Embed Size (px)
Citation preview

Data Migration- Two Separate Databases
Michael Odawa.

Overview
• Migration is the movement of data from one database to one master database.
• What happens if there are instances where there are some people present in both databases? Do you continue with the migration? How do you identify these individuals?
• Merging (in this context) refers to the process of identifying matching records in two separate databases and consolidating the information for these matching records into one record.

Importance of Merging Data.
• The data contained in both databases are different and they may belong to the same patient. By merging the data, it becomes easier to analyse the patient level data since they will be in one consolidated file.
• Clinically, it is advisable to have all patient records in one file. Fragmented data storage of patient records results in easier tracking of the patient’s medical history.
• This assists in programme management since the total number of patients who need medical assistance will be centralized and as such this reduces the possibility of duplicated efforts in making drug orders and other program interventions for these patients for those patients who exist in both databases.
• To monitor and evaluate the efficiency of linkage to care for patients who are identified as HIV positive by the HCT Research Assistants in the field into the HIV Care system offered by AMPATH.
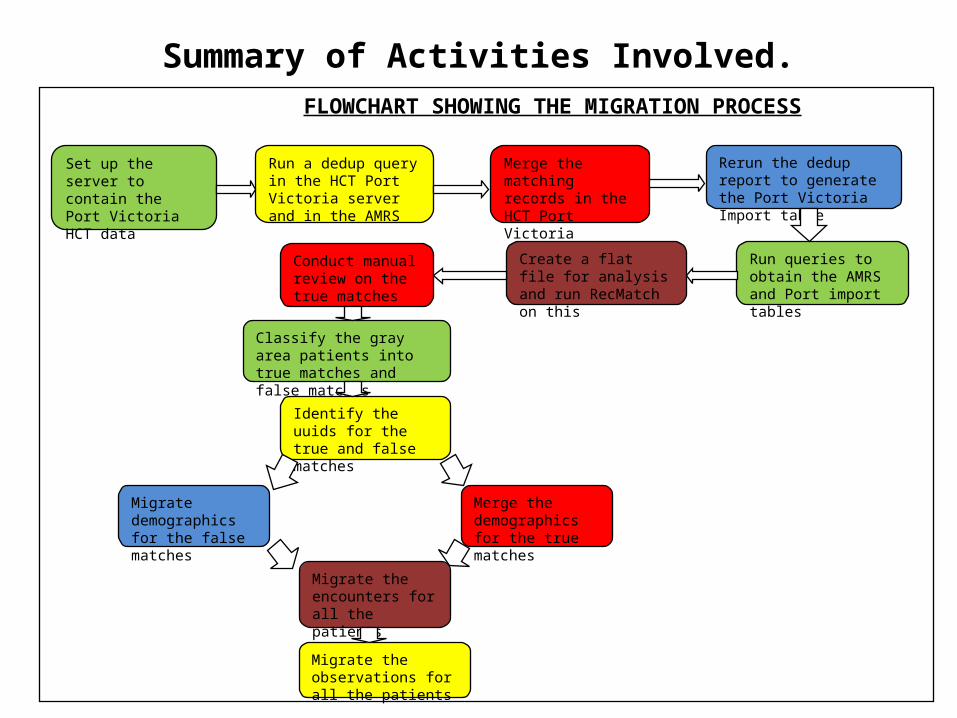
Summary of Activities Involved. FLOWCHART SHOWING THE MIGRATION PROCESS
Set up the server to contain the Port Victoria HCT data
Run a dedup query in the HCT Port Victoria server and in the AMRS
Merge the matching records in the HCT Port Victoria
Rerun the dedup report to generate the Port Victoria Import table
Run queries to obtain the AMRS and Port import tables
Create a flat file for analysis and run RecMatch on this
Conduct manual review on the true matches
Identify the uuids for the true and false matches
Migrate demographics for the false matches
Merge the demographics for the true matches
Classify the gray area patients into true matches and false matches
Migrate the encounters for all the patients
Migrate the observations for all the patients

RecMatch• This is a process by which the demographics
from the two databases are joined together and then processed to get potential true matches, true matches and false matches.
• The tool that does this disaggregation is a stand-alone Java patient matching file. org.regenstrief.linkage.gui.RecMatch.jar

How does it work?• The process involves measuring the
agreement rates of specific fields between true and false matches, then calculating the likelihood of a given pair being a true match, and assigns a score based on how well the fields match.
• Various algorithms can be used to do the matching, eg the Jaro-Winkler Estimation, Levenshtein Least Common Subsequence or the Exact Matching algorithm.
When not in Use
When in use

Summary of Softwares Used FLOWCHART SHOWING THE MIGRATION PROCESS
Set up the server to contain the Port Victoria HCT data
Run a dedup query in the HCT Port Victoria server and in the AMRS
Merge the matching records in the HCT Port Victoria
Rerun the dedup report to generate the Port Victoria Import table
Run queries to obtain the AMRS and Port import tables
Create a flat file for analysis and run RecMatch on this
Conduct manual review on the true matches
Identify the uuids for the true and false matches
Migrate demographics for the false matches
Merge the demographics for the true matches
Classify the gray area patients into true matches and false matches
Migrate the encounters for all the patients
Migrate the observations for all the patients
OpenMRS
MySQLSAS, R Statistical Programming
Language, STATA, Excel
OpenMRS- Yank
Module
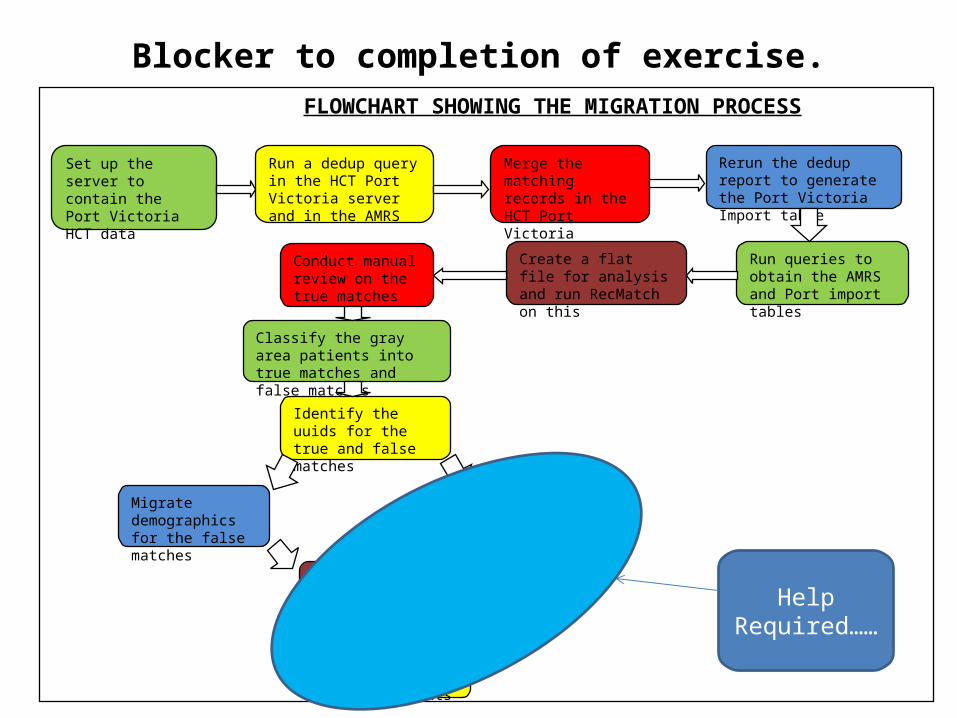
Blocker to completion of exercise. FLOWCHART SHOWING THE MIGRATION PROCESS
Set up the server to contain the Port Victoria HCT data
Run a dedup query in the HCT Port Victoria server and in the AMRS
Merge the matching records in the HCT Port Victoria
Rerun the dedup report to generate the Port Victoria Import table
Run queries to obtain the AMRS and Port import tables
Create a flat file for analysis and run RecMatch on this
Conduct manual review on the true matches
Identify the uuids for the true and false matches
Migrate demographics for the false matches
Merge the demographics for the true matches
Classify the gray area patients into true matches and false matches
Migrate the encounters for all the patients
Migrate the observations for all the patients
Help Required……

Sites to be reviewed• Port Victoria- HCT-AMRS (Done apart from
obstacles mentioned earlier)• Port Victoria – HCT-PHCT-AMRS (Ongoing-
Currently doing the Manual Data Review- hopefully to be done in 2-3 Weeks)
• Chulaimbo- HCT-PHCT-AMRS (Next to be tackled)
• Teso- HCT-PHCT-AMRS• All other HCT-PHCT Data stored in stand alone
databases.

Going Forward
• This process needs to be completed for the baseline HCT Data collected from the various sites from 2009 – 2012.
• Going forward, this data should ideally be sent directly to the AMRS but this can only be done successfully if the baseline data is already in the AMRS (for reasons mentioned in the importance section).

Thanks!!
Questions??





























