Embed Size (px)
DESCRIPTION
bbsrc biotechnology and biological sciences research council. Approaches to Storing and Querying Structural Information in Botanical Specimen Descriptions. Trevor Paterson. The Prometheus Database Project. Prometheus I: A Taxonomic Database ( POET OODB) - PowerPoint PPT Presentation
Citation preview

Approaches to Storing and Querying Structural Information in Botanical Specimen Descriptions.
Trevor Paterson
bbsrcbiotechnology and biological sciencesresearch council
The Prometheus Database Project

Prometheus II: Capturing Botanical Descriptions for Taxonomy (Oracle RDB)
A novel model for composing and recording taxonomic descriptions, using an ontology of defined terms.
JK, PB, GR, CR, Trevor Paterson, MP, MW, Sarah McDonald, Kate Armstrong
PII Visualisation and Data Entry Tools JK, MW, TP, Alan Cannon
Prometheus I: A Taxonomic Database (POET OODB)
A novel object-based representation of multiple overlapping taxonomic hierarchies – based on specimen circumscription.
Jessie Kennedy, Cédric Raguenaud, Mark Watson, Martin Pullan, Mark Newman, Peter Barclay
PI refactor Oracle RDB JK, Gordon Russell, Andrew Cumming
PI Visualisation Tools JK, Martin Graham

Characters are central to the taxonomic processthey describe specimens, species and higher ‘Taxa’ (groups)
they are the means of recognizing and categorizing diversity (forming taxonomies)
they are a major data output/resource generated from the process
e.g. - for reuse by other taxonomists - for reuse in other applications
e.g for specimen identification (field guides, keys etc.)
‘Character Descriptions’ in Taxonomy
Character 1
e.g.taxon1: petals lanceolate, petal length 5 mmtaxon2: petals ovate, petal length 2-4 mm
Character 2

Problems with Taxonomic Characters
No formal methodology or model for recognizing and
describing Characters
Language (terminology) used in descriptions is ill-defined
(natural language based)
A taxonomic revision is often the work of one individual
and can be highly idiosyncratic – (lack formalism, personal
terminology)
loss of data ( not recorded )
ambiguous / poorly-defined data
data not comparable between projects
Consequences

Prometheus System for Taxonomic Description
A standard conceptual model for the composition
of character descriptions
Ontologies of defined and related ‘terms’ to
record character descriptions
Store description data in electronic/database
form

The Prometheus II Character Model
Representing Characters as Atomic Statements: Description Elements
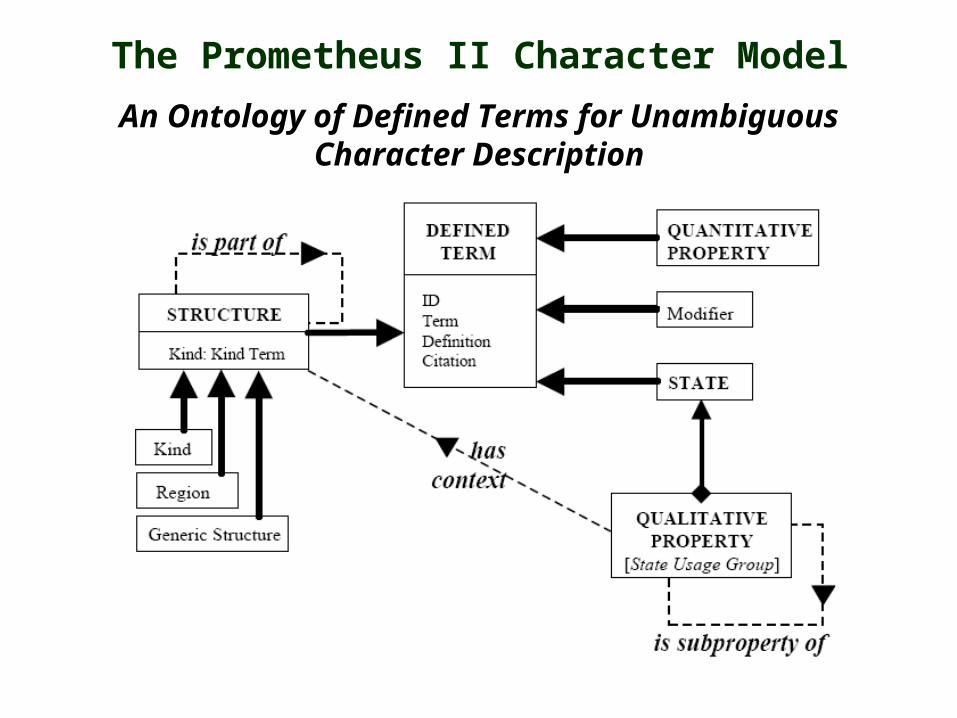
The Prometheus II Character Model
An Ontology of Defined Terms for Unambiguous Character Description
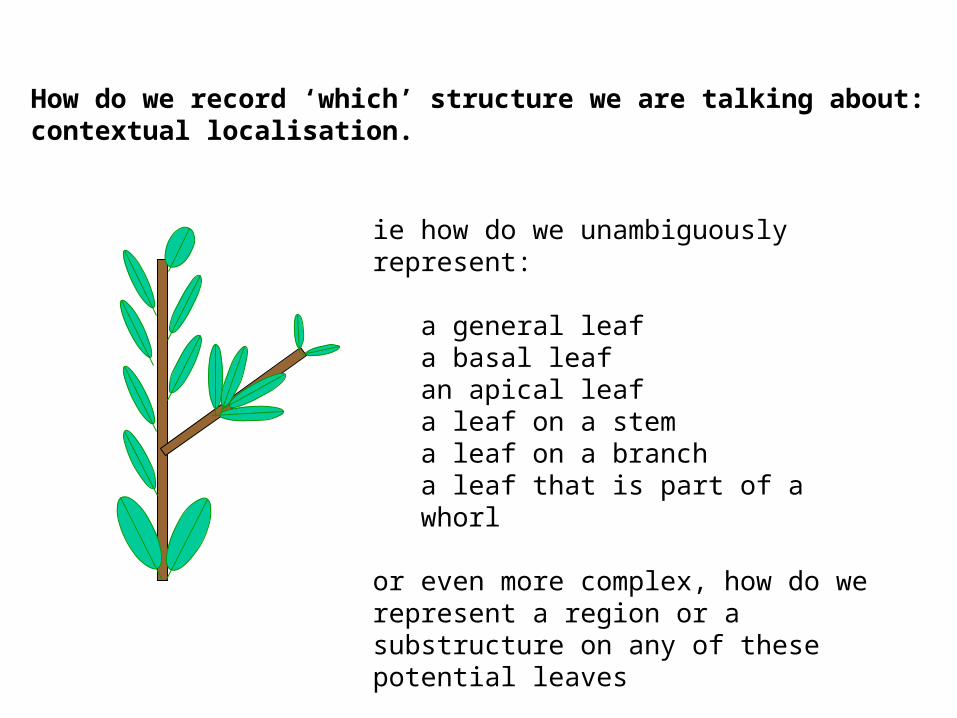
How do we record ‘which’ structure we are talking about:contextual localisation.
ie how do we unambiguously represent:
a general leafa basal leafan apical leaf a leaf on a stem a leaf on a branch a leaf that is part of a whorl
or even more complex, how do we represent a region or a substructure on any of these potential leaves

Our ontology records a PartOf relationship between
structures to capture these potential structural relationships
This PartOf relationship is OPTIONAL, i.e. ontologically a
leaf might be part of a stem, whorl, branch etc; but a given
specimen may only some of these possible structural
compositions
Only when a particular structural context is referred to in a
description is its reality asserted
The PartOf relationship encompasses any compositional
relationship, not only strict part/subpart, but also less clear
associations and attachments.
In order to provide a flexible, unambiguous yet non-prescriptive means of localizing structures ...

The PartOf relationship in the ontology specifies all the possible compositional relationships between anatomical structures
a given structure can potentially be PartOf a number of Parent Structures
PartOf forms an acyclic, directed graph
Can be materialized as a tree hierarchy (by duplicating structures with more than one potential parent)
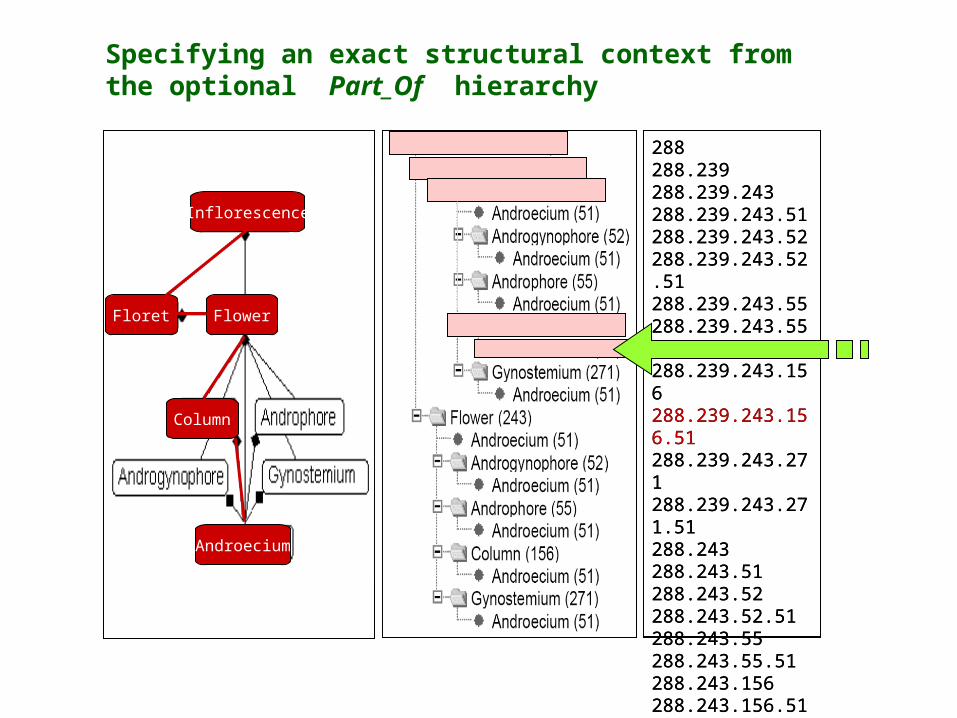
288288.239288.239.243288.239.243.51288.239.243.52288.239.243.52.51288.239.243.55288.239.243.55.51288.239.243.156288.239.243.156.51288.239.243.271288.239.243.271.51288.243288.243.51288.243.52288.243.52.51288.243.55288.243.55.51288.243.156288.243.156.51288.243.271288.243.271.51
Specifying an exact structural context from the optional Part_Of hierarchy
288288.239288.239.243288.239.243.51288.239.243.52288.239.243.52.51288.239.243.55288.239.243.55.51288.239.243.156288.239.243.156.51288.239.243.271288.239.243.271.51288.243288.243.51288.243.52288.243.52.51288.243.55288.243.55.51288.243.156288.243.156.51288.243.271288.243.271.51
Androecium
Column
FlowerFloret
Inflorescence

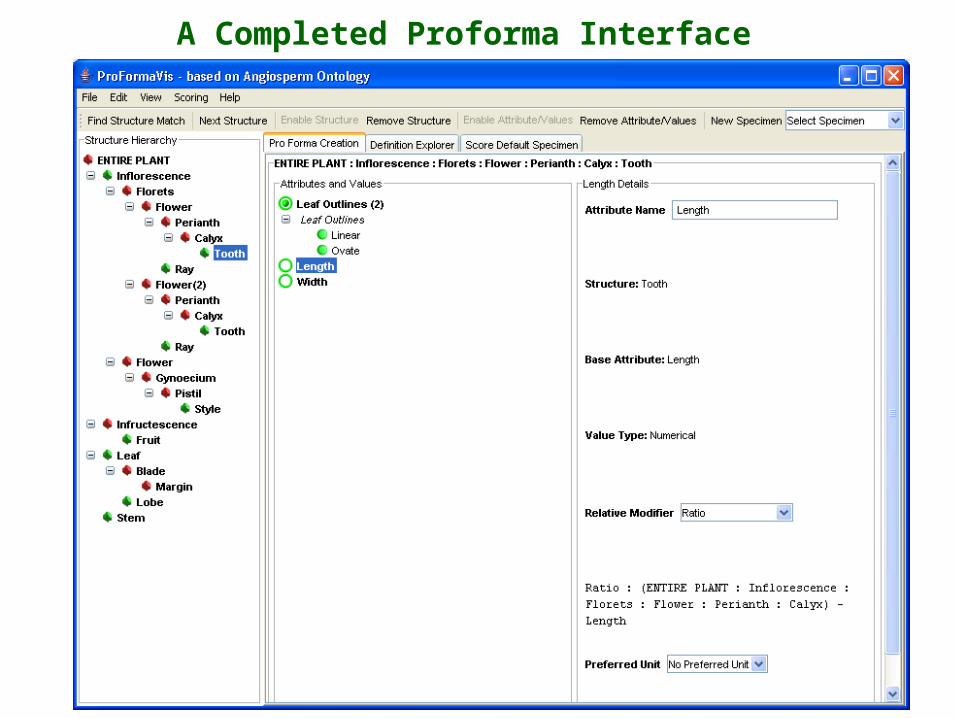
Software that we are developing for assisting a structured approach to taxonomic description uses the ontological PartOf hierarchy to organize data entry interfaces, for editing and scoring.
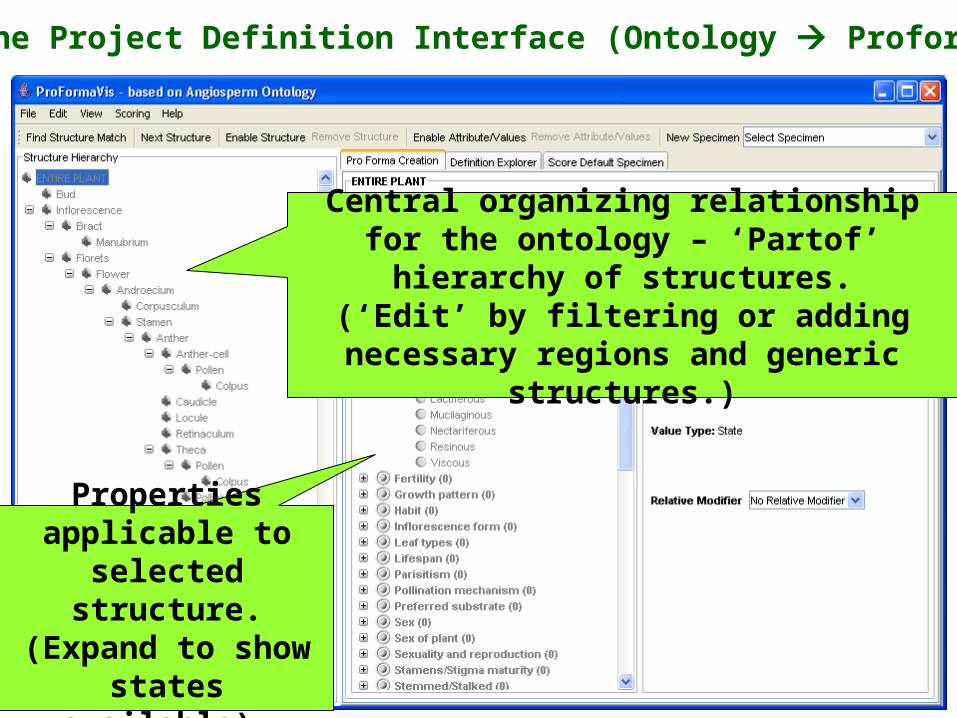
The Project Definition Interface (Ontology Proforma)
Central organizing relationship for the ontology – ‘Partof’ hierarchy of structures.
(‘Edit’ by filtering or adding necessary regions and generic structures.)
Properties applicable to
selected structure.(Expand to show states available).

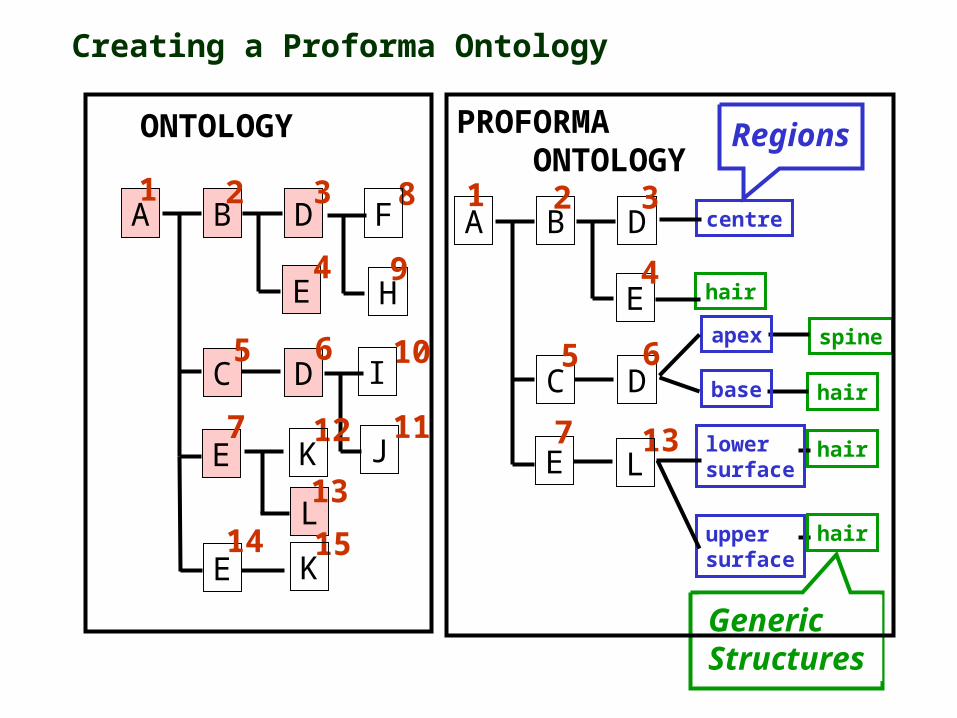
where only the structures of interest for a given project are included
and ‘generic structures’ and ‘regions’ are explicitly added to the compositional tree
This then represents a description template or ‘Proforma’ used for a particular project
Therefore the actual structural ‘Paths’ used vary from project to project
On a Project by Project basis a filtered version of the Ontology can be specified (A ‘Proforma’ Ontology)
BA
DC
D
E
1 2
4
3
65
H9
8
J11
10
F
I
E7
L13
12K
E14 15
K
ONTOLOGY
BA
DC
D
E
E
1 2
4
3
65
7 13L
spine
hair
hair
hair
hair
GenericStructures
lower surface
uppersurface
apex
base
centre
RegionsPROFORMA ONTOLOGY
Creating a Proforma Ontology
A Completed Proforma Interface

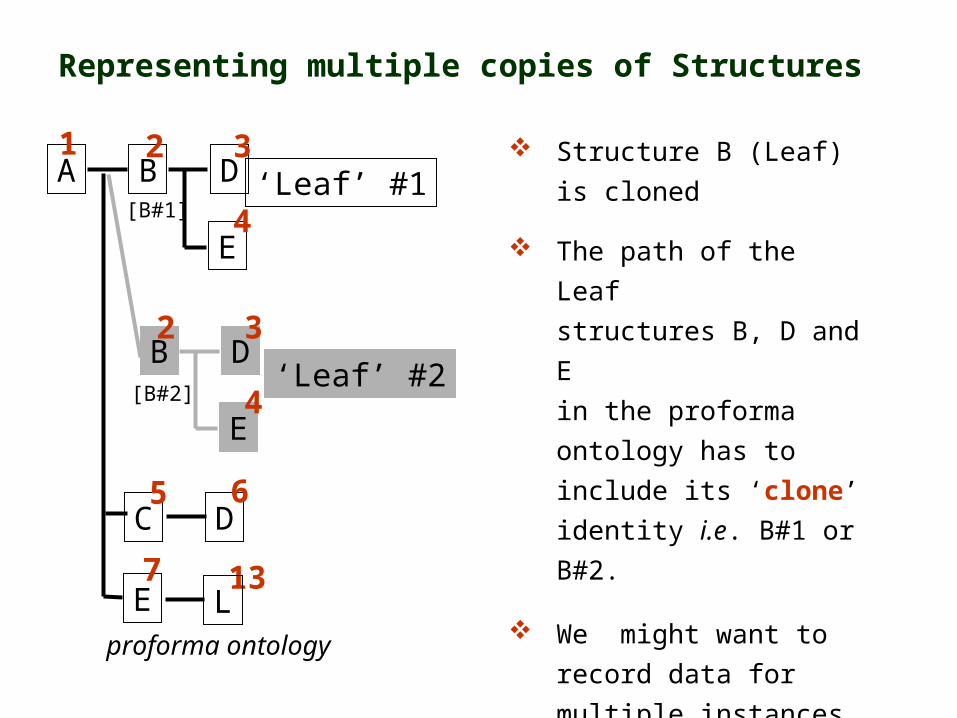
Yet another level of complexity is added by allowing any structure to be duplicated at the time of project definition ...
... and in fact multiple instances of structures might be required at scoring time to record observations for separate distinguishable instances of the same structure
Representing multiple copies of Structures
BA
DC
D
E
E
1 2
4
3
65
7 13L
‘Leaf’ #1
proforma ontology
Structure B (Leaf) is
cloned
The path of the Leaf
structures B, D and E
in the proforma ontology
has to include its ‘clone’
identity i.e. B#1 or B#2.
We might want to record
data for multiple instances
of each Leaf, and include
an ‘instance’ identity: eg
B#1: instance1,2,3...
B D
E
2
4
3
‘Leaf’ #2
[B#1]
[B#2]

We want to refer to a structure in the context of its parents
We need to take account of differences between project
specific versions of the ontology
We need to allow for changes (additions) to the ontology over
time
We want to be able to ‘clone’ more than one version of a
structure
We want to be able to score multiple instances of the same
structure
How can we store/represent (and query!) all this context/path information for structures in a relational database ?

A well-studied problem, various ‘solutions’
adjacency lists - calculate transitive closure
proprietary tree traversal queries (‘connect by’)
node numbering algorithms – maintenance problems
Need an easy and efficient solution
materialize the path – and traverse programmatically
what about XML? - as a native tree representation
Given that we are concerned with representing a structure hierarchy….. What do we know aboutHierarchical Trees in Relational Databases?
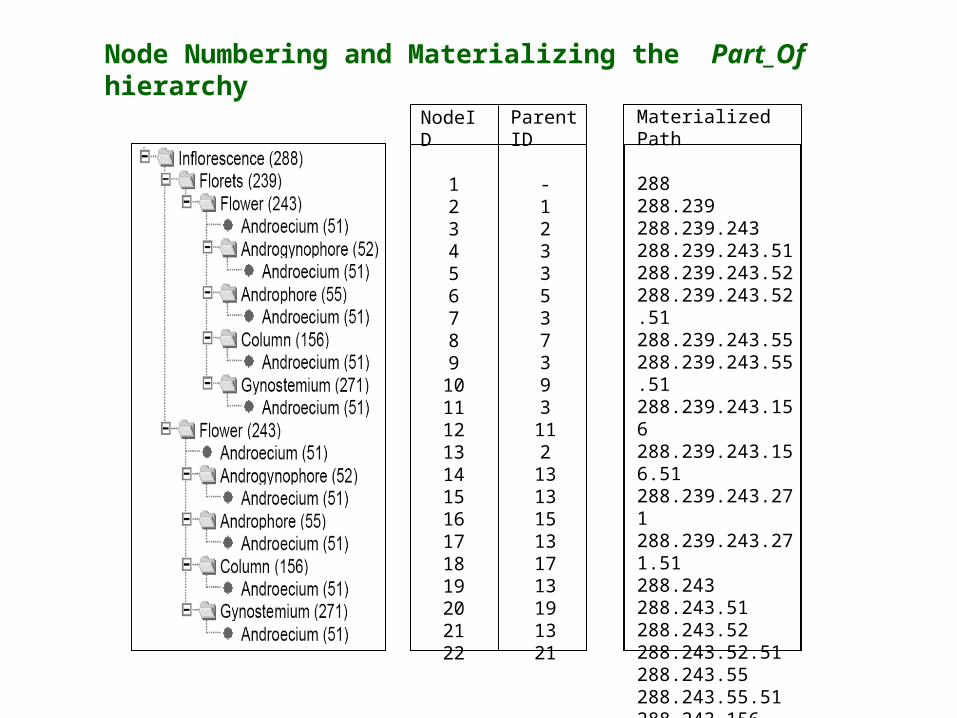
Node Numbering and Materializing the Part_Of hierarchy
NodeID
123456789
10111213141516171819202122
ParentID
-1233537393
112
131315131713191321
Materialized Path
288288.239288.239.243288.239.243.51288.239.243.52288.239.243.52.51288.239.243.55288.239.243.55.51288.239.243.156288.239.243.156.51288.239.243.271288.239.243.271.51288.243288.243.51288.243.52288.243.52.51288.243.55288.243.55.51288.243.156288.243.156.51288.243.271288.243.271.51
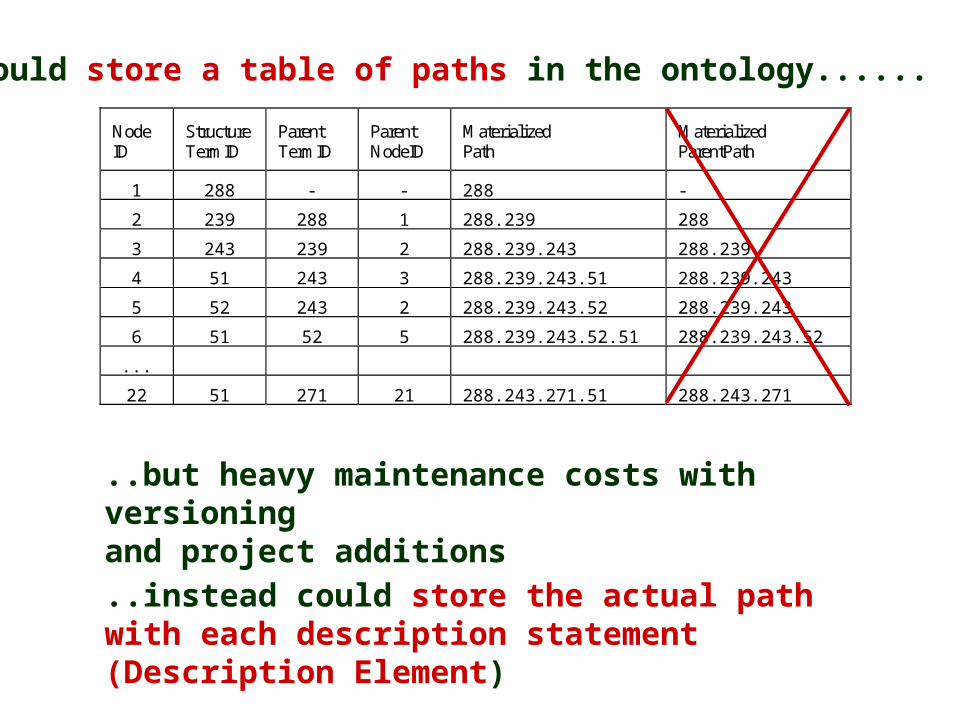
Node ID
Structure TermID
Parent TermID
Parent NodeID
Materialized Path
Materialized ParentPath
1 288 - - 288 -
2 239 288 1 288.239 288
3 243 239 2 288.239.243 288.239
4 51 243 3 288.239.243.51 288.239.243
5 52 243 2 288.239.243.52 288.239.243
6 51 52 5 288.239.243.52.51 288.239.243.52
...
22 51 271 21 288.243.271.51 288.243.271
Could store a table of paths in the ontology......
..but heavy maintenance costs with versioning and project additions
..instead could store the actual path with each description statement (Description Element)

XML and Trees
intuitively you can represent the whole structural hierarchy as an XML Tree.......
<STRUCTURE_TREE> <Node ID="1" ParentID="0" Path="288" TermID="288"> <Node ID="2" ParentID="1" Path="288.239" TermID="239"> <Node ID="3" ParentID="2" Path="288.239.243" TermID="243"> <Node ID="4" ParentID="3" Path="288.239.243.51" TermID="51" /> <Node ID="5" ParentID="3" Path="288.239.243.52" TermID="52" > <Node ID="6" ParentID="5" Path="288.239.243.52.51" TermID="51" />
. . . <Node ID = "22" ParentID="21" Path="288.243.271.51" TermID="51" /> </Node> </Node> </Node> </STRUCTURE_TREE>
....Again Node numbering algorithms and XML node indexing algorithms exist for XML databases - -still got maintenance problems

Or we can materialize the Path of each node as an XML fragment instead of as a string..
<Path nodeID="3"> <Term IDREF="288" >
<Term IDREF="239" > <Term IDREF="243" /> </Term> </Term> </Path>
equivalent to the string: 288.239.243
As with the strings – these could be stored as a table of paths for the ontology......
.....or the path can be stored as part of each description Statement (DE)
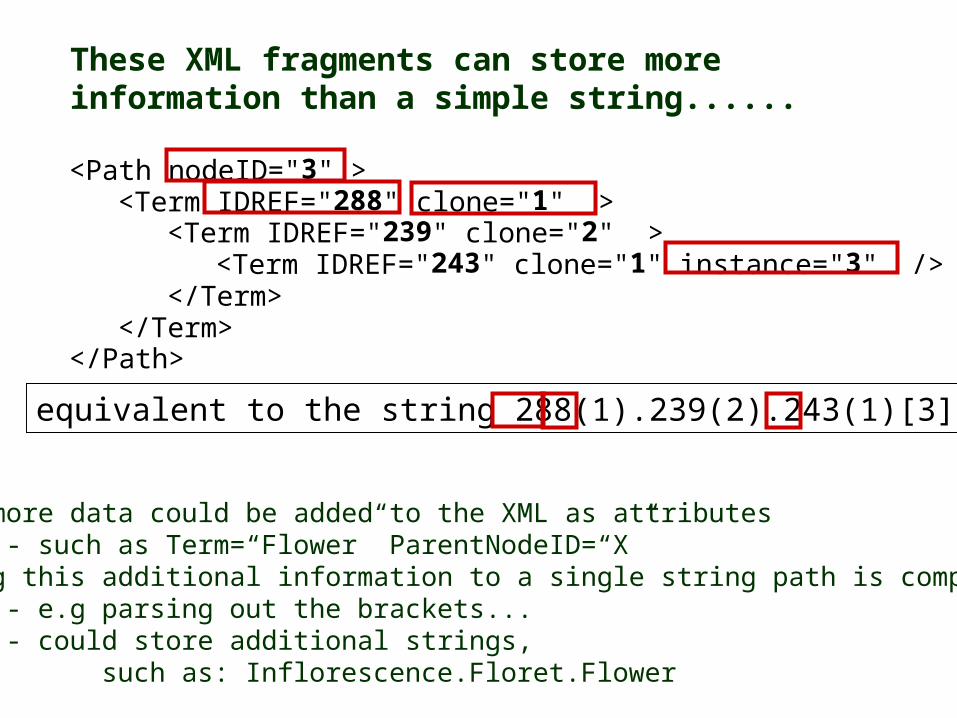
These XML fragments can store more information than a simple string......
<Path nodeID="3" > <Term IDREF="288" clone="1" > <Term IDREF="239" clone="2" > <Term IDREF="243" clone="1" instance="3" />
</Term> </Term> </Path>
equivalent to the string 288(1).239(2).243(1)[3]
Even more data could be added to the XML as attributes - such as Term=“Flower” ParentNodeID=“X”
Adding this additional information to a single string path is complex- e.g parsing out the brackets...- could store additional strings,
such as: Inflorescence.Floret.Flower

[note, because our XML fragment is recursive, it cannot be validated to an acceptable XSD schema to allow Oracle to Shred the XML to relational tables, therefore XML storage is essentially as a CLOB]
Testing the alternative representations of the Materialized Path for storage and retrieval of Structural Context Information in Plant Character descriptions
As dot separated string, parsed programmatically by PL/SQL
vs
As an XML fragment parsed by Oracle XML database functions
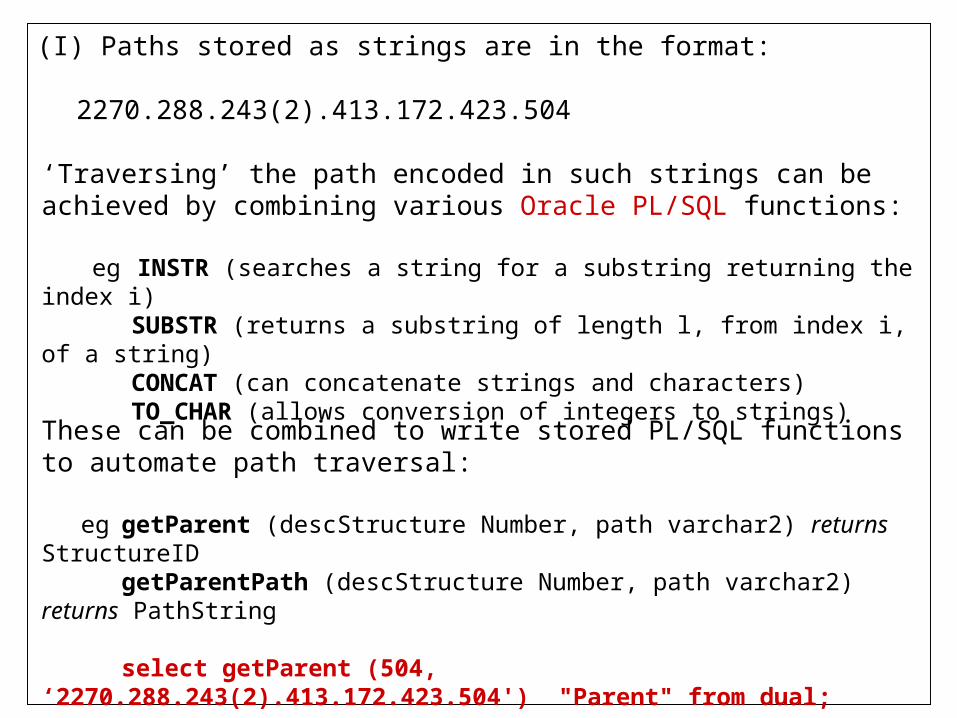
(I) Paths stored as strings are in the format:
2270.288.243(2).413.172.423.504
‘Traversing’ the path encoded in such strings can be achieved by combining various Oracle PL/SQL functions:
eg INSTR (searches a string for a substring returning the index i)SUBSTR (returns a substring of length l, from index i, of a string)CONCAT (can concatenate strings and characters)TO_CHAR (allows conversion of integers to strings)
These can be combined to write stored PL/SQL functions to automate path traversal:
eg getParent (descStructure Number, path varchar2) returns StructureID getParentPath (descStructure Number, path varchar2) returns PathString
select getParent (504, ‘2270.288.243(2).413.172.423.504') "Parent" from dual; Parent 423 1 row selected

(2) Stored XML Paths are in the format:
<Path nodeID="">><Term ID="2270" CloneID="1“>
<Term ID="288" CloneID="1"><Term ID="243" CloneID=“2">
<Term ID="413" CloneID="1"><Term ID="172" CloneID="1">
<Term ID="423" CloneID="1"><Term ID="504" CloneID="1“ InstanceID=“1” />
</Term></Term></Term></Term></Term></Term></Path>
Oracle XPath expressions allow traversal up and down the tree in a single query:
select unique extractValue(PATH, '//Term[@ID="504"]/..@ID') “504Parent” from DEwhere existsnode(PATH, '//Term[@ID="504"]') = 1and existsnode(PATH, '//Term[@ID="504"]/Term') = 0 ;
504Parent 100, 235, 373, 423, 521, 553, 96 7 rows selected.

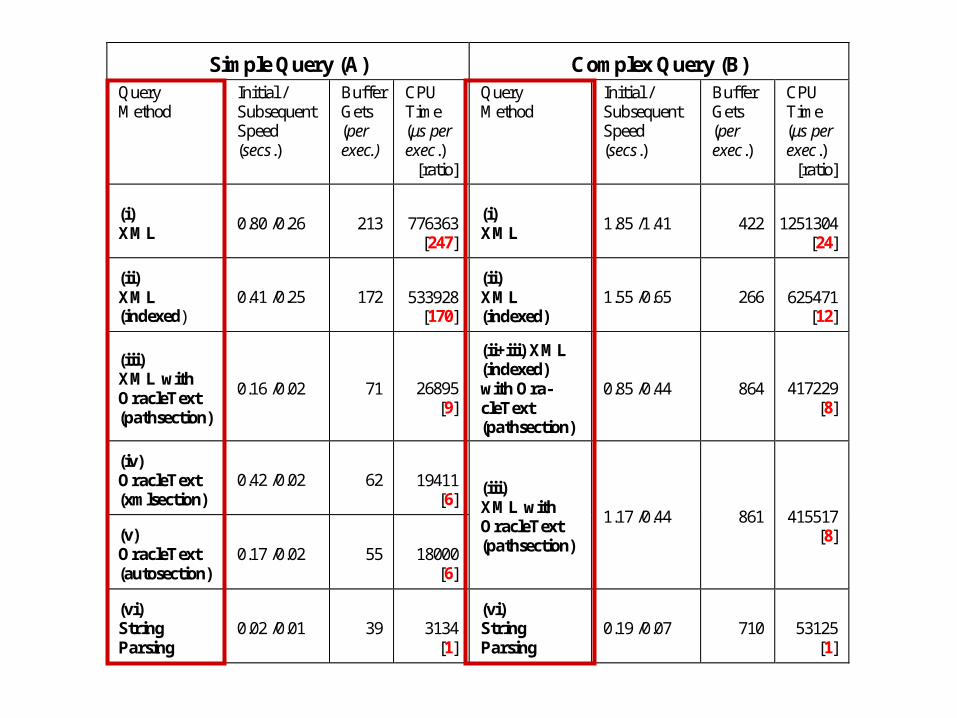
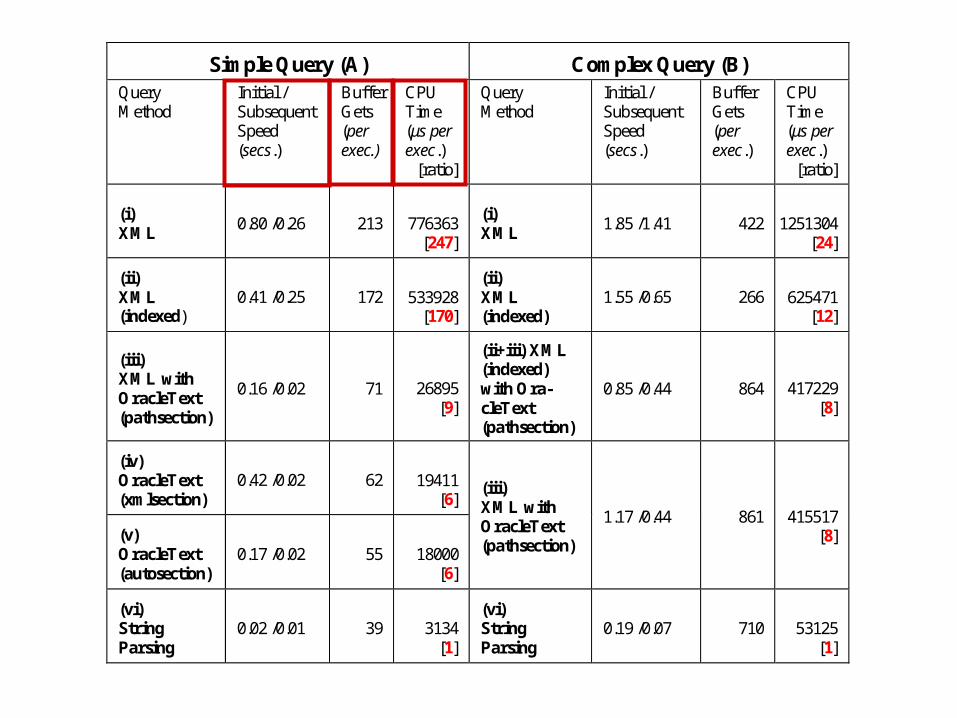
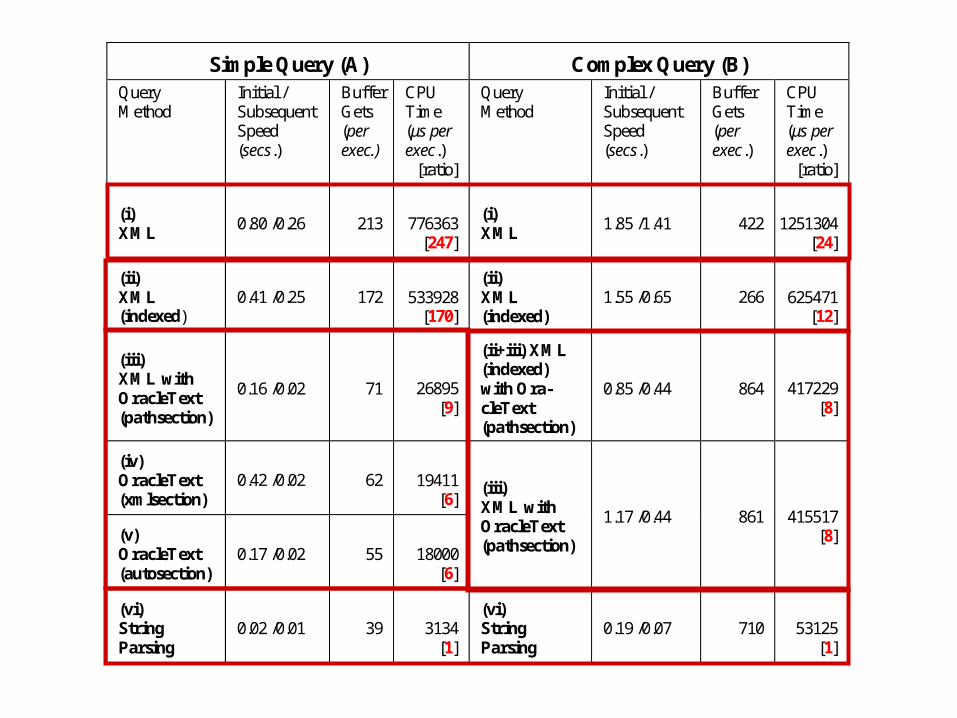
Two test queries to compare the efficiency of String based query versus XML Query:
Simple Query A:
Find all information pertaining to Flowers
- 1st need the ID of Flowers – trivial look up ( ID = ‘243’)
- then fetch all DescriptionElements that have flower in their path somewhere
more Complex Query B:
Find which descriptions have parts with scales [‘504’],
and what these parts are:
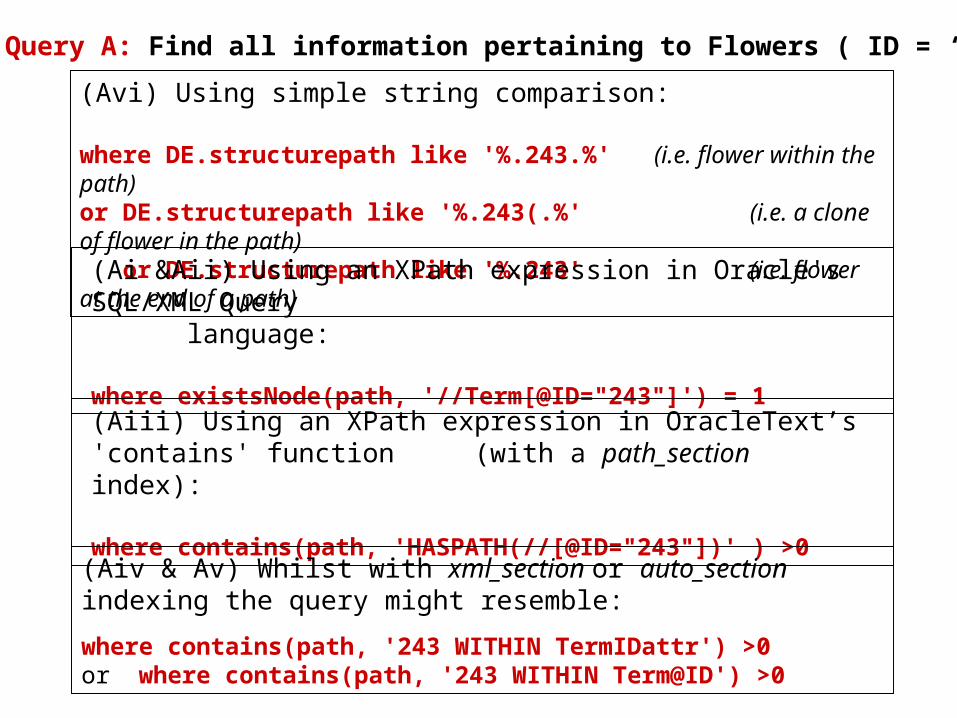
Simple Query A: Find all information pertaining to Flowers ( ID = ‘243’)
(Avi) Using simple string comparison: where DE.structurepath like '%.243.%' (i.e. flower within the path)or DE.structurepath like '%.243(.%' (i.e. a clone of flower in the path) or DE.structurepath like '%.243' (i.e. flower at the end of a path) (Ai &Aii) Using an XPath expression in Oracle's SQL/XML Query
language: where existsNode(path, '//Term[@ID="243"]') = 1
(Aiii) Using an XPath expression in OracleText’s 'contains' function (with a path_section index):
where contains(path, 'HASPATH(//[@ID="243"])' ) >0
(Aiv & Av) Whilst with xml_section or auto_section indexing the query might resemble:
where contains(path, '243 WITHIN TermIDattr') >0or where contains(path, '243 WITHIN Term@ID') >0

more complex example B:to find which descriptions have parts with scales [‘504’], and what these parts are:
we would want to search for:
• scale ID being present in the path of a description element• and get the parent of scale [ie a single path traversal]
checking that
• if presence has been scored for scale: it is present• that the DE is not marked ‘not scored’
its necessary to scope the query
• eg using ProformaID and OntologyID
could easily add increasing complexity/specificity
• eg to look for the same information but only where applies to scales found on Flowers
• get paths where flower ID [‘243’] precedes scale ID at any level[traversal up and down the path]
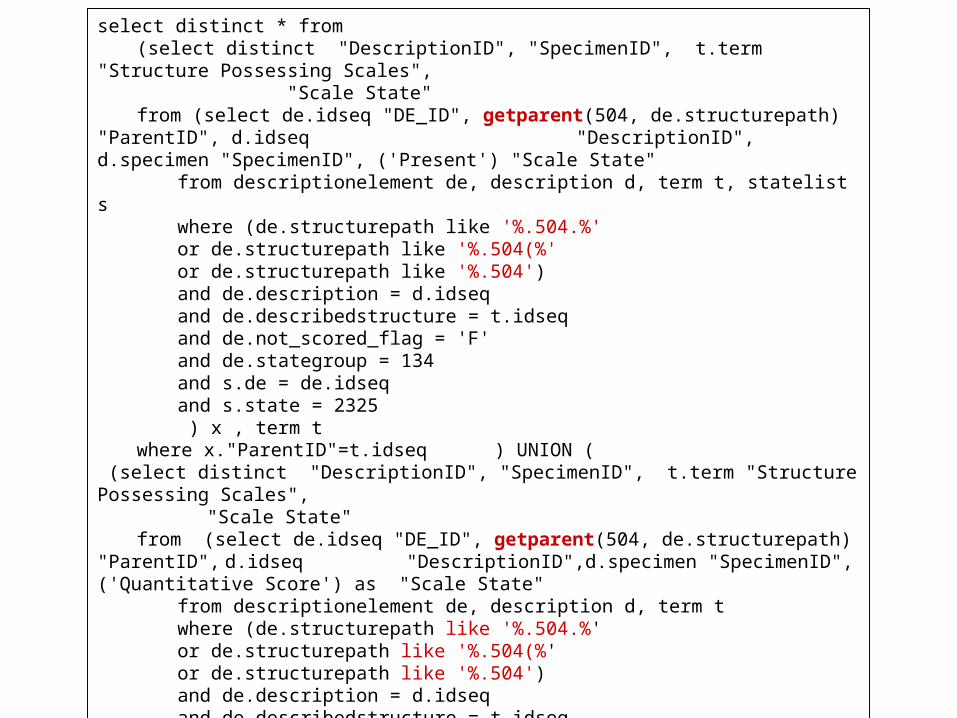
select distinct * from (select distinct "DescriptionID", "SpecimenID", t.term "Structure Possessing Scales",
"Scale State" from (select de.idseq "DE_ID", getparent(504, de.structurepath) "ParentID", d.idseq
"DescriptionID", d.specimen "SpecimenID", ('Present') "Scale State"from descriptionelement de, description d, term t, statelist swhere (de.structurepath like '%.504.%'or de.structurepath like '%.504(%'or de.structurepath like '%.504')and de.description = d.idseqand de.describedstructure = t.idseqand de.not_scored_flag = 'F'and de.stategroup = 134and s.de = de.idseqand s.state = 2325 ) x , term t
where x."ParentID"=t.idseq ) UNION ( (select distinct "DescriptionID", "SpecimenID", t.term "Structure Possessing Scales",
"Scale State" from (select de.idseq "DE_ID", getparent(504, de.structurepath) "ParentID", d.idseq
"DescriptionID",d.specimen "SpecimenID", ('Quantitative Score') as "Scale State"from descriptionelement de, description d, term twhere (de.structurepath like '%.504.%'or de.structurepath like '%.504(%'or de.structurepath like '%.504')and de.description = d.idseqand de.describedstructure = t.idseqand de.not_scored_flag = 'F'and ( de.stategroup != 134 or de.stategroup is null)
) x , term t where x."ParentID"=t.idseq) );
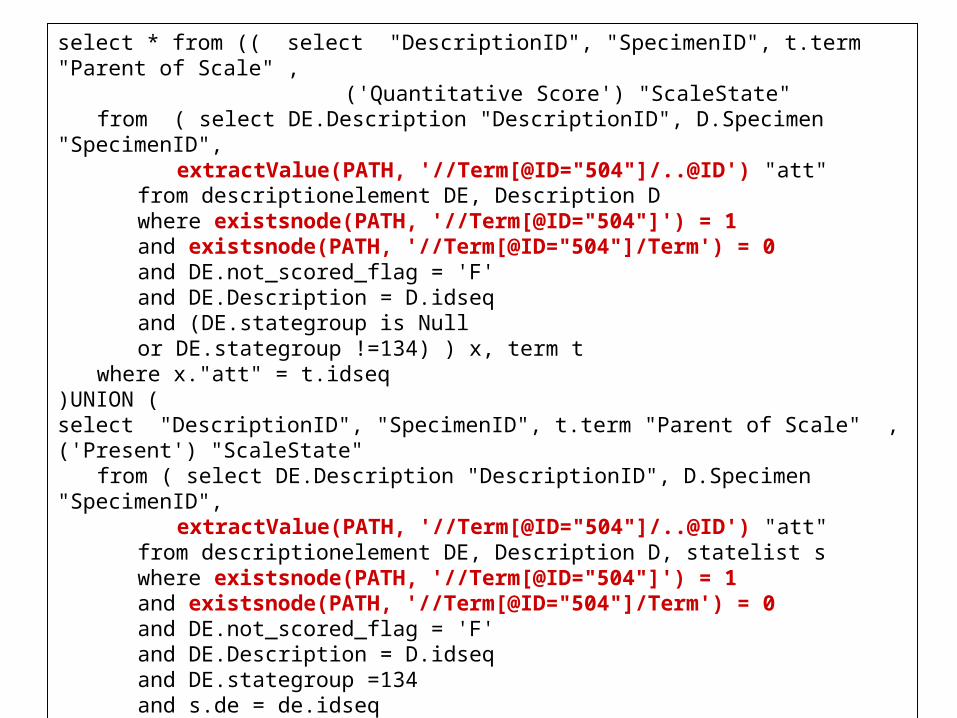
select * from (( select "DescriptionID", "SpecimenID", t.term "Parent of Scale" ,
('Quantitative Score') "ScaleState" from ( select DE.Description "DescriptionID", D.Specimen
"SpecimenID", extractValue(PATH, '//Term[@ID="504"]/..@ID') "att"
from descriptionelement DE, Description Dwhere existsnode(PATH, '//Term[@ID="504"]') = 1and existsnode(PATH, '//Term[@ID="504"]/Term') = 0and DE.not_scored_flag = 'F'and DE.Description = D.idseqand (DE.stategroup is Nullor DE.stategroup !=134) ) x, term t
where x."att" = t.idseq)UNION (select "DescriptionID", "SpecimenID", t.term "Parent of Scale" , ('Present') "ScaleState"
from ( select DE.Description "DescriptionID", D.Specimen "SpecimenID",
extractValue(PATH, '//Term[@ID="504"]/..@ID') "att"from descriptionelement DE, Description D, statelist swhere existsnode(PATH, '//Term[@ID="504"]') = 1and existsnode(PATH, '//Term[@ID="504"]/Term') = 0and DE.not_scored_flag = 'F'and DE.Description = D.idseqand DE.stategroup =134and s.de = de.idseqand s.state = 2325 ) x, term t
where x."att" = t.idseq));
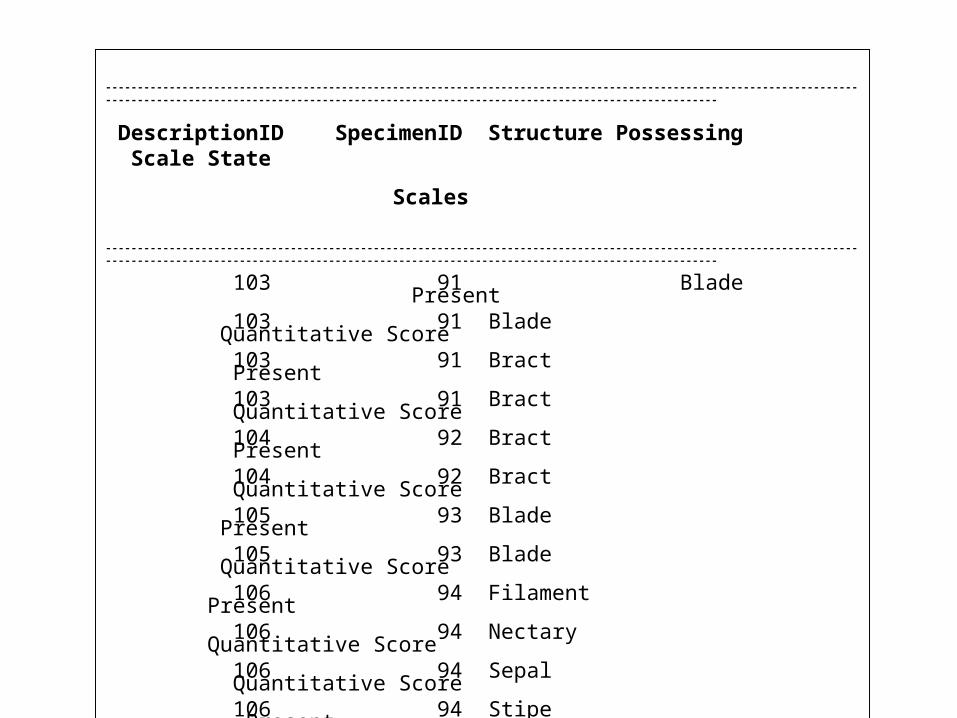
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
DescriptionID SpecimenID Structure Possessing Scale State
Scales
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
103 91 Blade Present 103 91 Blade Quantitative Score 103 91 Bract Present 103 91 Bract Quantitative Score 104 92 Bract Present 104 92 Bract Quantitative Score 105 93 Blade Present 105 93 Blade Quantitative Score 106 94 Filament Present 106 94 Nectary Quantitative Score 106 94 Sepal Quantitative Score 106 94 Stipe Present 107 95 Petal Quantitative Score 107 95 Stipe Quantitative Score 108 96 Nectary Present 108 96 Petal Quantitative Score-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
16 rows selected.
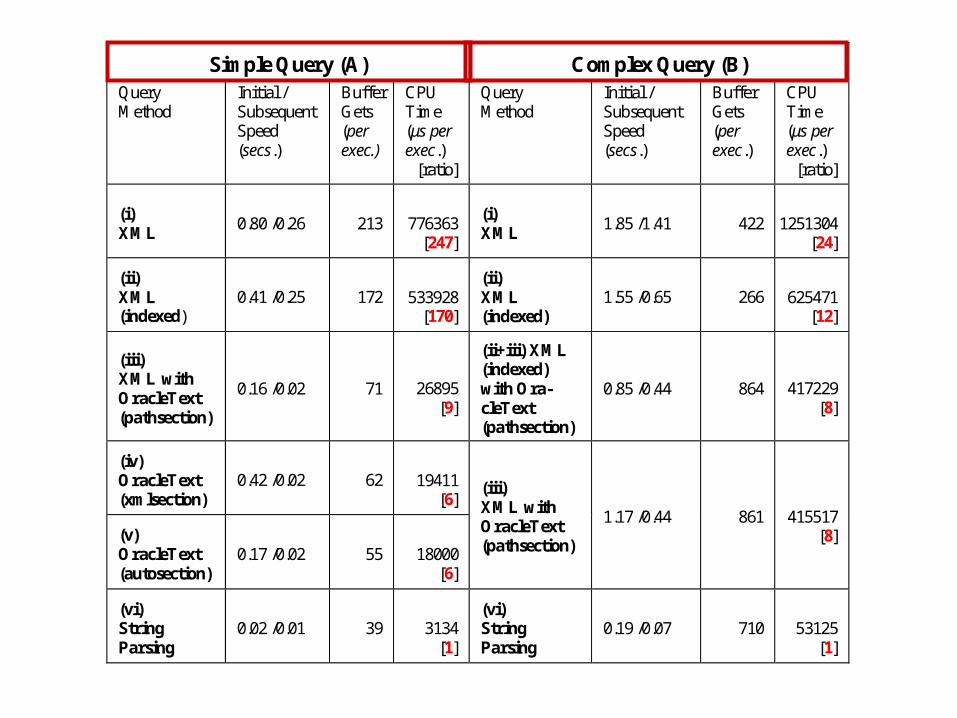
Simple Query (A) Complex Query (B) Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
(i) XML
0.80 /0.26 213
776363 [247]
(i) XML
1.85 /1.41 422
1251304 [24]
(ii) XML (indexed)
0.41 /0.25 172
533928 [170]
(ii) XML (indexed)
1.55 /0.65 266
625471 [12]
(iii) XML with OracleText (pathsection)
0.16 /0.02 71
26895 [9]
(ii+iii) XML (indexed) with Ora-cleText (pathsection)
0.85 /0.44 864
417229 [8]
(iv) OracleText (xmlsection)
0.42 /0.02 62
19411 [6]
(v) OracleText (autosection)
0.17 /0.02 55
18000 [6]
(iii) XML with OracleText (pathsection)
1.17 /0.44 861
415517 [8]
(vi) String Parsing
0.02 /0.01 39
3134 [1]
(vi) String Parsing
0.19 /0.07 710
53125 [1]
Simple Query (A) Complex Query (B) Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
(i) XML
0.80 /0.26 213
776363 [247]
(i) XML
1.85 /1.41 422
1251304 [24]
(ii) XML (indexed)
0.41 /0.25 172
533928 [170]
(ii) XML (indexed)
1.55 /0.65 266
625471 [12]
(iii) XML with OracleText (pathsection)
0.16 /0.02 71
26895 [9]
(ii+iii) XML (indexed) with Ora-cleText (pathsection)
0.85 /0.44 864
417229 [8]
(iv) OracleText (xmlsection)
0.42 /0.02 62
19411 [6]
(v) OracleText (autosection)
0.17 /0.02 55
18000 [6]
(iii) XML with OracleText (pathsection)
1.17 /0.44 861
415517 [8]
(vi) String Parsing
0.02 /0.01 39
3134 [1]
(vi) String Parsing
0.19 /0.07 710
53125 [1]
Simple Query (A) Complex Query (B) Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
(i) XML
0.80 /0.26 213
776363 [247]
(i) XML
1.85 /1.41 422
1251304 [24]
(ii) XML (indexed)
0.41 /0.25 172
533928 [170]
(ii) XML (indexed)
1.55 /0.65 266
625471 [12]
(iii) XML with OracleText (pathsection)
0.16 /0.02 71
26895 [9]
(ii+iii) XML (indexed) with Ora-cleText (pathsection)
0.85 /0.44 864
417229 [8]
(iv) OracleText (xmlsection)
0.42 /0.02 62
19411 [6]
(v) OracleText (autosection)
0.17 /0.02 55
18000 [6]
(iii) XML with OracleText (pathsection)
1.17 /0.44 861
415517 [8]
(vi) String Parsing
0.02 /0.01 39
3134 [1]
(vi) String Parsing
0.19 /0.07 710
53125 [1]
Simple Query (A) Complex Query (B) Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
Query Method
Initial / Subsequent Speed (secs.)
Buffer Gets (per exec.)
CPU Time (μs per exec.)
[ratio]
(i) XML
0.80 /0.26 213
776363 [247]
(i) XML
1.85 /1.41 422
1251304 [24]
(ii) XML (indexed)
0.41 /0.25 172
533928 [170]
(ii) XML (indexed)
1.55 /0.65 266
625471 [12]
(iii) XML with OracleText (pathsection)
0.16 /0.02 71
26895 [9]
(ii+iii) XML (indexed) with Ora-cleText (pathsection)
0.85 /0.44 864
417229 [8]
(iv) OracleText (xmlsection)
0.42 /0.02 62
19411 [6]
(v) OracleText (autosection)
0.17 /0.02 55
18000 [6]
(iii) XML with OracleText (pathsection)
1.17 /0.44 861
415517 [8]
(vi) String Parsing
0.02 /0.01 39
3134 [1]
(vi) String Parsing
0.19 /0.07 710
53125 [1]

Some Conclusions
to represent contextual information in plant descriptions we have stored a
materialized representation of the compositional path for each structure being
described – either as a delimited string or an XML fragment
our results show that this path is queried most efficiently in our database if stored
as a string and queried using string comparison functions
however, storing the materialized path as an XML fragment provides an attractive
alternative that allows more straightforward query design and might allow a richer
and more readable representation of the information
storage, indexing and query XML datatypes is database dependent, but simple
string-parsing functions are provided as part of most database systems
optimization of XML Query and indexing is complicated, although in many
respects the syntax of XPath queries allows simpler query formulation than parsing
the string path.

Jessie Kennedy, Cédric Raguenaud, Mark Watson, Martin Pullan, Mark Newman, Peter Barclay, Martin Graham, Gordon Russell, Andrew Cumming, Sarah MacDonald, Kate Armstrong, Alan Cannon, Robert Kukla, Trevor Paterson






















![Biotechnology and Biological Preparations758578294[1]](https://img.pdfslide.net/doc/110x75/577cd3f11a28ab9e7897c7c4/biotechnology-and-biological-preparations7585782941.jpg)






