Embed Size (px)
Citation preview

2017 Fighting Game AI CompetitionMakoto Ishihara lead programmer
Pujana Paliyawan programmer
Quentin Buathier programmer
Shubu Yoshida programmer
Soichiro Shimizu programmer, tester, etc.
Suguru Ito programmer, tester, etc.
Takahiro Kusano programmer, tester, etc.
Yuto Nakagawa advisor
Marco Tamassia visiting researcher
Tomohiro Harada vice director
Ruck Thawonmas director
Team FightingICE
Intelligent Computer Entertainment Laboratory
Ritsumeikan University
Japan
CIG 2017: Aug 22, 2017

About Us
FightingICE
Contest
Results
Contents
CIG 2017: Aug 22, 2017

Affiliations
College of Information
Science and Engineering
Graduate School of Information
Science and Engineering
Ritsumeikan Center for
Game Research Studies
More than 30 of our graduates work for KONAMI (7), KOEI TECMO (4), Dimps (4), SEGA (4), CAPCOM (3),
NHN PlayArt (2), FromSoftware (2), CROOZ, COLOPL, SQUARE ENIX, DWANGO, BANDAI NAMCO Studios, BANDAI NETWORKS, PlatinumGames, Marvelous AQL, SSD, etc.
ContentsIntelligent Computer Entertainment Laboratory, Ritsumeikan University
CIG 2017: Aug 22, 2017

Fighting game AI platform viable to develop with a small-size team in Java and also wrapped for Python
First of its kinds since 2013 & CIG 2014 with most previous
AI source codes available
Aims:
Towards general fighting
game AIs
Strong against any unseen
opponents (AIs or players) ,
character types, and play modes
FightingICE
CIG 2017: Aug 22, 2017

Has 16.67 ms response time (60 FPS)
Latest game state provided by the system is delayed by 15 frames, simulating human response time
Introduced for 2017 competition are
Wrapped for Python
Sample Python AIs available, including a visual-based AI
pre-trained with deep learning using Torch (presented in
CIG 2017 Short papers Session on Thursday)
Standard and Speedrunning Modes
Standard: Win as many fights as possible in a round-robin against another AI
Speedrunning: Beat our sample MctsAI as fast as possible
FightingICE’s Features
CIG 2017: Aug 22, 2017

Difficulty Adjustment
Monte Carlo Tree Search Based Algorithms for Dynamic Difficulty Adjustment (CIG 2017 Tree Search and Multiple Worlds Session this morning) by Simon Demediuk, Marco Tamassia, William Raffe, Fabio Zambetta, Xiaodong Li and Florian Floyd Mueller
High Performance AIs
Deep Q Networks for Visual Fighting Game AI (CIG 2017 Short papers Session on Thursday) by Seonghun Yoon and Kyung-Joong Kim
Opponent Modeling based on Action Table for MCTS-based Fighting Game AI (CIG 2017 Short papers Session on Thursday) by Man-Je Kim and Kyung-JoongKim
Health Promotion (by our group)
Health Promotion AI for Full-body Motion Gaming
(2017 AAAI Spring Symposium Series)
Procedural Play Generation (by our group)
Procedural Play Generation According to Play Arcs Using Monte-Carlo Tree Search (GAMEON®'2017)CIG 2017: Aug 22, 2017
Examples of Research Using FightingICE

About Us
FightingICE
Contest
Results
Contents
CIG 2017: Aug 22, 2017

Three tournaments for Standard and Speedrunningusing three characters:
ZEN, GARNET, and LUD (LUD’s character data not
revealed in advance)
Standard: considers the winner of a round as the one with the HP above zero at the time its opponent's HP has reached zero. (all AIs' initial HP = 400)
Speedrunning: the league winner of a given character type is the AI with the shortest average time to beat our sample MctsAi (all entry AIs' initial HP = 9999, MctsAi's initial HP = 300)
Contest RulesCIG 2017: Aug 22, 2017

9 AIs from 9 locations Algeria, Brazil (2 entries), China, Germany teaming
with UK, Japan, Korea, Taiwan, and USA
Techniques 4 AIs -> a combination of MCTS and rules for
limiting MCTS search space
2 AIs -> Q-learning (one for switching among three last year AIs and the other using perceptron as function approximator for decision making)
1 AI -> Hierarchical Task Network (HTN) Plannar
1 AI -> simulation (feed-forward)
1 AI -> rule-base
Summary of AI Fighters
CIG 2017: Aug 22, 2017P

About Us
FightingICE
Contest
Results
Contents
CIG 2017: Aug 22, 2017
CIG 2017: Aug 22, 2017
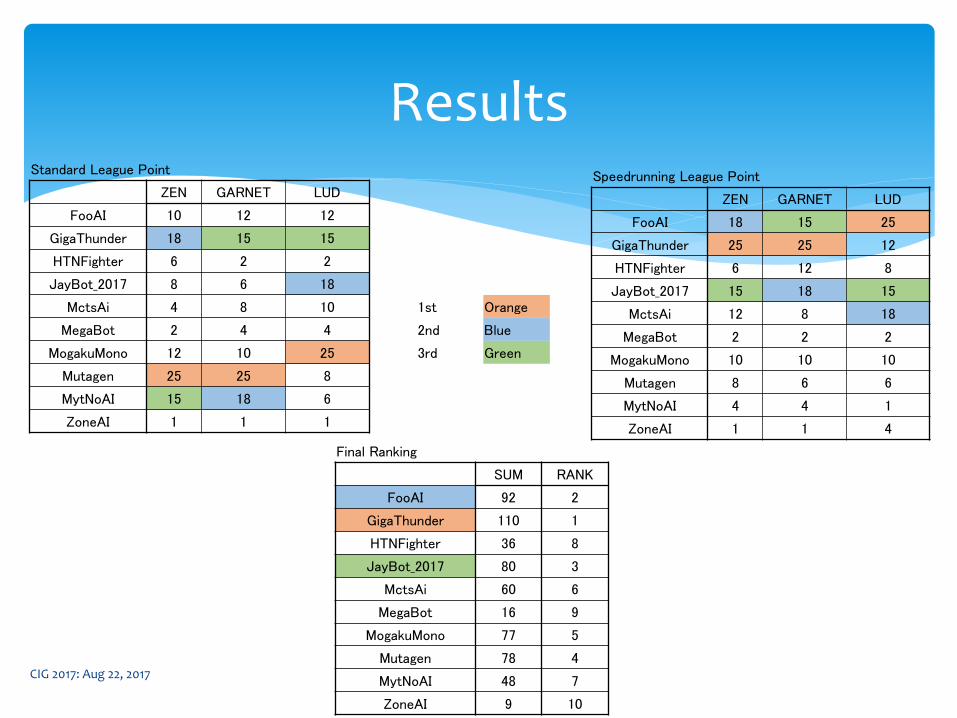
ResultsStandard League Point
ZEN GARNET LUD
FooAI 10 12 12
GigaThunder 18 15 15
HTNFighter 6 2 2
JayBot_2017 8 6 18
MctsAi 4 8 10
MegaBot 2 4 4
MogakuMono 12 10 25
Mutagen 25 25 8
MytNoAI 15 18 6
ZoneAI 1 1 1
Speedrunning League Point
ZEN GARNET LUD
FooAI 18 15 25
GigaThunder 25 25 12
HTNFighter 6 12 8
JayBot_2017 15 18 15
MctsAi 12 8 18
MegaBot 2 2 2
MogakuMono 10 10 10
Mutagen 8 6 6
MytNoAI 4 4 1
ZoneAI 1 1 4
Final Ranking
SUM RANK
FooAI 92 2
GigaThunder 110 1
HTNFighter 36 8
JayBot_2017 80 3
MctsAi 60 6
MegaBot 16 9
MogakuMono 77 5
Mutagen 78 4
MytNoAI 48 7
ZoneAI 9 10
1st Orange
2nd Blue
3rd Green
CIG 2017: Aug 22, 2017
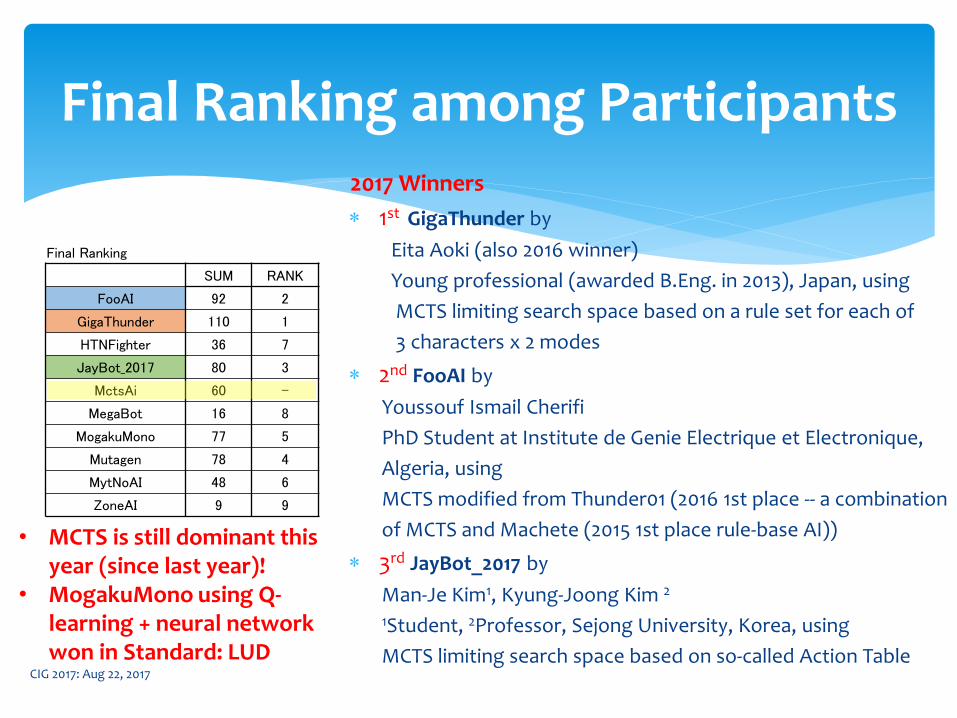
Final Ranking among Participants2017 Winners
1st GigaThunder by
Eita Aoki (also 2016 winner)
Young professional (awarded B.Eng. in 2013), Japan, using
MCTS limiting search space based on a rule set for each of
3 characters x 2 modes
2nd FooAI by
Youssouf Ismail Cherifi
PhD Student at Institute de Genie Electrique et Electronique,
Algeria, using
MCTS modified from Thunder01 (2016 1st place -- a combination
of MCTS and Machete (2015 1st place rule-base AI))
3rd JayBot_2017 by
Man-Je Kim1, Kyung-Joong Kim 2
1Student, 2Professor, Sejong University, Korea, using
MCTS limiting search space based on so-called Action Table
• MCTS is still dominant this year (since last year)!
• MogakuMono using Q-learning + neural network won in Standard: LUD
Final Ranking
SUM RANK
FooAI 92 2
GigaThunder 110 1
HTNFighter 36 7
JayBot_2017 80 3
MctsAi 60 -
MegaBot 16 8
MogakuMono 77 5
Mutagen 78 4
MytNoAI 48 6
ZoneAI 9 9

No entries in Python
No entries using deep learning
Only three papers using FightingICE in CIG 2017
Plan for 2018 Competition Not reveal the opponent AI for Speedrunning
Only reveal ZEN’s character data (both Standard and Speedrunning) in advance
Adjust character data for all characters
CIG 2017: Aug 22, 2017
Reflections and 2018 Plan

CIG 2017: Aug 22, 2017
Appendices: AI Details(in alphabetical order)


FooAI
Developed byYoussouf Ismail Cherifia PhD Student at Institute de Genie Electrique et Electroniquein Algeria

Outlines
-The AI is based on the Monte Carlo Search Tree which is commonly used in making game’s AI.
-The AI is built upon the sample project provided by the competition McstAI.
-A few adjustments were done added to it based on last year competition results. Like when using Zen there some moves that take priority over MCSTs as done by Thunder01.

GigaThunder~the final version of Thunder2017Midterm~
Eita Aoki
Young professional (I got my first degree at Nagoya University in 2013)
24

Outline
MCTS canceled useless movements
・make sure to hit the attack
・narrow the search space
・avoid being open to attack
・reduce energy consumption
Make 6 Independent AI(3 Character × 2 Mode)
・All AI use above MCTS canceled useless
movements
・Furthermore, ZEN and Garnet AI take advantage
of
Characteristic of Character and Game Mode
25

Normal AI
If Character can hit Attack
do Attack
If Character can’t hit Attack
・Adverse situation
get close to Oppornent.
・Advantageous situation
escape
(Chose move action
that can avoid Oppornent’s Attack )
26

Special Characteristic
of Zen and Garnet Normal AI
Zen
・repeat Crouch Kick at corner.
→Opponent can’t defend it.
Garnet
repeat Air Knee Kick on the Ground
→Opponent can’t defend it.
27

Speed AI
If Character can hit Attack
do Attack
If Character can’t hit Attack
get close to Opponent.
(Chose move action
that can avoid Oppornent’s Attack )
28

HTN Fighter
Xenija Neufeld
Faculty of Computer Science
Otto von Guericke University
Magdeburg, Germany
Sanaz Mostaghim
Faculty of Computer Science
Otto von Guericke University
Magdeburg, Germany
Diego Perez-Liebana
University of Essex
School of Computer Science
and Electronic Engineering,
Colchester, United Kingdom
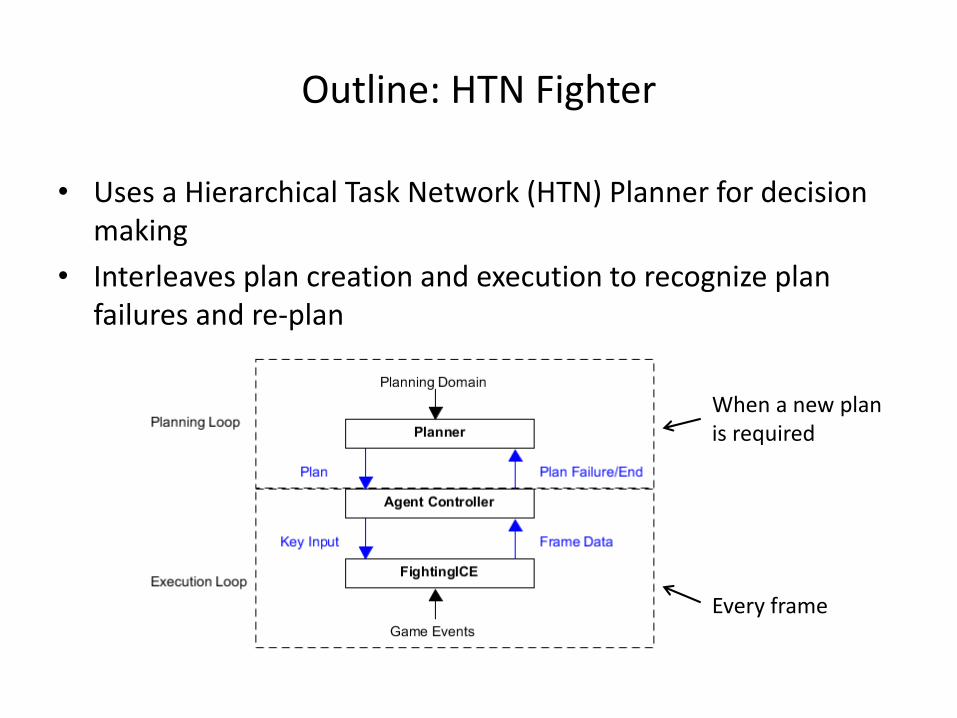
Outline: HTN Fighter
When a new plan is required
Every frame
• Uses a Hierarchical Task Network (HTN) Planner for decision making
• Interleaves plan creation and execution to recognize plan failures and re-plan

HTN of HTN Fighter
• Low-level methods of HTN are added dynamically depending on the corresponding actions’ parameters
• Preconditions of primitive tasks are defined in a generic way depending on the corresponding actions’ parametersNo need to create a distinct domain for every character
• In-built forward model allows for direct action simulation on copies of Frame Data No additional effect propagation needed
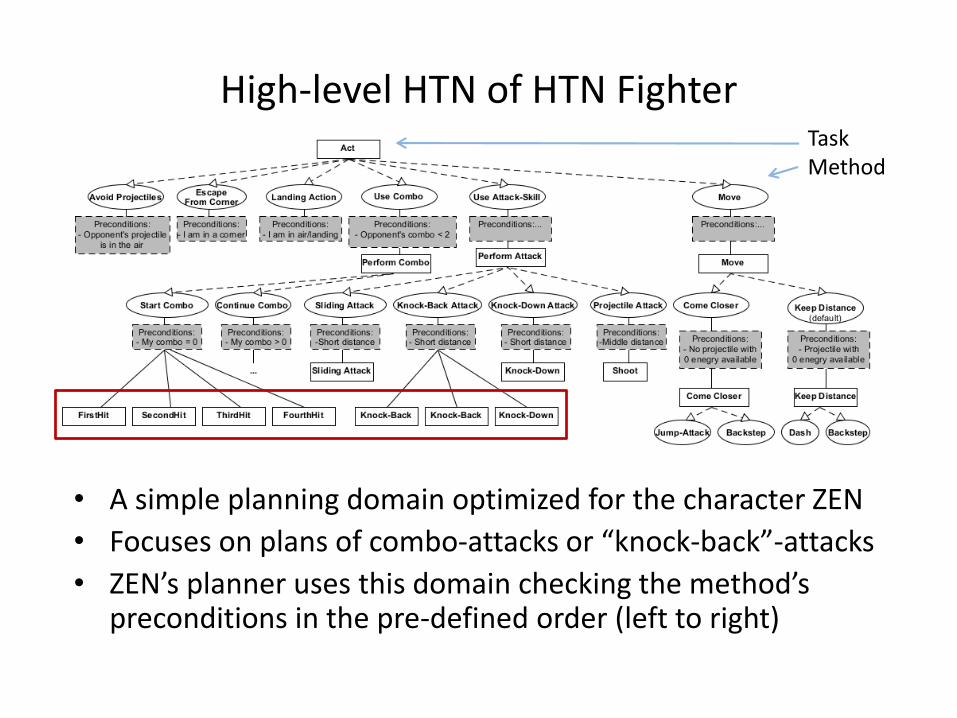
High-level HTN of HTN Fighter
• A simple planning domain optimized for the character ZEN
• Focuses on plans of combo-attacks or “knock-back”-attacks
• ZEN’s planner uses this domain checking the method’s preconditions in the pre-defined order (left to right)
TaskMethod

HTN with UCB
• GARNET and LUD use the same planning domain, but the selection of methods is done with the help of the Upper-Confidence-Bound (UCB) algorithm
• GARNET uses UCB-values that were learned in advance
• LUD learns these values during training games
• UCB balances between exploitation (selecting methods that lead to higher damage and succeed more often) and exploration (selecting methods that were selected less often)

Man-Je Kim, Kyung-Joong Kim
Sejong University

Introduction Member
Developer : Man-Je Kim
Advisor : Kyung-Joong Kim
Idea
Action Table + MCTS AI
Affiliation
Sejong University
Developer’s Position
Man-Je Kim (Undergraduate Student)

AI’s Outline Method
Action Table (AT) + Monte Carlo Tree Search (MCTS)
Action Table
The AT is a table that summarizes the actions that AIs frequently use at certain distances.
Existing AIs vary greatly in behavior at specific distances.
So, I divided the section into four parts. ( >50, >85, >105, Else)
I collected the behaviors of existing AIs in each section.
Finally, the collected action is inserted into the input of the MCTS.

Supplement Basic version AI's AT changed with each opponent every round. However,
this behavior was bad for AI with poor performance. Also, it is not appropriate for this competition where opponents change frequently.
So, in order to keep AI 's behavior robust, I put AT in its initial state.
If you play a lot of games against the same AI, I recommend changing the AT every round. But this version is not changed per round.

MetaBot – FTG-AI
Tiago Negrisoli de Oliveira
Anderson Rocha Tavares
Luiz Chaimowicz
Universidade Federal de Minas Gerais
Brazil

MetaBot
●Idea: algorithm selection in adversarial domains
– Algorithm: a playing bot
– MegaBot selects one amongst three algorithms to play a match
– Performance is registered to guide future selections
– Epsilon-greedy-like selection
– Q-learning-like value function updates
●Portfolio: Thunder01,BANZAI e Ranezi
– Rock, paper, scissors -like interaction
– Suggests complementarity (a good portfolio against a variety of opponents)

Reference
●“Tavares, A. R.; Azpúrua, H; Santos, A; Chaimowicz,
L.” Rock, Paper, StarCraft: Strategy Selection in
Real-Time Strategy Games. In AIIDE 2016.

Hierarchical Reinforcement
LearnerNick: 踠く者 (MogakuMono)
*Ivan de Jesus P.P. , Ginaldo Oliveira Morais
Graduate Students
*Intelligent Distributed Systems Laboratory(LSDI)
Federal University of Maranhão(UFMA) - Brazil

Reinforcement Learning● We implemented a Reinforcement Agent that plays ICE
FG
● Usually the Game is modelled as a Markov Decision
Problem
○ State: players position, life, motions, etc.
○ Actions: game inputs: up,down,left,right,a,b
○ Rewards: Damage inflicted and received.
● Simple Reinforcement learning has to learn a optimal
policy to solve the MDP
○ That policy has to learn many differents combos, and evaluate the
best strategy with them

Hierarchical Reinforcement Learner
● Learns a SMPD, that allows extended actions
● We call these extended actions “behaviours”
○ Can also been seen as Options
● We as players of fighting games, used our domain knowledge to create these
behaviours
○ Combos, movimentation
● We innovate by inducing behaviours from the Monte Carlo Search tree
● We manually create features describing the state
○ Ours and the opponent positions, distance from each other, projectiles on the field, etc

Hierarchical Reinforcement Learner
● We use a Perceptron as the Function approximator
○ Easy to debug and understand
● We use Q-Learning for the training
● Training against the Mcts Sample did not show better results.

Partial Results
● Zen learned a aggressive policy, with focus on Aerial attacks
○ Has combo corner, very specific situation
● Garnet plays a dance-like fight. Might not be too efficient, but it is beautiful.
● Lud plays a grab strategy, with damaging combos. They can been fled
though, by jumping.
● All 3 AIs shows promise, with the flaw of being too much aggressive/pro-
active.
● While the behaviours haven been made with domain knowledge, the AI
chooses what and when to use.

2017 Fighting Game AI Competition
Connor Gregorich-Trevor

Rule-based MCTS
●Mutagen is based on the sample Monte Carlo Tree Search
(MCTS) program included on the FTGC website.
●Actions are divided into several different arrays. Which array of
actions that Mutagen chooses from depends on the distance to the
opponent.
●Resulting playstyles:
– Zen plays very aggressively, in a high-risk high-reward manner. The AI focuses on exploiting knockdown mechanics.
– Garnet uses a defensive, grounded hit-and-run strategy.

Lud Implementation
●Lud uses an implementation of a Last-Good-Reply algorithm to
learn which moves are most effective based on the distance of the
opponent and the state of both AIs. These are saved as a
hashmap, and saved in files across games in order to learn and
adapt to the opponent.
●Moves are not considered by the MCTS algorithm for use in close
quarters if they have an endlag of greater than 45 frames.

Guarding
●Instituted a system to block the moves of opponents based on the
current information the AI has. The standard MCTS AI, along with
most of the submissions in 2016, almost never block any attacks,
or successfully input a guard action longer than a few frames.
– When getting up, the AI will input a guard action automatically, since most AI do not stop using moves regardless if the opponent is in a downed state.
– STAND_GUARD and CROUCH_GUARD are given a constant weight in the search tree, leading to them being chosen much more often.
– Guards are automatically input for a length of 22 frames.

Implementation Challenges and
Future Goals●Originally, the plan was for all AIs to use an implementation of the
Last-Good-Reply algorithm.
– Unfortunately, the algorithm did not interact well with the already good state-based rules of Zen and Garnet, so it was relegated to Lud alone. Zen and Garnet still write to a hashmap and file, but do not read from it during gameplay.
– I want to optimize this algorithm and implement it in such a way that it is beneficial for all three characters.
●I would like to make certain parts of the program more algorithmic,
such as the constant weight on guarding in MCTS.
●Contact me for more information:
– https://github.com/NullCGT

MytNoAiBy Ma Yuntian
No Affiliation

AI's Outline
• Use Simulator and no fighting game technique.
• Try to avoid attack and attack in best time(in ai perspective)
• Use no normal skill without “STAND_D_DF_FC”

Processing steps
1. Get a Simulation from all Simulations using now.
2. Simulate the Simulation and get result.
3. Update the Simulation.
4. Repeat 1-3 until time limit and return the best action in the best Simulation.

Step 1: How to get a Simulation
• At the start of one processing, it traversal the whole Simulations ArrayList for 5 times.
• After 5 times traversals, it will always select the Simulation with best score until processing end.
Step 3: How to update score
• Use the Subtraction of hp as score.
• Always use a average value.

ZoneAIDeveloper Name: Frank Ying
Affiliation: None

Description
• Inspired by the simplicity of the 2016 KeepYourDistanceBot and the effectiveness of other rule-based algorithms
• Currently only has simple rules without careful consideration of hitboxes and enemy range
• The current AI prioritizes ranged attacks while keeping a distance from the enemy by jumping backwards. When trapped between the enemy and a wall, it escapes by jumping forward. When it has no energy, it randomly picks a move with a decent hitbox in an attempt to hit the enemy.

TODO
• Different rules for close, mid, far range, character aerial state, time remaining, opponent energy...etc.
• Fix LUD moves
• Predict enemy attacks from recently used attacks

CIG 2017: Aug 22, 2017
Thank you and see you at CIG 2018!