Embed Size (px)
Citation preview

Department of Electrical and Computer Engineering Computer Architecture and Parallel Systems Laboratory - CAPSL
Guang R. Gao ACM Fellow and IEEE Fellow
Endowed Distinguished Professor
Electrical & Computer Engineering
University of Delaware
Topic A – Part 3 Dataflow Model of Computation
(From Dataflow to Multithreading)
Topic-Gao-Dataflow-part3 1 3/21/2014
CPEG 852 - Spring 2014
Advanced Topics in Computing
Systems
CPEG852-Spring14: Topic A - Dataflow - 1 2
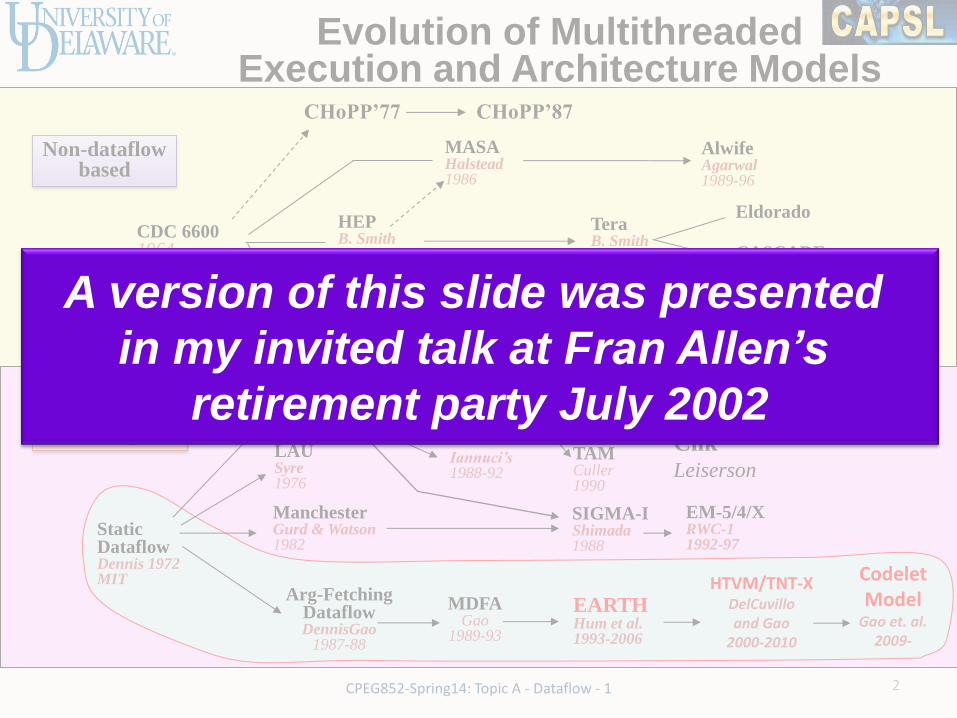
Evolution of Multithreaded Execution and Architecture Models
Non-dataflow based
CDC 6600 1964
MASA Halstead 1986
HEP B. Smith 1978
Cosmic Cube Seiltz 1985
J-Machine Dally 1988-93
M-Machine Dally 1994-98
Dataflow model inspired
MIT TTDA Arvind 1980
Manchester Gurd & Watson 1982
*T/Start-NG MIT/Motorola 1991-
SIGMA-I Shimada 1988
Monsoon Papadopoulos & Culler 1988
P-RISC Nikhil & Arvind 1989
EM-5/4/X RWC-1 1992-97
Iannuci’s 1988-92
Others: Multiscalar (1994), SMT (1995), etc.
Flynn’s Processor 1969
CHoPP’77 CHoPP’87
TAM Culler 1990
Tera B. Smith 1990-
Alwife Agarwal 1989-96
Cilk Leiserson
LAU Syre 1976
Eldorado
CASCADE
Static Dataflow Dennis 1972 MIT
Arg-Fetching Dataflow DennisGao
1987-88
MDFA Gao
1989-93
EARTH Hum et al. 1993-2006
HTVM/TNT-X DelCuvillo and Gao
2000-2010
Codelet Model
Gao et. al. 2009-
A version of this slide was presented
in my invited talk at Fran Allen’s
retirement party July 2002
3/21/2014 3 Topic-Gao-Dataflow-part3
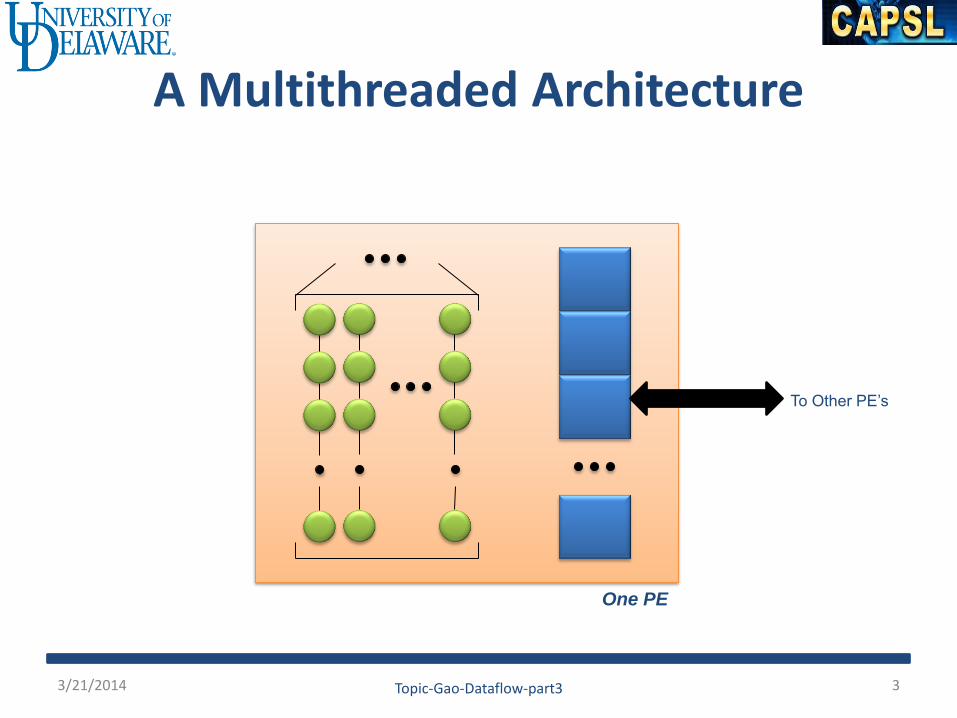
A Multithreaded Architecture
To Other PE’s
One PE

3/21/2014 4 Topic-Gao-Dataflow-part3
Case Studies – Dataflow Model Insired Multithreading
• McGill Dataflow Model (1988 - 1993)
• EARTH Model (1993 – mid 2000s )
• The UHPC/Runnemede Model (2010 - )

3/21/2014 5 Topic-Gao-Dataflow-part3
McGill Data Flow Architecture Model
(MDFA)
3/21/2014 6 Topic-Gao-Dataflow-part3
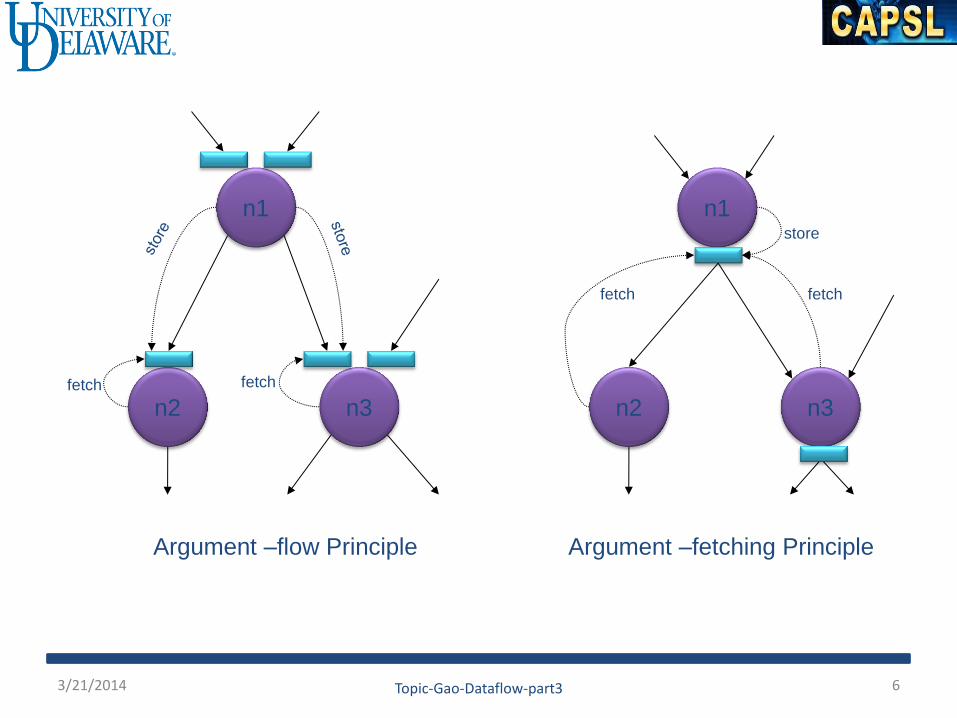
n1
n2 n3
fetch fetch
n1
n2 n3
store
fetch fetch
Argument –flow Principle Argument –fetching Principle
3/21/2014 7 Topic-Gao-Dataflow-part3
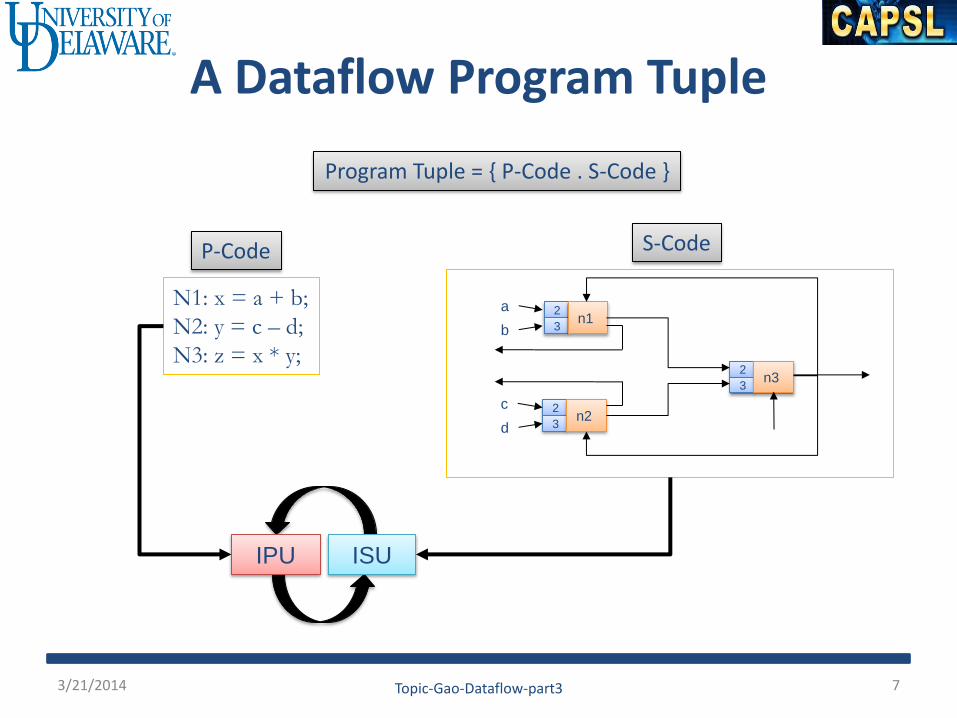
A Dataflow Program Tuple
Program Tuple = { P-Code . S-Code }
P-Code
N1: x = a + b;
N2: y = c – d;
N3: z = x * y;
S-Code
2
3 n1
a
b
2
3 n2
c
d
2
3 n3
IPU ISU
3/21/2014 8 Topic-Gao-Dataflow-part3
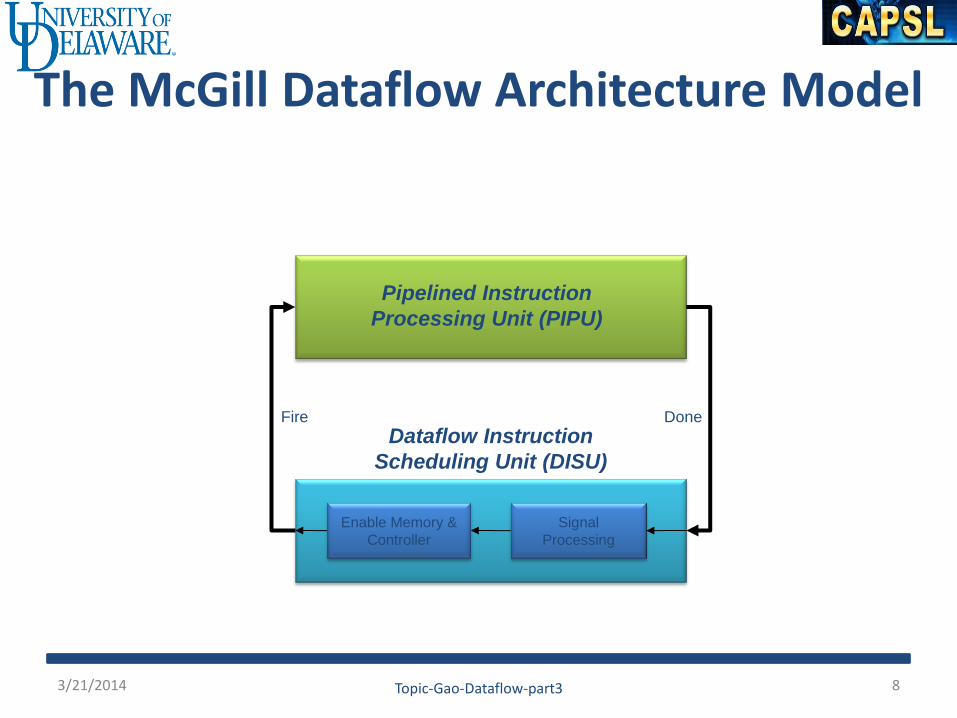
The McGill Dataflow Architecture Model
Pipelined Instruction
Processing Unit (PIPU)
Dataflow Instruction
Scheduling Unit (DISU)
Enable Memory &
Controller
Signal
Processing
Fire Done
3/21/2014 9 Topic-Gao-Dataflow-part3
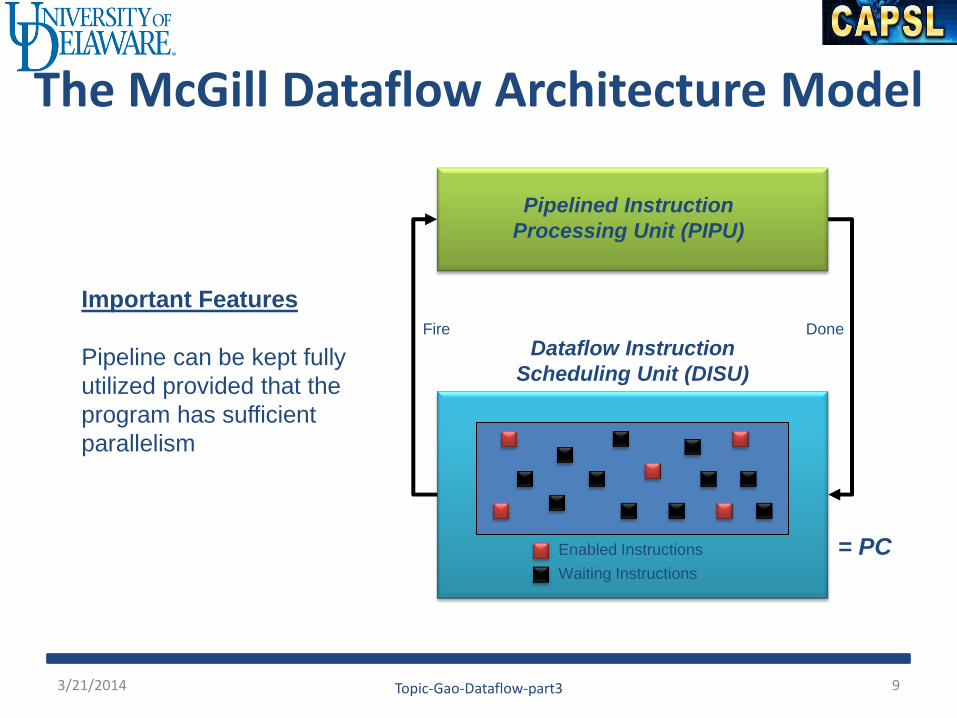
The McGill Dataflow Architecture Model
Pipelined Instruction
Processing Unit (PIPU)
Dataflow Instruction
Scheduling Unit (DISU)
Fire Done
Waiting Instructions
Enabled Instructions = PC
Important Features
Pipeline can be kept fully
utilized provided that the
program has sufficient
parallelism
3/21/2014 10 Topic-Gao-Dataflow-part3
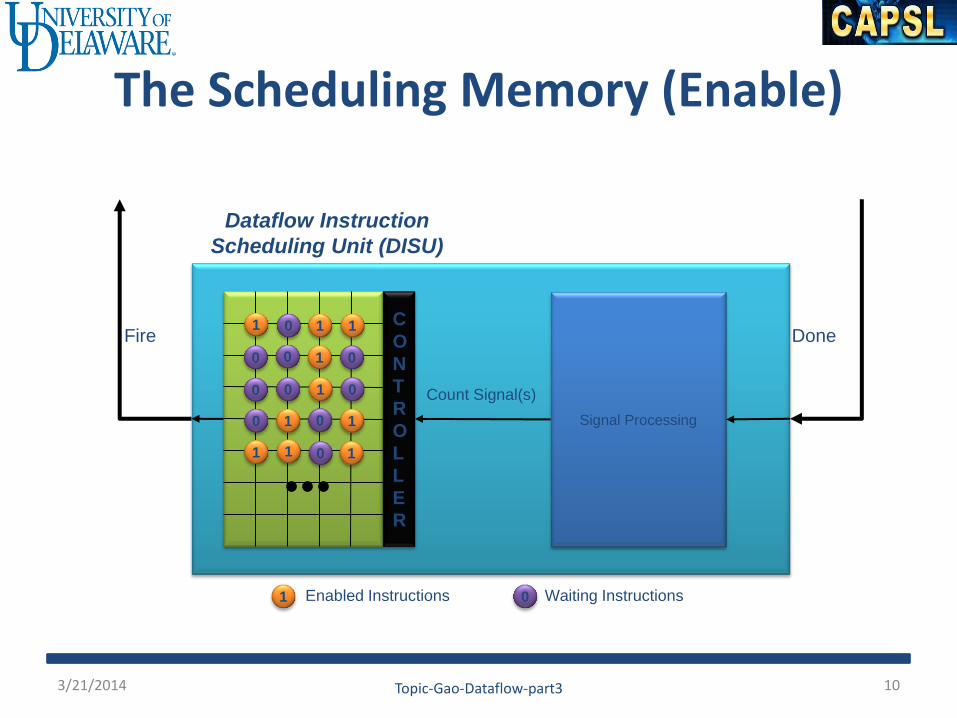
The Scheduling Memory (Enable)
Dataflow Instruction
Scheduling Unit (DISU)
C
O
N
T
R
O
L
L
E
R
1 1
1 1
0 1
0 0
0 0
0
1 1
1
1 0
0 0
0 1
Signal Processing
Fire Done
Count Signal(s)
0 Waiting Instructions 1 Enabled Instructions

3/21/2014 11 Topic-Gao-Dataflow-part3
Advantages of the McGill Dataflow Architecture Model
• Eliminate unnecessary token copying and transmission overhead.
• Instruction scheduling is separated from the main datapath of the processor (e.g. asynchronous, decoupled).
3/21/2014 12 Topic-Gao-Dataflow-part3
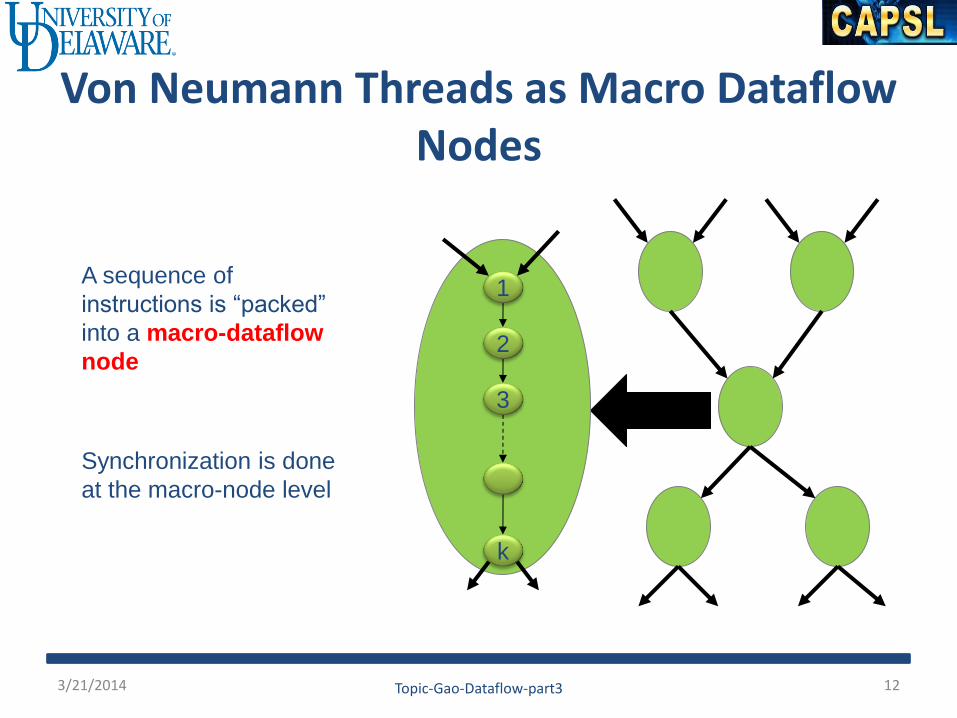
Von Neumann Threads as Macro Dataflow Nodes
1
2
3
k
A sequence of
instructions is “packed”
into a macro-dataflow
node
Synchronization is done
at the macro-node level
3/21/2014 13 Topic-Gao-Dataflow-part3
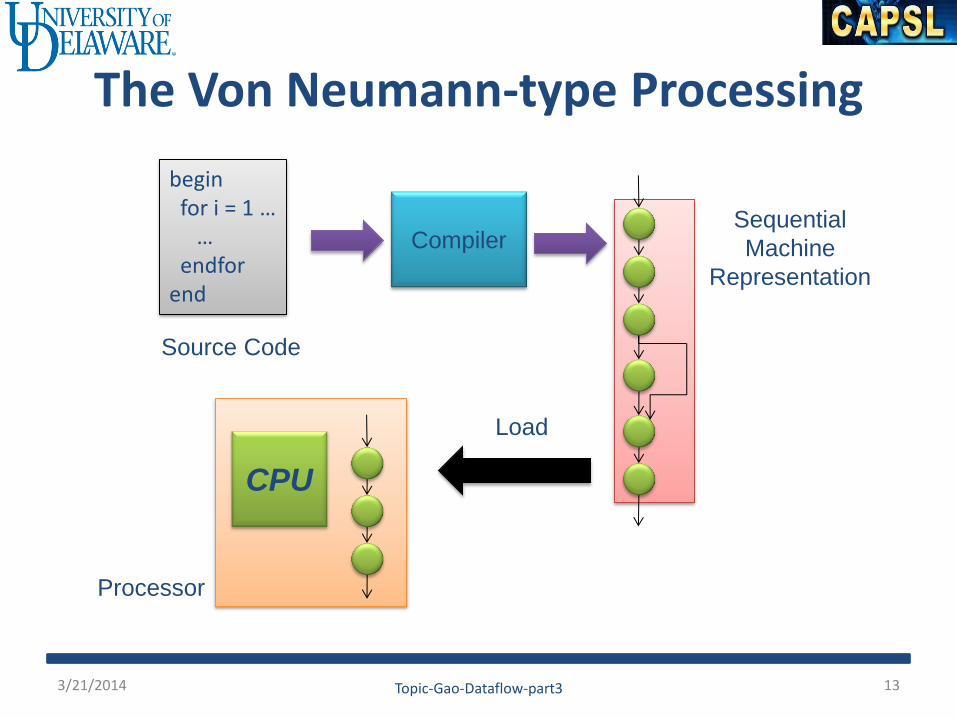
The Von Neumann-type Processing
begin for i = 1 … … endfor end
Source Code
Compiler Sequential
Machine
Representation
CPU
Load
Processor

3/21/2014 14 Topic-Gao-Dataflow-part3
Hybrid Evaluation Von Neumann Style Instruction Execution” on
the McGill Dataflow Architecture • Group a “sequence” of dataflow instruction into a “thread” or
a macro dataflow node. • Data-driven synchronization among threads. • “Von Neumann style sequencing” within a thread. Advantage: Preserves the parallelism among threads but avoids
unnecessary fine-grain synchronization between instructions within a sequential thread.

3/21/2014 15 Topic-Gao-Dataflow-part3
What Do We Get?
• A hybrid architecture model without sacrificing the advantage of fine-grain parallelism!
(latency-hiding, pipelining support)
3/21/2014 16 Topic-Gao-Dataflow-part3
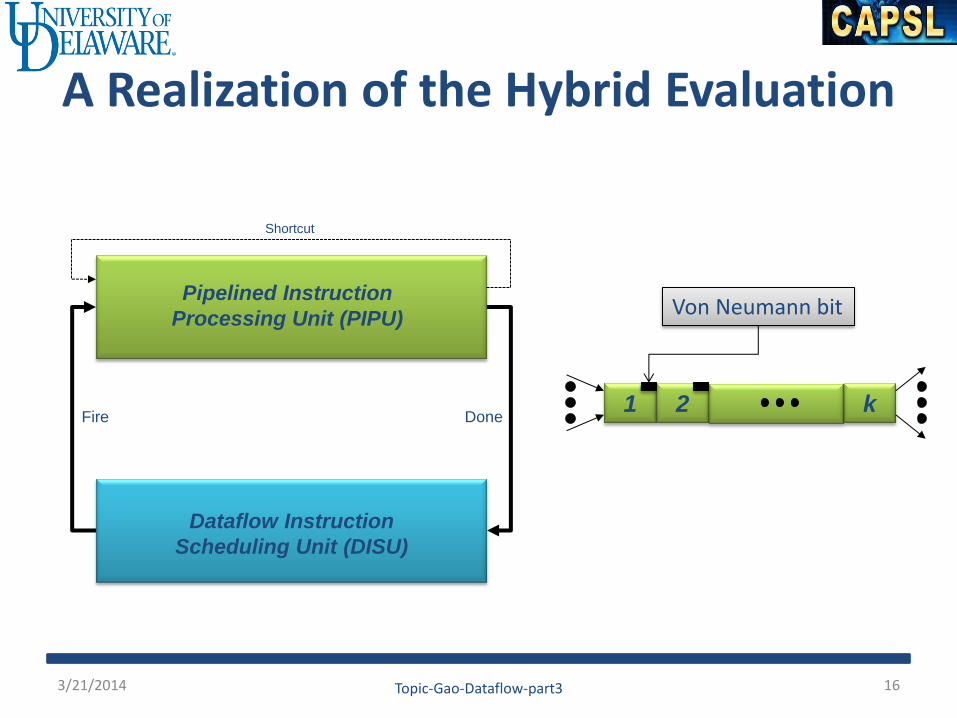
A Realization of the Hybrid Evaluation
Pipelined Instruction
Processing Unit (PIPU)
Dataflow Instruction
Scheduling Unit (DISU)
Fire Done
Shortcut
1 2 k
Von Neumann bit

3/21/2014 17 Topic-Gao-Dataflow-part3
Case Studies – Dataflow Model Inspired Multithreading
• McGill Dataflow Model (1988 - 1993)
• EARTH Model (1993 – mid 2000s )
• The UHPC/Runnemede Model (2010 - )
3/21/2014 18 Topic-Gao-Dataflow-part3
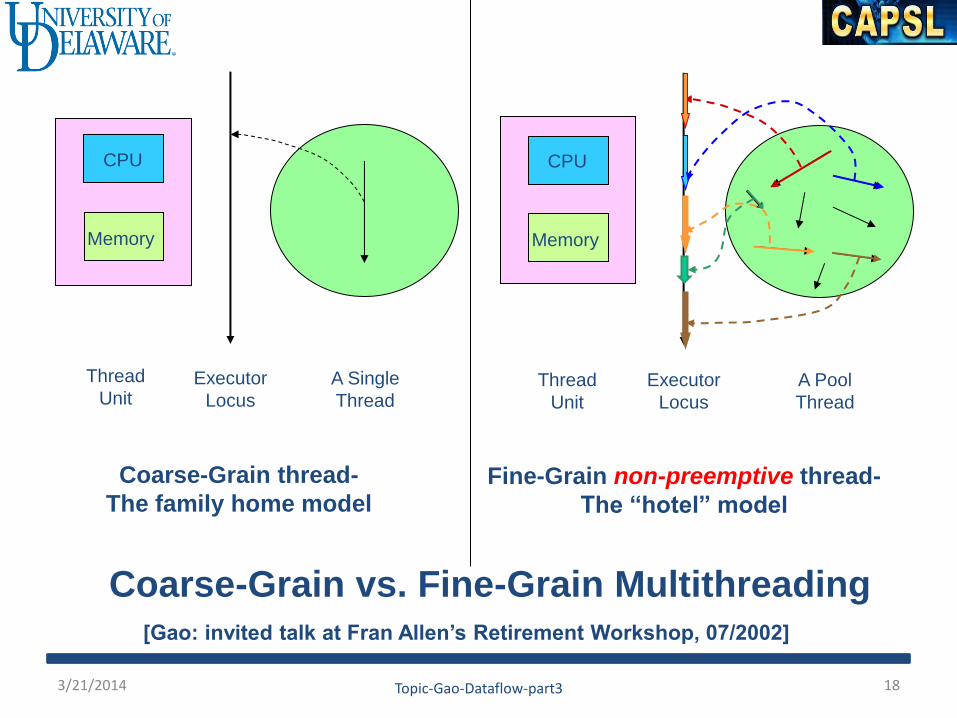
CPU
Memory
Fine-Grain non-preemptive thread-
The “hotel” model
Thread
Unit
Executor
Locus
Coarse-Grain vs. Fine-Grain Multithreading
A Pool
Thread
CPU
Memory
Executor
Locus
A Single
Thread
Coarse-Grain thread-
The family home model
Thread
Unit
[Gao: invited talk at Fran Allen’s Retirement Workshop, 07/2002]





























