Embed Size (px)
Citation preview

Orchestration for the rest of us
1 / 52

DisclaimerI gave this talk in 2015. Since then, the landscape of containerorchestration changed quite a bit.
While the ideas, concepts, and challenges that I mentionremain valid today, take the examples with a grain of salt.
(In fact, you should always take everything I say with a grainof salt, lest I become lazy and complacent.)
Thank you!
2 / 52

Who am I?French software engineer living in California
I have built and scaled the dotCloud PaaS
I know a few things about running containers (in production)
3 / 52

OutlineWhat's orchestration? (And when do we need it?)
What's scheduling? (And why is it hard?)
Taxonomy of schedulers (Depending on how they handle concurrency)
Mesos in action
Swarm in action
4 / 52

What'sorchestration?
5 / 52

6 / 52

Wikipedia to the rescue!Orchestration describes the automated arrangement,coordination, and management of complex computer systems,middleware, and services.
7 / 52

Wikipedia to the rescue!Orchestration describes the automated arrangement,coordination, and management of complex computer systems,middleware, and services.
[...] orchestration is often discussed in the context of service-oriented architecture, virtualization, provisioning, ConvergedInfrastructure and dynamic datacenter topics.
8 / 52

Wikipedia to the rescue!Orchestration describes the automated arrangement,coordination, and management of complex computer systems,middleware, and services.
[...] orchestration is often discussed in the context of service-oriented architecture, virtualization, provisioning, ConvergedInfrastructure and dynamic datacenter topics.
Uhhh, ok, what does that exactly mean?
9 / 52

Example 1: dynamic cloud instances
10 / 52

Example 1: dynamic cloud instancesQ: do we always use 100% of our servers?
11 / 52
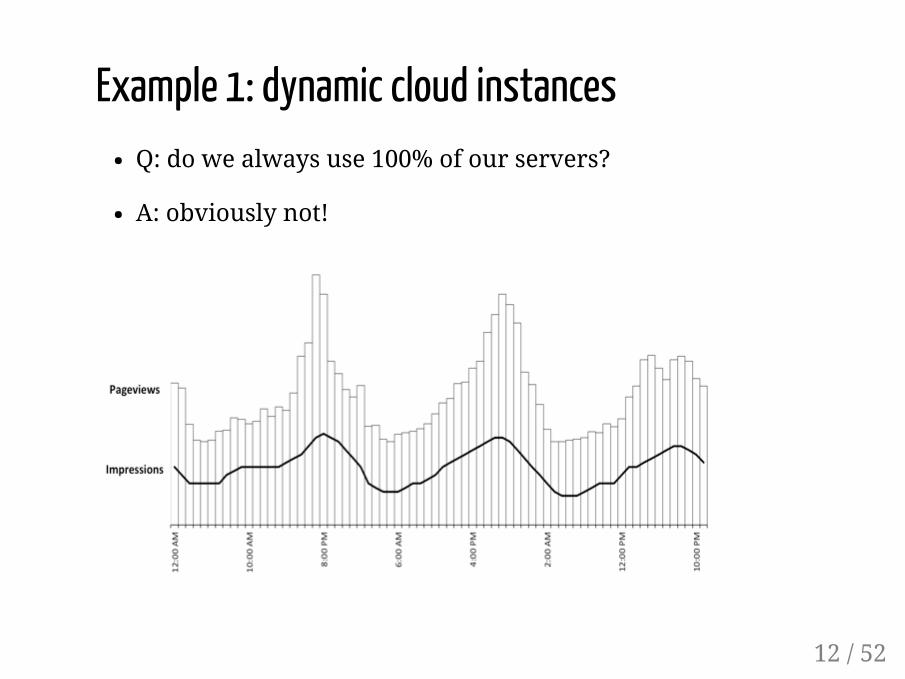
Example 1: dynamic cloud instancesQ: do we always use 100% of our servers?
A: obviously not!
12 / 52

Example 1: dynamic cloud instancesEvery night, scale down (by shutting down extraneous replicated instances)
Every morning, scale up (by deploying new copies)
"Pay for what you use" (i.e. save big $$$ here)
13 / 52

Example 1: dynamic cloud instancesHow do we implement this?
Crontab
Autoscaling (save even bigger $$$)
That's relatively easy.
Now, how are things for our IAAS provider?
14 / 52

Example 2: dynamic datacenterQ: what's the #1 cost in a datacenter?
15 / 52

Example 2: dynamic datacenterQ: what's the #1 cost in a datacenter?
A: electricity!
16 / 52

Example 2: dynamic datacenterQ: what's the #1 cost in a datacenter?
A: electricity!
Q: what uses electricity?
17 / 52

Example 2: dynamic datacenterQ: what's the #1 cost in a datacenter?
A: electricity!
Q: what uses electricity?
A: servers, obviously
A: ... and associated cooling
18 / 52

Example 2: dynamic datacenterQ: what's the #1 cost in a datacenter?
A: electricity!
Q: what uses electricity?
A: servers, obviously
A: ... and associated cooling
Q: do we always use 100% of our servers?
19 / 52

Example 2: dynamic datacenterQ: what's the #1 cost in a datacenter?
A: electricity!
Q: what uses electricity?
A: servers, obviously
A: ... and associated cooling
Q: do we always use 100% of our servers?
A: obviously not!
20 / 52

Example 2: dynamic datacenterIf only we could turn off unused servers during the night...
Problem: we can only turn off a server if it's totally empty! (i.e. all VMs on it are stopped/moved)
Solution: migrate VMs and shutdown empty servers (e.g. combine two hypervisors with 40% load into 80%+0%,and shutdown the one at 0%)
21 / 52

Example 2: dynamic datacenterHow do we implement this?
Shutdown empty hosts (but make sure that there is spare capacity!)
Restart hosts when capacity is low
Ability to "live migrate" VMs (Xen already did this 10+ years ago)
Rebalance VMs on a regular basis - what if a VM is stopped while we move it? - should we allow provisioning on hosts involved in a migration?
Scheduling becomes more complex.
22 / 52

What isscheduling?
23 / 52

Wikipedia to the rescue! (Again!)In computing, scheduling is the method by which threads,processes or data flows are given access to system resources.
The scheduler is concerned mainly with:
throughput (total amount or work done per time unit);turnaround time (between submission and completion);response time (between submission and start);waiting time (between job readiness and execution);fairness (appropriate times according to priorities).
In practice, these goals often conflict.
"Scheduling" = decide which resources to use.
24 / 52

Exercise 1You have:
5 hypervisors (physical machines)
Each server has:
16 GB RAM, 8 cores, 1 TB disk
Each week, your team asks:
one VM with X RAM, Y CPU, Z disk
Scheduling = deciding which hypervisor to use for each VM.
Difficulty: easy!
25 / 52

Exercise 2You have:
1000+ hypervisors (and counting!)
Each server has different resources:
8-500 GB of RAM, 4-64 cores, 1-100 TB disk
Multiple times a day, a different team asks for:
up to 50 VMs with different characteristics
Scheduling = deciding which hypervisor to use for each VM.
Difficulty: ???
26 / 52

Exercise 2You have:
1000+ hypervisors (and counting!)
Each server has different resources:
8-500 GB of RAM, 4-64 cores, 1-100 TB disk
Multiple times a day, a different team asks for:
up to 50 VMs with different characteristics
Scheduling = deciding which hypervisor to use for each VM.
27 / 52

Exercise 3You have machines (physical and/or virtual)
You have containers
You are trying to put the containers on the machines
Sounds familiar?
28 / 52
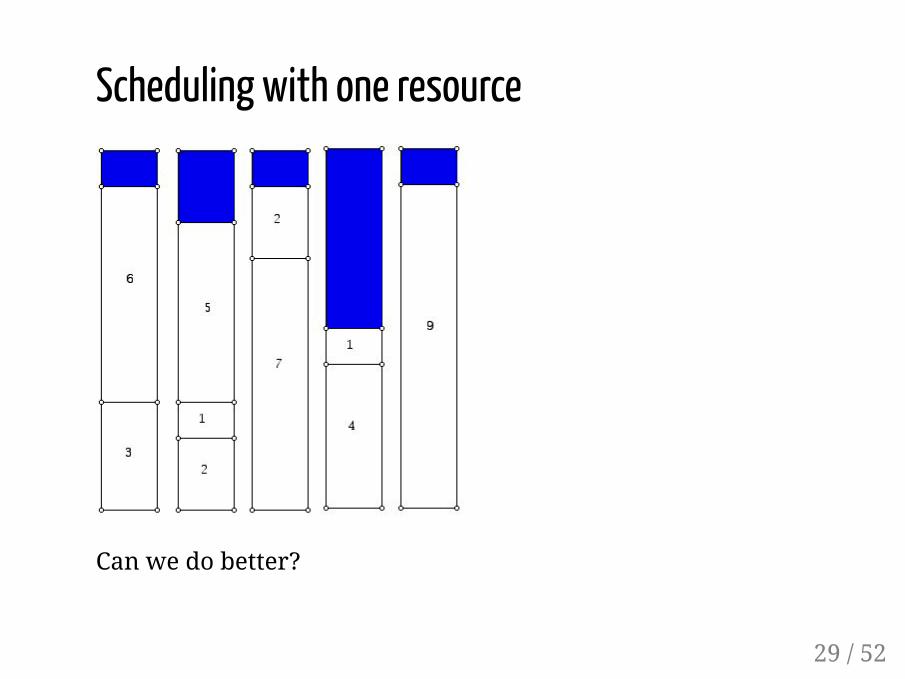
Scheduling with one resource
Can we do better?
29 / 52
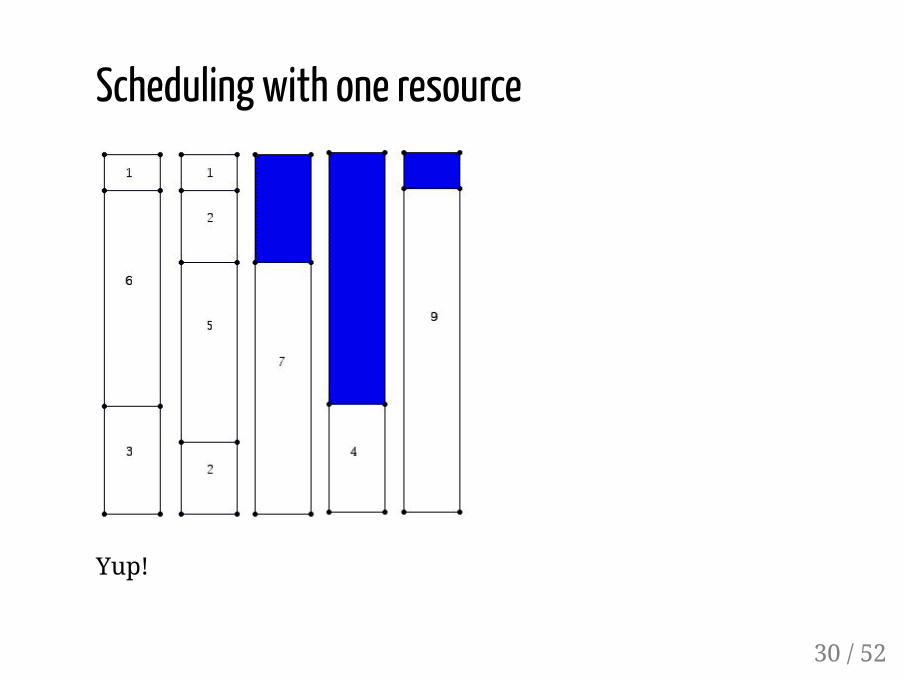
Scheduling with one resource
Yup!
30 / 52

Scheduling with two resources
31 / 52
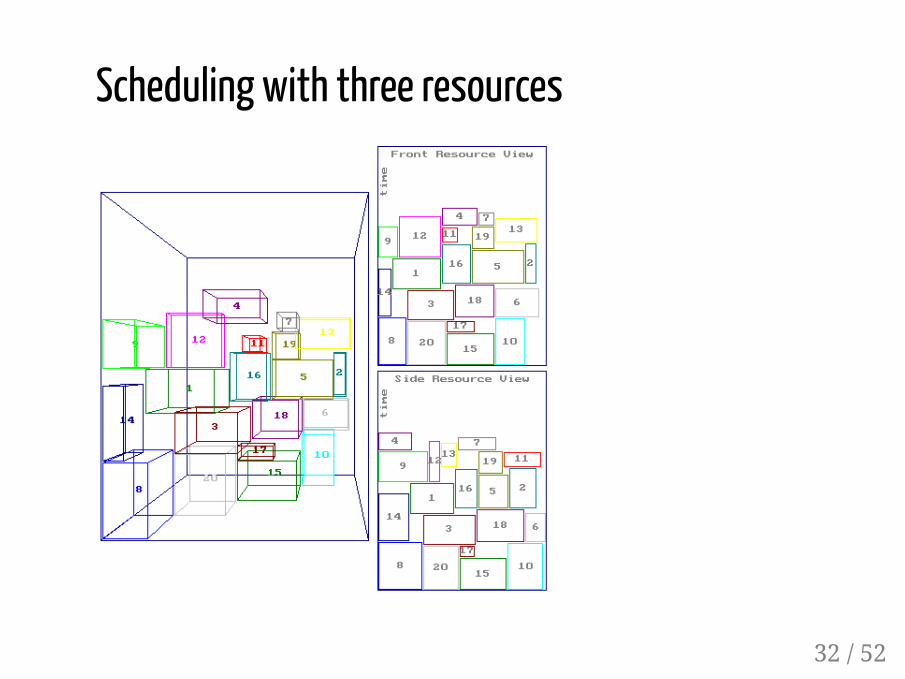
Scheduling with three resources
32 / 52
You need to be good at this
33 / 52
But also, you must be quick!
34 / 52
And be web scale!
35 / 52
And think outside (?) of the box!
36 / 52

Good luck!
37 / 52

TL,DRScheduling with multiple resources (dimensions) is hard
Don't expect to solve the problem with a Tiny Shell Script
There are literally tons of research papers written on this
38 / 52

TL,DRScheduling with multiple resources (dimensions) is hard
Don't expect to solve the problem with a Tiny Shell Script
There are literally tons of research papers written on this
Speaking of which...
39 / 52

Taxonomy ofschedulers
(According to the famous"Omega paper")
40 / 52

Monolithic schedulersConcurrency model: none
All scheduling requests go through a central place
The scheduler examines requests one at a time (usually)
No conflict is possible
41 / 52

Monolithic schedulers rankingPros:
simple to understand
no concurrency issue
Cons:
SPOF (need replication + master election)
prone to feature creep
head-of-line blocking (slow jobs blocking everybody)
supposedly not web scale (more on this later)
42 / 52

Monolithic schedulers examplesone-person manual scheduling ("Hello IT?")
Hadoop YARN
most grid schedulers for scientific compute
Google Borg (so they kind of scale anyway...)
http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/43438.pdf;
43 / 52

We are not sure where the ultimate scalability limit to Borg’scentralized architecture will come from; so far, every time wehave approached a limit, we’ve managed to eliminate it. Asingle Borgmaster can manage many thousands of machines ina cell, and several cells have arrival rates above 10 000 tasksper minute. A busy Borgmaster uses 10–14 CPU cores and up to50 GiB RAM. We use several techniques to achieve this scale.
44 / 52

Two-level schedulersConcurrency model: pessimistic
Top level: master who holds all the resources
Second level: frameworks
To run something, you talk to a framework
The frameworks are given offers by the master (chunks of resources)
A given resource is offered only once (hence "pessimistic" concurrency; no conflict can happen)
If a framework needs more resources, it hoards them (i.e. keeps them, without using them, waiting for more)
45 / 52

Two-level schedulers examplesMesos
Frameworks correspond to different ways to consume resources:
Marathon (keep something running forever)
Chronos (cron-like periodic execution)
Jenkins (spin-up Jenkins slave on demand)
and many more
46 / 52

Two-level schedulers rankingPros:
easy to implement custom behavior
(supposedly) reduced wait times
DEM SCALES! (run multiple copies of a framework)
Cons:
SPOF (need replication + master election)
hoarding is inefficient
well-suited for small, short-lived jobs; not so much for big, long-lived ones (increased decision time = bad!)
47 / 52

Shared state schedulersConcurrency model: optimistic
A master holds the authoritative state of the whole cluster
Multiple schedulers hold a (read-only) copy of that state (and keep it in sync)
You submit jobs to one of those schedulers
The scheduler does its magic and submits a transaction
The master can accept the transaction fully or partially (e.g. if another transaction caused overcommit on aspecific resource: memory >100% on a machine)
48 / 52

Shared state schedulers examplesFlynn
?
49 / 52

Shared state schedulers rankingPros:
easy to implement custom behavior
reduced wait times
super duper awesome scalability
Cons:
SPOF (need replication + master election)
need to handle partial transactions (I think)
haven't seen it in action at scale yet (but I'd be delighted to be enlightened!)
50 / 52

Demo
51 / 52

Thanks! Questions?
@jpetazzo @docker
52 / 52