Embed Size (px)
Citation preview

Computer Architecture
Key Points
John MorrisElectrical & Computer Enginering/Computer Science, The University of Auckland
Iolanthe II drifts off Waiheke Island

Memory Bottleneck
• State-of-the-art processor• f = 3 GHz
• tclock = 330ps
• 1-2 instructions per cycle• ~25% memory reference
• Memory response• 4 instructions x 330ps
• ~1.2ns needed!
• Bulk semiconductor RAM• 100ns+ for a ‘random’ access!Processor will spend most of its time waiting
for memory!
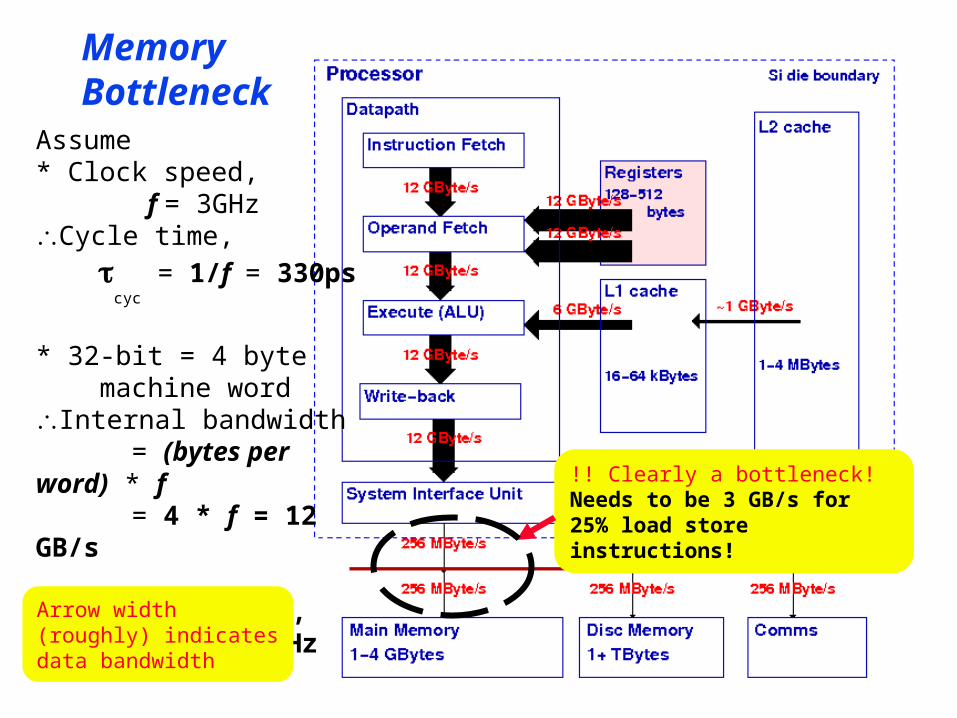
MemoryBottleneck
Assume* Clock speed, f = 3GHzCycle time,
cyc = 1/f = 330ps
* 32-bit = 4 byte machine wordInternal bandwidth = (bytes per word) * f = 4 * f = 12 GB/s
* 64-bit PCI bus, fbus = 32 MHz
Arrow width(roughly) indicatesdata bandwidth
!! Clearly a bottleneck!Needs to be 3 GB/s for 25% load store instructions!

Cache
• Small, fast memory• Typically ~50kbytes (1998)• 2 cycle access time
• Same die as processor• “Off-chip” cache possible
• Custom cache chip closely coupled to processor
• Use fast static RAM (SRAM) rather thanslower dynamic RAM
• Several levels possible
• 2nd level of the memory hierarchy• “Caches” most recently used memory
locations “closer” to the processor• closer = closer in time
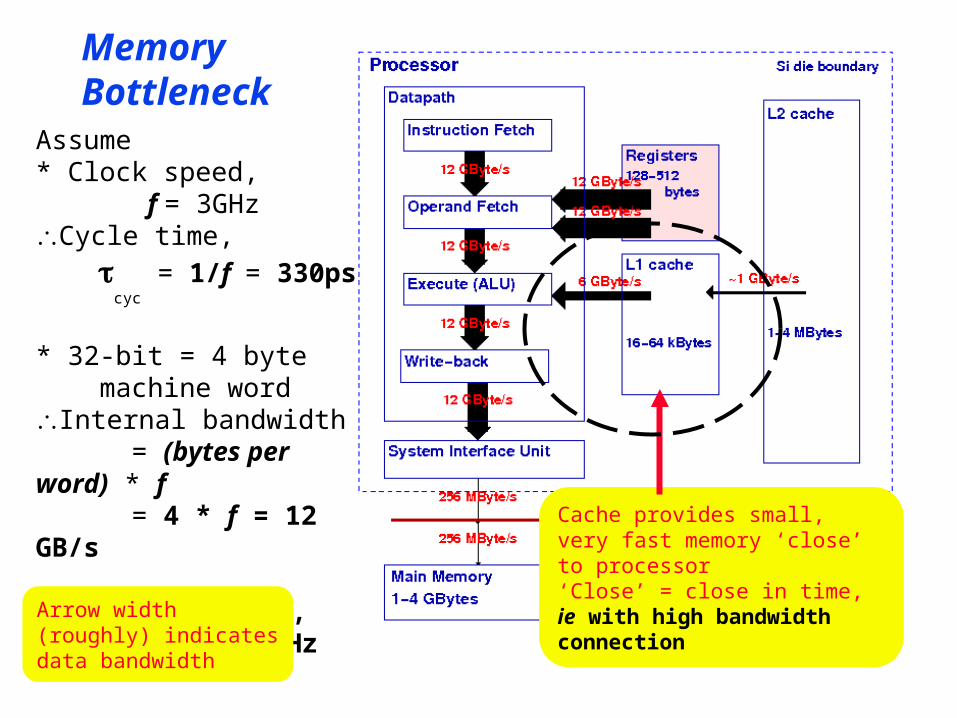
MemoryBottleneck
Assume* Clock speed, f = 3GHzCycle time,
cyc = 1/f = 330ps
* 32-bit = 4 byte machine wordInternal bandwidth = (bytes per word) * f = 4 * f = 12 GB/s
* 64-bit PCI bus, fbus = 32 MHz
Arrow width(roughly) indicatesdata bandwidth
Cache provides small, very fast memory ‘close’ to processor‘Close’ = close in time,ie with high bandwidth connection
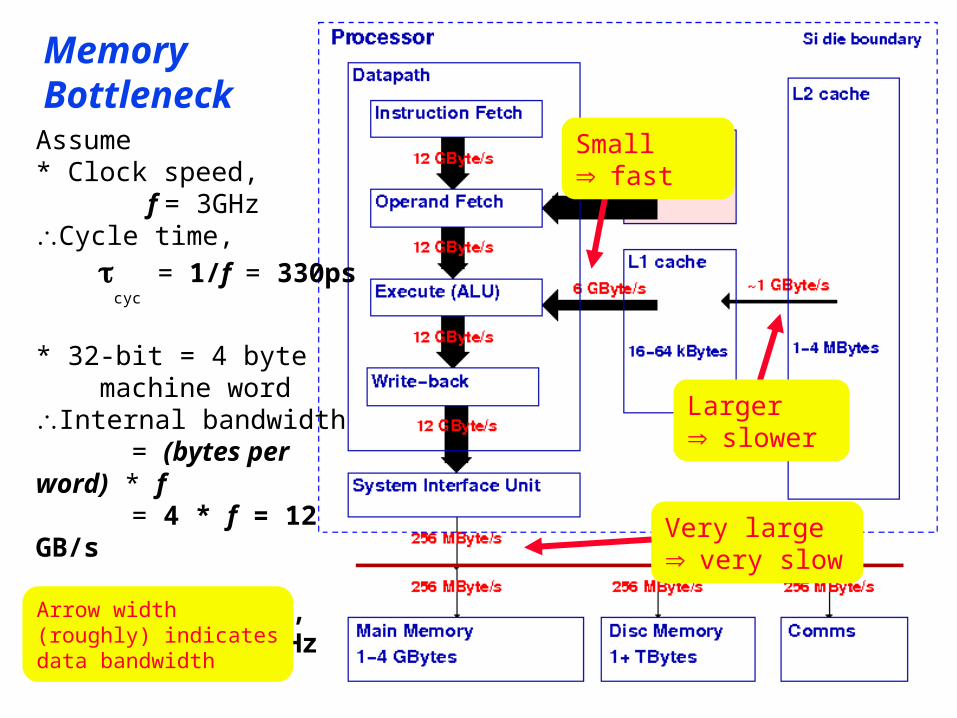
Very large very slow
MemoryBottleneckAssume* Clock speed, f = 3GHzCycle time,
cyc = 1/f = 330ps
* 32-bit = 4 byte machine wordInternal bandwidth = (bytes per word) * f = 4 * f = 12 GB/s
* 64-bit PCI bus, fbus = 32 MHz
Arrow width(roughly) indicatesdata bandwidth
Small fast
Larger slower

Memory hierarchy & performance
• Usual metric is machine cycle time, cyc = 1/f
• Visible to programmer• Registers < 1 cycle latency
(respond in same cycle)
• Transparent to programmer• Level 1 (L1) cache 2 cycle latency• L2 cache 5-6 cycles• L3 cache about 10 cycles• Main memory 100+ cycles
for a random access
• Disc > 1 ms or >106 cycles• Effective memory access time,
eff = fi ti
where fi = fraction of hits at level i, ti = access time at level i
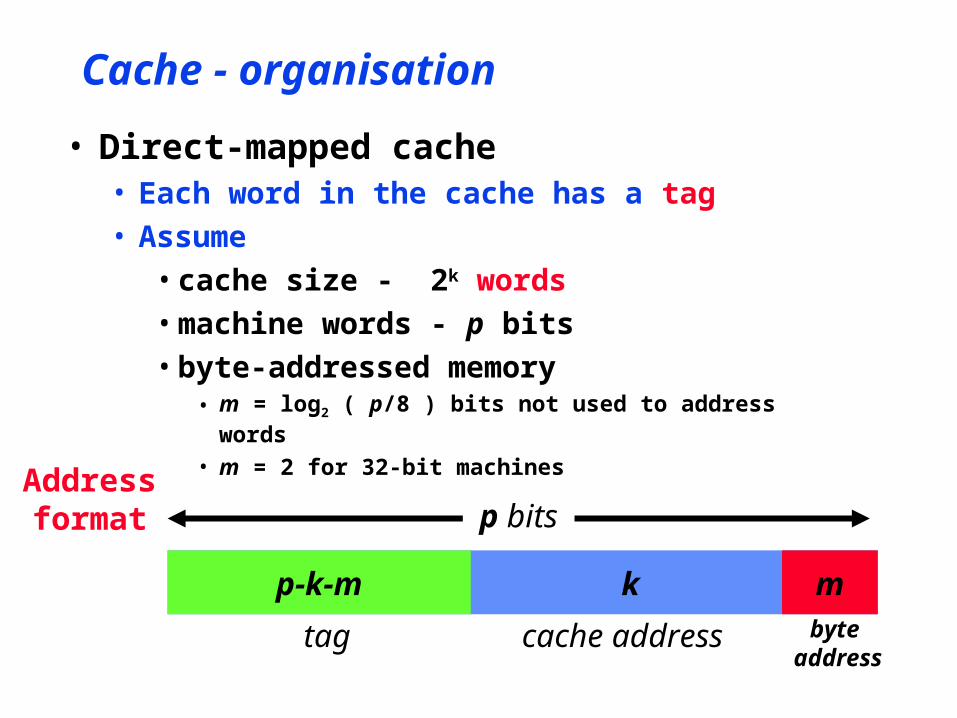
Cache - organisation
• Direct-mapped cache• Each word in the cache has a tag• Assume
• cache size - 2k words• machine words - p bits• byte-addressed memory
• m = log2 ( p/8 ) bits not used to address words
• m = 2 for 32-bit machines
p-k-m mk
p bits
tag cache address byte address
Addressformat
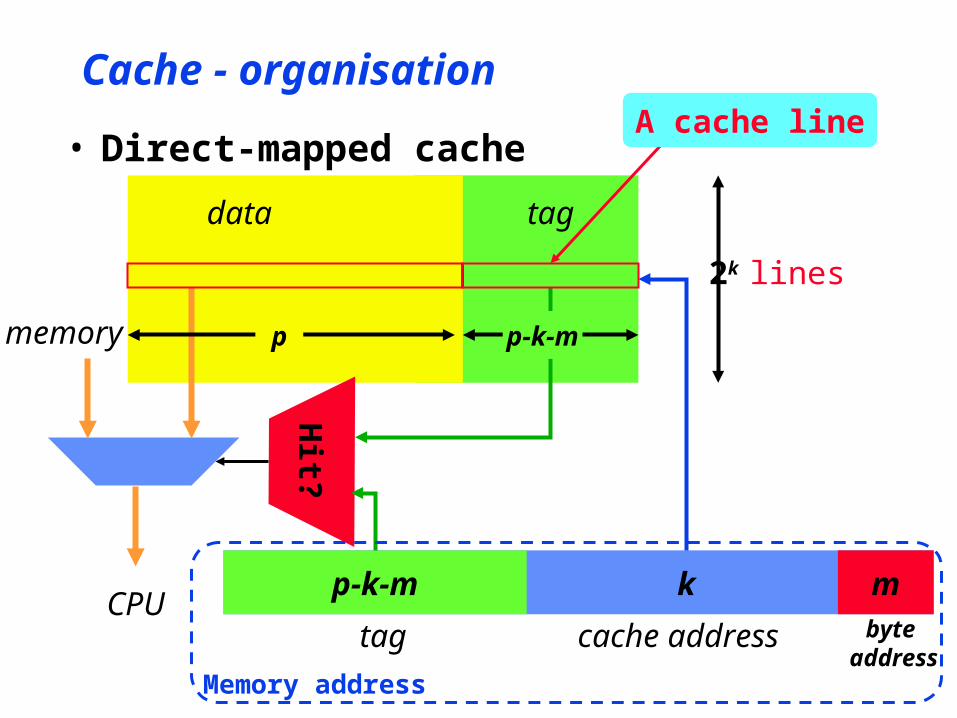
Cache - organisation
• Direct-mapped cache
p-k-m mk
tag cache address byte address
tagdata
Hit?
memory
CPU
2k lines
p-k-mp
A cache line
Memory address
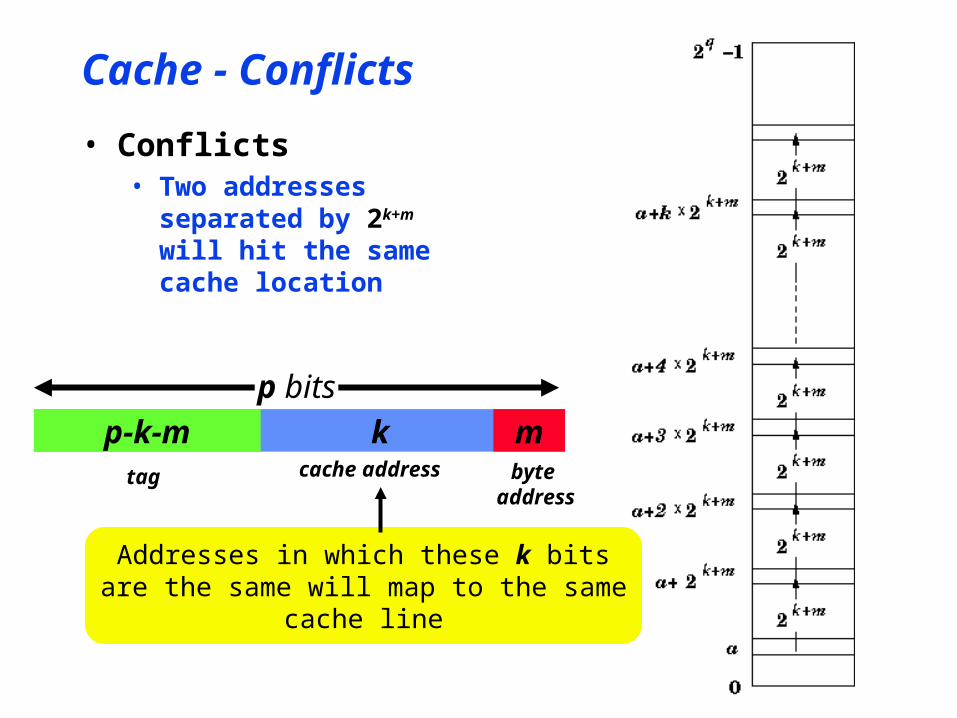
Cache - Conflicts
• Conflicts• Two addresses
separated by 2k+m
will hit the same cache location
p-k-m mk
p bits
tag cache address byte address
Addresses in which these k bitsare the same will map to the same
cache line

Cache - Conflicts
When a word is modified in cacheWrite-back cache
• Only writes data back when neededMissesTwo memory accesses
• Write modified word back
• Read new word
Write-through cache• Low priority write to main memory is queued• Processor is delayed by read only
• Memory write occurs in parallel with other work
• Instruction and necessary data fetches take priority

Cache - Write-through or write-back?
• Write-through• Seems a good idea!
but ...• Multiple writes to the same location waste
memory bus bandwidthTypical programs better with write-back caches
however• Often you can easily predict which will be bestSome processors (eg PowerPC) allow you to
classify memory regions as write-back or write-through

Cache - more bits
• Cache lines need some status bits• Tag bits + ..• Valid
• All set to false on power up• Set to true as words are loaded into cache
• Dirty• Needed by write-back cache• Write- through cache always queues the
write, so lines are never ‘dirty’
Tag V M DataCache line
p-k-m p1 1

Cache – Improving Performance• Conflicts ( addresses 2k+m bytes
apart )• Degrade cache performance
• Lower hit rate• Murphy’s Law operates
• Addresses are never random!• Some locations ‘thrash’ in cache
• Continually replaced and restored
• Alternatively• Ideal cache performance depends
on uniform access to all parts of memory
• Never happens in real programs!
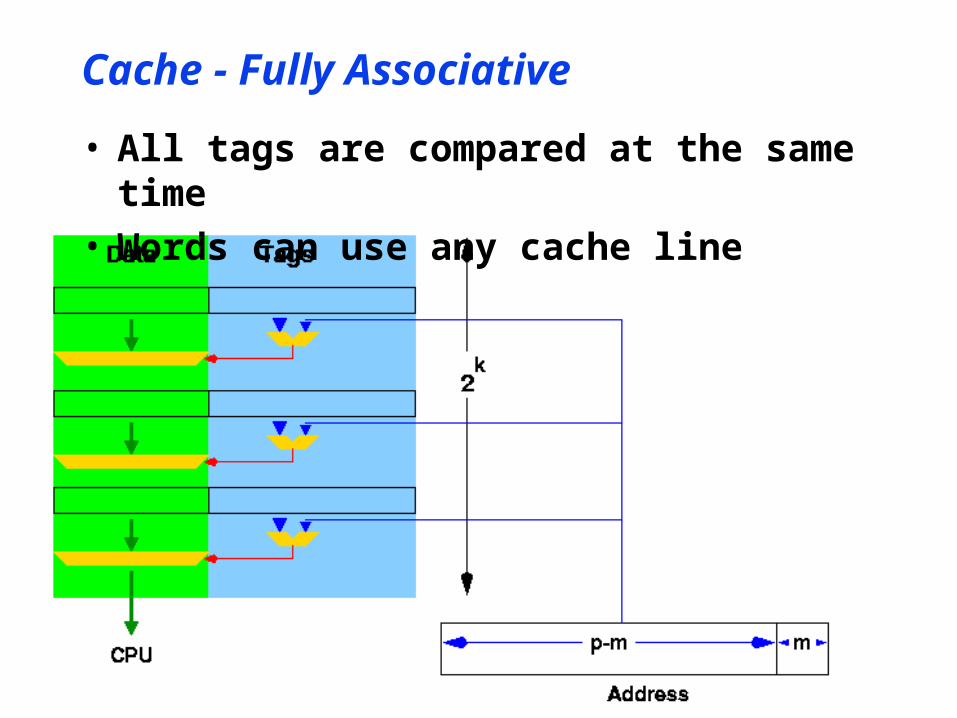
Cache - Fully Associative
• All tags are compared at the same time• Words can use any cache line

Cache - Fully Associative
• Associative• Each tag is compared at the same time• Any match hit
• Avoids ‘unnecessary’ flushing• Replacement
• Least Recently Used - LRU• Needs extra status bits
• Cycles since last accessed
• Hardware cost high• Extra comparators• Wider tags
• p-m bits vs p-k-m bits
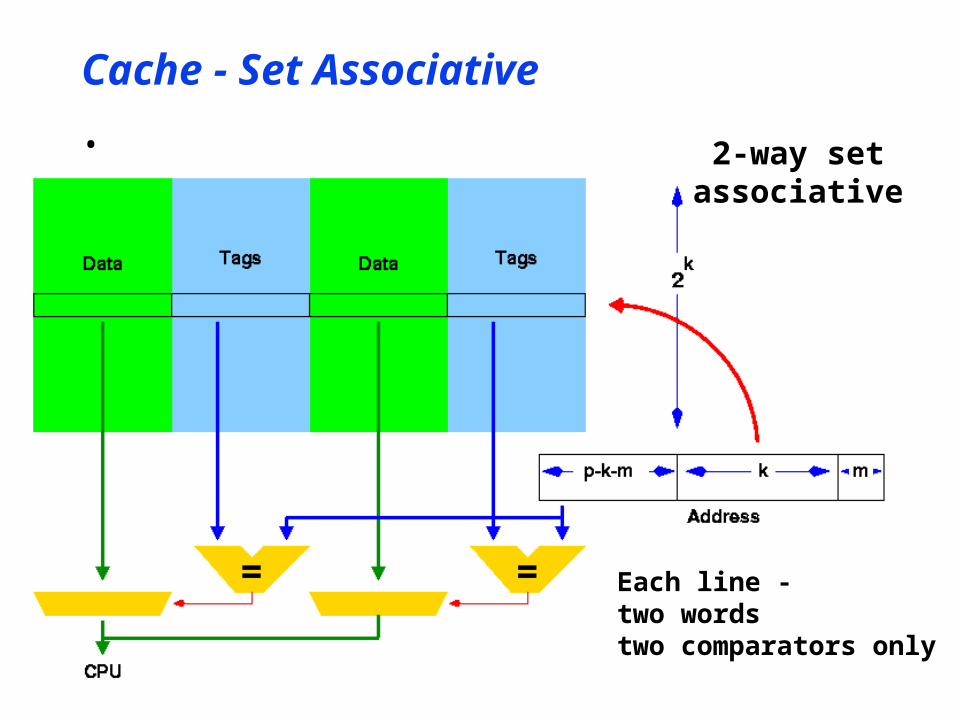
Cache - Set Associative
Each line -two wordstwo comparators only
• 2-way setassociative

Cache - Set Associative
• n-way set associative caches• n can be small: 2, 4, 8• Best performance• Reasonable hardware cost• Most high performance processors
• Replacement policy• LRU choice from n• Reasonable LRU approximation
• 1 or 2 bits• Set on access• Cleared / decremented by timer• Choose cleared word for replacement

Cache - Locality of Reference
Temporal Locality• Same location will be referenced again soon• Access same data again• Program loops - access same instruction again• Caches described so far exploit temporal
locality
Spatial Locality• Nearby locations will be referenced soon
• Next element of an array• Next instruction of a program

Cache - Line Length
• Spatial Locality• Use very long cache lines• Fetch one datum
Neighbours fetched also
• PowerPC 601 (Motorola/Apple/IBM)first of the single chip Power processors
• 64 sets• 8-way set associative• 32 bytes per line• 32 bytes (8 instructions) fetched into
instruction buffer in one cycle• 64 x 8 x 32 = 16k byte total

Cache - Separate I- and D-caches
• Unified cache• Instructions and Data in same cache
• Two caches - * Instructions * DataIncreases total bandwidth
• MIPS R10000• 32Kbyte Instruction; 32Kbyte Data• Instruction cache is pre-decoded! (32 36bits)• Data
• 8-word (64byte) line, 2-way set associative• 256 sets
• Replacement policy?

COMPSYS 304
Computer Architecture
Memory Management Units
Reefed down - heading for Great Barrier Island
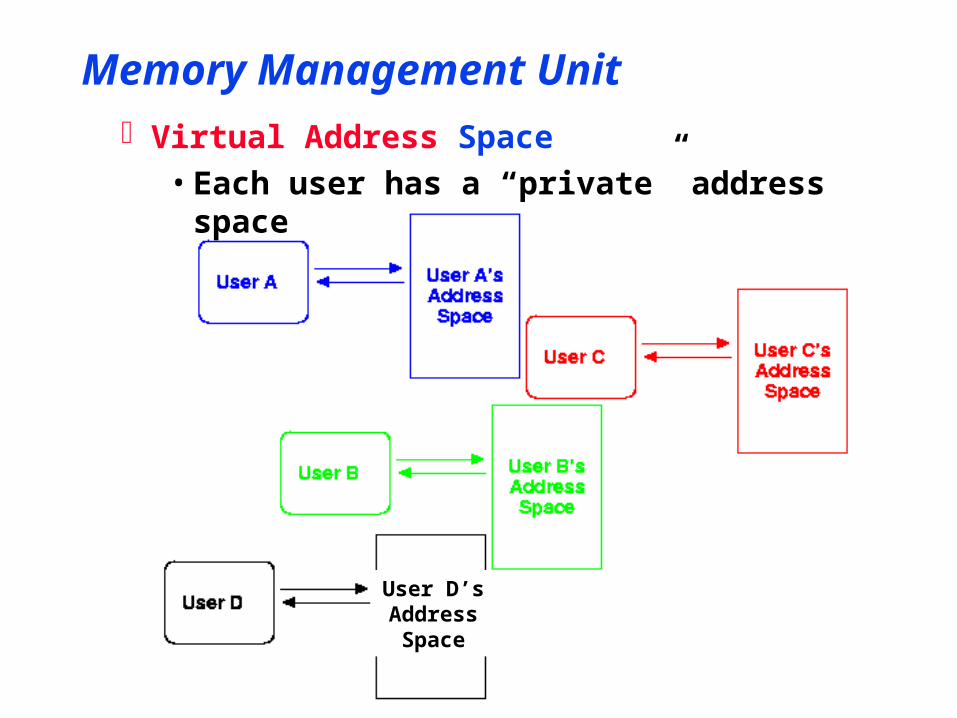
Memory Management UnitVirtual Address Space
• Each user has a “private” address space
User D’sAddressSpace
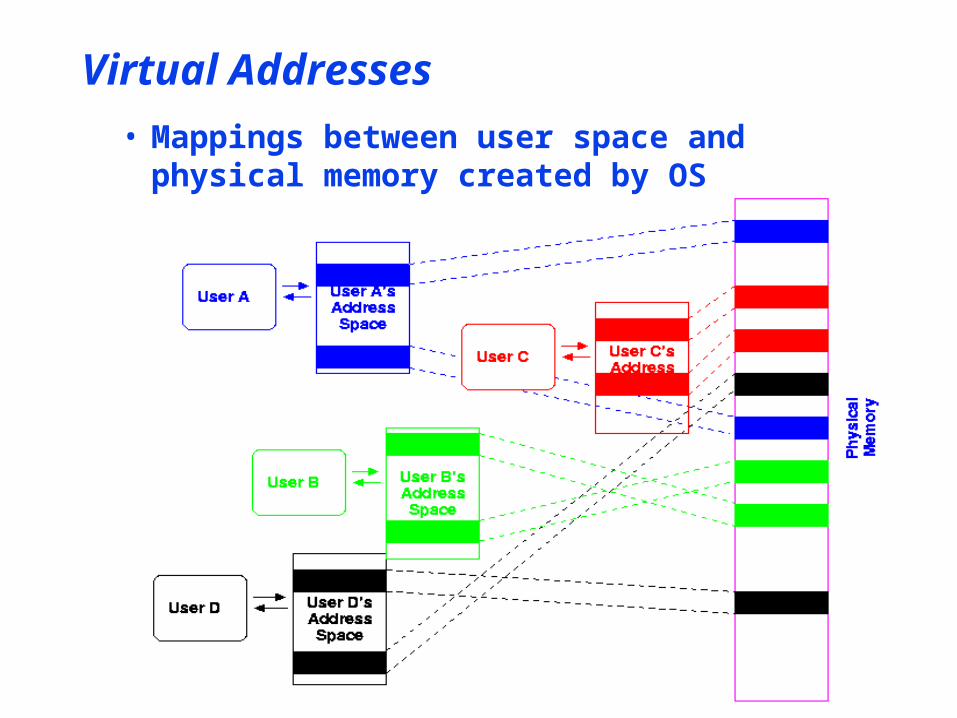
Virtual Addresses
• Mappings between user space and physical memory created by OS
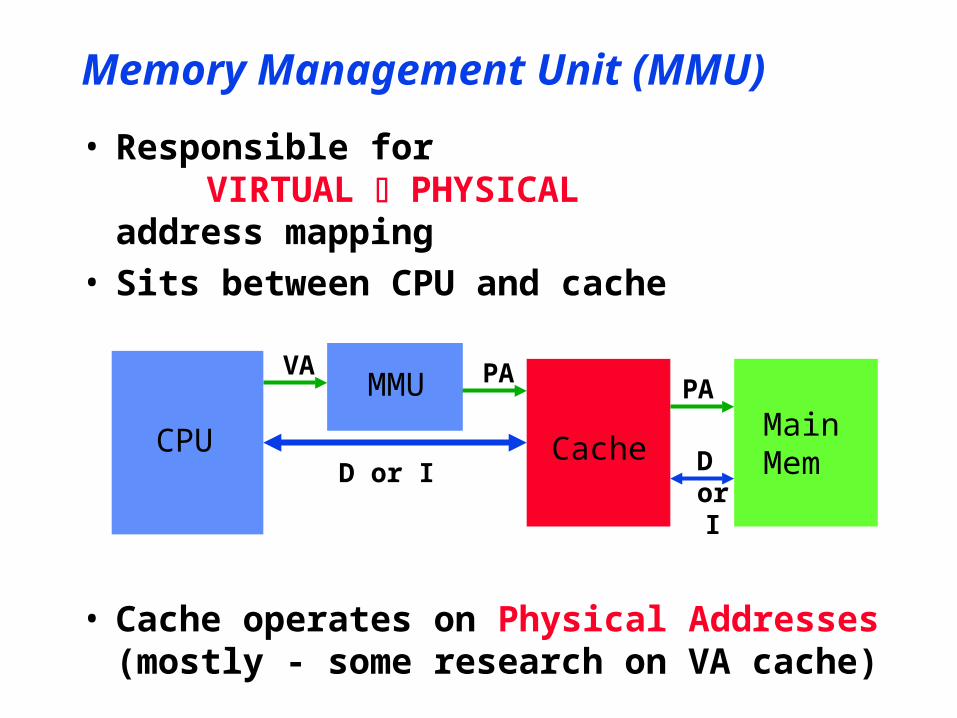
Memory Management Unit (MMU)
• Responsible forVIRTUAL PHYSICAL
address mapping• Sits between CPU and cache
• Cache operates on Physical Addresses(mostly - some research on VA cache)
CPU
MMU
CacheMainMemD or I
VA PAPA
D or I
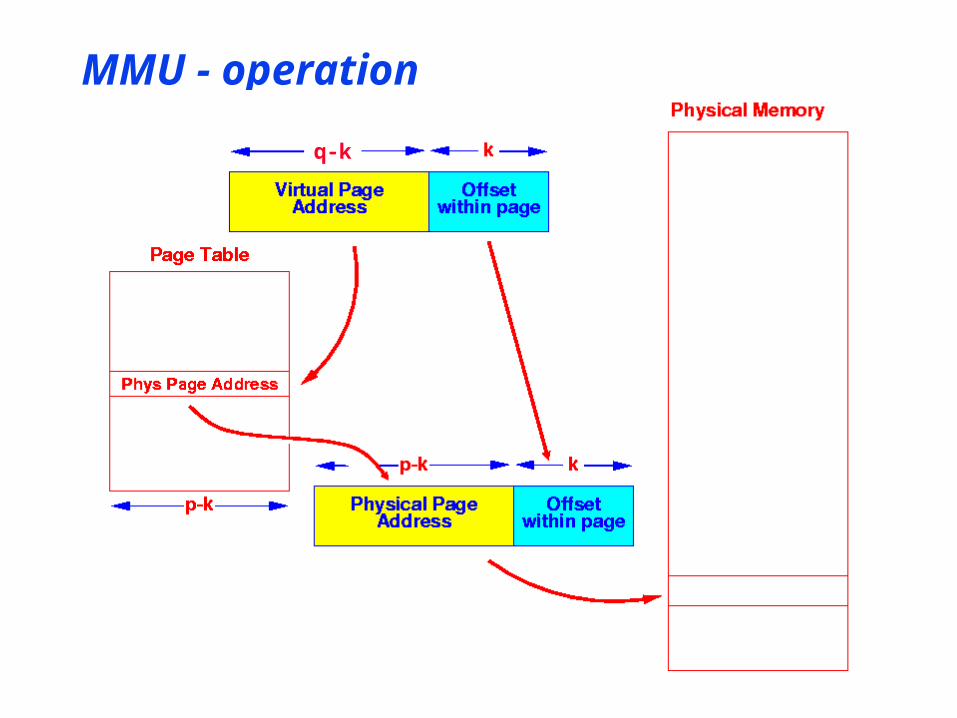
MMU - operation
q-k

MMU - Virtual memory space
• Page Table Entries can also point to disc blocks• Valid bit
• Set: page in memory address is physical page address
• Cleared: page “swapped out” address is disc block address
• MMU hardware generates page faultwhen swapped out page is requested
• Allows virtual memory space to be larger than physical memory• Only “working set” is in physical memory• Remainder on paging disc
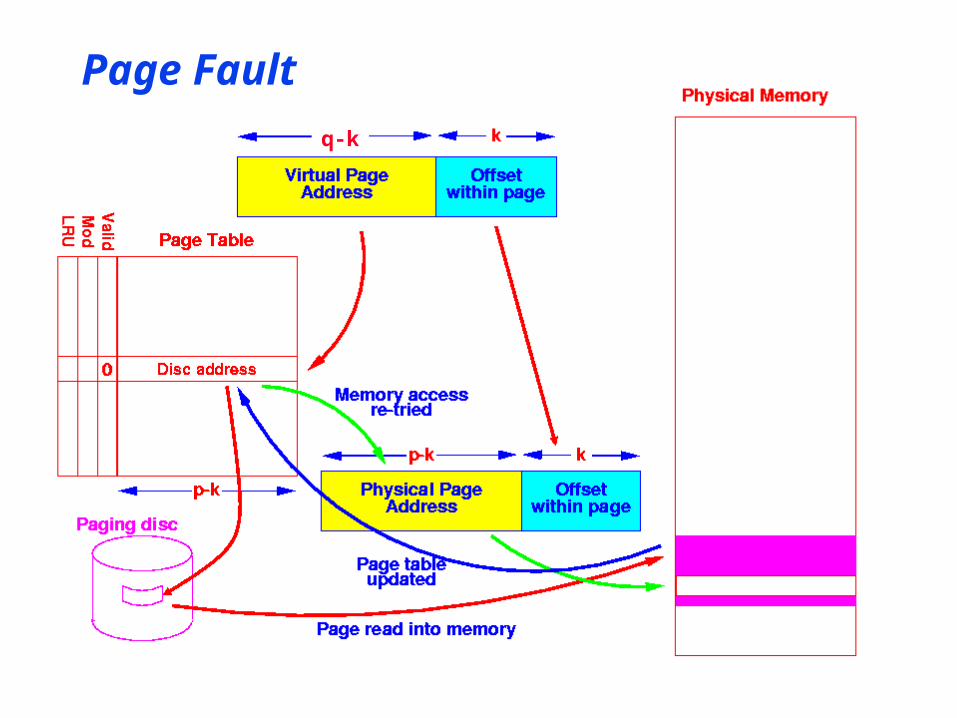
Page Fault
q-k

MMU – Page faults
• Very expensive!• Gap in access times
• Main memory ~100+ ns• Disc ~1+ ms• A factor of 104 slower!!
+ May require write-back of old (but modified) page
+ May require reading of Page Table Entries from disc!
• Good way to make a system thrash!

MMU – Access control
• Provides additional protection to programmer
• Pages can be marked• Read only• Execute only
• Can prevent wayward programmes from corrupting their own programme code or vital data• Protection is hardware!• MMU will raise exception if illegal access
attempted• OS traps the exception and process it

MMU
• Inverted page tables• Scheme which saves memory for page tables• One PTE per page of physical memory• Hash function used
Collisions probablePossibly slower
Sharing Map virtual pages for several users to same
physical page Good for sharing program code Data also (read/write control provided by OS) Saves physical memory Reduces pressure on main memory

MMU
• TLB• Cache for page table entries• Enables MMU to translate VA PA in time!• Can be quite small: 50-100 entries• Often fully associative
• Small size avoids one ‘cost’ of FA cache• Only 50-100 comparators needed
• TLB Coverage• Amount of memory covered by TLB entries• Size of a program for which VA PA
translation will be fast
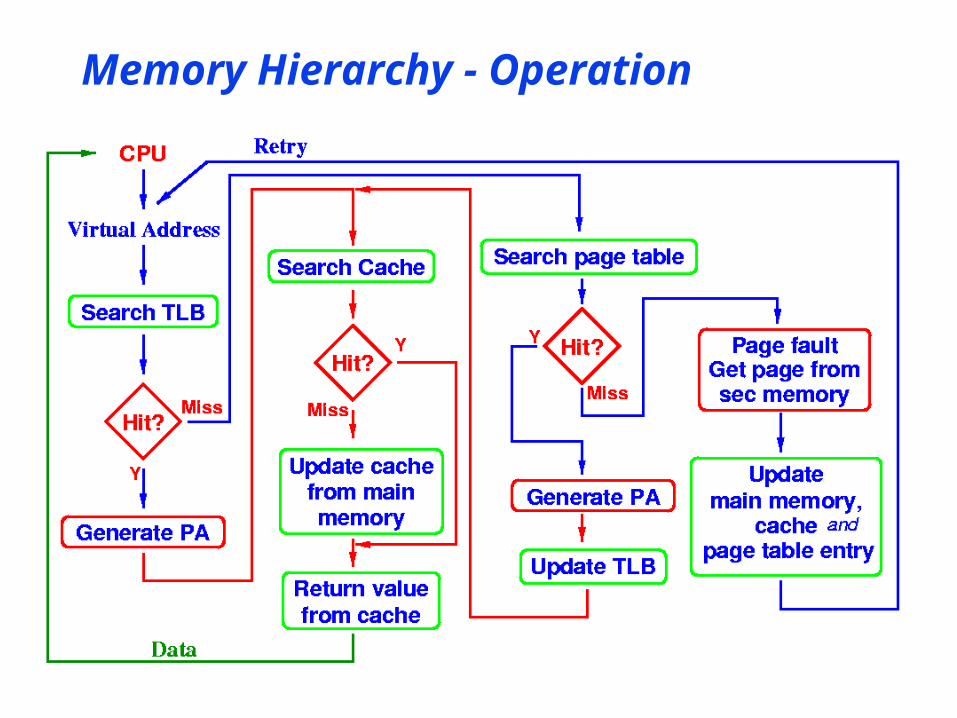
Memory Hierarchy - Operation





























