Embed Size (px)
Citation preview

C
Am
AJa
b
c
d
e
h
•••••
a
ARRAA
KPNOS
tT
ev
h0
Journal of Neuroscience Methods 253 (2015) 70–77
Contents lists available at ScienceDirect
Journal of Neuroscience Methods
jo ur nal home p age: www.elsev ier .com/ locate / jneumeth
linical neuroscience
ccelerometer-based automatic voice onset detection in speechapping with navigated repetitive transcranial magnetic stimulation
nne-Mari Vitikainena,b,∗, Elina Mäkeläa, Pantelis Lioumisa,c, Veikko Jousmäkid,e,yrki P. Mäkeläa
BioMag Laboratory, HUS Medical Imaging Center, University of Helsinki and Helsinki University Hospital, P.O. Box 340, FI-00029 HUS, Helsinki, FinlandDepartment of Physics, University of Helsinki, P.O. Box 64, FI-00014 University of Helsinki, Helsinki, FinlandNeuroscience Center, University of Helsinki, P.O. Box 56, FI-00014 University of Helsinki, Helsinki, FinlandDepartment of Neuroscience and Biomedical Engineering, Aalto University School of Science, P.O. Box 15100, FI-00076 Aalto, Espoo, FinlandAalto NeuroImaging, Aalto University School of Science, P.O. Box 15100, FI-00076 Aalto, Espoo, Finland
i g h l i g h t s
rTMS-induced modifications of naming are commonly analyzed from video recordings.Detection of vocalization-related larynx vibrations via accelerometer is introduced.Our setup offers additional information to the behavioral data.Automated routine correctly detected 96% of the voice onsets.The new method improves the repeatability and objectivity of rTMS language mappings.
r t i c l e i n f o
rticle history:eceived 3 February 2015eceived in revised form 19 May 2015ccepted 21 May 2015vailable online 28 May 2015
eywords:resurgical planningavigated TMS (nTMS)bject namingpeech mapping
a b s t r a c t
Background: The use of navigated repetitive transcranial magnetic stimulation (rTMS) in mapping ofspeech-related brain areas has recently shown to be useful in preoperative workflow of epilepsy andtumor patients. However, substantial inter- and intraobserver variability and non-optimal replicabilityof the rTMS results have been reported, and a need for additional development of the methodology isrecognized. In TMS motor cortex mappings the evoked responses can be quantitatively monitored byelectromyographic recordings; however, no such easily available setup exists for speech mappings.New method: We present an accelerometer-based setup for detection of vocalization-related larynx vibra-tions combined with an automatic routine for voice onset detection for rTMS speech mapping applyingnaming.Comparison with existing method(s): The results produced by the automatic routine were compared withthe manually reviewed video-recordings.Results: The new method was applied in the routine navigated rTMS speech mapping for 12 consecutivepatients during preoperative workup for epilepsy or tumor surgery. The automatic routine correctlydetected 96% of the voice onsets, resulting in 96% sensitivity and 71% specificity. Majority (63%) of the
misdetections were related to visible throat movements, extra voices before the response, or delayednaming of the previous stimuli. The no-response errors were correctly detected in 88% of events.Conclusion: The proposed setup for automatic detection of voice onsets provides quantitative additionaldata for analysis of the rTMS-induced speech response modifications. The objectively defined speechresponse latencies increase the repeatability, reliability and stratification of the rTMS results.∗ Corresponding author at: BioMag Laboratory, HUS Medical Imaging Cen-er, Helsinki University Hospital, P.O. Box 340, FI-00029 HUS, Helsinki, Finland.el.: +358 9471 1; fax: +358 9471 75781.
E-mail addresses: [email protected] (A.-M. Vitikainen),[email protected] (E. Mäkelä), [email protected] (P. Lioumis),[email protected] (V. Jousmäki), [email protected] (J.P. Mäkelä).
ttp://dx.doi.org/10.1016/j.jneumeth.2015.05.015165-0270/© 2015 Elsevier B.V. All rights reserved.
© 2015 Elsevier B.V. All rights reserved.
1. Introduction
Localization of speech-related brain areas by navigated repet-
itive transcranial magnetic stimulation (rTMS) during an objectnaming task has been suggested to be useful in planning of braintumor and epilepsy surgery (Lioumis et al., 2012; Sollmann et al.,2013a). Use of individual’s magnetic resonance imaging (MRI)
euros
bc(ercmartnt2mDVbss
a2ars(ijniipromg
bspdtauct2
ocnwoHr
ffAemm(
tm
A.-M. Vitikainen et al. / Journal of N
ased navigation with rTMS mapping enables the speech relatedortical sites to be transferred to the neuronavigation systemMäkelä et al., 2015) and to be used in surgical planning. Preop-rative speech mapping by navigated rTMS may aid in objectiveisk-benefit assessment of the planned surgery, enable more pre-isely targeted smaller craniotomies, faster and safer intraoperativeapping, and safer surgeries for patients that cannot undergo
wake craniotomy (Sollmann et al., 2013a; Picht et al., 2013). TheTMS speech mapping results have been compared to direct cor-ical stimulation (DCS) during awake craniotomy implying thatTMS is remarkably sensitive but relatively non-specific in detec-ing the sites producing speech disturbance in DCS (Picht et al.,013; Tarapore et al., 2013). In preoperative navigated TMS (nTMS)apping of motor cortex, shown to have a very good match withCS (Tarapore et al., 2013; Picht et al., 2011; Forster et al., 2011;itikainen et al., 2013), the responses to nTMS are monitoredy motor evoked potentials from the activated muscles. No suchtraightforward, easily recordable marker exists for detection ofpeech modifications induced by rTMS.
The navigated rTMS method has been accepted by US Foodnd Drug Administration (FDA) for presurgical speech mapping in012 (Eldaief et al., 2013), and, consequently, its use will prob-bly expand in the near future. Recently, rTMS speech mappingesults in patients with brain tumors and healthy subjects haveuggested tumor-induced plasticity of speech representation areasKrieg et al., 2013; Rösler et al., 2014), and demonstrated differencesn cortical areas related to object and action naming in healthy sub-ects (Hernandez-Pavon et al., 2014). Thus, nTMS during an objectaming task may have an impact on surgery planning and provide
nformation about the organization of speech-related brain areasn general. Nevertheless, the intraobserver and interobserver com-arisons of the nTMS speech mapping results show only limitedeplicability, and the currently used protocols need further devel-pment (Sollmann et al., 2013b; Krieg et al., 2014). Additionally, theethodology is not completely standardized between the surgical
roups applying it.The no-response (speech arrest) errors are the most replica-
le results of nTMS speech mapping (Krieg et al., 2013). However,peech disturbances such as semantic and phonological para-hasias, and performance errors during the pulse train are moreifficult to separate quantitatively from the recorded videos. Par-icularly, the value of hesitations, delayed but not completelybolished responses induced by rTMS, is not clear, as their eval-ation is quite subjective; interpretation of these errors has beenonsidered as a possible reason for a high rate of false posi-ive results of rTMS studies as compared with DCS (Ille et al.,015).
Microphone recording of vocalization to detect the voice onsetsbjectively is hampered by ambient noise from TMS pulses andoil cooling (Lioumis et al., 2012). Electromyographic (EMG) sig-als from cricothyroid muscles have been used in combinationith nTMS to monitor effects of nTMS to the inferior frontal cortex
n larynx muscles during object naming tasks (Rogic et al., 2014).owever, the insertion of the EMG wire electrodes to the cricothy-
oid muscle is invasive and requires skill (Deletis et al., 2011).Detection of larynx vibrations, coinciding with the fundamental
requency of the voice, with an accelerometer enables non-invasiveollow-up of speech vocalizations (Bourguignon et al., 2013).ccelerometers can accurately measure vocal activity (Hillmant al., 2006; Lindstrom et al., 2009; Orlikoff, 1995). Compared withicrophones, accelerometers are not sensitive to ambient environ-ental sounds and are therefore well suitable for voice assessment
Lindstrom et al., 2009).In this study, we tested the feasibility of using an accelerometer
o pick up the onsets of the vocalizations in navigated rTMS speechapping.
cience Methods 253 (2015) 70–77 71
2. Materials and methods
2.1. Subjects
We made the accelerometer recordings as part of the rTMSspeech mappings for twelve consecutive patients (4 females/8males, age range 12–39 years) going through tumor or epilepsysurgery workup. Both hemispheres were stimulated with rTMS ineleven patients; patient #4 did not tolerate the right-hemispherestimulation and only his left hemisphere was stimulated. For onepatient, the data during the baseline was not recorded due humanerror. For one patient the data was lost due technical difficulties,for patient #7 the data of the left hemisphere stimulation wasinaccessible, and for patient #6 a first part of data of left hemi-sphere stimulation was corrupted. The results of ten patients arepresented. The study was approved by the local Ethical Committee.
2.2. Experimental design
The experiment started with an initial baseline session withoutrTMS to select the images that were correctly named and pro-nounced. In order to enable the offline comparison of the responseswith and without the rTMS, the baseline image set was run twotimes more. During the second baseline session the rTMS coil washeld near the patient’s head in the navigation field of the rTMS sys-tem to ensure the trigger pulse output. The intensity of the baselinestimulation was held at 0 or 1% of the maximum stimulator out-put, i.e., no rTMS stimulation was applied. Images that were notnamed, not named correctly, not named clearly, not articulated cor-rectly and named with delay or hesitation were removed from theimage set after the first baseline round. Only the data from the sec-ond baseline round was used for the analysis and subsequent rTMSsessions. The images were displayed in random order. All sessionswere video-recorded for offline analysis.
The rTMS measurements were carried out at the BioMag Labo-ratory using eXimia NBS 4.3 (Nexstim Ltd., Helsinki, Finland) anda commercial speech mapping module (NexSpeech, Nexstim Ltd.,Helsinki, Finland). The navigation system estimates the strength ofthe maximum electric field at the stimulation location and over-lays the estimated field strength on-line on the 3-D reconstructionof the individual’s brain (Ruohonen and Karhu, 2010). Each stim-ulation site is tagged to the structural magnetic resonance (MR)images for subsequent analysis.
All rTMS stimulations were done with a figure-of-eight coil of a70-mm outer diameter and biphasic pulse shape. The resting motorthreshold (MT) was determined from the abductor pollicis brevismuscle controlled by the hemisphere affected by the epilepsy ortumor. The method used by Rossini et al. (Rossini et al., 1994)was used for the MT determination. The rTMS intensity for themapping was adjusted to produce roughly equally strong electricfield to all perisylvian cortical regions. If the stimulation causedintolerable discomfort to the subject, its intensity was lowered in5–10% decrements until tolerable. Thus, the stimulation intensityvaried somewhat across subjects. The estimated induced electricfield strength at the cortex was registered. The stimulations weredone with 5-pulse rTMS trains at 5 or 7 Hz (Lioumis et al., 2012;Epstein et al., 1996).
In nine patients, the images to be named were a subset of colorimages out of set of 84 images depicting everyday objects (Lioumiset al., 2012). In three patients, a selection of 92 images from astandardized image set (Brodeur et al., 2010) was used. The selec-tion from the standardized set was chosen to represent frequently
used items in Finnish every day life, whose names are common inFinnish language, and that have only few synonyms. The subjectswere asked to name the objects in Finnish as quickly and preciselyas possible. The images were displayed for 700 ms on a computer
7 euros
sst3mwtfwooct
2
vsemtdfim
2
weMt(ErSav
2
tsmtaew
2 A.-M. Vitikainen et al. / Journal of N
creen with 2.0–3.0 s interstimulus intervals (ISI). The experimenttarted with a 2.5 s ISI. If needed, the ISI was adjusted accordingo the baseline performance of the patient. The rTMS trains started00 ms after the image onset. The coil was hand-held and freelyovable between the pulse trains. During the stimulation, the coilas moved between the pulse trains following a grid-like pat-
ern so that the stimulated locations covered systematically a wideronto-temporo-parietal cortical area. The orientation of the coilas adjusted to induce current primarily perpendicular to the fibers
f the temporalis muscle to minimize muscle twitching, and sec-ndarily perpendicular to the sulcus at the stimulation location. Theortical sites where rTMS produced naming errors were revisitedo evaluate the repeatability of the effect.
.3. Manual review of the mapping data
The speech mappings were routinely reviewed offline from theideo by a neuropsychologist with expertise in effects of DCS onpeech. The categories available in the speech mapping module (norror, no-response error, performance error, semantic paraphasia,uscle stimulation and other) were applied in the analysis. Addi-
ionally information about performance errors’ subdivision (e.g.elays, phonological paraphasias) was noted in the free commenteld. The speech response latencies were not available in the speechapping module.
.4. Vibration recording
Subject’s vocal activity, i.e. fundamental frequency of the voice,as recorded during object naming with a three-axis accelerom-
ter (ADXL330 iMEMS® Accelerometer, Analog Devices, Norwood,A) attached to the skin on left side of the subject’s throat, onto
he larynx site producing palpable vibrations during vocalizationFig. 1). The analog accelerometer signals were connected to theMG system of the stimulator with a custom built interface. Theecorded frequency band was 10–500 Hz and sampling rate 3 kHz.imilar accelerometer has been used previously by Bourguignonnd co-workers to detect the fundamental frequency of the reader’soice (Bourguignon et al., 2013).
.5. Automated routine for voice onset detection
For the automated routine, the following files were collected:he tabular data of the speech mapping (speech-file containing thepeech event related data from the commercial speech mappingodule, including the name of the picture, speech exam identifica-
ions, and rTMS train sequence identifiers, converted to excel file),nd accelerometer and trigger signals (edf-files). Each accelerom-ter data file corresponding to each of the speech exams (sessions)ere identified and verified.
Fig. 1. The accelerometer attached to the throat.
cience Methods 253 (2015) 70–77
The accelerometer signals were high-pass filtered with Butter-worth filter (4th order, cut-off frequency of 80 Hz) to reduce lowfrequency interference and possible signal level drifts while main-taining the characteristics of the voice (Bourguignon et al., 2013;Orlikoff, 1995) (Fig. 2). The data was first filtered in forward andthen in reverse direction, preserving the waveform features exactlyat the same time point where they occur in the original signal(Oppenheim et al., 1999). To enable a robust automatic onset cal-culation routine, the envelope (see Fig. 2) of the filtered signal wascalculated using Hilbert transform. The signal envelope capturesthe slowly varying features of the signal generating the signal out-line, and its analytic representation enables fast calculations. Thisapproach is commonly used in sound signal processing (Samjin andZhongwei, 2008).
The recordings were split into several sessions (and thus severaldata files) controlled by the commercial program module. Some ofthe sessions may contain short but extremely intensive vibrationsdue to e.g. coughs while maintaining constant level of the vibrationsrelated to silence and speech responses. In order to enable uniformprocessing of the baseline and subsequent rTMS sessions, the meanof the signal envelope during the whole session was calculated torepresent the overall vibration level of the session. An active speechthreshold was formed by multiplying this general signal level withan individually adjustable constant.
The first rough estimate of the speech periods was formed bytaking into account the signal periods where the envelope of thesignal amplitude exceeded the active speech threshold (Myers andHansen, 2007). This was done sample by sample (sampling rate3000 Hz). Erroneous periods containing e.g. coughs, sighs, swallow-ing, moving of the jaw etc. were included in analysis, in additionto the speech response. To extract only the true speech responseonsets, and not the shorter signals originating from non-desirableevents, the envelope signal was then modified by applying a mov-ing average filter (implemented as convolution, with a rectangularunit pulse of 40 ms in length; Fig. 2). After this the first rising edgeof the resulting signal between successive rTMS train onsets wasdetermined as the speech response onset corresponding the givenrTMS train onset.
The active speech threshold limit and the length of the movingaverage filter window and shape of the convolution kernel (rect-angular unit pulse) were checked manually to be appropriate forour measurement setup with four randomly selected sessions (notincluded in the results).
The trigger pulses of the rTMS stimuli, collected together withthe accelerometer data, enabled the calculation of the onset laten-cies of vocalizations and the onsets of the stimuli (Fig. 3). Theresponses for each image from the rTMS session were matched withthe corresponding images in baseline, and the voice onset time dif-ference was calculated. To improve the usability of the routine, therTMS train sequence numbers are shown in the overview figures(see Supplementary Fig. A) and the image name in the responsecomparison figures. Finally, a list of the responses which onset timedifference exceeding a chosen value (default 100 ms) compared tothe baseline was printed. The results were visually crosscheckedfrom the recorded video and from the signals for erroneous onsetdetections.
2.6. Comparison of the data
The results produced by the automated routine were comparedwith the manually reviewed results from video with the follow-ing five components: (a) the number of detected rTMS pulse trains
compared with the number of the actually occurring rTMS trains,(b) the number of the correctly detected rTMS pulse trains, (c) thenumber of detected voice onsets, (d) the number of the correctlydetected voice onsets, and (e) the number of no-response errors.
A.-M. Vitikainen et al. / Journal of Neuroscience Methods 253 (2015) 70–77 73
Fig. 2. An example of the analysis steps of the automated routine and the corresponding audio waveform of a sample of data from patient #1. (A) The original accelerometers (D) rea S trat
Tndp
mc
ignal, (B) filtered signal, (C) signal envelope and the active threshold (dashed line),fter each rTMS train onset is determined as the speech response onset, (E) the rTMhe clicks induced by rTMS.
he voice onset latency could not be directly compared, as it couldot be defined precisely from the video recordings. However, weefined the delays of responses scored as “delays” by our neuro-
hysiologist.The correctness was evaluated against the response perfor-ance observed from the videos for every response in which the
orrectness was in doubt. The reason for misdetection of the rTMS
sulting modified signal after the moving average filter. The rising edge of the signalin trigger pulses, (F) The corresponding audio waveform. Note strong signals from
train onset resulted from not detecting the trigger signal, or detec-ting extra trigger signals. The reason for voice onset misdetectionswere classified to four categories according to the underlying cause:
(I) throat movement related problems (swallows, jaw movements,muscle stimulation, grimaces, etc.); such activity was detectedbefore the actual response or movement was detected withoutany vocalization, (II) extra voice and associated movements taking
74 A.-M. Vitikainen et al. / Journal of Neuroscience Methods 253 (2015) 70–77
Fig. 3. An example of the response comparison of one object naming baseline-rTMS session pair from patient #1. The voice onset time is prolonged by 227 ms when rTMSi namei o the w
psoe
3
ss
pbiarmsofotdet
3
matl
s applied, and instead of naming the image correctly as “pullo” (bottle), the patientnterpretation of the references to color in this figure legend, the reader is referred t
lace before the actual response (such as ‘hmm’, ‘eeeh’, coughs,ighs, etc.), (III) delayed naming of the previous image, and (IV)ther reasons. The reason for misdetection of the no-responserrors was analyzed as well.
. Results
The accelerometer signals were easily recorded with the EMGystem of the TMS device, enabling on-line visualization of theignal during the stimulation and detailed off-line analysis.
The rTMS train sequence was detected correctly in 98% of allatients with sensitivity of 99% and specificity of 86%. Detailedreakdown of the detection performance for each patient is given
n Supplementary Table A. A confirmed rTMS train sequence wasssociated in 98% of the shown images. The reason for not having anTMS train sequence while the image was present was the move-ent of the stimulation coil out of the navigation field of the rTMS
ystem. The sequence of images delivered by the speech module cannly be interrupted manually and is not directly related to success-ul detection of the stimulator coil by the navigation system. 78%f the misdetections were due to lack of the trigger pulses duringhe images: either the pulse sequence was not delivered, or it waselivered only partially. The rest of the misdetections resulted fromxtra trigger signals of unknown origin in between the confirmedrain sequences.
.1. Voice onset detection
The latencies of the vocalizations during rTMS were increased by
ore than 100 ms in, on average, 26 ± 13 trials (range 7–55 trials),nd by more than 500 ms in, on average 9 ± 5 trials (range 2–19rials) (For values with intermediate delays, see Table 2). Longeratency delays were less common than short ones in all patients.
d it as “kokis” (coke) (semantic error). This is seen as a divergent signal shape. (Foreb version of the article. The MATLAB figure is provided as Supplementary Fig. B.).
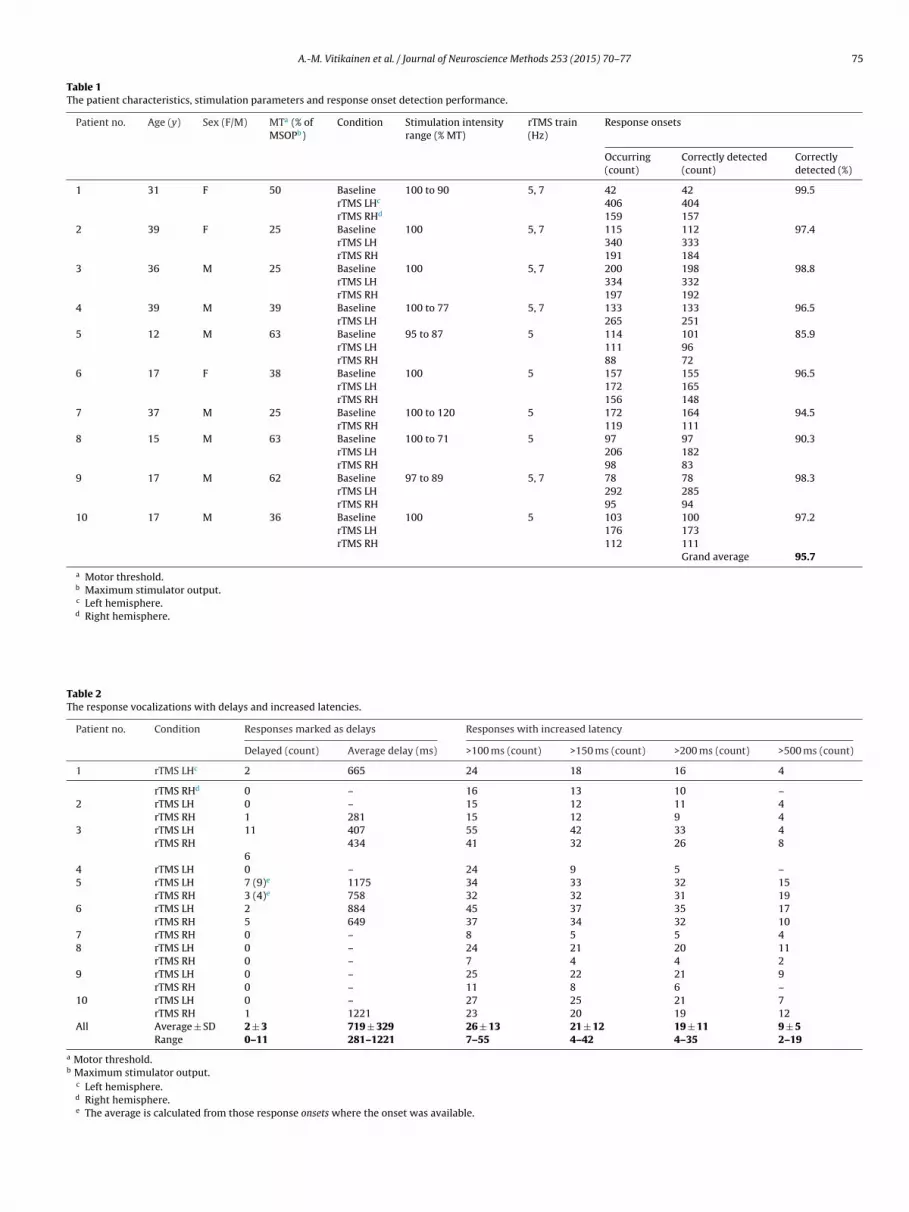
The voice onset detection performance was evaluated as portionof the correctly detected voice onsets of all voice response onsets;details are given in Table 1. The sensitivity of the automated rou-tine to correctly detect the voice onsets was 96%, and the specificity71%. Majority of the misdetections were related to visible throatmovements before the actual response (26%), to extra voice beforethe response (24%) or other, e.g. trigger related problems (36%).Delayed naming of the previous image was present in 13% ofthe misdetections. Detailed categorization of the misdetections foreach patient separately is provided as Supplementary Table B.
3.2. Detection of no-response errors
The no-response errors were detected correctly in 88% of allthe no-response errors, including the “no-response” events in thebaseline sessions. Details for the detection of no-response errors foreach patient is given in Supplementary Table C. As the accelerom-eter data also contains the first round of the images in the baselinesession, and thus also the responses to the images named incor-rectly, not named, not named clearly, not articulated correctlyand named with delay or hesitation, the following results arecalculated separately for baseline and rTMS sessions. In baselinesessions the sensitivity and specificity were 100%. In rTMS sessionsthe overall sensitivity was 82% and specificity 100%. The reasonsfor misdetection followed the same categories as in voice onsetmisdetections.
4. Discussion
The accelerometer-based method presented here measures thevoice onset latency to specific image stimuli. The accelerometerrecording produced high-quality signals and enabled automaticvoice onset time detection. The recordings were collected from
A.-M. Vitikainen et al. / Journal of Neuroscience Methods 253 (2015) 70–77 75
Table 1The patient characteristics, stimulation parameters and response onset detection performance.
Patient no. Age (y) Sex (F/M) MTa (% ofMSOPb)
Condition Stimulation intensityrange (% MT)
rTMS train(Hz)
Response onsets
Occurring(count)
Correctly detected(count)
Correctlydetected (%)
1 31 F 50 Baseline 100 to 90 5, 7 42 42 99.5rTMS LHc 406 404rTMS RHd 159 157
2 39 F 25 Baseline 100 5, 7 115 112 97.4rTMS LH 340 333rTMS RH 191 184
3 36 M 25 Baseline 100 5, 7 200 198 98.8rTMS LH 334 332rTMS RH 197 192
4 39 M 39 Baseline 100 to 77 5, 7 133 133 96.5rTMS LH 265 251
5 12 M 63 Baseline 95 to 87 5 114 101 85.9rTMS LH 111 96rTMS RH 88 72
6 17 F 38 Baseline 100 5 157 155 96.5rTMS LH 172 165rTMS RH 156 148
7 37 M 25 Baseline 100 to 120 5 172 164 94.5rTMS RH 119 111
8 15 M 63 Baseline 100 to 71 5 97 97 90.3rTMS LH 206 182rTMS RH 98 83
9 17 M 62 Baseline 97 to 89 5, 7 78 78 98.3rTMS LH 292 285rTMS RH 95 94
10 17 M 36 Baseline 100 5 103 100 97.2rTMS LH 176 173rTMS RH 112 111
Grand average 95.7
a Motor threshold.b Maximum stimulator output.c Left hemisphere.d Right hemisphere.
Table 2The response vocalizations with delays and increased latencies.
Patient no. Condition Responses marked as delays Responses with increased latency
Delayed (count) Average delay (ms) >100 ms (count) >150 ms (count) >200 ms (count) >500 ms (count)
1 rTMS LHc 2 665 24 18 16 4
rTMS RHd 0 – 16 13 10 –2 rTMS LH 0 – 15 12 11 4
rTMS RH 1 281 15 12 9 43 rTMS LH 11 407 55 42 33 4
rTMS RH 434 41 32 26 86
4 rTMS LH 0 – 24 9 5 –5 rTMS LH 7 (9)e 1175 34 33 32 15
rTMS RH 3 (4)e 758 32 32 31 196 rTMS LH 2 884 45 37 35 17
rTMS RH 5 649 37 34 32 107 rTMS RH 0 – 8 5 5 48 rTMS LH 0 – 24 21 20 11
rTMS RH 0 – 7 4 4 29 rTMS LH 0 – 25 22 21 9
rTMS RH 0 – 11 8 6 –10 rTMS LH 0 – 27 25 21 7
rTMS RH 1 1221 23 20 19 12All Average ± SD 2 ± 3 719 ± 329 26 ± 13 21 ± 12 19 ± 11 9 ± 5
Range 0–11 281–1221 7–55 4–42 4–35 2–19
a Motor threshold.b Maximum stimulator output.
c Left hemisphere.d Right hemisphere.e The average is calculated from those response onsets where the onset was available.

7 euros
1tirmtivanas
d2hdMoioia(nboorsvt
iddddcblcaidvdrlip
nifltseq
Foop
d
6 A.-M. Vitikainen et al. / Journal of N
2 consecutive patients who required rTMS speech mapping; thushey reflect overall feasibility of the presented setup in a real clin-cal situation. The automated routine was compared to a manualeview of the rTMS speech mapping videos, which is the presentethod to analyze the errors in the object naming task. We found
hat the presented method with the automated routine correctlydentified 98% of all presented rTMS trains onsets and 96% of theoice onsets. This suggests that the methodology could produce andditional reliable means to stratify the effects of rTMS in an objectaming task for presurgical planning. Moreover, it could provide
preliminary indicator to detect the no-response errors and thuspeed up the analysis of the videoed responses.
Our setup offers fast additional information to the behavioralata from video analysis of the naming performance (Lioumis et al.,012). Short delays may pass unnoticed in video analysis of severalundred images and responses in several sessions, but they can beetected and promptly quantified by the accelerometer recording.ost importantly our presented setup provides numeral values
f naming latencies, therefore reducing subjectivity and increas-ng repeatability and reliability of the analysis. We are not awaref reports studying just notifiable differences in delays of nam-ng. Healthy subjects distinguish a reliable speech asynchrony ifcoustical signal leads lip opening by 80 ms or lags it by 140 msSummerfield, 1992) probably minimum perceived differences inaming delay are in the same time range. The delays identifiedy visual scoring ranged from 300 to 1200 ms with an averagef 700 ms. This variability may relate, in part, to the regularityf the patient performance generating a background baseline foresponse variability in visual analysis. Our setup, however, enableselection of any delay for a more precise scrutiny. The final clinicalalue of different delays can only be identified by comparison withhe data obtained by DCS during awake craniotomy.
The automated routine may not recognize all stop consonantsn the beginning of a word as their signal amplitude is very smalluring the voice onset. The smaller thresholds required for theiretection is not feasible, as spikes caused by TMS and other ran-om disturbances would be classified as speech. However, thisrawback is not important as the latencies in rTMS condition areompared to the baseline latencies of the same word, and theeginning of the word is usually lost in both conditions. Only the
oudness variation between the baseline and rTMS condition mayause problems despite the use of relative detection threshold: theutomated routine may detect the onset only in the louder vocal-zation and cause an error in comparison of the baseline and rTMSata. Therefore, visual evaluation of the automatically detectedoice onsets is still important. Most observed erroneous latencyetections were induced by coughing or sighing before the actualesponse. These artifacts resulted in too short, not abnormally longatencies. Instead, the true effects of rTMS caused a delayed vocal-zation. Therefore, the design of our algorithm minimizes falseositive findings.
The automated analysis detected successfully latencies for theaming of presented images. Although the patients rehearsed nam-
ng, some of them had particular difficulties to name specific imagesuently during rTMS. This may indicate that image-related fac-ors, instead of rTMS-related ones, are the underlying reason foruch variability. Our algorithm reliably identifies such images andnables straightforward comparison with the DCS data to study thisuestion.
The analysis of the measured signals can be developed further.or example, a shape recognition algorithm (see Fig. 3) could rec-gnize rTMS-induced differences of pronunciation or word change
n the vowel-associated vibration pattern in comparison with theattern recorded during the baseline.We lost data in 2 out of 12 patients due to errors in proce-ures related to data saving. Closer integration of the accelerometer
cience Methods 253 (2015) 70–77
analysis into the speech mapping module probably would avoidsuch errors. Similar recordings could, in principle be done also withordinary microphones. However, recordings with microphonesduring the rTMS speech mapping paradigm can be problematicdue to the loud rTMS clicks, and also due to other environmen-tal sounds, such as arising from the coil cooling system, present inthe stimulation environment (See Fig. 2).
5. Conclusion
In this study, we developed an accelerometer signal-based auto-mated routine for voice onset detection from larynx vibrations to beused with navigated rTMS speech mapping. The automated routinewas found feasible and it detects excellently the rTMS stimula-tion train onsets, the corresponding vocalization onsets and theno-response errors. This method produces numerical result tablesindicating the latency of each response, thus adding reliability,repeatability, and objectivity to the rTMS speech mapping/objectnaming analysis.
Acknowledgements
This study was financially supported by a development grantfrom the HUS Medical Imaging Center (reference MLD81TK304).We thank Helge Kainulainen and Ronny Schreiber at the depart-ment of Neuroscience and Biomedical Engineering, Aalto UniversitySchool of Science, Finland, for the technical support with theaccelerometer.
Appendix A. Supplementary data
Supplementary data associated with this article can be found, inthe online version, at http://dx.doi.org/10.1016/j.jneumeth.2015.05.015
References
Bourguignon M, De Tiège X, de Beeck MO, Ligot N, Paquier P, Van Bogaert P, et al.The pace of prosodic phrasing couples the listener’s cortex to the reader’s voice.Hum Brain Mapp 2013;34(2):314–26.
Brodeur MB, Dionne-Dostie E, Montreuil T, Lepage M. The Bank of StandardizedStimuli (BOSS), a new set of 480 normative photos of objects to be used as visualstimuli in cognitive research. PLoS One 2010;5(5):e10773.
Deletis V, Fernández-Conejero I, Ulkatan S, Rogic M, Carbó EL, Hiltzik D. Methodologyfor intra-operative recording of the corticobulbar motor evoked potentials fromcricothyroid muscles. Clin Neurophysiol 2011;122(9):1883–9.
Eldaief MC, Press DZ, Pascual-Leone A. Transcranial magnetic stimulation in neu-rology: a review of established and prospective applications. Neurol Clin Pract2013;3(6):519–26.
Epstein CM, Lah JJ, Meador K, Weissman JD, Gaitan LE, Dihenia B. Optimum stimulusparameters for lateralized suppression of speech with magnetic brain stimula-tion. Neurology 1996;47(6):1590–3.
Forster M, Hattingen E, Senft C, Gasser T, Seifert V, Szelényi A. Navigated TranscranialMagnetic Stimulation and functional Magnetic Resonance Imaging—advancedadjuncts in preoperative planning for central region tumors. Neurosurgery2011;68(5):1317–25.
Hernandez-Pavon JC, Mäkelä N, Lehtinen H, Lioumis P, Mäkelä JP. Effects of navigatedTMS on object and action naming. Front Hum Neurosci 2014;8:660.
Hillman RE, Heaton JT, Masaki A, Zeitels SM, Cheyne HA. Ambulatory monitoring ofdisordered voices. Ann Otol Rhinol Laryngol 2006;115(11):795–801.
Ille S, Sollmann N, Hauck T, Maurer S, Tanigawa N, Obermueller T, et al.Impairment of preoperative language mapping by lesion location: afunctional magnetic resonance imaging, navigated transcranial magneticstimulation, and direct cortical stimulation study. J Neurosurg 2015.,http://dx.doi.org/10.3171/2014.10.JNS141582 (Epub ahead of print).
Krieg SM, Sollmann N, Hauck T, Ille S, Foerschler A, Meyer B, et al. Functional languageshift to the right hemisphere in patients with language-eloquent brain tumors.PLoS One 2013;8(9):e75403.
Krieg SM, Sollmann N, Hauck T, Ille S, Meyer B, Ringel F. Repeated mapping of corti-
cal language sites by preoperative navigated transcranial magnetic stimulationcompared to repeated intraoperative DCS mapping in awake craniotomy. BMCNeurosci 2014;15:20.Lindstrom F, Ren K, Li H, Waye KP. Comparison of two methods of voice activitydetection in field studies. J Speech Lang Hear Res 2009;52(6):1658–63.

euros
L
M
M
O
O
P
P
R
R
A.-M. Vitikainen et al. / Journal of N
ioumis P, Zhdanov A, Mäkelä N, Lehtinen H, Wilenius J, Neuvonen T, et al. A novelapproach for documenting naming errors induced by navigated transcranialmagnetic stimulation. J Neurosci Methods 2012;204(2):349–54.
äkelä T, Vitikainen AM, Laakso A, Mäkelä JP. Integrating nTMS data into a radiol-ogy picture archiving system. J Digit Imaging 2015., http://dx.doi.org/10.1007/s10278-015-9768-6 (Epub ahead of print).
yers S, Hansen BB. The origin of vowel lenght neutralization in final posi-tion: Evidence from Finnish speakers. Nat Lang Linguist Theory 2007;25(1):157–93.
ppenheim AV, Schafer RW, Buck JR. Discrete-Time Signal Processing. 2nd ed. UpperSaddle River, NJ 07458: Prentice Hall; 1999.
rlikoff RF. Vocal stability and vocal tract configuration: an acoustic and electroglot-tographic investigation. J Voice 1995;9(2):173–81.
icht T, Schmidt S, Brandt S, Frey D, Hannula H, Neuvonen T, et al. Preoperativefunctional mapping for rolandic brain tumor surgery: comparison of navigatedtranscranial magnetic stimulation to direct cortical stimulation. Neurosurgery2011;69(3):581–8.
icht T, Krieg SM, Sollmann N, Rösler J, Niraula B, Neuvonen T, et al. A comparisonof language mapping by preoperative navigated transcranial magnetic stim-ulation and direct cortical stimulation during awake surgery. Neurosurgery2013;72(5):808–19.
ogic M, Deletis V, Fernández-Conejero I. Inducing transient language disruptionsby mapping of Broca’s area with modified patterned repetitive transcranial mag-netic stimulation protocol. J Neurosurg 2014;120(5):1033–41.
ösler J, Niraula B, Strack V, Zdunczyk A, Schilt S, Savolainen P, et al. Lan-guage mapping in healthy volunteers and brain tumor patients with a novel
cience Methods 253 (2015) 70–77 77
navigated TMS system: evidence of tumor-induced plasticity. Clin Neurophysiol2014;125(3):526–36.
Rossini PM, Barker AT, Berardelli A, Caramia MD, Caruso G, Cracco RQ, et al.Non-invasive electrical and magnetic stimulation of the brain, spinal cordand roots: basic principles and procedures for routine clinical application.Report of an IFCN committee. Electroencephalogr Clin Neurophysiol 1994;91(2):79–92.
Ruohonen J, Karhu J. Navigated transcranial magnetic stimulation. Neurophysiol Clin2010;40(1):7–17.
Samjin C, Zhongwei J. Comparison of envelope extraction algorithms for cardiacsound signal segmentation. Expert Syst Appl 2008;34:1056–69.
Sollmann N, Picht T, Mäkelä JP, Meyer B, Ringel F, Krieg SM. Navigatedtranscranial magnetic stimulation for preoperative language mapping in apatient with a left frontoopercular glioblastoma. J Neurosurg 2013a;118(1):175–9.
Sollmann N, Hauck T, Hapfelmeier A, Meyer B, Ringel F, Krieg SM. Intra- and interob-server variability of language mapping by navigated transcranial magnetic brainstimulation. BMC Neurosci 2013b;14:150.
Summerfield Q. Lipreading and audio-visual speech perception. Philos Trans R SocLond B: Biol Sci 1992;335(1273):71–8.
Tarapore PE, Findlay AM, Honma SM, Mizuiri D, Houde JF, Berger MS, et al. Language
mapping with navigated repetitive TMS: proof of technique and validation. Neu-roImage 2013;82:260–72.Vitikainen AM, Salli E, Lioumis P, Mäkelä JP, Metsähonkala L. Applicability of nTMS inlocating the motor cortical representation areas in patients with epilepsy. ActaNeurochirurgica 2013;155(3):507–18.





























