Embed Size (px)
DESCRIPTION
Advanced File Processing. Objectives. Use the pipe operator to redirect the output of one command to another command Use the grep command to search for a specified pattern in a file Use the uniq command to remove duplicate lines from a file - PowerPoint PPT Presentation
Citation preview

Advanced File Processing

2
Objectives
• Use the pipe operator to redirect the output of one command to another command
• Use the grep command to search for a specified pattern in a file
• Use the uniq command to remove duplicate lines from a file
• Use the comm and diff commands to compare two files
• Use the wc command to count words, characters and lines in a file

3
Objectives (continued)
• Use manipulation and transformation commands, which include sed, tr, and pr
• Design a new file-processing application by creating, testing, and running shell scripts

4
Advancing YourFile-Processing Skills
• Selection commands focus on extracting specific information from files

5
Advancing YourFile Processing Skills (continued)
• Manipulation and transformation commands alter and transform extracted information into useful and appealing formats

6
Advancing YourFile Processing Skills (continued)

7
Using the Selection Commands
• Using the Pipe Operator
– The pipe operator (|) redirects the output of one command to the input of another
– An example would be to redirect the output of the ls command to the more command
– The pipe operator can connect several commands on the same command line

8
Using the Pipe Operator
Using pipe operators and connecting commands is useful when viewing directory information

9
Using the grep Command
• Used to search for a specific pattern in a file, such as a word or phrase
• grep’s options and wildcard support allow for powerful search operations
• You can increase grep’s usefulness by combining with other commands, such as head or tail

10
Using the uniq Command
• Removes duplicate lines from a file• Compares only consecutive lines, therefore uniq requires
sorted input
• uniq has an option that allows you to generate output
that contains a copy of each line that has a duplicate
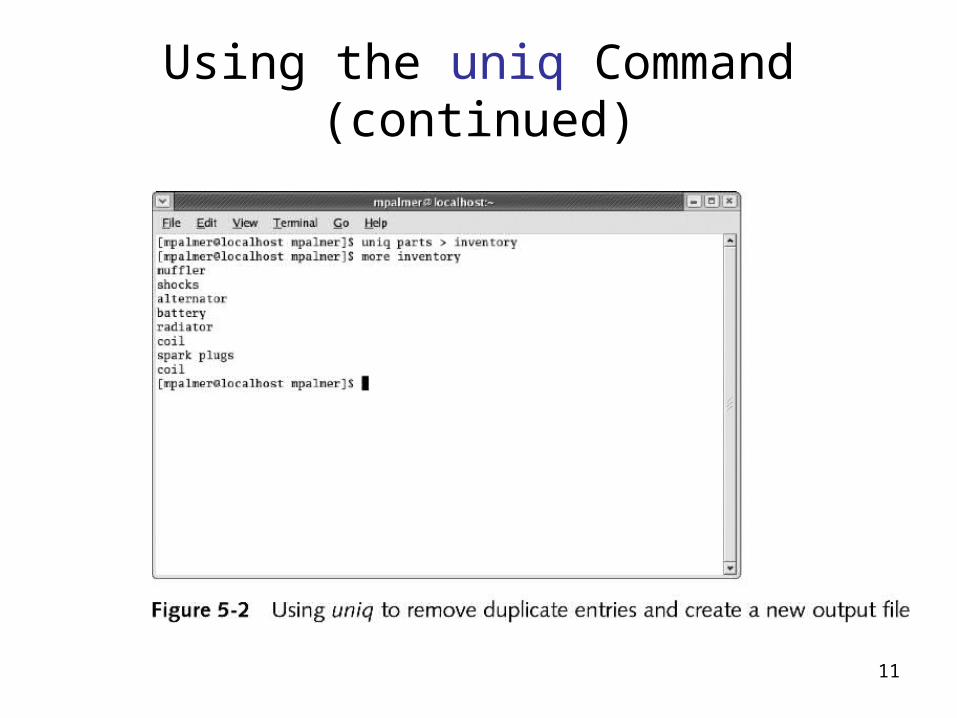
11
Using the uniq Command (continued)
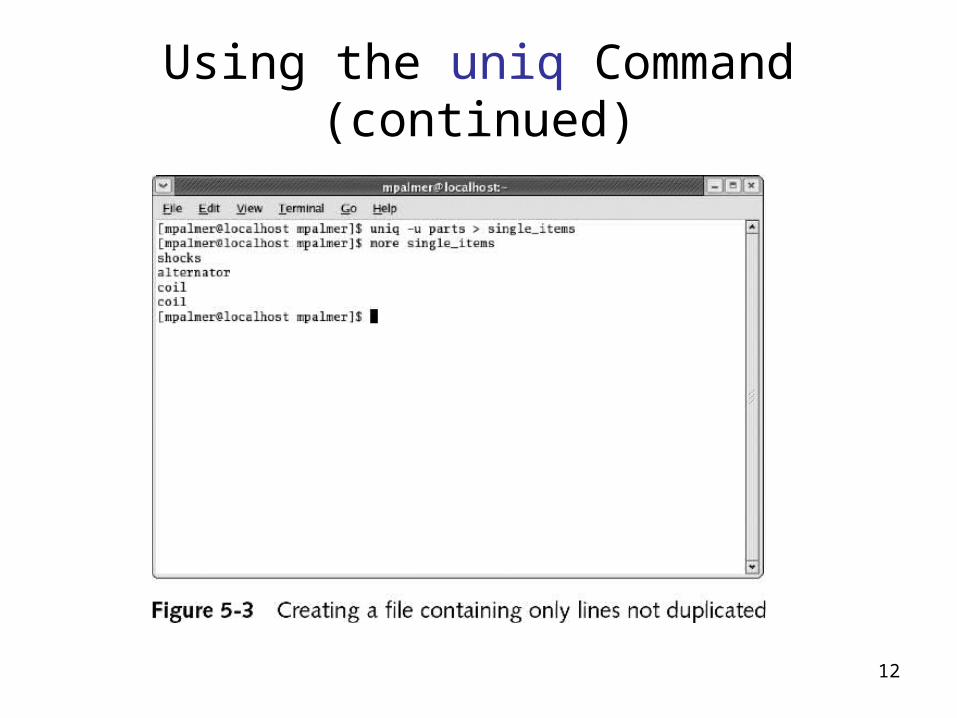
12
Using the uniq Command (continued)

13
Using the comm Command
• Used to identify duplicate lines in sorted files• Unlike uniq, it does not remove duplicates, and it works
with two files rather than one• It compares lines common to file1 and file2, and
produces three column output– Column one contains lines found only in file1– Column two contains lines found only in file2– Column three contains lines found in both files

14
Using the diff Command
• Attempts to determine the minimal changes needed to convert file1 to file2
• The output displays the line(s) that differ• Codes in the output indicate that in order for the files to
match, specific lines must be added or deleted

15
Using the wc Command
• Used to count the number of lines, words, and bytes or characters in text files
• You may specify all three options in one issuance of the command
• If you don’t specify any options, you see counts of lines, words, and characters (in that order)
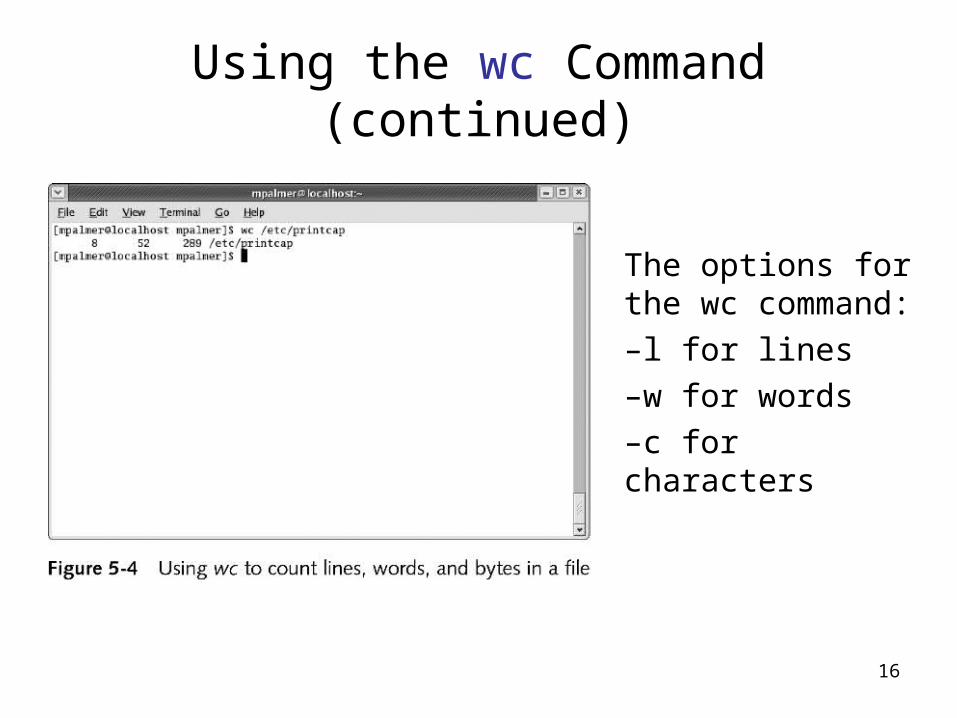
16
Using the wc Command (continued)
The options for the wc command:
–l for lines
–w for words
–c for characters

17
Using Manipulation and Transformation Commands
• These commands are: sed, tr, pr
• Used to edit and transform the appearance of data before it is displayed or printed

18
Introducing the sed Command
• sed is a UNIX/Linux editor that allows you to make global changes to large files
• Minimum requirements are an input file and a command that lets sed know what actions to apply to the file
• sed commands have two general forms– Specify an editing command on the command line– Specify a script file containing sed commands

19
Translating CharactersUsing the tr Command
• tr copies data from the standard input to the standard output, substituting or deleting characters specified by options and patterns
• The patterns are strings and the strings are sets of characters
• A popular use of tr is converting lowercase characters to uppercase

20
Using the pr Command toFormat Your Output
• pr prints specified files on the standard output in paginated form
• By default, pr formats the specified files into single-column pages of 66 lines
• Each page has a five-line header containing the file name, its latest modification date, and current page, and a five-line trailer consisting of blank lines

21
Designing a New File-Processing Application
• The most important phase in developing a new application is the design
• The design defines the information an application needs to produce
• The design also defines how to organize this information into files, records, and fields, which are called logical structures

22
Designing Records
• The first task is to define the fields in the records and produce a record layout
• A record layout identifies each field by name and data type (numeric or nonnumeric)
• Design the file record to store only those fields relevant to the record’s primary purpose

23
Linking Files with Keys
• Multiple files are joined by a key: a common field that each of the linked files share
• Another important task in the design phase is to plan a way to join the files
• The flexibility to gather information from multiple files comprised of simple, short records is the essence of a relational database system
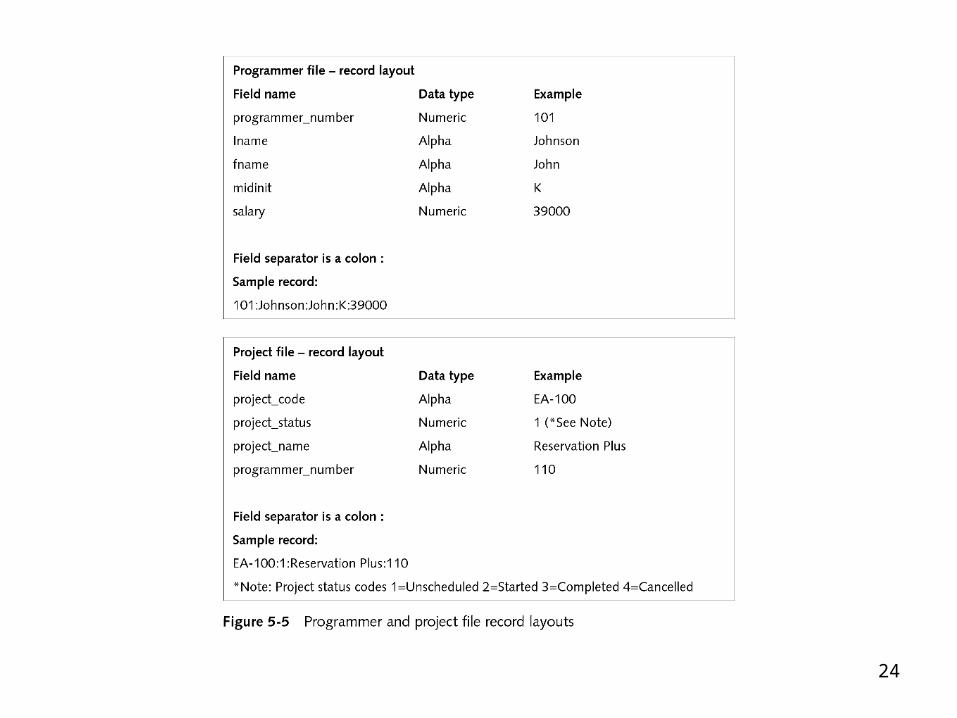
24

25
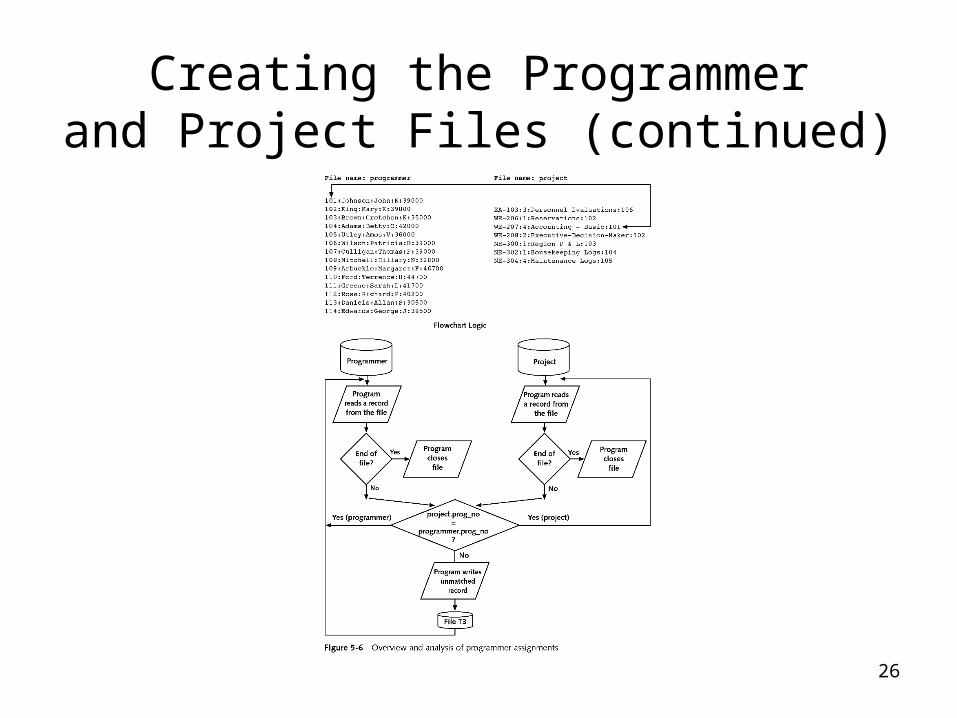
Creating the Programmerand Project Files
• With the basic design complete, you now implement your application design
• UNIX/Linux file processing predominantly uses flat files• Working with these files is easy, because you can create
and manipulate them with text editors like vi and Emacs
26
Creating the Programmerand Project Files (continued)

27
Formatting Output
• The awk command is used to prepare formatted output• For the purposes of developing a new file-processing
application, we will focus primarily on the printf action of the awk command
Awk provides a shortcut to other UNIX/Linux commands

28
Using a Shell Script toImplement the Application
• Shell scripts should contain:– The commands to execute– Comments to identify and explain the script so that
users or programmers other than the author can understand how it works
• Use the pound (#) character to mark comments in a script file

29
Running a Shell Script
• You can run a shell script in virtually any shell that you have on your system
• The Bash shell accepts more variations in command structures that other shells
• Run the script by typing sh followed by the name of the script, or make the script executable and type ./ prior to the script name

30
Putting it All Together toProduce the Report
• An effective way to develop applications is to combine many small scripts in a larger script file
• Have the last script added to the larger script print a report indicating script functions and results

31
Summary
• UNIX/Linux file-processing commands are (1) selection and (2) manipulation and transformation commands
• uniq removes duplicate lines from a sorted file• comm compares lines common to file1 and file2• diff tries to determine the minimal set of changes
needed to convert file1 into file2

32
Summary (continued)
• tr copies data read from the standard input to the standard output, substituting or deleting characters specified
• sed is a file editor designed to make global changes to large files
• pr prints the standard output in pages

33
Summary (continued)
• The design of a file-processing application reflects what the application needs to produce
• Use record layout to identify each field by name and data type
• Shell scripts should contain commands to execute programs and comments to identify and explain the programs





























