Embed Size (px)
DESCRIPTION
Deep Learning 輪講会@東京大学松尾研究室での講義資料
Citation preview

Deep Learning を実装するhttp://deeplearning.net/tutorial/
松尾研 修士1年 飯塚修平"@Deep Learning 輪講会

目次 • Deep Learning とは"
– 機械学習について"– 従来の NN とのちがい"– Deep Learning のブレイクスルー"
• dA (Denoising Autoencoders) をうごかす"– 数理モデルの解説"– Python で実装する前準備"– コードレビュー"– 実行結果"
• RBM (Restricted Boltzmann Machines) をうごかす"– 数理モデルの解説"– 実行結果"
• まとめ

DEEP LEARNING とは

Deep Learning とは • 入力信号からより抽象的な概念を学ぶ・特徴を抽出する機械学習の手法の集合です"
“ニューラルネットとどう違うの?”!• ニューラルネットを多層にしたんです "
“従来のニューラルネットワークと何が違うの?”!• ひとつひとつのレイヤー間でパラメタの調整(すなわち学習)を行うところが特徴なんです
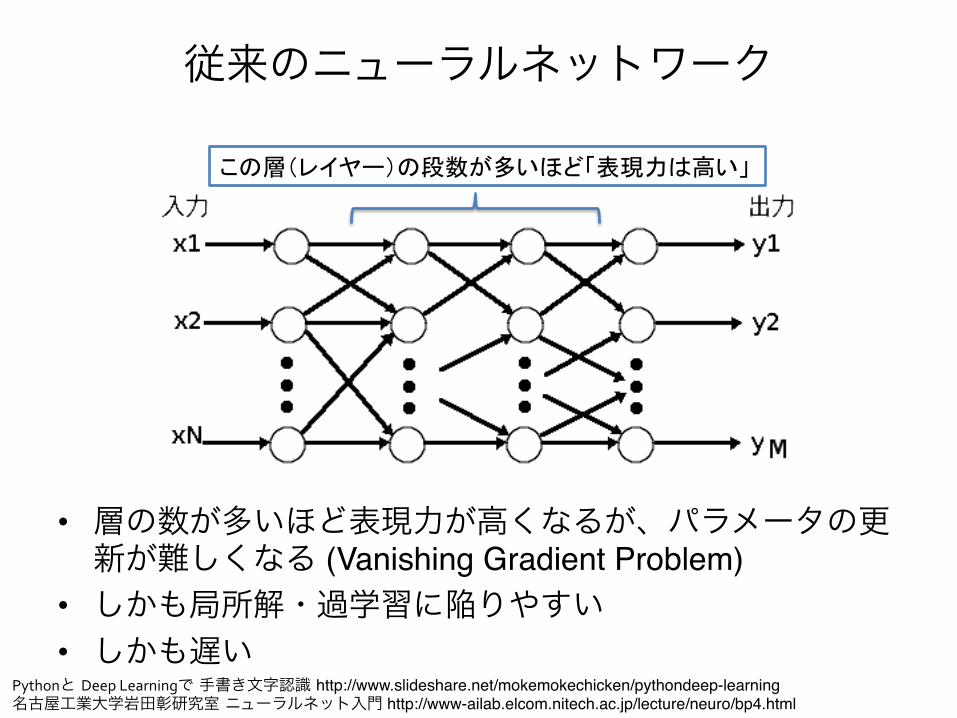
従来のニューラルネットワーク
• 層の数が多いほど表現力が高くなるが、パラメータの更新が難しくなる (Vanishing Gradient Problem)"
• しかも局所解・過学習に陥りやすい"• しかも遅い
l�ŝNNŝHğ®�
ĩĦ�
ńŝ`ƩơŹƛƦƪŝ¢�ľOĹŤřĶæ´3ŞĢĹķ�
ŗŪĶWÜķľęňĽœŐ�
Pythonと Deep Learningで 手書き文字認識 http://www.slideshare.net/mokemokechicken/pythondeep-learning"名古屋工業大学岩田彰研究室 ニューラルネット入門 http://www-ailab.elcom.nitech.ac.jp/lecture/neuro/bp4.html
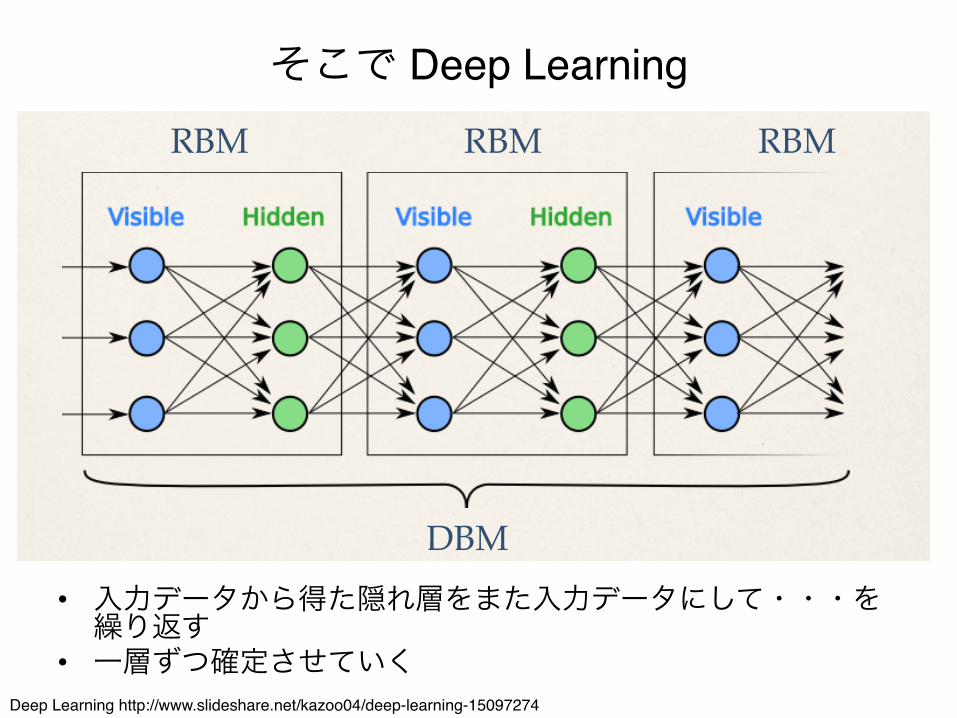
そこで Deep Learning
• 入力データから得た隠れ層をまた入力データにして・・・を繰り返す"
• 一層ずつ確定させていく
イメージ
Restricted Boltzmann Machine (RBM)をたくさん繋げたものがDeep Boltzmann Machines (DBM)
DBM
RBM RBM RBM
12年11月9日金曜日
Deep Learning http://www.slideshare.net/kazoo04/deep-learning-15097274
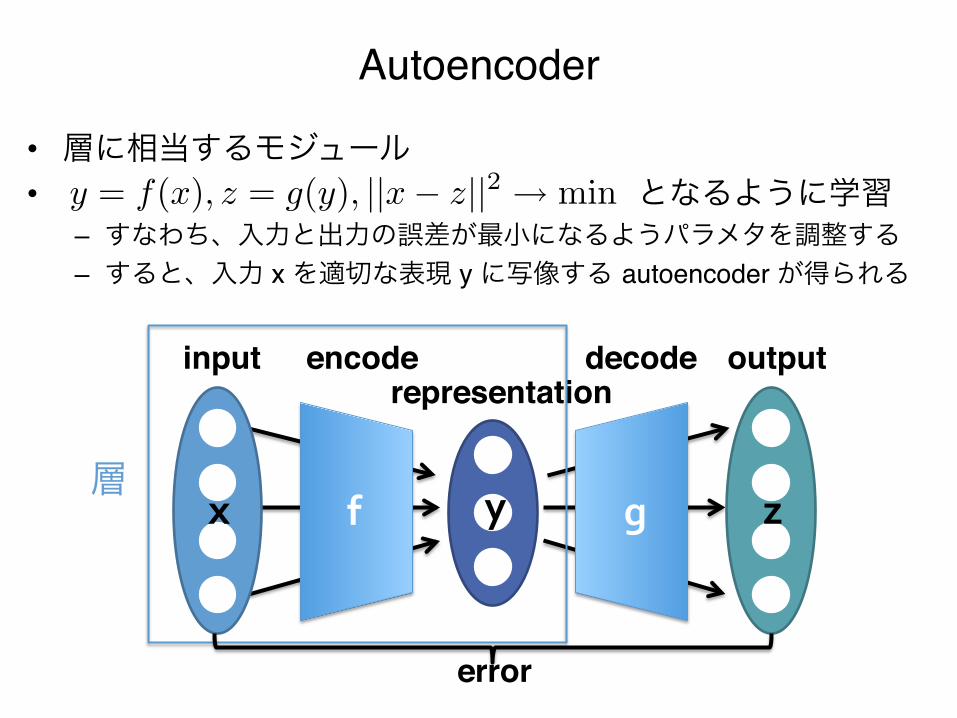
Autoencoder • 層に相当するモジュール"• となるように学習"
– すなわち、入力と出力の誤差が最小になるようパラメタを調整する"– すると、入力 x を適切な表現 y に写像する autoencoder が得られる"
y = f(x), z = g(y), ||x� z||2 � min
f g
input encode representation
decode output
x y z 層
error

dA をうごかす(Denoising Autoencoder)
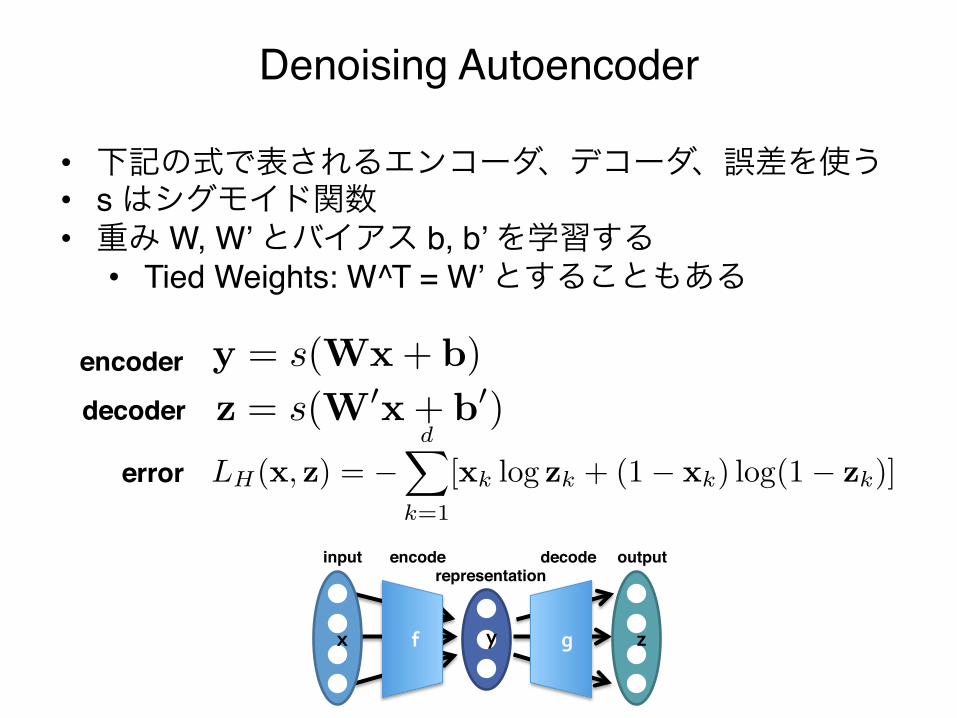
Denoising Autoencoder
f g
input encode representation
decode output
x y z
y = s(Wx + b), z = s(W�x + b�)
LH(x, z) = �d�
k=1
[xk log zk + (1� xk) log(1� zk)]
y = s(Wx + b), z = s(W�x + b�)
LH(x, z) = �d�
k=1
[xk log zk + (1� xk) log(1� zk)]y = s(Wx + b), z = s(W�x + b�)
LH(x, z) = �d�
k=1
[xk log zk + (1� xk) log(1� zk)]
encoder decoder
error
• 下記の式で表されるエンコーダ、デコーダ、誤差を使う"• s はシグモイド関数"• 重み W, W’ とバイアス b, b’ を学習する"• Tied Weights: W^T = W’ とすることもある"

Python で実装する前準備
• Theno を入れましょう"– 導関数を解析的に導出してくれる(自動微分という)"
• 近似的に微分係数を算出する数値微分とは異なる"• 導関数を導関数として扱える!"
– GPU に計算を行わせることも可能"– $ sudo pip install Theano"

>>> # Theano のかんたんな使い方>>> # まず、ふつうの演算...>>> import theano>>> import theano.tensor as T>>> x = T.dscalar(“x”) # x という名前のスカラー変数>>> y = x**2 + 4*x # 式を表現>>> f = theano.function([x], y) # 関数の生成。[]で囲まれた変数が関数の引数となる>>> f(0)array(0.0)>>> f(1)array(5.0)>>>>>> # 次に、自動微分をさせてみる...>>> z = T.grad(y, x) # y を微分した式を z として表現>>> f_prime = theano.function([x], z)>>> f_prime(0)array(4.0)>>> f_prime(1)array(6.0)
Getting Started
Deep Learning"http://deeplearning.net/tutorial/gettingstarted.htmlサンプルコードがあります" 今回はこれをもとに説明します
$ git clone git://github.com/lisa-lab/DeepLearningTutorials.git

擬似コード class dA (object):
def __init__(self, input, n_visible, n_hidden): self.input = input # 入力データ self.n_visible = n_visible # 可視層ノード数 self.n_hidden = n_hidden # 隠れ層ノード数 self.vbias = Array(size=n_visible) # b: 可視層のバイアス self.hbias = Array(size=n_hidden) # b’: 隠れ層のバイアス self.W = Matrix(size=(n_visible, n_hidden)) # 重み行列 W
def get_corrupted_input(self, input, corruption_level): # より一般的な特徴を学習させるため、あえてノイズを加える return Randomize(input, corruption_level)def get_hidden_values(self, input): # encode に相当 return T.nnet.sigmoid(T.dot(input, self.W) + self.vbias)
def get_reconstructed_input(self, hidden): # decode に相当 return T.nnet.sigmoid(T.dot(hidden, self.W.T) + self.hbias)

def get_cost_updates(self, corruption_level, learning_rate): tilde_x = self.get_corrupted_input(self.x, corruption_level)
y = encode(tilde_x) z = decode(y) L = - T.sum(self.x * T.log(z) + (1 - self.x) * T.log(1 - z), axis=1) cost = T.mean(L)
update(vbias, hbias, W) #パラメタの更新 return (cost, [vbias, hbias, W])
if __name__ == '__main__':
# 損傷率 0%, 30%, 50% の autoencoder for c_rate in [0., 0.3, 0.5]: da = dA(T.matrix(‘x’), 784, 500) cost, updates = da.get_cost_updates(c_rate, 0.1) train_da = theano.function(..., train_dataset, updates, cost) img = PIL.Image.fromarray(da)) img.save(‘hoge’+c_rate+‘.png’)

つまり • dA"
- 入力データ "input " " " "←与える"- ノード数 " "n_visible, n_hidden "←与える(経験と勘と試行錯誤)"- バイアス " "vbias, hbias" " "←パラメタ"- 重み行列 " "W " " " " "←パラメタ"+ ノイズ追加 "get_corrupted_input(input, corruption_level)"+ エンコード "get_hidden_values(input)"+ デコード " "get_reconstructed_input(hidden)"+ パラメタ更新 "get_cost_updates(corruption_level, learning_rate)""意外と簡単!"

使用するデータ MNIST手書き文字認識
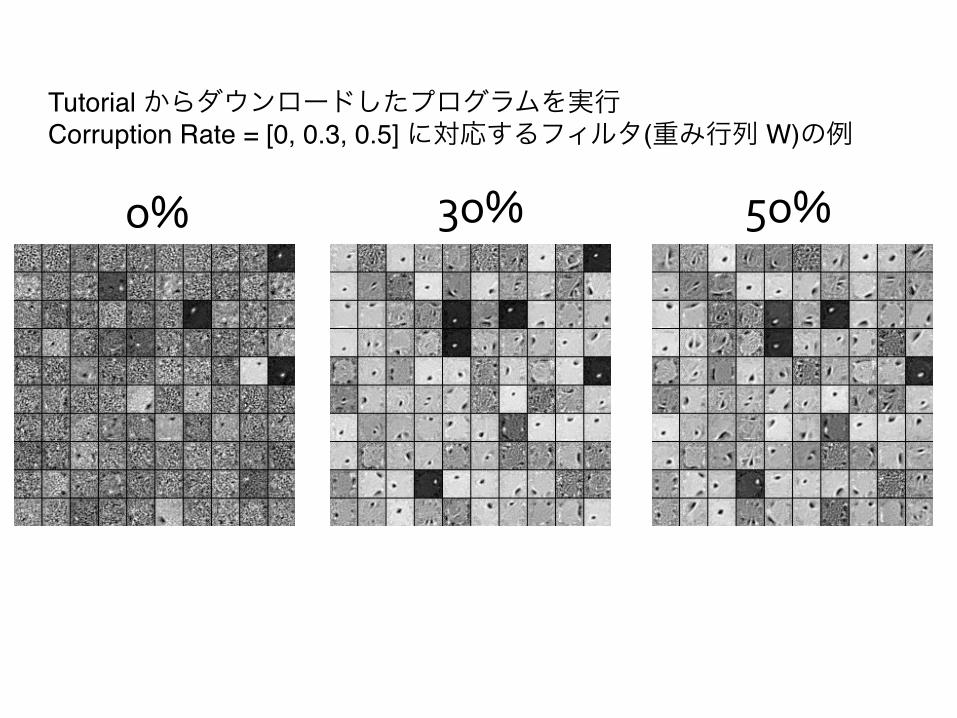
o% 3o% 5o%
Tutorial からダウンロードしたプログラムを実行"Corruption Rate = [0, 0.3, 0.5] に対応するフィルタ(重み行列 W)の例

30
Denoising Auto-Encoders: Benchmarks Larochelle et al., 2009
ちなみに:Corruption の方法にもいろいろある

RBM をうごかす(Restricted Boltzmann Machines)
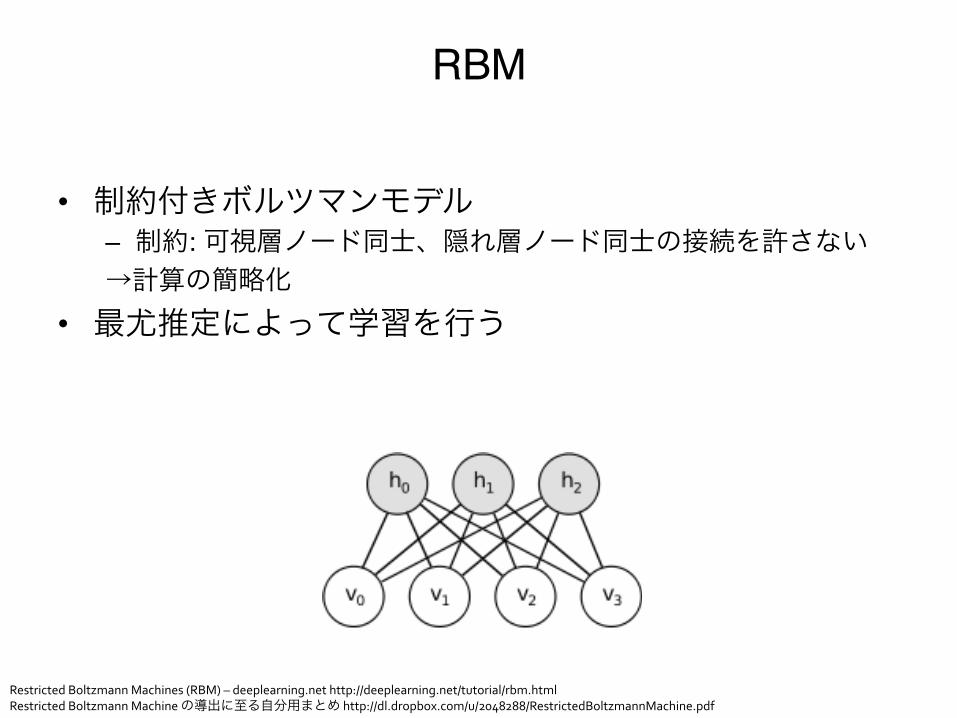
RBM
• 制約付きボルツマンモデル"– 制約: 可視層ノード同士、隠れ層ノード同士の接続を許さない"→計算の簡略化
• 最尤推定によって学習を行う
Restricted Boltzmann Machines (RBM) – deeplearning.net http://deeplearning.net/tutorial/rbm.html Restricted Boltzmann Machine の導出に至る自分用まとめ http://dl.dropbox.com/u/2048288/RestrictedBoltzmannMachine.pdf

可視ノード集合 v(�vi � 0, 1)と隠れノード集合 h(�hi � 0, 1)からなる系がその状態をとる確率 p(v,h)はエネルギー関数E(v,h)と分散関数を用いて以下のように定義される(c.f. カノニカル分布)。
p(v,h) =e�E(v,h)
Z(1)
エネルギー関数 : E(x) = �bT v � cT h� vT Wh (2)
分配関数 : Z =�
v
�
h
e�E(v,h) (3)
v,h,Wは可視層のバイアス、隠れ層のバイアス、重み行列と呼ばれるパラメタである。この系の尤度は、以下のように定義される。
尤度 J � �log�
h
p(v,h)�q = �log�
h
eE(v,h)�q � log Z (4)
ただし �f(v)�q =�
v f(v)q(v), すなわち ��q は観測データの確率分布 q(v)の期待値である。尤度 J を任意のパラメタ �について最大化するため、導関数を求める。
�J
��= �� 1�
h e�E
�
h
�E
��e�E�q +
1Z
�
v
�
h
�E
��e�E (5)
ここで、条件付き確率の定義 p(h|v) = e�E(v,h)P
h e�E(v,h) より、
�J
��= �
�
v
�
h
�E
��p(h|v)q(v) +
�
v
�
h
�E
��p(v,h) (6)
= ���E
���p(h|v)q(v) + ��E
���p(h,v) (7)
また、条件付き確率を計算して下記を得る(ここで厳密解を求められることが「制限付き」の特徴)。
p(h|v) = s(Wv + b�) (8)
p(v|h) = s(Wh + b) (9)
ただし、s(x) はシグモイド関数である。以上より、RBMは
• encoder: 式 (8)
• decoder: 式 (9)
• error: �J(式 (4))
• 更新式: 式 (7)
という対応付けを行うことで、Autoencoder の実装のひとつと捉えることが出来る。しかし、式 (7)の第 2項を求めることは困難であることが多いため、Contrastive Divergence という手法を用いる。

可視ノード集合 v(�vi � 0, 1)と隠れノード集合 h(�hi � 0, 1)からなる系がその状態をとる確率 p(v,h)はエネルギー関数E(v,h)と分散関数を用いて以下のように定義される(c.f. カノニカル分布)。
p(v,h) =e�E(v,h)
Z(1)
エネルギー関数 : E(x) = �bT v � cT h� vT Wh (2)
分配関数 : Z =�
v
�
h
e�E(v,h) (3)
v,h,Wは可視層のバイアス、隠れ層のバイアス、重み行列と呼ばれるパラメタである。この系の尤度は、以下のように定義される。
尤度 J � �log�
h
p(v,h)�q = �log�
h
eE(v,h)�q � log Z (4)
ただし �f(v)�q =�
v f(v)q(v), すなわち ��q は観測データの確率分布 q(v)の期待値である。尤度 J を任意のパラメタ �について最大化するため、導関数を求める。
�J
��= �� 1�
h e�E
�
h
�E
��e�E�q +
1Z
�
v
�
h
�E
��e�E (5)
ここで、条件付き確率の定義 p(h|v) = e�E(v,h)P
h e�E(v,h) より、
�J
��= �
�
v
�
h
�E
��p(h|v)q(v) +
�
v
�
h
�E
��p(v,h) (6)
= ���E
���p(h|v)q(v) + ��E
���p(h,v) (7)
また、条件付き確率を計算して下記を得る(ここで厳密解を求められることが「制限付き」の特徴)。
p(h|v) = s(Wv + b�) (8)
p(v|h) = s(Wh + b) (9)
ただし、s(x) はシグモイド関数である。以上より、RBMは
• encoder: 式 (8)
• decoder: 式 (9)
• error: �J(式 (4))
• 更新式: 式 (7)
という対応付けを行うことで、Autoencoder の実装のひとつと捉えることが出来る。しかし、式 (7)の第 2項を求めることは困難であることが多いため、Contrastive Divergence という手法を用いる。

可視ノード集合 v(�vi � 0, 1)と隠れノード集合 h(�hi � 0, 1)からなる系がその状態をとる確率 p(v,h)はエネルギー関数E(v,h)と分散関数を用いて以下のように定義される(c.f. カノニカル分布)。
p(v,h) =e�E(v,h)
Z(1)
エネルギー関数 : E(x) = �bT v � cT h� vT Wh (2)
分配関数 : Z =�
v
�
h
e�E(v,h) (3)
v,h,Wは可視層のバイアス、隠れ層のバイアス、重み行列と呼ばれるパラメタである。この系の尤度は、以下のように定義される。
尤度 J � �log�
h
p(v,h)�q = �log�
h
eE(v,h)�q � log Z (4)
ただし �f(v)�q =�
v f(v)q(v), すなわち ��q は観測データの確率分布 q(v)の期待値である。尤度 J を任意のパラメタ �について最大化するため、導関数を求める。
�J
��= �� 1�
h e�E
�
h
�E
��e�E�q +
1Z
�
v
�
h
�E
��e�E (5)
ここで、条件付き確率の定義 p(h|v) = e�E(v,h)P
h e�E(v,h) より、
�J
��= �
�
v
�
h
�E
��p(h|v)q(v) +
�
v
�
h
�E
��p(v,h) (6)
= ���E
���p(h|v)q(v) + ��E
���p(h,v) (7)
また、条件付き確率を計算して下記を得る(ここで厳密解を求められることが「制限付き」の特徴)。
p(h|v) = s(Wv + b�) (8)
p(v|h) = s(Wh + b) (9)
ただし、s(x) はシグモイド関数である。以上より、RBMは
• encoder: 式 (8)
• decoder: 式 (9)
• error: �J(式 (4))
• 更新式: 式 (7)
という対応付けを行うことで、Autoencoder の実装のひとつと捉えることが出来る。しかし、式 (7)の第 2項を求めることは困難であることが多いため、Contrastive Divergence という手法を用いる。
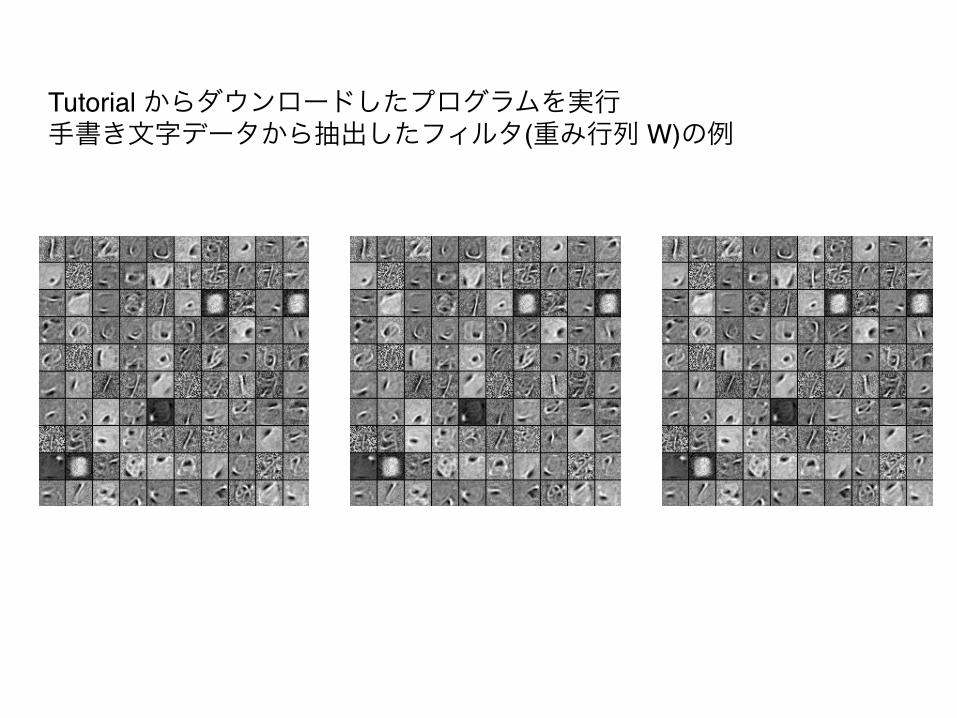
Tutorial からダウンロードしたプログラムを実行"手書き文字データから抽出したフィルタ(重み行列 W)の例

まとめ
• Deep Learning は多層のニューラルネットワーク"– Autoencoder をつかったものと RBM をつかったものがある"
• 深イイはつくれる!"– 特に、Autoencoder の実装はシンプルでわかりやすい"

References • Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation
Learning: A Review and New Perspectives."• Yoshua Bengio. Learning Deep Architectures for AI. "• Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, Pierre-
Antoine Manzagol. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion"
• Deeplearning.net http://deeplearning.net/"• Pythonと Deep Learningで 手書き文字認識
http://www.slideshare.net/mokemokechicken/pythondeep-learning"• 名古屋工業大学岩田彰研究室 ニューラルネット入門
http://www-ailab.elcom.nitech.ac.jp/lecture/neuro/bp4.html"• Deep Learning -株式会社ウサギィ 五木田 和也
http://www.slideshare.net/kazoo04/deep-learning-15097274"• Restricted Boltzmann Machineの学習手法についての簡単なまとめ
http://mglab.blogspot.jp/2012/08/restricted-boltzmann-machine.html














![[DLHacks 実装]Neural Machine Translation in Linear Time](https://img.pdfslide.net/doc/110x75/5a6479ae7f8b9a4c568b46f9/dlhacks-neural-machine-translation-in-linear-time.jpg)


![[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks](https://img.pdfslide.net/doc/110x75/5a64d62f7f8b9a88148b58a1/dlhacks-deeppose-human-pose-estimation-via-deep-neural-networks.jpg)











![[DLHacks 実装] The statistical recurrent unit](https://img.pdfslide.net/doc/110x75/5a64d62f7f8b9a88148b58a5/dlhacks-the-statistical-recurrent-unit.jpg)