Embed Size (px)
Citation preview

FilterAdapt
Filtros adaptativos de coeficientes variáveis
Paulo Alexandre Cristóvão Santa Rosa Pereira
Dissertação para obtenção do Grau de Mestre em
Engenharia Electrotécnica e de Computadores
Júri
Presidente: Prof. Marcelino Bicho dos Santos
Orientador: Prof. Paulo Ferreira Godinho Flores
Co-Orientador: Prof. José Carlos Alves Pereira Monteiro
Vogal: Prof. Fernando Manuel Duarte Gonçalves
Abril 2012

II

III
AGRADECIMENTOS
Agradeço a todas aquelas pessoas que ajudaram à execução desta
dissertação, e todos os outros trabalhos e projectos que surgiram ao longo do
mestrado.
Agradeço ao meu orientador, Professor Paulo Ferreira Godinho Flores, por
todo tempo, paciência e ajuda.
Agradeço aos meus amigos pela ajuda, pelo apoio e pelo conforto.
Agradeço à minha família, em especial aos meus pais e irmão, aos quais privei
de muito tempo e atenção nestes últimos anos da minha vida académica.

IV

V
ABSTRACT
This work presents a study on different parallel architectures to implementation of 2 digital filters
FIR in the same structure. Will be study parallels architectures FIR with multipliers or with
addition, subtraction and shifts. The architectures are automatically generated by a tool
developed for this work. The tools automatically generate synthesizable VHDL files necessary
to the FIR filters function.
Will be presented four architectures with multipliers, one with multipliers NxN, other with
multipliers NxM and two architectures that shared the multipliers. One of the architecture
maximize the share of multipliers and other that implement half filter with sharing multipliers. By
maximize the sharing of multipliers , we obtain better results in area and power.
In the architectures with adders, subtractors and shifts, will be present six architectures, were
two of them share the operators (adders and subtractors). In these two architectures, we
developed two algorithms to optimize architecture which share the operands (adders and
subtractions), a heuristic algorithm and another that use linear programming.
By comparing the area, power and delay, for a different input signal (8, 16 and 32 bits), the
architecture with multipliers needed more area and power than the others architecture, but for
small size of signal input they are the most faster. The architecture that use linear programming
present the best results in area and power.
KEYWORKS
FIR architectures; MCM; ILP; area; power; delay time.

VI

VII
RESUMO
Esta dissertação para a obtenção do grau de Mestre apresenta um estudo de diferentes
arquitecturas para a implementação de dois filtros digitais FIR na mesma estrutura. Vão ser
estudadas arquitecturas paralelas com multiplicadores e com somadores, subtractores e
deslocamentos. As arquitecturas são geradas automaticamente pela ferramenta desenvolvida
neste trabalho. A ferramenta gera todos os ficheiros VHDL sintetizáveis necessários para o
funcionamento dos filtros FIR.
Vamos apresentar quatro arquitecturas com multiplicadores, uma com multiplicadores NxN,
outra com multiplicadores NxM e duas arquitecturas que partilham os multiplicadores, uma que
maximiza a partilha dos multiplicadores e outra que implementa metade do filtro com partilha
dos multiplicadores. Ao maximizar a partilha dos multiplicadores, conseguimos obter melhores
resultados na área e potência.
Nas arquitecturas com somadores, subtractores e deslocamentos, serão apresentadas seis
arquitecturas, em que duas partilham os operadores (somadores e subtractores). Nestas duas
arquitecturas foram desenvolvidos dois algoritmos para optimizar a partilha. um algoritmo de
procura heurístico e outro que utiliza a programação linear.
Ao comparar a área, potência e tempo de atraso, para diferentes tamanhos do sinal de entrada
(8,16 e 32 bits), as arquitecturas com multiplicadores precisam de mais área e potência que as
arquitecturas com somadores e subtractores, mas para pequenos sinais de entrada, são mais
rápidas. A arquitectura que utiliza a programação linear apresenta os melhores resultados na
área e potência.
PALAVRAS-CHAVE
Arquitecturas FIR; MCM; ILP; área; potência; tempo de atraso.

VIII

IX
ÍNDICE
Lista de Figuras ............................................................................................................................ XI
Lista de Tabelas ......................................................................................................................... XIII
1. Introdução .............................................................................................................................. 1
1.1. Enquadramento ............................................................................................................. 1
1.2. Objectivos ...................................................................................................................... 2
1.3. Organização da dissertação .......................................................................................... 3
2. Filtros digitais configuráveis .................................................................................................. 5
2.1. Introdução ...................................................................................................................... 5
2.2. Vantagens ..................................................................................................................... 5
2.3. Filtros digitais ................................................................................................................. 6
2.4. Filtros configuráveis....................................................................................................... 8
2.5. Etapas no projecto de filtros digitais .............................................................................. 9
2.6. Especificações dos filtros utilizados ............................................................................ 10
3. Arquitecturas para filtros FIR com multiplicadores .............................................................. 13
3.1. Processo para juntar dois filtros FIR ........................................................................... 14
3.2. Optimização dos multiplicadores ................................................................................. 29
3.3. Partilha dos multiplicadores ........................................................................................ 32
3.3.1. Agrupando todos os Coeficientes ....................................................................... 33
3.3.2. Agrupando metade do filtro ................................................................................. 34
3.4. Resultados ................................................................................................................... 36
3.4.1. Área ..................................................................................................................... 38
3.4.2. Potência ............................................................................................................... 39
3.4.3. Tempo de atraso ................................................................................................. 40
4. Arquitectura para filtros FIR paralela com adições e deslocamentos ................................. 41
4.1. Implementação das arquitecturas ............................................................................... 43
4.1.1. Arquitecturas sem partilha dos somadores ......................................................... 43
4.1.2. Arquitectura com partilha dos somadores ........................................................... 46
4.2. Resultados ................................................................................................................... 58
4.2.1. Área ..................................................................................................................... 58
4.2.2. Potência ............................................................................................................... 59

X
4.2.3. Tempo de atraso ................................................................................................. 60
5. Geração e sintese de arquitecturas para filtros FIR ............................................................ 61
5.1. Ficheiro com os coeficientes do filtro .......................................................................... 61
5.2. Opções da ferramenta ................................................................................................. 62
6. Arquitecturas com Multiplicadores VS Arquitecturas com Somadores ............................... 69
6.1. Melhor Área ................................................................................................................. 69
6.2. Melhor Potência ........................................................................................................... 70
6.3. Melhor Tempo de Atraso ............................................................................................. 71
6.4. Classificação e resumo dos resultados ....................................................................... 71
7. Conclusões e Trabalho Futuro ............................................................................................ 75
7.1. Conclusão .................................................................................................................... 75
7.2. Trabalho Futuro ........................................................................................................... 77
Referências ................................................................................................................................. 79
Anexo A ....................................................................................................................................... 80
A – Resultados para os filtros FIR01 e FIR02 ......................................................................... 80
Anexo B ....................................................................................................................................... 81
B – Resultados para os filtros FIR06 e FIR07 ......................................................................... 81
Anexo C ....................................................................................................................................... 83
C – Resultados para os filtros FIR05 e FIR09 ........................................................................ 83
Anexo D ....................................................................................................................................... 84
Script ....................................................................................................................................... 84

XI
LISTA DE FIGURAS
Figura 2.1: Esquema de funcionamento de um filtro digital .......................................................... 5
Figura 2.2: Estrutura da Forma directa ......................................................................................... 8
Figura 2.3: Estrutura da forma transposta .................................................................................... 8
Figura 2.4 – Diagrama de processos a realizar para a implementação de filtros ......................... 9
Figura 3.1 – Diagrama de blocos da arquitectura com multiplicadores em paralelo .................. 13
Figura 3.2 – Diagrama de blocos da arquitectura de 2 filtros com multiplicadores em paralelo 14
Figura 3.3 – Diagrama de blocos com partilha do bloco acumulador. ........................................ 15
Figura 3.4 – Diagrama do bloco acumulador para o exemplo .................................................... 17
Figura 3.5 – Gráfico com as áreas do somador/subtractor e somador para 8,16,24 e 32 bits. . 18
Figura 3.6 – Gráfico com a potência consumida do somador/subtractor e somador para 8,16,24
e 32 bits. ...................................................................................................................................... 18
Figura 3.7 – Gráfico com o tempo de atraso do somador/subtractor e somador para 8,16,24 e
32 bits. ......................................................................................................................................... 19
Figura 3.8 – Diagrama de blocos com 2 multiplicadores ............................................................ 20
Figura 3.9 – Diagrama de blocos com 1 multiplicador e negação do sinal. ............................... 20
Figura 3.10 – Gráfico da área ocupada por 2 multiplicadores e 1 multiplicador com 1 conversor.
..................................................................................................................................................... 20
Figura 3.11 – Gráfico da potência consumida por 2 multiplicadores e 1 multiplicador com 1
conversor. .................................................................................................................................... 21
Figura 3.12 – Gráfico do tempo de atraso por 2 multiplicadores e 1 multiplicador com 1
conversor. .................................................................................................................................... 21
Figura 3.13 - Diagrama de blocos do deslocamento do 3 .......................................................... 23
Figura 3.14 – Etapa do processo para a optimização dos multiplicadores. ............................... 23
Figura 3.15 – Diagrama de blocos com a optimização dos multiplexeres .................................. 25
Figura 3.16 – Diagrama de blocos de 2 filtros FIR...................................................................... 27
Figura 3.17 – Diagrama de blocos de multiplicadores em paralelo ............................................ 29
Figura 3.18 – Gráfico da área ocupada pelo multiplicador nxn e nxm........................................ 30
Figura 3.19 – Gráfico da potência do multiplicador nxn e nxm. .................................................. 31
Figura 3.20 – Gráfico do tempo de atraso pelo multiplicador nxn e nxm.................................... 31
Figura 3.21 – Diagrama de Venn ................................................................................................ 32
Figura 3.22 – Diagrama de blocos da arquitectura FIR com multiplicadores partilhados em
paralelo (multiplicador c/ mux) .................................................................................................... 33
Figura 3.23 – Diagrama de blocos da arquitectura FIR paralela com multiplicadores partilhados
V2 (multiplicador c/ mux v2). ....................................................................................................... 36
Figura 3.24 – Gráfico com as áreas do bloco MCM com multiplicadores................................... 38
Figura 3.25 – Gráfico com as potências do bloco MCM com multiplicadores ............................ 39
Figura 3.26 – Gráfico com o tempo de atraso do bloco MCM com multiplicadores ................... 40
Figura 4.1 – Diagrama de blocos com partilha ........................................................................... 42

XII
Figura 4.2 – Diagrama de blocos com mínimo de operações em série...................................... 42
Figura 4.3 – Diagrama de blocos com dois MCM´s e dois blocos acumuladores(2 MCM 2
Blocos registos) ........................................................................................................................... 44
Figura 4.4 - Diagrama de blocos com dois MCM´s e um bloco acumulador (2 MCM 1 Bloco
registo) ......................................................................................................................................... 45
Figura 4.5 – Diagrama de blocos com um MCM e um bloco acumulador (1 MCM 1 Bloco
registo) ......................................................................................................................................... 46
Figura 4.6 – (a) Diagrama de blocos dos coeficientes 303x e 117x. (b) Diagrama de blocos do
resultados de partilhar os coeficientes 303x e 117x. .................................................................. 47
Figura 4.7 – Etapas efectuadas pelo algoritmo no emparelhamento dos coeficientes parciais . 48
Figura 4.8 – Área ocupada por vários componentes. ................................................................. 52
Figura 4.9 - Gráfico com as áreas do bloco MCM com somadores, subtractores e
deslocamentos ............................................................................................................................ 58
Figura 4.10 - Gráfico com as potências do bloco MCM com somadores, subtractores e
deslocamentos ............................................................................................................................ 59
Figura 4.11 - Gráfico com os tempos de atraso do bloco MCM com somadores, subtractores e
deslocamentos ............................................................................................................................ 60
Figura 5.1 – Exemplo de um ficheiro contendo os coeficientes e termos parciais do filtro. ....... 61
Figura 5.2 – Especificação do multiplicador genérico NxN. ........................................................ 64
Figura 5.3 – Especificação do multiplicador genérico NxM. ....................................................... 64
Figura 5.4 – Especificação do somador genérico. ...................................................................... 65
Figura 5.5 – Especificação do subtractor genérico. .................................................................... 65
Figura 5.6 – Especificação do somador/subtractor genérico. ..................................................... 65
Figura 5.7 - Especificação do registo genérico. .......................................................................... 66
Figura 5.8 – Especificação do multiplexer genérico.................................................................... 66
Figura 5.9 – Especificação do negador de sinal genérico. ......................................................... 66
Figura 5.10 – Excerto do bloco acumulador para os filtros 6 e 7 ao nível do bloco. .................. 67
Figura 5.11 – Exemplo do nível do bloco para um somador e para os dois tipos de
multiplicadores (NxN e NxM). ...................................................................................................... 67
Figura 5.12 – Exemplo do nível algoritmo para um somador e para os dois tipos de
multiplicadores (NxN e NxM). ...................................................................................................... 67
Figura 5.13 – Fluxograma da ferramenta .................................................................................... 68
Figura 6.1 – Gráfico com as arquitecturas com a área menor. ................................................... 69
Figura 6.2 – Gráfico com as arquitecturas com a potência menor ............................................. 70
Figura 6.3– Gráfico com as arquitecturas com o tempo de atraso menor .................................. 71

XIII
LISTA DE TABELAS
Tabela 2.1 Especificações dos filtros .......................................................................................... 10
Tabela 2.2 – Resposta ao escalão unitário e largura do sinal de saída face ao sinal de entrada
..................................................................................................................................................... 11
Tabela 3.1 – Número de multiplexeres nos filtros de teste ......................................................... 26
Tabela 3.2 – Multiplicadores a implementar nos filtros de teste ................................................. 28
Tabela 3.3 – Multiplicadores a implementar para todos os filtros. .............................................. 28
Tabela 3.4 – Total de bits nas saídas dos multiplicadores ......................................................... 30
Tabela 3.5 – Multiplicadores a implementar com e sem partilha ................................................ 34
Tabela 3.6 – Ajuste dos coeficientes dos dois filtros .................................................................. 35
Tabela 3.7 – Reajuste dos coeficientes dos filtros ...................................................................... 35
Tabela 3.8 – Coeficientes a implementar na arquitectura com partilha do multiplicador ........... 36
Tabela 3.9 – Tabela com o número de multiplicadores e negadores de sinal a implementar em
cada arquitectura ......................................................................................................................... 37
Tabela 4.1 – Cálculo dos coeficientes usando o MCM ............................................................... 41
Tabela 4.2 – Coeficientes parciais do filtro 6 e 7. ....................................................................... 49
Tabela 4.3 – As 6 etapas efectuadas aos filtros 6 e 7. ............................................................... 49
Tabela 4.4 – Declive dos vários tipos de componentes .............................................................. 52
Tabela 4.5 – Matriz de custo ....................................................................................................... 55
Tabela 4.6 - Valores dos pares de filtros para variações da barreira de decisão ....................... 57
Tabela 5.1 – Opções da ferramenta desenvolvida neste trabalho. ............................................ 62
Tabela 5.2 – Tabela com as diferentes opções de arquitectura. ................................................ 63
Tabela 6.1 – Classificação e resumo dos filtros para um sinal de entrada de 8 bits. ................. 72
Tabela 6.2 – Classificação e resumo dos filtros para um sinal de entrada de 16 bits. ............... 72
Tabela 6.3 – Classificação e resumo dos filtros para um sinal de entrada de 32 bits. ............... 73

XIV

1
CAPÍTULO 1
1. INTRODUÇÃO
1.1. ENQUADRAMENTO
Os processadores digitais de sinais são microprocessadores com características próprias que
podem ser programados e operam em tempo real, e têm a capacidade em repetir em extrema
velocidade instruções complexas (como por exemplo a MPYA: “Multiply and Accumulate
Previous Product”). O processamento de sinais (DSP) tem registado um número crescente de
aplicações nos últimos anos. Este facto está ligado à evolução do desempenho deste tipo de
processadores e à evolução das ferramentas computacionais de apoio ao desenvolvimento de
sistemas de processamento de sinal.
Entre os sistemas de processamento digital de sinais mais comuns, inclui-se os filtros do tipo
FIR e IIR, e o cálculo da Transformada de Fourier (FFT). A implementação destes, baseia-se
em operações numéricas de multiplicação e adição, envolvendo coeficientes constantes e
amostras do sinal a processar. Os filtros digitais são os blocos mais utilizados em
processamento de sinais digitais. Na maioria das vezes, os filtros são realizados por DSP´s ou
por processadores genéricos. No entanto, para terem um menor consumo de energia e serem
mais rápidos, recorre-se à implementação directa por hardware. Assim, em muitas aplicações,
para comunicações de alta velocidade e/ou de baixo consumo de energia, os filtros são
implementados directamente em hardware. No entanto, como a implementação directa em
hardware, recorre a muitas multiplicações, que apresenta custos muito elevados em termos de
área, atraso e energia consumida. Assim, ao longo desta última década foram desenvolvidas
várias técnicas de optimização de modo a reduzir a área, a energia consumida e o tempo de
atraso do circuito.
A realização de filtros digitais envolve converter uma dada função de transferência numa
adequada estrutura para filtros. Os filtros digitais podem ser divididos em duas classes: filtro de
resposta impulsiva finita (FIR1) e filtro de resposta impulsiva infinita (IIR
2). Os filtros FIR são
caracterizados por serem não recursivos, logo são estáveis e podem ter fase linear, enquanto
os filtros IIR sendo recursivos, não se pode garantir a estabilidade e não têm fase linear, mas
são mais fáceis de sintetizar e necessitam de um número menor de coeficientes que os filtros
FIR para a mesma resposta em frequência. Diagrama de blocos ou fluxogramas são muitas
vezes utilizadas para descrever as estruturas para filtros e mostrar o procedimento
1 FIR – Finite Impulsive Response.
2 IIR – Infinite Impulsive Response.

2
computacional para a implementação dos filtros digitais. A estrutura a usar depende se o filtro é
FIR ou IIR. As duas estruturas geralmente mais utilizadas são a forma directa e a transposta.
Um dos critérios mais importantes na implementação dos filtros FIR directamente em hardware
é satisfazer a característica do filtro que depende dos seus coeficientes. De modo a melhorar o
desempenho dos filtros digitais, diminuindo a sua complexidade não só reduz a área e a
energia consumida dos filtros, mas também resulta em arquitecturas mais rápidas [1]. As
operações de multiplicação por múltiplas constantes, (“Multiple Constant Multiplier”) ou MCM,
são muito comuns nos filtros digitais. Uma das arquitecturas para a implementação dos filtros
FIR directamente em hardware, consiste na substituição dos multiplicadores por adições,
subtracções e deslocamentos. Deste modo, a implementação dos filtros é menos complexa, do
que o projecto com multiplicadores. Existem várias técnicas que permitem a redução dos
somadores/subtractores, outras na melhor partilha dos coeficientes e por fim, um dos critérios
não menos importantes na implementação dos filtros digitais, o tempo de atraso.
Os filtros digitais são desenhados como objectivo de cumprir a resposta em frequência
estipulada. Os coeficientes são calculados para cumprir as características do filtro digital. Nos
filtros digitais, para mudar a sua característica é necessário alterar o conjunto de coeficientes
que descreve o filtro. Uma arquitectura que pode mudar os parâmetros do filtro é uma
arquitectura configurável. Uma arquitectura FIR configurável tem a vantagem de ter vários
filtros diferentes implementados num só circuito de forma optimizada. Estes tipos de filtros
podem ser aplicados em sistemas de som e imagem, onde existem muitas normas, o que
implica diferentes conjuntos de coeficientes. Por exemplo, pode ser aplicado a um sistema que
opere na Europa ou na América e que tenha de eliminar a frequência da tensão eléctrica, em
que a frequência é diferente, 50 Hz e 60 Hz respectivamente.
1.2. OBJECTIVOS
Os objectivos para a realização deste trabalho são:
O estudo de arquitecturas paralelas de filtros FIR configuráveis. Serão estudadas as
arquitecturas com multiplicadores e arquitecturas com adições, subtracções e
deslocamentos.
Estudar e analisar os resultados provenientes de todas as arquitecturas. Será feita uma
comparação entre as arquitecturas, de modo a eleger as arquitecturas com melhor
desempenho na área ocupada, na energia consumida e o tempo de atraso.
Usando somente a multiplicação por múltiplas constantes com adições, subtracções e
deslocamentos e as arquitecturas similares de outros autores, serão feitas uma
comparação entre as áreas, energia e frequência máxima de funcionamento.

3
Para o estudo de arquitecturas paralelas de filtros FIR configuráveis, foi criada uma aplicação
para gerar de forma automática as diferentes arquitecturas.
1.3. ORGANIZAÇÃO DA DISSERTAÇÃO
A dissertação encontra-se organizada com o objectivo de permitir expor de forma sistematizada
os aspectos teóricos e práticos considerados mais relevantes no estudo de arquitecturas FIR
paralelas configuráveis.
No Capítulo 2 apresenta-se uma breve introdução sobre os filtros FIR, sobre as suas
vantagens, fundamentos teóricos, estruturas mais utilizadas, e no fim do capítulo abordam-se
os filtros configuráveis, servindo de base para os capítulos seguintes.
No Capítulo 3 descrevem-se quatro arquitecturas FIR configuráveis paralelas com
multiplicadores, os critérios utilizados para a sua implementação, as diferenças entre elas. Será
apresentado os resultados obtidos por síntese e uma breve conclusão.
No Capítulo 4 serão apresentadas seis arquitecturas FIR configuráveis paralelas usando
apenas somadores/subtractores e deslocamentos. Serão apresentados os esquemas,
resultados obtidos através da síntese, e uma breve conclusão.
No Capítulo 5 descrevem-se as características do programa elaborado para a geração
automática de arquitecturas FIR configuráveis. Será explicado o seu funcionamento, todas as
opções tomadas ao longo do projecto.
No Capítulo 6 compara-se todas as arquitecturas apresentadas nos capítulos anteriores.
No Capítulo 7 resumem-se os principais aspectos a reter e as principais conclusões obtidas
com a realização deste trabalho. No fim referem-se algumas possibilidades a explorar em
futuros desenvolvimentos do trabalho contemplado nesta dissertação.

4

5
CAPÍTULO 2
2. FILTROS DIGITAIS CONFIGURÁVEIS
2.1. INTRODUÇÃO
Todas as recentes contribuições no domínio da filtragem digital, muitas delas propiciadas pelos
grandes avanços nas tecnologias da microelectrónica, ainda que inovadoras na abordagem,
suportam-se basilarmente na teoria do processamento de sinal desenvolvida nos anos 60,
particularmente no que respeita à análise do comportamento dos sistemas discretos.
O projecto e implementação em tempo real de filtros digitais em hardware é um processo
exigente face à diversidade de opções que colocam em cada fase do processo. No mundo
tecnológico em que vivemos, estamos interessados em medir sinais que variam com o tempo.
O processamento desses sinais, requer que primeiro sejam convertidos na forma digital. Para
tal, os sinais devem ser inicialmente amostrados, respeitando o Teorema da Amostragem.
Depois de amostrar o sinal, os valores são quantizados, ou seja, são atribuídos valores
discretos para um sinal cuja amplitude varia entre valores pré-definidos. Assim, os sinais
podem ser lidos pelo DSP como valores numéricos. No DSP são feitos os cálculos necessários
para fazer a filtragem, multiplicando o sinal de entrada por constantes e somando os produtos
resultantes.
Figura 2.1: Esquema de funcionamento de um filtro digital
2.2. VANTAGENS
A utilização de filtros digitais no processamento de sinais traz inúmeras vantagens em relação
aos filtros analógicos.
Os filtros digitais têm um papel muito importante em DSP;

6
Os filtros digitais em comparação com os filtros analógicos são preferíveis em mais
aplicações, por exemplo, compressão e transmissão de dados, áudio digital,
processamento de sinais biomédicos, voz e imagem e cancelamento do eco em
telefones;
Os filtros digitais podem ter características que não são possíveis nos filtros
analógicos, como uma verdadeira resposta de fase linear;
Ao contrário dos filtros analógicos, o desempenho dos filtros digitais não varia com as
mudanças ambientais, por exemplo as variações de temperatura. Isto elimina a
necessidade de calibrar o filtro periodicamente;
A resposta à frequência dos filtros digitais podem ser automaticamente ajustáveis, se
utilizados em filtros adaptativos;
Vários sinais de entrada ou canais podem ser filtrados por um único filtro, sem
necessidade de ser replicado em hardware;
Ambos os dados filtrados e não-filtrados podem ser guardados para uma utilização
futura nos filtros digitais;
O avanços tremendos na tecnologia VLSI é uma grande vantagem para o fabrico de
filtros digitais para torna-los mais pequenos, consumir menos potência e manter o
baixo custo;
Na prática, a precisão atingida nos filtros analógicos é restrita. Com os filtros digitais a
precisão só é limitada pela escolha do número de bits;
Os filtros digitais podem ser usados em muito baixas frequências, que se encontram
em muitas aplicações biomédicas por exemplo, onde o uso de filtros analógicos é
impraticável. Também os filtros digitais podem ser feitos para funcionar em uma ampla
faixa de frequências com uma simples mudança na frequência de amostragem.
2.3. FILTROS DIGITAIS
Os filtros digitais podem ser divididos em duas classes: filtro de resposta impulsiva finita (FIR3)
e filtro de resposta impulsiva infinita (IIR4). Existem grandes diferenças entre as duas classes:
Resposta da fase: os filtros FIR podem ter uma resposta da fase exactamente linear.
Isto implica que não existe distorção na fase do sinal provocado pelo filtro. Esta é um
requerimento muito importante em muitas aplicações. A fase dos filtros IIR é não-linear;
Estabilidade: Os filtros FIR são não-recursivos, logo são sempre estáveis. A
estabilidade nos filtros IRR nem sempre pode ser garantida;
Erros de quantização: O efeito de usar um número limitado de bits para implementar
filtros, que pode provocar ruído na saída, é muito menos grave nos FIR do que no IIR;
3 FIR – Finite Impulsive Response.
4 IIR – Infinite Impulsive Response.

7
Número de Coeficientes: O filtro FIR precisa de mais coeficientes do que o filtro IIR.
Para uma dada específica resposta de amplitude, o filtro FIR necessita de mais tempo
de processamento. Contudo, existem técnicas que podem melhorar significamente a
eficiência da implementação dos filtros FIR;
Transformação dos filtros analógicos: Os filtros analógicos podem ser facilmente
transformados num filtro IIR equivalente com especificações similares. Isto não é
possível com os filtros FIR que não têm uma contrapartida analógica. Contudo, com os
filtros FIR é muito fácil sintetizar filtros com uma resposta em frequência arbitrária;
Síntese: Em geral, os filtros FIR são algebricamente mais difíceis de sintetizar, se no
suporte para CAD não estiver disponível.
Os filtros digitais não recursivos têm uma implementação em hardware simples e eficaz,
definidos pela seguinte equação:
k
k knxhny ][.][ (1)
Em que x[n] é o sinal de entrada, y[n] o sinal de saída e hk os coeficientes do filtro. Este
processo é uma convolução do sinal de entrada com os coeficientes do filtro. Na
implementação do filtro, o somatório é limitado ao número de coeficientes do filtro. Pelo facto
de um filtro ser um sistema causal, o sinal de saída não pode depender de valores futuro do
sinal de entrada. Assim, a Equação 1 torna-se para o respectivo filtro FIR:
1
0
][.][N
k
k knxhny (2)
Também de pode descrever os filtros FIR pela sua Função de Transferência, usando a
Transformada Z:
1
0
.][N
k
k
k zhzT (3)
Na implementação de filtros digitais FIR, a estrutura escolhida pode ser importante para o
desempenho do mesmo. Utilizando a Equação (2), obtém-se a implementação na forma directa
que consiste na soma de sucessivas entradas atrasadas, multiplicadas pelos coeficientes dos
filtros. Na Figura 2.2 representa-se esquematicamente a estrutura do filtro quando
implementado na forma directa, em que z-1
representa o atraso do sinal de entrada e h(N)
representa os diferentes coeficientes do filtro. Para a forma transposta, Figura 2.3, invertem-se
todos os sinais da forma directa e substituem-se os nós divergentes, por nós convergentes
(somadores). Os nós onde se convergem sinais representam a soma dos sinais convergentes.

8
Figura 2.2: Estrutura da Forma directa
Figura 2.3: Estrutura da forma transposta
A forma directa ou transposta dos filtros FIR são canónicas, em que cada uma usa
exactamente N multiplicadores, N - 1 somadores, N - 1 registos e têm uma latência mínima de
N - 1 ciclos de relógios. Em muitas aplicações de filtragem ter a latência mínima é o factor mais
importante [3].
A forma transposta tem uma grande capacitância no sinal de entrada, que pode limitar o seu
desempenho, e o mais importante, geralmente exige uma área maior do que a da forma
directa. Uma das razões para o valor da área ser maior, é porque o tamanho da palavra dos
registos é normalmente superior ao tamanho da palavra do sinal de entrada. Isto acontece,
porque os registos estão no caminho da acumulação. Por outro lado, na forma directa o
caminho crítico aumenta com o tamanho do filtro. A forma transposta tem a vantagem de ter
um menor período de relógio, visto que o caminho crítico é a operação multiplicador-somador.
Neste trabalho será usado a forma transposta em todas as arquitecturas, por ter um menor
período de relógio.
2.4. FILTROS CONFIGURÁVEIS
Nos dias de hoje, é usual a utilização de generalizados sistemas de filtragem implementados
em circuitos digitais nas mais variadas aplicações, som, imagem, vídeo, etc. A resposta em
frequência desejada dos filtros variam com a aplicação/utilização a que destinam, resultando
em coeficientes diferentes. Existem sistemas que precisam de ter nos seus circuitos a
capacidade de escolher o filtro que se melhor adapta a cada situação. Em geral, sempre que
haja necessidade de processar sinais resultantes de ambientes com características
desconhecidas a utilização dum filtro adaptativo constitui uma solução atractiva quando

9
confrontada com os resultados obtidos pela utilização dum sistema desenhado pelos métodos
convencionais. O uso de filtros adaptativos permite estender as capacidades de
processamento de sinal que não seriam possíveis de outra forma. Actualmente este tipos de
sistemas são aplicados com sucesso em campos tão diversos como as comunicações, o
controlo, a engenharia biomédica, etc [2].
O filtro adaptativo desenha-se de forma automática, baseando-se num algoritmo recursivo para
ajuste dos seus parâmetros, com o intuito de minimizar uma função de custo. Em geral,
começa com um conjunto de parâmetros que demonstra desconhecimento do ambiente. Se
este for estacionário os parâmetros do filtro convergem, a cada iteração, para a solução óptima
do filtro de Wiener [2]. Num ambiente não estacionário o algoritmo adaptativo possibilita ao
filtro a capacidade de seguimento, conseguindo acompanhar as variações da característica do
sinal ao longo do tempo, desde que estas sejam suficientemente lentas.
O estudo realizado neste trabalho baseia-se no conceito de um filtro alterar as suas
características, não por usar um algoritmo recursivo, mas sim por seleccionar um de vários
filtros já implementados. Quero isto dizer, que em vez de obter uma solução óptima, como nos
filtros adaptativos, teremos um sistema com vários filtros FIR implementados, podendo ser o
utilizador ou um programa, a escolher o filtro que se adapta melhor ao processamento em cada
momento. Neste trabalho, todas as arquitecturas FIR foram desenvolvidas tendo em conta a
realização de dois filtros diferentes.
2.5. ETAPAS NO PROJECTO DE FILTROS DIGITAIS
Figura 2.4 – Diagrama de processos a realizar para a implementação de filtros
O diagrama de blocos da Figura 2.4 mostra todas etapas utilizadas para o estudo de
arquitecturas de filtros FIR configuráveis. A primeira etapa começa pelas especificações dos
filtros, onde são definidas as suas características, como a banda de passagem, a banda de
atenuação, a frequência de corte, ripple, etc. Estas especificações são inseridas no Matlab, que
gera os coeficientes para os filtros. Os coeficientes gerados são ainda convertidos no Matlab

10
em representação binária com o número de bits a desejar. A terceira etapa consiste na geração
das expressões para as arquitecturas com somas e deslocamentos. Apesar de nas
arquitecturas com multiplicadores só são necessários os coeficientes dos filtros, com a
introdução da terceira etapa, é possível abordar outros aspectos, com vista a optimizar a
arquitectura. As gerações do MCM para os dois filtros são efectuadas separadamente (zona a
tracejado). Mas no decorrer deste trabalho será abordada o estudo de uma união destes
blocos, ou seja, juntar os coeficientes dos dois filtros antes de executar a terceira etapa. As
primeiras 3 etapas explicadas anteriormente não fazem parte do âmbito deste trabalho.
Neste trabalho vamos focar-nos nas últimas etapas envolvidas no processo de implementação
de filtros (zona a sombreado na Figura 2.4). As arquitecturas estudadas serão explicadas no
Capítulo 3 e no Capítulo 4, usando respectivamente multiplicadores ou somas e deslocamento.
A síntese é executada depois da geração das arquitecturas em VHDL através da ferramenta
desenvolvida. Todo processo de geração das arquitecturas e sua síntese será explicado no
Capítulo 5. Os relatórios dos resultados provenientes da síntese das arquitecturas vão
aparecer ao longo dos Capítulos 3, 4, e 6, onde se comparam as arquitecturas apresentadas.
2.6. ESPECIFICAÇÕES DOS FILTROS UTILIZADOS
Para o teste e recolha de resultados das diferentes arquitecturas que serão apresentados nos
capítulos 3, 4 e 5 utilizaram-se 9 filtros passa-baixo diferentes com as características que se
encontram apresentadas na Tabela 2.1. Os filtros diferem entre si pelo número de coeficientes,
banda de passagem e banda de atenuação.
Tabela 2.1 Especificações dos filtros
Filtro Banda de Passagem Banda de Atenuação Nº. Coeficientes Coeficiente maior (bits)
1 0,20 0,25 121 8
2 0,10 0,25 101 10
3 0,15 0,25 30 12
4 0,20 0,25 81 12
5 0.24 0,25 121 12
6 0,15 0,25 60 14
7 0,15 0,20 60 14
8 0,10 0,15 60 14
9 0,10 0,15 100 16
As características dos filtros FIR dependem exclusivamente dos conjuntos dos coeficientes que
os definem. No entanto, um filtro com muitos coeficientes nulos (por exemplo, filtro 1 e 2), terá
11
um melhor desempenho em termos de área e potência do que qualquer outro filtro (por
exemplo, o filtro 9 que não tem nenhum coeficiente nulo). O número de coeficientes também
influencia o desempenho do filtro a implementar, visto que um filtro com muitos coeficientes
tem um custo maior na área e na potência do circuito. No entanto, o tamanho dos coeficientes
(número de bits) também influencia o seu desempenho. A representação dos coeficientes dos
filtros em binário, no caso de os bits dos coeficientes serem superiores aos bits do sinal de
entrada, tem implicações nas arquitecturas FIR, podendo ter um decréscimo da frequência de
funcionamento. Por exemplo, o filtro 9 tem um coeficiente com 16 bits, que no cálculo do filtro
terá um impacto maior que o coeficiente do filtro 1, que no máximo tem coeficientes com 8 bits.
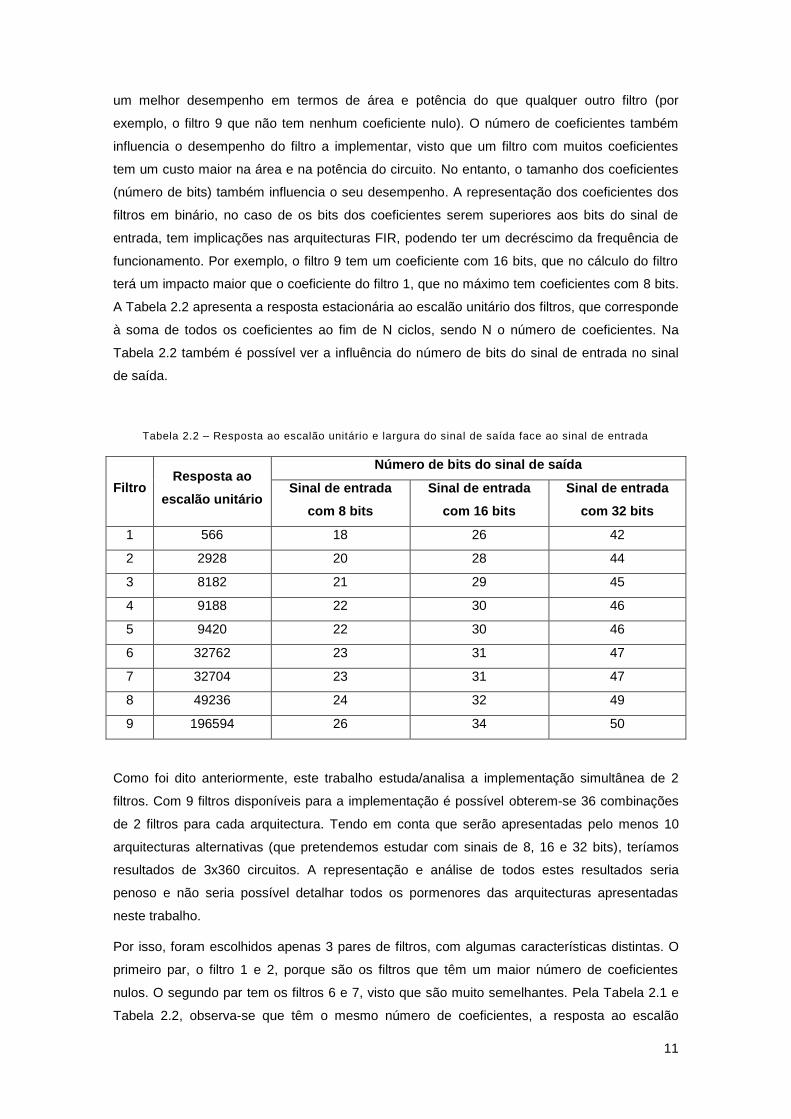
A Tabela 2.2 apresenta a resposta estacionária ao escalão unitário dos filtros, que corresponde
à soma de todos os coeficientes ao fim de N ciclos, sendo N o número de coeficientes. Na
Tabela 2.2 também é possível ver a influência do número de bits do sinal de entrada no sinal
de saída.
Tabela 2.2 – Resposta ao escalão unitário e largura do sinal de saída face ao sinal de entrada
Filtro Resposta ao
escalão unitário
Número de bits do sinal de saída
Sinal de entrada
com 8 bits
Sinal de entrada
com 16 bits
Sinal de entrada
com 32 bits
1 566 18 26 42
2 2928 20 28 44
3 8182 21 29 45
4 9188 22 30 46
5 9420 22 30 46
6 32762 23 31 47
7 32704 23 31 47
8 49236 24 32 49
9 196594 26 34 50
Como foi dito anteriormente, este trabalho estuda/analisa a implementação simultânea de 2
filtros. Com 9 filtros disponíveis para a implementação é possível obterem-se 36 combinações
de 2 filtros para cada arquitectura. Tendo em conta que serão apresentadas pelo menos 10
arquitecturas alternativas (que pretendemos estudar com sinais de 8, 16 e 32 bits), teríamos
resultados de 3x360 circuitos. A representação e análise de todos estes resultados seria
penoso e não seria possível detalhar todos os pormenores das arquitecturas apresentadas
neste trabalho.
Por isso, foram escolhidos apenas 3 pares de filtros, com algumas características distintas. O
primeiro par, o filtro 1 e 2, porque são os filtros que têm um maior número de coeficientes
nulos. O segundo par tem os filtros 6 e 7, visto que são muito semelhantes. Pela Tabela 2.1 e
Tabela 2.2, observa-se que têm o mesmo número de coeficientes, a resposta ao escalão

12
unitário é semelhante e a largura do sinal de saída são iguais. Por último, o terceiro par, os
filtros 5 e 9, porque têm características muito diferentes. O filtro 5 tem o maior número de
coeficientes (com nenhum nulo), enquanto o filtro 9 tem a máxima resposta ao escalão unitário.

13
CAPÍTULO 3
3. ARQUITECTURAS PARA FILTROS FIR COM
MULTIPLICADORES
Os multiplicadores são o elemento chave em muitos sistemas de alto desempenho, como os
filtros FIR, microprocessadores, processadores de sinais digitais, etc. O desempenho do
sistema, na maioria dos casos é determinado pelo desempenho do multiplicador, porque
geralmente é o elemento mais lento do sistema. Neste capítulo vamos abordar várias
arquitecturas FIR configuráveis com multiplicadores e possíveis optimizações.
As operações de multiplicação por múltiplas constantes (ou Multiple Constant Multiplication,
MCM), que realizam a multiplicação de um conjunto de constantes conhecidas por um sinal,
são as principais operações que limitam o desempenho em muitas aplicações em DSP, tais
como os filtros digitais FIR. [10]
As arquitecturas para filtros FIR com multiplicadores desenvolvidos neste trabalho têm como
objectivo a junção de 2 filtros. Podemos dividir estas arquitecturas em dois blocos, o bloco
Acumulador, composto pelos registos e somadores, e o bloco MCM, que pode ser composto
por multiplicadores ou adições, subtracções e deslocamentos. A Figura 3.1 apresenta uma
arquitectura para um filtro FIR com multiplicadores. Podemos observar os dois blocos referidos
anteriormente. A arquitectura da Figura 3.1 é a representação em diagrama de blocos da
estrutura na forma transposta dos filtros FIR da Figura 2.3. O sinal x(n) entra no bloco MCM,
saindo o resultado da multiplicação de x(n) pelas constantes do filtro. Estas saídas vão entrar
nos somadores, que realizam a soma com os valores acumulados, do ciclo anterior que estão
guardados em registos. A saída correspondente à última soma é a saída do filtro.
Figura 3.1 – Diagrama de blocos da arquitectura com multiplicadores em paralelo

14
3.1. PROCESSO PARA JUNTAR DOIS FILTROS FIR
A forma mais simples de juntar 2 filtros seria duplicar o diagrama de blocos da Figura 3.1. Esta
arquitectura seria composta por 2 blocos MCM, um para casa filtro, e 2 blocos de
acumuladores. Para escolher o modo de filtragem, ou seja qual o filtro aplicado ao sinal de
entrada é necessário inserir um multiplexer na saída. Com esta arquitectura é possível uma
junção de 2 filtros, como podemos ver na Figura 3.2. Esta figura apresenta dois filtros
independentes, em que não existe nenhuma partilha entre os dois. Cada filtro tem o seu bloco
MCM e o bloco acumulador, que possibilita uma rápida mudança no modo de filtragem
seleccionada. Os filtros encontram-se sempre em funcionamento, mesmo que as suas saídas
não são utilizadas num dado modo de filtragem.
Figura 3.2 – Diagrama de blocos da arquitectura de 2 filtros com multiplicadores em paralelo
A duplicação da arquitectura de um filtro FIR para criar uma arquitectura de dois filtros FIR,
parece ser a mais elementar, mas não é muito eficiente. Uma das desvantagens desta
arquitectura é possuir vários blocos acumuladores a ocupar a área, sendo apenas usado uma
delas. Um filtro com N coeficientes, precisa de N-1 registos e somadores. Com dois blocos
acumuladores, precisa-se de 2N-2 registos e somadores. Outra das razões da desvantagem de
ter dois blocos acumuladores é o facto de os dois filtros estarem sempre em funcionamento.
Com os dois filtros sempre em funcionamento, existirá sempre transições dos sinais nos blocos
acumuladores. Isso provocará um aumento excessivo da energia consumida nesta
arquitectura.
A solução para este problema é a junção dos dois blocos acumuladores. Assim, surge uma
nova arquitectura com dois blocos MCM com multiplicadores e um bloco acumulador. Nesta
nova arquitectura, só é realizada a acumulação de resultados de um dos filtros, o que diminui a
energia consumida. Com a partilha do bloco acumulador, consegue-se também diminuir a área
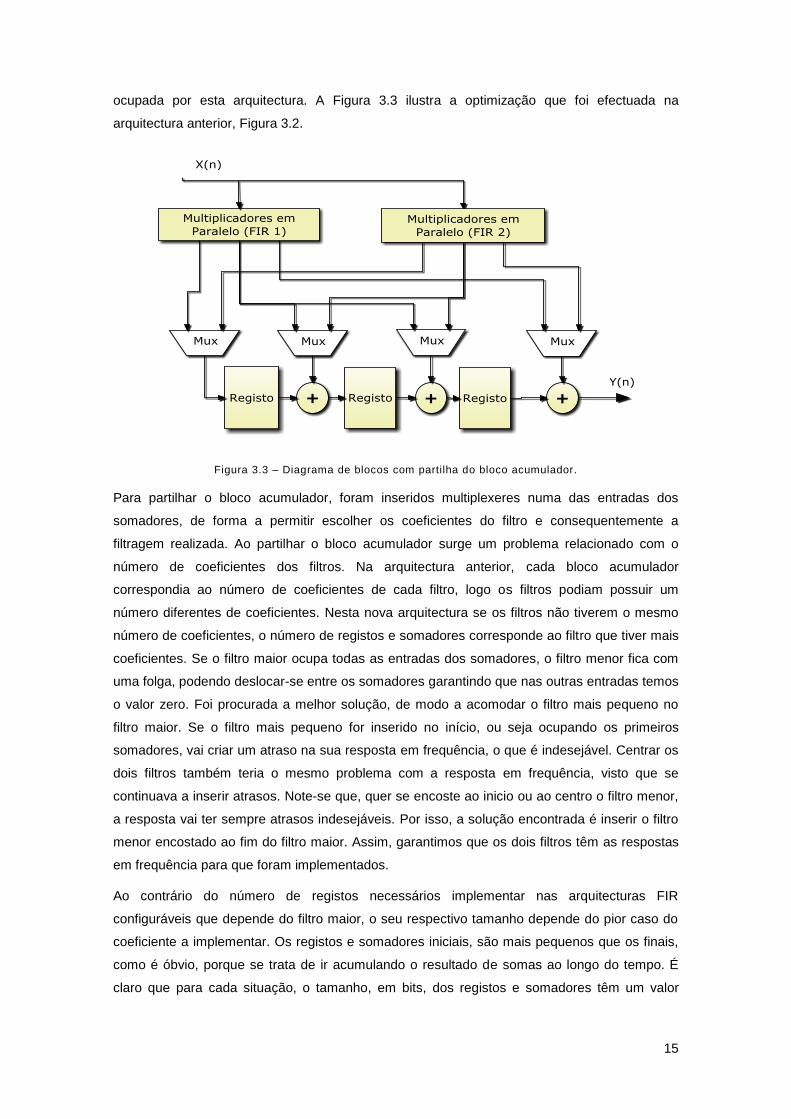
15
ocupada por esta arquitectura. A Figura 3.3 ilustra a optimização que foi efectuada na
arquitectura anterior, Figura 3.2.
Figura 3.3 – Diagrama de blocos com partilha do bloco acumulador.
Para partilhar o bloco acumulador, foram inseridos multiplexeres numa das entradas dos
somadores, de forma a permitir escolher os coeficientes do filtro e consequentemente a
filtragem realizada. Ao partilhar o bloco acumulador surge um problema relacionado com o
número de coeficientes dos filtros. Na arquitectura anterior, cada bloco acumulador
correspondia ao número de coeficientes de cada filtro, logo os filtros podiam possuir um
número diferentes de coeficientes. Nesta nova arquitectura se os filtros não tiverem o mesmo
número de coeficientes, o número de registos e somadores corresponde ao filtro que tiver mais
coeficientes. Se o filtro maior ocupa todas as entradas dos somadores, o filtro menor fica com
uma folga, podendo deslocar-se entre os somadores garantindo que nas outras entradas temos
o valor zero. Foi procurada a melhor solução, de modo a acomodar o filtro mais pequeno no
filtro maior. Se o filtro mais pequeno for inserido no início, ou seja ocupando os primeiros
somadores, vai criar um atraso na sua resposta em frequência, o que é indesejável. Centrar os
dois filtros também teria o mesmo problema com a resposta em frequência, visto que se
continuava a inserir atrasos. Note-se que, quer se encoste ao inicio ou ao centro o filtro menor,
a resposta vai ter sempre atrasos indesejáveis. Por isso, a solução encontrada é inserir o filtro
menor encostado ao fim do filtro maior. Assim, garantimos que os dois filtros têm as respostas
em frequência para que foram implementados.
Ao contrário do número de registos necessários implementar nas arquitecturas FIR
configuráveis que depende do filtro maior, o seu respectivo tamanho depende do pior caso do
coeficiente a implementar. Os registos e somadores iniciais, são mais pequenos que os finais,
como é óbvio, porque se trata de ir acumulando o resultado de somas ao longo do tempo. É
claro que para cada situação, o tamanho, em bits, dos registos e somadores têm um valor

16
máximo. Esse valor depende dos coeficientes dos dois filtros de modo a prevenir erros de
truncatura. Portanto, o filtro menor pode influenciar o tamanho do bloco acumulador.
Numa situação mais genérica, sendo { } e { } os conjuntos
de coeficientes do filtro 1 e filtro 2 respectivamente com N e M coeficientes. Admitamos por
simplicidade que N > M.
Seja d a diferença entre o número de coeficientes dos dois filtros:
(4)
O filtro mais pequeno é reajustado, e inserindo zeros nas posições iniciais, ou seja, de “0” até
d. O filtro mais pequeno é reajustado da seguinte forma:
(5)
Note-se que no final C’ tem o mesmo tamanho do conjunto K. No entanto, os primeiros d
coeficientes são nulos e os restantes coeficientes sofrem um deslocamento de d posições.
Assim, o número de bits necessário à saída de cada somador e respectivo registo, bsi é dado
por:
(6)
Em que bki e bci correspondem ao número de bits do somador necessário para cada filtro i e
bsi-1 o número de bits do somador do momento i-1.
É possível optimizar ainda mais o bloco de registos e somadores. No caso em que c’i = ki, com
c’i e ki diferentes de zero, prescinde-se do multiplexer antes dos somadores. E se c’i = ki = 0,
prescinde-se do multiplexer e do somador, ficando uma ligação registo-registo. Também
podem existir caso em que c’i = c’i+t e ki = ki+t, o que representa a duplicação do mesmo
multiplexer. Nestes casos, são retirados todos os multiplexeres duplicados. Para mostrar as
equações e as optimizações apresentadas, considere-se o seguinte pequeno exemplo e a
respectiva arquitectura a implementar:
{ } { }
A arquitectura vai ser composta por 4 registos (N-1), 4 somadores (N-1) e 5 multiplexeres (N).
O filtro C sofre um deslocamento de duas posições. Assim, o novo filtro C’ fica:
{ }
Considerando que o sinal de entrada são 8 bits, calculando os bits necessários para cada
registo e somador, pela equação (6), temos:

17
{ }
{ }
{ }
De seguida, as optimizações que se podem fazer no exemplo:
Na posição i=2, não se insere multiplexer nem somador, porque os dois coeficientes
são nulos;
Na posição i=3, não se insere multiplexer, porque os coeficientes são iguais;
Na posição i=0 e i=4, os multiplexeres são iguais, logo um deles é retirado.
Com as optimizações, a arquitectura final é composta por 4 registos, 3 somadores e 2
multiplexeres. A Figura 3.4 apresenta o bloco acumulador para o exemplo anterior.
Figura 3.4 – Diagrama do bloco acumulador para o exemplo
Estas optimizações permitem-nos diminuir a área ocupada e a energia consumida das
arquitecturas FIR. O número de registo nos filtros digitais FIR é inalterado, sendo sempre igual
a N-1, enquanto o número de somadores é sempre menor ou igual ao número de registos. O
número de multiplexeres a implementar no pior caso é igual ao número de somadores, logo
pode ser inferior ao número de registos.
Como foi referido anteriormente, a arquitectura da Figura 3.3 tem a grande vantagem de
partilhar o bloco acumulador, que permite reduzir a área ocupada e a energia consumida à
custa de introdução de multiplexeres. No entanto, um dos problemas que nos deparamos com
esta arquitectura é o facto de os coeficientes poderem ser positivos e negativos. No caso de
um coeficiente na posição i do filtro 1 ter sinal diferente do filtro 2, é necessário substituir no
bloco acumulador o somador por um somador/subtractor. Existem dois modos de proceder
nesta situação, ou utilizar um somador/subtractor, ou usar na mesma o somador e tratar a
inversão do sinal no bloco MCM. Foram testados os dois modos num circuito composto por um
registo na entrada e outro na saída e no meio um somador ou um somador/subtractor, para um
sinal de entrada de 8, 16, 24 e 32 bits. Serão apresentados os resultados da área ocupada,
potência e tempo de atraso. A síntese de todas as descrições VHDL das arquitecturas geradas
18
foi feita com a ferramenta design_vision do sofware Synopsys com a biblioteca c35_corelib
da tecnologia AMS 0,35 µm. A síntese foi efectuada com uma frequência de relógio de 20 MHz
(50 ns). Para os resultados de potência foram considerados uma comutação dos sinais de
entrada à frequência de relógio com uma probabilidade estática de 50%.
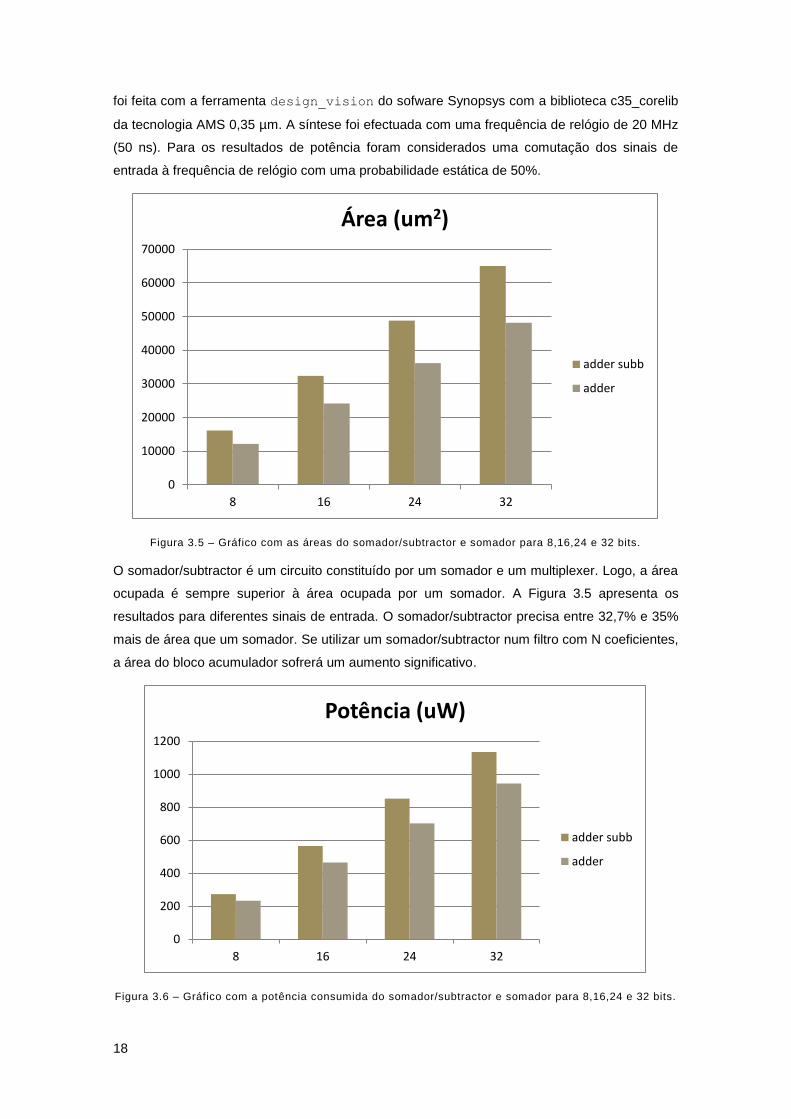
Figura 3.5 – Gráfico com as áreas do somador/subtractor e somador para 8,16,24 e 32 bits.
O somador/subtractor é um circuito constituído por um somador e um multiplexer. Logo, a área
ocupada é sempre superior à área ocupada por um somador. A Figura 3.5 apresenta os
resultados para diferentes sinais de entrada. O somador/subtractor precisa entre 32,7% e 35%
mais de área que um somador. Se utilizar um somador/subtractor num filtro com N coeficientes,
a área do bloco acumulador sofrerá um aumento significativo.
Figura 3.6 – Gráfico com a potência consumida do somador/subtractor e somador para 8,16,24 e 32 bits.
0
10000
20000
30000
40000
50000
60000
70000
8 16 24 32
Área (um2)
adder subb
adder
0
200
400
600
800
1000
1200
8 16 24 32
Potência (uW)
adder subb
adder
19
Com uma área maior, o somador/subtractor também precisa de uma potência maior. A potência
do somador/subtractor é superior, entre os 17,5% e os 21,6% face à potência necessária do
somador.
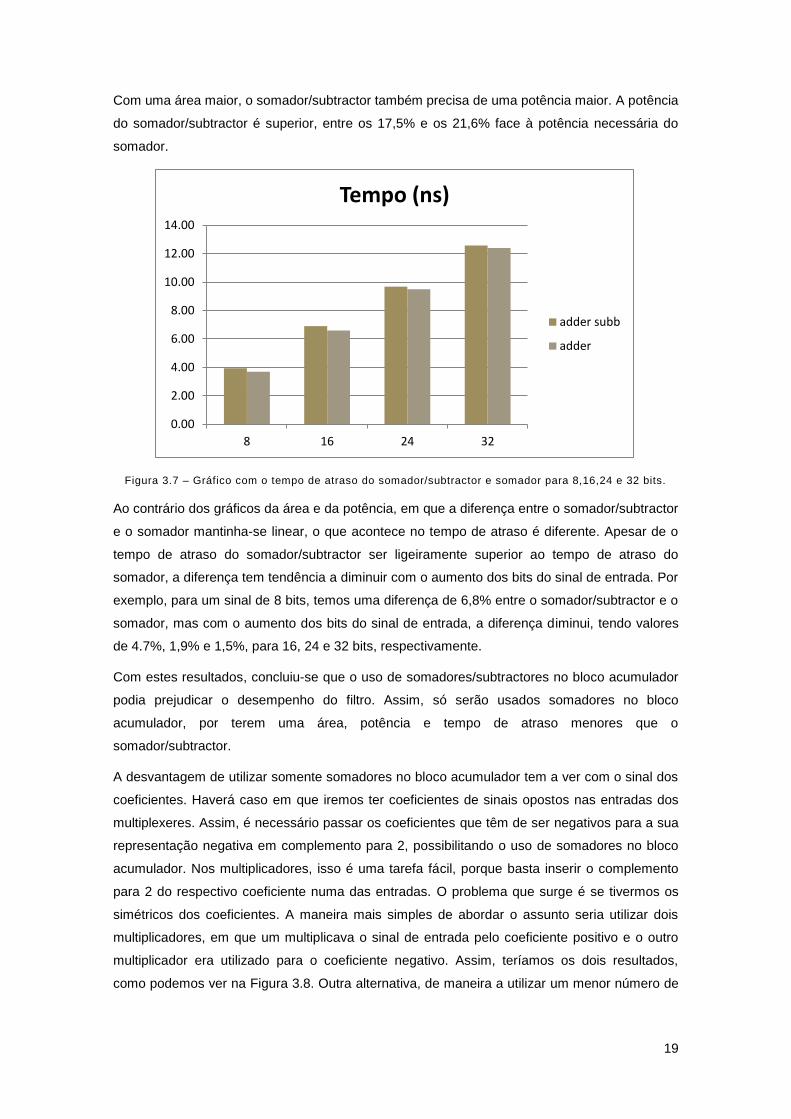
Figura 3.7 – Gráfico com o tempo de atraso do somador/subtractor e somador para 8,16,24 e 32 bits.
Ao contrário dos gráficos da área e da potência, em que a diferença entre o somador/subtractor
e o somador mantinha-se linear, o que acontece no tempo de atraso é diferente. Apesar de o
tempo de atraso do somador/subtractor ser ligeiramente superior ao tempo de atraso do
somador, a diferença tem tendência a diminuir com o aumento dos bits do sinal de entrada. Por
exemplo, para um sinal de 8 bits, temos uma diferença de 6,8% entre o somador/subtractor e o
somador, mas com o aumento dos bits do sinal de entrada, a diferença diminui, tendo valores
de 4.7%, 1,9% e 1,5%, para 16, 24 e 32 bits, respectivamente.
Com estes resultados, concluiu-se que o uso de somadores/subtractores no bloco acumulador
podia prejudicar o desempenho do filtro. Assim, só serão usados somadores no bloco
acumulador, por terem uma área, potência e tempo de atraso menores que o
somador/subtractor.
A desvantagem de utilizar somente somadores no bloco acumulador tem a ver com o sinal dos
coeficientes. Haverá caso em que iremos ter coeficientes de sinais opostos nas entradas dos
multiplexeres. Assim, é necessário passar os coeficientes que têm de ser negativos para a sua
representação negativa em complemento para 2, possibilitando o uso de somadores no bloco
acumulador. Nos multiplicadores, isso é uma tarefa fácil, porque basta inserir o complemento
para 2 do respectivo coeficiente numa das entradas. O problema que surge é se tivermos os
simétricos dos coeficientes. A maneira mais simples de abordar o assunto seria utilizar dois
multiplicadores, em que um multiplicava o sinal de entrada pelo coeficiente positivo e o outro
multiplicador era utilizado para o coeficiente negativo. Assim, teríamos os dois resultados,
como podemos ver na Figura 3.8. Outra alternativa, de maneira a utilizar um menor número de
0.00
2.00
4.00
6.00
8.00
10.00
12.00
14.00
8 16 24 32
Tempo (ns)
adder subb
adder
20
multiplicadores, seria multiplicar o sinal de entrada pelo coeficiente positivo e depois negar o
sinal do resultado, como apresenta a Figura 3.9.
Figura 3.8 – Diagrama de blocos com 2
multiplicadores
Figura 3.9 – Diagrama de blocos com 1
multiplicador e negação do sinal.
São duas soluções diferentes para o mesmo problema. A primeira tem a desvantagem de
utilizar dois multiplicadores, mas a vantagem de o caminho critico ser o multiplicador mais
lento, enquanto a segunda solução tem a vantagem de ter um único multiplicador, mas o
caminho crítico é composto pelo multiplicador e o bloco da negação do sinal. Apesar de
realçadas as desvantagens e vantagens de cada solução, é difícil prever qual a solução óptima
para o nosso problema. De maneira a dissipar as dúvidas, recorreu-se a várias sinteses das
duas soluções, para determinar a área ocupada, a potência consumida e o tempo de atraso. O
circuito a sintetizar é composto por um registo na entrada, o modelo a testar e dois registos na
saída, para um sinal de entrada de 8, 16 e 32 bits. A síntese foi efectuada com uma frequência
de relógio de 20 MHz (50 ns).
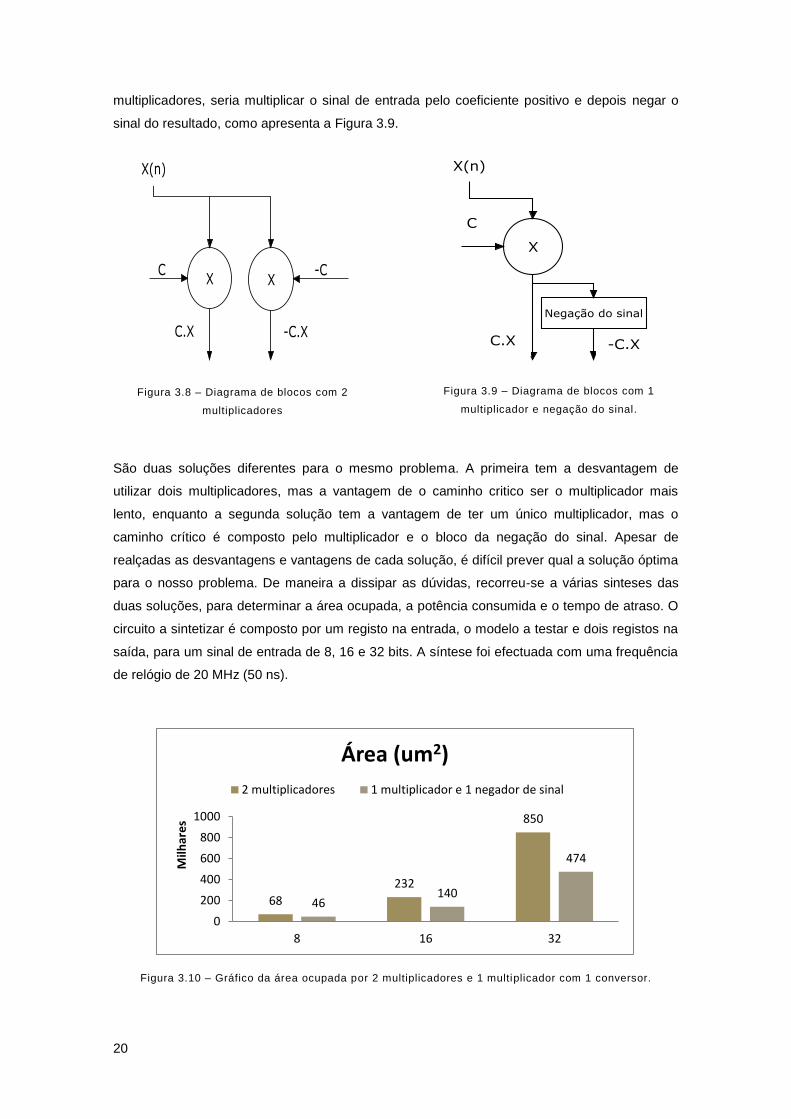
Figura 3.10 – Gráfico da área ocupada por 2 multiplicadores e 1 multiplicador com 1 conversor.
68
232
850
46 140
474
0
200
400
600
800
1000
8 16 32
Milh
are
s
Área (um2)
2 multiplicadores 1 multiplicador e 1 negador de sinal
21
O facto de utilizar dois multiplicadores ocupa uma área superior a um multiplicador e um
negador de sinal. A Figura 3.10 mostra a grande desvantagem de utilizar dois multiplicadores
em vez de apenas um multiplicador e um negador de sinal para o cálculo de coeficientes
simétricos. Pela Figura 3.10 podemos verificar que a diferença entre as duas soluções aumenta
com o número de bits do sinal de entrada. Para um sinal de entrada de 32 bits, área ocupada
por dois multiplicadores chega a ser aproximadamente o dobro da área ocupada por um
multiplicador e um negador de sinal. Em termos de área, a solução com um multiplicador e um
negador de sinal seria a melhor solução.
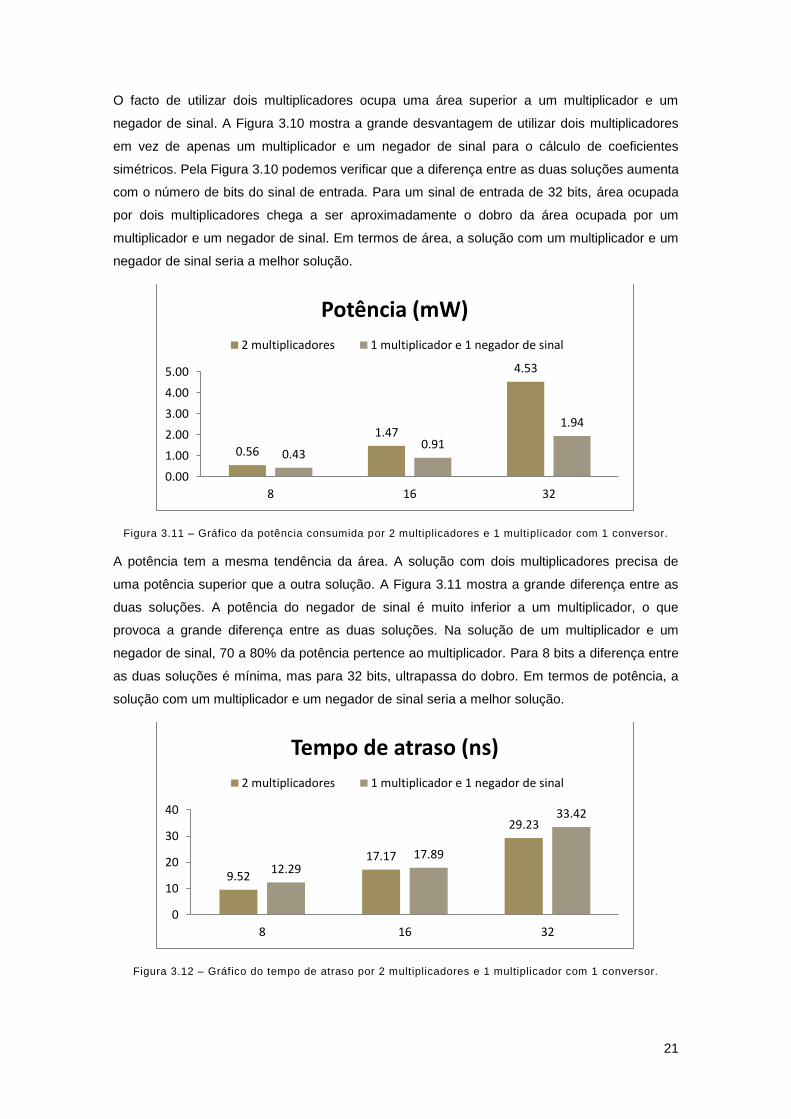
Figura 3.11 – Gráfico da potência consumida por 2 multiplicadores e 1 multiplicador com 1 conversor.
A potência tem a mesma tendência da área. A solução com dois multiplicadores precisa de
uma potência superior que a outra solução. A Figura 3.11 mostra a grande diferença entre as
duas soluções. A potência do negador de sinal é muito inferior a um multiplicador, o que
provoca a grande diferença entre as duas soluções. Na solução de um multiplicador e um
negador de sinal, 70 a 80% da potência pertence ao multiplicador. Para 8 bits a diferença entre
as duas soluções é mínima, mas para 32 bits, ultrapassa do dobro. Em termos de potência, a
solução com um multiplicador e um negador de sinal seria a melhor solução.
Figura 3.12 – Gráfico do tempo de atraso por 2 multiplicadores e 1 multiplicador com 1 conversor.
0.56
1.47
4.53
0.43 0.91
1.94
0.00
1.00
2.00
3.00
4.00
5.00
8 16 32
Potência (mW)
2 multiplicadores 1 multiplicador e 1 negador de sinal
9.52
17.17
29.23
12.29 17.89
33.42
0
10
20
30
40
8 16 32
Tempo de atraso (ns)
2 multiplicadores 1 multiplicador e 1 negador de sinal

22
A grande desvantagem de utilizar um multiplicar e um negador de sinal é o caminho crítico.
Pela Figura 3.12 podemos constatar que esta solução tem um tempo de atraso superior há
solução de dois multiplicadores. A solução mais rápida, com dois multiplicadores, consegue no
melhor caso reduzir o caminho crítico em 22.5%. Em termos do tempo crítico, a solução com
dois multiplicadores seria a melhor solução.
Tendo em conta os resultados, em que a solução de um multiplicador e um negador de sinal
ocupa uma área menor, uma potência mais baixa, mas precisa de um tempo de atraso maior
seria a solução mais indicada para o nosso problema. A única vantagem de utilizar dois
multiplicadores é o tempo de atraso, porque tanto na área ocupada e na potência, tem
resultados muito superiores há outra solução. Em todas as arquitecturas com multiplicadores,
em caso de haver coeficientes simétricos, foi usado o modelo com um multiplicador e um
negador de sinal.
Até este momento, tem-se explorado as possíveis melhorias somente no bloco acumulador.
Melhorias que permitiram diminuírem a área, potência e tempo de atraso nas arquitecturas FIR.
No entanto, a parte mais crítica nestas arquitecturas FIR não é o bloco acumulador mas o
bloco MCM, onde os multiplicadores têm uma grande influência no desempenho do filtro,
apresentando-se como um maior desafio na tentativa de reduzir a área e a potência
consumida. A intenção é diminuir o número de multiplicadores ou o seu tamanho. Qualquer das
situações nos permite diminuir a área e a potência das arquitecturas FIR.
Uma das grandes vantagens de se utilizar os filtros digitais FIR em processamento de sinais
tem a ver com a possibilidade da sua fase ser linear. Se o filtro tiver a fase linear, não é
necessário implementar todos os multiplicadores, bastando implementar metade (pois os
coeficientes da outra metade são iguais). Mas para os filtros que não têm fase linear, também é
possível reduzir o número de multiplicadores. Uma das opções que se tomou anteriormente foi
utilizar um multiplicador e um negador de sinal se houver coeficientes simétricos, em vez da
utilização de dois multiplicadores. Assim, podemos reduzir o número de multiplicadores a
implementar, reduzindo a área e a potência.
Se diminuir o número de multiplicadores é benéfico para as arquitecturas FIR, também se
aplica ao tamanho deles. Um multiplicador com o tamanho mais pequeno permite diminuir a
área, energia e o tempo de atraso. Para diminuir o tamanho dos multiplicadores, os
coeficientes pares foram transformados em coeficiente impar. Assim, consegue-se reduzir o
número de bits das multiplicações pelo sinal de entrada.
Um exemplo desta situação, em que usando o coeficiente 3, conseguimos ter os coeficientes 6,
12 e o 24, como mostra a Figura 3.13.

23
Figura 3.13 - Diagrama de blocos do deslocamento do 3
Se tivéssemos um filtro com estes coeficientes (3, 6, 12, 24) só era necessário implementar um
multiplicador. Ao multiplicar o sinal de entrada por 3, para os restantes resultados só é preciso
aplicar deslocamentos.
Outro modo de diminuir os multiplicadores a implementar nas arquitecturas FIR é retirar os
coeficientes “0” e “1”. Sendo o “0” o elemento absorvente da multiplicação e “1”, o elemento
neutro da multiplicação, não é preciso implementar multiplicadores para estes coeficientes. Por
fim, depois de todas as optimizações, retiram-se todos os coeficientes repetidos, diminuindo o
número de multiplicadores a implementar. Para ilustrar melhor todas as etapas das
optimizações efectuadas no bloco MCM, a Figura 3.14 mostra todo o processo que é efectuado
para cada filtro antes da sua implementação.
Figura 3.14 – Etapa do processo para a optimização dos multiplicadores.
1ª Etapa •Passar todos os coeficientes pares para impares
2º Etapa •Retirar coeficientes repetidos
3ª Etapa •Retirar os coeficientes "0" e "1"
4ª Etapa
•Se houver coeficientes simétricos, retirar os coeficientes que são negativos.
6 = 3 << 1
12 = 3 << 2
24 = 3 << 3
3 12
6
24

24
Com a optimização dos multiplicadores, conseguimos diminuir a área, potência e tempo de
atraso das arquitecturas FIR configuráveis. Depois de explicado que um coeficiente pode ser
decomposto em um coeficiente mais pequeno e com um deslocamento, é possível ainda
melhorar outro sector da arquitectura FIR. Quando falámos dos multiplexeres que antecedem
os somadores do bloco acumulador, inicialmente os valores das entradas nos multiplexeres
seriam os coeficientes sem nenhuma optimização. Como o caminho crítico das arquitecturas
FIR tem de passar obrigatoriamente pelos multiplexeres, é possível diminuir o tempo do
caminho critico e a área. Os valores que os multiplexeres recebem nas suas entradas é o
resultado da multiplicação do coeficiente pelo sinal de entrada e que no fim sofre um
deslocamento. Assim, para dois coeficientes que sofram deslocamentos (sejam pares) ou um
deles seja nulo, a implementação do multiplexer pode ser optimizada. É de salientar, se o
coeficiente for impar, o deslocamento é nulo. Se tivermos dois sinais e diferentes, para
obter 2 constantes pares temos:.
(14)
Consideramos que byp corresponde ao número de bits do sinal yp e bMux corresponde ao
número de bits necessário para cada multiplexer. Antes da optimização, o número de bits
necessário para o multiplexer seria:
(
) (15)
Todos os sinais do multiplexer têm o mesmo tamanho. Esta optimização consiste em passar os
deslocamentos dos sinais de entrada do multiplexer, para o sinal de saída do mesmo. O
deslocamento que é transferido para o sinal de saída corresponde ao mínimo de
deslocamentos dos sinais de entrada. Assim garantimos que o valor continua a ser o correcto.
Seja tmin o deslocamento mínimo entre os dois sinais de entrada.
(16)
No caso de um dos sinais de entrada for zero:
(17)
O tmin corresponde ao número de bits em que podemos diminuir o tamanho do multiplexer.
Note-se que quando um dos coeficientes é impar, tmin é sempre zero pelo que esta optimização
não resulta. O novo tamanho do multiplexeres representado por:
(18)
Os sinais de entrada também sofrem alterações.
(19)
Ao sinal de saída do multiplexer terão agora de ser adicionados os deslocamentos retirados
aos sinais de entrada para obter o sinal correspondente ao coeficiente par (Muxres).
(21)

25
Com um exemplo, podemos demonstrar esta optimização. Sejam o par de coeficientes 96 e
512 e um sinal de entrada tem 8 bits. O passo seguinte é decompor os coeficientes em
impares, equação (14).
Como os coeficientes são diferentes de zero, para o cálculo do deslocamento mínimo usamos
a equação (16):
O tamanho do multiplexer, equação (18) e os sinais de entrada, equação (20):
Os novos sinais de entrada, equação (19):
Agora aplicamos a equação (21):
(21)
Com esta optimização é possível diminuir o tempo de atraso, área e potência. A Figura 3.15
representa a optimização efectuada aos multiplexeres. Do lado esquerdo temos a versão
normal e do lado direito a versão optimizada. Como podemos reparar o multiplexer do lado
direito é menor que do lado esquerdo.
Figura 3.15 – Diagrama de blocos com a optimização dos multiplexeres
26
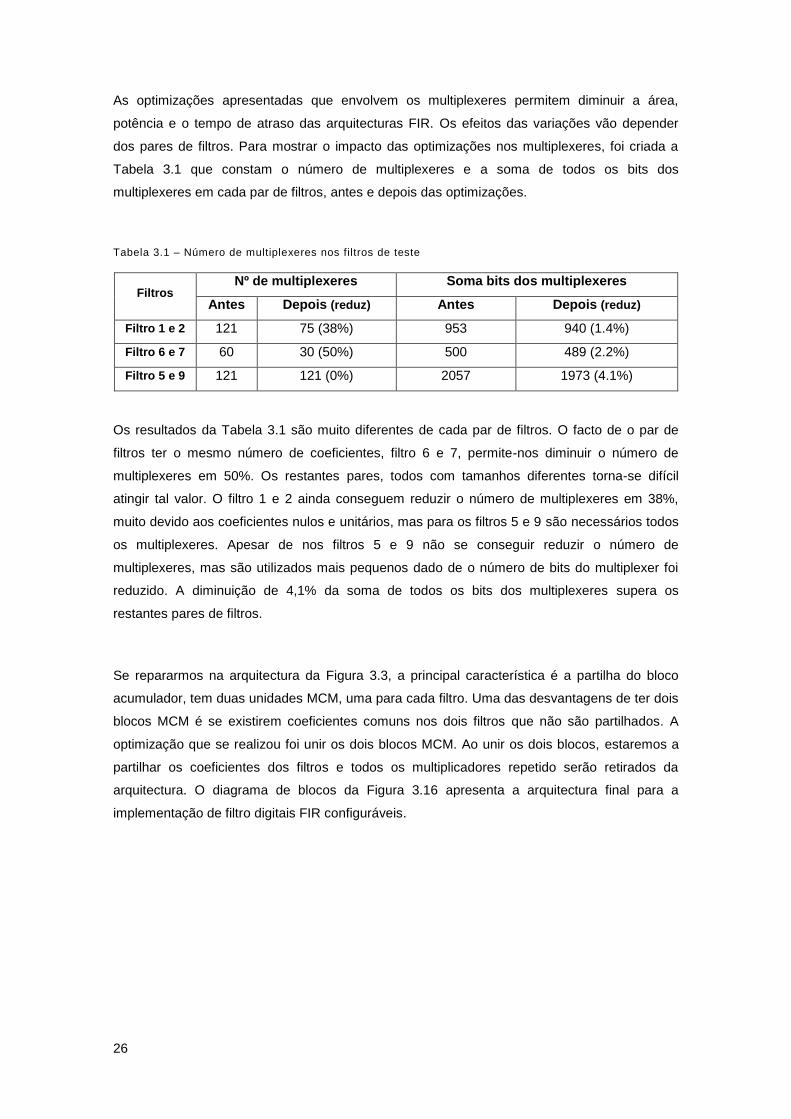
As optimizações apresentadas que envolvem os multiplexeres permitem diminuir a área,
potência e o tempo de atraso das arquitecturas FIR. Os efeitos das variações vão depender
dos pares de filtros. Para mostrar o impacto das optimizações nos multiplexeres, foi criada a
Tabela 3.1 que constam o número de multiplexeres e a soma de todos os bits dos
multiplexeres em cada par de filtros, antes e depois das optimizações.
Tabela 3.1 – Número de multiplexeres nos filtros de teste
Filtros Nº de multiplexeres Soma bits dos multiplexeres
Antes Depois (reduz) Antes Depois (reduz)
Filtro 1 e 2 121 75 (38%) 953 940 (1.4%)
Filtro 6 e 7 60 30 (50%) 500 489 (2.2%)
Filtro 5 e 9 121 121 (0%) 2057 1973 (4.1%)
Os resultados da Tabela 3.1 são muito diferentes de cada par de filtros. O facto de o par de
filtros ter o mesmo número de coeficientes, filtro 6 e 7, permite-nos diminuir o número de
multiplexeres em 50%. Os restantes pares, todos com tamanhos diferentes torna-se difícil
atingir tal valor. O filtro 1 e 2 ainda conseguem reduzir o número de multiplexeres em 38%,
muito devido aos coeficientes nulos e unitários, mas para os filtros 5 e 9 são necessários todos
os multiplexeres. Apesar de nos filtros 5 e 9 não se conseguir reduzir o número de
multiplexeres, mas são utilizados mais pequenos dado de o número de bits do multiplexer foi
reduzido. A diminuição de 4,1% da soma de todos os bits dos multiplexeres supera os
restantes pares de filtros.
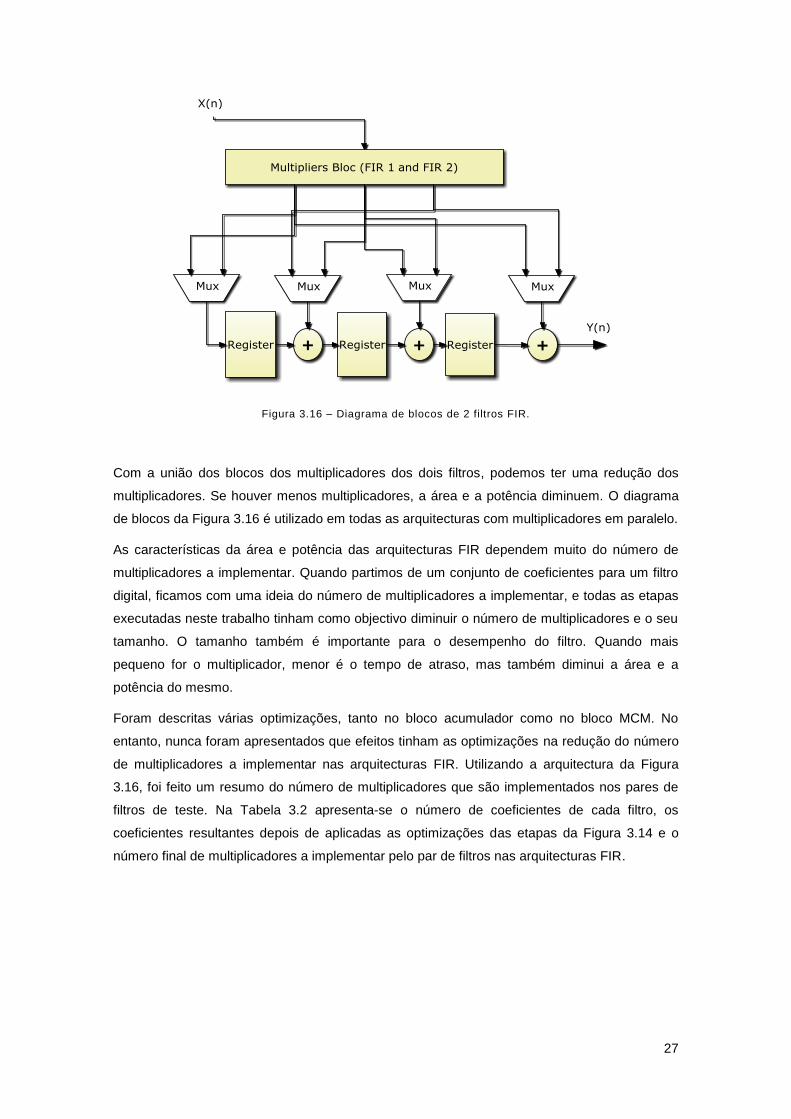
Se repararmos na arquitectura da Figura 3.3, a principal característica é a partilha do bloco
acumulador, tem duas unidades MCM, uma para cada filtro. Uma das desvantagens de ter dois
blocos MCM é se existirem coeficientes comuns nos dois filtros que não são partilhados. A
optimização que se realizou foi unir os dois blocos MCM. Ao unir os dois blocos, estaremos a
partilhar os coeficientes dos filtros e todos os multiplicadores repetido serão retirados da
arquitectura. O diagrama de blocos da Figura 3.16 apresenta a arquitectura final para a
implementação de filtro digitais FIR configuráveis.
27
Figura 3.16 – Diagrama de blocos de 2 filtros FIR.
Com a união dos blocos dos multiplicadores dos dois filtros, podemos ter uma redução dos
multiplicadores. Se houver menos multiplicadores, a área e a potência diminuem. O diagrama
de blocos da Figura 3.16 é utilizado em todas as arquitecturas com multiplicadores em paralelo.
As características da área e potência das arquitecturas FIR dependem muito do número de
multiplicadores a implementar. Quando partimos de um conjunto de coeficientes para um filtro
digital, ficamos com uma ideia do número de multiplicadores a implementar, e todas as etapas
executadas neste trabalho tinham como objectivo diminuir o número de multiplicadores e o seu
tamanho. O tamanho também é importante para o desempenho do filtro. Quando mais
pequeno for o multiplicador, menor é o tempo de atraso, mas também diminui a área e a
potência do mesmo.
Foram descritas várias optimizações, tanto no bloco acumulador como no bloco MCM. No
entanto, nunca foram apresentados que efeitos tinham as optimizações na redução do número
de multiplicadores a implementar nas arquitecturas FIR. Utilizando a arquitectura da Figura
3.16, foi feito um resumo do número de multiplicadores que são implementados nos pares de
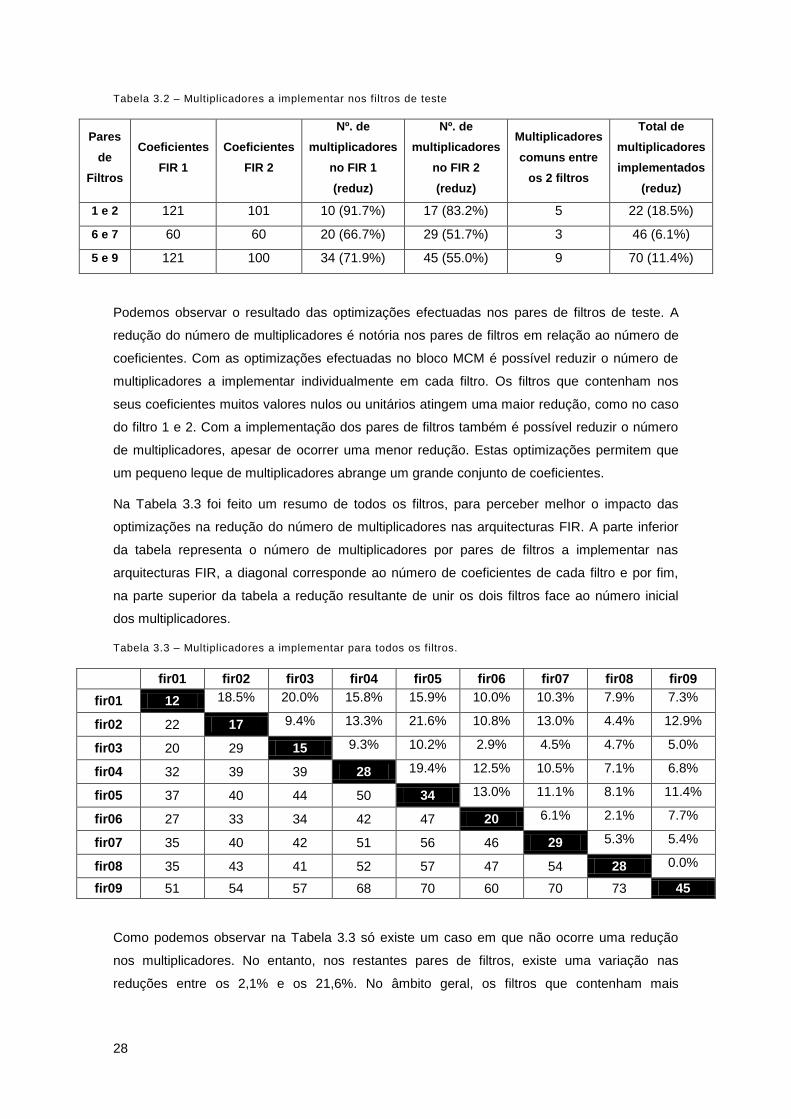
filtros de teste. Na Tabela 3.2 apresenta-se o número de coeficientes de cada filtro, os
coeficientes resultantes depois de aplicadas as optimizações das etapas da Figura 3.14 e o
número final de multiplicadores a implementar pelo par de filtros nas arquitecturas FIR.
28
Tabela 3.2 – Multiplicadores a implementar nos filtros de teste
Pares
de
Filtros
Coeficientes
FIR 1
Coeficientes
FIR 2
Nº. de
multiplicadores
no FIR 1
(reduz)
Nº. de
multiplicadores
no FIR 2
(reduz)
Multiplicadores
comuns entre
os 2 filtros
Total de
multiplicadores
implementados
(reduz)
1 e 2 121 101 10 (91.7%) 17 (83.2%) 5 22 (18.5%)
6 e 7 60 60 20 (66.7%) 29 (51.7%) 3 46 (6.1%)
5 e 9 121 100 34 (71.9%) 45 (55.0%) 9 70 (11.4%)
Podemos observar o resultado das optimizações efectuadas nos pares de filtros de teste. A
redução do número de multiplicadores é notória nos pares de filtros em relação ao número de
coeficientes. Com as optimizações efectuadas no bloco MCM é possível reduzir o número de
multiplicadores a implementar individualmente em cada filtro. Os filtros que contenham nos
seus coeficientes muitos valores nulos ou unitários atingem uma maior redução, como no caso
do filtro 1 e 2. Com a implementação dos pares de filtros também é possível reduzir o número
de multiplicadores, apesar de ocorrer uma menor redução. Estas optimizações permitem que
um pequeno leque de multiplicadores abrange um grande conjunto de coeficientes.
Na Tabela 3.3 foi feito um resumo de todos os filtros, para perceber melhor o impacto das
optimizações na redução do número de multiplicadores nas arquitecturas FIR. A parte inferior
da tabela representa o número de multiplicadores por pares de filtros a implementar nas
arquitecturas FIR, a diagonal corresponde ao número de coeficientes de cada filtro e por fim,
na parte superior da tabela a redução resultante de unir os dois filtros face ao número inicial
dos multiplicadores.
Tabela 3.3 – Multiplicadores a implementar para todos os filtros.
fir01 fir02 fir03 fir04 fir05 fir06 fir07 fir08 fir09
fir01 12 18.5% 20.0% 15.8% 15.9% 10.0% 10.3% 7.9% 7.3%
fir02 22 17 9.4% 13.3% 21.6% 10.8% 13.0% 4.4% 12.9%
fir03 20 29 15 9.3% 10.2% 2.9% 4.5% 4.7% 5.0%
fir04 32 39 39 28 19.4% 12.5% 10.5% 7.1% 6.8%
fir05 37 40 44 50 34 13.0% 11.1% 8.1% 11.4%
fir06 27 33 34 42 47 20 6.1% 2.1% 7.7%
fir07 35 40 42 51 56 46 29 5.3% 5.4%
fir08 35 43 41 52 57 47 54 28 0.0%
fir09 51 54 57 68 70 60 70 73 45
Como podemos observar na Tabela 3.3 só existe um caso em que não ocorre uma redução
nos multiplicadores. No entanto, nos restantes pares de filtros, existe uma variação nas
reduções entre os 2,1% e os 21,6%. No âmbito geral, os filtros que contenham mais

29
coeficientes para a sua implementação não necessitam obrigatoriamente de mais
multiplicadores que os filtros que tenham menos coeficientes
3.2. OPTIMIZAÇÃO DOS MULTIPLICADORES
É muito usual nas arquitecturas FIR com multiplicadores em paralelo ser necessário que cada
coeficiente tenha o seu multiplicador independente. O tamanho do multiplicador, em número de
bits, fica definido pelo maior operando, ou seja, pelo maior número de bits entre o sinal de
entrada e o coeficiente. Num multiplicador genérico (NxN), os dois operadores têm o mesmo
tamanho. No entanto, se um dos operandos for mais pequeno (número de bits) este tem de ser
dimensionado para o tamanho do operador maior, de modo a efectuar a multiplicação. Depois
da multiplicação o resultado tem de ser outra vez redimensionado, se os operadores não
tiverem o mesmo tamanho. Ao utilizar o multiplicador genérico, a probabilidade de desperdício
de bits do resultado da operação é grande.
Por exemplo, o coeficiente for o +3, que em binário é representado por “011” e o sinal de
entrada for de 8 bits, o resultado da multiplicação tem o tamanho de 16 bit, que equivale ao
dobro do tamanho do sinal maior usando um multiplicador genérico (NxN). Mas ao multiplicar o
sinal de entrada de 8 bits por um “+3”, o número máximo de bits do resultado não ultrapassa os
11 bits, logo os restantes bits não têm informação útil pelo que podem ser eliminados. Na
Figura 3.17, temos um exemplo em que os coeficientes 3, 19, 47 e 127 são multiplicados por
um sinal de entrada com 8 bits, sendo feita o redimensionamento dos sinais depois da
multiplicação de forma a eliminar os bits desnecessários.
Figura 3.17 – Diagrama de blocos de multiplicadores em paralelo

30
Na Figura 3.17 pode-se ver em grande parte dos casos conseguimos reduzir o número de bits
do resultado se redimensionamos o resultado após a multiplicação para a dimensão
necessária.
Uma maneia de evitar este redimensionamento, consiste em usar um multiplicador com as
dimensões NxM, em que N pode ser diferente de M. No caso do multiplicador NxN, o resultado
terá sempre em 2N bits, enquanto no multiplicador NxM, o resultado tem a dimensão N+M bits.
O desperdício de bits do resultado da multiplicação NxN em vez da operação necessária NxM
é sempre igual a |N – M|. Na Tabela 3.4 é apresentado a diferença de utilizar um multiplicador
NxN e NxM no que respeita ao número de bits do resultado para o filtro que usamos.
Tabela 3.4 – Total de bits nas saídas dos multiplicadores
Filtros Total de bits com
multiplicador NxN
Total de bits com multiplicador NxM
(reduz)
Bits do sinal
de entrada 8 bits 16 bits 32 bits 8 bits 16 bits 32 bits
1 e 2 364 704 1408 322 (11.5%) 498 (29.3%) 850 (39.6%)
6 e 7 870 1472 2944 772 (11.3%) 1140 (22.6%) 1876 (36.3%)
5 e 9 1372 2240 4480 1200 (12.5%) 1760 (21.4%) 2880 (35.7%)
Note-se que com o aumento do sinal de entrada, a redução de bits aumenta, devido a no
multiplicador NxN, na maioria dos casos é o sinal de entrada que define o tamanho do
multiplicador. Utilizar o multiplicador NxM permite diminuir o tamanho dos multiplicadores, o
que vai influenciar o desempenho das arquitecturas dos filtros FIR. Para apurar melhor as
diferenças entre os dois multiplicadores, foi realizada um estudo para saber os valores da área
ocupada, potência e tempo de atraso. Para isso foram implementados vários multiplicadores
pelas constantes 7, 15, 31, 63, 127, 255 e 511 por um sinal de entrada com 8 bits.
Figura 3.18 – Gráfico da área ocupada pelo multiplicador nxn e nxm.
36 36 36 36 36 43
52
22 25 29 32 36 39
43
0
20
40
60
7 15 31 63 127 255 511
Milh
are
s
Área (um2)
mult_nxn mult_nxm
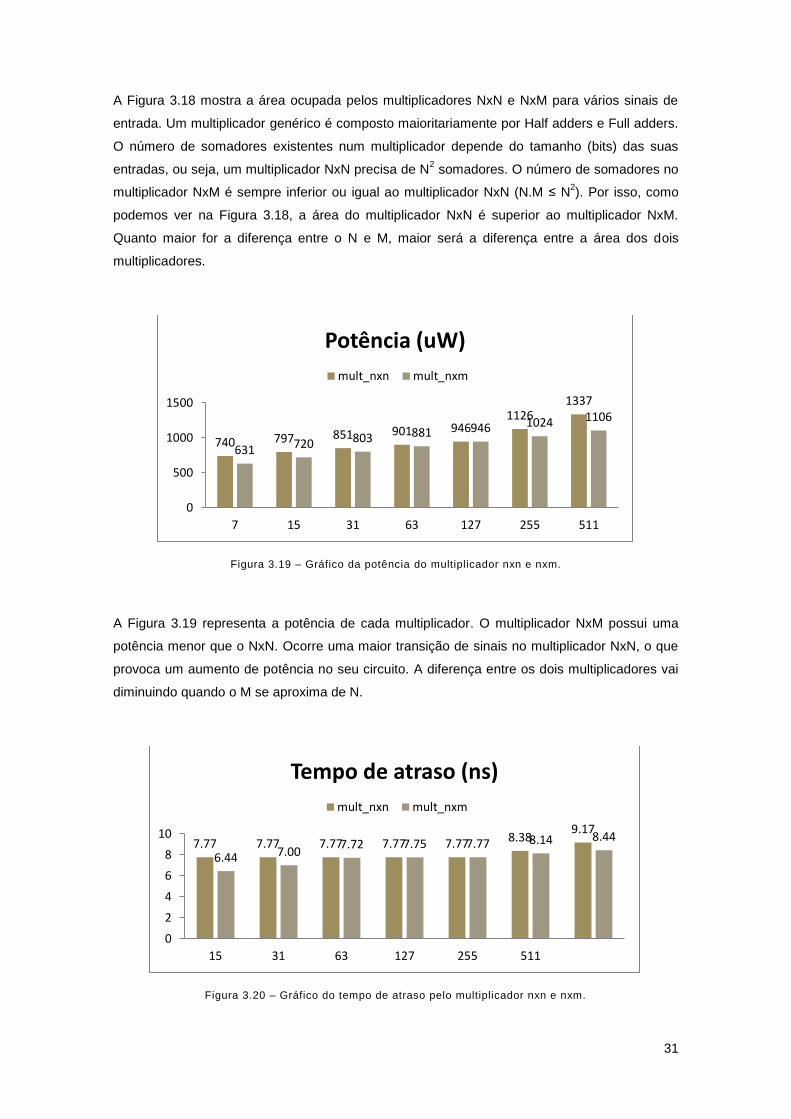
31
A Figura 3.18 mostra a área ocupada pelos multiplicadores NxN e NxM para vários sinais de
entrada. Um multiplicador genérico é composto maioritariamente por Half adders e Full adders.
O número de somadores existentes num multiplicador depende do tamanho (bits) das suas
entradas, ou seja, um multiplicador NxN precisa de N2 somadores. O número de somadores no
multiplicador NxM é sempre inferior ou igual ao multiplicador NxN (N.M ≤ N2). Por isso, como
podemos ver na Figura 3.18, a área do multiplicador NxN é superior ao multiplicador NxM.
Quanto maior for a diferença entre o N e M, maior será a diferença entre a área dos dois
multiplicadores.
Figura 3.19 – Gráfico da potência do multiplicador nxn e nxm.
A Figura 3.19 representa a potência de cada multiplicador. O multiplicador NxM possui uma
potência menor que o NxN. Ocorre uma maior transição de sinais no multiplicador NxN, o que
provoca um aumento de potência no seu circuito. A diferença entre os dois multiplicadores vai
diminuindo quando o M se aproxima de N.
Figura 3.20 – Gráfico do tempo de atraso pelo multiplicador nxn e nxm.
740 797 851 901 946 1126
1337
631 720 803 881 946 1024 1106
0
500
1000
1500
7 15 31 63 127 255 511
Potência (uW)
mult_nxn mult_nxm
7.77 7.77 7.77 7.77 7.77 8.38 9.17
6.44 7.00 7.72 7.75 7.77 8.14 8.44
0
2
4
6
8
10
15 31 63 127 255 511
Tempo de atraso (ns)
mult_nxn mult_nxm

32
A Figura 3.20 representa o tempo de atraso de cada multiplicador. Com uma área e uma
potência menor, o multiplicador NxM consegue ainda ser o mais rápido, como podemos ver na
Figura 3.20. A tendência do tempo de atraso segue os valores da área e da potência, quando
M tende para N, a diferença tende para zero. Quanto mais pequeno for o M, mais rápido é o
multiplicador. Isto acontece, porque o multiplicador NxM tem um caminho critico menor que o
NxN.
A substituição do multiplicador NxN por multiplicador NxM adaptado ao sinal de entrada a cada
coeficiente reduz a área, a potência e o tempo de atraso nas arquitecturas FIR. No capítulo dos
resultados, serão mostradas o comportamento destes dois multiplicadores nas arquitecturas
FIR configuráveis.
3.3. PARTILHA DOS MULTIPLICADORES
No tópico anterior ficou mostrado que a implementação de arquitecturas FIR com
multiplicadores NxM é mais eficientes que o uso dos multiplicadores tradicionais (NxN). Daqui
para a frente, todas as arquitecturas FIR com multiplicadores, têm implementado o
multiplicador NxM. No entanto, o uso de multiplicadores é sempre um custo elevado para a sua
implementação em hardware.
Com a implementação de arquitecturas FIR com 2 filtros, temos a liberdade de explorar novas
formas de elaborar e optimizar os filtros. No sentido de diminuir o número de multiplicadores a
implementar nas arquitecturas FIR, fez-se um estudo de como partilhá-los entre os dois filtros.
Nas arquitecturas FIR estudadas neste trabalho, os dois filtros implementados nunca são
usados simultaneamente, possibilitando a partilha dos multiplicadores. Os coeficientes dos dois
filtros podem partilhar os mesmos multiplicadores, diminuindo a área ocupada das
arquitecturas FIR. Podemos representar esta situação como um Diagrama de Veen, Figura
3.21.
Figura 3.21 – Diagrama de Venn
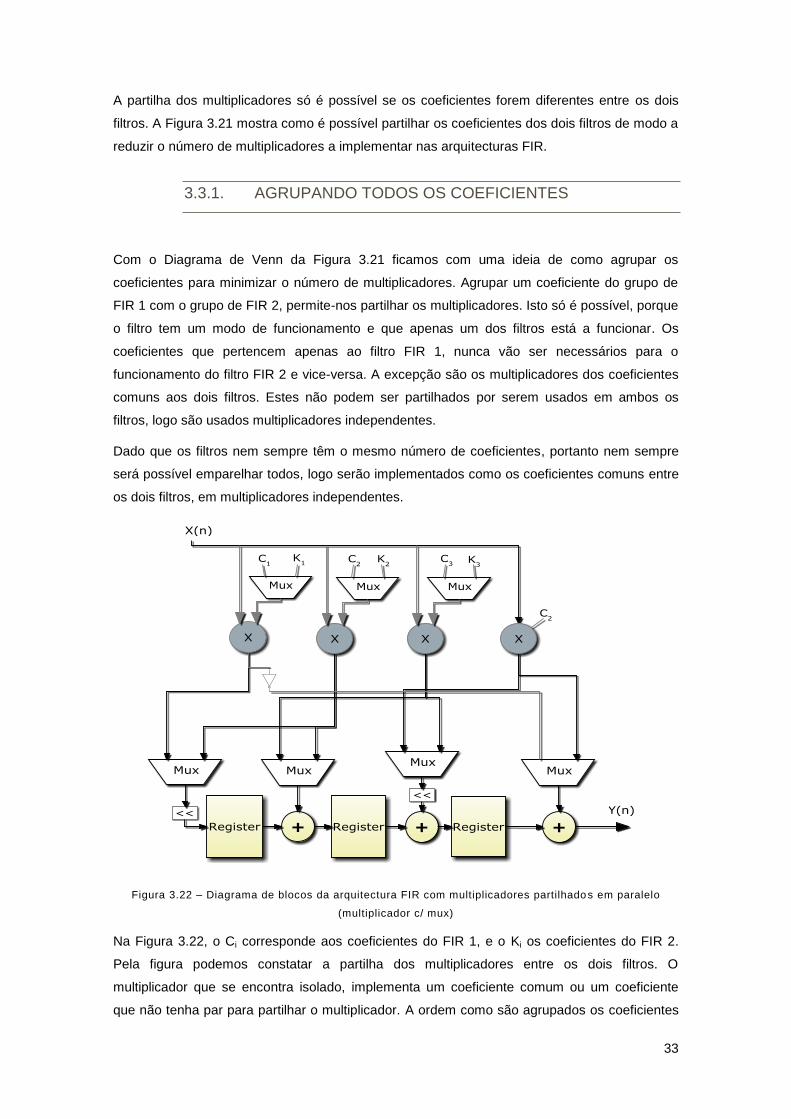
33
A partilha dos multiplicadores só é possível se os coeficientes forem diferentes entre os dois
filtros. A Figura 3.21 mostra como é possível partilhar os coeficientes dos dois filtros de modo a
reduzir o número de multiplicadores a implementar nas arquitecturas FIR.
3.3.1. AGRUPANDO TODOS OS COEFICIENTES
Com o Diagrama de Venn da Figura 3.21 ficamos com uma ideia de como agrupar os
coeficientes para minimizar o número de multiplicadores. Agrupar um coeficiente do grupo de
FIR 1 com o grupo de FIR 2, permite-nos partilhar os multiplicadores. Isto só é possível, porque
o filtro tem um modo de funcionamento e que apenas um dos filtros está a funcionar. Os
coeficientes que pertencem apenas ao filtro FIR 1, nunca vão ser necessários para o
funcionamento do filtro FIR 2 e vice-versa. A excepção são os multiplicadores dos coeficientes
comuns aos dois filtros. Estes não podem ser partilhados por serem usados em ambos os
filtros, logo são usados multiplicadores independentes.
Dado que os filtros nem sempre têm o mesmo número de coeficientes, portanto nem sempre
será possível emparelhar todos, logo serão implementados como os coeficientes comuns entre
os dois filtros, em multiplicadores independentes.
Figura 3.22 – Diagrama de blocos da arquitectura FIR com multiplicadores partilhados em paralelo
(multiplicador c/ mux)
Na Figura 3.22, o Ci corresponde aos coeficientes do FIR 1, e o Ki os coeficientes do FIR 2.
Pela figura podemos constatar a partilha dos multiplicadores entre os dois filtros. O
multiplicador que se encontra isolado, implementa um coeficiente comum ou um coeficiente
que não tenha par para partilhar o multiplicador. A ordem como são agrupados os coeficientes
34
também é fundamental para esta arquitectura. Os coeficientes que partilham os multiplicadores
são os mais pequenos. Esta decisão deve-se pelo motivo que nesta arquitectura o caminho
critico passar por dois multiplexeres. O multiplexer antes dos somadores, não pode ser
alterado, mas o multiplexer que escolhe os coeficientes a multiplicar pelo sinal de entrada, tem
o seu tamanho baseado nos coeficientes. Se tivermos os coeficientes mais pequenos do filtro a
partilhar, o multiplexer é menor, o que diminui o caminho critico. Os coeficientes que não
tenham par, ou seja, os coeficientes maiores serão implementados em multiplicadores
independentes.
A Tabela 3.5 apresenta os multiplicadores a implementar, com e sem partilha. Como veremos
mais à frente ao partilhar os multiplicadores, reduz.se a área e a potência consumida, mas
aumenta-se o caminho crítico do filtro. O facto de termos dois multiplexeres no caminho crítico,
limita a frequência de funcionamento do filtro. Por isso, será apresentada outra arquitectura que
partilha os coeficientes, mas permite aumentar a frequência de funcionamento.
Tabela 3.5 – Multiplicadores a implementar com e sem partilha
Filtros Multiplicadores a implementar
Sem partilha Com partilha (reduz)
1 e 2 22 17 (22.7%)
6 e 7 46 29 (37.0%)
5 e 9 70 45 (35.7%)
3.3.2. AGRUPANDO METADE DO FILTRO
Para melhorar a frequência de funcionamento, o caminho crítico não deve conter dois
multiplexeres. Dos dois multiplexeres da arquitectura da Figura 3.22, o que é maior e
consequentemente tem o tempo de atraso superior, é o que se encontra antes do bloco
acumulador. De maneira a diminuir o tempo de atraso, surgiu uma nova arquitectura que
prescinde desse multiplexer, ficando apenas os multiplexeres dos multiplicadores. Assim, a
saída dos multiplicadores liga directamente ao somador. Como temos dois filtros, tem de haver
um modo de poder escolher que filtro está a operar. Pelo facto de os multiplicadores terem um
multiplexer numa das entradas, permite-nos escolher o filtro. Isso implica, que tenha de existir
um multiplicador por cada somador. Deste modo, o número de multiplicadores tem de ser igual
ao número de somadores do filtro maior.
O facto de esta arquitectura necessitar de um multiplicador por par de coeficiente, tem à partida
um pior desempenho que as outras arquitecturas já estudadas. Se os filtros não tiverem fase
linear, no pior caso o número de multiplicadores é igual ao número de somadores. Para
ultrapassar isto, esta arquitectura só pode ser aplicada a filtros que tenham a sua fase linear.
Com a fase linear, só é necessário implementar metade do filtro. Nesta arquitectura não é

35
possível utilizar todas as optimizações efectuadas nos multiplicadores. A única optimização
efectuada aos multiplicadores nesta arquitectura foi passar os coeficientes pares para impares,
para utilizar as optimizações dos multiplexeres. Mas, a optimização dos multiplexeres, a que
permite passar os deslocamentos dos sinais de entrada para a saída foi alterada e levou-se
mais além, no sentido de realizar os deslocamentos o mais tarde possível. Os deslocamentos
são realizados depois dos multiplicadores. Assim, conseguimos reduzir a área dos
multiplexeres e dos multiplicadores.
A organização dos coeficientes dos dois filtros é fundamental para esta arquitectura. Para filtros
com o mesmo número de coeficientes o agrupamento dos coeficientes é trivial. Mas, para filtros
com tamanhos diferentes é necessário definir uma forma de agrupar os coeficientes. Assim, o
filtro mais pequeno ajusta-se aos extremos do filtro maior, em que o primeiro e o último
coeficiente de cada filtro formam o par. O filtro mais pequeno vai ficar com uma zona indefinida
no meio. Nessa zona, em que o filtro mais pequeno não contém coeficientes não é preciso
implementar multiplexeres, bastando multiplicar o sinal de entrada pelos coeficientes do filtro
maior.
Por exemplo, para implementar esta arquitectura, com os coeficientes C do FIR 1 e os
coeficientes K do FIR 2.
C = {-2670, 0, 6544, 6544, 0, -2670}
K = {0, 112, -42, 656, 2048, 656, -42, 112, 0}
Dado que |K| é maior que |C|, temos de dividir o FIR 2 (com menos coeficientes) a meio, para
ajustar aos extremos do FIR 1, conforme a Tabela 3.6:
Tabela 3.6 – Ajuste dos coeficientes dos dois filtros
FIR 1 -2670 0 6544 6544 0 -2670
FIR 2 0 112 -42 656 2048 656 -42 112 0
O objectivo é implementar metade do filtro (dado que é simétrico), em que são precisos 5
multiplicadores, 3 deles partilhados. Os multiplicadores partilhados utilizados são do tipo NxM
de forma a reduzir o tamanho dos multiplicadores. No entanto, antes de realizar as
multiplicações interessa-nos passar os coeficientes pares para impares.
Tabela 3.7 – Reajuste dos coeficientes dos filtros
FIR 1 -1335<<1 0 409<<4
FIR 2 0 7 <<4 -21<<1 41<<4 1<<11
Assim, os multiplicadores necessários são mais pequenos, conforme representados na Tabela
3.7. A redução dos multiplexeres e dos multiplicadores acontece quando o par de coeficientes
sofre um deslocamento, ou se um deles for nulo. O deslocamento vai ser realizado depois do
multiplicador. A Tabela 3.8 mostra as melhorias feitas à Tabela 3.7.

36
Tabela 3.8 – Coeficientes a implementar na arquitectura com partilha do multiplicador
FIR 1 -1335 0 409<<3
FIR 2 0 7 -21 41 1
Deslocamentos depois
do Multiplicador 1 4 1 4
11(não usa
multiplicador)
Como podemos ver pela Tabela 3.8, conseguimos reduzir o tamanho dos multiplexeres e dos
multiplicadores. Há caso, em que podemos prescindir de utilizar os multiplicadores, em que
neste exemplo, é o caso do multiplicador que não tem par, visto que o sinal a multiplicar
corresponde a um deslocamento de 11 posições do sinal de entrada. Na Figura 3.23
apresenta-se a implementação desta arquitectura.
Figura 3.23 – Diagrama de blocos da arquitectura FIR paralela com multiplicadores partilhados V2
(multiplicador c/ mux v2).
Nota-se que o multiplexer no bloco acumulador aparece se ao dividir os filtros a metade, estas
não forem do mesmo tamanho. Assim, ficamos com multiplicadores que só operam um
coeficiente de um dos filtros. Portanto quando queremos realizar a filtragem com o filtro mais
pequeno tem que ter forma de eliminar os coeficientes indesejáveis do filtro maior. Para
resolver a situação, inseriu-se um multiplexer, que faz saltar T registos, sendo T a diferença
entre a metade dos dois filtros, ficando os dois filtros, com os resultados correctos.
3.4. RESULTADOS
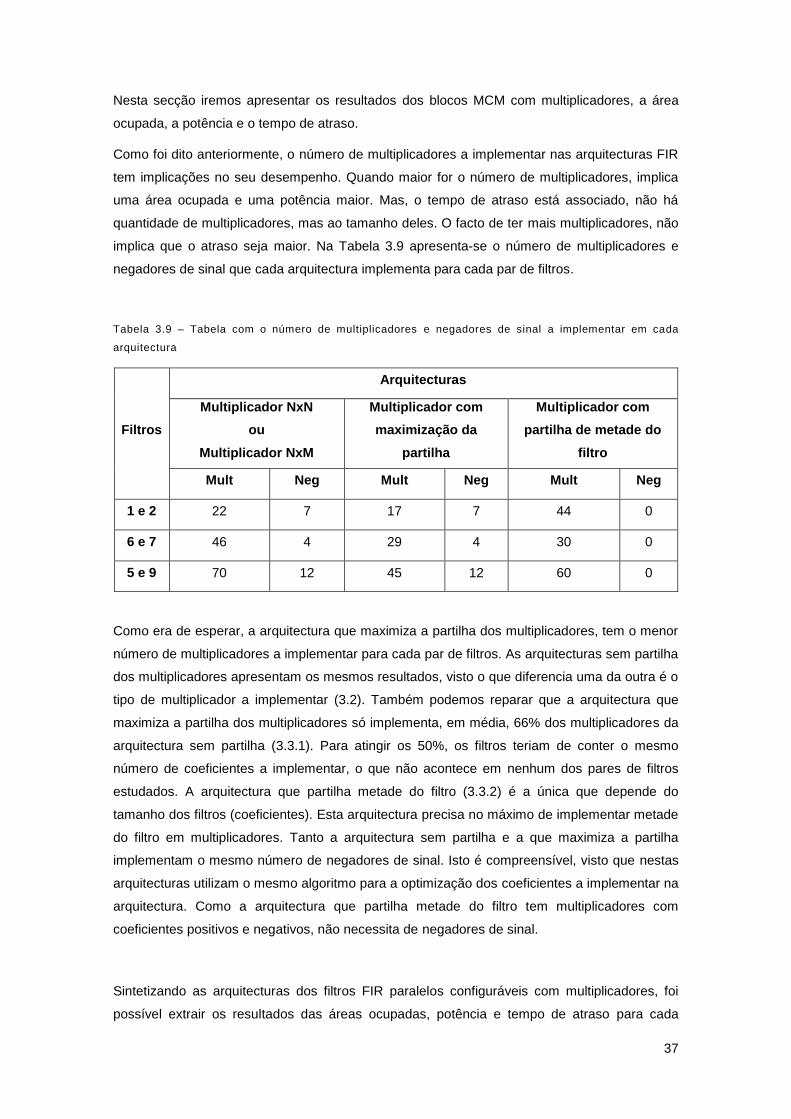
37
Nesta secção iremos apresentar os resultados dos blocos MCM com multiplicadores, a área
ocupada, a potência e o tempo de atraso.
Como foi dito anteriormente, o número de multiplicadores a implementar nas arquitecturas FIR
tem implicações no seu desempenho. Quando maior for o número de multiplicadores, implica
uma área ocupada e uma potência maior. Mas, o tempo de atraso está associado, não há
quantidade de multiplicadores, mas ao tamanho deles. O facto de ter mais multiplicadores, não
implica que o atraso seja maior. Na Tabela 3.9 apresenta-se o número de multiplicadores e
negadores de sinal que cada arquitectura implementa para cada par de filtros.
Tabela 3.9 – Tabela com o número de multiplicadores e negadores de sinal a implementar em cada
arquitectura
Filtros
Arquitecturas
Multiplicador NxN
ou
Multiplicador NxM
Multiplicador com
maximização da
partilha
Multiplicador com
partilha de metade do
filtro
Mult Neg Mult Neg Mult Neg
1 e 2 22 7 17 7 44 0
6 e 7 46 4 29 4 30 0
5 e 9 70 12 45 12 60 0
Como era de esperar, a arquitectura que maximiza a partilha dos multiplicadores, tem o menor
número de multiplicadores a implementar para cada par de filtros. As arquitecturas sem partilha
dos multiplicadores apresentam os mesmos resultados, visto o que diferencia uma da outra é o
tipo de multiplicador a implementar (3.2). Também podemos reparar que a arquitectura que
maximiza a partilha dos multiplicadores só implementa, em média, 66% dos multiplicadores da
arquitectura sem partilha (3.3.1). Para atingir os 50%, os filtros teriam de conter o mesmo
número de coeficientes a implementar, o que não acontece em nenhum dos pares de filtros
estudados. A arquitectura que partilha metade do filtro (3.3.2) é a única que depende do
tamanho dos filtros (coeficientes). Esta arquitectura precisa no máximo de implementar metade
do filtro em multiplicadores. Tanto a arquitectura sem partilha e a que maximiza a partilha
implementam o mesmo número de negadores de sinal. Isto é compreensível, visto que nestas
arquitecturas utilizam o mesmo algoritmo para a optimização dos coeficientes a implementar na
arquitectura. Como a arquitectura que partilha metade do filtro tem multiplicadores com
coeficientes positivos e negativos, não necessita de negadores de sinal.
Sintetizando as arquitecturas dos filtros FIR paralelos configuráveis com multiplicadores, foi
possível extrair os resultados das áreas ocupadas, potência e tempo de atraso para cada

38
arquitectura. A síntese foi realizada para sinais de entrada com 8, 16 e 32 bits. Só serão
mostrados os resultados referentes a 32 bits, sendo os que os restantes encontram-se em
anexo e em geral seguem a mesma tendência. O script usado para a síntese encontra-se em
anexo.
3.4.1. ÁREA
A área nas arquitecturas FIR paralelas, o bloco MCM ocupa uma área superior a 50% de todo
o filtro. Logo, uma diminuição do número de multiplicadores, deve implicar uma redução da
área ocupada. As arquitecturas aqui estudadas, não são compostas unicamente por
multiplicadores, tendo todas multiplexeres, que em geral são em maior número que os
multiplicadores, nalgumas delas contêm ainda negadores de sinal. Na Figura 3.24, é
apresentado os resultados da área ocupada pelo bloco MCM após a síntese para um sinal de
entrada de 32 bits.
Figura 3.24 – Gráfico com as áreas do bloco MCM com multiplicadores
Na Figura 3.24 apresenta-se a área ocupada pelo bloco MCM com multiplicadores para os
filtros usados como benchmarks. Pela análise da Figura 3.24, a arquitectura que maximiza a
partilha é a que ocupa menos área. Um resultado esperado, visto que é a arquitectura que
implementa menos multiplicadores. A escolha do tipo de multiplicador a utilizar também pode
influenciar a área. Utilizar o multiplicador NxN no bloco MCM implica ocupar uma área maior do
que utilizar o multiplicador NxM. A arquitectura que partilha metade do filtro consegue ser a
arquitectura com a área ocupada menor, se e só se, o número de multiplicadores a
implementar nas outras arquitecturas for superior a metade do número de coeficientes do filtro
maior. Nos restantes caso, é sempre superior à outra arquitectura que partilha os
2.71
6.94
10.78
1.37 2.55
4.32
1.36 2.35
4.18
2.14 2.47
5.10
0
2
4
6
8
10
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Milh
õe
s
Área (bloco MCM)
Multiplicador NxN Multiplicador NxM
Multiplicador c/ mux Multiplicador c/ mux v2
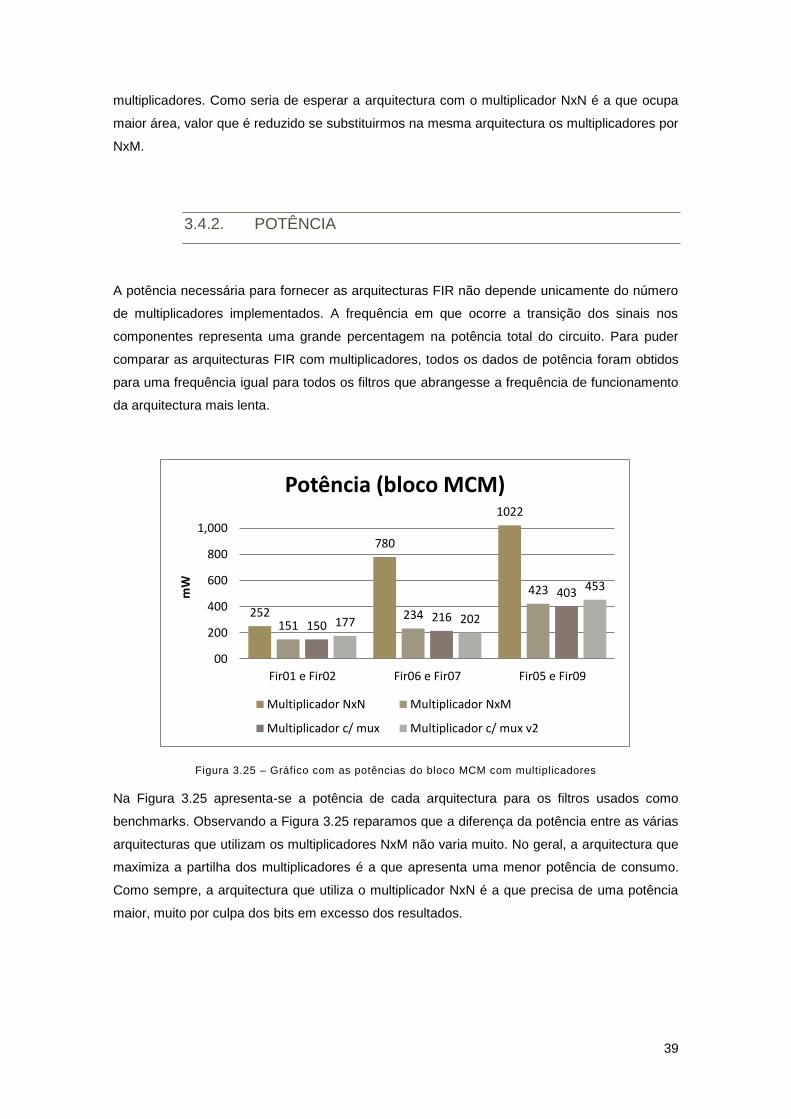
39
multiplicadores. Como seria de esperar a arquitectura com o multiplicador NxN é a que ocupa
maior área, valor que é reduzido se substituirmos na mesma arquitectura os multiplicadores por
NxM.
3.4.2. POTÊNCIA
A potência necessária para fornecer as arquitecturas FIR não depende unicamente do número
de multiplicadores implementados. A frequência em que ocorre a transição dos sinais nos
componentes representa uma grande percentagem na potência total do circuito. Para puder
comparar as arquitecturas FIR com multiplicadores, todos os dados de potência foram obtidos
para uma frequência igual para todos os filtros que abrangesse a frequência de funcionamento
da arquitectura mais lenta.
Figura 3.25 – Gráfico com as potências do bloco MCM com multiplicadores
Na Figura 3.25 apresenta-se a potência de cada arquitectura para os filtros usados como
benchmarks. Observando a Figura 3.25 reparamos que a diferença da potência entre as várias
arquitecturas que utilizam os multiplicadores NxM não varia muito. No geral, a arquitectura que
maximiza a partilha dos multiplicadores é a que apresenta uma menor potência de consumo.
Como sempre, a arquitectura que utiliza o multiplicador NxN é a que precisa de uma potência
maior, muito por culpa dos bits em excesso dos resultados.
252
780
1022
151 234
423
150 216
403
177 202
453
00
200
400
600
800
1,000
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
mW
Potência (bloco MCM)
Multiplicador NxN Multiplicador NxM
Multiplicador c/ mux Multiplicador c/ mux v2
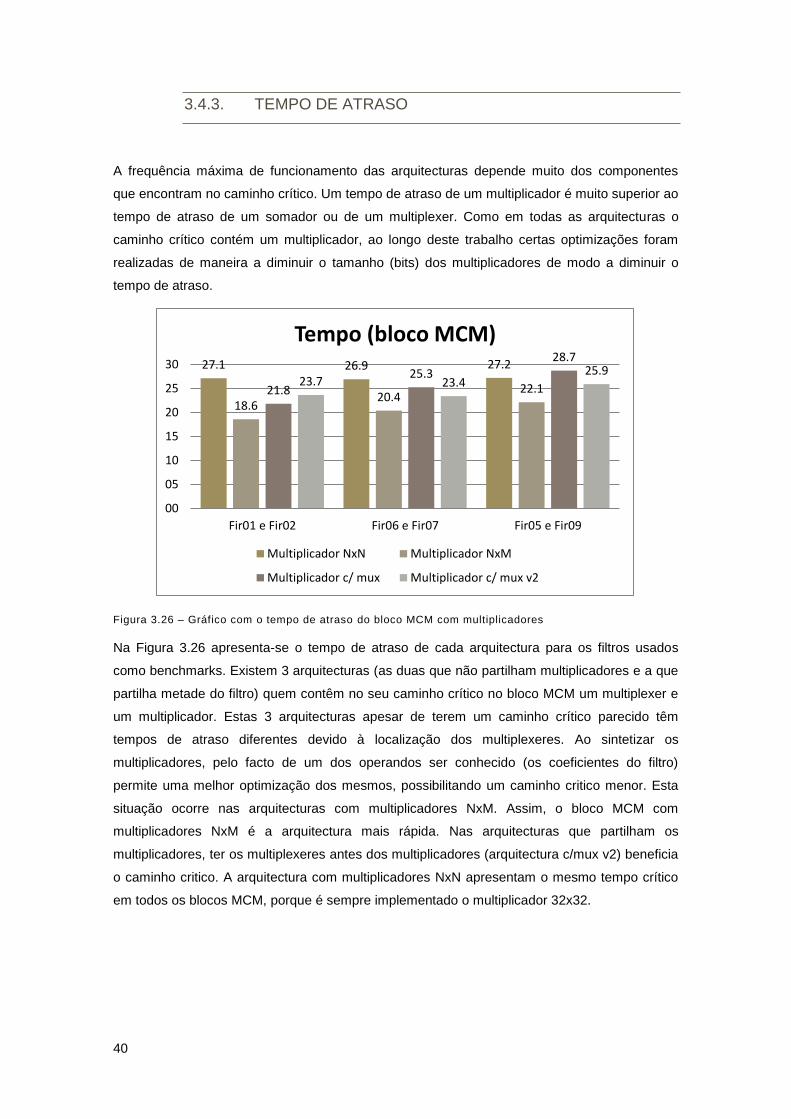
40
3.4.3. TEMPO DE ATRASO
A frequência máxima de funcionamento das arquitecturas depende muito dos componentes
que encontram no caminho crítico. Um tempo de atraso de um multiplicador é muito superior ao
tempo de atraso de um somador ou de um multiplexer. Como em todas as arquitecturas o
caminho crítico contém um multiplicador, ao longo deste trabalho certas optimizações foram
realizadas de maneira a diminuir o tamanho (bits) dos multiplicadores de modo a diminuir o
tempo de atraso.
Figura 3.26 – Gráfico com o tempo de atraso do bloco MCM com multiplicadores
Na Figura 3.26 apresenta-se o tempo de atraso de cada arquitectura para os filtros usados
como benchmarks. Existem 3 arquitecturas (as duas que não partilham multiplicadores e a que
partilha metade do filtro) quem contêm no seu caminho crítico no bloco MCM um multiplexer e
um multiplicador. Estas 3 arquitecturas apesar de terem um caminho crítico parecido têm
tempos de atraso diferentes devido à localização dos multiplexeres. Ao sintetizar os
multiplicadores, pelo facto de um dos operandos ser conhecido (os coeficientes do filtro)
permite uma melhor optimização dos mesmos, possibilitando um caminho critico menor. Esta
situação ocorre nas arquitecturas com multiplicadores NxM. Assim, o bloco MCM com
multiplicadores NxM é a arquitectura mais rápida. Nas arquitecturas que partilham os
multiplicadores, ter os multiplexeres antes dos multiplicadores (arquitectura c/mux v2) beneficia
o caminho critico. A arquitectura com multiplicadores NxN apresentam o mesmo tempo crítico
em todos os blocos MCM, porque é sempre implementado o multiplicador 32x32.
27.1 26.9 27.2
18.6 20.4
22.1 21.8
25.3
28.7
23.7 23.4 25.9
00
05
10
15
20
25
30
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Tempo (bloco MCM)
Multiplicador NxN Multiplicador NxM
Multiplicador c/ mux Multiplicador c/ mux v2

41
CAPÍTULO 4
4. ARQUITECTURA PARA FILTROS FIR PARALELA
COM ADIÇÕES E DESLOCAMENTOS
O problema de projectar filtros digitais tem recebido grande atenção durante a última década,
como os filtros requerem um grande número de multiplicadores, levam a área, potência
consumida e tempo de atraso excessivos, mesmo se forem implementados em circuito
integrado. As mais recentes propostas concentram-se na redução da área dos filtros
substituindo as operações de multiplicação por coeficientes constantes por adições,
subtracções e deslocamentos. Como os deslocamentos são gratuitos em termos de hardware,
o problema do projecto pode ser definido como a minimização do número de operações de
adição/subtracção para implementar as multiplicações dos coeficientes.
Os algoritmos propostos para a optimização do número de operações no projecto de filtros
digitais podem ser catalogados em duas classes: eliminação de expressões comuns (CSE) e a
técnica do grafo. Nos algoritmos CSE, as constantes são representadas na forma digital
canónica com sinal (CSD) ou no mínimo dígito com sinal (MSD). A representação em MSD é
obtida através da representação em CSD tirando o requerimento de não haver dois dígitos
consecutivos não-zeros [11].
Existem vários algoritmos para os nossos problemas de encontrar o número mínimo de
operações para o cálculo dos coeficientes, uns que permitem maximizar a partilha dos termos
parciais [11], ou o número mínimo de operações em série [12].
As constantes são representadas numa representação numérica, geralmente, na canónica
digital com sinal (CSD) e no mínimo digital com sinal (MSD). Ambas as representações CSD e
MSD usam um sistema digital com sinal com o conjunto digital {1,0,1}, onde 1 significa -1 e tem
a propriedade que o número de não-zeros é mínimo.
Tabela 4.1 – Cálculo dos coeficientes usando o MCM
Coeficientes
[11] [12]
Expressão Operações
em série Expressão
Operações em
série
3
1
1
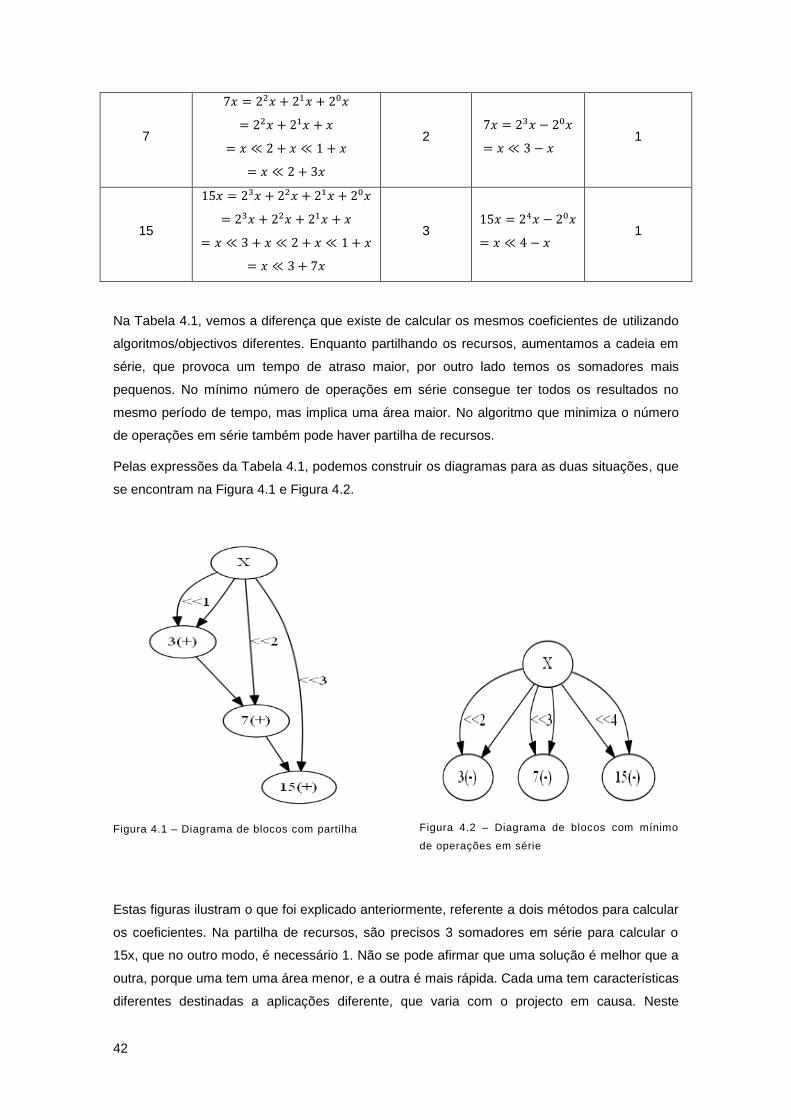
42
7
2
1
15
3
1
Na Tabela 4.1, vemos a diferença que existe de calcular os mesmos coeficientes de utilizando
algoritmos/objectivos diferentes. Enquanto partilhando os recursos, aumentamos a cadeia em
série, que provoca um tempo de atraso maior, por outro lado temos os somadores mais
pequenos. No mínimo número de operações em série consegue ter todos os resultados no
mesmo período de tempo, mas implica uma área maior. No algoritmo que minimiza o número
de operações em série também pode haver partilha de recursos.
Pelas expressões da Tabela 4.1, podemos construir os diagramas para as duas situações, que
se encontram na Figura 4.1 e Figura 4.2.
Figura 4.1 – Diagrama de blocos com partilha
Figura 4.2 – Diagrama de blocos com mínimo
de operações em série
Estas figuras ilustram o que foi explicado anteriormente, referente a dois métodos para calcular
os coeficientes. Na partilha de recursos, são precisos 3 somadores em série para calcular o
15x, que no outro modo, é necessário 1. Não se pode afirmar que uma solução é melhor que a
outra, porque uma tem uma área menor, e a outra é mais rápida. Cada uma tem características
diferentes destinadas a aplicações diferente, que varia com o projecto em causa. Neste

43
trabalho, e como estamos a comparar com as arquitecturas com multiplicadores, que são
indiferentes a estes processos de operações, o algoritmo utilizado nas arquitecturas com
adições e deslocamentos privilegia a frequência de funcionamento do filtro, ou seja, minimiza o
número de operações em série.
A estrutura das arquitecturas de filtros FIR com somas e deslocamentos, não são muito
diferentes da estrutura das arquitecturas com multiplicadores. O bloco acumulador é idêntico às
duas arquitecturas. A grande diferença está no bloco responsável pela multiplicação dos
coeficientes pelo sinal de entrada. Assim, muitas das decisões que foram tomadas nas
arquitecturas com multiplicadores, também se aplicam nestas arquitecturas:
Todas as optimizações realizadas no bloco acumulador, para redução do número de
somadores e multiplexeres;
No bloco MCM em caso de coeficientes negativos, será aplicado o modelo somador
seguido do negador de sinal;
4.1. IMPLEMENTAÇÃO DAS ARQUITECTURAS
A implementação das arquitecturas com adições e deslocamentos com dois filtros tem como
objectivo, melhorar os resultados apresentados pelas arquitecturas com multiplicadores. Tal
como nas arquitecturas com multiplicadores, nas arquitecturas com adições e deslocamentos
também podem ser implementadas de várias maneiras. Serão estudadas arquitecturas sem
partilha e com partilha de somadores.
4.1.1. ARQUITECTURAS SEM PARTILHA DOS SOMADORES
Uma das estruturas mais simples de implementar quando se pensa juntar dois filtros, é
semelhante à que já foi apresentada no âmbito das arquitecturas com multiplicadores. Na
Figura 4.3 apresenta-se esta arquitectura em que cada filtro tem o seu bloco acumulador e o
bloco MCM, terminando com um multiplexer, para escolher qual o filtro a utilizar.
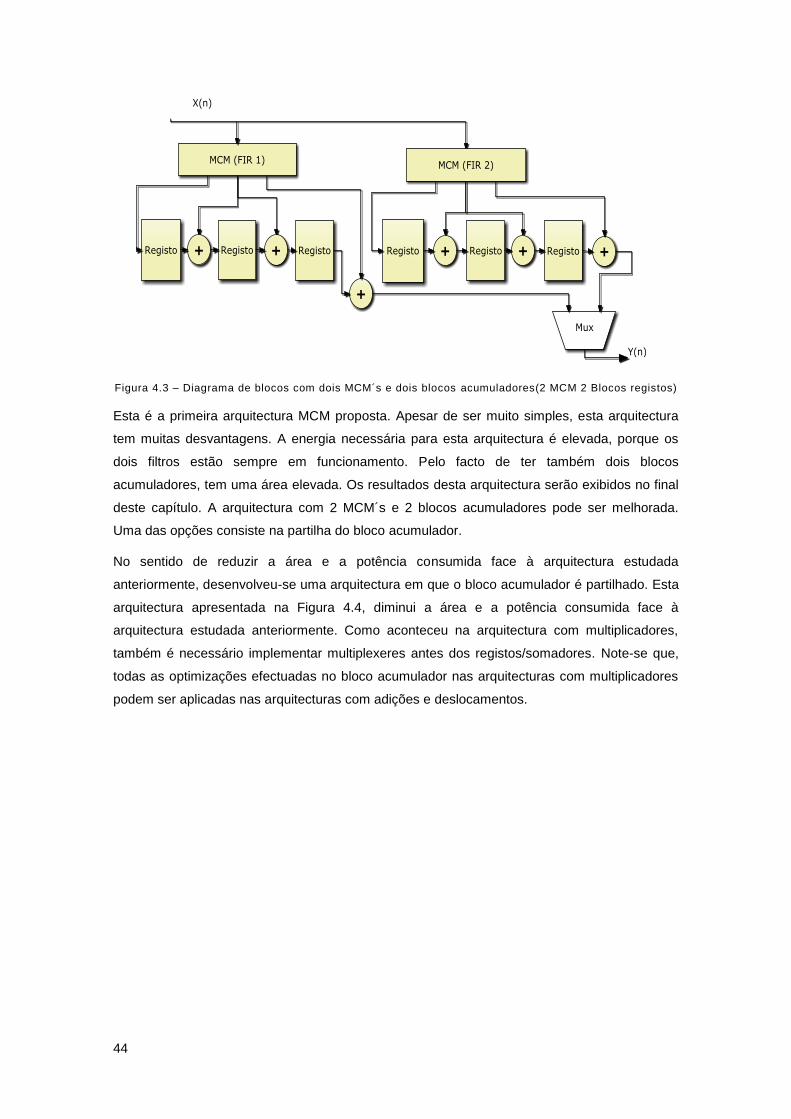
44
Figura 4.3 – Diagrama de blocos com dois MCM´s e dois blocos acumuladores(2 MCM 2 Blocos registos)
Esta é a primeira arquitectura MCM proposta. Apesar de ser muito simples, esta arquitectura
tem muitas desvantagens. A energia necessária para esta arquitectura é elevada, porque os
dois filtros estão sempre em funcionamento. Pelo facto de ter também dois blocos
acumuladores, tem uma área elevada. Os resultados desta arquitectura serão exibidos no final
deste capítulo. A arquitectura com 2 MCM´s e 2 blocos acumuladores pode ser melhorada.
Uma das opções consiste na partilha do bloco acumulador.
No sentido de reduzir a área e a potência consumida face à arquitectura estudada
anteriormente, desenvolveu-se uma arquitectura em que o bloco acumulador é partilhado. Esta
arquitectura apresentada na Figura 4.4, diminui a área e a potência consumida face à
arquitectura estudada anteriormente. Como aconteceu na arquitectura com multiplicadores,
também é necessário implementar multiplexeres antes dos registos/somadores. Note-se que,
todas as optimizações efectuadas no bloco acumulador nas arquitecturas com multiplicadores
podem ser aplicadas nas arquitecturas com adições e deslocamentos.
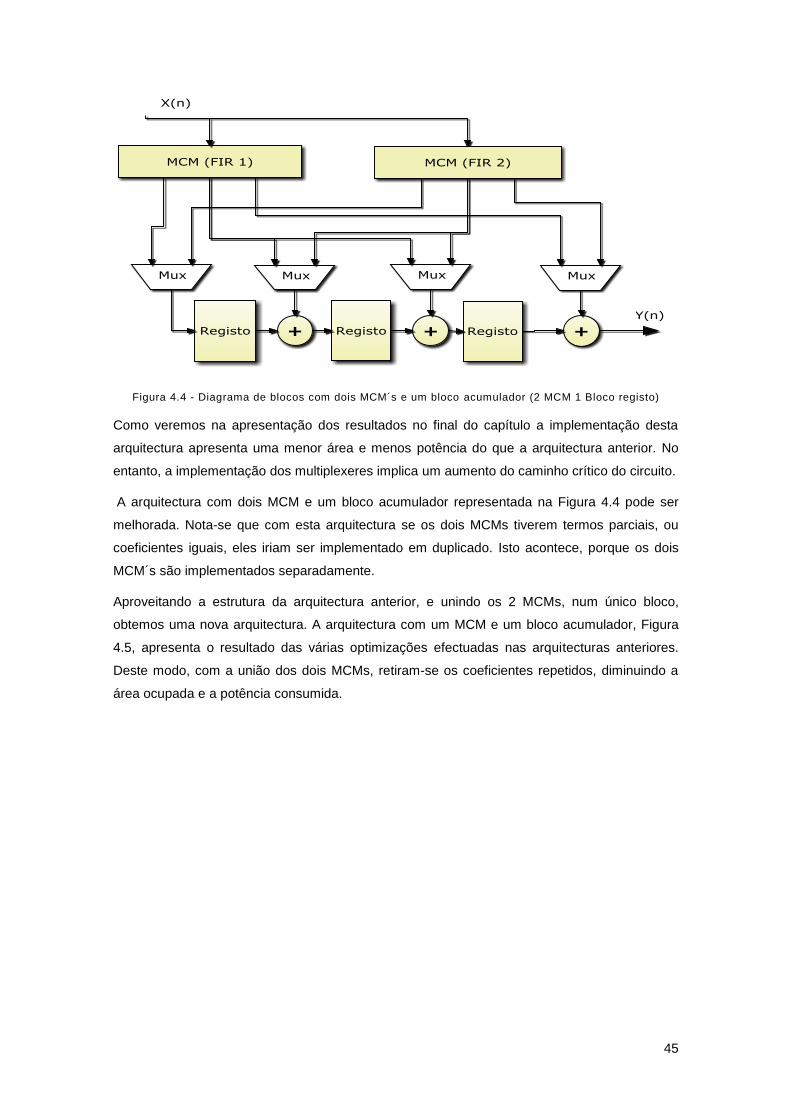
45
Figura 4.4 - Diagrama de blocos com dois MCM´s e um bloco acumulador (2 MCM 1 Bloco registo)
Como veremos na apresentação dos resultados no final do capítulo a implementação desta
arquitectura apresenta uma menor área e menos potência do que a arquitectura anterior. No
entanto, a implementação dos multiplexeres implica um aumento do caminho crítico do circuito.
A arquitectura com dois MCM e um bloco acumulador representada na Figura 4.4 pode ser
melhorada. Nota-se que com esta arquitectura se os dois MCMs tiverem termos parciais, ou
coeficientes iguais, eles iriam ser implementado em duplicado. Isto acontece, porque os dois
MCM´s são implementados separadamente.
Aproveitando a estrutura da arquitectura anterior, e unindo os 2 MCMs, num único bloco,
obtemos uma nova arquitectura. A arquitectura com um MCM e um bloco acumulador, Figura
4.5, apresenta o resultado das várias optimizações efectuadas nas arquitecturas anteriores.
Deste modo, com a união dos dois MCMs, retiram-se os coeficientes repetidos, diminuindo a
área ocupada e a potência consumida.
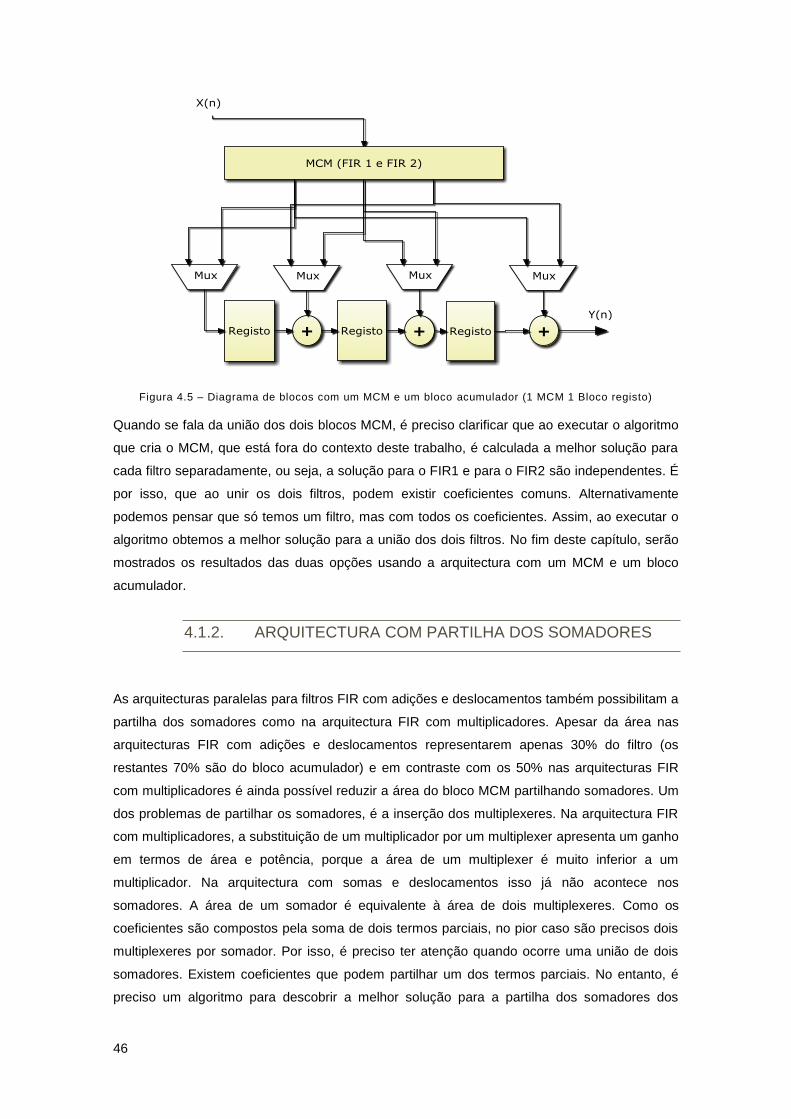
46
Figura 4.5 – Diagrama de blocos com um MCM e um bloco acumulador (1 MCM 1 Bloco registo)
Quando se fala da união dos dois blocos MCM, é preciso clarificar que ao executar o algoritmo
que cria o MCM, que está fora do contexto deste trabalho, é calculada a melhor solução para
cada filtro separadamente, ou seja, a solução para o FIR1 e para o FIR2 são independentes. É
por isso, que ao unir os dois filtros, podem existir coeficientes comuns. Alternativamente
podemos pensar que só temos um filtro, mas com todos os coeficientes. Assim, ao executar o
algoritmo obtemos a melhor solução para a união dos dois filtros. No fim deste capítulo, serão
mostrados os resultados das duas opções usando a arquitectura com um MCM e um bloco
acumulador.
4.1.2. ARQUITECTURA COM PARTILHA DOS SOMADORES
As arquitecturas paralelas para filtros FIR com adições e deslocamentos também possibilitam a
partilha dos somadores como na arquitectura FIR com multiplicadores. Apesar da área nas
arquitecturas FIR com adições e deslocamentos representarem apenas 30% do filtro (os
restantes 70% são do bloco acumulador) e em contraste com os 50% nas arquitecturas FIR
com multiplicadores é ainda possível reduzir a área do bloco MCM partilhando somadores. Um
dos problemas de partilhar os somadores, é a inserção dos multiplexeres. Na arquitectura FIR
com multiplicadores, a substituição de um multiplicador por um multiplexer apresenta um ganho
em termos de área e potência, porque a área de um multiplexer é muito inferior a um
multiplicador. Na arquitectura com somas e deslocamentos isso já não acontece nos
somadores. A área de um somador é equivalente à área de dois multiplexeres. Como os
coeficientes são compostos pela soma de dois termos parciais, no pior caso são precisos dois
multiplexeres por somador. Por isso, é preciso ter atenção quando ocorre uma união de dois
somadores. Existem coeficientes que podem partilhar um dos termos parciais. No entanto, é
preciso um algoritmo para descobrir a melhor solução para a partilha dos somadores dos

47
coeficientes. A solução que permite diminuir a área consiste na substituição de um somador
por um multiplexer. Haverá casos em que isso não será possível, em que será necessário
implementar dois multiplexeres. Foram desenvolvidos dois algoritmos distintos, para a procura
da melhor solução de emparelhamento dos somadores. Um dos algoritmos consiste numa
heurística de procura com o objectivo de emparelhar o máximo de somadores com um único
multiplexer, enquanto o outro algoritmo recorre a modelo de programação linear que
transformando o problema num conjunto de restrições e uma função de custo para minimizar a
área do circuito. A Figura 4.6 representa o resultado de partilhar o mesmo operador para os
coeficientes 303x e 117x.
Figura 4.6 – (a) Diagrama de blocos dos coeficientes 303x e 117x. (b) Diagrama de blocos do resultados
de partilhar os coeficientes 303x e 117x.
4.1.2.1. USANDO O ALGORITMO HEURISTICO DE PROCURA
Uma das soluções para o emparelhamento de coeficientes parciais das arquitecturas FIR foi
um algoritmo heurístico de procura. Antes de explicar o funcionamento do algoritmo, existem
alguns parâmetros que ainda não foram explicados ao longo deste trabalho. Os coeficientes
parciais, que provêem dos coeficientes dos filtros, podem ser tratados como um grafo
direccionado. Como o grafo não pode conter ciclos, temos dígrafo acíclico. Os vértices do grafo
são representados pelos coeficientes parciais. O grau de entrada de cada vértice não excede o
2, enquanto o grau de saída pode ser variado, logo o grafo não é balanceado. O nível a que se
encontra cada vértice corresponde à soma de todos os vértices anteriores, contado com o
próprio vértice. No emparelhamento dos coeficientes parciais, o nível a que cada vértice se
encontra é fundamental para o algoritmo desenvolvido. Outra das características a ter em conta
é na possibilidade de haver emparelhamento de coeficientes parciais com sinais diferentes.
Neste caso, todos esses pares serão rejeitados pelo algoritmo, evitanda a implementação de
somadores/subtractores.

48
O algoritmo pode ser dividido em 6 etapas distintas resumidas na Figura 4.7. A primeira etapa
é encontrar todos os coeficientes parciais comuns aos dois filtros. Estes coeficientes não
podem ser partilhados, por serem utilizados em ambos os filtros. Cada coeficiente comum será
implementado num somador independente. A segunda etapa consiste em emparelhar os
coeficientes parciais que tenham um dos termos parciais idênticos. No entanto, limitou-se esta
etapa a coeficientes que estejam no mesmo nível, evitando as alterações do nível, que
acontece quando se junta coeficientes de níveis diferentes. Esta alteração do nível não
prejudica o funcionamento do filtro, mas pode provocar um aumento de área, porque os
coeficientes parciais com níveis mais altos geralmente precisam de somadores maiores, pois
calculam valores maiores (logo maiores numero de bits) que, em geral, somadores do mesmo
nível têm uma diferença menor do número de bits. Mas, como podem existir termos parciais
iguais mas de níveis diferentes, a terceira etapa trata desses casos. Note-se que na segunda e
terceira etapa, em termos de hardware, foi feita a substituição de um somador por um
multiplexer.
Depois destas etapas, já não existem coeficientes parciais que sejam calculados com um
operando igual, logo, todos os emparelhamentos que se seguem, para a substituição de um
somador são necessários dois multiplexeres. Na quarta etapa, são efectuados todos os
emparelhamentos possíveis, do mesmo nível. A justificação da limitação é a mesma da etapa
2. Na quinta etapa, serão emparelhados todos os restantes coeficientes parciais de níveis
diferentes. Ao fim desta etapa, foram realizadas todos os possíveis emparelhamentos entre os
dois filtros. Como os dois filtros podem não conter o mesmo número de coeficientes parciais,
na sexta etapa são implementados em somadores independentes os coeficientes parciais do
filtro que restaram.
Figura 4.7 – Etapas efectuadas pelo algoritmo no emparelhamento dos coeficientes parciais
Para mostrar todas as etapas, foram utilizados os filtros 6 e 7 para o exemplo. Na Tabela 4.2
apresentam-se os coeficientes parciais de cada filtro e o nível a que se encontram. O cálculo
dos coeficientes parciais foi obtido usando o algoritmo de [12], e sendo o nível depois calculado
pelo algoritmo desenvolvido.
1ª Etapa
•Encontrar todos os
coeficientes comuns aos dois filtros
•Implementação dos mesmos
em somadores independentes
2ª Etapa
•Emparelhar todos
coeficientes que contenham um dos termos
parcais idênticos, mas
têm de estar no mesmo nivel
•Implementação dos pares que cumprem as
condições
3ª Etapa
•Emparelhar todos
coeficientes que contenham um dos termos
parcais idênticos
•Implementação dos pares que cumprem as
condições
4ª Etapa
•Emparelhar todo os
coeficientes que contenham
os termos parciais
diferentes, mas têm de estar no
mesmo nivel
•Implementação dos pares que cumprem as
condições
5ª Etapa
•Emparelhamento dos restantes coeficientes
parciais
•Implementação dos restantes
pares
6ª Etapa
•Implementação dos restantes coeficientes
parcias quem nao contenham
par
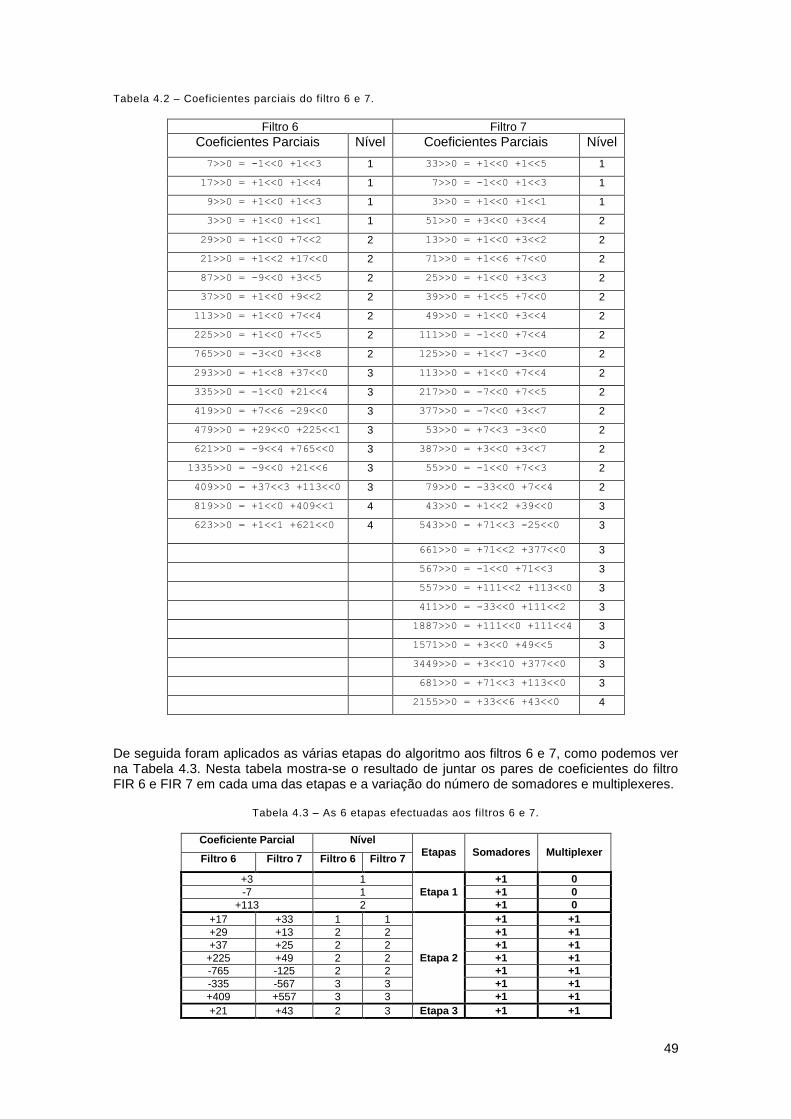
49
Tabela 4.2 – Coeficientes parciais do filtro 6 e 7.
Filtro 6 Filtro 7
Coeficientes Parciais Nível Coeficientes Parciais Nível
7>>0 = -1<<0 +1<<3 1 33>>0 = +1<<0 +1<<5 1
17>>0 = +1<<0 +1<<4 1 7>>0 = -1<<0 +1<<3 1
9>>0 = +1<<0 +1<<3 1 3>>0 = +1<<0 +1<<1 1
3>>0 = +1<<0 +1<<1 1 51>>0 = +3<<0 +3<<4 2
29>>0 = +1<<0 +7<<2 2 13>>0 = +1<<0 +3<<2 2
21>>0 = +1<<2 +17<<0 2 71>>0 = +1<<6 +7<<0 2
87>>0 = -9<<0 +3<<5 2 25>>0 = +1<<0 +3<<3 2
37>>0 = +1<<0 +9<<2 2 39>>0 = +1<<5 +7<<0 2
113>>0 = +1<<0 +7<<4 2 49>>0 = +1<<0 +3<<4 2
225>>0 = +1<<0 +7<<5 2 111>>0 = -1<<0 +7<<4 2
765>>0 = -3<<0 +3<<8 2 125>>0 = +1<<7 -3<<0 2
293>>0 = +1<<8 +37<<0 3 113>>0 = +1<<0 +7<<4 2
335>>0 = -1<<0 +21<<4 3 217>>0 = -7<<0 +7<<5 2
419>>0 = +7<<6 -29<<0 3 377>>0 = -7<<0 +3<<7 2
479>>0 = +29<<0 +225<<1 3 53>>0 = +7<<3 -3<<0 2
621>>0 = -9<<4 +765<<0 3 387>>0 = +3<<0 +3<<7 2
1335>>0 = -9<<0 +21<<6 3 55>>0 = -1<<0 +7<<3 2
409>>0 = +37<<3 +113<<0 3 79>>0 = -33<<0 +7<<4 2
819>>0 = +1<<0 +409<<1 4 43>>0 = +1<<2 +39<<0 3
623>>0 = +1<<1 +621<<0
4 543>>0 = +71<<3 -25<<0 3
661>>0 = +71<<2 +377<<0 3
567>>0 = -1<<0 +71<<3 3
557>>0 = +111<<2 +113<<0 3
411>>0 = -33<<0 +111<<2 3
1887>>0 = +111<<0 +111<<4 3
1571>>0 = +3<<0 +49<<5 3
3449>>0 = +3<<10 +377<<0 3
681>>0 = +71<<3 +113<<0 3
2155>>0 = +33<<6 +43<<0 4
De seguida foram aplicados as várias etapas do algoritmo aos filtros 6 e 7, como podemos ver na Tabela 4.3. Nesta tabela mostra-se o resultado de juntar os pares de coeficientes do filtro FIR 6 e FIR 7 em cada uma das etapas e a variação do número de somadores e multiplexeres.
Tabela 4.3 – As 6 etapas efectuadas aos filtros 6 e 7.
Coeficiente Parcial Nível Etapas Somadores Multiplexer
Filtro 6 Filtro 7 Filtro 6 Filtro 7
+3 1
Etapa 1
+1 0
-7 1 +1 0
+113 2 +1 0
+17 +33 1 1
Etapa 2
+1 +1
+29 +13 2 2 +1 +1
+37 +25 2 2 +1 +1
+225 +49 2 2 +1 +1
-765 -125 2 2 +1 +1
-335 -567 3 3 +1 +1
+409 +557 3 3 +1 +1
+21 +43 2 3 Etapa 3 +1 +1

50
-87 -111 2 2
Etapa 4
+1 +2
+293 +661 3 3 +1 +2
-419 -543 3 3 +1 +2
+479 +1887 3 3 +1 +2
-621 -411 3 3 +1 +2
+819 +2155 4 4 +1 +2
+9 +51 1 2
Etapa 5
+1 +2
-1335 -217 3 2 +1 +2
+623 +71 4 2 +1 +2
+39 2
Etapa 6
+1 0
-377 2 +1 0
-53 2 +1 0
+387 2 +1 0
-55 2 +1 0
-79 2 +1 0
+1571 3 +1 0
+3449 3 +1 0
+681 3 +1 0
TOTAL 39 26
Ao fim das seis etapas, ficam definidos os pares de coeficientes parciais a implementar. O sinal nos coeficientes parciais identificam se é realizado uma soma ou uma subtracção. Com este algoritmo é possível maximizar a partilha dos coeficientes parciais tendo em conta a diminuição da área ocupada. No fim deste capítulo, será mostrado o resultado desta arquitectura com partilha de somadores no bloco MCM (1 MCM ADD C/ MUX).
4.1.2.2. USANDO A PROGRAMAÇÃO LINEAR
A programação linear (LP, ou optimização linear) é um método matemático para maximizar (ou
minimizar) uma dada função linear de custo (que pode representar um lucro ou custo) sujeito a
um conjunto de restrições lineares. A programação linear pode ser aplicada em vários campos
de estudo, tais como o mundo dos negócios, a economia, ou em engenharia. As indústrias que
usam modelos de programação linear para resolver os seus problemas incluem os transportes,
energia, telecomunicações e manufactura.
Formalmente os problemas da programação linear inteira, em que as incógnitas do problema
só podem tornar valores inteiros, podem ser expressos na sua forma canónica:
Em que x representa o vector das variáveis a determinar (incógnitas), c e b são os vectores dos
coeficientes conhecidos e A a matriz dos coeficientes. A expressão a maximizar ou a minimizar
é chamada de função de custo.
Incorporando a ferramenta LP_SOLVE na linguagem C, foi possível implementar uma
arquitectura FIR com partilha dos somadores no bloco MCM. O objectivo da utilização desta
ferramenta é a criação de um modelo que nos permite explorar todas as combinações entre
dois filtros para partilha de componentes, no sentido de diminuir a sua área. Neste modelo, foi
elaborada uma função de custo que contenha a informação do custo de partilhar componentes.

51
O custo de dois coeficientes partilharem o mesmo operador depende do número de
multiplexeres a implementar (entre 1 e 2 multiplexeres) e do seu tamanho (bits), o tipo de
operador (somador, subtractor ou somador/subtractor) e o seu tamanho (bits). Cada
componente tem um impacto diferente na função de custo, porque a área ocupada por um
multiplexer é inferior à área de um dos operadores, logo, a função de custo tem de diferenciar a
contribuição de cada componente. Na resolução da função de custo obtém-se a melhor
solução para diminuir a área ocupada pelos filtros.
Para integrar o nosso problema na ferramenta LP_SOLVE, foram feitas algumas opções no
intuito de maximizar a eficiência da ferramenta. Como foi indicado em capítulos anteriores,
podem existir coeficientes parciais comuns aos dois filtros, por isso esses coeficientes parciais
foram retirados do problema. Se tivermos os conjuntos de coeficientes C e K:
{ }
{ }
Para generalizar o problema, podemos considerar que o conjunto C é sempre menor ou igual
ao conjunto K, ou seja N ≤ M. Da intersecção dos conjuntos C e K resulta o conjunto dos
coeficientes parciais comuns, o conjunto I.
{ }
Retirando os coeficientes parciais do conjunto I aos conjuntos C e K, ficamos com dois novos
conjuntos.
{ }
{ }
Neste instante, temos os dois conjuntos de coeficientes parciais para o nosso problema. Para
definir a função de custo é necessário saber a contribuição de cada componente. Para isso,
foram realizadas sínteses de vários componentes (somador/subtractror, subtractor, somador e
multiplexer) para saber como a área dos componentes varia com o número de bits destes.
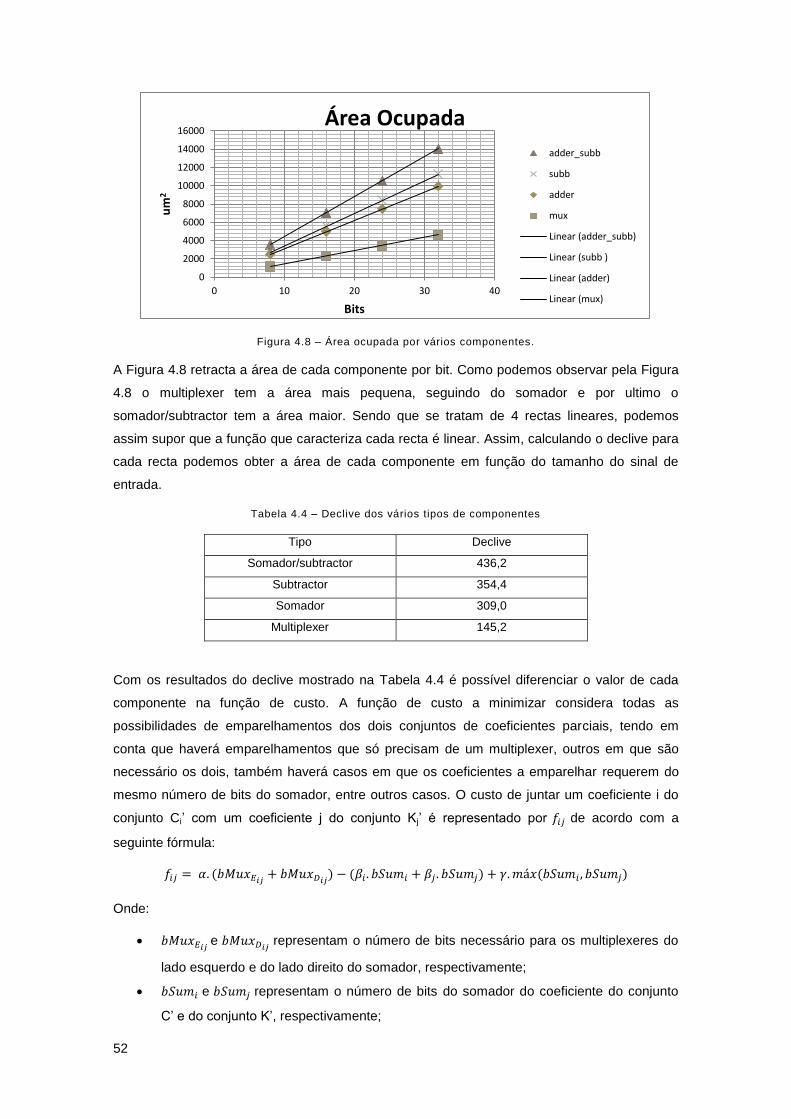
52
Figura 4.8 – Área ocupada por vários componentes.
A Figura 4.8 retracta a área de cada componente por bit. Como podemos observar pela Figura
4.8 o multiplexer tem a área mais pequena, seguindo do somador e por ultimo o
somador/subtractor tem a área maior. Sendo que se tratam de 4 rectas lineares, podemos
assim supor que a função que caracteriza cada recta é linear. Assim, calculando o declive para
cada recta podemos obter a área de cada componente em função do tamanho do sinal de
entrada.
Tabela 4.4 – Declive dos vários tipos de componentes
Tipo Declive
Somador/subtractor 436,2
Subtractor 354,4
Somador 309,0
Multiplexer 145,2
Com os resultados do declive mostrado na Tabela 4.4 é possível diferenciar o valor de cada
componente na função de custo. A função de custo a minimizar considera todas as
possibilidades de emparelhamentos dos dois conjuntos de coeficientes parciais, tendo em
conta que haverá emparelhamentos que só precisam de um multiplexer, outros em que são
necessário os dois, também haverá casos em que os coeficientes a emparelhar requerem do
mesmo número de bits do somador, entre outros casos. O custo de juntar um coeficiente i do
conjunto Ci’ com um coeficiente j do conjunto Kj’ é representado por de acordo com a
seguinte fórmula:
Onde:
e representam o número de bits necessário para os multiplexeres do
lado esquerdo e do lado direito do somador, respectivamente;
e representam o número de bits do somador do coeficiente do conjunto
C’ e do conjunto K’, respectivamente;
0
2000
4000
6000
8000
10000
12000
14000
16000
0 10 20 30 40
um
2
Bits
Área Ocupada
adder_subb
subb
adder
mux
Linear (adder_subb)
Linear (subb )
Linear (adder)
Linear (mux)

53
representa o custo da área do multiplexer por bit:
βi e βj representam o custo da área do somador (ou subtractor) por bit. βj e βj podem ter
valores diferente:
O γ pode representar três valores de área, um somador, um subtractor ou um
somador/subtractor:
{
O custo é a soma da área dos multiplexeres necessários, subtraindo a área do somador ou
subtractor que é retirado no emparelhamento dos coeficientes e no fim é adicionado a área do
novo elemento, que pode ser um somador, subtractor ou um somador/subtractor. Com esta
fórmula ficamos com uma interpretação da área ocupada por um emparelhamento de
coeficientes. Ao sintetizar o resultado proveniente da solução do LP_SOLVE, a área ocupada
era superior à solução sem emparelhamentos. Isto ocorre, porque os componentes a sintetizar
(os somadores, subtractores, multiplexeres e os somadores/subtractores) uma das suas
entradas sofre um deslocamento. No caso dos somadores, a redução da área em relação ao
número de bits que sofre deslocamentos é notória. Nos restantes elementos, apesar de
também existir, essa redução é muito pequena (nos somadores/subtractores não ocorrem
reduções de área quando uma das entradas é deslocada). Por isso, é necessário corrigir a
fórmula para o cálculo do custo de juntar dois coeficientes:
(
) (| |)
( )
( ( ) ( ))
Onde:
representa o custo da redução da área do multiplexer por bit de deslocamento:
representa o custo da redução da área do somador por bit de deslocamento:
representa o número de bits que o sinal é deslocado para a esquerda.

54
O cálculo do custo pode ser transformado numa matriz de custos, em que i representa a
linha e j a coluna. A intersecção da linha i com a coluna j é o custo de emparelhar dois
coeficientes parciais, Ci’ com Ki’. A matriz de custo tem a dimensão de N - P linhas e M – P
colunas de elementos fij. A cada elemento fij está associado uma variável binária xij, (incógnita
do problema LP) que nos vai dizer se o coeficiente Ci’ e Kj’ vão ser emparelhados no mesmo
operador ou não, consoante toma o valor 1 ou 0, respectivamente. A função de custo a
minimizar corresponde assim ao somatório de todas as posições da matriz, ou seja a todos os
custos de emparelha o coeficiente Ci’, Kj’ multiplicado pela variável que indica se esse
emparelhamento se vai realizar ou não.
∑ ∑
A matriz de custo mostra todas as possibilidades de emparelhamento entre os dois filtros. No
entanto, temos de garantir que cada elemento Ci’ emparelha apenas com um único elemento
Kj’. Para isso, é necessário inserir restrições em que a soma de todas as variáveis da linha i
têm de ser igual a 1, ou seja, só uma das variáveis pode estar activa na linha i.
∑
A segunda restrição proposta é nas colunas, a soma de todas as variáveis da coluna j têm de
ser menores ou iguais a 1, ou seja, pode haver colunas em que não existem variáveis activas.
∑
O facto de a restrição da coluna ser menor ou igual a 1 deve-se com as dimensões da matriz. A
matriz pode não ser quadrada, porque N ≤ M, logo temos de garantir que um elemento da linha
i não tenha vários elementos na coluna j.
O LP_SOLVE depois de resolver o problema vai retornar o valor de todas as variáveis que
minimiza a função de custo. As variáveis , que tiverem valor 1 vão-nos indicar a solução de
emparelhamentos possíveis com menor custo.
Para exemplificar a utilização deste modelo, vamos usar os filtros de teste 1 e 2 e ilustrar os
vários passos realizados, assim como as restrições obtidas do modelo LP. O primeiro passo é
identificar todos os coeficientes parciais de cada filtro. Como o filtro 1 tem menos coeficientes
parciais que o filtro 2, o conjunto C representa o filtro 1 e o conjunto K representa o filtro 2.
{ }
{ }
O passo seguinte é calcular a intersecção dos conjuntos C e K e criar os novos conjuntos:
{ }
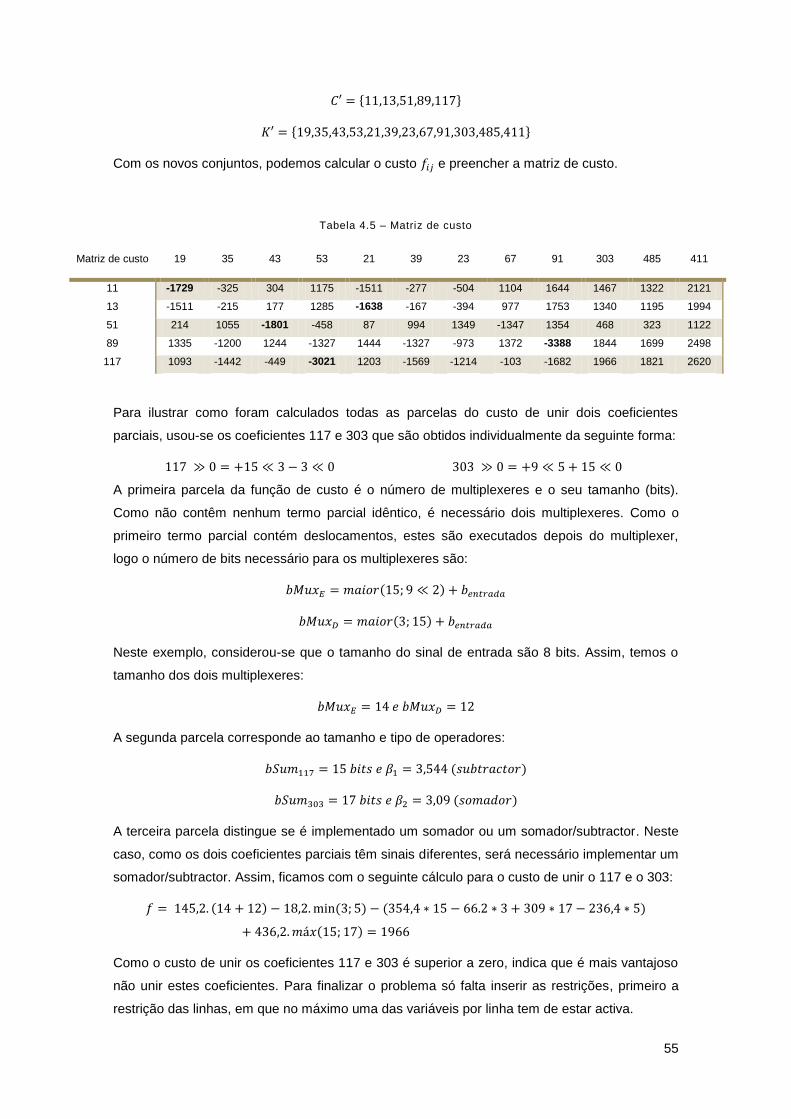
55
{ }
{ }
Com os novos conjuntos, podemos calcular o custo e preencher a matriz de custo.
Tabela 4.5 – Matriz de custo
Matriz de custo 19 35 43 53 21 39 23 67 91 303 485 411
11 -1729 -325 304 1175 -1511 -277 -504 1104 1644 1467 1322 2121
13 -1511 -215 177 1285 -1638 -167 -394 977 1753 1340 1195 1994
51 214 1055 -1801 -458 87 994 1349 -1347 1354 468 323 1122
89 1335 -1200 1244 -1327 1444 -1327 -973 1372 -3388 1844 1699 2498
117 1093 -1442 -449 -3021 1203 -1569 -1214 -103 -1682 1966 1821 2620
Para ilustrar como foram calculados todas as parcelas do custo de unir dois coeficientes
parciais, usou-se os coeficientes 117 e 303 que são obtidos individualmente da seguinte forma:
A primeira parcela da função de custo é o número de multiplexeres e o seu tamanho (bits).
Como não contêm nenhum termo parcial idêntico, é necessário dois multiplexeres. Como o
primeiro termo parcial contém deslocamentos, estes são executados depois do multiplexer,
logo o número de bits necessário para os multiplexeres são:
Neste exemplo, considerou-se que o tamanho do sinal de entrada são 8 bits. Assim, temos o
tamanho dos dois multiplexeres:
A segunda parcela corresponde ao tamanho e tipo de operadores:
A terceira parcela distingue se é implementado um somador ou um somador/subtractor. Neste
caso, como os dois coeficientes parciais têm sinais diferentes, será necessário implementar um
somador/subtractor. Assim, ficamos com o seguinte cálculo para o custo de unir o 117 e o 303:
Como o custo de unir os coeficientes 117 e 303 é superior a zero, indica que é mais vantajoso
não unir estes coeficientes. Para finalizar o problema só falta inserir as restrições, primeiro a
restrição das linhas, em que no máximo uma das variáveis por linha tem de estar activa.

56
Por último, as restrições das colunas, em que o número de variáveis activas por coluna é no
máximo 1:
Com estas etapas, temos todas as condições para a resolução do problema, que passa por
encontrar a melhor maneira de emparelhar os coeficientes parciais de dois filtros, tendo em
conta a diminuição da área ocupada. Na matriz de custo apresentado anteriormente, os valores
a bold representam a solução deste problema. Nesta solução passamos de 17 somadores (ou
subtractores) para apenas 12 dado que 5 operadores são partilhados pelos dois filtros. Os
pares de coeficientes (Ci’,Kj’) emparelhados num operador são (11,19), (51,43), (117,53),
(13,21) e (89,91). É de salientar, que esta solução depende do algoritmo utilizado para calcular
os coeficientes parciais e do tamanho do sinal de entrada. Com os mesmos coeficientes, mas
com diferentes algoritmos ou com outro tamanho do sinal de entrada, a solução do problema
pode ser diferente.
Foram apresentadas duas propostas para a partilha dos somadores nas arquitecturas FIR com
somadores. Usando os filtros do último exemplo, e aplicando à arquitectura que utiliza um
sistema de procura para a partilha de somadores, a solução encontra foi idêntica à utilizada
pela ferramenta LP_SOLVE. Uma explicação possível para este caso pode ser o pequeno
número de coeficientes parciais dos dois filtros e também porque em nenhuma das utilizações
é implementado o somador/subtractor. Nos outros pares de filtros não acontece esta situação,
tendo soluções diferentes para cada arquitectura.
A arquitectura com partilha dos somadores usando a programação linear pode apresentar
diferentes soluções para o mesmo conjunto de coeficientes, ao contrário da arquitectura que
usa o algoritmo heurístico. A solução com a programação linear é influenciada por vários
factores, como por exemplo o tamanho do sinal de entrada. Para o mesmo conjunto de
coeficientes, a variação do tamanho do sinal de entrada pode implicar diferentes soluções. Isto

57
acontece porque a fórmula do cálculo do custo tem em conta com o tamanho do sinal de
entrada. Outro dos factores que influencia a programação linear é a barreira de decisão, que
neste caso encontra-se a zero. Se repararmos na Tabela 4.5, a matriz de custo apresenta
valores negativos e positivos. Ao inserir essa matriz no LP_SOLVE, todos os valores maiores
que zero são descartados (com o valor da barreira de decisão a zero, os valores superiores a
zero significam que é mais vantajoso não unir os coeficientes) para o cálculo da melhor
solução, ou seja, alterando o valor da barreira de decisão, teremos diferentes soluções. As
seguintes tabelas exemplificam o que foi dito anteriormente.
Tabela 4.6 - Valores dos pares de filtros para variações da barreira de decisão
Sinal de
entrada
Barreira de
decisão
Fir01 e Fir02 Fir05 e Fir09 Fir06 e Fir07
Área (µm
2)
Custo LP_SOLVE
Área (µm
2)
Custo LP_SOLVE
Área (µm
2)
Custo LP_SOLVE
8 bits
> 0 316331 -11577 855447 -33052 431711 -25742
> -1000 316331 -11577 849015 -30099 424077 -24387
> -2000 319587 -6408 853679 -20089 419557 -11286
16 bits
> 0 525132 -18855 1330498 -54249 681520 -40653
> -1000 525132 -18855 1320925 -51979 674149 -39862
> -2000 525132 -18855 1322807 -48380 654766 -35548
32 bits
> 0 938700 -33412 2272730 -96642 1155668 -70685
> -1000 938700 -33412 2263114 -94269 1145538 -69001
> -2000 938700 -93182 2260456 -93182 1145538 -69001
A Tabela 4.6 apresenta a variação da área, potência e tempo de atraso para diferentes
tamanhos do sinal de entrada e barreira de decisão. Podemos concluir que puxar a barreira da
decisão do LP_SOLVE para valores menores que zero, permite diminuir a área ocupada pela
arquitectura. Apesar do custo final ser maior em módulo quando temos “>0”, o que devia
implicar uma área mais pequena, isso não acontece. Uma das explicações é a incerteza nos
valores das áreas na função de custo, o que influencia o suposto ganho que devia acontecer,
ou seja, valores negativos muito próximo de zero, podem representar na síntese da
arquitectura uma solução pior. No entanto, ao variar a barreira de decisão, ocorrem menos
partilhas de somadores entre os dois filtros.
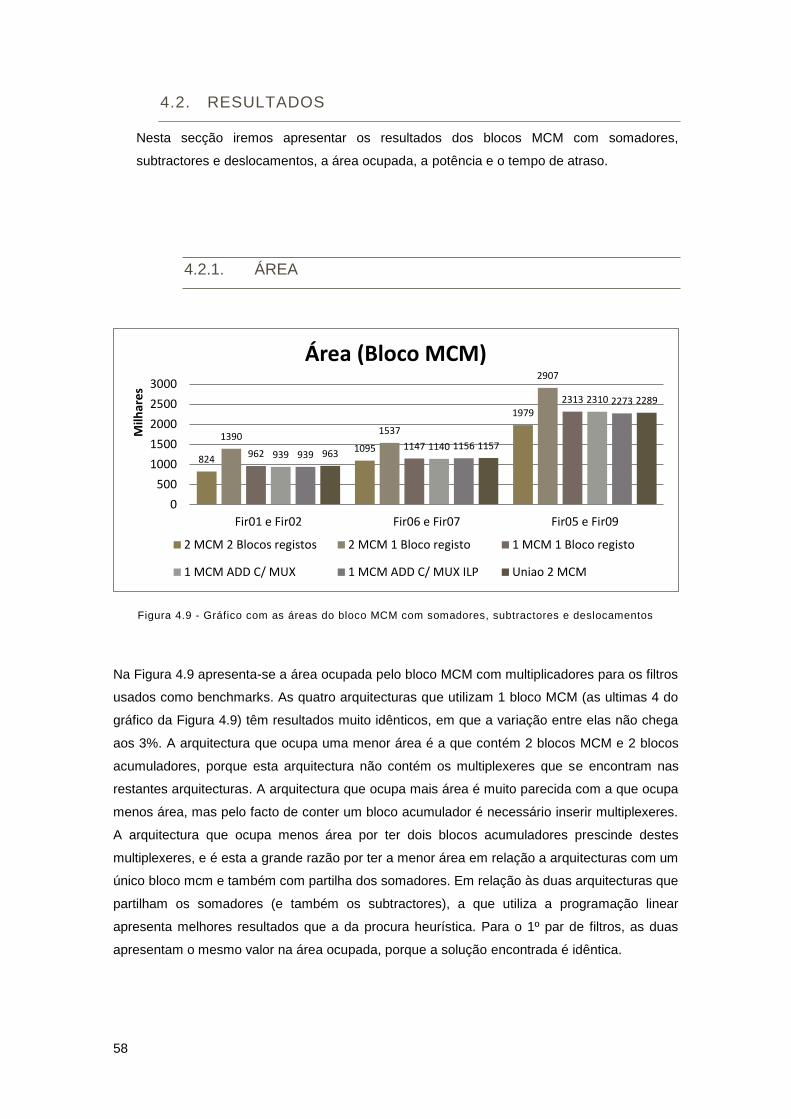
58
4.2. RESULTADOS
Nesta secção iremos apresentar os resultados dos blocos MCM com somadores,
subtractores e deslocamentos, a área ocupada, a potência e o tempo de atraso.
4.2.1. ÁREA
Figura 4.9 - Gráfico com as áreas do bloco MCM com somadores, subtractores e deslocamentos
Na Figura 4.9 apresenta-se a área ocupada pelo bloco MCM com multiplicadores para os filtros
usados como benchmarks. As quatro arquitecturas que utilizam 1 bloco MCM (as ultimas 4 do
gráfico da Figura 4.9) têm resultados muito idênticos, em que a variação entre elas não chega
aos 3%. A arquitectura que ocupa uma menor área é a que contém 2 blocos MCM e 2 blocos
acumuladores, porque esta arquitectura não contém os multiplexeres que se encontram nas
restantes arquitecturas. A arquitectura que ocupa mais área é muito parecida com a que ocupa
menos área, mas pelo facto de conter um bloco acumulador é necessário inserir multiplexeres.
A arquitectura que ocupa menos área por ter dois blocos acumuladores prescinde destes
multiplexeres, e é esta a grande razão por ter a menor área em relação a arquitecturas com um
único bloco mcm e também com partilha dos somadores. Em relação às duas arquitecturas que
partilham os somadores (e também os subtractores), a que utiliza a programação linear
apresenta melhores resultados que a da procura heurística. Para o 1º par de filtros, as duas
apresentam o mesmo valor na área ocupada, porque a solução encontrada é idêntica.
824 1095
1979
1390 1537
2907
962 1147
2313
939 1140
2310
939 1156
2273
963 1157
2289
0
500
1000
1500
2000
2500
3000
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Milh
are
s
Área (Bloco MCM)
2 MCM 2 Blocos registos 2 MCM 1 Bloco registo 1 MCM 1 Bloco registo
1 MCM ADD C/ MUX 1 MCM ADD C/ MUX ILP Uniao 2 MCM
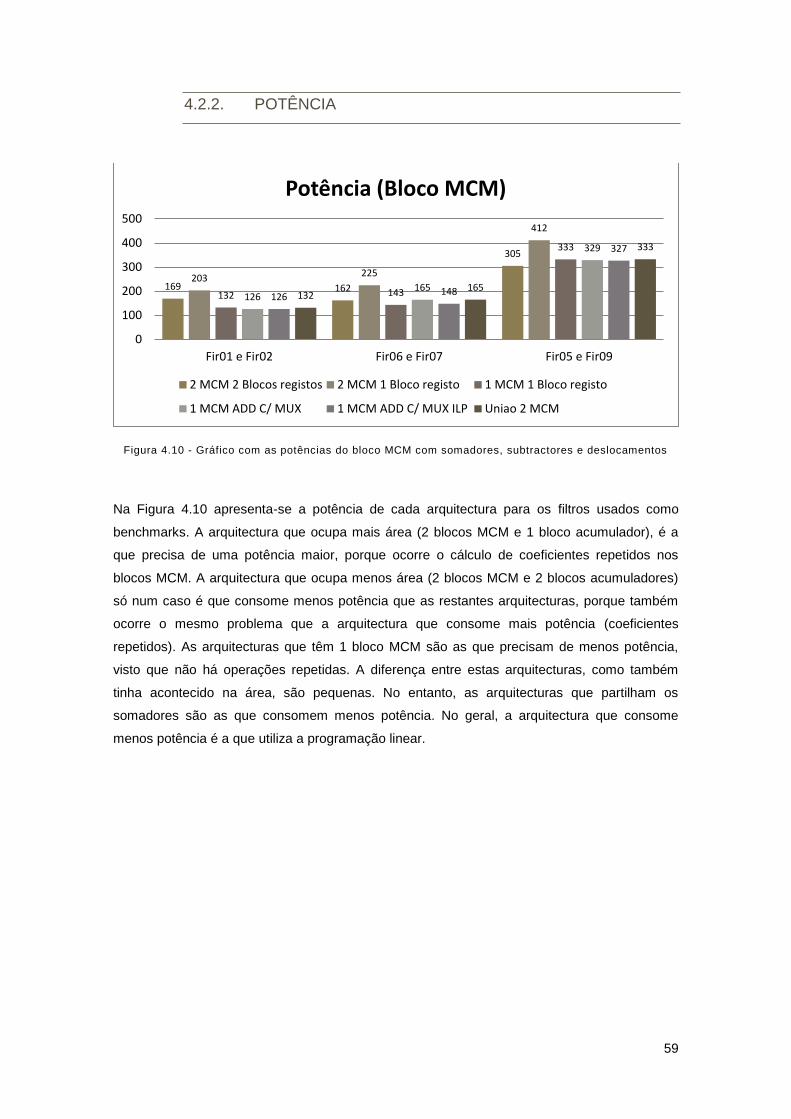
59
4.2.2. POTÊNCIA
Figura 4.10 - Gráfico com as potências do bloco MCM com somadores, subtractores e deslocamentos
Na Figura 4.10 apresenta-se a potência de cada arquitectura para os filtros usados como
benchmarks. A arquitectura que ocupa mais área (2 blocos MCM e 1 bloco acumulador), é a
que precisa de uma potência maior, porque ocorre o cálculo de coeficientes repetidos nos
blocos MCM. A arquitectura que ocupa menos área (2 blocos MCM e 2 blocos acumuladores)
só num caso é que consome menos potência que as restantes arquitecturas, porque também
ocorre o mesmo problema que a arquitectura que consome mais potência (coeficientes
repetidos). As arquitecturas que têm 1 bloco MCM são as que precisam de menos potência,
visto que não há operações repetidas. A diferença entre estas arquitecturas, como também
tinha acontecido na área, são pequenas. No entanto, as arquitecturas que partilham os
somadores são as que consomem menos potência. No geral, a arquitectura que consome
menos potência é a que utiliza a programação linear.
169 162
305
203 225
412
132 143
333
126 165
329
126 148
327
132 165
333
0
100
200
300
400
500
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Potência (Bloco MCM)
2 MCM 2 Blocos registos 2 MCM 1 Bloco registo 1 MCM 1 Bloco registo
1 MCM ADD C/ MUX 1 MCM ADD C/ MUX ILP Uniao 2 MCM
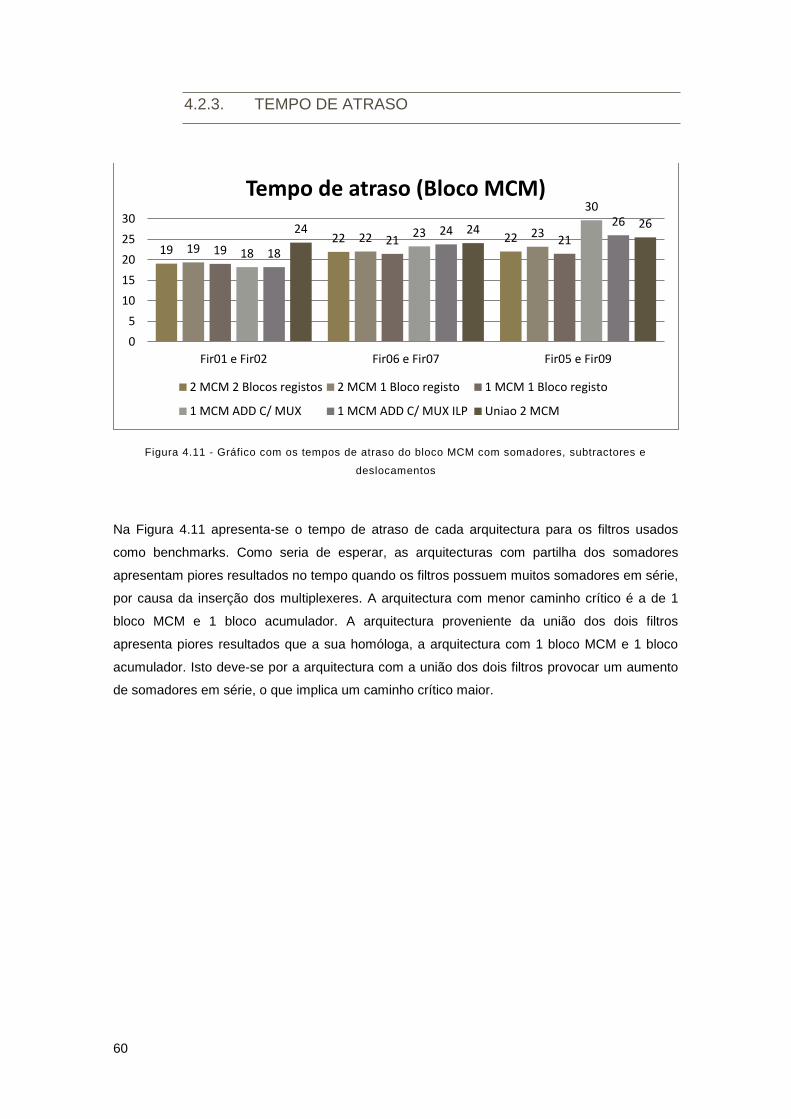
60
4.2.3. TEMPO DE ATRASO
Figura 4.11 - Gráfico com os tempos de atraso do bloco MCM com somadores, subtractores e
deslocamentos
Na Figura 4.11 apresenta-se o tempo de atraso de cada arquitectura para os filtros usados
como benchmarks. Como seria de esperar, as arquitecturas com partilha dos somadores
apresentam piores resultados no tempo quando os filtros possuem muitos somadores em série,
por causa da inserção dos multiplexeres. A arquitectura com menor caminho crítico é a de 1
bloco MCM e 1 bloco acumulador. A arquitectura proveniente da união dos dois filtros
apresenta piores resultados que a sua homóloga, a arquitectura com 1 bloco MCM e 1 bloco
acumulador. Isto deve-se por a arquitectura com a união dos dois filtros provocar um aumento
de somadores em série, o que implica um caminho crítico maior.
19 22 22
19 22 23
19 21 21
18
23
30
18
24 26
24 24 26
0
5
10
15
20
25
30
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Tempo de atraso (Bloco MCM)
2 MCM 2 Blocos registos 2 MCM 1 Bloco registo 1 MCM 1 Bloco registo
1 MCM ADD C/ MUX 1 MCM ADD C/ MUX ILP Uniao 2 MCM

61
CAPÍTULO 5
5. GERAÇÃO E SINTESE DE ARQUITECTURAS PARA
FILTROS FIR
Para a elaboração deste trabalho, onde se realiza um estudo de várias arquitecturas para filtros
digitais FIR, foi fundamental criar uma ferramenta que de forma automática gerasse todas as
arquitecturas FIR. Para esse efeito, foi criado um programa em linguagem C que a partir dos
coeficientes dos filtros e parâmetros configuráveis, produzisse os ficheiros com descrições em
VHDL sintetizáveis para a arquitectura desejada.
5.1. FICHEIRO COM OS COEFICIENTES DO FILTRO
A ferramenta desenvolvida, tem como entrada os ficheiros com os coeficientes dos filtros.
Todos os ficheiros com os coeficientes dos filtros têm de seguir a mesma estrutura, para que
seja possível a ferramenta processar correctamente a informação. Nos ficheiros dos filtros
podemos dividi-los em duas partes, numa os coeficientes dos filtros, em que são utilizados em
todas as arquitecturas estudadas (com multiplicadores e com somas, subtracções e
deslocamentos) e noutra parte as operações das arquitecturas com somadores, para o cálculo
dos coeficientes. Os ficheiros dos filtros terão sempre de conter estas duas frases, ***
Implementation of Coefficients ***, que antecede os coeficientes dos filtros e ***
Implementation of Partial Terms *** antes dos coeficientes parciais. Na Figura 5.1
apresentamos um exemplo de um ficheiro com os coeficientes e termos parciais de um filtro.
Figura 5.1 – Exemplo de um ficheiro contendo os coeficientes e termos parciais do filtro.
*** Implementation of Coefficients ***
51 = +51<<0
89 = +89<<0
117 = +117<<0
128 = +1<<7
117 = +117<<0
89 = +89<<0
51 = +51<<0
*** Implementation of Partial Terms ***
3>>0 = +1<<0 +1<<1
15>>0 = -1<<0 +1<<4
51>>0 = +3<<0 +3<<4
89>>0 = +3<<5 -7<<0
117>>0 = -3<<0 +15<<3

62
Os coeficientes e os termos parciais dos filtros também têm de seguir um certo formato. Os
coeficientes são compostos por 3 elementos e os termos parciais por 7 elementos. A
ferramenta desenvolvida precisa de adquirir a informação dos dois tipos de dados. Nos dados
dos coeficientes é necessário saber o coeficiente do filtro, que está associado a um termo
parcial e o número de deslocamentos à esquerda.
“Coeficiente” = “Termo parcial” << “nº de deslocamentos”;
Na recolha de informação dos termos parciais é necessário mais dados do que os coeficientes.
A cada termo parcial está associado um deslocamento à direita. Mas cada termo parcial
provém da operação de outros dois termos parciais, estes com deslocamentos à esquerda. A
operação entre os dois termos parciais pode ser uma soma ou uma subtracção.
“Termo parcial” >> “deslocamento” = “termos parcial” << “nº deslocamento” “+/-“
“termos parcial” << “nº deslocamento”.
Ao chamar a ferramenta na linha de comandos, é necessário indicar os ficheiros dos
coeficientes dos dois filtros. A ferramenta tem o nome de filterjoin e para dois ficheiros de
filtros de teste fir01.result e fir02.result a linha de comandos fica:
C:\FIR>./filterjoin fir01.result fir02.result
A ordem como são indicados os ficheiros dos filtros é irrelevante.
5.2. OPÇÕES DA FERRAMENTA
Como foi dito anteriormente, todas as arquitecturas estudadas foram desenvolvidas
automaticamente por esta ferramenta. A ferramenta foi desenvolvida de modo a ser possível a
configuração dos vários parâmetros das arquitecturas pelo utilizador. Na Tabela 5.1 é possível
ver todas as opções que a ferramenta oferece ao utilizador e que são inseridas depois do nome
dos ficheiros dos filtros.
Tabela 5.1 – Opções da ferramenta desenvolvida neste trabalho.
Opção Descrição Opções Válidas Valor Inicial
-t: Escolha da arquitectura a estudar -t: {a,b,c,d,e,f,g,h,i} -t:a
-b: Tamanho em bits do sinal de
entrada -b: {número de bits} -b:8
-a: Tipo de somador a implementar -a:{ nome do somador} -a:adder
-s Tipo de subtractor a implementar -b:{ nome do subtractor} -b:subb
-m: Tipo de multiplicador a
implementar
-m:{ nome do
multiplicador} -m:gen_mult
-c: Tipo de descrição VHDL:
estrutural ou comportamental -c:{0;1} -c:0

63
A Tabela 5.1 apresenta todas as opções da ferramenta desenvolvida neste trabalho, que vão
desde a escolha da arquitectura estudadas nos capítulos anteriores, passando pelo tamanho
do sinal de entrada (neste trabalho só foram utilizados sinais com 8, 16 e 32 bits) até ao tipo de
componentes e o tipo de descrição VHDL.
O primeiro parâmetro é a escolha das arquitecturas dos filtros FIR. Na linha de comandos é
possível indicar o tipo de arquitectura a gerar. A opção que designa o tipo de arquitectura é
–t:opção, cujos valores possíveis estão indicados na Tabela 5.2.
Tabela 5.2 – Tabela com as diferentes opções de arquitectura.
Opção Arquitectura
-t:a Multiplicador NxN
-t:b 2 blocos acumuladores e 2 MCM (somas e deslocamentos)
-t:c 1 bloco acumulador e 2 MCM (somas e deslocamentos)
-t:d 1 bloco acumulador e 1 MCM (somas e deslocamentos)
-t:e Multiplicador NxM
-t:f Com maximização da partilha dos multiplicadores NxM
-t:g Com implementação de metade do filtro com multiplicadores NxM
-t:h Com partilha dos somadores (algoritmo heurístico de procura)
-t:i Com partilha dos somadores (programação linear)
No entanto, se na linha de comandos não tiver a opção para o tipo de arquitectura, a
ferramenta toma por defeito a opção –t:a, ou seja a arquitectura com multiplicador NxN.
Outro dos parâmetros que se pode configurar é o número de bits do sinal de entrada das
arquitecturas. Na linha de comandos, a opção correspondente é –b:número de bits. Por
omissão, a ferramenta considera a opção –b:8, assumindo um sinal de entrada de 8 bits. O
número de bits pode variar consoante a opção tomada pelo utilizador. Neste trabalho só foram
utilizados 3 números de bit para o sinal de entrada, os 8 bits, 16 bits e 32 bits.
Os dois parâmetros explicados anteriormente são os mais importantes para o estudo das
arquitecturas FIR em paralelo. Permite-nos alterar a arquitectura em estudo e a dimensão do
sinal de entrada. Com somente estes dois parâmetros é possível fazer um estudo detalhado
sobre todas as arquitecturas FIR estudadas neste trabalho. No entanto, existem mais
parâmetros que podem ser explorados.
Na geração de VHDL sintetizável, existem várias formas de implementar determinados
componentes. Neste caso, existem muitas maneiras de implementar multiplicadores ou
somadores nas arquitecturas FIR. De modo a possibilitar o estudo do desempenho dos filtros

64
com diversos tipos de estruturas de multiplicadores ou somadores, existem dois parâmetros
que permite escolher o componente a implementar nas arquitecturas.
Multiplicadores:
Nas arquitecturas FIR com multiplicadores, consideramos dois tipos de multiplicadores, o NxN
e o NXM. Nos dois casos, é possível instanciar arquitecturas especificas de multiplicador se
forem cumpridas as especificações dos componentes, ou seja, os multiplicadores a
implementar têm de ter o mesmo número e nome dos sinais de entrada e saída. A opção para
seleccionar outro tipo de multiplicador é a –m: nome do multiplicador. Por omissão, no
caso do multiplicador NxN será a opção –m:generic_mul, enquanto no multiplicador NxM
será -m:mult_nxm.
As especificações das entidades VHDL que cada multiplicador tem de cumprir podem ser
observadas nas Figura 5.2 e Figura 5.3.
Figura 5.2 – Especificação do multiplicador genérico NxN.
Figura 5.3 – Especificação do multiplicador genérico NxM.
Somadores e Subtractores:
O caso dos somadores é diferente dos multiplicadores. Enquanto os multiplicadores só são
utilizados no bloco MCM, os somadores são usados em toda as estrutura das arquitecturas
FIR. Não é possível utilizar dois tipos diferentes de estruturas de somadores ou subtractores na
mesma arquitectura, ou seja, o tipo de somador do bloco MCM é do mesmo tipo do bloco
acumulador. A opção para instanciar outro tipo de somador é –a:nome do somador e para o
subtractor é –s:nome do subtractor. Por omissão de alguma das anteriores opções, será
usada a –a:adder e –s:subb.
entity generic_mul is
generic(SIZE: integer := 64);
Port (A : in signed (SIZE - 1 downto 0);
B : in signed (SIZE - 1 downto 0);
C : out signed (2*SIZE - 1 downto 0)
);
end generic_mul;
entity mult_nxm is
generic(SIZE1,SIZE2: integer := 64);
Port (A : in signed (SIZE1 - 1 downto 0);
B : in signed (SIZE2 - 1 downto 0);
C : out signed (SIZE1+SIZE2 - 1 downto 0)
);
end mult_nxm;

65
Nas seguintes figuras, podemos observar as especificações das entidades VHDL para o
somador e subtractor genérico.
Figura 5.4 – Especificação do somador genérico.
Figura 5.5 – Especificação do subtractor genérico.
Outros Elementos:
Nas arquitecturas existem mais elementos fundamentais para o seu bom funcionamento, mas
que não foram consideradas para serem alterados por esta ferramenta. Estão nesta situação
os registos, somadores/subtractores, multiplexeres e o negador de sinal. Nestes casos, serão
utilizados componentes genéricos, cujas entidades VHDL estão apresentadas na Figura 5.6 à
Figura 5.9.
Figura 5.6 – Especificação do somador/subtractor genérico.
entity adder is
generic(SIZE: integer :=64);
Port(A : in signed (SIZE - 1 downto 0);
B : in signed (SIZE - 1 downto 0);
C : out signed (SIZE - 1 downto 0)
);
end adder;
entity subb is
generic(SIZE: integer :=64);
Port(A : in signed (SIZE - 1 downto 0);
B : in signed (SIZE - 1 downto 0);
C : out signed (SIZE - 1 downto 0)
);
end subb;
entity adder_subb is
generic(SIZE: integer :=64); -- top bit
port (mode: in std_logic;
A : in signed (SIZE-1 downto 0);
B : in signed (SIZE-1 downto 0);
Y : out signed (SIZE-1 downto 0)
);
end adder_subb;

66
Figura 5.7 - Especificação do registo genérico.
Figura 5.8 – Especificação do multiplexer genérico.
Figura 5.9 – Especificação do negador de sinal genérico.
O último parâmetro configurável da ferramenta que falta explicar é a forma de descrever as
operações no bloco MCM das arquitecturas FIR. Na linguagem VHDL a arquitectura dos
componentes pode ser descrita a nível estrutural ou comportamental. Neste trabalho o bloco
acumulador é sempre descrito ao nível estrutural. Podemos ver na Figura 5.10 um pequeno
excerto da instanciação dos registos e somadores dos filtros de teste 6 e 7.
entity reg_generic is
generic(SIZE : integer := 64); -- top bit
port (clk : in std_logic;
rst : in std_logic;
input : in signed (SIZE-1 downto 0);
output : out signed (SIZE-1 downto 0)
);
end reg_generic;
entity mux is
generic(SIZE: integer :=64); -- top bit
port (mode: in std_logic;
A : in signed (SIZE-1 downto 0);
B : in signed (SIZE-1 downto 0);
Y : out signed (SIZE-1 downto 0)
);
end mux;
entity inverter is
generic (N:integer:=64);
Port (A : in signed (N-1 downto 0);
B : out signed (N-1 downto 0)
);
end inverter;

67
Figura 5.10 – Excerto do bloco acumulador para os filtros 6 e 7 ao nível do bloco.
No bloco MCM os multiplicadores, somadores ou subtractores, podem ser representados ao
nível estrutural ou comportamental. A opção –c: {0,1} permite escolher o nível da
implementação destes componentes. Se –c:0, estamos ao nível estrutural, onde as opções –
m, -a e –s são válidas. Na Figura 5.11 temos um exemplo da instanciação de um somador e
dois tipos de multiplicadores no nível estrutural.
Figura 5.11 – Exemplo do nível do bloco para um somador e para os dois tipos de multiplicadores (NxN e
NxM).
Quando é seleccionada a opção –c:1, estamos no nível comportamental, em que são
descartadas as opções definem o tipo de multiplicador (-m), somador (-a) e subtractor (–s).
Neste nível, os dois tipos de multiplicadores (NxN e NxM) são interpretados como sendo o
mesmo componente. Na Figura 5.12 temos um exemplo de um somador e dois tipos de
multiplicadores descritos ao nível comportamental.
Figura 5.12 – Exemplo do nível algoritmo para um somador e para os dois tipos de multiplicadores (NxN
e NxM).
Por omissão, as arquitecturas são desenvolvidas com a opção –c:0, garantindo a
configuração total da mesma. O fluxograma da Figura 5.13 descreve o funcionamento da
ferramenta dependendo das opções tomadas na linha de comando.
(……)
Reg_13: reg_generic generic map(17) port map(clk,reset,in13_217,out13_217);
ADDER_14: adder generic map(17) port map(out13_217,mult14_377,in14_377);
Reg_14: reg_generic generic map(17) port map(clk,reset,in14_377,out14_377);
ADDER_15: adder generic map(17) port map(out14_377,mult15_148,in15_148);
(……)
a_3 <= resize(s1 & "0",10);
b_3 <= resize(s1 ,10);
ADDER_3: adder generic map(10) port map(a_3,b_3,s3);
NxN: generic_mul generic map(8) port map (sig_in,"00000011",s3);
NxM: mult_nxm generic map(8,3) port map (sig_in,"011",s3);
a_3 <= resize(s1 & "0",10);
b_3 <= resize(s1 ,10);
s3 <= a_3 + b_3;
s3 <= sig_in * "00000011"; -- NxN
s3 <= sig_in * "011"; -- NxM

68
Figura 5.13 – Fluxograma da ferramenta
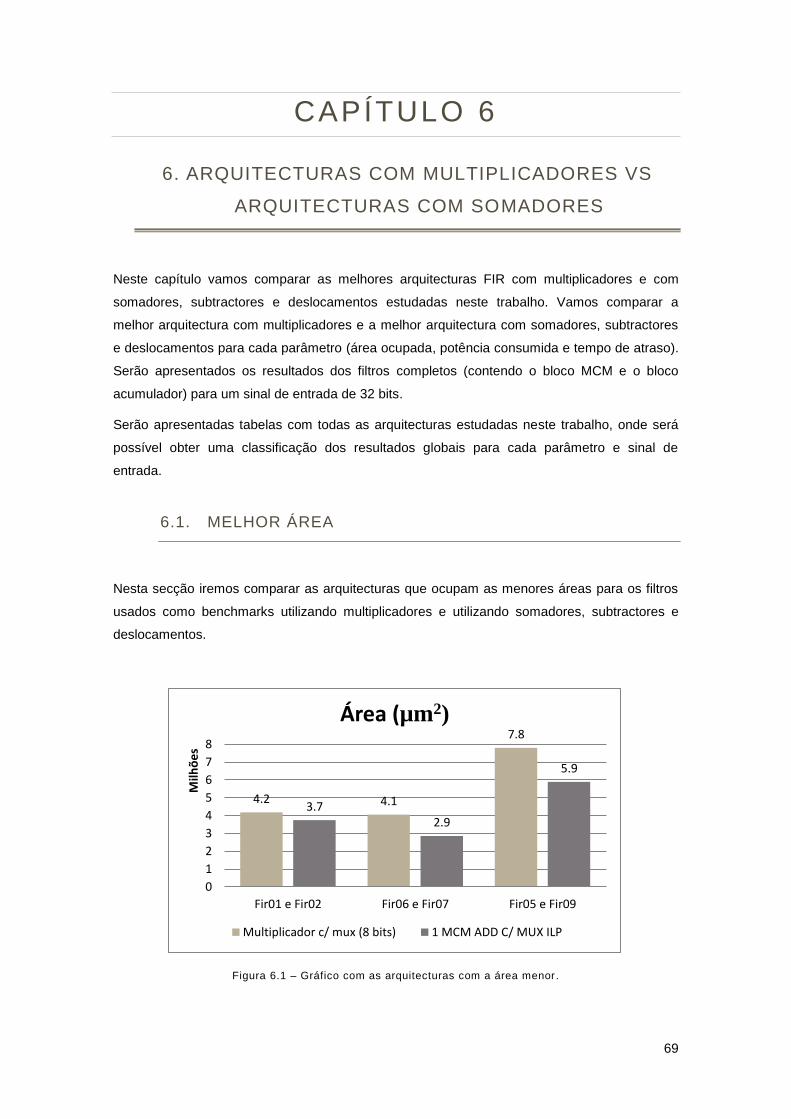
69
CAPÍTULO 6
6. ARQUITECTURAS COM MULTIPLICADORES VS
ARQUITECTURAS COM SOMADORES
Neste capítulo vamos comparar as melhores arquitecturas FIR com multiplicadores e com
somadores, subtractores e deslocamentos estudadas neste trabalho. Vamos comparar a
melhor arquitectura com multiplicadores e a melhor arquitectura com somadores, subtractores
e deslocamentos para cada parâmetro (área ocupada, potência consumida e tempo de atraso).
Serão apresentados os resultados dos filtros completos (contendo o bloco MCM e o bloco
acumulador) para um sinal de entrada de 32 bits.
Serão apresentadas tabelas com todas as arquitecturas estudadas neste trabalho, onde será
possível obter uma classificação dos resultados globais para cada parâmetro e sinal de
entrada.
6.1. MELHOR ÁREA
Nesta secção iremos comparar as arquitecturas que ocupam as menores áreas para os filtros
usados como benchmarks utilizando multiplicadores e utilizando somadores, subtractores e
deslocamentos.
Figura 6.1 – Gráfico com as arquitecturas com a área menor.
4.2 4.1
7.8
3.7 2.9
5.9
0
1
2
3
4
5
6
7
8
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Milh
õe
s
Área (µm2)
Multiplicador c/ mux (8 bits) 1 MCM ADD C/ MUX ILP
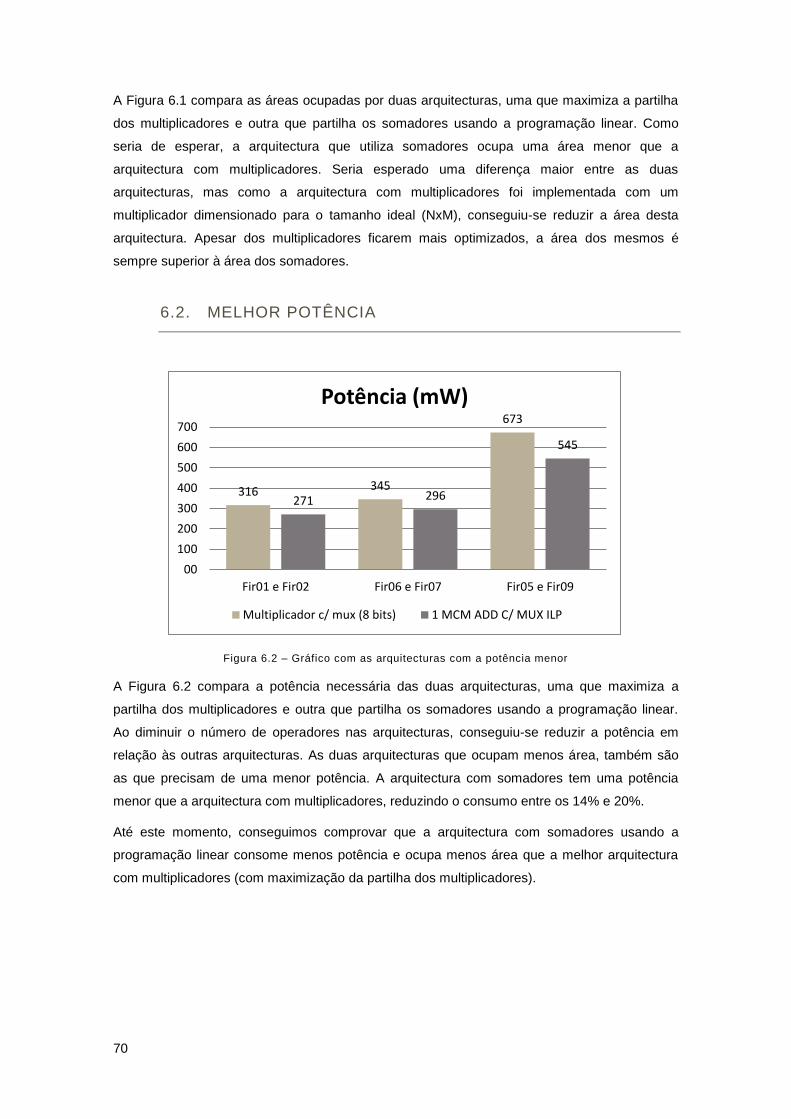
70
A Figura 6.1 compara as áreas ocupadas por duas arquitecturas, uma que maximiza a partilha
dos multiplicadores e outra que partilha os somadores usando a programação linear. Como
seria de esperar, a arquitectura que utiliza somadores ocupa uma área menor que a
arquitectura com multiplicadores. Seria esperado uma diferença maior entre as duas
arquitecturas, mas como a arquitectura com multiplicadores foi implementada com um
multiplicador dimensionado para o tamanho ideal (NxM), conseguiu-se reduzir a área desta
arquitectura. Apesar dos multiplicadores ficarem mais optimizados, a área dos mesmos é
sempre superior à área dos somadores.
6.2. MELHOR POTÊNCIA
Figura 6.2 – Gráfico com as arquitecturas com a potência menor
A Figura 6.2 compara a potência necessária das duas arquitecturas, uma que maximiza a
partilha dos multiplicadores e outra que partilha os somadores usando a programação linear.
Ao diminuir o número de operadores nas arquitecturas, conseguiu-se reduzir a potência em
relação às outras arquitecturas. As duas arquitecturas que ocupam menos área, também são
as que precisam de uma menor potência. A arquitectura com somadores tem uma potência
menor que a arquitectura com multiplicadores, reduzindo o consumo entre os 14% e 20%.
Até este momento, conseguimos comprovar que a arquitectura com somadores usando a
programação linear consome menos potência e ocupa menos área que a melhor arquitectura
com multiplicadores (com maximização da partilha dos multiplicadores).
316 345
673
271 296
545
00
100
200
300
400
500
600
700
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Potência (mW)
Multiplicador c/ mux (8 bits) 1 MCM ADD C/ MUX ILP
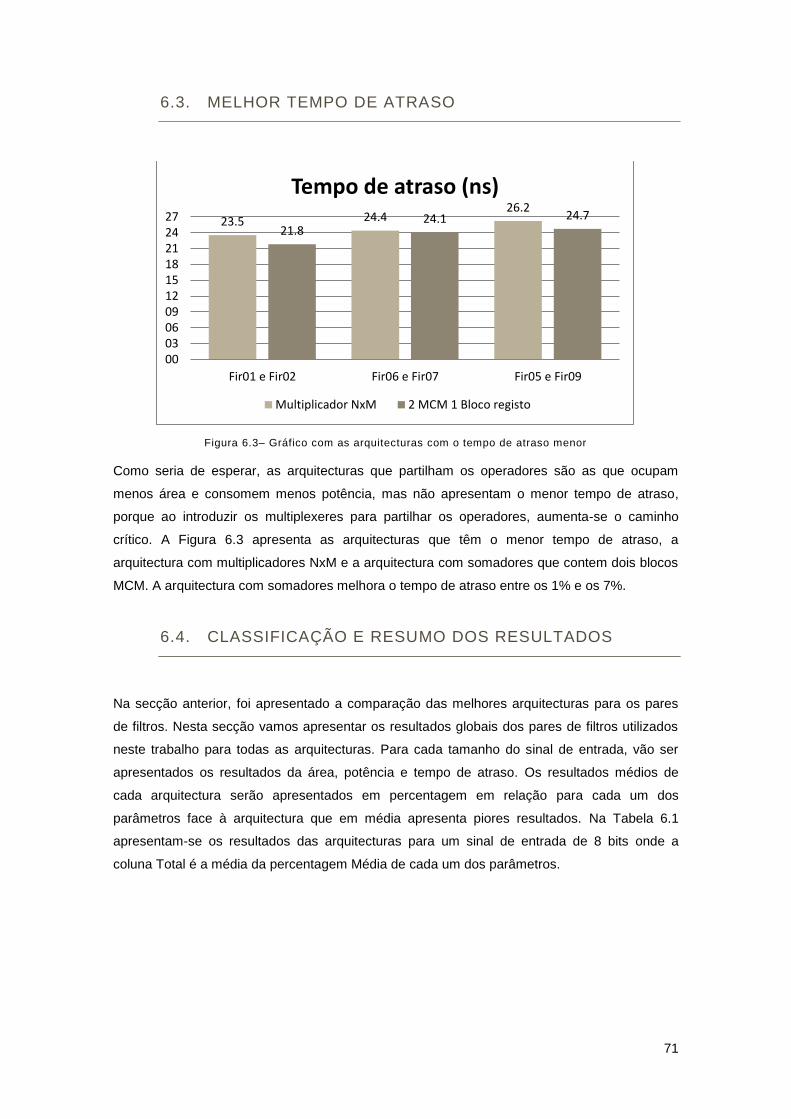
71
6.3. MELHOR TEMPO DE ATRASO
Figura 6.3– Gráfico com as arquitecturas com o tempo de atraso menor
Como seria de esperar, as arquitecturas que partilham os operadores são as que ocupam
menos área e consomem menos potência, mas não apresentam o menor tempo de atraso,
porque ao introduzir os multiplexeres para partilhar os operadores, aumenta-se o caminho
crítico. A Figura 6.3 apresenta as arquitecturas que têm o menor tempo de atraso, a
arquitectura com multiplicadores NxM e a arquitectura com somadores que contem dois blocos
MCM. A arquitectura com somadores melhora o tempo de atraso entre os 1% e os 7%.
6.4. CLASSIFICAÇÃO E RESUMO DOS RESULTADOS
Na secção anterior, foi apresentado a comparação das melhores arquitecturas para os pares
de filtros. Nesta secção vamos apresentar os resultados globais dos pares de filtros utilizados
neste trabalho para todas as arquitecturas. Para cada tamanho do sinal de entrada, vão ser
apresentados os resultados da área, potência e tempo de atraso. Os resultados médios de
cada arquitectura serão apresentados em percentagem em relação para cada um dos
parâmetros face à arquitectura que em média apresenta piores resultados. Na Tabela 6.1
apresentam-se os resultados das arquitecturas para um sinal de entrada de 8 bits onde a
coluna Total é a média da percentagem Média de cada um dos parâmetros.
23.5 24.4 26.2
21.8 24.1 24.7
00030609121518212427
Fir01 e Fir02 Fir06 e Fir07 Fir05 e Fir09
Tempo de atraso (ns)
Multiplicador NxM 2 MCM 1 Bloco registo
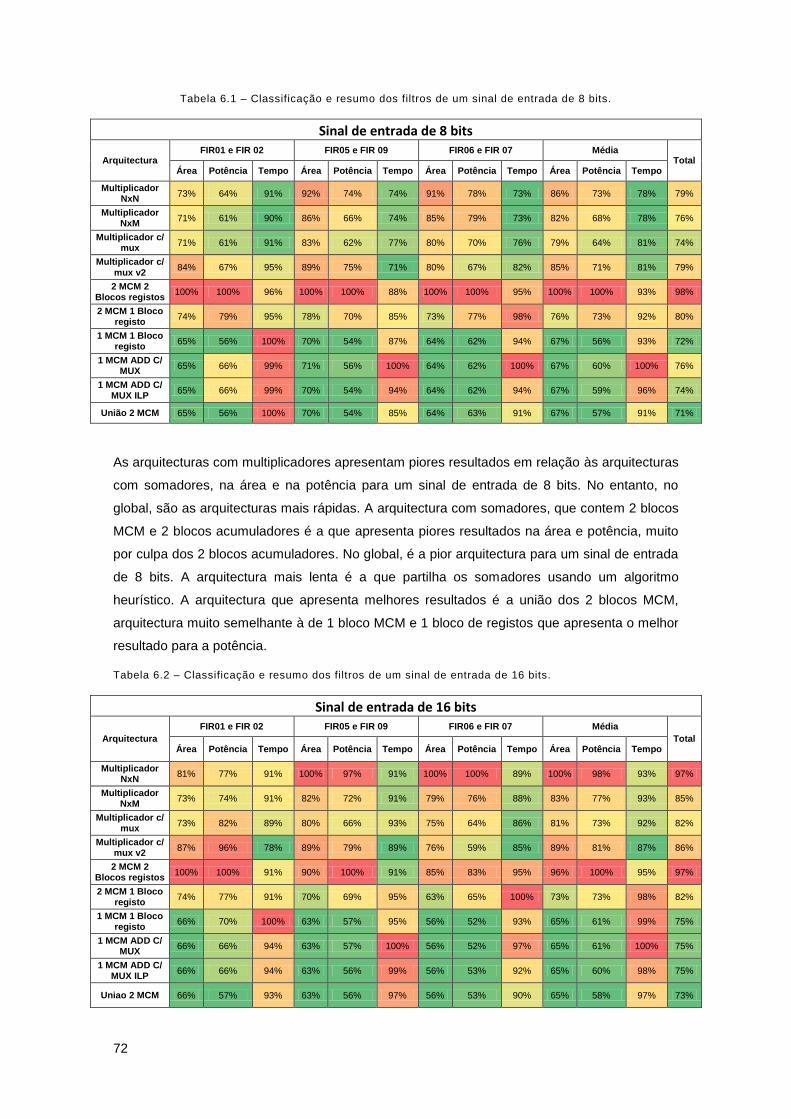
72
Tabela 6.1 – Classificação e resumo dos filtros de um sinal de entrada de 8 bits.
Sinal de entrada de 8 bits
Arquitectura FIR01 e FIR 02 FIR05 e FIR 09 FIR06 e FIR 07 Média
Total Área Potência Tempo Área Potência Tempo Área Potência Tempo Área Potência Tempo
Multiplicador NxN
73% 64% 91% 92% 74% 74% 91% 78% 73% 86% 73% 78% 79%
Multiplicador NxM
71% 61% 90% 86% 66% 74% 85% 79% 73% 82% 68% 78% 76%
Multiplicador c/ mux
71% 61% 91% 83% 62% 77% 80% 70% 76% 79% 64% 81% 74%
Multiplicador c/ mux v2
84% 67% 95% 89% 75% 71% 80% 67% 82% 85% 71% 81% 79%
2 MCM 2 Blocos registos
100% 100% 96% 100% 100% 88% 100% 100% 95% 100% 100% 93% 98%
2 MCM 1 Bloco registo
74% 79% 95% 78% 70% 85% 73% 77% 98% 76% 73% 92% 80%
1 MCM 1 Bloco registo
65% 56% 100% 70% 54% 87% 64% 62% 94% 67% 56% 93% 72%
1 MCM ADD C/ MUX
65% 66% 99% 71% 56% 100% 64% 62% 100% 67% 60% 100% 76%
1 MCM ADD C/ MUX ILP
65% 66% 99% 70% 54% 94% 64% 62% 94% 67% 59% 96% 74%
União 2 MCM 65% 56% 100% 70% 54% 85% 64% 63% 91% 67% 57% 91% 71%
As arquitecturas com multiplicadores apresentam piores resultados em relação às arquitecturas
com somadores, na área e na potência para um sinal de entrada de 8 bits. No entanto, no
global, são as arquitecturas mais rápidas. A arquitectura com somadores, que contem 2 blocos
MCM e 2 blocos acumuladores é a que apresenta piores resultados na área e potência, muito
por culpa dos 2 blocos acumuladores. No global, é a pior arquitectura para um sinal de entrada
de 8 bits. A arquitectura mais lenta é a que partilha os somadores usando um algoritmo
heurístico. A arquitectura que apresenta melhores resultados é a união dos 2 blocos MCM,
arquitectura muito semelhante à de 1 bloco MCM e 1 bloco de registos que apresenta o melhor
resultado para a potência.
Tabela 6.2 – Classificação e resumo dos filtros de um sinal de entrada de 16 bits.
Sinal de entrada de 16 bits
Arquitectura
FIR01 e FIR 02 FIR05 e FIR 09 FIR06 e FIR 07 Média
Total Área Potência Tempo Área Potência Tempo Área Potência Tempo Área Potência Tempo
Multiplicador NxN
81% 77% 91% 100% 97% 91% 100% 100% 89% 100% 98% 93% 97%
Multiplicador NxM
73% 74% 91% 82% 72% 91% 79% 76% 88% 83% 77% 93% 85%
Multiplicador c/ mux
73% 82% 89% 80% 66% 93% 75% 64% 86% 81% 73% 92% 82%
Multiplicador c/ mux v2
87% 96% 78% 89% 79% 89% 76% 59% 85% 89% 81% 87% 86%
2 MCM 2 Blocos registos
100% 100% 91% 90% 100% 91% 85% 83% 95% 96% 100% 95% 97%
2 MCM 1 Bloco registo
74% 77% 91% 70% 69% 95% 63% 65% 100% 73% 73% 98% 82%
1 MCM 1 Bloco registo
66% 70% 100% 63% 57% 95% 56% 52% 93% 65% 61% 99% 75%
1 MCM ADD C/ MUX
66% 66% 94% 63% 57% 100% 56% 52% 97% 65% 61% 100% 75%
1 MCM ADD C/ MUX ILP
66% 66% 94% 63% 56% 99% 56% 53% 92% 65% 60% 98% 75%
Uniao 2 MCM 66% 57% 93% 63% 56% 97% 56% 53% 90% 65% 58% 97% 73%
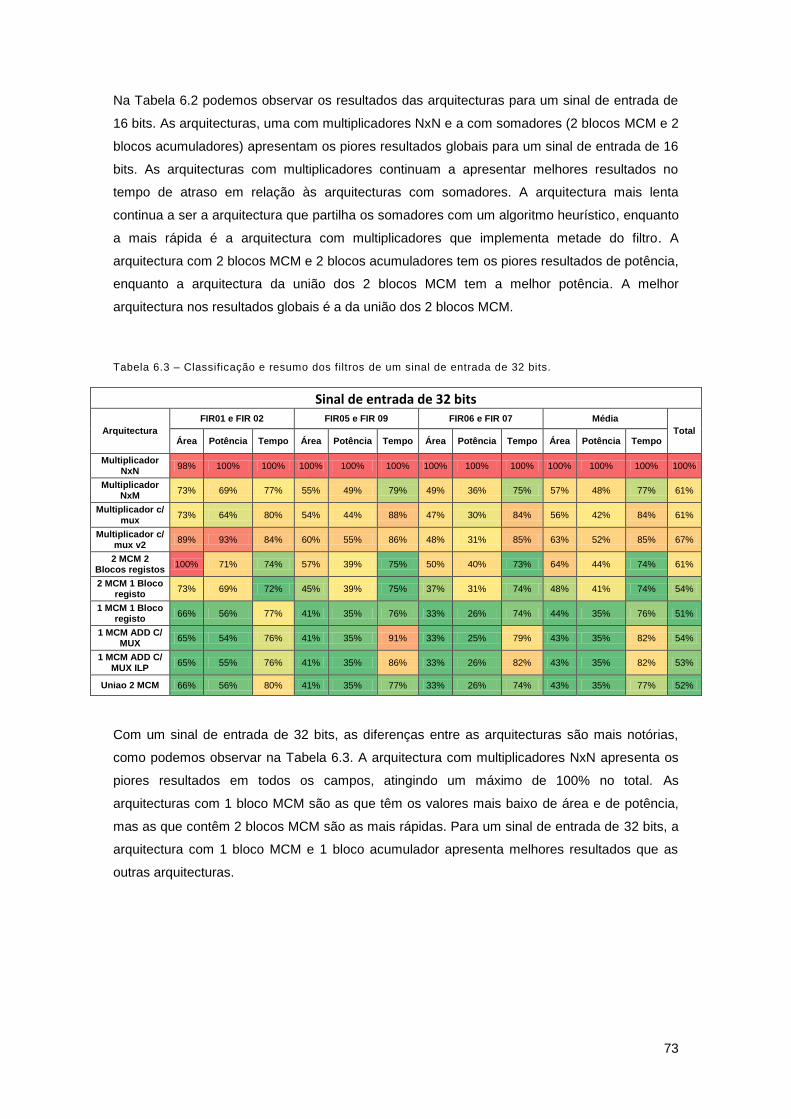
73
Na Tabela 6.2 podemos observar os resultados das arquitecturas para um sinal de entrada de
16 bits. As arquitecturas, uma com multiplicadores NxN e a com somadores (2 blocos MCM e 2
blocos acumuladores) apresentam os piores resultados globais para um sinal de entrada de 16
bits. As arquitecturas com multiplicadores continuam a apresentar melhores resultados no
tempo de atraso em relação às arquitecturas com somadores. A arquitectura mais lenta
continua a ser a arquitectura que partilha os somadores com um algoritmo heurístico, enquanto
a mais rápida é a arquitectura com multiplicadores que implementa metade do filtro. A
arquitectura com 2 blocos MCM e 2 blocos acumuladores tem os piores resultados de potência,
enquanto a arquitectura da união dos 2 blocos MCM tem a melhor potência. A melhor
arquitectura nos resultados globais é a da união dos 2 blocos MCM.
Tabela 6.3 – Classificação e resumo dos filtros de um sinal de entrada de 32 bits.
Sinal de entrada de 32 bits
Arquitectura
FIR01 e FIR 02 FIR05 e FIR 09 FIR06 e FIR 07 Média
Total Área Potência Tempo Área Potência Tempo Área Potência Tempo Área Potência Tempo
Multiplicador NxN
98% 100% 100% 100% 100% 100% 100% 100% 100% 100% 100% 100% 100%
Multiplicador NxM
73% 69% 77% 55% 49% 79% 49% 36% 75% 57% 48% 77% 61%
Multiplicador c/ mux
73% 64% 80% 54% 44% 88% 47% 30% 84% 56% 42% 84% 61%
Multiplicador c/ mux v2
89% 93% 84% 60% 55% 86% 48% 31% 85% 63% 52% 85% 67%
2 MCM 2 Blocos registos
100% 71% 74% 57% 39% 75% 50% 40% 73% 64% 44% 74% 61%
2 MCM 1 Bloco registo
73% 69% 72% 45% 39% 75% 37% 31% 74% 48% 41% 74% 54%
1 MCM 1 Bloco registo
66% 56% 77% 41% 35% 76% 33% 26% 74% 44% 35% 76% 51%
1 MCM ADD C/ MUX
65% 54% 76% 41% 35% 91% 33% 25% 79% 43% 35% 82% 54%
1 MCM ADD C/ MUX ILP
65% 55% 76% 41% 35% 86% 33% 26% 82% 43% 35% 82% 53%
Uniao 2 MCM 66% 56% 80% 41% 35% 77% 33% 26% 74% 43% 35% 77% 52%
Com um sinal de entrada de 32 bits, as diferenças entre as arquitecturas são mais notórias,
como podemos observar na Tabela 6.3. A arquitectura com multiplicadores NxN apresenta os
piores resultados em todos os campos, atingindo um máximo de 100% no total. As
arquitecturas com 1 bloco MCM são as que têm os valores mais baixo de área e de potência,
mas as que contêm 2 blocos MCM são as mais rápidas. Para um sinal de entrada de 32 bits, a
arquitectura com 1 bloco MCM e 1 bloco acumulador apresenta melhores resultados que as
outras arquitecturas.

74

75
CAPÍTULO 7
7. CONCLUSÕES E TRABALHO FUTURO
7.1. CONCLUSÃO
No âmbito do estudo de filtros digitais FIR, existe um grande leque de arquitecturas para a sua
implementação, umas no sentido de reduzir a área, outras a potência e também o tempo de
atraso. No decorrer desta dissertação foram estudadas dez possíveis arquitecturas paralelas
para a implementação de filtros digitais FIR na forma transposta, com duas configurações
diferentes, a que correspondem duas respostas em frequência diferentes. As arquitecturas são
compostas por dois blocos, o bloco MCM, onde ocorrem as multiplicações dos coeficientes
pelo sinal de entrada, e o bloco acumulador, onde são guardados e somados os valores
provenientes do bloco MCM. O que distingue entre as dez arquitecturas estudadas neste
trabalho é o bloco MCM. Assim, podemos dividir o bloco MCM em 2 grupos, os que utilizam
multiplicadores e os que utilizam somadores, subtractores e deslocamentos.
As arquitecturas que utilizam multiplicadores genéricos (NxN) no bloco MCM são as que
ocupam uma maior área e potência, independentemente do tamanho do sinal de entrada. Ao
trocar o multiplicador NxN por um NxM, conseguimos diminuir a área, potência e tempo de
atraso. Apesar de os multiplicadores NxN estarem mais optimizados, concluímos que a
utilização do multiplicador NxM nas arquitecturas FIR permite melhorar em todos os
parâmetros. Com este princípio, foram elaboradas 3 arquitecturas utilizando este multiplicador,
visto que traz mais vantagens. Também foi possível explorar o conceito de partilha em que se
maximiza a partilha dos operadores (multiplicadores), conseguindo reduzir a área e potência,
mas piorando o tempo de atraso. Outra das arquitecturas em que ocorre a partilha dos
multiplicadores, mas diferente da anterior, porque esta implementa metade do filtro,
conseguimos melhorar a frequência, mas com prejuízo na área e na potência. Entre as quatro
arquitecturas com multiplicadores, a que ocupa menos área e tem menos potência é a
arquitectura que maximiza a partilha dos multiplicadores NxM. A arquitectura mais rápida é
quando usamos multiplicadores NxM. Globalmente, podemos concluir que a arquitectura que
maximiza a partilha dos multiplicadores, é a melhor arquitectura com multiplicadores.
As restantes arquitecturas os multiplicadores são substituídos por somadores, subtractores e
deslocamentos. Existem muitos algoritmos que permitem obter a partir dos coeficientes dos
filtros todas as operações a realizar. Começamos com uma arquitectura com blocos
duplicados, ou seja, dois blocos MCM e dois blocos acumuladores, uma arquitectura com
claras desvantagens na área ocupada e potência consumida, mas conseguindo ser a
arquitectura mais rápida. A arquitectura seguinte estudada foi numa tentativa de melhorar a

76
área, ficando uma arquitectura com dois blocos MCM e um bloco acumulador. Foi possível
melhorar a área, mas também a potência, prejudicando ligeiramente a frequência máxima de
funcionamento. As restantes arquitecturas são muito parecidas, em que todas têm um bloco
MCM e um bloco acumulador. Existem duas arquitecturas muito semelhantes, em que a
diferença consiste na técnica utilizada para o cálculo dos termos parciais dos coeficientes. Uma
delas, em que os coeficientes dos dois filtros são calculados independentemente e a outra em
que consideramos os coeficientes dos dois filtros como um só conjunto, levando a uma
optimização diferente da anterior em alguns casos. Os resultados das duas arquitecturas são
muito semelhantes, mas a que provém da união dos coeficientes dos dois filtros apresenta
melhores resultados na potência e na frequência. Na área, os resultados são muito idênticos,
porque o número de operações implementadas no bloco MCM é igual, seja qual for a técnica.
Com as outras arquitecturas fomos explorar a partilha dos operadores (somadores e
subtractores). Para uma das arquitecturas foi criado um algoritmo heurístico, que maximiza a
partilha dos operadores e a outra arquitectura é obtida utilizado programação linear, através da
interacção com o programa LP_SOLVE. Estas duas arquitecturas pouco diminuem a área
ocupada do filtro e a sua potência, mas apresentam tempos de atraso maiores. Note-se que, a
arquitectura que utiliza a programação linear é a que ocupa menor área nas arquitecturas com
somadores. Nas arquitecturas com somadores a que precisa de menos potência é a da união
dos dois MCM, ao passo que a arquitectura com dois blocos MCM e dois blocos acumuladores
é a mais rápida. Em geral, a arquitectura da união dos dois MCM é a melhor arquitectura.
O que também chamou a atenção foi as arquitecturas que partilham os operadores. Se
usarmos os multiplicadores, a arquitectura que maximiza a partilha dos multiplicadores
conseguimos reduzir a área até aos 3% (em relação há arquitectura com multiplicadores NxM),
em vez dos 0.4% da arquitectura que utiliza a programação linear (em relação à arquitectura
com 1 bloco MCM e 1 bloco acumulador). Note-se que a maior redução é obtida quando
substituímos os multiplicadores por somadores e subtractores, com valores médios de 18.4%.
Na potência também ocorre a mesma situação, com a arquitectura com multiplicadores a atingir
uma redução de 9% e a com somadores a ficar pelos 2%. É verdade que a área ocupada e
potência de um simples multiplicador é superior a um simples somador, mas é mais vantajoso
partilhar um multiplicador que um somador.
Uma possível conclusão para este trabalho, se queremos uma arquitectura FIR com 2 filtros
com pouca área e baixa potência, temos de optar pelas arquitecturas com somadores,
subtractores e deslocamentos com um bloco MCM e um bloco acumulador, porque conseguem
reduções de 18.4% (área) e 15.8% (potência) em relação à melhor arquitectura com
multiplicadores (com maximização da partilha dos multiplicadores). No entanto, as arquitecturas
com somadores (1 bloco MCM e 1 bloco acumulador), para tamanhos pequenos do sinal de
entrada (8 e 16 bits) são mais lentas que as que usam multiplicadores, conseguindo estes
reduzirem o tempo de atraso em 16%. Para um sinal de entrada de 32 bits, teremos de recorrer
às arquitecturas com somadores com 2 blocos MCM para serem mais rápidas, reduzindo 3%
no tempo de atraso que as arquitecturas com multiplicadores.

77
Globalmente podem dizer que a arquitectura mais equilibrada em termos dos parâmetros
considerados (área, potência e tempo de atraso) é a arquitectura com somadores com um
bloco MCM e acumulador proveniente da união dos coeficientes. No entanto, se para um
projecto onde um dos parâmetros for mais importante que os restantes, existem arquitecturas
com melhores características.
7.2. TRABALHO FUTURO
No desenvolvimento deste trabalho foram utilizados componentes genéricos nas arquitecturas,
como somadores, subtractores e multiplicadores. Seria interessante estudar o comportamento
das arquitecturas dos filtros utilizando outro tipo de estrutura para os mesmos componentes.
A arquitectura que maximiza os multiplicadores foi realizada ordenando os coeficientes de
ordem crescente e agrupando sucessivamente. Tendo em conta que o multiplexer que escolhe
o operador a multiplicar, depende dos coeficientes um trabalho futuro seria utilizar a
programação linear para minimizar o tamanho dos multiplexeres, ou seja, agrupar os
coeficientes mais parecidos.
Outra ideia seria alterar o algoritmo heurístico de procura. Neste trabalho o algoritmo heurístico
foi dividido em 6 etapas para emparelhar o máximo possível de operadores. No entanto,
existem casos que é desvantajoso partilhar os operadores, por exemplo quando substituímos
um operador por dois multiplexeres, a área ocupada pode ser superior à área ocupada pelos
dois operadores. Assim, limitando o algoritmo heurístico à procura de pares de coeficientes que
só necessitem de um multiplexer é possível melhorar os resultados.

78

79
REFERÊNCIAS
[1] Hunsoo Choo, Khurram Muhammad, and Kaushik Roy, “Reduction of Digital Filters Using
Shift Inclusive Differential Coefficients”, IEEE TRANSACTIONS ON SIGNAL
PROCESSING, VOL. 52, NO. 6, JUNE 2004.
[2] Paulo Alexandre C. Marques, “Introdução à Filtragem Adaptativa”, Processamento Digital
de Sinal II, Instituto Superior de Engenharia de Lisboa.
[3] Kei-Yong Khoo, Zhan Yu, Alan N. Willson, A.N., Jr. “Design of optimal hybrid form FIR
filter”, The 2001 IEEE International Symposium on Circuits and Systems, 2001, ISCAS
2001, VOL. 2, 621-624, May 2001.
[4] Dempster, A. G. and MacLeod, M. “Digital filter design using subexpression elimination
and all signed-digit representations”, Proceedings of the 2004 International Symposium on
Circuits and Systems, 2004, ISCAS 2004, VOL. 3, III-169-72, 23-26 May 2004.
[5] L. Aksoy, E. Costa, P. Flores, and J. Monteiro, “Exact and Approximate Algorithms for the
Optimization of Area and Delay in Multiple Constant Multiplications,” IEEE Transactions
on Computer-Aided Design of Integrated Circuits and Systems, VOL. 27, NO. 6, JUNE
2008.
[6] Gustafsson, O., Dempster, A. G., and Wanhammer, L. “Extended results for minimum-
adder constant integer multipliers”, IEEE International Symposium on Circuits and
Systems, 2002, ISCAS 2002, VOL. 1, 73-76, 2002.
[7] Hartley, R I. "Subexpression sharing in filters using canonic signed digit multipliers”, IEEE
Transactions on Circuits and-PW Systems II, Vol. 43, No. 10, (1996), 677-688.
[8] Aksoy, L; Costa, E.; Flores, P,; Monteiro, J.; “Optimization of Area under a Delay
Constraint in Digital Filter Synthesis Using SAT-Based Integer Linear Programming”,
Design Automation Conference, 2006 43rd ACM/IEEE, pages 669-674.
[9] In-Cheol Park; Hyeong-Ju Kang, “Digital Filter Synthesis Based on an Algorithm to
Generate All Minimal Signed Digit Representations”, IEEE Transactions on Computer-
Aided Design of Integrated Circuits and Systems, Vol. 21, No. 12 (Dec 2002), 1525-1529.
[10] Levent Aksoy, Eduardo Costa, Paulo Flores e José Monteiro, “Design of Low-Power
Multiple Constant Multiplications Using Low-Complexity Minimum Depth Operations”,
Proceedings of the 21st edition of the great lakes symposium on Great lakes symposium on
VLSI, 79-84, 2011.
[11] Eduardo da Costa, Paulo Flores e José Monteiro, “Maximal Sharing of Partial Terms in
MCM under Minimal Signed Digit Representation” Proceedings of the 2005 European
Conference on Circuit Theory and Design, 2005, Vol. 2 (Sept 2005), 221-224.
[12] Levent Aksoy, Eduardo Costa, Paulo Flores e José Monteiro, “Minimum Number of
Operations under a General Number Representation for Digital Filter Synthesis”, 18th
European Conference on Circuit Theory and Design, 2007, ECCTD 2007 , 252-255, Aug
2007.
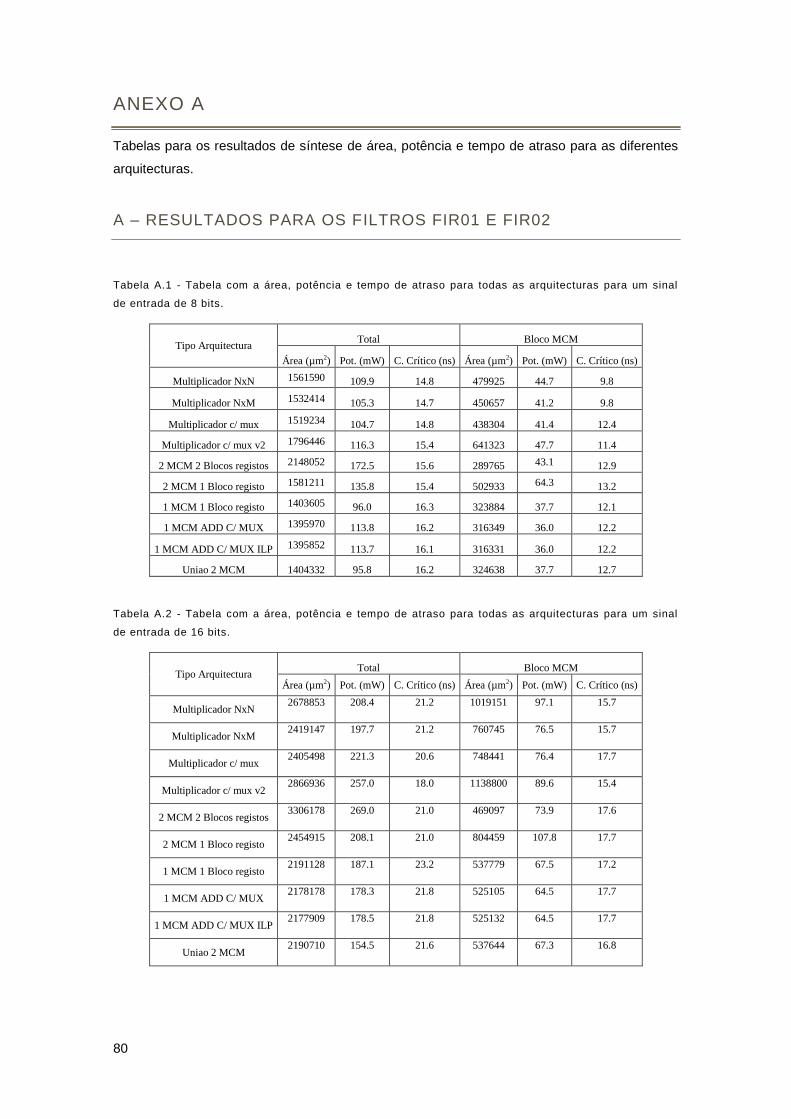
80
ANEXO A
Tabelas para os resultados de síntese de área, potência e tempo de atraso para as diferentes
arquitecturas.
A – RESULTADOS PARA OS FILTROS FIR01 E FIR02
Tabela A.1 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 8 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN 1561590 109.9 14.8 479925 44.7 9.8
Multiplicador NxM 1532414 105.3 14.7 450657 41.2 9.8
Multiplicador c/ mux 1519234 104.7 14.8 438304 41.4 12.4
Multiplicador c/ mux v2 1796446 116.3 15.4 641323 47.7 11.4
2 MCM 2 Blocos registos 2148052 172.5 15.6 289765 43.1 12.9
2 MCM 1 Bloco registo 1581211 135.8 15.4 502933 64.3 13.2
1 MCM 1 Bloco registo 1403605 96.0 16.3 323884 37.7 12.1
1 MCM ADD C/ MUX 1395970 113.8 16.2 316349 36.0 12.2
1 MCM ADD C/ MUX ILP 1395852 113.7 16.1 316331 36.0 12.2
Uniao 2 MCM 1404332 95.8 16.2 324638 37.7 12.7
Tabela A.2 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 16 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN 2678853 208.4 21.2 1019151 97.1 15.7
Multiplicador NxM 2419147 197.7 21.2 760745 76.5 15.7
Multiplicador c/ mux 2405498 221.3 20.6 748441 76.4 17.7
Multiplicador c/ mux v2 2866936 257.0 18.0 1138800 89.6 15.4
2 MCM 2 Blocos registos 3306178 269.0 21.0 469097 73.9 17.6
2 MCM 1 Bloco registo 2454915 208.1 21.0 804459 107.8 17.7
1 MCM 1 Bloco registo 2191128 187.1 23.2 537779 67.5 17.2
1 MCM ADD C/ MUX 2178178 178.3 21.8 525105 64.5 17.7
1 MCM ADD C/ MUX ILP 2177909 178.5 21.8 525132 64.5 17.7
Uniao 2 MCM 2190710 154.5 21.6 537644 67.3 16.8
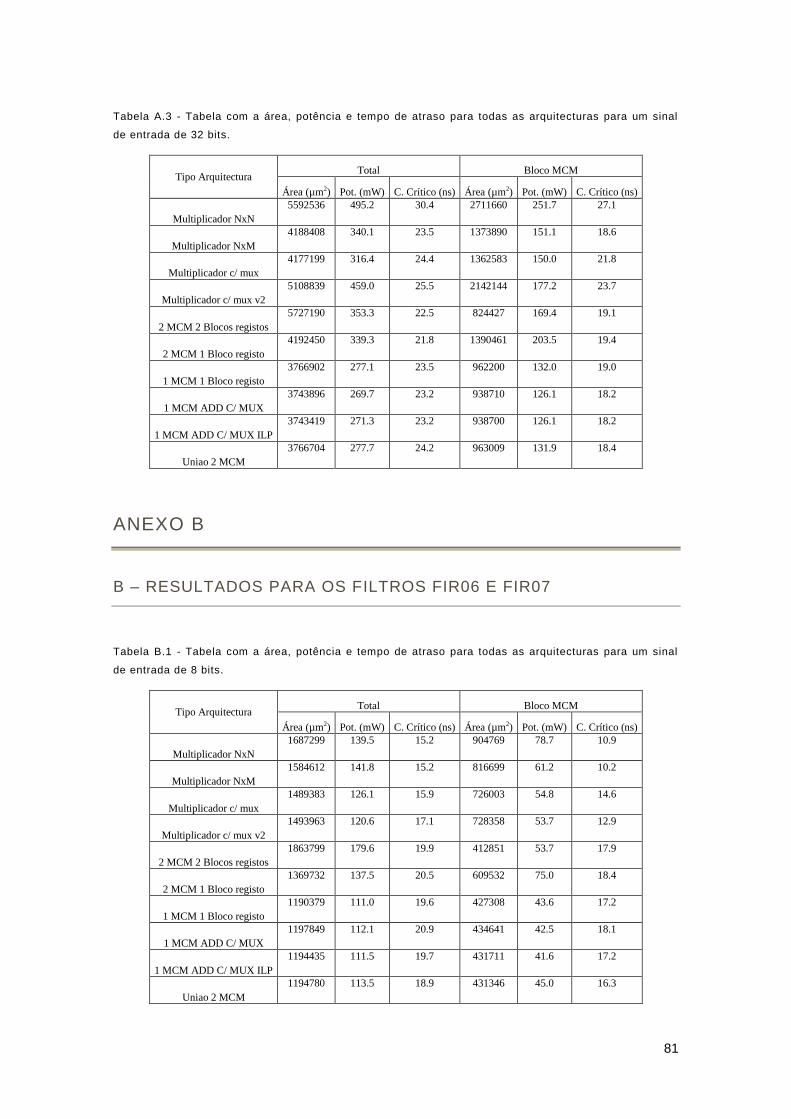
81
Tabela A.3 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 32 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN
5592536 495.2 30.4 2711660 251.7 27.1
Multiplicador NxM
4188408 340.1 23.5 1373890 151.1 18.6
Multiplicador c/ mux
4177199 316.4 24.4 1362583 150.0 21.8
Multiplicador c/ mux v2
5108839 459.0 25.5 2142144 177.2 23.7
2 MCM 2 Blocos registos
5727190 353.3 22.5 824427 169.4 19.1
2 MCM 1 Bloco registo
4192450 339.3 21.8 1390461 203.5 19.4
1 MCM 1 Bloco registo
3766902 277.1 23.5 962200 132.0 19.0
1 MCM ADD C/ MUX
3743896 269.7 23.2 938710 126.1 18.2
1 MCM ADD C/ MUX ILP
3743419 271.3 23.2 938700 126.1 18.2
Uniao 2 MCM
3766704 277.7 24.2 963009 131.9 18.4
ANEXO B
B – RESULTADOS PARA OS FILTROS FIR06 E FIR07
Tabela B.1 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 8 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN
1687299 139.5 15.2 904769 78.7 10.9
Multiplicador NxM
1584612 141.8 15.2 816699 61.2 10.2
Multiplicador c/ mux
1489383 126.1 15.9 726003 54.8 14.6
Multiplicador c/ mux v2
1493963 120.6 17.1 728358 53.7 12.9
2 MCM 2 Blocos registos
1863799 179.6 19.9 412851 53.7 17.9
2 MCM 1 Bloco registo
1369732 137.5 20.5 609532 75.0 18.4
1 MCM 1 Bloco registo
1190379 111.0 19.6 427308 43.6 17.2
1 MCM ADD C/ MUX
1197849 112.1 20.9 434641 42.5 18.1
1 MCM ADD C/ MUX ILP
1194435 111.5 19.7 431711 41.6 17.2
Uniao 2 MCM
1194780 113.5 18.9 431346 45.0 16.3

82
Tabela B.2 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 16 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN
3157616 335.5 21.1 2062560 165.9 15.4
Multiplicador NxM
2486977 254.7 20.8 1392808 130.2 14.4
Multiplicador c/ mux
2353535 215.3 20.4 1267222 109.9 17.8
Multiplicador c/ mux v2
2395119 199.3 20.2 1307139 105.3 16.9
2 MCM 2 Blocos registos
2686634 277.1 22.5 641000 89.8 17.0
2 MCM 1 Bloco registo
2002002 217.8 23.6 923701 124.5 17.5
1 MCM 1 Bloco registo
1752804 174.6 21.9 671506 77.5 16.2
1 MCM ADD C/ MUX
1764141 175.3 22.8 676388 89.6 18.1
1 MCM ADD C/ MUX ILP
1764141 176.6 21.7 681520 77.3 18.5
Uniao 2 MCM
1758594 179.1 21.25 677406 81.6 16.7
Tabela B.3 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 32 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN
8710955 1143.9 32.4 6940415 780.1 26.9
Multiplicador NxM
4265400 412.1 24.4 2553770 234.0 20.4
Multiplicador c/ mux
4051933 345.2 27.3 2353794 215.7 25.3
Multiplicador c/ mux v2
4171198 356.7 27.6 2468922 202.0 23.4
2 MCM 2 Blocos registos
4363299 452.7 23.7 1095425 162.1 22.0
2 MCM 1 Bloco registo
3233793 359.2 24.1 1536557 225.0 22.0
1 MCM 1 Bloco registo
2847030 295.7 24.0 1147224 143.4 21.4
1 MCM ADD C/ MUX
2843721 290.7 25.8 1139820 165.0 23.3
1 MCM ADD C/ MUX ILP
2860105 296.3 26.7 1155668 148.1 23.8
Uniao 2 MCM
2856310 299.7 24.1 1156992 165.1 19.7
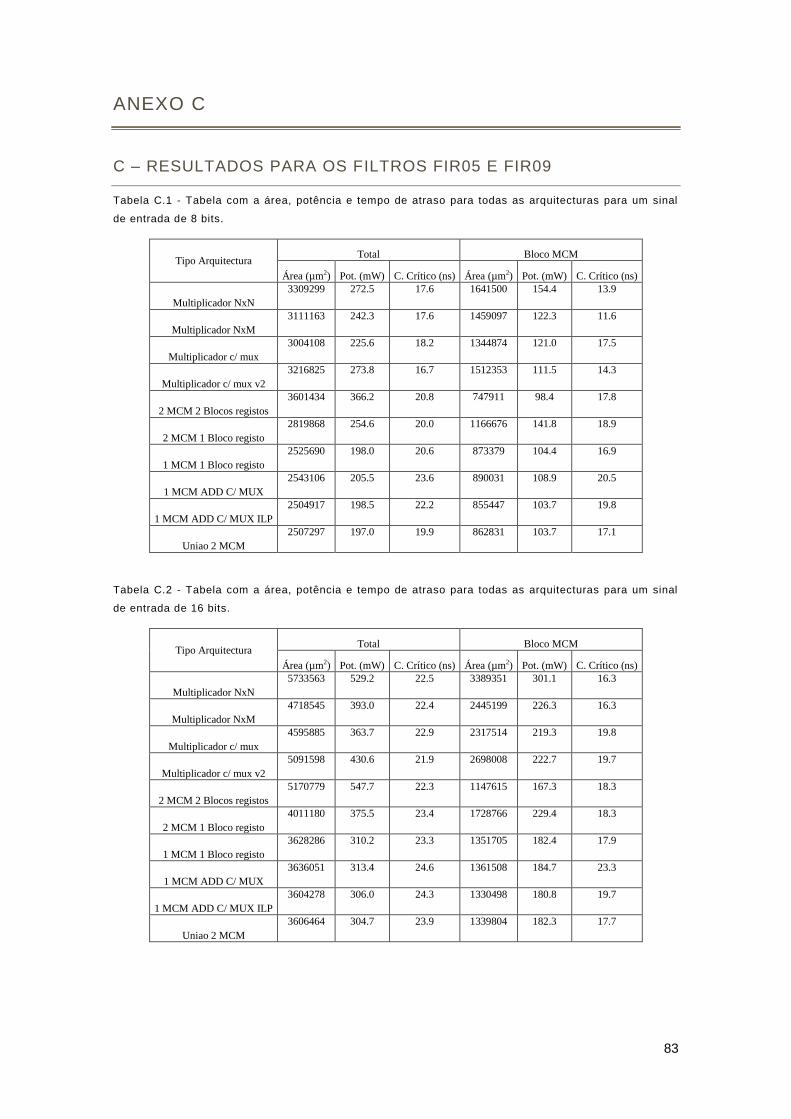
83
ANEXO C
C – RESULTADOS PARA OS FILTROS FIR05 E FIR09
Tabela C.1 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 8 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN
3309299 272.5 17.6 1641500 154.4 13.9
Multiplicador NxM
3111163 242.3 17.6 1459097 122.3 11.6
Multiplicador c/ mux
3004108 225.6 18.2 1344874 121.0 17.5
Multiplicador c/ mux v2
3216825 273.8 16.7 1512353 111.5 14.3
2 MCM 2 Blocos registos
3601434 366.2 20.8 747911 98.4 17.8
2 MCM 1 Bloco registo
2819868 254.6 20.0 1166676 141.8 18.9
1 MCM 1 Bloco registo
2525690 198.0 20.6 873379 104.4 16.9
1 MCM ADD C/ MUX
2543106 205.5 23.6 890031 108.9 20.5
1 MCM ADD C/ MUX ILP
2504917 198.5 22.2 855447 103.7 19.8
Uniao 2 MCM
2507297 197.0 19.9 862831 103.7 17.1
Tabela C.2 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 16 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN
5733563 529.2 22.5 3389351 301.1 16.3
Multiplicador NxM
4718545 393.0 22.4 2445199 226.3 16.3
Multiplicador c/ mux
4595885 363.7 22.9 2317514 219.3 19.8
Multiplicador c/ mux v2
5091598 430.6 21.9 2698008 222.7 19.7
2 MCM 2 Blocos registos
5170779 547.7 22.3 1147615 167.3 18.3
2 MCM 1 Bloco registo
4011180 375.5 23.4 1728766 229.4 18.3
1 MCM 1 Bloco registo
3628286 310.2 23.3 1351705 182.4 17.9
1 MCM ADD C/ MUX
3636051 313.4 24.6 1361508 184.7 23.3
1 MCM ADD C/ MUX ILP
3604278 306.0 24.3 1330498 180.8 19.7
Uniao 2 MCM
3606464 304.7 23.9 1339804 182.3 17.7

84
Tabela C.3 - Tabela com a área, potência e tempo de atraso para todas as arquitecturas para um sinal
de entrada de 32 bits.
Tipo Arquitectura Total Bloco MCM
Área (µm2) Pot. (mW) C. Crítico (ns) Área (µm2) Pot. (mW) C. Crítico (ns)
Multiplicador NxN
14463973 1540.7 33.1 10775492 1022.1 27.2
Multiplicador NxM
7961679 760.2 26.2 4324554 422.8 22.1
Multiplicador c/ mux
7803433 673.0 29.1 4176803 402.9 28.7
Multiplicador c/ mux v2
8746057 853.0 28.3 5097676 453.4 25.9
2 MCM 2 Blocos registos
8285315 603.7 24.8 1979254 305.2 22.1
2 MCM 1 Bloco registo
6496039 605.9 24.7 2906617 411.9 23.2
1 MCM 1 Bloco registo
5914029 543.0 25.3 2313388 332.5 21.5
1 MCM ADD C/ MUX
5903856 542.9 30.1 2310425 328.7 29.7
1 MCM ADD C/ MUX ILP
5862228 531.9 28.4 2272730 324.3 26.0
Uniao 2 MCM
5871544 534.8 25.5 2289249 333.2 21.7
ANEXO D
SCRIPT
Um exemplo do script utilizado para a síntese dos ficheiros VHDL.
read_file -format vhdl {…} #todos os ficheiros VHDL necessários para a arquitectura current_design fir01_wapprox_fir02_wapprox_reg_add
elaborate fir01_wapprox_fir02_wapprox_reg_add -architecture BEHAVIORAL -library
WORK -update
create_clock "clk" -period 50 -waveform {0 25}#criação do relógio de 50 ns set_fix_multiple_port_nets -all
set high_fanout_net_threshold 10000
check_design -multiple_designs
set_clock_uncertainty 0.1 clk
set_clock_latency 0.2 clk
set_clock_transition 0.1 clk
set_dont_touch_network clk
set_dont_touch mode
set_dont_touch reset
set_switching_activity -toggle_rate 2 -clock clk -static_probability 0.5 -select
inputs
compile -exact_map -boundary_optimization
report_constraint -all_violators
set_fix_hold clk
uplevel #0 check_timing
#uplevel #0 { report_clock -nosplit }
#uplevel #0 { report_constraint -all_violators -significant_digits 2 }
#uplevel #0 { report_clock -skew -nosplit }
compile -only_design_rule -incremental_mapping
report_timing
uplevel #0 { report_power -analysis_effort high} #relatório da potência
report_qor #relatório global com os valores da área e tempo de atraso





























