Embed Size (px)
Citation preview

Rachael LammeyProduct Manager, CrossRefUKSG 2015
CrossRef Text and Data Mining Services: one year in

Not-for-profit association of scholarly publishers
All subjects, all business models
5,000+ organizations from all over the world
83 non-publisher affiliates, 2000 library affiliates
72 million + DOIs assigned to content items

10.1098/ rst l.1665.0001
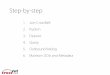
User clicks on CrossRef DOI reference link in Journal A
Tani, N., N. Tomaru, M. Araki, AND K. Ohba. 1996. Genetic diversity and differentiation in populations of Japanese stone pine (Pinus pumila) in Japan. Canadian Journal of Forest Research 26: 1454–1462.[CrossRef]
DOI directory
returns URL
User accesses cited art icle in
Journal B
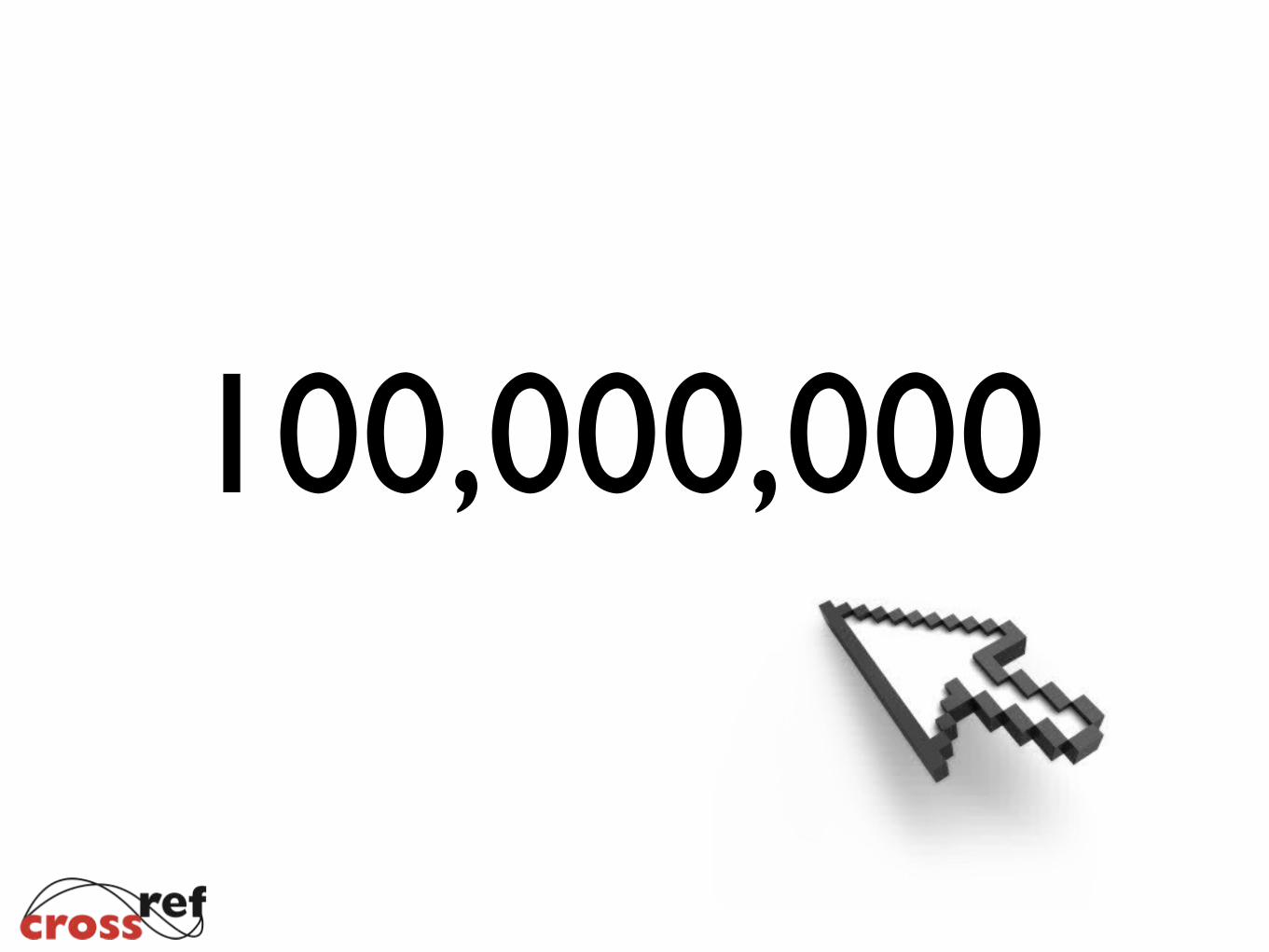
100,000,000

A Text and Data Mining Hub for Researchers

What is Text and Data Mining (TDM)?
Text Mining is an interdisciplinary field combining techniques from linguistics, computer science and statistics to build tools that can efficiently retrieve and extract information from digital text.
http://blogs.plos.org/everyone/2013/04/17/announcing-the-plos-text-mining-collection/
It uses powerful computers to find links between drugs and side effects, or genes and diseases, that are hidden within the vast scientific literature. These are discoveries that a person scouring through papers one by one may never notice.
http://www.theguardian.com/science/2012/may/23/text-mining-research-tool-forbidden

Why? • Researchers find it impractical to
negotiate multiple bilateral agreements with hundreds of subscription-based publishers in order to authorise TDM of subscribed content.
• Subscription-based publishers find it impractical to negotiate multiple bilateral agreements with thousands of researchers and institutions in order to authorise TDM of subscribed content.
• All parties would benefit from support of standard APIs and data representations in order to enable TDM across both open access and subscription-based publishers.


Build Cross-Publisher API for TDM

Access To Full Text
Problem: Researchers want to get full text content from publishers’ sites for OA or subscribed content. Solution:
Solution: Common API (protocol) for requesting machine readable full text from many different publishers

Negotiating Permissions
Problem: Researchers want to know whether text and data mining is allowed, and if not, get permission. Solution: Licensing information embedded in article metadata and a registry for supplemental text and data mining terms and conditions (licenses).

Text and Data Mining Steps• Define problem
• Identify potential corpus to mine
• Discovery (full text links)
• Identification of subset which can be accessed (license information)
• Download identified corpus
• Text and data mine corpus
The Basic Workflow

Publisher Participation
To enable their content for use by the service, publishers have to provide CrossRef with two additional pieces of metadata:
• Full text URIs (to show where the full-text is located)
• License URIs (to show the Terms & Conditions under which they can use it)
• Can implement rate limiting
CrossRef doesn’t charge publishers for participating in this service.

Researcher Use
• The CrossRef REST API is the main aspect of this service
• It is designed to allow researchers to easily harvest full text documents from all participating publishers regardless of their business model (e.g. open access, subscription).
• It makes use of CrossRef DOI content negotiation to provide researchers with links to the full text of content located on the publisher’s site.
• The publisher remains responsible for actually delivering the full text of the content requested
• CrossRef does not charge researchers for using the service

Publisher Metadata for CrossRef TDM: Hindawi

Publisher Metadata for CrossRef TDM: Elsevier

CrossRef TDM Demo

Click-ThroughService
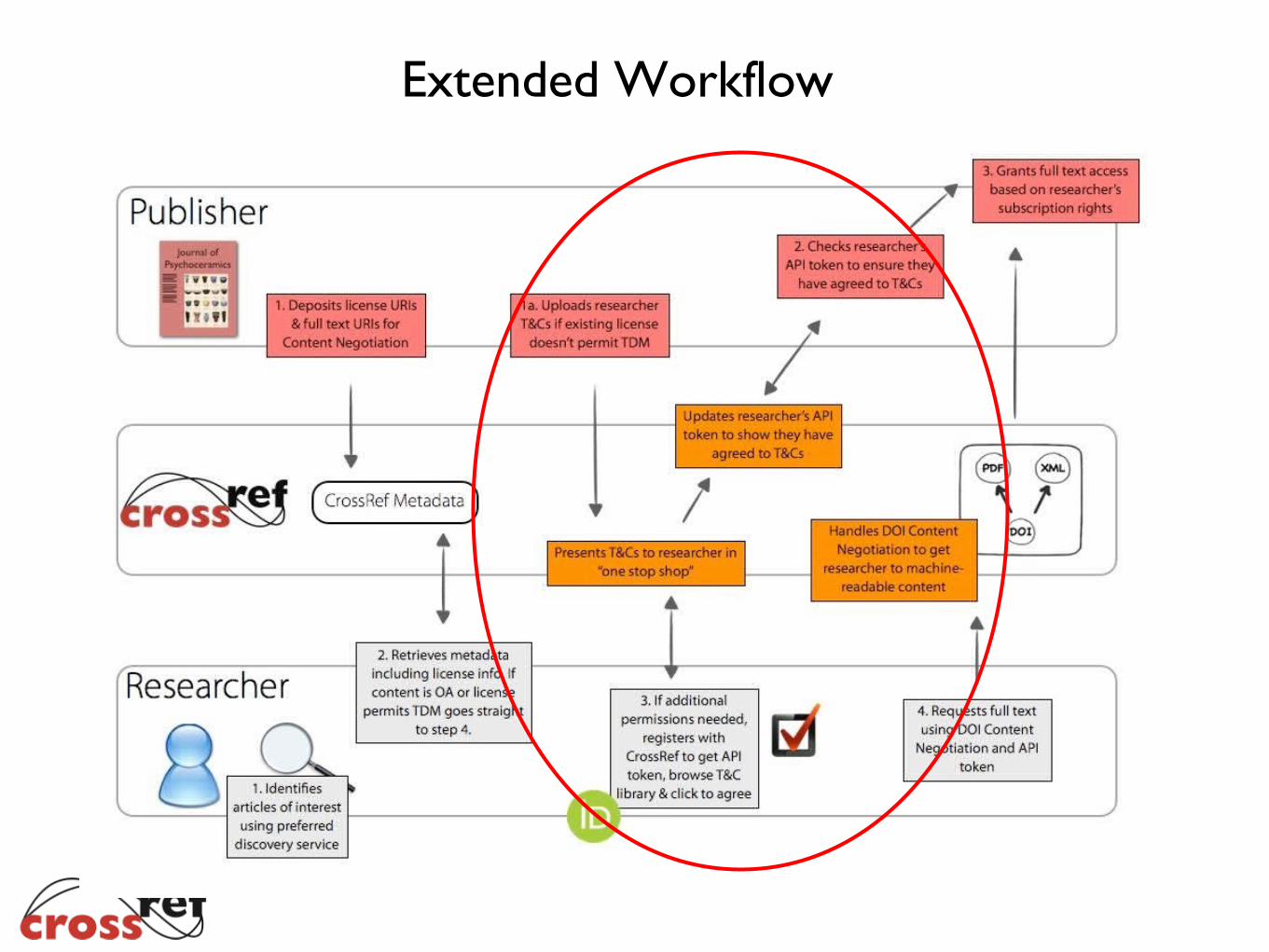
Extended Workflow
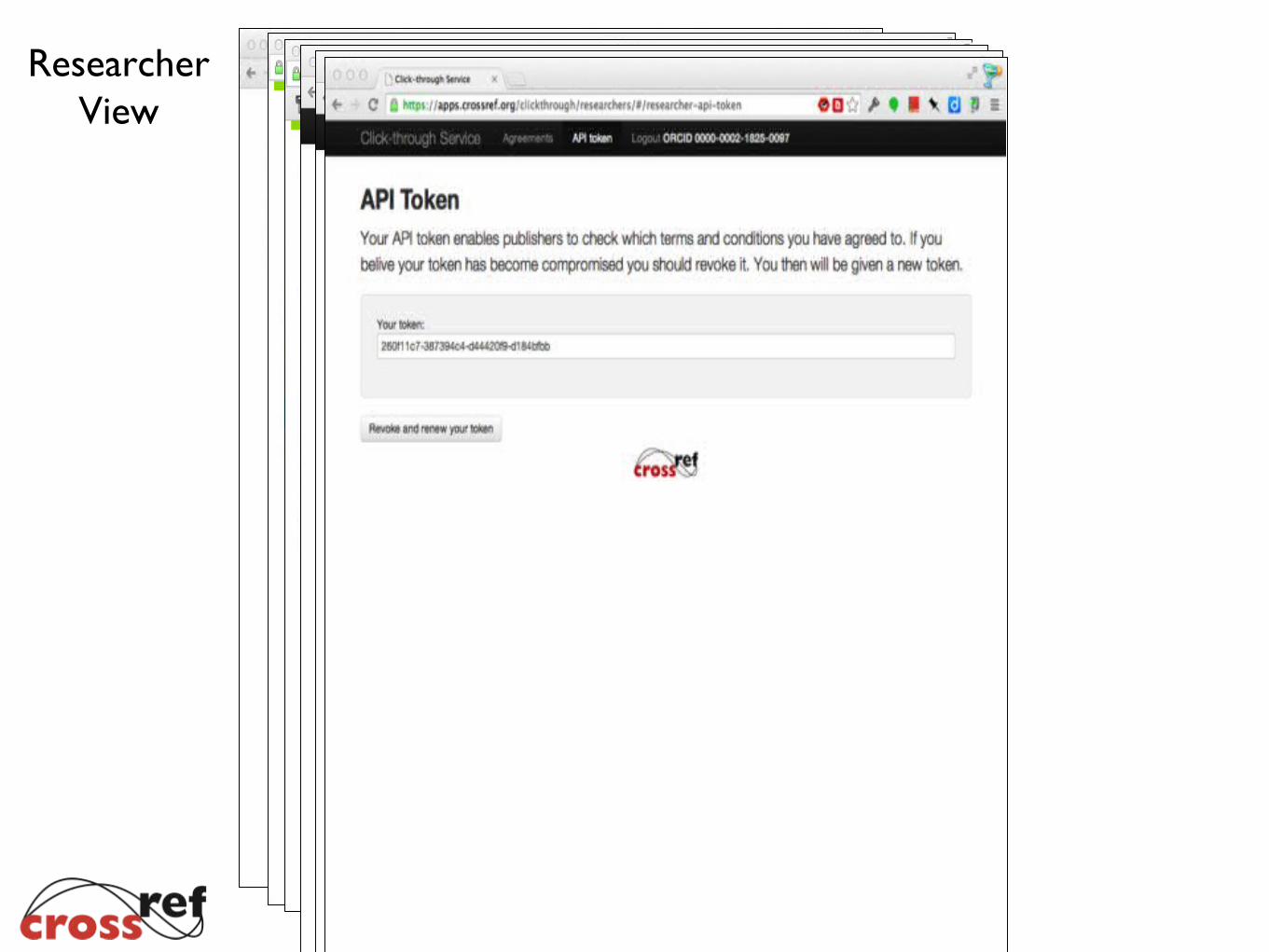
ResearcherView
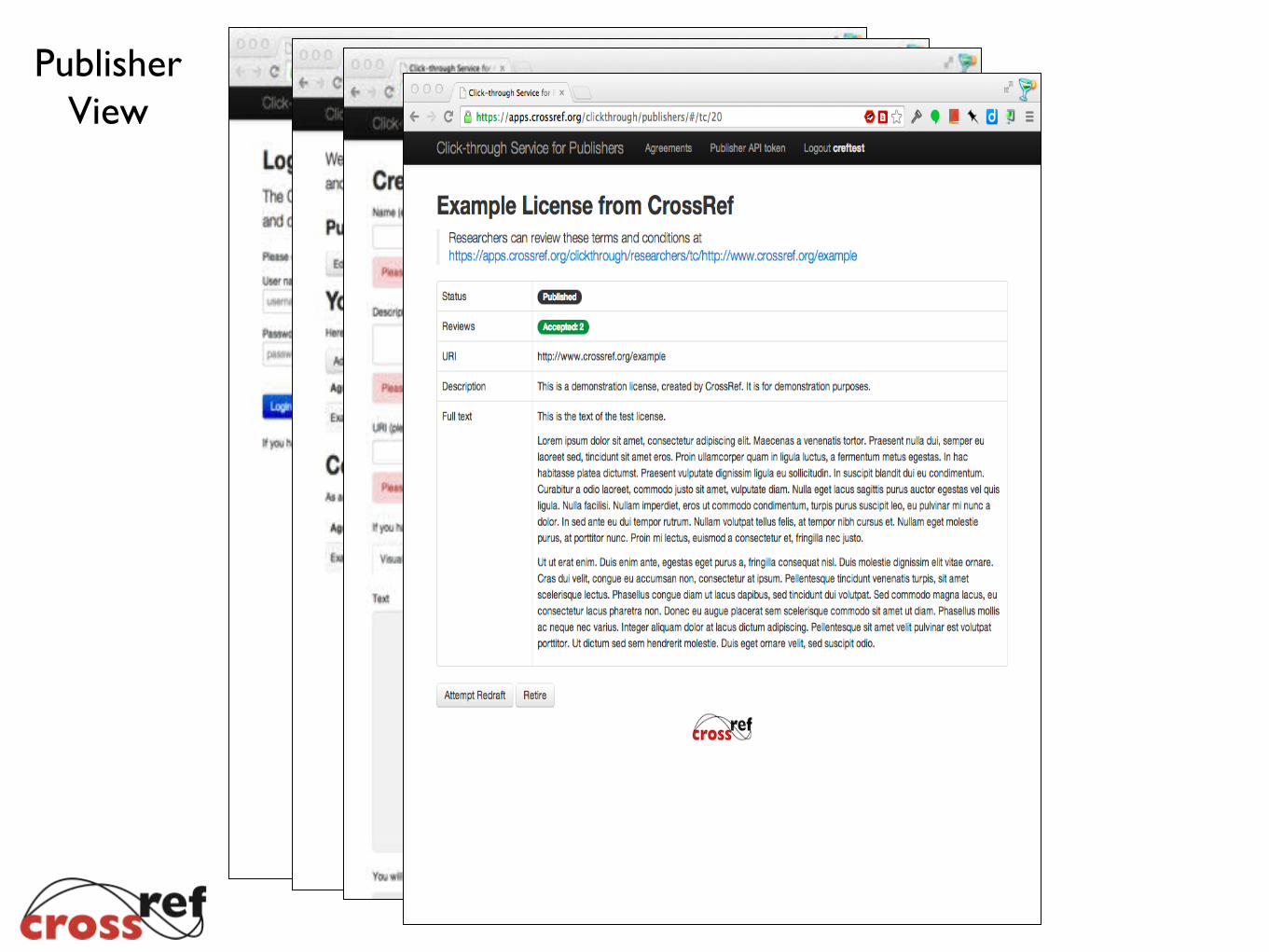
PublisherView
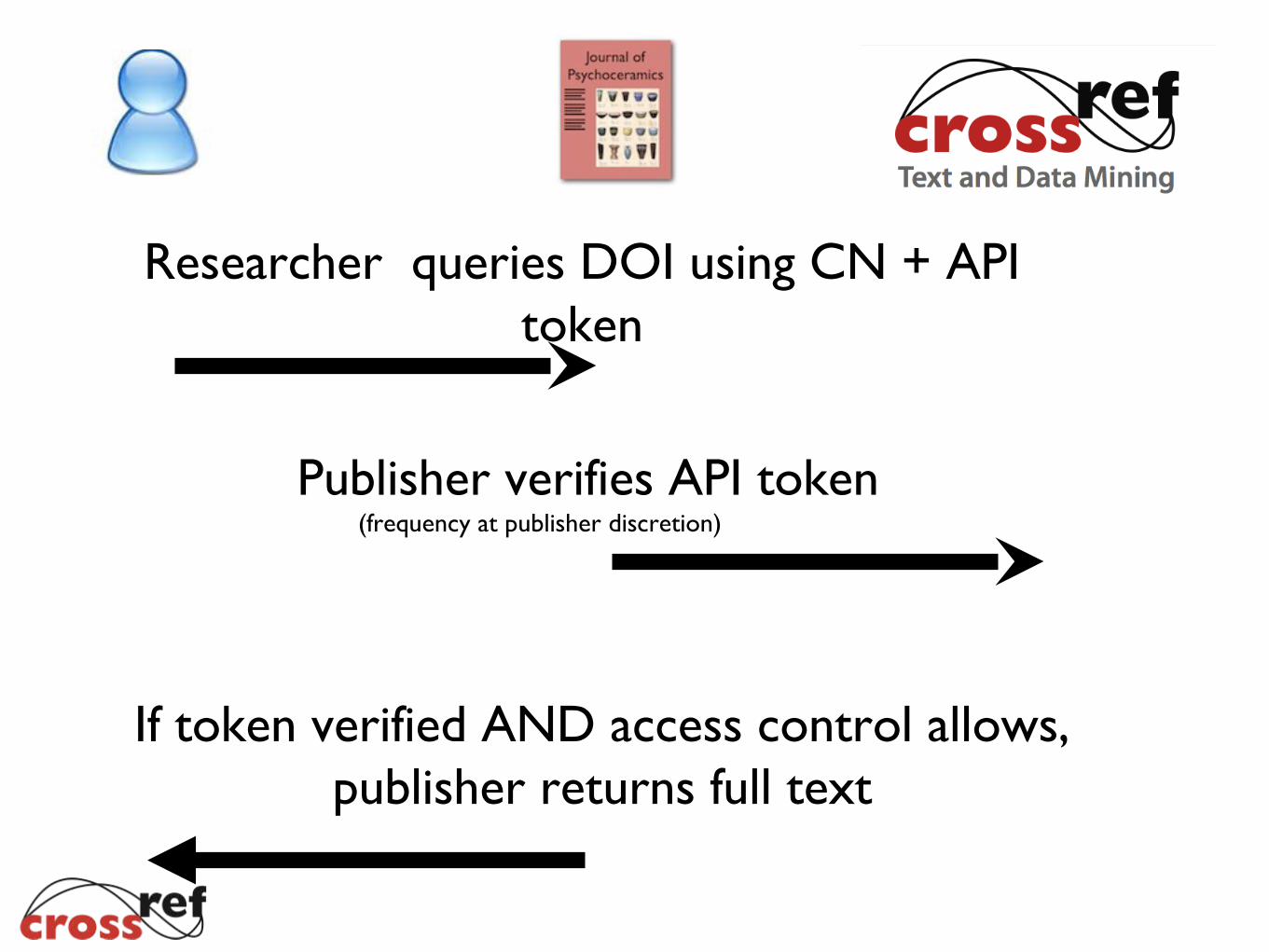
Researcher queries DOI using CN + API token
Publisher verifies API token
If token verified AND access control allows,publisher returns full text
(frequency at publisher discretion)

Benefits
• Streamlines researcher access to distributed full text for TDM
• Enables machine-to-machine, automated access for recognized TDM (i.e. researchers won’t be locked out of publisher sites)
• Enables article-level licensing info and easy mechanism for supplemental T&Cs for text and data mining (publishers discussing model license via STM)

Publishers
Over 14 million articles with full-text links and license information deposited

http://tdmsupport.crossref.org/

www.crossref.orghttp://www.crossref.org/tdm/index.html

How can researchers use the service?
• Modify TDM tools to make use of the API token
• Modify TDM tools to look for <lic_ref> elements
• Register with the click-through service and accept/decline licenses (if applicable)
• Details at: http://tdmsupport.crossref.org/researchers/

Using the DOI as the basis for a common text and data mining API provides several benefits. For example, the DOI provides:
•An easy way to de-duplicate documents that may be found on several sites.•Persistent provenance information. •An easy way to document, share and compare coropra without having to exchange the actual documents•A mechanism to ensure the reproducibility of TDM results using the source documents.•A mechanism to track the impact of updates, corrections retractions and withdrawals on corpora.
Why use the DOI?