Embed Size (px)
Citation preview

1
Achieving high performance throughput in production
networks Les Cottrell – SLAC
Presented at the Internet 2 HENP Networking Working Group kickoff meeting at Internet 2 Ann Arbor, Michigan, Oct 26 ‘01
Partially funded by DOE/MICS Field Work Proposal on Internet End-to-end Performance Monitoring (IEPM), also supported by IUPAP
www.slac.stanford.edu/grp/scs/net/talk/thru-i2henp-oct01.html
2
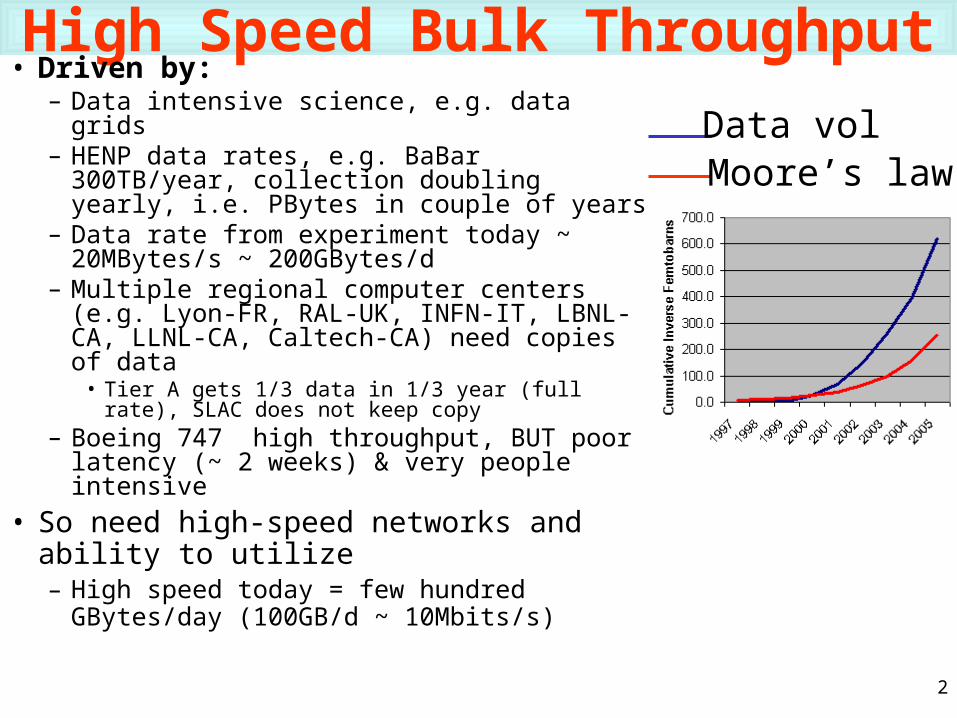
High Speed Bulk Throughput• Driven by:
– Data intensive science, e.g. data grids– HENP data rates, e.g. BaBar 300TB/year,
collection doubling yearly, i.e. PBytes in couple of years
– Data rate from experiment today ~ 20MBytes/s ~ 200GBytes/d
– Multiple regional computer centers (e.g. Lyon-FR, RAL-UK, INFN-IT, LBNL-CA, LLNL-CA, Caltech-CA) need copies of data
• Tier A gets 1/3 data in 1/3 year (full rate), SLAC does not keep copy
– Boeing 747 high throughput, BUT poor latency (~ 2 weeks) & very people intensive
• So need high-speed networks and ability to utilize– High speed today = few hundred GBytes/day
(100GB/d ~ 10Mbits/s)
Data vol Moore’s law

3
How to measure network throughput• Selected about 2 dozen major collaborator sites in US, CA, JP,
FR, CH, IT, UK over last year– Of interest to SLAC– Can get logon accounts
• Use iperf – Choose window size and # parallel streams– Run for 10 seconds together with ping (loaded)– Stop iperf, run ping (unloaded) for 10 seconds– Change window or number of streams & repeat
• Record # streams, window, throughput (Mbits/s), loaded & unloaded ping responses, cpu utilization, real time
• Verify window sizes are set properly by using tcpdump can’t believe what application tells you
• Note cpu speeds, interface speeds, operating system, path characteristics
4Solaris Default window size
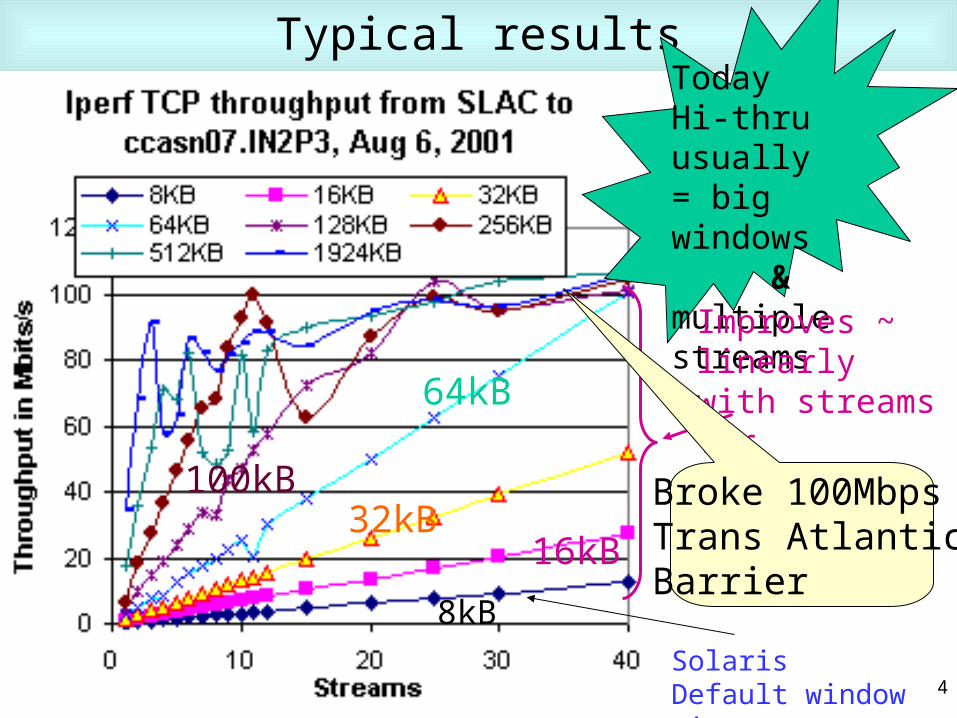
Typical resultsTodayHi-thru usually= big windows & multiple streams
Improves ~ linearlywith streams forsmall windows
8kB
16kB32kB
100kB
64kB
Broke 100MbpsTrans AtlanticBarrier
5
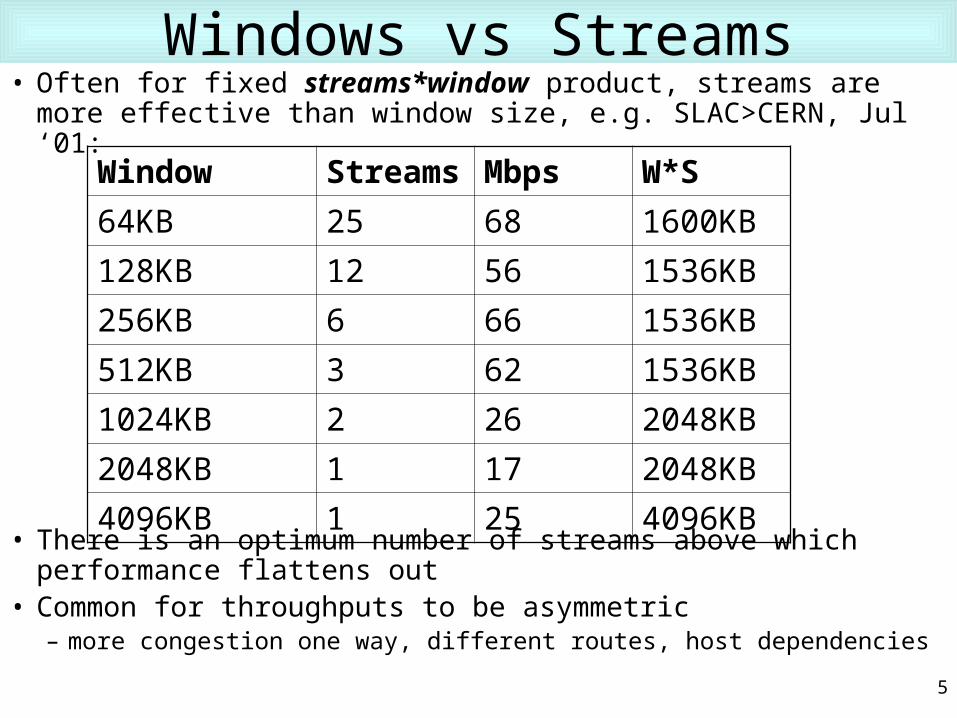
Windows vs Streams• Often for fixed streams*window product, streams are more
effective than window size, e.g. SLAC>CERN, Jul ‘01:
• There is an optimum number of streams above which performance flattens out
• Common for throughputs to be asymmetric– more congestion one way, different routes, host dependencies
Window Streams Mbps W*S
64KB 25 68 1600KB
128KB 12 56 1536KB
256KB 6 66 1536KB
512KB 3 62 1536KB
1024KB 2 26 2048KB
2048KB 1 17 2048KB
4096KB 1 25 4096KB

6
Windows vs Streams• Multi-streams often more effective than windows
– more agile in face of congestion
• Often easier to set up – Need root to configure kernel to set max window– Network components may not support big windows– Some OS’ treat max windows strangely
• May be able to take advantage of multiple paths
• But:– may be considered over-aggressive (RFC 2914) – can take more cpu cycles– how to know how many streams?
7
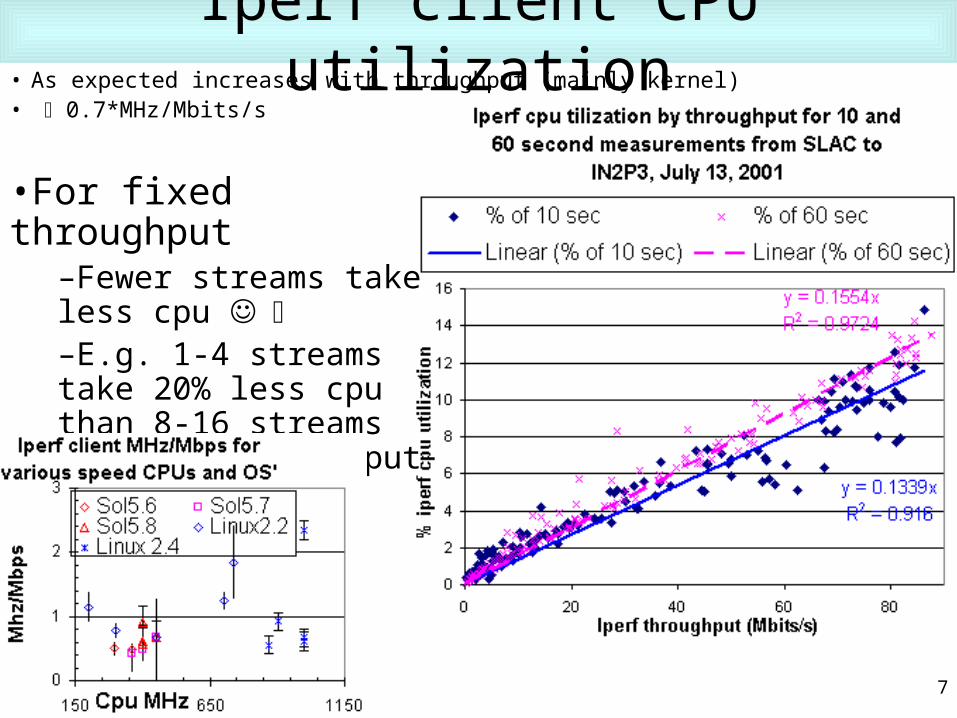
Iperf client CPU utilization• As expected increases with throughput (mainly kernel)• 0.7*MHz/Mbits/s
•For fixed throughput–Fewer streams take less cpu –E.g. 1-4 streams take 20% less cpu than 8-16 streams for same throughput (if can get it)
8
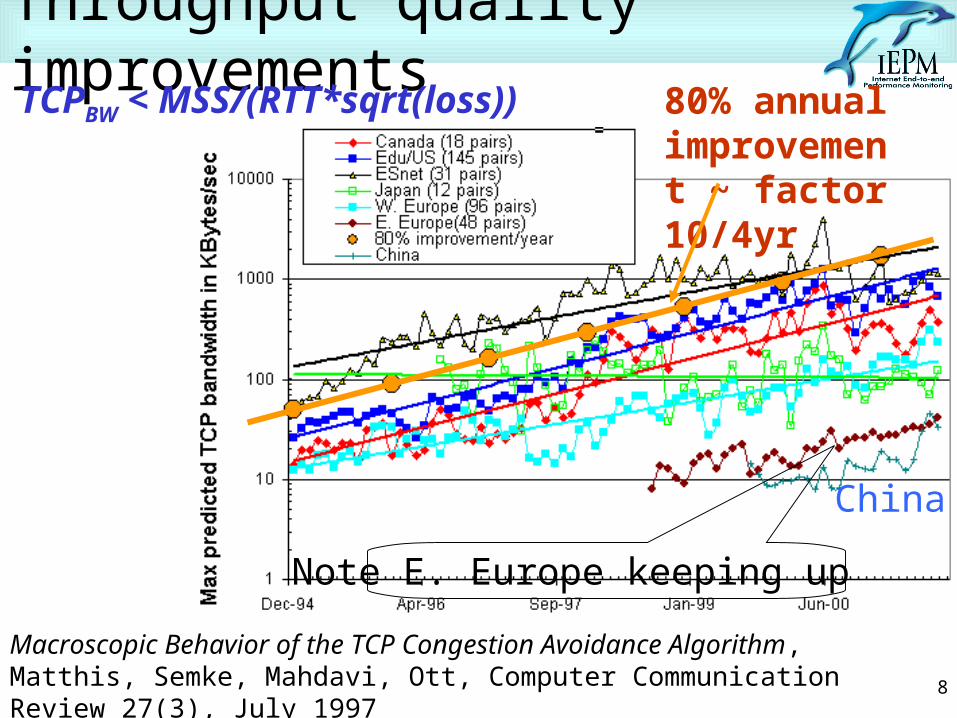
Throughput quality improvementsTCPBW < MSS/(RTT*sqrt(loss))
Macroscopic Behavior of the TCP Congestion Avoidance Algorithm, Matthis, Semke, Mahdavi, Ott, Computer Communication Review 27(3), July 1997
Note E. Europe keeping up
80% annual improvement ~ factor 10/4yr
China
9
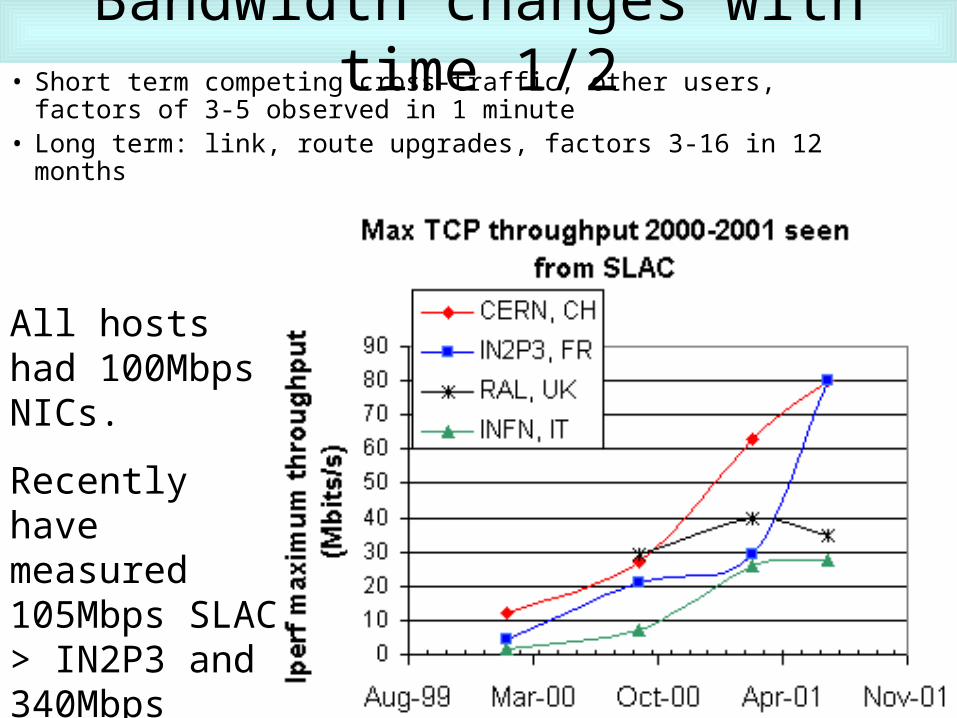
Bandwidth changes with time 1/2• Short term competing cross-traffic, other users, factors of 3-5
observed in 1 minute• Long term: link, route upgrades, factors 3-16 in 12 months
All hosts had 100Mbps NICs.
Recently have measured 105Mbps SLAC > IN2P3 and 340Mbps Caltech > SLAC with GE

10
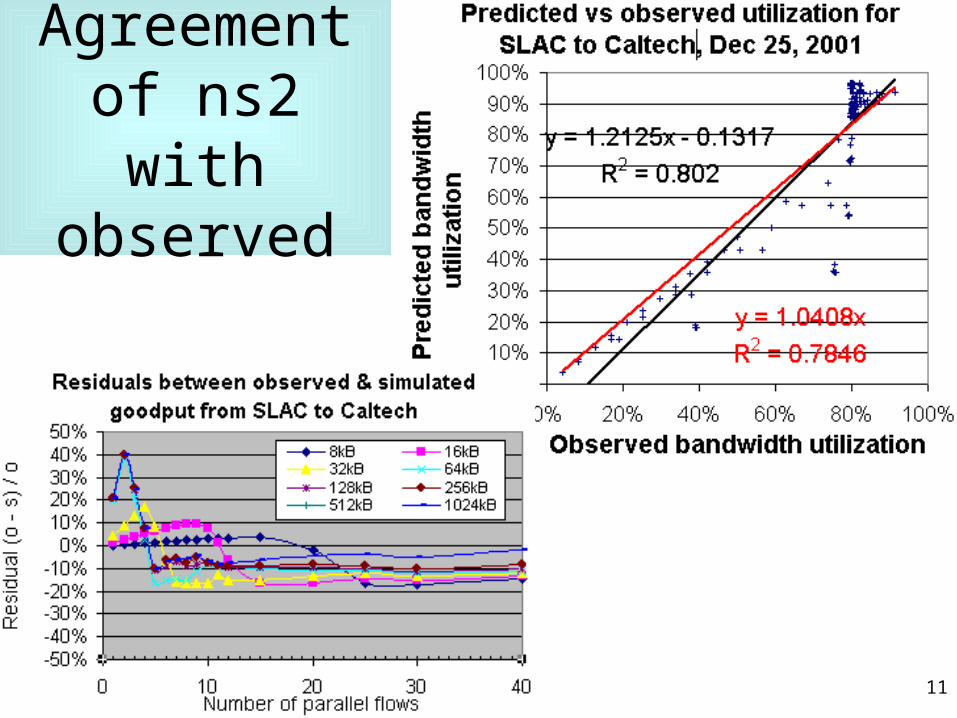
Network Simulator (ns-2)• From UCB, simulates network
– Choice of stack (Reno, Tahoe, Vegas, SACK…)– RTT, bandwidth, flows, windows, queue lengths …
• Compare with measured results– Agrees well– Confirms observations (e.g. linear growth in throughput
for small window sizes as increase number of flows)
11
Agreement of ns2 with observed
12
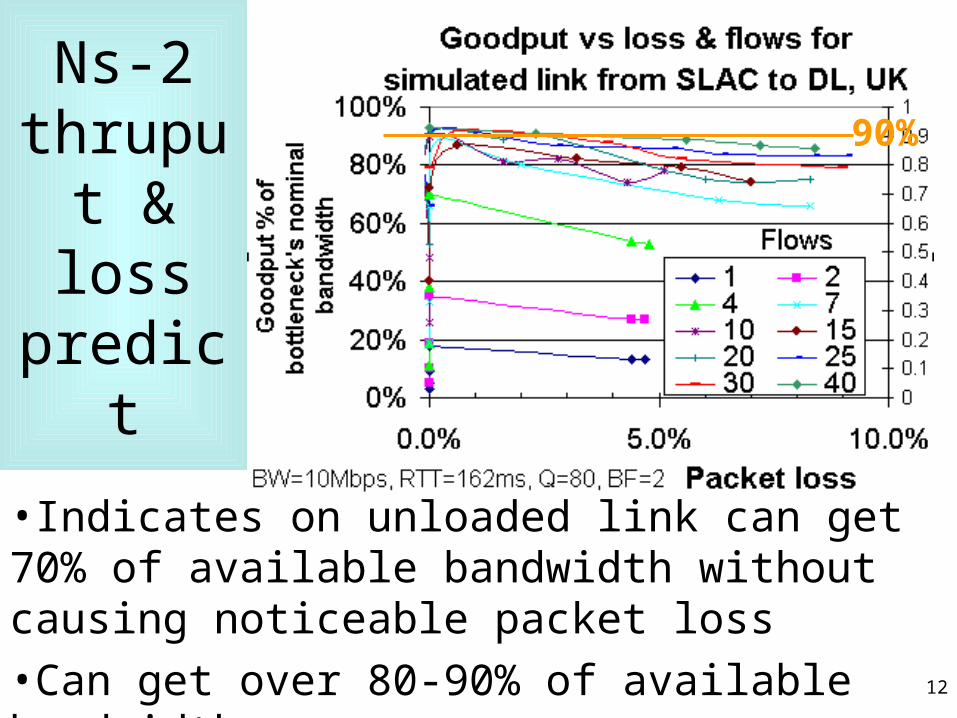
Ns-2 thruput & loss predict
•Indicates on unloaded link can get 70% of available bandwidth without causing noticeable packet loss
•Can get over 80-90% of available bandwidth
•Can overdrive: no extra throughput BUT extra loss
90%

13
Simulator benefits• No traffic on network (nb throughput can use 90%)• Can do what if experiments• No need to install iperf servers or have accounts• No need to configure host to allow large windows• BUT
– Need to estimate simulator parameters, e.g.• RTT use ping or synack• Bandwidth, use pchar, pipechar etc., moderately accurate
• AND its not the real thing– Need to validate vs. observed data– Need to simulate cross-traffic etc
14
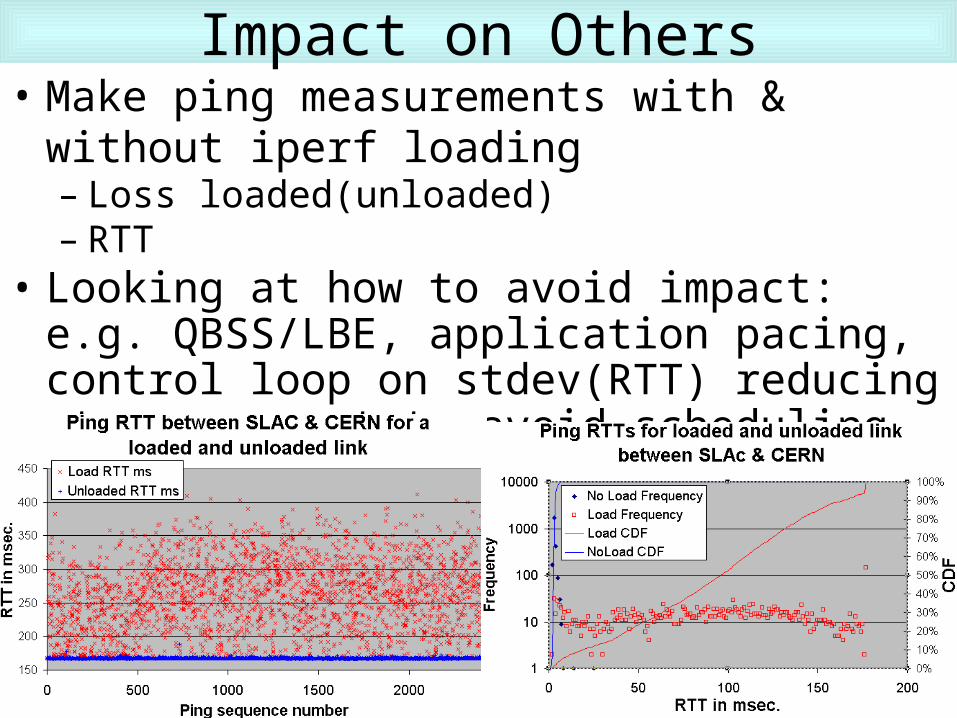
Impact on Others• Make ping measurements with & without iperf
loading– Loss loaded(unloaded)– RTT
• Looking at how to avoid impact: e.g. QBSS/LBE, application pacing, control loop on stdev(RTT) reducing streams, want to avoid scheduling

15
File Transfer• Used bbcp (written by Andy Hanushevsky)
– similar methodology to iperf, except ran for file length rather than time, provides incremental throughput reports, supports /dev/zero, adding duration
– looked at /afs/, /tmp/, /dev/null– checked different file sizes
• Behavior with windows & streams similar to iperf
• Thrubbcp ~0.8*Thruiperf
•For modest throughputs (< 50Mbits/s) rates are independent of whether destination is /afs/, /tmp/ or /dev/null. •Cpu utilization ~ 1MHz/Mbit/s is ~ 20% > than for iperf
16
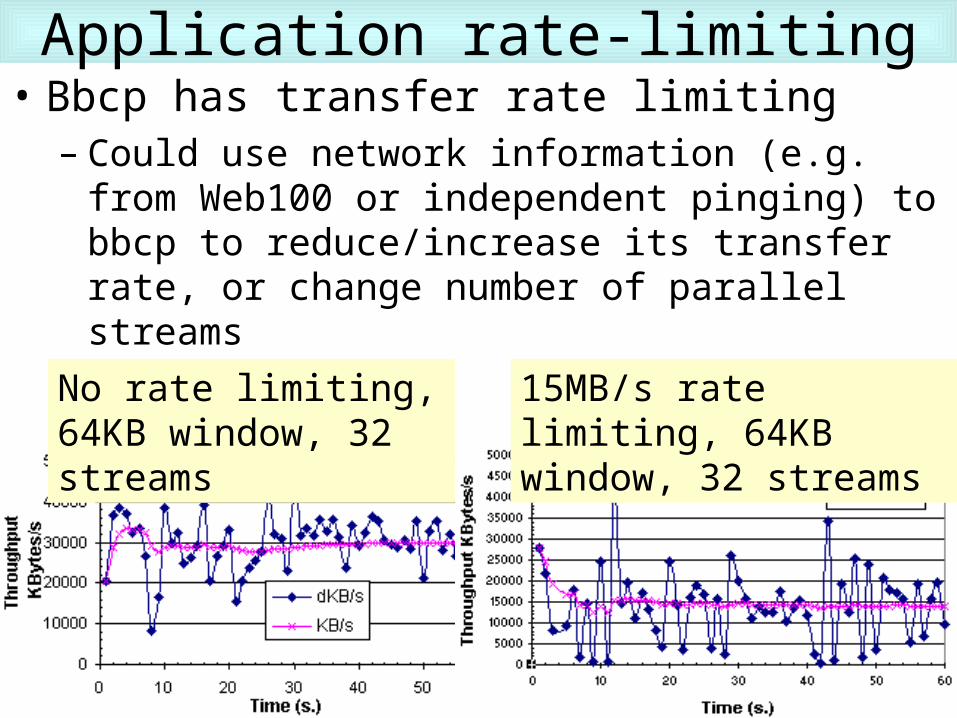
Application rate-limiting• Bbcp has transfer rate limiting
– Could use network information (e.g. from Web100 or independent pinging) to bbcp to reduce/increase its transfer rate, or change number of parallel streams
No rate limiting, 64KB window, 32 streams
15MB/s rate limiting, 64KB window, 32 streams

17
Using bbcp to make QBSS measurements
• Run bbcp src data /dev/zero, dst=/dev/null, report throughput at 1 second intervals– with TOS=32 (QBSS) – After 20 s. run bbcp with no TOS bits specified (BE)– After 20 s. run bbcp with TOS=40 (priority)– After 20 more secs turn off Priority– After 20 more secs turn off BE

18
QBSS test bed with Cisco 7200s• Set up QBSS testbed
• Configure router interfaces– 3 traffic types:
• QBSS, BE, Priority
– Define policy, e.g.• QBSS > 1%, priority < 30%
– Apply policy to router interface queues
10Mbps
100Mbps
100Mbps
100Mbps
1Gbps
Cisco 7200s
19
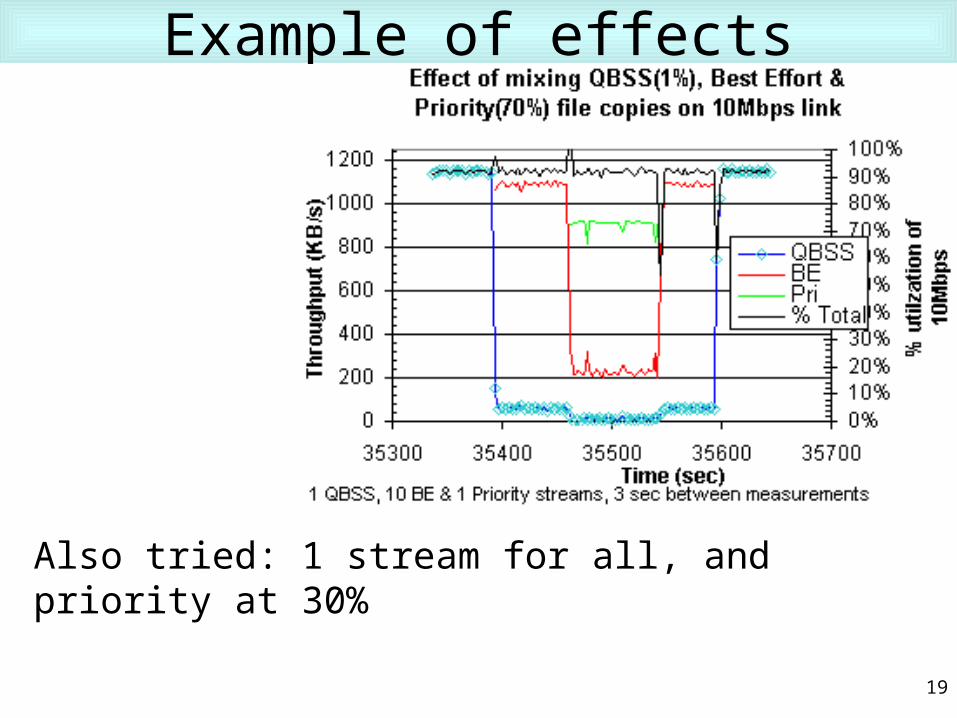
Example of effects
Also tried: 1 stream for all, and priority at 30%
20
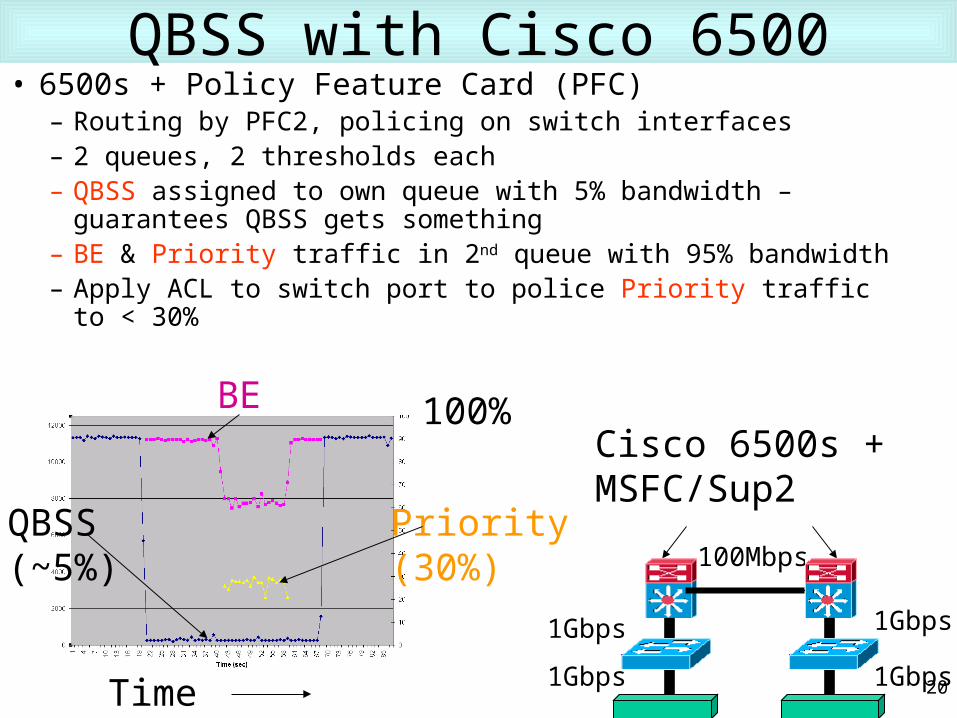
QBSS with Cisco 6500• 6500s + Policy Feature Card (PFC)
– Routing by PFC2, policing on switch interfaces– 2 queues, 2 thresholds each– QBSS assigned to own queue with 5% bandwidth – guarantees
QBSS gets something– BE & Priority traffic in 2nd queue with 95% bandwidth– Apply ACL to switch port to police Priority traffic to < 30%
100Mbps
1Gbps
1Gbps
1Gbps
1Gbps
Cisco 6500s + MSFC/Sup2
Time
100%BE
Priority(30%)
QBSS(~5%)

21
Impact on response time (RTT)• Run ping with Iperf loading with various QoS
settings, iperf ~ 93Mbps– No iperf ping avg RTT ~ 300usec (regardless of QoS)– Iperf = QBSS, ping=BE or Priority: RTT~550usec
• 70% greater than unloaded
– Iperf=Ping QoS (exc. Priority) then RTT~5msec• > factor of 10 larger RTT than unloaded
– If both ping & iperf have QoS=Priority then ping RTT very variable since iperf limited to 30%
• RTT quick when iperf limited, long when iperf transmits

22
Possible HEP usage• Apply priority to lower volume interactive
voice/video-conferencing and real time control• Apply QBSS to high volume data replication• Leave the rest as Best Effort• Since 40-65% of bytes to/from SLAC come from a
single application, we have modified to enable setting of TOS bits
• Need to identify bottlenecks and implement QBSS there
• Bottlenecks tend to be at edges so hope to try with a few HEP sites

23
Acknowledgements for SC2001• Many people assisted in getting accounts, setting up servers,
providing advice, software etc.– Suresh Man Singh, Harvey Newman, Julian Bunn (Caltech), Andy
Hanushevsky, Paola Grosso, Gary Buhrmaster, Connie Logg (SLAC), Olivier Martin (CERN), Loric Totay, Jerome Bernier (IN2P3), Dantong Yu (BNL), Robin Tasker, Paul Kummer (DL), John Gordon (RL), Brian Tierney, Bob Jacobsen, (LBL), Stanislav Shalunov (Internet 2), Joe Izen (UT Dallas), Linda Winkler, Bill Allcock (ANL), Ruth Pordes, Frank Nagy (FNAL), Emanuele Leonardi (INFN), Chip Watson (JLab), Yukio Karita (KEK), Tom Dunigan (ORNL), John Gordon (RL), Andrew Daviel (TRIUMF), Paul Avery, Greg Goddard (UFL), Paul Barford, Miron Livny (UWisc), Shane Canon (NERSC), Andy Germain (NASA), Andrew Daviel (TRIUMF), Richard baraniuk, Rold Reidi (Rice).

24
SC2001 demo• Send data from SLAC/FNAL booth computers
(emulate a tier 0 or 1 HENP site) to over 20 other sites with good connections in about 6 countries– Throughputs from SLAC range from 3Mbps to >
300Mbps
• Part of bandwidth challenge proposal• Saturate 2Gbps connection to floor network• Apply QBSS to some sites, priority to a few and rest
Best Effort– See how QBSS works at high speeds
• Competing bulk throughput streams• Interactive low throughput streams, look at RTT with ping

25
WAN thruput conclusions• High FTP performance across WAN links is possible
–Even with 20-30Mbps bottleneck can do > 100Gbytes/day–Can easily saturate a fast Ethernet interface over WAN–Need GE NICs, > OC3 WANs & to improve performance
• Performance is improving• OS must support big windows selectable by application• Need multiple parallel streams in some cases• Loss is important in particular interval between losses
• Can get close to max thruput with small (<=32Mbyte) with sufficient (5-10) streams
• Improvements of 5 to 60 in thruput by using multiple streams & larger windows
• Impacts others users, QBSS looks hopeful
26
More Information• IEPM/PingER home site:
– www-iepm.slac.stanford.edu/• Bulk throughput site:
– www-iepm.slac.stanford.edu/monitoring/bulk/• Transfer tools:
– http://dast.nlanr.net/Projects/Iperf/release.html– http://doc.in2p3.fr/bbftp/– www.slac.stanford.edu/~abh/bbcp/– http://hepwww.rl.ac.uk/Adye/talks/010402-ftp/html/sld015.htm
• TCP Tuning:– www.ncne.nlanr.net/training/presentations/tcp-tutorial.ppt– www-didc.lbl.gov/tcp-wan.html
• QBSS measurements– www-iepm.slac.stanford.edu/monitoring/qbss/measure.html





























