Embed Size (px)
Citation preview

Home of RedisSearching billions of documents with Redis(Dvir Volk)|(Itamar Haber)

Redis Labs – Home of Redis
• Founded in 2011• HQ in Mountain View CA, R&D center in Tel-Aviv IL
The commercial company behind Open Source Redis
Provider of the Redis Enterprise (Redise) technology, platform and products
Redise Cloud Private
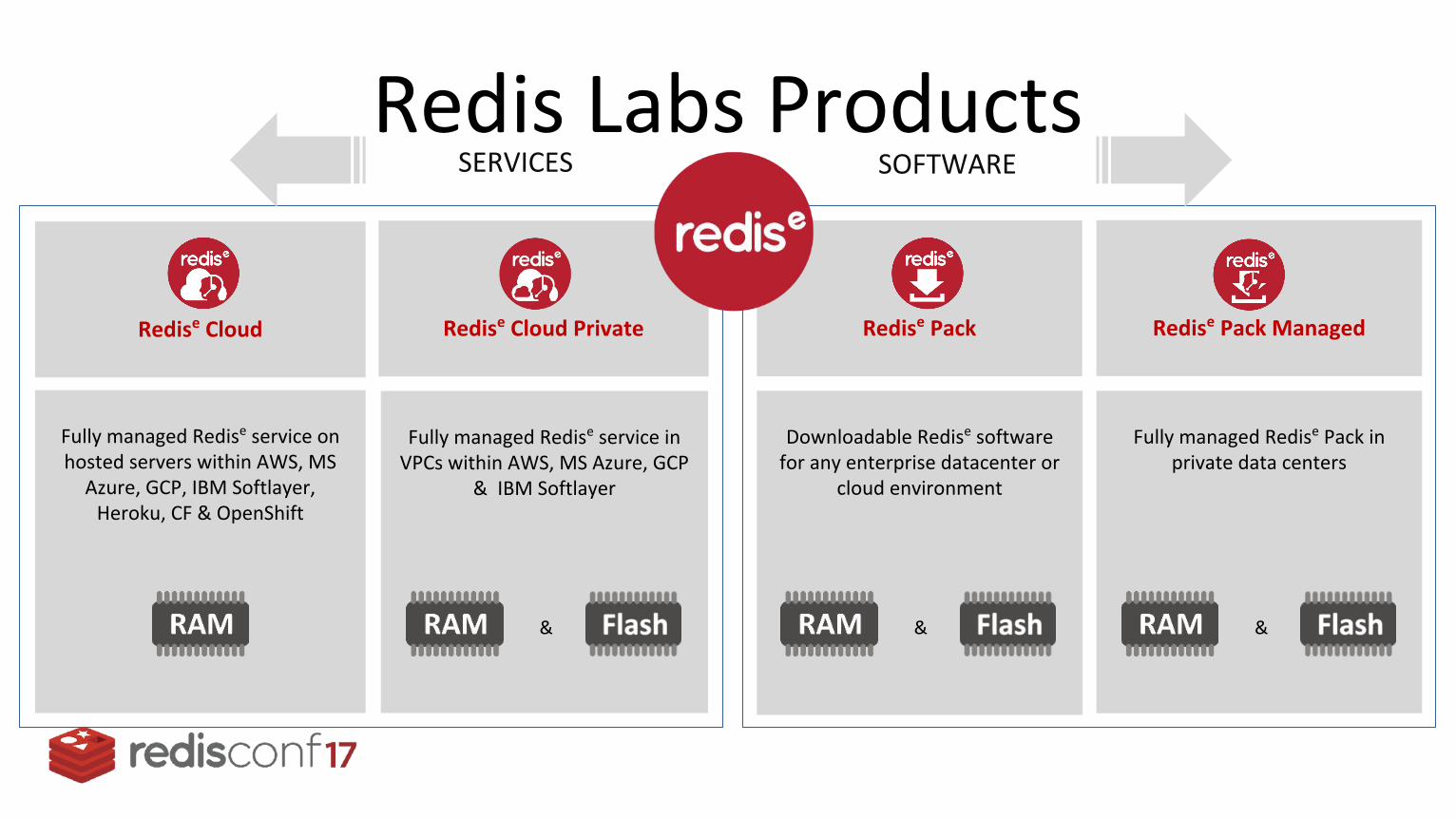
Redis Labs Products
Redise Cloud Redise Pack ManagedRedise Pack
SERVICES SOFTWARE
Fully managed Redise service in VPCs within AWS, MS Azure, GCP
& IBM Softlayer
Fully managed Redise service on hosted servers within AWS, MS
Azure, GCP, IBM Softlayer, Heroku, CF & OpenShift
Downloadable Redise software for any enterprise datacenter or
cloud environment
Fully managed Redise Pack in private data centers
&& &

So… Searching in Redis?
We all know and love Redis as a data store, but...
● GET user1? no problemo!
● HGETALL user1? sure thing!
● GET users WHERE name contains “jeff”? NOPE!
Redis has no built in concept of indexing or search, duh!
4

Search 101
The core concept: The Index
● Take a document
● Break it apart
● Map terms/properties ⇒ docs in a Posting List
Searching is getting documents that are linked to
the terms
5

Building an Index
doc1
{ title: “LCD TV”, price: 500, description: “foo” }
Indexing Process
Term Posting List
lcd doc1, doc3, doc5...
tv doc1, doc7, doc19...
foo doc1
bar doc1, doc100, ...
doc1
{ title: “LCD TV”, price: 500, description: “foo” }
doc1
{ title: “LCD TV”, price: 500, description: “foo” }
DocumentsIndex
Price Index
…. ….
500 doc1, doc7, doc19...
503 doc3
…. ...
6

So… Searching With Redis?
Redis is just Key=>Value, right?But can we use its advanced data types?
Key
"I'm a Plain Text String!"
{ A: “foo”, B: “bar”, C: “baz” }
Strings/Blobs/Bitmaps
Hash Tables (objects!)
Linked Lists
Sets
Sorted Sets
Geo Sets
HyperLogLog
{ A , B , C , D , E }
[ A → B → C → D → E ]
{ A: 0.1, B: 0.3, C: 100, D: 1337 }
{ A: (51.5, 0.12), B: (32.1, 34.7) }
00110101 11001110 10101010
Looks like a set will do!
7

Searching With Redis - Vanilla Style
● Two most suitable structures: Sorted Sets & Sets
● Remember, the core of searching is:
term ⇒ [doc_id, doc_id, ….]
● So how about this: redis> SADD hello doc1redis> SADD world doc1redis> SINTER hello world
8

Searching With Redis - Vanilla Style
Even better with Sorted Sets - we can have scores!
> ZADD hello 1.0 doc1 0.5 doc2> ZADD world 1.0 doc 0.5 doc2
> ZINTERSTORE hw 2 hello world> ZRANGE hw 0 -1
9

Vanilla Style Only Goes So Far...
● LOTS of memory - ZSETs take about 60B overhead per record!
● Intersections and unions can get slow● No exact phrase matching● No proximity boosting
● etc, etc...
10

Enter Redis Modules
● Since 4.0
● Dynamic libraries loaded to Redis
● With a C API
● Can extend Redis with:
New Capabilities
New Commands
New Data Types
11

Search With Modules
● So now Everything Is PossibleTM!
● We implement our own structures & algorithms!
● With less memory!
● And less CPU time!
● And more capabilities!
● And use existing libraries!
12

Why Write From Scratch?
● Most widely used search libraries are either:
○ In Java
○ Very complex and bloated
○ Written with disk in mind
Plus, where is the fun in that?
13

Introducing RediSearch
● Completely from-scratch, in C● Optimized data structures● Stores documents as Hashes● Extremely fast indexing and search● Text, numeric and geo filters● Fast non blocking updates and deletes● Scalable distributed mode up to billions of docs
14

RediSearch In Action
> FT.CREATE products SCHEMA title TEXT price NUMERIC
> FT.ADD products prod1 1.0 FIELDS title "Toshiba 32 LCD TV" price 250> FT.ADD products prod2 1.0 FIELDS title "Samsung 42 LCD TV" price 350
> FT.SEARCH products "lcd tv" 1) (integer) 22) "prod1"
…4) "prod2"
…> FT.SEARCH products "lcd tv" FILTER price 300 4001) (integer) 1"prod2"
15

RediSearch Data Structures
Key
[prod1, prod2, …]
{title:“Toshiba 32 LCD TV”, …}
Document Table
Posting Lists (Inverted Index)
Documents (HASHes)
AutoComplete (Trie)
Numeric Index (Range tree)
Geo Sets
{200..400: [prod1, prod2, …]… }
Toshib*
{ A: (51.5, 0.12), B: (32.1, 34.7) }
{1: prod1, 2: prod2, …}
16

Processing Search Queries
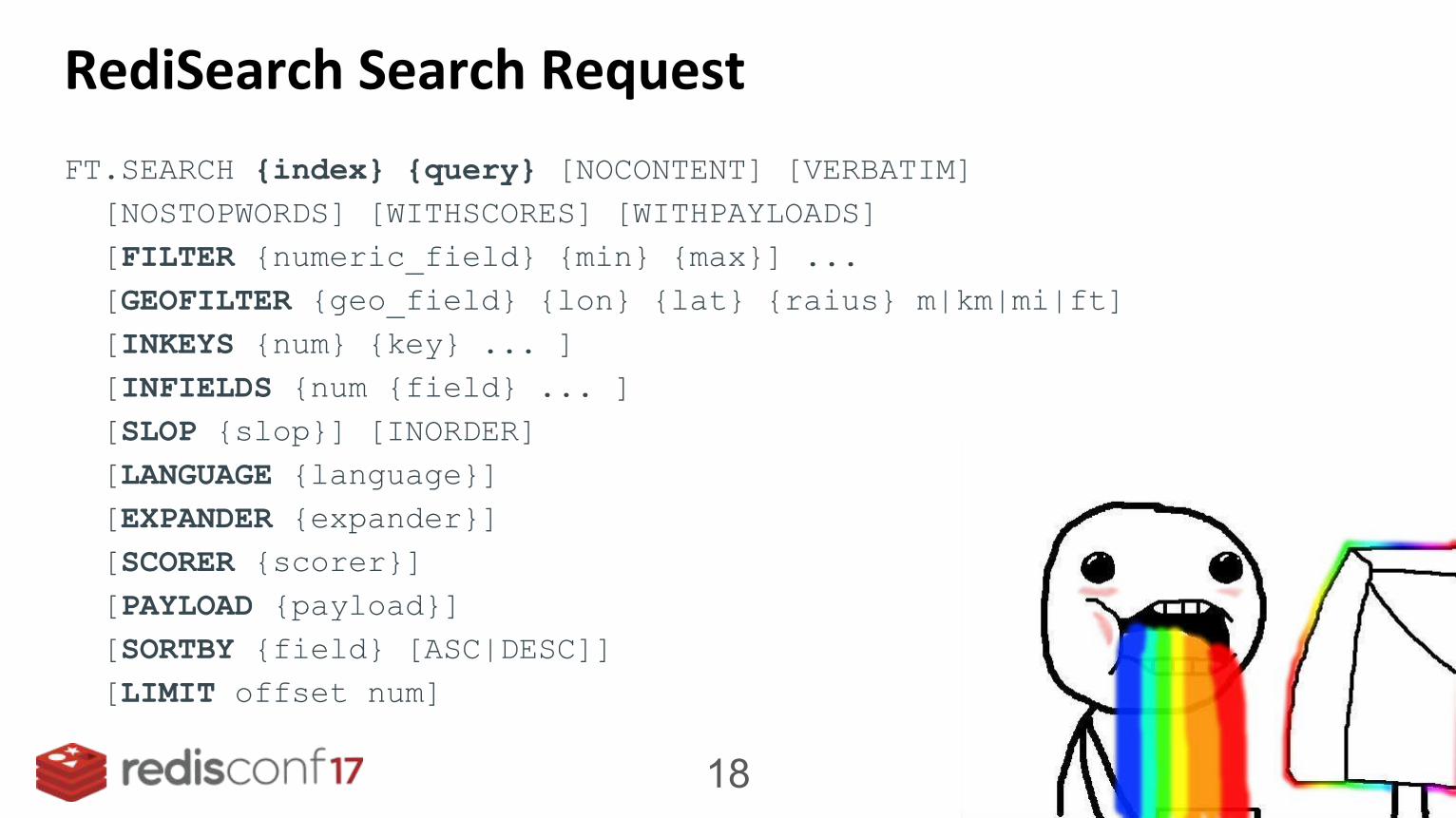
RediSearch Search Request
FT.SEARCH {index} {query} [NOCONTENT] [VERBATIM] [NOSTOPWORDS] [WITHSCORES] [WITHPAYLOADS] [FILTER {numeric_field} {min} {max}] ... [GEOFILTER {geo_field} {lon} {lat} {raius} m|km|mi|ft] [INKEYS {num} {key} ... ] [INFIELDS {num {field} ... ] [SLOP {slop}] [INORDER] [LANGUAGE {language}] [EXPANDER {expander}] [SCORER {scorer}] [PAYLOAD {payload}] [SORTBY {field} [ASC|DESC]] [LIMIT offset num]
18
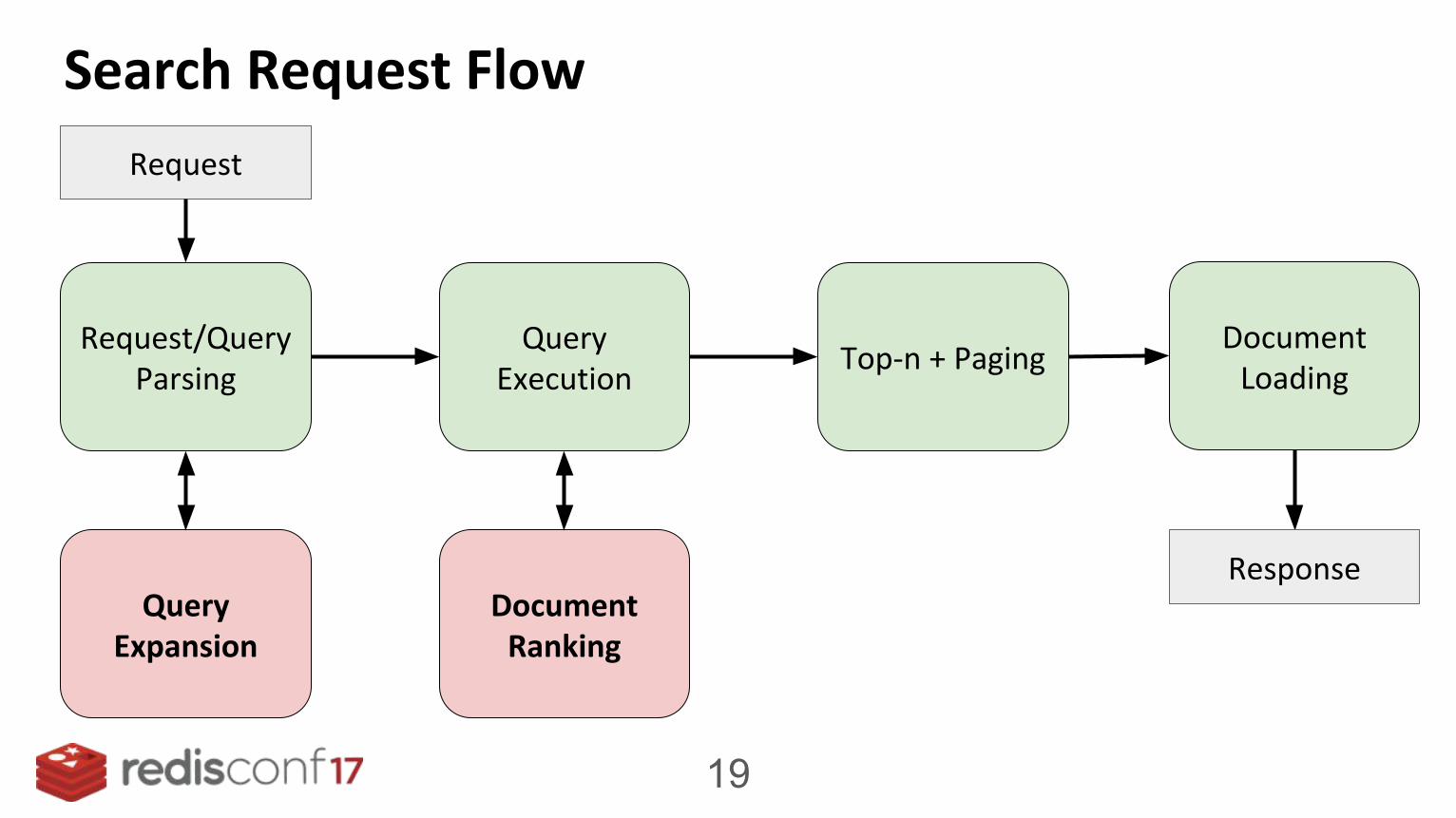
Search Request Flow
Request/Query Parsing
Query Expansion
Query Execution
Document Ranking
Top-n + PagingDocument
Loading
Response
Request
19
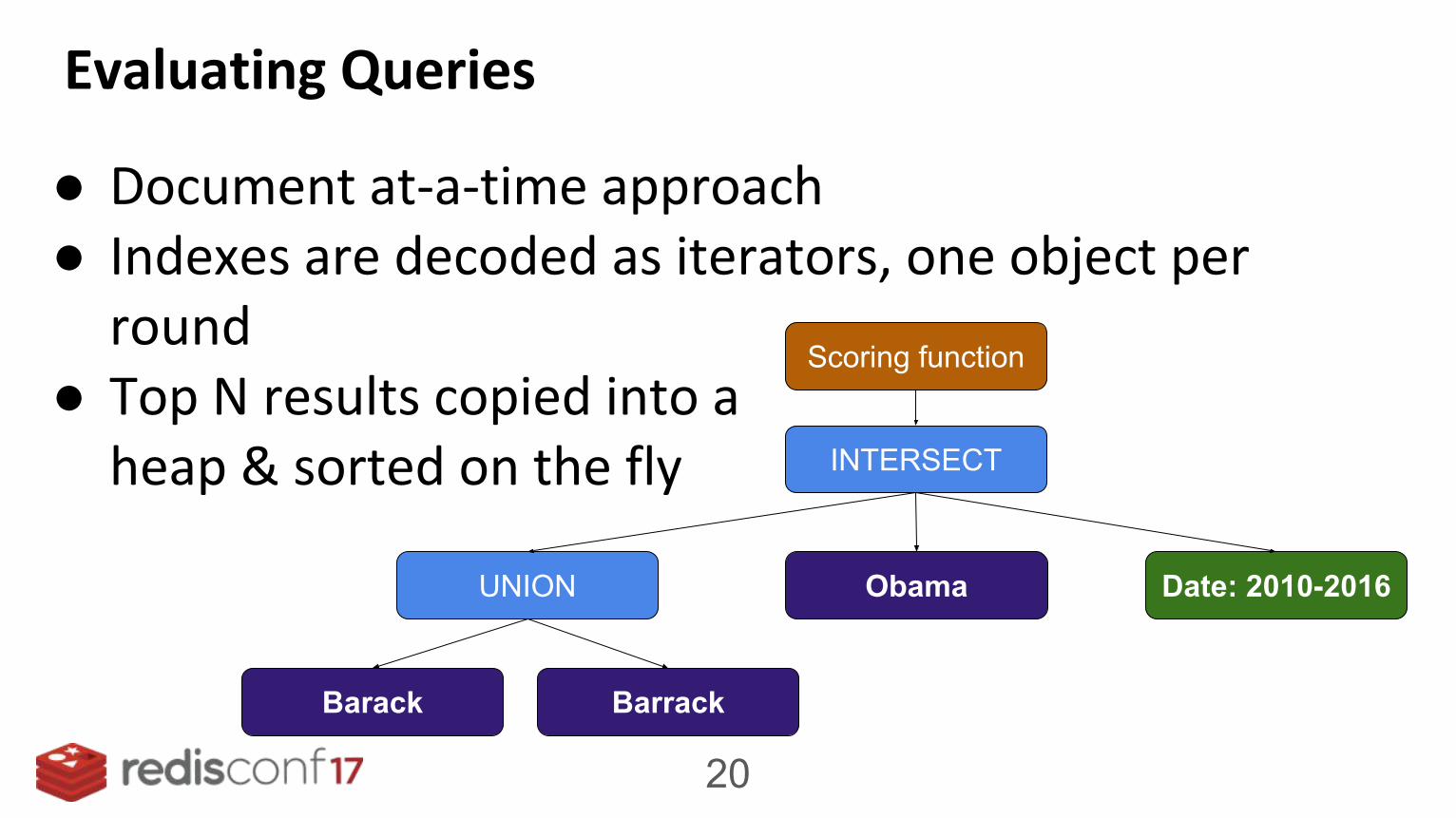
Evaluating Queries
● Document at-a-time approach● Indexes are decoded as iterators, one object per
round● Top N results copied into a
heap & sorted on the fly INTERSECT
UNION Obama
Barack Barrack
Date: 2010-2016
Scoring function
20

Scoring Results
● Each document in the query's result is evaluated by a Scoring Function
● Top-N scored documents are selected● The default uses:
○ Term Frequency–Inverse Document Frequency (TF-IDF)○ User given a priori document score○ Proximity boosting
● And you can write your own function!
21

Query Language

Simple Text Search
Hello world
equivalent to:
(Hello world)
23

Exact Phrase Search
"Hello world"
24

Or Search (Union)
Hello|hola world|mundo
(hello world)|(hola mundo)
25

Specific Field Matching
@title:Hello world
26

Multi Field Matching
@title|body:Hello world @pic:jpg
modifiers are implicitly "AND"ed
27

Numeric Filtering
@title:lcd tv @price:[100 300]
@title:lcd tv @price:[(100 +inf]
28

Optional Clauses
@title:tv ~@description:lcd
optional matches just increase score
29

Negative Clauses
@title:tv -plasma
30

Prefix Queries
Hello wo*
31

Complex Query Example
@title:(lcd tv)
~@tags|description:”42 inch”
@price:[100 500]
-@type:4K|Plasma
32

(a demo would be nice)

Extending RediSearch
● Has its own module system○ C/C++ API○ Minimal, simple API
● Supports custom queryexpanders (e.g. synonyms)
● Supports custom rankingfunctions
34
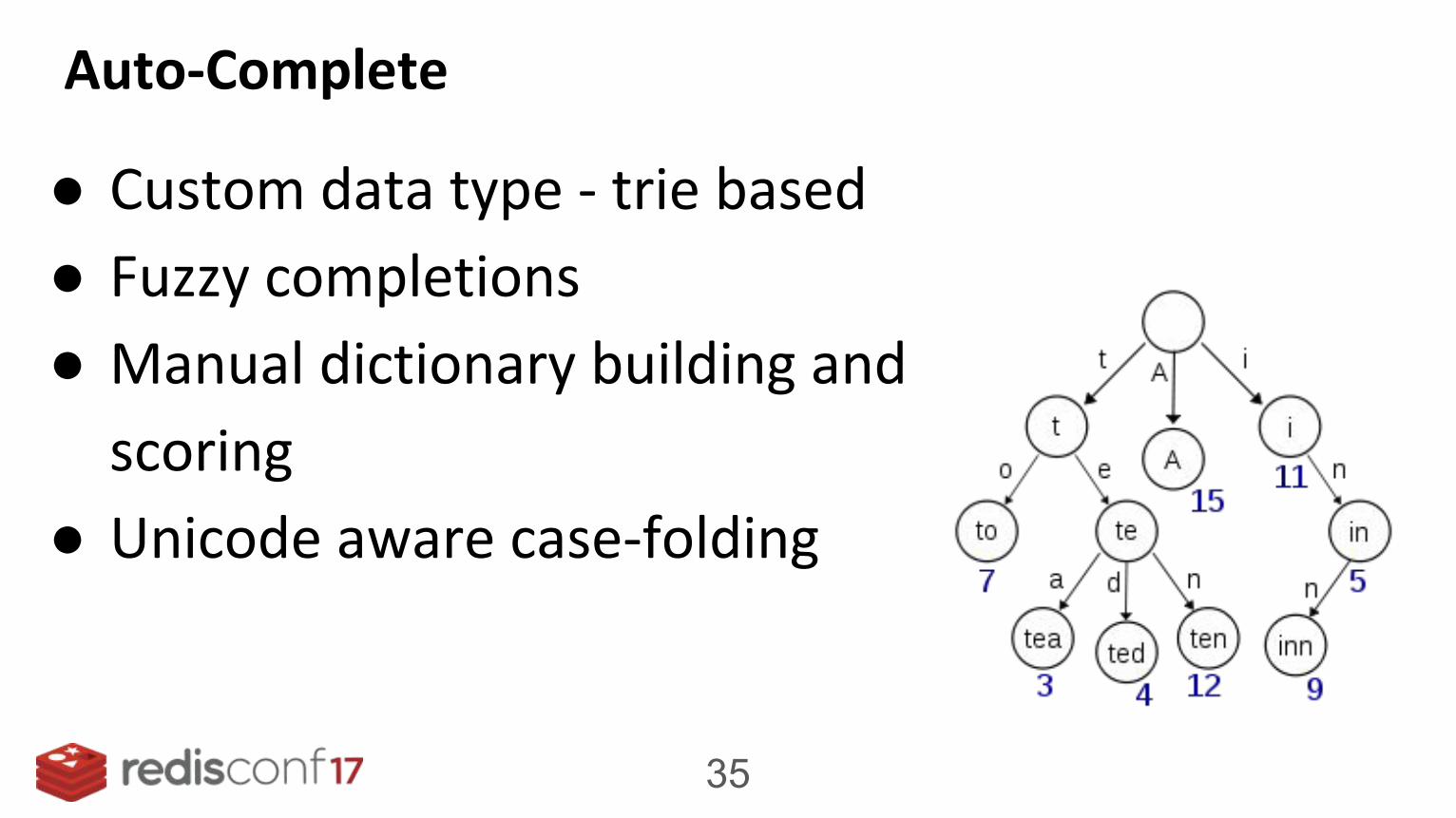
Auto-Complete
● Custom data type - trie based
● Fuzzy completions
● Manual dictionary building and
scoring
● Unicode aware case-folding
35

Scaling RediSearch
Scaling RediSearch
● What do we do when the index is too big for one
machine?
● We need to split the index on multiple machines
● But it’s not that simple!
37

Scaling RediSearch
● Partition by document id● Each partition contains a full index of 1/N of the
documents● All terms for a sub-index are stored on the same
shard● This means we need a query coordinator:
○ Distribute the queries to all shards○ Merge the results○ Top-N of Top-Ns
38
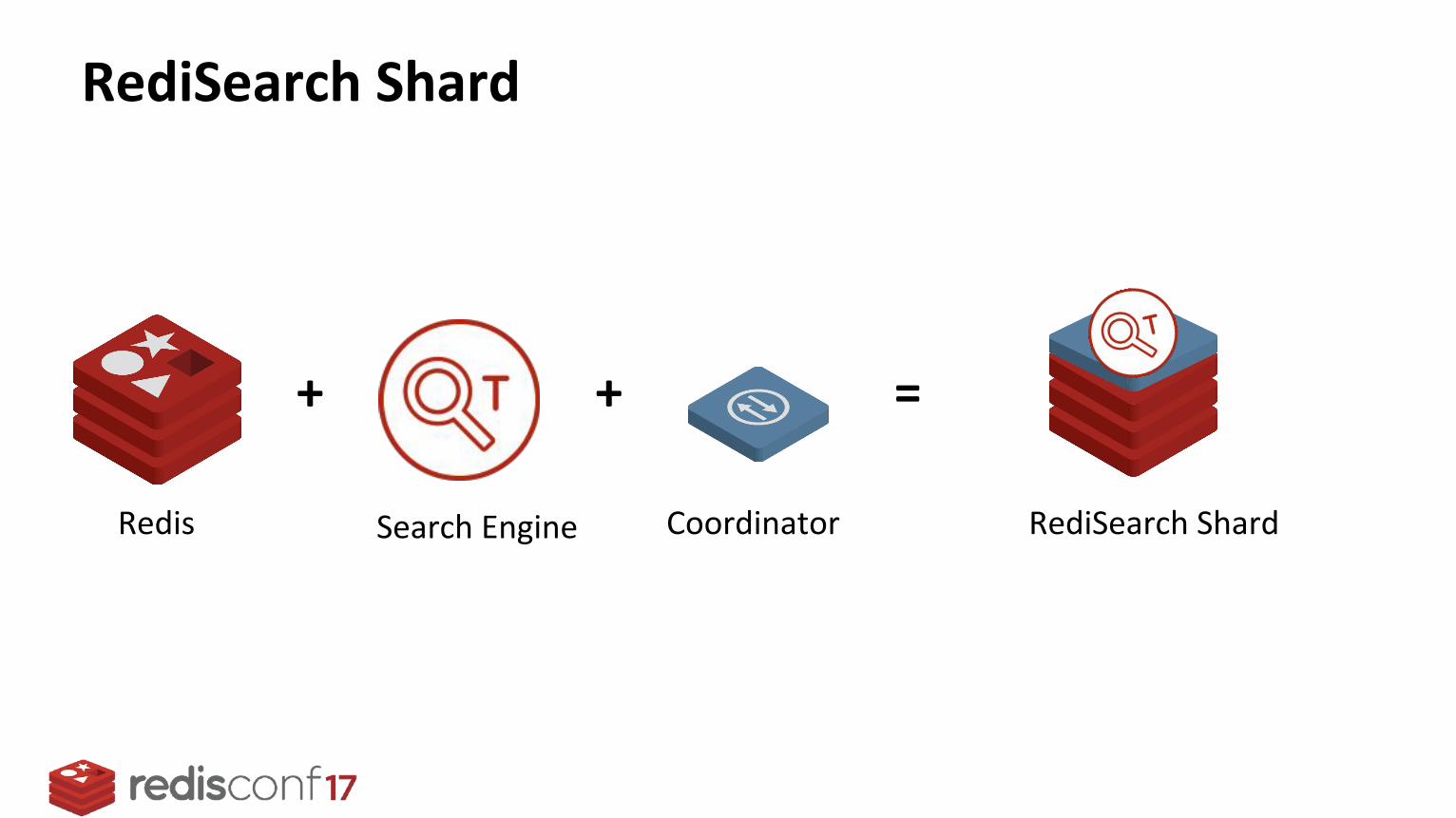
RediSearch Shard
Redis Search Engine Coordinator
+ + =
RediSearch Shard
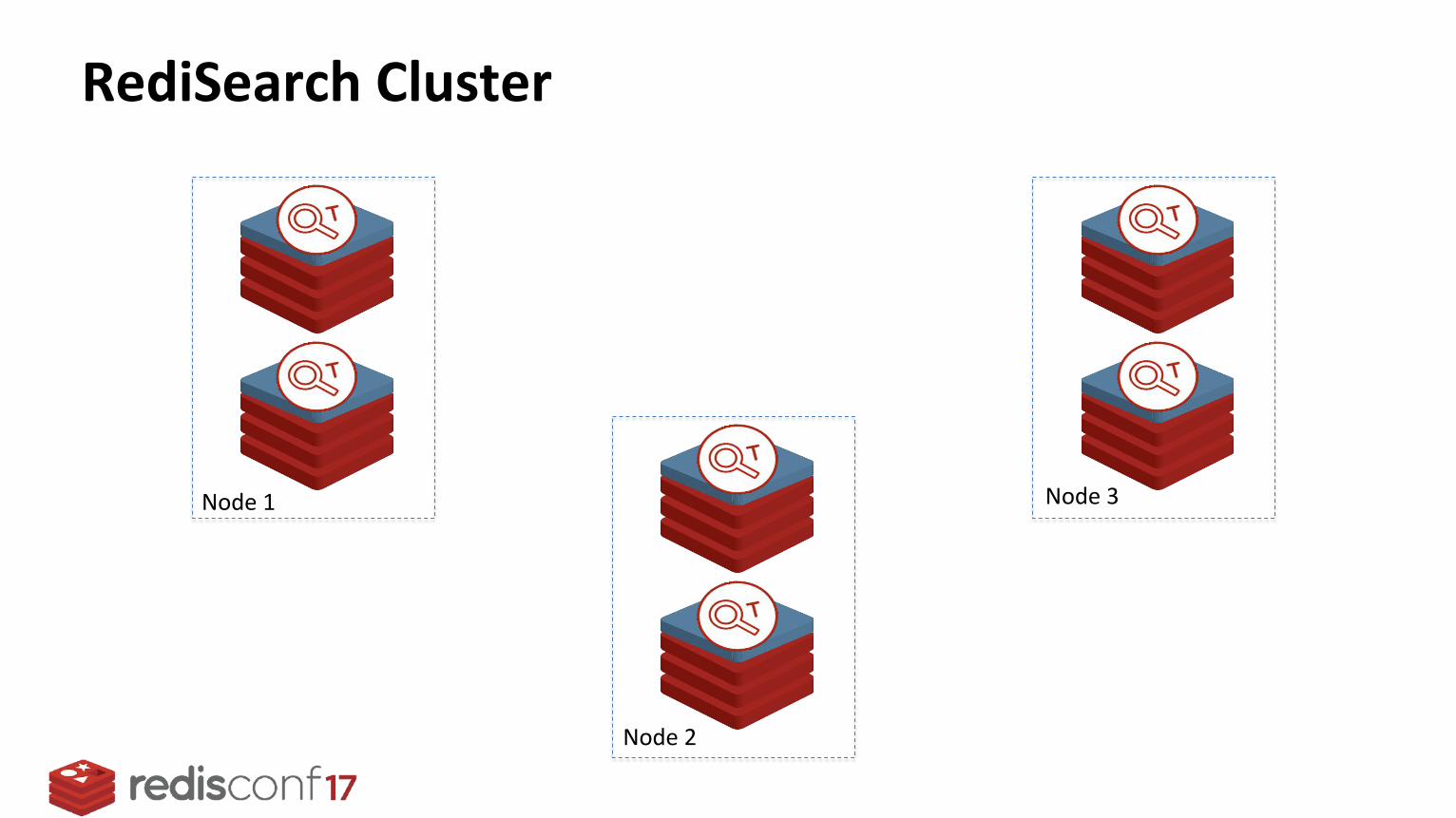
RediSearch Cluster
Node 1
Node 2
Node 3
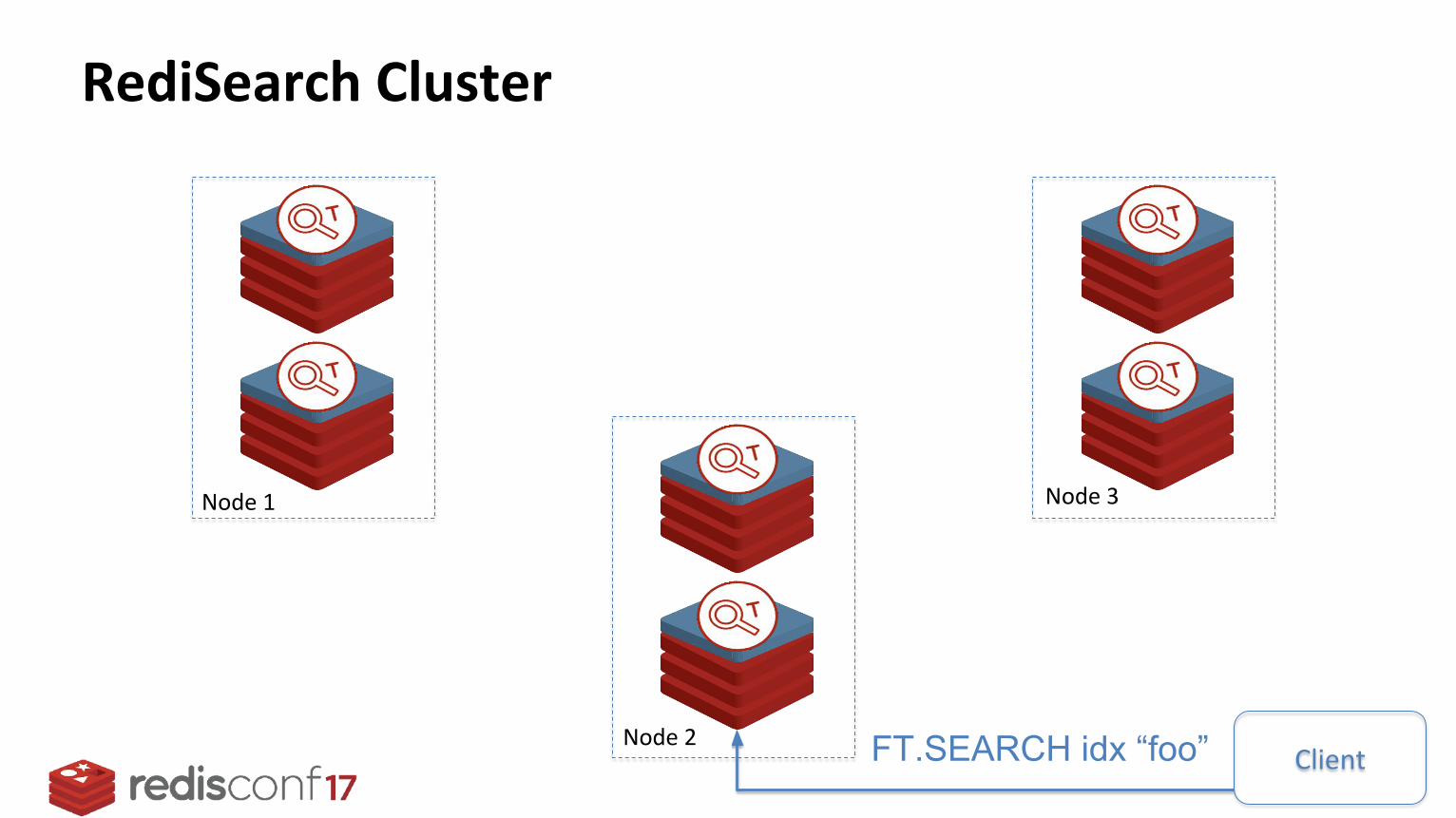
RediSearch Cluster
Node 1
Node 2
Node 3
ClientFT.SEARCH idx “foo”
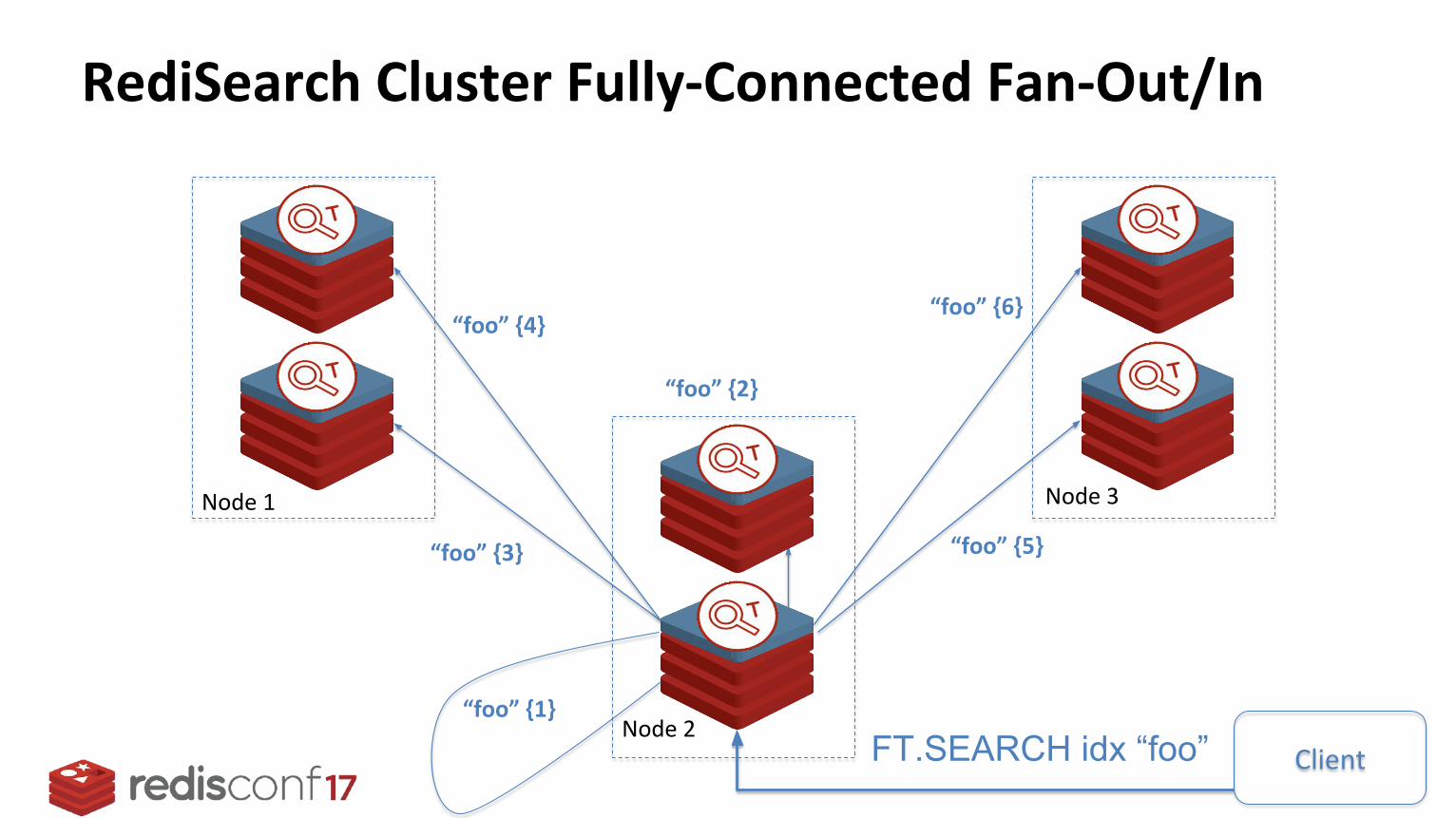
RediSearch Cluster Fully-Connected Fan-Out/In
Node 1 Node 3
“foo” {3}
“foo” {4}
“foo” {5}
“foo” {6}
“foo” {2}
“foo” {1}
ClientFT.SEARCH idx “foo”Node 2

When RediSearch Cluster Becomes Larger
Node 1
Node 2
Node 3
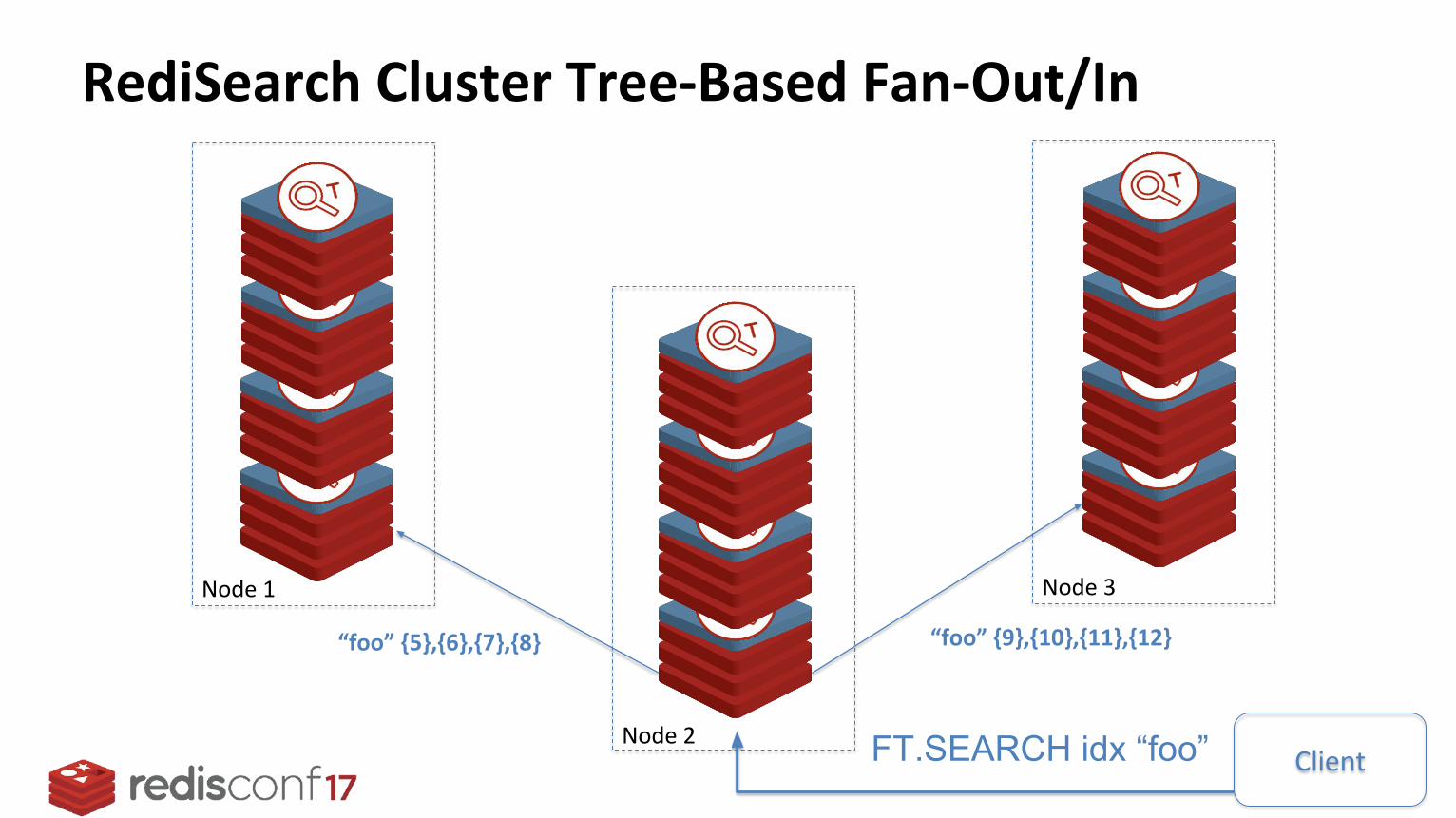
RediSearch Cluster Tree-Based Fan-Out/In
Node 1
Node 2
Node 3
“foo” {5},{6},{7},{8} “foo” {9},{10},{11},{12}
ClientFT.SEARCH idx “foo”
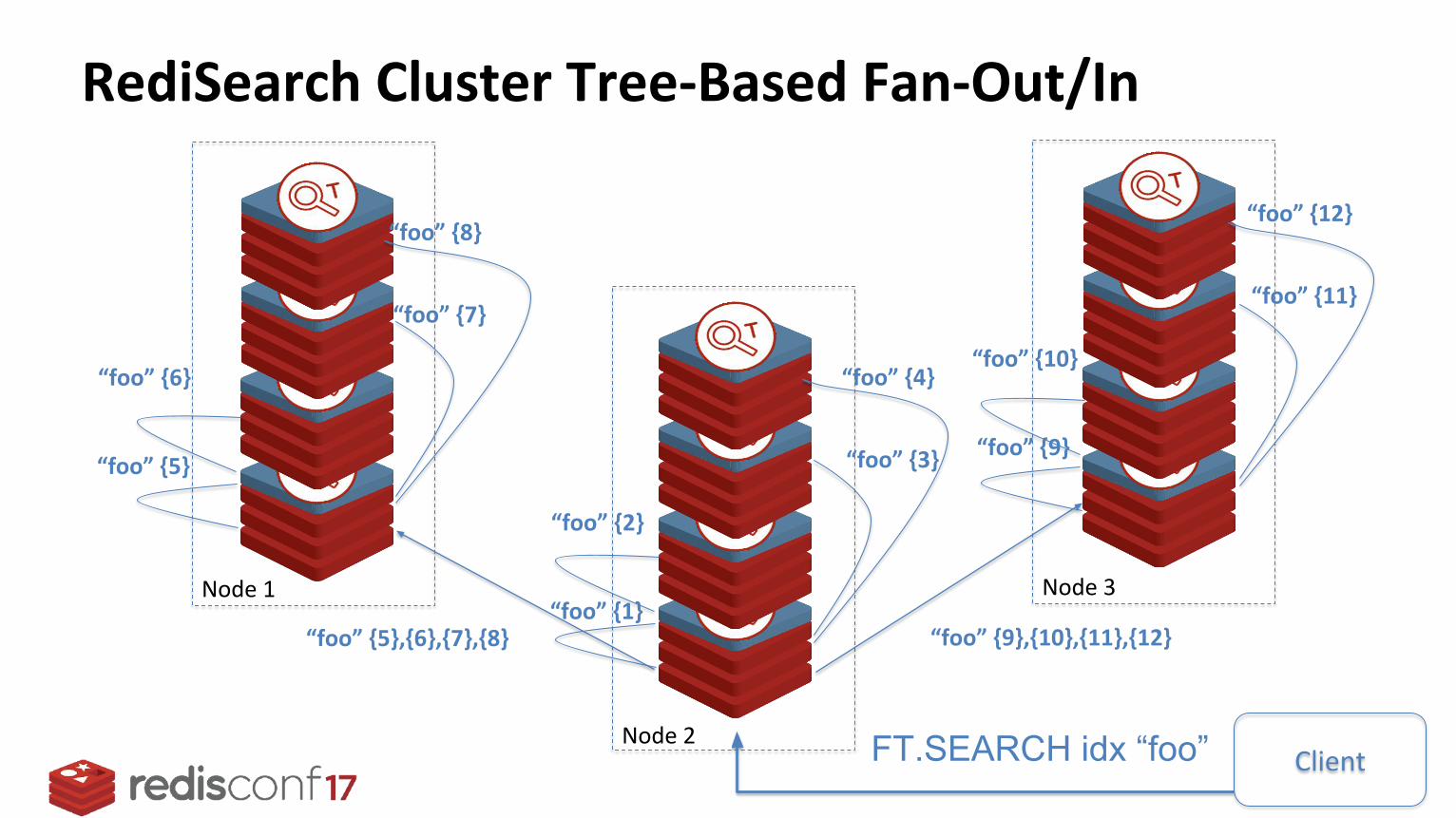
RediSearch Cluster Tree-Based Fan-Out/In
Node 1
Node 2
Node 3
“foo” {5},{6},{7},{8} “foo” {9},{10},{11},{12}
ClientFT.SEARCH idx “foo”
“foo” {5}
“foo” {7}
“foo” {6}
“foo” {8}
“foo” {1}
“foo” {3}
“foo” {2}
“foo” {4}
“foo” {9}
“foo” {11}
“foo” {10}
“foo” {12}
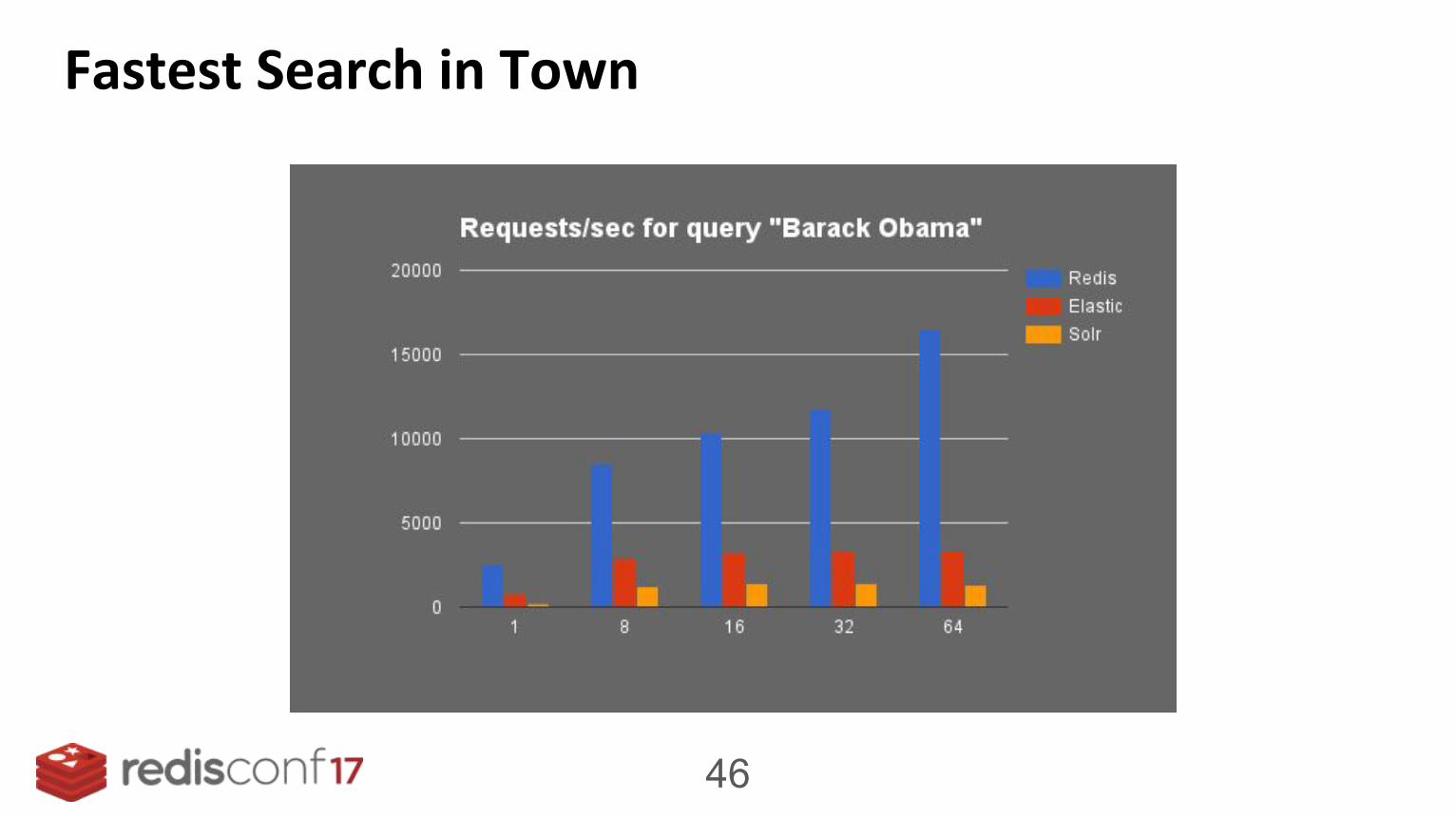
Fastest Search in Town
46

http://redisearch.io - Thank You!
Dvir VolkSenior ArchitectRedis Labs
@dvirsky
Itamar HaberChief OSS Education OfficerRedis Labs
@itamarhaber





























