Embed Size (px)
Citation preview

Pattern Recognition 40 (2007) 3481–3491www.elsevier.com/locate/pr
Robust lip region segmentation for lip images with complex background
Shi-Lin Wanga,∗, Wing-Hong Laub, Alan Wee-Chung Liewc, Shu-Hung Leungb
aSchool of Information Security Engineering, Shanghai Jiaotong University, Shanghai, ChinabDepartment of Electronic Engineering, City University of Hong Kong, Hong Kong, China
cSchool of Information and Communication Technology, Griffith University, Brisbane, Australia
Received 14 March 2006; accepted 19 March 2007
Abstract
Robust and accurate lip region segmentation is of vital importance for lip image analysis. However, most of the current techniques breakdown in the presence of mustaches and beards. With mustaches and beards, the background region becomes complex and inhomogeneous. Wepropose in this paper a novel multi-class, shape-guided FCM (MS-FCM) clustering algorithm to solve this problem. For this new approach,one cluster is set for the object, i.e. the lip region, and a combination of multiple clusters for the background which generally includes the skinregion, lip shadow or beards. The proper number of background clusters is derived automatically which maximizes a cluster validity index.A spatial penalty term considering the spatial location information is introduced and incorporated into the objective function such that pixelshaving similar color but located in different regions can be differentiated. This facilitates the separation of lip and background pixels thatotherwise are inseparable due to the similarity in color. Experimental results show that the proposed algorithm provides accurate lip-backgroundpartition even for the images with complex background features like mustaches and beards.� 2007 Pattern Recognition Society. Published by Elsevier Ltd. All rights reserved.
Keywords: Fuzzy clustering; Lip image; Lip segmentation; Spatial penalty term
1. Introduction
Speech recognition with the aid of visual information hasaroused the interest of many researchers [1–5]. The visual in-formation of lip movement can help enhancing the robustnessof automatic speech recognition systems especially in noisyenvironments [6,7]. Accurate and robust lip region segmenta-tion, as the first step of most lip extraction systems, is of keyimportance for the subsequent processing. However, low colorcontrast between the unadorned lip and the facial skin makesthe problem difficult.
Different methods for lip image segmentation have been pro-posed in the literature [8–18]. Edge information is one of thecommon features used to find the boundary of the lip region[8,9]. These methods can derive accurate lip region if there exist
∗ Corresponding author. Tel.: +86 21 6293 3767; fax: +86 21 6293 8292.E-mail addresses: [email protected] (S.-L. Wang), [email protected]
(W.-H. Lau), [email protected] (A.W.-C. Liew),[email protected] (S.-H. Leung).
0031-3203/$30.00 � 2007 Pattern Recognition Society. Published by Elsevier Ltd. All rights reserved.doi:10.1016/j.patcog.2007.03.016
prominent and consistent intensity changes around the bound-ary. However, this condition cannot be easily satisfied for somelip images with natural low contrast.
Some researchers try to detect lip region using color spaceanalysis and employ preset color filter to extract lip pixels [10].Post-processing procedures such as morphological open andclose are then applied to derive the final lip segmentation. Colortransformation has also been used to enlarge the color differ-ence between the lip and skin to aid the segmentation [11].The reduced processing time is a key advantage of these algo-rithms; however, they are sensitive to color contrast and noise.Moreover, methods solely depending on color space analysiswill result in large segmentation error if the color distributionof lip region overlaps with that of background region.
Some approaches based on Markov random field (MRF)technique have also been proposed in which the spatial conti-nuity is exploited to improve the robustness of segmentation.The red hue predominant region and motion in a spatiotempo-ral neighborhood have been used to segment the lip shape byMRF modeling [12]. Both the color and edge information canbe combined with an MRF framework to address the problem

3482 S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491
of lip region extraction [13]. These algorithms perform wellwhen dealing with images with “pepper” color noise.
Fuzzy clustering is another kind of widely used image seg-mentation techniques. The classical fuzzy c-means (FCM) al-gorithm attempts to assign a probability value for each pixel tominimize a fuzzy entropy measure [14]. In the past few years,various modified fuzzy clustering methods [15,16,18] have beenproposed to enhance the performance of FCM in different as-pects. Since the clustering method is an unsupervised learningmethod in which neither prior assumption about the underly-ing feature distribution nor training is needed, it is capable ofhandling lip and skin color variation due to makeup.
The methods mentioned above all produce satisfactory resultsto a certain extent for lip image without mustache or beards.However, most of them fail to provide accurate lip segmentationfor lip images with beards. We have previously proposed afuzzy clustering based algorithm that takes into considerationthe lip shape, i.e. fuzzy c-means with shape function (FCMS)[17], to segment the lip region. The FCMS exploits both theshape information and the color information to provide accuratesegmentation results even for lip images with low contrast.However, it still fails for image with a complex backgrounddue to the insufficient background modeling.
In this paper, a new fuzzy clustering based algorithm is pro-posed to solve the problem. The three distinctive features ofthe proposed lip segmentation algorithms are: (i) prior infor-mation of lip shape is seamlessly incorporated in the objectfunction which can effectively differentiate pixels of similarcolor but located in different regions; (ii) multiple spheroidal-shaped clusters are employed to model the inhomogeneous
Fig. 1. (a) Original lip image; (b) color distribution in CIELAB color space; (c) hue map of the lip image; (d) edge map based on hue information; and (e)edge map based on intensity information.
background region and the proper number of clusters is deter-mined automatically; (iii) with the information of probable liplocation, inner mouth features such as teeth and oral cavity canbe detected more accurately and thus the robustness of the lipsegmentation result is improved.
The detailed description of the proposed lip segmentationalgorithm is presented in Section 2. A succinct physical inter-pretation of the spatial penalty term is also provided for thefirst time in this paper. In Section 3, experimental results of theproposed algorithm and comparison with other lip segmenta-tion methods are discussed. Finally, the conclusion is given inSection 4.
2. Lip segmentation with complex background
2.1. Problems encountered in segmentation
Segmenting lip images with mustaches and beards surround-ing the lip region remains an open question for most existinglip segmentation techniques [12]. Fig. 1 illustrates an exampleof lip image and its corresponding color distribution of the lipand non-lip pixels in CIE-1976 CIELAB color space, where *and + represent the lip and background (or non-lip) pixels, re-spectively. The hue image, with the hue definition given in Ref.[13], and the edge map are also shown in Fig. 1.
Several observations can be drawn from these figures. First,the lip and background pixels overlap in the color space asshown in Fig. 1(b) and this causes problem to segmentationmethods based solely on color information. Although MRF hasbeen used to exploit the local spatial information to enhance

S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491 3483
Fig. 2. (a) Original lip image; lip-segmentation result obtained by the conventional FCM with (b) C = 2, (c) C = 3, (d) C = 4, (e) C = 5; lip-segmentationresult obtained by MS-FCM with (f) C = 2, (g) C = 3, (h) C = 4, (i) C = 5.
the robustness, patches outside and holes inside the lip regionare usually found if a large number of pixels of similar colorare aggregated. Mislabeled pixels due to the color similaritywill lead to undesirable disturbances to both membership mapand color centroids for the conventional FCM algorithm. Sec-ond, the presence of beards creates many luminance and hueedges in the background region and this hinders the use of edgeinformation to infer the lip boundary successfully. Finally, thebackground region is complex and inhomogeneous such thatappropriate modeling of the background region is not an easytask. Due to these difficulties, most lip segmentation algorithmsreported in the literatures cannot provide satisfactory segmen-tation results for lip images with beards.
2.2. The “multi-class, shape-guided” FCM (MS-FCM)clustering method
In order to overcome the difficulties in lip segmentation forlip images with complex background, a new fuzzy-clusteringbased lip segmentation algorithm, the multi-class, shape-guidedFCM (MS-FCM) clustering algorithm, is proposed. In this al-gorithm, the color information of each pixel is adopted as thediscriminative feature.
Due to the color overlap between lip and background pixels,the color information alone cannot provide accurate segmenta-
tion results. Since the lip pixels are aggregated to form a largepatch, their physical distances towards the lip center providesupportive information for the lip-background differentiation.In MS-FCM, such prior shape information is seamlessly incor-porated into the objective function to discriminate the non-lippixels that have similar color but located at a distance awayfrom the lip. As a result, the “shape-guided” feature of our algo-rithm helps to better handle the color overlap problem betweenthe lip and background.
Clusters obtained from the fuzzy clustering algorithm areof spheroidal shapes. However, the color information of thebackground pixels has a multimodal distribution due to back-ground inhomogeneity. Modeling it using one cluster wouldincur large segmentation error. In order to improve the model-ing sufficiency, multiple clusters are employed to describe thecomplex background region as in Gaussian mixture modeling.The “multi-class” feature of our algorithm helps to reduce themisclassification caused by inadequate background modeling.
The “multi-class” and the “shape-guided” features are thetwo key novelties of our algorithm and they work together toovercome the difficulties of segmenting lip images with com-plex background. Fig. 2 illustrates the typical segmentation re-sults obtained from both the conventional FCM and the MS-FCM algorithm using different numbers of background clusters(where C is the total number of clusters). It is observed that

3484 S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491
the conventional FCM is unable to segment the lip region ac-curately for an image with multiple background features evenwith different setting of C; whereas MS-FCM is able to clearlysegment the lip region for C larger than 2 since it requires atleast 2 clusters to represent background region which containstwo distinguishing parts, the beards and the skin. It is clearfrom the results that the use of prior shape information andmultiple-background-cluster are both necessary. Without usingmultiple-background-cluster, large segmentation error occursdue to insufficient background modeling even if the shape in-formation is considered (Fig. 2(f)). Without the prior shape in-formation, poor segmentation result is obtained even if multiplebackground clusters are employed (Fig. 2(c)–(e)).
3. Details of the proposed algorithm
3.1. Objective function of MS-FCM
Let us consider an image I of size N by M. X ={x1,1, . . . , xr,s , . . . , xN,M} denotes the set of feature vectorswhere xr,s ∈ Rq is a q-dimensional color vector for pixellocated at (r, s). The Euclidean distance between the colorfeature vector xr,s and the color centroid vi of the ith cluster(i = 0 for the lip cluster and i �= 0 for the background clusters)is represented by di,r,s . The objective function of MS-FCM isformulated as:
J = JCLR + JSPA = JCLR,OBJ + JCLR,BKG
+ JSPA,OBJ + JSPA,BKG
=N∑
r=1
M∑s=1
um0,r,sd
20,r,s +
N∑r=1
M∑s=1
C−1∑i=1
umi,r,sd
2i,r,s
+N∑
r=1
M∑s=1
f (u0,r,s)gOBJ (r, s)
+N∑
r=1
M∑s=1
C−1∑i=1
f (ui,r,s)gi,BKG(r, s) (1)
subject toC−1∑i=0
ui,r,s = 1, ∀(r, s) ∈ I , (2)
where the N × M × C matrix U ∈ Mf c is a fuzzy c-partitionof X, V = {v0, v1, . . . , vC−1} ∈ RCq with vi ∈ Rq is the set offuzzy cluster centroids, m ∈ (1, ∞) defines the fuzziness of theclustering, and ui,r,s is the membership value of the (r, s)-thpixel in cluster Ci .
The first and second terms in Eq. (1) are the color penaltyterms for the lip (i = 0) and background classes (i �= 0), re-spectively, which penalize the membership value of a certaincluster for a pixel whose color is dissimilar to the color cen-troid of the cluster. The color penalty terms result in a singlespheroidal-shaped distribution for the lip region (only one clus-ter is assigned to the lip) and a mixture of spheroidal-shapeddistributions for the background region which provides a betterdescription of the background.
The third and fourth terms in Eq. (1) are the spatial penaltyterms which help to incorporate the prior lip shape information.The spatial penalty terms for the object (i.e. lip) cluster and thebackground clusters are the product of f (u) and g(r, s), wheref (u) is proportional to the membership u and g(r, s) is only re-lated to the spatial location (r, s) of the pixel. We note that anyform of f and g is appropriate as long as the spatial penalty termsatisfies: (i) for pixels inside the lip region, JSPA,OBJ is smallwhile JSPA,BKGis large which penalizes the background mem-bership in this region. Moreover, the closer to the lip center, thelarger JSPA,BKG should be. (ii) For pixels near the lip bound-ary, both JSPA,OBJ and JSPA,BKG are small as pixels in thisregion have similar probability to be lip or background pixels.Spatial information in this region can hardly help differentiatebetween lip and background. (iii) For pixels faraway from thelip region, JSPA,OBJ is large while JSPA,BKG is small whichpenalizes the lip membership in this region. Moreover, the far-ther away from the lip center, the larger JSPA,OBJ should be.(iv) For different background cluster, the spatial penalty termJi,SPA,BKG should be the same since no prior spatial distribu-tion of any background cluster is available.
Since the shape of the outer lip contour resembles an ellipse,the spatial location information is naturally defined as the ellip-tic distance of a pixel to the lip center. The elliptic distance canbe described with the parameter set p={xc, yc, w, h, �} in which(xc, yc) is the center of the ellipse, w and h are, respectively, thesemi-major axis and the semi-minor axis, and � is the inclina-tion angle about (xc, yc). For a pixel located at (r, s), the ellipticdistance dist is formulated as dist(r, s, p) = ((r − xc) cos � +(s − yc) sin �)2/w2 + ((s − yc) cos � − (r − xc) sin �)2/h2 andthus g(r, s) can be directly expressed as g(dist). In our algo-rithm, f (u) is set to um for simplicity and gOBJ and gi,BKG
are in the sigmoidal form, i.e.
gOBJ (dist) = pOBJ /(1 + exp(−(dist(r, s, p)
− mOBJ )/�OBJ )), (3)
gi,BKG(dist) = gBKG(dist)
= pBKG/(1 + exp((dist(r, s, p)
− mBKG)/�BKG)), (4)
where pOBJ and pBKG are the maximum penalty, mOBJ andmBKG are the mean values and �OBJ and �BKG control thesteepness of the sigmoid curve.
The objective function J is now given by,
J (U,V, p) =N∑
r=1
M∑s=1
C−1∑i=0
umi,r,sd
2i,r,s +
N∑r=1
M∑s=1
um0,r,spOBJ /
(1 + exp(−(dist(r, s, p) − mOBJ )/�OBJ ))
+N∑
r=1
M∑s=1
C−1∑i=1
umi,r,spBKG/
(1 + exp((dist(r, s, p) − mBKG)/�BKG)). (5)

S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491 3485
3.2. Parameter updating formulae
Since the optimal solution for minMf c×Rcq×R5{J (U,V, p)}is the stationary point of the objective function, Picard itera-tion is used to solve for the optimum point (U∗, V∗, p∗). Thederivation of the parameter updating formulae in each iterationis described in the following.
Let � : Mf c → R, �(U) = J (U,V, p) with V ∈ Rcq andp ∈ R5 remain unchanged. Taking the partial derivative of�(U) with respect to U subject to the constraint (2), the up-dated membership value u+
i,r,s can be obtained by setting thederivative to zero and it is given by:
u+0,r,s =
⎡⎣1 +
C−1∑j=1
(d2
0,r,s + gOBJ (r, s)
d2j,r,s + gBKG(r, s)
)1/(m−1)⎤⎦
−1
, (6)
u+i,r,s =
⎡⎣(d2
i,r,s + gBKG(r, s)
d20,r,s + gOBJ (r, s)
)1/(m−1)
+C−1∑j=1
(d2i,r,s + gBKG(r, s)
d2j,r,s + gBKG(r, s)
)1/(m−1)⎤⎦
−1
, i �= 0.(7)
Similarly, let � : Rcq → R, �(V) = J (U,V, p) with U ∈Mf c and p ∈ R5 remain unchanged. The partial derivative of�(V) with respect to V is given by:
d�
dV= �J
�V= �JCLR
�V+(
�JSPA,OBJ
�V+ �JSPA,BKG
�V
). (8)
Since JSPA,OBJ and JSPA,BKG are constants when U ∈ Mf c
and p ∈ R5 are fixed, the second term on the right hand side ofEq. (8) vanishes and the derivative d�/dV is identical to thatof the FCM. Following the derivation in Ref. [19], the updatedcentroid can be computed as follows:
v+i =
N∑r=1
M∑s=1
umi,r,sxr,s
/N∑
r=1
M∑s=1
umi,r,s . (9)
Finally, the partial derivative of J (U,V, p) with respect to pis given by
�J (U,V, p)
�p= �JCLR
�p+(
�JSPA,OBJ
�p+ �JSPA,BKG
�p
). (10)
The first term on the right-hand side of Eq. (10) vanishes sinceJCLR is a function of the color features and is independent ofthe spatial parameter set p. By setting the partial derivative inEq. (10) to zero,
N∑r=1
M∑s=1
⎛⎜⎜⎝
pOBJ um0,r,s
exp(−(dist(r, s, p) − mOBJ )/�OBJ )
(1 + exp(−(dist(r, s, p) − mOBJ )/�OBJ ))2
−C−1∑i=1
pBKGumi,r,s
exp((dist(r, s, p) − mBKG)/�BKG)
(1 + exp((dist(r, s, p) − mBKG)/�BKG))2
⎞⎟⎟⎠ � dist(r, s)
�p= 0. (11)
Since direct solving p+ with Eq. (11) is complex, the con-jugate gradient (CG) method is adopted instead to solve p+numerically for its fast convergence.
Eqs. (6) and (9) together with p+ obtained via CG forma Picard iteration to find the optimal solution (U∗, V∗, p∗).The iterative sequence converges to a local minimum since theobjective function J is a continuous function of (U,V, p), andJ is positive and ever decreasing in each updating process of(U,V, p), and xr,s is bounded by Rq .
The computational cost for updating the spatial parametervector p is quite expensive as it requires an iterative procedure.From the experimental results, it was observed that the opti-mized ellipse obtained by the CG method always lies close tothe boundary of the lip cluster. Hence, the best-fit ellipse [20]for the lip cluster is a good approximation of p+ which re-quires less computation to obtain. In order to reduce the effectof noise to the calculation of the best-fit ellipse, the member-ship map of each cluster is first smoothed by a 3 × 3 Gaussianlow-pass filter. Details derivation of the best-fit ellipse can befound in Appendix.
By using p+ obtained via the best-fit ellipse approach toperform the segmentation, it is observed that the convergenceproperty of the Picard iteration has not been affected and thesegmentation result is very close to that of using the p+ obtainedvia the CG method.
3.3. Determining the number of background clusters
Since the MS-FCM algorithm uses multiple clusters to rep-resent the background region, the number of clusters used willaffect both the processing time and segmentation quality. Set-ting an inadequate number of clusters may result in segmenta-tion errors due to misclassifying some nearby background pix-els as lip pixels since their color information is closer to that ofthe lip than other background features. Nevertheless, this kindof misclassifying error can be reduced by increasing the num-ber of clusters at the expense of increasing processing time.To determine an adequate number of background clusters, thefollowing method is used:
1. Set the initial number of clusters C = 2.2. Perform the MS-FCM segmentation algorithm with C − 1
background cluster(s).3. Calculate index-I of the fuzzy distribution.4. Repeat step 2 with C increased by 1 if current index-I is
greater than that of the previous iteration, otherwise stop.5. The proper number of clusters is set to C − 1.
In step 3, index-I is the cluster validity index to evaluatethe partitioning by different number of clusters and is defined

3486 S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491
Fig. 3. The five elliptic regions of a lip image.
as follows [27]:
I (C) =(
1
C× E1
EC
× DC
)q
, (12)
where C is the number of clusters and
EC =C−1∑i=0
N∑r=1
M∑s=1
ui,r,sdi,r,s ,
DC = Cmaxi,j=1
‖vi − vj‖, q = 2.
3.4. Physical interpretation of the spatial penalty term
Consider the lip image divided into 5 different regions asshown in Fig. 3. The lip-boundary approximated by an ellipseis shown as a dashed line in region III. The ellipse is describedby the spatial parameter set p which is derived from the mem-bership distribution.
Region I: In this region, the spatial distance of a pixel to thelip center is small so that gOBJ is much smaller while gBKG
is much larger compared to the color distance d2i,r,s , i.e.:
gOBJ (r, s)>d2i,r,s>gBKG(r, s). (13)
According to Eqs. (6) and (7), the updated membership valuesassociated with the clusters of a pixel in this region is given by
u+0,r,s ≈ 1, u+
i,r,s ≈ 0 (i �= 0). (14)
Region V: In this region, the spatial distance of a pixel to thelip center is large so that gBKG is much smaller while gOBJ ismuch larger compared to the color distance d2
i,r,s , i.e.
gBKG(r, s)>d2i,r,s>gOBJ (r, s). (15)
According to Eqs. (6) and (7), the updated membership valuesassociated with the clusters of a pixel in this region is given by
u+0,r,s ≈ 0, u+
i,r,s≈⎡⎣C−1∑
j=1
(di,r,s
dj,r,s
)2/(m−1)⎤⎦
−1
(i �= 0). (16)
It is observed from Eq. (16) that the membership of a pixelin this region associated with the lip cluster decreases to a
very small value and the membership values associated withthe background clusters are solely dependent on their colordistance. In fact the formula is identical to that of the FCMwithout considering the lip cluster and thus the spatial penaltyterm has no effect on the color centroids of the backgroundclusters.
Region III: The spatial distance of a pixel in this region to thelip center is around 1 and is far less than the color distances, i.e.
gOBJ (r, s)>d2i,r,s , gBKG(r, s)>d2
i,r,s . (17)
The updated membership value is then given by:
u+i,r,s ≈
⎡⎣C−1∑
j=0
(di,r,s
dj,r,s
)2/(m−1)⎤⎦
−1
. (18)
It can be seen from Eq. (18) that the membership value of pixelsnear the lip boundary is not affected by the spatial distancemeasure. Although the approximate boundary is described inan elliptic form, the proposed algorithm is suitable for variouslip shapes segmentation since the elliptic function is a goodapproximation to most lip shapes.
Region II and region IV: The membership values of pixels inthese two regions are influenced by both the color and spatialdistance measures. In region II, gBKG is comparable to thecolor distances d2
i,r,s and gOBJ is negligible, i.e.
gOBJ>gBKG, gOBJ>d2i,r,s . (19)
The updated membership value is then given by
⇒ d20,r,s + gOBJ (r, s)
d2i,r,s + gBKG(r, s)
≈ d20,r,s
d2i,r,s + gBKG(r, s)
<d2
0,r,s
d2i,r,s
for i �= 0,
⇒ u+0,r,s >
⎡⎣C−1∑
j=0
(d0,r,s
dj,r,s
)2/(m−1)⎤⎦
−1
. (20)
Eq. (20) shows that the membership u+0,r,s of MS-FCM in
region II is always better than that of FCM using color infor-mation alone.
In region IV, gOBJ is comparable to the color distances d2i,r,s
and gBKG is negligible, i.e.
gBKG>gOBJ , gBKG>d2i,r,s . (21)
The updated membership value is then given by
⇒ d20,r,s + gOBJ (r, s)
d2i,r,s + gBKG(r, s)
≈ d20,r,s + gOBJ (r, s)
d2i,r,s
>d2
0,r,s
d2i,r,s
for i �= 0
⇒ u+0,r,s <
⎡⎣C−1∑
j=0
(d0,r,s
dj,r,s
)2/(m−1)⎤⎦
−1
. (22)
From the inequality in Eq. (22), it is observed that thelip-class membership in the background region (region IV) is
S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491 3487
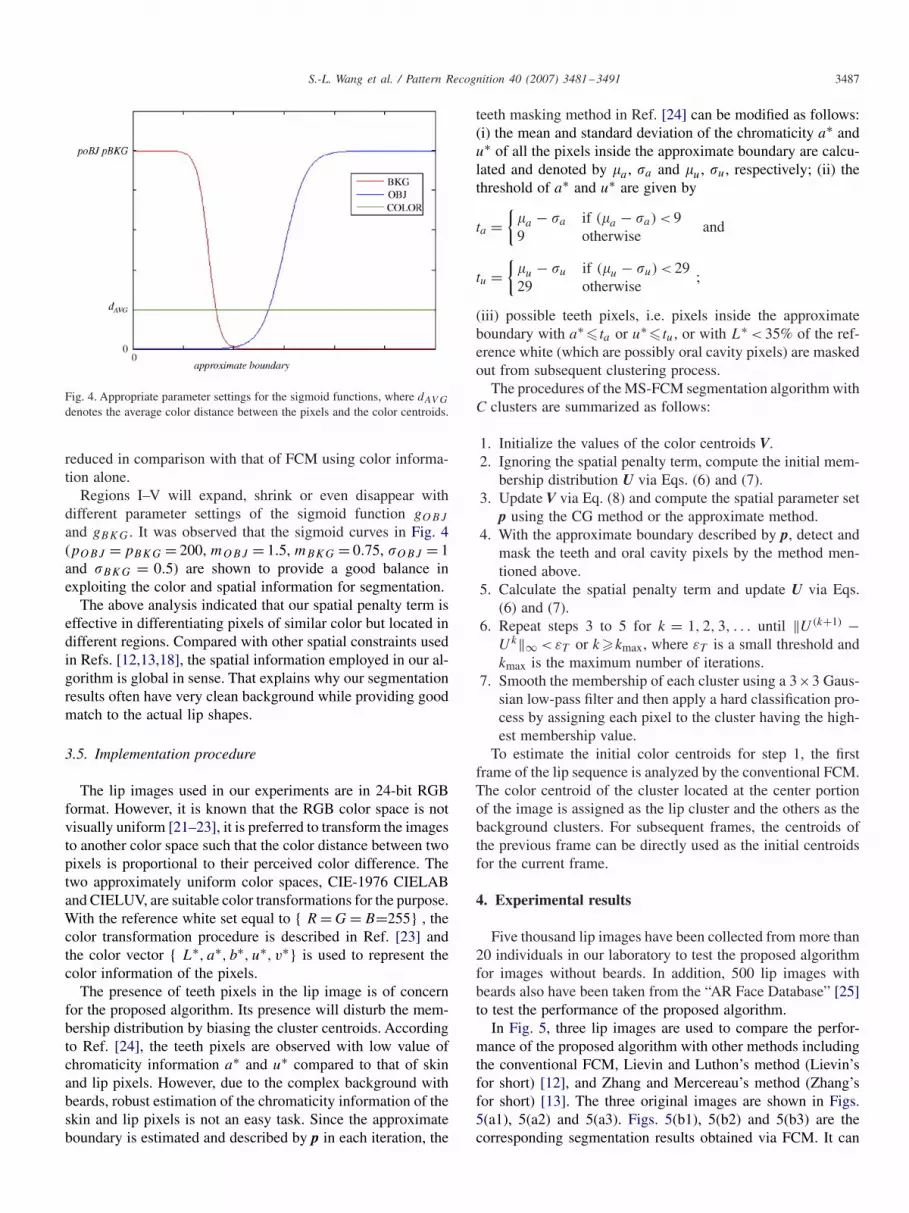
Fig. 4. Appropriate parameter settings for the sigmoid functions, where dAV G
denotes the average color distance between the pixels and the color centroids.
reduced in comparison with that of FCM using color informa-tion alone.
Regions I–V will expand, shrink or even disappear withdifferent parameter settings of the sigmoid function gOBJ
and gBKG. It was observed that the sigmoid curves in Fig. 4(pOBJ = pBKG = 200, mOBJ = 1.5, mBKG = 0.75, �OBJ = 1and �BKG = 0.5) are shown to provide a good balance inexploiting the color and spatial information for segmentation.
The above analysis indicated that our spatial penalty term iseffective in differentiating pixels of similar color but located indifferent regions. Compared with other spatial constraints usedin Refs. [12,13,18], the spatial information employed in our al-gorithm is global in sense. That explains why our segmentationresults often have very clean background while providing goodmatch to the actual lip shapes.
3.5. Implementation procedure
The lip images used in our experiments are in 24-bit RGBformat. However, it is known that the RGB color space is notvisually uniform [21–23], it is preferred to transform the imagesto another color space such that the color distance between twopixels is proportional to their perceived color difference. Thetwo approximately uniform color spaces, CIE-1976 CIELABand CIELUV, are suitable color transformations for the purpose.With the reference white set equal to { R = G = B=255} , thecolor transformation procedure is described in Ref. [23] andthe color vector { L∗, a∗, b∗, u∗, v∗} is used to represent thecolor information of the pixels.
The presence of teeth pixels in the lip image is of concernfor the proposed algorithm. Its presence will disturb the mem-bership distribution by biasing the cluster centroids. Accordingto Ref. [24], the teeth pixels are observed with low value ofchromaticity information a∗ and u∗ compared to that of skinand lip pixels. However, due to the complex background withbeards, robust estimation of the chromaticity information of theskin and lip pixels is not an easy task. Since the approximateboundary is estimated and described by p in each iteration, the
teeth masking method in Ref. [24] can be modified as follows:(i) the mean and standard deviation of the chromaticity a∗ andu∗ of all the pixels inside the approximate boundary are calcu-lated and denoted by �a , �a and �u, �u, respectively; (ii) thethreshold of a∗ and u∗ are given by
ta ={
�a − �a if (�a − �a) < 99 otherwise
and
tu ={
�u − �u if (�u − �u) < 2929 otherwise
;
(iii) possible teeth pixels, i.e. pixels inside the approximateboundary with a∗ � ta or u∗ � tu, or with L∗ < 35% of the ref-erence white (which are possibly oral cavity pixels) are maskedout from subsequent clustering process.
The procedures of the MS-FCM segmentation algorithm withC clusters are summarized as follows:
1. Initialize the values of the color centroids V.2. Ignoring the spatial penalty term, compute the initial mem-
bership distribution U via Eqs. (6) and (7).3. Update V via Eq. (8) and compute the spatial parameter set
p using the CG method or the approximate method.4. With the approximate boundary described by p, detect and
mask the teeth and oral cavity pixels by the method men-tioned above.
5. Calculate the spatial penalty term and update U via Eqs.(6) and (7).
6. Repeat steps 3 to 5 for k = 1, 2, 3, . . . until ‖U(k+1) −Uk‖∞ < εT or k�kmax, where εT is a small threshold andkmax is the maximum number of iterations.
7. Smooth the membership of each cluster using a 3×3 Gaus-sian low-pass filter and then apply a hard classification pro-cess by assigning each pixel to the cluster having the high-est membership value.
To estimate the initial color centroids for step 1, the firstframe of the lip sequence is analyzed by the conventional FCM.The color centroid of the cluster located at the center portionof the image is assigned as the lip cluster and the others as thebackground clusters. For subsequent frames, the centroids ofthe previous frame can be directly used as the initial centroidsfor the current frame.
4. Experimental results
Five thousand lip images have been collected from more than20 individuals in our laboratory to test the proposed algorithmfor images without beards. In addition, 500 lip images withbeards also have been taken from the “AR Face Database” [25]to test the performance of the proposed algorithm.
In Fig. 5, three lip images are used to compare the perfor-mance of the proposed algorithm with other methods includingthe conventional FCM, Lievin and Luthon’s method (Lievin’sfor short) [12], and Zhang and Mercereau’s method (Zhang’sfor short) [13]. The three original images are shown in Figs.5(a1), 5(a2) and 5(a3). Figs. 5(b1), 5(b2) and 5(b3) are thecorresponding segmentation results obtained via FCM. It can

3488 S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491
Fig. 5. (a1), (a2), (a3) Original lip images. Segmentation results obtained from: (b1), (b2), (b3) conventional FCM; (c1), (c2), (c3) Lievin’s method; (d1), (d2),(d3) Zhang’s method; and (e1), (e2), (e3) MS-FCM.
be seen that the conventional FCM can deliver acceptable re-sults if the lip and the background are well differentiated (seeFig. 5(b1) with three clusters). However, when the lip colorand part of the background color are close, the conventionalFCM is unable to produce good segmentation even with moreclusters (see Fig. 5(b3) with five clusters).
Figs. 5(c1)–(c3) and 5(d1)–(d3) show the segmentation re-sults obtained from Lievin’s and Zhang’s methods, respectively.Lievin’s and Zhang’s methods basically use two clusters to seg-ment the image from the hue information. When the hue for thelip region and the background are close, the two-class assump-tion becomes inappropriate. Zhang’s method further makes useof the edge map information to aid the segmentation. It pro-duces large segmentation errors since the edge map is quitenoisy for lip image with beards.
Finally, Figs. 5(e1)–(e3) show the segmentations obtainedfrom the proposed algorithm with three clusters. It is seen thatour algorithm outperforms the other three methods for lip im-ages with mustaches and beards.
For quantitative comparison, the boundary of the lip region ismanually drawn and compared with the segmented lip region.A quantitative index, segmentation error (SE) as defined in Ref.[26] and given in Eq. (23), is used to evaluate the performanceof the proposed algorithm.
SE = P(O) · P(B|O) + P(B) · P(O|B), (23)
where P(B|O) is the probability of classifying backgroundas object, P(O|B) is the probability of classifying object asbackground. P(O) and P(B) are the a priori probabilities ofthe object and the background of an image, respectively. Thesegmentation error as well as the two misclassifying probabilityof the four algorithms are tabulated in Table 1.
It can be clearly seen that the segmentation error of MS-FCM is much smaller than that of the other algorithms. Moresegmentation results for images with or without beards pro-duced by MS-FCM are given in Fig. 6. The average segmen-tation error for the 500 lip images selected from the “AR FaceDatabase” is around 3%. These results demonstrate that the

S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491 3489
Table 1The P {B|O}, P {O|B} and SE of the conventional FCM, Lievin’s, Zhang’s and MS-FCM for the three lip images shown in Fig. 5
Fig. 4(a1) Fig. 4(a2) Fig. 4(a3)
P(B|O) P (O|B) SE (%) P(B|O) P (O|B) SE (%) P(B|O) P (O|B) SE (%)
FCM 0.125 0.033 5.40 1.683 0.080 26.77 2.214 0.032 19.15Lievin’s 0.847 0.046 23.10 1.400 0.013 17.53 1.601 0.005 12.18Zhang’s 0.538 0 12.51 3.119 0 36.56 7.026 0 51.40MS-FCM 0.162 0.015 4.87 0.014 0.03 2.81 0.031 0.008 0.95
Fig. 6. More segmentation results obtained by MS-FCM with the segmented lip region shown in white.
Fig. 7. Segmentation results obtained by MS-FCM with different kind of segmentation error (the segmented lip region is shown in white).
segmented lip region obtained by our algorithm fits well tothe lip.
However, for some special cases (less than 5% of all thelip images we tested), the MS-FCM algorithm still cannot pro-vide accurate segmentation results. Fig. 7 demonstrates someof such lip images and it can be observed that the lip cornersare classified as non-lip pixels because these pixels are of darkcolor which is similar to that of beard-pixels. Moreover, theirlocation is close to the approximate boundary so that the priorlip shape cannot provide useful assistance. Such drawback insegmenting dark lip corners can be overcome by some lip mod-eling approaches with lip shape validation since the major part
of lip region is correctly identified. For the last figure in Fig. 7,the lower part of the lip region is segmented as non-lip sinceits color is close to that of the skin region due to the stress ofthe lip. Such segmentation error can be rectified by exploitingthe lip region information from the previous lip images in asequence. With the post-processing methods mentioned above,the segmentation accuracy of MS-FCM can be improved.
5. Conclusions
Segmentation of lip images with multiple background fea-tures is a difficult problem for most existing lip segmentation

3490 S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491
algorithms. In this paper, a novel fuzzy-clustering-based algo-rithm, the multi-class, shape-guided FCM (MS-FCM) cluster-ing algorithm, is presented to solve this problem. In MS-FCM,multiple clusters are adopted to model the background regionsufficiently and a spatial penalty term is introduced to effec-tively differentiate the non-lip pixels that have similar colorfeatures as the lip pixels but located in different regions. Ex-perimental results demonstrate that the proposed algorithmhas excellent segmentation results over other segmentationtechniques.
Acknowledgments
The work described in this paper is supported by both anRGC Grant (CityU 1215/01E) from HKSAR, China and theShanghai Natural Science Fund (05ZR14080).
Appendix A.
A.1. Derivation of the best-fit ellipse for the lip region
For a given U, the parameters of the best-fit ellipse are com-puted as follows:
�x,y ={
1 u0,x,y �ui,x,y for any i �= 0,
0 otherwise,(A.1)
xc =M∑
x=1
N∑y=1
x · �x,y
/M∑
x=1
N∑y=1
�x,y ,
yc =M∑
x=1
N∑y=1
y · �x,y
/M∑
x=1
N∑y=1
�x,y , (A.2)
� = 1
2tan−1
{2�11
�20 − �02
}, (A.3)
w =(
4
�
)1/4[
(Iy)3
Ix
]1/8
, h =(
4
�
)1/4[
(Ix)3
Iy
]1/8
, (A.4)
where
�ij =M∑
x=1
N∑y=1
(x − xc)i(y − yc)
j�x,y , (A.5)
Ix =M∑
x=1
N∑y=1
((y − yc) cos � − (x − xc) sin �)2�x,y , (A.6)
Iy =M∑
x=1
N∑y=1
((x − xc) cos � + (y − yc) sin �)2�x,y . (A.7)
References
[1] N.P. Erber, Interaction of audition and vision in the recognition of oralspeech stimuli, J. Speech Hear. Res. 12 (1969) 423–425.
[2] M.T. Chan, HMM-based audio-visual speech recognition integratinggeometric and appearance-based visual features, IEEE Fourth Workshopon Multimedia Signal Processing, Cannes, France, October 2001, pp.9–14.
[3] M.N. Kaynak, Q. Zhi, A.D. Cheok, K. Sengupta, K.C. Chung, Audio-visual modeling for bimodal speech recognition, Proceedings of IEEEInternational Conference on Systems, Man, and Cybernetics, October2001, Tucson, AZ, USA, vol. 1, pp. 181–186.
[4] Y. Zhang, S. Levinson, T. Huang, Speaker independent audio-visualspeech recognition, Proceedings of IEEE International Conference onMultimedia and Expo, July 2000, New York, USA, vol. 2, pp. 1073–1076.
[5] G. Rabi, S. Lu, Visual speech recognition by recurrent neural networks,Electrical and Computer Engineering, 1997, Engineering Innovation:Voyage of Discovery, Canadian Conference, May 1997, St. Johns,Newfoundland, Canada, vol. 1, pp. 55–58.
[6] E.D. Petajan, Automatic lipreading to enhance speech recognition,Proceedings of IEEE Conference on Computer Vision and PatternRecognition, 1985, pp. 40–47.
[7] C. Bregler, H. Hild, S. Manke, A. Waibel, Improving connected letterrecognition by lipreading, Proceedings of IEEE International Conferenceon Acoustics, Speech, Signal Processing, 1993, pp. 557–560.
[8] M.E. Hennecke, K.V. Prasad, D.G. Stork, Using deformable templatesto infer visual speech dynamics, 1994 Conference Record of theTwenty-Eighth Asilomar Conference on Signals, Systems and Computers,October 1994, Pacific Grove, CA, USA, vol. 1, pp. 578–582.
[9] A. Caplier, Lip Detection and Tracking, Proceedings of 11th InternationalConference on Image Analysis and Processing, September 2001,Palermo, Italy, pp. 8–13.
[10] T. Wark, S. Sridharan, V. Chandran, An approach to statistical lipmodelling for speaker identification via chromatic feature extraction,Proceedings of Fourteenth International Conference on PatternRecognition, August 1998, Brisbane, Australia, vol. 1, pp. 123–125.
[11] N. Eveno, A. Caplier, P.Y. Coulon, New color transformation for lipssegmentation, Proceedings of IEEE Fourth Workshop on MultimediaSignal Processing, October 2001, Cannes, France, pp. 3–8.
[12] M. Lievin, F. Luthon, Lip features automatic extraction, Proceedingsof IEEE International Conference on Image Processing, March 1999,Chicago, IL, USA, vol. 3, pp. 168–172.
[13] X. Zhang, R.M. Mersereau, Lip feature extraction towards an automaticspeechreading system, Proceedings of IEEE International Conference onImage Processing, September 2000, Vancouver, BC, Canada, vol. 3, pp.226–229.
[14] J.C. Bezdek, Pattern Recognition with Fuzzy Objective FunctionAlgorithms, Plenum Press, New York, 1981.
[15] T.A. Runkler, J.C. Bezdek, Image segmentation using fuzzy clusteringwith fractal features, Proceedings of the Sixth IEEE InternationalConference, July 1997, Barcelona, Spain, vol. 3, pp. 1393–1398.
[16] Y.A. Tolias, S.M. Panas, On applying spatial constraints in fuzzy imageclustering using a fuzzy rule-based system, IEEE Signal Process. Lett.5 (1998) 245–247.
[17] S.H. Leung, S.L. Wang, W.H. Lau, Lip image segmentation using fuzzyclustering incorporating an elliptic shape function, IEEE Trans. ImageProcess. 13 (1) (2004) 51–62.
[18] A.W.C. Liew, S.H. Leung, W.H. Lau, Segmentation of color lip imagesby spatial fuzzy clustering, IEEE Trans. Fuzzy Syst. 11 (4) (2003)542–549.
[19] J.C. Bezdek, A convergence theorem for the fuzzy ISODATA clusteringalgorithms, IEEE Trans. Pattern Anal. Mach. Intell. 2 (1980) 1–8.
[20] A.W.C. Liew, S.H. Leung, W.H. Lau, Lip contour extraction fromcolor images using a deformable model, Pattern Recognition 35 (2002)2949–2962.
[21] CIE, Colorimetry, CIE Pub. No. 15.2, Bureau Central de la CIE, Vienna,Austria, 1986.

S.-L. Wang et al. / Pattern Recognition 40 (2007) 3481–3491 3491
[22] G. Sharma, M.J. Vrhel, H.J. Trussell, Color imaging for multimedia,Proc. IEEE 86 (1998) 1088–1108.
[23] R.W.G. Hunt, Measuring Color, second ed., Ellis is Horwood Series inApplied Science and Industrial Technology, Ellis Horwood, Chichester,UK, 1991.
[24] A.W.C. Liew, S.H. Leung, W.H. Lau, Segmentation of color lip imagesby spatial fuzzy clustering, IEEE Trans. Fuzzy Syst. 11 (4) (2003)542–549.
[25] A.M. Martinez, R. Benavente, The AR face database (online), CVCTechnical Report #24, June 1998.
[26] S.U. Lee, S.Y. Chung, R.H. Park, A comparative performance study ofseveral global thresholding techniques for segmentation, Comput. VisionGraphics Image Process. 52 (1990) 171–190.
[27] U. Maulik, S. Bandyopadhyay, Performance evaluation of someclustering algorithms and validity indices, IEEE Trans. Pattern Anal.Mach. Learn. 24 (12) (2002) 1650–1654.





























