Embed Size (px)
Citation preview

Pattern Recognition Letters 29 (2008) 1344–1350
Contents lists available at ScienceDirect
Pattern Recognition Letters
journal homepage: www.elsevier .com/locate /patrec
A multi-modal method based on the competitors of FVC2004and on palm data combined with tokenised random numbers
Loris Nanni *, Alessandra LuminiDEIS, IEIIT – CNR, Università di Bologna, Viale Risorgimento 2, 40136 Bologna, Italy
a r t i c l e i n f o
Article history:Received 30 May 2006Received in revised form 29 January 2008Available online 7 March 2008
Communicated by T. Tan
Keywords:FingerprintPalmMulti-modal fusionPseudo-random numbersBioHashing
0167-8655/$ - see front matter � 2008 Elsevier B.V. Adoi:10.1016/j.patrec.2008.02.020
* Corresponding author. Fax: +39 0547 338890.E-mail address: [email protected] (L. Nanni).
a b s t r a c t
In this work, we propose a multi-modal method that combines the scores of selected fingerprint matcherswith the score obtained by a palm authenticator where the palm features are combined with pseudo-ran-dom numbers. We use a random subspace of AdaBoost.M1 to combine the scores of the best fingerprintmatchers automatically selected among the competitors of FVC2004, and we study the performancewhen a different number of competitors are involved in the fusion. Moreover a deep study is carriedout to design a hybrid system based on the combination of palm image features and a personal key.In conclusion, the aim of this work is to design a multi-modal biometric system and to analyze the ben-efits and the limits of fusion approaches in order to boost the performance of hybrid system in the worsttesting hypothesis when an ‘‘impostor” steal the personal key of the user A before he tries to authenticateas A. The experimental results reported in this paper confirm that using a multi-modal ensemble ofmatchers it is possible to overcome some of the limitations of each single matcher leading to a consider-able performance improvement.
� 2008 Elsevier B.V. All rights reserved.
1. Introduction
Denial of access in biometric systems greatly impacts on theusability of the system by failing to identify a genuine user. Mul-ti-modal biometrics can reduce the probability of denial of accesswithout sacrificing the false acceptation performance: the key isthe combination of the various biometric characteristics at the fea-ture extraction, match score, or decision level (Maltoni et al., 2003).The fusion among several fingerprint matchers is studied in severalpapers (e.g. Fierrez-Aguilar et al., 2005; Lumini and Nanni, 2007;Maio and Nanni, 2006). In (Fierrez-Aguilar et al., 2005) the authorsconcentrate on score-level fusion of different fingerprint algo-rithms, studying the correlation between them by using featuresubset selection techniques. The purpose of Lumini and Nanni(2007) is to investigate whether the integration of Iris and finger-print biometrics can achieve performance that may not be possibleusing a single biometric technology. Particularly interesting is theresult obtained by combining Iris and fingerprint biometrics interms of equal error rate (the most used parameter in the evalua-tion of real identification systems), which is significantly lowerthan for other approaches.
In the literature several hybrid approaches have been proposedto solve the problem of high false rejection, based on the combina-
ll rights reserved.
tion of the biometric information with a personal key: (1) in (Jinet al., 2004 and Teoh et al., 2006) the authors propose a technique,called BioHashing, based on the combination between tokenisedpseudo-random numbers and the user biometrics; (2) in (Luminiand Nanni, 2007) an improved version of the BioHashing approachis proposed in order to solve the drawback of the original method(also reported in (Kong et al., 2006)) in presence of a key stealing;and (3) in (Yuang et al., 2005) a simpler method, called multi-spacerandom mapping (MRM), is proposed which uses a pseudo-randomprojection matrix for the biometric data.
In (Maio and Nanni, 2006) the authors present a multi-modal sys-tem based on the fusion between ‘‘BioHashed” face features (facefeatures combined with pseudo-random numbers) and the scoresobtained by some of the fingerprint verification methods submittedto FVC2004. They showed that the fusion permits to obtain good per-formance (similar to that obtained by the standard fusion betweenface and fingerprint) also when an ‘‘impostor” steals an hash key.
In this paper, we improve the results of Maio and Nanni (2006)by proposing the following novelties:
� A new trained approach for the fusion of fingerprint verificationmethods based on a random subspace (RS) of AdaBoost.M1(using a three-layer backpropagation neural network as a weaklearner).
� A deep study on the fusion between a BioHashing system basedon palm image features and the above cited ensemble.

Fig. 1. Proposed system.
Datum Points
Fig. 2. Example of an hand image and its extracted palm, the palm image is extr-acted using the datum points as in (Li et al., 2004).
L. Nanni, A. Lumini / Pattern Recognition Letters 29 (2008) 1344–1350 1345
Several experiments are carried out and the analysis of theresults demonstrates that the RS of AdaBoost.M1 dramatically out-performs support vector machines when many competitors areinvolved in the fusion. Moreover the fusion among a hybrid meth-od, which combines biometrics and a personal token (MRM andBioHashing), and a pure biometric matcher trained using onlythe biometric features, confirms the results obtained in (Maioand Nanni, 2006 and Lumini and Nanni, 2006), i.e. the combinedsystem permits to obtain very good performance also when an‘‘impostor” steals the personal key.
2. The proposed method
A popular approach to combine multiple classifiers in biometricrecognition is to treat the combination stage as a second-level pat-tern recognition problem on the matching scores that are to befused (Maio and Nanni, 2006), and then to use standard learningparadigms in order to obtain combining functions. The similarityscore of each system is seen as a different feature, and the two clas-ses to be distinguished correspond to impostor and genuine at-tempts, respectively.
In Fig. 1, the complete scheme of the proposed system is re-ported. We combine the scores of (1) some selected competitorsof FVC2004 (SCF), (2) a pure biometric palm matcher (PM) and(3) a hybrid system, named hybrid palm authenticator (HPA)where the biometric features are combined with pseudo-randomnumbers.
2.1. Selection of FVC2004 competitors
In order to study the effects of the combination among differentfingerprint systems, we argue that a feature selection method maybe very useful due to the different characteristics of the matchers.Therefore we select the fingerprint systems to be combined (as in(Maio and Nanni, 2006)) by running sequential forward floatingselection (SFFS)1 (Pudil et al., 1994) on the similarity scores avail-able from the participants to FVC2004 competition. Please note that,as in (Maio and Nanni, 2006), the ‘‘goodness” of the fingerprint sys-tems selected by SFFS is defined as the empirical equal error rate ob-tained by a multi-matcher which combines by the ‘‘Sum rule” theselected k fingerprint matchers. Considering the similarity score esti-mated by each of the k matchers, the ‘‘Sum rule” selects as final scorethe sum of the k scores.
1 Implemented as in PRTools 3.1.7 <ftp://ftp.ph.tn.tudelft.nl/pub/bob/prtoolsprtools3.1.7>. 2 Matlab code shared by Mikhail Belkin and Partha Niyogi.
/
2.2. The palm matcher
We use an image-based approach for palm authentication,which grants good performance and it is easy to implement. Thepalm image is extracted using the datum points as in (Li et al.,2004) (Fig. 2) and the biometric palm features are extracted by di-rectly applying the Laplacian Eigenmaps (LEM)2 (He et al., 2005) togrey level pixels and retaining only a subset of 100 coefficients. Fi-nally, a nearest neighbor classifier1 is trained to produce the scoreof PM.
2.3. The hybrid palm authenticator
The hybrid palm authenticator is designed by combining thepalm features described above with a personal token (pseudo-ran-dom numbers generated by a secret key) in order to obtain userspecific codes. In order to evaluate the performance, the HPAshould be tested in two different test cases: the best hypothesis,when never an impostors steals the personal code, and the worsthypothesis, when always an impostors steals the personal codeof a user A and tries to authenticate as A.
The following approaches for the combination of the biometricinformation with a personal key have been tested: multi-spacerandom mapping (MRM), BioHashing (BH) and improved BioHash-ing (IBH).
2.3.1. Multi-space random mappingMulti-space random mapping consists in projecting the biomet-
ric feature vector into a random projection space. A set of pseudo-

Fig. 3. A fingerprint image from each database, at the same scale factor.
1346 L. Nanni, A. Lumini / Pattern Recognition Letters 29 (2008) 1344–1350
random vectors is generated starting from a personal key andarranged into a matrix to be orthonormalized using singular vectordecomposition (SVD) to construct the transformation matrix R. Therandom projection can be expressed as: v = Rx, where x is the ori-ginal feature vector. Finally the projected vectors are comparedusing the Euclidean distance.
2.3.2. BioHashing and improved BioHashingBioHashing generates a vector of bits starting from the biomet-
ric features and a seed which represents the hash key. The biomet-ric vector data x 2 Rn is reduced down to a bit vector b 2 f0;1gm
with m the length of the bit string. The algorithm for the creationof the vector b (BioHash code) can be detailed as follows:
(1) Given a secret seed K (the hash key), generate a sequence ofreal numbers to produce a set of pseudo-random vectorsri 2 Rn, i ¼ 1; . . . ;m. Since the vectors have to be a basis ofthe projection space they must be linearly independent,therefore the random generation is re-iterated until this con-straint is not fulfilled.
(2) Apply the Gram–Schmidt orthonormalization procedure totransform the basis ri into an orthonormal set of vectorsori, i ¼ 1; . . . ;m.
(3) Compute the inner product between the biometric featurevector x and ori ðhx j oriiÞ, i ¼ 1; . . . ;m and compute bi
ði ¼ 1; . . . ;mÞ as bi ¼0 if hx j orii 6 s1 if hx j orii > s
� �, where s is a pre-
set threshold. We normalize the biometric vectors by theirmodule such that the scalar product is within the range[�1,1].
The hash key K is given to the user during the enrollment, and itis different among users and applications. The resulting bit vector bis compared by the Hamming distance (Jin et al., 2004) for the sim-ilarity matching. We also use an improved version of BioHashing(Lumini and Nanni, 2007), called IBH, aimed at reducing the depen-dence of performance on the parameters s and m: (1) varying s be-tween smax and smin (with p steps), instead of using a fixed value,and combining the resulting scores with the ‘‘Sum rule”; (2) usingk projection spaces in order to generate more BioHash codes peruser. The verification task is performed by combining the set ofclassifiers (one for each BioHash code) with the ‘‘Sum rule”. In thispaper, smax ¼ 0:1; s ¼ 0; smin ¼ �0:1; p ¼ 5; k ¼ 5.
3 Matlab code shared by Xu-Cheng Yin (all the parameters have been leftnchanged to the default values).4 We obtain the best performance using the linear SVM.5 The datasets FVC2004 are available at: <http://bias.csr.unibo.it/fvc2004>.
2.4. Fusion step
The fusion is performed in two separate steps (see Fig. 1): firstthe two palm matchers on one hand and the selected fingerprintmatchers on the other hand are separately combined into the
ensembles PE and FE, respectively, secondly the two ensemblesare fused together (GE).
To combine PM and HPA we use a trained rule (AdaBoost.M13).AdaBoost.M1 (AM) is a meta learning method that tries to build a‘‘good” learning algorithm based on a group of ‘‘weak” classifiers.Boosting algorithm works by calling a weak classifier several times,each time providing the training patterns with different weights, andcombining the hypotheses from all iterations into one hypothesis. Asa weak learner we use a three-layer back-propagation neural net-work with n input nodes (n is dimension of the feature vector), c out-put nodes (c is the number of classes) and n� ð2=3Þ hidden nodes.The number of rounds in boosting is 200.
To combine the scores of the fingerprint matchers we use a ran-dom subspace ensemble (RS) of AM classifiers. RS is a combinationtechnique proposed by Ho (1998), which modifies the training dataset (generating NTr new training sets), builds classifiers on thesemodified sets, and then combines them into a final decision rule.The new training sets contain only a random subset of all the fea-tures. The percentage of the features retained in each training set isdenoted by NFe. In our experiments, we set NFe ¼ 50%, NTr ¼ 10,and we combine the classifiers using the ‘‘Sum rule”. Probably thegood behaviour of RS is due to the presence of correlation amongthe features (RS works well when the features are correlated Ho,1998).
Comparative studies about the fusion of fingerprint matchers(Maio and Nanni, 2006) have shown that the support vector ma-chine (SVM) based fusion approach outperforms other non-trainedapproaches. Our experiments reveal that if we combine many fin-gerprint matchers, the performance of SVM4 does not increase,while the performance of AM increases. Moreover they show thata RS of AM is more reliable than a ‘‘stand-alone” AM.
Finally the two scores (from fingerprint and from palm) arecombined together by AM.
3. Experiments and discussion
Details of the FVC2004 competition and results are presented in(Cappelli et al., 2006).5 Two different sub-competitions (open andlight) were organized. In this work, we focus on combining the 41algorithms competing in the open category, which have no restric-tion in computing and memory usage. Data for the competition con-sists of 4 different databases (DB1, DB2, DB3, DB4), obtained bydifferent sensors. Each database comprises 100 different fingers with8 impressions per finger. The 8 impressions of each finger were
u
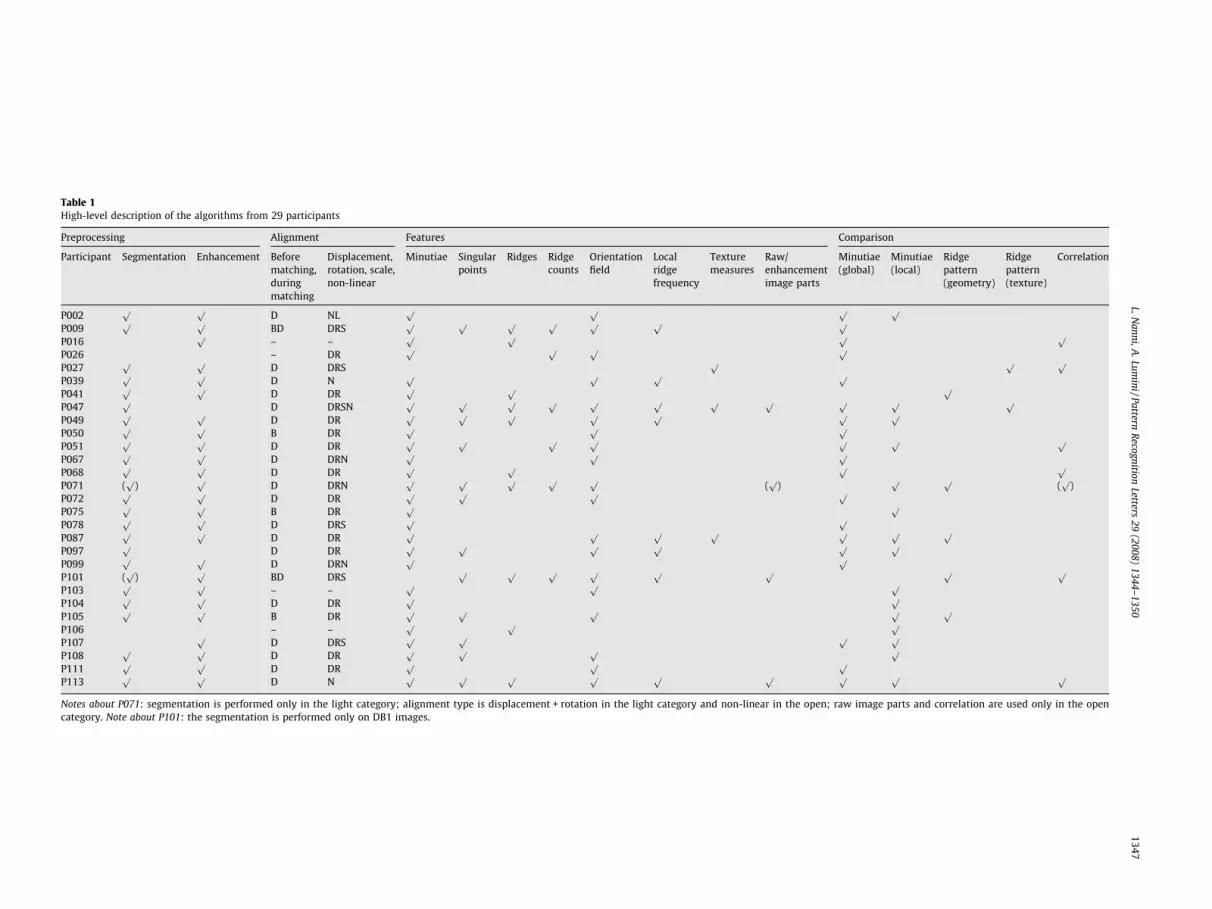
Table 1High-level description of the algorithms from 29 participants
Preprocessing Alignment Features Comparison
Participant Segmentation Enhancement Beforematching,duringmatching
Displacement,rotation, scale,non-linear
Minutiae Singularpoints
Ridges Ridgecounts
Orientationfield
Localridgefrequency
Texturemeasures
Raw/enhancementimage parts
Minutiae(global)
Minutiae(local)
Ridgepattern(geometry)
Ridgepattern(texture)
Correlation
P002p p
D NLp p p p
P009p p
BD DRSp p p p p p p
P016p
– –p p p p
P026 – DRp p p p
P027p p
D DRSp p p
P039p p
D Np p p p
P041p p
D DRp p p
P047p
D DRSNp p p p p p p p p p p
P049p p
D DRp p p p p p p
P050p p
B DRp p p
P051p p
D DRp p p p p p p
P067p p
D DRNp p p
P068p p
D DRp p p p
P071 (p
)p
D DRNp p p p p
(p
)p p
(p
)P072
p pD DR
p p p p
P075p p
B DRp p
P078p p
D DRSp p
P087p p
D DRp p p p p p p
P097p
D DRp p p p p p
P099p p
D DRNp p
P101 (p
)p
BD DRSp p p p p p p p
P103p p
– –p p p
P104p p
D DRp p
P105p p
B DRp p p p p
P106 – –p p p
P107p
D DRSp p p p
P108p p
D DRp p p p
P111p p
D DRp p p
P113p p
D Np p p p p p p p p
Notes about P071: segmentation is performed only in the light category; alignment type is displacement + rotation in the light category and non-linear in the open; raw image parts and correlation are used only in the opencategory. Note about P101: the segmentation is performed only on DB1 images.
L.Nanni,A
.Lumini/Pattern
Recognition
Letters29
(2008)1344–
13501347

EER
EER
0123456
PA M BH IBHFUS1
FUS2
FUS3FUS4 PE
012345678
PAMRM BH IBH
FUS1FUS2
FUS3FUS4 PE
Fig. 5. EER obtained on the palm database by the tested systems when (a) never/(b)always an impostor steals personal key.
EER
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
3 5 24 41
LSVM AMRSA SUM
Fig. 4. Average EER (on the 4 DBs) obtained by the different fusion rules as afunction of the number k of selected competitors.
1348 L. Nanni, A. Lumini / Pattern Recognition Letters 29 (2008) 1344–1350
matched against each other avoiding symmetric matches, thus gen-erating ð100� 8� 7Þ=2 ¼ 2800 genuine matching scores. The firstimpression of each user was also matched against the first impres-sion of every other user avoiding symmetric matches, thus generat-ing ð100� 99Þ=2 ¼ 4950 impostor matching scores. The imagequality is low to medium due to exaggerated plastic distortions,and artificial dryness and moistness. In Fig. 3 a fingerprint imagefrom each database is shown.
In Table 1 (from Cappelli et al., 2006; Maio and Nanni, 2006)some of the fingerprint matchers of FVC2004 are described.
We have conducted our experiments on 4 databases that con-tain 100 persons and for each person 8 fingerprint samples and 8palm samples. The databases have been constructed by joiningone of the four DBs of fingerprints constituting the FVC2004 bench-mark and a palm image database. Obviously, the FVC2004 dat-abases do not come with corresponding palm, so to eachfingerprint, we assign an arbitrary (but fixed) palm. The palm data-base has the same dimension as the FVC2004 databases (100 userand for each user 8 images).
The performance indicator adopted in this work is the Equal Er-ror Rate (EER). EER is the error rate where the frequency of fraud-ulent accesses (FAR) and the frequency of rejections of people whoshould be correctly verified (FRR) assume the same value; it can beadopted as a unique measure for characterizing the security levelof a biometric system. For the trained fusion a 2-fold cross-valida-tion is used for training, dividing the available scores in twopartitions.
The aim of the first test is to prove the advantage of adopting anAdaBoost.M1 to combine the scores of the fingerprint systems. InFig. 4 we plot the average EER on the 4 fingerprint DBs obtainedcombining the best k (k = 3,5,24,41) FVC2004 competitors selectedby SFFS. We show that AM outperforms linear support vector ma-chine (LSVM)6 when k > 5 and that a RS of AM is more reliable thanAM (RS of AM obtains performance equal or better than that ob-tained by LSVM for each value of k). The performance of LSVM doesnot increase when combining more than three systems.
Please note that, due to computational reasons, it would beunfeasible to run SFFS using a classifier in the objective function,therefore the EER obtained by the fusion by ‘‘Sum Rule” of the se-lected matchers has been used (as proposed in (Fierrez-Aguilaret al., 2005)).
In Fig. 4 we denote the ensemble of matchers as SUM if fused bythe ‘‘Sum Rule”, AM if fused by AdaBoost.M1, LSVM if fused by lin-
6 In our tests LSVM outperforms non-linear SVM.
ear support vector machine and RSA is fused by random subspaceof AdaBoost.M1.
In our tests, the simple fusion approach based on the ‘‘Sum rule”is outperformed by the more complex trained fusion approaches(Kuncheva, 2004). Using ‘‘Sum Rule” to combine the matchersthe performance improves with the first 5 competitors and deteri-orates when combining more than 10 systems. This is probably dueto the correlation among the matchers (Maio and Nanni, 2006;Fierrez-Aguilar et al., 2005) that deteriorates the performance.The presence of correlation among classifiers is damaging forensembles based on non-trained fusion rules, while in the litera-ture it is well known that a Random Subspace classifier works wellwith correlated features (Ho, 1998; Kuncheva, 2004). Our resultsconfirm this finding: in fact RSA is the best method tested in thiswork.
The aim of the second test is find out the best matcher based onpalm features. Hence in Fig. 5 we compared the performance of thefollowing matchers:
� PM, the palm matcher described in Section 2.2.� MRM, the hybrid palm authenticator (see Section 2.3) obtained
by multi-space random mapping.� BH, the hybrid palm authenticator obtained by BioHashing.� IBH, the hybrid palm authenticator obtained by improved
BioHashing.� FUS1, the fusion, by ‘‘Sum rule”, between PM and IBH.� FUS2, the fusion, by ‘‘Sum rule”, between PM and MRM.� FUS3, the fusion, by ‘‘Sum rule”, among PM, MRM and IBH.� FUS4, the fusion, by AdaBoost.M1, among PM, MRM and IBH.� PE, the fusion, by AdaBoost.M1, between PM and IBH (the
ensemble described in Section 2.4).
The results show that the improved BioHashing is the best ap-proach for obtaining a hybrid classifier in the both the testinghypotheses; MRM gives better performance than BioHashing onlyin the worst hypothesis.
Finally, the third experiment is intended to evaluate the perfor-mance of the full method GE (see Fig. 1) detailed in Section 2. In

Table 2Average comparison time (on a Athlon 1600+ (1.41 GHz)) on each database of the first5 selected participants to FVC2004
Average comparison time (s)
DB1 DB2 DB3 DB4 Average
P039 1.32 0.83 1.09 1.53 1.19P047 1.87 2.18 2.30 1.93 2.07P071 0.77 0.57 0.81 0.53 0.67P075 0.44 0.30 0.68 0.29 0.43P101 3.19 0.81 0.85 1.06 1.48
0
1
2
3
4 DB1 DB2DB3 DB4
DB1 0.33 0.16 0.98 0.05 2.65
DB2 0.4 0.24 0.29 0.17 3.54
DB3 0 0.7 0.09 0.07 1.23
DB4 0.08 0.42 0.3 0.09 0.75
3 5 24 41 P101
0
0.05
0.1
0.15 DB1 DB2DB3 DB4
DB1 0.13 0.05 0.01 0.02
DB2 0.01 0.11 0.08 0.06
DB3 0 0.01 0.02 0
DB4 0.02 0.04 0.01 0.07
3 5 24 41
EER
EER
Fig. 6. EER obtained on the 4 combined DBs by our ensemble GE when (a) always/(b) never an impostor steals the personal key. P101 is the fingerprint matcherswinner of FVC2004 (palm information is not considered for the decision).
L. Nanni, A. Lumini / Pattern Recognition Letters 29 (2008) 1344–1350 1349
Fig. 6, we plot the EERs obtained by GE as a function of the numberk ðk ¼ 3;5;24;41Þ of FVC2004 competitors selected for the fusion.These results have been compared with the winner of FVC2004considered alone (P101).
The experimental results show that the proposed ensemble GEobtain a very impressive EER in the best hypothesis (b), and, aboveall, its performance is very better than the best fingerprint matcheralso in the worst hypothesis when always the personal key is stolen.
In Table 2 the average comparison time of the selected k ¼ 5competitors of FVC2004 is given (the complete table is in (Cappelliet al. (2006))). The verification time of the palm matchers PM andHPA is about 1 s each7 (Matlab code). Of course, the matchers may
7 Non-optimized Matlab code.
work in parallel, in any case, a comparison time of about 5 s (in an‘‘old” Athlon 1600+) may be considered acceptable for a real-timeapplication.
4. Conclusions
In this work, we proposed a multi-modal method combining thescores produced by:
– An ensemble of selected fingerprint matchers from the FVC2004competition combined by a random subspace of AdaBoost.M1.
– A pure biometric palm matcher.– A hybrid system where palm features are combined with
pseudo-random numbers.
The aim of this work was to design a multi-modal biometricsystem and analyze the benefits and limits of considering a hybridsystems in the worst and more difficult testing hypothesis when an‘‘impostor” steal the personal key of the user A before he tries toauthenticate as A.
Experimental results obtained on 4 large fingerprint databases(FVC2004) and a palm dataset show that the proposed multi-mod-al method leads to obtain an amazing near zero-EER on FVC2004,which is much lower than that obtained by the winner ofFVC2004 (the really state-of-the-art in fingerprint matching) con-sidered alone.
The results of this paper confirm that using a multi-modalensemble of matchers it is possible to overcome some of the limi-tations of each single matcher leading to a considerable perfor-mance improvement. This means that our multi-modal methodcould be used in a very high security application.
Finally a comment is due on the different results obtained onthe four datasets: the performance of our multi-modal biometricsystem are much better on DB3 than on DB2. In the worst hypoth-esis, when always the impostors steal the pseudo-random num-bers, it obtains an EER of 0 on DB3 and of 0.17 on DB2; probably,this is due to the different fingerprint image quality. For this rea-son, an interesting further work could be the study of the effectsof fingerprint image quality (Simon-Zorita et al., 2003) on the per-formance of a multi-classifier system.
Acknowledgement
This work has been supported by European Commission IST-2002-507634 Biosecure NoE Projects.
References
Cappelli, R., Maio, D., Maltoni, D., Wayman, J.L., Jain, A.K., 2006. Performanceevaluation of fingerprint verification systems. IEEE Trans. Pattern Anal. MachineIntell. 28 (1), 3–18.
Fierrez-Aguilar, J., Nanni, L., Ortega-Garcia, J., Cappelli, R., Maltoni, D., 2005.Combining Multiple Classifiers for Fingerprint Verification: A Case Study inFVC2004. ICIAP.
He, X., Yan, S., Hu, Y., Niyogi, P., Zhang, H.-J., 2005. Face recognition using Laplacianfaces. IEEE Trans. Pattern Anal. Machine Intell. 27 (3), 328–340.
Ho, T.K., 1998. The random subspace method for constructing decision forests. IEEETrans. Pattern Anal. Machine Intell. 20 (8), 832–844.
Jin, A.T.B., Ling, D.N.C., Goh, A., 2004. BioHashing: Two factor authenticationfeaturing fingerprint data and tokenised random number. Pattern Recognition37 (11), 2245–2255.
Kong, A., Cheung, K.H., Zhang, D., Kamel, M., You, J., 2006. An analysis of BioHashingand its variants. Pattern Recognition 39 (7), 1359–1368.
Kuncheva, L.I., 2004. Combining Pattern Classifiers. Methods and Algorithms. Wiley.Li, Q., Qiu, Z., Sun, D., Wu, J., 2004. Personal identification using Knuckleprint.
Sinobiometrics, 680–689.Lumini, A., Nanni, L., 2006. An advanced multi-modal method for human
authentication featuring biometrics data and tokenised random number.NeuroComputing 69 (13–15), 1706–1710.

1350 L. Nanni, A. Lumini / Pattern Recognition Letters 29 (2008) 1344–1350
Lumini, A., Nanni, L., 2007. An improved BioHashing for human authentication.Pattern Recognition 40 (3), 1057–1065.
Lumini, A., Nanni, L., 2007. When fingerprints are combined with Iris, a case study:FVC2004 and CASIA. Internat. J. Network Security 4 (1), 27–34.
Maio, D., Nanni, L., 2006. Combination of different fingerprint systems: A case studyFVC2004. Sensor Rev. 26 (1), 51–57.
Maio, D., Nanni, L., 2006. MultiHashing, human authentication featuring biometricsdata and tokenised random number: A case study FVC2004. NeuroComputing69 (7–9), 858–861.
Maltoni, D., Maio, D., Jain, A.K., Prabhakar, S., 2003. Handbook of FingerprintRecognition. Springer, New York.
Pudil, P., Novovicova, J., Kittler, J., 1994. Floating search methods in featureselection. Pattern Recognition Lett. 15 (11), 1119–1125.
Simon-Zorita, D., Ortega-Garcia, J., Fierrez-Aguilar, J., Gonzalez-Rodriguez, J.,2003. Image quality and position variability assessment in minutiae-basedfingerprint verification. IEE Proc. Vision Image Signal Process. 150, 402–408.
Teoh, A.B.J., Goh, A., Ngo, D.C.L., 2006. Random multispace quantization as ananalytic mechanism for BioHashing of biometric and random identity inputs.IEEE PAMI 28 (12), 1892–1901.
Yuang, C.T., Teoh, A., Ngo, D., Goh, M., 2005. Multi-space random mapping forspeaker identification. IEICE Electron. Exp. 7 (2), 226–231.





























