Embed Size (px)
Citation preview

i
KLASIFIKASI LEVEL KEMAMPUAN BERBAHASA INGGRIS
BERDASARKAN HASIL PLACEMENT TEST
MENGGUNAKAN METODE NAIVE BAYES
SKRIPSI
Diajukan untuk memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
Oleh:
Indah Permata Sari
165314113
PROGRAM STUDI INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ii
THE CLASSIFICATION OF ENGLISH ABILITY
BASED ON PLACEMENT TEST RESULT
USING NAIVE BAYES METHOD
THESIS
Present as Patrial Fulfillment of the Reiquirements
to Obtain Sarjana Komputer Degree
in Informatics Study Program
By:
Indah Permata Sari
165314113
INFORMATICS STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

v
HALAMAN PERSEMBAHAN
“Selalu berpikir optimis, jangan menyerah dulu.
Berusaha semaksimal mungkin, masalah hasil belakangan.”
Ayah (14 Juni 2020)
“Skripsi ini saya persembahkan kepada ayah dan ibu yang sudah merawat
dan mendidik putri tunggalnya menjadi manusia yang seperti sekarang.
Jarang terucap, terima kasih atas segalanya.”-Indah Permata Sari
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

viii
ABSTRAK
Saat ini banyak sekali tempat yang menyediakan kursus untuk melatih
kemampuan berbahasa inggris di Jogja. Salah satunya Lembaga Bahasa
Universitas Sanata Dharma Yogyakarta. Lembaga Bahasa USD memiliki banyak
program kursus bahasa inggris, salah satunya yaitu Center of English for
International Communication (CEIC). Peserta yang akan mengikuti tes ini akan
ditempatkan di level yang sesuai dengan hasil tes. Level-level yang ada yaitu
Real Beginner, Mid Beginner, Upper Beginner dan Pre Intermediate. Pihak
Lembaga Bahasa harus melakukan penempatan level yang selama ini dilakukan
dengan cara yang manual. Pada penelitian ini data program CEIC tahun 2019
diolah menggunakan salah satu teknik Data Mining dengan menggunakan Naive
Bayes. Data yang digunakan sebanyak 240 data, terdiri dari 6 atribut (Question 1-
10, Question 11-20, Question 21-30, Question 31-40, Reading dan Listening) dan
4 label (Level 2, Level 3, Level 4 dan Level 5).
Pengujian dilakukan dengan dua skenario yaitu menggunakan berbagai
jumlah fold, dengan atau tanpa outlier. Secara keseluruhan pada setiap skenario
dilakukan dengan menguji berbagai jumlah atribut dan menggunakan semua label
yang ada. Pada skenario pertama menggunakan 240 data, dan dilakukan dengan 3,
4 dan 5 fold. Dari skenario pertama menghasilkan akurasi tertinggi pada
pengujian dengan menggunakan 3 atribut dan menggunakan 4-fold dan 5-fold,
yaitu 65%. Sedangkan pada skenario kedua menggunakan 3-fold dan outlier
dengan 226 data, diperoleh akurasi tertinggi pada uji coba menggunakan 3 atribut,
yaitu 67.5556%.
.
Kata kunci : Level Bahasa Inggris, Naive Bayes, Klasifikasi, Cross
Validation.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ix
ABSTRACT
Currently, many places are providing courses to practice English skills in
Jogja. One of them is the Yogyakarta Sanata Dharma Language Institute. The
Sanata Dharma Language Institute has many English courses, one of which is the
Center of English for International Communication (CEIC). Participants who sign
up for the course, need to take the English test first and then will be placed at the
level that matches the test results. Participants who will take this test will be
placed at the level that matches the test results. The levels are Basic, Real
Beginner, Mid Beginner, Upper Beginner and Pre Intermediate. The Language
Institution must place the level in a manual way. From the 2019 CEIC program
data will be processed using one of the Data Mining techniques using Naive
Bayes. The data used are 240 data, consisting of 6 attributesn (Question 1-10,
Question 11-20, Question 21-30, Question 31-40, Reading dan Listening) and 4
labels (Level 2, Level 3, Level 4 dan Level 5).
There are two scenarios used, namely using various folds, with or without
outliers. Overall, each scenario is done by testing various numbers of attributes
and using all existing labels. In the first scenario using 240 data, and performed
with 3, 4 and 5-fold, from the first scenario the highest accuracy in testing using 3
attributes using 5-fold and 4-fold is 65%. While in the second scenario using 3-
fold with outlier. The data used were 226 data. As in the first scenario, the highest
accuracy is in the trial using 3 attributes, namely 67.5556%.
Keywords : Level, Language Institute, Naive Bayes, Classification, Cross
Validation.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

x
KATA PENGANTAR
Puji dan syukur kepada Allah swt atas berkat dan rahmat-Nya penulis dapat
menyelesaikan penyusunan skripsi yang berjudul “Klasifikasi Level Kemampuan
Berbahasa Inggris Berdasarkan Hasil Placement Test Menggunakan Metode
Naive Bayes ”. Penulis mendapatkan banyak bimbingan, bantuan dan dukungan
dari berbagai pihak. Penulis mengucapkan banyak terima kasih kepada:
1. Ayah dan ibu yang tiada henti selalu mendoakan, memberikan motivasi
dan semangat kepada penulis.
2. Bapak Robertus Adi Nugroho, S.T., M.Eng. selaku ketua program studi
Informatika.
3. Ibu Agnes Maria Polina S.Kom., M.Sc. selaku dosen pembimbing skripsi
yang telah meluangkan waktu untuk membimbing dan memberikan
dukungan sehingga penulis dapat menyelesaikan skripsi.
4. Bapak Eduardus Hardika Sandy Atmaja, S.Kom., M.Cs. selaku dosen
pembimbing selama masa kolokium.
5. Ibu Paulina Heruningsih Prima Rosa M.Sc. selaku dosen pembimbing
akademik yang telah memberikan dukungan dan bimbingan selama
perkuliahan.
6. Lembaga Bahasa Universitas Sanata Dharma yang telah mempercayakan
data program CEIC tahun 2019 untuk dijadikan sebagai data penelitian
penulis.
7. Vincen dan Michelle selaku tetangga kos dari jaman maba yang selalu
mendengar keluh kesah, tempat bertukar pikir dan memberi semangat
kepada penulis.
8. Sobat Toileterzzz, Palenjuseyo dan Yicing yang telah menjadi sohib dari
awal perkuliahan, berbagi segala jenis ilmu, pandangan hidup, masalah
perkuliahan dan motivasi untuk menuju S.Kom.
9. Grup ~ yang terdiri dari Dodi, Caroline, Dian, Hananto, Paulina, Rachel
dan Alfri, yang telah menemani dan membantu penulis.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xi
10. Kepada teman-teman Informatika 16 yang menemani dan menghibur
penulis semasa menjalani perkuliahan di kampus Paingan.
11. Reni, Fitria dan Maylana yang memberi semangat dan selalu menanyakan
progres skripsi.
12. Kru Bulprof yang sudah menemani dan memberikan banyak warna warni
kehidupan dari awal hingga akhir perkuliahan. Semoga sehat, bahagia dan
sukses selalu! We Are Bulprof!
13. Role model penulis saat ini, yaitu T∞ dan grup lawak G0SE yang telah
hadir dan menemani disaat penulis mengalami kesulitan dan menjadi
mood booster penulis saat sedang stres menghadapi that thing who cannot
be named (Skripsi). Semoga sehat, bahagia dan sukses bersama kru!
Always together until the last Say The Name!!
14. Indah, terima kasih sudah berjuang dan bertahan dengan pilihannya,
hingga bisa menyelesaikan studinya dengan baik. Selamat dan tetap
semangat untuk perjuangan-perjuangan selanjutnya.
Penulis sadar masih banyak kekurangan dalam penelitian ini, maka penulis
mengharapkan saran dan kritikan yang kiranya dapat membangun penelitian ini.
Akhir kata penulis mengucapkan terima kasih.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xii
DAFTAR ISI
HALAMAN PERSETUJUAN PEMBIMBING .................................................iii HALAMAN PENGESAHAN .............................................................................iv HALAMAN PERSEMBAHAN .........................................................................v
PERNYATAAN KEASLIAN KARYA .............................................................vi LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS ...........................................................vii ABSTRAK ..........................................................................................................viii ABSTRACT ........................................................................................................ix KATA PENGANTAR ........................................................................................x DAFTAR ISI .......................................................................................................xii
DAFTAR TABEL ...............................................................................................xiv DAFTAR GAMBAR ..........................................................................................xvi Bab I. PENDAHULUAN ...................................................................................1
I.1. Latar Belakang 1
I.2. Rumusan Masalah 3 I.3. Tujuan 3
I.4. Batasan Masalah 3 I.5. Sistematika Penulisan 3
Bab II. LANDASAN TEORI ...............................................................................5 II.1. Lembaga Bahasa 5 II.2. Penambangan Data 6
II.3. Klasifikasi 8 II.4. Naive Bayes 8
II.5. Confusion Matrix 11 Bab III. METODE PENELITIAN .......................................................................13
III.1. Data 13 III.2. Spesifikasi Alat Penelitian 15
III.3. Desain Alat Uji 15 III.4. Preprocessing 18
III.5. Modeling Naive Bayes 19 III.6. Desain User Interface 20
a. Baca Data 20
b. Panel jumlah atribut 20
c. Tabel confussion matrix 21
d. Tombol Akurasi 21
e. Tabel uji data kelompok 21
f. Tabel uji data tunggal 21
Bab IV. IMPLEMENTASI SISTEM ...................................................................22 4.1 Implementasi Preprocessing 22
4.1.1 Data Selection 22
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiii
4.1.2 Transformasi Data 23
4.1.3 Source Code Preprocessing 23
4.2 Implementasi Naive Bayes 24 4.2.1 Klasifikasi 24
4.2.2 Source Code Naive Bayes 25
4.3 Implementasi 5-fold Cross Validation 26
4.3.1 Source Code 5-fold Cross Validation 26
4.4 Implementasi Confusion Matrix 28 4.4.1 Source Code Confusion Matrix 28
4.5 Implementasi Uji Data Tunggal 29
4.5.1 Uji Data Tunggal 29
4.5.1.1 Uji Data 1 29
4.5.1.2 Uji Data 2 29
4.5.1.3 Uji Data 3 30
4.5.1.4 Uji Data 4 30
4.5.2 Source Code Uji Data Tunggal 31
4.6 Implementasi Uji Data Kelompok 31 4.6.1 Uji Data Kelompok 31
4.6.2 Source Code Uji Data Kelompok 32
4.7 User Interface Sistem 33 Bab V. ANALISIS HASIL .................................................................................35
5.1 Uji Validasi 35
5.1.1 Perhitungan Manual Naive Bayes 35
5.1.2 Hasil Run Sistem Dengan 20 Data 46
5.2 Uji Akurasi dengan 240 Data Menggunakan Sistem 47
5.2.1 Dengan 5 k-fold 47
5.2.2 Dengan 4 k-fold 48
5.2.3 Dengan 3 k-fold 49
5.3 Uji Akurasi Dengan Data Tunggal Menggunakan Sistem 50 5.4 Uji Akurasi Menggunakan Outlier 51
Bab VI. PENUTUP ..............................................................................................55 6.1 Kesimpulan 55 6.2 Saran 56
DAFTAR PUSTAKA ............................................................................................57
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiv
DAFTAR TABEL
Tabel 2.1 Confusion Matrix ........................................................................ 11
Tabel 3.1 Keterangan Atribut ..................................................................... 12
Tabel 3.2 Indikator Placement Test Section 1 ............................................ 13
Tabel 3.3 Indikator Placement Test Section 2 ............................................ 13
Tabel 3.4 Indikator Placement Test Section 3 ............................................ 13
Tabel 4.1 Atribut Sebelum Dilakukan Seleksi Atribut ............................... 21
Tabel 4.2 Seleksi Atribut Berdasarkan Information Gained ........................ 21
Tabel 4.3 Contoh Data Sebelum Di Transformasi ....................................... 22
Tabel 4.4 Contoh Data Setelah Di Transformasi ......................................... 22
Tabel 4.5 Uji Coba Dengan Berbagai Jumlah Atribut ................................. 23
Tabel 5.1 Contoh Data ................................................................................. 34
Tabel 5.2 Nilai Mean dan Standar Deviasi Question 1-10 .......................... 35
Tabel 5.3 Nilai Mean dan Standar Deviasi Question 11-21 ........................ 35
Tabel 5.4 Nilai Mean dan Standar Deviasi Question 21-30 ........................ 35
Tabel 5.5 Nilai Mean dan Standar Deviasi Question 31-40 ........................ 35
Tabel 5.6 Nilai Mean dan Standar Deviasi Reading ................................... 36
Tabel 5.7 Nilai Mean dan Standar Deviasi Listening .................................. 36
Tabel 5.8 Probabilitas Kelas ........................................................................ 36
Tabel 5.9 Data Testing ................................................................................. 36
Tabel 5.10 Probabilitas Setiap Atribut ........................................................ 40
Tabel 5.11 Klasfikasi Data Testing .............................................................. 43
Tabel 5.12 Confusion Matrix ....................................................................... 43
Tabel 5.13 Confusion Matrix 1..................................................................... 44
Tabel 5.14 Confusion Matrix 2..................................................................... 44
Tabel 5.15 Confusion Matrix 3..................................................................... 44
Tabel 5.16 Confusion Matrix 4..................................................................... 45
Tabel 5.17 Confusion Matrix 5..................................................................... 45
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xv
Tabel 5.18 Uji Coba Dengan 5 k-fold .......................................................... 46
Tabel 5.19 Uji Coba Dengan 4 k-fold .......................................................... 47
Tabel 5.20 Uji Coba Dengan 3 k-fold .......................................................... 48
Tabel 5.21 Uji Akurasi Data Tunggal .......................................................... 49
Tabel 5.22 Information Gained Percobaan kedua ....................................... 50
Tabel 5.23 Uji Akurasi Sebelum Menggunakan Outlier ............................. 51
Tabel 5.24 Uji Akurasi Setelah Menggunakan Outlier ............................... 52
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xvi
DAFTAR GAMBAR
Gambar 2.1 Cross Validation ..............................................................................10
Gambar 3.1 Desain Alat Uji ................................................................................14
Gambar 3.2 Diagram Flowchart Umum Sistem ..................................................15
Gambar 3.3 Diagram Flowchart Uji Data Tunggal ............................................16
Gambar 3.4 Diagram Flowchart Uji Data Kelompok .........................................17
Gambar 3.5 Tampilan User Interface ..................................................................19
Gambar 4.1 Tampilan Confusion Matrix dengan 5k-fold.................................... 24
Gambar 4.2 Uji Data 1 ........................................................................................ 28
Gambar 4.3 Uji Data 2 ........................................................................................ 28
Gambar 4.4 Uji Data 3 ........................................................................................ 29
Gambar 4.5 Uji Data 4 ........................................................................................ 29
Gambar 4.6 Uji Data Kelompok ......................................................................... 31
Gambar 4.7 User Interface Sistem ..................................................................... 32
Gambar 5.1 Hasil Sistem Dengan 20 Data ......................................................... 46
Gambar 5.2 Dengan 5 k-fold .............................................................................. 47
Gambar 5.3 Dengan 4 k-fold .............................................................................. 48
Gambar 5.4 Dengan 3 k-fold .............................................................................. 49
Gambar 5.5 Uji Sistem Menggunakan Outlier ................................................... 53
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

1
Bab I. PENDAHULUAN
I.1. Latar Belakang
Bahasa Inggris merupakan bahasa universal yang berlaku secara
internasional untuk berkomunikasi antar manusia dari negara yang berbeda. Selain
untuk berkomunikasi, Bahasa Inggris diperlukan sebagai pembelajaran bagi anak
sekolah dari Sekolah Dasar (SD), Sekolah Menengah Pertama (SMP), Sekolah
Menengah Atas (SMA), hingga tahap perguruan tinggi dan untuk interview saat
melamar kerja atau keperluan pekerjaan. Saat ini banyak institusi pendidikan
menyediakan les atau kursus Bahasa Inggris, terutama di wilayah Yogyakarta.
Salah satunya Universitas Sanata Dharma, yang memiliki program-program
kursus Bahasa Inggris yang disediakan oleh Lembaga Bahasa.
Lembaga Bahasa Universitas Sanata Dharma (USD) merupakan suatu
lembaga yang menyediakan program-program untuk belajar berbagai bahasa.
Bahasa yang ada yaitu Bahasa Inggris, Mandarin, Korea, Jepang dan Indonesia.
Lembaga Bahasa USD juga menyediakan beberapa program kursus Bahasa
Inggris, seperti Center of English for International Communication (CEIC),
Center of English for Specific Purposes (CESP), English Extension Course (EEC)
dan tes kemampuan berbahasa Inggris, speperti TOEFL, IELTS dan TOEIC.
Center of English for International Communication (CEIC) adalah program
yang dirancang untuk pelajar Indonesia atau pelajar asing yang ingin belajar dan
mengembangkan keterampilan komunikasi mereka dalam berbahasa Inggris.
Pelajar yang mengikuti program ini, akan mengikuti tes yang terdiri Reading,
Writing dan Listening. Kemudian dari hasil tes tersebut akan ditempatkan pada
level yang sesuai dengan hasil tes. Level - level yang ada yaitu Level 2: Real
Beginner, Level 3: Mid Beginner, Level 4: Upper Beginner, Level 5: Pre
Intermediate. Pihak Lembaga Bahasa USD melakukan penempatan level dengan
cara yang masih manual dan hanya tersimpan dalam bentuk hard copy.
Cara manual yang dilakukan oleh pihak Lembaga Bahasa USD dalam
penempatan level yaitu dengan berpedoman pada indikator yang telah dibuat. Tes
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

2
dibagi menjadi 3 kategori, yaitu Language Use, Reading dan Listening. Untuk
Language Use penilaian yang dilakukan yaitu jika nomor 1-10 jawabannya benar
semua maka akan ditempatkan di level 2, seterusnya hingga nomor 40 dengan
toleransi kesalahan maksimal 4 kali. Sedangkan Reading dan Listening dilihat dari
jumlah soal yang benar dan disesuaikan dengan levelnya.
Penelitian menggunakan metode Naive Bayes pernah dilakukan oleh
Antonius Rachmat C dan Yuan Lukito (2018) dengan judul Klasifikasi Sentimen
Komentar Politik dari Facebook Page menggunakan Naive Bayes. Data yang
digunakan adalah data status dan komentar Pemilu Presiden tahun 2014 dari
Facebook page. Nilai akurasi dari penelitian ini sebesar 82%.
Penelitian lain yang menggunakan metode Naive Bayes yaitu Klasifikasi
Status Gizi Menggunakan Naive Bayesian Classification oleh Sri Kusumadewi.
Data yang digunakan adalah data hasil pengukuran Antropometri Mahasiswa.
Naive Bayesian Classification dapat digunakan sebagai salah satu metode untuk
klasifikasi dan memiliki kinerja yang baik karena hasil pengujian menunjukkan
total kinerja sebesar 93,2%.
Berdasarkan permasalahan diatas, penelitian ini bertujuan untuk
mengklasifikasi data penempatan level program CEIC menggunakan metode
Naïve Bayes. Data yang digunakan yaitu data hasil tes penempatan level program
CEIC tahun 2019 di Lembaga Bahasa Universitas Sanata Dharma. Atribut data
hasil penempatan terdiri dari 6 atribut, yaitu Question 1-10, Question 11-20,
Question 21-30, Question 31-40, Reading dan Listening. Empat level (Level 2:
Real Beginner, Level 3: Mid Beginner, Level 4: Upper Beginner, Level 5: Pre
Intermediate) yang sudah disebutkan diatas dijadikan sebagai label. Penulis
berharap hasil dari penelitian ini dapat membantu Lembaga Bahasa Universitas
Sanata Dharma dalam penempatan level program CEIC untuk kedepannya.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

3
I.2. Rumusan Masalah
Berdasarkan latar belakang yang telah disebutkan sebelumnya, beberapa rumusan
masalah yang akan diselesaikan adalah sebagai berikut :
1. Apakah metode Naïve Bayes dapat melakukan klasifikasi data hasil
penempatan level program CEIC?
2. Berapa akurasi klasifikasi data hasil penempatan level program CEIC
dengan menggunakan metode Naïve Bayes?
I.3. Tujuan
Adapun tujuan dari penelitian ini sebagai berikut :
1. Menerapkan metode Naïve Bayes untuk mengklasifikasikan data
penempatan level program CEIC ke dalam program komputer.
2. Mengetahui akurasi klasifikasi data hasil penempatan level progran CEIC
dengan menggunakan metode Naïve Bayes .
I.4. Batasan Masalah
Penelitian yang dilakukan untuk tugas akhir ini, memiliki beberapa batasan
masalah, sebagai berikut :
1. Data yang digunakan adalah data penempatan level program CEIC yang
ada di Lembaga Bahasa Universitas Sanata Dharma pada tahun 2019
dengan jumlah 240 data.
2. Data yang digunakan berupa hard copy yang diubah ke dalam file bertipe
.xsl.
3. Metode yang digunakan dalam penelitian ini adalah metode Naive Bayes.
I.5. Sistematika Penulisan
BAB 1. Pendahuluan
Dalam bab ini berisi mengenai latar belakang, rumusan masalah, tujuan,
batasan masalah dan sistematika penulisan.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

4
BAB 2. Landasan Teori
Dalam bab ini dibahas mengenai objek studi kasus, teori atau metode yang
digunakan dalam penelitian ini meliputi : Lembaga Bahasa, Penambangan Data,
Klasifikasi, Naive Bayes, Cross Validation dan Confusion Matrix.
BAB 3. Metodologi Penelitian
Dalam bab ini dibahas mengenai langkah-langkah yang dilakukan dalam
penelitian dengan menggunakan metode yang berkaitan, meliputi : Data,
Spesifikasi Alat Penelitian, Desain Alat Uji, Preprocessing, Modeling Naive
Bayes dan desain User Interface.
BAB 4. Implementasi Sistem
Dalam bab ini dibahas mengenai Implementasi Preprocessing,
Implementasi Naive Bayes, Implementasi 5-Fold Cross Validation, Implementasi
Confusion Matrix, Implementasi Uji Data Tunggal, Implementasi Uji Data
Kelompok dan Implementasi User Interface Sistem.
BAB 5. Analisis Hasil
Dalam bab ini dibahas mengenai uji validasi, uji akurasi dengan
menggunakan sistem untuk 240 data tanpa menggunakan outlier, uji akurasi
dengan menggunakan sistem untuk 226 data dengan outlier, serta uji akurasi
dengan data tunggal menggunakan sistem.
BAB 6. Penutup
Dalam bab ini berisi mengenai kesimpulan dan saran penulis untuk
penelitian yang lebih baik.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

5
Bab II. LANDASAN TEORI
II.1. Lembaga Bahasa
Lembaga bahasa terdiri dari dua kata, yaitu Lembaga dan Bahasa. Kata
Lembaga dalam Kamus Besar Bahasa Indonesia (KBBI) memiliki arti badan
(organisasi) yang tujuannya melakukan suatu penyelidikan keilmuan atau
melakukan suatu usaha. Sedangkan, kata Bahasa memiliki arti sistem lambang
bunyi yang arbitrer, yang digunakan oleh anggota suatu masyarakat untuk bekerja
sama, berinteraksi, dan mengidentifikasi diri.
Lembaga Bahasa Sanata Dharma pada awalnya bernama Pusat Pengembangan
dan Pelatihan Bahasa Universitas Sanata Dharma. Institusi ini awalnya membuka
layanan untuk pelatihan intensif budaya dan Bahasa Indonesia untuk mahasiswa
dan dosen dari luar Indonesia. Seiring berkembangnya, layanan yang ditawarkan
berupa ekpatriat yang ingin bekerja di Indonesia maupun mahasiswa asing dan
mahasiswa Indonesia yang ingin mendalami bahasa dan budaya di universitas.
Lembaga Bahasa Sanatha Dharma memiliki beberapa divisi yaitu Indonesia
Language Course, Korean Language Course, Japanese Language Course,
Chinese Language Course dan English for Communication. Tiap divisi memiliki
program-program yang berbeda. Salah satunya divisi English for Communication
yang memiliki program CEIC. Tujuan dari program ini adalah agar pelajar
Indonesia atau pelajar asing yang ingin belajar dan mengembangkan keterampilan
komunikasi mereka dalam berbahasa Inggris. Peserta yang akan mengikuti
program ini harus mendaftar administrasi terlebih dahulu, lalu mengikuti tes yang
terdiri dari dua tahap, pertama tes tertulis berupa Writing, Reading dan Listening,
dan tes wawancara. Level-level tersebut terdiri dari Level 2: Real Beginner,
Level 3: Mid Beginner, Level 4: Upper Beginner, Level 5: Pre Intermediate.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

6
II.2. Penambangan Data
Penambangan Data atau Knowledge Discovery in Database merupakan
salah satu teknik yang digunakan untuk mendapatkan pengetahuan baru
dengan memanfaatkan jumlah data yang sangat besar (Nurul Rohmawati W,
et.al. 2015). Data mining mengacu pada mining knowledge dari data
jumlah besar (Han dan Kamber, 2006). Data mining dikenal dengan
Knowledge Discovery from Data (KDD), yaitu:
1. Pembersihan Data
Proses ini bertujuan untuk membersihkan data yang tidak konsisten atau
menghilangkan gangguan yang ada pada data.
2. Integrasi Data
Proses ini bertujuan untuk menyatukan atau menggabungkan data dari
sumber yang berbeda.
3. Seleksi Data
Proses ini bertujuan untuk memilih atribut yang baik atau relevan dengan
penelitian.
4. Transformasi Data
Proses ini bertujuan untuk menggabungkan data kedalam bank yang sesuai.
5. Penambangan Data
Proses ini bertujuan untuk menerapkan metode yang tepat untuk mengolah
data.
6. Evaluasi Pola
Pada tahap ini bertujuan untuk mengidentifikasi pola dalam pengetahuan
7. Presentasi Pengetahuan
Pada tahap ini akan menyajikan hasil klasifikasi data CEIC dalam bentuk
tampilan yang mudah dipahami user.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

7
Pengelompokan Penambangan Data
Penambangan data dibagi menjadi beberapak kelompok berdasarkan tugas
yang dapat dilakukan, yaitu (Kursini dan Luthfi, 2009) :
1. Deskripsi
Deskripsi dalam Penambangan Data adalah menggambarkan penjelasan
suatu pola.
2. Estimasi
Estimasi merupakan numerik pada variabel target. Nilai dari variabel
target dibuat dari nilai prediksi, itu lah yang dimaksud dengan estimasi.
3. Prediksi
Seperti Estimasi, prediksi juga dipakai dalam klasifikasi. Prediksi adalah
memperkirakan sesuatu yang akan terjadi pada masa yang akan
mendatang.
4. Klasifikasi
Klasifikasi adalah pemrosesan untuk menemukan sebuah model atau
fungsi yang menjelaskan dan mencirikan konsep atau kelas data, untuk
kepentingan tertentu [2].
5. Pengklusteran
Pengklusteran digunakan untuk pengelompokkan data berdasarkan
kemiripan pada objek data dan sebaliknya meminimalkan kemiripan
terhadap kluster yang lain [3].
6. Asosiasi
Asosiasi atau Market Basket Analysis adalah metode untuk menemukan
suatu kombinasi atribut yang muncul bersamaan (Andriyana Veronica,
2015).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

8
II.3. Klasifikasi
Klasifikasi adalah pemrosesan untuk menemukan sebuah model atau fungsi
yang menjelaskan dan mencirikan konsep atau kelas data, untuk kepentingan
tertentu. Ada berbagai klasifikasi dalam Penambangan Data, yaitu :
1. Decision Tree
Decision Tree merupakan suatu metode yang bentuk klasifikasi seperti
struktur pohon.
2. K-Nearest Neighbor
K-Nearest Neighbor merupakan metode pengkalasifikasian data berdasarkan
jarak terdekat. Metode ini biasanya sering digunakan dalam pencarian jarak
3. Neural Network
Neural Network merupakan metode yang memproses data dengan meniru
cara kerja sistem saraf manusia.
4. Naive Bayes
Klasifikasi dengan metode Naive Bayes yaitu mengklasifikasi data untuk
memprediksi probabilitas anggota suatu kelas.
II.4. Naive Bayes
Naive Bayes adalah suatu pengklasifikasian dengan metode probabilsitik
yang dikemukakan oleh ilmuan Inggris bernama Thomas Bayes. Metode ini
menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan
kombinasi nilai dari dataset yang diberikan. Algoritma menggunakan teorema
Bayes dan mengasumsikan semua atribut independen atau tidak saling
ketergantungan yang diberikan oleh nilai pada variabel kelas (Patil dan Sherekar,
2013). Keuntungan dari Naive Bayes yaitu metode ini memperlukan jumlah data
Training yang kecil untuk menentukan atribut yang diperlukan (Saleh, 2015).
Berikut merupakan rumus Naive Bayes:
𝑃(𝑐|𝑥) =P(x|C)p(c)
p(x) (2.1)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

9
Keterangan :
x : Data dengan class yang belum diketahui
c : Hipotesis data merupakan suatu class spesifik
P(c|x) : Probabilitas hipotesis berdasar kondisi (posteriori probability)
P(c) : Probabilitas hipotesis (prior probability)
P(x|c) : Probabilitas berdasarkan kondisi pada hipotesis
P(x) : Probabilitas c
Dalam proses klasifikasi diperlukan sejumlah petunjuk untuk memutuskan kelas
yang cocok untuk sampel yang akan di analisa. Oleh karena itu rumus 2.1 di
jabarkan sebagai berikut :
𝑃(𝑐|𝑓1 … 𝑓𝑛) =P(f1 … fn|c)p(c)
p(f1 … fn) (2.2)
Variabel C merupakan kelas, sedangkan F1...Fn merupakan karakteristik petunjuk
yang menentukan klasifikasi. Rumus (2.2) menjelaskan peluang dari suatu sampel
karakteristik tertentu pada kelas C (Posterior) merupakan peluang kemunculan
kelas C, lalu dikali dengan peluang karakteristik – karakteristik sampel kelas C
(Likelihood), kemudian dibagi dengan peluang karakteristik-karakteristik secara
global (evidence). Maka penjelasan diatas dapat dijabarkan sebagai berikut (Saleh,
2015) :
𝑃𝑜𝑠𝑡𝑒𝑟𝑖𝑜𝑟 =𝑝𝑟𝑖𝑜𝑟 𝑥 𝑙𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑
𝐸𝑣𝑖𝑑𝑒𝑛𝑐𝑒 (2.3)
Setiap kelas pada satu sampel akan selalu tetap disebut nilai Evidence. Lalu, nilai
Posterior dibandingkan dengan nilai –nilai posterior kelas yang lain untuk
menentukan klasifikasi suatu sampel ke kelas apa.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

10
Mengklasifikasi data kontinyu dengan menggunakan persamaan densitas gauss :
𝑃(𝑋𝑖 = 𝑥𝑖|𝑌 = 𝑦𝑖) =1
√2𝜋(𝜎)𝑒
−(𝑥𝑖−µ)2
2(𝜎)2 (2.4)
Keterangan:
P = Peluang
Xi = Atribut ke-i
Xi = Nilai atribut ke-i
Y = Kelas yang dicari
µ= Mean (rata-rata)
σ = Standar Deviasi
2.5 Cross Validation
Cross Validation atau k-fold cross validation adalah data yang akan
digunakan untuk pelatihan (Training Data) dan pengujian (Testing Data). Cross
validation akan membagi set menjadi k set data dengan ukuran yang sama. Jika
setiap kali berjalan, data yang lain akan menjadi data latih dan data yang lain
menjadi data latih sebanyak k-kali. Jumlahkan semua error dari k-kali proses
untuk mendapatkan total error. Berdasarkan gambar 2.1, akan dilakukan 5-fold
cross validation. Untuk tiap fold akan menjadi data training sebanyak empat kali
dan menjadi data testing hanya sekali. Fold yang memiliki nilai tertinggi akan
menjadi pembagian data yang terbaik.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

11
Gambar 2.1 Cross Validation
II.5. Confusion Matrix
Confusion Matrix merupakan metode yang digunakan untuk mengukur
kinerja suatu metode klasifikasi. Confusion matrix memiliki informasi yang
membandingkan hasil klasifikasi yang dilakukan oleh sistem dengan klasifikasi
yang seharusnya (E. Prasetyo, 2012).
Tabel 2.1 Contoh Confusion Matrix
Fij Label hasil prediksi (j)
True = 1 False = 0
Label asli (i) True = 1 f11 f10
False = 0 f01 f00
Diatas ini merupakan tabel yang akan melakukan klasifikasi dengan
penggunaan biner untuk kelas True (1) dan False (0). f11 merupakan sel yang
bernilai benar dan memiliki hasil prediksi benar, sedangkan f10 yaitu sel yang
bernilai benar dan memiliki hasil prediksi yang salah. f01 adalah sel label asli yang
bernilai salah dan memiliki hasil prediksi benar dan yang terakhir f00 memiliki
label asli bernilai salah dan hasil prediksi yang salah. Berdasarkan isi tabel
tersebut, dapat diketahui hasil jumlah data yang diprediksi secara benar (f11 + f00)
dan hasil jumlah data yang diprediksi secara salah (f10 + f01). Hasil jumlah data
yang diklasifikasi secara benar diketahui sebagai hasil akurasi prediksi, sedangkan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

12
jumlah data yang diketahui secara salah diketahui sebagai laju error. Berikut
adalah formulasi untuk menghitung akurasi :
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =jumlah data yang diprediksi secara benar
jumlah prediksi yang dilakukan 𝑥 100 (2.5)
Akurasi =f11 + f00
f11 + f10 + f01 + f00 𝑥 100% (2.6)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

13
Bab III. METODE PENELITIAN
III.1. Data
Data yang digunakan dalam penelitian ini merupakan data dari program
Center of English for International Communication (CEIC) tahun 2019 dari
Lembaga Bahasa Universitas Sanata Dharma. Total jumlah data yang digunakan
sebanyak 240 data. Pada program CEIC terdapat enam atribut yaitu Question 1-
10, Question 11-20, Question 21-30, Question 31-40, Reading dan Listening
dan lima label kelas yaitu Level 1, Level 2, Level 3, Level 4 dan Level 5.
Namun karena tidak terdapat data dengan atribut <Question 1-10 dan label Level
1, maka label tersebut tidak diikut sertakan. Keterangan atribut dapat dilihat
pada tabel 3.1.
Tabel 3.1 Keterangan Atribut
No Atribut Keterangan
1 Question 1-10
Jika terdapat banyak jawaban yang salah maka
akan ditempatkan Level 2 : Real Beginner
2 Question 11-20
Jika terdapat banyak jawaban yang salah maka
akan ditempatkan Level 3 : Mid Beginner
3 Question 21-30
Jika terdapat banyak jawaban yang salah maka
akan ditempatkan Level 4 : Upper Beginner
4 Question 31-40
Jika terdapat banyak jawaban yang salah maka
akan ditempatkan Level 5 : Pre Intermediate
5 Reading Nilai dari section Reading
6 Listening Nilai dari section Listening
Indikator level yang telah disebutkan di atas dapat dilihat pada tabel 3.2, 3.3 dan
3.4.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

14
Tabel 3.2 Indikator Placement Test Section 1
Section 1 Language Use
Question 1-10 Level 2
Question 11-20 Level 3
Question 21-30 Level 4
Question 31-40 Level 5
Tabel 3.3 Indikator Placement Test Section 2
Section 2 Reading
5-10 correct answers Level 2
11-15 correct answers Level 3
16-20 correct answers Level 4
21-25 correct answers Level 5
Tabel 3.4 Indikator Placement Test Section 3
Section 2 Listening
5-10 correct answers Level 2
11-15 correct answers Level 3
16-20 correct answers Level 4
21-25 correct answers Level 5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

15
III.2. Spesifikasi Alat Penelitian
3.2.1 Spesifikasi Hardware
a) Laptop : Asus X453M
b) Processor : Intel(R) Celeron(R) CPU N2840 @ 2.16GHz 2.16
GHz
c) Memori : 4GB
d) Graphic Card : Intel IGP
e) Storage : 500GB
3.2.2 Spesifikasi Software
a) Sistem Operasi : Windows 8.1 Pro
b) Matlab : R2016b
III.3. Desain Alat Uji
Gambar 3.1 Desain Alat Uji
Gambar 3.1 merupakan desain alat uji yang digunakan dalam penelitian
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

16
ini. Pada tahap pertama dilakukan preprocessing data, yaitu data akan langsung
di proses dalam model Naive Bayes, dimana data Training dan data Testing
dibuat jadi modelnya. Kemudian, data uji kelompok dan tunggal dilakukan
untuk menghasilkan klasifikasi dan akurasi.
Gambar 3.2 Diagram Flowchart Umum Sistem
Gambar 3.2 merupakan alur data yang digunakan dalam sistem yang akan
melewati dari proses inputan data awal menjadi output nilai akurasi.
Algoritma Umum Sistem:
1. Baca data mentah.
2. Masuk tahap preprocessing, seleksi atribut dan transformasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

17
3. Data siap pakai.
4. Bagi menjadi k bagian, kemudian masukkan ke masing-masing variabel
fold-1 sampe fold-k
5. Masuk ke model Naive Bayes
a. Mencari nilai mean untuk setiap atribut ke semua label data Training .
b. Mencari nilai standar deviasi untuk setiap atribut ke semua kelas data
Training.
c. Mencari nilai probabilitas dengan menggunakan persamaan (2.4)
Densitas Gauss untuk tiap atribut pada semua label.
d. Mencari nilai likelihood dengan mengalikan semua atribut untuk tiap
label, lalu dikalikan dengan nilai probabilitas kelas.
6. Mencari hasil confusion matrix
7. Mendapatkan hasil akurasi dengan menjumlahkan data yang diprediksi
secara benar dibagi dengan jumlah total data Testing.
8. Hasil klasifikasi didapatkan.
Sedangkan Gambar 3.3 merupakan alur data dari data uji tanggal yang
menghasilkan keluaran hasil klasifikasi.
Gambar 3.3 Diagram Flowchart Uji Data Tunggal
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

18
Algoritma :
1. Masukkan data uji tunggal yang diinputkan.
2. Masuk ke model Naive Bayes yang sudah mengelola data Training.
3. Hasil klasfikasi keluar.
4. Selesai
Gambar 3.4 Diagram Flowchart Uji Data Kelompok
Algoritma :
1. Baca data uji data kelompok.
2. Masuk ke model Naive Bayes yang sudah mengelola data Training.
3. Hasil klasifikasi keluar.
4. Selesai.
III.4. Preprocessing
Pada tahap ini ada dua proses yang dilakukan, yang pertama yaitu seleksi
data dan transformasi data. Seleksi data dilakukan dengan cara meranking atribut
dengan menggunakan information gained. Pada tahap ini bertujuan untuk
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

19
mencari atribut mana yang relevan dan menghapus atribut yang tidak diperlukan.
Seleksi data dilakukan dengan menggunakan Weka tools. Selanjutnya adalah
transformasi data. Proses ini dilakukan dengan mengubah kolom label, yaitu
Level. Dilakukan transformasi sebagai berikut :
Level 2 : 2
Level 3 : 3
Level 4 : 4
Level 5 : 5
III.5. Modeling Naive Bayes
Pada tahap ini dilakukan proses klasifikasi menggunakan metode Naive
Bayes. Data akan dibagi menjadi dua, yaitu data Testing dan data Training, lalu
data akan diolah menggunakan perhitungan algoritma. Berikut merupakan tahap-
tahap pengolahan data menggunakan modeling Naive Bayes.
1. Data Training dibaca
2. Karena data yang digunakan adalah numerik, maka perlu mencari
nilai mean dan standar deviasi tiap atribut. Berikut adalah
persamaan untuk menghitung nilai mean (nilai rata-rata):
Keterangan :
µ : mean (rata -rata)
xi : nilai sampel ke-i
n : jumlah sampel
untuk menghitung standar deviasi digunakan persamaan berikut:
3. Menghitung nilai probabilistik dengan menghitung jumlah data
𝜇 =∑ 𝑥𝑖𝑛
𝑖=1
𝑛 (2.3)
s =∑ ( 𝑥𝑖−𝑥)2𝑛
𝑖=1
𝑛 −1 (2.4)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

20
dari kategori yang sama dibagi dengan jumlah data pada kategori.
4. Sistem akan menghasilkan output.
III.6. Desain User Interface
Penulis membuat sebuah interface pada penilitan ini dengan tujuan
mempermudah proses membaca data, menghitung confesion matrix, proses
klasifikasi dan hasil akurasi. Berikut ini adalah gambar dari user interface.
Gambar 3.5 Tampilan User Interface
Gambar 3.5 adalah sketsa user interface sistem yang dibuat untuk
mempermudah user dalam menggunakan sistem tersebut. User interface tersebut
memiliki beberapa fitur yang berbeda-beda penggunaannya. berikut adalah
penjelasan kegunaan untuk tiap fitur :
a. Baca Data
Pada tombol ini akan menginputkan file data yang akan digunakan dalam
sistem ini.
b. Panel jumlah atribut
Pada panel ini akan dilakukan uji coba dengan berbagai jumlah atribut dan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

21
terdapat tombol preprocessing yang bertujuan untuk melakukan tahap
preprocessing seperti yang sudah dijelaskan diatas.
c. Tabel confussion matrix
Pada fitur ini akan menghasilkan hasil perhitungang confusion matrix
dengan menggunakan 5 k-fold, yang mana hasil perhitungan ini akan
menghasilkan akurasi.
d. Tombol Akurasi
Saat tombol ini ditekan, akan menghasilkan akurasi dari perhitungan
confusion matrix dengan menggunakan percobaan berbagai jumlah atribut.
e. Tabel uji data kelompok
Pada tahap ini akan dilakukan uji coba dengan menggunakan data yang
lebih dari satu. Menginputkan file data yang berformat .xls, lalu menekan
tombol klasifikasi, maka pada tabel kedua akan menghasilkan klasifikasi
yang dilakukan.
f. Tabel uji data tunggal
Seperti yang dilakukan pada tabel uji data kelompok, hal yang sama juga
dilakukan pada tahap ini. Hal yang membedakan antara keduanya, yaitu
pada tahap ini inputan data yang dilakukan hanya satu data untuk tiap
atribut, setelah dilakukan inputan, tekan tombol klasifikasi untuk melihat
hasil klasifikasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

22
Bab IV. IMPLEMENTASI SISTEM
.
4.1 Implementasi Preprocessing
4.1.1 Data Selection
Pada tahap ini data diseleksi dengan cara menghitung information
gained. Seleksi atribut dilakukan menggunakan Weka Tools. Tabel
merupakan atribut sebelum dirankingkan.
Tabel 4 .1 Atribut sebelum dilakukan seleksi atribut
No Atribut
1 Question 1-10
2 Question 11-20
3 Question 21-30
4 Question 31-40
5 Reading
6 Listening
Setelah dilakukan perankingan menggunakan Weka menghasilkan
urutan yang terlihat pada tabel 4.2.
Tabel 4.2 Seleksi Atribut Berdasarkan Information Gained
Atribut Persentase
Listening 0.737%
Reading 0.449%
Question 11-20 0.379%
Question 21-30 0.266%
Question 1-10 0.27%
Question 31-40 0%
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

23
4.1.2 Transformasi Data
Transformasi Data
Pada tahap ini akan dilakukan transformasi pada data, yaitu
mengubah Label yang awalnya bertipe String menjadi bertipe
numerik. Tabel 4.3 merupakan label data yang belum
ditransformasi.
Tabel 4.3 Contoh Data sebelum di Transformasi
Label
Level 2
Level 3
Level 4
Level 5
Berikut merupakan label yang sudah ditransformasikan.
Tabel 4.4 Contoh Data setelah di Transformasi
Label Setelah di Transformasi
Level 2 2
Level 3 3
Level 4 4
Level 5 5
4.1.3 Source Code Preprocessing
global row;
a = row(:,7);
[m,n]= size(a);
for i=1:m
if (strcmp(row(i,7),'Level 2'))
row(i,7)={2};
elseif (strcmp(row(i,7),'Level 3'))
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

24
row(i,7)={3};
elseif(strcmp(row(i,7),'Level 4'))
row(i,7)={4};
else
row(i,7)={5};
end
end
d = row;
rating = [6,5,2,1,3,4];
jumlahCiri =str2num(get(handles.edit27,'String'));
if jumlahCiri > size(rating,2)-1
jumlahCiri = size (rating,2);
end
for i=1:jumlahCiri
if i ==1
Data = d(:,rating(i));
else
Data = [Data,d(:,rating(i))];
end
end
global datapakai;
datapakai=[Data,d(:,7)];
set(handles.uitable8,'data',datapakai);
4.2 Implementasi Naive Bayes
4.2.1 Klasifikasi
Data yang digunakan pada proses ini sudah melalui proses
perankingan dan transformasi. Data yang dipakai dalam proses
ini sebanyak 240 data dengan 3 atribut dan 4 label. Selanjutnya
dilakukan uji coba dengan jumlah atribut untuk melihat akurasi
yang optimal pada tabel 4.5.
Tabel 4.5 Uji Coba dengan berbagai jumlah atribut
Jumlah Atribut Akurasi
6 atribut 64,5833%
5 atribut 63,3333%
4 atribut 62,0833%
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

25
3 atribut 65%
2 atribut 64,1667%
1 atribut 58,75%
Berdasarkan tabel 4.5 dengan jumlah 3 atribut mendapat akurasi
optimal sebesar 65%.
Gambar 4.1 Tampilan Confusion Matrix dengan 5 k-folds
4.2.2 Source Code Naive Bayes
function output = naiveBayes( DataTr,LabelTr,DataTs )
Label = [2,3,4,5];
DataTr = cell2mat(DataTr);
LabelTr = cell2mat(LabelTr);
DataTs = cell2mat(DataTs);
Level2 = find(LabelTr(:) == 2);
Level3 = find(LabelTr(:) == 3);
Level4 = find(LabelTr(:) == 4);
Level5 = find(LabelTr(:) == 5);
%nilai prior
probabilitas_Level2 = length(Level2)/length(LabelTr);
probabilitas_Level3 = length(Level3)/length(LabelTr);
probabilitas_Level4 = length(Level4)/length(LabelTr);
probabilitas_Level5 = length(Level5)/length(LabelTr);
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

26
probabilitas =
[probabilitas_Level2,probabilitas_Level3,probabilitas_Level4,prob
abilitas_Level5];
%nilai Likehood
for i=1:length(Label(1,:))
mn(i,:) = mean(DataTr(LabelTr == Label(1,i),:));
st_dev(i,:) = std(DataTr(LabelTr == Label(1,i),:));
end
%nilai Posterior
for j=1:size(Label,2)
likelihood = normpdf(DataTs, mn(j,:),st_dev(j,:));
posterior(j) = prod(likelihood)*probabilitas(j);
end
assignin('base', 'posterior', posterior);
if posterior(1) > posterior(2) && posterior(1) > posterior(3) &&
posterior(1) > posterior(4)
output = 2;
elseif posterior(2) > posterior(1) && posterior(2) posterior(3) &&
posterior(2) > posterior(4)
output = 3;
elseif posterior(3) > posterior(1) && posterior(3) posterior(2) &&
posterior(3) > posterior(4)
output = 4;
else
output = 5;
end
end
4.3 Implementasi 5-fold Cross Validation
4.3.1 Source Code 5-fold Cross Validation
global datapakai;
Baca = datapakai;
dataSize = size(Baca,2);
X = Baca(:,1:dataSize-1);
Y = Baca(:,dataSize);
totalData = size(X);
training = X;
LabelTraining = Y;
save 'LabelTraining.mat' 'LabelTraining';
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

27
range = totalData(1)/5;
kel1 = X(1:range,:);
kel2 = X(range+1:range*2,:);
kel3 = X(range*2+1:range*3,:);
kel4 = X(range*3+1:range*4,:);
kel5 = X(range*4+1:range*5,:);
dataTr1 = [kel2;kel3;kel4;kel5];
dataTs1 = kel1;
dataTr2 = [kel1;kel3;kel4;kel5];
dataTs2 = kel2;
dataTr3 = [kel1;kel2;kel4;kel5];
dataTs3 = kel3;
dataTr4 = [kel1;kel2;kel3;kel5];
dataTs4 = kel4;
dataTr5 = [kel1;kel2;kel3;kel4];
dataTs5 = kel5;
LabelKel1 = Y(1:range,:);
LabelKel2 = Y(range+1:range*2,:);
LabelKel3 = Y(range*2+1:range*3,:);
LabelKel4 = Y(range*3+1:range*4,:);
LabelKel5 = Y(range*4+1:range*5,:);
LabelTr1 = [LabelKel2;LabelKel3;LabelKel4;LabelKel5];
LabelTs1 = LabelKel1;
LabelTs1 = cell2mat(LabelTs1);
LabelTr2 = [LabelKel1;LabelKel3;LabelKel4;LabelKel5];
LabelTs2 = LabelKel2;
LabelTs2 = cell2mat(LabelTs2);
LabelTr3 = [LabelKel1;LabelKel2;LabelKel4;LabelKel5];
LabelTs3 = LabelKel3;
LabelTs3 = cell2mat(LabelTs3);
LabelTr4 = [LabelKel1;LabelKel2;LabelKel3;LabelKel5];
LabelTs4 = LabelKel4;
LabelTs4 = cell2mat(LabelTs4);
LabelTr5 = [LabelKel1;LabelKel2;LabelKel3;LabelKel4];
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

28
LabelTs5 = LabelKel5;
LabelTs5 = cell2mat(LabelTs5);
4.4 Implementasi Confusion Matrix
4.4.1 Source Code Confusion Matrix
for i=1:size(dataTs1,1)
hasil(i,1) = naiveBayes(dataTr1,LabelTr1,dataTs1(i,:));
end
cf1 = confusionmat(LabelTs1,hasil);
output1 = (sum(diag(cf1))/sum(sum(cf1)))*100;
set(handles.uitable5,'data', cf1);
for i=1:size(dataTs2,1)
hasil(i,1) =
naiveBayes(dataTr2,LabelTr2,dataTs2(i,:));
end
cf2 = confusionmat(LabelTs2,hasil);
output2 = (sum(diag(cf2))/sum(sum(cf2)))*100;
set(handles.uitable1,'data', cf2);
for i=1:size(dataTs3,1)
hasil(i,1) =naiveBayes(dataTr3,LabelTr3,dataTs3(i,:));
end
cf3 = confusionmat(LabelTs3,hasil);
output3 = (sum(diag(cf3))/sum(sum(cf3)))*100;
set(handles.uitable3,'data', cf3);
for i=1:size(dataTs4,1)
hasil(i,1) naiveBayes(dataTr4,LabelTr4,dataTs4(i,:));
end
cf4 = confusionmat(LabelTs4,hasil);
output4 = (sum(diag(cf4))/sum(sum(cf4)))*100;
set(handles.uitable4,'data', cf4);
for i=1:size(dataTs5,1)
hasil(i,1) =naiveBayes(dataTr5,LabelTr5,dataTs5(i,:));
end
cf5 = confusionmat(LabelTs5,hasil);
output5 = (sum(diag(cf5))/sum(sum(cf5)))*100;
set(handles.uitable9,'data', cf5);
akurasi = (output1+output2+output3+output4+output5)/5;
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

29
set(handles.text32,'String',['Akurasi : ' num2str(akurasi)
'%']);
4.5 Implementasi Uji Data Tunggal
4.5.1 Uji Data Tunggal
Tampilan dari sistem dengan uji data tunggal dapat dilihat pada
gambar 4.2, 4.3, 4.4, dan 4.5.
4.5.1.1 Uji Data 1
Pada uji data tunggal, data 1 berhasil diklasifikasi menjadi
Level 2.
Gambar 4.2 Uji Data 1
4.5.1.2 Uji Data 2
Pada uji data tunggal, data 2 berhasil diklasifikasi menjadi
Level 3.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

30
Gambar 4.3 Uji Data 2
4.5.1.3 Uji Data 3
Pada uji data tunggal, data 3 berhasil diklasifikasi menjadi
Level 4.
Gambar 4.4 Uji Data 3
4.5.1.4 Uji Data 4
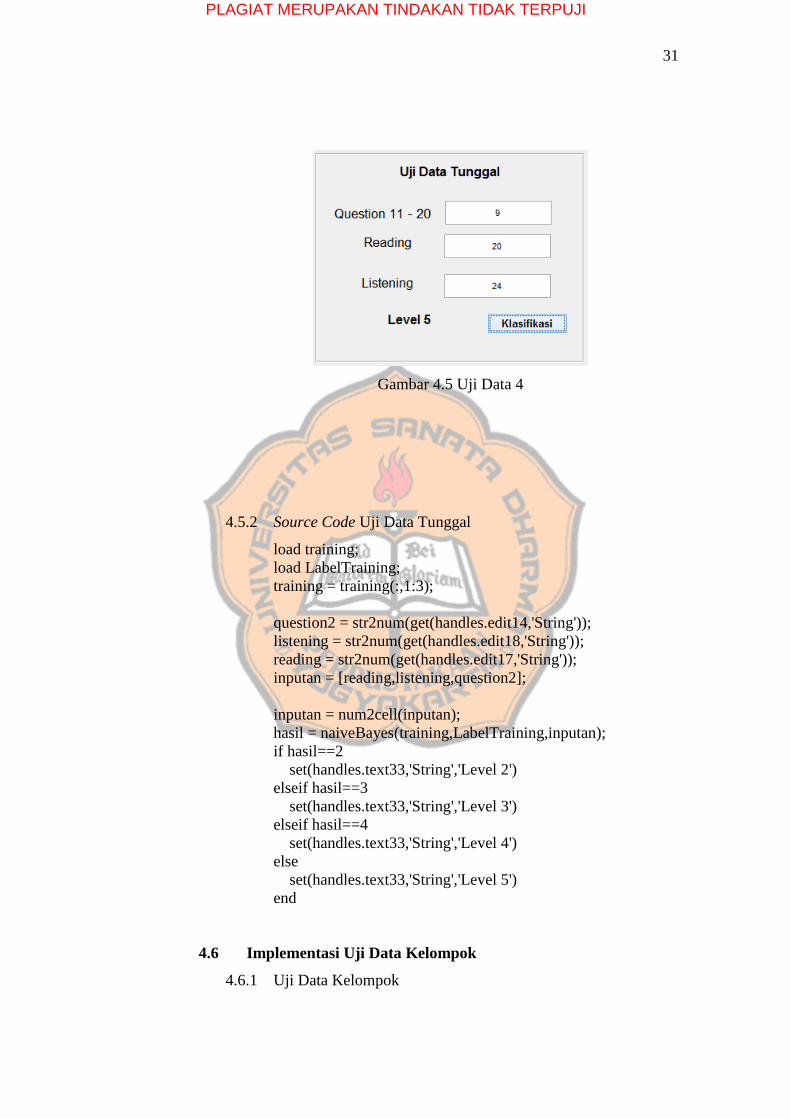
Pada uji data tunggal, data 4 berhasil diklasifikasi menjadi
Level 5.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
31
Gambar 4.5 Uji Data 4
4.5.2 Source Code Uji Data Tunggal
load training;
load LabelTraining;
training = training(:,1:3);
question2 = str2num(get(handles.edit14,'String'));
listening = str2num(get(handles.edit18,'String'));
reading = str2num(get(handles.edit17,'String'));
inputan = [reading,listening,question2];
inputan = num2cell(inputan);
hasil = naiveBayes(training,LabelTraining,inputan);
if hasil==2
set(handles.text33,'String','Level 2')
elseif hasil==3
set(handles.text33,'String','Level 3')
elseif hasil==4
set(handles.text33,'String','Level 4')
else
set(handles.text33,'String','Level 5')
end
4.6 Implementasi Uji Data Kelompok
4.6.1 Uji Data Kelompok
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

32
Tampilan dari Sistem Uji Data Kelompok dapat dilihat pada
gambar
Gambar 4.6 Uji Data Kelompok
4.6.2 Source Code Uji Data Kelompok
global row1;
load training;
load LabelTraining;
training = training(:,1:3);
LabelTraining = LabelTraining;
testing = row1(:,[6 5 2]);
tampil= row1(:,[2 5 6]);
tampil= cell2mat(tampil);
ukuran = testing(:,1);
[m,n] = size(ukuran);
for i=1:m
hasil(i) = naiveBayes(training,LabelTraining,testing(i,:));
if hasil(i)==2
output(i,1)=2;
elseif hasil(i)==3
output(i,1)=3;
elseif hasil(i)==4
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

33
output(i,1)=4;
else
output(i,1)=5;
end
end
gabung = [tampil,output];
set(handles.hasilKlasifikasi,'ColumnName',{'Question 11-20',
'Reading', 'Listening', 'Level'});
set(handles.hasilKlasifikasi,'ColumnWidth',{'auto', 'auto', 'auto',
'auto'});
set(handles.hasilKlasifikasi,'ColumnFormat',{'short', 'short',
'long'});
set(handles.hasilKlasifikasi,'data',gabung);
4.7 User Interface Sistem
Gambar 4.1 User Interface Sistem
Berikut ini adalah keterangan mengenai fitur-fitur yang terdapat
pada User Interface Sistem :
1. Tombol Pilih File digunakan untuk mengambil file yang
diinginkan, lalu isi data file akan ditampilkan pada tabel.
2. Jumlah Atribut digunakan untuk mnguji dengan berbagai
jumlah atribut, namun untuk pemodelan naive bayes
menggunakan jumlah atribut dengan hasil akurasi yang
optimal. Setelah itu tekan tombol preprocessing untuk
1
2
3
4
5 6
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

34
dilakukan preprocessing.
3. Tombol akurasi digunakan untuk menampilkan nilai
akurasi yang merupakan hasil dari model naive bayes.
Selain itu, terdapat lima tabel confusion matrix yang
berfungsi untuk menampilkan nilai confusion matrix pada
tiap fold.
4. Tombol Pilih File pada Uji Data Kelompok, berfungsi
untuk mengambil file data kelompok, lalu isi dari file
tersebut akan ditampilkan pada tabel.
5. Tombol klasifikasi berfungsi untuk mengklasifikasi isi file
data yang sebelumnya belum diklasifikasikan. Setelah
menekan tombol klasifikasi, akan muncul hasil klasifikasi.
6. Uji Data Tunggal, memiliki tiga kolom inputan yang
berfungsi untuk menginput data, kemudian dari data
tersebut akan diklasifikasikan dengan menggunakan tombol
klasifikasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

35
Bab V. ANALISIS HASIL
5.1 Uji Validasi
5.1.1 Perhitungan Manual Naive Bayes
Berikut merupakan contoh perhitungan manual menggunakan excel. Data
yang digunakan ada sebanyak 20 data. Data pada baris 1 - 4 digunakan
sebagai data Testing pada fold-1, sedangkan data ke 5 – 20 digunakan sebagai
data Training.
Tabel 5.1 Contoh Data
No Question
1-10
Question
11-20
Question
21-30
Question
31-40
Reading Listening Level
1 8 3 4 2 18 16 Level 4
2 7 4 2 7 5 12 Level 2
3 4 1 2 3 13 11 Level 3
4 9 7 8 4 24 23 Level 5
5 10 8 10 6 26 24 Level 5
6 6 4 7 2 14 14 Level 3
7 7 6 4 2 23 20 Level 4
8 9 2 3 4 16 10 Level 2
9 8 8 4 3 21 20 Level 4
10 5 2 2 1 13 10 Level 2
11 10 6 9 4 25 21 Level 5
12 10 6 7 4 20 17 Level 3
13 10 9 8 1 24 18 Level 4
14 9 6 3 3 21 13 Level 3
15 6 5 1 1 8 10 Level 2
16 9 6 6 3 23 21 Level 5
17 8 10 7 4 25 21 Level 5
18 7 4 2 7 5 12 Level 2
19 9 8 9 5 26 19 Level 4
20 10 5 4 2 22 12 Level 3
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

36
Berikut ini adalah contoh perhitungan nilai mean dan standar deviasi untuk tiap
atribut terhadap semua kelas. Hasil dari perhitungan mean dan standar deviasi
ditunjukkan pada Tabel 5.2, 5.3, 5.4, 5.5, 5.6 dan 5.7.
Tabel 5.2 Nilai mean dan standar deviasi Question 1-10 terhadap semua atribut
Question 1-10 Level 2 Level 3 Level 4 Level 5
Mean 6,75 8,75 8,5 9,25
Standar Deviasi 1,707825 1,892969 0,129099 0,957427
Tabel 5.3 Nilai mean dan standar deviasi Question 11-20 terhadap semua atribut
Question 11-20 Level 2 Level 3 Level 4 Level 5
Mean 3,25 5,25 7,25 7,5
Standar Deviasi 1,5 0,957427 2,217355 1,914854
Tabel 5.4 Nilai mean dan standar deviasi Question 21-30 terhadap semua atribut
Question 21-30 Level 2 Level 3 Level 4 Level 5
Mean 2 5,25 6,25 8
Standar Deviasi 0,816496 2,06155 2,629955 1,825741
Tabel 5.5 Nilai mean dan standar deviasi Question 31-40 terhadap semua atribut
Question 31-40 Level 2 Level 3 Level 4 Level 5
Mean 3,25 2,75 2,75 4,25
Standar Deviasi 2,87228 0,95743 1,707825 1,25830
Tabel 5.6 Nilai mean dan standar deviasi Reading terhadap semua atribut
Reading Level 2 Level 3 Level 4 Level 5
Mean 10,5 19,25 23,5 24,75
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

37
Standar Deviasi 4,93288 3,59398 2,08166 1,258305
Tabel 5.7 Nilai mean dan standar deviasi Listening terhadap semua atribut
Listening Level 2 Level 3 Level 4 Level 5
Mean 10,5 14 19,25 21,75
Standar Deviasi 1 2,160247 0,957427 1,5
Kemudian menghitung nilai probabilitas kelas seperti yang ditunjukkan pada
Tabel 5.8.
Tabel 5.8 Probabilitas kelas
Jumlah Kelas Probabilitas Kelas
Level 2 Level 3 Level 4 Level 5 Level 2 Level 3 Level 4 Level 5
4 4 4 4 4/16 4/16 4/16 4/16
Tabel 5.9 Tabel data Testing
Perhitungan dengan data Testing no 1
Question 1-10 = 8, hitung menggunakan persamaan (gaus)
P(Question 1-10 = 8 | Level 2)
No Question
1-10
Question
11-20
Question
21-30
Question
31-40 Reading Listening Level
1 8 3 4 2 18 16 Level 4
2 7 4 2 7 5 12 Level 2
3 4 1 2 3 13 11 Level 3
4 9 7 8 4 24 23 Level 5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

38
=1
√2𝜋(1,707825128)𝑒
−(8−6,75)2
2(1,707825128)2 = 0,178705446
P(Question 1-10 = 8 | Level 3):
=1
√2𝜋(1,892969)𝑒
−(8−8,75)2
2(1,892969)2 = 0,194840571
P(Question 1-10 = 8 | Level 4):
=1
√2𝜋(1,290994)𝑒
−(8−8,5)2
2(1,290994)2 = 0,2866907
(Question 1-10 = 8 | Level 5):
=1
√2𝜋(0,9574271)𝑒
−(8−9,25)2
2(0,9574271)2 = 0,1776916
Question 11-20 = 3, hitung menggunakan persamaan (gaus)
P(Question 11-20 = 3 | Level 2)
=1
√2𝜋(1,5)𝑒
−(3−1,5)2
2(1,5)2 = 0,2622931
P(Question 11-20 = 3 | Level 3)
=1
√2𝜋(0,9574271)𝑒
−(3−5,25)2
2(2,986078811)2 = 0,0263365
P(Question 11-20 = 3 | Level 4):
=1
√2𝜋(2,2173557)𝑒
−(3−7,25)2
2(2,2173557)2 = 0,0286638
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

39
P(Question 11-20 = 3 | Level 5):
=1
√2𝜋(1,9148542)𝑒
−(3−7,5)2
2(1,9148542)2 = 0,0131682
Question 21-30 = 4, hitung menggunakan persamaan (gaus)
P(Question 21-30 = 4 | Level 2)
=1
√2𝜋(0,8164965)𝑒
−(2−4)2
2(0,8164965)2 = 0,0243260
P(Question 21-30 = 4 | Level 3)
=1
√2𝜋(2,0615528)𝑒
−(4−5,25)2
2(2,0615528)2 = 0,1610208
P(Question 21-30 = 4 | Level 4)
=1
√2𝜋(2,6299556)𝑒
−(4−6,25)2
2(2,6299556)2 = 0,1052023
P(Question 21-30 = 4 | Level 5)
=1
√2𝜋(1,8257418)𝑒
−(4−8)2
2(1,8257418)2 = 0,0198227
Question 31-40 = 2, hitung menggunakan persamaan (gaus)
P(Question 31-40 = 2 | Level 2)
=1
√2𝜋(2,872281)𝑒
−(2−3,25)2
2(2,872281)2 = 0,1263446
P(Question 31-40 = 2 | Level 3)
=1
√2𝜋(0,957427)𝑒
−(2−2,75)2
2(0,957427)2 = 0,3065878
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

40
P(Question 31-40 = 2 | Level 4):
=1
√2𝜋(1,7078251)𝑒
−(2−2,75)2
2(1,7078251)2 = 0,2121232
P(Question 31-40 = 2 | Level 5):
=1
√2𝜋(1,2583057)𝑒
−(2−4,25)2
2(1,2583057)2 = 0,0640950
Reading = 18, hitung menggunakan persamaan (gaus)
P(Reading = 18 | Level 2)
=1
√2𝜋(4,932883)𝑒
−(18−10,5)2
2(4,932883)2 = 0,02545904
P(Reading = 18 | Level 3)
=1
√2𝜋(3,593976)𝑒
−(18−19,25)2
2(3,593976)2 = 0,1044881
P(Reading = 18 | Level 4):
=1
√2𝜋(2,0816659)𝑒
−(18−23,5)2
2(2,0816659)2 = 0,0058431
P(Reading = 18 | Level 5):
=1
√2𝜋(1,2583057)𝑒
−(18−24,75)2
2(1,2583057)2 = 0,00000017
Listening = 16, hitung menggunakan persamaan (gaus)
P(Listening = 16 | Level 2)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

41
=1
√2𝜋(1)𝑒
−(16−10,5)2
2(1)2 = 0,00000010769
P(Listening = 16 | Level 3)
=1
√2𝜋(2,160247)𝑒
−(16−14)2
2(2,160247)2 = 0,1203041
P(Reading = 16 | Level 4)
=1
√2𝜋(0,9574271)𝑒
−(16−19,25)2
2(0,9574271)2 = 0,0013112
P(Reading = 18 | Level 5):
=1
√2𝜋(1,5)𝑒
−(18−21,75)2
2(1,5)2 = 0,00017138
Untuk melihat hasil dari probabilitas pada tiap atribut bisa dilihat pada Tabel 5.10
dibawah ini.
Tabel 5.10 Probabilitias setiap atribut
Level 2 Level 3 Level 4 Level 5
Question 1-10 0,1787054 0,194840 0,2866907 0,17769164
Question 11-20 0,2622931 0,026336 0,0286638 0,0131682
Question 21-30 0,0243260 0,161020 0,1052023 0,01982275
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

42
Question 31-40 0,1263446 0,306587 0,2121232 0,064095
Reading 0,0254590 0,104488 0,0058431 0,00000017
Listening
0,0000001 0,120304 0,0013112 0,00017138
Mencari nilai likelihood pada data testing nomor 1
Likelihood Level 2
= P(Question 1-10) * P(Question 11-20) * P(Question 21-30) *
P(Question 31-40) * P(Reading) * P(Listening)
= 0,1787054*0,2622931*0,0243260* 0,1263446* 0,0254590* 0,0000001
= 0,0000000000003950043
Likelihood Level 3
=P(Question 1-10) * P(Question 11-20) * P(Question 21-30) * P(Question
31-40) * P(Reading) * P(Listening)
= 0,194840* 0,026336* 0,161020* 0,306587* 0,104488* 0,120304
= 0,00000318436
Likelihood Level 4
= P(Question 1-10) * P(Question 11-20) * P(Question 21-30) * P(Question
31-40) * P(Reading) * P(Listening)
= 0,2866907* 0,0286638* 0,2121232* 0,0058431* 0,0013112
= 0,0000000014050
Likelihood Level 5
= P(Question 1-10) * P(Question 11-20) * P(Question 21-30) * P(Question
31-40) * P(Reading) * P(Listening)
=0,17769164*0,0131682*0,01982275*0,064095*0,00000017*0,00017138
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

43
= 0,00000000000000009111
Berikut ini adalah nilai hasil dari likelihood pada data Testing no 1
Level 2
= 0,0000000000003950043
0,00000000000039500430,00000318436 + 0,0000000014050
+ 0,00000000000000009111
= 0,000000123990
Level 3
= 0,00000318436
0,0000000000003950043 +0,00000318436 + 0,00000000014050
+ 0,00000000000000009111
= 0,999558
Level 4
= 0,0000000014050
0,0000000000003950043 +0,00000318436 + 0,0000000014050
+ 0,00000000000000009111
= 0,0004410
Level 5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

44
= 0,00000000000000009111
0,0000000000003950043 +0,00000318436 + 0,0000000014050
+ 0,00000000000000009111
= 0,00000000003
Berdarkan nilai probabilitas untuk semua kelas pada data Testing no 1, hasil yang
mendekati angka 1 terdapat pada Level 3.
Dari empat data Testing pada Tabel 5.14, hasil klasifikasi Data Testing dapat
dilihat pada Tabel 5.15.
Tabel 5.11 Klasifikasi Data Testing
Question
1-10
Question
11-20
Question
21-30
Question
31-40
Reading Listening Kelas Hasil
Klasifikasi
8 3 4 2 18 16 Level 4 Level 3
7 4 2 7 5 12 Level 2 Level 2
4 1 2 3 13 11 Level 3 Level 2
9 7 8 4 24 23 Level 5 Level 5
Hasil perhitungan Confusion Matrix dapat dilihat pada Tabel 5.12.
Tabel 5.12 Confusion Matrix
Level 2 Level 3 Level 4 Level 5
Level 2 1 0 0 0
Level 3 1 0 0 0
Level 4 0 1 0 0
Level 5 0 0 0 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

45
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =1 + 0 + 0 + 1
4 𝑥 100 = 50%
Berdasarkan hasil perhitungan exel dengan menggunakan 5-fold cross validation
didapatkan hasil sebagai berikut.
Tabel 5.13 Confusion Matrix 1
Level 2 Level 3 Level 4 Level 5
Level 2 1 0 0 0
Level 3 1 0 0 0
Level 4 0 1 0 0
Level 5 0 0 0 1
Pada fold pertama mendapatkan akurasi sebesar 50%.
Tabel 5.14 Confusion Matrix 2
Level 2 Level 3 Level 4 Level 5
Level 2 0 1 0 0
Level 3 0 1 0 0
Level 4 0 0 1 0
Level 5 0 0 1 0
Pada fold kedua mendapatkan akurasi sebesar 50%.
Tabel 5.15 Confusion Matrix 3
Level 2 Level 3 Level 4 Level 5
Level 2 1 0 0 0
Level 3 0 0 1 0
Level 4 0 0 1 0
Level 5 0 0 0 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
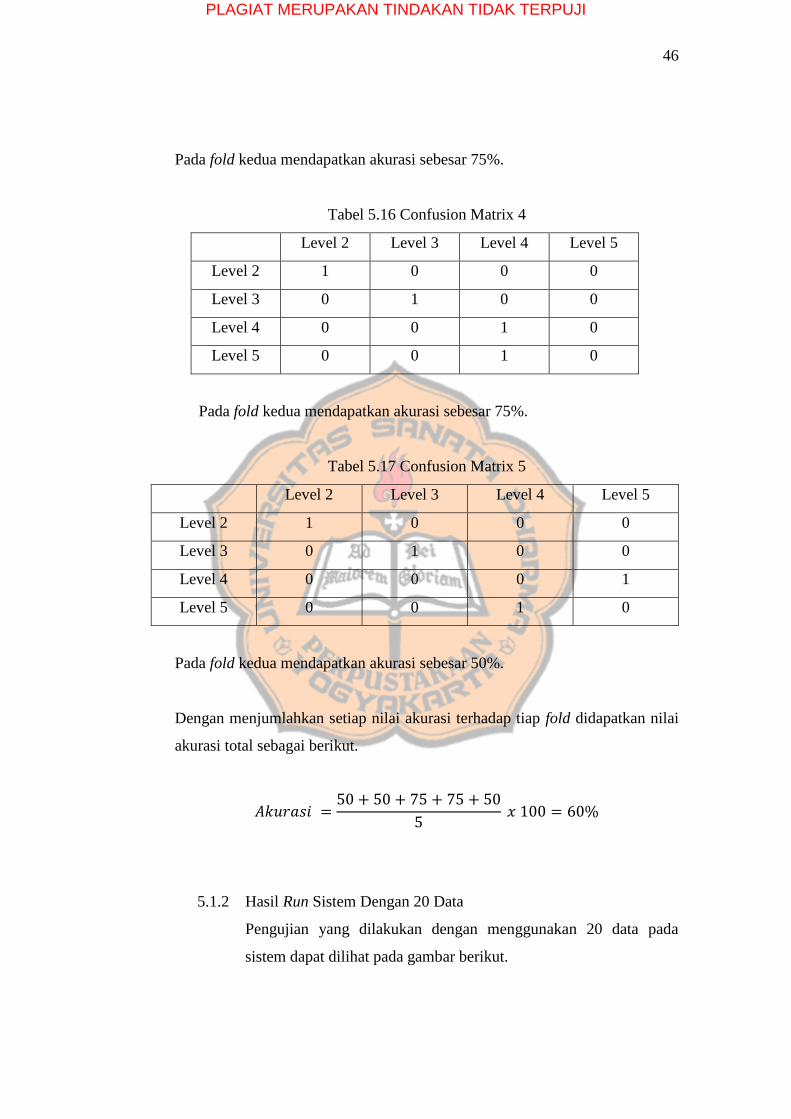
46
Pada fold kedua mendapatkan akurasi sebesar 75%.
Tabel 5.16 Confusion Matrix 4
Level 2 Level 3 Level 4 Level 5
Level 2 1 0 0 0
Level 3 0 1 0 0
Level 4 0 0 1 0
Level 5 0 0 1 0
Pada fold kedua mendapatkan akurasi sebesar 75%.
Tabel 5.17 Confusion Matrix 5
Level 2 Level 3 Level 4 Level 5
Level 2 1 0 0 0
Level 3 0 1 0 0
Level 4 0 0 0 1
Level 5 0 0 1 0
Pada fold kedua mendapatkan akurasi sebesar 50%.
Dengan menjumlahkan setiap nilai akurasi terhadap tiap fold didapatkan nilai
akurasi total sebagai berikut.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =50 + 50 + 75 + 75 + 50
5 𝑥 100 = 60%
5.1.2 Hasil Run Sistem Dengan 20 Data
Pengujian yang dilakukan dengan menggunakan 20 data pada
sistem dapat dilihat pada gambar berikut.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

47
Gambar 5.1 Hasil Sistem Dengan 20 Data
5.2 Uji Akurasi dengan 240 Data Menggunakan Sistem
5.2.1 Dengan 5 k-fold
Uji coba yang dilakukan dengan 4 k-fold menghasilkan akurasi seperti
pada tabel berikut :
Tabel 5.18 Uji Coba Dengan 5 k-fold
6 atribut 64.5833%
5 atribut 63.3333%
4 atribut 62.0833%
3 atribut 65%
2 atribut 64.1677%
1 atribut 58.75%
Berdasarkan dari hasil tabel diatas, akurasi paling optimal dengan
menggunakan 5 k-fold terdapat pada uji coba dengan 3 atribut, yaitu 65%.
Hasil tersebut telah di coba dengan menggunakan sistem seperti pada
gambar berikut.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
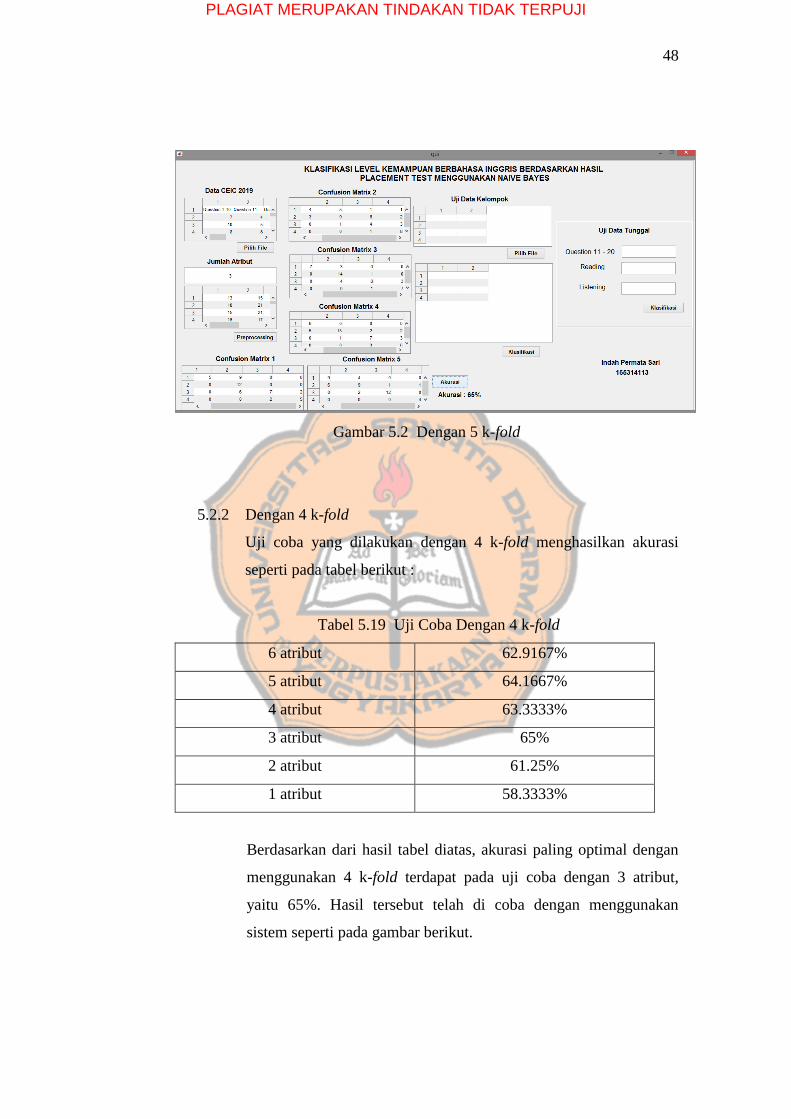
48
Gambar 5.2 Dengan 5 k-fold
5.2.2 Dengan 4 k-fold
Uji coba yang dilakukan dengan 4 k-fold menghasilkan akurasi
seperti pada tabel berikut :
Tabel 5.19 Uji Coba Dengan 4 k-fold
6 atribut 62.9167%
5 atribut 64.1667%
4 atribut 63.3333%
3 atribut 65%
2 atribut 61.25%
1 atribut 58.3333%
Berdasarkan dari hasil tabel diatas, akurasi paling optimal dengan
menggunakan 4 k-fold terdapat pada uji coba dengan 3 atribut,
yaitu 65%. Hasil tersebut telah di coba dengan menggunakan
sistem seperti pada gambar berikut.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

49
Gambar 5.3 Dengan 4 k-fold
5.2.3 Dengan 3 k-fold
Uji coba yang dilakukan dengan 3 k-fold menghasilkan akurasi
seperti pada tabel berikut :
Tabel 5.20 Uji Coba Dengan 3 k-fold
6 atribut 62.0833%
5 atribut 62.0833%
4 atribut 60.4167%
3 atribut 64.1667%
2 atribut 62.0833%
1 atribut 59.5833%
Berdasarkan dari hasil tabel diatas, akurasi paling optimal dengan
menggunakan 3 k-fold terdapat pada uji coba dengan 3 atribut,
yaitu 64.1667%. Hasil tersebut telah di coba dengan menggunakan
sistem seperti pada gambar berikut.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

50
Gambar 5.4 Dengan 3 k-fold
5.3 Uji Akurasi Dengan Data Tunggal Menggunakan Sistem
Tabel berikut adalah contoh data yang di ujikan menggunakan sistem uji data
tunggal. Data yang digunakan ada sebanyak 12 data.
Tabel 5.21 Uji Akurasi Data Tunggal
Question 11-20 Reading Listening Klasifikasi
Dari
Lembaga
Bahasa
Klasifikasi
Dari Sistem
6 9 15 Level 2 Level 2
4 21 11 Level 3 Level 2
7 22 14 Level 4 Level 4
10 25 21 Level 5 Level 5
3 22 14 Level 2 Level 3
7 21 15 Level 3 Level 4
8 26 19 Level 4 Level 4
8 25 20 Level 5 Level 4
4 15 15 Level 3 Level 3
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
51
9 26 25 Level 5 Level 5
4 5 12 Level 2 Level 2
7 24 20 Level 4 Level 4
Berdasarkan dari hasil klasifikasi dengan uji data tunggal, dari 12 data terdapat 4
data yang di klasifikasikan tidak sesuai dengan label pada data CEIC 2019 yang
sudah diklasifikasikan dari pihak lembaga. Sedangkan, 8 data lainnya
diklasifikasikan sama dengan label pada data CEIC 2019. Dengan demikian,
akurasi yang di dapatkan sebesar 60% dari uji data tunggal diatas yaitu 66,666%.
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =8
12 𝑥 100 = 66.6666%
5.4 Uji Akurasi Menggunakan Outlier
Pada tahap ini dilakukan penghapusan data yang bernilai 0 dan sistem
menggunakan 3-fold untuk pembagian datanya. Jumlah data pada tiap level
diseimbangkan. Langkah pertama dilakukan Information Gained dengan
menggunakan Weka Tools. Hasil dari Information Gained dapat dilihat pada tabel
5.22.
Tabel 5.22 Information Gained Percobaan kedua No Urut
Atribut Atribut Information Gained
6 Listening 0.646%
5 Reading 0.439%
2 Question 11-20 0.395%
1 Question 1-10 0.333%
3 Question 21-30 0.279%
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

52
4 Question 31-40 0.07%
Pada percobaan ini jumlah label pada tiap data seimbang. Setelah itu
dilakukan uji sistem menggunakan data yang terdapat data 0. Pengujian sistem
dilakukan dengan uji coba berbagai jumlah atribut. Hasil dapat dilihat pada tabel
5.23.
Tabel 5.23 Uji Akurasi Sebelum Menggunakan Outlier
Uji Berbagai Atribut Akurasi
6 atribut
(Listening, Reading, Question 11-20,
Question 1-10, Question 21-30 dan
Question 31-40)
63.75%
5 atribut
(Listening, Reading, Question 11-20,
Question 1-10 dan Question 21-30)
64.5833%
4 atribut
(Listening, Reading, Question 11-20 dan
Question 1-10)
65.8883%
3 atribut
(Listening, Reading dan Question 11-20) 67.5%
2 atribut
(Listening dan Reading) 63.3333%
1 atribut
(Listening) 59.1667%
Pada percobaan diatas akurasi optimal tampak pada percobaan dengan
menggunakan 3 atribut, yaitu 67.5%.
Seperti yang sudah di jelaskan pada bab III, data yang digunakan berjumlah 240
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

53
data, setelah menghapus data yang bernilai 0, data berkurang menjadi 226 data.
Data yang memiliki nilai 0 ada sebanyak 14 data. Perngujian dilakukan
menggunakan sistem dengan uji coba berbagai jumlah atribut. Hasilnya dapat
dilihat pada tabel 5.24 berikut ini :
Tabel 5.24 Uji Akurasi Setelah Menggunakan Outlier
Uji Berbagai Atribut Akurasi
6 atribut
(Listening, Reading, Question 11-20,
Question 1-10, Question 21-30 dan
Question 31-40)
61.778%
5 atribut
(Listening, Reading, Question 11-20,
Question 1-10 dan Question 21-30)
64%
4 atribut
(Listening, Reading, Question 11-20 dan
Question 1-10)
65.778%
3 atribut
(Listening, Reading dan Question 11-20) 67.5556%
2 atribut
(Listening dan Reading) 60.8889%
1 atribut
(Listening) 58.2222%
Pada percobaan diatas akurasi optimal terdapat percobaan dengan menggunakan 3
atribut, yaitu 67.5556%.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

54
Berikut ini adalah tampilan uji sistem dengan menggunakan outlier :
Gambar 5.5 Uji Sistem Menggunakan Outlier
Berdasarkan dari 2 hasil diatas, akurasi paling optimal terdapat pada uji coba
menggunakan 3 atribut, yang mana akurasi pada percobaan dengan data sebelum
menggunakan outlier menghasilkan 67.5% dan setelah menggunakan outlier
menghasilkan akurasi 67.5556%. Hanya terdapat peningkatan sebesar 0.0001%.
Dapat disimpulkan bahwa dengan pembagian jumlah label (Level) yang seimbang
pada tiap fold dan penghapusan data yang bernilai 0 tidak menaikkan akurasi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

55
Bab VI. PENUTUP
6.1 Kesimpulan
Dari hasil penelitian Klasifikasi Level Kemampuan Berbahasa Inggris
Berdasarkan Hasil Placement Test Menggunakan Naive Bayes, penulis mengambil
kesimpulan sebagai berikut :
1. Metode Naïve Bayes kurang dapat mengklasifikasi dengan baik untuk
klasifikasi kemampuan Bahasa Inggris berdasarkan hasil Placement Test
dengan studi kasus pada Lembaga Bahasa USD. Hal ini dikarenakan
jumlah data yang sedikit dan terdapat data yang bernilai 0, sehingga
akurasi pengklasifikasian kurang maksimal.
2. Akurasi yang diperoleh sebesar 65% (dari percobaan pertama, tanpa
oulier, jumlah label tidak seimbang, menggunakan 5 k-fold, pada data
sebanyak 240 data dengan 3 atribut dan 4 label.
3. Percobaan kedua tanpa menggunakan outlier dan menggunakan outlier.
Pada percobaan tanpa menggunakan outlier menghasilkan akurasi sebesar
67% dengan menggunakan 3-fold, 3 atribut dan 4 label. Data yang
digunakan sebanyak 226 dan jumlah label belum diseimbangkan.
Sedangkan dengan menggunakan outlier menghasilkan akurasi 67.5556%
dengan 3-fold, 3 atribut dan 4 label. Pada percobaan ini menggunakan
sebanyak 226 data, 3-fold, 4 label dan jumlah label pada tiap fold
seimbang.
4. Pembagian label yang seimbang untuk tiap fold dapat meningkatkan
akurasi, yang awalnya 65% menjadi 67.5556%. (Pembagian label yang
seimbang yaitu membagi dengan seimbang jumlah tiap label pada tiap
fold. Misal jumlah Level 2 pada data CEIC 2019 ada sebanyak 54 data,
karena menggunakan 3-fold, maka data yang memiliki label Level 2 akan
berjumlah sebanyak 18 data pada tiap fold).
5. Dari percobaan pertama dan kedua, akurasi optimal terdapat pada uji coba
dengan menggunakan 3 atribut yaitu 65% pada percobaan pertama dan
67.5556% pada percobaan kedua.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

56
6.2 Saran
Saran yang dapat diberikan penulis untuk mengembangkan penelitian di masa
yang akan datang:
1. Melakukan penambahan data.
2. Melakukan percobaan dengan menggunakan metode klasifikasi lain.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

57
DAFTAR PUSTAKA
C, Antonius Rachmat C dan Yuan Lukito. 2018. Klasifikasi Sentimen Komentar
Politik dari Facebook Page menggunakan Naive Bayes. Jurnal. Teknik
Informatika. Universitas Kristen Duta Wacana.
E. Prasetyo, Data Mining: Konsep dan Aplikasi menggunakan Matlab, 1 ed.
Yogyakarta: Andi Offset, 2012.
Han & Kamber. 2006. Data Mining: Concepts and Techniques, 2end ed.
Kusriani dan Luthfi, E.T. 2009. Algoritma Data Mining. Yogyakarta: Andi.
Kusuma Dewi, Sri. 2003. Klasifikasi Status Gizi Menggunakan Naive Bayes
Classfification. Jurnal. Teknik Inormatika. Universitas Islam Indonesia.
Patil, T. R., Sherekar, M. S. (2013). Performance Analysis of Naive Bayes and
J48 Classification Algorithm for Data Classification, International Journal of
Computer Science and Applications, Vol. 6, No. 2.
Saleh, Alfa. 2015. Implementasi Metode Klasifikasi Naive Bayes dalam
Memeroleh Besarnya Penggunaan Listrik Rumah Tangga Creative Information
Technology.
W, Nurul Rohmawati, dkk. 2015. Implementasi Algoritma K-Means Dalam
Pengklasteran Mahasiswa Pelamar Beasiswa. Jurnal. Teknik Informatika.
Universitas Singaperbangsa Karawang.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI





























