Embed Size (px)
Citation preview

Proteomic analysis of sea urchin immune
responses and characterisation of highly
variable immune response proteins
Dheilly Nolwenn Marie
(B.Sc.) Licence de biologie des organismes option toxicologie (UBO, Brest)
(M.Sc.) Maîtrise de biologie des populations et écosystèmes marins options biodiversité
et biochimie, Institut Universitaire Européen de la Mer (UBO, Brest)
(M.Sc.) Master de protéomique (USTL, Lille)
Macquarie University
A thesis submitted to Macquarie University in partial fulfilment of the
requirements of the degree of Doctor of Philosophy
Department of Biological Sciences
Macquarie University
Sydney, NSW
Australia
November 2009

ii

iii
TABLE OF CONTENTS
Title page i
Table of contents iii
List of Figures and Tables ix
List of abbreviations xiii
Summary xv
Declaration of authorship and originality xvii
Acknowledgements xix
CHAPTER I: General Introduction 1
1.1. Sea urchins 3
1.1.1. Echinoderms and other deuterostomes 3
1.1.2. Evolutionary considerations within the echinoderms 5
1.1.3. Classification 5
1.1.4. Sea urchin anatomy 7
1.1.5. Coelomic fluid and coelomocytes 10
1.1.6. The sea urchin genome project 14
1.2. Comparative immunology of echinoderms 16
1.2.1. Sea urchin immune response molecules 16
1.2.2. The complement system of sea urchins 17
1.2.3. The lectin-mediated complement system in sea urchins 19
1.2.4. Immunoglobulin superfamily rearrangement 19
1.3. Highly variable gene systems associated with pathogen defence 23
1.3.1. Life history strategies 24
1.3.2. Variable lymphocyte receptors (VLRs) 25

iv
1.3.3. V-region-containing chitin-binding protein (VCBPs) 26
1.3.4. Fibrinogens related proteins (FREPs) 27
1.3.5. Down’s syndrome cell adhesion molecules (Dscam) 28
1.4. The 185/333 family 30
1.4.1. Discovery 30
1.4.2. Variability of 185/333 mRNAs 31
1.4.3. 185/333 genes 35
1.4.4. Transcriptional and posttranscriptional modifications 39
1.4.5. 185/333 proteins expression and localization 40
1.5. Proteomics and sea urchins 43
1.5.1. From the static image to the dynamic image 43
1.5.2. Gel-based versus gel-free proteomics 45
1.5.3. Gel-based comparative proteomics 47
1.5.4. Gel-free comparative proteomics 49
1.5.5. Proteomics and sea urchins 50
1.6. The aims of this thesis 52
1.7. References 53
CHAPTER II: Shotgun proteomic analysis of coelomocytes from the purple sea
urchin, Strongylocentrotus purpuratus 71
2.1. Preface 73
2.2. Abstract 75
2.3. Dataset Brief 76
2.4. Acknowledgments 87
2.5. References 88

v
CHAPTER III: Proteomic analysis of sea urchin responses to bacterial injection 113
3.1. Preface 115
3.2. Abstract 117
3.3. Introduction 118
3.4. Materials and Methods 120
3.4.1. Sea urchins 120
3.4.2. Immunological challenge and sample collection 120
3.4.3. Protein extraction 120
3.4.4. Two-dimensional gel electrophoresis 121
3.4.5. Gel analysis and selection of protein spots for mass spectrometry
analysis 122
3.4.6. Peptides extraction 123
3.4.7. Nanoflow liquid chromatography – tandem mass spectrometry 123
3.4.8. Protein identification 124
3.5. Results 125
3.6. Discussion 134
3.7. References 137
CHAPTER IV: Timecourse proteomic profiling of cellular responses to
immunological challenge in sea urchins (Heliocidaris erythrogramma) 147
4.1. Preface 149
4.2. Summary 151
4.3. Introduction 152

vi
4.4. Experimental procedures 155
4.4.1. Sea urchins 155
4.4.2. Injections and sample collections 155
4.4.3. Protein extraction 156
4.4.4. One-dimensional sodium dodecyl sulfate – polyacrylamide gel
electrophoresis (1DE SDS-PAGE) 157
4.4.5. Nanoflow liquid chromatography – tandem mass spectrometry 157
4.4.6. Protein identification 158
4.4.7. Data analysis 158
4.5. Results 161
4.5.1. Reproducibility and threshold levels of shotgun MS/MS analysis 161
4.5.2. Functional classification of proteins 163
4.5.3. Identification of individual proteins affected by saline or LPS injection 167
4.6. Discussion 177
4.7. Acknowledgments 185
4.8. References 186
CHAPTER V: Highly variable immune-response (185/333) from the sea urchin,
Strongylocentrotus purpuratus: Proteomic analysis identifies diversity within and
between individuals. 209
5.1. Preface 211
5.2. Abstract 213
5.3. Introduction 214
5.4. Materials and Methods 218
5.4.1. Sea urchins 218

vii
5.4.2. Immunological challenge and sample collection 218
5.4.3. One-dimensional electrophoresis (1DE) 219
5.4.4. Two-dimensional electrophoresis (2DE) 219
5.4.5. Antibodies 220
5.4.6. Western blotting and immunostaining 220
5.4.7. Anti-185/333 ELISA 221
5.4.8. Mass spectrometry and data analysis 222
5.5. Results 225
5.5.1. One-dimensional SDS-PAGE analysis of CF proteins 225
5.5.2. Two-dimensional Western blots of CF proteins 227
5.5.3. Diversity of 185/333 proteins between individuals 229
5.5.4. MS analysis of 185/333+ proteins 233
5.5.5. 185/333 protein expression increases after LPS challenge 237
5.5.6. Diversity of 185/333 protein expression after immunological challenge 239
5.6. Discussion 243
5.7. Acknowledgments 250
5.8. Disclosures 250
5.9. References 251
CHAPTER VI: Ultrastructural localization of a highly variable immune response
protein (185/333) within coelomocytes and the gut of sea urchins 257
6.1. Preface 259
6.2. Summary 261
6.3. Introduction 262
6.4. Materials and Methods 265

viii
6.4.1. Sea urchins 265
6.4.2. Electron microscopy 266
6.4.3. Localization of 185/333 proteins 267
6.4.3.1. Anti-185/333 antisera 267
6.4.3.2. Immunofluorescence microscopy of whole cell 267
6.4.3.3. Immunofluorescence staining of semi-thin resin sections 268
6.4.3.4. Immuno-gold labelling for transmission electron microscopy 269
6.5. Results 271
6.5.1. Characterization of coelomocyte types 271
6.5.2. Immunofluorescence identification of 185/333 proteins in filopodial
amoebocytes and colorless spherule cells 273
6.5.3. Ultrastructure and 185/333 localization of coelomocytes 273
6.5.4. 185/333 proteins in the gut 281
6.5.5. Phagocytosis by coelomocytes 283
6.6. Discussion 286
6.7. References 291
CHAPTER VII: General discussion 297
7.1. General discussion 299
7.2. Caveats and future directions 306
7.3. Concluding remarks 307
7.4. References 308

ix
LIST OF FIGURES AND TABLES
CHAPTER I
Table 1.1: Taxonomy of the two sea urchin species studied in this thesis
Table 1.2: Coelomocytes cell types and functions in the purple sea urchin, S.
purpuratus 11
Table 1.3: General characteristics of highly variable gene systems associated with
pathogen defence in animals 22
Table 1.4: Methods of protein detection for gel-based proteomics 48
Figure 1.1: Position of echinoderms in animal phylogeny relative to the four genera of
animals from which genomes have so far been sequenced 4
Figure 1.2: Internal anatomy of the sea urchin 8
Figure 1.3:Coelomocytes in sea urchin (S. purpuratus) coelomic fluid 12
Figure 1.4: A cDNA-based alignment of 185/333 transcripts 32
Figure 1.5: Five sub-families of 185/333 proteins 33
Figure 1.6: Structure of part of the 185/333 locus 34
Figure 1.7: Repeat-based alignment of the 185/333 genes 36
Figure 1.8: Schematic representation of the consensus 185/333 protein sequence 38
Figure 1.9: Complexity of the proteome 42
Figure 1.10: Flow chart for gel-based and gel-free proteomics 44
CHAPTER II
Table 2.1: The thirty most abundant proteins identified in the coelomic fluid of 3
individual sea urchins 79
Figure 2.1: Functional classification of proteins identified from sea urchin CF 78

x
Figure 2.2: Predicted structure of the 16 scavenger receptor cysteine-rich (SRCR)
proteins identified in the coelomic fluid proteome 82
Supplementary Data 2.1: Detailed Materials and Methods 95
Supplementary Data 2.2: Proteins identified in the coelomic fluid of 3 individual sea
urchins 101
CHAPTER III
Table 3.1: Protein identification of 2DE gel spots from Figure 3.4 131
Figure 3.1: Principal components analysis of proteome profiles after the injection of
saline or bacteria 126
Figure 3.2: Number of 2DE spots that varied significantly in abundance after saline
and bacterial injections, as determined by quantitative analysis of Lava Purple
stained 2DE gels 128
Figure 3.3: Lava Purple stained 2DE maps of CF proteins following Vibrio Sp.
injection 129
Figure 3.4: Log2 normalized volumes of differentially regulated protein spots 130
Figure 3.5: Selected areas of 2DE maps showing proteins (spots 5 and 6) with
abundances that differed significantly (p<0.05) in response to the injection of
bacteria when compared to both non-injected controls and saline-injected sea
urchins 132
Supplementary Data 3.1: Mass spectrometric (LC-MS/MS) data for protein spots
isolated from 2DE gels 141
CHAPTER IV
Table 4.1: Individual proteins with significantly altered relative abundance 169
Figure 4.1: Experimental design 154

xi
Figure 4.2: Alteration in whole proteomes in response to injections 160
Figure 4.3: Relative abundance and functional classification of proteins 164
Figure 4.4: Consistency of the relative abundance data 168
Figure 4.5: Examples of proteins that differed in relative abundance over time but not
between treatments 174
Figure 4.6: Examples of proteins that differed in relative abundance over time and
between treatments 176
Supplementary Data 4.1: Normalized spectral abundance factors 195
CHAPTER V
Table 5.1: Mass spectrometric (LC-MS/MS) data for peptides isolated from 1DE gels
of S. purpuratus CF that match known 185/333 sequences 235
Figure 5.1: 1DE SDS-PAGE and Western blot of CF proteins from an individual sea
urchin 226
Figure 5.2: 2DE Western blot of 185/333+ proteins 228
Figure 5.3: Composite image of a 2DE Western blot 230
Figure 5.4: Enlarged region of a 2DE Western blot of CF proteins 230
Figure 5.5: Different anti-185 sera recognize subsets of 185/333 proteins 231
Figure 5.6: 1DE Western blots of CF from 13 different sea urchins sampled before (A)
and 96 h after (B) challenge with LPS 232
Figure 5.7: 1DE Western blots of CF proteins from three different sea urchins 234
Figure 5.8: The titer of 185/333 proteins in CF increases after immune challenge 238
Figure 5.9: 1DE Western blots of CF collected after sea urchins had been injected with
LPS or PG 240
Figure 5.10: 2DE Western blots of CF collected from a single sea urchin (animal 31)
that had been injected first with LPS and then 360 hours later with PG 242

xii
CHAPTER VI
Figure 6.1: Coelomocyte types in live cells preparation of H erythrogramma CF 270
Figure 6.2: Confocal images of 185/333-positive coelomocytes 272
Figure 6.3: Anti-185/333 immunogold stained transmission electron micrograph of a
colorless spherule cell 274
Figure 6.4: Anti-185/333 immunogold stained transmission electron micrograph of a
filopodial amoebocyte 276
Figure 6.5: Anti-185/333 immunogold stained transmission electron micrograph of a
Golgi apparatus in a filopodial amoebocyte 277
Figure 6.6: Transmission electron micrograph of 185/333-positive vesicles in
filopodial amoebocytes 278
Figure 6.7: Anti-185/333 immunogold stained transmission electron micrograph of
filopodial amoebocyte cell surface 279
Figure 6.8: Anti-185/333 immunogold stained transmission electron micrograph of
gut-associated amoebocytes. 280
Figure 6.9: Anti-185/333 immunogold stained transmission electron micrograph of
vesicles in anuclear bodies in gut tissue 282
Figure 6.10: Phagocytosis by petaloide amoebocytes 284
Figure 6.11: Anti-185/333 immunogold stained transmission electron micrograph of
colorless spherule cells 285

xiii
LIST OF ABBREVIATIONS
1DE; one-dimensional gel
electrophoresis
2DE; two-dimensional gel
electrophoresis
aa; amino acid
aCF; artificial coelomic fluid
ACN; acetonitrile
ANOVA; analyse of variance
ApoLp; apolipoprotein
BCP; 1-bromo-3-chloropropane
BSA; bovine serum albumine
CCT; chaperonin containing TCP1
CBD; chitin binding region
CC; coiled coil domain
CF; coelomic fluid
CID; collision induced dissociation
CMFSW-EI; calcium magnesium free
seawater with EDTA and imidazole
CR3; complement receptor 3
CT; cytoplasmic tail
Dscam; Down’s syndrome cell adhesion
molecule
DTT; dithiothreitol
ER; endoplasmic reticulum
EST; expressed sequence tag
emPAI; exponentially modified protein
abundance index
ESI; electrospray
FBS; fetal bovin serum
FDR; false discovery rate
FREP; fibrinogen-related protein
FSW; filtered seawater
GNBP; gram negative binding protein
G protein; guanine nucleotide binding
protein
GPI; glycosyl phosphatidulinositol
GPM; global proteome machine
HPLC; high performance liquid
chromatography
HSP; heat shock protein
IAA; iodoacetamide
IEF; isoelectrofocalisation
Ig; Immunoglobulin
IgSF; Immunoglobulin superfamily
IPG; immobilized pH gradient
LDL; low density lipoprotein
LLTP; large lipid transfer protein
LPS; lipopolysaccharides

xiv
LRR; leucine-rich region
MALDI; matrix-assisted laser
desorption/ionization
MBP; mannose binding protein
MS; mass spectrometry
MS/MS; tandem mass spectrometry
MudPIT; multidimensional protein
identification technology
MW; molecular weight
MYP; major yolk protein
m/z; mass/charge ratio
nano-LC; nano-liquid chromatography
NBS; nucleotide binding site
NITR; novel immune-type receptor
NLR; NOD-like receptor
NSAF; Normalized spectral abundance
factor
PAMP; pathogen-associated molecular
pattern
PBS; phosphate buffered saline
PC; principal component
PCA; principal component analysis
PDI; protein disulfide isomerase
PG; peptidoglycan
PGRP; peptidoglycan recognition
protein
pI; isoelectric point
PMF; peptide mass fingerprinting
p.i.; post-injection
RACK; receptor of activated C kinase
RAG; recombination activator gene
SDS; sodium dodecyl sulfate
SpBf; S. purpuratus factor B
SpC3; S. purpuratus complement
component 3
SpC; spectral count
SRCR; Scavenger receptor cysteine-rich
SSH; suppressive substractive
hybridization
TdT; terminal deoxynucleotidyl
transferase
TIMP; tissue inhibitor of
metalloproteinase
TLR; Toll-like receptors
TM; transmembrane region
TEM; transmission electron microscopy
TOF; time-of-flight
VCBP; variable chitin-binding protein
VDAC; voltage dependent anion channel
vWF; von Willebrand factor
vWD; von Willebrand-factor type D



xv
SUMMARY
The sea urchin genome sequence identified a large repertoire of genes with
similarities to the immune response genes of vertebrates. This led to the prediction that sea
urchins have a complex immune system, involving a broad array of recognition and
effector proteins. An additional family of highly variable immune response genes (the
185/333 family) distinct from those of vertebrates has been identified in sea urchins by
transcriptomic analysis. Despite this detailed information at the genomic and
transcriptomic levels, complementary analyses have not been undertaken at the level of
proteins.
This thesis takes a proteomic approach to studying sea urchin immune systems. It
reveals a biphasic immune response involving a broad array of proteins. The initial
changes in the coelomic fluid proteome after immunological challenge involved alterations
associated with coelomocyte morphology and plasticity. These early responses did not
differ significantly between sea urchins injected with bacteria, lipopolysaccharides or
saline, suggesting that they were wounding responses. These wound reactions were
followed by a cellular response that showed more specificity to immunological challenge.
This suggests that sea urchin coelomocytes activate different cellular pathways in response
to wounding, as opposed to the presence of purified pathogen associated molecular
patterns (PAMPs) or whole bacteria.
It was also demonstrated that responses to PAMPs involved highly variable
immune response proteins, such as scavenger receptor cysteine rich proteins and 185/333
molecules. It was shown that the large suites of 185/333 proteins expressed by sea urchins
differed between individuals and were altered after challenge with different PAMPs.
185/333 proteins were localized in filopodial amoebocytes, gut-associated amoebocytes
and colorless spherule cells. The patterns of 185/333 protein expression after the injection

xvi
of pathogens suggest that they are involved in the ingestion of degenerative material within
the gut, and may be associated with wound healing and cytotoxicity in the coelomic fluid.
Overall, this thesis demonstrates the efficiency of proteomics in complementing
genomic and transcriptomic data to build a comprehensive picture of the biological
pathways involved in the inducible host defence responses of sea urchins.

xvii
DECLARATION OF AUTHORSHIP AND ORIGINALITY
The work presented in this thesis has not previously been submitted for a degree as
part of the requirements for a degree at any other university or institution. This thesis
contains only original material that has been written by me.
Any additional assistance received during the research work or in preparation of the
thesis itself has been indicated in the appropriate section. I also certify that all information
and literature sources used during the preparation of this thesis have been acknowledged.
Nolwenn M. Dheilly
Department of biological sciences
Macquarie University
North Ryde
NSW, 2109
Australia

xviii

xix
ACKNOWLEDGEMENTS
I left France 4 years ago, wishing to enrol in a PhD and to learn to speak English. I
could have taken a postgraduate course in France but a nagging voice in my head was
telling me that if I didn't go now, I never would. Even though these two aims were fulfilled,
that's not all I remember of this wonderful experience. I immersed myself in a fascinating
foreign culture, I learned a lot at university and met wonderful people that accompanied
me through the emotional highs and lows. My time in Sydney as a PhD candidate has
been an adventure, a love-hate relationship, charged with so much energy that it would be
hard to explain. I have many people to thank for these memories that I will cherish
forever. I might not be able to thank them all within this short section but I will do my
best.
First of all, I thank A. Prof David Raftos and Dr. Sham Nair for inviting me to come
to Australia to undertake my PhD in the Marine and Freshwater Biology Laboratory of
Macquarie University. At the time, I could barely speak English but they trusted me and
believed I could learn. David was very supportive and made me feel like I was wanted in
the lab, which encouraged me study English harder. Unable to make friends with my
limited linguistic abilities, lost in this newly discovered country, his friendship was all I
had and I probably did not thank him enough for that at the time. Over the past three and
a half years, David proved to be a great supervisor and I thank him for his kindness,
accessibility and support. He is a fantastic writer and his help during the writing of my
manuscripts was extremely precious. Most of all, his presence was reassuring and helped
me throughout the hard times, always knowing that he would be there.
My co-supervisor, Dr. Sham Nair was of tremendous help too. He is always there,
always available, always supportive, always kind even if we, students, abuse his
availability much of the time. The door to his office is always open and whatever the

xx
problem is, he tries to solve it. His broad knowledge of the technologies we use is
precious. Most of all, I loved talking with him about science. Our conversations, even
when they were unrelated to my research project, always motivated me and made me want
to do more and try new things in the lab. His love of science is contagious. The ideas we
shared and the hypotheses that came out of our discussions will surely influence many of
my future research projects. From the bottom of my heart, I hope I will have the chance to
work with Sham again in the future.
Over the course of my PhD, I learned a number of new techniques and developed
others. These shaped my thesis and I have many people to thank for their help throughout.
First of all, I would like to thank our collaborator, Prof. Courtney Smith, who I finally met
this year. Even though we mostly communicated via emails, she was actively involved in
the work I undertook on 185/333 proteins. She had many ideas and inspired a number of
my experiments. Courtney's comments on my writing were also very helpful. She always
explained her comments, which helped improve all my manuscripts.
A. Prof. Paul Haynes’ unexpected help shaped the content of my thesis like few
others did. His challenging questions were at times frustrating but they always had an
insightful meaning. His knowledge in mass spectrometry was precious and also helped in
analysing my data and choosing the appropriate normalization methods. Paul, thanks a
lot for your help, without you my thesis would not have been so interesting and novel.
I would also like to thank Debra Birch and Nicole Vella for their tremendous help
when it came to microscopy. Their knowledge in microscopy techniques is extremely
valuable for Macquarie University. Microscopy is not easy; it requires patience, precision,
and time. Without the two of them, I would never have had the patience to keep going and
would not have produced such beautiful pictures that I am now proud to publish.
There are so many others that influenced me over the course of my PhD. I would
like to thank all the students that came through the lab overtime and also the staff and

xxi
students of the Australian Proteomic Analysis Facility, the Grain Foods CRC Group and
the Marine Mammals Research Group to name a few. We shared ideas, lab frustrations,
good news, chemicals, and also beers, food, coffee, laughter, and sport. Their friendship
was greatly appreciated and I wish them all the best for the future.
Because my time in Australia would have not been the same without them, I would
like to thank the new friends I made. They came from all over the world but all shared the
same qualities: a pure heart and a curiosity over foreign cultures. I learned a lot from
them and I hope I also gave them the best of myself. To name a few, I would like to thank
Andrew “Mooloo”, the best flatmate I ever had. I discovered Woolloomooloo with you and
fell in love with this area of Sydney. Thank you also to Gaetane, Esther, Chris and The
Banghlassi. I love your music guys. Thank you to all the bar flies of the Old Fitzroy. I had
the best time ever. Ellie Wilson was my first friend in Australia. I should say that we met
in the most awkward/funny way. Discovering Sydney and then Tasmania with you was a
great adventure. Mdaulin, I will miss our Sunday lunches, please come over and visit me,
wherever I am. Finally, I could never thank enough Ante Jerkovic and all his family for
their friendship, for welcoming me into their home and make me feel part of it. I feel lucky
I met the kindest people of all. Hvala mnogo.
Last but not least, I would like to thank my friends and family that I left behind
when I left France. Their love and support was my strength. Thank you for being you.
Merci a tous.
Firstly, I thank my Mum for always believing in me. Thank you for always telling
me that I could do it. Thank you also for your strength, happiness and all the fun. You are
the best example ever. I also would like to thank my forever gone Dad because he is the
one that introduced me to science and shared with me his love for the ocean. I only have
few memories of these old days but they are precious. Thank you Morgane, Pierre Yves
and Gaëtan, because growing up with you was quite a life experience in itself. You are

xxii
smart, challenging, funny, full-hearted people and I am glad that you all found somebody
that could see it and love you for it. I wish you all the best for the future.
Thank you Muriel, because asking me to be the godmother of your first child was
the best present you could ever give me. I promise you I will do my best to be somebody
special in Luna’s life, somebody she can always count on. I thank you for your friendship,
your support, your trust, and for the hours we spent on the phone sharing our experiences.
I also thank my friends Alex, Damien, Aurélien, and my symbiote Cédric. The bonds of love
that we share are so special that they will remain in my heart forever. I thank you for your
friendship and encouragements and for all the fun. See you soon boys.
Thank you all, Merci a tous.

1
CHAPTER I
General Introduction

2

3
1.1. Sea urchins
1.1.1. Echinoderms and other deuterostomes
Sea urchins are deuterostome invertebrates. “Deuterostome” comes from the Greek
“mouth second”, which refers to the initial formation of the anus by the blastopore during
development while the mouth forms later. Deuterostomes (hemichordates, echinoderms,
cephalochordates, urochordates and vertebrates) share other features, such as radial
cleavage of cells in early development and bilateral symmetry (at least during the early
stages) that further distinguish them from the protostome lineage of metazoans (mouth
first). Deuterostome divergence occurred approximately 575 million years ago in
Precambrian times [1]. Phylogenetic relationships among deuterostome animals have been
debated for many years with numerous hypotheses proposed based on both morphological
and molecular data. DNA analyses of the complete mitochondrial genome and 18S nuclear
RNA now supports the idea that hemichordates constitute a sister group to echinoderms
[2]. The position of urochordates and cephalochordates with regards to vertebrates has also
been a controversial topic. New evidence supports the conclusion that urochordates
represent the closest living relatives of vertebrates and that gene loss played a major role in
structuring the urochordate genome. Chordates are now thought to represent a
monophyletic clade (Figure 1.1).

4
Figure 1.1: Position of echinoderms in animal phylogeny relative to the four genera of
animals from which genomes have so far been sequenced (blue shading). Modified
from [3].
!"#$%&'(& )*+,%-.*&/-"+& 0*,&#"12$3& ,41$.$,3& +-#4*& 2#+,3&
5*"%*6",%*4&7"-12-".,%*4&8*92,:-12-".,%*4&;12$3-.*"+4&<*+$12-".,%*4&;1.(4-=-,34&>-92-%"-12-=-,34&
!"#$#%$#&'%(
)*+,$'"*,-%(
.'/$'"#%$#&'%(
01#".,$'%(
,+92$-?$#4&

5
1.1.2. Evolutionary considerations within the echinoderms
The name echinoderm comes from the Greek for “spiny skin”. There are around
7,000 echinoderm species, all of which inhabit marine environments. Most have a five fold
radial (pentamerous) body plan. They have several shared features that distinguish them
from other animals, such as a sea water vascular system and a calcium carbonate
endoskeleton, the stereom. Echinoderms first appeared in the fossil record around 520
million years ago during the lower Cambrian. Five taxonomic classes have been defined:
Crinoidea (sea lilies and feather stars); Asteroidea (starfishes); Ophiuroidea (basket stars
and brittle stars); Holothuroidea (sea cucumbers); and Echinoidea (sea urchins, sand
dollars and sea biscuits). Most echinoderms begin life as bilateral larvae and undergo
complex metamorphosis to form radially symmetrical adults.
1.1.3. Classification
Echinoids apparently first appeared during the Ordovician. They have imperforate,
non-crenulate tubercles, solid spines and shallow gill slits. There are numerous tropical and
temperate species. Euechinoids became the dominant echinoid form 250 million years ago,
after the great Permisian-Triassic extinction. Within the order Echninoidea there are four
families: Echinidae [4] (Echinus, Paracentrotus, parechinus, Psammechinus,
Pseudocentrotus, Colobocentrotus, Sterechinus and Loxechinus); Echinometridae [5]
(Anthocidaris, Heliocidaris, Echinometra, Heterocentrotus, Coenocentrotus and
Evehinus); Parasaleniidae [6] (Paraselinia) and Strongylocentrotidae [7] (Hemicentrotus,
Allocentrotus and Strongylocentrotus) that are principally distinguished by the character of
their pedicellariae.

6
Strongylocentrotidae and Echinometridae diverged around 35-45 million years ago
[8]. Evolution has been rapid among both lineages, leading to the direct development of
different species. Among the two genera studied in this thesis, Strongylocentrotus and
Heliocidaris (Table 1.1), the genus Heliocidaris is exclusively restricted to Australia.
Table 1.1: Taxonomy of the two sea urchin species studied in this thesis
Phylum Echinodermata Echinodermata
Eleutherozoa Eleutherozoa
Superclass Echinozoa Echinozoa
Class Echinoidea (Leske 1778) Echinoidea
Subclass Euechinoidea (Bronn 1860) Euechinoidea
Superorder Echinacea (Claus, 1876) Echinacea
Order Echinoida (Claus, 1876) Echinoida
Family Strongylocentrotidae Echinometridae
Genus Strongylocentrotus Heliocidaris

7
1.1.4. Sea urchin anatomy
The external morphology of sea urchins is characterized by a hemispheric test with
a flat oral surface and a curved anal surface (Figure 1.2). The surface of the body consists
of 20 meridional rows of thin, fused calcareous ossicles. It encloses and protects most of
the soft tissues. The endoskeleton is located in the connective tissue dermis of the body
wall and is covered by a thin epidermis. The surface of the test is covered with a large
number of articulated, movable spines and pedicelaria. The tube feet (podia) are arranged
radially forming 10 rows in 5 ambulacrae. Pairs of podia are separated by an
interambulacrum. Tube feet are used for locomotion and respiration. Aristotle’s lantern,
which is located in the center of the oral surface, is the masticatory apparatus [9] or mouth.
A persitomial membrane is located all around Aristotle’s lantern and harbors 5 pairs of
short tube feet, called buccal podia. Five pairs of small peristomial gills are located around
the margin of the peristome. These gills seem to have little respiratory role in sea urchins
[10, 11]. Farmanfarmaian [12] showed that excision of the gills does not reduce oxygen
consumption by S. purpuratus, whilst Cobb and Sneddon [11] concluded that the main
function of gills is waste removal. Aristotle’s lantern is surrounded by the peripharyngeal
peritoneum and opens into the pharynx. The pharynx extends into the oesophagus, which
turns towards the periphery and widens to become the stomach. At the end of the stomach,
the gut reverses direction forming the intestine. It completes a clockwise loop and becomes
the rectum, which extends to the anus and attaches to the outer surface of the test. The
intestine has abundant microvilli and mitochondria, and seems to be the site of absorption
of digested products. Absorption in the intestine involves active transport [13].
The nervous system of sea urchins consists of a nerve ring that lies in the peristomial
epidermis, and a radial nerve that extends along the radial canal of the water vascular
system.

8
Figure 1.2: Internal anatomy of the sea urchin. A/ Schematic representation of the
anatomy of sea urchins. Modified from [14]. B,C,D/ 3D reconstructions of selected
internal organs of S. purpuratus. B/ aboral view. C/ lateral view. D/ oral view. The color
legend specifies organ designation. Modified From [15].

9
The water vascular system is comprised of canals lined with ciliated epithelium that
connects with the exterior surface, through a cluster of pores called the madreporite. A ring
canal circles the mouth and a stone canal is linked with the anus. The axial gland is
situated along the stone canal, whilst Tiedmann’s bodies are situated interradially on the
inner side of the ring canal. Fluid in the water vascular system has similar chemical
properties to sea water, except for a higher concentration in potassium. The water vascular
system is mostly involved in supporting the locomotory tube feet, but is also involved in
gas exchange, excretion, and feeding. Free wandering coelomocytes are found within the
water vascular system.
Results obtained by Holm et al. [16] support the idea that the coelomic epithelium,
Tiedemann’s bodies and the axial organs are the hematopoietic tissues in echinoderms.
They showed that cell proliferation was rapidly induced within 4 hours post injection of
bacterial lipopolysaccharide (LPS), but that saline injection induced a delayed increase in
cell proliferation after 24 hours. The free wandering cells within the coelomic fluid
(coelomocytes) are not proliferative. However, a significant increase in the number of
circulating coelomocytes was observed by Holm et al. [16] after only 4 hours post
injection, suggesting that coelomocytes were released from the coelomic epithelium,
Tiedemann’s bodies or the axial organ.

10
1.1.5. Coelomic fluid and coelomocytes
The coelomic cavity can be divided into the oral region (near the peristomial
membrane) and the aboral region (close to the madreporite) [17]. Perivisceral coelomic
fluid resembles seawater in chemical composition. However, it contains a higher
concentration of potassium and low quantities of lipids, proteins, sugars [17, 18]. Coelomic
fluid fulfills many functions, such as excretion, locomotion, protection of the viscera and
immunological reactivity [18].
Coelomocytes populate the coelomic fluid. In S. purpuratus there are 1×106-5×106
coelomocytes per millilitre of coelomic fluid. They are comprised of at least four
coelomocyte types [19, 20], including a sub-population of phagocytic cells that can be
further subdivided into three types based on differences in morphology and gene
expression (Table 1.2) [21, 22]. Type 1 phagocytes, (also known as discoidal cells or
petaloide phagocytes), can be readily differentiated from type 2 phagocytes (also known as
polygonal cells or filopodial phagocytes) by their distinct cytoskeletal morphologies when
spread on microscopy slides (Figure 1.3) [21, 23, 24]. These two cell types can also be
separated by density gradient centrifugation, with type 1 phagocytes showing a low-
density and type 2 phagocytes having high-density [21]. The third type, small phagocytes,
is smaller with less cytoplasm than either of the two other phagocyte types [22, 25]. About
two thirds of these cells are actively phagocytic [26, 27]. Other types of coelomocytes
include vibratile cells, colorless spherule cells, and red spherule cells (also called morula
cells) (Figure 1.3). Vibratile cells are spherical and show no amoeboid movement but have
a single flagellum that may propel themselves through the coelomic fluid. The two types of
spherule cells are both amoeboid [28].

11
Table 1.2: Coelomocytes cell types and functions in the purple sea urchin, S.
purpuratus. From [29].

12
Figure 1.3: Coelomocytes in sea urchin (S. purpuratus) coelomic fluid. Polygonal
phagocytes (A) and discoidal phagocytes (B) can be differentiated by the ultrastructure of
their cytoskeleton (actin, green). C/ phagocyte. D/ red spherule cell. E/ vibratile cell. F/
colorless spherule cell. From [30].
A B C
D E F

13
A number of coelomocyte types function as mediators of the immune system [31].
Experimental observations demonstrate that they carry out many different immunological
functions: including chemotaxis, phagocytosis, encapsulation, cytotoxicity, immune gene
expression and secretion [31, 32]. As such, they are involved in the formation of cellular
clots, chemotactic accumulation at sites of injury, and allograft rejection.
Early studies of allograft rejection kinetics, and of the function of coelomocytes,
provided evidence for non-adaptive immunity in the deuterostome invertebrates [32]. Sea
urchins can reject allogeneic tissues and hence differentiate between self and non-self [33,
34]. The rejection rates for second-set allografts were accelerated relative to first-set
rejections, but they were not different from the rejection of third-party allografts [26, 35,
36]. Because similar results were obtained for clearance rates of foreign particles, the sea
urchin immune response has been thought of as non-specific and similar to the innate
immune system in higher vertebrates [31, 32].
Coelomocytes clear bacteria and other foreign substances from the coelomic cavity
with great efficiency [37-39]. In vitro, a major shape transformation of petaloide
phagocytes to a filopodial form has been observed during bacterial clearance [40]. In sea
cucumbers, this occurs after the ingestion of beads by the phagocytes [41]. Petaloide
phagocytes are believed to phagocytose foreign particles, whereas filopodial phagocytes
mostly participate in wound healing and clotting [17].
Arizza et al. [42] showed that filopodial phagocytes and colorless spherule cells are
cytotoxic and function coordinately. Phagocytes release an eliciting factor into the
coelomic fluid that activates colorless spherule cells resulting in the cytolysis of rabbit
erythrocytes and K562 tumor cells. Lin et al. [43] confirmed this result by generating
antibodies against cytotoxic coelomic fluid proteins that appeared to be specifically
localized in phagocytes and colorless spherule cells.

14
Injury increases the number of red spherule cells in the coelomic fluid [44]. These
cells have been reported to respond to injury by degranulation of their echinochrome
pigment, which is a bactericidal agent [45]. Another coelomic fluid protein, vitellogenin
exhibits hemagglutinating and antibacterial activities. Even though it is the precursor of
yolk protein in eggs, it occurs in the coelomic fluid of both male and female adults,
confirming that its function is not restricted to egg yolk. This protein is localised in
colorless spherule cells that discharged vitellogenin into the coelomic fluid in response to
stress [46].
Initial searches for immune response genes expressed in coelomocytes revealed an
increase in profilin (SpCoel1) in response to injury and LPS injection [27, 47]. It has been
suggested that this protein modulates the restructuring of the cytoskeleton during amoeboid
movement, encapsulation and clot formation. Further studies of expressed sequence tags
(ESTs) revealed that the expression of numerous other immune related proteins is also
altered by immune challenge [48]. In particular, Smith et al. [49, 50] identified
complement component C3 (SpC3; Sp064) [49] and complement factor B (SpBf; Sp152)
[50] homologues. They showed that SpC3 is specifically expressed by phagocytic
coelomocytes, confirming its importance in innate immune response.
1.1.6. The sea urchin genome project
Echinoderms have a long history as an experimental model, with some of the
discoveries made in these animals being recognized by Nobel prizes. Elie Metchnikoff’s
exploration of cellular immunity constitutes a classic example of the fundamental
biological concepts that have arisen from the study of echinoderms. For this body of work,
Metchnikoff was awarded the 1908 Nobel Prize in Medicine [51].

15
The importance of sea urchins as experimental models led to the sequencing of the
Californian purple sea urchin (Strongylocentrotus purpuratus) genome, which was
completed in 2006 [52]. The S. purpuratus genome contains more than 814 million base
pairs encoding 23,500 genes. Most of the gene families identified in this sea urchin are also
found in humans. However, the size of the gene families is often larger in humans, in part
reflecting two whole genome duplication events during vertebrate evolution. Two
unexpected exceptions to this pattern are the sensory and immune systems. The number of
sea urchin genes with putative immunological functions is ten to twenty times greater than
in humans [53]. The large expansion of innate immune receptor proteins (TLRs, NLRs and
SRCRs), together with the identification of some proteins involved in the vertebrate
adaptive immune system (Rag1/2 genes), suggests that the sea urchin immune system is far
more complex than was previously suspected.

16
1.2. Comparative immunology of echinoderms
The sea urchin genome sequence revealed the presence of an elaborate repertoire of
genes associated with immunity, most of which are more related to the vertebrate immune
gene repertoire than to the host defence molecules of other invertebrates [53]. Therefore,
the following description of echinoderm immune responses is based on comparisons with
the vertebrate immune system.
1.2.1. Sea urchin immune response molecules
Throughout the animal kingdom, the recognition of pathogens seems to be
mediated by a complex set of pattern-recognition receptors (PRRs) that bind pathogen-
associated molecular patterns (PAMPs). Five major classes of innate immune recognition
proteins are commonly observed in the animal kingdom: Toll-like receptors (TLR),
NACHT and leucine-rich repeat containing proteins (NLR), multidomain scavenger
receptor cysteine-rich (SRCR) proteins, peptidoglycan recognition proteins (PGRPs) and
Gram negative binding proteins (GNBPs). Each of these gene classes participate in
pathogen recognition through direct or indirect binding to PAMPs [54].
The S. purpuratus genome revealed a substantial expansion of many PRRs [30, 53].
Two hundred and twenty-two TLR gene models were found, which contrasts with the nine
TLR genes present in the human genome [55]. Most of the S. purpuratus TLR genes
(211/222) are more similar to each other than to homologues in other animals, suggesting
an expansion of these genes within the sea urchin lineage. Two hundred and three NLR
genes were predicted in the S. purpuratus genome, which contrasts with the 20 NLR genes
found in the human genome. The variability of NLR genes in sea urchins is thought to be
driven by gut associated pathogenesis. NLR are only expressed within the mesentery, the

17
gut and the testis of sea urchins, and are absent in all coelomocyte types [30]. A large array
of 218 sea urchin genes encode a total of 1095 SRCR domains, while in humans there are
only 16 gene models, encoding 81 SRCR domains. Among other pattern recognition
receptors, only 5 PGRP and 3 GNBP gene models were observed in the sea urchin
genome. GNBP genes are absent in vertebrates, but 4 have been found in the fruit fly
genome, suggesting that these genes were lost during chordate evolution [30, 52].
1.2.2. The complement system of sea urchins
The presence of molecules in sea urchins with clear homology to complement
components was initially revealed by investigations of the genes expressed in LPS-
activated coelomocytes [22, 32, 48]. Of the 307 expressed sequence tags (ESTs) that were
reported by Smith et al. [48], two encoded homologues of mammalian complement
components: EST064 (SpC3) is a homologue of complement component C3 [49] and
EST152 (SpBf) is a homologue of complement factor B (Bf) [50].
The presence of SpC3 and SpBf in sea urchins suggested the existence of a
complement system with similarities to the vertebrate alternative pathway. SpC3 has an
amino acid sequence with 27.9% amino acid identity to human C3 [48, 49]. It has a non
reduced molecular weight of 210 kDa, and reduces to an α-chain (130 kDa) and a β-chain
(80 kDa) that are of equivalent molecular weight to C3α and C3β from gnathostomes.
Homology of SpC3 to vertebrate C3 is concentrated around the functionally critical
thioester group and a number of other functional regions. SpC3 possesses five consensus
N-linked glycosilation sites, putative cleavage sites for factor I and C3 convertase and
cysteines in conserved positions. Functional studies have confirmed that SpC3 has an
active thioester site and opsonizes targets for phagocytosis [56, 57]. Its synthesis can be
induced by challenge with LPS in immunoquiescent sea urchins and it is specifically

18
expressed by two subpopulations of coelomocytes [22, 58]. Two other C3-like genes
(SpC3-2 and Sp-TCP1) and a C4-like gene (Sp-TCP2) have been identified in the genome
of the sea urchin [30, 59]. SpC3-2 has been found to be predominantly expressed during
larval development [59].
The deduced amino acid sequence of SpBf also shows significant similarity to
vertebrate Bf/C2 family proteins [50]. It has a mosaic structure, which includes five short
consensus repeats (SCR; as opposed to the three found in vertebrate Bf proteins), a Von
Willebrand factor domain, a serine protease domain and a conserved cleavage site for a
putative factor D protease [50]. Phylogenetic analysis of SpBf indicated that it is the most
ancient member of the vertebrate Bf/C2 family. More recently, evidence of alternative
splicing has been found [60]. The sea urchin genome revealed the presence of two
additional homologues of vertebrate Bf/C2 proteins with 5 SCRs in Sp-Bf-2 and four SCRs
in Sp-Bf-3 [30].
Together, SpBf and SpC3 may function in a similar way to the alternative pathway
in vertebrates [61]. They could result in opsonization of foreign cells or particles to
augment phagocytosis by coelomocytes. The existence of multiple homologous proteins
and/or splice variants of C3 and Bf suggests that multiple alternative pathways may exist
in sea urchins working at different times in the life cycle, in response to different
challenges, or in different cell types.

19
1.2.3. The lectin-mediated complement system in sea urchins
Evidence from tunicates and “lower” vertebrates suggests that the lectin pathway
originated earlier than the classical pathway [62-65]. Homologues of collectins, C1q (four
genes) and MBP (one gene) have also been found within the sea urchin genome. A total of
46 gene models were found containing fibrinogen domains comparable to those of ficolins.
Ficolins (collagen-fibrinogen domains) are structurally analogous to collectins and could
be involved in the activation of a lectin-like pathway [66]. However, members of
MASP/C1r/C1s, which are critical to lectin-mediated pathways, have not been identified in
sea urchins.
1.2.4. Immunoglobulin superfamily rearrangement
The sudden emergence of the entire complex of Ig/TCR/MHC mediated adaptive
immunity in ancestral jawed vertebrates has previously been correlated with the
appearance of recombination activator genes (Rag). It has been assumed that combinatorial
diversity among immunoglobulin superfamily (IgSF) genes arose with the acquisition of
Rag genes by original gene transfer of a mobile DNA element [67]. The theory was
supported by the absence of homologous Rag genes in jawless vertebrates or invertebrates.
Antibody and T-cells receptor (TCR) genes are assembled from individual variable (V),
diversity (D), and joining (J) gene segments. The Rag 1 and Rag 2 proteins are the key
mediators of this process of somatic V(D)J recombination, which also utilises terminal
deoxynucleotidyl transferase (TdT) for enhanced diversity [68, 69]. Fungmann et al. [70]
have since revealed the presence of sequences in the S. purpuratus genome with similarity
to regions of the Rag 1 and Rag 2 genes from vertebrates. This discovery suggests that the
apparent evolutionary discontinuity of genes involved in generating hypervariability in the

20
IgSF could be a consequence of genes loss or undersampling. A longer evolutionary
process may underlie the emergence of the key elements of the vertebrate adaptive immune
system.
S. purpuratus Rag 1 (SpRag1L) has 31% amino acid homology to the core region of
mouse Rag1, and similarities extend into the non-core region [70]. All three residues of the
DDE active site are conserved, as well as surrounding residues. The zinc finger B motif,
critical for the interaction with Rag 2, and most of the basic residues implicated in DNA
binding in the region of the nonamer-binding-complex (NBD) are also conserved. Finally,
a 108 aa-stretch shows significant similarity to a putative zinc-binding domain (ZBD) in
mouse Rag 1. The RING finger domain, which separates the two stretches of sequence
similarities in all known vertebrate Rag 1 proteins, is absent from the sea urchin sequence
but a repetitive coding region containing 11 repeats of an 8-aa peptide has been observed.
The S. purpuratus Rag 2 (SpRag2L) gene lies downstream of the SpRag1L gene within the
range of intergenic distances for vertebrates Rag genes (3,181 bp downstream). The first
424 aa of SpRag2L are predicted to encode a six-bladed β-propeller, which like vertebrate
Rag2, matches the β-propeller of the galactose oxidase central domain SCOP profile.
Furthermore, as for vertebrate Rag2, a C-terminal plant homeodomain (PHD) is present in
the sea urchin gene [70].
Further analysis showed that, like their vertebrate homologues, SpRag1L and
SpRag2L are co-expressed, and evidence of interaction of the two molecules to form a
heterodimer complex has been obtained by pull-down assays [70]. The ability of SpRag1L
and SpRag2L to interact with shark Rag1/2 provides additional evidence that this complex
may be functionally equivalent to the vertebrate Rag1/2 complex. Finally, similar DNA-
binding properties to the Rag1 central NBD complex were evident in the central domain of
SpRag1L when purified as a recombinant protein from Escherichia coli. SpRag1L may use
DNA as its substrate and facilitate somatic rearrangement of yet unidentified genes in the

21
sea urchin genome. The identification of the cognate target motif and the SpRag1L/2L
complex will be important for further studies.
A homologue of Terminal deoxynucleotidyl Transferase (TdT) and DNA
polymerase mu (Polµ) has also been found in the sea urchin genome [53]. Polµ appears as
a mutator (error prone) DNA polymerase potentially responsible for somatic
hypermutation of immunoglobulin genes [71]. It plays an important role in non-
homologous end joining of incompatible ends and in terminal transferase activity [72].
TdT is a DNA independante polymerase with a strict terminal transferase activity. This
enzyme increases antigen receptor diversity in gnathostomes by adding nucleotides during
the DNA joining phase of V(D)J recombination. Indeed, homologues of all enzymes
involved in DNA repair and the non-homologous end-joining pathway have been found in
the sea urchin genome, thus providing the sea urchin with the complete enzymatic
machinery required for V(D)J recombination. In addition, a total of 500 gene models
containing about 1500 Ig domains, some of which showed weak but relatively specific
identity to Ig/TCR/MHC, have been identified in the S. purpuratus genome [53]. However,
there is still no evidence for V(D)J rearranging system outside of the jawed vertebrates.

22
Table 1.3: General characteristics of highly variable gene systems associated with
pathogen defence in animals. From [73].
a includes somatic recombination and alternative splicing.
? not tested or speculative
Abbreviations: CBD, chitin binding domain; CC, coiled coil domain; CT,
cytoplasmic tail; Dscam, Down’s syndrome cell adhesion molecule; FBG, fibrinogen-like
domain; FnIII, fibronectin type III domain; FREP, fibrinogen related protein; GPI,
glycosylphosphatidylinositol; Ig, Immunoglobulin; IgSF, Immunoglobulin superfamily;
LRR, leucine rich repeat; ND, structure not determined; NBS, nucleotide binding site; TM,
transmembrane region; VCBP, variable chitin-binding protein; VLR, variable lymphocyte
receptor.

23
1.3. Highly variable gene systems associated with pathogen defence
Any receptor system showing high degrees of intra-individual variability could in
principle be a candidate recognition molecule in a pathogen-specific immune system (as
distinct from pattern recognition systems). Numerous studies investigating pathogen
specific immune responses of non-mammalian jawed vertebrates, jawless vertebrates,
protochordates and other invertebrates suggest that we may have underestimated the
diversity of such highly variable receptors [74]. Convergent evolution has given rise to
many functionally analogous immune response molecules that do not always share
evolutionary histories (Table 1.3). This is exemplified by the recent identification of highly
variable molecular systems, such as 185/333 proteins from sea urchins [75], variable
lymphocyte receptors (VLRs) from lampreys [76, 77], fibrinogen related proteins (FREPs)
from snails [78-84], Down’s syndrome cell adhesion molecules (Dscams) from insects
[78], and V-region-containing chitin-binding proteins (VCBPs) from cephalochordates and
tunicates [79] (Table 1.2). These systems are all based on high levels of molecular
variability within individuals, but are otherwise unrelated [76].

24
1.3.1. Life history strategies
The absence of adaptive immunity in invertebrates has previously been explained
by the fact that invertebrates have relatively short life spans compared with vertebrates, so
that they are less likely to encounter the same pathogen twice [80-82]. Another argument is
that invertebrates are usually small organisms with high fecundity, so that there are likely
to be numerous survivors of disease epizootics at the level of the population [83]. These
theories were mostly based on the r/K selection hypothesis and suggested that invertebrates
are r-selected (high fecundity, large populations), while vertebrates are K-selected (low
fecundity, small population). But r and K selection strategies do not neatly differentiate
invertebrates from vertebrates, and there are members with both life history strategies in
both clades [80, 81]. Some invertebrates can live for many decades, while some lower
vertebrates have short life spans and reproduce extensively [84]. For example, sea urchins
can live for over 100 years [85]. Additional selection pressures, such as the size and
density of the population, the level of eusociality within the population and the
involvement of asexual reproduction, which reduces genetic variability, are also variable
[86]. Sea urchin population structure is complex and significant fluctuations in population
size have been observed over time [87]. They are also often victims of disease outbreaks
and their disappearance from communities can have significant impacts on the entire
ecosystem of an area [88-90].
These evolutionary perspectives suggest that invertebrates would, like vertebrates,
benefit from a complex immune system. So, not surprisingly, classical immunization
experiments have now confirmed that some invertebrates can develop pathogen specific
responses [91, 92]. This pathogen specific discrimination is sometimes fine scaled,
suggesting the existence of immune processes providing both specificity and memory [93,

25
94]. However, the molecular processes responsible for pathogen-specific immunity in
these organisms are not well understood, even though a number of highly variable
recognition proteins have been identified among invertebrates. These include:
1.3.2. Variable lymphocyte receptors (VLRs)
Hagfish and lampreys are agnathans, which possess an adaptive immune system in
terms of allograft rejection and immunization [95-98]. However, their adaptive immune
responses are not due to variability of the immunoglobulin receptors used by jawed
vertebrates. Instead, they express variable lymphocyte receptors (VLR) composed of
highly diverse leucine-rich repeats (LRR) [77]. Lamprey immunized with anthrax spores
showed an increase in VLR positive lymphocytes from 4 to 98%, and an increase of 8 to
10 fold in soluble antigen-specific VLRs [99].
VLRs include a conserved signal peptide, an N-terminal LRR, up to seven internal
LRRs, a connecting peptide and a conserved C-terminus region with a GPI-anchor and a
hydrophobic tail [77]. The N-terminal and C-terminal regions are invariant. The
hypervariability of VLRs is concentrated on the concave surface of the horseshoe-shaped
molecule, where the LRR modules undertake antigen recognition. Antigen specificity is
confered by variation in the number of LRR domains and variation in their amino acid
composition [100, 101]. Lamprey and hagfish generate a potential repertoire of 1014 and
1017 unique VLRs [99], which is greater than the potential number of TCR in vertebrates
(108). A single VLR gene has been identified in lampreys, while hagfishs have two VLR
genes, designated VLR-A and VLR-B, located on the same chromosome. These two VLR
genes are made up of significantly different LRR modules [99] promoting their functional
specialization [102]. The complex somatic diversification of VLRs occurs through the
random selection of LRRs from a large bank of flanking cassettes. Diversification arranges

26
various copies of LRRs in different combinations and uses multiple sites in LRR gene
fragments for priming, a process called ‘copy choice’. It has also been demonstrated using
mutagenesis and recombination assays that AID-like cytosine deaminase may also be
involved in VLR diversification [103]. It is noteworthy that the AID/APOBECs cytosine
deaminases of vertebrates are DNA mutators acting in antigen-driven antibody
diversification processes. The recombinatorial assembly of LRRs in agnathans and of Ig in
higher vertebrates, and the involvement of cytosine deaminases, demonstrate the
convergent evolution of different strategies for generating lymphocyte-based adaptive
immune responses.
1.3.3. V-region-containing chitin-binding proteins (VCBPs)
Protochordates, such as Amphioxus, lack an antibody-based adaptive immune
system. However, a family of genes encoding secreted proteins with two immunoglobulin-
like variable (V) domains and a chitin binding domain have been identified by Cannon et
al. [104]. These molecules are designated V-region-containing chitin-binding proteins
(VCBP). Ig-like V domains are often associated with adaptive immunity, while chitin
binding domains are associated with innate immune functions. The complexity of the
VCBP family is based on multiple amino acid substitution and potential combinatorial
rearrangement that result in substantial variability among the expressed proteins within and
between indivduals [105]. The annotation of the Amphoxius genome enabled the
characterization of the entire VCBP locus [106]. Substantial allelic variation based on the
complexity of haplotypes has been observed, with multiple indels of repeats (inverted
repeats, small repeats and microsattelites) and non-coding segments. The number of
VCBPs genes can vary among individuals of the same population [106]. Investigations of
the crystallized structure of VCBP revealed that their V domains are structurally similar to

27
Ig V domains [107]. It has been suggested that VCBP constitute a transitional molecule
between innate and adaptive immunity and that they have bi-functional properties [106].
However, no functional studies have yet been undertaken, so it can only be assumed that
VCBPs are involved in pathogen defense.
1.3.4. Fibrinogens related proteins (FREPs)
Fibrinogen related proteins constitute a family of highly variable haemolymph
proteins originally found by Adema et al. [109] in the snail, Biomphalaria glabrata. This
schistosome snail produced large amounts of circulating FREPs after injection of
secretory/excretory products (SEP) derived from cultured Echinostoma paraensei
intramolluscan larvae. The secreted molecules incorporate both IgSF domains and a C-
terminal fibrinogen-β/γ domain (FBG). They can precipitate SEPs and have similar
properties to lectins [109]. Further studies revealed the large size of the FREP family with
up to 13 different genes [110]. FREPs have since been identified in a number of other
invertebrates, as well as in vertebrates [111-117]. FREPs with one or two IgSF domains
have been found, as well as truncated forms. This is consistent with alternative splicing of
full-length FREP genes [118]. A more thorough investigation of the variability of FREP3
revealed the presence of an unknown system for diversification that involves nucleotide
point mutation and/or recombinatorial diversification [119]. The frequency of point
mutation in parents is higher than that of their offspring, but the rate of recombinatorial
diversification did not differ. Multimerisation of FREPs has also been observed, with up to
24 molecules partially covalently bounded, substantially increasing the potential diversity
of these molecules [120].
It was previously thought that exposure to bacteria or wounding did not upregulate
the expression of FREPs [121, 122]. However, new evidence suggests that different

28
members of FREP gene subfamilies are differentially expressed following exposure of B.
glabrata to different trematodes [122, 123]. Anti-pathogen activities of FREPs have also
been demonstrated in other species. For instance, mosquito FREP is up-regulated after
challenge with bacteria, fungi and Plasmodium [106, 124]. Amphioxus FREP has direct
antibacterial activity revealed by binding to E. coli and S. aureus via interactions with
lipopolysaccharide (LPS), lipoteichoic acid (LTA), or peptidoglycan (PG) [125]. FREPs
are also up-regulated (after 9 hours) in the bay scallop (Argopecten irradians) responding
to Listonella anguillarum, while recombinant A. irradians FREPs can agglutinate
erythrocytes and bacteria in a calcium dependent manner [126]. Overall, it appears that
FREPs participate in a new form of inducible, pathogen specific immune response in a
broad range of species, including molluscs and insects.
1.3 5 Down’s syndrome cell adhesion molecules (Dscam)
The Drosophila homologue of human Down’s syndrome cell adhesion molecules
(Dscam) was originally described as a guidance receptor in neuronal wiring [127]. The
Drosophila Dscam differs from its human counterparts in terms of its gene organisation.
Drosophila Dscam genes appear as clusters of variable exons flanked by constant exons.
These are subjected to mutually exclusive splicing that potentially generates as many as
38,016 different isoforms [127]. All variants of Drosophila Dscam have a conserved
architecture containing variable immunoglobulin domains and a transmembrane domain
[127]. Analysis of Dscam mRNA isoforms expressed by individual cells revealed that each
cell expresses a unique repertoire of splice variants [128].
Recently, Watson et al. [129] demonstrated the importance of Dscam in the
immune system of insects. They showed that the enginered loss of Dscam impaired the
efficiency of phagocytosis. Similarly, Dong et al. [130] showed that different splice

29
variants of Anopheles gambiae Dscams enable pathogen specific immunological
protection. Alternative splicing of different exons induced an over or under expression of
different Ig domains depending on which pathogen the host cell was exposed to. The
various A. gambiae Dscam molecules (AgDscam) produced in response to particular
pathogen also showed different adhesive characteristics and interaction specificity.
Silencing of AgDscam genes via double stranded RNA decreased survival rates after
bacterial infection [130].
The majority of non-spliced Dscams exons are extremely conserved between D.
melanogaster and A. gambiae (70-95% amino acid homology), while the spliced Ig
domain exons are far less homologous (30-70% homology), suggesting that the two types
of exons are under different selection pressure. It has been suggested that the constitutive
(non-spliced) region undertake more conserved functions, such as regulation of
intracellular signalling pathway, while the alternatively spliced Ig domains are under
constant environmental selection pressure for diversification. In support of this suggestion,
phylogenetic analysis of alternatively spliced Dscam exons from honey bees, fruit flies and
mosquitoes revealed major modifications since divergence that can be explained by
differences in life history and environment [131]. Identification of Dscam homologues in
haemocytes of the crustacean Daphnia, which are also diversified by alternative splicing,
indicates that the highly variable forms of these genes evolved from non-diversified forms
before the divergence of insects and crustaceans [132]. Comparisons between fly and
Daphnia Dscams also support the idea that the variable exons have evolved through a birth
and death process based on duplication in a nearest-neighbour scenario, meaning that
exons physically closer to each other are also more similar to each other [132].

30
1.4. The 185/333 family
1.4.1. Discovery
The 185/333 family was initially identified as uncharacterised EST from a cDNA
library of LPS-activated coelomocytes [48, 133]. They were originally designated DD185
(Genbank accession no. AF228877) and EST333 (Genbank accession no. R62011), hence
their current name 185/333. Northern blots revealed a significant up-regulation of the
DD185 and EST333 sequences in response to bacterial challenge. The significance of the
185/333 family in immune responses was further established by a suppressive substractive
hybridization (SSH) study carried out by Nair et al. [75]. cDNA substraction employed
coelomocyte RNA from an LPS-activated sea urchin, which was substracted from RNA
prepared from the same animal before challenge. Transcripts that matched DD185 and
EST333 represented up to 60% of the ESTs analysed. Re-screens showed that 185/333
transcripts constituted 6.45% of the clones in the bacterially activated coelomocyte library,
compared to only 0.09% in the non-activated coelomocyte library (a 75-fold increase).
Alignment of the 1,247 ESTs that matched 185/333 messages revealed their inherent
variability. To allow this alignment, large gaps had to be inserted, revealing blocks of
shared sequence found in multiple 185/333 sequences. These blocks were designated
“elements”. A total of 15 elements were required for the original alignment, and not all
were present in every 185/333 sequence. The authors suggested that this variability
between transcripts was due to alternative splicing.

31
1.4.2. Variability of 185/333 mRNAs
Subsequent full length cDNA sequencing allowed a thorough analysis of 185/333
diversity [132]. More optimal sequence alignments required additional gaps that defined a
total of 25 elements. On the basis of the presence or absence of these elements, 22 distinct
element patterns were identified (Figure 1.4). In addition to the element patterns, these
alignments revealed substantial nucleotide diversity reflecting indels and single nucleotide
polymorphisms (Figure 1.4). Five types of repeats were identified [134], and these were
located throughout the sequence. Within each element, single nucleotide polymorphisms
were not randomly distributed. Instead, they were located at specific sites. These positions
were not limited to element boundaries, suggesting that they do not simply result from
alternative splicing. More importantly, nucleotide substitutions were functionally
significant and not selectively neutral. This implies that diversification of 185/333
sequences is under selective pressure for variability.
Terwilliger et al. [134] also identified a correlation between element patterns and
the presence/absence or length of a specific element (element 15). The sequence groups
defined by element 15 may be representative of subfamilies of transcripts or genes,
reflecting the evolutionary diversification of 185/333 genes. This observation was
supported by the fact that sets of cDNAs with shared element patterns tend to be more
similar in terms of nucleotide sequence. Phylogenetic analysis of the transcripts collapsed
the classification of 185/333 proteins into 5 sub-families that present conserved nucleotide
substitutions, similar element patterns and conserved physico-chemical properties (Dheilly
et al., unpublished data; Figure 1.5).

32
Figure 1.4 : A cDNA-based alignment of 185/333 transcripts. Elements (numbered at
top), are represented by colored boxes. cDNAs are organized into groups (numbered at left,
identified by gray background shading) based on element 15. Group 1 is defined by sub-
element 15a, group 2 by sub-element 15b, group 3 by sub-element 15c, group 4 by sub-
element 15d, and group 5 by sub-element 15e. Groups 6 and 7 do not have element 15.
Groups are also indicated by pattern designations: group 1 is pattern A, group 2 is pattern
B, etc. Element 25 was subdivided into 3 sub-elements, 25a, -b, and -c, based on the
location of the stop codon (black vertical lines). A frame shift (white X) in element 4 of
clone D1.1 leads to an early stop codon (black vertical lines) in element 5 (black/purple).
The remainder of the D1.1 sequence is shown as smaller blocks to show that the sequence
is present but may not be translated. Eight sets of cDNAs (E2, D1, C1, 01, E3, A2, E1, C3)
are composed of multiple members that have identical element patterns (#). From [134].

33
Figure 1.5: Five sub-families of 185/333 proteins. A/ Circular representation of a
neighbour joining tree obtained with 185/333 cDNAs sequences. The same tree was
obtained using the maximum parsimony method. Bootstrap values obtained with 1000
replicates from both neighbour joining (NJ) and maximum parsimony (MP) are shown
along the branches (NJ/MP). B/ the 5 sub-families identified are compared with the groups
based on element 15 (Ex15 Figures 1.4 and Er10 Figure 1.7). Within each sub-family,
predicted proteins show homogeneous molecular weight.
!"#$%&'()*+,+
!"#$%&'()*+,,+
!"#$%&'()*++,,,+!"#$%&'()*+,-+
!"#$%&'()*++-+
!"#"$%
&$$#&$$%
"!#&$$%
&$$#&$$%
'$#()%
($#*)%
'"#'&%
!+#,,%
'+#'+%
-.#/0%
Sub-family groups Molecular weight
Sub-family I Groups A and G 53.0 ± 2.7 kDa
Sub-family II Groups B and F 39.7 ± 1.8 kDa
Sub-family III Group C 41.1 ± 1.5 kDa
Sub-family IV Gourp D 42.0 ± 1.2 kDa
Sub-family V Group E 32.0 ± 0.1 kDa
Pattern E2.1 14.7 ± 0.03 kDa
Group 0 29.5 ± 1.5 kDa
1%
2%

34
Figure 1.6: Structure of part of the 185/333 locus. Scaffold_v2_79421 from the S.
purpuratus genome assembly (Version 2, June 15, 2006) contains four linked 185/333
genes (diagram not to scale). Each of the genes includes a single intron in the predicted
location. The element patterns of the genes based on cDNA-based alignments are
indicated. Pattern D8 was not isolated from the cloned genes. However, it is similar to
pattern D1, but contains Ex12 rather than Ex10. The orientations of the genes are indicated
by the arrows. Dinucleotides (GA; striped ovals) flank the genes, and trinucleotide repeats
(GAT; solid parallelograms) are present on the 5' side of the genes. From [135].

35
Terwilliger et al. [136] further investigated the variability of 185/333 transcripts in
response to challenge with different PAMPs (LPS, β-1,3-glucan or double stranded RNA).
The authors showed that each individual sea urchin expressed a different set of transcripts
before challenge. This set changed in response to challenge and trends in these changes
were observed between individuals. The element patterns C1 and E2.1 (Figure 1.4) were
the most commonly expressed in immunoquiescent sea urchins, while the pattern E2
(Figure 1.4) was found most often after injury, or the injection of LPS or β-1,3-glucan.
Interestingly, pattern E2.1 (65% of 185/333 messages prior to challenge) has a single
nucleotide polymorphism-generated stop codon that differentiates it from pattern E2 and it
has not been found in any of the genomic sequences [136].
1.4.3. 185/333 genes
The diversity observed among their cDNA sequences initially suggested that
185/333 genes (genomically encoded loci) have many exons independently encoding all of
the different elements, or that a large family of 185/333 genes encoding all different
variants was present. Surprisingly, genome blots performed on sperm gDNA from three
sea urchins revealed that 185/333 genes are small [134]. Further examination of the
partially assembled sea urchin genome revealed that 185/333 genes were composed of just
two exons and one intron (Figure 1.6) [135]. The first exon encoded the leader and the
second encoded elements 1-25. Because very few unique 185/333 genes were identified in
the genome, quantitative PCR (qPCR) was used to evaluate gene copy number. The results
suggested that there are about 80-120 185/333 alleles per diploid genome [134]. The
approximate age of their last common ancestor was calculated using average element
pairwise differences and indicated that the family might only exist within the echinoid
lineage.

36
Figure 1.7: Repeat-based alignment of the 185/333 genes. This alignment was optimized
for repeats, and 27 elements (colored boxes) were defined. Gaps due to missing elements
are indicated by horizontal black lines. There are 17 different exon element patterns,
which, when combined with the intron types, form a total of 21 unique gene patterns. The
frequency (Freq) of patterns indicates how often the pattern was identified. The source
animal for each pattern is indicated by the presence of a colored dot. The subtype of
element Er10 (which corresponds to Ex15, Figure 1.4) is indicated by the letter in the box.
From [135].

37
Buckley and Smith [135] sequenced 171 gDNA clones of 185/333 and obtained
121 unique sequences, meaning that 71% of the cloned sequences were unique. The gDNA
clones were classified into 33 element patterns, about 50% of which were newly described.
A phylogenetic analysis of the intron sequences was used to separate them into five major
clades (α - ε) [135]. A strong correlation was observed between exon element patterns and
intron type, suggesting the existence of different sub-families; most sequences from sub-
family I had intron type γ, sub-families III and IV had intron type α, sub-family V had
intro type δ and sub-family II had intron types α, β, or ε (Dheilly et al., unpublished data).
BAC screening revealed that few genes were intronless. Intergenic regions varied from 1.6
kb to 8 kb, and genes were flanked on both sides by a stretch of microsatellites
(approximately 15 dinucleotide GA repeats both upstream and downstream, and
trinucleotide GAT repeats at the 5' end) (Figure 1.6).
These data suggest that 185/333 represent a family of linked genes that occupy long
stretches of repeats along the genome. It has also been suggested that the dinucleotide
repeat stretches might facilitate diversification events through gene conversion,
recombination, duplication and/or deletion of intact genes [135, 137]. A total of 16
individual sea urchins have been studied at the genomic or transcriptomic level and not a
single identical sequence has been found in two different individuals.
To further define the evolution of 185/333 genes, the six different repeats identified
within 185/333 sequences [134, 135, 138] have been used to generate a new repeat-based
alignment of the gene sequences (Figure 1.7) [135]. Type 1 repeats, present in the 5’
region of the gene, seem to be arranged in tandem. This contrasts with the five other types
of repeats, which are mixed and interspersed along the 3’ region. The relatively simple
organisation of type 1 repeats permitted a thorough investigation of their molecular
evolution. Individuals contain between two and four type 1 repeats.

38
Figure 1.8: Schematic representation of the consensus 185/333 protein sequence. The
deduced protein sequence is separated into a glycine-rich region (gly-rich; orange line) and
histidine-rich region (his-rich; purple line). Symbols indicate the presence of an RGD
motif in element 7 (black circle), N-linked glycosylation sites (red circles) and O-linked
glycosylation sites (green circle), 5 types of repeats (colored diamonds: type 1 in red, type
2 in blue, type 3 in green, type 4 in purple, and type 5 in yellow), secondary structure
predictions (α-helices and β-strands), patches of acidic amino acids (red vertical bars),
patches of histidines (purple vertical bars), and 5 elements surrounded by cryptic splice
signals. All elements are drawn to scale. From [134].

39
In total, 292 type 1 repeats have been identified, corresponding to 52 unique repeats from
121 unique genes. Computational phylogenetic analysis revealed the involvement of point
mutations and gene recombination in generating the type 1 repeats [138].
This supports the hypothesis that the 185/333 family appeared through a recent
gene diversification event. It also raises the possibility that the gene family may be subject
to frequent birth and death evolution, and that the size of the family may vary between
individuals [138].
1.4.4. Transcriptional and posttranscriptional modifications
The first level of variability among 185/333 molecules appears to be generated by
recombination/duplication events. However, Buckley et al. [139] have also investigated the
potential of 185/333 genes to undertake intergenic splicing to generate element pattern
variations. Although cryptic donor splice sites were found, it appeared unlikely that
185/333 genes undergo intergenic splicing. So, Buckley et al. [140] further investigated the
presence of a second level of diversification, involving posttranscriptional modification.
To do so, they compared the sequences of genes (genomic loci) and messages (mRNA
transcripts) in individual sea urchins. The data showed that most of the nucleotide
substitutions between genes and transcripts were transitions (3:1 transition/transversion
ratio), with a strong bias towards cytidine to uridine transitions that is consistent with
cytidine deaminase activity.

40
1.4.5. 185/333 proteins expression and localization
The predicted proteins described by Terwilliger et al. [134] have a NH2-terminal
hydrophobic leader, a glycine rich domain with multiple protease cleavage sites and an
RGD motif, a histidine rich region with 11 patches of histidines varying from 2 to 17
amino-acids in length that are interspersed with Gly, Arg and Gln; and a COOH terminal
region (Figure 1.8). Conserved N-linked glycosylation sites are present in 16 locations and
there are numerous acidic patches. Seven conserved O-linked glycosylation sites can be
identified within a short region of nine amino acids. Finally, none of the predicted 185/333
proteins contain cysteines or have any discernable secondary structure other than the
hydrophobic leader containing a short β-strand followed by a short α-helical region that
extends into element 1. The deduced 185/333 proteins vary in length and sequence based
on element patterns, amino acid sequence variability and the position of translational
modification. With no known homologs, predictions of tertiary structure for these proteins
are problematic [134, 136].
Sequence comparisons suggested that 185/333 proteins could be antimicrobial
molecules or opsonins, although there is not yet any data on their function. The only
185/333 sequences that bear significant homology to molecules from other organisms are
the RGD motif and one of the histidine rich regions. The histidine rich region is similar to
histatins, a group of mammalian proteins that have powerful antibacterial and antifungal
activities [141]. The apparent lack of tertiary structure in predicted 185/333 proteins results
from their lack of cysteines, which is also a common characteristic of histatins and other
anti-microbial molecules that form a amphipathic α-helixes when they interact with target
cell surfaces [141].

41
The presence of the RGD motif in predicted 185/333 proteins suggests that they are
involved in defensive activity. RGD motifs are common among both vertebrates and
invertebrates. Their capacity to interact with cell surface integrins is thought to be a key
mechanism by which cellular effector activities, such as phagocytosis, are activated [142].
Immunocytology showed that 185/333 proteins are localized within two sub-sets of
coelomocytes: small and polygonal amoebocytes. Both cell types express 185/333 proteins
within vesicles in the perinuclear region. The expression of 185/333 proteins within small
amoebocytes was so intense that an exact localization was difficult to discern. However, by
limiting the penetration of antibodies within the cell, the authors demonstrated that
185/333 proteins are present on the surface of these cells.

42
Figure 1.9: Complexity of the proteome. One gene can produce multiple mature mRNAs
via alternative splicing of pre-mRNA transcripts. Following translation, a myriad of post-
translational modifications can produce further variations in the number and types of
protein forms. from [143].

43
1.5. Proteomics and sea urchins
1.5.1. From the static image to the dynamic image
Genome sequences have provided valuable information for comparative
immunologists. Bioinformatic technology for the detection of gene homologies has
improved so that we can now overcome problems associated with the accelerated rate at
which immune systems have evolved. However, the existence of nucleotide sequence
homologues is only a starting point for further experiments, because genes perform
different functions in different organisms. To help elucidate the function of proteins
encoded by genes, experimental characterisations at the cellular and protein levels are
required.
The two most striking features of the sea urchin genome were the diversity of
immune receptors and the presence of homologues of the genes involved in V(D)J
recombination in vertebrates. These results suggest a complex immune system [53].
However, the complexity of the immune response molecules in sea urchins observed at the
genetic level is likely to represent only a fraction of molecular diversity at the protein
level. Due to posttranslational modifications and alternative splicing, each gene may be
transcribed into 5 to 10 times more distinct mRNAs (Figure 1.9) [143]. Posttranscriptional
modifications are then likely to further increase the number of proteins expressed (Figure
1.9). Such posttranslational modifications are important regulators of activity but are
invisible to DNA-based methods. This partly explains why transcripts and proteins are not
always correlated. Therefore, proteomic analyses of immune responses are important to
confirm the biological significance of transcriptomic and genomic data.

44
Figure 1.10: Flow chart for gel-based and gel-free proteomics.
!"##$#%&'(")$*&&+"$,-$.+/0$
1'23#"$4-'5*,6'*,6$
7"#89'&"0$5,23'-'*:"$
3-,(",2/5&$
7"#84-""$5,23'-'*:"$
3-,(",2/5&$
;8<=$
7"#$'6'#%&/&$
>+'6*('*,6$,4$3-,("/6$
'9+60'65"&$
</?"&*,6$'60$
@!8A1BA1$
<'('9'&"$&"'-5C"&$4,-$
3-,("/6$/0"6*D5'*,6$
<'('9'&"$&"'-5C"&$4,-$
3-,("/6$/0"6*D5'*,6$
</?"&*,6$'60$
@!8A1BA1$
@'9"##/6?$
@'9"##/6?$
>+'6*('*,6$,4$3-,("/6$
'9+60'65"&$

45
Comparative immunology requires a comprehensive understanding of the
physiology of the animal and of the selection processes that it is subjected to. Natural
selection taking place during the arm’s race between hosts and pathogens puts pressure on
the phenotypes but not necessarily the genotypes of individuals. Comprehensive pictures
of phenotypes requires comparative analysis of proteomes, as well as genomes and
transcriptomes, to provide a dynamic image of biological processes.
1.5.2. Gel-based versus gel-free proteomics
Proteomes can be analysed either by using two-dimensional gel electrophoresis
(2DE) or by gel-free methods (Figure 1.10). Both techniques rely on mass spectrometric
analysis for protein identification (Figure 1.10).
2DE was first described by O’Farrell in 1975 [144]. The most popular 2DE method
separates proteins by isoelectric focusing (IEF) in the first dimension, using an
immobilized pH gradient (IPG) polyacrylamide gel, and then by molecular weight using
sodium dodecyl sulfate (SDS) electrophoresis in the second dimension. High resolution
2DE provides a powerful method for reproducible separation, visualization and
quantitation of hundreds to thousands of proteins on a single gel. The subsequent use of
mass spectrometry (MS) facilitates the identification of almost any protein spot on a 2DE
that can be visualized by Coomassie blue staining.
Mass spectrometers measure the mass/charge ratio (m/z) of ionized peptides
produced by enzymatic digestion of proteins. Two different approaches can be used for the
identification of proteins: peptide mass fingerprinting (PMF) or peptide sequencing. PMF
is achieved by matrix-assisted laser desorption/ionization (MALDI) coupled with a Time-
of-flight (TOF) mass analyzer. Peptides are identified by matching their mass/charge ratio
with the calculated masses of all predicted peptides deduced from protein databases. In

46
contrast, peptide sequencing employs electrospray ionization (ESI) and tandem mass
spectrometry (MS/MS). The peptide ion is fragmented by collision-induced dissociation
(CID) and the fragment ion is recorded. CID spectra show the masses of all ions generated
from the fragmentation of the peptide and provides information about their sequence.
Database searches are more accurate with CID spectra than with PMF. MALDI-
TOF, which is less expensive, is generally used for high throughput identification of
proteins from 2DE gels when the complete genome sequence of the species is available.
ESI-MS/MS is more accurate, but also more expensive and time consuming. However, it is
often required for the identification of proteins from species in which the genome has not
been sequenced, and for identification of post-translational modifications. ESI-MS/MS
also allows for de novo sequencing when database searches fail to definitely identify
peptides.
Although these techniques based on 2DE are more common, new proteomics tools
are being developed. Among these gel-free methods, multidimensional protein
identification technology (MudPIT) incorporates multidimensional high performance
liquid chromatography (HPLC) coupled with ESI-MS/MS for direct analyses of complex
proteomics mixtures. Alternatively, “shotgun” methods couple the separation of proteins
using one dimensional SDS-PAGE (1DE) or IEF electrophoresis with nano-LC and ESI-
MS/MS. Using only 10 to 20 runs on a mass spectrometer, shotgun proteomics can identify
hundreds of proteins simultaneously. These new proteomic methods allow for the
systematic analysis of protein identity, and more importantly allow individual proteins to
be quantified within complex protein mixtures [143].

47
1.5.3. Gel-based comparative proteomics
The reproducibility and resolution of protein separation by 2DE has improved
greatly over the past two decades. Gorg and coworkers [145] initiated the use of IPG strips
for first dimension separation and made significant improvements in sample preparation
protocols. Higher resolution of protein separation can be achieved by using several 2DE
gels with overlapping narrow pH gradients in order to reduce the occurrence of multiple
proteins within a single 2DE spot. The use of narrow pH gradients also allows for the
visualization of posttranslational modifications [146]. Methods for protein detection have
also improved significantly, allowing for a more accurate quantitation of proteins (Table
1.4).
For comparative analyses, 2DE gels are traditionally prepared from individual
experimental treatments, and compared with each other to identify proteins that show
differential abundance between treatments. Alternatively, using DIGE technology, samples
can be covalently labelled with succinimidyl esters of different cyanide dyes (Cy2, Cy3
and Cy5) (Figure 1.10). Samples from different treatments are then pooled and
electrophoresed on the same IPG strips and 2DE gels, so that differences in protein
expression can be calculated by comparing differential fluorescence intensities of the dyes.
New software for relative 2DE spot pattern analysis allow for relative quantification of
proteins visualized using all staining/labelling methods.

48
Com
men
ts
Com
patib
le w
ith a
naly
sis b
y M
S.
This
met
hod,
whi
ch u
ses t
richo
loro
acet
ic a
cid
and
alco
hol i
n th
e st
aini
ng so
lutio
n, re
sults
in
este
rific
atio
n of
asp
artic
and
glu
tam
ic si
de c
hain
ca
rbox
yl g
roup
s, co
mpl
icat
ing
the
inte
rpre
tatio
n of
th
e m
ass s
pect
ra
Som
e pr
otoc
ols c
ompa
tible
with
ana
lysi
s by
MS.
Stai
ning
tim
es a
nd re
actio
n te
mpe
ratu
re a
re c
ritic
al fo
r re
prod
ucib
ility
C
ompa
tible
with
ana
lysi
s by
MS.
Rev
erse
stai
ning
allo
ws h
ighe
r pro
tein
reco
very
Rap
id (5
-15
min
utes
)
Sam
ple
over
load
ing
decr
ease
s the
cap
acity
of
dist
ingu
ishi
ng b
etw
een
diff
eren
t ban
ds (1
-DE)
or
spot
s (2-
DE)
.
Com
patib
le w
ith a
naly
sis b
y M
S.
Allo
ws f
or b
oth
intra
gel a
nd in
terg
el re
lativ
e qu
antif
icat
ion
of p
rote
in sp
ots f
rom
sam
ples
. C
ompa
tible
with
ana
lysi
s by
MS.
Rap
id.
Stai
ning
tim
e is
not
crit
ical
and
can
be
varie
d fr
om
expe
rimen
t to
expe
rimen
t with
out o
verd
evel
opin
g
No.
of
sam
ples
/ G
el
1 1 1
2-3 1
Det
ectio
n
Den
sito
met
ry
Den
sito
met
ry
Den
sito
met
ry
Fluo
resc
ence
Fluo
resc
ence
Dyn
amic
ran
ge
20-f
old
Line
ar re
spon
se re
stric
ted
to
high
ng
amou
nts o
f pro
tein
s
8- to
10-
fold
Line
ar re
spon
se re
stric
ted
to
low
ng
amou
nts o
f pro
tein
s Li
near
resp
onse
rest
ricte
d to
hi
gh n
g to
µg
amou
nts o
f pr
otei
ns
1000
-fol
d
Line
ar re
spon
se o
n w
ide
rang
e 10
00-f
old
Line
ar re
spon
se o
n w
ide
rang
e
Lim
it of
de
tect
ion,
ng
8-10
2-10
5-10
5-10
1-8
Tabl
e 1.
4: M
etho
ds o
f pro
tein
det
ectio
n fo
r ge
l-bas
ed p
rote
omic
s. M
odifi
ed fr
om [1
47].
Vis
ualiz
atio
n m
etho
d
Col
loid
al C
oom
assi
e bl
ue
Silv
er
Zinc
-imid
azol
e
Cy3
,Cy5
SYPR
O-R
uby

49
1.5.4. Gel-free comparative proteomics
The original alternative to gel based comparative proteomics was the use of stable
isotope labelling coupled with shotgun methods. Isotopic labels were incorporated either in
peptide or protein samples, or during cell culture. Variations in protein abundance were
then calculated by comparing the relative intensity of the reporter ions from each sample.
The use of these techniques was, however, limited due to the high cost of the labelling
reagents (iTRAQ or ICAT) and their low throughput.
As a result of improvements in mass spectrometer performance, label-free
quantitative shotgun proteomics approaches have now been developed. Using these new
techniques relative protein abundance can be determined by either spectral counting, or
chromatographic peak intensity measurement. Spectral counts (SpC) have proven to be
more accurate than chromatographic peak intensity measurements, so that SpC is now used
preferentially [148, 149]. Shotgun proteomics and SpC allow absolute protein contents to
be estimated [150], and for relative quantitation of all proteins present within a complex
mixture. Using this technology, Zybailov et al. [148] developed methods for the relative
quantification of proteins using normalized spectral abundance factors (NSAFs). Natural
log transformations of NSAF values provide a normal distribution of protein concentration
data and allow for statistical analysis to compare the abundance of proteins between
samples.

50
1.5.5. Proteomics and sea urchins
Sea urchins have long been a model organism in reproduction and fertilization
biology. As early as 1976 [151], proteomics was used to evaluate patterns of protein
biosynthesis immediately after fertilization and up to gastrulation.
Immediately after the completion of the S. purpuratus genome sequencing project,
a number of laboratories around the world realized the opportunity to apply functional
genomics and proteomics to investigate the physiology of this invertebrate deuterostome.
First, Roux et al. [152] used a 2DE approach to investigate calcium signalling during egg
activation. Signalling components predicted by the genome were confirmed using
proteomics. They demonstrated that the initial release of calcium by the endoplasmic
reticulum after fertilisation induced multiple post-translational modifications, especially
protein phosphorylations, which coordinate egg activation. More recently, Sewell et al.
[153] used both 2DE and MudPIT to generate the first proteome map of the mature sea
urchin ovary. Twenty protein spots observed on 2DE were extracted for identification by
mass spectrometry, but only four could be unequivocally identified. Using MudPIT, a total
of 138 proteins were identified, confirming the ability of shotgun proteomics to cover a
broader proteome, and confirming that such techniques can be used to study sea urchins of
different families (Echinometridae and Strongylocentrotidae respectively)
Soon after, Mann et al. [154, 155] investigated the proteome of the test, spine and
tooth organic matrix. They took the opportunity to build a proteome map of the organic
matrix of adult sea urchins, since most previous studies had been undertaken on embryonic
spicules [156, 157]. The authors chose to use shotgun proteomics and deduced the relative
abundance of the identified proteins by calculating the exponentially modified protein
abundance index (emPAI) [150]. Over 95% of the 110 proteins identified had never been
observed within the skeletal matrices (test and spine) using traditional protein

51
characterization techniques. An additional 82 proteins were identified while studying the
tooth organic matrix.
In the most recent advance in this field, the S. purpuratus genome sequence has
rendered possible the direct identification of proteins by in-depth, high accuracy proteomic
analyses. Preliminary studies on the developing embryo, gonads and matrices of skeletal
elements have paved the way for a better understanding of sea urchin physiology. This
thesis exploits these technological advances by applying proteomics to analyse immune
responses in sea urchins.

52
1.6. The aims of this thesis
This thesis investigates the immune system of sea urchins at the protein level. So
far, our understanding has been limited to the use of genomic and transcriptomic methods,
which do not provide information on translated proteins. One hallmark of the sea urchin
genome/transcriptome is the presence of highly variable immune response gene families.
Hence, this thesis investigates whether the genomic and transcriptomic variability
corresponds at the protein level. It aims to:
- provide the first proteome map of the sea urchin immune system
- indentify proteins involved in immune responses
- clarify the extent of molecular variability among 185/333 proteins
- provide clues to the function of 185/333 proteins
The following Chapter presents the first proteome map of sea urchin coelomic fluid
and discusses the abundance of immune related proteins. The next two Chapters
investigate immune responses over time in response to challenge with LPS or whole
bacteria. Chapter Five uses proteomics to investigate variability among expressed 185/333
proteins, whilst the final “results” Chapter provides new information on the localization of
185/333 proteins and discusses their potential functions.

53
1.7. References
[1] Chen, J.-Y., Huang, D.-Y., Peng, Q.-Q., Chi, H.-M., et al., The first tunicate from the
Early Cambrian of South China. Proc Natl Acad Sci U S A 2003, 100, 8314-8318.
[2] Bromham, L. D., Degnan, B. M., Hemichordates and deuterostome evolution: robust
molecular phylogenetic support for a hemichordate + echinoderm clade. Evolution &
Development 1999, 1, 166-171.
[3] Davidson, E. H., Cameron, R. A., Arguments for sequencing the genome of the sea
urchin Strongylocentrotus purpuratus.
www.genome.gov/pages/research/sequencing/SegProposals/SeaUrchin _Genome.
prob.2002. 2002.
[4] Gray, J., An attempt to divide the Echinida, or sea eggs, into natural families. Ann.
Philos. 1825, 26, 423-431.
[5] Gray, J., Arrangement of families of Echinidea. Proc. Zool. Soc. London, III. 1855, 23,
35-39.
[6] Fell, F., Echinodermata, McGraw-Hill, New-York 1982.
[7] Gregory, J., The echinoidea, in Lankester, E.R.: A treatise on zoology, Adam and
Charles Black, London 1900.
[8] Springer, M., Tusneem, N., Davidson, E., Britten, R., Phylogeny, rates of evolution,
and patterns of codon usage among sea urchin retroviral-like elements, with
implications for the recognition of horizontal transfer. Mol Biol Evol 1995, 12, 219-
230.
[9] Klein, I., Naturalis dispositio Echinodermatum, Officina Gleditschiana, Leipzig 1734.
[10] Smith, A., Echinoid palaeobiology, George Allen and Unwin, London 1984.
[11] Cobb, J., Sneddon, E., An ultra-structural study of the gills of Echinus esculentus. Cell
Tissue Res. 1977, 182, 265-274.

54
[12] Farmanfarmaian, A., Stanford University, Stanford, Calif. 1959.
[13] Bamford, D., Echinoderm nutrition, M. Jangoux and J.M. Lawrence, Balkema,
rotterdam 1982, pp. 317-330.
[14] Ruppert, E. E., Barnes, R. D., invertebrate zoology. 6th ed., Saunders College
Publishers, Philadelphia 1994.
[15] Ziegler, A., Faber, C., Mueller, S., Bartolomaeus, T., Systematic comparison and
reconstruction of sea urchin (Echinoidea) internal anatomy: a novel approach using
magnetic resonance imaging. BMC Biology 2008, 6, 33.
[16] Holm, K., Dupont, S., Skold, H., Stenius, A., et al., Induced cell proliferation in
putative haematopoietic tissues of the sea star, Asterias rubens (L.). J Exp Biol 2008,
211, 2551-2558.
[17] Smith, V., The echinoderms, Academic Press, New York 1981.
[18] Chia, F. S., Xing, J., Echinoderm coelomocytes. Zoological studies 1996, 35, 231-
254.
[19] Boolootian, R., Geise, C., Coelomic corpuscles of echinoderms. Biol. Bull. 1958, 15,
53-56.
[20] Johnson, P., The coelomic elements of the sea urchins (Strongylocentrotus) III. In
vitro reaction to bacteria. J. Invert. Pathol. 1969, 13, 42-62.
[21] Edds, K. T., Cell biology of echinoid coelomocytes. I. Diversity and characterization
of cell types. J. Invert. Biol. 1993, 61, 173-178.
[22] Gross, P. S., Clow, L. A., Smith, L. C., SpC3, the complement homologue from the
purple sea urchin, Strongylocentrotus purpuratus, is expressed in two subpopulations
of the phagocytic coelomocytes. Immunogenetics 2000, 51, 1034-1044.
[23] Henson, J. H., Nesbitt, D., Wright, B. D., Sholey, J. S., Immunolocalization of kinesin
in sea urchin coelomocytes: association of kinesin with intracellular organelles. J.
Cell. Sci. 1992, 103, 309-320.

55
[24] Henson, J. H., Svitkina, T. M., Burns, A. R., Hughes, H. E., et al., Two components of
actin-based retrograde flow in sea urchin coelomocytes. Mol Biol Cell 1999, 10,
4075-4090.
[25] Brockton, V., Henson, J. H., Raftos, D. A., Majeske, A. J., et al., Localization and
diversity of 185/333 proteins from the purple sea urchin - unexpected protein-size
range and protein expression in a new coelomocyte type. J Cell Sci 2008, 121, 339-
348.
[26] Smith, L. C., Davidson, E. H., The echinoid immune system and the phylogenetic
occurrence of immune mechanisms in deuterostomes. Immunol. Today 1992, 13,
356-362.
[27] Smith, L., Britten, R., Davidson, E., Lipopolysaccharide activates the sea urchin
immune system. Dev Comp Immunol 1995, 19, 217-224.
[28] Matranga, V., Pinsino, A., Celi, M., Bella, G., Natoli, A., Impacts of UV-B radiation
on short-term cultures of sea urchin coelomocytes. Mar Biol 2006, 149, 25-34.
[29] Smith, L., Rast, J., Brockton, V., Terwilliger, D., et al., The sea urchin immune
system. Invertebrate Survival Journal 2006, 3, 25-39.
[30] Hibino, T., Loza-Coll, M., Messier, C., Majeske, A., et al., The immune gene
repertoire encoded in the purple sea urchin genome. Dev Biol 2006, 300, 349-365.
[31] Smith, L. C., Davidson, E. H., The echinoderm immune system. Characters shared
with vertebrate immune systems and characters arising later in deuterostome
phylogeny. Ann. NY Acad. Sci. 1994, 712, 213-226.
[32] Gross, P. S., Al-Sharif, W. Z., Clow, L. A., Smith, L. C., Echinoderm immunity and
the evolution of the complement system. Dev Comp Immunol 1999, 23, 429-442.
[33] Hildemann, W. H., Dix, T. G., Transplantation reactions of tropical Australian
echinoderms. Transplantation 1972, 15, 624-633.

56
[34] Karp, R. D., Hildemann, W. H., Specific allograft reactivity in the seastar
Dermasterias imbricata. Transplantation 1976, 22, 434-439.
[35] Coffaro, K. A., Phylogeny of immunological memory, M.J. Manning. Elsevier / North-
Holland Biomedical Press, Amsterdam 1980, p. 77.
[36] Coffaro, K., Hinegardner, R., Immune response in the sea urchin Lytechinus pictus.
Science 1977, 197, 1389-1390.
[37] Coffaro, K. A., Clearance of bacteriophage T4 in the sea urchin Lytechinus pictus. J.
Invert. Pathol. 1978, 32, 384-385.
[38] Stabili, L., Pagliara, M., Metrangolo, M., Canicatti, C., Comparative aspects of
Echinoidea cytolysins: the cytolytic activity of Spherechinus granularis (Echinoidea)
coelomic fluid. Comp. Biochem. Physiol. 1992, 101A, 553-556.
[39] Gerardi, G., Lassegues, M., Canicatti, C., Cellular distribution of sea urchin
antibacterial activity. Biol. Cell. 1990, 70, 153-157.
[40] Edds, K., Dynamic aspects of filopodial formation by reorganization of
microfilaments. J Cell Biol 1977, 73, 479-491.
[41] Xing, J., Chia, F. S., Phagocytosis of sea cucumber amoebocytes: a flow cytometric
study. Invertebr Biol 1998, 117, 67-74.
[42] Arizza, V., Giaramita, F. T., Parrinello, D., Cammarata, M., Parrinello, N., Cell
cooperation in coelomocyte cytotoxic activity of Paracentrotus lividus
coelomocytes. Comp Biochem Physiol A Mol Integr Physiol 2007, 147, 389-394.
[43] Lin, W., Grant, S., Beck, G., Generation of monoclonal antibodies to coelomocytes of
the purple sea urchin Arbacia punctulata: Characterization and phenotyping. Dev
Comp Immunol 2007, 31, 465-475.
[44] Matranga, V., Toia, G., Bonaventura, R., Muller, W., Cellular and biochemical
responses to environmental and experimentally induced stress in sea urchin
coelomocytes. Cell stress chaperones 2000, 5, 158-165.

57
[45] Service, M., Wardlaw, A., Echinochrome-A as a bactericidal substance in the
coelomic fluid of Echinus esculentus (L.). Comp Biochem Physiol B Biochem Mol
Biol 1984, 79, 161-165.
[46] Cervello, M., Arizza, V., Lattuca, G., Parrinello, N., Matranga, V., Detection of
vitellogenin in a subpopulation of sea urchin coelomocytes. Eur J Cell Biol 1994, 64,
314-319.
[47] Smith, L., Britten, R., Davidson, E., SpCoel1: a sea urchin profilin gene expressed
specifically in coelomocytes in response to injury. Mol Biol Cell 1992, 3, 403-414.
[48] Smith, L., Chang, L., Britten, R., Davidson, E., Sea urchin genes expressed in
activated coelomocytes are identified by expressed sequence tags. Complement
homologues and other putative immune response genes suggest immune system
homology within the deuterostomes. J Immunol 1996, 156, 593-602.
[49] Al-Sharif, W. Z., Sunyer, J. O., Lambris, J. D., Smith, L. C., Sea urchin coelomocytes
specifically express a homologue of the complement component C3. J Immunol
1998, 160, 2983-2997.
[50] Smith, L. C., Shih, C.-S., Dachenhausen, S. G., Coelomocytes express SpBf, a
homologue of factor B, the second component in the sea urchin complement system.
J Immunol 1998, 161, 6784-6793.
[51] Beck, G., Habicht, G. S., Immunity and the invertebrates. Scientific american 1996,
275, 60-66.
[52] Sodergren, E., Weinstock, G.M., Davidson, E.H., Cameron, R., A. et al. The genome
of the sea urchin Strongylocentrotus purpuratus. Science 2006, 314, 941-952.
[53] Rast, J. P., Smith, L. C., Loza-Coll, M., Hibino, T., Litman, G. W., Genomic insights
into the immune system of the sea urchin. Science 2006, 314, 952-956.
[54] Rast, J. P., Messier-Solek, C., Marine invertebrate genome sequences and our
evolving understanding of animal immunity. Biol Bull 2008, 214, 274-283.

58
[55] Du, X., Poltorak, A., Wei, Y., Beutler, B., Three novel mammalian toll-like receptors:
gene structure, expression, and evolution. European Cytokine Network 2000, 11,
362-371.
[56] Clow, L. A., Raftos, D. A., Gross, P. S., Smith, L. C., The sea urchin complement
homologue, SpC3, functions as an opsonin. J Exp Biol 2004, 207, 2147-2155.
[57] Smith, L. C., Thioester function is conserved in SpC3, the sea urchin homologue of
the complement component C3. Dev Comp Immunol 2002, 26, 603-614.
[58] Clow, L. A., Gross, P. S., Shih, C.-S., Smith, L. C., Expression of SpC3, the sea
urchin complement component, in response to lipopolysaccharide. Immunogenetics
2000, 51, 1021-1033.
[59] Shah, M., Brown, K., Smith, L., The gene encoding the sea urchin complement
protein, SpC3, is expressed in embryos and can be upregulated by bacteria. Dev
Comp Immunol 2003, 27, 529-538.
[60] Terwilliger, D., Clow, L., Gross, P., Smith, L., Constitutive expression and alternative
splicing of the exons encoding SCRs in Sp152, the sea urchin homologue of
complement factor B. Implications on the evolution of the Bf/C2 gene family.
Immunogenetics 2004, 56, 531-543.
[61] Smith, L. C., Clow, L. A., Terwilliger, D. P., The ancestral complement system in sea
urchins. Immunological Reviews 2001, 180, 16-34.
[62] Ji, X., Azumi, K., Sasaki, M., Nonaka, M., Ancient origin of the complement lectin
pathway revealed by molecular cloning of mannan binding protein-associated serine
protease from a urochordate, the Japanese ascidian, Halocynthia roretzi. Proc Natl
Acad Sci U S A 1997, 94, 6340-6345.
[63] Nakao, M., Kajiya, T., Sato, Y., Somamoto, T., et al., Lectin pathway of bony fish
complement: Identification of two homologs of the mannose-binding lectin

59
associated with MASP2 in the common carp (Cyprinus carpio). J Immunol 2006,
177, 5471-5479.
[64] Takahashi, K., Ip, W. K. E., Michelow, I. C., Ezekowitz, R. A. B., The mannose-
binding lectin: a prototypic pattern recognition molecule. Current Opinion in
Immunology 2006, 18, 16-23.
[65] Fujita, T., Evolution of the lectin-complement pathway and its role in innate
immunity. Nat Rev Immunol 2002, 2, 346-353.
[66] Fujita, T., Matsushita, M., Endo, Y., The lectin-complement pathway -- its role in
innate immunity and evolution. Immunological Reviews 2004, 198, 185-202.
[67] Agrawal, A., Eastman, Q. M., Schatz, D. G., Transposition mediated by RAG1 and
RAG2 and its implications for the evolution of the immune system. Nature 1998,
394, 744-751.
[68] Miracle, A. L., Anderson, M. K., Litman, R. T., Walsh, C. J., et al., Complex
expression patterns of lymphocyte-specific genes during the development of
cartilaginous fish implicate unique lymphoid tissues in generating an immune
repertoire. Int. Immunol. 2001, 13, 567-580.
[69] Bartl, S., Miracle, A. L., Rumfelt, L. L., Kepler, T. B., et al., Terminal
deoxynucleotidyl transferases from elasmobranchs reveal structural conservation
within vertebrates. Immunogenetics 2003, 55, 594-604.
[70] Fugmann, S. D., Messier, C., Novack, L. A., Cameron, R. A., Rast, J. P., An ancient
evolutionary origin of the Rag1/2 gene locus. Proceedings of the National Academy
of Sciences of the United States of America 2006, 103, 3728-3733.
[71] Dominguez. O., Ruiz, J., F., Lain de Lera, T., Garcia-Diaz, M., Gonzalez, M., A.,
Kirchhoff, T., Martinez-A, C., Bernard, A., Blanco, L., DNA polymerase mu (Polµ),
homologous to TdT, could act as a DNA mutator in eukaryotic cells. The EMBO
Journal 2000, 19, 1731-1742.

60
[72] Ruiz, J., F., Dominguez, O., Lain de Lera, T., Garcia-Diaz, M., Bernard, A., Blanco,
L., DNA polymerase mu, a candidate hypermutase? Philos Trans R Soc Lond B Biol
Sci 2001, 356, 99-109.
[73] Raftos, D., Raison, R. L., Evolutionary immunology: Early vertebrates reveal diverse
immune recognition strategies. Immunol Cell Biol 2008, 86, 479-481.
[74] Kurtz, J., Memory in the innate and adaptive immune systems. Microbes and Infection
2004, 6, 1410-1417.
[75] Nair, S. V., Del Valle, H., Gross, P. S., Terwilliger, D. P., Smith, L. C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin.
Identification of unexpected immune diversity in an invertebrate. Physiol Genomics
2005, 22, 33-47.
[76] Flajnik, M., Du Pasquier, L., Evolution of innate and adaptive immunity: can we draw
a line? Trends Immunol 2004, 25, 640-644.
[77] Pancer, Z., Amemiya, C., Ehrhardt, G., Ceitlin, J., et al., Somatic diversification of
variable lymphocyte receptors in the agnathan sea lamprey. Nature 2004, 430, 174-
180.
[78] Watson, F. L., Puttmann-Holgado, R., Thomas, F., Lamar, D. L., et al., Extensive
diversity of Ig-superfamily proteins in the immune system of insects. Science 2005,
309, 1874-1878.
[79] Cannon, J. P., Haire, R. N., Litman, G. W., Identification of diversified genes that
contain immunoglobulin-like variable regions in a protochordate. Nature
Immunology 2002, 3, 1200-1207.
[80] Stearns, S. C., Evolution of life-history traits - critique of theory and a review of data.
Ann. rev. Ecol. Systematics 1977, 8, 145-171.

61
[81] Getz, W. M., Metaphysiological and evolutionnary dynamics of populations
exploiting constant and interactive resources - r-K selection revisited. Evol. Ecol.
1993, 7, 287-305.
[82] Klein, J., Are invertebrates capable of anticipatory immune response? Scand. J.
Immunol. 1989, 29, 499-505.
[83] Van Valen, L. A., A new evolutionnary law. Evol. Theory 1973, 1, 1-30.
[84] Bowden, L., Dheilly, N. M., Raftos, D. A., Nair, S. V., New immune systems:
pathogen-specific host defense, life history strategies and hypervariable immune-
response genes of invertebrates. Invertebrate survival journal 2007, 4, 127-136.
[85] Ebert, T. A., Southon, J. R., Red sea urchins (Strongylocentrotus franciscanus) can
live over 100 years: confirmation with A-bomb 14 carbon. Fish bulletin
(Sacramento, Calif.) 2003, 101, 915.
[86] Stow, A., Briscoe, D., Gillings, M., Holley, M., et al., Antimicrobial defences increase
with sociality in bees. Biology Letters 2007, 3, 422-424.
[87] Sala, E., Ribes, M., Hereu, B., Zabala, M., et al., Temporal variability in abundance of
the sea urchins Paracentrotus lividus and Arbacia lixula in the northwestern
Mediterranean: comparison between a marine reserve and an unprotected area.
Marine ecology progress series 1998, 168, 135-145.
[88] Becker, P. T., Egea, E., Eeckhaut, I., Characterization of the bacterial communities
associated with the bald sea urchin disease of the echinoid Paracentrotus lividus. J
Invertebr Pathol 2008, 98, 136-147.
[89] Lester, S. E., Tobin, E. D., Behrens, M. D., Disease dynamics and the potential role of
thermal stress in the sea urchin, Strongylocentrotus purpuratus. Can. J. Fish. Aquat.
Sci. 2007, 64, 314-323.
[90] Scheibling, R. E., Hennigar, A. W., Recurrent outbreaks of disease in sea urchins
Strongylocentrotus droebachiensis in Nova Scotia: evidence for a link with large-

62
scale meteorologic and oceanographic events. Marine ecology progress series 1997,
152, 155-165.
[91] Little, T. J., Hultmark, D., Read, A. F., Invertebrate immunity and the limits of
mechanistic immunology. Nat Immunol 2005, 6, 651-654.
[92] Lemaitre, B., Reichhart, J.-M., Hoffmann, J. A., Drosophila host defense: Differential
induction of antimicrobial peptide genes after infection by various classes of
microorganisms. Proc Natl Acad Sci U S A 1997, 94, 14614-14619.
[93] Pham, L. N., Dionne, M. S., Shirasu-Hiza, M., Schneider, D. S., A specific primed
immune response in Drosophila is dependent on phagocytes. PLoS Pathogens 2007,
3, e26.
[94] Sadd, B. M., Schmid-Hempel, P., Insect immunity shows specificity in protection
upon secondary pathogen exposure. Curr Biol 2006, 16, 1206-1210.
[95] Good, R. A., Finstad, J., Litman , G. W., The biology of Lampreys, Academic, London
1972.
[96] Hildemann, W. H., Transplantation immunity in fishes: Agnathan, Chondrichthyes
and Osteichthyes. Transplant. Proc. 1970, 2, 253-259.
[97] Hagen, M., Filosa, M. F., Youson, J. H., The immune response in adult sea lamprey
(Petromyzon marinus L.): The effect of temperature. Comp Biochem Physiol A
Physiol 1985, 82, 207-210.
[98] Perey, D. Y., Finstad, J., Pollara, B., Good, R. A., Evolution of the immune response.
VI. First and second set skin homograft rejections in primitive fishes. Lab. Invest.
1968, 19, 591-597.
[99] Alder, M. N., Rogozin, I. B., Iyer, L. M., Glazko, G. V., et al., Diversity and function
of adaptive immune receptors in a jawless vertebrate. Science 2005, 310, 1970-1973.
[100] Kim, H. M., Oh, S. C., Lim, K. J., Kasamatsu, J., et al., Structural diversity of the
hagfish variable lymphocyte receptors. J Biol Chem 2007, 282, 6726-6732.

63
[101] Han, B. W., Herrin, B. R., Cooper, M. D., Wilson, I. A., Antigen recognition by
variable lymphocyte receptors. Science 2008, 321, 1834-1837.
[102] Kasamatsu, J., Suzuki, T., Ishijima, J., Matsuda, Y., Kasahara, M., Two variable
lymphocyte receptor genes of the inshore hagfish are located far apart on the same
chromosome. Immunogenetics 2007, 59, 329-331.
[103] Rogozin, I. B., Iyer, L. M., Liang, L., Glazko, G. V., et al., Evolution and
diversification of lamprey antigen receptors: evidence for involvement of an AID-
APOBEC family cytosine deaminase. Nat Immunol 2007, 8, 647-656.
[104] Cannon, J., Haire, R., Litman, G., Identification of diversified genes that contain
immunoglobulin-like variable regions in a protochordate. Nat Immunol 2002, 3,
1200-1207.
[105] Cannon, J., Haire, R., Schnitker, N., Mueller, M., Litman, G., Individual
protochordates have unique immune-type receptor repertoires. Curr Biol 2004, 14,
R465 - 466.
[106] Dishaw, L., Mueller, M. G., Gwatney, N., Cannon, J., et al., Genomic complexity of
the variable region-containing chitin-binding proteins in amphioxus. BMC Genetics
2008, 9, 78.
[107] Hernandez Prada, J., Haire, R., Allaire, M., Jakoncic, J., et al., Ancient evolutionary
origin of diversified variable regions revealed by crystal structures of an immune-
type receptor in amphioxus. Nat Immunol 2006, 7, 875-882.
[108] Litman, G., Cannon, J., Dishaw, L., Reconstructing immune phylogeny: new
perspectives. Nat Rev Immunol 2005, 5, 866-879.
[109] Adema, C. M., Hertel, L. A., Miller, R. D., Loker, E. S., A family of fibrinogen-
related proteins that precipitates parasite-derived molecules is produced by an
invertebrate after infection. Proc Natl Acad Sci U S A 1997, 94, 8691-8696.

64
[110] Léonard, P. M., Adema, C. M., Zhang, S.-M., Loker, E. S., Structure of two FREP
genes that combine IgSF and fibrinogen domains, with comments on diversity of the
FREP gene family in the snail Biomphalaria glabrata. Gene 2001, 269, 155-165.
[111] Kurachi, S., Song, Z., Takagaki, M., Yang, Q., et al., Sialic-acid-binding lectin from
the slug Limax flavus: cloning, expression of the polypeptide, and tissue location.
European Journal of Biochemistry 1998, 253, 217-222.
[112] Gokudan, S., Muta, T., Tsuda, R., Koori, K., et al., Horseshoe crab acetyl group-
recognizing lectins involved in innate immunity are structurally related to fibrinogen.
Proc Natl Acad Sci USA 1999, 96, 10086-10091.
[113] Gregorio, E. D., Spellman, P. T., Rubin, G. M., Lemaitre, B., Genome-wide analysis
of the Drosophila immune response by using oligonucleotide microarrays. Proc Nat
Acad Sci USA 2001, 98, 12590-12595.
[114] Kenjo, A., Takahashi, M., Matsushita, M., Endo, Y., et al., Cloning and
characterization of novel ficolins from the solitary ascidian, Halocynthia roretzi. J
Biol Chem 2001, 276, 19959-19965.
[115] Dehal, P., Satou, Y., Campbell, R. K., Chapman, J., et al., The draft genome of
Ciona intestinalis: insights into chordate and vertebrate origins. Science 2002, 298,
2157-2167.
[116] Zdobnov, E. M., von Mering, C., Letunic, I., Torrents, D., et al., Comparative
genome and proteome analysis of Anopheles gambiae and Drosophila melanogaster.
Science 2002, 298, 149-159.
[117] Holmskov, U., Thiel, S., Jensenius, J. C., Collectins and ficolins: humoral lectins of
the innate immune defense. Annual Review of Immunology 2003, 21, 547-578.
[118] Zhang, S.-M., Loker, E. S., The FREP gene family in the snail Biomphalaria
glabrata: additional members, and evidence consistent with alternative splicing and
FREP retrosequences. Dev Comp Immunol 2003, 27, 175-187.

65
[119] Zhang, S., Adema, C., Kepler, T., Loker, E., Diversification of Ig superfamily genes
in an invertebrate. Science 2004, 305, 251-254.
[120] Zhang, S.-M., Yong Zeng, Loker, E. S., Expression profiling and binding properties
of fibrinogen-related proteins (FREPs), plasma proteins from the schistosome snail
host Biomphalaria glabrata. Innate Immunity 2008, 14, 175-189.
[121] Adema, C. M., Hertel, L. A., Loker, E. S., Evidence from two planorbid snails of a
complex and dedicated response to digenean (echinostome) infection. Parasitology
1999, 119, 395-404.
[122] Hertel, L. A., Adema, C. M., Loker, E. S., Differential expression of FREP genes in
two strains of Biomphalaria glabrata following exposure to the digenetic trematodes
Schistosoma mansoni and Echinostoma paraensei. Dev Comp Immunol 2005, 29,
295-303.
[123] Zhang, S.-M., Nian, H., Zeng, Y., DeJong, R. J., Fibrinogen-bearing protein genes in
the snail Biomphalaria glabrata: Characterization of two novel genes and expression
studies during ontogenesis and trematode infection. Developmental & Comparative
Immunology 2008, 32, 1119-1130.
[124] Dong, Y., Dimopoulos, G., Anopheles fibrinogen-related proteins provide expanded
pattern recognition capacity against bacteria and Malaria parasites. J. Biol. Chem.
2009, 284, 9835-9844.
[125] Fan, C., Zhang, S., Li, L., Chao, Y., Fibrinogen-related protein from amphioxus
Branchiostoma belcheri is a multivalent pattern recognition receptor with a
bacteriolytic activity. Mol Immunol 2008, 45, 3338-3346.
[126] Zhang, H., Wang, L., Song, L., Song, X., et al., A fibrinogen-related protein from
bay scallop Argopecten irradians involved in innate immunity as pattern recognition
receptor. Fish Shellfish Immunol 2009, 26, 56-64.

66
[127] Schmucker, D., Clemens, J., Shu, H., Worby, C., et al., Drosophila Dscam is an axon
guidance receptor exhibiting extraordinary molecular diversity. Cell 2000, 101, 671-
684.
[128] Neves, G., Zucker, J., Daly, M., Chess, A., Stochastic yet biased expression of
multiple Dscam splice variants by individual cells. Nature genetics 2004, 36, 240-
246.
[129] Watson, F., Puttmann-Holgado, R., Thomas, F., Lamar, D., et al., Extensive
diversity of Ig-superfamily proteins in the immune system of insects. Science 2005,
309, 1874-1878.
[130] Dong, Y., Taylor, H., Dimopoulos, G., AgDscam, a hypervariable immunoglobulin
domain-containing receptor of the Anopheles gambiae innate immune system. PLoS
Biol 2006, 4, e229.
[131] Crayton, M., Powell, B., Vision, T., Giddings, M., Tracking the evolution of
alternatively spliced exons within the Dscam family. BMC Evolutionary Biology
2006, 6, 16.
[132] Brites, D., McTaggart, S., Morris, K., Anderson, J., et al., The Dscam homologue of
the crustacean Daphnia is diversified by alternative splicing like in insects. Mol Biol
Evol 2008, 25, 1429-1439.
[133] Rast, J., Pancer, Z., Davidson, E., New approaches towards an understanding of
deuterostome immunity. Curr Top Microbiol Immunol 2000, 248, 3-16.
[134] Terwilliger, D., Buckley, K., Mehta, D., Moorjani, P., Smith, L., Unexpected
diversity displayed in cDNAs expressed by the immune cells of the purple sea
urchin, Strongylocentrotus purpuratus. Physiol Genomics 2006, 26, 134-144.
[135] Buckley, K., Smith, L., Extraordinary diversity among members of the large gene
family, 185/333, from the purple sea urchin, Strongylocentrotus purpuratus. BMC
Mol Biol 2007, 8, 68.

67
[136] Terwilliger, D., Buckley, K., Brockton, V., Ritter, N., Smith, L. C., Distinctive
expression patterns of 185/333 genes in the purple sea urchin, Strongylocentrotus
purpuratus: an unexpectedly diverse family of transcripts in response to LPS, beta-
1,3-glucan, and dsRNA. BMC Mol Biol 2007, 8, 16.
[137] Rogaev, E. I., Simple human DNA-repeats associated with genomic hypervariability,
flanking the genomic retroposons and similar to retroviral sites. Nucl. Acids Res.
1990, 18, 1879-1885.
[138] Buckley, K. M., Munshaw, S., Kepler, T. B., Smith, L. C., The 185/333 gene family
is a rapidly diversifying host-defense gene cluster in the purple sea urchin
Strongylocentrotus purpuratus. J Mol Biol 2008, 379, 912-928.
[139] Buckley, K., Florea, L., Smith, L. C., A method for identifying alternative or cryptic
donor splice sites within gene and mRNA sequences. Comparisons among sequences
from vertebrates, echinoderms and other groups. BMC Genomics 2009, 10, 318.
[140] Buckley, K. M., Terwilliger, D. P., Smith, L. C., Sequence variations in 185/333
messages from the purple sea urchin suggest posttranscriptional modifications to
increase immune diversity. J Immunol 2008, 181, 8585-8594.
[141] Tsai, H., Bobek, L. A., Human salivary histatins: promising anti-fungal therapeutic
agents. Critical Reviews in Oral Biology & Medicine 1998, 9, 480-497.
[142] Johansson, M. W., Cell adhesion molecules in invertebrate immunity.
Developmental & Comparative Immunology 1999, 23, 303-315.
[143] Peng, J., Gygi, S. P., Proteomics: the move to mixtures. Journal of Mass
Spectrometry 2001, 36, 1083-1091.
[144] O'Farrell, P. H., High resolution two-dimensional electrophoresis of proteins. J. Biol.
Chem. 1975, 250, 4007-4021.

68
[145] Rabilloud, T., Adessi, C., Guiraudel, A., Lunardi, J., Improvement of the
solubilization of proteins in two-dimensional electrophoresis with immobilized pH
gradients. Electrophoresis 1997, 18, 307-316.
[146] Hoving, S., Voshol, H., van Oostrum, J., Towards high performance two-
dimensional gel electrophoresis using ultrazoom gels. Electrophoresis 2000, 21,
2617-2621.
[147] Cristea, I. M., Gaskell, S. J., Whetton, A. D., Proteomics techniques and their
application to hematology. Blood 2004, 103, 3624-3634.
[148] Zybailov, B. L., Florens, L., P., W. M., Quantitative shotgun proteomics using a
protease with broad specificity and normalized spectral abundance factors. Mol
Biosyst 2007, 3, 354-360.
[149] Old, W. M., Meyer-Arendt, K., Aveline-Wolf, L., Pierce, K. G., et al., Comparison
of label-free methods for quantifying human proteins by shotgun proteomics. Mol
Cell Proteomics 2005, 4, 1487-1502.
[150] Ishihama, Y., Oda, Y., Tabata, T., Sato, T., et al., Exponentially modified protein
abundance index (emPAI) for estimation of absolute protein amount in proteomics
by the number of sequenced peptides per protein. Mol Cell Proteomics 2005, 4,
1265-1272.
[151] Brandhorst, B. P., Two-dimensional gel patterns of protein synthesis before and after
fertilization of sea urchin eggs. Dev Biol 1976, 52, 310-317.
[152] Roux, M. M., Townley, I. K., Raisch, M., Reade, A., et al., A functional genomic
and proteomic perspective of sea urchin calcium signaling and egg activation.
Developmental Biology 2006, 300, 416-433.
[153] Sewell, M. A., Eriksen, S., Middleditch, M. J., Identification of protein components
from the mature ovary of the sea urchin Evechinus chloroticus (Echinodermata:
Echinoidea). Proteomics 2008, 8, 2531-2542.

69
[154] Mann, K., Poustka, A., Mann, M., The sea urchin (Strongylocentrotus purpuratus)
test and spine proteomes. Proteome Science 2008, 6, 22.
[155] Mann, K., Poustka, A., Mann, M., In-depth, high-accuracy proteomics of sea urchin
tooth organic matrix. Proteome Science 2008, 6, 33.
[156] Wilt, F. H., Killian, C. E., Livingston, B. T., Development of calcareous skeletal
elements in invertebrates. Differentiation 2003, 71, 237-250.
[157] Wilt, F. H., Matrix and mineral in the sea urchin larval skeleton. Journal of
Structural Biology 1999, 126, 216-226.

70

71
CHAPTER II
Shotgun proteomic analysis of coelomocytes from the purple sea urchin,
Strongylocentrotus purpuratus.
Submitted as a Dataset Brief to
Proteomics
Author contributions:
Haynes PA2 - Experimental design - Technical support
Smith LC3 - Sample preparation
Raftos DA1 - Projet supervision
Nair SV1 – Experimental design - Project supervision
1Department of Biological Sciences, Macquarie University, North Ryde, NSW 2109, Australia.
2Department of Chemistry and Biomolecular Sciences, Macquarie University, North Ryde, NSW 2109,
Australia
3Department of Biological Sciences, George Washington University, Washington, DC, 20052, USA.

72

73
2.1. Preface
As outlined in Chapter 1 of this thesis, there is already extensive genomic and
trancriptomic data on the immune system of sea urchins. These predicted a complex
immune system that with some similarities to vertebrate immune responses. Coelomocytes
appear to be the main effector cells of sea urchins immune responses. However, little is
known about the proteins expressed by coelomocytes. The objective of this Chapter was to
draw an initial proteome map of the sea urchin coelomic fluid as a first step in assessing
changes in that proteome after immunological challenge.
Remarks: The following Chapter has been submitted to Proteomics as a Dataset
Brief. As such, it has been prepared accordingly to the following instructions for authors:
“Dataset briefs describing novel proteomic datasets of specific types of samples, such as organisms,
tissues,organelles,andcells.ThesedatasetscanbegeneratedwithanyproteomicPlatformincluding
two‐dimensionalgels,massspectrometryorproteinarrays.Animportantcriterionisthatthedataset
containsasignificantnumberofidentifiedproteinsthatwillbenefitfurtherresearchonthatparticular
sampletype.Themanuscriptsshouldbearthewords“DatasetBrief”immediatelyabovethetitleonthe
firstpage.Theyshouldnotbesubdividedintotitledsectionsbutwritteninacontinuousstyle.Dataset
briefsshouldnotexceed2500words(includingreferencesandFigurelegends)andcontainnomore
than 3 display elements (Figures and tables). Authors are encouraged to submit supporting
information,suchasannotatedtwo‐dimensionalgelimagesandtablesofproteinidentifications,which
willonlyappearonline.”

74

75
2.2. Abstract
Recent genome sequencing and transcriptomic analyses have revealed a complex
immune system in sea urchins that appears to be mediated by coelomocytes (blood cells).
However, the broad array of proteins that comprise the coelomocyte proteome remains
unknown. Here, we identified 319 proteins present in sea urchin coelomocytes. Proteins
involved in the coelomocyte cytoskeleton were the most abundant. This is consistent with
the capacity of coelomocytes for pseudopodium formation and phagocytosis. A number of
immune response proteins were also identified, including a preponderance of complement
components and scavenger receptor cysteine rich (SRCR) proteins. The relative abundance
of dual oxidase 1, apextrin, echinonectin, major yolk protein, apolipoprotein B,
ceruloplasmin, ferritin and transferrin suggest that these proteins may also be involved in
host defense. Overall, the function of many coelomocytes proteins could ultimately be
related to anti-pathogen defense, which supports the role of coelomocytes as the primary
immune mediators of sea urchins.

76
2.3. Dataset Brief
The last common ancestor of the deuterostomes lived during the Cambrian period,
520-530 million years ago [1]. This ancestor gave rise to echinoderms, of which sea
urchins (class Echinodidea) constitute a major taxon [2]. Their phylogenetic position, as
well as their importance in the studies of early deuterostome development, were the
motivations for sequencing the genome of the purple sea urchin, Strongylocentrotus
purpuratus [3]. That genome sequence confirmed the kinship between echinoderms and
chordates, but also revealed some unexpected results. Among these surprises was the
complexity of immune response genes in sea urchins [3-5].
Given this complexity, it is essential to analyze the functional immunome of sea
urchins at the protein level. The current study uses large scale shotgun proteomics to
provide the first assessment of the sea urchin coelomocyte proteome. Shotgun proteomics
allows the majority of proteins in a particular cell type (coelomocytes in our study) to be
identified and characterized simultaneously, providing a comprehensive picture of these
cells at the protein level. In this study, we identify 319 proteins expressed in coelomocytes
and discuss their putative functions with an emphasis on their role in immunological
reactivity.
Three adult S. purpuratus were challenged with lipopolysaccharide (LPS) as
described previously [6-11] (For detailed descriptions of methodology see Supplementary
Data 2.1). Coelomic fluid (CF) proteins were extracted and separated on SDS-PAGE gels
and digested with trypsin before being analyzed by nanoLC-MS/MS using a LTQ-XL ion-
trap mass spectrometer. MS/MS spectra were searched against a local database that
contained all 44,037 Strongylocentrotus protein sequences held by NCBI as of April 2008.
The relative abundance of identified proteins (FDR< 0.1%) were calculated based on
normalized spectral abundance factor (NSAF) values as described previously [12]. For

77
each protein, k, the sum (S) of all spectral counts obtained from the three sea urchins was
calculated, and the corresponding NSAFS deduced. NSAFS values were used as a measure
of protein abundance. The NSAFi values for each of the individual sea urchins were
strongly correlated with these NSAFS values (R2, 0.85-0.92), suggesting that NSAFS values
were representative of protein abundances within the three CF samples. The natural log of
the NSAFs values were plotted against the number of proteins obtained, which showed a
normal distribution with a mean of -4.78 and a standard deviation of ± 0.62.
Shotgun proteomic analysis identified 319 distinct coelomocyte proteins with high
confidence (Table 2.1, for detailed description of results, see Supplementary Data 2.2).
Most (284 of 319) of the proteins were predicted from the genome of S. purpuratus, but
had not been previously identified at the protein level using non-genomic methods.
Hypothetical proteins predicted in the S. purpuratus genome without a known or putative
function accounted for 48 of the 319 proteins. Protein BLAST and conserved domain
searches against the entire NCBI database showed strong matches to homologous proteins
in all but 16 of these cases.
Proteins were grouped into 11 functional categories based on the annotations for
the corresponding genes in the S. purpuratus genome or other homologies. Figure 2.1
shows the number of proteins that fell within defined functional categories and the relative
abundance (NSAFs values) of each category within the total coelomocyte proteome.
Proteins involved in cell structure, shape and mobility were the most common in the
coelomocyte proteome, including 52 distinct proteins that accounted for 53% of all NSAFs
values. These included the cytoskeletal actins (CyIIb and CyIIIb), profilin, fascin, cofilin,
gelsolin, myosin, microtubule associated protein, coronin, tubulin, α-actinin and collagen.
This agrees with physiological studies, which have shown that phagocytic coelomocytes
represent up to 82% of the cells in the CF [13, 8]. They are highly mobile cells that can
quickly develop extended filopodia and lamellipodia [14] and are avidly phagocytic [15].

78
Figure 2.1: Functional classification of proteins identified from sea urchin CF. The
relative abundance of each category was based on either (A) the total number of proteins in
each functional category, or (B) the normalized spectral abundance factors (NSAFs)
obtained from the 3 individual sea urchins for each protein. The total number of proteins
included in this analysis is 319, as detailed in Supplementary Data 2.1.
B
NSAFs
A
Number of
Proteins
Cell structure, shape and mobility
Cell adhesion
Immune response
Lysosomes, proteases and peptidases
Intracellular transport
Exchanger and ATPases
Cell signaling
Stress response, detoxification
Energy metabolism
Nucleic acid and protein metabolism and processing
Cell proliferation, reproduction and development
Others
Unknown

79
Table 2.1: The thirty most abundant proteins identified in the coelomic fluid of 3
individual sea urchins 24 hours after injection of lipopolysaccharide. NSAFs values
correspond to the normal spectral abundance factor of the sum of rI from the three
individuals. Protein numbers correspond to those in Supplementary Data 2.2. Proteins
that had previously been identified are shown in bold. Proteins predicted by genome
annotation are shown in normal font. The function of hypothetical proteins was deduced
from Blast and conserved domains searches and is shown in brackets and underlined.
Prot Nb
Accession number Protein identification MW
(kDa) pI NSAFs
1 gi|47551037| cytoskeletal actin CyIIb . 41.8 5.3 1.6E-03
2 gi|115956638| PREDICTED: similar to cytoskeletal actin CyIIb . 41.8 5.3 1.3E-03 3 gi|47550921| actin . 41.8 5.3 1.2E-03
4 gi|115949854| PREDICTED: similar to cytoskeletal actin . 41.7 5.3 1.1E-03
5 gi|47551035| cytoskeletal actin CyIIIb . 41.8 5.2 8.5E-04
6 gi|1703135| Actin, cytoskeletal 3A (Actin, cytoskeletal IIIA). class: standard . 41.9 5.4 6.0E-04
7 gi|115943916| PREDICTED: similar to actin . 41.8 5.3 5.5E-04
85 gi|47551123| major yolk protein 153.9 7 4.1E-04
86 gi|115970375| PREDICTED: similar to melanotransferrin/EOS47 . 79.1 4.5 4.1E-04
8 gi|115971461| PREDICTED: similar to actin . 42 5.6 3.1E-04 114 gi|47551235| amassin . 56.4 4.7 3.0E-04
53 gi|115970610| PREDICTED: hypothetical protein, partial (complement control protein) . 33.4 4.7 2.8E-04
192 gi|47551061| H4 histone protein . 11.4 11.2 2.7E-04 304 gi|115971048| PREDICTED: hypothetical protein . 35.3 4.7 2.2E-04
9 gi|115961140| PREDICTED: similar to gelsolin . 41.2 5.1 2.2E-04
54 gi|115618101| PREDICTED: similar to complement component C3, partial . 24.2 4.9 2.1E-04
10 gi|47551153| profilin . 15.3 6.1 2.1E-04
55 gi|47551023| complement component C3 . 186.1 4.9 1.9E-04
144 gi|115685173| PREDICTED: similar to Low density lipoprotein receptor-related protein 6 . 35.2 7 1.9E-04
115 gi|115963381| PREDICTED: similar to amassin-2, partial . 9.8 4.4 1.8E-04
11 gi|47551049| fascin . 54.9 5.5 1.7E-04 56 gi|115950487| PREDICTED: similar to arylsulfatase isoform 2 . 63.6 5.5 1.7E-04
12 gi|115955758| PREDICTED: similar to related to cofilin . 18.9 5.2 1.7E-04
116 gi|118601062| amassin-2 . 53.9 4.4 1.4E-04
13 gi|115955651| PREDICTED: similar to Col protein . 44.3 4.8 1.3E-04
117 gi|115955254| PREDICTED: similar to alpha macroglobulin . 157.7 4.9 1.2E-04
57 gi|115974487| PREDICTED: hypothetical protein, partial (Cub and sushi multiple domains) . 93.7 4.9 1.1E-04
230 gi|115956476| PREDICTED: similar to apextrin . 49.5 4.3 9.8E-05
58 gi|115934253| PREDICTED: similar to scavenger receptor cysteine-rich protein . 62.8 6 9.5E-05
305 gi|115963910| PREDICTED: hypothetical protein, partial . 41.8 4.7 9.3E-05

80
Coelomocyte proteins that matched molecules directly involved in immune
responses represented 8.7% of the proteome (32 coelomocyte proteins). The most abundant
of these proteins were members of the complement cascade (Table 2.1). They included two
homologues of complement component C3, which comprised 2.3% of the total NSAFs
values. Complement protein Bf and a complement control protein were also identified
along with a complement-related long precursor that had similarities to factors H and I,
both of which are complement regulatory proteins [16]. Additional complement-like
proteins with CUB and SUSHI domains, which are found in a variety of complement
related proteins [17-19], were also found. The co-expression of SpBf and SpC3 supports
previous work that described a basic complement system in S. purpuratus [18-21]. The
identification of additional complement proteins, and putative complement related
proteins, suggests that the integrated complement system of coelomocytes may be more
extensive than previously thought.
Other immune response proteins that we identified included scavenger receptor
cysteine rich proteins (SRCRs). In mammals, members of the SRCR family are cell surface
receptors that play an important role in innate immunity [22]. There are an estimated 1,200
distinct SRCR-like domains encoded in the S. purpuratus genome [3-4]. A previous study
[23] has shown that coelomocytes transcribe numerous SRCR genes through the swapping
of exons that encode these domains, thus yielding different patterns of SRCR expression in
each individual sea urchin. Our study identified 16 proteins with similarities to SRCRs
(Figure 2.2). Of these, eight were similar to the previously characterized sea urchin SRCR
proteins that are similar to mammalian SRCR1, SRCR5, SRCR7 variant 2, SRCR12 or
SRCR20 [23], whilst the remaining eight SRCRs were encoded by S. purpuratus genes
with domain structures that are unique to sea urchins (Figure 2.2).

81
Stress response and detoxification proteins identified in coelomocytes included 29
distinct proteins, which accounted for 7.7 % of the NSAFS values. The most abundant of
these proteins included homologues of tranferrin, melanotransferrin, major yolk protein,
ferritin, and ceruloplasmin. Major yolk protein and melanotransferrin, were the 8th and 9th
most abundant proteins in coelomocytes respectively (Table 2.1). Transferrin, which is
involved in iron metabolism and transport [24], promotes lymphocyte proliferation in
vertebrates [25] and stimulates nitric oxide responses in macrophages [26]. Ceruloplasmin
is the major copper transporter (ferroxidase) in vertebrate blood, where it also plays a role
in iron metabolism and acts as an intercellular adhesion molecule [27-28]. In sea urchins,
major yolk protein is a transferrin-like molecule that transports iron, but may have other
activities [29-30]. Ferritin sequesters iron in the coelomic fluid of sea stars so that it is
unavailable to support bacterial proliferation, thereby acting as an acute phase protein
during immune responses [31] in a manner similar to vertebrates [32-33]. The abundance
of these putative iron-binding proteins in sea urchins suggest that they may play a critical
role in their immune systems, providing defense against infection via cell proliferation,
activating nitric oxide responses or depleting iron.
Homologues of dual oxidase 1 and dual oxidase maturation factor were also
relatively abundant in coelomocytes. Dual oxidases are involved in the production of
reactive oxygen species in organisms as diverse as yeast and mammals [34]. They help
control microbial activities in the gut of Drosophila melanogaster [35] and are involved in
the production of hydrogen peroxide in vertebrate macrophages during host defense
reactions [36]. In sea urchin CF, they might also be involved in post-phagocytic
intracellular killing mechanisms.

82
2153aa
gi 47551157
RGD
840 aa
precursor, partial: gi 115949177
gi 47550953
749 aa
partial: gi 115752650
437 aa
973 aa
gi 47550951
1036aa
gi 47551161
RGD
528aa
gi 47551167
short: gi 115977060
391 aa
SRCR similar to SRCR protein type 12 precursor, partial: gi 115973483
405aa
842aa
SRCR hyothetical protein: gi 115944063
SRCR similar to SRCR protein precursor, partial: gi 115936114
872aa
1363 aa
SRCR similar to SRCR protein type 12 precursor: gi 115968906
866 aa
SRCR similar to deleted in malignant brain tumor 1: gi 115975788
582aa
SRCR similar to SRCR rich protein: gi 115934253
RGD
2083aa
SRCR similar to SRCR protein type 12 precursor: gi 115950182
RGD
SpSRCR12
SpSRCR20
SpSRCR7.2
SpSRCR1
SpSRCR5
764 aa
SRCR similar to SRCR protein type 12 precursor: gi 115968904
Von willebrand factor repeats
Transmembrane
Short consensus repeats
SRCR repeats
Extracellular matrix like domain
CUB domain
HYR domain
Identified peptides

83
Figure 2.2: Predicted structure of the 16 scavenger receptor cysteine-rich (SRCR)
proteins identified in the coelomic fluid proteome. The predicted SRCR proteins have
between 1 and 20 SRCR domains. The non-SRCR domains shown are: Von Willebrand
factor repeats, transmembrane domains, short consensus repeats, CUB domains and HYR
domains. The position of the peptides identified by shotgun mass spectrometry within
each protein is given below each protein model. For each protein, a minimum of 2 unique
peptides were obtained. The length of the protein is given as the total number of amino
acids to the right of the sequence. Eight of these SRCRs identified had previously been
characterized and classified into five classes: SpSRCR12, SpSRCR20, SpSRCR5,
SpSRCR7.2, and SpSRCR1. For the remaining 8 SRCRs, the predicted protein description
is provided above the sequence.

84
Thirty coelomocyte proteins were putatively involved in cell adhesion and
accounted for 7.3% of the total NSAFs values. The most abundant of these were amassins
(Table 2.1), which are proteins with olfactomedin domains that are known to be involved
in cell adhesion during the clotting of CF. The expression of amassins is enhanced after
LPS injection [7, 37]. Other cell adhesion proteins identified were similar to Von
Willebrand factor (vWF), annexins, and α2-macroglobulin. These proteins may be involved
the sequestration of pathogens and potentially their opsonization.
Of the 15 proteins classified as lysosymes, proteases or peptidases, those that were
similar to serine proteases and thrombin were relatively abundant. In mammals, these
proteins are also involved in the coagulation cascade, including the serine proteases,
factors XII, XI, IX, X and VII, thrombin and plasmin [38]. Serine proteases also have a
special role linking the complement and coagulation pathways [39]. These proteins may
form a complex network of factors involved in CF clotting and coagulation. Other cell
adhesion molecules may also play a role in these reactions and stimulate phagocytosis.
This is illustrated by the presence of proteins that are similar to cadherin, selectin, talin and
a galectin-like protein. Selectins have C-type lectin domains that are activated during
inflammatory responses and mediate the calcium dependent binding of cadherins [40].
Galectins are a family of large carbohydrate-binding proteins found in a range of species
that participate in opsonization of pathogens [41-44].
Proteins putatively involved in cell proliferation, reproduction and development
accounted for 2.5% (17 of 319 proteins) of the coelomocyte proteome. Numerous variants
of echinonectin were identified in this category. Echinonectin is a highly variable protein
in sea urchin species with 162 unique protein sequences in the NCBI database for S.
purpuratus alone. Echinonectin, which has been described as an adhesion protein
expressed during embryonic development, incorporates domains with similarities to
coagulation factors V and VIII [45]. A protein similar to apextrin was also relatively

85
abundant in coelomocytes. Apextrin, which is also involved in cell adhesion, was initially
identified in the secretory vesicles of sea urchin eggs [46]. Interestingly, the expression of
apextrin is induced during acute immune responses of the protochordate, Amphioxus [47].
Forty-eight coelomocyte proteins were putatively involved in intracellular
signaling. However, most were present in low abundance and this category constituted
only 6.7% of the total NSAFs. Homologues of calcium binding proteins, such as calponin,
calcistorin and calcium binding protein p22, were the most commonly identified
intracellular signaling proteins suggesting that calcium is an important intermediate
messenger in coelomocytes [48-50]. Proteins putatively involved in GTP-based signaling
systems were also relatively abundant in S. purpuratus coelomocytes. Overall, the
diversity of proteins falling within this functional category suggested that coelomocytes
have an extensive capacity to modulate intracellular activity. In other species, homologues
of these proteins have roles in regulating cellular immune responses, including oxidative
killing mechanisms and the induction of antimicrobial activity.
We also identified proteins with similarities to apolipoprotein B (ApoB), an
apolipophorin (ApoLp) precursor of the large lipid transfer protein (LLTP) superfamily
and proteins homologous to low density lipoprotein (LDL) receptor-related proteins 4 and
6. Avarre et al. [51] noted that LLTP family members containing von Willebrand-factor
type-D (vWD) domains tend to be involved in clotting and defense reactions. Insect
ApoLps in particular are involved in inactivation of LPS by formation of insoluble
aggregates and activation of immune responses [52-54]. The data suggest an important role
for lipid metabolism in coelomocytes that might be involved in the induction of
immunological responses [55-56].
Overall, our shotgun proteomic analysis revealed a complex network of proteins in
S. purpuratus coelomocytes that is focused on cellular plasticity and host defense. This
agrees with previous transcriptome analysis of LPS-challenged sea urchins by Nair et al.

86
[7]. Transcripts for the majority of the proteins identified in the current study were also
identified by subtractive cDNA probing of an arrayed coelomocyte cDNA library [7]. The
advantage of our shotgun proteomic analysis is that it is quantitative. It allowed us to build
a model of cellular activities at the protein level, based on the relative abundance of the
proteins in sea urchin CF. So, our proteomic data provides a framework for the
development of realistic models of cellular activity.
From this quantitative analysis, it is clear that proteins involved in a dynamic actin-
based cytoskeleton are the most abundant within coelomocytes. The high capacity of
coelomocytes for amoeboid movement and pseudopodia formation [57-58] can be
explained by the fact that sea urchins have a low pressure, open circulatory system in
which cells have to rely on amoeboid movement to exert their key functions. In this
context, it has been shown that coelomocytes can actively migrate from the coelomic
cavity to the peristomial connective tissue at sites of injury [57]. Our data also support the
role of coelomocytes in important host defense mechanisms including clotting,
phagocytosis, coagulation and iron sequestration. Phagocytic coelomocytes, which are the
most abundant cells in echinoderm CF, have a high capacity for pseudopodium formation
and phagocytosis [56-57]. Pathogen recognition receptors (eg. SRCRs and C3) that
facilitate phagocytosis were abundant in coelomocytes as were proteins associated with
phagocytosis or post-phagocytic intracellular killing mechanisms.
The commonality in our data is that the function of most proteins in coelomocytes
could ultimately be related to immune defense mechanisms. This provides a framework for
future investigations that will provide a broader picture of the coordinated functions of
these proteins in the immunological defense of sea urchins.

87
2.4. Acknowledgments
This study was funded in part by an Australian Research Council Discovery grant to
DA Raftos and LC Smith (DP0880316). NM Dheilly is the recipient of an iMURS
postgraduate scholarship from Macquarie University. The research has been facilitated by
access to the Australian Proteome Analysis Facility established under the Australian
Government’s Major National Research Facilities Program. PA Haynes acknowledges
financial support from the NSW Government Office of Science and Medical Research in
the form of a Biofirst Fellowship and would like to thank Paul Mas for continued support
and encouragement.

88
2.5. References
[1] Peterson, K., J., Lyons, J., B., Nowak, K., S., Takacs, C., M. et al., Estimating
metazoan divergence times with a molecular clock. Proc. Natl. Acad. Sci. USA
2004, 101, 6536-6541.
[2] Littlewood, D., T., J., Smith, A., B., A., Combined morphological and molecular
phylogeny for sea urchins (Echnoidea: Echinodermata). Philos. Trans. R. Soc.
Lond. B. Biol. Sci. 1995, 347, 213-234.
[3] Sodergren, E., Weinstock, G., M., Davidson, E., H., Cameron, R., A. et al., The
genome of the sea urchin Strongylocentrotus purpuratus. Science 2006, 314, 941-
952.
[4] Hibino, T., Loza-Coll, M., Messier, C., Majeske, A., J. et al., The immune gene
repertoire encoded in the purple sea urchin genome. Dev. Biol. 2006, 300, 349–365.
[5] Rast, J., P., Smith, L., C., Loza-Coll, M., Hibino, T., Litman, G., W., Genomic insights
into the immune system of the sea urchin. Science 2006, 314, 952-956.
[6] Gross, P., S., Al-Sharif, W., Z., Clow, L., A., Smith, L., C., Echinoderm immunity and
the evolution of the complement system. Dev. Comp. Immunol. 1999, 23, 429-442.
[7] Nair, S., V., Del Valle, H., Gross, P., S., Terwilliger, D., P., Smith, L., C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin.
Identification of unexpected immune diversity in an invertebrate. Physiol.
Genomics 2005, 22, 33-47.
[8] Gross, P., S., Clow, L., A., Smith, L., C., SpC3, the complement homologue from the
purple sea urchin, Strongylocentrotus purpuratus, is expressed in two
subpopulations of the phagocytic coelomocytes. Immunogenet. 2000, 51, 1034-
1044.

89
[9] Clow, L., A., Gross, P., S., Shih, C., S., Smith, L., C., Expression of SpC3, the sea
urchin complement component, in response to lipopolysaccharide. Immunogenet.
2000, 51, 1021-1033.
[10] Smith, L., C., Chang, L., Britten, R., J., Davidson, E., H., Sea urchin genes expressed
in activated coelomocytes are identified by expressed sequence tags. Complement
homologues and other putative immune response genes suggest immune system
homology within the deuterostomes. J. Immunol. 1996, 156, 593-602.
[11] Smith, L., C., Britten, R., J., Davidson, E., H., Lipopolysaccharide activates the sea
urchin immune system. Dev. Comp. Immunol. 1995, 19, 217-224.
[12] Zybailov, B., L., Florens, L., Washburn, M., P., Quantitative shotgun proteomics
using a protease with broad specificity and normal spectral abundance factors. Mol.
Biosyst. 2007, 3, 354-360.
[13] Smith, L., C., Rast, J., P., Brockton, V., Terwilliger, D., P. et al., The sea urchin
immune system. Invertebr. Survival J. 2006, 3, 25-39.
[14] Edds, K., T., Chambers, C., Allen, R., D., Coelomocyte motility. Cell motil. cytoskel.
2005, 3, 113-121.
[15] Yui, M., A., Bayne, C., J., Echinoderm immunology: bacterial clearance by the sea
urchin Strongylocentrotus purpuratus. J. Biol. Bull. 1983, 165, 473-486.
[16] Multerer, K., A., Smith, L., C., Two cDNAs from the purple sea urchin,
Strongylocentrotus purpuratus, encoding mosaic proteins with domains found in
factor H, factor I and complement components C6 and C7. Immunogenet. 2004, 56,
89-106.
[17] Kirkitadze, M., D., Barlow, P., N., Structure and flexibility of the multiple domain
proteins that regulate complement activation - immunobiology of complement.
Immunol. Rev. 2001, 180, 146-161.

90
[18] Bork, P., Beckmann, G., The CUB domain: a widespread module in developmentally
regulated proteins. J. Mol. Biol. 1993, 231, 539-545.
[19] Gaboriaud, C., Rossi, V., Bally, I., Arlaud, G., J., Fontecilla-Camps, J., C., Crystal
structure of the catalytic domain of human complement C1s: a serine protease with
a handle. EMBO J. 2000, 19, 1755-1765.
[20] Smith, L., C., Clow, L., A., Terwilliger, D., P., The ancestral complement system in
sea urchins. Immunol. Rev. 2001, 180, 16-34.
[21] Smith, L., C., Shih, C.-S., Dachenhausen, S., G., Coelomocytes express SpBf, a
homologue of factor B, the second component in the sea urchin complement
system. J. Immunol. 1998, 161, 6784-6793.
[22] Yamada, Y., Doi, T., Hamakubo, T., Kodama, T., Scavenger receptor family proteins:
roles for atherosclerosis, host defence and disorders of the central nervous system.
Cell. Mol. Life Sci. 1997, 54, 628–640.
[23] Pancer, Z., Dynamic expression of multiple scavenger receptor cysteine-rich genes in
coelomocytes of the purple sea urchin. Proc. Natl. Acad. Sci. USA 2000, 97, 13156-
13161.
[24] Baker, E., N., Lindley, P., F., New perspectives on the structure and function of
transferrins. J. Inorg. Biochem. 1992, 47, 147-160.
[25] Brock, J., H., de Sousa, M., Immunoregulation by iron-binding proteins. Immunol.
today 1986, 7, 30-31.
[26] Stafford, J., L., Belosevic, M., Transferrin and the innate immune response of fish:
identification of a novel mechanism of macrophage activation. Dev. Comp.
Immunol. 2003, 27, 539-554.
[27] Sekyere, E., Richardson, D., R., The membrane-bound transferrin homologue
melanotransferrin: roles other than iron transport? FEBS letters 2000, 48, 11-16.

91
[28] Fox, P., L., The copper-iron chronicles: the story of an intimate relationship.
Biometals 2003, 16, 9-40.
[29] Yokota, Y., Unuma, T., Moriyama, A., Yamano, K., Cleavage site of a major yolk
protein (MYP) determined by cDNA isolation and amino acid sequencing in sea
urchin, Hemicentrotus pulcherrimus. Comp. Biochem and Physiol. Part B:
Biochem. And Mol. Biol. 2003, 135, 71-81.
[30] Brooks, J., M., Wessel, G., M., The major yolk protein in sea urchins is a transferrin-
like, iron binding protein. Dev. Biol. 2002, 245, 1-12.
[31] Beck, G., Ellis, T., W., Habicht, G., S., Schluter, S., F., Marchalonis, J., J., Evolution
of the acute phase response: iron release by echinoderms (Asterias forbesi)
coelomocytes, and cloning of an echinoderm ferritin molecule. Dev. Comp.
Immunol. 2002, 26, 11-26.
[32] Brock, J., H., Mulero, V., Cellular and molecular aspects of iron and immune
function. Proc. Natl. Acad. Sci. 2000, 59, 537-540.
[33] Ganz, T., Iron in innate immunity: starve the invaders. Curr. Opin. Immunol. 2009,
21, 63-67.
[34] Donkó, A., Péterfi, Z., Sum, A., Leto, T., Geiszt1, M., Dual oxidases. Philos. Trans.
R. Soc. Lond. B. Biol. Sci. 2005, 360, 2301–2308.
[35] Ha, E., M., Oh, C.-T., Bae, Y., S., Lee1, W., J., A direct role for dual oxidase in
Drosophila gut immunity. Science 2005, 310, 847-850.
[36] Forman, H., J., Torres, M., Reactive oxygen species and cell signaling – respiratory
burst in macrophage signaling. Am. J. Respir. Crit. Care. Med. 2002, 166, 54-58.
[37] Hillier, B., J., Vacquier, V., D., Amassin, an olfactomedin protein, mediates the
massive intercellular adhesion of sea urchin coelomocytes. J. Cell Biol. 2003, 160,
597-604.

92
[38] Davie, E., W., Fujikawa, K., Kiesel, W., The coagulation cascade: initiation,
maintenance, and regulation. Biochem. 1991, 30, 10363-10370.
[39] Amara, U., Albers, S., Gebhard, F., Bruckner, U., B., Huber-Lang, M., Crosstalk of
the complement and coagulation system. Fed. Am. Soc. Exp. Biol. J. 2008, 22,
673.4
[40] Aplin, A., E., Howe, A., Alahari, S., K., Juliano, R., L., Signal transduction and signal
modulation by cell adhesion receptors: the role of integrins, cadherins,
immunoglobulin-cell adhesion molecules, and selectins. Pharmacol. Rev. 1998, 50,
197-263.
[41] Barondes, S., H., Cooper, D., N., W., Gitt, M., A., Leffler, H., Galectins. Structure
and function of a large family of animal lectins. J. Biol. Chem. 1994, 269, 20807-
20810.
[42] Kima, J., Y., Kima, Y., M., Chob, S., K., Choic, K., S., Choa, M., Noble tandem-
repeat galectin of Manila clam Ruditapes philippinarum is induced upon infection
with the protozoan parasite Perkinsus olseni. Dev. Comp. Immunol. 2008, 32, 1131-
1141.
[43] Tasum, S., Vasta, G., R., A galectin of unique domain organization from hemocytes
of the eastern oyster (Crassostrea virginica) is a receptor for the protictan parasite
Perkinsus marinus. J. Immunol. 2007, 179, 3086-3098.
[44] Vasta, G., R., Quensenberry, M., Ahmed, H., O’Leary, N., C-type lectins and
galectins mediate innate and adaptive immune functions: their roles in the
complement activation pathway. Dev. Comp. Immunol. 1999, 23, 401-420.
[45] Alliegro, M., C., Alliegro, M., A., A., Echinonectin is a Del-1-like molecule with
regulated expression in sea urchin embryos. Gene Expr. Patterns 2007, 7, 651-656.

93
[46] Haag, E., S., Sly, B., J., Adrews, M., E., Raff, R., A., Apextrin, a novel extracellular
protein associated with larval ectoderm evolution in Heliocidaris erythrogramma.
Dev. Biol. 1999, 211, 77-87.
[47] Huang, G., Liu, H., Han, Y., Fan, L. et al., Profile of acute immune response in
Chinese amphioxus upon Staphylococcus aureus and Vibrio parahaemolyticus
infection. Dev. Comp. Immunol. 2007, 31, 1013-1023.
[48] Berridge, M., J., Inositol trisphosphate and calcium signaling. Ann. NY Acad. Sci.
2006, 766, 31-43.
[49] Lebeche, D., Kaminer, B., Characterization of a calsequestrin-like protein from sea-
urchin eggs. Biochem. 1992, 287, 741-747.
[50] Feske, S., Calcium signaling in lymphocyte activation and disease. Nat. Rev.
Immunol. 2007, 7, 690-702.
[51] Avarre, J.-C., Lubzens, E., Babin, P., J., Apolipocrustacein, formerly vitellogenin, is
the major egg yolk precursor protein in decapod crustaceans and is homologous to
insect apolipophorin II/I and vertebrates apolipoprotein B. BMC Evol. Biol. 2007,
7, 3-12.
[52] Kin, J., H., Je, H., J., Park, S., Y., Lee, I., H. et al., Immune activation of
apolipophorin-III and its distribution on hemocyte from Hyphantria cunea. Insect
Biochem. Mol. Biol. 2004, 34, 1011-1023.
[53] Cheon, H., M., Shin, S., W., Bian, G., Park, J., H., Raikhel, A., S., Regulation of lipid
metabolism genes, lipid carrier protein lipophorin, and its receptor during immune
challenge in the mosquito Aedes aegypti. J. Biol. Chem. 2006, 281, 8426-8435.
[54] Ma, G., Hay, D., Li, D., Asgari, S., Schmidt, O., Recognition and inactivation of LPS
by lipophorin particles. Dev. Comp. Immunol. 2006, 30, 619-626.

94
[55] Miller, Y., I., Chang, M.-K., Binder, C., J., Shaw, P., X., Witztum, J., L., Oxidized
low density lipoprotein and innate immune receptors. Curr. Opin. Lipido. 2003, 14,
437-445.
[56] Van den Elzen, P., Garg, S., Leon, L., Brigl, M. et al., Apolipoprotein-mediated
pathways of lipid antigen presentation. Nature 2005, 437, 906-910.
[57] Edds, K., T., The formation and elongation of filopodia during transformation of sea
urchin coelomocytes. Cell Mot. 1980, 1, 131-140.
[58] Mangiaterra, M., B., B., C., D., Silva, J., R., M., C., Induced inflammatory process in
the sea urchin Lytechinus variegates. Inv. Biol. 2001, 120, 178-184.

95
Supplementary Data 2.1: Detailed Materials and Methods
1. Sea urchins and sample collection
Three adult S. purpuratus were supplied by Marinus Scientific Inc. (Long Beach,
CA) after collection from the coast of southern California (USA). They were maintained
in the laboratory as described previously [1-3]. Purple sea urchins become
immunoquiescent after long-term housing in the laboratory (greater than eight months
without significant disturbance [4]). So, prior to coelomic fluid (CF) sample collection,
the three sea urchins were challenged by injecting 2 µg of lipopolysaccharide (LPS)
(Sigma Aldrich, St. Louis, MO) per ml of CF, as previously described [3-6]. The injection
of LPS has been shown to reverse immunoquiescence and return sea urchins to an
immunologically active state [4]. These conditions were designed to mimic previous
studies of coelomocyte structure, function and gene expression [1, 4-7]. Twenty four
hours after injection, 23-gauge needles attached to 1 ml syringes were inserted through the
peristomeum into the coelomic cavity of each sea urchin and CF was withdrawn, without
anticoagulant, from each of the three sea urchins. The CF was immediately expelled into a
1 ml tube and mixed with 100 µl of urea sample buffer (2.4 M Tris-HCl pH 6.8; 0.25%
SDS; 4 M urea; 20% glycerol) and stored at -70°C until use. Samples were lyophilized
and the extracted proteins were resuspended in sodium dodecyl sulfate (SDS) sample
buffer (0.05 M Tris HCl, 10% glycerol, 10% SDS, 1% DTT). Total protein content of
each sample was determined using Bradford reagent (Biorad, Hercules, CA).

96
2. One-dimensional sodium dodecyl sulfate - polyacrylamide gel electrophoresis (1DE)
Coelomic fluid proteins in SDS sample buffer (10 µg per well) were separated on
7.5% Bis-Tris polyacrylamide gels at 180 V for 1 hour [8]. After electrophoresis, proteins
were visualized using Coomassie Blue [9]. The gels were washed twice in sterile Milli-Q
water (10 minutes per wash), before individual lanes were cut into 16 slices of equal sizes
from top to bottom. Proteins in each slice were reduced, alkylated and subjected to trypsin
digestion as previously described [10].
3. Nanoflow liquid chromatography – tandem mass spectrometry
The tryptic digest extracts from 1DE gel slices were analyzed by nanoLC-MS/MS
using a LTQ-XL ion-trap mass spectrometer (Thermo, CA, USA) according to Breci et al.
[11]. Reversed phase columns were packed in-house to approximately 7 cm (100 µm i.d.)
using 100 Å, 5 mM Zorbax C18 resin (Agilent Technologies, CA, USA) in a fused silica
capillary with an integrated electrospray tip. A 1.8 kV electrospray voltage was applied
via a liquid junction up-stream of the C18 column. Samples were injected onto the C18
column using a Surveyor autosampler (Thermo, CA, USA). Each sample was loaded onto
the C18 column followed by an initial wash step with buffer A (5% (v/v) ACN, 0.1% (v/v)
formic acid) for 10 minutes at 1 µL min-1. Peptides were subsequently eluted from the
C18 column with 0%-50% Buffer B (95% (v/v) ACN, 0.1% (v/v) formic acid) over 58
minutes at 500 nL min-1, followed by 50%-95% Buffer B over 5 minutes at 500 nL min-1.
The column eluate was directed into a nanospray ionization source of the mass
spectrometer.

97
Spectra were scanned over the range 400–1500 amu. Automated peak recognition,
dynamic exclusion, and tandem MS of the top six most intense precursor ions at 35%
normalization collision energy were performed using the Xcalibur software (version 2.06)
(Thermo, CA, USA).
4. Protein identification
Raw data files were converted to mzXML format and processed through the Global
Proteome Machine (GPM) software using version 2.1.1 of the X!Tandem algorithm, freely
available from www.thegpm.org [12-13]. For each experiment, the 16 fractions were
processed sequentially with output files for each individual fraction. A merged, non-
redundant output file was then generated for protein identification with log(e) values less
than -1.
MS/MS spectra were searched against a combined Strongylocentrotus database
created with sequences downloaded from NCBI. This FASTA format database contained
44,037 protein sequences comprising all S. purpuratus predicted protein sequences and
identified proteins held by NCBI as of April 2008. The database also incorporated a list of
common human and trypsin peptide contaminants. The search was also performed against
a reversed sequence database to evaluate the false discovery rate (FDR) [14]. Search
parameters included MS and MS/MS tolerances of ± 2 Da and ± 0.2 Da, tolerance of up to
3 missed tryptic cleavages and K/R-P cleavages. Fixed modifications were set for
carbamidomethylation of cysteine and variable modifications were set for oxidation of
methionine.

98
Only proteins that were present in at least two out of the three sea urchins analyzed, that
had log(e) values < -9, and that yielded at least four spectral counts over the three samples
were retained for subsequent analysis. After this filtering, no reversed peptide sequences
were identified, at a protein level FDR of < 0.1%.
5. Quantitative proteomic analysis
Protein abundance data were calculated based on normalized spectral abundance
factor (NSAF) values as described previously [14]. For each sample, i, the number of
spectral counts (SpC) identifying a protein, k, was divided by the molecular weight of the
protein in kDa to give and (SpC/MW)k value. (SpC/MW)k values were then divided by the
sum of (SpC/MW) for all (N) proteins in the experiment to give the NSAFi values for each
protein and CF sample (eqn (1))
(1)
For each protein, k, the sum S of all spectral counts obtained from the three sea
urchins was calculated, and the corresponding NSAFS deduced. NSAFS values were used
as a measure of protein abundance. The NSAFi values for each of the individual sea
urchins were strongly correlated with these NSAFS values (R2, 0.85-0.92), suggesting that
NSAFS values were representative of protein abundance. The natural log of the NSAFs
values were plotted against the number of proteins obtained which showed a normal
distribution with a mean of -4.78 and a standard deviation of ± 0.62. For each protein, k,
the sum of the log(e) value obtained from the three sea urchins were calculated and the
corresponding Sum(log(e)) values deduced.

99
6. References for Detailed Materials and Methods
[1] Nair, S., V., Del Valle, H., Gross, P., S., Terwilliger, D., P., Smith, L., C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin.
Identification of unexpected immune diversity in an invertebrate. Physiol.
Genomics 2005, 22, 33-47.
[2] Gross, P., S., Clow, L., A., Smith, L., C., SpC3, the complement homologue from the
purple sea urchin, Strongylocentrotus purpuratus, is expressed in two
subpopulations of the phagocytic coelomocytes. Immunogenet. 2000, 51, 1034-
1044.
[3] Clow, L., A., Gross, P., S., Shih, C., S., Smith, L., C., Expression of SpC3, the sea
urchin complement component, in response to lipopolysaccharide. Immunogenet.
2000, 51, 1021-1033.
[4] Gross, P., S., Al-Sharif, W., Z., Clow, L., A., Smith, L., C., Echinoderm immunity and
the evolution of the complement system. Dev. Comp. Immunol. 1999, 23, 429-442.
[5] Smith, L., C., Chang, L., Britten, R., J., Davidson, E., H., Sea urchin genes expressed in
activated coelomocytes are identified by expressed sequence tags. Complement
homologues and other putative immune response genes suggest immune system
homology within the deuterostomes. J. Immunol. 1996, 156, 593-602.
[6] Smith, L., C., Britten, R., J., Davidson, E., H., Lipopolysaccharide activates the sea
urchin immune system. Dev. Comp. Immunol. 1995, 19, 217-224.
[7] Smith, L., C., Rast, J., P., Brockton, V., Terwilliger, D., P. et al., The sea urchin
immune system. Invertebr. Survival J. 2006, 3, 25-39.
[8] Laemmli, U., K., Cleavage of structural proteins during the assembly of the head of
bacteriophage T4. Nature 1970, 227, 680-685.

100
[9] Candiano, G., Bruschi, M., Musante, L., Santucci, L. et al., Blue silver: a very sensitive
colloidal coomassie G-250 staining for proteome analysis. Electrophoresis 2004,
25, 1327-1333.
[10] Dheilly, N., M., Nair, S., V., Smith, L., C., Raftos, D., A., Highly variable immune-
response proteins (185/333) from the sea urchin, Strongylocentrotus purpuratus:
proteomic analysis identifies diversity within and between individuals. J. Immunol.
2009, 182, 2203-2212.
[11] Breci, L., Hattrup, E., Keeler, M., Letarte, J. et al., Comprehensive proteomics in
yeast using chromatographic fractionation, gas phase fractionation, protein gel
electrophoresis and isoelectric focusing. Proteomics 2005, 5, 2018-2028.
[12] Craig, R., Beavis, R., C., A., method for reducing the time required to match protein
sequences with tandem mass spectra. Rapid Commun. Mass Spectrom. 2003, 17,
2310-2316.
[13] Craig, R., Beavis, R., C., TANDEM: matching proteins with tandem mass spectra.
Bioinformatics 2004, 20, 1466-1467.
[14] Zybailov, B., L., Florens, L., Washburn, M., P., Quantitative shotgun proteomics
using a protease with broad specificity and normal spectral abundance factors. Mol.
Biosyst. 2007, 3, 354-360.

101
Supplementary Data 2.2: Proteins identified in the coelomic fluid of 3 individual sea
urchins, conducted 24 hours after injection of lipopolysaccharide. The database search
was conducted using MudPIT merged results. rI corresponds to the total number of
spectral counts. The log(e) value indicates the probability that a putative peptide sequence
corresponding to a mass spectrum arose stochastically. The lower the log(e) value, the
more significant the assignment of the peptide sequence to the mass spectrum. # indicates
the number of unique peptides identified. NSAFs values correspond to the normal spectral
abundance factor of the sum of rI from the three individuals. Proteins that had previously
been identified are shown in bold. Proteins predicted by genome annotation are shown in
normal font. The function of hypothetical proteins was deduced from Blast and conserved
domain searches, and are shown in brackets and underlined.

102
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
9.3
E-0
3
1gi|47551037|
cyto
skel
etal
act
in C
yII
b41
.85
518
-423
3596
0-5
1039
484
-350
301.
6E-0
3
2gi|115956638|
PR
ED
ICT
ED
: si
mil
ar t
o c
yto
skel
etal
act
in C
yII
b .
41.8
539
8-3
702
786
-445
238
5-3
153
1.3E
-03
3gi|47550921|
act
in41
.85
516
-420
195
8-5
032
1.2E
-03
4gi|115949854|
PR
ED
ICT
ED
: si
mil
ar t
o c
yto
skel
etal
act
in .
41.7
536
9-3
177
641
-287
436
0-2
251
1.1E
-03
5gi|47551035|
cyto
skel
etal
act
in C
yII
Ib .
41.8
536
5-3
262
690
-353
18.
5E-0
4
6gi|1703135|
Act
in, cy
tosk
elet
al
3A
(A
ctin
, cy
tosk
elet
al
IIIA
). c
lass
: st
an
dard
.41
.95
374
-366
137
2-2
911
6.0E
-04
7gi|115943916|
PR
ED
ICT
ED
: si
mil
ar t
o a
ctin
.41
.85
145
-158
135
9-1
763
171
-137
25.
5E-0
4
8gi|115971461|
PR
ED
ICT
ED
: si
mil
ar t
o a
ctin
.42
610
6-8
3.1
117
3-8
9.5
310
9-6
5.1
23.
1E-0
4
9gi|115961140|
PR
ED
ICT
ED
: si
mil
ar t
o g
elso
lin .
41.2
523
-139
1319
4-2
3620
55-1
4413
2.2E
-04
10
gi|47551153|
pro
fili
n15
.36
36-1
4211
43-1
3211
15-7
1.6
72.
1E-0
4
11
gi|47551049|
fasc
in .
54.9
635
-102
1114
1-2
2420
103
-175
161.
7E-0
4
12
gi|115955758|
PR
ED
ICT
ED
: si
mil
ar t
o r
elat
ed t
o c
ofi
lin .
18.9
530
-92.
29
48-9
7.2
915
-39.
44
1.7E
-04
13
gi|115955651|
PR
ED
ICT
ED
: si
mil
ar t
o C
ol
pro
tein
.44
.35
50-5
5.2
683
-81
732
-52.
35
1.3E
-04
14
gi|115971215|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
tubuli
n)
50.1
518
-85.
28
85-2
9520
31-9
8.1
99.
0E-0
5
15
gi|115974666|
PR
ED
ICT
ED
: si
mil
ar t
o c
oro
nin
.53
.87
13-3
9.4
484
-221
1834
-101
98.
2E-0
5
16
gi|115968818|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000003616 (
Act
in l
ike
pro
tein
)24
57
80-3
1929
250
-652
5619
6-5
2944
7.3E
-05
17
gi|115896589|
PR
ED
ICT
ED
: si
mil
ar t
o C
ol
pro
tein
.42
.35
28-5
1.4
340
-52
215
-39.
32
6.6E
-05
18
gi|115951109|
PR
ED
ICT
ED
: si
mil
ar t
o t
ensi
lin .
32.7
631
-110
1016
-76.
87
11-4
1.8
56.
0E-0
5
19
gi|115977085|
PR
ED
ICT
ED
: si
mil
ar t
o a
lpha-
1 t
ubuli
n .
50.2
58
-26.
53
56-1
434
22-6
3.2
75.
8E-0
5
20
gi|115960585|
PR
ED
ICT
ED
: si
mil
ar t
o t
ubuli
n, al
pha
2 i
sofo
rm 1
.46
.45
8-2
1.9
150
-134
620
-47.
72
5.7E
-05
21
gi|115976308|
PR
ED
ICT
ED
: si
mil
ar t
o L
ym
phocy
te c
yto
soli
c pro
tein
1, par
tial
.9.
55
3-1
3.8
23
-14.
32
8-1
5.9
25.
0E-0
5
22
gi|115929203|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000011796 (
alpha
acti
nin
)10
45
32-1
3414
80-3
0528
25-9
0.4
104.
5E-0
5
23
gi|115945717|
PR
ED
ICT
ED
: si
mil
ar t
o E
nab
led h
om
olo
g (
Dro
sophil
a) .
44.9
1023
-108
1020
-107
93.
3E-0
5
24
gi|115751610|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
acti
n b
indin
g p
rote
in)
26.4
65
-36
219
-75.
32
3.1E
-05
25
gi|115939656|
PR
ED
ICT
ED
: si
mil
ar t
o A
DP
-rib
osy
lati
on f
acto
r 1 .
20.6
65
-13.
81
7-4
0.3
55
-13.
42
2.8E
-05
26
gi|47550983|
nu
clea
r in
term
edia
te f
ilam
ent
pro
tein
.64
.66
4-2
1.9
334
-122
1315
-77.
39
2.8E
-05
27
gi|115936071|
PR
ED
ICT
ED
: si
mil
ar t
o A
rp2/3
com
ple
x s
ubunit
.20
.39
6-2
13
10-5
1.6
52.
7E-0
5
28
gi|115960968|
PR
ED
ICT
ED
: si
mil
ar t
o s
ea u
rchin
Arp
3 (
SU
Arp
3)
.47
.16
4-2
73
19-9
2.2
97
-39
52.
2E-0
5
29
gi|115963096|
PR
ED
ICT
ED
: si
mil
ar t
o C
G15792-P
D, par
tial
(m
yosi
n)
133
61
-81
58-2
1718
13-9
7.1
91.
8E-0
5
30
gi|115958283|
PR
ED
ICT
ED
: si
mil
ar t
o M
GC
69420 p
rote
in (
acti
n r
elat
ed p
rote
in)
19.6
95
-19.
33
3-1
1.2
21
-4.3
11.
6E-0
5
31
gi|115974054|
PR
ED
ICT
ED
: si
mil
ar t
o f
ibro
pel
lin I
a .
24.7
65
-19.
92
4-1
7.7
32
-21.
12
1.5E
-05
32
gi|115630732|
PR
ED
ICT
ED
: si
mil
ar t
o m
yosi
n, hea
vy p
oly
pep
tide
10, non-m
usc
le .
915
1-1
.61
32-1
4113
4-1
2.7
21.
4E-0
5
33
gi|115944135|
PR
ED
ICT
ED
: si
mil
ar t
o s
ea u
rchin
Arp
2 (
SU
Arp
2)
.44
.47
6-3
6.2
48
-48.
95
4-2
4.2
31.
4E-0
5
34
gi|115931813|
PR
ED
ICT
ED
: si
mil
ar t
o L
IM a
nd S
H3 p
rote
in .
27.2
85
-18.
63
3-1
2.1
23
-11.
52
1.4E
-05
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3
Cel
l st
ruct
ure
, sh
ap
e an
d m
ob
ilit
y*

103
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
35
gi|115961398|
PR
ED
ICT
ED
: si
mil
ar t
o C
apzb
-pro
v p
rote
in (
F a
ctin
cap
pin
g p
rote
in b
eta)
27.4
53
-5.8
17
-48
51
-2.3
11.
4E-0
5
36
gi|115948375|
PR
ED
ICT
ED
: si
mil
ar t
o C
G10540-P
A i
sofo
rm 1
(F
act
in C
appin
g p
rote
in a
lpha)
30.6
89
-41.
44
3-1
0.8
21.
3E-0
5
37
gi|115939472|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000023777 (
CD
C42, ce
ll d
ivis
ion c
ycl
e 42
)21
.37
2-9
.12
6-2
9.9
41.
3E-0
5
38
gi|115971193|
PR
ED
ICT
ED
: si
mil
ar t
o R
ac1 p
rote
in .
21.6
95
-17.
32
3-1
1.8
21.
3E-0
5
39
gi|115930179|
PR
ED
ICT
ED
: si
mil
ar t
o g
elso
lin .
40.3
64
-27.
33
6-3
7.5
54
-29
31.
2E-0
5
40
gi|115974358|
PR
ED
ICT
ED
: si
mil
ar t
o L
OC
398551 p
rote
in i
sofo
rm 1
(A
DP
rib
osy
lati
on f
acto
r)17
.85
1-2
14
-21.
91
9.9E
-06
41
gi|115964477|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
acti
n r
elat
ed p
rote
in)
40.8
95
-33
44
-21
32
-11.
82
9.1E
-06
42
gi|115933962|
PR
ED
ICT
ED
: si
mil
ar t
o g
elso
lin .
40.8
52
-15.
62
3-1
4.5
24
-19.
42
7.5E
-06
43
gi|115975440|
PR
ED
ICT
ED
: si
mil
ar t
o m
oes
in .
67.4
51
-4.7
15
-18.
33
3-9
.62
4.5E
-06
44
gi|166795321|
ad
vil
lin
.93
.18
3-1
2.8
26
-12.
12
3-1
3.7
24.
4E-0
6
45
gi|115925936|
PR
ED
ICT
ED
: si
mil
ar t
o M
GC
84047 p
rote
in (
dre
bri
n l
ike
isofo
rm)
345
1-1
.91
2-1
3.2
21
-1.4
14.
0E-0
6
46
gi|115950170|
PR
ED
ICT
ED
: si
mil
ar t
o l
ong m
icro
tubule
-ass
oci
ated
pro
tein
1A
; lo
ng M
AP
1A
.22
14
3-1
8.7
314
-34.
54
7-3
4.9
43.
7E-0
6
47
gi|115974031|
PR
ED
ICT
ED
: si
mil
ar t
o r
etic
ulo
n 4
iso
form
B2 .
105
91
-2.4
12
-14.
82
3-1
4.8
21.
9E-0
6
48
gi|115960644|
PR
ED
ICT
ED
: si
mil
ar t
o m
yosi
n h
eavy c
hai
n .
224
65
-38.
15
5-5
0.6
51.
5E-0
6
49
gi|115939091|
PR
ED
ICT
ED
: si
mil
ar t
o M
GC
83833 p
rote
in (
leth
al g
iant
larv
ae h
om
olo
gue)
98.5
71
-1.6
13
-19.
43
1.4E
-06
50
gi|115945231|
PR
ED
ICT
ED
: si
mil
ar t
o K
IAA
0587 p
rote
in (
NC
R a
ssoci
ate
pro
tein
)12
86
2-9
21
-6.7
12
-14.
22
1.3E
-06
51
gi|115945063|
PR
ED
ICT
ED
: si
mil
ar t
o f
ibro
surf
in, par
tial
.20
04
1-6
.11
6-3
0.9
31.
2E-0
6
52
gi|115925414|
PR
ED
ICT
ED
: si
mil
ar t
o K
IAA
0727 p
rote
in (
myosi
n)
118
92
-9.9
22
-6.5
11.
2E-0
6
1.5
E-0
3
53
gi|115970610|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(co
mple
men
t co
ntr
ol
pro
tein
)33
.45
54-1
181
179
-167
340
-90.
52
2.8E
-04
54
gi|115618101|
PR
ED
ICT
ED
: si
mil
ar t
o c
om
ple
men
t co
mponen
t C
3, par
tial
.24
.25
55-6
5.7
554
-60
443
-57.
44
2.1E
-04
55
gi|47551023|
com
ple
men
t co
mp
on
ent
C3 .
186
534
3-5
3247
456
-598
5025
1-4
1236
1.9E
-04
56
gi|115950487|
PR
ED
ICT
ED
: si
mil
ar t
o a
ryls
ulf
atas
e is
ofo
rm 2
.63
.66
127
-170
1613
9-1
4712
56-1
1411
1.7E
-04
57
gi|115974487|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(C
ub a
nd s
ush
i m
ult
iple
dom
ains)
93.7
560
-145
1319
5-1
8116
49-1
039
1.1E
-04
58
gi|115934253|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
.62
.86
14-7
7.2
814
9-1
4812
13-3
8.7
49.
5E-0
5
59
gi|115940254|
PR
ED
ICT
ED
: si
mil
ar t
o c
ycl
ophil
in .
17.6
99
-31.
23
17-6
5.3
714
-43.
35
7.7E
-05
60
gi|115619038|
PR
ED
ICT
ED
: si
mil
ar t
o a
ryls
ulf
atas
e .
60.8
578
-206
1820
-91.
89
34-8
0.6
77.
3E-0
5
61
gi|47550953|
scaven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
.77
.14
40-5
3.8
632
-62.
57
9-4
1.8
53.
5E-0
5
62
gi|118421783|
Sp
185/3
33 .
23.8
111
-1.3
121
-60.
21
3.2E
-05
63
gi|47550955|
DD
104 p
rote
in, u
pre
gu
late
d u
pon
bact
eria
l ch
all
enge
an
d t
rau
ma .
31.3
516
-21
39
-13.
12
3-1
2.2
23.
0E-0
5
64
gi|47551161|
scaven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
.11
04
21-4
1.9
558
-40.
25
17-1
9.9
33.
0E-0
5
65
gi|115752650|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
, par
tial
.44
.84
15-2
1.2
119
-24.
21
2.6E
-05
66
gi|47551167|
scaven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
typ
e 5 .
58.2
417
-48.
75
10-5
35
12-2
8.6
42.
3E-0
5
67
gi|115944063|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
SR
CR
)94
.66
7-2
0.2
344
-68.
27
1.8E
-05
68
gi|115977060|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
type
5 p
recu
rsor
.42
.95
13-2
6.6
110
-43.
71
1.8E
-05
Imm
un
e re
spon
se*
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

104
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
69
gi|115968904|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
type
12 p
recu
rsor
.82
.84
6-1
8.7
334
-38.
94
3-1
2.1
21.
8E-0
5
70
gi|47825406|
com
ple
men
t re
late
d-l
on
g p
recu
rsor
. 20
45
23-7
1.4
744
-116
1220
-93.
19
1.4E
-05
71
gi|115968659|
PR
ED
ICT
ED
: si
mil
ar t
o r
ham
nose
-bin
din
g l
ecti
n (
SA
L),
par
tial
.32
.48
8-3
1.9
44
-15.
52
1.3E
-05
72
gi|47551047|
com
ple
men
t fa
ctor
B .
91.2
66
-20.
23
13-5
6.7
710
-38.
35
1.1E
-05
73
gi|115940188|
PR
ED
ICT
ED
: si
mil
ar t
o p
epti
dylp
roly
l is
om
eras
e B
iso
form
2 (
cycl
ophil
in)
.23
.49
4-6
.91
3-1
1.3
21.
0E-0
5
74
gi|115936114|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
pre
curs
or,
par
tial
.94
415
-27.
33
9-3
1.4
44
-3.6
11.
0E-0
5
75
gi|115975788|
PR
ED
ICT
ED
: si
mil
ar t
o d
elet
ed i
n m
alig
nan
t bra
in t
um
ors
1 (
SR
CR
)89
.44
6-1
0.6
213
-22.
93
7.3E
-06
76
gi|47550951|
scaven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
vari
an
t 2
105
517
-54.
56
5-2
8.1
47.
1E-0
6
77
gi|115973483|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
type
12 p
recu
rsor,
par
tial
.45
.35
5-2
8.6
14
-12.
42
6.9E
-06
78
gi|115949177|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
type
12 p
recu
rsor,
par
tial
.90
.95
8-3
3.6
410
-77.
48
6.8E
-06
79
gi|115950182|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
type
12 p
recu
rsor
.22
25
8-3
6.3
411
-44
66
-26.
84
3.8E
-06
80
gi|115968906|
PR
ED
ICT
ED
: si
mil
ar t
o s
caven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
type
12 p
recu
rsor
.14
75
3-5
.41
7-1
6.6
21
-3.6
12.
5E-0
6
81
gi|115960292|
PR
ED
ICT
ED
: si
mil
ar t
o c
om
ple
men
t re
late
d-l
ong p
recu
rsor,
par
tial
.70
.16
1-1
.81
4-1
1.1
22.
5E-0
6
82
gi|115966254|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
SA
M d
om
ain a
nd H
D d
om
ain c
onta
inin
g)
61.2
91
-1.9
13
-13.
22
2.3E
-06
83
gi|115970612|
PR
ED
ICT
ED
: si
mil
ar t
o C
UB
and S
ush
i m
ult
iple
dom
ains
1 v
aria
nt,
par
tial
.89
.65
2-1
02
3-2
.61
2.0E
-06
84
gi|47551157|
scaven
ger
rec
epto
r cy
stei
ne-
rich
pro
tein
typ
e 12
226
54
-28.
34
4-3
1.1
42
-10.
12
1.5E
-06
1.3
E-0
3
85
gi|47551123|
majo
r yolk
pro
tein
154
776
5-1
065
9276
3-9
5668
335
-539
494.
1E-0
4
86
gi|115970375|
PR
ED
ICT
ED
: si
mil
ar t
o m
elan
otr
ansf
erri
n/E
OS
47 .
79.1
523
8-4
8936
511
-500
3820
1-3
4526
4.1E
-04
87
gi|115685450|
PR
ED
ICT
ED
: si
mil
ar t
o M
GC
68486 p
rote
in, par
tial
(phosp
hoglu
conat
e deh
ydro
gen
ase
)8.
95
9-2
4.6
38
-28.
22
7-2
4.8
29.
1E-0
5
88
gi|115944169|
PR
ED
ICT
ED
: si
mil
ar t
o d
ual
oxid
ase
1 i
sofo
rm 1
.18
66
32-1
4916
189
-441
4341
-172
194.
8E-0
5
89
gi|115972586|
PR
ED
ICT
ED
: si
mil
ar t
o 7
1 K
d h
eat
shock
cognat
e pro
tein
.71
.75
16-1
059
46-1
8816
31-1
4413
4.4E
-05
90
gi|115968538|
PR
ED
ICT
ED
: si
mil
ar t
o f
erri
tin .
19.6
83
-9.3
28
-24.
93
13-3
24
4.1E
-05
91
gi|115944173|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000006016 i
sofo
rm 1
(dual
oxid
ase
mat
ura
tion f
acto
r)48
.75
6-3
7.8
443
-82.
67
6-1
3.8
23.
8E-0
5
92
gi|115926107|
PR
ED
ICT
ED
: si
mil
ar t
o f
erro
xid
ase
(EC
1.1
6.3
.1)
pre
curs
or
- ra
t .
115
525
-122
1234
-150
1435
-125
112.
8E-0
5
93
gi|115963949|
PR
ED
ICT
ED
: si
mil
ar t
o f
erro
xid
ase
(EC
1.1
6.3
.1)
pre
curs
or
- ra
t .
39.2
54
-6.2
126
-67.
66
1-2
.21
2.7E
-05
94
gi|115926010|
PR
ED
ICT
ED
: si
mil
ar t
o g
luta
thio
ne
per
oxid
ase,
par
tial
.21
73
-14
211
-43.
85
1-6
.51
2.4E
-05
95
gi|115926884|
PR
ED
ICT
ED
: si
mil
ar t
o C
G7820-P
A (
carb
onic
anhydra
se a
lpha
ver
tebra
te l
ike)
29.7
67
-29
49
-43.
25
5-3
3.6
52.
4E-0
5
96
gi|115963947|
PR
ED
ICT
ED
: si
mil
ar t
o c
erulo
pla
smin
.52
.84
35-6
9.9
61
-7.6
12.
3E-0
5
97
gi|115972590|
PR
ED
ICT
ED
: si
mil
ar t
o h
eat
shock
pro
tein
70 i
sofo
rm 1
.53
.96
20-6
81
16-5
6.5
12.
3E-0
5
98
gi|115893581|
PR
ED
ICT
ED
: si
mil
ar t
o h
eat
shock
pro
tein
pro
tein
.60
621
-84
416
-59.
21
2.1E
-05
99
gi|115954976|
PR
ED
ICT
ED
: si
mil
ar t
o h
eat
shock
pro
tein
pro
tein
.68
.66
17-6
3.2
116
-62.
71
1.6E
-05
100
gi|115937420|
PR
ED
ICT
ED
: ca
tala
se .
58.2
81
-4.9
118
-78.
58
5-3
6.9
41.
4E-0
5
101
gi|115956665|
PR
ED
ICT
ED
: si
mil
ar t
o h
eat
shock
pro
tein
pro
tein
.68
.36
6-4
0.7
117
-63.
41
1.1E
-05
Str
ess
resp
on
se, d
etoxif
icati
on
*
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

105
Prot
Nb
Accessio
n
nu
mb
er
Prote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
102
gi|115815329|
PR
ED
ICT
ED
: si
mil
ar t
o C
ct6a
pro
tein
, par
tial
(ch
aper
onin
conta
inin
g T
CP
1)
276
5-2
4.8
12
-11.
31
9.0E
-06
103
gi|115891388|
PR
ED
ICT
ED
: si
mil
ar t
o h
eat
shock
90 k
Da
pro
tein
, par
tial
.57
.65
2-1
1.7
212
-39.
25
8.3E
-06
104
gi|115954867|
PR
ED
ICT
ED
: si
mil
ar t
o C
hap
eronin
conta
inin
g T
CP
1, su
bunit
4 (
del
ta)
.57
.16
1-1
.71
8-6
0.9
73
-12.
82
7.1E
-06
105
gi|115944450|
PR
ED
ICT
ED
: si
mil
ar t
o c
hap
eronin
subunit
8 t
het
a57
.45
7-4
5.2
54
-19.
93
6.6E
-06
106
gi|115661720|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
suci
nat
e se
mia
ldeh
yde
deh
ydro
gen
ase)
52.3
61
-5.3
17
-45.
15
1-4
.21
5.8E
-06
107
gi|115945316|
PR
ED
ICT
ED
: si
mil
ar t
o C
holi
ne
deh
ydro
gen
ase
.66
.29
8-4
6.6
61
-1.4
14.
7E-0
6
108
gi|115964822|
PR
ED
ICT
ED
: si
mil
ar t
o m
itoch
ondri
al c
hap
eronin
Hsp
56 .
62.2
54
-33.
84
2-9
.42
3.4E
-06
109
gi|115924889|
PR
ED
ICT
ED
: si
mil
ar t
o C
hap
eronin
conta
inin
g T
CP
1, su
bunit
5 (
epsi
lon)
.59
.86
3-1
8.4
32
-2.5
12.
9E-0
6
110
gi|115930256|
PR
ED
ICT
ED
: si
mil
ar t
o C
hap
eronin
conta
inin
g T
CP
1, su
bunit
3 (
gam
ma)
.60
.28
3-1
0.9
22
-8.7
22.
9E-0
6
111
gi|115956641|
PR
ED
ICT
ED
: si
mil
ar t
o L
OC
495278 p
rote
in (
chap
eronin
conta
inin
g T
CP
1)
627
3-1
6.8
21
-1.4
12.
3E-0
6
112
gi|115958481|
PR
ED
ICT
ED
: si
mil
ar t
o 7
0 k
Da
hea
t sh
ock
pro
tein
pre
curs
or
.76
.25
1-3
.81
3-1
7.8
21.
9E-0
6
113
gi|115959568|
PR
ED
ICT
ED
: si
mil
ar t
o g
luta
thio
ne
reduct
ase
.13
36
2-1
22
3-1
1.6
21.
3E-0
6
1.3
E-0
3
114
gi|47551235|
am
assin
.56
.45
146
-183
1918
8-2
2822
171
-163
173.
0E-0
4
115
gi|115963381|
PR
ED
ICT
ED
: si
mil
ar t
o a
mas
sin-2
, par
tial
.9.
84
17-1
8.6
115
-19.
91
19-1
8.8
11.
8E-0
4
116
gi|118601062|
am
assin
-2 .
53.9
460
-142
1381
-141
1378
-110
101.
4E-0
4
117
gi|115955254|
PR
ED
ICT
ED
: si
mil
ar t
o a
lpha
mac
roglo
buli
n .
158
527
9-5
2444
220
-337
2860
-171
171.
2E-0
4
118
gi|115963192|
PR
ED
ICT
ED
: si
mil
ar t
o A
nnex
in A
4 (
Annex
in I
V)
(Lip
oco
rtin
IV
) (E
ndonex
in I
)
(Chro
mobin
din
-4)
(Pro
tein
II)
(P
32.5
) (P
lace
nta
l34
.86
22-1
0010
44-1
4713
18-7
38
8.2E
-05
119
gi|115851666|
PR
ED
ICT
ED
: si
mil
ar t
o C
G7002-P
A, par
tial
(V
on w
ille
bra
nd f
acto
r)27
.36
19-3
0.3
227
-26.
21
3-1
2.6
16.
1E-0
5
120
gi|115944296|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
Gal
ecti
n)
31.5
1013
-58.
16
36-8
4.4
82
-3.5
15.
5E-0
5
121
gi|118601058|
am
assin
4 .
52.6
422
-63.
58
35-8
8.2
828
-34.
71
5.5E
-05
122
gi|115720465|
PR
ED
ICT
ED
: si
mil
ar t
o s
elec
tin-l
ike
pro
tein
, par
tial
.35
.55
14-5
26
21-6
0.8
712
-25.
33
4.5E
-05
123
gi|115956497|
PR
ED
ICT
ED
: si
mil
ar t
o t
etra
span
in f
amil
y p
rote
in .
26.2
47
-23
38
-6.6
111
-13.
82
3.4E
-05
124
gi|118601054|
am
assin
-3 .
53.5
416
-46.
92
15-4
0.1
121
-40.
15
3.3E
-05
125
gi|115970015|
PR
ED
ICT
ED
: si
mil
ar t
o v
on W
ille
bra
nd f
acto
r .
275
956
-286
1215
9-5
8625
2.6E
-05
126
gi|115970125|
PR
ED
ICT
ED
: si
mil
ar t
o M
GC
139263 p
rote
in (
Annex
in)
61.9
811
-67.
57
16-4
4.9
512
-37.
54
2.1E
-05
127
gi|115663188|
PR
ED
ICT
ED
: si
mil
ar t
o t
etra
span
in, par
tial
.21
.54
4-6
.21
6-1
6.1
21
-2.8
11.
7E-0
5
128
gi|115786699|
PR
ED
ICT
ED
: si
mil
ar t
o a
lpha-
2-m
acro
glo
buli
n, par
tial
.40
.14
7-1
82
13-1
0.6
11.
7E-0
5
129
gi|115960842|
PR
ED
ICT
ED
: si
mil
ar t
o t
alin
.27
46
4-2
5.3
363
-291
2626
-175
171.
1E-0
5
130
gi|115963196|
PR
ED
ICT
ED
: si
mil
ar t
o A
nnex
in A
5 .
32.5
57
-41.
34
2-8
.52
2-7
.92
1.1E
-05
131
gi|115949647|
PR
ED
ICT
ED
: si
mil
ar t
o a
lpha
mac
roglo
buli
n, par
tial
.64
.36
12-2
8.4
17
-25.
11
1.0E
-05
132
gi|115950639|
PR
ED
ICT
ED
: si
mil
ar t
o v
incu
lin, par
tial
.39
.58
1-2
.71
1-2
.31
9-1
3.6
29.
4E-0
6
133
gi|115924509|
PR
ED
ICT
ED
: si
mil
ar t
o c
alpai
n B
.69
.15
5-3
8.5
412
-45.
25
8.4E
-06
134
gi|115949077|
PR
ED
ICT
ED
: si
mil
ar t
o i
nte
gri
n a
lpha
1 .
42.6
42
-9.5
27
-18.
62
1-3
.81
7.9E
-06
Cell
ad
hesio
n*
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

106
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
135
gi|47551105|
inte
gri
n b
eta L
su
bu
nit
.87
.95
6-3
3.3
412
-64
62
-14.
52
7.7E
-06
136
gi|115967683|
PR
ED
ICT
ED
: si
mil
ar t
o N
CA
M-1
40 (
Neu
ral
cell
adhes
ion m
ole
cule
)98
.44
10-3
9.7
47
-31.
54
4-1
1.1
27.
2E-0
6
137
gi|47551115|
inte
gri
n b
eta G
su
bu
nit
.85
.55
4-2
0.1
211
-60.
36
6.0E
-06
138
gi|115975224|
PR
ED
ICT
ED
: si
mil
ar t
o G
-cad
her
in .
302
418
-90.
79
22-9
5.5
97
-37.
54
5.3E
-06
139
gi|115945577|
PR
ED
ICT
ED
: si
mil
ar t
o p
uta
tive
cell
adhes
ion p
rote
in S
ym
32 .
54.5
62
-9.1
11
-21
4-1
9.7
34.
3E-0
6
140
gi|115906323|
PR
ED
ICT
ED
: si
mil
ar t
o v
incu
lin .
44.9
61
-1.4
11
-7.1
13
-10.
71
3.8E
-06
141
gi|115910910|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(F
ibro
nec
tin
)23
65
3-1
02
17-4
7.4
52.
9E-0
6
142
gi|47551111|
inte
gri
n b
eta-C
su
bu
nit
.89
.35
1-3
.21
3-1
1.3
21
-2.4
11.
9E-0
6
143
gi|115975625|
PR
ED
ICT
ED
: si
mil
ar t
o p
lexin
A2 .
186
54
-13.
32
3-8
.72
1.3E
-06
1.2
E-0
3
144
gi|115685173|
PR
ED
ICT
ED
: si
mil
ar t
o L
ow
den
sity
lip
opro
tein
rec
epto
r-re
late
d p
rote
in 6
.35
.27
65-1
334
68-1
303
60-1
142
1.9E
-04
145
gi|115964065|
PR
ED
ICT
ED
: si
mil
ar t
o a
den
yly
l cy
clas
e-as
soci
ated
pro
tein
.21
.15
1-2
.41
44-6
3.7
613
-31.
33
9.3E
-05
146
gi|115964067|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
cap a
den
yla
te c
ycl
ase
asso
ciat
ed p
rote
in)
298
1-7
.11
53-1
6415
15-7
7.7
98.
0E-0
5
147
gi|115973265|
PR
ED
ICT
ED
: si
mil
ar t
o M
GC
79770 p
rote
in (
rho G
DP
dis
soci
atio
n i
nhib
itor)
22.7
513
-65.
37
34-1
0610
2-1
3.8
27.
3E-0
5
148
gi|115976887|
PR
ED
ICT
ED
: si
mil
ar t
o S
TA
RT
dom
ain c
onta
inin
g p
rote
in .
27.3
59
-32.
74
33-6
4.4
714
-50.
75
6.9E
-05
149
gi|115958629|
PR
ED
ICT
ED
: si
mil
ar t
o L
ow
-den
sity
lip
opro
tein
rec
epto
r-re
late
d p
rote
in 4
pre
curs
or
(Mult
iple
epid
erm
al g
row
th f
acto
r-li
ke
dom
ains
129
658
-163
1693
-200
2089
-186
186.
3E-0
5
150
gi|115976312|
PR
ED
ICT
ED
: si
mil
ar t
o C
G8649-P
C (
calp
onin
)51
.86
14-6
3.6
746
-192
1615
-47.
85
4.9E
-05
151
gi|115940166|
PR
ED
ICT
ED
: si
mil
ar t
o a
poli
popro
tein
B .
609
822
2-9
4285
600
-178
9#
4.6E
-05
152
gi|115929815|
PR
ED
ICT
ED
: si
mil
ar t
o N
ucl
eosi
de
dip
hosp
hat
e kin
ase
fam
ily p
rote
in .
19.2
76
-30.
64
13-5
96
6-1
52
4.4E
-05
153
gi|47551041|
ER
calc
isto
rin
.54
.94
43-1
7516
7-4
9.6
53.
1E-0
5
154
gi|115968621|
PR
ED
ICT
ED
: si
mil
ar t
o c
alponin
.17
.510
3-1
1.4
25
-19.
72
8-3
6.6
53.
1E-0
5
155
gi|115970013|
PR
ED
ICT
ED
: si
mil
ar t
o a
poli
popro
tein
B .
202
640
-140
314
2-3
6815
2-9
.42
3.1E
-05
156
gi|115936803|
PR
ED
ICT
ED
: si
mil
ar t
o h
eter
otr
imer
ic g
uan
ine
nucl
eoti
de-
bin
din
g p
rote
in b
eta
subunit
isofo
rm 3
.37
.76
9-4
9.3
512
-51
69
-52.
15
2.7E
-05
157
gi|115940411|
PR
ED
ICT
ED
: si
mil
ar t
o 1
4-3
-3-l
ike
pro
tein
2 .
31.7
53
-13.
91
13-7
0.5
77
-32.
54
2.5E
-05
158
gi|115945715|
PR
ED
ICT
ED
: si
mil
ar t
o R
as-r
elat
ed p
rote
in O
RA
B-1
.20
.65
3-1
5.3
28
-43.
35
3-1
4.3
22.
3E-0
5
159
gi|160623362|
pu
tati
ve
14-3
-3 e
psi
lon
iso
form
.24
.15
3-2
6.5
39
-23
34
-20.
72
2.2E
-05
160
gi|115944489|
PR
ED
ICT
ED
: si
mil
ar t
o C
G2082-P
A (
este
rase
lip
ase)
37.6
77
-38.
64
7-3
4.2
48
-25.
53
2.0E
-05
161
gi|115940258|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
lipid
raf
t as
ssoci
taed
pro
tein
2)
279
3-1
3.9
26
-25.
73
6-2
5.9
31.
9E-0
5
162
gi|115976839|
PR
ED
ICT
ED
: si
mil
ar t
o G
DP
-dis
soci
atio
n i
nhib
itor
.37
.28
2-1
0.4
215
-114
103
-18.
73
1.8E
-05
163
gi|115949757|
PR
ED
ICT
ED
: si
mil
ar t
o R
ap1b-p
rov p
rote
in .
21.2
83
-10.
42
5-1
4.9
23
-22.
83
1.8E
-05
164
gi|115974451|
PR
ED
ICT
ED
: si
mil
ar t
o G
TP
ase
SU
rab10p (
Ras
onco
gen
e fa
mil
y)
25.4
85
-20.
63
5-1
8.2
22
-9.4
11.
6E-0
5
165
gi|115974362|
PR
ED
ICT
ED
: si
mil
ar t
o R
ab7 .
23.1
65
-24
35
-21.
53
1.5E
-05
166
gi|115973453|
PR
ED
ICT
ED
: si
mil
ar t
o c
alponin
.23
.86
5-1
9.9
24
-20.
22
1-1
.51
1.4E
-05
Intr
ace
llu
lar
sign
ali
ng*
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

107
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
167
gi|47825400|
gu
an
ine
nu
cleo
tid
e-b
ind
ing p
rote
in G
(i)
alp
ha s
ub
un
it .
40.3
53
-12.
52
10-3
74
3-2
2.2
31.
3E-0
5
168
gi|115973105|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
pyru
vat
e kin
ase
)50
.68
2-3
114
-65.
87
2-4
.71
1.2E
-05
169
gi|115954188|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
Sorc
in)
20.1
55
-34.
14
1-2
.31
1.0E
-05
170
gi|115966293|
PR
ED
ICT
ED
: si
mil
ar t
o R
AS
-rel
ated
pro
tein
ME
L .
23.5
95
-20
22
-11.
41
1.0E
-05
171
gi|115968932|
PR
ED
ICT
ED
: si
mil
ar t
o c
onse
rved
hypoth
etic
al p
rote
in (
Arr
esti
n N
super
fam
ily
)66
.86
2-9
.12
17-7
5.6
99.
7E-0
6
172
gi|115937346|
PR
ED
ICT
ED
: si
mil
ar t
o a
poli
pophori
n pre
curs
or
pro
tein
.40
25
43-2
9331
68-3
1330
9.3E
-06
173
gi|115927899|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(pro
gra
mm
ed c
ell
dea
th 8
. ap
opto
sis
induci
ng
fact
or)
15.7
51
-1.8
13
-11.
12
9.0E
-06
174
gi|115975006|
PR
ED
ICT
ED
: si
mil
ar t
o R
AB
2 i
sofo
rm 2
.23
.76
2-2
.31
2-3
.41
2-1
6.1
28.
6E-0
6
175
gi|115934007|
PR
ED
ICT
ED
: si
mil
ar t
o T
RA
F4-a
ssoci
ated
fac
tor
2 .
47.5
62
-12.
22
9-7
3.5
88.
0E-0
6
176
gi|115894557|
PR
ED
ICT
ED
: si
mil
ar t
o R
AC
K .
308
4-1
5.7
31
-2.9
11
-1.4
16.
8E-0
6
177
gi|115935133|
PR
ED
ICT
ED
: si
mil
ar t
o a
den
yla
te k
inas
e 2 i
sofo
rm 2
.27
.18
4-2
0.3
31
-6.2
16.
5E-0
6
178
gi|115926610|
PR
ED
ICT
ED
: si
mil
ar t
o p
ropro
tein
conver
tase
subti
lisi
n/k
exin
type
9 p
repro
pro
tein
.37
.95
3-1
72
4-1
1.7
26.
4E-0
6
179
gi|115945701|
PR
ED
ICT
ED
: si
mil
ar t
o c
alci
um
-bin
din
g p
rote
in p
22 .
22.2
53
-18
21
-4.5
16.
4E-0
6
180
gi|115945943|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000011972 (
GD
P d
isso
ciat
ion i
nhib
itor)
495
2-6
.71
7-4
5.2
46.
3E-0
6
181
gi|47551197|
src-
fam
ily p
rote
in t
yro
sin
e k
inase
.57
.78
8-4
3.7
42
-4.8
16.
0E-0
6
182
gi|115954217|
PR
ED
ICT
ED
: si
mil
ar t
o h
exokin
ase
I .
435
2-1
3.8
25
-19.
23
5.7E
-06
183
gi|115938855|
PR
ED
ICT
ED
: si
mil
ar t
o R
ab11b .
24.4
62
-9.1
21
-3.4
11
-2.2
15.
5E-0
6
184
gi|115929326|
PR
ED
ICT
ED
: si
mil
ar t
o K
IAA
1646 p
rote
in (
cera
mid
e kin
ase
)68
.69
1-5
.21
6-2
3.9
33
-17.
23
4.9E
-06
185
gi|115968426|
PR
ED
ICT
ED
: si
mil
ar t
o a
rgin
ine
kin
ase
.41
.96
1-4
.91
3-1
4.8
22
-6.8
14.
8E-0
6
186
gi|42794334|
ph
osp
holi
pase
C d
elta
iso
form
.85
.56
1-1
.51
8-5
2.3
61
-2.6
14.
0E-0
6
187
gi|115940967|
PR
ED
ICT
ED
: si
mil
ar t
o D
ynam
in 2
, par
tial
.57
.89
4-2
1.2
32
-9.9
23.
6E-0
6
188
gi|47825404|
gu
an
ine
nu
cleo
tid
e-b
ind
ing p
rote
in G
(12)
alp
ha s
ub
un
it .
42.1
93
-18.
52
1-2
.11
3.4E
-06
189
gi|115936246|
PR
ED
ICT
ED
: si
mil
ar t
o s
erin
e/th
reonin
e pro
tein
kin
ase
.56
.26
1-2
.41
4-2
2.3
33.
1E-0
6
190
gi|115966000|
PR
ED
ICT
ED
: si
mil
ar t
o l
ipopro
tein
rec
epto
r-re
late
d p
rote
in 6
.15
55
2-7
.91
10-7
38
2.7E
-06
191
gi|115943069|
PR
ED
ICT
ED
: si
mil
ar t
o C
G18076-P
B (
calp
onin
)10
615
1-1
.91
3-1
7.4
31.
3E-0
7
9.4
E-0
4
192
gi|47551061|
H4 h
isto
ne
pro
tein
.11
.411
38-5
4.2
654
-60.
36
2.7E
-04
193
gi|62177162|
his
ton
e H
2A
.13
.311
4-1
0.8
124
-21.
61
5-1
6.1
18.
4E-0
5
194
gi|115970523|
PR
ED
ICT
ED
: si
mil
ar t
o e
longat
ion f
acto
r 1 a
lpha
isofo
rm 2
.50
.49
15-5
6.3
749
-138
1428
-70.
48
6.2E
-05
195
gi|115718598|
PR
ED
ICT
ED
: si
mil
ar t
o H
isto
ne
H2A
V (
H2A
.F/Z
) .
13.4
115
-11.
12
13-2
5.8
44
-19.
43
5.5E
-05
196
gi|115970083|
PR
ED
ICT
ED
: si
mil
ar t
o u
biq
uit
in/4
0S
rib
oso
mal
pro
tein
S27a
fusi
on p
rote
in .
17.8
109
-30.
54
9-2
5.1
36
-22.
83
4.6E
-05
197
gi|47551075|
late
his
ton
e L
1 H
2b
.13
.611
4-1
9.2
19
-25.
53
3.3E
-05
198
gi|47551095|
his
ton
e H
1-d
elta
.19
.311
7-1
6.7
27
-36.
64
3-6
.41
3.0E
-05
199
gi|47551065|
his
ton
e H
3 .
15.3
112
-2.9
18
-10.
81
3-1
.91
2.9E
-05
se
a u
rch
in 1
Nu
clei
c aci
d a
nd
pro
tein
met
ab
oli
sm a
nd
pro
cess
ing*
se
a u
rch
in 2
se
a u
rch
in 3

108
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
200
gi|115976983|
PR
ED
ICT
ED
: si
mil
ar t
o r
iboso
mal
pro
tein
L36 .
12.6
114
-25
23
-17.
42
3-1
92
2.7E
-05
201
gi|115940855|
PR
ED
ICT
ED
: si
mil
ar t
o W
D r
epea
t dom
ain 1
, par
tial
.48
.56
7-3
7.3
515
-35
412
-49.
26
2.4E
-05
202
gi|115940461|
PR
ED
ICT
ED
: si
mil
ar t
o G
rp58-p
rov p
rote
in (
pro
tein
dis
ulf
ate
isom
eras
e)
525
3-2
3.2
319
-112
1012
-61.
76
2.2E
-05
203
gi|115974148|
PR
ED
ICT
ED
: si
mil
ar t
o R
ibophori
n I
.
67.2
66
-36.
84
15-4
3.4
413
-56.
36
1.7E
-05
204
gi|115959136|
PR
ED
ICT
ED
: si
mil
ar t
o r
iboso
mal
pro
tein
S8e
.26
.910
6-3
8.9
44
-26.
73
2-1
8.6
21.
5E-0
5
205
gi|115974434|
PR
ED
ICT
ED
: si
mil
ar t
o a
den
osy
lhom
ocy
stei
nas
e .
47.5
66
-35.
44
14-7
6.5
81
-2.6
11.
5E-0
5
206
gi|115974576|
PR
ED
ICT
ED
: si
mil
ar t
o p
uta
tive
riboso
mal
pro
tein
S14e
.16
.111
3-5
.11
3-1
3.1
21
-3.9
11.
5E-0
5
207
gi|47551091|
late
his
ton
e H
1-g
am
ma .
22.6
114
-3.1
15
-28.
23
11.
4E-0
5
208
gi|115946250|
PR
ED
ICT
ED
: si
mil
ar t
o S
hm
t2 p
rote
in, par
tial
.17
.78
6-3
74
1-4
.41
1.4E
-05
209
gi|115921067|
PR
ED
ICT
ED
: si
mil
ar t
o r
iboso
mal
pro
tein
L23a
.19
.911
3-1
12
3-1
2.1
22
-12.
82
1.4E
-05
210
gi|115929116|
PR
ED
ICT
ED
: si
mil
ar t
o a
min
oim
idaz
ole
-4-c
arboxam
ide
ribonucl
eoti
det
ransf
orm
yla
se/I
MP
cycl
ohydro
lase
(In
osi
ne
monophosp
hat
e sy
nth
ase)
64.3
63
-11.
52
15-1
0611
6-2
8.4
41.
3E-0
5
211
gi|115926828|
PR
ED
ICT
ED
: si
mil
ar t
o e
ukar
yoti
c tr
ansl
atio
n e
longat
ion f
acto
r is
ofo
rm 2
.94
.37
7-3
7.4
523
-117
125
-22.
43
1.3E
-05
212
gi|115649138|
PR
ED
ICT
ED
: si
mil
ar t
o r
iboso
mal
pro
tein
S3 .
30.7
101
-1.4
17
-27.
53
2-1
4.7
21.
1E-0
5
213
gi|115954953|
PR
ED
ICT
ED
: si
mil
ar t
o r
iboso
mal
pro
tein
L28 .
15.6
122
-7.5
11
-1.6
12
-13.
92
1.1E
-05
214
gi|148539566|
euk
ary
oti
c in
itia
tion
fact
or
4a . X
P_001177759 X
P_780907 X
P_802068 X
P_802102
48.2
53
-23.
13
12-6
6.6
61.
1E-0
5
215
gi|115933954|
PR
ED
ICT
ED
: si
mil
ar t
o r
iboso
mal
pro
tein
L13, par
tial
.16
.311
1-1
.81
1-4
.51
3-9
.62
1.0E
-05
216
gi|115975522|
PR
ED
ICT
ED
: si
mil
ar t
o R
ibophori
n I
I .
89.2
615
-86.
48
10-4
9.4
59.
5E-0
6
217
gi|115928298|
PR
ED
ICT
ED
: si
mil
ar t
o 4
0S
rib
oso
mal
pro
tein
S24 .
15.1
113
-9.5
21
-5.5
19.
4E-0
6
218
gi|47551089|
his
ton
e H
1-b
eta .
22.2
112
-51
3-1
0.5
21
-2.1
19.
1E-0
6
219
gi|115924286|
PR
ED
ICT
ED
: si
mil
ar t
o t
ransl
atio
nal
ly c
ontr
oll
ed t
um
or
pro
tein
iso
form
2 .
22.2
52
-9.3
23
-18.
43
1-1
.31
9.1E
-06
220
gi|115955282|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
het
erogen
ous
nucl
ear
ribonucl
eopro
tein
K)
46.8
95
-13.
22
5-3
0.9
57.
4E-0
6
221
gi|115958412|
PR
ED
ICT
ED
: si
mil
ar t
o 3
4/6
7 k
D l
amin
in b
indin
g p
rote
in (
Rib
oso
mal
pro
tein
40S
)36
.65
4-1
9.4
32
-4.6
15.
7E-0
6
222
gi|115940610|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(R
iboso
mal
pro
tein
)31
.411
2-1
1.3
21
-1.4
12
-11.
92
5.4E
-06
223
gi|115957127|
PR
ED
ICT
ED
: si
mil
ar t
o r
iboso
mal
pro
tein
L5 .
34.1
102
-3.5
13
-11.
72
5.2E
-06
224
gi|115911567|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(as
par
tyl
tRN
A s
ynth
ase
)50
56
-44
51
-51
4.9E
-06
225
gi|115973107|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(N
AD
H c
yto
chro
me
reduct
ase)
399
3-9
.52
2-8
.32
4.5E
-06
226
gi|115934350|
PR
ED
ICT
ED
: si
mil
ar t
o u
biq
uit
in-a
ctiv
atin
g e
nzy
me
E1 .
118
55
-34.
63
7-4
5.3
53.
5E-0
6
227
gi|115966085|
PR
ED
ICT
ED
: si
mil
ar t
o e
ndo-b
eta-
N-a
cety
lglu
cosa
min
idas
e, p
arti
al .
85.3
66
-19.
63
2-5
.31
3.2E
-06
228
gi|115950386|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000016786 (
tran
sport
pro
tein
sec
61 a
lpha)
52.2
92
-9.2
22
-2.2
12.
7E-0
6
229
gi|115652043|
PR
ED
ICT
ED
: si
mil
ar t
o h
isti
dyl-
tRN
A s
ynth
etas
e, p
arti
al .
56.1
83
-18.
53
1-2
12.
5E-0
6
4.4
E-0
4
230
gi|115956476|
PR
ED
ICT
ED
: si
mil
ar t
o a
pex
trin
.49
.54
54-1
7215
79-1
4013
10-4
1.5
59.
8E-0
5
231
gi|115951163|
PR
ED
ICT
ED
: si
mil
ar t
o e
chin
onec
tin .
55.6
687
-148
539
-96
33
-8.8
17.
8E-0
5
232
gi|115620061|
PR
ED
ICT
ED
: si
mil
ar t
o e
chin
onec
tin, par
tial
.66
.16
102
-263
2327
-97.
29
4-2
0.1
36.
8E-0
5
Cel
l p
roli
fera
tion
, re
pro
du
ctio
n a
nd
dev
elop
men
t*
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

109
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
233
gi|115973518|
PR
ED
ICT
ED
: si
mil
ar t
o e
chin
onec
tin, par
tial
.49
.46
67-9
8.7
818
-50.
96
1-1
.81
5.9E
-05
234
gi|115899605|
PR
ED
ICT
ED
: si
mil
ar t
o e
chin
onec
tin, par
tial
.56
.75
18-4
6.4
234
-56.
73
3.1E
-05
235
gi|115945705|
PR
ED
ICT
ED
: si
mil
ar t
o E
H-d
om
ain-c
onta
inin
g p
rote
in 1
(T
esti
lin)
(hPA
ST
1)
.62
.27
36-1
6015
17-8
7.8
102.
9E-0
5
236
gi|115924200|
PR
ED
ICT
ED
: si
mil
ar t
o s
ecre
ted l
ecti
n h
om
olo
g;
HeE
L-1
.20
.24
4-1
7.7
15
-19.
93
1.5E
-05
237
gi|115952980|
PR
ED
ICT
ED
: si
mil
ar t
o e
chin
onec
tin, par
tial
.18
.35
3-2
.51
3-9
.62
1.1E
-05
238
gi|115945319|
PR
ED
ICT
ED
: si
mil
ar t
o p
rim
ary m
esen
chym
e sp
ecif
ic p
rote
in M
SP
130-r
elat
ed-1
.56
.85
11-4
3.2
53
-19.
93
5-1
4.7
21.
1E-0
5
239
gi|115955360|
PR
ED
ICT
ED
: si
mil
ar t
o a
pex
trin
.62
.35
2-5
.61
12-6
5.4
52
-3.1
18.
7E-0
6
240
gi|115948485|
PR
ED
ICT
ED
: si
mil
ar t
o m
oll
usk
-der
ived
gro
wth
fac
tor;
MD
GF, par
tial
.60
.17
4-1
8.7
37
-33.
44
6.3E
-06
241
gi|115964625|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
nm
rA l
ike
fam
ily d
om
ain c
onta
inin
g )
32.5
62
-5.4
13
-20.
83
5.4E
-06
242
gi|115960970|
PR
ED
ICT
ED
: si
mil
ar t
o p
roli
fera
tion-a
ssoci
ated
pro
tein
1 .
44.8
64
-38
42
-2.2
14.
7E-0
6
243
gi|115956777|
PR
ED
ICT
ED
: si
mil
ar t
o E
CM
18 .
267
417
-57.
47
17-4
6.5
44.
3E-0
6
244
gi|115968740|
PR
ED
ICT
ED
: si
mil
ar t
o S
epti
n 6
.50
.36
4-1
3.7
22
-13.
62
4.2E
-06
245
gi|115770276|
PR
ED
ICT
ED
: si
mil
ar t
o z
onad
hes
in
89.3
46
-22.
13
4-1
8.9
33.
9E-0
6
246
gi|115957151|
PR
ED
ICT
ED
: si
mil
ar t
o v
itel
logen
in .
244
64
-21.
33
4-1
9.3
23
-21.
73
1.5E
-06
2.8
E-0
4
247
gi|115935979|
PR
ED
ICT
ED
: si
mil
ar t
o v
olt
age-
dep
enden
t an
ion c
han
nel
2 .
30.4
621
-90
934
-105
1028
-86.
49
9.2E
-05
248
gi|115966189|
PR
ED
ICT
ED
: si
mil
ar t
o H
(+)-
tran
sport
ing A
TP
ase
bet
a su
bunit
.55
.95
16-1
1411
48-1
9415
15-9
8.1
104.
8E-0
5
249
gi|115941346|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(A
TP
ase
H+
tra
nsp
ort
ing
)8.
45
3-1
4.1
24
-8.5
14
-16.
72
4.4E
-05
250
gi|47551121|
mit
och
on
dri
al A
TP
syn
thase
alp
ha s
ub
un
it p
recu
rsor
.59
.68
17-7
6.7
832
-145
139
-55.
76
3.3E
-05
251
gi|115956824|
PR
ED
ICT
ED
: si
mil
ar t
o S
olu
te c
arri
er f
amil
y 2
5 (
mit
och
ondri
al c
arri
er;
aden
ine
nucl
eoti
de
tran
sloca
tor)
, m
ember
433
.310
10-5
6.3
78
-23.
73
5-2
7.8
42.
3E-0
5
252
gi|115710920|
PR
ED
ICT
ED
: si
mil
ar t
o N
a+/K
+ A
TP
ase
alpha
subunit
.11
45
3-2
4.2
327
-139
131
-7.6
19.
2E-0
6
253
gi|115940494|
PR
ED
ICT
ED
: si
mil
ar t
o M
GC
69168 p
rote
in (
solu
te c
arri
er f
amil
y, m
itoch
ondri
al)
77.1
92
-13.
52
15-8
9.3
92
-10.
52
8.3E
-06
254
gi|115926312|
PR
ED
ICT
ED
: si
mil
ar t
o L
OC
446923 p
rote
in (
H t
ransp
ort
ing A
TP
synth
ase)
22.8
104
-17.
83
1-3
.71
7.7E
-06
255
gi|115926329|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
solu
te c
arri
er f
amil
y 8
sodiu
m c
alci
um
exch
anger
)48
.45
8-4
9.8
51
-3.1
16.
4E-0
6
256
gi|115939138|
PR
ED
ICT
ED
: si
mil
ar t
o S
lc25a3
-pro
v p
rote
in (
solu
te c
arri
er f
amil
y 2
5 m
ember
3)
39.1
92
-7.7
13
-10.
22
1-6
.11
5.2E
-06
257
gi|115926327|
PR
ED
ICT
ED
: si
mil
ar t
o N
a/C
a ex
chan
ger
.40
.46
3-1
2.5
22
-17
24.
3E-0
6
258
gi|115697801|
PR
ED
ICT
ED
: si
mil
ar t
o N
icoti
nam
ide
nucl
eoti
de
tran
shydro
gen
ase
.11
36
4-1
3.8
21
-4.6
12
-13.
62
2.1E
-06
259
gi|115924511|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000007239 (
myosi
n +
atp
bin
din
g c
asse
tte
AB
C)
304
61
-3.5
14
-24.
24
5.8E
-07
2.9
E-0
4
260
gi|115964543|
PR
ED
ICT
ED
: si
mil
ar t
o t
ransa
ldola
se .
33.4
620
-90.
17
21-9
1.9
820
-97.
49
6.2E
-05
261
gi|115738231|
PR
ED
ICT
ED
: si
mil
ar t
o g
lyce
rald
ehydep
hosp
hat
e deh
ydro
gen
ase
isofo
rm 1
.36
.57
26-1
059
20-1
0810
15-5
5.8
55.
6E-0
5
262
gi|115944251|
PR
ED
ICT
ED
: si
mil
ar t
o t
ransk
etola
se i
sofo
rm 1
.66
.16
3-1
1.2
231
-140
1416
-58
62.
6E-0
5
263
gi|115929324|
PR
ED
ICT
ED
: si
mil
ar t
o g
luco
se-6
-phosp
hat
e 1-d
ehydro
gen
ase,
par
tial
.43
.38
27-1
1913
4-1
93
2.4E
-05
En
ergy m
etab
oli
sm*
Exch
an
ger
an
d A
TP
ase
s*
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

110
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
264
gi|115972829|
PR
ED
ICT
ED
: si
mil
ar t
o g
luco
se-6
-phosp
hat
e is
om
eras
e .
60.1
75
-34.
24
16-6
4.6
66
-40.
75
1.5E
-05
265
gi|115959412|
PR
ED
ICT
ED
: si
mil
ar t
o f
ruct
ose
-bip
hosp
hat
e al
dola
se .
39.3
77
-39.
84
10-5
0.4
51.
5E-0
5
266
gi|115663344|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(phosp
hoglu
cose
iso
mer
ase)
12.8
62
-5.2
13
-11.
61
1.4E
-05
267
gi|115939485|
PR
ED
ICT
ED
: si
mil
ar t
o m
alat
e deh
ydro
gen
ase
.35
.26
5-3
2.2
38
-56.
66
1-1
.71
1.3E
-05
268
gi|115680328|
PR
ED
ICT
ED
: si
mil
ar t
o c
yto
soli
c m
alat
e deh
ydro
gen
ase
.36
.26
3-8
29
-46.
75
1-8
.61
1.2E
-05
269
gi|115955959|
PR
ED
ICT
ED
: si
mil
ar t
o G
luco
sam
ine-
6-p
hosp
hat
e is
om
eras
e (G
luco
sam
ine-
6-p
hosp
hat
e
dea
min
ase)
(G
NP
DA
) (G
lcN
6P
dea
min
ase)
32.1
62
-16.
32
4-1
2.3
26.
5E-0
6
270
gi|115924009|
PR
ED
ICT
ED
: si
mil
ar t
o M
ethylt
hio
aden
osi
ne
phosp
hory
lase
.28
64
-16.
22
1-2
.21
6.3E
-06
271
gi|115945027|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in i
sofo
rm 1
(in
tegra
l m
embra
ne
pro
tein
1
oli
gosa
cchar
ylt
ransf
eras
e co
mple
x)
82.8
713
-50.
16
2-1
1.4
26.
2E-0
6
272
gi|115931669|
PR
ED
ICT
ED
: si
mil
ar t
o a
ldeh
yde
deh
ydro
gen
ase
1A
2 i
sofo
rm 1
.53
.36
3-1
6.2
36
-34.
54
5.8E
-06
273
gi|115961332|
PR
ED
ICT
ED
: si
mil
ar t
o g
luta
mat
e deh
ydro
gen
ase
1 .
61.3
75
-27.
83
4-1
1.4
25.
1E-0
6
274
gi|115970392|
PR
ED
ICT
ED
: si
mil
ar t
o i
ndep
enden
t phosp
hogly
cera
te m
uta
se .
47.6
65
-22.
63
1-1
.91
4.4E
-06
275
gi|115926187|
PR
ED
ICT
ED
: si
mil
ar t
o H
ydro
xyac
yl-
Coen
zym
e A
deh
ydro
gen
ase/
3-k
etoac
yl-
Coen
zym
e A
thio
lase
/enoyl-
Coen
zym
e A
75.9
94
-18.
13
3-1
22
2-8
.52
4.0E
-06
276
gi|115958742|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(la
ctat
e deh
ydro
gen
ase
)36
.36
3-1
2.1
21
-2.2
13.
9E-0
6
277
gi|115968074|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
aldeh
yde
deh
ydro
gen
ase
)61
.15
2-1
0.4
14
-30.
73
3.4E
-06
278
gi|115978426|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
dih
ydro
lipoyll
ysi
n S
succ
inylt
ransf
eras
e)
557
3-1
2.4
22
-9.4
23.
2E-0
6
279
gi|84688617|
insu
lin
rec
epto
r p
recu
rsor
.12
05
1-2
.71
3-9
.71
1.2E
-06
2.3
E-0
4
280
gi|115971190|
PR
ED
ICT
ED
: si
mil
ar t
o s
erin
e pro
teas
e .
12.3
513
-35.
64
10-2
7.6
31
-1.5
16.
6E-0
5
281
gi|115769879|
PR
ED
ICT
ED
: si
mil
ar t
o e
ndoder
min
, par
tial
.8.
66
3-4
.91
4-5
.81
2-1
0.5
23.
5E-0
5
282
gi|115959123|
PR
ED
ICT
ED
: si
mil
ar t
o L
pa-
pro
v p
rote
in, par
tial
(T
hro
mbin
)57
.95
4-1
7.8
222
-89.
29
20-4
15
2.7E
-05
283
gi|115958627|
PR
ED
ICT
ED
: si
mil
ar t
o t
hro
mbin
.72
.25
6-1
2.5
29
-44.
15
32-7
18
2.2E
-05
284
gi|115971224|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
amin
opep
tidas
e)
55.3
61
-3.9
115
-84.
98
7-4
6.2
51.
4E-0
5
285
gi|115938941|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
lyso
som
al m
embra
ne
gly
copro
tein
)51
.96
11-4
5.2
57
-8.5
11.
2E-0
5
286
gi|115958371|
PR
ED
ICT
ED
: si
mil
ar t
o l
yso
zym
e .
15.4
93
-13.
32
2-1
1.9
21.
1E-0
5
287
gi|115925688|
PR
ED
ICT
ED
: si
mil
ar t
o C
ND
P d
ipep
tidas
e 2 (
met
allo
pep
tidas
e M
20 f
amil
y)
.52
.55
6-3
2.8
46
-23.
93
7.9E
-06
288
gi|115970724|
PR
ED
ICT
ED
: si
mil
ar t
o V
alosi
n c
onta
inin
g p
rote
in, par
tial
.59
.65
11-8
6.3
72
-3.4
17.
5E-0
6
289
gi|115940918|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
amin
opep
tidas
e li
ke
1)
55.9
87
-54.
45
2-5
.51
5.6E
-06
290
gi|115955224|
PR
ED
ICT
ED
: si
mil
ar t
o L
OC
494800 p
rote
in (
cath
epsi
n)
31.6
62
-3.4
13
-10.
72
5.6E
-06
291
gi|115975288|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
Thro
mbosp
ondin
)10
35
7-2
5.2
31
-5.2
16
-29.
34
4.6E
-06
292
gi|115924999|
PR
ED
ICT
ED
: si
mil
ar t
o t
issu
e in
hib
itor
of
met
allo
pro
tein
ase
TIM
P32
.37
3-1
9.7
31
-31
4.4E
-06
293
gi|115774731|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
(le
ukotr
iene
A4 h
ydro
lase
)63
.45
4-1
3.1
21
-1.4
12.
8E-0
6
294
gi|115953033|
PR
ED
ICT
ED
: si
mil
ar t
o A
min
opep
tidas
e puro
myci
n s
ensi
tive
.87
.45
1-3
.61
3-1
5.4
22
-3.5
12.
3E-0
6
Lyso
som
es, p
rote
ase
s an
d p
epti
dase
s*
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

111
Pro
t
Nb
Acc
essi
on
nu
mb
erP
rote
in i
den
tifi
cati
on
MW
(kD
a)pI
rIlo
g(e)
#rI
log(
e)#
rIlo
g(e)
#N
SA
Fs
1.1
E-0
4
295
gi|115936009|
PR
ED
ICT
ED
: si
mil
ar t
o E
NS
AN
GP
00000009431 (
floti
lin
)46
.96
22-1
5914
36-1
9217
14-8
9.4
95.
2E-0
5
296
gi|115931510|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
sort
ing n
exin
)39
.39
4-2
2.3
313
-69.
16
10-4
5.3
52.
3E-0
5
297
gi|115963658|
PR
ED
ICT
ED
: m
ajor
vau
lt p
rote
in .
95.9
65
-26.
14
31-1
3114
3-8
.92
1.4E
-05
298
gi|115928607|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
floti
lin
)76
.65
4-2
1.6
326
-116
121.
3E-0
5
299
gi|115950948|
PR
ED
ICT
ED
: si
mil
ar t
o A
dap
tor-
rela
ted p
rote
in c
om
ple
x 2
, bet
a 1 s
ubunit
, par
tial
.28
.59
1-3
.61
5-4
0.7
47.
3E-0
6
300
gi|115968951|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in (
adap
tor
pro
tein
com
ple
x A
P2
)49
.910
2-2
.91
3-1
4.9
23.
5E-0
6
9.1
E-0
5
301
gi|115925590|
PR
ED
ICT
ED
: si
mil
ar t
o m
uci
n 5
, par
tial
.56
.45
30-7
8.2
751
-80.
67
14-4
14
5.7E
-05
302
gi|115955764|
PR
ED
ICT
ED
: si
mil
ar t
o C
ry5 p
rote
in .
64.5
910
-72.
88
28-1
1211
2.0E
-05
303
gi|115976552|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in i
sofo
rm 2
(re
cepto
r ac
cess
ory
pro
tein
5)
22.4
56
-23.
82
3-1
9.2
21.
4E-0
5
5.0
E-0
4
304
gi|115971048|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
35.3
545
-104
613
3-1
416
57-9
1.3
52.
2E-0
4
305
gi|115963910|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
.41
.85
19-6
7.9
760
-93.
89
36-9
7.6
99.
3E-0
5
306
gi|115967751|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
174
3-3
111
-19.
52
2.8E
-05
307
gi|115940889|
PR
ED
ICT
ED
: si
mil
ar t
o E
GF
-lik
e pro
tein
.54
.14
26-3
5.9
114
-29.
61
2.5E
-05
308
gi|115930346|
PR
ED
ICT
ED
: si
mil
ar t
o c
onse
rved
hypoth
etic
al p
rote
in .
24.6
53
-6.3
113
-25.
23
2.2E
-05
309
gi|115969396|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
13.7
53
-18.
92
5-2
23
2.0E
-05
310
gi|115953252|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
28.6
413
-25
31
-1.8
13
-10
22.
0E-0
5
311
gi|115964419|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
122
528
-80.
58
28-1
3714
2-5
.71
1.6E
-05
312
gi|115937367|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in, par
tial
.13
.66
4-2
6.2
41
-1.5
11.
3E-0
5
313
gi|115935672|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
18.1
91
-5.8
14
-14.
81
9.7E
-06
314
gi|115948973|
PR
ED
ICT
ED
: si
mil
ar t
o C
G8253-P
A .
23.3
52
-5.4
13
-13.
92
1-2
.21
8.7E
-06
315
gi|115928947|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
114
920
-10.
41
6-1
0.5
17.
7E-0
6
316
gi|115925007|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in50
.85
1-1
.81
6-2
8.4
44.
8E-0
6
317
gi|115932265|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
68.3
65
-34.
14
2-1
.71
2-2
.51
4.5E
-06
318
gi|115967840|
PR
ED
ICT
ED
: si
mil
ar t
o 0
910001A
06R
ik p
rote
in i
sofo
rm 2
.37
.36
1-2
.41
3-1
4.6
23.
8E-0
6
319
gi|115967917|
PR
ED
ICT
ED
: hypoth
etic
al p
rote
in .
57.7
91
-1.8
13
-17.
53
2.5E
-06
Un
kn
ow
n
Intr
ace
llu
lar
tran
sport
*
Oth
ers
* B
iolo
gic
al fu
nctions w
ere
assessed a
ccord
ing to the follo
win
g G
ene o
nto
logy c
ate
gories; C
ell
str
uctu
re, shape a
nd m
obili
ty: G
O:0
007010, G
O:0
008360, G
O:0
006909,
GO
:0022607, G
O:0
022411, G
O:0
032989; Im
mune r
esponse: G
O:0
002376, G
O:0
006952, G
O:0
052200; S
tress r
esponse, deto
xific
ation: G
O:0
009636, G
O:0
006979,
GO
:0070482 ; C
ell
adhesio
n: G
O:0
007155, G
O:0
007242; In
tracellu
lar
sig
nalin
g: G
O:0
065007, G
O:0
004871, G
O:0
017127; N
ucle
ic a
cid
and p
rote
in m
eta
bolis
m a
nd
pro
cessin
g: G
O:0
006139, G
O:0
019538; C
ell
pro
lifera
tion, re
pro
duction a
nd d
evelo
pm
ent: G
O:0
008283, G
O:0
000003; E
xchanger
and A
TP
ase: G
O:0
006873,
GO
:0006754, G
O:0
005391, G
O:0
006814; E
nerg
y m
eta
bolis
m: G
O:0
006112; Lysosom
es, pro
teases a
nd p
eptidases: G
O:0
008333, G
O:0
002203; In
tracellu
lar
transport
:
GO
:0046907; G
O:0
006886, G
O:0
006897.
se
a u
rch
in 1
se
a u
rch
in 2
se
a u
rch
in 3

112

113
CHAPTER III
Proteomic analysis of sea urchin responses to bacterial injection
In preparation for submission to
Journal of Proteomics
Author contributions:
Bove U1 – Experimental design - Technical support
Haynes PA2 – Technical support
Nair SV1 – Project supervision
Raftos DA1 – Experimental design – Project supervision
1 Department of Biological Sciences, Macquarie University, North Ryde, NSW 2109, Australia
2 Department of Chemistry and Biomolecular Sciences, Macquarie University, North Ryde, NSW 2109,
Australia

114

115
3.1. Preface
After describing the fundamental proteome of the coelomic fluid of sea urchins
(Chapter 2), the next aim of this thesis was to identify proteins involved in immune
responses. The goal of this Chapter was to identify immune response proteins that are
specifically expressed in response to the injection of bacteria. To do this, the proteomes of
coelomocytes from naïve sea urchins were compared to those of sea urchins injected with
saline or bacteria by two-dimensional electrophoresis (2DE).

116

117
3.2. Abstract
Echinoderms evolved early in the deuterostome lineage, and as such constitute model
organisms for comparative physiology and immunology. The sea urchin genome sequence
revealed a complex repertoire of genes with similarities to the immune response genes of
other species. To complement these genomic data, we investigated the responses of sea
urchins to the injection of bacteria using a comparative proteomics approach. The relative
abundance of many proteins was altered in response to the injection of both bacteria and
saline, suggesting their involvement in wounding response, while others were differentially
altered in response to bacteria only. The identities of 15 proteins that differed in relative
abundance were determined by mass spectrometry. These proteins revealed a significant
modification in energy metabolism in coelomocytes towards the consumption of glutamate
and the production of NADPH after injection, as well as an increased concentration of cell
signalling molecules, such as heterotrimeric guanine nucleotide binding protein. The
injection of bacteria specifically increased the abundance of apextrin and calreticulin,
suggesting that these two proteins are involved in the sequestration or inactivation of
bacteria.

118
3.3. Introduction
Sea urchins are deuterostome invertebrates, and their position within this
phylogenetic lineage provides a unique view point to study the evolution of immunological
responses. These animals can live up to 100 years [1] and are abundant in the marine
environment. Sea urchins also have a large number of blood cells (coelomocytes), and can
survive multiple rounds of immunological challenge and collection of coelomic fluid,
permitting long-term challenge experiments. As such, sea urchins are ideal model
organisms for the study of early deuterostome immune responses.
Coelomocytes populate the coelomic fluid and fulfil many functions, including
protection of the viscera and cellular immunity [2]. In S. purpuratus there are between
1×106-5×106 coelomocytes per mL of coelomic fluid. About two thirds of these cells are
actively phagocytic [3, 4]. Other cell types carry out antibacterial, cytotoxic and clotting
functions [5]. Coelomocytes clear bacteria from the coelomic fluid with high efficiency [6,
7]. In vitro, phagocytes undergo substantial morphological transformations in response to
the presence of bacteria, and red spherule cells release a bactericidal agent, echinochrome
A [8]. Both transcriptome and protein studies have revealed the activation of numerous
immune-related genes in coelomocytes that are similar to those of vertebrates in response
to the injection of lipopolysaccharide (LPS). These immune response genes and proteins
include complement component C3, complement factor Bf and profilin homologues [3, 4,
9, 10].
Recently, the sea urchin genome sequencing project revealed the presence of an
elaborate repertoire of genes associated with immunity, most of which are closely related
to those of vertebrates. It also showed that the size of many immune response gene
families is greatly expanded in sea urchins relative to other deuterostomes [11]. The
pattern recognition receptors of sea urchins include 222 Toll-like receptor genes, 203

119
NACHT and leucine rich repeat containing (NLR) genes, 1095 SRCR domains distributed
among 218 gene models, and 46 genes containing fibrinogen domains [12]. Sea urchins
also express 185/333 genes, which appear to be restricted to echinoderms. 185/333 genes
constitute an additional family of highly variable immune response genes [13]. Overall, the
genome sequence predicted a complex immune system in sea urchins.
In the present study, we used proteomics to assess changes in protein abundances
after injecting saline or bacteria into sea urchins. Alterations in the cellular responses of
coelomocytes to the injection of bacteria were examined using a comparative two-
dimensional electrophoresis (2DE) approach. We observed substantial differences in
protein concentrations in response to the injection of saline and Vibrio sp. The identities of
15 proteins involved in these responses were determined by mass spectrometry, and the
potential functions of these proteins are discussed in detail.

120
3.4. Materials and Methods
3.4.1. Sea urchins
H. erythrogramma were collected from Camp Cove in Sydney Harbour. They were
housed in a recirculating sea water facility at Macquarie University as described previously
[14]. The sea urchins were left undisturbed in the aquaria for 12 months. Previous work
has shown that sea urchins become immunoquiescent after long-term housing of greater
than 8 months without significant disturbance [5, 14]. Immunoquiescence can be reversed
by injecting microbes, or in response to injury [14-16].
3.4.2. Immunological challenge and sample collection
Three sea urchins were injected with 500 µL of heat killed Vibrio sp. (VPSYS2; EF
S84094; OD600nm = 0.5 [17]) in sterile artificial CF (aCF; [18]). Three more animals
were injected with 500 µL of aCF, and a further three non-injected control animals were
left unchallenged. Injections were made by inserting a 23-gauge needle attached to a 1 mL
syringe through the peristomium into the coelomic cavity. Previous studies have shown
that microbial challenges elevate gene expression levels within 24 hours [13, 19]. To
mimic these conditions, the 12 sea urchins were left undisturbed for 20 hours after
injection before CF (approx 15 mL per animal) was withdrawn by dissecting the oral face.
3.4.3. Protein extraction
The CF was immediately mixed with an equal volume of calcium-magnesium-free
sea water with EDTA and imidazole (CMFSW-EI; 10 mM KCl, 7 mM Na2SO4, 2.4 mM
NaHCO3, 460 mM NaCl, 70 mM EDTA and 50 mM imidazole, pH 7.4) on ice to prevent

121
clotting, and centrifuged at 12000 × g for 2 minutes. The cell free CF was discarded and
the pellet of cells was resuspended in 700 µl of TriReagent (Sigma Aldrich). The
suspension was vortexed for 10 minutes before adding 70 µl of 1-bromo-3-chloropropane
(BCP). The solution was then held at room temperature for 10-15 minutes and centrifuged
at 12000 × g for 15 minutes at 4°C. The phenol chloroform phase was extracted and mixed
with 3 volumes of acetone and 200 µl of ethanol before centrifugation at 12000 × g for 10
minutes at 4°C. The supernatant was discarded and the protein pellet was resuspended in
phosphate buffered saline (PBS; 8.06 mM sodium phosphate, 1.94 mM potassium
phosphate, 2.7 mM KCl and 0.137 M NaCl, pH7.4). Re-suspended proteins were stored (-
80°C ) for further analysis.
3.4.4. Two-dimensional gel electrophoresis
The proteins were prepared for 2DE electrophoresis using 2D clean up kits (GE
Healthcare) according to the manufacturer’s instructions and were re-suspended in 2DE
sample buffer (8 M urea, 4% CHAPS, 60 mM dithiothreitol [DTT]). The total protein
content of each sample was determined with 2-D Quant kits (GE Healthcare).
Isoelectrofocusing was performed on an IPGphor IEF system (Amersham Biosciences).
Immobilized pH gradients (IPG) gel strips (11 cm, pH 3-6 and pH 5-8, GE Healthcare)
were equilibrated overnight with 100 µg of CF proteins in a final volume of 200 µL of
rehydration buffer containing 0.5 % immobiline (8 M urea, 2% CHAPS, 50 mM DTT and
0.5% carrier ampholytes; Immobiline GE Healthcare). Isoelectrofocusing was performed at
20°C in four stages: calibration (100 V for 3 hours), active rehydration (300 V for 1 hours),
a voltage ramping (up to 8000 V for 8 hours), and focusing (8000 V for 11.5 hours), to
obtain a total of 120-130,000 Vh. The current was limited to 45 µA per strip. After
isoelectric focusing, the IPG strips were reduced (1% DTT, 15 minutes) and alkylated

122
(2.5% iodoacetamide, IAA, 15 minutes) before separation in the second dimension by
SDS-PAGE. The proteins on the IPG strips were separated in the second dimension by
SDS-PAGE using 8-16% Tris-HCl precast polyacrylamide gels (Criterion Gel System,
BioRad). After electrophoresis, protein spots on the gels were visualized with Lava Purple
(also known as Deep Purple; FLUOROtechnics, GE-Healthcare) [20].
3.4.5. Gel analysis and selection of protein spots for mass spectrometry analysis
Digital gel images (Typhoon UV scanner) were analysed using Progenesis (Non-
Linear Dynamics). Spot detection and background subtraction were performed on all gel
images. Artefacts (dust particles or streaks) were removed by manual editing. Where
appropriate, spots were split manually into separate entities. A total of 385 protein spots
were identified. The gel images were then analysed for differences in spot intensity. A
normalization procedure was employed to allow for variation in total protein loading onto
different gels. Total spot volume was calculated for each gel and each spot was ascribed a
normalized spot volume as a proportion of this total value. Log2 normalized spot volumes
were then used to compare all spots present on all 12 sea urchin proteome maps in each of
the isoelectric point ranges (pI 3-6 and 5-8). We then performed a principal component
analysis (PCA) using XL stat 2009 to identify global proteome changes in response to
challenge. T tests (p<0.05) were employed to identify significant differences in the relative
abundance of individual proteins between treatments (non-injected, saline-injected and
bacteria-injected).

123
3.4.6. Peptide extraction
Proteins that differed significantly in relative abundance between treatments (T test,
p<0.05) were excised from 2DE gels and transferred to sterile Eppendorf tubes. The gel
pieces were washed briefly with 100 mM ammonium carbonate (NH4HCO3) and de-
stained in a solution of 25 mM NH4HCO3, and 50% acetonitrile (ACN) for 3 times for 10
minutes, before being dehydrated with 100% ACN for 5 minutes. The solution was
discarded and the gel pieces air-dried. After de-staining, the proteins were reduced with 10
mM DTT in 100 mM NH4HCO3 for 45-60 minutes at 56°C and alkylated with 55 mM IAA
in 100 mM NH4HCO3 for 45 minutes in the dark at room temperature. The gel pieces were
washed again with 100 mM NH4HCO3 for 5 minutes, then twice with 25 mM NH4HCO3,
50% ACN for 5 minutes, before being dehydrated with 100% ACN as above. They were
then left to air dry before rehydration in trypsin solution (12.5 ng/µl in 50 mM NH4HCO3,
Promega, WI.) for 30 minutes at 4°C. Additional 50 mM NH4HCO3 was added and the
proteins were digested at 37ºC overnight. The resulting tryptic peptides were extracted
from the gel slices by washing 2 times with 2% formic acid in 50% acetonitrile. The
extracts were combined and concentrated to 10 µl by vacuum centrifugation.
3.4.7. Nanoflow liquid chromatography – tandem mass spectrometry
Mass spectrometric analyses were performed at the Australian Proteome Analysis
Facility (APAF; Macquarie University). The tryptic digest extracts from 2DE gel slices
were analyzed by nanoLC-MS/MS using a LTQ-XL ion-trap mass spectrometer (Thermo
Dynamics) according to Breci et al. [21]. Reversed phase columns were packed in-house
to approximately 7 cm (100 µm i.d.) using 100 Å, 5 mM Zorbax C18 resin (Agilent
Technologies) in a fused silica capillary with an integrated electrospray tip. A 1.8 kV

124
electrospray voltage was applied via a liquid junction up-stream of the C18 column.
Samples were injected onto the C18 column using a Surveyor autosampler (Thermo
Dynamics). Each sample was loaded onto the C18 column followed by an initial wash
step with buffer A (5% (v/v) ACN, 0.1% (v/v) formic acid) for 10 minutes at 1 µL min-1.
Peptides were subsequently eluted from the C18 column with 0%-50% Buffer B (95%
(v/v) ACN, 0.1% (v/v) formic acid) over 58 minutes at 500 nL min-1 followed by 50%-
95% Buffer B over 5 minutes at 500 nL min-1. The column eluate was directed into a
nanospray ionization source of the mass spectrometer. Spectra were scanned over the
range 400–1500 amu. Automated peak recognition, dynamic exclusion, and tandem MS of
the top six most intense precursor ions at 35% normalization collision energy were
performed using the Xcalibur software (version 2.06) (Thermo Dynamics).
3.4.8. Protein identification
Raw files were converted to mzXML format and processed through Global
Proteome Machine (GPM) software using version 2.1.1 of the X!Tandem algorithm
(www.thegpm.org) [22, 23]. MS/MS spectra were searched against a combined
Strongylocentrotus database created with sequences downloaded from NCBI. This
FASTA format database contained 44,037 protein sequences comprising all S. purpuratus
predicted protein sequences and characterized proteins held by NCBI as of April 2008.
The database also incorporated a list of common human and trypsin peptide contaminants.
Search parameters included MS and MS/MS tolerances of ± 2 Da and ± 0.2 Da, tolerance
of up to 3 missed tryptic cleavages and K/R-P cleavages. Fixed modifications were set for
carbamidomethylation of cysteine and variable modifications were set for oxidation of
methionine.

125
3.5. Results
A total of 384 protein spots were identified, of which 166 spots were detected on 2DE gels
using pI 3-6 strips and 268 spots were present on 2DE gels in the pI 5-8 range. We initially
investigated the effect of saline and bacteria injections by principal components analysis. A
first step was to define the number of principal components (PC) to extract. A screeplot
was generated to determine if a clear break point was present (Figure 3.1A). The Eigen
values in Figure 3.1A correspond to the proportion of variance for each PC, while the
upper line shows the cumulative variance explained by the 8 components. The PCs were
sorted in decreasing order of variance so that the most representative PCs were listed first.
In this dataset, the first three PCs explained more of the variance in the data (31.3%, 17.7%
and 15.4% respectively) than all subsequent PCs. These three first PCs accounted for 64%
of the total variance (Figure 3.1A). Figure 3.1B shows a 3D score plot obtained using these
three PCs. In this plot, sea urchin samples with similar protein abundance profiles appear
closer in space, whereas significantly different samples appear more distant from each
other. Samples from saline-injected and bacteria-injected sea urchins clustered together
with high PC1 values, and low PC2 and PC3 values. In contrast, samples from non-
injected sea urchins all had low PC1 values and variable PC2 and PC3 values. Thus, PC1
was deemed to represent variations in the proteome due to the wound produced by the
needle during the injection, the injection of aCF, and/or the increase in CF volume
resulting from injection.

126
Figure 3.1: Principal components analysis of proteome profiles after the injection of
saline or bacteria. A/ Screeplot showing the Eigen values (proportion of variance) for
each principal component (PC; histogram) and the cumulative proportion of variances
(curve) explained by consecutive principal components. B/ 3D score plot using the first
three PCs shown in A. The Figure shows cumulative data for all of the protein spots
observed on 2DE gels from the CF of sea urchins non-injected, saline-injected and
bacteria-injected.
0
20
40
60
80
100
0
0.5
1
1.5
2
2.5
3
PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8
Cu
mu
lative
va
ria
bili
ty (
%)
Eig
en
va
lue
Axis
Axis X = PC1 Axis Y = PC3
Axis Z = PC2
!
!
Non injected
Saline injected
Bacteria injected
PC1
PC3
PC2
!"
#"

127
The analysis of individual proteins on 2DE maps of saline-injected sea urchins
revealed 24 proteins with differential concentrations relative to non-injected controls,
whereas 42 proteins were altered in response to the injection of bacteria (Figure 3.2).
Seventeen spots corresponding to the most abundant of these differentially regulated
proteins were excised from the gels and subjected to in-gel trypsin digestion and MS
analysis (Figure 3.3). For 12 of these spots, at least two unique peptide matches to the
same protein in the S. purpuratus database were discerned (Table 3.1, Supplementary Data
3.1, Figure 3.3) so that identities could be assigned to these proteins. In the case of spot 4,
which was less abundant in response to saline and bacterial injection (Figure 3.4), two
different matches were obtained with high confidence for the same spot (Table 3.1,
Supplementary Data 3.1). One match corresponded to cytoskeletal actin CyIIb
(gi47551037), whilst the second was to a succinate CoA ligase (gi115975381). It is likely
that the match to CyIIb came from contamination from the neighboring spot 3. All of the
spots in proximity to spot 3 (spots 1, 2, 4, 7), had peptides matching CyIIb. Cytoskeletal
actin CyIIb (spot 3; gi47551037) was the most abundant protein in all samples.
PCA suggested that the most substantial alterations to the proteome were similar
after saline and bacterial injections. Of these proteins, which are putatively involved in
wounding responses, 10 protein spots were extracted and 6 proteins were identified. Most
of these proteins decreased in abundance in response to wounding. These included proteins
similar to vacuolar (V-type) H(+)-ATPase B subunit isoform 1 (spot 1; gi115935893) and
JIA crystalline, ADP-ribosylglycohydrolase (spot 16; gi115955510), a putative 14-3-3
epsilon isoform (spot 8; gi160623362) and a potential carbonic anhydrase alpha (spot 17;
gi115926884). The proteins that increased equally in abundance after both saline and
bacteria injection included a cytosolic malate dehydrogenase (spot 12; gi115680328) and a
protein similar to a heterotrimeric guanine nucleotide binding protein beta subunit (spot
13; gi115936805).

128
Figure 3.2: Number of 2DE spots that varied significantly in abundance after saline
and bacterial injections, as determined by quantitative analysis of Lava Purple
stained 2DE gels. This Venn Diagram shows the number of proteins that differed
significantly between treatments (T test, p<0.05); non-injected controls versus saline-
injected (C vs S), saline-injected versus bacteria-injected (S vs B) and non-injected
controls versus bacteria-injected (C vs B).
!"
#"$"
%"&'"&#"
!("
!"#$"%" %"#$"&"
!"#$"&"

129
Figure 3.3: Lava Purple stained 2DE maps of CF proteins following Vibrio Sp.
injection. One hundred micrograms of proteins were loaded on 2DE gels (IEF on pH 3-6,
top, and 5-8, bottom, 11 cm IPG strips followed by 8-16% SDS-Page). Spot detection was
performed using Lava Purple staining. Labeled spots were analysed by quantitative
Progenesis analysis to identify proteins that vary significantly in relative abundance (T test,
p<0.05) after saline or bacterial injection. Those 17 spots were extracted for identification
by mass spectrometry.
2
1
7
4
5
6
8 9
10
3 6
11
12 13 14
15
16 17
8 5
8-1
6%
SD
S-P
AG
E
8-1
6%
SD
S-P
AG
E
pI
pI
3

130
Log 2
nor
mal
ized
vol
umes

131
Figure 3.4: Log2 normalized volumes of differentially regulated protein spots. Spot
numbers correspond to those allocated in Figure 3.3 and Table 3.1. NI: non-injected; S:
saline injection; B: bacterial injection. The letters a, b and c indicate significantly different
log2 normalized volumes between treatments (T test, P<0.05). Like letters are not
significantly different (T test, P<0.05). Bars = SEM, n = 3.
Table 3.1: Protein identification of 2DE gel spots from Figure 3.4. The Genbank
accession numbers of the identified proteins are shown. Matching peptides are detailed in
Supplementary Data 3.1. Parameter definitions are: log(e), the probability that a protein
match arises stochastically. The lower the log(e) value, the more significant the protein
identification. %, percentage of coverage of the sequence. #, number of unique peptides
identified. Total, total number of peptide sequences corresponding to a mass spectrum. Mr,
predicted molecular weight of the protein.
Ref. Spot
GenBank Accession
No. Description log(e) % # Total Mr 1 gi115935893 PREDICTED: similar to vacuolar (V-type) H(+)-
ATPase B subunit isoform 1 -254.3 40 19 55 54.1
2 gi115945943 PREDICTED: similar to ENSANGP00000011972 (rab GDP dissociation inhibitor)
-53.7 15 6 10 49
3 gi47551037 cytoskeletal actin CyIIb -144 27 12 28 41.8 4 gi47551037 cytoskeletal actin CyIIb -124.6 26 11 22 41.8 gi115975381 PREDICTED: hypothetical protein (succinate CoA
ligase, ADP forming, beta subunit) -109.3 23 9 16 49
5 gi115956476 PREDICTED: similar to apextrin -121 17 14 65 49.5 6 gi47550939 calreticulin -210.2 28 19 36 48.8 8 gi160623362 putative 14-3-3 epsilon isoform -26.6 15 3 4 24.1 11 gi115972829 PREDICTED: similar to glucose-6-phosphate
isomerase -98.8 23 10 21 60.1
12 gi115680328 PREDICTED: similar to cytosolic malate dehydrogenase
-67.7 13 7 18 36.2
13 gi115936805 PREDICTED: similar to heterotrimeric guanine nucleotide-binding protein beta subunit isoform 2
-102.2 21 9 23 37.5
16 gi115955510 PREDICTED: similar to J1A crystallin (ADP-ribosylglycohydrolase)
-141.5 16 12 31 33.9
17 gi115926884 PREDICTED: similar to CG7820-PA (carbonic anhydrase alpha)
-55.8 13 6 9 29.7

132
Figure 3.5: Selected areas of 2DE maps showing proteins (spots 5 and 6) with
abundances that differed significantly (p<0.05) in response to the injection of bacteria
when compared to both non-injected controls and saline-injected sea urchins.

133
In addition to the major shift in protein abundances in response to wounding, 42
proteins had significantly altered abundance in bacteria-injected samples when compared
to either non-injected controls or saline-injected sea urchins. Of these, 7 had significantly
different concentrations compared with both non-injected and saline-injected samples.
Among the proteins identified by mass spectrometry, a molecule similar to Rab GDP
dissociation inhibitor (spot 2; GDI; gi115945943) and another similar to glucose-6-
phosphate isomerase (spot 11; gi115972829) had significantly (p<0.05) reduced
concentrations in presence of bacteria relative to the other treatments. However, other
proteins that were low in abundance or absent in unchallenged sea urchins and after saline
injection, were more abundant after the injection of bacteria. These included spots 5 and 6
shown in Figure 3.5, which were significantly more abundant in response to bacterial
injection. These two proteins matched apextrin (spot 5; gi115956476) and calreticulin
(spot 6; gi47550939).

134
3.6. Discussion
This study employed a 2DE based comparative proteomic analysis to identify
proteins involved in the response of sea urchin coelomocytes to the injection of bacteria. It
identified two discrete components within the host defense responses of sea urchins,
reflecting different pathways involved in the responses to wounding and bacterial
injection.
Injection alone induced a consistent response among all sea urchins regardless of the
presence or absence of bacteria. Numerous proteins varied in concentration after injection,
which resulted in a major shift in the first principal component when proteomes were
compared by PCA. This shift seemed to include a significant modification of energy
metabolism towards the consumption of glutamate and the production of NADPH
necessary for the production of free radicals such as O-2 or NO [13, 24, 25]. This is
reflected by the significant alteration in abundance of a vacuolar H(+)-ATPase and a
protein similar to cytosolic malate dehydrogenase. Proteins altered by wounding also
included those involved in cell signalling, which could ultimately regulate various cell
functions, including antimicrobial activity, wound healing, and actin restructuring [24-26].
These signalling molecules included a ADP-ribosylglycohydrolase, a putative 14-3-3
epsilon isoform, and a heterotrimeric guanine nucleotide binding protein. The changes
evident in the concentration of these proteins might reflect major cytoskeletal and
functional modification of coelomocytes, allowing the recruitement of coelomocytes to the
site of injury for wound repair [29-31].
In addition to this wounding response, the injection of bacteria, as opposed to just
saline, induced discrete modifications in coelomocyte proteome. The more substantial
decrease in glucose-6-phosphate isomerase after bacterial injection supports the previously
implied shift in metabolism towards the production of NADPH, which may be essential for

135
phagocytosis. The abundance of Rab GDP dissociation inhibitor was also altered more
substantially by bacterial injection, compared to saline. GDI regulates vesicular transport
through interaction with Rab GTPase and is necessary for phagocytosis. These changes
detected in both glucose-6-phosphate isomerase and Rab GDP dissociation inhibitor
suggest that the presence of bacteria triggers additional cellular pathways involved in
phagocytosis.
Two proteins (apextrin and calreticulin) that were absent or in very low abundance in
non-injected controls or saline-injected animals were substantially up-regulated in the
presence of bacteria. This suggests that they both have important functions in the
sequestration or neutralization of pathogens. Apextrin has been described as a membrane
attack complex/perforin domain (MAC/PF) protein [27, 28]. However, it is not yet known
whether this protein has any lytic activity. Apextrin was initially identified in secretory
vesicles within sea urchin eggs and is involved in cell adhesion during embryonic
development [29]. Interestingly, the expression of apextrin is also induced during acute
immune responses of the protochordate, Amphioxus [30]. As many as 56 unique sequences
of proteins similar to apextrin have been recorded on NCBI for S. purpuratus alone,
suggesting that this protein might be involved in a range of functions including embryonic
development [29] and neutralization of pathogens [30].
The significant increase in calreticulin suggests that calcium regulation also plays an
important role during bacterially induce processes. Calreticulin is an important
multifunctional calcium (Ca2+)-binding protein involved in the regulation of intracellular
Ca2+ homeostasis and endoplasmic reticulum (ER) Ca2+ storage [31]. Its increase in
abundance supports previous studies, which showed the importance of calcium signalling
in immune cells [32, 33]. Calreticulin is a multifunctional protein and might also be
involved at other levels of the immune response process. Human calreticulin is expressed
on the surface of activated T lymphocytes in association with MHC molecules [34], and is

136
released from lytic granules with perforins [35]. This supports previous studies that
demonstrated the calcium dependent antibacterial and cytotoxic activity of sea urchins
coelomocytes [36].
Despite our ability to identify a range of proteins involved in apparently discrete
responses to wounding and the presence of bacteria, the current study was limited to
assessing just a single time point after challenge. We are now using more high throughput
proteomic techniques to investigate a broader time scale during sea urchin immune
responses.

137
3.7. References
[1] Ebert, T. A., Southon, J. R., Red sea urchins (Strongylocentrotus franciscanus) can live
over 100 years: confirmation with A-bomb 14 carbon. Fish bulletin (Sacramento,
Calif.) 2003, 101, 915.
[2] Chia, F. S., Xing, J., Echinoderm coelomocytes. Zoological studies 1996, 35, 231-254.
[3] Smith, L., Britten, R., Davidson, E., Lipopolysaccharide activates the sea urchin
immune system. Dev Comp Immunol 1995, 19, 217-224.
[4] Smith, L., Britten, R., Davidson, E., SpCoel1: a sea urchin profilin gene expressed
specifically in coelomocytes in response to injury. Mol Biol Cell 1992, 3, 403-414.
[5] Gross, P. S., Al-Sharif, W. Z., Clow, L. A., Smith, L. C., Echinoderm immunity and the
evolution of the complement system. Dev Comp Immunol 1999, 23, 429-442.
[6] Gerardi, G., Lassegues, M., Canicatti, C., Cellular distribution of sea urchin
antibacterial activity. Biol. Cell. 1990, 70, 153-157.
[7] Stabili, L., Pagliara, M., Metrangolo, M., Canicatti, C., Comparative aspects of
Echinoidea cytolysins: the cytolytic activity of Spherechinus granularis
(Echinoidea) coelomic fluid. Comp. Biochem. Physiol. 1992, 101A, 553-556.
[8] Service, M., Wardlaw, A., Echinochrome-A as a bactericidal substance in the coelomic
fluid of Echinus esculentus (L.). Comp Biochem Physiol B Biochem Mol Biol 1984,
79, 161-165.
[9] Al-Sharif, W. Z., Sunyer, J. O., Lambris, J. D., Smith, L. C., Sea urchin coelomocytes
specifically express a homologue of the complement component C3. J Immunol
1998, 160, 2983-2997.
[10] Smith, L. C., Shih, C.-S., Dachenhausen, S. G., Coelomocytes express SpBf, a
homologue of factor B, the second component in the sea urchin complement
system. J Immunol 1998, 161, 6784-6793.

138
[11] Rast, J. P., Smith, L. C., Loza-Coll, M., Hibino, T., Litman, G. W., Genomic insights
into the immune system of the sea urchin. Science 2006, 314, 952-956.
[12] Hibino, T., Loza-Coll, M., Messier, C., Majeske, A., et al., The immune gene
repertoire encoded in the purple sea urchin genome. Dev Biol 2006, 300, 349-365.
[13] Nair, S. V., Del Valle, H., Gross, P. S., Terwilliger, D. P., Smith, L. C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin.
Identification of unexpected immune diversity in an invertebrate. Physiol Genomics
2005, 22, 33-47.
[14] Clow, L. A., Gross, P. S., Shih, C.-S., Smith, L. C., Expression of SpC3, the sea
urchin complement component, in response to lipopolysaccharide. Immunogenetics
2000, 51, 1021-1033.
[15] Gross, P. S., Clow, L. A., Smith, L. C., SpC3, the complement homologue from the
purple sea urchin, Strongylocentrotus purpuratus, is expressed in two
subpopulations of the phagocytic coelomocytes. Immunogenetics 2000, 51, 1034-
1044.
[16] Clow, L. A., Raftos, D. A., Gross, P. S., Smith, L. C., The sea urchin complement
homologue, SpC3, functions as an opsonin. J Exp Biol 2004, 207, 2147-2155.
[17] Wilson, G. S., Raftos, D. A., Corrigan, S. L., Nair, S. V., Diversity and antimicrobial
activities of surface-attached marine bacteria from Sydney Harbour, Australia.
Microbiol Res 2009. In Press.
[18] Terwilliger, D., Buckley, K., Brockton, V., Ritter, N., Smith, L. C., Distinctive
expression patterns of 185/333 genes in the purple sea urchin, Strongylocentrotus
purpuratus: an unexpectedly diverse family of transcripts in response to LPS, beta-
1,3-glucan, and dsRNA. BMC Mol Biol 2007, 8, 16.
[19] Smith, L., Chang, L., Britten, R., Davidson, E., Sea urchin genes expressed in
activated coelomocytes are identified by expressed sequence tags. Complement

139
homologues and other putative immune response genes suggest immune system
homology within the deuterostomes. J Immunol 1996, 156, 593-602.
[20] Ball, M. S., Karuso, P., Mass spectral compatibility of four proteomics stains. J
Proteome Res 2007, 6, 4313-4320.
[21] Breci, L., Hattrup, E., Keeler, M., Letarte, J., et al., Comprehensive proteomics in
yeast using chromatographic fractionation, gas phase fractionation, protein gel
electrophoresis, and isoelectric focusing. Proteomics 2005, 5, 2018-2028.
[22] Haynes, P. A., Miller, S., Radabaugh, T., Galligan, M., et al., The wildcat toolbox: a
set of perl script utilities for use in peptide mass spectral database searching and
proteomics experiments. J Biomol Tech 2008, 17, 97-102.
[23] Rohrbough, J. G., Breci, L., Merchant, N., Miller, S., Haynes, P. A., Verification of
single-peptide protein identifications by the application of complementary database
search algorithms. J Biomol Tech 2006, 17, 327-332.
[24] Corda, D., Di Girolamo, M., Mono-ADP-Ribosylation: a tool for modulating immune
response and cell signaling. Sci. STKE 2002, 2002, 53.
[25] Roberts, M. R., de Bruxelles, G. L., Plant 14-3-3 protein families: evidence for
isoform-specific functions? Biochem. Soc. Trans. 2002, 30, 373-378.
[26] Hamm, H. E., The many faces of G protein signaling. J Biol Chem 1998, 273, 669-
672.
[27] Miller, D., Hemmrich, G., Ball, E., Hayward, D., et al., The innate immune repertoire
in cnidaria-ancestral complexity and stochastic gene loss. Genome Biology 2007, 8,
R59.
[28] Rosado, C. J., Kondos, S., Bull, T. E., Kuiper, M. J., et al., The MACPF/CDC family
of pore-forming toxins. Cell Microbiol 2008, 10, 1765-1774.

140
[29] Haag, E. S., Sly, B. J., Andrews, M. E., Raff, R. A., Apextrin, a novel extracellular
protein associated with larval ectoderm evolution in Heliocidaris erythrogramma.
Dev Biol 1999, 211, 77-87.
[30] Huang, G., Liu, H., Han, Y., Fan, L., et al., Profile of acute immune response in
Chinese amphioxus upon Staphylococcus aureus and Vibrio parahaemolyticus
infection. Dev Comp Immunol 2007, 31, 1013-1023.
[31] Gelebart, P., Opas, M., Michalak, M., Calreticulin, a Ca2+-binding chaperone of the
endoplasmic reticulum. The International Journal of Biochemistry & Cell Biology
2005, 37, 260-266.
[32] Berridge, M. J., Lipp, P., Bootman, M. D., The versatility and universality of calcium
signalling. Nat Rev Mol Cell Biol 2000, 1, 11-21.
[33] Oh-hora, M., Rao, A., Calcium signaling in lymphocytes. Current Opinion in
Immunology 2008, 20, 250-258.
[34] Arosa, F. A., de Jesus, O., Porto, G., Carmo, A. M., de Sousa, M., Calreticulin is
expressed on the cell surface of activated human peripheral blood T lymphocytes in
association with major histocompatibility complex class I molecules. J Biol Chem
1999, 274, 16917-16922.
[35] Dupuis, M., Schaerer, E., Krause, K., Tschopp, J., The calcium-binding protein
calreticulin is a major constituent of lytic granules in cytolytic T lymphocytes. J
Exp Med 1993, 177, 1-7.
[36] Haug, T., Kjuul, A. K., Styrvold, O. B., Sandsdalen, E., et al., Antibacterial activity in
Strongylocentrotus droebachiensis (Echinoidea), Cucumaria frondosa
(Holothuroidea), and Asterias rubens (Asteroidea). J Invertebr Pathol 2002, 81, 94-
102.

141
Supplementary Data 3.1: Mass spectrometric (LC-MS/MS) data for protein spots
isolated from 2DE gels. The Genbank accession numbers of the identified proteins are
shown. The amino acid sequences shown are the matching peptides. Parameter definitions
are: log(e), the probability that a putative peptide sequence corresponding to a mass
spectrum arises stochastically. The lower the log(e) value, the more significant the
assignment of the peptide sequence to the mass spectrum. m + h, peptide mass in Da + 1. z,
peptide charge.
142
Ref.
Spot
GenBank
Accessio
n N
o.
Description
log(e
)m
+h
zPeptide s
equences
1gi1
15935893
PRED
ICTED
: sim
ilar
to v
acuola
r (V
-type)
H(+
)-
ATPase B
subunit isofo
rm 1
-2.7
1197
2[me 3 AAKEHTLAVTR 13 nyit
-4.3
1665
2kfpk 44 FAEIVTLTNDGSKR 58 sgqv
-1.3
1317
2kfae 47 IVTLTNDGSKR 58 sgqv
-7.4
2928
3sgtt 70 AVVQVFEGTSGIDAKNTTCEFTGDILR 96 mpvs
-6.7
1521
2sgtt 70 AVVQVFEGTSGIDAK 84 nttc
-5.4
2574
3idak 85 NTTCEFTGDILRMPVSEDMLGR 106 vfng
-4.5
1427
2idak 85 NTTCEFTGDILR 96 mpvs
-11857
3dilr 97 MPVSEDMLGRVFNGSGK 113 aidk
-4.8
1151
2dilr 97 MPVSEDMLGR 106 vfng
-14
2451
2pqsr 140 IYPEEMIQTGISAIDVMNSIAR 161 gqki
-5.3
2492
3siar 162 GQKIPIFSAA GLPHNEIAAQICR 184 qagl
-12.6
2178
2rgqk 165 IPIFSAAGLPHNEIAAQICR 184 qagl
-5.4
1728
3itpr 254 LALTAAEFLAYQCEK 268 hvlv
-1.5
1456
2ealr 286 EVSAAREEVPGRR 298 gfpg
-8.6
1897
2pgrr 299 GFPGYMYTDLATIYER 314 agrv
-4.4
1597
2ldsr 364 QIYPPINVLPSLSR 377 lmks
-17
2679
3dmtr 390 KDHADVSNQLYANYAIGKDVQAMK 413 avvg
-5.2
2007
3dmtr 390 KDHADVSNQLYANYAIGK 407 dvqa
-5.9
1356
2kfek 438 NFITQGNYENR 448 svfe
2gi1
15945943
PRED
ICTED
: sim
ilar
to E
NSAN
GP00000011972 (
rab
GD
P d
issocia
tion inhib
itor)
-2.2
1313
2smgr 70 GRDWNVDLIPK 80 flma
-1.7
1336
3ktir 207 RIKLYSESLAR 217 ygks
-1.3
1180
2tirr 208 IKLYSESLAR 217 ygks
-5.2
2523
3slar 218 YGKSPYLYPMYGLGELPQGFAR 239 lsai
-8.9
1448
2gfar 240 LSAIYGGTYMLDK 252 pide
-1.2
1748
2mldk 253 PIDEITMEDGKVTGVK 268 sgge
3gi4
7551037
cyto
skele
tal actin C
yII
b-1
1.8
1761
2[mc 3 DDDVAALVIDNGSGMVK 19 agfa
-5.2
2156
3gmvk 20 AGFAGDDAPRAVFPSIVGRPR 40 hqgv
-2.7
976.4
1gmvk 20 AGFAGDDAPR 29 acfp
-1.7
881.5
2ravf 33 PSIVGRPR 40 hqgv
-3.7
2540
3grpr 41 HQGVMVGMGQKDSYVGDEAQSKR 63 gilt

143
Ref.
Spot
GenBank
Accessio
n N
o.
Description
log(e
)m
+h
zPeptide s
equences
-92383
3grpr 41 HQGVMVGMGQKDSYVGDEAQSK 62 rgil
-3.8
1204
2grpr 41 HQGVMVGMGQK 51 dsyv
-4.3
1355
2mgqk 52 DSYCGDEAQSKR 63 gilt
-6.1
1199
2mgqk 52 DSYVGDEAQSK 62 rgil
-6.8
1954
2nelr 97 VAPEEHPVLLTEAPLNPK 114 anre
-11.2
1791
2slek 240 SYELPDGQVITIGNER 255 frap
-1.3
1575
3iadr 314 MQKEITALAPPTMK 327 ikii
4gi4
7551037
cyto
skele
tal actin C
yII
b-5
.11777
2[mc 3 DDDVAALVIDNGSGMVK 19 agfa
-5.1
2156
3gmvk 20 AGFAGDDAPRAVFPSIVGRPR 40 hqgv
-2.7
976.4
1gmvk 20 AGFAGDDAPR 29 avfp
-1.4
881.5
2ravf 33 PDIVGRPR 40 hqgv
-6.6
2540
3grpr 41 HQGVMVGMGQKDSYVGDEAQSKR 63 gilt
-8.1
2384
3grpr 41 HQGVMVGMGQKDSYVGDEAQSK 62 rgil
-2.2
1188
2grpr 41 HQGVMVGMGQK 51 dsyv
-4.5
1355
2mgqk 52 DSYVGDEAQSKR 63 gilt
-9.1
1954
2nelr 97 VAPEEHPVLLTEAPLNPK 114 anre
-9.1
1791
2slek 240 SYELPDGQVITIGNER 255 frap
-1.2
1165
2ptmk 328 IKIIAPPERK 337 ysvw
gi1
15975381
PRED
ICTED
: hypoth
etical pro
tein
(succin
ate
CoA
ligase,
AD
P f
orm
ing,
beta
subunit)
-3.4
1623
2pipr 62 AEVATTAQRAYEIAK 76 slgs
-2.3
1713
3eiak 77 SLGSGDVVVKAGVLAGGR 94 gkga
-2.1
771.4
1vvvk 87 AQVLAGGR 94 gkga
-5.7
2093
2ggvk 109 LAFSPEEVKDLASQMIGNK 127 lvtk
-4.6
1339
2yvrr 154 EYYFAITMER 163 afng
-5.2
2125
3diik 326 LHGGTPANFLDVGGGATADQVK 347 qafk
-6.4
2724
3eaka 408 IIAHSDLRILACDDLDEAAKMVVR 431 lsti
-9.1
1819
2sdlr 416 ILACDDLDEAAKMVVR 431 lsti
-5.7
1334
2sdlr 416 ILACDDLDEAAK 427 mvvr
5gi1
15956476
PRED
ICTED
: sim
ilar
to a
pextr
in-1
.42261
2fcmk 88 TQSSLDGEAWPAGSYCIYKK 107 gdcp
-1.3
1187
1geaw 98 PAGSYCIYKK 107 gdcp
-2.3
1019
2awpa 100 GSYCIYKK 107 gdcp
-1.8
2829
3ciyk 107 KGDCPSGFQSGSIRWDDEDSANINR 131 eggt
-1.3
1337
2gsir 121 WDDEDSANINR 131 eggt

144
Ref.
Spot
GenBank
Accessio
n N
o.
Description
log(e
)m
+h
zPeptide s
equences
-1.3
2145
3sipk 166 ADRFMLLSRFDSCQQVR 182 gmtv
-1.3
1109
2slpk 166 ADRFMLLSR 174 fdsc
-1.3
1803
2kadr 169 FMLLSRFDSCQQVR 182 gmtv
-5.5
1255
2qqvr 183 GMTVTKEWFR 192 wdne
-21198
2qvrg 184 MTVTKEWFR 192 wdne
-2.2
1067
2rgmt 186 TVTKEWFR 192 wdne
-1.5
965.5
2rgmt 186 VTKEWFR 192 wdne
-2.3
1357
1srad 306 WPQGNYCIYR 315 wdgs
-3.7
1171
2radw 307 PQGNYCIYR 315 wdgs
6gi4
7550939
calreticulin
-1.2
1075
2vesv 40 HKGSDAGKFK 49 wsag
-1.6
799.4
2vesv 40 HKGSDAGK 47 fkws
-7.1
2767
3sagk 55 FYGDAEQDKGIQTSQDAKFYGLSAK 79 ftdf
-12.6
2001
2sagk 55 FYGDAEQDKGIQTSQDAK 72 fygl
-3.4
1072
2sagk 55 FYGDAEQDK 63 giqt
-1.5
829.3
1sagk 55 FYGDAEQ 61 dkgi
-2.6
1957
3daeq 62 DKGIQTSQDAKFYGLSAK 79 ftdf
-3.5
1191
2daeq 62 DKGIQTSQDAK 72 fygl
-7.3
1714
2eqdk 64 GIQTSQDAKFYGLSAK 79 ftdf
-3947.5
2eqdk 64 GIQTSQDAK 72 fygl
-1.6
785.4
1qdak 73 FYGLSAK 79 ftdf
-2.4
2234
3ftvk 98 HEQKIDCGGGYAKIFPADLD 117 qedm
-1.4
3584
3gyak 111 IFPADLDQEDMHGDSPYNIMFGPDICGPGTKK 142 vhvi
-4.1
1915
3pgtk 142 KVHVIFNYKGKNLLIK 157 kdir
-3.9
1334
3pgtk 142 KVHVIFNYKGK 152 nlli
-4.9
1205
3gtkk 143 VHVIFNYKGK 152 nlli
-3.7
1319
2pmin 267 NPEYKGEWAPK 277 kien
-3.6
1205
2minn 268 PEYKGEWAPK 277 kien
-10.4
1728
2nlys 307 YPSFGAIGFDLWQVK 321 sgti
8gi1
60623362
puta
tive 1
4-3
-3 e
psilon isofo
rm-1
.71204
2dvar 16 VNEELSVEER 25 nlls
-6.6
1518
2veer 26 NLLSVAYKNVIGAR 39 rasw
-5.3
1329
2dyhr 115 YLAEFSLDSKR 125 ksas

145
Ref.
Spot
GenBank
Accessio
n N
o.
Description
log(e
)m
+h
zPeptide s
equences
11
gi1
15972829
PRED
ICTED
: sim
ilar
to g
lucose-6
-phosphate
isom
era
se
-1.4
1561
3ardr 107 MFGGEKINFTEDR 119 avlh
-2.2
878.6
2tedr 120 AVLHVALR 127 nrsn
-1.8
866.5
1crvr 154 KFTESVR 160 sgew
-3.5
1083
2esvr 161 SGEWKGTSGK 170 aitd
-2.1
1658
3kgfs 169 GKAITDAVNIGIGGSDLG 186 pvmv
-9.8
1614
2iask 234 TFTTQETITNATSAK 248 nwfl
-5.4
1218
2hvak 264 HFVALSTNAEK 274 vsaf
-1.2
1827
3nffg 355 AETHALLPYDQYLHR 369 faay
-2.5
2228
3ylhr 370 FAAYFQQGDMESNGKYVTR 388 dgrr
-7.4
2164
3mtgk 463 TKEEAEKELVASGMSAENIK 482 lilp
12
gi1
15680328
PRED
ICTED
: sim
ilar
to c
yto
solic m
ala
te
dehydro
genase
-2.4
1590
3mprr 94 EGMERADLLKANVK 107 ifes
-4.8
1761
3gmer ADLLKANVKIFESQGQ 114 ains
-4.1
971.6
2gmer ADLLKANVK 107 ifes
-81221
2dllk 104 ANVKIFESQGQ 114 ains
-3.7
1921
3ktvk 126 VLVVGNPANTNCLVCMK 142 naps
-2.7
993.5
1ikar 239 KLSSAMSSAK 248 aicd
-1.3
865.4
1kark 240 LSSAMSAAK 248 aicd
13
gi1
15936805
PRED
ICTED
: sim
ilar
to h
ete
rotr
imeric g
uanin
e
nucle
otide-b
indin
g p
rote
in b
eta
subunit isofo
rm 2
-3.2
1011
2[m 2 ATELEHLR 9 hege
-8.8
2248
3rdar 24 KAVQDTTLMQVTQNMDPVGR 43 iqmr
-8.5
2681
3dark 25 AVQDTTLMQVTQNMDPVGRIQMR 47 trrt
-6.6
2120
3dark 25 AVQDTTLMQVTQNMDPVGR 43 iqmr
-4.6
2448
3lktr 131 EGNVRVSREL PGHTGYLSCCR 151 fidd
-2.2
1892
3gnvr 136 VSRELPGHTGYLSCCR 151 fidd
-2.3
1550
2rvsr 139 ELPGHTGYLSCCR 151 fidd
-81214
2pdnr 199 TFVSGACDASAK 210 twdi
-3.3
1010
2kger 306 AGVLAGHDNR 315 vscl
16
gi1
15955510
PRED
ICTED
: sim
ilar
to J
1A c
rysta
llin
(AD
P-
ribosylg
lycohydro
lase)
-1.2
1989
3pyyk 57 LPTGKNSAYGDHLYVLLK 74 svve
-7.1
1493
2ptgk 62 NSAYGDHLYVLLK 74 svve
-2.9
1379
2tgkn 63 SAYGDHLYVLLK 74 svve
-11.2
1876
2eavk 170 VVQNTPICIKYALTGAK 186 lleg

146
Ref.
Spot
GenBank
Accessio
n N
o.
Description
log(e
)m
+h
zPeptide s
equences
-5.5
1172
2eavk 170 VVQNTPICIK 179 yalt
-1.1
723.4
1icik 180 YALTGAK 186 lleg
-8.5
2242
3llak 301 VERGQEVKALAEQLVAMRQS 320 ]
-6.2
2044
3llak 301 VERGQEVKALAEQLVAMR 318 qs]
-9.5
1858
2kver 304 GQEVKALAEQLVAMRQS 320 ]
-3.3
1659
3kver 304 GQEVKALAEQLVAMR 318 qs]
-41334
2qevk 309 ALAEQLVAMRQS 320 ]
-5.2
1118
2qevk 309 ALAEQLVAMR 318 qs]
17
gi1
15926884
PRED
ICTED
: sim
ilar
to C
G7820-P
A (
carb
onic
anhydra
se a
lpha)
-2.7
1005
1kcdk 139 GIAVLGSFIK 148 vgkp
-11402
2pclk 165 KALNKNCTAPVEG 177 gfdp
-6.4
2759
3clkk 166 ALNKNVTAPVEGGFDPSCLLPENKK 190 dywt
-3.9
1331
2clkk 166 ALNKNVTAPVEGG 178 fdps
-5.5
1274
2clkk 166 ALNKNVTAPVEG 177 gfdp
-1.9
2334
3alnk 170 NCTAPVEGGFDPSCLLPENKK 190 dywt

147
CHAPTER IV
Time course proteomic profiling of cellular responses to immunological challenge in
sea urchins (Heliocidaris erythrogramma).
Submitted to
Molecular and Cellular Proteomics
Author contributions:
Haynes PA2 – Experimental design – Technical support
Raftos DA1 – Project supervision
Nair SV1 – Experimental design – Project supervision
1 Department of Biological Sciences, Macquarie University, North Ryde, NSW 2109, Australia
2 Department of Chemistry and Biomolecular Sciences, Macquarie University, North Ryde, NSW 2109,
Australia

148

149
4.1. Preface
The 2DE gel based analysis employed in Chapter 3 revealed major modifications of
the coelomic fluid proteome resulting from injection itself, but relatively few alterations
that were specifically due to the presence of bacteria. We hypothesised that more
substantial differences in protein abundances due to the injection of pathogens might occur
over a broader time course than that assessed in Chapter 3 (20 hours p.i.). In order to better
understand protein alterations due to wounding, and identify molecules specifically
involved in anti-pathogen responses, Chapter 4 is a time course study of the coelomocyte
proteome in response to the injection of a bacterial PAMP (LPS) or saline. In this case, we
used shotgun proteomics, which was successful in identifying and quantifying a broader
range of proteins (Chapter 2) than could be identified by 2DE.

150

151
4.2. Summary
Genome sequences and high diversity cDNA arrays have provided a detailed
molecular understanding of immune responses in a number of invertebrates, including sea
urchins. However, complementary analyses have not been undertaken at the level of
proteins. Here, we use shotgun proteomics to describe changes in the abundance of
proteins from coelomocytes of sea urchins after immunological challenge and wounding.
The relative abundances of 345 reproducibly identified proteins were measured 6, 24 and
48 hours after injection. Significant changes in the relative abundance of 188 proteins were
detected. These included pathogen-binding proteins, such as the complement component
C3 and scavenger receptor cysteine rich proteins, as well as proteins responsible for
cytoskeletal remodeling, endocytosis and intracellular signaling. An initial systemic
reaction to wounding was followed by a more specific response to immunological
challenge involving proteins such as apolipophorin, dual oxidase, fibrocystin L,
aminopeptidase N, and α-2-macroglobulin.

152
4.3. Introduction
The vertebrate immune system comprises both innate and immunoglobulin-based
adaptive components. Both systems work cooperatively to recognize and kill pathogens.
Invertebrates do not express immunoglobulin antibodies or TCR, but their innate immune
systems resemble that of vertebrates with similar effectors, receptors and regulation of
gene expression. Many molecules that were first identified in invertebrates, such as
Drosophila melanogaster Toll-like receptors, have homologues in humans that are now
recognized as critical components of innate immunity [1, 2].
Sea urchins are deuterostome invertebrates and as such, they are often more similar
to vertebrates than to other invertebrates [3]. Their phylogenetic position explains why
they have been extensively used as model organisms in studies of fertilization and
developmental biology. It was also the main motivation for sequencing the genome of the
purple sea urchin, Strongylocentrotus purpuratus [4]. Sea urchins possess a broad array of
immune response genes, including components of the alternative and lectin-mediated
complement pathways, a diverse array of Toll-like receptors, NOD/NALP-like cytoplasmic
recognition proteins, and a new family of highly variable immune response proteins (the
185/333 family) [5-7]. Homologues of the vertebrate recombination activating genes, Rag
1 and Rag 2, are also present in the genome but their function in sea urchins is unknown
[8].
Despite the extensive data at the genome level, there is relatively little information
available on the involvement of many of these newly discovered molecules in the inducible
immune responses of sea urchins. Coelomocytes, which are wandering amoeboid cells
within the coelomic cavity, are the primary mediators of immunological activity in sea
urchins. They are responsible for phagocytosis and encapsulation of foreign particles, as
well as other physiological activities, such as gas exchange and transport [9]. The current

153
study uses shotgun proteomics to identify proteins involved in inducible responses to the
bacterial antigen lipopolysaccharide (LPS), as well as reactions to sterile saline injection,
in coelomocytes of sea urchins. We employed an SDS-PAGE gel slice fractionation
approach as a initial step in the shotgun proteomic analysis of coelomic fluid. Peptides, and
their corresponding proteins, were then identified using tandem mass spectrometry.
Proteins were quantified by spectral counting and normalized spectral abundance factors
(NSAFs) [10]. Using this approach, we identified significant changes in the levels of 188
coelomocyte proteins over time, of which 40 differed in relative abundance between sea
urchins injected with LPS as opposed to saline.

154
Figure 4.1: Experimental design: Twenty-one sea urchin CF samples were collected over
48 hours. 3 samples were collected from unchallenged sea urchins, one each at 6, 24 and
48 hours after the beginning of the experiment. 9 samples were collected after saline
injection: 3 after 6 hours, 3 after 24 hours and 3 after 48 hours. 9 more CF samples were
collected after the injection of LPS: 3 after 6 hours, 3 after 24 hours and 3 after 48 hours.
3 sea urchins
3 sea urchins
Saline injection
LPS injection
48 h 24 h 6 h Non injected
3 sea urchins
3 sea urchins
3 sea urchins
3 sea urchins
3 sea urchins

155
4.4. Experimental procedures
4.4.1. Sea urchins
Sea urchins (H. erythrogramma) were collected from Camp Cove in Sydney
Harbour, Australia. They were housed in a recirculating seawater facility at Macquarie
University as previously described [5, 11]. The sea urchins were left undisturbed in the
aquaria for 2 months prior to experimentation to allow them to acclimatize to aquarium
conditions [11, 12].
4.4.2. Injections and sample collections
Animals were subjected to immunological challenge by inserting 23-gauge needles
attached to 1 mL syringes through the peristomium into the coelomic cavity. Nine animals
were injected with 30 µg of LPS in 1 mL of sterile artificial coelomic fluid (aCF; 10 mM
CaCl2, 14 mM KCl, 50 mM MgCl2, 398 mM NaCl, 1.7 mM Na2SO4, 0.22 µm filtration)
[13]. This corresponds to approximately 2 µg of LPS per mL of coelomic fluid (CF) as
previously described [12, 14]. A further 9 animals were injected with an equivalent volume
of aCF without LPS (saline treatment), and three animals were left undisturbed (non-
injected controls).
Three sea urchins from each treatment (saline or LPS injections), and one animal
from the non-injected control group, were sampled 6, 24 or 48 hours after injection (Figure
4.1). Coelomic fluid was withdrawn by dissecting the Aristotle’s lantern and removing CF
directly from the coelomic cavity.

156
The CF was harvested into an equal volume of calcium-magnesium-free seawater with
EDTA and imidazole (CMFSW-EI; 10 mM KCl, 7 mM Na2SO4, 2.4 mM NaHCO3, 460
mM NaCl, 70 mM EDTA and 50 mM imidazole; pH 7.4) on ice to avoid clotting and
French pressed at 800 Pa to lyse the coelomocytes. The lysates were stored frozen at -80oC
degrees and were lyophilized overnight under vacuum immediately before protein
extraction.
4.4.3. Protein extraction
Lyophilized samples were resuspended in 3 mL of sodium dodecyl sulfate
polyacrylamide gel (SDS-PAGE) sample buffer (10% glycerol, 2% SDS, 0.1 M Tris-HCl,
pH 8.0 and 1% DTT). They were then vortexed for 10 minutes before 3 mL of phenol was
added. The samples were further vortexed for 1 minute and centrifuged at 11,000 × g for 5
minutes at -4 oC. Five volumes of ice-cold methanol containing 0.1 M ammonium acetate
were added to the phenol extracts. The tubes were then held at -20 oC for 1 hour to
precipitate the proteins. The samples were centrifuged for 5 minutes at 14,000 × g at -4 oC
and the supernatant removed. The protein pellets were then washed twice with ice-cold
methanol containing 0.1 M ammonium acetate and twice with 80% acetone. For each
wash, samples were centrifuged for 5 minutes at 14,000 × g at -4 oC and the protein pellets
were re-suspended by vortexing for 30 seconds. After the final wash, pellets were left to air
dry before being solubilized in SDS-PAGE sample buffer. The total protein content of
each sample was determined using Bradford reagent (BioRad).

157
4.4.4. One-dimensional sodium dodecyl sulfate - polyacrylamide gel electrophoresis (1DE
SDS-PAGE)
Coelomic fluid proteins (10 µg per well) were separated on 7.5% Bis-Tris
polyacrylamide gels at 180 V for 1 hour [15]. After electrophoresis, proteins were
visualized by blue silver staining as described previously [16]. After staining, the gels were
washed twice in sterile deionised water (10 minutes per wash), before individual lanes
were cut into 16 slices of equal sizes from top to bottom. Proteins in each slice were
reduced, alkylated and subjected to trypsin digestion as previously described [17].
4.4.5. Nanoflow liquid chromatography – tandem mass spectrometry
The tryptic digest extracts from 1DE gel slices were analyzed by nanoLC-MS/MS
using a LTQ-XL ion-trap mass spectrometer (Thermo, CA, USA) essentially according to
Breci et al. [18]. Reversed phase columns were packed in-house to approximately 7 cm
(100 mm i.d.) using 100 Å, 5 mM Zorbax C18 resin (Agilent Technologies, CA, USA) in a
fused silica capillary column with an integrated electrospray tip. A 1.8 kV electrospray
voltage was applied via a liquid junction up-stream of the C18 column. Samples (in buffer
A: 5% (v/v) ACN, 0.1% (v/v) formic acid) were injected onto the C18 column using a
Surveyor autosampler (Thermo, CA, USA). Each sample was loaded onto the C18 column
followed by an initial wash step with buffer A (5% (v/v) ACN, 0.1% (v/v) formic acid) for
10 minutes at 1 µL min-1. Peptides were subsequently eluted from the C18 column on a
gradient of 0-50% Buffer B (95% (v/v) ACN, 0.1% (v/v) formic acid) over 58 minutes at
500 nL min-1 followed by a gradient of 50-95% Buffer B over 5 minutes at 500 nL min-1.
The column eluate was directed into the nanospray ionization source of the mass
spectrometer. Spectra were scanned over the range 400–1500 amu. Automated peak

158
recognition, dynamic exclusion and tandem MS of the top six most intense precursor ions
at 35% normalization collision energy were performed using the Xcalibur software
(version 2.06) (Thermo, CA, USA).
4.4.6. Protein identification
Raw MS spectra files were converted to mzXML format and analyzed using Global
Proteome Machine (GPM) software (version 2.1.1; X!Tandem algorithm,
www.thegpm.org [19, 20]. For each experiment, the 16 SDS-PAGE fractions were
processed sequentially generating output files for each individual fraction, as well as a
merged, non-redundant output file. The merged files were used for protein identification.
MS/MS spectra were searched against a combined S. purpuratus database created with
downloaded sequences from NCBI. This FASTA format database contained 44,037 protein
sequences, which comprise all S. purpuratus predicted protein sequences and identified
proteins held by NCBI as of April 2008. Search parameters included MS and MS/MS
tolerances of ± 2 Da and ± 0.2 Da, tolerance of up to 3 missed tryptic cleavages and K/R-P
cleavages. Fixed modifications were set for carbamidomethylation of cysteine and variable
modifications were set for oxidation of methionine.
4.4.7. Data analysis
To be positively identified, proteins had to; (1) match a known sequence in the S.
purpuratus database with log (e) values of less than -1; (2) be represented by at least 10
spectra from amongst all samples, with a minimum of 2 unique peptides obtained in at
least 2 different individuals, and; (3) be represented by spectral counts from all three sea
urchins in a particular treatment group (LPS- or saline-injected) at the same time point.

159
Searches were also performed against a reversed sequence database to evaluate the false
discovery rate (FDR) [21, 22]. No protein matches were detected in the reversed database
searches, indicating a protein identification confidence level of greater than 99% [23]. A
total of 345 proteins fitted these selection criteria and were subjected to further analysis.
The normalized spectral abundance factors (NSAF) of these 345 proteins were calculated
as previously described [24] and a matrix of protein abundance was generated, where each
row corresponds to a different protein and each column corresponds to one sea urchin
(Supplementary Data 4.1).
To obtain a normal distribution of the data, we applied natural log transformations to
all NSAF values [24]. The 345 proteins were considered as 345 variables, using the log
(NSAF) data set. These data were further centered and scaled to have unit standard
deviations for both rows and columns. The 21 sea urchin CF proteomes were then
subjected to principal component analysis (PCA) using the XLstats 2009 package. The
proportion of variance for each principal component and the cumulative variance were
obtained. The three components with the highest proportion of variance were used to draw
a 3D scater plot organizing the 21 sea urchin proteomes along the principal components.
PCA confirmed that the three non-injected sea urchins proteomes could be used as a
common reference point for further analysis (see Results). So, NSAF values (NSAFt) were
normalized by dividing them by the average NSAF value of the non-injected samples
(NSAFc). A new normalized and centered dataset corresponding to the log2 of the NSAFt
divided by the NSAFc was created (log2 (NSAFt/NSAFc). The log2 (NSAFt/NSAFc) data
for individual proteins were subjected to two factor ANOVA (Factor 1 - Time: 0, 6, 24 and
48 hours; Factor 2 - Challenge: saline and LPS injection) with Tuckey’s Post Hoc test to
identify individual proteins that varied in concentration over time and/or in response to the
injection of LPS or saline solution. Differences in these analyses were considered to be
significant if p<0.05.

160
Figure 4.2: Alteration in whole proteomes in response to injections. A/ Scree plot
showing the proportion of variance for each principal component (PC; histogram) and the
cumulative proportion of variances (curve) explained by consecutive PCs. B/ 3D score plot
using the first 3 PCs shown in A. The Figure shows cumulative data for all of the proteins
identified in the CF of sea urchins; non-injected (NI), 6 hours after saline injection (W6),
24 hours after saline injection (W24), 48 hours after saline injection (W48), 6 hours after
LPS injection (LPS6), 24 hours after LPS injection (LPS24) and 48 hours after LPS
injection (LPS48).
A
0
20
40
60
80
100
0
1
2
3
4
5
6
7
8
PC
1
PC
2
PC
3
PC
4
PC
5
PC
6
PC
7
PC
8
PC
9
PC
10
PC
11
PC
12
PC
13
PC
14
PC
15
PC
16
PC
17
PC
18
PC
19
PC
20
PC
21
Cu
mu
lative
va
ria
bili
ty (
%)
Eig
en
va
lue
B PC1
PC2
PC3
NI
W6
W24
W48
LPS6
LPS24
LPS48

161
4.5. Results
4.5.1. Reproducibility and threshold levels of shotgun MS/MS analysis
Three hundred and forty five distinct coelomocyte proteins were identified by
shotgun proteomics. The false discovery rate was <1 %, suggesting that the identities of
these proteins were robust. One of the most decisive steps in protein profiling is the
reproducibility of the data among the biological replicates. Hence, coelomic fluid samples
from three individual sea urchins per treatment were collected 6, 24, and 48 hours after
saline and LPS injection. An additional three sea urchins were left uninjected and the CF
from one of these sea urchins was collected at each time point (giving a total of 21 CF
samples).
To confirm that the variations observed between samples were due to the
experimental treatments rather than chance, we undertook PCA of the 21 CF proteomes. A
first step was to determine the number of principal components (PC) to extract. A Scree
plot was created to determine if a clear breaking point was observed in variances (Figure
4.2). The Scree Plot has two forms of information: the histogram shows the proportion of
variance for each PC, while the upper line shows the cumulative variance explained by the
21 components. The PCs were sorted in decreasing order of variance, so that the most
representative PCs were listed first. In this dataset, the first three PCs explain much more
of the variance in the data (roughly 32%, 9% and 7% respectively) than do all of the
subsequent PCs, leading us to further investigate these first 3 PCs. In total, 48.7% of the
total variance was explained by these first three PCs.
Figure 4.2 shows the 3D score plot obtained using the first three PCs. The different
sea urchin proteomes were explained by different proportions of the PCs, indicating that
fundamental differences existed between samples. In this plot, sea urchin samples with

162
similar protein abundance profiles appear closer in space, whereas significantly different
samples appear more distant from each other. The three non-injected samples clustered
together with low values for PC1 and PC3, and high values for PC2. This confirmed that
the differences observed between these sea urchins and those injected with LPS or saline
were due to the experimental conditions to which the animals were subjected, and that non-
injected sea urchin samples could be used as a T=0 hour reference point. Samples collected
at 6 and 24 hours post injection (p.i.) from both treatments (LPS and saline injection)
yielded high PC1 but low PC2 and PC3 values. This suggests that a significant
modification of the total CF proteome occurs within the first 6 hours after injection.
Samples collected after 6 and 24 hours p.i. tended to cluster together regardless of
collection time or challenge conditions, indicating that significant differences did not exist
between treatments (saline vs bacteria at these time points; Figure 4.2B). However,
samples collected 48 hours p.i. formed distinct groups, with intermediate values for PC1
and PC3 but low PC2 values. Among these, samples from LPS-injected sea urchins had
lower PC1 and PC3 values than those from saline-injected animals. The significant
distinction between samples collected 48 hours after LPS and saline injections indicated
that most of the alterations in protein concentration specifically induced by LPS occurred
at 48 hours p.i.. The relative decrease along the PC1 axis of the 48 hours p.i. samples
suggests that the relative abundance of most proteins from both saline- or LPS-injected
animals began return to pre-injection levels within 48 hours, even though the 48 hours p.i.
samples from LPS- and saline-injected sea urchins remained clearly different from each
other, and from non-injected controls.

163
4.5.2. Functional classification of proteins
The 345 proteins identified in this study were grouped into 9 functional categories
based on the annotation for the corresponding genes in the S. purpuratus genome. Ten
proteins could not be assigned to any of these categories and so were grouped as ‘others’.
Hypothetical proteins in the S. purpuratus genome without a known putative function
accounted for 52 of the 345 proteins identified. To understand the potential activities of
these proteins, we undertook protein Blast searches and conserved domain searches against
the entire NCBI database. The results of these searches showed strong matches to
homologous proteins from other species in all but 6 cases. The remaining 6 proteins did
not exhibit significant similarities to proteins with predicted functions, and so were
designated as ‘unknown’ in terms of protein ontology (Figure 4.3).
Proteomes of CF samples from non-injected sea urchins were dominated by
molecules involved in cell structure shape and mobility, as well as cell signalling (Figure
4.3A). Actin, tubulin and myosin were abundant in all of these samples, followed closely
by SUArp 2 and 3 proteins, a protein similar to F actin capping proteins, alpha actinin and
gelsolin. Molecules involved in cell structure shape and mobility made up 16% of all
proteins identified (Figure 4.3A), and between 56% (non-injected) to 86% (6 hours post-
saline injection) of the total protein content of coelomocytes (NSAFs values) (Figure 4.3B-
D). Proteins involved in cell signalling were also numerous (13% of all proteins
identified), but they represented only 1.3% (24 hours post LPS injection) to 7.3% (non-
injected) of the relative CF protein content (Figure 4.3B-D). Stress response and
detoxification proteins, as well as those involved in nucleic acid/protein metabolism
represented 8% and 24% of the total number of proteins identified. Higher relative
abundance values (NSAFs) for these proteins were evident in non-injected sea urchins,
where they respectively comprised 4.8% and 10.6% of the CF protein content.

164
Number of proteins
2% 2% 3%
4%
8%
8%
12%
8%
13%
16%
24%
A
B
C
D

165
Figure 4.3: Relative abundance and functional classification of proteins. These Figures
show the functional categories of proteins identified in the CF of non-injected sea urchins
(NI), 6 hours after saline injection (W6), 24 hours after saline injection (W24), 48 hours
after saline injection (W48), 6 hours after LPS injection (LPS6), 24 hours after LPS
injection (LPS24) and 48 hours after LPS injection (LPS48). A/ Pie chart showing the
functional classification of the 345 proteins identified in all of the sea urchin CFs analysed.
Data are percentages calculated by dividing the number of proteins in a category by the
total number of proteins identified. B,C,D/ show the relative abundance of the proteins of
each functional category proportional to the sum of the NSAF values of all proteins
identified (% NSAFs).

166
Immune response proteins comprised 8% of all proteins identified and represented between
1.7% (6 hours post saline injection) and 7.6% (non-injected) of the protein content, while
those involved in energy metabolism made up to 12% of the proteins identified and
comprised between 2.7% (24 hours post LPS injection) to 7.2% (non-injected) of the
relative CF protein content (Figure 4.3B-D).
In CF samples from LPS-injected and saline-injected sea urchins, significant changes
in the relative abundance of proteins involved in the different functional categories were
observed during the course of the experiment (ANOVA p<0.01; Figure 4.3). The
abundance of proteins putatively involved in cell structure, shape and mobility increased at
6 hours after injection, comprising over 80 % of the total protein content, and decreased
over the following 42 hours to represent 60%-70% of the total protein content at 48 hours
p.i. (Figure 4.3B). Molecules involved in stress responses decreased in relative abundance
from 4.8% of the proteome at T=0 hours (non-injected sea urchins) to ~2% at 6 hours p.i.
(1.9% 6 hours after saline and 2.1% 6 hours after LPS), increasing again after 24 hours p.i.
(4% after saline and 6% after LPS) (Figure 4.3D). Proteins in all other functional
categories decreased in relative abundance over the period T=0 to T=24, and then
increased in relative concentration at 48 hours p.i. (Figure 4.3C,D). These results suggest
that the major shift in the proteome along the PC1 and PC2 axes at 6 hours p.i. was due to
a significant increase in proteins involved in cell structure, shape and mobility, resulting in
a decrease in the relative concentrations of most other proteins. Protein levels in all
categories began to return to pre-injection levels at 48 hours after challenge, confirming
that proteomes collected at 48 hours p.i. were more similar to non-injected sea urchins than
those collected at 6 or 24 hours p.i..

167
4.5.3. Identification of individual proteins affected by saline or LPS injection
Significant differences in the levels of individual proteins between LPS-and saline-
injected sea urchins during the course of the experiment were detected using two-way
ANOVA and Tuckey’s Post Hoc test on the log2 (NSAFt/NSAFc) values. The null
hypotheses tested were that there were no differences between LPS- and saline-injected sea
urchins (factor 1: challenge), and that there were no differences over time (factor 2: time).
These tests showed that the relative abundances of 188 proteins were significantly altered
by LPS and saline injections (p<0.05) (Table 4.1). Many proteins were significantly altered
for both main effects, “challenge” and “time”. Hence, ANOVA results are presented in
three categories; “time significant”, “challenge significant” and “time and challenge
significant”. Two proteins differed significantly between “challenges” only, 135 differed
significantly over time but not between challenges, and 40 differed significantly over time
and between challenges (Table 4.1).
Overall, changes in the relative abundance of individual proteins were consistent
among the three sea urchins tested at each time point for each treatment (Figure 4.4). As a
result, the sum of NSAF (NSAFs) values from each set of three individuals (same
treatment, same time point) were representative of the data and could be used to simplify
visual representation of the data (Figures 4.4, 4.5 and 4.6).

168
Figure 4.4: Consistency of the relative abundance data. The NSAF values for major
yolk protein (A) in each individual sea urchin from each treatment and (B) summed NSAF
values (NSAFs) for the three sea urchins in each treatment at each time point (LPS
injection, LPS; saline injection, W; non-injected, NI).
!"
!#!!!$"
!#!!!%"
!#!!!&"
!#!!!'"
!#!!("
(" $" )" (" $" )" (" $" )" (" $" )" (" $" )" (" $" )" (" $" )"
*+"!",-./0" 1"&",-./0" 1"$%",-./0" 1"%'",-./0" 234"&",-./0" 234"$%",-./0" 234"%'",-./0"
*4567"89:-/";-<=">/-7?@A"
!"
!#!!!%"
!#!!!'"
!#!!($"
!#!!(&"
!#!!$"
*+" 1&" 1$%" 1%'" 234&" 234$%" 234%'"
*4560"89:-/";-<=">/-7?@A"
5"
B"

169
Table 4.1: Individual proteins with significantly altered relative abundance (ANOVA
p<0.01) over time and/or between challenges (LPS- or saline-injected). Proteins that
differed significantly between challenges but not over time are classified as “challenge
significant”. Proteins that differed significantly over time but not between treatments are
classified as “time significant”. Proteins that differed significantly both over time and
between the two challenges are classified as “time and challenge significant”.
Identifier Description gi|115618052| similar to Actin, cytoskeletal IIIB, partial Challenge
Significant gi|115971469| similar to Actin, cytoplasmic gi|115945106| similar to cytosolic nonspecific dipeptidase, partial gi|115956413| similar to glutamine synthetase . gi|115976312| similar to CG8649-PC (calponin) gi|115974673| similar to LOC407663 protein (short chain dehydrogenase) gi|115753213| similar to beta COP, partial gi|115928607| hypothetical protein (flotillin) gi|115803435| hypothetical protein (similar to cleavage stimulation factor fusion) gi|115891186| hypothetical protein, partial (kynurenine aminotransferase) gi|115671024| similar to KIAA0051, partial (IQ motif containing GTPase activating protein) gi|115934826| similar to Fructose-1,6-bisphosphatase 1 (D-fructose-1,6-bisphosphate 1-phosphohydrolase 1) (FBPase 1) gi|115944296| hypothetical protein (Galectin) gi|115929526| similar to aminopeptidase N . gi|115955254| similar to alpha macroglobulin . gi|160623368| putative flotillin* gi|115968722| similar to DEAD-box RNA-dependent helicase p68 isoform 2 gi|115931135| similar to putative RNA binding protein KOC gi|115770276| similar to zonadhesin gi|115952079| hypothetical protein, partial (vacuolar protein sorting 35) gi|115924997| similar to MGC84288 protein (tissue inhibitor of metalloproteinase TIMP) gi|115950705| similar to Ribosomal protein S5 gi|115894557| similar to RACK gi|115924764| similar to formin binding protein 1 gi|115968476| similar to ENSANGP00000018350 (centaurin) gi|115940610| hypothetical protein, partial (Ribosomal protein) gi|47551023| complement component C3 gi|115926118| similar to CG6950-PC (kynurenine aminotransferase) gi|115934021| similar to Psmc6 protein (proteasome 26S subunit, ATPase) gi|115974704| similar to scavenger receptor cysteine-rich protein type 12 precursor, partial gi|115944055| similar to fibrocystin L gi|115944169| similar to dual oxidase 1 isoform 1 . gi|115933977| similar to histone H2A-3 gi|47551261| MAP kinase gi|115957127| similar to ribosomal protein L5 gi|115951428| similar to LOC615074 protein isoform 2 cAMP-dependent protein kinase) gi|115944978| similar to COP9 complex subunit 4 gi|115963308| similar to ribosomal protein L32 gi|115944173| similar to ENSANGP00000006016 isoform 1 (dual oxidase maturation factor) gi|47551251| heat shock protein gp96 gi|115940166| similar to apolipoprotein B
Time and Challenge Significant
gi|47551303| guanine nucleotide-binding protein G(q) alpha subunit gi|115953630| hypothetical protein (N-acetylneuraminic acid synthase) gi|224306| actin gi|115939823| similar to catalytic subunit of cAMP-dependent histone kinase gi|115977049| hypothetical protein (chaperonin containing TCP1) gi|115972622| similar to GA19181-PA, partial (NAD dependent epimerase/dehydratase) gi|115970015| similar to von Willebrand factor gi|115937346| similar to apolipophorin precursor protein
Time Significant
gi|115946171| similar to beta-arrestin 1, putative

170
Identifier Description gi|115975006| similar to RAB2 isoform 2 gi|115974054| similar to fibropellin Ia gi|115970592| similar to tropomyosin 1 gi|115967840| similar to 0910001A06Rik protein isoform 2 gi|115931665| similar to MGC89020 protein (mitochondrial aldehyde dehydrogenase 2) gi|115972829| similar to glucose-6-phosphate isomerase . gi|115956030| similar to chaperonin gi|115970013| similar to apolipoprotein B gi|47551123| major yolk protein gi|47551085| late histone L3 H2a gi|115697859| hypothetical protein (succinyl CoA ligase) gi|115955282| hypothetical protein (heterogenous nuclear ribonucleoprotein K) gi|115931510| hypothetical protein (sorting nexin) gi|115691123| similar to Eukaryotic translation initiation factor 2, subunit 1 alpha, 35kDa isoform 1 gi|115970523| similar to elongation factor 1 alpha isoform 2 gi|115974451| similar to GTPase SUrab10p gi|115954217| similar to hexokinase I gi|115945280| hypothetical protein, partial (ADP ribosylation factor) gi|115774726| hypothetical protein, partial (phosphatidylinositol-5-phosphate 4-kinase) gi|47825404| guanine nucleotide-binding protein G(12) alpha subunit . gi|115959822| similar to annexin gi|47551041| ER calcistorin gi|115956476| similar to apextrin gi|115943916| similar to actin gi|115956824| similar to Solute carrier family 25 (mitochondrial carrier; adenine nucleotide translocator), member 4 gi|73746392| major yolk protein gi|47551049| fascin gi|115974713| hypothetical protein (dysferlin C2 superfamily) gi|115968818| similar to ENSANGP00000003616 (Actin like protein) gi|115931821| hypothetical protein (fibronectin) gi|115965680| hypothetical protein (Heterogeneous nuclear ribonucleoprotein L) gi|115968684| similar to retinoblastoma binding protein 4 variant isoform 1 gi|115950487| similar to arylsulfatase isoform 2 . gi|115954976| similar to heat shock protein protein gi|115928686| similar to alpha isoform of regulatory subunit A, protein phosphatase 2, partial gi|115936805| similar to heterotrimeric guanine nucleotide-binding protein beta subunit isoform 2 . gi|47825400| guanine nucleotide-binding protein G(i) alpha subunit . gi|47825398| guanine nucleotide-binding protein G(s) alpha subunit . gi|115939698| similar to 26S proteasome subunit p44.5 gi|115944135| similar to sea urchin Arp2 (SUArp2) . gi|115975046| similar to GTP-binding nuclear protein Ran gi|115966189| similar to H(+)-transporting ATPase beta subunit gi|115925449| similar to Fructose-1,6-bisphosphatase 1, like gi|115972586| similar to 71 Kd heat shock cognate protein gi|115963192| similar to Annexin A4 (Annexin IV) (Lipocortin IV) (Endonexin I) (Chromobindin-4) (Protein II) (P32.5) gi|115966293| similar to RAS-related protein MEL . gi|115921420| hypothetical protein, partial (phosphoglycerate dehydrogenase) gi|115960968| similar to sea urchin Arp3 (SUArp3) gi|115891388| similar to heat shock 90 kDa protein, partial gi|115940258| hypothetical protein (lipid raft asssocitaed protein 2) gi|115961140| similar to gelsolin gi|115972933| similar to B-cell receptor associated protein gi|115968951| hypothetical protein (adaptor protein complex AP2) gi|115971224| hypothetical protein (aminopeptidase) gi|115937294| similar to beta-parvin gi|47551035| cytoskeletal actin CyIIIb gi|115955418| similar to 5-aminoimidazole ribonucleotide (AIR) (SAICAR) synthetase isoform 1 gi|115939485| similar to malate dehydrogenase . gi|115652043| similar to histidyl-tRNA synthetase, partial gi|115926010| similar to glutathione peroxidase, partial gi|115959476| hypothetical protein, partial (translation initiation factor eIF-2B) gi|115964543| similar to transaldolase gi|115963185| hypothetical protein isoform 2 (ribosomal protein L15) gi|115965220| similar to histone macroH2A1.1 gi|115960271| similar to protein Phosphatase 2C beta
gi|115960970| similar to proliferation-associated protein 1

171
Identifier Description gi|115958373| similar to Rab5 protein gi|115925359| similar to LZP (CCP and zona pellucida superfamily) gi|115970724| similar to Valosin containing protein, partial gi|115932417| similar to ribosomal protein S10 isoform 2 gi|115746860| similar to actin, partial gi|115929978| similar to OTTHUMP00000039401 (similar to leucine rich repeat containing 16 isoform) gi|115959301| similar to Protein phosphatase 2A, catalytic subunit, beta isoform gi|115968753| similar to scavenger receptor cysteine-rich protein type 12 precursor gi|115939093| hypothetical protein (septin 9 fusion) gi|115910910| hypothetical protein, partial (Fibronectin) gi|115961398| similar to Capzb-prov protein (F actin capping protein beta) gi|115963096| similar to CG15792-PD, partial (myosin) gi|115956638| similar to cytoskeletal actin CyIIb . gi|115744264| similar to Isocitrate dehydrogenase 2 (NADP+), mitochondrial . gi|47551147| N-ethylmaleimide-sensitive factor (NSF) gi|115973107| hypothetical protein, partial (NADH cytochrome reductase) gi|115974434| similar to adenosylhomocysteinase gi|115710920| similar to Na+/K+ ATPase alpha subunit gi|115942229| similar to integrin-linked kinase gi|115940188| similar to peptidylprolyl isomerase B isoform 2 . gi|115963700| similar to Ribosomal protein L14, partial gi|115911567| hypothetical protein, partial (aspartyl tRNA synthase) gi|115968341| similar to Ribosomal protein L3 gi|115929247| similar to heterogeneous nuclear ribonucleoprotein H . gi|115945705| similar to EH-domain-containing protein 1 (Testilin) (hPAST1) gi|115738335| similar to beta-adaptin Drosophila 1 isoform 7 gi|115943043| similar to VPS13C-1A protein (vacuolar protein sorting 13 homolog C) gi|115930179| similar to gelsolin gi|115940857| similar to aldose reductase . gi|115934007| similar to TRAF4-associated factor 2 . gi|115922509| similar to glutamic-oxaloacetic transaminase 2, mitochondrial (aspartate aminotransferase 2) isoform 2 gi|47550983| nuclear intermediate filament protein gi|115929203| similar to ENSANGP00000011796 (alpha actinin) gi|115970125| similar to MGC139263 protein (Annexin) gi|115729152| similar to triosephosphate isomerase gi|115940910| hypothetical protein (septin7) gi|115630732| similar to myosin, heavy polypeptide 10, non-muscle gi|115924280| similar to flavoprotein subunit of complex II, partial gi|115960644| similar to myosin heavy chain gi|115968074| hypothetical protein (aldehyde dehydrogenase) gi|47551307| syntaxin binding protein 1 gi|115944458| similar to calponin gi|115968724| similar to transglutaminase-like protein . gi|115905691| similar to Pkm2 protein, partial (Pyruvate kinase isoenzyme type M2) gi|115965257| similar to heterogeneous nuclear ribonucleoprotein R gi|115968696| similar to paraspeckle protein 1 isoform beta gi|115759362| similar to sulfotransferase ST1B2 . gi|47551157| scavenger receptor cysteine-rich protein type 12 . gi|115944450| similar to chaperonin subunit 8 theta gi|115973804| similar to non-receptor protein tyrosine phosphatase gi|115964994| similar to Fumarylacetoacetase (Fumarylacetoacetate hydrolase) (Beta-diketonase) (FAA), partial gi|115954867| similar to Chaperonin containing TCP1, subunit 4 (delta) gi|115673346| similar to alpha-cop protein, partial gi|115720465| similar to selectin-like protein, partial . gi|115950170| similar to long microtubule-associated protein 1A; long MAP1A gi|115971193| similar to Rac1 protein gi|115955810| hypothetical protein (ribosomal protein L4) gi|115941920| similar to ribosomal protein L7, partial gi|115972878| similar to Rps9-prov protein (ribosomal protein S9) gi|5532389| microtubule-associated protein gi|115951468| similar to coatomer protein gamma 2-subunit, partial gi|115945943| similar to ENSANGP00000011972 (GDP dissociation inhibitor) gi|115628087| similar to chaperonin containing TCP1, subunit 6A isoform 1 gi|115978426| hypothetical protein (dihydrolipoyllysin S succinyltransferase) gi|115975235| similar to signal transducer and activator of transcription 5B
gi|47550939| calreticulin

172
Identifier Description gi|115951109| similar to tensilin gi|166795321| advillin gi|115956784| similar to epsin 2 gi|115951499| hypothetical protein (septin2) gi|115940967| similar to Dynamin 2, partial
gi|115939472| similar to ENSANGP00000023777 (CDC42, cell division cycle 42)
The identity of hypothetical proteins was deduced from Blast and conserved domain
searches and is shown in brackets and Italics.
* Molecules previously characterized at the protein level are shown in bold.

173
The proteins that varied over time but not between saline- and LPS-injected sea
urchins were from all functional categories. Most of these decreased in relative abundance
at 6 and/or 24 hours after injection and returned to relative concentrations close to those of
non-injected sea urchins after 48 hours. Proteins following this pattern included myosin,
fibronectin, calreticulin, GDP dissociation inhibitor, RabGTPases, ER calcistorin and
proteins involved in glycolysis. Exceptions to this overall pattern included proteins similar
to actin (Figure 4.5), fascin (Figure 4.5), cdc42, Rac1, leucyl aminopeptidase, heat shock
protein and a nuclear intermediate filament protein. These proteins increased in relative
abundance at 6 hours after both injections. This agrees with the previous observation that
the proportional representation of proteins involved in cell structure, shape and mobility
increased at this time point. The relative increase described previously among stress
response proteins at 24 hours after injection can be explained by changes in a single
molecule in this functional category, major yolk protein (Figure 4.4). We also identified
some proteins after challenge that were not detected in non-injected samples. These
included cytoskeletal actins CyIIIb and CyIIb (Figure 4.5), a flavoprotein, an annexin A7
and a triosephosphate isomerase. Conversely, some other proteins identified in non-
injected samples were absent among LPS-injected and saline-injected sea urchins. These
included advillin, F actin capping protein, alpha actinin, tensilin, dysferlin C2, beta parvin
and apextrin.
Most of the proteins that differed significantly both over time and between
challenges increased in relative concentration in response to the injection of LPS but not
saline. The relative abundance of many of these proteins was modified 48 hours after
injection, which agrees with the previous observation that differences between LPS- and
saline-injected sea urchin proteomes were most prominent at this time point.

174
Figure 4.5: Examples of proteins that differed in relative abundance over time but not
between treatments. The sum of the NSAF values (NSAFs) for each triplicate of sea
urchins in a particular treatment/time point is shown for the cytoskeletal actins CyIIb and
CyIIIb (A), fascin (B), proteins similar to apolipoprotein B and apolipophorin precursor
(C), and for proteins similar to septins (D) (LPS injection, LPS; saline injection, W; non-
injected, NI).
!" #"
$" %"

175
The LPS-specific proteins primarily fell into three categories; proteins involved in
vesicular trafficking, including a beta subunit of the coatomer protein complex, a receptor
for activated C-kinase and a vacuolar protein sorting 35; immune response proteins,
including dual oxidase 1 and dual oxidase maturation factor, an α-2-macroglobulin, a
complement component C3, a fibrocystin L, and three scavenger receptor cysteine rich
(SRCR) proteins; and proteins with suspected accessory roles in immune response, such as
two kinurenine aminotransferases and an aminopeptidase N. Other proteins that were
relatively more abundant after challenge with LPS included a guanine nucleotide binding
protein G(q) alpha subunit, a MAP kinase, an apolipoprotein B and a tissue inhibitor of
metalloproteinase (TIMP).
For some of the proteins that differed between LPS- and saline-injected animals,
differences were “all or none”, meaning that the protein was not detected in one treatment
but was relatively abundant in the other treatment. For example, fibrocystin L (Figure 4.6)
was absent directly after saline injection, but was abundant 48 hours after LPS injection. In
addition to these on/off differences, there were also proteins that were present in all
treatments, but differed substantially in relative abundance between treatments. For
instance, complement component C3 (Figure 4.6) was 3.3 fold more abundant 48 hours
post-LPS injection than 48 hours after saline injection.

176
Figure 4.6: Examples of proteins that differed in relative abundance both over time
and between treatments. The sum of the NSAF values (NSAFs) for each triplicate of sea
urchins in a particular treatment/time point is shown for a protein similar to dual oxidase
maturation factor (A), a protein similar to dual oxidase 1, isoform 1 (B), a protein similar
to aminopeptidase N (C), a protein similar to fibrocystin L (D), a protein similar to alpha 2
macroglobulin (E), and complement component C3 (F). (LPS injection, LPS; saline
injection, W).
!" #"
$" %"
&" '"

177
4.6. Discussion
This is the first differential proteomic analysis of sea urchin responses to
immunological challenge, paving the way for further study of the individual proteins and
protein networks affected during this process. Previous transcriptomic approaches [5, 25]
have identified differentially regulated genes. These studies measured gene expression at a
single time point after challenge. However, proteomic studies of Drosophila hemocytes
showed that immune responses are dynamic processes and that the proteome varies at
different time points after challenge [2]. In order to provide a dynamic image of the
immune response in sea urchins, we used a strategy that allowed us to monitor hundreds of
proteins over several time points.
Principal component analysis suggested that CF responses to saline and LPS
injection are similar at 6 and 24 hours after challenges, and that differences specifically
due to the presence of LPS occurred mostly 48 hours after injection. This result was
confirmed by analyzing the differential abundance of individual proteins. The
concentration of 135 proteins was significantly altered over time in both the saline and
LPS treatments. Such responses probably reflect the effects of injection, such as the
puncture wound caused by the needle and the increase in CF volume caused by the
introduction of aCF (with or without LPS). A further 40 proteins differed significantly
between saline- and LPS-injected sea urchins, suggesting that these molecules participate
in a discrete LPS-induced response.
Changes in the concentration of the 135 proteins that differed in both saline and LPS-
injected animals implies that there were 3 distinct components to wounding responses:
initial changes in coelomocyte morphology and plasticity, followed by systemic responses
primarily involving the major yolk protein, and finally the induction of wound repair
mechanisms.

178
The initial (T=6 hours) changes observed in the CF proteome primarily involve
alterations in major cytoskeletal proteins. This might reflect an increased capacity for
coelomocyte agglutination at the wound site, the restructuring of actin filaments allowing
the development of filopodia and the recruitment of coelomocytes to the site of injury. We
identified a significant increase in the levels of actin isoforms at T=6 hours suggesting
significant changes in cell shape and amoeboid activity (Figure 4.5). One of these
isoforms, actin CyIIIb, was abundant only at 6 hours p.i. (Figure 4.5). Other proteins that
were abundant during this initial phase included fascin (Figure 4.5), a protein with
similarities to lipid raft associated protein 2, Rac 1 and cdc42. In mouse fibroblasts, cdc 42
activates Rac and together they control the assembly and organization of the actin
cytoskeleton, leading to the formation of filopodia and adhesion complexes [26, 27].
Similarly, fascin is involved in elongation and bundling of filopodia. It is the only actin
cross-linker localized in filopodia [28]. The relatively increased concentration of these
proteins supports previous cytological studies, which demonstrated that phagocytic
coelomocytes grow extensive filopodia that induce the formation of clots involved in
sealing wounds [29-31]. A previous study [32] compared the intense clotting of sea urchin
coelomocytes with a palisade protecting the organism against infectious agents.
Changes in the relative abundance of other proteins classified in the cell structure,
shape and mobility category occurred later in the response, reflecting ongoing changes in
the coelomocyte cytoskeleton. For example, gelsolin, which is involved in severing actin
filaments [33], as well as septins 2, 6 and 7, increased significantly in relative
concentration (Figure 4.5). Septins are a family of GTP-binding proteins that have been
found to regulate the formation of microtubules in mammalian cells and the overall
organization of the cytoskeleton under the influence of rho and cdc42 signaling modules
[34, 35]. Septin 2 can arrange itself in filaments and is necessary for phagocytosis [36, 37],
whereas septins 2, 6, and 7 form a complex of filamentous septins [38]. Our results suggest

179
the existence of the Sept2/6/7 complex that is involved in the modulation of microtubule
stability in sea urchin coelomocytes during wound repair [34].
In addition to effects on cytoskeletal activity, wounding also seemed to result in
systemic changes in the CF. This was reflected by major yolk protein (MYP; also called
vitellogenin) [39], which increased significantly in relative abundance between 6 and 24
hours p.i., before declining in concentration after 48 hours (Figure 4.4). Major yolk protein
is a member of the large lipid transfer protein (LLTP) family [40]. It is a transferrin-like
protein used to shuttle iron, but its exact activity has not yet been defined [41]. The high
relative abundance of MYP at 24 hours after challenge suggests that it has an important
role in wounding responses. Cervello et al. [42] demonstrated that this protein is stored
within the colorless spherule cells of sea urchins and is discharged into the coelomic fluid
in response to stress. As a transferrin, MYP could be involved in iron depletion to prevent
bacterial infection in a systemic response to wounding.
Other members of the LLTP family, an apolipophorin precursor and two
apolipoprotein B, were relatively abundant 48 hours after injection (Figure 4.5). This
suggests an important role for lipid metabolism in coelomocytes that might be implicated
in the induction of clotting reactions or immunological responses [43, 44]. Avarre et al.
[45] found that among insects as well as vertebrates, members of the LLTP family with a
vWD domain tend to be involved in clotting and defense reactions. The two ApoB-like
proteins included a vWD domain suggesting their involvement in clotting reactions. In
insects, ApoLp is involved in the activation of immune responses [46, 47] and is able to
recognize and inactivate LPS by forming insoluble aggregates [48]. Our data showed that
ApoB was relatively more abundant 24 hours after LPS injection than after saline
injection, suggesting that in sea urchins, these proteins may also be involved in reaction to
LPS.

180
Other evidence for the induction of clotting and wound healing activity 48 hours after
injection included the identification of proteins similar to von Willebrand factor,
cyclophilin B, selectins, and other molecules putatively involved in protein degradation,
such as the COP9/signalosome complex, 26S proteasome, TIMP and a
fumarylacetoacetase. In vertebrates, Von willebrand factor and cyclophilin B contribute to
platelet adhesion to collagen exposed at wounded sites [49, 50]. Vertebrate selectins
mediate cell migration to sites of injury during the process of wound healing [51]. In the
context of wound healing, the proteolytic systems identified could be involved in the
degradation of superfluous or damaged proteins [52]. TIMPs in particular are involved in
the degradation of connective tissue during wound healing [53]. Interestingly, the TIMP
identified in our study was more abundant after LPS injection than after saline injection. In
insects, TIMPs can act as direct effectors of defense mechanisms, by inhibiting
metalloproteases that allow pathogens to penetrate and proliferate within the host [54]. In
the oyster, Crassostrea gigas, the number of transcripts of Cg-Timp increases significantly
in response to the injection of Vibrio [55]. A number of G proteins were also significantly
altered over time after injection (G(i), G(s), G(12)) but not between different challenges.
Overall, these data suggest that there were generalized wounding responses to
injection, involving components of coagulation cascades, cytoskeletal remodelling,
systemic responses and protein degradation. These responses occurred in both the presence
or absence of LPS. However, additional cellular processes appeared to be specifically
activated in response to the injection of LPS. These LPS specific responses involved
proteins associated with vesicular transport, immunological reactions and intracellular
signaling. Most often, the induction of these proteins occurred 48 hours after LPS
injection.
The vesicular transport proteins that differed significantly in relative abundance
between LPS- and saline-injected sea urchins included homologues of coatomer protein

181
complex I (COPI), beta subunit, which functions as a receptor of activated C kinase
(RACK) [56], and another protein similar to RACK. RACK is an adaptor molecule that
binds the activated form of protein kinase C and directs the localization of the activated
enzyme to distinct cellular compartments [56]. This protein also increases after injection of
LPS in flies [57].
Other signalling proteins that were more abundant in LPS-injected sea urchins after 6
or 24 hours included guanine nucleotide binding protein (G protein) alpha subunit G(q)
and MAP kinase. G protein coupled receptors modify the activity of numerous enzymes,
including MAP kinase [58]. MAP kinase pathways regulate a large range of biological
process in cells from yeast to mammals, including wound healing and immune responses.
In response to stimuli from upstream regulators (beta-arrestin, Ras, rac1, cdc42, TRAF, all
found in our samples and regulated over time), they phosphorylate serine and threonine
residues on numerous target proteins, which in turn induce cell proliferation, inflammation,
cell motility, differentiation or apoptosis [59]. The enhanced relative abundance of G(q)
and MAP kinase in response to LPS injection suggests that LPS specifically induces a
range of sub-cellular signaling processes that are not activated after wounding.
Most of the immune response proteins that were specifically induced by LPS
potentially contribute to the activity of phagocytes. These included proteins similar to dual
oxidase 1 and dual oxidase maturation factor, complement component C3, α-2
macroglobulin, fibrocystin L, SRCRs and aminopeptidase N (Figure 4.6). Dual oxidase 1
and dual oxidase maturation factor are involved in catalyzing the one-electron reduction of
molecular oxygen to superoxide. In vertebrates, the NADPH oxidase is primarily found in
professional phagocytic cells, such as monocytes and macrophages, where it actively
participates in the killing of invading bacteria [60]. α2-macroglobulin and complement
component C3 are members of the complement component thioester protein family [61].
α2-macroglobulin proteins are acute phase proteins in vertebrates and have also been

182
identified in a range of invertebrates. They undertake C3-like functions such as
opsonisation, whilst also acting as protease inhibitors [61]. In sea urchins, complement
component SpC3 [62] is known to function as an opsonin promoting phagocytosis [12, 63].
Previous studies of the induction of SpC3 after LPS injection are in close agreement with
our data, showing a marked increase in SpC3 expression 48 hours after injection [12, 62,
63]. These results suggest that the sea urchin complement pathway is activated in response
to LPS injection, but not by saline.
The induction of opsonins, such as SpC3, and oxidative killing systems suggest that
LPS activates the phagolysosomal system of coelomocytes. This activation may also
involve aminopeptidase N, which was specifically induced by LPS 48 hours after injection.
Even though it has a range of functions, aminopeptidase N has been implicated in
FcgammaR mediated phagocytosis in mammals [64]. It spontaneously redistributes to the
zones of phagocyte–target interaction and is internalized into phagosomes. The most
actively phagocytic cells express more than twice the amount of aminopeptidase N than
less phagocytic cells [65]. Interestingly, galectin, a carbohydrate binding C-type lectin that
we also found in abundance 48 hours after challenge, binds aminopeptidase N and
activates NADPH-oxidase [66, 67]. There are 7 complete aminopeptidase N genes in the
sea urchin genome that are sufficiently similar to human aminopeptidase N gene to suggest
that they have similar functions [68].
A number of immunological receptor proteins were also found to be relatively more
abundant 48 hours after LPS injection. These included a protein similar to fibrocystin L
(Figure 4.6) and a SRCR. In humans, fibrocystin L is a receptor protein upregulated
specifically in T lymphocytes activated by lectins [69]. The corresponding sea urchin gene
has a similar structure to its human counterparts, with ten TIG and two G8 domains
(TMEM homology) [7, 69], suggesting that it may also have a receptor function. SRCRs
constitute a family of highly variable cell surface receptors and secreted proteins involved

183
in the recognition of pathogens, the development of immune systems and the regulation of
immune responses. In the S. purpuratus genome, there are an estimated 1,200 distinct
SRCR-like domains [70], and numerous SRCR proteins with variable expression patterns
have already been characterized in sea urchin coelomocytes [70, 71].
The time course analysis reported in the current study extends previous proteomic
and transcriptomic analyses of inducible immune responses in S. purpuratus that
investigated just a single timepoint (Dheilly et al., unpublished data)[5]. In a previous
proteome analysis, a total of 323 proteins were identified in S. purpuratus CF collected 24
hours after LPS injection into immunoquiescent animals (Dheilly et al., unpublished data).
We identified 236 (73%) of these proteins in the current analysis of H. erythrogramma CF,
and an additional 109 proteins that were not identified in the previous study. The strong
similarities between our analysis of H. erythrogramma CF proteome with the one
undertaken on S. purpuratus suggest that the two species of sea urchins undertake
comparable responses to LPS. Similarly, a macroarray analysis of coelomocyte gene
expression undertaken by Nair et al. [5] revealed that the injection of LPS into
immunoquiescent S. purpuratus significantly altered the transcriptional state of
coelomocytes. A large proportion of the proteins encoded by the transcripts identified in
Nair et al.’s work were also found to be significantly up-regulated in the current study.
These included defense related proteins, such as amassin, integrin, galactin, lectins,
complement component C3, cathepsin, MAP kinase, arylsulfatase. Nair et al. [5] also
highlighted the abundance of transcripts involved in amoeboid movement, such as actin,
profilin, cofilin or gelsolin.
The combination of genomic, transcriptomic and proteomic analysis is beginning to
build a comprehensive picture of the biology of sea urchin coelomocytes. In order to better
characterize the biological pathways involved in the inducible immune response of sea
urchins, future proteomics studies could make use of cell separation and sub-cellular

184
fractionation techniques to improve the characterization of low abundance proteins and
determine their precise role in sea urchin immunity. Regardless, the current study clearly
shows that coelomocytes are professional amoebocytes and phagocytes equipped to
respond to wounding and infection. The major advance made by the current study is to
characterize distinct molecules responsible in sea urchin responses to wounding and to the
presence of pathogen-associated antigens, such as LPS. In particular, it shows that there
are discrete suites of proteins that respond specifically to immunological challenge.

185
4.7. Acknowledgments
We thank Dr. Dana Pascovici for assistance with statistical analysis. The research
has been facilitated by access to the Australian Proteome Analysis Facility established
under the Australian Government’s Major National Research Facilities Program. NM
Dheilly is the recipient of an iMURS postgraduate scholarship from Macquarie University.
This study was funded in part by an Australian Research Council Discovery grant to DA
Raftos and LC Smith (DP0880316).

186
4.8. References
[1] Rock, F. L., Hardiman, G., Timans, J. C., Kastelein, R. A., Bazan, J. F., A family of
human receptors structurally related to Drosophila Toll. Proc Natl Acad Sci U S A
1998, 95, 588-593.
[2] Hoffmann, J. A., The immune response of Drosophila. Nature 2003, 426, 33-38.
[3] Sodergren, E., Weinstock, G.M., Davidson, E.H., Cameron, R., A. et al. The genome of
the sea urchin Strongylocentrotus purpuratus. Science 2006, 314, 941-952.
[4] Cameron, R., Mahairas, G., Rast, J., Martinez, P., et al., A sea urchin genome project:
sequence scan, virtual map, and additional resources. Proc Natl Acad Sci U S A
2000, 97, 9514-9518.
[5] Nair, S. V., Del Valle, H., Gross, P. S., Terwilliger, D. P., Smith, L. C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin.
Identification of unexpected immune diversity in an invertebrate. Physiol Genomics
2005, 22, 33-47.
[6] Smith, L. C., Clow, L. A., Terwilliger, D. P., The ancestral complement system in sea
urchins. Immunol Rev 2001, 180, 16-34.
[7] Rast, J. P., Smith, L. C., Loza-Coll, M., Hibino, T., Litman, G. W., Genomic insights
into the immune system of the sea urchin. Science 2006, 314, 952-956.
[8] Fugmann, S. D., Messier, C., Novack, L. A., Cameron, R. A., Rast, J. P., An ancient
evolutionary origin of the Rag1/2 gene locus. Proc Natl Acad Sci U S A 2006, 103,
3728-3733.
[9] Gross, P. S., Al-Sharif, W. Z., Clow, L. A., Smith, L. C., Echinoderm immunity and the
evolution of the complement system. Dev Comp Immunol 1999, 23, 429-442.
[10] Domon, B., Aebersold, R., Mass spectrometry and protein analysis. Science 2006,
312, 212-217.

187
[11] Gross, P. S., Clow, L. A., Smith, L. C., SpC3, the complement homologue from the
purple sea urchin, Strongylocentrotus purpuratus, is expressed in two
subpopulations of the phagocytic coelomocytes. Immunogenetics 2000, 51, 1034-
1044.
[12] Clow, L. A., Gross, P. S., Shih, C.-S., Smith, L. C., Expression of SpC3, the sea
urchin complement component, in response to lipopolysaccharide. Immunogenetics
2000, 51, 1021-1033.
[13] Terwilliger, D., Buckley, K., Brockton, V., Ritter, N., Smith, L. C., Distinctive
expression patterns of 185/333 genes in the purple sea urchin, Strongylocentrotus
purpuratus: an unexpectedly diverse family of transcripts in response to LPS, beta-
1,3-glucan, and dsRNA. BMC Mol Biol 2007, 8, 16.
[14] Smith, L., Britten, R., Davidson, E., Lipopolysaccharide activates the sea urchin
immune system. Dev Comp Immunol 1995, 19, 217-224.
[15] Laemmli, U. K., Cleavage of structural proteins during the assembly of the head of
bacteriophage T4. Nature 1970, 227, 680-685.
[16] Candiano, G., Bruschi, M., Musante, L., Santucci, L., et al., Blue silver: a very
sensitive colloidal coomassie G-250 staining for proteome analysis. Electrophoresis
2004, 25, 1327-1333.
[17] Dheilly, N. M., Nair, S. V., Smith, L. C., Raftos, D. A., Highly variable immune-
response proteins (185/333) from the sea urchin, Strongylocentrotus purpuratus:
proteomic analysis identifies diversity within and between individuals. J Immunol
2009, 182, 2203-2212.
[18] Breci, L., Hattrup, E., Keeler, M., Letarte, J., et al., Comprehensive proteomics in
yeast using chromatographic fractionation, gas phase fractionation, protein gel
electrophoresis, and isoelectric focusing. Proteomics 2005, 5, 2018-2028.

188
[19] Craig, R., Beavis, R. C., A method for reducing the time required to match protein
sequences with tandem mass spectra. Rapid Communications in Mass Spectrometry
2003, 17, 2310-2316.
[20] Craig, R., Beavis, R. C., TANDEM: matching proteins with tandem mass spectra.
Bioinformatics 2004, 20, 1466-1467.
[21] Peng, J., Elias, J. E., Thoreen, C. C., Licklider, L. J., Gygi, S. P., Evaluation of
multidimensional chromatography coupled with tandem mass spectrometry
(LC/LC‚ MS/MS) for large-scale protein analysis: the yeast proteome. J Proteome
Res 2002, 2, 43-50.
[22] Haynes, P. A., Miller, S., Radabaugh, T., Galligan, M., et al., The wildcat toolbox: a
set of perl script utilities for use in peptide mass spectral database searching and
proteomics experiments. J Biomol Tech 2008, 17, 97-102.
[23] Rohrbough, J. G., Breci, L., Merchant, N., Miller, S., Haynes, P. A., Verification of
single-peptide protein identifications by the application of complementary database
search algorithms. J Biomol Tech 2006, 17, 327-332.
[24] Zybailov, B. L., Florens, L., P., W. M., Quantitative shotgun proteomics using a
protease with broad specificity and normalized spectral abundance factors. Mol
Biosyst 2007, 3, 354-360.
[25] Smith, L., Chang, L., Britten, R., Davidson, E., Sea urchin genes expressed in
activated coelomocytes are identified by expressed sequence tags. Complement
homologues and other putative immune response genes suggest immune system
homology within the deuterostomes. J Immunol 1996, 156, 593-602.
[26] Nobes, C. D., Hall, A., Rho, Rac, and Cdc42 GTPases regulate the assembly of
multimolecular focal complexes associated with actin stress fibers, lamellipodia,
and filopodia. Cell 1995, 81, 53-62.
[27] Hall, A., Rho GTPases and the actin cytoskeleton. Science 1998, 279, 509-514.

189
[28] Vignjevic, D., Kojima, S.-i., Aratyn, Y., Danciu, O., et al., Role of fascin in filopodial
protrusion. J Cell Biol 2006, 174, 863-875.
[29] Edds, K., Dynamic aspects of filopodial formation by reorganization of
microfilaments. J Cell Biol 1977, 73, 479-491.
[30] Edds, K. T., The formation and elongation of filopodia during transformation of sea
urchin coelomocytes. Cell Motil Cytoskeleton 1980, 1, 131-140.
[31] Chien, P. K., Johnson, P. T., Holland, N. D., Chapman, F. A., The coelomic elements
of sea urchins (Strongylocentrotus). Protoplasma 1970, 71, 419-442.
[32] Johnson, P., The coelomic elements of the sea urchins (Strongulocentrotus) III. In
vitro reaction to bacteria. J. Invert. Pathol. 1969, 13, 42-62.
[33] Wang, L., Spudich, J., A 45,000-mol-wt protein from unfertilized sea urchin eggs
severs actin filaments in a calcium-dependent manner and increases the steady-state
concentration of nonfilamentous actin. J. Cell Biol. 1984, 99, 844-851.
[34] Kremer, B. E., Haystead, T., Macara, I. G., Mammalian septins regulate microtubule
stability through interaction with the microtubule-binding protein MAP4. Mol Biol
Cell 2005, 16, 4648-4659.
[35] Spiliotis, E. T., Nelson, W. J., Here come the septins: novel polymers that coordinate
intracellular functions and organization. J Cell Sci 2006, 119, 4-10.
[36] Huang, Y.-W., Yan, M., Collins, R. F., DiCiccio, J. E., et al., Mammalian septins are
required for phagosome formation. Mol Biol Cell 2008, 19, 1717-1726.
[37] Mendoza, M., Hyman, A. A., Glotzer, M., GTP binding induces filament assembly of
a recombinant septin. Curr Biol 2002, 12, 1858-1863.
[38] Low, C., Macara, I. G., Structural analysis of septin 2, 6, and 7 complexes. J Biol
Chem 2006, 281, 30697-30706.
[39] Shyu, A. B., Raff, R. A., Blumenthal, T., Expression of the vitellogenin gene in
female and male sea urchin. Proc Natl Acad Sci U S A 1986, 83, 3865-3869.

190
[40] Smolenaars, M. M. W., Madsen, O., Rodenburg, K. W., Van der Horst, D. J.,
Molecular diversity and evolution of the large lipid transfer protein superfamily. J
Lipid Res 2007, 48, 489-502.
[41] Brooks, J. M., Wessel, G. M., The major yolk protein in sea urchins is a transferrin-
like, iron binding protein. Dev Biol 2002, 245, 1-12.
[42] Cervello, M., Arizza, V., Lattuca, G., Parrinello, N., Matranga, V., Detection of
vitellogenin in a subpopulation of sea urchin coelomocytes. Eur J Cell Biol 1994,
64, 314-319.
[43] Miller, Y. I., Chang, M. K., Binder, C. J., Shaw, P. X., Witztum, J. L., Oxidized low
density lipoprotein and innate immune receptors. Curr Opin Lipidol 2003, 14, 437-
445.
[44] Elzen, P. v. d., Garg, S., Leon, L., Brigl, M., et al., Apolipoprotein-mediated pathways
of lipid antigen presentation. Nature 2005, 437, 906-910.
[45] Avarre, J.-C., Lubzens, E., Babin, P., Apolipocrustacein, formerly vitellogenin, is the
major egg yolk precursor protein in decapod crustaceans and is homologous to
insect apolipophorin II/I and vertebrate apolipoprotein B. BMC Evol Biol 2007, 7,
3.
[46] Kim, H. J., Je, H. J., Park, S. Y., Lee, I. H., et al., Immune activation of
apolipophorin-III and its distribution in hemocyte from Hyphantria cunea. Insect
Biochem Mol Biol 2004, 34, 1011-1023.
[47] Cheon, H., Shin, S., Bian, G., Park, J., Raikhel, A., Regulation of lipid metabolism
genes, lipid carrier protein lipophorin, and its receptor during immune challenge in
the mosquito Aedes aegypti. J Biol Chem 2006, 281, 8426-8435.
[48] Ma, G., Hay, D., Li, D., Asgari, S., Schmidt, O., Recognition and inactivation of LPS
by lipophorin particles. Dev Comp Immunol 2006, 30, 619-626.

191
[49] Allain, F., Durieux, S., Denys, A., Carpentier, M., Spik, G., Cyclophilin B binding to
platelets supports calcium-dependent adhesion to collagen. Blood 1999, 94, 976-
983.
[50] Farndale, R. W., Sixma, J. J., Barnes, M. J., Groot, P. G. D., The role of collagen in
thrombosis and hemostasis. Journal of Thrombosis and Haemostasis 2004, 2, 561-
573.
[51] Vasta, G. R., Quesenberry, M., Ahmed, H., O'Leary, N., C-type lectins and galectins
mediate innate and adaptive immune functions: their roles in the complement
activation pathway. Dev Comp Immunol 1999, 23, 401-420.
[52] Schwechheimer, C., Deng, X.-W., COP9 signalosome revisited: a novel mediator of
protein degradation. Trends Cell Biol 2001, 11, 420-426.
[53] Nagase, H., Woessner, J. F., Jr., Matrix metalloproteinases. J Biol Chem 1999, 274,
21491-21494.
[54] Lepore, L. S., Roelvink, P. R., Granados, R. R., Enhancin, the granulosis virus protein
that facilitates nucleopolyhedrovirus (NPV) infections, is a metalloprotease. J
Invertebr Pathol 1996, 68, 131-140.
[55] Montagnani, C., Le Roux, F., Berthe, F., Escoubas, J.-M., Cg-TIMP, an inducible
tissue inhibitor of metalloproteinase from the Pacific oyster Crassostrea gigas with
a potential role in wound healing and defense mechanisms. FEBS Lett 2001, 500,
64-70.
[56] Csukai, M., Chen, C.-H., De Matteis, M. A., Mochly-Rosen, D., The coatomer protein
beta-COP, a selective binding protein (RACK) for protein kinase C epsilon. J Biol
Chem 1997, 272, 29200-29206.
[57] Loseva, O., Engstrom, Y., Analysis of signal-dependent changes in the proteome of
Drosophila blood cells during an immune response. Mol Cell Proteomics 2004, 3,
796-808.

192
[58] Eglen, R. M., Bosse, R., Reisine, T., Emerging concepts of guanine nucleotide-
binding protein-coupled receptor (GPCR) function and implications for high
throughput screening. Assay Drug Dev Technol 2007, 5, 425-452.
[59] Qi, M., Elion, E. A., MAP kinase pathways. J Cell Sci 2005, 118, 3569-3572.
[60] Rada, B. K., Geiszt, M., Kaldi, K., Timar, C., Ligeti, E., Dual role of phagocytic
NADPH oxidase in bacterial killing. Blood 2004, 104, 2947-2953.
[61] Blandin, S., Levashina, E. A., Thioester-containing proteins and insect immunity. Mol
Immunol 2004, 40, 903-908.
[62] Al-Sharif, W. Z., Sunyer, J. O., Lambris, J. D., Smith, L. C., Sea urchin coelomocytes
specifically express a homologue of the complement component C3. J Immunol
1998, 160, 2983-2997.
[63] Clow, L. A., Raftos, D. A., Gross, P. S., Smith, L. C., The sea urchin complement
homologue, SpC3, functions as an opsonin. J Exp Biol 2004, 207, 2147-2155.
[64] Mina-Osorio, P., Ortega, E., Aminopeptidase N (CD13) functionally interacts with Fc
gamma Rs in human monocytes. J Leukoc Biol 2005, 77, 1008-1017.
[65] Tokuda, N., Levy, R. B., 1,25-dihydroxyvitamin D3 stimulates phagocytosis but
supresses HLA-DR and CD13 antigen expression in human mononuclear
phagocytes. Proceedings of the society for experimental biology and medicine
1996, 211, 244-250.
[66] Granhagen, K., Lundstron, A., Bjorstad, A., Bylund, J., et al., Galectin-3 binds CD 13,
activates the NADPH-oxidase, and augments neutrophil inactivation of the
chemotactic peptide fMLF: 69. Eur J Clin Invest 2007, 37, 23.
[67] Mina-Osorio, P., Soto-Cruz, I., Ortega, E., A role for galectin-3 in CD13-mediated
homotypic aggregation of monocytes. Biochem Biophys Res Commun 2007, 353,
605-610.

193
[68] Ingersoll, E., An analysis of aminopeptidase N genes in the sea urchin genome. Dev
Biol 2008, 319, 566-566.
[69] Hogan, M. C., Griffin, M. D., Rossetti, S., Torres, V. E., et al., PKHDL1, a homolog
of the autosomal recessive polycystic kidney disease gene, encodes a receptor with
inducible T lymphocyte expression. Hum Mol Genet 2003, 12, 685-698.
[70] Pancer, Z., Rast, J. P., Davidson, E. H., Origins of immunity: transcription factors and
homologues of effector genes of the vertebrate immune system expressed in sea
urchin coelomocytes. Immunogenetics 1999, 49, 773-786.
[71] Pancer, Z., Dynamic expression of multiple scavenger receptor cysteine-rich genes in
coelomocytes of the purple sea urchin. Proc Natl Acad Sci U S A 2000, 97, 13156-
13161.

194

195
Supplementary Data 4.1: Normalized spectral abundance factors. NSAF values for the
345 proteins identified in the CF of non-injected sea urchins (NI), 6 hours after saline
injection (W6), 24 hours after saline injection (W24), 48 hours after saline injection
(W48), 6 hours after LPS injection (LPS6), 24 hours after LPS injection (LPS24) and 48
hours after LPS injection (LPS48).

196
Identifier Description NI1 NI2 NI3 W61 W62 W63
gi|115942229| PREDICTED: similar to integrin-linked kinase 1E-09 3E-06 7E-06 3E-06 3E-06 2E-06
gi|115959822| PREDICTED: similar to annexin 2E-05 2E-05 2E-05 1E-09 1E-09 1E-05
gi|115940188| PREDICTED: similar to peptidylprolyl isomerase B isoform 2 . 6E-06 6E-06 7E-06 1E-05 1E-09 1E-09
gi|115975224| PREDICTED: similar to G-cadherin 3E-06 1E-09 1E-06 4E-07 1E-09 1E-09
gi|115910910| PREDICTED: hypothetical protein, partial (Fibronectin) 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115720465| PREDICTED: similar to selectin-like protein, partial . 1E-09 1E-09 1E-09 1E-09 1E-05 1E-09
gi|115960842| PREDICTED: similar to talin 2E-06 4E-06 3E-06 5E-07 1E-06 2E-06
gi|115970015| PREDICTED: similar to von Willebrand factor 1E-05 1E-05 8E-06 1E-09 1E-06 1E-09
gi|115963192| PREDICTED: similar to Annexin A4 (Annexin IV) (Lipocortin
IV) (Endonexin I) (Chromobindin-4) (Protein II) (P32.5)
(Placental
6E-05 9E-05 6E-05 6E-05 3E-05 5E-05
gi|115944296| PREDICTED: hypothetical protein (Galectin) 5E-05 7E-05 0.0001 6E-05 1E-09 7E-05
gi|75753591| amassin 5E-05 1E-05 5E-05 6E-05 2E-05 2E-06
gi|115951499| PREDICTED: hypothetical protein (septin2) 6E-06 3E-06 4E-06 1E-09 1E-09 1E-09
gi|115968740| PREDICTED: similar to Septin 6 3E-06 6E-06 1E-09 5E-06 3E-06 1E-05
gi|115940910| PREDICTED: hypothetical protein (septin7) 3E-06 1E-05 3E-06 1E-09 1E-09 5E-06
gi|115939093| PREDICTED: hypothetical protein (septin 9 fusion) 2E-05 2E-05 1E-05 1E-09 1E-09 8E-06
gi|115955362| PREDICTED: similar to apextrin 1E-09 7E-06 1E-05 1E-09 1E-09 1E-09
gi|115956476| PREDICTED: similar to apextrin 6E-06 9E-05 0.0001 5E-06 2E-05 1E-09
gi|115959937| PREDICTED: similar to echinonectin 6E-06 8E-06 8E-06 3E-06 1E-09 2E-06
gi|115770276| PREDICTED: similar to zonadhesin 2E-05 5E-05 4E-05 6E-06 2E-06 3E-06
gi|115899605| PREDICTED: similar to echinonectin, partial 3E-05 3E-05 2E-05 4E-05 1E-09 1E-09
gi|115945705| PREDICTED: similar to EH-domain-containing protein 1
(Testilin) (hPAST1)
9E-05 9E-05 9E-05 7E-05 7E-05 8E-05
gi|115944978| PREDICTED: similar to COP9 complex subunit 4 3E-06 4E-06 1E-09 1E-09 1E-09 1E-09
gi|34100406| calmodulin-dependent protein kinase type II 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09
gi|115958659| PREDICTED: hypothetical protein (arfaptin) 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09
gi|115894557| PREDICTED: similar to RACK 1E-05 1E-05 6E-06 1E-09 1E-09 1E-09
gi|115940258| PREDICTED: hypothetical protein (lipid raft asssocitaed
protein 2)
1E-09 1E-09 1E-09 1E-09 1E-09 5E-06
gi|115955418| PREDICTED: similar to 5-aminoimidazole ribonucleotide (AIR)
carboxylase-5- aminoimidazole-4-N-succinocarboxamide
ribonucleotide (SAICAR) synthetase isoform 1
3E-06 6E-06 4E-06 1E-09 1E-09 1E-09
gi|115969931| PREDICTED: similar to Creatine kinase, flagellar 3E-06 1E-09 8E-06 1E-06 1E-09 1E-09
gi|115671024| PREDICTED: similar to KIAA0051, partial (IQ motif containing
GTPase activating protein)
3E-06 1E-05 1E-05 1E-09 1E-09 1E-09
gi|47551303| guanine nucleotide-binding protein G(q) alpha subunit 1E-05 2E-05 1E-05 1E-09 1E-09 1E-09
gi|115975377| PREDICTED: similar to protein kinase C, partial 1E-09 7E-06 8E-06 1E-09 1E-09 1E-09
gi|115926118| PREDICTED: similar to CG6950-PC (kynurenine
aminotransferase)
9E-06 3E-06 7E-06 1E-05 7E-06 5E-06
gi|115973422| PREDICTED: similar to adenylate kinase 2 5E-06 2E-05 1E-05 2E-05 1E-09 1E-09
gi|115951428| PREDICTED: similar to LOC615074 protein isoform 2 cAMP-
dependent protein kinase)
1E-05 7E-06 8E-06 1E-09 1E-09 3E-06
gi|115959301| PREDICTED: similar to Protein phosphatase 2A, catalytic
subunit, beta isoform
8E-06 8E-06 9E-06 1E-09 1E-09 1E-09
gi|115960271| PREDICTED: similar to protein Phosphatase 2C beta 3E-06 7E-06 3E-05 1E-09 1E-09 1E-09
gi|115946171| PREDICTED: similar to beta-arrestin 1, putative 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115937294| PREDICTED: similar to beta-parvin 1E-05 2E-05 1E-05 1E-09 4E-06 1E-09
gi|115974058| PREDICTED: similar to GTP binding protein 3E-06 3E-06 2E-05 9E-06 4E-06 3E-06
gi|115944458| PREDICTED: similar to calponin 7E-06 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115974451| PREDICTED: similar to GTPase SUrab10p 6E-05 1E-09 6E-05 5E-06 1E-09 1E-09
gi|115965021| PREDICTED: similar to BAI1-associated protein 2 9E-07 4E-06 2E-06 2E-06 3E-06 3E-06
gi|47550939| calreticulin 6E-06 6E-06 1E-09 1E-09 1E-09 1E-09
gi|115975046| PREDICTED: similar to GTP-binding nuclear protein Ran 2E-05 2E-05 3E-05 2E-05 1E-09 1E-09
gi|115960970| PREDICTED: similar to proliferation-associated protein 1 6E-06 2E-05 4E-05 1E-09 1E-09 1E-09
gi|115975006| PREDICTED: similar to RAB2 isoform 2 3E-05 4E-05 4E-05 1E-09 1E-09 1E-09
gi|115940411| PREDICTED: similar to 14-3-3-like protein 2 3E-05 1E-09 1E-09 1E-05 1E-09 1E-09
gi|115971397| PREDICTED: similar to centaurin, alpha 1 2E-05 5E-05 1E-09 1E-09 1E-09 1E-05
gi|115945715| PREDICTED: similar to Ras-related protein ORAB-1 1E-05 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115958373| PREDICTED: similar to Rab5 protein 4E-05 2E-05 1E-05 5E-06 1E-09 1E-05
gi|115774726| PREDICTED: hypothetical protein, partial
(phosphatidylinositol-5-phosphate 4-kinase)
7E-06 7E-06 2E-05 1E-09 1E-09 1E-09
gi|115968476| PREDICTED: similar to ENSANGP00000018350 (centaurin) 3E-05 4E-05 4E-06 7E-06 1E-09 1E-09
gi|115926041| PREDICTED: similar to protein-tyrosine phosphatase 1E-09 7E-06 8E-06 1E-09 1E-09 6E-06
gi|115939472| PREDICTED: similar to ENSANGP00000023777 (CDC42, cell
division cycle 42)
1E-09 1E-09 1E-09 1E-05 1E-09 3E-05
gi|115976839| PREDICTED: similar to GDP-dissociation inhibitor 1E-09 2E-05 1E-05 1E-05 4E-06 1E-09
gi|115938855| PREDICTED: similar to Rab11b 3E-05 6E-06 3E-05 4E-05 7E-06 2E-05
gi|115939823| PREDICTED: similar to catalytic subunit of cAMP-dependent
histone kinase
2E-05 3E-05 1E-05 6E-06 4E-06 3E-06
gi|47825404| guanine nucleotide-binding protein G(12) alpha subunit . 2E-05 2E-05 4E-05 9E-06 1E-09 1E-09
gi|115953926| PREDICTED: similar to Rho1 GTPase isoform 2 3E-05 1E-09 2E-05 2E-05 1E-09 1E-09
gi|47551197| src-family protein tyrosine kinase 1E-09 7E-06 3E-06 9E-06 6E-06 1E-09
gi|47825398| guanine nucleotide-binding protein G(s) alpha subunit . 3E-05 5E-05 2E-05 2E-05 1E-05 8E-06
gi|115929326| PREDICTED: similar to KIAA1646 protein (ceramide kinase) 1E-05 2E-06 7E-06 2E-06 2E-06 2E-06
gi|115949757| PREDICTED: similar to Rap1b-prov protein 7E-06 2E-05 1E-09 6E-06 1E-09 1E-05
gi|115966293| PREDICTED: similar to RAS-related protein MEL . 7E-05 7E-05 7E-05 1E-05 1E-09 5E-06
gi|160623362| putative 14-3-3 epsilon isoform 6E-05 1E-09 1E-09 4E-05 7E-06 3E-05
NSAF

197
NSAF
W241 W242 W243 W481 W482 W483 LPS61 LPS62 LPS63 LPS241 LPS242 LPS243 LPS481 LPS482 LPS483
1E-09 1E-09 1E-09 5E-06 7E-06 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09 6E-06 9E-06 1E-05
4E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09
2E-06 1E-09 3E-05 4E-06 5E-06 2E-05 1E-09 1E-09 1E-09 1E-05 1E-05 1E-05 1E-05 2E-05 2E-05
3E-07 1E-09 1E-09 1E-09 3E-06 2E-06 8E-07 5E-07 1E-06 1E-09 1E-09 4E-07 2E-06 1E-06 3E-06
1E-09 3E-06 1E-09 1E-06 2E-06 4E-06 1E-09 1E-09 1E-09 1E-09 1E-09 2E-06 8E-06 9E-06 7E-05
2E-06 3E-05 4E-05 6E-05 6E-05 4E-05 1E-09 2E-05 1E-09 3E-06 3E-06 2E-05 7E-05 0.0001 0.0001
3E-06 1E-09 3E-06 8E-06 7E-06 5E-06 1E-06 3E-06 2E-06 1E-09 8E-07 2E-06 1E-05 1E-05 1E-09
3E-07 1E-09 1E-06 3E-06 2E-06 1E-06 1E-09 1E-06 1E-09 8E-06 8E-07 2E-06 5E-06 6E-06 1E-05
9E-06 1E-05 2E-05 3E-05 3E-05 2E-05 3E-05 3E-05 4E-05 9E-06 9E-06 1E-05 5E-05 5E-05 1E-09
2E-05 7E-06 4E-05 0.0001 0.0002 5E-05 5E-05 0.0001 3E-05 2E-06 2E-06 1E-09 0.0001 0.0001 4E-05
2E-05 4E-05 5E-05 8E-05 5E-05 7E-05 5E-05 0.0001 1E-06 3E-05 1E-05 2E-05 6E-05 4E-05 0.0002
1E-09 1E-09 1E-09 1E-05 3E-05 5E-06 1E-09 3E-06 1E-09 2E-06 1E-09 1E-09 1E-05 2E-05 4E-06
9E-07 1E-09 1E-09 1E-05 1E-05 1E-09 1E-09 1E-09 1E-06 1E-06 3E-06 1E-09 1E-05 2E-05 1E-09
2E-06 1E-09 1E-09 2E-05 1E-05 6E-06 1E-09 1E-09 1E-06 2E-06 2E-06 1E-06 9E-06 8E-06 8E-06
4E-06 1E-09 2E-06 7E-06 1E-09 1E-09 1E-09 2E-06 1E-09 1E-09 2E-06 4E-06 1E-09 2E-06 1E-09
1E-06 1E-09 6E-06 1E-05 2E-05 2E-06 2E-06 1E-09 9E-06 1E-09 1E-09 3E-06 8E-06 1E-05 4E-05
1E-09 9E-06 4E-06 2E-05 1E-09 1E-09 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 1E-05 1E-09 1E-09
2E-06 4E-06 1E-06 3E-06 5E-06 1E-06 3E-06 2E-06 2E-06 1E-09 2E-06 2E-06 2E-06 3E-06 1E-05
3E-06 5E-06 4E-06 2E-05 2E-05 1E-05 2E-05 6E-06 1E-05 1E-06 3E-06 1E-06 2E-05 2E-05 3E-05
2E-05 2E-05 3E-06 2E-05 7E-05 7E-05 2E-05 2E-05 5E-06 1E-09 9E-06 2E-05 3E-05 3E-05 1E-04
4E-05 3E-05 6E-05 4E-05 4E-05 5E-05 4E-05 4E-05 0.0001 9E-05 3E-05 4E-05 5E-05 7E-05 6E-05
2E-06 1E-09 1E-09 7E-06 8E-06 3E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-05
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 3E-06 1E-09 5E-06 1E-06 1E-06 1E-09 1E-05 4E-06
3E-06 1E-05 1E-09 4E-06 5E-06 3E-06 1E-09 1E-09 5E-06 1E-09 1E-09 1E-09 1E-09 3E-06 1E-09
1E-06 1E-09 1E-09 3E-06 4E-06 1E-09 1E-09 1E-09 1E-09 1E-09 2E-06 1E-09 1E-05 1E-05 7E-06
1E-09 1E-09 1E-09 3E-06 1E-05 2E-05 2E-05 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09 1E-09 2E-05
2E-06 1E-09 1E-09 4E-06 1E-05 1E-09 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09 6E-06 4E-06
7E-07 1E-09 1E-06 7E-07 2E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 4E-06 1E-06 2E-06
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 2E-06 1E-09 1E-09 1E-09 1E-09 4E-06 5E-06 1E-09
1E-06 1E-09 1E-09 4E-06 3E-06 1E-05 1E-09 1E-09 1E-09 1E-09 1E-06 1E-09 1E-09 7E-06 1E-09
1E-09 1E-09 1E-09 5E-06 1E-05 1E-09 1E-09 7E-06 1E-09 1E-09 4E-06 1E-09 1E-05 2E-05 1E-09
1E-09 1E-09 1E-09 1E-09 2E-06 1E-09 2E-06 1E-09 3E-06 1E-09 1E-09 1E-09 7E-06 6E-06 9E-06
2E-06 1E-09 1E-09 7E-06 9E-06 1E-09 1E-09 1E-09 3E-06 8E-06 6E-06 1E-09 6E-06 1E-09 8E-06
2E-06 1E-09 1E-09 9E-06 2E-05 3E-06 1E-09 1E-09 1E-09 1E-09 1E-06 1E-09 1E-09 1E-09 1E-05
2E-06 1E-09 1E-09 8E-06 1E-05 1E-09 1E-09 1E-09 1E-09 4E-06 3E-06 3E-06 9E-06 8E-06 1E-09
1E-09 1E-09 1E-09 6E-06 8E-06 1E-09 1E-09 7E-06 1E-09 2E-06 1E-06 1E-06 4E-06 3E-06 1E-09
1E-09 1E-09 1E-09 5E-06 2E-05 6E-06 1E-09 4E-06 1E-09 7E-06 6E-06 1E-06 2E-05 4E-06 5E-06
1E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-05 4E-06 8E-06 1E-09 1E-09
1E-09 1E-09 1E-09 8E-06 5E-06 1E-09 1E-09 9E-06 1E-09 1E-06 1E-06 1E-06 1E-05 7E-06 5E-06
4E-06 3E-05 9E-06 8E-06 4E-05 1E-05 1E-05 1E-09 4E-06 2E-06 3E-06 3E-06 2E-05 7E-06 2E-05
1E-09 1E-09 1E-09 7E-06 2E-05 1E-05 1E-09 1E-09 9E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
3E-07 1E-09 1E-06 1E-09 1E-06 7E-07 1E-09 1E-09 3E-06 3E-07 1E-09 7E-07 1E-09 9E-07 1E-09
1E-09 1E-09 1E-09 1E-05 7E-06 9E-06 1E-09 6E-06 1E-09 1E-09 2E-06 1E-09 1E-05 3E-05 1E-09
3E-06 1E-09 7E-06 7E-06 1E-09 1E-09 5E-06 1E-05 3E-06 2E-05 6E-06 6E-06 1E-09 1E-09 1E-09
1E-09 1E-09 1E-09 2E-05 5E-06 1E-05 1E-09 1E-09 1E-09 1E-06 1E-09 1E-06 4E-06 1E-05 1E-09
2E-06 1E-09 1E-09 2E-05 5E-06 1E-05 1E-09 1E-05 3E-06 6E-06 5E-06 7E-06 7E-06 1E-05 1E-09
1E-09 2E-05 1E-09 8E-06 1E-05 1E-05 4E-06 1E-05 7E-06 6E-06 1E-09 1E-09 1E-09 1E-05 2E-05
1E-09 1E-09 1E-09 1E-05 9E-06 9E-06 1E-09 2E-05 6E-06 8E-06 1E-09 6E-06 7E-06 2E-05 1E-09
1E-05 1E-09 1E-09 2E-05 3E-05 1E-05 1E-09 2E-05 1E-05 1E-09 5E-06 1E-05 3E-05 3E-05 1E-05
4E-06 1E-09 2E-05 2E-05 1E-05 2E-05 1E-05 1E-09 9E-06 4E-06 2E-06 5E-06 1E-05 1E-05 1E-09
1E-09 1E-09 1E-09 2E-05 3E-06 8E-06 1E-09 3E-06 2E-06 1E-09 1E-09 3E-06 3E-05 4E-05 1E-05
1E-06 1E-09 1E-09 1E-05 9E-06 6E-06 1E-09 1E-09 1E-09 9E-06 7E-06 1E-05 1E-09 7E-06 1E-09
2E-06 1E-09 1E-09 1E-05 9E-06 8E-06 1E-09 2E-06 9E-06 3E-06 1E-09 9E-07 8E-06 1E-05 7E-06
1E-09 1E-09 1E-09 3E-05 5E-05 1E-05 5E-06 6E-05 2E-05 5E-06 1E-09 1E-09 2E-05 7E-05 1E-09
7E-06 1E-09 1E-09 2E-05 3E-05 9E-06 1E-09 1E-09 1E-09 8E-06 4E-06 1E-09 2E-05 2E-05 1E-09
4E-06 1E-09 1E-05 2E-05 9E-06 9E-06 3E-05 1E-09 9E-06 1E-09 1E-09 2E-06 3E-05 4E-05 1E-09
1E-09 1E-09 1E-09 2E-05 3E-05 3E-05 1E-09 3E-06 1E-09 2E-06 1E-06 1E-09 3E-05 1E-09 1E-09
5E-06 1E-09 1E-09 2E-06 1E-09 5E-06 1E-09 1E-09 9E-06 8E-06 5E-06 1E-05 1E-05 7E-06 1E-09
4E-06 1E-05 2E-05 4E-06 2E-05 2E-05 3E-05 0.0001 7E-06 5E-06 1E-09 7E-06 3E-05 7E-05 1E-09
8E-06 1E-09 1E-09 1E-05 2E-06 8E-06 1E-09 2E-05 4E-06 6E-06 6E-06 1E-09 1E-05 1E-05 4E-06
1E-09 1E-09 1E-09 1E-05 1E-05 1E-09 1E-09 2E-05 2E-05 1E-09 1E-09 1E-09 1E-09 3E-05 1E-09
3E-06 7E-06 2E-05 4E-06 2E-06 3E-06 3E-06 4E-06 5E-06 6E-06 8E-06 5E-06 1E-05 2E-05 1E-09
2E-05 2E-05 5E-05 2E-05 3E-05 1E-09 1E-05 5E-05 1E-05 2E-05 5E-06 2E-05 2E-05 8E-05 1E-09
9E-06 1E-09 4E-05 2E-05 1E-09 1E-09 2E-05 2E-05 2E-05 6E-06 1E-09 9E-06 3E-05 2E-05 1E-09
1E-05 1E-05 2E-05 2E-05 1E-09 5E-05 1E-09 7E-05 1E-09 1E-09 1E-09 1E-09 3E-05 5E-05 4E-05

198
Identifier Description NI1 NI2 NI3 W61 W62 W63
gi|115891186| PREDICTED: hypothetical protein, partial (kynurenine
aminotransferase)
1E-09 1E-09 6E-06 4E-05 2E-05 2E-05
gi|47551261| MAP kinase 1E-05 7E-06 2E-05 6E-06 4E-06 6E-06
gi|115974362| PREDICTED: similar to Rab7 4E-05 6E-05 7E-05 2E-05 1E-09 1E-05
gi|115960532| PREDICTED: similar to Src-type protein tyrosine kinase
isoform 2
7E-06 1E-05 1E-05 2E-05 2E-05 1E-09
gi|115934007| PREDICTED: similar to TRAF4-associated factor 2 . 2E-05 3E-05 2E-05 2E-05 2E-05 2E-05
gi|115976312| PREDICTED: similar to CG8649-PC (calponin) 3E-05 2E-05 2E-05 1E-09 6E-06 1E-09
gi|47825400| guanine nucleotide-binding protein G(i) alpha subunit . 5E-05 5E-05 4E-05 3E-05 1E-09 3E-05
gi|115945943| PREDICTED: similar to ENSANGP00000011972 (GDP
dissociation inhibitor)
5E-05 3E-05 5E-05 2E-05 1E-05 2E-05
gi|115968621| PREDICTED: similar to calponin 0.0001 0.0001 0.0001 9E-05 2E-05 9E-05
gi|115936805| PREDICTED: similar to heterotrimeric guanine nucleotide-
binding protein beta subunit isoform 2 .
0.0002 0.0003 0.0004 2E-05 1E-09 4E-05
gi|115970013| PREDICTED: similar to apolipoprotein B 1E-05 9E-06 1E-05 7E-06 2E-06 4E-06
gi|115940166| PREDICTED: similar to apolipoprotein B 1E-05 8E-06 2E-05 1E-09 1E-09 1E-09
gi|115956784| PREDICTED: similar to epsin 2 5E-06 2E-06 3E-06 1E-09 1E-09 1E-09
gi|115964211| PREDICTED: similar to Actr1a-prov protein (actin related
protein 1 homologue A)
1E-09 1E-09 1E-09 6E-06 4E-06 6E-06
gi|115699240| PREDICTED: similar to ankyrin 2,3/unc44 1E-09 1E-09 3E-06 1E-09 2E-06 1E-09
gi|115974713| PREDICTED: hypothetical protein (dysferlin C2 superfamily) 1E-05 2E-05 1E-05 1E-09 1E-09 1E-09
gi|115951109| PREDICTED: similar to tensilin 3E-05 2E-05 2E-05 1E-09 1E-09 4E-06
gi|115974054| PREDICTED: similar to fibropellin Ia 6E-06 6E-06 7E-06 1E-09 1E-09 1E-09
gi|115975440| PREDICTED: similar to moesin 2E-06 2E-06 2E-06 1E-09 5E-06 1E-09
gi|115961148| PREDICTED: similar to gelsolin 1E-09 1E-09 2E-05 3E-06 4E-06 1E-09
gi|115974666| PREDICTED: similar to coronin 3E-06 5E-06 6E-06 1E-05 1E-09 2E-06
gi|115950170| PREDICTED: similar to long microtubule-associated protein
1A; long MAP1A
2E-06 3E-06 3E-06 1E-09 1E-09 1E-09
gi|115925414| PREDICTED: similar to KIAA0727 protein (myosin) 1E-06 4E-06 1E-06 2E-06 7E-06 1E-09
gi|115746860| PREDICTED: similar to actin, partial 1E-09 1E-09 1E-09 3E-05 2E-05 6E-06
gi|115945231| PREDICTED: similar to KIAA0587 protein (NCR associate
protein)
1E-06 3E-06 2E-05 1E-06 1E-06 1E-06
gi|115971193| PREDICTED: similar to Rac1 protein 1E-09 1E-09 1E-09 2E-05 1E-09 2E-05
gi|115970592| PREDICTED: similar to tropomyosin 1 4E-06 9E-06 3E-05 1E-05 1E-09 4E-06
gi|115945717| PREDICTED: similar to Enabled homolog (Drosophila) 1E-05 2E-05 2E-05 6E-06 7E-06 8E-06
gi|115630732| PREDICTED: similar to myosin, heavy polypeptide 10, non-
muscle
6E-06 1E-05 3E-05 1E-09 1E-09 1E-06
gi|115961398| PREDICTED: similar to Capzb-prov protein (F actin capping
protein beta)
9E-05 6E-05 5E-05 3E-05 1E-09 1E-05
gi|115955651| PREDICTED: similar to Col protein 1E-09 1E-09 1E-05 6E-05 4E-05 3E-06
gi|115944055| PREDICTED: similar to fibrocystin L 3E-06 2E-06 7E-06 1E-09 1E-09 1E-09
gi|166795321| advillin 2E-05 1E-05 1E-05 8E-06 5E-06 1E-05
gi|115930179| PREDICTED: similar to gelsolin 1E-09 3E-05 4E-05 6E-06 4E-06 2E-05
gi|115931821| PREDICTED: hypothetical protein (fibronectin) 6E-06 1E-05 1E-05 1E-09 1E-09 1E-09
gi|115960968| PREDICTED: similar to sea urchin Arp3 (SUArp3) 4E-05 3E-05 5E-05 2E-05 2E-05 2E-05
gi|115961140| PREDICTED: similar to gelsolin 2E-05 3E-05 2E-05 2E-05 5E-05 3E-05
gi|115960587| PREDICTED: similar to alpha tubulin 8E-05 1E-09 8E-05 1E-09 1E-09 1E-09
gi|115944135| PREDICTED: similar to sea urchin Arp2 (SUArp2) . 0.0002 0.0002 0.0002 4E-05 2E-05 6E-05
gi|115951150| PREDICTED: similar to beta tubulin 9E-05 1E-09 0.0001 1E-09 7E-05 1E-09
gi|115929203| PREDICTED: similar to ENSANGP00000011796 (alpha
actinin)
6E-05 4E-05 5E-05 1E-05 2E-05 3E-05
gi|115963096| PREDICTED: similar to CG15792-PD, partial (myosin) 6E-05 9E-05 0.0001 4E-06 2E-05 1E-05
gi|115960585| PREDICTED: similar to tubulin, alpha 2 isoform 1 1E-09 0.0001 1E-09 6E-05 1E-09 3E-05
gi|115938253| PREDICTED: similar to Tubulin, beta 2, partial 9E-05 0.0001 0.0001 5E-05 0.0001 1E-09
gi|21667225| alpha-tubulin 3 0.0001 0.0001 0.0001 6E-05 0.0001 3E-05
gi|115960583| PREDICTED: similar to tubulin, alpha 2 isoform 3 0.0001 1E-09 0.0001 1E-09 0.0001 1E-09
gi|115960644| PREDICTED: similar to myosin heavy chain 2E-05 4E-05 7E-05 1E-05 9E-06 3E-06
gi|115618052| PREDICTED: similar to Actin, cytoskeletal IIIB, partial 1E-09 0.0007 0.0007 0.0008 1E-09 1E-09
gi|47551049| fascin 0.0001 5E-05 5E-05 0.0001 8E-05 0.0002
gi|115974233| PREDICTED: similar to Actin, cytoplasmic 0.0005 0.0005 1E-09 0.0003 1E-09 0.0003
gi|115971215| PREDICTED: hypothetical protein (tubulin) 0.0002 0.0002 0.0002 0.0002 0.0002 3E-05
gi|115968818| PREDICTED: similar to ENSANGP00000003616 (Actin like
protein)
0.0001 1E-04 0.0002 3E-05 4E-05 7E-05
gi|115971469| PREDICTED: similar to Actin, cytoplasmic 0.0003 0.0004 0.0005 0.0004 0.0004 0.0006
gi|224306| actin 1E-09 1E-09 1E-09 1E-09 0.0017 1E-09
gi|115747662| PREDICTED: similar to actin 1E-09 0.0006 1E-09 0.0007 0.0006 0.0008
gi|115974235| PREDICTED: similar to Actin, cytoskeletal IIIB 1E-09 1E-09 1E-09 0.0008 0.0007 0.0008
gi|115971461| PREDICTED: similar to actin 1E-09 0.0005 1E-09 0.0006 0.0006 0.0007
gi|47551035| cytoskeletal actin CyIIIb 1E-09 1E-09 1E-09 0.0019 0.0017 0.0021
gi|115943916| PREDICTED: similar to actin 0.0004 0.0005 0.0005 0.0011 0.001 0.0012
gi|871546| actin 0.0009 0.001 1E-09 0.0012 1E-09 0.0013
gi|1703135| Actin, cytoskeletal 3A (Actin, cytoskeletal IIIA) 1E-09 0.0013 0.0014 0.0019 0.0017 0.0021
gi|81158087| actin 2 1E-09 0.0015 0.0016 0.002 0.0017 0.0023
gi|115956638| PREDICTED: similar to cytoskeletal actin CyIIb . 1E-09 1E-09 1E-09 0.0021 0.0019 1E-09
gi|115949854| PREDICTED: similar to cytoskeletal actin . 0.0012 0.0013 0.0014 0.0019 0.0017 0.0021
gi|115940604| PREDICTED: similar to CyI cytoplasmic actin 0.0013 0.0014 0.0014 1E-09 0.002 0.0025
gi|47551037| cytoskeletal actin CyIIb 0.0017 0.0018 1E-09 0.0025 0.0023 0.0029
gi|115935893| PREDICTED: similar to vacuolar (V-type) H(+)-ATPase B
subunit isoform 1 .
1E-05 3E-05 3E-05 7E-06 1E-09 1E-09
NSAF

199
NSAF
W241 W242 W243 W481 W482 W483 LPS61 LPS62 LPS63 LPS241 LPS242 LPS243 LPS481 LPS482 LPS483
1E-05 8E-06 2E-05 3E-06 1E-05 1E-09 2E-05 2E-05 8E-06 2E-05 2E-05 1E-05 3E-05 3E-05 2E-05
4E-06 1E-09 4E-06 3E-05 3E-05 1E-05 8E-06 1E-05 2E-05 6E-06 5E-06 6E-06 3E-05 3E-05 3E-05
6E-06 1E-09 5E-05 4E-05 3E-05 1E-05 2E-05 4E-05 2E-05 2E-05 9E-06 2E-05 2E-05 4E-05 9E-06
9E-06 1E-09 1E-09 3E-05 1E-05 1E-09 2E-05 2E-05 2E-05 7E-06 1E-09 7E-06 1E-09 1E-05 1E-09
4E-06 1E-09 8E-06 2E-05 2E-05 1E-05 2E-06 2E-05 2E-05 7E-06 7E-06 1E-06 1E-05 2E-05 2E-05
9E-06 4E-06 1E-05 2E-05 2E-05 3E-05 3E-05 2E-05 1E-05 2E-05 5E-06 1E-05 2E-05 1E-05 3E-05
9E-06 1E-09 1E-05 2E-05 2E-05 1E-05 3E-05 5E-05 2E-05 4E-06 8E-06 5E-06 3E-05 5E-05 1E-05
1E-05 1E-09 4E-06 5E-05 2E-05 4E-05 2E-06 2E-05 2E-05 1E-05 1E-05 4E-06 3E-05 3E-05 8E-06
4E-05 5E-05 9E-05 0.0001 7E-05 1E-09 0.0002 0.0002 0.0001 1E-05 3E-05 5E-05 9E-05 0.0002 2E-05
3E-05 6E-05 1E-09 4E-05 7E-05 5E-05 5E-05 4E-05 3E-05 3E-05 3E-05 4E-05 1E-05 4E-05 4E-05
6E-06 1E-09 8E-06 5E-05 2E-05 1E-05 4E-06 1E-05 2E-06 2E-05 6E-06 2E-05 2E-05 2E-05 5E-05
3E-06 5E-06 1E-09 2E-05 1E-05 1E-09 2E-06 5E-06 1E-09 2E-05 2E-06 9E-06 9E-06 1E-05 3E-05
1E-09 1E-09 1E-09 1E-06 2E-06 6E-06 1E-09 1E-09 1E-06 8E-07 2E-06 1E-09 1E-09 5E-06 1E-09
1E-09 1E-09 1E-09 4E-06 2E-05 1E-09 1E-09 1E-09 7E-06 1E-06 1E-09 1E-09 4E-06 7E-06 1E-09
3E-07 1E-09 1E-09 4E-06 4E-06 3E-06 9E-07 2E-06 1E-09 1E-09 4E-07 8E-07 1E-09 1E-06 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 4E-06 1E-09 1E-09 1E-09 1E-09 2E-06 4E-06 1E-09
1E-09 1E-09 1E-09 1E-09 2E-05 1E-09 1E-09 9E-06 1E-09 1E-09 1E-09 7E-06 5E-06 1E-09 1E-09
1E-09 2E-05 1E-09 2E-05 2E-05 2E-05 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 6E-06 7E-05
7E-07 1E-09 1E-09 5E-06 1E-09 5E-06 1E-09 4E-06 1E-06 1E-06 1E-09 2E-06 1E-05 1E-05 1E-09
2E-06 2E-05 1E-09 4E-06 2E-05 8E-06 1E-09 1E-09 1E-09 1E-06 1E-06 4E-06 4E-06 1E-09 3E-05
3E-06 1E-09 3E-06 3E-06 4E-06 6E-06 1E-09 1E-09 1E-09 3E-06 5E-06 4E-06 9E-06 1E-05 1E-09
6E-07 1E-09 1E-09 4E-06 1E-06 1E-06 1E-09 6E-07 3E-07 5E-07 1E-09 2E-07 2E-06 7E-06 1E-09
4E-07 1E-09 1E-09 5E-06 1E-09 7E-06 1E-09 1E-06 3E-06 2E-06 1E-09 9E-07 4E-06 6E-06 1E-09
2E-05 2E-05 2E-05 1E-09 6E-06 1E-09 3E-05 7E-06 2E-05 8E-06 1E-05 2E-05 2E-05 8E-06 1E-09
2E-06 1E-09 1E-09 3E-06 9E-07 3E-06 1E-09 1E-09 3E-06 8E-07 1E-09 4E-07 8E-06 2E-06 1E-09
4E-06 1E-09 2E-05 1E-05 2E-05 1E-05 5E-05 5E-05 1E-05 1E-09 1E-09 5E-06 2E-05 8E-05 1E-09
4E-06 2E-05 6E-06 3E-05 7E-05 2E-05 1E-09 1E-09 2E-06 5E-06 1E-09 7E-06 3E-05 2E-05 8E-05
8E-06 1E-09 1E-09 1E-05 1E-05 2E-05 1E-09 1E-09 2E-05 8E-06 2E-06 5E-06 4E-05 2E-05 1E-09
1E-06 5E-06 1E-09 1E-05 6E-06 6E-06 1E-06 1E-09 2E-06 5E-07 1E-09 6E-07 2E-05 3E-05 2E-06
8E-06 3E-05 3E-05 1E-05 2E-05 1E-05 2E-05 3E-05 3E-05 5E-06 1E-09 4E-06 3E-05 3E-05 1E-09
1E-09 1E-09 1E-09 3E-05 1E-09 7E-05 1E-09 1E-09 1E-09 1E-06 5E-06 8E-06 1E-09 1E-09 9E-05
1E-09 1E-09 1E-09 6E-07 2E-06 1E-09 1E-09 2E-06 1E-09 1E-06 4E-07 2E-06 4E-06 3E-06 1E-05
2E-06 1E-09 1E-09 2E-06 7E-06 6E-06 1E-09 1E-06 2E-05 4E-06 6E-06 3E-06 2E-06 5E-06 4E-06
1E-09 1E-09 1E-09 2E-05 6E-05 7E-05 6E-06 2E-05 7E-06 1E-09 1E-09 1E-09 3E-05 4E-05 3E-05
2E-07 1E-09 1E-09 1E-09 1E-06 3E-06 1E-09 1E-09 1E-09 3E-07 3E-07 2E-06 1E-09 1E-05 7E-05
7E-06 5E-06 3E-05 2E-05 3E-05 3E-05 3E-05 3E-05 3E-05 3E-06 7E-06 3E-06 3E-05 4E-05 4E-06
1E-05 1E-05 1E-05 0.0001 1E-04 7E-05 2E-05 7E-05 7E-06 5E-06 4E-05 5E-06 6E-05 8E-05 4E-05
1E-09 1E-09 1E-09 8E-05 7E-05 0.0001 1E-09 0.0001 0.0001 8E-05 6E-05 1E-09 7E-05 7E-05 1E-09
4E-05 1E-09 3E-05 4E-05 6E-05 5E-05 6E-05 4E-05 3E-05 4E-05 2E-05 4E-05 5E-05 5E-05 6E-05
2E-05 1E-09 1E-09 9E-05 0.0001 7E-05 8E-05 0.0001 3E-05 7E-05 5E-05 1E-09 7E-05 6E-05 1E-09
2E-05 1E-05 2E-05 4E-05 3E-05 4E-05 1E-05 2E-05 2E-05 1E-05 2E-05 2E-05 3E-05 5E-05 1E-05
7E-06 2E-06 7E-06 2E-05 2E-05 1E-05 4E-06 2E-05 4E-06 8E-06 1E-05 6E-06 4E-05 6E-05 6E-06
0.0001 7E-05 0.0002 1E-09 0.0002 1E-09 0.0002 1E-09 1E-09 1E-09 0.0001 8E-05 0.0001 1E-09 0.0001
5E-05 5E-05 0.0001 9E-05 0.0001 0.0001 1E-09 0.0001 4E-05 0.0001 0.0001 7E-05 9E-05 8E-05 7E-05
0.0001 1E-09 1E-09 0.0002 0.0001 0.0002 1E-09 0.0002 0.0001 0.0001 1E-09 9E-05 0.0001 1E-09 1E-09
1E-04 1E-09 1E-09 0.0002 0.0001 0.0002 1E-09 0.0002 0.0001 0.0001 0.0001 7E-05 1E-09 0.0001 1E-09
5E-06 5E-05 1E-09 2E-05 8E-05 8E-05 3E-06 1E-05 6E-06 2E-06 7E-06 1E-05 6E-05 3E-05 0.0002
0.0015 0.0006 1E-09 0.0008 0.001 0.0011 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
0.0001 8E-05 1E-04 0.0002 0.0001 0.0002 0.0002 0.0001 0.0002 0.0002 0.0001 0.0001 0.0003 0.0002 0.0002
1E-09 0.0003 0.0004 0.0004 1E-09 0.0004 0.0004 1E-09 0.0003 0.0004 1E-09 1E-09 0.0005 0.0004 0.0003
0.0001 0.0001 0.0003 0.0003 0.0003 0.0003 0.0002 0.0004 0.0001 0.0002 0.0002 0.0001 0.0002 0.0002 0.0003
4E-05 2E-05 1E-05 0.0001 5E-05 3E-05 2E-05 3E-05 1E-05 9E-06 1E-05 2E-05 8E-05 0.0001 3E-05
0.0006 0.0004 1E-09 0.0003 0.0004 0.0005 1E-09 1E-09 0.0004 1E-09 1E-09 0.0006 1E-09 1E-09 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 0.0021 0.0018 0.0018 1E-09 1E-09 1E-09 1E-09 0.0016 1E-09
1E-09 0.0007 0.0011 1E-09 1E-09 1E-09 0.0007 0.0006 0.0007 1E-09 0.0006 0.0008 1E-09 0.0005 1E-09
1E-09 0.0003 0.0005 0.0007 0.0009 1E-09 1E-09 1E-09 0.0009 1E-09 1E-09 0.0012 0.0012 1E-09 0.001
0.0007 1E-09 1E-09 0.0004 0.0005 1E-09 0.0006 0.0005 0.0005 0.0004 1E-09 0.0007 1E-09 1E-09 0.0004
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 0.0022 0.0018 0.0018 1E-09 1E-09 1E-09 1E-09 1E-09 0.0019
0.0006 0.0012 0.0017 0.0006 0.0006 0.0008 0.0011 0.0009 0.001 0.0009 0.0006 0.0005 0.0007 0.0007 0.0009
0.001 0.0009 0.0013 0.0009 1E-09 0.0009 1E-09 0.0012 0.0011 0.0009 0.0008 0.001 0.0013 1E-09 1E-09
0.0017 1E-09 1E-09 0.0012 0.0014 0.0016 1E-09 1E-09 0.0018 0.0017 1E-09 0.0015 0.0019 1E-09 1E-09
0.0018 1E-09 1E-09 0.0013 0.0015 0.0016 1E-09 0.0018 0.0019 0.0017 0.0015 1E-09 1E-09 1E-09 1E-09
0.0018 0.0019 0.0025 0.0013 0.0014 0.0016 0.0024 0.002 0.002 0.0019 0.0015 0.0017 1E-09 0.0017 1E-09
0.0017 0.0017 0.0022 0.0012 0.0014 0.0016 0.0021 1E-09 1E-09 0.0017 0.0014 0.0016 0.0019 0.0016 0.002
0.0019 0.0018 0.0026 0.0015 0.0017 0.0019 0.0024 0.0019 0.0021 0.002 0.0017 0.0017 0.0019 0.0017 1E-09
0.0024 0.0022 0.0032 0.0017 0.0021 0.0022 0.003 0.0024 0.0025 0.0025 0.002 0.002 0.0021 0.002 0.0025
2E-05 1E-09 1E-09 1E-05 8E-06 1E-05 1E-09 1E-05 4E-06 8E-06 8E-06 5E-06 2E-05 2E-05 2E-05

200
Identifier Description NI1 NI2 NI3 W61 W62 W63
gi|115926329| PREDICTED: hypothetical protein (solute carrier family 8
sodium calcium exchanger)
3E-06 9E-06 2E-05 1E-09 7E-06 1E-09
gi|115955930| PREDICTED: similar to CG16944-PC (solute carrier family 25) 1E-09 2E-05 1E-09 1E-09 5E-06 4E-06
gi|115940494| PREDICTED: similar to MGC69168 protein (solute carrier
family, mitochondrial)
1E-09 1E-09 1E-09 1E-09 2E-06 3E-06
gi|115956824| PREDICTED: similar to Solute carrier family 25
(mitochondrial carrier; adenine nucleotide translocator),
member 4
5E-05 4E-05 5E-05 2E-05 1E-09 1E-09
gi|115935979| PREDICTED: similar to voltage-dependent anion channel 2 . 7E-05 8E-05 9E-05 2E-05 1E-09 5E-05
gi|115940270| PREDICTED: hypothetical protein, partial (oxoglutarate) 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09
gi|115940857| PREDICTED: similar to aldose reductase . 1E-05 1E-05 2E-05 1E-09 1E-09 1E-09
gi|115978426| PREDICTED: hypothetical protein (dihydrolipoyllysin S
succinyltransferase)
5E-06 1E-05 3E-06 1E-09 1E-09 1E-09
gi|115945027| PREDICTED: hypothetical protein isoform 1 (integral
membrane protein 1 oligosaccharyltransferase complex)
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115968074| PREDICTED: hypothetical protein (aldehyde dehydrogenase) 5E-06 7E-06 8E-06 1E-09 1E-09 6E-06
gi|115929988| PREDICTED: similar to Dihydrolipoyl dehydrogenase,
mitochondrial precursor (Dihydrolipoamide dehydrogenase)
1E-09 5E-06 6E-06 1E-09 1E-09 2E-06
gi|115924009| PREDICTED: similar to Methylthioadenosine phosphorylase 1E-09 1E-09 1E-09 3E-05 1E-09 2E-05
gi|115956413| PREDICTED: similar to glutamine synthetase . 1E-05 3E-05 1E-05 7E-06 4E-06 3E-06
gi|115729152| PREDICTED: similar to triosephosphate isomerase 1E-09 1E-09 6E-06 5E-06 1E-09 5E-06
gi|115697859| PREDICTED: hypothetical protein (succinyl CoA ligase) 6E-06 1E-05 1E-05 1E-09 1E-09 1E-05
gi|115925449| PREDICTED: similar to Fructose-1,6-bisphosphatase 1, like 3E-05 2E-05 4E-05 1E-09 1E-09 1E-09
gi|115968426| PREDICTED: similar to arginine kinase 7E-06 3E-06 4E-06 6E-06 4E-06 3E-06
gi|115961332| PREDICTED: similar to glutamate dehydrogenase 1 9E-06 7E-06 1E-09 1E-09 1E-09 1E-09
gi|115931667| PREDICTED: similar to aldehyde dehydrogenase 1A2 isoform
2 .
1E-05 8E-06 9E-06 7E-06 1E-09 1E-09
gi|115922509| PREDICTED: similar to glutamic-oxaloacetic transaminase 2,
mitochondrial (aspartate aminotransferase 2) isoform 2
6E-06 1E-05 2E-05 1E-09 1E-09 1E-09
gi|115697801| PREDICTED: similar to Nicotinamide nucleotide
transhydrogenase
4E-06 1E-09 9E-06 2E-06 1E-06 1E-09
gi|115964994| PREDICTED: similar to Fumarylacetoacetase
(Fumarylacetoacetate hydrolase) (Beta-diketonase) (FAA),
partial
1E-09 1E-09 8E-06 1E-09 1E-09 3E-06
gi|115924987| PREDICTED: similar to Aldehyde dehydrogenase 9 family,
member A1 like 1
6E-06 1E-05 4E-06 6E-06 7E-06 5E-06
gi|115932265| PREDICTED: hypothetical protein (glutamic-oxaloacetic
transaminase 1 fusion)
2E-06 8E-06 1E-05 1E-09 7E-06 1E-09
gi|115934826| PREDICTED: similar to Fructose-1,6-bisphosphatase 1 (D-
fructose-1,6-bisphosphate 1-phosphohydrolase 1) (FBPase 1)
2E-05 3E-05 4E-05 3E-06 1E-09 3E-06
gi|115921420| PREDICTED: hypothetical protein, partial ((phosphoglycerate
dehydrogenase)
5E-05 0.0001 0.0001 0.0001 6E-05 0.0003
gi|115972622| PREDICTED: similar to GA19181-PA, partial (NAD dependent
epimerase/dehydratase)
2E-05 5E-05 5E-05 3E-06 4E-06 1E-05
gi|115744264| PREDICTED: similar to Isocitrate dehydrogenase 2 (NADP+),
mitochondrial .
1E-05 1E-05 2E-05 8E-06 6E-06 7E-06
gi|115954217| PREDICTED: similar to hexokinase I 4E-05 3E-05 5E-05 1E-05 1E-05 1E-05
gi|115735613| PREDICTED: similar to D-3-phosphoglycerate dehydrogenase
.
2E-05 3E-05 2E-05 1E-05 9E-06 3E-05
gi|115929815| PREDICTED: similar to Nucleoside diphosphate kinase family
protein
4E-05 4E-05 1E-09 1E-09 1E-09 1E-09
gi|115929324| PREDICTED: similar to glucose-6-phosphate 1-
dehydrogenase, partial
2E-05 2E-05 2E-05 9E-06 7E-06 1E-05
gi|115964543| PREDICTED: similar to transaldolase 7E-05 8E-05 8E-05 8E-06 1E-05 3E-05
gi|115973105| PREDICTED: hypothetical protein (pyruvate kinase) 3E-05 1E-05 3E-05 2E-05 2E-05 1E-05
gi|115944251| PREDICTED: similar to transketolase isoform 1 1E-05 3E-05 3E-05 6E-06 1E-05 1E-05
gi|115959412| PREDICTED: similar to fructose-biphosphate aldolase . 5E-05 4E-05 4E-05 5E-05 2E-05 2E-05
gi|115972829| PREDICTED: similar to glucose-6-phosphate isomerase . 4E-05 3E-05 3E-05 2E-05 2E-05 1E-05
gi|115685450| PREDICTED: similar to MGC68486 protein, partial
(phosphogluconate dehydrogenase)
0.0002 0.0001 0.0003 0.0002 0.0005 0.0006
gi|115738231| PREDICTED: similar to glyceraldehydephosphate
dehydrogenase isoform 1
8E-05 6E-05 5E-05 5E-05 3E-05 0.0001
gi|115939485| PREDICTED: similar to malate dehydrogenase . 2E-05 4E-05 5E-05 7E-06 1E-09 7E-06
gi|115929978| PREDICTED: similar to OTTHUMP00000039401 (similar to
leucine rich repeat containing 16 isoform)
7E-06 1E-06 7E-06 1E-09 1E-09 1E-09
gi|115939602| PREDICTED: similar to GRAAL2 protein (SRCR, kringle,pan
apple, trypsin domains)
3E-06 1E-09 1E-06 1E-09 1E-09 1E-09
gi|115972933| PREDICTED: similar to B-cell receptor associated protein 1E-05 4E-05 3E-05 1E-09 1E-09 1E-09
gi|115941346| PREDICTED: hypothetical protein, partial (ATPase H+
transporting)
5E-05 7E-05 2E-05 2E-05 4E-05 3E-05
gi|115939860| PREDICTED: similar to ENSANGP00000014225 (lectin,
mannose binding)
2E-06 2E-06 1E-05 1E-09 1E-09 1E-09
gi|115929116| PREDICTED: similar to aminoimidazole-4-carboxamide
ribonucleotidetransformylase/IMP cyclohydrolase
1E-05 1E-05 1E-05 2E-06 1E-09 4E-06
gi|115710920| PREDICTED: similar to Na+/K+ ATPase alpha subunit 1E-05 2E-05 1E-05 6E-06 8E-06 9E-06
gi|115944063| PREDICTED: hypothetical protein (srcr domains) 3E-05 2E-05 2E-05 7E-06 3E-05 1E-09
NSAF

201
NSAF
W241 W242 W243 W481 W482 W483 LPS61 LPS62 LPS63 LPS241 LPS242 LPS243 LPS481 LPS482 LPS483
2E-06 1E-09 1E-09 6E-06 5E-06 1E-09 1E-09 1E-09 2E-06 1E-09 1E-06 3E-06 3E-06 3E-06 9E-06
1E-09 1E-09 1E-09 1E-05 3E-05 2E-05 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 2E-05 1E-09
5E-06 1E-09 5E-06 6E-06 1E-06 1E-06 2E-06 7E-06 1E-09 1E-06 1E-09 7E-07 4E-06 6E-06 1E-09
5E-06 1E-09 5E-06 2E-05 4E-05 2E-05 1E-05 3E-05 1E-09 1E-05 1E-05 5E-06 4E-05 5E-05 3E-05
2E-05 1E-09 7E-05 5E-05 5E-05 4E-05 2E-05 3E-05 4E-05 2E-05 1E-05 9E-06 4E-05 1E-04 1E-05
9E-07 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 8E-07 5E-07 2E-06 6E-07 1E-09 2E-06 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 5E-06 1E-09 2E-06 1E-09 1E-09 1E-09 1E-09 1E-09
2E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-06 1E-09 1E-09 5E-06 1E-09
1E-09 1E-09 1E-09 6E-06 1E-09 1E-06 1E-09 1E-09 1E-09 2E-06 1E-06 6E-07 1E-09 5E-06 2E-06
1E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 2E-06 1E-09 2E-06 1E-09 1E-09 1E-09 7E-06 3E-06
2E-06 1E-09 1E-09 5E-06 6E-06 2E-06 1E-09 1E-09 4E-06 1E-09 1E-09 1E-09 1E-09 8E-06 4E-06
1E-09 4E-05 1E-09 3E-06 4E-06 1E-05 2E-05 1E-09 3E-06 1E-09 1E-09 1E-09 6E-06 1E-09 7E-06
1E-09 1E-09 1E-09 1E-05 6E-06 6E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 4E-06 4E-06 1E-09
1E-09 9E-06 1E-09 7E-06 2E-05 1E-05 1E-05 1E-09 6E-06 1E-09 1E-09 1E-09 2E-05 1E-05 2E-05
5E-06 1E-09 1E-09 6E-06 2E-06 1E-09 1E-09 1E-09 1E-09 4E-06 2E-06 1E-09 1E-09 1E-09 1E-09
4E-06 1E-09 1E-09 1E-09 9E-06 3E-06 1E-09 1E-09 1E-09 1E-09 4E-06 3E-06 1E-09 1E-09 1E-09
1E-09 1E-05 1E-09 2E-05 2E-05 8E-06 1E-09 7E-06 1E-09 1E-06 1E-09 3E-06 1E-09 7E-06 5E-06
1E-06 1E-09 1E-09 3E-06 1E-09 7E-06 4E-06 9E-06 2E-06 2E-06 4E-06 2E-06 1E-05 5E-06 1E-09
4E-06 1E-09 1E-09 8E-06 1E-09 2E-05 1E-09 7E-06 4E-06 2E-06 1E-09 1E-09 3E-06 3E-06 1E-09
3E-06 1E-05 8E-06 1E-05 7E-06 1E-05 1E-09 2E-05 1E-09 4E-06 5E-06 2E-06 7E-06 9E-06 1E-09
2E-06 1E-09 1E-09 6E-06 2E-06 1E-06 1E-09 2E-06 1E-09 3E-06 2E-06 2E-06 3E-06 6E-06 1E-09
1E-09 1E-05 1E-09 2E-05 2E-05 2E-05 8E-06 7E-06 1E-09 1E-09 1E-06 1E-09 3E-05 4E-05 5E-06
1E-05 1E-09 1E-09 2E-05 7E-06 5E-06 5E-06 9E-06 3E-06 1E-09 2E-06 5E-06 7E-06 2E-05 9E-06
1E-09 1E-09 1E-09 9E-06 1E-05 2E-06 1E-09 6E-06 8E-06 6E-06 6E-06 2E-06 7E-06 1E-05 6E-06
7E-06 1E-09 1E-09 2E-05 9E-06 3E-06 1E-09 1E-09 1E-09 1E-05 1E-05 6E-06 1E-09 1E-09 5E-06
3E-05 4E-05 1E-09 3E-05 1E-09 4E-05 4E-05 5E-05 0.0001 3E-05 2E-05 2E-05 0.0001 0.0001 8E-05
5E-06 1E-09 1E-05 1E-05 2E-05 6E-06 3E-06 4E-06 1E-09 1E-06 3E-06 9E-06 9E-06 4E-06 1E-09
3E-06 1E-09 4E-06 2E-05 2E-05 5E-06 2E-06 1E-05 3E-06 6E-06 4E-06 2E-06 3E-06 1E-05 8E-06
7E-06 1E-09 2E-05 8E-06 2E-05 5E-06 1E-09 6E-06 1E-05 3E-06 8E-06 1E-06 4E-06 1E-05 1E-05
9E-06 1E-09 4E-06 1E-05 7E-06 2E-06 1E-05 1E-09 7E-06 5E-06 2E-06 1E-06 1E-05 3E-05 1E-09
3E-05 1E-09 7E-05 2E-05 5E-05 2E-05 2E-05 2E-05 2E-05 3E-05 2E-05 2E-05 4E-05 8E-05 1E-09
2E-05 1E-09 8E-06 2E-05 2E-05 2E-05 8E-06 2E-05 2E-06 2E-05 1E-05 9E-06 2E-05 3E-05 5E-06
2E-05 1E-09 5E-05 4E-05 3E-05 5E-05 2E-05 4E-06 3E-05 2E-05 3E-06 6E-06 3E-05 5E-05 1E-05
2E-05 3E-05 7E-06 3E-05 3E-05 2E-05 1E-05 2E-05 2E-05 1E-05 1E-05 2E-05 3E-05 3E-05 4E-05
2E-05 3E-06 1E-05 3E-05 2E-05 2E-05 2E-06 3E-05 8E-06 1E-05 9E-06 9E-06 3E-05 4E-05 2E-05
2E-05 2E-05 4E-05 2E-05 3E-05 2E-05 1E-05 5E-05 3E-05 3E-05 2E-05 2E-05 4E-05 4E-05 4E-05
2E-05 1E-09 1E-09 5E-05 2E-05 6E-05 2E-05 2E-05 2E-05 1E-05 2E-05 1E-05 3E-05 4E-05 3E-05
0.0002 0.0002 0.0003 0.0003 0.0002 0.0002 0.0001 0.0003 0.0001 0.0002 0.0002 0.0001 0.0003 0.0003 0.0003
4E-05 6E-05 7E-05 9E-05 0.0001 5E-05 0.0001 9E-05 6E-05 2E-05 3E-05 3E-05 8E-05 0.0001 0.0001
7E-06 1E-09 1E-09 4E-05 4E-05 3E-05 2E-05 2E-05 6E-06 6E-06 9E-06 1E-09 3E-05 4E-05 2E-05
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 9E-07 1E-09 1E-09 4E-06 1E-09 1E-09
6E-07 1E-09 1E-09 6E-07 1E-09 8E-07 1E-09 1E-09 1E-09 3E-07 7E-07 1E-06 1E-09 3E-06 1E-06
1E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 4E-06 5E-06 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09
2E-05 1E-09 2E-05 4E-05 4E-05 1E-09 1E-09 3E-05 2E-05 1E-05 1E-05 1E-05 1E-04 7E-05 1E-09
2E-06 1E-09 6E-06 2E-05 1E-05 1E-05 1E-09 5E-06 6E-06 2E-06 5E-06 1E-09 2E-05 3E-05 1E-09
5E-06 4E-06 1E-09 1E-05 7E-06 2E-05 1E-09 1E-05 2E-06 2E-06 4E-06 2E-06 2E-05 2E-05 6E-06
3E-06 6E-06 2E-06 1E-05 6E-06 3E-05 2E-06 1E-05 7E-07 6E-06 2E-06 5E-06 2E-05 2E-05 1E-05
4E-06 3E-05 2E-05 2E-06 7E-06 2E-05 2E-05 2E-05 9E-06 1E-05 2E-05 9E-06 1E-09 5E-06 2E-06

202
Identifier Description NI1 NI2 NI3 W61 W62 W63
gi|115619038| PREDICTED: similar to arylsulfatase 1E-09 1E-05 2E-05 1E-09 1E-09 4E-06
gi|115968753| PREDICTED: similar to scavenger receptor cysteine-rich
protein type 12 precursor
0.0006 0.0003 0.0004 0.0001 1E-09 1E-09
gi|115974704| PREDICTED: similar to scavenger receptor cysteine-rich
protein type 12 precursor, partial
2E-05 2E-05 6E-06 1E-09 1E-09 1E-09
gi|115967944| PREDICTED: similar to scavenger receptor cysteine-rich
protein type 12 precursor, partial
1E-09 1E-09 2E-06 1E-09 1E-09 1E-09
gi|47551157| scavenger receptor cysteine-rich protein type 12 . 5E-05 3E-05 4E-05 1E-05 1E-05 1E-09
gi|115950487| PREDICTED: similar to arylsulfatase isoform 2 . 4E-05 7E-05 8E-05 3E-05 2E-05 8E-06
gi|47551023| complement component C3 4E-05 4E-05 3E-05 3E-06 3E-06 1E-05
gi|115937346| PREDICTED: similar to apolipophorin precursor protein 8E-06 1E-05 1E-05 2E-06 3E-06 2E-06
gi|115966189| PREDICTED: similar to H(+)-transporting ATPase beta
subunit
8E-05 0.0001 0.0001 6E-05 8E-05 6E-05
gi|115970375| PREDICTED: similar to melanotransferrin/EOS47 9E-05 6E-05 3E-05 7E-05 7E-05 6E-05
gi|115973483| PREDICTED: similar to scavenger receptor cysteine-rich
protein type 12 precursor, partial
0.0003 0.0002 0.0003 4E-05 0.0001 2E-05
gi|115757308| PREDICTED: hypothetical protein (clathrin coat assembly
protein)
3E-06 3E-06 1E-09 1E-09 1E-09 1E-09
gi|115924764| PREDICTED: similar to formin binding protein 1 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115951468| PREDICTED: similar to coatomer protein gamma 2-subunit,
partial
9E-06 1E-05 1E-05 1E-09 1E-09 1E-09
gi|115943043| PREDICTED: similar to VPS13C-1A protein (vacuolar protein
sorting 13 homolog C)
5E-07 3E-06 2E-06 1E-09 1E-09 1E-09
gi|47551307| syntaxin binding protein 1 4E-06 2E-06 5E-06 1E-09 1E-09 1E-09
gi|115753213| PREDICTED: similar to beta COP, partial 7E-06 2E-05 2E-05 1E-09 1E-09 1E-09
gi|115932047| PREDICTED: similar to archain 1E-09 7E-06 1E-09 1E-09 1E-09 1E-09
gi|115673346| PREDICTED: similar to alpha-cop protein, partial 1E-06 3E-06 5E-06 1E-09 2E-06 1E-09
gi|115934500| PREDICTED: similar to Adaptor protein complex AP-2, alpha
2 subunit
1E-09 1E-09 1E-06 2E-06 2E-06 1E-09
gi|47551147| N-ethylmaleimide-sensitive factor (NSF) 2E-06 2E-06 2E-06 3E-06 2E-06 1E-06
gi|115738335| PREDICTED: similar to beta-adaptin Drosophila 1 isoform 7 2E-06 5E-06 8E-06 1E-09 1E-09 1E-09
gi|115928436| PREDICTED: hypothetical protein (SH3-domain GRB2-like
endophilin B1)
1E-05 7E-06 4E-06 6E-06 1E-09 3E-06
gi|115976584| PREDICTED: similar to Coatomer protein complex, subunit
beta 2 (beta prime)
1E-09 1E-06 6E-06 1E-06 1E-06 1E-09
gi|115662788| PREDICTED: similar to ENSANGP00000019991, partial
(adaptin)
1E-09 1E-05 6E-06 1E-05 1E-05 1E-09
gi|115940967| PREDICTED: similar to Dynamin 2, partial 2E-05 2E-05 2E-05 1E-09 1E-09 1E-09
gi|115931510| PREDICTED: hypothetical protein (sorting nexin) 2E-05 1E-05 2E-05 3E-06 1E-09 1E-09
gi|115968951| PREDICTED: hypothetical protein (adaptor protein complex
AP2)
8E-06 6E-06 2E-05 1E-05 1E-09 2E-06
gi|160623368| putative flotillin 2E-05 1E-05 2E-05 3E-05 1E-09 1E-05
gi|115952079| PREDICTED: hypothetical protein, partial (vacuolar protein
sorting 35)
1E-05 2E-05 2E-05 2E-06 2E-06 1E-09
gi|115889707| PREDICTED: similar to Pdcd6ip protein (Programmed cell
death 6 interacting protein)
1E-05 1E-05 7E-06 4E-06 5E-06 1E-06
gi|115970724| PREDICTED: similar to Valosin containing protein, partial 2E-06 7E-06 1E-05 4E-06 1E-09 1E-09
gi|115928607| PREDICTED: hypothetical protein (flotillin) 1E-05 1E-05 2E-05 1E-09 1E-05 1E-09
gi|115963658| PREDICTED: major vault protein 2E-05 3E-05 2E-05 1E-05 5E-06 3E-05
gi|115936009| PREDICTED: similar to ENSANGP00000009431 (flotilin) 4E-05 7E-05 1E-04 2E-05 2E-05 3E-05
gi|115759362| PREDICTED: similar to sulfotransferase ST1B2 . 1E-05 8E-06 1E-05 1E-09 1E-09 7E-06
gi|115955254| PREDICTED: similar to alpha macroglobulin . 9E-07 1E-09 2E-06 1E-09 1E-09 1E-09
gi|115929526| PREDICTED: similar to aminopeptidase N . 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115940918| PREDICTED: hypothetical protein (aminopeptidase like 1) 3E-06 5E-06 6E-06 1E-09 6E-06 1E-09
gi|115945106| PREDICTED: similar to cytosolic nonspecific dipeptidase,
partial
1E-05 5E-06 1E-05 1E-09 1E-09 1E-09
gi|115953922| PREDICTED: similar to Peptidase (mitochondrial processing)
beta isoform 1
3E-06 5E-06 1E-05 7E-06 9E-06 9E-06
gi|115924997| PREDICTED: similar to MGC84288 protein (tissue inhibitor of
metalloproteinase TIMP)
2E-05 3E-05 1E-05 5E-06 1E-09 1E-05
gi|115971224| PREDICTED: hypothetical protein (aminopeptidase) 1E-09 1E-09 3E-06 5E-06 1E-05 1E-05
gi|115972931| PREDICTED: similar to sulfatase 1 precursor 1E-09 1E-09 3E-05 2E-06 1E-09 1E-09
gi|115968724| PREDICTED: similar to transglutaminase-like protein . 8E-06 2E-05 1E-05 5E-06 8E-06 1E-06
gi|115953033| PREDICTED: similar to Aminopeptidase puromycin sensitive 2E-06 1E-05 8E-06 1E-05 9E-06 3E-06
gi|115973804| PREDICTED: similar to non-receptor protein tyrosine
phosphatase
6E-06 6E-06 7E-06 3E-06 1E-09 1E-09
gi|115958557| PREDICTED: similar to Arginyl-tRNA synthetase 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115691123| PREDICTED: similar to Eukaryotic translation initiation factor
2, subunit 1 alpha, 35kDa isoform 1
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115652043| PREDICTED: similar to histidyl-tRNA synthetase, partial 1E-09 1E-09 1E-09 2E-06 1E-09 1E-09
gi|115941920| PREDICTED: similar to ribosomal protein L7, partial 2E-05 5E-05 4E-05 1E-09 1E-09 1E-09
gi|115963308| PREDICTED: similar to ribosomal protein L32 1E-09 1E-09 1E-09 4E-05 1E-09 6E-05
gi|115963185| PREDICTED: hypothetical protein isoform 2 (ribosomal
protein L15)
6E-06 2E-05 2E-05 1E-09 1E-09 2E-05
gi|115970594| PREDICTED: similar to interleukin enhancer binding factor 3,
partial
1E-09 5E-06 3E-06 1E-09 1E-09 1E-09
gi|115921067| PREDICTED: similar to ribosomal protein L23a 1E-09 1E-09 8E-06 1E-09 1E-09 1E-05
gi|115972878| PREDICTED: similar to Rps9-prov protein (ribosomal protein
S9)
1E-05 2E-05 7E-06 1E-09 1E-09 1E-09
NSAF

203
NSAF
W241 W242 W243 W481 W482 W483 LPS61 LPS62 LPS63 LPS241 LPS242 LPS243 LPS481 LPS482 LPS483
1E-05 1E-09 1E-09 6E-05 7E-05 2E-05 1E-05 8E-05 1E-05 8E-06 2E-05 2E-05 4E-05 8E-05 2E-05
5E-05 0.0002 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 0.0002 0.0002 7E-05 1E-09 6E-05 1E-09
3E-06 1E-09 1E-09 3E-06 3E-05 3E-05 6E-06 5E-06 3E-06 1E-05 4E-06 1E-05 6E-06 2E-05 6E-05
1E-09 2E-06 1E-09 1E-09 1E-09 2E-06 8E-07 1E-06 2E-06 1E-09 1E-09 2E-06 1E-09 1E-09 4E-06
2E-06 8E-06 1E-05 1E-05 2E-05 2E-05 4E-06 9E-06 4E-06 4E-06 3E-06 9E-06 1E-05 1E-05 2E-05
2E-05 1E-09 5E-05 3E-05 8E-05 6E-05 5E-05 0.0001 3E-05 1E-05 1E-05 1E-05 4E-05 6E-05 8E-05
1E-05 9E-06 2E-05 2E-05 1E-05 1E-05 2E-06 7E-06 6E-06 8E-06 3E-06 4E-06 3E-05 4E-05 6E-05
5E-07 9E-06 1E-09 3E-05 8E-06 6E-06 2E-06 4E-06 1E-06 9E-06 1E-05 1E-05 9E-06 7E-06 3E-05
5E-05 2E-05 7E-05 7E-05 9E-05 8E-05 4E-05 7E-05 5E-05 6E-05 5E-05 2E-05 6E-05 7E-05 3E-05
1E-05 6E-05 6E-05 2E-05 2E-05 3E-05 4E-05 2E-05 7E-05 4E-05 2E-05 4E-05 7E-05 6E-05 4E-05
7E-05 8E-05 6E-05 1E-09 0.0001 7E-05 2E-05 3E-05 2E-05 9E-05 9E-05 6E-05 7E-06 5E-05 9E-05
2E-06 1E-09 1E-09 8E-06 1E-09 3E-06 1E-09 1E-09 1E-09 2E-06 1E-06 3E-06 1E-09 7E-06 1E-09
1E-09 1E-09 1E-09 3E-06 7E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 5E-06 5E-05 6E-06
1E-09 1E-09 1E-09 1E-09 1E-09 1E-05 1E-09 1E-09 1E-09 1E-06 1E-09 1E-09 1E-05 1E-09 1E-09
3E-07 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 6E-07 2E-07 6E-07 1E-09 1E-09
1E-09 1E-09 1E-09 1E-06 5E-06 1E-09 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 5E-06 6E-06 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-06 1E-09 1E-09 8E-06 1E-05 5E-06
3E-06 1E-09 1E-09 6E-06 8E-06 6E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 6E-06 1E-09 1E-09
1E-09 1E-09 1E-09 2E-06 2E-06 1E-09 1E-09 1E-09 1E-09 4E-07 1E-09 1E-09 7E-06 5E-06 1E-09
6E-07 1E-09 1E-09 3E-06 1E-09 1E-09 9E-07 1E-09 2E-06 7E-07 2E-06 4E-07 2E-06 1E-06 2E-06
5E-07 1E-09 1E-09 6E-06 6E-06 1E-09 1E-09 2E-06 2E-06 1E-09 1E-09 6E-07 6E-06 7E-06 2E-06
2E-06 1E-09 1E-09 7E-06 3E-06 1E-09 1E-09 2E-06 1E-09 1E-09 1E-09 1E-09 1E-05 9E-06 1E-09
6E-06 1E-09 1E-09 4E-06 3E-06 1E-09 1E-09 4E-06 9E-06 5E-06 4E-06 3E-06 1E-09 1E-05 1E-09
8E-07 2E-06 1E-09 2E-06 1E-06 1E-06 1E-09 4E-06 7E-07 1E-09 2E-06 9E-07 6E-06 5E-06 4E-06
6E-06 1E-09 1E-09 3E-06 1E-09 1E-05 1E-09 5E-06 1E-05 3E-06 7E-06 6E-06 2E-05 1E-05 1E-09
8E-07 1E-09 1E-09 2E-06 2E-06 1E-05 1E-09 1E-09 3E-06 9E-07 1E-09 1E-09 1E-05 1E-05 1E-09
1E-09 1E-09 1E-09 2E-06 1E-05 3E-05 3E-06 7E-06 1E-05 4E-06 1E-09 1E-09 1E-05 1E-05 2E-05
4E-06 1E-09 1E-09 2E-05 1E-05 9E-06 1E-09 6E-06 1E-09 3E-06 1E-06 2E-06 1E-05 9E-06 4E-06
1E-09 1E-09 1E-05 1E-09 1E-09 1E-09 7E-06 1E-05 2E-05 1E-09 1E-09 1E-09 5E-05 4E-05 1E-09
1E-06 1E-09 1E-09 6E-06 1E-09 6E-06 1E-09 1E-09 1E-09 7E-06 6E-06 4E-06 6E-06 8E-06 1E-09
6E-06 1E-09 1E-09 5E-06 4E-06 1E-06 5E-06 7E-06 5E-06 2E-06 3E-06 4E-06 7E-06 8E-06 2E-06
2E-06 8E-06 1E-09 3E-05 3E-05 2E-05 2E-06 7E-06 7E-06 3E-06 5E-06 9E-07 2E-05 1E-05 1E-05
6E-06 1E-09 1E-09 2E-05 3E-05 2E-05 1E-09 1E-09 1E-09 5E-06 4E-06 3E-06 1E-09 1E-09 8E-06
6E-06 1E-09 1E-05 3E-05 7E-06 1E-05 1E-09 1E-05 8E-06 3E-06 4E-06 2E-06 2E-05 3E-05 1E-05
3E-05 1E-09 2E-05 7E-05 6E-05 5E-05 1E-05 4E-05 2E-05 2E-05 3E-05 2E-05 6E-05 6E-05 2E-05
1E-09 1E-09 1E-09 1E-09 7E-06 1E-05 1E-05 1E-09 2E-06 1E-09 3E-06 3E-06 1E-09 4E-06 1E-09
1E-06 1E-09 1E-09 1E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 7E-07 4E-06 7E-06 5E-06
4E-07 1E-09 3E-06 3E-06 1E-09 2E-06 1E-06 1E-09 1E-06 1E-09 1E-09 5E-07 6E-06 8E-06 8E-06
2E-06 1E-09 6E-06 1E-09 2E-06 4E-06 1E-09 5E-06 3E-06 4E-06 3E-06 1E-06 3E-06 8E-06 1E-09
5E-06 1E-09 1E-09 2E-05 4E-05 1E-05 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 6E-06 5E-06 7E-06
4E-06 1E-09 1E-09 5E-06 6E-06 2E-06 1E-09 1E-09 1E-09 4E-06 1E-06 1E-09 9E-06 2E-05 1E-09
1E-09 9E-06 1E-09 4E-06 2E-05 9E-06 3E-05 5E-05 1E-05 1E-09 1E-09 1E-09 6E-06 2E-05 2E-05
2E-06 1E-09 1E-09 6E-06 6E-06 1E-05 1E-09 5E-06 5E-06 9E-07 1E-06 1E-06 1E-05 1E-05 1E-05
5E-06 1E-09 1E-09 5E-06 1E-09 1E-09 1E-09 1E-09 1E-09 4E-06 1E-09 5E-06 3E-05 2E-05 4E-05
6E-06 3E-06 7E-06 3E-06 1E-09 1E-09 1E-09 7E-06 9E-07 4E-06 3E-06 5E-06 1E-05 4E-06 2E-06
9E-06 5E-06 2E-05 8E-06 1E-05 1E-05 4E-06 1E-05 3E-06 3E-06 4E-06 7E-06 7E-06 2E-05 7E-06
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 3E-06 1E-09
6E-07 1E-09 1E-09 2E-06 5E-06 2E-06 1E-09 4E-06 1E-09 1E-09 7E-07 1E-09 4E-06 1E-09 1E-09
1E-09 1E-09 1E-09 5E-06 1E-09 6E-06 1E-09 1E-09 1E-09 3E-06 3E-06 3E-06 1E-09 8E-06 1E-05
1E-09 1E-09 1E-09 3E-06 8E-06 2E-06 1E-09 2E-06 4E-06 1E-09 1E-09 1E-09 3E-06 3E-06 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 3E-05 1E-09 1E-09 7E-06 1E-09 1E-09 1E-09 1E-09 1E-09 4E-05
1E-09 1E-09 1E-09 3E-05 6E-05 4E-05 1E-09 1E-09 2E-05 1E-09 1E-09 1E-09 1E-09 5E-05 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 2E-05 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-05 9E-06
1E-09 1E-09 1E-09 2E-06 1E-09 1E-09 1E-09 1E-06 1E-09 1E-09 5E-07 5E-07 3E-06 4E-06 4E-06
1E-09 1E-09 1E-09 2E-05 1E-05 6E-06 6E-06 7E-06 1E-09 5E-06 5E-06 1E-09 8E-06 7E-06 1E-09
6E-06 1E-09 1E-09 1E-05 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 2E-06 7E-06 1E-05 1E-09 1E-09

204
Identifier Description NI1 NI2 NI3 W61 W62 W63
gi|115954825| PREDICTED: similar to S6 ribosomal protein isoform 1 1E-09 5E-06 1E-09 9E-06 1E-09 2E-05
gi|115957127| PREDICTED: similar to ribosomal protein L5 1E-05 2E-05 2E-05 1E-09 1E-09 1E-09
gi|5532389| microtubule-associated protein 8E-06 2E-06 1E-09 1E-09 1E-09 1E-09
gi|115936334| PREDICTED: hypothetical protein (proteasome subunit) 1E-05 2E-05 1E-09 4E-06 1E-09 1E-09
gi|115965220| PREDICTED: similar to histone macroH2A1.1 7E-06 1E-05 1E-05 1E-09 1E-09 1E-09
gi|115949865| PREDICTED: similar to putative eukaryotic petide chain
release factor subunit 1
1E-09 3E-06 7E-06 1E-09 1E-09 1E-09
gi|115935400| PREDICTED: hypothetical protein (inosine monophosphate
dehydrogenase)
6E-06 1E-09 1E-05 6E-06 3E-06 3E-06
gi|115934021| PREDICTED: similar to Psmc6 protein (proteasome 26S
subunit, ATPase)
5E-06 1E-05 3E-06 5E-06 1E-09 4E-06
gi|115968684| PREDICTED: similar to retinoblastoma binding protein 4
variant isoform 1
8E-06 3E-06 7E-06 1E-09 1E-09 1E-09
gi|115965680| PREDICTED: hypothetical protein (Heterogeneous nuclear
ribonucleoprotein L)
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115959476| PREDICTED: hypothetical protein, partial (translation
initiation factor eIF-2B)
2E-05 4E-06 1E-05 1E-09 9E-06 1E-09
gi|115939698| PREDICTED: similar to 26S proteasome subunit p44.5 1E-09 1E-09 1E-09 1E-09 1E-09 3E-06
gi|115940610| PREDICTED: hypothetical protein, partial (Ribosomal protein) 1E-05 9E-06 2E-05 8E-06 1E-09 8E-06
gi|115932417| PREDICTED: similar to ribosomal protein S10 isoform 2 1E-09 1E-09 9E-06 1E-09 1E-09 1E-09
gi|115968696| PREDICTED: similar to paraspeckle protein 1 isoform beta 6E-06 8E-06 5E-06 1E-09 1E-09 1E-09
gi|115963700| PREDICTED: similar to Ribosomal protein L14, partial 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115968722| PREDICTED: similar to DEAD-box RNA-dependent helicase
p68 isoform 2
6E-06 9E-06 9E-06 1E-06 1E-09 1E-09
gi|115946250| PREDICTED: similar to Shmt2 protein, partial 8E-06 8E-06 1E-09 1E-05 2E-05 1E-05
gi|115970676| PREDICTED: similar to 40S ribosomal protein S13 1E-09 1E-09 3E-05 7E-06 1E-09 1E-09
gi|115840564| PREDICTED: similar to DEAD (Asp-Glu-Ala-Asp) box
polypeptide 48
3E-06 3E-06 1E-09 1E-09 1E-09 1E-09
gi|68534982| translation elongation factor 1B gamma subunit 1E-05 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115934350| PREDICTED: similar to ubiquitin-activating enzyme E1 1E-09 2E-06 6E-06 1E-09 1E-09 3E-06
gi|115975522| PREDICTED: similar to Ribophorin II 1E-09 2E-06 4E-06 1E-09 1E-09 3E-06
gi|115951495| PREDICTED: similar to ribosomal protein L6 isoform 2 5E-06 1E-09 1E-05 9E-06 1E-09 8E-06
gi|115673317| PREDICTED: similar to translation initiation factor 2 gamma
subunit
3E-06 3E-06 1E-09 3E-06 3E-06 1E-05
gi|115939546| PREDICTED: similar to Ribosomal protein S2 9E-06 1E-09 1E-05 2E-05 1E-09 2E-05
gi|148539604| polyA-binding protein 4E-06 1E-09 1E-09 2E-06 1E-09 7E-06
gi|115936872| PREDICTED: similar to 26S proteasome regulatory chain 4 8E-06 6E-06 1E-09 1E-09 1E-09 1E-09
gi|115955282| PREDICTED: hypothetical protein (heterogenous nuclear
ribonucleoprotein K)
3E-06 3E-06 4E-06 1E-09 1E-09 1E-09
gi|115945280| PREDICTED: hypothetical protein, partial (ADP ribosylation
factor)
0.0001 0.0001 7E-05 1E-09 1E-09 1E-09
gi|115953630| PREDICTED: hypothetical protein (N-acetylneuraminic acid
synthase)
4E-05 2E-05 5E-05 4E-06 1E-09 7E-06
gi|115661720| PREDICTED: hypothetical protein (sucinate semialdehyde
dehydrogenase)
1E-09 1E-09 6E-06 5E-06 6E-06 1E-05
gi|115950705| PREDICTED: similar to Ribosomal protein S5 1E-09 1E-09 1E-09 1E-05 1E-09 1E-05
gi|115936522| PREDICTED: similar to ribosomal protein S26e 1E-09 9E-06 1E-09 1E-09 1E-09 7E-06
gi|115973107| PREDICTED: hypothetical protein, partial (NADH cytochrome
reductase)
3E-05 6E-05 4E-05 1E-09 1E-09 1E-09
gi|115958412| PREDICTED: similar to 34/67 kD laminin binding protein 1E-09 8E-06 5E-06 1E-05 2E-05 2E-05
gi|115929247| PREDICTED: similar to heterogeneous nuclear
ribonucleoprotein H .
2E-05 1E-05 3E-05 1E-09 2E-05 1E-09
gi|115950168| PREDICTED: similar to ubiquitin-activating enzyme E1-like 2 2E-06 3E-06 7E-06 2E-06 1E-06 1E-09
gi|115960623| PREDICTED: similar to LOC496154 protein (poly (ADP-ribose)
polymerase family)
2E-06 5E-06 6E-06 6E-06 1E-09 1E-09
gi|115975235| PREDICTED: similar to signal transducer and activator of
transcription 5B
2E-06 6E-06 9E-06 1E-09 4E-06 1E-09
gi|158327684| cytochrome oxidase subunit 2 3E-05 3E-05 4E-05 2E-05 1E-09 1E-09
gi|115970083| PREDICTED: similar to ubiquitin/40S ribosomal protein S27a
fusion protein
1E-09 1E-09 5E-05 1E-09 1E-09 1E-09
gi|115959136| PREDICTED: similar to ribosomal protein S8e 5E-06 2E-05 1E-05 1E-09 1E-09 4E-05
gi|115928686| PREDICTED: similar to alpha isoform of regulatory subunit A,
protein phosphatase 2, partial
1E-09 1E-09 1E-09 5E-06 6E-06 1E-09
gi|115946604| PREDICTED: similar to nuclear RNA helicase Bat1 isoform 2 6E-06 6E-06 1E-05 5E-06 3E-06 1E-09
gi|115968341| PREDICTED: similar to Ribosomal protein L3 2E-05 3E-05 4E-05 3E-06 1E-09 2E-05
gi|115911567| PREDICTED: hypothetical protein, partial (aspartyl tRNA
synthase)
4E-05 4E-05 3E-05 8E-06 6E-06 7E-06
gi|115970525| PREDICTED: similar to elongation factor 1 alpha isoform 1 1E-09 1E-09 1E-09 3E-05 4E-05 4E-05
gi|115649138| PREDICTED: similar to ribosomal protein S3 4E-05 6E-05 3E-05 2E-05 2E-05 4E-05
gi|115965257| PREDICTED: similar to heterogeneous nuclear
ribonucleoprotein R
2E-05 3E-05 2E-05 5E-06 7E-06 2E-06
gi|115946394| PREDICTED: similar to RNA binding motif protein 28 2E-05 3E-05 5E-06 1E-09 1E-09 1E-09
gi|47550983| nuclear intermediate filament protein 4E-06 7E-06 1E-09 4E-06 1E-09 1E-05
gi|148539566| eukaryotic initiation factor 4a 1E-05 1E-05 2E-05 2E-05 2E-05 5E-06
gi|115955810| PREDICTED: hypothetical protein (ribosomal protein L4) 3E-05 6E-05 5E-05 1E-09 1E-05 2E-05
gi|115974148| PREDICTED: similar to Ribophorin I 3E-05 3E-05 3E-05 2E-05 1E-09 7E-06
gi|47551065| histone H3 1E-09 5E-05 4E-05 8E-05 5E-05 0.0002
gi|115926828| PREDICTED: similar to eukaryotic translation elongation
factor isoform 2
9E-06 6E-06 9E-06 8E-06 2E-06 2E-05
NSAF

205
NSAF
W241 W242 W243 W481 W482 W483 LPS61 LPS62 LPS63 LPS241 LPS242 LPS243 LPS481 LPS482 LPS483
1E-09 1E-09 1E-09 1E-05 8E-06 8E-06 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09 1E-05 1E-09
1E-09 1E-09 1E-09 1E-05 7E-06 3E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 6E-06
6E-07 1E-09 1E-09 7E-06 1E-09 2E-06 1E-09 1E-09 1E-09 1E-09 1E-09 7E-07 2E-06 8E-06 3E-06
1E-06 1E-09 6E-06 3E-06 8E-06 4E-06 8E-06 1E-09 5E-06 2E-06 2E-06 1E-09 1E-09 1E-09 1E-09
2E-06 1E-09 1E-09 7E-06 1E-09 3E-06 1E-09 1E-05 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 1E-09
1E-09 1E-09 1E-09 8E-06 1E-09 1E-09 1E-09 3E-06 5E-06 2E-06 1E-06 1E-09 1E-05 3E-06 9E-06
1E-09 1E-09 1E-09 2E-06 1E-09 7E-06 1E-09 6E-06 1E-09 1E-09 1E-06 1E-09 1E-09 2E-05 1E-09
3E-06 1E-09 1E-09 5E-06 4E-06 2E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
4E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 4E-06 3E-06 1E-09 7E-06 3E-06 1E-09
1E-06 1E-09 1E-09 1E-05 1E-05 8E-06 1E-09 3E-06 2E-06 1E-09 1E-09 1E-06 4E-06 1E-05 1E-09
1E-09 1E-09 1E-09 8E-06 2E-05 1E-09 1E-09 1E-09 7E-06 1E-06 1E-09 1E-09 1E-09 1E-09 6E-06
1E-09 1E-09 1E-09 1E-05 2E-05 2E-06 1E-09 1E-09 2E-06 2E-06 1E-09 1E-09 1E-09 2E-05 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 7E-06 1E-09 1E-09 1E-09 3E-06 5E-06 3E-06 1E-09 1E-05 1E-09
2E-06 1E-09 1E-09 3E-05 1E-05 1E-05 1E-09 1E-09 1E-09 5E-06 1E-09 1E-09 3E-05 5E-05 1E-09
1E-09 1E-09 1E-09 8E-06 3E-06 1E-09 1E-09 1E-09 1E-06 1E-06 1E-09 1E-09 5E-06 6E-06 1E-09
8E-06 1E-09 1E-09 1E-05 1E-05 1E-05 7E-06 9E-06 1E-09 1E-09 3E-06 2E-05 4E-05 4E-05 1E-09
9E-07 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-06 6E-07 1E-09 3E-06 5E-06 1E-09
1E-09 1E-09 1E-05 2E-05 1E-05 1E-09 1E-09 2E-05 2E-05 8E-06 6E-06 1E-09 1E-09 1E-09 1E-09
1E-05 1E-09 1E-09 2E-05 7E-06 1E-05 1E-09 2E-05 1E-09 3E-06 1E-05 3E-06 1E-09 3E-05 1E-05
3E-06 1E-09 4E-06 1E-05 8E-06 3E-06 3E-06 1E-09 4E-06 1E-06 1E-09 1E-09 1E-05 2E-05 1E-09
2E-06 1E-09 1E-09 1E-05 5E-06 1E-09 1E-09 1E-09 1E-09 4E-06 1E-09 1E-06 2E-05 1E-05 1E-09
2E-06 1E-09 1E-09 2E-06 1E-09 1E-06 1E-09 1E-06 1E-09 4E-07 1E-09 1E-09 6E-06 7E-06 1E-09
1E-06 1E-09 2E-06 8E-06 1E-06 1E-06 1E-09 2E-06 1E-09 2E-06 6E-07 6E-07 7E-06 5E-06 1E-09
3E-06 1E-09 1E-09 9E-06 1E-09 8E-06 4E-06 1E-05 1E-05 5E-06 4E-06 1E-09 2E-05 5E-06 1E-09
4E-06 1E-09 1E-09 7E-06 7E-06 2E-06 1E-09 1E-09 1E-09 2E-06 3E-06 1E-09 1E-05 1E-05 1E-09
7E-06 1E-09 6E-06 6E-06 1E-05 1E-09 8E-06 9E-06 1E-09 2E-06 1E-09 1E-09 1E-09 5E-06 1E-05
4E-06 1E-09 1E-09 4E-06 1E-09 1E-09 1E-09 1E-09 1E-09 2E-06 4E-06 2E-06 9E-06 6E-06 1E-09
4E-06 5E-06 1E-09 5E-06 5E-06 1E-09 1E-09 1E-05 1E-09 6E-06 6E-06 3E-06 1E-09 1E-09 1E-09
9E-07 1E-09 2E-05 2E-05 5E-06 1E-05 1E-09 1E-09 2E-06 1E-09 3E-06 1E-09 1E-09 6E-06 9E-06
1E-09 1E-09 1E-09 3E-05 8E-06 1E-09 1E-09 1E-05 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
1E-06 1E-09 3E-05 1E-09 1E-09 3E-06 7E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
8E-07 1E-09 1E-09 3E-06 1E-05 2E-06 1E-09 1E-09 4E-06 4E-06 1E-06 1E-09 1E-09 2E-05 1E-09
4E-06 3E-05 1E-09 1E-05 9E-06 1E-09 1E-05 5E-05 1E-05 1E-09 1E-09 1E-09 7E-06 3E-05 1E-09
8E-06 4E-05 1E-09 2E-05 2E-05 3E-05 1E-05 1E-09 1E-05 9E-06 1E-05 1E-09 7E-05 2E-05 1E-09
1E-09 1E-09 1E-09 5E-06 3E-06 3E-06 1E-09 1E-05 2E-06 1E-09 3E-06 1E-09 4E-06 4E-06 1E-09
5E-06 2E-05 2E-05 7E-06 9E-06 1E-09 3E-06 2E-05 1E-09 5E-06 3E-06 1E-06 1E-09 1E-09 1E-09
2E-06 1E-09 1E-09 7E-06 1E-09 1E-09 1E-09 1E-09 1E-09 3E-06 2E-06 5E-06 6E-06 8E-06 1E-09
6E-07 1E-09 1E-09 3E-06 3E-06 8E-07 1E-09 3E-06 2E-06 1E-06 4E-07 1E-06 5E-06 2E-06 1E-09
1E-09 1E-09 1E-09 4E-06 8E-06 1E-05 1E-09 5E-06 7E-06 8E-06 9E-07 2E-06 1E-05 2E-06 1E-09
3E-06 1E-09 1E-09 8E-06 3E-06 6E-06 1E-09 2E-06 8E-07 6E-07 2E-06 1E-09 7E-06 1E-05 7E-06
8E-06 1E-09 7E-06 2E-05 1E-05 4E-06 9E-06 2E-05 1E-09 4E-06 4E-06 4E-06 3E-05 2E-05 1E-09
5E-06 4E-05 1E-09 4E-05 3E-05 4E-05 1E-09 4E-05 4E-05 1E-09 1E-05 1E-09 1E-09 1E-09 0.0001
2E-05 1E-09 2E-05 1E-09 8E-06 8E-06 4E-06 2E-05 1E-09 1E-09 1E-05 1E-05 3E-05 2E-05 1E-09
5E-06 9E-06 7E-06 2E-05 7E-06 3E-05 1E-09 1E-05 6E-06 3E-06 3E-06 1E-06 2E-05 1E-09 2E-05
4E-06 1E-09 1E-09 3E-05 2E-05 1E-05 1E-09 6E-06 5E-06 4E-06 2E-06 1E-09 2E-05 2E-05 1E-09
6E-06 1E-09 4E-06 8E-06 1E-05 1E-05 3E-06 6E-06 5E-06 1E-05 1E-09 2E-06 4E-06 1E-05 5E-06
4E-06 5E-06 1E-09 7E-06 5E-06 2E-06 1E-09 8E-06 3E-06 4E-06 4E-06 2E-06 2E-05 6E-06 1E-09
1E-09 1E-09 4E-05 1E-09 1E-09 1E-09 1E-09 1E-09 3E-05 1E-09 1E-09 4E-05 1E-09 1E-09 1E-09
1E-05 1E-09 6E-06 2E-05 3E-05 2E-05 1E-09 9E-06 5E-06 8E-06 5E-06 5E-06 3E-05 4E-05 1E-09
4E-06 3E-06 1E-09 2E-05 1E-05 1E-05 3E-06 1E-05 6E-06 4E-06 3E-06 3E-06 2E-06 2E-06 9E-06
1E-06 3E-06 1E-09 1E-09 1E-09 1E-05 2E-06 1E-09 1E-09 1E-09 1E-09 5E-05 2E-06 2E-06 1E-09
7E-07 1E-09 1E-05 2E-05 4E-05 2E-05 2E-06 1E-05 1E-05 2E-06 2E-06 2E-06 3E-05 2E-05 3E-05
9E-06 1E-09 2E-05 2E-05 1E-05 2E-05 2E-05 1E-05 2E-05 1E-05 7E-06 7E-06 2E-05 4E-05 2E-05
1E-05 1E-09 1E-09 4E-05 3E-05 2E-05 8E-06 6E-06 2E-06 1E-05 1E-05 6E-06 1E-05 1E-05 5E-06
8E-06 1E-09 5E-06 5E-06 1E-05 2E-06 1E-09 2E-05 7E-06 1E-05 6E-06 8E-06 3E-05 1E-05 9E-06
2E-05 0.0001 8E-05 3E-05 4E-05 2E-05 0.0002 0.0001 7E-05 1E-05 7E-06 7E-06 4E-05 1E-09 3E-05
5E-06 1E-09 6E-06 8E-06 8E-06 1E-05 5E-06 1E-05 1E-05 5E-06 5E-06 3E-06 3E-05 2E-05 9E-06

206
Identifier Description NI1 NI2 NI3 W61 W62 W63
gi|115933977| PREDICTED: similar to histone H2A-3 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|47551085| late histone L3 H2a 0.0002 0.0001 0.0002 6E-05 1E-09 1E-09
gi|47551121| mitochondrial ATP synthase alpha subunit precursor 4E-05 3E-05 5E-05 2E-05 5E-05 2E-05
gi|115974434| PREDICTED: similar to adenosylhomocysteinase 6E-05 5E-05 0.0001 4E-05 4E-05 8E-05
gi|47551075| late histone L1 H2b 1E-09 0.0001 9E-05 8E-05 1E-09 0.0001
gi|115970523| PREDICTED: similar to elongation factor 1 alpha isoform 2 8E-05 8E-05 0.0001 1E-09 1E-09 1E-09
gi|47551061| H4 histone protein 0.0005 0.0006 0.0009 0.0004 0.0002 0.0002
gi|115974576| PREDICTED: similar to putative ribosomal protein S14e 1E-09 9E-06 2E-05 1E-09 1E-09 2E-05
gi|115970054| PREDICTED: similar to putative RNA helicase (DEAD box) 7E-06 1E-09 1E-09 2E-05 2E-05 2E-05
gi|115931135| PREDICTED: similar to putative RNA binding protein KOC 1E-05 1E-05 5E-06 7E-06 7E-06 7E-06
gi|115955764| PREDICTED: similar to Cry5 protein 9E-06 7E-06 1E-09 1E-09 1E-09 1E-09
gi|115976887| PREDICTED: similar to START domain containing protein 9E-05 0.0001 7E-05 6E-05 2E-05 4E-06
gi|47551041| ER calcistorin 5E-06 3E-05 3E-05 1E-09 1E-09 1E-09
gi|115937420| PREDICTED: catalase 1E-09 2E-05 2E-05 2E-06 8E-06 1E-05
gi|115924280| PREDICTED: similar to flavoprotein subunit of complex II,
partial
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
gi|115926010| PREDICTED: similar to glutathione peroxidase, partial 2E-05 1E-05 2E-05 2E-05 1E-09 1E-09
gi|115977049| PREDICTED: hypothetical protein (chaperonin containing
TCP1)
3E-06 9E-06 4E-06 8E-06 3E-06 5E-06
gi|115959568| PREDICTED: similar to glutathione reductase 2E-06 1E-09 3E-06 3E-06 1E-09 3E-06
gi|115628087| PREDICTED: similar to chaperonin containing TCP1, subunit
6A isoform 1
8E-06 1E-05 6E-06 1E-09 1E-09 5E-06
gi|115815329| PREDICTED: similar to Cct6a protein, partial (chaperonin
containing TCP1)
2E-05 1E-09 1E-09 5E-06 1E-05 1E-09
gi|115905691| PREDICTED: similar to Pkm2 protein, partial (Pyruvate kinase
isoenzyme type M2)
9E-05 5E-05 8E-05 1E-09 1E-09 1E-09
gi|115956030| REDICTED: similar to chaperonin 1E-09 1E-09 1E-09 6E-06 5E-06 6E-06
gi|115936458| PREDICTED: similar to Aconitase 2, mitochondrial isoform 1 1E-05 2E-05 1E-09 4E-06 1E-09 1E-05
gi|115924889| PREDICTED: similar to Chaperonin containing TCP1, subunit
5 (epsilon)
7E-06 1E-09 1E-09 1E-05 1E-05 4E-06
gi|115954976| PREDICTED: similar to heat shock protein protein 70kDa 1E-09 1E-09 1E-09 2E-05 1E-05 2E-05
gi|115944173| PREDICTED: similar to ENSANGP00000006016 isoform 1
(dual oxidase maturation factor)
9E-06 1E-05 1E-05 1E-09 1E-09 1E-09
gi|115956641| PREDICTED: similar to LOC495278 protein (chaperonin
containing TCP1)
5E-06 1E-05 1E-05 2E-06 1E-09 2E-06
gi|115954867| PREDICTED: similar to Chaperonin containing TCP1, subunit
4 (delta)
7E-06 1E-05 6E-06 1E-09 3E-06 2E-06
gi|115970125| PREDICTED: similar to MGC139263 protein (Annexin) 5E-06 5E-06 3E-06 1E-09 1E-09 6E-06
gi|115964822| PREDICTED: similar to mitochondrial chaperonin Hsp56 5E-06 5E-06 1E-05 1E-09 1E-09 6E-06
gi|115944450| PREDICTED: similar to chaperonin subunit 8 theta 1E-09 7E-06 6E-06 2E-06 1E-09 1E-09
gi|115930256| PREDICTED: similar to Chaperonin containing TCP1, subunit
3 (gamma)
2E-06 1E-09 3E-06 4E-06 1E-09 8E-06
gi|115956665| PREDICTED: similar to heat shock protein protein 70kDa 2E-05 3E-05 2E-05 2E-05 1E-09 3E-05
gi|115891388| PREDICTED: similar to heat shock 90 kDa protein, partial 3E-05 4E-05 6E-05 4E-06 3E-06 1E-09
gi|115931665| PREDICTED: similar to MGC89020 protein (mitochondrial
aldehyde dehydrogenase 2)
7E-06 8E-06 1E-05 2E-05 1E-05 6E-05
gi|115944169| PREDICTED: similar to dual oxidase 1 isoform 1 . 2E-05 3E-05 3E-05 7E-07 1E-05 1E-09
gi|47551251| heat shock protein gp96 5E-05 3E-05 4E-05 1E-09 1E-09 1E-09
gi|115972586| PREDICTED: similar to 71 Kd heat shock cognate protein 7E-05 7E-05 7E-05 6E-05 8E-05 7E-05
gi|115924727| PREDICTED: similar to major yolk protein precursor 1E-09 1E-09 1E-09 0.0002 1E-09 1E-09
gi|47551123| major yolk protein 0.0007 0.0004 0.0004 0.0002 0.0002 6E-05
gi|53913428| major yolk protein 0.0007 1E-09 0.0005 1E-09 0.0002 1E-09
gi|73746392| major yolk protein 0.0009 0.0005 0.0006 0.0002 0.0002 6E-05
gi|115974673| PREDICTED: similar to LOC407663 protein (shor chain
dehydrogenase)
2E-05 1E-05 1E-05 1E-09 4E-06 1E-09
gi|115803435| PREDICTED: hypothetical protein (similar to cleavage
stimulation factor fusion)
6E-06 6E-06 5E-06 2E-06 1E-09 1E-09
gi|115967840| PREDICTED: similar to 0910001A06Rik protein isoform 2 2E-05 3E-05 9E-06 1E-09 1E-09 1E-09
gi|115760426| PREDICTED: similar to conserved hypothetical protein 7E-06 2E-06 1E-09 2E-06 1E-09 1E-09
gi|115934013| PREDICTED: hypothetical protein (ANK domain and SH3
domain)
1E-09 1E-06 1E-09 1E-06 1E-09 5E-06
gi|115929076| PREDICTED: hypothetical protein 1E-09 1E-09 2E-05 1E-09 1E-09 1E-09
gi|115925359| PREDICTED: similar to LZP (CCP and zona pellucida
superfamily)
2E-06 6E-06 2E-05 2E-06 1E-09 1E-09
gi|115964419| PREDICTED: hypothetical protein . 1E-05 5E-06 1E-05 1E-06 5E-06 1E-09
gi|115963910| PREDICTED: hypothetical protein, partial . 2E-05 2E-05 1E-05 5E-05 5E-05 1E-09
gi|115621989| PREDICTED: hypothetical protein 3E-05 6E-06 9E-05 3E-06 1E-09 8E-06
NSAF

207
NSAF
W241 W242 W243 W481 W482 W483 LPS61 LPS62 LPS63 LPS241 LPS242 LPS243 LPS481 LPS482 LPS483
1E-09 1E-09 1E-09 0.0004 1E-09 0.0001 0.0001 0.0002 5E-05 2E-05 1E-09 1E-09 0.0003 0.0004 6E-05
2E-05 1E-09 1E-09 0.0003 0.0004 1E-09 5E-05 1E-09 4E-05 2E-05 2E-05 2E-05 0.0003 0.0003 0.0001
2E-05 2E-05 2E-05 2E-05 2E-05 4E-05 4E-06 2E-05 2E-05 2E-05 2E-05 4E-06 8E-06 3E-05 1E-05
3E-05 1E-09 2E-05 5E-05 6E-05 3E-05 3E-05 6E-05 3E-05 2E-05 1E-05 2E-05 7E-05 6E-05 3E-05
0.0002 1E-09 3E-05 0.0002 1E-09 0.0002 0.0002 0.0003 0.0001 0.0002 0.0002 0.0001 0.0003 1E-09 1E-09
5E-05 1E-09 1E-09 6E-05 6E-05 4E-05 3E-05 5E-05 1E-09 7E-05 5E-05 1E-09 7E-05 8E-05 6E-05
0.0003 0.0002 0.0003 0.0005 0.0005 0.0006 1E-09 0.0005 0.0004 0.0005 1E-09 0.0002 0.0009 1E-09 0.0004
5E-06 1E-09 1E-09 1E-05 2E-05 7E-06 1E-05 9E-06 1E-09 1E-09 7E-06 1E-05 2E-05 1E-09 1E-09
7E-06 1E-05 1E-09 1E-05 8E-06 8E-06 1E-09 3E-06 9E-06 5E-06 1E-06 1E-06 1E-05 7E-06 1E-09
6E-06 1E-09 3E-06 1E-05 3E-06 2E-06 2E-06 1E-09 3E-06 2E-06 7E-07 7E-07 2E-05 3E-05 6E-06
7E-07 1E-09 1E-09 1E-06 4E-06 1E-05 1E-09 1E-09 1E-06 3E-06 1E-09 1E-09 5E-06 9E-06 3E-05
2E-06 8E-05 9E-05 6E-05 4E-05 8E-05 6E-05 3E-05 0.0001 0.0001 4E-05 7E-05 0.0001 9E-05 8E-05
4E-06 1E-09 1E-05 3E-05 1E-05 1E-05 1E-09 2E-05 5E-06 1E-05 2E-06 5E-06 9E-06 1E-05 2E-05
5E-06 1E-09 1E-09 3E-05 2E-05 3E-05 1E-09 1E-09 4E-06 5E-06 7E-06 9E-06 2E-05 2E-05 2E-05
1E-09 1E-09 1E-09 3E-06 6E-06 1E-06 1E-09 1E-09 1E-09 6E-07 1E-09 1E-09 8E-06 1E-09 1E-05
2E-06 1E-09 1E-09 1E-09 1E-05 1E-09 1E-09 1E-09 1E-09 2E-06 1E-09 1E-09 3E-05 1E-09 1E-09
1E-09 1E-09 1E-09 9E-06 5E-06 2E-06 1E-09 1E-09 5E-06 1E-09 1E-09 1E-09 1E-09 2E-05 1E-09
1E-06 1E-09 1E-06 2E-06 3E-06 1E-09 1E-09 3E-06 1E-09 8E-07 1E-06 8E-07 1E-06 1E-09 1E-09
1E-09 1E-09 1E-09 8E-06 2E-06 1E-09 1E-09 1E-09 3E-06 1E-09 1E-09 1E-09 2E-05 2E-05 1E-09
8E-06 1E-09 1E-09 1E-09 4E-06 1E-09 1E-09 1E-05 5E-06 9E-06 4E-06 4E-06 2E-05 2E-05 1E-09
1E-05 1E-09 1E-09 3E-05 6E-05 6E-05 1E-09 3E-05 1E-09 1E-09 7E-06 7E-06 2E-05 4E-05 5E-05
2E-06 1E-09 1E-09 9E-06 9E-06 2E-06 1E-09 2E-06 6E-06 8E-07 9E-07 9E-07 5E-06 7E-06 1E-09
6E-07 1E-09 1E-09 1E-06 2E-06 1E-09 1E-09 1E-09 1E-09 4E-06 1E-09 2E-06 9E-06 6E-06 3E-06
3E-06 8E-06 1E-09 6E-06 2E-06 8E-06 4E-06 9E-06 6E-06 8E-07 1E-09 9E-07 1E-09 7E-06 3E-06
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-05 2E-05 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
4E-06 1E-09 1E-09 5E-06 7E-06 5E-06 1E-09 6E-06 1E-09 6E-06 1E-05 4E-06 7E-06 2E-05 8E-06
8E-06 1E-09 1E-09 7E-06 1E-09 6E-06 1E-09 9E-06 5E-06 1E-09 3E-06 3E-06 8E-06 7E-06 1E-09
5E-06 1E-09 1E-09 1E-05 8E-06 1E-05 1E-09 2E-06 4E-06 3E-06 3E-06 1E-09 9E-06 2E-05 4E-06
1E-09 1E-09 1E-09 2E-05 1E-05 1E-05 1E-09 1E-09 8E-06 1E-09 1E-09 1E-09 4E-05 9E-06 1E-05
9E-06 1E-09 3E-06 2E-05 2E-05 4E-06 1E-09 9E-06 4E-06 1E-09 9E-07 2E-06 8E-06 3E-05 1E-09
4E-06 1E-09 3E-06 2E-05 1E-05 2E-05 1E-09 1E-05 1E-09 4E-06 2E-06 4E-06 3E-05 4E-05 4E-06
9E-06 4E-06 1E-09 2E-05 9E-06 2E-06 1E-09 2E-05 9E-06 2E-06 3E-06 4E-06 2E-05 3E-05 1E-09
1E-09 1E-09 1E-09 1E-09 2E-05 1E-09 1E-09 1E-09 2E-05 1E-05 1E-09 1E-09 2E-05 3E-05 8E-05
2E-06 1E-09 2E-05 3E-05 3E-05 3E-05 1E-09 1E-05 5E-06 1E-05 1E-05 9E-07 5E-05 4E-05 6E-05
2E-05 8E-06 3E-06 3E-05 5E-05 4E-05 2E-06 3E-05 1E-05 3E-06 8E-06 1E-06 3E-05 7E-05 2E-05
2E-06 1E-06 1E-06 1E-09 1E-09 3E-06 2E-06 2E-05 2E-06 3E-06 3E-06 8E-06 3E-05 3E-05 3E-06
1E-09 1E-09 2E-06 5E-05 3E-05 4E-05 1E-09 3E-05 2E-06 9E-06 1E-05 6E-07 5E-05 5E-05 4E-05
3E-05 4E-05 4E-05 9E-05 6E-05 7E-05 4E-05 4E-05 7E-05 4E-05 2E-05 2E-05 6E-05 0.0001 0.0001
1E-09 0.0006 0.0004 0.0002 0.0002 0.0002 0.0002 1E-09 9E-05 0.0004 0.0005 1E-09 1E-09 1E-09 0.0003
0.0005 0.0007 0.0004 0.0002 0.0002 0.0002 0.0003 0.0002 9E-05 0.0004 0.0008 0.0007 0.0003 0.0004 0.0003
0.0005 0.0007 0.0004 0.0003 0.0003 0.0003 0.0003 0.0002 9E-05 0.0004 0.0008 0.0007 0.0003 0.0004 0.0004
0.0005 0.0009 0.0005 0.0003 0.0003 0.0003 0.0003 0.0003 0.0001 0.0005 0.0009 0.0007 0.0004 0.0004 0.0005
1E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09
3E-06 7E-06 1E-09 3E-06 1E-09 1E-09 1E-09 2E-06 1E-09 1E-09 1E-09 1E-09 5E-06 1E-09 1E-09
1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 6E-06 1E-09 2E-06 5E-06 1E-09 1E-09 9E-06 1E-09 1E-09
1E-09 1E-09 1E-09 2E-06 1E-06 1E-06 1E-09 1E-09 1E-09 6E-07 1E-09 3E-06 8E-06 4E-06 1E-09
1E-09 4E-06 2E-06 1E-09 2E-06 1E-06 3E-06 4E-06 2E-06 4E-07 9E-07 5E-07 3E-06 1E-06 2E-06
1E-09 1E-09 1E-09 3E-05 2E-05 1E-05 1E-09 3E-05 1E-09 2E-05 1E-05 1E-09 1E-05 5E-05 1E-09
4E-07 1E-09 2E-06 8E-07 2E-06 1E-09 1E-09 1E-09 1E-09 1E-09 1E-09 7E-06 1E-09 2E-06 1E-09
1E-06 2E-05 7E-06 1E-05 2E-06 1E-05 4E-06 5E-06 1E-06 1E-09 5E-06 2E-06 1E-05 1E-05 2E-05
7E-06 1E-05 4E-05 5E-05 2E-05 5E-05 3E-05 2E-05 6E-05 1E-05 8E-06 1E-05 3E-05 3E-05 5E-05
2E-05 3E-05 4E-06 6E-06 1E-05 3E-05 4E-05 4E-05 5E-06 9E-06 5E-06 5E-06 3E-05 2E-05 0.0004

208

209
CHAPTER V
Highly variable immune-response proteins (185/333) from the sea urchin,
Strongylocentrotus purpuratus: Proteomic analysis identifies diversity within and
between individuals.
Published in
Journal of Immunology
182(4): 2203-2212
Author contributions:
Nair SV1 - Experimental design -Project supervision
Smith LC2 – Technical support
Raftos DA1 - Experimental design - Project supervision
1Department of Biological Sciences, Macquarie University, North Ryde, NSW 2109, Australia.
2Department of Biological Sciences, George Washington University, Washington, DC, 20052, USA.
Dheilly N.M., Nair S.V., Smith L.C., Raftos D.A. (2009) Highly variable immune-
response (185/333) from the sea urchin Strongylocentrotus purpuratus: Proteomic analysis
identifies diversity within and between individuals. Journal of Immunology. 182(4): 2203-
12.

210

211
5.1. Preface
A major difference observed between previous macroarray analysis and the current
proteomics studies (Chapters 2 to 4) was the low abundance of 185/333 proteins identified
by 2DE and shotgun proteomics. Even though these molecules constituted up to 60% of
bacterially challenged cDNA library, only a single 185/333 protein was identified in the
coelomic fluid proteome of S. purpuratus and none were found in H. erythrogramma. The
following two Chapters of this thesis specifically investigated 185/333 proteins with the
aims of further characterizing their variability and providing new clues on their function in
the sea urchin immune system. In Chapter 5, we characterized the variability of 185/333
proteins within and between individuals and identified differences in expression in
response to different challenges using a combination of proteomics technologies.

212

213
5.2. Abstract
185/333 genes and transcripts from the purple sea urchin, Strongylocentrotus
purpuratus, predict high levels of amino acid diversity within the encoded proteins. Based
on their expression patterns, 185/333 proteins appear to be involved in immune responses.
In the present study, one- and two-dimensional Western blots show that 185/333 proteins
exhibit high levels of molecular diversity within and between individual sea urchins. The
molecular masses of 185/333-positive bands or spots range from 30 to 250 kDa with a
broad array of isoelectric points. The observed molecular masses are higher than those
predicted from mRNAs, suggesting that 185/333 proteins form strong associations with
other molecules or with each other. Some sea urchins expressed > 200 distinct 185/333
proteins, and each animal had a unique suite of the proteins that differed from all other
individuals. When sea urchins were challenged in vivo with pathogen-associated molecular
patterns (PAMPs; bacterial LPS and peptidoglycan), the expression of 185/333 proteins
increased. More importantly, different suites of 185/333 proteins were expressed in
response to different PAMPs. This suggests that the expression of 185/333 proteins can be
tailored toward different PAMPs in a form of pathogen-specific immune response.

214
5.3. Introduction
Recent studies of host defense have uncovered profound differences among animal
phyla in the molecules used to mediate immune responses [1-3]. It seems that the immune
systems of different animals have evolved a variety of solutions to meet a basic
requirement to combat pathogens. The resulting, highly diversified immune responses may
reflect the specific physiology, lifespan, habitat, and associated microbial populations of
particular animal groups, or they may have arisen by chance via evolutionary radiation. A
number of metazoan phyla have now been studied, identifying a range of alternative
immunological mechanisms that exhibit high levels of molecular diversity [2]. These
discoveries have driven a paradigm shift in our understanding of invertebrate immune
responses, from systems that are simple and static, to those that are complex and have
novel mechanisms for generating molecular hypervariability, a key requirement for
keeping pace in the “arms race” against microbial pathogens.
Some invertebrate immune systems are proving to be surprisingly complex. Recent
analyses of the purple sea urchin (Strongylocentrotus purpuratus) genome identified
several large gene families, including gene models for 222 TLRs, 203 NOD-like receptors
(NLR), 218 scavenger receptor cysteine-rich (SRCR) molecules, and 104 C-type lectins [4-
6]. The complexity and large size of these gene families suggest that the receptors they
encode may recognize individual pathogen-associated molecular patterns (PAMPs) with a
high degree of specificity. They might also act combinatorially, providing highly diverse
recognitive capabilities [5]. In addition to diversified receptors, the S. purpuratus genome
contains homologues of Rag 1 and Rag 2, the molecules responsible for the somatic
recombination of immunoglobulins in vertebrates [7]. This suggests that the molecular
tools required to generate molecular hypervariability might also exist among invertebrates.

215
185/333 genes represent another high-diversity immune response system in sea
urchins. This family was first identified during a transcriptome analysis of sea urchin
immune response genes [8]. Genes that were up-regulated in coelomocytes (immune cells)
after the injection of LPS were identified by screening high-density arrayed, conventional
cDNA libraries with probes generated by subtractive suppression hybridization.
Surprisingly, ~ 60% of the expressed sequence tags (ESTs) characterized in this
transcriptome analysis were members of a set of closely related transcripts with similarities
to two uncharacterized sequences from S. purpuratus, called DD185 (GenBank accession
AF228877 [9]) and EST333 (GenBank accession R62081 [10]), hence the designation
185/333.
Screening an arrayed cDNA library constructed from immunologically activated
coelomocytes indicated that the frequency of 185/333 mRNAs was enhanced more than
75-fold compared with a nonactivated arrayed cDNA library [8]. Northern blots also
showed striking increases in 185/333 expression in coelomocytes from bacterially
activated sea urchins compared with injury controls [9]. Based on this significant increase
in gene expression, 185/333 transcripts were investigated in more detail, revealing an
unexpected level of sequence diversity [8, 11]. To date, for 185/333 cDNAs, 689 have
been characterized from 14 sea urchins. These sequences are predicted to encode 286
different proteins [11, 12].
The diversity evident among 185/333 transcripts is generated in several ways.
185/333 mRNAs are comprised of 25 different blocks or “elements” of nucleotide
sequence, that are present or absent in numerous combinations. This results in “element
patterns” that are repeatedly identified in different mRNAs [8, 12], contributing significant
diversity to the family of 185/333 messages. Single nucleotide polymorphisms (SNPs) and
small insertions or deletions (indels) are also frequent in all 185/333 sequences, adding to
diversity. Additionally, there are surprisingly high levels of frame shifts and the insertion

216
of early stop codons in the mRNA sequences [11]. The processes that generate this
diversity among 185/333 mRNAs are not yet well defined, but they may include
differences among the estimated fifty 185/333 gene loci [11, 13, 14], high levels of allelic
polymorphism at each locus, RNA editing, and/or low-fidelity RNA polymerases [15],
followed by posttranslational modifications. All of these processes may have been driven
by positive selection associated with anti-pathogen defense [8, 11, 12, 14]. Nucleotide
sequence variability results in high levels of nonconservative amino acid substitutions
among predicted proteins of the type consistent with intense evolutionary selection
pressure [8, 12, 14, 15].
185/333 mRNAs are predicted to encode proteins with a hydrophobic leader, a
glycine-rich region with multiple endoprotease cleavage sites, an RGD motif, a histidine-
rich region, numerous N-linked and O-linked glycosylation sites, acidic patches, and
several types of tandem and interspersed repeats [11]. The deduced proteins do not contain
cysteines, transmembrane regions, GPI linkage sites, identifiable domains, or any
predictable folding patterns. The only regions with at least some similarity to other
molecules are the RGD motif and one of the histidine-rich domains, which is comparable
to histatins, a group of mammalian salivary proteins with powerful antifungal activities
[16, 17]. Brockton et al. [18] have shown that 185/333 proteins are expressed by two
subsets of coelomocytes (small phagocytes and polygonal cells), and that the number of
185/333+ cells increases in response to immunological challenge. Initial analyses of the
185/333 proteins indicated that recombinant 185/333 proteins appear as multimers and that
native proteins are present in a broad range of sizes, in agreement with the mRNA
sequences [18].

217
Here, we present the first comprehensive analysis of 185/333 proteins. It reveals a
broad diversity of these proteins within individual sea urchins. Different sea urchins
express different suites of 185/333 proteins, and expression is altered by immunological
challenge. The data indicate that differential expression or posttranslational modification of
185/333 proteins might allow S. purpuratus to tailor immune responses toward specific
pathogens.

218
5.4. Materials and Methods
5.4.1. Sea urchins
Adult S. purpuratus were purchased from Marinus Scientific after collection from
the coast of southern California. They were maintained in the laboratory as described
previously [19]. S. purpuratus becomes immunoquiescent after long-term housing of >8
months without significant disturbance [19, 20]. Immunoquiescence can easily be reversed
by injecting PAMPs, or in response to injury [19-21].
5.4.2. Immunological challenge and sample collection
Animals were challenged by injecting 2 µg of LPS or 4 µg of peptidoglycan (Sigma-
Aldrich) per milliliter of coelomic fluid (CF), as previously described [10, 19]. Control
animals were injected with an equivalent volume of artificial CF (aCF) [11]. CF (100 µl)
was withdrawn from each sea urchin immediately before injection, and then at various
times after injection. A 23-gauge needle attached to a 1-ml syringe was inserted through
the peristomium into the coelomic cavity and CF was withdrawn without anticoagulant.
The CF was immediately expelled into a 1-ml tube and mixed with 100 µl of urea sample
buffer (2.4 M Tris-HCl (pH 6.8), 0.25% SDS, 4 M urea, 20% glycerol). Samples were
stored at -70°C until used. Proteins were precipitated using 2-D Clean Up kits (GE
Healthcare) according to the manufacturer’s instructions and resuspended in urea sample
buffer (8 M urea, 4% CHAPS, 60 mM DTT). The total protein content of each sample was
determined with 2-D Quant kits (GE Healthcare).

219
5.4.3. One-dimensional electrophoresis (1DE)
CF proteins in urea sample buffer (~100 µg/well) were separated on 10% Tris-
glycine precast polyacrylamide gels (Criterion Gel System; BioRad) at 130 V for 2 hours ,
or on 7.5% bis-Tris polyacrylamide gels at 180 V for 1 hour. After electrophoresis,
proteins were visualized using Sypro Ruby (Sigma-Aldrich) following the manufacturer’s
protocol, or with Coomassie Blue using standard protocols. Alternatively, the proteins
were transferred to nitrocellulose membranes by Western blotting as described below.
5.4.4. Two-dimensional electrophoresis (2DE)
Isoelectrofocusing was performed using an IPGphor IEF system (GE Healthcare).
Immobilized pH gradient (IPG) gel strips (11 cm, pH 3-6 or pH 3-10; GE Healthcare) were
rehydrated overnight with 200 µg of CF proteins in 200 µL rehydration buffer (8 M urea,
2% CHAPS, 50 mM DTT, and 0.5% carrier ampholytes; Immobiline; GE Healthcare).
Isoelectrofocusing was undertaken at 100 V for 3 hours, 250 V for 20 minutes, and 8000 V
for 6 hours, to obtain a total of 26,000-30,000 Vh. The proteins in the IPG strips were
reduced (1% DTT, 15 minutes) and alkylated (2.5% iodoacetamide, 15 minutes) before
separation in the second dimension by SDS-PAGE using 10% Tris-glycine precast
polyacrylamide gels (Criterion Gel System, BioRad) [22].
After electrophoresis, protein spots on the gels were visualized by Coomassie blue staining
or with Sypro Ruby. Alternatively, proteins were transferred to nitrocellulose membranes,
as described see below.

220
5.4.5. Antibodies
The polyclonal antisera against 185/333 proteins used in this study were the same as
those reported by Brockton et al. [18]. Antisera were generated against synthetic peptides
corresponding to elements 1, 7 and 25a, which are present in most 185/333 cDNAs (see
Ref. 11 and Figure 5.5). The peptides were conjugated to keyhole limpet haemocyanin and
injected into two rabbits per peptide on four separate occasions (Quality Controlled
Biochemicals). Only those antisera for which the preimmunization bleeds did not cross-
react with sea urchin CF proteins by Western blot [18] were used in this study. The three
antisera used were designated anti-185-66, anti-185-68, and anti-185-71.
5.4.6. Western blotting and immunostaining
Proteins separated by 1DE or 2DE were transferred from polyacrylamide gels to
nitrocellulose membranes by electroblotting using a Criterion blotting system (Bio-Rad).
Transfers were performed at 100 V for 1 hour at room temperature using Towbin buffer
(0.25 M Tris-HCl, 1.92 M glycine (pH 8.3)) with 20% methanol. Once transfer was
complete, membranes were blocked by incubation in skim milk solution (7% skim milk
powder in TBST; 10 mM Tris-HCl, 137 mM NaCl, 0.5% Tween 20 (pH 7.5)) overnight.
Following several washes with TBST (3 times for 5 minutes), membranes were incubated
with anti-185/333 antisera (1/20,000 dilution of an equal mix of anti-185-66, -68 and -71
in TBST, or each antiserum separately) for 1 hour at room temperature. The blots were
washed with TBST (3 times for 5 minutes) and incubated for 1 hour at room temperature
with goat anti-rabbit IgG conjugated with HRP (1/30,000 in TBST; Sigma-Aldrich). After
washing in TBST (3 times for 5 minutes), 185/333+ proteins were visualized using ECL
chemiluminescence (GE Healthcare) with blue light-sensitive high-performance

221
chemiluminescence film (Hyperfilm ECL, GE Healthcare). Each blot was exposed to film
for varying lengths of time (1-15 minutes) to optimize the exposure. In some cases, image
processing (Photoshop; Adobe Systems) was used to combine autoradiographs from the
various exposures into composite images. Proteome maps for 185/333+ protein spots on
2DE Western blots were established using Progenesis software (Perkin Elmer) to plot
molecular mass and isoelectric point (pI). The relative intensities of different protein spots
were calculated using Adobe Photoshop (Adobe Systems).
5.4.7. Anti-185/333 ELISA
CF from LPS- and aCF-injected sea urchins was adjusted to 5 × 105 coelomocytes/ml
with calcium-magnesium-free seawater with EDTA and imidazole (CMFSW-EI; 10 mM
KCl, 7 mM Na2SO4, 2.4 mM NaHCO3, 460 mM NaCl, 70 mM EDTA, and 50 mM
imidazole (pH 7.4)) and was mixed with an equal volume of CMFSW-EI containing 1%
(v/v) Nonidet P-40 to lyse the cells, followed by centrifugation (12,000 × g, 10 seconds) to
remove debris. The supernatant was diluted 1/20 with TBS and aliquoted in triplicate into
96-well ELISA plates (200 µl/well; Corning). Plates were incubated overnight at 4°C so
that proteins could adhere to the wells. The plates were washed once with TBS and
blocked for 1 hour with TBS containing 4% (w/v) BSA. After blocking, 100 µl of anti-185
antisera (1/20,000 dilution of an equal mix of anti-185-66, -68 and -71 in TBST) was
added per well for 2 hours at room temperature with gentle shaking. The plates were
washed three times for five minutes each with TBST before adding 100 µl anti-rabbit IgG-
alkaline phosphatase conjugate (1/20,000 in TBST; Sigma-Aldrich) per well. The plates
were incubated with the secondary Ab for 2 hours before being washed three times with
TBST. After the final wash, 200 µl of p-nitrophenyl phosphate (2 mg/ml in 0.1 M glycine,
1 mM MgCl2, 1 mM ZnCl2 (pH 10.4); Sigma-Aldrich) was added per well and incubated

222
for 30 minutes before absorbance was read in a microplate spectrophotometer at 415 nm.
Data were corrected for the absorbance in wells prepared without sea urchin proteins.
Controls included wells in which the primary (anti-185) Abs or both the primary and
secondary Abs were omitted, and wells in which an irrelevant Ab (rabbit anti-tunicate
collectin peptide [24, 25]) was used in place of the anti-185 antisera.
5.4.8. Mass spectrometry and data analysis
Mass spectrometry (MS) was performed on CF proteins separated by either 1DE or
2DE. To extract proteins from 1DE, Coomassie blue-stained gels were washed twice in
water (10 minutes each). Individual lanes were cut into 16 slices of equal sizes so that
proteins in different molecular mass ranges could be analyzed separately by MS (see
Figure 5.8). To extract proteins after 2DE, spots from 2DE gels that corresponded to
individual 185/333+ proteins on Western blots were excised.
Gel slices or excised protein spots were washed briefly with 100 mM NH4HCO3
before being destained (3 times for 10 minutes) with 25 mM NH4HCO3/acetonitrile (ACN)
(1/1) and dehydrated in 100% ACN for 5 minutes. After dehydration, gel pieces were air-
dried, reduced with 10 mM DTT in 100 mM NH4HCO3 for 45-60 minutes at 56°C, and
alkylated with 55 mM iodoacetamide in 100 mM NH4HCO3 for 45 minutes at room
temperature. The gel pieces were washed once with 100 mM NH4HCO3 for 5 minutes and
twice with 25 mM NH4HCO3,/ACN (1/1) for 5 minutes before being dehydrated with
100% ACN. The dehydrated gel slices were air-dried and rehydrated with trypsin
(12.5ng/µl in 50 mM NH4HCO3; Promega) for 30 minutes at 4°C. An additional aliquot of
50 mM NH4HCO3 was added before the proteins were digested at 37ºC overnight. The
resulting tryptic peptides were extracted from the gel pieces by washing them twice with

223
2% formic acid in 50% ACN. Extracts were combined and concentrated to 10 µl by
vacuum centrifugation.
Mass spectrometry was performed at the Australian Proteome Analysis Facility
(Macquarie University). The tryptic digest extracts from 1DE gel slices were subjected to
data-dependent nanocapillary reversed phase liquid chromatography followed by
electrospray ionization using a Thermo LCQ Deca ion trap mass spectrometer (Thermo
Scientific; liquid chromatography (LC)-MS/MS). For LC-MS/MS, a microbore HPLC
system (TSP4000; Thermo Scientific) was modified to operate at capillary flow rates using
a simple T-piece flow-splitter. Columns (8 cm × 100 µm inside diameter) were pack with
100 Å, 5-µm Zorbax C18 resin at 500 ψ. Integrated electrospray tips for the columns were
made from fused silica, pulled to a 5-µm tip using a laser puller (Sutter Instrument). An
electrospray voltage of 1.8 kV was applied using a gold electrode via a liquid junction
upstream of the column. Samples were introduced onto the analytical column using a
Surveyor autosampler (Thermo Scientific). The HPLC column eluent was eluted directly
into the electrospray ionization source of the ion trap mass spectrometer. Peptides were
eluted with a linear gradient of buffer A (0.1% formic acid) and buffer B (ACN containing
0.1% formic acid) at a flow rate of 500 nl/min. Automated peak recognition, dynamic
exclusion, and daughter ion scanning of the top three most intense ions were performed
using the Xcalibur software as previously described [23].
GPM open source software (Global Proteome Machine Organization;
www.thegpm.org) was used to search peptide sequences against a combined
Strongylocentrotus database created with sequences downloaded from the National Center
for Biotechnology Information (NCBI). This FASTA format database contained 44,037
protein sequences comprising all S. purpuratus sequences held by NCBI as of April 2008.
This database also incorporated a list of common human and trypsin peptide contaminants.
Search parameters included MS and MS/MS tolerances of ±2 Da and ±0.2 Da, tolerance of

224
up to three missed tryptic cleavages, and K/R-P cleavages. Fixed modifications were set
for carbamidomethylation of cysteine, and variable modifications were set for oxidation of
methionine. Peptides isolated from 1DE gel slices were deemed to significantly match
corresponding peptides in the available databases if their GPM log(e) score was lower than
the statistically significant cut-off values assigned by the GPM algorithm.
Protein spots from 2DE gels were analyzed using MALDI-TOF-TOF using an LTQ
FT Ultra hybrid mass spectrometer (Thermo Scientific). MS ion searches were compared
with 185/333 sequences in a custom database containing 81 translated full-length 185/333
cDNA sequences [12] and 689 EST sequences [8] using the Mascot search engine (Matrix
Sciences; www.matrixscience.com/) set for carbomethylation (C) and oxidation (M)
variable modifications, with peptide and fragment mass tolerances of ±50 ppm and ±0.5
Da respectively, and a maximum missed cleavage of one.

225
5.5. Results
5.5.1. One-dimensional SDS-PAGE analysis of CF proteins
1DE was used to provide a preliminary assessment of the diversity of proteins in CF,
particularly those that were detected by anti-185 Abs (Figure 5.1). The molecular masses
of CF proteins from all of the sea urchins analyzed in the present study (n = 13) ranged
from 20 kDa to >193 kDa (see Figure 5.6). Sypro Ruby-stained CF proteins from the
individual sea urchins ranged from 30 kDa to > 193 kDa (Figure 5.1, lane 1). There were
substantial differences in banding patterns when electrophoretically separated CF proteins
from the same sea urchin were stained with Coomassie blue compared to Sypro Ruby
(Figure 5.1, compare lanes 1 and 2). This was probably due to different sensitivities and
physiochemical properties of the stains [26].
Immunostained 1DE Western blots of CF proteins identified numerous 185/333+
bands ranging from ~20 kDa to >193 kDa (Figure 5.1, lane 3). Controls that omitted the
primary (anti-185) and/or secondary (anti-IgG) Abs, and irrelevant controls using anti-
tunicate collectin Abs instead of anti-185 antisera, were negative (data not shown). Most
185/333+ bands from all of the sea urchin samples analyzed (n = 13) had molecular masses
ranging from 50 kDa to >193 kDa, although some were as low as 20 kDa (see Figure 5.6).
Many of the 185/333+ bands on Western blots were not visible on Sypro Ruby- and
Coomassie blue-stained 1DE gels, suggesting that the 185/333 proteins were present at
extremely low concentrations.

226
Figure 5.1: 1DE SDS-PAGE and Western blot of CF proteins from an individual sea
urchin. CF proteins were loaded at 100 µg/well onto 10% SDS-Page gels. Lane 1/ Sypro
Ruby staining. Lane 2/ Coomassie blue staining. Lane 3/ Western blot immunostained with
an equal mixture of anti-185 sera (anti-185-68, -66, and -71; 1/20,000). The positions of
molecular mass markers are shown on the left.
1 2 3
kDa
193 -
112 -
64 -
30 -

227
5.5.2. Two-dimensional Western blots of CF proteins
Given that cDNA analyses predicted a broad array of 185/333 proteins in the CF [8,
11, 12], we extended our analysis of 185/333 proteins using 2DE, which affords far greater
resolution than does 1DE. Sea urchin CF proteins were initially separated by isoelectric
focusing (pH 3-10) and then by 10% SDS-PAGE. Large numbers of 185/333+ spots were
evident after 2DE, to the extent that they often appeared as dense smears (Figure 5.2).
Most of the 185/333 proteins recognized by the antisera in all of the sea urchins analyzed
(n = 13) had pIs between 3 and 7 with apparent molecular masses of 40 kDa to >193 kDa.
To improve the resolution of individual 185/333+ proteins on 2DE Western blots,
additional isoelectric focusing separations were conducted on immobilized pH gradient
(IPG) strips with a pH range of 3-6. Composite images obtained from film exposures of
three different time intervals were used to visualize 185/333+ proteins of varying
abundance (Figure 5.3). For the individual sea urchin shown in Figure 5.3, image analysis
of the different exposures revealed that fifty-one 185/333+ spots were evident after a 1-
minute film exposure. An additional 117 spots were evident after 5 minutes, and a further
96 spots appeared after 10 minutes, making a total of 264 spots that were detected on the
composite image for this individual. The number of discrete 185/333+ spots varied
substantially among individuals. Three of the 13 sea urchins tested did not express
detectable levels of 185/333 proteins. However, the number of discrete 185/333+ spots was
often >200 in other individuals.
The enhanced protein separation capabilities of 2DE also showed that each discrete
185/333+ band evident in 1DE contained numerous variants with similar molecular masses
but different pIs. For example, at least fifteen 185/333+ spots with different pIs were
evident at ~75 kDa (Figure 5.3). A further eight 185/333+ spots appeared at ~60 kDa and at
least six different 185/333+ spots were present at ~30 kDa (Figure 5.3).

228
Figure 5.2: 2DE Western blot of 185/333+ proteins. The gel was loaded with 200 µg of
CF proteins from a single sea urchin and the blot was immunostained with an equal
mixture of anti-185 sera (anti-185-66, -68, and -71; 1/20,000). pIs are shown as pH units
on the top of the blot, and molecular masses (kDa) are indicated on the left.
3 4 5 6 7 8 9 10
30 -
64 -
193 - 112 -
pI
kDa

229
These pI variants were often regularly spaced from each other, differing by ~0.1-0.2 pH
units. There were also numerous 185/333+ spots with identical pI but different molecular
masses (Figure 5.4). For instance, three proteins in the pI 7.5-7.75 range each had three
different molecular mass forms at ~150 kDa, 193 kDa and >193 kDa (Figure 5.4).
The three different anti-185 sera, which were raised against different regions of the
most commonly predicted 185/333 polypeptide sequences, identified subsets of 185/333
proteins (Figure 5.5). Within the small region of 2DE Western blot (pI range of 4-5 and
molecular masses of 30 kDa or lower), anti-185-66 resolved 14 distinct variants, of which
7 were 30 kDa and had a pI range of 4-5 (Figure 5.5A). An additional seven anti-186-66-
positive spots were smaller than 30 kDa with a pI range of 4.5-5. In comparison, anti-185-
68 recognized five of the seven proteins at 30 kDa with a pI range of 4-5 that were present
on the anti-185-66 blot, but did not recognize the set of seven lower molecular mass spots.
Anti-185-71 recognized only two of the 30 kDa proteins that were recognized by the other
two antisera. This result is consistent with the expression of truncated 185/333 cDNAs
[11].
5.5.3. Diversity of 185/333 proteins between individuals
There were major differences in the expression profiles of 185/333 proteins among
different sea urchins. Some animals did not show 185/333 expression before LPS injection
(Figure 5.6A, lanes 3 and 11), although expression was evident after challenge (Figure
5.6B, lanes 3 and 11). In other cases, 185/333 expression, which was very low in
preinjection samples, increased significantly after LPS injection. A broad distribution of
185/333 molecular masses ranging from 20 kDa to >193 kDa was apparent among the 13
animals analyzed by 1DE Western blots (Figure 5.6).

230
Figure 5.3: Composite image of a 2DE Western blot. The gel was loaded with 200 µg of
CF proteins from sea urchin 12. The blot was immunostained with an equal mixture of the
three anti-185 antisera (anti-185-66, -68, and -71; 1/20,000) and exposed to
autoradiographic film for 1, 5, or 10 minutes. The different exposures were merged to give
a final composite image. pIs are shown on the top as pH units, and molecular masses (kDa)
are shown on the left.
Figure 5.4: Enlarged region of a 2DE Western blot of CF proteins from animal 12
immunostained with an equal mixture of the three different anti-185 sera (anti-185-66, -68,
and -71; 1/20,000). pIs are shown on the top as pH units, and molecular masses (kDa) are
shown on the left.
6 |
3 l
193 -
64 -
112 -
30 -
kDa 1 min
5 min
10 min
10 min
pI
7.5 8 8.5 9 9.5 10 ! ! ! ! ! !
112 -
64 -
193 -
pI
kDa

231
Figure 5.5: Different anti-185 sera recognize subsets of 185/333 proteins. A/ Enlarged
regions of three different 2DE Western blots loaded with 200 µg of CF proteins from the
same sea urchin and immunostained separately with anti-185-66, anti-185-68, or anti-185-
71 (1/20,000). B/ Schematic diagram of a 185/333 protein showing the peptides used to
generate the three different anti-185 sera. The rectangle represents the protein sequence,
which is composed of the leader and 25 nucleotide sequence “elements”. The positions and
sequences of the synthetic peptides against which the three anti-185 sera were raised are
indicated [15].
4
!
5
!
4
!
5
!
4
!
5
! 30 -
68 66 71
kDa
A.
B.
66 - element 1 (AHAQRDFNERRGKENDTER)
68 - element 7 (GGRRGDGEEETDAAQQIGDGLC)
71 - element 25a (GTEEGSPRRDGQRRPYGNR)
pI

232
Figure 5.6.: 1DE Western blots of CF from 13 different sea urchins sampled before
(A) and 96 hours after (B) challenge with LPS. The equivalent lane numbers in both
panels refer to the same animals from which CF samples were obtained before and after
LPS challenge. The blots were immunostained with an equal mixture of the three different
anti-185 sera (anti-185-66, -68, and -71; 1/20,000).
193 -
112 -
64 -
kDa
1 2 3 4 5 6 7 8 9 10 11 12 13
30 -
1 2 3 4 5 6 7 8 9 10 11 12 13
193 -
112 -
64 -
kDa
30 -
A
B

233
Although many individuals expressed some 185/333 proteins with identical
molecular masses (e.g., 112 kDa, Figure 5.6, lanes 1-4; 100 and 120 kDa, Figure 5.6, lanes
7 and 8), the suite of 185/333+ bands expressed by each individual sea urchin was unique.
Three animals did not express detectable 185/333 proteins, even after challenge with LPS
(data not shown). In total, nineteen 185/333+ bands with distinct molecular masses were
identified among the 13 sea urchins analyzed by 1DE. The molecular masses of these
proteins seemed to be evenly spaced at 8-10 kDa apart over the molecular mass range of
20 to >193 kDa (Figure 5.6).
5.5.4. MS analysis of 185/333+ proteins
Proteins on coomassie blue-stained 2DE gels that corresponded to 185/333+ spots on
Western blots were analyzed by MS. This analysis failed to identify 185/333 proteins
unambiguously using the default criteria on the Mascot search engine. Although MS of
each of the protein successfully identified ion fragments with mass/charge properties that
were similar to known 185/333 sequences, these matches did not yield sufficiently high
statistical probabilities to confirm the identity of any of the proteins (data not shown).
In contrast, MS analysis of CF proteins separated by 1DE unequivocally identified
185/333 proteins. A total of 41 peptides isolated from 1DE gel slices matched with known
185/333 sequences from the NCBI database (Table 5.1). The same 185/333 peptide was
often identified in more than one gel slice. For example, the peptide
FDGPESGAPQMEGR appeared in gel slices 2-4 from animal 17. It is unlikely that the
occurrence of the same peptide in multiple fractions was due to contamination of the
different fractions with exactly the same 185/333 protein. If the same protein was present
in more than one fraction, we would expect to find exactly the same combination of
peptides from that protein in more than one fraction.

234
Figure 5.7: 1DE Western blots of CF proteins from three different sea urchins
(animals 6, 17 and 22) immunostained with an equal mixture of anti-185 sera (anti-185-66,
-68, and -71; 1/20,000). The numbers on the right show the approximate positions of slices
cut from 1DE gels for analysis by mass spectrometry (see Table 5.1). In total, gels were cut
into 16 slices. The positions of only eight of those slices containing the highest molecular
mass proteins are shown here.
8
7
6
5
4
3
2
1 104 -
59 -
27 -
kDa gel slice
number
6 17 22
animal number

235
Table 5.1: Mass spectrometric (LC-MS/MS) data for peptides isolated from 1DE gels
of S. purpuratus CF that match known 185/333 sequencesa
Animal Gel Slice Log(e) m + h z Sequence Genbank Accession No.
6 6 -1.30 2594.5 3 MAVLTLATMAATTSIIIATTQKVTK1 gb|ABK88425.1|
-3.20 1735.8 3 GQGGFGGRPGGMQMGGPR gb|ABR22418.1|
-3.20 1735.8 3 GQGGFGGRPGGMQTGSPR gb|ABZ10666.1
-3.30 1493.6 2 FDGPESGAPQMEGR gb|ABZ10664.1|
-9.80 2886.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGPGR gb|ABZ10668.1|
-2.40 1735.8 3 GQGGFGGRPGGMQMGGLR gb|ABK88417.1|
-3.30 2131.9 3 RGDGEEETDAAQQIGDGLGGR gb|ABZ10666.1|
-1.70 1506.7 2 FDGPGFGAPQMGGPR gb|ABR22467.1|
-4.60 1157.6 2 KPFGDHPFGR gb|ABR22410.1|
2
-2.00 2819.2 3 GDGEEETDAAQQIGDGLGGSGQFDGPRR gb|ABR22477.1|
-2.40 1735.8 3 GQGGFGGRPGGMQMGGPR gb|ABR22418.1|
-2.40 1735.8 3 GQGGFGGRPGGMQTGSPR gb|ABZ10666.1|
-4.20 1649.7 3 RFDGPESGAPQMEGR gb|ABZ10664.1|
-5.20 1493.6 2 FDGPESGAPQMEGR gb|ABZ10664.1|
-3.00 2131.9 3 RGDGEEETDAAQQIGDGLGGR gb|ABZ10666.1|
-1.50 2320.2 2 PQTDQRNNRLVSATKAAMRM1 gb|ABK88425.1|
-5.80 2887.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGPGR gb|ABZ10668.1|
-1.40 1735.8 3 GQGGFGGRPGGMQMGGLR gb|ABK88417.1|
-2.60 1979.9 3 MGGRNSTNPEFGGSRPDGAG1 gb|ABR22330.1|
-1.70 2744.3 3 RNSTNPEFGGSRPDGAGGRPLFGQGGR1 gb|ABR22330.1|
3
-4.60 2927.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGHGR gb|ABZ10669.1|
-2.40 1479.6 2 FDGPESGAPQMDGR gb|ABZ10666.1|
-4.00 1980.0 3 FGGSRPDGAGGRPFFGQGGR gb|ABZ10669.1|
-2.40 2886.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGPGR gb|ABZ10668.1|
-2.00 1157.6 2 KPFGDHPFGR gb|ABR22410.1|
-5.10 1633.7 2 RFDGPESGAPQMEGR gb|ABZ10664.1|
-0.17 2564.1 3 FDGPESGAPQMEGRRQNGVPMGGR gb|ABK88329.1|
-3.10 2132.0 3 RGDGKEETDAAQQIGDGLGGR gb|ABR22436.1|
4
-1.40 1926.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGHGR gb|ABZ10669.1|
-1.7 3398.5 3 DFNERREKENDTERGQGGFGGRPGGMQMGGP gb|ABK88476.1|
-3.5 1980.0 3 FGGSRPDGAGGRPFFGQGGR gb|ABZ10669.1|
5
-1.5 1831.9 3 RFDGPEPGAPQMEGRR gb|ABK88803.1|
-2.7 2131.0 3 RGDGEEETDAAQQIGDGLGGR gb|ABZ10666.1| 6
-1.8 2927.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGHGR gb|ABZ10669.1|
-1.6 1515.7 2 ADVVEIAVNEEDVN1 gb|ABA19607.1|
-3.3 1649.7 3 RFDGPESGAPQMEGR gb|ABZ10664.1|
-4 1493.6 2 FDGPESGAPQMEGR gb|ABZ10664.1|
17
7
-3.5 1980.0 3 FGGSRPDGAGGRPFFGQGGR gb|ABZ10664.1|
-2.50 1033.5 2 FGAPQMGGPR gb|ABR22467.1|
-1.40 2814.3 3 RGRGQGRFGGRPGGMQMGGPRQDGGPMG gb|ABK88373.1|
22 2
-3.70 1649.7 3 RFDGPESGAPQMEGR gb|ABZ10664.1|
a The data are from 1DE gel slices of CF from three different sea urchins. The GenBank accession numbers of the 185/333 sequences that matched peptides from 1DE gels are also shown. The amino acid sequences shown are the matching 185/333 peptides from the NCBI database. Parameter definitions are: log(e), values indicate the probability that a putative peptide sequence corresponding to a mass spectrum arises stochastically. The lower the log(e) value, the more significant the assignment of the peptide sequence to the mass spectrum. The log(e) values listed in this table are all lower than the significance cutoff values assigned by the GPM algorithm, and so they are deemed to be statistically significant (43); m + h, peptide mass in Da + 1; z, peptide charge. b Peptides that matched sequences for previous analysis of nucleotide sequences that might represent frameshift mutations [12, 13].

236
However, this was not the case. Only single peptides were found in each fraction. Given
this repetitive identification of the same peptide in different gel slices, a total of 23 unique
185/333 peptides were identified among all of the gel slices. In some cases, the GPM
algorithm allocated slightly different predicted amino acid sequences to the same MS
spectrum. For instance, GPM identified two peptides (GQGGFGGRPGGMQMGGPR and
GQGGFGGRPGGMQTGSPR; underlining identifies amino acids that differ) from the
same MS spectrum. This occurred because the amino acid differences between these two
peptides were predicted to yield peptides with indistinguishable mass/charge ratios.
Matches to both of these peptides were present in the NCBI database. In some cases, the
subtle differences between peptides involved in the inclusion of an arginine resulting in
closely related peptides of different lengths, such as RGDGEEETDAAQQIGDGLGGR
and RGDGEEETDAAQQIGDGLGGPGQFDGHGR. It is noteworthy that of the 41
peptides identified, 36 were located in the glycine-rich (N-terminal) and central regions of
the predicted proteins. This is consistent with frameshifts and early stop codons that have
been identified in about half of the cDNAs [11]. In many cases, the introduction of these
frameshifts or early stop codons would have resulted in the loss of epitopes for the
antiserum anti-185-68, which was raised against the C-terminal region of full-length
185/333 proteins, and to a lesser extent, the epitope for anti-185-71, which is in the central
region of predicted full-length 185/333 proteins. As a result, these antisera would not have
identified many of the 185/333 proteins encoded by truncated mRNAs in the Western blot
shown in Figure 5.5A. Some of the peptides shown in Table 5.1 matched sequences that
previous analyses have suggested are derived from frameshift mutations [12, 13].

237
All of the peptides that matched 185/333 sequences came from gel slices 2-7, which were
also shown by Western blot to contain the vast majority of 185/333 proteins (Figures 5.6
and 5.7). Of the three sea urchins analyzed by 1DE and LC-MS/MS, animal 17 had the
highest overall expression levels for 185/333 proteins (Figure 5.7) and yielded 37 of the 41
peptides that matched 185/333 sequences.
5.5.5. 185/333 protein expression increases after LPS challenge
1DE Western blots of CF from five out of the six animals injected with LPS showed
increases in 185/333+ protein expression between 24 and 192 hours (representative results
are shown in Figure 5.8A). Repeated injections with LPS performed 14 days after the
primary challenge increased 185/333 protein expression to levels that were higher than
those evident after the first injection (Figure 5.8A). Sea urchins injected with aCF either
did not respond to the injection or showed weak responses in terms of 185/333 protein
expression (data not shown).
These Western blot data were confirmed by ELISA (Figure 5.8B). Injecting LPS into
sea urchins significantly (p < 0.05) increased the titer of 185/333 proteins detected in CF
by ELISA. By 48 hours after LPS injection, anti-185 reactivity had increased 2.4-fold
compared with the 0 hour time point (p < 0.05). It returned to levels that were
indistinguishable (p > 0.05) from those before LPS challenge by 96 h. In response to aCF
(control) injections, the titer of 185/333 proteins in CF also increased up to 48 hours
postinjection, but only to a level that was 1.4-fold greater than the preinjection time point.
This increase was significantly less than the response to LPS (p < 0.05). Negative controls
confirmed the specificity of the ELISA.

238
Figure 5.8: The titer of 185/333 proteins in CF increases after immune challenge. A/
1DE Western blots of CF from a single sea urchin collected at various times after the
animal was injected twice with LPS. The second LPS injection was administered 360
hours after the first. B/ 185/333 protein expression levels determined by ELISA (ΔODU415)
at various times after naive sea urchins (n = 5) were injected with LPS or aCF (controls).
Bars indicate SEM. Asteriks denote time points that differed significantly (p <0.05)
between LPS-injected sea urchins and controls.
0.05 -
0.10 -
0.15 -
0.20 -
0.25 -
0 20 40 60 80 100
LPS
control
time after injection (hours)
!O
DU
415
B
193 -
A first LPS injection second LPS injection
0 24 48 192 24 48 192
kDa
time after injection (hours)
* *

239
Wells in which the primary (anti-185 antisera) or secondary (anti-rabbit IgG) Abs
were omitted, or when the primary Ab was replaced by an irrelevant control (anti-tunicate
collectin), did not yield absorbance readings that were significantly greater than
background levels (p > 0.05, data not shown).
5.5.6. Diversity of 185/333 protein expression after immunological challenge
1DE analysis did not detect changes in the types of 185/333 proteins expressed by
individual sea urchins in response to LPS or PG injections, even though densitometry (data
not shown) indicated there was an increase in the relative quantity of 185/333 proteins
after repeated challenge (Figure 5.9). The molecular masses of the predominant 185/333
proteins in CF from animals 6 and 25 did not change in response to an initial injection of
LPS, or after a second LPS injection 2 weeks later. A similar result was apparent for
animals 22 and 31, which were challenged with LPS followed by PG 2 weeks later. The
185/333+ bands of these two animals did not show any major changes in molecular mass
when the challenge was switched from LPS to PG.
In contrast, 2DE revealed clearly discernable changes in the pIs of 185/333 proteins
when sea urchins were challenged with PG after initially responding to LPS, even though
the molecular masses of the predominant forms remained the same (Figure 5.10). This is
best exemplified in the small region of the 2DE Western blots of CF from animal 31 (pIs
of 4-6, molecular masses of 40-65 kDa) shown in Figure 5.10B. CF from this sea urchin
was collected after an initial challenge with LPS (Figure 5.10B, upper panel), and then
again after a subsequent injection of PG (Figure 5.10B, lower panel). Of the thirty
185/333+ spots in this region, seven were found only after LPS challenge (e.g., 63 kDa, pI
4.8), and six were found only after challenge with PG (e.g. 42 kDa, pI 5.5). The remaining
17 proteins were present after both the LPS and PG challenges.

240
Figure 5.9: 1DE Western blots of CF collected after sea urchins had been injected with
LPS or PG. Animals 6 and 25 were injected with LPS twice at 360-hours interval, while
animals 22 and 31 were injected first with LPS and then with PG 360 hours later. CF was
collected 96 hours after each injection, and the Western blots were immunostained with an
equal mixture of the three different anti-185 sera (anti-185-66, -68, and -71; 1/20,000).
193 -
112 -
64 -
LPS ! LPS LPS ! PG
6 25 22 31
animal number
kDa

241
The relative expression levels of some of these shared proteins also differed between
challenges. For instance, one of the proteins (63 kDa, pI 5.2) had a densitometry value of
5.1 after LPS injection and 1224 after PG challenge, representing a 240-fold increase in
expression intensity in response to PG.

242
Figure 5.10: 2DE Western blots of CF collected from a single sea urchin (animal 31)
that had been injected first with LPS and then 360 hours later with PG. CF was
withdrawn at 96 hours after each injection. Western blots were immunostained with an
equal mixture of the three different anti-185 sera (anti-185-66, -68, and -71; 1/20,000). A/
Full proteome maps (pI of 3-6; 40-150 kDa; 30-seconds film exposure) of the CF samples
after LPS and PG challenges. B/ Enlargements (pI of 4.0-6.3; 40-85 kDa; 5-minutes film
exposure) of the boxed area in A. The numbers shown in each panel are the relative
expression intensities of five 185/333+ spots that differed substantially in expression after
LPS compared with PG injections.
3 4 5 6
64 -
64 -
kDa
LPS
PG
A
B
pI
LPS
PG
2.5
0
4.1
0 1224
261
0
5.1
1.5
0
64 -
64 -
kDa
4 6 pI

243
5.6. Discussion
This study has identified substantial diversity among 185/333 proteins, as reflected
by their broad range of molecular masses and pIs. Most importantly, there are obvious
differences in the suites of 185/333 proteins expressed by different sea urchins, and these
suites of proteins undergo subtle but extensive changes in response to different types of
immune challenge. The diversity of 185/333 proteins and the changes in their expression
detected by the current proteomic analysis correspond with previous studies of mRNAs
from sea urchins responding to different PAMPs [11]. All of these data suggest that sea
urchins may be capable of altering the expression of 185/333 proteins to tailor specific
responses against different PAMPs.
Despite the overall agreement between our current observations of 185/333 proteins
and predictions based on the prior analyses of 185/333 nucleotide sequences [11, 12], there
are some discrepancies. The predicted sizes of 185/333 proteins based on cDNA sequences
range from 4 to 55.3 kDa [11, 12], with predicted pIs ranging from 5.42 to 11.54.
However, the present study shows that native 185/333 proteins have a far wider range of
molecular masses (20 to >193 kDa using 1DE analysis), with predominant bands often
being at the high end of this range. They also have far more acidic pIs than expected,
mainly between 3 and 7. It is unlikely that the discrepancy between predicted and observed
molecular masses is due to disulphide-bonded oligomerization because none of the
predicted 185/333 amino acid sequences identified to date contains cysteines [8, 11]. Even
if cysteines were present in missense sequences of frame-shifted proteins, the strong
reducing conditions used to prepare samples would have disrupted any oligomers held
together by disulphide bonds. Another explanation for the discrepancy in molecular masses
is that 185/333 proteins are glycosylated and form large complexes covalently linked to
carbohydrates. There are numerous conserved sites for N-linked glycosylation within the

244
histidine-rich region of the 185/333 proteins (elements 11-25), and there are conserved
sites for O-linked glycosylation in the carboxyl-terminal region [8, 11]. However,
deglycosylation of N-linked oligosaccharides failed to decrease the molecular masses of
185/333 proteins to the size of predicted monomers (Smith LC, unpublished data). Given
these results, it seems likely that the disparity between predicted and observed molecular
masses reflects oligomerization based on mechanisms other than disulphide bond
formation that are resistant to the reducing treatments used in 1DE and 2DE. This
conclusion is supported by studies of recombinant 185/333 proteins, in which the
expression of a single form of 185/333 protein yields a range of expressed proteins with
molecular masses corresponding to monomers, homodimers and higher order oligomers
[18].
Other data also suggest that the diversity of molecular masses evident among
185/333 proteins is increased by the expression of truncated molecules. Many of the SNPs
and indels found previously in 185/333 transcripts are predicted to result in frameshifts,
and the encoded proteins may be either truncated and/or have missense sequences [11, 13].
No such frameshifts have been identified in the 185/333 genes. However, comparisons of
gene and mRNA sequences from individual animals suggest that posttranscriptional
modification may be responsible for these missense proteins [15]. If these messages are
translated, it would explain why the three different anti-185 antisera used in the present
study detected different subsets of 185/333 proteins. The antisera were raised against
amino acid sequences in N-terminus (element 1), the middle (element 7) and the C-
terminus (element 25a) of the predicted proteins. The antiserum targeted to the N-terminus
(anti-185-66) identified the largest number of 185/333 proteins on 2DE Western blots,
presumably because its epitope is most likely to be present in every protein, including the
shortest truncated forms. Of the 689 translated cDNA sequences identified to date, 676
contain the epitope within element 1 that is recognized by the anti-66 antiserum [11].

245
Antisera directed toward more C-terminal regions recognize decreasing numbers of
185/333+ spots, probably because these epitopes are not present on truncated proteins or
those with missense sequence at the C-terminus. Current cDNA sequence data from
Terwilliger et al. [11] show that 660 of 689 cDNA sequences contain the anti-68 epitope in
element 7, while only 375 cDNA sequences contain the anti-71 epitope in element 25a.
The variability evident in the molecular masses of 185/333 proteins, was matched by
substantial diversity in their pIs. One source for this diversity is found in mRNAs where
sequence variability results in changes in charged amino acids at particular positions
leading to predicted proteins with very similar molecular masses but different pIs [8, 11,
12]. Terwilliger et al. (see supplemental Figures S1 and S2 in Refs. 11, 12) identified
numerous sequence positions in 185/333 mRNAs that encode two to four different amino
acids, many with different charges. In the present study, similar subtle differences were
detected by MS, which identified a number of 185/333 peptides that differ by just a single
amino acid. 2DE Western blots also showed a variety of pIs for 185/333 proteins that had
very similar molecular masses. In many cases, the charge variants making up a single
molecular mass class of 185/333 proteins had a pI spanning the full pH range from 3 to 10,
although most variants had a pI within the range of 3-6. The different pI forms were often
equally spaced, suggesting that adjacent protein spots represent variants that differ by just
a single charged residue.
Although the variability in pI detected in the current study agrees with the diversity
seen among cDNA sequences, our proteomic data also provide evidence for additional
posttranslational modifications. Some 185/333 proteins have identical isoelectric points but
significantly different molecular masses. This suggests that individual 185/333 proteins
may be conjugated with some other molecule(s) that alters their molecular mass but not
their isoelectric point. Such conjugation would provide another explanation for why many
185/333+ bands are much larger in molecular mass than predicted. However, the cDNA

246
data suggest that it is also feasible for 185/333 proteins with significantly different
sequences and different pIs to have the same molecular mass, resulting in a vertical ladder
of spots on 2DE Western blots.
The diversity of 185/333 proteins explains our inability to unequivocally identify
185/333 proteins by MS of individual proteins isolated by 2DE. MS analysis of the
185/333+ spots from 2DE gels did not identify any statistically significant matches to
proteins in a custom database of 185/333 sequences. However, all the 185/333 proteins
isolated by 2DE yielded ion fragments that possessed mass/charge characteristics similar to
those of known 185/333 protein sequences. The available evidence suggests that the
existing database of 185/333 sequences may represent only a small fraction of the 185/333
variants present in sea urchin populations. Consequently, the chance of finding a
statistically significant match in this restricted data set to a single 185/333 protein isolated
from the CF of an individual sea urchin may be extremely low, even though the purity of
the proteins isolated by 2DE would have been high. In other words, we may not have
identified matches because the variability of 185/333 sequences means that many 185/333
proteins will not yet be in our database of 185/333 sequences and so cannot be identified
by MS. Our difficulties in matching isolated proteins to the existing 185/333 database
highlight the problems of employing MS techniques, which search for precise similarities
between peptides to characterize hypervariable proteins. It is interesting that even though
members of the Down syndrome cell adhesion molecule (Dscam) family are important
proteins in the immunological responses of insects, proteomics analysis of hemolymph
extracts from immunologically challenged Drosophila have not yet been able to identify
Dscams by MS.
To circumvent the problem of matching individual 185/333+ proteins to our
restricted sequence data set, we employed “shotgun” MS (LC-MS/MS), in which all of the
CF proteins within a particular molecular mass range from 1DE gels were analyzed

247
simultaneously by MS. Unlike 2DE, in which the individual protein spots analyzed by MS
presumably contain just a single 185/333 isotype, the 1DE gel slices subjected to shotgun
MS were likely to contain numerous different 185/333 isotypes. This greatly increased the
chance that at least one of these isotypes would match a previously identified sequence in
our 185/333 database. 1DE also has the advantage that it is not limited by the complex
separation characteristics of 2DE, which, for instance, is relatively inefficient in separating
hydrophobic proteins. Additionally, we used an alternative search engine (GPM as
opposed to Mascot) with slightly altered search stringencies (three missed tryptic
cleavages) to increase our chances of identifying matching 185/333 peptides in the
available databases. This process successfully identified numerous peptides that matched
precisely to sequences in the NCBI database without affecting the robustness of the
sequence matches. The gel slices in which matching peptides were identified corresponded
to regions on 1DE and 2DE Western blots that contained high concentrations of 185/333
proteins, which confirms the specificities of the anti-185 sera used in this study. However,
shotgun MS probably still identified just a small fraction of the 185/333 peptides present
within the peptide mixture, because of the limited numbers of potentially matching
peptides in the currently available dataset. The limited sensitivity of MS in identifying
highly variable proteins in the absence of comprehensive sequence databases also explains
why our MS analysis identified multiple forms of 185/333 proteins in one of the sea
urchins analyzed, even though both 1DE and 2DE Western blotting revealed substantial
intraindividual diversity in all sea urchins.
The difficulties associated with analyzing the diversity of 185/333 proteins were
compounded by the substantial variation evident in the suites of 185/333 proteins
expressed by different sea urchins. None of the 13 sea urchins analyzed by 1DE Western
blotting expressed the same pattern of 185/333+ bands, even though there were a number
of molecular mass forms that were shared by some individuals. On average, two to three

248
major bands were evident in each sea urchin, along with numerous minor bands. The
differences between individuals implie that there may be a variety of mechanisms acting in
concert to produce novel arrays of 185/333 proteins in individual sea urchins. These
factors could include the presence or absence of different 185/333 genes in different sea
urchins, the presence of different alleles at a given 185/333 gene locus, differential gene
expression of 185/333 family members, posttranscriptional processing or editing of the
transcripts that insert frameshifts and SNPs [15], and posttranslational processing of the
proteins [13].
Our data suggest that these potential mechanisms for molecular diversification may
allow sea urchins to vary the suites of 185/333 proteins that they express in response to
different types of immunological challenge. ELISA provided direct evidence that 185/333
expression increases after the injection of PAMPs, while 2DE analysis of 185/333 proteins
from individual sea urchins identified many subtle changes in the patterns of 185/333
proteins responding to different PAMPs. There were clear differences in the pIs and
molecular masses of the proteins expressed in response to LPS compared with those
synthesized by the same sea urchin in response to PG. These results agree with changes
that are apparent in the cDNAs from animals responding to different PAMPs, including
LPS, β-1,3-glucan, or dsRNA [11]. Terwilliger et al. [11] showed that a diverse size range
of 185/333 messages was present in the CF of immunoquiescent sea urchins, but this broad
expression profile changed to one single, major mRNA size after immune challenge.
Sequence analysis of mRNAs from animals responding to immune challenge also indicated
that the predominant 185/333 variants in CF are different before and after challenge. Such
alterations in 185/333 transcription explain the changes detected during the present study
in the suites of 185/333 proteins found in the CF of the same sea urchin responding to
different PAMPs.

249
The identification of PAMP-specific responses suggests that 185/333 protein
expression can be tailored to meet different forms of immunological challenge. The
obvious implication is that 185/333 proteins are involved in some form of pathogen-
specific immunological response. There is growing evidence for this level of
immunological specificity among a variety of invertebrates [1, 2, 5, 27-29]. For instance,
bacterial immunization in bumble bees can induce acquired immune responses that are
highly specific to the original, inoculating species of bacteria [29], although the
mechanisms underlying this response are not knwon. In addition to 185/333 proteins, other
large gene families may be capable of fine-scale discrimination between pathogens. These
gene families encode variable lymphocyte receptors from agnathans [30-34], V-region-
containing chitin-binding proteins (VCBPs) from cephalochordates and tunicates [3, 35,
36], Dscams in insects [37, 38] and fibrinogen-related proteins (FREPs) from molluscs
[39-42]. A repertoire of >19,000 different Dscams is expressed in hemocytes of
Drosophila and mosquitoes [37, 38], and thousands of FREPs are present in freshwater
snails [39-42]. None of these gene families is closely related to one another, suggesting
that mechanisms for immune diversification have evolved many times and that additional
unique systems are likely to be identified among other organisms in the future. In this
context, our continuing investigations of 185/333 proteins will provide insights into how
animals other than mammals adapt in the “arms race” against the microbes.

250
5.7. Acknowledgments
We thank Dr. Virginia Brockton for assistance in processing and shipping protein
samples and Dr. Katherine Buckley for suggesting improvements to the manuscript. The
research has been facilitated by access to the Australian Proteome Analysis Facility
established under the Australian Government’s Major National Research Facilities
Program.
5.8. Disclosures
The authors have no financial conflicts of interest.

251
5.9. References
[1] Flajnik, M. F., Immunology: another manifestation of GOD. Nature 2004, 430, 157–
158.
[2] Flajnik, M. F., Du Pasquier, L., Evolution of innate and adaptive immunity: can we
draw a line? Trends Immunol. 2004, 25, 640–644.
[3] Litman, G. W., Cannon, J. P., Dishaw, L. J., Reconstructing immune phylogeny: new
perspectives. Nat. Rev. Immunol. 2005, 5, 866–879.
[4] Hibino, T., Loza-Coll, M., Messier, C., Majeske, A. J., et al., The immune gene
repertoire encoded in the purple sea urchin genome. Dev. Biol. 2006, 300, 349–365.
[5] Rast, J. P., Smith, L. C., Loza-Coll, M., Hibino, T., Litman, G. W., Genomic insights
into the immune system of the sea urchin. Science 2006, 314, 952–956.
[6] Sodergren, E., Weinstock, G. M., Davidson, E. H., Cameron, R. A., et al., The genome
of the sea urchin Strongylocentrotus purpuratus. Science 2006, 314, 941–952.
[7] Fugmann, S. D., Messier, C., Novack, L. A., Cameron, R. A., Rast, J. P., An ancient
evolutionary origin of the RAG1/2 gene locus. Proc. Natl. Acad. Sci. USA 2006,
103, 3728–3733.
[8] Nair, S. V., Del Valle, H., Gross, P. S., Terwilliger, D. P., Smith, L. C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin:
identification of unexpected immune diversity in an invertebrate. Physiol.
Genomics 2005, 22, 33–47.
[9] Rast, J. P., Pancer, Z., Davidson, E. H., New approaches towards an understanding of
deuterostome immunity. Curr. Top. Microbiol. Immunol. 2000, 248, 3–16.
[10] Smith, L. C., Chang, L., Britten, R. J., Davidson, E. H., Sea urchin genes expressed in
activated coelomocytes are identified by expressed sequence tags: complement

252
homologues and other putative immune response genes suggest immune system
homology within the deuterostomes. J. Immunol. 1996, 156, 593–602.
[11] Terwilliger, D. P., Buckley, K. M., Brockton, V., Ritter, N. J., Smith, L. C.,
Distinctive expression patterns of 185/333 genes in the purple sea urchin,
Strongylocentrotus purpuratus: an unexpectedly diverse family of transcripts in
response to LPS, _-1,3-glucan, and dsRNA. BMC Mol. Biol. 2007, 8, 16.
[12] Terwilliger, D. P., Buckley, K. M., Mehta, D., Moorjani, P. G., Smith, L. C.,
Unexpected diversity displayed in cDNAs expressed by the immune cells of the
purple sea urchin, Strongylocentrotus purpuratus. Physiol. Genomics 2006, 26,
134–144.
[13] Buckley, K. M., Smith, L. C., Extraordinary diversity among members of the large
gene family, 185/333, from the purple sea urchin, Strongylocentrotus purpuratus.
BMC Mol. Biol. 2007, 8, 68.
[14] Buckley, K. M., Munshaw, S., Kepler, T. B., Smith, L. C., The 185/333 gene family is
a rapidly diversifying host-defense gene cluster in the purple sea urchin,
Strongylocentrotus purpuratus. J.Mol. Biol. 2008, 379, 912–928.
[15] Buckley, K. M., Terwilliger, D. P., Smith, L. C., Sequence variations in 185/ 333
messages from the purple sea urchin suggest posttranscriptional modifications to
increase diversity. J. Immunol. 2007, 181, 8585–8594.
[16] Tsai, H., Bobek, L. A., Human salivary histatins: promising anti-fungal therapeutic
agents. Crit. Rev. Oral Biol. Med. 1998, 9, 480–497.
[17] Xu, T., Telser, E., Troxler, R. F., Oppenheim, F. G., Primary structure and
anticandidal activity of the major histatin from parotid secretion of the subhuman
primate, Macaca fascicularis. J. Dent. Res. 1990, 69, 1717–1723.
[18] Brockton, V., Henson, J. H., Raftos, D. A., Majeske, A. J., et al., Localization and
diversity of 185/333 proteins from the purple sea urchin – unexpected protein-size

253
range and protein expression in a new coelomocyte type. J. Cell Sci. 2008, 121,
339–348.
[19] Clow, L. A., Gross, P. S., Shih, C. S., Smith, L. C., Expression of SpC3, the sea
urchin complement component, in response to lipopolysaccharide. Immunogenetics
2000, 51, 1021–1033.
[20] Gross, P. S., Al-Sharif, W. Z., Clow, L. A., Smith, L. C., Echinoderm immunity and
the evolution of the complement system. Dev. Comp. Immunol. 1999, 23, 429–442.
[21] Clow, L. A., Raftos, D. A., Gross, P. S., Smith, L. C., The sea urchin complement
homologue, SpC3, functions as an opsonin. J. Exp. Biol. 2004, 207, 2147–2155.
[22] Laemmli, U. K., Cleavage of structural proteins during the assembly of the head of
bacteriophage T4. Nature 1970, 227, 680–685.
[23] Andon, N. L., Hollingworth, S., Koller, A., Greenland, A. J., et al., Proteomic
characterization of wheat amyloplasts using identification of proteins by tandem
mass spectrometry. Proteomics 2002, 2, 1156–1168.
[24] Green, P., Luty, A., Nair, S., Radford, J., Raftos, D., A second form of collagenous
lectin from the tunicate, Styela plicata. Comp. Biochem. Physiol. B Biochem. Mol.
Biol. 2006, 144, 343–350.
[25] Green, P. L., Nair, S. V., Raftos, D. A., Secretion of a collectin-like protein in
tunicates is enhanced during inflammatory responses. Dev. Comp. Immunol. 2003,
27, 3–9.
[26] Miller, I., Crawford, J., Gianazza, E., Protein stains for proteomic applications: which,
when, why? Proteomics 2006, 6, 5385–5408.
[27] Kurtz, J., Franz, K., Innate defence: evidence for memory in invertebrate immunity.
Nature 2003, 425, 37–38.
[28] Kurtz, J., Armitage, S. A., Alternative adaptive immunity in invertebrates. Trends
Immunol. 2006, 27, 493–496.

254
[29] Sadd, B. M., Schmid-Hempel, P., Insect immunity shows specificity in protection
upon secondary pathogen exposure. Curr. Biol. 2006, 16, 1206–1210.
[30] Litman, G. W., Cannon, J. P., Rast, J. P., New insights into alternative mechanisms of
immune receptor diversification. Adv. Immunol. 2005, 87, 209–236.
[31] Litman, G. W., Hawke, N. A., Yoder, J. A., Novel immune-type receptor genes.
Immunol. Rev. 2001, 181, 250–259.
[32] Pancer, Z., Amemiya, C. T., Ehrhardt, G. R., Ceitlin, J., et al., Somatic diversification
of variable lymphocyte receptors in the agnathan sea lamprey. Nature 2004, 430,
174–180.
[33] Pancer, Z., Mayer, W. E., Klein, J., Cooper, M. D., Prototypic T cell receptor and
CD4-like coreceptor are expressed by lymphocytes in the agnathan sea lamprey.
Proc. Natl. Acad. Sci. USA 2004, 101, 13273–13278.
[34] Pancer, Z., Saha, N. R., Kasamatsu, J., Suzuki, T., et al., Variable lymphocyte
receptors in hagfish. Proc. Natl. Acad. Sci. USA 2005, 102, 9224–9229.
[35] Cannon, J. P., Haire, R. N., Litman, G. W., Identification of diversified genes that
contain immunoglobulin-like variable regions in a protochordate. Nat. Immunol.
2002, 3, 1200–1207
[36] Cannon, J. P., Haire, R. N., Rast, J. P., Litman, G. W., The phylogenetic origins of the
antigen-binding receptors and somatic diversification mechanisms. Immunol. Rev.
2004, 200, 12–22.
[37] Dong, Y., Taylor, H. E., Dimopoulos, G., AgDscam, a hypervariable immunoglobulin
domain-containing receptor of the Anopheles gambiae innate immune system.
PLoS Biol. 2006, 4, e229.
[38] Watson, F. L., Puttmann-Holgado, R., Thomas, F., Lamar, D. L., et al., Extensive
diversity of Ig superfamily proteins in the immune system of insects. Science 2005,
309, 1874–1878.

255
[39] Adema, C. M., Hertel, L. A., Miller, R. D., Loker, E. S., A family of fibrinogen-
related proteins that precipitates parasite-derived molecules is produced by an
invertebrate after infection. Proc. Natl. Acad. Sci. USA 1997, 94, 8691–8696.
[40] Leonard, P. M., Adema, C. M., Zhang, S. M., Loker, E. S., Structure of two FREP
genes that combine IgSF and fibrinogen domains, with comments on diversity of
the FREP gene family in the snail Biomphalaria glabrata. Gene 2001, 269, 155–
165.
[41] Zhang, S. M., Loker, E. S., Representation of an immune responsive gene family
encoding fibrinogen-related proteins in the freshwater mollusc Biomphalaria
glabrata, an intermediate host for Schistosoma mansoni. Gene 2004, 341, 255–266.
[42] Zhang, S. M., Loker,E. S., The FREP gene family in the snail Biomphalaria glabrata:
additional members, and evidence consistent with alternative splicing and FREP
retrosequences: fibrinogen-related proteins. Dev. Comp. Immunol. 2003, 27, 175–
187.
[43] Fenyo, D., Beavis, R. C., A method for assessing the statistical significance of
mass spectrometry-based protein identifications using general scoring schemes.
Anal. Chem. 2003, 75, 768–774.

256

257
CHAPTER VI
Ultrastructural localization of a highly variable immune response protein (185/333)
within coelomocytes and the gut of sea urchins.
In preparation for submission to
Journal of Cell Sciences
Author contributions:
Birch D1 – Technical support
Nair SV1 – Project supervision
Raftos DA1 – Experimental design – Project supervision
1 Department of Biological Sciences, Macquarie University, North Ryde, NSW 2109, Australia

258

259
6.1. Preface
Chapter 5 revealed the variability of 185/333 proteins both within and between
individual sea urchins. The proteins were more abundant after the injection of PAMPs and
it appeared that different 185/333 proteins are expressed in response to the injection of
different PAMPs. Based on these data, and the transcriptomic and genomic analyses
described in Chapter 1, it has been postulated that 185/333 proteins are involved in
pathogen recognition, specifically in the encapsulation of pathogens or phagocytosis. In the
current Chapter, we further investigated the potential functions of 185/333 proteins by
studying their ultrastructural localization in coelomocytes and in the gut of sea urchins.

260

261
6.2. Summary
There is renewed interest in the immune reponses of sea urchins. This has been
heightened by the discovery of 185/333 proteins, a family of highly variable immune
response molecules with no homology to any known proteins. In this study, we show that
185/333 proteins are expressed by filopodial amoebocytes and colorless spherule cells,
which have been shown previously to cooperate in immune responses. Filopodial
amoebocytes express 185/333 proteins on the membranes of vesicles emanating from the
trans-Golgi and later fuse with the plasma membrane of the cell. Colorless spherule cells
contain 185/333 proteins within large spherules. In the presence of bacteria and yeast, the
ultrastucture of colourless spherule cells changes, as does the profile of expression of
185/333 proteins in those cells. However, 185/333 proteins were not found in phagosomes
of coelomocytes. Another previously uncharacterized amoebocyte type, which is localized
within the connective tissue of the gut, also expressed 185/333 proteins at high
concentrations. As in filopodial amoebocytes, these gut-associated amoebocytes express
185/333 proteins on the membrane of intracellular vesicles and on the cell surface. The
abundance of 185/333 proteins within gut amoebocytes and their ultrastructural similarities
with filopodial amoebocytes suggest that these two cell types may be related. The 185/333-
positive gut amoebocytes were often associated with anuclear bodies that appeared to
incorporate material of microbial origin that was also surrounded by 185/333 proteins.
The association between 185/333 proteins on gut amoebocytes and anuclear bodies suggest
that these proteins may be involved in the phagocytosis of microbes in the gut epithelium.

262
6.3. Introduction
The immune systems of invertebrates lack antibody-based adaptive immune
responses. However, there are still strong similarities between other components of
invertebrate and vertebrate immune systems. The sea urchin genome revealed broad
homologies between the immune response genes of these deuterostome invertebrates and
those of vertebrates [1]. Many of the sea urchin gene families that are putatively involved
in pathogen recognition are highly diversified compared to their vertebrate homologues
[2]. Two hundred and three NOD/NALP-like cytoplasmic recognition receptors (NLR)
were identified in the S. purpuratus genome, whilst humans possess only about 20 of these
genes. There are also 222 Toll-like receptors (TLR) and 218 scavenger receptor cysteine
rich (SRCR) genes present in the sea urchin genome, but the human genome encodes only
16 SRCR proteins and 13 TLRs [2]. It has been suggested that gut-associated pathogenesis
and regulation of normal gut flora might have driven the expansion of these immune
response gene families in sea urchins [3]. Recently, sequencing of Amphoxius genome has
revealed a similar expansion of pathogen recognition genes in this early chordate [4].
The 185/333 gene family of sea urchin represents an exception to the homologies
that exist between echinoderms and vertebrates because they lack homology to any known
vertebrate gene and seem to be absent from the Amphoxius genome. Nair et al. [5] first
revealed the importance of 185/333 molecules in sea urchin immune responses. They
showed that 185/333 mRNA expression increased up to 75 fold in immunologically
activated coelomocytes so that over 60% of sequences in a subtracted cDNA library of
immune response ESTs were 185/333 mRNAs. Further studies revealed high levels of
variability within this new gene family [5, 6]. A total of 689 full length 185/333 cDNAs
have so far been sequenced from S. purpuratus [6, 7], and 171 genes have been cloned and
sequenced [8]. Alignment of these sequences necessitated the insertion of large gaps that

263
identified 25 blocks of shared sequences designated “elements”. Based on the presence or
absence of different elements, over 30 distinct element patterns have so far been described
[6, 8]. In addition to these element patterns, which appear to be generated by
recombination/duplication events [9], another level of variability is generated by single
nucleotide substitutions. A bias towards cytidine to uridine transitions was observed, which
is consistent with post-transcriptional cytidine deaminase activity [10]. Transcriptomic
analysis also showed that different 185/333 mRNAs are expressed in response to different
pathogen-associated molecules [7].
The absence of cysteines and discernable secondary structure has limited structural
predictions for 185/333 proteins [6]. It is therefore difficult to hypothesise about the
function of these proteins. However, it is known that the expression of 185/333 proteins is
induced in response to the injection of different pathogen-associated molecules [5, 11].
When sea urchins are injected with LPS or peptidoglycans, the expression of 185/333
proteins increases by up to 2.4-fold [11].
The variability among 185/333 genes and transcripts is matched by differences
among the transcribed proteins, both within and between individual sea urchins [11]. Over
two hundred 185/333 proteins can be detected by two-dimensional electrophoresis (2DE)
of coelomic fluid proteins from a single individual, and the pattern of proteins expressed
by each individual sea urchin is unique. Again, the suite of 185/333 proteins expressed by
coelomocytes changes when sea urchins are challenged with different types of pathogen-
associated molecules, such as LPS and peptidoglycans.
Previous studies have identified 4 major types of coelomocytes in sea urchins:
amoebocytes, colorless spherule cells, red spherule cells, and vibratile cells [12-14]. In
addition, 3 subtypes of amoebocytes are present in S. purpuratus: polygonal (or filopodial)
amoebocytes, and discoidal (or petaloide) amoebocytes, and small filopodial amoebocytes
[15]. These amoebocytes can be differentiated by their cytoskeletal architecture. Discoidal

264
amoebocytes are believed to be primarily phagocytic, whereas polygonal amoebocytes
play a major role in wound healing and clotting [16]. Arizza et al. [17] showed that
amoebocytes and colorless spherule cells are also cytotoxic and function co-operatively.
Amoebocytes appear to release factors into the coelomic fluid that activate colorless
spherule cells, resulting in cytolysis of rabbit erythrocytes and K562 tumor cells. Lin et al.
[18] used depletion studies to demonstrate that cytotoxic molecules in the coelomic fluid
originate from both amoebocytes and colourless spherule cells. In addition to the coelomic
fluid, amoebocytes have been observed within gonads and the axial organ of sea urchins,
but little is known about their presence in the gut and other tissues [2].
Immunofluorescence microscopy has revealed that 185/333 proteins are localized
on the surface of small amoebocytes and within perinuclear vesicles of both small
amoebocytes and polygonal amoebocytes [15]. A significant increase in the percentage of
small amoebocytes expressing 185/333 proteins was observed in response to the injection
of LPS, further supporting the idea that these molecules are involved in immune responses.
Brockton et al. [15] speculated that 185/333 proteins are secreted from coelomocytes and
subsequently associate with the cell surface, forming aggregates between cells that lead to
the encapsulation of pathogens. This was supported by the observation that 185/333-
positive amoebocytes often form aggregates or syncitia.
The current study describes the ultrastructural localization of 185/333 proteins
within coelomocytes and in the gut of sea urchins. It focuses on the pathways by which
185/333 proteins are localized on the cell surface of filopodial amoebocytes, and their role
in antimicrobial defense.

265
6.4. Materials and Methods
6.4.1. Sea urchins
Heliocidaris erythrogramma were collected from Camp Cove in Sydney Harbour,
Australia. They were housed in a recirculating sea water facility at Macquarie University
using methods previously described [5, 19]. The sea urchins were left undisturbed in the
aquaria for 2 months prior to experimentation to allow them to acclimatize to aquarium
conditions [19, 20]. Some animals were then injected with bacteria or yeast by inserting a
23-gauge needle attached to a 1 mL syringe through the peristomium into the coelomic
cavity. Yeast (Saccharomices cerevisciae, 0.25 g) were re-suspended in 0.8% of congo red
in artificial coelomic fluid [aCF; 7], heated to 95ºC for one hour and washed 3 times in
aCF. The cell pellet was re-suspended in 10 mL of aCF and 100 µL of the suspension
were injected per sea urchin. Congo red was omitted for electron microscopy observations.
Late logarithmic phase Vibrio sp. (VPSYS2, accession number EF584094; [21])
were centrifuged at 8,000 rpm for 2 minutes, and re-suspended to 1/10 of their original
volume in 0.2 M NaCl. Bacteria were then inactivated with 10% acetic acid (room
temperature, 10 minutes). The solution was neutralized with five volumes of 1 M Tris HCl
(pH 8.0) before the bacteria were washed three times with phosphate buffer saline (PBS)
and re-suspended in aCF. 100 µL of this suspension were injected per sea urchin.
Coelomic fluid (CF, 1 mL) was harvested into syringes using 23-gauge needles one
hour after injection. CF from non-injected sea urchins was also collected. An aliquot of
live coelomocytes was viewed using an Olympus BH2 optical microscope (Olympus,
Japan), and images were captured with a CCD camera (SCION and Visicapture).
Alternatively, coelomocytes were processed for immunofluorescence microscopy or
transmission electron microscopy as described below.

266
6.4.2. Electron microscopy
Coelomic fluid (750 µL) was mixed with an equal volume of fixative solution (5%
paraformaldehyde and 2% glutaraldehyde in 0.2 M PIPES buffer). Cells were fixed
overnight, washed in 0.2 M PIPES buffer (3 times for 10 minutes), and then embedded in
melted 1% agarose. Cells in 1mm agarose blocks were dehydrated in a graded series of
ethanol (70% - 100%) for 10 minutes in each solution and infiltrated with LR White Resin
for 24 hours. Samples were then embedded in gelatine capsules and polymerised at 60° C
for 48 hours. Samples of gut tissue were also extracted using syringes and 23-gauge
needles, and processed in the same way as CF.
Semi-thin resin sections (1 µm) for light microscopy were cut using glass knives
with an ultramicrotome (Ultracut S , Leica), and stained with methylene blue (1%
methylene blue, 0.6% sodium hydroxide, 40% glycerol) for 10 seconds. Sections were
viewed using an Olympus BX2 microscope (Olympus, Japan), and images were captured
with a CCD camera (SCION and Visicapture). Ultrathin sections (70 nm) were cut with a
diamond knife (Drukker,) using an Ultracut –S ultramicrotome (Leica) and mounted on
300 mesh nickel grids. Ultrathin sections were immunogold labelled (see section 6.4.3.4)
or stained with uranyl acetate (saturated aqueous) for 30 minutes and lead citrate
(Reynold’s) for 4 minutes. They were viewed using a Philips CM10 Transmission Electron
microscope (Philips, Eindhoven) at an operating voltage of 100 kV

267
6.4.3. Localization of 185/333 proteins
6.4.3.1. Anti-185/333 antisera
The polyclonal antisera used to localize 185/333 proteins have been described
previously by Brockton et al. [15]. They were prepared by injecting rabbits with three
different synthetic 185/333 peptides designated anti-185-66, anti-185-68 and anti-185-71
(Quality Controlled Biochemicals, Hopkinton MA) corresponding to three highly
conserved regions of 185/333 cDNAs (Table 1). The three different antisera were mixed in
equal proportions before use, as previously described [11, 15].
6.4.3.2. Immunofluorescence microscopy of whole cell
CF was mixed with an equal volume of chilled calcium and magnesium free sea
water (CMFSW; 460 mM NaCl, 10.73 mM KCl, 7.04 mM Na2SO4, 2.38 mM NaHCO3 in
deionised H2O) and 30 µL of the cell suspension was loaded onto microscope slides. The
cells were kept at room temperature for 30 minutes before the CMFSW was removed.
They were overlaid with cell free CF and held at room temperature for 20 minutes until
they developed filopodia. The cells were then fixed in filtered seawater (FSW) containing
4% w/v paraformaldehyde for 20 minutes. After washing (3 times for 5 minutes in FSW),
the cells were overlaid with cytology blocking buffer (10% w/v bovine serum albumin,
BSA, 10% v/v normal goat serum in FSW) for 60 minutes at 4°C. Excess buffer was
removed before adding the anti-185/333 antisera (1:250 in PBS) for 60 minutes at 4°C.
One set of controls used serum collected from rabbits before they were immunized with
the 185/333 peptides (pre-immune serum; 1:250 in PBS). Other control slides (no primary

268
antibody) were overlaid with blocking buffer rather than antisera. Following incubation,
the antisera were removed, and the slides were washed with PBS (3 times for 5 minutes)
and then overlaid with anti-rabbit Ig- Alexa Fluor® 488 (1:400 in PBS) for 60 minutes at 4
°C in the dark. To counter-stain nuclei, slides were incubated with TO-PRO® 3-iodide
(1:500 in PBS) for 5 minutes (4°C; in dark). The slides were then washed in PBS (3 times
for 5 minutes) before being mounted in GelMount™ aqueous mounting media. Cells were
visualized using a laser scanning confocal microscope (Olympus Fluoview 300 equipped
with an inverted microscope, IX70, Olympus, Japan) with a 100 oil immersion objective
(N.A 1.4). Images were sequentially scanned with an argon 488 nm laser for Alexafluor®
488, and a helium neon 633 nm laser for TO-PRO® 3-iodide. The images were captured
and analyzed using Fluoview version 4.3 software (Olympus, Japan).
6.4.3.3. Immunofluorescence staining of semi-thin resin sections
Semi-thin sections (see above) were mounted onto glass slides. Immunolabelling
was conducted at room temperature. All sections were incubated in blocking solution
(10% fetal bovine serum, FBS, in PBS) for 30 minutes. Excess buffer was then drawn off
before adding the anti-185/333 antisera (1:250 in PBS) for 1 hour. Control sections were
overlaid with blocking buffer only or pre-immune sera (1:250 in PBS). Following
incubation, the solutions were removed and the sections were washed with PBS (5 times
for 5 minutes). All sections were then incubated with anti-rabbit Ig- Alexa Fluor® 488
(1:400 in PBS) for 1 hour in the dark. Nuclei were counterstained with propidium iodide
(1:1000 in PBS) for 5 minutes in the dark. The sections were washed in PBS, and mounted
in GelMount™ (Pro Sci Tech). Cells were visualized using a laser scanning confocal
microscope as described above (helium neon 543 nm laser for propidium iodide).

269
6.4.3.4. Immuno-gold labelling for transmission electron microscopy
Ultrathin sections on 300 mesh nickel grids were incubated with 0.05 M glycine in
PBS for 15 minutes and blocking solution (5% FBS, 5% BSA in 1 PBS) for 1 hour
before being washed (3 times for 5 minutes) in incubation buffer (0.1% BSA in PBS).
Sections were then incubated in anti-185/333 antisera (1:250 in incubation buffer) for 1
hour. Controls were incubated in blocking buffer or pre-immune serum (1:250) for 1 hour.
Following five washes in incubation buffer (3 minutes each), grids were incubated in gold-
conjugated secondary antibody (1/150 in incubation buffer, BBI goat anti-rabbit IgG
F(ab’)2, EM grade, 5 nm gold, Pro Sci Tech) for 1 hour. Sections were then washed in
incubation buffer (5 times for 3 minutes), post-fixed with 2% glutaraldehyde in PBS for 5
minutes, and washed in PBS (2 times for 5 minutes) and Milli-Q water (2 times for 5
minutes). All sections were counter stained in uranyl acetate (saturated, aqueous) for 30
minutes and lead citrate for 4 minutes. Sections were analyzed using a Philips CM10
transmission electron microscope (TEM; Philips, Eindhoven) at an operating voltage of
100 kV.
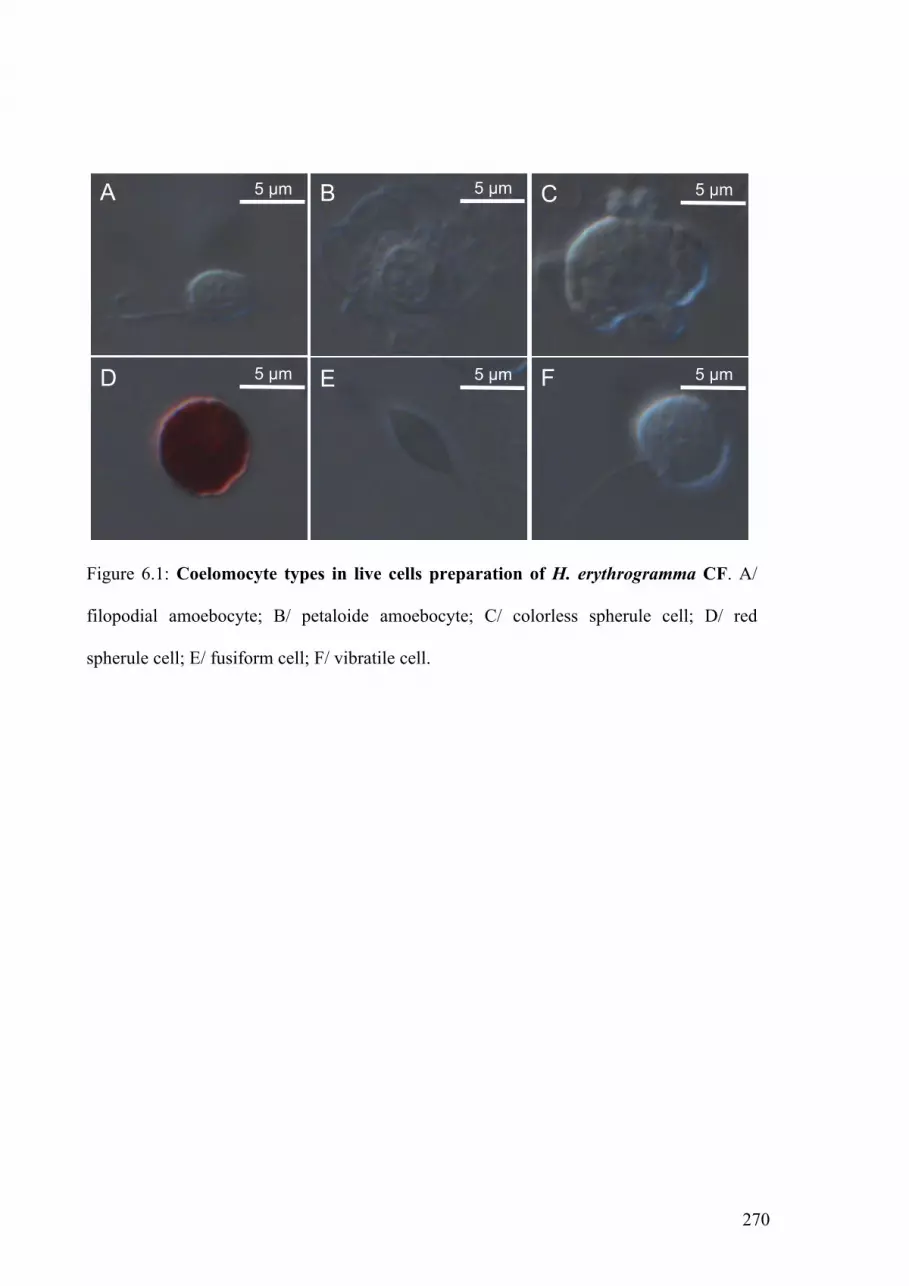
270
Figure 6.1: Coelomocyte types in live cells preparation of H. erythrogramma CF. A/
filopodial amoebocyte; B/ petaloide amoebocyte; C/ colorless spherule cell; D/ red
spherule cell; E/ fusiform cell; F/ vibratile cell.
5 µm 5 µm 5 µm
5 µm 5 µm 5 µm
A B C
D E F

271
6.5. Results
6.5.1. Characterization of coelomocyte types
Analysis of live cells identified the four major types of coelomocytes that had
previously been described in S. purpuratus; amoebocytes, colorless spherule cells, red
spherule cells and vibratile cells [11, 15]. An additional cell type, designated fusiform
cells, was also observed in H. erythrogramma, (Figure 6.1E). This cell type was
characterized by the presence of two flagella on opposite poles of the cell. A comparable
cell type has previously been described in holothurians [12-14, 22, 23]. Only two
amoebocyte types could readily be identified in live cell samples of H. erythrogramma;
filopodial and petaloide amoebocytes (Figure 6.1A,B). Discoidal and polygonal
amoebocytes, as described by Brockton et al. [15], could not be differentiated because the
cells were not allowed to adhere on slides before observation. Colorless spherule cells
were seen as large amoeboid cells packed with large clear spherules (Figure 6.1C), which
contrasted with the bright red bodies of red spherule cells (Figure 6.1D). Vibratile cells, as
previously described by Johnson et al. [13], had scant cytoplasm and a single long
flagellum (Figure 6.1F).

272
Figure 6.2: Confocal images of 185/333-positive coelomocytes. Adherent filopodial
coelomocyte (A) and semi-thin sections (1 µm) of coelomocytes (B,C,D,E) stained with
anti-185/333 antisera and Alexa fluor® 488 (green) (A,B,C) or methylene blue (D,E). In
immunofluorescence micrographs, nuclei were counter stained with TO-PRO 3™ (blue) or
with propidium iodide (red). 185/333 proteins were observed in both filopodial
amoebocytes (A,B,D) and colorless spherule cells (C,E). Arrows show intense “knobs” of
185/333 staining on filopodia.
A B C
E D
2µm
Dheilly et al., Fig 2
2µm
2µm 2µm 5µm

273
6.5.2. Immunofluorescence identification of 185/333 proteins in filopodial amoebocytes
and colorless spherule cells
Immunofluorescence 185/333 staining among coelomocytes adhered to slides was
observed only on the surface of filopodial amoebocytes (Figure 6.2A). These cells had
long filopodia with discrete packets (previously called knobs; [15]) of 185/333 staining
(Figure 6.2A). However, immunofluorescence microscopy of semi-thin sections also
revealed the presence of 185/333 proteins in colourless spherule cells (Figure 6.2B,C).
In sectioned filopodial amoebocytes, 185/333 proteins were localized on the cell
membrane and within small vesicles scattered throughout the cytoplasm (Figure 6.2B,D).
In colorless spherule cells, 185/333 proteins were abundant within the large spherules that
fill the cytoplasm of these cells (Figure 6.2C,E).
6.5.3. Ultrastructure and 185/333 localization of coelomocytes
On examination by TEM, colorless spherule cells were found to possess numerous
large membrane bound vesicles (spherules) and an irregularly shaped hyperchromatic
nucleus (Figure 6.3). Free cytoplasm was scant, since most of the cell was filled with
spherules. The spherules of any one cell were uniform in size. The electron density of the
spherules was extremely variable (Figure 6.3). Gold immunolabelling confirmed that
185/333 proteins were localized within the spherules. Some spherules appeared more
185/333 positive than others (Figure 6.3). However, this variability in the concentration of
185/333 proteins seemed unrelated to variability in the electron density of the spherules.

274
Figure 6.3: Anti-185/333 immunogold stained transmission electron micrograph of a
colorless spherule cell. Colorless spherules fill the cytoplasm of colorless spherule cells
(A). A highly 185/333+ spherule (arrows show gold particles) is shown adjacent to a less
intensely stained spherule (B).
B
sp
sp
0.1 µm
A
sp
sp
sp
n
2 µm
Dheilly et al., Fig. 3

275
Filopodial amoebocytes could readily be discerned in methylene blue stained semi-
thin sections. Their cytoplasm appeared blue with dark granules, and filopodial formations
could be observed. The ultrathin sections used for electron microscopy often did not allow
the visualisation of filopodia. As a result, filopodial amoebocytes were difficult to
characterize by TEM apart from the high electron density of their cytoplasm, which
contrasted with the low-density cytoplasm of petaloide amoebocytes (Figure 6.4). In
addition, the nuclei of filopodial amoebocytes under TEM were often rounded with dense
heterochromatin beneath the nuclear envelop. The larger cells in this class contained
numerous membrane bound vesicles. Small round mitochondria were often observed and
Golgi apparati were frequent.
185/333 labelling was evident in the golgi network of filopodial amoebocytes and
was more intense on the trans-Golgi network than on the cis-face (Figure 6.5). Additional
gold labelling appeared on the extremities of the Golgi, within what seem to be transport
vesicles (Figure 6.5).
Different types of membrane bound 185/333 positive vesicles were observed in
filopodial amoebocytes. Some were electron lucent (Figure 6.4 and 6.6A), others had
electron dense material (Figure 6.4 and 6.6B), and a third type showed structured
concentric lamellae and a granular center (Figure 6.6C). The lumen of the vesicle
generally did not contain 185/333 proteins. However, the membranes of these three types
of vesicles were highly positive when stained with anti-185/333 antisera (Figure 6.6A-C).
A fourth type of membrane bound vesicle was sometimes observed. No 185/333 proteins
appeared on the membrane of these vesicles, but the granular content had anti-185/333
gold labelling throughout (Figure 6.6D).

276
Figure 6.4: Anti-185/333 immunogold stained transmission electron micrograph of a
filopodial amoebocyte. A/ whole cell. B,C/ Insets showing details of 185/333 localization.
185/333 proteins are highly expressed on the plasma membrane (arrowhead in B) and
within small vesicles (arrows in B and C). n: nucleus, m: mitochondria, pm: plasma
membrane, v: vesicle.
A
C
B
n
v
pm B
!"
!"
C
!"v

277
Figure 6.5: Anti-185/333 immunogold stained transmission electron micrograph of a
Golgi apparatus in a filopodial amoebocyte. Panel B is an enlargement of the boxed
inset in panel A. 185/333 proteins are found on the trans face of the Golgi apparatus,
within small vesicles and on the cell surface. Arrows point to gold particles. G: Golgi, n:
nucleus, v: vesicle, -cis: cis face of the Golgi, -trans: trans face of the Golgi
n
G
-trans
-cis
- trans
- cis
v
v
v
!"#$%&$
! "#
Dheilly et al., Fig. 5

278
Figure 6.6: Transmission electron micrograph of 185/333-positive vesicles in filopodial
amoebocytes. Vesicles appeared empty (A), contained an electron dense material (B), had
structured concentric lamellae (C) or diffuse granular material (D). 185/333 proteins were
usually membrane bound (A,B,C), but were sometimes seen within the vesicles that
contain diffuse granular material (D).
0.1 µm 0.1 µm
A B
0.1 µm 0.2 µm
C D
Dheilly et al., Fig. 6

279
Figure 6.7: Anti-185/333 immunogold stained transmission electron micrograph of
filopodial amoebocyte cell surface. Panels B and D are boxed inset of panels A and C.
A,B/ bundles of 185/333 proteins on the cell surface are shown by arrows. C,D/ membrane
bound 185/333-positive discs (arrow heads) dissociated from a filopodial amoebocyte.
Arrows point to gold particles.
A
0.5 µm
C D
BB
D
0.5 µm
0.2 µm
0.2 µm
Dheilly et al., Fig.7

280
Figure 6.8: Anti-185/333 immunogold stained transmission electron micrograph of
gut-associated amoebocytes. Panels B, C, and D are enlargements of the boxed insets in
panels A, B and C. Gut-associated amoebocytes are found adjacent to anuclear bodies (A).
Arrows point to gold particles. ab: anuclear bodies, am: amoebocyte, en: enterocytes, ER:
endoplasmic reticulum, G: Golgi apparatus, m: mitochondria, n: nucleus, v: vesicles.
am ab
en en
en
en
en
n
m
m
ER
G
en
!"#$%&$
m
A B
!"'$%&$
v v
v
v
G
ab
ER
D
B
!"
D C
Dheilly et al., Fig. 8

281
185/333 proteins were also commonly found on the surface of filopodial
amoebocytes. When filopodia could be observed under TEM, gold particles were
extremely abundant on their surface (Figure 6.7A). 185/333 proteins often appeared
concentrated in bundles on the filopodia. These may correspond to “knobs” of 185/333
proteins reported by Brockton et al. [15] and under immunofluorescence microscopy in the
current study. Positively stained, round formations were also seen adjacent to 185/333
positive filopodial amoebocytes (Figure 6.7B). We could not determine whether these were
excreted granules or cross sections of filopodia. However, previous immunofluorescence
analysis identified dissociated discs (or “frizbees”) of 185/333 material floating free in the
coelomic fluid (Raftos DA, unpublished data)
6.5.4. 185/333 proteins in the gut
185/333 expression was also identified in gut amoebocytes, which were located on
the basal coelomic fluid face of the gut endothelium (Figure 6.8). The cytoplasm of these
amoebocytes was granular and their nuclei had dense heterochromatin beneath the nuclear
envelop. (Figure 6.8A). Mitochondria were oblong. Adjacent to the nucleus, we often
observed faint membrane bound lamellae that resemble Golgi apparati (Figure 6.8B). As in
filopodial amoebocytes from coelomic fluid samples, 185/333 proteins were abundant on
the cell surface of gut amoebocytes, on the trans face of the putative Golgi apparatus and
membrane bound within the numerous small vesicles that filled the cytoplasm (Figure
6.8D).

282
Figure 6.9: Anti-185/333 immunogold stained transmission electron micrograph of
vesicles in anuclear bodies in gut tissue. Panels B, D and F are enlargements of boxed
insets in panels A, C and E. The vesicles in anuclear bodies had various types of content
(A,C,E) and their membranes were highly 185/333+ (B,D,F, arrows). Structures
ressembling bacteria were sometimes seen (E,F). Arrows point to gold particles. b:
bacteria.
1 µm
1 µm
1 µm
0.1 µm
0.1 µm
0.1 µm
b b
b
b
A B
C D
E F
Dheilly et al., Fig 9

283
Numerous anuclear bodies were observed adjacent to these 185/333 positive
amoebocytes (Figure 6.9). The anuclear bodies appeared homogeneously light blue in
methylene blue stained sections. TEM revealed the abundance of 185/333 proteins on the
surface and on the membrane of vesicles within these anuclear bodies (Figure 6.9).
Structures within these vesicles were mostly unrecognizable. However, bacteria-like
structures were observed within some vesicles (Figure 6.9E,F). 185/333 staining was also
apparent on the surface of these bacteria-like structures.
6.5.5. Phagocytosis by coelomocytes
TEM examination of CF from sea urchins injected with yeast and bacteria showed
that none of the phagocytic cells that ingested these particles were 185/333-positive
(Figure 6.10). Only 185-333-negative petaloide amoebocytes were seen phagocytosing
yeast, bacteria and other coelomocytes. Within these cells, no compartmentalisation of the
cytoplasm was observed and the nucleus had a dense chromatin and was rarely rounded
(Figure 6.10). The numerous lamellipodia protruding in all directions had the appearance
of extremely large empty vesicles (Figure 6.10C).
Even though they were not phagocytic, colorless spherule cells were also affected
by the injection of bacteria. After challenge, the density of the spherules changed (Figure
6.11). They developed an inner core that was less electron-dense than the surrounding area
(Figure 6.11B,C). Eventually, they had a central electron dense core in a loose fibrillar
shell (Figure 6.11D). During this last stage, 185/333 proteins were rarely found within the
spherules.

284
Figure 6.10: Phagocytosis by petaloide amoebocytes. Live cell preparation (A), and
transmission electron micrographs (B-F) of petaloide amoebocytes phagocytosing bacteria
(C-F) and yeast cells (B). No 185/333+ staining was observed on bacteria free in the
coelomic fluid (D), undergoing phagocytosis (E) or within phagosomes (F). y : yeast cells.
b: bacteria, n:nucleus.
5µm
y A
n
b b
b
C
bbbD E F
0.5 µm 0.5 µm 0.5 µm
2µm
B y
n
Dheilly et al., Fig.10

285
Figure 6.11: Anti-185/333 immunogold stained transmission electron micrograph of
colorless spherule cells. A/ Spherules had an homogenous electron density before the
injection of bacteria or yeast. B,C,D/ Electron density changed after microbial injection.
No 185/333 proteins were observed in empty spherules with electron dense cores (D).
0.5 µm
0.5 µm 0.5 µm
A
C D
0.5 µm
B

286
6.6. Discussion
Coelomocytes are the immune effector cells of sea urchins [24]. They express highly
variable family of 185/333 proteins, the concentration of which increases after immune
challenge [5, 11, 15]. In the current study, we localized 185/333 proteins within
coelomocytes and gut amoebocytes at the ultrastructural level and investigated their role in
phagocytosis. As a prerequisite for this analysis, we first characterized coelomocyte types
by light microscopy. Six different cell types were found in the coelomic fluid: filopodial
amoebocytes, petaloide amoebocytes, vibratile cells, fusiform cells, colorless spherule cells
and red spherule cells. All these cell types have been observed previously in sea urchins,
except for the fusiform cells [14]. However, fusiform cells have been found in other
echinoderms, such as the star fish, Asterias rubens [25], and the sea cucumber,
Apostichopus japonicus [26]. They are rare in coelomic fluid and their function is
unknown.
The expression of 185/333 proteins in coelomocytes has previously been studied in
S. purpuratus by Brockton et al. [15]. They used anti-185/333 antisera and
immunofluorescence microscopy to identify intense 185/333 staining on the surface of
small amoebocytes, and within perinuclear vesicles of both small amoebocytes and
polygonal amoebocytes. However, the expression of 185/333 proteins was extremely
variable between cells and some seemed to express 185/333 proteins throughout the
cytoplasm [15]. Immunofluorescence analysis was repeated in the current study with H.
erythrogramma coelomocytes using adherent coelomocytes fixed to microscopy slides. We
could not discriminate between the two forms of filopodial amoebocyte (polygonal and
small amoebocytes) previously described [15, 19], but observed intense anti-185/333
immunostaining of filopodial amoebocytes, while all other coelomocyte types remained
unstained (Figure 6.2A). Anti-185/333 reactivity on filopodia was localized into discrete

287
packets (“knobs”) of intense staining similar to that previously observed on the small
amoebocytes of S. purpuratus (Figure 6.2A).
We also repeated the immunofluorescence experiments using semi-thin sections of
fixed cells (Figure 6.2B,C). In this case, immunofluorescence microscopy revealed the
presence of 185/333 proteins within both filopodial amoebocytes and colorless spherule
cells. The expression of 185/333 proteins in colorless spherule cells may not have been
detected previously because this cell type often does not adhere to glass slides (Smith LC,
personal communication).
Immunogold TEM analysis demonstrated that filopodial amoebocytes had well-
developed Golgi apparati and that 185/333 proteins were found in abundance within the
trans-Golgi network. They were also found on the internal membrane surfaces of vesicles
within the cytoplasm, and in abundance on the cell surface, especially along filopodial
formations. Brockton et al. [15] had suggested that, since predicted 185/333 proteins have
no obvious membrane anchoring motifs, such as transmembrane domains or GPI anchors,
185/333 proteins are secreted from coelomocytes and then re-attached to surface
membranes. However, our ultrastructural observations suggest a more conventional
pathway, with 185/333 proteins transported to the cell surface via the Golgi apparatus and
membrane transport vesicles. This leaves open the question of how 185/333 proteins are
anchored to the membrane. It may be that they are oligomerized with other membrane-
anchored proteins. Oligomerization is supported by the previously reported disparity in
molecular weights between predicted 185/333 proteins and those observed on one- and
two-dimensional Western blots [11].
Bulbous protuberances on the filopodia of amoebocytes, which have previously been
observed by Edds [27] and Brockton et al. [15], appeared to contain more 185/333 proteins
than other areas of the membrane. We also observed membranous discs of 185/333
positive material that appeared to be dissociated from the surface of filopodial cells. Whilst

288
these may simply be filopodia caught in cross-section, they might also equate to the discs
(“frizbees”) of 185/333 positive material previously found free in the coelomic fluid
(Raftos DA, unpublished data). If this was the case, it would suggest that dicrete
membranous discs of 185/333 rich material can detach from the cell surface.
In addition to filopodial amoebocytes, 185/333 proteins were detected within gut-
associated amoebocytes. As with filopodial amoebocytes in coelomic fluid, 185/333
proteins in these cells were membrane bound within cytoplasmic vesicles and on the
external face of the cell membrane. Interestingly, the 185/333 positive staining of the gut-
associated amoebocytes appeared more intense than that within filopodial amoebocytes of
the coelomic fluid. However, the ultrastructure of both gut-associated amoebocytes and
filopodial amoebocytes was similar, suggesting that the two cell types may be related.
Most significantly, we observed gut-associated amoebocytes adjacent to anuclear
bodies, located mostly in the basal region of the intestinal endothelium. The content of the
anuclear bodies was mostly uncharacterized. They seemed to contain cellular debris or
bacteria within large vesicles. Briot [28] and Arvy [29] showed that similar “brown
bodies” in the intestine of holothurians contain debris of parasitic origin. Hence, it is
possible that the anuclear bodies in H. erythrogramma are encapsulated microbial material
or degenerative amoebocytes containing phagosomes. 185/333 proteins were extremely
abundant on the membranes of anuclear bodies. This suggests that in the gut, 185/333
proteins may be involved in phagocytosis or encapsulation of microbial pathogens. Such a
hypothesis fits with previous speculation that the sea urchin immune system focuses on
control of intestinal infections or regulation of gut microflora [3].
Even though 185/333 proteins may play a role in phagocytosis in gut, we found no
evidence that they are involved in this process in the coelomic fluid. After the injection of
bacteria and yeast into the coelomic cavity, only petaloide amoebocytes, which do not
express 185/333 proteins, appeared phagocytic. 185/333 proteins were not found bound to

289
injected bacteria or yeast, and 185/333-positive coelomocytes were not phagocytic. This
agrees with previous studies, which showed that petaloide amoebocytes are involved in
phagocytosing foreign particles in the coelomic fluid, whereas filopodial amoebocytes
have roles in wound healing and clotting [19]. This includes the formation of syncitia by
185/333 positive amoebocytes, forming aggregates between cells that might lead to the
encapsulation of pathogens [15].
In addition to filopodial cells, 185/333 proteins were identified in colorless spherule
cells in the coelomic fluid. 185/333 proteins were not associated with membranes within
this cell types, as they were in amoebocytes, but were enclosed within the large membrane
bound spherules that fill the cytoplasm. These spherules had a homogeneous electron
dense content that was modified after the injection of yeast and bacteria. After injection,
the electron density of the spherules changed leaving some cells with empty spherules, or
spherules with an electron dense core but a loose outer cortex. A corresponding decrease in
the concentration of 185/333 proteins was observed with the disappearance of the content
of the spherules. Similar alterations of electron density in spherules have been observed in
holothurians [30, 31]. The changes suggest that the contents of spherules are secreted in
response to the presence of bacteria or yeast.
The nature of the contents within spherules is a long standing question that has not
yet been resolved. The general view is that spherules contain mucopolysaccharides, which
are responsible for their tinctorial properties [31-33]. In holothurians, similar spherules
contain proteins, neutral polysaccharides and sometimes lipid, as well as
mucopolysaccharides [34]. Byrne [35] suggested that spherules contain molecules that
participate in fibrogenesis (ECM deposition). Indeed, colorless spherule cells release their
vesicular content within the regenerating intestine [36] and have been associated with
wound healing. In sea urchins, Menton and Heisen [30] showed an accumulation of
colorless spherule cells within minutes after wounding, whilst Cervello et al. [37]

290
demonstrated that the spherules of colorless spherule cells contain vitellogenin, a large
glycoprotein, that is discharged in the coelomic fluid in response to stress. Because the
protein is highly adhesive, they suggested that it is involved in the clotting reaction. In
Amphoxius, vitellogenin has both hemaglutinating and antibacterial activities [38]. Thus,
colorless spherule cells might not only be involved in wound healing, but could also
contribute to the first line of immune defense. This suggestion is supported by Arizza et al.
[17] who used a plaque-forming assay on whole coelomic fluid preparations and density
gradient separated coelomocytes to show that colorless spherule cells are cytotoxic and
that this toxicity is activated by soluble factors released from amoebocytes. Monoclonal
antibodies were found to inhibit the cytotoxicity of both colorless spherule cells and
amoebocytes by interacting with unidentified 45 kDa and 100 kDa proteins [18]. In this
context, the modification of spherules in response to microbial injection and the
subsequent disappearance of 185/333 proteins may be due to either wounding or the
presence of bacteria and yeast cells.
The different cellular localization of 185/333 proteins in filopodial amoebocytes
and colorless spherule cells suggests that these proteins may have different biological
activities in the different cell types. This may fit with the observation that there are number
of discrete groups of 185/333 molecules that could be cell specific. The cellular
localization of 185/333 proteins revealed by ultrastructural analysis in the current study
provides the first definitive clues to the function of the 185/333 family. In gut-associated
amoebocytes, they may be involved in the phagocytosis of microbial material, whilst they
might be associated with wound healing and cytotoxicity in the coelomic fluid.

291
6.7. References
[1] Sodergren, E., Weinstock, G., Davidson, E., Cameron, R., et al., The genome of the sea
urchin Strongylocentrotus purpuratus. Science 2006, 314, 941-952.
[2] Rast, J. P., Smith, L. C., Loza-Coll, M., Hibino, T., Litman, G. W., Genomic insights
into the immune system of the sea urchin. Science 2006, 314, 952-956.
[3] Pancer, Z., Cooper, M. D., The evolution of adaptive immunity. Annual Review of
Immunology 2006, 24, 497-518.
[4] Holland, L. Z., Albalat, R., Azumi, K., Benito-Gutiérrez, E., et al., The amphioxus
genome illuminates vertebrate origins and cephalochordate biology. Genome Res
2008, 18, 1100-1111.
[5] Nair, S. V., Del Valle, H., Gross, P. S., Terwilliger, D. P., Smith, L. C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin.
Identification of unexpected immune diversity in an invertebrate. Physiol Genomics
2005, 22, 33-47.
[6] Terwilliger, D., Buckley, K., Mehta, D., Moorjani, P., Smith, L., Unexpected diversity
displayed in cDNAs expressed by the immune cells of the purple sea urchin,
Strongylocentrotus purpuratus. Physiol Genomics 2006, 26, 134-144.
[7] Terwilliger, D., Buckley, K., Brockton, V., Ritter, N., Smith, L. C., Distinctive
expression patterns of 185/333 genes in the purple sea urchin, Strongylocentrotus
purpuratus: an unexpectedly diverse family of transcripts in response to LPS, beta-
1,3-glucan, and dsRNA. BMC Mol Biol 2007, 8, 16.
[8] Buckley, K., Smith, L., Extraordinary diversity among members of the large gene
family, 185/333, from the purple sea urchin, Strongylocentrotus purpuratus. BMC
Mol Biol 2007, 8, 68.

292
[9] Buckley, K. M., Munshaw, S., Kepler, T. B., Smith, L. C., The 185/333 gene family is
a rapidly diversifying host-defense gene cluster in the purple sea urchin
Strongylocentrotus purpuratus. J Mol Biol 2008, 379, 912-928.
[10] Buckley, K. M., Terwilliger, D. P., Smith, L. C., Sequence variations in 185/333
messages from the purple sea urchin suggest posttranscriptional modifications to
increase immune diversity. J Immunol 2008, 181, 8585-8594.
[11] Dheilly, N. M., Nair, S. V., Smith, L. C., Raftos, D. A., Highly variable immune-
response proteins (185/333) from the sea urchin, Strongylocentrotus purpuratus:
proteomic analysis identifies diversity within and between individuals. J Immunol
2009, 182, 2203-2212.
[12] Chien, P. K., Johnson, P. T., Holland, N. D., Chapman, F. A., The coelomic elements
of sea urchins (Strongylocentrotus). Protoplasma 1970, 71, 419-442.
[13] Johnson, P., The coelomic elements of the sea urchins (Strongylocentrotus) III. In
vitro reaction to bacteria. J. Invert. Pathol. 1969, 13, 42-62.
[14] Smith, L., Rast, J., Brockton, V., Terwilliger, D., et al., The sea urchin immune
system. Invertebrate Survival Journal 2006, 3, 25-39.
[15] Brockton, V., Henson, J. H., Raftos, D. A., Majeske, A. J., et al., Localization and
diversity of 185/333 proteins from the purple sea urchin - unexpected protein-size
range and protein expression in a new coelomocyte type. J Cell Sci 2008, 121, 339-
348.
[16] Smith, V., The echinoderms, Academic Press, New York 1981.
[17] Arizza, V., Giaramita, F. T., Parrinello, D., Cammarata, M., Parrinello, N., Cell
cooperation in coelomocyte cytotoxic activity of Paracentrotus lividus
coelomocytes. Comp Biochem Physiol A Mol Integr Physiol 2007, 147, 389-394.

293
[18] Lin, W., Grant, S., Beck, G., Generation of monoclonal antibodies to coelomocytes of
the purple sea urchin Arbacia punctulata: Characterization and phenotyping. Dev
Comp Immunol 2007, 31, 465-475.
[19] Gross, P. S., Clow, L. A., Smith, L. C., SpC3, the complement homologue from the
purple sea urchin, Strongylocentrotus purpuratus, is expressed in two
subpopulations of the phagocytic coelomocytes. Immunogenetics 2000, 51, 1034-
1044.
[20] Clow, L. A., Gross, P. S., Shih, C.-S., Smith, L. C., Expression of SpC3, the sea
urchin complement component, in response to lipopolysaccharide. Immunogenetics
2000, 51, 1021-1033.
[21] Wilson, G. S., Raftos, D. A., Corrigan, S. L., Nair, S. V., Diversity and antimicrobial
activities of surface-attached marine bacteria from Sydney Harbour, Australia.
Microbiol Res 2009. In Press.
[22] Holland, N. D., Giese, A. C., An autoradiographic investigation of the gonads of the
purple sea urhcin (Strongylocentrotus purpuratus). Biol Bull 1965, 128, 241-258.
[23] Gross, P. S., Al-Sharif, W. Z., Clow, L. A., Smith, L. C., Echinoderm immunity and
the evolution of the complement system. Dev Comp Immunol 1999, 23, 429-442.
[24] Smith, L. C., Davidson, E. H., The echinoderm immune system. Characters shared
with vertebrate immune systems and characters arising later in deuterostome
phylogeny. Ann. NY Acad. Sci. 1994, 712, 213-226.
[25] Kozlova, A. B., Petukhova, O. A., Pinaev, G. P., The analysis of cellular elements in
coelomic fluid of the starfish Asterias rubens L. in early regeneration time.
tsitologiia 2006, 48, 175-183.
[26] Xing, J., Chia, F. S., Phagocytosis of sea cucumber amoebocytes: a flow cytometric
study. Invertebr Biol 1998, 117, 67-74.

294
[27] Edds, K. T., The formation and elongation of filopodia during transformation of sea
urchin coelomocytes. Cell Motil Cytoskeleton 1980, 1, 131-140.
[28] Briot, A., Sur les corps bruns des holothuries. C R Seances Soc Biol Fil 1906, 60,
1156-1157.
[29] Arvy, L., Contribution a la connaissance des 'corps bruns' des Holothuridae. C R Hebd
Seances Acad Sci 1957, 245, 2543-2545.
[30] Menton, D. N., Eisen, A. Z., The structure of the integument of the sea cucumber
Thyone briareus. J. Morphol. 1970, 131, 17-36.
[31] Hetzel, H. R., Studies on holthurian coelomocytes. I. A survey of coelomocyte types
Biol Bull 1963, 125, 289-301.
[32] Endean, R., Physiology of echinodermata, Intersciences Publishers, London 1966.
[33] Cowden, R. R., Cytological and histochemical observations on connective tissue cells
and cutaneous wound healing in the sea cucumber Stichopus badionotus. J
Invertebr Pathol 1968, 10, 151-159.
[34] Eliseikina, M. G., Magarlamov, T. Y., Coelomocyte morphology in the holothurians
Apostichopus japonicus (Aspidochirota: Stichopodidae) and Cucumaria japonica
(Dendrochirota: Cucumariidae). Russ J Mar Biol 2002, 28, 197-202.
[35] Byrne, M., the ultrastructure of the morula cells of Eupencttacta quinquesemita
(Echinodermata: Holothuroidea) and their role in the maintenance of the
extracellular matrix. J. Morphol. 1986, 188, 179-189.
[36] Garcia-Arrares, J. E., Schenk, C., Rodrigues-Ramirez, R., Torres, I. I., et al.,
Spherulocytes in the echinoderm Holothuria glaberrima and their involvement in
intestinal regeneration. Dev Dyn 2006, 235, 3259-3267.
[37] Cervello, M., Arizza, V., Lattuca, G., Parrinello, N., Matranga, V., Detection of
vitellogenin in a subpopulation of sea urchin coelomocytes. Eur J Cell Biol 1994,
64, 314-319.

295
[38] Zhang, S., Sun, Y., Pang, Q., Shi, X., Hemagglutinating and antibacterial activities of
vitellogenin. Fish Shellfish Immunol 2005, 19, 93-95.

296

297
CHAPTER VII
General discussion

298

299
7.1. General discussion
The experiments described in this thesis have provided fundamental information on
the immune responses of sea urchins. The thesis tested whether the complex immune
system predicted by genomic and transcriptomic data is evident at the level of expressed
proteins [1-3]. As such, this work provides essential information on the proteins expressed
in response to wounding and immune challenge, with particular emphasis on 185/333
proteins within the second half of this thesis.
The aim of the initial investigation (Chapter 2) was to establish the first proteome
map for the CF of sea urchins. This allowed comparison with proteomes of immune
responsive cells from vertebrates and other invertebrate species. A total of 323 proteins
were identified in S. purpuratus CF, and homologues of 236 of these were later identified
in H. erythrogramma CF (Chapter 4). This confirmed that most protein sequences are
conserved between these two species, which validates our approach of using the genome of
S. purpuratus for the identification of proteins in H. erythrogramma.
Proteins associated with cell shape and mobility were the most abundant in both
proteomes confirming the preponderance of amoeboid coelomocytes within the CF. These
cells have previously been implicated in clotting reactions and phagocytosis, and have
been shown to express complement component C3 [4, 5]. It is interesting that a large panel
of proteins involved in clotting and the complement system in vertebrates were among the
most abundant proteins in our samples. These data suggest that similarities with the
corresponding vertebrate systems are more extensive than previously thought.
Investigation of the CF proteome also revealed the abundance of a variety of homologues
of iron-binding proteins. This indicates that iron metabolism has an important role in the
function of coelomocytes, either in cell proliferation, activation of nitric oxide responses or
depletion of iron [6-16].

300
Even though most proteins identified within CF had homologues in vertebrate
immune systems and could ultimately be related to immune responses, the precise
functions of most proteins have not been tested experimentally in sea urchins. Chapter 3
and Chapter 4 used comparative proteomic techniques to determine the role of CF proteins
in anti-pathogen responses. In the experiments, sea urchins were injected with microbes,
PAMPs, or aCF as controls. In Chapter 3, PCA identified a significant modification of the
proteome 24 hours after saline injection, with few additional differences due to the
injection of bacteria. This modification of the proteome most likely reflects responses to
the wound created by the needle used for injection or the increased volume of CF due to
the injection of aCF. Sea urchins have open circulatory system, which makes coelomocyte
coagulation in response to wounding one of the most important defense reactions to
prevent the lost of CF when injured, and to limit the spread of microbes in the coelom.
In Chapter 4, we further investigated this wounding response over time. In the first
instance, a major modification of the proteome due to injection was observed after 6 and
24 hours p.i.. The first phase of the response involved major cytoskeletal proteins,
including actin, fascin, Rac1 and cdc42. These proteins probably lead to the formation of
filopodia and adhesion complexes necessary for the formation of clots involved in sealing
wounds [17-20]. This was quickly followed by a humoral response, mostly involving an
iron-binding protein of the LLTP family, major yolk protein [12, 21]. A second discrete
phase occurred 48 hours p.i.. At this time-point, the induction of wound repair mechanisms
was evident. This included the increased abundance of proteins such as Von willebrand
factor, cyclophilin B, and selectins, which are involved in cell migration to sites of injury
and adhesion to collagen [22-24].
In addition to wounding responses, Chapters 3 and 4 also identified proteins whose
relative abundance was substantially altered specifically in response to the injection of
bacteria or PAMPs. In Chapter 3, we employed a classical 2DE based comparative

301
proteomics analysis in which the major shift in protein abundances due to the wound
response mostly masked other more specific responses to the injection of bacteria. In
addition, many significantly altered proteins isolated from 2DE gels were often not
abundant enough to be identified by mass spectrometry. However, two of the proteins
(apextrin and calreticulin) that could be identified were significantly more abundant in
response to the injection of bacteria, as opposed to saline, suggesting that they are both
involved in immunological reactions or pathogen sequestration. These results are
supported by their involvement in immunological reactions in other species [25-27].
In Chapter 4, we turned to a more sensitive shotgun proteomic method to investigate
the response to LPS injection over time. It was obvious from PCA that the alteration in
protein concentrations due to the presence of LPS occurred mostly 48 hours p.i.. Vesicular
transport proteins, such a coatomer proteins and RACK, and cellular signalling molecules,
such as G(q) and MAP kinase, increased in relative abundance after LPS injection. Many
immune response molecules such as SpC3, dual oxidase maturation factor, dual oxidase 1,
α-2 macroglobulin, SRCRs, fibrocystin L and aminopeptidase N were also more abundant
48 hours after the injection of LPS as opposed to aCF. These results suggest their
involvement in inducible immune responses in sea urchins. More specifically, fibrocystin
L and aminopeptidase N were only found 48 hours after LPS injection, indicating that
these proteins are expressed only during PAMP-induced immune responses. Both show
strong sequence similarities with their vertebrate homologues, suggesting that they could
perform similar functions in sea urchins [2, 28, 29]. In vertebrates, they are receptor
proteins expressed on immune responsive cells that bind lectins and participate in
regulating phagocytosis [29-34].
Comparisons of the results presented within Chapters 3 and 4 also revealed
differences in responses to whole microbes and PAMPs. No differences in the relative
abundance of calreticulin and apextrin were observed between saline- and LPS-injected sea

302
urchins. This contrasted with the significant increase in the abundance of these two
proteins in Chapter 3, in which sea urchins were injected with whole bacteria. This
inconsistency indicates that coelomocytes respond differently to LPS than to whole
microorganisms. Similar observations have been made in Drosophila hemocytes, which
activate different cellular pathways in response to purified PAMPs compared to live
bacteria [35]. Perhaps, the injection of whole organisms favours increased phagocytosis,
clotting and encapsulation, whilst PAMPs activate different cellular processes via distinct
pattern recognition receptors.
The comparative proteomic analyses reported in this thesis suggest that a complex
array of proteins respond to wounding and immunological challenge. A biphasic response
has been described. There is an early generalized response that shows many similarities to
reactions to sterile wounding followed by a delayed response that appeared to be specific
towards the PAMPs/microbes. Another reason to believe that the immune system of sea
urchins is extremely complex comes from the identification in its genome sequence of an
expanded array of pathogen recognition gene families when compared with humans and
insects [1]. For instance, 218 different SRCRs genes can be found in S. purpuratus
genome. In Chapter 2, we identified 16 SRCRs, of which 8 had not been characterised
previously. This confirms that a number of the available SRCRs are expressed in
coelomocytes, and agrees with previous work, which has shown that coelomocytes use
exon swapping to generate different patterns of SRCR expression [36].
Two other families of diversified proteins were also expected to be abundant in
coelomocytes based on genomic and transcriptomic data. Transcripts of 185/333 proteins
represented over 70% of novel mRNAs in an immunologically-activated coelomocyte
transcriptome, and as many as 222 distinct TLRs genes have been identified in the S.
purpuratus genome sequence [1, 2]. However, only a single member of the 185/333 family
and no TLRs were found in coelomocytes studied by proteomic analysis. The low

303
abundance of these two protein families in coelomocytes is difficult to explain. It may be
that individual 185/333 proteins and TLRs are not expressed at sufficiently high densities
in coelomocytes to enable identification by mass spectrometry. Hence, Chapters 5 and 6 of
the thesis, used more targeted methods to investigate the variability of 185/333 proteins
and study their potential role in immune defense.
Chapter 5 investigated the pattern of 185/333 protein expression in sea urchins
challenged with different PAMPs. Over 200 185/333+ protein spots could be identified on
2DE Western blots of CF from a single individual. Even though 185/333 proteins had
predicted molecular masses ranging from 27 to 56 kDa, their observed molecular masses
ranged from 20 to >193 kDa. Moreover, based on their amino acid sequences, 185/333
proteins were predicted to have pIs ranging from 6 to 11, due to single nucleotide
substitutions that are often conservative and result in amino acid substitutions of highly
charged amino acids. However, the transcribed 185/333 proteins identified on 2DE
Western blots had a range of pIs from 3 to 12 with most proteins having pIs between 3 and
6. This inconsistency between predicted and observed results suggests that 185/333
proteins interact with other molecules that have lower pIs. The fact that 185/333 proteins
have no transmembrane region nor a GPI anchor motif but are still expressed on the
surface of both filopodial amoebocytes and gut associated amoebocytes (Chapter 6) also
suggests that they may bind to other molecules that anchor them to cell membranes. Thus,
we expect future studies to demonstrate that 185/333 proteins form complexes with
membrane bound proteins.
In addition to the variability among 185/333 proteins within a single individual, we
found that the pattern of 185/333 proteins differed between individuals (Chapter 5). The
differences observed between individuals suggest variability in the expression of the
different 185/333 protein sub-families or the presence/absence of loci or alleles. However,
it was not possible to characterize unique protein spots from 2DE gels using mass

304
spectrometry to determine if single protein spots contained proteins from the same 185/333
sub-family. Instead, 185/333 proteins separated on 1DE gels were successfully identified
by shotgun mass spectrometry. Different combinations of peptide sequences were obtained
from each gel slice, suggesting that different combination of 185/333 proteins were present
within each MW range.
We also found evidence that 185/333 proteins contribute to immune responses [37].
The previously described transcription of 185/333 proteins in response to the injection of
LPS [1] was confirmed at the protein level by ELISA and Western blotting (Chapter 6).
Some modifications of the pattern of 185/333 proteins on Western blots of CF from sea
urchins stimulated with different PAMPs were also identified. Again, this corresponds with
previous transcriptomic analysis, which suggested that different groups of 185/333 proteins
are transcribed in response to different PAMPs [38].
Based on their responses to immunological challenge and their cytological
distribution, it had been assumed that 185/333 proteins are involved in pathogen
recognition, specifically in the encapsulation of pathogens or phagocytosis. In Chapter 6,
185/333 proteins were found within filopodial amoebocytes and colorless spherule cells in
the coelomic fluid. However, after the injection of yeast or bacteria into the coelomic fluid,
no 185/333+ filopodial amoebocytes or colorless spherule cells were seen undertaking
phagocytosis. This result is in accordance with previous observations that filopodial
amoebocytes are mostly involved in clotting and wound repair, while petaloide
amoebocytes are highly phagocytic [39]. However, colorless spherule cells, which
expressed 185/333 proteins within their spherules, appeared to release the content of these
spherules in response to injection. Previous studies suggested that colorless spherule cells
are involved in wounding responses and are cytotoxic [21, 40-42].
Investigation of 185/333 protein expression within gut tissue revealed that they are
also highly expressed within amoebocytes but absent in enterocytes (Chapter 6). The

305
ultrastructural localisation of 185/333 proteins in these gut-associated amoebocytes was
similar to that of filopodial amoebocytes and these two cell types shared numerous other
ultrastructural similarities, suggesting that they are closely related. Gut-associated
amoebocytes were always found adjacent to large anuclear bodies. 185/333 proteins were
also abundant on the membrane of these bodies, which appeared to be packed with
heterogeneous granular contents resembling cell debris and bacteria. The expression of
185/333 proteins in gut-associated amoebocytes and on the cell membrane of anuclear
bodies constitute the first indication that 185/333 proteins are specifically expressed by
immune cells that are involved in the ingestion of non-self.

306
7.2. Caveats and future directions
The logical extension of the proteomic characterization of coelomocytes would be to
analyse purified sub-populations of coelomocytes. This would allow us (1) to resolve the
proteome of each cell type and predict their functions and (2) to determine whether
different groups of 185/333 proteins are expressed in different cell types. Testing whether
different sub-families of 185/333 proteins are found in amoebocytes and colorless spherule
cell spherules, and defining the exact function of these different coelomocyte types, will
allow new hypotheses on the function of this highly variable family of proteins to be
developed. It will also be of interest to continue investigations on the ability of sea urchin
immune systems to discriminate between different pathogens. Sea urchins can live up to
100 years [43] and they succeed in the continuous arms race with pathogens suggesting
that the existence of specificity and memory in their immune responses might be an
evolutionary advantage. Sea urchins also constitute ideal model organisms for such studies
because they are abundant in aquatic environment, have large number of blood cells, and
can survive multiple injections and collection of coelomic fluid, permitting long-term
primary and secondary challenge experiments. Resolving whether memory and specificity
are characteristics of invertebrate immune responses is the major outstanding question in
comparative immunology.

307
7.3. Concluding remarks
The proteomic analysis of sea urchin immune responses presented in this thesis is a
first step in determining how the immune system of sea urchins works, and identifying the
actors of this system. This thesis showed that 185/333 proteins are just one component of a
complex protein system involved in host defense. Proteomic analysis paints a picture of
coelomocytes as being primarily amoeboid cells that express a large range of immune
response genes and proteins that could contribute to host defence. Many CF proteins
appear to be involved in wounding responses. However, there is also a substantial suite of
proteins that respond specifically to the presence of bacteria or PAMPs. Different sub-
populations of coelomocytes appear to be involved in the different components of this
immune response. This supports the growing realization that sea urchin immune responses
are complex and highly directed. The abundance of highly variable immune response
proteins (185/333) within gut-associated amoebocytes indicates a link between gut-
associated pathogenesis and the sea urchin immune system. Most significantly, 185/333
proteins do appear to be involved in the ingestion of degenerative material in the gut,
including bacteria. This supports their role in active host defense responses and leaves
open the possibility that the high variability of immune response protein families in sea
urchins is associated with regulation of gut flora.

308
7.4. References
[1] Nair, S. V., Del Valle, H., Gross, P. S., Terwilliger, D. P., Smith, L. C., Macroarray
analysis of coelomocyte gene expression in response to LPS in the sea urchin.
Identification of unexpected immune diversity in an invertebrate. Physiol Genomics
2005, 22, 33-47.
[2] Rast, J. P., Smith, L. C., Loza-Coll, M., Hibino, T., Litman, G. W., Genomic insights
into the immune system of the sea urchin. Science 2006, 314, 952-956.
[3] Smith, L., Chang, L., Britten, R., Davidson, E., Sea urchin genes expressed in activated
coelomocytes are identified by expressed sequence tags. Complement homologues
and other putative immune response genes suggest immune system homology
within the deuterostomes. J Immunol 1996, 156, 593-602.
[4] Smith, L., Rast, J., Brockton, V., Terwilliger, D., et al., The sea urchin immune system.
Invertebrate Survival Journal 2006, 3, 25-39.
[5] Gross, P. S., Clow, L. A., Smith, L. C., SpC3, the complement homologue from the
purple sea urchin, Strongylocentrotus purpuratus, is expressed in two
subpopulations of the phagocytic coelomocytes. Immunogenetics 2000, 51, 1034-
1044.
[6] Baker, M., Lindley, P., New perspectives on the structure and function of transferrins. J
Inorg Biochem 1992, 47, 147-160.
[7] Brock, J., de Sousa, M., Immunoregulation by iron-binding proteins. Immunol today
1986, 7, 30-31.

309
[8] Stafford, J., M, B., Transferrin and the inante immune response of fish: identification of
a novel mechanism of macrophage activation. Dev Comp Immunol 2003, 27.
[9] Sekyere, E., Richardson, D., The membrane-bound transferrin homologue
melanotrasnferrin: roles other than iron transport? FEBS Lett 2000, 48, 11-16.
[10] Dunn, L., Sekyere, E., Rahmanto YS, Richardson, D., The function of
melanotransferrin: a role in melanoma cell proliferation and tumorigenesis.
Carcinogenesis 2006, 27, 2157-2169.
[11] Yokota, Y., Unuma, T., Moriyama, A., Yamano, K., Cleavage site of a major yolk
protein (MYP) determined by cDNA isolation and amino acid sequencing in sea
urchin, Hemicentrotus pulcherrimus. Comp Biochem Physiol B Biochem Mol Biol
2003, 135, 71-81.
[12] Brooks, J. M., Wessel, G. M., The major yolk protein in sea urchins is a transferrin-
like, iron binding protein. Dev Biol 2002, 245, 1-12.
[13] Beck, G., Ellis, T., Habicht, G. S., Schluter, S., Marchalonis, J., Evolution of the acute
phase response: iron release by echinoderms (Asterias forbesi) coelomocytes, and
cloning of an echinoderm ferritin molecule. Dev Comp Immunol 2002, 26, 11-26.
[14] Brock, J., Mulero, V., Cellular and molecular aspects of iron and immune function.
Proc Natl Acad Sci USA 2000, 59, 537-540.
[15] Ganz, T., Iron in innate immunity: starve the invaders. Current Opinion in
Immunology 2009, 21, 63-67.
[16] Fox, P., The copper-iron chronicles: the story of an intimate relationship. Biometals
2003, 16, 9-40.

310
[17] Vignevic, D., Kojima, S.-i., Aratyn, Y., Danciu, O., et al., Role of fascin in filopodial
protrusion. J Cell Biol 2006, 174, 863-875.
[18] Edds, K., Dynamic aspects of filopodial formation by reorganization of
microfilaments. J Cell Biol 1977, 73, 479-491.
[19] Edds, K. T., The formation and elongation of filopodia during transformation of sea
urchin coelomocytes. Cell Motil Cytoskeleton 1980, 1, 131-140.
[20] Chien, P. K., Johnson, P. T., Holland, N. D., Chapman, F. A., The coelomic elements
of sea urchins (Strongylocentrotus). Protoplasma 1970, 71, 419-442.
[21] Cervello, M., Arizza, V., Lattuca, G., Parrinello, N., Matranga, V., Detection of
vitellogenin in a subpopulation of sea urchin coelomocytes. Eur J Cell Biol 1994,
64, 314-319.
[22] Allain, F., Durieux, S., Denys, A., Carpentier, M., Spik, G., Cyclophilin B binding to
platelets supports calcium-dependent adhesion to collagen. Blood 1999, 94, 976-
983.
[23] Farndale, R. W., Sixma, J. J., Barnes, M. J., Groot, P. G. D., The role of collagen in
thrombosis and hemostasis. Journal of Thrombosis and Haemostasis 2004, 2, 561-
573.
[24] Vasta, G. R., Quesenberry, M., Ahmed, H., O'Leary, N., C-type lectins and galectins
mediate innate and adaptive immune functions: their roles in the complement
activation pathway. Dev Comp Immunol 1999, 23, 401-420.
[25] Arosa, F. A., de Jesus, O., Porto, G., Carmo, A. M., de Sousa, M., Calreticulin is
expressed on the cell surface of activated human peripheral blood T lymphocytes in

311
association with major histocompatibility complex class I molecules. J Biol Chem
1999, 274, 16917-16922.
[26] Dupuis, M., Schaerer, E., Krause, K., Tschopp, J., The calcium-binding protein
calreticulin is a major constituent of lytic granules in cytolytic T lymphocytes. J
Exp Med 1993, 177, 1-7.
[27] Huang, G., Liu, H., Han, Y., Fan, L., et al., Profile of acute immune response in
Chinese amphioxus upon Staphylococcus aureus and Vibrio parahaemolyticus
infection. Dev Comp Immunol 2007, 31, 1013-1023.
[28] Ingersoll, E., An analysis of aminopeptidase N genes in the sea urchin genome. Dev
Biol 2008, 319, 566-566.
[29] Hogan, M. C., Griffin, M. D., Rossetti, S., Torres, V. E., et al., PKHDL1, a homolog
of the autosomal recessive polycystic kidney disease gene, encodes a receptor with
inducible T lymphocyte expression. Hum Mol Genet 2003, 12, 685-698.
[30] Mina-Osorio, P., Ortega, E., Aminopeptidase N (CD13) functionally interacts with
Fc{gamma}Rs in human monocytes. J Leukoc Biol 2005, 77, 1008-1017.
[31] Tokuda, N., Levy, R. B., 1,25-dihydroxyvitamin D3 stimulates phagocytosis but
supresses HLA-DR and CD13 antigen expression in human mononuclear
phagocytes. Proc Soc Exp Biol Med 1996, 211, 244-250.
[32] Granhagen, K., Lundstron, A., Bjorstad, A., Bylund, J., et al., Galectin-3 binds CD 13,
activates the NADPH-oxidase, and augments neutrophil inactivation of the
chemotactic peptide fMLF: 69. Eur J Clin Invest 2007, 37, 23.

312
[33] Mina-Osorio, P., Soto-Cruz, I., Ortega, E., A role for galectin-3 in CD13-mediated
homotypic aggregation of monocytes. Biochem Biophys Res Commun 2007, 353,
605-610.
[34] Mina-Osorio, P., The moonlighting enzyme CD13: old and new functions to target.
Trends Mol Med 2008, 14, 361-371.
[35] Johansson, K. C., Metzendorf, C., Soderholl, K., Microarray analysis of immune
challenged Drosophila hemocytes. Exp Cell Res 2005, 305, 145-155.
[36] Pancer, Z., Dynamic expression of multiple scavenger receptor cysteine-rich genes in
coelomocytes of the purple sea urchin. Proc Natl Acad Sci U S A 2000, 97, 13156-
13161.
[37] Kurtz, J., Memory in the innate and adaptive immune systems. Microbes and Infection
2004, 6, 1410-1417.
[38] Terwilliger, D., Buckley, K., Brockton, V., Ritter, N., Smith, L. C., Distinctive
expression patterns of 185/333 genes in the purple sea urchin, Strongylocentrotus
purpuratus: an unexpectedly diverse family of transcripts in response to LPS, beta-
1,3-glucan, and dsRNA. BMC Mol Biol 2007, 8, 16.
[39] Smith, V., The echinoderms, Academic Press, New York 1981.
[40] Arizza, V., Giaramita, F. T., Parrinello, D., Cammarata, M., Parrinello, N., Cell
cooperation in coelomocyte cytotoxic activity of Paracentrotus lividus
coelomocytes. Comp Biochem Physiol A Mol Integr Physiol 2007, 147, 389-394.

313
[41] Lin, W., Grant, S., Beck, G., Generation of monoclonal antibodies to coelomocytes of
the purple sea urchin Arbacia punctulata: Characterization and phenotyping. Dev
Comp Immunol 2007, 31, 465-475.
[42] GarcÌa-Arrares, J. E., Schenk, C., RodrÌgues-RamÌrez, R., Torres, I. I., et al.,
Spherulocytes in the echinoderm Holothuria glaberrima and their involvement in
intestinal regeneration. Dev Dyn 2006, 235, 3259-3267.
[43] Ebert, T. A., Southon, J. R., Red sea urchins (Strongylocentrotus franciscanus) can
live over 100 years: confirmation with A-bomb 14 carbon. Fish bulletin
(Sacramento, Calif.) 2003, 101, 915.

314

Highly Variable Immune-Response Proteins (185/333) from theSea Urchin, Strongylocentrotus purpuratus: Proteomic AnalysisIdentifies Diversity within and between Individuals1
Nolwenn M. Dheilly,* Sham V. Nair,2* L. Courtney Smith,† and David A. Raftos*
185/333 genes and transcripts from the purple sea urchin, Strongylocentrotus purpuratus, predict high levels of amino acid diversitywithin the encoded proteins. Based on their expression patterns, 185/333 proteins appear to be involved in immune responses. Inthe present study, one- and two-dimensional Western blots show that 185/333 proteins exhibit high levels of molecular diversitywithin and between individual sea urchins. The molecular masses of 185/333-positive bands or spots range from 30 to 250 kDa witha broad array of isoelectric points. The observed molecular masses are higher than those predicted from mRNAs, suggesting that185/333 proteins form strong associations with other molecules or with each other. Some sea urchins expressed >200 distinct185/333 proteins, and each animal had a unique suite of the proteins that differed from all other individuals. When sea urchinswere challenged in vivo with pathogen-associated molecular patterns (PAMPs; bacterial LPS and peptidoglycan), the expressionof 185/333 proteins increased. More importantly, different suites of 185/333 proteins were expressed in response to differentPAMPs. This suggests that the expression of 185/333 proteins can be tailored toward different PAMPs in a form of pathogen-specific immune response. The Journal of Immunology, 2009, 182: 2203–2212.
R ecent studies of host defense have uncovered profounddifferences among animal phyla in the molecules used tomediate immune responses (1–3). It seems that the im-
mune systems of different animals have evolved a variety of so-lutions to meet a basic requirement to combat pathogens. The re-sulting, highly diversified immune responses may reflect thespecific physiology, lifespan, habitat, and associated microbialpopulations of particular animal groups, or they may have arisenby chance via evolutionary radiation. A number of metazoan phylahave now been studied, identifying a range of alternative immu-nological mechanisms that exhibit high levels of molecular diver-sity (2). These discoveries have driven a paradigm shift in ourunderstanding of invertebrate immune responses, from systemsthat are simple and static, to those that are complex and have novelmechanisms for generating molecular hypervariability, a key re-quirement for keeping pace in the “arms race” against microbialpathogens.
Some invertebrate immune systems are proving to be surpris-ingly complex. Recent analyses of the purple sea urchin (Strongy-locentrotus purpuratus) genome identified several large gene fam-ilies, including gene models for 222 TLRs, 203 NOD-likereceptors (NLR), 218 scavenger receptor cysteine-rich (SRCR)molecules, and 104 C-type lectins (4–6). The complexity and
large size of these gene families suggest that the receptors theyencode may recognize individual pathogen-associated molecularpatterns (PAMPs)3 with a high degree of specificity. They mightalso act combinatorially, providing highly diverse recognitive ca-pabilities (5). In addition to diversified receptors, the S. purpuratusgenome contains homologs of RAG1 and RAG2, the moleculesresponsible for the somatic recombination of immunoglobulins invertebrates (7). This suggests that the molecular tools required togenerate molecular hypervariability might also exist amonginvertebrates.
185/333 genes represent another high-diversity immune re-sponse system in sea urchins. This family was first identified dur-ing a transcriptome analysis of sea urchin immune response genes(8). Genes that were up-regulated in coelomocytes (immune cells)after the injection of LPS were identified by screening high-densityarrayed, conventional cDNA libraries with probes generated bysubtractive suppression hybridization. Surprisingly, �60% of theexpressed sequence tags (ESTs) characterized in this transcriptomeanalysis were members of a set of closely related transcripts withsimilarities to two uncharacterized sequences from S. purpuratus,called DD185 (GenBank accession AF228877 (9)) and EST333(GenBank accession R62081 (10)), hence the designation 185/333.
Screening an arrayed cDNA library constructed from immuno-logically activated coelomocytes indicated that the frequency of185/333 mRNAs was enhanced more than 75-fold compared witha nonactivated arrayed cDNA library (8). Northern blots alsoshowed striking increases in 185/333 expression in coelomocytesfrom bacterially activated sea urchins compared with injury con-trols (9). Based on this significant increase in gene expression,185/333 transcripts were investigated in more detail, revealing an
*Department of Biological Sciences, Macquarie University, North Ryde, New SouthWales, Australia; and †Department of Biological Sciences, George Washington Uni-versity, Washington, DC 20052
Received for publication September 18, 2007. Accepted for publication December 3,2008.
The costs of publication of this article were defrayed in part by the payment of pagecharges. This article must therefore be hereby marked advertisement in accordancewith 18 U.S.C. Section 1734 solely to indicate this fact.1 This study was funded in part by an Australian Research Council Discovery grantto D.A.R. (DP0880316) and by a United States National Science Foundation grant toL.C.S. (MCB 04-24235). N.D. is the recipient of an International Macquarie Univer-sity Research Scholarship postgraduate scholarship.2 Address correspondence and reprint requests to Dr. Sham V. Nair Department ofBiological Sciences, Macquarie University, North Ryde, NSW 2109, Australia.E-mail address: [email protected]
3 Abbreviations used in this paper: PAMP, pathogen-associated molecular pattern;aCF, artificial coelomic fluid; CF, coelomic fluid; EST, expressed sequence tag; IPG,immobilized pH gradient; LC, liquid chromatography; MS, mass spectrometry; 1DE,one-dimensional electrophoresis; pI, isoelectric point; SNP, single nucleotide poly-morphism; 2DE, two-dimensional electrophoresis.
Copyright © 2009 by The American Association of Immunologists, Inc. 0022-1767/09/$2.00
The Journal of Immunology
www.jimmunol.org/cgi/doi/10.4049/jimmunol.07012766

unexpected level of sequence diversity (8, 11). To date, for 185/333 cDNAs, 689 have been characterized from 14 sea urchins.These sequences are predicted to encode 286 different proteins(11, 12).
The diversity evident among 185/333 transcripts is generated inseveral ways. 185/333 mRNAs are comprised of 25 differentblocks or “elements” of nucleotide sequence that are present orabsent in numerous combinations. This results in “element pat-terns” that are repeatedly identified in different mRNAs (8, 12),contributing significant diversity to the family of 185/333 mes-sages. Single nucleotide polymorphisms (SNPs) and small inser-tions or deletions (indels) are also frequent in all 185/333 se-quences, adding to diversity. Additionally, there are surprisinglyhigh levels of frame shifts and the insertion of early stop codons inthe mRNA sequences (11). The processes that generate this diver-sity among 185/333 mRNAs are not yet well defined, but they mayinclude differences among the estimated fifty 185/333 gene loci(11, 13, 14), high levels of allelic polymorphism at each locus,RNA editing, and/or low-fidelity RNA polymerases (15), followedby posttranslational modifications. All of these processes may havebeen driven by positive selection associated with anti-pathogendefense (8, 11, 12, 14). Nucleotide sequence variability results inhigh levels of nonconservative amino acid substitutions amongpredicted proteins of the type consistent with intense evolutionaryselection pressure (8, 12, 14, 15).
185/333 mRNAs are predicted to encode proteins with a hydro-phobic leader, a glycine-rich region with multiple endoproteasecleavage sites, an RGD motif, a histidine-rich region, numerousN-linked and O-linked glycosylation sites, acidic patches, and sev-eral types of tandem and interspersed repeats (11). The deducedproteins do not contain cysteines, transmembrane regions, GPIlinkage sites, identifiable domains, or any predictable folding pat-terns. The only regions with at least some similarity to other mol-ecules are the RGD motif and one of the histidine-rich domains,which is comparable to histatins, a group of mammalian salivaryproteins with powerful antifungal activities (16, 17). Brockton etal. (18) have shown that 185/333 proteins are expressed by twosubsets of coelomocytes (small phagocytes and polygonal cells),and that the number of 185/333� cells increases in response toimmunological challenge. Initial analyses of 185/333 proteins in-dicated that recombinant 185/333 proteins appear as multimers andthat native proteins are present in a broad range of sizes in agree-ment with the mRNA sequences (18).
Here, we present the first comprehensive analysis of 185/333proteins. It reveals a broad diversity of these proteins within indi-vidual sea urchins. Different sea urchins express different suites of185/333 proteins, and expression is altered by immunological chal-lenge. The data indicate that differential expression or posttrans-lational modification of 185/333 proteins might allow S. purpura-tus to tailor immune responses toward specific pathogens.
Materials and MethodsSea urchins
Adult S. purpuratus were purchased from Marinus Scientific after collec-tion from the coast of southern California. They were maintained in thelaboratory as described previously (19). S. purpuratus becomes immuno-quiescent after long-term housing of �8 mo without significant disturbance(19, 20). Immunoquiescence can easily be reversed by injecting PAMPs, orin response to injury (19–21).
Immunological challenge and sample collection
Animals were challenged by injecting 2 �g of LPS or 4 �g of peptidogly-can (Sigma-Aldrich) per milliliter of coelomic fluid (CF), as previouslydescribed (10, 19). Control animals were injected with an equivalent vol-ume of artificial CF (aCF) (11). CF (100 �l) was withdrawn from each sea
urchin immediately before injection, and then at various times after injec-tion. A 23-gauge needle attached to a 1-ml syringe was inserted through theperistomium into the coelomic cavity and CF was withdrawn without an-ticoagulant. The CF was immediately expelled into a 1-ml tube and mixedwith 100 �l of urea sample buffer (2.4 M Tris-HCl (pH 6.8), 0.25% SDS,4 M urea, 20% glycerol). Samples were stored at �70°C until used. Pro-teins were precipitated using 2-D Clean-Up kits (GE Healthcare) accordingto the manufacturer’s instructions and resuspended in urea sample buffer (8M urea, 4% CHAPS, 60 mM DTT). The total protein content of eachsample was determined with 2-D Quant kits (GE Healthcare).
One-dimensional electrophoresis (1DE)
CF proteins in urea sample buffer (�100 �g/well) were separated on 10%Tris-glycine precast polyacrylamide gels (Criterion gel system; Bio-Rad) at130 V for 2 h, or on 7.5% bis-Tris polyacrylamide gels at 180 V for 1 h.After electrophoresis, proteins were visualized using Sypro Ruby (Sigma-Aldrich) following the manufacturer’s protocol, or with Coomassie blueusing standard protocols. Alternatively, the proteins were transferred tonitrocellulose membranes by Western blotting as described below.
Two-dimensional electrophoresis (2DE)
Isoelectrofocusing was performed using an IPGphor IEF system (GEHealthcare). Immobilized pH gradient (IPG) gel strips (11 cm, pH 3–6 orpH 3–10; GE Healthcare) were rehydrated overnight with 200 �g of CFproteins in 200 �l of rehydration buffer (8 M urea, 2% CHAPS, 50 mMDTT. and 0.5% carrier ampholytes; Immobiline; GE Healthcare). Isoelec-trofocusing was undertaken at 100 V for 3 h, 250 V for 20 min, and 8000V for 6 h, to obtain a total of 26,000–30,000 Vh. The proteins in the IPGstrips were reduced (1% DTT, 15 min) and alkylated (2.5% iodoacetamide,15 min) before separation in the second dimension by SDS-PAGE using10% Tris-glycine precast polyacrylamide gels (Criterion gel system; Bio-Rad) (22). After electrophoresis, protein spots on the gels were visualizedby Coomassie blue staining or with Sypro Ruby. Alternatively, proteinswere transferred to nitrocellulose membranes, as described see below.
Antibodies
The polyclonal antisera against 185/333 proteins used in this study werethe same as those reported by Brockton et al. (18). Antisera were generatedagainst synthetic peptides corresponding to elements 1, 7, and 25a, whichare present in most 185/333 cDNAs (see Ref. 11 and Fig. 5). The peptideswere conjugated to keyhole limpet hemocyanin and injected into two rab-bits per peptide on four separate occasions (Quality Controlled Biochemi-cals). Only those antisera for which the preimmunization bleeds did notcross-react with sea urchin CF proteins by Western blot (18) were used inthis study. The three antisera used were designated anti-185-66, anti-185-68, and anti-185-71.
Western blotting and immunostaining
Proteins separated by 1DE or 2DE were transferred from polyacrylamidegels to nitrocellulose membranes by electroblotting using a Criterion blot-ting system (Bio-Rad). Transfers were performed at 100 V for 1 h at roomtemperature using Towbin buffer (0.25 M Tris-HCl, 1.92 M glycine (pH8.3)) with 20% methanol. Once transfer was complete, membranes wereblocked by incubation in skim milk solution (7% skim milk powder inTBST; 10 mM Tris-HCl, 137 mM NaCl, 0.5% Tween 20 (pH 7.5)) over-night. Following several washes with TBST (three times for 5 min), mem-branes were incubated with anti-185/333 antisera (1/20,000 dilution of anequal mix of anti-185-66, -68, and -71 in TBST, or each antiserum sepa-rately) for 1 h at room temperature. The blots were washed with TBST(three times for 5 min) and incubated for 1 h at room temperature with goatanti-rabbit IgG conjugated with HRP (1/30,000 in TBST; Sigma-Aldrich).After washing in TBST (three times for 5 min), 185/333� proteins werevisualized using ECL chemiluminescence (GE Healthcare) with blue light-sensitive high-performance chemiluminescence film (Hyperfilm ECL, GEHealthcare). Each blot was exposed to film for varying lengths of time(1–15 min) to optimize the exposure. In some cases, image processing(Photoshop; Adobe Systems) was used to combine autoradiographs fromthe various exposures into composite images. Proteome maps for 185/333�
protein spots on 2DE Western blots were established using Progenesissoftware (PerkinElmer) to plot molecular mass and isoelectric point (pI).The relative intensities of different protein spots were calculated usingAdobe Photoshop (Adobe Systems).
Anti-185/333 ELISA
CF from LPS- and aCF-injected sea urchins was adjusted to 5 � 105
coelomocytes/ml with calcium-magnesium-free seawater with EDTA and
2204 185/333 PROTEIN DIVERSITY IN SEA URCHINS

imidazole (CMFSW-EI; 10 mM KCl, 7 mM Na2SO4, 2.4 mM NaHCO3,460 mM NaCl, 70 mM EDTA, and 50 mM imidazole (pH 7.4)) and wasmixed with an equal volume of CMFSW-EI containing 1% (v/v) NonidetP-40 to lyse the cells, followed by centrifugation (12,000 � g, 10 s) toremove debris. The supernatant was diluted 1/20 with TBS and aliquotedin triplicate into 96-well ELISA plates (200 �l/well; Corning). Plates wereincubated overnight at 4°C so that proteins could adhere to the wells. Theplates were washed once with TBS and blocked for 1 h with TBS con-taining 4% (w/v) BSA. After blocking, 100 �l of anti-185 antisera (1/20,000 dilution of an equal mix of anti-185-66, -68, and -71 in TBST) wasadded per well for 2 h at room temperature with gentle shaking. The plateswere washed three times for five minutes each with TBST before adding100 �l of anti-rabbit IgG-alkaline phosphatase conjugate (1/20,000 inTBST; Sigma-Aldrich) per well. The plates were incubated with the sec-ondary Ab for 2 h before being washed three times with TBST. After thefinal wash, 200 �l of p-nitrophenyl phosphate (2 mg/ml in 0.1 M glycine,1 mM MgCl2, 1 mM ZnCl2 (pH 10.4); Sigma-Aldrich) was added per welland incubated for 30 min before absorbance was read in a microplate spec-trophotometer at 415 nm. Data were corrected for the absorbance in wellsprepared without sea urchin proteins. Controls included wells in which theprimary (anti-185) Abs or both the primary and secondary Abs were omit-ted, and wells in which an irrelevant Ab (rabbit anti-tunicate collectinpeptide (24, 25)) was used in place of the anti-185 antisera.
Mass spectrometry and data analysis
Mass spectrometry (MS) was performed on CF proteins separated by either1DE or 2DE. To extract proteins from 1DE, Coomasssie blue-stained gelswere washed twice in water (10 min each). Individual lanes were cut into16 slices of equal sizes so that proteins in different molecular mass rangescould be analyzed separately by MS (see Fig. 8). To extract proteins after2DE, spots from 2DE gels that corresponded to individual 185/333� pro-teins on Western blots were excised.
Gel slices or excised protein spots were washed briefly with 100 mMNH4HCO3 before being destained (3 � 10 min) with 25 mM NH4HCO3/acetonitrile (1/1) and dehydrated in 100% acetonitrile for 5 min. Afterdehydration, gel pieces were air-dried, reduced with 10 mM DTT in 100mM NH4HCO3 for 45–60 min at 56°C, and alkylated with 55 mM iodoac-etamide in 100 mM NH4HCO3 for 45 min at room temperature. The gelpieces were washed once with 100 mM NH4HCO3 for 5 min and twicewith 25 mM NH4HCO3/acetonitrile (1/1) for 5 min before being dehy-drated with 100% acetonitrile. The dehydrated gel slices were air-dried andrehydrated with trypsin (12.5 ng/�l in 50 mM NH4HCO3; Promega) for 30min at 4°C. An additional aliquot of 50 mM NH4HCO3 was added beforethe proteins were digested at 37°C overnight. The resulting tryptic peptideswere extracted from the gel pieces by washing twice with 2% formic acidin 50% acetonitrile. Extracts were combined and concentrated to 10 �l byvacuum centrifugation.
Mass spectrometry was performed at the Australian Proteome AnalysisFacility (Macquarie University). The tryptic digest extracts from 1DE gelslices were subjected to data-dependent nanocapillary reversed phase liq-uid chromatography followed by electrospray ionization using a ThermoLCQ Deca ion trap mass spectrometer (Thermo Scientific; liquid chroma-tography (LC)-MS/MS). For LC-MS/MS, a microbore HPLC system(TSP4000; Thermo Scientific) was modified to operate at capillary flowrates using a simple T-piece flow-splitter. Columns (8 cm � 100 �m insidediameter) were packed with 100 Å, 5-�m Zorbax C18 resin at 500 �.Integrated electrospray tips for the columns were made from fused silica,pulled to a 5-�m tip using a laser puller (Sutter Instrument). An electros-pray voltage of 1.8 kV was applied using a gold electrode via a liquidjunction upstream of the column. Samples were introduced onto the ana-lytical column using a Surveyor autosampler (Thermo Scientific). TheHPLC column eluent was eluted directly into the electrospray ionizationsource of the ion trap mass spectrometer. Peptides were eluted with a lineargradient of buffer A (0.1% formic acid) and buffer B (acetonitrile contain-ing 0.1% formic acid) at a flow rate of 500 nl/min. Automated peak rec-ognition, dynamic exclusion, and daughter ion scanning of the top threemost intense ions were performed using the Xcalibur software as previ-ously described (23).
GPM open source software (Global Proteome Machine Organization;www.thegpm.org) was used to search peptide sequences against a com-bined S. purpuratus database created with sequences downloaded from theNational Center for Biotechnology Information (NCBI). This FASTA for-mat database contained 44,037 protein sequences comprising all S. purpu-ratus sequences held by NCBI as of April 2008. This database also incor-porated a list of common human and trypsin peptide contaminants. Searchparameters included MS and MS/MS tolerances of �2 Da and �0.2 Da,tolerance of up to three missed tryptic cleavages, and K/R-P cleavages.
Fixed modifications were set for carbamidomethylation of cysteine, andvariable modifications were set for oxidation of methionine. Peptides iso-lated from 1DE gel slices were deemed to significantly match correspond-ing peptides in the available databases if their GPM loge score was lowerthan the statistically significant cutoff values assigned by the GPMalgorithm.
Protein spots from 2DE gels were analyzed using MALDI-TOF-TOFusing an LTQ FT Ultra hybrid mass spectrometer (Thermo Scientific). MSion searches were compared with 185/333 sequences in a custom databasecontaining 81 translated full-length 185/333 cDNA sequences (12) and 689EST sequences (8) using the Mascot search engine (Matrix Sciences; www.matrixscience.com/) set for carbomethylation (C) and oxidation (M) vari-able modifications, with peptide and fragment mass tolerances of �50 ppmand �0.5 Da respectively, and a maximum missed cleavage of one.
ResultsOne-dimensional SDS-PAGE analysis of CF proteins
1DE was used to provide a preliminary assessment of the diversityof proteins in CF, particularly those that were detected by anti-185Abs (Fig. 1). The molecular masses of CF proteins from all of thesea urchins analyzed in the present study (n � 13) ranged from 20kDa to �193 kDa (see Fig. 6). Sypro Ruby-stained CF proteinsfrom the individual sea urchin ranged from 30 kDa to �193 kDa(Fig. 1, lane 1). There were substantial differences in banding pat-terns when electrophoretically separated CF proteins from thesame sea urchin were stained with Coomassie blue compared withSypro Ruby (Fig. 1, compare lanes 1 and 2). This was probablydue to different sensitivities and physiochemical properties of thestains (26).
Immunostained 1DE Western blots of CF proteins identified nu-merous 185/333� bands ranging from �20 kDa to �193 kDa (Fig.1, lane 3). Controls that omitted the primary (anti-185) and/orsecondary (anti-IgG) Abs, and irrelevant controls using anti-tunicate collectin Abs instead of anti-185 antisera, were negative(data not shown). Most 185/333� bands from all of the sea urchinsamples analyzed (n � 13) had molecular masses ranging from 50kDa to �193 kDa, although some were as low as 20 kDa (see Fig.6). Many of the 185/333� bands on Western blots were not visibleon Sypro Ruby- and Coomassie blue-stained 1DE gels, suggestingthat the 185/333 proteins were present at extremely lowconcentrations.
FIGURE 1. 1DE SDS-PAGE and Western blot of CF proteins from anindividual sea urchin. CF proteins were loaded at 100 �g/well onto 10%SDS-PAGE gels. Lane 1, Sypro Ruby staining. Lane 2, Coomassie bluestaining. Lane 3, Western blot immunostained with an equal mixture ofanti-185 sera (anti-185-68, -66, and -71; 1/20,000). The positions of mo-lecular mass markers are shown on the left.
2205The Journal of Immunology

Two-dimensional Western blots of CF proteins
Given that cDNA analyses predicted a broad array of 185/333proteins in the CF (8, 11, 12), we extended our analysis of 185/333proteins using 2DE, which affords far greater resolution than does1DE. Sea urchin CF proteins were initially separated by isoelectricfocusing (pH 3–10) and then by 10% SDS-PAGE. Large numbersof 185/333� spots were evident after 2DE, to the extent that theyoften appeared as dense smears (Fig. 2). Most of the 185/333 pro-teins recognized by the antisera in all of the sea urchins analyzed(n � 13) had pIs between 3 and 7 with apparent molecular massesof 40 kDa to �193 kDa.
To improve the resolution of individual 185/333� proteins on2DE Western blots, additional isoelectric focusing separationswere conducted on immobilized pH gradient (IPG) strips with apH range of 3–6. Composite images obtained from film exposuresof three different time intervals were used to visualize 185/333�
proteins of varying abundance (Fig. 3). For the individual sea ur-chin shown in Fig. 3, image analysis of the different exposuresrevealed that fifty-one 185/333� spots were evident after a 1-minfilm exposure. An additional 117 spots were evident after 5 min,and a further 96 spots appeared after 10 min, making a total of 264spots that were detected on the composite image for this individ-ual. The number of discrete 185/333� spots varied substantiallyamong individuals. Three of the 13 sea urchins tested did not ex-press detectable levels of 185/333 proteins. However, the numberof discrete 185/333� spots was often �200 in other individuals.
The enhanced protein separation capabilities of 2DE alsoshowed that each discrete 185/333� band evident in 1DE con-tained numerous variants with similar molecular masses but dif-ferent pIs. For example, at least fifteen 185/333� spots with dif-
ferent pIs were evident at �75 kDa (Fig. 3). A further eight 185/333� spots appeared at �60 kDa and at least six different 185/333� spots were present at �30 kDa (Fig. 3). These pI variantswere often regularly spaced from each other, differing by �0.1–0.2 pH units. There were also numerous 185/333� spots with iden-tical pI but different molecular masses (Fig. 4). For instance, threeproteins in the pI 7.5–7.75 range each had three different molecularmass forms at �150 kDa, 193 kDa, and �193 kDa (Fig. 4).
The three different anti-185 sera, which were raised against dif-ferent regions of the most commonly predicted 185/333 polypep-tide sequences, identified subsets of 185/333 proteins (Fig. 5).Within the small region of a 2DE Western blot (pI range of 4–5and molecular masses of 30 kDa or lower), anti-185-66 resolved14 distinct variants, of which 7 were 30 kDa and had a pI range of4–5 (Fig. 5A). An additional seven anti-186-66-positive spots weresmaller than 30 kDa, with a pI range of 4.5–5. In comparison,anti-185-68 recognized five of the seven proteins at 30 kDa with apI range of 4–5 that were present on the anti-185-66 blot, but didnot recognize the set of seven lower molecular mass spots. Anti-185-71 recognized only two of the 30 kDa proteins that were rec-ognized by the other two antisera. This result is consistent with theexpression of truncated 185/333 cDNAs (11).
Diversity of 185/333 proteins between individuals
There were major differences in the expression profiles of 185/333proteins among different sea urchins. Some animals did not show185/333 expression before LPS injection (Fig. 6A, lanes 3 and 11),although expression was evident after challenge (Fig. 6B, lanes 3and 11). In other cases, 185/333 expression, which was very low
FIGURE 2. 2DE Western blot of 185/333� proteins. The gel wasloaded with 200 �g of CF proteins from a single sea urchin and the blotwas immunostained with an equal mixture of anti-185 sera (anti-185-66,-68, and -71; 1/20,000). pIs are shown as pH units on the top of the blot,and molecular masses (kDa) are indicated on the left.
FIGURE 3. Composite image of a 2DE Western blot. The gel wasloaded with 200 �g of CF proteins from sea urchin 12. The blot wasimmunostained with an equal mixture of the three anti-185 antisera (anti-185-66, -68, and -71; 1/20,000) and exposed to autoradiographic film for 1,5, or 10 min. The different exposures were merged to give a final compositeimage. pIs are shown on the top as pH units, and molecular masses (kDa)are shown on the left.
FIGURE 4. Enlarged region of a 2DE Western blot of CF proteins fromanimal 12 immunostained with an equal mixture of the three different anti-185 sera (anti-185-66, -68, and -71; 1/20,000). pIs are shown on the top aspH units, and molecular masses (kDa) are shown on the left.
FIGURE 5. Different anti-185 sera recognize subsets of 185/333 pro-teins. A, Enlarged regions of three different 2DE Western blots loaded with200 �g of CF proteins from the same sea urchin and immunostained sep-arately with anti-185-66, anti-185-68, or anti-185-71 (1/20,000). B, Sche-matic diagram of a 185/333 protein showing the peptides used to generatethe three different anti-185 sera. The rectangle represents the protein se-quence, which is composed of the leader and 25 nucleotide sequence “el-ements”. The positions and sequences of the synthetic peptides againstwhich the three anti-185 sera were raised are indicated (15).
2206 185/333 PROTEIN DIVERSITY IN SEA URCHINS

in preinjection samples, increased significantly after LPS injection.A broad distribution of 185/333 molecular masses ranging from 20kDa to �193 kDa was apparent among the 13 animals analyzed by1DE Western blots (Fig. 6). Although many individuals expressedsome 185/333 proteins with identical molecular masses (e.g., 112kDa, Fig. 6, lanes 1–4; 100 and 120 kDa, Fig. 6, lanes 7 and 8), thesuite of 185/333� bands expressed by each individual sea urchin wasunique. Three animals did not express detectable 185/333 proteins,even after challenge with LPS (data not shown). In total, nineteen185/333� bands with distinct molecular masses were identifiedamong the 13 sea urchins analyzed by 1DE. The molecular masses ofthese proteins seemed to be evenly spaced at 8–10 kDa apart over themolecular mass range of 20 to �193 kDa (Fig. 6).
MS analysis of 185/333� proteins
Proteins on Coomassie blue-stained 2DE gels that corresponded to185/333� spots on Western blots were analyzed by MS. This anal-ysis failed to identify 185/333 proteins unambiguously using thedefault criteria on the Mascot search engine. Although MS of each
FIGURE 6. 1DE Western blots of CF from 13 different sea urchinssampled before (A) and 96 h after (B) challenge with LPS. The equivalentlane numbers in both panels refer to the same animals from which CFsamples were obtained before and after LPS challenge. The blots wereimmunostained with an equal mixture of the three different anti-185 sera(anti-185-66, -68, and -71; 1/20,000).
Table I. Mass spectrometric (LC-MS/MS) data for peptides isolated from 1DE gels of S. purpuratus CF that match known185/333 sequencesa
Animal Gel Slice Loge m � h z Sequence GenBank Accession No.
6 6 �1.30 2594.5 3 MAVLTLATMAATTSIIIATTQKVTKb gb ABK88425.117 2 �3.20 1735.8 3 GQGGFGGRPGGMQMGGPR gb ABR22418.1
�3.20 1735.8 3 GQGGFGGRPGGMQTGSPR gb ABZ10666.1�3.30 1493.6 2 FDGPESGAPQMEGR gb ABZ10664.1�9.80 2886.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGPGR gb ABZ10668.1�2.40 1735.8 3 GQGGFGGRPGGMQMGGLR gb ABK88417.1�3.30 2131.9 3 RGDGEEETDAAQQIGDGLGGR gb ABZ10666.1�1.70 1506.7 2 FDGPGFGAPQMGGPR gb ABR22467.1�4.60 1157.6 2 KPFGDHPFGR gb ABR22410.1�2.00 2819.2 3 GDGEEETDAAQQIGDGLGGSGQFDGPRR gb ABR22477.1
3 �2.40 1735.8 3 GQGGFGGRPGGMQMGGPR gb ABR22418.1�2.40 1735.8 3 GQGGFGGRPGGMQTGSPR gb ABZ10666.1�4.20 1649.7 3 RFDGPESGAPQMEGR gb ABZ10664.1�5.20 1493.6 2 FDGPESGAPQMEGR gb ABZ10664.1�3.00 2131.9 3 RGDGEEETDAAQQIGDGLGGR gb ABZ10666.1�1.50 2320.2 2 PQTDQRNNRLVSATKAAMRMb gb ABK88425.1�5.80 2887.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGPGR gb ABZ10668.1�1.40 1735.8 3 GQGGFGGRPGGMQMGGLR gb ABK88417.1�2.60 1979.9 3 MGGRNSTNPEFGGSRPDGAGb gb ABR22330.1�1.70 2744.3 3 RNSTNPEFGGSRPDGAGGRPLFGQGGRb gb ABR22330.1�4.60 2927.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGHGR gb ABZ10669.1
4 �2.40 1479.6 2 FDGPESGAPQMDGR gb ABZ10666.1�4.00 1980.0 3 FGGSRPDGAGGRPFFGQGGR gb ABZ10669.1�2.40 2886.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGPGR gb ABZ10668.1�2.00 1157.6 2 KPFGDHPFGR gb ABR22410.1�5.10 1633.7 2 RFDGPESGAPQMEGR gb ABZ10664.1�0.17 2564.1 3 FDGPESGAPQMEGRRQNGVPMGGR gb ABK88329.1�3.10 2132.0 3 RGDGKEETDAAQQIGDGLGGR gb ABR22436.1�1.40 1926.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGHGR gb ABZ10669.1
5 �1.7 3398.5 3 DFNERREKENDTERGQGGFGGRPGGMQMGGP gb ABK88476.1�3.5 1980.0 3 FGGSRPDGAGGRPFFGQGGR gb ABZ10669.1�1.5 1831.9 3 RFDGPEPGAPQMEGRR gb ABK88803.1
6 �2.7 2131.0 3 RGDGEEETDAAQQIGDGLGGR gb ABZ10666.1�1.8 2927.3 3 RGDGEEETDAAQQIGDGLGGPGQFDGHGR gb ABZ10669.1
7 �1.6 1515.7 2 ADVVEIAVNEEDVNb gb ABA19607.1�3.3 1649.7 3 RFDGPESGAPQMEGR gb ABZ10664.1�4 1493.6 2 FDGPESGAPQMEGR gb ABZ10664.1�3.5 1980.0 3 FGGSRPDGAGGRPFFGQGGR gb ABZ10664.1
22 2 �2.50 1033.5 2 FGAPQMGGPR gb ABR22467.1�1.40 2814.3 3 RGRGQGRFGGRPGGMQMGGPRQDGGPMG gb ABK88373.1�3.70 1649.7 3 RFDGPESGAPQMEGR gb ABZ10664.1
a The data are from 1DE gel slices of CF from three different sea urchins. The GenBank accession numbers of the 185/333 sequences that matched peptidesfrom 1DE gels are also shown. The amino acid sequences shown are the matching 185/333 peptides from the NCBI database. Parameter definitions are: loge,values indicate the probability that a putative peptide sequence corresponding to a mass spectrum arises stochastically. The lower the loge value, the moresignificant the assignment of the peptide sequence to the mass spectrum. The loge values listed in this table are all lower than the significance cutoff valuesassigned by the GPM algorithm, and so they are deemed to be statistically significant (43); m � h, peptide mass in Da � 1; z, peptide charge.
b Peptides that matched sequences for previous analysis of nucleotide sequences that might represent frameshift mutations (12, 13).
2207The Journal of Immunology

protein successfully identified ion fragments with mass/chargeproperties that were similar to known 185/333 sequences, thesematches did not yield sufficiently high statistical probabilities toconfirm the identity of any of the proteins (data not shown).
In contrast, MS analysis of CF proteins separated by 1DE un-equivocally identified 185/333 proteins. A total of 41 peptides iso-lated from 1DE gel slices matched with known 185/333 sequencesfrom the NCBI database (Table I). The same 185/333 peptide wasoften identified in more than one gel slice. For example, the pep-tide FDGPESGAPQMEGR appeared in gel slices 2–4 from ani-mal 17. It is unlikely that the occurrence of the same peptide inmultiple fractions was due to contamination of the different frac-tions with exactly the same 185/333 protein. If the same proteinwas present in more than one fraction, we would expect to findexactly the same combination of peptides from that protein in morethan one fraction. However, this was not the case. Only singlepeptides were found in each fraction. Given this repetitive identi-fication of the same peptide in different gel slices, a total of 23unique 185/333 peptides were identified among all of the gelslices. In some cases, the GPM algorithm allocated slightly differ-ent predicted amino acid sequences to the same MS spectrum. Forinstance, GPM identified two peptides (GQGGFGGRPGGMQMGGPR and GQGGFGGRPGGMQTGSPR; underlining identi-fies amino acids that differ) from the same MS spectrum. Thisoccurred because the amino acid differences between these twopeptides were predicted to yield peptides with indistinguishablemass/charge ratios. Matches to both of these peptides were presentin the NCBI database. In some cases, the subtle differences be-tween peptides involved the inclusion of an arginine resulting inclosely related peptides of different lengths, such as RGDGEEETDAAQQIGDGLGGR and RGDGEEETDAAQQIGDGLGGPGQFDGHGR. It is noteworthy that of the 41 peptides identified, 36were located in the glycine-rich (N-terminal) and central regions ofthe predicted proteins. This is consistent with frameshifts and earlystop codons that have been identified in about half of the cDNAs(11). In many cases, the introduction of these frameshifts or earlystop codons would have resulted in the loss of epitopes for theantiserum anti-185-68, which was raised against the C-terminalregion of full-length 185/333 proteins, and to a lesser extent, theepitope for anti-185-71, which is in the central region of predictedfull-length 185/333 proteins. As a result, these antisera would nothave identified many of the 185/333 proteins encoded by truncatedmRNAs in the Western blot shown in Fig. 5A. Some of the pep-tides shown in Table I matched sequences that previous analyseshave suggested are derived from frameshift mutations (12, 13). Allof the peptides that matched 185/333 sequences came from gelslices 2–7, which were also shown by Western blot to contain thevast majority of 185/333 proteins (Figs. 6 and 7). Of the three seaurchins analyzed by 1DE and LC-MS/MS, animal 17 had the high-est overall expression levels for 185/333 proteins (Fig. 7) andyielded 37 of the 41 peptides that matched 185/333 sequences.
185/333 protein expression increases after LPS challenge
1DE Western blots of CF from five of the six animals injected withLPS showed increases in 185/333� protein expression between 24and 192 h (representative results are shown in Fig. 8A). Repeatedinjections with LPS performed 14 days after the primary challengeincreased 185/333 protein expression to levels that were higherthan those evident after the first injection (Fig. 8A). Sea urchinsinjected with aCF either did not respond to the injection or showedweak responses in terms of 185/333 protein expression (data notshown).
These Western blot data were confirmed by ELISA (Fig. 8B).Injecting LPS into sea urchins significantly ( p � 0.05) increased
the titer of 185/333 proteins detected in CF by ELISA. By 48 hafter LPS injection, anti-185 reactivity had increased 2.4-fold com-pared with the 0 h time point ( p � 0.05). It returned to levels thatwere indistinguishable ( p � 0.05) from those before LPS chal-lenge by 96 h. In response to aCF (control) injections, the titer of185/333 proteins in CF also increased up to 48 h postinjection, butonly to a level that was 1.4-fold greater than the preinjection timepoint. This increase was significantly less than the response to LPS
FIGURE 7. 1DE Western blots of CF proteins from three different seaurchins (animals 6, 17, and 22) immunostained with an equal mixture ofanti-185 sera (anti-185-66, -68, and -71; 1/20,000). The numbers on the leftshow the approximate positions of slices cut from 1DE gels for analysis bymass spectrometry (see Table I). In total, gels were cut into 16 slices. Thepositions of only eight of those slices containing the highest molecularmass proteins are shown here.
FIGURE 8. The titer of 185/333 proteins in CF increases after immunechallenge. A, 1DE Western blots of CF from a single sea urchin collectedat various times after the animal was injected twice with LPS. The secondLPS injection was administered 360 h after the first. B, 185/333 proteinexpression levels determined by ELISA (ODU415) at various times afternaive sea urchins (n � 5) were injected with LPS or aCF (controls). Barsindicate SEM. Asterisks denote time points that differed significantly (p �0.05) between LPS-injected sea urchins and controls.
2208 185/333 PROTEIN DIVERSITY IN SEA URCHINS

( p � 0.05). Negative controls confirmed the specificity of theELISA. Wells in which the primary (anti-185 sera) or secondary(anti-rabbit IgG) Abs were omitted, or when the primary Ab wasreplaced by an irrelevant control (anti-tunicate collectin), did notyield absorbance readings that were significantly greater thanbackground levels ( p � 0.05, data not shown).
Diversity of 185/333 protein expression after immunologicalchallenge
1DE analysis did not detect changes in the types of 185/333 pro-teins expressed by individual sea urchins in response to LPS or PGinjections, even though densitometry (data not shown) indicatedthere was an increase in the relative quantity of 185/333 proteinsafter repeated challenge (Fig. 9). The molecular masses of thepredominant 185/333 proteins in CF from animals 6 and 25 did notchange in response to an initial injection of LPS, or after a secondLPS injection 2 wk later. A similar result was apparent for animals
22 and 31, which were challenged with LPS followed by PG 2 wklater. The 185/333� bands of these two animals did not show anymajor changes in molecular mass when the challenge was switchedfrom LPS to PG.
In contrast, 2DE revealed clearly discernable changes in the pIsof 185/333 proteins when sea urchins were challenged with PGafter initially responding to LPS, even though the molecularmasses of the predominant forms remained the same (Fig. 10).This is best exemplified in the small region of the 2DE Westernblots of CF from animal 31 (pIs of 4–6, molecular masses of40–65 kDa) shown in Fig. 10B. CF from this sea urchin wascollected after an initial challenge with LPS (Fig. 10B, upperpanel), and then again after a subsequent injection of PG (Fig. 10B,lower panel). Of the thirty 185/333� spots in this region, sevenwere found only after LPS challenge (e.g., 63 kDa, pI 4.8), and sixwere found only after challenge with PG (e.g., 42 kDa, pI 5.5). Theremaining 17 proteins were present after both the LPS and PGchallenges. The relative expression levels of some of these sharedproteins also differed between challenges. For instance, one of theproteins (63 kDa, pI 5.2) had a densitometry value of 5.1 after LPSinjection and 1224 after PG challenge, representing a 240-foldincrease in expression intensity in response to PG.
DiscussionThis study has identified substantial diversity among 185/333 pro-teins, as reflected by their broad range of molecular masses andpIs. Most importantly, there are obvious differences in the suites of185/333 proteins expressed by different sea urchins, and thesesuites of proteins undergo subtle but extensive changes in responseto different types of immune challenge. The diversity of 185/333proteins and the changes in their expression detected by the currentproteomic analysis correspond with previous studies of mRNAsfrom sea urchins responding to different PAMPs (11). All of thesedata suggest that sea urchins may be capable of altering the ex-pression of 185/333 proteins to tailor specific responses againstdifferent PAMPs.
Despite the overall agreement between our current observationsof 185/333 proteins and predictions based on the prior analyses of185/333 nucleotide sequences (11, 12), there are some discrepan-cies. The predicted sizes of 185/333 proteins based on cDNA se-quences range from 4 to 55.3 kDa (11, 12), with predicted pIsranging from 5.42 to 11.54. However, the present study shows thatnative 185/333 proteins have a far wider range of molecularmasses (20 to �193 kDa using 1DE analysis), with predominantbands often being at the high end of this range. They also have farmore acidic pIs than expected, mainly between 3 and 7. It is un-likely that the discrepancy between predicted and observed mo-lecular masses is due to disulfide-bonded oligomerization becausenone of the predicted 185/333 amino acid sequences identified todate contains cysteines (8, 11). Even if cysteines were present inmissense sequences of frame-shifted proteins, the strong reducingconditions used to prepare samples would have disrupted any oli-gomers held together by disulfide bonds. Another explanation forthe discrepancy in molecular masses is that 185/333 proteins areglycosylated and form large complexes covalently linked to car-bohydrates. There are numerous conserved sites for N-linked gly-cosylation within the histidine-rich region of the 185/333 proteins(elements 11–25), and there are conserved sites for O-linked gly-cosylation in the carboxyl-terminal region (8, 11). However, deg-lycosylation of N-linked oligosaccharides failed to decrease themolecular masses of 185/333 proteins to the size of predictedmonomers (L. C. Smith, unpublished data). Given these results, itseems likely that the disparity between predicted and observedmolecular masses reflects oligomerization based on mechanisms
FIGURE 9. 1DE Western blots of CF collected after sea urchins hadbeen injected with LPS or PG. Animals 6 and 25 were injected with LPStwice with a 360-h interval, while animals 22 and 31 were injected firstwith LPS and then with PG 360 h later. CF was collected 96 h after eachinjection, and the Western blots were immunostained with an equal mixtureof the three different anti-185 sera (anti-185-66, -68, and -71; 1/20,000).
FIGURE 10. 2DE Western blots of CF collected from a single sea ur-chin (animal 31) that had been injected first with LPS and then 360 h laterwith PG. CF was withdrawn at 96 h after each injection. Western blotswere immunostained with an equal mixture of the three different anti-185sera (anti-185-66, -68, and -71; 1/20,000). A, Full proteome maps (pI of3–6; 40–150 kDa; 30-s film exposure) of the CF samples after LPS and PGchallenges. B, Enlargements (pI of 4.0–6.3; 40–85 kDa; 5-min film ex-posure) of the boxed areas in A. The numbers shown in each panel are therelative expression intensities of five 185/333� spots that differed substan-tially in expression after LPS compared with PG injections.
2209The Journal of Immunology

other than disulfide bond formation that are resistant to the reduc-ing treatments used in 1DE and 2DE. This conclusion is supportedby studies of recombinant 185/333 proteins, in which the expres-sion of a single form of 185/333 protein yields a range of ex-pressed proteins with molecular masses corresponding to mono-mers, homodimers, and higher order oligomers (18).
Other data also suggest that the diversity of molecular massesevident among 185/333 proteins is increased by the expression oftruncated molecules. Many of the SNPs and indels found previ-ously in 185/333 transcripts are predicted to result in frameshifts,and the encoded proteins may be either truncated and/or have mis-sense sequences (11, 13). No such frameshifts have been identifiedin the 185/333 genes. However, comparisons of gene and mRNAsequences from individual animals suggest that posttranscriptionalmodifications may be responsible for these missense proteins (15).If these messages are translated, it would explain why the threedifferent anti-185 antisera used in the present study detected dif-ferent subsets of 185/333 proteins. The antisera were raised againstamino acid sequences in N terminus (element 1), the middle (el-ement 7), and the C terminus (element 25a) of the predicted pro-teins. The antiserum targeted to the N terminus (anti-185-66) iden-tified the largest number of 185/333 proteins on 2DE Westernblots, presumably because its epitope is most likely to be presentin every protein, including the shortest truncated forms. Of the 689translated cDNA sequences identified to date, 676 contain theepitope within element 1 that is recognized by the anti-66 anti-serum (11). Antisera directed toward more C-terminal regions rec-ognize decreasing numbers of 185/333� spots, probably becausethese epitopes are not present on truncated proteins or those withmissense sequence at the C terminus. Current cDNA sequence datafrom Terwilliger et al. (11) show that 660 of 689 cDNA sequencescontain the anti-68 epitope in element 7, while only 375 cDNAsequences contain the anti-71 epitope in element 25a.
The variability evident in the molecular masses of 185/333 pro-teins was matched by substantial diversity in their pIs. One sourcefor this diversity is found in mRNAs where sequence variabilityresults in changes in charged amino acids at particular positionsleading to predicted proteins with very similar molecular massesbut different pIs (8, 11, 12). Terwilliger et al. (see supplementalfigures S1 and S2 in Refs. 11, 12) identified numerous sequencepositions in 185/333 mRNAs that encode two to four differentamino acids, many with different charges. In the present study,similar subtle differences were detected by MS, which identified anumber of 185/333 peptides that differ by just a single amino acid.2DE Western blots also showed a variety of pIs for 185/333 pro-teins that had very similar molecular masses. In many cases, thecharge variants making up a single molecular mass class of 185/333 proteins had pIs spanning the full pH range from 3 to 10,although most variants had a pI within the range of 3–6. Thedifferent pI forms were often equally spaced, suggesting that ad-jacent protein spots represent variants that differ by just a singlecharged residue.
Although the variability in pI detected in the present studyagrees with the diversity seen among cDNA sequences, our pro-teomic data also provide evidence for additional posttranslationalmodifications. Some 185/333 proteins have identical isoelectricpoints but significantly different molecular masses. This suggeststhat individual 185/333 proteins may be conjugated with someother molecule(s) that alters their molecular mass but not theirisoelectric point. Such conjugation would provide another expla-nation for why many 185/333� bands are much larger in molecularmass than predicted. However, the cDNA data suggest that it isalso feasible for 185/333 proteins with significantly different se-
quences and different pIs to have the same molecular mass, result-ing in a vertical ladder of spots on 2DE Western blots.
The diversity of 185/333 proteins explains our inability to un-equivocally identify 185/333 proteins by MS of individual proteinsisolated by 2DE. MS analysis of the 185/333� spots from 2DEgels did not identify any statistically significant matches to pro-teins in a custom database of 185/333 sequences. However, all ofthe 185/333 proteins isolated by 2DE yielded ion fragments thatpossessed mass/charge characteristics similar to those of known185/333 protein sequences. The available evidence suggests thatthe existing database of 185/333 sequences may represent only asmall fraction of the 185/333 variants present in sea urchin pop-ulations. Consequently, the chance of finding a statistically sig-nificant match in this restricted data set to a single 185/333protein isolated from the CF of an individual sea urchin may beextremely low, even though the purity of the proteins isolatedby 2DE would have been high. In other words, we may not haveidentified matches because the variability of 185/333 sequencemeans that many 185/333 proteins will not yet be in our data-base of 185/333 sequences and so cannot be identified by MS.Our difficulties in matching isolated proteins to the existing185/333 database highlight the problems of employing MStechniques, which search for precise similarities between pep-tides to characterize hypervariable proteins. It is interesting thateven though members of the Down syndrome cell adhesionmolecule (DSCAM) family are important proteins in the immu-nological responses of insects, proteomic analyses of hemo-lymph extracts from immunologically challenged Drosophilahave not yet been able to identify DSCAMs by MS.
To circumvent the problem of matching individual 185/333�
spots to our restricted sequence data set, we employed “shotgun”MS (LC-MS/MS), in which all of the CF proteins within a partic-ular molecular mass range from 1DE gels were analyzed simulta-neously by MS. Unlike 2DE, in which the individual proteins spotsanalyzed by MS presumably contain just a single 185/333 isotype,the 1DE gel slices subjected to shotgun MS were likely to containnumerous different 185/333 isotypes. This greatly increased thechance that at least one of these isotypes would match a previouslyidentified sequence in our 185/333 database. 1DE also has theadvantage that it is not limited by the complex separation charac-teristics of 2DE, which, for instance, is relatively inefficient inseparating hydrophobic proteins. Additionally, we used an alter-native search engine (GPM as opposed to Mascot) with slightlyaltered search stringencies (three missed tryptic cleavages) to in-crease our chances of identifying matching 185/333 peptides in theavailable databases. This process successfully identified numerouspeptides that matched precisely to sequences in the NCBI databasewithout affecting the robustness of the sequence matches. The gelslices in which matching peptides were identified corresponded toregions on 1DE and 2DE Western blots that contained high con-centrations of 185/333 proteins, which confirms the specificities ofthe anti-185 sera used in this study. However, shotgun MS prob-ably still identified just a small fraction of the 185/333 peptidespresent within the peptide mixture, because of the limited numbersof potentially matching peptides in the currently available dataset.The limited sensitivity of MS in identifying highly variable pro-teins in the absence of comprehensive sequence databases alsoexplains why our MS analysis only identified multiple forms of185/333 proteins in one of the sea urchins analyzed, even thoughboth 1DE and 2DE Western blotting revealed substantial intrain-dividual diversity in all sea urchins.
The difficulties associated with analyzing the diversity of 185/333 proteins were compounded by the substantial variation evidentin the suites of 185/333 proteins expressed by different sea urchins.
2210 185/333 PROTEIN DIVERSITY IN SEA URCHINS

None of the 13 sea urchins analyzed by 1DE Western blottingexpressed the same pattern of 185/333� bands, even though therewere a number of molecular mass forms that were shared by someindividuals. On average, two to three major bands were evident ineach sea urchin, along with numerous minor bands. The differ-ences between individuals implies that there may be a variety ofmechanisms acting in concert to produce novel arrays of 185/333proteins in individual sea urchins. These factors could include thepresence or absence of different 185/333 genes in different seaurchins, the presence of different alleles at a given 185/333 genelocus, differential gene expression of 185/333 family members,posttranscriptional processing or editing of the transcripts that in-sert frameshifts and SNPs (15), and posttranslational processing ofthe proteins (13).
Our data suggest that these potential mechanisms for moleculardiversification may allow sea urchins to vary the suites of 185/333proteins that they express in response to different types of immu-nological challenge. ELISA provided direct evidence that 185/333expression increases after the injection of PAMPs, while 2DEanalysis of 185/333 proteins from individual sea urchins identifiedmany subtle changes in the patterns of 185/333 proteins respond-ing to different PAMPs. There were clear differences in the pIs andmolecular masses of the proteins expressed in response to LPScompared with those synthesized by the same sea urchin in re-sponse PG. These results agree with changes that are apparent inthe cDNAs from animals responding to different PAMPs, includ-ing LPS, �-1,3-glucan, or dsRNA (11). Terwilliger et al. (11)showed that a diverse size range of 185/333 messages was presentin the CF of immunoquiescent sea urchins, but this broad expres-sion profile changed to one single, major mRNA size after immunechallenge. Sequence analysis of mRNAs from animals respondingto immune challenge also indicated that the predominant 185/333variants in CF are different before and after challenge. Such alter-ations in 185/333 transcription explain the changes detected duringthe present study in the suites of 185/333 proteins found in the CFof the same sea urchin responding to different PAMPs.
The identification of PAMP-specific responses suggests that185/333 protein expression can be tailored to meet different formsof immunological challenge. The obvious implication is that 185/333 proteins are involved in some form of pathogen-specific im-munological response. There is growing evidence for this level ofimmunological specificity among a variety of invertebrates (1, 2, 5,27–29). For instance, bacterial immunization in bumble bees caninduce acquired immune responses that are highly specific to theoriginal, inoculating species of bacteria (29), although the mech-anisms underlying this response are not known. In addition to 185/333 proteins, other large gene families may be capable of fine-scale discrimination between pathogens. These gene familiesencode variable lymphocyte receptors from agnathans (30–34), Vregion-containing chitin-binding proteins (VCBPs) from cephalo-chordates and tunicates (3, 35, 36), DSCAMs in insects (37, 38),and fibrinogen-related proteins (FREPs) from molluscs (39–42).A repertoire of �19,000 different DSCAMs is expressed in hemo-cytes of Drosophila and mosquitoes (37, 38), and thousands ofFREPs are present in freshwater snails (39–42). None of thesegene families is closely related to one another, suggesting thatmechanisms for immune diversification have evolved many timesand that additional unique systems are likely to be identifiedamong other organisms in the future. In this context, our continu-ing investigations of 185/333 proteins will provide insights intohow animals other than mammals adapt in the “arms race” againstthe microbes.
AcknowledgmentsWe thank Dr. Virginia Brockton for assistance in processing and shippingprotein samples, and Dr. Katherine Buckley for suggesting improvementsto the manuscript. The research has been facilitated by access to the Aus-tralian Proteome Analysis Facility established under the Australian Gov-ernment’s Major National Research Facilities Program.
DisclosuresThe authors have no financial conflicts of interest.
References1. Flajnik, M. F. 2004. Immunology: another manifestation of GOD. Nature 430:
157–158.2. Flajnik, M. F., and L. Du Pasquier. 2004. Evolution of innate and adaptive im-
munity: can we draw a line? Trends Immunol. 25: 640–644.3. Litman, G. W., J. P. Cannon, and L. J. Dishaw. 2005. Reconstructing immune
phylogeny: new perspectives. Nat. Rev. Immunol. 5: 866–879.4. Hibino, T., M. Loza-Coll, C. Messier, A. J. Majeske, A. H. Cohen,
D. P. Terwilliger, K. M. Buckley, V. Brockton, S. V. Nair, K. Berney, et al. 2006.The immune gene repertoire encoded in the purple sea urchin genome. Dev. Biol.300: 349–365.
5. Rast, J. P., L. C. Smith, M. Loza-Coll, T. Hibino, and G. W. Litman. 2006.Genomic insights into the immune system of the sea urchin. Science 314:952–956.
6. Sodergren, E., G. M. Weinstock, E. H. Davidson, R. A. Cameron, R. A. Gibbs,R. C. Angerer, L. M. Angerer, M. I. Arnone, D. R. Burgess, R. D. Burke, et al.2006. The genome of the sea urchin Strongylocentrotus purpuratus. Science 314:941–952.
7. Fugmann, S. D., C. Messier, L. A. Novack, R. A. Cameron, and J. P. Rast. 2006.An ancient evolutionary origin of the RAG1/2 gene locus. Proc. Natl. Acad. Sci.USA 103: 3728–3733.
8. Nair, S. V., H. Del Valle, P. S. Gross, D. P. Terwilliger, and L. C. Smith. 2005.Macroarray analysis of coelomocyte gene expression in response to LPS in thesea urchin: identification of unexpected immune diversity in an invertebrate.Physiol. Genomics 22: 33–47.
9. Rast, J. P., Z. Pancer, and E. H. Davidson. 2000. New approaches towards anunderstanding of deuterostome immunity. Curr. Top. Microbiol. Immunol. 248:3–16.
10. Smith, L. C., L. Chang, R. J. Britten, and E. H. Davidson. 1996. Sea urchin genesexpressed in activated coelomocytes are identified by expressed sequence tags:complement homologues and other putative immune response genes suggest im-mune system homology within the deuterostomes. J. Immunol. 156: 593–602.
11. Terwilliger, D. P., K. M. Buckley, V. Brockton, N. J. Ritter, and L. C. Smith.2007. Distinctive expression patterns of 185/333 genes in the purple sea urchin,Strongylocentrotus purpuratus: an unexpectedly diverse family of transcripts inresponse to LPS, �-1,3-glucan, and dsRNA. BMC Mol. Biol. 8: 16.
12. Terwilliger, D. P., K. M. Buckley, D. Mehta, P. G. Moorjani, and L. C. Smith.2006. Unexpected diversity displayed in cDNAs expressed by the immune cellsof the purple sea urchin, Strongylocentrotus purpuratus. Physiol. Genomics 26:134–144.
13. Buckley, K. M., and L. C. Smith. 2007. Extraordinary diversity among membersof the large gene family, 185/333, from the purple sea urchin, Strongylocentrotuspurpuratus. BMC Mol. Biol. 8: 68.
14. Buckley, K. M., S. Munshaw, T. B. Kepler, and L. C. Smith. 2008. The 185/333gene family is a rapidly diversifying host-defense gene cluster in the purple seaurchin, Strongylocentrotus purpuratus. J.Mol. Biol. 379: 912–928.
15. Buckley, K. M., D. P. Terwilliger, and L. C. Smith. Sequence variations in 185/333 messages from the purple sea urchin suggest posttranscriptional modifica-tions to increase diversity. J. Immunol. 181: 8585–8594.
16. Tsai, H., and L. A. Bobek. 1998. Human salivary histatins: promising anti-fungaltherapeutic agents. Crit. Rev. Oral Biol. Med. 9: 480–497.
17. Xu, T., E. Telser, R. F. Troxler, and F. G. Oppenheim. 1990. Primary structureand anticandidal activity of the major histatin from parotid secretion of the sub-human primate, Macaca fascicularis. J. Dent. Res. 69: 1717–1723.
18. Brockton, V., J. H. Henson, D. A. Raftos, A. J. Majeske, Y. O. Kim, andL. C. Smith. 2008. Localization and diversity of 185/333 proteins from the purplesea urchin – unexpected protein-size range and protein expression in a new coe-lomocyte type. J. Cell Sci. 121: 339–348.
19. Clow, L. A., P. S. Gross, C. S. Shih, and L. C. Smith. 2000. Expression of SpC3,the sea urchin complement component, in response to lipopolysaccharide. Im-munogenetics 51: 1021–1033.
20. Gross, P. S., W. Z. Al-Sharif, L. A. Clow, and L. C. Smith. 1999. Echinodermimmunity and the evolution of the complement system. Dev. Comp. Immunol. 23:429–442.
21. Clow, L. A., D. A. Raftos, P. S. Gross, and L. C. Smith. 2004. The sea urchincomplement homologue, SpC3, functions as an opsonin. J. Exp. Biol. 207:2147–2155.
22. Laemmli, U. K. 1970. Cleavage of structural proteins during the assembly of thehead of bacteriophage T4. Nature 227: 680–685.
23. Andon, N. L., S. Hollingworth, A. Koller, A. J. Greenland, J. R. Yates, andP. A. Haynes. 2002. Proteomic characterization of wheat amyloplasts using iden-tification of proteins by tandem mass spectrometry. Proteomics 2: 1156–1168.
2211The Journal of Immunology

24. Green, P., A. Luty, S. Nair, J. Radford, and D. Raftos. 2006. A second form ofcollagenous lectin from the tunicate, Styela plicata. Comp. Biochem. Physiol. BBiochem. Mol. Biol. 144: 343–350.
25. Green, P. L., S. V. Nair, and D. A. Raftos. 2003. Secretion of a collectin-likeprotein in tunicates is enhanced during inflammatory responses. Dev. Comp. Im-munol. 27: 3–9.
26. Miller, I., J. Crawford, and E. Gianazza. 2006. Protein stains for proteomic ap-plications: which, when, why? Proteomics 6: 5385–5408.
27. Kurtz, J., and K. Franz. 2003. Innate defence: evidence for memory in inverte-brate immunity. Nature 425: 37–38.
28. Kurtz, J., and S. A. Armitage. 2006. Alternative adaptive immunity in inverte-brates. Trends Immunol. 27: 493–496.
29. Sadd, B. M., and P. Schmid-Hempel. 2006. Insect immunity shows specificity inprotection upon secondary pathogen exposure. Curr. Biol. 16: 1206–1210.
30. Litman, G. W., J. P. Cannon, and J. P. Rast. 2005. New insights into alternativemechanisms of immune receptor diversification. Adv. Immunol. 87: 209–236.
31. Litman, G. W., N. A. Hawke, and J. A. Yoder. 2001. Novel immune-type re-ceptor genes. Immunol. Rev. 181: 250–259.
32. Pancer, Z., C. T. Amemiya, G. R. Ehrhardt, J. Ceitlin, G. L. Gartland, andM. D. Cooper. 2004. Somatic diversification of variable lymphocyte receptors inthe agnathan sea lamprey. Nature 430: 174–180.
33. Pancer, Z., W. E. Mayer, J. Klein, and M. D. Cooper. 2004. Prototypic T cellreceptor and CD4-like coreceptor are expressed by lymphocytes in the agnathansea lamprey. Proc. Natl. Acad. Sci. USA 101: 13273–13278.
34. Pancer, Z., N. R. Saha, J. Kasamatsu, T. Suzuki, C. T. Amemiya, M. Kasahara,and M. D. Cooper. 2005. Variable lymphocyte receptors in hagfish. Proc. Natl.Acad. Sci. USA 102: 9224–9229.
35. Cannon, J. P., R. N. Haire, and G. W. Litman. 2002. Identification of diversifiedgenes that contain immunoglobulin-like variable regions in a protochordate. Nat.Immunol. 3: 1200–1207.
36. Cannon, J. P., R. N. Haire, J. P. Rast, and G. W. Litman. 2004. The phylogeneticorigins of the antigen-binding receptors and somatic diversification mechanisms.Immunol. Rev. 200: 12–22.
37. Dong, Y., H. E. Taylor, and G. Dimopoulos. 2006. AgDscam, a hypervariableimmunoglobulin domain-containing receptor of the Anopheles gambiae innateimmune system. PLoS Biol. 4: e229.
38. Watson, F. L., R. Puttmann-Holgado, F. Thomas, D. L. Lamar, M. Hughes,M. Kondo, V. I. Rebel, and D. Schmucker. 2005. Extensive diversity of Ig-superfamily proteins in the immune system of insects. Science 309: 1874–1878.
39. Adema, C. M., L. A. Hertel, R. D. Miller, and E. S. Loker. 1997. A family offibrinogen-related proteins that precipitates parasite-derived molecules is pro-duced by an invertebrate after infection. Proc. Natl. Acad. Sci. USA 94:8691–8696.
40. Leonard, P. M., C. M. Adema, S. M. Zhang, and E. S. Loker. 2001. Structure oftwo FREP genes that combine IgSF and fibrinogen domains, with comments ondiversity of the FREP gene family in the snail Biomphalaria glabrata. Gene 269:155–165.
41. Zhang, S. M., and E. S. Loker. 2004. Representation of an immune responsivegene family encoding fibrinogen-related proteins in the freshwater mollusc Bi-omphalaria glabrata, an intermediate host for Schistosoma mansoni. Gene 341:255–266.
42. Zhang, S. M., and E. S. Loker. 2003. The FREP gene family in the snail Bi-omphalaria glabrata: additional members, and evidence consistent with alterna-tive splicing and FREP retrosequences: fibrinogen-related proteins. Dev. Comp.Immunol. 27: 175–187.
43. Fenyo, D., and R. C. Beavis. 2003. A method for assessing the statistical signif-icance of mass spectrometry-based protein identifications using general scoringschemes. Anal. Chem. 75: 768–774.
2212 185/333 PROTEIN DIVERSITY IN SEA URCHINS





























