Embed Size (px)
Citation preview

Parallel Programming in MPI and OpenMP
Victor Eijkhout
1st edition 2017

Public draft - open for comments
2 Parallel Computing – r428

This book will be open source under CC-BY license.
Victor Eijkhout 3

Two of the most common software systems for parallel programming in scientific computing are MPI andOpenMP. They target different types of parallelism, and use very different constructs. Thus, by coveringboth of them in one book we can offer a treatment of parallelism that spans a large range of possibleapplications.
4 Parallel Computing – r428

Contents
I MPI 111 Getting started with MPI 121.1 Distributed memory and message passing 121.2 History 121.3 Basic model 131.4 Making and running an MPI program 141.5 Language bindings 151.6 Review 182 MPI topic: Functional parallelism 192.1 The SPMD model 192.2 Starting and running MPI processes 212.3 Processor identification 242.4 Functional parallelism 263 MPI topic: Collectives 283.1 Working with global information 283.2 Reduction 313.3 Rooted collectives: broadcast, reduce 333.4 Rooted collectives: gather and scatter 393.5 All-to-all 433.6 Reduce-scatter 443.7 Barrier 473.8 Variable-size-input collectives 483.9 Scan operations 513.10 MPI Operators 533.11 Non-blocking collectives 563.12 Performance of collectives 593.13 Collectives and synchronization 603.14 Implementation and performance of collectives 633.15 Sources used in this chapter 654 MPI topic: Point-to-point 714.1 Distributed computing and distributed data 714.2 Blocking point-to-point operations 724.3 Non-blocking point-to-point operations 86
5

Contents
4.4 More about point-to-point communication 974.5 Sources used in this chapter 1085 MPI topic: Data types 1185.1 MPI Datatypes 1185.2 Elementary data types 1185.3 Derived datatypes 1215.4 More about data 1365.5 Sources used in this chapter 1396 MPI topic: Communicators 1476.1 Communicator basics 1476.2 Subcommunications 1486.3 Duplicating communicators 1496.4 Splitting a communicator 1516.5 Communicators and groups 1546.6 Inter-communicators 1556.7 Sources used in this chapter 1577 MPI topic: Process management 1587.1 Process spawning 1587.2 Socket-style communications 1617.3 Sources used in this chapter 1638 MPI topic: One-sided communication 1648.1 Windows 1658.2 Active target synchronization: epochs 1688.3 Put, get, accumulate 1708.4 Passive target synchronization 1818.5 Details 1858.6 Implementation 1878.7 Sources used in this chapter 1889 MPI topic: File I/O 1909.1 File handling 1909.2 File access 1919.3 Constants 19510 MPI topic: Topologies 19610.1 Cartesian grid topology 19710.2 Distributed graph topology 19810.3 Sources used in this chapter 20211 MPI topic: Shared memory 20311.1 Recognizing shared memory 20311.2 Shared memory for windows 20411.3 Sources used in this chapter 20612 MPI leftover topics 20812.1 Info objects 20812.2 Error handling 210
6 Parallel Computing – r428

Contents
12.3 Machine-specific information 21212.4 Fortran issues 21212.5 Fault tolerance 21312.6 Context information 21312.7 Performance 21512.8 Determinism 21912.9 Subtleties with processor synchronization 21912.10 Multi-threading 22012.11 Shell interaction 22112.12 The origin of one-sided communication in ShMem 22212.13 Leftover topics 22312.14 Literature 22512.15 Sources used in this chapter 22613 MPI Reference 22713.1 Elementary datatypes 22713.2 Communicators 22813.3 Leftover topics 22813.4 Timing 23013.5 Sources used in this chapter 23114 MPI Review 23214.1 Conceptual 23214.2 Communicators 23214.3 Point-to-point 23214.4 Collectives 23514.5 Datatypes 23514.6 Theory 235
II OpenMP 23715 Getting started with OpenMP 23815.1 The OpenMP model 23815.2 Compiling and running an OpenMP program 24115.3 Your first OpenMP program 24216 OpenMP topic: Parallel regions 24616.1 Nested parallelism 24816.2 Sources used in this chapter 24917 OpenMP topic: Loop parallelism 25017.1 Loop parallelism 25017.2 Loop schedules 25217.3 Reductions 25617.4 Collapsing nested loops 25617.5 Ordered iterations 25717.6 nowait 257
Victor Eijkhout 7

Contents
17.7 While loops 25818 OpenMP topic: Work sharing 26018.1 Sections 26018.2 Single/master 26118.3 Fortran array syntax parallelization 26219 OpenMP topic: Controlling thread data 26319.1 Shared data 26319.2 Private data 26319.3 Data in dynamic scope 26519.4 Temporary variables in a loop 26519.5 Default 26519.6 Array data 26619.7 First and last private 26719.8 Persistent data through threadprivate 26719.9 Sources used in this chapter 26920 OpenMP topic: Reductions 27020.1 Built-in reduction operators 27220.2 Initial value for reductions 27220.3 User-defined reductions 27320.4 Reductions and floating-point math 27420.5 Sources used in this chapter 27421 OpenMP topic: Synchronization 27521.1 Barrier 27521.2 Mutual exclusion 27721.3 Locks 27821.4 Example: Fibonacci computation 28022 OpenMP topic: Tasks 28322.1 Task data 28422.2 Task synchronization 28622.3 Task dependencies 28722.4 More 28922.5 Examples 28922.6 Sources used in this chapter 29123 OpenMP topic: Affinity 29223.1 OpenMP thread affinity control 29223.2 First-touch 29623.3 Affinity control outside OpenMP 29723.4 Sources used in this chapter 29724 OpenMP tocic: Memory model 29824.1 Thread synchronization 29824.2 Data races 29924.3 Relaxed memory model 30025 OpenMP tocic: SIMD processing 301
8 Parallel Computing – r428

Contents
25.1 Sources used in this chapter 30426 OpenMP remaining topics 30526.1 Runtime functions and internal control variables 30526.2 Timing 30726.3 Thread safety 30726.4 Performance and tuning 30826.5 Accelerators 30927 OpenMP Review 31027.1 Concepts review 31027.2 Review questions 311
III PETSc 32128 PETSc basics 32228.1 Language support 32228.2 Startup 32228.3 Commandline options 32328.4 Printing 32329 PETSc objects 32529.1 Vectors 32529.2 Matrices 32829.3 KSP: iterative solvers 33029.4 DMDA: distributed arrays 33130 PETSc topics 33230.1 Communicators 332
IV The Rest 33331 Exploring computer architecture 33431.1 Tools for discovery 33432 Process and thread affinity 33532.1 What does the hardware look like? 33632.2 Affinity control 33833 Hybrid computing 33933.1 Discussion 34033.2 Hybrid MPI-plus-threads execution 34133.3 Sources used in this chapter 34234 Random number generation 34335 Parallel I/O 34435.1 Sources used in this chapter 34436 Support libraries 34536.1 SimGrid 34536.2 Other 345
Victor Eijkhout 9

Contents
V Tutorials 34736.3 Debugging 34936.4 Tracing 35736.5 SimGrid 359
VI Projects, index 36137 Class projects 36237.1 A Style Guide to Project Submissions 36237.2 Warmup Exercises 36537.3 Mandelbrot set 36937.4 Data parallel grids 37637.5 N-body problems 37938 Bibliography, index, and list of acronyms 38038.1 Bibliography 38038.2 List of acronyms 38238.3 Index 383
10 Parallel Computing – r428

PART I
MPI

Chapter 1
Getting started with MPI
In this chapter you will learn the use of the main tool for distributed memory programming: the MessagePassing Interface (MPI) library. The MPI library has about 250 routines, many of which you may neverneed. Since this is a textbook, not a reference manual, we will focus on the important concepts and give theimportant routines for each concept. What you learn here should be enough for most common purposes.You are advised to keep a reference document handy, in case there is a specialized routine, or to look upsubtleties about the routines you use.
1.1 Distributed memory and message passing
In its simplest form, a distributed memory machine is a collection of single computers hooked up withnetwork cables. In fact, this has a name: a Beowulf cluster . As you recognize from that setup, each pro-cessor can run an independent program, and has its own memory without direct access to other processors’memory. MPI is the magic that makes multiple instantiations of the same executable run so that they knowabout each other and can exchange data through the network.
One of the reasons that MPI is so successful as a tool for high performance on clusters is that it is veryexplicit: the programmer controls many details of the data motion between the processors. Consequently, acapable programmer can write very efficient code with MPI. Unfortunately, that programmer will have tospell things out in considerable detail. For this reason, people sometimes call MPI ‘the assembly language ofparallel programming’. If that sounds scary, be assured that things are not that bad. You can get started fairlyquickly with MPI, using just the basics, and coming to the more sophisticated tools only when necessary.
Another reason that MPI was a big hit with programmers is that it does not ask you to learn a new language:it is a library that can be interface to C/C++ or Fortran; there are even bindings to Python. A related point isthat it is easy to install: there are free implementations that you can download and install on any computerthat has a Unix-like operating system, even if that is not a parallel machine.
1.2 History
Before the MPI standard was developed in 1993-4, there were many libraries for distributed memory com-puting, often proprietary to a vendor platform. MPI standardized the inter-process communication mecha-
12

1.3. Basic model
nisms. Other features, such as process management in PVM , or parallel I/O were omitted. Later versionsof the standard have included many of these features.
Since MPI was designed by a large number of academic and commercial participants, it quickly became astandard. A few packages from the pre-MPI era, such as Charmpp [10], are still in use since they supportmechanisms that do not exist in MPI.
1.3 Basic model
Here we sketch the two most common scenarios for using MPI. In the first, the user is working on aninteractive machine, which has network access to a number of hosts, typically a network of workstations;see figure 1.1. The user types the command mpiexec1 and supplies
Figure 1.1: Interactive MPI setup
• The number of hosts involved,• their names, possibly in a hostfile,• and other parameters, such as whether to include the interactive host; followed by• the name of the program and its parameters.
The mpirun program then makes an ssh connection to each of the hosts, giving them sufficient informa-tion that they can find each other. All the output of the processors is piped through the mpirun program,and appears on the interactive console.
In the second scenario (figure 1.2) the user prepares a batch job script with commands, and these will berun when the batch scheduler gives a number of hosts to the job. Now the batch script contains the mpiruncommand, and the hostfile is dynamically generated when the job starts. Since the job now runs at a timewhen the user may not be logged in, any screen output goes into an output file.
You see that in both scenarios the parallel program is started by the mpirun command using an SingleProgram Multiple Data (SPMD) mode of execution: all hosts execute the same program. It is possible fordifferent hosts to execute different programs, but we will not consider that in this book.
1. A command variant is mpirun; your local cluster may have a different mechanism.
Victor Eijkhout 13

1. Getting started with MPI
Figure 1.2: Batch MPI setup
1.4 Making and running an MPI program
MPI is a library, called from programs in ordinary programming languages such as C/C++ or Fortran. Tocompile such a program you use your regular compiler:
gcc -c my_mpi_prog.c -I/path/to/mpi.hgcc -o my_mpi_prog my_mpi_prog.o -L/path/to/mpi -lmpich
However, MPI libraries may have different names between different architectures, making it hard to have aportable makefile. Therefore, MPI typically has shell scripts around your compiler call:
mpicc -c my_mpi_prog.cmpicc -o my_mpi_prog my_mpi_prog.o
MPI programs can be run on many different architectures. Obviously it is your ambition (or at least yourdream) to run your code on a cluster with a hundred thousand processors and a fast network. But maybeyou only have a small cluster with plain ethernet . Or maybe you’re sitting in a plane, with just your laptop.An MPI program can be run in all these circumstances – within the limits of your available memory ofcourse.
The way this works is that you do not start your executable directly, but you use a program, typically calledmpirun or something similar, which makes a connection to all available processors and starts a run ofyour executable there. So if you have a thousand nodes in your cluster, mpirun can start your programonce on each, and if you only have your laptop it can start a few instances there. In the latter case you willof course not get great performance, but at least you can test your code for correctness.
Python note. Load the TACC-provided python:module load python
and run it as:ibrun python-mpi yourprogram.py
14 Parallel Computing – r428

1.5. Language bindings
1.5 Language bindings
1.5.1 C/C++
The MPI library is written in C. Thus, its bindings are the most natural for that language.
C++ bindings existed at one point, but they were declared deprecated, and have been officially removed inthe MPI 3 The boost library has its own version of MPI, but it seems not to be under further development.A recent effort at idiomatic C++ support is MPL http://numbercrunch.de/blog/2015/08/mpl-a-message-passing-library/.
1.5.2 Fortran
The Fortran bindings for MPI look very much like the C ones, except that each routine has a final errorreturn parameter.
Fortran note. Fortran-specific notes will be indicated with a note like this.
In the MPI 3 standard it is recommended that an MPI implementation providing a Fortran interface pro-vide a module named mpi_f08 that can be used in a Fortran program. This defines MPI functions thatreturn an integer result, rather than having a final parameter. It also defines proper interfaces, making typechecking possible. For details see http://mpi-forum.org/docs/mpi-3.1/mpi31-report/node409.htm.
There are some visible implications of using the mpi_f08 module, mostly related to the fact that someof the ‘MPI datatypes’ such as MPI_Comm, which were declared as Integer previously, are now a FortranType. See the following sections for details: Communicator 6.1, Datatype 5.3.1.1, Info 12.3, Op 3.2.4,Request 4.3.2, Status 4.2.5, Window 8.1.
The mpi_f08 module solves a problem with previous Fortran90 bindings: Fortran90 is a strongly typedlanguage, so it is not possible to pass argument by reference to their address, as C/C++ do with the void*type for send and receive buffers. This was solved by having separate routines for each datatype, andproviding an Interface block in the MPI module. If you manage to request a version that does not exist,the compiler will display a message like
There is no matching specificsubroutine for this generic subroutine call [MPI_Send]
1.5.3 Python
The mpi4py package of python bindings is not defined by the MPI standards committee. Instead, it is thework of an individual, Lisandro Dalcin .
Notable about the Python bindings is that many communication routines exist in two variants:
• a version that can send native Python objects. These routines have lowercase names such asbcast; and• a version that sends numpy objects; these routines have names such as Bcast. Their syntax can
be slightly different.
Victor Eijkhout 15

1. Getting started with MPI
The first version looks more ‘pythonic’, is easier to write, and can do things like sending python objects,but it is also decidedly less efficient since data is packed and unpacked with pickle. As a common senseguideline, use the numpy interface in the performance-critical parts of your code, and the native interfaceonly for complicated actions in a setup phase.
Codes with mpi4py can be interfaced to other languages through Swig or conversion routines.
Data in numpy can be specified as a simple object, or [data, (count,displ), datatype].
1.5.4 How to read routine prototypes
Throughout the MPI part of this book we will give the reference syntax of the routines. This typicallycomprises:
• The semantics: routine name and list of parameters and what they mean.• C synxtax: the routine definition as it appears in the mpi.h file.• Fortran syntax: routine definition with parameters, giving in/out specification.• Python syntax: routine name, indicating to what class it applies, and parameter, indicating which
ones are optional.
These ‘routine prototypes’ look like code but they are not! Here is how you translate them.
1.5.4.1 C
The typically C routine specification in MPI looks like:
int MPI_Comm_size(MPI_Comm comm,int *nprocs)
This means that
• The routine returns an int parameter. Strictly speaking you should test against MPI_SUCCESS(for all error codes, see section 12.2.1):
MPI_Comm comm = MPI_COMM_WORLD;int nprocs;int errorcode;errorcode = MPI_Comm_world( MPI_COMM_WORLD,&nprocs);if (errorcode!=MPI_SUCCESS) {printf("Routine MPI_Comm_world failed! code=%d\n",
errorcode);return 1;
}
However, the error codes are hardly ever useful, and there is not much your program can do torecover from an error. Most people call the routine as
MPI_Comm_world( /* parameter ... */ );
For more on error handling, see section 12.2.• The first argument is of type MPI_Comm. This is not a C built-in datatype, but it behaves like one.
There are many of these MPI_something datatypes in MPI. So you can write:
16 Parallel Computing – r428

1.5. Language bindings
MPI_Comm my_comm =MPI_COMM_WORLD; // using a predefined value
MPI_Comm_size( comm, /* remaining parameters */ );
• Finally, there is a ‘star’ parameter. This means that the routine wants an address, rather than avalue. You would typically write:
MPI_Comm my_comm = MPI_COMM_WORLD; // using a predefined valueint nprocs;MPI_Comm_size( comm, &nprocs );
Seeing a ‘star’ parameter usually means either: the routine has an array argument, or: the routineinternally sets the value of a variable. The latter is the case here.
1.5.4.2 Fortran
The Fortran specification looks like:
MPI_Comm_size(comm, size, ierror)INTEGER, INTENT(IN) :: commINTEGER, INTENT(OUT) :: sizeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
The syntax of using this routine is close to this specification: you write
integer :: comm = MPI_COMM_WORLDinteger :: sizeCALL MPI_Comm_size( comm, size, ierr )
• Most Fortran routines have the same parameters as the corresponding C routine, except that theyall have the error code as final parameter, instead of as a function result. As with C, you canignore the value of that parameter. Just don’t forget it.• The types of the parameters are given in the specification.• Where C routines have MPI_Comm and MPI_Request and such parameters, Fortran has INTEGER
parameters, or sometimes arrays of integers.
1.5.4.3 Python
The Python interface to MPI uses classes and objects. Thus, a specification like:
MPI.Comm.Send(self, buf, int dest, int tag=0)
should be parsed as follows.
• First of all, you need the MPI class:
from mpi4py import MPI
• Next, you need a Comm object. Often you will use the predefined communicator
comm = MPI.COMM_WORLD
• The keyword self indicates that the actual routine Send is a method of the Comm object, soyou call:
Victor Eijkhout 17

1. Getting started with MPI
comm.Send( .... )
• Parameters that are listed by themselves, such as buf, as positional. Parameters that are listedwith a type, such as int dest are keyword parameters. Keyword parameters that have a valuespecified, such as int tag=0 are optional, with the default value indicated. Thus, the typicallcall for this routine is:
comm.Send(sendbuf,dest=other)
specifying the send buffer as positional parameter, the destination as keyword parameter, andusing the default value for the optional tag.
Some python routines are ‘class methods’, and their specification lacks the self keyword. For instance:
MPI.Request.Waitall(type cls, requests, statuses=None)
would be used as
MPI.Request.Waitall(requests)
1.6 Review
Review 1.1. What determines the parallelism of an MPI job?• The size of the cluster you run on.• The number of cores per cluster node.• The parameters of the MPI starter (mpiexec, ibrun,. . . )
Review 1.2. Which languages have an object-oriented interface to MPI?• C• C++• Fortran2008• Python
18 Parallel Computing – r428

Chapter 2
MPI topic: Functional parallelism
2.1 The SPMD model
MPI programs conform (mostly) to the Single Program Multiple Data (SPMD) model, where each proces-sor runs the same executable. This running executable we call a process .
When MPI was first written, 20 years ago, it was clear what a processor was: it was what was in a computeron someone’s desk, or in a rack. If this computer was part of a networked cluster, you called it a node . Soif you ran an MPI program, each node would have one MPI process; figure 2.1. You could of course run
Figure 2.1: Cluster structure as of the mid 1990s
more than one process, using the time slicing of the Operating System (OS), but that would give you noextra performance.
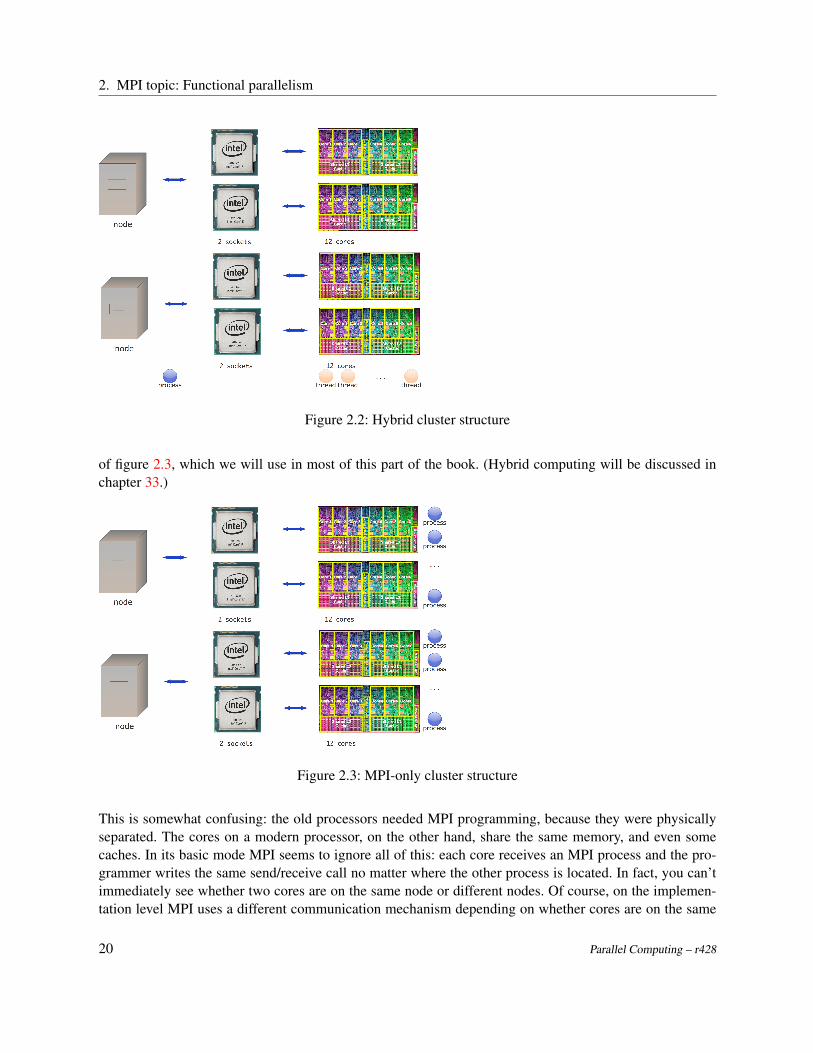
These days the situation is more complicated. You can still talk about a node in a cluster, but now a nodecan contain more than one processor chip (sometimes called a socket), and each processor chip probablyhas multiple cores . Figure 2.2 shows how you could explore this using a mix of MPI between the nodes,and a shared memory programming system on the nodes.
However, since each core can act like an independent processor, you can also have multiple MPI processesper node. To MPI, the cores look like the old completely separate processors. This is the ‘pure MPI’ model
19
2. MPI topic: Functional parallelism
Figure 2.2: Hybrid cluster structure
of figure 2.3, which we will use in most of this part of the book. (Hybrid computing will be discussed inchapter 33.)
Figure 2.3: MPI-only cluster structure
This is somewhat confusing: the old processors needed MPI programming, because they were physicallyseparated. The cores on a modern processor, on the other hand, share the same memory, and even somecaches. In its basic mode MPI seems to ignore all of this: each core receives an MPI process and the pro-grammer writes the same send/receive call no matter where the other process is located. In fact, you can’timmediately see whether two cores are on the same node or different nodes. Of course, on the implemen-tation level MPI uses a different communication mechanism depending on whether cores are on the same
20 Parallel Computing – r428
2.2. Starting and running MPI processes
socket or on different nodes, so you don’t have to worry about lack of efficiency.
Remark 1 In some rare cases you may want to run in an Multiple Program Multiple Data (MPMD) mode,rather than SPMD. This can be achieved either on the OS level, using options of the mpiexec mechanism,or you can use MPI’s built-in process management; chapter 7. Like I said, this concerns only rare cases.
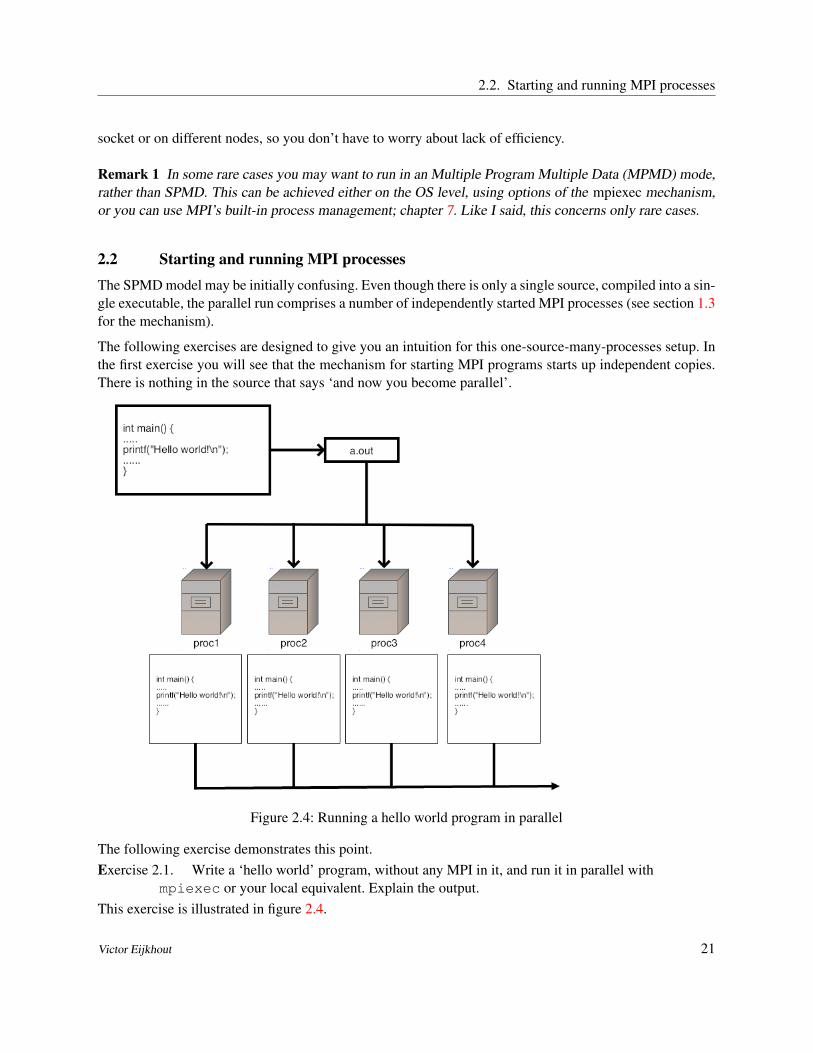
2.2 Starting and running MPI processesThe SPMD model may be initially confusing. Even though there is only a single source, compiled into a sin-gle executable, the parallel run comprises a number of independently started MPI processes (see section 1.3for the mechanism).
The following exercises are designed to give you an intuition for this one-source-many-processes setup. Inthe first exercise you will see that the mechanism for starting MPI programs starts up independent copies.There is nothing in the source that says ‘and now you become parallel’.
Figure 2.4: Running a hello world program in parallel
The following exercise demonstrates this point.Exercise 2.1. Write a ‘hello world’ program, without any MPI in it, and run it in parallel with
mpiexec or your local equivalent. Explain the output.This exercise is illustrated in figure 2.4.
Victor Eijkhout 21

2. MPI topic: Functional parallelism
2.2.1 Headers
If you use MPI commands in a program file, be sure to include the proper header file, mpi.h or mpif.h .
#include "mpi.h" // for C#include "mpif.h" ! for Fortran
For Fortran90 , many MPI installations also have an MPI module, so you can write
use mpi ! pre 3.0use mpi_f08 ! 3.0 standard
The internals of these files can be different between MPI installations, so you can not compile one fileagainst one mpi.h file and another file, even with the same compiler on the same machine, against adifferent MPI.
2.2.2 Initialization / finalization
To get a useful MPI program you need at least the calls MPI_Init and MPI_Finalize surrounding yourcode.
Python note. There are no initialize and finalize calls: the import statement per-forms the initialization.
Every MPI program has to start with MPI initialization:C:int MPI_Init(int *argc, char ***argv)
Fortran:MPI_Init(ierror)INTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
where argc and argv are the arguments of a C language main program:
int main(int argc,char **argv) {....return 0;
}
(It is allowed to pass NULL for these arguments.)
Note that the MPI_Init call is one of the few that differs between C and Fortran: the C routine takes thecommandline arguments, which Fortran lacks.
This may look a bit like declaring ‘this is the parallel part of a program’, but that’s not true: again, the wholecode is executed multiple times in parallel.
The regular way to conclude an MPI program is:
22 Parallel Computing – r428

2.2. Starting and running MPI processes
C:int MPI_Finalize(void)
Fortran:MPI_Finalize(ierror)INTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
Exercise 2.2. Add the commands MPI_Init and MPI_Finalize to your code. Put threedifferent print statements in your code: one before the init, one between init andfinalize, and one after the finalize. Again explain the output.
2.2.2.1 Aborting an MPI run
Apart from MPI_Finalize, which signals a successful conclusion of the MPI run, an abnormal end to a runcan be forced by MPI_Abort:
Synopsis:int MPI_Abort(MPI_Comm comm, int errorcode)
Input Parameterscomm : communicator of tasks to aborterrorcode : error code to return to invoking environment
Python:MPI.Comm.Abort(self, int errorcode=0)
How to read routine prototypes: 1.5.4.
This aborts execution on all processes associated with the communicator, but many implementations simplyabort all processes. The value parameter is returned to the environment.
2.2.2.2 Testing the initialized/finalized status
The commandline arguments argc and argv are only guaranteed to be passed to process zero, so the bestway to pass commandline information is by a broadcast (section 3.3.3).
There are a few commands, such as MPI_Get_processor_name, that are allowed before MPI_Init.
If MPI is used in a library, MPI can have already been initialized in a main program. For this reason, onecan test where MPI_Init has been called with
C:int MPI_Initialized(int *flag)
Fortran:MPI_Initialized(flag, ierror)LOGICAL, INTENT(OUT) :: flagINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Victor Eijkhout 23

2. MPI topic: Functional parallelism
How to read routine prototypes: 1.5.4.
You can test whether MPI_Finalize has been called with
C:int MPI_Finalized( int *flag )
Fortran:MPI_Finalized(flag, ierror)LOGICAL, INTENT(OUT) :: flagINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
2.2.2.3 Commandline arguments
The MPI_Init routines takes a reference to argc and argv for the following reason: the MPI_Init callsfilters out the arguments to mpirun or mpiexec , thereby lowering the value of argc and elimitating someof the argv arguments.
On the other hand, the commandline arguments that are meant for mpiexec wind up in the MPI_INFO_ENVobject as a set of key/value pairs; see section 12.3
2.2.2.4 Information about the run
Once MPI has been initialized, the MPI_INFO_ENV object contains a number of key/value pairs describingrun-specific information; see section 12.3.1.
2.3 Processor identification
Since all processes in an MPI job are instantiations of the same executable, you’d think that they all executethe exact same instructions, which would not be terribly useful. You will now learn how to distinguishprocesses from each other, so that together they can start doing useful work.
2.3.1 Processor name
In the following exercise you will print out the hostname of each MPI process as a first way of distinguishingbetween processes.
Exercise 2.3. Now use the command MPI_Get_processor_name in between the init andfinalize statement, and print out on what processor your process runs. Confirm thatyou are able to run a program that uses two different nodes.The character buffer needs to be allocated by you, it is not created by MPI, with sizeat least MPI_MAX_PROCESSOR_NAME.
24 Parallel Computing – r428

2.3. Processor identification
C:int MPI_Get_processor_name(char *name, int *resultlen)name : buffer char[MPI_MAX_PROCESSOR_NAME]
Fortran:MPI_Get_processor_name(name, resultlen, ierror)CHARACTER(LEN=MPI_MAX_PROCESSOR_NAME), INTENT(OUT) :: nameINTEGER, INTENT(OUT) :: resultlenINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Get_processor_name()
How to read routine prototypes: 1.5.4.
The character storage is provided by the user: the character array must be at least MPI_MAX_PROCESSOR_NAMEcharacters long. The actual length of the name is returned in the resultlen parameter.
2.3.2 Process and communicator properties: rank and size
First we need to introduce the concept of communicator , which is an abstract description of a group ofprocesses. For now you only need to know about the existence of the MPI_Comm data type, and that there isa pre-defined communicator MPI_COMM_WORLD which describes all the processes involved in your parallelrun. You will learn much more about communicators in chapter 6.
To distinguish between processes in a communicator, MPI provides two calls
1. MPI_Comm_size reports how many processes there are in all; and2. MPI_Comm_rank states what the number of the process is that calls this routine.
If every process executes the MPI_Comm_size call, they all get the same result, namely the total number ofprocesses in your run.
Semantics:MPI_COMM_SIZE(comm, size)IN comm: communicator (handle)OUT size: number of processes in the group of comm (integer)
C:int MPI_Comm_size(MPI_Comm comm, int *size)
Fortran:MPI_Comm_size(comm, size, ierror)TYPE(MPI_Comm), INTENT(IN) :: commINTEGER, INTENT(OUT) :: sizeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Comm.Get_size(self)
Victor Eijkhout 25

2. MPI topic: Functional parallelism
How to read routine prototypes: 1.5.4.
On the other hand, if every process executes MPI_Comm_rank, they all get a different result, namely their ownunique number, an integer in the range from zero to the the number of processes minus 1. See figure 2.5.
Semantics:MPI_COMM_RANK(comm, rank)IN comm: communicator (handle)OUT rank: rank of the calling process in group of comm (integer)
C:int MPI_Comm_rank(MPI_Comm comm, int *rank)
Fortran:MPI_Comm_rank(comm, rank, ierror)TYPE(MPI_Comm), INTENT(IN) :: commINTEGER, INTENT(OUT) :: rankINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Comm.Get_rank(self)
How to read routine prototypes: 1.5.4.
In other words, each process can find out ‘I am process 5 out of a total of 20’.
Exercise 2.4. Write a program where each process prints out a message reporting its number,and how many processes there are:
Hello from process 2 out of 5!
Write a second version of this program, where each process opens a unique file andwrites to it. On some clusters this may not be advisable if you have large numbers ofprocessors, since it can overload the file system.
Exercise 2.5. Write a program where only the process with number zero reports on howmany processes there are in total.
2.4 Functional parallelism
Being able to tell processes apart is already enough for some applications. Based on its rank, a processorcan find its section of a search space. For instance, in Monte Carlo codes a large number of random samplesis generated and some computation performed on each. (This particular example requires each MPI processto run an independent random number generator, which is not entirely trivial.)
Exercise 2.6. Is the number N = 2, 000, 000, 111 prime? Let each process test a range ofintegers, and print out any factor they find. You don’t have to test all integers < N :any factor is at most
√N ≈ 45, 200.
(Hint: i%0 probably gives a runtime error.)
26 Parallel Computing – r428

2.4. Functional parallelism
Figure 2.5: Running a hello world program in parallel
As another example, in Boolean satisfiability problems a number of points in a search space needs to beevaluated. Knowing a process’s rank is enough to let it generate its own portion of the search space. Thecomputation of the Mandelbrot set can also be considered as a case of functional parallelism. However, theimage that is constructed is data that needs to be kept on one processor, which breaks the symmetry of theparallel run.
Of course, at the end of a functionally parallel run you need to summarize the results, for instance printingout some total. The mechanisms for that you will learn next.
Victor Eijkhout 27

Chapter 3
MPI topic: Collectives
3.1 Working with global information
If all processes have individual data, for instance the result of a local computation, you may want to bringthat information together, for instance to find the maximal computed value or the sum of all values. Con-versely, sometimes one processor has information that needs to be shared with all. For this sort of operation,MPI has collectives .
There are various cases, illustrated in figure 3.1, which you can (sort of) motivated by considering some
Figure 3.1: The four most common collectives
classroom activities:
28

3.1. Working with global information
• The teacher tells the class when the exam will be. This is a broadcast : the same item of informa-tion goes to everyone.• After the exam, the teacher performs a gather operation to collect the invidivual exams.• On the other hand, when the teacher computes the average grade, each student has an individual
number, but these are now combined to compute a single number. This is a reduction .• Now the teacher has a list of grades and gives each student their grade. This is a scatter operation,
where one process has multiple data items, and gives a different one to all the other processes.This story is a little different from what happens with MPI processes, because these are more symmetric;the process doing the reducing and broadcasting is no different from the others. Any process can functionas the root process in such a collective.Exercise 3.1. How would you realize the following scenarios with MPI collectives?
• Let each process compute a random number. You want to print the maximum ofthese numbers to your screen.• Each process computes a random number again. Now you want to scale these
numbers by their maximum.• Let each process compute a random number. You want to print on what
processor the maximum value is computed.
3.1.1 Practical use of collectives
Collectives are quite common in scientific applications. For instance, if one process reads data from discor the commandline, it can use a broadcast or a gather to get the information to other processes. Likewise,at the end of a program run, a gather or reduction can be used to collect summary information about theprogram run.
However, a more common scenario is that the result of a collective is needed on all processes.
Consider the computation of the standard deviation:
σ =
√√√√ 1
N − 1
N∑i
(xi − µ)2 where µ =
∑Ni xiN
and assume that every process stores just one xi value.1. The calculation of the average µ is a reduction, since all the distributed values need to be added.2. Now every process needs to compute xi − µ for its value xi, so µ is needed everywhere. You
can compute this by doing a reduction followed by a broadcast, but it is better to use a so-calledallreduce operation, which does the reduction and leaves the result on all processors.
3. The calculation of∑
i(xi − µ) is another sum of distributed data, so we need another reductionoperation. Depending on whether each process needs to know σ, we can again use an allreduce.
For instance, if x, y are distributed vector objects, and you want to compute
y − (xty)x
which is part of the Gramm-Schmidt algorithm; see HPSC-12.2. Now you need the inner product value onall processors. You could do this by writing a reduction followed by a broadcast:
Victor Eijkhout 29

3. MPI topic: Collectives
// compute local valuelocalvalue = innerproduct( x[ localpart], y[ localpart ] );// compute inner product on the rootReduce( localvalue, reducedvalue, root );// send root value to all other from the rootBroadcast( reducedvalue, root );
or combine the last two steps in an allreduce,
Surprisingly, an allreduce operation takes as long as a rooted reduction (see HPSC-6.1 for details), andtherefore half the time of a reduction followed by a broadcast.
3.1.2 Synchronization
Collectives are operations that involve all processes in a communicator. A collective is a single call, and itblocks on all processors. That does not mean that all processors exit the call at the same time: because ofimplementational details and network latency they need not be synchronized in their execution. However,semantically we can say that a process can not finish a collective until every other process has at leaststarted the collective.
In addition to these collective operations, there are operations that are said to be ‘collective on their com-municator’, but which do not involve data movement. Collective then means that all processors must callthis routine; not to do so is an error that will manifest itself in ‘hanging’ code. One such example isMPI_Win_fence.
3.1.3 Collectives in MPI
We will now explain the MPI collectives in the following order.
Allreduce We use the allreduce as an introduction to the concepts behind collectives; section 3.2.1. Asexplained above, this routines servers many practical scenarios.
Broadcast and reduce We then introduce the concept of a root in the reduce (section 3.3.1) and broadcast(section 3.3.3) collectives.
Gather and scatter The gather/scatter collectives deal with more than a single data item.
There are more collectives or variants on the above.
• If you want to gather or scatter information, but the contribution of each processor is of a differentsize, there are ‘variable’ collectives; they have a v in the name (section 3.8).• Sometimes you want a reduction with partial results, where each processor computes the sum (or
other operation) on the values of lower-numbered processors. For this, you use a scan collective(section 3.9).• If every processor needs to broadcast to every other, you use an all-to-all operation (section 3.5).• A barrier is an operation that makes all processes wait until every process has reached the barrier
(section 3.7).
Finally, there are some advanced topics in collectives.
• Non-blocking collectives; section 3.11.• User-defined reduction operators; section 3.2.4.
30 Parallel Computing – r428

3.2. Reduction
3.2 Reduction
3.2.1 Reduce to all
Above we saw a couple of scenarios where a quantity is reduced, with all proceses getting the result. TheMPI call for this is:
C:int MPI_Allreduce(const void* sendbuf,void* recvbuf, int count, MPI_Datatype datatype,MPI_Op op, MPI_Comm comm)
Semantics:IN sendbuf: starting address of send buffer (choice)OUT recvbuf: starting address of receive buffer (choice)IN count: number of elements in send buffer (non-negative integer)IN datatype: data type of elements of send buffer (handle)IN op: operation (handle)IN comm: communicator (handle)
Fortran:MPI_Allreduce(sendbuf, recvbuf, count, datatype, op, comm, ierror)TYPE(*), DIMENSION(..), INTENT(IN) :: sendbufTYPE(*), DIMENSION(..) :: recvbufINTEGER, INTENT(IN) :: countTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Op), INTENT(IN) :: opTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python native:recvobj = MPI.Comm.allreduce(self, sendobj, op=SUM)Python numpy:MPI.Comm.Allreduce(self, sendbuf, recvbuf, Op op=SUM)
How to read routine prototypes: 1.5.4.
Example: we give each process a random number, and sum these numbers together. The result should beapproximately 1/2 times the number of processes.
// allreduce.cfloat myrandom,sumrandom;myrandom = (float) rand()/(float)RAND_MAX;// add the random variables togetherMPI_Allreduce(&myrandom,&sumrandom,
1,MPI_FLOAT,MPI_SUM,comm);// the result should be approx nprocs/2:if (procno==nprocs-1)printf("Result %6.9f compared to .5\n",sumrandom/nprocs);
Victor Eijkhout 31

3. MPI topic: Collectives
For Python we illustrate both the native and the numpy variant. In the numpy variant we create an array forthe receive buffer, even though only one element is used.
## allreduce.pyrandom_number = random.randint(1,nprocs*nprocs)print "[%d] random=%d" % (procid,random_number)
max_random = comm.allreduce(random_number,op=MPI.MAX)if procid==0:
print "Python native:\n max=%d" % max_random
myrandom = np.empty(1,dtype=np.int)myrandom[0] = random_numberallrandom = np.empty(nprocs,dtype=np.int)
comm.Allreduce(myrandom,allrandom[:1],op=MPI.MAX)
Exercise 3.2. Let each process compute a random number, and compute the sum of thesenumbers using the MPI_Allreduce routine.(The operator is MPI_SUM for C/Fortran, or MPI.SUM for Python.)Each process then scales its value by this sum. Compute the sum of the scalednumbers and check that it is 1.
3.2.2 Reduction of distributed data
One of the more common applications of the reduction operation is the inner product computation. Typi-cally, you have two vectors x, y that have the same distribution, that is, where all processes store equal partsof x and y. The computation is then
local_inprod = 0;for (i=0; i<localsize; i++)local_inprod += x[i]*y[i];
MPI_Allreduce( &local_inprod, &global_inprod, 1,MPI_DOUBLE ... )
3.2.3 Reduce in place
By default MPI will not overwrite the original data with the reduction result, but you can tell it to do sousing the MPI_IN_PLACE specifier:
// allreduceinplace.cint nrandoms = 500000;float *myrandoms;myrandoms = (float*) malloc(nrandoms*sizeof(float));for (int irand=0; irand<nrandoms; irand++)myrandoms[irand] = (float) rand()/(float)RAND_MAX;
// add all the random variables togetherMPI_Allreduce(MPI_IN_PLACE,myrandoms,
nrandoms,MPI_FLOAT,MPI_SUM,comm);// the result should be approx nprocs/2:if (procno==nprocs-1) {float sum=0.;
32 Parallel Computing – r428

3.3. Rooted collectives: broadcast, reduce
for (int i=0; i<nrandoms; i++) sum += myrandoms[i];sum /= nrandoms*nprocs;printf("Result %6.9f compared to .5\n",sum);
}
This has the advantage of saving half the memory.
3.2.4 Reduction operations
Several MPI_Op values are pre-defined. For the list, see section 3.10.1.
For use in reductions and scans it is possible to define your own operator.
MPI_Op_create( MPI_User_function *func, int commute, MPI_Op *op);
For more details, see section 3.10.2.
3.3 Rooted collectives: broadcast, reduce
In some scenarios there is a certain process that has a privileged status.
• One process can generate or read in the initial data for a program run. This then needs to becommunicated to all other processes.• At the end of a program run, often one process needs to output some summary information.
This process is called the root process, and we will now consider routines that have a root.
3.3.1 Reduce to a root
In the broadcast operation a single data item was communicated to all processes. Reduction operations gothe other way: each process has a data item, and these are all brought together into a single item.
Here are the essential elements of a reduction operation:
MPI_Reduce( senddata, recvdata..., operator,root, comm );
• There is the original data, and the data resulting from the reduction. It is a design decision ofMPI that it will not by default overwrite the original data. The send data and receive data are ofthe same size and type: if every processor has one real number, the reduced result is again onereal number.• There is a reduction operator. Popular choices are MPI_SUM, MPI_PROD and MPI_MAX, but com-
plicated operators such as finding the location of the maximum value exist. You can also defineyour own operators; section 3.2.4.• There is a root process that receives the result of the reduction. Since the non-root processes do
not receive the reduced data, they can actually leave the receive buffer undefined.
Victor Eijkhout 33

3. MPI topic: Collectives
// reduce.cfloat myrandom = (float) rand()/(float)RAND_MAX,result;
int target_proc = nprocs-1;// add all the random variables togetherMPI_Reduce(&myrandom,&result,1,MPI_FLOAT,MPI_SUM,
target_proc,comm);// the result should be approx nprocs/2:if (procno==target_proc)printf("Result %6.3f compared to nprocs/2=%5.2f\n",
result,nprocs/2.);
C:int MPI_Reduce(
const void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype,MPI_Op op, int root, MPI_Comm comm)
Fortran:MPI_Reduce(sendbuf, recvbuf, count, datatype, op, root, comm, ierror)TYPE(*), DIMENSION(..), INTENT(IN) :: sendbufTYPE(*), DIMENSION(..) :: recvbufINTEGER, INTENT(IN) :: count, rootTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Op), INTENT(IN) :: opTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:native:comm.reduce(self, sendobj=None, recvobj=None, op=SUM, int root=0)numpy:comm.Reduce(self, sendbuf, recvbuf, Op op=SUM, int root=0)
How to read routine prototypes: 1.5.4.
Exercise 3.3. Write a program where each process computes a random number, and process 0finds and prints the maximum generated value. Let each process print its value, justto check the correctness of your program.
Collective operations can also take an array argument, instead of just a scalar. In that case, the operation isapplied pointwise to each location in the array.
Exercise 3.4. Create on each process an array of length 2 integers, and put the values 1, 2 in iton each process. Do a sum reduction on that array. Can you predict what the resultshould be? Code it. Was your prediction right?
3.3.2 Reduce in place
Instead of using a send and a receive buffer in the reduction, it is possible to avoid the send buffer by puttingthe send data in the receive buffer. We see this mechanism in section 3.2.3 for the allreduce operation.
34 Parallel Computing – r428

3.3. Rooted collectives: broadcast, reduce
For the rooted call MPI_Reduce, it is similarly possible to use the value in the receive buffer on the root.However, on all other processes, data is placed in the send buffer and the receive buffer is null or ignoredas before.
This example sets the buffer values through some pointer cleverness in order to have the same reduce callon all processes.
// reduceinplace.cfloat mynumber,result,*sendbuf,*recvbuf;mynumber = (float) procno;int target_proc = nprocs-1;// add all the random variables togetherif (procno==target_proc) {sendbuf = (float*)MPI_IN_PLACE; recvbuf = &result;result = mynumber;
} else {sendbuf = &mynumber; recvbuf = NULL;
}MPI_Reduce(sendbuf,recvbuf,1,MPI_FLOAT,MPI_SUM,
target_proc,comm);// the result should be nprocs*(nprocs-1)/2:if (procno==target_proc)printf("Result %6.3f compared to n(n-1)/2=%5.2f\n",
result,nprocs*(nprocs-1)/2.);
In Fortran the code is less elegant because you can not do these address calculations:
// reduceinplace.F90call random_number(mynumber)target_proc = ntids-1;! add all the random variables togetherif (mytid.eq.target_proc) then
result = mytidcall MPI_Reduce(MPI_IN_PLACE,result,1,MPI_REAL,MPI_SUM,&
target_proc,comm,err)else
mynumber = mytidcall MPI_Reduce(mynumber,result,1,MPI_REAL,MPI_SUM,&
target_proc,comm,err)end if! the result should be ntids*(ntids-1)/2:if (mytid.eq.target_proc) thenwrite(*,’("Result ",f5.2," compared to n(n-1)/2=",f5.2)’) &
result,ntids*(ntids-1)/2.end if
3.3.3 Broadcast
The broadcast call has the following structure:
MPI_Bcast( data..., root , comm);
Victor Eijkhout 35

3. MPI topic: Collectives
The root is the process that is sending its data. Typically, it will be the root of a broadcast tree. The commargument is a communicator: for now you can use MPI_COMM_WORLD. Unlike with send/receive there is nomessage tag, because collectives are blocking, so you can have only one collective active at a time.
The data in a broadcast (or any other MPI operation for that matter) is specified as• A buffer. In C this is the address in memory of the data. This means that you broadcast a single
scalar as MPI_Bcast( &value, ... ), but an array as MPI_Bcast( array, ... ).• The number of items and their datatype. The allowable datatypes are such things as MPI_INT and
MPI_FLOAT for C, and MPI_INTEGER and MPI_REAL for Fortran, or more complicated types. Seesection 5 for details.Python note. In python it is both possible to send objects, and to send more C-likebuffers. The two possibilities correspond (see section 1.5.3) to different routine names;the buffers have to be created as numpy objects.
Example: in general we can not assume that all processes get the commandline arguments, so we broadcastthem from process 0.
// init.cif (procno==0) {if ( argc==1 || // the program is called without parameter
( argc>1 && !strcmp(argv[1],"-h") ) // user asked for help) {
printf("\nUsage: init [0-9]+\n");MPI_Abort(comm,1);
}input_argument = atoi(argv[1]);
}MPI_Bcast(&input_argument,1,MPI_INT,0,comm);
C:int MPI_Bcast(
void* buffer, int count, MPI_Datatype datatype,int root, MPI_Comm comm)
Fortran:MPI_Bcast(buffer, count, datatype, root, comm, ierror)TYPE(*), DIMENSION(..) :: bufferINTEGER, INTENT(IN) :: count, rootTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python native:rbuf = MPI.Comm.bcast(self, obj=None, int root=0)Python numpy:MPI.Comm.Bcast(self, buf, int root=0)
How to read routine prototypes: 1.5.4.
Exercise 3.5. If you give a commandline argument to a program, that argument is available asa character string as part of the argv,argc pair that you typically use as the
36 Parallel Computing – r428

3.3. Rooted collectives: broadcast, reduce
arguments to your main program. You can use the function atoi to convert such astring to integer.Write a program where process 0 looks for an integer on the commandline, andbroadcasts it to the other processes. Initialize the buffer on all processes, and let allprocesses print out the broadcast number, just to check that you solved the problemcorrectly.
In python we illustrate the native and numpy variants. In the native variant the result is given as a functionreturn; in the numpy variant the send buffer is reused.
## bcast.py# first nativeif procid==root:
buffer = [ 5.0 ] * dsizebuffer = comm.bcast(obj=buffer,root=root)if not reduce( lambda x,y:x and y,
[ buffer[i]==5.0 for i in range(len(buffer)) ] ):print "Something wrong on proc %d: native buffer <<%s>>" \
% (procid,str(buffer))
# then with NumPybuffer = np.arange(dsize, dtype=np.float64)if procid==root:
for i in range(dsize):buffer[i] = 5.0
comm.Bcast( buffer,root=root )if not all( buffer==5.0 ):
print "Something wrong on proc %d: numpy buffer <<%s>>" \% (procid,str(buffer))
For the following exercise, study figure 3.2.
Exercise 3.6. The Gauss-Jordan algorithm for solving a linear system with a matrix A (orcomputing its inverse) runs as follows:for pivot k = 1, . . . , n
let the vector of scalings `(k)i = Aik/Akk
for row r 6= kfor column c = 1, . . . , n
Arc ← Arc − `(k)r Arc
where we ignore the update of the righthand side, or the formation of the inverse.Let a matrix be distributed with each process storing one column. Implement theGauss-Jordan algorithm as a series of broadcasts: in iteration k process k computesand broadcasts the scaling vector {`(k)i }i. Replicate the right-hand side on allprocessors.
Exercise 3.7. Add partial pivoting to your implementation of Gauss-Jordan elimination.Change your implementation to let each processor store multiple columns, but still doone broadcast per column. Is there a way to have only one broadcast per processor?
Victor Eijkhout 37

3. MPI topic: Collectives
Initial:
matrix sol rhs action2 2 13 1 17
4 5 32 1 41
-2 -3 -16 1 -21
Step 1:
matrix sol rhs action2 2 13 1 17 take this row
4 5 32 1 41
-2 -3 -16 1 -21
Step 2:
matrix sol rhs action2 2 13 1 17 take this row↓ ↓ ↓4 5 32 1 41 minus×2
-2 -3 -16 1 -21
Step 3:
matrix sol rhs action2 2 13 1 17 take this row
0 1 6 1 7
-2 -3 -16 1 -21
Step 4:
matrix sol rhs action2 2 13 1 17 take this row� � �0 1 6 1 7
-2 -3 -16 1 -21 plus×1
Step 5:
matrix sol rhs action2 2 13 1 17 take this row
0 1 6 1 7
0 -1 -3 1 -4
Step 6:
matrix sol rhs action2 2 13 1 17 first column done
0 1 6 1 7
0 -1 -3 1 -4
Step 7:
matrix sol rhs action2 2 13 1 17
0 1 6 1 7 take this row
0 -1 -3 1 -4
Step 8:
matrix sol rhs action2 2 13 1 17 minus×2↑ ↑ ↑0 1 6 1 7 take this row
0 -1 -3 1 -4
Step 9:
matrix sol rhs action2 0 1 1 3
0 1 6 1 7 take this row
0 -1 -3 1 -4
Step 10:
matrix sol rhs action2 0 1 1 3
0 1 6 1 7 take this row↓ ↓ ↓0 -1 -3 1 -4 plus×1
Step 11:
matrix sol rhs action2 0 1 1 3
0 1 6 1 7 take this row
0 0 3 1 3
Step 12:
matrix sol rhs action2 0 1 1 3
0 1 6 1 7 second column done
0 0 3 1 3
Step 13:
matrix sol rhs action2 0 1 1 3
0 1 6 1 7
0 0 3 1 3 take this row
Step 14:
matrix sol rhs action2 0 1 1 3 minus×1/3
0 1 6 1 7� � �0 0 3 1 3 take this row
Step 15:
matrix sol rhs action2 0 0 1 2
0 1 6 1 7
0 0 3 1 3 take this row
Step 16:
matrix sol rhs action2 0 0 1 2
0 1 6 1 7 minus×2↑ ↑ ↑0 0 3 1 3 take this row
Step 17:
matrix sol rhs action2 0 0 1 2
0 1 0 1 1
0 0 3 1 3 take this row
Step 18:
matrix sol rhs action2 0 0 1 2
0 1 0 1 1
0 0 3 1 3 third column done
Finished:
matrix sol rhs action2 0 0 1 2
0 1 0 1 1
0 0 3 1 3
Figure 3.2: Gauss-Jordan elimination example
38 Parallel Computing – r428

3.4. Rooted collectives: gather and scatter
3.4 Rooted collectives: gather and scatter
Figure 3.3: Gather collects all data onto a root
In the MPI_Scatter operation, the root spreads information to all other processes. The difference witha broadcast is that it involves individual information from/to every process. Thus, the gather operationtypically has an array of items, one coming from each sending process, and scatter has an array, with an
Figure 3.4: A scatter operation
individual item for each receiving process; see figure 3.4.
These gather and scatter collectives have a different parameter list from the broadcast/reduce. The broad-cast/reduce involves the same amount of data on each process, so it was enough to have a buffer, datatype,and size. In the gather/scatter calls you have
• a large buffer on the root, with a datatype and size specification, and• a smaller buffer on each process, with its own type and size specification.
Of course, since we’re in SPMD mode, even non-root processes have the argument for the send buffer, butthey ignore it. For instance:
int MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype,void* recvbuf, int recvcount, MPI_Datatype recvtype,int root, MPI_Comm comm)
Victor Eijkhout 39

3. MPI topic: Collectives
The sendcount is not, as you might expect, the total length of the sendbuffer; instead, it is the amount ofdata sent to each process.
Exercise 3.8. Let each process compute a random number. You want to print the maximumvalue and on what processor it is computed. What collective(s) do you use? Write ashort program.
In the gather and scatter calls, each processor has n elements of individual data. There is also a root pro-cessor that has an array of length np, where p is the number of processors. The gather call collects all thisdata from the processors to the root; the scatter call assumes that the information is initially on the root andit is spread to the individual processors.
The prototype for MPI_Gather has two ‘count’ parameters, one for the length of the individual send buffers,and one for the receive buffer. However, confusingly, the second parameter (which is only relevant on theroot) does not indicate the total amount of information coming in, but rather the size of each contribution.Thus, the two count parameters will usually be the same (at least on the root); they can differ if you usedifferent MPI_Datatype values for the sending and receiving processors.
C:int MPI_Gather(
const void* sendbuf, int sendcount, MPI_Datatype sendtype,void* recvbuf, int recvcount, MPI_Datatype recvtype,int root, MPI_Comm comm)
Semantics:IN sendbuf: starting address of send buffer (choice)IN sendcount: number of elements in send buffer (non-negative integer)IN sendtype: data type of send buffer elements (handle)OUT recvbuf: address of receive buffer (choice, significant only at root)IN recvcount: number of elements for any single receive (non-negative integer, significant only at root)IN recvtype: data type of recv buffer elements (significant only at root) (handle)IN root: rank of receiving process (integer)IN comm: communicator (handle)
Fortran:MPI_Gather
(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype,root, comm, ierror)
TYPE(*), DIMENSION(..), INTENT(IN) :: sendbufTYPE(*), DIMENSION(..) :: recvbufINTEGER, INTENT(IN) :: sendcount, recvcount, rootTYPE(MPI_Datatype), INTENT(IN) :: sendtype, recvtypeTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Comm.Gather
(self, sendbuf, recvbuf, int root=0)
How to read routine prototypes: 1.5.4.
40 Parallel Computing – r428

3.4. Rooted collectives: gather and scatter
Here is a small example:// gather.c// we assume that each process has a value "localsize"// the root process collectes these values
if (procno==root)localsizes = (int*) malloc( (nprocs+1)*sizeof(int) );
// everyone contributes their infoMPI_Gather(&localsize,1,MPI_INT,
localsizes,1,MPI_INT,root,comm);
This will also be the basis of a more elaborate example in section 3.8.
The MPI_IN_PLACE option can be used for the send buffer on the root; the data for the root is then assumedto be already in the correct location in the receive buffer.
The MPI_Scatter operation is in some sense the inverse of the gather: the root process has an array oflength np where p is the number of processors and n the number of elements each processor will receive.
int MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype,void* recvbuf, int recvcount, MPI_Datatype recvtype,int root, MPI_Comm comm)
3.4.1 Example
In some applications, each process computes a row or column of a matrix, but for some calculation (suchas the determinant) it is more efficient to have the whole matrix on one process. You should of course onlydo this if this matrix is essentially smaller than the full problem, such as an interface system or the lastcoarsening level in multigrid.
Figure 3.5: Gather a distributed matrix onto one process
Figure 3.5 pictures this. Note that conceptually we are gathering a two-dimensional object, but the bufferis of course one-dimensional. You will later see how this can be done more elegantly with the ‘subarray’datatype; section 5.3.3.2.
Victor Eijkhout 41

3. MPI topic: Collectives
3.4.2 Allgather
Figure 3.6: All gather collects all data onto every process
The MPI_Allgather routine does the same gather onto every process: each process winds up with thetotality of all data; figure 3.6.
C:int MPI_Allgather(const void *sendbuf, int sendcount,
MPI_Datatype sendtype, void *recvbuf, int recvcount,MPI_Datatype recvtype, MPI_Comm comm)
int MPI_Iallgather(const void *sendbuf, int sendcount,MPI_Datatype sendtype, void *recvbuf, int recvcount,MPI_Datatype recvtype, MPI_Comm comm, MPI_Request *request)
Fortran:MPI_ALLGATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT,
RECVTYPE, COMM, IERROR)<type> SENDBUF (*), RECVBUF (*)INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, COMM,INTEGER IERROR
MPI_IALLGATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT,RECVTYPE, COMM, REQUEST, IERROR)
<type> SENDBUF(*), RECVBUF (*)INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, COMMINTEGER REQUEST, IERROR
C++ Syntax
Parameters:sendbuf : Starting address of send buffer (choice).sendcount: Number of elements in send buffer (integer).sendtype: Datatype of send buffer elements (handle).recvbuf: Starting address of recv buffer (choice).recvcount: Number of elements received from any process (integer).recvtype: Datatype of receive buffer elements (handle).comm; Communicator (handle).
recvbuf: Address of receive buffer (choice).
42 Parallel Computing – r428

3.5. All-to-all
request: Request (handle, non-blocking only).
How to read routine prototypes: 1.5.4.
This routine can be used in the simplest implementation of the dense matrix-vector product to give eachprocessor the full input; see HPSC-6.2.2.
Some cases look like an all-gather but can be implemented more efficiently. Suppose you have two dis-tributed vectors, and you want to create a new vector that contains those elements of the one that do notappear in the other. You could implement this by gathering the second vector on each processor, but thismay be prohibitive in memory usage.
Exercise 3.9. Can you think of another algorithm for taking the set difference of twodistributed vectors. Hint: look up ‘bucket-brigade algorithm’ in [4]. What is the timeand space complexity of this algorithm? Can you think of other advantages beside areduction in workspace?
3.5 All-to-all
The all-to-all operation can be seen as a collection of simultaneous broadcasts or simultaneous gathers.The parameter specification is much like an allgather, with a separate send and receive buffer, and no rootspecified. As with the gather call, the receive count corresponds to an individual receive, not the totalamount.
Unlike the gather call, the send buffer now obeys the same principle: with a send count of 1, the buffer hasa length of the number of processes.
int MPI_Alltoallv(void *sendbuf, int sendcnt, MPI_Datatype sendtype,void *recvbuf, int recvcnt, MPI_Datatype recvtype,MPI_Comm comm)
How to read routine prototypes: 1.5.4.
3.5.1 All-to-all as data transpose
The all-to-all operation can be considered as a data transpose. For instance, assume that each process knowshow much data to send to every other process. If you draw a connectivity matrix of size P × P , denotingwho-sends-to-who, then the send information can be put in rows:
∀i : C[i, j] > 0 if process i sends to process j.
Conversely, the columns then denote the receive information:
∀j : C[i, j] > 0 if process j receives from process i.
Victor Eijkhout 43

3. MPI topic: Collectives
Figure 3.7: All-to-all transposes data
Exercise 3.10. In the initial stage of radix sorting , each process considers how manyelements to send to every other process. Use MPI_Alltoall to derive from this howmany elements they will receive from every other process.
On a larger scale, the typical application for the all-to-all operation is in the Fast Fourier Transform (FFT)algorithm, where it can take tens of percents of the running time.
3.5.2 All-to-all-v
Exercise 3.11. The actual data shuffle of a radix sort can be done with MPI_Alltoallv.Finish the code of exercise 3.10.
3.6 Reduce-scatter
There are several MPI collectives that are functionally equivalent to a combination of others. You havealready seen MPI_Allreduce which is equivalent to a reduction followed by a broadcast. Often such com-binations can be more efficient than using the individual calls; see HPSC-6.1.
Here is another example: MPI_Reduce_scatter is equivalent to a reduction on an array of data (meaning apointwise reduction on each array location) followed by a scatter of this array to the individual processes.
We can look at reduce-scatter as a limited form of the all-to-all data transposition discussed above (sec-tion 3.5.1). Suppose that the matrix C contains only 0/1, indicating whether or not a messages is send,rather than the actual amounts. If a receiving process only needs to know how many messages to receive,rather than where they come from, it is enough to know the column sum, rather than the full column (seefigure 3.8).
One important example of this command is the sparse matrix-vector product ; see HPSC-6.5.1 for back-ground information. Each process contains one or more matrix rows, so by looking at indices the process
44 Parallel Computing – r428

3.6. Reduce-scatter
Figure 3.8: Reduce scatter
can decide what other processes it needs data from. The problem is for a process to find out what otherprocesses it needs to send data to.
Using MPI_Reduce_scatter the process goes as follows:
• Each process creates an array of ones and zeros, describing who it needs data from.• The reduce part of the reduce-scatter yields an array of requester counts; after the scatter each
process knows how many processes request data from it.• Next, the sender processes need to find out what elements are requested from it. For this, each
process sends out arrays of indices.• The big trick is that each process now knows how many of these requests will be coming in, so
it can post precisely that many MPI_Irecv calls, with a source of MPI_ANY_SOURCE.
The MPI_Reduce_scatter command is equivalent to a reduction on an array of data, followed by a scatterof that data to the individual processes.
To be precise, there is an array recvcounts where recvcounts[i] gives the number of elements thatultimate wind up on process i. The result is equivalent to doing a reduction with a length equal to the sum ofthe recvcounts[i] values, followed by a scatter where process i receives recvcounts[i] values.(Since the amount of data to be scattered depends on the process, this is in fact equivalent to MPI_Scattervrather than a regular scatter.)
Semantics:MPI_REDUCE_SCATTER
( sendbuf, recvbuf, recvcounts, datatype, op, comm)MPI_Reduce_scatter_block
( sendbuf, recvbuf, recvcount, datatype, op, comm)
Input parameters:sendbuf: starting address of send buffer (choice)recvcount: element count per block (non-negative integer)recvcounts: non-negative integer array (of length group size)
specifying the number of elements of the result distributed to eachprocess.
Victor Eijkhout 45

3. MPI topic: Collectives
datatype: data type of elements of send and receive buffers (handle)op: operation (handle)comm: communicator (handle)
Output parameters:recvbuf: starting address of receive buffer (choice)
C:int MPI_Reduce_scatter
(const void* sendbuf, void* recvbuf, const int recvcounts[],MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
F:MPI_Reduce_scatter(sendbuf, recvbuf, recvcounts, datatype, op, comm,ierror)TYPE(*), DIMENSION(..), INTENT(IN) :: sendbufTYPE(*), DIMENSION(..) :: recvbufINTEGER, INTENT(IN) :: recvcounts(*)TYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Op), INTENT(IN) :: opTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Py:comm.Reduce_scatter(sendbuf, recvbuf, recvcounts=None, Op op=SUM)
How to read routine prototypes: 1.5.4.
For instance, if all recvcounts[i] values are 1, the sendbuffer has one element for each process, andthe receive buffer has length 1.
3.6.1 Examples
An important application of this is establishing an irregular communication pattern. Assume that each pro-cess knows which other processes it wants to communicate with; the problem is to let the other processesknow about this. The solution is to use MPI_Reduce_scatter to find out how many processes want to com-municate with you, and then wait for precisely that many messages with a source value of MPI_ANY_SOURCE.
// reducescatter.c// record what processes you will communicate withint *recv_requests;// find how many procs want to communicate with youMPI_Reduce_scatter(recv_requests,&nsend_requests,counts,MPI_INT,MPI_SUM,comm);
// send a msg to the selected processesfor (int i=0; i<nprocs; i++)if (recv_requests[i]>0)
MPI_Isend(&msg,1,MPI_INT, /*to:*/ i,0,comm,
46 Parallel Computing – r428

3.7. Barrier
mpi_requests+irequest++);// do as many receives as you know are coming infor (int i=0; i<nsend_requests; i++)MPI_Irecv(&msg,1,MPI_INT,MPI_ANY_SOURCE,MPI_ANY_TAG,comm,
mpi_requests+irequest++);MPI_Waitall(irequest,mpi_requests,MPI_STATUSES_IGNORE);
Use of MPI_Reduce_scatter to implement the two-dimensional matrix-vector product. Set up separate rowand column communicators with MPI_Comm_split, use MPI_Reduce_scatter to combine local products.
MPI_Allgather(&my_x,1,MPI_DOUBLE,local_x,1,MPI_DOUBLE,environ.col_comm);
// bli_dgemv( BLIS_NO_TRANSPOSE,// BLIS_NO_CONJUGATE,// size_y, size_x,// &one,// local_matrix, 1, size_y,// local_x, 1,// &zero,// local_y, 1 );// blas_dgemv(CblasColMajor,CblasNoTrans,// size_y,size_x,1.e0,// local_matrix,size_y,// local_x,1,0.e0,local_y,1);MPI_Reduce_scatter(local_y,&my_y,&ione,MPI_DOUBLE,
MPI_SUM,environ.row_comm);
3.7 BarrierA barrier is a routine that blocks all processes until they have all reached the barrier call. Thus it achievestime synchronization of the processes.
C:int MPI_Barrier( MPI_Comm comm )
Fortran2008:MPI_BARRIER(COMM, IERROR)Type(MPI_Comm),intent(int) :: COMMINTEGER,intent(out) :: IERROR
Fortran 95:MPI_BARRIER(COMM, IERROR)INTEGER :: COMM, IERROR
Input parameter:comm : Communicator (handle)
Output parameter:Ierror : Error status (integer), Fortran only
Victor Eijkhout 47

3. MPI topic: Collectives
How to read routine prototypes: 1.5.4.
This call’s simplicity is contrasted with its usefulness, which is very limited. It is almost never necessaryto synchronize processes through a barrier: for most purposes it does not matter if processors are out ofsync. Conversely, collectives (except the new non-blocking ones; section 3.11) introduce a barrier of sortsthemselves.
3.8 Variable-size-input collectives
In the gather and scatter call above each processor received or sent an identical number of items. In manycases this is appropriate, but sometimes each processor wants or contributes an individual number of items.
Let’s take the gather calls as an example. Assume that each processor does a local computation that producesa number of data elements, and this number is different for each processor (or at least not the same for all).In the regular MPI_Gather call the root processor had a buffer of size nP , where n is the number of elementsproduced on each processor, and P the number of processors. The contribution from processor p would gointo locations pn, . . . , (p+ 1)n− 1.
For the variable case, we first need to compute the total required buffer size. This can be done through asimple MPI_Reduce with MPI_SUM as reduction operator: the buffer size is
∑p np where np is the number
of elements on processor p. But you can also postpone this calculation for a minute.
The next question is where the contributions of the processor will go into this buffer. For the contributionfrom processor p that is
∑q<p np, . . .
∑q≤p np − 1. To compute this, the root processor needs to have all
the np numbers, and it can collect them with an MPI_Gather call.
We now have all the ingredients. All the processors specify a send buffer just as with MPI_Gather. However,the receive buffer specification on the root is more complicated. It now consists of:
outbuffer, array-of-outcounts, array-of-displacements, outtype
and you have just seen how to construct that information.
For example, in an MPI_Gatherv call each process has an individual number of items to contribute. Togather this, the root process needs to find these individual amounts with an MPI_Gather call, and locallyconstruct the offsets array. Note how the offsets array has size ntids+1: the final offset value is automat-ically the total size of all incoming data. See the example below.
There are various calls where processors can have buffers of differing sizes.
• In MPI_Scatterv the root process has a different amount of data for each recipient.• In MPI_Gatherv, conversely, each process contributes a different sized send buffer to the received
result; MPI_Allgatherv does the same, but leaves its result on all processes; MPI_Alltoallvdoes a different variable-sized gather on each process.int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype,void* recvbuf, int recvcount, MPI_Datatype recvtype,int root, MPI_Comm comm)
48 Parallel Computing – r428
3.8. Variable-size-input collectives
C:int MPI_Gatherv(
const void* sendbuf, int sendcount, MPI_Datatype sendtype,void* recvbuf, const int recvcounts[], const int displs[],MPI_Datatype recvtype, int root, MPI_Comm comm)
Semantics:IN sendbuf: starting address of send buffer (choice)IN sendcount: number of elements in send buffer (non-negative integer)IN sendtype: data type of send buffer elements (handle)OUT recvbuf: address of receive buffer (choice, significant only at root)IN recvcounts: non-negative integer array (of length group size) containing the number of elements that are received from each process (significant only at root)IN displs: integer array (of length group size). Entry i specifies the displacement relative to recvbuf at which to place the incoming data from process i (significant only at root)IN recvtype: data type of recv buffer elements (significant only at root) (handle)IN root: rank of receiving process (integer)IN comm: communicator (handle)
Fortran:MPI_Gatherv(sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype, root, comm, ierror)TYPE(*), DIMENSION(..), INTENT(IN) :: sendbufTYPE(*), DIMENSION(..) :: recvbufINTEGER, INTENT(IN) :: sendcount, recvcounts(*), displs(*), rootTYPE(MPI_Datatype), INTENT(IN) :: sendtype, recvtypeTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:Gatherv(self, sendbuf, [recvbuf,counts], int root=0)
How to read routine prototypes: 1.5.4.
int MPI_Allgatherv(void *sendbuf, int sendcount, MPI_Datatype sendtype,void *recvbuf, int *recvcounts, int *displs,MPI_Datatype recvtype, MPI_Comm comm)
3.8.1 Example of Gatherv
We use MPI_Gatherv to do an irregular gather onto a root. We first need an MPI_Gather to determineoffsets.
// gatherv.c// we assume that each process has an array "localdata"// of size "localsize"
// the root process decides how much data will be coming:// allocate arrays to contain size and offset informationif (procno==root) {localsizes = (int*) malloc( (nprocs+1)*sizeof(int) );offsets = (int*) malloc( nprocs*sizeof(int) );
Victor Eijkhout 49

3. MPI topic: Collectives
}// everyone contributes their infoMPI_Gather(&localsize,1,MPI_INT,
localsizes,1,MPI_INT,root,comm);// the root constructs the offsets arrayif (procno==root) {offsets[0] = 0;for (int i=0; i<nprocs; i++)
offsets[i+1] = offsets[i]+localsizes[i];alldata = (int*) malloc( offsets[nprocs]*sizeof(int) );
}// everyone contributes their dataMPI_Gatherv(localdata,localsize,MPI_INT,
alldata,localsizes,offsets,MPI_INT,root,comm);
## gatherv.py# implicitly using root=0globalsize = comm.reduce(localsize)if procid==0:
print "Global size=%d" % globalsizecollecteddata = np.empty(globalsize,dtype=np.int)counts = comm.gather(localsize)comm.Gatherv(localdata, [collecteddata, counts])
3.8.2 Example of Allgatherv
Prior to the actual gatherv call, we need to construct the count and displacement arrays. The easiest way isto use a reduction.
// allgatherv.cMPI_Allgather( &my_count,1,MPI_INT,
recv_counts,1,MPI_INT, comm );int accumulate = 0;for (int i=0; i<nprocs; i++) {recv_displs[i] = accumulate; accumulate += recv_counts[i]; }
int *global_array = (int*) malloc(accumulate*sizeof(int));MPI_Allgatherv( my_array,procno+1,MPI_INT,
global_array,recv_counts,recv_displs,MPI_INT, comm );
In python the receive buffer has to contain the counts and displacements arrays.
## allgatherv.pymy_count = np.empty(1,dtype=np.int)my_count[0] = mycountcomm.Allgather( my_count,recv_counts )
accumulate = 0for p in range(nprocs):
recv_displs[p] = accumulate; accumulate += recv_counts[p]global_array = np.empty(accumulate,dtype=np.float64)
50 Parallel Computing – r428

3.9. Scan operations
comm.Allgatherv( my_array, [global_array,recv_counts,recv_displs,MPI.DOUBLE])
3.8.3 Variable all-to-all
int MPI_Alltoallv(void *sendbuf, int *sendcnts, int *sdispls, MPI_Datatype sendtype,void *recvbuf, int *recvcnts, int *rdispls, MPI_Datatype recvtype,MPI_Comm comm)
How to read routine prototypes: 1.5.4.
3.9 Scan operations
The MPI_Scan operation also performs a reduction, but it keeps the partial results. That is, if processor icontains a number xi, and ⊕ is an operator, then the scan operation leaves x0 ⊕ · · · ⊕ xi on processor i.This type of operation is often called a prefix operation; see HPSC-19.
The MPI_Scan routine is an inclusive scan operation.C:int MPI_Scan(const void* sendbuf, void* recvbuf,
int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)IN sendbuf: starting address of send buffer (choice)OUT recvbuf: starting address of receive buffer (choice)IN count: number of elements in input buffer (non-negative integer)IN datatype: data type of elements of input buffer (handle)IN op: operation (handle)IN comm: communicator (handle)
Fortran:MPI_Scan(sendbuf, recvbuf, count, datatype, op, comm, ierror)TYPE(*), DIMENSION(..), INTENT(IN) :: sendbufTYPE(*), DIMENSION(..) :: recvbufINTEGER, INTENT(IN) :: countTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Op), INTENT(IN) :: opTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:res = Intracomm.scan( sendobj=None,recvobj=None,op=MPI.SUM)res = Intracomm.exscan( sendobj=None,recvobj=None,op=MPI.SUM)
How to read routine prototypes: 1.5.4.
The MPI_Op operations do not return an error code.
Victor Eijkhout 51

3. MPI topic: Collectives
In python native mode the result is a function return value.
## scan.pymycontrib = 10+random.randint(1,nprocs)myfirst = 0mypartial = comm.scan(mycontrib)sbuf = np.empty(1,dtype=np.int)rbuf = np.empty(1,dtype=np.int)sbuf[0] = mycontribcomm.Scan(sbuf,rbuf)
3.9.1 Exclusive scan
Often, the more useful variant is the exclusive scanC:int MPI_Exscan(const void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)int MPI_Iexscan(const void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm,MPI_Request *request)
Fortran:
MPI_EXSCAN(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR)<type> SENDBUF(*), RECVBUF(*)INTEGER COUNT, DATATYPE, OP, COMM, IERROR
MPI_IEXSCAN(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, REQUEST, IERROR)<type> SENDBUF(*), RECVBUF(*)INTEGER COUNT, DATATYPE, OP, COMM, REQUEST, IERROR
Input Parameters
sendbuf: Send buffer (choice).count: Number of elements in input buffer (integer).datatype: Data type of elements of input buffer (handle).op: Operation (handle).comm: Communicator (handle).
Output Parameters
recvbuf: Receive buffer (choice).request: Request (handle, non-blocking only).
How to read routine prototypes: 1.5.4.
with the same prototype.
The result of the exclusive scan is undefined on processor 0 (None in python), and on processor 1 it is acopy of the send value of processor 1. In particular, the MPI_Op need not be called on these two processors.
52 Parallel Computing – r428

3.10. MPI Operators
Exercise 3.12. The exclusive definition, which computes x0 ⊕ xi−1 on processor i, can easilybe derived from the inclusive operation for operations such as MPI_SUM or MPI_MULT.Are there operators where that is not the case?
3.9.2 Use of scan operations
The MPI_Scan operation is often useful with indexing data. Suppose that every processor p has a local vectorwhere the number of elements np is dynamically determined. In order to translate the local numbering0 . . . np − 1 to a global numbering one does a scan with the number of local elements as input. The outputis then the global number of the first local variable.Exercise 3.13. Do you use MPI_Scan or MPI_Exscan for this operation? How would you
describe the result of the other scan operation, given the same input?Exclusive scan examples:
// exscan.cint my_first=0,localsize;// localsize = ..... result of local computation ....// find myfirst location based on the local sizeserr = MPI_Exscan(&localsize,&my_first,
1,MPI_INT,MPI_SUM,comm); CHK(err);
## exscan.pylocalsize = 10+random.randint(1,nprocs)myfirst = 0mypartial = comm.exscan(localsize,0)
It is possible to do a segmented scan . Let xi be a series of numbers that we want to sum to Xi as follows.Let yi be a series of booleans such that{
Xi = xi if yi = 0
Xi = Xi−1 + xi if yi = 1
(This is the basis for the implementation of the sparse matrix vector product as prefix operation; see HPSC-19.2.) This means thatXi sums the segments between locations where yi = 0 and the first subsequent placewhere yi = 1. To implement this, you need a user-defined operatorXx
y
=
X1
x1y1
⊕X2
x2y2
:
{X = x1 + x2 if y2 == 1
X = x2 if y2 == 0
This operator is not communitative, and it needs to be declared as such with MPI_Op_create; see sec-tion 3.2.4
3.10 MPI Operators
MPI operators are used in reduction operators. Most common operators, such as sum or maximum, havebeen built into the MPI library, but it is possible to define new operators.
Victor Eijkhout 53

3. MPI topic: Collectives
3.10.1 Pre-defined operators
The following is the list of pre-defined operators MPI_OP values.
MPI type meaning applies toMPI_MAX maximum integer, floating pointMPI_MIN minimumMPI_SUM sum integer, floating point, complex, multilanguage typesMPI_PROD productMPI_LAND logical and C integer, logicalMPI_LOR logical orMPI_LXOR logical xorMPI_BAND bitwise and integer, byte, multilanguage typesMPI_BOR bitwise orMPI_BXOR bitwise xorMPI_MAXLOC max value and location MPI_DOUBLE_INT and suchMPI_MINLOC min value and location
The MPI_MAXLOC operation yields both the maximum and the rank on which it occurs. However, to use itthe input should be an array of real/int structs, where the int is the rank of the number.
3.10.2 User-defined operators
In addition to predefined operators, MPI has the possibility of user-defined operators to use in a reductionor scan operation.
Semantics:MPI_OP_CREATE( function, commute, op)[ IN function] user defined function (function)[ IN commute] true if commutative; false otherwise.[ OUT op] operation (handle)
C:int MPI_Op_create(MPI_User_function *function, int commute,
MPI_Op *op)
Fortran:MPI_OP_CREATE( FUNCTION, COMMUTE, OP, IERROR)EXTERNAL FUNCTIONLOGICAL COMMUTEINTEGER OP, IERROR
How to read routine prototypes: 1.5.4.
The function needs to have the following prototype:
typedef void MPI_User_function( void *invec, void *inoutvec, int *len,MPI_Datatype *datatype);
54 Parallel Computing – r428

3.10. MPI Operators
FUNCTION USER_FUNCTION( INVEC(*), INOUTVEC(*), LEN, TYPE)<type> INVEC(LEN), INOUTVEC(LEN)INTEGER LEN, TYPE
The function has an array length argument len, to allow for pointwise reduction on a whole array at once.The inoutvec array contains partially reduced results, and is typically overwritten by the function.
There are some restrictions on the user function:
• It may not call MPI functions, except for MPI_Abort.• It must be associative; it can be optionally commutative, which fact is passed to the MPI_Op_create
call.
For example, here is an operator for finding the smallest non-zero number in an array of nonnegativeintegers:
// reductpositive.cvoid reduce_without_zero(void *in,void *inout,int *len,MPI_Datatype *type) {// r is the already reduced value, n is the new valueint n = *(int*)in, r = *(int*)inout;int m;if (n==0) { // new value is zero: keep r
m = r;} else if (r==0) {
m = n;} else if (n<r) { // new value is less but not zero: use n
m = n;} else { // new value is more: use r
m = r;};
*(int*)inout = m;}
Exercise 3.14. Write the reduction function to implement the one-norm of a vector:
‖x‖1 ≡∑i
|xi|.
You can query the commutativity of an operator:Semantics:MPI_Op_commutative(op, commute)IN op : handleOUT commute : true/false
C:int MPI_Op_commutative(MPI_Op op, int *commute)
Fortran:MPI_OP_COMMUTATIVE( op, commute)TYPE(MPI_Op), INTENT(IN) :: op
Victor Eijkhout 55

3. MPI topic: Collectives
LOGICAL, INTENT(OUT) :: commuteINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
A created MPI_Op can be freed again:
int MPI_Op_free(MPI_Op *op)
This sets the operator to MPI_OP_NULL.
3.10.3 Local reduction
The application of an MPI_Op can be performed with the routine MPI_Reduce_local. Using this routine andsome send/receive scheme you can build your own global reductions. Note that this routine does not take acommunicator because it is purely local.
Semantics:MPI_REDUCE_LOCAL( inbuf, inoutbuf, count, datatype, op)
Input parameters:inbuf: input buffer (choice)count: number of elements in inbuf and inoutbuf buffers
(non-negative integer)datatype: data type of elements of inbuf and inoutbuf buffers
(handle)op: operation (handle)
Input/output parameters:inoutbuf: combined input and output buffer (choice)
C:int MPI_Reduce_local
(void* inbuf, void* inoutbuf, int count,MPI_Datatype datatype, MPI_Op op)
Fortran:MPI_REDUCE_LOCAL(INBUF, INOUBUF, COUNT, DATATYPE, OP, IERROR)<type> INBUF(*), INOUTBUF(*)INTEGER :: COUNT, DATATYPE, OP, IERROR
How to read routine prototypes: 1.5.4.
3.11 Non-blocking collectives
Above you have seen how the ‘Isend’ and ‘Irecv’ routines can overlap communication with computation.This is not possible with the collectives you have seen so far: they act like blocking sends or receives.However, there are also non-blocking collectives . These have roughly the same calling sequence as their
56 Parallel Computing – r428

3.11. Non-blocking collectives
blocking counterparts, except that they output an MPI_Request. You can then use an MPI_Wait call to makesure the collective has completed.
Such operations can be used to increase efficiency. For instance, computing
y ← Ax+ (xtx)y
involves a matrix-vector product, which is dominated by computation in the sparse matrix case, and aninner product which is typically dominated by the communication cost. You would code this as
MPI_Iallreduce( .... x ..., &request);// compute the matrix vector productMPI_Wait(request);// do the addition
This can also be used for 3D FFT operations [7]. Occasionally, a non-blocking collective can be used fornon-obvious purposes, such as the MPI_Ibarrier in [8].
The same calling sequence as the blocking counterpart, except for the addition of an MPI_Request param-eter. For instance MPI_Ibcast:
int MPI_Ibcast(void *buffer, int count, MPI_Datatype datatype,int root, MPI_Comm comm,MPI_Request *request)
Non-blocking collectives offer a number of performance advantages:
• Do two reductions (on the same communicator) with different operators simultaneously;• do collectives on overlapping communicators simultaneously;• overlap a non-blocking collective with a blocking one. (However, note that blocking and non-
blocking don’t match: either all process call the non-blocking or all call the blocking one.)
Exercise 3.15. Revisit exercise 6.1. Let only the first row and first column have certain data,which they broadcast through columns and rows respectively. Each process is nowinvolved in two simultaneous collectives. Implement this with non-blockingbroadcasts, and time the difference between a blocking and a non-blocking solution.C:int MPI_Ibcast(
void* buffer, int count, MPI_Datatype datatype,int root, MPI_Comm comm,MPI_Request *request)
Fortran:MPI_Ibcast(buffer, count, datatype, root, comm, ierror)TYPE(*), DIMENSION(..) :: bufferINTEGER, INTENT(IN) :: count, rootTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Victor Eijkhout 57

3. MPI topic: Collectives
TYPE(MPI_Request),intent(out) :: request
How to read routine prototypes: 1.5.4.
Semantics
int MPI_Iallreduce(const void *sendbuf, void *recvbuf,int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm,MPI_Request *request)
Input Parameters
sendbuf : starting address of send buffer (choice)count : number of elements in send buffer (integer)datatype : data type of elements of send buffer (handle)op : operation (handle)comm : communicator (handle)
Output Parameters
recvbuf : starting address of receive buffer (choice)request : communication request (handle)
How to read routine prototypes: 1.5.4.
Semantics
int MPI_Iallgather(const void *sendbuf, int sendcount, MPI_Datatype sendtype,void *recvbuf, int recvcount, MPI_Datatype recvtype,MPI_Comm comm, MPI_Request *request)
Input Parameters
sendbuf : starting address of send buffer (choice)sendcount : number of elements in send buffer (integer)sendtype : data type of send buffer elements (handle)recvcount : number of elements received from any process (integer)recvtype : data type of receive buffer elements (handle)comm : communicator (handle)
Output Parameters
recvbuf : address of receive buffer (choice)request : communication request (handle)
How to read routine prototypes: 1.5.4.
58 Parallel Computing – r428

3.12. Performance of collectives
3.11.1 Non-blocking barrier
Probably the most surprising non-blocking collective is the non-blocking barrier MPI_Ibarrier. The wayto understand this is to think of a barrier not in terms of temporal synchronization, but state agreement:reaching a barrier is a sign that a process has attained a certain state, and leaving a barrier means that allprocesses are in the same state. The ordinary barrier is then a blocking wait for agreement, while with anon-blocking barrier:
• Posting the barrier means that a process has reached a certain state; and• the request being fullfilled means that all processes have reached the barrier.C:int MPI_Ibarrier(MPI_Comm comm, MPI_Request *request)
Input Parameterscomm : communicator (handle)
Output Parametersrequest : communication request (handle)
Fortran2008:MPI_Ibarrier(comm, request, ierror)Type(MPI_Comm),intent(int) :: commTYPE(MPI_Request),intent(out) :: requestINTEGER,intent(out) :: ierror
How to read routine prototypes: 1.5.4.
We can use a non-blocking barrier to good effect, utilizing the idle time that would result from a blockingbarrier. In the following code fragment processes test for completion of the barrier, and failing to detectsuch completion, perform some local work.
// ibarriertest.cfor ( ; ; step++) {int barrier_done_flag=0;MPI_Test(&barrier_request,&barrier_done_flag,MPI_STATUS_IGNORE);if (barrier_done_flag) {
break;} else {
int flag; MPI_Status status;MPI_Iprobe( MPI_ANY_SOURCE,MPI_ANY_TAG,
comm, &flag, &status );}
}
3.12 Performance of collectives
It is easy to visualize a broadcast as in figure 3.9: see figure 3.9. the root sends all of its data directly to
Victor Eijkhout 59

3. MPI topic: Collectives
Figure 3.9: A simple broadcast
every other process. While this describes the semantics of the operation, in practice the implementationworks quite differently.
The time that a message takes can simply be modeled as
α+ βn,
where α is the latency, a one time delay from establishing the communication between two processes, andβ is the time-per-byte, or the inverse of the bandwidth , and n the number of bytes sent.
Under the assumption that a processor can only send one message at a time, the broadcast in figure 3.9would take a time proportional to the number of processors.
Exercise 3.16. What is the total time required for a broadcast involving p processes? Give αand β terms separately.
One way to ameliorate that is to structure the broadcast in a tree-like fashion. This is depicted in figure 3.10.
Figure 3.10: A tree-based broadcast
Exercise 3.17. How does the communication time now depend on the number of processors,again α and β terms separately.What would be a lower bound on the α, β terms?
The theory of the complexity of collectives is described in more detail in HPSC-6.1; see also [1].
3.13 Collectives and synchronization
Collectives, other than a barrier, have a synchronizing effect between processors. For instance, in
MPI_Bcast( ....data... root);MPI_Send(....);
60 Parallel Computing – r428
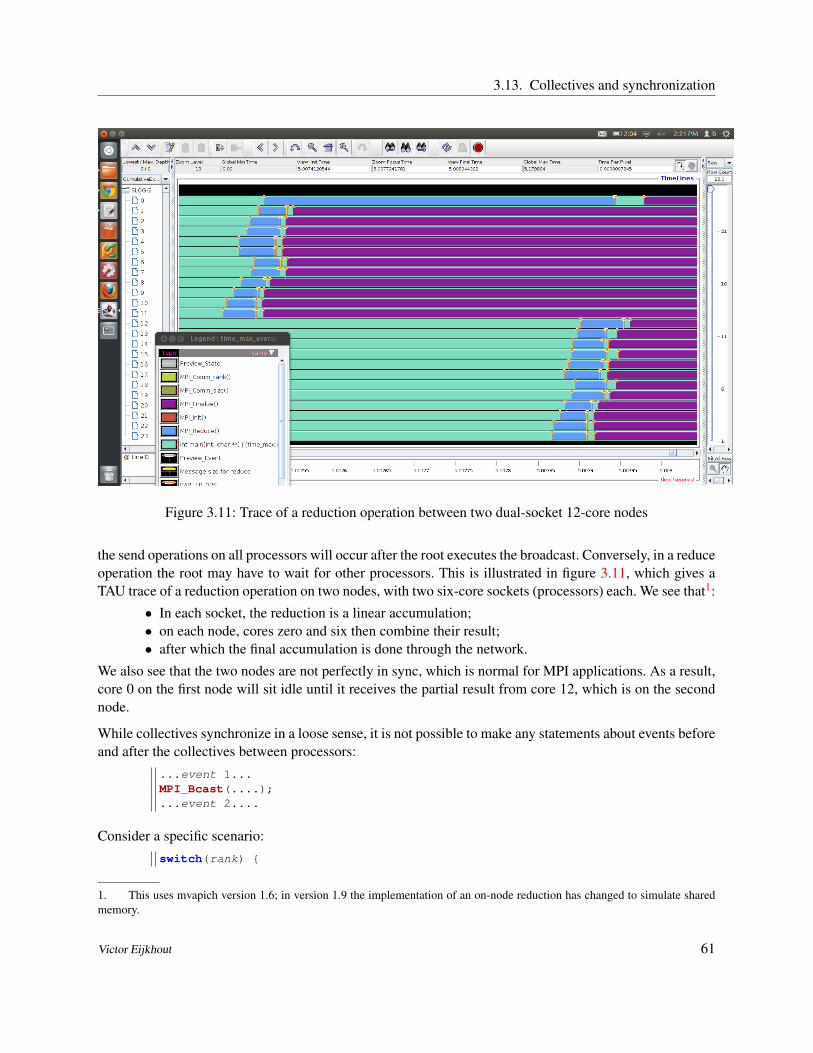
3.13. Collectives and synchronization
Figure 3.11: Trace of a reduction operation between two dual-socket 12-core nodes
the send operations on all processors will occur after the root executes the broadcast. Conversely, in a reduceoperation the root may have to wait for other processors. This is illustrated in figure 3.11, which gives aTAU trace of a reduction operation on two nodes, with two six-core sockets (processors) each. We see that1:
• In each socket, the reduction is a linear accumulation;• on each node, cores zero and six then combine their result;• after which the final accumulation is done through the network.
We also see that the two nodes are not perfectly in sync, which is normal for MPI applications. As a result,core 0 on the first node will sit idle until it receives the partial result from core 12, which is on the secondnode.
While collectives synchronize in a loose sense, it is not possible to make any statements about events beforeand after the collectives between processors:
...event 1...MPI_Bcast(....);...event 2....
Consider a specific scenario:switch(rank) {
1. This uses mvapich version 1.6; in version 1.9 the implementation of an on-node reduction has changed to simulate sharedmemory.
Victor Eijkhout 61

3. MPI topic: Collectives
Code:
switch(rank) {case 0:
MPI_Bcast(buf1, count, type, 0, comm);MPI_Send(buf2, count, type, 1, tag, comm);break;
case 1:MPI_Recv(buf2, count, type, MPI_ANY_SOURCE, tag, comm, status);MPI_Bcast(buf1, count, type, 0, comm);MPI_Recv(buf2, count, type, MPI_ANY_SOURCE, tag, comm, status);break;
case 2:MPI_Send(buf2, count, type, 1, tag, comm);MPI_Bcast(buf1, count, type, 0, comm);break;
}
The most logical execution is:
However, this ordering is allowed too:
Which looks from a distance like:
In other words, one of the messages seems to go ‘back in time’.
Figure 3.12: Possible temporal orderings of send and collective calls
62 Parallel Computing – r428

3.14. Implementation and performance of collectives
case 0:MPI_Bcast(buf1, count, type, 0, comm);MPI_Send(buf2, count, type, 1, tag, comm);break;
case 1:MPI_Recv(buf2, count, type, MPI_ANY_SOURCE, tag, comm, status);MPI_Bcast(buf1, count, type, 0, comm);MPI_Recv(buf2, count, type, MPI_ANY_SOURCE, tag, comm, status);break;
case 2:MPI_Send(buf2, count, type, 1, tag, comm);MPI_Bcast(buf1, count, type, 0, comm);break;
}
Note the MPI_ANY_SOURCE parameter in the receive calls on processor 1. One obvious execution of thiswould be:
1. The send from 2 is caught by processor 1;2. Everyone executes the broadcast;3. The send from 0 is caught by processor 1.
However, it is equally possible to have this execution:
1. Processor 0 starts its broadcast, then executes the send;2. Processor 1’s receive catches the data from 0, then it executes its part of the broadcast;3. Processor 1 catches the data sent by 2, and finally processor 2 does its part of the broadcast.
This is illustrated in figure 3.12.
3.14 Implementation and performance of collectives
In this section we will consider how collectives can be implemented in multiple ways, and the performanceimplications of such decisions. You can test the algorithms described here using SimGrid (section 36.5).
3.14.1 Broadcast
Naive broadcast Write a broadcast operation where the root does an MPI_Send to each other process.
What is the expected performance of this in terms of α, β?
Run some tests and confirm.
Simple ring Let the root only send to the next process, and that one send to its neighbour. This scheme isknown as a bucket brigade; see also section 4.2.3.
What is the expected performance of this in terms of α, β?
Run some tests and confirm.
Victor Eijkhout 63

3. MPI topic: Collectives
Figure 3.13: A pipelined bucket brigade
Pipelined ring In a ring broadcast, each process needs to receive the whole message before it can passit on. We can increase the efficiency by breaking up the message and sending it in multiple parts. (Seefigure 3.13.) This will be advantageous for messages that are long enough that the bandwidth cost dominatesthe latency.
Assume a send buffer of length more than 1. Divide the send buffer into a number of chunks. The root sendsthe chunks successively to the next process, and each process sends on whatever chunks it receives.
What is the expected performance of this in terms of α, β? Why is this better than the simple ring?
Run some tests and confirm.
Recursive doubling Collectives such as broadcast can be implemented through recursive doubling ,where the root sends to another process, then the root and the other process send to two more, those foursend to four more, et cetera. However, in an actual physical architecture this scheme can be realized inmultiple ways that have drastically different performance.
First consider the implementation where process 0 is the root, and it starts by sending to process 1; thenthey send to 2 and 3; these four send to 4–7, et cetera. If the architecture is a linear array of procesors, thiswill lead to contention: multiple messages wanting to go through the same wire. (This is also related to theconcept of bisecection bandwidth .)
In the following analyses we will assume wormhole routing: a message sets up a path through the network,reserving the necessary wires, and performing a send in time independent of the distance through the
64 Parallel Computing – r428

3.15. Sources used in this chapter
network. That is, the send time for any message can be modeled as
T (n) = α+ βn
regardless source and destination, as long as the necessary connections are available.
Exercise 3.18. Analyze the running time of a recursive doubling broad cast as just described,with wormhole routing.Implement this broadcast in terms of blocking MPI send and receive calls. If youhave SimGrid available, run tests with a number of parameters.
The alternative, that avoids contention, is to let each doubling stage divide the network into separate halves.That is, process 0 sends to P/2, after which these two repeat the algorithm in the two halves of the network,sending to P/4 and 3P/4 respectively.
Exercise 3.19. Analyze this variant of recursive doubling. Code it and measure runtimes onSimGrid.
Exercise 3.20. Revisit exercise 3.18 and replace the blocking calls by non-blockingMPI_Isend / MPI_Irecv calls.Make sure to test that the data is correctly propagated.
3.15 Sources used in this chapter
Listing of code examples/mpi/c/allreducec.c:
Listing of code examples/mpi/c/allreducep.c:
Listing of code examples/mpi/c/allreduceinplace.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-7%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
//snippet allreduceinplaceint nrandoms = 500000;
Victor Eijkhout 65

3. MPI topic: Collectives
float *myrandoms;myrandoms = (float*) malloc(nrandoms*sizeof(float));for (int irand=0; irand<nrandoms; irand++)myrandoms[irand] = (float) rand()/(float)RAND_MAX;
// add all the random variables togetherMPI_Allreduce(MPI_IN_PLACE,myrandoms,
nrandoms,MPI_FLOAT,MPI_SUM,comm);// the result should be approx nprocs/2:if (procno==nprocs-1) {float sum=0.;for (int i=0; i<nrandoms; i++) sum += myrandoms[i];sum /= nrandoms*nprocs;printf("Result %6.9f compared to .5\n",sum);
}//snippet endfree(myrandoms);
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/reduce.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% reduce.c : reduction%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
//snippet reducefloat myrandom = (float) rand()/(float)RAND_MAX,result;
int target_proc = nprocs-1;// add all the random variables togetherMPI_Reduce(&myrandom,&result,1,MPI_FLOAT,MPI_SUM,
target_proc,comm);// the result should be approx nprocs/2:if (procno==target_proc)
66 Parallel Computing – r428

3.15. Sources used in this chapter
printf("Result %6.3f compared to nprocs/2=%5.2f\n",result,nprocs/2.);
//snippet end
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/reduceinplace.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% reduceinplace.c : reduction in place%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
//snippet reduceinplacefloat mynumber,result,*sendbuf,*recvbuf;mynumber = (float) procno;int target_proc = nprocs-1;// add all the random variables togetherif (procno==target_proc) {sendbuf = (float*)MPI_IN_PLACE; recvbuf = &result;result = mynumber;
} else {sendbuf = &mynumber; recvbuf = NULL;
}MPI_Reduce(sendbuf,recvbuf,1,MPI_FLOAT,MPI_SUM,
target_proc,comm);// the result should be nprocs*(nprocs-1)/2:if (procno==target_proc)printf("Result %6.3f compared to n(n-1)/2=%5.2f\n",
result,nprocs*(nprocs-1)/2.);//snippet end
MPI_Finalize();return 0;
}
Victor Eijkhout 67

3. MPI topic: Collectives
Listing of code examples/mpi/c/usage.c:
Listing of code examples/mpi/c/gather.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% gather.c : illustrating MPI_Gather%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"int localsize = 10+10*( (float) rand()/(float)RAND_MAX - .5),
root = nprocs-1;
int *localsizes=NULL;// create local dataint *localdata = (int*) malloc( localsize*sizeof(int) );for (int i=0; i<localsize; i++)localdata[i] = procno+1;
//snippet gather// we assume that each process has a value "localsize"// the root process collectes these values
if (procno==root)localsizes = (int*) malloc( (nprocs+1)*sizeof(int) );
// everyone contributes their infoMPI_Gather(&localsize,1,MPI_INT,
localsizes,1,MPI_INT,root,comm);//snippet endif (procno==root) {printf("Local sizes: ");for (int i=0; i<nprocs; i++)printf("%d, ",localsizes[i]);
printf("\n");}
MPI_Finalize();return 0;
68 Parallel Computing – r428

3.15. Sources used in this chapter
}
Listing of code examples/mpi/c/reducescatter.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-5%%%%%%%% reducescatter.c : simple illustration of reduce_scatter%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
//snippet reducescatter// record what processes you will communicate withint *recv_requests;//snippet endint *counts,nrecv_requests=0,nsend_requests;recv_requests = (int*) malloc(nprocs*sizeof(int));counts = (int*) malloc(nprocs*sizeof(int));for (int i=0; i<nprocs; i++) {recv_requests[i] = 0;counts[i] = 1;
}
// generate random requestsfor (int i=0; i<nprocs; i++)if ( (float) rand()/(float)RAND_MAX < 2./nprocs ) {recv_requests[i] = 1; nrecv_requests++;
}printf("[%d]: ",procno);for (int i=0; i<nprocs; i++)printf("%d ",recv_requests[i]);
printf("\n");//snippet reducescatter// find how many procs want to communicate with youMPI_Reduce_scatter(recv_requests,&nsend_requests,counts,MPI_INT,MPI_SUM,comm);
//snippet endprintf("[%d]: %d requests\n",procno,nsend_requests);
Victor Eijkhout 69

3. MPI topic: Collectives
MPI_Request *mpi_requests,irequest=0;mpi_requests = (MPI_Request*) malloc((nrecv_requests+nsend_requests)*sizeof(MPI_Request));int msg=1;//snippet reducescatter// send a msg to the selected processesfor (int i=0; i<nprocs; i++)if (recv_requests[i]>0)MPI_Isend(&msg,1,MPI_INT, /*to:*/ i,0,comm,mpi_requests+irequest++);
// do as many receives as you know are coming infor (int i=0; i<nsend_requests; i++)MPI_Irecv(&msg,1,MPI_INT,MPI_ANY_SOURCE,MPI_ANY_TAG,comm,
mpi_requests+irequest++);MPI_Waitall(irequest,mpi_requests,MPI_STATUSES_IGNORE);//snippet end
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/mvp2d.c:
Listing of code XX:
Listing of code XX:
Listing of code XX:
Listing of code XX:
Listing of code XX:
70 Parallel Computing – r428

Chapter 4
MPI topic: Point-to-point
4.1 Distributed computing and distributed data
One reason for using MPI is that sometimes you need to work on more data than can fit in the memory of asingle processor. With distributed memory, each processor then gets a part of the whole data structure andonly works on that.
So let’s say we have a large array, and we want to distribute the data over the processors. That means that,with p processes and n elements per processor, we have a total of n · p elements.
Figure 4.1: Local parts of a distributed array
We sometimes say that data is the local part of a distributed array with a total size of n · p elements.However, this array only exists conceptually: each processor has an array with lowest index zero, and youhave to translate that yourself to an index in the global array. In other words, you have to write your code insuch a way that it acts like you’re working with a large array that is distributed over the processors, whileactually manipulating only the local arrays on the processors.
Your typical code then looks like
int myfirst = .....;for (int ilocal=0; ilocal<nlocal; ilocal++) {
int iglobal = myfirst+ilocal;array[ilocal] = f(iglobal);
}
71

4. MPI topic: Point-to-point
Exercise 4.1. Implement a (very simple-minded) Fourier transform: if f is a function on theinterval [0, 1], then the n-th Fourier coefficient is
fn=
∫ 1
0f(t)e−t/π dt
which we approximate by
fn=N−1∑i=0
f(ih)e−in/π
• Make one distributed array for the e−inh coefficients,• make one distributed array for the f(ih) values• calculate a couple of coefficients
Exercise 4.2. In the previous exercise you worked with a distributed array, computing a localquantity and combining that into a global quantity. Why is it not a good idea to gatherthe whole distributed array on a single processor, and do all the computation locally?
If the array size is not perfectly divisible by the number of processors, we have to come up with a divisionthat is uneven, but not too much. You could for instance, write
int Nglobal, // is something largeNlocal = Nglobal/ntids,excess = Nglobal%ntids;
if (mytid==ntids-1)Nlocal += excess;
Exercise 4.3. Argue that this strategy is not optimal. Can you come up with a betterdistribution? Load balancing is further discussed in HPSC-2.10.
Exercise 4.4. Implement an inner product routine: let x be a distributed vector of size N withelements x[i] = i, and compute xtx. As before, the right value is(2N3 + 3N2 +N)/6.Use the inner product value to scale to vector so that it has norm 1. Check that yourcomputation is correct.
4.2 Blocking point-to-point operations
Suppose you have an array of numbers xi : i = 0, . . . , N and you want to compute yi = (xi−1 + xi +xi+1)/3: i = 1, . . . , N − 1. As before (see figure 4.1), we give each processor a subset of the xis and yis.Let’s define ip as the first index of y that is computed by processor p. (What is the last index computed byprocessor p? How many indices are computed on that processor?)
We often talk about the owner computes model of parallel computing: each processor ‘owns’ certain dataitems, and it computes their value.
72 Parallel Computing – r428

4.2. Blocking point-to-point operations
Now let’s investigate how processor p goes about computing yi for the i-values it owns. Let’s assume thatprocessor p also stores the values xi for these same indices. Now, for many values it can compute
yi = (xi−1 + xi + xi+1)/3
(figure 4.3). However, there is a problem with computing the first index ip:
Figure 4.2: Three point averaging
Figure 4.3: Three point averaging in parallel
yip = (xip−1 + xip + xip+1)/3
since xip is not stored on processor p: it is stored on p− 1 (figure 4.4). There is a similar story with the last
Figure 4.4: Three point averaging in parallel, case of edge points
index that p tries to compute: that involves a value that is only present on p+ 1.
You see that there is a need for processor-to-processor, or technically point-to-point , information exchange.MPI realizes this through matched send and receive calls:
Victor Eijkhout 73

4. MPI topic: Point-to-point
• One process does a send to a specific other process;• the other process does a specific receive from that source.
4.2.1 Send example: ping-pong
A simple scenario for information exchange between just two processes is the ping-pong: process A sendsdata to process B, which sends data back to A. This means that process A executes the code
MPI_Send( /* to: */ B ..... );MPI_Recv( /* from: */ B ... );
while process B executes
MPI_Recv( /* from: */ A ... );MPI_Send( /* to: */ A ..... );
Since we are programming in SPMD mode, this means our program looks like:
if ( /* I am process A */ ) {MPI_Send( /* to: */ B ..... );MPI_Recv( /* from: */ B ... );
} else if ( /* I am process B */ ) {MPI_Recv( /* from: */ A ... );MPI_Send( /* to: */ A ..... );
}
The blocking send command:C:int MPI_Send(const void* buf, int count, MPI_Datatype datatype,int dest, int tag, MPI_Comm comm)
Semantics:IN buf: initial address of send buffer (choice)IN count: number of elements in send buffer (non-negative integer)IN datatype: datatype of each send buffer element (handle)IN dest: rank of destination (integer)IN tag: message tag (integer)IN comm: communicator (handle)
Fortran:MPI_Send(buf, count, datatype, dest, tag, comm, ierror)TYPE(*), DIMENSION(..), INTENT(IN) :: bufINTEGER, INTENT(IN) :: count, dest, tagTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Comm), INTENT(IN) :: commINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python native:MPI.Comm.send(self, obj, int dest, int tag=0)
74 Parallel Computing – r428

4.2. Blocking point-to-point operations
Python numpy:MPI.Comm.Send(self, buf, int dest, int tag=0)
How to read routine prototypes: 1.5.4.
This routine may not blocking for small messages; to force blocking behaviour use MPI_Ssend with thesame argument list. http://www.mcs.anl.gov/research/projects/mpi/www/www3/MPI_Ssend.html
The basic blocking receive command:C:int MPI_Recv(void* buf, int count, MPI_Datatype datatype,int source, int tag, MPI_Comm comm, MPI_Status *status)
Semantics:OUT buf: initial address of receive buffer (choice)IN count: number of elements in receive buffer (non-negative integer)IN datatype: datatype of each receive buffer element (handle)IN source: rank of source or MPI_ANY_SOURCE (integer)IN tag: message tag or MPI_ANY_TAG (integer)IN comm: communicator (handle)OUT status: status object (Status)
Fortran:MPI_Recv(buf, count, datatype, source, tag, comm, status, ierror)TYPE(*), DIMENSION(..) :: bufINTEGER, INTENT(IN) :: count, source, tagTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Status) :: statusINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python native:recvbuf = Comm.recv(self, buf=None, int source=ANY_SOURCE, int tag=ANY_TAG,
Status status=None)Python numpy:Comm.Recv(self, buf, int source=ANY_SOURCE, int tag=ANY_TAG,
Status status=None)
How to read routine prototypes: 1.5.4.
The count argument indicates the maximum length of a message; the actual length of the received messagecan be determined from the status object. See section 4.2.5 for more about the status object.
Exercise 4.5. Implement the ping-pong program. Add a timer using MPI_Wtime. For thestatus argument of the receive call, use MPI_STATUS_IGNORE.• Run multiple ping-pongs (say a thousand) and put the timer around the loop.
The first run may take longer; try to discard it.
Victor Eijkhout 75

4. MPI topic: Point-to-point
• Run your code with the two communicating processes first on the same node,then on different nodes. Do you see a difference?• Then modify the program to use longer messages. How does the timing
increase with message size?For bonus points, can you do a regression to determine α, β?
Exercise 4.6. Take your pingpong program and modify it to let half the processors be sourceand the other half the targets. Does the pingpong time increase?
In the syntax of the MPI_Recv command you saw one parameter that the send call lacks: the MPI_Status
object. This serves the following purpose: the receive call can have a ‘wildcard’ behaviour, for instancespecifying that the message can come from any source rather than a specific one. The status object thenallows you to find out where the message actually came from.
4.2.2 Problems with blocking communication
The use of MPI_Send and MPI_Recv is known as blocking communication: when your code reaches a sendor receive call, it blocks until the call is succesfully completed. For a receive call it is clear that the receivingcode will wait until the data has actually come in, but for a send call this is more subtle.
You may be tempted to think that the send call puts the data somewhere in the network, and the sendingcode can progress, as in figure 4.5, left. But this ideal scenario is not realistic: it assumes that somewhere
Figure 4.5: Illustration of an ideal (left) and actual (right) send-receive interaction
in the network there is buffer capacity for all messages that are in transit. This is not the case: data resideson the sender, and the sending call blocks, until the receiver has received all of it. (There is a exception forsmall messages, as explained in the next section.)
4.2.2.1 Deadlock
Suppose two process need to exchange data, and consider the following pseudo-code, which purports toexchange data between processes 0 and 1:
other = 1-mytid; /* if I am 0, other is 1; and vice versa */receive(source=other);send(target=other);
Imagine that the two processes execute this code. They both issue the send call. . . and then can’t go on,because they are both waiting for the other to issue a receive call. This is known as deadlock .
76 Parallel Computing – r428

4.2. Blocking point-to-point operations
4.2.2.2 Eager limit
If you reverse the send and receive call, you should get deadlock, but in practice that code will often work.The reason is that MPI implementations sometimes send small messages regardless of whether the receivehas been posted. This relies on the availability of some amount of available buffer space. The size underwhich this behaviour is used is sometimes referred to as the eager limit.)
The following code is guaranteed to block, since a MPI_Recv always blocks:// recvblock.cother = 1-procno;MPI_Recv(&recvbuf,1,MPI_INT,other,0,comm,&status);MPI_Send(&sendbuf,1,MPI_INT,other,0,comm);printf("This statement will not be reached on %d\n",procno);
On the other hand, if we put the send call before the receive, code may not block for small messages thatfall under the eager limit.
In this example we send gradually larger messages. From the screen output you can see what the largestmessage was that fell under the eager limit; after that the code hangs because of a deadlock.
// sendblock.cother = 1-procno;/* loop over increasingly large messages */for (int size=1; size<2000000000; size*=10) {sendbuf = (int*) malloc(size*sizeof(int));recvbuf = (int*) malloc(size*sizeof(int));if (!sendbuf || !recvbuf) {
printf("Out of memory\n"); MPI_Abort(comm,1);}MPI_Send(sendbuf,size,MPI_INT,other,0,comm);MPI_Recv(recvbuf,size,MPI_INT,other,0,comm,&status);/* If control reaches this point, the send call
did not block. If the send call blocks,we do not reach this point, and the program will hang.
*/if (procno==0)
printf("Send did not block for size %d\n",size);free(sendbuf); free(recvbuf);
}
// sendblock.F90other = 1-mytidsize = 1do
allocate(sendbuf(size)); allocate(recvbuf(size))print *,sizecall MPI_Send(sendbuf,size,MPI_INTEGER,other,0,comm,err)call MPI_Recv(recvbuf,size,MPI_INTEGER,other,0,comm,status,err)if (mytid==0) then
print *,"MPI_Send did not block for size",sizeend ifdeallocate(sendbuf); deallocate(recvbuf)size = size*10
Victor Eijkhout 77

4. MPI topic: Point-to-point
if (size>2000000000) goto 20end do20 continue
## sendblock.pysize = 1while size<2000000000:
sendbuf = np.empty(size, dtype=np.int)recvbuf = np.empty(size, dtype=np.int)comm.Send(sendbuf,dest=other)comm.Recv(sendbuf,source=other)if procid<other:
print "Send did not block for",sizesize *= 10
If you want a code to behave the same for all message sizes, you force the send call to be blocking by usingMPI_Ssend:
// ssendblock.cother = 1-procno;sendbuf = (int*) malloc(sizeof(int));recvbuf = (int*) malloc(sizeof(int));size = 1;MPI_Ssend(sendbuf,size,MPI_INT,other,0,comm);MPI_Recv(recvbuf,size,MPI_INT,other,0,comm,&status);printf("This statement is not reached\n");
Formally you can describe deadlock as follows. Draw up a graph where every process is a node, and drawa directed arc from process A to B if A is waiting for B. There is deadlock if this directed graph has a loop.
The solution to the deadlock in the above example is to first do the send from 0 to 1, and then from 1 to 0(or the other way around). So the code would look like:
if ( /* I am processor 0 */ ) {send(target=other);receive(source=other);
} else {receive(source=other);send(target=other);
}
The eager limit is implementation-specific. For instance, for Intel mpi there is a variable I_MPI_EAGER_THRESHOLD,for mvapich2 it is MV2_IBA_EAGER_THRESHOLD, and for OpenMPI the --mca options btl_openib_eager_limitand btl_openib_rndv_eager_limit.
4.2.2.3 Serialization
There is a second, even more subtle problem with blocking communication. Consider the scenario whereevery processor needs to pass data to its successor, that is, the processor with the next higher rank. Thebasic idea would be to first send to your successor, then receive from your predecessor. Since the lastprocessor does not have a successor it skips the send, and likewise the first processor skips the receive. Thepseudo-code looks like:
78 Parallel Computing – r428

4.2. Blocking point-to-point operations
successor = mytid+1; predecessor = mytid-1;if ( /* I am not the last processor */ )send(target=successor);
if ( /* I am not the first processor */ )receive(source=predecessor)
This code does not deadlock. All processors but the last one block on the send call, but the last processorexecutes the receive call. Thus, the processor before the last one can do its send, and subsequently continueto its receive, which enables another send, et cetera.
In one way this code does what you intended to do: it will terminate (instead of hanging forever on a dead-lock) and exchange data the right way. However, the execution now suffers from unexpected serialization:only one processor is active at any time, so what should have been a parallel operation becomes a sequential
Figure 4.6: Trace of a simple send-recv code
one. This is illustrated in figure 4.6.
Exercise 4.7. (Classroom exercise) Each student holds a piece of paper in the right hand– keep your left hand behind your back – and we want to execute:
1. Give the paper to your right neighbour;2. Accept the paper from your left neighbour.
Including boundary conditions for first and last process, that becomes the followingprogram:
1. If you are not the rightmost student, turn to the right and give the paper to yourright neighbour.
2. If you are not the leftmost student, turn to your left and accept the paper fromyour left neighbour.
Exercise 4.8. Implement the above algorithm using MPI_Send and MPI_Recv calls. Run thecode, and use TAU to reproduce the trace output of figure 4.6. If you don’t haveTAU, can you show this serialization behaviour using timings?
Victor Eijkhout 79

4. MPI topic: Point-to-point
It is possible to orchestrate your processes to get an efficient and deadlock-free execution, but doing so is abit cumbersome.
Exercise 4.9. The above solution treated every processor equally. Can you come up with asolution that uses blocking sends and receives, but does not suffer from theserialization behaviour?
There are better solutions which we will explore in the next section.
4.2.3 Bucket brigade
The problem with the previous exercise was that an operation that was conceptually parallel, became serialin execution. On the other hand, sometimes the operation is actually serial in nature. One example is thebucket brigade operation, where a piece of data is successively passed down a sequence of processors.
Exercise 4.10. Take the code of exercise 4.8 and modify it so that the data from process zerogets propagated to every process. Specifically: compute{
x0 = 1 on process zeroxp = xp−1 + (p+ 1)2 on process p
Use MPI_Send and MPI_Recv; make sure to get the order right.
4.2.4 Pairwise exchange
Above you saw that with blocking sends the precise ordering of the send and receive calls is crucial. Usethe wrong ordering and you get either deadlock, or something that is not efficient at all in parallel. MPI hasa way out of this problem that is sufficient for many purposes: the combined send/recv call MPI_Sendrecv:
Semantics:
MPI_SENDRECV(sendbuf, sendcount, sendtype, dest, sendtag,recvbuf, recvcount, recvtype, source, recvtag,comm, status)
IN sendbuf: initial address of send buffer (choice)IN sendcount: number of elements in send buffer (non-negative integer)IN sendtype: type of elements in send buffer (handle)IN dest: rank of destination (integer)IN sendtag: send tag (integer)OUT recvbuf: initial address of receive buffer (choice)IN recvcount: number of elements in receive buffer (non-negative integer)IN recvtype: type of elements in receive buffer (handle)IN source: rank of source or MPI_ANY_SOURCE (integer)IN recvtag: receive tag or MPI_ANY_TAG (integer)IN comm: communicator (handle)OUT status: status object (Status)
C:
80 Parallel Computing – r428

4.2. Blocking point-to-point operations
int MPI_Sendrecv(const void *sendbuf, int sendcount, MPI_Datatype sendtype,int dest, int sendtag,void *recvbuf, int recvcount, MPI_Datatype recvtype,int source, int recvtag,MPI_Comm comm, MPI_Status *status)
Fortran:MPI_Sendrecv(sendbuf, sendcount, sendtype, dest, sendtag, recvbuf,recvcount, recvtype, source, recvtag, comm, status, ierror)TYPE(*), DIMENSION(..), INTENT(IN) :: sendbufTYPE(*), DIMENSION(..) :: recvbufINTEGER, INTENT(IN) :: sendcount, dest, sendtag, recvcount, source,recvtagTYPE(MPI_Datatype), INTENT(IN) :: sendtype, recvtypeTYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Status) :: statusINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:Sendrecv(self, sendbuf, int dest, int sendtag=0,
recvbuf=None, int source=ANY_SOURCE, int recvtag=ANY_TAG,Status status=None)
How to read routine prototypes: 1.5.4.
The sendrecv call works great if every process is paired up. You would then write
sendrecv( ....from... ...to... );
with the right choice of source and destination. For instance, to send data to your right neighbour:
MPI_Comm_rank(comm,&procno);MPI_Sendrecv( ....
/* from: */ procno-1... .../* to: */ procno+1... );
This scheme is correct for all processes but the first and last. MPI allows for the following solution whichmakes the code slightly more homogeneous:
MPI_Comm_rank( .... &mytid );if ( /* I am not the first processor */ )predecessor = mytid-1;
elsepredecessor = MPI_PROC_NULL;
if ( /* I am not the last processor */ )successor = mytid+1;
elsesuccessor = MPI_PROC_NULL;
sendrecv(from=predecessor,to=successor);
Victor Eijkhout 81

4. MPI topic: Point-to-point
where the sendrecv call is executed by all processors.
All processors but the last one send to their neighbour; the target value of MPI_PROC_NULL for the lastprocessor means a ‘send to the null processor’: no actual send is done.
C:#include "mpi.h"MPI_PROC_NULL
Fortran:#include "mpif.h"MPI_PROC_NULL
Python:MPI.PROC_NULL = -1
How to read routine prototypes: 1.5.4.
The null processor value is also of use with the MPI_Sendrecv call; section 4.2.4
Likewise, receive from MPI_PROC_NULL succeeds without altering the receive buffer. The correspondingMPI_Status object has source MPI_PROC_NULL, tag MPI_ANY_TAG, and count zero.
Exercise 4.11. Revisit exercise 4.7 and solve it using MPI_Sendrecv.If you have TAU installed, make a trace. Does it look different from the serializedsend/recv code? If you don’t have TAU, run your code with different numbers ofprocesses and show that the runtime is essentially constant.
This call makes it easy to exchange data between two processors: both specify the other as both target andsource. However, there need not be any such relation between target and source: it is possible to receivefrom a predecessor in some ordering, and send to a successor in that ordering; see figure 4.7.
Figure 4.7: An MPI Sendrecv call
For the above three-point combination scheme you need to move data both left right, so you need twoMPI_Sendrecv calls; see figure 4.8.
Exercise 4.12. Implement the above three-point combination scheme using MPI_Sendrecv;every processor only has a single number to send to its neighbour.
• Each process does one send and one receive; if a process needs to skip one or the other, you canspecify MPI_PROC_NULL as the other process in the send or receive specification. In that case thecorresponding action is not taken.
82 Parallel Computing – r428
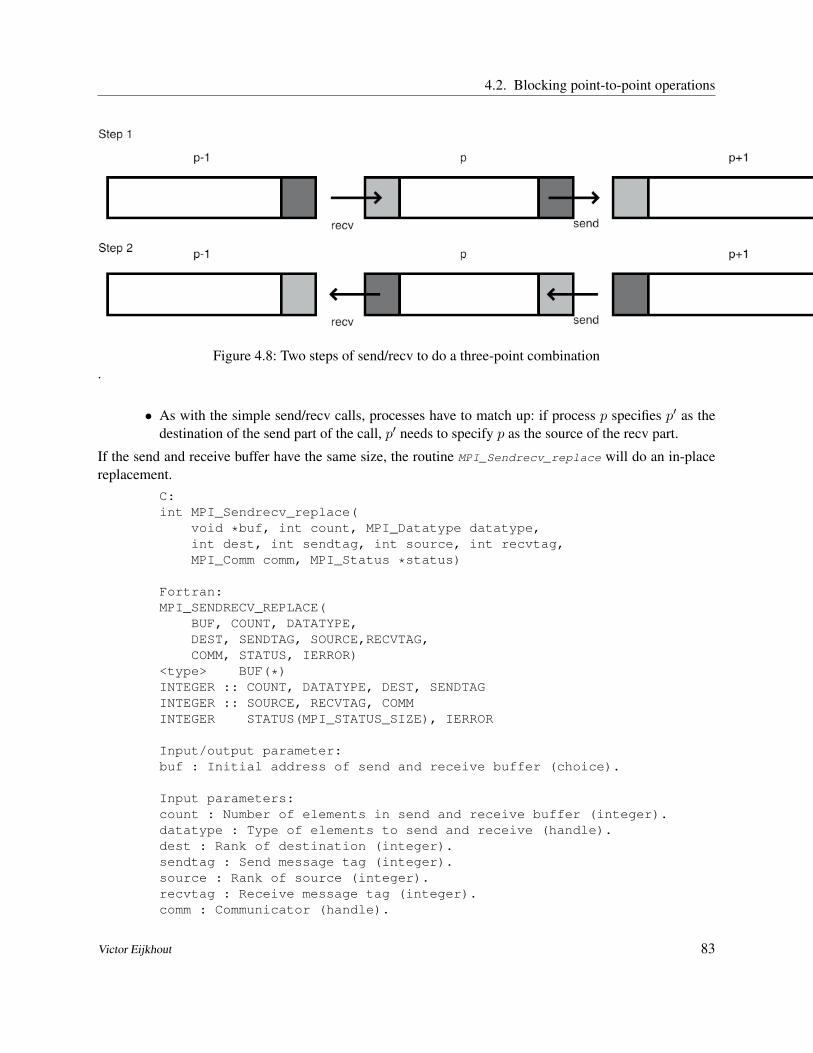
4.2. Blocking point-to-point operations
Figure 4.8: Two steps of send/recv to do a three-point combination.
• As with the simple send/recv calls, processes have to match up: if process p specifies p′ as thedestination of the send part of the call, p′ needs to specify p as the source of the recv part.
If the send and receive buffer have the same size, the routine MPI_Sendrecv_replace will do an in-placereplacement.
C:int MPI_Sendrecv_replace(
void *buf, int count, MPI_Datatype datatype,int dest, int sendtag, int source, int recvtag,MPI_Comm comm, MPI_Status *status)
Fortran:MPI_SENDRECV_REPLACE(
BUF, COUNT, DATATYPE,DEST, SENDTAG, SOURCE,RECVTAG,COMM, STATUS, IERROR)
<type> BUF(*)INTEGER :: COUNT, DATATYPE, DEST, SENDTAGINTEGER :: SOURCE, RECVTAG, COMMINTEGER STATUS(MPI_STATUS_SIZE), IERROR
Input/output parameter:buf : Initial address of send and receive buffer (choice).
Input parameters:count : Number of elements in send and receive buffer (integer).datatype : Type of elements to send and receive (handle).dest : Rank of destination (integer).sendtag : Send message tag (integer).source : Rank of source (integer).recvtag : Receive message tag (integer).comm : Communicator (handle).
Victor Eijkhout 83

4. MPI topic: Point-to-point
Output parameters:
status : Status object (status).IERROR : Fortran only: Error status (integer).
How to read routine prototypes: 1.5.4.
The following exercise lets you implement a sorting algorithm with the send-receive call1.
Figure 4.9: Odd-even transposition sort on 4 elements.
Exercise 4.13. A very simple sorting algorithm is swap sort or odd-even transposition sort :pairs of processors compare data, and if necessary exchange. The elementary step iscalled a compare-and-swap: in a pair of processors each sends their data to the other;one keeps the minimum values, and the other the maximum. For simplicity, in thisexercise we give each processor just a single number.The exchange sort algorithm is split in even and odd stages, where in the even stage,processors 2i and 2i+ 1 compare and swap data, and in the odd stage, processors2i+ 1 and 2i+ 2 compare and swap. You need to repeat this P/2 times, where P isthe number of processors; see figure 4.9.Implement this algorithm using MPI_Sendrecv. (Use MPI_PROC_NULL for the edgecases if needed.) Use a gather call to print the global state of the distributed array atthe beginning and end of the sorting process.
Exercise 4.14. Extend this exercise to the case where each process hold an equal number ofelements, more than 1. Consider figure 4.10 for inspiration. Is it coincidence that thealgorithm takes the same number of steps as in the single scalar case?
4.2.5 Message statusIn section 4.2.1 you saw that MPI_Receive has a ‘status’ argument of type MPI_STATUS that MPI_Sendlacks.
1. There is an MPI Compare and swap call. Do not use that.
84 Parallel Computing – r428

4.2. Blocking point-to-point operations
Figure 4.10: Odd-even transposition sort on 4 processes, holding 2 elements each.
C:MPI_Status status;
Fortran:integer :: status(MPI_STATUS_SIZE)
Fortran2008:type(MPI_Status) :: recv_status
Python:MPI.Status() # returns object
How to read routine prototypes: 1.5.4.
(The various MPI_Wait... routines also have a status argument; see section 4.3.2.) The reason for thisargument is as follows.
In some circumstances the recipient may not know all details of a message when you make the receive call,so MPI has a way of querying the status of the message:
• If you are expecting multiple incoming messages, it may be most efficient to deal with them inthe order in which they arrive. So, instead of waiting for specific message, you would specifyMPI_ANY_SOURCE or MPI_ANY_TAG in the description of the receive message. Now you have to beable to ask ‘who did this message come from, and what is in it’.• Maybe you know the sender of a message, but the amount of data is unknown. In that case you
can overallocate your receive buffer, and after the message is received ask how big it was, or youcan ‘probe’ an incoming message and allocate enough data when you find out how much data isbeing sent.
If you precisely know what is going to be sent, the status argument tells you nothing new. Therefore, thereis a special value MPI_STATUS_IGNORE that you can supply instead of a status object, which tells MPI that
Victor Eijkhout 85

4. MPI topic: Point-to-point
Figure 4.11: Processors with unbalanced send/receive patterns
the status does not have to be reported. For routines such as MPI_Waitany where an array of statuses isneeded, you can supply MPI_STATUSES_IGNORE.
This subject is further discussed in section 4.4.2.
4.3 Non-blocking point-to-point operations
4.3.1 Irregular data exchange
The structure of communication is often a reflection of the structure of the operation. With some regularapplications we also get a regular communication pattern. Consider again the above operation:
yi = xi−1 + xi + xi+1 : i = 1, . . . , N − 1
Doing this in parallel induces communication, as pictured in figure 4.2.
We note:
• The data is one-dimensional, and we have a linear ordering of the processors.• The operation involves neighbouring data points, and we communicate with neighbouring pro-
cessors.
Above you saw how you can use information exchange between pairs of processors
• using MPI_Send and MPI_Recv, if you are careful; or• using MPI_Sendrecv, as long as there is indeed some sort of pairing of processors.
However, there are circumstances where it is not possible, not efficient, or simply not convenient, to havesuch a deterministic setup of the send and receive calls. Figure 4.11 illustrates such a case, where processorsare organized in a general graph pattern. Here, the numbers of sends and receive of a processor do not needto match.
In such cases, one wants a possibility to state ‘these are the expected incoming messages’, without havingto wait for them in sequence. Likewise, one wants to declare the outgoing messages without having to dothem in any particular sequence. Imposing any sequence on the sends and receives is likely to run intothe serialization behaviour observed above, or at least be inefficient since processors will be waiting formessages.
86 Parallel Computing – r428

4.3. Non-blocking point-to-point operations
4.3.2 Non-blocking communication
In the previous section you saw that blocking communication makes programming tricky if you want toavoid deadlock and performance problems. The main advantage of these routines is that you have fullcontrol about where the data is: if the send call returns the data has been successfully received, and the sendbuffer can be used for other purposes or de-allocated.
Figure 4.12: Non-blocking send
By contrast, the non-blocking calls MPI_Isend and MPI_Irecv do not wait for their counterpart: in effectthey tell the runtime system ‘here is some data and please send it as follows’ or ‘here is some buffer space,and expect such-and-such data to come’. This is illustrated in figure 4.12. Issuing the Isend/Irecv callis sometimes referred to as posting a send/receive.
C:int MPI_Isend(void *buf,int count, MPI_Datatype datatype, int dest, int tag,MPI_Comm comm, MPI_Request *request)
Fortran:the request parameter is an integer
Python:request = MPI.Comm.Isend(self, buf, int dest, int tag=0)
How to read routine prototypes: 1.5.4.
C:int MPI_Irecv(
void* buf, int count, MPI_Datatype datatype,int source, int tag, MPI_Comm comm, MPI_Request *request)
Semantics:OUT buf: initial address of receive buffer (choice)IN count: number of elements in receive buffer (non-negative integer)IN datatype: datatype of each receive buffer element (handle)IN source: rank of source or MPI_ANY_SOURCE (integer)IN tag: message tag or MPI_ANY_TAG (integer)
Victor Eijkhout 87

4. MPI topic: Point-to-point
IN comm: communicator (handle)OUT request: request object (Request)
Fortran:MPI_Irecv(buf, count, datatype, source, tag, comm, request, ierror)TYPE(*), DIMENSION(..) :: bufINTEGER, INTENT(IN) :: count, source, tagTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Request), INTENT(out) :: requestINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python native:recvbuf = Comm.irecv(self, buf=None, int source=ANY_SOURCE, int tag=ANY_TAG,
Request request=None)Python numpy:Comm.Irecv(self, buf, int source=ANY_SOURCE, int tag=ANY_TAG,
Request status=None)
How to read routine prototypes: 1.5.4.
4.3.2.1 Request completion
From the definition of MPI_Isend / MPI_Irecv, you seen that non-blocking routinew yields an MPI_Request
object. This request can then be used to query whether the operation has concluded. You may also notice thatthe MPI_Irecv routine does not yield an MPI_Status object. This makes sense: the status object describesthe actually received data, and at the completion of the MPI_Irecv call there is no received data yet.
C:MPI_Request request ;
Fortran2008:Type(MPI_Request) :: request
How to read routine prototypes: 1.5.4.
Waiting for the request is done with a number of routines. We first consider MPI_Wait. It takes the re-quest as input, and gives an MPI_Status as output. If you don’t need the status object, you can passMPI_STATUS_IGNORE.
Semantics:MPI_Wait( request, status)
INOUT request: request object (handle)OUT status: status objects (handle)
C:int MPI_Wait(
88 Parallel Computing – r428

4.3. Non-blocking point-to-point operations
MPI_Request *requests,MPI_Status *statuses)
Fortran:MPI_Wait( request, status, ierror)TYPE(MPI_Request), INTENT(INOUT) :: requestsTYPE(MPI_Status),INTENT(OUT) :: statusesINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Request.Wait(type cls, request, status=None)
Use MPI_STATUS_IGNORE to ignore
How to read routine prototypes: 1.5.4.
Note that the request is passed by reference, so that the wait routine can free it.
4.3.2.2 Buffer issues in non-blocking communication
While the use of non-blocking routines prevents deadlock, it introduces two new problems:1. When the send call returns, the actual send may not have been executed, so the send buffer may
not be safe to overwrite. When the recv call returns, you do not know for sure that the expecteddata is in it. Thus, you need a mechanism to make sure that data was actually sent or received.
2. With a blocking send call, you could repeatedly fill the send buffer and send it off.double *buffer;for ( ... p ... ) {
buffer = // fill in the dataMPI_Send( buffer, ... /* to: */ p );
To send multiple messages with non-blocking calls you have to allocate multiple buffers.double **buffers;for ( ... p ... ) {
buffers[p] = // fill in the dataMPI_Send( buffers[p], ... /* to: */ p );
// irecvloop.cMPI_Request requests =(MPI_Request*) malloc( 2*nprocs*sizeof(MPI_Request) );
recv_buffers = (int*) malloc( nprocs*sizeof(int) );send_buffers = (int*) malloc( nprocs*sizeof(int) );for (int p=0; p<nprocs; p++) {int left_p = (p-1) % nprocs,
right_p = (p+1) % nprocs;send_buffer[p] = nprocs-p;MPI_Isend(sendbuffer+p,1,MPI_INT, right_p,0, requests+2*p);MPI_Irecv(recvbuffer+p,1,MPI_INT, left_p,0, requests+2*p+1);
}/* your useful code here */MPI_Waitall(2*nprocs,requests,MPI_STATUSES_IGNORE);
Victor Eijkhout 89

4. MPI topic: Point-to-point
4.3.2.3 More wait calls
MPI has two types of routines for handling requests; we will start with the MPI_Wait... routines. Thesecalls are blocking: when you issue such a call, your execution will wait until the specified requests havebeen completed. A typical way of using them is:
// start non-blocking communicationMPI_Isend( ... ); MPI_Irecv( ... );// wait for the Isend/Irecv calls to finish in any orderMPI_Waitall( ... );
Semantics:MPI_WAITALL( count, array_of_requests, array_of_statuses)IN count: lists length (non-negative integer)INOUT array_of_requests: array of requests (array of handles)OUT array_of_statuses: array of status objects (array of Status)
C:int MPI_Waitall(
int count, MPI_Request array_of_requests[],MPI_Status array_of_statuses[])
Fortran:MPI_Waitall(count, array_of_requests, array_of_statuses, ierror)INTEGER, INTENT(IN) :: countTYPE(MPI_Request), INTENT(INOUT) :: array_of_requests(count)TYPE(MPI_Status) :: array_of_statuses(*)INTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Request.Waitall(type cls, requests, statuses=None)
Use MPI_STATUSES_IGNORE to ignore
How to read routine prototypes: 1.5.4.
If you don’t need the status objects, you can pass MPI_STATUSES_IGNORE.Exercise 4.15. Revisit exercise 4.10 and consider replacing the blocking calls by
non-blocking ones. How far apart can you put the MPI_Isend / MPI_Irecv calls andthe corresponding MPI_Waits?
4.3.2.4 Receive status of the wait calls
The MPI_Wait... routines have the MPI_Status objects as output. If you are not interested in the status in-formation, you can use the values MPI_STATUS_IGNORE for MPI_Wait and MPI_Waitany, or MPI_STATUSES_IGNOREfor MPI_Waitall and MPI_Waitsome.Exercise 4.16. Now use nonblocking send/receive routines to implement the three-point
averaging operation
yi =(xi−1 + xi + xi+1
)/3: i = 1, . . . , N − 1
90 Parallel Computing – r428

4.3. Non-blocking point-to-point operations
on a distributed array. (Hint: use MPI_PROC_NULL at the ends.)
There is a second motivation for the Isend/Irecv calls: if your hardware supports it, the communicationcan progress while your program can continue to do useful work:
// start non-blocking communicationMPI_Isend( ... ); MPI_Irecv( ... );// do work that does not depend on incoming data....// wait for the Isend/Irecv calls to finishMPI_Wait( ... );// now do the work that absolutely needs the incoming data....
This is known as overlapping computation and communication, or latency hiding .
Unfortunately, a lot of this communication involves activity in user space, so the solution would have beento let it be handled by a separate thread. Until recently, processors were not efficient at doing such multi-threading, so true overlap stayed a promise for the future. Some network cards have support for this overlap,but it requires a non-trivial combination of hardware, firmware, and MPI implementation.
Exercise 4.17. Take your code of exercise 4.16 and modify it to use latency hiding.Operations that can be performed without needing data from neighbours should beperformed in between the MPI_Isend / MPI_Irecv calls and the correspondingMPI_Wait calls.
Remark 2 There is nothing special about a non-blocking or synchronous message. The MPI_Recv call canmatch any of the send routines you have seen so far (but not MPI_Sendrecv), and conversely a messagesent with MPI_Send can be received by MPI_Irecv.
4.3.2.5 Asynchronous progress
Above we saw that Isend/Irecv calls can overlap communication and computation. However, for thisto happen we need for the MPI implementation to make asynchronous progress: the message needs to makeits way through the network while the application is busy computing. However, communication of this sortcan typically not be off-loaded to the network card, so different mechanisms are needed.
This can happen in a number of ways:
• Compute nodes may have a dedicated communications processor. The Intel Paragon was of thisdesign; modern multicore processors are a more efficient realization of this idea.• The MPI library may reserve a core or thread for communications processing. This is implemen-
tation dependent; for instance, Intel MPI has a number of I_MPI_ASYNC_PROGRESS_...variables.• Absent such dedicated resources, the application can force MPI to make progress by occasional
calls to a polling routine such as MPI_Iprobe.
A similar problem arises with passive target synchronization: it is possible that the origin process may hanguntil the target process makes an MPI call.
Victor Eijkhout 91

4. MPI topic: Point-to-point
4.3.2.6 Wait and test calls
There are several wait calls: you can wait for a single request, all outstanding requests, or any of theoutstanding requests.
MPI_Wait waits for a a single request. If you are indeed waiting for a single nonblocking communicationto complete, this is the right routine. If you are waiting for multiple requests you could call this routine ina loop.
for (p=0; p<nrequests ; p++) // Not efficient!MPI_Wait(request[p],&(status[p]));
However, this would be inefficient if the first request is fulfilled much later than the others: your waitingprocess would have lots of idle time. In that case, use one of the following routines.
MPI_Waitall allows you to wait for a number of requests, and it does not matter in what sequence they aresatisfied. Using this routine is easier to code than the loop above, and it could be more efficient.
Semantics:MPI_WAITALL( count, array_of_requests, array_of_statuses)IN count: lists length (non-negative integer)INOUT array_of_requests: array of requests (array of handles)OUT array_of_statuses: array of status objects (array of Status)
C:int MPI_Waitall(
int count, MPI_Request array_of_requests[],MPI_Status array_of_statuses[])
Fortran:MPI_Waitall(count, array_of_requests, array_of_statuses, ierror)INTEGER, INTENT(IN) :: countTYPE(MPI_Request), INTENT(INOUT) :: array_of_requests(count)TYPE(MPI_Status) :: array_of_statuses(*)INTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Request.Waitall(type cls, requests, statuses=None)
Use MPI_STATUSES_IGNORE to ignore
How to read routine prototypes: 1.5.4.
The ‘waitall’ routine is good if you need all nonblocking communications to be finished before you canproceed with the rest of the program. However, sometimes it is possible to take action as each request issatisfied. In that case you could use MPI_Waitany and write:
for (p=0; p<nrequests; p++) {MPI_Waitany(nrequests,request_array,&index,&status);// operate on buffer[index]
}
92 Parallel Computing – r428

4.3. Non-blocking point-to-point operations
Note that this routine takes a single status argument, passed by reference, and not an array of statuses!Semantics:int MPI_Waitany(
int count, MPI_Request array_of_requests[], int *index,MPI_Status *status)
IN count: list length (non-negative integer)INOUT array_of_requests: array of requests (array of handles)OUT index: index of handle for operation that completed (integer)OUT status: status object (Status)
C:MPI_Waitany(count, array_of_requests, index, status, ierror)
Fortran:INTEGER, INTENT(IN) :: countTYPE(MPI_Request), INTENT(INOUT) :: array_of_requests(count)INTEGER, INTENT(OUT) :: indexTYPE(MPI_Status) :: statusINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Request.Waitany( requests,status=None )class method, returns index
How to read routine prototypes: 1.5.4.
Finally, MPI_Waitsome is very much like Waitany, except that it returns multiple numbers, if multiplerequests are satisfied. Now the status argument is an array of MPI_STATUS objects.
Figure 4.13 shows the trace of a non-blocking execution using MPI_Waitall.
4.3.2.7 Implementing polling with Waitany
The MPI_Waitany routine can be used to implement polling: occasionally check for incoming messageswhile other work is going on.
// irecv_source.cif (procno==nprocs-1) {int *recv_buffer;MPI_Request *request; MPI_Status status;recv_buffer = (int*) malloc((nprocs-1)*sizeof(int));request = (MPI_Request*) malloc((nprocs-1)*sizeof(MPI_Request));
for (int p=0; p<nprocs-1; p++) {ierr = MPI_Irecv(recv_buffer+p,1,MPI_INT, p,0,comm,
request+p); CHK(ierr);}for (int p=0; p<nprocs-1; p++) {
int index,sender;
Victor Eijkhout 93

4. MPI topic: Point-to-point
Figure 4.13: A trace of a nonblocking send between neighbouring processors
MPI_Waitany(nprocs-1,request,&index,&status); //MPI_STATUS_IGNORE);if (index!=status.MPI_SOURCE)
printf("Mismatch index %d vs source %d\n",index,status.MPI_SOURCE);printf("Message from %d: %d\n",index,recv_buffer[index]);
}} else {ierr = MPI_Send(&procno,1,MPI_INT, nprocs-1,0,comm); CHK(ierr);
}
## irecv_source.pyif procid==nprocs-1:
receive_buffer = np.empty(nprocs-1,dtype=np.int)requests = [ None ] * (nprocs-1)for sender in range(nprocs-1):
requests[sender] = comm.Irecv(receive_buffer[sender:sender+1],source=sender)# alternatively: requests = [ comm.Irecv(s) for s in .... ]status = MPI.Status()for sender in range(nprocs-1):
ind = MPI.Request.Waitany(requests,status=status)if ind!=status.Get_source():
print "sender mismatch: %d vs %d" % (ind,status.Get_source())print "received from",ind
else:mywait = random.randint(1,2*nprocs)print "[%d] wait for %d seconds" % (procid,mywait)time.sleep(mywait)mydata = np.empty(1,dtype=np.int)mydata[0] = procidcomm.Send([mydata,MPI.INT],dest=nprocs-1)
Each process except for the root does a blocking send; the root posts MPI_Irecv from all other processors,
94 Parallel Computing – r428

4.3. Non-blocking point-to-point operations
then loops with MPI_Waitany until all requests have come in. Use MPI_SOURCE to test the index parameterof the wait call.
Note the MPI_STATUS_IGNORE parameter: we know everything about the incoming message, so we do notneed to query a status object. Contrast this with the example in section 37.3.
Python note. In python creating the array for the returned requests is somewhattricky.
## irecvloop.pyrequests = [ None ] * (2*nprocs)sendbuffer = np.empty( nprocs, dtype=np.int )recvbuffer = np.empty( nprocs, dtype=np.int )
for p in range(nprocs):left_p = (p-1) % nprocsright_p = (p+1) % nprocsrequests[2*p] = comm.Isend( sendbuffer[p:p+1],dest=left_p)requests[2*p+1] = comm.Irecv( sendbuffer[p:p+1],source=right_p)
MPI.Request.Waitall(requests)
Fortran note. The index parameter is the index in the array of requests, so it uses1-based indexing .
// irecv_source.F90if (mytid==ntids-1) then
do p=1,ntids-1print *,"post"call MPI_Irecv(recv_buffer(p),1,MPI_INTEGER,p-1,0,comm
,&requests(p),err)
end dodo p=1,ntids-1
call MPI_Waitany(ntids-1,requests,index,MPI_STATUS_IGNORE,err)
write(*,’("Message from",i3,":",i5)’) index,recv_buffer(index)end do
4.3.2.8 Test: non-blocking request wait
The MPI_Wait... routines are blocking. Thus, they are a good solution if the receiving process cannot do anything until the data (or at least some data) is actually received. The MPI_Test.... calls arethemselves non-blocking: they test for whether one or more requests have been fullfilled, but otherwiseimmediately return. This can be used in the manager-worker model : the manager process creates tasks, andsends them to whichever worker process has finished its work. (This uses a receive from MPI_ANY_SOURCE,and a subsequent test on the MPI_SOURCE field of the receive status.) While waiting for the workers, themanager can do useful work too, which requires a periodic check on incoming message.
Pseudo-code:
Victor Eijkhout 95

4. MPI topic: Point-to-point
while ( not done ) {// create new inputs for a while....// see if anyone has finishedMPI_Test( .... &index, &flag );if ( flag ) {
// receive processed data and send new}
C:int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)
Input Parametersrequest : MPI request (handle)
Output Parametersflag : true if operation completed (logical)status : status object (Status). May be MPI_STATUS_IGNORE.
Python:reqest.Test()
How to read routine prototypes: 1.5.4.
C:int MPI_Testany(
int count, MPI_Request array_of_requests[],int *index, int *flag, MPI_Status *status)
Fortran:
MPI_Testany(count, array_of_requests, index, flag, status, ierror)INTEGER, INTENT(IN) :: countTYPE(MPI_Request), INTENT(INOUT) :: array_of_requests(count)INTEGER, INTENT(OUT) :: indexLOGICAL, INTENT(OUT) :: flagTYPE(MPI_Status) :: statusINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
Semantics:MPI_TESTALL(count, array_of_requests, flag, array_of_statuses)IN countlists length (non-negative integer)INOUT array_of_requestsarray of requests (array of handles)OUT flag(logical)OUT array_of_statusesarray of status objects (array of Status)
C:int MPI_Testall(
int count, MPI_Request array_of_requests[],
96 Parallel Computing – r428

4.4. More about point-to-point communication
int *flag, MPI_Status array_of_statuses[])
Fortran:MPI_Testall(count, array_of_requests, flag, array_of_statuses, ierror)INTEGER, INTENT(IN) :: countTYPE(MPI_Request), INTENT(INOUT) :: array_of_requests(count)LOGICAL, INTENT(OUT) :: flagTYPE(MPI_Status) :: array_of_statuses(*)INTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
Exercise 4.18. Read section HPSC-6.5 and give pseudo-code for the distributed sparsematrix-vector product using the above idiom for using MPI_Test... calls.Discuss the advantages and disadvantages of this approach. The answer is not goingto be black and white: discuss when you expect which approach to be preferable.
4.3.2.9 More about requests
Every non-blocking call allocates an MPI_Request object. One effect of the various MPI_Wait... callsis to deallocate these objects. Thus, it is wise to issue wait calls even if you know that the operation hassucceeded. For instance, if all receive calls are concluded, you know that the corresponding send calls arefinished and there is no strict need to wait for their requests. However, omitting the wait calls would lead toa memory leak.
Another way around this is to call MPI_Request_free, which sets the request variable to MPI_REQUEST_NULL
, and marks the object for deallocation after completion of the operation.
Note that MPI_Test... routines also deallocates the request object, setting the handle to MPI_REQUEST_NULL
, but MPI_Request_get_status does not alter the request handle or object.
4.4 More about point-to-point communication
4.4.1 Message probing
MPI receive calls specify a receive buffer, and its size has to be enough for any data sent. In case you reallyhave no idea how much data is being sent, and you don’t want to overallocate the receive buffer, you canuse a ‘probe’ call.
The routine MPI_Probe (and MPI_Iprobe, for which see section 4.3.2.5), accepts a message, but does notcopy the data. Instead, when probing tells you that there is a message, you can use MPI_Get_count todetermine its size, allocate a large enough receive buffer, and do a regular receive to have the data copied.
// probe.cif (procno==receiver) {MPI_Status status;MPI_Probe(sender,0,comm,&status);int count;
Victor Eijkhout 97

4. MPI topic: Point-to-point
MPI_Get_count(&status,MPI_FLOAT,&count);float recv_buffer[count];MPI_Recv(recv_buffer,count,MPI_FLOAT, sender,0,comm,MPI_STATUS_IGNORE);
} else if (procno==sender) {float buffer[buffer_size];ierr = MPI_Send(buffer,buffer_size,MPI_FLOAT, receiver,0,comm); CHK(ierr);
}
int MPI_Probe( int source, int tag, MPI_Comm comm,MPI_Status *status )
int MPI_Iprobe(int source, int tag, MPI_Comm comm, int *flag,MPI_Status *status)
Input parameters:source : source rank, or MPI_ANY_SOURCE (integer)tag : tag value or MPI_ANY_TAG (integer)comm : communicator (handle)
Output parameter:flag : True if a message with the specified
source, tag, and communicator is availablestatus : message status
How to read routine prototypes: 1.5.4.
There is a problem with the MPI_Probe call in a multithreaded environment: the following scenario canhappen.
1. A thread determines by probing that a certain message has come in.2. It issues a blocking receive call for that message. . .3. But in between the probe and the receive call another thread has already received the message.4. . . . Leaving the first thread in a blocked state with not message to receive.
This is solved by MPI_Mprobe, which after a successful probe removes the message from the matchingqueue: the list of messages that can be matched by a receive call. The thread that matched the probe nowissues an MPI_Mrecv call on that message through an object of type MPI_Message.
int MPI_Mprobe(int source, int tag, MPI_Comm comm,MPI_Message *message, MPI_Status *status)
Input Parameters:source - rank of source or MPI_ANY_SOURCE (integer)tag - message tag or MPI_ANY_TAG (integer)comm - communicator (handle)
Output Parameters:
message - returned message (handle)status - status object (status)
98 Parallel Computing – r428

4.4. More about point-to-point communication
How to read routine prototypes: 1.5.4.
int MPI_Mrecv(void *buf, int count, MPI_Datatype type,MPI_Message *message, MPI_Status *status)
Input Parameters:count - Number of elements to receive (nonnegative integer).datatype - Datatype of each send buffer element (handle).message - Message (handle).
Output Parameters:buf - Initial address of receive buffer (choice).status - Status object (status).IERROR - Fortran only: Error status (integer).
MPI_MRECV(BUF, COUNT, DATATYPE, MESSAGE, STATUS, IERROR)<type> BUF(*)
INTEGER COUNT, DATATYPE, MESSAGEINTEGER STATUS(MPI_STATUS_SIZE), IERROR
How to read routine prototypes: 1.5.4.
4.4.2 The Status object and wildcards
With some receive calls you know everything about the message in advance: its source, tag, and size. Inother cases you want to leave some options open, and inspect the message for them after it was received.To do this, the receive call has a MPI_Status parameter. This was discussed in section 4.2.5.
This status is a property of the actually received messsage, so MPI_Irecv does not have a status parameter,but MPI_Wait does.
The MPI_Status object is a structure with the following freely accessible members:
4.4.2.1 Source
In some applications it makes sense that a message can come from one of a number of processes. In thiscase, it is possible to specify MPI_ANY_SOURCE as the source. To find out the source where the messageactually came from, you would use the MPI_SOURCE field of the status object that is delivered by MPI_Recv
or the MPI_Wait... call after an MPI_Irecv.
MPI_Recv(recv_buffer+p,1,MPI_INT, MPI_ANY_SOURCE,0,comm,&status);
sender = status.MPI_SOURCE;
The source of a message is a member of the status structure.Semantics:MPI_SOURCE is the name of an integer fieldin an MPI_STATUS structure
Victor Eijkhout 99

4. MPI topic: Point-to-point
C:status.MPI_SOURCE // is int
F:status_object%MPI_SOURCE ! is integer
Python:status.Get_source() # returns int
How to read routine prototypes: 1.5.4.
There are various scenarios where receiving from ‘any source’ makes sense. One is that of the master-worker model . The master task would first send data to the worker tasks, then issues a blocking wait forthe data of whichever process finishes first.
4.4.2.2 Tag
If a processor is expecting more than one messsage from a single other processor, message tags are used todistinguish between them. In that case, a value of MPI_ANY_TAG can be used, and the actual tag of a messagecan be retrieved from the status structure.
C:int status.MPI_TAG;
F:integer :: MPI_TAG
Python:status.Get_tag() # returns int
How to read routine prototypes: 1.5.4.
4.4.2.3 Error
Any errors during the receive operation can be found in the status structurelC:int status.MPI_ERROR;
F:integer :: MPI_ERROR
Python:status.Get_error() # returns int
How to read routine prototypes: 1.5.4.
100 Parallel Computing – r428

4.4. More about point-to-point communication
4.4.2.4 Count
If the amount of data received is not known a priori, the count of elements received can be found as
MPI_Get_count(&recv_status,MPI_INT,&recv_count);
This may be necessary since the count argument to MPI_Recv is the buffer size, not an indication of theactually expected number of data items.
Note that unlike the above this is not directly a member of the status structure.// C:int MPI_Get_count(MPI_Status *status,MPI_Datatype datatype,
int *count)
! Fortran:MPI_Get_count(INTEGER status(MPI_STATUS_SIZE),INTEGER datatype,
INTEGER count,INTEGER ierror)
Python:status.Get_count( Datatype datatype=BYTE )
How to read routine prototypes: 1.5.4.
4.4.2.5 Example: receiving from any source
Using the MPI_ANY_SOURCE specifier. We retrieve the actual source from the MPI_Status object throughthe MPI_SOURCE field.
// anysource.cif (procno==nprocs-1) {int *recv_buffer;MPI_Status status;
recv_buffer = (int*) malloc((nprocs-1)*sizeof(int));
for (int p=0; p<nprocs-1; p++) {err = MPI_Recv(recv_buffer+p,1,MPI_INT, MPI_ANY_SOURCE,0,comm,
&status); CHK(err);int sender = status.MPI_SOURCE;printf("Message from sender=%d: %d\n",
sender,recv_buffer[p]);}
} else {float randomfraction = (rand() / (double)RAND_MAX);int randomwait = (int) ( nprocs * randomfraction );printf("process %d waits for %e/%d=%d\n",
procno,randomfraction,nprocs,randomwait);sleep(randomwait);err = MPI_Send(&randomwait,1,MPI_INT, nprocs-1,0,comm); CHK(err);
}
Victor Eijkhout 101

4. MPI topic: Point-to-point
## anysource.pyrstatus = MPI.Status()comm.Recv(rbuf,source=MPI.ANY_SOURCE,status=rstatus)print "Message came from %d" % rstatus.Get_source()
In sections 37.3 and 4.3.2.8 we explained the manager-worker model, and how it offers an opportunity forinspecting the MPI_SOURCE field of the MPI_Status object describing the data that was received.
4.4.3 Synchronous and asynchronous communication
It is easiest to think of blocking as a form of synchronization with the other process, but that is not quitetrue. Synchronization is a concept in itself, and we talk about synchronous communication if there is actualcoordination going on with the other process, and asynchronous communication if there is not. Blockingthen only refers to the program waiting until the user data is safe to reuse; in the synchronous case ablocking call means that the data is indeed transferred, in the asynchronous case it only means that the datahas been transferred to some system buffer. The four possible cases are illustrated in figure 4.14.
Figure 4.14: Blocking and synchronicity
MPI has a number of routines for synchronous communication, such as MPI_Ssend.// ssendblock.cother = 1-procno;sendbuf = (int*) malloc(sizeof(int));recvbuf = (int*) malloc(sizeof(int));size = 1;MPI_Ssend(sendbuf,size,MPI_INT,other,0,comm);MPI_Recv(recvbuf,size,MPI_INT,other,0,comm,&status);printf("This statement is not reached\n");
102 Parallel Computing – r428

4.4. More about point-to-point communication
4.4.4 Persistent communication
An MPI_Isend or MPI_Irecv call has an MPI_Request parameter. This is an object that gets created in thesend/recv call, and deleted in the wait call. You can imagine that this carries some overhead, and if the samecommunication is repeated many times you may want to avoid this overhead by reusing the request object.
To do this, MPI has persistent communication:
• You describe the communication with MPI_Send_init, which has the same calling sequence asMPI_Isend, or MPI_Recv_init, which has the same calling sequence as MPI_Irecv.• The actual communication is performed by calling MPI_Start, for a single request, or MPI_Startall
for an array or requests.• Completion of the communication is confirmed with MPI_Wait or similar routines as you have
seen in the explanation of non-blocking communication.• The wait call does not release the request object: that is done with MPI_Request_free.
The calls MPI_Send_init and MPI_Recv_init for creating a persistent communication have the same syn-tax as those for non-blocking sends and receives. The difference is that they do not start an actual commu-nication, they only create the request object.
C:int MPI_Send_init(const void* buf, int count, MPI_Datatype datatype,int dest, int tag, MPI_Comm comm, MPI_Request *request)
Fortran:MPI_Send_init(buf, count, datatype, dest, tag, comm, request, ierror)TYPE(*), DIMENSION(..), INTENT(IN), ASYNCHRONOUS :: bufINTEGER, INTENT(IN) :: count, dest, tagTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Request), INTENT(OUT) :: requestINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Comm.Send_init(self, buf, int dest, int tag=0)
Semantics:IN buf: initial address of send buffer (choice)IN count: number of elements sent (non-negative integer)IN datatype: type of each element (handle)IN dest: rank of destination (integer)IN tag: message tag (integer)IN comm: communicator (handle)OUT request: communication request (handle)
How to read routine prototypes: 1.5.4.
C:int MPI_Recv_init(
void* buf, int count, MPI_Datatype datatype,
Victor Eijkhout 103

4. MPI topic: Point-to-point
int source, int tag, MPI_Comm comm, MPI_Request *request)
Fortran:MPI_Recv_init(buf, count, datatype, source, tag, comm, request,ierror)TYPE(*), DIMENSION(..), ASYNCHRONOUS :: bufINTEGER, INTENT(IN) :: count, source, tagTYPE(MPI_Datatype), INTENT(IN) :: datatypeTYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Request), INTENT(OUT) :: requestINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Comm.Recv_init(
self, buf, int source=ANY_SOURCE, int tag=ANY_TAG)
Semantics:OUT buf: initial address of receive buffer (choice)IN count: number of elements received (non-negative integer)IN datatype: type of each element (handle)IN source: rank of source or MPI_ANY_SOURCE (integer)IN tag: message tag or MPI_ANY_TAG (integer)IN com: mcommunicator (handle)OUT request: communication request (handle)
How to read routine prototypes: 1.5.4.
Given these request object, a communication (both send and receive) is then started with MPI_Start for asingle request or MPI_Start_all for multiple requests, given in an array.
C:int MPI_Start(MPI_Request request)
Fortran:MPI_Start(request, ierror)TYPE(MPI_Request), INTENT(INOUT) :: requestINTEGER, OPTIONAL, INTENT(OUT) :: ierror
MPI_START(REQUEST, IERROR)INTEGER REQUESTS, IERROR
Python:MPI.Prequest.Start(type cls, request)
Semantics:INOUT request : request (handle)
How to read routine prototypes: 1.5.4.C:int MPI_Startall(int count, MPI_Request array_of_requests[])
104 Parallel Computing – r428

4.4. More about point-to-point communication
Fortran:MPI_Startall(count, array_of_requests, ierror)INTEGER, INTENT(IN) :: countTYPE(MPI_Request), INTENT(INOUT) :: array_of_requests(count)INTEGER, OPTIONAL, INTENT(OUT) :: ierrorMPI_STARTALL(COUNT, ARRAY_OF_REQUESTS, IERROR)INTEGER COUNT, ARRAY_OF_REQUESTS(*), IERROR
Python:MPI.Prequest.Startall(type cls, requests)
Semantics:IN countlist length (non-negative integer)INOUT array_of_requestsarray of requests (array of handle)
How to read routine prototypes: 1.5.4.
These are equivalent to starting an MPI_Isend or MPI_Isend; correspondingly, it is necessary to issue anMPI_Wait... call (section 4.3.2) to determine their completion.
After a request object has been used, possibly multiple times, it can be freed; see 4.4.6.
In the following example a ping-pong is implemented with persistent communication.// persist.cif (procno==src) {MPI_Send_init(send,s,MPI_DOUBLE,tgt,0,comm,requests+0);MPI_Recv_init(recv,s,MPI_DOUBLE,tgt,0,comm,requests+1);printf("Size %d\n",s);t[cnt] = MPI_Wtime();for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Startall(2,requests);MPI_Waitall(2,requests,MPI_STATUSES_IGNORE);
}t[cnt] = MPI_Wtime()-t[cnt];MPI_Request_free(requests+0); MPI_Request_free(requests+1);
} else if (procno==tgt) {for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Recv(recv,s,MPI_DOUBLE,src,0,comm,MPI_STATUS_IGNORE);MPI_Send(recv,s,MPI_DOUBLE,src,0,comm);
}}
## persist.pysendbuf = np.ones(size,dtype=np.int)recvbuf = np.ones(size,dtype=np.int)if procid==src:
print "Size:",sizetimes[isize] = MPI.Wtime()for n in range(nexperiments):
requests[0] = comm.Isend(sendbuf[0:size],dest=tgt)requests[1] = comm.Irecv(recvbuf[0:size],source=tgt)
Victor Eijkhout 105

4. MPI topic: Point-to-point
MPI.Request.Waitall(requests)sendbuf[0] = sendbuf[0]+1
times[isize] = MPI.Wtime()-times[isize]elif procid==tgt:
for n in range(nexperiments):comm.Recv(recvbuf[0:size],source=src)comm.Send(recvbuf[0:size],dest=src)
As with ordinary send commands, there are the variants MPI_Bsend_init, MPI_Ssend_init, MPI_Rsend_init.
4.4.5 Buffered communication
Figure 4.15: User communication routed through an attached buffer
By now you have probably got the notion that managing buffer space in MPI is important: data has tobe somewhere, either in user-allocated arrays or in system buffers. Using buffered communication is yetanother way of managing buffer space.
1. You allocate your own buffer space, and you attach it to your process. This buffer is not a sendbuffer: it is a replacement for buffer space used inside the MPI library or on the network card;figure 4.15. If high-bandwdith memory is available, you could create your buffer there.
2. You use the MPI_Bsend call for sending, using otherwise normal send and receive buffers;3. You detach the buffer when you’re done with the buffered sends.
4.4.5.1 Bufferend send calls
Section 4.3 discusses non-blocking communication, where multiple sends will be under way. Since thesesends are under way with possibly no receive having been posted, the send buffers can not be reused. Itwould be possible to reuse the send buffers if MPI had enough internal buffer space. For this, there is thebuffered send mode, where you first give MPI internal buffer space; subsequently only a single send bufferis needed. The MPI_Bsend call is non-blocking.
C:int MPI_Bsend
(const void *buf, int count, MPI_Datatype datatype,
106 Parallel Computing – r428

4.4. More about point-to-point communication
int dest, int tag,MPI_Comm comm)
Input Parametersbuf : initial address of send buffer (choice)count : number of elements in send buffer (nonnegative integer)datatype : datatype of each send buffer element (handle)dest : rank of destination (integer)tag : message tag (integer)comm : communicator (handle)
How to read routine prototypes: 1.5.4.
There can be only one buffer per process; its size should be enough for all outstanding MPI_Bsend calls thatare simultaneously outstanding, plus MPI_BSEND_OVERHEAD. You can compute the needed size of the bufferwith MPI_Pack_size; see section 5.4.3.
int MPI_Buffer_attach( void *buffer, int size );
Input arguments:buffer : initial buffer address (choice)size : buffer size, in bytes (integer)
How to read routine prototypes: 1.5.4.
The possible error codes are
• MPI_SUCCESS the routine completed successfully.• MPI_ERR_BUFFER The buffer pointer is invalid; this typically means that you have supplied a null
pointer.• MPI_ERR_INTERN An internal error in MPI has been detected.
The buffer is detached with MPI_Buffer_detach:
int MPI_Buffer_detach(void *buffer, int *size);
This returns the address and size of the buffer; the call blocks until all buffered messages have been deliv-ered.
You can force delivery by
MPI_Buffer_detach( &b, &n );MPI_Buffer_attach( b, n );
The asynchronous version is MPI_Ibsend, the persistent (see section 4.4.4) call is MPI_Bsend_init.
4.4.5.2 Persistent buffered communication
There is a persistent variant of buffered sends, as with regular sends (section 4.4.4).
Victor Eijkhout 107

4. MPI topic: Point-to-point
Synopsisint MPI_Bsend_init
(const void *buf, int count, MPI_Datatype datatype,int dest, int tag, MPI_Comm comm,MPI_Request *request)
Input Parametersbuf : initial address of send buffer (choice)count : number of elements sent (integer)datatype : type of each element (handle)dest : rank of destination (integer)tag : message tag (integer)comm : communicator (handle)
Output Parametersrequest : communication request (handle)
How to read routine prototypes: 1.5.4.
4.4.6 More about requests
An MPI_Request object is not actually an object, unlike MPI_STATUS. Instead it is an (opaque) pointer. Thismeeans that when you call, for instance, MPI_Irecv, MPI will allocate an actual request object, and returnits address in the MPI_Request variable.
Correspondingly, calls to MPI_Wait... or MPI_Test free this object. If your application is such that you donot use ‘wait’ call, you can free the request object explicitly with MPI_Request_free.
int MPI_Request_free(MPI_Request *request)
You can inspect the status of a request without freeing the request object with MPI_Request_get_status:
int MPI_Request_get_status(MPI_Request request,int *flag,MPI_Status *status
);
4.5 Sources used in this chapterListing of code examples/mpi/c/recvblock.c:
/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-7%%%%
108 Parallel Computing – r428

4.5. Sources used in this chapter
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {int other, recvbuf=2, sendbuf=3;
#include "globalinit.c"MPI_Status status;
//snippet recvblockother = 1-procno;
//snippet endif (procno>1) goto skip;
//snippet recvblockMPI_Recv(&recvbuf,1,MPI_INT,other,0,comm,&status);MPI_Send(&sendbuf,1,MPI_INT,other,0,comm);printf("This statement will not be reached on %d\n",procno);
//snippet end
skip:MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/sendblock.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% sendblock.c : illustration of the eager limit%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
/** This program shows deadlocking behaviourwhen two processes exchange data with blockingsend and receive calls.Under a certain limit MPI_Send may actually not be
Victor Eijkhout 109

4. MPI topic: Point-to-point
blocking; we loop, increasing the message size,to find roughly the crossover point.
*/int main(int argc,char **argv) {int *recvbuf, *sendbuf;MPI_Status status;
#include "globalinit.c"
/* we only use processors 0 and 1 */int other;if (procno>1) goto skip;//snippet sendblockother = 1-procno;/* loop over increasingly large messages */for (int size=1; size<2000000000; size*=10) {
sendbuf = (int*) malloc(size*sizeof(int));recvbuf = (int*) malloc(size*sizeof(int));if (!sendbuf || !recvbuf) {printf("Out of memory\n"); MPI_Abort(comm,1);
}MPI_Send(sendbuf,size,MPI_INT,other,0,comm);MPI_Recv(recvbuf,size,MPI_INT,other,0,comm,&status);/* If control reaches this point, the send call
did not block. If the send call blocks,we do not reach this point, and the program will hang.
*/if (procno==0)printf("Send did not block for size %d\n",size);
free(sendbuf); free(recvbuf);}//snippet end
skip:MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/ssendblock.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% ssendblock.c : with synchronous sends not eager limit applies%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>
110 Parallel Computing – r428

4.5. Sources used in this chapter
#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {int other, size, *recvbuf, *sendbuf;MPI_Status status;
#include "globalinit.c"
if (procno>1) goto skip;//snippet ssendblockother = 1-procno;sendbuf = (int*) malloc(sizeof(int));recvbuf = (int*) malloc(sizeof(int));size = 1;MPI_Ssend(sendbuf,size,MPI_INT,other,0,comm);MPI_Recv(recvbuf,size,MPI_INT,other,0,comm,&status);printf("This statement is not reached\n");//snippet endfree(sendbuf); free(recvbuf);
skip:MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/irecvloop.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% irecvloop.c : use non-blocking send/recv to communicate%%%% all-to-all with left/right neighbours in a circular fashion%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {int procno,nprocs, other, recvbuf=2, sendbuf=3;MPI_Comm comm;
MPI_Init(&argc,&argv);comm = MPI_COMM_WORLD;
Victor Eijkhout 111

4. MPI topic: Point-to-point
MPI_Comm_rank(comm,&procno);MPI_Comm_size(comm,&nprocs);//snippet irecvloopMPI_Request requests =(MPI_Request*) malloc( 2*nprocs*sizeof(MPI_Request) );
recv_buffers = (int*) malloc( nprocs*sizeof(int) );send_buffers = (int*) malloc( nprocs*sizeof(int) );for (int p=0; p<nprocs; p++) {int left_p = (p-1) % nprocs,right_p = (p+1) % nprocs;
send_buffer[p] = nprocs-p;MPI_Isend(sendbuffer+p,1,MPI_INT, right_p,0, requests+2*p);MPI_Irecv(recvbuffer+p,1,MPI_INT, left_p,0, requests+2*p+1);
}/* your useful code here */MPI_Waitall(2*nprocs,requests,MPI_STATUSES_IGNORE);//snippet end
skip:MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/waitforany.c:
Listing of code examples/mpi/c/probe.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% probe.c : use Probe to get information about message%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include <unistd.h>#include "mpi.h"
int main(int argc,char **argv) {int procno,nprocs, ierr;MPI_Comm comm;
MPI_Init(&argc,&argv);comm = MPI_COMM_WORLD;MPI_Comm_rank(comm,&procno);
112 Parallel Computing – r428

4.5. Sources used in this chapter
MPI_Comm_size(comm,&nprocs);
MPI_Comm_set_errhandler(comm,MPI_ERRORS_RETURN);#define CHK(x) if (x) { \
char errtxt[200]; int len=200; \MPI_Error_string(x,errtxt,&len); \printf("p=%d, line=%d, err=%d, %s\n",procno,__LINE__,x,errtxt); \return x;}
// Initialize the random number generatorsrand((int)(procno*(double)RAND_MAX/nprocs));
int sender = 0, receiver = nprocs-1;//snippet probe
if (procno==receiver) {MPI_Status status;MPI_Probe(sender,0,comm,&status);int count;MPI_Get_count(&status,MPI_FLOAT,&count);//snippet endprintf("Receiving %d floats\n",count);//snippet probefloat recv_buffer[count];MPI_Recv(recv_buffer,count,MPI_FLOAT, sender,0,comm,MPI_STATUS_IGNORE);
} else if (procno==sender) {//snippet endfloat randomfraction = (rand() / (double)RAND_MAX);int buffer_size = (int) ( 10 * nprocs * randomfraction );printf("Sending %d floats\n",buffer_size);//snippet probefloat buffer[buffer_size];ierr = MPI_Send(buffer,buffer_size,MPI_FLOAT, receiver,0,comm); CHK(ierr);
}//snippet end
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/anysource.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% anysource.c : receive from any source%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
Victor Eijkhout 113

4. MPI topic: Point-to-point
#include <stdlib.h>#include <stdio.h>#include <string.h>#include <unistd.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
//snippet anysourceif (procno==nprocs-1) {int *recv_buffer;MPI_Status status;
recv_buffer = (int*) malloc((nprocs-1)*sizeof(int));
for (int p=0; p<nprocs-1; p++) {err = MPI_Recv(recv_buffer+p,1,MPI_INT, MPI_ANY_SOURCE,0,comm,&status); CHK(err);int sender = status.MPI_SOURCE;printf("Message from sender=%d: %d\n",
sender,recv_buffer[p]);}
} else {float randomfraction = (rand() / (double)RAND_MAX);int randomwait = (int) ( nprocs * randomfraction );printf("process %d waits for %e/%d=%d\n",
procno,randomfraction,nprocs,randomwait);sleep(randomwait);err = MPI_Send(&randomwait,1,MPI_INT, nprocs-1,0,comm); CHK(err);
}//snippet end
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/ssendblock.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% ssendblock.c : with synchronous sends not eager limit applies%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
114 Parallel Computing – r428

4.5. Sources used in this chapter
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {int other, size, *recvbuf, *sendbuf;MPI_Status status;
#include "globalinit.c"
if (procno>1) goto skip;//snippet ssendblockother = 1-procno;sendbuf = (int*) malloc(sizeof(int));recvbuf = (int*) malloc(sizeof(int));size = 1;MPI_Ssend(sendbuf,size,MPI_INT,other,0,comm);MPI_Recv(recvbuf,size,MPI_INT,other,0,comm,&status);printf("This statement is not reached\n");//snippet endfree(sendbuf); free(recvbuf);
skip:MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/persist.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% persist.c : test of persistent communication%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
#define NEXPERIMENTS 10#define NSIZES 6
Victor Eijkhout 115

4. MPI topic: Point-to-point
int src = 0,tgt = nprocs-1,maxsize=1000000;double t[NSIZES], send[maxsize],recv[maxsize];
MPI_Request requests[2];
// First ordinary communicationfor (int cnt=0,s=1; cnt<NSIZES && s<maxsize; s*=10,cnt++) {if (procno==src) {printf("Size %d\n",s);t[cnt] = MPI_Wtime();for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Isend(send,s,MPI_DOUBLE,tgt,0,comm,requests+0);MPI_Irecv(recv,s,MPI_DOUBLE,tgt,0,comm,requests+1);MPI_Waitall(2,requests,MPI_STATUSES_IGNORE);
}t[cnt] = MPI_Wtime()-t[cnt];
} else if (procno==tgt) {for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Recv(recv,s,MPI_DOUBLE,src,0,comm,MPI_STATUS_IGNORE);MPI_Send(recv,s,MPI_DOUBLE,src,0,comm);
}}
}if (procno==src) {for (int cnt=0,s=1; cnt<NSIZES; s*=10,cnt++) {
t[cnt] /= NEXPERIMENTS;printf("Time for pingpong of size %d: %e\n",s,t[cnt]);
}}
// Now persistent communicationfor (int cnt=0,s=1; cnt<NSIZES; s*=10,cnt++) {//snippet persistif (procno==src) {MPI_Send_init(send,s,MPI_DOUBLE,tgt,0,comm,requests+0);MPI_Recv_init(recv,s,MPI_DOUBLE,tgt,0,comm,requests+1);printf("Size %d\n",s);t[cnt] = MPI_Wtime();for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Startall(2,requests);MPI_Waitall(2,requests,MPI_STATUSES_IGNORE);
}t[cnt] = MPI_Wtime()-t[cnt];MPI_Request_free(requests+0); MPI_Request_free(requests+1);
} else if (procno==tgt) {for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Recv(recv,s,MPI_DOUBLE,src,0,comm,MPI_STATUS_IGNORE);MPI_Send(recv,s,MPI_DOUBLE,src,0,comm);
}}
//snippet end}if (procno==src) {
116 Parallel Computing – r428

4.5. Sources used in this chapter
for (int cnt=0,s=1; cnt<NSIZES; s*=10,cnt++) {t[cnt] /= NEXPERIMENTS;printf("Time for persistent pingpong of size %d: %e\n",s,t[cnt]);
}}
MPI_Finalize();return 0;
}
Victor Eijkhout 117

Chapter 5
MPI topic: Data types
5.1 MPI Datatypes
In the examples you have seen so far, every time data was sent, it was as a contiguous buffer with elementsof a single type. In practice you may want to send heterogeneous data, or non-contiguous data.
• Communicating the real parts of an array of complex numbers means specifying every othernumber.• Communicating a C structure of Fortran type with more than one type of element is not equiva-
lent to sending an array of elements of a single type.
The datatypes you have dealt with so far are known as elementary datatypes; irregular objects are knownas derived datatypes .
5.2 Elementary data types
MPI has a number of elementary data types, corresponding to the simple data types of programminglanguages. The names are made to resemble the types of C and Fortran, for instance MPI_FLOAT andMPI_DOUBLE versus MPI_REAL and MPI_DOUBLE_PRECISION.
MPI calls accept arrays of elements:
double x[20];MPI_Send( x,20,MPI_DOUBLE, ..... )
so for a single element you need to take its address:
double x;MPI_Send( &x,1,MPI_DOUBLE, ..... )
118

5.2. Elementary data types
5.2.1 C/C++MPI_CHAR only for text data, do not use for small integersMPI_UNSIGNED_CHARMPI_SIGNED_CHARMPI_SHORTMPI_UNSIGNED_SHORTMPI_INTMPI_UNSIGNEDMPI_LONGMPI_UNSIGNED_LONGMPI_FLOATMPI_DOUBLEMPI_LONG_DOUBLE
There is some, but not complete, support for C99 types.
5.2.2 FortranMPI_CHARACTER Character(Len=1)MPI_LOGICALMPI_INTEGERMPI_REALMPI_DOUBLE_PRECISIONMPI_COMPLEXMPI_DOUBLE_COMPLEX Complex(Kind=Kind(0.d0))
Addresses have type MPI_Aint or INTEGER (KIND=MPI_ADDRESS_KIND) in Fortran. The start ofthe address range is given in MPI_BOTTOM.
5.2.2.1 Fortran90 kind-defined types
If your Fortran code uses KIND to define scalar types with specified precision, these do not in generalcorrespond to any predefined MPI datatypes. Hence the following routines exist to make MPI equivalencesof Fortran scalar types:
C:int MPI_Type_create_f90_integer(int r, MPI_Datatype *newtype);
Fortran:MPI_TYPE_CREATE_F90_INTEGER(INTEGER R, INTEGER NEWTYPE, INTEGER IERROR)
Input Parameterr : Precision, in decimal digits (integer).
Output Parametersnewtype : New data type (handle).IERROR : Fortran only: Error status (integer).
Victor Eijkhout 119

5. MPI topic: Data types
How to read routine prototypes: 1.5.4.C:int MPI_Type_create_f90_real(int p, int r, MPI_Datatype *newtype)
Fortran:MPI_TYPE_CREATE_F90_REAL (P, R, NEWTYPE, IERROR)
Input Parametersp : Precision, in decimal digits (integer).r : Decimal exponent range (integer).
Output Parametersnewtype : New data type (handle).IERROR : Fortran only: Error status (integer).
Either p or r, but not both, may be omitted from calls toSELECTED_REAL_KIND. Similarly, either argument toMPI_Type_create_f90_real may be set to MPI_UNDEFINED.
How to read routine prototypes: 1.5.4.C:int MPI_Type_create_f90_real(int p, int r, MPI_Datatype *newtype)
Fortran:MPI_TYPE_CREATE_F90_REAL (P, R, NEWTYPE, IERROR)
Input Parametersp : Precision, in decimal digits (integer).r : Decimal exponent range (integer).
Output Parametersnewtype : New data type (handle).IERROR : Fortran only: Error status (integer).
Either p or r, but not both, may be omitted from calls toSELECTED_REAL_KIND. Similarly, either argument toMPI_Type_create_f90_complex may be set to MPI_UNDEFINED.
How to read routine prototypes: 1.5.4.
Examples:INTEGER ( KIND = SELECTED_INTEGER_KIND(15) ) , &DIMENSION(100) :: array INTEGER :: root , integertype , error
CALL MPI_Type_create_f90_integer( 15 , integertype , error )CALL MPI_Bcast ( array , 100 ,& integertype , root ,& MPI_COMM_WORLD , error )
120 Parallel Computing – r428

5.3. Derived datatypes
REAL ( KIND = SELECTED_REAL_KIND(15 ,300) ) , &DIMENSION(100) :: array
CALL MPI_Type_create_f90_real( 15 , 300 , realtype , error )
COMPLEX ( KIND = SELECTED_REAL_KIND(15 ,300) ) , &DIMENSION(100) :: array
CALL MPI_Type_create_f90_complex( 15 , 300 , complextype , error )
5.2.3 Python
mpi4py type NumPy typeMPI.INT np.intcMPI.LONG np.intMPI.FLOAT np.float32MPI.DOUBLE np.float64
5.2.4 Byte addressing type
So far we have mostly been taking about datatypes in the context of sending them. The MPI_Aint type isnot so much for sending, as it is for describing the size of objects, such as the size of an MPI_Win object;section 8.1.
See also the MPI_Sizeof routine.
5.2.4.1 Fortran
The equivalent of MPI_Aint in Fortran is
integer(kind=MPI_ADDRESS_KIND) :: winsize
5.2.4.2 Python
The MPI_Win_create routine needs a displacement in bytes. Here is a good way for finding the size ofnumpy datatypes:
numpy.dtype(’i’).itemsize
5.3 Derived datatypes
MPI allows you to create your own data types, somewhat (but not completely. . . ) analogous to definingstructures in a programming language. MPI data types are mostly of use if you want to send multiple itemsin one message.
There are two problems with using only elementary datatypes as you have seen so far.
Victor Eijkhout 121

5. MPI topic: Data types
• MPI communication routines can only send multiples of a single data type: it is not possible tosend items of different types, even if they are contiguous in memory. It would be possible to usethe MPI_BYTE data type, but this is not advisable.• It is also ordinarily not possible to send items of one type if they are not contiguous in memory.
You could of course send a contiguous memory area that contains the items you want to send,but that is wasteful of bandwidth.
With MPI data types you can solve these problems in several ways.
• You can create a new contiguous data type consisting of an array of elements of another datatype. There is no essential difference between sending one element of such a type and multipleelements of the component type.• You can create a vector data type consisting of regularly spaced blocks of elements of a compo-
nent type. This is a first solution to the problem of sending non-contiguous data.• For not regularly spaced data, there is the indexed data type , where you specify an array of index
locations for blocks of elements of a component type. The blocks can each be of a different size.• The struct data type can accomodate multiple data types.
And you can combine these mechanisms to get irregularly spaced heterogeneous data, et cetera.
5.3.1 Basic calls
The typical sequence of calls for creating a new datatype is as follows:
MPI_Datatype newtype;MPI_Type_<sometype>( < oldtype specifications >, &newtype );MPI_Type_commit( &newtype );/* code that uses your new type */MPI_Type_free( &newtype );
5.3.1.1 Datatype objects
MPI derived data types are stored in variables of type MPI_Datatype.C:MPI_Datatype datatype ;
Fortran:Type(MPI_Datatype) datatype
How to read routine prototypes: 1.5.4.
5.3.1.2 Create calls
The MPI_Datatype varriable gets its value by a call to one of the following routines:
• MPI_Type_contiguous for contiguous blocks of data; section 5.3.2;• MPI_Type_vector for regularly strided data; section 5.3.3;
122 Parallel Computing – r428

5.3. Derived datatypes
• MPI_Type_create_subarray for subsets out higher dimensional block; section 5.3.3.2;• MPI_Type_struct for heterogeneous irregular data; section 5.3.5;• MPI_Type_indexed and MPI_Type_hindexed for irregularly strided data; section 5.3.4.
These calls take an existing type, whether elementary or also derived, and produce a new type.
5.3.1.3 Commit and free
It is necessary to call MPI_Type_commit on a new data type, which makes MPI do the indexing calculationsfor the data type.
C:int MPI_Type_commit(MPI_Datatype *datatype)
Fortran:MPI_Type_commit(datatype, ierror)TYPE(MPI_Datatype), INTENT(INOUT) :: datatypeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
When you no longer need the data type, you call MPI_Type_free.
int MPI_Type_free (MPI_Datatype *datatype)
• The definition of the datatype identifier will be changed to MPI_DATATYPE_NULL.• Any communication using this data type, that was already started, will be completed succesfully.• Datatypes that are defined in terms of this data type will still be usable.
5.3.2 Contiguous type
The simplest derived type is the ‘contiguous’ type, constructed with MPI_Type_contiguous.Semantics:MPI_TYPE_CONTIGUOUS
(count, oldtype, newtype)IN count: replication count (non-negative integer)IN oldtype: old datatype (handle)OUT newtype: new datatype (handle)
C:int MPI_Type_contiguous
(int count, MPI_Datatype oldtype, MPI_Datatype *newtype)
Fortran:MPI_Type_contiguous
(count, oldtype, newtype, ierror)INTEGER, INTENT(IN) :: countTYPE(MPI_Datatype), INTENT(IN) :: oldtypeTYPE(MPI_Datatype), INTENT(OUT) :: newtypeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Victor Eijkhout 123

5. MPI topic: Data types
Python:Create_contiguous(self, int count)
How to read routine prototypes: 1.5.4.
A contigous type describes an array of items of an elementary or earlier defined type. There is no differencebetween sending one item of a contiguous type and multiple items of the constituent type. This is illustrated
Figure 5.1: A contiguous datatype is built up out of elements of a constituent type
in figure 5.1.// contiguous.cMPI_Datatype newvectortype;if (procno==sender) {MPI_Type_contiguous(count,MPI_DOUBLE,&newvectortype);MPI_Type_commit(&newvectortype);MPI_Send(source,1,newvectortype,receiver,0,comm);MPI_Type_free(&newvectortype);
} else if (procno==receiver) {MPI_Status recv_status;int recv_count;MPI_Recv(target,count,MPI_DOUBLE,sender,0,comm,
&recv_status);MPI_Get_count(&recv_status,MPI_DOUBLE,&recv_count);ASSERT(count==recv_count);
}
// contiguous.F90integer :: newvectortypeif (mytid==sender) then
call MPI_Type_contiguous(count,MPI_DOUBLE_PRECISION,newvectortype,err)call MPI_Type_commit(newvectortype,err)call MPI_Send(source,1,newvectortype,receiver,0,comm,err)call MPI_Type_free(newvectortype,err)
else if (mytid==receiver) thencall MPI_Recv(target,count,MPI_DOUBLE_PRECISION,sender,0,comm,&
recv_status,err)call MPI_Get_count(recv_status,MPI_DOUBLE_PRECISION,recv_count,err)!ASSERT(count==recv_count);
end if
5.3.3 Vector type
The simplest non-contiguous datatype is the ‘vector’ type, constructed with MPI_Type_vector.
124 Parallel Computing – r428

5.3. Derived datatypes
Semantics:MPI_TYPE_VECTOR(count, blocklength, stride, oldtype, newtype)IN count: number of blocks (non-negative integer)IN blocklength: number of elements in each block (non-negative integer)IN stride: number of elements between start of each block (integer)IN oldtype: old datatype (handle)OUT newtype: new datatype (handle)
C:int MPI_Type_vector
(int count, int blocklength, int stride,MPI_Datatype oldtype, MPI_Datatype *newtype)
Fortran:MPI_Type_vector(count, blocklength, stride, oldtype, newtype, ierror)INTEGER, INTENT(IN) :: count, blocklength, strideTYPE(MPI_Datatype), INTENT(IN) :: oldtypeTYPE(MPI_Datatype), INTENT(OUT) :: newtypeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Datatype.Create_vector(self, int count, int blocklength, int stride)
How to read routine prototypes: 1.5.4.
A vector type describes a series of blocks, all of equal size, spaced with a constant stride. This is illustrated
Figure 5.2: A vector datatype is built up out of strided blocks of elements of a constituent type
in figure 5.2.
The vector datatype gives the first non-trivial illustration that datatypes can be different on the sender andreceiver . If the sender sends b blocks of length l each, the receiver can receive them as bl contiguouselements, either as a contiguous datatype, or as a contiguous buffer of an elementary type; see figure 5.3.In this case, the receiver has no knowledge of the stride of the datatype on the sender.
In this example a vector type is created only on the sender, in order to send a strided subset of an array; the
Victor Eijkhout 125

5. MPI topic: Data types
Figure 5.3: Sending a vector datatype and receiving it as elementary or contiguous
receiver receives the data as a contiguous block.// vector.csource = (double*) malloc(stride*count*sizeof(double));target = (double*) malloc(count*sizeof(double));MPI_Datatype newvectortype;if (procno==sender) {MPI_Type_vector(count,1,stride,MPI_DOUBLE,&newvectortype);MPI_Type_commit(&newvectortype);MPI_Send(source,1,newvectortype,the_other,0,comm);MPI_Type_free(&newvectortype);
} else if (procno==receiver) {MPI_Status recv_status;int recv_count;MPI_Recv(target,count,MPI_DOUBLE,the_other,0,comm,
&recv_status);MPI_Get_count(&recv_status,MPI_DOUBLE,&recv_count);ASSERT(recv_count==count);
}
// vector.F90integer :: newvectortypeALLOCATE(source(stride*count))ALLOCATE(target(stride*count))if (mytid==sender) then
call MPI_Type_vector(count,1,stride,MPI_DOUBLE_PRECISION,&newvectortype,err)
call MPI_Type_commit(newvectortype,err)call MPI_Send(source,1,newvectortype,receiver,0,comm,err)call MPI_Type_free(newvectortype,err)
else if (mytid==receiver) thencall MPI_Recv(target,count,MPI_DOUBLE_PRECISION,sender,0,comm,&
recv_status,err)call MPI_Get_count(recv_status,MPI_DOUBLE_PRECISION,recv_count,err)
end if
126 Parallel Computing – r428

5.3. Derived datatypes
## vector.pysource = np.empty(stride*count,dtype=np.float64)target = np.empty(count,dtype=np.float64)if procid==sender:
newvectortype = MPI.DOUBLE.Create_vector(count,1,stride)newvectortype.Commit()comm.Send([source,1,newvectortype],dest=the_other)newvectortype.Free()
elif procid==receiver:comm.Recv([target,count,MPI.DOUBLE],source=the_other)
As an example of this datatype, consider the example of transposing a matrix, for instance to convertbetween C and Fortran arrays (see section HPSC-28.2). Suppose that a processor has a matrix stored in C,row-major, layout, and it needs to send a column to another processor. If the matrix is declared as
int M,N; double mat[M][N]
then a column has M blocks of one element, spaced N locations apart. In other words:MPI_Datatype MPI_column;MPI_Type_vector(
/* count= */ M, /* blocklength= */ 1, /* stride= */ N,MPI_DOUBLE, &MPI_column );
Sending the first column is easy:MPI_Send( mat, 1,MPI_column, ... );
The second column is just a little trickier: you now need to pick out elements with the same stride, butstarting at A[0][1].
MPI_Send( &(mat[0][1]), 1,MPI_column, ... );
You can make this marginally more efficient (and harder to read) by replacing the index expression bymat+1.Exercise 5.1. Suppose you have a matrix of size 4N × 4N , and you want to send the elements
A[4*i][4*j] with i, j = 0, . . . , N − 1. How would you send these elements witha single transfer?
Exercise 5.2. Allocate a matrix on processor zero, using Fortran column-major storage.Using P sendrecv calls, distribute the rows of this matrix among the processors.
Exercise 5.3. Let processor 0 have an array x of length 10P , where P is the number ofprocessors. Elements 0, P, 2P, . . . , 9P should go to processor zero,1, P + 1, 2P + 1, . . . to processor 1, et cetera. Code this as a sequence of send/recvcalls, using a vector datatype for the send, and a contiguous buffer for the receive.For simplicity, skip the send to/from zero. What is the most elegant solution if youwant to include that case?For testing, define the array as x[i] = i.
Exercise 5.4. Write code to compare the time it takes to send a strided subset from an array:copy the elements by hand to a smaller buffer, or use a vector data type. What do youfind? You may need to test on fairly large arrays.
Victor Eijkhout 127

5. MPI topic: Data types
Figure 5.4: Send strided data from process zero to all others
5.3.3.1 Subarrays as vector data
Figure 5.5 indicates one source of irregular data: with a matrix on column-major storage , a column is stored
Figure 5.5: Memory layout of a row and column of a matrix in column-major storage
in contiguous memory. However, a row of such a matrix is not contiguous; its elements being separated bya stride equal to the column length.
Exercise 5.5. How would you describe the memory layout of a submatrix, if the whole matrixhas size M ×N and the submatrix m× n?
5.3.3.2 Subarray type
The vector datatype can be used for blocks in an array of dimension more than 2 by using it recursively.However, this gets tedious. Instead, there is an explicit subarray type
Semantics:
128 Parallel Computing – r428

5.3. Derived datatypes
MPI_TYPE_CREATE_SUBARRAY(ndims, array_of_sizes, array_of_subsizes,array_of_starts, order, oldtype, newtype)
IN ndims: number of array dimensions (positive integer)IN array_of_sizes: number of elements of type oldtype in each dimension
of the full array (array of positive integers)IN array_of_subsizes: number of elements of type oldtype in each
dimension of the subarray (array of positive integers)IN array_of_starts: starting coordinates of the subarray in each
dimension (array of non-negative integers)IN order: array storage order flag (state)IN oldtype: array element datatype (handle)OUT newtype: new datatype (handle)
C:int MPI_Type_create_subarray(
int ndims, const int array_of_sizes[],const int array_of_subsizes[], const int array_of_starts[],int order, MPI_Datatype oldtype, MPI_Datatype *newtype)
Fortran:MPI_Type_create_subarray(ndims, array_of_sizes, array_of_subsizes,
array_of_starts, order, oldtype, newtype, ierror)INTEGER, INTENT(IN) :: ndims, array_of_sizes(ndims),
array_of_subsizes(ndims), array_of_starts(ndims), orderTYPE(MPI_Datatype), INTENT(IN) :: oldtypeTYPE(MPI_Datatype), INTENT(OUT) :: newtypeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Datatype.Create_subarray
(self, sizes, subsizes, starts, int order=ORDER_C)
How to read routine prototypes: 1.5.4.
This describes the dimensionality and extent of the array, and the starting point (the ‘upper left corner’) andextent of the subarray. The possibilities for the order parameter are MPI_ORDER_C and MPI_ORDER_FORTRAN
.
Exercise 5.6.Assume that your number of processors is P = Q3, and that each process has anarray of identical size. Use MPI_Type_create_subarray to gather all data onto a rootprocess. Use a sequence of send and receive calls; MPI_Gather does not work here.
5.3.4 Indexed type
The indexed datatype, constructed with MPI_Type_indexed can send arbitrarily located elements from anarray of a single datatype. You need to supply an array of index locations, plus an array of blocklengths witha separate blocklength for each index. The total number of elements sent is the sum of the blocklengths.
Victor Eijkhout 129
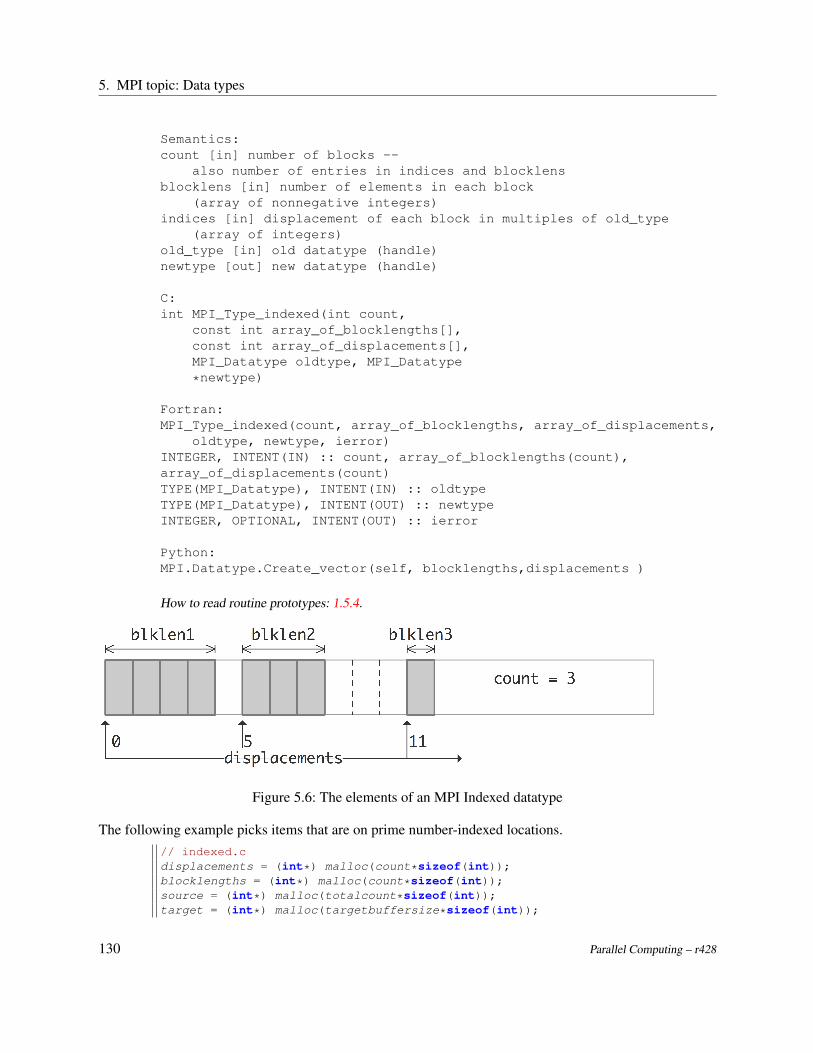
5. MPI topic: Data types
Semantics:count [in] number of blocks --
also number of entries in indices and blocklensblocklens [in] number of elements in each block
(array of nonnegative integers)indices [in] displacement of each block in multiples of old_type
(array of integers)old_type [in] old datatype (handle)newtype [out] new datatype (handle)
C:int MPI_Type_indexed(int count,
const int array_of_blocklengths[],const int array_of_displacements[],MPI_Datatype oldtype, MPI_Datatype
*newtype)
Fortran:MPI_Type_indexed(count, array_of_blocklengths, array_of_displacements,
oldtype, newtype, ierror)INTEGER, INTENT(IN) :: count, array_of_blocklengths(count),array_of_displacements(count)TYPE(MPI_Datatype), INTENT(IN) :: oldtypeTYPE(MPI_Datatype), INTENT(OUT) :: newtypeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Datatype.Create_vector(self, blocklengths,displacements )
How to read routine prototypes: 1.5.4.
Figure 5.6: The elements of an MPI Indexed datatype
The following example picks items that are on prime number-indexed locations.// indexed.cdisplacements = (int*) malloc(count*sizeof(int));blocklengths = (int*) malloc(count*sizeof(int));source = (int*) malloc(totalcount*sizeof(int));target = (int*) malloc(targetbuffersize*sizeof(int));
130 Parallel Computing – r428

5.3. Derived datatypes
MPI_Datatype newvectortype;if (procno==sender) {MPI_Type_indexed(count,blocklengths,displacements,MPI_INT,&newvectortype);MPI_Type_commit(&newvectortype);MPI_Send(source,1,newvectortype,the_other,0,comm);MPI_Type_free(&newvectortype);
} else if (procno==receiver) {MPI_Status recv_status;int recv_count;MPI_Recv(target,targetbuffersize,MPI_INT,the_other,0,comm,
&recv_status);MPI_Get_count(&recv_status,MPI_INT,&recv_count);ASSERT(recv_count==count);
}
// indexed.F90integer :: newvectortype;ALLOCATE(indices(count))ALLOCATE(blocklengths(count))ALLOCATE(source(totalcount))ALLOCATE(targt(count))if (mytid==sender) then
call MPI_Type_indexed(count,blocklengths,indices,MPI_INT,&newvectortype,err)
call MPI_Type_commit(newvectortype,err)call MPI_Send(source,1,newvectortype,receiver,0,comm,err)call MPI_Type_free(newvectortype,err)
else if (mytid==receiver) thencall MPI_Recv(targt,count,MPI_INT,sender,0,comm,&
recv_status,err)call MPI_Get_count(recv_status,MPI_INT,recv_count,err)! ASSERT(recv_count==count);
end if
## indexed.pydisplacements = np.empty(count,dtype=np.int)blocklengths = np.empty(count,dtype=np.int)source = np.empty(totalcount,dtype=np.float64)target = np.empty(count,dtype=np.float64)if procid==sender:
newindextype = MPI.DOUBLE.Create_indexed(blocklengths,displacements)newindextype.Commit()comm.Send([source,1,newindextype],dest=the_other)newindextype.Free()
elif procid==receiver:comm.Recv([target,count,MPI.DOUBLE],source=the_other)
You can also MPI_Type_create_hindexed which describes blocks of a single old type, but with indixlocations in bytes, rather than in multiples of the old type.
int MPI_Type_create_hindexed(int count, int blocklens[], MPI_Aint indices[],MPI_Datatype old_type,MPI_Datatype *newtype)
Victor Eijkhout 131

5. MPI topic: Data types
A slightly simpler version assumes constant block length:int MPI_Type_create_hindexed_block
(int count,int blocklength,const MPI_Aint array_of_displacements[],MPI_Datatype oldtype, MPI_Datatype *newtype)
Input Parameters:count : length of array of displacements (integer)blocklength : size of block (integer)array_of_displacements : array of displacements (array of integer)oldtype : old datatype (handle)
Output Parameter:newtype : new datatype (handle)
How to read routine prototypes: 1.5.4.
There is an important difference with the above MPI_Type_indexed: that one described offsets from abase location; these routines describes absolute memory addresses. You can use this to send for instancethe elements of a linked list. You would traverse the list, recording the addresses of the elements withMPI_Get_address.
C:int MPI_Get_address
(void *location,MPI_Aint *address);
Input Parameters:location : location in caller memory (choice)
Output parameters:address : address of location (address)
How to read routine prototypes: 1.5.4.
In C++ you can use this to send an stl<vector>, that is, a vector object from the C++ standard library ,if the component type is a pointer.
5.3.5 Struct type
The structure type, created with MPI_Type_create_struct, can contain multiple data types. The speci-fication contains a ‘count’ parameter that specifies how many blocks there are in a single structure. Forinstance,
struct {int i;float x,y;
} point;
132 Parallel Computing – r428

5.3. Derived datatypes
Figure 5.7: The elements of an MPI Struct datatype
has two blocks, one of a single integer, and one of two floats. This is illustrated in figure 5.7.
int MPI_Type_create_struct(int count, int blocklengths[], MPI_Aint displacements[],MPI_Datatype types[], MPI_Datatype *newtype);
count The number of blocks in this datatype. The blocklengths, displacements, types argu-ments have to be at least of this length.
blocklengths array containing the lengths of the blocks of each datatype.displacements array describing the relative location of the blocks of each datatype.types array containing the datatypes; each block in the new type is of a single datatype; there can be
multiple blocks consisting of the same type.
In this example, unlike the previous ones, both sender and receiver create the structure type. With structuresit is no longer possible to send as a derived type and receive as a array of a simple type. (It would be possibleto send as one structure type and receive as another, as long as they have the same datatype signature .)
// struct.cstruct object {char c;double x[2];int i;
};MPI_Datatype newstructuretype;int structlen = 3;int blocklengths[structlen]; MPI_Datatype types[structlen];MPI_Aint displacements[structlen];// where are the components relative to the structure?blocklengths[0] = 1; types[0] = MPI_CHAR;displacements[0] = (size_t)&(myobject.c) - (size_t)&myobject;blocklengths[1] = 2; types[1] = MPI_DOUBLE;displacements[1] = (size_t)&(myobject.x[0]) - (size_t)&myobject;blocklengths[2] = 1; types[2] = MPI_INT;displacements[2] = (size_t)&(myobject.i) - (size_t)&myobject;MPI_Type_create_struct(structlen,blocklengths,displacements,types,&
newstructuretype);MPI_Type_commit(&newstructuretype);{MPI_Aint typesize;
Victor Eijkhout 133

5. MPI topic: Data types
MPI_Type_extent(newstructuretype,&typesize);if (procno==0) printf("Type extent: %d bytes\n",typesize);
}if (procno==sender) {MPI_Send(&myobject,1,newstructuretype,the_other,0,comm);
} else if (procno==receiver) {MPI_Recv(&myobject,1,newstructuretype,the_other,0,comm,MPI_STATUS_IGNORE);
}MPI_Type_free(&newstructuretype);
Note the displacement calculations in this example, which involve some not so elegant pointer arith-metic. It would have been incorrect to write
displacement[0] = 0;displacement[1] = displacement[0] + sizeof(char);
since you do not know the way the compiler lays out the structure in memory1.
If you want to send more than one structure, you have to worry more about padding in the structure. Youcan solve this by adding an extra type MPI_UB for the ‘upper bound’ on the structure:
displacements[3] = sizeof(myobject); types[3] = MPI_UB;MPI_Type_create_struct(struclen+1,.....);
The structure type is very similar in functionality to MPI_Type_hindexed, which uses byte-based indexing.The structure-based type is probably cleaner in use.
5.3.6 Type size
The space that MPI takes for a structure type can be queried in a variety of ways. First of all MPI_Type_sizecounts the datatype size as the number of bytes occupied by the data in a type. That means that in an MPI
vector datatype it does not count the gaps.// typesize.cMPI_Type_vector(count,bs,stride,MPI_DOUBLE,&newtype);MPI_Type_commit(&newtype);MPI_Type_size(newtype,&size);ASSERT( size==(count*bs)*sizeof(double) );MPI_Type_free(&newtype);
Semantics:
int MPI_Type_size(MPI_Datatype datatype,int *size);
datatype: [in] datatype to get information on (handle)size: [out] datatype size in bytes
1. Homework question: what does the language standard say about this?
134 Parallel Computing – r428

5.3. Derived datatypes
How to read routine prototypes: 1.5.4.
On the other hand, the datatype extent is strictly the distance from the first to the last data item of the type,that is, with counting the gaps in the type.
MPI_Type_vector(count,bs,stride,MPI_DOUBLE,&newtype);MPI_Type_commit(&newtype);MPI_Type_get_extent(newtype,&lb,&asize);ASSERT( lb==0 );ASSERT( asize==((count-1)*stride+bs)*sizeof(double) );MPI_Type_free(&newtype);
Semantics:
int MPI_Type_get_extent(MPI_Datatype datatype,MPI_Aint *lb, MPI_Aint *extent);
datatype: [in] datatype to get information on (handle)lb: [out] lower bound of datatype (integer)extent: [out] extent of datatype (integer)
How to read routine prototypes: 1.5.4.
(There is a deprecated function MPI_Type_extent with the same functionality.)
The subarray datatype need not start at the first element of the buffer, so the extent is an overstatement ofhow much data is involved. The routine MPI_Type_get_true_extent returns the lower bound, indicatingwhere the data starts, and the extent from that point.
Semantics:MPI_Type_get_true_extent(datatype,true_lb,true_extent)
Input argument:datatype: Data type for which information is wanted (handle).Output arguments:true_lb: True lower bound of data type (integer).true_extent: True size of data type (integer).
C:int MPI_Type_get_true_extent(
MPI_Datatype datatype,MPI_Aint *true_lb, MPI_Aint *true_extent)
int MPI_Type_get_true_extent_x(MPI_Datatype datatype,MPI_Count *true_lb, MPI_Count *true_extent)
FortranMPI_TYPE_GET_TRUE_EXTENT(DATATYPE, TRUE_LB, TRUE_EXTENT, IERROR)
INTEGER DATATYPE, IERRORINTEGER(KIND=MPI_ADDRESS_KIND) TRUE_LB, TRUE_EXTENT
Victor Eijkhout 135

5. MPI topic: Data types
MPI_TYPE_GET_TRUE_EXTENT_X(DATATYPE, TRUE_LB, TRUE_EXTENT, IERROR)INTEGER DATATYPE, IERRORINTEGER(KIND=MPI_COUNT_KIND) TRUE_LB, TRUE_EXTENT
How to read routine prototypes: 1.5.4.
// trueextent.cint sender = 0, receiver = 1, the_other = 1-procno,count = 4;
int sizes[2] = {4,6},subsizes[2] = {2,3},starts[2] = {1,2};MPI_Datatype subarraytype;if (procno==sender) {MPI_Type_create_subarray
(2,sizes,subsizes,starts,MPI_ORDER_C,MPI_DOUBLE,&subarraytype);MPI_Type_commit(&subarraytype);
MPI_Aint true_lb,true_extent,extent;// MPI_Type_get_extent(subarraytype,&extent);MPI_Type_get_true_extent
(subarraytype,&true_lb,&true_extent);MPI_Aint
comp_lb =( starts[0]*sizes[1]+starts[1] )*sizeof(double),
comp_extent =( (starts[0]+subsizes[0]-1)*sizes[1] + starts[1]+subsizes[1] )
*sizeof(double) - comp_lb;// ASSERT(extent==true_lb+extent);ASSERT(true_lb==comp_lb);ASSERT(true_extent==comp_extent);
MPI_Send(source,1,subarraytype,the_other,0,comm);MPI_Type_free(&subarraytype);
5.4 More about data
5.4.1 Datatype signatures
With the primitive types it pretty much went without saying that if the sender sends an array of doubles,the receiver had to declare the datatype also as doubles. With derived types that is no longer the case: thesender and receiver can declare a different datatype for the send and receive buffer, as long as these havethe same datatype signature .
The signature of a datatype is the internal representation of that datatype. For instance, if the sender declaresa datatype consisting of two doubles, and it sends four elements of that type, the receiver can receive it astwo elements of a type consisting of four doubles.
You can also look at the signature as the form ‘under the hood’ in which MPI sends the data.
136 Parallel Computing – r428

5.4. More about data
5.4.2 Big data types
The size parameter in MPI send and receive calls is of type integer, meaning that it’s maximally 231 − 1.These day computers are big enough that this is a limitation. Derived types offer some way out: to sendabig data type of 1040 elements you would
• create a contiguous type with 1020 elements, and• send 1020 elements of that type.
This often works, but it’s not perfect. For instance, the routine returns the total number of basic elementssent (as opposed to MPI_Get_count which would return the number of elements of the derived type). Sinceits output argument is of integer type, it can’t store the right value.
The MPI 3 standard has addressed this as follows.
• To preserve backwards compatibility, the size parameter keeps being of type integer.• The trick with sending elements of a derived type still works, but• There are new routines that can return the correct information about the total amount of data; for
instance, MPI_Get_elements_x returns its result as a MPI_Count.
5.4.3 Packing
One of the reasons for derived datatypes is dealing with non-contiguous data. In older communicationlibraries this could only be done by packing data from its original containers into a buffer, and likewiseunpacking it at the receiver into its destination data structures.
MPI offers this packing facility, partly for compatibility with such libraries, but also for reasons of flexibil-ity. Unlike with derived datatypes, which transfers data atomically, packing routines add data sequentiallyto the buffer and unpacking takes them sequentially.
This means that one could pack an integer describing how many floating point numbers are in the rest ofthe packed message. Correspondingly, the unpack routine could then investigate the first integer and basedon it unpack the right number of floating point numbers.
MPI offers the following:
• The MPI_Pack command adds data to a send buffer;• the MPI_Unpack command retrieves data from a receive buffer;• the buffer is sent with a datatype of MPI_PACKED.
With MPI_Pack data elements can be added to a buffer one at a time. The position parameter is updatedeach time by the packing routine.
int MPI_Pack(void *inbuf, int incount, MPI_Datatype datatype,void *outbuf, int outcount, int *position,MPI_Comm comm);
Conversely, MPI_Unpack retrieves one element from the buffer at a time. You need to specify the MPIdatatype.
Victor Eijkhout 137

5. MPI topic: Data types
int MPI_Unpack(void *inbuf, int insize, int *position,void *outbuf, int outcount, MPI_Datatype datatype,MPI_Comm comm);
A packed buffer is sent or received with a datatype of MPI_PACKED. The sending routine uses the positionparameter to specify how much data is sent, but the receiving routine does not know this value a priori, sohas to specify an upper bound.
// pack.cif (procno==sender) {MPI_Pack(&nsends,1,MPI_INT,buffer,buflen,&position,comm);for (int i=0; i<nsends; i++) {
double value = rand()/(double)RAND_MAX;MPI_Pack(&value,1,MPI_DOUBLE,buffer,buflen,&position,comm);
}MPI_Pack(&nsends,1,MPI_INT,buffer,buflen,&position,comm);MPI_Send(buffer,position,MPI_PACKED,other,0,comm);
} else if (procno==receiver) {int irecv_value;double xrecv_value;MPI_Recv(buffer,buflen,MPI_PACKED,other,0,comm,MPI_STATUS_IGNORE);MPI_Unpack(buffer,buflen,&position,&nsends,1,MPI_INT,comm);for (int i=0; i<nsends; i++) {
MPI_Unpack(buffer,buflen,&position,&xrecv_value,1,MPI_DOUBLE,comm);}MPI_Unpack(buffer,buflen,&position,&irecv_value,1,MPI_INT,comm);ASSERT(irecv_value==nsends);
}
You can precompute the size of the required buffer as follows:C:int MPI_Pack_size
(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size)
Input parameters:incount : Count argument to packing call (integer).datatype : Datatype argument to packing call (handle).comm : Communicator argument to packing call (handle).
Output parameters:size : Upper bound on size of packed message, in bytes (integer).
Fortran:MPI_PACK_SIZE(INCOUNT, DATATYPE, COMM, SIZE, IERROR)input parameters:INTEGER :: INCOUNT, DATATYPE, COMMINTEGER :: SIZE, IERROR
How to read routine prototypes: 1.5.4.
Add one time MPI_BSEND_OVERHEAD.
138 Parallel Computing – r428

5.5. Sources used in this chapter
Exercise 5.7. Suppose you have a ‘structure of arrays’
struct aos {int length;double *reals;double *imags;
};
with dynamically created arrays. Write code to send and receive this structure.
5.5 Sources used in this chapterListing of code examples/mpi/c/contiguous.c:
/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% contiguous.c : using contiguous data type%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
if (nprocs<2) {printf("This program needs at least two processes\n");return -1;
}int sender = 0, receiver = 1, count = 5;double *source,*target;source = (double*) malloc(count*sizeof(double));target = (double*) malloc(count*sizeof(double));
for (int i=0; i<count; i++)source[i] = i+.5;
//snippet contiguousMPI_Datatype newvectortype;if (procno==sender) {MPI_Type_contiguous(count,MPI_DOUBLE,&newvectortype);MPI_Type_commit(&newvectortype);
Victor Eijkhout 139

5. MPI topic: Data types
MPI_Send(source,1,newvectortype,receiver,0,comm);MPI_Type_free(&newvectortype);
} else if (procno==receiver) {MPI_Status recv_status;int recv_count;MPI_Recv(target,count,MPI_DOUBLE,sender,0,comm,&recv_status);
MPI_Get_count(&recv_status,MPI_DOUBLE,&recv_count);ASSERT(count==recv_count);
}//snippet end
if (procno==receiver) {for (int i=0; i<count; i++)if (target[i]!=source[i])
printf("location %d %e s/b %e\n",i,target[i],source[i]);}
if (procno==0)printf("Finished\n");
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/vector.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% vector.c : vector datatype%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
if (nprocs<2) {printf("This program needs at least two processes\n");return -1;
}int sender = 0, receiver = 1, the_other = 1-procno,
140 Parallel Computing – r428

5.5. Sources used in this chapter
count = 5,stride=2;double *source,*target;//snippet vectorsource = (double*) malloc(stride*count*sizeof(double));target = (double*) malloc(count*sizeof(double));//snippet end
for (int i=0; i<stride*count; i++)source[i] = i+.5;
//snippet vectorMPI_Datatype newvectortype;if (procno==sender) {MPI_Type_vector(count,1,stride,MPI_DOUBLE,&newvectortype);MPI_Type_commit(&newvectortype);MPI_Send(source,1,newvectortype,the_other,0,comm);MPI_Type_free(&newvectortype);
} else if (procno==receiver) {MPI_Status recv_status;int recv_count;MPI_Recv(target,count,MPI_DOUBLE,the_other,0,comm,&recv_status);
MPI_Get_count(&recv_status,MPI_DOUBLE,&recv_count);ASSERT(recv_count==count);
}//snippet end
if (procno==receiver) {for (int i=0; i<count; i++)if (target[i]!=source[stride*i])
printf("location %d %e s/b %e\n",i,target[i],source[stride*i]);}
if (procno==0)printf("Finished\n");
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/indexed.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% indexed.c : MPI_Type_indexed%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
Victor Eijkhout 141

5. MPI topic: Data types
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
if (nprocs<2) {printf("This program needs at least two processes\n");return -1;
}int sender = 0, receiver = 1, the_other = 1-procno,count = 5,totalcount = 15, targetbuffersize = 2*totalcount;
int *source,*target;int *displacements,*blocklengths;
//snippet indexeddisplacements = (int*) malloc(count*sizeof(int));blocklengths = (int*) malloc(count*sizeof(int));source = (int*) malloc(totalcount*sizeof(int));target = (int*) malloc(targetbuffersize*sizeof(int));//snippet end
displacements[0] = 2; displacements[1] = 3; displacements[2] = 5;displacements[3] = 7; displacements[4] = 11;for (int i=0; i<count; ++i)blocklengths[i] = 1;
for (int i=0; i<totalcount; ++i)source[i] = i;
//snippet indexedMPI_Datatype newvectortype;if (procno==sender) {MPI_Type_indexed(count,blocklengths,displacements,MPI_INT,&newvectortype);MPI_Type_commit(&newvectortype);MPI_Send(source,1,newvectortype,the_other,0,comm);MPI_Type_free(&newvectortype);
} else if (procno==receiver) {MPI_Status recv_status;int recv_count;MPI_Recv(target,targetbuffersize,MPI_INT,the_other,0,comm,&recv_status);
MPI_Get_count(&recv_status,MPI_INT,&recv_count);ASSERT(recv_count==count);
}//snippet end
if (procno==receiver) {int i=3,val=7;if (target[i]!=val)
142 Parallel Computing – r428

5.5. Sources used in this chapter
printf("location %d %d s/b %d\n",i,target[i],val);i=4; val=11;if (target[i]!=val)printf("location %d %d s/b %d\n",i,target[i],val);
}if (procno==0)printf("Finished\n");
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/struct.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% struct.c : illustrating type struct%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
if (nprocs<2) {printf("This program needs at least two processes\n");return -1;
}int sender = 0, receiver = 1, the_other = 1-procno;//snippet structurestruct object {char c;double x[2];int i;
};//snippet end
if (procno==sender)printf("Structure has size %d, naive size %d\n",
sizeof(struct object),sizeof(char)+2*sizeof(double)+sizeof(int));
struct object myobject;
Victor Eijkhout 143

5. MPI topic: Data types
if (procno==sender) {myobject.c = ’x’; myobject.x[0] = 2.7;myobject.x[1] = 1.5; myobject.i = 37;
}
//snippet structureMPI_Datatype newstructuretype;int structlen = 3;int blocklengths[structlen]; MPI_Datatype types[structlen];MPI_Aint displacements[structlen];// where are the components relative to the structure?blocklengths[0] = 1; types[0] = MPI_CHAR;displacements[0] = (size_t)&(myobject.c) - (size_t)&myobject;blocklengths[1] = 2; types[1] = MPI_DOUBLE;displacements[1] = (size_t)&(myobject.x[0]) - (size_t)&myobject;blocklengths[2] = 1; types[2] = MPI_INT;displacements[2] = (size_t)&(myobject.i) - (size_t)&myobject;MPI_Type_create_struct(structlen,blocklengths,displacements,types,&newstructuretype);MPI_Type_commit(&newstructuretype);{MPI_Aint typesize;MPI_Type_extent(newstructuretype,&typesize);if (procno==0) printf("Type extent: %d bytes\n",typesize);
}if (procno==sender) {MPI_Send(&myobject,1,newstructuretype,the_other,0,comm);
} else if (procno==receiver) {MPI_Recv(&myobject,1,newstructuretype,the_other,0,comm,MPI_STATUS_IGNORE);
}MPI_Type_free(&newstructuretype);//snippet end
if (procno==receiver) {printf("%c %e %e %d\n",myobject.c,myobject.x[0],myobject.x[1],myobject.i);ASSERT(myobject.x[1]==1.5);ASSERT(myobject.i==37);
}
if (procno==0)printf("Finished\n");
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/vectortypesize.c:
Listing of code examples/mpi/c/vectortypeextent.c:
Listing of code examples/mpi/c/trueextent.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
144 Parallel Computing – r428

5.5. Sources used in this chapter
%%%% This program file is part of the book and course%%%% "Parallel Computing"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% subarray.c : subarray datatype%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <stdio.h>#include <string.h>#include "mpi.h"
int main(int argc,char **argv) {
#include "globalinit.c"
if (nprocs<2) {printf("This program needs at least two processes\n");return -1;
}//snippet trueextentint sender = 0, receiver = 1, the_other = 1-procno,count = 4;
int sizes[2] = {4,6},subsizes[2] = {2,3},starts[2] = {1,2};//snippet enddouble *source,*target;source = (double*) malloc(sizes[0]*sizes[1]*sizeof(double));target = (double*) malloc(subsizes[0]*subsizes[1]*sizeof(double));
for (int i=0; i<sizes[0]*sizes[1]; i++)source[i] = i+.5;
//snippet trueextentMPI_Datatype subarraytype;if (procno==sender) {MPI_Type_create_subarray(2,sizes,subsizes,starts,MPI_ORDER_C,MPI_DOUBLE,&subarraytype);
MPI_Type_commit(&subarraytype);
MPI_Aint true_lb,true_extent,extent;// MPI_Type_get_extent(subarraytype,&extent);MPI_Type_get_true_extent(subarraytype,&true_lb,&true_extent);
MPI_Aintcomp_lb =
( starts[0]*sizes[1]+starts[1] )*sizeof(double),comp_extent =
( (starts[0]+subsizes[0]-1)*sizes[1] + starts[1]+subsizes[1] )
*sizeof(double) - comp_lb;//snippet end
Victor Eijkhout 145

5. MPI topic: Data types
printf("Found lb=%ld, extent=%ld\n",true_lb,true_extent);printf("Computing lb=%ld extent=%ld\n",comp_lb,comp_extent);//snippet trueextent// ASSERT(extent==true_lb+extent);ASSERT(true_lb==comp_lb);ASSERT(true_extent==comp_extent);
MPI_Send(source,1,subarraytype,the_other,0,comm);MPI_Type_free(&subarraytype);//snippet end
} else if (procno==receiver) {MPI_Status recv_status;int recv_count;MPI_Recv(target,count,MPI_DOUBLE,the_other,0,comm,&recv_status);
MPI_Get_count(&recv_status,MPI_DOUBLE,&recv_count);ASSERT(recv_count==count);
}
if (procno==receiver) {printf("received:");for (int i=0; i<count; i++)printf(" %6.3f",target[i]);
printf("\n");int icnt = 0;for (int i=starts[0]; i<starts[0]+subsizes[0]; i++) {for (int j=starts[1]; j<starts[1]+subsizes[1]; j++) {
printf("%d,%d\n",i,j);ASSERTm(icnt<count,"icnt too hight");int isrc = i*sizes[1]+j;if (source[isrc]!=target[icnt])printf("target location (%d,%d)->%d %e s/b %e\n",i,j,icnt,target[icnt],source[isrc]);
icnt ++;}
}}
if (procno==0)printf("Finished\n");
/* MPI_Finalize(); */return 0;
}
Listing of code examples/mpi/pack/pack.c:
146 Parallel Computing – r428

Chapter 6
MPI topic: Communicators
6.1 Communicator basics
A communicator is an object describing a group of processes. In many applications all processes worktogether closely coupled, and the only communicator you need is MPI_COMM_WORLD, the group describingall processes that your job starts with.
If you don’t want to write MPI_COMM_WORLD repeatedly, you can assign that value to a variable of typeMPI_Comm:
C:MPI_Comm commvariable; // datatype is defined in mpi.h
Fortran with 2008 support:Type(MPI_Comm) :: commvariable
Fortran legacy interface:Integer :: commvariable
Python:MPI.Comm : class of communicatorsMPI.IntracommMPI.Intercomm : subclasses of the MPI.Comm class.MPI.Comm.Is_inter()MPI.Comm.Is_intra() : convenience functions, not part of the MPI standard.
How to read routine prototypes: 1.5.4.
Examples:
// C:#include <mpi.h>MPI_Comm comm = MPI_COMM_WORLD;
!! Fortran 2008 interfaceuse mpi_f08Type(MPI_Comm) :: comm = MPI_COMM_WORLD
147

6. MPI topic: Communicators
!! Fortran legacy interface#include <mpif.h>Integer :: comm = MPI_COMM_WORLD
However, there are circumstances where you want one subset of processes to operate independently ofanother subset. For example:
• If processors are organized in a 2×2 grid, you may want to do broadcasts inside a row or column.• For an application that includes a producer and a consumer part, it makes sense to split the
processors accordingly.
In this section we will see mechanisms for defining new communicators and sending messages betweencommunicators.
An important reason for using communicators is the development of software libraries. If the routines ina library use their own communicator (even if it is a duplicate of the ‘outside’ communicator), there willnever be a confusion between message tags inside and outside the library.
There are three predefined communicators:
• MPI_COMM_WORLD comprises all processes that were started together by mpirun (or some relatedprogram).• MPI_COMM_SELF is the communicator that contains only the current process.• MPI_COMM_NULL is the invalid communicator. Routines that construct communicators can give
this as result if an error occurs.
In some applications you will find yourself regularly creating new communicators, using the mechanismsdescribed below. In that case, you should de-allocate communicators with MPI_Comm_free when you’redone with them.
6.2 Subcommunications
In many scenarios you divide a large job over all the available processors. However, your job has twoor more parts that can be considered as jobs by themselves. In that case it makes sense to divide yourprocessors into subgroups accordingly.
Suppose for instance that you are running a simulation where inputs are generated, a computation is per-formed on them, and the results of this computation are analyzed or rendered graphically. You could thenconsider dividing your processors in three groups corresponding to generation, computation, rendering.
As long as you only do sends and receives, this division works fine. However, if one group of processesneeds to perform a collective operation, you don’t want the other groups involved in this. Thus, you reallywant the three groups to be really distinct from each other.
In order to make such subsets of processes, MPI has the mechanism of taking a subset of MPI_COMM_WORLDand turning that subset into a new communicator.
148 Parallel Computing – r428

6.3. Duplicating communicators
Now you understand why the MPI collective calls had an argument for the communicator: a collective in-volves all processes of that communicator. By making a communicator that contains a subset of all availableprocesses, you can do a collective on that subset.
6.2.1 Scenario: distributed linear algebra
For scalability reasons, matrices should often be distributed in a 2D manner, that is, each process receivesa subblock that is not a block of columns or rows. This means that the processors themselves are, at leastlogically, organized in a 2D grid. Operations then involve reductions or broadcasts inside rows or columns.For this, a row or column of processors needs to be in a subcommunicator.
6.2.2 Scenario: climate model
A climate simulation code has several components, for instance corresponding to land, air, ocean, and ice.You can imagine that each needs a different set of equations and algorithms to simulate. You can then divideyour processes, where each subset simulates one component of the climate, occasionally communicatingwith the other components.
6.2.3 Scenario: quicksort
The popular quicksort algorithm works by splitting the data into two subsets that each can be sorted indi-vidually. If you want to sort in parallel, you could implement this by making two subcommunicators, andsorting the data on these, creating recursively more subcommunicators.
6.3 Duplicating communicators
With MPI_Comm_dup you can make an exact duplicate of a communicator. This may seem pointless, but itis actually very useful for the design of software libraries. Image that you have a code
MPI_Isend(...); MPI_Irecv(...);// library callMPI_Waitall(...);
and suppose that the library has receive calls. Now it is possible that the receive in the library inadvertentlycatches the message that was sent in the outer environment.
In section 12.8 it was explained that MPI messages are non-overtaking. This may lead to confusing situ-ations, witness the following. First of all, here is code where the library stores the communicator of thecalling program:
// commdup_wrong.cxxclass library {private:MPI_Comm comm;int procno,nprocs,other;MPI_Request *request;
Victor Eijkhout 149

6. MPI topic: Communicators
public:library(MPI_Comm incomm) {
comm = incomm;MPI_Comm_rank(comm,&procno);other = 1-procno;request = new MPI_Request[2];
};int communication_start();int communication_end();
};
This models a main program that does a simple message exchange, and it makes two calls to library routines.Unbeknown to the user, the library also issues send and receive calls, and they turn out to interfere.
Here
• The main program does a send,• the library call function_start does a send and a receive; because the receive can match
either send, it is paired with the first one;• the main program does a receive, which will be paired with the send of the library call;• both the main program and the library do a wait call, and in both cases all requests are succesfully
fulfilled, just not the way you intended.
To prevent this confusion, the library should duplicate the outer communicator, and send all messages withrespect to its duplicate. Now messages from the user code can never reach the library software, since theyare on different communicators.
Semantics:MPI_COMM_DUP(comm, newcomm)IN comm: communicator (handle)OUT newcomm: copy of comm (handle)
C:int MPI_Comm_dup(MPI_Comm comm, MPI_Comm *newcomm)
F:MPI_Comm_dup(comm, newcomm, ierror)TYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Comm), INTENT(OUT) :: newcommINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Py:newcomm = oldcomm.Dup(Info info=None)
How to read routine prototypes: 1.5.4.
// commdup_right.cxxclass library {private:MPI_Comm comm;int procno,nprocs,other;MPI_Request *request;
150 Parallel Computing – r428

6.4. Splitting a communicator
public:library(MPI_Comm incomm) {
MPI_Comm_dup(incomm,&comm);MPI_Comm_rank(comm,&procno);other = 1-procno;request = new MPI_Request[2];
};˜library() {
MPI_Comm_free(&comm);}int communication_start();int communication_end();
};
## commdup.pyclass Library():
def __init__(self,comm):# wrong: self.comm = commself.comm = comm.Dup()self.other = self.comm.Get_size()-self.comm.Get_rank()-1self.requests = [ None ] * 2
def communication_start(self):sendbuf = np.empty(1,dtype=np.int); sendbuf[0] = 37recvbuf = np.empty(1,dtype=np.int)self.requests[0] = self.comm.Isend( sendbuf, dest=other,tag=2 )self.requests[1] = self.comm.Irecv( recvbuf, source=other )
def communication_end(self):MPI.Request.Waitall(self.requests)
mylibrary = Library(comm)my_requests[0] = comm.Isend( sendbuffer,dest=other,tag=1 )mylibrary.communication_start()my_requests[1] = comm.Irecv( recvbuffer,source=other )MPI.Request.Waitall(my_requests,my_status)mylibrary.communication_end()
Newly created communicators should be released again with MPI_Comm_free.
6.4 Splitting a communicatorSplitting a communicator into multiple disjoint communicators can be done with MPI_Comm_split. Thisuses a ‘colour’:
Semantics:MPI_COMM_SPLIT(comm, color, key, newcomm)IN comm: communicator (handle)IN color: control of subset assignment (integer)IN key: control of rank assigment (integer)OUT newcomm: new communicator (handle)
C:
Victor Eijkhout 151

6. MPI topic: Communicators
int MPI_Comm_split(MPI_Comm comm, int color, int key,MPI_Comm *newcomm)
F:MPI_Comm_split(comm, color, key, newcomm, ierror)TYPE(MPI_Comm), INTENT(IN) :: commINTEGER, INTENT(IN) :: color, keyTYPE(MPI_Comm), INTENT(OUT) :: newcommINTEGER, OPTIONAL, INTENT(OUT) :: ierrorMPI_COMM_SPLIT(COMM, COLOR, KEY, NEWCOMM, IERROR)INTEGER COMM, COLOR, KEY, NEWCOMM, IERROR
Py:newcomm = comm.Split(int color=0, int key=0)
How to read routine prototypes: 1.5.4.
and all processes in the old communicator with the same colour wind up in a new communicator together.The old communicator still exists, so processes now have two different contexts in which to communicate.
The ranking of processes in the new communicator is determined by a ‘key’ value. Most of the time, thereis no reason to use a relative ranking that is different from the global ranking, so the MPI_Comm_rank valueof the global communicator is a good choice.
Here is one example of communicator splitting. Suppose your processors are in a two-dimensional grid:
MPI_Comm_rank( MPI_COMM_WORLD, &mytid );proc_i = mytid % proc_column_length;proc_j = mytid / proc_column_length;
You can now create a communicator per column:
MPI_Comm column_comm;MPI_Comm_split( MPI_COMM_WORLD, proc_j, mytid, &column_comm );
and do a broadcast in that column:
MPI_Bcast( data, /* tag: */ 0, column_comm );
Because of the SPMD nature of the program, you are now doing in parallel a broadcast in every processorcolumn. Such operations often appear in dense linear algebra .
The MPI_Comm_split routine has a ‘key’ parameter, which controls how the processes in the new commu-nicator are ordered. By supplying the rank from the original communicator you let them be arranged in thesame order.
One application of communicator splitting is setting up a processor grid, with the possibility of using MPIsolely within one row or column; see figure 6.1.
Exercise 6.1. Organize your processes in a grid, and make subcommunicators for the rowsand columns. For this compute the row and column number of each process.
152 Parallel Computing – r428

6.4. Splitting a communicator
Figure 6.1: Row and column broadcasts in subcommunicators
In the row and column communicator, compute the rank. For instance, on a 2× 3processor grid you should find:
Global ranks: Ranks in row: Ranks in colum:0 1 2 0 1 2 0 0 03 4 5 0 1 2 1 1 1
Check that the rank in the row communicator is the column number, and the otherway around.Run your code on different number of processes, for instance a number of rows andcolumns that is a power of 2, or that is a prime number.
As an example of communicator splitting, consider the recursive algorithm for matrix transposition . Pro-cessors are organized in a square grid. The matrix is divided on 2× 2 block form.
Exercise 6.2. Implement a recursive algorithm for matrix transposition:
• Swap blocks (1, 2) and (2, 1); then
• Divide the processors into four subcommunicators, and apply this algorithmrecursively on each;
• If the communicator has only one process, transpose the matrix in place.
There is an important application of communicator splitting in the context of one-sided communication,grouping processes by whether they access the same shared memory area; see section 11.1.
Victor Eijkhout 153

6. MPI topic: Communicators
6.5 Communicators and groups
You saw in section 6.4 that it is possible derive communicators that have a subset of the processes of anothercommunicator. There is a more general mechanism, using MPI_Group objects.
C:MPI_Group groupvariable; // datatype is defined in mpi.h
Fortran with 2008 support:Type(MPI_Group) :: groupvariable
Fortran legacy interface:Integer :: groupvariable
Python:MPI.Group is a class
How to read routine prototypes: 1.5.4.
Using groups, it takes three steps to create a new communicator:
1. Access the MPI_Group of a communicator object using MPI_Comm_group.Synopsisint MPI_Comm_group(MPI_Comm comm, MPI_Group *group)
Input Parameters:comm : Communicator (handle)
Output Parametersgroup : Group in communicator (handle)
How to read routine prototypes: 1.5.4.2. Use various routines, discussed next, to form a new group.3. Make a new communicator object from the group with MPI_Group.
Synopsis
MPI_Comm_create( MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm )
Input parameters:comm : Communicator (handle).group : Group, which is a subset of the group of comm (handle).
Output parameters:newcomm : New communicator (handle).
C:int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)
Fortran90:MPI_COMM_CREATE(COMM, GROUP, NEWCOMM, IERROR)INTEGER COMM, GROUP, NEWCOMM, IERROR
154 Parallel Computing – r428

6.6. Inter-communicators
Fortran2008:MPI_Comm_create(comm, group, newcomm, ierror)TYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Group), INTENT(IN) :: groupTYPE(MPI_Comm), INTENT(OUT) :: newcommINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
Creating a new communicator from a group is collective on the old communicator. There is also a routineMPI_Comm_create_group that only needs to be called on the group that constitutes the new communicator.
6.5.1 Process groups
Groups are manipulated with MPI_Group_incl, MPI_Group_excl, MPI_Group_difference and a few more.
You can name your communicators with MPI_Comm_set_name, which could improve the quality of errormessages when they arise.
MPI_Comm_group (comm, group, ierr)MPI_Comm_create (MPI_Comm comm,MPI_Group group, MPI_Comm newcomm, ierr)
MPI_Group_union(group1, group2, newgroup, ierr)MPI_Group_intersection(group1, group2, newgroup, ierr)MPI_Group_difference(group1, group2, newgroup, ierr)
MPI_Group_incl(group, n, ranks, newgroup, ierr)MPI_Group_excl(group, n, ranks, newgroup, ierr)
MPI_Group_size(group, size, ierr)MPI_Group_rank(group, rank, ierr)
6.6 Inter-communicators
If two disjoint communicators exist, it may be necessary to communicate between them. This can of coursebe done by creating a new communicator that overlaps them, but this would be complicated: since the ‘inter’communication happens in the overlap communicator, you have to translate its ordering into those of the twoworker communicators. It would be easier to express messages directly in terms of those communicators,and this can be done with ‘inter-communicators’.
Synopsis:
int MPI_Intercomm_create(MPI_Comm local_comm,int local_leader,MPI_Comm peer_comm,int remote_leader,int tag,
Victor Eijkhout 155

6. MPI topic: Communicators
MPI_Comm *newintercomm);
Input parameters:
local_comm : Local (intra)communicatorlocal_leader : Rank in local_comm of leader (often 0)peer_comm : Communicator used to communicate between a designated process in
the other communicator. Significant only at the process in local_commwith rank local_leader.
remote_leader : Rank in peer_comm of remote leader (often 0)tag : Message tag to use in constructing intercommunicator; if multiple
MPI_Intercomm_creates are being made, they should use different tags(more precisely, ensure that the local and remote leaders are usingdifferent tags for each MPI_intercomm_create).
Output Parameter:comm_out : Created intercommunicator
How to read routine prototypes: 1.5.4.
After this, the intercommunicator can be used in collectives such as a broadcast.
Example:MPI_Bcast (buff, count, dtype, root, comm, ierr)
• In group A, the root process passes MPI_ROOT as ‘root’ value; all others use MPI_PROC_NULL.• In group B, all processes use a ‘root’ value that is the rank of the root process in the root group.
Gather and scatter behave similarly; the allgather is different: all send buffers of group A are concatenatedin rank order, and places on all processes of group B.
Inter-communicators can be used if two groups of process work asynchronously with respect to each other;another application is fault tolerance (section 12.5).
Some rules on intercommunicators:• The local and remote groups must be disjoint (a given process cannot be in both).• Only point-to-point communication is allowed between the two intracommunicators.• Only blocking process-to-process communication is allowed.• Collective communication calls cannot be made in an intercommunicator (still allowed in the
local and remote intracommunicators internally). This rule naturally follows from the previousrule.• The syntax for MPI_Send and MPI_Recv is the same for an intercommunication as a ‘normal’
intracommunication. Of course, the communicator specified must be the name of the intercom-municator. Most importantly, the ranks used must be the relative ranks in the local and remoteintracommunicators.This rule illustrates a syntax advantage in using an intercommunicator. Processes are indentifiedby their ‘natural’ local and remote intracommunicator ranks. Not by the ‘global’ ranks they are
156 Parallel Computing – r428

6.7. Sources used in this chapter
assigned in MPI_COMM_WORLD. Virtual topologies cannot be created with an intercommunicator.To set up virtual topologies, first transform the intercommunicator to an intracommunicator withthe function MPI_Intercomm_merge
Create an intracommuncator from an intercommunicator:Synopsis:int MPI_Intercomm_merge
(MPI_Comm intercomm, int high,MPI_Comm *newintracomm)
Input Parameters:intercomm : Intercommunicator (handle)high : Used to order the groups within comm (logical) when creating the new
communicator. This is a boolean value; the group that sets high truehas its processes ordered after the group that sets this value tofalse. If all processes in the intercommunicator provide the samevalue, the choice of which group is ordered first is arbitrary.
Output Parameters:newintracomm : Created intracommunicator (handle)
How to read routine prototypes: 1.5.4.
6.7 Sources used in this chapter
Listing of code examples/mpi/c/wrongcatchlib.cxx:
Listing of code examples/mpi/c/rightcatchlib.c:
Victor Eijkhout 157

Chapter 7
MPI topic: Process management
In this course we have up to now only considered the SPMD model of running MPI programs. In some rarecases you may want to run in an MPMD mode, rather than SPMD. This can be achieved either on the OSlevel, using options of the mpiexec mechanism, or you can use MPI’s built-in process management. Readon if you’re interested in the latter.
7.1 Process spawning
The first version of MPI did not contain any process management routines, even though the earlier PVMproject did have that functionality. Process management was later added with MPI-2.
Unlike what you might think, newly added processes do not become part of MPI_COMM_WORLD; rather, theyget their own communicator, and an intercommunicator is established between this new group and theexisting one. The first routine is MPI_Comm_spawn, which tries to fire up multiple copies of a single namedexecutable. You could imagine using this mechanism to start the whole of your MPI code, but that is likelyto be inefficient.
Semantics:MPI_COMM_SPAWN(command, argv, maxprocs, info, root, comm,
intercomm,array_of_errcodes)
IN command: name of program to be spawned(string, significant only at root)
IN argv: arguments to command(array of strings, significant only at root)
IN maxprocs: maximum number of processes to start(integer, significant only at root)
IN info: a set of key-value pairs telling the runtime system where andhow to start the processes (handle, significant only at root)
IN root: rank of process in which previous arguments are examined(integer)
IN comm: intracommunicator containing group of spawning processes(handle)
OUT intercomm: intercommunicator between original group and thenewly spawned group (handle)
158

7.1. Process spawning
OUT array_of_errcodes: one code per process (array of integer)
C:int MPI_Comm_spawn(const char *command, char *argv[], int maxprocs,
MPI_Info info, int root, MPI_Comm comm,MPI_Comm *intercomm, int array_of_errcodes[])
Fortran:MPI_Comm_spawn(command, argv, maxprocs, info, root, comm, intercomm,array_of_errcodes, ierror)CHARACTER(LEN=*), INTENT(IN) :: command, argv(*)INTEGER, INTENT(IN) :: maxprocs, rootTYPE(MPI_Info), INTENT(IN) :: infoTYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Comm), INTENT(OUT) :: intercommINTEGER :: array_of_errcodes(*)INTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:
MPI.Intracomm.Spawn(self,command, args=None, int maxprocs=1, Info info=INFO_NULL,int root=0, errcodes=None)
returns an intracommunicator
How to read routine prototypes: 1.5.4.
(If you’re feeling sure of yourself, specify MPI_ERRCODES_IGNORE.)
Here is an example of a work manager.
// spawn_manager.cMPI_Comm_size(MPI_COMM_WORLD, &world_size);MPI_Comm_rank(MPI_COMM_WORLD, &manager_rank);
MPI_Attr_get(MPI_COMM_WORLD, MPI_UNIVERSE_SIZE,(void*)&universe_sizep, &flag);
if (!flag) {if (manager_rank==0) {
printf("This MPI does not support UNIVERSE_SIZE.\nHow many processestotal?");scanf("%d", &universe_size);
}MPI_Bcast(&universe_size,1,MPI_INTEGER,0,MPI_COMM_WORLD);
} else {universe_size = *universe_sizep;if (manager_rank==0)
printf("Universe size deduced as %d\n",universe_size);}ASSERTm(universe_size>world_size,"No room to start workers");int nworkers = universe_size-world_size;
Victor Eijkhout 159

7. MPI topic: Process management
const char *worker_program = "spawn_worker";int errorcodes[nworkers];MPI_Comm everyone; /* intercommunicator */MPI_Comm_spawn(worker_program, MPI_ARGV_NULL, nworkers,
MPI_INFO_NULL, 0, MPI_COMM_WORLD, &everyone,errorcodes);
## spawn_manager.pynworkers = universe_size - nprocs
itercomm = comm.Spawn("spawn_worker.py", maxprocs=nworkers)
You could start up a single copy of this program with
mpirun -np 1 spawn_manager
but with a hostfile that has more than one host. In that case the attribute MPI_UNIVERSE_SIZE, retrieved withMPI_Attr_get, will tell you to the total number of hosts available. If this option is not supported, you candetermine yourself how many processes you want to spawn. If you exceed the hardware resources, yourmulti-tasking operating system (which is some variant of Unix for almost everyone) will use time-slicing ,but you will not gain any performance.
TACC note. Intel mpi requires you to pass an option -usize to mpiexec in-dicating the size of the comm universe. With the TACC jobs starter ibrun do thefollowing:
MY_MPIRUN_OPTIONS="-usize 8" ibrun -np 4 spawn_manager
The spawned program looks very much like a regular MPI program, with its own initialization and finalizecalls.
// spawn_worker.cMPI_Comm_size(MPI_COMM_WORLD,&nworkers);MPI_Comm_rank(MPI_COMM_WORLD,&workerno);MPI_Comm_get_parent(&parent);ASSERTm(parent!=MPI_COMM_NULL,"No parent!");
MPI_Comm_remote_size(parent, &remotesize);if (workerno==0) {printf("Deducing %d workers and %d parents\n",nworkers,remotesize);
}// ASSERTm(nworkers==size-1,"nworkers mismatch. probably misunderstanding");
## spawn_worker.pyparentcomm = comm.Get_parent()nparents = parentcomm.Get_remote_size()
Spawned processes wind up with a value of MPI_COMM_WORLD of their own, but managers and workerscan find each other regardless. The spawn routine returns the intercommunicator to the parent; the chil-dren can find it through MPI_Comm_get_parent. The number of spawning processes can be found throughMPI_Comm_remote_size on the parent communicator.
160 Parallel Computing – r428

7.2. Socket-style communications
Semantics:MPI_COMM_REMOTE_SIZE(comm, size)IN comm: inter-communicator (handle)OUT size: number of processes in the remote group of comm (integer)
C:int MPI_Comm_remote_size(MPI_Comm comm, int *size)
Fortran:MPI_Comm_remote_size(comm, size, ierror)TYPE(MPI_Comm), INTENT(IN) :: commINTEGER, INTENT(OUT) :: sizeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:Intercomm.Get_remote_size(self)
How to read routine prototypes: 1.5.4.
7.1.1 MPMD
Instead of spawning a single executable, you can spawn multiple with MPI_Comm_spawn_multiple.
7.2 Socket-style communications
It is possible to establish connections with running MPI programs that have their own world communicator.
• The server process establishes a port with MPI_Open_port, and calls MPI_Comm_accept to acceptconnections to its port.• The client process specifies that port in an MPI_Comm_connect call. This establishes the connec-
tion.
7.2.1 Server calls
The server calls MPI_Open_port, yielding a port name. Port names are generated by the system and copiedinto a character buffer of length at most MPI_MAX_PORT_NAME.
C:#include <mpi.h>int MPI_Open_port(MPI_Info info, char *port_name)
Input parameters:info : Options on how to establish an address (handle). No options currently supported.
Output parameters:port_name : Newly established port (string).
Victor Eijkhout 161

7. MPI topic: Process management
How to read routine prototypes: 1.5.4.
The server then needs to call MPI_Comm_accept prior to the client doing a connect call. This is collectiveover the calling communicator. It returns an intercommunicator that allows communication with the client.
Synopsis:int MPI_Comm_accept
(const char *port_name, MPI_Info info, int root,MPI_Comm comm, MPI_Comm *newcomm)
Input parameters:port_name : Port name (string, used only on root).info : Options given by root for the accept (handle, used only on
root). No options currently supported.root : Rank in comm of root node (integer).comm : Intracommunicator over which call is collective (handle).
Output parameters:newcomm : Intercommunicator with client as remote group (handle)
How to read routine prototypes: 1.5.4.
The port can be closed with MPI_Close_port.
7.2.2 Client calls
After the server has generated a port name, the client needs to connect to it with MPI_Comm_connect, againspecifying the port through a character buffer.
Synopsisint MPI_Comm_connect
(const char *port_name, MPI_Info info, int root,MPI_Comm comm, MPI_Comm * newcomm)
Input Parametersport_name : network address (string, used only on root)info : implementation-dependent information (handle, used only on root)root : rank in comm of root node (integer)comm : intracommunicator over which call is collective (handle)
Output Parametersnewcomm : intercommunicator with server as remote group (handle)
How to read routine prototypes: 1.5.4.
If the named port does not exist (or has been closed), MPI_Comm_connect raises an error of class MPI_ERR_PORT.
The client can sever the connection with MPI_Comm_disconnect
The connect call is collective over its communicator.
162 Parallel Computing – r428

7.3. Sources used in this chapter
7.2.3 Published service names
Synopsis:MPI_Publish_name(service_name, info, port_name)
Input parameters:service_name : a service name to associate with the port (string)info : implementation-specific information (handle)port_name : a port name (string)
C:int MPI_Publish_name
(char *service_name, MPI_Info info, char *port_name)
Fortran77:MPI_PUBLISH_NAME(SERVICE_NAME, INFO, PORT_NAME, IERROR)INTEGER INFO, IERRORCHARACTER*(*) SERVICE_NAME, PORT_NAME
How to read routine prototypes: 1.5.4.
MPI_Unpublish_name
Unpublishing a non-existing or already unpublished service gives an error code of MPI_ERR_SERVICE.
MPI_Comm_join
MPI provides no guarantee of fairness in servicing connection attempts. That is, connection attempts arenot necessarily satisfied in the order in which they were initiated, and competition from other connectionattempts may prevent a particular connection attempt from being satisfied.
7.3 Sources used in this chapter
Listing of code XX:
Listing of code XX:
Victor Eijkhout 163

Chapter 8
MPI topic: One-sided communication
Above, you saw point-to-point operations of the two-sided type: they require the co-operation of a senderand receiver. This co-operation could be loose: you can post a receive with MPI_ANY_SOURCE as sender, butthere had to be both a send and receive call. In this section, you will see one-sided communication routineswhere a process can do a ‘put’ or ‘get’ operation, writing data to or reading it from another processor,without that other processor’s involvement.
In one-sided MPI operations, also known as Remote Direct Memory Access (RDMA) or Remote MemoryAccess (RMA) operations, there are still two processes involved: the origin , which is the process thatoriginates the transfer, whether this is a ‘put’ or a ‘get’, and the target whose memory is being accessed.Unlike with two-sided operations, the target does not perform an action that is the counterpart of the actionon the origin.
That does not mean that the origin can access arbitrary data on the target at arbitrary times. First of all,one-sided communication in MPI is limited to accessing only a specifically declared memory area on thetarget: the target declares an area of user-space memory that is accessible to other processes. This is knownas a window . Windows limit how origin processes can access the target’s memory: you can only ‘get’ datafrom a window or ‘put’ it into a window; all the other memory is not reachable from other processes.
The alternative to having windows is to use distributed shared memory or virtual shared memory: memoryis distributed but acts as if it shared. The so-called Partitioned Global Address Space (PGAS) languagessuch as Unified Parallel C (UPC) use this model. The MPI RMA model makes it possible to lock a windowwhich makes programming slightly more cumbersome, but the implementation more efficient.
Within one-sided communication, MPI has two modes: active RMA and passive RMA. In active RMA , oractive target synchronization , the target sets boundaries on the time period (the ‘epoch’) during which itswindow can be accessed. The main advantage of this mode is that the origin program can perform manysmall transfers, which are aggregated behind the scenes. Active RMA acts much like asynchronous transferwith a concluding MPI_Waitall.
In passive RMA , or passive target synchronization , the target process puts no limitation on when its windowcan be accessed. (PGAS languages such as UPC are based on this model: data is simply read or written atwill.) While intuitively it is attractive to be able to write to and read from a target at arbitrary time, thereare problems. For instance, it requires a remote agent on the target, which may interfere with execution of
164

8.1. Windows
the main thread, or conversely it may not be activated at the optimal time. Passive RMA is also very hardto debug and can lead to strange deadlocks.
8.1 Windows
Figure 8.1: Collective definition of a window for one-sided data access
In one-sided communication, each processor can make an area of memory, called a window, available toone-sided transfers. A process can put an arbitrary item from its own memory to the window of anotherprocess, or get something from the other process’ window in its own memory.
A window can be characteristized as follows:• The window is defined on a communicator, so the create call is collective; see figure 8.1.• The window size can be set individually on each process. A zero size is allowed, but since
window creation is collective, it is not possible to skip the create call.• The datatype can also be set individually on each process. This makes it possible to use a derived
type on one process, for instance for copying strided data into a contiguous buffer.• The window is the target of data in a put operation, or the source of data in a get operation; see
figure 8.2.• There can be memory associated with a window, so it needs to be freed explicitly.C:MPI_Win win ;
Fortran:Type(MPI_Win) win
How to read routine prototypes: 1.5.4.
The typical calls involved are:MPI_Info info;MPI_Win window;MPI_Win_allocate( /* size info */, info, comm, &memory, &window );// do put and get callsMPI_Win_free( &window );
Victor Eijkhout 165

8. MPI topic: One-sided communication
Figure 8.2: Put and get between process memory and windows
8.1.1 Window creation and allocation
The memory for a window is ordinary data in user space. There are multiple ways you can associate datawith a window:
1. You can pass a user buffer to MPI_Win_create. This buffer can be an ordinary array, or it can becreated with MPI_Alloc_mem.
2. You can let MPI do the allocation, so that MPI can perform various optimizations regardingplacement of the memory. The user code then receives the pointer to the data from MPI. Thiscan again be done in two ways:• Use MPI_Win_allocate to create the data and the window in one call, and its variant• If a communicator is on a shared memory (see section 11.1) you can create a window in
that shared memory with MPI_Win_allocate_shared.3. Finally, you can create a window with MPI_Win_create_dynamic which postpones the alloca-
tion; see section ??.First of all, the create call from a pointer to memory:
C:int MPI_Win_create
(void *base, MPI_Aint size, int disp_unit,MPI_Info info, MPI_Comm comm, MPI_Win *win)
Fortran:MPI_Win_create(base, size, disp_unit, info, comm, win, ierror)TYPE(*), DIMENSION(..), ASYNCHRONOUS :: baseINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(IN) :: sizeINTEGER, INTENT(IN) :: disp_unitTYPE(MPI_Info), INTENT(IN) :: infoTYPE(MPI_Comm), INTENT(IN) :: commTYPE(MPI_Win), INTENT(OUT) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Win.Create
(memory, int disp_unit=1,Info info=INFO_NULL, Intracomm comm=COMM_SELF)
166 Parallel Computing – r428

8.1. Windows
How to read routine prototypes: 1.5.4.
The data array must not be PARAMETER or static const.
The size parameter is measured in bytes. In C this is easily done with the sizeof operator; for doing thiscalculation in Fortran, see section 13.3.3.3.
Next, one can obtain the memory from MPI by usingSemantics:MPI_WIN_ALLOCATE(size, disp_unit, info, comm, baseptr, win)
Input parameters:size: size of local window in bytes (non-negative integer)disp_unit local unit size for displacements, in bytes (positiveinteger)info: info argument (handle)comm: intra-communicator (handle)
Output parameters:baseptr: address of local allocated window segment (choice)win: window object returned by the call (handle)
C:int MPI_Win_allocate
(MPI_Aint size, int disp_unit, MPI_Info info,MPI_Comm comm, void *baseptr, MPI_Win *win)
Fortran:MPI_Win_allocate
(size, disp_unit, info, comm, baseptr, win, ierror)USE, INTRINSIC :: ISO_C_BINDING, ONLY : C_PTRINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(IN) :: sizeINTEGER, INTENT(IN) :: disp_unitTYPE(MPI_Info), INTENT(IN) :: infoTYPE(MPI_Comm), INTENT(IN) :: commTYPE(C_PTR), INTENT(OUT) :: baseptrTYPE(MPI_Win), INTENT(OUT) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
which has the data pointer as output. Note the void* in the C prototype; it is still necessary to pass apointer to a pointer:
double *window_data;MPI_Win_allocate( ... &window_data ... );
The routine MPI_Alloc_mem performs only the allocation part of MPI_Win_allocate, after which you needto MPI_Win_create:
Victor Eijkhout 167

8. MPI topic: One-sided communication
int MPI_Alloc_mem(MPI_Aint size, MPI_Info info, void *baseptr)
How to read routine prototypes: 1.5.4.
This memory is freed with
MPI_Free_mem()
These calls reduce to malloc and free if there is no special memory area; SGI is an example where suchmemory does exist.
There will be more discussion of window memory in section 8.5.1.
8.2 Active target synchronization: epochs
One-sided communication has an obvious complication over two-sided: if you do a put call instead of asend, how does the recipient know that the data is there? This process of letting the target know the stateof affairs is called ‘synchronization’, and there are various mechanisms for it. First of all we will consideractive target synchronization . Here the target knows when the transfer may happen (the communicationepoch ), but does not do any data-related calls.
In this section we look at the first mechanism, which is to use a fence operation:
MPI_Win_fence (int assert, MPI_Win win)
This operation is collective on the communicator of the window. It is comparable to MPI_Wait calls fornon-blocking communication.
The use of fences is somewhat complicated. The interval between two fences is known as an epoch . Youcan give various hints to the system about this epoch versus the ones before and after through the assertparameter.
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);MPI_Get( /* operands */, win);MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
In between the two fences the window is exposed, and while it is you should not access it locally. If youabsolutely need to access it locally, you can use an RMA operation for that. Also, there can be only oneremote process that does a put; multiple accumulate accesses are allowed.
Fences are, together with other window calls, collective operations. That means they imply some amountof synchronization between processes. Consider:
MPI_Win_fence( ... win ... ); // start an epochif (mytid==0) // do lots of workelse // do almost nothingMPI_Win_fence( ... win ... ); // end the epoch
168 Parallel Computing – r428

8.2. Active target synchronization: epochs
Figure 8.3: A trace of a one-sided communication epoch where process zero only originates a one-sidedtransfer
and assume that all processes execute the first fence more or less at the same time. The zero process doeswork before it can do the second fence call, but all other processes can call it immediately. However, theycan not finish that second fence call until all one-sided communication is finished, which means they waitfor the zero process.
// putblock.cMPI_Win_create(&other_number,1,sizeof(int),
MPI_INFO_NULL,comm,&the_window);MPI_Win_fence(0,the_window);if (mytid==0) {MPI_Put( /* data on origin: */ &my_number, 1,MPI_INT,
/* data on target: */ 1,0, 1,MPI_INT,the_window);
sleep(.5);}MPI_Win_fence(0,the_window);if (mytid==1)printf("I got the following: %d\n",other_number);
As a further restriction, you can not mix MPI_Get with MPI_Put or MPI_Accumulate calls in a single epoch.Hence, we can characterize an epoch as an access epoch on the origin, and as an exposure epoch on thetarget.
Assertions are an integer parameter: you can combine assertions by adding them or using logical-or. Thevalue zero is always correct. For further information, see section 8.3.7.
Victor Eijkhout 169

8. MPI topic: One-sided communication
8.3 Put, get, accumulate
We will now look at the first three routines for doing one-sided operations: the Put, Get, and Accumulatecall. (We will look at so-called ‘atomic’ operations in section 8.3.9.) These calls are somewhat similar to aSend, Receive and Reduce, except that of course only one process makes a call. Since one process does allthe work, its calling sequence contains both a description of the data on the origin (the calling process) andthe target (the affect other process).
As in the two-sided case, MPI_PROC_NULL can be used as a target rank.
8.3.1 Put
The MPI_Put call can be considered as a one-sided send. As such, it needs to specify
• the target rank• the data to be sent from the origin, and• the location where it is to be written on the target.
The description of the data on the origin is the usual trio of buffer/count/datatype. However, the descriptionof the data on the target is more complicated. It has a count and a datatype, but instead of an address it hasa displacement unit with respect to the start of the window on the target. This displacement can be givenin bytes, so its type is MPI_Aint, but strictly speaking it is a multiple of the displacement unit that wasspecified in the window definition.
Specifically, data is written starting at
window base + target disp× disp unit.
C:int MPI_Put(const void *origin_addr, int origin_count, MPI_Datatype origin_datatype,int target_rank,MPI_Aint target_disp, int target_count, MPI_Datatype target_datatype,MPI_Win win)
Semantics:IN origin_addr: initial address of origin buffer (choice)IN origin_count: number of entries in origin buffer (non-negative integer)IN origin_datatype: datatype of each entry in origin buffer (handle)IN target_rank: rank of target (non-negative integer)IN target_disp: displacement from start of window to target buffer (non-negative integer)IN target_count: number of entries in target buffer (non-negative integer)IN target_datatype: datatype of each entry in target buffer (handle)IN win: window object used for communication (handle)
170 Parallel Computing – r428

8.3. Put, get, accumulate
Fortran:MPI_Put(origin_addr, origin_count, origin_datatype,
target_rank, target_disp, target_count, target_datatype, win, ierror)TYPE(*), DIMENSION(..), INTENT(IN), ASYNCHRONOUS :: origin_addrINTEGER, INTENT(IN) :: origin_count, target_rank, target_countTYPE(MPI_Datatype), INTENT(IN) :: origin_datatype, target_datatypeINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(IN) :: target_dispTYPE(MPI_Win), INTENT(IN) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:
win.Put(self, origin, int target_rank, target=None)
How to read routine prototypes: 1.5.4.
Fortran note. The disp_unit variable is declared as
integer(kind=MPI_ADDRESS_KIND) :: displacement
Specifying a literal constant, such as 0, can lead to bizarre runtime errors.
Here is a single put operation. Note that the window create and window fence calls are collective, so theyhave to be performed on all processors of the communicator that was used in the create call.
// putblock.cMPI_Win_create(&other_number,1,sizeof(int),
MPI_INFO_NULL,comm,&the_window);MPI_Win_fence(0,the_window);if (mytid==0) {MPI_Put( /* data on origin: */ &my_number, 1,MPI_INT,
/* data on target: */ 1,0, 1,MPI_INT,the_window);
sleep(.5);}MPI_Win_fence(0,the_window);if (mytid==1)printf("I got the following: %d\n",other_number);
Exercise 8.1. Revisit exercise 4.7 and solve it using MPI_Put.
Exercise 8.2. Write code where process 0 randomly writes in the window on 1 or 2.
8.3.2 Get
The MPI_Get call is very similar.C:int MPI_Get(const void *origin_addr, int origin_count, MPI_Datatype origin_datatype,int target_rank,MPI_Aint target_disp, int target_count, MPI_Datatype target_datatype,MPI_Win win)
Victor Eijkhout 171

8. MPI topic: One-sided communication
Semantics:IN origin_addr: initial address of origin buffer (choice)IN origin_count: number of entries in origin buffer (non-negative integer)IN origin_datatype: datatype of each entry in origin buffer (handle)IN target_rank: rank of target (non-negative integer)IN target_disp: displacement from start of window to target buffer (non-negative integer)IN target_count: number of entries in target buffer (non-negative integer)IN target_datatype: datatype of each entry in target buffer (handle)IN win: window object used for communication (handle)
Fortran:MPI_Get(origin_addr, origin_count, origin_datatype,target_rank, target_disp, target_count, target_datatype, win, ierror)
TYPE(*), DIMENSION(..), INTENT(IN), ASYNCHRONOUS :: origin_addrINTEGER, INTENT(IN) :: origin_count, target_rank, target_countTYPE(MPI_Datatype), INTENT(IN) :: origin_datatype, target_datatypeINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(IN) :: target_dispTYPE(MPI_Win), INTENT(IN) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:
win.Get(self, origin, int target_rank, target=None)
How to read routine prototypes: 1.5.4.
Example:
// getfence.cMPI_Win_create(&other_number,2*sizeof(int),sizeof(int),
MPI_INFO_NULL,comm,&the_window);MPI_Win_fence(0,the_window);if (procno==0) {MPI_Get( /* data on origin: */ &my_number, 1,MPI_INT,
/* data on target: */ other,1, 1,MPI_INT,the_window);
}MPI_Win_fence(0,the_window);
We make a null window on processes that do not participate.
## getfence.pyif procid==0 or procid==nprocs-1:
win_mem = np.empty( 1,dtype=np.float64 )win = MPI.Win.Create( win_mem,comm=comm )
else:win = MPI.Win.Create( None,comm=comm )
# put data on another processwin.Fence()if procid==0 or procid==nprocs-1:
172 Parallel Computing – r428

8.3. Put, get, accumulate
putdata = np.empty( 1,dtype=np.float64 )putdata[0] = mydataprint "[%d] putting %e" % (procid,mydata)win.Put( putdata,other )
win.Fence()
8.3.3 Put and get example: halo update
As an example, let’s look at halo update . The array A isupdated using the local values and the halo that comesfrom bordering processors, either through Put or Getoperations.
In a first version we separate computation and commu-nication. Each iteration has two fences. Between thetwo fences in the loop body we do the MPI_Put op-eration; between the second and and first one of thenext iteration there is only computation, so we add theNOPRECEDE and NOSUCCEED assertions. (For muchmore about assertions, see section 8.3.7 below.) TheNOSTORE assertion states that the local window wasnot updated: the Put operation only works on remotewindows.
for ( .... ) {update(A);MPI_Win_fence(MPI_MODE_NOPRECEDE, win);for(i=0; i < toneighbors; i++)
MPI_Put( ... );MPI_Win_fence((MPI_MODE_NOSTORE | MPI_MODE_NOSUCCEED), win);}
Next, we split the update in the core part, which can be done purely from local values, and the boundary,which needs local and halo values. Update of the core can overlap the communication of the halo.
for ( .... ) {update_boundary(A);MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);for(i=0; i < fromneighbors; i++)
MPI_Get( ... );update_core(A);MPI_Win_fence(MPI_MODE_NOSUCCEED, win);}
The NOPRECEDE and NOSUCCEED assertions still hold, but the Get operation implies that instead ofNOSTORE in the second fence, we use NOPUT in the first.
Victor Eijkhout 173
8. MPI topic: One-sided communication
8.3.4 Accumulate
A third one-sided routine is MPI_Accumulate which does a reduction operation on the results that are beingput:
C:int MPI_Accumulate
(const void *origin_addr, int origin_count,MPI_Datatype origin_datatype,int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_datatype,MPI_Op op, MPI_Win win)
int MPI_Raccumulate(const void *origin_addr, int origin_count,MPI_Datatype origin_datatype,int target_rank,MPI_Aint target_disp, int target_count,MPI_Datatype target_datatype,MPI_Op op, MPI_Win win,MPI_Request *request)
Input Parameters
origin_addr : Initial address of buffer (choice).origin_count : Number of entries in buffer (nonnegative integer).origin_datatype : Data type of each buffer entry (handle).target_rank : Rank of target (nonnegative integer).target_disp : Displacement from start of window to beginning of target buffer (nonnegative integer).target_count : Number of entries in target buffer (nonnegative integer).target_datatype : Data type of each entry in target buffer (handle).op : Reduce operation (handle).win : Window object (handle).
Output Parameter
MPI_Raccumulate: RMA requestIERROR (Fortran only): Error status (integer).
Fortran:
MPI_ACCUMULATE(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK,TARGET_DISP, TARGET_COUNT, TARGET_DATATYPE,OP, WIN, IERROR)
<type> ORIGIN_ADDR(*)INTEGER(KIND=MPI_ADDRESS_KIND) :: TARGET_DISPINTEGER :: ORIGIN_COUNT, ORIGIN_DATATYPE,
TARGET_RANK, TARGET_COUNT,TARGET_DATATYPE,OP, WIN, IERROR
MPI_RACCUMULATE(ORIGIN_ADDR, ORIGIN_COUNT, ORIGIN_DATATYPE,TARGET_RANK,TARGET_DISP, TARGET_COUNT, TARGET_DATATYPE,OP, WIN, REQUEST, IERROR)
<type> ORIGIN_ADDR(*)INTEGER(KIND=MPI_ADDRESS_KIND) :: TARGET_DISPINTEGER :: ORIGIN_COUNT, ORIGIN_DATATYPE, TARGET_RANK, TARGET_COUNT, TARGET_DATATYPE,
174 Parallel Computing – r428

8.3. Put, get, accumulate
OP, WIN, REQUEST, IERROR
Python:MPI.Win.Accumulate(self, origin, int target_rank, target=None, Op op=SUM)
How to read routine prototypes: 1.5.4.
Accumulate is a reduction with remote result. As with MPI_Reduce, the order in which the operands areaccumulated is undefined. The same predefined operators are available, but no user-defined ones. There isone extra operator: MPI_REPLACE, this has the effect that only the last result to arrive is retained.
Exercise 8.3. Implement an ‘all-gather’ operation using one-sided communication: eachprocessor stores a single number, and you want each processor to build up an arraythat contains the values from all processors. Note that you do not need a special casefor a processor collecting its own value: doing ‘communication’ between a processorand itself is perfectly legal.
Exercise 8.4.Implement a shared counter:• One process maintains a counter;• Iterate: all others at random moments update this counter.• When the counter is no longer positive, everyone stops iterating.
The problem here is data synchronization: does everyone see the counter the sameway?
8.3.5 Ordering and coherence of RMA operations
There are few guarantees about what happens inside one epoch.
• No ordering of Get and Put/Accumulate operations: if you do both, there is no guarantee whetherthe Get will find the value before or after the update.• No ordering of multiple Puts. It is safer to do an Accumulate.
The following operations are well-defined inside one epoch:
• Instead of multiple Put operations, use Accumulate with MPI_REPLACE.• MPI_Get_accumulate with MPI_NO_OP is safe.• Multiple Accumulate operations from one origin are done in program order by default. To allow
reordering, for instance to have all reads happen after all writes, use the info parameter when thewindow is created; section 8.5.2.
8.3.6 Request-based operations
Analogous to MPI_Isend there are request based one-sided operations:C:int MPI_Rput(
const void *origin_addr, int origin_count, MPI_Datatype origin_datatype,int target_rank, MPI_Aint target_disp, int target_count, MPI_Datatype target_datatype,MPI_Win win, MPI_Request *request)
Victor Eijkhout 175

8. MPI topic: One-sided communication
Semantics:IN origin_addr: initial address of origin buffer (choice)IN origin_count: number of entries in origin buffer (non-negative integer)IN origin_datatype: datatype of each entry in origin buffer (handle)IN target_rank: rank of target (non-negative integer)IN target_disp: displacement from start of window to target buffer (non-negative integer)IN target_count: number of entries in target buffer (non-negative integer)IN target_datatype: datatype of each entry in target buffer (handle)IN win: window object used for communication (handle)OUT request: RMA request (handle)
How to read routine prototypes: 1.5.4.
and similarly MPI_Rget and MPI_Raccumulate.
These only apply to passive target synchronization. Any MPI_Win_flush... call also terminates thesetransfers.
8.3.7 Assertions
The MPI_Win_fence call, as well MPI_Win_start and such, take an argument through which assertions canbe passed about the activity before, after, and during the epoch. The value zero is always allowed, by youcan make your program more efficient by specifying one or more of the following, combined by bitwiseOR in C/C++ or IOR in Fortran.
Supports the option:the matching calls to MPI_WIN_POST have already completed on all target processeswhen the call to MPI_WIN_START is made. The nocheck option can be specified in astart call if and only if it is specified in each matching post call. This is similar to theoptimization of “ready-send” that may save a handshake when the handshake is implicitin the code. (However, ready-send is matched by a regular receive, whereas both start andpost must specify the nocheck option.)
MPI_Win_start MPI_MODE_NOCHECKMPI_Win_post supports the following options:the matching calls to MPI_WIN_START have not yet occurred on any origin processeswhen the call to MPI_WIN_POST is made. The nocheck option can be specified by a postcall if and only if it is specified by each matching start call.the local window was not updated by local stores (or local get or receive calls) since lastsynchronization. This may avoid the need for cache synchronization at the post call.the local window will not be updated by put or accumulate calls after the post call, until theensuing (wait) synchronization. This may avoid the need for cache synchronization at thewait call.
MPI_MODE_NOCHECK MPI_MODE_NOSTOREMPI_MODE_NOPUTMPI_Win_fence supports the following options:the local window was not updated by local stores (or local get or receive calls) since lastsynchronization.the local window will not be updated by put or accumulate calls after the fence call, untilthe ensuing (fence) synchronization.
176 Parallel Computing – r428

8.3. Put, get, accumulate
the fence does not complete any sequence of locally issued RMA calls. If this assertion isgiven by any process in the window group, then it must be given by all processes in thegroup.the fence does not start any sequence of locally issued RMA calls. If the assertion is givenby any process in the window group, then it must be given by all processes in the group.
MPI_MODE_NOSTORE MPI_MODE_NOPUTMPI_MODE_NOPRECEDEMPI_MODE_NOSUCCEEDMPI_Win_lock supports the following option:no other process holds, or will attempt to acquire a conflicting lock, while the caller holdsthe window lock. This is useful when mutual exclusion is achieved by other means, but thecoherence operations that may be attached to the lock and unlock calls are still required.
8.3.8 More active target synchronization
The ‘fence’ mechanism (section 8.2) uses a global synchronization on the communicator of the window. Assuch it is good for applications where the processes are largely synchronized, but it may lead to performanceinefficiencies if processors are not in step which each other. There is a mechanism that is more fine-grained,by using synchronization only on a processor group . This takes four different calls, two for starting and twofor ending the epoch, separately for target and origin.
Figure 8.4: Window locking calls in fine-grained active target synchronization
You start and complete an exposure epoch with:
int MPI_Win_post(MPI_Group group, int assert, MPI_Win win)int MPI_Win_wait(MPI_Win win)
In other words, this turns your window into the target for a remote access.
You start and complete an access epoch with:
int MPI_Win_start(MPI_Group group, int assert, MPI_Win win)int MPI_Win_complete(MPI_Win win)
Victor Eijkhout 177

8. MPI topic: One-sided communication
In other words, these calls border the access to a remote window, with the current processor being the originof the remote access.
In the following snippet a single processor puts data on one other. Note that they both have their owndefinition of the group, and that the receiving process only does the post and wait calls.
// postwaitwin.cif (procno==origin) {MPI_Group_incl(all_group,1,&target,&two_group);// accessMPI_Win_start(two_group,0,the_window);MPI_Put( /* data on origin: */ &my_number, 1,MPI_INT,
/* data on target: */ target,0, 1,MPI_INT,the_window);
MPI_Win_complete(the_window);}
if (procno==target) {MPI_Group_incl(all_group,1,&origin,&two_group);// exposureMPI_Win_post(two_group,0,the_window);MPI_Win_wait(the_window);
}
Both pairs of operations declare a group of processors; see section 6.5.1 for how to get such a group from acommunicator. On an origin processor you would specify a group that includes the targets you will interactwith, on a target processor you specify a group that includes the possible origins.
8.3.9 Atomic operations
One-sided calls are said to emulate shared memory in MPI, but the put and get calls are not enough forcertain scenarios with shared data. Consider the scenario where:
MPI_MODE_NOCHECK• One process stores a table of work descriptors, and a pointer to the firt unpro-cessed descriptor;• Each process reads the pointer, reads the corresponding descriptor, and increments the pointer;
and• A process that has read a descriptor then executes the corresponding task.
The problem is that reading and updating the pointer is not an atomic operation , so it is possible thatmultiple processes get hold of the same value; conversely, multiple updates of the pointer may lead to workdescriptors being skipped. These inconsistent views of the data are called a race condition .
In MPI 3 some atomic routines have been added. Both and atomically retrieve data from the windowindicated, and apply an operator, combining the data on the target with the data on the origin.
Semantics:
MPI_FETCH_AND_OP(origin_addr, result_addr, datatype, target_rank,target_disp, op, win)
IN origin_addr: initial address of buffer (choice)OUT result_addr: initial address of result buffer (choice)
178 Parallel Computing – r428

8.3. Put, get, accumulate
IN datatype: datatype of the entry in origin, result, and target buffers(handle)IN target_rank: rank of target (non-negative integer)IN target_disp: displacement from start of window to beginning of targetbuffer (non-negative integer)IN op: reduce operation (handle)IN win: window object (handle)
C:int MPI_Fetch_and_op
(const void *origin_addr, void *result_addr,MPI_Datatype datatype, int target_rank, MPI_Aint target_disp,MPI_Op op, MPI_Win win)
Fortran:MPI_Fetch_and_op(origin_addr, result_addr, datatype, target_rank,
target_disp, op, win, ierror)TYPE(*), DIMENSION(..), INTENT(IN), ASYNCHRONOUS :: origin_addrTYPE(*), DIMENSION(..), ASYNCHRONOUS :: result_addrTYPE(MPI_Datatype), INTENT(IN) :: datatypeINTEGER, INTENT(IN) :: target_rankINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(IN) :: target_dispTYPE(MPI_Op), INTENT(IN) :: opTYPE(MPI_Win), INTENT(IN) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.C:int MPI_Get_accumulate
(const void *origin_addr, int origin_count,MPI_Datatype origin_datatype,void *result_addr, int result_count, MPI_Datatype result_datatype,int target_rank,MPI_Aint target_disp, int target_count, MPI_Datatype target_datatype,MPI_Op op, MPI_Win win)
Input Parametersorigin_addr : initial address of buffer (choice)origin_count : number of entries in buffer (nonnegative integer)origin_datatype : datatype of each buffer entry (handle)
result_addr : initial address of result buffer (choice)result_count : number of entries in result buffer (non-negative integer)result_datatype : datatype of each entry in result buffer (handle)target_rank : rank of target (nonnegative integer)target_disp : displacement from start of window to beginning
of target buffer (nonnegative integer)target_count : number of entries in target buffer (nonnegative integer)target_datatype : datatype of each entry in target buffer (handle)op : predefined reduce operation (handle)
Victor Eijkhout 179

8. MPI topic: One-sided communication
win : window object (handle)
How to read routine prototypes: 1.5.4.
Both routines perform the same operations: return data before the operation, then atomically update dataon the target, but MPI_Get_accumulate is more flexible in data type handling. The more simple routine,MPI_Fetch_and_op, which operates on only a single element, allows for faster implementations, in partic-ular through hardware support.
Exercise 8.5. Redo exercise 8.4 using MPI_Fetch_and_op. The problem is again to makesure all processes have the same view of the shared counter.Does it work to make the fetch-and-op conditional? Is there a way to do itunconditionally? What should the ‘break’ test be, seeing that multiple processes canupdate the counter at the same time?
Example. A root process has a table of data; the other processes do atomic getsand update of that data using passive target synchronization through MPI_Win_lock.
// passive.cxxif (procno==repository) {// Repository processor creates a table of inputs// and associates that with the window
}if (procno!=repository) {float contribution=(float)procno,table_element;int loc=0;MPI_Win_lock(MPI_LOCK_EXCLUSIVE,repository,0,the_window);// read the table element by getting the result fromadding zero
err = MPI_Fetch_and_op(&contribution,&table_element,MPI_FLOAT,repository,loc,MPI_SUM,the_window); CHK(err);
MPI_Win_unlock(repository,the_window);}
## passive.pyif procid==repository:
# repository process creates a table of inputs# and associates it with the windowwin_mem = np.empty( ninputs,dtype=np.float32 )win = MPI.Win.Create( win_mem,comm=comm )
else:# everyone else has an empty windowwin = MPI.Win.Create( None,comm=comm )
if procid!=repository:contribution = np.empty( 1,dtype=np.float32 )contribution[0] = 1.*procidtable_element = np.empty( 1,dtype=np.float32 )win.Lock( repository,lock_type=MPI.LOCK_EXCLUSIVE )win.Fetch_and_op( contribution,table_element,repository,0,MPI.SUM)win.Unlock( repository )
180 Parallel Computing – r428

8.4. Passive target synchronization
Finally, MPI_Compare_and_swap swaps the origin and target data if the target data equals some comparisonvalue.
C:int MPI_Compare_and_swap
(const void *origin_addr, const void *compare_addr,void *result_addr, MPI_Datatype datatype,int target_rank, MPI_Aint target_disp,MPI_Win win)
Input Parameters
origin_addr : initial address of buffer (choice)compare_addr : initial address of compare buffer (choice)result_addr : initial address of result buffer (choice)datatype : datatype of the entry in origin, result, and target buffers (handle)target_rank : rank of target (nonnegative integer)target_disp : displacement from start of window to beginning
of target buffer (non-negative integer)win : window object (handle)
How to read routine prototypes: 1.5.4.
8.4 Passive target synchronization
In passive target synchronization only the origin is actively involved: the target makes no calls whatsoever.This means that the origin process remotely locks the window on the target, performs a one-sided transfer,and releases the window by unlocking it again.
During access epoch, also called an passive target epoch in this case, a process can initiate and finish aone-sided transfer.
If (rank == 0) {MPI_Win_lock (MPI_LOCK_EXCLUSIVE, 1, 0, win);MPI_Put (outbuf, n, MPI_INT, 1, 0, n, MPI_INT, win);MPI_Win_unlock (1, win);
}
The two lock types are:
• MPI_LOCK_SHARED which should be used for Get calls: since multiple processors are allowed toread from a window in the same epoch, the lock can be shared.• MPI_LOCK_EXCLUSIVE which should be used for Put and Accumulate calls: since only one
processor is allowed to write to a window during one epoch, the lock should be exclusive.These routines make MPI behave like a shared memory system; the instructions between locking and un-locking the window effectively become atomic operations .
C:int MPI_Win_lock(int lock_type, int rank, int assert, MPI_Win win)
Victor Eijkhout 181

8. MPI topic: One-sided communication
Input Parameters:lock_type - Indicates whether other processes may access the target window at the
same time (if MPI_LOCK_SHARED) or not (MPI_LOCK_EXCLUSIVE)rank - rank of locked window (nonnegative integer)assert - Used to optimize this call; zero may be used as a default. (integer)win - window object (handle)
Python:MPI.Win.Lock(self,
int rank, int lock_type=LOCK_EXCLUSIVE, int assertion=0)
How to read routine prototypes: 1.5.4.
To lock the windows of all processes in the group of the windows, use MPI_Win_lock_all:C:int MPI_Win_lock( int assert, MPI_Win win)
Input Parameters:assert - Used to optimize this call; zero may be used as a default. (integer)win - window object (handle)
How to read routine prototypes: 1.5.4.
To unlock a window, use MPI_Win_unlock and MPI_Win_unlock_all.C:
Py:MPI.Win.Unlock(self, int rank)MPI.Win.Unlock_all(self)
How to read routine prototypes: 1.5.4.
8.4.1 Completion and consistency
In one-sided transfer one should keep straight the multiple instances of the data, and the various completionsthat effect their consistency.
• The user data. This is the buffer that is passed to a Put or Get call. For instance, after a Putcall, but still in an access epoch, the user buffer is not safe to reuse. Making sure the buffer hasbeen transferred is called local completion .• The window data. While this may be publicly accessible, it is not necessarily always consistent
with internal copies.• The remote data. Even a successful Put does not guarantee that the other process has received
the data. A successful transfer is a remote completion .You can force the remote completition, that is, update on the target with MPI_Win_unlock or some variantof it, concluding the epoch.
There is also MPI_Win_flush or MPI_Win_flush_all, which has to come inside the passive target epoch .
182 Parallel Computing – r428

8.4. Passive target synchronization
SynopsisMPI_WIN_FLUSH(rank, win)Input arguments:rank : rank of target window (non-negative integer)win : window object (handle)
C:int MPI_Win_flush(int rank, MPI_Win win)
Fortran:MPI_Win_flush(rank, win, ierror)INTEGER, INTENT(IN) :: rankTYPE(MPI_Win), INTENT(IN) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierrorMPI_WIN_FLUSH(RANK, WIN, IERROR)INTEGER RANK, WIN, IERROR
Synopsis:MPI_WIN_FLUSH_ALL(win)Input arguments:win : window object (handle)
C:int MPI_Win_flush_all(MPI_Win win)
Fortran:MPI_Win_flush_all(win, ierror)TYPE(MPI_Win), INTENT(IN) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierrorMPI_WIN_FLUSH_ALL(WIN, IERROR)INTEGER WIN, IERROR
How to read routine prototypes: 1.5.4.
Local completion, again: during the epoch, is done with with MPI_Win_flush_local or MPI_Win_flush_local_all. After these, buffers involved in the call can be reused.
Synopsis:MPI_WIN_FLUSH_LOCAL(rank, win)Input arguments:rank: rank of target window (non-negative integer)win : window object (handle)
C:int MPI_Win_flush_local(int rank, MPI_Win win)
Fortran:MPI_Win_flush_local(rank, win, ierror)INTEGER, INTENT(IN) :: rankTYPE(MPI_Win), INTENT(IN) :: win
Victor Eijkhout 183

8. MPI topic: One-sided communication
INTEGER, OPTIONAL, INTENT(OUT) :: ierrorMPI_WIN_FLUSH_LOCAL(RANK, WIN, IERROR)INTEGER RANK, WIN, IERROR
Synopsis:MPI_WIN_FLUSH_LOCAL_ALL(win)Input arguments:win : window object (handle)
C:int MPI_Win_flush_local_all(MPI_Win win)
Fortran:MPI_Win_flush_local_all(win, ierror)TYPE(MPI_Win), INTENT(IN) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierrorMPI_WIN_FLUSH_LOCAL_ALL(WIN, IERROR)INTEGER WIN, IERROR
How to read routine prototypes: 1.5.4.
Finally, there is MPI_Win_sync which synchronizes private and public copies of the window.
8.4.2 Atomic shared memory operations
The above example is of limited use. Suppose processor zero has a data structure work_table with itemsthat need to be processed. A counter first_work keeps track of the lowest numbered item that still needsprocessing. You can imagine the following master-worker scenario:
• Each process connects to the master,• inspects the first_work variable,• retrieves the corresponding work item, and• increments the first_work variable.
It is important here to avoid a race condition (see section HPSC-2.6.1.5) that would result from a secondprocess reading the first_work variable before the first process could have updated it. Therefore, thereading and updating needs to be an atomic operation .
Unfortunately, you can not have a put and get call in the same access epoch. For this reason, MPI version 3has added certain atomic operations, such as MPI_Fetch_and_op.
Exercise 8.6.• Let each process have an empty array of sufficient length and a stack pointer
that maintains the first free location.• Now let each process randomly put data in a free location of another process’
array.• Use window locking. (Why is active target synchronization not possible?)
184 Parallel Computing – r428

8.5. Details
8.5 Details
8.5.1 More about window memory
In section 8.1.1 we looked at simple ways to create a window and its memory.
It is also possible to have windows where the size is dynamically set.int MPI_Win_create_dynamic(MPI_Info info, MPI_Comm comm, MPI_Win *win)
Input Parametersinfo : info argument (handle)comm : communicator (handle)
Output Parameterswin : window object returned by the call (handle)
How to read routine prototypes: 1.5.4.
Memory is attached to the window:Semantics:MPI_Win_attach(win, base, size)
Input Parameters:win : window object (handle)base : initial address of memory to be attachedsize : size of memory to be attached in bytes
C:int MPI_Win_attach(MPI_Win win, void *base, MPI_Aint size)
Fortran:MPI_Win_attach(win, base, size, ierror)TYPE(MPI_Win), INTENT(IN) :: winTYPE(*), DIMENSION(..), ASYNCHRONOUS :: baseINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(IN) :: sizeINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
and its inverse:Semantics:MPI_Win_detach(win, base)
Input parameters:win : window object (handle)base : initial address of memory to be detached
C:int MPI_Win_detach(MPI_Win win, const void *base)
Victor Eijkhout 185

8. MPI topic: One-sided communication
Fortran:MPI_Win_detach(win, base, ierror)TYPE(MPI_Win), INTENT(IN) :: winTYPE(*), DIMENSION(..), ASYNCHRONOUS :: baseINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
You may now think that the window memory is the same as the buffer you pass to MPI_Win_create or thatyou get from MPI_Win_allocate. This is not necessarily true, and the actual state of affairs is called thememory model . There are two memory models:
• Under the unified memory model, the buffer in process space is indeed the window memory.This means that after completion of an epoch you can read the window contents from the buffer.• Under the separate memory model, the buffer in process space is the private window and the
target of put/get operations is the public window and the two are not the same and are not keptcoherent. Under this model, you need to do an explicit get to read the window contents.
See also section 8.5.3.
8.5.2 Window usage hints
The following keys can be passed as info argument:
• no_locks: if set to true, passive target synchronization (section 8.4) will not be used on thiswindow.• accumulate_ordering: a comma-separated list of the keywords rar, raw, war, waw can be
specified. This indicates that reads or writes from MPI_Accumulate or MPI_Get_accumulate canbe reordered, subject to certain constraints.• accumulate_ops: the value same_op indicates that concurrent Accumulate calls use the same
operator; same_op_no_op indicates the same operator or MPI_NO_OP.
8.5.3 Window information
The MPI_Info parameter can be used to pass implementation-dependent information; see section 12.3.
A number of attributes are stored with a window when it is created.
Obtaining a pointer to the start of the window area:void *base;MPI_Win_get_attr(win, MPI_WIN_BASE, &base, &flag)
Obtaining the size and window displacement unit :MPI_Aint *size;MPI_Win_get_attr(win, MPI_WIN_SIZE, &size, &flag),int *disp_unit;MPI_Win_get_attr(win, MPI_WIN_DISP_UNIT, &disp_unit, &flag),
The type of create call used:
186 Parallel Computing – r428

8.6. Implementation
int *create_kind;MPI_Win_get_attr(win, MPI_WIN_CREATE_FLAVOR, &create_kind, &flag)
with possible values:
• MPI_WIN_FLAVOR_CREATE if the window was create with MPI_Win_create;• MPI_WIN_FLAVOR_ALLOCATE if the window was create with MPI_Win_allocate;• MPI_WIN_FLAVOR_DYNAMIC if the window was create with MPI_Win_create_dynamic. In this
case the base is MPI_BOTTOM and the size is zero;• MPI_WIN_FLAVOR_SHARED if the window was create with MPI_Win_allocate_shared;
The window model:int *memory_model;MPI_Win_get_attr(win, MPI_WIN_MODEL, &memory_model, &flag);
with possible values:
• MPI_WIN_SEPARATE,• MPI_WIN_UNIFIED,
Get the group of processes associated with a window:
int MPI_Win_get_group(MPI_Win win, MPI_Group *group)MPI_Win_get_group(win, group, ierror)TYPE(MPI_Win), INTENT(IN) :: winTYPE(MPI_Group), INTENT(OUT) :: groupINTEGER, OPTIONAL, INTENT(OUT) :: ierror
int MPI_Win_set_info(MPI_Win win, MPI_Info info)MPI_Win_set_info(win, info, ierror)TYPE(MPI_Win), INTENT(IN) :: winTYPE(MPI_Info), INTENT(IN) :: infoINTEGER, OPTIONAL, INTENT(OUT) :: ierror
int MPI_Win_get_info(MPI_Win win, MPI_Info *info_used)MPI_Win_get_info(win, info_used, ierror)TYPE(MPI_Win), INTENT(IN) :: winTYPE(MPI_Info), INTENT(OUT) :: info_usedINTEGER, OPTIONAL, INTENT(OUT) :: ierror
8.6 Implementation
You may wonder how one-sided communication is realized1. Can a processor somehow get at anotherprocessor’s data? Unfortunately, no.
1. For more on this subject, see [13].
Victor Eijkhout 187

8. MPI topic: One-sided communication
Active target synchronization is implemented in terms of two-sided communication. Imagine that the firstfence operation does nothing, unless it concludes prior one-sided operations. The Put and Get calls donothing involving communication, except for marking with what processors they exchange data. The con-cluding fence is where everything happens: first a global operation determines which targets need to issuesend or receive calls, then the actual sends and receive are executed.
Exercise 8.7. Assume that only Get operations are performed during an epoch. Sketch howthese are translated to send/receive pairs. The problem here is how the senders findout that they need to send. Show that you can solve this with anMPI_Reduce_scatter call.
The previous paragraph noted that a collective operation was necessary to determine the two-sided traffic.Since collective operations induce some amount of synchronization, you may want to limit this.
Exercise 8.8. Argue that the mechanism with window post/wait/start/complete operations stillneeds a collective, but that this is less burdensome.
Passive target synchronization needs another mechanism entirely. Here the target process needs to have abackground task (process, thread, daemon,. . . ) running that listens for requests to lock the window. Thiscan potentially be expensive.
8.7 Sources used in this chapter
Listing of code examples/mpi/c/putblock.c:
Listing of code examples/mpi/c/putblock.c:
Listing of code examples/mpi/c/getfence.c:/* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% This program file is part of the book and course%%%% "Parallel Computing for Science and Engineering"%%%% by Victor Eijkhout, copyright 2013-6%%%%%%%% getfence.c : MPI_Get with fences%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
*/
#include <stdlib.h>#include <mpi.h>#include <stdio.h>#include <unistd.h>
int main(int argc,char **argv) {
#include "globalinit.c"
{
188 Parallel Computing – r428

8.7. Sources used in this chapter
MPI_Win the_window;int my_number, other_number[2], other = nprocs-1;if (procno==other)other_number[1] = 27;
//snippet getfenceMPI_Win_create(&other_number,2*sizeof(int),sizeof(int),
MPI_INFO_NULL,comm,&the_window);MPI_Win_fence(0,the_window);if (procno==0) {MPI_Get( /* data on origin: */ &my_number, 1,MPI_INT,/* data on target: */ other,1, 1,MPI_INT,the_window);
}MPI_Win_fence(0,the_window);
//snippet endif (procno==0)printf("I got the following: %d\n",my_number);
MPI_Win_free(&the_window);}
MPI_Finalize();return 0;
}
Listing of code examples/mpi/c/postwaittwo.c:
Listing of code examples/mpi/c/fetchop.c:
Victor Eijkhout 189

Chapter 9
MPI topic: File I/O
File input and output in parallel is a little more complicated than sequentially.
• There is nothing against every process opening an existing file for reading, and using an individ-ual file pointer to get its unique data.• . . . but having every process open the same file for output is probably not a good idea.• Based on the process rank it is easy enough to have every process create a unique file, but that
can put a lot of strain on the file system, and it means you may have to post-process to get all thedata in one file.
Wouldn’t it be nice if there was a way to open one file in parallel, and have every process read from andwrite to its own location? That’s where MPI/O comes in.
There are dedicated libraries for file I/O, such as hdf5 , netcdf , or silo . However, these often add headerinforation to a file that may not be understandable to post-processing applications. With MPI I/O you arein complete control of what goes to the file. (A useful tool for viewing your file is the unix utility od.)
9.1 File handlingMPI has its own file handle:
C:MPI_File file ;
Fortran:Type(MPI_File) file
How to read routine prototypes: 1.5.4.
File open:Semantics:MPI_FILE_OPEN(comm, filename, amode, info, fh)IN comm: communicator (handle)IN filename: name of file to open (string)IN amode: file access mode (integer)
190

9.2. File access
IN info: info object (handle)OUT fh: new file handle (handle)
C:int MPI_File_open
(MPI_Comm comm, char *filename, int amode,MPI_Info info, MPI_File *fh)
Fortran:MPI_FILE_OPEN(COMM, FILENAME, AMODE, INFO, FH, IERROR)CHARACTER*(*) FILENAMEINTEGER COMM, AMODE, INFO, FH, IERROR
Python:Open(type cls, Intracomm comm, filename,
int amode=MODE_RDONLY, Info info=INFO_NULL)
How to read routine prototypes: 1.5.4.
This routine is collective, even if only certain processes will access the file with a read or write call. Simi-larly, MPI_File_close is collective.
Python note. Note the slightly unusual syntax for opening a file: even though thefile is opened on a communicator, it is a class method for the MPI.File class, ratherthan for the communicator object. The latter is passed in as an argument.
File access modes:
• MPI_MODE_RDONLY: read only,• MPI_MODE_RDWR: reading and writing,• MPI_MODE_WRONLY: write only,• MPI_MODE_CREATE: create the file if it does not exist,• MPI_MODE_EXCL: error if creating file that already exists,• MPI_MODE_DELETE_ON_CLOSE: delete file on close,• MPI_MODE_UNIQUE_OPEN: file will not be concurrently opened elsewhere,• MPI_MODE_SEQUENTIAL: file will only be accessed sequentially,• MPI_MODE_APPEND: set initial position of all file pointers to end of file.
These modes can be added or bitwise-or’ed.
You can delete a file with MPI_File_delete.
9.2 File access
Writing to and reading from a parallel file is rather similar to sending a receiving:
• The process uses an elementary data type or a derived datatype to describe what elements in anarray go to file, or are read from file.
Victor Eijkhout 191

9. MPI topic: File I/O
• In the simplest case, your read or write that data to the file using an offset, or first having done aseek operation.• But you can also set a ‘file view’ to describe explicitly what elements in the file will be involved.
File accesses:
• MPI_File_seek
• MPI_File_read
• MPI_File_read_all
• MPI_File_read_ordered
• MPI_File_read_shared
• MPI_File_read_at: combine read and seek.• MPI_File_write
• MPI_File_write_all
• MPI_File_write_ordered
• MPI_File_write_shared
• MPI_File_write_at: combine write and seek
Figure 9.1: Writing at an offset
Exercise 9.1. Create a buffer of length nwords=3 on each process, and write these buffersas a sequence to one file with MPI_File_write_at.
These modes are enough for writing simple contiguous blocks. However, you can also access non-contiguousareas in the file. For this you use
Semantics:MPI_FILE_SET_VIEW(fh, disp, etype, filetype, datarep, info)INOUT fh: file handle (handle)IN disp: displacement (integer)IN etype: elementary datatype (handle)IN filetype: filetype (handle)IN datarep: data representation (string)IN info: info object (handle)
C:int MPI_File_set_view
(MPI_File fh,MPI_Offset disp, MPI_Datatype etype, MPI_Datatype filetype,char *datarep, MPI_Info info)
192 Parallel Computing – r428

9.2. File access
Fortran:MPI_FILE_SET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, INFO, IERROR)INTEGER FH, ETYPE, FILETYPE, INFO, IERRORCHARACTER*(*) DATAREPINTEGER(KIND=MPI_OFFSET_KIND) DISP
Python:mpifile = MPI.File.Open( .... )mpifile.Set_view
(self,Offset disp=0, Datatype etype=None, Datatype filetype=None,datarep=None, Info info=INFO_NULL)
How to read routine prototypes: 1.5.4.
This call is collective, even if not all processes access the file.
• The etype describes the data type of the file, it needs to be the same on all processes.• The filetype describes how this process sees the file, so it can differ between processes.• The disp displacement parameters is measured in bytes. It can differ between processes. On
sequential files such as tapes or network streams it does not make sense to set a displacement;for those the MPI_DISPLACEMENT_CURRENT value can be used.
Figure 9.2: Writing at a view
MPI_File_write_at(fh,offset,buf,count,datatype)
Semantics:Input Parametersfh : File handle (handle).offset : File offset (integer).buf : Initial address of buffer (choice).
Victor Eijkhout 193

9. MPI topic: File I/O
count : Number of elements in buffer (integer).datatype : Data type of each buffer element (handle).
Output Parameters:status : Status object (status).
C:int MPI_File_write_at
(MPI_File fh, MPI_Offset offset, const void *buf,int count, MPI_Datatype datatype, MPI_Status *status)
Fortran:MPI_FILE_WRITE_AT
(FH, OFFSET, BUF, COUNT, DATATYPE, STATUS, IERROR)<type> BUF(*)INTEGER :: FH, COUNT, DATATYPE, STATUS(MPI_STATUS_SIZE), IERRORINTEGER(KIND=MPI_OFFSET_KIND) :: OFFSET
Python:MPI.File.Write_at(self, Offset offset, buf, Status status=None)
How to read routine prototypes: 1.5.4.
Exercise 9.2. Write a file in the same way as in exercise 9.1, but now useMPI_File_write and use MPI_File_set_view to set a view that determines wherethe data is written.
You can get very creative effects by setting the view to a derived datatype.
Figure 9.3: Writing at a derived type
Fortran note. In Fortran you have to assure that the displacement parameter is of
194 Parallel Computing – r428

9.3. Constants
‘kind’ . In particular, you can not specify a literal zero ‘0’ as the displacement; use0_MPI_OFFSET_KIND instead.
More: MPI_File_set_size MPI_File_get_size MPI_File_preallocate MPI_File_get_view
9.3 Constants
MPI_SEEK_SET used to be called SEEK_SET which gave conflicts with the C++ library. This had to becircumvented with
make CPPFLAGS="-DMPICH_IGNORE_CXX_SEEK -DMPICH_SKIP_MPICXX"
and such.
Victor Eijkhout 195

Chapter 10
MPI topic: Topologies
A communicator describes a group of processes, but the structure of your computation may not be suchthat every process will communicate with every other process. For instance, in a computation that is math-ematically defined on a Cartesian 2D grid, the processes themselves act as if they are two-dimensionallyordered and communicate with N/S/E/W neighbours. If MPI had this knowledge about your application, itcould conceivably optimize for it, for instance by renumbering the ranks so that communicating processesare closer together physically in your cluster.
The mechanism to declare this structure of a computation to MPI is known as a virtual topology . Thefollowing types of topology are defined:
• MPI_UNDEFINED: this values holds for communicators where no topology has explicitly beenspecified.• MPI_CART: this value holds for Cartesian toppologies, where processes act as if they are ordered
in a multi-dimensional ‘brick’; see section 10.1.• MPI_GRAPH: this value describes the graph topology that was defined in MPI 1 ; section 10.2.4.
It is unnecessarily burdensome, since each process needs to know the total graph, and shouldtherefore be considered obsolete; the type MPI_DIST_GRAPH should be used instead.• MPI_DIST_GRAPH: this value describes the distributed graph topology where each process only
describes the edges in the process graph that touch itself; see section 10.2.
These values can be discovered with the routine MPI_Topo_test.
int MPI_Topo_test(MPI_Comm comm, int *status)
status:MPI_UNDEFINEDMPI_CARTMPI_GRAPHMPI_DIST_GRAPH
How to read routine prototypes: 1.5.4.
196

10.1. Cartesian grid topology
10.1 Cartesian grid topology
A Cartesian grid is a structure, typically in 2 or 3 dimensions, of points that have two neighbours in eachof the dimensions. Thus, if a Cartesian grid has sizes K ×M × N , its points have coordinates (k,m, n)with 0 ≤ k < K et cetera. Most points have six neighbours (k± 1,m, n), (k,m± 1, n), (k,m, n± 1); theexception are the edge points. A grid where edge processors are connected through wraparound connectionsis called a periodic grid .
The most common use of Cartesian coordinates is to find the rank of process by referring to it in grid terms.For instance, one could ask ‘what are my neighbours offset by (1, 0, 0), (−1, 0, 0), (0, 1, 0) et cetera’.
While the Cartesian topology interface is fairly easy to use, as opposed to the more complicated generalgraph topology below, it is not actually sufficient for all Cartesian graph uses. Notably, in a so-called starstencil , such as the nine-point stencil , there are diagonal connections, which can not be described in a singlestep. Instead, it is necessary to take a separate step along each coordinate dimension. In higher dimensionsthis is of course fairly awkward.
Thus, even for Cartesian structures, it may be advisable to use the general graph topology interface.
10.1.1 Cartesian routines
The cartesian topology is specified by giving MPI_Cart_create the sizes of the processor grid along eachaxis, and whether the grid is periodic along that axis.
int MPI_Cart_create(MPI_Comm comm_old, int ndims, int *dims, int *periods,int reorder, MPI_Comm *comm_cart)
Each point in this new communicator has a coordinate and a rank. They can be queried with MPI_Cart_coords
and MPI_Cart_rank respectively.int MPI_Cart_coords(MPI_Comm comm, int rank, int maxdims,int *coords);
int MPI_Cart_rank(MPI_Comm comm, init *coords,int *rank);
Note that these routines can give the coordinates for any rank, not just for the current process.// cart.cMPI_Comm comm2d;ndim = 2; periodic[0] = periodic[1] = 0;dimensions[0] = idim; dimensions[1] = jdim;MPI_Cart_create(comm,ndim,dimensions,periodic,1,&comm2d);MPI_Cart_coords(comm2d,procno,ndim,coord_2d);MPI_Cart_rank(comm2d,coord_2d,&rank_2d);printf("I am %d: (%d,%d); originally %d\n",rank_2d,coord_2d[0],coord_2d[1],
procno);
The reorder parameter to MPI_Cart_create indicates whether processes can have a rank in the newcommunicator that is different from in the old one.
Victor Eijkhout 197

10. MPI topic: Topologies
Figure 10.1: Illustration of a distributed graph topology where each node has four neighbours
Strangely enough you can only shift in one direction, you can not specify a shift vector.int MPI_Cart_shift(MPI_Comm comm, int direction, int displ, int *source,
int *dest)
If you specify a processor outside the grid the result is MPI_PROC_NULL.char mychar = 65+procno;MPI_Cart_shift(comm2d,0,+1,&rank_2d,&rank_right);MPI_Cart_shift(comm2d,0,-1,&rank_2d,&rank_left);MPI_Cart_shift(comm2d,1,+1,&rank_2d,&rank_up);MPI_Cart_shift(comm2d,1,-1,&rank_2d,&rank_down);int irequest = 0; MPI_Request *requests = malloc(8*sizeof(MPI_Request));MPI_Isend(&mychar,1,MPI_CHAR,rank_right, 0,comm, requests+irequest++);MPI_Isend(&mychar,1,MPI_CHAR,rank_left, 0,comm, requests+irequest++);MPI_Isend(&mychar,1,MPI_CHAR,rank_up, 0,comm, requests+irequest++);MPI_Isend(&mychar,1,MPI_CHAR,rank_down, 0,comm, requests+irequest++);MPI_Irecv( indata+idata++, 1,MPI_CHAR, rank_right, 0,comm, requests+irequest
++);MPI_Irecv( indata+idata++, 1,MPI_CHAR, rank_left, 0,comm, requests+irequest
++);MPI_Irecv( indata+idata++, 1,MPI_CHAR, rank_up, 0,comm, requests+irequest
++);MPI_Irecv( indata+idata++, 1,MPI_CHAR, rank_down, 0,comm, requests+irequest
++);
10.2 Distributed graph topology
In many calculations on a grid (using the term in its mathematical, Finite Element Method (FEM), sense), agrid point will collect information from grid points around it. Under a sensible distribution of the grid over
198 Parallel Computing – r428

10.2. Distributed graph topology
processes, this means that each process will collect information from a number of neighbour processes. Thenumber of neighbours is dependent on that process. For instance, in a 2D grid (and assuming a five-pointstencil for the computation) most processes communicate with four neighbours; processes on the edge withthree, and processes in the corners with two.
Such a topology is illustrated in figure 10.1.
MPI’s notion of graph topology, and the neighbourhood collectives , offer an elegant way of expressingsuch communication structures. There are various reasons for using graph topologies over the older, simplermethods.
• MPI is allowed to reorder the ranks, so that network proximity in the cluster corresponds toproximity in the structure of the code.• Ordinary collectives could not directly be used for graph problems, unless one would adopt
a subcommunicator for each graph neighbourhood. However, scheduling would then lead todeadlock or serialization.• The normal way of dealing with graph problems is through non-blocking communications. How-
ever, since the user indicates an explicit order in which they are posted, congestion at certainprocesses may occur.• Collectives can pipeline data, while send/receive operations need to transfer their data in its
entirety.• Collectives can use spanning trees, while send/receive uses a direct connection.
Thus the minimal description of a process graph contains for each process:• Degree: the number of neighbour processes; and• the ranks of the processes to communicate with.
However, this ignores that communication is not always symmetric: maybe the processes you receive fromare not the ones you send to. Worse, maybe only one side of this duality is easily described. Therefore,there are two routines:
• MPI_Dist_graph_create_adjacent assumes that a process knows both who it is sending it, andwho will send to it. This is the most work for the programmer to specify, but it is ultimately themost efficient.• MPI_Dist_graph_create specifies on each process only what it is the source for; that is, who
this process will be sending to.1. Consequently, some amount of processing – including com-munication – is needed to build the converse information, the ranks that will be sending to aprocess.
10.2.1 Graph creation
There are two creation routines for process graphs. These routines are fairly general in that they allow anyprocess to specify any part of the topology. In practice, of course, you will mostly let each process describeits own neighbour structure.
The routine MPI_Dist_graph_create_adjacent assumes that a process knows both who it is sending it,and who will send to it. This means that every edge in the communication graph is represented twice, so the
1. I disagree with this design decision. Specifying your sources is usually easier than specifying your destinations.
Victor Eijkhout 199

10. MPI topic: Topologies
memory footprint is double of what is strictly necessary. However, no communication is needed to buildthe graph.
The second creation routine, MPI_Dist_graph_create, is probably easier to use, especially in cases wherethe communication structure of your program is symmetric, meaning that a process sends to the sameneighbours that it receives from. Now you specify on each process only what it is the source for; that is, whothis process will be sending to.2. Consequently, some amount of processing – including communication –is needed to build the converse information, the ranks that will be sending to a process.
int MPI_Dist_graph_create(MPI_Comm comm_old, int n, const int sources[],const int degrees[], const int destinations[], const int weights[],MPI_Info info, int reorder,MPI_Comm *comm_dist_graph)
Input Parameters:comm_old : input communicator (handle)n : number of source nodes for which this process specifies edges (non-negative integer)sources : array containing the n source nodes for which this process specifies edges (array of non-negative integers)degrees : array specifying the number of destinations for each source node in the source node array (array of non-negative integers)destinations : destination nodes for the source nodes in the sourcenode array (array ofnon-negativeintegers)weights : weights for source to destination edges (array ofnon-negative integers or MPI_UNWEIGHTED)info : hints on optimization and interpretation of weights (handle)reorder : the process may be reordered (true) or not (false) (logical)
Output Parameters:comm_dist_graph : communicator with distributed graph topology added (handle)
How to read routine prototypes: 1.5.4.
Figure 10.1 describes the common five-point stencil structure. If we let each process only describe itself,we get the following:
• nsources= 1 because the calling process describes on node in the graph: itself.• sources is an array of length 1, containing the rank of the calling process.• degrees is an array of length 1, containing the degree (probably: 4) of this process.• destinations is an array of length the degree of this process, probably again 4. The elements
of this array are the ranks of the neighbour nodes; strictly speaking the ones that this process willsend to.• weights is an array declaring the relative importance of the destinations. For an unweighted
graph use MPI_UNWEIGHTED.• reorder (int in C, LOGICAL in Fortran) indicates whether MPI is allowed to shuffle ranks
to achieve greater locality.
2. I disagree with this design decision. Specifying your sources is usually easier than specifying your destinations.
200 Parallel Computing – r428

10.2. Distributed graph topology
The resulting communicator has all the processes of the original communicator, with the same ranks. Itsmain point is usage in the so-called ‘neighbour collectives’.
10.2.2 Neighbour collectives
We can now use the graph topology to perform a gather or allgather that combines only the processesdirectly connected to the calling process.
Synopsis
int MPI_Neighbor_allgather(const void *sendbuf, int sendcount,MPI_Datatype sendtype,void *recvbuf, int recvcount, MPI_Datatype recvtype,MPI_Comm comm)
Input Parameters:sendbuf : starting address of the send buffer (choice)sendcount : number of elements sent to each neighbor (non-negative integer)sendtype : data type of send buffer elements (handle)recvcount : number of elements received from each neighbor (non-negative integer)recvtype : data type of receive buffer elements (handle)comm : communicator (handle)
Output Parametersrecvbuf : starting address of the receive buffer (choice)
How to read routine prototypes: 1.5.4.
The neighbour collectives have the same argument list as the regular collectives, but they apply to a graphcommunicator.
Figure 10.2: Solving the right-send exercise with neighbourhood collectives
Exercise 10.1. Revisit exercise 4.7 and solve it using MPI_Dist_graph_create. Usefigure 10.2 for inspiration.
The other collective is MPI_Neighbor_alltoall.
The vector variants are MPI_Neighbor_allgatherv and MPI_Neighbor_alltoallv.
There is a heterogenous (multiple datatypes) variant: MPI_Neighbor_alltoallw.
For unclear reasons there is no MPI_Neighbor_allreduce.
Victor Eijkhout 201

10. MPI topic: Topologies
10.2.3 Query
Statistics query: MPI_Dist_graph_neighbors_count MPI_Dist_graph_neighbors_count
10.2.4 Graph topology (deprecated)
The original MPI 1 had a graph topology interface which required each process to specify the full processgraph. Since this is not scalable, it should be considered deprecated. Use the distributed graph topology(section 10.2) instead.
int MPI_Graph_create(MPI_Comm comm_old, int nnodes, const int indx[],const int edges[], int reorder,MPI_Comm *comm_graph)
Input Parameters:comm_old : input communicator without topology (handle)nnodes : number of nodes in graph (integer)indx : array of integers describing node degreesedges : array of integers describing graph edgesreorder : ranking may be reordered (true) or not (false) (logical)
Output Parameterscomm_graph : communicator with graph topology added (handle)
How to read routine prototypes: 1.5.4.
10.3 Sources used in this chapter
Listing of code XX:
Listing of code XX:
202 Parallel Computing – r428

Chapter 11
MPI topic: Shared memory
The one-sided MPI calls (chapter 8) can be used to emulate shared memory. In this chapter we will lookat the ways MPI can interact with the presence of actual shared memory. Many MPI implementations haveoptimizations that detect shared memory and can exploit it, but that is not exposed to the programmer. TheMPI 3 standard added routines that do give the programmer that knowledge.
11.1 Recognizing shared memory
MPI’s one-sided routines take a very symmetric view of processes: each process can access the windowof every other process (within a communicator). Of course, in practice there will be a difference in per-formance depending on whether the origin and target are actually on the same shared memory, or whetherthey can only communicate through the network. For this reason MPI makes it easy to group processes byshared memory domains using MPI_Comm_split_type.
C:int MPI_Comm_split_type(
MPI_Comm comm, int split_type, int key,MPI_Info info, MPI_Comm *newcomm)
Fortran:MPI_Comm_split_type(comm, split_type, key, info, newcomm, ierror)TYPE(MPI_Comm), INTENT(IN) :: commINTEGER, INTENT(IN) :: split_type, keyTYPE(MPI_Info), INTENT(IN) :: infoTYPE(MPI_Comm), INTENT(OUT) :: newcommINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:MPI.Comm.Split_type(
self, int split_type, int key=0, Info info=INFO_NULL)
How to read routine prototypes: 1.5.4.
Here the split_type parameter has to be from the following (short) list:
203

11. MPI topic: Shared memory
• MPI_COMM_TYPE_SHARED: split the communicator into subcommunicators of processes sharing amemory area.
In the following example, CORES_PER_NODE is a platform-dependent constant:
// commsplittype.cMPI_Info info;MPI_Comm_split_type(MPI_COMM_WORLD,MPI_COMM_TYPE_SHARED,procno,info,&
sharedcomm);MPI_Comm_size(sharedcomm,&new_nprocs);MPI_Comm_rank(sharedcomm,&new_procno);
ASSERT(new_procno<CORES_PER_NODE);
11.2 Shared memory for windows
Processes that exist on the same physical shared memory should be able to move data by copying, ratherthan through MPI send/receive calls – which of course will do a copy operation under the hood. In order todo such user-level copying:
1. We need to create a shared memory area with MPI_Win_allocate_shared, and2. We need to get pointers to where a process’ area is in this shared space; this is done with
MPI_Win_shared_query.
11.2.1 Pointers to a shared window
The first step is to create a window (in the sense of one-sided MPI; section 8.1) on the processes on onenode. Using the MPI_Win_allocate_shared call presumably will put the memory close to the socket onwhich the process runs.
// shared.cMPI_Aint window_size; double *window_data; MPI_Win node_window;if (onnode_procid==0)window_size = sizeof(double);
else window_size = 0;MPI_Win_allocate_shared( window_size,sizeof(double),MPI_INFO_NULL,
nodecomm,&window_data,&node_window);
Semantics:MPI_WIN_ALLOCATE_SHARED(size, disp_unit, info, comm, baseptr, win)
Input parameters:size: size of local window in bytes (non-negative integer)disp_unit local unit size for displacements, in bytes (positiveinteger)info: info argument (handle)comm: intra-communicator (handle)
204 Parallel Computing – r428

11.2. Shared memory for windows
Output parameters:baseptr: address of local allocated window segment (choice)win: window object returned by the call (handle)
C:int MPI_Win_allocate_shared
(MPI_Aint size, int disp_unit, MPI_Info info,MPI_Comm comm, void *baseptr, MPI_Win *win)
Fortran:MPI_Win_allocate_shared
(size, disp_unit, info, comm, baseptr, win, ierror)USE, INTRINSIC :: ISO_C_BINDING, ONLY : C_PTRINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(IN) :: sizeINTEGER, INTENT(IN) :: disp_unitTYPE(MPI_Info), INTENT(IN) :: infoTYPE(MPI_Comm), INTENT(IN) :: commTYPE(C_PTR), INTENT(OUT) :: baseptrTYPE(MPI_Win), INTENT(OUT) :: winINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
The memory allocated by MPI_Win_allocate_shared is contiguous between the processes. This makes itpossible to do address calculation. However, if a cluster node has a Non-Uniform Memory Access (NUMA)structure, for instance if two sockets have memory directly attached to each, this would increase latency forsome processes. To prevent this, the key alloc_shared_noncontig can be set to true in the MPI_Info
object.
11.2.2 Querying the shared structure
Even though the window created above is shared, that doesn’t mean it’s contiguous. Hence it is necessaryto retrieve the pointer to the area of each process that you want to communicate with.
MPI_Aint window_size0; int window_unit; double *win0_addr;MPI_Win_shared_query( node_window,0,
&window_size0,&window_unit, &win0_addr );
Semantics:MPI_WIN_SHARED_QUERY(win, rank, size, disp_unit, baseptr)
Input arguments:win: shared memory window object (handle)rank: rank in the group of window win (non-negative integer)
or MPI_PROC_NULL
Output arguments:size: size of the window segment (non-negative integer)
Victor Eijkhout 205

11. MPI topic: Shared memory
disp_unit: local unit size for displacements,in bytes (positive integer)
baseptr: address for load/store access to window segment (choice)
C:int MPI_Win_shared_query
(MPI_Win win, int rank, MPI_Aint *size, int *disp_unit,void *baseptr)
Fortran:MPI_Win_shared_query(win, rank, size, disp_unit, baseptr, ierror)USE, INTRINSIC :: ISO_C_BINDING, ONLY : C_PTRTYPE(MPI_Win), INTENT(IN) :: winINTEGER, INTENT(IN) :: rankINTEGER(KIND=MPI_ADDRESS_KIND), INTENT(OUT) :: sizeINTEGER, INTENT(OUT) :: disp_unitTYPE(C_PTR), INTENT(OUT) :: baseptrINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
11.2.3 Heat equation example
As an example, which consider the 1D heat equation. On each process we create a local area of three point:
// sharedshared.cMPI_Win_allocate_shared(3,sizeof(int),info,sharedcomm,&shared_baseptr,&
shared_window);
11.2.4 Shared bulk data
In applications such as ray tracing , there is a read-only large data object (the objects in the scene to berendered) that is needed by all processes. In traditional MPI, this would need to be stored redundantlyon each process, which leads to large memory demands. With MPI shared memory we can store the dataobject once per node. Using as above MPI_Comm_split_type to find a communicator per NUMA domain,we store the object on process zero of this node communicator.
Exercise 11.1. Let the ‘shared’ data originate on process zero in MPI_COMM_WORLD. Then:• create a communicator per shared memory domain;• create a communicator for all the processes with number zero on their node;• broadcast the shared data to the processes zero on each node.
11.3 Sources used in this chapter
Listing of code XX:
Listing of code code/mpi/shared.c:
206 Parallel Computing – r428

11.3. Sources used in this chapter
Listing of code code/mpi/shared.c:
Listing of code XX:
Victor Eijkhout 207

Chapter 12
MPI leftover topics
12.1 Info objects
MPI_Info_create
MPI_INFO_CREATE(info)OUT info info object created (handle)
C:int MPI_Info_create(MPI_Info *info)
Fortran legacy:MPI_INFO_CREATE(INFO, IERROR)INTEGER INFO, IERROR
MPI_Info_delete
MPI_INFO_DELETE(info, key)INOUT infoinfo object (handle)IN keykey (string)int MPI_Info_delete(MPI_Info info, char *key)MPI_INFO_DELETE(INFO, KEY, IERROR)INTEGER INFO, IERRORCHARACTER*(*) KEY
MPI_Info_set
MPI_INFO_SET(info, key, value)INOUT infoinfo object (handle)IN keykey (string)IN valuevalue (string)int MPI_Info_set(MPI_Info info, char *key, char *value)MPI_INFO_SET(INFO, KEY, VALUE, IERROR)INTEGER INFO, IERROR
208

12.1. Info objects
CHARACTER*(*) KEY, VALUE
MPI_Info_get
MPI_INFO_GET(info, key, valuelen, value, flag)IN infoinfo object (handle)IN keykey (string)IN valuelenlength of value arg (integer)OUT valuevalue (string)OUT flagtrue if key defined, false if not (boolean)
int MPI_Info_get(MPI_Info info, char *key, int valuelen, char *value,int *flag)MPI_INFO_GET(INFO, KEY, VALUELEN, VALUE, FLAG, IERROR)INTEGER INFO, VALUELEN, IERRORCHARACTER*(*) KEY, VALUELOGICAL FLAG
Maximum length of a key: MPI_MAX_INFO_KEY.
MPI_Info_get_nkeys
MPI_INFO_GET_NKEYS(info, nkeys)IN infoinfo object (handle)OUT nkeysnumber of defined keys (integer)int MPI_Info_get_nkeys(MPI_Info info, int *nkeys)MPI_INFO_GET_NKEYS(INFO, NKEYS, IERROR)INTEGER INFO, NKEYS, IERROR
MPI_Info_free
MPI_INFO_FREE(info)INOUT infoinfo object (handle)int MPI_Info_free(MPI_Info *info)MPI_INFO_FREE(INFO, IERROR)INTEGER INFO, IERROR
MPI_Info_dup
MPI_INFO_DUP(info, newinfo)IN infoinfo object (handle)OUT newinfoinfo object (handle)int MPI_Info_dup(MPI_Info info, MPI_Info *newinfo)MPI_INFO_DUP(INFO, NEWINFO, IERROR)INTEGER INFO, NEWINFO, IERROR
MPI_Info_get_nthkey
Victor Eijkhout 209

12. MPI leftover topics
MPI_INFO_GET_NTHKEY(info, n, key)IN infoinfo object (handle)IN nkey number (integer)OUT keykey (string)int MPI_Info_get_nthkey(MPI_Info info, int n, char *key)MPI_INFO_GET_NTHKEY(INFO, N, KEY, IERROR)INTEGER INFO, N, IERRORCHARACTER*(*) KEY
12.2 Error handling
Errors in normal programs can be tricky to deal with; errors in parallel programs can be even harder. This isbecause in addition to everything that can go wrong with a single executable (floating point errors, memoryviolation) you now get errors that come from faulty interaction between multiple executables.
A few examples of what can go wrong:
• MPI errors: an MPI routine can abort for various reasons, such as receiving much more datathan its buffer can accomodate. Such errors, as well as the more common type mentioned above,typically cause your whole execution to abort. That is, if one incarnation of your executableaborts, the MPI runtime will kill all others.• Deadlocks and other hanging executions: there are various scenarios where your processes in-
dividually do not abort, but are all waiting for each other. This can happen if two processes areboth waiting for a message from each other, and this can be helped by using non-blocking calls.In another scenario, through an error in program logic, one process will be waiting for moremessages (including non-blocking ones) than are sent to it.
12.2.1 Error codes
• MPI_ERR_ARG: an argument was invalid that is not covered by another error code.• MPI_ERR_BUFFER The buffer pointer is invalid; this typically means that you have supplied a null
pointer.• MPI_ERR_COMM: invalid communicator. A common error is to use a null communicator in a call.• MPI_ERR_INTERN An internal error in MPI has been detected.• MPI_ERR_INFO: invalid info object.• MPI_ERR_OTHER: an error occurred; use MPI_Error_string to retrieve further information about
this error.• MPI_ERR_PORT: invalid port; this applies to MPI_Comm_connect and such.• MPI_ERR_SERVICE: invalid service in MPI_Unpublish_name.• MPI_SUCCESS: no error; MPI routine completed successfully.
210 Parallel Computing – r428

12.2. Error handling
12.2.2 Error handling
The MPI library has a general mechanism for dealing with errors that it detects. The default behaviour,where the full run is aborted, is equivalent to your code having the following call1:
MPI_Comm_set_errhandler(MPI_COMM_WORLD,MPI_ERRORS_ARE_FATAL);
Another simple possibility is to specifyMPI_Comm_set_errhandler(MPI_COMM_WORLD,MPI_ERRORS_RETURN);
which gives you the opportunity to write code that handles the error return value. The values MPI_ERRORS_ARE_FATALand MPI_ERRORS_RETURN are of type MPI_Errhandler.
In most cases where an MPI error occurs a complete abort is the sensible thing, since there are few waysto recover. Alternatively, you could compare the return code to MPI_SUCCESS and print out debugginginformation:
int ierr;ierr = MPI_Something();if (ierr!=MPI_SUCCESS) {
// print out information about what your programming is doingMPI_Abort();
}
For instance,Fatal error in MPI_Waitall:See the MPI_ERROR field in MPI_Status for the error code
You could then retrieve the MPI_ERROR field of the status, and print out an error string with MPI_Error_string
or maximal size MPI_MAX_ERROR_STRING:MPI_Comm_set_errhandler(MPI_COMM_WORLD,MPI_ERRORS_RETURN);ierr = MPI_Waitall(2*ntids-2,requests,status);if (ierr!=0) {
char errtxt[MPI_MAX_ERROR_STRING];for (int i=0; i<2*ntids-2; i++) {int err = status[i].MPI_ERROR;int len=MPI_MAX_ERROR_STRING;MPI_Error_string(err,errtxt,&len);printf("Waitall error: %d %s\n",err,errtxt);
}MPI_Abort(MPI_COMM_WORLD,0);
}
One cases where errors can be handled is that of MPI file I/O : if an output file has the wrong permissions,code can possibly progress without writing data, or writing to a temporary file.
MPI operators (MPI_Op) do not return an error code. In case of an error they call MPI_Abort; if MPI_ERRORS_RETURNis the error handler, errors may be silently ignore.
1. The routine MPI Errhandler set is deprecated.
Victor Eijkhout 211

12. MPI leftover topics
You can create your own error handler with MPI_Comm_create_errhandler, which is then installed withMPI_Comm_set_errhandler. You can retrieve the error handler with MPI_Comm_get_errhandler.
12.3 Machine-specific information
You can create information objects, for instance for use in a library that you write based on MPI.CMPI_Info info ;
Fortran:Type(MPI_Info) info
Python:
How to read routine prototypes: 1.5.4.
12.3.1 Environment information
The object MPI_INFO_ENV is predefined, containing:• command Name of program executed.• argv Space separated arguments to command.• maxprocs Maximum number of MPI processes to start.• soft Allowed values for number of processors.• host Hostname.• arch Architecture name.• wdir Working directory of the MPI process.• file Value is the name of a file in which additional information is specified.• thread_level Requested level of thread support, if requested before the program started
execution.Note that these are the requested values; the running program can for instance have lower thread support.
12.3.2 Communicator and window information
MPI has a built-in possibility of attaching information to communicators and windows using the callsMPI_Comm_get_info MPI_Comm_set_info, MPI_Win_get_info, MPI_Win_set_info.
Copying a communicator with MPI_Comm_dup would cause the info to be copied; to attach new informationto the copy there is MPI_Comm_dup_with_info.
12.4 Fortran issues
MPI is typically written in C, what if you program Fortran?
See section 5.2.2.1 for MPI types corresponding to Fortran90 types .
212 Parallel Computing – r428

12.5. Fault tolerance
12.4.1 Assumed-shape arrays
Use of other than contiguous data, for instance A(1:N:2), was a problem in MPI calls, especially non-blocking ones. In that case it was best to copy the data to a contiguous array. This has been fixed in MPI3.
• Fortran routines have the same prototype as C routines except for the addition of an integer errorparameter.• The call for MPI_Init in Fortran does not have the commandline arguments; they need
to be handled separately.• The routine MPI_Sizeof is only available in Fortran, it provides the functionality of the C/C++
operator sizeof.
12.5 Fault tolerance
Processors are not completely reliable, so it may happen that one ‘breaks’: for software or hardware reasonsit becomes unresponsive. For an MPI program this means that it becomes impossible to send data to it, andany collective operation involving it will hang. Can we deal with this case? Yes, but it involves someprogramming.
First of all, one of the possible MPI error return codes (section 12.2) is MPI_ERR_COMM, which can bereturned if a processor in the communicator is unavailable. You may want to catch this error, and add a‘replacement processor’ to the program. For this, the MPI_Comm_spawn can be used (see 7.1 for details). Butthis requires a change of program design: the communicator containing the new process(es) is not part ofthe old MPI_COMM_WORLD, so it is better to set up your code as a collection of inter-communicators to beginwith.
12.6 Context information
See also section 12.6.3.
12.6.1 Processor name
You can query the hostname of a processor. This name need not be unique between different processorranks.
C:int MPI_Get_processor_name(char *name, int *resultlen)name : buffer char[MPI_MAX_PROCESSOR_NAME]
Fortran:MPI_Get_processor_name(name, resultlen, ierror)CHARACTER(LEN=MPI_MAX_PROCESSOR_NAME), INTENT(OUT) :: nameINTEGER, INTENT(OUT) :: resultlenINTEGER, OPTIONAL, INTENT(OUT) :: ierror
Python:
Victor Eijkhout 213

12. MPI leftover topics
MPI.Get_processor_name()
How to read routine prototypes: 1.5.4.
You have to pass in the character storage: the character array must be at least MPI_MAX_PROCESSOR_NAMEcharacters long. The actual length of the name is returned in the resultlen parameter.
12.6.2 Version information
For runtime determination, The MPI version is available through two parameters MPI_VERSION and MPI_SUBVERSION
or the function MPI_Get_version:Semantics:MPI_GET_VERSION( version, subversion )OUT version version number (integer)OUT subversion subversion number (integer)
C:int MPI_Get_version(int *version, int *subversion)
Fortran:MPI_GET_VERSION(VERSION, SUBVERSION, IERROR)INTEGER VERSION, SUBVERSION, IERROR
How to read routine prototypes: 1.5.4.
12.6.3 Attributes
int MPI_Attr_get(MPI_Comm comm, int keyval, void *attribute_val, int *flag)
How to read routine prototypes: 1.5.4.
Attributes are:
• MPI_TAG_UB Upper bound for tag value .• MPI_HOST Host process rank, if such exists, MPI_PROC_NULL, otherwise.• MPI_IO rank of a node that has regular I/O facilities (possibly myrank). Nodes in the same com-
municator may return different values for this parameter.• MPI_WTIME_IS_GLOBAL Boolean variable that indicates whether clocks are synchronized.
Also:
• MPI_UNIVERSE_SIZE: the total number of processes that can be created. This can be more thanthe size of MPI_COMM_WORLD if the host list is larger than the number of initially started processes.See section 7.1.• MPI_APPNUM: if MPI is used in MPMD mode, or if MPI_Comm_spawn_multiple is used, this
attribute reports the how-manieth program we are in.
214 Parallel Computing – r428

12.7. Performance
12.7 Performance
In most of this book we talk about functionality of the MPI library. There are cases where a problem can besolved in more than one way, and then we wonder which one is the most efficient. In this section we willexplicitly address performance. We start with two sections on the mere act of measuring performance.
12.7.1 Timing
MPI has a wall clock timer: MPI_WtimeC:
double MPI_Wtime(void);
Fortran:DOUBLE PRECISION MPI_WTIME()
Python:MPI.Wtime()
How to read routine prototypes: 1.5.4.
which gives the number of seconds from a certain point in the past. (Note the absence of the error parameterin the fortran call.)
// pingpong.cint src = 0,tgt = nprocs/2;double t, send=1.1,recv;if (procno==src) {t = MPI_Wtime();for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Send(&send,1,MPI_DOUBLE,tgt,0,comm);MPI_Recv(&recv,1,MPI_DOUBLE,tgt,0,comm,MPI_STATUS_IGNORE);
}t = MPI_Wtime()-t; t /= NEXPERIMENTS;printf("Time for pingpong: %e\n",t);
} else if (procno==tgt) {for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Recv(&recv,1,MPI_DOUBLE,src,0,comm,MPI_STATUS_IGNORE);MPI_Send(&recv,1,MPI_DOUBLE,src,0,comm);
}}
The timer has a resolution of MPI_Wtick:C:double MPI_Wtick(void);
Fortran:DOUBLE PRECISION MPI_WTICK()
PythonMPI.Wtick()
Victor Eijkhout 215

12. MPI leftover topics
How to read routine prototypes: 1.5.4.
Timing in parallel is a tricky issue. For instance, most clusters do not have a central clock, so you can notrelate start and stop times on one process to those on another. You can test for a global clock as follows:
int *v,flag;MPI_Attr_get( comm, MPI_WTIME_IS_GLOBAL, &v, &flag );if (mytid==0) printf(‘‘Time synchronized? %d->%d\n’’,flag,*v);
Normally you don’t worry about the starting point for this timer: you call it before and after an event andsubtract the values.
t = MPI_Wtime();// something happens heret = MPI_Wtime()-t;
If you execute this on a single processor you get fairly reliable timings, except that you would need tosubtract the overhead for the timer. This is the usual way to measure timer overhead:
t = MPI_Wtime();// absolutely nothing heret = MPI_Wtime()-t;
12.7.1.1 Global timing
However, if you try to time a parallel application you will most likely get different times for each process,so you would have to take the average or maximum. Another solution is to synchronize the processors byusing a barrier:
MPI_Barrier(comm)t = MPI_Wtime();// something happens hereMPI_Barrier(comm)t = MPI_Wtime()-t;
Exercise 12.1. This scheme also has some overhead associated with it. How would youmeasure that?
12.7.1.2 Local timing
Now suppose you want to measure the time for a single send. It is not possible to start a clock on the senderand do the second measurement on the receiver, because the two clocks need not be synchronized. Usuallya ping-pong is done:
if ( proc_source ) {MPI_Send( /* to target */ );MPI_Recv( /* from target */ );
else if ( proc_target ) {MPI_Recv( /* from source */ );MPI_Send( /* to source */ );
}
216 Parallel Computing – r428

12.7. Performance
Exercise 12.2. Why is it generally not a good idea to use processes 0 and 1 for the source andtarget processor? Can you come up with a better guess?
No matter what sort of timing you are doing, it is good to know the accuracy of your timer. The routineMPI_Wtick gives the smallest possible timer increment. If you find that your timing result is too close tothis ‘tick’, you need to find a better timer (for CPU measurements there are cycle-accurate timers), or youneed to increase your running time, for instance by increasing the amount of data.
12.7.2 Profiling
MPI allows you to write your own profiling interface. To make this possible, every routine MPI_Somethingcalls a routine PMPI_Something that does the actual work. You can now write your MPI_... routinewhich calls PMPI_..., and inserting your own profiling calls. As you can see in figure 12.1, normally only
Figure 12.1: A stack trace, showing the PMPI calls.
the PMPI routines show up in the stack trace.
Does the standard mandate this?
12.7.3 Programming for performance
We outline some issues pertaining to performance.
Eager limit Short blocking messages are handled by a simpler mechanism than longer. The limit onwhat is considered ‘short’ is known as the eager limit (section 4.2.2.2), and you could tune your code byincreasing its value. However, note that a process may likely have a buffer accomodating eager sends forevery single other process. This may eat into your available memory.
Victor Eijkhout 217

12. MPI leftover topics
Blocking versus non-blocking The issue of blocking versus non-blocking communication is somethingof a red herring. While non-blocking communication allows latency hiding , we can not consider it analternative to blocking sends, since replacing non-blocking by blocking calls will usually give deadlock .
Still, even if you use non-blocking communication for the mere avoidance of deadlock or serialization(section 4.2.2.3), bear in mind the possibility of overlap of communication and computation. This alsobrings us to our next point.
Looking at it the other way around, in a code with blocking sends you may get better performance fromnon-blocking, even if that is not structurally necessary.
Progress MPI is not magically active in the background, especially if the user code is doing scalar workthat does not involve MPI. As sketched in section 4.3.2.5, there are various ways of ensuring that latencyhiding actually happens.
Persistent sends If a communication between the same pair of processes, involving the same buffer,happens regularly, it is possible to set up a persistent communication . See section 4.4.4.
Buffering MPI uses internal buffers, and the copying from user data to these buffers may affect perfor-mance. For instance, derived types (section 5.3) can typically not be streamed straight through the network(this requires special hardware support [11]) so they are first copied. Somewhat surprisingly, we find thatbuffered communication (section 4.4.5) does not help. Perhaps MPI implementors have not optimized thismode since it is so rarely used.
This is issue is extensively investigated in [3].
Graph topology and neighborhood collectives Load balancing and communication minimization areimportant in irregular applications. There are dedicated programs for this (ParMetis , Zoltan), and librariessuch as PETSc may offer convenient access to such capabilities.
In the declaration of a graph topology (section 10.2) MPI is allowed to reorder processes, which couldbe used to support such activities. It can also serve for better message sequencing when neighbourhoodcollectives are used.
Network issues In the discussion so far we have assumed that the network is a perfect conduit for data.However, there are issues of port design, in particular caused by oversubscription that adversely affectperformance. While in an ideal world it may be possible to set up routine to avoid this, in the actual practiceof a supercomputer cluster, network contention or message collision from different user jobs is hard toavoid.
218 Parallel Computing – r428

12.8. Determinism
Offloading and onloading There are different philosophies of network card design: Mellanox , being anetwork card manufacturer, believes in off-loading network activity to the NIC! (NIC!), while Intel , beinga processor manufacturer, believes in ‘on-loading’ activity to the process. There are argument either way.
Either way, investigate the capabilities of your network.
12.8 Determinism
MPI processes are only synchronized to a certain extent, so you may wonder what guarantees there are thatrunning a code twice will give the same result. You need to consider two cases: first of all, if the two runsare on different numbers of processors there are already numerical problems; see HPSC-3.3.7.
Let us then limit ourselves to two runs on the same set of processors. In that case, MPI is deterministic aslong as you do not use wildcards such as MPI_ANY_SOURCE. Formally, MPI messages are ‘non-overtaking’:two messages between the same sender-receiver pair will arrive in sequence. Actually, they may not arrivein sequence: they are matched in sequence in the user program. If the second message is much smaller thanthe first, it may actually arrive earlier in the lower transport layer.
12.9 Subtleties with processor synchronization
Blocking communication involves a complicated dialog between the two processors involved. Processorone says ‘I have this much data to send; do you have space for that?’, to which processor two replies ‘yes,I do; go ahead and send’, upon which processor one does the actual send. This back-and-forth (technicallyknown as a handshake) takes a certain amount of communication overhead. For this reason, network hard-ware will sometimes forgo the handshake for small messages, and just send them regardless, knowing thatthe other process has a small buffer for such occasions.
One strange side-effect of this strategy is that a code that should deadlock according to the MPI specifi-cation does not do so. In effect, you may be shielded from you own programming mistake! Of course, ifyou then run a larger problem, and the small message becomes larger than the threshold, the deadlock willsuddenly occur. So you find yourself in the situation that a bug only manifests itself on large problems,which are usually harder to debug. In this case, replacing every MPI_Send with a MPI_Ssend will force thehandshake, even for small messages.
Conversely, you may sometimes wish to avoid the handshake on large messages. MPI as a solution for this:the MPI_Rsend (‘ready send’) routine sends its data immediately, but it needs the receiver to be ready forthis. How can you guarantee that the receiving process is ready? You could for instance do the following(this uses non-blocking routines, which are explained below in section 4.3.2):
if ( receiving ) {MPI_Irecv() // post non-blocking receiveMPI_Barrier() // synchronize
else if ( sending ) {MPI_Barrier() // synchronizeMPI_Rsend() // send data fast
Victor Eijkhout 219

12. MPI leftover topics
When the barrier is reached, the receive has been posted, so it is safe to do a ready send. However, globalbarriers are not a good idea. Instead you would just synchronize the two processes involved.
Exercise 12.3. Give pseudo-code for a scheme where you synchronize the two processesthrough the exchange of a blocking zero-size message.
12.10 Multi-threading
Hybrid MPI/threaded codes need to replace MPI_Init by MPI_Init_thread:
C:int MPI_Init_thread(int *argc, char ***argv, int required, int *provided)
Fortran:MPI_Init_thread(required, provided, ierror)INTEGER, INTENT(IN) :: requiredINTEGER, INTENT(OUT) :: providedINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
With the required parameter the user requests a certain level of support, and MPI reports the actualcapabilities in the provided parameter.
The following constants are defined:
• MPI_THREAD_SINGLE: each MPI process can only have a single thread.• MPI_THREAD_FUNNELED: an MPI process can be multithreaded, but all MPI calls need to be done
from a single thread.• MPI_THREAD_SERIALIZED: a processes can sustain multiple threads that make MPI calls, but
these threads can not be simultaneous: they need to be for instance in an OpenMP critical section .• MPI_THREAD_MULTIPLE: processes can be fully generally multi-threaded.
These values are monotonically increasing.
After the initialization call, you can query the support level with MPI_Query_thread:
C:int MPI_Query_thread(int *provided)
Fortran:MPI_Query_thread(provided, ierror)INTEGER, INTENT(OUT) :: providedINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
In case more than one thread performs communication, the following routine can determine whether athread is the main thread:
220 Parallel Computing – r428

12.11. Shell interaction
C:int MPI_Is_thread_main(int *flag)
Fortran:MPI_Is_thread_main(flag, ierror)LOGICAL, INTENT(OUT) :: flagINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
12.11 Shell interaction
MPI programs are not run directly from the shell, but are started through an ssh tunnel . We briefly discussramifications of this.
12.11.1 Standard input
Letting MPI processes interact with the environment is not entirely straightforward. For instance, shell inputredirection as in
mpirun -np 2 mpiprogram < someinput
may not work.
Instead, use a script programscript that has one parameter:
#!/bin/bashmpirunprogram < $1
and run this in parallel:
mpirun -np 2 programscript someinput
12.11.2 Standard out and error
The stdout and stderr streams of an MPI process are returned through the ssh tunnel. Thus they can becaught as the stdout/err ofmpirun.
// outerr.cfprintf(stdout,"This goes to std out\n");fprintf(stderr,"This goes to std err\n");
Victor Eijkhout 221

12. MPI leftover topics
12.11.3 Process status
The return code of MPI_Abort is returned as the processes status ofmpirun. Running// abort.cif (procno==nprocs-1)
MPI_Abort(comm,37);
asmpirun -np 4 ./abort ; \echo "Return code from ${MPIRUN} is <<$$?>>"
givesTACC: Starting up job 3760534TACC: Starting parallel tasks...application called MPI_Abort(MPI_COMM_WORLD, 37) - process 3TACC: MPI job exited with code: 37TACC: Shutdown complete. Exiting.Return code from ibrun is <<37>>
12.11.4 Multiple program start
The sort of script of section 12.11.1 can also be used to implement MPMD runs: we let the script startone of a number of programs. For this, we use the fact that the MPI rank is known in the environment asPMI_RANK. Use a script mpmdscript:
#!/bin/bashif [ ${PMI_RANK} -eq 0 ] ; then
./programmasterelse
./programworkerfi
which is then run in parallel:mpirun -np 25 mpmdscript
12.12 The origin of one-sided communication in ShMemThe Cray T3E had a library called shmem which offered a type of shared memory. Rather than having atrue global address space it worked by supporting variables that were guaranteed to be identical betweenprocessors, and indeed, were guaranteed to occupy the same location in memory. Variables could be de-clared to be shared a ‘symmetric’ pragma or directive; their values could be retrieved or set by shmem_getand shmem_put calls.
222 Parallel Computing – r428

12.13. Leftover topics
12.13 Leftover topics
12.13.1 MPI constants
MPI has a number of built-in constants. These do not all behave the same.
• Some are compile-time constants. Examples are MPI_VERSION and MPI_MAX_PROCESSOR_NAME.Thus, they can be used in array size declarations, even before MPI_Init.• Some link-time constants get their value by MPI initialization, such as MPI_COMM_WORLD. Such
symbols, which include all predefined handles, can be used in initialization expressions.• Some link-time symbols can not be used in initialization expressions, such as MPI_BOTTOM and
MPI_STATUS_IGNORE.
For symbols, the binary realization is not defined. For instance, MPI_COMM_WORLD is of type MPI_Comm, butthe implementation of that type is not specified.
See Annex A of the 3.1 standard for full lists.
The following are the compile-time constants:
• MPI_MAX_PROCESSOR_NAME
• MPI_MAX_LIBRARY_VERSION_STRING
• MPI_MAX_ERROR_STRING
• MPI_MAX_DATAREP_STRING
• MPI_MAX_INFO_KEY
• MPI_MAX_INFO_VAL
• MPI_MAX_OBJECT_NAME
• MPI_MAX_PORT_NAME
• MPI_VERSION
• MPI_SUBVERSION
• MPI_STATUS_SIZE (Fortran only)• MPI_ADDRESS_KIND (Fortran only)• MPI_COUNT_KIND (Fortran only)• MPI_INTEGER_KIND (Fortran only)• MPI_OFFSET_KIND (Fortran only)• MPI_SUBARRAYS_SUPPORTED (Fortran only)• MPI_ASYNC_PROTECTS_NONBLOCKING (Fortran only)
The following are the link-time constants:
• MPI_BOTTOM
• MPI_STATUS_IGNORE
• MPI_STATUSES_IGNORE
• MPI_ERRCODES_IGNORE
• MPI_IN_PLACE
• MPI_ARGV_NULL
• MPI_ARGVS_NULL
• MPI_UNWEIGHTED
• MPI_WEIGHTS_EMPTY
Victor Eijkhout 223

12. MPI leftover topics
Assorted constants:
• MPI_PROC_NULL
• MPI_ANY_SOURCE
• MPI_ANY_TAG
• MPI_UNDEFINED
• MPI_BSEND_OVERHEAD
• MPI_KEYVAL_INVALID
• MPI_LOCK_EXCLUSIVE
• MPI_LOCK_SHARED
• MPI_ROOT
(This section was inspired by http://blogs.cisco.com/performance/mpi-outside-of-c-and-fortran.)
12.13.2 32-bit size issues
The size parameter in MPI routines is defined as an int, meaning that it is limited to 32-bit quantities.There are ways around this, such as sending a number of MPI_Type_contiguous blocks that add up to morethan 231.
12.13.3 Python issues
12.13.3.1 Byte calculations
The MPI_Win_create routine needs a displacement in bytes. Here is a good way for finding the size ofnumpy datatypes:
numpy.dtype(’i’).itemsize
12.13.3.2 Arrays of objects
Objects of type MPI.Status or MPI.Request often need to be created in an array, for instance whenlooping through a number of Isend calls. In that case the following idiom may come in handy:
requests = [ None ] * nprocsfor p in range(nprocs):requests[p] = comm.Irecv( ... )
12.13.4 Cancelling messages
In section 37.3 we showed a master-worker example where the master accepts in arbitrary order the mes-sages from the workers. Here we will show a slightly more complicated example, where only the result ofthe first task to complete is needed. Thus, we issue an MPI_Recv with MPI_ANY_SOURCE as source. Whena result comes, we broadcast its source to all processes. All the other workers then use this information tocancel their message with an MPI_Cancel operation.
224 Parallel Computing – r428

12.14. Literature
// cancel.cif (procno==nprocs-1) {MPI_Status status;ierr = MPI_Recv(dummy,0,MPI_INT, MPI_ANY_SOURCE,0,comm,
&status); CHK(ierr);first_tid = status.MPI_SOURCE;ierr = MPI_Bcast(&first_tid,1,MPI_INT, nprocs-1,comm); CHK(ierr);printf("first msg came from %d\n",first_tid);
} else {float randomfraction = (rand() / (double)RAND_MAX);int randomwait = (int) ( nprocs * randomfraction );MPI_Request request;printf("process %d waits for %e/%d=%d\n",
procno,randomfraction,nprocs,randomwait);sleep(randomwait);ierr = MPI_Isend(dummy,0,MPI_INT, nprocs-1,0,comm,
&request); CHK(ierr);ierr = MPI_Bcast(&first_tid,1,MPI_INT, nprocs-1,comm
); CHK(ierr);if (procno!=first_tid) {
ierr = MPI_Cancel(&request); CHK(ierr);}
}
12.13.5 Constants
MPI constants such as MPI_COMM_WORLD or MPI_INT are not necessarily statitally defined, such as by a#define statement: the best you can say is that they have a value after MPI_Init or MPI_Init_thread.That means you can not transfer a compiled MPI file between platforms, or even between compilers on oneplatform. However, a working MPI source on one MPI implementation will also work on another.
12.14 Literature
Online resources:
• MPI 1 Complete reference:http://www.netlib.org/utk/papers/mpi-book/mpi-book.html
• Official MPI documents:http://www.mpi-forum.org/docs/
• List of all MPI routines:http://www.mcs.anl.gov/research/projects/mpi/www/www3/
Tutorial books on MPI:
• Using MPI [6] by some of the original authors.
Victor Eijkhout 225

12. MPI leftover topics
12.15 Sources used in this chapter
Listing of code XX:
Listing of code XX:
226 Parallel Computing – r428

Chapter 13
MPI Reference
This section gives reference information and illustrative examples of the use of MPI. While the code snip-pets given here should be enough, full programs can be found in the repository for this book https://bitbucket.org/VictorEijkhout/parallel-computing-book.
13.1 Elementary datatypes
List of predefined MPI_Datatype values:
227

13. MPI Reference
C Fortran meaningMPI_CHAR MPI_CHARACTERMPI_SHORT MPI_BYTEMPI_INT MPI_INTEGERMPI_LONGMPI_UNSIGNED_CHARMPI_UNSIGNED_SHORTMPI_UNSIGNEDMPI_UNSIGNED_LONGMPI_FLOAT MPI_REALMPI_DOUBLE MPI_DOUBLE_PRECISIONMPI_LONG_DOUBLEMPI_BYTEMPI_PACKED MPI_PACKED
MPI_COMPLEXMPI_DOUBLE_COMPLEXMPI_LOGICAL
optionalMPI_LONG_LONG_INT
MPI_INTEGER1MPI_INTEGER2MPI_INTEGER4MPI_REAL2MPI_REAL4MPI_REAL8
13.2 Communicators
13.2.1 Process topologies
13.2.1.1 Cartesian grid topology
13.3 Leftover topics
13.3.1 MPI constants
MPI has a number of built-in constants. These do not all behave the same.
• Some are compile-time constants. Examples are MPI_VERSION and MPI_MAX_PROCESSOR_NAME.Thus, they can be used in array size declarations, even before MPI_Init.• Some link-time constants get their value by MPI initialization, such as MPI_COMM_WORLD. Such
symbols, which include all predefined handles, can be used in initialization expressions.• Some link-time symbols can not be used in initialization expressions, such as MPI_BOTTOM and
MPI_STATUS_IGNORE.
228 Parallel Computing – r428
13.3. Leftover topics
For symbols, the binary realization is not defined. For instance, MPI_COMM_WORLD is of type MPI_Comm, butthe implementation of that type is not specified.
See Annex A of the 3.1 standard for full lists.
The following are the compile-time constants:
MPI_MAX_PROCESSOR_NAMEMPI_MAX_LIBRARY_VERSION_STRINGMPI_MAX_ERROR_STRINGMPI_MAX_DATAREP_STRINGMPI_MAX_INFO_KEYMPI_MAX_INFO_VALMPI_MAX_OBJECT_NAMEMPI_MAX_PORT_NAMEMPI_VERSIONMPI_SUBVERSIONMPI_STATUS_SIZE (Fortran only)MPI_ADDRESS_KIND (Fortran only)MPI_COUNT_KIND (Fortran only)MPI_INTEGER_KIND (Fortran only)MPI_OFFSET_KIND (Fortran only)MPI_SUBARRAYS_SUPPORTED (Fortran only)MPI_ASYNC_PROTECTS_NONBLOCKING (Fortran only)
The following are the link-time constants:
MPI_BOTTOMMPI_STATUS_IGNOREMPI_STATUSES_IGNOREMPI_ERRCODES_IGNOREMPI_IN_PLACEMPI_ARGV_NULLMPI_ARGVS_NULLMPI_UNWEIGHTEDMPI_WEIGHTS_EMPTY
Assorted constants:
C type: const int (or unnamed enum)Fortran type: INTEGER
MPI_PROC_NULLMPI_ANY_SOURCEMPI_ANY_TAGMPI_UNDEFINEDMPI_BSEND_OVERHEADMPI_KEYVAL_INVALIDMPI_LOCK_EXCLUSIVEMPI_LOCK_SHAREDMPI_ROOT
(This section was inspired by http://blogs.cisco.com/performance/mpi-outside-of-c-and-fortran.)
Victor Eijkhout 229

13. MPI Reference
13.3.2 32-bit size issues
The size parameter in MPI routines is defined as an int, meaning that it is limited to 32-bit quantities.There are ways around this, such as sending a number of MPI_Type_contiguous blocks that add up to morethan 231.
13.3.3 Fortran issues
13.3.3.1 Data types
The equivalent of MPI_Aint in Fortran is
integer(kind=MPI_ADDRESS_KIND) :: winsize
13.3.3.2 Type issues
Fortran90 is a strongly typed language, so it is not possible to pass argument by reference to their address,as C/C++ do with the void* type for send and receive buffers. In Fortran this is solved by having separateroutines for each datatype, and providing an Interface block in the MPI module. If you manage torequest a version that does not exist, the compiler will display a message like
There is no matching specificsubroutine for this generic subroutine call [MPI_Send]
13.3.3.3 Byte calculations
Fortran lacks a sizeof operator to query the sizes of datatypes. Since sometimes exact byte counts arenecessary, for instance in one-sided communication, Fortran can use the MPI_Sizeof routine, for instancefor MPI_Win_create:
call MPI_Sizeof(windowdata,window_element_size,ierr)window_size = window_element_size*500call MPI_Win_create( windowdata,window_size,window_element_size,... );
13.4 TimingMPI has a wall clock timer: MPI_Wtime
C:double MPI_Wtime(void);
Fortran:DOUBLE PRECISION MPI_WTIME()
Python:MPI.Wtime()
230 Parallel Computing – r428

13.5. Sources used in this chapter
How to read routine prototypes: 1.5.4.
which gives the number of seconds from a certain point in the past. (Note the absence of the error parameterin the fortran call.)
// pingpong.cint src = 0,tgt = nprocs/2;double t, send=1.1,recv;if (procno==src) {t = MPI_Wtime();for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Send(&send,1,MPI_DOUBLE,tgt,0,comm);MPI_Recv(&recv,1,MPI_DOUBLE,tgt,0,comm,MPI_STATUS_IGNORE);
}t = MPI_Wtime()-t; t /= NEXPERIMENTS;printf("Time for pingpong: %e\n",t);
} else if (procno==tgt) {for (int n=0; n<NEXPERIMENTS; n++) {
MPI_Recv(&recv,1,MPI_DOUBLE,src,0,comm,MPI_STATUS_IGNORE);MPI_Send(&recv,1,MPI_DOUBLE,src,0,comm);
}}
The timer has a resolution of MPI_Wtick:C:double MPI_Wtick(void);
Fortran:DOUBLE PRECISION MPI_WTICK()
PythonMPI.Wtick()
How to read routine prototypes: 1.5.4.
Timing in parallel is a tricky issue. For instance, most clusters do not have a central clock, so you can notrelate start and stop times on one process to those on another. You can test for a global clock as follows:
int *v,flag;MPI_Attr_get( comm, MPI_WTIME_IS_GLOBAL, &v, &flag );if (mytid==0) printf(‘‘Time synchronized? %d->%d\n’’,flag,*v);
13.5 Sources used in this chapter
Listing of code XX:
Victor Eijkhout 231

Chapter 14
MPI Review
For all true/false questions, if you answer that a statement is false, give a one-line explanation.
14.1 Conceptual
Exercise 14.1. True or false: mpicc is a compiler.
Exercise 14.2. What is the function of a hostfile?
14.2 Communicators
1. True or false: in each communicator, processes are numbered consecutively from zero.2. If a process is in two communicators, it has the same rank in both.
14.3 Point-to-point
1. Describe a deadlock scenario involving three processors.2. True or false: a message sent with MPI_Isend from one processor can be received with an
MPI_Recv call on another processor.3. True or false: a message sent with MPI_Send from one processor can be received with an
MPI_Irecv on another processor.4. Why does the MPI_Irecv call not have an MPI_Status argument?5. What is the relation between the concepts of ‘origin’, ‘target’, ‘fence’, and ‘window’ in one-sided
communication.6. What are the three routines for one-sided data transfer?7. In the following fragments assume that all buffers have been allocated with sufficient size. For
each fragment note whether it deadlocks or not. Discuss performance issues.
232

14.3. Point-to-point
// block1.cfor (int p=0; p<nprocs; p++)if (p!=procid)MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm);
for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Recv(rbuffer,buflen,MPI_INT,p,0,comm,MPI_STATUS_IGNORE);
// block2.cfor (int p=0; p<nprocs; p++)if (p!=procid)MPI_Recv(rbuffer,buflen,MPI_INT,p,0,comm,MPI_STATUS_IGNORE);
for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm);
// block3.cint ireq = 0;for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Isend(sbuffers[p],buflen,MPI_INT,p,0,comm,&(requests[ireq++]));
for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Recv(rbuffer,buflen,MPI_INT,p,0,comm,MPI_STATUS_IGNORE);
MPI_Waitall(nprocs-1,requests,MPI_STATUSES_IGNORE);
// block4.cint ireq = 0;for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Irecv(rbuffers[p],buflen,MPI_INT,p,0,comm,&(requests[ireq++]));
for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm);
MPI_Waitall(nprocs-1,requests,MPI_STATUSES_IGNORE);
// block5.cint ireq = 0;for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Irecv(rbuffers[p],buflen,MPI_INT,p,0,comm,&(requests[ireq++]));
MPI_Waitall(nprocs-1,requests,MPI_STATUSES_IGNORE);for (int p=0; p<nprocs; p++)if (p!=procid)MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm);
Victor Eijkhout 233

14. MPI Review
Fortran codes:
// block1.F90do p=0,nprocs-1
if (p/=procid) thencall MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm,ierr)
end ifend dodo p=0,nprocs-1
if (p/=procid) thencall MPI_Recv(rbuffer,buflen,MPI_INT,p,0,comm,MPI_STATUS_IGNORE
,ierr)end if
end do
// block2.F90do p=0,nprocs-1
if (p/=procid) thencall MPI_Recv(rbuffer,buflen,MPI_INT,p,0,comm,MPI_STATUS_IGNORE
,ierr)end if
end dodo p=0,nprocs-1
if (p/=procid) thencall MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm,ierr)
end ifend do
// block3.F90ireq = 0do p=0,nprocs-1
if (p/=procid) thencall MPI_Isend(sbuffers(1,p+1),buflen,MPI_INT,p,0,comm,&
requests(ireq+1),ierr)ireq = ireq+1
end ifend dodo p=0,nprocs-1
if (p/=procid) thencall MPI_Recv(rbuffer,buflen,MPI_INT,p,0,comm,MPI_STATUS_IGNORE
,ierr)end if
end docall MPI_Waitall(nprocs-1,requests,MPI_STATUSES_IGNORE,ierr)
// block4.F90ireq = 0do p=0,nprocs-1
if (p/=procid) thencall MPI_Irecv(rbuffers(1,p+1),buflen,MPI_INT,p,0,comm,&
requests(ireq+1),ierr)ireq = ireq+1
end ifend do
234 Parallel Computing – r428

14.4. Collectives
do p=0,nprocs-1if (p/=procid) then
call MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm,ierr)end if
end docall MPI_Waitall(nprocs-1,requests,MPI_STATUSES_IGNORE,ierr)
// block5.F90ireq = 0do p=0,nprocs-1
if (p/=procid) thencall MPI_Irecv(rbuffers(1,p+1),buflen,MPI_INT,p,0,comm,&
requests(ireq+1),ierr)ireq = ireq+1
end ifend docall MPI_Waitall(nprocs-1,requests,MPI_STATUSES_IGNORE,ierr)do p=0,nprocs-1
if (p/=procid) thencall MPI_Send(sbuffer,buflen,MPI_INT,p,0,comm,ierr)
end ifend do
14.4 Collectives
1. MPI collectives can be divided into (a) rooted vs rootless (b) using uniform buffer lengths vsvariable length buffers (c) blocking vs non-blocking. Give examples of each type.
2. True or false: an MPI_Scatter call puts the same data on each process.3. Given a distributed array, with every processor storing
double x[N]; // N can vary per processor
give the approximate MPI-based code that computes the maximum value in the array, and leavesthe result on every processor.
4. With data as in the previous question, given the code for normalizing the array.
14.5 Datatypes
1. Give two examples of MPI derived datatypes. What parameters are used to describe them?2. Give a practical example where the sender uses a different type to send than the receiver uses in
the corresponding receive call. Name the types involved.
14.6 Theory
1. Give a simple model for the time a send operation takes.2. Give a simple model for the time a broadcast of a single scalar takes.
Victor Eijkhout 235

14. MPI Review
236 Parallel Computing – r428

PART II
OPENMP

Chapter 15
Getting started with OpenMP
This chapter explains the basic concepts of OpenMP, and helps you get started on running your firstOpenMP program.
15.1 The OpenMP model
We start by establishing a mental picture of the hardware and software that OpenMP targets.
15.1.1 Target hardware
Modern computers have a multi-layered design. Maybe you have access to a cluster, and maybe you havelearned how to use MPI to communicate between cluster nodes. OpenMP, the topic of this chapter, isconcerned with a single cluster node or motherboard , and getting the most out of the available parallelismavailable there.
Figure 15.1: A node with two sockets and a co-processor
Figure 15.1 pictures a typical design of a node: within one enclosure you find two sockets: single processorchips. Your personal laptop of computer will probably have one socket, most supercomputers have nodes
238

15.1. The OpenMP model
with two or four sockets (the picture is of a Stampede node with two sockets)1, although the recent IntelKnight’s Landing is again a single-socket design.
Figure 15.2: Structure of an Intel Sandybridge eight-core socket
To see where OpenMP operates we need to dig into the sockets. Figure 15.2 shows a picture of an IntelSandybridge socket. You recognize a structure with eight corescore: independent processing units, that allhave access to the same memory. (In figure 15.1 you saw four memory banks attached to each of the twosockets; all of the sixteen cores have access to all that memory.)
To summarize the structure of the architecture that OpenMP targets:• A node has up to four sockets;• each socket has up to 60 cores;• each core is an independent processing unit, with access to all the memory on the node.
15.1.2 Target software
OpenMP is based on on two concepts: the use of threads and the fork/join model of parallelism. Fornow you can think of a thread as a sort of process: the computer executes a sequence of instructions. Thefork/join model says that a thread can split itself (‘fork’) into a number of threads that are identical copies.At some point these copies go away and the original thread is left (‘join’), but while the team of threads
1. In that picture you also see a co-processor: OpenMP is increasingly targeting those too.
Victor Eijkhout 239

15. Getting started with OpenMP
created by the fork exists, you have parallelism available to you. The part of the execution between forkand join is known as a parallel region .
Figure 15.3 gives a simple picture of this: a thread forks into a team of threads, and these threads themselvescan fork again.
Figure 15.3: Thread creation and deletion during parallel execution
The threads that are forked are all copies of the master thread : they have access to all that was computedso far; this is their shared data . Of course, if the threads were completely identical the parallelism would bepointless, so they also have private data, and they can identify themselves: they know their thread number.This allows you to do meaningful parallel computations with threads.
This brings us to the third important concept: that of work sharing constructs. In a team of threads, initiallythere will be replicated execution; a work sharing construct divides available parallelism over the threads.
So there you have it: OpenMP uses teams of threads, and inside a parallel region thework is distributed over the threads with a work sharing construct. Threads can accessshared data, and they have some private data.
An important difference between OpenMP and MPI is that parallelism in OpenMP is dynamically activatedby a thread spawning a team of threads. Furthermore, the number of threads used can differ between parallelregions, and threads can create threads recursively. This is known as as dynamic mode . By contrast, in anMPI program the number of running processes is (mostly) constant throughout the run, and determined byfactors external to the program.
15.1.3 About threads and cores
OpenMP programming is typically done to take advantage of multicore processors. Thus, to get a goodspeedup you would typically let your number of threads be equal to the number of cores. However, there isnothing to prevent you from creating more threads: the operating system will use time slicing to let themall be executed. You just don’t get a speedup beyond the number of actually available cores.
On some modern processors there are hardware threads , meaning that a core can actually let more thanthread be executed, with some speedup over the single thread. To use such a processor efficiently youwould let the number of OpenMP threads be 2× or 4× the number of cores, depending on the hardware.
15.1.4 About thread data
In most programming languages, visibility of data is governed by rules on the scope of variables: a variableis declared in a block, and it is then visible to any statement in that block and blocks with a lexical scope
240 Parallel Computing – r428

15.2. Compiling and running an OpenMP program
contained in it, but not in surrounding blocks:main () {
// no variable ‘x’ define here{
int x = 5;if (somecondition) { x = 6; }printf("x=%e\n",x); // prints 5 or 6
}printf("x=%e\n",x); // syntax error: ‘x’ undefined
}
In C, you can redeclare a variable inside a nested scope:{
int x;if (something) {
double x; // same name, different entity}x = ... // this refers to the integer again
}
Doing so makes the outer variable inaccessible.
Fortran has simpler rules, since it does not have blocks inside blocks.
Figure 15.4: Locality of variables in threads
In OpenMP the situation is a bit more tricky because of the threads. When a team of threads is created theycan all see the data of the master thread. However, they can also create data of their own. This is illustratedin figure 15.4. We will go into the details later.
15.2 Compiling and running an OpenMP program
15.2.1 Compiling
Your file or Fortran module needs to contain
Victor Eijkhout 241

15. Getting started with OpenMP
#include "omp.h"
in C, and
use omp_lib
or
#include "omp_lib.h"
for Fortran.
OpenMP is handled by extensions to your regular compiler, typically by adding an option to your comman-dline:
# gccgcc -o foo foo.c -fopenmp# Intel compilericc -o foo foo.c -openmp
If you have separate compile and link stages, you need that option in both.
When you use the openmp compiler option, a cpp variable _OPENMP will be defined. Thus, you can haveconditional compilation by writing
#ifdef _OPENMP...
#else...
#endif
15.2.2 Running an OpenMP program
You run an OpenMP program by invoking it the regular way (for instance ./a.out), but its behaviour isinfluenced by some OpenMP environment variables . The most important one is OMP_NUM_THREADS:
export OMP_NUM_THREADS=8
which sets the number of threads that a program will use. See section 26.1 for a list of all environmentvariables.
15.3 Your first OpenMP program
In this section you will see just enough of OpenMP to write a first program and to explore its behaviour.For this we need to introduce a couple of OpenMP language constructs. They will all be discussed in muchgreater detail in later chapters.
242 Parallel Computing – r428

15.3. Your first OpenMP program
15.3.1 Directives
OpenMP is not magic, so you have to tell it when something can be done in parallel. This is mostly donethrough directives; additional specifications can be done through library calls.
In C/C++ the pragma mechanism is used: annotations for the benefit of the compiler that are otherwise notpart of the language. This looks like:
#pragma omp somedirective clause(value,othervalue)parallel statement;
#pragma omp somedirective clause(value,othervalue){parallel statement 1;parallel statement 2;}
with• the #pragma omp sentinel to indicate that an OpenMP directive is coming;• a directive, such as parallel;• and possibly clauses with values.• After the directive comes either a single statement or a block in curly braces .
Directives in C/C++ are case-sensitive. Directives can be broken over multiple lines by escaping the lineend.
The sentinel in Fortran looks like a comment:!$omp directive clause(value)statements
!$omp end directive
The difference with the C directive is that Fortran can not have a block, so there is an explicit end-ofdirective line.
If you break a directive over more than one line, all but the last line need to have a continuation character,and each line needs to have the sentinel:
!$OMP parallel do &!%OMP copyin(x),copyout(y)
The directives are case-insensitive. In Fortran fixed-form source files, c$omp and *$omp are allowed too.
15.3.2 Parallel regions
The simplest way to create parallelism in OpenMP is to use the parallel pragma. A block preceded bythe omp parallel pragma is called a parallel region; it is executed by a newly created team of threads.This is an instance of the Single Program Multiple Data (SPMD) model: all threads execute the samesegment of code.
Victor Eijkhout 243

15. Getting started with OpenMP
#pragma omp parallel{// this is executed by a team of threads
}
We will go into much more detail in section 16.
15.3.3 An actual OpenMP program!
Exercise 15.1. Write a program that contains the following lines:printf("There are %d processors\n",omp_get_num_procs());
#pragma omp parallelprintf("There are %d threads\n",
/* !!!! something missing here !!!! */ );
The first print statement tells you the number of available cores in the hardware. Yourassignment is to supply the missing function that reports the number of threads used.Compile and run the program. Experiment with the OMP_NUM_THREADSenvironment variable. What do you notice about the number of lines printed?
Exercise 15.2. Extend the program from exercise 15.1. Make a complete program based onthese lines:
int tsum=0;#pragma omp parallel
tsum += /* the thread number */printf("Sum is %d\n",tsum);
Compile and run again. (In fact, run your program a number of times.) Do you seesomething unexpected? Can you think of an explanation?
15.3.4 Code and execution structure
Here are a couple of important concepts:
Definition 1
structured block An OpenMP directive is followed by an structured block; in C this is a single statement, acompound statement, or a block in braces; In Fortran it is delimited by the directive and its matching ‘end’directive.
A structured block can not be jumped into, so it can not start with a labeled statement, or contain a jumpstatement leaving the block.
construct An OpenMP construct is the section of code starting with a directive and spanning the followingstructured block, plus in Fortran the end-directive. This is a lexical concept: it contains the statementsdirectly enclosed, and not any subroutines called from them.
244 Parallel Computing – r428

15.3. Your first OpenMP program
region of code A region of code is defined as all statements that are dynamically encountered while execut-ing the code of an OpenMP construct. This is a dynamic concept: unlike a ‘construct’, it does include anysubroutines that are called from the code in the structured block.
Victor Eijkhout 245

Chapter 16
OpenMP topic: Parallel regions
The simplest way to create parallelism in OpenMP is to use the parallel pragma. A block preceded bythe omp parallel pragma is called a parallel region; it is executed by a newly created team of threads.This is an instance of the SPMD model: all threads execute the same segment of code.
#pragma omp parallel{
// this is executed by a team of threads}
It would be pointless to have the block be executed identically by all threads. One way to get a meaningfulparallel code is to use the function omp_get_thread_num, to find out which thread you are, and executework that is individual to that thread. There is also a function omp_get_num_threads to find outthe total number of threads. Both these functions give a number relative to the current team; recall fromfigure 15.3 that new teams can be created recursively.
For instance, if you program computes
result = f(x)+g(x)+h(x)
you could parallelize this as
double result,fresult,gresult,hresult;#pragma omp parallel{ int num = omp_get_thread_num();
if (num==0) fresult = f(x);else if (num==1) gresult = g(x);else if (num==2) hresult = h(x);
}result = fresult + gresult + hresult;
The first thing we want to do is create a team of threads. This is done with a parallel region . Here is a verysimple example:
246

// hello.c#pragma omp parallel{
int t = omp_get_thread_num();printf("Hello world from %d!\n",t);
}
or in Fortran
// hellocount.F90!$omp parallelnthreads = omp_get_num_threads()mythread = omp_get_thread_num()write(*,’("Hello from",i3," out of",i3)’) mythread,nthreads
!$omp end parallel
This code corresponds to the model we just discussed:
• Immediately preceding the parallel block, one thread will be executing the code. In the mainprogram this is the initial thread .• At the start of the block, a new team of threads is created, and the thread that was active before
the block becomes the master thread of that team.• After the block only the master thread is active.• Inside the block there is team of threads: each thread in the team executes the body of the block,
and it will have access to all variables of the surrounding environment. How many threads thereare can be determined in a number of ways; we will get to that later.
Exercise 16.1. Make a full program based on this fragment. Insert different print statementsbefore, inside, and after the parallel region. Run this example. How many times iseach print statement executed?
You see that the parallel directive
• Is preceded by a special marker: a #pragma omp for C/C++, and the !$OMP sentinel forFortran;• Is followed by a single statement or a block in C/C++, or followed by a block in Fortran which
is delimited by an !$omp end directive.
Directives look like cpp directives , but they are actually handled by the compiler, not the preprocessor.
Exercise 16.2. Take the ‘hello world’ program above, and modify it so that you get multiplemessages to you screen, saying
Hello from thread 0 out of 4!Hello from thread 1 out of 4!
and so on. (The messages may very well appear out of sequence.)What happens if you set your number of threads larger than the available cores onyour computer?
Exercise 16.3. What happens if you call omp_get_thread_num andomp_get_num_threads outside a parallel region?
Victor Eijkhout 247

16. OpenMP topic: Parallel regions
omp_get_thread_limit
OMP_WAIT_POLICY values: ACTIVE,PASSIVE
16.1 Nested parallelism
What happens if you call a function from inside a parallel region, and that function itself contains a parallelregion?
int main() {...
#pragma omp parallel{...func(...)...}
} // end of mainvoid func(...) {#pragma omp parallel
{...}
}
By default, the nested parallel region will have only one thread. To allow nested thread creation, setOMP_NESTED=trueoromp_set_nested(1)
Exercise 16.4. Test nested parallelism by writing an OpenMP program as follows:1. Write a subprogram that contains a parallel region.2. Write a main program with a parallel region; call the subprogram both inside
and outside the parallel region.3. Insert print statements
(a) in the main program outside the parallel region,(b) in the parallel region in the main program,(c) in the subprogram outside the parallel region,(d) in the parallel region inside the subprogram.
Run your program and count how many print statements of each type you get.Writing subprograms that are called in a parallel region illustrates the following point: directives are eval-uation with respect to the dynamic scope of the parallel region, not just the lexical scope. In the followingexample:
248 Parallel Computing – r428

16.2. Sources used in this chapter
#pragma omp parallel{
f();}void f() {#pragma omp for
for ( .... ) {...
}}
the body of the function f falls in the dynamic scope of the parallel region, so the for loop will be paral-lelized.
If the function may be called both from inside and outside parallel regions, you can test which is the casewith omp_in_parallel.
The amount of nested parallelism can be set:
OMP_NUM_THREADS=4,2
means that initially a parallel region will have four threads, and each thread can create two more threads.
OMP_MAX_ACTIVE_LEVELS=123
omp_set_max_active_levels( n )n = omp_get_max_active_levels()
OMP_THREAD_LIMIT=123
n = omp_get_thread_limit()
omp_set_max_active_levelsomp_get_max_active_levelsomp_get_levelomp_get_active_levelomp_get_ancestor_thread_num
omp_get_team_size(level)
16.2 Sources used in this chapter
Listing of code XX:
Victor Eijkhout 249

Chapter 17
OpenMP topic: Loop parallelism
17.1 Loop parallelism
Loop parallelism is a very common type of parallelism in scientific codes, so OpenMP has an easy mecha-nism for it. OpenMP parallel loops are a first example of OpenMP ‘worksharing’ constructs (see section 18for the full list): constructs that take an amount of work and distribute it over the available threads in aparallel region.
The parallel execution of a loop can be handled a number of different ways. For instance, you can create aparallel region around the loop, and adjust the loop bounds:
#pragma omp parallel{int threadnum = omp_get_thread_num(),numthreads = omp_get_num_threads();
int low = N*threadnum/numthreads,high = N*(threadnum+1)/numthreads;
for (i=low; i<high; i++)// do something with i
}
A more natural option is to use the parallel for pragma:
#pragma omp parallel#pragma omp forfor (i=0; i<N; i++) {
// do something with i}
This has several advantages. For one, you don’t have to calculate the loop bounds for the threads yourself,but you can also tell OpenMP to assign the loop iterations according to different schedules (section 17.2).
Figure 17.1 shows the execution on four threads of
250

17.1. Loop parallelism
#pragma omp parallel{
code1();#pragma omp for
for (i=1; i<=4*N; i++) {code2();
}code3();
}
The code before and after the loop is executed identically in each thread; the loop iterations are spread overthe four threads.
Figure 17.1: Execution of parallel code inside and outside a loop
Note that the parallel do and parallel for pragmas do not create a team of threads: they take theteam of threads that is active, and divide the loop iterations over them.
This means that the omp for or omp do directive needs to be inside a parallel region. It is also possibleto have a combined omp parallel for or omp parallel do directive.
If your parallel region only contains a loop, you can combine the pragmas for the parallel region anddistribution of the loop iterations:
#pragma omp parallel forfor (i=0; .....
Exercise 17.1. Compute π by numerical integration . We use the fact that π is the area of theunit circle, and we approximate this by computing the area of a quarter circle usingRiemann sums .
Victor Eijkhout 251

17. OpenMP topic: Loop parallelism
• Let f(x) =√
1− x2 be the function that describes the quarter circle forx = 0 . . . 1;• Then we compute
π/4 ≈N−1∑i=0
∆xf(xi) where xi = i∆x and ∆x = 1/N
Write a program for this, and parallelize it using OpenMP parallel for directives.1. Put a parallel directive around your loop. Does it still compute the right
result? Does the time go down with the number of threads? (The answersshould be no and no.)
2. Change the parallel to parallel for (or parallel do). Now is theresult correct? Does execution speed up? (The answers should now be no andyes.)
3. Put a critical directive in front of the update. (Yes and very much no.)4. Remove the critical and add a clause reduction(+:quarterpi) to
the for directive. Now it should be correct and efficient.Use different numbers of cores and compute the speedup you attain over thesequential computation. Is there a performance difference between the OpenMP codewith 1 thread and the sequential code?
Remark 3 In this exercise you may have seen the runtime go up a couple of times where you weren’texpecting it. The issue here is false sharing; see HPSC-3.3.7 for more explanation.
There are some restrictions on the loop: basically, OpenMP needs to be able to determine in advance howmany iterations there will be.
• The loop can not contains break, return, exit statements, or goto to a label outside theloop.• The continue (C) or cycle (F) statement is allowed.• The index update has to be an increment (or decrement) by a fixed amount.• The loop index variable is automatically private, and not changes to it inside the loop are allowed.
17.2 Loop schedules
Usually you will have many more iterations in a loop than there are threads. Thus, there are several waysyou can assign your loop iterations to the threads. OpenMP lets you specify this with the scheduleclause.
#pragma omp for schedule(....)
The first distinction we now have to make is between static and dynamic schedules. With static schedules,the iterations are assigned purely based on the number of iterations and the number of threads (and thechunk parameter; see later). In dynamic schedules, on the other hand, iterations are assigned to threads
252 Parallel Computing – r428

17.2. Loop schedules
that are unoccupied. Dynamic schedules are a good idea if iterations take an unpredictable amount of time,so that load balancing is needed.
Figure 17.2: Illustration static round-robin scheduling versus dynamic
Figure 17.2 illustrates this: assume that each core gets assigned two (blocks of) iterations and these blockstake gradually less and less time. You see from the left picture that thread 1 gets two fairly long blocks,where as thread 4 gets two short blocks, thus finishing much earlier. (This phenomenon of threads havingunequal amounts of work is known as load imbalance .) On the other hand, in the right figure thread 4 getsblock 5, since it finishes the first set of blocks early. The effect is a perfect load balancing.
Figure 17.3: Illustration of the scheduling strategies of loop iterations
The default static schedule is to assign one consecutive block of iterations to each thread. If you wantdifferent sized blocks you can defined a chunk size:
#pragma omp for schedule(static[,chunk])
(where the square brackets indicate an optional argument). With static scheduling, the compiler will splitup the loop iterations at compile time, so, provided the iterations take roughly the same amount of time,this is the most efficient at runtime.
The choice of a chunk size is often a balance between the low overhead of having only a few chunks, versusthe load balancing effect of having smaller chunks.Exercise 17.2. Why is a chunk size of 1 typically a bad idea? (Hint: think about cache lines,
and read HPSC-1.4.1.2.)
Victor Eijkhout 253

17. OpenMP topic: Loop parallelism
In dynamic scheduling OpenMP will put blocks of iterations (the default chunk size is 1) in a task queue,and the threads take one of these tasks whenever they are finished with the previous.
#pragma omp for schedule(static[,chunk])
While this schedule may give good load balancing if the iterations take very differing amounts of time toexecute, it does carry runtime overhead for managing the queue of iteration tasks.
Finally, there is the guided schedule, which gradually decreases the chunk size. The thinking here isthat large chunks carry the least overhead, but smaller chunks are better for load balancing. The variousschedules are illustrated in figure 17.3.
If you don’t want to decide on a schedule in your code, you can specify the runtime schedule. The actualschedule will then at runtime be read from the OMP_SCHEDULE environment variable. You can even justleave it to the runtime library by specifying auto
Exercise 17.3. We continue with exercise 17.1. We add ‘adaptive integration’: where needed,the program refines the step size1. This means that the iterations no longer take apredictable amount of time.
for (i=0; i<nsteps; i++) {double
x = i*h,x2 = (i+1)*h,y = sqrt(1-x*x),y2 = sqrt(1-x2*x2),slope = (y-y2)/h;
if (slope>15) slope = 15;int
samples = 1+(int)slope, is;for (is=0; is<samples; is++) {
doublehs = h/samples,xs = x+ is*hs,ys = sqrt(1-xs*xs);
quarterpi += hs*ys;nsamples++;
}}pi = 4*quarterpi;
1. Use the omp parallel for construct to parallelize the loop. As in theprevious lab, you may at first see an incorrect result. Use the reductionclause to fix this.
2. Your code should now see a decent speedup, using up to 8 cores. However, it ispossible to get completely linear speedup. For this you need to adjust theschedule.Start by using schedule(static,$n$). Experiment with values for n.When can you get a better speedup? Explain this.
1. It doesn’t actually do this in a mathematically sophisticated way, so this code is more for the sake of the example.
254 Parallel Computing – r428

17.2. Loop schedules
3. Since this code is somewhat dynamic, try schedule(dynamic). This willactually give a fairly bad result. Why? Use schedule(dynamic,$n$)instead, and experiment with values for n.
4. Finally, use schedule(guided), where OpenMP uses a heuristic. Whatresults does that give?
Exercise 17.4. Program the LU factorization algorithm without pivoting.for k=1,n:
A[k,k] = 1./A[k,k]for i=k+1,n:
A[i,k] = A[i,k]/A[k,k]for j=k+1,n:A[i,j] = A[i,j] - A[i,k]*A[k,j]
1. Argue that it is not possible to parallelize the outer loop.2. Argue that it is possible to parallelize both the i and j loops.3. Parallelize the algorithm by focusing on the i loop. Why is the algorithm as
given here best for a matrix on row-storage? What would you do if the matrixwas on column storage?
4. Argue that with the default schedule, if a row is updated by one thread in oneiteration, it may very well be updated by another thread in another. Can youfind a way to schedule loop iterations so that this does not happen? Whatpractical reason is there for doing so?
The schedule can be declared explicitly, set at runtime through the OMP_SCHEDULE environment variable,or left up to the runtime system by specifying auto. Especially in the last two cases you may want toenquire what schedule is currently being used with omp_get_schedule.
int omp_get_schedule(omp_sched_t * kind, int * modifier );
Its mirror call is omp_set_schedule, which sets the value that is used when schedule value runtimeis used. It is in effect equivalent to setting the environment variable OMP_SCHEDULE.
void omp_set_schedule (omp_sched_t kind, int modifier);
Type environment variable clause modifier defaultOMP SCHEDULE= schedule( ... )
static static[,n] static[,n] N/nthreadsdynamic dynamic[,n] dynamic[,n] 1guided guided[,n] guided[,n]
Here are the various schedules you can set with the schedule clause:
affinity Set by using value omp_sched_affinityauto The schedule is left up to the implementation. Set by using value omp_sched_autodynamic value: 2. The modifier parameter is the chunk size; default 1. Set by using value omp_sched_dynamicguided Value: 3. The modifier parameter is the chunk size. Set by using value omp_sched_guidedruntime Use the value of the OMP_SCHEDULE environment variable. Set by using value omp_sched_runtime
Victor Eijkhout 255

17. OpenMP topic: Loop parallelism
static value: 1. The modifier parameter is the chunk size. Set by using value omp_sched_static
17.3 Reductions
So far we have focused on loops with independent iterations. Reductions are a common type of loop withdependencies. There is an extended discussion of reductions in section 20.
17.4 Collapsing nested loops
In general, the more work there is to divide over a number of threads, the more efficient the parallelizationwill be. In the context of parallel loops, it is possible to increase the amount of work by parallelizing alllevels of loops instead of just the outer one.
Example: in
for ( i=0; i<N; i++ )for ( j=0; j<N; j++ )A[i][j] = B[i][j] + C[i][j]
all N2 iterations are independent, but a regular omp for directive will only parallelize one level. Thecollapse clause will parallelize more than one level:
#pragma omp for collapse(2)for ( i=0; i<N; i++ )for ( j=0; j<N; j++ )A[i][j] = B[i][j] + C[i][j]
It is only possible to collapse perfectly nested loops, that is, the loop body of the outer loop can consist onlyof the inner loop; there can be no statements before or after the inner loop in the loop body of the outerloop. That is, the two loops in
for (i=0; i<N; i++) {y[i] = 0.;for (j=0; j<N; j++)y[i] += A[i][j] * x[j]
}
can not be collapsed.
Exercise 17.5. Can you rewrite the preceding code example so that it can be collapsed? Dotiming tests to see if you can notice the improvement from collapsing.
256 Parallel Computing – r428

17.5. Ordered iterations
17.5 Ordered iterations
Iterations in a parallel loop that are execution in parallel do not execute in lockstep. That means that in
#pragma omp parallel forfor ( ... i ... ) {
... f(i) ...printf("something with %d\n",i);
}
it is not true that all function evaluations happen more or less at the same time, followed by all printstatements. The print statements can really happen in any order. The ordered clause coupled with theordered directive can force execution in the right order:
#pragma omp parallel for orderedfor ( ... i ... ) {... f(i) ...
#pragma omp orderedprintf("something with %d\n",i);
}
Example code structure:
#pragma omp parallel for shared(y) orderedfor ( ... i ... ) {
int x = f(i)#pragma omp ordered
y[i] += f(x)z[i] = g(y[i])
}
There is a limitation: each iteration can encounter only one ordered directive.
17.6 nowait
The implicit barrier at the end of a work sharing construct can be cancelled with a nowait clause. Thishas the effect that threads that are finished can continue with the next code in the parallel region:
#pragma omp parallel{#pragma omp for nowaitfor (i=0; i<N; i++) { ... }// more parallel code
}
Victor Eijkhout 257

17. OpenMP topic: Loop parallelism
In the following example, threads that are finished with the first loop can start on the second. Note thatthis requires both loops to have the same schedule. We specify the static schedule here to have an identicalscheduling of iterations over threads:
#pragma omp parallel{x = local_computation()
#pragma omp for schedule(static) nowaitfor (i=0; i<N; i++) {x[i] = ...
}#pragma omp for schedule(static)
for (i=0; i<N; i++) {y[i] = ... x[i] ...
}}
17.7 While loops
OpenMP can only handle ‘for’ loops: while loops can not be parallelized. So you have to find a way aroundthat. While loops are for instance used to search through data:
while ( a[i]!=0 && i<imax ) {i++; }// now i is the first index for which \n{a[i]} is zero.
We replace the while loop by a for loop that examines all locations:result = -1;#pragma omp parallel forfor (i=0; i<imax; i++) {
if (a[i]!=0 && result<0) result = i;}
Exercise 17.6. Show that this code has a race condition.You can fix the race condition by making the condition into a critical section; section 21.2.1. In this par-ticular example, with a very small amount of work per iteration, that is likely to be inefficient in this case(why?). A more efficient solution uses the lastprivate pragma:
result = -1;#pragma omp parallel for lastprivate(result)for (i=0; i<imax; i++) {
if (a[i]!=0) result = i;}
258 Parallel Computing – r428

17.7. While loops
You have now solved a slightly different problem: the result variable contains the last location where a[i]is zero.
Victor Eijkhout 259

Chapter 18
OpenMP topic: Work sharing
The declaration of a parallel region establishes a team of threads. This offers the possibility of parallelism,but to actually get meaningful parallel activity you need something more. OpenMP uses the concept of awork sharing construct : a way of dividing parallelizable work over a team of threads. The work sharingconstructs are:
• for/do The threads divide up the loop iterations among themselves; see 17.1.• sections The threads divide a fixed number of sections between themselves; see section 18.1.• single The section is executed by a single thread; section 18.2.• task See section 22.• workshare Can parallelize Fortran array syntax; section 18.3.
18.1 Sections
A parallel loop is an example of independent work units that are numbered. If you have a pre-determinednumber of independent work units, the sections is more appropriate. In a sections construct canbe any number of section constructs. These need to be independent, and they can be execute by anyavailable thread in the current team, including having multiple sections done by the same thread.
#pragma omp sections{#pragma omp section
// one calculation#pragma omp section
// another calculation}
This construct can be used to divide large blocks of independent work. Suppose that in the following line,both f(x) and g(x) are big calculations:
y = f(x) + g(x)
You could then write
260

18.2. Single/master
double y1,y2;#pragma omp sections{#pragma omp section
y1 = f(x)#pragma omp section
y2 = g(x)}y = y1+y2;
Instead of using two temporaries, you could also use a critical section; see section 21.2.1. However, the bestsolution is have a reduction clause on the sections directive:
y = f(x) + g(x)
You could then write
y = 0;#pragma omp sections reduction(+:y){#pragma omp sectiony += f(x)
#pragma omp sectiony += g(x)
}
18.2 Single/master
The single and master pragma limit the execution of a block to a single thread. This can for instancebe used to print tracing information or doing I/O operations.
#pragma omp parallel{#pragma omp single
printf("We are starting this section!\n");// parallel stuff
}
Another use of single is to perform initializations in a parallel region:
int a;#pragma omp parallel{
#pragma omp single
Victor Eijkhout 261

18. OpenMP topic: Work sharing
a = f(); // some computation#pragma omp sections// various different computations using a
}
The point of the single directive in this last example is that the computation needs to be done only once,because of the shared memory. Since it’s a work sharing construct there is an implicit barrier after it, whichguarantees that all threads have the correct value in their local memory (see section 24.3.
Exercise 18.1. What is the difference between this approach and how the same computationwould be parallelized in MPI?
The master directive, also enforces execution on a single thread, specifically the master thread of theteam, but it does not have the synchronization through the implicit barrier.
Exercise 18.2. Modify the above code to read:int a;#pragma omp parallel{
#pragma omp mastera = f(); // some computation
#pragma omp sections// various different computations using a
}
This code is no longer correct. Explain.
Above we motivated the single directive as a way of initializing shared variables. It is also possible touse single to initialize private variables. In that case you add the copyprivate clause. This is a goodsolution if setting the variable takes I/O.
Exercise 18.3. Give two other ways to initialize a private variable, with all threads receivingthe same value. Can you give scenarios where each of the three strategies would bepreferable?
18.3 Fortran array syntax parallelization
The parallel do directive is used to parallelize loops, and this applies to both C and Fortran. However,Fortran also has implied loops in its array syntax. To parallelize array syntax you can use the worksharedirective.
The workshare directive exists only in Fortran. It can be used to parallelize the implied loops in arraysyntax , as well as forall loops.
262 Parallel Computing – r428

Chapter 19
OpenMP topic: Controlling thread data
In a parallel region there are two types of data: private and shared. In this sections we will see the variousway you can control what category your data falls under; for private data items we also discuss how theirvalues relate to shared data.
19.1 Shared dataIn a parallel region, any data declared outside it will be shared: any thread using a variable x will accessthe same memory location associated with that variable.
Example:int x = 5;
#pragma omp parallel{
x = x+1;printf("shared: x is %d\n",x);
}
All threads increment the same variable, so after the loop it will have a value of five plus the number ofthreads; or maybe less because of the data races involved. See HPSC-2.6.1.5 for an explanation of the issuesinvolved; see 21.2.1 for a solution in OpenMP.
Sometimes this global update is what you want; in other cases the variable is intended only for intermediateresults in a computation. In that case there are various ways of creating data that is local to a thread, andtherefore invisible to other threads.
19.2 Private dataIn the C/C++ language it is possible to declare variables inside a lexical scope; roughly: inside curly braces.This concept extends to OpenMP parallel regions and directives: any variable declared in a block followingan OpenMP directive will be local to the executing thread.
Example:
263

19. OpenMP topic: Controlling thread data
int x = 5;#pragma omp parallel
{int x; x = 3;printf("local: x is %d\n",x);
}
After the parallel region the outer variable x will still have the value 5: there is no storage associationbetween the private variable and global one.
The Fortran language does not have this concept of scope, so you have to use a private clause:
!$OMP parallel private(x)
The private directive declares data to have a separate copy in the memory of each thread. Such privatevariables are initialized as they would be in a main program. Any computed value goes away at the end ofthe parallel region. (However, see below.) Thus, you should not rely on any initial value, or on the value ofthe outer variable after the region.
int x = 5;#pragma omp parallel private(x)
{x = x+1; // dangerousprintf("private: x is %d\n",x);
}printf("after: x is %d\n",x); // also dangerous
Data that is declared private with the private directive is put on a separate stack per thread . The OpenMPstandard does not dictate the size of these stacks, but beware of stack overflow. A typical default is a fewmegabyte; you can control it with the environment variable OMP_STACKSIZE. Its values can be literal orwith suffixes:
123 456k 567K 678m 789M 246g 357G
A normal Unix process also has a stack, but this is independent of the OpenMP stacks for private data. Youcan query or set the Unix stack with ulimit:
[] ulimit -s64000[] ulimit -s 8192[] ulimit -s8192
The Unix stack can grow dynamically as space is needed. This does not hold for the OpenMP stacks: theyare immediately allocated at their requested size. Thus it is important not too make them too large.
264 Parallel Computing – r428

19.3. Data in dynamic scope
19.3 Data in dynamic scope
Functions that are called from a parallel region fall in the dynamic scope of that parallel region. The rulesfor variables in that function are as follows:
• Any variables locally defined to the function are private.• static variables in C and save variables in Fortran are shared.• The function arguments inherit their status from the calling environment.
19.4 Temporary variables in a loop
It is common to have a variable that is set and used in each loop iteration:#pragma omp parallel forfor ( ... i ... ) {
x = i*h;s = sin(x); c = cos(x);a[i] = s+c;b[i] = s-c;
}
By the above rules, the variables x,s,c are all shared variables. However, the values they receive in oneiteration are not used in a next iteration, so they behave in fact like private variables to each iteration.
• In both C and Fortran you can declare these variables private in the parallel for directive.• In C, you can also redefine the variables inside the loop.
Sometimes, even if you forget to declare these temporaries as private, the code may still give the correctoutput. That is because the compiler can sometimes eliminate them from the loop body, since it detects thattheir values are not otherwise used.
19.5 Default
• Loop variables in an omp for are private;• Local variables in the parallel region are private.
You can alter this default behaviour with the default clause:#pragma omp parallel default(shared) private(x){ ... }#pragma omp parallel default(private) shared(matrix){ ... }
and if you want to play it safe:#pragma omp parallel default(none) private(x) shared(matrix){ ... }
Victor Eijkhout 265

19. OpenMP topic: Controlling thread data
• The shared clause means that all variables from the outer scope are shared in the parallelregion; any private variables need to be declared explicitly. This is the default behaviour.• The private clause means that all outer variables become private in the parallel region. They
are not initialized; see the next option. Any shared variables in the parallel region need to bedeclared explicitly. This value is not available in C.• The firstprivate clause means all outer variables are private in the parallel region, and
initialized with their outer value. Any shared variables need to be declared explicitly. This valueis not available in C.• The none option is good for debugging, because it forces you to specify for each variable in the
parallel region whether it’s private or shared. Also, if your code behaves differently in parallelfrom sequential there is probably a data race. Specifying the status of every variable is a goodway to debug this.
19.6 Array data
The rules for arrays are slightly different from those for scalar data:
1. Statically allocated data, that is with a syntax likeint array[100];integer,dimension(:) :: array(100}
can be shared or private, depending on the clause you use.2. Dynamically allocated data, that is, created with malloc or allocate, can only be shared.
Example of the first type: in
// alloc3.cint array[nthreads];{int t = 2;array += t;array[0] = t;
}
each thread gets a private copy of the array, properly initialized.
On the other hand, in
// alloc1.cint *array = (int*) malloc(nthreads*sizeof(int));#pragma omp parallel firstprivate(array){int t = omp_get_thread_num();array += t;array[0] = t;
}
each thread gets a private pointer, but all pointers point to the same object.
266 Parallel Computing – r428

19.7. First and last private
19.7 First and last private
Above, you saw that private variables are completely separate from any variables by the same name in thesurrounding scope. However, there are two cases where you may want some storage association between aprivate variable and a global counterpart.
First of all, private variables are created with an undefined value. You can force their initialization withfirstprivate.
int t=2;#pragma omp parallel firstprivate(t)
{t += f( omp_get_thread_num() );g(t);
}
The variable t behaves like a private variable, except that it is initialized to the outside value.
Secondly, you may want a private value to be preserved to the environment outside the parallel region.This really only makes sense in one case, where you preserve a private variable from the last iteration of aparallel loop, or the last section in an sections construct. This is done with lastprivate:
#pragma omp parallel for \lastprivate(tmp)
for (i=0; i<N; i+) {tmp = ......x[i] = .... tmp ....
}..... tmp ....
19.8 Persistent data through threadprivate
Most data in OpenMP parallel regions is either inherited from the master thread and therefore shared, ortemporary within the scope of the region and fully private. There is also a mechanism for thread-privatedata , which is not limited in lifetime to one parallel region. The threadprivate pragma is used todeclare that each thread is to have a private copy of a variable:
#pragma omp threadprivate(var)
The variable needs be:
• a file or static variable in C,• a static class member in C++, or• a program variable or common block in Fortran.
Victor Eijkhout 267

19. OpenMP topic: Controlling thread data
19.8.1 Thread private initialization
If each thread needs a different value in its threadprivate variable, the initialization needs to happen in aparallel region.
In the following example a team of 7 threads is created, all of which set their thread-private variable. Later,this variable is read by a larger team: the variables that have not been set are undefined, though often simplyzero:
// threadprivate.c#include <stdlib.h>#include <stdio.h>#include <omp.h>
static int tp;
int main(int argc,char **argv) {
#pragma omp threadprivate(tp)
#pragma omp parallel num_threads(7)tp = omp_get_thread_num();
#pragma omp parallel num_threads(9)printf("Thread %d has %d\n",omp_get_thread_num(),tp);
return 0;}
On the other hand, if the thread private data starts out identical in all threads, the copyin clause can beused:
#pragma omp threadprivate(private_var)
private_var = 1;#pragma omp parallel copyin(private_var)
private_var += omp_get_thread_num()
If one thread needs to set all thread private data to its value, the copyprivate clause can be used:
#pragma omp parallel{
...#pragma omp single copyprivate(private_var)
private_var = read_data();...
}
268 Parallel Computing – r428

19.9. Sources used in this chapter
19.8.2 Thread private example
The typical application for thread-private variables is in random number generation . A random numbergenerator needs saved state, since it computes each next value from the current one. To have a parallelgenerator, each thread will create and initialize a private ‘current value’ variable. This will persist evenwhen the execution is not in a parallel region; it gets updated only in a parallel region.
Exercise 19.1. Calculate the area of the Mandelbrot set by random sampling. Initialize therandom number generator separately for each thread; then use a parallel loop toevaluate the points. Explore performance implications of the different loopscheduling strategies.
Fortran note. Named common blocks can be made thread-private with the syntax$!OMP threadprivate( /blockname/ )
Threadprivate variables require OMP_DYNAMIC to be switched off.
19.9 Sources used in this chapter
Listing of code XX:
Listing of code XX:
Listing of code XX:
Victor Eijkhout 269

Chapter 20
OpenMP topic: Reductions
Parallel tasks often produce some quantity that needs to be summed or otherwise combined. In section 16you saw an example, and it was stated that the solution given there was not very good.
The problem in that example was the race condition involving the result variable. The simplest solutionis to eliminate the race condition by declaring a critical section:
double result = 0;#pragma omp parallel{
double local_result;int num = omp_get_thread_num();if (num==0) local_result = f(x);else if (num==1) local_result = g(x);else if (num==2) local_result = h(x);
#pragma omp criticalresult += local_result;
}
This is a good solution if the amount of serialization in the critical section is small compared to computingthe functions f, g, h. On the other hand, you may not want to do that in a loop:
double result = 0;#pragma omp parallel{
double local_result;#pragma omp for
for (i=0; i<N; i++) {local_result = f(x,i);
#pragma omp criticalresult += local_result;
} // end of for loop}
270

Exercise 20.1. Can you think of a small modification of this code, that still uses a criticalsection, that is more efficient? Time both codes.
The easiest way to effect a reduction is of course to use the reduction clause. Adding this to an ompfor or an omp sections construct has the following effect:
• OpenMP will make a copy of the reduction variable per thread, initialized to the identity of thereduction operator, for instance 1 for multiplication.• Each thread will then reduce into its local variable;• At the end of the loop, the local results are combined, again using the reduction operator, into
the global variable.
This is one of those cases where the parallel execution can have a slightly different value from the one thatis computed sequentially, because floating point operations are not associative. See HPSC-3.3.7 for moreexplanation.
If your code can not be easily structure as a reduction, you can realize the above scheme by hand by‘duplicating’ the global variable and gather the contributions later. This example presumes three threads,and gives each a location of their own to store the result computed on that thread:
double result,local_results[3];#pragma omp parallel{
int num = omp_get_thread_num();if (num==0) local_results[num] = f(x)else if (num==1) local_results[num] = g(x)else if (num==2) local_results[num] = h(x)
}result = local_results[0]+local_results[1]+local_results[2]
While this code is correct, it may be inefficient because of a phenomemon called false sharing . Even thoughthe threads write to separate variables, those variables are likely to be on the same cacheline (see HPSC-1.4.1.2 for an explanation). This means that the cores will be wasting a lot of time and bandwidth updatingeach other’s copy of this cacheline.
False sharing can be prevent by giving each thread its own cacheline:
double result,local_results[3][8];#pragma omp parallel{int num = omp_get_thread_num();if (num==0) local_results[num][1] = f(x)
// et cetera}
A more elegant solution gives each thread a true local variable, and uses a critical section to sum these, atthe very end:
Victor Eijkhout 271

20. OpenMP topic: Reductions
double result = 0;#pragma omp parallel{double local_result;local_result = .....
#pragam omp criticalresult += local_result;
}
20.1 Built-in reduction operators
Arithmetic reductions: +, ∗,−,max,min
Logical operator reductions in C: & && | || ˆ
Logical operator reductions in Fortran: .and. .or. .eqv. .neqv. .iand. .ior. .ieor.
Exercise 20.2. The maximum and minimum reductions were not added to OpenMP untilversion 3.1. Write a parallel loop that computes the maximum and minimum valuesin an array. Discuss the various options. Do timings to evaluate the speedup that isattained and to find the best option.
20.2 Initial value for reductions
The treatment of initial values in reductions is slightly involved.
x = init_x#pragma omp parallel for reduction(min:x)
for (int i=0; i<N; i++)x = min(x,data[i]);
Each thread does a partial reduction, but its initial value is not the user-supplied init_x value, but a valuedependent on the operator. In the end, the partial results will then be combined with the user initial value.The initialization values are mostly self-evident, such as zero for addition and one for multiplication. Formin and max they are respectively the maximal and minimal representable value of the result type.
Figure 20.1 illustrates this, where 1,2,3,4 are four data items, i is the OpenMP initialization, and u isthe user initialization; each p stands for a partial reduction value. The figure is based on execution usingtwo threads.
Exercise 20.3. Write a program to test the fact that the partial results are initialized to the unitof the reduction operator.
272 Parallel Computing – r428

20.3. User-defined reductions
Figure 20.1: Reduction of four items on two threads, taking into account initial values.
20.3 User-defined reductions
With user-defined reductions, the programmer specifies the function that does the elementwise comparison.This takes two steps.
1. You need a function of two arguments that returns the result of the comparison. You can do thisyourself, but, especially with the C++ standard library, you can use functions such as std::vector::insert.
2. Specifying how this function operates on two variables omp_out and omp_in, correspondingto the partially reduced result and the new operand respectively. The new partial result should beleft in omp_out.
3. Optionally, you can specify the value to which the reduction should be initialized.
This is the syntax of the definition of the reduction, which can then be used in multiple reductionclauses.
#pragma omp declare reduction( identifier : typelist : combiner )[initializer(initializer-expression)]
where:
identifier is a name; this can be overloaded for different types, and redefined in inner scopes.typelist is a list of types.combiner is an expression that updates the internal variable omp_out as function of itself and omp_in.initializer sets omp_priv to the identity of the reduction; this can be an expression or a brace
initializer.
For instance, recreating the maximum reduction would look like this:
// ireduct.cint mymax(int r,int n) {// r is the already reduced value// n is the new valueint m;
Victor Eijkhout 273

20. OpenMP topic: Reductions
if (n>r) {m = n;
} else {m = r;
}return m;
}#pragma omp declare reduction \(rwz:int:omp_out=mymax(omp_out,omp_in)) \initializer(omp_priv=INT_MIN)m = INT_MIN;
#pragma omp parallel for reduction(rwz:m)for (int idata=0; idata<ndata; idata++)
m = mymax(m,data[idata]);
Exercise 20.4. Write a reduction routine that operates on an array of non-negative integers,finding the smallest nonzero one. If the array has size zero, or entirely consists ofzeros, return -1.
20.4 Reductions and floating-point math
The mechanisms that OpenMP uses to make a reduction parallel go against the strict rules for floating pointexpression evaluation in C; see HPSC-3.4. OpenMP ignores this issue: it is the programmer’s job to ensureproper rounding behaviour.
20.5 Sources used in this chapter
Listing of code XX:
274 Parallel Computing – r428

Chapter 21
OpenMP topic: Synchronization
In the constructs for declaring parallel regions above, you had little control over in what order threadsexecuted the work they were assigned. This section will discuss synchronization constructs: ways of tellingthreads to bring a certain order to the sequence in which they do things.
• critical: a section of code can only be executed by one thread at a time; see 21.2.1.• atomic Update of a single memory location. Only certain specified syntax pattterns are sup-
ported. This was added in order to be able to use hardware support for atomic updates.• barrier: section 21.1.• ordered: section 17.5.• locks: section 21.3.• flush: section 24.3.• nowait: section 17.6.
21.1 Barrier
A barrier defines a point in the code where all active threads will stop until all threads have arrived at thatpoint. With this, you can guarantee that certain calculations are finished. For instance, in this code snippet,computation of y can not proceed until another thread has computed its value of x.
#pragma omp parallel{
int mytid = omp_get_thread_num();x[mytid] = some_calculation();y[mytid] = x[mytid]+x[mytid+1];
}
This can be guaranteed with a barrier pragma:
#pragma omp parallel{
int mytid = omp_get_thread_num();x[mytid] = some_calculation();
275

21. OpenMP topic: Synchronization
#pragma omp barriery[mytid] = x[mytid]+x[mytid+1];
}
Apart from the barrier directive, which inserts an explicit barrier, OpenMP has implicit barriers after a loadsharing construct. Thus the following code is well defined:
#pragma omp parallel{#pragma omp for
for (int mytid=0; mytid<number_of_threads; mytid++)x[mytid] = some_calculation();
#pragma omp forfor (int mytid=0; mytid<number_of_threads-1; mytid++)y[mytid] = x[mytid]+x[mytid+1];
}
You can also put each parallel loop in a parallel region of its own, but there is some overhead associatedwith creating and deleting the team of threads in between the regions.
21.1.1 Implicit barriers
At the end of a parallel region the team of threads is dissolved and only the master thread continues.Therefore, there is an implicit barrier at the end of a parallel region .
There is some barrier behaviour associated with omp for loops and other worksharing constructs (seesection 18.3). For instance, there is an implicit barrier at the end of the loop. This barrier behaviour can becancelled with the nowait clause.
You will often see the idiom
#pragma omp parallel{#pragma omp for nowait
for (i=0; i<N; i++)a[i] = // some expression
#pragma omp forfor (i=0; i<N; i++)
b[i] = ...... a[i] ......
Here the nowait clause implies that threads can start on the second loop while other threads are stillworking on the first. Since the two loops use the same schedule here, an iteration that uses a[i] canindeed rely on it that that value has been computed.
276 Parallel Computing – r428

21.2. Mutual exclusion
21.2 Mutual exclusion
Sometimes it is necessary to let only one thread execute a piece of code. Such a piece of code is called acritical section , and OpenMP has several mechanisms for realizing this.
The most common use of critical sections is to update a variable. Since updating involves reading the oldvalue, and writing back the new, this has the possibility for a race condition: another thread reads the currentvalue before the first can update it; the second thread the updates to the wrong value.
Critical sections are an easy way to turn an existing code into a correct parallel code. However, there aredisadvantages to this, and sometimes a more drastic rewrite is called for.
21.2.1 critical and atomic
There are two pragmas for critical sections: critical and atomic. The second one is more limited buthas performance advantages.
The typical application of a critical section is to update a variable:
#pragma omp parallel{int mytid = omp_get_thread_num();double tmp = some_function(mytid);
#pragma omp criticalsum += tmp;
}
Exercise 21.1. Consider a loop where each iteration updates a variable.#pragma omp parallel for shared(result)
for ( i ) {result += some_function_of(i);
}
Discuss qualitatively the difference between:• turning the update statement into a critical section, versus• letting the threads accumulate into a private variable tmp as above, and
summing these after the loop.Do an Ahmdal-style quantitative analysis of the first case, assuming that you do niterations on p threads, and each iteration has a critical section that takes a fraction f .Assume the number of iterations n is a multiple of the number of threads p. Alsoassume the default static distribution of loop iterations over the threads.
A critical section works by acquiring a lock, which carries a substantial overhead. Furthermore, if yourcode has multiple critical sections, they are all mutually exclusive: if a thread is in one critical section, theother ones are all blocked.
On the other hand, the syntax for atomic sections is limited to the update of a single memory location, butsuch sections are not exclusive and they can be more efficient, since they assume that there is a hardware
Victor Eijkhout 277

21. OpenMP topic: Synchronization
mechanism for making them critical.
The problem with critical sections being mutually exclusive can be mitigated by naming them:
#pragma omp critical (optional_name_in_parens)
21.3 Locks
OpenMP also has the traditional mechanism of a lock . A lock is somewhat similar to a critical section:it guarantees that some instructions can only be performed by one process at a time. However, a criticalsection is indeed about code; a lock is about data. With a lock you make sure that some data elements canonly be touched by one process at a time.
One simple example of the use of locks is generation of a histogram . A histogram consists of a number ofbins, that get updated depending on some data. Here is the basic structure of such a code:
int count[100];float x = some_function();int ix = (int)x;if (ix>=100)
error();else
count[ix]++;
It would be possible to guard the last line:
#pragma omp criticalcount[ix]++;
but that is unnecessarily restrictive. If there are enough bins in the histogram, and if the some_functiontakes enough time, there are unlikely to be conflicting writes. The solution then is to create an array oflocks, with one lock for each count location.
Create/destroy:
void omp_init_lock(omp_lock_t *lock);void omp_destroy_lock(omp_lock_t *lock);
Set and release:
void omp_set_lock(omp_lock_t *lock);void omp_unset_lock(omp_lock_t *lock);
Since the set call is blocking, there is also
omp_test_lock();
278 Parallel Computing – r428

21.3. Locks
Unsetting a lock needs to be done by the thread that set it.
Lock operations implicitly have a flush.
Exercise 21.2. In the following code, one process sets array A and then uses it to update B;the other process sets array B and then uses it to update A. Argue that this code candeadlock. How could you fix this?
#pragma omp parallel shared(a, b, nthreads, locka, lockb)#pragma omp sections nowait
{#pragma omp section{omp_set_lock(&locka);for (i=0; i<N; i++)
a[i] = ..
omp_set_lock(&lockb);for (i=0; i<N; i++)
b[i] = .. a[i] ..omp_unset_lock(&lockb);omp_unset_lock(&locka);}
#pragma omp section{omp_set_lock(&lockb);for (i=0; i<N; i++)
b[i] = ...
omp_set_lock(&locka);for (i=0; i<N; i++)
a[i] = .. b[i] ..omp_unset_lock(&locka);omp_unset_lock(&lockb);}
} /* end of sections */} /* end of parallel region */
21.3.1 Nested locks
A lock as explained above can not be locked if it is already locked. A nested lock can be locked multipletimes by the same thread before being unlocked.
• omp_init_nest_lock
• omp_destroy_nest_lock
Victor Eijkhout 279

21. OpenMP topic: Synchronization
• omp_set_nest_lock
• omp_unset_nest_lock
• omp_test_nest_lock
lock—)
21.4 Example: Fibonacci computation
The Fibonacci sequence is recursively defined as
F (0) = 1, F (1) = 1, F (n) = F (n− 1) + F (n− 2) for n ≥ 2.
We start by sketching the basic single-threaded solution. The naive code looks like:
int main() {value = new int[nmax+1];value[0] = 1;value[1] = 1;fib(10);
}
int fib(int n) {int i, j, result;if (n>=2) {
i=fib(n-1); j=fib(n-2);value[n] = i+j;
}return value[n];
}
Howver, this is inefficienty, since most intermediate values will be computed more than once. We solve thisby keeping track of which results are known:
...done = new int[nmax+1];for (i=0; i<=nmax; i++)
done[i] = 0;done[0] = 1;done[1] = 1;...
int fib(int n) {int i, j;if (!done[n]) {
i = fib(n-1); j = fib(n-2);value[n] = i+j; done[n] = 1;
280 Parallel Computing – r428

21.4. Example: Fibonacci computation
}return value[n];
}
The OpenMP parallel solution calls for two different ideas. First of all, we parallelize the recursion by usingtasks (section 22:
int fib(int n) {int i, j;if (n>=2) {
#pragma omp task shared(i) firstprivate(n)i=fib(n-1);
#pragma omp task shared(j) firstprivate(n)j=fib(n-2);
#pragma omp taskwaitvalue[n] = i+j;
}return value[n];
}
This computes the right solution, but, as in the naive single-threaded solution, it recomputes many of theintermediate values.
A naive addition of the done array leads to data races, and probably an incorrect solution:
int fib(int n) {int i, j, result;if (!done[n]) {
#pragma omp task shared(i) firstprivate(n)i=fib(n-1);
#pragma omp task shared(i) firstprivate(n)j=fib(n-2);
#pragma omp taskwaitvalue[n] = i+j;done[n] = 1;
}return value[n];
}
For instance, there is no guarantee that the done array is updated later than the value array, so a threadcan think that done[n-1] is true, but value[n-1] does not have the right value yet.
One solution to this problem is to use a lock, and make sure that, for a given index n, the values done[n]and value[n] are never touched by more than one thread at a time:
int fib(int n)
Victor Eijkhout 281

21. OpenMP topic: Synchronization
{int i, j;omp_set_lock( &(dolock[n]) );if (!done[n]) {
#pragma omp task shared(i) firstprivate(n)i = fib(n-1);
#pragma omp task shared(j) firstprivate(n)j = fib(n-2);
#pragma omp taskwaitvalue[n] = i+j;done[n] = 1;
}omp_unset_lock( &(dolock[n]) );return value[n];
}
This solution is correct, optimally efficient in the sense that it does not recompute anything, and it usestasks to obtain a parallel execution.
However, the efficiency of this solution is only up to a constant. A lock is still being set, even if a valueis already computed and therefore will only be read. This can be solved with a complicated use of criticalsections, but we will forego this.
282 Parallel Computing – r428

Chapter 22
OpenMP topic: Tasks
Tasks are a mechanism that OpenMP uses under the cover: if you specify something as being parallel,OpenMP will create a ‘block of work’: a section of code plus the data environment in which it occurred.This block is set aside for execution at some later point.
Let’s look at a simple example using the task directive.
Code Executionx = f(); the variable x gets a value#pragma omp task
a task is created with the current value of x{ y = g(x); }z = h(); the variable z gets a value
The thread that executes this code segment creates a task, which will later be executed, probably by adifferent thread. The exact timing of the execution of the task is up to a task scheduler , which operatesinvisible to the user.
The task mechanism allows you to do things that are hard or impossible with the loop and section constructs.For instance, a while loop traversing a linked list can be implemented with tasks:
Code Executionp = head_of_list(); one thread traverses the listwhile (!end_of_list(p)) {#pragma omp task a task is created,process( p ); one for each elementp = next_element(p); the generating thread goes on without waiting} the tasks are executed while more are being generated.
The way tasks and threads interact is different from the worksharing constructs you’ve seen so far. Typically,one thread will generate the tasks, adding them to a queue, from which all threads can take and executethem. This leads to the following idiom:
#pragma omp parallel#pragma omp single{
...#pragma omp task
283

22. OpenMP topic: Tasks
{ ... }...
}
1. A parallel region creates a team of threads;2. a single thread then creates the tasks, adding them to a queue that belongs to the team,3. and all the threads in that team (possibly including the one that generated the tasks)
With tasks it becomes possible to parallelize processes that did not fit the earlier OpenMP constructs. Forinstance, if a certain operation needs to be applied to all elements of a linked list, you can have one threadgo down the list, generating a task for each element of the list.
Another concept that was hard to parallelize earlier is the ‘while loop’. This does not fit the requirement forOpenMP parallel loops that the loop bound needs to be known before the loop executes.Exercise 22.1. Use tasks to find the smallest factor of a large number (using 2999 · 3001 as
test case): generate a task for each trial factor. Start with this code:int factor=0;
#pragma omp parallel#pragma omp single
for (int f=2; f<4000; f++) {{ // see if ‘f’ is a factor
if (N%f==0) { // found factor!factor = f;
}}if (factor>0)
break;}if (factor>0)
printf("Found a factor: %d\n",factor);
• Turn the factor finding block into a task.• Run your program a number of times:
for i in ‘seq 1 1000‘ ; do ./taskfactor ; done | grep -v 2999
Does it find the wrong factor? Why? Try to fix this.• Once a factor has been found, you should stop generating tasks. Let tasks that
should not have been generated, meaning that they test a candidate larger thanthe factor found, print out a message.
22.1 Task data
Treatment of data in a task is somewhat subtle. The basic problem is that a task gets created at one time,and executed at another. Thus, if shared data is accessed, does the task see the value at creation time or at
284 Parallel Computing – r428

22.1. Task data
execution time? In fact, both possibilities make sense depending on the application, so we need to discussthe rules when which possibility applies.
The first rule is that shared data is shared in the task, but private data becomes firstprivate. To seethe distinction, consider two code fragments. In the first example:
int count = 100;#pragma omp parallel#pragma omp single{while (count>0) {
#pragma omp task{
int countcopy = count;if (count==50) {
sleep(1);printf("%d,%d\n",count,countcopy);
} // end if} // end taskcount--;
} // end while} // end single
the variable count is declared outside the parallel region and is therefore shared. When the print statementis executed, all tasks will have been generated, and so count will be zero. Thus, the output will likely be0,50.
In the second example:
#pragma omp parallel#pragma omp single{int count = 100;while (count>0) {
#pragma omp task{
int countcopy = count;if (count==50) {
sleep(1);printf("%d,%d\n",count,countcopy);
} // end if} // end taskcount--;
} // end while} // end single
Victor Eijkhout 285

22. OpenMP topic: Tasks
the count variable is private to the thread creating the tasks, and so it will be firstprivate in thetask, preserving the value that was current when the task was created.
22.2 Task synchronization
Even though the above segment looks like a linear set of statements, it is impossible to say when the codeafter the task directive will be executed. This means that the following code is incorrect:
x = f();#pragma omp task
{ y = g(x); }z = h(y);
Explanation: when the statement computing z is executed, the task computing y has only been scheduled;it has not necessarily been executed yet.
In order to have a guarantee that a task is finished, you need the taskwait directive. The following createstwo tasks, which can be executed in parallel, and then waits for the results:
Code Executionx = f(); the variable x gets a value
#pragma omp task
two tasks are created with the current value of x{ y1 = g1(x); }
#pragma omp task{ y2 = g2(x); }
#pragma omp taskwait the thread waits until the tasks are finishedz = h(y1)+h(y2); the variable z is computed using the task results
The task pragma is followed by a structured block. Each time the structured block is encountered, a newtask is generated. On the other hand taskwait is a standalone directive; the code that follows is just code,it is not a structured block belonging to the directive.
Another aspect of the distinction between generating tasks and executing them: usually the tasks are gen-erated by one thread, but executed by many threads. Thus, the typical idiom is:
#pragma omp parallel#pragma omp single{
// code that generates tasks}
This makes it possible to execute loops in parallel that do not have the right kind of iteration structure for aomp parallel for. As an example, you could traverse and process a linked list:
#pragma omp parallel#pragma omp single{
286 Parallel Computing – r428

22.3. Task dependencies
while (!tail(p)) {p = p->next();
#pragma omp taskprocess(p)
}#pragma omp taskwait}
One task traverses the linked list creating an independent task for each element in the list. These tasks arethen executed in parallel; their assignment to threads is done by the task scheduler.
You can indicate task dependencies in several ways:
1. Using the ‘task wait’ directive you can explicitly indicate the join of the forked tasks. The in-struction after the wait directive will therefore be dependent on the spawned tasks.
2. The taskgroup directive, followed by a structured block, ensures completion of all tasks cre-ated in the block, even if recursively created.
3. Each OpenMP task can have a depend clause, indicating what data dependency of the task.By indicating what data is produced or absorbed by the tasks, the scheduler can construct thedependency graph for you.
Another mechanism for dealing with tasks is the taskgroup: a task group is a code block that can containtask directives; all these tasks need to be finished before any statement after the block is executed.
A task group is somewhat similar to having a taskwait directive after the block. The big difference isthat that taskwait directive does not wait for tasks that are recursively generated, while a taskgroupdoes.
22.3 Task dependencies
It is possible to put a partial ordering on tasks through use of the depend clause. For example, in
#pragma omp taskx = f()
#pragma omp tasky = g(x)
it is conceivable that the second task is executed before the first, possibly leading to an incorrect result. Thisis remedied by specifying:
#pragma omp task depend(out:x)x = f()
#pragma omp task depend(in:x)y = g(x)
Exercise 22.2. Consider the following code:
Victor Eijkhout 287

22. OpenMP topic: Tasks
for i in [1:N]:x[0,i] = some_function_of(i)x[i,0] = some_function_of(i)
for i in [1:N]:for j in [1:N]:
x[i,j] = x[i-1,j]+x[i,j-1]
• Observe that the second loop nest is not amenable to OpenMP loop parallelism.• Can you think of a way to realize the computation with OpenMP loop
parallelism? Hint: you need to rewrite the code so that the same operations aredone in a different order.• Use tasks with dependencies to make this code parallel without any rewriting:
the only change is to add OpenMP directives.
Tasks dependencies are used to indicated how two uses of one data item relate to each other. Since eitheruse can be a read or a write, there are four types of dependencies.
RaW (Read after Write) The second task reads an item that the first task writes. The second task has tobe executed after the first:
... omp task depend(OUT:x)foo(x)
... omp task depend( IN:x)foo(x)
WaR (Write after Read) The first task reads and item, and the second task overwrites it. The second taskhas to be executed second to prevent overwriting the initial value:
... omp task depend( IN:x)foo(x)
... omp task depend(OUT:x)foo(x)
WaW (Write after Write) Both tasks set the same variable. Since the variable can be used by an interme-diate task, the two writes have to be executed in this order.
... omp task depend(OUT:x)foo(x)
... omp task depend(OUT:x)foo(x)
RaR (Read after Read) Both tasks read a variable. Since neither tasks has an ‘out’ declaration, they canrun in either order.
... omp task depend(IN:x)foo(x)
... omp task depend(IN:x)foo(x)
288 Parallel Computing – r428

22.4. More
22.4 More
22.4.1 Scheduling points
Normally, a task stays tied to the thread that first executes it. However, at a task scheduling point the threadmay switch to the execution of another task created by the same team.
• There is a scheduling point after explicit task creation. This means that, in the above examples,the thread creating the tasks can also participate in executing them.• There is a scheduling point at taskwait and taskyield.
On the other hand a task created with them untied clause on the task pragma is never tied to one thread.This means that after suspension at a scheduling point any thread can resume execution of the task. If youdo this, beware that the value of a thread-id does not stay fixed. Also locks become a problem.
Example: if a thread is waiting for a lock, with a scheduling point it can suspend the task and work onanother task.
while (!omp_test_lock(lock))#pragma omp taskyield;
22.4.2 Task cancelling
It is possible (in OpenMP version 4 ) to cancel tasks. This is useful when tasks are used to perform a search:the task that finds the result first can cancel any outstanding search tasks.
The directive cancel takes an argument of the surrounding construct (parallel, for, sections,taskgroup) in which the tasks are cancelled.
Exercise 22.3. Modify the prime finding example.
22.5 Examples
22.5.1 Fibonacci
As an example of the use of tasks, consider computing an array of Fibonacci values:
// taskgroup0.cfor (int i=2; i<N; i++){
fibo_values[i] = fibo_values[i-1]+fibo_values[i-2];}
If you simply turn each calculation into a task, results will be unpredictable (confirm this!) since tasks canbe executed in any sequence. To solve this, we put dependencies on the tasks:
Victor Eijkhout 289

22. OpenMP topic: Tasks
// taskgroup2.cfor (int i=2; i<N; i++)#pragma omp task \depend(out:fibo_values[i]) \depend(in:fibo_values[i-1],fibo_values[i-2]){
fibo_values[i] = fibo_values[i-1]+fibo_values[i-2];}
22.5.2 Binomial coefficients
Exercise 22.4. An array of binomial coefficients can be computed as follows:
// binomial1.cfor (int row=1; row<=n; row++)for (int col=1; col<=row; col++)
if (row==1 || col==1 || col==row)array[row][col] = 1;
elsearray[row][col] = array[row-1][col-1] + array[row
-1][col];
Putting a single task group around the double loop, and use depend clauses to makethe execution satisfy the proper dependencies.
22.5.3 Tree traversal
OpenMP tasks are a great way of handling trees.
22.5.3.1 Post-order traversal
In post-order tree traversal you visit the subtrees before visiting the root. This is the traversal that you useto find summary information about a tree, for instance the sum of all nodes, and the sums of nodes of allsubtrees:
for all children c docompute the sum sc
s←∑
c sc
Another example is matrix factorization:
S = A33 −A31A−111 A13 −A32A
−122 A23
where the two inverses A−111 , A−122 can be computed indepedently and recursively.
290 Parallel Computing – r428

22.6. Sources used in this chapter
22.5.3.2 Pre-order traversal
If a property needs to propagate from the root to all subtrees and nodes, you can use pre-order tree traversal :
Update node value s
for all children c doupdate c with the new value s
22.6 Sources used in this chapter
Listing of code XX:
Listing of code XX:
Listing of code XX:
Victor Eijkhout 291

Chapter 23
OpenMP topic: Affinity
23.1 OpenMP thread affinity control
The matter of thread affinity becomes important on multi-socket nodes; see the example in section 23.2.
Thread placement can be controlled with two environment variables:
• the environment variable OMP_PROC_BIND describes how threads are bound to OpenMP places;while• the variable OMP_PLACES describes these places in terms of the available hardware.• When you’re experimenting with these variables it is a good idea to set OMP_DISPLAY_ENV to
true, so that OpenMP will print out at runtime how it has interpreted your specification. Theexamples in the following sections will display this output.
23.1.1 Thread binding
The variable OMP_PLACES defines a series of places to which the threads are assigned.
Example: if you have two sockets and you define
OMP_PLACES=sockets
then
• thread 0 goes to socket 0,• thread 1 goes to socket 1,• thread 2 goes to socket 0 again,• and so on.
On the other hand, if the two sockets have a total of sixteen cores and you define
OMP_PLACES=coresOMP_PROC_BIND=close
then
• thread 0 goes to core 0, which is on socket 0,• thread 1 goes to core 1, which is on socket 0,
292

23.1. OpenMP thread affinity control
• thread 2 goes to core 2, which is on socket 0,• and so on, until thread 7 goes to core 7 on socket 0, and• thread 8 goes to core 8, which is on socket 1,• et cetera.
The value OMP_PROC_BIND=close means that the assignment goes successively through the availableplaces. The variable OMP_PROC_BIND can also be set to spread, which spreads the threads over theplaces. With
OMP_PLACES=coresOMP_PROC_BIND=spread
you find that
• thread 0 goes to core 0, which is on socket 0,• thread 1 goes to core 8, which is on socket 1,• thread 2 goes to core 1, which is on socket 0,• thread 3 goes to core 9, which is on socket 1,• and so on, until thread 14 goes to core 7 on socket 0, and• thread 15 goes to core 15, which is on socket 1.
So you see that OMP_PLACES=cores and OMP_PROC_BIND=spread very similar to OMP_PLACES=sockets.The difference is that the latter choice does not bind a thread to a specific core, so the operating system canmove threads about, and it can put more than one thread on the same core, even if there is another core stillunused.
The value OMP_PROC_BIND=master puts the threads in the same place as the master of the team. Thisis convenient if you create teams recursively. In that case you would use the proc bind clause rather thanthe environment variable, set to spread for the initial team, and to master for the recursively createdteam.
23.1.2 Effects of thread binding
Let’s consider two example program. First we consider the program for computing π, which is purelycompute-bound.
#threads close/cores spread/sockets spread/cores1 0.359 0.354 0.3532 0.177 0.177 0.1774 0.088 0.088 0.0886 0.059 0.059 0.0598 0.044 0.044 0.044
12 0.029 0.045 0.02916 0.022 0.050 0.022
We see pretty much perfect speedup for the OMP_PLACES=cores strategy; with OMP_PLACES=socketswe probably get occasional collisions where two threads wind up on the same core.
Victor Eijkhout 293

23. OpenMP topic: Affinity
Next we take a program for computing the time evolution of the heat equation:
t = 0, 1, 2, . . . : ∀i : x(t+1)i = 2x
(t)i − x
(t)i−1 − x
(t)i+1
This is a bandwidth-bound operation because the amount of computation per data item is low.
#threads close/cores spread/sockets spread/cores1 2.88 2.89 2.882 1.71 1.41 1.424 1.11 0.74 0.746 1.09 0.57 0.578 1.12 0.57 0.53
12 0.72 0.53 0.5216 0.52 0.61 0.53
Again we see that OMP_PLACES=sockets gives worse performance for high core counts, probablybecause of threads winding up on the same core. The thing to observe in this example is that with 6 or 8 coresthe OMP_PROC_BIND=spread strategy gives twice the performance of OMP_PROC_BIND=close.
The reason for this is that a single socket does not have enough bandwidth for all eight cores on the socket.Therefore, dividing the eight threads over two sockets gives each thread a higher available bandwidth thanputting all threads on one socket.
23.1.3 Place definition
There are three predefined values for the OMP_PLACES variable: sockets, cores, threads. Youhave already seen the first two; the threads value becomes relevant on processors that have hardwarethreads. In that case, OMP_PLACES=cores does not tie a thread to a specific hardware thread, leadingagain to possible collisions as in the above example. Setting OMP_PLACES=threads ties each OpenMPthread to a specific hardware thread.
There is also a very general syntax for defining places that uses a
location:number:stride
syntax. Examples:
• OMP_PLACES="{0:8:1},{8:8:1}"
is equivalent to sockets on a two-socket design with eight cores per socket: it defines twoplaces, each having eight consecutive cores. The threads are then places alternating between thetwo places, but not further specified inside the place.• The setting cores is equivalent to
OMP_PLACES="{0},{1},{2},...,{15}"
• On a four-socket design, the specificationOMP_PLACES="{0:4:8}:4:1"
294 Parallel Computing – r428

23.1. OpenMP thread affinity control
states that the place 0,8,16,24 needs to be repeated four times, with a stride of one. In otherwords, thread 0 winds up on core 0 of some socket, the thread 1 winds up on core 1 of somesocket, et cetera.
23.1.4 Binding possibilities
Values for OMP_PROC_BIND are: false, true, master, close, spread.
• false: set no binding• true: lock threads to a core• master: collocate threads with the master thread• close: place threads close to the master in the places list• spread: spread out threads as much as possible
This effect can be made local by giving the proc bind clause in the parallel directive.
A safe default setting is
export OMP_PROC_BIND=true
which prevents the operating system from migrating a thread . This prevents many scaling problems.
Good examples of thread placement on the Intel Knight’s Landing: https://software.intel.com/en-us/articles/process-and-thread-affinity-for-intel-xeon-phi-processors-x200
As an example, consider a code where two threads write to a shared location.
// sharing.c#pragma omp parallel{ // not a parallel for: just a bunch of reps
for (int j = 0; j < reps; j++) {#pragma omp for schedule(static,1)
for (int i = 0; i < N; i++){#pragma omp atomic
a++;}
}}
There is now a big difference in runtime depending on how close the threads are. We test this on a processorwith both cores and hyperthreads. First we bind the OpenMP threads to the cores:
OMP_NUM_THREADS=2 OMP_PLACES=cores OMP_PROC_BIND=close ./sharingrun time = 4752.231836usecsum = 80000000.0
Next we force the OpenMP threads to bind to hyperthreads inside one core:
OMP_PLACES=threads OMP_PROC_BIND=close ./sharingrun time = 941.970110usec
Victor Eijkhout 295

23. OpenMP topic: Affinity
sum = 80000000.0
Of course in this example the inner loop is pretty much meaningless and parallelism does not speed upanything:
OMP_NUM_THREADS=1 OMP_PLACES=cores OMP_PROC_BIND=close ./sharingrun time = 806.669950usecsum = 80000000.0
However, we see that the two-thread result is almost as fast, meaning that there is very little parallelizationoverhead.
23.2 First-touch
The affinity issue shows up in the first-touch phenomemon. Memory allocated with malloc and likeroutines is not actually allocated; that only happens when data is written to it. In light of this, consider thefollowing OpenMP code:
double *x = (double*) malloc(N*sizeof(double));
for (i=0; i<N; i++)x[i] = 0;
#pragma omp parallel forfor (i=0; i<N; i++)
.... something with x[i] ...
Since the initialization loop is not parallel it is executed by the master thread, making all the memoryassociated with the socket of that thread. Subsequent access by the other socket will then access data frommemory not attached to that socket.
Exercise 23.1. Finish the following fragment and run it with first all the cores of one socket,then all cores of both sockets. (If you know how to do explicit placement, you canalso try fewer cores.)
for (int i=0; i<nlocal+2; i++)in[i] = 1.;
for (int i=0; i<nlocal; i++)out[i] = 0.;
for (int step=0; step<nsteps; step++) {#pragma omp parallel for schedule(static)
for (int i=0; i<nlocal; i++) {out[i] = ( in[i]+in[i+1]+in[i+2] )/3.;
}
296 Parallel Computing – r428

23.3. Affinity control outside OpenMP
#pragma omp parallel for schedule(static)for (int i=0; i<nlocal; i++)in[i+1] = out[i];
in[0] = 0; in[nlocal+1] = 1;}
Exercise 23.2. How do the OpenMP dynamic schedules relate to this?
C++ valarray does initialization, so it will allocate memory on thread 0.
You could move pages with move_pages.
By regarding affinity, in effect you are adopting an SPMD style of programming. You could make thisexplicit by having each thread allocate its part of the arrays separately, and storing a private pointer asthreadprivate [12]. However, this makes it impossible for threads to access each other’s parts of thedistributed array, so this is only suitable for total data parallel or embarrassingly parallel applications.
23.3 Affinity control outside OpenMP
There are various utilities to control process and thread placement.
Process placement can be controlled on the Operating system level by numactl (the TACC utility tacc_affinity
is a wrapper around this) on Linux (also taskset); Windows start/affinity.
Corresponding system calls: pbing on Solaris, sched_setaffinity on Linux, SetThreadAffinityMaskon Windows.
Corresponding environment variables: SUNW_MP_PROCBIND on Solaris, KMP_AFFINITY on Intel.
The Intel compiler has an environment variable for affinity control:
export KMP_AFFINITY=verbose,scatter
values: none,scatter,compact
For gcc:
export GOMP_CPU_AFFINITY=0,8,1,9
For the Sun compiler:
SUNW_MP_PROCBIND
23.4 Sources used in this chapter
Listing of code XX:
Victor Eijkhout 297

Chapter 24
OpenMP tocic: Memory model
24.1 Thread synchronization
Let’s do a producer-consumer model1. This can be implemented with sections, where one section, theproducer, sets a flag when data is available, and the other, the consumer, waits until the flag is set.
#pragma omp parallel sections{
// the producer#pragma omp section{... do some producing work ...flag = 1;
}// the consumer#pragma omp section{while (flag==0) { }... do some consuming work ...
}}
One reason this doesn’t work, is that the compiler will see that the flag is never used in the producingsection, and that is never changed in the consuming section, so it may optimize these statements, to thepoint of optimizing them away.
The producer then needs to do:... do some producing work ...#pragma omp flush#pragma atomic write
flag = 1;#pragma omp flush(flag)
1. This example is from Intel’s excellent OMP course by Tim Mattson
298

24.2. Data races
and the consumer does:
#pragma omp flush(flag)while (flag==0) {
#pragma omp flush(flag)}#pragma omp flush
This code strictly speaking has a race condition on the flag variable. It is better to use an atomic pragmahere: the producer has
#pragma atomic writeflag = 1;
and the consumer:
while (1) {#pragma omp flush(flag)#pragma omp atomic read
flag_read = flagif (flag_read==1) break;
}
24.2 Data races
OpenMP, being based on shared memory, has a potential for race conditions. These happen when twothreads access the same data item. The problem with race conditions is that programmer convenience runscounter to efficient execution. For this reason, OpenMP simply does not allow some things that would bedesirable.
The basic rule about multiple-thread access of a single data item is:
Any memory location that is written by one thread, can not be read by another threadin the same parallel region, if no synchronization is done.
To start with that last clause: any workshare construct ends with an implicit barrier , so data written beforethat barrier can safely be read after it.
As an illustration of a possible problem:
c = d = 0;#pragma omp sections{#pragma omp section{ a = 1; c = b; }
Victor Eijkhout 299

24. OpenMP tocic: Memory model
#pragma omp section{ b = 1; d = a; }
}
Under any reasonable interpretation of parallel execution, the possible values for c,d are 1, 1 0, 1 or 1, 0.This is known as sequential consistency: the parallel outcome is consistent with a sequential execution thatinterleaves the parallel computations, respecting their local statement orderings. (See also HPSC-2.6.1.6.)
However, without synchronization, threads are allowed to maintain a value for a variable locally that is notthe same as the stored value. In this example, that means that the thread executing the first section need notwrite its value of a to memory, and likewise b in the second thread, so 0, 0 is in fact a possible outcome.
In order to resolve multiple accesses:
1. Thread one reads the variable.2. Thread one flushes the variable.3. Thread two flushes the variable.4. Thread two reads the variable.
24.3 Relaxed memory model
flush
• There is an implicit flush of all variables at the start and end of a parallel region .• There is a flush at each barrier, whether explicit or implicit, such as at the end of a work sharing .• At entry and exit of a critical section• When a lock is set or unset.
300 Parallel Computing – r428

Chapter 25
OpenMP tocic: SIMD processing
You can declare a loop to be executable with vector instructions with simd
The simd pragma has the following clauses:
• safelen(n): limits the number of iterations in a SIMD chunk. Presumably useful if you com-bine parallel for simd.• linear: lists variables that have a linear relation to the iteration parameter.• aligned: specifies alignment of variables.
If your SIMD loop includes a function call, you can declare that the function can be turned into vectorinstructions with declare simd
If a loop is both multi-threadable and vectorizable, you can combine directives as pragma omp parallelfor simd.
Compilers can be made to report whether a loop was vectorized:
LOOP BEGIN at simdf.c(61,15)remark #15301: OpenMP SIMD LOOP WAS VECTORIZED
LOOP END
with such options as -Qvec-report=3 for the Intel compiler.
Performance improvements of these directives need not be immediately obvious. In cases where the op-eration is bandwidth-limited, using simd parallelism may give the same or worse performance as threadparallelism.
The following function can be vectorized:
// tools.c#pragma omp declare simddouble cs(double x1,double x2,double y1,double y2) {double
inprod = x1*x2+y1*y2,xnorm = sqrt(x1*x1 + x2*x2),ynorm = sqrt(y1*y1 + y2*y2);
return inprod / (xnorm*ynorm);}
301

25. OpenMP tocic: SIMD processing
#pragma omp declare simd uniform(x1,x2,y1,y2) linear(i)double csa(double *x1,double *x2,double *y1,double *y2, int i) {double
inprod = x1[i]*x2[i]+y1[i]*y2[i],xnorm = sqrt(x1[i]*x1[i] + x2[i]*x2[i]),ynorm = sqrt(y1[i]*y1[i] + y2[i]*y2[i]);
return inprod / (xnorm*ynorm);}
Compiling this the regular way
# parameter 1(x1): %xmm0# parameter 2(x2): %xmm1# parameter 3(y1): %xmm2# parameter 4(y2): %xmm3
movaps %xmm0, %xmm5 5 <- x1movaps %xmm2, %xmm4 4 <- y1mulsd %xmm1, %xmm5 5 <- 5 * x2 = x1 * x2mulsd %xmm3, %xmm4 4 <- 4 * y2 = y1 * y2mulsd %xmm0, %xmm0 0 <- 0 * 0 = x1 * x1mulsd %xmm1, %xmm1 1 <- 1 * 1 = x2 * x2addsd %xmm4, %xmm5 5 <- 5 + 4 = x1*x2 + y1*y2mulsd %xmm2, %xmm2 2 <- 2 * 2 = y1 * y1mulsd %xmm3, %xmm3 3 <- 3 * 3 = y2 * y2addsd %xmm1, %xmm0 0 <- 0 + 1 = x1*x1 + x2*x2addsd %xmm3, %xmm2 2 <- 2 + 3 = y1*y1 + y2*y2sqrtsd %xmm0, %xmm0 0 <- sqrt(0) = sqrt( x1*x1 + x2*x2 )sqrtsd %xmm2, %xmm2 2 <- sqrt(2) = sqrt( y1*y1 + y2*y2 )
which uses the scalar instruction mulsd: multiply scalar double precision.
With a declare simd directive:
movaps %xmm0, %xmm7movaps %xmm2, %xmm4mulpd %xmm1, %xmm7mulpd %xmm3, %xmm4
which uses the vector instruction mulpd: multiply packed double precision, operating on 128-bit SSE2registers.
Compiling for the Intel Knight’s Landing gives more complicated code:
# parameter 1(x1): %xmm0# parameter 2(x2): %xmm1# parameter 3(y1): %xmm2# parameter 4(y2): %xmm3
302 Parallel Computing – r428

vmulpd %xmm3, %xmm2, %xmm4 4 <- y1*y2vmulpd %xmm1, %xmm1, %xmm5 5 <- x1*x2vbroadcastsd .L_2il0floatpacket.0(%rip), %zmm21movl $3, %eax set accumulator EAXvbroadcastsd .L_2il0floatpacket.5(%rip), %zmm24kmovw %eax, %k3 set mask k3vmulpd %xmm3, %xmm3, %xmm6 6 <-y1*y1 (stall)vfmadd231pd %xmm0, %xmm1, %xmm4 4 <- 4 + x1*x2 (no reuse!)vfmadd213pd %xmm5, %xmm0, %xmm0 0 <- 0 + 0*5 = x1 + x1*(x1*x2)vmovaps %zmm21, %zmm18 #25.26 c7vmovapd %zmm0, %zmm3{%k3}{z} #25.26 c11vfmadd213pd %xmm6, %xmm2, %xmm2 #24.29 c13vpcmpgtq %zmm0, %zmm21, %k1{%k3} #25.26 c13vscalefpd .L_2il0floatpacket.1(%rip){1to8}, %zmm0, %zmm3{%k1} #25.26 c15vmovaps %zmm4, %zmm26 #25.26 c15vmovapd %zmm2, %zmm7{%k3}{z} #25.26 c17vpcmpgtq %zmm2, %zmm21, %k2{%k3} #25.26 c17vscalefpd .L_2il0floatpacket.1(%rip){1to8}, %zmm2, %zmm7{%k2} #25.26 c19vrsqrt28pd %zmm3, %zmm16{%k3}{z} #25.26 c19vpxorq %zmm4, %zmm4, %zmm26{%k3} #25.26 c19vrsqrt28pd %zmm7, %zmm20{%k3}{z} #25.26 c21vmulpd {rn-sae}, %zmm3, %zmm16, %zmm19{%k3}{z} #25.26 c27 stall 2vscalefpd .L_2il0floatpacket.2(%rip){1to8}, %zmm16, %zmm17{%k3}{z} #25.26 c27vmulpd {rn-sae}, %zmm7, %zmm20, %zmm23{%k3}{z} #25.26 c29vscalefpd .L_2il0floatpacket.2(%rip){1to8}, %zmm20, %zmm22{%k3}{z} #25.26 c29vfnmadd231pd {rn-sae}, %zmm17, %zmm19, %zmm18{%k3} #25.26 c33 stall 1vfnmadd231pd {rn-sae}, %zmm22, %zmm23, %zmm21{%k3} #25.26 c35vfmadd231pd {rn-sae}, %zmm19, %zmm18, %zmm19{%k3} #25.26 c39 stall 1vfmadd231pd {rn-sae}, %zmm23, %zmm21, %zmm23{%k3} #25.26 c41vfmadd213pd {rn-sae}, %zmm17, %zmm17, %zmm18{%k3} #25.26 c45 stall 1vfnmadd231pd {rn-sae}, %zmm19, %zmm19, %zmm3{%k3} #25.26 c47vfmadd213pd {rn-sae}, %zmm22, %zmm22, %zmm21{%k3} #25.26 c51 stall 1vfnmadd231pd {rn-sae}, %zmm23, %zmm23, %zmm7{%k3} #25.26 c53vfmadd213pd %zmm19, %zmm18, %zmm3{%k3} #25.26 c57 stall 1vfmadd213pd %zmm23, %zmm21, %zmm7{%k3} #25.26 c59vscalefpd .L_2il0floatpacket.3(%rip){1to8}, %zmm3, %zmm3{%k1} #25.26 c63 stall 1vscalefpd .L_2il0floatpacket.3(%rip){1to8}, %zmm7, %zmm7{%k2} #25.26 c65vfixupimmpd $112, .L_2il0floatpacket.4(%rip){1to8}, %zmm0, %zmm3{%k3} #25.26 c65vfixupimmpd $112, .L_2il0floatpacket.4(%rip){1to8}, %zmm2, %zmm7{%k3} #25.26 c67vmulpd %xmm7, %xmm3, %xmm0 #25.26 c71vmovaps %zmm0, %zmm27 #25.26 c79vmovaps %zmm0, %zmm25 #25.26 c79
Victor Eijkhout 303

25. OpenMP tocic: SIMD processing
vrcp28pd {sae}, %zmm0, %zmm27{%k3} #25.26 c81vfnmadd213pd {rn-sae}, %zmm24, %zmm27, %zmm25{%k3} #25.26 c89 stall 3vfmadd213pd {rn-sae}, %zmm27, %zmm25, %zmm27{%k3} #25.26 c95 stall 2vcmppd $8, %zmm26, %zmm27, %k1{%k3} #25.26 c101 stall 2vmulpd %zmm27, %zmm4, %zmm1{%k3}{z} #25.26 c101kortestw %k1, %k1 #25.26 c103je ..B1.3 # Prob 25% #25.26 c105vdivpd %zmm0, %zmm4, %zmm1{%k1} #25.26 c3 stall 1vmovaps %xmm1, %xmm0 #25.26 c77ret #25.26 c79
#pragma omp declare simd uniform(op1) linear(k) notinbranchdouble SqrtMul(double *op1, double op2, int k) {return (sqrt(op1[k]) * sqrt(op2));
}
25.1 Sources used in this chapter
Listing of code XX:
304 Parallel Computing – r428

Chapter 26
OpenMP remaining topics
26.1 Runtime functions and internal control variables
OpenMP has a number of settings that can be set through environment variables, and both queried and setthrough library routines. These settings are called Internal Control Variables (ICVs): an OpenMP imple-mentation behaves as if there is an internal variable storing this setting.
The runtime functions are:
• omp_set_num_threads
• omp_get_num_threads
• omp_get_max_threads
• omp_get_thread_num
• omp_get_num_procs
• omp_in_parallel
• omp_set_dynamic
• omp_get_dynamic
• omp_set_nested
• omp_get_nested
• omp_get_wtime
• omp_get_wtick
• omp_set_schedule
• omp_get_schedule
• omp_set_max_active_levels
• omp_get_max_active_levels
• omp_get_thread_limit
• omp_get_level
• omp_get_active_level
• omp_get_ancestor_thread_num
• omp_get_team_size
Here are the OpenMP environment variables:
• OMP_CANCELLATION Set whether cancellation is activated• OMP_DISPLAY_ENV Show OpenMP version and environment variables
305

26. OpenMP remaining topics
• OMP_DEFAULT_DEVICE Set the device used in target regions• OMP_DYNAMIC Dynamic adjustment of threads• OMP_MAX_ACTIVE_LEVELS Set the maximum number of nested parallel regions• OMP_MAX_TASK_PRIORITY Set the maximum task priority value• OMP_NESTED Nested parallel regions• OMP_NUM_THREADS Specifies the number of threads to use• OMP_PROC_BIND Whether theads may be moved between CPUs• OMP_PLACES Specifies on which CPUs the theads should be placed• OMP_STACKSIZE Set default thread stack size• OMP_SCHEDULE How threads are scheduled• OMP_THREAD_LIMIT Set the maximum number of threads• OMP_WAIT_POLICY How waiting threads are handled
There are 4 ICVs that behave as if each thread has its own copy of them. The default is implementation-defined unless otherwise noted.
• It may be possible to adjust dynamically the number of threads for a parallel region. Variable:OMP_DYNAMIC; routines: omp_set_dynamic, omp_get_dynamic.• If a code contains nested parallel regions , the inner regions may create new teams, or they
may be executed by the single thread that encounters them. Variable: OMP_NESTED; routinesomp_set_nested, omp_get_nested. Allowed values are TRUE and FALSE; the defaultis false.• The number of threads used for an encountered parallel region can be controlled. Variable:OMP_NUM_THREADS; routines omp_set_num_threads, omp_get_max_threads.• The schedule for a parallel loop can be set. Variable: OMP_SCHEDULE; routines omp_set_schedule,omp_get_schedule.
Non-obvious syntax:
export OMP_SCHEDULE="static,100"
Other settings:
• omp_get_num_threads: query the number of threads active at the current place in the code;this can be lower than what was set with omp_set_num_threads. For a meaningful answer,this should be done in a parallel region.• omp_get_thread_num• omp_in_parallel: test if you are in a parallel region (see for instance section 16).• omp_get_num_procs: query the physical number of cores available.
Other environment variables:
• OMP_STACKSIZE controls the amount of space that is allocated as per-thread stack ; the spacefor private variables.• OMP_WAIT_POLICY determines the behaviour of threads that wait, for instance for critical
section:– ACTIVE puts the thread in a spin-lock , where it actively checks whether it can continue;– PASSIVE puts the thread to sleep until the Operating System (OS) wakes it up.
306 Parallel Computing – r428

26.2. Timing
The ‘active’ strategy uses CPU while the thread is waiting; on the other hand, activating it afterthe wait is instantaneous. With the ‘passive’ strategy, the thread does not use any CPU while wait-ing, but activating it again is expensive. Thus, the passive strategy only makes sense if threadswill be waiting for a (relatively) long time.• OMP_PROC_BIND with values TRUE and FALSE can bind threads to a processor. On the one
hand, doing so can minimize data movement; on the other hand, it may increase load imbalance.
26.2 Timing
OpenMP has a wall clock timer routine omp_get_wtime
double omp_get_wtime(void);
The starting point is arbitrary and is different for each program run; however, in one run it is identical forall threads. This timer has a resolution given by omp_get_wtick.
Exercise 26.1. Use the timing routines to demonstrate speedup from using multiple threads.• Write a code segment that takes a measurable amount of time, that is, it should
take a multiple of the tick time.• Write a parallel loop and measure the speedup. You can for instance do this
for (int use_threads=1; use_threads<=nthreads; use_threads++) {#pragma omp parallel for num_threads(use_threads)
for (int i=0; i<nthreads; i++) {.....
}if (use_threads==1)
time1 = tend-tstart;else // compute speedup
• In order to prevent the compiler from optimizing your loop away, let the bodycompute a result and use a reduction to preserve these results.
26.3 Thread safety
With OpenMP it is relatively easy to take existing code and make it parallel by introducing parallel sections.If you’re careful to declare the appropriate variables shared and private, this may work fine. However, yourcode may include calls to library routines that include a race condition; such code is said not to be thread-safe.
For example a routine
static int isave;int next_one() {int i = isave;
Victor Eijkhout 307

26. OpenMP remaining topics
isave += 1;return i;}
...for ( .... ) {int ivalue = next_one();
}
has a clear race condition, as the iterations of the loop may get different next_one values, as they aresupposed to, or not. This can be solved by using an critical pragma for the next_one call; anothersolution is to use an threadprivate declaration for isave. This is for instance the right solution if thenext_one routine implements a random number generator .
26.4 Performance and tuningThe performance of an OpenMP code can be influenced by the following.Amdahl effects Your code needs to have enough parts that are parallel (see HPSC-2.2.3). Sequential parts
may be sped up by having them executed redundantly on each thread, since that keeps datalocally.
Dynamism Creating a thread team takes time. In practice, a team is not created and deleted for eachparallel region, but creating teams of different sizes, or recursize thread creation, may introduceoverhead.
Load imbalance Even if your program is parallel, you need to worry about load balance. In the case ofa parallel loop you can set the schedule clause to dynamic, which evens out the work, butmay cause increased communication.
Communication Cache coherence causes communication. Threads should, as much as possible, refer totheir own data.• Threads are likely to read from each other’s data. That is largely unavoidable.• Threads writing to each other’s data should be avoided: it may require synchronization, and
it causes coherence traffic.• If threads can migrate, data that was local at one time is no longer local after migration.• Reading data from one socket that was allocated on another socket is inefficient; see sec-
tion 23.2.Affinity Both data and execution threads can be bound to a specific locale to some extent. Using local
data is more efficient than remote data, so you want to use local data, and minimize the extent towhich data or execution can move.• See the above points about phenomena that cause communication.• Section 23.1.1 describes how you can specify the binding of threads to places. There can,
but does not need, to be an effect on affinity. For instance, if an OpenMP thread can mi-grate between hardware threads, cached data will stay local. Leaving an OpenMP threadcompletely free to migrate can be advantageous for load balancing, but you should only dothat if data affinity is of lesser importance.
308 Parallel Computing – r428

26.5. Accelerators
• Static loop schedules have a higher chance of using data that has affinity with the place ofexecution, but they are worse for load balancing. On the other hand, the nowait clausecan aleviate some of the problems with static loop schedules.
Binding You can choose to put OpenMP threads close together or to spread them apart. Having themclose together makes sense if they use lots of shared data. Spreading them apart may increasebandwidth. (See the examples in section 23.1.2.)
Synchronization Barriers are a form of synchronization. They are expensive by themselves, and theyexpose load imbalance. Implicit barriers happen at the end of worksharing constructs; they canbe removed with nowait.Critical sections imply a loss of parallelism, but they are also slow as they are realized throughoperating system functions. These are often quite costly, taking many thousands of cycles. Crit-ical sections should be used only if the parallel work far outweighs it.
26.5 Accelerators
In OpenMP 4.0 there is support for offloading work to an accelerator or co-processor:
#pragma omp target [clauses]
with clauses such as
• data: place data• update: make data consistent between host and device
Victor Eijkhout 309

Chapter 27
OpenMP Review
27.1 Concepts review
27.1.1 Basic concepts
• process / thread / thread team• threads / cores / tasks• directives / library functions / environ-
ment variables
27.1.2 Parallel regions
execution by a team
27.1.3 Work sharing
• loop / sections / single / workshare• implied barrier• loop scheduling, reduction• sections• single vs master• (F) workshare
27.1.4 Data scope
• shared vs private, C vs F• loop variables and reduction variables• default declaration• firstprivate, lastprivate
27.1.5 Synchronization
• barriers, implied and explicit• nowait• critical sections• locks, difference with critical
27.1.6 Tasks
• generation vs execution• dependencies
310

27.2. Review questions
27.2 Review questions
27.2.1 Directives
What do the following program output?
int main() {printf("procs %d\n",
omp_get_num_procs());printf("threads %d\n",
omp_get_num_threads());printf("num %d\n",
omp_get_thread_num());return 0;
}
int main() {#pragma omp parallel{printf("procs %d\n",
omp_get_num_procs());printf("threads %d\n",
omp_get_num_threads());printf("num %d\n",
omp_get_thread_num());}return 0;
}
Program mainuse omp_libprint *,"Procs:",&
omp_get_num_procs()print *,"Threads:",&
omp_get_num_threads()print *,"Num:",&
omp_get_thread_num()End Program
Program mainuse omp_lib
!$OMP parallelprint *,"Procs:",&
omp_get_num_procs()print *,"Threads:",&
omp_get_num_threads()print *,"Num:",&
omp_get_thread_num()!$OMP end parallelEnd Program
Victor Eijkhout 311

27. OpenMP Review
27.2.2 Parallelism
Can the following loops be parallelized? If so, how? (Assume that all arrays are already filled in, and thatthere are no out-of-bounds errors.)
// variant #1for (i=0; i<N; i++) {x[i] = a[i]+b[i+1];a[i] = 2*x[i] + c[i+1];
}
// variant #2for (i=0; i<N; i++) {x[i] = a[i]+b[i+1];a[i] = 2*x[i+1] + c[i+1];
}
// variant #3for (i=1; i<N; i++) {
x[i] = a[i]+b[i+1];a[i] = 2*x[i-1] + c[i+1];
}
// variant #4for (i=1; i<N; i++) {
x[i] = a[i]+b[i+1];a[i+1] = 2*x[i-1] + c[i+1];
}
! variant #1do i=1,Nx(i) = a(i)+b(i+1)a(i) = 2*x(i) + c(i+1)
end do
! variant #2do i=1,Nx(i) = a(i)+b(i+1)a(i) = 2*x(i+1) + c(i+1)
end do
! variant #3do i=2,N
x(i) = a(i)+b(i+1)a(i) = 2*x(i-1) + c(i+1)
end do
! variant #3do i=2,N
x(i) = a(i)+b(i+1)a(i+1) = 2*x(i-1) + c(i+1)
end do
312 Parallel Computing – r428

27.2. Review questions
27.2.3 Data and synchronization
27.2.3.1
What is the output of the following fragments? Assume that there are four threads.
// variant #1int nt;#pragma omp parallel{nt = omp_get_thread_num();printf("thread number: %d\n",nt);
}
// variant #2int nt;#pragma omp parallel private(nt){nt = omp_get_thread_num();printf("thread number: %d\n",nt);
}
// variant #3int nt;#pragma omp parallel{
#pragma omp single{nt = omp_get_thread_num();printf("thread number: %d\n",nt);}
}
// variant #4int nt;#pragma omp parallel{
#pragma omp master{nt = omp_get_thread_num();printf("thread number: %d\n",nt);}
}
// variant #5int nt;#pragma omp parallel{
#pragma omp critical{nt = omp_get_thread_num();printf("thread number: %d\n",nt);}
}
! variant #1integer nt
!$OMP parallelnt = omp_get_thread_num()print *,"thread number:",nt
!$OMP end parallel
! variant #2integer nt
!$OMP parallel private(nt)nt = omp_get_thread_num()print *,"thread number:",nt
!$OMP end parallel
! variant #3integer nt
!$OMP parallel!$OMP single
nt = omp_get_thread_num()print *,"thread number:",nt
!$OMP end single!$OMP end parallel
Victor Eijkhout 313

27. OpenMP Review
! variant #4integer nt
!$OMP parallel!$OMP master
nt = omp_get_thread_num()print *,"thread number:",nt
!$OMP end master!$OMP end parallel
! variant #5integer nt
!$OMP parallel!$OMP critical
nt = omp_get_thread_num()print *,"thread number:",nt
!$OMP end critical!$OMP end parallel
27.2.3.2
The following is an attempt to parallelize a serial code. Assume that all variables and arrays are defined.What errors and potential problems do you see in this code? How would you fix them?
#pragma omp parallel{x = f();#pragma omp forfor (i=0; i<N; i++)
y[i] = g(x,i);z = h(y);
}
!$OMP parallelx = f()
!$OMP dodo i=1,Ny(i) = g(x,i)
end do!$OMP end do
z = h(y)!$OMP end parallel
314 Parallel Computing – r428

27.2. Review questions
27.2.3.3
Assume two threads. What does the following program output?
int a;#pragma omp parallel private(a) {...a = 0;#pragma omp forfor (int i = 0; i < 10; i++){
#pragma omp atomica++; }
#pragma omp singleprintf("a=%e\n",a);
}
27.2.4 Reductions
27.2.4.1
Is the following code correct? Is it efficient? If not, can you improve it?
#pragma omp parallel shared(r){
int x;x = f(omp_get_thread_num());
#pragma omp criticalr += f(x);
}
27.2.4.2
Compare two fragments:
// variant 1#pragma omp parallel reduction(+:
s)#pragma omp forfor (i=0; i<N; i++)
s += f(i);
// variant 2#pragma omp parallel#pragma omp for reduction(+:s)for (i=0; i<N; i++)
s += f(i);
! variant 1!$OMP parallel reduction(+:s)!$OMP dodo i=1,N
s += f(i);
end do!$OMP end do!$OMP end parallel
Victor Eijkhout 315

27. OpenMP Review
! variant 2!$OMP parallel!$OMP do reduction(+:s)do i=1,N
s += f(i);end do
!$OMP end do!$OMP end parallel
Do they compute the same thing?
316 Parallel Computing – r428

27.2. Review questions
27.2.5 Barriers
Are the following two code fragments well defined?
#pragma omp parallel{#pragma omp forfor (mytid=0; mytid<nthreads;
mytid++)x[mytid] = some_calculation();
#pragma omp forfor (mytid=0; mytid<nthreads-1;
mytid++)y[mytid] = x[mytid]+x[mytid+1];
}
#pragma omp parallel{#pragma omp forfor (mytid=0; mytid<nthreads;
mytid++)x[mytid] = some_calculation();
#pragma omp for nowaitfor (mytid=0; mytid<nthreads-1;
mytid++)y[mytid] = x[mytid]+x[mytid+1];
}
27.2.6 Data scope
The following program is supposed to initialize as many rows of the array as there are threads.
int main() {int i,icount,iarray[100][100];icount = -1;
#pragma omp parallel private(i){
#pragma omp critical{ icount++; }for (i=0; i<100; i++)iarray[icount][i] = 1;
}return 0;
}
Program maininteger :: i,icount,iarray(100,100)
icount = 0!$OMP parallel private(i)!$OMP critical
icount = icount + 1!$OMP end critical
do i=1,100iarray(icount,i) = 1
end do!$OMP end parallelEnd program
Describe the behaviour of the program, with argumentation,
• as given;• if you add a clause private(icount) to the parallel directive;• if you add a clause firstprivate(icount).
What do you think of this solution:
#pragma omp parallel private(i)shared(icount)
{#pragma omp critical
{ icount++;
for (i=0; i<100; i++)iarray[icount][i] = 1;
}}return 0;
Victor Eijkhout 317

27. OpenMP Review
}!$OMP parallel private(i) shared(
icount)!$OMP critical
icount = icount+1do i=1,100
iarray(icount,i) = 1end do
!$OMP critical!$OMP end parallel
27.2.7 Tasks
Fix two things in the following example:
#pragma omp parallel#pragma omp single{int x,y,z;
#pragma omp taskx = f();
#pragma omp tasky = g();
#pragma omp taskz = h();printf("sum=%d\n",x+y+z);
}
integer :: x,y,z!$OMP parallel!$OMP single
!$OMP taskx = f()
!$OMP end task
!$OMP tasky = g()
!$OMP end task
!$OMP taskz = h()
!$OMP end task
print *,"sum=",x+y+z!$OMP end single!$OMP end parallel
27.2.8 Scheduling
Compare these two fragments. Do they compute the same result? What can you say about their efficiency?
#pragma omp parallel#pragma omp single{
for (i=0; i<N; i++) {#pragma omp taskx[i] = f(i)
}#pragma omp taskwait
}
#pragma omp parallel#pragma omp for schedule(dynamic)
{for (i=0; i<N; i++) {
x[i] = f(i)}
}
318 Parallel Computing – r428

27.2. Review questions
How would you make the second loop more efficient? Can you do something similar for the first loop?
Victor Eijkhout 319

27. OpenMP Review
320 Parallel Computing – r428

PART III
PETSC

Chapter 28
PETSc basics
28.1 Language support
PETSc is implemented in C, so there is a natural interface to C. A Fortran90 interface exists. The Fortran77interface is only of interest for historical reasons.
A python interface was written by Lisandro Dalcin, and requires separate installation, based on alreadydefined PETSC_DIR and PETSC_ARCH variables. This can be downloaded at https://bitbucket.org/petsc/petsc4py/src/master/, with documentation at https://www.mcs.anl.gov/petsc/petsc4py-current/docs/.
28.2 Startup
ierr = PetscInitialize(&Argc,&Args,PETSC_NULL,PETSC_NULL);MPI_Comm comm = PETSC_COMM_WORLD;
MPI_Comm_rank(comm,&mytid);MPI_Comm_size(comm,&ntids);
Python note. The following works if you don’t need commandline options.from petsc4py import PETSc
To pass commandline arguments to PETSc, do:import sysfrom petsc4py import initinit(sys.argv)from petsc4py import PETSc
comm = PETSc.COMM_WORLDnprocs = comm.getSize(self)procno = comm.getRank(self)
322

28.3. Commandline options
28.3 Commandline options
See section 28.2 about passing the commandline options.
Python note. In Python, do not specify the initial hyphen of an option name.hasn = PETSc.Options().hasName("n")
28.4 Printing
Printing screen output in parallel is tricky. If two processes execute a print statement at more or less thesame time there is no guarantee as to in what order they may appear on screen. (Even attempts to havethem print one after the other may not result in the right ordering.) Furthermore, lines from multi-line printactions on two processes may wind up on the screen interleaved.
PETSc has two routines that fix this problem. First of all, often the information printed is the same on allprocesses, so it is enough if only one process, for instance process 0, prints it.
C:PetscErrorCode PetscPrintf(MPI_Comm comm,const char format[],...)
Fortran:PetscPrintf(MPI_Comm, character(*), PetscErrorCode ierr)
Python:PETSc.Sys.Print(type cls, *args, **kwargs)kwargs:comm : communicator object
How to read routine prototypes: 1.5.4.
If all processes need to print, there is a routine that forces the output to appear in process order.C:PetscErrorCode PetscSynchronizedPrintf(
MPI_Comm comm,const char format[],...)
Fortran:PetscSynchronizedPrintf(MPI_Comm, character(*), PetscErrorCode ierr)
python:PETSc.Sys.syncPrint(type cls, *args, **kargs)kwargs:comm : communicator objectflush : if True, do synchronizedFlushother keyword args as for python3 print function
How to read routine prototypes: 1.5.4.
To make sure that output is properly flushed from all system buffers use a flush routine:
Victor Eijkhout 323

28. PETSc basics
C:PetscErrorCode PetscSynchronizedFlush(MPI_Comm comm,FILE *fd)fd : output file pointer, needs to be valid on process zero
python:PETSc.Sys.syncFlush(type cls, comm=None)
How to read routine prototypes: 1.5.4.
where for ordinary screen output you would use stdout for the file.
Python note. Since the print routines use the python print call, they automaticallyinclude the trailing newline. You don’t have to specify it as in the C calls.
324 Parallel Computing – r428

Chapter 29
PETSc objects
29.1 Vectors
Create a vector:
C:PetscErrorCode VecCreate(MPI_Comm comm,Vec *v);
Python:vec = PETSc.Vec()vec.create()# or:vec = PETSc.Vec().create()
How to read routine prototypes: 1.5.4.
Python note. In python, PETSc.Vec() creates an object with null handle, so asubsequent create() call is needed.
In C and Fortran, the vector type is a keyword; in Python it is a member of PETSc.Vec.Type.
You can set both local and global size, or set one and let the other be derived:
C:#include "petscvec.h"PetscErrorCode VecSetSizes(Vec v, PetscInt n, PetscInt N)Collective on Vec
Input Parametersv :the vectorn : the local size (or PETSC_DECIDE to have it set)N : the global size (or PETSC_DECIDE)
Python:PETSc.Vec.setSizes(self, size, bsize=None)size is a tuple of local/global
325

29. PETSc objects
How to read routine prototypes: 1.5.4.
To query the sizes:C:#include "petscvec.h"PetscErrorCode VecGetSize(Vec x,PetscInt *size)
Input Parameterx -the vector
Output Parameterssize -the global length of the vector
PetscErrorCode VecGetLocalSize(Vec x,PetscInt *size)
Input Parameterx -the vector
Output Parametersize -the length of the local piece of the vector
Python:PETSc.Vec.getLocalSize(self)PETSc.Vec.getSize(self)PETSc.Vec.getSizes(self)
How to read routine prototypes: 1.5.4.
There are many routines operating on vectors.C:#include "petscvec.h"PetscErrorCode VecNorm(Vec x,NormType type,PetscReal *val)where type is
NORM_1, NORM_2, NORM_FROBENIUS, NORM_INFINITY
Python:PETSc.Vec.norm(self, norm_type=None)
where norm is variable in PETSc.NormType:NORM_1, NORM_2, NORM_FROBENIUS, NORM_INFINITY orN1, N2, FRB, INF
How to read routine prototypes: 1.5.4.
The VecView routine can be used to display vectors on screen as ascii outputC:#include "petscvec.h"PetscErrorCode VecView(Vec vec,PetscViewer viewer)
326 Parallel Computing – r428

29.1. Vectors
for ascii output use:PETSC_VIEWER_STDOUT_WORLD
Python:PETSc.Vec.view(self, Viewer viewer=None)
ascii output is default or use:PETSc.Viewer.STDOUT(type cls, comm=None)
How to read routine prototypes: 1.5.4.
but the routine call also use more general Viewer objects.
For most operations on vectors you don’t need the actual data. But should you need it, here are the routines:C:#include "petscvec.h"PetscErrorCode VecGetArray(Vec x,PetscScalar **a)
Input Parameterx : the vector
Output Parametera : location to put pointer to the array
PetscErrorCode VecRestoreArray(Vec x,PetscScalar **a)
Input Parametersx : the vectora : location of pointer to array obtained from VecGetArray()
Fortran:VecGetArrayF90(Vec x,{Scalar, pointer :: xx_v(:)},integer ierr)(there is a Fortran77 version)
Input Parameterx : vector
Output Parametersxx_v- the Fortran90 pointer to the arrayierr- error code
VecRestoreArrayF90(Vec x,{Scalar, pointer :: xx_v(:)},integer ierr)
Input Parametersx : vectorxx_v : the Fortran90 pointer to the array
Output Parameterierr : error code
Victor Eijkhout 327

29. PETSc objects
Python:PETSc.Vec.getArray(self, readonly=False)?? PETSc.Vec.resetArray(self, force=False)
How to read routine prototypes: 1.5.4.
29.2 MatricesCreate a matrix:
C:PetscErrorCode MatCreate(MPI_Comm comm,Mat *v);
Python:mat = PETSc.Mat()mat.create()# or:mat = PETSc.Mat().create()
How to read routine prototypes: 1.5.4.
Just as with vectors, there is a local and global size; except that that now applies to rows and columns.C:#include "petscmat.h"PetscErrorCode MatSetSizes(Mat A,
PetscInt m, PetscInt n, PetscInt M, PetscInt N)
Input ParametersA : the matrixm : number of local rows (or PETSC_DECIDE)n : number of local columns (or PETSC_DECIDE)M : number of global rows (or PETSC_DETERMINE)N : number of global columns (or PETSC_DETERMINE)
Python:PETSc.Mat.setSizes(self, size, bsize=None)where ’size’ is a tuple of 2 global sizesor a tuple of 2 local/global pairs
How to read routine prototypes: 1.5.4.
C:#include "petscmat.h"PetscErrorCode MatGetSize(Mat mat,PetscInt *m,PetscInt *n)PetscErrorCode MatGetLocalSize(Mat mat,PetscInt *m,PetscInt *n)
Python:PETSc.Mat.getSize(self) # tuple of global sizes
328 Parallel Computing – r428

29.2. Matrices
PETSc.Mat.getLocalSize(self) # tuple of local sizesPETSc.Mat.getSizes(self) # tuple of local/global size tuples
How to read routine prototypes: 1.5.4.
You can set a single matrix element, or a block of them, where you supply a set of i and j indices:C:#include <petscmat.h>PetscErrorCode MatSetValue(
Mat m,PetscInt row,PetscInt col,PetscScalar value,InsertMode mode)
Input Parametersm : the matrixrow : the row location of the entrycol : the column location of the entryvalue : the value to insertmode : either INSERT_VALUES or ADD_VALUES
Python:PETSc.Mat.setValue(self, row, col, value, addv=None)also supported:A[row,col] = value
How to read routine prototypes: 1.5.4.
After setting matrix elements, the matrix needs to be assembled. This is where PETSc moves matrix ele-ments to the right processor, if they were specified elsewhere.
C:#include "petscmat.h"PetscErrorCode MatAssemblyBegin(Mat mat,MatAssemblyType type)PetscErrorCode MatAssemblyEnd(Mat mat,MatAssemblyType type)
Input Parametersmat- the matrixtype- type of assembly, either MAT_FLUSH_ASSEMBLY
or MAT_FINAL_ASSEMBLY
Python:assemble(self, assembly=None)assemblyBegin(self, assembly=None)assemblyEnd(self, assembly=None)
there is a class PETSc.Mat.AssemblyType:FINAL = FINAL_ASSEMBLY = 0FLUSH = FLUSH_ASSEMBLY = 1
How to read routine prototypes: 1.5.4.
PETSc sparse matrices are very flexible: you can create them empty and then start adding elements. How-ever, this is very inefficient in execution since the OS needs to reallocate the matrix every time it grows
Victor Eijkhout 329

29. PETSc objects
a little. Therefore, PETSc has calls for the user to indicate how many elements the matrix will ultimatelycontain.
#include "petscmat.h"PetscErrorCode MatSeqAIJSetPreallocation(Mat B,PetscInt nz,const PetscInt nnz[])
PetscErrorCode MatMPIAIJSetPreallocation(Mat B,PetscInt d_nz,const PetscInt d_nnz[],PetscInt o_nz,const PetscInt o_nnz[])
Input Parameters
B - the matrixnz/d_nz/o_nz - number of nonzeros per row in matrix or
diagonal/off-diagonal portion of local submatrixnnz/d_nnz/o_nnz - array containing the number of nonzeros in the various rows of
the sequential matrix / diagonal / offdiagonal part of the local submatrixor NULL (PETSC_NULL_INTEGER in Fortran) if nz/d_nz/o_nz is used.
Python:PETSc.Mat.setPreallocationNNZ(self, [nnz_d,nnz_o] )PETSc.Mat.setPreallocationCSR(self, csr)PETSc.Mat.setPreallocationDense(self, array)
How to read routine prototypes: 1.5.4.
MatSetOption(A, MAT_NEW_NONZERO_ALLOCATION_ERR, PETSC_FALSE)
29.3 KSP: iterative solversCreate a KSP object:
C:PetscErrorCode KSPCreate(MPI_Comm comm,KSP *v);
Python:ksp = PETSc.KSP()ksp.create()# or:ksp = PETSc.KSP().create()
How to read routine prototypes: 1.5.4.
Get the reason KSPSolve stopped:C:PetscErrorCode KSPGetConvergedReason
(KSP ksp,KSPConvergedReason *reason)
330 Parallel Computing – r428

29.4. DMDA: distributed arrays
Not Collective
Input Parameterksp -the KSP context
Output Parameterreason -negative value indicates diverged, positive value converged,see KSPConvergedReason
Python:r = KSP.getConvergedReason(self)where r in PETSc.KSP.ConvergedReason
How to read routine prototypes: 1.5.4.
29.4 DMDA: distributed arrays#include "petscdmda.h"PetscErrorCode DMDACreate2d(MPI_Comm comm,
DMBoundaryType bx,DMBoundaryType by,DMDAStencilType stencil_type,PetscInt M,PetscInt N,PetscInt m,PetscInt n,PetscInt dof,PetscInt s,const PetscInt lx[],const PetscInt ly[],DM *da)
Input Parameters
comm - MPI communicatorbx,by - type of ghost nodes: DM_BOUNDARY_NONE, DM_BOUNDARY_GHOSTED, DM_BOUNDARY_PERIODIC.stencil_type - stencil type: DMDA_STENCIL_BOX or DMDA_STENCIL_STAR.M,N - global dimension in each direction ofm,n - corresponding number of processors in each dimension (or PETSC_DECIDE)dof - number of degrees of freedom per nodes - stencil widthlx, ly - arrays containing the number of
nodes in each cell along the x and y coordinates, or NULL.
Output Parameter
da -the resulting distributed array object
How to read routine prototypes: 1.5.4.
Victor Eijkhout 331

Chapter 30
PETSc topics
30.1 CommunicatorsPETSc has a ‘world’ communicator, which by default equals MPI_COMM_WORLD. If you want to runPETSc on a subset of processes, you can assign a subcommunicator to the variable PETSC_COMM_WORLDin between the calls to MPI_Init and PetscInitialize.
C:#include <petscsys.h>F:#include "petsc/finclude.petscsys.h"
PETSC_COMM_WORLDPETSC_COMM_SELFvariables of type MPI_Comm
Python:PETSc.COMM_WORLDPETSc.COMM_SELFPETSc.COMM_NULL
How to read routine prototypes: 1.5.4.
332

PART IV
THE REST

Chapter 31
Exploring computer architecture
There is much that can be said about computer architecture. However, in the context of parallel program-ming we are mostly concerned with the following:
• How many networked nodes are there, and does the network have a structure that we need to payattention to?• On a compute node, how many sockets (or other Non-Uniform Memory Access (NUMA) do-
mains) are there?• For each socket, how many cores and hyperthreads are there? Are caches shared?
31.1 Tools for discovery
An easy way for discovering the structure of your parallel machine is to use tools that are written especiallyfor this purpose.
31.1.1 Intel cpuinfo
The Intel compiler suite comes with a tool cpuinfo that reports on the structure of the node you are runningon. It reports on the number of packages, that is: sockets, cores, and threads.
31.1.2 hwloc
The open source package hwloc does similar reporting to cpuinfo, but it has been ported to many platforms.Additionally, it can generate ascii and pdf graphic renderings of the architecture.
334

Chapter 32
Process and thread affinity
In the preceeding chapters we mostly considered all MPI nodes or OpenMP thread as being in one flat pool.However, for high performance you need to worry about affinity: the question of which process or threadis placed where, and how efficiently they can interact.
Figure 32.1: The NUMA structure of a Ranger node
Here are some situations where you affinity becomes a concern.• In pure MPI mode processes that are on the same node can typically communicate faster than
processes on different nodes. Since processes are typically placed sequentially, this means that ascheme where process p interacts mostly with p+ 1 will be efficient, while communication withlarge jumps will be less so.• If the cluster network has a structure (processor grid as opposed to fat-tree), placement of pro-
cesses has an effect on program efficiency. MPI tries to address this with graph topology; sec-tion 10.2.• Even on a single node there can be asymmetries. Figure 32.1 illustrates the structure of the
four sockets of the Ranger supercomputer (no longer in production). Two cores have no directconnection.
335

32. Process and thread affinity
This asymmetry affects both MPI processes and threads on that node.• Another problem with multi-socket designs is that each socket has memory attached to it. While
every socket can address all the memory on the node, its local memory is faster to access. Thisasymmetry becomes quite visible in the first-touch phenomemon; section 23.2.• If a node has fewer MPI processes than there are cores, you want to be in control of their
placement. Also, the operating system can migrate processes, which is detrimental to perfor-mance since it negates data locality. For this reason, utilities such as numactl (and at TACCtacc_affinity) can be used to pin a thread or process to a specific core.• Processors with hyperthreading or hardware threads introduce another level or worry about
where threads go.
32.1 What does the hardware look like?
If you want to optimize affinity, you should first know what the hardware looks like. The hwloc utility isvaluable here [5] (https://www.open-mpi.org/projects/hwloc/).
Host: c401−402.stampede.tacc.utexas.edu
Indexes: physical
Date: Tue 07 Jun 2016 01:06:43 PM CDT
Machine (32GB)
Socket P#0
NUMANode P#1 (16GB)
NUMANode P#0 (16GB)
Socket P#1
L3 (20MB)
L3 (20MB)
PCI 8086:1d02
L2 (256KB)
L2 (256KB) L2 (256KB)
sda
L2 (256KB) L2 (256KB)
PCI 8086:225c
PCI 8086:1521
PCI 8086:1521
PCI 15b3:1003
L2 (256KB)L2 (256KB)L2 (256KB)L2 (256KB)
L2 (256KB)
L2 (256KB)
L2 (256KB)
L2 (256KB)
L2 (256KB)
L2 (256KB)
L2 (256KB)
L1d (32KB)L1d (32KB) L1d (32KB)
ib0
mlx4_0
eth0
eth1L1d (32KB)
PCI 1a03:2000
L1d (32KB)L1d (32KB)L1d (32KB)L1d (32KB)
L1d (32KB) L1d (32KB)
L1d (32KB)
L1d (32KB) L1d (32KB)
L1d (32KB) L1d (32KB)
L1d (32KB)
L1i (32KB)
L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB)
L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB) L1i (32KB)
Core P#4
Core P#4 Core P#5 Core P#6 Core P#7
Core P#7Core P#6Core P#5Core P#3
Core P#0
Core P#2
Core P#1
Core P#1
Core P#2
Core P#0
Core P#3
PU P#0 PU P#4
PU P#15PU P#14PU P#8
PU P#2
PU P#11
PU P#7
PU P#13PU P#9
PU P#1 PU P#5 PU P#6
PU P#12PU P#10
PU P#3
Figure 32.2: Structure of a Stampede compute node
Figure 32.2 depicts a Stampede compute node , which is a two-socket Intel SandyBridge design; figure 32.3shows a Stampede largemem node , which is a four-socket design. Finally, figure 32.4 shows a Lonestar5compute node, a two-socket design with 12-core Intel Haswell processors with two hardware threads each.
336 Parallel Computing – r428
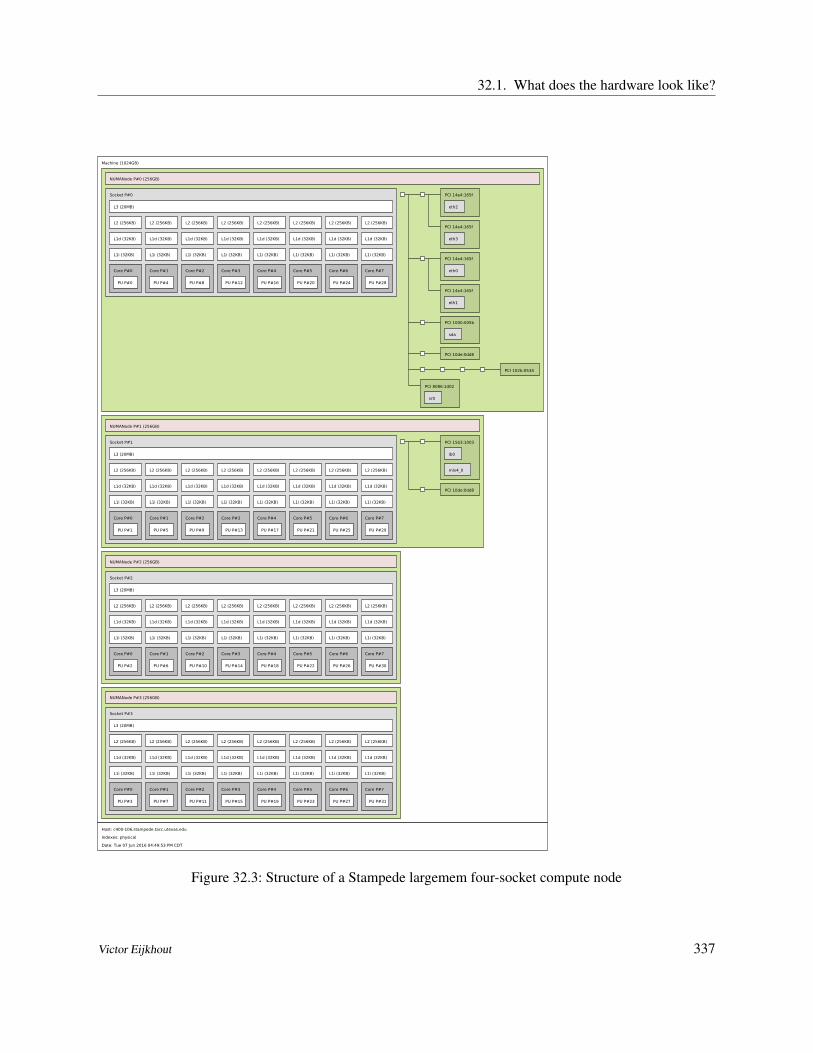
32.1. What does the hardware look like?
Machine (1024GB)
NUMANode P#0 (256GB)
Socket P#0
L3 (20MB)
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#0
PU P#0
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#1
PU P#4
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#2
PU P#8
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#3
PU P#12
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#4
PU P#16
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#5
PU P#20
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#6
PU P#24
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#7
PU P#28
PCI 14e4:165f
eth2
PCI 14e4:165f
eth3
PCI 14e4:165f
eth0
PCI 14e4:165f
eth1
PCI 1000:005b
sda
PCI 10de:0dd8
PCI 102b:0534
PCI 8086:1d02
sr0
NUMANode P#1 (256GB)
Socket P#1
L3 (20MB)
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#0
PU P#1
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#1
PU P#5
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#2
PU P#9
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#3
PU P#13
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#4
PU P#17
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#5
PU P#21
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#6
PU P#25
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#7
PU P#29
PCI 15b3:1003
ib0
mlx4_0
PCI 10de:0dd8
NUMANode P#2 (256GB)
Socket P#2
L3 (20MB)
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#0
PU P#2
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#1
PU P#6
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#2
PU P#10
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#3
PU P#14
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#4
PU P#18
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#5
PU P#22
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#6
PU P#26
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#7
PU P#30
NUMANode P#3 (256GB)
Socket P#3
L3 (20MB)
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#0
PU P#3
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#1
PU P#7
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#2
PU P#11
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#3
PU P#15
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#4
PU P#19
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#5
PU P#23
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#6
PU P#27
L2 (256KB)
L1d (32KB)
L1i (32KB)
Core P#7
PU P#31
Host: c400-106.stampede.tacc.utexas.edu
Indexes: physical
Date: Tue 07 Jun 2016 04:49:53 PM CDT
Figure 32.3: Structure of a Stampede largemem four-socket compute node
Victor Eijkhout 337

32. Process and thread affinity
Machine (64GB)
NUMANode P#0 (32GB)
Socket P#0
L3 (30MB)
L2 (256KB)
L1 (32KB)
Core P#0
PU P#0
PU P#24
L2 (256KB)
L1 (32KB)
Core P#1
PU P#1
PU P#25
L2 (256KB)
L1 (32KB)
Core P#2
PU P#2
PU P#26
L2 (256KB)
L1 (32KB)
Core P#3
PU P#3
PU P#27
L2 (256KB)
L1 (32KB)
Core P#4
PU P#4
PU P#28
L2 (256KB)
L1 (32KB)
Core P#5
PU P#5
PU P#29
L2 (256KB)
L1 (32KB)
Core P#8
PU P#6
PU P#30
L2 (256KB)
L1 (32KB)
Core P#9
PU P#7
PU P#31
L2 (256KB)
L1 (32KB)
Core P#10
PU P#8
PU P#32
L2 (256KB)
L1 (32KB)
Core P#11
PU P#9
PU P#33
L2 (256KB)
L1 (32KB)
Core P#12
PU P#10
PU P#34
L2 (256KB)
L1 (32KB)
Core P#13
PU P#11
PU P#35
NUMANode P#1 (32GB)
Socket P#1
L3 (30MB)
L2 (256KB)
L1 (32KB)
Core P#0
PU P#12
PU P#36
L2 (256KB)
L1 (32KB)
Core P#1
PU P#13
PU P#37
L2 (256KB)
L1 (32KB)
Core P#2
PU P#14
PU P#38
L2 (256KB)
L1 (32KB)
Core P#3
PU P#15
PU P#39
L2 (256KB)
L1 (32KB)
Core P#4
PU P#16
PU P#40
L2 (256KB)
L1 (32KB)
Core P#5
PU P#17
PU P#41
L2 (256KB)
L1 (32KB)
Core P#8
PU P#18
PU P#42
L2 (256KB)
L1 (32KB)
Core P#9
PU P#19
PU P#43
L2 (256KB)
L1 (32KB)
Core P#10
PU P#20
PU P#44
L2 (256KB)
L1 (32KB)
Core P#11
PU P#21
PU P#45
L2 (256KB)
L1 (32KB)
Core P#12
PU P#22
PU P#46
L2 (256KB)
L1 (32KB)
Core P#13
PU P#23
PU P#47
Host: nid00015
Indexes: physical
Date: Tue 07 Jun 2016 04:18:47 PM CDT
Figure 32.4: Structure of a Lonestar5 compute node
32.2 Affinity control
See chapter 23 for OpenMP affinity control.
338 Parallel Computing – r428

Chapter 33
Hybrid computing
So far, you have learned to use MPI for distributed memory and OpenMP for shared memory parallelprogramming. However, distribute memory architectures actually have a shared memory component, sinceeach cluster node is typically of a multicore design. Accordingly, you could program your cluster usingMPI for inter-node and OpenMP for intra-node parallelism.
Say you use 100 cluster nodes, each with 16 cores. You could then start 1600 MPI processes, one for eachcore, but you could also start 100 processes, and give each access to 16 OpenMP threads.
In your slurm scripts, the first scenario would be specified -N 100 -n 1600, and the second as
#$ SBATCH -N 100#$ SBATCH -n 100
export OMP_NUM_THREADS=16
There is a third choice, in between these extremes, that makes sense. A cluster node often has more thanone socket, so you could put one MPI process on each socket , and use a number of threads equal to thenumber of cores per socket.
The script for this would be:
#$ SBATCH -N 100#$ SBATCH -n 200
export OMP_NUM_THREADS=8ibrun tacc_affinity yourprogram
The tacc_affinity script unsets the following variables:
export MV2_USE_AFFINITY=0export MV2_ENABLE_AFFINITY=0export VIADEV_USE_AFFINITY=0export VIADEV_ENABLE_AFFINITY=0
339

33. Hybrid computing
If you don’t use tacc_affinity you may want to do this by hand, otherwise mvapich2 will use itsown affinity rules.
Figure 33.1: Three modes of MPI/OpenMP usage on a multi-core cluster
Figure 33.1 illustrates these three modes: pure MPI with no threads used; one MPI process per node andfull multi-threading; two MPI processes per node, one per socket, and multiple threads on each socket.
33.1 Discussion
The performance implications of the pure MPI strategy versus hybrid are subtle.
• First of all, we note that there is no obvious speedup: in a well balanced MPI application all coresare busy all the time, so using threading can give no immediate improvement.• Both MPI and OpenMP are subject to Amdahl’s law that quantifies the influence of sequential
code; in hybrid computing there is a new version of this law regarding the amount of code thatis MPI-parallel, but not OpenMP-parallel.• MPI processes run unsynchronized, so small variations in load or in processor behaviour can be
tolerated. The frequent barriers in OpenMP constructs make a hybrid code more tightly synchro-nized, so load balancing becomes more critical.• On the other hand, in OpenMP codes it is easier to divide the work into more tasks than there are
threads, so statistically a certain amount of load balancing happens automatically.• Each MPI process has its own buffers, so hybrid takes less buffer overhead.
Exercise 33.1. Review the scalability argument for 1D versus 2D matrix decomposition inHPSC-6.2. Would you get scalable performance from doing a 1D decomposition (forinstance, of the rows) over MPI processes, and decomposing the other directions (thecolumns) over OpenMP threads?
Another performance argument we need to consider concerns message traffic. If let all threads make MPIcalls (see section 33.2) there is going to be little difference. However, in one popular hybrid computingstrategy we would keep MPI calls out of the OpenMP regions and have them in effect done by the masterthread. In that case there are only MPI messages between nodes, instead of between cores. This leads to adecrease in message traffic, though this is hard to quantify. The number of messages goes down approxi-mately by the number of cores per node, so this is an advantage if the average message size is small. On theother hand, the amount of data sent is only reduced if there is overlap in content between the messages.
340 Parallel Computing – r428

33.2. Hybrid MPI-plus-threads execution
Limiting MPI traffic to the master thread also means that no buffer space is needed for the on-node com-munication.
33.2 Hybrid MPI-plus-threads executionIn hybrid execution, the main question is whether all threads are allowed to make MPI calls. To determinethis, replace the MPI_Init call by
C:int MPI_Init_thread(int *argc, char ***argv, int required, int *provided)
Fortran:MPI_Init_thread(required, provided, ierror)INTEGER, INTENT(IN) :: requiredINTEGER, INTENT(OUT) :: providedINTEGER, OPTIONAL, INTENT(OUT) :: ierror
How to read routine prototypes: 1.5.4.
Here the required and provided parameters can take the following values:
MPI THREAD SINGLE Only a single thread will execute.MPI THREAD FUNNELLED The program may use multiple threads, but only the main thread will make
MPI calls.The main thread is usually the one selected by the master directive, but technically it is theonly that executes MPI_Init_thread. If you call this routine in a parallel region, the main threadmay be different from the master.
MPI THREAD SERIAL The program may use multiple threads, all of which may make MPI calls, butthere will never be simultaneous MPI calls in more than one thread.
MPI THREAD MULTIPLE Multiple threads may issue MPI calls, without restrictions.
The mvapich implementation of MPI does have the required threading support, but you need to set thisenvironment variable:
export MV2_ENABLE_AFFINITY=0
Another solution is to run your code like this:
ibrun tacc_affinity <my_multithreaded_mpi_executable
The mpirun program usually propagates environment variables , so the value of OMP_NUM_THREADSwhen you call mpirun will be seen by each MPI process.
• It is possible to use blocking sends in threads, and let the threads block. This does away with theneed for polling.• You can not send to a thread number: use the MPI message tag to send to a specific thread.
Exercise 33.2. Consider the 2D heat equation and explore the mix of MPI/OpenMPparallelism:
Victor Eijkhout 341

33. Hybrid computing
• Give each node one MPI process that is fully multi-threaded.• Give each core an MPI process and don’t use multi-threading.
Discuss theoretically why the former can give higher performance. Implement bothschemes as special cases of the general hybrid case, and run tests to find the optimalmix.// thread.cMPI_Init_thread(&argc,&argv,MPI_THREAD_MULTIPLE,&threading);comm = MPI_COMM_WORLD;MPI_Comm_rank(comm,&procno);MPI_Comm_size(comm,&nprocs);
if (procno==0) {switch (threading) {case MPI_THREAD_MULTIPLE : printf("Glorious multithreaded MPI\n"); break;case MPI_THREAD_SERIALIZED : printf("No simultaneous MPI from threads\n");break;
case MPI_THREAD_FUNNELED : printf("MPI from main thread\n"); break;case MPI_THREAD_SINGLE : printf("no threading supported\n"); break;}
}MPI_Finalize();
33.3 Sources used in this chapter
Listing of code XX:
342 Parallel Computing – r428

Chapter 34
Random number generation
Here is how you initialize the random number generator uniquely on each process:C:
// Initialize the random number generatorsrand((int)(mytid*(double)RAND_MAX/ntids));// compute a random numberrandomfraction = (rand() / (double)RAND_MAX);
Fortran:
integer :: randsizeinteger,allocatable,dimension(:) :: randseedreal :: random_value
call random_seed(size=randsize)allocate(randseed(randsize))randseed(:) = 1023*mytidcall random_seed(put=randseed)
343

Chapter 35
Parallel I/O
Parallel I/O is a tricky subject. You can try to let all processors jointly write one file, or to write a file perprocess and combine them later. With the standard mechanisms of your programming language there arethe following considerations:
• On clusters where the processes have individual file systems, the only way to write a single fileis to let it be generated by a single processor.• Writing one file per process is easy to do, but
– You need a post-processing script;– if the files are not on a shared file system (such as Lustre), it takes additional effort to bring
them together;– if the files are on a shared file system, writing many files may be a burden on the metadata
server.• On a shared file system it is possible for all files to open the same file and set the file pointer
individually. This can be difficult if the amount of data per process is not uniform.
Illustrating the last point:
// pseek.cFILE *pfile;pfile = fopen("pseek.dat","w");fseek(pfile,procid*sizeof(int),SEEK_CUR);fseek(pfile,procid*sizeof(char),SEEK_CUR);fprintf(pfile,"%d\n",procid);fclose(pfile);
MPI also has its own portable I/O: MPI I/O , for which see chapter 9.
Alternatively, one could use a library such as hdf5 .
35.1 Sources used in this chapter
Listing of code XX:
344

Chapter 36
Support libraries
There are many libraries related to parallel programming to make life easier, or at least more interesting,for you.
36.1 SimGrid
SimGrid [9] is a simulator for distributed systems. It can for instance be used to explore the effects ofarchitectural parameters. It has been used to simulate large scale operations such as HPL! (HPL!) [2].
36.2 Other
ParaMesh
Global Arrays
Hdf5 and Silo
345

36. Support libraries
346 Parallel Computing – r428

PART V
TUTORIALS

here are some tutorials
348 Parallel Computing – r428

36.3. Debugging
36.3 Debugging
When a program misbehaves, debugging is the process of finding out why. There are various strategies offinding errors in a program. The crudest one is debugging by print statements. If you have a notion of wherein your code the error arises, you can edit your code to insert print statements, recompile, rerun, and see ifthe output gives you any suggestions. There are several problems with this:
• The edit/compile/run cycle is time consuming, especially since• often the error will be caused by an earlier section of code, requiring you to edit, compile, and
rerun repeatedly. Furthermore,• the amount of data produced by your program can be too large to display and inspect effectively,
and• if your program is parallel, you probably need to print out data from all proccessors, making the
inspection process very tedious.For these reasons, the best way to debug is by the use of an interactive debugger , a program that allowsyou to monitor and control the behaviour of a running program. In this section you will familiarize yourselfwith gdb , which is the open source debugger of the GNU project. Other debuggers are proprietary, andtypically come with a compiler suite. Another distinction is that gdb is a commandline debugger; there aregraphical debuggers such as ddd (a frontend to gdb) or DDT and TotalView (debuggers for parallel codes).We limit ourselves to gdb, since it incorporates the basic concepts common to all debuggers.
In this tutorial you will debug a number of simple programs with gdb and valgrind. The files can be foundin the repository in the directory tutorials/debug_tutorial_files.
36.3.1 Step 0: compiling for debug
You often need to recompile your code before you can debug it. A first reason for this is that the binary codetypically knows nothing about what variable names corresponded to what memory locations, or what linesin the source to what instructions. In order to make the binary executable know this, you have to includethe symbol table in it, which is done by adding the -g option to the compiler line.
Usually, you also need to lower the compiler optimization level : a production code will often be compiledwith flags such as -O2 or -Xhost that try to make the code as fast as possible, but for debugging youneed to replace this by -O0 (‘oh-zero’). The reason is that higher levels will reorganize your code, makingit hard to relate the execution to the source1.
36.3.2 Invoking gdb
There are three ways of using gdb: using it to start a program, attaching it to an already running program,or using it to inspect a core dump . We will only consider the first possibility.
Here is an exaple of how to start gdb with program that has no arguments (Fortran users, use hello.F):
tutorials/gdb/c/hello.c
1. Typically, actual code motion is done by -O3, but at level -O2 the compiler will inline functions and make other simplifi-cations.
Victor Eijkhout 349

%% cc -g -o hello hello.c# regular invocation:%% ./hellohello world# invocation from gdb:%% gdb helloGNU gdb 6.3.50-20050815 # ..... version infoCopyright 2004 Free Software Foundation, Inc. .... copyright info ....(gdb) runStarting program: /home/eijkhout/tutorials/gdb/helloReading symbols for shared libraries +. donehello world
Program exited normally.(gdb) quit%%
Important note: the program was compiled with the debug flag -g. This causes the symbol table (that is,the translation from machine address to program variables) and other debug information to be included inthe binary. This will make your binary larger than strictly necessary, but it will also make it slower, forinstance because the compiler will not perform certain optimizations2.
To illustrate the presence of the symbol table do%% cc -g -o hello hello.c%% gdb helloGNU gdb 6.3.50-20050815 # ..... version info(gdb) list
and compare it with leaving out the -g flag:%% cc -o hello hello.c%% gdb helloGNU gdb 6.3.50-20050815 # ..... version info(gdb) list
For a program with commandline input we give the arguments to the run command (Fortran users usesay.F):
tutorials/gdb/c/say.c
%% cc -o say -g say.c%% ./say 2
2. Compiler optimizations are not supposed to change the semantics of a program, but sometimes do. This can lead to thenightmare scenario where a program crashes or gives incorrect results, but magically works correctly with compiled with debugand run in a debugger.
350 Parallel Computing – r428

36.3. Debugging
hello worldhello world%% gdb say.... the usual messages ...(gdb) run 2Starting program: /home/eijkhout/tutorials/gdb/c/say 2Reading symbols for shared libraries +. donehello worldhello world
Program exited normally.
36.3.3 Finding errors
Let us now consider some programs with errors.
36.3.3.1 C programs
tutorials/gdb/c/square.c
%% cc -g -o square square.c%% ./square
5000Segmentation fault
The segmentation fault (other messages are possible too) indicates that we are accessing memory that weare not allowed to, making the program abort. A debugger will quickly tell us where this happens:
%% gdb square(gdb) run50000
Program received signal EXC_BAD_ACCESS, Could not access memory.Reason: KERN_INVALID_ADDRESS at address: 0x000000000000eb4a0x00007fff824295ca in __svfscanf_l ()
Apparently the error occurred in a function __svfscanf_l, which is not one of ours, but a systemfunction. Using the backtrace (or bt, also where or w) command we quickly find out how this cameto be called:
(gdb) backtrace#0 0x00007fff824295ca in __svfscanf_l ()#1 0x00007fff8244011b in fscanf ()#2 0x0000000100000e89 in main (argc=1, argv=0x7fff5fbfc7c0) at square.c:7
Victor Eijkhout 351

We take a close look at line 7, and see that we need to change nmax to &nmax.
There is still an error in our program:
(gdb) run50000
Program received signal EXC_BAD_ACCESS, Could not access memory.Reason: KERN_PROTECTION_FAILURE at address: 0x000000010000f0000x0000000100000ebe in main (argc=2, argv=0x7fff5fbfc7a8) at square1.c:99 squares[i] = 1./(i*i); sum += squares[i];
We investigate further:
(gdb) print i$1 = 11237(gdb) print squares[i]Cannot access memory at address 0x10000f000
and we quickly see that we forgot to allocate squares.
By the way, we were lucky here: this sort of memory errors is not always detected. Starting our programmwith a smaller input does not lead to an error:
(gdb) run50Sum: 1.625133e+00
Program exited normally.
36.3.3.2 Fortran programs
Compile and run the following program:
tutorials/gdb/f/square.F It should abort with a message such as ‘Illegal instruction’. Running the programin gdb quickly tells you where the problem lies:
(gdb) runStarting program: tutorials/gdb//fsquareReading symbols for shared libraries ++++. done
Program received signal EXC_BAD_INSTRUCTION, Illegal instruction/operand.0x0000000100000da3 in square () at square.F:77 sum = sum + squares(i)
We take a close look at the code and see that we did not allocate squares properly.
352 Parallel Computing – r428

36.3. Debugging
36.3.4 Memory debugging with Valgrind
Insert the following allocation of squares in your program:
squares = (float *) malloc( nmax*sizeof(float) );
Compile and run your program. The output will likely be correct, although the program is not. Can you seethe problem?
To find such subtle memory errors you need a different tool: a memory debugging tool. A popular (becauseopen source) one is valgrind ; a common commercial tool is purify.
tutorials/gdb/c/square1.c Compile this program with cc -o square1 square1.c and run it withvalgrind square1 (you need to type the input value). You will lots of output, starting with:
%% valgrind square1==53695== Memcheck, a memory error detector==53695== Copyright (C) 2002-2010, and GNU GPL’d, by Julian Seward et al.==53695== Using Valgrind-3.6.1 and LibVEX; rerun with -h for copyright info==53695== Command: a.out==53695==10==53695== Invalid write of size 4==53695== at 0x100000EB0: main (square1.c:10)==53695== Address 0x10027e148 is 0 bytes after a block of size 40 alloc’d==53695== at 0x1000101EF: malloc (vg_replace_malloc.c:236)==53695== by 0x100000E77: main (square1.c:8)==53695====53695== Invalid read of size 4==53695== at 0x100000EC1: main (square1.c:11)==53695== Address 0x10027e148 is 0 bytes after a block of size 40 alloc’d==53695== at 0x1000101EF: malloc (vg_replace_malloc.c:236)==53695== by 0x100000E77: main (square1.c:8)
Valgrind is informative but cryptic, since it works on the bare memory, not on variables. Thus, these errormessages take some exegesis. They state that a line 10 writes a 4-byte object immediately after a block of40 bytes that was allocated. In other words: the code is writing outside the bounds of an allocated array. Doyou see what the problem in the code is?
Note that valgrind also reports at the end of the program run how much memory is still in use, meaning notproperly freed.
If you fix the array bounds and recompile and rerun the program, valgrind still complains:==53785== Conditional jump or move depends on uninitialised value(s)==53785== at 0x10006FC68: __dtoa (in /usr/lib/libSystem.B.dylib)==53785== by 0x10003199F: __vfprintf (in /usr/lib/libSystem.B.dylib)==53785== by 0x1000738AA: vfprintf_l (in /usr/lib/libSystem.B.dylib)==53785== by 0x1000A1006: printf (in /usr/lib/libSystem.B.dylib)==53785== by 0x100000EF3: main (in ./square2)
Victor Eijkhout 353

Although no line number is given, the mention of printf gives an indication where the problem lies.The reference to an ‘uninitialized value’ is again cryptic: the only value being output is sum, and that isnot uninitialized: it has been added to several times. Do you see why valgrind calls is uninitialized all thesame?
36.3.5 Stepping through a program
Often the error in a program is sufficiently obscure that you need to investigate the program run in detail.Compile the following program
tutorials/gdb/c/roots.c and run it:
%% ./rootssum: nan
Start it in gdb as follows:
%% gdb rootsGNU gdb 6.3.50-20050815 (Apple version gdb-1469) (Wed May 5 04:36:56 UTC 2010)Copyright 2004 Free Software Foundation, Inc.....(gdb) break mainBreakpoint 1 at 0x100000ea6: file root.c, line 14.(gdb) runStarting program: tutorials/gdb/c/rootsReading symbols for shared libraries +. done
Breakpoint 1, main () at roots.c:1414 float x=0;
Here you have done the following:
• Before calling run you set a breakpoint at the main program, meaning that the execution willstop when it reaches the main program.• You then call run and the program execution starts;• The execution stops at the first instruction in main.
If execution is stopped at a breakpoint, you can do various things, such as issuing the step command:
Breakpoint 1, main () at roots.c:1414 float x=0;(gdb) step15 for (i=100; i>-100; i--)(gdb)16 x += root(i);(gdb)
354 Parallel Computing – r428

36.3. Debugging
(if you just hit return, the previously issued command is repeated). Do a number of steps in a row byhitting return. What do you notice about the function and the loop?
Switch from doing step to doing next. Now what do you notice about the loop and the function?
Set another breakpoint: break 17 and do cont. What happens?
Rerun the program after you set a breakpoint on the line with the sqrt call. When the execution stopsthere do where and list.
• If you set many breakpoints, you can find out what they are with info breakpoints.• You can remove breakpoints with delete n where n is the number of the breakpoint.• If you restart your program with run without leaving gdb, the breakpoints stay in effect.• If you leave gdb, the breakpoints are cleared but you can save them: save breakpoints<file>. Use source <file> to read them in on the next gdb run.
36.3.6 Inspecting values
Run the previous program again in gdb: set a breakpoint at the line that does the sqrt call before youactually call run. When the program gets to line 8 you can do print n. Do cont. Where does theprogram stop?
If you want to repair a variable, you can do set var=value. Change the variable n and confirm that thesquare root of the new value is computed. Which commands do you do?
If a problem occurs in a loop, it can be tedious keep typing cont and inspecting the variable with print.Instead you can add a condition to an existing breakpoint: the following:
condition 1 if (n<0)
or set the condition when you define the breakpoint:
break 8 if (n<0)
Another possibility is to use ignore 1 50, which will not stop at breakpoint 1 the next 50 times.
Remove the existing breakpoint, redefine it with the condition n<0 and rerun your program. When theprogram breaks, find for what value of the loop variable it happened. What is the sequence of commandsyou use?
36.3.7 Parallel debugging
Debugging parallel programs is harder than than sequential programs, because every sequential bug mayshow up, plus a number of new types, caused by the interaction of the various processes.
Here are a few possible parallel bugs:
• Processes can deadlock because they are waiting for a message that never comes. This typicallyhappens with blocking send/receive calls due to an error in program logic.• If an incoming message is unexpectedly larger than anticipated, a memory error can occur.
Victor Eijkhout 355

• A collective call will hang if somehow one of the processes does not call the routine.
There are few low-budget solutions to parallel debugging. The main one is to create an xterm for eachprocess. We will describe this next. There are also commercial packages such as DDT and TotalView,that offer a GUI. They are very convenient but also expensive. The Eclipse project has a parallel package,Eclipse PTP , that includes a graphic debugger.
36.3.7.1 MPI debugging with gdb
You can not run parallel programs in gdb, but you can start multiple gdb processes that behave just likeMPI processes! The command
mpirun -np <NP> xterm -e gdb ./program
create a number of xterm windows, each of which execute the commandline gdb ./program. Andbecause these xterms have been started with mpirun, they actually form a communicator.
36.3.8 Further reading
A good tutorial: http://www.dirac.org/linux/gdb/.
Reference manual: http://www.ofb.net/gnu/gdb/gdb_toc.html.
356 Parallel Computing – r428

36.4. Tracing
36.4 Tracing
36.4.1 TAU profiling and tracing
TAU http://www.cs.uoregon.edu/Research/tau/home.php is a utility for profiling andtracing your parallel programs. Profiling is the gathering and displaying of bulk statistics, for instanceshowing you which routines take the most time, or whether communication takes a large portion of yourruntime. When you get concerned about performance, a good profiling tool is indispensible.
Tracing is the construction and displaying of time-dependent information on your program run, for instanceshowing you if one process lags behind others. For understanding a program’s behaviour, and the reasonsbehind profiling statistics, a tracing tool can be very insightful.
TAU works by adding instrumentation to your code: in effect it is a source-to-source translator that takesyour code and turns it into one that generates run-time statistics. Doing this instrumentation is fortunatelysimple: start by having this code fragment in your makefile:
ifdef TACC_TAU_DIRCC = tau_cc.sh
elseCC = mpicc
endif
% : %.c<TAB>${CC} -o $@ $ˆ
It is a good move to create a directory for your tracing and profiling information. You can use two separatedirectories, but there is no harm in using the same for both:
mkdir tau_tracemkdir tau_profileexport PROFILEDIR=tau_profileexport TRACEDIR=tau_trace
export TAU_PROFILE=1export TAU_TRACE=1
mpirun myprogram
After this, you view profiling information with paraprof
paraprof tau_profile
Viewing the traces takes a few steps:
cd tau_tracerm -f tau.trc tau.edftau_treemerge.pl
Victor Eijkhout 357

tau2slog2 tau.trc tau.edf -o yourprogram.slog2
The slog2 file can then be viewed with jumpshot:
jumpshot yourprogram.slog2
358 Parallel Computing – r428

36.5. SimGrid
36.5 SimGrid
Many readers of this book will have access to some sort of parallel machine so that they can run simulations,maybe even some realistic scaling studies. However, not many people will have access to more than onecluster type so that they can evaluate the influence of the interconnect . Even then, for didactic purposesone would often wish for interconnect types (fully connected, linear processor array) that are unlikely to beavailable.
In order to explore architectural issues pertaining to the network, we then resort to a simulation tool, Sim-Grid.
Installation
Compilation You write plain MPI files, but compile them with the SimGrid compiler smpicc.
Running SimGrid has its own version of mpirun: smpirun. You need to supply this with options:
• -np 123456 for the number of (virtual) processors;• -hostfile simgridhostfile which lists the names of these processors. You can basi-
cally make these up, but are defined in:• -platform arch.xml which defines the connectivity between the processors.
For instance, with a hostfile of 8 hosts, a linearly connected network would be defined as:
<?xml version=’1.0’?><!DOCTYPE platform SYSTEM "http://simgrid.gforge.inria.fr/simgrid/simgrid.dtd">
<platform version="4">
<zone id="first zone" routing="Floyd"><!-- the resources --><host id="host1" speed="1Mf"/><host id="host2" speed="1Mf"/><host id="host3" speed="1Mf"/><host id="host4" speed="1Mf"/><host id="host5" speed="1Mf"/><host id="host6" speed="1Mf"/><host id="host7" speed="1Mf"/><host id="host8" speed="1Mf"/><link id="link1" bandwidth="125MBps" latency="100us"/><!-- the routing: specify how the hosts are interconnected --><route src="host1" dst="host2"><link_ctn id="link1"/></route><route src="host2" dst="host3"><link_ctn id="link1"/></route><route src="host3" dst="host4"><link_ctn id="link1"/></route><route src="host4" dst="host5"><link_ctn id="link1"/></route>
Victor Eijkhout 359

<route src="host5" dst="host6"><link_ctn id="link1"/></route><route src="host6" dst="host7"><link_ctn id="link1"/></route><route src="host7" dst="host8"><link_ctn id="link1"/></route>
</zone>
</platform>
(such files are easily generated with a shell script).
The Floyd designation of the routing means that any route using the transitive closure of the paths givencan be used. It is also possible to use routing="Full" which requires full specification of all pairs thatcan communicate.
360 Parallel Computing – r428

PART VI
PROJECTS, INDEX

Chapter 37
Class projects
37.1 A Style Guide to Project Submissions
Here are some guidelines for how to submit assignments and projects. As a general rule, consider program-ming as an experimental science, and your writeup as a report on some tests you have done: explain theproblem you’re addressing, your strategy, your results.
Structure of your writeup Most of the exercises in this book test whether you are able to code thesolution to a certain problem. That does not mean that turning in the code is sufficient, nor code plussample output. Turn in a writeup in pdf form that was generated from a text processing program such asWord or (preferably) LATEX (for a tutorial, see HPSC-29). Your writeup should have
• The relevant fragments of your code,• an explanation of your algorithms or solution strategy,• a discussion of what you observed,• graphs of runtimes and TAU plots; see 36.4.
Observe, measure, hypothesize, deduce In most applications of computing machinery we care about theefficiency with which we find the solution. Thus, make sure that you do measurements. In general, makeobservations that allow you to judge whether your program behaves the way you would expect it to.
Quite often your program will display unexpected behaviour. It is important to observe this, and hypothesizewhat the reason might be for your observed behaviour.
Including code If you include code samples in your writeup, make sure they look good. For starters, use amono-spaced font. In LATEX, you can use the verbatim environment or the verbatiminput command.In that section option the source is included automatically, rather than cut and pasted. This is to be preferred,since your writeup will stay current after you edit the source file.
Including whole source files makes for a long and boring writeup. The code samples in this book weregenerated as follows. In the source files, the relevant snippet was marked as
362

37.1. A Style Guide to Project Submissions
... boring stuff#pragma samplex
.. interesting! ..#pragma end... more boring stuff
The files were then processed with the following command line (actually, included in a makefile, whichrequires doubling the dollar signs):
for f in *.{c,cxx,h} ; docat $x | awk ’BEGIN {f=0}
/#pragma end/ {f=0}f==1 {print $0 > file}/pragma/ {f=1; file=$2 }
’done
which gives (in this example) a file samplex. Other solutions are of course possible.
Code formatting Code without proper indentation is very hard to read. Fortunately, most editors havesome knowledge of the syntax of the most popular languages. The emacs editor will, most of the time,automatically activate the appropriate mode based on the file extension. If this does not happen, you canactivate a mode by ESC x fortran-mode et cetera, or by putting the string -*- fortran -*- in acomment on the first line of your file.
The vi editor also has syntax support: use the commands :synxtax on to get syntax colouring, and:set cindent to get automatic indentation while you’re entering text. Some of the more common ques-tions are addressed in http://stackoverflow.com/questions/97694/auto-indent-spaces-with-c-in-vim.
Running your code A single run doesn’t prove anything. For a good report, you need to run your codefor more than one input dataset (if available) and in more than one processor configuration. When youchoose problem sizes, be aware that an average processor can do a billion operations per second: you needto make your problem large enough for the timings to rise above the level of random variations and startupphenomena.
When you run a code in parallel, beware that on clusters the behaviour of a parallel code will alwaysbe different between one node and multiple nodes. On a single node the MPI implementation is likelyoptimized to use the shared memory. This means that results obtained from a single node run will beunrepresentative. In fact, in timing and scaling tests you will often see a drop in (relative) performancegoing from one node to two. Therefore you need to run your code in a variety of scenarios, using more thanone node.
Reporting scaling If you do a scaling analysis, a graph reporting runtimes should not have a linear timeaxis: a logarithmic graph is much easier to read. A speedup graph can also be informative.
Victor Eijkhout 363

37. Class projects
Some algorithms are mathematically equivalent in their sequential and parallel versions. Others, such asiterative processes, can take more operations in parallel than sequentially, for instance because the numberof iterations goes up. In this case, report both the speedup of a single iteration, and the total improvementof running the full algorithm in parallel.
Repository organization If you submit your work through a repository, make sure you organize yoursubmissions in subdirectories, and that you give a clear name to all files. Object files and binaries shouldnot be in a repository since they are dependent on hardware and things like compilers.
364 Parallel Computing – r428

37.2. Warmup Exercises
37.2 Warmup Exercises
We start with some simple exercises.
37.2.1 Hello world
The exercises in this section are about the routines introduced in section 2.3; for the referenceinformation see section ??.
First of all we need to make sure that you have a working setup for parallel jobs. The example programhelloworld.c does the following:
// helloworld.cMPI_Init(&argc,&argv);MPI_Comm_size(MPI_COMM_WORLD,&ntids);MPI_Comm_rank(MPI_COMM_WORLD,&mytid);printf("Hello, this is processor %d out of %d\n",mytid,ntids);MPI_Finalize();
Compile this program and run it in parallel. Make sure that the processors do not all say that they areprocessor 0 out of 1!
37.2.2 Collectives
It is a good idea to be able to collect statistics, so before we do anything interesting, we will look at MPIcollectives; section 3.1.
Take a look at time_max.cxx. This program sleeps for a random number of seconds:
// time_max.cxxwait = (int) ( 6.*rand() / (double)RAND_MAX );tstart = MPI_Wtime();sleep(wait);tstop = MPI_Wtime();jitter = tstop-tstart-wait;
and measures how long the sleep actually was:
if (mytid==0)sendbuf = MPI_IN_PLACE;else sendbuf = (void*)&jitter;MPI_Reduce(sendbuf,(void*)&jitter,1,MPI_DOUBLE,MPI_MAX,0,comm);
In the code, this quantity is called ‘jitter’, which is a term for random deviations in a system.
Exercise 37.1. Change this program to compute the average jitter by changing the reductionoperator.
Victor Eijkhout 365

37. Class projects
Exercise 37.2. Now compute the standard deviation
σ =
√∑i(xi −m)2
n
where m is the average value you computed in the previous exercise.• Solve this exercise twice: once by following the reduce by a broadcast
operation and once by using an Allreduce.• Run your code both on a single cluster node and on multiple nodes, and inspect
the TAU trace. Some MPI implementations are optimized for shared memory,so the trace on a single node may not look as expected.• Can you see from the trace how the allreduce is implemented?
Exercise 37.3. Finally, use a gather call to collect all the values on processor zero, and printthem out. Is there any process that behaves very differently from the others?
37.2.3 Linear arrays of processors
In this section you are going to write a number of variations on a very simple operation: all processors passa data item to the processor with the next higher number.
• In the file linear-serial.c you will find an implementation using blocking send and re-ceive calls.• You will change this code to use non-blocking sends and receives; they require an MPI_Wait
call to finalize them.• Next, you will use MPI_Sendrecv to arrive at a synchronous, but deadlock-free implementa-
tion.• Finally, you will use two different one-sided scenarios.
In the reference code linear-serial.c, each process defines two buffers:
// linear-serial.cint my_number = mytid, other_number=-1.;
where other_number is the location where the data from the left neighbour is going to be stored.
To check the correctness of the program, there is a gather operation on processor zero:
int *gather_buffer=NULL;if (mytid==0) {
gather_buffer = (int*) malloc(ntids*sizeof(int));if (!gather_buffer) MPI_Abort(comm,1);
}MPI_Gather(&other_number,1,MPI_INT,
gather_buffer,1,MPI_INT, 0,comm);if (mytid==0) {
int i,error=0;for (i=0; i<ntids; i++)
366 Parallel Computing – r428

37.2. Warmup Exercises
if (gather_buffer[i]!=i-1) {printf("Processor %d was incorrect: %d should be %d\n",
i,gather_buffer[i],i-1);error =1;
}if (!error) printf("Success!\n");free(gather_buffer);
}
37.2.3.1 Coding with blocking calls
Passing data to a neighbouring processor should be a very parallel operation. However, if we code thisnaively, with MPI_Send and MPI_Recv, we get an unexpected serial behaviour, as was explained insection 4.2.2.
if (mytid<ntids-1)MPI_Ssend( /* data: */ &my_number,1,MPI_INT,
/* to: */ mytid+1, /* tag: */ 0, comm);if (mytid>0)MPI_Recv( /* data: */ &other_number,1,MPI_INT,
/* from: */ mytid-1, 0, comm, &status);
(Note that this uses an Ssend; see section 12.9 for the explanation why.)Exercise 37.4. Compile and run this code, and generate a TAU trace file. Confirm that the
execution is serial. Does replacing the Ssend by Send change this?Let’s clean up the code a little.Exercise 37.5. First write this code more elegantly by using MPI_PROC_NULL.
37.2.3.2 A better blocking solution
The easiest way to prevent the serialization problem of the previous exercises is to use the MPI_Sendrecv
call. This routine acknowledges that often a processor will have a receive call whenever there is a send.For border cases where a send or receive is unmatched you can use MPI_PROC_NULL.Exercise 37.6. Rewrite the code using MPI_Sendrecv. Confirm with a TAU trace that
execution is no longer serial.Note that the Sendrecv call itself is still blocking, but at least the ordering of its constituent send andrecv are no longer ordered in time.
37.2.3.3 Non-blocking calls
The other way around the blocking behaviour is to use Isend and Irecv calls, which do not block.Of course, now you need a guarantee that these send and receive actions are concluded; in this case, useMPI_Waitall.
Victor Eijkhout 367

37. Class projects
Exercise 37.7. Implement a fully parallel version by using MPI_Isend and MPI_Irecv.
37.2.3.4 One-sided communication
Another way to have non-blocking behaviour is to use one-sided communication. During a Put or Getoperation, execution will only block while the data is being transferred out of or into the origin process,but it is not blocked by the target. Again, you need a guarantee that the transfer is concluded; here useMPI_Win_fence.
Exercise 37.8. Write two versions of the code: one using MPI_Put and one with MPI_Get.Make TAU traces.
Investigate blocking behaviour through TAU visualizations.
Exercise 37.9. If you transfer a large amount of data, and the target processor is occupied, canyou see any effect on the origin? Are the fences synchronized?
368 Parallel Computing – r428

37.3. Mandelbrot set
37.3 Mandelbrot set
If you’ve never heard the name Mandelbrot set , you probably recognize the picture; figure 37.1 Its formal
Figure 37.1: The Mandelbrot set
definition is as follows:
A point c in the complex plane is part of the Mandelbrot set if the series xn defined by{x0 = 0
xn+1 = x2n + c
satisfies
∀n : |xn| ≤ 2.
It is easy to see that only points c in the bounding circle |c| < 2 qualify, but apart from that it’s hard to saymuch without a lot more thinking. Or computing; and that’s what we’re going to do.
In this set of exercises you are going to take an example program mandel_main.cxx and extend it touse a variety of MPI programming constructs. This program has been set up as a manager-worker model:there is one manager processor (for a change this is the last processor, rather than zero) which gives outwork to, and accepts results from, the worker processors. It then takes the results and constructs an imagefile from them.
37.3.1 Invocation
The mandel_main program is called as
Victor Eijkhout 369

37. Class projects
mpirun -np 123 mandel_main steps 456 iters 789
where the steps parameter indicates how many steps in x, y direction there are in the image, and itersgives the maximum number of iterations in the belong test.
If you forget the parameter, you can call the program with
mandel_serial -h
and it will print out the usage information.
37.3.2 Tools
The driver part of the Mandelbrot program is simple. There is a circle object that can generate coordinates
// mandel.hclass circle {public :circle(int pxls,int bound,int bs);void next_coordinate(struct coordinate& xy);int is_valid_coordinate(struct coordinate xy);void invalid_coordinate(struct coordinate& xy);
and a global routine that tests whether a coordinate is in the set, at least up to an iteration bound. It returnszero if the series from the given starting point has not diverged, or the iteration number in which it divergedif it did so.
int belongs(struct coordinate xy,int itbound) {double x=xy.x, y=xy.y; int it;for (it=0; it<itbound; it++) {
double xx,yy;xx = x*x - y*y + xy.x;yy = 2*x*y + xy.y;x = xx; y = yy;if (x*x+y*y>4.) {return it;
}}return 0;}
In the former case, the point could be in the Mandelbrot set, and we colour it black, in the latter case wegive it a colour depending on the iteration number.
if (iteration==0)memset(colour,0,3*sizeof(float));
370 Parallel Computing – r428

37.3. Mandelbrot set
else {float rfloat = ((float) iteration) / workcircle->infty;colour[0] = rfloat;colour[1] = MAX((float)0,(float)(1-2*rfloat));colour[2] = MAX((float)0,(float)(2*(rfloat-.5)));}
We use a fairly simple code for the worker processes: they execute a loop in which they wait for input,process it, return the result.
void queue::wait_for_work(MPI_Comm comm,circle *workcircle) {MPI_Status status; int ntids;MPI_Comm_size(comm,&ntids);int stop = 0;
while (!stop) {struct coordinate xy;int res;
MPI_Recv(&xy,1,coordinate_type,ntids-1,0, comm,&status);stop = !workcircle->is_valid_coordinate(xy);if (stop) break; //res = 0;else {
res = belongs(xy,workcircle->infty);}MPI_Send(&res,1,MPI_INT,ntids-1,0, comm);
}return;}
A very simple solution using blocking sends on the manager is given:// mandel_serial.cxxclass serialqueue : public queue {private :
int free_processor;public :
serialqueue(MPI_Comm queue_comm,circle *workcircle): queue(queue_comm,workcircle) {free_processor=0;
};/**
The ‘addtask’ routine adds a task to the queue. In thissimple case it immediately sends the task to a workerand waits for the result, which is added to the image.
Victor Eijkhout 371

37. Class projects
This routine is only called with valid coordinates;the calling environment will stop the process oncean invalid coordinate is encountered.
*/int addtask(struct coordinate xy) {MPI_Status status; int contribution, err;
err = MPI_Send(&xy,1,coordinate_type,free_processor,0,comm); CHK(err);
err = MPI_Recv(&contribution,1,MPI_INT,free_processor,0,comm, &status); CHK(err);
coordinate_to_image(xy,contribution);total_tasks++;free_processor = (free_processor+1)%(ntids-1);
return 0;};
Exercise 37.10. Explain why this solution is very inefficient. Make a trace of its executionthat bears this out.
Figure 37.2: Trace of a serial Mandelbrot calculation
372 Parallel Computing – r428
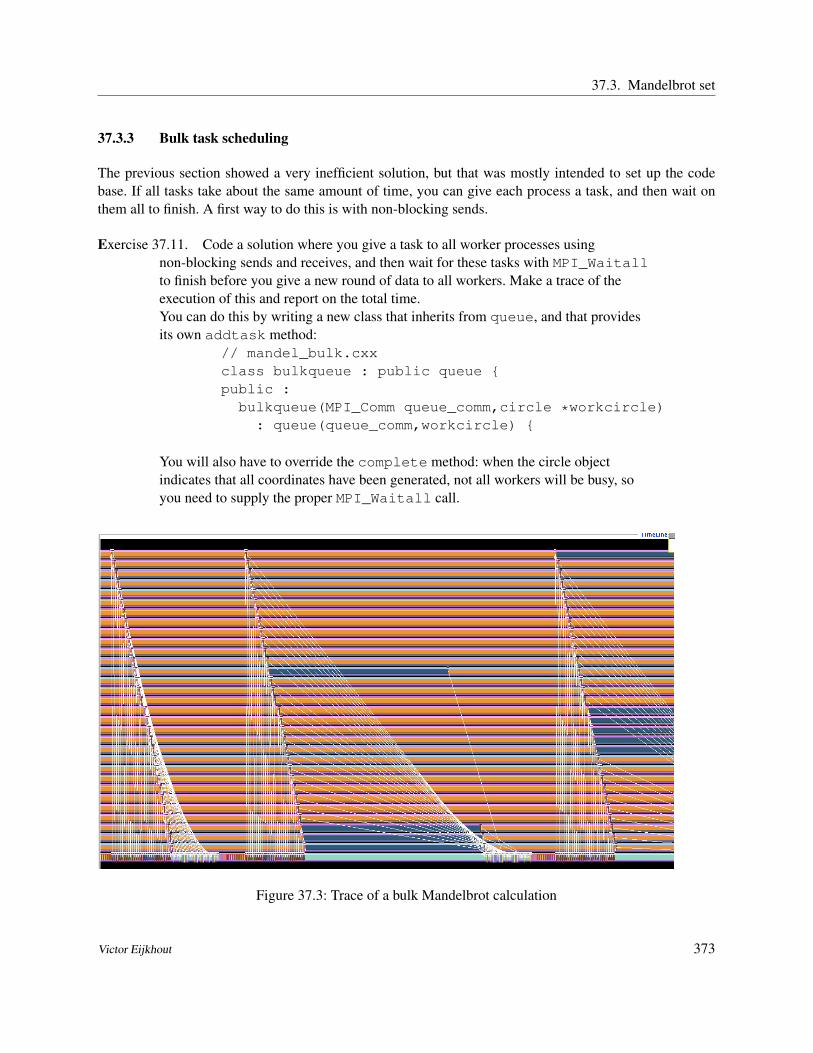
37.3. Mandelbrot set
37.3.3 Bulk task scheduling
The previous section showed a very inefficient solution, but that was mostly intended to set up the codebase. If all tasks take about the same amount of time, you can give each process a task, and then wait onthem all to finish. A first way to do this is with non-blocking sends.
Exercise 37.11. Code a solution where you give a task to all worker processes usingnon-blocking sends and receives, and then wait for these tasks with MPI_Waitallto finish before you give a new round of data to all workers. Make a trace of theexecution of this and report on the total time.You can do this by writing a new class that inherits from queue, and that providesits own addtask method:
// mandel_bulk.cxxclass bulkqueue : public queue {public :
bulkqueue(MPI_Comm queue_comm,circle *workcircle): queue(queue_comm,workcircle) {
You will also have to override the complete method: when the circle objectindicates that all coordinates have been generated, not all workers will be busy, soyou need to supply the proper MPI_Waitall call.
Figure 37.3: Trace of a bulk Mandelbrot calculation
Victor Eijkhout 373

37. Class projects
37.3.4 Collective task scheduling
Another implementation of the bulk scheduling of the previous section would be through using collectives.
Exercise 37.12. Code a solution which uses scatter to distribute data to the worker tasks, andgather to collect the results. Is this solution more or less efficient than the previous?
37.3.5 Asynchronous task scheduling
At the start of section 37.3.3 we said that bulk scheduling mostly makes sense if all tasks take similar timeto complete. In the Mandelbrot case this is clearly not the case.
Exercise 37.13. Code a fully dynamic solution that uses MPI_Probe or MPI_Waitany.Make an execution trace and report on the total running time.
Figure 37.4: Trace of an asynchronous Mandelbrot calculation
37.3.6 One-sided solution
Let us reason about whether it is possible (or advisable) to code a one-sided solution to computing theMandelbrot set. With active target synchronization you could have an exposure window on the host towhich the worker tasks would write. To prevent conflicts you would allocate an array and have each workerwrite to a separate location in it. The problem here is that the workers may not be sufficiently synchronizedbecause of the differing time for computation.
Consider then passive target synchronization. Now the worker tasks could write to the window on themanager whenever they have something to report; by locking the window they prevent other tasks from
374 Parallel Computing – r428

37.3. Mandelbrot set
interfering. After a worker writes a result, it can get new data from an array of all coordinates on themanager.
It is hard to get results into the image as they become available. For this, the manager would continuouslyhave to scan the results array. Therefore, constructing the image is easiest done when all tasks are concluded.
Victor Eijkhout 375

37. Class projects
Figure 37.5: A grid divided over processors, with the ‘ghost’ region indicated
37.4 Data parallel grids
In this section we will gradually build a semi-realistic example program. To get you started some pieceshave already been written: as a starting point look at code/mpi/c/grid.cxx.
37.4.1 Description of the problem
With this example you will investigate several strategies for implementing a simple iterative method. Let’ssay you have a two-dimensional grid of datapoints G = {gij : 0 ≤ i < ni, 0 ≤ j < nj} and you want tocompute G′ where
g′ij = 1/4 · (gi+1,j + gi−1,j + gi,j+1 + gi,j−1). (37.1)
This is easy enough to implement sequentially, but in parallel this requires some care.
Let’s divide the gridG and divide it over a two-dimension grid of pi×pj processors. (Other strategies exist,but this one scales best; see section HPSC-6.5.) Formally, we define two sequences of points
0 = i0 < · · · < ipi < ipi+1 = ni, 0 < j0 < · · · < jpj < ipj+1 = nj
and we say that processor (p, q) computes gij for
ip ≤ i < ip+1, jq ≤ j < jq+1.
From formula (37.1) you see that the processor then needs one row of points on each side surrounding itspart of the grid. A picture makes this clear; see figure 37.5. These elements surrounding the processor’sown part are called the halo or ghost region of that processor.
The problem is now that the elements in the halo are stored on a different processor, so communication isneeded to gather them. In the upcoming exercises you will have to use different strategies for doing so.
376 Parallel Computing – r428

37.4. Data parallel grids
37.4.2 Code basics
The program needs to read the values of the grid size and the processor grid size from the commandline, aswell as the number of iterations. This routine does some error checking: if the number of processors doesnot add up to the size of MPI_COMM_WORLD, a nonzero error code is returned.
ierr = parameters_from_commandline(argc,argv,comm,&ni,&nj,&pi,&pj,&nit);
if (ierr) return MPI_Abort(comm,1);
From the processor parameters we make a processor grid object:
processor_grid *pgrid = new processor_grid(comm,pi,pj);
and from the numerical parameters we make a number grid:
number_grid *grid = new number_grid(pgrid,ni,nj);
Number grids have a number of methods defined. To set the value of all the elements belonging to aprocessor to that processor’s number:
grid->set_test_values();
To set random values:
grid->set_random_values();
If you want to visualize the whole grid, the following call gathers all values on processor zero and printsthem:
grid->gather_and_print();
Next we need to look at some data structure details.
The definition of the number_grid object starts as follows:
class number_grid {public:processor_grid *pgrid;double *values,*shadow;
where values contains the elements owned by the processor, and shadow is intended to contain thevalues plus the ghost region. So how does shadow receive those values? Well, the call looks like
grid->build_shadow();
and you will need to supply the implementation of that. Once you’ve done so, there is a routine that printsout the shadow array of each processor
Victor Eijkhout 377

37. Class projects
grid->print_shadow();
This routine does the sequenced printing that you implemented in exercise ??.
In the file code/mpi/c/grid_impl.cxx you can see several uses of the macro INDEX. This trans-lates from a two-dimensional coordinate system to one-dimensional. Its main use is letting you use (i, j)coordinates for indexing the processor grid and the number grid: for processors you need the translation tothe linear rank, and for the grid you need the translation to the linear array that holds the values.
A good example of the use of INDEX is in the number_grid::relax routine: this takes points fromthe shadow array and averages them into a point of the values array. (To understand the reason for thisparticular averaging, see HPSC-4.2.3 and HPSC-5.5.3.) Note how the INDEX macro is used to index in ailength× jlength target array values, while reading from a (ilength + 2)× (jlength + 2) sourcearray shadow.
for (i=0; i<ilength; i++) {for (j=0; j<jlength; j++) {int c=0;double new_value=0.;for (c=0; c<5; c++) {
int ioff=i+1+ioffsets[c],joff=j+1+joffsets[c];new_value += coefficients[c] *shadow[ INDEX(ioff,joff,ilength+2,jlength+2) ];}values[ INDEX(i,j,ilength,jlength) ] = new_value/8.;
}}
378 Parallel Computing – r428

37.5. N-body problems
37.5 N-body problems
N-body problems describe the motion of particles under the influence of forces such as gravity. There aremany approaches to this problem, some exact, some approximate. Here we will explore a number of them.
For background reading see HPSC-10.
37.5.1 Solution methods
It is not in the scope of this course to give a systematic treatment of all methods for solving the N-bodyproblem, whether exactly or approximately, so we will just consider a representative selection.
1. Full N2 methods. These compute all interactions, which is the most accurate strategy, but alsothe most computationally demanding.
2. Cutoff-based methods. These use the basic idea of theN2 interactions, but reduce the complexityby imposing a cutoff on the interaction distance.
3. Tree-based methods. These apply a coarsening scheme to distant interactions to lower the com-putational complexity.
37.5.2 Shared memory approaches
37.5.3 Distributed memory approaches
Victor Eijkhout 379

Chapter 38
Bibliography, index, and list of acronyms
38.1 Bibliography
[1] Ernie Chan, Marcel Heimlich, Avi Purkayastha, and Robert van de Geijn. Collective communication:theory, practice, and experience. Concurrency and Computation: Practice and Experience, 19:1749–1783, 2007.
[2] Tom Cornebize, Franz C Heinrich, Arnaud Legrand, and Jerome Vienne. Emulating High Perfor-mance Linpack on a Commodity Server at the Scale of a Supercomputer. working paper or preprint,December 2017.
[3] Victor Eijkhout. Performance of MPI sends of non-contiguous data. arXiv e-prints, pagearXiv:1809.10778, Sep 2018.
[4] Eijkhout, Victor with Robert van de Geijn and Edmond Chow. Introduction to High Performance Sci-entific Computing. lulu.com, 2011. http://www.tacc.utexas.edu/˜eijkhout/istc/istc.html.
[5] Brice Goglin. Managing the Topology of Heterogeneous Cluster Nodes with Hardware Locality(hwloc). In International Conference on High Performance Computing & Simulation (HPCS 2014),Bologna, Italy, July 2014. IEEE.
[6] W. Gropp, E. Lusk, and A. Skjellum. Using MPI. The MIT Press, 1994.[7] Torsten Hoefler, Prabhanjan Kambadur, Richard L. Graham, Galen Shipman, and Andrew Lums-
daine. A case for standard non-blocking collective operations. In Proceedings, Euro PVM/MPI,Paris, France, October 2007.
[8] Torsten Hoefler, Christian Siebert, and Andrew Lumsdaine. Scalable communication protocols fordynamic sparse data exchange. SIGPLAN Not., 45(5):159–168, January 2010.
[9] INRIA. SimGrid homepage. http://simgrid.gforge.inria.fr/.[10] L. V. Kale and S. Krishnan. Charm++: Parallel programming with message-driven objects. In Parallel
Programming using C++, G. V. Wilson and P. Lu, editors, pages 175–213. MIT Press, 1996.[11] M. Li, H. Subramoni, K. Hamidouche, X. Lu, and D. K. Panda. High performance mpi datatype
support with user-mode memory registration: Challenges, designs, and benefits. In 2015 IEEE Inter-national Conference on Cluster Computing, pages 226–235, Sept 2015.
[12] Zhenying Liu, Barbara Chapman, Tien-Hsiung Weng, and Oscar Hernandez. Improving the perfor-mance of openmp by array privatization. In Proceedings of the OpenMP Applications and Tools 2003International Conference on OpenMP Shared Memory Parallel Programming, WOMPAT’03, pages244–259, Berlin, Heidelberg, 2003. Springer-Verlag.
380

[13] R. Thakur, W. Gropp, and B. Toonen. Optimizing the synchronization operations in MPI one-sidedcommunication. Int’l Journal of High Performance Computing Applications, 19:119–128, 2005.
Victor Eijkhout 381

38.2 List of acronyms
AVX Advanced Vector ExtensionsBSP Bulk Synchronous ParallelCAF Co-array FortranCUDA Compute-Unified Device ArchitectureDAG Directed Acyclic GraphDSP Digital Signal ProcessingFEM Finite Element MethodFPU Floating Point UnitFFT Fast Fourier TransformFSA Finite State AutomatonGPU Graphics Processing UnitHPC High-Performance ComputingHPF High Performance FortranICV Internal Control VariableMIC Many Integrated CoresMPMD Multiple Program Multiple DataMIMD Multiple Instruction Multiple DataMPI Message Passing InterfaceMTA Multi-Threaded ArchitectureNUMA Non-Uniform Memory AccessOS Operating System
PGAS Partitioned Global Address SpacePDE Partial Diffential EquationPRAM Parallel Random Access MachineRDMA Remote Direct Memory AccessRMA Remote Memory AccessSAN Storage Area NetworkSaaS Software as-a ServiceSFC Space-Filling CurveSIMD Single Instruction Multiple DataSIMT Single Instruction Multiple ThreadSM Streaming MultiprocessorSMP Symmetric Multi ProcessingSOR Successive Over-RelaxationSP Streaming ProcessorSPMD Single Program Multiple DataSPD symmetric positive definiteSSE SIMD Streaming ExtensionsTLB Translation Look-aside BufferUMA Uniform Memory AccessUPC Unified Parallel CWAN Wide Area Network
382 Parallel Computing – r428

38.3. Index
38.3 Index
Bold reference: defining passage; italic reference: illustration.
38.3.1 General Index
active target synchronization, 164, 168affinity, 335
process and thread, 335–338thread
on multi-socket nodes, 292all-to-all, 30allocate
and private/shared data, 266allreduce, 29argc, 22, 24argv, 22, 24atomic operation, 178, 184atomic operations, 181
bandwidth, 60bisecection, 64
barrier, 216implicit, 299non-blocking, 59
batchjob, 13scheduler, 13
Beowulf cluster, 12Boolean satisfiability, 27boost, 15breakpoint, 354broadcast, 29btl_openib_eager_limit, 78btl_openib_rndv_eager_limit, 78bucket brigade, 63, 80
CMPI bindigs, see MPI, C/C++ bindings
C++MPI bindigs, see MPI, C/C++ bindingsstandard library, 132
vector, 132C99, 119
cacheline, 271Charmpp, 13chunk, 255, 256chunk, 255client, 161collectives, 28
neighbourhood, 199, 218non-blocking, 56
column-major storage, 128communication
asynchronous, 102blocking, 76–80
vs non-blocking, 218buffered, 106, 218non-blocking, 87–97one-sided, 164–188one-sided, implementation of, 187–188persistent, 103–106, 218synchronous, 102two-sided, 108
communicator, 25, 148–157info object, 212
compare-and-swap, 84compiler, 134
optimization level, 349completion, 182
local, 182remote, 182
construct, 244contention, 64contiguous
data type, 122core, 19, 239core dump, 349cpp, 242cpuinfo, 334Cray
Victor Eijkhout 383

INDEX
T3E, 222critical section
flush at, 300critical section, 220, 270, 277, 306curly braces, 243
DalcinLisandro, 15
data dependency, 287data race, see race conditiondatatype, 118–139
big, 137derived, 121different on sender and receiver, 125elementary, 118–121
in C, 119in Fortran, 119in Python, 121
signature, 133, 136datatypes
derived, 118elementary, 118
ddd, 349DDT, 349, 356deadlock, 76, 87, 218, 219, 355debug flag, 350debugger, 349debugging, 349–356
parallel, 355dense linear algebra, 152directive
end-of, 243directives, 243, 243
cpp, 247distributed array, 71distributed shared memory, 164doubling
recursive, see recursive doublingdynamic mode, 240
eager limit, 77–78, 217Eclipse, 356
PTP, 356emacs, 363
environment variables, 341epoch, 168
access, 169, 177communication, 168completion, 186exposure, 169, 177passive target, 181, 182
error return, 15ethernet, 14
false sharing, 252, 271fat-tree, 335fence, 168Fibonacci sequence, 280–282first-touch, 296, 336fork/join model, 239, 287Fortran
1-based indexing, 9590
bindings, 15array syntax, 262assumed-shape arrays in MPI, 213fixed-form source, 243forall loops, 262Fortran90, 22MPI bindings, see MPI, Fortran bindingsMPI equivalences of scalar types, 119MPI issues, 212–213
Fortran2008MPI bindings, see MPI, Fortran2008 bindings
Fortran77PETSc interface, 322
Fortran90PETSc interface, 322
Fortran90 typesin MPI, 212
gather, 29Gauss-Jordan algorithm, 37gcc
thread affinity, 297gdb, 349–356ghost region, 376GNU, 349
384 Parallel Computing – r428

INDEX
gdb, see gdbgraph
topology, 199, 218unweighted, 200
graph topology, 335grid
Cartesian, 197periodic, 197processor, 335
group, 177group of
processors, 178
halo, 376update, 173
handshake, 219hdf5, 190, 344heat equation, 294histogram, 278hostname, 213hwloc, 334hyperthreading, 336
I/Oin OpenMP, 261
I_MPI_ASYNC_PROGRESS_..., 91I_MPI_EAGER_THRESHOLD, 78ibrun, 160implicit barrier, 276
after single directive, 262indexed
data type, 122inner product, 32input redirection
shell, 221instrumentation, 357Intel, 219
compilerthread affinity, 297
compiler suite, 334Haswell, 336Knight’s Landing, 239, 302
thread placement, 295MPI, 91
mpi, 78, 160Paragon, 91SandyBridge, 336Sandybridge, 239
intercommunicator, 158interconnect, 359Internal Control Variable (ICV), 305–307
jumpshot, 358
KMP_AFFINITY, 297
latency, 60hiding, 91, 218
lexical scope, 263linked list, 283load balancing, 253load imbalance, 253lock, 278, 278–280
flush at, 300nested, 279
Lonestar5, 336LU factorization, 255Lustre, 344
mallocand private/shared data, 266
malloc, 296manager-worker, 369manager-worker model, 95Mandelbrot set, 27, 269, 369master-worker, 184master-worker model, 100matching, 219matching queue, 98matrix
sparse, 57transposition, 153
matrix-vector productdense, 43sparse, 44
Mellanox, 219message
collision, 218count, 101
Victor Eijkhout 385

INDEX
status, 84–86, 99error, 100source, 99tag, 100
tag, 341Monte Carlo codes, 26motherboard, 238move_pages, 297MPI
1, 196, 2023, 137, 178, 203
C++ bindings removed, 15Fortran2008 interface, 15
C/C++ bindings, 15constants, 223–224, 228–229
compile-time, 223, 228link-time, 223, 228
datatypeextent, 135size, 134subarray, 135vector, 134
Fortran bindings, 15Fortran issues, see Fortran, MPI issues, 230Fortran2008 bindings, 15I/O, 211, 344initialization, 22Python bindings, 15–16Python issues, 224semantics, 219version, 214
mpi.h, 22mpi.h, 16MPI/O, 190–195mpi4py, 15mpi_f08, 15mpiexec, 13, 21, 24, 158mpiexec, 21mpif.h, 22mpirun, 13, 14, 24, 148
and environment variables, 341MPL, 15mulpd, 302
mulsd, 302multicore, 240Multiple Program Multiple Data (MPMD), 222MV2_IBA_EAGER_THRESHOLD, 78mvapich, 341mvapich2, 78mvapich2, 340
nested parallelism, 248–249netcdf, 190network
card, 219contention, 218port
oversubscription, 218node, 19
cluster, 238norm
one, 55numactl, 336numerical integration, 251numpy, 15, 121, 224
od, 190omp
barrierimplicit, 276
forbarrier behaviour, 276
reduction, 270–274user-defined, 273–274
OMP_NUM_THREADS, 341OpenMP
accelerator support in, 309co-processor support in, 309compiling, 241–242environment variables, 242, 305–307library routines, 305–307places, 292running, 242tasks, 283–291
data, 284–286dependencies, 287–289synchronization, 286–287
386 Parallel Computing – r428

INDEX
version 4, 289OpenMPI, 78operating system, 309operator, 53–56
predefined, 54user-defined, 54
origin, 164, 178owner computes, 72
package, 334packing, 137parallel
data, 297embarrassingly, 297
parallel region, 240, 246–249, 260barrier at the end of, 276dynamic scope, 248, 265flush at, 300
parallel regionsnested, 306
paraprof, 357ParMetis, 218passive target synchronization, 164, 180, 181pbing, 297persistent communication, see communication, per-
sistentPETSc, 218PETSC_ARCH, 322PETSC_DIR, 322pin a thread, 336ping-pong, 74, 216PMI_RANK, 222point-to-point, 73polling, 91, 93posting, 87pragma, see for list see under ‘omp’, 243prefix operation, 51process, 19processes status of, 222producer-consumer, 298progress
asynchronous, 91purify, 353PVM, 13, 158
PythonMPI bindigs, see MPI, Python bindingsPETSc interface, 322
race condition, 178, 184, 270, 277, 299, 307in OpenMP, 299–300
random number generation, 269random number generator, 308Ranger, 335rar, 186raw, 186ray tracing, 206recursive doubling, 64redirection, see shell, input redirectionreduction, 29region of code, 245register
SSE2, 302Riemann sums, 251RMA
active, 164passive, 164
root, 33root process, 29
scan, 30exclusive, 52inclusive, 51
scatter, 29sched_setaffinity, 297schedule
clause, 255scope
lexical, 240of variables, 240
SEEK_SET, 195segmentation fault, 351segmented scan, 53send
buffered, 106sentinel, 243, 247sequential consistency, 300serialization, 79server, 161
Victor Eijkhout 387

INDEX
SetThreadAffinityMask, 297shared data, 240shmem, 222silo, 190SimGrid, 63, 359–360
compiler, 359Single Program Multiple Data (SPMD), 243, 246sizeof, 167, 213smpicc, 359smpirun, 359socket, 19, 204, 238, 339sort
odd-even transposition, 84radix, 44swap, 84
sortingradix, 44
sparse matrix vector product, 53spin-lock, 306ssh, 13stack, 306
overflow, 264per thread, 264
Stampedecompute node, 336largemem node, 336node, 239
standard deviation, 29start/affinity, 297status
of received message, 85stderr, 221stdout, 221stdout/err of, 221stencil
nine-point, 197star, 197
storage association, 264, 267stride, 128struct
data type, 122structured block, 244Sun
compiler, 297SUNW_MP_PROCBIND, 297symbol table, 349, 350synchronization
in OpenMP, 275–282
tacc_affinity, 336, 339tag
bound on value, 214target, 164, 177
active synchronization, see active target syn-chronization
passive synchronization, see passive target syn-chronization
taskscheduler, 283scheduling point, 289
taskset, 297TAU, 357–358thread
affinity, 292–296migrating a, 295private data, 267
thread-safe, 307–308threads, 239
hardware, 240, 336initial, 247master, 240, 247team of, 239, 247
time slicing, 19, 240time-slicing, 160timing
MPI, 215–217topology
virtual, 196TotalView, 349, 356tree
traversalpost-order, 290pre-order, 291
tunnelssh, 221
ulimit, 264
388 Parallel Computing – r428

INDEX
Unixprocess, 264
valarray, 297valgrind, 353–354vector
data type, 122instructions, 301
vi, 363virtual shared memory, 164
wall clock, 215, 230war, 186waw, 186while loop, 283while loops, 258window, 164–169
consistency, 182displacement unit, 170, 186info object, 212memory
model, 186separate, 186unified, 186
memory allocation, 166–168private, 186public, 186
work sharing, 240work sharing construct, 260workshare
flush after, 300worksharing constructs
implied barriers at, 276wormhole routing, 64wraparound connections, 197
Zoltan, 218
Victor Eijkhout 389

INDEX
38.3.2 Index of MPI commands
0_MPI_OFFSET_KIND, 195
accumulate_ops, 186accumulate_ordering, 186alloc_shared_noncontig, 205
DMDACreate2d, 331
hwloc, 336
KSPCreate, 330KSPGetConvergedReason, 330KSPSolve, 330
MatAssemblyBegin, 329MatCreate, 328MatSetPreallocation, 330MatSetSizes, 328MatSetValue, 329MatSizes, 328MPI.SUM, 32MPI_Aint
in Fortran, 121, 230MPI_Init
in Fortran, 213MPI_Abort, 23, 23, 55, 211, 222MPI_Accumulate, 169, 174, 174, 186MPI_ADDRESS_KIND, 223MPI_Aint, 119, 121, 170MPI_Allgather, 42, 42MPI_Allgatherv, 48MPI_Alloc_mem, 166, 167, 167MPI_Allreduce, 31, 32, 44MPI_Alltoall, 43, 44MPI_Alltoallv, 44, 48, 51MPI_ANY_SOURCE, 45, 46, 63, 85, 95, 99, 101,
164, 219, 224MPI_ANY_TAG, 82, 85, 100, 224MPI_APPNUM, 214MPI_ARGV_NULL, 223MPI_ARGVS_NULL, 223MPI_ASYNC_PROTECTS_NONBLOCKING, 223MPI_Attr_get, 160, 214
MPI_BAND, 54MPI_Barrier, 47, 216MPI_Bcast, 36, 36MPI_BOR, 54MPI_BOTTOM, 119, 187, 223, 228MPI_Bsend, 106, 106, 107MPI_Bsend_init, 106, 107, 107MPI_BSEND_OVERHEAD, 107, 138, 224MPI_Buffer_attach, 107MPI_Buffer_detach, 107MPI_BXOR, 54MPI_BYTE, 122MPI_Cancel, 224MPI_CART, 196MPI_Cart_coords, 197MPI_Cart_create, 197MPI_Cart_rank, 197MPI_Close_port, 162MPI_Comm, 15–17, 25, 147, 147, 223, 229MPI_Comm_accept, 161, 162, 162MPI_Comm_connect, 161, 162, 162, 210MPI_Comm_create, 154MPI_Comm_create_errhandler, 212MPI_Comm_create_group, 155MPI_Comm_disconnect, 162MPI_Comm_dup, 149, 150, 212MPI_Comm_dup_with_info, 212MPI_Comm_free, 148, 151MPI_Comm_get_errhandler, 212MPI_Comm_get_info, 212MPI_Comm_get_parent, 160MPI_Comm_group, 154, 154MPI_Comm_join, 163MPI_COMM_NULL, 148MPI_Comm_rank, 25, 26, 26, 152MPI_Comm_remote_size, 160, 160MPI_COMM_SELF, 148MPI_Comm_set_errhandler, 211, 212MPI_Comm_set_info, 212MPI_Comm_set_name, 155MPI_Comm_size, 25, 25
390 Parallel Computing – r428

INDEX
MPI_Comm_spawn, 158, 158, 213MPI_Comm_spawn_multiple, 161, 214MPI_Comm_split, 47, 151, 151, 152MPI_Comm_split_type, 203, 203, 206MPI_COMM_TYPE_SHARED, 204MPI_COMM_WORLD, 25, 36, 147, 148, 157, 158,
160, 206, 213, 214, 223, 225, 228, 229MPI_Compare_and_swap, 181, 181MPI_Count, 137MPI_COUNT_KIND, 223MPI_Datatype, 40, 122, 122, 227MPI_DATATYPE_NULL, 123MPI_DISPLACEMENT_CURRENT, 193MPI_DIST_GRAPH, 196MPI_Dist_graph_create, 199, 200, 200, 201MPI_Dist_graph_create_adjacent, 199MPI_Dist_graph_neighbors_count, 202MPI_DOUBLE, 118MPI_DOUBLE_INT, 54MPI_DOUBLE_PRECISION, 118MPI_ERR_ARG, 210MPI_ERR_BUFFER, 107, 210MPI_ERR_COMM, 210, 213MPI_ERR_INFO, 210MPI_ERR_INTERN, 107, 210MPI_ERR_OTHER, 210MPI_ERR_PORT, 162, 210MPI_ERR_SERVICE, 163, 210MPI_ERRCODES_IGNORE, 159, 223MPI_Errhandler, 211MPI_ERROR, 100, 211MPI_Error_string, 210, 211MPI_ERRORS_ARE_FATAL, 211MPI_ERRORS_RETURN, 211, 211MPI_Exscan, 52, 53mpi_f08, 15MPI_Fetch_and_op, 178, 178, 180, 184MPI_File, 190MPI_File_close, 191MPI_File_delete, 191MPI_File_get_size, 195MPI_File_get_view, 195MPI_File_open, 190
MPI_File_preallocate, 195MPI_File_read, 192MPI_File_read_all, 192MPI_File_read_at, 192MPI_File_read_ordered, 192MPI_File_read_shared, 192MPI_File_seek, 192MPI_File_set_size, 195MPI_File_set_view, 192, 194MPI_File_write, 192, 194MPI_File_write_all, 192MPI_File_write_at, 192, 193MPI_File_write_ordered, 192MPI_File_write_shared, 192MPI_Finalize, 22, 22–24MPI_Finalized, 24MPI_FLOAT, 36, 118MPI_Gather, 40, 40, 48, 49, 129MPI_Gatherv, 48, 49, 49MPI_Get, 169, 171, 171MPI_Get_accumulate, 175, 178, 179, 180, 186MPI_Get_address, 132, 132MPI_Get_count, 97, 101, 137MPI_Get_elements, 137MPI_Get_elements_x, 137MPI_Get_processor_name, 23, 24, 25, 213MPI_Get_version, 214, 214MPI_GRAPH, 196MPI_Graph_create, 202MPI_Group, 154, 154MPI_Group_difference, 155MPI_Group_excl, 155MPI_Group_incl, 155MPI_HOST, 214MPI_Iallgather, 58MPI_Iallreduce, 58MPI_Ibarrier, 57, 59, 59MPI_Ibcast, 57, 57MPI_Ibsend, 107MPI_IN_PLACE, 32, 41, 223MPI_Info, 186, 205, 212MPI_Info_create, 208, 212MPI_Info_delete, 208
Victor Eijkhout 391

INDEX
MPI_Info_dup, 209MPI_INFO_ENV, 24, 212MPI_Info_free, 209, 212MPI_Info_get, 209, 212MPI_Info_get_nkeys, 209MPI_Info_get_nthkey, 209MPI_Info_nkeys, 212MPI_Info_set, 208, 212MPI_Init, 22, 22–24, 220, 223, 225, 228, 332MPI_Init_thread, 220, 220, 225, 341, 341MPI_Initialized, 23MPI_INT, 36, 225MPI_INTEGER, 36MPI_INTEGER_KIND, 223MPI_Intercomm_create, 155MPI_Intercomm_merge, 157, 157MPI_IO, 214MPI_Iprobe, 91, 97MPI_Irecv, 45, 65, 87, 87, 88, 91, 94, 99, 103,
108MPI_Is_thread_main, 220MPI_Isend, 65, 87, 87, 88, 103, 105, 175MPI_KEYVAL_INVALID , 224MPI_LAND, 54MPI_LOCK_EXCLUSIVE, 181, 224MPI_LOCK_SHARED, 181, 224MPI_LOR, 54MPI_LXOR, 54MPI_MAX, 33, 54MPI_MAX_DATAREP_STRING, 223MPI_MAX_ERROR_STRING, 211, 223MPI_MAX_INFO_KEY, 209, 223MPI_MAX_INFO_VAL, 223MPI_MAX_LIBRARY_VERSION_STRING, 223MPI_MAX_OBJECT_NAME, 223MPI_MAX_PORT_NAME, 161, 223MPI_MAX_PROCESSOR_NAME, 24, 25, 214, 223,
228MPI_MAXLOC, 54, 54MPI_Message, 98MPI_MIN, 54MPI_MINLOC, 54MPI_MODE_APPEND, 191
MPI_MODE_CREATE, 191MPI_MODE_DELETE_ON_CLOSE, 191MPI_MODE_EXCL, 191MPI_MODE_NOCHECK, 176, 178MPI_MODE_NOPRECEDE, 177MPI_MODE_NOPUT, 176, 177MPI_MODE_NOSTORE, 176, 177MPI_MODE_NOSUCCEED, 177MPI_MODE_RDONLY, 191MPI_MODE_RDWR, 191MPI_MODE_SEQUENTIAL, 191MPI_MODE_UNIQUE_OPEN, 191MPI_MODE_WRONLY, 191MPI_Mprobe, 98, 98MPI_Mrecv, 98, 99MPI_MULT, 53MPI_Neighbor_allgather, 201MPI_Neighbor_allgatherv, 201MPI_Neighbor_allreduce, 201MPI_Neighbor_alltoall, 201MPI_Neighbor_alltoallv, 201MPI_Neighbor_alltoallw, 201MPI_NO_OP, 175, 186MPI_OFFSET_KIND, 195, 223MPI_OP, 54MPI_Op, 33, 51, 52, 56, 211MPI_Op_commutative, 55MPI_Op_create, 53, 54, 55MPI_OP_NULL, 56MPI_Open_port, 161, 161MPI_ORDER_C, 129MPI_ORDER_FORTRAN, 129MPI_Pack, 137MPI_Pack_size, 107, 138MPI_PACKED, 137, 138MPI_Probe, 97, 98, 98MPI_PROC_NULL, 82, 82, 84, 91, 156, 170, 198,
214, 224, 367MPI_PROD, 33, 54MPI_Publish_name, 163MPI_Put, 169, 170, 170, 171, 173MPI_Query_thread, 220, 220MPI_Raccumulate, 176
392 Parallel Computing – r428

INDEX
MPI_REAL, 36, 118MPI_Receive, 84MPI_Recv, 75, 76, 77, 79, 80, 86, 91, 99, 101, 156,
224MPI_Recv_init, 103, 103MPI_Reduce, 34, 35, 48, 175MPI_Reduce_local, 56, 56MPI_Reduce_scatter, 44, 45, 45–47, 188MPI_REPLACE, 175, 175MPI_Request, 17, 57, 88, 97, 103, 108MPI_Request_free, 97, 103, 108MPI_Request_get_status, 97, 108MPI_REQUEST_NULL, 97MPI_Rget, 176MPI_ROOT, 156, 224MPI_Rput, 175MPI_Rsend, 219MPI_Rsend_init, 106MPI_Scan, 51, 51, 53MPI_Scatter, 39, 41MPI_Scatterv, 45, 48MPI_SEEK_SET, 195MPI_Send, 63, 74, 76, 79, 80, 84, 86, 91, 156, 219MPI_Send_init, 103, 103MPI_Sendrecv, 80, 80, 82, 84, 86, 91, 367MPI_Sendrecv_replace, 83, 83MPI_Sizeof, 121, 213, 230MPI_SOURCE, 95, 99, 99, 101, 102MPI_Ssend, 75, 78, 102, 219MPI_Ssend_init, 106MPI_Start, 103, 104, 104MPI_Start_all, 104MPI_Startall, 103, 104MPI_STATUS, 84, 93, 108MPI_Status, 76, 82, 84, 88, 90, 99, 101, 102MPI_STATUS_IGNORE, 75, 85, 88, 90, 95, 223,
228MPI_STATUS_SIZE, 223MPI_STATUSES_IGNORE, 86, 90, 223MPI_SUBARRAYS_SUPPORTED, 223MPI_SUBVERSION, 214, 223MPI_SUCCESS, 16, 107, 210, 211MPI_SUM, 32, 33, 48, 53, 54
MPI_TAG, 100MPI_TAG_UB, 214MPI_Test, 96, 108MPI_Test..., 97MPI_Test...., 95MPI_Testall, 96MPI_Testany, 96MPI_THREAD_FUNNELED, 220MPI_THREAD_FUNNELLED, 341MPI_THREAD_MULTIPLE, 220, 341MPI_THREAD_SERIAL, 341MPI_THREAD_SERIALIZED, 220MPI_THREAD_SINGLE, 220, 341MPI_Topo_test, 196, 196MPI_Type_commit, 123, 123MPI_Type_contiguous, 122, 123, 123, 224,
230MPI_Type_create_f90_complex, 120MPI_Type_create_f90_integer, 119MPI_Type_create_f90_real, 120MPI_Type_create_hindexed, 131MPI_Type_create_hindexed_block, 132MPI_Type_create_struct, 132MPI_Type_create_subarray, 123, 128, 129MPI_Type_extent, 135MPI_Type_free, 123MPI_Type_get_extent, 135MPI_Type_get_true_extent, 135, 135MPI_Type_hindexed, 123, 134MPI_Type_indexed, 123, 129, 129, 132MPI_Type_size, 134, 134MPI_Type_struct, 123MPI_Type_vector, 122, 124, 124MPI_UB, 134MPI_UNDEFINED, 196, 224MPI_UNIVERSE_SIZE, 160, 214MPI_Unpack, 137MPI_Unpublish_name, 163, 210MPI_UNWEIGHTED, 200, 223MPI_VERSION, 214, 223, 228MPI_Wait, 57, 88, 88, 90, 92, 99, 103, 168MPI_Wait..., 85, 90, 97, 99, 105, 108MPI_Waitall, 90, 90, 92, 92, 93, 164
Victor Eijkhout 393

INDEX
MPI_Waitany, 86, 90, 92, 93, 93, 95MPI_Waitsome, 90, 93MPI_WEIGHTS_EMPTY, 223MPI_Win, 121, 165MPI_Win_allocate, 166, 167, 167, 186, 187MPI_Win_allocate_shared, 166, 187, 204,
204, 205MPI_Win_attach, 185MPI_Win_complete, 177MPI_Win_create, 121, 166, 166, 167, 186, 187,
224, 230MPI_Win_create_dynamic, 166, 185, 187MPI_Win_detach, 185MPI_Win_fence, 30, 168, 176, 368MPI_WIN_FLAVOR_ALLOCATE, 187MPI_WIN_FLAVOR_CREATE, 187MPI_WIN_FLAVOR_DYNAMIC, 187MPI_WIN_FLAVOR_SHARED, 187MPI_Win_flush, 182, 182MPI_Win_flush..., 176MPI_Win_flush_all, 182MPI_Win_flush_local, 183, 183MPI_Win_flush_local_all, 183MPI_Win_get_info, 212MPI_Win_lock, 177, 180, 181MPI_Win_lock_all, 182, 182MPI_Win_post, 176, 177MPI_WIN_SEPARATE, 187MPI_Win_set_info, 212MPI_Win_shared_query, 204, 205MPI_Win_start, 176, 177MPI_Win_sync, 184MPI_WIN_UNIFIED, 187MPI_Win_unlock, 182, 182MPI_Win_unlock_all, 182MPI_Win_wait, 177MPI_Wtick, 215, 215, 217, 231, 231MPI_Wtime, 75, 215, 215, 230, 230MPI_WTIME_IS_GLOBAL, 214, 216, 231
no_locks, 186numactl, 297
omp_get_wtick, 307
omp_get_wtime, 307
PetscComm, 332PetscInitialize, 332PetscPrintf, 323PetscSynchronizedFlush, 323PetscSynchronizedPrintf, 323PMPI_..., 217
same_op, 186same_op_no_op, 186
tacc_affinity, 297
VecCreate, 325VecGetArray, 327VecGetSize, 326VecNorm, 326VecSetSize, 325VecView, 326
394 Parallel Computing – r428

INDEX
38.3.3 Index of OpenMP commands
_OPENMP, 242
ompatomic, 277, 299barrier, 275cancel, 289critical, 277, 308declare simd, 301flush, 279, 300lastprivate, 258master, 261, 262, 341ordered, 257parallel, 243, 246, 295parallel for, 250private, 264section, 260sections, 260, 267simd, 301, 301single, 261task, 283, 286, 287taskgroup, 287taskwait, 286, 287, 289taskyield, 289threadprivate, 267, 297, 308workshare, 262
omp clausealigned, 301collapse, 256copyin, 268copyprivate, 262, 268default, 265
firstprivate, 266none, 266private, 266shared, 266
depend, 287firstprivate, 267, 285lastprivate, 267linear, 301nowait, 257, 276, 309ordered, 257private, 264
proc bind, 293, 295reduction, 271, 273safelen(n), 301schedule, 308
auto, 254chunk, 253guided, 254runtime, 254
untied, 289OMP_CANCELLATION, 305OMP_DEFAULT_DEVICE, 306omp_destroy_nest_lock, 279OMP_DISPLAY_ENV, 292, 305OMP_DYNAMIC, 269, 306, 306omp_get_active_level, 305omp_get_ancestor_thread_num, 305omp_get_dynamic, 305, 306omp_get_level, 305omp_get_max_active_levels, 305omp_get_max_threads, 305, 306omp_get_nested, 305, 306omp_get_num_procs, 305, 306omp_get_num_threads, 246, 305, 306omp_get_schedule, 255, 305, 306omp_get_team_size, 305omp_get_thread_limit, 305omp_get_thread_num, 246, 305, 306omp_get_wtick, 305omp_get_wtime, 305omp_in, 273omp_in_parallel, 249, 305, 306omp_init_nest_lock, 279OMP_MAX_ACTIVE_LEVELS, 306OMP_MAX_TASK_PRIORITY, 306OMP_NESTED, 306, 306OMP_NUM_THREADS, 242, 306, 306omp_out, 273OMP_PLACES, 292, 294, 306omp_priv, 273OMP_PROC_BIND, 292, 295, 306, 307omp_sched_affinity, 255
Victor Eijkhout 395

INDEX
omp_sched_auto, 255omp_sched_dynamic, 255omp_sched_guided, 255omp_sched_runtime, 255omp_sched_static, 256OMP_SCHEDULE, 254, 255, 306, 306omp_set_dynamic, 305, 306omp_set_max_active_levels, 305omp_set_nest_lock, 280omp_set_nested, 305, 306omp_set_num_threads, 305, 306omp_set_schedule, 255, 305, 306OMP_STACKSIZE, 264, 306, 306omp_test_nest_lock, 280OMP_THREAD_LIMIT, 306omp_unset_nest_lock, 280OMP_WAIT_POLICY, 248, 306, 306
schedule, 252
396 Parallel Computing – r428

INDEX
4002877813879
ISBN 978-1-387-40028-790000
Victor Eijkhout 397





























