Embed Size (px)
Citation preview

Proceeding ofNLP-KE'O5
Two-Phase Base Noun Phrase Alignment in
Chinese-English Parallel Corpora*Jun ZHAO, Feifan LIJ
National Laboratory of Pattern Recognition,Institute of Automation, Chinese Academic of Sciences, Beijing
{jzhao,ffliu} @nlpr.ia.ac.cn
Abstract-A two-phase approach of automatically aligningbilingual base noun phrases from sentence-alignedChinese-English parallel corpus is proposed in this paper. Weconduct alignment in two phases: one deals with high-frequencybase noun phrases by statistical co-occurrence informationbetween parallel corpus, and the other deals with low-frequencybase noun phrases using the bilingual lexical information and Dicecoefficient similarity metrics. This can be reasonably considered toacquire higher recall without degrading the precision on the whole.Furthermore, our approach can escape from complex Chineseparsing problems and don't need to recognize Chinese base nounphrases accurately before the aligning process. Also, it can alsorelieve, to some extent, the serious impacts of error spread whichmay result from the unstable and impractical Chinese base nounphrases extraction tools. Another, dealing with high frequencynoun phrases with statistical information also can realize therecognition of some non-compositional phrase pairs, which isdifficult for pure syntax-based or lexicon-based systems to handle.
Index Terms-Base noun phrase, Bilingual alignment,Cross-lingual information retrieval.
I. INTRODUCTION
It's notoriously difficult to obtain good alignments betweenbilingual corpora on the word level for some morphological,syntactic or pragmatic phenomena. Phrase alignment is widelyrecognized as a better choice which can get a compromisebetween word and sentence level due to being less ambiguousand more flexible. Therefore, automatic bilingual phrasealignment plays a significantly important role in the applicationsof machine translation, bilingual term extraction, multilingualinformation retrieval, etc. In addition, noun phrases especiallybase noun phrases usually carry abundant and importantinformation which is extremely useful for natural languagecomprehension [9]. In other words, bilingual base noun phrasealignment is of great significance in many cross-languageapplications.
* This work was supported by the Natural SciencesFoundation of China(60372016,60272041) and the NaturalScience Foundation of Beijing(4052027).
Dongming LIUDepartment of Computer Science & Technology
North University of China, Taiyuanyangaimei_45@ 163.com
This paper aims at aligning base noun phrases fromChinese-English sentence-aligned parallel corpus. Since thereare many differences between the two languages, such assyntactic structure etc, traditional aligning strategies which havebeen successfully applied to Indo-European parallel corporamay be unsuitable for Chinese-English languages. Sometraditional methods extract base noun phrases respectively fromeach monolingual corpus, then align the bilingual base nounphrases. This kind of methods may suffer from the followingproblems: (many base noun phrases extracted cannot getaligned at all; ©error spread problem may exist.From the methodological point of view, statistical methods
have been proven efficient in both monolingual and bilingualphrase extraction problems. But it is extremely difficult forstatistical evidence to handle those low frequency phrases,which consequently will reduce the recall to some extent.Although lexicon information will be helpful in some cases, itcan also introduce some noises when blindly combined withstatistical methods.Based on considerations mentioned above, the paper proposes atwo-phase approach of automatically aligning bilingual basenoun phrases from sentence-aligned Chinese-English parallelcorpus, which has the following characteristics.
(1) We conduct alignment in two separate phases, which cancorrespondingly deal with high-frequency base noun phrases bystatistical co-occurrence information between parallel corpusand low-frequency base noun phrases using the bilingual lexicalinformation and Dice coefficient similarity metrics. This can bereasonably considered to acquire higher recall withoutdegrading the precision on the whole.
(2) Another, our approach can escape from complex Chineseparsing problems and don't need to recognize Chinese basenoun phrases accurately before the aligning process. Also, it canalso relieve, to some extent, the serious impacts of error spreadwhich may result from the unstable and impractical Chinesebase noun phrases extraction tools.
(3) Finally, dealing with high frequency noun phrases withstatistical information also can realize the recognition of somenon-compositional phrase pairs, which is difficult for puresyntax-based or lexicon-based systems to handle.
0-7803-9361-9105/$20.00 02005 IEEE
360

II. RELATED WORK
Much research work has been done on extracting Englishnoun phrases [1,5,9,10] as well as Chinese noun phrases [6,12]in recent years. Based on the existing techniques, automaticbilingual noun phrase alignment has also been conducted.
Ref. [3] put forward inversion transduction grammar (ITG)for bilingual parsing. The stochastic ITG brings bilingualconstraints to bear upon problematic corpus analysis tasks suchas segmentation, bracketing and phrasal alignment. This methodperforms very well for short and regular sentences. However, itis difficult to write a broad bilingual grammar to deal with longsentences. Ref. [13] proposed methods based on parsing,bilingual lexicon and heuristic information, whereas it can'tcope with non-compositional phrases.
Ref. [14] proposed an integrated algorithm to performstructure alignment, in which parsing and alignment wereconducted together, and got good precision. However, thismethod needs quite a lot of prior knowledge, such as tree bankand word alignment information, etc. That knowledge,especially word alignment information, is very difficult to get.
Ref. [4] describes an algorithm that employs English andFrench text taggers to associate noun phrases in an alignedbilingual corpus, which employs simple iterative re-estimationto make correspondences between bilingual noun phrases. Ref.[11] presented an algorithm for automatic extraction of bilingualmulti-word units, which is based on the Local Bests algorithmsupplemented by two heuristic strategies: excluding words in astop-list and preferring longer multi-word units. As justmentioned, the two methods are only statistic-based and can'thandle low frequency noun phrases effectively.
Ref. [8] proposed an approach for acquiring bilingual namedentity translations from content-aligned corpora, which arehardly dependent on the performance of named entityextraction.
III. TWO-PHASE BASE NOUN PHRASE ALIGNMENT
With the observation that Chinese and English come fromdifferent phylums, it should be a reasonable preference to takebase noun phrases of one language as a standard. Here we useEnglish base noun phrases as the anchors to find thecorresponding Chinese noun phrases. English base noun phrasesare classified into two types by their occurrence counts:high-frequency base noun phrases and low-frequency ones. Weuse different strategies respectively for the two types. For theformer, we can acquire from the parallel corpus relativelyaccurate association information between English and Chinesewords. For the latter, however, there is no exact statisticalinformation to use, so we resort to the bilingual dictionary andTONG YI CI CI LIN (Chinese Thesaurus) to get enoughaligning infornation. Fig. 1 shows the whole alignment process.
Fig. 1 Worldlow of Bilingual Base Noun Phrase Aligmment
A. English Base Noun Phrases Recognition and ChineseSentence Preprocessing
Using transformation-based method [2] we first recognizeEnglish base noun phrases. Then we employ some templates toprocess the recognition results which has been assigned Englishbase noun phrases tags, in order to expand some general nounphases with high cohesion. This kind of expansion is based onthe observation that although some English noun phrases are notbase noun phrases, their corresponding Chinese translations arebase noun phrases, and vice versa. That is to say, the definitionof base noun phrases here is actually an extension to the originalone in both English and Chinese languages. For instance, thetemplate "base noun phrase of base noun phrase" will beconstructed for some instances such as "[the Department] of[Health]" which is aligned with a base noun phrase in Chineselanguage.
Simultaneously, a simple automata was developed to find thecandidate word sequences which may possibly include Chinesebase noun phrases in Chinese sentences. This is not a exactChinese base noun phrases recognition process, by which wecan only find some candidate word sequences. Chinese basenoun phrases will be identified inside these candidates based onthe English base noun phrases. This preprocess can reduce timecomplexity and avoid statistical noises effectively, as well asproviding some useful information for phrase alignment.
B. Aligning Strategyfor High-frequency PhrasesFirstly, Chinese words associated with each English base nounphrase and their corresponding association degrees are acquiredfrom bilingual corpus using statistical methods. Then Chinesebase noun phrase aligned with an English base noun phrase canbe recognized in the bilingual sentence pairs according to theassociation information.An iterative re-evaluation algorithm was designed to get the
association information between English base phrases and therelated Chinese words.
361

C. Aligning Strategyfor Low-frequency PhrasesWe resort to bilingual lexicon to conduct phrase alignment
for English low-frequency base noun phrases. Because of thepossible change of the word sequence while English phrases aretranslated into Chinese, firstly, we use some manually writtenrules to get the beginning words and ending words in theEnglish phrases corresponding to the begin and end position intheir aligning Chinese phrases. Secondly, we find the wordsassociated with the English phrase in the Chinese sentence bycomputing the similarity between Chinese and English words,which is based on a bilingual dictionary, TONG YI CI CI LIN(Chinese Thesaurus) and Dice weighted coefficient.
IV. PHASE oNE: HIGH-FREQUENCY PHRASES ALIGNMENT
A. Association Information AcquisitionAssociation information between English base noun phrase anda Chinese word can be obtained from the corpus. Generallyspeaking, Mutual information (Ml) and cohesion degree t-valueare often used to denote association information in statisticalmethods. Here mutual information denotes the confident degreeof the alignment between the English base noun phrase and aChinese word; t-value indicates the creditable degree of thestatistical information. They can be formulated respectively asfollows:
Mutual Information: MI (e, c) = log P(e)(c)
t-value: t(e, c)_ P(e, c) - P(e)P(c)
-P(e,c)where N denotes the number of sentences; e denotes an
English phrase; c denotes a Chinese word; P(e, c) denotes theco-occurrence frequency of e and c; P(e) denotes the occurrencefiequency of e; P(c) denotes the occurrence frequency of c.
B. The Iterative Re-evaluation AlgorithmIterative re-evaluation algorithm used here is an iterativealgorithm based on EM. Assume that an English phrase isassigned an aligning probability with each Chinese word, andthe sum of all the probabilities for an English phrase is equal to1. Firstly, an initial value is given to each probability mentionedabove, and then iterative learning will be conducted tocontinuously update the last values according to theco-occurrence between English phrases and Chinese words,eventually we can obtain satisfied association information. Thealgorithm can be described in detail as follows.
Let e denote an English phrase, c indicate a Chinese word,and W (e, c) denote the weighted co-occurrence frequency(product of co-occurrence time and corresponding probability)for each English phrase e and each Chinese word c, P (e, c)denote the aligning probability of e and c, then
Pr (e, c)= Wri, (e, c) (where P(e, q) =1)SWr-l(elq) qEVF
qEVFN
W, (e, c)= F ,e,c)P,l (e,c)i=l
where r denotes iterative times; N denotes the number of thealigned sentence pairs in the bilingual corpus; VF denotes aword set which consist of all content words in candidate wordsequences recognized by the specified automata described insection 3.1; F (i, e, c) denotes the co-occurrence times of e and cin the ith sentence pair. And the initial value of weightedfrequency can be computed by the following formula:
N 1
Wo(e, c)= EF U,e,c) )
where 0(i) denotes the number of the content words in theith Chinese sentence which may be included in base nounphrase. In other words, we use the reciprocal of the number ofall possible aligned Chinese content words in the correspondingsentence pair as the initial aligning probability of e and c, whichis also intuitive and reasonable.
After each iteration we get the Chinese word c with thelargest aligning probability value with an English phrase, and ifIPr (e, c)- Pri_ (e, c)1<0.001 is satisfied, the iteration willterminate (we set the iterative threshold as 0.001). Theexperiments show that the iteration process will terminate after2-4 times for all the English phrases.
In the iteration process, we can find the following phenomena.For a correctly-aligned Chinese word, its initial aligningprobability value may be relatively low for a long sentence.However, through the iteration process, the Chinese word'sweighted frequency will be increased because of the its highco-occurrence with the English phrase. The increase of theweighted frequency can lead to the increase of the word'sproportion in the sum of weighted frequency of all the words,which results in increasing the aligning probability of thecorrectly-aligned Chinese word. At the same time, the weightedfrequency's proportion of other words will be reduced, i.e. itwill reduce the aligning probability for wrongly-alignedChinese words. Consequently, the difference between thealigning probability of the correctly-aligned Chinese words andwrongly-aligned Chinese words will become greater andgreater.
This mechanism can therefore consider the aligninginformation as a whole and overcome the shortcoming of thestatistical algorithm based on mutual information.
C. Aligning the High-frequency Phrase in the CorpusFor every high-frequency English base noun phrase, we can
obtain the corresponding Chinese word set by the associationinformation. Matching the Chinese word set with the candidate
362

word sequence in the corresponding Chinese sentence, thelongest matching word sequence is labeled as the aligningChinese noun phrase. If different word sequences have the samematching length, we will compute the sum of the aligningprobability of all the words in the sequence, and prefer thelargest value.
V. PHASE Two: LOW-FREQUENCY PHRASES ALIGNMENT
A. Required Dictionary ResourcesAs mentioned above it is very hard for statistical methods toperform low-frequency bilingual phrases alignment. Theavailable English-Chinese dictionary cannot meet therequirement because of its low coverage rate. So we makeexpansions to the bilingual dictionary using TONG YI CI CILIN (Chinese Thesaurus). In order to reduce the expansion error,the most common sense of each Chinese polysemous word isused for expansion.
B. Similarity CalculationIn case that no exact match is found even by the aboveexpansion, we define a kind of similarity measurement withDice coefficient as follows:
Si(, )-2xlD n clSim(D,c)= IDI+where c denotes the set of Chinese characters included in a
Chinese word; D denotes the collection for synonyms of theChinese word, which is the translation word of an English wordin bilingual dictionary; IDI denotes the number of Chinesecharacters included in D(including repetitions); Icl denotes thenumber of Chinese characters included in c (includingrepetitions); IDncl denotes the number of Chinese charactersincluded both in D and c (if the character is repeated in D, thenthe number is the character's repeating times in D).
For example, we look up the word "umbra"(*Cf) in thedictionary, and get the Chinese translation { I t /YinlYing3/shadow} in the bilingual dictionary. Then, by TONG YICI CI LIN (Chinese Thesaurus), we can get { o V/An4Ying3/shadow, *V,Tou2 Ying3[Projection}. So D is equalto { ;1/Yinl Ying3/shadow, Ufi/An4 Ying3/shadow, &V/Tou2 Ying3/Projection }. Assume that c is ",*/Ben3
2x3Ying3/umbra", we can get Sim (D, c)= =0.75; And
6+2assume that c is "[JE/Yin1 An4/grayness", we can get Sim (D,
2x1c)= =0.25.
6+2As for the above example, we count the repetitions to assign
each character in D a different weight which means each
character makes different contribution in similarity computation,e.g. "V/Ying3" affects more than "IN/Yin1".
If an English word has N senses, we will acquire N Chineseword set D, and we define the similarity of English word e andChinese word c as follows:
ECSim(e, c)=mnax Sim(Di,c) i =1,2...NC. Finding the Beginning and Ending WordThere are differences in the word order between the English andChinese phrases. For the sake of finding the aligning phrasesfrom the corresponding Chinese sentence, we will seek thebeginning and the ending word in the English base noun phraseswhich should be the first word and last word while they aretranslated into Chinese. For example, mainland of China, itstranslation should be "+ /Zhong1 Zuo2/China P *t/Nei4Di4/Mainland", then the beginning word should be "China",and the ending word should be "mainland". We can easily getrelatively satisfied function for the beginning and ending wordas long as several simple rules are developed according to theEnglish phrase structure.
D. Aligning the Low-frequency Phrase in the CorpusFor each low-frequency English phrase, we can call the functionto get the beginning and the ending word in the English phrase,and then stem them before looking them up in the bilingualdictionary to get the corresponding set of their Chinesetranslation respectively. Then we match the two sets to thecorresponding Chinese sentence, and if both the beginning andthe ending words are matched, we will mark the word sequencebetween the two words in Chinese sentence as the aligning nounphrase. Otherwise, we will computer the similarity of thebeginning or ending word and each Chinese word, and theChinese word with the largest similarity value can be taken asthe anchor point for alignment. If even such a word can't befound, we will neglect it.
VI. EXPERIMENTS AND ANALYSISWe have built a large scale sentence aligned Chinese-English
parallel corpus which consists of about 170,000 sentence pairsand has been included in Chinese Linguistic Data Consortium(ChineseLDC). Our work is then based on the resource and11 182 Chinese-English sentence pairs are selected in ourexperiments from the Hong Kong Yearbook and lectures of theChief Executive. The English base noun phrases whoseoccurrence counts exceed 10 are regarded as high-frequencyphrases. We define the coverage rate and accuracy rate asfollows:
Coverage =N
X100%N
NRoughAccuracy = - x 100%
N1
363
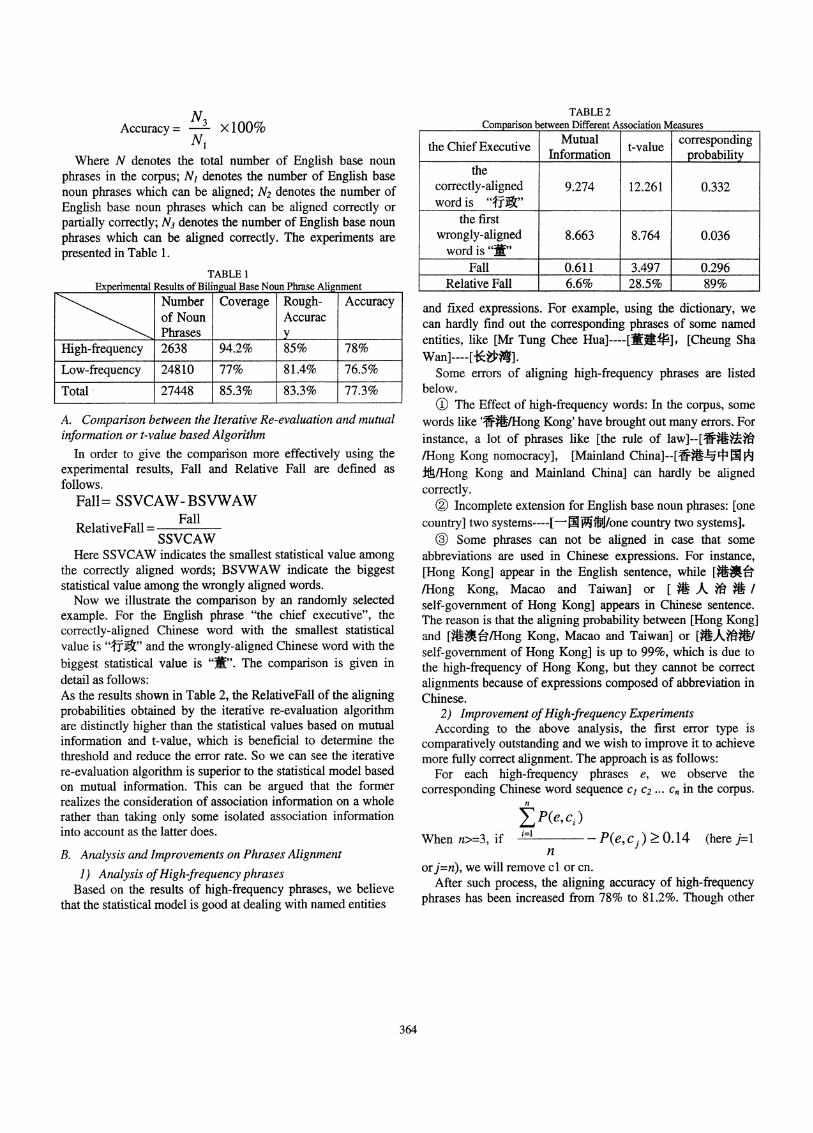
Accuracy = 3 x 100%N1
Where N denotes the total number of English base nounphrases in the corpus; N1 denotes the number of English basenoun phrases which can be aligned; N2 denotes the number ofEnglish base noun phrases which can be aligned correctly orpartially correctly; N3 denotes the number of English base nounphrases which can be aligned correctly. The experiments arepresented in Table 1.
TABLE IExperimental Results of Bilingual Base Noun Phmse Alignment
Number Coverage Rough- Accuracyof Noun Accurac
.___ .___\__ Phrases yHigh-frequency 2638 94.2% 85% 78%Low-frequency 24810 77% 81.4% 76.5%Total 27448 85.3% 83.3% 77.3%
A. Comparison between the Iterative Re-evaluation and mutualinformation or t-value based Algorithm
In order to give the comparison more effectively using theexperimental results, Fall and Relative Fall are defined asfollows.
Fall= SSVCAW-BSVWAWRelativeFall = Fall
SSVCAWHere SSVCAW indicates the smallest statistical value among
the correctly aligned words; BSVWAW indicate the biggeststatistical value among the wrongly aligned words.Now we illustrate the comparison by an randomly selected
example. For the English phrase "the chief executive", thecorrectly-aligned Chinese word with the smallest statisticalvalue is "4jf& and the wrongly-aligned Chinese word with thebiggest statistical value is "I". The comparison is given indetail as follows:As the results shown in Table 2, the RelativeFall of the aligningprobabilities obtained by the iterative re-evaluation algorithmare distinctly higher than the statistical values based on mutualinfornation and t-vaiue, which is beneficial to determine thethreshold and reduce the error rate. So we can see the iterativere-evaluation algorithm is superior to the statistical model basedon mutual information. This can be argued that the formerrealizes the consideration of association information on a wholerather than taking only some isolated association informationinto account as the latter does.
B. Analysis and Improvements on Phrases Alignment1) Analysis ofHigh-frequency phrasesBased on the results of high-frequency phrases, we believe
that the statistical model is good at dealing with named entities
TABLE 2Comparison between Different Association Measures
the Chief Executive Mutual t-value correspondingInformation probability
thecoffectly-aligned 9.274 12.261 0.332word is "_
the firstwrongly-aligned 8.663 8.764 0.036word is "' _ _ _
Fall 0.611 3.497 0.296Relative Fall 6.6% 28.5% 89%
and fixed expressions. For example, using the dictionary, wecan hardly find out the corresponding phrases of some namedentities, like [Mr Tung Chee Hua]----[ tlP], [Cheung ShaWan]----[']Some errors of aligning high-frequency phrases are listed
below.(i) The Effect of high-frequency words: In the corpus, some
words like '**/Hong Kong' have brought out many errors. Forinstance, a lot of phrases like [the rule of law]--[Ui**$t/Hong Kong nomocracy], [Mainland China]--L kj-+4 RN*fWIHong Kong and Mainland China] can hardly be alignedcorrectly.© Incomplete extension for English base noun phrases: [one
country] two systems----[-RX1$/6one country two systems].) Some phrases can not be aligned in case that some
abbreviations are used in Chinese expressions. For instance,[Hong Kong] appear in the English sentence, while [Z^*[Hong Kong, Macao and Taiwan] or [ 4 A e I/self-government of Hong Kong] appears in Chinese sentence.The reason is that the aligning probability between [Hong Kong]and [44§I/Hong Kong, Macao and Taiwan] or [k I*self-govemment of Hong Kong] is up to 99%, which is due tothe high-frequency of Hong Kong, but they cannot be correctalignments because of expressions composed of abbreviation inChinese.
2) Improvement ofHigh-frequency ExperimentsAccording to the above analysis, the first efror type is
comparatively outstanding and we wish to improve it to achievemore fully correct alignment. The approach is as follows:
For each high-frequency phrases e, we observe thecorresponding Chinese word sequence cl C2 ... Cn in the corpus.
n
Z P(e,c,)When n>=3, if i= -P(e,c1).0.14 (herej=1
norj=n), we will remove cl or cn.
After such process, the aligning accuracy of high-frequencyphrases has been increased from 78% to 81.2%. Though other
364

errors are introduced, the overall perfonnance is highlyimproved.
3) Analysis ofLow-frequency PhrasesThe result of low-frequency phrases shows that the
performance can be increased highly by using similaritymeasurement compared with using bilingual dictionary merely.The alignments like [the translation of the speech]-[itis-i:9Cspeech text], [the advent of the rainy season] ---- X*/rainy *[&/advent], are achieved just according to similaritycomputation, and the errors can mainly be listed as follows:
(DSuch errors may be brought out by similarity measurement.For example, [our conceived vision] is aligned wrongly to [P.it] flV{*2/our faith] rather than [ t-Jf35/ the conceivedvision]. Because there is the expression like [ltkt41i/theconceived vision] but no [9Afri YJtYtMl our conceived vision] incorresponding sentences, so the similarity value between [ourconceived vision ] and [V.JF Ii l{T'i our faith] is bigger.O Null alignment or wrong alignment is brought out by the
error recognition of beginning and ending words. For example,the alignment failure of [a century of vicissitudes] ---- `ff @:,4/a century of vicissitudes" is just because of the rule - thebeginning word is often followed by "of'.© Low coverage rate of low frequency phrases lies in that
some proper names can't be looked up in dictionary such asperson names, location names and so on.
(Q) Errors can be brought out due to phenomena such asomission, anaphora etc. existing in the bilingual parallel corpora.For example, phrase pairs such as [Distinguished Guests][4ft%L/every guest], [its future] ---- [@flvJ**/HongKong's future] and etc., cannot be correctly aligned, which isbecause of the failure to find the beginning word in thecorresponding Chinese sentences.
VII. CONCLUSIONS AND FUTURE WORKIn this paper, a two-phase approach of bilingual base noun
phrases alignment is proposed. This method integratesstatistic-based and rule-based approach so that it can deal withefficiently both high-frequency phrases and low-frequency ones.Iterative re-evaluation algorithm presented in the paper canconsiderate much useful information on the whole, overcomingthe shortcoming of traditional statistical methods based onmutual information and t-value. Expansion to dictionary-basedmethod using TONG YI CI CI LIN (Chinese Thesaurus) indealing with low-frequency phrases can also improve theoverall performance of the system, which has been testified bythe encouraging results in our experiments.
In the future, we will concentrate our efforts on combiningstatistics and dictionary information more efficiently andsystematically in order to obtain better performance forbilingual base noun phrase alignment. Another, we will furtherapply the mechanism proposed in the paper to some
cross-language applications such as query expansion inmulti-lingual infonnation retrieval, etc.
REFERENCES[1] Xun, E., Zhou, M., and Huang, C. (2000). A Unified Statistical Model for
the Identification of English Base NP. In: The 38th Annual Meeting of theAssociationfor Computational Linguistics, Hong Kong 3-6 October.
[2] Lance A. Ramshaw and Mitchell P. Marcus, Text Chunking UsingTransformation-Based Learning. In: "Proceedings of the T7hird ACLWorkshop on Very Large Corpora", Cambridge MA, USA, 1995.
[3] Dekai Wu: Stochastic Inversion Transduction Grammars and BilingualParsing of Parallel Corpora. Computational Linguistics 23(3): 377403(1997)
[4] Jlian M. Kupiec. An Algorithm for Finding Base Noun PhraseCorrespondences in Bilingual Corpora.In Proceedings of the 31st Annual Meeting of the ACL, Columbus/Ohio,1993.
[5] Frank Smadja. Retrieving Collocations from Text: Xtract. ComputationalLinguistics, 19(1): 143-177, 1993.
[6] Jun Zhao, Changning Huang, Transformation-based Model for ChineseBase Noun Phrase Recognition, Journal of Chinese InformationProcessing, 1999, 13(2), 1-7
[7] Qiang Zhou, Shiwen Yu. Determination of Tag Set for Chinese PhraseAnnotation. Journal ofChinese Information Processing, 1996, v4, p 1-11
[8] Tadashi Kumano and Hideki Kashioka. Acquiring Bilingual Named EntityTranslations from Content-aligned Corpora. In: Proceedings of the FirstInternational Joint Conference on Natural Language Processing(IJCNLP-2004), 22-24 March, 2004, Sanya, Hainan Island, China.
[9] Chen, K.-H. and Chen, H.-H. "Extracting Noun Phrases from Large-ScaleTexts: A Hybrid Approach and Its Automatic Evaluation". In: Proceedingsofthe 32nd Annual Meeting ofACL, pp: 234-241,1994.
[10] Church, K. A stochastic parts program and noun phrase parser forunrestricted text. In Proceedings of the Second Conference on AppliedNatural Language Processing, pp:136-143, 1988.
[11] Boxing Chen, Limin Du. Preparatory Work on Automatic Extraction ofBilingual Multi-Word Units from Parallel Corpora. ComputationalLinguistics and Chinese Language Processing, Vol. 8, No. 2,2003,pp:77-92.
[12] Qiang Zhou. 1997. Automatically Bracket and Tag Chinese Phrase.Journal ofChinese Information Processing, 11(1): 1-10.
[13] Watanabe H., Kurohashi S., Aramaki E. 2000. Finding StructuralCorrespondences from Bilingual Parsed Corpus for Corpus-basedTranslation. COLING 2000.
[14] Wei Wang, Ming Zhou, Jinxia Huang and Changning Huang. 2002.Structure Alignment Using Bilingual Chunking. In: Proc. of COLING2002, 24 Agust - 1 September, Taipei.
365





























