Embed Size (px)
Citation preview

BYODBring your own data
Joerg Blumtritt
@jbenno
1

BYOD - Bring your own data
• zur Unterstützung von Patienten
• für den Hausarzt
• für die Forschung
• Datenschutz - Nicht-Anonymisierbarkeit
• Algorithmen-Ethik
2

The Quantified Self
• Die Bewegung des Quantified Self wurde 2007 von den beiden Wired-Redakteuren Kevin Kelly und Gary Wolf gegründet.
• Quantified Self bedeutet "Selbst-Tracking", also sich selbst vermessen.
• Das ist natürlich gar nicht so ungewöhnlich. Die meisten Menschen haben eine Badezimmerwaage. Wir machen Striche an die Wand um die größe unserer Kinder zu dokumentieren.
• Neu ist, dass man die Daten digital erfassen kann - unter Umständen sogar kontinuierlich - und dass sich die Daten leicht mit anderen teilen lassen.
• 60% der US-Amerikaner nutzen Self-Tracking, und auch in Deutschland haben Fitness-Apps wie Runtastic oder Fitbit Millionen von Nutzern. Die meisten Selbst-Tracker geben an, dass es für sie wesentlich leichter ist, ihr Verhalten positiv zu verändern, wenn sie mit anderen gemeinsam auf die Daten blicken.
• Quantified Self geht aber weiter: Schlaf-Tracking hilft dabei, Schlafstörungen auf den Grund zu kommen. Jawbone, abieter der erfolgreichsten Schlaftracking-Lösung "Up" wird schon als "Nachfolger von Apple" gehandelt und ist mit über 1 Mrd. US$ bewertet.
• Lifelogging - ein visuelles Tagebuch führen; Gadgets wie der Narrative-Clip machen automatisch alle 30 Sek. ein Bild. Bekannt geworden ist das LIfetracking durch die zahlreichen Videos, die automatische Kameras aus der Windschutzscheibe beim Fahren von dem spektakulären Metor gemacht hatten, der über Russland explodierte. Dort verlangen Versicherungen, dass Autofahrer ihre Fahrt komplett visuell aufzeichnen.
• Am intimsten wird Quantified Self, wenn es daran geht, das eigene Genom zu entschlüsseln.
3
"Bring your own data!"
• Quantified Self -> Quantified Life
• Menschen wollen über sich lernen und eine solide Datengrundlage über ihr Leben besitzen..
• In den USA und vielen Ländern mit schwach ausgeprägter Krankenversicherung wird es zunehmend üblich, selbst gemessene Daten zum Arzt mitzubringen. Bei vielen Untersuchungen spart dies wesentlich Kosten ein und beschleunigt die Behandlung.
• Für viele Menschen ist es durch Quantified Self zum ersten Mal überhaupt möglich geworden, gute Laborwerte über ihre Gesundheit zu erhalten. Beispiele sind Kits zur Blutuntersuchung, die automatisch via Smartphone die Ergebnisse in Labors schicken und sofort die Resultate anzeigen. Solche Kits sind z.B. in Indien weit verbreitet. Auch die Verbesserung, die Self-Tracking chronisch Kranken bringen kann, ist ein so starkes Argument für Quantified Self, dass Datenschutz davon überstimmt wird.
• Eine "Black-Box" im Auto oder (wie in Russland vorgeschrieben), eine Video-Aufzeichnung durch die Windschutzscheibe senkt die Versicherungskosten so drastisch, dass alle Datenschutzbedenken sofort weggewischt werden.
4

Badezimmer-Waage
5
klassisches "Self Tracking"

6
Zahlen in Kontext bringen
7
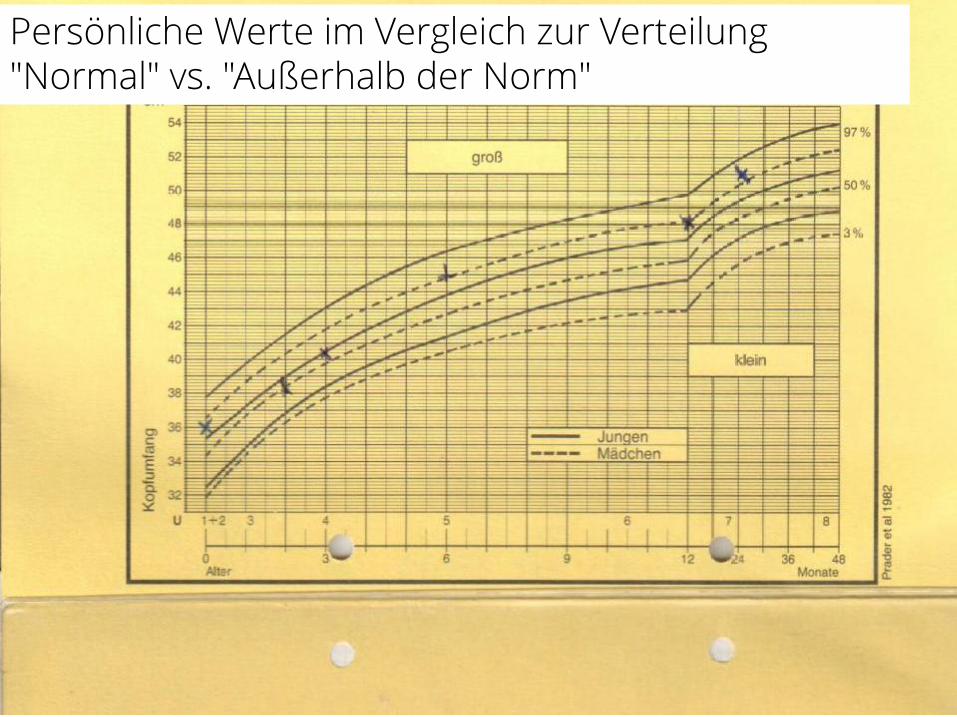
Persönliche Werte im Vergleich zur Verteilung"Normal" vs. "Außerhalb der Norm"

8
" ... Dabei schränken Patienten mit dauerhaft schlechtem Gesundheitszustand die Anzahl ihrer Arztbesuche im Vergleich zum Bevölkerungs-durchschnitt am stärksten ein: Bei den chronisch Kranken sank die Zahl der Arztbesuche im Zeitraum von 2003 bis 2005 um ein Drittel"
(Gesundheitsmonitor, Bertelsmannstiftung)
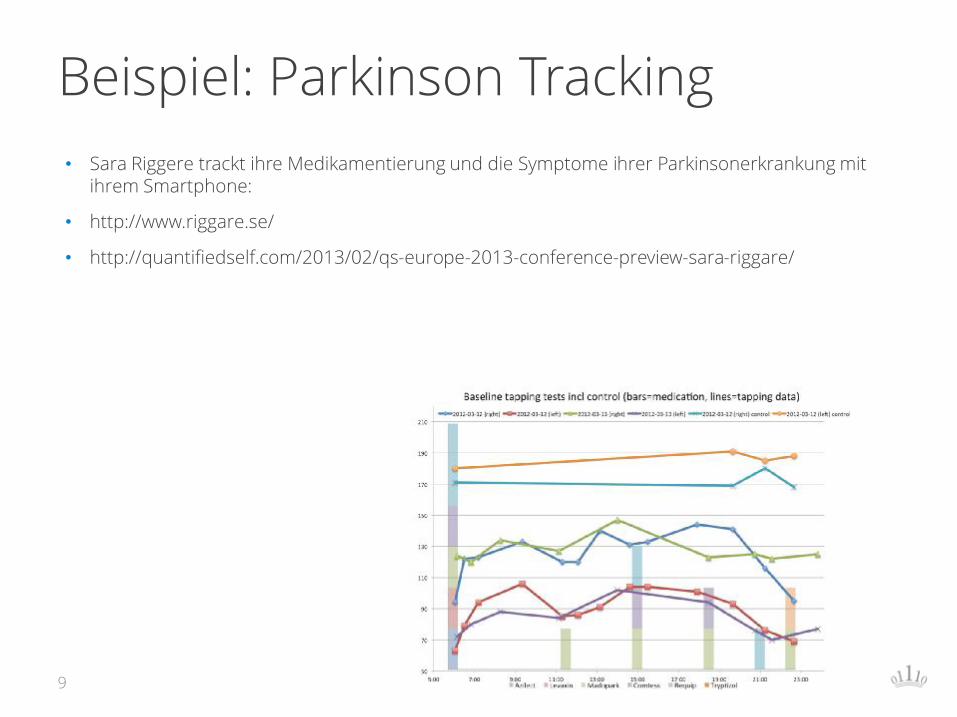
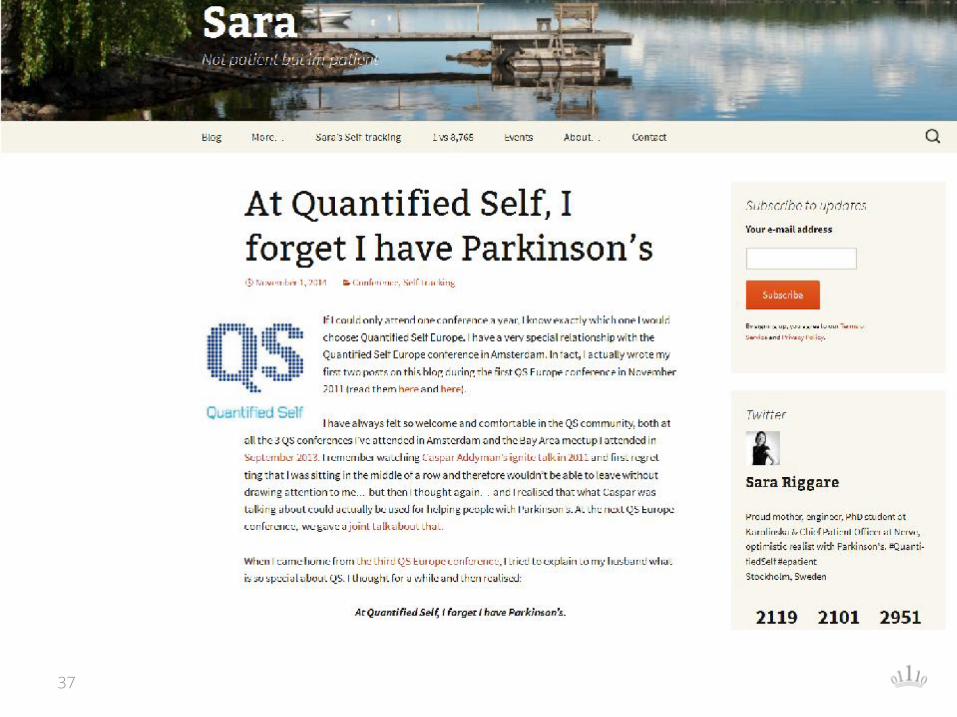
Beispiel: Parkinson Tracking
• Sara Riggere trackt ihre Medikamentierung und die Symptome ihrer Parkinsonerkrankung mit ihrem Smartphone:
• http://www.riggare.se/
• http://quantifiedself.com/2013/02/qs-europe-2013-conference-preview-sara-riggare/
9

Beispiel: Mood Tracking
10 soundfeelings.com

Datarella OsteoGuide
• Unterstützung von Osteoporosepatientinnen
• Ernährung und Medikation
• Erreichen selbstgesetzter Mobilitätsziele
• Objektives Bild des Zustandes und des Verhaltensder Patientinnen für den Arzt
11

12
explore: Mobile App mit offline Funktionalität und Backend
Sensor Framework 'explore'Die Daten, welche durch die Sensoren im Telefon getrackt werden, sind allerdings nicht leicht zugänglich.Mit dem von Datarella entwickelten 'explore App Framework' können die Daten sämtlicher Sensoren gesammelt, gespeichert und ausgewertet werden.
Complex Event Processing Engine (CEPE)Mit den Smartphone-Daten beliebige Aktionen auf dem Smartphone steuern - diese Aufgabe löst die von Datarella entwickelte 'explore CEPE'. Beliebige Kombinationen von Ereignissen, die auf dem Smartphone gemessen werden, triggern über die CEPE die gewünschte Reaktion, von Location-Based-Services bis zu Gesundheitstips in Abhängigkeit des Nutzerverhaltens.
APIZum Abruf der Daten steht, neben dem Zugriff auf die Datenbank im Backend, eine Web-API zur Verfügung. Nach Authentifizierung können über die API Datensätze abgerufen und in Drittsystemen (z.B. anderen Apps) dargestellt oder ausgewertet werden.
Fragebögen – mobil optimiert'explore' bietet alle gängigen Fragebogen-Typen, maßgeschneidert auf die Nutzbarkeit auf Smartphones. Zusätzlich verfügt 'explore' über ein Infografik-Modul, mit dem Ergebnisse an die Teilnehmer zurückgespielt werde können (z.B. für Delphi-Umfragen). Alle Interaktionen arbeiten offline und übertragen die Daten, wenn eine geeignete Internetverbindung zur Verfügung steht.
explore OsteoporoseguideDen Nutzern wird das eigene Verhalten analysiert und visualisiert, über Hinweise und Tipps wird das Verhalten interpretiert und über Notifications werden die Nutzer daran erinnert, die Dinge zu tun, die für ihre Gesundheit wichtig sind. Die Daten, Analysen und Hilfestellungen sind dabei zunächst nur für den Nutzer bestimmt und selbstverständlich strengster Datensicherheit unterworfen. Die Patenten können dann entscheiden, die Daten mit ihrem Arzt, ihrer Familie oder anderen Patienten zu teilen.
Die Vorteile: des OsteoporoseguidePatienten können selbst besser einschätzen, wie es um ihre Gesundheit und den Erfolg ihrer Bemühungen bestellt ist. Sie können ihre eigenen Daten zu den Daten anderer Nutzer ins Verhältnis setzen, und sie werden durch individuelle Programme motiviert, ihre Beweglichkeit zu fördern.Die betreuungsarmen Zeitintervalle zwischen Arztbesuchen können mit 'explore' besser überbrückt und eine Verschlechterung ihres Zustands kann schneller erkannt werden.Der Arzt erhält ein objektives und nahezu vollständiges Bild des Patientenverhaltens. Die Daten ergänzen die punktuelle Anamnese in der Sprechstunde und die subjektive Selbsteinschätzung des Patienten. Das gleiche gilt für Angehörige, die stets über den Zustand des Patienten informiert bleiben und so besser auf Veränderungen reagieren können.
13
Gemeinschaftliche Verantwortung oder liberale Fehlschluss?
Wenn Menschen ihr Verhalten im Blick behalten, sich selbst tracken und die Daten mit anderen Teilen, hat das viele Vorteile, für sie selbst und besonders für die Gemenschaft:- Besserer Blick auf die Gesundheit- Bessere Daten über den Verlauf von Krankheiten, und zwar nicht
erst nach deren Ausbruch- Unterstützung bei der Rehabilitation
Besonders deutlich ist der Vorteil bei der Kontrolle von "schädlichem Verhalten". Studien mit Autofahrern zeigen, dass es bereits reicht, einmal pro Woche eine automatische Auswertung zu erhalten, die einem Rückmeldung gibt, wie man gefahren ist. Fährt man zu schnell? Fährt man zu dicht auf? etc.Die meisten Autofahrer wollen offensichtlich nicht "schlecht" oder aggressiv fahren und korrigieren ihr Verhalten, wenn man ihnen "einen Spiegel vorhält".
Die Vorteile für die Gemeinschaft sind also groß. Werden wir also bald eine Kultur erleben, wie es sie früher in ländlcihen Gegenden, auf dem Dorfe gegeben hat: jeder seines Nachbarn hüter?
Dieser Aspekt von Kontrolle durch unsere Mitmenschen ist einerseits erschreckend, andererseits ist es vielleicht ein Weg, ohne staatliche Gewalt das Leben von so vielen Menschen nachhaltig zu organisieren.
Aber eines bleibt offen: Was geschieht mit den Menschen, die den Normen der gemeinschaft nicht entsprechen? Nur dadurch, dass wir Leuten Self-Tracking-Werkzeuge an die Hand geben, werden viele ihr Verhalten nicht ändern können. Ein gelähmter Mensch wird nicht aufstehen und Sport machen, nur weil wir ihm oder ihr ein Fitness-Tracker-Armband geben.
Wir müssen uns darum kümmern, dass wir nicht noch mehr Verantwortung auf die Einzelnen häufen, die wir als moralische Verpflichtung als Gemeinschaft und Gesellschaft für sie haben.
Das ist keine technologische oder medizinische Frage. Es ist eine politische Frage.

14
http://www.npr.org/blogs/goatsandsoda/2014/12/05/366405541/babys-necklace-could-end-up-being-a-life-saver

Telemedizin
• Ferndiagnose über mobile Daten
15

Telemedizin
• Ständige Messung
• Implantate
16

Daten teilen
• "Digital exhaust", "Dust"
• Nicht nur medizinische Daten, sondern das gesamte Verhalten kann potenziell geteilt werden
• Große Bereitschaft bei chronisch Kranken
("Im Krankenhaus hast du sowieso keine Privatsphäre.")
17

Sharing Economy
• Die Almende ("Commons"); bis zum Ende des Mittelalters übliche Form der Besitzteilung. In der Neuzeit wird sie durch individuelle Wertschöpfung und Bezahlung der Leistung des Einzelnen abgelöst ("Leistungsschutz"; Besitz von Schöpfungen)
• Frühe, moderne Formen der Sharing Economy sind Genossenschaften. Im heutigen Sinn ist die Sharing Economy aber weniger stark Inkorporiert, sondern lose über das Netz organisiert.
• Geschätztes Marktvolumen 2012 (Thomson Reuters): >500B$
• Global Sharing Day (2.6.) >70 Mio Teilnehmer in 192 Ländern
• Das Web als "Read-Write-Web" (im Gegensatz zu den davor üblichen "Read only"-Publishern): Remix Culture, Sampling, File Sharing, Piracy
• Creative Commons "CC" (Flickr; Wikipedia, Arduino als führende Platform für Harware Entwicklung), GNU (Debian Linux), FSF, Github (größte Sammlung von Programmcode), Maker-Bot (3-D-Druck, bei dem die Designs stets in die Almende einfließen), Pumpipumpe (Gegenseitiger Verleih von Werkzeug und Maschinen in der Schweiz), Mundraub (Verfügbarmachung von Obstbäumen für die Allgemeinheit), Bookcrossing (Weitergabe von Büchern)
• Shared Office Spaces, Maker Spaces, Car Sharing
• http://www.trust.org/item/?map=is-the-sharing-economy-a-hippy-pipedream
18

Peer-to-Peer (P2P)
• "De-Intermediarization" - statt der Kette Produzent-(mehrere) Zwischenhändler-Konsument werden Akteuren über eine technologische Plattform direkt miteinander verbunden. Die Plattform regelt ggf. Zahlungsverkehr, Versicherung, Versand und fungiert als Streitschlichter.
Beispiele:
• Freifunk (P2P Internetverbindung unter Umgehung der klassischen Telekommunikationsunternehmen)
• Ebay (Direkter Online-Retail, nicht nur von Privat, sondern auch Professionell)
• Amazon (Händlernetz, Verkauf von gebrauchten Büchern)
• AirBnB (P2P-Zimmervermietung; ist für die Hotels bereits so bedrohlich geworden, dass diese Sturm laufen und in Lobby-nahen Stadtregierungen wie z.B. Berlin versuchen, ein Verbot durchsetzen)
• Uber (Direkte Vermittlung von Chauffeuren unter Umgehung der Taxi-Genossenschaften)
• P2P-Lending (Direkte Vermittlung von Krediten zwischen Privatleuten, ohne Bank dazwischen)
• Kickstarter, Indiegogo, etc.: Crowd Funding (und zwar in z.T. erheblichem Umfang) macht zunehmend die Seed-Finanzierung und Series A überflüssig.
19
20

21
Big Data:
"More information is created faster than organisations can make sense of it."
Jeff Jonas
http://youtu.be/lxLcvsNexK4

Big Data Paradigmenwechsel
• "Data Lake" statt Silos
• Explorativ statt Hypothesengetrieben
• Einzelfallbetrachtung statt Repräsentativität
• Keine "Meta-Daten", nur noch Daten
"You dont need a high percentage as long as your sample size is large enough"
22
23

Big Data
• Paradigmenwechsel in Verarbeitung, Analyse und Interpretation von Daten
• Von festen Strukturen zu beliebigen Inputs
• Von vorgefassten Hypothesen zu Mustererkennung
• Völlig neue Player im Bereich Software und Infrastruktur
• "Demokratisierung" von Datenanalyse - "Ende des Herrschaftswissens"
• Wechsel Von Statistik und Business Intelligence zu Data Science
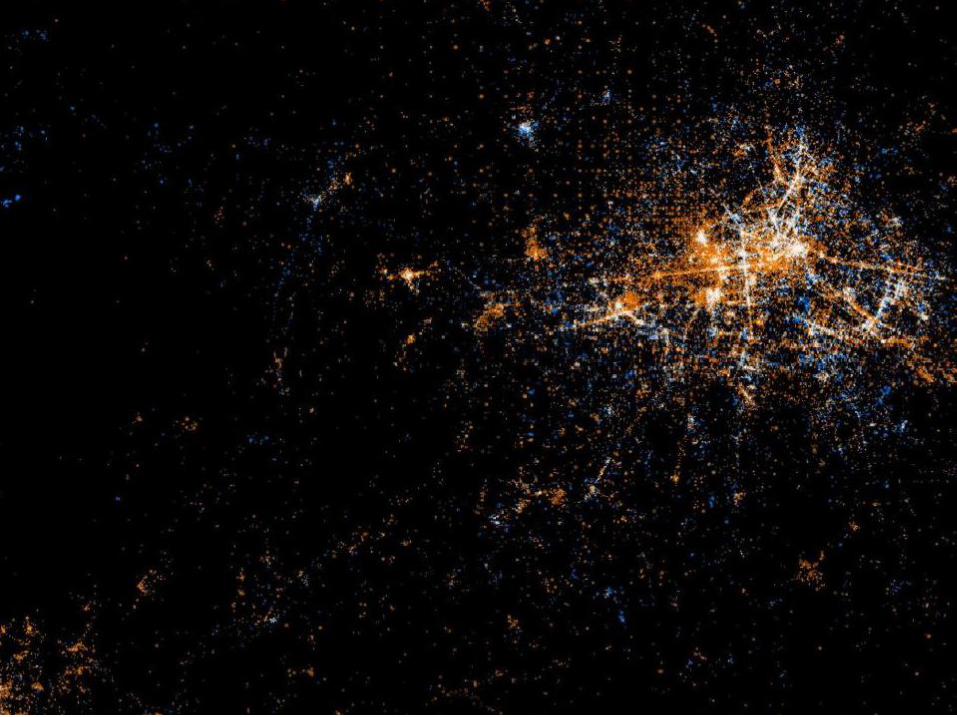
Das erste Chart zeigt eine Karte von Berlin, die Eric Fisher aus den Geodaten von Tweets (Blau) und Flickr-Bildern erstellt hat. Es sind die Metadaten, die die interessante Information tragen. Die Karte ist völlig ohne "geografisches Knowhow" entstanden.
Dieses Beispiel ist typisch für Big Data: Strukturen aus Daten erkennen, die nicht explizit dafür gesammelt worden waren.
Link: https://www.flickr.com/photos/walkingsf/
(unter Creative Commons-Lizenz cc-by-sa veröffentlicht)
24

• Der "Rohstoff" für Big Data sind Menschen. Die Daten widerspiegeln unser Leben, entwerfen ein Bild von uns, machen uns analysierbar.
• Daten sind nicht "virtuell", sondern Teil der Wirklichkeit (wörtlich: sie haben Wirkung auf unser Leben). Man kann sich das versinnbildlichen, dass Daten uns wie eine, für unsere Augen unsichtbare, zusätzliche Dimension umgeben.
• Vergleichbar zum Mikroskop, das uns die unsichtbare Welt der Mikroorganismen um uns herum sichtbar macht, werden die Daten für uns durch Datenanalyse und Visualisierung greifbar.
• Daten zeichnen ein extrem präzises Bild unseres Verhaltens. Sie ermöglichen uns, persönliche Vorhersagen auf einzelne Menschen zu machen, statt wie bisher auf grobe Aggregate wie "Geschlecht" oder "Alter" zurückfallen zu müssen.
• Marketing, mit Search, Online-Retail, Online-Targeting und Social Media, ist der wichtigste Treiber für den technologischen Fortschritt bei Big Data.
25
D3Visualization
MachineLearning
Infrastruktur
Velocity
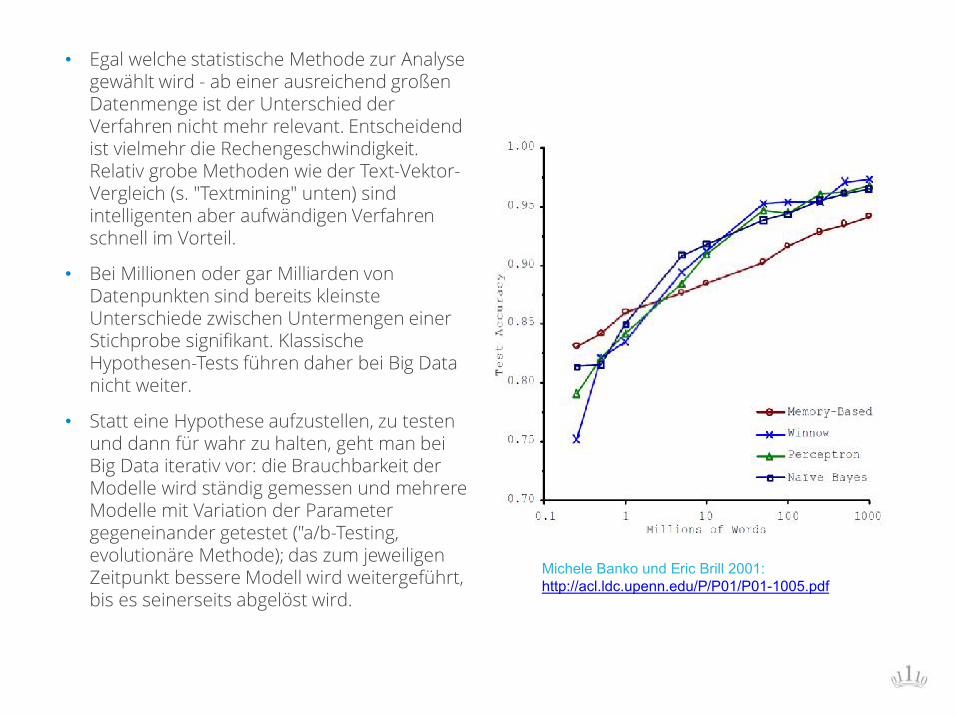
Michele Banko und Eric Brill 2001: http://acl.ldc.upenn.edu/P/P01/P01-1005.pdf
• Egal welche statistische Methode zur Analyse gewählt wird - ab einer ausreichend großen Datenmenge ist der Unterschied der Verfahren nicht mehr relevant. Entscheidend ist vielmehr die Rechengeschwindigkeit. Relativ grobe Methoden wie der Text-Vektor-Vergleich (s. "Textmining" unten) sind intelligenten aber aufwändigen Verfahren schnell im Vorteil.
• Bei Millionen oder gar Milliarden von Datenpunkten sind bereits kleinste Unterschiede zwischen Untermengen einer Stichprobe signifikant. Klassische Hypothesen-Tests führen daher bei Big Data nicht weiter.
• Statt eine Hypothese aufzustellen, zu testen und dann für wahr zu halten, geht man bei Big Data iterativ vor: die Brauchbarkeit der Modelle wird ständig gemessen und mehrere Modelle mit Variation der Parameter gegeneinander getestet ("a/b-Testing, evolutionäre Methode); das zum jeweiligen Zeitpunkt bessere Modell wird weitergeführt, bis es seinerseits abgelöst wird.

• Alle Daten können relevante Aussagen für unsere Zwecke liefern. Was früher Meta-Daten waren, sind heute häufig viel aussagekräftigere Inputs für unsere Modelle.
• Es ist auch nicht sinnvoll, zwischen Stammdaten und Bewegungsdaten zu unterscheiden. Während sich Stammdaten über die Zeit sehr wohl ändern können (z.B. die Adresse durch Umzug, die Firmierung, etc.), sind Bewegungsdaten wertvolle Beschreibungen von Einstellung und Verhalten von Menschen: Was jemand kauft, sagt oft mehr ober ihn aus, als sein Alter.
• Beim Modelling sind natürlich Kollinearitäten und Redundanzen zu beachten. Moderne Modelling-Packages unterstützen allerdings die sinnvolle Reduzierung der Variablen.

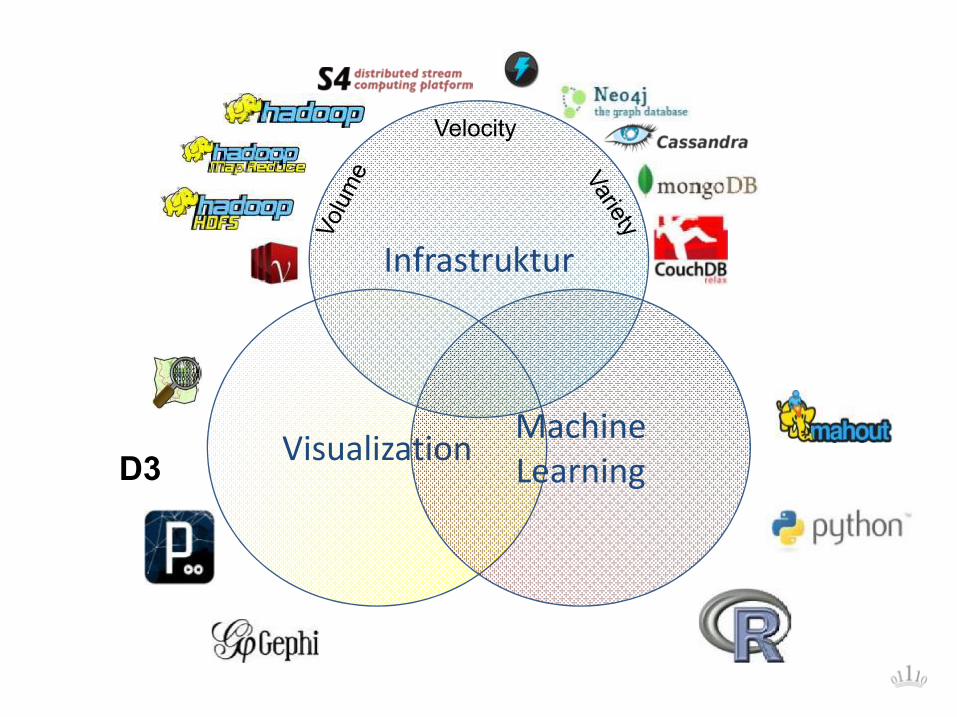
Data Science
http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram
• Data Science unterscheidet sich von Statistik und empirischer Sozialforschung:
• Data Science bedeutet nicht nur, Verfahren aus vorgegebenen Packages wie SPSS oder SAS einsetzen zu können, sondern den gesamten Prozess, von der Datenerhebung bis zur Programmierung des Produktivsystems zu überblicken. "Statisticians use software, data scientists code."
• Im Focus der Data Science steht Recheneffizienz und Anwendbarkeit. Modelle müssen agil angepasst werden können. Ausgabe der Ergebnisse erfolgt in der Regel als interaktives Web-Dashboard. Neben Standard-Tools wie Tableau Software werden diese Dashboards in JavaScript D3, HTML5 etc. umgesetzt.

30
"Facebook would never change their advertsing relying on a sample size as small as we do medical research on."
(David Wilbanks)
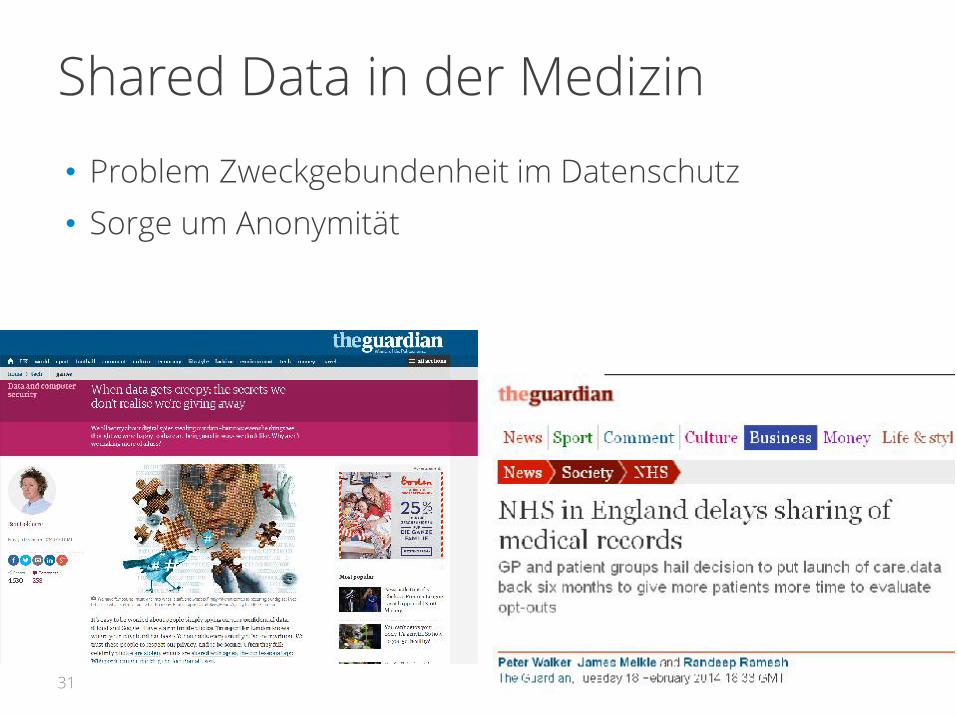
Shared Data in der Medizin
• Problem Zweckgebundenheit im Datenschutz
• Sorge um Anonymität
31

Data Fingerprinting
• Die Daten, die wir ununterbrochen hinterlassen, sind so reichhaltig, dass schon wenige Datenpunkte ausreichen, uns stets eindeutig zu identifizieren.
• Die Abbildung rechts stammt aus einer Studie zum Thema Data Fingerprinting: "Wieviele Datenpunkte sind ausreichend, um einen beliebigen Mobilfunknutzer eindeutig anhand seiner Spur durch die Funkzellen zu identifizieren?" Die Antwort: vier zufällig herausgegriffene Zeitpunkte reichen aus, um 95% der Mobilfunknutzer zu identifizieren, obwohl die Funkzellen mit ca. 250m Durchmesser ein, im Vergleich zu anderen Daten wie etwa GPS-Location, eher grobes Raster liefern.
• Fazit: Die Daten über die wir im Zusammenhang mit Gesundheit sprechen, lassen sich meistens nicht sinnvoll anonymisieren. Der Personenbezug bleibt erhalten.
32
33
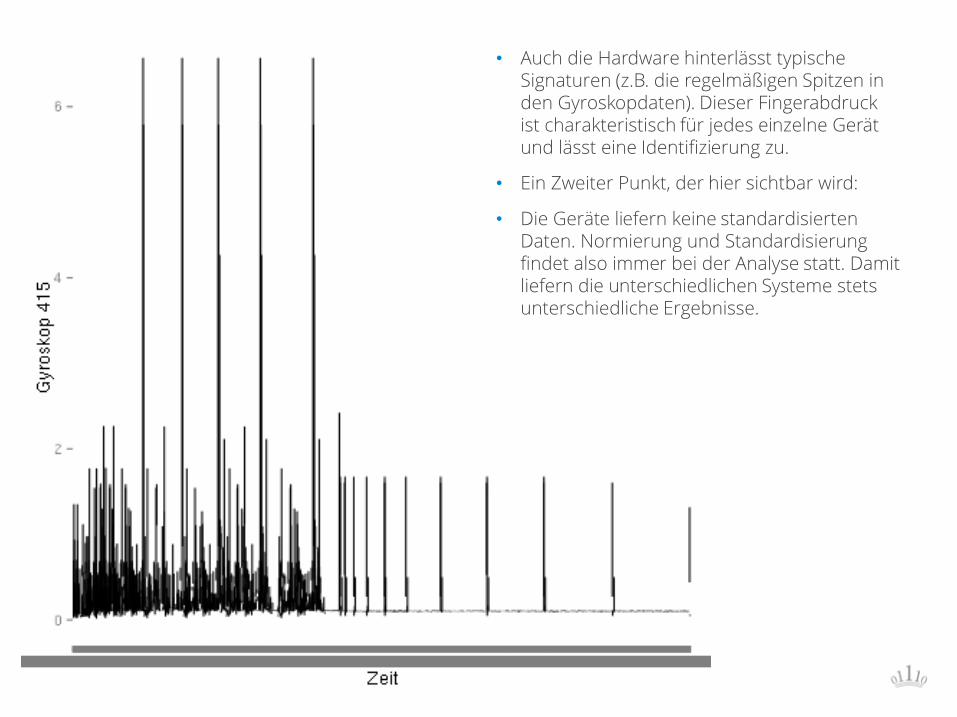
• Auch die Hardware hinterlässt typische Signaturen (z.B. die regelmäßigen Spitzen in den Gyroskopdaten). Dieser Fingerabdruck ist charakteristisch für jedes einzelne Gerät und lässt eine Identifizierung zu.
• Ein Zweiter Punkt, der hier sichtbar wird:
• Die Geräte liefern keine standardisierten Daten. Normierung und Standardisierung findet also immer bei der Analyse statt. Damit liefern die unterschiedlichen Systeme stets unterschiedliche Ergebnisse.

34

Shared Data in der Medizin
• Problem Zweckgebundenheit im Datenschutz
• Sorge um Anonymität
zusätlich:
• Heterogenität
• Keine Standards
• Implizite Werturteile: "Algorithmen Ethik"
35

Datenschutz und informationelle Selbstbestimmung• Die Snowden-Enthüllungen haben deutlich gemacht, dass Datenschutz nichts hilft, gegen staatliche
Überwachung. Schon heute haben die Finanzämter vollen Zugriff auf unsere Konten. Die Voratsdatenspeicherung wurde zwar vom Europäischen Gerichtshof vor kurzem für rechtswidrig und nichtig erklärt. Dennoch werden insbesondere Mobilfunkdaten in unglaublichem Umfang von den Sicherheitsbehörden ausgewertet. Zwei Millionen Funkzellenabfragen gab es 2012 alleine in Schleswig-Holstein!
• Unternehmen wie Google und selbst das viel gescholtene Facebook scheinen dagegen bis heute relativ pfleglich mit unseren Daten umzugehen - ihre Furcht vor Imageverlust und daraus folgendem wirtschaftlichem Schaden ist zu groß, als dass sie sich Fehler erlauben könnten.
• Durch die "Heartbleed"-Sicherheitslücke, die im April bekannt wurde, sind Passwörter, vertrauliche Nachrichten und alle möglichen anderen persönlichen Daten im gesamten Internet über Monate, wenn nicht Jahre mehr oder weniger ungeschützt zugänglich gewesen, - zumindest für die, die von der Sicherheitslücke wussten.
• Datenschutz wiegt uns in falscher Sicherheit, macht uns unaufmerksam. Statt Daten zu schützen, sollten wir stärker auf offene Daten drängen. Wenn jeder Zugriff hat, gibt es kein hierarchisches Gefälle mehr. Wenn wir uns bewusst sind, dass die Daten potenziell von jedem Menschen eingesehen werden können, werden wir uns so verhalten, dass wir nicht mehr erpressbar sind.
• Die Vorstellung von "persönlichen Daten", von Privatheit, ist zu tiefst bürgerlich (im wörtlichen Sinne); sie ist dem Wunsch der Bürger entsprungen, sich vom Adel abzugrenzen. Wie öffenltich die Aristokratie im Feudalismus lebte, kann man bis heute in den offenen Zimmerfluchten der Barockschlösser bewundern. Für Menschen auf den Dörfern gab es keine Privatsphäre. Alle lebten in einer Kammer zusammen. Erst mit der bürgerlichen "Familienwohnung" des 19 Jhd. konnte sich Privatsphäre als kultureller Wert entwickeln.
• Die Digitalisierung ist nicht mehr rückgängig zu machen. Die Vorteile, Daten zu teilen sind so überwältigend, dass die Gesellschaften einen "Datenschutz" oder "Informationelle Selbstbestimmung" wie im 20. Jahrhundert nicht mehr zulassen werden. Lernen wir, damit zu leben!
36
37

Joerg Blumtritt
@jbenno
Datarella GmbH
Oskar-von-Miller-Ring 36
80333 München
089/44 23 69 99






















![BYOD Guide Created using iThoughts [...] [...]. BYOD Guide](https://img.pdfslide.net/doc/110x75/56649c935503460f9494f988/byod-guide-created-using-ithoughts-byod-guide.jpg)





