Embed Size (px)
Citation preview

DEPSPACE: A Communication Infrastructure for Dynamic andUntrusted Environments
Alysson Neves Bessani∗‡ Eduardo Pelison Alchieri† Miguel Correia‡Joni da Silva Fraga† Lau Cheuk Lung§
‡ LASIGE, Faculdade de Ciencias da Universidade de Lisboa – Portugal
† Departamento de Automacao e Sistemas, Universidade Federal de Santa Catarina – Brazil
§ Prog. de Pos-Grad. em Informatica Aplicada, Pontifıcia Universidade Catolica do Parana – Brazil
Abstract
The tuple space coordination model is one of the most inter-esting communication models for open distributed systemsdue to its space and time decoupling and its synchronizationpower. Several works have tried to improve the dependabilityof tuple spaces. Some have made tuple spaces fault-tolerant,using mechanisms like replication and transactions. Othershave focused on security, using access control and cryptog-raphy. However, many practical applications in the Internetrequire both these dimensions. This paper describes the de-sign and implementation of DEPSPACE, a dependable com-munication infrastructure based on the tuple space coordina-tion model. DEPSPACE is dependable in a strong sense of theword: it is secure, fault-tolerant and intrusion-tolerant, i.e. itbehaves as expected even if some of the machines that im-plement it are successfully attacked. Moreover, it is a policy-enforced augmented tuple space, a shared memory object thatwe have recently proven to be universal, i.e., capable of im-plementing any other shared memory object. Also, some ex-perimental evaluation of the latency and throughput of theservices provided by DEPSPACE are presented.
1 Introduction
The generative(or tuple space) coordinationmodel, origi-nally introduced in the LINDA programming language [21],relies on a shared memory object called atuple spacetosupport coordination between distributed processes. Tuplespaces can support communication that is decoupled in time– processes do not have to be active at the same time – andspace – processes do not need to know each others locationsor addresses [8], providing some level of synchronization atthe same time. The operations supported by a tuple space areessentially the insertion, reading and removal of tuples, i.e.,of finite sequences of values.
There has been some research aboutfault tolerancein thegenerative coordination model, both in the construction offault-tolerant tuple spaces [48, 4] and in application levelfault tolerance mechanisms [26]. The objective of theseworks is essentially to guarantee that(i.) the service providedby the tuple space is available even if some of the servers thatimplement it crash, and that(ii.) the state of the tuple space
∗Corresponding author. Email:[email protected]
satisfies the semantics of the application, even when appli-cation processes crash. The main mechanism employed inproviding(i.) is replication, while(ii.) is usually ensured us-ing transactions. There has been also some research aboutsecure tuple spaces(e.g. [34, 7, 15, 47]). These works essen-tially use access control mechanisms at space and tuple levelsto ensure that malicious processes cannot execute tuple spaceoperations without permission.
Those works on fault-tolerant and secure tuple spaces havea narrow focus in two senses: they consider only simplefaults (crashes) or simple attacks (invalid access); and theyare abouteither fault toleranceor security. The present pa-per goes one step further by investigating the implementationof secure and fault-tolerant tuple spaces. The solution is in-spired on a current trend in dependability that applies faulttolerance concepts and mechanisms in the domain of security,intrusion tolerance[19, 46]. The proposed tuple space is notcentralized but implemented by a set of tuple space servers(see Figure 1). This set of tuple spaces forms a tuple spacethat isdependable, meaning that it enforces the attributes ofreliability, availability, integrity and confidentiality [3], de-spite the occurrence of arbitrary faults, including Byzantinefaults [30], like attacks and intrusions in some servers.
� � � � � � �
� � � � � �
� � � � � � � � � � � � � � �
� �
� � � � � �
� �
� �
� �
Figure 1: General architecture of a dependable tuple space.
The implementation of a dependable tuple space with theabove-mentioned attributes presents some interesting chal-lenges. Our design is based on thestate machine approach,a classical solution for implementing both (accidental) fault-tolerant [39] and intrusion-tolerant [11] systems. However,this approach does not guarantee the confidentiality of thedata stored in the servers; quite on the contrary, replicatingdata in several servers is usually considered to reduce theconfidentiality since the potential attacker has more servers
1

where to attempt to read the data, instead of just one. There-fore, combining the state machine approach with confiden-tiality is a non-trivial challenge that has to be addressed. Asecond challenge is intrinsically related to the tuple spacemodel. Tuple spaces resemble associative memories: whena process wants to read a tuple, it provides a template and thetuple space returns a tuple that “matches” the template. Thismatch operation involves comparing data in the tuple withdata in the template, but how can this comparison be possibleif tuples are encrypted to guarantee confidentiality? In thispaper we present DEPSPACE, a system that addresses thesechallenges using a particular kind of secret sharing schemetogether with cryptographic hash functions in such a way thatit guarantees that a tuple stored in the system will have itscontent revealed only to authorized parties.
The design of a dependable tuple space is not a merely aca-demic exercise. The tuple space system presented in this pa-per might be useful in several practical application domains,like the following. (i.) Ad hoc networksare an important cur-rent trend in computer science. It has been shown that tuplespaces can be a powerful solution to coordinate activities inthose environments, and systems like LIME [36] already ex-plore this paradigm.(ii.) Mobile agentsare programs thatmigrate from node to node in the network, usually to gatherdata or to perform computations close to the data source.The interaction of these agents is usually complex due to thelack of fixed location. Tuple spaces are an obvious solutionto support this communication since they provide time andspace decoupling [8].(iii.) Grid computing involves usingresources in large numbers of computers to perform complexcomputations (e.g., SETI@HOME). These computations aredecoupled both in space and time so a tuple space would be agood solution to coordinate the tasks performed by the com-puters [49]. Besides that, we must remember that the tuplespaces model was originally developed for parallel program-ming, so its application to grid computing is almost direct[10]. (iv.) Web servicesis a currently much used web-relatedmiddleware. TheWS-Coordinationspecification defines a setof interfaces that web services can use to ask for interactionsusing arbitrary communication mechanisms [28]. In applica-tions with more than two participants, tuple spaces are a goodchoice to support this communication that is probably decou-pled in time [31]. (v.) Advanced network architectures, likethe Internet Indirection Infrastructure [42], exploit the spaceand time decoupling of the model in order to provide flexiblemulticast, anycast and mobility support in the Internet.
The DEPSPACE system described in this paper has animportant characteristic. Recently, we have shown that apolicy-enforced augmented tuple space(PEATS) is a univer-sal shared memory object, i.e., an object that can be usedto implement any shared memory object [5]. Moreover, wehave also shown that algorithms based on this type of tuplespaces are much simpler and use less memory that previousalgorithms based on access control lists and sticky bits. TheDEPSPACEsystem is the first design of a dependable PEATS.This object differs from a conventional tuple space in twoways: (i.) it allows the definition of powerful access controlpolicies to the space (policy-enforced);(ii.) it provides anadditional operation: conditional atomic swap (augmented).
Algorithms based on a PEATS are well suited for coor-dination of non-trusted processes in practical dynamic sys-tems. Instead of trying to compute some distributed coordina-tion task using a complete dynamic model (like, for instance,the one proposed in [35]), we pursue a more pragmatic ap-proach where a PEATS (like DEPSPACE) is deployed on afixed and small set of servers and is used by a unknown, dy-namic and unreliable set of processes that need to coordinatethemselves. An example of scenario were this kind of systemcan be deployed are peer-to-peer systems and infrastructuredwireless networks.
The paper has three main contributions. The first is thepresentation of the dependable and intrusion-tolerant tuplespace. This design involves a non-trivial combination of se-curity and fault tolerance mechanisms: state machine replica-tion, space and tuple level access control, and cryptography.To the best of our knowledge this is the first work to imple-ment Byzantine state machine replication for tuple spaces andto integrate this technique with a confidentiality scheme. Thesecond is the presentation of the first implementation of aPEATS, a universal shared memory object that can be used toimplement simple and efficient distributed algorithms. Thethird contribution is the first practical assessment of the per-formance of an intrusion-tolerant scheme that provides dataconfidentiality even when there are intrusions in some of theservers. We are not aware of any other practical assessmentof such a scheme in the literature.
The paper is organized as follows. Section 2 provides adefinition of a dependable tuple space in terms of depend-ability attributes. The dependable tuple space architecture ispresented in Section 3. Section 4 presents the implementa-tion of DEPSPACE. Section 5 makes a theoretical assessmentof the tuple space performance and Section 6 gives experi-mental results. The related work is discussed in Section 7.Finally, Section 8 presents some final remarks.
2 Defining a Dependable Tuple Space
A tuple spacecan be seen as a shared memory object that pro-vides operations for storing and retrieving ordered data setscalledtuples. A tuple t with all its fields defined is called anentry, and can be inserted in the tuple space using theout(t)operation. A tuple in the space is read using the operationrd(t), wheret is atemplate, i.e. a special tuple in which someof the fields can be wild-cards or formal fields (e.g.?v, mean-ing the variablev will take the value read). The operationrd(t) returns any tuple in the space thatmatchesthe template,i.e. any tuple with the same number of fields and with the fieldvalues equal to all corresponding defined values int. A tuplecan be readandremoved from the space using thein(t) oper-ation. Thein andrd operations are blocking. Non-blockingversions,inp andrdp, are also usually provided [21].
This paper presents the implementation of a policy-enforced augmented tuple space (PEATS) [5] so we provideanother operation usually not considered by most tuple spaceworks: cas(t, t) (conditional atomic swap) [4, 41]. This op-eration works like an indivisible execution of the code:if¬rdp(t) then out(t) (t is a template andt an entry). Theoperation insertst in the space iffrdp(t) does not return any
2

tuple, i.e. if there is no tuple in the space that matchest. Thecas operation is important mainly because a tuple space thatsupports it is capable of solving the consensus problem [41],which is a building block for solving many important dis-tributed synchronization problems like atomic commit, totalorder multicast, leader election and fault-tolerant mutual ex-clusion. This also means that such a tuple space is a universalshared memory object [24], i.e. it can implement any othershared memory object.
2.1 Dependability Attributes
A tuple space is dependable if it satisfies thedependabilityattributes [3]. Like in many other systems, some of theseattributes do not apply or are orthogonal to the core of the de-sign (e.g. safety and maintainability). The relevant attributesin this case are:reliability (the operations on the tuple spacehave to behave according to their specification),availability(the tuple space has to be ready to execute the operations re-quested),integrity (no improper alteration of the tuple spacecan occur.), andconfidentiality(the content of (some) tuplefields cannot be disclosed to unauthorized parties).
The difficulty of guaranteeing these attributes comes fromthe occurrence offaults, either due to accidental causes(e.g. a software bug that crashes a server) or malicious causes(e.g. an attacker that modifies some tuples in a server). Theobjective is to avoid that these faults cause thefailure of thetuple space, i.e. that one or more of the four attributes aboveare violated. Malicious faults are particularly naughty since itis hard to make assumptions about what the attacker can andcannot do [46]. These faults are usually modeled in terms ofthe most generic class of faults – arbitrary or Byzantine faults– so the solution we propose here is quite generic in terms ofthe faults it handles.
The meaning of reliability and availability should be clear,but integrity and confidentiality need some discussion. An al-teration of the tuple space is said to be proper (vs. improper)if and only if (i.) it is the outcome of one of the operationsout , in or inp; and (ii.) the operation satisfies theaccesspolicy of the tuple space. A basic access policy must definewhich processes are allowed to execute which operations ina tuple space. The most simple way to specify this policy isby defining who can insert tuples in a tuple space and, foreach tuple inserted, who can read and who can remove it. APEATS, however, supports more elaborated access policiesthat allow or disallow the execution of operations in the tuplespace depending on three types of parameters: the identifierof the invoker; the operation and its arguments; the tuplescurrently in the space [5]. An example access policy statedinformally might be: Allow only (i.) anyrd /rdp operationand (ii.) anyout operation invoked by clientsp1 or p2 withthe first field with a positive integer.We call these policiesfine-grainedbecause they allow the use of a considerable va-riety of parameters [34, 5].
This discussion also helps clarifying the meaning of theconfidentiality attribute. The general idea is that the con-tent of a tuple cannot be disclosed except for an operationthat satisfies the tuple space’s access policy, even if a serverbehaves maliciously. This policy defines who are the autho-rized (vs. unauthorized) parties for each operation. The idea
is slightly more complicated though: confidentiality may berequested for some fields but not for others (details below).
3 Building a Dependable Tuple Space
This section presents the design of DEPSPACE, a dependabletuple space that satisfies the definition presented the previoussection. We begin with a model of the underlying systemand the basic assumptions of our design, then delve into thegeneral layered archietcture and finally into each layer.
3.1 System Model
The system is composed by an infinite set ofclients Π ={p1, p2, p3, ...} which interact with a set ofn serversU ={s1, s2, ..., sn} that implement a dependable tuple space withthe properties introduced in the previous section. We considerthat each client and each server has a unique id.
All communication between clients and servers is madeover reliable authenticated point-to-point channels. Thesechannels can be implemented using TCP and some crypto-graphic mechanism such as MACs (Message AuthenticationCodes) with session keys.
The dependable tuple space does not require any explicittime assumption, however, since it is based on thestate ma-chine replicationmodel [39], it requires a total order multi-cast primitive that cannot be implemented deterministicallywithout some time guarantees [18]. We use the BYZAN -TINE PAXOS consensus protocol [11, 50, 33] for implement-ing this communication primitive, so we use aneventuallysynchronous systemmodel [17].
We assume that an arbitrary number of clients and a boundof up to f servers can be subject toByzantine failures,i.e. they can deviate arbitrarily from the algorithm they arespecified to execute and work in collusion to corrupt the sys-tem behavior. Our architecture requiresn ≥ 3f + 1 serversto tolerate the aforementionedf faulty servers. This ratio be-tweenn andf is the best that can be attained in practical sys-tems (like the Internet) for implementing Byzantine-resilientactive replication [11]. Clients that do not follow their algo-rithm in some way are said to befaulty. A client that is notfaulty is said to becorrect. We assumefault independenceforservers, i.e. that the failures of the servers are uncorrelated.This assumption can be substantiated in practice using sev-eral types of diversity [16, 12], therefore each server shouldhave a different tuple space.
3.2 DEPSPACE Architecture Overview
The architecture of the dependable tuple space consists in aseries of integrated layers that enforce each one of the de-pendability attributes stated in Section 2. Figure 2 presentsthe DEPSPACE architecture with all its layers.
On the top of the client-side stack is the proxy layer, whichprovides access to the replicated tuple space, while on thetop of the server-side stack is the tuple space implementation(a local tuple space). The communication follows a schemesimilar to remote procedure calls. The application interactswith the system by calling functions with the usual signaturesof tuple spaces’ operations:out(t), rd(t), . . . These functionsare called on the proxy. The layer below handles tuple level
3

� � � � � � � � � � � �
� � � � � � � � � � � � �
� � � � � � � � �
� � � � � � � � � � � �
� � � � � � � � � � � � � � � �
� � � � � � � � � � � � �
� � � � � � � � �
� � � � � �� � � � � � � � �
� � � � � � � � � �
� �
� � � �
Figure 2: DEPSPACE architecture
access control (Section 3.5). After, there is a layer that takescare of confidentiality (Section 3.4) and then one that handlesreplication (Section 3.3). The server-side is similar, exceptthat there is a new layer to check the access policy for eachoperation requested (policy-enforcement, Section 3.6).
We must remark that not all of these layers must be used inevery tuple space configuration. The idea is that the layers areadded or removed according to the desired quality of servicerequired for the system.
3.3 Replication
The dependability of the tuple space is enforced using a com-bination of several mechanisms. The most basic mechanismis replication: the tuple space is maintained copied in a setof n servers in such a way that the failure of up tof of themdoes not impair the reliability, availability and integrity of thesystem. The idea is that if some servers fail (e.g. by crash-ing of by being controlled by an attacker and behaving ma-liciously), the tuple space is still ready (availability) and theoperations work correctly (reliability and integrity) becausethe correct replicas manage to overcome the misbehavior ofthe faulty replicas. A simple approach for replication isstatemachine replication[39]. This approach guarantees lineariz-ability [25], which is a strong form of consistency in whichall replicas appear to take the same sequence of states.
The state machine approach requires that all replicas(i.)start in the same state and(ii.) execute all requests (i.e. tuplespace operations) in the same order [39]. The first point iseasy to ensure, e.g. by starting the tuple space with no tuples.The second requires a fault-toleranttotal order reliable mul-ticastprotocol, which is the crux of the problem. Some pro-tocols of this kind that tolerate Byzantine faults are available[11, 27, 33, 37]. The state machine approach also requiresthat the replicas are deterministic, i.e. that the same opera-tion executed in the same initial state generates the same finalstate in every replica. This implies that a read (or removal)in different servers in the same state (i.e. with the same setof tuples) must return the same response. If the tuple spacesused are not deterministic, determinism can be emulated us-ing abstract specifications and abstraction functions [12].
The protocol executed by the replication layer in the clientand server sides is in Algorithm 1. The algorithm assumesthe existence of a total order multicast protocol. To multicasta messagem using this protocol, the algorithm calls functionTO-multicast(U,m), while the total order multicast protocol
calls the functionTO-receive(p, m) to receive a messagemdelivered by the communication network.
Algorithm 1 Replication Layers (clientpi and serversj).{CLIENT}
procedureout(t)
1: execute op(OUT, t)
procedurerdp(t) {The same forinp(t), rd(t) andin(t)}2: return execute op(RDP, t) {INP for inp(t), etc...}
procedurecas(t, t)
3: return execute op(CAS, 〈t, t〉)
procedureexecute op(op, arg)
4: TO-multicast(U, 〈op, arg〉)5: ∀k ∈ {1, ..., n}, R[k]← ⊥6: repeat7: receive(sj , 〈RESP, rs〉)8: R[j]← rs
9: r ← extract resp(R)10: until r 6= ⊥11: return r
{SERVER}ts: server side upper layerblocking : set of blocking operations
upon TO-receive(pi, 〈op, arg〉) ∧pi /∈ blacklist
12: if op = OUT then13: t← arg14: ts.out(t)15: tr ← t16: else ifop = CAS then17: t← arg[0]; t← arg[1]18: tr ← ts.cas(t, t)19: else ifop = IN ∨ op = INP then20: tr ← ts.inp(arg)21: else ifop = RD∨ op = RDP then22: tr ← ts.rdp(arg)23: end if24: if tr = NM ∧ (op = IN ∨ op = RD) then25: blocking ← blocking ∪ {〈op, arg, pi〉}26: else27: send(pi, 〈RESP, tr〉)28: end if29: if op = OUT∨ (op = CAS∧ tr = t) then30: for all 〈RD, t, pk〉 ∈ blocking : m(tr, t) do31: send(pk, 〈RESP, tr〉)32: blocking ← blocking \ {〈RD, t, pk〉}33: end for34: if ∃〈IN, t, pk〉 ∈ blocking : m(tr, t) then35: ts.inp(t)36: send(pk, 〈RESP, tr〉)37: blocking ← blocking \ {〈IN, t, pk〉}38: end if39: end if
Client side. The client part of the replication protocol isvery simple. All operations are executed by calling theexecute op procedure, passing the operation name (OUT,RDP, INP, CAS, RD or IN) and arguments (lines 1-3). In thisprocedure, the client issues the requested operation to allnservers using the total order multicast communication primi-tive (line 4). Then it waits for replies until some response canbe extracted from the reply vectorR (lines 5-10). This ex-traction is made through the functionextract response thatverifies if there aref + 1 positions of the vectorR with thesame response and returns it. This is what is usually done instandard (Byzantine-tolerant) state machine replication pro-
4

tocols, where response will be accepted if it is replied by atleastf + 1 distinct servers, thus ensuring that some correctserver replied it. However, in our system, the confidential-ity layer imposes different constraints on a request result ex-traction as will be discussed in next section. Consequently,when confidentiality is used, theextract response functiondescribed in the next section will be used instead of the sim-ple one described above.
Server side. The server side of the replication protocol isactivated when the total order multicast protocol delivers amessage and its sender is not in the system’s blacklist (whichthe purpose will be explained in the next section). In thefirst part of the algorithm (lines 12-23) the required opera-tion is executed by the server in its upper layerts. This callwill eventually reach the tuple space layer of the server. No-tice that the blocking operations of the tuple space are nevercalled, to avoid blocking the server. When a blocking opera-tion is requested, its non-blocking version is executed (lines20-22) and if it is not successful because there is no matchingtuple (tr = NM) the operation is stored in a set of pendingoperations for future execution (lines 24-25). If the requestedoperation is executed, a response is sent back to the client(line 27). Finally, if some tuple is inserted ints, the algorithmchecks if some pending operation can be executed (lines 29-39). In order to maximize the amount of blocking operationsbeing resolved, we first resolve allrd operations that matchthe tuple inserted (lines 30-33) and then somein that can beanswered by the inserted tuple is resolved (lines 34-38).
Read optimization. An optimization that can be made forthe rd /rdp operations is to try to execute them first withouttotal order multicast and wait forn − f responses. If all ofthem are equal, the returned value is the result of the oper-ation, otherwise the normal protocol operation must be exe-cuted. This optimization is quite effective when there is littleconcurrency and no faults in the system.
3.4 Confidentiality
Replication is often seen not as a helper but as an impedi-ment for confidentiality. The reason is easy to understand: ifsecret information is stored not in one but in several servers,it probably becomes easier for an attacker to get it, not harder.Therefore, the enforcement of confidentiality in a replicatedtuple space is not trivial. Several solutions that come to mindsimply do not work or are unacceptable for the generativecoordination model. One of those solutions would be to en-crypt the client-server communication and let the tuple spaceencrypt the tuple fields with its own key(s). This is unaccept-able because we assumef servers can fail maliciously, sothey might decrypt the tuple fields and disclose their contents.A second solution would be to let the client that inserts a tu-ple to encrypt the tuple fields either with a secret key (with asymmetric cryptography algorithm like AES) or with its pri-vate key (with a public-key algorithm like RSA). The prob-lem of this solution is that it requires all clients that mightread and/or remove this tuple to know the decryption key.This contradicts the anonymity property of the generative co-ordination model [21], which states that clients should not
need to know information about each other. Notice that foran intrusion-tolerant tuple space, the possibility of a serverbeing controlled by a malicious adversary, turns all previousproposed tuple space security mechanisms useless in our sys-tem model since they assume a trusted tuple space [7, 47].
The solution we propose follows in some way the idea ofletting the servers handle the confidentiality. However, in-stead of trusting each server to keep the confidentiality of thetuple fields, we trust asetof servers. The solution is basedon a(n, k)–publicly verifiable secret sharingscheme (PVSS)[40], with k = f+1. Each serversi has a private keyxi and apublic keyyi. The clients know the public keys of all servers.Clients play the role of the dealer of the scheme, encryptingthe tuple with the public keys of each server and obtaininga set of tupleshares(function share of the PVSS scheme).Any tuple can be decrypted withk = f + 1 shares (functioncombine), therefore a collusion of malicious servers cannotdisclose the contents of confidential tuple fields (we assumeat mostf servers can be faulty). A server can use a functionprove to buid a proof that the share that it is giving to theclient is correct. The PVSS scheme also provides two veri-fication functions, one for each server to verify the share itreceived from the dealer (functionverifyD) and other for theclient/combiner to verify if the shares collected from serversare not corrupted (functionverifyS).
The confidentiality scheme has also to handle the prob-lem of matching (possibly encrypted) tuples with templates.When a client callsout(t), it chooses one of three types ofprotection for each tuple field:
• public: the field is not encrypted so it can be comparedarbitrarily (e.g. if it belongs to a range of values) but itscontent may be disclosed if a server is faulty1;
• comparable: the field is encrypted but a cryptographichashof the field is also stored so equality comparisonsare possible (details below);
• private: the field is encrypted and no hash is stored sono comparisons are possible.
The type of the protection for each field of a tuple is de-fined in aprotection type vector. Given a tuplet, we defineits protection type vectorvt as a sequence of protection types,one for each field oft. The possible values for the fields ofa protection type vector are PU, CO and PR, indicating ifthe corresponding tuple field is public, comparable or pri-vate, respectively. Therefore, each field ofvt describes theprotection type required by the corresponding field oft. Forexample, if a tuplet = 〈7, 8〉 has a protection type vectorvt = 〈CO, PR〉, we know that the first field (witch containsthe value7) is comparable and that the second field (value8)is private. Notice that the protection type vector is defined bythe application, so we make the (reasonable) assumption thatthe application’s processes know the protection type vectorsfor all tuples they use.
A collision-resistant hash functionH(v) (e.g. SHA-1)maps an arbitrarily length input to a fixed length output, sat-isfying two properties: it is computationally infeasible to find
1This type of protection may be needed, for example, in fine-grainedpolicy enforcement (Section 3.6).
5

two valuesv 6= v′ such thatH(v) = H(v′) (collision resis-tance); given an output it is computationally infeasible to findan input that produces that output (unidirectionality). We in-formally call the output of such functiona hash.
The idea behindcomparable fieldsis the following. Sup-pose clientp1 wants to insert in the space a tuplet with asingle comparable fieldf1. p1 sendst encrypted andH(f1)to the servers. Suppose later a clientp2 requestsrd(t) andthe tuple space needs to check ift and t match. p2 calcu-latesH(f1) and sends it to tuple space that verifies if thishash is equal toH(f1). This scheme works for equalities butclearly does not work with more complex comparisons likeinequalities. The scheme has another limitation. Althoughhash functions are unidirectional, if the range of values that afield can take is known and limited, then a brute-force attackcan disclose its content. Suppose a field takes 32 bit values.An attacker can simply calculate the hashes of all232 pos-sible values to discover the hashed value. This limitation isa motivation for not using typed fields in a dependable tu-ple spaces. Also, the limitation of comparable fields is thereason why we also defineprivate fields: no hash is sent tothe servers so comparisons are impossible, but their contentcannot be disclosed.
The confidentiality scheme is implemented by the confi-dentiality layers in the client and server sides. The algorithmsfor these layers are presented in Algorithm 2. Both the client-side and the server-side layers have one procedure to processeach tuple space operation. In the client (viz. server), theseprocedures are called by the layer above (viz. below) theconfidentiality layer – lines 1-20 (viz. 29-31). In the client(viz. server), the confidentiality layer calls the layer below(viz. above) using a pseudo-objectts. The confidentialitylayers transform the tuples and templates that are sent andreceived.
Client side. In the client side, the templates used to reador remove a tuple are transformed in afingerprint (lines 3,10and 13). The idea is to transform each tuple field accordingto its protection type vector (see lines 25-28). Private fieldsare simply substituted by a constant PR since no informationabout the field value can be disclosed. Consequently, privatefields are only matched by the constant PR or the wildcard(‘*’). Also in the client side, tuples to be inserted usingoutor cas aremasked, i.e. the content of each of its fields is pro-tected from disclosure depending on its protection type (lines21-24). This masking procedure starts by obtaining a finger-print of the tuple (line 21), then uses the PVSS scheme to ob-tain shares of the tuple (line 22) and encrypts each share withthe secret key shared by the client and each of the servers(line 23). This encryption solves the problem of the total or-der multicast sending all the shares to all servers. If a server ismalicious, it can only decrypt its share, so it cannot disclosethe content of the tuple. The PVSS scheme also generates aproof PROOF t that the shares are really shares of the tuple(line 22). The encrypted shares andPROOF t are concate-nated with the fingerprint of the tuple (‘.’ operator, line 24)and passed to the replication layer.
Algorithm 2 Confidentiality Layers (clientpi and serversj).{CLIENT}ts: client side replication layer
procedureout(t)
1: ts.out(mask(t))
procedurerdp(t) {the same forrd(t)}2: repeat3: r ← ts.rdp(fingerprint(t))4: if ¬valid(r) then5: TO-multicast(U, 〈CLEAN, r〉)6: end if7: until valid(r)8: return r
procedure inp(t) {the same forin(t)}9: repeat
10: r ← ts.inp(fingerprint(t))11: until valid(r)12: return r
procedurecas(t, t)
13: t′ ← fingerprint(t); t′ ← mask(t)
14: repeat15: r ← ts.cas(t
′, t′)
16: if ¬valid(r) then17: TO-multicast(U, 〈CLEAN, r〉)18: end if19: until valid(r)20: return r
proceduremask(t)
21: th ← fingerprint(t)22: 〈s1, ..., sn,PROOF t〉 ← share(t)23: s← 〈E(s1, ki1), ..., E(sn, kin)〉24: return th.PROOF t.s
procedurefingerprint(t = 〈f1, ..., fm〉)25: for all 1 ≤ i ≤ m do
26: f ′i ←
∗ if fi = *fi if fi is public or formalH(fi) if fi is comparablePR if fi is private
27: end for28: return 〈f ′
1, ..., f ′m〉
{SERVER}ts: server side upper layer
procedureout(t)
29: ts.out(unmask(t))
procedurerdp(t) {The same forinp(t)}30: return ts.rdp(t. ∗ . ∗ .∗) {ts.inp(t. ∗ . ∗ .∗) for inp(t)}
procedurecas(t, t)
31: return ts.cas(t. ∗ . ∗ .∗, unmask(t))
procedureunmask(th.PROOF t.s)
32: si ← D(s[j], kij)33: PROOF i ← prove(s,PROOF t)34: return th.PROOF t.si.PROOF i
upon TO-receive(pi, 〈CLEAN, r〉)35: if ¬valid(r) then36: t← local delete(ts, r)37: blacklist ← blacklist ∪ {sender(t)}38: end if
Server side. In the server side, tuples to be inserted are un-masked (lines 29, 31-34): the tuple share corresponding tothe server is decrypted with the key shared with the client(line 32), a proof that the share is correct is generated (line33), and these two pieces of information are concatenated
6

with the tuple fingerprint and itsPROOF t (line 34). Noticethat a server does not verify the share received. This happensfor two reasons:(i.) this verification is the most expensivecryptographic operation of the PVSS scheme we are usingand it is executed at server side, potentially limiting the scal-ability of the system; and(ii.) the verification does not ensureanything useful. A malicious client might send invalid sharesonly to some servers in order to make them discard the tu-ple while other servers would store it. This situation wouldleave the system in an inconsistent state, where different tu-ple space replicas would have different sets of stored tuples.Therefore, a low-overhead lazy mechanism for removing in-valid tuples from the space is used (see below).
Still at the server side, templates are simply passed to theupper layer concatenated with three wild-card fields (‘*’)with the objective of reading some tuple that matches the tem-plate fingerprint whatever its share and proof (lines 21-23).Blocking operations do not appear in Algorithm 2 becausethe server-side replication layer never calls them.
Result extraction. The replication algorithm in the previ-ous section, used anextract responseprocedure to obtain theresult of an operation (line 12 of Algorithm 1). Now, we willpresent the version of this procedure used with the confiden-tiality layer. The code is presented in Algorithm 3.
Algorithm 3 Extract response procedure.procedureextract response(R)
1: if ∃v : #vR ≥ f + 1 then2: return v {f + 1 equal responses}3: else if∃th,PROOF t : #〈th,PROOFt,∗,∗〉(R) ≥ f + 1 then4: for all k = 1..n : R[k] = 〈th,PROOF t, sk,PROOFk〉 do5: if verifyS(sk, yk,PROOF t,PROOFk) then6: S[th.PROOFt ]← S[th.PROOFt ] ∪ {sk}7: end if8: end for9: if |S[th.PROOF t]| ≥ f + 1 then
10: tr ← combine(S[th.PROOF t])11: if fingerprint(tr) = th then12: return tr {fingerprint matches tuple}13: else14: return 〈INVALID , R〉 {wrong fingerprint}15: end if16: else if∃th,PROOF t : #〈th,PROOFt,∗,∗〉(R) ≥ n− f then17: return 〈INVALID , R〉 {there are more thanf invalid shares}18: end if19: end if20: return ⊥ {no response to be extracted yet}
The procedure starts by verifying if there are more thanf + 1 responses with the same value and, if this is the case,this value is returned (lines 1-2). This condition is used to ex-tract results in three cases:(i.) a response for anout request,(ii.) a no match (NM) response for an read/remove operationand (iii.) a response for acas operation that inserts a tuplein the space. If this first condition does not hold, the proce-dure verifies if there are at leastf + 1 responses for the samefingerprint and dealer proof (line 3; function#t(R) gives thenumber of occurrences of the tuplet in the vectorR). If thiscondition is met, the procedure verifies if the shares alreadyreceived are correct (lines 4-8); iff + 1 are (line 9), then itcombines the shares and obtains the original tuple (line 10).
There is a possibility that the tuple obtained will not sat-
isfy the template used to read/remove it: the client that hasinserted the tuple might be malicious and have inserted a fin-gerprint that did not correspond to the tuple (e.g. some hashesof comparable fields are different from the hashes of thosefields). A malicious client could also insert a tuple with in-valid shares. If any of these cases are detected, the extractedresponse is consideredinvalid (lines 14 and 17) and a recov-ery procedure is executed to remove this tuple from the space.
The recovery procedureworks as follows: if the client isonly reading the tuple (lines 2-8 of Algorithm 2), it has tosend the tuple and the proofs to the servers (using total or-der multicast) in a CLEAN message so that they can discardthe tuple (Algorithm 2, lines 3,4 and 35-38). The server dis-cards the tuple if the CLEAN request is valid and the serverresponses are correctly signed. Each server puts the senderof the invalid tuple in a blacklist so that all its future requestswill be ignored by the system (see Algorithm 1). Since thecas operation can work like a read, the procedure is the same(lines 13-20 of Algorithm 2). If the executed operation isan in/inp no CLEAN message is sent since the invalid tuplehas already been removed (lines 9-12 of Algorithm 2). Af-ter the recovery procedure, the read/remove operation has tobe reissued. Notice that this recover scheme requires that theresponses sent by the servers to the clients are signed.
Discussion. Some comments about the confidentialityscheme are presented bellow:
Read optimization.The read optimization described at theend of Section 3.3 still works with the confidentiality layer.The extract responde procedure described in algorithm 3 iscalled only whenn − f responses are received and the con-ditions of lines 1 and 3 of this algorithm are modified to holdonly if there aren − f responses with the same value. If⊥is returned, then there are faults or concurrency in the systemand the normal procedure must be executed.
Linearizability. The confidentiality layer weakens our tu-ple space semantics since it no longer satisfies linearizabilityin all situations. The problem is that a malicious client can in-sert invalid shares in some servers and valid shares in others,so it is not possible to ensure that the same read/remove op-eration executed in the same state of the tuple space will havethe same result: the result depends of then − f responsescollected. However, our tuple space satisfies this conditionfor all tuples that have been inserted by correct processes.
Lazy recovery.The recovery procedure uses a blacklist toensure that a malicious client cannot insert tuples after someof its invalid insertions have been recovered (cleaned). Thismeans that the damage caused by malicious clients isrecov-erableandbounded. A question one can ask is that if it ispossible to prevent the insertion of tuple shares that do notcorrespond to the fingerprint, i.e. if it is possible to inte-grate the fingerprint calculation inside the PVSS scheme insuch a way that the servers can verify if the share deliveredto them corresponds to the tuple that originated the finger-print without revealing the value of the tuple to them. Weinvestigated this question and the answer isno for the generalcase. The PVSS scheme requires a symmetric cryptographyalgorithm in order to be used to share arbitrary secrets (liketuples) [40]. This fact, together with the hash function used
7

to compute fingerprints and required by the PVSS schememeans that, in order for such verification to be executed inthe servers, it would be needed that functionsshare (PVSSshares’ generation function),E (encryption function) andH(hash function) have some mathematical relationship such asshare(v) = E(v) + H(v). Clearly, there is no such relation-ship for arbitrary functionsshare, E andH. We do not know ifthere is some set of cryptographic functions with these prop-erties but, even if there are, we believe that a lazy and recover-oriented approach like the one used here would be more ef-ficient in the common case (no malicious faults) since we donot use any verification at server side and the recover is ex-ecuted only when tuples inserted by malicious processes areread from the space (one time per invalid tuple).
3.5 Access Control
Access control has been shown to be a fundamental secu-rity mechanism for tuple spaces [7]. We do not make a deci-sion about the specific access control model to be used, sincethe better one depends on the application. For instance, ac-cess control lists (ACLs) might be used for closed systems,but some type of role-based access control (RBAC) might bemore suited for open collaborative systems [45]. To accom-modate these different mechanisms in our dependability ar-chitecture, access control mechanisms are defined in terms ofcredentials: each tuple spaceTS has a set of required creden-tialsCTS and each tuplet has two sets of required credentialsCt
rd andCtin. To insert a tuple in a tuple spaceTS, a client
must provide credentials that matchCTS . Analogously, toread (resp. remove) a tuplet from a space, a client must pro-vide credentials that matchCt
rd (resp.Ctin).
The credentials needed for inserting a tuple inTS are de-fined by the administrator that configures the tuple space. IfACLs are used,CTS is the set of processes allowed to inserttuples inTS. Analogously, with ACLs the credentialsCt
rd
andCtin associated with tuplet would be the sets of processes
allowed to read and remove the tuple, respectively.The implementation of access control in our architecture
is done in the access control layers in the clients and servers,as show in Figure 2. In the client side, when anout or acasoperation are invoked, the associated credentialsCt
rd andCtin
are appended to the tuple as two public fields. Additionally,the client credentials are appended as another public field ofthe tuple, either if the tuple is a entry (out or cas) or a tem-plate (cas and read/remove operations).
In the server side layer, each (correct) server tests if theoperation can be executed. If the operation is a tuple inser-tion, sayt, client credentials (appended tot) must be suffi-cient for insertingt in the space. If this condition holds,t isinserted in the space (with its associated required credentialsCt
rd andCtin as public fields). If the requested operation is
a read/remove, the credentials associated with the templatet passed, must be sufficient for executing the operation. Inpractice the server side layer may have to read several tuplesfrom the tuple space to find one that can be read/removed bythe client. This reading of several tuples may be supportedby the tuple space (e.g. thescanoperation in TSPACES[44])or may have to be implemented. If several tuples are read,they have to be checked in the same deterministic order in all
servers, to guarantee that all correct servers choose the same.
3.6 Policy Enforcement
In a recent paper we have shown that tuple spaces that imple-ment a more generic form of access control – policy-enforcedaugmented tuple spaces – have interesting properties for thecoordination of clients that can fail in a Byzantine (or arbi-trary) way [5]. Here we describe how policy enforcement isimplemented in our tuple space, in the policy enforcementlayer (see Figure 2).
The idea behindpolicy enforcementis that the tuple spaceis governed by afine-grained access policy. This kind ofpolicies takes into account the already mentioned three typesof parameters: identifier of the invoker; operation and argu-ments; tuples currently in the space. An example policy is inFigure 3. Operations without rules are prohibited so this pol-icy allows onlyrd andout operations. The rule forrd statesthat anyrd invoked is executed. The rule forout states thatonly tuples with two values can be inserted and only if thereis no tuple in the space with the same second value as the onethat the invoker is trying to insert.
Tuple Space stateTSRrd: execute(rd(t)) :- invoke(p, rd(t))Rout: execute(out(〈a, b〉)) :-
invoke(p, out(〈a, b〉)) ∧ ∀c : 〈a, c〉 /∈ TS
Figure 3: Example access policy.
A tuple space has a single access policy. It should bedefined during the system setup by the system administra-tor. Whenever an operation invocation is received in a server,there is a verification if the operation satisfies the access pol-icy of the space in the policy enforcement layer. This kindof verifications is usually assumed to be made in a referencemonitor, which guarantees properties like being impossibleto call an operation circumventing the verification [2]. How-ever, in our replicated tuple space we simply consider thatcorrect servers correctly verify the access policy, while faultyservers can behave arbitrarily. The verification itself is a sim-ple local computation of a condition expressed in the ruleof the operation invoked. When an operation is rejected theserver returns an error code to the invoker. The client acceptsthe rejection if it receivesf +1 copies of the same error code.
4 DEPSPACE Implementation
The DEPSPACE was implemented in the Java programminglanguage, and at present it is a simple but fully functional de-pendable tuple space. The Byzantine-resilient state machinereplication algorithm implemented is the PAXOS AT WAR de-scribed in [50] (which makes consensus in two communica-tion steps as long as there are no faulty servers in the system),combined with a total ordering scheme inspired by the onedefined by [11]2. Authentication was implemented using theSHA-1 algorithm for producing HMACs (providing an ap-proximation for authenticated channels on top of Java TCPSockets). SHA-1 was also used for computing the hashes
2Our algorithm is an extension to the PAXOS AT WAR algorithm to pro-vide total order multicast. It fundamentally differs from BFT [11] since wedo not use checkpoints.
8

of comparable fields. For symmetric cryptography we em-ployed the Triple DES algorithm while RSA with exponentsof 1024 bits was used for digital signatures (used for leaderelection in the PAXOS AT WAR). The agreement over mes-sage hashes optimization of PAXOS [11] was implementedusing MD5 hash function. All the cryptographic primitivesused in the prototype were provided by the default provider ofversion 1.5 of JCE (Java Cryptography Extensions). The onlyexception was the PVSS scheme, which we implemented fol-lowing the specification in [40], using algebraic groups of192 bits (more than the 160 bits recommended in [40]). Thisimplementation makes extensive use of theBigIntegerclass, provided by the Java API, which provide several utilitymethods for implementing cryptography. Since we are notusing typed fields, we implemented all fields as strings. Thissimplifies our design since any type can easily be convertedto a string and vice-versa.
There are several interesting points about our implementa-tion and they are explained bellow.
4.1 Layer Interface and Tuple Structure
All layers, both at client and server sides, implement the sametuple space abstraction. This abstraction is represented bythe DepSpace interface, implemented by all layers in thesystem. This interface is presented in Figure 4.
public interface DepSpace {void out(DepTuple tuple, Context ctx)
throws DepSpaceException;
DepTuple rd(DepTuple template, Context ctx) throws ...;DepTuple in(DepTuple template, Context ctx) throws ...;
DepTuple rdp(DepTuple template, Context ctx) throws ...;DepTuple inp(DepTuple template, Context ctx) throws ...;
DepTuple cas(DepTuple template, DepTuple tuple,Context ctx) throws DepSpaceException;
}
Figure 4: DEPSPACE layer interface.
The most interesting point about this interface is that allits methods (representing tuple space operations) have an ex-tra argument, the invocation context. The context is used atclient and server side to pass invocation-specific informationbetween layers. For instance, at client side, the context isused to define the protection type vector for the operationarguments (tuples and templates). At server side this con-text object contains the invoker id which is used in the accesscontrol layer.
As can be seen in Figure 4, in the DEPSPACE system thetuple abstraction is represented by the classDepTuple . Ashort view of this class is presented in Figure 5.
This class contains all information related to a tuple inDEPSPACE: the tuple fields (represented by an array ofObject ), ACLs for reading and removing the tuple (theid of a process is anint ) and extra information for theconfidentiality scheme (PublishedShares represent thePROOF t and the encrypted shares andShare is the de-crypted share).
We choose to represent the different kinds of tuples usingthis single class instead of building a class hierarchy for dif-ferent types of tuples to avoid managing different classes andto turn our design more simple.
public class DepTuple implements Serializable {
private Object[] fields;
//ACLs for read and removeprivate final int[] c_rd;private final int[] c_in;
//confidentiality dataprivate PublishedShares publishedShares;private Share share = null;
//create methods for several kinds of tuplespublic static DepTuple createTuple(Object... fields) {
return new DepTuple(fields,null,null,null);}public static DepTuple createAccessControledTuple(
int[] c_rd, int[] c_in, Object... fields) {return new DepTuple(fields,c_rd,c_in,null);
}...
}
Figure 5: Tuple class in DEPSPACE.
4.2 Tuple space creation
The DEPSPACE system supports multiple tuple spaces. Atuple space is created through a message sent to servers us-ing total order multicast. This message specifies the logicalname, the required credentials to insert tuples in the spaceand the quality of service supported by it. The space qual-ity of service defines what optional layers (confidentialityand policy-enforcement) must be used by it. If the policy-enforcement layer is used, the policy for the space must besent in this message. A client creates a space using theDepSpaceAdmin class, that can be accessed by all clients3.
4.3 Advanced Java Features
In order to maximize the performance and scalabilityof our implementation, we used some new features of-fered by Java platform, namelly theNIO API (packagejavax.nio) and several concurrency utility classes (packagesjava.util.concurrentandjava.util.concurrent.locks).
TheNIO API provides a series of classes for scalable bufferand connection management, like theSelector class, thatprovides the same channel selection functionality of theselect UNIX system call.
The concurrency utility packages provides classes like aBlockingQueue and several types of locks that allowsmore efficient and scalable thread synchronization than theusual approach (based on monitors and in the use of thesyn-chronizedkeyword).
Beside the use of these features, we always used the Just-In-Time (JIT) compiler in all our experiments, something thatwe concluded to cut the cryptographic delays around 10 times(see the next section).
4.4 Access Control
Our current implementation of the access control layer isbased on ACLs. In this way, we assume that each processhas an unique id (a 32 bit integer) wich is know by a server inthe moment that the client stabilishes an authenticated chan-nel with it. As can be seen in Figure 5, the required creden-tials for reading and removing some tuple are specified as the
3Additional access control mechanisms can be activated to allow onlysome clients to create spaces.
9

set of authorized processes ids for these operations, in theDepTuple class (fieldsc rd andc in ). The same is donefor the processes that can insert a tuple on the space.
The blacklist is implemented as a linked list of process ids.A correct server does not accept incoming connections fromprocesses wich id appears in this list. Consequently, a serverdoes not execute a PAXOS instance to order operations issuedby faulty processes.
4.5 Policy Enforcement
The DEPSPACE implementation requires that the policies tobe enforced in a tuple space be passed as an argument in thetuple space creation. Currently, the system accepts policiesspecified in the GROOVY programming language [13]. Thislanguage is the first fully specified scripting language for theJVM. It is totally compliant with the Java programming lan-guage and at the same time it offers several features that makeit very agile and easy to program. The idea is that the policyfor a space is defined in a GROOVY class and then passed asan string to the tuple space servers. At the server, the policy istransformed in a binary Java class and instantiated as a policyenforcer. Every time an operation have to be processed at theserver, some authorization method is called on the policy en-forcer, if the method result istrue, the operation is executedin the upper layer, otherwise its access is denied.
The policy script must extends thePolicyEnforcerabstract class, that defines the authorization methodscanExecuteOp , canExecuteRd , canExecuteIn andcanExecuteCas . The default implementation of thesemethods always returnfalse.
To ensure that no malicious code will be executed by thescript4, the class loader used to instantiate the policy enforceris protected by a security manager that only gives to it theright to read the contents of the tuple space. No I/O and noexternal call can be executed by the script.
Notice that after the script is processed during tuple spacecreation its execution comprises only a usual Java methodinvocation, no script interpretation is made.
4.6 Some Optimizations
Laziness in share extraction and proof generation: The un-maskprocedure (lines 32-34 of Algorithm 2) define the stepsto be executed by the servers to extract its shares and generateits corresponding proofs. According with the algorithm, thisprocedure is executed when the tuple is inserted. However,as will be seen in Section 6, the tuple insertion contains themost expensive cryptographic operations. In order to aliviatethis processing weight, we delay this operation until the tupleis first read.
Signatures in read tuples: Recall that the responses forread operations must be signed to allow the recover proce-dure. Since the processing cost for assymetric cryptographyis still very high, instead of signing all read responses, theservers first send them without signatures and the clients mustrequest signed responses for the operation if they find that theread tuple is invalid. Since it is expected that invalid tupleswill be very rare, in most cases the read operations will notrequire digital signatures.
4For example, aSystem.exit(0) call can shutdown the server.
5 Cost of Dependability
This section makes a theoretical assessment of the costs ofmaking a tuple space dependable. The most significativecosts are related to two mechanisms: replication and confi-dentiality. Policy enforcement and access control cause mi-nor performance overheads since they involve only to evalu-ate locally some rules for each request performed.
The main costs of the replication protocol presented in Al-gorithm 1 can be measured in terms of(i.) the total numberof servers required to toleratef faulty servers, and(ii.) thecommunication delay in fault-free scenarios. Both these val-ues are imposed by the state machine replication algorithmused. BYZANTINE PAXOS protocols are an important fla-vor of consensus for asynchronous systems, which can beadapted to implement state machine replication [11, 50, 33].These adaptations are interesting because they guarantee thatmessages are always delivered in total order (safety property),while ensuring that messages are delivered only when the net-work is timely (liveness property)5. This kind of algorithmrequires at least3f + 1 servers to toleratef Byzantine faults,which is the optimal resilience for consensus and total ordermulticast in asynchronous systems [14]. A total order multi-cast protocol based on the fastest BYZANTINE PAXOS termi-nates in only 3 communication steps in timely and fault-freeexecutions [50, 33].
The main costs of the confidentiality mechanism are due(i.) to communication overhead, since several control fieldsmust be sent together with the encrypted tuple, and(ii.) tothe processing of the cryptographic operations. Concerningthe message size, most of the overhead is due to the shareproof (PROOF t) and the encrypted shares, which comprises(2n+f +2)q bits, beingq the size of the algebraic field usedin our scheme (the same size of the protocol keysxi andyi).For our setting with a field with192 bits andn = 4 servers(f = 1), the tuple/message overhead will be264 bytes. Themost expensive aspect of the confidentiality scheme is thecryptographic processing. Specifically, we have found thatmost of the performance cost of the mechanism comes fromthe number of exponentiations with big integers, used to gen-erate the proofs for the shares. Next section shows the weightof this processing measured in practice.
6 Experimental Evaluation
This section presents an experimental evaluation ofDEPSPACE. The execution environment was composed bya set of five Athlon 2.4GHz PCs with 512 Mb of memoryand running Linux (kernel 2.6.12). They were connected bya 100Mbps switched Ethernet network. The Java runtimeenvironment used was Sun’s JDK 1.5.006 and, as alreadypointed, the just-in-time compiler was always turned on.
Two factors are considered in our experiments: the numberof servers and the size of tuples. We consideredn = 4, 7, 10servers6 (tolerating1, 2, and3 faulty servers, respectively)
5This is the best that can be achieved since a fundamental result in dis-tributed computing states that agreement based protocols cannot be imple-mented deterministically in completely asynchronous systems [18].
6Due to resource constraints, we deployed more than one server per ma-chine in the experiments with7 and10 servers.
10

0 4 8
12 16 20 24 28 32 36 40
10 7 4
Late
ncy
(ms)
Number of Servers
not conf.conf.
(a) out
0 4 8
12 16 20 24 28 32 36 40
10 7 4
Late
ncy
(ms)
Number of Servers
not conf.conf.
(b) rdp
0 4 8
12 16 20 24 28 32 36 40
10 7 4
Late
ncy
(ms)
Number of Servers
not conf.conf.
(c) inp
0 4 8
12 16 20 24 28 32 36 40
10 7 4
Late
ncy
(ms)
Number of Servers
not conf.r conf.o conf.
(d) cas
0 2 4 6 8
10 12 14 16 18 20 22 24
1024 256 64
Late
ncy
(ms)
Tuple Size (bytes)
not conf.conf.
(e) out
0 2 4 6 8
10 12 14 16 18 20 22 24
1024 256 64
Late
ncy
(ms)
Tuple Size (bytes)
not conf.conf.
(f) rdp
0 2 4 6 8
10 12 14 16 18 20 22 24
1024 256 64
Late
ncy
(ms)
Tuple Size (bytes)
not conf.conf.
(g) inp
0 2 4 6 8
10 12 14 16 18 20 22 24
1024 256 64
Late
ncy
(ms)
Tuple Size (bytes)
not conf.r conf.o conf.
(h) cas
Figure 6: Latency of DEPSPACE operations considering different numbers of servers and different tuple sizes.
using tuples with4 comparable fields (and a total size of64bytes). Concerning the tuple size, the experiments consideredtuples with4 comparable fields and sizes equal to64, 256,and 1024 bytes, running on a system with4 servers. Twocases were considered in all experiments: the complete sys-tem (with confidentiality) and the system with the confiden-tiality scheme deactivated. All our experiments consideredfault-free executions.
Latency. The first experiments (Figure 6) measured the de-lay perceived by the client for each one of the tuple spacenon-blocking operations:out , rdp, inp andcas. The clientwas in one of the machines and the servers in the other four.We executed each operation 1000 times and obtained themean time discarding the 5% values with greater variance.
The results presented in the figure show thatout , inp andcas have almost the same latency when the confidentialitylayer is not used – Figures 6(a), 6(c) and 6(d) (the solid lines).This is the latency imposed by the total order multicast proto-col: from 6 ms (4 servers) to12 ms (10 servers).rdp, on theother hand, is much more efficient (about2 ms) due to theoptimization presented in Section 3.3, which avoids runningthe total order multicast protocol (Figure 6(b)).
The dotted lines in the graphs show the latency of the pro-tocols when the confidentiality layer is used. In these exper-iments all tuples inserted and read have all their fields com-parable. In fact, the number of comparable fields is not rel-evant since the overhead for producing a hash is negligiblewhen compared to the overhead of the PVSS scheme. Thecas operation (Figure 6(d)) has two dotted lines, one measur-ing the cases where a tuple is inserted and other for the caseswhen some tuple is read. The additional latency cost causedby the confidentiality scheme is mostly due to the client-sideprocessing of the operations. Table 1 presents the confiden-tiality processing cost. The two values for the server-sideprocessing of operationsrdp, inp andcas are due to the ex-traction/decryption of the share when a tuple is first accessed(see Section 4.6). This small share extraction cost is the onlycryptographic processing at server side and is executed onlyonce. The two values for the client-side costs of operation
cas report times corresponding to execution when a tuple isinserted and read, respectively. The global cost of the confi-dentiality scheme is also higher forout since this is the onlyoperation in which the shares and their proofs have to be gen-erated. Notice that the processing cost of thecas operationwhen a tuple is read is approximately the cost ofout plus thecost ofrdp. This reflects the fact that the client side of thecasinvolves the masking of a tuple and a template, and, when theresult is a read, the client must combine the received shares.
Concerning the tuple sizes (Figures 6(e)-6(h)), it is clearthat the size of the tuple being inserted has almost no effect onthe latency experienced by the protocols. This happens dueto two implementation features:(i.) the PAXOS agreement ismade over message hashes; and(ii.) the secret shared in thePVSS scheme is not the tuple, but a symmetric key used toencrypt the tuple.(i.) implies that it is not the entire messagethat it ordered by the PAXOS protocol, but only its hash (MD5hashes always have128 bits), consequently the message sizehas little effect over the agreement protocol. With feature(ii.) we can execute all the required PVSS cryptographic inthe same, relatively small algebraic field of192 bits, whichmeans that the tuple size has no effect in these computationsand the use of the confidentiality scheme implies almost thesame overhead regardless the size of the tuple.
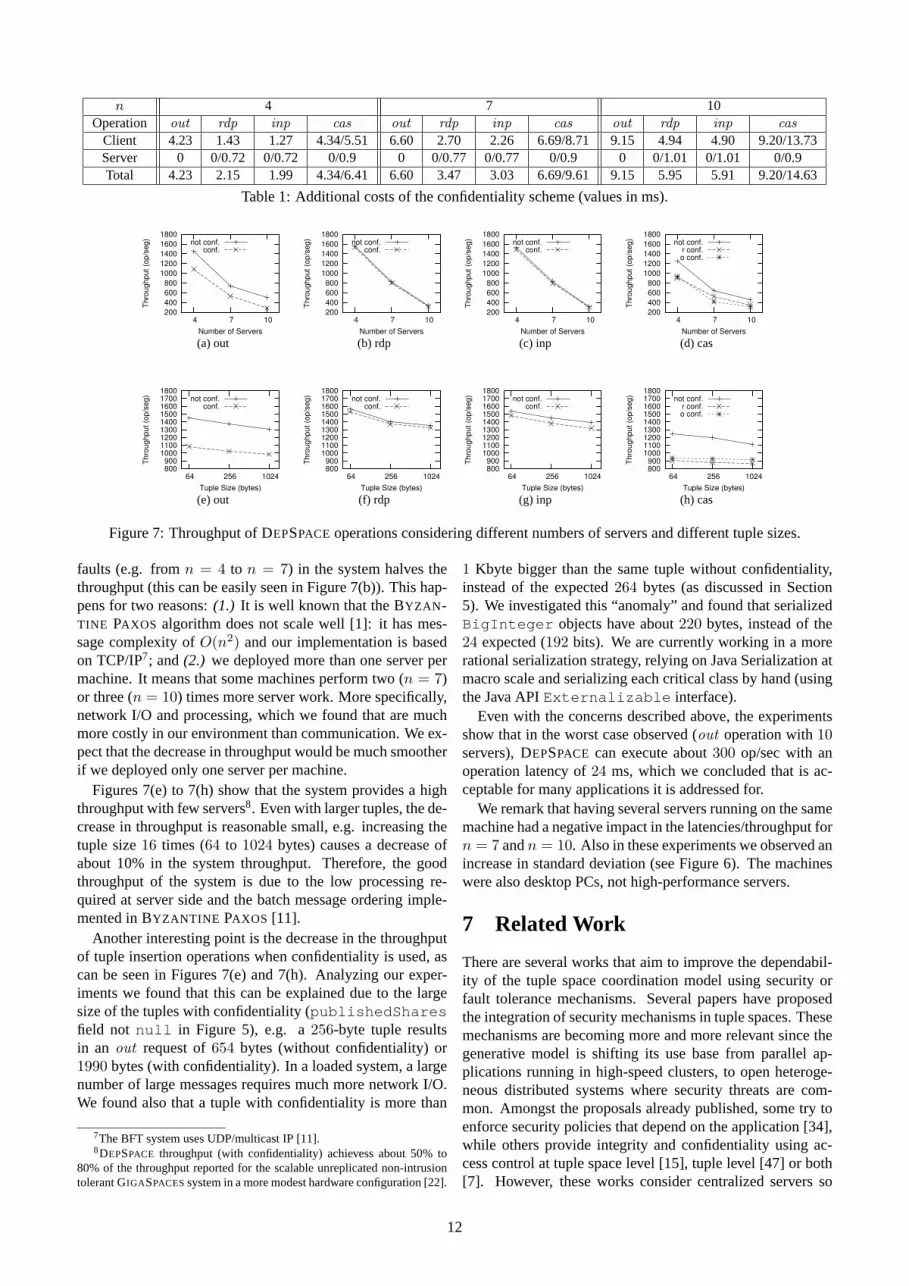
Throughput. The second set of experiments measured thethroughput of DEPSPACE for the two factors considered(number of servers and tuple sizes). For these experiments weused a modified client process that pre-processesC requestsfor the operation of interest (executing the client-side pro-cessing) and send then one-by-one to the servers. We mea-sured the timeT taken to process all these requests at theleader replica, from the moment it receives the first request tothe moment it sends the response for the last one. WithC andT we can calculate the throughput of the system asC/T . Theresults are presented in Figure 7 and there are at least threeinteresting points about these results.
Figures 7(a) to 7(d) show a dramatic decrease in the systemthroughput as the number of servers increase. In fact, the re-sults show that an unitary increase in the number of tolerated
11
n 4 7 10Operation out rdp inp cas out rdp inp cas out rdp inp cas
Client 4.23 1.43 1.27 4.34/5.51 6.60 2.70 2.26 6.69/8.71 9.15 4.94 4.90 9.20/13.73Server 0 0/0.72 0/0.72 0/0.9 0 0/0.77 0/0.77 0/0.9 0 0/1.01 0/1.01 0/0.9Total 4.23 2.15 1.99 4.34/6.41 6.60 3.47 3.03 6.69/9.61 9.15 5.95 5.91 9.20/14.63
Table 1: Additional costs of the confidentiality scheme (values in ms).
200 400 600 800
1000 1200 1400 1600 1800
10 7 4
Thro
ughp
ut (o
p/se
g)
Number of Servers
not conf.conf.
(a) out
200 400 600 800
1000 1200 1400 1600 1800
10 7 4
Thro
ughp
ut (o
p/se
g)
Number of Servers
not conf.conf.
(b) rdp
200 400 600 800
1000 1200 1400 1600 1800
10 7 4
Thro
ughp
ut (o
p/se
g)
Number of Servers
not conf.conf.
(c) inp
200 400 600 800
1000 1200 1400 1600 1800
10 7 4
Thro
ughp
ut (o
p/se
g)
Number of Servers
not conf.r conf.o conf.
(d) cas
800 900
1000 1100 1200 1300 1400 1500 1600 1700 1800
1024 256 64
Thro
ughp
ut (o
p/se
g)
Tuple Size (bytes)
not conf.conf.
(e) out
800 900
1000 1100 1200 1300 1400 1500 1600 1700 1800
1024 256 64
Thro
ughp
ut (o
p/se
g)
Tuple Size (bytes)
not conf.conf.
(f) rdp
800 900
1000 1100 1200 1300 1400 1500 1600 1700 1800
1024 256 64Th
roug
hput
(op/
seg)
Tuple Size (bytes)
not conf.conf.
(g) inp
800 900
1000 1100 1200 1300 1400 1500 1600 1700 1800
1024 256 64
Thro
ughp
ut (o
p/se
g)
Tuple Size (bytes)
not conf.r conf.o conf.
(h) cas
Figure 7: Throughput of DEPSPACE operations considering different numbers of servers and different tuple sizes.
faults (e.g. fromn = 4 to n = 7) in the system halves thethroughput (this can be easily seen in Figure 7(b)). This hap-pens for two reasons:(1.) It is well known that the BYZAN -TINE PAXOS algorithm does not scale well [1]: it has mes-sage complexity ofO(n2) and our implementation is basedon TCP/IP7; and(2.) we deployed more than one server permachine. It means that some machines perform two (n = 7)or three (n = 10) times more server work. More specifically,network I/O and processing, which we found that are muchmore costly in our environment than communication. We ex-pect that the decrease in throughput would be much smootherif we deployed only one server per machine.
Figures 7(e) to 7(h) show that the system provides a highthroughput with few servers8. Even with larger tuples, the de-crease in throughput is reasonable small, e.g. increasing thetuple size16 times (64 to 1024 bytes) causes a decrease ofabout 10% in the system throughput. Therefore, the goodthroughput of the system is due to the low processing re-quired at server side and the batch message ordering imple-mented in BYZANTINE PAXOS [11].
Another interesting point is the decrease in the throughputof tuple insertion operations when confidentiality is used, ascan be seen in Figures 7(e) and 7(h). Analyzing our exper-iments we found that this can be explained due to the largesize of the tuples with confidentiality (publishedSharesfield not null in Figure 5), e.g. a256-byte tuple resultsin an out request of654 bytes (without confidentiality) or1990 bytes (with confidentiality). In a loaded system, a largenumber of large messages requires much more network I/O.We found also that a tuple with confidentiality is more than
7The BFT system uses UDP/multicast IP [11].8DEPSPACE throughput (with confidentiality) achievess about 50% to
80% of the throughput reported for the scalable unreplicated non-intrusiontolerant GIGASPACESsystem in a more modest hardware configuration [22].
1 Kbyte bigger than the same tuple without confidentiality,instead of the expected264 bytes (as discussed in Section5). We investigated this “anomaly” and found that serializedBigInteger objects have about220 bytes, instead of the24 expected (192 bits). We are currently working in a morerational serialization strategy, relying on Java Serialization atmacro scale and serializing each critical class by hand (usingthe Java APIExternalizable interface).
Even with the concerns described above, the experimentsshow that in the worst case observed (out operation with10servers), DEPSPACE can execute about300 op/sec with anoperation latency of24 ms, which we concluded that is ac-ceptable for many applications it is addressed for.
We remark that having several servers running on the samemachine had a negative impact in the latencies/throughput forn = 7 andn = 10. Also in these experiments we observed anincrease in standard deviation (see Figure 6). The machineswere also desktop PCs, not high-performance servers.
7 Related Work
There are several works that aim to improve the dependabil-ity of the tuple space coordination model using security orfault tolerance mechanisms. Several papers have proposedthe integration of security mechanisms in tuple spaces. Thesemechanisms are becoming more and more relevant since thegenerative model is shifting its use base from parallel ap-plications running in high-speed clusters, to open heteroge-neous distributed systems where security threats are com-mon. Amongst the proposals already published, some try toenforce security policies that depend on the application [34],while others provide integrity and confidentiality using ac-cess control at tuple space level [15], tuple level [47] or both[7]. However, these works consider centralized servers so
12

they are not fault-tolerant, neither propose a confidentialityscheme like the one proposed in this paper.
Some of the work on fault tolerance for tuples spaces, aimsto increase the dependability of the coordination infrastruc-ture – the tuple space – using replication. Some of theseworks are based on the state machine approach [4], whileothers use quorum systems [48]. However, all of these pro-posals are concerned with crash failures and do not toleratemalicious faults, the main requirement for intrusion toler-ance. DEPSPACE is the first system to employ state-of-the-art Byzantine state machine replication to implement a tuplespace abstraction.
There is also work that focus on providing fault tolerancemechanisms at application level, providing features like sup-port for transactions [26]. This kind of feature have been ex-tensively used by comercial tuple space systems like JAVA S-PACES [43], TSPACES [44] and GIGASPACES [22]. Thesesystems provide the ACID properties (Atomicity, Consis-tency, Isolation and Durability), i.e. they guarantee that whenexecuting a sequence of tuple space operations, either all ornone of these operations are executed. We recognize theneed for application level support for fault tolerance, how-ever, in this paper we do not provide these mechanisms sincein Byzantine-prone settings they are problematic. For in-stance, if transactions are used, a malicious process can beginand abort transactions all the time affecting the liveness of theapplication. Currently our approach is to design algorithmsthat do not need this kind of application level support, likethose in [5].
Recently, some of the authors have presented a Byzantine-resilient tuple space – BTS [6]. That work proposes an effi-cient solution that requires Byzantine agreement only for theinp() operation and provides weak shared memory semantics(it does not satisfy linearizability [25]). The work presentedin the current paper differs from BTS in several importantways: it presents a complete solution for building a depend-able tuple space (BTS does not tolerate malicious clients, hasno access control and does not guarantee confidentiality); andit is based on Byzantine state machine replication (BTS isbased on Byzantine quorum systems [32]). Moreover, BTSis not a PEATS and was not implemented as a complete sys-tem like DEPSPACE.
A different area of important related work is on intrusiontolerance and confidentiality of the data in the servers. Theseminal paper in the area had a partial solution for confiden-tiality since data was scattered in several servers [19].
The first work to consider the security of state machinereplication is presented in [38]. That work presents a mod-ified state machine replication scheme that ensures integrity,availability and input causality, but not confidentiality. Later,when intrusion tolerance gained momentum, several solu-tions for replication using the Byzantine fault-tolerant statemachine approach were proposed, but none of them consid-ers confidentiality of the data in the servers (e.g. [11, 27, 37]).
We are aware of only two works that guarantee the con-fidentiality of replicated data in asynchronous systems withByzantine faulty clients. The first is the Secure Store, whichuses a secret sharing scheme to split data among the servers[29]. To reconstruct the original data, the collaboration of at
leastf +1 servers is needed. The scheme is not very efficientso the data shares created are replicated in several servers,thus using a large number of servers. Moreover, the systemdoes not tolerate malicious clients. The second solution isused to store (large) files efficiently in a set of servers so ituses an information dispersal scheme [9]. The idea is essen-tially to encrypt the file with a random secret key, split it inparts using an erasure code scheme, and send these parts tothe servers. The secret key is also split in shares and sent tothe servers, which use a threshold cryptography scheme to re-construct the key (requires the collaboration off +1 servers).Works in the same line are presented in [20, 23]. DEPSPACE
does not employ information dispersal since tuples are ex-pected of be reasonable small pieces of data. Our solutionis closer to the Secure Store since it uses secret sharing, butdoes not have an impact in terms of number of servers andtolerates any number of malicious clients. Moreover, ours isthe first work to combine state machine replication and a con-fidentiality scheme, presenting also a practical assessment ofthe performance of this kind of scheme.
8 Final Remarks
The paper presents a solution for the implementation of a de-pendable – fault- and intrusion-tolerant – tuple space. Theproposed architecture integrates several dependability and se-curity mechanisms in order to enforce the required proper-ties. This architecture was implemented in a system calledDEPSPACE, which is interesting in itself, since it is a policy-enforced augmented tuple space (PEATS), a shared memoryobject that we recently have shown to be useful to implementsimple and efficient distributed algorithms.
Another interesting aspect of this work is the integration ofreplication with confidentiality. To the best of our knowledge,this is the first paper to integrate state machine replication andconfidentiality of data stored in the servers. Moreover, al-though there are a couple of other works that integrated repli-cation (based on quorum systems) with confidentiality, thisis the first that used a prototype to assess the performanceof such a scheme. The results show that although the confi-dentiality scheme has some impact in the performance of thesystem, it can be argued that it is practical for a wide rangeof applications.
All code used in DEPSPACE is available at theJITT (JavaIntrusion Tolerant Tools)project homepage:http://www.das.ufsc.br/˜neves/jitt .
References[1] M. Abd-El-Malek, G. Ganger, G. Goodson, M. Reiter, and J. Wylie.
Fault-scalable Byzantine fault-tolerant services. InProceedings of the20th ACM Symposium on Operating Systems Principles - SOSP’05,pages 59–74, Oct. 2005.
[2] J. P. Anderson. Computer security technology planning study. ESD-TR73-51, U. S. Air Force Electronic Systems Division, Oct. 1972.
[3] A. Avizienis, J.-C. Laprie, B. Randell, and C. Landwehr. Basic con-cepts and taxonomy of dependable and secure computing.IEEE Trans-actions on Dependable and Secure Computing, 1(1):11–33, Mar. 2004.
[4] D. E. Bakken and R. D. Schlichting. Supporting fault-tolerant parallelprograming in Linda.IEEE Transactions on Parallel and DistributedSystems, 6(3):287–302, Mar. 1995.
13

[5] A. N. Bessani, M. Correia, J. da Silva Fraga, and L. C. Lung. Shar-ing memory between Byzantine processes using policy-enforced tuplespaces. InProceedings of 26th IEEE International Conference on Dis-tributed Computing Systems - ICDCS 2006, July 2006.
[6] A. N. Bessani, J. da Silva Fraga, and L. C. Lung. BTS: A Byzantinefault-tolerant tuple space. InProceedings of the 21st ACM Symposiumon Applied Computing - SAC 2006, pages 429–433, Apr. 2006.
[7] N. Busi, R. Gorrieri, R. Lucchi, and G. Zavattaro. SecSpaces: adata-driven coordination model for environments open to untrustedagents.Electronic Notes in Theoretical Computer Science, 68(3):310–327, Mar. 2003.
[8] G. Cabri, L. Leonardi, and F. Zambonelli. Mobile agents coordinationmodels for Internet applications.IEEE Computer, 33(2):82–89, Feb.2000.
[9] C. Cachin and S. Tessaro. Asynchronous verifiable information dis-persal. InProceedings of the 24th IEEE Symposium on Reliable Dis-tributed Systems - SRDS 2005, pages 191–202, Oct. 2005.
[10] N. Carriero and D. Gelernter. How to write parallel programs: a guideto the perplexed.ACM Computing Surveys, 21(3):323–357, Sept. 1989.
[11] M. Castro and B. Liskov. Practical Byzantine fault-tolerance andproactive recovery.ACM Transactions Computer Systems, 20(4):398–461, Nov. 2002.
[12] M. Castro, R. Rodrigues, and B. Liskov. BASE: Using abstractionto improve fault tolerance. ACM Transactions Computer Systems,21(3):236–269, Aug. 2003.
[13] Codehaus. Groovy programing language homepage. Avaliable athttp://groovy.codehaus.org/, 2006.
[14] M. Correia, N. F. Neves, and P. Verıssimo. From consensus to atomicbroadcast: Time-free Byzantine-resistant protocols without signatures.The Computer Journal, 49(1):82–96, Jan. 2006.
[15] R. De Nicola, G. L. Ferrari, and R. Pugliese. Klaim: A kernel languagefor agents interaction and mobility.IEEE Transactions on SoftwareEngineering, 24(5):315–330, May 1998.
[16] Y. Deswarte, K. Kanoun, and J.-C. Laprie. Diversity against accidentaland deliberate faults. InComputer Security, Dependability, & Assur-ance: From Needs to Solutions - CSDA’98, pages 171–181. July 1998.
[17] C. Dwork, N. A. Lynch, and L. Stockmeyer. Consensus in the presenceof partial synchrony.Journal of ACM, 35(2):288–322, Apr. 1988.
[18] M. J. Fischer, N. A. Lynch, and M. S. Paterson. Impossibility ofdistributed consensus with one faulty process.Journal of the ACM,32(2):374–382, Apr. 1985.
[19] J. Fraga and D. Powell. A fault- and intrusion-tolerant file system. InProceedings of the 3rd International Conference on Computer Secu-rity, pages 203–218, 1985.
[20] J. Garay, R. Gennaro, C. Jutla, and T. Rabin. Secure distributed storageand retrieval.Theoretical Computer Science, 243(1-2):363–389, 2000.
[21] D. Gelernter. Generative communication in Linda.ACM Transactionson Programing Languages and Systems, 7(1):80–112, Jan. 1985.
[22] GigaSpaces. GigaSpaces homepage. Avaliable athttp://www.gigaspaces.com/, 2006.
[23] G. R. Goodson, J. J. Wylie, G. R. Ganger, and M. K. Reiter. EfficientByzantine-tolerant erasure-coded storage. InProceedings of Depend-able Systems and Networks - DSN 2004, pages 135–144, June 2004.
[24] M. Herlihy. Wait-free synchronization.ACM Transactions on Pro-graming Languages and Systems, 13(1):124–149, Jan. 1991.
[25] M. Herlihy and J. M. Wing. Linearizability: A correctness conditionfor concurrent objects.ACM Transactions on Programing Languagesand Systems, 12(3):463–492, July 1990.
[26] K. Jeong and D. Shasha. PLinda 2.0: A transactional checkpointing ap-proach to fault tolerant Linda. InProceedings of the 13th IEEE Sympo-sium on Reliable Distributed Systems - SRDS’94, pages 96–105, Oct.1994.
[27] K. P. Kihlstrom, L. E. Moser, and P. M. Melliar-Smith. The SecureRinggroup communication system.ACM Transactions on Information andSystem Security, 4(4):371–406, Nov. 2001.
[28] L. F. Cabrera et al. Web Services Coordination Spec-ification - version 1.0. Disponıvel em http://www-128.ibm.com/developerworks/library/specification/ws-tx/, 2005.
[29] S. Lakshmanan, M. Ahamad, and H. Venkateswaran. Responsive se-curity for stored data.IEEE Transactions on Parallel and DistributedSystems, 14(9):818–828, Sept. 2003.
[30] L. Lamport, R. Shostak, and M. Pease. The Byzantine generals prob-lem. ACM Transactions on Programing Languages and Systems,4(3):382–401, July 1982.
[31] R. Lucchi and G. Zavattaro. WSSecSpaces: a secure data-driven co-ordination service for web services applications. InProceedings ofthe 19th ACM Symposium on Applied Computing - SAC 2004, pages487–491, Mar. 2004.
[32] D. Malkhi and M. Reiter. Byzantine quorum systems.DistributedComputing, 11(4):203–213, Oct. 1998.
[33] J.-P. Martin and L. Alvisi. Fast Byzantine consensus. InProceedingsof the Dependable Systems and Networks - DSN 2005, pages 402–411,June 2005.
[34] N. H. Minsky, Y. M. Minsky, and V. Ungureanu. Making tuple-spacessafe for heterogeneous distributed systems. InProceedings of the 15thACM Symposium on Applied Computing - SAC 2000, pages 218–226,Mar. 2000.
[35] A. Mostefaoui, M. Raynal, C. Travers, S. Patterson, D. Agrawal, andA. E. Abbadi. From static distributed systems to dynamic systems.In Proceedings of the 24th IEEE Symposium on Reliable DistributedSystems - SRDS 2005, pages 109–118, Oct. 2005.
[36] A. Murphy, G. Picco, and G.-C. Roman. LIME: A coordination modeland middleware supporting mobility of hosts and agents.ACM Trans-actions on Software Engineering and Methodology, 15(3):279–328,July 2006.
[37] M. K. Reiter. The Rampart toolkit for building high-integrity services.In Theory and Practice in Distributed Systems, number 938 in LectureNotes in Computer Science, pages 99–110. Springer-Verlag, 1995.
[38] M. K. Reiter and K. P. Birman. How to securely replicate ser-vices. ACM Transactions on Programing Languages and Systems,16(3):986–1009, May 1994.
[39] F. B. Schneider. Implementing fault-tolerant service using the statemachine aproach: A tutorial.ACM Computing Surveys, 22(4):299–319, Dec. 1990.
[40] B. Schoenmakers. A simple publicly verifiable secret sharing schemeand its application to electronic voting. InProceedings of the 19th An-nual International Cryptology Conference on Advances in Cryptology- CRYPTO’99, pages 148–164, Aug. 1999.
[41] E. J. Segall. Resilient distributed objects: Basic results and applica-tions to shared spaces. InProceedings of the 7th Symposium on Paral-lel and Distributed Processing - SPDP’95, pages 320–327, Oct. 1995.
[42] I. Stoica, D. Adkins, S. Zhuang, S. Shenker, and S. Surana. Inter-net indirection infrastructure.IEEE/ACM Transactions on Networking,12(2):205–218, 2004.
[43] Sun Microsystems. JavaSpaces service specification. Especificacaodisponıvel emhttp://www.jini.org/standards, 2003.
[44] Toby J. Lehman et al. Hitting the distributed computing sweet spotwith TSpaces.Computer Networks, 35(4):457–472, Mar. 2001.
[45] W. Tolone, G.-J. Ahn, T. Pai, and S.-P. Hong. Access control in collab-orative systems.ACM Computing Surveys, 37(1):29–41, Mar. 2005.
[46] P. Verıssimo, N. F. Neves, and M. P. Correia. Intrusion-tolerant archi-tectures: Concepts and design. In R. Lemos, C. Gacek, and A. Ro-manovsky, editors,Architecting Dependable Systems, volume 2677 ofLecture Notes in Computer Science. Springer-Verlag, 2003.
[47] J. Vitek, C. Bryce, and M. Oriol. Coordination processes with SecureSpaces. Science of Computer Programming, 46(1-2):163–193, Jan.2003.
[48] A. Xu and B. Liskov. A design for a fault-tolerant, distributed imple-mentation of Linda. InProceedings of the 19th Symposium on Fault-Tolerant Computing - FTCS’89, pages 199–206, June 1989.
[49] J. Yu and R. Buyya. A novel architecture for realizing grid workflowusing tuple spaces. InProc. of the 5th IEEE/ACM International Work-shop on Grid Computing, GRID 2004, pages 119–128, Nov. 2004.
[50] P. Zielinski. Paxos at war. Technical Report UCAM-CL-TR-593,University of Cambridge Computer Laboratory, Cambridge, UK, June2004.
14





























