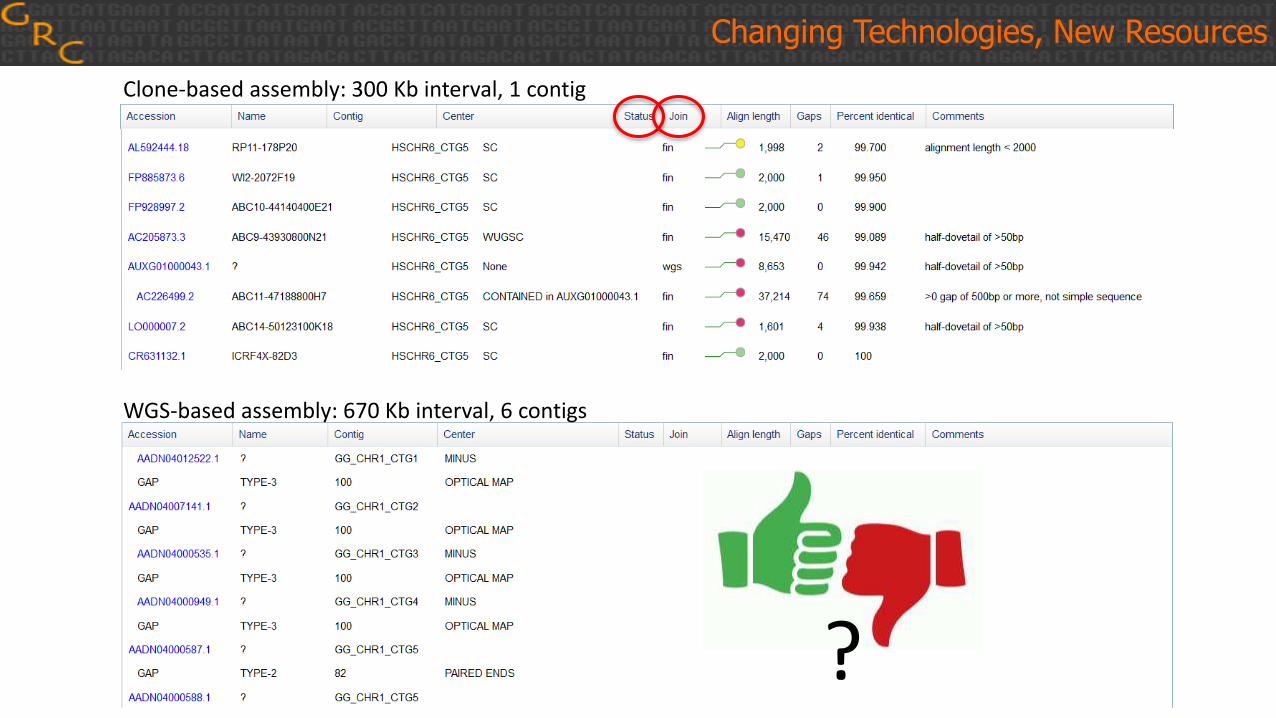
Clone-based assembly: 300 Kb interval, 1 contig
WGS-based assembly: 670 Kb interval, 6 contigs
?
Changing Technologies, New Resources

GCA_001297185.1
Changing Technologies, New Resources
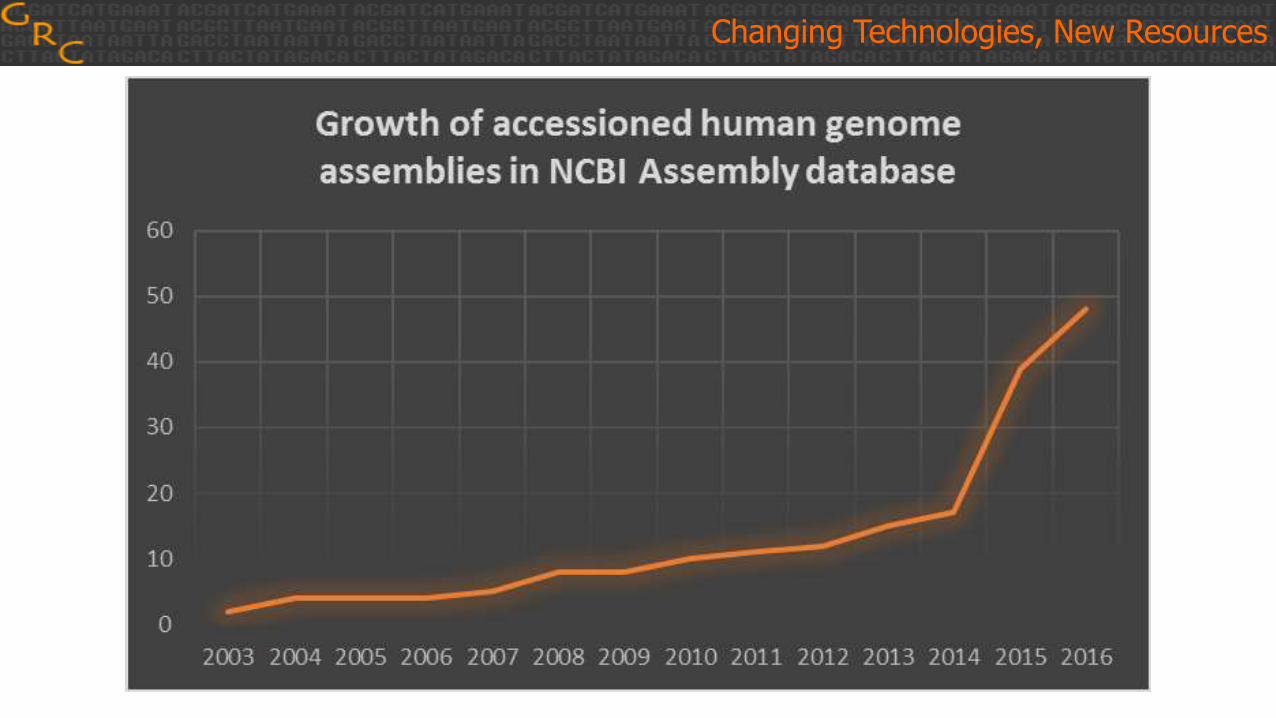
Changing Technologies, New Resources

Lander and Waterman
(1988) Genomics
SequencedNot sequenced
1X Coverage
5X Coverage
10X Coverage
37% 63%
0.6% 99.4%
0.005% 99.995%
The likelihood a base is seq’d.Coverage
N50
HuRef
SOAPdenovoNA12878
ALLPATHSNA12878
MHAPCHM1
Chaisson and Eichler (2015)
AK1HX1
Changing Technologies, New Resources
Measure of contiguity. Half of the assembly is in contigs this length or greater.
Variant analysis
Annotation
Clinical Diagnostics
Comparative genomics
Transcriptomics
?
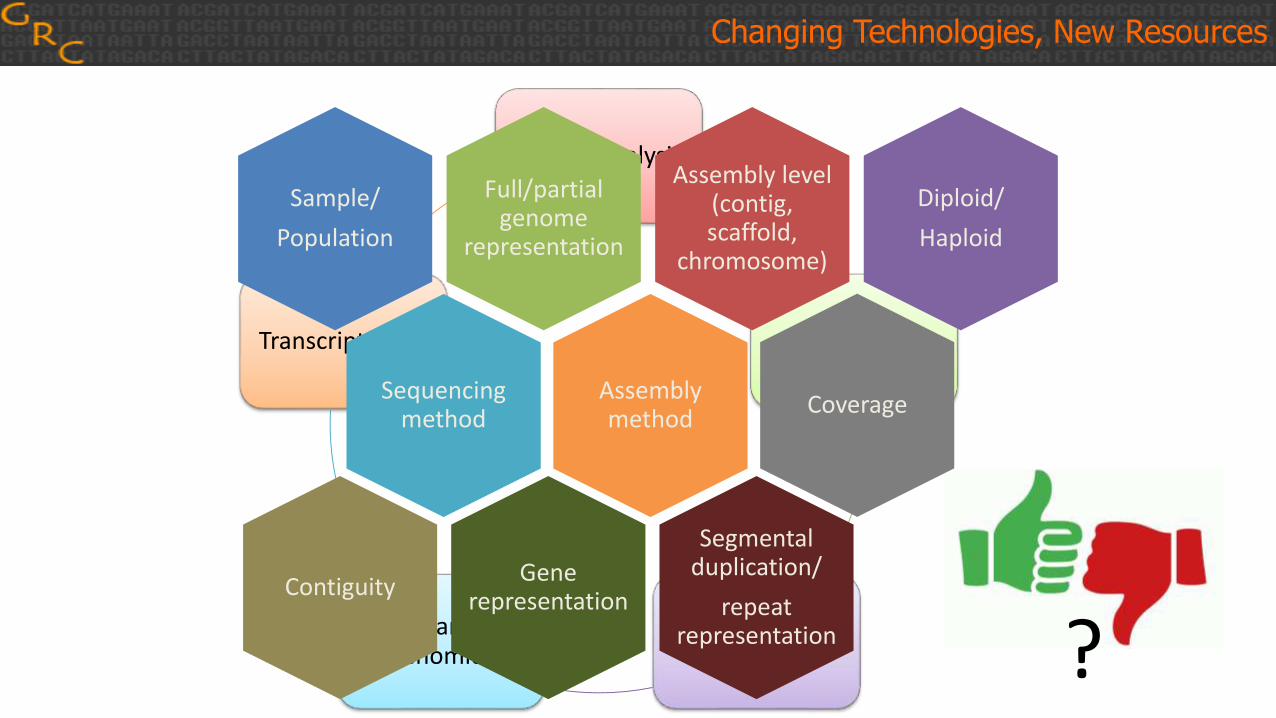
Sample/
Population
Assembly level (contig, scaffold,
chromosome)
Full/partial genome
representation
Sequencing method
Assembly method
Contiguity
Coverage
Segmental duplication/
repeat representation
Gene representation
Diploid/
Haploid
Changing Technologies, New Resources

• Reference assembly management
• Challenges of changing technologies, new resources
• De novo assembly assessment
Evolution of Human Reference Assembly Management
De novo assembly assessment
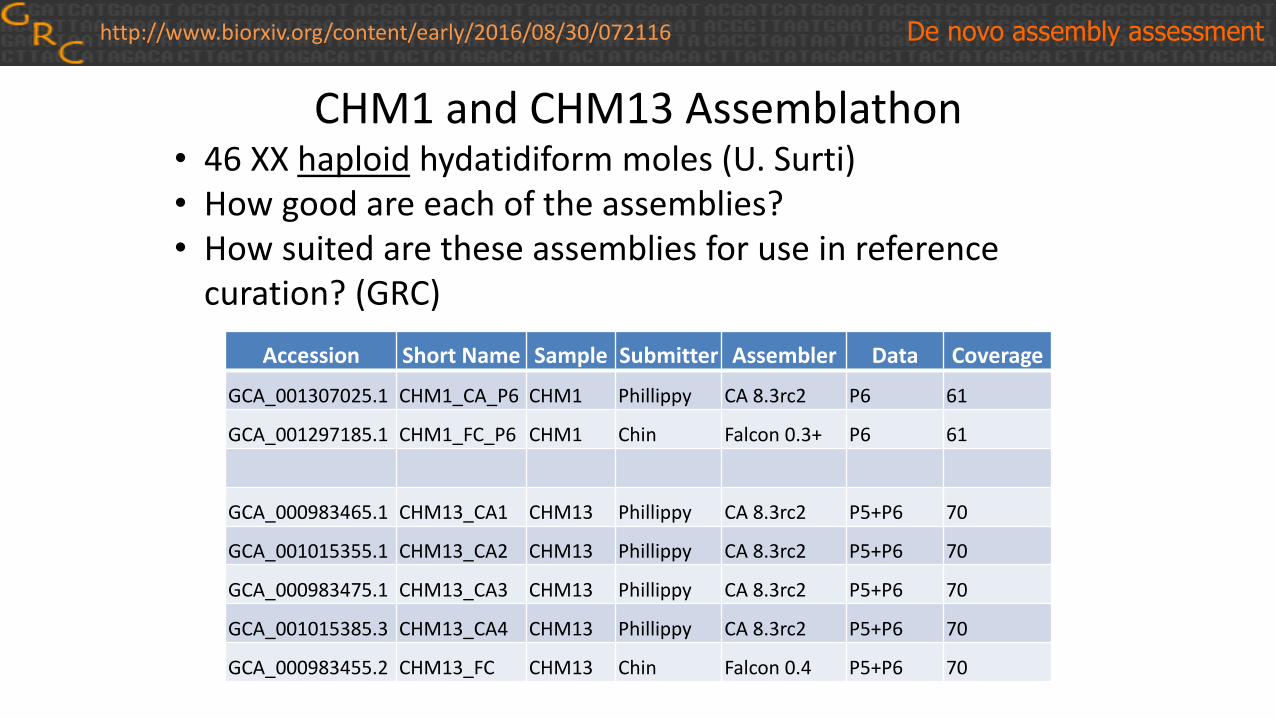
CHM1 and CHM13 Assemblathon• 46 XX haploid hydatidiform moles (U. Surti)• How good are each of the assemblies?• How suited are these assemblies for use in reference
curation? (GRC)
Accession Short Name Sample Submitter Assembler Data Coverage
GCA_001307025.1 CHM1_CA_P6 CHM1 Phillippy CA 8.3rc2 P6 61
GCA_001297185.1 CHM1_FC_P6 CHM1 Chin Falcon 0.3+ P6 61
GCA_000983465.1 CHM13_CA1 CHM13 Phillippy CA 8.3rc2 P5+P6 70
GCA_001015355.1 CHM13_CA2 CHM13 Phillippy CA 8.3rc2 P5+P6 70
GCA_000983475.1 CHM13_CA3 CHM13 Phillippy CA 8.3rc2 P5+P6 70
GCA_001015385.3 CHM13_CA4 CHM13 Phillippy CA 8.3rc2 P5+P6 70
GCA_000983455.2 CHM13_FC CHM13 Chin Falcon 0.4 P5+P6 70
http://www.biorxiv.org/content/early/2016/08/30/072116

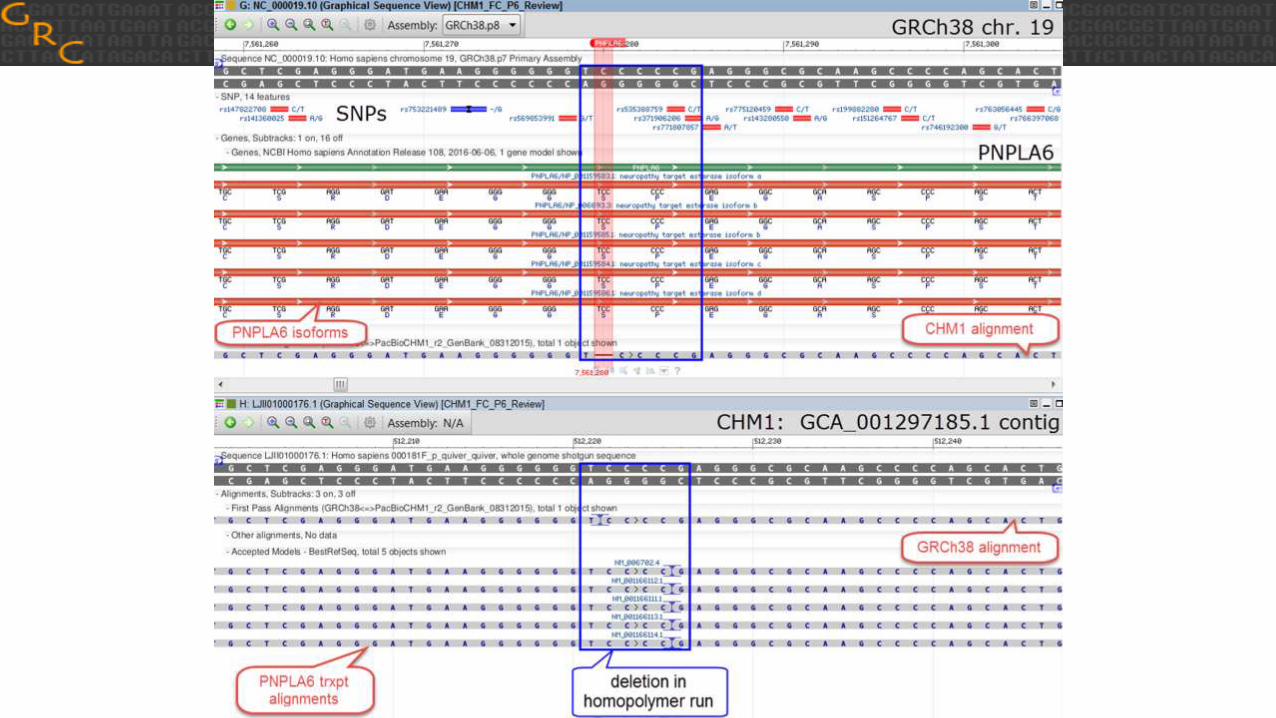
Assembly Assessments• General QA (NCBI)
• Assembly stats (length, contiguity)• Annotation• Assembly-assembly alignment to reference• Comparison to BAC inserts • BAC end placements (CHM1 only)
• BioNano map comparison (MGI)• Illumina alignments (Phillippy, Li)
• Quality/Errors• Coverage• Paired end distribution
Resource Sample
Illumina reads CHM1, CHM13
BioNano map CHM1, CHM13
BAC library CHM1, CHM13
BAC library end seqs CHM1
Fingerprint Map CHM1
De novo assembly assessment
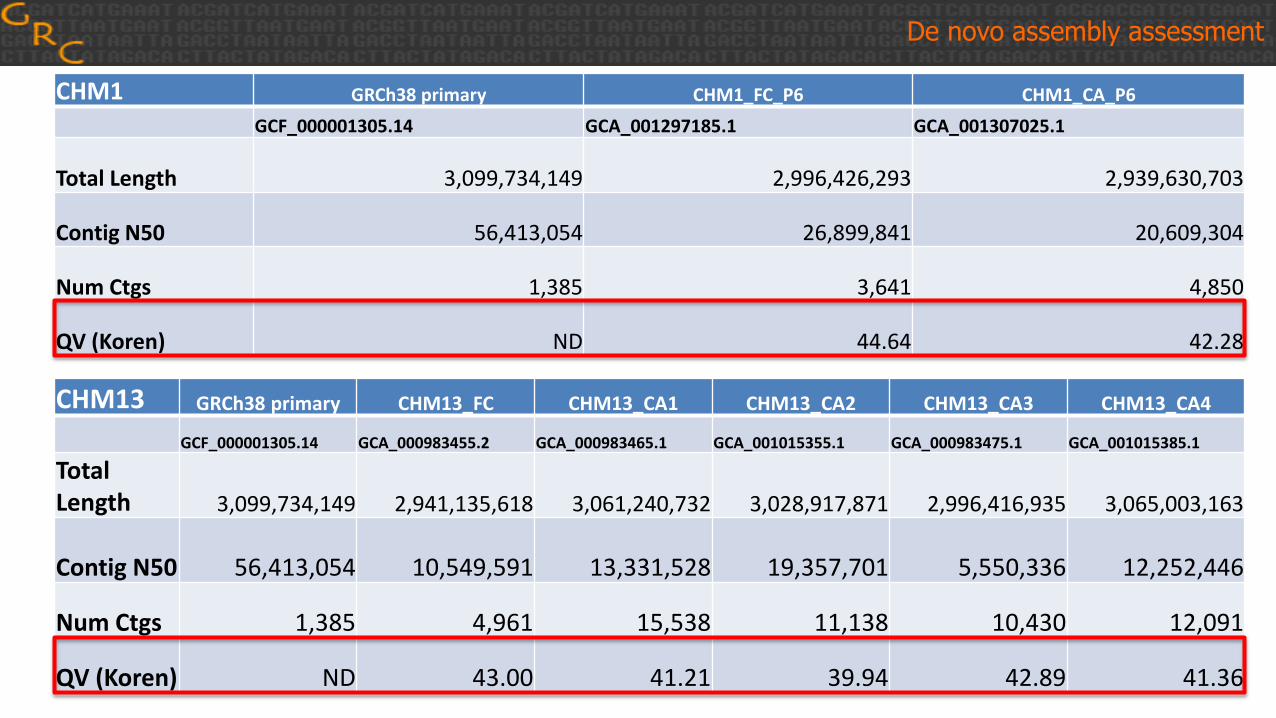
CHM1 GRCh38 primary CHM1_FC_P6 CHM1_CA_P6
GCF_000001305.14 GCA_001297185.1 GCA_001307025.1
Total Length 3,099,734,149 2,996,426,293 2,939,630,703
Contig N50 56,413,054 26,899,841 20,609,304
Num Ctgs 1,385 3,641 4,850
QV (Koren) ND 44.64 42.28
CHM13 GRCh38 primary CHM13_FC CHM13_CA1 CHM13_CA2 CHM13_CA3 CHM13_CA4
GCF_000001305.14 GCA_000983455.2 GCA_000983465.1 GCA_001015355.1 GCA_000983475.1 GCA_001015385.1
Total Length 3,099,734,149 2,941,135,618 3,061,240,732 3,028,917,871 2,996,416,935 3,065,003,163
Contig N50 56,413,054 10,549,591 13,331,528 19,357,701 5,550,336 12,252,446
Num Ctgs 1,385 4,961 15,538 11,138 10,430 12,091
QV (Koren) ND 43.00 41.21 39.94 42.89 41.36
De novo assembly assessment
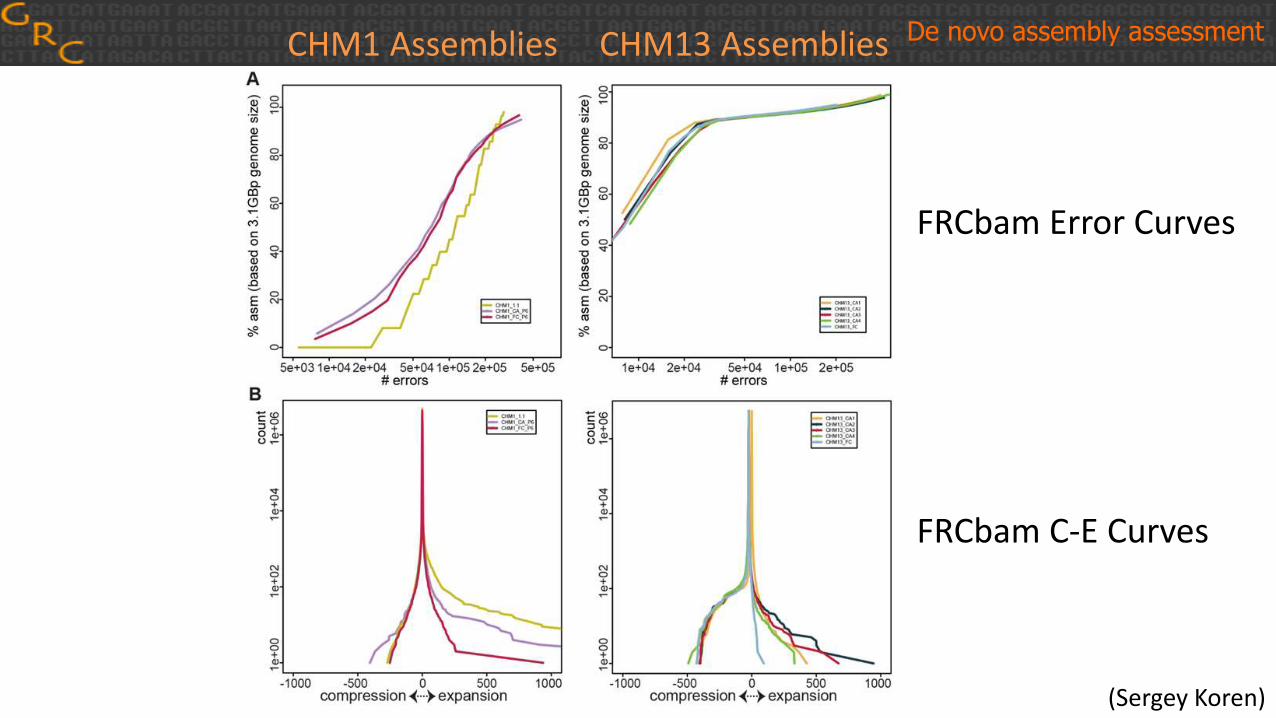
CHM1 Assemblies CHM13 Assemblies De novo assembly assessment
FRCbam Error Curves
FRCbam C-E Curves
(Sergey Koren)

De novo assembly assessment
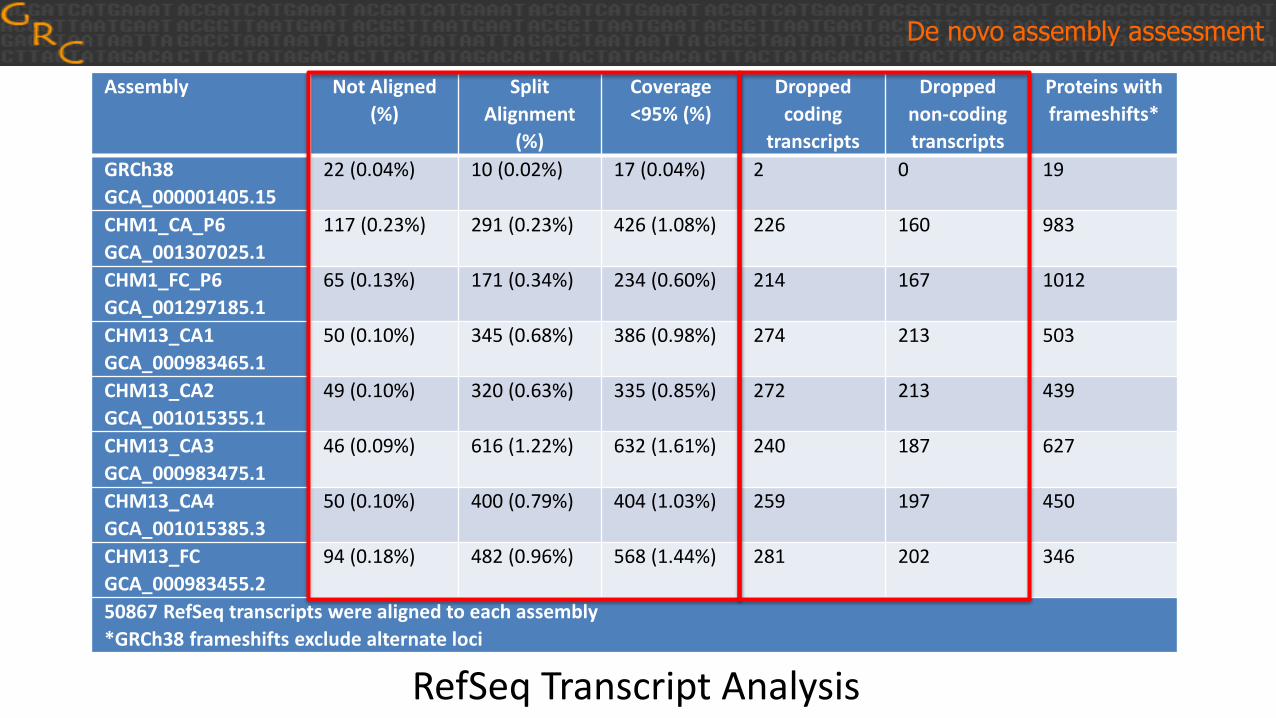
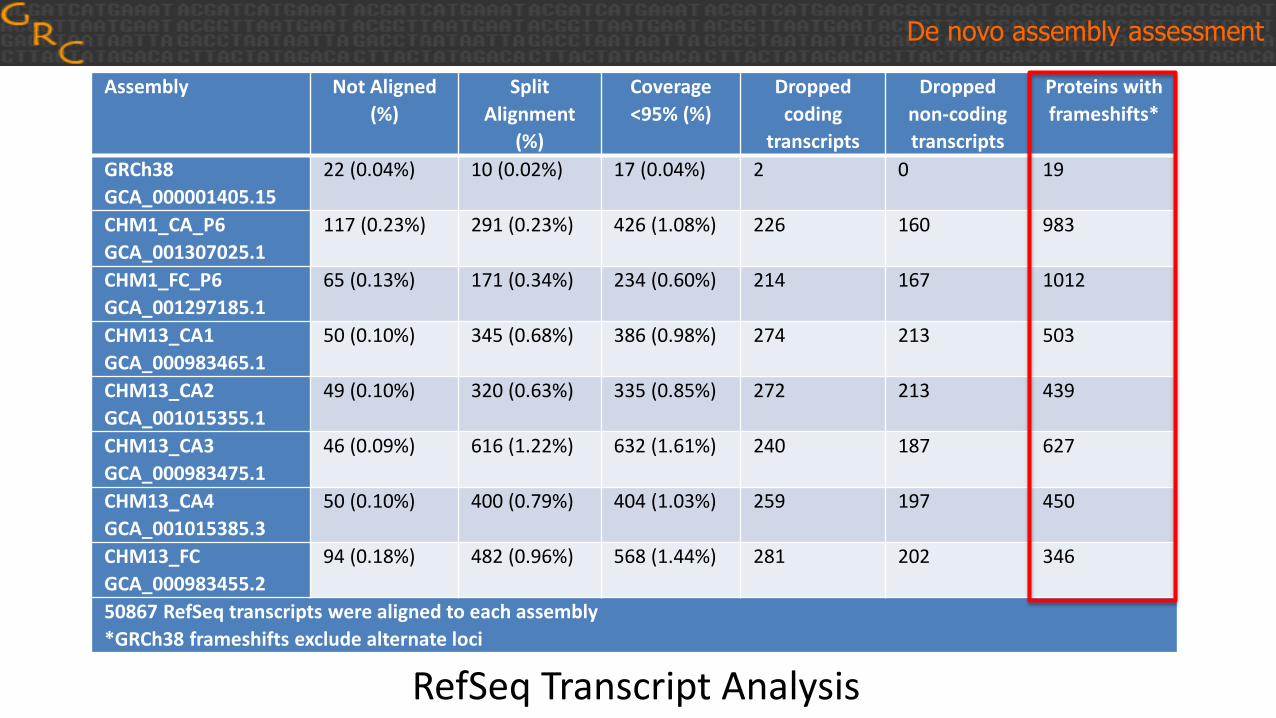
Assembly Not Aligned
(%)
Split
Alignment
(%)
Coverage
<95% (%)
Dropped
coding
transcripts
Dropped
non-coding
transcripts
Proteins with
frameshifts*
GRCh38
GCA_000001405.15
22 (0.04%) 10 (0.02%) 17 (0.04%) 2 0 19
CHM1_CA_P6
GCA_001307025.1
117 (0.23%) 291 (0.23%) 426 (1.08%) 226 160 983
CHM1_FC_P6
GCA_001297185.1
65 (0.13%) 171 (0.34%) 234 (0.60%) 214 167 1012
CHM13_CA1
GCA_000983465.1
50 (0.10%) 345 (0.68%) 386 (0.98%) 274 213 503
CHM13_CA2
GCA_001015355.1
49 (0.10%) 320 (0.63%) 335 (0.85%) 272 213 439
CHM13_CA3
GCA_000983475.1
46 (0.09%) 616 (1.22%) 632 (1.61%) 240 187 627
CHM13_CA4
GCA_001015385.3
50 (0.10%) 400 (0.79%) 404 (1.03%) 259 197 450
CHM13_FC
GCA_000983455.2
94 (0.18%) 482 (0.96%) 568 (1.44%) 281 202 346
50867 RefSeq transcripts were aligned to each assembly
*GRCh38 frameshifts exclude alternate loci
De novo assembly assessment
RefSeq Transcript Analysis
Assembly Not Aligned
(%)
Split
Alignment
(%)
Coverage
<95% (%)
Dropped
coding
transcripts
Dropped
non-coding
transcripts
Proteins with
frameshifts*
GRCh38
GCA_000001405.15
22 (0.04%) 10 (0.02%) 17 (0.04%) 2 0 19
CHM1_CA_P6
GCA_001307025.1
117 (0.23%) 291 (0.23%) 426 (1.08%) 226 160 983
CHM1_FC_P6
GCA_001297185.1
65 (0.13%) 171 (0.34%) 234 (0.60%) 214 167 1012
CHM13_CA1
GCA_000983465.1
50 (0.10%) 345 (0.68%) 386 (0.98%) 274 213 503
CHM13_CA2
GCA_001015355.1
49 (0.10%) 320 (0.63%) 335 (0.85%) 272 213 439
CHM13_CA3
GCA_000983475.1
46 (0.09%) 616 (1.22%) 632 (1.61%) 240 187 627
CHM13_CA4
GCA_001015385.3
50 (0.10%) 400 (0.79%) 404 (1.03%) 259 197 450
CHM13_FC
GCA_000983455.2
94 (0.18%) 482 (0.96%) 568 (1.44%) 281 202 346
50867 RefSeq transcripts were aligned to each assembly
*GRCh38 frameshifts exclude alternate loci
De novo assembly assessment
RefSeq Transcript Analysis

• Reference assembly management
• Challenges of changing technologies, new resources
• De novo assembly assessment
Evolution of Human Reference Assembly Management

Credits
GRCh38 Collaborators• NCBI RefSeq and gpipe annotation team• Havana annotators• Karen Miga• David Schwartz• Steve Goldstein• Mario Caceres• Giulio Genovese• Jeff Kidd• Peter Lansdorp• Mark Hills• David Page• Jim Knight• Stephan Schuster• 1000 Genomes
GRC SAB• Rick Myers• Granger Sutton• Evan Eichler• Jim Kent• Roderic Guigo• Carol Bult• Derek Stemple• Jan Korbel• Liz Worthey• Matthew Hurles• Richard Gibbs
Assemblathon Collaborators• Jason Chin• Adam Phillippy• Sergey Koren• Heng Li
GRCTina Graves-LindsayKaryn Meltz SteinbergKerstin HoweRichard DurbinPaul FlicekLaura ClarkeDeanna ChurchCurators!Developers!
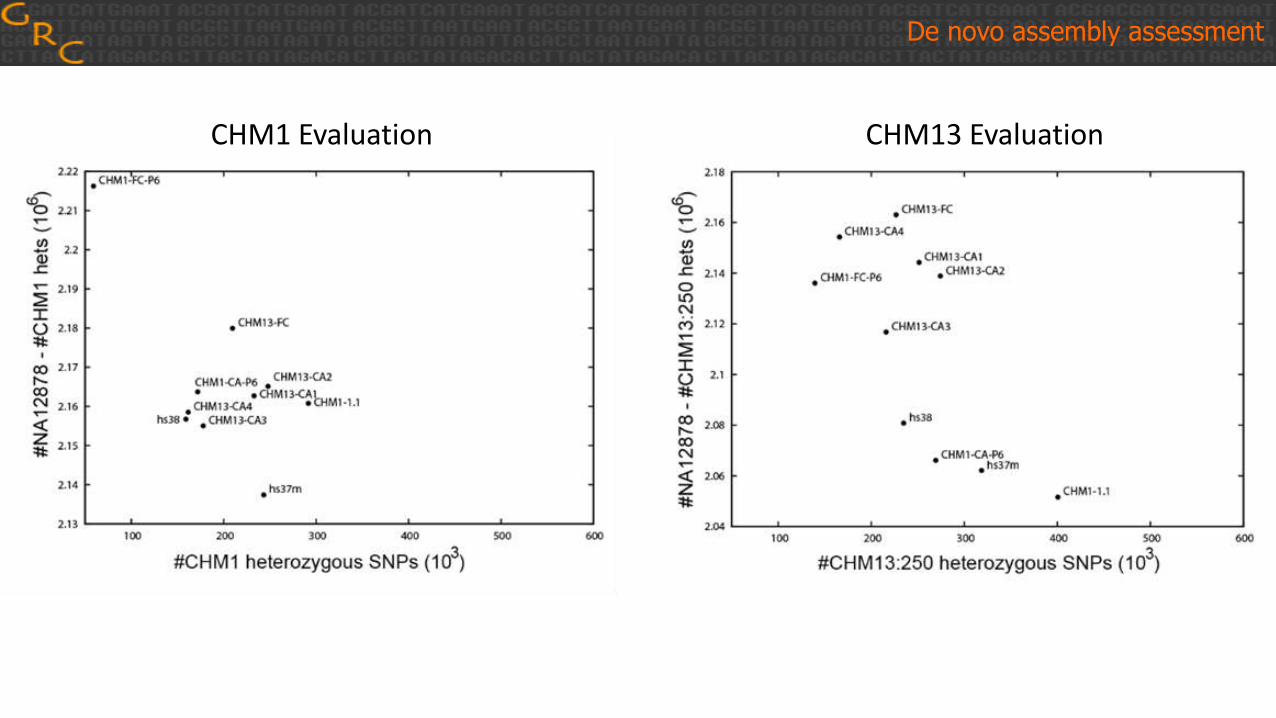
CHM1 Evaluation CHM13 Evaluation
De novo assembly assessment






![Altivar Machine ATV320 - Schneider ElectricINPUTS / OUTPUTS CFG] ... REFERENCE MEMORIZING ... Use only electrically insulated tools](https://img.pdfslide.net/doc/110x75/5aff3e787f8b9a864d902bcd/altivar-machine-atv320-schneider-inputs-outputs-cfg-reference-memorizing.jpg)