Embed Size (px)
Citation preview

CudaDMA: Emulating DMA engines on GPUs for Performance and Programmability
Brucek Khailany (NVIDIA Research) Michael Bauer (Stanford) Henry Cook (UC Berkeley)

CudaDMA overview
A library for efficient bulk transfers between global and
shared memory in CUDA kernels (not host<->device copies)
Motivation: Ease programmer burden for high performance
http://code.google.com/p/cudadma/
GPU
CPU SM
Shared
DRAM
DRAM
L2
PCIe
SM
Shared
SM
Shared
SM
Shared …
global<->shared
transfers
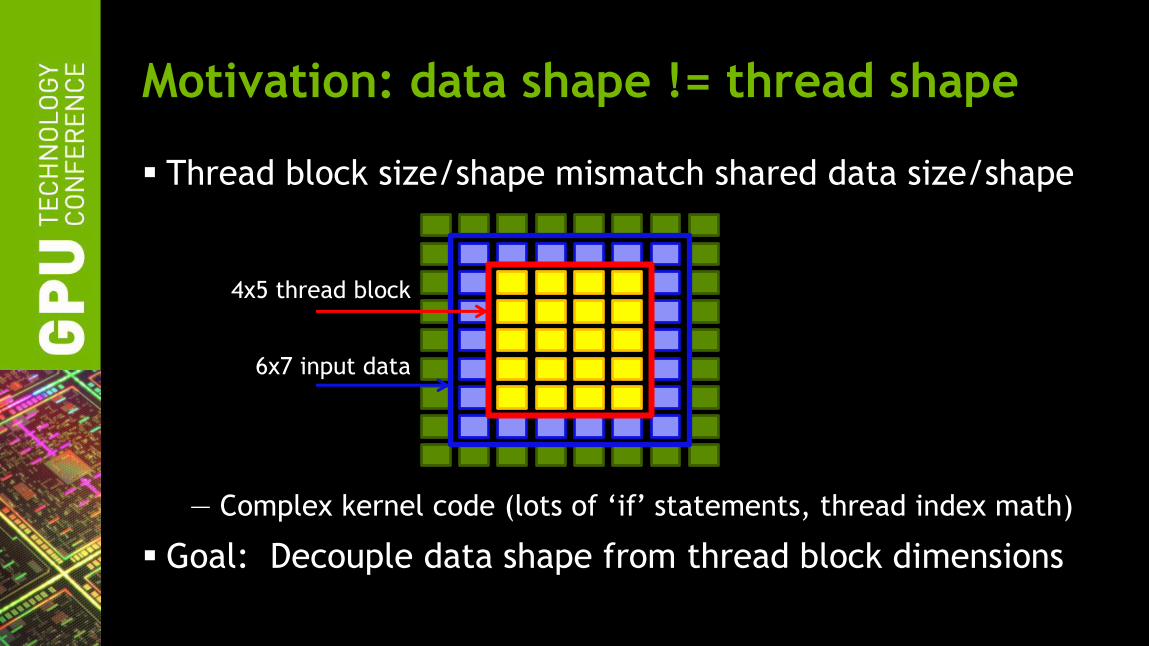
Motivation: data shape != thread shape
Thread block size/shape mismatch shared data size/shape
— Complex kernel code (lots of ‘if’ statements, thread index math)
Goal: Decouple data shape from thread block dimensions
6x7 input data
4x5 thread block

Example: 3D finite difference stencil
8th order in space, 1st order in time computation
— Thread per (x,y) location
— Step through Z-dimension
— Load 2D halos into shared for
each step in Z-dimension
Programmer challenges
— How to split halo xfers across threads?
— Memory B/W optimizations

/////////////////////////////////////////
// update the data slice in smem
s_data[ty][tx] = local_input1[radius];
s_data[ty][tx+BDIMX] = local_input2[radius];
if( threadIdx.y<radius ) // halo above/below
{
s_data[threadIdx.y][tx] = g_curr[c_offset - radius*dimx];
s_data[threadIdx.y][tx+BDIMX] = g_curr[c_offset - radius*dimx + BDIMX];
}
if( threadIdx.y >= radius && threadIdx.y < 2*radius )
{
s_data[threadIdx.y+BDIMY][tx] = g_curr[c_offset + (BDIMY-radius)*dimx];
s_data[threadIdx.y+BDIMY][tx+BDIMX] = g_curr[c_offset + (BDIMY-radius)*dimx + BDIMX];
}
if(threadIdx.x<radius) // halo left/right
{
s_data[ty][threadIdx.x] = g_curr[c_offset - radius];
s_data[ty][threadIdx.x+2*BDIMX+radius] = g_curr[c_offset + 2*BDIMX];
}
__syncthreads();
Example copy code for 3D stencil

CudaDMA approach
CudaDMA library
— Block transfers explicitly declared in CUDA kernels
— Primarily used for “streaming” data through shared memory
— Common access patterns supported
— Implemented as C++ objects instantiated in CUDA kernels
Object member functions used to initiate “DMA transfers”
Advantages
— Simple, maintainable user code
— Access patterns independent of thread block dimensions
— Optimized library implementations for global memory bandwidth

Kernel pseudocode with CudaDMA
CudaDMA objects declared
at top of the kernel
— Fixed access pattern
Kernel loops over large
dataset
— Copy data to shared
— Barrier
— Process data in shared
— Barrier
— …
__global__
void cuda_dma_kernel(float *data)
{
__shared__ float buffer[NUM_ELMTS];
cudaDMAStrided<false,ALIGNMENT>
dma_ld(EL_SZ,EL_CNT,EL_STRIDE);
for (int i=0; i<NUM_ITERS; i++) {
dma_ld.execute_dma
(data[A*i],buffer);
__syncthreads();
process_buffer(buffer);
__syncthreads();
}
}

Supported access patterns
CudaDMASequential
CudaDMAStrided
CudaDMAIndirect
— Scatter/Gather
CudaDMAHalo
— 2D halo regions

Specifying access patterns
Access pattern described with parameters
Up to 5 parameters for strided patterns
— BYTES_PER_ELMT - the size of each element in bytes
— NUM_ELMTS - the number of elements to be transfered
— ALIGNMENT – whether elements are 4-,8-, or 16-byte aligned
— src_stride - the stride between the source elements in bytes
— dst_stride - the stride between elements after they have been
transferred in bytes
Similar parameters used for other patterns
# of threads independent of access pattern

Optimizations and tuning
Optimizations performed by CudaDMA implementations
— Pointer casting enables vector loads and stores
— Hoisting of pointer arithmetic into the constructor
— Memory coalescing and shared memory bank conflict avoidance
Considerations for memory bandwidth performance
— Use compile-time constant template parameters if possible
— Load at maximum alignment (highest performance at 16 bytes)
— Size, #threads: Highest performance with <=64 bytes per thread
64 threads: 4 KB transfers; 128 threads: 8KB transfers, …

Predictable performance
Strided access pattern
— 2 KB transfers
— Tesla C2070 (ECC Off)
— 128 threads per thread block
participating in the DMA
— 2 thread blocks per SM
Similar results for other
access patterns
Element
size
(Bytes)
Total
elements
GB/s
32 64 73.4
64 32 73.5
128 16 73.6
256 8 73.5
512 4 73.5
1024 2 83.7
2048 1 84.5

Optimizations using warp specialization
CudaDMA supports splitting
thread blocks into
compute and DMA warps
Supports producer-consumer
synchronization functions
— On compute warps:
Non-blocking start_async_dma()
Blocking wait_for_dma_finish()
— On DMA warps: execute_dma()
includes synchronization
Compute
Warps
DMA
Warps
Barrier 1
Barrier 2
Barrier 1
Barrier 2
Itera
tion i
Itera
tion i+
1
execute_dma()
start_async_dma()
wait_for_dma_finish()
execute_dma()
start_async_dma()
wait_for_dma_finish()
Uses named barriers in ptx
— bar.arrive, bar.sync

Warp specialization buffering techniques
Usually one set of DMA warps per buffer
Single-Buffering
— 1 buffer, 1 warp group
Double-buffering
— 2 buffers, 2 warp groups
Manual double-buffering
— 2 buffers, 2 warp groups
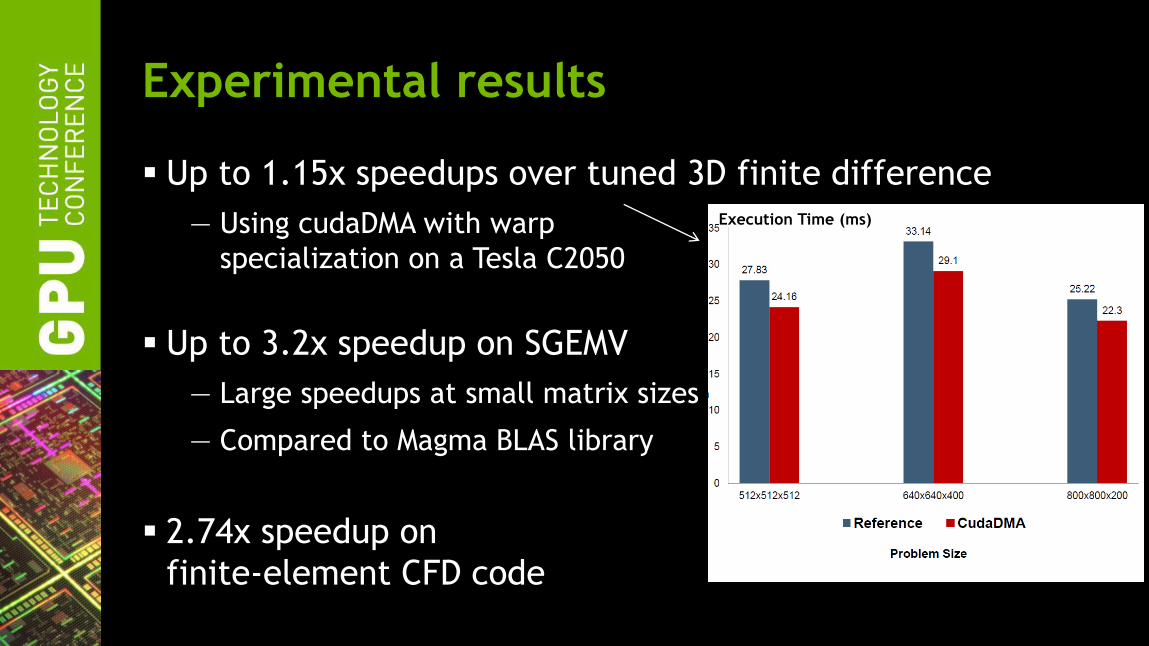
Experimental results
Up to 1.15x speedups over tuned 3D finite difference
— Using cudaDMA with warp
specialization on a Tesla C2050
Up to 3.2x speedup on SGEMV
— Large speedups at small matrix sizes
— Compared to Magma BLAS library
2.74x speedup on
finite-element CFD code
Execution Time (ms)

Status
Recent library changes
— [Nov, 2011] Library released on Google Code
Included optimized implementations for many sequential, strided, and halo
access patterns
cudaDMA objects with and without warp specialization supported
— [May, 2012] Enhancements to cudaDMAIndirect
In progress
— Kepler-optimized implementation
Exploring the use of loads through the texture cache
— Future productization discussions

Summary
CudaDMA
— A library for efficient bulk transfers between global and shared
memory in CUDA kernels
— Supports asynchronous “DMA” transfers using warp specialization
and inline ptx producer-consumer synchronization instructions
Detailed documentation and source code:
— http://code.google.com/p/cudadma/
— Bauer, Cook, and Khailany, “CudaDMA: Optimizing GPU Memory
Bandwidth via Warp Specialization”, SC’11
Feedback? [email protected]





























