Embed Size (px)
Citation preview

© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Matthew Williams, DevOps Evangelist, Datadog
@technovangelist - [email protected]
October 2015
DVO204
Monitoring StrategiesFinding Signal in the Noise

Collecting data is cheap;
not having it when you
need it is expensive.

Instrument all the things.

Operational complexity
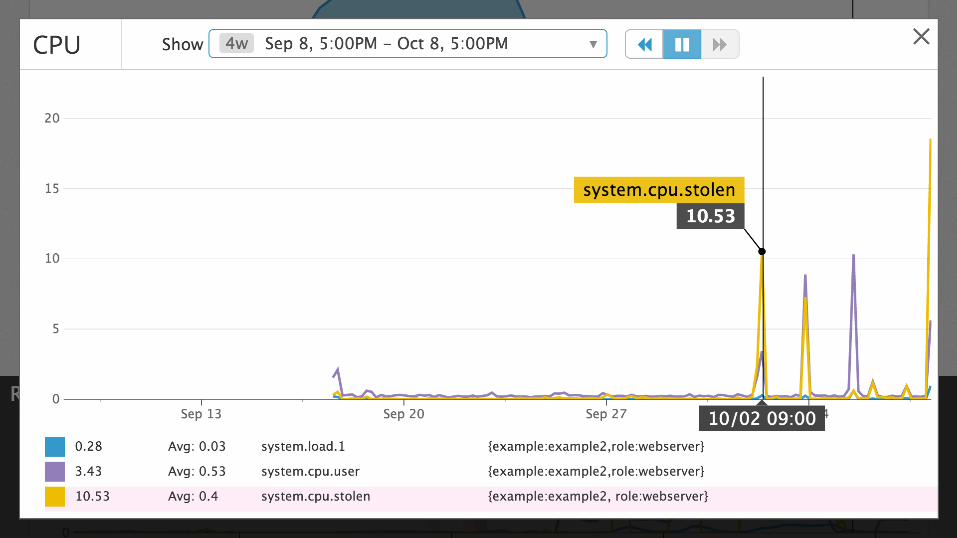
Average containers per host: N (N=2, 10/2015)
N times as many “hosts” to manage
Effects:
• Provisioning: Prepping and building containers
• Configuration: Passing config to containers
• Orchestration: Deciding where/when containers run
• Monitoring: Making sure containers run properly

Complexity increases with the…
• Number of things to measure
• Velocity of change

…the number of things to measure
1 hosted virtual machine
• ~10 metrics, depending on vendor
1 operating system (e.g., Linux)
• 100 metrics
N containers
• 100*N metrics
110 + 100*N metrics per VM

Combinatorial multiplication
Assuming 2 containers per host
virtual machines
200

Combinatorial multiplication
Assuming 2 containers per host
310

Combinatorial multiplication
Assuming only 2 containers per host
virtual machines
31,000
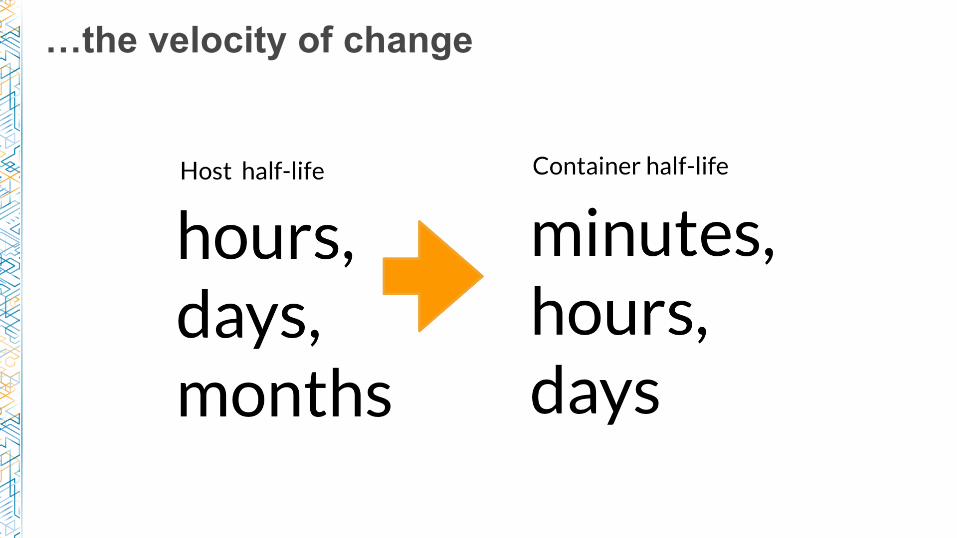
…the velocity of change

Tags

“Monitor all Docker containers running image
web in region us-west-2 across all Availability
Zones and make sure resident set size < 1GB
on c3.xl”

“Monitor all Docker containers running image
web in region us-west-2 across all Availability
Zones” and make sure resident set size < 1GB
on c3.xl”

“Monitor all Docker containers running image
web in region us-west-2 across all
Availability Zones that use more than 1.5x
the average on c3.xl”

Tags
demo:nginx
demo:docker
demo:redis
demo:php
role:demo
platform:aws (platform:hpcloud, platform:fusion, platform:azure)
Tags are greatbut you need more
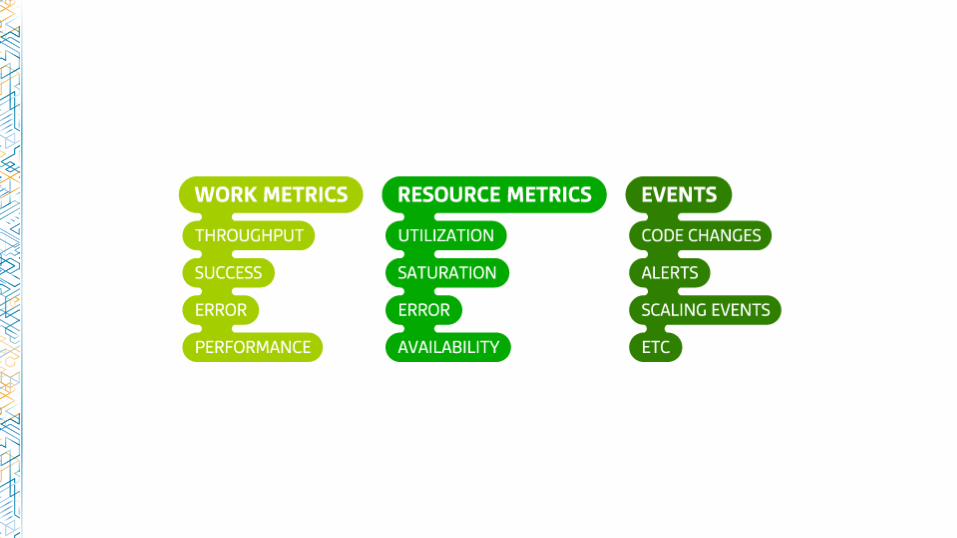

Alert liberally; page judiciously
Page on symptoms, rather than causes
Alerts as record
Alerts as notifications
Alerts as pages

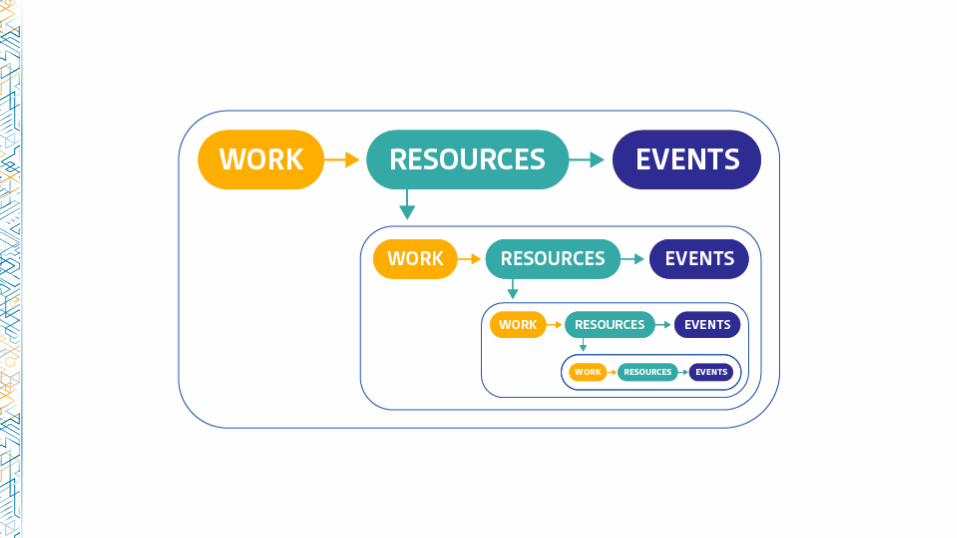
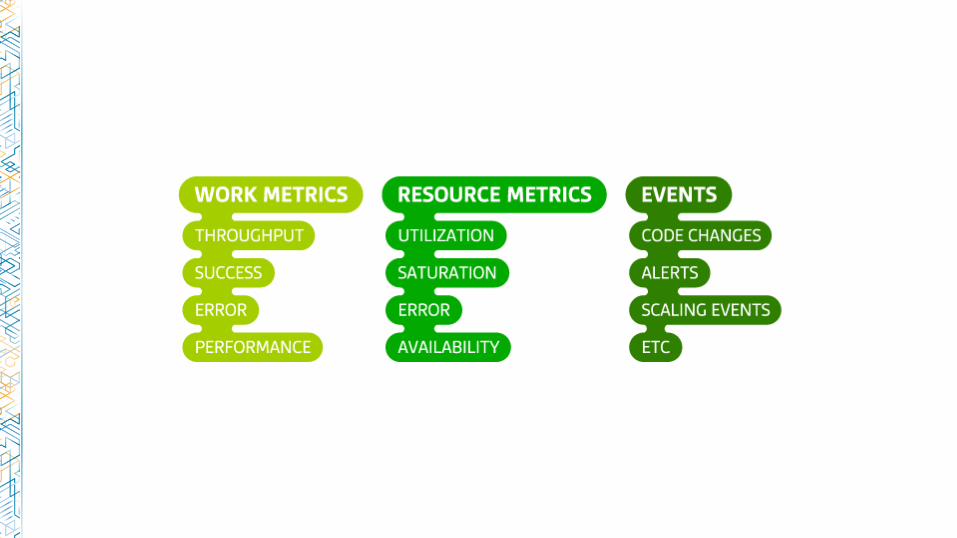

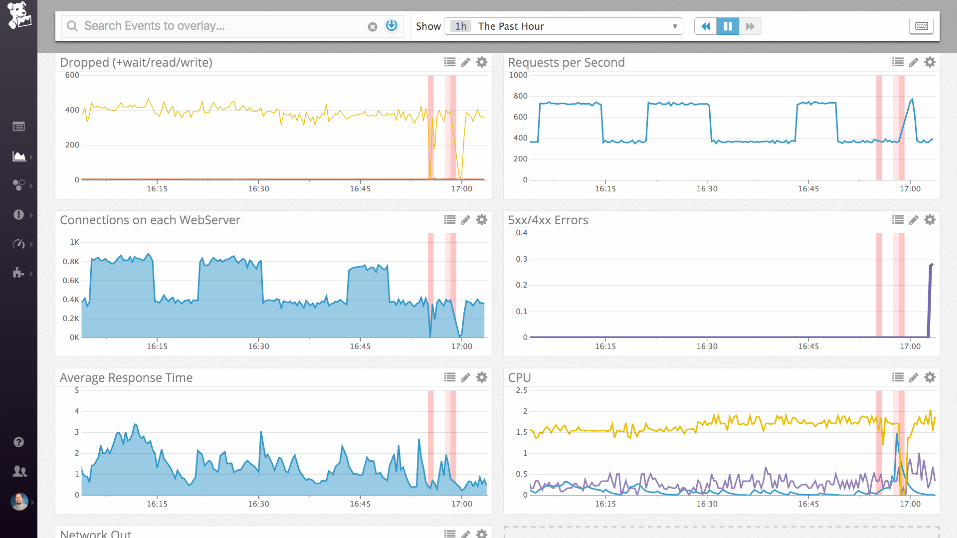
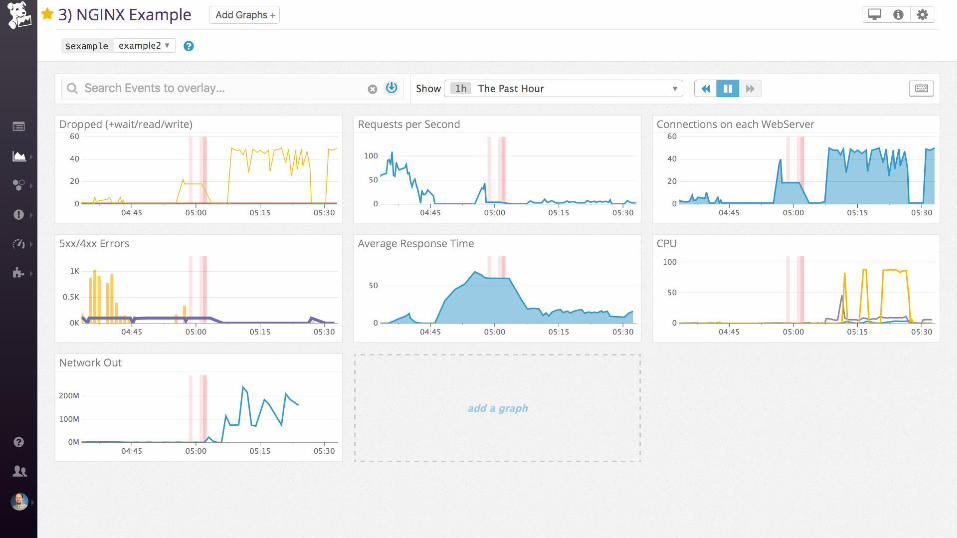
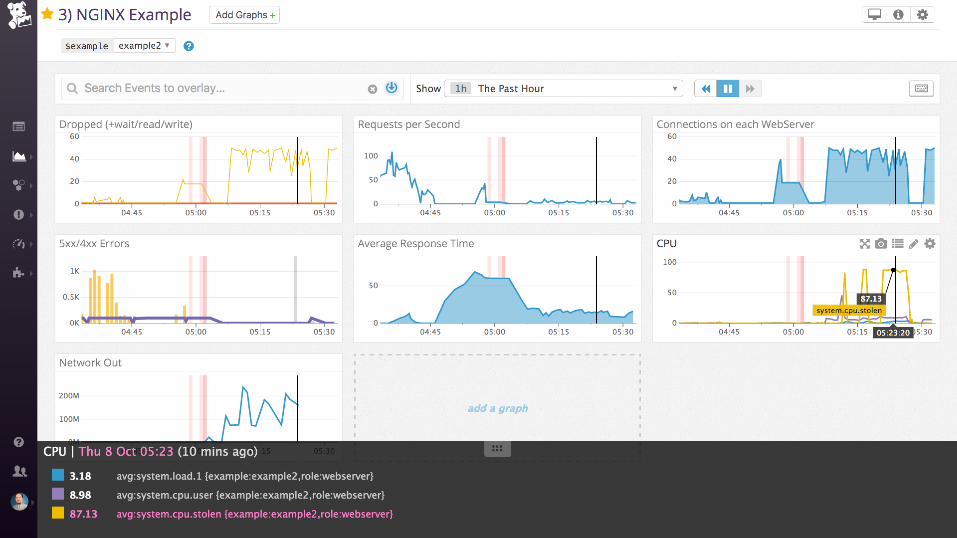
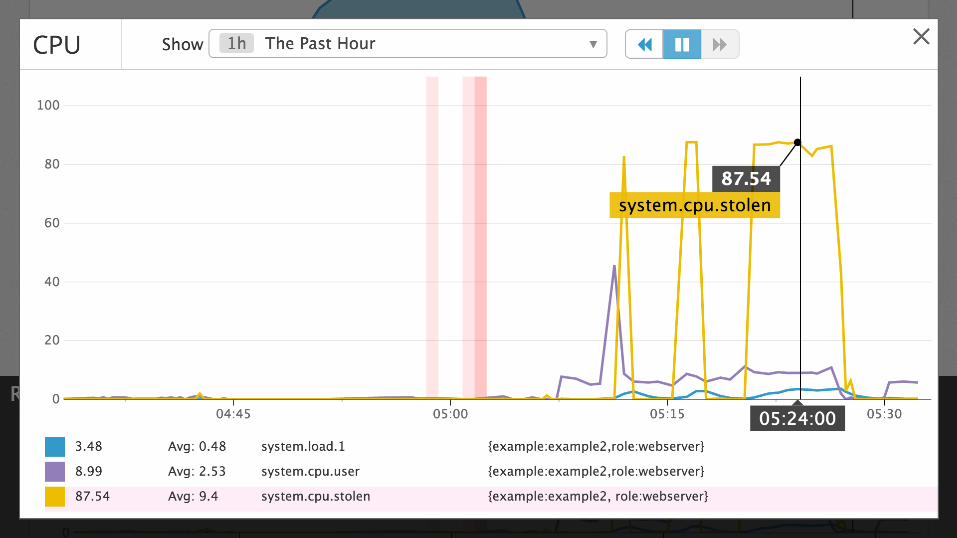
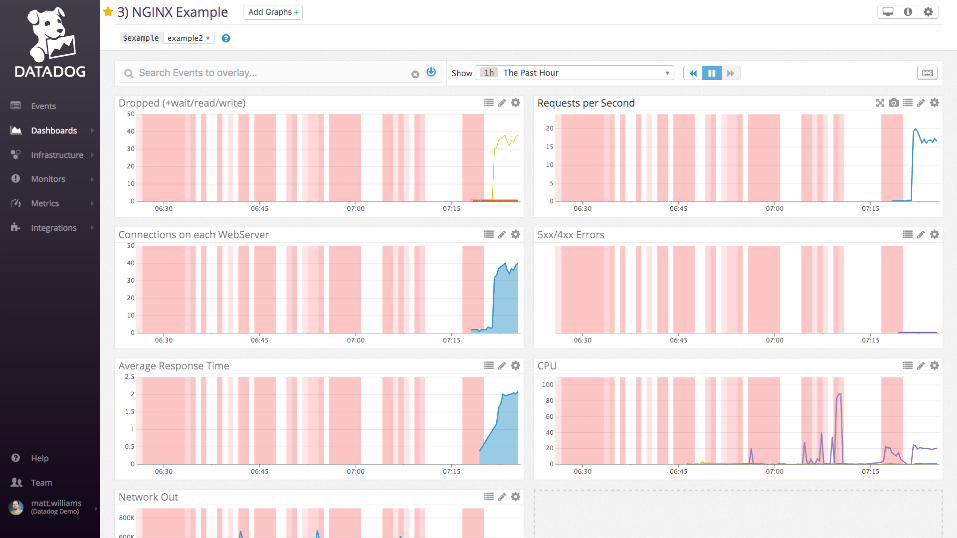
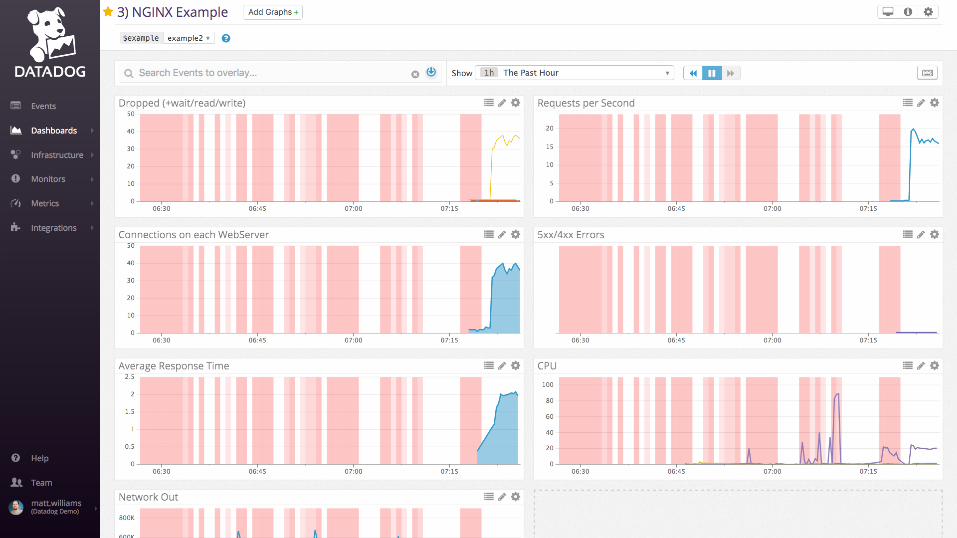
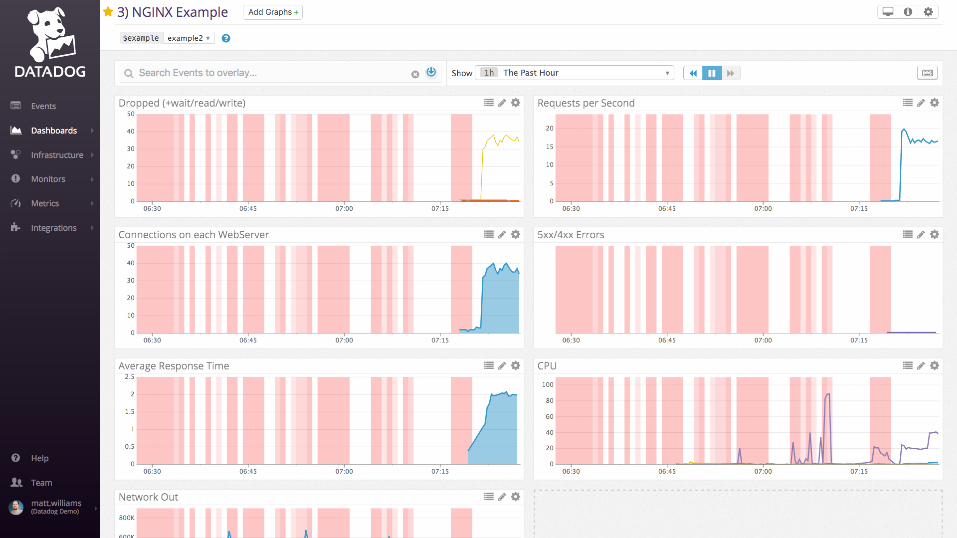
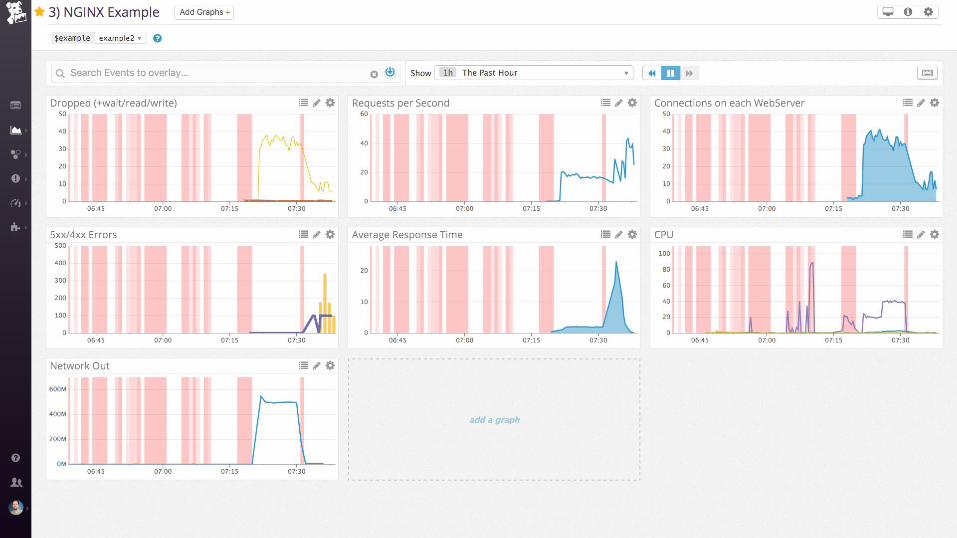
Examples: nginx
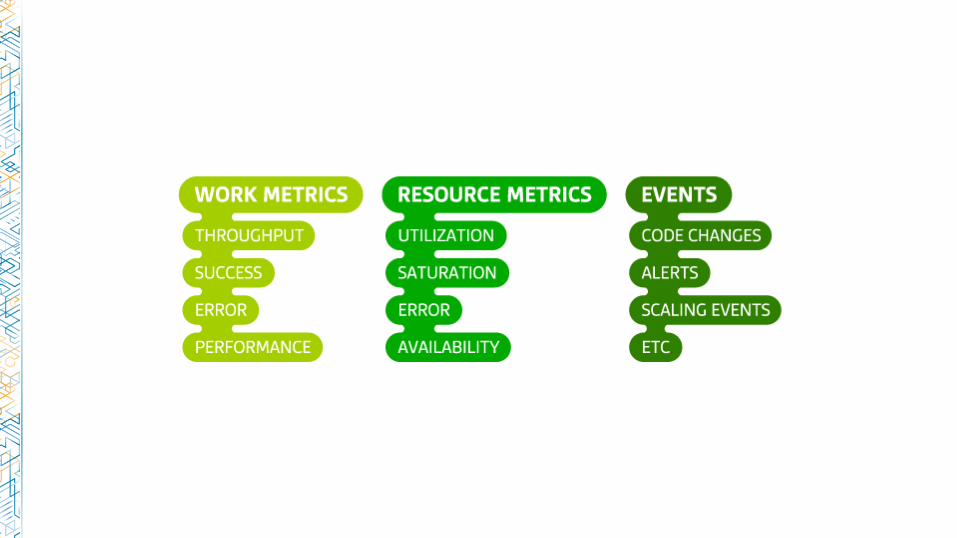
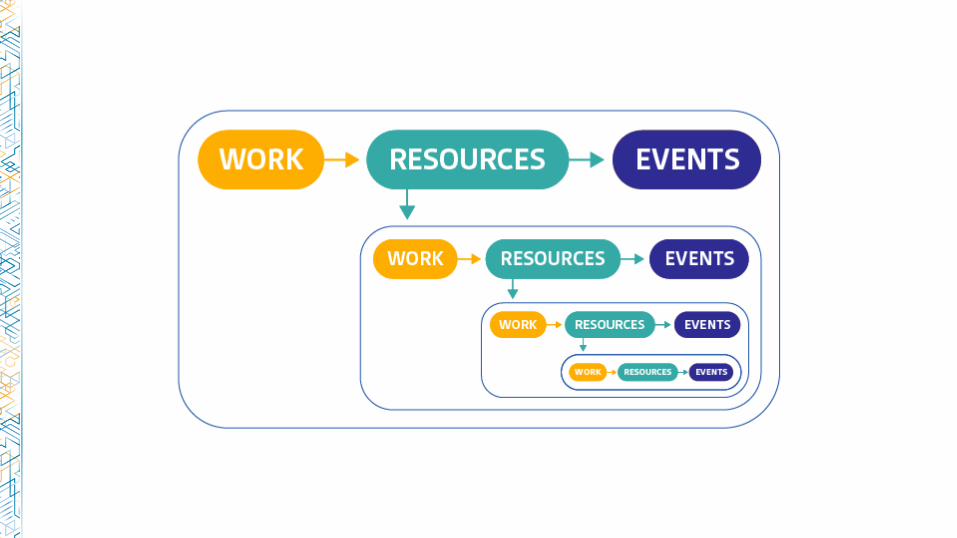
Work metrics:
• Requests per second
• Dropped connections
• Request time
• Server error rate
Resource metrics:
• Accepted connections
• Active connections
• Idle connections
Events:
• nginx started

Examples: redis
Work metrics:
• Latency
• Ops per second
• Hit rate
Resource metrics:
• Used memory
• Memory fragmentation ratio
• Evicted keys
• Connected clients

Examples: varnish
Work metrics:
• # client requests
• Back-end failed
connections
Resource metrics:
• # sessions
• Least recently used nuked
objects
• Back-end connections

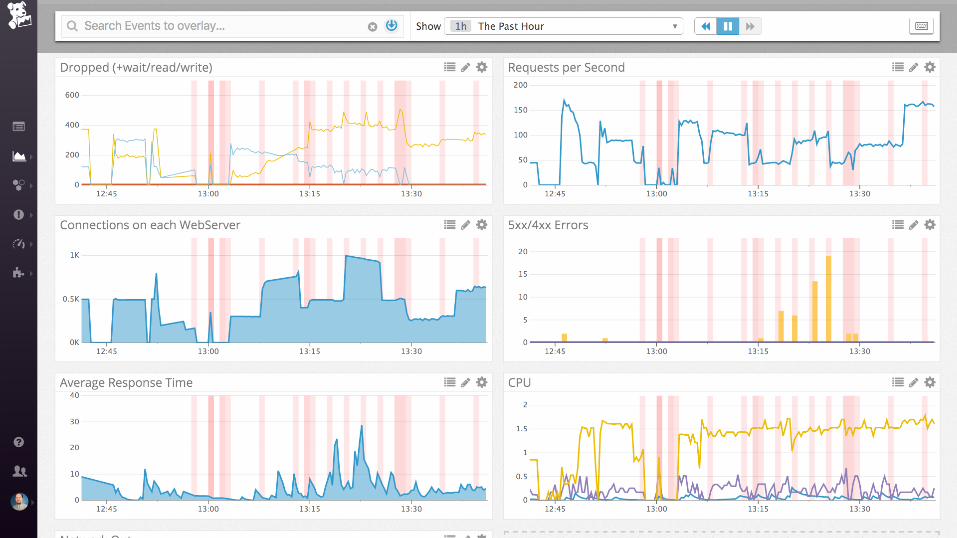
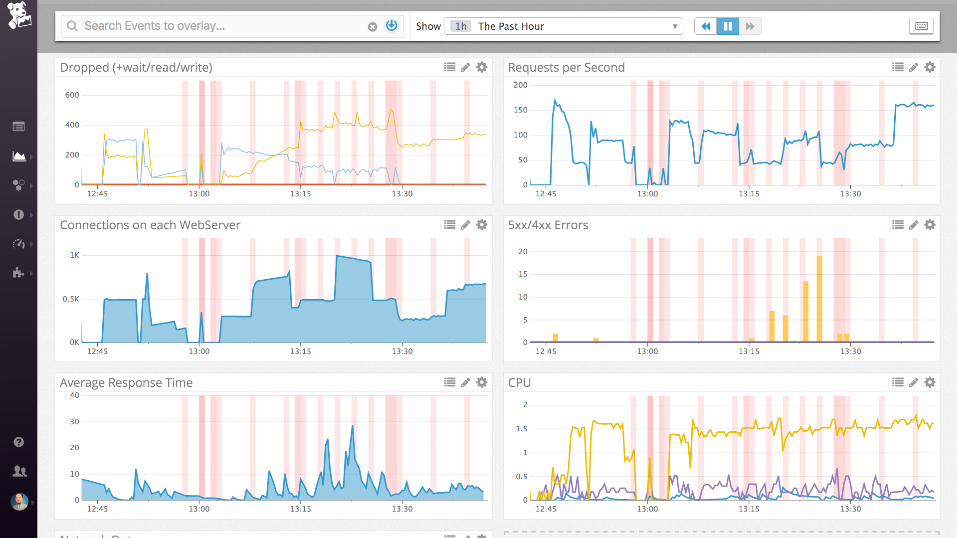
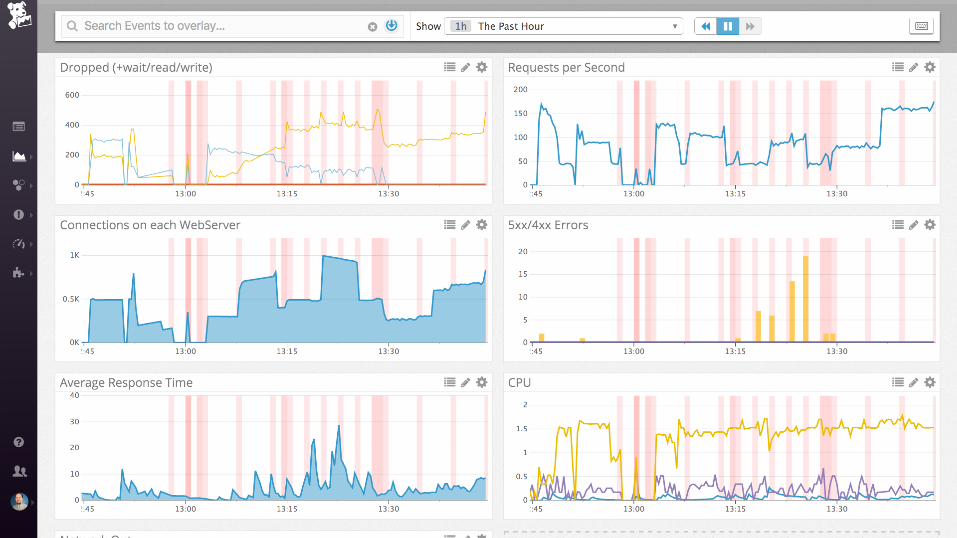
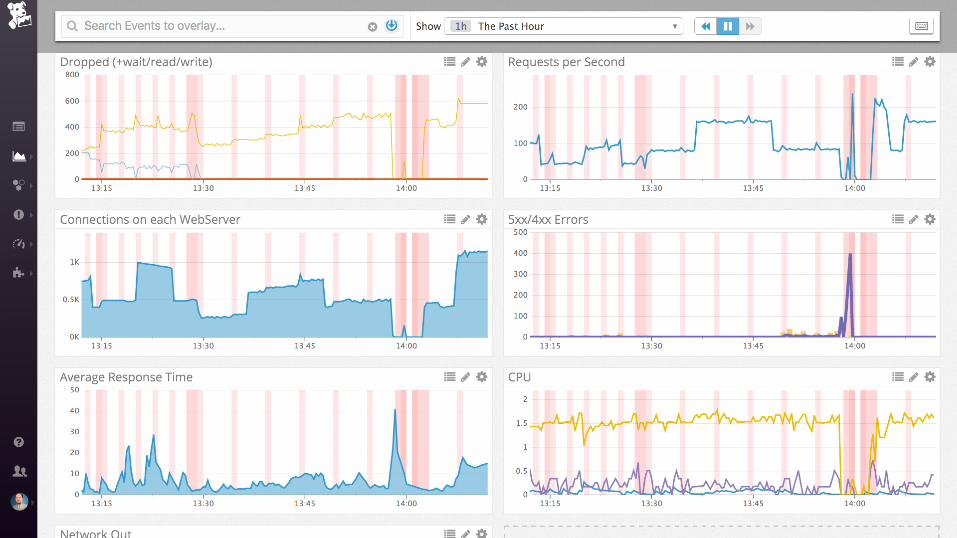
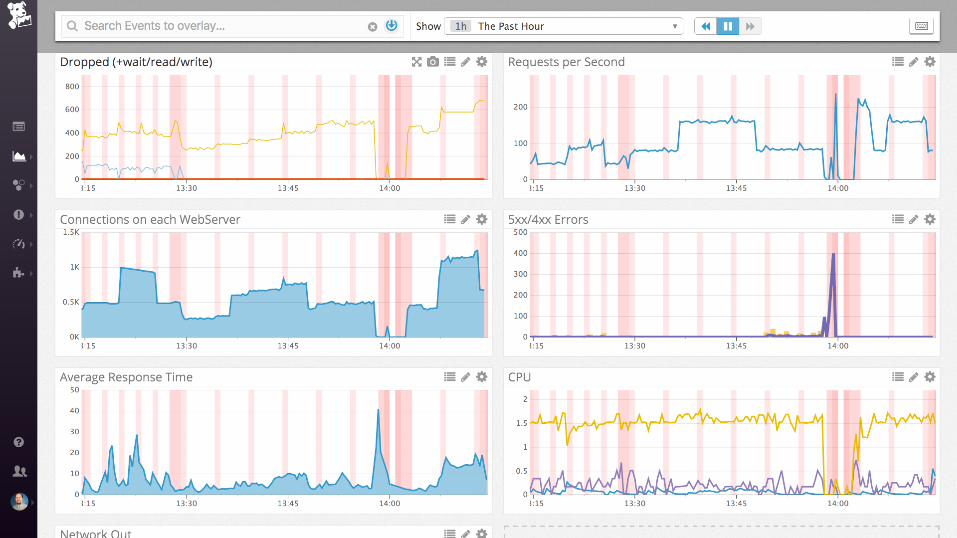
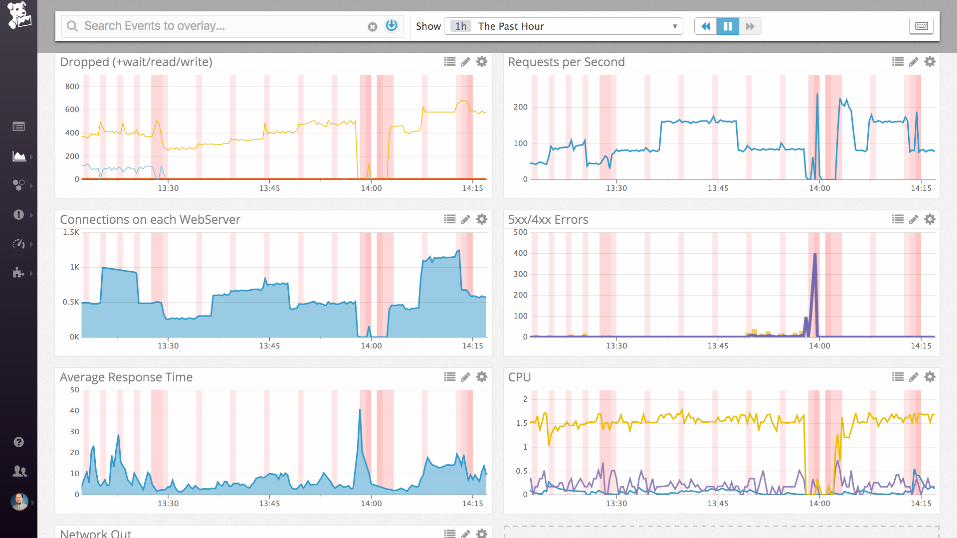
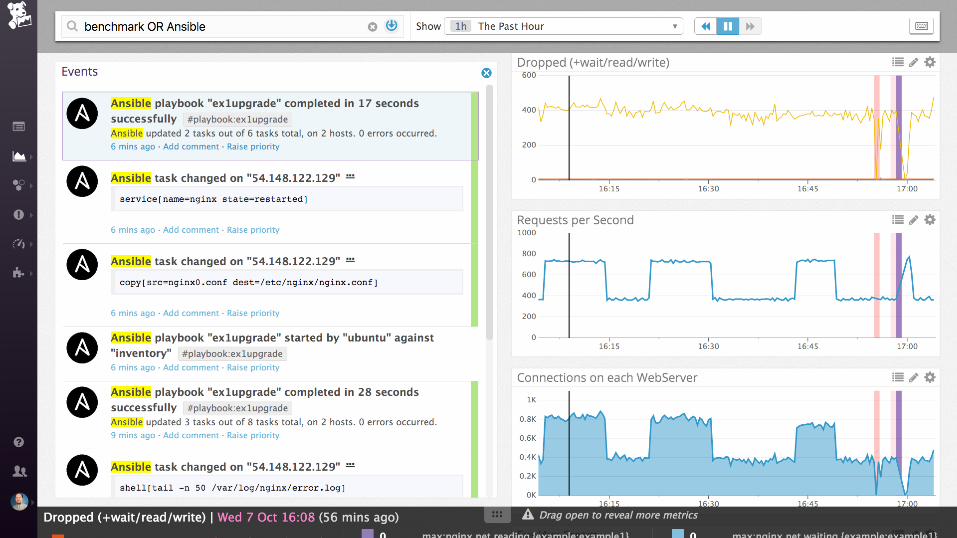
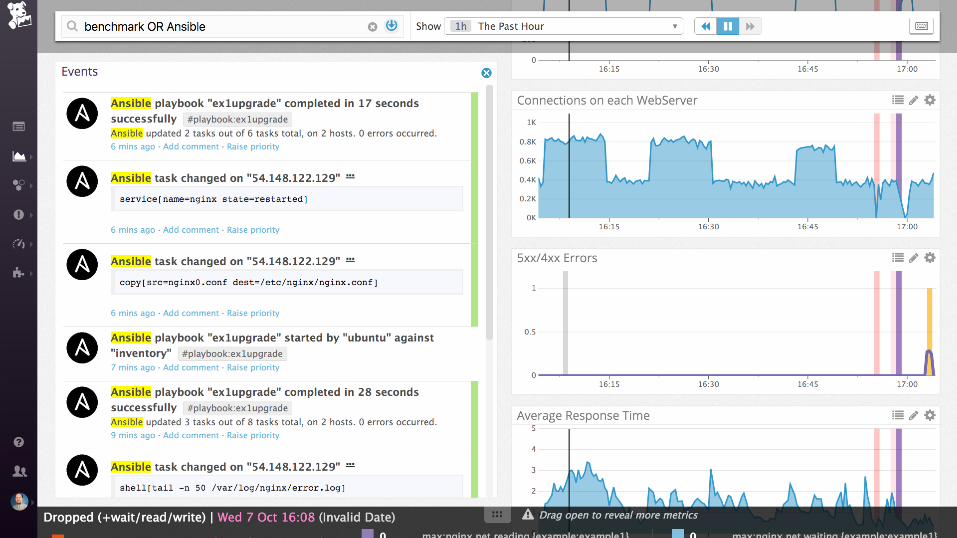
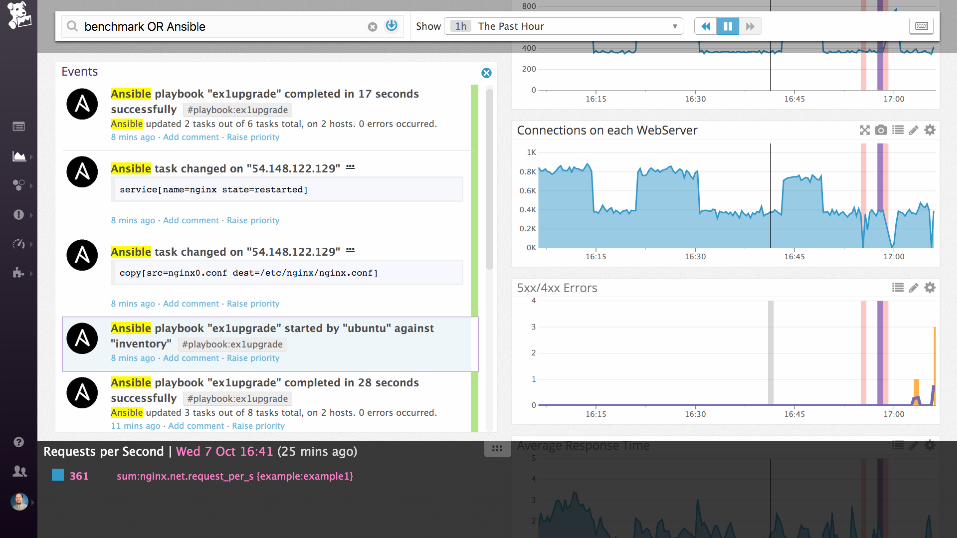
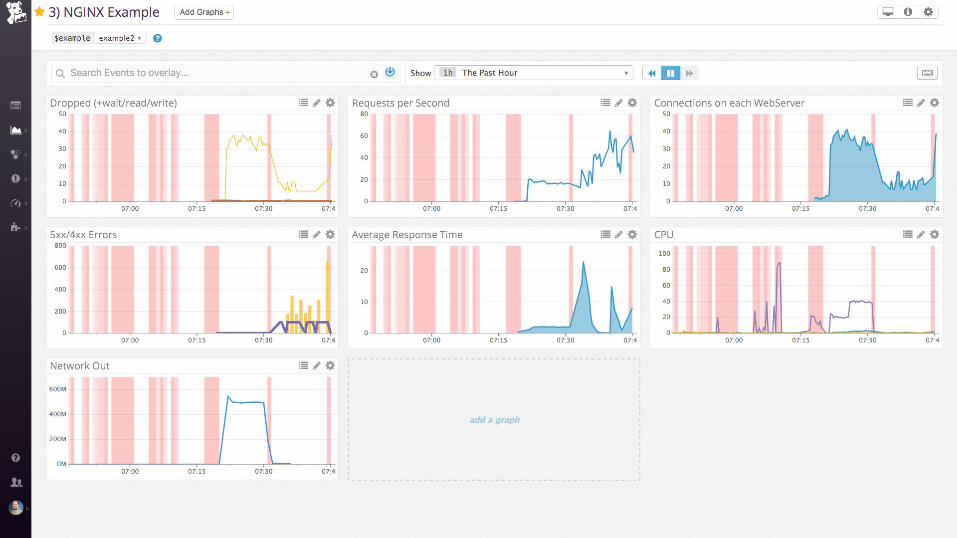
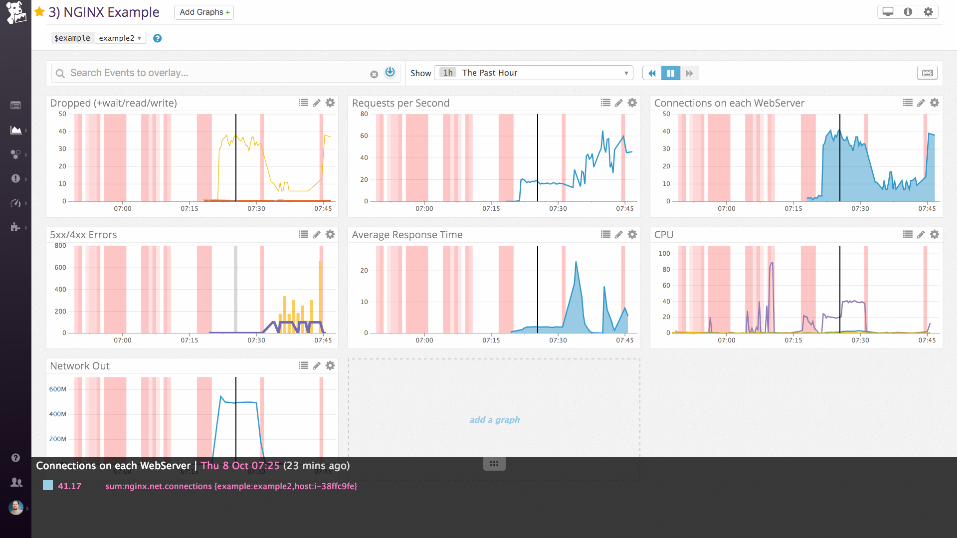
Demo

nginx (static files)
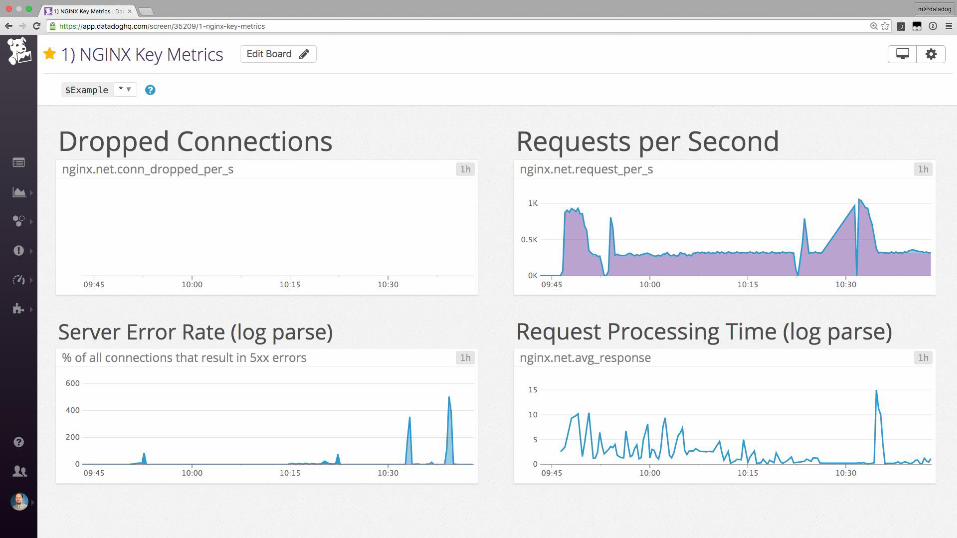

Collecting process time and error rate
log_format time_log '$time_local \
"$request” S=$status $bytes_sent \
T=$request_time R=$http_x_forwarded_for';

Parsing log files
• Dogstream (http://dtdg.co/lpdogstream)
• Sumo Logic
• Splunk
• et.al.
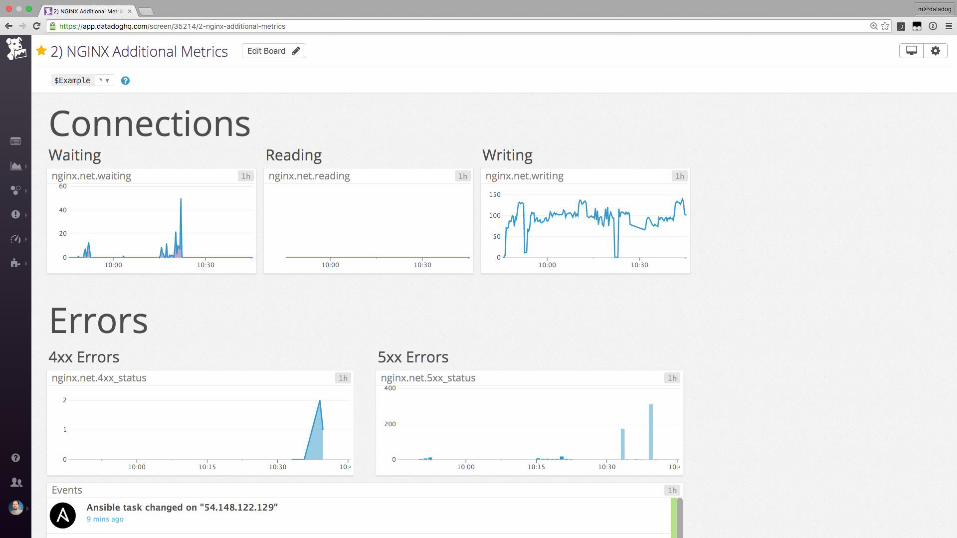
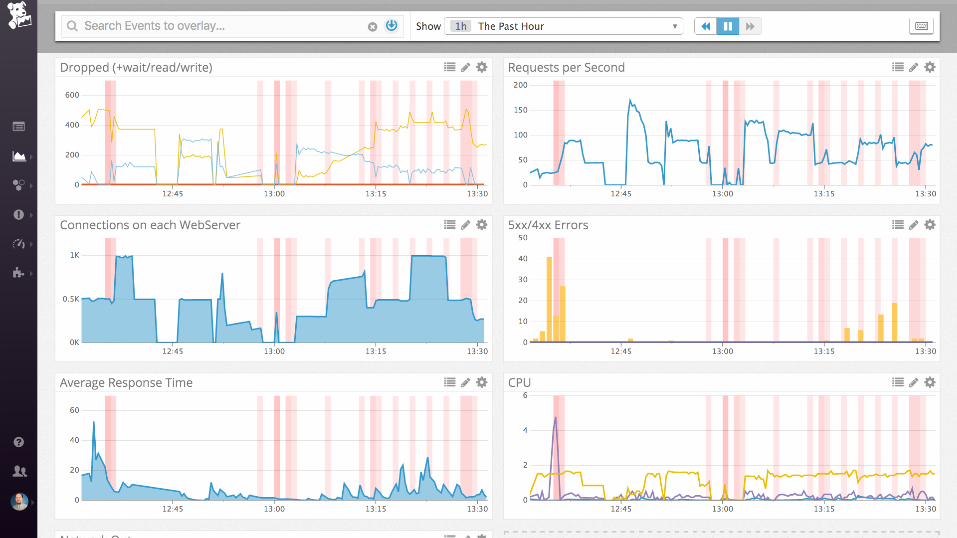
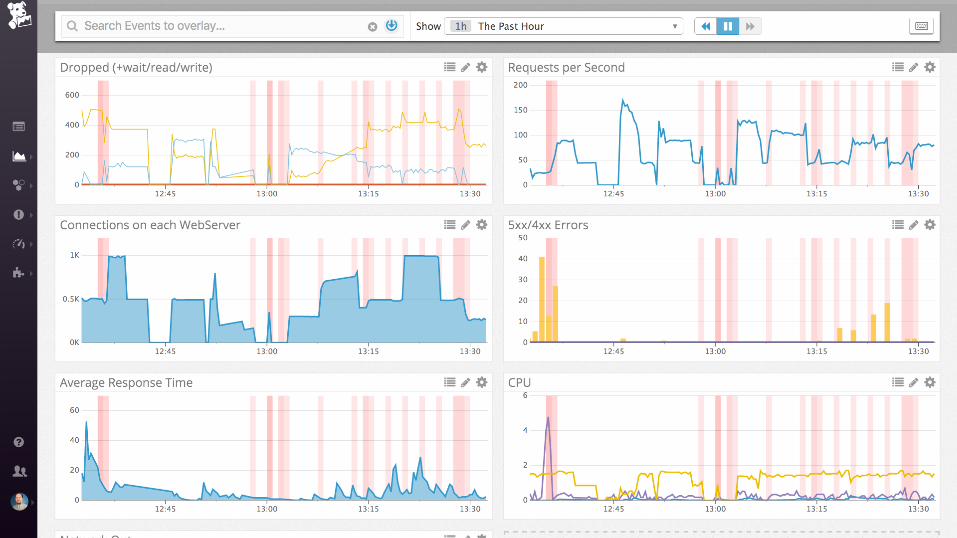
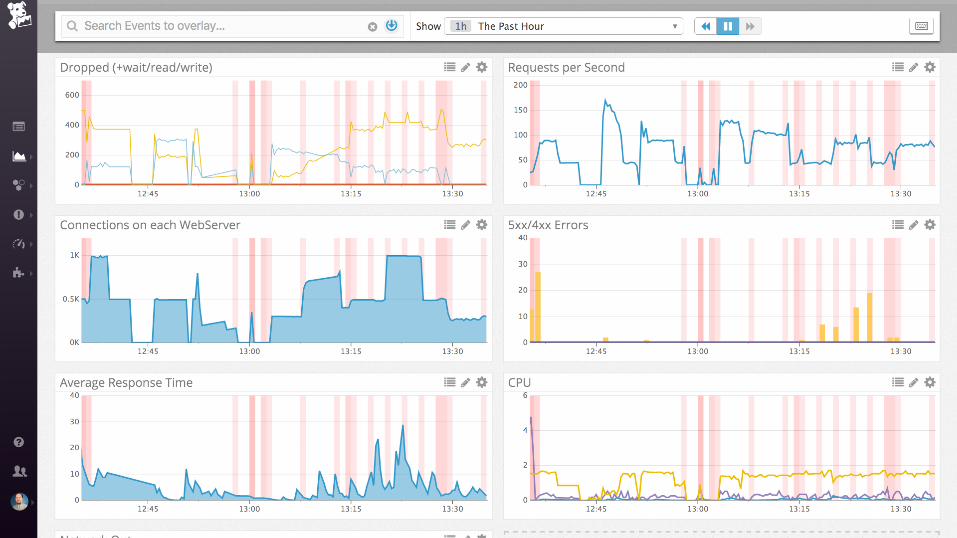
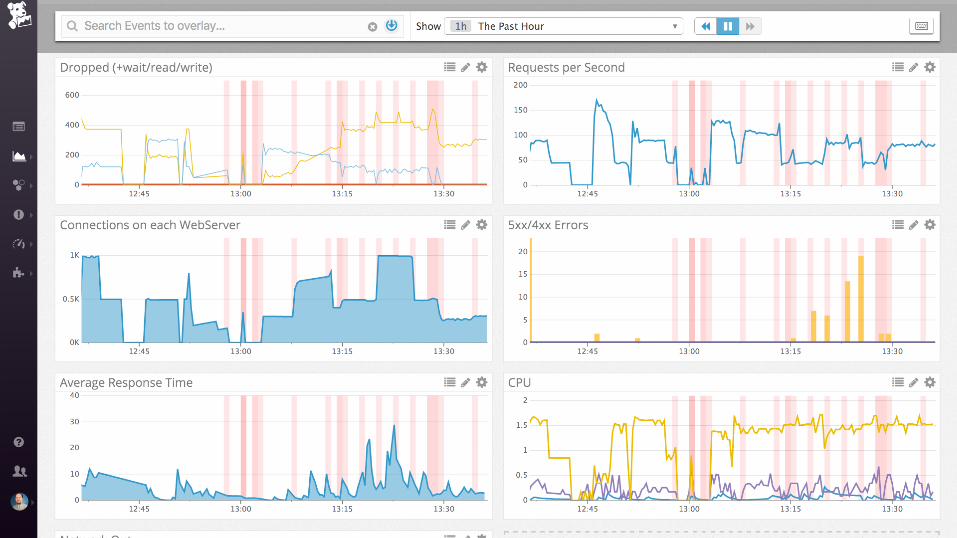
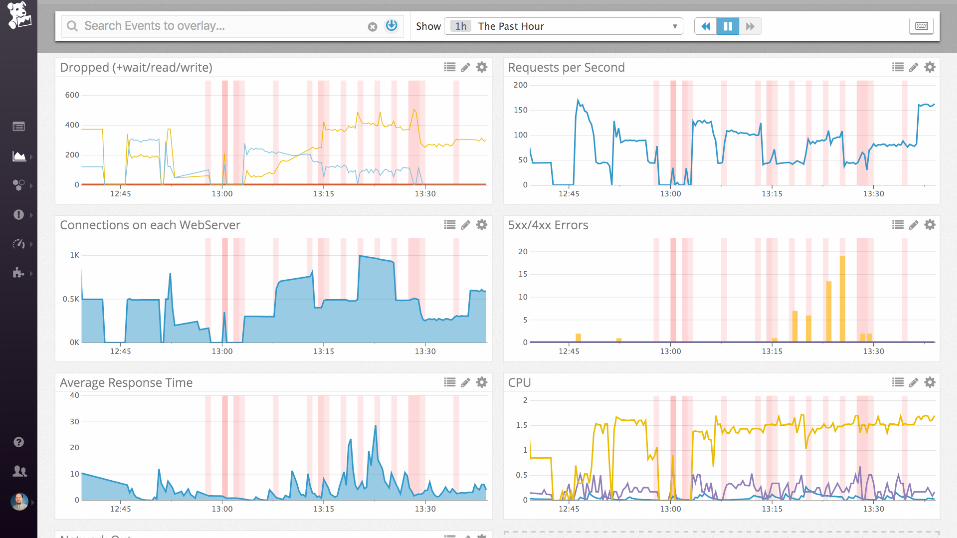
... and then ....
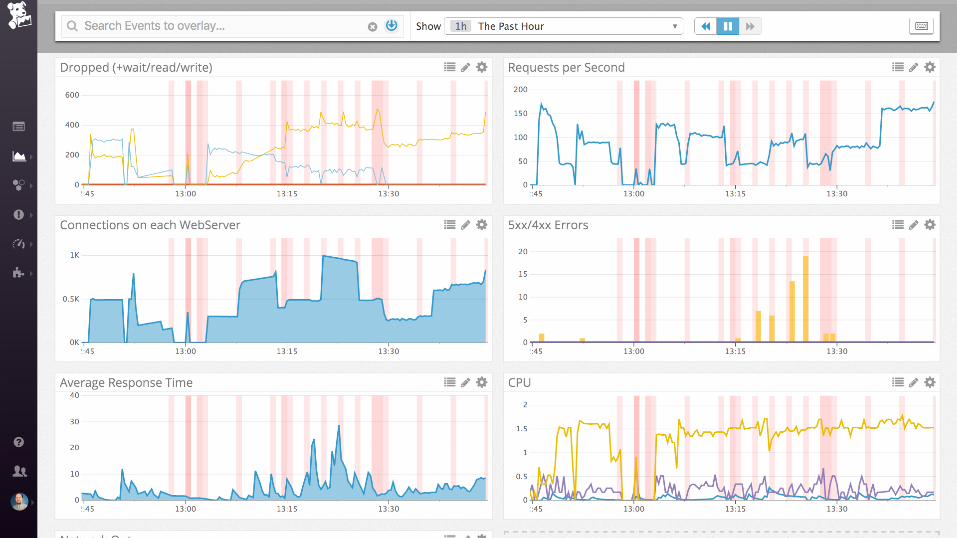
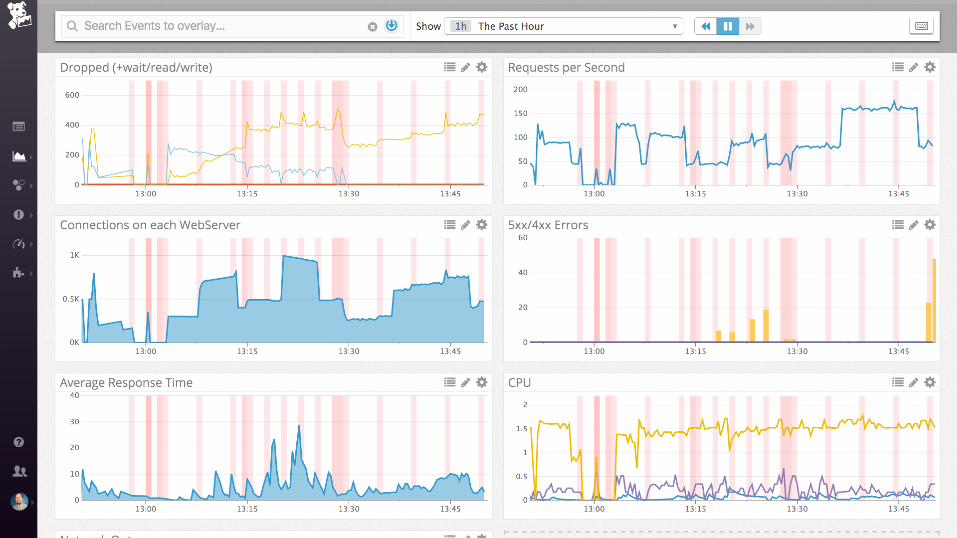
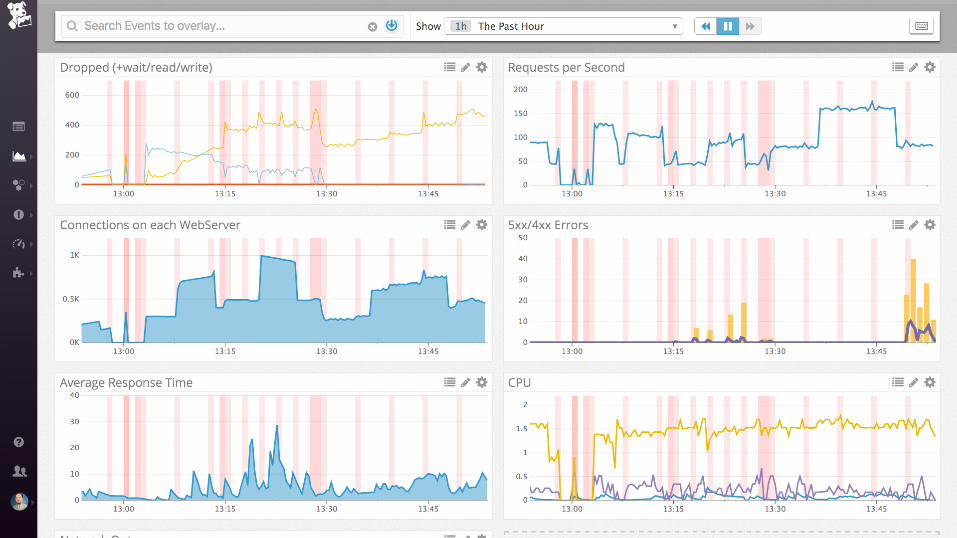
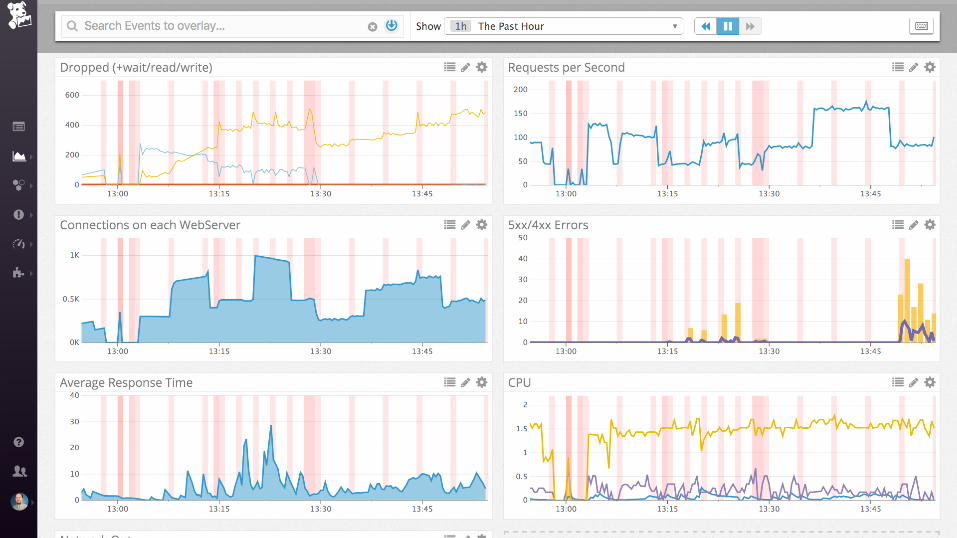
time to tweak my
config files...
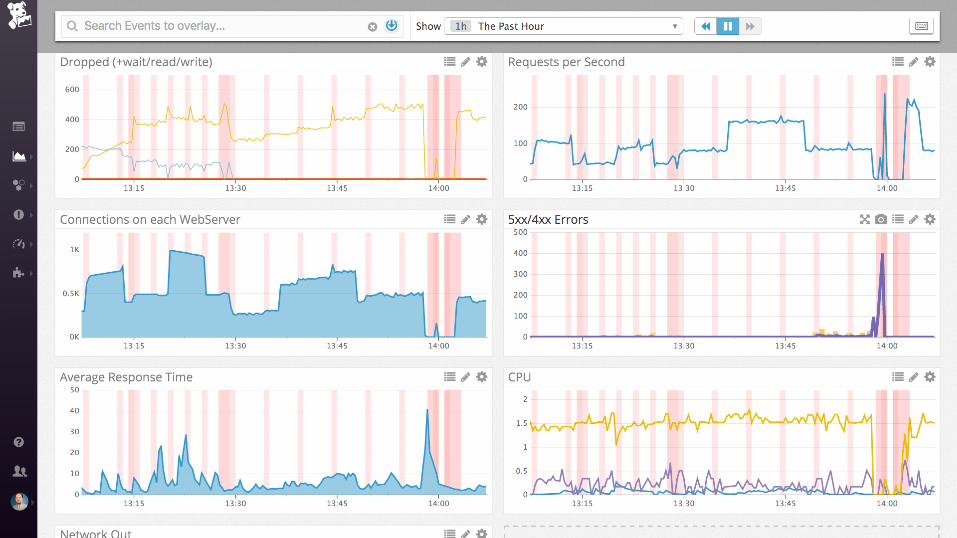
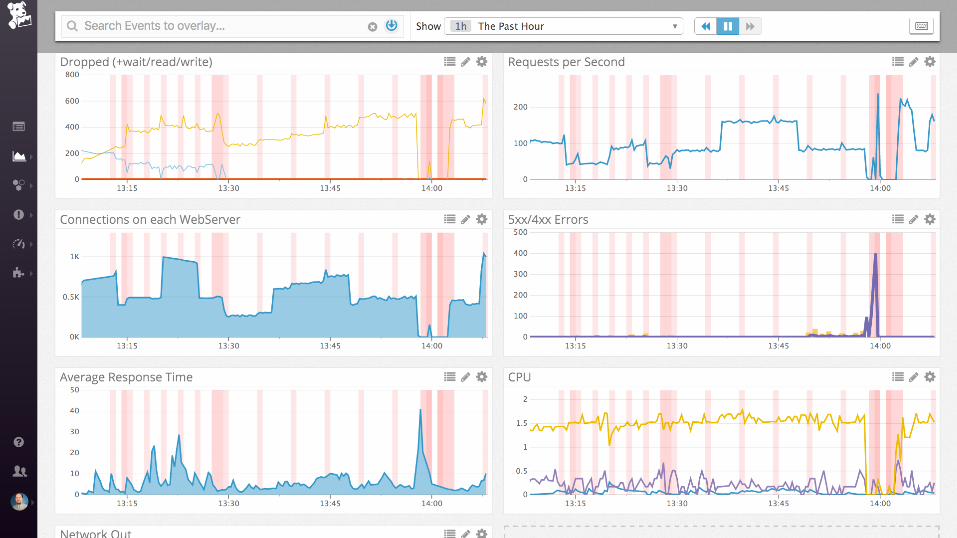
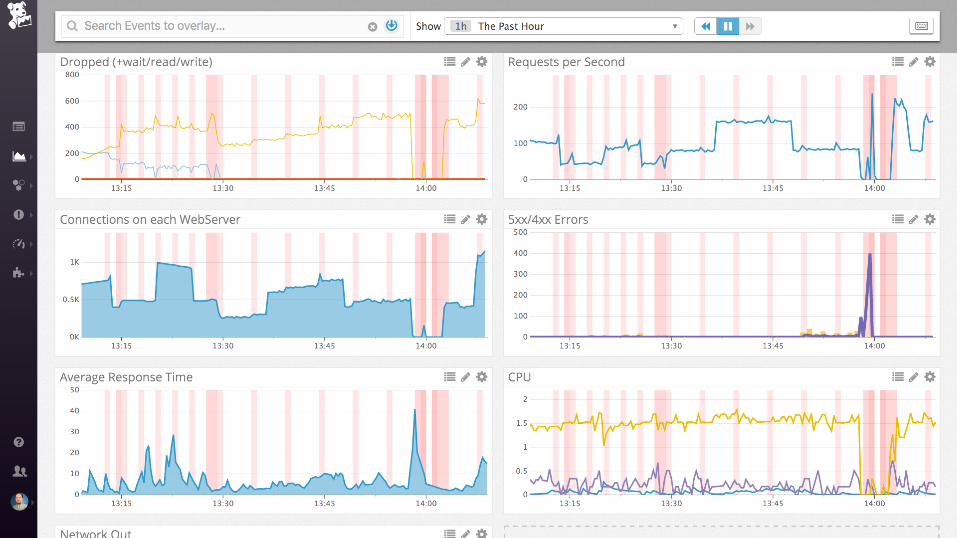
...getting there...
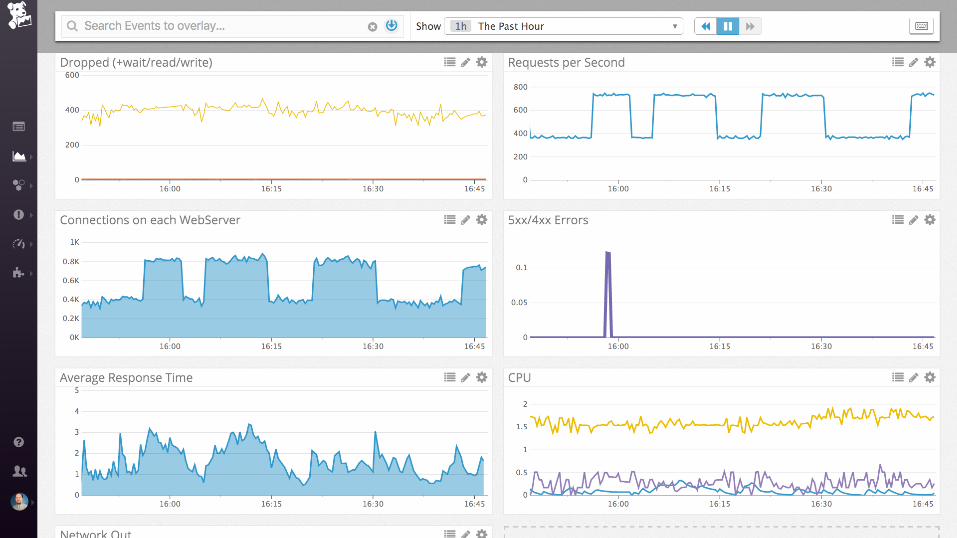
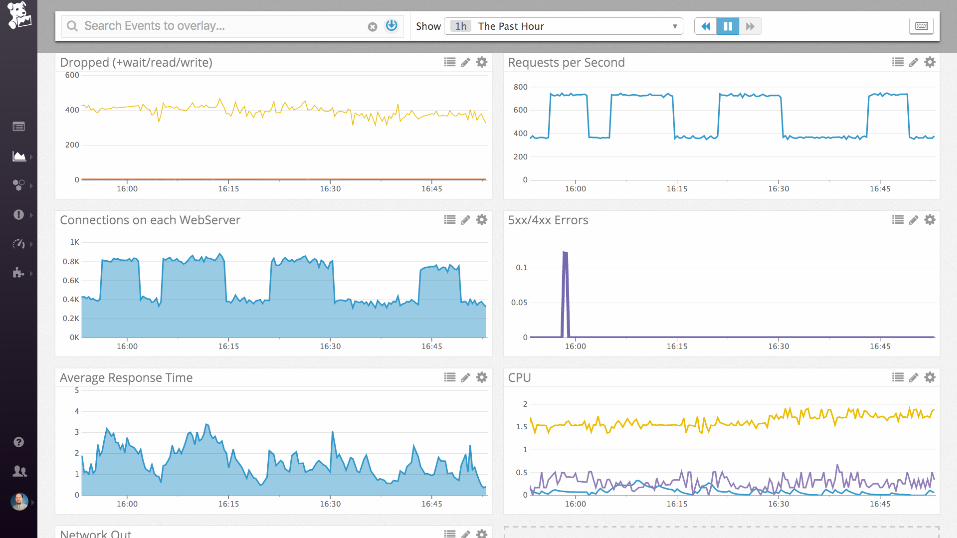
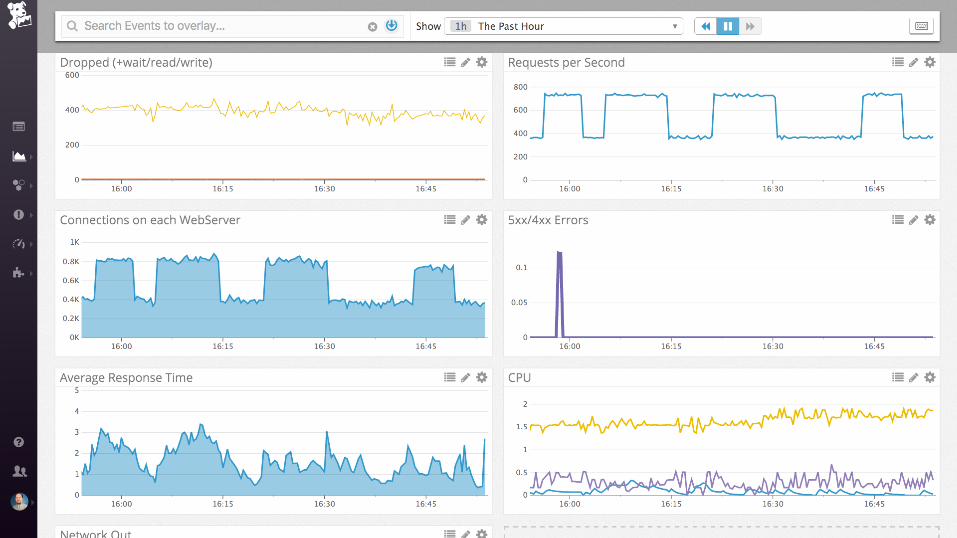
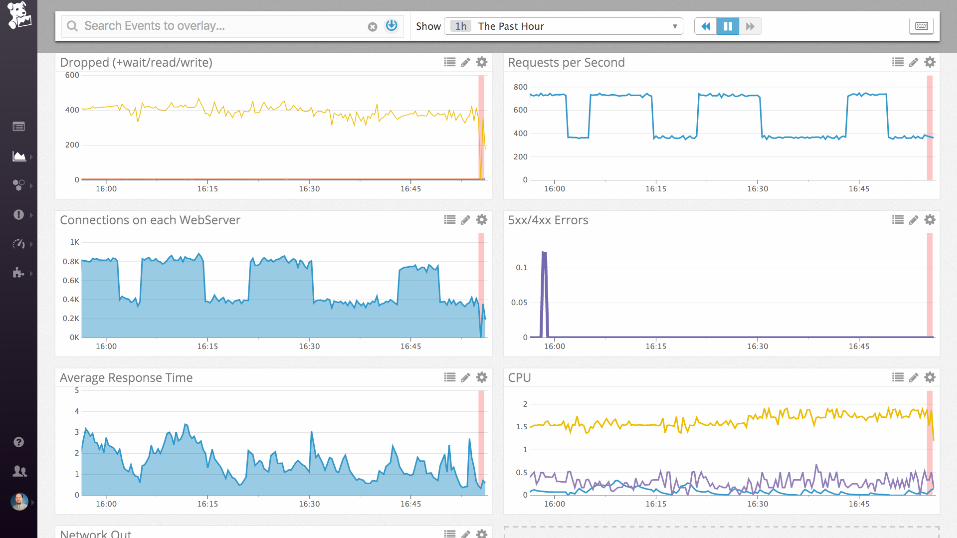
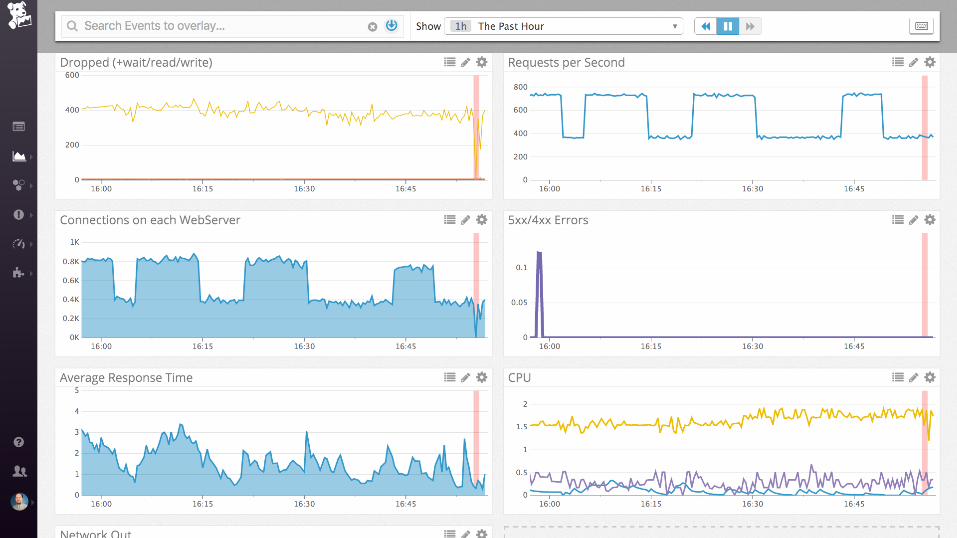
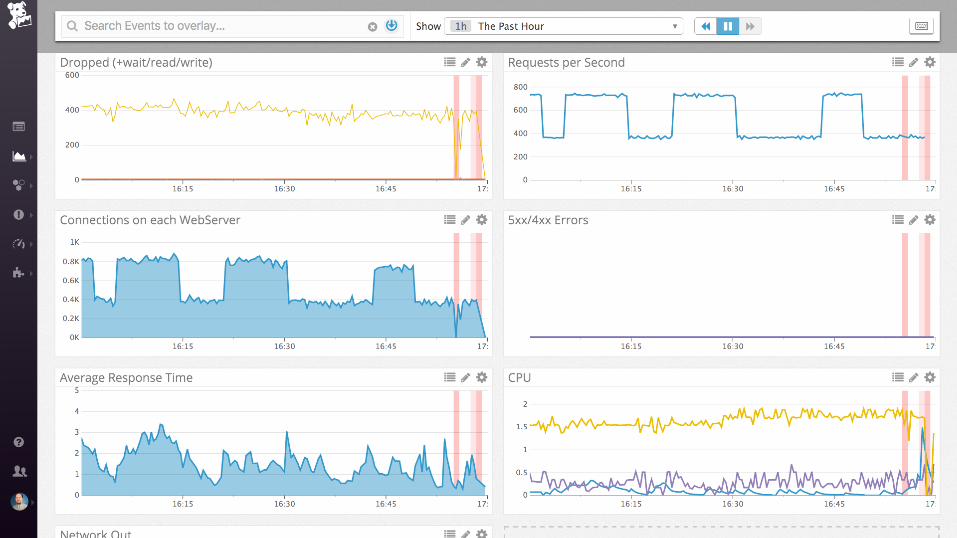
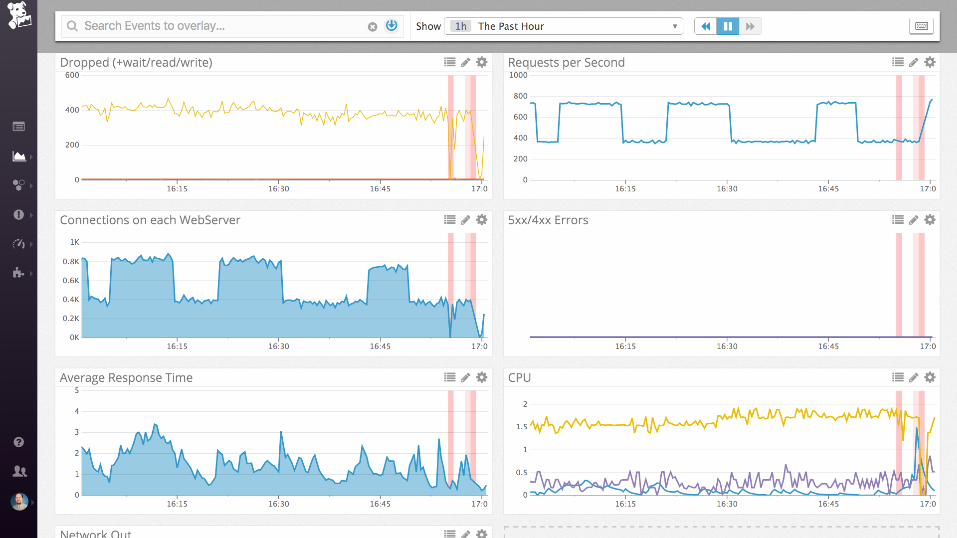
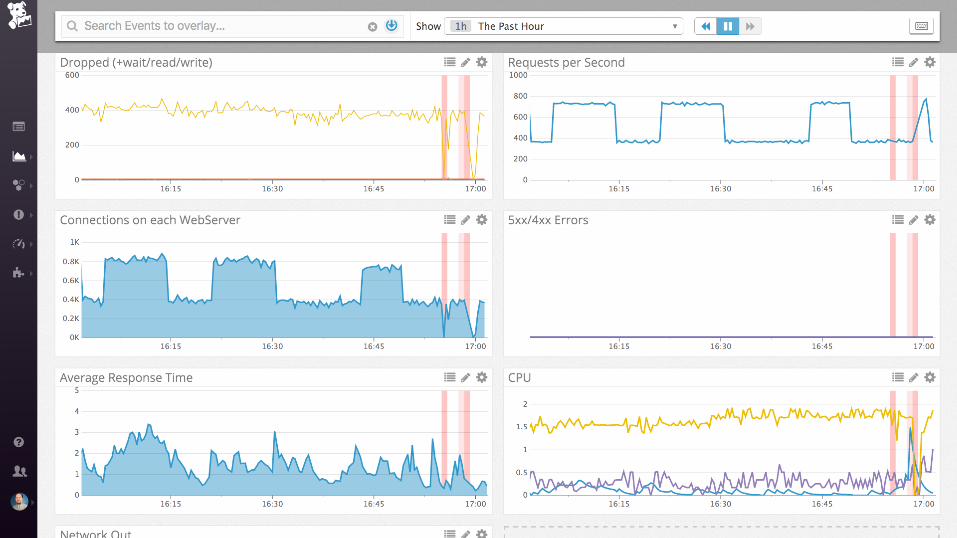
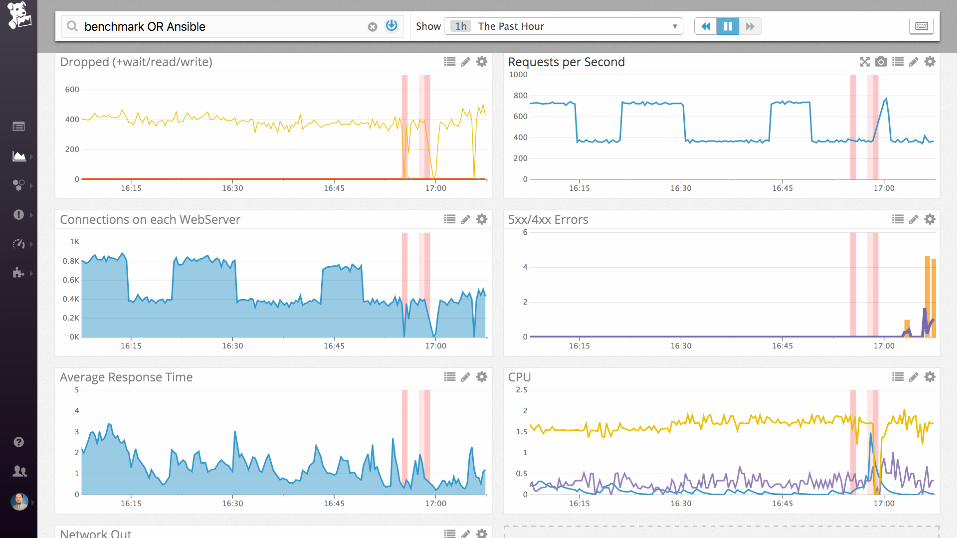
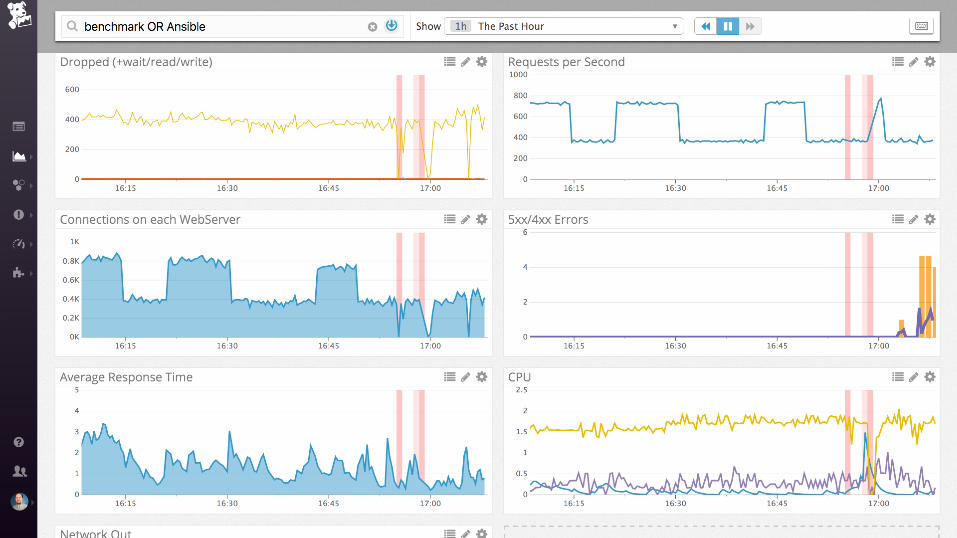

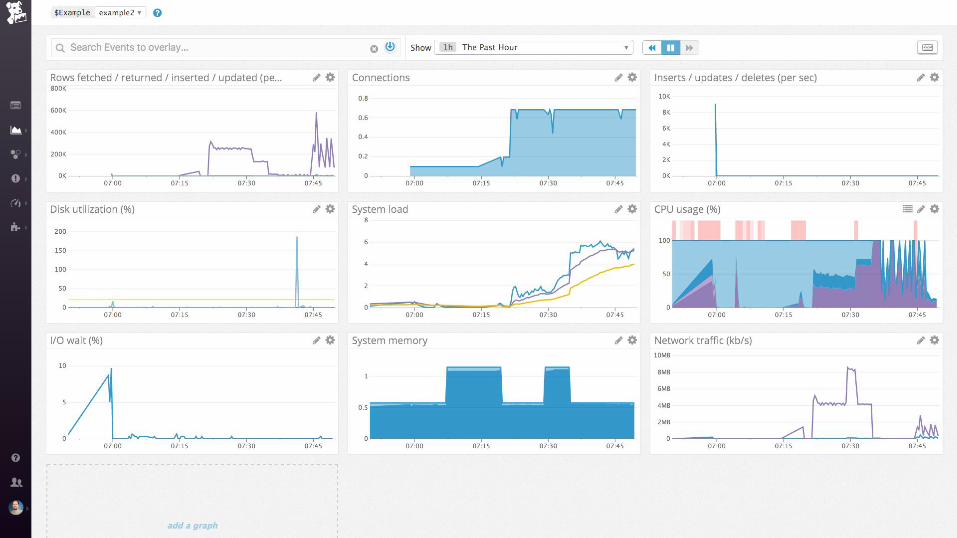
nginx + postgres
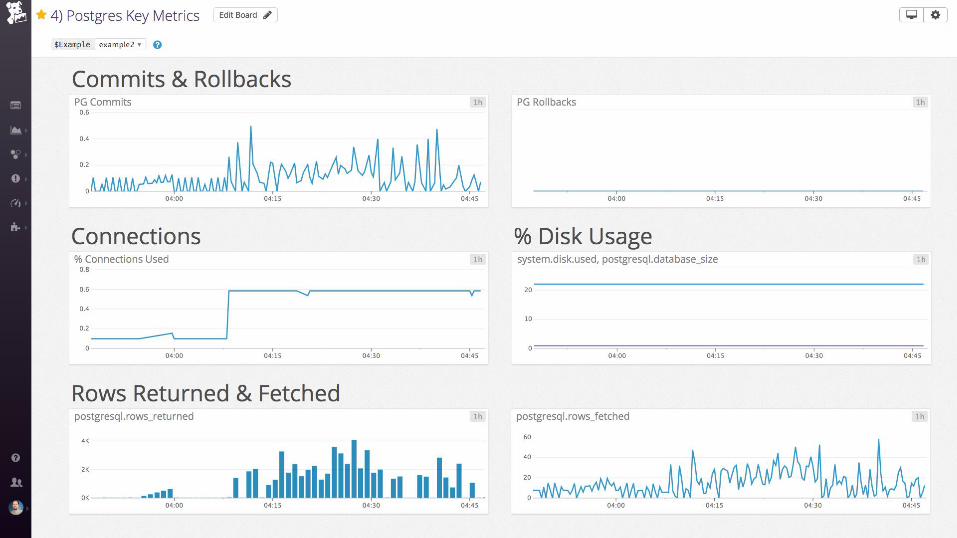
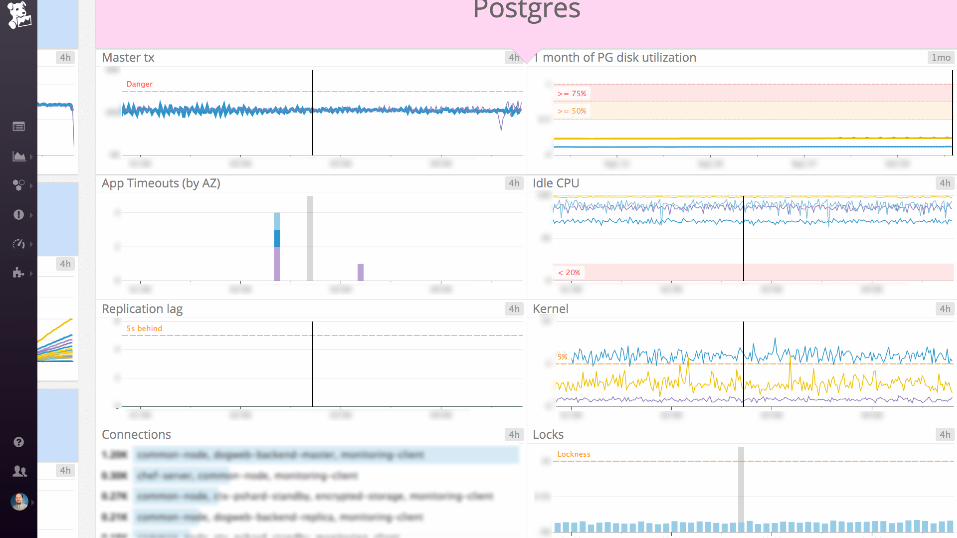
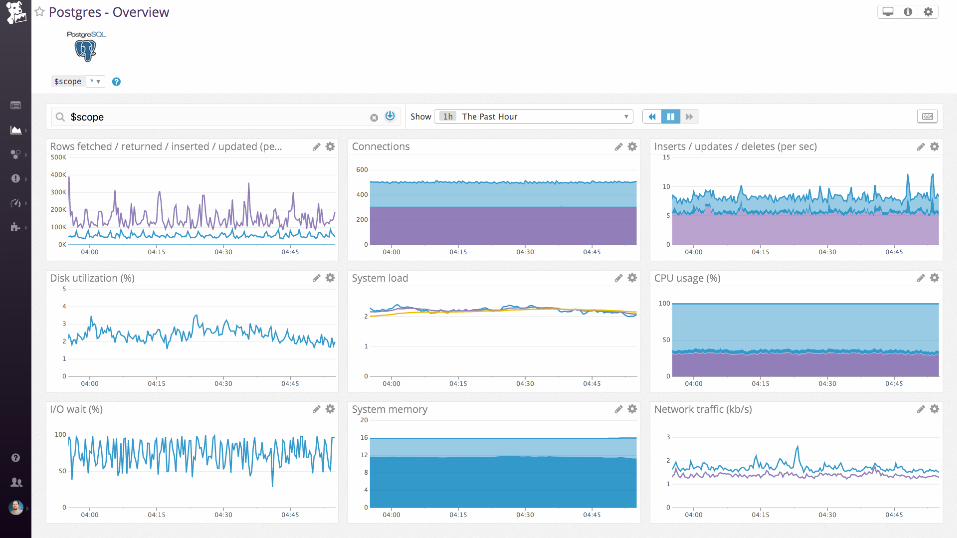

SELECT ol.prod_id, ol.quantity, p.title,
p.category, p.price
FROM orderlines ol
JOIN products p
ON ol.prod_id = p.prod_id
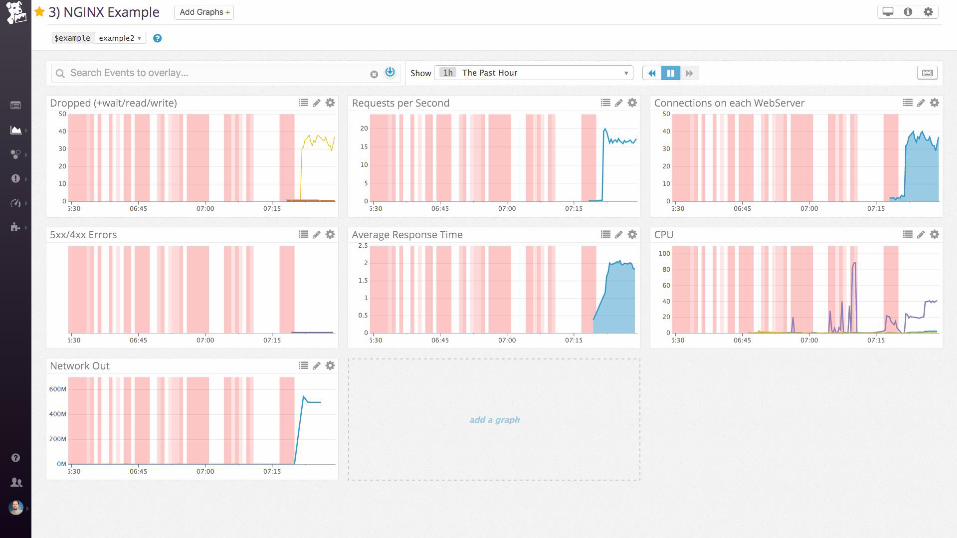

SELECT ol.prod_id, ol.quantity, p.title,
p.category, p.price
FROM orderlines ol
JOIN products p
ON ol.prod_id = p.prod_id
WHERE ol.prod_id = any(array[1, 2, 3, …5000])
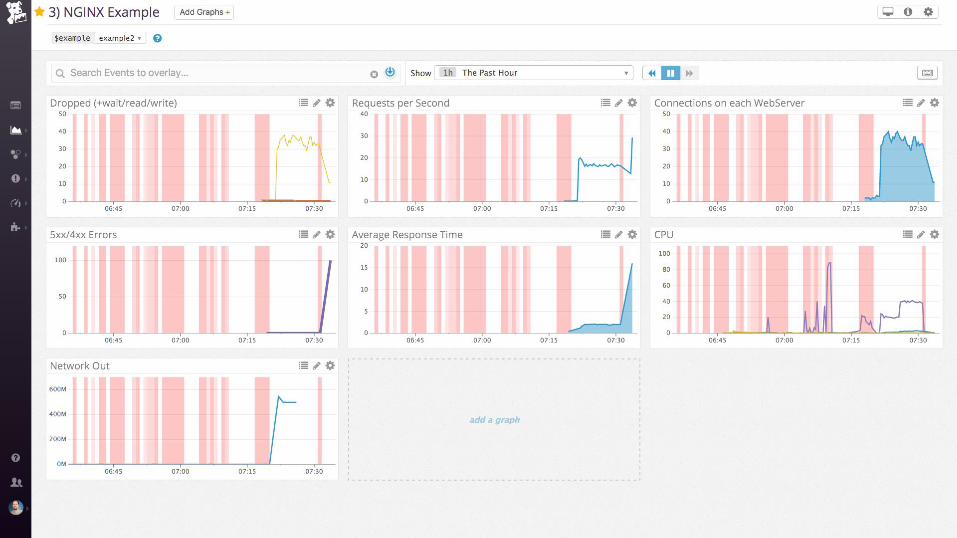
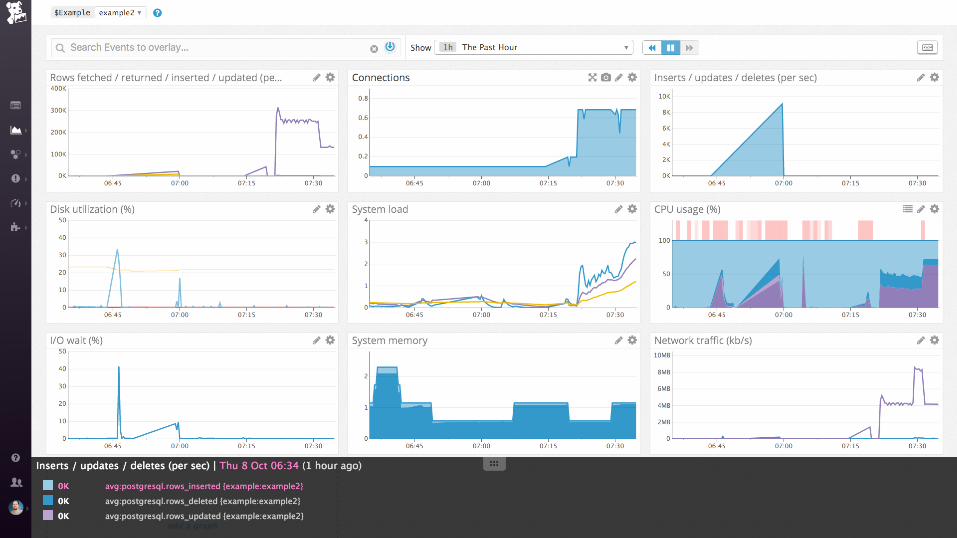
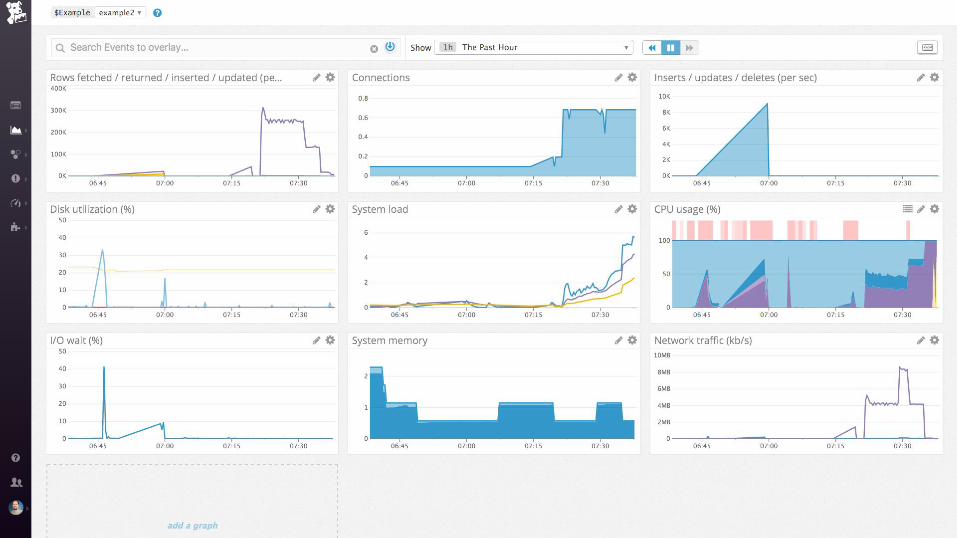

SELECT ol.prod_id, ol.quantity, p.title,
p.category, p.price
FROM orderlines ol
JOIN products p
ON ol.prod_id = p.prod_id
WHERE ol.prod_id = any(array[1, 2, 3, …5000])

SELECT ol.prod_id, ol.quantity, p.title,
p.category, p.price
FROM orderlines ol
JOIN products p
ON ol.prod_id = p.prod_id
WHERE ol.prod_id = any(values(1), (2), (3), …)


Thank you!

Remember to complete
your evaluations!





























