Embed Size (px)
Citation preview

OHS#3 論文紹介Object Detection & Instance
Segmentation
半谷
Contents
• Object Detection• タスクについて• R-CNN• Faster R-CNN• Region Proposal Network のしくみ• SSD: Single Shot Multibox Detector
• Instance Segmentation• タスクについて• End-to-End Instance Segmentation and Counting with Recurrent
Attention
2

一般物体認識分野での Deep Learning
• 静止の分類タスクは、 CNN による特徴量抽出および学習により発展• より高度なタスクである物体検出、物体領域抽出へと発展
Classification Object Detection Semantic Segmentation
Instance Segmentation
Plants
http://www.nlab.ci.i.u-tokyo.ac.jp/pdf/CNN_survey.pdfhttp://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/index.html
PlantsPlants Plants
より高度
3

Object Detection紹介する論文:SSD: Single Shot MultiBox Detector

Object Detection
• 画像中の複数の物体を漏れなく/重複無く検出することが目的。• 物体の検出精度( Precision )と、漏れなく検出できているかの指標である適
合率( Recall )の関係 (Precision-recall curve) から算出した、 Average Precision (AP) が主な指標。
• 実問題への応用が期待され、 AP のほか予測時の計算時間も重要で、リアルタイム性が求められている。
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
Precision
Recall1
1
面積 = AP
5

主なモデル (1): Regions with CNN
• R-CNN (Regions with CNN)• 物体領域候補の生成に Selective Search ( SS )などの手法を利用• 生成した領域を画像分類用の CNN に入力し、各領域に何が写っているか
(あるいは背景か)を分類する。• Recall を確保するためには領域候補が 2000 程度必要であり、全てを
CNN に入力し計算するため非常に時間が掛かる• また多段階の学習が必要となり煩雑である
R-CNN: http://arxiv.org/abs/1311.2524 6

主なモデル (2): Faster R-CNN
• Faster R-CNN• 特徴抽出部分を共通化(これは Fast R-CNN で提案された方法)• 特徴マップを入力に物体領域候補を生成する Region Proposal Network
を提案• 300 程度の領域候補で十分な精度が確保できる• 1 枚あたり 0.2 ~ 0.3 秒で処理できる
Region Proposal Net(RPN)
CNN( 特徴抽出) Classifier
物体領域候補を生成(~ 300 程度)各領域候補に写る物体を分類する
Faster R-CNN: http://arxiv.org/abs/1506.014977

Region Proposal Network
• 特徴マップ上に Anchor を定義(方眼紙に見立てて、各マスの中心のイメージ)
• 各 Anchor 毎に k 個の Anchor Box を定義(スケールとアスペクト比の組み合わせ)
• 各 Anchor Box 毎に、物体らしさのスコアと位置・サイズの修正項を予測するように訓練する
Faster R-CNN: http://arxiv.org/abs/1506.01497
画像特徴マップ
CNN( 特徴抽
出)
・・・
スケール アスペクト比
×
各アンカーごとに k 個の Box (例 : k = 3 × 3 )
2k scores(物体 or 背景)
4k coordinates( x, y, w, h の
修正項)
H x W x 3 H/16 x W/16 x 3
8

SSD: Single Shot Multibox Detector
Region Proposal Net(RPN)
CNN( 特徴抽
出)Classifier
① 物体領域候補を生成(物体らしさのスコア)
② 各クラスに分類
CNN( 特徴抽
出)
Region Proposal
+Classifier
物体領域候補を生成(クラス毎のスコア)SSD
FasterR-CNN
• Faster RCNN よりも高速で精度も良いモデル• 入力画像サイズの小さいモデル(精度はそこそこ)では 58FPS を達成
• Faster において①領域候補生成、②各領域の特徴ベクトルを切り出して分類、と 2 段階で行っていた処理を一気に行う。
• 深さの異なる複数の特徴マップを使い、浅い側は小さい物体、深い側は大きい物体を検出。
SSD: http://arxiv.org/abs/1512.023259

SSD: Single Shot Multibox Detector
• Faster RCNN よりも高速で精度も良いモデル• 入力画像サイズの小さいモデル(精度はそこそこ)では 58FPS を達成
• Faster において①領域候補生成、②各領域の特徴ベクトルを切り出して分類、と 2 段階で行っていた処理を一気に行う。
• 深さの異なる複数の特徴マップを使い、浅い側は小さい物体、深い側は大きい物体を検出。(深さにより、デフォルトの Box サイズを変えている)
浅い側の特徴マップからは
小さい物体を検出する
深い側の特徴マップからは
大きい物体を検出するSSD: http://arxiv.org/abs/1512.02325 10

SSD: Single Shot Multibox Detector
• Pascal VOC 2007 の Detection タスクの結果• 入力画像サイズが 300x300 のモデル( SSD300) では 58FPS を達成し、
mean AP も 70% を超えている。• 入力画像サイズが 500x500 のモデル (SSD500) では、 Faster R-CNN よ
り精度も高く処理速度も速い。
SSD: http://arxiv.org/abs/1512.02325
11

Instance Segmentation紹介する論文:End-to-End Instance Segmentation and Counting with Recurrent Attention
Instance Segmentation
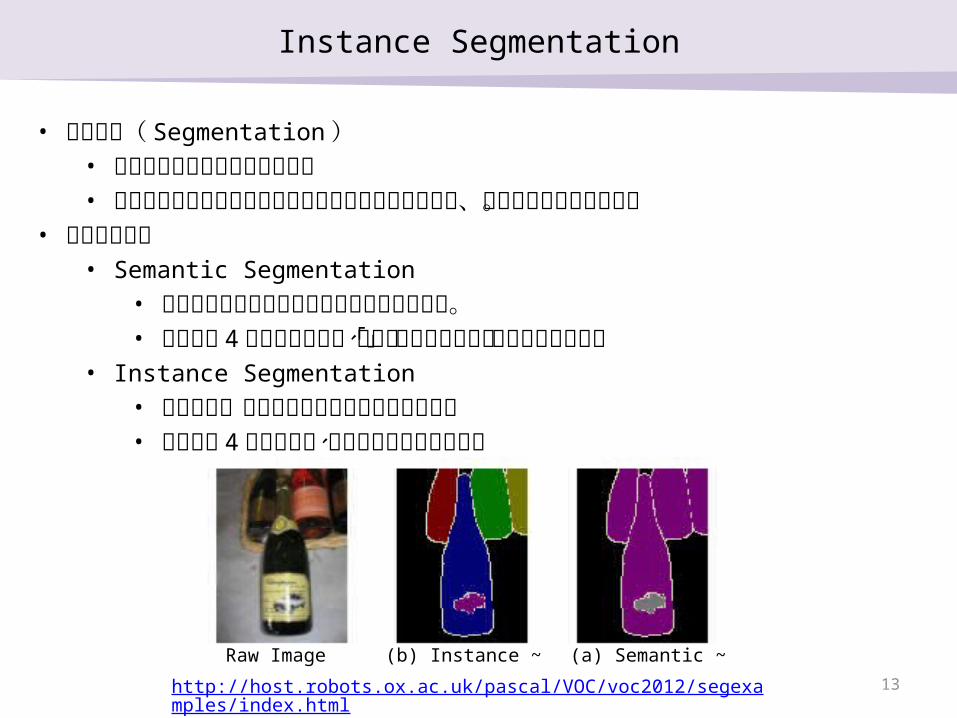
• 領域分割( Segmentation )• ピクセル毎のラベルを予測する• 形状や面積といった情報が得られるため応用先も多く、活発に研究されて
いる。• タスクの分類
• Semantic Segmentation• 各ピクセルにクラスのラベルを付与する問題。• ボトルが 4 本ある場合でも、全て「ボトルクラス」のラベルをつける
• Instance Segmentation• 個々の物体ごとに別のラベルを付与する問題• ボトルが 4 本ある場合、別々のラベルを付与する
(b) Instance ~ (a) Semantic ~Raw Imagehttp://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/index.html 13

突然ですが問題です。
葉っぱは何枚あるでしょうか?
http://juser.fz-juelich.de/record/154525/files/FZJ-2014-03837.pdf 14

どのように数えましたか?
http://juser.fz-juelich.de/record/154525/files/FZJ-2014-03837.pdf
• 目線を移しながら一枚一枚注目する• 一度見たものは記憶しておくといった感じで数えたのではないでしょうか・・・?
15

End-to-End Instance Segmentation and Counting with Recurrent Attention
• Instance Segmentation 用のニューラルネットワーク• ステップ毎に1つの物体に注目して領域分割する• 一度見た領域は記憶しておく
(人間の数え方を参考にしている)
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
16

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
• モデルの全体像:
17

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
一度見た領域を記憶しておく部品
18

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
どこに注目するかを決める
19

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
注目した領域の Segmentation を行う
20

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
物体が見つかったかどうかの判定を行う(スコアが 0.5 以下になったら終了)
21

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
一度見た部分は記憶する。(以下繰返し)
22

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
• 結果(1)葉っぱの領域分割
23

End-to-End Instance Segmentation and Counting with Recurrent Attention
End-to-End Instance Segmentation and Counting with Recurrent Attention: https://arxiv.org/abs/1605.09410
• 結果( 2 )車両の領域分割
24





























