Embed Size (px)
Citation preview

The Bayesian Crowd: scalable informa�on combina�on for Ci�zen
Science and Crowdsourcing
Stephen Roberts
Machine Learning Research Group & Oxford-Man Ins�tuteUniversity of Oxford
&Alan Turing Ins�tute
Joint work with Edwin Simpson, Steven Reece & Ma-eo Venanzi
Bayes Nets Mee�ng, January 2017


• Bayesian modelling allows for explicit incorporation of all desiderata
• Effort focused not only on theory development, but algorithmic
implementations that are timely & practical for real-world, real-time
scenarios
• Single, under- and over-arching philosophy…
“one method to rule them all… and in the darkness bind them”
“The language is that of Bayesian inference, which I will not utter
here...”
p(a|b
) =
p(b|a)p
(a)/p
(b)
Core methodology – Bayesian inference

• Uncertainty at all levels of inference is naturally taken into account
• Optimal fusion of information: subjective, objective
• Handling missing values
• Handling of noise
• Principled inference of confidence and risk
• Optimal decision making
What does this buy us?

The scaling issue...
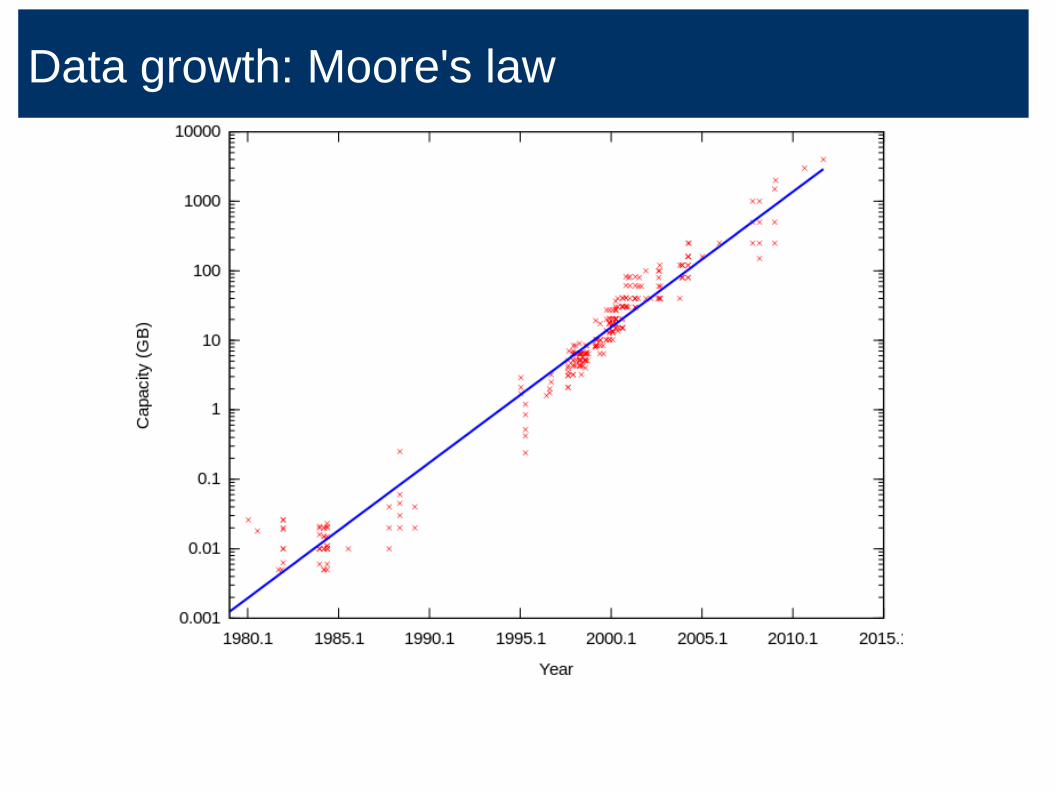
Data growth: Moore's law

The scale of things
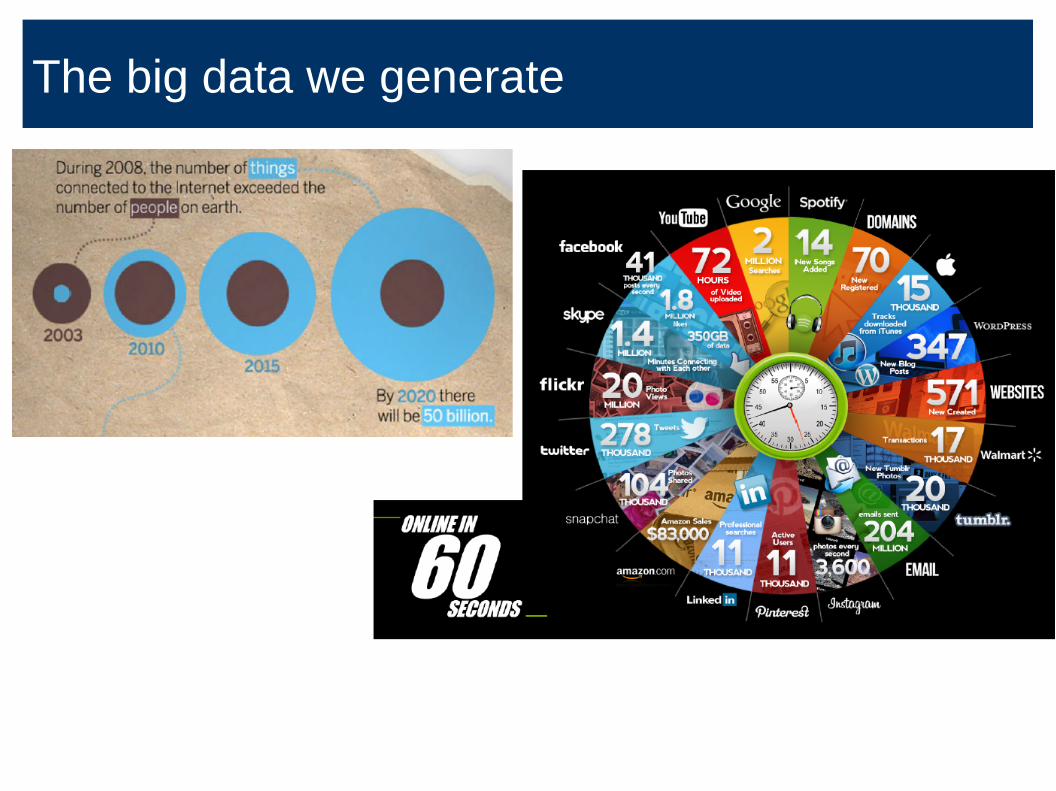
The big data we generate
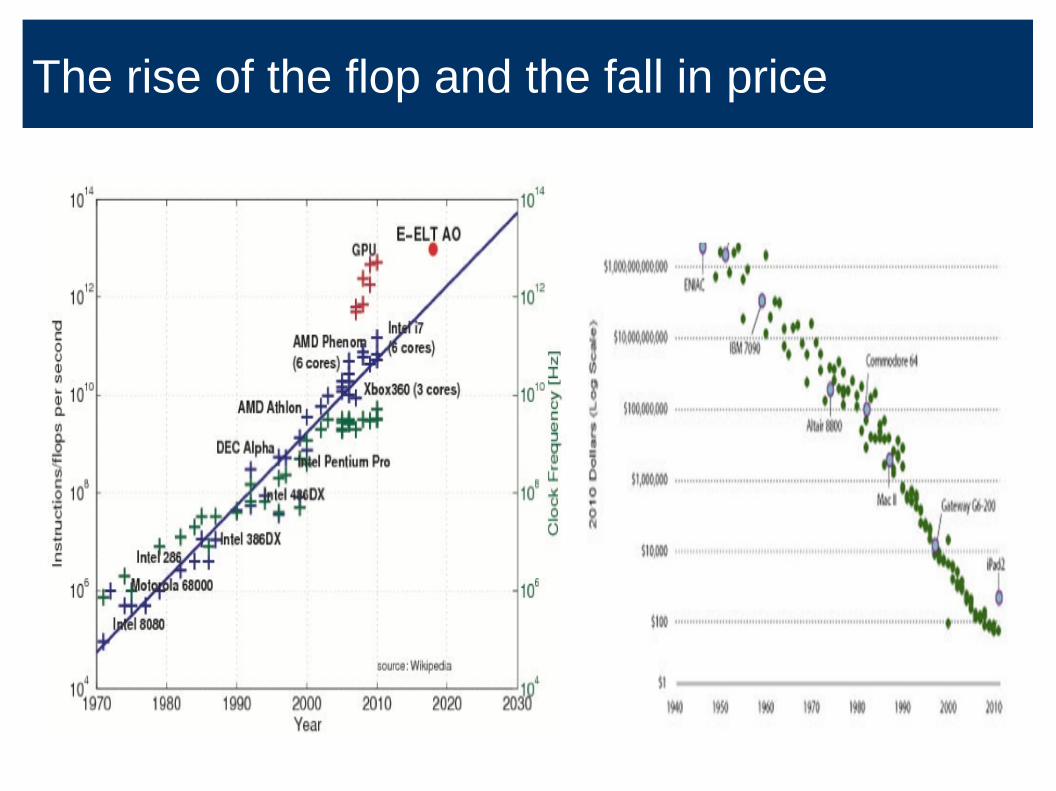
The rise of the flop and the fall in price

Science: the 4th paradigm?

Decision
Combination

How can we deal with unreliable worker responses and
very large datasets?
Big data: Square Kilometer Array,
10 petabytes compressed images/day
Noisy reports: Twi-er, Typhoon Haiyan

Aims: Reliability and E9ciency
● Challenge: volunteers have varying reliability
– Di;erent knowledge, interests, skills
– Typically handled with redundancy → build a consensus
● Challenge: datasets are large, what to priori�se?
● Aim: increase accuracy by learning reliability
● Aim: use our volunteers' �me e�ciently
– Reduce redundant decisions
– Deploy experts where needed
– Use addi�onal data to scale up to larger datasets
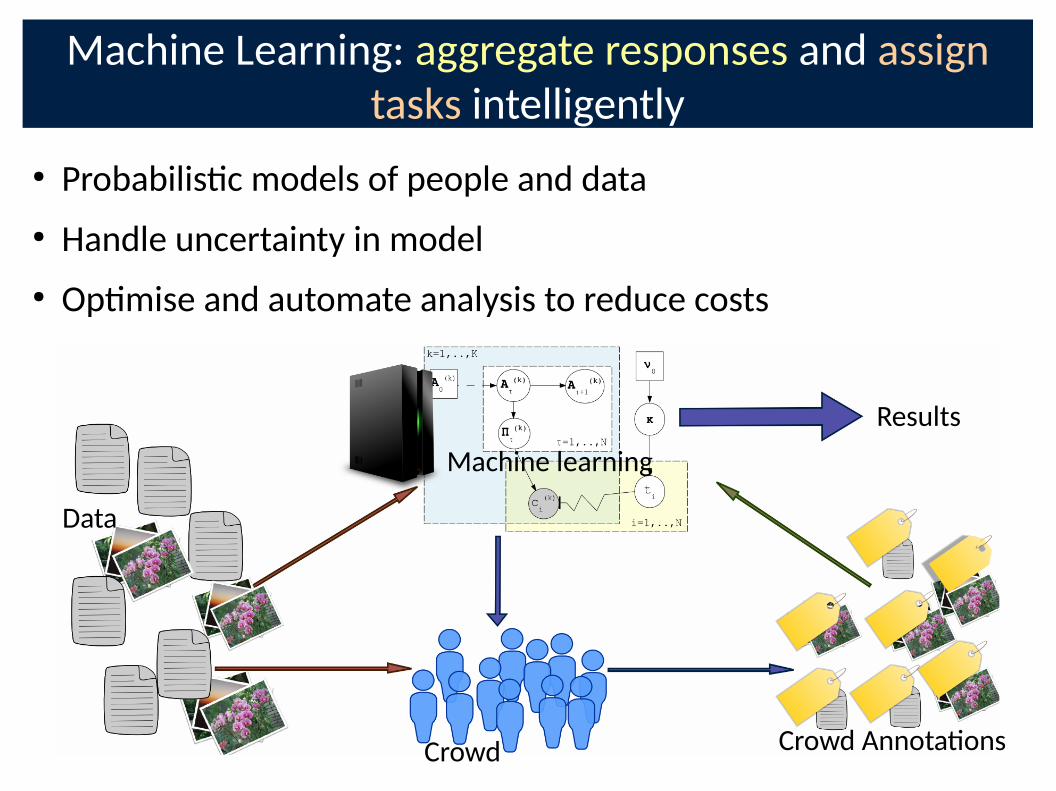
Machine Learning: aggregate responses and assign
tasks intelligently
● Probabilis�c models of people and data
● Handle uncertainty in model
● Op�mise and automate analysis to reduce costs
Machine learning
Data
Crowd Annota�ons Crowd
Results

Zooniverse has 26 current applica�ons across a range of domains, with > 1 million volunteers
● Can we use ML to handle varia�ons in ability?
● Or to match tasks to people's interests and skills?
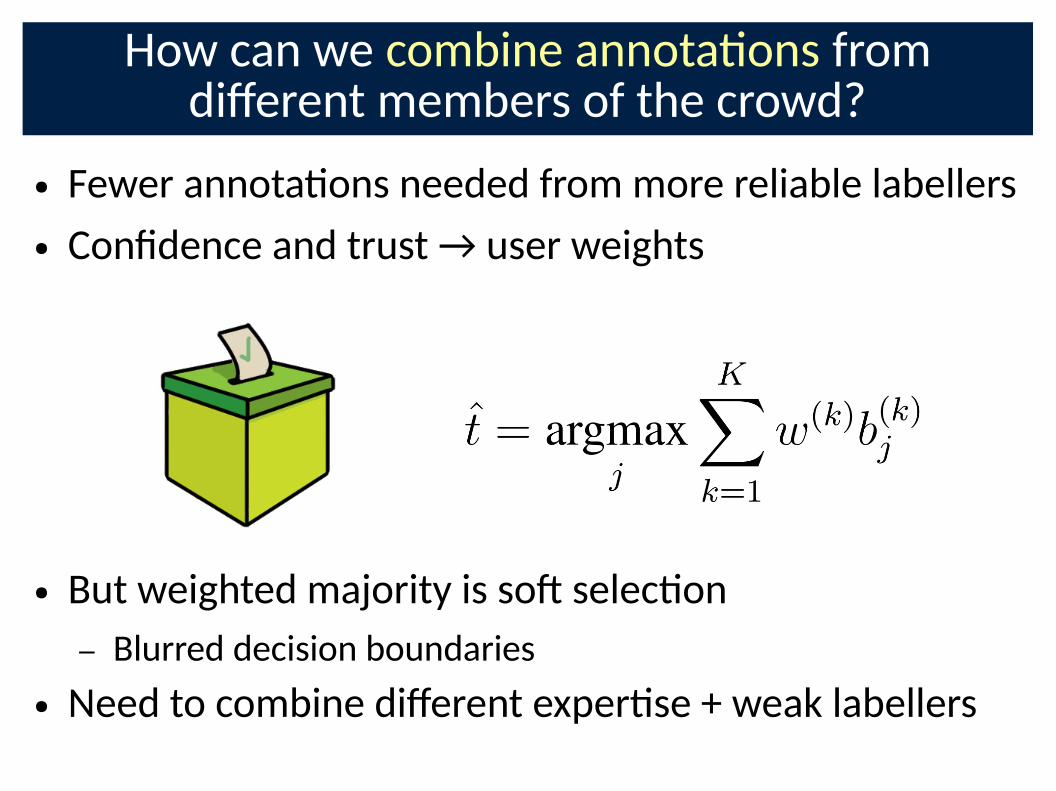
How can we combine annota�ons from di;erent members of the crowd?
● Fewer annota�ons needed from more reliable labellers
● ConCdence and trust → user weights
● But weighted majority is soE selec�on
– Blurred decision boundaries
● Need to combine di;erent exper�se + weak labellers

Bayesian Methods
● Op�mal framework for combining evidence
● Quan�fy prior beliefs explicitly
– E.g. workers are mostly be-er than random
● Quan�Ces uncertainty at all levels
– Which agents are reliable?
– Do we need more evidence for an object's target class?
● Principled approach
– Move away from Cne-tuning each project
– E.g. avoid trial-and-error thresholds to determine when consensus reached
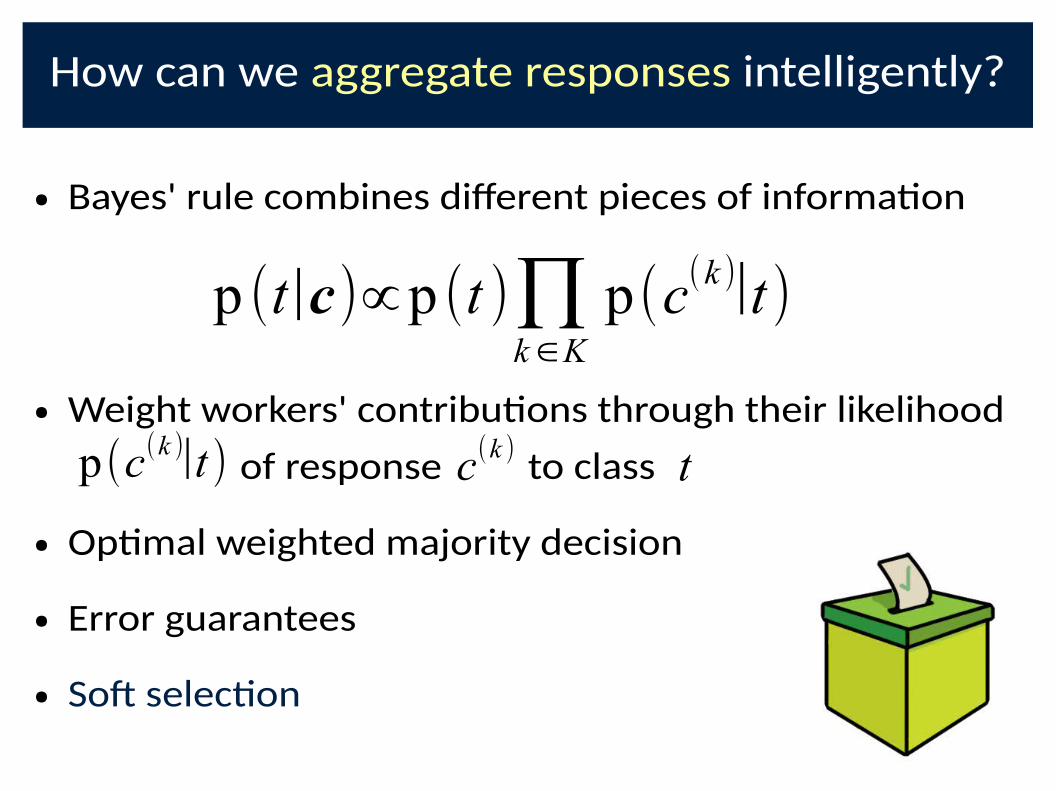
How can we aggregate responses intelligently?
● Bayes' rule combines di@erent pieces of informa�on
● Weight workers' contribu�ons through their likelihood
of response to class
● Op�mal weighted majority decision
● Error guarantees
● SoD selec�on
p (t|c)∝p (t )∏k∈K
p(c(k )|t)
p(c(k )|t) c(k )
t

Likelihood deCned by a confusion matrix
● Likelihood = of response to class :
● Richer than user accuracy weights:
– Di;ering skill levels in each class
– Responses need not be votes
p(c(k)|t )
Response c(k)
Targetclasst
A B C
1 0.7 0.1 0.2
2 0.4 0.4 0.2
π(k) c(k )
t
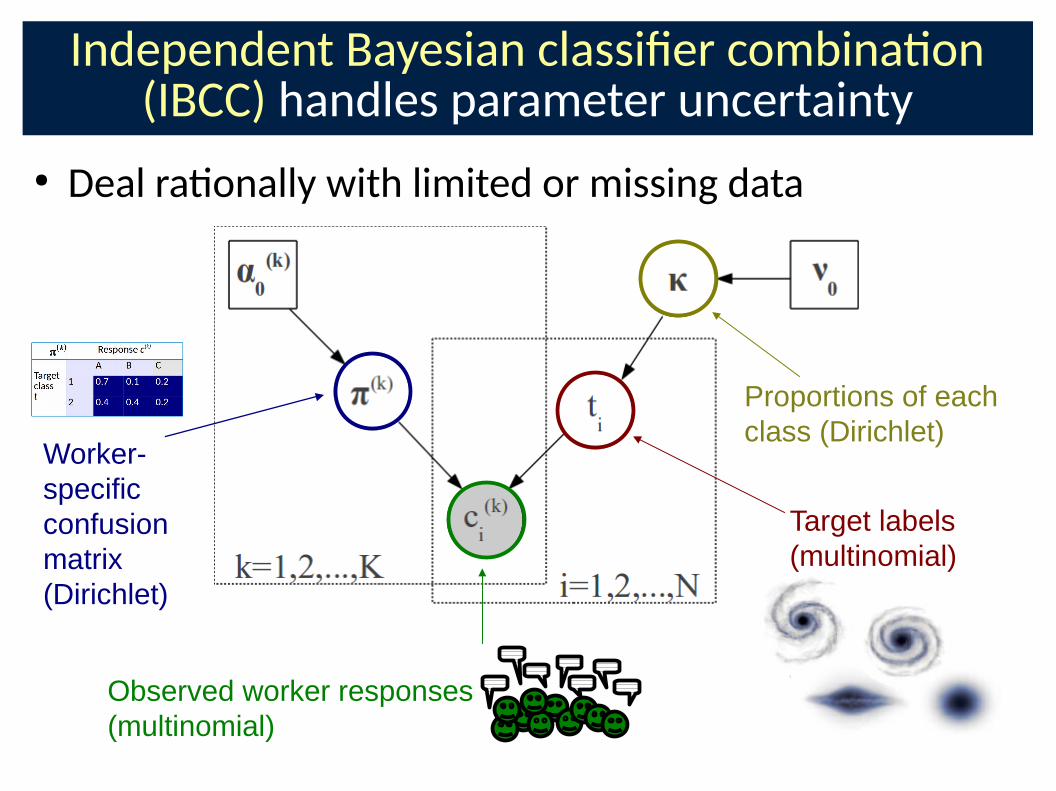
Independent Bayesian classiCer combina�on (IBCC) handles parameter uncertainty
Target labels
(multinomial)
Observed worker responses
(multinomial)
Worker-
specific
confusion
matrix
(Dirichlet)
Proportions of each
class (Dirichlet)
● Deal ra�onally with limited or missing data

Hyperparameters encode prior beliefs in worker
behaviour, e.g. worker is be-er than random
● Op�mise/marginalise to handle model uncertainty
● Share prior pseudo-counts between similar projects
● Ra�o → rela�ve
probability of
agent
responses given
class t
● Magnitude →
strength of
prior beliefs
c(k)
t
A B C
1 7 1 2
2 4 4 2

Joint, condi oned on hyper-hyper parameters
Inference
Gibbs sampling – rather slow
Varia�onal Bayes – o;ers fast inference, at expense of approxima�ons
Inference

-ve free energy Kullback-Leibler divergence
Variational Bayes

Variational Bayes

Varia�onal Bayes: inOa�ng the balloon
Varia�onal Bayes: inOa�ng the balloon
Varia�onal Bayes: inOa�ng the balloon

Users rate each presented object which provides a score of
-1 : very unlikely SN object
1 : possible SN object
3 : likely SN object
(“true” labels obtained retrospectively via Palomar Transient Factory
spectrographic analysis)
Zooniverse: Galaxy Zoo Supernovae
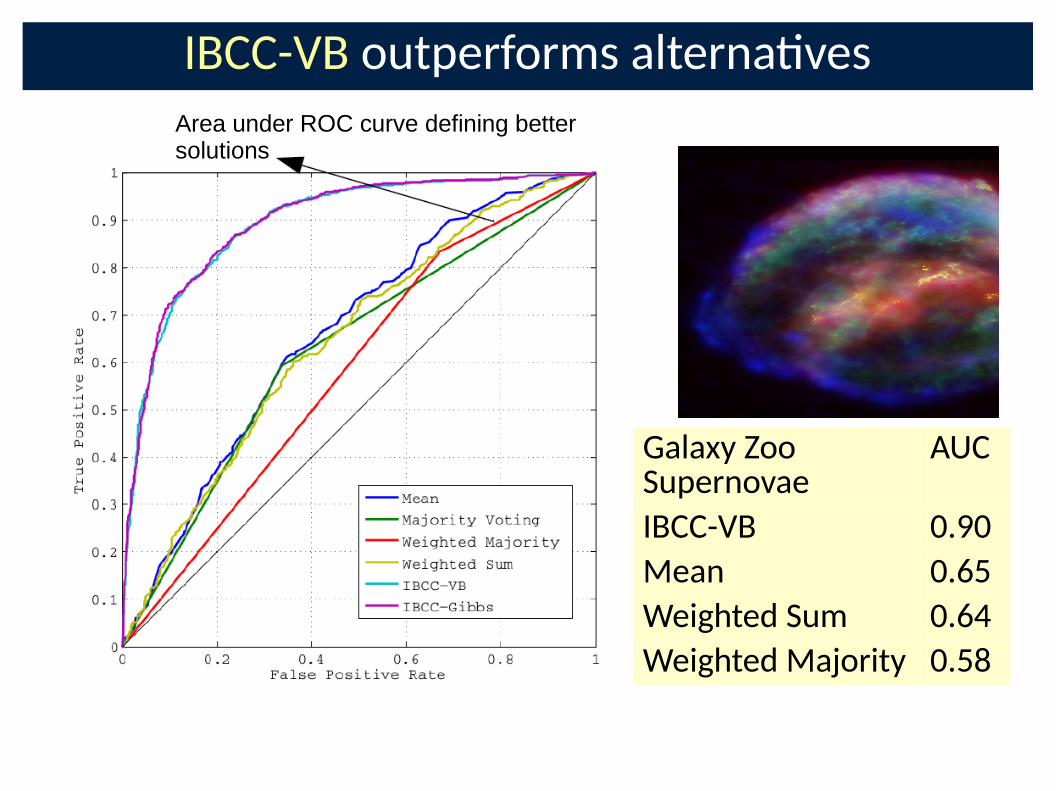
IBCC-VB outperforms alterna�ves
Galaxy Zoo Supernovae
AUC
IBCC-VB 0.90
Mean 0.65
Weighted Sum 0.64
Weighted Majority 0.58
Area under ROC curve defining better solutions
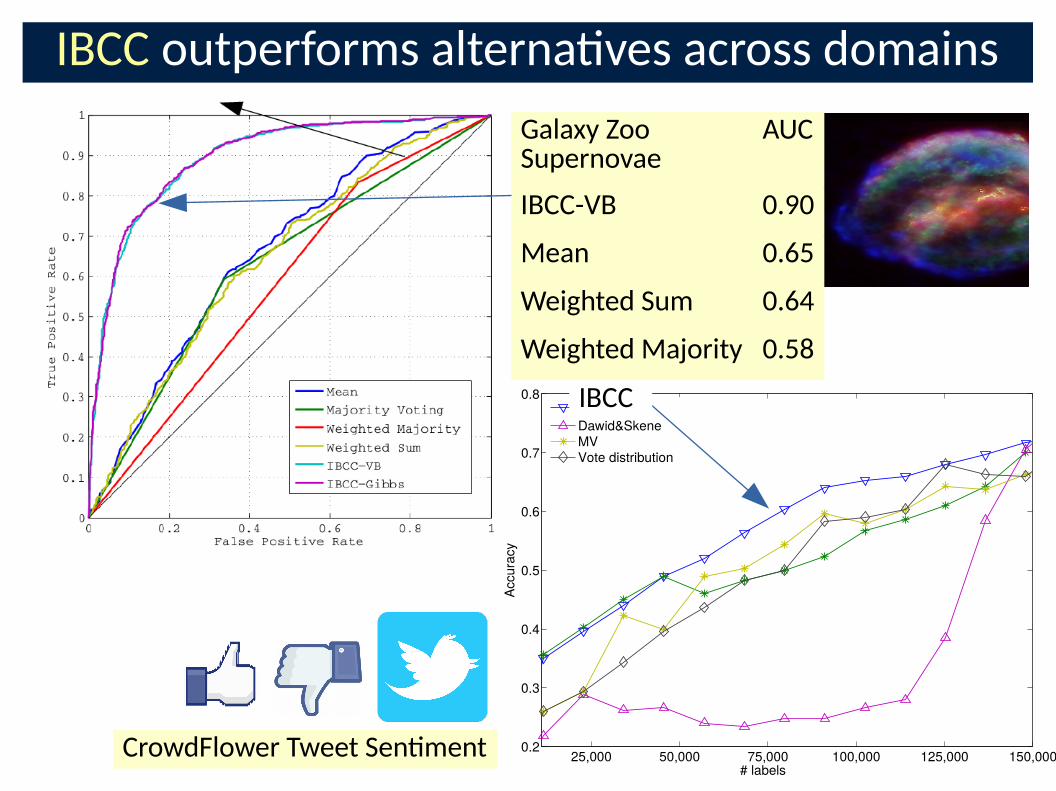
25,000 50,000 75,000 100,000 125,000 150,0000.2
0.3
0.4
0.5
0.6
0.7
0.8
# labels
Accuracy
IBCCDawid&SkeneMVVote distribution
IBCC outperforms alterna�ves across domains
CrowdFlower Tweet Sen�ment
IBCC
Galaxy Zoo Supernovae
AUC
IBCC-VB 0.90
Mean 0.65
Weighted Sum 0.64
Weighted Majority 0.58

Community detec�on over E[π] matrices: behaviour types among Zooniverse users
Sensible Extreme Random Op�mist Pessimist
● vbIBCC provides insights into crowd behaviour using Bayesian community analysis
● Design training to inOuence these types
● CommunityBCC builds these types into the model to be-er predict new workers
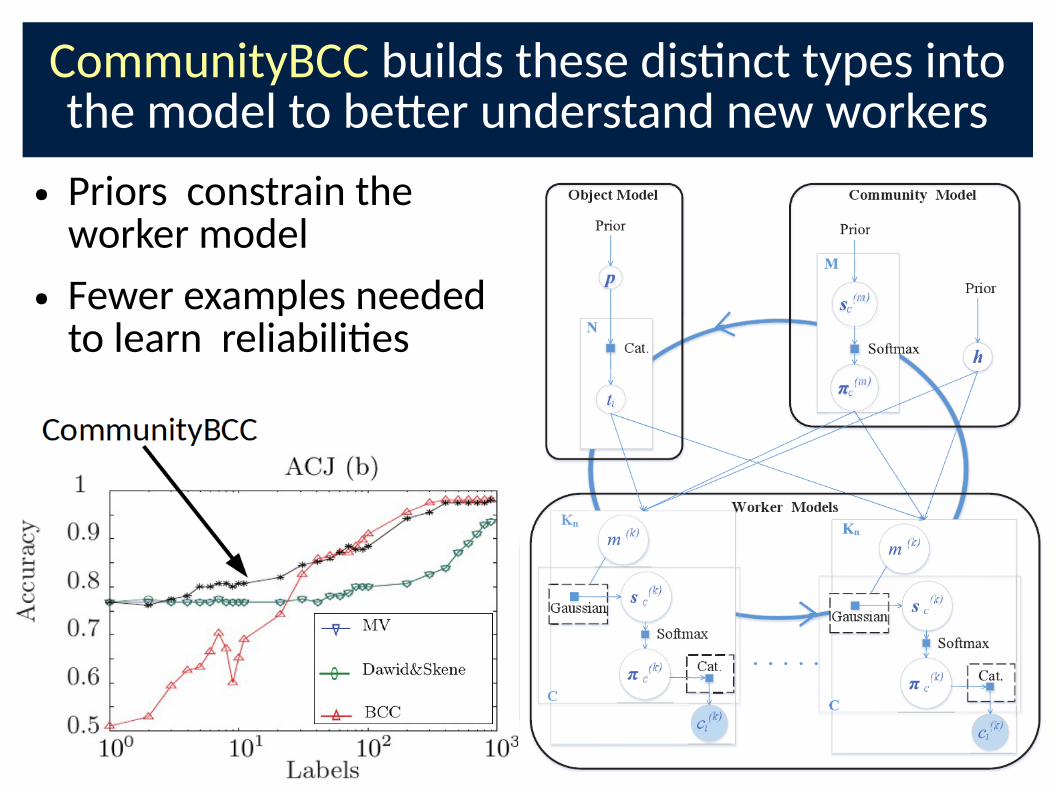
CommunityBCC builds these dis�nct types into the model to be-er understand new workers
● Priors constrain the worker model
● Fewer examples needed to learn reliabili�es
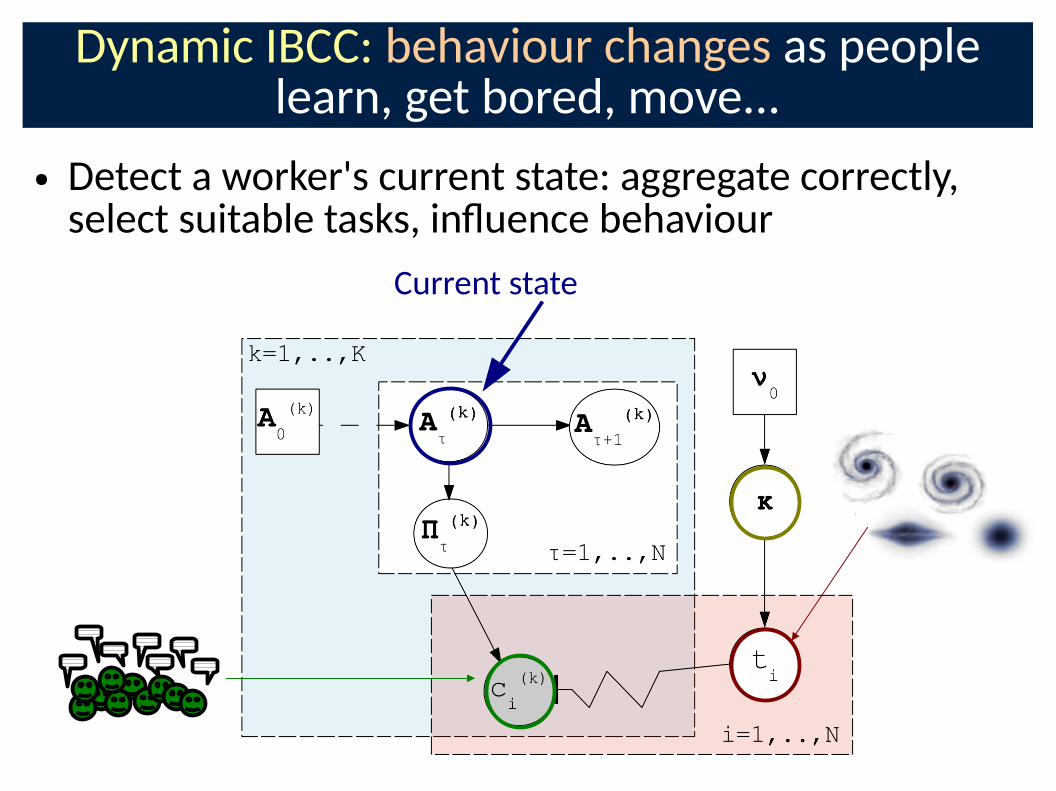
Dynamic IBCC: behaviour changes as people learn, get bored, move...
● Detect a worker's current state: aggregate correctly, select suitable tasks, inOuence behaviour
Current state
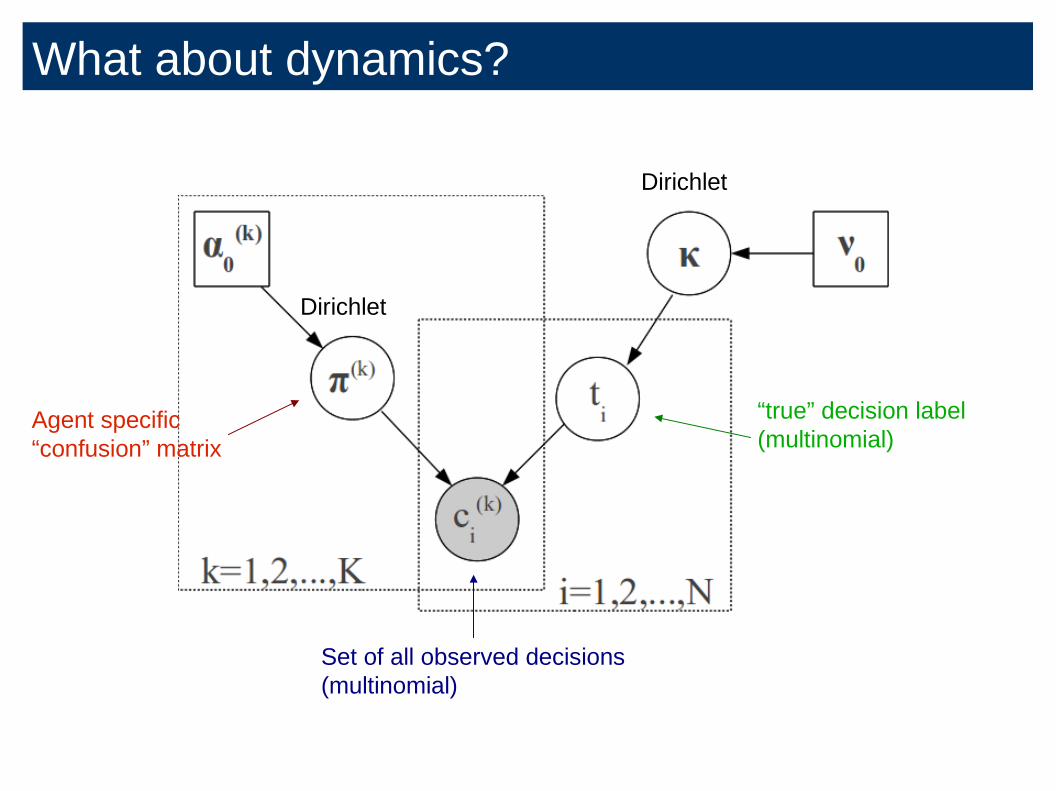
“true” decision label
(multinomial)
Set of all observed decisions
(multinomial)
Dirichlet
Dirichlet
Agent specific
“confusion” matrix
What about dynamics?
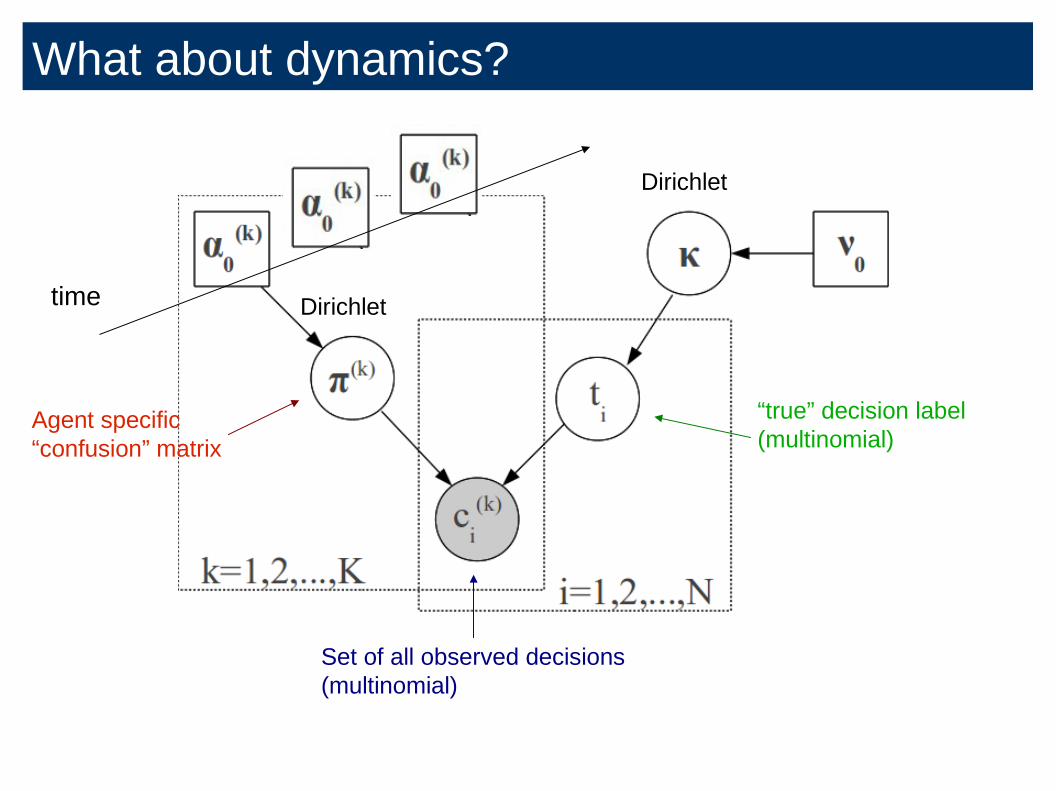
“true” decision label
(multinomial)
Set of all observed decisions
(multinomial)
Dirichlet
Dirichlet
Agent specific
“confusion” matrix
time
What about dynamics?
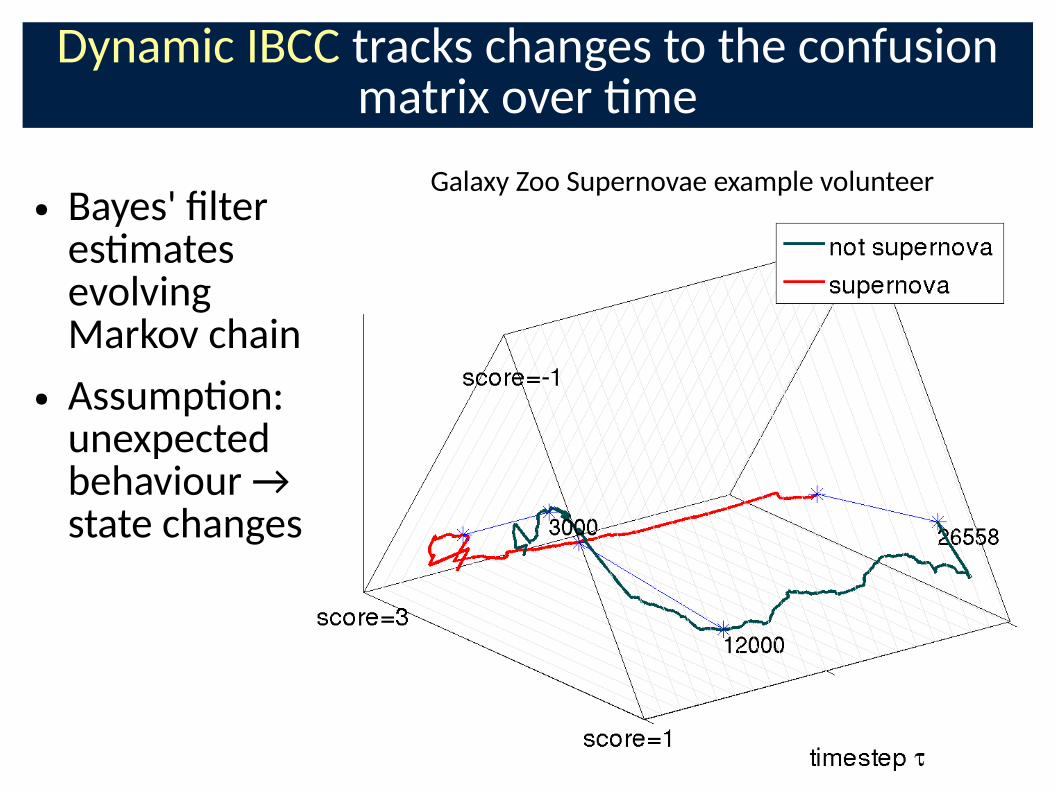
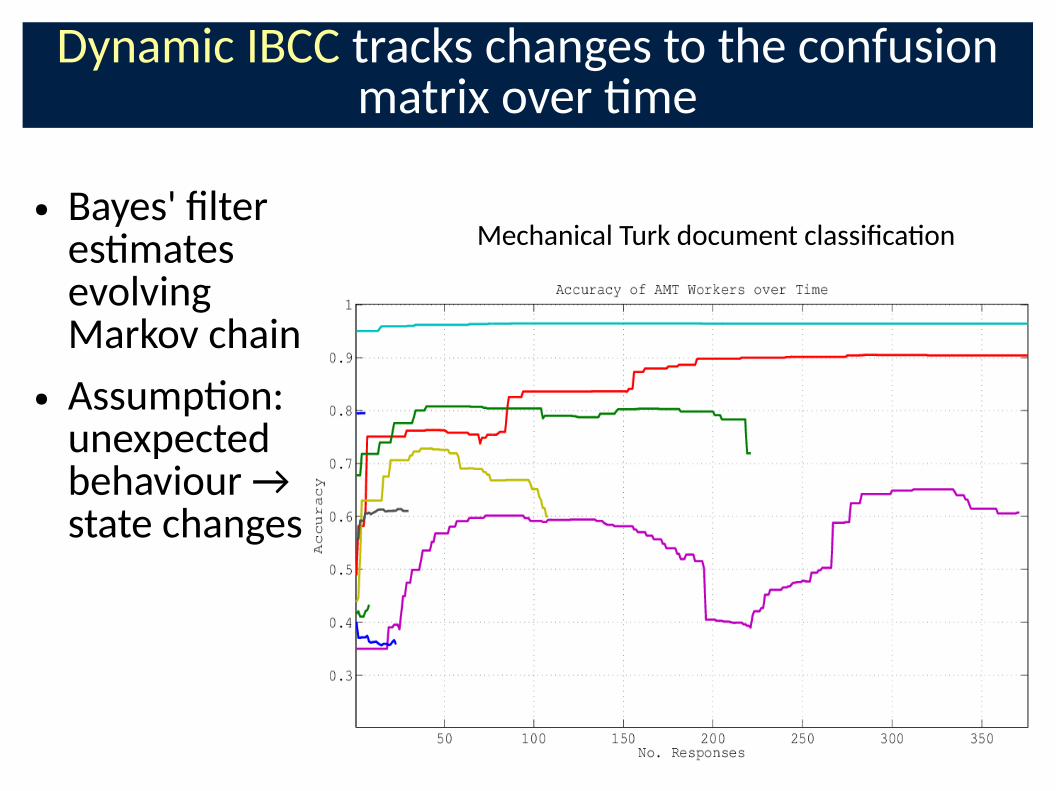
Dynamic IBCC tracks changes to the confusion matrix over �me
● Bayes' Clter es�mates evolving Markov chain
● Assump�on: unexpected behaviour → state changes
Galaxy Zoo Supernovae example volunteer
Dynamic IBCC tracks changes to the confusion matrix over �me
● Bayes' Clter es�mates evolving Markov chain
● Assump�on: unexpected behaviour → state changes
Mechanical Turk document classiCca�on

Modelling the data so we can deploy the crowd more e9ciently...

Combining the crowd with features: TREC Crowdsourcing Challenge
● IBCC + 2000 LDA features ac�ng as addi�onal classiCers [11]
● Classify unlabelled documents
● Results:
– 0.81 AUC with only 16% documents labelled at all
– 0.77 for next-best approach
– 1st place required mul�ple labellings of all documents

BCCWords: an e9cient way to learn language in new contexts
25,000 50,000 75,000 100,000 125,000 150,0000.2
0.3
0.4
0.5
0.6
0.7
0.8
# labels
Accuracy
IBCCCBCCScalBCCWordsMV(Text classi+erDawid&SkeneMVVote distribution
CrowdFlower Tweet Sen�ment
Posi�ve words about the weather learnt by
BCCWords
BCCWords increases accuracy with limited
labels

Unstructured data in social media: a rich source of �mely informa�on
Real-�me, local events – e.g. emergency reports aDer an earthquake
Sen�ment about products, health and social issues – e.g. opinions about H1N1, product reviews
Butler 2013, Morrow et al. 2011
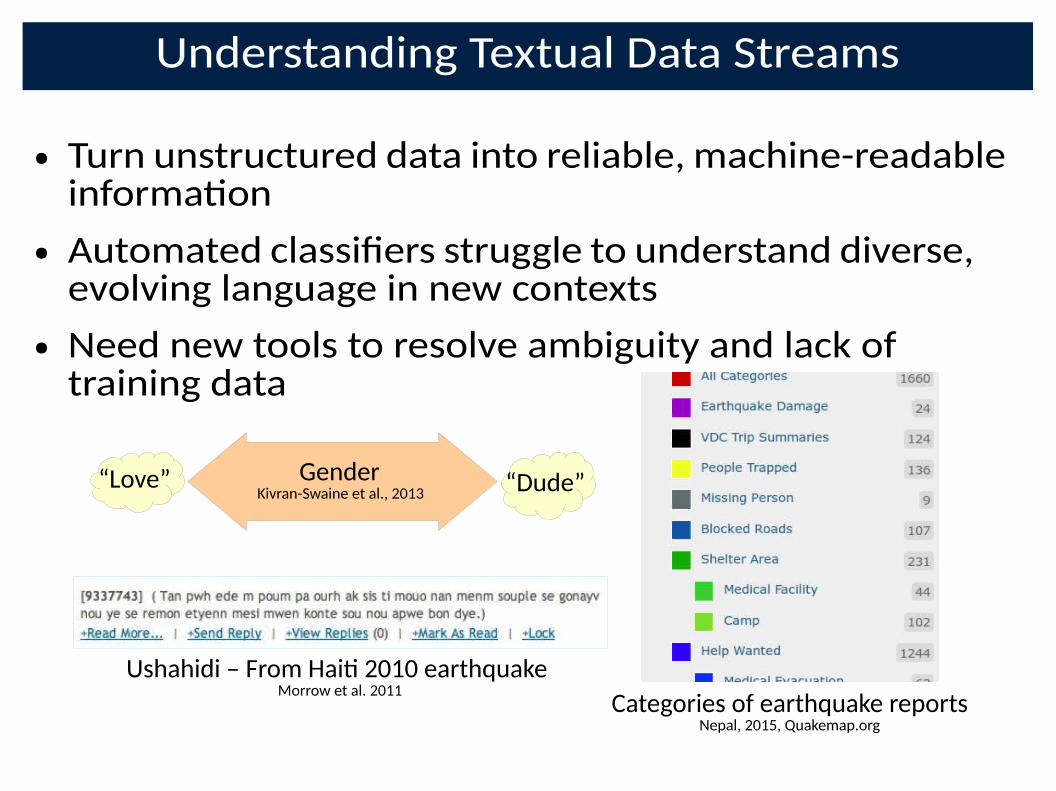
Understanding Textual Data Streams
● Turn unstructured data into reliable, machine-readable
informa�on
● Automated classiBers struggle to understand diverse, evolving language in new contexts
● Need new tools to resolve ambiguity and lack of training data
Ushahidi – From Hai� 2010 earthquake Morrow et al. 2011
Categories of earthquake reportsNepal, 2015, Quakemap.org
Gender Kivran-Swaine et al., 2013
“Love” “Dude”
Interpre�ng Language through Crowdsourcing
● Biased and noisy interpreta�ons
● Scalability: the workers cannot label everything mul�ple �mes
● New techniques needed to reduce the workload of labellers using textual informa�on
● How to learn a language model from unreliable judgements?
++
-
+
Repe��ve TasksRepe��ve Tasks Time Costs
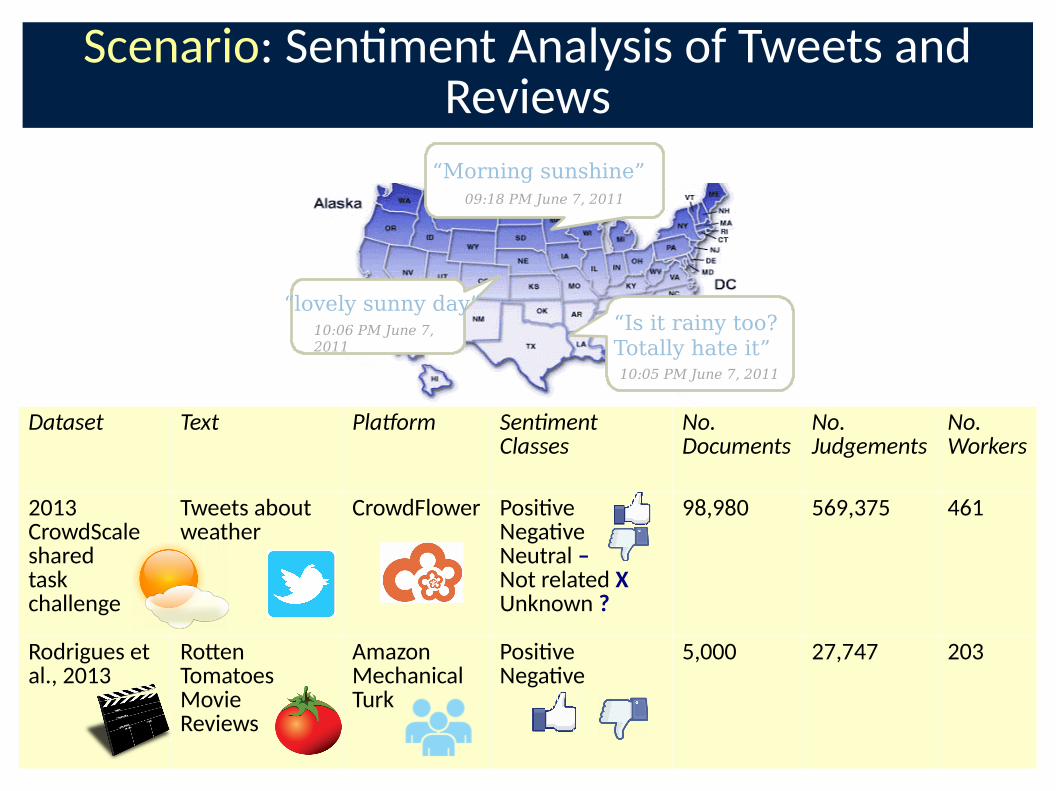
Scenario: Sen�ment Analysis of Tweets and Reviews
Dataset Text Pla�orm Sen ment Classes
No. Documents
No. Judgements
No. Workers
2013 CrowdScale sharedtask challenge
Tweets about weather
CrowdFlower Posi�veNega�veNeutral – Not related XUnknown ?
98,980 569,375 461
Rodrigues et al., 2013
Ro-en Tomatoes Movie Reviews
Amazon Mechanical Turk
Posi�veNega�ve
5,000 27,747 203
“Morning sunshine”09:18 PM June 7, 2011
“Is it rainy too?Totally hate it”10:05 PM June 7, 2011
“lovely sunny day”10:06 PM June 7,
2011
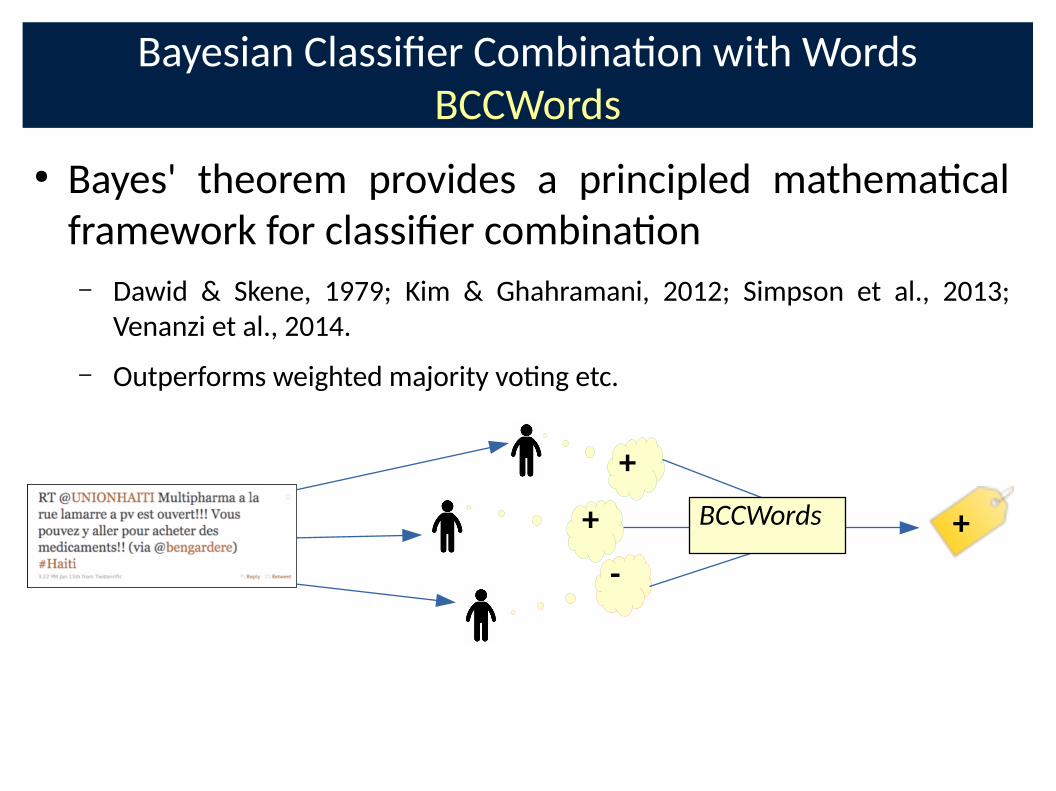
Bayesian ClassiCer Combina�on with Words
BCCWords
● Bayes' theorem provides a principled mathema�cal
framework for classiCer combina�on
– Dawid & Skene, 1979; Kim & Ghahramani, 2012; Simpson et al., 2013;
Venanzi et al., 2014.
– Outperforms weighted majority vo�ng etc.
+
+
-
+BCCWords
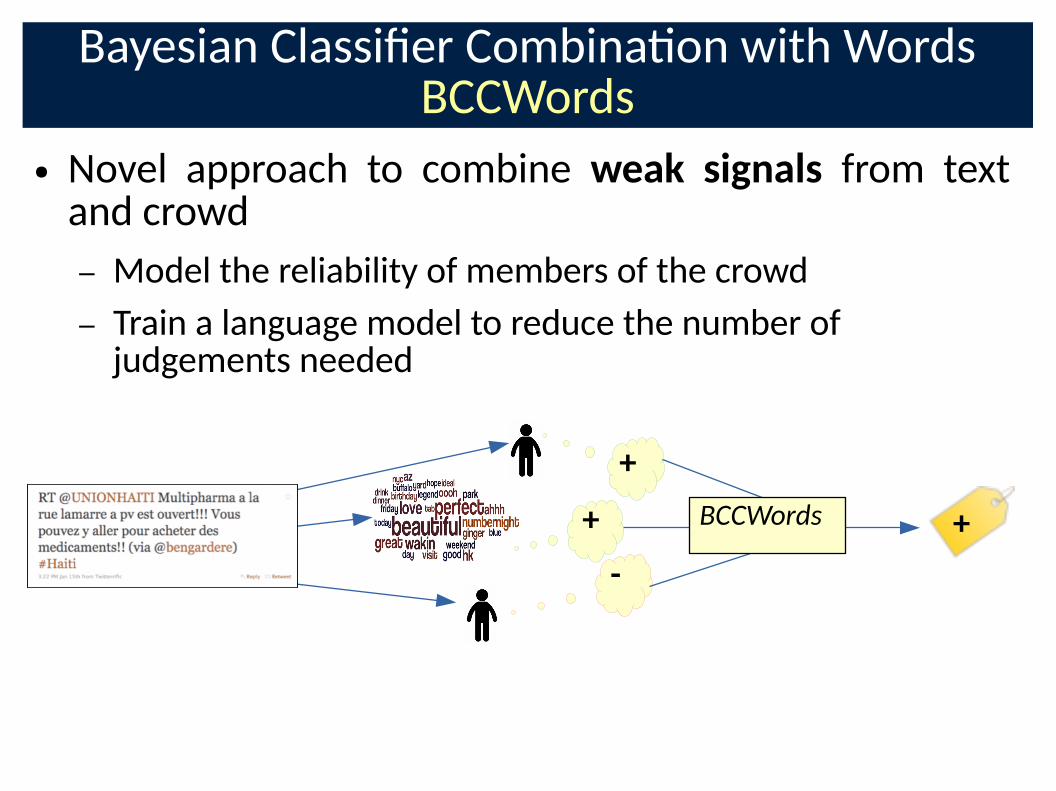
Bayesian ClassiCer Combina�on with WordsBCCWords
● Novel approach to combine weak signals from text and crowd
– Model the reliability of members of the crowd
– Train a language model to reduce the number of judgements needed
+
+
-
+BCCWords

Reliability of judgements deBned by a confusion matrix for each worker
● DeBnes likelihood for worker k:
● Aggregate support for class c using Bayes' rule:
● Richer than weigh�ng by overall accuracy:
– Accounts for bias and random noise
– Di@ering skill levels in each class
– Labels need not be votes for true class
p(label(k )|true class)
label(k)
Trueclass
+ve uncertain -ve
+ve 0.7 0.1 0.2
-ve 0.4 0.4 0.2
∏k∈K
p(label(k )|true class=c)

Likelihood of text features in each class: bag-of-words
ωc=p(wordn|true class=c)
● Words have di;erent likelihoods in each sen�ment class
● Prior distribu�on over word likelihoods in each class
● Learning posterior : update pseudo-counts as we observe words
in document of class c
Good, niceMore likely
Terrible
More likely
ωc
ωc

BCCWords: integra�ng this into one model...
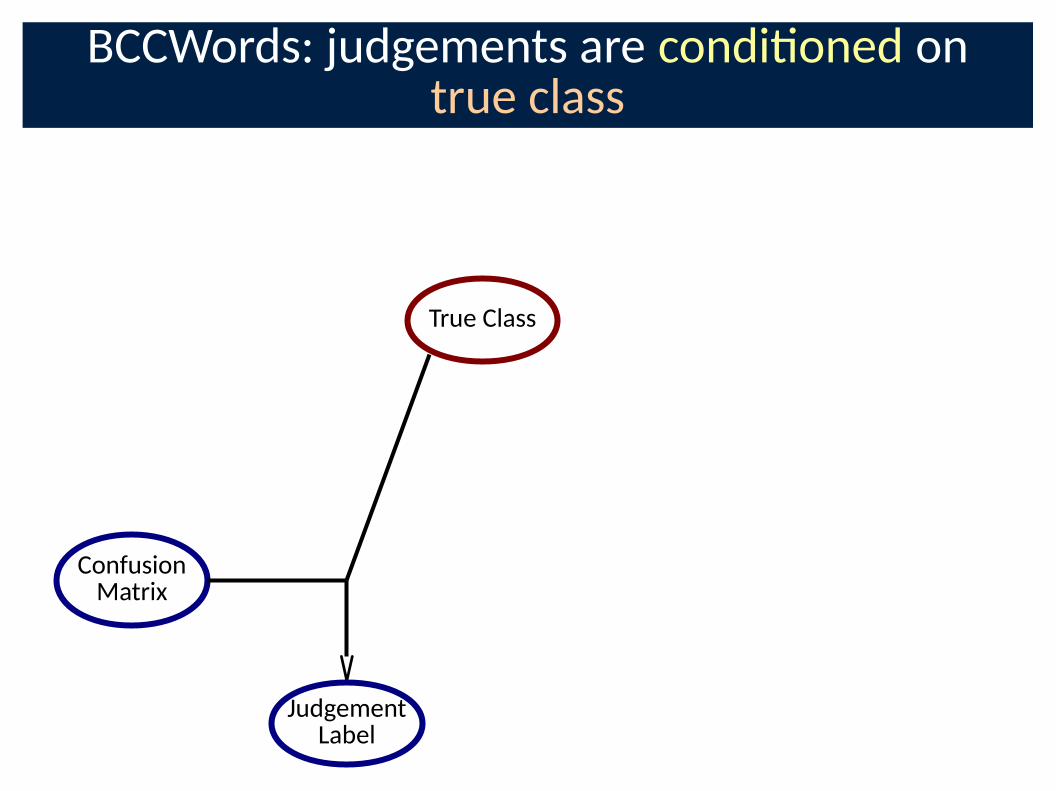
BCCWords: judgements are condi�oned on true class
ConfusionMatrix
JudgementLabel
True Class
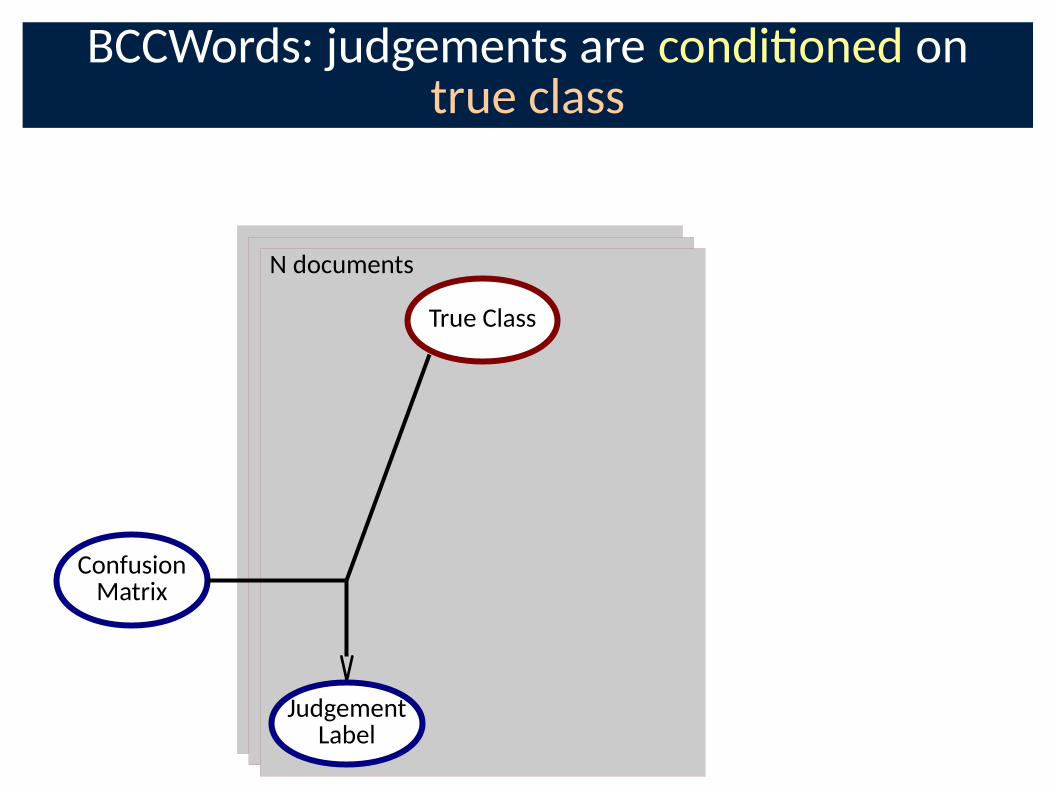
BCCWords: judgements are condi�oned on true class
ConfusionMatrix
JudgementLabel
True Class
N documents
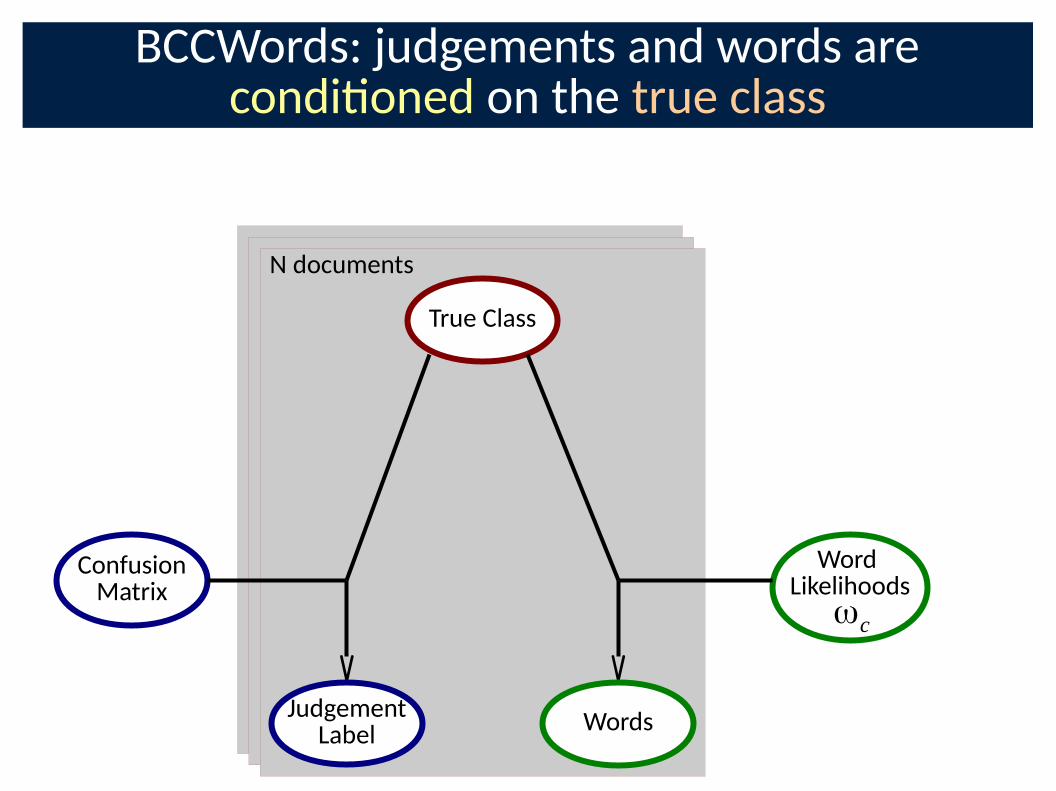
BCCWords: judgements and words are condi�oned on the true class
ConfusionMatrix
JudgementLabel
True Class
Word Likelihoods
Words
ωc
N documents
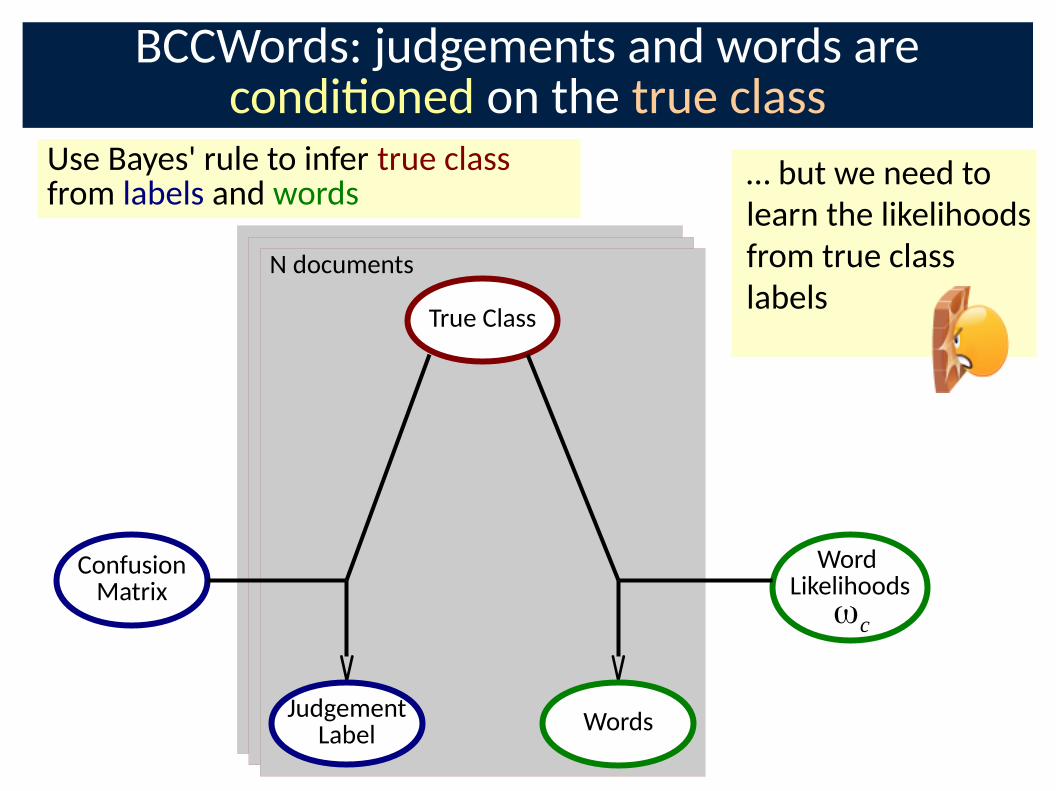
BCCWords: judgements and words are condi�oned on the true class
Use Bayes' rule to infer true class from labels and words
ConfusionMatrix
JudgementLabel
True Class
Word Likelihoods
Words
ωc
N documents
… but we need to
learn the likelihoods
from true class
labels
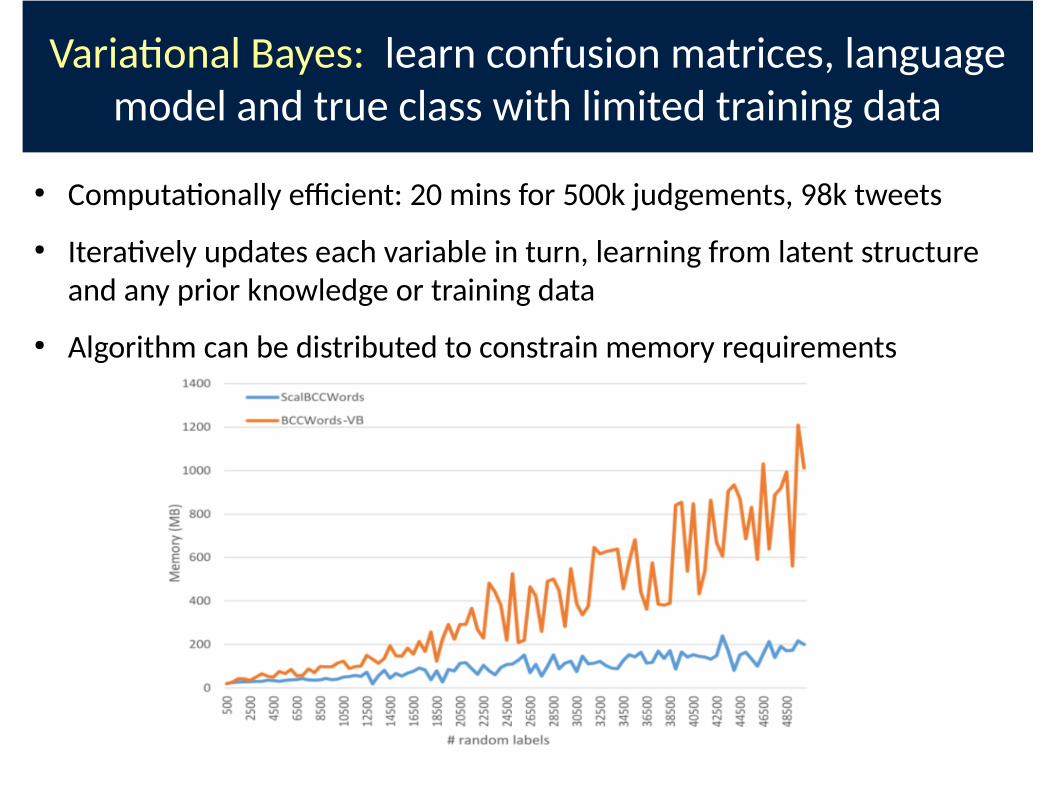
Varia�onal Bayes: learn confusion matrices, language
model and true class with limited training data
● Computa�onally e9cient: 20 mins for 500k judgements, 98k tweets
● Itera�vely updates each variable in turn, learning from latent structure
and any prior knowledge or training data
● Algorithm can be distributed to constrain memory requirements
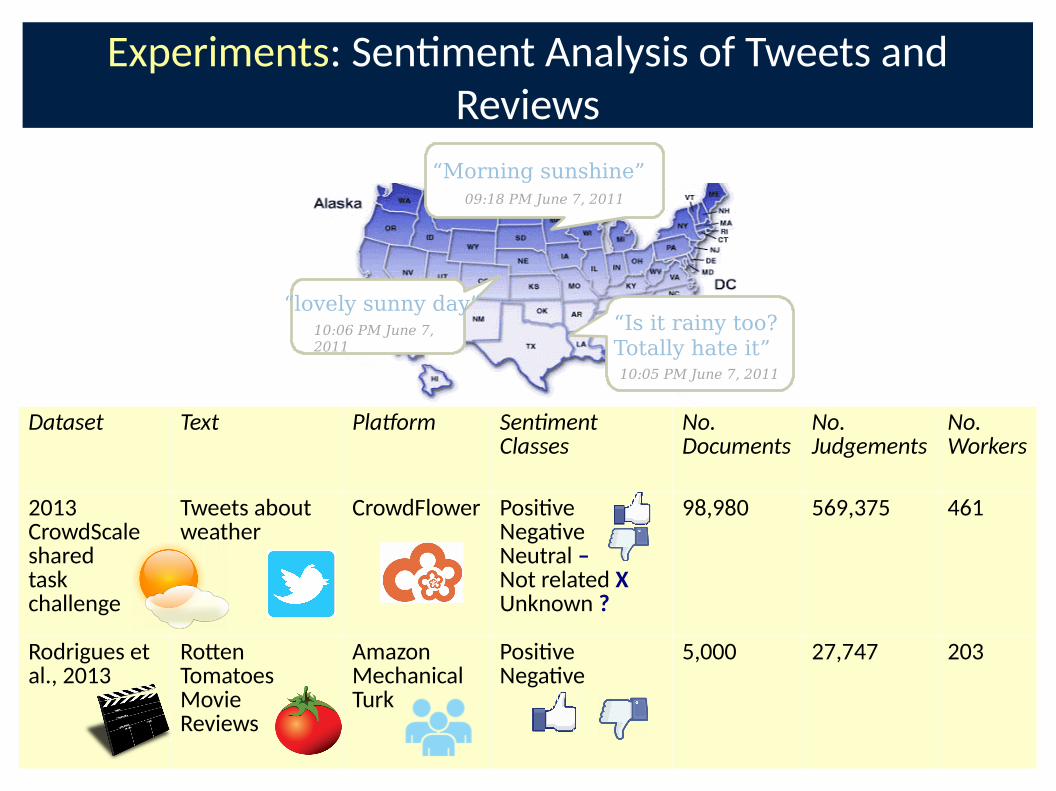
Experiments: Sen�ment Analysis of Tweets and
Reviews
Dataset Text Pla�orm Sen ment Classes
No. Documents
No. Judgements
No. Workers
2013 CrowdScale sharedtask challenge
Tweets about weather
CrowdFlower Posi�veNega�veNeutral – Not related XUnknown ?
98,980 569,375 461
Rodrigues et al., 2013
Ro-en Tomatoes Movie Reviews
Amazon Mechanical Turk
Posi�veNega�ve
5,000 27,747 203
“Morning sunshine”09:18 PM June 7, 2011
“Is it rainy too?Totally hate it”10:05 PM June 7, 2011
“lovely sunny day”10:06 PM June 7,
2011

Language Model for Weather Sen�ment
Posi�ve Nega�veMost Likely Words
Discrimina�ve Words
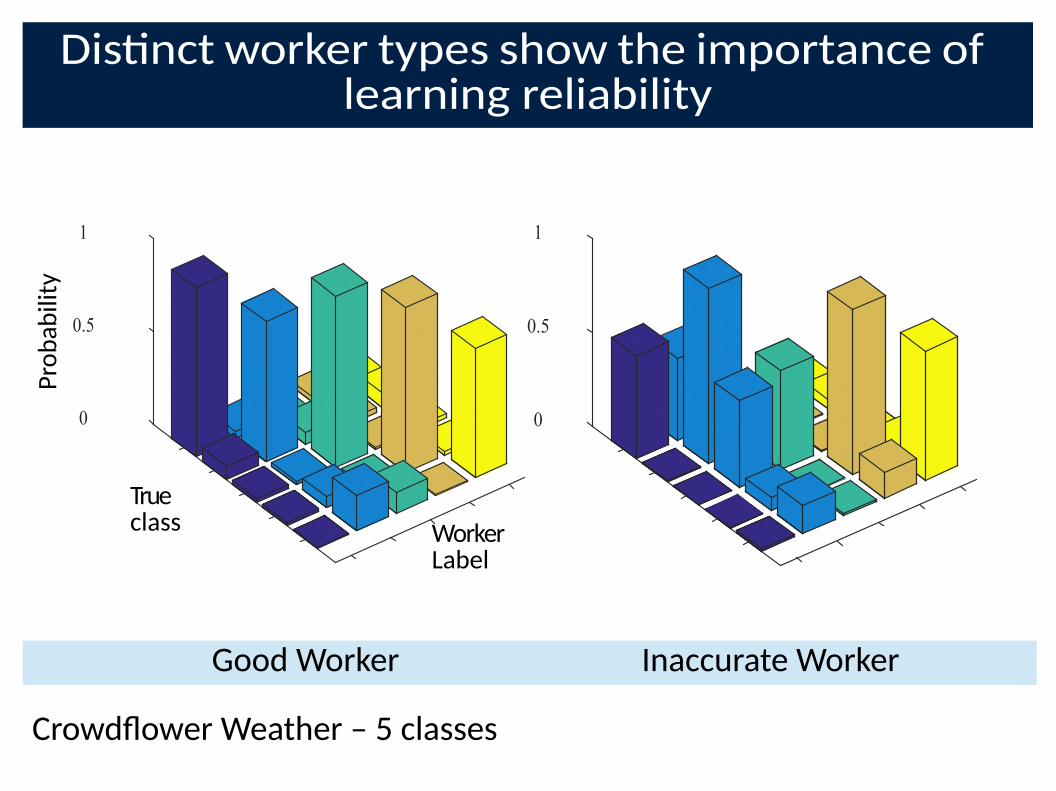
Dis�nct worker types show the importance of learning reliability
1
0.5
0
1
0.5
0
1
0.5
0
1
0.5
0
True class Worker
Label
Pro
ba
bil
ity
Good Worker Inaccurate Worker
CrowdLower Weather – 5 classes
Summary: BCCWords fuses subjec�ve interpreta�ons to learn models of language in
the wild
● Important to account for skills and bias of individuals in crowd
● Learns worker reliability and language model in a single integrated inference algorithm
● Uses textual informa�on to reduce the number of judgements required
● Bayesian inference
– Proven framework for fusing informa�on
– Handles uncertainty in true class labels and model itself
1
0.5
0
1
0.5
0
1
0.5
0
1
0.5
0
Moving towards e9cient learning withCrowd in-the-Loop
● Turn masses of unstructured, heterogeneous data into reliable, machine-readable informa�on
● Use the model to choose who does what task
1
0.5
0
1
0.5
0
1
0.5
0
1
0.5
0
● Detect di;erent interpreta�ons of language between communi�es in the crowd?
Intelligent agent-task assignment: who should classify which object?
● Aim: direct crowd's e;ort to learn quickly & cheaply
● Priori�se tasks by considering their features and conCdence in their classiCca�on
● Task choice depends on the workers available
● Maximise expected u�lity
DynIBCC confusion matrix describes individual skills

U�lity of response: informa�on gain about targets when DynIBCC is updated
● Naturally balances explora�on & exploita�on
● Explore an agent's behaviour from silver tasks
– Objects already labelled conCdently by crowd
– Increases u�lity of past responses
● Exploit an agent's skills to learn uncertain targets t
E[U τ (k , i)]=E[ I (t ; ci
(k)∣Dτ )]
Index of target objectWorker ID
Crowdsourced data collected so far
Time index
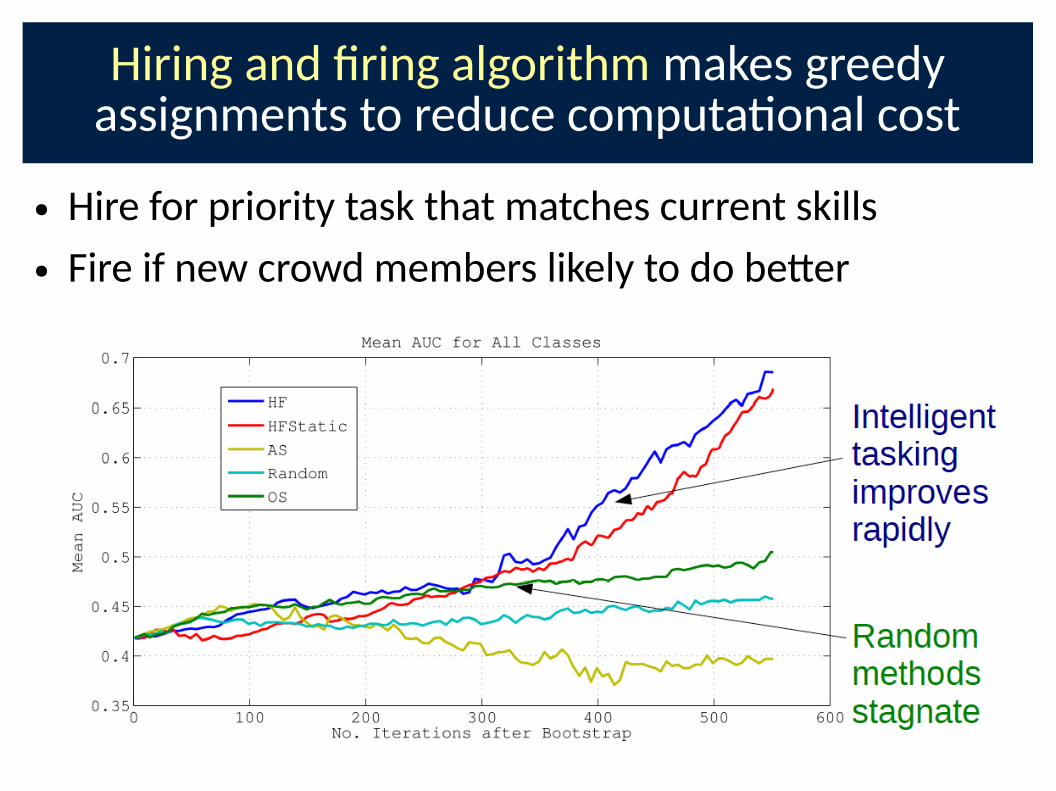
Hiring and Cring algorithm makes greedy assignments to reduce computa�onal cost
● Hire for priority task that matches current skills
● Fire if new crowd members likely to do be-er

Loose crowds on the web & in organisa�ons: Disaster Response
● Extrac�ng key informa�on from noisy background
– Text: Twi-er, Ushahidi >15000 messages in a few weeks [8]
– Images: Satellite, Social Media
– Team communica�ons, other agencies
● Loca�ons of emergencies:
– con�nuous target func�on
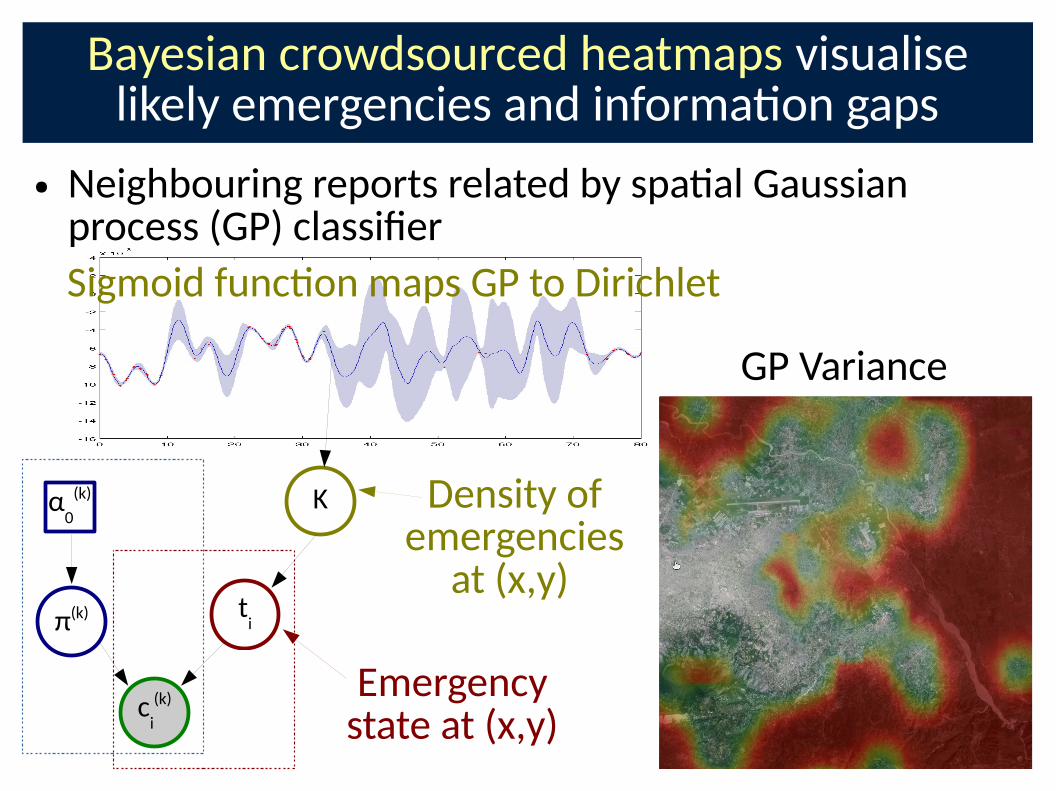
Bayesian crowdsourced heatmaps visualise likely emergencies and informa�on gaps
● Neighbouring reports related by spa�al Gaussian process (GP) classiCer
Κ
ti
Density of emergencies
at (x,y)
Emergency state at (x,y)
ci
(k)
π(k)
α0
(k)
Sigmoid func�on maps GP to Dirichlet
GP Variance

Bayesian crowdsourced heatmaps visualise likely emergencies and informa�on gaps
Ushahidi crowd + trusted report from Crst responder

Future Opportuni�es

Adap�ve training and mo�va�on to create diverse
skills and s�mulate workers
● Model worker preferences, rewards
● Fast approxima�ons to future u�lity
– Deduct cost of rewards
– Add reten�on, work rate, reliability
– Target clusters of workers
● Selec�ng tasks/training: consider person's
history
Appren�ceship/Peer Training
Infer improvements in confusion matrices from e;ect of task on others
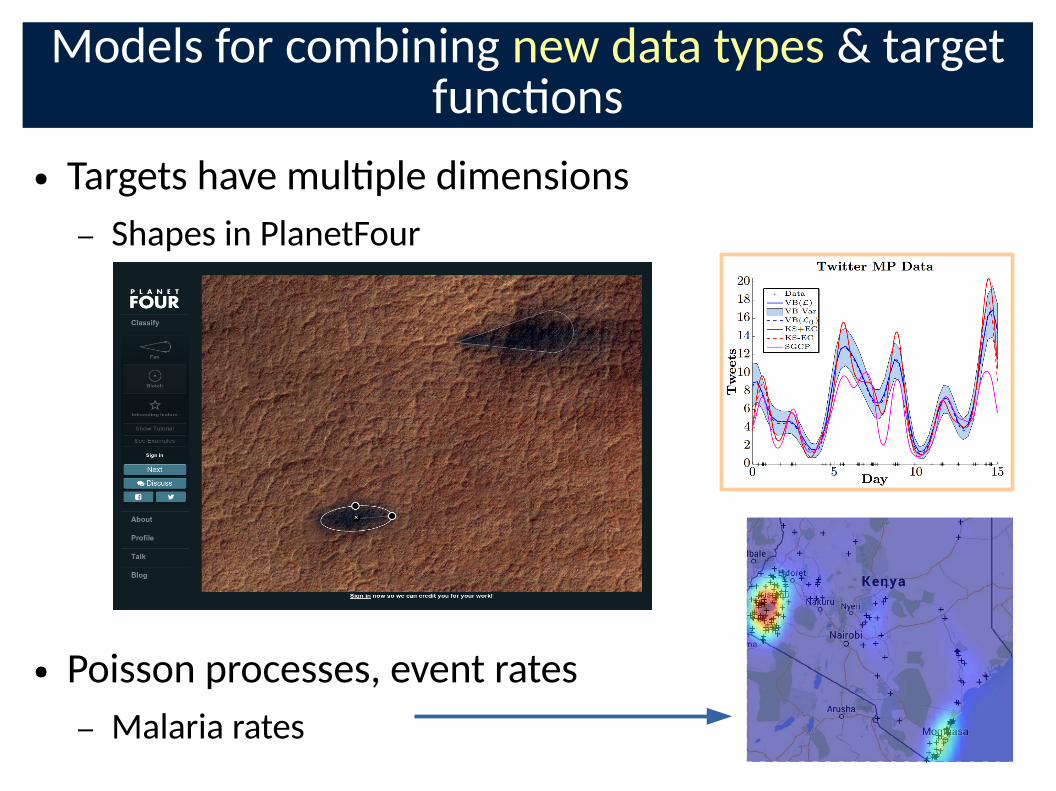
Models for combining new data types & target func�ons
● Targets have mul�ple dimensions
– Shapes in PlanetFour
● Poisson processes, event rates
– Malaria rates
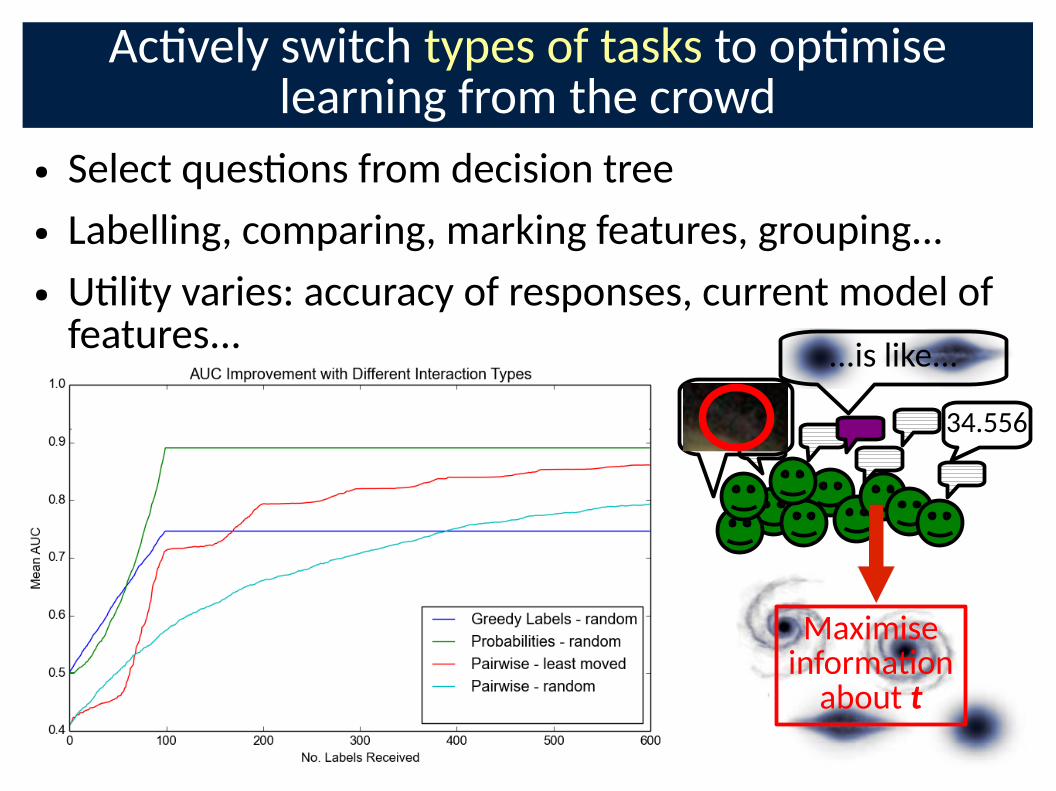
Ac�vely switch types of tasks to op�mise learning from the crowd
● Select ques�ons from decision tree
● Labelling, comparing, marking features, grouping...
● U�lity varies: accuracy of responses, current model of features...
34.556
Maximise informa�on
about t
...is like...
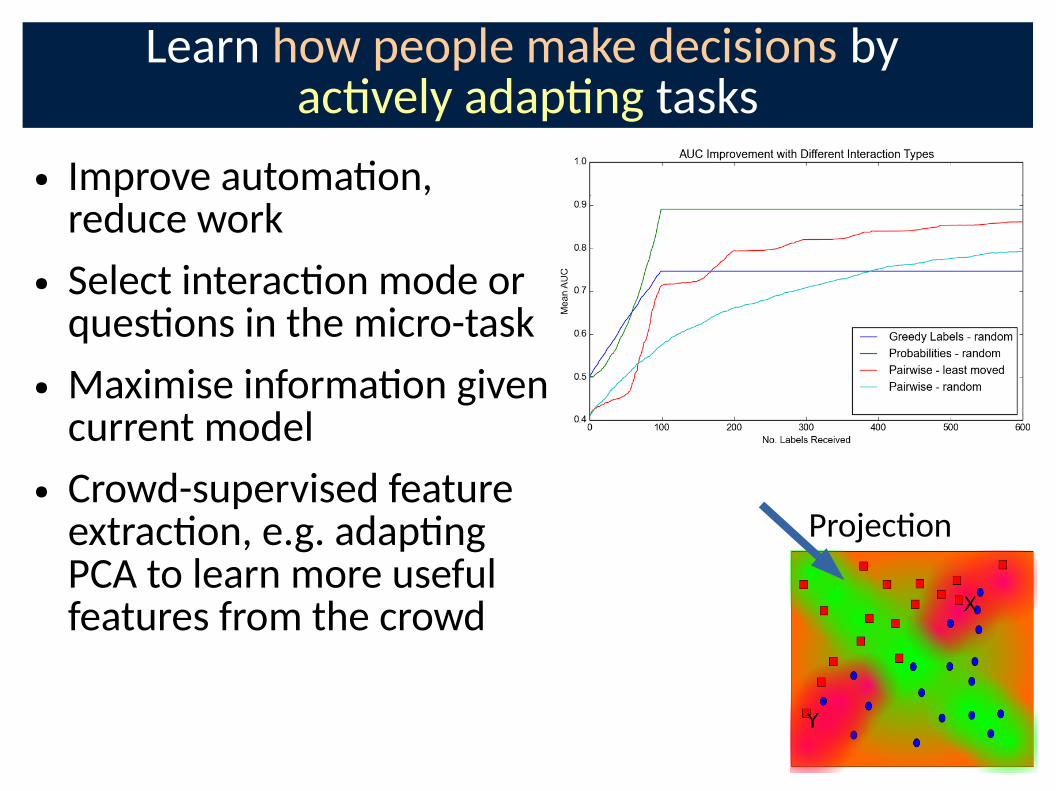
Learn how people make decisions by ac�vely adap�ng tasks
● Improve automa�on, reduce work
● Select interac�on mode or ques�ons in the micro-task
● Maximise informa�on given current model
● Crowd-supervised feature extrac�on, e.g. adap�ng PCA to learn more useful features from the crowd
Projec�on
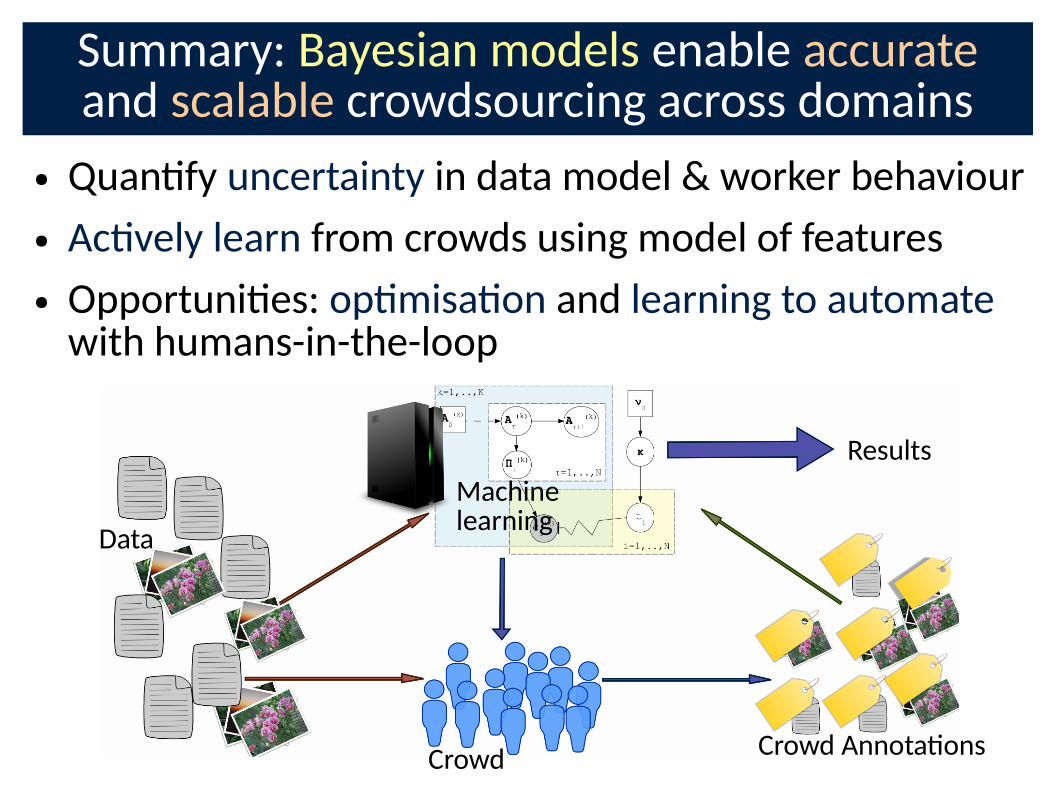
Summary: Bayesian models enable accurate and scalable crowdsourcing across domains
● Quan�fy uncertainty in data model & worker behaviour
● Ac�vely learn from crowds using model of features
● Opportuni�es: op�misa�on and learning to automate with humans-in-the-loop
Machine learning
Data
Crowd Annota�ons Crowd
Results

ORCHID and Zooniverse collaborators worked with Rescue Global to iden�fy and then reCne their cri�cal informa�on requirements.
• placement of life detectors and water Clters within 50 mile radius of Kathmandu.
Crowd labelled 1200 Planet Labs satellite images using Zooniverse soEware.
• Recruited 25 image labellers from within Oxford University and Rescue Global sta; (they worked hard over the bank holiday weekend).
Folded in OpenStreetMap building density data and inferred popula�on density map using ORCHID data processing algorithms.
Delivered map overlay to Rescue Global for dissemina�on to their CaDRA partners (SARaid, Team Rubicon, CADENA).
29/04/15 to
2/05/15
02/05/15 to
20:13 GMT 05/05/15
00:15 GMT
06/05/15
05/05/15
25/04/15, 7.8 Earthquake in Gorkha District of Nepal

SoDware on Github
● h+p://www.robots.ox.ac.uk/~edwin/
– Please use and report bugs
● PyIBCC: IBCC-VB and DynIBCC-VB in Python 2
– Collabora�ng with Zooniverse
● MatlabIBCC: IBCC-VB and DynIBCC-VB in Matlab
Acknowledgements
● Uni of Southampton: Nick Jennings, Alex Rogers, Sarvapali Ramchurn, Ma+eo Venanzi
● Oxford: Edwin Simpson, Steve Reece, Chris Linto+ & Zooniverse team
● EPSRC (UK research council), the ORCHID project, Rescue Global, MicrosoD, Zooniverse

References[1] Dawid, A. P., & Skene, A. M. (1979). Maximum likelihood es�ma�on of observer error-rates using the EM algorithm. Applied sta�s�cs, 20-28.
[2] Kim, H. C., & Ghahramani, Z. (2012). Bayesian classiCer combina�on. In Interna�onal conference on ar�Ccial intelligence and sta�s�cs (pp. 619-
627).
[3] E. Simpson, S. Roberts, I. Psorakis, A. Smith and C. Linto- (2011). Bayesian Combina�on of Mul�ple, Imperfect ClassiCers. Proceedings of NIPS
2011 workshop
[4] Simpson, E., Roberts, S., Psorakis, I., & Smith, A. (2013). Dynamic bayesian combina�on of mul�ple imperfect classiCers. In Decision Making and
Imperfec�on (pp. 1-35). Springer.
[5] Psorakis, I., Roberts, S., Ebden, M., & Sheldon, B. (2011). Overlapping Community Detec�on using Bayesian Nonnega�ve Matrix Factoriza�on.
Physical Review E, 83.
[6] Venanzi, M., Guiver, J., Kazai, G., Kohli, P., & Shokouhi, M. (2014). Community-based bayesian aggrega�on models for crowdsourcing. In
Proceedings of the 23rd interna�onal conference on World wide web (pp. 155-164). Interna�onal World Wide Web Conferences Steering
Commi-ee.
[7] E. Simpson, S. Roberts (2015 – to appear). Bayesian Methods for Intelligent Task Assignment in Crowdsourcing Systems, Scalable Decision
Making: Uncertainty, Imperfec�on, Delibera�on; Studies in Computa�onal Intelligence, Springer
[8] N. Morrow, N. Mock, A. Papendieck, and N. Kocmich (2011). Independent Evalua�on of the Ushahidi Hai� Project. Development Informa�on
Systems., 8:2011.
[9] MacKay, David J. C. (1992). Informa�on-based objec�ve func�ons for ac�ve data selec�on. Neural computa�on, 4(4):590–604.
[10] Chen, X., Benne-, P. N., Collins-Thompson, K., and Horvitz, E. (2013). Pairwise ranking aggrega�on in a crowdsourced se`ng. In Proceedings of
the sixth ACM interna�onal conference on Web search and data mining. ACM
[11] E. Simpson, S. Reece, A. Penta, G. Ramchurn, and S. Roberts (2012). Using a Bayesian Model to Combine LDA Features with Crowdsourced
Responses. In The Twenty-First Text REtrieval Conference (TREC 2012), Crowdsourcing Track, NIST.
[12] S. Nitzan, J. Paroush (1982). Op�mal decision rules in uncertain dichotomous choice situa�ons. Interna�onal Economic Review, 23(2):289–297,
1982.
[13] D. Berend, A. Kontorovich (2014). Consistency of Weighted Majority Votes. NIPS
[14] Y. Zhang, X. Chen, D. Zhou, M. Jordan (2014). Spectral methods meet EM: a Provable Op�mal Algorithm for Crowdsourcing.

Ques�ons?





























