Embed Size (px)
Citation preview

28
Backward recovery through check-pointing and rollback is a popular approachin modern processors to providing recoveryfrom transient and intermittent faults.1 Thisapproach is especially attractive when design-ers can implement it with very low overhead,typically using dedicated hardware support.
The many proposals for low-overheadcheckpointing and rollback schemes differ ina variety of ways, including the level of thememory hierarchy checkpointed and theorganization of the checkpoint relative to theactive data. Schemes that checkpoint at thecache level occupy an especially attractivedesign point.2,3 The hardware for theseschemes, which works by regularly saving thedata in the cache in a checkpoint that can laterserve for fault recovery, can be integrated rel-atively inexpensively and used efficiently inmodern processor microarchitectures.
Unfortunately, cache-level checkpointingschemes such as Carer2 and Sequoia3 don’t con-
tinuously support a large rollback window—the set of instructions that the processor canundo by returning to a previous checkpoint ifit detects a fault. Specifically, in these schemes,immediately after the processor takes a check-point, the window of code that it can roll backtypically is reduced to zero.
In this article, we describe the microarchi-tecture of a new cache-level checkpointingscheme that designers can efficiently and inex-pensively implement in modern processorsand that supports a large rollback windowcontinuously. To do this, the cache keeps datafrom two consecutive checkpoints (or epochs)at all times. We call this approach a sliding roll-back window, and we’ve named our schemeSwich—for Sliding-Window Cache-LevelCheckpointing.
We’ve implemented a prototype of Swichusing field-programmable gate arrays(FPGAs), and our evaluation of the prototypeshows that supporting cache-level check-
Radu TeodorescuJun Nakano
Josep TorrellasUniversity of Illinois at
Urbana-Champaign
EXISTING CACHE-LEVEL CHECKPOINTING SCHEMES DO NOT CONTINUOUSLY
SUPPORT A LARGE ROLLBACK WINDOW. IMMEDIATELY AFTER A CHECKPOINT,
THE NUMBER OF INSTRUCTIONS THAT THE PROCESSOR CAN UNDO FALLS TO
ZERO. TO ADDRESS THIS PROBLEM, WE INTRODUCE SWICH, AN FPGA-BASED
PROTOTYPE OF A NEW CACHE-LEVEL SCHEME THAT KEEPS TWO LIVE
CHECKPOINTS AT ALL TIMES, FORMING A SLIDING ROLLBACK WINDOW THAT
MAINTAINS A LARGE MINIMUM AND AVERAGE LENGTH.
SWICH: A PROTOTYPE FOREFFICIENT CACHE-LEVEL
CHECKPOINTING AND ROLLBACK
Published by the IEEE Computer Society 0272-1732/06/$20.00 © 2006 IEEE

pointing with a sliding window is promising.For applications without frequent I/O or sys-tem calls, the technique sustains a large min-imum rollback window and adds littleadditional logic and memory hardware to asimple processor.
Low-overhead checkpointing schemesTo help in situating Swich among the alter-
natives, it’s useful to classify hardware-basedcheckpointing and rollback schemes into ataxonomy with three axes:
• the scope of the sphere of backward errorrecovery (BER),
• the relative location of the checkpointand active data (the most current ver-sions), and
• the way the scheme separates the check-point from the active data.
Figure 1 shows the taxonomy.The sphere of BER is the part of the system
that is checkpointed and, upon fault detec-tion, rolls back to a previous state. Any schemeassumes that a datum that propagates outsidethe sphere is correct, because it has no mech-anism to roll it back. Typically, the sphere ofBER encloses the memory hierarchy up to a
particular level. Consequently, we define threedesign points on this axis, depending onwhether the sphere extends to the registers, thecaches, or the main memory (Figure 2).
The second axis in the taxonomy comparesthe level of the memory hierarchy checkpoint-ed (M, where M is register, cache, or memory)and the level where the checkpoint is stored.This axis has two design points:4 Dual meansthat the two levels are the same. This includesschemes that store the checkpoint in a specialhardware structure closely attached to M. Lev-eled means the scheme saves the checkpoint at
29SEPTEMBER–OCTOBER 2006
Register
Cache
Memory
Scope of the sphere of BER
Relativecheckpoint
location
Separation of checkpointand active data
Dual Leveled
Full
Partial
Buffering
Renaming
Logging
Figure 1. Taxonomy of hardware-based checkpointing and rollback schemes.
Register
Cache
Memory
Register
Cache
Memory
Register
Cache
Memory
IBM G5 Carer/Sequoia ReVive/SafetyNet/COMA
Figure 2. Design points based on the scope of the sphere of backward errorrecovery (BER).
a lower level than M—for example, a schememight save a checkpoint of a cache in memory.
The third axis, which considers how thescheme separates the checkpoint from the activedata, has two design points.5 In full separation,the checkpoint is completely separated from theactive data. In partial separation, the checkpointand the active data are one and the same, exceptthe data that has been modified since the lastcheckpoint. For this data, the checkpoint keepsboth the old value at the time of the last check-point and the most current value.
Partial separation includes the subcategoriesbuffering, renaming, and logging. In buffering,any modification to location L accumulatesin a special buffer; at the next checkpoint, themodification is applied to L. In renaming, amodification to L does not overwrite the oldvalue but is written to a different place, andthe mapping of L is updated to point to thisnew place; at the next checkpoint, the newmapping of L is committed. In logging, amodification to L occurs in place, but the oldvalue is copied elsewhere; at the next check-point, the old value is discarded.
Table 1 lists characteristics of severalexisting hardware-based checkpointingschemes and where they fit in our taxono-my. The “Checkpointing scheme compari-son” sidebar provides more details on theschemes listed.
Trade-offsThe design points in our taxonomy in Fig-
ure 1 correspond to different trade-offs amongfault detection latency, execution overhead,recovery latency, space overhead, type of faultssupported, and hardware required. Figure 3illustrates the trade-offs.
Consider the maximum tolerable faultdetection latency. Moving from register-, tocache-, to memory-level checkpointing, thetolerable fault detection latency increases. Thisis because the corresponding checkpointsincrease in size and can thus hold more exe-cution history. Consequently, the timebetween when the error occurs and when it isdetected can be larger while still allowing sys-tem recovery.
The fault-free execution overhead has aninteresting shape. In register-level check-pointing, the overhead is negligible becausethese schemes save at most a few hundredbytes (for example, a few registers or the reg-ister alias table), and efficiently copy themnearby in hardware. At the other levels, acheckpoint has significant overhead, becausethe processors copy larger chunks of data overlonger distances. An individual checkpoint’soverhead tends to increase moving fromcache- to memory-level checkpointing. How-ever, designers tune the different designs’checkpointing frequencies to keep the overall
30
CACHE-LEVEL CHECKPOINTING
IEEE MICRO
Table 1. Characteristics of some existing hardware-based checkpointing and rollback schemes.
Design point Tolerable fault Fault-free in the Hardware detection Recovery execution
Scheme taxonomy support latency latency overheadIBM G5 Register, dual, full Redundant copy of Pipeline depth 1,000 cycles Negligible
register unit (R-unit), lock-stepping units
Sparc64, out-of-order Register, dual, Register alias table (RAT) processor renaming copy and restore on Pipeline depth 10 to100 cycles Negligible
branch speculationCarer Cache, dual, logging Extra cache line state Cache fill time Cache invalidation Not availableSequoia Cache, leveled, full Cache flush Cache fill time Cache invalidation Not availableSwich Cache, dual, logging Extra cache line states Cache fill time Cache invalidation 1%ReVive Memory, dual, logging Memory logging, flush 100 ms 0.1 to 1 s 5%
cache at checkpointSafetyNet Memory, dual, logging Cache and memory 0.1 to 1 ms Not available 1%
loggingCache-Only Memory Memory, dual, Mirroring by cache 2 to 200 ms Not available 5 to 35%
Architecture renaming coherence protocol

31SEPTEMBER–OCTOBER 2006
Register-level checkpointingIBM’s S/390 G5 processor (in our taxonomy from Figure 1, dual; full
separation) includes a redundant copy of the register file called the R-unit, which lets the processor roll back by one instruction.1 In addition, ithas duplicate lock-stepping instruction and execution units, and it candetect errors by comparing the signals from these units.
Fujitsu’s Sparc64 processor leverages a mechanism present in mostout-of-order processors: To handle branch misspeculation, processors candiscard the uncommitted state in the pipeline and resume execution froman older instruction.2 The register writes update renamed register loca-tions (dual; partial separation by renaming). For this mechanism to providerecovery, it must detect faults before the affected instruction commits.In Sparc64, parity protects about 80 percent of the latches, and the exe-cution units have a residue check mechanism—for instance, the Sparc64checks integer multiplication using mod3(A × B) = mod3[mod3(A) × mod3(B)].
Cache-level checkpointingCarer checkpoints the cache by writing back dirty lines to memory (lev-
eled; full separation).3 An optimized protocol introduces a new cache linestate called unchangeable. Under this protocol, at a checkpoint, theprocessor does not write back dirty lines; it simply write-protects them andmarks them as unchangeable. Execution continues, and the processorlazily writes these lines back to memory either when they need to beupdated or when space is needed (dual; partial separation by logging).For this optimization, the cache needs some forward error recovery (FER)protection such as error-correcting code (ECC), because the unchange-able lines in the cache are part of a checkpoint.
Sequoia flushes all dirty cache lines to the memory when the cacheoverflows or when an I/O operation is initiated.4 Thus, the memory con-tains the checkpointed state (leveled; full separation).
Our proposed mechanism, Swich, is similar to Carer in that it can holdcheckpointed data in the cache (dual; partial separation by logging). UnlikeCarer, Swich holds two checkpoints simultaneously in the cache. Thus, Swichmakes a large rollback window available continuously during execution.
Memory-level checkpointingReVive flushes dirty lines in the cache to memory at checkpoints.5 It also
uses a special directory controller to log memory updates in the memory(dual; partial separation by logging). SafetyNet logs updates to memory(and caches) in special checkpoint log buffers.6 Therefore, we categorizeSafetyNet’s memory checkpointing as dual; partial separation by logging.
Morin et al. modified the cache coherence protocol of Cache-Only Mem-ory Architecture (COMA) machines to ensure that at any time, every mem-ory line has exactly two copies of data from the last checkpoint in twodistinct nodes.7 Thus, the machines can recover the memory from single-node failures (dual; partial separation by renaming).
References1. T.J. Slegel et al., “IBM’s S/390 G5 Microprocessor Design,”
IEEE Micro, vol. 19, no. 2, Mar.-Apr. 1999, pp. 12-23.2. H. Ando et al., “A 1.3GHz Fifth Generation SPARC64 Micro-
processor,” IEEE J. Solid-State Circuits, vol. 38, no. 11, Nov.2003, pp. 1896-1905.
3. D.B. Hunt and P.N. Marinos, “General-Purpose Cache-AidedRollback Error Recovery (CARER) Technique,” Proc. 17th Int’lSymp. Fault-Tolerant Computing Systems (FTCS 87), IEEE CSPress, 1987, pp. 170-175.
4. P.A. Bernstein, “Sequoia: A Fault-Tolerant Tightly CoupledMultiprocessor for Transaction Processing,” Computer, vol.21, no. 2, Feb. 1988, pp. 37-45.
5. M. Prvulovic, Z. Zhang, and J. Torrellas, “ReVive: Cost-EffectiveArchitectural Support for Rollback Recovery in Shared-MemoryMultiprocessors,” Proc. 29th Ann. Int’l Symp. Computer Archi-tecture (ISCA 02), IEEE CS Press, 2002, pp. 111-122.
6. D.J. Sorin et al., “SafetyNet: Improving the Availability ofShared Memory Multiprocessors with Global Checkpoint/Recovery,” Proc. 29th Ann. Int’l Symp. Computer Architec-ture (ISCA 02), IEEE CS Press, 2002, pp. 123-134.
7. C. Morin et al., “COMA: An Opportunity for Building Fault-Tol-erant Scalable Shared Memory Multiprocessors,” Proc. 23rdAnn. Int’l Symp. Computer Architecture (ISCA 96), IEEE CSPress, 1996, pp. 56-65.
Checkpointing scheme comparison
Register
Cache
Memory
Tolerable faultdetection latency
Recoverylatency
Spaceoverhead
100 bytes
Mbytes–Gbytes
10–1,000 cycles
0.1–1 s
~10 cycles
~100 ms
Sco
pe o
f the
sp
here
of B
ER
Number ofrecoverable faults
Several
Many
Dual or partial Leveled or full
Executionoverhead
~0%
~5%
Figure 3. Trade-offs for design points in the checkpointing taxonomy.
execution time overhead tolerable—about 5percent, as shown in Figure 3.
The designs with relatively more expensiveindividual checkpoints take less frequentcheckpoints. As a result, both their recoverylatency and their space overhead increasealong the axis from cache- to memory-levelcheckpoints. The trend is the same movingfrom dual systems (solid lines in Figure 3) toleveled systems (dashed lines) because indi-vidual checkpoints in leveled systems involvemoving data between levels and, therefore, aremore expensive. A similar effect also occurs aswe move from partial- (solid lines in Figure3) to full-separation designs (dashed lines),which require more data copying.
Finally, moving from register-, to cache-, tomemory-level checkpointing, the number ofrecoverable faults increases. The reason istwofold: First, these schemes support morefaults of a given type, thanks to the longerdetection latencies tolerated. Second, theysupport more types of faults (for example,faults that occur at the new hierarchy level).However, recovering from these faults requiresadditional hardware support, which is moreexpensive because it is spread more widelythroughout the machine.
Motivation for the Swich architectureClearly, the different checkpointing
schemes address a large set of trade-offs; ourmain focus in this article is cache-level check-pointing schemes with their advantages anddrawbacks.
On the positive side, trends in technologyare making the cache level more attractive.More on-chip integration means the possibil-ity of larger caches, which let cache-levelcheckpointing offer increased fault detection
latencies. In addition, the hardware for cache-level checkpointing is relatively inexpensiveand functions efficiently in modern architec-tures. Specifically, the primary hardware theseschemes require is new cache line states tomark lines related to the checkpoint. Modifi-cation of the cache replacement algorithmmight be necessary to encourage these lines toremain cached. Cache-level checkpointingschemes also need to change the state ofgroups of cache lines at commit and rollbackpoints. Schemes can support this by accessingthe cache tags one at a time to change eachconcerned tag individually, or by adding hard-ware signals that modify all the concerned tagsin one shot. Finally, processors using cache-level checkpointing must save registers effi-ciently at a checkpoint and restore them at arollback—similarly to the way processors han-dle branch speculation.
On the negative side, it is difficult to con-trol the checkpointing frequency in cache-level checkpointing schemes because thedisplacement of a dirty cache line triggers acheckpoint.6 Such displacements are highlydependent on the application and the cacheorganization. Thus, a system’s performancewith a cache-level checkpointing scheme isrelatively unpredictable.
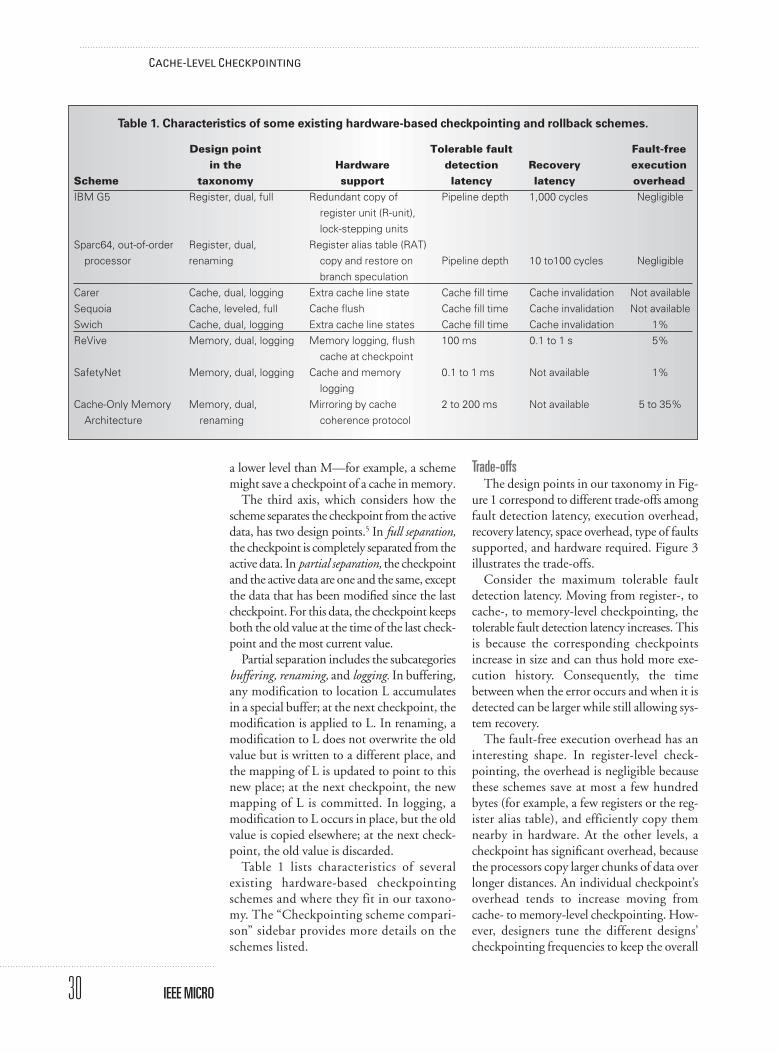
Another problem of existing implementa-tions of cache-level checkpointing2,3 is that thelength of the code that they can roll back (therollback window) is at times very small.Specifically, suppose a fault occurs immedi-ately before a checkpoint, and is only detect-ed after the checkpoint has completed (whenthe data from the previous checkpoint hasbeen discarded). At this point, the amount ofcode that can be rolled back is very small, oreven zero. Figure 4a shows how the rollback
32
CACHE-LEVEL CHECKPOINTING
IEEE MICRO
CkptTime
Min
Cache fills
Ckpt
(a)
CkptTime
Min
Half cache fills
Ckpt
(b)
Rol
lbac
kw
indo
w le
ngth
Rol
lbac
kw
indo
w le
ngth
Ckpt Ckpt
Figure 4. Evolution of the rollback window length with time for Sequoia and Carer (a) and forSwich (b).

window length evolves in existing cache-levelcheckpointing schemes. Right after eachcheckpoint, the window empties completely.
Sliding-window cache-level checkpointingSwich addresses the problem of the empty
rollback window by providing a sliding roll-back window, increasing the chances that therollback window always has a significant min-imum length. The basic idea is to always keepin the cache the state generated by two uncom-mitted checkpoint intervals, which we call spec-ulative epochs. Each epoch lasts as long as ittakes to generate a dirty data footprint abouthalf the cache size. When the cache is gettingfull of speculative data, the older epoch is com-mitted and a newer one starts. With thisapproach, the evolution of the rollback win-dow length is closer to that illustrated in Fig-ure 4b. When rollback is necessary, the schemerolls back both speculative epochs. In the worstcase (when rollback is necessary immediatelyafter a checkpoint), the system can roll back atleast one whole speculative epoch. Previouslyproposed schemes have a worst-case scenario ofan empty rollback window.
Checkpoint, commit, and rollbackWe extend each line in the cache with two
epoch bits, E1E0. If the line contains non-speculative (that is, committed) data, E1E0 are00; if it contains data generated by one of thetwo active speculative epochs, E1E0 are 01 or10. Only dirty lines (those with the Dirty bitset) can have E1E0 other than 00.
A checkpoint consists of three steps: com-mitting the older speculative epoch, savingthe current register file and processor state,and starting a new speculative epoch with thesame E1E0 identifier as the one just commit-ted. Committing a speculative epoch involvesdiscarding its saved register file and processorstate and clearing the epoch bits of all thecache lines whose E1E0 bits are equal to theepoch’s identifier. It is preferable to clear suchbits all in one shot, with a hardware signalconnected to all the tags that takes no morethan a handful of cycles to actuate.
On a fault, the two speculative epochs rollback. This involves restoring the older of thetwo saved register files and processor states,invalidating all the cache lines whose E1E0 bitsare not 00, and clearing all the E1E0 bits. A
one-shot hardware signal is sufficient for theoperations on the E1E0 bits. However, becauserollback is probably infrequent, these opera-tions can also use slower hardware that walksthe cache tags and individually sets the bits ofthe relevant tags. For a write-through L1 cache,it is simpler to invalidate the entire cache.
Speculative line managementSwich manages the speculative versions of
lines, namely those belonging to the specula-tive epochs, following two invariants. First,only writes can create speculative versions oflines. Second, the cache can contain only asingle version of a given line. Such a versioncan be nonspeculative or speculative with agiven E1E0 identifier. In the latter case, the lineis necessarily dirty and cannot be displacedfrom the cache. Following the first invariant,a processor read simply returns the data cur-rently in the cache and does not change itsline’s E1E0 identifier. If the read misses in thecache, the line is brought from memory, andE1E0 are set to 00.
The second invariant determines theactions on a write. There are four cases: First,if the write misses, the line is brought frommemory, it is updated in the cache, and itsE1E0 bits are set to the epoch identifier. Sec-ond, if the write hits on a nonspeculative linein the cache, the line is first written back tomemory (if dirty), then it is updated in thecache, and finally its E1E0 bits are set to theepoch identifier. In these two cases, a countof the number of lines belonging to this epoch(SpecCnt) is incremented. Third, if the writehits on a speculative line of the same epoch,the update proceeds normally. Finally, if thewrite from current epoch i hits on a specula-tive line from the other epoch (i – 1), thenepoch i − 1 is committed, and the write initi-ates a new epoch, i + 1. The line is writtenback to memory, then updated in the cache,and finally its E1E0 bits are set to the newepoch identifier. When the SpecCnt count ofa given epoch (say, epoch i) reaches the equiv-alent of half the cache size, epoch i – 1 is com-mitted, and epoch i + 1 begins.
Recall that speculative lines cannot be dis-placed from the cache. Consequently, if spaceis needed in a cache set, the algorithm firstchooses a nonspeculative line as its victim. If alllines in the set are speculative, Swich commits
33SEPTEMBER–OCTOBER 2006

the older speculative epoch (say, epoch i – 1)and starts a new epoch (epoch i + 1). Then,the algorithm chooses one of the lines justcommitted as a victim for displacement.
A fourth condition that also leads to anepoch commitment occurs when the currentepoch (say epoch i) is about to use all the linesof a given cache set. If the scheme allows it todo so, the sliding window becomes vulnera-ble: If the epoch later needs an additional linein the same set, the hardware would have tocommit i (and i – 1), decreasing the slidingwindow size to zero. To avoid this, when anepoch is about to use all the lines in a set, thehardware first commits the previous epoch (i – 1) and then starts a new epoch with theaccess that requires a new line.
Finally, in the current design, when the pro-gram performs I/O or issues a system call thathas side effects beyond generating cachedstate, the two speculative epochs are commit-ted. At that point, the size of the sliding win-dow falls to zero.
Two-level cache hierarchiesIn a two-level cache hierarchy, the algo-
rithm we have described is implemented inthe L2 cache. The L1 cache can use a simpleralgorithm and does not need the E1E0 bits perline. For example, consider a write-through,no-allocate L1. On a read, L1 provides thedata that it has or that it obtains from L2. Ona write hit, L1 is updated, and both the updateand epoch bits are propagated to L2. On acommit, no action is taken, whereas in therare case of a rollback, all of L1 is invalidated.
Multiprocessor issuesSwich is compatible with existing techniques
that support cache-level checkpointing in ashared-memory multiprocessor.7,8 For exam-ple, assume we use the approach of Wu et al.8
In this case, when a cache must supply a spec-ulative dirty line to another cache, the sourcecache must commit the epoch that owns theline to ensure that the line’s data never rollsback to a previous value. The additional advan-tage of Swich is that the source cache needsonly to commit a single speculative epoch, ifthe line provided belonged to its older specu-lative epoch. In this case, the rollback windowlength in the source cache does not fall to zero.A similar operation occurs when a cache
receives an invalidation for a speculative dirtyline. The epoch commits, and the line is pro-vided and then invalidated. Invalidations to allother types of lines proceed as usual. A similardiscussion can be presented for other existingtechniques for shared-memory multiprocessorcheckpointing.
Swich prototypeWe implemented a hardware prototype of
Swich using FPGAs. As the base for ourimplementation, we used Leon2, a 32-bitprocessor core compliant with the Sparc V8architecture (http://www.gaisler.com). Leon2is in synthesizable VHDL format. It has anin-order, single-issue, five-stage pipeline. Mostinstructions take five cycles to complete if nostalls occur. The processor has a windowedregister file, and the instruction cache is 4Kbytes. The data cache size, associativity, andline size are configurable. In our experiments,we set the line size to 32 bytes and the asso-ciativity to 8, and we varied the cache size.Because the processor initially had a write-through data cache, we implemented a write-back data cache controller.
We extended the processor in two majorways: with cache support for buffering spec-ulative data and rollback, and with registersupport for checkpointing and rollback. Wealso leveraged, in part, the rollback mecha-nism presented elsewhere.9
Data cache extensionsAlthough the prototype implements most
of the design we described earlier, there are afew differences. First, the prototype has a sin-gle-level data cache. Second, for simplicity, weallowed a speculative epoch to own at mosthalf the lines in any cache set. Third, the pro-totype doesn’t perform epoch commit androllback using a one-shot hardware signal.Instead, we designed a hardware state machinethat walks the cache tags performing the oper-ations on the relevant cache lines. The reasonfor this design is that we implemented thecache with the synchronous RAM blocks pre-sent in the Xilinx Virtex II series of FPGAs.Such memory structures have only the ordi-nary address and data inputs; they are diffi-cult to modify to incorporate additionalcontrol signals, such as those needed to sup-port one-shot commit and rollback signals.
34
CACHE-LEVEL CHECKPOINTING
IEEE MICRO

We extended the cache controller with acache walk state machine (CWSM) that tra-verses the cache tags and clears the corre-sponding epoch bits (in a commit) and validbits (in a rollback). A commit or rollback sig-nal activates the CWSM. At that point, thepipeline stalls and the CWSM walks thecache tags. The CWSM has three states,shown in Figure 5a: idle, walk, and restore. Inidle, the CWSM is inactive. In walk, its mainworking state, the CWSM can operate on oneor both of the speculative epochs. The tra-versal takes one cycle for each line in thecache. The restore state resumes the normalcache controller operation and releases thepipeline.
When operating system code is executed,we conservatively assume that it cannot berolled back and, therefore, we commit bothspeculative epochs and execute the systemcode nonspeculatively. A more careful imple-mentation would identify the sections of sys-tem code that have no side effects beyondmemory updates, and allow their executionto remain speculative.
Register extensionsSwich performs register checkpointing and
restoration using two shadow register files,SRF0 and SRF1. Each of these memory struc-tures is identical to the main register file.When a checkpoint is to be taken, the pipelinestalls and passes control to the register check-pointing state machine (RCSM), which hasthe four states shown in Figure 5b.
The RCSM is in the idle state while thepipeline executes normally. When a registercheckpoint must be taken, it transitions to thecheckpoint state. In this state, the RCSMcopies the valid registers in the main registerfile to one of the SRFs. The register files areimplemented in SRAM and have two readports and one write port. This means that theRCSM can copy only one register per cycle.Thus, the checkpoint stage takes about as manycycles as there are valid registers in the regis-ter file. The rollback state is activated whenthe pipeline receives a rollback signal. In thisstate, the RCSM restores the contents of theregister file from the checkpoint. Similarly,this takes about as many cycles as there arevalid registers. The restore state reinitializes thepipeline.
Evaluating the Swich prototypeThe processor is part of a SoC infrastruc-
ture that includes a synthesizable SDRAMcontroller, and PCI and Ethernet interfaces.We synthesized the system using Xilinx ISEv6.1.03 (http://www.xilinx.com). The targetFPGA chip was a Xilinx Virtex II XC2V3000running on a GR-PCI-XC2V developmentboard (http://www.pender.ch). The processorruns at 40 MHz, and the board has 64 Mbytesof SDRAM for main memory. Communica-tion with the board and loading of programsin memory take place through the PCI inter-face from a host computer.
On this hardware, we run a special versionof the SnapGear Embedded Linux distribu-tion (http://www.snapgear.org). SnapGearLinux is a full-source package, containing ker-nel, libraries, and application code for rapiddevelopment of embedded Linux systems. Weused a cross-compilation tool chain for theSparc architecture to compile the kernel andapplications.
We experimented with the prototype usinga set of applications that included open-sourceLinux applications and microbenchmarks thatwe ran atop SnapGear Linux. We chose codesthat exhibited a variety of memory and sys-tem code access patterns to give us a sense of
35SEPTEMBER–OCTOBER 2006
Idle
Walk Restore
Idle
Checkpoint Rollback
Restore
(a)
(b)
Figure 5. Swich state machines: cache walk state machine(a) and register checkpointing state machine (b).

how workload characteristics affect Swich.Table 2 describes the applications we used.
ResultsWe have not yet accurately measured
Swich’s execution overhead or recoverylatency, because of the limitations of ourimplementation—specifically that we imple-mented epoch commit and rollback withinefficient cache tag walking rather than withan efficient one-shot hardware signal. Thisproblem slows down the Swich FPGA pro-totype, but it would not be present in aCMOS implementation.
Consequently, we focused our evaluationon measuring Swich’s hardware overhead androllback window size, and on roughly esti-mating Swich’s performance overhead andrecovery latency using a simple model.
Hardware overheadFor each of Swich’s two components—the
register checkpointing mechanism and thedata cache support for speculative data—wemeasured the hardware overhead in both logicand memory structures. Our measurementsconsidered only the processor core and caches,not the other on-chip modules such as thePCI and memory controllers. As a reference,we also measured the overheads of a cachecheckpointing scheme with one speculativeepoch at a time (a system similar to Sequoia3).
Figure 6 shows the logic consumed, mea-sured in number of configurable logic block(CLB) slices. CLBs are the FPGA blocks usedto build combinational and synchronous logiccomponents. A CLB comprises four similarslices; each slice includes two four-input func-tion generators, carry logic, arithmetic logic
36
CACHE-LEVEL CHECKPOINTING
IEEE MICRO
Table 2. Applications evaluated using Swich.
Application Descriptionhennessy Collection of small, computation-intensive applications; little or no system codepolymorph Converts Windows-style file names to Unix; moderate system codememtest Microbenchmark that simulates large array traversals; no system codesort Linux utility that sorts lines in text files; system-code intensivencompress Compression and decompression utility; moderate system codeps Linux process status command; very system-code intensive
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
9,000
4 8 16 32 64 4 8 16
Data cache size (Kbytes)
32 64
Har
dwar
e ov
erhe
ad (
CLB
slic
es)
basereg ckptspec cache
Sequoia Swich
Figure 6. Amount of logic consumed by different designs and components.

gates, wide-function multiplexers, and twostorage elements. Figure 6 graphs hardwareoverhead for the Sequoia-like system and theSwich system, each with several different datacache sizes (ranging from 4 Kbytes to 64Kbytes). Each bar shows the CLBs consumedby the logic to support speculative data in thecache (spec cache), register checkpointing (regckpt), and the original processor (base).
With Swich, the logic overhead of the com-bined extensions was only 6.5 percent on aver-age and relatively constant across the range ofcaches we evaluated; the support we proposedoes not use much logic. In addition, thenumber of CLBs used for Swich is only about2 percent higher than for the Sequoia-like sys-tem. In other words, the difference in logicbetween a simple window and a sliding win-dow is small.
Figure 7 shows the memory consumed,measured in number of SelectRAM memoryblocks. These blocks, used to implement thecaches, register files, and other structures, are18-Kbit, dual-port RAM blocks with twoindependently clocked and independentlycontrolled synchronous ports that access acommon storage area. The overhead in mem-ory blocks of the combined Swich extensionsis again small for all the caches that we evalu-ated, indicating that the support we proposeconsumes few hardware resources. In addi-tion, Swich’s overhead in memory blocks is
again very similar to that of the Sequoia-likesystem. The Swich additions are primarilyadditional register checkpoint storage andadditional state bits in the cache tags.
Size of the rollback windowWe particularly wanted to determine the
size of the Swich rollback window in numberof dynamic instructions. This number deter-mines how far the system can roll back at agiven time if it detects a fault. We were espe-cially interested in the minimum points inFigure 4b, which represent the cases whenonly the shortest rollback windows are avail-able. Figure 4b shows an ideal case. In prac-tice, the minima aren’t all at the same value.The actual values of the minimum pointsdepend on the code being executed: the actu-al memory footprint of the code and the pres-ence of system code. In our currentimplementation, execution of system codecauses the commit of both speculative epochsand, therefore, induces a minimum in the roll-back window.
For our experiments, we measured the win-dow size at each of the minima and took per-application averages. Figure 8 shows theaverage window size at minimum points forthe different applications and cache sizes rang-ing from 8 Kbytes to 64 Kbytes. The sameinformation for the Sequoia and Carer systemswould show rollback windows of size zero.
37SEPTEMBER–OCTOBER 2006
04 8 16 32 64 4 8 16
Data cache size (Kbytes)
32 64
basereg ckptspec cache
Sequoia Swich
5
10
15
20
25
30
35
40
45
50
Har
dwar
e ov
erhe
ad (
RA
M b
lock
s)
Figure 7. Amount of RAM consumed by the different designs and components.

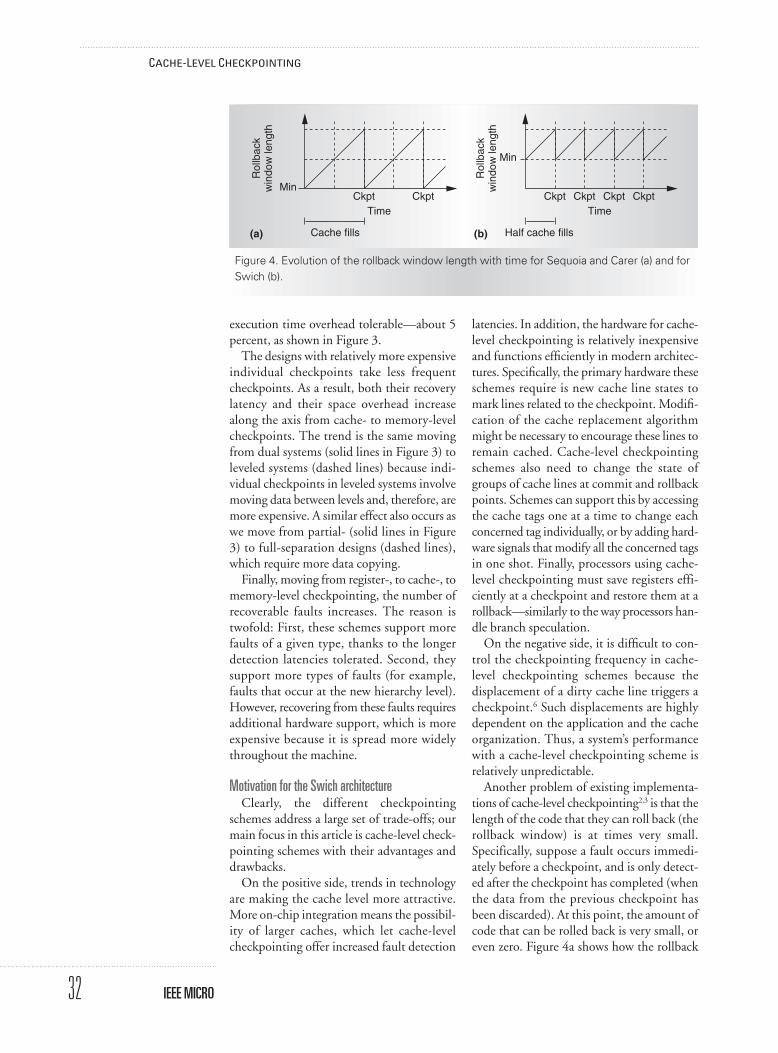
As Figure 8 shows, the hennessymicrobenchmark has the largest minimumrollback window. The application is compu-tationally intensive, has little system code, andhas a relatively small memory footprint. Asthe cache increases, the window size increas-es. For 8- to 64-Kbyte caches, the minimumrollback window ranges from 120,000 to180,000 instructions. The polymorph andmemtest applications have more system codeand a larger memory footprint, respectively.Their rollback windows are smaller, althoughthey increase substantially with the cache size,to reach 120,000 and 80,000 instructions,respectively, for the 64-Kbyte cache. The sort,ncompress, and ps applications are system-code-intensive applications with short roll-back windows, regardless of the cache size.One way to increase their minimum rollbackwindows is to identify the sections of systemcode that have no side effects beyond memo-ry updates and allow their execution to remainspeculative.
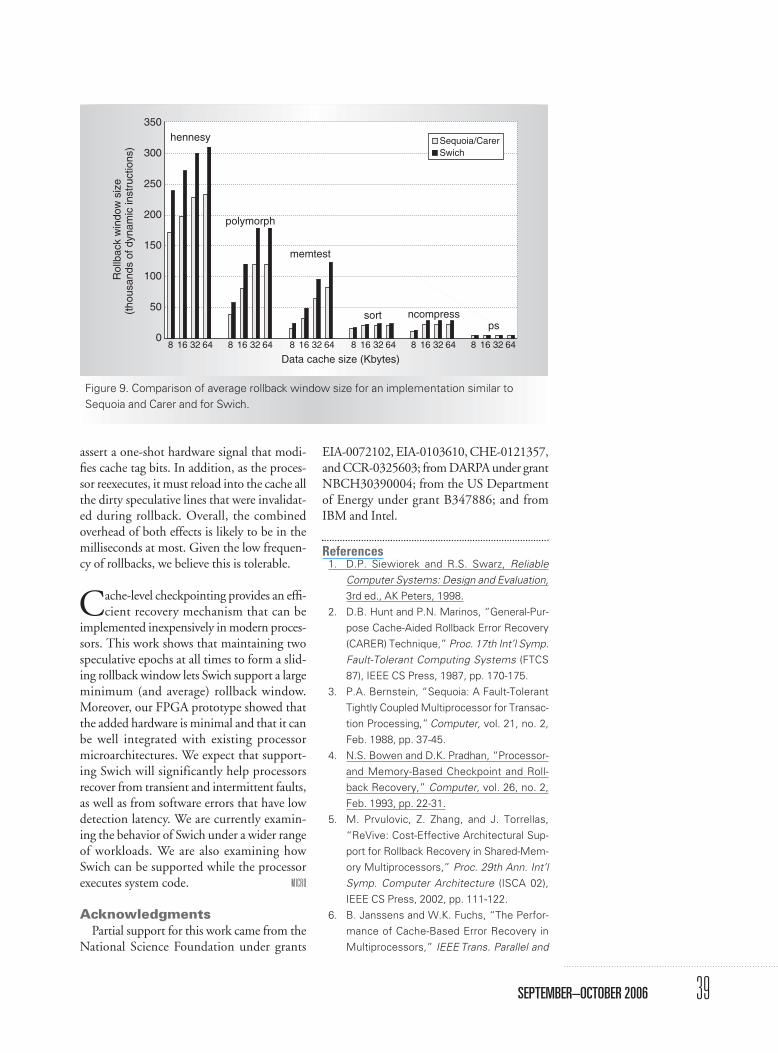
For completeness, we also measured Swich’saverage rollback window size and comparedit to that of the implementation similar toSequoia and Carer. Again, we looked at fourdifferent data cache sizes and six applications;Figure 9 shows the results. Except in system-code-intensive applications, Swich’s averagerollback window is significantly larger thanthat of Sequoia-Carer. The reason, as Figure 8
shows, is that for Swich the rollback windowhas a nonzero average minimum value. For psand the other two system-intensive applica-tions, there is little difference between the twoschemes. Overall, at least for applicationswithout frequent system code, Swich supportsa large minimum rollback window.
Estimating performance overhead and recoverylatency
A rough way of estimating Swich’s perfor-mance overhead is to compute the ratiobetween the time needed to generate a check-point and the duration of the executionbetween checkpoints. This approach, ofcourse, neglects any overheads that the schememight induce between checkpoints. To modelworst-case conditions, we used the average sizeof the rollback window at minimum points(Figure 8) as the number of instructionsbetween checkpoints. Across all the applica-tions, this is about 60,000 instructions for 64-Kbyte caches. If we assume an average of onecycle per instruction, this corresponds to60,000 cycles. On the other hand, a check-point can very conservatively take about 256cycles, because it involves saving registers andasserting a one-shot hardware signal that mod-ifies cache tag bits. Overall, the ratio resultsin a 0.4 percent overhead.
We estimated the recovery latency by assum-ing 256 cycles to both restore the registers and
38
CACHE-LEVEL CHECKPOINTING
IEEE MICRO
20
0
40
60
80
100
120
140
160
180
200
8 16 32 64
Data cache size (Kbytes)
Rol
lbac
k w
indo
w s
ize
(tho
usan
ds o
f dyn
amic
inst
ruct
ions
)
hennesypolymorphmemtestsortncompressps
Figure 8. Minimum rollback window size in Swich, per-application averages.
assert a one-shot hardware signal that modi-fies cache tag bits. In addition, as the proces-sor reexecutes, it must reload into the cache allthe dirty speculative lines that were invalidat-ed during rollback. Overall, the combinedoverhead of both effects is likely to be in themilliseconds at most. Given the low frequen-cy of rollbacks, we believe this is tolerable.
Cache-level checkpointing provides an effi-cient recovery mechanism that can be
implemented inexpensively in modern proces-sors. This work shows that maintaining twospeculative epochs at all times to form a slid-ing rollback window lets Swich support a largeminimum (and average) rollback window.Moreover, our FPGA prototype showed thatthe added hardware is minimal and that it canbe well integrated with existing processormicroarchitectures. We expect that support-ing Swich will significantly help processorsrecover from transient and intermittent faults,as well as from software errors that have lowdetection latency. We are currently examin-ing the behavior of Swich under a wider rangeof workloads. We are also examining howSwich can be supported while the processorexecutes system code. MICRO
AcknowledgmentsPartial support for this work came from the
National Science Foundation under grants
EIA-0072102, EIA-0103610, CHE-0121357,and CCR-0325603; from DARPA under grantNBCH30390004; from the US Departmentof Energy under grant B347886; and fromIBM and Intel.
References1. D.P. Siewiorek and R.S. Swarz, Reliable
Computer Systems: Design and Evaluation,3rd ed., AK Peters, 1998.
2. D.B. Hunt and P.N. Marinos, “General-Pur-pose Cache-Aided Rollback Error Recovery(CARER) Technique,” Proc. 17th Int’l Symp.Fault-Tolerant Computing Systems (FTCS87), IEEE CS Press, 1987, pp. 170-175.
3. P.A. Bernstein, “Sequoia: A Fault-TolerantTightly Coupled Multiprocessor for Transac-tion Processing,” Computer, vol. 21, no. 2,Feb. 1988, pp. 37-45.
4. N.S. Bowen and D.K. Pradhan, “Processor-and Memory-Based Checkpoint and Roll-back Recovery,” Computer, vol. 26, no. 2,Feb. 1993, pp. 22-31.
5. M. Prvulovic, Z. Zhang, and J. Torrellas,“ReVive: Cost-Effective Architectural Sup-port for Rollback Recovery in Shared-Mem-ory Multiprocessors,” Proc. 29th Ann. Int’lSymp. Computer Architecture (ISCA 02),IEEE CS Press, 2002, pp. 111-122.
6. B. Janssens and W.K. Fuchs, “The Perfor-mance of Cache-Based Error Recovery inMultiprocessors,” IEEE Trans. Parallel and
39SEPTEMBER–OCTOBER 2006
0
50
100
150
200
250
300
350
Sequoia/CarerSwich
Rol
lbac
k w
indo
w s
ize
(tho
usan
ds o
f dyn
amic
inst
ruct
ions
) hennesy
polymorph
memtest
sort ncompressps
8 16 32 64 8 16 32 64 8 16 32 64 8 16 32 64 8 16 32 64 8 16 32 64
Data cache size (Kbytes)
Figure 9. Comparison of average rollback window size for an implementation similar toSequoia and Carer and for Swich.

Distributed Systems, vol. 5, no. 10, Oct.1994, pp. 1033-1043.
7. R.E. Ahmed, R.C. Frazier, and P.N. Marinos,“Cache-Aided Rollback Error Recovery(CARER) Algorithms for Shared-MemoryMultiprocessor Systems,” Proc. 20th Int’lSymp. Fault-Tolerant Computing (FTCS 90),IEEE CS Press, 1990, pp. 82-88.
8. K.L. Wu, W.K. Fuchs, and J.H. Patel, “ErrorRecovery in Shared-Memory Multiproces-sors Using Private Cache,” IEEE Trans. Par-allel and Distributed Systems, vol. 1, no. 10,Apr. 1990, pp. 231-240.
9. R. Teodorescu and J. Torrellas, “PrototypingArchitectural Support for Program RollbackUsing FPGAs,” IEEE Symp. Field-Program-mable Custom Computing Machines(FCCM), IEEE CS Press, 2005, pp. 23-32.
Radu Teodorescu is a PhD candidate in theComputer Science Department of the Univer-sity of Illinois at Urbana-Champaign. Hisresearch interests include processor design forreliability, debuggability, and variability toler-ance. Teodorescu has a BS in computer sciencefrom the Technical University of Cluj-Napoca,Romania, and an MS in computer science fromUniversity of Illinois at Urbana-Champaign.He is a student member of the IEEE.
Jun Nakano is an Advisory IT Specialist at IBMJapan. His research interests include reliabilityin computer architecture and variability insemiconductor manufacturing. Nakano has anMS in physics from the University of Tokyoand a PhD in computer science from the Uni-versity of Illinois at Urbana-Champaign. He isa member of the IEEE and the ACM.
Josep Torrellas is a professor of computer sci-ence and Willett Faculty Scholar at the Uni-versity of Illinois at Urbana-Champaign. Healso chairs the IEEE Technical Committee onComputer Architecture (TCCA). His researchinterests include multiprocessor computerarchitecture, thread-level speculation, low-power design, reliability, and debuggability.Torrellas has a PhD in electrical engineeringfrom Stanford University. He is an IEEE Fel-low and a member of the ACM.
Direct questions and comments about thisarticle to Radu Teodorescu, Siebel Center forComputer Science, Room 4238, 201 NorthGoodwin Ave., Urbana, IL 61801;[email protected].
For further information on this or any othercomputing topic, visit our Digital Library athttp://www.computer.org/publications/dlib.
40
CACHE-LEVEL CHECKPOINTING
IEEE MICRO
Get accessto individual IEEE Computer Society documents online.
More than 100,000 articles and conference papers available!
$9US per article for members
$19US for nonmembers
www.computer.org/publications/dlib





























