Embed Size (px)
Citation preview

Computer Architecture II
1
Computer architecture II
Lecture 8

Computer Architecture II
2
Shared Memory Multiprocessors

Computer Architecture II
3
Outline:NOW:
• Bus based shared memory (chapters 5, 6 Culler)
– Cache Coherence
– Snooping Cache Coherence Protocols
– Consistency
– Synchronization
LATER:
• NUMA machines (chapters 7, 8)
– Directory based coherency protocols

Computer Architecture II
4
Shared Memory Multiprocessors
• Symmetric Multiprocessors (SMPs)– Symmetric access to the whole main memory from
any processor• Dominate the server market• Attractive as throughput servers and for parallel
programs– Efficient resource sharing (processors, memory)– Uniform access via loads/stores– Automatic data movement and coherent replication in
cache

Computer Architecture II
5
Supporting Programming Models
– Address translation and protection in hardware (hardware SAS)
– Message passing using shared memory buffers
• can be very high performance since no OS involvement necessary
– We focus today on supporting coherent shared address space
Multiprogramming
Shared address space
Message passing Programming models
Communication abstractionUser/system boundary
Compilationor library
Operating systems support
Communication hardwar e
Physical communication medium
Hardware/software boundary

Computer Architecture II
6
I/O devicesMem
P1
$ $
Pn
P1
Switch
Main memory
Pn
(Interleaved)
(Interleaved)
P1
$
Interconnection network
$
Pn
Mem Mem
(b) Bus-based shared memory
(c) Dancehall
(a) Shared cache
First-level $
Bus
P1
$
Interconnection network
$
Pn
Mem Mem
(d) Distributed-memory
Memory Systems in Multiprocessors80s, UMA, 2-8 processors Actual SMPs,UMA, 20-30 processors
Scalable, UMA, memory far Most scalable, NUMA
– b, c, d : private caches
– b: small scale configuration
– d: scalable machines
– a, c: rarely used

Computer Architecture II
7
Compo-nent
Access Random Random Random Direct Sequential
Capa- 64-1024+ 8KB-8MB 64MB-2GB 8GB 1TBcity,bytes
Latency .4-10ns .4-20ns 10-50ns 10ms 10ms-10s
Block 4 B 64 B 64 B 4KB 4KBsize
Band- System System 10-4000 50MB/s 1MB/swidth clock Clock MB/s
Rate rate-80MB/s
Cost/MB High $10 $.25 $0.002 $0.01
The Memory Hierarchy
CPUCache Main Memory Disk Memory
TapeMemory
Some Typical Values:†
†As of 2003-4. They go out of date immediately.

Computer Architecture II
8
Caches• Caches play a key role in all cases
– Address temporal locality – Reduce average data access time to memory
• Some data in cache, some only in memory – Reduce bandwidth demands placed on shared interconnect
• Cache types based on write access– Write-through: the value is also written to memory– Write-back: the value is written to memory only at block
replacement
Cache
Memory
X:0
X=5
X:0
5
5
WRITE-THROUGH
Cache X:0
X=5
X:0
5
WRITE-BACK

Computer Architecture II
9
Write-through vs. write-back• Write-though
– Every write from every processor goes to shared bus and memory
– Easy protocol– Write-through unpopular for SMPs
• Write-back
– absorb most writes as cache hits– Write hits don’t go on bus– But now how do we ensure write propagation and serialization?– Need more sophisticated protocols
Cache
Memory
X:0
X=5
X:0
5
5
WRITE-THROUGH
Cache X:0
X=5
X:0
5
WRITE-BACK

Computer Architecture II
10
Caches and Cache Coherence
• Private processor caches create a problem– Copies of a variable can be present in multiple caches – A write by one processor may not become visible to
others• Other processors may access stale value in their caches
– Cache coherence problem

Computer Architecture II
11
Example Cache Coherence Problem
– How can this problem be solved?
I/O devices
Memory
P1
$ $ $
P2 P3
12
34 5
u = ?u = ?
u:5
u:5
u:5
u = 71. P1 reads u
2. P3 reads u
3. P3 : u=7
4. P1 reads u
5. P2 reads u
What do P1 and P2 see in steps 4 and 5?

Computer Architecture II
12
A Coherent Memory System: Intuition
• Reading a location should return latest value written (by any process)
• Easy in uniprocessors– Except for I/O: coherence between I/O devices and processors– Problem: DMA and the processor write to main memory, but the
processor through the cache – Infrequent => software solutions work fine
• uncacheable operations, uncached loads/store for I/O memory regions, flush pages, pass I/O data through caches
• The coherence problem is more performance-critical in multiprocessors– Fast hardware solutions desired

Computer Architecture II
13
Problems with the Intuition
• Recall: – Value returned by read should be last value written
• But “last” is not well-defined!• Even in sequential case:
– “last” is defined in terms of program order, not time• Order of operations in the machine language presented to processor• “Subsequent” defined in analogous way, and well defined
• In parallel case:– program order defined within a process, but need to make sense of
orders across processes• Must define a meaningful semantics
– the answer involves both “cache coherence” (TODAY) and an appropriate “memory consistency model” (NEXT TIME)

Computer Architecture II
14
Program order
• Sequential program order
– P1: 1a->1b
– P2: 2a->2b
• Parallel program order: a arbitrary interleaving of sequential orders of P1 and P2
– 1a->1b->2a->2b – 1a->2a->1b->2b– 2a->1a->1b->2b– 2a->2b->1a->1b
P1 P2
(1a) A = 1; (2a) print B;
(1b) B = 2; (2b) print A;

Computer Architecture II
15
Formal Definition of Coherence
• Results of a program: values returned by its read operations• A memory system is coherent if the results of any execution of a program
are such that, for each location, it is possible to construct a hypothetical serial order of all operations to the given location that is consistent with the results of the execution and in which:
1. operations issued by any particular process occur in the order issued by that process, and
2. the value returned by a read is the value written by the last write to that location in the serial order
• Two necessary features:–Write propagation: value written must become visible to others –Write serialization: writes to location seen in same order by all
• if I see w1 after w2, you should not see w2 before w1• no need for read serialization since reads not visible to others

Computer Architecture II
16
Cache Coherence Solutions• Software Based:
– often used in clusters of workstations or PCs (e.g., “Treadmarks DSM”)
– extend virtual memory system to perform more work on page faults• send messages to remote machines if necessary
• Hardware Based:– two most common variations:
• “snoopy” schemes– rely on broadcast to observe all coherence traffic– well suited for buses and small-scale systems– example: Almost all dual-processor SMPs
• directory schemes– uses centralized information to avoid broadcast– scales well to larger numbers of processors– example: SGI Origin 2000
Today
Later

Computer Architecture II
17
Ex: Cache Coherence Problem
Solution INVALIDATE write-through:
1) before completing P3 :u=7
1) send a signal on the bus to invalidate all the copies of the block cache where u is stored ( cache of P1)
2) Write through the new value to the memory
2) P1 and P2 will read 7 from main memory (the copy of P1 has been invalidated)
1. P1 reads u
2. P3 reads u
3. P3 : u=7
4. P1 reads u
5. P2 reads u
What do P1 and P2 see in steps 4 and 5?
I/O devices
Memory
P1
$ $ $
P2 P3
12
34 5
u = ?u = ?
u:5
u:5
u:5
u = 7
invalidate
Write-through
7

Computer Architecture II
18
Ex: Cache Coherence Problem
Solution UPDATE write-through:
1) before completing P3 :u=7
1) send a signal on the bus to update all the copies of the block cache where u is stored ( cache of P1)
2) Write through the new value to the memory
2) P1 reads 7 from its cache (the copy has been updated) and P2 will read 7 from main memory
1. P1 reads u
2. P3 reads u
3. P3 : u=7
4. P1 reads u
5. P2 reads u
What do P1 and P2 see in steps 4 and 5?
I/O devices
Memory
P1
$ $ $
P2 P3
12
34 5
u = ?u = ?
u:5
u:5
u:5
u = 7
update
Write-through
7
7

Computer Architecture II
19
Outline:NOW:
• Bus based shared memory (chapters 5, 6 Culler)
– Cache Coherence
– Snooping Cache Coherence Protocols
– Consistency
– Synchronization
LATER:
• NUMA machines (chapters 7, 8)
– Directory based coherency protocols

Computer Architecture II
20
I/O devicesMem
P1
$ $
Pn
P1
Switch
Main memory
Pn
(Interleaved)
(Interleaved)
P1
$
Interconnection network
$
Pn
Mem Mem
(b) Bus-based shared memory
(c) Dancehall
(a) Shared cache
First-level $
Bus
P1
$
Interconnection network
$
Pn
Mem Mem
(d) Distributed-memory
Memory Systems in Multiprocessors80s, UMA, 2-8 processors Actual SMPs,UMA, 20-30 processors
Scalable, UMA, memory far away Most scalable, NUMA
WE WILL DISCUSS NOW b !

Computer Architecture II
21
Bus-based Cache Coherence
• Built on top of two fundamentals of uni-processor systems
– Bus transactions
– State transition diagram in cache
• Uni-processor bus transaction:
– Three phases• Arbitration: decide who will get control of the bus
• command/address
• data transfer
– All devices observe addresses, one is responsible for answering
• Uni-processor cache states:
– A finite-state machine for every block
– Write-through: two states: valid, invalid
– Write-back: one more state: modified (“dirty”)

Computer Architecture II
22
Snooping-based Coherence• Basic Idea
– Transactions on bus are visible to all processors– Processors or their representatives can snoop (monitor) bus and take
action on relevant events (e.g. change state)
• Implementing a Protocol– Cache controller receives inputs:
• Requests from processor• Bus requests/responses from snooper
– Cache controller actions on input• Updates state, responds with data, generates new bus transactions
– Protocol is a distributed algorithm: cooperating state machines• Set of states, state transition diagram, actions
– Granularity of coherence is typically cache block (e.g.: 32 bytes)• The same with granularity of allocation in cache and of transfer
to/from cache

Computer Architecture II
23
Coherence with Write-through Caches
– Key extensions to uniprocessor: snooping, invalidating/updating caches• no new states or bus transactions in this case• invalidation- versus update-based protocols
– Write propagation: even in invalidation case, later reads will see new value• invalidation causes miss on later access, and memory up-to-date via write-through
I/O devicesMem
P1
$
Bus snoop
$
Pn
Cache-memorytransaction
Computer Architecture II
24
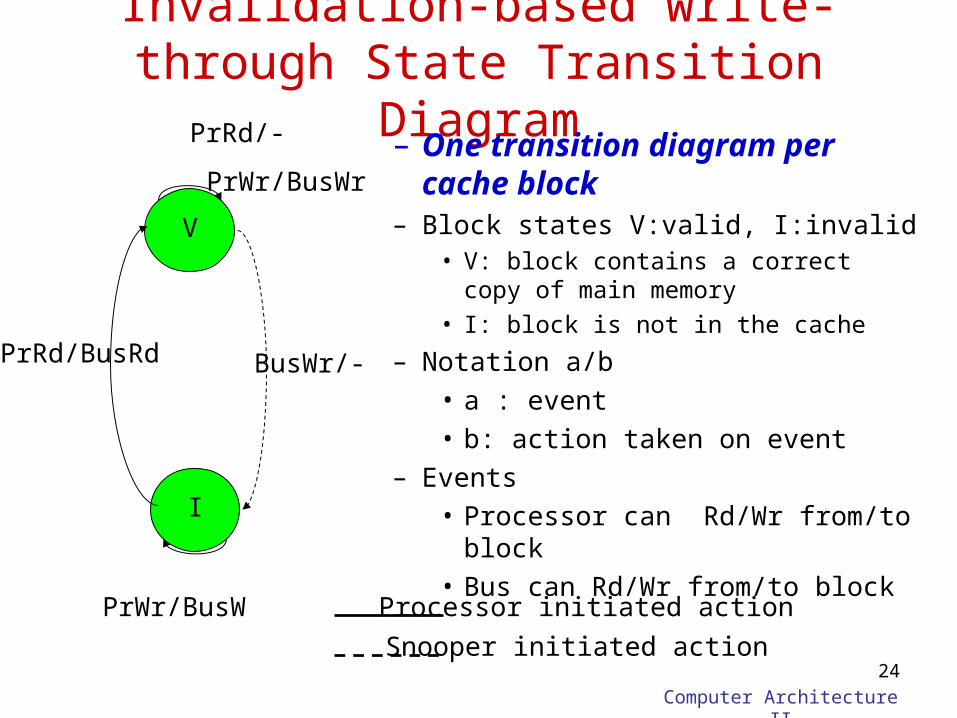
Invalidation-based write-through State Transition Diagram
– One transition diagram per cache block
– Block states V:valid, I:invalid• V: block contains a correct copy of main
memory
• I: block is not in the cache
– Notation a/b• a : event• b: action taken on event
– Events• Processor can Rd/Wr from/to block• Bus can Rd/Wr from/to block
V
I
PrRd/-
PrWr/BusWr
BusWr/-PrRd/BusRd
PrWr/BusW Processor initiated action
Snooper initiated action
Computer Architecture II
25
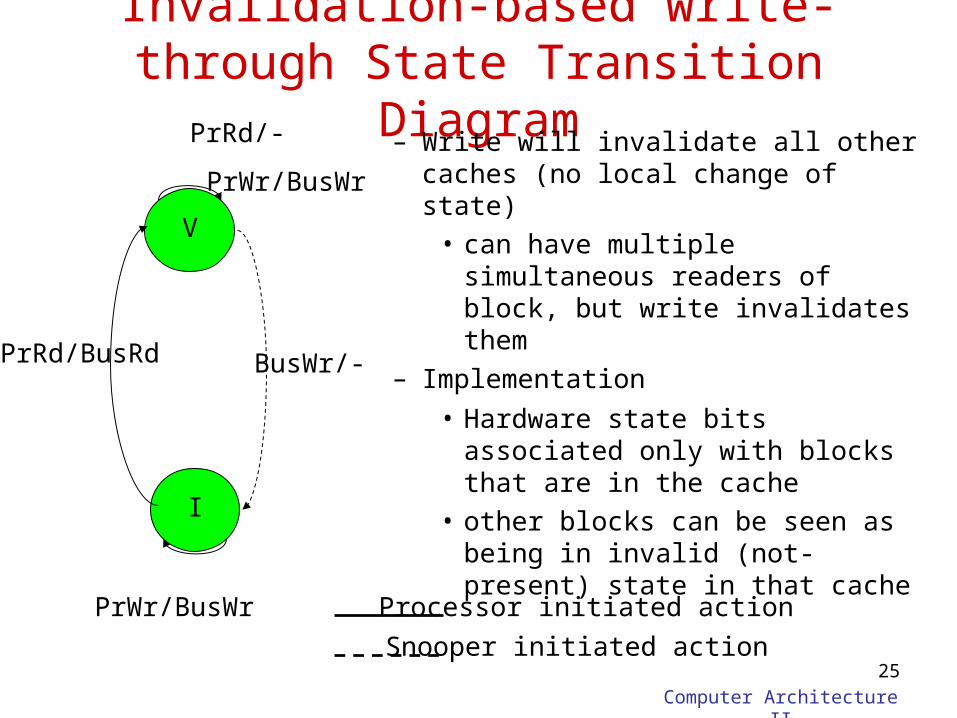
Invalidation-based write-through State Transition Diagram
– Write will invalidate all other caches (no local change of state)
• can have multiple simultaneous readers of block, but write invalidates them
– Implementation
• Hardware state bits associated only with blocks that are in the cache
• other blocks can be seen as being in invalid (not-present) state in that cache
V
I
PrRd/-
PrWr/BusWr
BusWr/-PrRd/BusRd
PrWr/BusWr Processor initiated action
Snooper initiated action

Computer Architecture II
26
Problems with Write Through
• High bandwidth requirements– Every write from every processor goes to shared bus
and memory– Write-through unpopular for SMPs
• Write-back caches absorb most writes as cache hits– Write hits don’t go on bus– But now how do we ensure write propagation and
serialization?– Need more sophisticated protocols: large design space

Computer Architecture II
27
Write-Back Snoopy Protocols
• No need to change processor, main memory, cache …– Extend cache controller (not only V and I states) and
exploit bus (provides serialization)• Dirty state now also indicates exclusive ownership
– Exclusive: only cache with a valid copy (main memory may be too)
– Owner: responsible for supplying block upon a request for it
• 2 types of protocols– Invalidation based – Update based

Computer Architecture II
28
Basic MSI Write-back Invalidation Protocol
• States
– Invalid (I)
– Shared (S): one or more
– Dirty or Modified (M): one only• Processor Events:
– PrRd (read)– PrWr (write)
• Bus Transactions
– BusRd (read): asks for copy with no intent to modify
– BusRdX (read exclusive): asks for copy with intent to modify
– BusWB (write back): updates memory • Actions
– Update state, perform bus transaction, flush value onto bus

Computer Architecture II
29
State Transition Diagram
–Replacement and write backs are not shown
–Rd/Wr in M and Rd in S state do not cause bus transaction
–But: Rd/Wr in I state cause 2 bus transactions
–Wr in S state 2 bus transactions• And data sent at RdX• Can spare the data transfer, because already have latest data: can use upgrade (BusUpgr) instead of BusRdX
PrRd/—
PrRd/—
PrWr/BusRdXBusRd/—
PrWr/-
S
M
I
BusRdX/Flush
BusRdX/—
BusRd/Flush
PrWr/BusRdX
PrRd/BusRd

Computer Architecture II
30
Example: Write-Back Protocol
I/O devices
Memory
u :5
P1 P2 P3PrRd U
U S 5
BusRd U
PrRd U
BusRd U
U S 5
PrWr U 7
U M 7
BusRdx U
PrRd U
U S 7 U S 7
7
BusRd
Flush
PrRd/—
PrRd/—
PrWr/BusRdXBusRd/—
PrWr/—
S
M
I
BusRdX/Flush
BusRdX/—
BusRd/Flush
PrWr/BusRdX
PrRd/BusRd1. P1 reads u
2. P3 reads u
3. P3 : u=7
4. P1 reads u
5. P2 reads u

Computer Architecture II
31
MESI (4-state) Invalidation Protocol
• Problem with MSI protocol– Reading and modifying data is 2 bus transactions, even if no sharing!
• even in a sequential program!
• BusRd (I->S) followed by BusRdX or BusUpgr (S->M)• Add exclusive state: not modified block resides only in local cache =>
write locally without bus transaction• States
– invalid– exclusive or exclusive-clean (only this cache has copy, but not
modified)– shared (two or more caches may have copies)– modified (dirty)

Computer Architecture II
32
MESI State Transition Diagram
– Goal: no bus transaction on E • When does I go to E and when to
S?• I -> E on PrRd if no other processor
has a copy
• I -> S otherwise
– S additional signal on bus– BusRd(S): on BusRd signal, if
one processor holds the block it asserts S (makes it 1)
PrWr/-
BusRd/Flush
PrRd/
BusRdX/Flush
PrWr/
BusRdX
PrWr/-
PrRd/—
PrRd/—BusRd/Flush
E
M
I
S
PrRd/-
BusRd(S)
BusRdX/Flush
BusRdX/Flush
BusRd/Flush
PrWr/BusRdX
PrRd/BusRd(S))

Computer Architecture II
33
Dragon Write-Back Update Protocol
• 4 states– Exclusive-clean or exclusive (E): locally and memory have it– Shared clean (Sc): locally, others, and maybe memory, but I’m not
owner– Shared modified (Sm): locally and others but not memory, and I’m the
owner• Sm and Sc can coexist in different caches, with only one Sm
– Modified or dirty (D): locally and nowhere else• No invalid state
– If in cache, cannot be invalid– If not present in cache, can view as being in not-present or invalid state
• New processor events: PrRdMiss, PrWrMiss– Introduced to specify actions when block not present in cache
• New bus transaction: BusUpd– Broadcasts single word written on bus; updates caches that hold a copy

Computer Architecture II
34
Dragon State Transition Diagram
E Sc
Sm M
PrWr/—PrRd/—
PrRd/—
PrRd/—
PrRdMiss/BusRd(S)PrRdMiss/BusRd(S)
PrWr/—
PrWrMiss/(BusRd(S); BusUpd) PrWrMiss/BusRd(S)
PrWr/BusUpd(S)
PrWr/BusUpd(S)
BusRd/—
BusRd/Flush
PrRd/— BusUpd/Update
BusUpd/Update
BusRd/Flush
PrWr/BusUpd(S)
PrWr/BusUpd(S)

Computer Architecture II
35
Invalidate versus Update
• Basic question of program behavior– Is a block written by one processor read by others before it is
rewritten?• Invalidation:
– Yes => readers will take a miss– No => multiple writes without additional traffic
• Update:– Yes => readers will not miss if they had a copy previously
• single bus transaction to update all copies– No => multiple useless updates, even to dead copies
• Invalidate or update may be better depending on the application• Invalidation protocols much more popular
– Some systems provide both, or even hybrid





![Cse.m-ii-Advances in Computer Architecture [12scs23]-Notes](https://img.pdfslide.net/doc/110x75/55cf989b550346d0339899ef/csem-ii-advances-in-computer-architecture-12scs23-notes.jpg)























