Embed Size (px)
Citation preview

Availability Models with Age-Dependent Checkpointing *
Tadashi Dohit Naoto Kaiot Kishor S. Triveditt
tDepartment of Information Engineering, Hiroshima University Higashi-Hiroshima 739-8527, Japan; dohiere1 . hiroshima-u. ac . jp
*Department of Economic Informatics, Hiroshima Shudo University Hiroshima731-3195, Japan; kaioashudo-u.ac. jp
ttDepartment Electrical and Computer Engineering, Duke University Durham, NC 27708-029 I , USA; ksteee .duke. edu
Abstract
In rhis papec we consider a new srochasric model for a j l e recove? action with checkpointing when the system failure occurs according to a homogeneous Poisson pm- cess. The presenr checkpoint model srrongly depends on the sysrem age and is qirite differeritfrom the earlier mod- els by Gelenbe (1979) and Goes and Sumita (1995). We propose three kinds of appmximation schemes ro determine the optimal checkpoinr interval which marimiies the system availability, taking accoimt of queueing effecr due ro idle periods in rhe rransaction processing swrein. In niimeri- cal examples, the checkpoint model based oit rhree approx- imation schemes is compared with earlier models quanri- tarively, and ir is shown rhar rhe preseiir checkpoint model can reduce the system overhead njhich may occur in an U I I -
planned sysrem downtime.
Keywords: checkpoint, rollback recovery, availability. f i le system, age-dependent model, approximation
1 Introduction
Checkpointing and rollback recovery is a commonly used technique for improving the reliability/availability o f fault-tolerant computing systems. Especially, when the l i l e system to write and/or read data is designed in terms of pre- ventive maintenance, checkpoint generations play an impor- tant role to l imit the amount of data processing for the re- covery actions after system failures occur. I f checkpoints are frequently taken, a larger overhead wil l be incurred.
'This m a t e d i s bared upon the suppan by the Ministry of Education. Culture. Sports. Science and Trchnology: Grants-in-Aid for Scientific Re- search in Japan, Grant No.13780367. and the Research Program 2002 un- der the Institute for Advanced Studies of lhe Hiroshima Shudo University. Hiroshima, Japan.
Conversely, i f only a few checkpoints are taken, a larger overhead after system failures wil l be required in the roll- back recovery actions. Hence. i t i s important to determine the optimal checkpoint interval taking account the trade-off between two kinds of overhead factors above. Several prob- lems o f determining the optimal checkpoint sequence have been studied in the literature.
Young [I] obtained the optimal checkpoint interval ap- proximately for the computation restan after system fail- ures. Chandy er al. [2, 31, Gelenbe and Derochette [4], Gelenbe [5] , Kulkarni er a/ . [ 6 ] , Grassi er al. [7] and Ge- lenbe and Hernandez [SI proposed performance models for database recovery. and calculated the optimal checkpoint in- tervals which maximize the system availability or minimize the mean overhead during the normal operation. Toueg and Babaoglu [9] developed a dynamic programming algorithm which minimizes expected execution time o f tasks placing checkpoints between two consecutive tasks under very gen- eral assumptions. Baccelli [IO]. Sumita eral. [I I ] and Ge- lenbe and Hernandez [ I21 extended the standard periodic checkpoint model in [ 5 ] , and provided more general per- formance models, under the assumption that system fail- ures occur in accordance with a non-homogeneous Pois- son process and incorporated with the rollback procedure dependent on the cumulative operation time since the last checkpoint. Ziv and Bruck [13], Vaidya [I41 and Plank and Elwasif [ I S ] pointed out several problems in earlier checkpoint models and suggested to modify the theoreti- cal results. Recently, Neves and Fuchs [ 161 and Ssu et al. [ 171 discussed adaptive checkpointing and recovery strate- gies for mobile environments.
An interesting attempt was made by Nicola and Van Spanje [ IS] . They developed so-called the control-limirt)pe "fpolicy to make checkpoint decision based on the num- ber o f transactions that have arrived, and compared different checkpoint models. Also, Goes and Sumita [I91 and Goes
1060-9857102 $17.00 Q 2002 IEEE 130

[ZO] proposed new checkpoint models with restart, instead of periodic checkpoint placement. The main advantage for the periodic checkpointing in previous works [ I -& 10-121 is the ease of administration, since the checkpoint is placed periodically even if a number of system failures occur dur- ing the checkpoint interval. However, it should be noted that in periodic checkpoint models, the information recov- ered by the rollback procedure after a system failure is not always backed-up in the seconday medium. This fact will affect the data maintainability strongly and will reduce the checkpointing effect, especially, in an unreliable system cir- cumstance.
In general, the information in primary memory should he backed-up after completing the rollback recovery as well as at the time of the checkpoint in a secondary medium. Note, however, that an additional checkpoint after the roll- back recovery has never been assumed in many periodic models [l-8, 10-121. An interesting hut somewhat differ- ent checkpoint 'model from the periodic one was developed by Goes and Sumita [191. They assumed in their model that the system is restarted after the rollback procedure, hut the recovery procedure under consideration is questionable in terms of preventive maintenance, since they assumed that the system is renewed after the recovery procedure. This will be incorrect due to the reason that the system can not be renewed without checkpointing, as mentioned in the lat- ter part. Thus, the earlier checkpoint models involve an un- realistic assumption. This motivates us to develop a new checkpointing strategy depending on the system age. The main purpose of this paper is to develop a new stochas- tic model to overcome the problem mentioned above. The present checkpoint model strongly depends on the system age, and is similar but somewhat different from the earlier model proposed by Gelenbe [5 ] and Goes and Sumita [19].
The paper is organized as follows. Section 2 describes two ealier availability models for a file recovery action with checkpointing when the system failure occurs according to a homogeneous Poisson process. In Section 3, under the as- sumption that the system is continuously used, we develop a new type of age-dependent checkpointing model. After some mathematical preliminaries, we derive necessary and sufficient conditions on the existence of the optimal check- point.interval which maximizes the system availability. Sec- tion-4 is devoted to approximate the system availability, when the file system is used intermittently used. That is, we suppose that transactions arrive at the system according to a homogeneous Poisson process and that the processing times are independent and identically distributed (i.i.d.) random variables having the common exponential distribution. In order to model such a dynamic circumstance consistently. we model the system availability. and derive the optimal
.Checkpoint intervals approximately. The basic idea is due to an interesting insight based on the ergodic conditional
recovery overhead
I ( f ) = I
C / ( I ) = 0
Figure 1. Configuration of Model 1.
probability that the system is idle (see [SI). In Section S. numerical examples are presented, where three checkpoint models under different approximation schemes are com- pared quantitatively. It is shown that the present checkpoint model can reduce the system overhead which may result in an unplanned system downtime.
2 Earlier Results
2.1 Model 1 [5]
Following Gelenbe [SI. we describe the basic stochas- tic model (Model I ) with periodic checkpointing. System failures occur according to a homogeneous Poisson pro- cess with intensity X (> 0). More specifically, let X ( t ) be the cumulative operation time for the file system at time t since the last checkpoint. Then the probability that a sys- tem failure occurs in the time interval ( t , t + A ] is given by AA +.(A). Upon a failure, a rollback recovery takes place where both the information of transactions saved at the last checkpoint creation and that recorded in the log file is used for restoring the system to a usable state. The length of the rollback recovery is assumed to depend on the number of transactions executed, i.e., on the value of X ( t ) at the time of failure.
We employ a generic random variable V, denoting the length of the rollback recovery given that a failure occurs at time t with X ( t ) = 2. The distribution of V, is de- noted by B,(y) = Pr{V, < y} with density b,(y). Inter- vals between two consecutive checkpoints are determined by the total operation time excluding rollback periods.' The i-th checkpoint is generated as soon as the total operation time excluding rollback periods since the (i - 1)st check- point reaches the length S, (i = 1 , 2 , . . .). Assume that Si (i = I, 2 , . . . ) constitute a sequence of random vari-
131

ables with common distribution A ( z ) = Pr{S, 5 z} and - hazard rate ~ ( x ) = ( d A ( z ) / d z ) / x ( z ) , where in general b(.) = 1 - $(.). Times (overheads) required for creating checkpoints also form a sequence of i.i.d. random variables C, (i = 1,2 , . . .) with W ( z ) = Pr(Ci 5 z ) and density
Let S; (i = 1: 2,. . . ) be the actual time interval be- tween the (i - 1)st and the i-th checkpoints. Then, since Si (i = 1 , 2 : . . .) is a sequence of i.i.d. random vari- ables, checkpoints are clearly renewal points. From the well-known renewal reward argument 1211. it is sufficient to consider only the system behavior for one cycle and hence we drop the discrete time index i (i = 1,2, . . . ) in the fol- lowing discussion. For convenience, define the stochastic process { I ( t ) , t 2 0) as follows.
m(x) = dW(z)/dz .
0 if a checkpoint is being created at time t 1 if the file system is operating normally
I((.) = at timet 2 if the file system is recovering from i a system failure at time t .
To simplify the discussion, we assume X ( t ) = 0 at the time of departure from state I ( t ) = 0. Further, we define the stochastic process (Y ( t ) ; t 2 0) as the elapsed time since the last failure interruption, given I ( t ) = 2. In other words, Y ( t ) isdef inedtobezeroifI( t ) # 2.
We now are in the position to characterize the stochastic system by the trivariate process { X ( t ) , Y ( t ) , I ( t ) , t 2 0). Because of the renewal nature of both checkpointing and recovery, the stochastic behavior of the trivariate process has a cyclic structure as depicted i n Fig. I . Since one cycle is defined as the time period between commencing at the end of one checkpoint and ending at another checkpoint. the mean length of one cycle is Ew[C] + E[Ses], where
is called rhe effedve operaring rime. Consequently, the steady-state system availability is given by:
where
E [ S ~ ~ I = EA[S] + J m d ~ ( z ) [ X E ~ [ K I ~ ~ . (2) 0 0
If one focuses on the constant checkpoint strategy (such a treatment is validated theoretically), then the randomized policy A(z) is translated to the constant policy T. More specifically, putting
1 i f z > T 0 otherwise, A(z) = U ( z - T) =
where U ( . ) is the unit step function, the system availability with constant checkpoint strategy is given by
and the problem can be reduced lo the simple algebraic one, i.e. maxO<T<- AV, (7’).
2.2 Model 2 [191
recovery overhead
A
Figure 2. Configuration of Model 2.
Next, we introduce a different checkpoint model (Model 2) with restart by Goes and Sumita [191. With the same no- tation as Model 1, suppose that the checkpoint is placed at the random sequence S; (i = 1,2,. . .). If the system failure occurs at time x before the scheduled checkpoint creation, then the rollback procedure is started immediately. After the time length V, is spent for the rollback recovery, the check- pointing clock is reset. It should be noted that the informa- tion recovered after the rollback procedure is not saved until the next checkpoint, even in Model 2. From the similar re- newal nature to Model I , one cycle is defined as the time pe- riod between commencements of system operation. Figure 2 illustrates the possible realization of the system behavior in Model 2. In this model, the checkpoint is never placed if the system failure occurs before S time unit elapses. In other words, the time lengh to place a checkpoint during one cycle is a random variable depending on the age x.
Goes and Sumita 1191 derived the mean effective operat- ing-time for Model 2 as
””
+ lm X e - ” E ~ [ V ~ ] ~ ( z ) d z . (4)
Since the mean overhead by the checkpointing during one cycle is
oc = x ~ - A = E ~ [ c I A ( ~ ) ~ ~ , ( 5 )
132

recovery overhead
Figure 3. Configuration of Model 3.
the system availability in Model 2 becomes
Replacing A(z) by the unit step function U ( z - T ) i n Eq.(3). the system availability with the constant checkpoint strategy i s
AV2(T) =
3 The New Checkpointing Model
Note that in both Model I and Model 2 the information in the primary memory is recovered by the rollback proce- dure after the system failure occurs, but i s not saved in the secondary medium. This fact tells us that two earlier avail- ability models can not represent the well-behaved check- pointing and rollback recovery procedure i n practice. That is. i f an additional system failure occurs after completing the rollback recovery for the first failure, the next rollback procedure has to be made again with both pieces of infor- mation saved at the last checkpoint creation and retained in the log file. The present model (Model 3) i s developed to overcome this problem. Suppose that the checkpointing i s always performed after rollback recovery actions when the system failure occurs as well as in the scheduled checkpoint interval.
In order tu complete our discussion. begin from the for- mal definition of the new model. Suppose that the file sys- tem i s operated i n continuous time. System failures occur at the i.i.d. exponential random variables with parameter
X (> 0). Upon a failure, a rollback recovely takes place where both pieces of information saved at the last check- point creation and recorded in the log file are used for restor- ing the system to a usable state. A checkpoint i s placed just after the rollback recovery, and all information i s backed-up from the primary memory to the secondary medium. Ad- ditionally, a scheduled checkpoint is placed at the end of interval with the length Si (i = 1 , 2 , . -.) . Assume that S, (i 1 , 2 , . . . ) constitutes a sequence of random vari- ables with common distribution A ( s ) = Pr{Si 5 z) with density a(.) and hazard rate U(.) = a(z) /x(z) . Times (overheads) required for creating checkpoints also form a sequence of i.i.d. random variables C, (i = 1,2;. . .) with W ( z ) = Pr{C, 5 z } and density w(z) = dW(z)/dz. Similar to Model I and Model 2, we drop the subscript of Si and Ci
Of our interest i n this section i s the effective operating time Se, describing the cumulative elapsed time since the last checkpoint. Using the well-known state-space method, we obtain the following results.
LEMMA 3.1. The Laplace rransform of the effective opera- tion rime se^ in Model 3 is
where, in general, &s) = J,"exp(--sz)$(z)dz.
COROLLARY 3.2. The meart effecrive operation rime and the variance in Model 3 are
E[S,R] = 1- e-(S+A)TdA(z)
+/om Xe-(s+A)5i(z)&,(s)dz (9)
and
Var[S,~l =EIS$] - {E[Se~]}*; (10)
respectively, where m
E[S&] = 1 0 {2z(l+ XEBIV,]) + XEB[I/:]}
Xe-A=Z(Z)dZ. (11)
From the results above, we obtain the steady-state prob- abilities as follows:
133

(14)
The system availability i s then AV? = Ill. Funher, we de- fine a set of all A ( x ) s as JT. Then, the optimal checkpoint interval which maximizes AV3 can be characterized as fol- lows.
LEMMA 3.3. Let JT be a set ofall A(z)s with fired ex- pectation T € [0, CO). Then. the elemenr A ( z ) of the set
JT which maximizes the system availabilit?. AV, is also A ( x ) = U ( x - T).
From Lemma 3.3, the randomized policy A ( z ) i s translated totheconstant poliy T, and wecan replace AV4 by AVJ(T), where
Jc e-’=dx
Jc{ 1 + XE~[l / , ]}e-”dz + Ew[C] AVs(T) = (15)
Then, the problem i s to obtain the optimal checkpoint inter- val T’ which maximizes AVs(T).
Define the functions li(:c) = XEB[V=] and
T h e following results give the optimal checkpoint strategy which maximizes the system availability in Model 3.
THEOREM 3.4. There exists at least one optimal checkpoint itirerval which marimizes the system ar,ailabiliry. Ifq(co) < 0. then it should befinite.
THEOREM 3.5. (i) Suppose that thefunction h(x) is strictly increasing in x. ,fq(m) < 0, then there exists nfnite and unique optimal checkpoint interval T’ (0 < T’ < co) saf- ishing the non-linear equation q(T’) = 0. and :he m i - mum system availabiliQ is given bv
(ii) If q(m) 2 0 with strictly increasing h ( x ) or ifthefunc- tion h(z) is decreasing in x . then the optimal checkpoint interval is T’ - 03, i.e.. no checkpoint should be placed and the maximum system availability is given by
AV’(CO) =
I n this section, we consider the simple model where the file system i s operating in continuous time. However. i t
should be noted that the actual file management system should be treated as an intermittently used system. That is. the file system i s alternatively operative and inoperative, and strictly speaking, should be formulated as a queueing model. In the following section. we re-formulate the under- lying problem taking account of queueing effect and derive the optimal checkpoint strategy approximately.
4 Approximating System Availabilities
Three models mentioned in the previous sections assume implicitly that the system i s operating in continuous time. Since the real file system i s alternatively operative and in- operative, however, one needs to model the intermmitently used environment. More precisely, consider the following queueing model. Suppose that transactions arrive at the sys- tem according to a homogeneous Poisson process with in- tensity U (> 0) and that the processing times are i.i.d. ran: dom variables having the common exponential distribution with mean l / p (> 0). where p = v / p i s the utilization factor (traffic intensity). I n other words, the file system un- der consideration i s modeled by an iU/Al/llm queueing system. In this situation, the recovery time required in the rollback procedure should he measured by the cumulative operating time during the busy period.
Now, we specify the random variable V, denoting the length of the rollback recovery. Following the literature [I- 5, 10-12, 19,201, define the affine form:
ER[V=] = ax + P, a t 0: ,O t 0, (19)
where the first term denotes the mean time necessary to re- execute transactions which were processed in time interval [O,z], and the second term i s a tixed time associated with reloading the information stored at the checkpoint hack into primary memory. Intuitively, the recovery parameter a has to he a function of arrival and processing parameters, v and f i , When the system can he regarded to he continuously operating (heavy loaded), roughly speaking, the parameter a can he approximated as constant. i.e. a = I; (> 0 : constant).
However, i f the system i s influenced by the ar- rivallprocess of transactions and i s light loaded, the param- eter depends on the length of busy period. Chandy er al. [Z, 31 and Gelenbe and Derochette [4] assumed that the re- covery parameter i s proportional to the utilization factor p which denotes the probability that the system i s busy in the steady state, i.e. a = kp. Further. Gelenbe [51 introduced the ergodic conditional probability that the system i s busy given that the system i s operating. and developed a sophis- ticated approximation scheme. In fact, since i t i s difficult to capture completely the transient behavior of the busy period even for the Mlhl/llca, these approximation schemes are
134

useful to represent the system availability under an intermit- tently used environment.
In this paper, we use the following classification:
Approximation Scheme 1: a = k (constant),
Approximation Scheme 2: a kp.
Approximation Scheme 3: a % k ( l - p * ) ,
where p' is defined as the ergodic conditional probability that the file system is idle given that the system is operating. Without any loss of generality. we suppose the light traffic condition i.e. p < 1 and focus on Approximation Scheme 3 in the rest part of this section.
Denote the number of transactions anived at the system until time t by { N ( t ) , t 2 0}, where N ( 0 ) = 0 at the end of state I ( t ) = 0. Define the following joint conditional probability:
F(n;z;. t) = Pr{N(t) = n , X ( t ) 5 z 1 I ( t ) = I}, (20)
where
(21) a
f(n, z, t ) = --F(n: 5; t ) . ax
Also, define
m
Q ( u , s ) = C."i(n,s), n=O
(25)
where i ( n , s) = J," exp(-sz)f(n, z)dz. In the time interval [t , t + A), let us consider the case of
n > .O and z > 0. Then, a simple probabilistic argument yields
f ( n , z + A , t + A ) = ( l - ~ A ) ( l - p A ) ( l -AA) x (1 - ~ ( z ) A ) f ( n : %, t ) + ~ A f ( n - 1, Z, t ) +pAf(n + l ,z , t ) + o(A).
(26)
If n = 0 and z > 0, one sees that
f(0,z + A , t + A) = (1 - uA)(l - AA)(l - v(z)A) xf(O,z,t) +pAf (Lzc , t ) +o(A). (27)
If n 2 0 and z > 0, it holds that f(n, z,O) = 0. On the other hand, for n 2 0 and z = 0, one has
- =- {UZ} ' 1 i Z T xl)(z)w(z)dzdr + xe-"'Af(n - j , z , t - z )b , I w(r)dzdz,
(28)
where b, * w(z) denotes the convolution of the functions b,(z) and ~ ( 2 ) .
In the case of n > 0 and z > 0, letting A - 0, we have the following differential equation:
Similarly. in the case of n = 0 and z > 0, it can be seen that
a a (at + z ) f ( O ; z ; t ) = - { u + + a(z) } x f ( O , z , t ) + u f ( n - 1, z : t ) + pf(I ;z , t ) . (30)
We assume throughout the remaining parl of this paper that the queueing system is ergodic.
LEMMA 4.1. If there exisr the solirrions in Eqs. (29) and (30), fken
- e - " = } X a ( u , z)dz, (31)
where
X&,(V(l -U)) - l ]As(u ,z )dz)
e-"(l-u)* ur(z)dz, (33)
b,(z)dz . (34)
I=- Z;(u(l- .)) =
b&(l -U)) =
135

LEMMA 4.2. r'fthere exisr rhe solutions in Eqs. (29) and (30). then
THEOREM 4.3. There exisr rhe soluriom in Eqs. (29) and (30). iff
(36)
For studying the optimal checkpoint interval, i t is nec- essary to derive the ergodic conditional probability p* that the file system is idle given that the state of the process ( I ( t ) ; t 2 0) is in State 1. Define the ergodic conditional probability by
U - < AV3(T). P
p' = J , f ( 0 : z)ds = j (0 ,O) . (37)
Following Gelenbe [SI. one then has
a = k ( 1 - p * ) . (38)
The following are the main results of this paper.
THEOREM 4.4.
THEOREM 4.5. Under rhe approximation scheme a %
k(l - p*) . define rhefuncrion
T qp(T) = {1-,,AT}{/ e - A 2 d z + o ( l - e - A = )
0
+Ew[cl} - (1 + P A ) { (1 - kp)
x l T e - ~ z d z + kpTe- *z } . (40)
( i ) If qP(3o) < 0. rhen there exisrs a finite and unique op- timal checkpoint inrerval T' (0 < T' < 00) satisfiing rhe non-linear equation qp(T*) = 0, und rhe maximum system availabilip is
(ii) r'fq.(m) 2 0, rhen the optimal checkpoinr inrerval is T' + 00 and rhe maximum system availabilip is
( 1 - kp)X A + P + Ew[C]
AVs(m) = (42)
Similar results for Model I were derived by Gelenbe U]. On the other hand. the approximation results for Model 2 were not found in the literature [19], but can be obtained with the similar state-space method as the above.
5 Performance Comparison
Of our interest in this section is the comparison of three models: Model 1, Model 2 and Model 3. We compare three checkpoint models numerically, under different approxima- tion schemes. Define the following probabilities for Model j (j = 1,2,3) .
A R j ( T ) : probability that the rollback procedure takes place in the steady state
ACj(T): probability that the checkpointing is performed
It is evident that AI/,(T) + ARj(T) + ACj(T) = 1. ( j = 1,2,3) . In the following, we give those probabilities for respective models.
in the steady state
JT Ae-X'Es[V,]dz sT(l +XEB[V, ] )~ -"~&C +Ew[C]'
Ew[Cl s,'(l+ X E B [ V ~ ] ) ~ - ~ % Z + Ew[C]'
ARs(T) =
(47)
ACs(T) =
(48)
under an arbitrary approximation scheme. First, let us consider Approximation Scheme I. Tables
I - 3 present the dependence of the failure rate X on the optimal checkpoint interval and its associated system avil- ability for Model 1 - Model 3. For the same failure rate, Approximation Scheme I provides the smallest checkpoint interval and availability. This is because the other schemes, Approximation Scheme 2 and Approximation Scheme 3, assume an idle period due to the anivallprocess of transac- tions in the file system operation. Hence, the system over- heads, ARj(T*) and ACj(T') ( j = 1,2,3) , in Approxi- mation Scheme I are larger than those in both Approxima-
136

lion Scheme 2 and Approximation Scheme 3. Since Ap- proximation Scheme 1 can be considered as an approxima- tion method under the heavy traffic condition, the above ob- servation seems to he quite valid. Also, it is seen that the op- timal checkpoint interval and the corresponding maximum system availability in Approximation Scheme 2 are larger than or equal to those in Approximation Scheme 3. Espe- cially. as the failure rate increases, the system availability in Approximation Scheme 3 decreases for that in Method 2. As Gelenbe (51 pointed out, since Approximation Scheme 2 is based on the approximation U % k p [2 . 3, 41 where p is the ergodic unconditional probability that the system is busy, note that it involves a theoretical problem. On the other hand, Approximation Scheme 3 can provide a theoret- ical valid approximation scheme U % k ( l - p' ) 151 based on the ergodic conditional probability. This result tells us that Approximation Scheme 2 may often underestimate the system availability for the larger failure rate. Also, even if the failure rate is quite small, Approximation Scheme 2 gives a little larger checkpoint interval than Approximation Scheme 3. and provides the optimistic checkpointing deci- sion from the reason that the corresponding system over- heads, AR,(T*) and ACj(T') ( j = I;2,3), take small values.
0.00010 664.3390 0.00050 295.4160 0.00100 207.8010 0.00500 90.1237 0.01000 61.7720 .
Next, we cumpare three different Checkpoint models. From Tables I - 3, it can be found that the system avail- ability for Model 2 is the largest. This tendency becomes re- markable as the failure rate increases. Hence, if one wishes to maximize only the system availability, it can be con- cluded that Model 2 is the best checkpoint model, i.e. if the system failure occurs, the checkpointing clock should be reset after the rollback procedure is completed. How- ever, it is noted that Model 2 also gives the largest overhead ARj(T') ( j = 1; 2: 3) in almost cases. Since AR,(T*) is the steady-state probability that the system is recovered af- ter a failure, the largest AR,(T*) means the largest system overhead which may occur in an unplanned system down- time. It is well known that the unplanned downtime is ex- tremely more expensive than the planned downtime by the scheduled checkpointing. Especially, if the failure rate is larger than 0.00500. the system overhead by the rollback recovery can be expected to be larger. This fact claims that the checkpoint scheme such as Model 2 will not be used for a crilial file system with the expensive cost for the un- planned downtime. On the other hand, Model 3 can pro- vide the smallest ARj(T ' ) and the largest AC,(T') exept for the case of X = 0.00001 in Approximation Scheme I . If the planned downtime cost is relatively cheaper than the unplanned downtime cost and if the absolute value of the downtime cost per unit time is larger than the reward rate in the operation, our new checkpoint model can give a very reasonable checkpointing scheme.
0.9930 0.0040 0.0030 0.9818 0.0116 0.0066 0.9716 0.0191 0.0093 0.9138 0.0660 0.0202 0.8586 0.1137 0.0277
Table 1. Dependence of the failure rate on the optimal checkpoint interval (Model 1): k =
0.3! S W [ C ] = 2.0! q3 = 10.0 and p = 0.3.
(a) Approximalion Scheme I .
( c ) Approximation Scheme 3.
0.00001 I2106.0800 0.9980 I 0.0010 1 0.0010 X I T' 1 AVl(T*) I A R , ( T * ) . / AC,(T')
o.00005 I 940.5770 I 0.9953 I 0.0026 I 0.0021
Finally, we examine the effect of the utilization factor on the optimal checkpoint interval. Table 4 present the depen- dence of p on the optimal checkpoint policy and its associ- ated ergodic probabilities in Model 3. As p increases, i.e. the traffic condition becomes heavy, the optimal checkpoint interval based on Approximation Scheme 2 and Approxi- mation Scheme 3 monotonically decreases. In particular, the difference between these two approximation methods becomes remarkable for a relatively large utilization factor. In other words, two approximation methods, Approxima- tion Scheme 2 and Approximation Scheme 3, do not give a significant difference with small utilization factor. Though the result for Approximation Scheme 2 approaches to that for Approximation Scheme I when the utilization factor is approximately unity, this does not mean that Approxima- tion Scheme 2 can approximate better than Approximation Scheme 3.
137

Table 2. Dependence of the failure rate on the Table 3. Dependence of the failure rate on the optimal checkpoint interval (Model 2): k = optimal checkpoint interval (Model 3): k = 0.3! $3Ecrr[G] = 2.0! $9 = 10.0 and p = 0.3. 0.3! $EW[C] = 2.0! = IO 0 and p = 0.3.
6 Conclusion
In this paper, we have developed a new age-dependent checkpoint model and evaluated its availability perfor- mance. It is shown numerically that the proposed age- dependent checkpointing method can reduce the system overhead which may occur in an unplanned system down- time. In addition, this new model describes a reasonable checkpoint generation scheme from the practical point of view, and at the same time satisfies our intuition. The basic idea is due to Goes and Sumita [19], but it should be noted that their model is questionable since the checkpointing is performed only when the system failure does not occur dur- ing pre-determined time interval. Also, the existing periodic method by Gelenbe 151 and others determines the check- pointing schedule by only the calendar time, but our model is based on both the system age and the calendar time. In future, an on-line checkpoint algorithm based upon the age- dependent structure should be developed. Then, the com-
(b) Approximation Scheme 2.
parative results given in this paper will be useful to evaluate the model performance.
References
[ I ] Young, 1. W. (1974). A first order approximation to the optimum checkpint interval, Comm. of the ACM, 17 (9). 530-531.
[Z] Chandy, K. M. (1975). A survey of analytic models of roll-back and recovery strategies. Comprrfer. 8 (5 ) . 40-47.
[3] Chandy, K. M., Browne, I. C.. Dissly. C. W. and Uhrig, W. R. (1975). Analytic models for rollback and recovery strategies in database systems, lEEE Trans. Sofiwre Eng., SE-1 ( I ) , 100-1 IO.
138
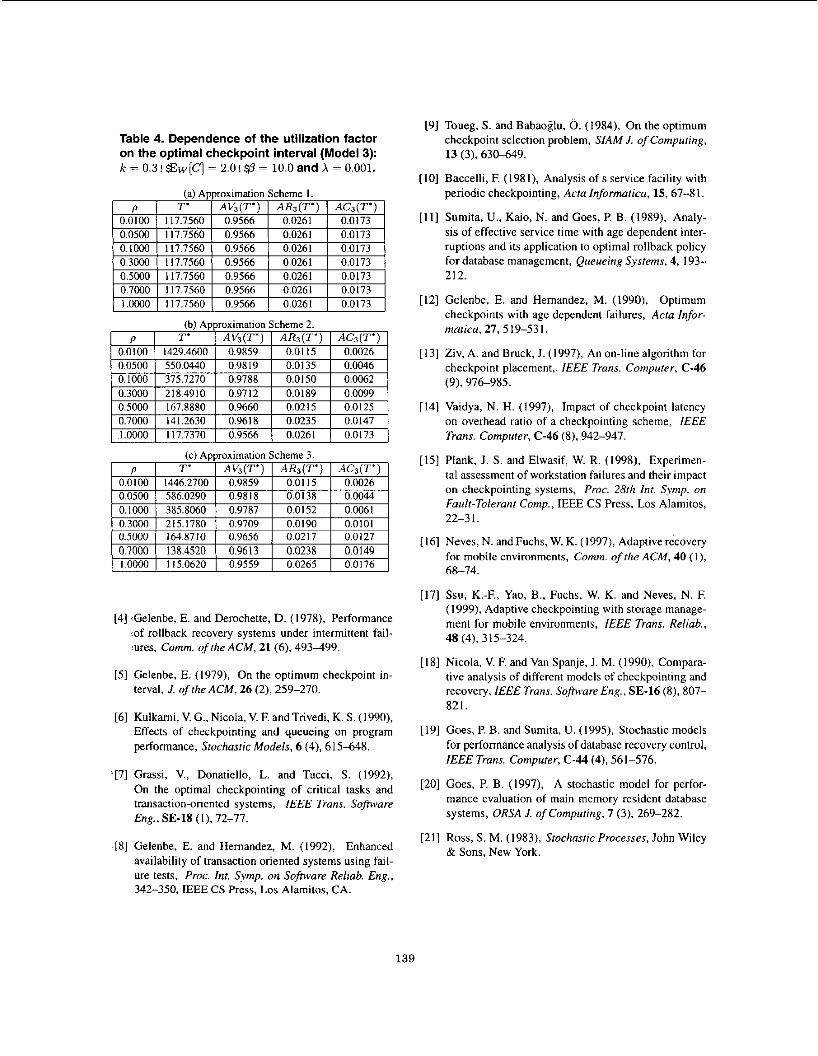
Table 4. Dependence of the utilization factor on the optimal checkpoint interval (Model 3): I; = 0.3! $&[Cl = 2.0! 4 = 10.0 and X = 0.001.
(a) Approximation Scheme 1.
0.0100 I 117.7560 I 0.9566 I 0.0261 I 0.0173 P I T' I AV3(T') I ARJ(T*) I AC3(T')
141 Gelenbe, E. and Derochette, D. (1978), Performance <of rollback recovery systems under intermittent fail- iures. Comm. ofthe ACM, 21 (6). 493499.
I51 Gelenbe, E. (19791, On the optimum checkpoint in- terval, J. ofrhe ACM, 26 (2). 259-270.
I61 Kulkarni, V. G.. Nicola, V. E andTrivedi, K. S. (1990). Effects of checkpointing and queueing on program performance, Srochasric Models. 6 (4). 615-648.
'[7l Grassi, V., Donatiello, L. and Tucci, S. (1992). On the optimal checkpointing of critical tasks and transaction-oriented systems, IEEE Trans. Sofrware Eng., SE-18 (I), 72-77.
[ S I Gelenbe, E. and Hernandez, M. (1992), Enhanced availability of transaction oriented systems using fail- ure tests. Proc. Int. Symp. on Sofiare Reliab. Eng., 342-350, IEEE CS Press, Los Alamitos, CA,
I91 Toueg, S . and Babaoglu, 0. (1984). On the optimum checkpoint selection problem, SIAM J. of Computing, 13 (3), 6 3 W 9 .
[IO] Baccelli, E (1981). Analysis of s service facility with periodic checkpointing, Acta Informatica, 15, 67-81.
[ I l l Sumita. U., Kaio, N. and Goes, P. B. (1989). Analy- sis of effective service time with age dependent inter- ruptions and its application to optimal rollback policy for database management, Queueing Systems, 4, 193- 212.
I121 Gelenbe, E. and Hernandez, M. (1990). Optimum checkpoints with age dependent failures, Acta Infor- matico, 27,519-531.
I131 Ziv, A. and Bruck, 1. (1997). An on-line algorithm for checkpoint placement, IEEE Trans. Computer, C-46 (9). 976-985.
cl41 Vaidya, N. H. (1997). Impact of checkpoint latency on overhead ratio of a checkpointing scheme, IEEE Trans. Computer, C-46 (8), 942-947.
1151 Plank. J. S. and Elwasif, W. R. (1998). Experimen- tal assessment of workstation failures and their impact on checkpointing systems. Proc. 28th Int. Symp. on Faulr-Tolerant Camp., IEEE CS Press, Los Alamitos, 22-3 I
1161 Neves, N. and Fuchs, W. K. (1997), Adaptive re'covery for mobile environments, Comm. of the ACM. 40 ( I ) , 68-74.
(171 Ssu, K.-E, Yao, B., Fuchs, W. K. and Neves, N. E (1999). Adaptive checkpointing with storage manage- ment for mobile environments, IEEE Trans. Reliab., 48 (4), 315-324.
1181 Nicola, V. E and Van Spanje. 1. M. (1990). Compara- tive analysis of different models of checkpointing and recovery, IEEE Trans. Sofiare Eng., SE-16 (8). 807- 821.
[I91 Goes, P. B. and Sumita, U. (199% Stochastic models for performance analysis of database recovery control, IEEE Trans. Computer, C-44 (4). 561-576.
[201 Goes, P. B. (1997). A stochastic model for perfor- mance evaluation of main memory resident database systems, ORSA J. of Compuring, 7 (3), 269-282.
1211 Ross, S. M. (1983). Stochastic Processes, John Wiley & Sons. New York.
139





























