Embed Size (px)
Citation preview

PERANCANGAN DATA WAREHOUSE DAN PENERAPAN DATA MINING ANGGOTA COBRAND PADA SISTEM
FREQUENT FLYER : STUDI KASUS PT. GARUDA INDONESIA
KARYA AKHIR
MUJOKO 0706193813
UNIVERSITAS INDONESIA
FAKULTAS ILMU KOMPUTER
PROGRAM STUDI MAGISTER TEKNOLOGI INFORMASI
JAKARTA
JANUARI 2009

PERANCANGAN DATA WAREHOUSE DAN PENERAPAN DATA MINING ANGGOTA COBRAND PADA SISTEM
FREQUENT FLYER : STUDI KASUS PT. GARUDA INDONESIA
KARYA AKHIR Diajukan sebagai salah satu syarat
untuk memperoleh gelar Magister Teknologi Informasi
MUJOKO 0706193813
UNIVERSITAS INDONESIA
FAKULTAS ILMU KOMPUTER
PROGRAM STUDI MAGISTER TEKNOLOGI INFORMASI
JAKARTA
JANUARI 2009

ii
HALAMAN PERNYATAAN ORISINALITAS
Karya Akhir ini adalah hasil karya saya sendiri,
dan semua sumber baik yang dikutip maupun dirujuk
telah saya nyatakan dengan benar.
Nama : Mujoko
NPM : 0706193813
Tanda tangan :
Tanggal : 09 Januari 2009

iii
HALAMAN PENGESAHAN
Karya Akhir ini diajukan oleh : Nama : Mujoko NPM : 0706193813 Program Studi : Magister Teknologi Informasi Judul Karya Akhir : Perancangan Data Warehouse dan Penerapan Data Mining Anggota Cobrand Pada Sistem Frequent Flyer : Studi Kasus PT. Garuda Indonesia Telah berhasil dipertahankan di hadapan Dewan Penguji dan diterima sebagai bagian persyaratan yang diperlukan untuk memperoleh gelar Magister Teknologi Informasi pada Program Studi Magister Teknologi Informasi, Fakultas Ilmu Komputer, Universitas Indonesia.
DEWAN PENGUJI
Pembimbing : Yova Ruldeviyani, M.Kom ( ………………….……... )
Pembimbing : Yudho Giri Sucahyo, Ph.D, CISA ( …….. .………….……... )
Penguji : Dr. Indra Budi ( .………………….…….. )
Penguji : Dr. Achmad Nizar H ( …….................. ……... )
Ditetapkan di : Jakarta
Tanggal : 9 Januari 2009

i
KATA PENGANTAR
Segala puji syukur kepada Allah SWT, karena hanya dengan berkat dan
karunia-Nya penulis dapat menyelesaikan tesis yang berjudul “PERANCANGAN
DATA WAREHOUSE DAN PENERAPAN DATA MINING ANGGOTA
COBRAND PADA SISTEM FREQUENT FLYER STUDI KASUS PT. GARUDA
INDONESIA” ini sesuai dengan yang direncanakan. Tesis ini dibuat guna
melengkapi persyaratan kelulusan pada Program Studi Magister Teknologi
Informasi, Fakultas Imu Komputer, Universitas Indonesia. Saya menyadari bahwa,
tanpa bantuan dan bimbingan dari berbagai pihak, dari masa perkuliahan sampai pada
penyusunan karya akhir ini, sangatlah sulit bagi saya untuk menyelesaikannya. Oleh
karena itu, saya mengucapkan terima kasih kepada:
(1) Orang tua, istri dan ananda Muhammad Ihsan yang telah memberikan dukungan
bantuan berupa api semangat.
(2) Ibu Yova Ruldeviyani, M.Kom sebagai dosen pembimbing yang telah membimbing
penulis selama mengerjakan Tesis ini.
(3) Bapak Yudho Giri Sucahyo, Ph.D, CISA, selaku dosen pembimbing akademik dan
ketua program studi Studi Magister Teknologi Informasi, yang telah menyediakan
waktu, tenaga, dan pikiran untuk mengarahkan saya dalam penyusunan skripsi ini
mulai dari penyusunan proposal hingga Tesis dan jabatannya berakhir
(4) Bapak Dr.Indra Budi selaku penguji dalam sidang tesis
(5) Bapak Dr.Achmad Nizar H. selaku penguji dalam sidang tesis, sekaligus ketua
program studi Magister Teknologi Informasi mendatang dan selamat atas
jabatannya.
(6) Bapak K. Budiyanto, Ibu Lusi, Ibu Cita, Pak Sonny dan segenap staff karyawan
Garuda yang telah bersedia meluangkan waktu untuk menjawab pertanyaan-
pertanyaan penulis dan menyediakan data, semoga Allah membalas kebaikan rekan
semua.
(7) Ibu Connie dan Pak Heru selaku atasan saya yang memberi kesempatan pada saya
untuk mengeksplorasi FFP sebagai bahan kajian.
(8) Sahabat-sahabat saya di FFP yang telah berjuang siang dan malam, Bank
Dukun/Mukhlis, Pak Dipo, Iin, Vera, Jonny dan Gardiary sang pejantan, yang
telah banyak membantu saya dalam menyelesaikan karya akhir ini.

ii
(9) Bang Haikal, yang tela membantu saya selama saya sakit atas dukungannya
berupa materi dan material. Semoga Allah membalas kebaikan abang.
(10) Rekan kelas B dan kelompok ABUDOMM, terima kasih atas kebersamaan
dan kenangan indah yan tak terlupakan selama di MTI.
(11) Kang Asep dan Dodick dengan tumpangan kendaraan setiap saya pulang
selama kuliah.
(12) Mas Ganda yang telah menyumpahi saya agar mendapat nilai yang terbaik.
Akhir kata, saya berharap Tuhan Yang Maha Esa berkenan membalas
segala kebaikan semua pihak yang telah membantu. Semoga karya akhir ini
membawa manfaat bagi pengembangan ilmu.
Jakarta, 9 Januari 2009
Penulis

iii
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA AKHIR UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademik Universitas Indonesia, saya yang bertanda tangan di bawah ini: Nama : Mujoko NPM : 0706193813 Program Studi : Magister Teknologi Informasi Departemen : Magister Teknologi Informasi Fakultas : Ilmu Komputer Jenis Karya : Tesis Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Indonesia Hak Bebas Royalti Nonekslusif (Non-exclusive Royalty-Free Right) atas karya ilmiah saya yang berjudul : Perancangan Data Warehouse dan Penerapan Data Mining Anggota Cobrand Pada Sistem Frequent Flyer : Studi Kasus PT. Garuda Indonesia Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-ekskutif ini Universitas Indonesia berhak menyimpan, mengalihmedia/formatkan, mengelola dalam bentuk pangkalan data (database). Merawat, dan mempublikasikan karya akhir saya tanpa meminta izin dari saya selama tetap mencantumkan saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta. Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Jakarta Pada tanggal : .09 Januari 2009
Yang menyatakan
(………Mujoko…………)

iv
ABSTRACT
Globalization is now inevitable, which causes airlines to face a major problem nowadays. Time becomes major influence in decission making. If the management takes a lot of time in decision making, then company will be stagnant or even decline. There are needs to execute business decision with little time consuming, so that more opportunities can be captured with less cost. In addition to time consuming, accuracy is also a vital necessity for mature analysis and rational calculation. Any information from the insignificant one, as long as it is relevance and accurate can be used as an opportunity for increasing revenue. The main principle is how to optimize aircraft load to its maximum capacity as often as possible. In the context of winning a competition, the combination of a flexible management style and utilization of Information Technology become a vital element. Any business entity can survive depends on the existence of its customer. In order to gain more customer, business player has to execute strategy and innovation. This is necessary to influence people in choosing services provider. In this case, the context is airline service business. Any kind of Loyality Program such as Garuda Frequent Flyer (GFF), has important role in targeting core customer, i.e. customer that give the highest revenue to the company. GFF operational system that keeps information of customer profile and flight transaction, needs to be collected into a single form of data warehouse and updated periodically, so that reporting function can be executed without affecting operational performance. The extensive use of data with datamining technique could assist management in making the right decision based on historical data. Additionally, datamining has to be relevance and being part of business process in order to improve business performance. The focus of this research is to develop initial phase of datamining that can be scaled up in future, not a practical solution that can be directly used. Keyword : Data Warehouse, Data Mining, Frequent Flyer, Garuda Frequent Flyer xii+109 pages; 35 figures; 10 tables; 8 attachments; 0 technical documentation Bibliography: 16 (2001- 2008)

v
ABSTRAK
Globalisasi memang arus yang tidak bisa ditangkal. Airlines menghadapi masalah besar pada saat ini dan hari-hari mendatang. Manajemen yang terbiasa lambat mengambil keputusan dipastikan hanya akan membawa perusahaannya stall. Diperlukan kecepatan dalam mengeksekusi bisnis, agar kesempatan dapat diraih lebih banyak. Selain kecepatan, diperlukan juga ketepatan pengambilan keputusan, berdasarkan analisa perhitungan yang rasional dan matang. Persaingan mengkondisikan bisnis airlines dalam kondisi perang total. Informasi yang sekecil apapun tetapi relevan dimanfaatkan sebagai sebuah peluang untuk meningkatkan pendapatan. Prinsipnya adalah bagaimana memenuhi kapasitas angkut pesawat secara maksimal dan sesering mungkin. Dalam konteks memenangkan persaingan ini perpaduan antara gaya manajemen yang fleksibel dan peran teknologi informasi menjadi amat vital. Setiap bisnis akan tetap eksis jika dia memiliki customer. Untuk mendapatkan customer, pelaku bisnis melakukan berbagai strategi dan inovasi yang akan mempengaruhi ketertarikan orang dan memutuskan menggunakan layanan yang ditawarkan oleh penyedia layanan jasa/barang, dalam hal ini layanan angkutan penerbangan. Loyality program semacam Garuda Frequent Flyer (GFF), memegang peranan penting untuk membidik core customer, customer yang paling banyak memberikan benefit bagi perusahaan. Sistem operasional GFF yang menyimpan data anggota dan transaksi penerbangan, perlu dikumpulkan dalam satu bentuk data warehouse dan secara periodik di-update, sehingga reporting dapat dieksekusi dari data warehouse tanpa mempengaruhi kinerja operasional. Penggunaan data yang ekstensif dengan menggunakan teknik data mining dapat membantu managemen dalam mengambil kebijakan yang tepat berdasar data-data historical. Agar data mining dapat mempengaruhi bisnis, maka data mining sendiri harus relevan dan menjadi bagian dari bisnis proses. Kata Kunci : Data Warehouse, Data Mining, Frequent Flyer, Garuda Frequent Flyer xii+109 halaman; 35 gambar; 10 table; 8 lampiran; 0 technical documentation Bibliography: 16 (2001- 2008)

vi
DAFTAR ISI
KATA PENGANTAR........................................................................................................................ I
ABSTRACT....................................................................................................................................... IV
ABSTRAK..........................................................................................................................................V
DAFTAR ISI .................................................................................................................................... VI
DAFTAR GAMBAR.........................................................................................................................X
DAFTAR TABEL...........................................................................................................................XII
BAB I PENDAHULUAN...................................................................................................................1
1.1 LATAR BELAKANG .....................................................................................................................1 1.2 PERMASALAHAN ........................................................................................................................2 1.3 PEMBATASAN MASALAH............................................................................................................3 1.4 TUJUAN DAN MANFAAT PENELITIAN.........................................................................................4
BAB II LANDASAN TEORI ............................................................................................................5
2.1 DATA WAREHOUSE ......................................................................................................................5 2.1.1 Definisi Data Warehouse ..................................................................................................5 2.1.2 Penelitian Implementasi Data Warehouse .......................................................................6 2.1.3 Sistem Operasional dan Sistem Pendukung Pengambilan Keputusan ............................7 2.1.4 Keuntungan Data Warehouse ...........................................................................................8 2.1.5 Kategori Data pada Data Warehouse ............................................................................10 2.1.6 Arsitektur Data Warehouse.............................................................................................10 2.1.7 Tahapan Data Warehouse...............................................................................................12 2.1.8 Desain Data Warehouse..................................................................................................15
2.2 DATA MINING ............................................................................................................................17 2.2.1 Definisi Data Mining.......................................................................................................17 2.2.2 Teknik Data Mining.........................................................................................................18 2.2.2.1 Predictive Modeling .....................................................................................................19 2.2.2.2 Database Segmentation dengan Clustering.................................................................21 2.2.2.3 Link Analysis ................................................................................................................22 2.2.2.4 Deviation Detection......................................................................................................23 2.2.3 Tahap-Tahap Data Mining .............................................................................................24
2.3 BISNIS AIRLINE DAN DATA MINING ...........................................................................................27

vii
2.3.1 Loyalty Program dan Frequent Flyer Program .............................................................28 2.4 TOOLS DEVELOPMENT...............................................................................................................30
2.4.1 Pentaho Data Integration (PDI/Kettle) ..........................................................................30 2.4.2 Mondrian .........................................................................................................................31
2.5 KEBUTUHAN DATA MINING DALAM FREQUENT FLYER PROGRAM ............................................31
BAB III METODOLOGI PENELITIAN......................................................................................32
3.1 PENGUMPULAN DATA ..............................................................................................................32 3.2 KEBUTUHAN BISNIS DAN INFORMASI ......................................................................................32 3.3 PERANCANGAN DATA WAREHOUSE ..........................................................................................33 3.4 IMPLEMENTASI DATA MINING...................................................................................................33
BAB IV PERANCANGAN DATA WAREHOUSE .....................................................................36
4.1 PROFIL PERUSAHAAN...............................................................................................................36 4.1.1 Latar Belakang Perusahaan ...........................................................................................37 4.1.2 Visi dan Misi Perusahaan ...............................................................................................37 4.1.3 Struktur Organisasi Perusahaan ....................................................................................38
4.2 PEMAHAMAN TERHADAP PROSES BISNIS ................................................................................40 4.2.1 Pendaftaran (Enrollment) ...............................................................................................42 4.2.2 Upgrade/Downgrade Tier ...............................................................................................43 4.2.3 Aktifitas Earning Anggota...............................................................................................44 4.2.4 Aktifitas Redeem Anggota ...............................................................................................44 4.2.5 Keseimbangan Accrual dan Reedem........................................................................45 4.2.6 Kerja Sama Partner.........................................................................................................45
4.3 PERANCANGAN ARSITEKTUR ...................................................................................................45 4.3.1 Arsitektur logical .............................................................................................................46 4.3.2 Arsitektur Fisik ................................................................................................................47 4.3.4 Sumber Data....................................................................................................................48 4.3.5 Data Staging....................................................................................................................49 4.3.6 Proses ETL ......................................................................................................................50 4.3.6.1 Proses Extract .......................................................................................................50 4.3.6.2 Proses Cleansing...................................................................................................51 4.3.6.3 Proses Transformasi .............................................................................................52 4.3.6.4 Proses Loading......................................................................................................53 4.3.7 Model Data Warehouse...................................................................................................55 4.3.6.1 Model Customer....................................................................................................55 4.3.6.2 Model Air Transaction (Earning).........................................................................56 4.3.6.3 Model Non Air Transaction (Earning) .................................................................57 4.3.6.4 Model Certificate Transaction (Spending)..........................................................58

viii
4.3.6.5 Tabel Dimensi .......................................................................................................60 4.3.6.5.1 Dimensi Airport.........................................................................................................60 4.3.6.5.2 Dimensi Location ......................................................................................................60 4.3.6.5.3 Dimensi Gender.........................................................................................................60 4.3.6.5.4 Dimensi Customer Status ..........................................................................................61 4.3.6.5.5 Dimensi Member Tier Composition..........................................................................61 4.3.6.5.6 Dimensi Booking Class .............................................................................................61 4.3.6.5.7 Dimensi Time.............................................................................................................61 4.3.6.5.8 Dimensi Operating Flight Number ...........................................................................62 4.3.6.5.9 Dimensi Partner ........................................................................................................62
BAB V IMPLEMENTASI DATA WAREHOUSE ......................................................................63
5.1 PRESENTASI DATA WAREHOUSE................................................................................................63 5.2 PENYEDIAAN INFORMASI .........................................................................................................64
5.2.1 Informasi Customer.........................................................................................................65 5.2.2 Informasi Earning/Accrual Traffic .................................................................................69
5.2.3 INFORMASI REDEEM TRAFFIC ................................................................................................70 5.3 PENGARUH PERUBAHAN ..........................................................................................................71
BAB VI IMPLEMENTASI DATA MINING.................................................................................74
6.1 PEMAHAMAN TERHADAP BISNIS..............................................................................................74 6.2 SUMBER DATA .........................................................................................................................75 6.3 PEMILIHAN TEKNIK DAN PERANGKAT LUNAK DATA MINING.................................................76 6.4 PERSIAPAN DATA ............................................................................................................77
6.4.1 Persiapan Data Teknik Association Rule..................................................................77 6.4.2 Persiapan Data Teknik Decision Tree ......................................................................81
6.5 ANALISA HASIL UJI COBA...............................................................................................82 6.5.1 Analisa Hasil Uji Coba Dengan Teknik Association Rule.......................................82 6.5.2 Analisa Hasil Uji Coba Dengan Teknik Decision Tree ...........................................85
BAB VII KESIMPULAN ................................................................................................................89
7.1 KESIMPULAN ...................................................................................................................89 7.2 SARAN .............................................................................................................................90
DAFTAR PUSTAKA.......................................................................................................................91
LAMPIRAN-LAMPIRAN ..............................................................................................................93
LAMPIRAN 1 ...................................................................................................................................93
LAMPIRAN 2 ...................................................................................................................................97
LAMPIRAN 3 .................................................................................................................................102

ix
LAMPIRAN 4 .................................................................................................................................103
LAMPIRAN 5 .................................................................................................................................104
LAMPIRAN 6 .................................................................................................................................107
LAMPIRAN 7 .................................................................................................................................108
LAMPIRAN 8 .................................................................................................................................109

x
DAFTAR GAMBAR
Gambar 2.1 Arsitektur data warehouse (Ponniah, 2001)..................................... 11
Gambar 2.2 – Contoh transformasi single-field (Zain, 2008) ............................... 14
Gambar 2.3 – Contoh transformasi multi-field (Zain, 2008) ................................ 14
Gambar 2.4 Star Schema (Ponniah, 2001) ............................................................ 16
Gambar 2.5 Snow flake Schema (Ponniah, 2001) ................................................. 17
Gambar 2.6 Clasification menggunakan tree induction
(http://www.cse.unsw.edu.au/~billw/cs9414/notes/ml/06prop/id3/id3.html)....... 20
Gambar 2.7 Clasification menggunakan neural network (Connonly and Begg,
2005) ..................................................................................................................... 20
Gambar 2.9 Tahap-tahap data mining (Zein, 2008).............................................. 24
Gambar 3.1 Tahap-tahap metodologi penelitian................................................... 34
Gambar 4.1-Struktur Organisasi Executive Vice President .................................. 38
Gambar 4.2- Struktur Organisasi Customer Relation Management. .................... 39
Gambar 4.3- Arsitektur logical Garuda Frequent Flyer....................................... 47
Gambar 4.4- Arsitektur fisik data warehouse Garuda Frequent Flyer ................ 48
Gambar 4.5- Alur transformasi transaksi penerbangan anggota GFF................... 52
Gambar 4.6- Alur transformasi tabel AIRPORT ................................................... 53
Gambar 4.7- Skema job pada Spoon yang mengurutkan pengerjaan transformasi
yang telah dibuat sebelumnya ............................................................................... 54
Gambar 4.8- Model skema bintang enrollment anggota GFF............................... 55
Gambar 4.9- Model skema bintang aktifitas penerbangan anggota...................... 57
Gambar 4.10- Model skema bintang aktifitas bukan penerbangan (non air activity)
anggota GFF.......................................................................................................... 58
Gambar 4.11- Model skema bintang redeem (penggunaan mileage) anggota GFF
............................................................................................................................... 59
Gambar 5.1- Contoh report Customer per branch office pada tahun 2007........... 66
Gambar 5.2- Contoh report Customer per Tier Composition pada tahun 2007.... 67
Gambar 5.3 - Contoh report Customer per yang melakukan aktivasi pada tahun
2007....................................................................................................................... 67

xi
Gambar 5.4 Informasi Customer yang terdistribusi dalam beberapa tier yang di
slice hanya tahun 2007 dan drill-down berdasar usianya...................................... 68
Gambar 5.5 Informasi Enrolment Customer yang terdistribusi dalam dalam tahun
pendaftaran dilengkapi dengan grafik trend enrollment. ...................................... 68
Gambar 5.6- Earning mileage customer yang di-slice berdasarkan Origin
Destination airport penerbangan .......................................................................... 69
Gambar 5.7- Earning mileage customer yang di slice berdasarkan Origin
Destination airport penerbangan yang dilengkap dengan grafik pie chart. ......... 70
Gambar 5.8- Contoh report redeem activity per branch office pada tahun 2007 . 71
Gambar 5.9- Langkah-langkah implementasi jenis report baru. .......................... 72
Gambar 6.1 Building block menggunakan Rapid miner Community 4.2 dengan
teknik data mining association rule ...................................................................... 78
Gambar 6.2 Building block metode Decision tree menggunakan Rapidminer
Community 4.2 ...................................................................................................... 82
Gambar 6.3 Bagian dari diagram pohon karakter anggota Cobrand yang
mendaftar melalui channel Cobrand atau Citibank .............................................. 85
Gambar 6.4 Bagian diagram pohon karakter anggota Cobrand yang mendaftar
melalui Customer Self Service (CSS).................................................................... 86
Gambar 8.1 Pola anggota GFF Cobrand yang melakukan pendaftaran melalui
jalur BO............................................................................................................... 102
Gambar 8.2 Pola anggota GFF Cobrand yang melakukan pendaftaran melalui
jalur BO, CSS dan jalur Citibank atau disebut channel Cobrand...................... 103

xii
DAFTAR TABEL
Tabel 2.1 Tabel operasi data mining dan teknik yang digunakannya (Zein, 2008)
............................................................................................................................... 19
Tabel 3.1 Alur Pengerjaan..................................................................................... 35
Tabel 4.1- Platform database sistem GFF operasional dan pertambahan data.... 49
Tabel 4.2-Perbandingan sumber data GFF dan DatabaseTemp............................ 50
Tabel 4.3-Perbedaan format data .......................................................................... 51
Tabel 4.4-Ketidak konsistenan data penerbangan anggota GFF karena duplikasi
data. ....................................................................................................................... 51
Tabel 6.1 Tabel sebelum transformasi ................................................................. 79
Tabel 6.2 Tabel setelah transformasi/preprocessing ........................................... 80
Tabel 6.3 Model Rule dengan kesimpulan masa keanggotaan Cobrand dalam
mendaftar melalui channel BO ............................................................................. 83
Tabel 6.4 Model Rule dengan kesimpulan masa keanggotaan Cobrand dalam
range1, range2, dan range2. ................................................................................. 84

1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Kebutuhan informasi bagi organisasi bisnis adalah kebutuhan utama yang
harus dipenuhi agar bisnis organisasi tersebut dapat bertahan dalam persaingan.
Pemanfaatan teknologi untuk menggali dan menyimpan berbagai informasi
menjadi penting adanya agar pengolahan dan pengelolaannya bisa optimal.
Teknologi data warehouse dan teknik data mining adalah salah satu teknologi
yang digunakan dalam Bisnis Intelligent (BI). Baik data warehouse dan data
mning bersumber pada aktifitas organisasi yang bersangkutan dengan tujuan
mendapat competitive advantage melalui analisis data internal
Frequent Flyer Program adalah program yang memberikan apresiasi
berdasarkan loyalitasnya. Frequent Flyer Program setiap airline brand-nya
berbeda-beda. Lufthansa Airline memiliki miles and more, Singapore Airline
memiliki KrisFlyer dan Garuda Airline (GA) memiliki Garuda Frequent Flyer
atau disingkat GFF. Program frequent flyer pada prinsip adalah customer akan
mendapatkan reward berupa poin (disebut miles) untuk setiap penerbangan
bersama pemilik airline atau airline partner, dan besarnya reward tergantung
pada jarak terbang, frekuensi terbang dan level member .
Jumlah anggota aktif GFF saat ini mencapai sekitar 300 000, meningkat 100
000 orang di tahun sebelumnya. Anggota GFF memiliki tingkatan/level disebut
Tier. Semakin banyak transaksi anggota dengan GA semakin besar pula poin
yang dikumpulkan dan tingkatan member. Tier tersebut berturut-turut dari rendah
ke tinggi adalah Temp, Blue, Silver , Gold dan Platinum dengan fasilitas dan
keuntungan yang berbeda.

2
Seiring waktu, data transaksi GFF terus meningkat seiring bertambah
banyaknya promosi-promosi juga peningkatan data customer. Data-data tersebut
disimpan dalam database. Tetapi pertumbuhan data yang pesat tersebut telah
menciptakan kondisi menumpuknya data tidak bisa diutilisasi sebagai sumber
informasi dan bernilai hanya sebagai tumpukan data. Data-data tersebut harus
dapat dikonversikan menjadi suatu informasi yang berguna.
Diperlukan suatu tools atau teknik yang dapat digunakan untuk menggali
lebih dalam informasi penting yang dapat diperoleh di dalam database. Business
Intelligence (BI) merupakan tools yang mampu menjawab kebutuhan di atas. BI
telah banyak digunakan oleh berbagai perusahaan dalam mengelola data dan
informasi sampai dengan dukungan pengambilan keputusan.
Anggota GFF Cobrand adalah jenis anggota yang memiliki kartu kredit
Citibank. Level tier anggota Cobrand menempati posisi Platinum, posisi tertinggi
dalam level GFF. Anggota jenis ini tidak harus melalui tier yang lebih rendah
yakni Temp, Blue, Silver dan Gold. Anggota Cobrand dianggap sebagai customer
yang potensial karena dengan kepemilikan kartu kredit, maka diasumsikan
customer tersebut masuk pada golongan orang yang memiliki pendapatan tinggi.
Timbul pertanyaan “Bagaimanakah rancangan data warehouse yang
mendukung penerapan data mining anggota Cobrand pada Sistem Frequent Flyer
di Garuda Indonesia?”.
1.2 Permasalahan
Kondisi sistem operasional GFF menampung banyak data yang lebih
banyak penggunaannya digunakan untuk kegiatan oprasional. Penggunaan data
sebagai sumber analisis adalah melalui modul reporting dari sistem GFF sendiri.
Beberapa kendala dalam penyediaan data analisis tersebut adalah;
Sistem report GFF dapat secara signifikan mengurangi performance
aplikasi hingga mengganggu jalannya aplikasi.

3
Standar report yang tersedia belum memadai dengan adanya report yang
terus berkembang.
Adanya kecenderungan permintaan report yang semakin kompleks dari
waktu ke waktu.
Terus bertambahnya jumlah report dengan tingkat kompleksitas yang
makin beragam.
Report yang tersedia belum belum memiliki informasi yang ditampilkan
secara visual sehingga mudah di baca oleh stakeholder.
Sering terjadi request report yang harus tersedia saat itu juga.
Informasi rutin maupun insidental yang dibutuhkan oleh level-level
pimpinan untuk proses perencanaan maupun pengambilan keputusan
terkadang relatif sulit disajikan.
Rumusan masalah dalam penelitian ini adalah merancang bangun sistem
pengelolaan data yang baik dan dapat menghasilkan informasi sesuai kebutuhan
secara cepat dan mudah dimengerti.
1.3 Pembatasan Masalah
Penelitian ini bertujuan untuk membantu divisi Customer Loyalty Garuda
dalam pembangunan data warehouse dan penerapan teknik data mining, sehingga
dapat mempermudah proses ekstraksi informasi yang dibutuhkan guna menggali
dan memprediksi potensi-potensi yang ada.
Pembangunan BI meliputi perancangan data warehouse dan pemanfaatan
data mining. Berdasarkan pertanyaan di sub bab latar belakang, ruang lingkup
penelitian yaitu perancangan data warehouse dan pemanfaatan data mining,
dalam rangka meningkatkan kualitas dan pelayanan Garuda Airlines. Lingkup
organisasi dibatasi pada divisi Customer Loyality.

4
1.4 Tujuan dan Manfaat Penelitian
Penelitian ini bertujuan untuk membantu divisi Customer Loyalty Garuda
dalam pembangunan BI dengan cakupan data warehouse dan penerapan teknik
data mining untuk anggota Cobrand, sehingga dapat mempermudah proses
ekstraksi informasi yang dibutuhkan guna menggali dan memprediksi potensi-
potensi yang ada atau lebih spesifik untuk menilai customer equity untuk setiap
jenis customer.
Dengan pengumpulan data ke dalam data warehouse dan penerapan data
mining diharapkan dapat membantu perusahaan dalam menghadirkan quality of
service yang baik. Dengan dipisahnya data online transaction processing (OLTP)
dan data warehouse diharapkan performance tidak terganggu saat membuat
report. dan diharapkan dapat memperoleh informasi-informasi strategic dari data
sistem GFF.

5
BAB II
LANDASAN TEORI
Pada bagian ini penulis menjelaskan landasan teori yang menjadi acuan
dalam penelitian ini yaitu landasan teori mengenai data warehouse dan data
mining. Pada sub bab data warehouse penulis menjelaskan pengertian data
warehouse, model arsitektur data warehouse yang akan digunakan berikut teknik
dan proses yang akan dilakukan untuk membentuknya. Pada sub data mining akan
dijelaskan mengenai pengertian dan kegunaan data mining berikut teknik dan
proses membuatnya.
2.1 Data Warehouse
Data warehouse merupakan database relational yang didesain untuk
melakukan lebih dari sekedar proses transaksi tapi lebih mengarah pada proses
query dan analisa. Biasanya terdiri dari historical data yang diambil dari
transaction data, tapi bisa juga berasal dari sumber yang lain. Data warehouse
memisahkan antara analisa dan transaksi dan memungkinkan suatu organisasi
untuk mengkonsolidasikan data dari beberapa source.
2.1.1 Definisi Data Warehouse
Muntean (2007) mendefinisikan data warehouse sebagai kumpulan
informasi yang disimpan dalam database yang digunakan untuk mendukung
pengambilan keputusan dalam sebuah organisasi. Data dikumpulkan dari berbagai
aplikasi yang telah ada. Data yang telah dikumpulkan tersebut kemudian
divalidasi dan direstrukturisasi lagi, untuk selanjutnya disimpan dalam data
warehouse. Pengumpulan data ini memungkinkan para pengambil keputusan
untuk pergi hanya ke satu tempat untuk mengakses data yang ada tentang
organisasinya.
Sebagai tambahan, data memuat proses extraction, transportation,
transformation, and loading (ETL) solution, mesin online analytical processing

6
(OLAP), client analysis tools, dan aplikasi lainnya yang mengatur proses
pengumpulan dan pengiriman data ke user.
Data warehouse sering menjadi bagian inti dari infrastruktur business
intelligent (BI) organisasi. Data warehouse adalah kumpulan dari basis data yang
terintegrasi dan subject oriented yang didesign untuk mendukung DSS (Decision
Support Systems). Karakter utama dari data warehouse antara adalah lain
(Muntean et al, 2007):
• Subject oriented, data disusun dan diorganisasikan berdasarkan
bagaimana users menggunakannya.
• Semua sifat ketidak konsistenan yang disebabkan oleh kesepakatan
penamaan dan representasi nama dihilangkan
• Time Variant, data bersifat kekinian tapi lebih bersifat time series.
• Non volatile, data di simpan dalam dalam format read-only dan tidak
akan berubah.
2.1.2 Penelitian Implementasi Data Warehouse
Bentuk-bentuk penelitian dalam perancangan data warehouse meliputi
berbagai bidang. Data warehouse dimanfaatkan untuk mendapatkan informasi
kinerja dosen (jumlah mata kuliah yang diajarkan, jumlah kelulusan/
ketidakllusan), kinerja mahasiswa (jumlah mata kuliah yang lulus/tidak lulus
dibanding mata kuliah yang diambil), summary tiap nilai mata kuliah yang
memiliki nilai A, B, dan C, (Handojo et al, 2004). Data warehouse juga
digunakan dibidang medis untuk membantu menyediakan sumber data dalam
infrastruktur BI dunia medis. BI dalam mengambil keputusan dalam memberikan
tindakan terbaik terhadap pasien (Bhattacharyya ,2005).
Menurut Bhattacharyya (2005), BI adalah serangkaian proses untuk
mengubah data menjadi informasi yang pada akhirnya menjadi pengetahuan
Data adalah angka-angka, gambar, kata-kata dan lain-lain. Data mendorong
terbentuknya informasi atau pengetahuan. Aplikasi operasional menyimpan data
transaksi secara simultan, sehingga pertambahan data tidak bisa dihindarkan.

7
Semakin besar data tersimpan, akan mempengaruhi performace aplikasi, terutama
modul reporting.
Handojo dan Silivia (2004) melaporkan bahwa pada kasus implementasi
data warehouse di Universitas Petra Surabaya, dengan adanya data warehouse,
proses penyusunan laporan menjadi lebih sederhana, karena pengguna bisa
melakukan customization report sesuai dengan yang diinginkan, sehingga tercipta
efisiensi waktu dari yang sebelumnya satu bulan (dengan program tambahan) atau
seminggu (manual) menjadi satu hari.
Ariana (2007) juga menyebutkan hal yang sama bahwa implementasi data
warehouse dalam organisasinya (Universitas Nasional) membantu pengambil
kebijakan. Pada kasus UNAS lebih spesifik digunakan untuk mengenali pola
karakterisitik mahasiswa yang mengambil program peminatan tertentu di program
studi Manajemen Perusahaan UNAS dengan dibantu data mining.
2.1.3 Sistem Operasional dan Sistem Pendukung Pengambilan Keputusan
Data operasional dan data yang tersimpan berbeda. Ponniah (2001)
memaparkan perbedaan tersebut diantaranya;
1. Dalam sistem operasional, data yang disimpan menunjukan data yang
sekarang (Current Values), sedangkan apa yang tersimpan dalam data
warehouse adalah data archived atau data sebagai hasil penurunan-
penurunan atau summarized dari suatu data besar.
2. Dilihat dari struktur keduanya juga berbeda, data operasional didesign
dengan sedemikian sehingga optimum untuk melakukan transaksi,
sedangkan dalam data warehouse dioptimalkan untuk menghandle query
yang rumit.
3. Penggunaan data operasional bersifat perulangan, sedangkan data
warehouse bersifat ad-hoc, acak dan heuristic.
4. Ditinjau dari frequency mengaksesnya, data operasional sangat sering
diakses sedangkan data warehouse levelnya sedang atau jarang.
5. Jika dalam data operasional akses terhadap datanya bisa read, update atau
bahkan delete, maka dalam data warehouse hanya bisa read.

8
6. Jumlah pengguna juga berbeda, jika operasional digunakan oleh orang
banyak, sedangkan data warehouse oleh beberapa orang saja untuk
mendukung analisa keputusan.
Perbedaan tersebut adalah karena memang adanya perbedaan tujuan dari
dibuatnya sistem. Data Operasional digunakan untuk menjalankan operasional
bisnis dengan cara memasukan data-data kedalamnya. Dalam data warehouse
tujuannya adalah mendapatkan informasi yang bisa mendukung pengambilan
keputusan. Pengguna bisa produk mana yang menjadi favorit, daerah mana yang
banyak mengalami masalah penjualan, kenapa bisa terjadi masalah (drill down),
yang pada prinsipnya untuk menangkap peluang dan mengurangi resiko dalam
menjalankan bisnis.
2.1.4 Keuntungan Data Warehouse
Implementasi data warehouse yang tepat dapat memberikan keuntungan-
keuntungan antara lain:
1. Meningkatkan produktifitas dari pengambil keputusan perusahaan
Data warehouse meningkatkan produktifitas dari pengambil keputusan
perusahaan dengan membuat integrasi database yang konsisten, berorientasi
subject dan historical data. Data warehouse mengintegrasikan data dari banyak
sistem yang tidak kompatibel menjadi suatu bentuk yang menyediakan satu
tampilan yang konsisten mengenai perusahaan. Dengan mentransformasikan
data menjadi informasi yang berguna, data warehouse mengijinkan si
pengambil keputusan untuk melakukan analisis lebih sesuai dengan kenyataan ,
akurat dan konsisten.
2. Potensi ROI (Return On Investment) yang besar
Suatu perusahaan akan mengeluarkan sumber daya yang cukup besar
untuk mengimplemtasikan data warehouse dan pengeluaran yan berbeda-beda
sesuai dengan variasi solusi teknikal yang akan diterapkan pada perusahaan.
Bagaimana pun juga. Suatu studi oleh International Data Corporation (IDC)

9
pada tahun 1996 melaporkan bahwa rata-rata tiga tahun return of investment
(ROI) dalam data warehouse mencapai 401% dengan lebih dari 90% dari
perusahaan yang disurvei mencapai lebih dari 40% ROI, setengah dari
perusahaan mencapai lebih dari 160% ROI, dan seperempat lebih mendapat
lebih dari 600% ROI (IDC, 1996);
3. Competitive Advantage
Return on investment yang besar dari perusahaan yang berhasil
mengimplementasikan suatu data warehouse adalah bukti dari sangat besarnya
competitive advantage yang dapat diperoleh dengan menggunakan teknologi in.
Competitive advantage diperoleh dengan mengijinkan si pengambil keputusan
untuk mengakses data tersembunyi yang sebelumnya tidak tersedia, tidak di
ketahui, dan tidak dimanfaatkan seperti data mengenai pelanggan, tren, dan
permintaan.
Berikut adalah contoh-contoh peluang yang ada karena ketersediaan
informasi strategic menurut Ponniah (2001):
Ketersediaan informasi strategic di salah satu bank terbesar di United
States dengan asset $250 billion memberikan kesempatan pada users untuk
membuat keputusan yang cepat untuk mempertahankan nilai mereka pada
customer.
Pada kasus organisasi pelayanan kesehatan yang besar, terjadi peningkatan
yang signifikan program-program pelayanan kesehatan yang terealisasi,
dengan hasil 22% penurunan kunjungan emergency room, 29% penurunan
terhadap pasien anak asma, diabetes dan peningkatan tingkat vaksinasi dan
lebih 100.000 performance report dibuat untuk pasien dan apoteker.
Komunitas apoteker yang bersaing dalam skala nasional dengan lebih dari
800 franchise apotik mengerti betul apa yang dibutuhkan oleh customer,
hasilnya penurunan level inventory, meningkatkan efektifitas promosi dan
marketing, meningkatkan keuntungan bagi perusahaan.

10
2.1.5 Kategori Data pada Data Warehouse
Untuk memahami data warehouse lebih dalam, ada dua aspek penting
yang harus di pahami yaitu pertama adalah memahami tipe spesifik
(classification) dari data yang akan disimpan di data warehouse dan kedua
mengenai tahapan proses dalam pembuatan data warehouse . Mengenai kategori
pada data warehouse, kategori ini diakomodasikan berdasarkan time-dependent
data sources.
Adapun klasifikasinya adalah sebagai berikut ini: (Kantardzic, 2003)
1. Old detail data (data lama)
2. Current (new) detail data (data saat ini atau baru)
3. Lightly summarize data (data yang disimpulkan secara ringan)
4. Highly summarize data (data yang disimpulkan secara berat)
5. Metadata (direktori data atau panduan tentang data)
2.1.6 Arsitektur Data Warehouse
Arsitektur dalam data warehouse mencakup pengaturan yang benar
komponen-komponen penyusun data warehouse, baik itu software ataupun
hardware. Untuk mempermudah proses pembangunan suatu data warehouse
diperlukan pemilihan arsitektur yang tepat dan pemahaman yang baik terhadap
arsitektur data warehouse. Berikut adalah komponen-komponen penyusun data
warehouse.
Pada sub bab ini ini di jelaskan mengenai arsitektur dan komponen utama
dari data warehouse (Anahory dan Murray, 1997) beserta proses tools, dan
teknologi yang berhubungan dengan data warehouse. Untuk lebih jelasnya dapat
dilihat pada Gambar 2.1 berikut ini.
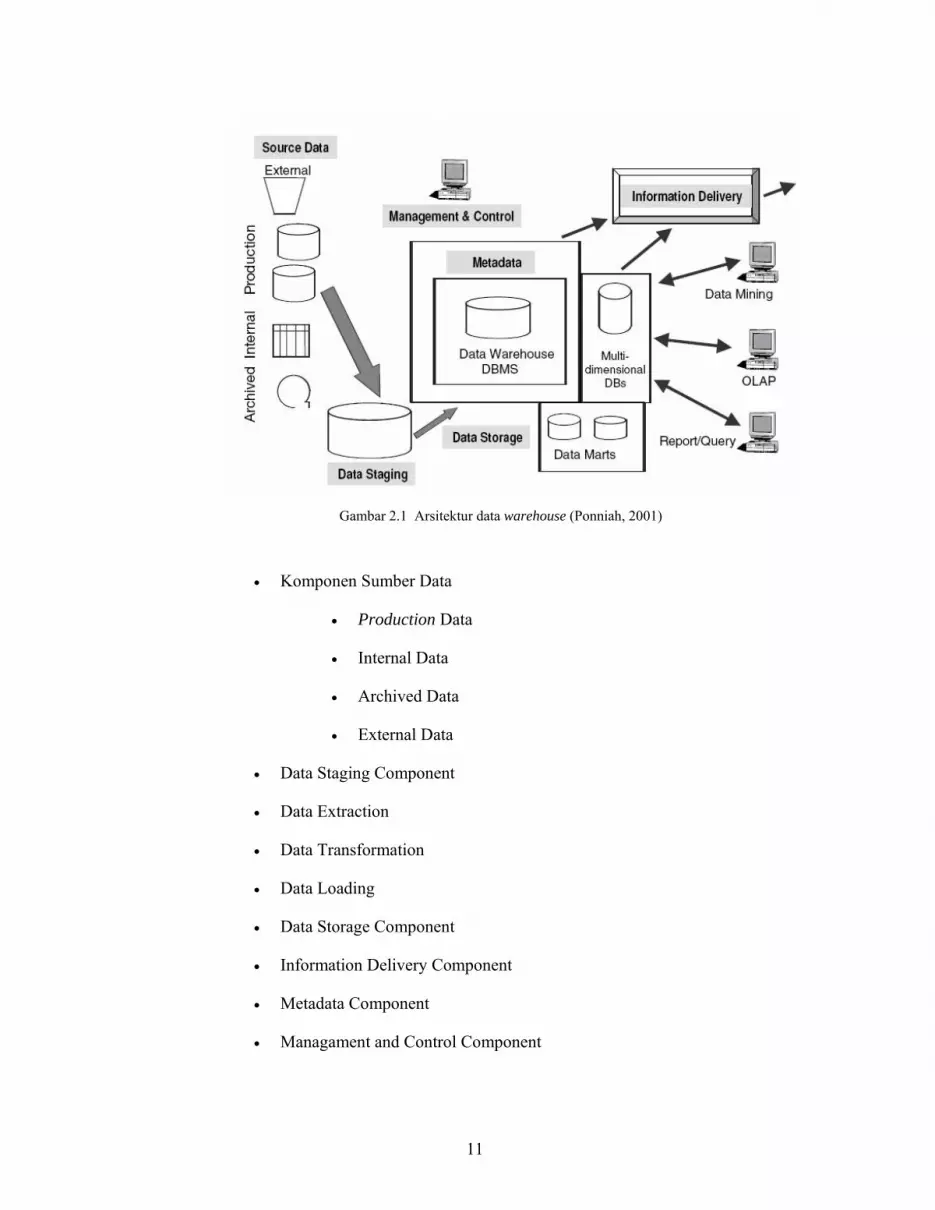
11
Gambar 2.1 Arsitektur data warehouse (Ponniah, 2001)
• Komponen Sumber Data
• Production Data
• Internal Data
• Archived Data
• External Data
• Data Staging Component
• Data Extraction
• Data Transformation
• Data Loading
• Data Storage Component
• Information Delivery Component
• Metadata Component
• Managament and Control Component

12
2.1.7 Tahapan Data Warehouse
1. Studi kelayakan, pada phase ini melakukan kajian strategic analysis,
termasuk mengevaluasi bisnis line organisasi. Studi kelayakan mencakup
mendefinisikan aktifitas-aktifitas, biaya-biaya, keuntungan, faktor-faktor
untuk kesuksesan sistem dimasa yang akan datang.
2. Analisa bentuk perusahaan, pengertian/pengetahuan bisnis yang
dijalankan dan mengidentifikasi kebutuhan bisnis (business requirements
identification).
3. Perancangan arsitektur data warehouse, arsitektur logic dan arsitektur
fisik. Tahap ini dilakukan setelah komponen-komponen dalam organisasi
didefinisikan terlebih dahulu.
4. Pemilihan teknologi sebagai solusi, mengidentifikasi teknologi-teknologi
yang mungkin di gunakan untuk implemetasi arsitektur data dan arsitektur
aplikasi dan juga untuk arsitektur sistem support.
5. Perencanaan iterasi project, implementasi data warehouse dengan satu
subject area dalam satu waktu yang diukur dengan skala prioritas dan
kebutuhan bisnis.
6. Detail designing (data warehouse modeling), adalah pemodelan data
warehouse secara lengkap.
Memilih tahapan atau proses yang tepat untuk mengkonstruksi data
warehouse adalah langkah yang kritis dalam pembuatan suatu data warehouse.
Data pada data warehouse harus distandarisasi terlebih dahulu sebelum
dimasukkan. Proses yang digunakan dalam memproses data sebelum dimasukkan
ke dalam suatu data warehouse adalah proses ETL (extract, transform and load).
Penjelasan dari masing-masing adalah sebagai berikut;
1. Extract
Proses extract adalah proses mengekstrak (extracting) dan pengambilan data
dari sumber pada sistem untuk diload ke data warehouse. Sumber data dapat

13
diperoleh secara alternatif melalui ODS (Operational Data Storage). Data harus
dikonstruksi ulang sebelum dimasukkan ke dalam data warehouse.
Proses konstruksi ini melibatkan proses:
a) Cleansing data, yaitu proses pembersihan data kotor. Kotor dalam hal ini
adalah data berkualitas rendah seperti ketidakkonsistenan penulisan nama,
kode id, duplikasi data, data tidak lengkap dan lain-lain.
b) Restrukturisasi data pada data warehouse untuk memahami kebutuhan
yang ada. Contoh: penambahan atau pengurangan fields dan denormalisasi
data
c) Memastikan sumber data konsisten dengan data yang sudah ada di dalam
data warehouse
2. Transform
Proses transform adalah proses pengubahan data, dimana dat yang
diperoleh dari proses extract (dalam format operasional) menjadi data dalam
bentuk data warehouse. Proses transform ini melibatkan proses:
1. Summarizing the data, dengan cara pemilihan (selection), proyeksi
(projecting) , penggabungan (joining), normalisasi (normalization),
agregasi (aggregation) dan grouping relasional data menjadi views
yang lebih nyaman dan berguna bagi pengguna.
2. Packaging the data, dengan mengkonversi detail data atau
summarized data menjadi format yang lebih berguna seperti
spredsheets, text documents, private database , dan lainnya.
Terdapat dua cara transformasi yaitu dengan menggunakan fungsi record-
level, dan fungsi field-level. Fungsi record-level melibatkan proses
Summarizing the data, sedangkan fungsi field-level adalah single-field dan
multi-field. Transformasi single-field mengubah satu field menjadi field yang
lain. Berbeda dengan multi-field dimana satu data atau lebih diubah menjadi
field baru. Gambar mengenai single-field dan multi-field dapat dilihat pada
Gambar 2.2 dan 2.3.

14
ID NAME ADDRESS
ID NAME CITY
Gambar 2.2 – Contoh transformasi single-field (Zain, 2008)
ID FIRST NAME MIDDLE
NAME
LAST NAME TITLE
ID NAME TITLE ADDRESS PHONE
Gambar 2.3 – Contoh transformasi multi-field (Zain, 2008)
GEGER KALONG BANDUNG
BANDUNG
Concatenate

15
3. Load
Proses load adalah proses tahapan terakhir dari proses ETL. Pada proses
ini akan dilakukan proses pemuatan data dari proses transform ke dalam suatu
data warehouse. Pada proses ini dilakukan juga proses indexing untuk
memberikan indeks ke masing-masing data untuk mempercepat proses query.
Terdapat dua mode loading ke dalam data warehouse yaitu refresh dan update.
Mode refresh yaitu proses menuliskan kembali keseluruhan data di dalam data
warehouse pada suatu interval waktu. Sedangkan untuk mode update yaitu suatu
proses untuk meng-update (tidak menghapus atau menimpa data lain) data yang
berubah ke tempat tujuan pada data warehouse. Mode refresh digunakan pertama
kali ketika data warehouse berjalan dan hendak dimuat, sedangkan mode update
umumnya digunakan ketika pemeliharaan data atau ketika data warehouse
sedang running.
2.1.8 Desain Data Warehouse
Untuk memulai pembuatan data warehouse database harus
memperhatikan keperluan yang utama dan memilih data yang harus didahulukan
terlebih dahulu, baru setelah itu bisa diperoleh komponen-komponen database
dari data warehouse adalah dimensional modelling (DM). Pengertian dari
dimensional modeling adalah suatu teknik desain secara logikal yang memiliki
sasaran untuk mempresentasikan data dengan standar, bentuk intuitif yang
mengijinkan akses secara sangat cepat. Setiap tabel dimensional model memiliki
komposisi dari satu tabel dengan composite key yang dinamakan fact table dan
sekumpulan set tabel yang lebih kecil yang dinamakan dimension table.
Dimensional modelling memiliki beberapa struktur skema, yaitu:
Skema bintang (Star Schema)
Struktur logical yang memiliki fact table mengandung data fakta
posisi tengah, dikelilingi oleh dimension tables yang mengandung
referensi data (yang bisa didenormalisasi). Contoh dapat dilihat pada
Gambar 2.4

16
Gambar 2.4 Star Schema (Ponniah, 2001)
Skema bola salju (snowflake schema)
Snowflake schema merupakan perluasan dari skema bintang
dengan tambahan beberapa tambahan tabel dimensi yang tidak
berhubungan secara langsung dengan tabel fakta. Tabel dimensi tersebut
berhubungan dengan tabel dimensi yang lain. Skema ini memperbolehkan
dimensi memiliki dimensi.
Varian dari star schema dimana tabel dimensi tidak mengandung
denormalisasi data. Sebagai contoh kita bisa melakukan normalisasi
location data(atribut city, region, dan country) pada branch di dimension
table dari 2.4 untuk membuat dimension tables dari property sales schema
ditampilkan pada Gambar 2.5

17
Gambar 2.5 Snow flake Schema (Ponniah, 2001)
2.2 Data Mining
2.2.1 Definisi Data Mining
Data mining adalah suatu proses mengekstraksi secara valid, sebelumnya
belum diketahui, komprehensif dan informasi yang dapat memberikan aksi dari
database besar dan menggunakannya untuk membuat keputusan bisnis yang
krusial (Simoudis, 1996). Data mining berhubungan dengan analisis dari data dan
penggunaan teknik software untuk menemukan pola yang tersembunyi dan tidak
diharapkan dan relasinya dalam bentuk set suatu data. Fokus dari data mining
adalah memunculkan informasi yang tersembunyi dan tidak diharapkan. Informasi
yang tersembunyi tersebut dapat memberikan nilai tambah pada bisnis
perusahaan. Selain alasan diatas terdapat pula alasan-alasan lain mengapa
diperlukan penggunaan data mining berikut ini;

18
• Data yang tersedia berjumlah sangat besar
Dalam dekade terakhir ini, harga dari perangkat keras terutama hardisk
telah turun secara drastis. Disamping itu perusahaan telah mengumpulkan
sejumlah data yang sangat besar dari banyak aplikasi yang dimiliki.
Dengan sejumlah data ini, perusahaan melakukan eksplorasi data untuk
mencari pola tersembunyi sebagai panduan untuk membantu strategi bisnis
yang akan dijalankan
• Kompetisi yang meningkat
Kompetisi yang ada sangat tinggi sebagai hasil dari marketing dan dengan
adanya saluran distribusi seperti internet dan telekomunikasi. Perusahaan
akan menghadapi kompetisi dunia, karena itu kunci suksesnya bisnis
adalah kemampuan untuk membina pelanggan yang sudah ada dan
mendapatkan yang baru. Teknologi data mining dapat membantu
perusahaan untuk menganalisa faktor yang mempengaruhi hal tersebut.
• Kemampuan Teknologi
Teknologi data mining sebelumnya hanya ada pada lingkungan akademik
tetapi saat ini banyak teknologi seperti ini semakin canggih dan siap untuk
diterapkan pada industri. Algoritma yang ada semakin akurat, efisien dan
dapat menangani komplikasi data yang meningkat. Sebagai tambahan,
data mining application programming interfaces (APIs) telah
distandarisasi, sehingga mengijinkan pengembang untuk membuat aplikasi
data mining yang lebih baik.
2.2.2 Teknik Data Mining
Ada empat operasi utama yang dapat dilakukan pada teknik data mining
yaitu predictive modelling, database segmentation, link analysis, dan deviation
detection. Meskipun salah satu dari operasi utama dapat digunakan untuk
mengimplementasikan aplikasi bisnis apapun, ada keterhubungan yang ditemukan
antara aplikasi dan operasi yang bersangkutan. Teknik adalah implementasi secara
spesifik dari operasi data mining. Bagaimanapun juga masing-masing operasi
memiliki kekuatan dan kelemahannya masing-masing. Untuk lebih jelasnya

19
mengenai teknik yang berasosiasi dengan salah satu dari empat operasi utama
data mining (Cabena 1997 dalam Zein 2008) dapat dilihat pada Tabel 2.1 berikut
ini:
Operations Data Mining Techniques
Predictive modelling Classification
Value Prediction
Database segmentation Demographic clustering
Neural clustering
Link analysis Association discovery
Sequential pattern discovery
Similar time sequence discovery
Deviation detection Statistics
Visualization Tabel 2.1 Tabel operasi data mining dan teknik yang digunakannya (Zein, 2008)
2.2.2.1 Predictive Modeling
Predictive Modeling menggunakan pendekatan generalisasi dari ’real
world’ dan kemampuan menempatkan data baru ke kerangka utama. Predictive
modeling bisa digunakan untuk menentukan karakteristik (model) mengenai data
set. Model ini dikembangkan dengan menggunakan supervised learning yang
terdiri dari dua fase: training dan testing. Training membuat model menggunakan
sampel besar dari data yang dinamakan training set, sedangkan testing mencoba
model baru, data yang sebelumnya tidak terlihat untuk menentukan keakurasian
dan karakteristik performa fisik. Ada dua teknik yang berasosiasi dengan
predictive modeling: classification dan value prediction.
Classification digunakan untuk membangun kelas spesifik yang telah
ditentukan sebelumnya untuk masing-masing record di database, dari suatu set
terbatas ke nilai kelas yang memungkinkan. Ini adalah dua spesialisasi dari
klasifikasi: tree induction dan neural induction. Contoh dari klasifikasi
menggunakan induction ada pada Gambar 2.7. Pada contoh ini menggambarkan

20
bagaimana institusi keuangan memuruskan kelayakan calon nasabahnya layak
diberikan pinjaman atau tidak. Predictive model telah menentukan bahwa dua
variabel yang digunakan yaitu: range pendapatan applicant. catatan kriminal dan
lama waktu selama bekerja. Model ini membantu menentukan applicant yang
layak mendapatkan pinjaman, jika applicant memliki pendapatan antara $30-$70
dan bekerja kurang dari setahun ditempat kerja terkahir, maka applicant ini tidak
boleh diberikan pinjaman.
Gambar 2.6 Clasification menggunakan tree induction
(http://www.cse.unsw.edu.au/~billw/cs9414/notes/ml/06prop/id3/id3.html)
Contoh Classification dengan mengunakan neural induction ditunjukkan
pada Gambar 2.7
Gambar 2.7 Clasification menggunakan neural network (Connonly and Begg, 2005)
Customer renting property >2 years
Customer age >25 years
0.5
0.3
0.3
0.6
0.7
0.4
Class (Rent or buy property)

21
Pada kasus ini, classification dari data diperoleh dengan menggunakan nueral
network. Neural network mengadung koleksi dari titik-titik yang terkoneksi
dengan input, output, dan processing pada masing-masing titik. Antara lapisan
input dan output mungkin sebagai sejumlah lapisan proses tersembunyi. Masing-
masing proses unit dalam satu lapisan saling berhubungan dengan proses unit di
lapisan berikutnya oleh weighted value yang menggambarkan kekuatan hubungan.
2.2.2.2 Database Segmentation dengan Clustering
Berbeda dengan clasification dimana kelas data telah ditentukan
sebelumnya, clustering melakukan pengelompokan data tanpa berdasarkan kelas
data tertentu. Bahkan clustering dapat dipakai untuk memberikan label pada kelas
data yang belum diketahui itu. Karena itu clustering sering digolongkan sebagai
metode unsupervised learning.
Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota
satu kelas dan meminimumkan kesamaan antar kelas/cluster. Clustering dapat
dilakukan pada data yang memiliki beberapa atribut yang dipetakan sebagai ruang
multidimensi. Ilustrasi dari clustering dapat dilihat di Gambar 2.8 dimana lokasi,
dinyatakan dengan bidang dua dimensi, dari pelanggan suatu toko dapat
dikelompokkan menjadi beberapa cluster dengan pusat cluster ditunjukkan oleh
tanda positif (+).
Gambar 2.8 Contoh Clustering (Ponniah, 2001)

22
Beberapa kategori algoritma clustering yang banyak dikenal adalah metode
partisi dimana pemakai harus menentukan jumlah k partisi yang diinginkan lalu
setiap data dites untuk dimasukkan pada salah satu partisi, metode lain yang telah
lama dikenal adalah metode hierarki yang terbagi dua lagi : bottom-up yang
menggabungkan cluster kecil menjadi cluster lebih besar dan top-down yang
memecah cluster besar menjadi cluster yang lebih kecil. Kelemahan metode ini
adalah bila salah satu penggabungan/pemecahan dilakukan pada tempat yang
salah, tidak dapat didapatkan cluster yang optimal. Pendekatan yang banyak
diambil adalah menggabungkan metode hierarki dengan metode clustering .
2.2.2.3 Link Analysis
Link analysis memiliki sasaran untuk membangun jaringan yang
dinamakan associations antara individual records atau sets of records di dalam
database. Ada tiga spesialisasi dari analysis jaringan: associations discovery,
sequential pattern discovery dan similar time sequence discovery. Associations
discovery digunakan untuk menemukan item yang menyatakan keberadaan dari
item yang lain didalam event yang sama. Sequencial pattern discovery
menemukan pattern antara event seperti keberadaan satu set dari kelompok item
yang diikuti oleh satu set dari sekelompok item yang diikuti oleh satu set dari
sekelompok item didalam database dalam beberapa periode waktu. Similar time
sequence discovery digunakan seperti contoh: dalam discovery of links antara dua
set data yang bergantung terhadap waktu dan berdasarkan derajat kesamaan antara
pola dari suatu seri waktu.
Association Rule Mining merupakan bagian dari Frequent Pattern Mining.
Frequent Pattern Mining merupakan salah satu task data mining yang sangat
penting. Task ini mencari hubungan/relasi, assosiasi, dan korelasi dalam data.
Pengetahuan yang dihasilkan juga sangat berguna untuk klasifikasi, clustering,
dan task data mining yang lain. Selain Association Rule Mining, masih ada
Sequential Pattern, dan Structured Pattern yang termasuk dalam Frequent
Pattern Mining. Association Rule Mining dapat juga disebut Frequent Itemset
Mining karena pola yang dihasilkan adalah pola item yang sering muncul
bersamaan dalam sebuah database. Contoh klasik yang sering digunakan untuk

23
menjelaskan Association Rule Mining adalah market basket analisis. Pada market
basket analisis, kita menganalisa kebiasaan konsumen dalam membeli barang.
Secara umum, Association Rule Mining dapat dibagi menjadi dua tahap
yaitu pencarian Frequent Itemset (Frequent Itemset Candidate Generation) dan
Rule Generation. Pada tahap Frequent Itemset Candidate Generation terdapat
beberapa kendala yang harus dihadapi untuk memperoleh Frequent Itemset seperti
banyaknya jumlah kandidat yang memenuhi minimum support, dan proses
perhitungan minimum support dari Frequent Itemset yang harus melakukan scan
database berulang-ulang. Pendekatan apriori sangat membantu dalam mengurangi
jumlah kandidat Frequent Itemset.
Dengan menggunakan FP-growth, dapat dilakukan Frequent Itemset
Mining tanpa melakukan candidate generation. FP-growth menggunakan struktur
data FP-tree. Dengan menggunakan cara ini scan database hanya dilakukan dua
kali saja, tidak perlu berulang-ulang. Data akan direpresentasikan dalam bentuk
FP-tree. Setelah FP-tree terbentuk, digunakan pendekatan divide and conquer
untuk memperoleh Frequent Itemset. FP-tree merupakan struktur data yang baik
sekali untuk Frequent Pattern mining. Struktur ini memberikan informasi yang
lengkap untuk membentuk Frequent Pattern. Item-item yang tidak frequent
(infrequent) sudah tidak ada dalam FP-tree.
2.2.2.4 Deviation Detection
Deviation detection adalah teknik yang relatif masih baru dalam teknik
data mining. Namun Deviation detection sering kali menjadi sumber penemuan
baru karena teknik ini mengidentifikasi outlier yang mengekspresikan deviasi dari
penemuan sebelumnya. Operasi ditampilkan menggunakan teknik statistics dan
visulazation atau sebagai suatu produk dari data mining. sebagai contoh regresi
linier memfasilitasi pengidentifikasian data dalam teknik visualisasi modern yang
menampilkan kesimpulan dan representasi grafik yang membuat deviasi mudah
untuk dideteksi.

24
2.2.3 Tahap-Tahap Data Mining
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi
beberapa tahap yang diilustrasikan di Gambar 2.9. Tahap-tahap tersebut, bersifat
interaktif dimana pemakai terlibat langsung atau dengan perantaraan knowledge
base.
Gambar 2.9 Tahap-tahap data mining (Zein, 2008)
• Pembersihan data (untuk membuang data yang tidak konsisten dan noise)
Pada umumnya data yang diperoleh, baik dari database suatu
perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak
sempurna seperti data yang hilang, data yang tidak valid atau juga hanya
sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak
relevan dengan hipotesa data mining yang kita miliki. Data-data yang tidak
relevan itu juga lebih baik dibuang karena keberadaannya bisa mengurangi
mutu atau akurasi dari hasil data mining nantinya. ”Garbage in garbage
out” (hanya sampah yang akan dihasilkan bila yang dimasukkan juga

25
sampah) merupakan istilah yang sering dipakai untuk menggambarkan
tahap ini. Pembersihan data juga akan mempengaruhi performa dari sistem
data mining karena data yang ditangani akan berkurang jumlah dan
kompleksitasnya.
• Integrasi data (penggabungan data dari beberapa sumber)
Tidak jarang data yang diperlukan untuk data mining tidak hanya
berasal dari satu database tetapi juga berasal dari beberapa database atau file
teks. Integrasi data dilakukan pada atribut-atribut yang mengidentifikasikan
entitas-entitas yang unik seperti atribut nama, jenis produk, nomor
pelanggan dsb. Integrasi data perlu dilakukan secara cermat karena
kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang
dan bahkan menyesatkan pengambilan aksi nantinya. Sebagai contoh bila
integrasi data berdasarkan jenis produk ternyata menggabungkan produk
dari kategori yang berbeda maka akan didapatkan korelasi antar produk
yang sebenarnya tidak ada. Dalam integrasi data ini juga perlu dilakukan
transformasi dan pembersihan data karena seringkali data dari dua database
berbeda tidak sama cara penulisannya atau bahkan data yang ada di satu
database ternyata tidak ada di database lainnya.
Hasil integrasi data sering diwujudkan dalam sebuah data warehouse
karena dengan data warehouse, data dikonsolidasikan dengan struktur
khusus yang efisien. Selain itu data warehouse juga memungkinkan tipe
analisa seperti OLAP. Untuk membangun data warehouse juga tersedia
paket-paket software yang mapan seperti database-nya dan piranti
pendukung yang sering disebut sebagai ETL (Extract Transform Loading).
Banyak paket software ETL sudah mencakup tahap pembersihan dan
integrasi data.
• Transformasi data (data diubah menjadi bentuk yang sesuai untuk di-
mining)
Beberapa teknik data mining membutuhkan format data yang khusus
sebelum bisa diaplikasikan. Sebagai contoh beberapa teknik standar seperti
analisis asosiasi dan clustering hanya bisa menerima input data kategorikal.
Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi

26
menjadi beberapa interval. Proses ini sering disebut binning. Disini juga
dilakukan pemilihan data yang diperlukan oleh teknik data mining yang
dipakai. Transformasi dan pemilihan data ini juga menentukan kualitas dari
hasil data mining nantinya karena ada beberapa karakteristik dari teknik-
teknik data mining tertentu yang tergantung pada tahapan ini.
• Aplikasi teknik data mining
Aplikasi teknik data mining sendiri hanya merupakan salah satu
bagian dari proses data mining. Ada beberapa teknik data mining yang
sudah umum dipakai. Kita akan membahas lebih jauh mengenai teknik-
teknik yang ada di seksi berikutnya. Perlu diperhatikan bahwa ada kalanya
teknik-teknik data mining umum yang tersedia di pasar tidak mencukupi
untuk melaksanakan data mining di bidang tertentu atau untuk data tertentu.
Sebagai contoh akhir-akhir ini dikembangkan berbagai teknik data mining
baru untuk penerapan dibidang bioinformatika seperti analisa hasil
microarray untuk mengidentifikasi DNA dan fungsi-fungsinya.
• Evaluasi pola yang ditemukan (untuk menemukan yang menarik/bernilai)
Dalam tahap ini hasil dari teknik data mining berupa pola-pola
yang khas maupun model prediksi dievaluasi untuk menilai apakah
hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh
tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti :
menjadikannya umpan balik untuk memperbaiki proses data mining,
mencoba teknik data mining lain yang lebih sesuai, atau menerima hasil
ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
Ada beberapa teknik data mining yang menghasilkan hasil analisa
berjumlah besar seperti analisis asosiasi. Visualisasi hasil analisa akan
sangat membantu untuk memudahkan pemahaman dari hasil data mining.
• Presentasi pola yang ditemukan untuk menghasilkan aksi
Tahap terakhir dari proses data mining adalah bagaimana
memformulasikan keputusan atau aksi dari hasil analisa yang didapat. Ada
kalanya hal ini harus melibatkan orang-orang yang tidak memahami data

27
mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan
yang bisa dipahami semua orang adalah satu tahapan yang diperlukan
dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa
membantu mengkomunikasikan hasil data mining.
2.3 Bisnis Airline dan Data Mining
Pelayanan terhadap penumpang yang bersifat individu sebagai hasil dari
segmentasi terhadap pelanggan harus dapat dijelaskan dan nilai tambahnya juga
harus dapat dibuktikan. Hasil segmentasi terhadap penumpang adalah
mendapatkan pemahaman yang lebih baik mengenai konsumen airline. Pritscher
(2001) mengatakan, peluang data mining dalam industri airline dapat dilakukan
dengan memilah-milah customer yang katagori pembagian tersebut dapat
dilakukan berdasarkan:
1 Region : Kebutuhan penumpang akan terlayani dengan lebih baik jika
diketahui geografi yang disukai diketahui dengan baik atau tempat
penumpang. Penumpang dapat dipilah-pilah berdasarkan asal dan tujuan
perjalanan atau branch office yang terdekat dengan tempat tinggal
penumpang.
2 Market: Dari sudut pandang sales, market dibedakan menjadi market
home, market pihak ketiga yang dilayani karena penumpang dari airline
lain (connecting passenger). Penumpang dapat dipilah berdasarkan market
yang mereka gunakan dan tempat tinggal mereka.
3 Travel Preference: Agar dapat melayani penumpang dengan penawaran
yang tepat, diperlukan perjananan/travel yan bagaimana yang diinginkan
oleh penumpang. Penumpang dapat bedakan berdasarkan rasio dari
penerbangan longhaul (intercontinental) dan penerbangan shorthaul,
berdasarkan rasio dari tiket yang hight fare dan low fare juga kombinasi
keduanya.
4 Travel Behaviour: Salah satu informasi penting pelanggan adalah jenis
tiket yang dibeli secara berkala. Tipe tiket ini terkait erat dengan tujuan

28
perjalanan misalnya untuk berlibur atau untuk perjalanan bisnis. Data
penting yang tercatat adalah booking class yang digunakan untuk
penerbangan, sedangkan waktu dan harga tiket tidak terekam karena
tergantung pada ketersediaan dan waktu.
Menurut McIlroy dan Barnett (2000) dalam Wijaya (2005), biaya untuk
mendapatkan konsumen yang baru dapat mencapai 5 kali dari mempertahankan
konsumen yang sudah ada. Keanggotaan dalam loyalty program dibagi menjadi 2
jenis, open dan limited. Limited loyalty tidak dapat dikuti oleh semua orang, ada
mekanisme tertentu untuk menjadi anggota limited ini seperti membayar uang
pendaftaran dan kadang-kadang disertai syarat-syarat lainnya seperti melakukan
pmbelian dengan volume tertentu atau memiliki penghasilan tertentu (Wijaya,
2005).
2.3.1 Loyalty Program dan Frequent Flyer Program
Menarik dan mempertahanan konsumen memerlukan biaya yang tinggi,
khususnya untuk industri jasa. Loyalitas didefinisikan Oliver (Celuch dan
Goodwin, 1999) sebagai komitmen yang tinggi untuk membeli kembali suatu
produk atau jasa yang disukai di masa mendatang, disamping pengaruh situasi dan
usaha pemasar dalam merubah perilaku. Dengan kata lain konsumen akan setia
untuk melakukan pembelian ulang secara terus-menerus.
Menurut Shoemaker dan Lewis (1998) dalam Wijaya (2005), loyalty
program adalah adalah program yang ditawarkan pada konsumen untuk
membangun ikatan terhadap merek/brand tertentu. Lebih lanjut Wijaya (2005)
menyatakan bahwa sebagian besar konsumen melakukan pembelian ulang dalam
rangka menambah keuntungan yang ditawaran kemudian redeem dengan
menggunakan reward yang telah dikumpulkan. Konsumen loyal terhadap
program, bukan kepada perusahaannya. Tidak ada hubungan langsung antara
program dengan ikatan emosional konsumen terhadap perusahaan. Hubungan
emosional dapat terbentuk salah satunya dengan memberikan pelayanan yang
baik.

29
Lebih dalam lagi Gramer dan Brown (Utomo, 2006) memberikan definisi
mengenai loyalitas (loyalitas jasa), yaitu derajat sejauh mana seorang konsumen
menunjukkan perilaku pembelian berulang dari suatu penyedia jasa, memiliki
suatu desposisi atau kecenderungan sikap positif terhadap penyedia jasa, dan
hanya mempertimbangkan untuk menggunakan penyedia jasa ini pada saat
muncul kebutuhan untuk memakai jasa ini. Dari definisi yang disampaikan
Gramer dan Brown, konsumen yang loyal tidak hanya seorang pembeli yang
melakukan pembelian berulang, tetapi juga mempertahankan sikap positif
terhadap penyedia jasa.
Frequent flyer program (FFP) adalah loyalty program yang ditujukan bagi
para pengguna jasa penerbangan. Airline pengelola FFP memberikan poin reward
pada konsumen (disebut miles) yang bisa digunakan untuk membeli tiket (Emch,
2007). Ada 3 alasan bagaimana FFPs dapat mengurangi ongkos produksi dalam
dunia penerbangan (Adrian Emch , 2007);
1. Mempertahankan konsumen yang sudah jadi pelanggan lebih murah
dibandingkan dengan mencari pelanggan baru.
2. Pelanggan yang setia lebih menguntungkan dari pada pelangggan baru
3. FFP dapat digunakan untuk meningkatkan pelayanan melalui personalisasi
dari setiap service yang diberikan untuk penumpang.
Pada prinsipnya setiap tiket gratis yang dibeli dengan menggunakan
mileage yang dimiliki oleh anggota FFP adalah tiket untuk tempat duduk yang
kosong. Tidak ada biaya yang harus dikeluarkan untuk tiket yang dikeluarkan,
hanya pada tataran praktis, hal ini belum dikaji mekanismenya. Di GFF sendiri,
setiap tiket yang dibeli oleh penumpang ada prosentase bagian awardnya.

30
2.4 Tools Development
2.4.1 Pentaho Data Integration (PDI/Kettle)
Kettle adalah aplikasi ETL (Extract, Transformation and Load). Aplikasi
Kettle sendiri merupakan bagian dari aplikasi BI Pentaho. Sebelumnya proyek ini
berdiri sendiri dan kemudian diakuisisi oleh Pentaho pada tahun 2006.
Kettle terdiri dari 4 aplikasi, yaitu :
Spoon, yaitu aplikasi grafis berbasis swing yang digunakan untuk
merancang file skema job dan transformation
Pan, yaitu script yang digunakan untuk menjalankan file skema
transformation melalui terminal / command line
Kitchen, yaitu script yang digunakan untuk menjalankan file skema job
melalui terminal / command line
Carte, yaitu temporary web server yang digunakan untuk mengeksekusi
job/transformation secara cluster atau parallel
Kesemua aplikasi tersebut di atas dijalankan melalui shell atau batch script yang
berkaitan. Fitur-fitur Kettle antara lain :
• Memiliki utilitas grafik yang dapat digunakan merancang skema step atau
langkah kontrol dan transformasi data.
• Multi platform - karena dikembangkan di atas Java yang notabene
berjalan di banyak platform.
• Bersifat concurrent, dalam arti row-row data diambil oleh suatu step dan
diserahkan ke step lain secara parallel. Artinya tidak menunggu sampai
suatu koleksi data diambil secara keseluruhan terlebih dahulu.
• Scalable - dapat beradaptasi dengan penambahan kapasitas memori RAM
atau pun storage (scale up) dan dapat beradaptasi dengan penambahan
node komputer atau cluster lain (scale out).

31
2.4.2 Mondrian
Mondrian adalah web aplikasi yang berbasis open source. Mondrian
memiliki fitur-fitur untuk melakukan drill-down, drill-up seperti halnya tools
untuk presentasi data warehouse lainnya.
2.5 Kebutuhan Data Mining dalam Frequent Flyer Program
Frequent Flyer Program menyimpan data-data anggota yang juga
pelanggan setia dari penerbangannya. Data penerbangan anggota Frequent Flyer
adalah sekedar tumpukan data operasional bagi airline yang memiliki sistem
tersebut. Infrastruktur IT untuk operasional Frequent Flyer dapat mudah ditiru
oleh airline lainnya dan saat itu Frequent Flyer bukan lagi menjadi pembeda bagi
sebuah airline dari pesaingnya karena Frequent Flyer Program sudah menjadi
komoditas yang mudah dimiliki oleh setiap industri penerbangan.
Penggunaan data yang dimiliki secara ekstensif dapat menjadi keunggulan
kompetitif bagi suatu airline. Hal ini menjadikan airline tersebut berbeda dengan
airline lainnya ketika data tersebut diolah dan dianalisa dengan metode statistik
atau teknik data mining lainnya dalam BI. Hasil dari analisa tersebut sulit ditiru
oleh perusahaan lain dan bisa menjadi keunggulan kompetitif bagi perusahaan
yang bersangkutan.
Sebagai gambaran adalah promo-promo yang diadakan oleh sebuah airline
bisa menggunakan data anggota FFP agar promo tersebut bisa tepat sasaran.
Airline juga bisa membuat jadwal penerbangan dan memprediksi penerbangan
dari mana kemana yang pada waktu tertentu seperti peak season dapat lebih
optimal. Juga penggunaan data FFP untuk memberikan personalisasi untuk setiap
service yang diberikan airline.

32
BAB III
METODOLOGI PENELITIAN
Metodologi yang digunakan dalam penelitian terbagi dalam beberapa tahap,
yaitu: Pengumpulan Data, Menelaah Kebutuhan Bisnis dan Informasi, Menelaah
Data dan Perancangan Data Warehouse, dan terakhir Implementasi Data Mining.
3.1 Pengumpulan Data
Tahap pertama dalam penelitian adalah pengumpulan data. Untuk
keperluan tersebut penulis melakukan pengumpulan data dengan cara melakukan
observasi ke obyek penelitian dan melakukan pengkajian dokumen atau literatur
untuk menggali dokumen organisasi yang berkaitan, struktur organisasi, tugas dan
gambaran proses bisnisnya.
Dalam penelitian ini penulis melakukannya dengan pendekatan top-down,
pendekatan ini dimulai dengan mendefinisikan sasaran dan kebijakan organisasi
kemudian dilakukan analisis kebutuhan informasi lalu turun ke pemrosesan
transaksi. Sebelum mulai membuat data model untuk data warehouse, sebaiknya
spesifikasi kebutuhan informasi dan data yang tersedia (sumber data) sudah harus
diketahui. Tahap pertama adalah tahap pengumpulan data. Input dari tahap ini
adalah permasalahan-permasalahan dalam sistem operasional GFF, salah satunya
adalah masalah dalam modul reporting yang mempengaruhi performance sistem
operasional GFF.
3.2 Kebutuhan Bisnis dan Informasi
Tahap ini dilakukan analisis lebih dalam mengenai kebutuhan bisnis dan
informasi yang diharapkan oleh manajemen perusahaan. Data yang telah
dikumpulkan sebelumnya akan dijadikan sebagai masukan dalam proses analisis
terhadap kebutuhan bisnis dan informasi tersebut.

33
3.3 Perancangan Data Warehouse
Data diekstrak dari database operasional dan sumber eksternal, dibersihkan
untuk meminimalisasi error dan mengisikan informasi yang kurang jika
dimungkinkan, dan ditransformasikan untuk memperbaiki ketidakcocokan
semantik. Mentransformasikan data biasanya dilakukan dengan mendefinisikan
view relational pada tabel dalam sumber data. Loading data terdiri dari
mematerialisasi view dan menyimpannya dalam data warehouse. Data yang
dibersihkan dan ditransformasikan akhirnya di-load ke dalam data warehouse.
Berkaitan dengan volume data yang besar, loading merupakan proses yang
lambat. Oleh karena itu paralelisme penting untuk loading warehouse. Setelah
data di-load ke dalam warehouse, pengukuran tambahan harus dilakukan untuk
menjamin data dalam warehouse di-refresh secara periodik untuk merefleksikan
pembaruan sumber data dan secara periodik membuang data lama (mungkin
kedalam media pengarsipan)
Spesifikasi kebutuhan fungsional informasi secara teknis menyatakan data
apa yang harus disimpan didalam data warehouse untuk memenuhi analisa yang
akan dilakukan oleh pemakai. Ini dapat dinyatakan dalam bentuk pertanyaan yang
harus dapat dijawab oleh data didalam data warehouse, seperti: berapa jumlah
member GFF yang mendaftar pada bulan September hingga Desember, perbulan,
pertahun. Berapa member aktif yang melakukan penerbangan dibulan Desember.
Berapa jumlah member yang mengikuti promo-promo yang diselenggarakan oleh
GFF, berapa jumlah member GFF yang branch officenya di Bali, dan lain
sebagainya.
3.4 Implementasi Data Mining
Pada tahap ini informasi penting digali untuk kepentingan pengambilan
keputusan dengan menggunakan salah satu teknik data mining (clustering). Pada
tahap ini ini akan digunakan tools data mining yan sudah tersedia, yaitu
Rapidminer data mining versi Community development.

34
Proses yang dillakukan pada tahap ini adalah implementasi data mining
mengenai kebutuhan bisnis dan informasi yan telah diidentifikasi. Data mining
dilakukan untuk menggali informasi penring yang berguna bagi kepentingan
perusahaan dalam pengambilan keputusan.
Dalam bentuk flow diagram, keempat langkah metodologi penelitian
tersebut , nampak gambar 3.1 sebagai berikut :
Pengumpulan Data
Output:Rumusan masalah
Metode:Observasi ke lapangan
Output:Gambaran sistem operasional,
data dan jenis report
Metode:Kajian dokumen dan literature
wawancara
OutputProses bisnis, tujuan GFF,
organisasi
Analisa
Output:Kebutuhan bisnis
dan informasi
Perancanganan
Output:Rancangan data warehouse
Implementasi
Output:Presentasi data mining
Kesimpulan
Output:Kesimpulan dan saran
Gambar 3.1 Tahap-tahap metodologi penelitian

35
Penjelasan lebih detail dari masing-masing tahapan pada alur pengerjaan
seperti metode yang digunakan berikut hasil dari masing-masin tahapan dapat
dilihat pada Tabel 3.1 berikut ini.
Tahap Pengumpulan Data
Metode : Observasi, Studi literature Output : Rumusan masalah
Analisa Kebutuhan Informasi Bisnis
Metode : Analisa kebutuhan bisnis dan informasi Output : Kebutuhan bisnis dan informasi
Perancangan Data Warehouse
Metode : Tahapan Data Warehouse Merancang arsitektur data warehouse Menentukan tabel fakta dan tabel dimensi Melakukan proses cleansing dan ETL Melakukan perancangan OLAP Output : Rancangan data warehouse
Implementasi Data Mining
Metode : Tahapan-tahapan data mining. Output : Presentasi data mining
Menarik kesimpulan Metode :deduktif Output : kesimpulan dan saran atas hasil penelitian (Perancangan Data Warehouse & implementasi Data Mining)
Tabel 3.1 Alur Pengerjaan

36
BAB IV
PERANCANGAN DATA WAREHOUSE
Data yang disimpan dalam data warehouse adalah data historis
berorientasi subyek yang dapat mendukung proses pengambilan keputusan bagi
manajemen. Artinya data tersebut harus kita susun sedemikian rupa sehingga
dapat dianalisis menjadi berbagai informasi yang dibutuhkan manajemen saat
proses pengambilan keputusan.
Oleh karena itu, tahap pertama dari perancangan data warehouse adalah
mendefinisikan informasi-informasi apa saja yang dibutuhkan oleh manajemen.
Supaya kebutuhan ini dapat didefinisikan dengan tepat, maka pemahaman akan
peran dan tugas manajemen yang membutuhkan informasi tersebut mutlak harus
dilakukan lebih dulu
Pada tahap identifikasi ini, mengacu pada struktur organisasi didukung
oleh tipe data report yang dibutuhkan, selanjutnya setelah diidentifikasi
kebutuhan informasi, maka ditentukan sumber data yang selanjutnya dilakukan
proses ETL (extract, transform, load). Pada bagian ini dijelaskan profil
perusahaan serta langkah-langkah yang akan dilakukan dalam perancangan data
warehouse di PT Garuda Indonesia, yaitu mengenai proses identifikasi,
perencanaan secara teknis, penentuan sumber data yang digunakan dan proses
persiapan dan melalui proses ETL.
4.1 Profil Perusahaan
Perusahaan yang dijadikan objek penelitian oleh penulis dalam bentuk
perseroan terbatas yaitu PT. Garuda Indonesia. Perusahaan ini didirikan pada
tahun 1949. PT. Garuda Indonesia berkantor pusat di Jakarta.

37
4.1.1 Latar Belakang Perusahaan
Garuda Indonesia mendapatkan konsesi monopoli penerbangan dari
Pemerintah Republik Indonesia pada tahun 1950 dari Koninklijke Nederlandsch
Indie Luchtvaart Maatschappij (KNILM), perusahaan penerbangan nasional
Hindia Belanda. Garuda adalah hasil joint venture antara Pemerintah Indonesia
dengan maskapai Belanda Koninklijke Luchtvaart Maatschappij (KLM). Pada
awalnya, Pemerintah Indonesia memiliki 51% saham dan selama 10 tahun
pertama, perusahaan ini dikelola oleh KLM. Pada tahun 1954, KLM menjual
sebagian dari sahamnya ke pemerintah Indonesia. Pada mulanya, Garuda memiliki
27 pesawat terbang, staf terdidik, bandara dan jadwal penerbangan, sebagai
kelanjutan dari KNILM. Saat ini, Garuda Indonesia telah menerapkan standar
internasional sesuai dengan standar ISO 9001 – 2001.
Garuda merilis GFF pada tahun 1999 untuk penerbangan domestic yang
meluas pada tahun 2001 dengan tambahan tidak hanya domestic tapi juga
Singapura, Hongkong dan Tokyo. Kemudian di tahun-tahun selanjutnya didaerah-
daerah lainnya hingga Mekkah. GFF mengalami perubahan sistem dan
managemen pada tahun 2007. Dengan adanya kebijakan Garuda untuk efisiensi
bagian IT Garuda, maka pengelolaan GFF bersama sistem IT lainnya, yang
awalnya dikelola sendiri, menjadi dikelola oleh pihak ketiga. Pihak ketiga dalam
hal ini adalah Lufthansa Systems Indonesia, perusahaan patungan antara Garuda
dan Lufthansa Systems German. Adanya GFF bagi Garuda bertujuan untuk
menjaga marketshare dengan meningkatkan customer-nya yang loyal dan untuk
mendukung program-program promosi Garuda.
4.1.2 Visi dan Misi Perusahaan
Visi PT. Garuda Indonesia adalah menjadi perusahaan penerbangan yang
handal dengan menawarkan pelayanan berkualitas kepada masyarakat dunia
menggunakan keramahan Indonesia. Misinya adalah sebagai perusahaan
penerbangan pembawa bendera bangsa (flag carrier) Indonesia yang
mempromosikan Indonesia kepada dunia guna menunjang pembangunan ekonomi

38
nasional dengan memberikan pelayanan yang profesional dan pelayanan
penerbangan yang menguntungkan.
4.1.3 Struktur Organisasi Perusahaan
PT. Garuda Indonesia terdiri dari 6 direktorat, yang dipimpin oleh 6
Executive Vice President ; EVP Business Support & Corporate Affairs, EVP
Operations, EVP Commersial, EVP Engineering, Maintenance, EVP Finance,
EVP Strategic & IT. Berikut adalah struktur organisasi yang dipimpin oleh EVP
Commercial. Berikut adalah struktur organisasi PT. Garuda Indonesia pada level
directorate Commercial.
Gambar 4.1-Struktur Organisasi Executive Vice President

39
Gambar 4.2- Struktur Organisasi Customer Relation Management.
Berikut adalah struktur organisasi yang akan dalam ruang lingkup yang
lebih kecil sesuai dengan ruang lingkup yang telah dibatasi oleh penulis Garuda
Frequent Flyer dikelola oleh departemen Customer Relation Management. Untuk
mengetahui lebih jelasnya dapat dilihat pada gambar 4.2.
Departemen Marketing menggunakan data yang dideliver oleh
departement CRM untuk membuat promosi-promosi untuk untuk jalur
penerbangan yang penumpangnya sedikit. Departemen Revenue menggunakan
untuk menentukan harga tiket dan konversi nilai award mileage. Harga tiket yang
dijual pada penumpang, salah satu komponen penyusunnya adalah jumlah award
mileage. Baik penumpang yang member GFF ataupun bukan, membayar jumlah
yang sama terhadap tiket yang digunakannya untuk terbang.
Di dalam departemen CRM sendiri, yang menggunakan data dari GFF
adalah divisi Customer Affairs. Customer affairs berkepentingan dengan keluhan-
keluhan pelanggan dan tindak lanjut terhadap keluhan, seperti masalah bagasi
yang hilang. Unit GFF juga membuat laporan pemasukan keuangan yang berasal

40
dari anggota berbayar dan bisa juga billing partner yang digunakan oleh bagian
finance.
Kebijakan garuda untuk fokus pada core bussines penerbangan, menggeser
IT GFF untuk dikelola oleh pihak ketiga bersama dengan sistem lainnya yang
mendukung operasional penerbangan. Application Service Provider (ASP) yang
mengelola sistem GFF adalah Lufthansa Systems Indonesia, yang juga diserahi
tugas untuk mengelola service-service IT yang lain untuk garuda dan penerbangan
lainnya. Lufthansa Systems Indonesia sendiri adalah adalah shareholder antara
PT. Garuda Indonesia dan Lufthansa Systems.
4.2 Pemahaman Terhadap Proses Bisnis
Tujuan adanya GFF bagi Garuda adalah untuk menjaga marketshare
dengan meningkatkan jumlah konsumen yang loyal terhadap jasa penerbangan
Garuda. Tujuan lainnya adalah untuk mendukung program marketing. Dalam
perancangan data warehouse perlu mempertimbangkan tujuan dari adanya sistem
GFF.
Untuk lebih memahami istilah dalam komponen-komponen Frequent
Flyer adalah sebagai berikut;
1. Tier, adalah tingkatan tingkatan anggota dalam GFF. Terbagi menjadi
tingkatan, secara berturut-turut dari yang paling rendah adalah TEMP,
Blue, Silver, Gold dan Platinum. Pada OLTP Tier ini disimpan menjadi
satu tabel tersendiri dan menjadi catalog.
2. Member Type, adalah jenis keanggotaan anggota GFF yakni Reguler,
Cobrand, VIP dan Junior. Member type disimpan pada satu tabel catalog.
3. Award Mileage, point yang diberikan oleh GFF kepada setiap anggotanya
sebagai bentuk penghargaan atas loyalitas yang diberikan oleh anggota.
Point ini diakumulasikan dan akan terus bertambah jika anggota
melakukan aktivitas penerbangannya dengan Garuda atau dengan partner

41
Garuda baik airlines ataupun perusahaan lainnya seperti hotel, bank,
telekomunikasi.
4. Tier Mileage, adalah jumlah point yang diberikan GFF setiap kali terbang
dengan Garuda dan digunakan untuk menentukan tingkat loyalitas anggota
GFF. Tier Mileage dihitung dari 1 Januari hingga 31 Desember dan akan
di reset setiap awal tahun, sehingga nilai tier per 1 Januari akan bernilai 0
pada tahun berikutnya.
5. Frequency, setiap satu kali penerbangan yang sifatnya eligible to earn
akan di nilai 1 point frequency. Frequency ini juga bisa menentukan
tingkat loyalitas anggota GFF.
6. Accrual rules, adalah yang mengatur jumlah mileage, baik tier mileage
maupun award mileage, yang diberikan untuk kepada anggota GFF untuk
setiap aktivitasnya dengan Garuda atau partner Garuda. Untuk aktivitas
penerbangan dengan dengan memperhatikan origin airport, destination
airport, tier member dan booking class yang digunakan. Jika aktivitas
adalah bukan penerbangan, maka yang menjadi parameter adalah partner
Garuda dan jenis aktifitasnya.
Setiap aktifitas anggota GFF disimpan dalam database. Aktifitas tersebut
di-rating oleh batch proses dengan menggunakan Accrual rules yang
berlaku saat transaksi berlangsung, maka dibuat catatan transaksi dan
menandai setiap aktifitas anggota yang dengan flag bahwa aktivitas
tersebut sudah di-rating. Hasil perhitungan award mileage, tier mileage,
dan frequency yang merupakan hasil perhitungan ketika rating, masuk ke
dalam field curr_one, curr_two dan curr_three dalam transaksi anggota
GFF yang bersangkutan.
7. Redeem award, salah satu keuntungan keanggotaan GFF adalah dengan
menggunakan award mileage yang dimilikinya untuk mendapatkan tiket

42
gratis, mengupgrade class atau yang lainnnya baik untuk diri sendiri,
kerabat ataupun teman. Anggota yang melakukan redeem award seperti
halnya membelanjakan award yang dimilikinya yang akan memotong
jumlah award yang dimilikinya. Untuk saat ini award yang bisa di-redeem
dan disediakan adalah Free Flight award dan Upgrade award baik untuk
anggota GFF yang bersangkutan, atau orang lain (companion).
8. Upgrade award, misalnya seorang anggota GFF memiliki account balance
award milage 20000 miles. Anggota tersebut membeli tiket kelas ekonomi
dan harga Upgrade award untuk penerbangan kelas W (bisnis) adalah 9000
miles. Maka ia setelah redeem upgrade, account balance award milage
menjadi 11000, demikian juga aturan yang berlaku untuk freeflight award.
4.2.1 Pendaftaran (Enrollment)
Keanggotaan dalam loyalty program dibagi menjadi 2 jenis, open dan
limited. Limited loyalty tidak dapat dikuti oleh semua orang, ada mekanisme
tertentu untuk menjadi anggota limited ini seperti membayar uang pendaftaran dan
kadang-kadang disertai syarat-syarat lainnya seperti melakukan pmbelian dengan
volume tertentu atau memiliki penghasilan tertentu (Wijaya, 2005).
Dalam GFF, jenis keanggotaan untuk yang open bersifat gratis (Reguler
Member Type, Junior Member Type). Keanggotaan limited terbagi menjadi 3;
VIP, Cobrand dan ECPlus. Member type VIP adalah untuk kalangan pejabat dan
anggota DPR yang mendapatkan penawaran khusus untuk menjadi anggota GFF
atau untuk kalangan tertentu selain pejabat. Member type Cobrand adalah pemilik
kartu kredit Citibank yang mendaftarkan diri melalui Citibank, dan GFF akan
memberikan tagihan pada Citibank untuk setiap mileage yang diberikan pada
anggota tersebut. Member type ECPlus adalah jenis anggota yang secara rutin
membayar iuran pada GFF. Pendapatan GFF yang berasal dari limited member,
dibuatkan report yang diberikan pada bagian finance (keuangan) untuk diaudit.

43
4.2.2 Upgrade/Downgrade Tier
Level keanggotaan dalam program frequent flyer disebut tier. Kenaikan
level kenggotaan dalam program frequent flyer disebut upgrade tier, sedangkan
penurunan level keanggotaan disebut downgrade tier. Proses upgrade/downgrade,
sistem melakukan langkah-langkah berikut;
a) Sistem akan membuat tier yang baru dan menonaktifkan tier yang lama
dengan masa berlaku tertentu.
b) Sistem membuat kartu yang memiliki durasi tertentu dengan tier yang sesuai
dengan tier.
c) Sistem membuat mailing card untuk untuk anggota ini yang berisi paket-paket
yang harus dikirim oleh GFF melalui pihak ketiga. Mailing card ini berisi
penjelasan status card pada awal ‘siap untuk dikirim’ dan akan diupdate oleh
sistem ketika kartu sudah diterima oleh anggota menjadi ’terkirim’. Paket ini
bisa berbeda-beda untuk setiap tier.
d) Untuk jenis anggota tertentu, anggota mendapatkan luggage mailing yang
mekanisme pengirimannya sama dan berbarengan dengan mailing card.
Baik downgrade ataupun upgrade, langkah-langkah yang ditempuh oleh
sistem sama, yang membedakannya adalah tier yang dihasilkan oleh sistem
berbeda, Untuk upgrade tier yang baru, tier pada card yang baru lebih tinggi dari
sebelumnya. Untuk downgrade, adalah sebaliknya, tier saat ini lebih rendah dari
tier sebelumnya.
Anggota GFF dapat melakukan enrollment baik melalui CSS (Customer
Self Service) atau BO (Back Office). Saat itu, anggota GFF akan memilki tier
TEMP ketika pertama kali mendaftar (untuk member type Reguler), selanjutnya
akan diupgrade menjadi BLUE setelah melakukan penerbangan perdananya
terhitung sejak anggota terdaftar. Jumlah member yang melakukan aktivasi dan
yang ugrade menjadi BLUE menjadi indikator keberhasilan/kinerja unit Customer
Loyalty.

44
4.2.3 Aktifitas Earning Anggota
Aktifitas anggota GFF terbagi menjadi aktifitas penerbangan (air actvity)
dan aktifitas bukan penerbangan (non air actvity). Aktifitas penerbangan mencatat
asal dan tujuan penerbangan anggota GFF, tanggal penerbangan dan flight
number yang digunakan. Aktifitas bukan penerbangan merupakan aktifitas
anggota dengan partner GFF, seperti melakukan transfer uang dengan
menggunakan kartu kredit Citibank, anggota menginap di hotel partner GFF,
belanja di Roda Mas dan aktiftas-aktifitas semacam ini dengan berbagai partner
GFF. Setiap aktifitas anggota akan dirating dan angota mendapatkan reward
berupa award mileage, tier milage dan frequency. Jumlah milage yang dihasilkan
oleh anggota, besarnya tergantung pada accrual rule yaitu jarak penerbangan
(untuk bukan aktifitas penerbangan), level tier saat anggota terbang, booking class
(untuk aktifitas penerbangan), jumlah volume sesuai kesepakatan antara partner
dengan GFF (untuk bukan aktifitas penerbangan). Proses rating melibatkan
accrual rule, yang berisi aturan pemberian mileage sebagai dasar perhitungan.
Setelah didapatkan nilai award mileage, tier mileage dan frequency dari proses
rating, di tambahkan record mileage transaction milik anggota tersebut.
4.2.4 Aktifitas Redeem Anggota
Award mileage yang dikumpulkan oleh anggota dapat dibelanjakan atau
ditukar dengan penawaran-penawaran dari Garuda dan partner. Award yang
tersedia saat berupa award free ticket dan upgrade booking class. Setiap anggota
membeli award akan tercatat dalam certificate activity dan mileage transaction
dengan tipe spending. Sistem meng-issued certificate untuk setiap pembelian
award dengan voucher number bersifat unik, bisa berupa certificate companion
(certificate yang digunakan oleh bukan anggota) atau self usage.

45
4.2.5 Keseimbangan Accrual dan Reedem
Accrual artinya anggota mendapatkan point terkait aktivitasnya dengan
GFF Sebagai ilustrasi, GFF sebagai organisasi berhutang sejumlah mileage (saat
ini sekitar Rp 110,-) yang dikumpulkan oleh anggota. Saat anggota GFF
melakukan redeem, artinya GFF membayar utangnya kepada anggotanya.
Jika anggota GFF banyak melakukan accrual tanpa membelanjakannya,
maka utang GFF terus bertambah dan bisa menjadi bom waktu bagi garuda jika
suatu saat anggota-anggota GFF melakukan penerbangannya secara serentak.
Untuk itu perlu keseimbangan antara jumlah accrual dan redeem sehingga utang
GFF tidak terus bertambah. Jadi, selain jumlah transaksi accrual dan redeem.
Perbandingan jumlah antara anggota yang melakukan accrual dan redeem
menjadi indikator bagi kinerja GFF, semakin seimbang maka semakin baik.
4.2.6 Kerja Sama Partner
Dari partner GFF, seperti Citibank, ABN Amro, Danamon, Hotel Aston
group dan partner GFF lainnya, bisa mendapatkan penghasilan dan mendapat
benefit secara langsung. GFF melakukan billing untuk setiap mileage yang
dikeluarkan untuk anggota karena aktifitas bukan penerbangan. Selain benefit
langsung, benefit secara tidak langsung adalah jumlah anggota GFF bisa
bertambah karena adanya partner dengan tersedianya channel-channel alternative
bagi anggota dalam melakukan aktifitasnya bersama Garuda. Hal salah satu
strategi memperkuat brand Garuda dan menambah core customer. Jumlah partner
Garuda dijadikan indicator performace GFF sebagai departemen dalam lingkup
kerja divisi Customer Loyalty.
4.3 Perancangan Arsitektur
Untuk memulai perancangan arsitektur data warehouse, didefinisikan
kebutuhan dari pengguna yang paling dibutuhkan dan data mana yang harus

46
diutamakan. Rancangan arsitektur data warehouse dibagi menjadi dua, arsitektur
logical dan arsitektur fisikal. Arsitektur logical adalah tahapan alur data dari
sumber data yang digunakan sampai data warehouse yang digunakan, sedangkan
arsitektur fisik adalah gambaran teknis dari konfigurasi yang diterapkan pada data
warehouse.
4.3.1 Arsitektur logical
Berikut adalah perancangan arsitektur logical pada data warehouse.
Sumber data yang digunakan adalah sumber data yang diperoleh dari data
operasional. RDBMS, yang digunakan untuk penyimpanan data operasional
frequent flyer. Dari sumber data ODS (Operational Data Store), dilakukan proses
selection. Proses selection yaitu proses pemilihan data yang diperlukan dalam
sistem data warehouse dari sumber data. Tidak semua data dari sumber data
digunakan untuk data warehouse, untuk itulah proses selection dilakukan. Proses
selanjutnya setelah selection adalah extraction, memindahkan data yang sudah
dipilah kedalam sistem database yang terpisah dari sistem database operasional.
Pemisahan database ini adalah agar sistem operasional tidak terganggu oleh
proses dalam data warehouse.
Data yang sudah terseleksi kemudian dilakukan proses dilakukan proses
cleansing, yaitu proses pembersihan data dan proses tranformasi yang kedua
proses tersebut dilakukan data staging atau temporary database. Kemudian proses
loading, yaitu proses memasukan data hasil proses sebelumnya ke dalam data
warehouse. Aliran data dari arsitektur logical tersebut dapat dilihat pada gambar
4.3.

47
Garuda Frequent Flyer
Data Souce Data Staging Data Warehouse
Operasional Data Store
(ODS)
Database Temp
Transformation Data Warehouse
Archive/ Backup Data
LOADINGSelection, Extraction
Gambar 4.3- Arsitektur logical Garuda Frequent Flyer
4.3.2 Arsitektur Fisik
Berikut adalah perancangan arsitektur fisik pada data warehouse Garuda
Frequent Flyer, dapat dilihat gambar 4.4. Database operasional GFF
menggunakan platform Oracle 9i begitu juga untuk database yang digunakan
untuk data staging dan data warehouse. Hanya saja mesin yang digunakan
berbeda dengan mesin yang digunakan oleh mesin operasi. Kesamaan platform
database dengan pertimbangan karena pengembangan kedepan dan lisensi yang
dimiliki saat ini adalah Oracle. User yang dapat mengakses sistem data
warehouse adalah user yang terhubung dengan web server.

48
Gambar 4.4- Arsitektur fisik data warehouse Garuda Frequent Flyer
4.3.4 Sumber Data
Sumber data yang akan digunakan adalah sumber data yang diperoleh dari
sumber database Oracle 9i. Database berisi informasi anggota GFF lengkap
dengan profilenya, transaksi harian anggota GFF baik yang diinput manual
maupun melalui proses batch.
Oracle 9i Oracle 9i

49
Tabel 4.1- Platform database sistem GFF operasional dan pertambahan data
Jumlah tabel operasional adalah 167 tabel dengan total kolom 2152 dan
ukuran data saat dilakukan penelitian ini adalah 25 giga bytes. Dari 167 tabel
tersebut tidak semua tabel akan disimpan dalam data warehouse dan dari masing-
masing tabel yang digunakan, tidak semua kolom akan disimpan. Tabel-tabel
yang diproses dan disimpan dalam data warehouse adalah tabel AIRPORT, TIER,
MEMBER_TYPE, ACCRUAL_RULE, BRANCH_OFFICE, TRANSACTION,
ACTIVITY, CUSTOMER dan MEMBER_ACCOUNT.
4.3.5 Data Staging
Tidak semua data yang berasal dari sumber data digunakan, hanya data
yang mendukung keperluan data warehouse yang digunakan. Tempat untuk
melakukan seleksi informasi yang diperlukan dan mempersiapkan data untuk
diproses lebih lanjut ke data warehouse adalah staging area, sedangkan data pada
kondisi tersebut pada pada kondisi tersebut dinamakan data staging. Pada tahap
data staging, dilakukan proses selection, filtering, editing, summarizing,
combining, dan loading data tersebut terhadap sumber data untuk mempersiapkan
data dalam pemrosesan lebih lanjut ke data warehouse.
Tipe Database RDBMS
Engine Oracle 9i
Platform Linux SUSE enterprise edition
Nama Database Oracle
Jumlah total tabel 167
Jumlah total kolom 2303
Pertambahan data 3 Mbytes/1 hari
Ukuran data 25 Giga Bytes

50
4.3.6 Proses ETL
Proses ETL (extract, transform, load) adalah proses yang digunakan
dalam memproses data sebelum dimasukkan ke dalam suatu data warehouse yang
akan dilakukan oleh load manager. Proses ini dilakukan untuk men-
standarisasikan data yang akan digunakan pada data warehouse. ETL adalah
langkah kritis dalam pembuatan data warehouse. Proses ETL dilakukan secara
periodic dan otomotis.
4.3.6.1 Proses Extract
Ekstraksi dilakukan dari sumber data yang digunakan melalui proses
pemilihan data yang kemudian disimpan pada temporary database. Penempatan
temporary database diletakkan pada penyimpanan database, mesin dan platform
yang sama dengan data warehouse agar proses ETL dapat dilakukan lebih cepat
dan tidak mengganggu proses operasional. Adapun database operasional yang
digunakan dan diekstrak dapat dilihat pada lampiran 1 dan 2 beserta penjelasan
atribut yang digunakan dan yang tidak digunakan. Untuk lebih detailnya
mengenai perbedaan karakteristik perbedaan database operasional GF dan
temporary database.
EKSTRAKSI
Source Destination
Engine Oracle 9i Oracle 9i
Platform Open Suse Microsoft Windows Server 2003
Sumber Data DB , GFF Operasional DWTemp
Jumlah Total Table 167 12
Jumlah Total Field 2303 152
Jumlah Total Row 36679283 9169821 Tabel 4.2-Perbandingan sumber data GFF dan DatabaseTemp

51
4.3.6.2 Proses Cleansing
Proses yang dilakukan selanjutnya adalah pembersihan data (cleansing).
Proses yang dilakukan pada proses cleansing ini adalah proses untuk
membersihkan data yang redundant dan data yang tidak konsisten satu sama lain.
Contoh dari ketidak konsistenan data adalah seperti data yang rusak (corrupt)
sehingga isi datanya tidak benar.
Ketidak konsistenan Format Data
Tabel Contoh Format
Transaction mm-dd-yy 02-30-07
Activity mm-dd-yyyy 03-30-2007
Member_account dd-mm-yy 23-02-2007
Customer dd-mm-yyyy 01-30-2007 Tabel 4.3-Perbedaan format data
Tanggal dalam sistem operasional mencatat tanggal hingga jam, menit
dan detik. Kebutuhan bisnis yang diwakili oleh report yang ada dan keseragaman,
format tanggal diubah menjadi dd-mm-yyyy. Untuk mengatasi permasalahan pada
tabel, maka dilakukan penyeragaman format data waktu mengikuti format dd-
mm-yyyy, hal ini juga untuk menghindari data yang tidak konsisten yang dapat
menimbulkan data yang bias.
Tabel 4.4-Ketidak konsistenan data penerbangan anggota GFF karena duplikasi data.
Transaksi anggota GFF yang tercatat oleh sistem melalui batch proses juga
berpeluang besar terjadi ketidak konsistenan dengan adanya duplikasi transaksi
anggota yang ternyata aktifitas penerbangannya hanya satu. Hal ini biasanya
Ketidak konsistenan karena adanya duplikasi data transaksi ENTITY_ID CREATED_ON TRANS_DATE CURR_ONE CERTIFICATE_ID ACCOUNT_ID ORIG DEST
1068117 15-DEC-06 01-23 -07 10000 101536 20 CGK PLM 1068118 16-DEC-06 01-23 -07 10000 101537 20 CGK PLM

52
karena sistem reservasi mengupload file penerbangan yang sama dua kali pada
hari yang berbeda, sehingga tercatat dua kali.
4.3.6.3 Proses Transformasi
Transformation pada prinsipnya mengubah bentuk data dari data yang
telah diextract menjadi bentuk yang sesuai dengan kebutuhan pengguna. Proses
ini dilakukan setelah data yang ada sudah melewati proses ekstraksi dan
pembersihan. Proses transformasi yang dilakukan dibagi berdasarkan level, yaitu
record-level dan field-level, pada proses ini dilakukan proses pemilihan,
penggabungan dan agregasi untuk mendapatkan data ringkasan sesuai dengan
dimensi yang akan dibuat. Proses transformasi menggunakan step-step
transformation yang ada pada Kettle.
Gambar 4.5- Alur transformasi transaksi penerbangan anggota GFF
Pada tranformasi diagram Kettle gambar 4.5, data transaksi anggota GFF
mengalami beberapa transformasi. Transformasi yang pertama adalah
denormalisasi customer, kemudian branch office, branch office counttry, country,

53
membersihkan data tanggal transaksi dalam penyamaan format, denormalisasi
tanggal dan pemisahan data sesuai dengan data model.
Semua jenis transaksi dalam sistem operasional disatukan dalam satu tabel
TRANSACTION. Proses transformasi ini membagi dan memisahkan setiap jenis
transaksi ke dalam 3 tabel terpisah untuk transaksi penerbangan (accrual),
transaksi bukan penerbangan (accrual) dan transaksi penerbangan jenis redeem.
Gambar 4.6- Alur transformasi tabel AIRPORT
Data-data catalog dari tabel TIER, AIRPORT, FLIGHT_SCHEDULE,
MEMBER_TYPE, ACCRUAL_RULES, COUNTRY, dan TIER proses
transformasinya berupa denormalisasi. Pada gambar 4.6 di atas, catalog
AIRPORT, field idCountry tidak lagi look_up ke tabel COUNTRY, tapi langsung
langsung diisi field name dari tabel country.
4.3.6.4 Proses Loading
Proses yang dilakukan pada tahap akhir adalah pemuatan data (loading).
Data yang digunakan pada tahap ini merupakan data dari proses-proses yang
dilakukan sebelumnya, yaitu ekstraksi, pembersihan (cleansing), dan transformasi

54
ke dalam data warehouse dengan menggunakan Spoon, Pan dan Kitchen . Semua
Tools tersebut merupakan produk Pentaho. Spoon digunakan untuk mendesign
pengolahan data untuk cleansing, selecting, transformasi dan mapping dari data
operasional ke data staging atau data warehouse. Pan digunakan untuk
mengeksekusi file-file Spoon. Kitchen untuk mengeksekusi Pan secara periodik
dengan scheduler.
Cara pemuatan data ke dalam data warehouse adalah dengan
menggunakan tool Pentaho yang dijalankan secara periodik dengan feature
scheduler milik Kitchen. Skema transformasi yang dibuat oleh Spoon, ada
beberapa yang dieksekusi secara berurutan karena satu transformasi tergantung
pada step transformasi yang lain.
Gambar 4.7- Skema job pada Spoon yang mengurutkan pengerjaan transformasi yang telah
dibuat sebelumnya
Sebagai contoh pada gambar 4.7 di atas, proses ekstraksi, transformasi dan
loading dari tabel catalog airport yang urutannya adalah dimulai dengan
pembuatan tabel airport_dim dan mengosongkan jika tabel itu sudah ada dan
mengupdate jika ada perubahan.

55
4.3.7 Model Data Warehouse
Data warehouse dan OLAP dibangun berdasarkan multidimensional data
model. Pada model ini diperlukan tabel fakta dan tabel dimensi. Tabel fakta berisi
fakta numerik yang memiliki ciri-ciri : panjang, kurus, dan besar, serta sering
berubah dan berguna untuk mengukur (measure). Sedangkan tabel dimensi berisi
kolom yang bersifat deskriptif, kecil, pendek, dan lebar yang berguna untuk
filtering (menyaring) dan didasarkan pada atribut dimensi.
4.3.6.1 Model Customer
Model Customer ini menyimpan informasi data angota GFF. Contoh
informasi yang bisa diperoleh adalah jumlah anggota GFF yang mendaftar hari,
bulan dan tahun tertentu untuk dilihat trend perkembangannya relatif terhadap
waktu. Berikut adalah model skema bintang Customer pada gambar 4.8 sebagai
berikut.
class Customer
dim_member_tier_composition
«column»*PK tierCompositionId memberType tier
«PK»+ PK_dim_member_type()
dim_cus_status
«column»*PK statusId status
«PK»+ PK_dim_cus_status()
fact_customer
«column» tierCompositionKey locationKey genderKey processKey registeredDateKey totalCustomer totalEnrolled totalProcessTier
dim_location
«column»*PK locationId branchOffice country city
«PK»+ PK_dim_location()
dim_gender
«column»*PK genderId gender
«PK»+ PK_dim_gender()
dim_process_tier
«column»*PK processId processName
«PK»+ PK_dim_process()
dim_time
«column»*PK time_id year month day
«PK»+ PK_dim_time()
1
0..*
1
0..*
1
0..*
1
0..*
1
0..*
Gambar 4.8- Model skema bintang enrollment anggota GFF

56
Ditentukannya subject ini selain berdasarkan report yang ada saat ini juga
mempertimbangkan tujuan bisnis dari sistem GFF yaitu untuk meningkatkan
market share Tabel fakta fact_customer ini menyimpan data anggota GFF yang
telah terdaftar. Peranannya adalah menyediakan informasi dan laporan tentang
jumlah customer dengan kondisi sesuai dengan atribut dari dimensi yang ada.
Measure yang ada pada tabel fakta ini ada 3 measure, yaitu totalCustomer,
totalEnrolled, dan totalProcessTier. TotalCustomer adalah measure yang
menerangkan jumlah anggota GFF. Measure totalEnrolled adalah orang yang
melakukan pendaftaran. Measure totalProcessTier adalah jumlah anggota GFF
yang mengalami perubahan level tier, baik upgrade, downgrade ataupun maintain
tier.
4.3.6.2 Model Air Transaction (Earning)
Jumlah penerbangan anggota GFF yang masuk dalam katagori earning
mileage, atau menambah jumlah mileage bagi anggota yang bersangkutan.
Measure-measure dalam tabel fakta air_transaction adalah award_mileage,
tier_mileage, flown_frequency dan frequency_mileage. Dalam accrual rule,
beberapa jenis penerbangan dinilai 0 sehingga untuk melihat jumlah penerbangan
tidak dari frequency_mileage tapi dibuat measure terpisah, yakni flown_frequency
yang menunjukan jumlah penerbangan.

57
class Air Transaction Model
fact_air_trans
«column» originAirportKey destAirportKey memberAddressKey operatorFlightNumKey bookingClassKey statusKey tierKey timeKey awarMileage tierMilaege frequencyMileage flownFrequency
dim_tier
«column» tierName
dim_time
«column» year quarter month day
dim_customer
«column» enrolledBranchOffice enrolledCity enrolledChannel gender
dim_airport
«column» iataCode country
dim_book_class
«column» bcName
dim_oper_flight
«column» fl ightNumber
dim_mem_address
«column» city country
status
«column» name
1
0..*
1
0..*
1
0..*
1 0..*
1
0..*
1
0..*
1
0..*
10..*
Gambar 4.9- Model skema bintang aktifitas penerbangan anggota
Berikut adalah skema bintang transaksi penerbangan yang menambah
mileage anggota, pada gambar 4.8. Tabel fact_air_trans ini digunakan untuk
menyimpan informasi penerbangan anggota GFF. Setiap penerbangan yang
dilakukan oleh anggota GFF tercatat ditabel ini bersama atribut-atribut yang ada
dalam dimensi. Aktivitas penerbangan akan dihargai oleh GFF dan anggota akan
mendapatkan point atas penggunaan jasa tersebut yang terdiri dari 3 macam yakni
awardMileage, tierMileage dan frequencyMileage. Ketiga mileage ditambah
dengan atribut flownFrequency menjadi measure dalam tabel fact_air_trans ini.
4.3.6.3 Model Non Air Transaction (Earning)
Model star skema untuk transaksi bukan penerbangan adalah seperti
terlihat pada gambar 4.9. Measure yang dimiliki oleh tabel fakta
non_air_transaction adalah award_mileage dan tier_mileage. Dimensi yang

58
dimiliki model ini juga berbeda dengan tabel fakta fact_air_transaction. Pada
model ini measure yan ada hanya award mileage dan tier mileage tanpa frequency
karena tidak diperhitungkan frequency tapi lebih kesepakatan paket-paket yang
menjadi kerja sama antara GFF dan partner.
class Non Air Transaction
dim_partner
«column»*PK partnerId name location
«PK»+ PK_dim_partner()
fact_non_air_trans
«column» partnerKey timeKey memberAccountKey awardMileage tierMileage
dim_time
«column»*PK timeId year quarter month day
«PK»+ PK_dim_time()
dim_customer
«column»*PK customerId enrolledBranchOffice enrolledCity enrolledChannel gender
«PK»+ PK_dim_customer()
1
0..*
10..*1 0..*
Gambar 4.10- Model skema bintang aktifitas bukan penerbangan (non air activity) anggota
GFF
Peranan dari tabel fact_non_air_trans ini adalah menyimpan informasi
data aktifitas anggota GFF yang dilakukan bersama partner GFF seperti misalnya
aktivitas melakukan credit dengan melalui kartu GFF Cobrand, kartu yang
diissued oleh CitiBank dan bekerja sama dengan GFF. Contoh aktivitas lainnya
adalah aktivitas menginap di hotel Aston, karena Aston adalah partner GFF maka
anggota tersebut mendapatkan sejumlah awardMileage. Transaksi bukan
penerbangan ini measurenya hanya satu, yakni awardMileage karena mileage
yang dihasilkan memang hanya awardMileage.
4.3.6.4 Model Certificate Transaction (Spending)
Anggota GFF yang melakukan redeem, membelanjakan mileage (award
mileage) yang dimilikinya, tercatat dan diaudit oleh bagian keuangan. Berapa

59
jumlah voucher yang telah direedem dan mileage yang telah digunakan oleh
anggota dengan berbagai dimensi. Award mileage anggota GFF bisa digunakan
untuk mendapatkan tiket gratis penerbangan atau untuk meng-upgrade tiket
booking class ekonomi yang dibeli masuk ke booking class bisnis.
class Certificate Transaction
dim_airport
«column»*PK airportId iataCode country
«PK»+ PK_dim_airport()
fact_trans_cert
«column» originAirportKey destAirportKey memberAccountKey issuedDateKey transDateKey awardMileage
dim_customer
«column»*PK customerId enrolledBranchOffice enrolledChannel enrolledCity gender
«PK»+ PK_dim_customer()
dim_ticket_office
«column»*PK ticketOfficeId boName countryName ticketOffice
«PK»+ PK_dim_ticket_office()
dim_time
«column»*PK timeId year month day
«PK»+ PK_dim_time()
dim_trans_type
«column»*PK transTypeId type
«PK»+ PK_dim_trans_type()
dim_status
«column»*PK statusId name
«PK»+ PK_dim_status()
1
0..*
1
0..*
1
0..*
1
0..*
1
0..*
1
0..*
Gambar 4.11- Model skema bintang redeem (penggunaan mileage) anggota GFF
Peranan dari tabel fakta fact_trans_cert adalah menyediakan informasi dan
laporan penggunaan awardMileage untuk mendapatkan tiket gratis. Measure yang
diperlukan untuk tabel fakta fact_trans_cert ini adalah awardMileage yang akan
mengurangi jumlah atau saldo award mileage anggota.

60
4.3.6.5 Tabel Dimensi
Tabel dimensi adalah tabel yang berisikan data dari berbagai perspektif
atau dengan kata lain tabel dimensi adalah tabel yang berisikan user-defined
metadata. Dimensi-dimensi itu dipilih dalam upaya meningkatkan kualitas
pelaporan yang sudah ada menjadi lebih baik dengan cara memberikan laporan
secara rinci berdasarkan dimensi-dimensi tersebut. Dalam model ini beberapa
dimensi digunakan bersama-sama oleh tabel fakta yang berlainan.
4.3.6.5.1 Dimensi Airport
Dimensi airport digunakan oleh tabel fakta yang berisi transaksi
penerbangan baik untuk untuk earning atau spending. Airport ini menunjukan asal
penerbangan dan tujuan penerbangan. Dalam dunia penerbangan, untuk
mengidentifikasi lokasi airport digunakan IATA code yang terdiri dari 3 huruf.
Setiap airport memiliki IATA airport code. Seluruh airport dunia diassign IATA
code dan lembaga yang mendefinisikannya adalah International Airport
Transport Association (IATA) yang bermarkas di Montreal,
4.3.6.5.2 Dimensi Location
Garuda memiliki branch office yang tersebar di hampir seluruh kota-kota
besar Indonesia dan beberapa kota besar di luar negeri. Ketika mendaftar pertama
kali, anggota GFF terdaftar di branch office terdekat yang sesuai dengan alamat
yang digunakannya. Aktifitas promosi pada anggota GFF sering dilakukan
spesifik untuk branch office tententu.
4.3.6.5.3 Dimensi Gender
Anggota GFF terdaftar dengan jenis kelamin saat dia terdaftar. Data yang
ada adalah M yang berarti Male atau pria dan F yang berarti Female atau
perempuan.

61
4.3.6.5.4 Dimensi Customer Status
Setelah anggota GFF mengaktifkan keanggotaanya dengan melakukan
penerbangannya. Status anggota GFF yang awalnya inactive menjadi active.
Setelah masa setahun hingga dua tahun (tergantung tier yang dimilikinya),
keanggotaannya dievaluasi apakah masih layak atau tidak dan jika tidak layak
maka statusnya menjadi deleted.
4.3.6.5.5 Dimensi Member Tier Composition
Tier Composition kombinasi antara catalog member type dan catalog
member tier. Member type adalah jenis keanggotaan dalam GFF. Beberapa jenis
keanggotaan GFF adalah berbayar yang berbeda bisnis prosesnya dengan yang
tidak berbayar. Tier merupakan level dalam GFF yang dijadikan indikator
loyalitas anggota pada GFF.
4.3.6.5.6 Dimensi Booking Class
Garuda Indonesia adalah full-service airline yang berbeda dengan 'no-frill’
low cost carrier. Konfigurasi kelas penerbangannya terbagi menjadi kelas
executive dan kelas ekonomi. Pembagian ini terkait dengan in-flight service yang
diberikan. Dalam sistem GFF, kelas excutive juga mendapat rate yang lebih tinggi
dibandingkan dengan kelas ekonomi. Kode booking class menggunakan kode
huruf dan yang masuk kategori class executive adalah C, D dan I. Selain ketiga
code tersebut masuk kategori class ekonomi.
4.3.6.5.7 Dimensi Time
Data yang termasuk kedalam tabel dimensi time yaitu id tanggal, tanggal
lengkap (dd-mm-yyyy), periode bulan , periode 3 bulanan (quarterly) dan tahun.

62
4.3.6.5.8 Dimensi Operating Flight Number
Aktifitas penerbangan mencatat data operator flight number, yakni flight
yang digunakan untuk terbang. Karena beberapa penerbangan bisa jadi melibatkan
berapa operator penerbangan. Primary key dari tabel dimensi ini adalah flightId.
4.3.6.5.9 Dimensi Partner
Dimensi ini berisi data-data partner GFF. Satu partner bisa berisi lebih
dari satu record dengan harus lokasi yang berbeda. Contohnya adalah partner
hotel Accor group yang memiliki beberapa hotel. Setiap hotel akan memiliki satu
key location dan satu partner memiliki satu location atau lebih.

63
BAB V
IMPLEMENTASI DATA WAREHOUSE
Tujuan adanya Frequent Flyer Program seperti GFF adalah menjaga dan
meningkatkan market share dengan mempertahankan valueable customer dengan
mengetahui dan mengerti secara proactive kebutuhan dan keinginan setiap
konsumen. Konsumen tesebut berharga karena menggunakan jasa yang disediakan
oleh Garuda secara berulang (generate repeat business among core customers)
dan menjadi core customer dan salah satu jalan meningkatkan customer equity
(CE). Konsumen menggunakan jasa Garuda secara berulang terkait dengan
kualitas pelayanan Garuda. Selain itu, GFF juga bertujuan untuk mendukung
program yang diadakan oleh bagian marketing.
Kemampuan penyediaan informasi dari data warehouse untuk melakukan
analisa terhadap kegiatan anggota Garuda Frequent Flyer, baik dari enrollment,
proses upgrade dan downgrade, sehingga managemen Garuda dapat menentukan
langkah apa yang bisa dilakukan untuk meningkatkan kualitas pelayanan terhadap
customer.
Data warehouse Garuda Frequent Flyer dibangun agar dapat
menyediakan informasi yang cepat, tepat dan akurat sehingga manajemen Garuda
dapat mengambil keputusan yang tepat dalam meningkatkan pelayanannya
terhadap penumpang dan penumpang melakukan pembelian yang terus berulang
dan menjadi penumpang yang loyal.
5.1 Presentasi Data Warehouse
Kemampuan data warehouse dalam menyajikan informasi pada pengguna
adalah hal yang paling penting. Penggunaan tools dalam presentasi data perlu
dipertimbangkan hal-hal seperti fitur yang ada, biaya saat development dan
maintain setelah data warehouse beroperasi. Tools yang digunakan sebisa

64
mungkin tidak terikat (loosely coupled) pada satu platform database supaya
pengembangan di layer bisnis tidak perlu mengubah mengubah terlalu banyak
arsitektur dibawahnya (separation of concern) . Tools yang digunakan adalah:
• Mondrian adalah OLAP engine yang menggunakan bahasa pemrograman
java. Mondrian digunakan untuk analisis interaktif dari database yang
besar, menggunakan bahasa MDX (Multi Dimensional eXpression) untuk
mengeksekusi Query. MDX merupakan query yang digunakan untuk data
multidimensional dan menggunakan sintaks yang sama dengan SQL.
Perbedaannya adalah SQL digunakan untuk query relational table
sedangkan MDX digunakan untuk query multidimensional table.
• JPivot adalah JSP yang dapat menampilkan OLAP table dan chart. JPivot
mempunyai kemampuan navigasi OLAP seperti drill down, slice dan dice.
JPivot adalah taglib Java Server Pages (JSP) yang yang bersifat open
source.
Kemampuan Mondrian dalam berintergrasi dengan berbagai platform
database memberi kebebasan bagi pengembang data warehouse untuk memilih
database sesuai dengan kebutuhan dan mengurangi ketergantungan pada satu
vendor saja (vendor lock-in). Meskipun tools ini bersifat open source dan
penggunaan tools yang bersifat open source tetapi Mondrian dan JPivot memiliki
kemampuan yang baik sebagai OLAP engine dan melakukan presentasi data
warehouse.
5.2 Penyediaan Informasi
Media yang digunakan untuk menampilkan presentasi tersebut adalah
media web. Dengan media web diharapkan dapat mempermudah pengguna dalam
melihat informasi tersebut, kapan dan dimana saja selama terhubung dengan
jaringan dan memiliki browser, yakni web browser yang mengakses aplikasi
aplikasi Mondrian yang dideploy di web server. Kemampuan yang dimiliki
aplikasi data warehouse ini antara lain:

65
• Kemampuan roll-up dan drill-down sehingga memudahkan analisa
data, seberapa dalam tingkat kedetailan yang diinginkan oleh
pengguna.
• Roll-up adalah kemampuan menampilkan data dengan tingkat rincian
yang lebih rendah. Drill –down adalah kemampuan menampilkan data
dengan tingkat rincian yang lebih tinggi.
• Kemampuanuntuk membuat query sendiri seusai dengan kebutuhan
• Kemampuan report customization sesuai dengan kebutuhan informasi.
• Kemampuan untuk membuat chart atau grafik sesuai dengan laporan
yang diinginkan.
• Kemampuan membuat report dalam format Excel dan dan PDF
5.2.1 Informasi Customer
Apapun bentuk dan jenis bisnis model, supaya tetap eksis diperlukan
customer. Ukuran keberhasilan loyality program seperti GFF salah satunya adalah
banyaknya customer atau penumpang yang terdaftar sebagai anggota GFF.
Penumpang memiliki kebutuhan yang spesifik yang perlu dipenuhi. Pembagian
kelompok dalam sistem GFF adalah dalam bentuk tier level composition.
Pembagian kelompok ini secara tidak langsung adalah salah satu upaya GFF
dalam menerapkan strategi segmentasi pelanggannya berdasarkan tingkat
penggunaan layanan jasa Garuda.
Sebagai gambaran adalah, anggota GFF yang memiliki “tier composition“
Temp Reguler, artinya anggota tersebut belum melakukan aktifitas
penerbangannya dengan dengan Garuda. Garuda akan mencoba menarik anggota
Temp Reguler ini ke dalam tier Blue untuk melakukan aktifitas penerbangannya.
Garuda memberikan paket promosi “Welcome Blue” pada anggota GFF Temp
yang melakukan penerbangan perdananya. Perlakuan Garuda terhadap anggota
GFF yang memiliki level Platinum, berbeda dengan level yang dibawahnya.
Anggota Gold dan Platinum diberikan kartu “luggage” bersamaan dengan
pengiriman kartu anggota yang baru, yang dapat digunakan oleh anggota agar
bagasinya mendapat prioritas.

66
Berikut ini adalah jenis-jenis laporan yang berkaitan dengan informasi
customer:
Laporan jumlah anggota per-branch office terdekat dari tempat tinggalnya
(Gambar 5.1).
Laporan jumlah anggota yang melakukan aktivasi (Gambar 5.2)
Laporan jumlah anggota per-tier composition (Gambar 5.3)
Gambar 5.1- Contoh report Customer per branch office pada tahun 2007

67
Gambar 5.2- Contoh report Customer per Tier Composition pada tahun 2007
Gambar 5.3 - Contoh report Customer per yang melakukan aktivasi pada tahun 2007

68
Gambar 5.4 Informasi Customer yang terdistribusi dalam beberapa tier yang di slice hanya
tahun 2007 dan drill-down berdasar usianya.
Gambar 5.5 Informasi Enrolment Customer yang terdistribusi dalam dalam tahun pendaftaran
dilengkapi dengan grafik trend enrollment.

69
5.2.2 Informasi Earning/Accrual Traffic
Aktifitas anggota GFF bersama Garuda dan partner GFF diberikan
apresiasi oleh Garuda dalam bentuk mileage atau disebut accrual mileage yang
bersifat earning point bagi anggota GFF. Anggota mendapatkan award mileage,
tier milage dan frequency.
Berikut adalah contoh informasi earning mileage customer GFF. Jumlah
mileage yang dikeluarkan oleh Garuda adalah utang garuda pada palanggannya
dan tercatat untuk audit oleh bagian keuangan. Bagian keuangan mengalokasikan
sejumlah mileage anggota yang tercatat sebagai liquid cash.
Gambar 5.6- Earning mileage customer yang di-slice berdasarkan Origin Destination airport
penerbangan

70
Gambar 5.7- Earning mileage customer yang di slice berdasarkan Origin Destination airport
penerbangan yang dilengkap dengan grafik pie chart.
5.2.3 Informasi Redeem Traffic
Traffic penerbangan anggota GFF yang merupakan penerbangan redeem,
menjadi salah satu indikator kinerja divisi loyalty. Reedem adalah penggunaan
/pembelanjaan mileage anggota GFF untuk mendapatkan award dari penyedia
loyality program, dalam hal ini Garuda.

71
Gambar 5.8- Contoh report redeem activity per branch office pada tahun 2007
5.3 Pengaruh Perubahan
Modul report dalam sistem operasional GFF adalah bagian dari sistem
GFF yang menangani berbagai bentuk report. Query yang disubmit kedalam
sistem akan di eksekusi secara periodik oleh batch proses sesuai dengan
kebutuhan. Format yang dihasilkan oleh sistem GFF adalah format microsoft
excel.
Kebutuhan untuk mendapatkan laporan, baik laporan harian, mingguan,
bulanan atau 3 bulanan saat ini ditangani sepenuhnya oleh pengelola sistem GFF.
Flow jika ada kebutuhan report yang tidak tersedia dalam sistem, flow berikut
harus dilalui dan flow ini akan memerlukan waktu hingga 1 bulan. Diawali
dengan change request dari garuda pada pihak pengelola sistem GFF. Pengelola
sistem akan melakukan analisa terhadap dampak setiap perubahan, termasuk
adanya report pada live systems. Setelah diketahui dampak-dampak perubahan,
hasil analisa ini akan dibicarakan dalam CAB meeting dan penyusunan skenario
deployment, skenario jika deployment gagal dan step-step detail untuk fall back,
menetapkan tanggal, dan team yang melakukan perubahan. Setelah CAB selesai

72
yang dilengkap dokumen perubahan (biasanya 2 kali CAB meeting), proses CAB
dilakukan pada tanggal yang telah ditetapkan. Dalam bentuk diagram alir, proses
CAB adalah sebagai berikut, pada gambar 5.9.
Gambar 5.9- Langkah-langkah implementasi jenis report baru.
Dengan adanya data warehouse, penyusunan laporan menjadi lebih
sederhana, karena pengguna dapat melakukan customization report sesuai dengan
yang diinginkan, sehingga dapat diperoleh efisiensi waktu dari yang awalnya 3
minggu untuk melakukan change request hingga dapat digunakan dan 5 hari kerja
jika diselesaikan secara ad hoc query¸ menjadi satu hari. Dengan demikian GFF
dapat mengoptimalkan sumber daya manusia yang sebelumnya dialokasikan
untuk penyusunan laporan menjadi lebih fokus pada hal yang sifatnya strategis
mengelola partnership yang strategic atau merancang promosi yang tepat untuk
diajukan ke Garuda. Hal lainnya yang diperoleh dari data warehouse adalah
tersedianya data history setiap customer baik yang statusnya active ataupun yang
tidak active lagi untuk kebutuhan data mining misalnya.
Change Request dalam bentuk RFC dan analisa dampak perubahan terhadap
Change Advisory Board Meeting (Membahas skenario jika berhasil dan gagal, dan
gagal step-step untuk fall back)
Deployment dan monitoring dampak perubahan
Change Advisory Board Meeting (Evaluasi terhadap perubahan)

73
Saat report dieksekusi langsung terhadap data operasional, sistem yang
berjalan menjadi jauh lebih lambat bahkan tidak jarang sistem menjadi tidak
stabil. Hal ini dikarenakan database yang digunakan oleh sistem operasional
resourcenya digunakan oleh query report yang jumlahnya hingga jutaan transaksi.
Setelah sistem data warehouse diimplementasikan, maka sistem operasional tidak
terganggu saat repot digenerate. Performance sistem operasional juga tidak
terganggu terkait kebutuhan report saat melakukan uji report yang baru sebagai
bagian dari proses CAB.

74
BAB VI
IMPLEMENTASI DATA MINING
Pada bab ini dijelaskan mengenai implementasi data mining untuk
mendapatkan dan menggali informasi yang tersembunyi dalam data warehouse.
Untuk mendapatkan hasil yang baik dan bermanfaat diperlukan proses data
mining yang terstruktur dengan baik melalui tahapan data mining. Karena itu
pada bab ini akan dijabarkan bagaimana implementasi data mining dijalankan
melalui tahapan data mining yang sebelumnya dijelaskan pada bab II.
6.1 Pemahaman Terhadap Bisnis
Tujuan dari adanya GFF ada dua yakni; 1) untuk menjaga dan
meningkatkan marketshare dengan cara meningkatkan jumlah customer yang
loyal, 2) mendukung program-program pemasaran. Seperti yang diuraikan
sebelumnya pada bab II, bahwa biaya untuk mendapatkan customer baru akan
jauh lebih mahal dari pada mempertahankan customer yang loyal.
Salah satu program/promosi yang ditawarkan oleh GFF dalam rangka
meningkatkan customer yang loyal adalah dengan adanya keanggotaan yang
langsung menempati posisi tertinggi dalam tingkatan tier adalah dengan adanya
program Cobrand. GFF bekerja sama dengan Citibank menjaring anggota secara
bersamaan. Cara kerjanya adalah anggota pemilik kartu kredit Citibank akan
ditawari untuk menjadi anggota GFF dengan imbalan keanggotaan eksklusif
dengan level tier tertinggi tanpa harus memiliki mileage yang cukup dan tidak
harus memenuhi kriteria seperti halnya anggota biasa. Penawaran keanggotaan ini
saat anggota akan masuk menjadi pemilik kartu kredit Citibank. Citibank menjadi
intermediary untuk melakukan cross selling GFF. Aktifitas anggota baik bersama
GFF atau bersama Citibank akan mendapatkan poin mileage.

75
Adanya program Cobrand ini cukup beralasan, karena orang-orang yang
memiliki kartu kredit Citibank berpeluang besar untuk menggunakan jasa
penerbangan Garuda terkait dengan tingkat penghasilannya yang diasumsikan
menengah keatas. Bagi GFF, selain mendapatkan Customer yang potensial untuk
memberikan revenue, juga mendapatkan prosentase membership fee dari anggota
yang dibayarkan ke Citibank.
6.2 Sumber Data
Saat anggota GFF tercatat dalam sistem, anggota tersebut dan akan
memiliki kartu Temp. Dengan level tier Temp, customer tersebut belum
melakukan penerbangan dengan Garuda, kemudian sesaat setelah anggota Temp
melakukan penerbangan maka ia berubah menjadi ber-level Blue dan selanjutnya
itu level tier bergantung pada seberapa banyak anggota melakukan aktifitasnya
bersama Garuda atau partner-nya. Sewaktu-waktu anggota tersebut bisa naik ke
level yang lebih tinggi. Dan setiap tahun, dievaluasi apakah tier-nya turun atau
tidak tergantung akumulasi aktifitas selama setahun. Aturan seperti ini berlaku
untuk anggota tidak berbayar dan bersifat terbuka dan berbeda dengan
keanggotaan yang bersifat tertutup.
Salah satu keanggotaan yang bersifat tertutup adalah Cobrand. Tidak
seperti keanggotaan terbuka atau Reguler, masa berlaku Cobrand adalah selama
tiga tahun terhitung sejak anggota tersebut mendaftar. Hanya saja, bisa saja
anggota tersebut berhenti dari Cobrand (Terminate Cobrand) dan GFF otomatis
merubah jenis kenggotaannya menjadi keanggotaan biasa (Reguler member type)
yang pada akhir tahun akan dievaluasi kelayakan level tier-nya. Pada prinsipnya,
saat anggota melakukan terminasi keanggotaan Cobrand anggota tersebut
mengundurkan diri dari kepemilikan kartu kredit Citibank, dan masih anggota
GFF.
Mekanisme melakukan terminasi Cobrand adalah dimulai dari anggota
yang mengundurkan diri melalui Citibank yang selanjutnya Citibank mengirimkan
file berisi daftar anggota yang berhenti menjadi Cobrand dan sistem operasional
memproses file tersebut.

76
Masa keanggotaan GFF Cobrand terhitung sejak terdaftar sejak anggota
tanggal mengajukan terdaftar, hingga sehari sebelum terdaftar menjadi anggota
biasa dapat dihitung sebagai lamanya anggota tersebut telah memberikan revenue
pada Garuda dengan iuran yang anggota bayar tiap tahun. Semakin lama seorang
anggota GFF menjadi Cobrand maka nilai Customer Equity semakin lebih besar
yang artinya anggota tersebut memiliki potensi menjadi sumber pendapatan GFF.
Pilihan bagi anggota untuk menggunakan alamat pribadi atau alamat
kantor diasumsikan bahwa saat anggota menggunakan alamat kantor maka
perjalanan dan aktifitasnya bersama Garuda adalah aktifitas atau perjalanan bisnis.
Karena data adalah hasil dari data warehouse, maka cleansing data tidak perlu
dilakukan, yang perlu dilakukan adalah membuat kedalam bentuk artifact (data
bukan dalam bentuk transaksi dimana customer bisa mempunyai banyak transaksi
atau satu customer bisa punya banyak baris karena transaksinya lebih dari satu,
tetapi data bisa di jadikan menjadi data aggregat sehingga satu user itu satu baris
dengan seluruh atribut yang melekat ke dia di tempatkan di memanjang sebagai
kolom-kolom). Langkah selanjutnya diskretisasi/binning. Ditentukan keperluan
untuk merubah semua atribut numerik menjadi kategori atau dipilih atribut yang
akan dibinning.
6.3 Pemilihan Teknik dan Perangkat lunak Data Mining
Teknik data mining yang digunakan untuk data mining pada sistem GFF
adalah Decision Tree dan Association Rule sesuai dengan tujuan untuk memahami
karakteristik anggota GFF Cobrand selama keanggotaannya sebelum melakukan
terminasi.
Perangkat lunak yang digunakan untuk penelitian ini adalah Rapidminer
(sebelumnya bernama Yale) versi komunitas. Rapidminer memiliki dua lisensi,
lisensi yang bersifat propietary (AGPL) dan yang bersifat free. Dari segi product
Rapidminer terdapat dua versi yaitu versi enterprise dan Rapidminer versi
komunitas. Perbedaan keduanya terutama dalam hal support yang diberikan oleh
Rapid-I sebagai pengembang.

77
6.4 Persiapan Data
Pemodelan data mining dirancang berdasarkan kebutuhan dan
karakteristik data yang ada pada data warehouse GFF. Jumlah data
anggota/customer GFF yang aktif adalah sekitar 300 000 orang. Dari jumlah
tersebut tersebut kemudian dipilih customer yang member type-nya pernah
menjadi atau memiliki Cobrand berdasarkan history dari dimensi tier composition
dan statusnya active yang jumlahnya menjadi 22 970 orang.
Tujuan dari data mining ini adalah untuk melihat karakteristik anggota
Cobrand yang mengundurkan diri melalui Citibank sebagai partner GFF. Dengan
tujuan demikian, maka customer yang dianalisa adalah customer yang telah
mengundurkan diri sebelum masa berlaku keanggotaanya habis, sehingga dari 22
970 orang, mengkerucut menjadi 990 orang yang melakukan terminasi
keanggotaan Cobrand dan berubah menjadi Reguler.
6.4.1 Persiapan Data Teknik Association Rule
Tahap pertama adalah tahap preprocessing yang meliputi operator
frequency discretization dan filter operator nominal to binominal. Frequency
discretization mengubah atribut angka menjadi disktrit dengan memasukan nilai
bins pada operator frequency discretization.
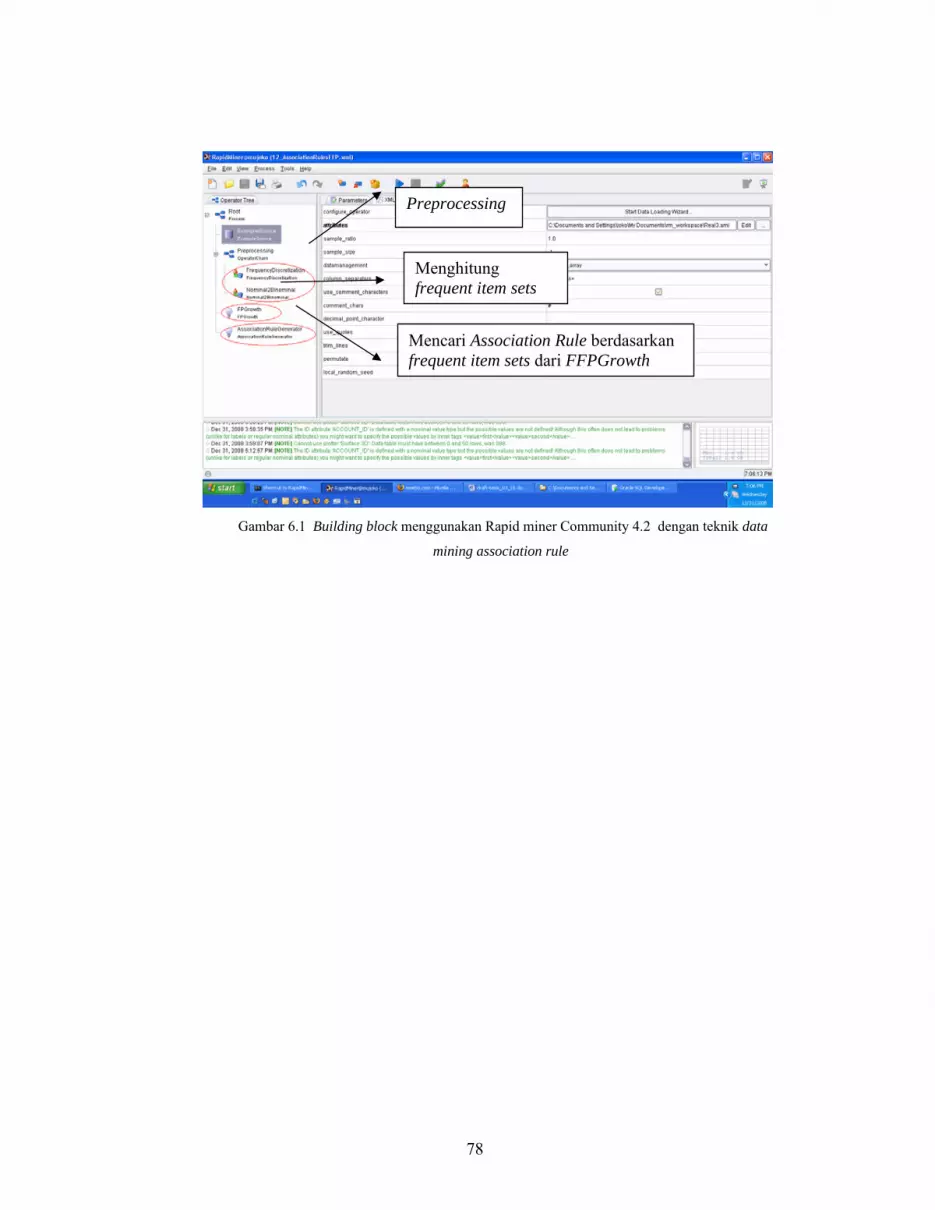
78
Gambar 6.1 Building block menggunakan Rapid miner Community 4.2 dengan teknik data
mining association rule
Preprocessing
Menghitung frequent item sets
Mencari Association Rule berdasarkan frequent item sets dari FFPGrowth

79
ACCOUNT_ID GEN- DER
ENROLL_ CHANNEL
ADDRESS_TYPE
CURRENT- TIERNAME
LIFEDURA- TIONIN- MONTH
DURATION- FROMREGIS- TERINMONTH
725 M BO PRIVATE Silver 10.07 95.63 1377 F BO BUSINESS Blue 11.6 50.03 1448 F BO PRIVATE Silver 1.27 34.73 1528 M BO PRIVATE Silver 0.27 33.83 2190 M BO BUSINESS Gold 1.77 107.2 2239 M BO PRIVATE Platinum 0.03 98.9 2367 M BO BUSINESS Gold 0.07 83.3 2555 M BO PRIVATE Platinum 10.07 85.4 2730 M BO BUSINESS Platinum 0.73 62.73 5304 M CSS BUSINESS Blue 1.07 19.57 7480 M CSS PRIVATE Silver 0.3 14 7787 M CSS PRIVATE Blue 1.37 19.2 9255 M CSS BUSINESS Silver 0.43 2.33
11871 M BO PRIVATE Blue 2.37 47.63 12043 M BO PRIVATE Silver 6 39.07 12045 M BO BUSINESS Blue 11.87 57.27 12700 M BO BUSINESS Blue 4.8 57.8 14208 M BO PRIVATE Blue 2.77 48.4 14773 M BO PRIVATE Blue 13.5 48.4 15433 F BO PRIVATE Blue 5.27 47.27 16375 F BO BUSINESS Silver 1.13 33.63 17128 F BO BUSINESS Blue 2.53 39.37 18692 M BO BUSINESS Blue 0.17 36.5 21893 M BO BUSINESS Silver 2.17 84.33 22147 M BO PRIVATE Blue 4.13 21 25268 F BO PRIVATE Blue 9.83 33.27 28911 M BO PRIVATE Blue 12 19.27 36070 M COBRAND BUSINESS Gold 0 25.73
… … … … … … …
Tabel 6.1 Tabel sebelum transformasi

80
Tabel 6.2 Tabel setelah transformasi/preprocessing
ACCOUNT_ID
CURRENTTIERNAME
GENDER = M
GENDER = F
GENDER = \\N
ENROLL_CHANNEL = BO
ENROLL_CHANNEL = CSS
ENROLL_CHANNEL = COBRAND
ADDRESS_TYPE = PRIVATE
ADDRESS_TYPE = BUSINESS
LIFEDURATIONINMONTH = range1 [-∞ - 0.450]
LIFEDURATIONINMONTH = range2 [0.450 - 1.150]
LIFEDURATIONINMONTH = range3 [1.150 - 2.315]
LIFEDURATIONINMONTH = range4 [2.315 - 5.315]
LIFEDURATIONINMONTH = range5 [5.315 - ∞]
DURATIONFROMREGISTERINMONTH = range1 [-∞ - 0.850]
DURATIONFROMREGISTERINMONTH = range2 [0.850 - 2.415]
DURATIONFROMREGISTERINMONTH = range3 [2.415 - 8.465]
DURATIONFROMREGISTERINMONTH = range4 [8.465 - 29.565]
DURATIONFROMREGISTERINMONTH = range5 [29.565 - ∞]
725
Silver
TRUE
FALSE
FALSE
TRUE
FALSE
FALSE
TRUE
FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE
1377
Blue
FALSE
TRUE
FALSE
TRUE
FALSE
FALSE
FALSE
TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE
1448
Silver
FALSE
TRUE
FALSE
TRUE
FALSE
FALSE
TRUE
FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
1528
Silver
TRUE
FALSE
FALSE
TRUE
FALSE
FALSE
TRUE
FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
2190
Gold
TRUE
FALSE
FALSE
TRUE
FALSE
FALSE
FALSE
TRUE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
2239
Platinum
TRUE
FALSE
FALSE
TRUE
FALSE
FALSE
TRUE
FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
… … … … … … … … … … … … … … … .. … … … …

81
Langkah pertama dalam melakukan teknik association rule adalah
preprocessing yang meliputi operator Frequency Discretization dan filter
operator Nominal To Binominal. Frequency Discretization mengubah atribut
angka menjadi disktrit dengan memasukan nilai bins pada operator Frequency
Discretization. Tahap selanjutnya adalah menghitung frequent items dengan
menggunakan FFGrowth operator dan output dari FFGrowth akan menjadi
masukan bagi operator AssociationRuleGenerator untuk menghitung frequent
items.
6.4.2 Persiapan Data Teknik Decision Tree
Teknik Decision Tree adalah metode clasification yang mudah dipahami.
Teknik data mining ini sangat fleksibel terhadap berbagai tipe data input yang
diolah sehingga tidak diperlukan preprocessing pada atribut-atribut yang
digunakan seperti teknik Association Rule dan yang menjadi class/label yang
diprediksi adalah tier, apakah tiernya naik atau turun setelah anggota GFF
tersebut menghentikan keanggotaan Cobrand-nya. Gambar 6.2 menunjukan
building block data mining dengan teknik Decision tree yang tidak memerlukan
preprocessing terhadap atribut inputnya.

82
Gambar 6.2 Building block metode Decision tree menggunakan Rapidminer Community 4.2
6.5 Analisa Hasil Uji Coba
6.5.1 Analisa Hasil Uji Coba Dengan Teknik Association Rule
Pada uji coba ini, minimum support yang digunakan adalah 10%, sehingga
jika persentase kombinasi item dalam dataset lebih dari 10% maka akan dibuatkan
rule yang berkaitan dengan kombinasi item tersebut tetapi jika tidak maka akan
diabaikan dan dengan minimal confidence sebesar 70%. Dari percobaan ini tidak
ditemukan rule-rule yang berhubungan dengan atribut jenis alamat yang
digunakan oleh anggota GFF Cobrand. Hasil uji coba adalah sebagai berikut:
Berdasarkan hasil pemodelan yang nampak pada tabel 6.4 pada tabel
diatas, diperoleh karakteristik anggota Cobrand yang melakukan pendaftarannya
melalui channel Cobrand Citibank dan life duration Cobrand kurang dari 4 bulan,
maka kemungkinan masa keanggotaan GFF-nya kurang dari 8 bulan atau berada
pada range1 (rule no 147 dan 150) dengan nilai confidence rata-rata 98%% dan
nilai support rata-rata 12%.
Prosess Decision tree

83
No Rule Premises Conclusion Support Confidence
156
DURATIONFROMREGISTERINMONTH = range5 [29.565 - ∞]
ENROLL_CHANNEL = BO 0.200405 1
158
GENDER = M, DURATIONFROMREGISTERINMONTH = range5 [29.565 - ∞]
ENROLL_CHANNEL = BO 0.158907 1
163
ADDRESS_TYPE = PRIVATE, DURATIONFROMREGISTERINMONTH = range5 [29.565 - ∞]
ENROLL_CHANNEL = BO 0.112348 1
164
ADDRESS_TYPE = BUSINESS, DURATIONFROMREGISTERINMONTH = range5 [29.565 - ∞]
ENROLL_CHANNEL = BO 0.088057 1
170
GENDER = M, ADDRESS_TYPE = PRIVATE, DURATIONFROMREGISTERINMONTH = range5 [29.565 - ∞]
ENROLL_CHANNEL = BO 0.087045 1
171
GENDER = M, ADDRESS_TYPE = BUSINESS, DURATIONFROMREGISTERINMONTH = range5 [29.565 - ∞]
ENROLL_CHANNEL = BO 0.071862 1
Tabel 6.3 Model Rule dengan kesimpulan masa keanggotaan Cobrand dalam mendaftar melalui
channel BO
Berdasarkan hasil pemodelan yang nampak pada tabel 6.1 pada tabel
diatas, diperoleh karakteristik anggota Cobrand yang melakukan terminasi
setelah masa keanggotaan GFF-nya lebih dari 29.56 bulan adalah anggota
Cobrand yang mendaftar GFF melalui channel BO, dengan nilai confidence 100%
dan support 20%. Dapat dilihat dari rule no 156.
Channel BO atau Back Office adalah adalah channel pendaftaran yang
disediakan GFF yang dapat dilakukan di kantor cabang Garuda, ticket office atau
kantor check in Garuda dengan mengisi formulir yang telah disediakan Garuda.
Cobrand adalah salah satu jalan pintas bagi anggota GFF untuk mendapat posisi
tier tertinggi. Anggota GFF yang telah lama dan ditawari keanggotaan Cobrand,
sehingga jika keanggotaannya berada pada range5 dan anggota tersebut adalah
Cobrand, maka dapat dipastikan sebelumnya adalah anggota Reguler.

84
No Rule Premises Conclusion Support Confidence
147
GENDER = M, ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range1 [-∞ - 0.450]
DURATIONFROMREGISTER INMONTH = range1 [-∞ - 0.850] 0.112348 0.982301
150
ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range1 [-∞ - 0.450]
DURATIONFROMREGISTER INMONTH = range1 [-∞ - 0.850] 0.13664 0.985401
153
ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range3 [1.150 - 2.315]
DURATIONFROM REGISTER INMONTH = range2 [0.850 - 2.415] 0.121457 0.991736
127
ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range4 [2.315 - 5.315]
DURATIONFROMREGISTER INMONTH = range3 [2.415 - 8.465] 0.126518 0.925926
Tabel 6.4 Model Rule dengan kesimpulan masa keanggotaan Cobrand dalam range1, range2, dan range2.
Anggota Cobrand yang melakukan terminasi saat life duration-nya antara
1 hingga 2 bulan dan melakukan channel Cobrand, maka kemungkinan masa
keanggotaan GFF-nya antara 0.8 bulan hingga 2 bulan (rule 153). Pada rule ini
nilai confidence-nya 99% dan nilai support rata-rata 12%.
Dari hasil data mining dengan teknik association rule ini ditemukan
bahwa anggota GFF yang memiliki telah mendaftar dan usia GFF-nya 8 bulan
hingga 2 tahun berkecenderungan akan loyal dengan keanggotaanya sebagai
anggota Cobrand dengan masa lebih 5 dari bulan. Jika keanggotaan GFF-nya
berusia lebih dari 2 tahun maka kemungkinan besar adalah anggota yang
melakukan pendaftaran melalui BO.
Dari hasil data tersebut sebagai hasil data mining, maka bagian marketing
bisa menindak lanjuti dengan menggunakan promosi yang lebih tertarget terhadap
anggota Cobrand. Anggota Cobrand channel BO, memiliki banyak anggota yang
menempati posisi tier Platinum, meskipun telah berubah menjadi anggota
Reguler. Artinya, intensitas penggunaan jasa Garuda mencukupi dan jenis
customer ini memiliki nilai customer equity yang besar untuk ditawarkan produk-
produk dari Garuda atau anak perusahaannya seperti jasa Hotel.

85
6.5.2 Analisa Hasil Uji Coba Dengan Teknik Decision Tree
Pada uji coba dengan menggunakan operator Decision three ini class atau
label yang digunakan adalah tier dari setiap anggota. Nilai confidence saat
eksekusi adalah 10% dan criterion yang digunakan adalah information gain,
atribut selection measure yang digunakan untuk memilih test atribut dari suatu
node. Hasil uji coba adalah sebagai berikut:
Gambar 6.3 Bagian dari diagram pohon karakter anggota Cobrand yang mendaftar melalui
channel Cobrand atau Citibank
Channel Cobrand adalah jalur pendaftaran GFF melalui partner, dalam
hal ini Citibank. Anggota Cobrand yang melakukan pendaftaran melalui channel
Cobrand atau dengan kata lain melakukan pendaftaran melalui Citibank memiliki
pola seperti gambar 6.3 di atas. Nilai confidence yang yang digunakan untuk
memproses data ini adalah sebesar 25%. Level tier anggota setelah melakukan
terminasi, untuk anggota seperti di atas berada pada posisi Blue atau Silver,
tergantung pada berapa lama sudah menjadi anggota GFF dan berapa lama durasi
keanggotaan Cobrand –nya hingga saat melakukan terminasi (mengundurkan diri
dari keanggotaan Cobrand).
Anggota yang memiliki masa keanggotaan, terhitung sejak mendaftar,
kurang dari 12.13 bulan berada pada posisi Blue. Tapi jika masa keanggotaanya
lebih dari 12.13 bulan maka posisi tier bisa menjadi Blue atau Silver, tergantung
pada berapa lama durasi keanggotaan Cobrand-nya.

86
Gambar 6.4 Bagian diagram pohon karakter anggota Cobrand yang mendaftar melalui
Customer Self Service (CSS)
Customer Self Service adalah channel/jalur yang disediakan oleh GFF
bagi customer Garuda untuk melakukan pendaftaran keanggotaan GFF, secara
mandiri melalui media internet. Anggota GFF Cobrand yang melakukan
pendaftaran melalui jalur CSS pun memiliki pola yang hampir sama dengan
anggota Cobrand yang melakukan pendaftaran melalui Citibank, nampak pada
gambar 6.4. Sebagian besar anggota turun level keanggotaannya dari level
Platinum menjadi Blue atau Silver.
Baik anggota yang bergabung melalui CSS atau Citibank memiliki tier
Blue dan Silver. Hal ini dapat dimengerti karena keanggotaan Cobrand yang
bersifat tertutup mengabaikan loyalitas, diabaikan jumlah aktifitasnya bersama
Garuda dan Partner, dan digantikan oleh iuran tahunan yang harus dibayarnya.
Anggota Cobrand langsung menempati posisi tier pada level Platinum. Sehingga
saat anggota mengajukan pengunduran diri dari Cobrand (terminate Cobrand)
yang secara otomatis akan mengganti jenis keanggotaanya menjadi Reguler atau
jenis yang terbuka. Karena jenis keanggotaanya sudah menjadi Reguler, maka
GFF mulai memperhitungkan seberapa setia anggota yang awalnya Cobrand
dengan menjumlah transaksi yang telah dilakukannya.

87
Durasi anggota GFF tidaklah berbanding lurus terhadap level tier yang
dimilikinya. Sistem GFF akan mereset nilai tier mileage dan frequency anggota
GFF setiap tahunnya. Tier mileage berbeda dengan award mileage yang dimana
award mileage tidak akan pernah di reset dan akan terus diakumulasi dan yang
digunakan untuk membeli award dari Garuda adalah award mileage. Sehingga
akan ditemui anggota yang keanggotaanya kurang dari 12 bulan justru mendapat
tier Blue, tier yang paling rendah. Dan yang mendapat tier Silver karena transaksi
selama keanggotaan Cobrand ikut diperhitungkan sehingga masih mencukupi
untuk berada diposisi Silver. Untuk berada di level Blue, anggota tersebut cukup
melakukan aktifitas penerbangan sekali atau melakukan aktifitas bukan
penerbangan sekali, sedangkan untuk berada pada posisi Silver, anggota minimal
melakukan penerbangan 10 kali atau tier mileage yang dimiliki adalah 5000 poin.
Anggota Cobrand yang mendaftarkan diri menggunakan jalur BO (Back
Office) melalui kantor cabang, ticket office, atau kantor check in Garuda dengan
mengisi formulir yang telah disediakan Garuda, didapati karakternya lebih
beragam dibandingkan dengan anggota GFF Cobrand yang melakukan
pendaftaran melalui CSS dan Citibank. Bisa dilihat hasil proses data miningnya
pada lampiran 4.
Keberagaman ini salah satu penyebabnya adalah anggota yang mendaftar
channel BO ini pada awalnya adalah anggota Reguler yang kemudian mengubah
jenis membership-nya menjadi Cobrand. Hal ini bisa dilihat dari tanggal saat
anggota mendaftar yang beberapa bulan bahkan tahun lebih awal daripada tanggal
pertama kali membership Cobrand. Penawaran untuk mendapatkan anggota
Cobrand terhadap anggota Reguler adalah salah satu strategi cross-selling yang
dilakukan oleh Garuda, karena setiap transaksi anggota dengan menggunakan
kartu Citibank-nya akan diberi award mileage oleh Garuda dan Garuda akan
mengirimkan billing untuk setiap mileage yang diberikan pada anggota Cobrand.
Selain itu dengan penawaran ini akan lebih mengelompokkan tidak hanya
berdasar tier tapi berdasar kepemilikan kartu kredit Citibank, sehingga dengan
adanya segementasi yang lebih spesifik akan meningkatkan efisiensi bagian
marketing.

88
Dari hasil data mining, divisi Customer Loyality perlu mendefinisikan
kembali bagaimana managemen tier bagi anggota yang pernah menjadi anggota
Cobrand, sehingga anggota tersebut tidak turun drastis level tier-nya setelah status
keanggotaan Cobrand-nya dihentikan. Hal ini dengan alasan peluang bagi Garuda
untuk menawarkan product-product yang lain terhadap anggota yang memiliki
standar hidup menengah ke atas. Pada prinsipnya berhentinya mereka dari
keanggotaan Cobrand adalah sangat mungkin kecewa terhadap Citibank bukan
terhadap GFF karena terminasi terhadap Cobrand saat ini hanya bisa dilakukan
melalui Citibank sebagai penerbit kartu kredit.

89
BAB VII
KESIMPULAN
Bab ini berisi kesimpulan dan saran dari penelitian yang telah dilakukan.
Kesimpulan yang diperoleh merupakan hasil dari pelaksanaan proses perancangan
data warehouse dan pemanfaatan teknik data nining. Sedangkan saran yang
diberikan merupakan saran yang berguna untuk pengembangan penelitian
selanjutnya.
7.1 Kesimpulan
Kesimpulan yang dapat diambil dari perancangan data warehouse dan
penerapan teknik data mining di GFF antara lain:
a) Perancangan BI dengan cakupan pembangunan data warehouse dan data
mining anggota Cobrand pada tesis ini mengacu kepada kebutuhan bisnis
dengan melihat kebutuhan jenis dan bentuk report pada sistem yang sedang
berjalan. Selain itu juga mempertimbangkan indikator kinerja divisi Customer
Loyality.
b) Platform database yang digunakan untuk data warehouse adalah Oracle 9i
tools yang digunakan untuk presentasi data adalah Mondrian dan JPivot.
Pengembangan data warehouse dan implementasi data mining ini
membutuhkan waktu sekitar 4 bulan.
c) Keberadaan data warehouse sangat membantu dalam membuat report. Proses
yang awalnya memerlukan 3 minggu (mengikuti change request) menjadi satu
hari. Perubahan-perubahan atau kebutuhan report yang baru dapat terpenuhi
satu hari karena pengguna bisa melakukan customization report sesuai dengan
yang diinginkan sesuai dengan kebutuhan stakeholder.
Performance sistem operasional yang pada awalnya terganggu karena report
dibuat dengan mengandalkan modul report GFF yang juga bagian dari sistem

90
operasional, kini tidak lagi karena kebutuhan report disediakan oleh data
warehouse.
d) Penggunaan teknik data mining dapat digunakan untuk mengevaluasi pola
anggota Cobrand yang melakukan terminasi sebelum masa berlakunya selesai.
Hasilnya adalah perlunya peningkatan penawaran-penawaran keanggotaan
anggota GFF Cobrand dengan tujuan melakukan strategi cross-selling
terhadap anggota yang mendaftar melalui channel CSS dan Cobrand Citibank
dan perlunya evaluasi terhadap tier management bagi anggota Cobrand setelah
melakukan proses terminasi.
7.2 Saran
Dari proses pelaksanaan perancangan perancangan data warehouse dan
pemanfaatan teknik data mining yang telah dilakukan, terdapat beberapa saran
yang berguna untuk penelitian selanjutnya maupun untuk pengimplementasian
data warehouse dan data mining pada bidang yang sama. Saran-saran tersebut
adalah:
• Dalam pengembangan selanjutnya, cakupan data warehouse bisa diperluas
lagi ke divisi dan department yang lain untuk memperoleh gambaran utuh
perusahaan dengan informasi dari semua departemen.
• Dari hasil data mining bisa dilakukan umpan balik untuk memperbaiki
proses data mining yang ada dan mencoba teknik data mining dan
algoritma lain yang sesuai untuk menemukan pola-pola yang bisa berguna
bagi penelitian selanjutnya.
Uraian diatas, dapat diketahui kesimpulan dan saran dari penelitian yang
telah dilakukan. Kesimpulan pada bab ini merupakan ringkasan mengenai
pelaksanaan dalam perancangan data warehouse dan penerapan data mining
dalam usaha menghadirkan quality of service yang baik. Sedangkan saran-saran
yang telah diuraikan bisa dijadikan acuan untuk melakukan penelitian selanjutnya.

91
Daftar Pustaka
Ariana, Azimah. 2007. Penggunaan Data Warehouse dan Data Mining Untuk
Data Akademik Sebuah Studi Kasus Pada Universitas Nasional. Jurnal Sistem
Informasi MTI UI Vol.3-No 2.
Berry, Michael J. A, 2004, Data Mining Techniques: for marketing sales and
customer relationship management.
Bilotkach, Volodymyr 2005. Frequent Flyer Program Partnerships,
Substitutability, dan Airlines' Profit
Connoly, Thomas and Carolyn Begg, 2005, “Database Systems A Practical
Approach to Design, Implementation, and Management 4th ed”, England: Addison
Wessley
Emch, Adrian 2007 . Frequent Flyer Programs Under Article 82 EC – Is The Sky
the Only Limit?. World Competition, Vol. 4
Handojo, Andreas dan Silvia Rostianingsih, (2004). Pembuatan Data Warehouse
Pengukuran Kinerja Proses Belajar Mengajar Di Jurusan Teknik Informatika
Universitas Kristen Petra. Jurnal Informatika Vol. 5, No. 1: 53 - 58
http://www.cse.unsw.edu.au/~billw/cs9414/notes/ml/06prop/id3/id3.html. Akses
tanggal 27 October 2008. Induction of Decision Trees.
http://www.vibiznews.com/1new/column.php?sub=column&id=499&page=servic
es. Akses tanggal 8 Desember 2008. Mengenal Customer Equity

92
Pritscher, Lisa dan Hans Feyen. (2001). Data Mining And Strategic Marketing In
The Airline Industry. WS Proceeding September.
Lungu, Ion C. dan Bara, Adela . 2005. Executive Information Systems
Development Lifecycle. Economy Informatics Review, No. 1-4, pp. 19-22
Miele, Raffaele dan Mola, Francesco. 2005 .An Open Source Based Data
Warehouse Architecture to Support Decision Making in the Tourism Sector.
FEEM Working Paper No. 142.05
Muntean, Mihaela dan Brandas, Claudiu. 2007 . Business Intelligence Support
Systems dan Infrastructures. Economy Informatics, No. 7, pp. 100-104
Moertini, Veronica S. 2002. Data Mining Sebagai Solusi Bisnis. Integral, vol. 7
no. 1
Ponniah, Paulraj. 2001. Data Warehousing Fundamentals: A Comprehensive
Guide for IT Professionals., John Wiley & Sons, Inc
Utomo, Priyanto Doyo, 2006, Analisis Terhadap Faktor-Faktor Yang
Mempengaruhi Loyalitas Konsumen Pada Operator Telepon Seluler. Thesis:
Universitas Gadjah Mada
Velicanu, Manole dan Matei, Gheorghe. 2007. Building a Data Warehouse Step
by Step. Economic Informatics, Forthcoming
Velicanu, Manole dan Matei, Gheorghe. 2007. Database versus Data Warehouse.
Editura Economicǎ.
Wijaya , Serli . 2005. The Effect Of Loyalty Programs On Customer Loyalty In
The Hospitality Industry . Jurnal Manajemen Perhotelan, Vol. 1, No. 1: 24-31

93
Zain, Syahreza, 2008, Perancangan Data Warehouse dan Penerapan Data Mining
Pada Sistem Monitoring Jaringan GSM Studi Kasus: PT. INDOSAT TBK. Thesis:
Universitas Indonesia
LAMPIRAN-LAMPIRAN
Lampiran 1
Tabel sistem GFF yang datanya terus bertambah dan update dalam hitungan
harian (lihat bab IV PERANCANGAN DATA WAREHOUSE)
Y= digunakan dalam data warehouse
N= tidak digunakan dalam perancangan data warehouse.
Tabel ACTIVITY:
Nama Field Data Type Digunakan DW ENTITY_ID NUMBER(10,0) Y Id DISCR VARCHAR2(32 CHAR) N ENTITY_STATUS VARCHAR2(20 CHAR) Y ENTITY_STATUS CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N INFO VARCHAR2(64 CHAR) N TITLE VARCHAR2(12 CHAR) N LAST_NAME VARCHAR2(32 CHAR) N FIRST_NAME VARCHAR2(32 CHAR) N CARD_NUMBER VARCHAR2(12 CHAR) N START_DATE TIMESTAMP(6) Y START_DATE END_DATE TIMESTAMP(6) Y END_DATE REF_CODE VARCHAR2(32 CHAR) N ENTRY_TYPE VARCHAR2(32 CHAR) N VOUCHER VARCHAR2(32 CHAR) N EARN_ELIGIBLE NUMBER(1,0) N BOOKING_PERSON_ALIAS VARCHAR2(64 CHAR) N SALES_OFFICE VARCHAR2(32 CHAR) Y SALES_OFFICE PAYMENT_CARD_NUMBER VARCHAR2(60 CHAR) N SENT_OUT_ACTIVITY_STATUS VARCHAR2(10 CHAR) N VOLUME FLOAT Y VOLUME PROMOTION_DATE TIMESTAMP(6) N PROMOTION_REF VARCHAR2(64 CHAR) N OPER_FLIGHT_NO VARCHAR2(10 CHAR) Y FLIGHT_NUMBER MRKT_FLIGHT_NO VARCHAR2(10 CHAR) N OPER_BOOK_CLASS VARCHAR2(10 CHAR) Y BOOKING_CLASS MRKT_BOOK_CLASS VARCHAR2(10 CHAR) N FLOWN_BOOK_CLASS VARCHAR2(10 CHAR) N

94
COMPARTMENT VARCHAR2(255 CHAR) N PAYMENT_TYPE VARCHAR2(20 CHAR) N CHECK_IN_TYPE VARCHAR2(20 CHAR) N BOOKING_IN_TYPE VARCHAR2(20 CHAR) N TKT_NO VARCHAR2(20 CHAR) N COUPON_NO VARCHAR2(20 CHAR) N SEAT_NO VARCHAR2(20 CHAR) N BOARDING_NO VARCHAR2(10 CHAR) N CODESHARE_INDICATOR VARCHAR2(20 CHAR) N DELAYED_DAYS NUMBER(10,0) N DELAYED_HOURS NUMBER(10,0) N LOST_BAGGAGE NUMBER(1,0) N FFP_ID NUMBER(10,0) N AIRLINE_ID NUMBER(10,0) N NON_AIR_ACRL_RULE_ID NUMBER(10,0) Y RULE_NAME SENT_OUT_PARTNER_ID NUMBER(10,0) N PARTNER_ID NUMBER(10,0) Y PARTNER_ID LOCATION_ID NUMBER(10,0) Y LOCATION_ID ACTIVITY_TYPE_ID NUMBER(10,0) N MARKETINGAIRLINE_ENTITY_ID NUMBER(10,0) N OD_RULE_ID NUMBER(10,0) Y OD_RULE_ID ORIGIN_AIRPORT_ID NUMBER(10,0) Y ORI_AIRPORT_ID ACCOUNT_ID NUMBER(10,0) Y ACCOUNT_ID BC_RULE_ID NUMBER(10,0) Y BOOKING_CLASS_ID DEST_AIRPORT_ID NUMBER(10,0) Y DEST_AIRPORT_ID EARN_MILES_RULE_ID NUMBER(10,0) N
Tabel Transaction:
Nama Field Data Type Digunakan DW ENTITY_ID NUMBER(10,0) Y TRANSACTION_ID DISCR VARCHAR2(32 CHAR) Y TRANSACTION_TYPE ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N TRX_COMMENT VARCHAR2(255 CHAR) N HAS_SEEN NUMBER(1,0) N TRANS_TYPE VARCHAR2(20 CHAR) N TRANS_DATE DATE Y TRANSACTION_DATE CURR_TWO NUMBER(10,0) Y AWARD_MILEAGE CURR_THREE NUMBER(10,0) Y FREQUENCY CURR_ONE NUMBER(10,0) Y TIER_MILEAGE BILLED NUMBER(1,0) N CURR_FOUR NUMBER(10,0) N CURR_FIVE NUMBER(10,0) N FREE_TEXT_DESCRIPTION VARCHAR2(255 CHAR) N PROMO_CODE VARCHAR2(255 CHAR) N

95
INCENTIVE_ID NUMBER(10,0) N ODRULE_ID NUMBER(10,0) Y ORIGIN_DEST_RULE_ID ACTIVITY_ID NUMBER(10,0) Y ACTIVITY_ID INCENTIVE_FULFILLMENT_ID NUMBER(10,0) N TRANSACTION_ID NUMBER(10,0) N STMT_TEMPLATE_ID NUMBER(10,0) N CERTIFICATE_ID NUMBER(10,0) Y CERTIFICATE_ID AIR_ACTIVITY_ID NUMBER(10,0) Y AIR_TRANSACTION_ID BCRULE_ID NUMBER(10,0) Y BOOKING_CLASS_ID NON_AIR_ACT_ID NUMBER(10,0) Y NON_AIR_TRANSAC_ID NON_AIR_ACCRL_RULE_ID NUMBER(10,0) N ACCOUNT_ID NUMBER(10,0) Y ACCOUNT_ID STATEMENT_ID NUMBER(10,0) N INCFULMENT_ACT_ID NUMBER(10,0) N

96
Tabel Customer
Nama Field Data Type Di Gunakan
DW
ENTITY_ID NUMBER(10,0) Y ID DISC VARCHAR2(31 CHAR) N ENTITY_STATUS VARCHAR2(20 CHAR) Y ENTITY_STATUS CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N ENTITY_NAME VARCHAR2(64 CHAR) N ADDRESS VARCHAR2(255 CHAR) N BOUNCECOUNTER NUMBER(10,0) N EMAILSTATUS VARCHAR2(255 CHAR) N VALIDDATE TIMESTAMP(6) Y ENROLMENT_DATE PASSWORD_HASH VARCHAR2(200 CHAR) N ACCOUNTSTATEMENTMEDIA VARCHAR2(255 CHAR) N RECEIVEEMAILNEWSLETTER NUMBER(1,0) N RECEIVESMSINFO NUMBER(1,0) N ACCOUNTINFODELIVERY VARCHAR2(255 CHAR) N ENROLL_CHANNEL VARCHAR2(255 CHAR) Y CHANNEL ENROLLMENT_STATUS VARCHAR2(32 CHAR) N ACTIVATION_CODE VARCHAR2(64 CHAR) N CALL_CENTER_PIN VARCHAR2(200 CHAR) N NOTE CLOB N SPONSOR_NUM VARCHAR2(30 CHAR) N NAME_ON_CARD VARCHAR2(100 CHAR) N FIRST_NAME VARCHAR2(100 CHAR) N DATE_OF_BIRTH TIMESTAMP(6) Y DATE_OF_BIRTH MIDDLE_NAME VARCHAR2(100 CHAR) N GENDER VARCHAR2(10 CHAR) Y GENDER FORM_ENROLLMENT_CODE VARCHAR2(15 CHAR) N REGISTRATIONFORM VARCHAR2(255 CHAR) N IDENTITY_ENTITY_ID NUMBER(10,0) N ADDR_ID NUMBER(10,0) Y ADDRESS_ID CELLPHONENUMBER_ENTITY_ID NUMBER(10,0) Y CELL_PHONE_ID SALUTATION_ID NUMBER(10,0) N PREFERED_LANG_ID NUMBER(10,0) N ACCOUNT_ID NUMBER(10,0) Y ACCOUNT_ID BRANCH_OFFICE_ID NUMBER(10,0) Y BRANCH_OFFICE_ID

97
Lampiran 2
Tabel-tabel catalog yang jarang direfresh.
Y= digunakan dalam data warehouse
N= tidak digunakan dalam perancangan data warehouse.
Tabel ACCRUAL_RULE;
Nama Field Data Type Digunakan DW and DWTEMP ENTITY_ID NUMBER(10,0) Y ACCRUAL_RULE_ID DISCRTR VARCHAR2(20 CHAR) Y DISCRIMINATOR ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N ENTITY_NAME VARCHAR2(64 CHAR) N START_DATE DATE Y START_DATE END_DATE DATE Y END_DATE TIER_MILEAGE FLOAT Y TIER_MILEAGE AWARD_MILEAGE FLOAT Y AWARD_MILEAGE USE_ACTIVITY_VOLUME NUMBER(1,0) N FREQUENCY NUMBER(10,0) Y FREQUENCY FACTOR FLOAT Y FACTOR MIN_MILES NUMBER(10,0) N BOOKING_CLASS_ID NUMBER(10,0) Y BOOKING_CLASS_ID FFP_ID NUMBER(10,0) Y AIRLINE_ID NUMBER(10,0) N NON_AIR_ACTIVITY_ID NUMBER(10,0) N DEST_AIRPORT_ID NUMBER(10,0) Y ORIG_AIRPORT_ID ORIG_AIRPORT_ID NUMBER(10,0) Y DEST_AIRPORT_ID TIER_ID NUMBER(10,0) Y TIER_ID
Tabel BOOKING_CLASS
Nama Field Data Type Digunakan DW dan DWTEMP ENTITY_ID NUMBER(10,0) Y BOOKING_CLASS_ID ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N EFFECTIVE_DATE TIMESTAMP(6) Y START_DATE DISCONTINUE_DATE TIMESTAMP(6) Y END_DATE BOOKING_CLASS_CODE VARCHAR2(10 CHAR) Y BOOKING_CLASS_CODE COMPARTMENT VARCHAR2(15 CHAR) Y COMPARTMENT EARN_MILES NUMBER(1,0) N AIRLINE_ID NUMBER(10,0) Y AIRLINE_ID

98
Tabel AIRPORT
Nama Field Data Type Digunakan DW dan DWTEMP
ENTITY_ID NUMBER(10,0) Y AIRPORT_ID ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N ENTITY_NAME VARCHAR2(64 CHAR) Y AIRPORT_NAME IATA_CODE VARCHAR2(3 CHAR) Y IATA_CODE CITY_NAME VARCHAR2(255 CHAR) Y CITY_NAME PARENT_AIRPORT_ID NUMBER(10,0) N COUNTRY_ID NUMBER(10,0) Y COUNTRY_ID REGION_ID NUMBER(10,0) N
Tabel TICKET_OFFICE
Nama Field Data Type Digunakan DW dan DWTEMP ENTITY_ID NUMBER(10,0) Y TICKET_OFFICE_ID ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N ENTITY_NAME VARCHAR2(64 CHAR) Y TICKET_OFFICE_NAME TICKET_OFFICE_CODE VARCHAR2(10 CHAR) Y TICKET_OFFICE_CODE BRANCH_OFFICE_ID NUMBER(10,0) Y BRANCH_OFFICE_ID

99
Tabel COUNTRY
Nama Field Data Type Digunakan DW and DWTEMP
ENTITY_ID NUMBER(10,0) Y COUNTRY_ID ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N ENTITY_NAME VARCHAR2(64 CHAR) Y COUNTRY_NAME IATACODE VARCHAR2(255 CHAR) Y IATA_COUNTRY CITYLINE1 VARCHAR2(255 CHAR) N CITYLINE2 VARCHAR2(255 CHAR) N NAMELINE VARCHAR2(255 CHAR) N SALUTATIONLINE NUMBER(1,0) N ADDRESSORDER VARCHAR2(255 CHAR) N REGIONCODEREQUIRED NUMBER(1,0) N POSTALCODELENGTH NUMBER(10,0) N POSTALCODEREQUIRED NUMBER(1,0) N PHONECODE VARCHAR2(255 CHAR) N POSTALCODEEXAMPLE VARCHAR2(255 CHAR) N POSTALCODEPATTERN VARCHAR2(255 CHAR) N TIMEZONE VARCHAR2(255 CHAR) N PREFERREDLANGUAGE_ENTITY_ID NUMBER(10,0) N
Tabel ADDRESS
Nama Field Data Type Digunakan DW and DWTEMP
ENTITY_ID NUMBER(10,0) Y ADDRESS_ID DISC VARCHAR2(31 CHAR) Y ADDDRESS_TYPE ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N VALID NUMBER(1,0) N CITY VARCHAR2(50 CHAR) Y CITY STREET_1 VARCHAR2(128 CHAR) N STREET_2 VARCHAR2(128 CHAR) N STREET_3 VARCHAR2(128 CHAR) N POSTAL_CODE VARCHAR2(255 CHAR) N REGION_CODE VARCHAR2(255 CHAR) N VALID_DATE TIMESTAMP(6) N COMPANY VARCHAR2(64 CHAR) N DEPARTMENT VARCHAR2(64 CHAR) N COUNTRY_ID NUMBER(10,0) Y COUNTRY_ID CUSTOMER_ID NUMBER(10,0) Y CUSTOMER_ID

100
Tabel TIER
Nama Field Data Type Digunakan DW and DWTEMP
ENTITY_ID NUMBER(10,0) Y TIER_ID ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N NAME VARCHAR2(255 CHAR) Y TIER_NAME CODE_NUMBER_CSS NUMBER(10,0) N CODE_NUMBER_PARTNER NUMBER(10,0) N CODE_NUMBER_BO NUMBER(10,0) N TEMPORARYTIER NUMBER(1,0) N SEQUENCE NUMBER(10,0) Y SEQUENCE BONUS_TIER FLOAT N CODE_STRING_BO VARCHAR2(255 CHAR) N CODE_STRING_CSS VARCHAR2(255 CHAR) N CODE_STRING_PARTNER VARCHAR2(255 CHAR) N TERMINATABLE NUMBER(1,0) N ELIGIBLE_TO_SPEND_MILEAGE NUMBER(1,0) N
Tabel MEMBER_TYPE
Nama Field Data Type Digunakan DW and DWTEMP ENTITY_ID NUMBER(10,0) Y MEMBER_TYPE_ID ENTITY_STATUS VARCHAR2(20 CHAR) N CREATED_BY VARCHAR2(32 CHAR) N CREATED_ON TIMESTAMP(6) N UPDATED_BY VARCHAR2(32 CHAR) N UPDATED_ON TIMESTAMP(6) N TYPE VARCHAR2(255 CHAR) Y TYPE CODE_NUMBER NUMBER(10,0) N EXPIRY_DATE TIMESTAMP(6) N PERIODE NUMBER(10,0) N EFFECTIVE_DATE TIMESTAMP(6) N DEFINABLE_NUMBER NUMBER(1,0) N EXPIRES NUMBER(1,0) N UPGRADABLE NUMBER(1,0) N ANNUAL_FEE1 FLOAT Y ANNUAL_FEE1 ANNUAL_FEE2 FLOAT Y ANNUAL_FEE2 DELETE_INACTIVE NUMBER(10,0) N CODE_STRING VARCHAR2(255 CHAR) N TIER_ID NUMBER(10,0) Y TIER_ID MIN_AGE NUMBER N MAX_AGE NUMBER N

101

102
Lampiran 3
Lihat BAB VI. Implementasi data mining
Gambar 8.1 Pola anggota GFF Cobrand yang melakukan pendaftaran melalui jalur BO.

103
Lampiran 4
Gambar 8.2 Pola anggota GFF Cobrand yang melakukan pendaftaran melalui jalur BO, CSS dan jalur Citibank atau disebut channel Cobrand.

104
Lampiran 5
(lihat bab VI bagian 6.5.2)
ENROLL_CHANNEL = BO | DURATIONFROMREGISTERINMONTH <= 76.415 | | DURATIONFROMREGISTERINMONTH <= 17.615 | | | LIFEDURATIONINMONTH <= 4.235 | | | | LIFEDURATIONINMONTH <= 1.915 | | | | | LIFEDURATIONINMONTH <= 1.700 | | | | | | LIFEDURATIONINMONTH <= 1.465 | | | | | | | LIFEDURATIONINMONTH <= 1.200 | | | | | | | | DURATIONFROMREGISTERINMONTH <= 16.865: Silver {Silver=15, Blue=15, Gold=0, Platinum=0} | | | | | | | | DURATIONFROMREGISTERINMONTH > 16.865: Blue {Silver=0, Blue=2, Gold=0, Platinum=0} | | | | | | | LIFEDURATIONINMONTH > 1.200: Blue {Silver=0, Blue=4, Gold=0, Platinum=0} | | | | | | LIFEDURATIONINMONTH > 1.465: Silver {Silver=2, Blue=0, Gold=0, Platinum=0} | | | | | LIFEDURATIONINMONTH > 1.700: Blue {Silver=0, Blue=2, Gold=0, Platinum=0} | | | | LIFEDURATIONINMONTH > 1.915: Silver {Silver=8, Blue=1, Gold=0, Platinum=0} | | | LIFEDURATIONINMONTH > 4.235: Blue {Silver=1, Blue=9, Gold=0, Platinum=0} | | DURATIONFROMREGISTERINMONTH > 17.615 | | | LIFEDURATIONINMONTH <= 2.400 | | | | DURATIONFROMREGISTERINMONTH <= 19.800 | | | | | GENDER = F | | | | | | LIFEDURATIONINMONTH <= 0.965: Platinum {Silver=0, Blue=0, Gold=0, Platinum=2} | | | | | | LIFEDURATIONINMONTH > 0.965: Silver {Silver=1, Blue=1, Gold=0, Platinum=0} | | | | | GENDER = M: Gold {Silver=0, Blue=0, Gold=3, Platinum=0} | | | | DURATIONFROMREGISTERINMONTH > 19.800 | | | | | DURATIONFROMREGISTERINMONTH <= 28.865 | | | | | | DURATIONFROMREGISTERINMONTH <= 27.220 | | | | | | | DURATIONFROMREGISTERINMONTH <= 20.585: Blue {Silver=0, Blue=4, Gold=0, Platinum=0} | | | | | | | DURATIONFROMREGISTERINMONTH > 20.585 | | | | | | | | DURATIONFROMREGISTERINMONTH <= 23.235: Silver {Silver=8, Blue=0, Gold=0, Platinum=0} | | | | | | | | DURATIONFROMREGISTERINMONTH > 23.235: Blue {Silver=5, Blue=8, Gold=1, Platinum=0} | | | | | | DURATIONFROMREGISTERINMONTH > 27.220: Blue {Silver=0, Blue=6, Gold=1, Platinum=0} | | | | | DURATIONFROMREGISTERINMONTH > 28.865 | | | | | | DURATIONFROMREGISTERINMONTH <= 48.600 | | | | | | | DURATIONFROMREGISTERINMONTH <= 31.600 | | | | | | | | DURATIONFROMREGISTERINMONTH <= 29.615: Silver {Silver=3, Blue=0, Gold=0, Platinum=1} | | | | | | | | DURATIONFROMREGISTERINMONTH > 29.615: Blue {Silver=1, Blue=3, Gold=0, Platinum=1} | | | | | | | DURATIONFROMREGISTERINMONTH > 31.600 | | | | | | | | DURATIONFROMREGISTERINMONTH <= 44.185: Silver {Silver=24, Blue=6, Gold=0, Platinum=0}

105
| | | | | | | | DURATIONFROMREGISTERINMONTH > 44.185: Blue {Silver=2, Blue=4, Gold=0, Platinum=0} | | | | | | DURATIONFROMREGISTERINMONTH > 48.600 | | | | | | | DURATIONFROMREGISTERINMONTH <= 52.400: Gold {Silver=1, Blue=1, Gold=5, Platinum=1} | | | | | | | DURATIONFROMREGISTERINMONTH > 52.400 | | | | | | | | LIFEDURATIONINMONTH <= 0.915: Silver {Silver=14, Blue=2, Gold=1, Platinum=3} | | | | | | | | LIFEDURATIONINMONTH > 0.915: Blue {Silver=8, Blue=9, Gold=0, Platinum=0} | | | LIFEDURATIONINMONTH > 2.400 | | | | DURATIONFROMREGISTERINMONTH <= 58.515 | | | | | GENDER = F | | | | | | DURATIONFROMREGISTERINMONTH <= 47.335: Blue {Silver=2, Blue=13, Gold=0, Platinum=0} | | | | | | DURATIONFROMREGISTERINMONTH > 47.335 | | | | | | | ADDRESS_TYPE = BUSINESS: Blue {Silver=0, Blue=2, Gold=0, Platinum=0} | | | | | | | ADDRESS_TYPE = PRIVATE: Gold {Silver=0, Blue=0, Gold=2, Platinum=0} | | | | | GENDER = M | | | | | | DURATIONFROMREGISTERINMONTH <= 41.170 | | | | | | | DURATIONFROMREGISTERINMONTH <= 39.400: Blue {Silver=12, Blue=18, Gold=7, Platinum=1} | | | | | | | DURATIONFROMREGISTERINMONTH > 39.400: Gold {Silver=0, Blue=0, Gold=2, Platinum=1} | | | | | | DURATIONFROMREGISTERINMONTH > 41.170 | | | | | | | LIFEDURATIONINMONTH <= 9.950 | | | | | | | | DURATIONFROMREGISTERINMONTH <= 43.100: Blue {Silver=0, Blue=2, Gold=0, Platinum=0} | | | | | | | | DURATIONFROMREGISTERINMONTH > 43.100: Silver {Silver=6, Blue=4, Gold=0, Platinum=0} | | | | | | | LIFEDURATIONINMONTH > 9.950: Blue {Silver=1, Blue=8, Gold=0, Platinum=0} | | | | DURATIONFROMREGISTERINMONTH > 58.515 | | | | | DURATIONFROMREGISTERINMONTH <= 67.085: Silver {Silver=6, Blue=1, Gold=0, Platinum=0} | | | | | DURATIONFROMREGISTERINMONTH > 67.085: Blue {Silver=1, Blue=3, Gold=2, Platinum=0} | DURATIONFROMREGISTERINMONTH > 76.415 | | LIFEDURATIONINMONTH <= 0.820 | | | LIFEDURATIONINMONTH <= 0.085 | | | | ADDRESS_TYPE = PRIVATE: Platinum {Silver=1, Blue=0, Gold=0, Platinum=1} | | | | ADDRESS_TYPE = BUSINESS: Gold {Silver=0, Blue=0, Gold=3, Platinum=0} | | | LIFEDURATIONINMONTH > 0.085 | | | | DURATIONFROMREGISTERINMONTH <= 82.050 | | | | | DURATIONFROMREGISTERINMONTH <= 79.770: Silver {Silver=3, Blue=0, Gold=0, Platinum=0} | | | | | DURATIONFROMREGISTERINMONTH > 79.770: Platinum {Silver=0, Blue=0, Gold=0, Platinum=2} | | | | DURATIONFROMREGISTERINMONTH > 82.050: Silver {Silver=6, Blue=0, Gold=0, Platinum=0} | | LIFEDURATIONINMONTH > 0.820 | | | DURATIONFROMREGISTERINMONTH <= 84.700 | | | | LIFEDURATIONINMONTH <= 3.135: Silver {Silver=6, Blue=1, Gold=0, Platinum=0} | | | | LIFEDURATIONINMONTH > 3.135: Blue {Silver=1,

106
Blue=2, Gold=1, Platinum=0} | | | DURATIONFROMREGISTERINMONTH > 84.700 | | | | LIFEDURATIONINMONTH <= 1.800: Gold {Silver=0, Blue=0, Gold=5, Platinum=0} | | | | LIFEDURATIONINMONTH > 1.800 | | | | | ADDRESS_TYPE = PRIVATE: Gold {Silver=2, Blue=0, Gold=4, Platinum=1} | | | | | ADDRESS_TYPE = BUSINESS | | | | | | DURATIONFROMREGISTERINMONTH <= 86.715: Blue {Silver=0, Blue=2, Gold=1, Platinum=0} | | | | | | DURATIONFROMREGISTERINMONTH > 86.715: Silver {Silver=2, Blue=1, Gold=0, Platinum=0} ENROLL_CHANNEL = CSS | DURATIONFROMREGISTERINMONTH <= 14.965 | | DURATIONFROMREGISTERINMONTH <= 11.120 | | | LIFEDURATIONINMONTH <= 0.650: Silver {Silver=2, Blue=1, Gold=0, Platinum=0} | | | LIFEDURATIONINMONTH > 0.650: Blue {Silver=0, Blue=3, Gold=0, Platinum=0} | | DURATIONFROMREGISTERINMONTH > 11.120: Silver {Silver=3, Blue=0, Gold=0, Platinum=0} | DURATIONFROMREGISTERINMONTH > 14.965: Blue {Silver=0, Blue=4, Gold=1, Platinum=1} ENROLL_CHANNEL = COBRAND | DURATIONFROMREGISTERINMONTH <= 12.130: Blue {Silver=15, Blue=583, Gold=1, Platinum=13} | DURATIONFROMREGISTERINMONTH > 12.130 | | LIFEDURATIONINMONTH <= 12.515: Silver {Silver=3, Blue=3, Gold=1, Platinum=0} | | LIFEDURATIONINMONTH > 12.515: Blue {Silver=0, Blue=25, Gold=1, Platinum=0}

107
Lampiran 6
Discretization (lihat bab VI bagian 6.4.1)
DURATIONFROMREGISTERINMONTH -Infinity <= range1 [-∞ - 0.850] <= 0.85 <= range2 [0.850 - 2.415] <= 2.415 <= range3 [2.415 - 8.465] <= 8.465 <= range4 [8.465 - 29.565] <= 29.564999999999998 <= range5 [29.565 - ∞] <= Infinity LIFEDURATIONINMONTH -Infinity <= range1 [-∞ - 0.450] <= 0.44999999999999996 <= range2 [0.450 - 1.150] <= 1.15 <= range3 [1.150 - 2.315] <= 2.315 <= range4 [2.315 - 5.315] <= 5.3149999999999995 <= range5 [5.315 - ∞] <= Infinity

108
Lampiran 7
Sebagian hasil dari data mining dengan teknik association rule (lihat bab VI
bagian 6.5.1)
No Rule Premises Conclusion Support Confidence
147
GENDER = M, ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range1 [-∞ - 0.450]
DURATIONFROMREGISTER INMONTH = range1 [-∞ - 0.850] 0.112348 0.982301
150
ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range1 [-∞ - 0.450]
DURATIONFROMREGISTER INMONTH = range1 [-∞ - 0.850] 0.13664 0.985401
153
ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range3 [1.150 - 2.315]
DURATIONFROM REGISTER INMONTH = range2 [0.850 - 2.415] 0.121457 0.991736
127
ENROLL_CHANNEL = COBRAND, LIFEDURATIONINMONTH = range4 [2.315 - 5.315]
DURATIONFROMREGISTER INMONTH = range3 [2.415 - 8.465] 0.126518 0.925926
No Rule Premises Conclusion Support Confidence
20
ENROLL_CHANNEL = COBRAND, DURATIONFROMREGISTERINMONTH = range3 [2.415 – 8.465]
LIFEDURATIONINMONTH = Range4 [2.315 - 5.315] 0.126518 0.718391

109
Lampiran 8
TANGGAL : 13 November 2008
TEMPAT :
NARASUMBER : Manager Member Service & Production GFF dan 2. IT
Specialist GFF .
Q : Bagaimanakah bisnis proses GFF?
A : Secara umum, GFF berfungsi sebagai custimer loyalty program, berusaha
mendapatkan anggota sebanyak-banyaknya dan berusaha agar anggota dapat
menggunakan jasa Garuda dan partner sehingga anggota dapat mengumpulkan
poin atau mileage dan menggunakan mileage mereka.
Q : Apakah GFF mendapatkan keuntungan langsung atau revenue yang bisa
dikalkulasi?
A : Ada beberapa revenue yang bisa didapatkan dengan berjalannya GFF. Dari
keanggotaan iuran tahunan Gold ECPlus dan Platinum Cobrand. Kedua jenis
keanggotaan tersebut secara langsung dapat memberikan keutungan baik bagi
GFF ataupun Garuda. Selain itu, GFF melakukan penaikan kepada partner atas
setiap mileage yang diberikan Garuda terhadap anggota karena aktivitas angggota
GFF di partner.
Q : Bagaimana mengukur keberhasilan program GFF?
A : Bisa dilihat dari seberapa banak jumlah anggota yang melakukan aktivasi,
jumlah mileage untuk transaksi earning atau pembelian tiket , transaksi redeem
dan peningkatan jumlah partner .
Q : Bagaimana penghitungan mileage dan siapa yang menentukan?
A : Bagian keuangan menentukan konversi mileage ke dalam rupiah. Nilai tukar
itu yang dijasikan dasar penagihan transakasi ke partner sesaui dengan nilai saat
penandatangan kerja sama. Nilai tukar mileage saat ini adalah Rp.110,-





























