Embed Size (px)
Citation preview

ICDE2014勉強会Graphs III: Distributed Processing
新井 淳也
NTT
スライド中の図はそれぞれの論文からの引用です
1

• GLog: A High Level Graph Analysis System Using MapReduce• MapReduce ジョブに変換可能なグラフ分析言語
GLog の提案
• Continuous Pattern Detection over Billion-Edge Graph Using Distributed Framework• 変化するグラフに対するグラフパターンマッチを Giraph
上で行う近似解法の提案
• How to Partition a Billion-Node Graph• 実世界のグラフを分割するためのスケーラブルなアルゴリ
ズムの提案
2

• GLog: A High Level Graph Analysis System Using MapReduce• MapReduce ジョブに変換可能なグラフ分析言語
GLog の提案
• Continuous Pattern Detection over Billion-Edge Graph Using Distributed Framework• 変化するグラフに対するグラフパターンマッチを Giraph
上で行う近似解法の提案
• How to Partition a Billion-Node Graph• 実世界のグラフを分割するためのスケーラブルなアルゴリ
ズムの提案
3

GLog: A High Level Graph Analysis System Using MapReduce
Jun Gao, Jiashuai Zhou, Chang Zhou and Jeffrey Xu Yu
• グラフ分析言語を使ってグラフ分散処理を効率的に記述したい• Well-accepted な既存言語はない
• 簡潔で表現力が高いグラフ分析言語 GLog を提案• GLog 用のデータ形式として RG テーブルも提案
• GLog クエリは最適化して MapReduce ジョブに変換
• Pig より短く書ける上に 1.3~5.8 倍高速
4

大規模グラフの処理には分散処理
•MapReduce, Pregel, GraphLab, ...
•しかし効率的なプログラムを書くのが難しい
• 大規模: 100M+ vertices
5

グラフ分析言語
•グラフ分析言語とクエリエンジンの組合せで評価手順の最適化が可能• Pig, Hive, YSmart, SystemML, ...
•しかし広く使われているグラフ分析言語はない• 簡潔さと表現力の高さを両立できていない
• e.g. PigLatin は繰り返し処理を記述できない
6

貢献
•グラフデータ保存用の RG (Relational-Graph) テーブルと分析言語 GLog の提案
•GLog クエリを一連の MapReduce (MR) ジョブに変換する手法の発明
•変換されたMRジョブの最適化戦略の設計
• 28ノード Hadoop クラスタ上での性能評価
7

グラフ分析システムの構造
が Hive, Pig, YSmart 等との違い
MR ジョブとジョブ管理プログラムを生成
8

RGテーブル
•関係テーブルをグラフのために拡張したもの• ネストしたデータも扱える
•GLog の基盤となるデータモデル
9

GLog
•Datalog ベースのクエリ言語• Datalog: Prolog ベースのクエリ言語
•Datalog よりグラフ分析が書きやすい• 再帰の代わりに繰り返し文を使う
• 複雑で柔軟なグラフ処理のため
• 終了状態判定のために変数を使える
• 関係テーブルではなく RG テーブル上で動作する
10

GLog による Landmark Index 構築
• aaa
11

GLog による Landmark Index 構築
• aaa
GLog rule
Variable rule
繰り返し
12

GLogからMRジョブへの変換
• 各ルールを関係DB上の操作へ変換• Selection, projection, join, union, ...
• 基本的に1ルール1ジョブ
13

MRジョブの最適化
•最適化 ≒ ジョブ数の削減• ジョブの数が性能に大きく影響する
•最適化テクニック1. Rule merging
• 1-side/2-side Operation のマージ
• Shuffle-Shared Operation のマージ
2. Iteration rewriting
14

Rule merging:
1-side Operation のマージ
Mapper 1
Reducer 1
Mapper 2
Reducer 2
Mapper 3
Reducer 3
1-side operation 2-side operation 1-side operation
依存
依存
MR ジョブへ変換したときに mapper か reducer の片方にしかならない操作はマージできる場合がある
15
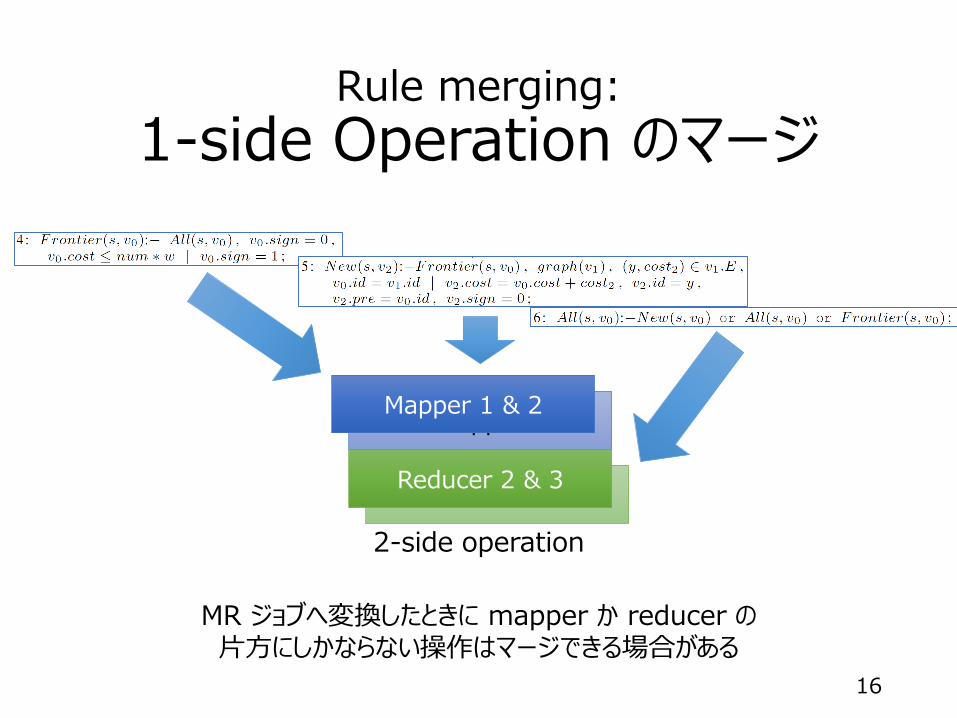
Rule merging:
1-side Operation のマージ
MapperMapper 1 & 2
ReducerReducer 2 & 3
2-side operation
MR ジョブへ変換したときに mapper か reducer の片方にしかならない操作はマージできる場合がある
16

Rule merging:
Shuffle-Shared Operationのマージ
• 一定の条件を満たすと 2-side op. 同士もマージできる• 詳しくは論文で
17
Mapper 2
Reducer 2
2-side operation
Mapper 1
Reducer 1
2-side operation
依存

Rule merging:
Shuffle-Shared Operationのマージ
• 一定の条件を満たすと 2-side op. 同士もマージできる• 詳しくは論文で
18
Mapper 2
2-side operation
ReducerReducer
Mapper 1 & Reducer 1 & Reducer 2

Iteration rewriting
• ループ内のルールの順序を入れ替えることでマージできる箇所を増やす• ループ内先頭のルールをループ前に出す
• Shuffle-Shared operations になる場合がある
2-side operation
2-side operation2-side operation
2-side operation
2-side operation
マージ可能Shuffle-Shared ops.
元のコード
Iteration rewriting 後のコード 19

評価
1. GLog の簡潔さと表現力について
2. GLog クエリの性能について
•環境• 28ノードの Hadoop 0.20.3 クラスタ
• Opteron 4180 2.60GHz 6コア, 48GB RAM
• 1ノードあたり map と reduce それぞれ6スロット
20

簡潔さと表現力• Java が何百行も要す処理を2~13行で実現
• PigLatin も短いが、繰り返し処理のためには Java のコードを別に書く必要がある
21

Speed-up vs. Pig• Pig と比べ 1.3~5.8 倍高速
• 繰り返し処理最適化等グラフ向けサポートがあるため• 繰り返し処理のジョブ数が少ない:
Connected Components で GLog の1ジョブに対し Pig は5ジョブ
※ Queries は TABLE II にある各クエリ名の頭文字22

• GLog: A High Level Graph Analysis System Using MapReduce• MapReduce ジョブに変換可能なグラフ分析言語
GLog の提案
• Continuous Pattern Detection over Billion-Edge Graph Using Distributed Framework• 変化するグラフに対するグラフパターンマッチを Giraph
上で行う近似解法の提案
• How to Partition a Billion-Node Graph• 実世界のグラフを分割するためのスケーラブルなアルゴリ
ズムの提案
23

Continuous Pattern Detection over Billion-Edge Graph Using Distributed
FrameworkJun Gao, Chang Zhou, Jiashuai Zhou and Jeffrey Xu Yu
• 変化するグラフ (e.g. ソーシャルネットワーク) の監視によりグラフパターンを検出したい• パターン: 特定の属性を持つ頂点同士の結合
• パターン検出のインクリメンタルな近似解法を提案• グラフの変化の影響を受ける部分だけを再計算する
• Giraph 上に実装し評価• およそ 0~30% の false-positive な検出
• 変化時に完全に再計算するより5~10倍高速
24

グラフ監視で検出したいパターン
•例えば絶えず変化するソーシャルグラフ上で• 企業が:
ライバル社とサプライヤや販売会社のつながり
• 警察が:
2つのギャングの構成員間のつながり
• リアルタイムに近い速さで検出したい
25

グラフパターン検出
• 所与のグラフの部分グラフがクエリと同形かどうかを判定
• 頂点 (だけ) が「ラベル」を持つ無向グラフを想定
アルファベット: ラベル頂点傍の数字: 頂点ID
26

パターン検出アルゴリズムの基本アイデア
• グラフ上でメッセージを流す• メッセージには通過した頂点の情報が含まれる
• クエリと同じラベルの頂点を同じ順序で辿った部分がマッチ• ‘Sink’ の頂点に全経路からのメッセージが集まったら全体がマッ
チしたということ• Sink はクエリパターンの中から適当に決める
a0
b0
c0
d0
a1
b1
c1
a2
d1 c3
e0 d3
a3 a4
c2 d4
Graph
これをどう検出するか?
a e
b d
c
c
a d
a d
c
Query
0 1
2
3
45 6
7 8
9 10
27
Sink
Sink

Transition Rule によるパターン検出• Transition rule で「クエリと同じラベルの頂点を同じ順序で
辿った」ことを検出する• ルールに従って配送されたメッセージが sink に揃ったらマッチ
a0
b0
c0
d0
a1
b1
c1
a2
d1 c3
e0 d3
a3 a4
c2 d4
GraphTransition Rules
頂点へ割当て生成
a e
b dc
c
a d
a d
c
Query
0 1
2
3
45 6
7 8
9 10
自身のラベルが a のとき、ラベル d の頂点からメッセージを受け取ったら、隣接するラベル c の頂点へ転送
28
ルール例:

インクリメンタルなパターン検出
• エッジ追加時:• エッジ両端の頂点で transition rule を再度確認し、充足され
たものがあればメッセージを再送
• エッジ削除や頂点追加/削除も同様にルールを再確認する
a0
b0
c0
d0
a1
b1
c1
a2
d1 c3
e0 d3
a3 a4
c2 d4
Graph
新しいエッジによって transition rule を満たせるようになる可能性がある
29
自身のラベルが a のとき、ラベル dの頂点からメッセージを受け取ったら、
隣接するラベル c の頂点へ転送

評価
• データセット
• ラベルはランダムに与える
• クエリは頂点にランダムなラベルとエッジを与え生成
• 28ノードの Giraph 1.0 & Hadoop 0.20.3 クラスタを使用
30

クエリの頂点数×エッジ密度 vs. 精度
• およそ 0~30% の false-positive な検出• Patten Density: クエリパターンのエッジ密度 (1.0で完全グラフ)
• pcs (precision): 正解マッチ数 / 近似手法によるマッチ数• False-positive が出ると値が 1.0 より小さくなる
31

応答時間
32
提案手法
既存の厳密解法との比較インクリメンタル計算と完全再計算の比較
• 既存手法よりずっと大きいクエリパターンを扱える
• グラフ変化の都度再計算するより5~10倍高速

• GLog: A High Level Graph Analysis System Using MapReduce• MapReduce ジョブに変換可能なグラフ分析言語
GLog の提案
• Continuous Pattern Detection over Billion-Edge Graph Using Distributed Framework• 変化するグラフに対するグラフパターンマッチを Giraph
上で行う近似解法の提案
• How to Partition a Billion-Node Graph• 実世界のグラフを分割するためのスケーラブルなアルゴリ
ズムの提案
33

How to Partitiona Billion-Node Graph
Lu Wang, Yanghua Xiao, Bin Shao, Haixun Wang
• 実世界の大規模グラフを分散メモリ環境で分割したい• 分散処理時の効率的な負荷分散のため
• Multilevel label propagation (MLP) を提案• Label propagation (LP) でノードを集約してから
METIS で分割
• Trinity 上に MLP を実装し評価• 逐次実行 (METIS 比):
エッジカット最大2倍増 (悪化)、最大約30倍高速化
• 8ノード実行:
6.5B edges のグラフを約4時間で分割
34

グラフ分割の既存手法: METIS
• エッジカット (分割間を跨ぐエッジ数) の最小化を目指す
• 3ステップの処理で分割
グラフを coarse にする(粗くする)
極大マッチング (頂点を共有しないエッジの集合) を探し、エッジの
両端点を1頂点へ集約
1. グラフを coarseにする (粗くする)
極大マッチング (頂点を共有しないエッジの集合) を探し、エッジの
両端点を1頂点へ集約
2. グラフを分割する
3. グラフを元に戻す
(uncoarsening)
35

METIS の問題点
•極大マッチングによる coarsening は
1. 実世界のグラフに適さない
2. Billion-edge グラフに適さない
36

METIS の問題点1:
実世界のグラフに適さない• クラスタ性を無視した頂点集約を行ってしまう
• 実世界のグラフ:スケールフリー性、スモールワールド性、クラスタ性を持つグラフ
37

METIS の問題点2:
Billion-edge グラフに適さない
•ディスク上のデータアクセス効率が悪い• メモリに収まらないグラフデータはディスク上にある
• 極大マッチング探索アルゴリズムはランダムアクセスを要求する
• メモリの消費が多い• Coarsen 前後の頂点の対応情報を保持する
• 何段階も coarsen を繰り返すためサイズが増大
38

これらの問題を解決するcoarsening 手法が必要
39

Label Propagation (LP)• コミュニティ (クラスタ) を発見できるグラフ分析手法
• Coarsening に用いたときの利点• 省メモリかつ高速
• Coarsen 前後の頂点対応データが小さい
• 意味のある分割が可能• コミュニティ構造に基づく分割になる
40
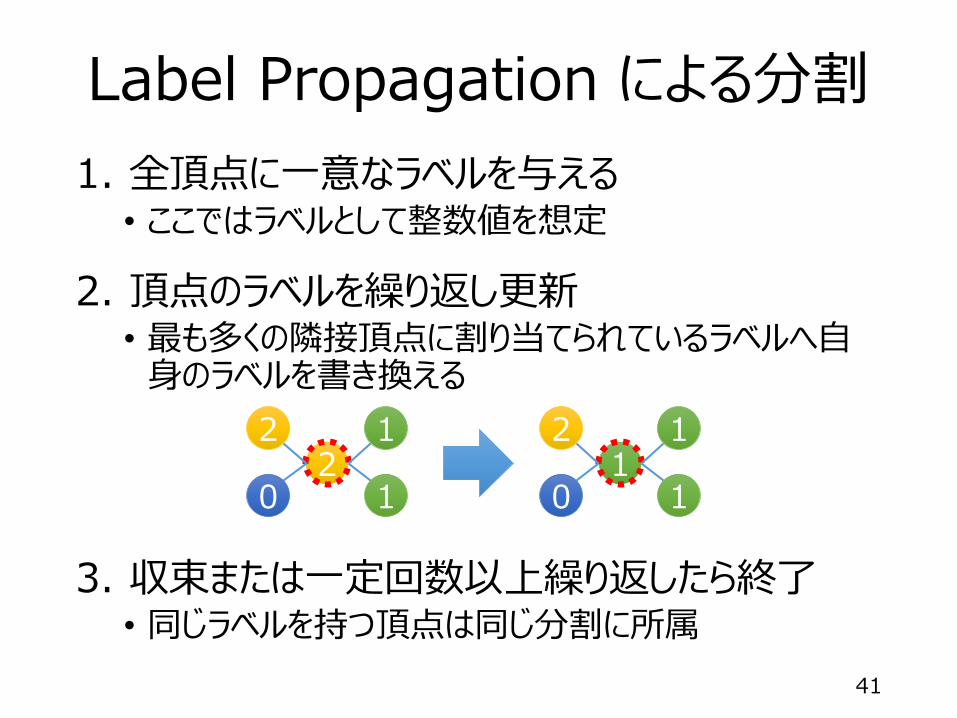
Label Propagation による分割
1. 全頂点に一意なラベルを与える• ここではラベルとして整数値を想定
2. 頂点のラベルを繰り返し更新• 最も多くの隣接頂点に割り当てられているラベルへ自
身のラベルを書き換える
3. 収束または一定回数以上繰り返したら終了• 同じラベルを持つ頂点は同じ分割に所属
22
0
1
11
2
0
1
1
41

Multi-level Label Propagation (MLP)
• 3ステップの処理で分割1. Coarsening
• LP でグラフを coarse にする
2. Refinement• Coarse graph に対し METIS を適用して分割
3. Uncoarsening• Coarse graph を元に戻す
•METIS と異なり coarsen 後も意味・構造が保たれる
42

Pipelined MLP (pMLP)
•分散環境でもメモリに載らないような巨大グラフを分散処理で分割するための手法
• Coarsening ステップをディスクベース化• LP はディスクベースでも効率が良い
• ラベルを更新しようとしている頂点の隣接頂点さえメモリ上にあればよく、連続アクセスで読み込める• 全頂点のラベルはメモリ上に保持しなければならないが、グラフ
データサイズで支配的なのは |E| であって、|V| は小さい
• Coarsen 後はグラフが小さくなるのでメモリに載る
43

評価: Sequential MLP
•MLP を C 言語で実装し METIS と比較
•データセット• 頂点数 2M~5M、エッジ数 5M~40M
44

• METIS に比肩するエッジカット数
• 省メモリかつ高速
45
提案手法METIS
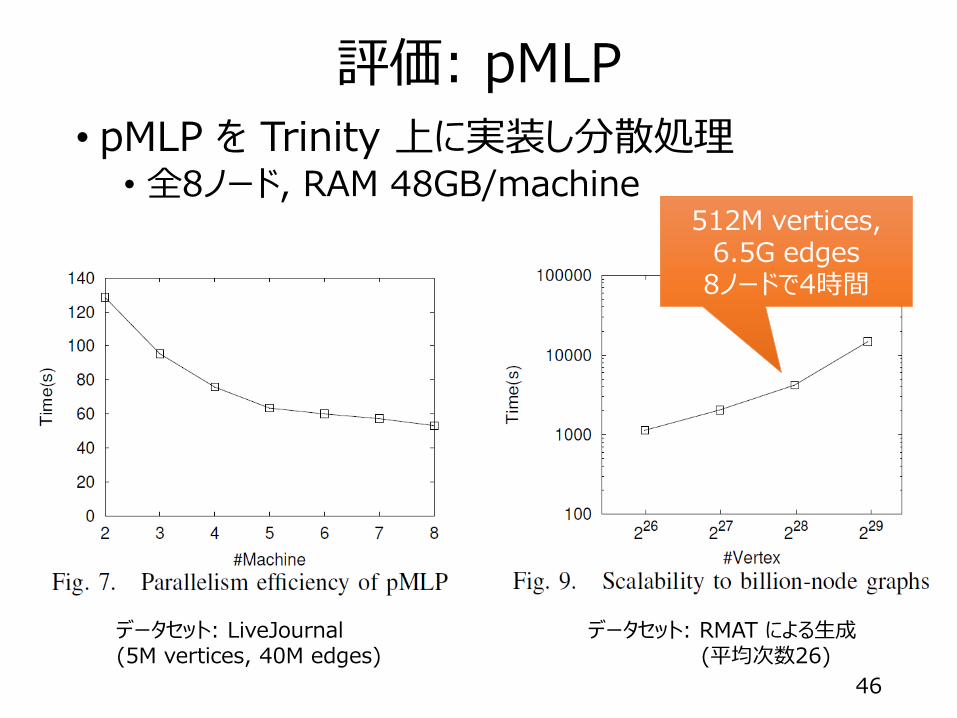
評価: pMLP
• pMLP を Trinity 上に実装し分散処理• 全8ノード, RAM 48GB/machine
データセット: LiveJournal(5M vertices, 40M edges)
データセット: RMAT による生成(平均次数26)
512M vertices,6.5G edges
8ノードで4時間
46

47
![The Monument - NATO[The Monument] Staff 美 術 = 内山 勉 照 明 = 桜井 真澄 音 響 = 井出比呂之 衣 裳 = 樋口 藍 舞 台 監 督 = 小島 とら 制 作](https://img.pdfslide.net/doc/110x75/60ff4dfa66fac303915a39ca/the-monument-nato-the-monument-staff-c-e-i-c-i-oe.jpg)