Embed Size (px)
Citation preview

SYSADMIN’S TOOLBOX TOOLS FOR RUNNING CEPH IN
PRODUCTION
Paul Evansprincipal architect
daystrom technology groupPaul at Daystrom dot com
san francisco
ceph day
March 12, 2015

WHAT’S IN THIS TALK
• Tools to help Understand Ceph Status
• Tips for Troubleshooting Faster
• Won’t Cover it All
• Maybe some Fun

HOW THINGS ARE IN THE LAB
AND THEN THERE IS PRODUCTION

Is there a Simple way to run Ceph that isn’t Rocket Science?

WHAT COULD BE SIMPLER THAN THE….CLI ?
Ceph’s CLI is Great, but…
REALITY: many Operations Teams juggle too many technologies already…
Do they need to learn another CLI?

Need Info Fast? GUIInkScope VSM
Calamariceph-dash
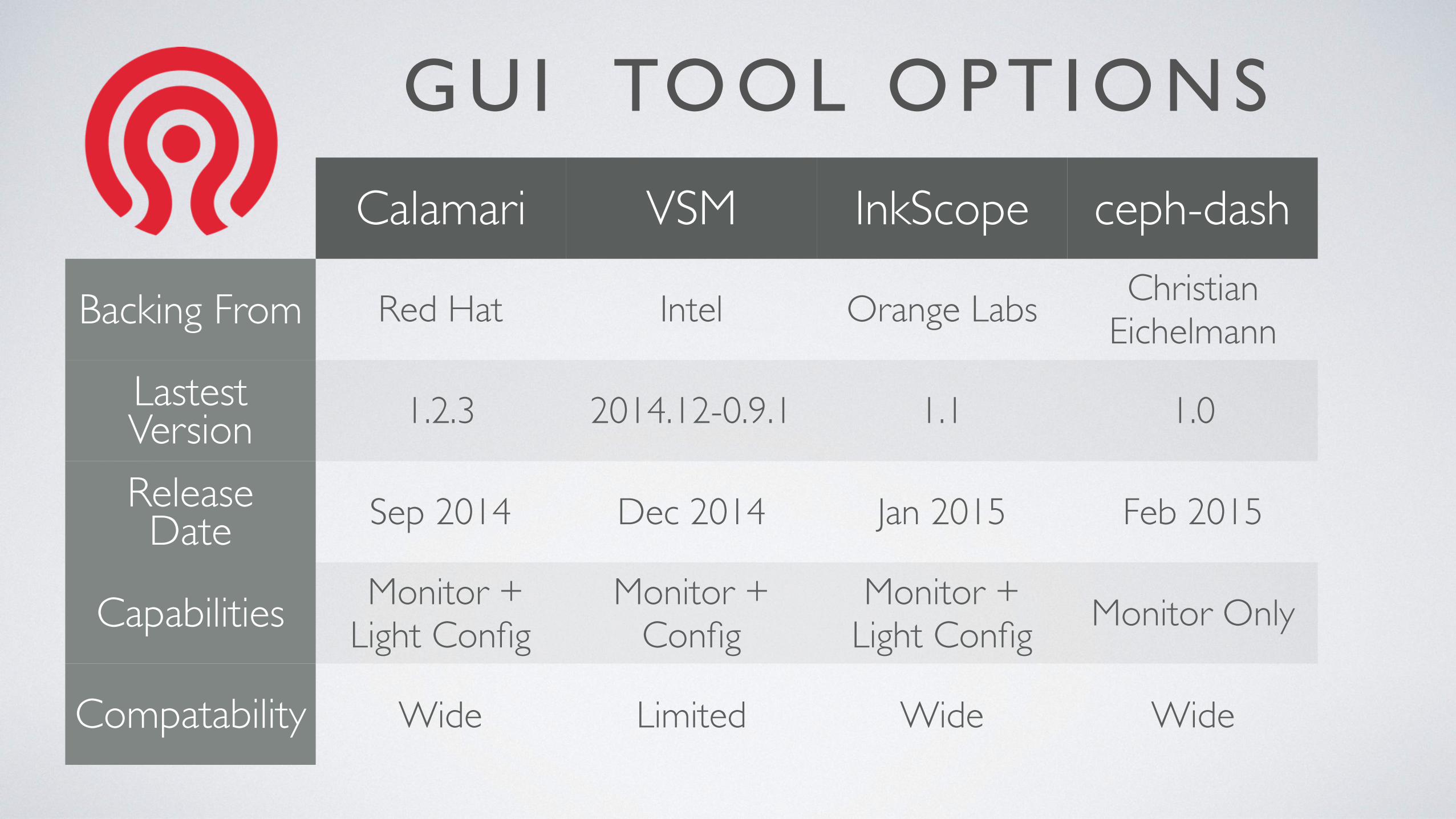
GUI TOOL OPT IONS
Calamari VSM InkScope ceph-dash
Backing From Red Hat Intel Orange Labs Christian Eichelmann
Lastest Version 1.2.3 2014.12-0.9.1 1.1 1.0
Release Date Sep 2014 Dec 2014 Jan 2015 Feb 2015
Capabilities Monitor + Light Config
Monitor + Config
Monitor + Light Config Monitor Only
Compatability Wide Limited Wide Wide
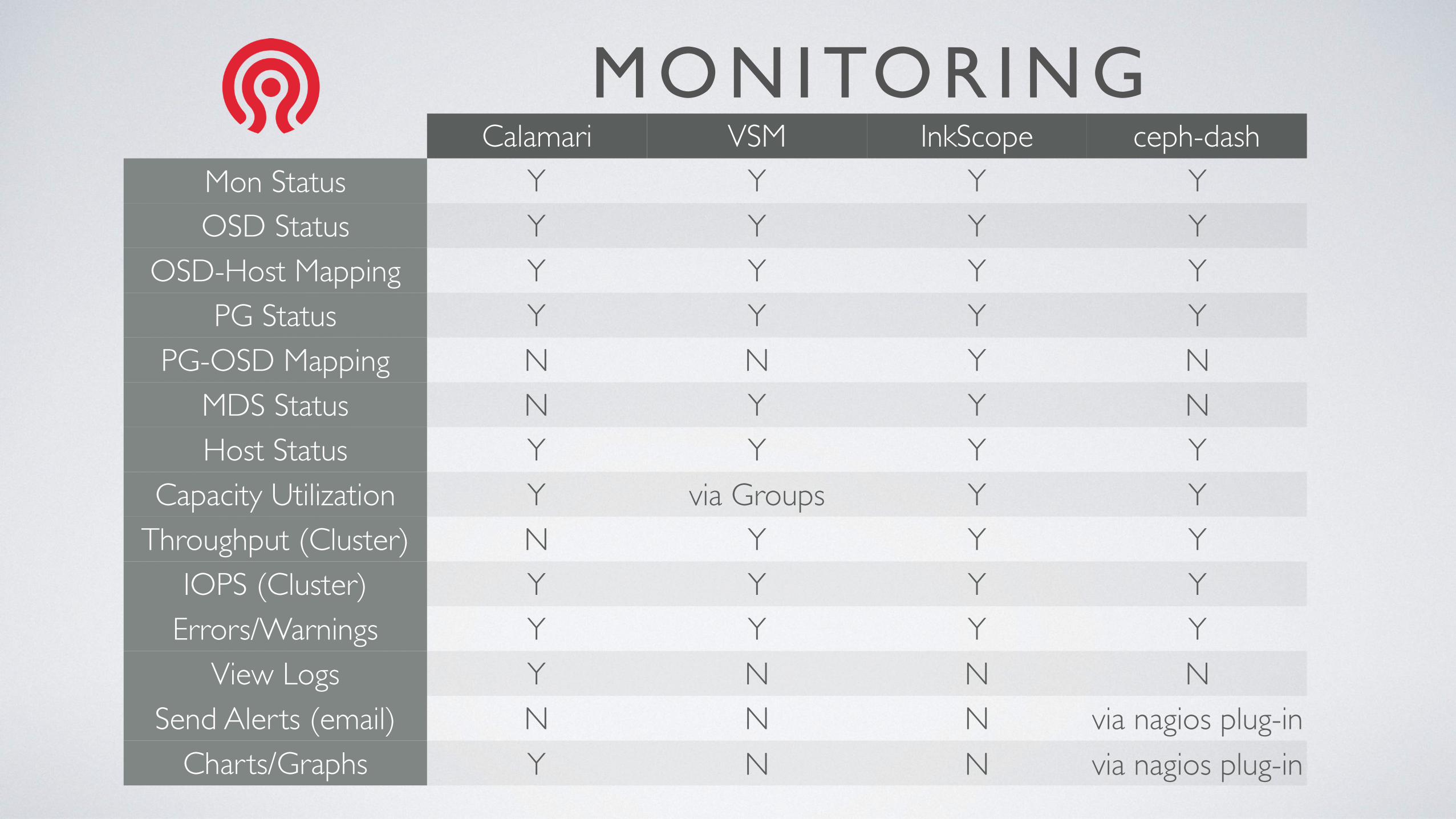
MONITORINGCalamari VSM InkScope ceph-dash
Mon Status Y Y Y YOSD Status Y Y Y Y
OSD-Host Mapping Y Y Y YPG Status Y Y Y Y
PG-OSD Mapping N N Y NMDS Status N Y Y NHost Status Y Y Y Y
Capacity Utilization Y via Groups Y YThroughput (Cluster) N Y Y Y
IOPS (Cluster) Y Y Y YErrors/Warnings Y Y Y Y
View Logs Y N N NSend Alerts (email) N N N via nagios plug-in
Charts/Graphs Y N N via nagios plug-in

MANAGEMENTCalamari VSM InkScope ceph-dash
Deploy a Cluster N Y N NDeploy Hosts (add/remove) N Y N N
Deploy Storage Groups (create)
N Y N NCluster Services (daemons) OSD only Y N(?) NCluster Settings (ops flags) Y N Y N
Cluster Settings (parameters) Y N View NCluster Settings (CRUSH
map/rrules)N Partial View N
Cluster Settings (EC Profiles) N Y Y NOSD (start/stop/in/out) Partial Y Y N
Pools (Replicated) Y (limited) Y Y NPools (EC & Tiering) N Y Partial N
RBDs N Partial N NS3/Swift Users/Buckets N N Y N
Link to OpenStack Nova N Y N N

CA
LA
MA
RI

VIR
TU
AL
ST
OR
AG
EM
AN
AG
ER
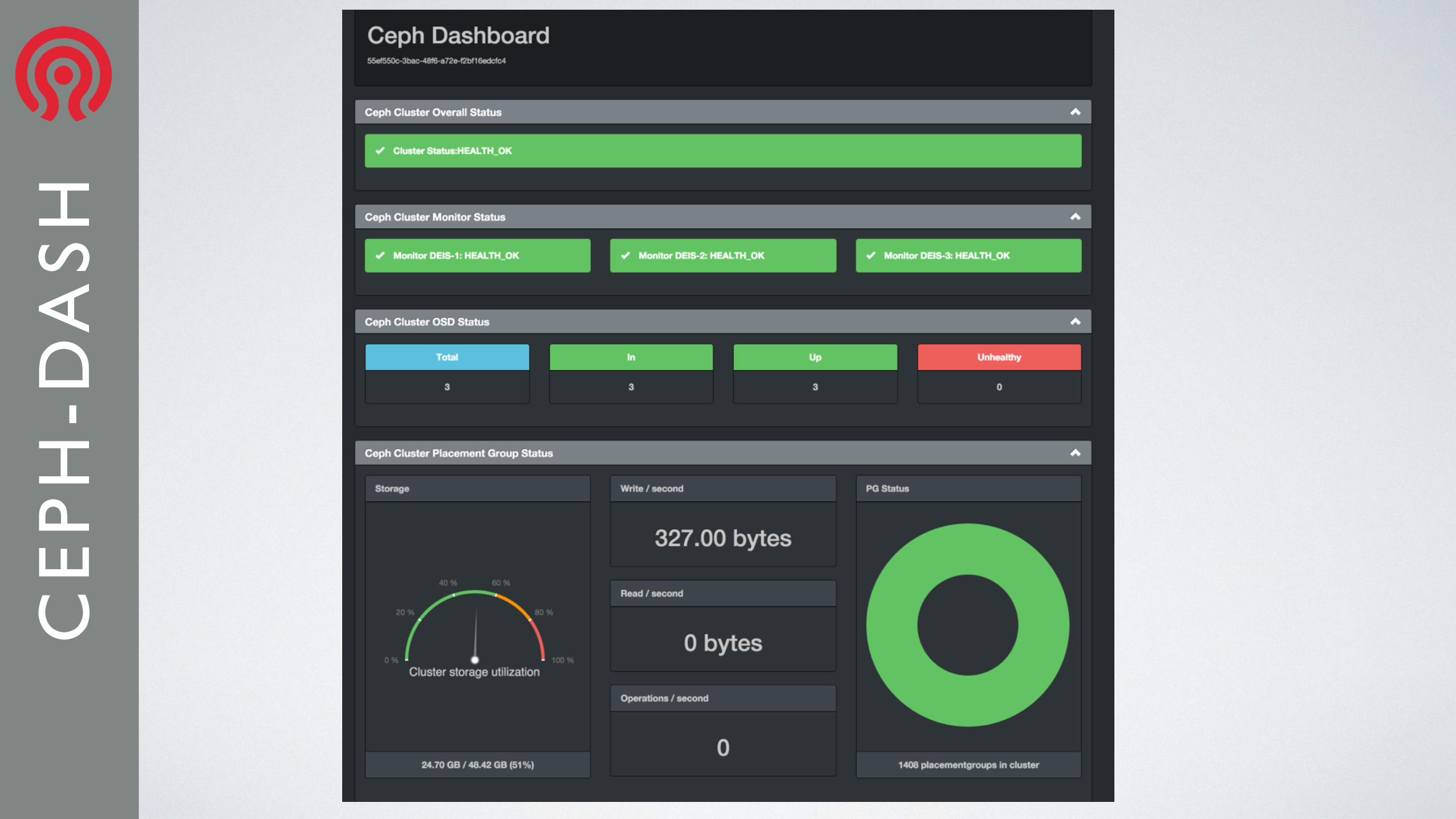
CE
PH
-DA
SH

INK
SC
OP
E

NOW THAT WE HAVE V IS IB I L ITY….
What are we looking for?

WHAT WE WANT ✓ Monitor Quorum
✓ Working OSDs
✓ Happy Placement Groups

OS
D W
OR
KB
EN
CH

PG
ST
AT
ES
✓ I’m Making Things Right
๏ I (may) Need Help
All Good - Bring Data

TH
E ‘
NO
GU
I’ O
PT
ION
ceph@m01:~$ ceph osd tree# id weight type nameup/down reweight-1 213.6 root default
-2 43.44 host s019 3.62 osd.9 down 010 3.62 osd.10 down 00 3.62 osd.0 down 05 3.62 osd.5 down 01 3.62 osd.1 down 07 3.62 osd.7 down 03 3.62 osd.3 down 04 3.62 osd.4 down 02 3.62 osd.2 down 011 3.62 osd.11 down 0
-4 43.44 host s0324 3.62 osd.24 up 125 3.62 osd.25 up 126 3.62 osd.26 up 127 3.62 osd.27 up 128 3.62 osd.28 up 129 3.62 osd.29 up 130 3.62 osd.30 up 131 3.62 osd.31 up 132 3.62 osd.32 up 133 3.62 osd.33 up 1
ceph osd treeceph health detailHEALTH_ERR 7 pgs degraded; 12 pgs down; 12 pgs peering; 1 pgs recovering; 6 pgs stuck unclean; 114/3300 degraded (3.455%); 1/3 in osds are down...pg 0.5 is down+peeringpg 1.4 is down+peering...osd.1 is down since epoch 69, last address 192.168.106.220:6801/865
ceph health
ceph pg dump_stuck staleceph pg dump_stuck inactiveceph pg dump_stuck unclean
ceph pg dump_stuck

TH
E ‘
NO
GU
I’ O
PT
ION
pg_stat objects bytes status up up_pri 10.f8 3042 25474961408 active+remapped [58,2147483647,24,20,55,59,2147483647,27] 58 10.7fa 3029 25375584256 active+remapped [51,20,60,28,2147483647,61,2147483647,11] 51 10.716 2990 25052532736 inactive [9,44,10,55,24,2147483647,47,2147483647] 9
ceph pg dump_stuck

VS
M:
TR
OU
BL
ES
HO
OT
ING
Repeated'auto*out'or'inability'to'restart'auto*out'OSD'
suggests'failed'or'failing'disk'
VSM'periodically'probes'drive'path'–'missing'drive'path'missing'indicates'complete'disk'failure'
A'set'of'auto*out'OSDs'that'share'the'same'
journal'SSD'suggests'failed'or'failing'journal'SSD'
VSM'periodically'probes'drive'path'–'missing'drive'path'indicates'complete'disk'(or'
controller)'failure'

VS
M:
TR
OU
BL
ES
HO
OT
ING
Restore'OSDs Managing&Storage&Devices&
Restore&OSDs&
Wait&
Select&
Sort&
Confirm&
Verify&(may&need&to&sort&again)&
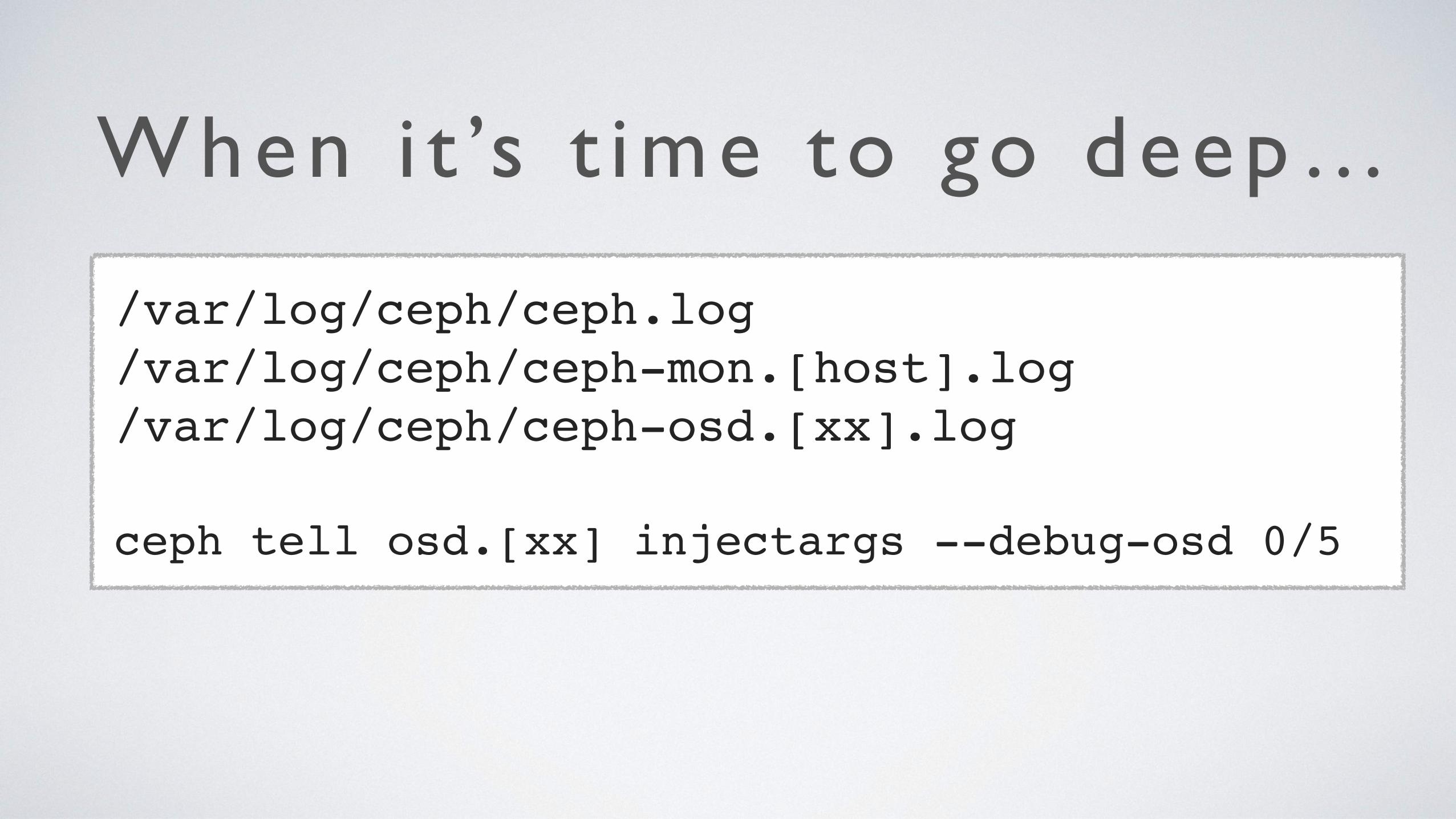
When i t ’s t ime to go deep…
/var/log/ceph/ceph.log/var/log/ceph/ceph-mon.[host].log/var/log/ceph/ceph-osd.[xx].log
ceph tell osd.[xx] injectargs --debug-osd 0/5

REMINDER ABOUT CLUSTERSClusters rarely do things instantly.
Clusters can be like a Flock of Sheep - it starts to move in the right directly slowly and then picks up speed
(don’t run it off a cliff)

VS
M:
FAS
T D
EP
LO
YCreate&Cluster Ge#ng&Started&
Create&new&Ceph&cluster&
All&servers&present&
Correct&subnets&and&IP&addresses&
Correct&number&of&disks&iden>fied&
At&least&three&monitors&&&odd&number&of&
monitors&
Servers&located&in&correct&zone&
Servers&responsive&
One&Zone&with&serverDlevel&replica>on&

VS
M:
FAS
T D
EP
LO
YCreate&Cluster
Step%1%
Step%2:%Confirm%

VS
M:
FAS
T D
EP
LO
YCreate&Cluster&*&Status&Sequence Ge#ng&Started&

Remember to…

IN TIME YOUR CLUSTER WILL LEARN TO FOLLOW YOU

The 3 Keys to Ceph in
Production
Happy PGs
Happy Monitors
Happy OSDs

thank you!
Paul Evansprincipal architect
Paul at Daystrom dot com
technology grouptechnology group
san franciscoceph days





























