Embed Size (px)
Citation preview

INTRODUCCIÓ A L’ANÀLISI DE REGRESSIÓ LINEAL
Magdalena Cladera Munar Antoni Matas Mir


7
SUMARI
1. Introducció ........................................................................................ 9 1.1. Econometria i anàlisi de regressió ................................................... 11
1.2. Etapes de la metodologia economètrica .......................................... 13
2. El model de regressió lineal simple................................................ 17 2.1. Aleatorietat de la relació entre les variables del model ................. 19
2.2. Especificació del model..................................................................... 24 2.2.1. Hipòtesis bàsiques del model de regressió clàssic.................................... 26
2.3. Estimació dels paràmetres per mínims quadrats ordinaris .......... 28 2.3.1. Interpretació econòmica dels paràmetres estimats ................................... 34
2.4. Bondat d’ajust. El coeficient de determinació R2........................... 35
2.5. Inferència en el model de regressió lineal simple ........................... 40 2.5.1. Distribució de mostreig dels estimadors de MQO.................................... 40 2.5.2. Contrastació de la significació individual de la variable explicativa ....... 46
2.6. Estimació dels paràmetres per altres mètodes ............................... 50 2.6.1. Estimació per màxima versemblança ....................................................... 50 2.6.2. Estimació per moments ............................................................................ 52
2.7. Predicció en el model de regressió lineal simple............................. 52 2.7.1. Predicció de la mitjana ............................................................................. 53 2.7.2. Predicció d’un valor individual ................................................................ 55
3. El model de regressió lineal múltiple ............................................. 61 3.1. Especificació del model..................................................................... 63
3.1.1. Hipòtesis bàsiques del model de regressió clàssic amb més d’una variable explicativa .......................................................................................................... 65
3.2. Estimació dels paràmetres per MQO.............................................. 66
3.3. Bondat d’ajust. Coeficient de determinació i coeficient de determinació corregit ............................................................................... 71
3.4. Inferència en el model de regressió lineal múltiple ........................ 75 3.4.1. Distribució de mostreig dels estimadors de MQO.................................... 75 3.4.2. Contrastació de la significació individual de les variables explicatives... 79 3.4.3. Contrastació de la significació conjunta de les variables explicatives ..... 81 3.4.4. Contrastació de restriccions lineals entre els paràmetres ......................... 84 3.4.5. Contrastació de la nul·litat d’un subconjunt de paràmetres...................... 89

8
3.5. Predicció en el model de regressió lineal múltiple.......................... 90 3.5.1. Predicció de la mitjana ............................................................................. 90 3.5.2. Predicció d’un valor individual ................................................................ 91
4. Problemes amb la informació mostral ........................................... 93 4.1. Problemes amb la mostra................................................................. 95
4.2. Multicolinealitat ................................................................................ 96 4.2.1. Definició i conseqüències de la multicolinealitat ..................................... 97 4.2.2. Detecció de la multicolinealitat ................................................................ 99 4.2.3. Mesures per combatre la multicolinealitat.............................................. 103
4.3. Observacions influents i observacions atípiques .......................... 106 4.3.1. Mesures per a l’anàlisi d’observacions estranyes................................... 109
Aplicació............................................................................................. 117
Exercicis resolts ................................................................................. 127
Bibliografia recomanada................................................................... 145

1. Introducció


Introducció a l’Anàlisi de Regressió Lineal
11
El contingut d’aquest material didàctic fa referència a l’anàlisi de regressió lineal, que és una de les tècniques bàsiques de l’Econometria.
En aquest capítol es farà una breu introducció al concepte i els objectius de l’Econometria i de l’anàlisi de regressió, i després es descriurà el procediment que se segueix habitualment per fer un estudi economètric aplicat.
1.1. Econometria i anàlisi de regressió Diversos autors han proposat diferents definicions d’Econometria, la majoria de les quals remarquen la interrelació que existeix dins aquesta disciplina entre la teoria econòmica, les matemàtiques i la inferència estadística.
L’Econometria té com a objectiu l’anàlisi de les variables econòmiques per explicar-ne i predir-ne el comportament. Per assolir aquests propòsits s’utilitzen models expressats en forma matemàtica i mètodes d’inferència estadística d’estimació i contrastació.
Per tant, el contingut de l’Econometria és constituït per totes les qüestions relatives a l’estimació, la contrastació i la predicció amb models economètrics. Dins aquest contingut es poden distingir dues parts: la teoria economètrica i l’econometria aplicada.
La teoria economètrica és la part de l’Econometria que estudia els mètodes economètrics d’estimació, contrastació i avaluació dels models. Aquesta part de l’Econometria inclou diverses tècniques estadístiques d’aplicació general, així com determinats mètodes desenvolupats pels econòmetres amb la finalitat de resoldre problemes propis de l’Economia.
Per altra banda, l’econometria aplicada es refereix a les investigacions realitzades mitjançant mètodes economètrics en diversos camps de l’Economia.
Habitualment l’objectiu dels estudis economètrics és conèixer la forma en què es relacionen determinades variables econòmiques amb la finalitat, per exemple, de contrastar teories o d’utilitzar aquest coneixement per a la presa de decisions en distints àmbits de l’Economia.
La teoria econòmica planteja múltiples situacions en les quals es tracten relacions entre diverses variables econòmiques: la relació entre el consum i la renda, de la producció amb els factors productius, etc. La teoria econòmica ofereix una primera aproximació a aquestes relacions, però a l’hora de traslladar-les a situacions concretes es fa necessari contrastar si les teories són consistents amb el comportament observat per les variables d’interès, així com

M. Cladera; A. Matas
12
concretar la forma funcional de la relació. L’anàlisi de regressió permet aproximar-se a aquestes qüestions, per tal com proporciona els instruments necessaris per quantificar les relacions entre variables.
Exemple 1.1. Algunes situacions en les quals seria aplicable l’anàlisi de regressió
Situació 1: Un analista econòmic està interessat a estudiar la dependència de la despesa en consum personal en l’ingrés personal disponible, per tal d’estimar la propensió marginal a consumir, és a dir, el canvi mitjà en la despesa en consum davant un canvi d’una unitat monetària a l’ingrés.
Situació 2: Un empresari està interessat a conèixer la resposta de la demanda del seu producte davant canvis en el preu, per estimar l’elasticitat-preu de la demanda del producte i utilitzar aquesta informació per decidir quin és el preu de venda que l’interessa fixar.
Situació 3: L’encarregat de la promoció d’una empresa vol estudiar la dependència de la demanda del seu producte de les despeses en publicitat, per estimar l’elasticitat de la demanda respecte a aquestes despeses, coneixement que seria útil per determinar el pressupost òptim en publicitat.
Com es posa de manifest a l’Exemple 1.1, conèixer la forma en què es relacionen determinades variables econòmiques pot ajudar a la presa de decisions en distints àmbits de l’Economia.
Quan es vol aplicar l’anàlisi de regressió per estudiar el comportament d’una determinada variable econòmica, en primer lloc s’ha d’expressar matemàticament la relació entre la variable que es vol analitzar i les variables que es consideren factors potencialment explicatius del seu comportament. Després s’han de recollir dades estadístiques sobre les variables involucrades en la relació, que, mitjançant l’aplicació de les tècniques de regressió convenients, permetran estimar els paràmetres desconeguts que caracteritzen la relació i contrastar la validesa de les estimacions obtingudes. A partir d’aquí es podran aplicar mètodes de contrastació d’hipòtesis i predicció, en funció dels objectius de l’estudi.
A continuació s’expliquen de manera més detallada les etapes que habitualment intervenen en el procediment general d’anàlisi economètrica, aplicable a l’anàlisi de regressió.

Introducció a l’Anàlisi de Regressió Lineal
13
1.2. Etapes de la metodologia economètrica Com ja s’ha comentat, l’anàlisi de regressió és un dels instruments amb els quals compta l’Econometria per a l’estudi de les relacions entre variables econòmiques, generalment amb l’objectiu de conèixer el comportament d’una determinada variable en funció d’una altra o d’unes altres variables.
En termes generals, el procediment bàsic de l’anàlisi economètrica, i en concret de l’anàlisi de regressió, consisteix a especificar, estimar i contrastar un model que reflecteixi la relació entre les variables relatives a una determinada qüestió. A continuació es detallen les etapes que generalment formen part d’aquest procediment.
1. Plantejament dels objectius de l’estudi
Abans de començar qualsevol estudi economètric, la primera etapa és definir clarament els objectius que es volen assolir i plantejar el marc teòric de la qüestió.
2. Especificació del model
La relació entre la variable de la qual es vol estudiar el comportament i les variables que es consideren possibles factors explicatius s’ha de plantejar matemàticament.
Així, si se suposa que es vol analitzar l’evolució d’una variable Y que es creu que depèn d’un conjunt de variables X1, X2,...,Xk, la relació entre elles es pot plantejar com a:
Y = f(X1, X2,..., Xk, β)
On Y és la variable de la qual es vol analitzar el comportament i s’anomena variable dependent, explicada o endògena; les Xj són les variables que es consideren factors potencialment influents del comportament de la variable dependent i s’anomenen variables explicatives, independents, exògenes o regressors; i β és un vector que denota un conjunt de paràmetres que recullen la magnitud amb què les variacions de les variables explicatives es transmeten a variacions de la variable dependent. Aquests paràmetres són constants desconegudes que s’hauran d’estimar.
En aquest text es farà referència a l’anàlisi de regressió lineal, i per tant, les funcions que s’utilitzaran per especificar les relacions entre les variables seran funcions lineals de la forma següent:
Y = β0 + β1·X1 + β2·X2 +···+βk·Xk

M. Cladera; A. Matas
14
En conseqüència, els models que es tractaran seran models de regressió lineals, en els quals els paràmetres β representen directament els efectes de les variacions de les variables Xj sobre la variable Y. Si la variable Xj no tingués efecte sobre Y, llavors el paràmetre que l’acompanya hauria de ser zero: βj = 0.
A més de les variables explicatives que s’inclouen a l’especificació del model, poden existir altres variables que no s’hagin tingut en compte, per diverses raons, però que tinguin influència sobre la variable dependent. Per aquest motiu s’afegeix a l’especificació una variable, u, que no és observable i es denomina pertorbació aleatòria, terme de pertorbació o terme d’error i s’inclou habitualment en els models economètrics per expressar la diferència entre el vertader valor de la variable dependent i el valor que resulta del model. Aquesta pertorbació recull els efectes de diversos factors que no s’inclouen explícitament en el model com a variables explicatives. Així, el model de regressió lineal quedaria especificat de la manera següent:
Y = β0 + β1·X1 + β2·X2 +···+ βk·Xk + u
Quan en el model s’especifica una única variable explicativa, es parla de model de regressió lineal simple, i quan s’especifiquen dues o més variables explicatives es té un model de regressió múltiple.
3. Recopilació de dades estadístiques
Els βj són paràmetres desconeguts que representen els efectes marginals de les variables explicatives sobre la dependent. Per estimar aquests paràmetres es necessiten dades sobre les variables que intervenen en el model. A partir de la informació mostral recopilada sobre les variables explicatives i la variable dependent es tractarà de quantificar la relació entre aquestes mitjançant l’estimació dels paràmetres βj.
Les dades utilitzades per a l’estimació dels paràmetres del model poden ser:
- Dades de sèries temporals. Es disposa de dades en diferents moments del temps per a una mateixa unitat econòmica.
- Dades atemporals o de cross-section. Es disposa de dades de diverses unitats econòmiques en un mateix moment del temps.
- Dades de panel. Es disposa de dades temporals i transversals, és a dir, de distintes unitats econòmiques en distints moments del temps.

Introducció a l’Anàlisi de Regressió Lineal
15
4. Estimació dels paràmetres del model
Una vegada que es tenen les dades sobre les variables que intervenen a la relació que es vol analitzar, aquesta informació s’utilitzarà per estimar els valors dels paràmetres del model. Per fer-ho s’utilitzaran les tècniques d’estimació pròpies de l’anàlisi de regressió, que es comentaran detalladament més endavant.
5. Avaluació de les estimacions
Una vegada obtingudes les estimacions dels paràmetres del model és necessari avaluar la validesa dels resultats. Per fer-ho es disposa de determinades mesures estadístiques que també es comentaran en aquest text.
6. Utilització dels resultats de l’anàlisi de regressió
El model de regressió estimat s’utilitzarà per assolir els objectius de l’anàlisi que s’havien plantejat inicialment. Aquests poden ser el simple coneixement de la relació entre les variables, és a dir conèixer quines variables influeixen en el comportament de la variable dependent i conèixer el valor dels seus efectes; la contrastació d’hipòtesis referents a la relació entre les variables que intervenen en el model, mitjançant la contrastació d’hipòtesis sobre els paràmetres; la predicció del valor de la variable dependent en funció dels valors esperats de les variables explicatives; l’avaluació de polítiques econòmiques per poder elegir entre polítiques alternatives, etc.
Cal dir que, normalment, a les etapes d’especificació i estimació no es fa feina amb un únic model, sinó que s’especifiquen i estimen diversos models alternatius i a continuació es fan determinats contrasts estadístics per avaluar-los i seleccionar l’especificació més adequada per representar el comportament de la variable d’interès.
Exemple. 1.2. Procediment d’estimació de la funció de demanda d’un producte
La teoria microeconòmica estableix que s’espera que la relació entre el preu d’un producte i la seva demanda sigui una relació inversa. Però la teoria no proporciona una mesura numèrica de la relació entre les dues variables, no indica en quant variarà la demanda del producte davant variacions en el preu.
Per quantificar numèricament aquesta relació, s’especifica i estima un model de regressió lineal.
L’especificació del model és la següent:

M. Cladera; A. Matas
16
D = β0 + β1P + u
segons la qual la demanda d’aquest producte, D, depèn del seu preu, P, i d’altres factors que no s’especifiquen explícitament i que es recullen dins la pertorbació aleatòria, u.
β0 i β1 són paràmetres desconeguts, i per estimar-ne el valor es necessiten dades de les variables que intervenen en el model, és a dir, dades de les unitats demanades del producte i del seu preu. Concretament es disposa d’una mostra de vint observacions corresponents als preus i les quantitats demanades del producte durant els darrers vint mesos. Utilitzant les tècniques pròpies de l’anàlisi de regressió, s’utilitzen aquestes dades mostrals per estimar els paràmetres del model.
Una vegada que s’ha estimat el model, les estimacions obtingudes es poden utilitzar per contrastar hipòtesis sobre els paràmetres del model. A la situació que es considera podria contrastar-se si l’efecte del preu sobre la demanda és negatiu, és a dir si β1 és més petit que zero, tal com cal esperar d’acord amb la teoria econòmica. El model estimat també podria utilitzar-se per predir quina seria la demanda del producte si es fixàs un preu determinat.
En aquest text s’exposaran les tècniques economètriques pròpies de l’anàlisi de regressió per a la implementació de les distintes etapes que s’han comentat en aquest apartat. És a dir, es tractaran les tècniques habituals d’estimació, contrastació, avaluació i predicció de models de regressió lineals.
El contingut d’aquest material, pel seu caràcter introductori, es refereix a l’anàlisi de regressió clàssica, aplicable a situacions en les quals es compleixen un conjunt d'hipòtesis bàsiques. En els casos en què aquestes hipòtesis no es compleixen es requereixen mètodes economètrics addicionals, que no són objecte d’aquest text.
Concretament, s’exposaran els punts següents:
- Especificació i hipòtesis bàsiques del model de regressió lineal clàssic. - Estimació dels paràmetres del model i inferència. - Mesures de bondat d’ajust i avaluació del model. - Predicció en el model de regressió lineal. - Problemes amb la informació mostral i els seus efectes sobre els mètodes
d’estimació i avaluació del model.

2. El model de regressió lineal simple


Introducció a l’Anàlisi de Regressió Lineal
19
En aquest capítol es considerarà l’anàlisi de regressió en el cas més senzill, en el qual s’inclou únicament una variable explicativa en el model i s’obté, per tant, un model de regressió simple:
Y = β0 + β1 X + u
En relació amb l’anàlisi de regressió lineal simple s’exposarà l’especificació del model, les hipòtesis bàsiques, els procediments d’estimació, avaluació i contrastació del model i, finalment, la utilització del model de regressió estimat per fer prediccions sobre el valor de la variable dependent.
L’objecte d’estudi de l’anàlisi de regressió és, com s’ha comentat a la Introducció, la relació de dependència entre dues o més variables econòmiques. Per aquest motiu, abans d’iniciar l’exposició del model de regressió lineal, interessa diferenciar dos tipus de relacions entre variables, les relacions deterministes i les relacions estocàstiques o aleatòries, i establir quin tipus de relacions s’assumeix que es dóna en el context de l’anàlisi de regressió. Encara que l’argumentació es farà en el marc de la relació entre dues variables, també és aplicable en el cas de més variables.
2.1. Aleatorietat de la relació entre les variables del model Si es planteja una relació de dependència entre dues variables econòmiques, aquesta relació serà determinista o matemàtica si coneixent el valor de la variable explicativa es pot predir exactament el valor de la variable dependent. En canvi, serà una relació aleatòria o estocàstica si el valor de la variable dependent no es pot predir amb exactitud sigui quin sigui el nombre de variables explicatives que s’incloguin a la relació.
Així, a l’Exemple 2.1 es mostra que la relació entre el consum i la renda familiar disponible té naturalesa aleatòria, ja que conèixer la renda d’una família no permet predir exactament quin serà el seu consum, pel fet que hi ha tota una sèrie de factors que afecten les decisions de consum d’una família, a més de la renda. Hi ha una variabilitat intrínseca en el consum familiar que no es pot explicar en la seva totalitat per moltes variables explicatives que es considerin.
En quasi la totalitat dels casos en què es treballa amb variables econòmiques interessa especificar relacions aleatòries, ja que el comportament d’una variable econòmica es veu influït per molts de factors que per diverses raons no es poden observar o quantificar. Aquests factors es tracten de representar mitjançant el terme de pertorbació.

M. Cladera; A. Matas
20
La forma habitual de representar la pertorbació aleatòria és assumint que és una variable aleatòria que té una distribució de probabilitat contínua, com per exemple la normal,
Y = β0 + β1 X + u
on u és una variable aleatòria amb distribució normal i esperança zero, ja que en el seu comportament no hi ha d’haver cap biaix sistemàtic, ni positiu ni negatiu, i per tant se suposa que el seu efecte mitjà sobre la variable dependent és nul.
En aquest cas, per a cada valor de X es té una distribució normal per a Y, i el valor de Y que es doni per a un determinat valor de X pot ser qualsevol valor d’aquesta distribució. És a dir, el fet d’incloure un terme de pertorbació al model dóna lloc al fet que s’assumeixi un comportament aleatori per a la variable dependent.
Com a variable aleatòria, la variable dependent tindrà una distribució de probabilitat. Atès que els paràmetres del model són constants i que el valor de la variable explicativa se suposa donat, la distribució de la variable dependent depèn de la distribució del terme de pertorbació. Així, si se suposa distribució normal per a la pertorbació aleatòria, la variable dependent també és normal.
L’esperança de la variable dependent, Y, és:
E[Y] = β0 + β1 X + E[u]
Llavors, com que E[u]= 0,
E[Y] = β0 + β1 X
Per tant, el valor esperat de la variable dependent depèn del valor de la variable explicativa; per això es fa referència a l’esperança de Y condicionada al valor de X,
E[Y | X] = β0 + β1 X
La variància de la variable dependent és:
var[Y] = var(β0 + β1 X) + var[u]
Llavors,
var[Y] = var[u]
Per tant, la variància de la variable dependent és igual a la variància del terme de pertorbació pel fet que, per a un determinat valor de la variable explicativa, la resta és constant.

Introducció a l’Anàlisi de Regressió Lineal
21
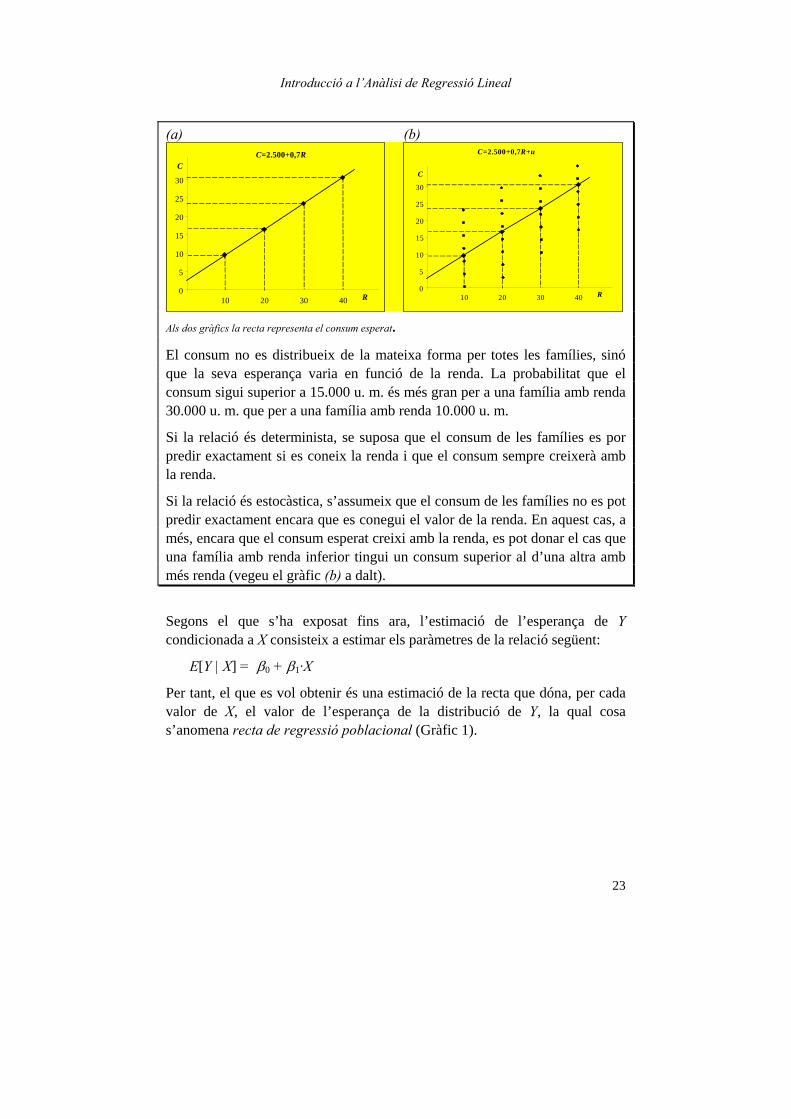
Exemple 2.1. Relació entre el consum familiar i la renda familiar disponible. Determinista o aleatòria?
Se suposa que la relació de dependència entre el consum familiar, C, i la renda familiar disponible, R, és una relació lineal, de manera que:
C = 2.500 + 0,7·R
Aquesta seria una relació determinista, ja que el consum es pot predir exactament si es coneix el valor de la renda familiar. Per exemple:
R C 10.000 9.500 20.000 16.500 30.000 23.500 40.000 30.500
Per altra banda, si se suposa que la relació entre el consum i la renda és aquesta:
C = 2.500 + 0,7·R + u
On u és una variable aleatòria amb la següent distribució de probabilitats:
u = 21at probabilit amb 500 21at probabilit amb 500
−
i, per tant, el valor esperat de la variable u és igual a zero.
En aquest cas el valor del consum no es pot predir exactament, encara que es conegui el valor de la renda, ja que també depèn del valor que prengui u. Per a una determinada família no se sap a priori quin valor prendrà aquesta variable, només se sap que pot valer 500 o –500, amb probabilitat ½ per a cada valor. Llavors, el valor del consum no es pot predir exactament però sí probabilísticament:
R C E[C] 10.000 9.000 9.500 10.000 20.000 16.000 16.500 17.000 30.000 23.000 23.500 24.000 40.000 30.000 30.500 31.000

M. Cladera; A. Matas
22
Així, per exemple, si la renda és de 20.000 u. m., el consum pot ser de 16.000 u. m., si u val –500, amb probabilitat ½, o de 17.000 u. m., si u val 500, també amb probabilitat ½.
C ha passat a ser una variable aleatòria que es pot descriure en termes de probabilitat. La seva esperança és:
E[C] = 2.500 + 0,7·R + E[u]
E[C] = 2.500 + 0,7·R
La relació determinista s’estableix en termes de l’esperança de C.
Per exemple, suposem ara que la relació entre el consum i la renda s’especifica de manera que la pertorbació aleatòria se suposa que és una variable aleatòria normal amb mitjana 0 i variància 302,
u∼N(0, 302)
De manera que, donat el valor de la renda, el valor del consum dependrà del valor que es doni per a la pertorbació aleatòria, que pot ser qualsevol dels corresponents a la seva distribució (u∼N(0, 302)). Llavors, C passa a ser també una variable aleatòria i la seva distribució és determinada per la distribució de la pertorbació aleatòria, ja que els paràmetres de la relació són constants i el valor de la variable explicativa se suposa donat. En aquest cas la distribució de C és normal, igual que la de u:
L’esperança de C és:
E[C] = 2.500 + 0,7·R + E[u], llavors, com que E[u] = 0, E[C] = 2.500 + 0,7·R
Així, el valor esperat del consum depèn del valor de la renda, encara que el valor concret del consum que acaba fent una família es veu influït també per altres factors, és a dir, pel valor de la pertorbació aleatòria, que pot provocar que el consum d’una família no coincideixi amb el seu valor esperat.
La variància de C és:
var[C] = var(2.500 + 0,7·R) + var[u], llavors var[C] = var[u]
Per tant, la variància del consum és igual a la variància del terme de pertorbació, pel fet que, per a un determinat valor de la renda, la resta és constant.
Introducció a l’Anàlisi de Regressió Lineal
23
(a) (b) C=2.500+0,7R
0
5
10
15
20
25
30
10 20 30 40 R
C
C=2.500+0,7R+u
0
5
10
15
20
25
30
10 20 30 40 R
C
Als dos gràfics la recta representa el consum esperat.
El consum no es distribueix de la mateixa forma per totes les famílies, sinó que la seva esperança varia en funció de la renda. La probabilitat que el consum sigui superior a 15.000 u. m. és més gran per a una família amb renda 30.000 u. m. que per a una família amb renda 10.000 u. m.
Si la relació és determinista, se suposa que el consum de les famílies es por predir exactament si es coneix la renda i que el consum sempre creixerà amb la renda.
Si la relació és estocàstica, s’assumeix que el consum de les famílies no es pot predir exactament encara que es conegui el valor de la renda. En aquest cas, a més, encara que el consum esperat creixi amb la renda, es pot donar el cas que una família amb renda inferior tingui un consum superior al d’una altra amb més renda (vegeu el gràfic (b) a dalt).
Segons el que s’ha exposat fins ara, l’estimació de l’esperança de Y condicionada a X consisteix a estimar els paràmetres de la relació següent:
E[Y | X] = β0 + β1·X
Per tant, el que es vol obtenir és una estimació de la recta que dóna, per cada valor de X, el valor de l’esperança de la distribució de Y, la qual cosa s’anomena recta de regressió poblacional (Gràfic 1).

M. Cladera; A. Matas
24
Gràfic 1. Representació de la recta de regressió poblacional
Y
X
E[Y | X] = β0 + β1 X
2.2. Especificació del model El model de regressió lineal simple planteja una relació de dependència entre una variable dependent, Y, i una variable explicativa, X. La relació entre aquestes dues variables no se suposa determinista sinó aleatòria, de manera que també s’inclou en el model un terme de pertorbació:
Yi = β0 + β1 Xi + ui
El model de regressió especificat d’aquesta manera indica que el valor de la variable dependent per a l’individu i, Yi, és influït pel valor de la variable explicativa per a aquest individu, Xi, i per determinats factors aleatoris, ui.
El subíndex i s’utilitza quan es treballa amb dades de tall transversal. Si es fa feina amb dades de tipus temporal, s’utilitza el subíndex t. A partir d’ara, per a l’exposició se suposarà que si no es diu el contrari s’utilitzen dades transversals.
El paràmetre β0 és el terme constant del model i β1 el coeficient de regressió, que indica quin és l’efecte marginal de la variable explicativa sobre la variable dependent. És a dir,

Introducció a l’Anàlisi de Regressió Lineal
25
1β=∂∂
i
i
XY
β1 diu en quant varia la variable dependent si la variable explicativa varia en una unitat.
Per què s’especifica un terme de pertorbació?
El terme de pertorbació és una variable aleatòria inobservable que representa la desviació de la variable dependent respecte del seu valor esperat:
Yi = β0 + β1 Xi + ui i E[Yi|Xi] = β0 + β1 Xi
Llavors,
ui = Yi – E[Yi|Xi]
Hi ha diverses raons que fan necessària l’especificació d’aquesta variable al model de regressió, algunes de les quals són:
A la majoria de problemes econòmics hi ha implicades relacions complexes entre variables. És bastant poc realista esperar una relació lineal determinista entre dues variables econòmiques. Normalment, hi ha moltes variables que es relacionen amb la variable dependent, però per a la modelització s’utilitza només un petit nombre de variables explicatives que es pensa que poden determinar la major part de la variació de la variable dependent. Per tant, una primera raó per justificar l’especificació del terme de pertorbació és que representa l’efecte de totes aquelles variables que influeixen en el comportament de la variable dependent però no s’han especificat explícitament en el model. Aquestes poden ser variables amb una influència petita, o factors que no es poden identificar o quantificar.
La forma funcional de la relació entre la variable dependent i les explicatives pot diferir de l’especificada. El model no seria vàlid per representar la relació entre les variables si la forma funcional vertadera fos molt diferent de la relació lineal especificada. Però si la forma especificada és una aproximació raonable de la vertadera relació, el model pot ser útil per als objectius de predicció i comprensió de la relació. Les divergències entre el valor esperat de la variable dependent i el valor observat, degudes al fet d’utilitzar una aproximació de la vertadera forma funcional, quedarien recollides pel terme de pertorbació.
Els errors de mesura en la variable dependent i les explicatives són un altre motiu per justificar l’especificació del terme de pertorbació.

M. Cladera; A. Matas
26
Les relacions entre variables econòmiques solen fer referència a comportaments humans, i cal tenir en compte que hi ha un element d’aleatorietat inevitable en aquest comportament. Davant una mateixa situació, diferents persones poden actuar de manera distinta. Per exemple, distintes famílies amb la mateixa renda poden tenir distints valors de consum; també la mateixa família pot tenir diferències en el consum en distints moments del temps encara que la seva renda es mantingui.
El fet que la relació entre dues variables no sigui determinista sinó estocàstica fa que estimar-les impliqui un problema d’inferència. Si per a un mateix valor de la variable explicativa, la variable dependent pot prendre distints valors, en dues mostres distintes, encara que els valors de les explicatives siguin els mateixos, els de la dependent probablement seran diferents i, per tant, les estimacions dels paràmetres de la relació poden ser diferents utilitzant una mostra o una altra. Per tant, a partir de les dades mostrals no es podrà conèixer el valor exacte dels paràmetres del model, sinó que només se’n podran obtenir aproximacions.
El model al qual es fa referència en aquest text és el model de regressió clàssic, el qual suposa que es compleixen determinades hipòtesis bàsiques referents als distints components del model. Que es compleixin aquestes hipòtesis és necessari perquè les tècniques d’estimació que es presentaran proporcionin estimadors amb determinades propietats i perquè la inferència sobre els paràmetres del model que s’exposarà sigui l’adient.
A continuació s’enumeren aquestes hipòtesis bàsiques en el context del model de regressió simple, i al capítol 3 es presentaran en el marc del model de regressió múltiple.
2.2.1. Hipòtesis bàsiques del model de regressió clàssic
Les hipòtesis del model de regressió clàssic són les següents:
La relació entre la variable dependent i la variable explicativa és del tipus següent:
Yi = β0 + β1·Xi + ui
Per tant, el model de regressió és lineal en les variables. Hi ha casos en què la relació entre la variable dependent i l’explicativa no és lineal però es pot linealitzar fàcilment, de manera que continua sent aplicable l’anàlisi de regressió lineal.
A més, el model de regressió també és lineal en els paràmetres.

Introducció a l’Anàlisi de Regressió Lineal
27
El nombre d’observacions ha de ser més gran que el nombre de paràmetres que s’hagin d’estimar.
La variable explicativa es considera no estocàstica. És a dir, els valors que pren la variable explicativa se suposen donats. Això implica que l’únic factor d’aleatorietat del model és el terme de pertorbació.
Totes les variables rellevants per explicar el comportament de la variable dependent s’han inclòs al model, i no s’hi han inclòs variables irrellevants.
Hi ha variabilitat en els valors de la variable explicativa, de manera que a la mostra no tots els valors de la variable explicativa són iguals.
Hipòtesis sobre el terme de pertorbació:
- E(ui|Xi) = 0, ∀i
Donat el valor de la variable explicativa, el valor esperat del terme de pertorbació és zero.
Això vol dir que els factors que no estan inclosos en el model i que estan incorporats en el terme de pertorbació ui, no afecten sistemàticament el valor de la mitjana de la variable dependent, sinó que els valors positius de ui es compensen amb els valors negatius de ui de manera que l’efecte mitjà sobre la variable dependent és zero.
- var(ui|Xi) = E( 2iu |Xi) = σ2, ∀i
La variància del terme de pertorbació ui és la mateixa per a totes les observacions. És a dir, les variàncies condicionades de ui són idèntiques. Al Gràfic 1 s’observa que la dispersió de les distribucions de Y, per a cada valor de X, és la mateixa.
Aquesta hipòtesi es coneix com a hipòtesi d’homoscedasticitat. La situació en la qual aquesta hipòtesi no es compleix es coneix com a heteroscedasticitat: var(ui|Xi) = 2
iσ .
- cov(ui,uj|Xi,Xj) = E[(ui|Xi)( uj|Xj)] = 0, ∀i≠j
Donats dos valors qualssevol de la variable explicativa, Xi i Xj, i≠j, la correlació entre ui i uj és zero. És a dir, les pertorbacions ui i uj no estan correlacionades. Aquesta hipòtesi es coneix com a hipòtesi de no autocorrelació.

M. Cladera; A. Matas
28
- cov(ui,Xi) = E(uiXi) = 0, ∀i
La covariància entre el terme de pertorbació i la variable explicativa és zero.
Si això no fos així, la variable explicativa variaria quan ho fes la pertorbació aleatòria, i llavors seria difícil aïllar la influència de la variable explicativa sobre la variable dependent.
Aquesta hipòtesi es compleix si es dóna el supòsit que la variable explicativa sigui no estocàstica.
- ui|Xi ∼ N (0, σ2)
Per a un valor donat de la variable explicativa, el terme de pertorbació té distribució normal.
Les conseqüències de les hipòtesis referents al terme de pertorbació sobre la variable dependent consisteixen en el fet que, si el terme de pertorbació és aleatori, també ho és la variable dependent, i la seva distribució depèn de la del terme de pertorbació:
Yi|Xi ∼ N (β0 + β1 Xi, σ2)
2.3. Estimació dels paràmetres per mínims quadrats ordinaris
Especificant el model de regressió
Yi = β0 + β1 Xi + ui
i suposant que es compleixen les hipòtesis enumerades a l’apartat 2.2.1, es dedueix que:
E[Yi|Xi] = β0 + β1·Xi
Per estimar aquesta recta de regressió poblacional s’utilitzen dades mostrals sobre les variables que intervenen en el model, Y i X. Una manera simple de fer-ho consisteix a representar gràficament el conjunt d’observacions mostrals i ajustar una recta al nigul de punts. Aquesta recta serà una estimació de la recta de regressió poblacional, és a dir, serà una recta de regressió mostral, que es representa de la manera següent:
ii XˆˆY 10 ββ +=
on iY és l’estimador de E[Yi|Xi], 0β és l’estimador de β0 i 1β és l’estimador de β1.

Introducció a l’Anàlisi de Regressió Lineal
29
Però per la naturalesa estocàstica de la relació que se suposa que hi ha entre les variables, en funció de la mostra utilitzada es poden obtenir distintes rectes de regressió mostrals, és a dir, estimacions distintes dels paràmetres poblacionals (Gràfic 2).
Gràfic 2. Rectes de regressió mostrals
0,4
0,5
0,6
0,7
0,8
0,9
1
1,1
1,2
0 2 4 6 8 10X
Y
× primera mostra − − − − recta de regressió mostral basada en la primera mostra ♦ segona mostra ⎯⎯⎯ recta de regressió mostral basada en la segona mostra
Per altra banda, a un mateix nigul de punts s’hi poden ajustar moltes rectes (Gràfic 3), però es tracta de trobar quina és la que s’hi ajusta més bé.
Si es compleixen els supòsits establerts a l’apartat 2.2.1, la recta que s’ajusta més bé al nigul de punts mostrals és la que es deriva de l’aplicació del mètode dels mínims quadrats ordinaris (MQO). És a dir, si es compleixen els supòsits que s’han establert, el millor mètode per estimar els paràmetres del model de regressió, β0 i β1, és el mètode de MQO.
El mètode de MQO tracta de trobar la recta que s’ajusta més bé al nigul de punts de les dades mostrals de la variable dependent i l’explicativa. Per fer-ho, el procediment que se segueix és el que es descriu a continuació.

M. Cladera; A. Matas
30
Gràfic 3. Ajust de rectes al nigul de punts
1,2
10X
Y
Gràfic 4. Errors o residus de la recta de regressió mostral
1,2
10X
Y
ei
yi
iy
ii XˆˆY 10 ββ +=
Les diferències entre els valors observats de la variable dependent, Yi, i els valors estimats o ajustats, iY , són el que s’anomenen errors o residus, ei, (Gràfic 4):

Introducció a l’Anàlisi de Regressió Lineal
31
ei = Yi – iY
= Yi – iXˆˆ10 ββ −
La recta que s’ajusti més bé al nigul de punts serà aquella per a la qual els valors observats estiguin tan a prop com sigui possible dels valors ajustats, és a dir, aquella per a la qual els errors o residus siguin mínims. Per tant, com a criteri per seleccionar la recta de regressió mostral es pot establir el següent: elegir aquella recta que faci mínima la suma dels residus,
Min ( )∑∑==
−=n
ii
n
ii i
YYe11
Si s’utilitza aquest criteri pot ocórrer que els residus positius i negatius es compensin i la suma total sigui molt petita, o zero, encara que la magnitud dels residus sigui important. Per evitar aquest problema s’utilitza el criteri de la minimització de la suma dels quadrats dels residus (SQR):
Min ( )∑∑==
−=n
ii
n
ii i
YYe1
2
1
2
( )∑=
−−=n
ii i
XˆˆY1
210 ββ
Minimitzant aquesta expressió respecte de 0β i 1β s’obtenen els estimadors de MQO de β0 i β1.
Derivant la SQR respecte de 0β i 1β i igualant a zero s’obté:
( )0
1
210
β
ββ
ˆ
XˆˆYn
iii
∂
⎥⎦
⎤⎢⎣
⎡−−∂ ∑
= = ( )∑=
−−−n
iii XˆˆY
1102 ββ = 0
( )1
1
210
β
ββ
ˆ
XˆˆYn
iii
∂
⎥⎦
⎤⎢⎣
⎡−−∂ ∑
= = ( ) i
n
iii XXˆˆY 2
110∑
=
−−− ββ = 0
Aquestes dues equacions normals es poden escriure de la manera següent:
01
=∑=
n
iie i, per tant, la mitjana dels residus és zero.

M. Cladera; A. Matas
32
01
=∑=
n
iii Xe , de manera que els residus no estan correlacionats amb la
variable explicativa.
De la primera equació s’obté:
01
101
=−− ∑∑==
n
i
n
ii i
XˆˆnY ββ
Dividint tota l’expressió per n es té que l’estimador de MQO de 0β és:
XˆYˆ10 ββ −=
A partir de la segona equació es deriva:
∑∑∑===
+=n
ii
n
ii
n
iii XˆXˆXY
1
21
10
1
ββ
Substituint 0β per la seva expressió,
( ) ∑∑∑===
+−=n
ii
n
ii
n
iii XˆXXˆYXY
1
21
11
1
ββ
multiplicant i dividint per n el primer membre de la part dreta i simplificant,
∑∑==
+−=n
ii
n
iii XˆXnˆXnYXY
1
21
21
1
ββ
D’aquí s’obté que l’estimador de β1 de MQO és:
2
1
2
11
XnX
XYnXYˆ
n
ii
n
iii
−
−=
∑
∑
=
=β
Si es compleixen les hipòtesis bàsiques del model de regressió clàssic,1 els estimadors de MQO dels paràmetres del model, β0 i β1, són estimadors lineals, centrats, de variància mínima, consistents i tenen distribució normal.
1 Vegeu l’apartat 2.2.1.

Introducció a l’Anàlisi de Regressió Lineal
33
Exemple 2.2. Estimació de la funció de consum
Per estimar la relació entre el consum, C, i la renda, R, s’especifica el següent model de regressió lineal simple:
Ci = β0 + β1·Ri + ui
On ui és un terme de pertorbació que compleix les hipòtesis bàsiques del model de regressió lineal.
Per estimar aquest model es disposa de dades sobre la renda i el consum de deu famílies d’una determinada regió el darrer mes, que es presenten a la taula següent:
Observació C R C 2 R 2 C·R1 1.742 1.803 3.034.564 3.250.809 3.140.8262 841 902 707.281 813.604 758.5823 2.500 3.005 6.250.000 9.030.025 7.512.5004 1.141 1.653 1.301.881 2.732.409 1.886.0735 2.723 3.606 7.414.729 13.003.236 9.819.1386 1.962 2.404 3.849.444 5.779.216 4.716.6487 1.051 1.202 1.104.601 1.444.804 1.263.3028 1.802 2.224 3.247.204 4.946.176 4.007.6489 2.246 3.155 5.044.516 9.954.025 7.086.130
10 1.262 1.743 1.592.644 3.038.049 2.199.666Suma 17.270 21.697 33.546.864 53.992.353 42.390.513
A partir d’aquestes dades, les estimacions dels paràmetres del model per MQO són:
2
1
2
11
RnR
RCnRCˆ
n
ii
n
iii
−
−=
∑
∑
=
=β = 27169210353992537169272711051339042
,...,....
⋅−⋅⋅− = 0,7113
RˆCˆ10 ββ −= = 1.727 – 0,7113·2.169,7 = 183,692
Llavors, la recta de regressió mostral és
ii R,,C ⋅+= 71130692183
El coeficient β1 és l’efecte marginal de la renda sobre el consum, per tant, es pot interpretar el resultat obtingut dient que l’estimació de la propensió marginal a consumir és 0,7113.

M. Cladera; A. Matas
34
Gràficament:
C = 183,64 + 0,7113R
0
500
1.000
1.500
2.000
2.500
3.000
3.500
0 1.000 2.000 3.000 4.000 5.000
Renda
Con
sum
2.3.1. Interpretació econòmica dels paràmetres estimats
Una vegada que s’han estimat els paràmetres del model, s’han d’interpretar.
Si el model està especificat en nivells, el coeficient de regressió representa l’efecte que té, en mitjana, una variació unitària de la variable explicativa sobre la variable dependent:
Yi = β0 + β1 Xi + ui
1β=∂∂
i
i
XY
Si el model no està especificat en nivells sinó en logaritmes, el coeficient de regressió representa l’elasticitat de la variable dependent respecte a la variable explicativa:
lnYi = β0 + β1 lnXi + ui
1β=∂∂
=∂∂
i
i
i
i
i
i
YX
XY
XlnYln
Sigui quina sigui l’especificació del model, és important comprovar si els signes i la magnitud dels paràmetres estimats són coherents amb la teoria econòmica. Si no és així, pot ser un símptoma de l’existència d’algun tipus de

Introducció a l’Anàlisi de Regressió Lineal
35
problema a les dades utilitzades per a l’estimació i, per tant, s’hauran de revisar.
2.4. Bondat d’ajust. El coeficient de determinació R2
El procediment de MQO que s’ha utilitzat per determinar els estimadors 0β i
1β garanteix que la recta de regressió obtinguda és la que proporciona la menor SQR que és possible obtenir traçant rectes a través del nigul de punts mostral. Malgrat això, de vegades el millor ajust pot ser excel·lent i de vegades pot no ser tan bo. Per tant, és necessari disposar d’una mesura que indiqui com és de bo l’ajust de la recta de regressió mostral al nigul de punts, és a dir, una mesura que indiqui la bondat de l’ajust.
Gràfic 5. Bondat d'ajust de la recta de regressió al nigul de punts
1,2
10
X
Y
ii XˆˆY 10 ββ +=1,2
10X
Y
ii XˆˆY 10 ββ +=1,2
10
X
Y
ii XˆˆY 10 ββ +=
(a) (b) (c)
Si totes les observacions caiguessin sobre la recta de regressió, com ocorre a la figura (a) del Gràfic 5, l’ajust seria perfecte, però aquesta situació es dóna rarament. A les figures (b) i (c) l’ajust no és perfecte, però és millor el de la figura (b) que el de la (c).
El coeficient de determinació R2 és una mesura que indica com s’ajusta de bé la recta de regressió mostral al nigul de punts. Per derivar l’expressió que s’ha d’utilitzar per calcular el R2 es pot procedir de la manera que es descriu a continuació.
La variació mostral de la variable dependent és:
YYi −
i es pot descompondre en la part que s’aconsegueix explicar pel model i la part que no aconsegueix explicar el model (Gràfic 6):

M. Cladera; A. Matas
36
Part explicada: YYi −
Part no explicada: ii YY − = ei
YYi −
Gràfic 6. Descomposició de la variació mostral de la variable dependent
YYi −YYi −
X
Y ii XˆˆY 10 ββ +=
iii YYe −=
Llavors es té que
iiii YYYYYY −+−=−
Com que ii XˆˆY 10 ββ += , XˆˆY 10 ββ += i iii eYY =− ,
iii eXˆˆXˆˆYY +−−+=− 1010 ββββ
i simplificant s’obté l’expressió següent:
( ) iii eXXˆYY +−=− 1β
Elevant al quadrat ambdues parts de l’expressió i sumant pel total d’observacions mostrals, n,
( ) ( ) ( ) ∑∑∑∑====
+−+−=−n
ii
n
iii
n
ii
n
ii eeXXˆXXˆYY
1
2
11
1
221
1
2 2ββ
De les equacions normals resultants de l’aplicació del mètode de MQO es té
que 01
=∑=
n
iiieX i 0
1
=∑=
n
iieX i, per tant, l’expressió queda simplificada a

Introducció a l’Anàlisi de Regressió Lineal
37
( ) ( ) ∑∑∑===
+−=−n
ii
n
ii
n
ii eXXˆYY
1
2
1
221
1
2 β
que és equivalent a
( ) ( ) ∑∑∑===
+−=−n
ii
n
ii
n
ii eYYYY
1
2
1
2
1
2
Aquestes sumes de quadrats es denominen variació total (VT), variació explicada (VE) i variació residual (VR):
( )∑=
−=n
ii YYVT
1
2
( )∑=
−=n
ii YYVE
1
2
∑=
=n
iieVR
1
2
De manera que
VT = VE + VR
La variació total és la suma dels quadrats de les desviacions dels valors observats de la variable dependent respecte a la seva mitjana. També s’anomena suma total de quadrats (STQ).
La variació explicada és la suma dels quadrats de les desviacions dels valors ajustats de la variable dependent al voltant de la seva mitjana.2 La variació explicada també rep el nom de suma explicada de quadrats (SEQ).
La variació residual és la suma dels quadrats de les diferències entre els valors observats i els valors ajustats de la variable dependent, és a dir, és la suma dels quadrats dels errors o residus. També s’anomena suma dels quadrats dels residus (SQR).
La variació explicada es pot escriure, alternativament, com a
2 Cal notar que la mitjana dels valors ajustats és igual a la mitjana dels valors
observats: ( )
YnY
neY
neY
nY
Y iiiiii ==−
=−
== ∑∑∑∑∑

M. Cladera; A. Matas
38
( ) ( )∑∑
∑∑
=
=
=
=
−⋅
⎟⎟⎠
⎞⎜⎜⎝
⎛−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=−=n
ii
n
ii
n
iiin
ii XX
XnX
XYnXYXXˆVE
1
22
2
1
2
2
1
1
221β
i, per tant,
2
1
2
2
1
XnX
XYnXYVE n
ii
n
iii
−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=
∑
∑
=
=
Amb els valors de les variacions total, explicada i residual es calcula el valor del coeficient de determinació R2.
VTVER =2
O substituint les variacions per les seves expressions:
⎟⎟⎠
⎞⎜⎜⎝
⎛−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=
∑∑
∑
==
=
2
1
22
1
2
2
12
YnYXnX
XYnXYR
n
ii
n
ii
n
iii
El R2 és un valor positiu que està entre 0 i 1, i indica la proporció de la variació total de la variable dependent Y explicada per la variable explicativa X. Com més a prop d’1 més bo és l’ajust, ja que significa que el model aconsegueix explicar gran part de la variació de la variable dependent. Si és a prop de 0, en canvi, l’ajust és dolent, ja que la part de la variació de la variable dependent explicada pel model és petita.
Alternativament el coeficient de determinació es pot calcular com a
VTVRR −= 12

Introducció a l’Anàlisi de Regressió Lineal
39
Exemple 2.3. Càlcul del coeficient de determinació
Per avaluar la bondat d’ajust de la funció de consum estimada a l’Exemple 2.2 es calcula a continuació el R2:
∑ −= 22 CnCVT i = 33.546.864 – 10·1.7272 = 3.721.574
2
1
2
2
1
RnR
RCnRCVE n
ii
n
iii
−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=
∑
∑
=
= = ( )2
2
7169210353992537169272711051339042
,...,....
⋅−⋅⋅− =3.499.576,462
=−== ∑=
VEVTeVRn
ii
1
2 3.721.574 – 3.499.576,462 = 221.997,538
9403.721.574
4623.499.576,2 ,VTVER ===
El valor del R2 indica que un 94% de les variacions mostrals del consum són explicades per les variacions mostrals de la renda.
Al model de regressió lineal simple el R2 té una estreta relació amb el coeficient de correlació r, que és una mesura del grau d’associació entre dues variables:
n
YnY
n
XnX
n
XYnXY
rn
ii
n
ii
n
iii
XY2
1
22
1
2
1
−−
−
=
∑∑
∑
==
=
⎟⎟⎠
⎞⎜⎜⎝
⎛−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
−=
∑∑
∑
==
=
2
1
22
1
2
1
YnYXnX
XYnXY
n
ii
n
ii
n
iii
Si el coeficient de correlació s’eleva al quadrat, s’obté:

M. Cladera; A. Matas
40
⎟⎟⎠
⎞⎜⎜⎝
⎛−⎟⎟
⎠
⎞⎜⎜⎝
⎛−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=
∑∑
∑
==
=
2
1
22
1
2
2
12
YnYXnX
XYnXYr
n
ii
n
ii
n
iii
XY
que és igual al R2.
2.5. Inferència en el model de regressió lineal simple A l’apartat 2.3 s’ha explicat l’estimació puntual dels paràmetres del model de regressió lineal simple mitjançant el mètode de MQO. En aquest apartat s’exposaran els mètodes per construir intervals de confiança per a aquests paràmetres i per contrastar hipòtesis sobre els seus valors. Per fer-ho és necessari conèixer la distribució de mostreig dels estimadors de MQO.
2.5.1. Distribució de mostreig dels estimadors de MQO
Distribució de mostreig de l’estimador de MQO del coeficient de regressió
L’estimador de MQO del coeficient de regressió és:
2
1
2
11
XnX
XYnXYˆ
n
ii
n
iii
−
−=
∑
∑
=
=β
Reagrupant els termes d’aquesta expressió, es pot escriure de la manera següent:
( )( )( )∑
∑ =
=
−−−
=n
iiin
ii
XXYYXX
ˆ1
1
21
1β
( )
( ) ( )⎥⎦
⎤⎢⎣
⎡−−−
−= ∑∑
∑ ==
=
n
ii
n
iiin
ii
XXYXXYXX 11
1
2
1
Com que ( )∑=
−n
ii XX
1
és igual a zero, el segon membre de l’expressió
desapareix, i queda:

Introducció a l’Anàlisi de Regressió Lineal
41
( )( )∑
∑ =
=
−−
=n
iiin
ii
XXYXX
ˆ1
1
21
1β
Definint ( )∑
=
−
−= n
ii
ii
XX
XXC
1
2 com la part no aleatòria de l’expressió, a causa
del supòsit que la variable explicativa, X, és determinista, es pot escriure:
∑=
=n
iiiYCˆ
11β
D’aquesta expressió es dedueix en primer lloc que l’estimador de MQO del coeficient de regressió és un estimador lineal.
Per altra banda, si se satisfan les hipòtesis bàsiques especificades a l’apartat 2.2.1, cada Yi és una variable aleatòria amb distribució de probabilitat Yi ∼ N(β0 + β1Xi, σ2). Llavors, l’estimador 1β és una combinació lineal de variables aleatòries normals i, per tant, la seva distribució també és normal:
1β ∼ Normal
Quant a l’esperança d’aquest estimador, com que la variable explicativa se suposa determinista:
( ) ( )∑=
=n
iii YECˆE
11β
Atès que ( ) ii XYE 10 ββ += ,
( )( )
( )∑∑=
=
+−
−=
n
iin
ii
i XXX
XXˆE1
10
1
21 βββ
( )
( )
( )
( )1
1
2
10
1
2
1 ββ
∑
∑
∑
∑
=
=
=
=
−
−+
−
−= n
ii
n
iii
n
ii
n
ii
XX
XXX
XX
XX
Com que ( )∑=
−n
ii XX
1
és igual a zero, el primer terme desapareix i queda:

M. Cladera; A. Matas
42
( )( )
( )11
1
2
11 βββ =
−
−=
∑
∑
=
=n
ii
n
iii
XX
XXXˆE
Per tant, l’esperança de l’estimador de MQO del coeficient del regressió coincideix amb el paràmetre poblacional, llavors és un estimador centrat.
Pel que fa a la variància de 1β de MQO, anteriorment s’ha vist que aquest estimador es pot escriure com a:
( )( )∑
∑ =
=
−−
=n
iiin
ii
XXYXX
ˆ1
1
21
1β
llavors, la variància de 1β és:
( )( )
( )⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
−−
= ∑∑ =
=
n
iiin
ii
XXYXX
varˆvar1
1
21
1β
Atès que la variable explicativa se suposa no estocàstica, es té:
( )( )
( )⎟⎟⎠
⎞⎜⎜⎝
⎛−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
= ∑∑ =
=
n
iii
n
ii
XXYvar
XX
ˆvar1
2
1
21
1β
Per hipòtesi, la covariància entre els termes de pertorbació és zero, i consegüentment també ho és la covariància entre els valors de la variable dependent. Per tant, la variància de la suma que figura a l’expressió anterior es pot expressar com la suma de les variàncies, i considerant novament la naturalesa determinista de la variable explicativa, es té:
( )( )
( ) ( )∑∑ =
=
−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=n
iii
n
ii
YvarXX
XX
ˆvar1
22
1
21
1β
Per la hipòtesi d’homoscedasticitat se sap que la variància de la variable dependent és constant per a qualsevol valor de la variable explicativa, llavors:

Introducció a l’Anàlisi de Regressió Lineal
43
( )( )∑
=
−= n
ii XX
ˆvar
1
2
2
1σβ
Per tant, si es compleixen les hipòtesis bàsiques del model de regressió clàssic, l’estimador de MQO del coeficient de regressió, 1β , es distribueix de la manera següent:
( ) ⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
−∼
∑=
n
ii XX
,Nˆ
1
2
2
11σββ
Conèixer la distribució de mostreig d’aquest estimador permet construir intervals de confiança i contrastar hipòtesis sobre el valor del coeficient de regressió.
Així, estandarditzant la distribució de mostreig de 1β :
( )
( )1 0
1
2
211 ,N
XX
ˆ
n
ii
∼
−
−
∑=
σ
ββ
Per tant, l’interval de confiança del (1 – α)100% de nivell de confiança per a β1 és:
IC(β1)(1-α)100% = ( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−±
∑=
n
ii XX
zˆ
1
2
2
21
σβ α
I l’estadístic de contrast que s’ha d’utilitzar per a la contrastació d’hipòtesis sobre el valor del coeficient de regressió:
H0: β1 = 01β
HA: β1 ≠ 01β

M. Cladera; A. Matas
44
( )
( )1 0
1
2
2
11
0
0 ,N
XX
ˆd
certaH
n
ii
∼
−
−=
∑=
σ
ββ
Distribució de mostreig de l’estimador de MQO del terme constant
De la mateixa manera que per a 1β , es pot derivar la distribució de mostreig
de 0β , encara que habitualment l’objecte d’interès serà la construcció d’intervals de confiança i la contrastació d’hipòtesis sobre el coeficient de regressió, més que sobre el terme constant. Per aquest motiu la descripció del procediment de derivació de la distribució de mostreig de 0β s’omet, encara
que seria similar al seguit per a 1β .
La distribució de mostreig de l’estimador de MQO del terme constant del model de regressió, 0β , és:
( ) ⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
−∼
∑
∑
=
= 2
1
2
1
2
00 σββ n
ii
n
i
XXn
X,Nˆ
i
Coneixent la distribució de 0β és possible també construir intervals de confiança i contrastar hipòtesis sobre el valor de β0.
Distribució de mostreig de l’estimador de la variància del terme de pertorbació
En els dos punts anteriors s’ha vist que tant la variància de l’estimador de MQO del coeficient de regressió com la de l’estimador del terme constant depenen de la variància del terme de pertorbació, σ2, que és desconeguda. Per tant, per fer inferència sobre els paràmetres del model s’haurà d’estimar la variància de la pertorbació aleatòria.
L’estimador de MQO de la variància de la pertorbació aleatòria es pot obtenir de la manera que es descriu a continuació.

Introducció a l’Anàlisi de Regressió Lineal
45
El principal problema per obtenir un estimador de la variància del terme de pertorbació és que els seus valors són inobservables. Això es pot solucionar utilitzant els residus com a estimadors dels termes de pertorbació:
iiii XˆˆYue 10 ββ −−==
A partir d’aquí es pot definir la variància residual, l’estimador no esbiaixat de la variància del terme de pertorbació, com a:
21
2
2
−=
∑=
n
eS
n
ii
R
i l’arrel de la variància residual és l’error estàndard de la regressió.
Com que 21
2
σ
∑=
n
iie
és una variable aleatòria que té una distribució χ2 amb n – 2
graus de llibertat, llavors la variància residual té la distribució següent:
22
22
2 −−∼ nR n
S χσ
A partir d’aquí es poden construir intervals de confiança i contrastar hipòtesis sobre els paràmetres del model, encara que la variància del terme de pertorbació sigui desconeguda.
Per exemple, anteriorment s’ha demostrat que la distribució estandarditzada de l’estimador de MQO 1β és:
( )
( )1 0
1
2
211 ,N
XX
ˆ
n
ii
∼
−
−
∑=
σ
ββ
Com que la variància del terme de pertorbació, σ2, és desconeguda, s’utilitza el seu estimador, i l’estadístic resultant té una distribució t de Student amb n – 2 graus de llibertat:

M. Cladera; A. Matas
46
( )
2
1
2
211
−
=
∼
−
−
∑
n
n
ii
R
t
XX
S
ˆ ββ
D’aquí es poden derivar fàcilment les expressions dels intervals de confiança per a β1 i l’estadístic de contrast per a la contrastació d’hipòtesis sobre β1.
El denominador d’aquest estadístic és l’error estàndard de 1β :
( )( )∑
=
−= n
ii
R
XX
Sˆes
1
2
2
1β
2.5.2. Contrastació de la significació individual de la variable explicativa
El coeficient de regressió del model indica com afecten les variacions de la variable explicativa a la variable dependent. Si el coeficient de regressió és igual a zero, indica que la variable explicativa no afecta el comportament de la variable dependent. Però encara que el vertader coeficient poblacional sigui zero, l’estimació obtinguda pot tenir un valor distint. Per aquest motiu, una vegada estimat el coeficient de regressió s’ha de contrastar si el valor poblacional és realment distint de zero o si l’estimació obtinguda és diferent de zero a causa de l’atzar mostral. És a dir, s’ha de comprovar si l’estimació calculada amb els valors mostrals és suficientment distinta de zero per dir que la variable explicativa té efecte sobre la variable dependent.
Sota el compliment de les hipòtesis del model clàssic, es pot utilitzar el contrast de la t o t-ràtio per contrastar hipòtesis sobre el coeficient del model de regressió. Aquest contrast consisteix en el fet que per contrastar la hipòtesi nul·la H0: β1 =
01β es pot utilitzar el següent estadístic de contrast, basant-se
en els resultats sobre la distribució de 1β de l’apartat anterior:
( ) 2
1
11
0
0−∼
−= n
certaH
tˆes
ˆt
β
ββ
Si l’objectiu és contrastar si la variable explicativa té efecte sobre la variable dependent, es planteja el següent contrast sobre el valor del coeficient de regressió:

Introducció a l’Anàlisi de Regressió Lineal
47
H0: β1 = 0
HA: β1 ≠ 0
Si es rebutja la hipòtesi nul·la, vol dir que la variable explicativa té efecte sobre la variable dependent i, per tant, es diu que la variable explicativa és significativa per explicar el comportament de la variable dependent.
Si no es rebutja la hipòtesi nul·la no es pot afirmar que la variable explicativa afecti la variable dependent i, per tant, es diu que és no significativa per explicar el comportament de la variable dependent.
L’estadístic que s’ha d’utilitzar per a aquest contrast és el següent:
( ) 2 1
1
0
−∼= ncertaH
tˆes
ˆt
ββ
Exemple 2.4. Anàlisi de la relació entre la producció i el nombre de treballadors
Es vol analitzar la relació existent entre la producció de les empreses d’una determinada indústria i el nombre de treballadors. D’acord amb la teoria econòmica, s’espera que el nombre de treballadors tingui un efecte positiu sobre la producció de les empreses.
El model que s’especifica és un model de regressió lineal simple que se suposa que compleix les hipòtesis bàsiques sobre els seus components:
Yi = β0 + β1 Xi + ui
On Y són les unitats produïdes i X és el nombre de treballadors.
Per estimar la relació es disposa d’una mostra de sis empreses que han proporcionat informació sobre les unitats produïdes el darrer mes i el nombre de treballadors que tenen contractats:
Observació Y X YX X 2 Y 2
1 20.000 28 560.000 784 400.000.0002 24.500 34 833.000 1.156 600.250.0003 23.000 32 736.000 1.024 529.000.0004 25.000 38 950.000 1.444 625.000.0005 20.000 32 640.000 1.024 400.000.0006 22.500 34 765.000 1.156 506.250.000
135.000 198 4.484.000 6.588 3.060.500.000 50022.Y = 33=X

M. Cladera; A. Matas
48
Les estimacions de MQO dels paràmetres del model són:
0375373365886
3350022600048442
2
1
2
11 ,
....
XnX
XYnXYˆ
n
i
n
iii
i
=⋅−
⋅⋅−=
−
−=
∑
∑
=
=β
7797774330375375002200 ,.,.XˆYˆ =⋅−=−= ββ
Per avaluar la bondat d’ajust del model estimat es calcula el coeficient de determinació:
( ) 67705002260005000603
33658860375372
22
2
1
2
2
1
221
2 ,....
.,
YnY
XnXˆ
VTVER n
i
n
i
i
i
=⋅−
⋅−=
−
⎟⎟⎠
⎞⎜⎜⎝
⎛−
==
∑
∑
=
=
β
El valor del coeficient de determinació indica que el 67,7% de les variacions mostrals de la producció s’expliquen per les variacions mostrals del nombre de treballadors.
La variància residual, l’estimador no esbiaixat de la variància del terme de pertorbació, és:
48285614
928425722
2 ....n
VEVTnVRSR ==
−−
=−
=
De manera que l’error estàndard de la regressió, l’arrel de la variància residual, té un valor de 1.362,528.
Així, ja és possible calcular els errors estàndards dels paràmetres estimats:
( )( ) ( ) 416185
33658865283621
2
1
2
2
1 ,.
,.
XX
Sˆes n
ii
R =⋅−
=−
=
∑=
β
( )( ) ( ) 97814364828561
3310588665886
22
1
2
1
2
0 ,....
.SXXn
Xˆes
R
i
n
ii
n
i =⋅−
=−
=
∑
∑
=
=β

Introducció a l’Anàlisi de Regressió Lineal
49
Habitualment els resultats de l’estimació del model es presenten de la manera següent:
( ) ( ) i,,.
i X,,.Y41618597814360375377797774 += R2 = 0,677
on davall de l’estimació del paràmetre es té, entre parèntesis, l’error estàndard. A més de l’error estàndard també es pot presentar el valor de l’estadístic t o el p-valor del contrast de significació individual.
Amb la informació de què es disposa es pot contrastar la significació del nombre de treballadors com a variable explicativa del nombre d’unitats produïdes:
H0: β1 = 0
HA: β1 ≠ 0
L’estadístic t val:
( ) 8962416185037537
1
1 ,,,
ˆes
ˆt ===
ββ
L’estadístic t té una distribució t de Student amb n – 2 graus de llibertat. Per tant, al nivell de significació del 5% el valor crític és 77620250
4 ,t , = .
Com que el valor de l’estadístic de contrast és més gran que el valor crític, es rebutja la hipòtesi nul·la i es pot dir que el coeficient de regressió és distint de zero i, per tant, el nombre de treballadors és una variable significativa per explicar el nombre d’unitats produïdes.
Els resultats obtinguts són coherents amb la teoria econòmica, ja que s’espera que la producció augmenti quan s’incrementa el nombre de treballadors. Això és precisament el que indica l’estimació del coeficient de regressió: el nombre de treballadors influeix sobre el nombre d’unitats produïdes i aquesta influència és de signe positiu.
Finalment, es pot calcular també un interval de confiança per al coeficient de regressió. Així, l’interval de confiança al 95% de nivell de confiança és el següent:
( ) ( ) 41618577620375371221951 ,,,ˆestˆIC n% ⋅±=±= − βββ α
[ ]7520511 32222 ,.,,=

M. Cladera; A. Matas
50
A un nivell de confiança del 95% es pot dir que l’efecte marginal del nombre de treballadors sobre el nombre d’unitats produïdes està entre 22,322 i 1.051,752.
L’interval de confiança és molt ample i això indica que les estimacions són poc precises. La raó és que la mostra, de sis observacions, és molt petita. Si s’augmentàs el nombre d’observacions milloraria la precisió.
2.6. Estimació dels paràmetres per altres mètodes A l’apartat 2.3 s’ha vist que si es compleixen les hipòtesis bàsiques del model clàssic, els millors estimadors per als paràmetres del model de regressió són els proporcionats pel mètode de MQO.
Però a més d’aquest mètode hi ha altres procediments d’estimació que es poden utilitzar per estimar els paràmetres del model de regressió. En aquest apartat es veuran dos d’aquests procediments: el mètode de màxima versemblança i el mètode dels moments. Si se satisfan les hipòtesis del model de regressió clàssic, ambdós mètodes proporcionen els mateixos estimadors que el mètode de MQO.
2.6.1. Estimació per màxima versemblança
El mètode de màxima versemblança és un mètode d’estimació general que es por aplicar a múltiples situacions. En el context del model de regressió lineal simple els estimadors de màxima versemblança dels paràmetres del model s’obtenen de la forma que es descriu a continuació.
L’especificació del model és:
Yi = β0 + β1·Xi + ui ui ∼ N(0, σ2)
En conseqüència, cada Yi té distribució normal amb mitjana β0 + β1·Xi i variància σ2. Per tant, la funció de versemblança és:
( ) ( )∏=
=n
iin Yf,,Y,...,Y,YL
1
21021 σββ
( )∏=
⎥⎦⎤
⎢⎣⎡ −−−=
n
iii XYexp
1
21022
121 ββ
σσπ
El mètode de màxima versemblança consisteix en el fet que per estimar els paràmetres s’elegeixen els valors que maximitzen la funció de versemblança.

Introducció a l’Anàlisi de Regressió Lineal
51
Per simplicitat normalment se sol maximitzar el logaritme d’aquesta funció, és a dir, la funció de log-versemblança:
( ) ( )∑=
=n
iin Yfln,,Y,...,Y,YLln
1
21021 σββ
( ) ( )∑=
⎥⎦⎤
⎢⎣⎡ −−−−=
n
iii XYln
1
2102
2
212
21 ββ
σπσ
Derivant la funció de log-versemblança respecte de cada un dels paràmetres que s’han d’estimar i igualant les derivades a zero es tenen tres equacions de les quals s’obtenen els estimadors de màxima versemblança dels paràmetres del model:
XˆYˆLln10
0
0 βββ
−=→=∂
∂
2
1
2
11
1
0XnX
XYnXYˆLln
n
ii
n
iii
−
−=→=
∂
∂
∑
∑
=
=ββ
n
eˆLln
n
ii∑
==→=∂∂ 1
2
22 0 σ
σ
Encara que els estimadors del terme constant i del coeficient de regressió són els mateixos que els de MQO, l’estimador de la variància del terme de pertorbació és diferent, ja que el denominador és n en lloc de n – 2. Però el mètode de màxima versemblança és un mètode d’estimació per a mostres grans, i en aquest cas les estimacions obtingudes amb els dos estimadors són molt semblants, ja que la diferència entre n i n – 2 és petita.
Si, per exemple, la hipòtesi de normalitat dels termes de pertorbació no es donàs, el mètode de màxima versemblança continuaria sent aplicable. El que variaria seria la forma de la distribució de probabilitat que s’hauria d’utilitzar per construir la funció de versemblança. Els estimadors obtinguts en aquest cas no coincidirien amb els de MQO.

M. Cladera; A. Matas
52
2.6.2. Estimació per moments
Dos dels supòsits del model de regressió clàssic són que l’esperança del terme de pertorbació és zero i que la covariància entre els termes de pertorbació també és zero.
Per aplicar el mètode dels moments s’utilitzen les contraparts mostrals d’aquestes dues hipòtesis:
Hipòtesi poblacional Contrapart mostral
E(ui) = 0 01
1
=∑=
n
iie
n o 0
1
=∑=
n
iie
Cov(ui, uj) = 0 01
1
=∑=
n
iiieX
n o 0
1
=∑=
n
iiieX
Les dues equacions que es deriven de les contraparts mostrals de les hipòtesis poblacionals coincideixen amb les equacions normals que a l’apartat 2.3 donaven lloc als estimadors de MQO. Per tant, els estimadors per moments coincideixen amb els de MQO.
Si alguna de les hipòtesis clàssiques no es compleix, els estimadors per moments no coincidiran amb els de MQO.
2.7. Predicció en el model de regressió lineal simple Una de les aplicacions de l’anàlisi de regressió és la utilització del model estimat per fer predicció dels valors de la variable dependent, donat el valor de la variable explicativa.
Si es fa feina amb dades temporals, l’objectiu pot ser predir els valors de la variable dependent en el futur, i si es treballa amb dades transversals el que pot interessar és predir el valor de la variable dependent per a individus que no pertanyen a la mostra utilitzada per a les estimacions.
La fiabilitat de les prediccions que s’obtinguin depèn de la bondat de les estimacions dels paràmetres del model i del fet que la relació entre les variables es mantingui estable en el moment o per als individus per als quals es vol fer la predicció.
Es poden distingir dos tipus de predicció: la predicció d’un valor individual i la predicció de la mitjana. El primer tipus es refereix a la predicció del valor de la variable dependent per a un determinat valor de la variable explicativa.

Introducció a l’Anàlisi de Regressió Lineal
53
El segon consisteix en la predicció del valor esperat o mitjà de la variable dependent per a un determinat valor de la variable explicativa. En totes dues situacions es poden obtenir prediccions puntuals o prediccions per intervals.
2.7.1. Predicció de la mitjana
Per a un determinat valor de X, X0, es vol predir quin és el valor esperat de la variable dependent:
E(Y0|X0) = β0 + β1 X0
Si es compleixen les hipòtesis bàsiques del model clàssic, la millor predicció de β0 i β1 són els seus estimadors de MQO: 0β i 1β . Per tant, la millor predicció de E(Y0|X0) és:
( ) 01000 XˆˆX|YE ββ +=
és a dir, el valor estimat o ajustat: 0Y .
Atès que 0Y és un estimador, és probable que el seu valor sigui diferent del vertader valor esperat de la variable dependent. La diferència entre aquests dos valors és l’error de predicció:
( ) 010010000 XXˆˆX|YEY ββββ −−+=−
( ) ( ) 01100 Xˆˆ ββββ −+−=
El valor esperat de l’error de predicció és:
( ) ( ) ( ) 0110000 XˆEˆEYYE ββββ −+−=− = 0
per tal com 0β i 1β són estimadors no esbiaixats i X0 és no estocàstica.
Per tant, 0Y és un predictor no esbiaixat de la mitjana de la variable dependent quan la variable explicativa és X0.
Per avaluar la precisió de les prediccions és necessari conèixer la distribució de mostreig de 0Y . Com que els estimadors de MQO dels paràmetres del model tenen distribució normal i la variable explicativa se suposa no estocàstica, llavors 0Y és una variable aleatòria amb distribució normal.
L’esperança de 0Y és:
( ) ( ) ( ) 0100 XˆEˆEYE ββ += = β0 + β1 X0

M. Cladera; A. Matas
54
I la variància,
( ) ( ) ( ) ( )10012000 2 ββββ ˆ,ˆcovXˆvarXˆvarYvar ++=
Utilitzant les expressions de les variàncies de 0β i 1β mostrades a l’apartat
2.5.1 i sabent que la covariància entre 0β i 1β és:
( )( )∑
=
−
−= n
ii XX
Xˆ,ˆcov
1
2
2
10σββ
llavors, la variància de 0Y és:
( ) ( )( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−
−+=
∑=
n
ii XX
XXn
Yvar
1
2
202
01σ
Com que la variància de la pertorbació aleatòria és desconeguda, s’utilitza el seu estimador, la variància residual, i s’obté que l’error estàndard de 0Y és:
( ) ( )( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−
−+=
∑=
n
ii
R
XX
XXn
SYes
1
2
202
01
Llavors es té que l’estadístic
( )( )0
0100
Yes
XY ββ +−
té distribució t de Student amb n – 2 graus de llibertat.
Aquest estadístic es pot utilitzar per construir intervals de confiança per al vertader valor de E(Y0|X0).
Així, l’interval de confiança al nivell de confiança (1 – α)100% per a E(Y0|X0) és:
( )[ ]( ) ( )[ ]0220100100 YestYX|YEIC n%
αα −− ±=

Introducció a l’Anàlisi de Regressió Lineal
55
2.7.2. Predicció d’un valor individual
L’equació de regressió estimada és:
ii XˆˆY 10 ββ +=
Donat un valor per a X determinat, X0, quina és la millor predicció que es pot fer sobre el valor que prendrà Y?
Si la relació poblacional és:
Yi = β0 + β1 Xi + ui
Per a X = X0,
Y0 = β0 + β1 X0 + u0
Si es compleixen les hipòtesis bàsiques del model clàssic, la millor predicció de β0 i β1 són els seus estimadors de MQO: 0β i 1β .
Per altra banda, el terme de pertorbació és inobservable i la millor predicció del valor que prendrà és el seu valor esperat:
E(u0) = 0
Per tant, la millor predicció de Y0 és:
0100 XˆˆY ββ +=
és a dir, el valor estimat o ajustat.
Com es pot observar, la predicció puntual d’un valor individual és la mateixa que la de la mitjana.
En aquest cas l’error de predicció és:
001001000 uXXˆˆYY −−−+=− ββββ
( ) ( ) 001100 uXˆˆ −−+−= ββββ
El valor esperat de l’error de predicció és:
( ) ( ) ( ) ( )00110000 uEXˆEˆEYYE −−+−=− ββββ = 0
pel fet que 0β i 1β són estimadors no esbiaixats, X0 és no estocàstic i E(u0) = 0 per hipòtesi.
La variància de l’error de predicció és:

M. Cladera; A. Matas
56
( ) ( ) ( ) ( ) ( )0100120000 2 uvarˆ,ˆcovXˆvarXˆvarYYvar +++=− ββββ
Utilitzant les expressions de les variàncies de 0β i 1β mostrades a l’apartat
2.5.1 i l’expressió de la covariància entre 0β i 1β mostrada a l’apartat anterior i sota la hipòtesi d’homoscedasticitat, segons la qual la variància del terme de pertorbació és constant i igual a σ2, es té que la variància de l’error de predicció és:
( ) ( )( ) ⎥
⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
−
−++=−
∑=
n
ii XX
XXn
YYvar
1
2
202
0011σ
Com que la variància de la pertorbació aleatòria és desconeguda, s’utilitza el seu estimador, la variància residual, i s’obté que l’error estàndard de 00 YY − és:
( ) ( )( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−
−++=−
∑=
n
ii
R
XX
XXn
SYYes
1
2
202
0011
Llavors es té que l’estadístic
( )00
00
YYes
YY
−
−
té distribució t de Student amb n – 2 graus de llibertat.
Aquest estadístic es pot utilitzar per construir intervals de confiança per al vertader valor de Y0.
Així l’interval de confiança al nivell de confiança (1 – α)100% per a Y0 és:
( )( ) ( )[ ]0022010010 YYestYYIC n% −±= −−
αα
Es pot observar que l’error estàndard de 00 YY − és més gran que l’error estàndard de 0Y . Per tant, l’interval de confiança per a la predicció d’un valor individual és més ample que l’interval de confiança per a la predicció de la mitjana (Gràfic 7).

Introducció a l’Anàlisi de Regressió Lineal
57
En tots dos casos s’observa que com més enfora és X0 de X més variància té la predicció, és a dir, més amples són els intervals de confiança.
Al Gràfic 7 es pot apreciar que l’amplitud més petita de les bandes de confiança es dóna quan X0 = X . Per altra banda, aquesta augmenta considerablement a mesura que X0 s’allunya de X . Aquest canvi suggeriria que la capacitat de predicció de la recta de regressió mostral es redueix a mesura que X0 s’allunya de X . Per tant, s’ha d’anar alerta a l’hora de fer predicció per a valors de la variable explicativa molt diferents dels valors mostrals d’aquesta variable que s’han utilitzat per a l’estimació del model.
Gràfic 7. Bandes de confiança per a la predicció de la mitjana i per a la d'un valor individual
Y
XX
− − − − Bandes de confiança per a la mitjana de Y. ⎯⎯⎯ Bandes de confiança per al valor individual de Y.
Exemple 2.5. Predicció del nombre d’unitats produïdes en funció del nombre de treballadors
A l’Exemple 2.4 s’ha estimat el següent model de relació entre les unitats produïdes i el nombre de treballadors:
i),(),.(
i X,,.Y ⋅+=41618597814360375377797774
Aquestes estimacions es poden utilitzar per fer predicció de la mitjana condicional del nombre d’unitats produïdes o per fer predicció d’un valor individual.

M. Cladera; A. Matas
58
En primer lloc es vol predir el nombre d’unitats produïdes en mitjana (esperades) per les empreses que tenen contractats 30 treballadors. A partir de la recta de regressió estimada s’obté la predicció puntual del valor esperat del nombre d’unitats produïdes si el nombre de treballadors és 30:
889888203003753777977740 ,.,,.Y =⋅+=
Per construir un interval de confiança per a aquesta predicció es necessita calcular l’error estàndard de 0Y :
( ) ( )( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−
−+=
∑=
n
ii
R
XX
XXn
SYes
1
2
202
01
( ) 6557863365886
3330614828561 2
2
,.
.. =⎥⎥⎦
⎤
⎢⎢⎣
⎡
⋅−−
+=
Per tant, l’interval de confiança del 95% per a E(Y0|X0) seria:
IC[E(Y0|X0)] 95% = [ 0Y ± 22
α−nt es( 0Y )]
= [20.888,889 ± 2,776·786,655]
= [18.705,134, 23.072,643]
De manera similar, si se suposa que el nombre de treballadors és 38, l’interval de confiança del 95% per a la mitjana condicional s’obté de la manera següent:
185185253803753777977740 ,.,,.Y =⋅+=
( ) ( ) 15508113365886
3338614828561 2
2
0 ,..
..Yes =⎥⎥⎦
⎤
⎢⎢⎣
⎡
⋅−−
+=
IC[E(Y0|X0)] 95% = [25.185,185 ± 2,776·1.081,155]
= [22.183,898, 28.186,471]
La incertesa estadística sobre la predicció augmenta a mesura que el quadrat de la distància entre X0 i X augmenta. Això s’observa en els resultats obtinguts:

Introducció a l’Anàlisi de Regressió Lineal
59
(X0 – X ) ( )0Yes (30 – 33) 786,655 (38 – 33) 1.081,155
La incertesa és la menor possible quan X0 = X i augmenta quan el valor de X0 s’allunya d’aquest punt, donant lloc a intervals de confiança de major amplitud.
En segon lloc, es vol predir el nombre d’unitats produïdes per una empresa que té un determinat nombre de treballadors. Procedint de la mateixa manera que per a la predicció de la mitjana es poden obtenir prediccions puntuals i intervals de confiança per a la predicció d’un valor individual. Les prediccions puntuals són les mateixes, el que varia és l’error estàndard de la predicció i, en conseqüència, els intervals de confiança.
Si X0 és 30, la predicció puntual és:
889888203003753777977740 ,.,,.Y =⋅+=
i l’error estàndard,
( ) ( )( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−
−++=−
∑=
n
ii
R
XX
XXn
SYYes
1
2
202
0011
( ) 31157313365886
33306114828561 2
2
,..
.. =⎥⎥⎦
⎤
⎢⎢⎣
⎡
⋅−−
++=
IC(Y0) 95% = [20.888,889 ± 2.776·1.573,311]
= [16.521,377, 25.256,400]
Si X0 és 38, la predicció puntual és:
185185253803753777977740 ,.,,.Y =⋅+=
i l’error estàndard,
( ) ( ) 36173913365886
33386114828561 2
2
00 ,..
..YYes =⎥⎥⎦
⎤
⎢⎢⎣
⎡
⋅−−
++=−

M. Cladera; A. Matas
60
IC(Y0) 95% = [25.185,185 ± 2,776·1.739,361]
= [20.356,718, 30.013,651]
Aquests resultats confirmen que la incertesa sobre les prediccions per a valors individuals també s’incrementa a mesura que ho fa la distància entre X0 i X .
Els resultats d’aquest exemple es resumeixen a continuació:
Distància Error estàndard (X0 – X ) Predicció de la mitjana Predicció individual (30 – 33) 786,655 1.573,311 (38 – 33) 1.081,155 1.739,361
Per a la mateixa distància, la incertesa és més gran si es vol estimar un valor individual que si es vol estimar una mitjana.

3. El model de regressió lineal múltiple


Introducció a l’Anàlisi de Regressió Lineal
63
Al capítol anterior s’ha considerat l’anàlisi de regressió simple, en la qual s’inclou únicament una variable explicativa en el model, i s’han analitzat les qüestions relacionades amb l’especificació del model, les hipòtesis bàsiques i els procediments d’estimació, avaluació, contrastació i predicció.
A la pràctica el model simple és insuficient, ja que habitualment el comportament d’una variable econòmica es veu afectat per més d’una variable. En els casos en què es fa necessari especificar models amb més d’una variable explicativa, es parla d’anàlisi de regressió múltiple.
En tractar l’anàlisi de regressió múltiple, igual que s’ha fet amb la simple, es consideraran models lineals que compleixen determinades hipòtesis bàsiques en relació amb els seus components.
Per tant, en aquest apartat s’explicaran els mètodes d’estimació, avaluació, contrastació i predicció aplicables en el context del model de regressió múltiple clàssic.
3.1. Especificació del model El model de regressió lineal múltiple suposa una relació de dependència entre una variable dependent, Y, i dues o més variables explicatives, X1, X2,...,Xk. A més el model inclou un terme de pertorbació, u, que recull tots els factors no especificats explícitament al model com a variables explicatives.
Així, l’especificació general del model de regressió lineal múltiple és la següent:
Yi = β1 + β2 X2i + β3 X3i +···+ βk Xki + ui
Notem que segons aquesta especificació hi ha k paràmetres i k – 1 variables explicatives. β1 és el terme constant, no hi ha una variable explicativa X1i. Alternativament, es pot interpretar que la variable X1i pren valor 1 per a qualsevol i.
Al model de regressió lineal múltiple cada βk és l’efecte marginal individual de la variable Xk sobre l’esperança condicional de la variable dependent.
Si s’expressa l’equació de regressió per a cada un dels n individus de la mostra es té:

M. Cladera; A. Matas
64
Y1 = β1 + β2 X21 + β3 X31 +···+ βk Xk1 + u1
Y2 = β1 + β2 X22 + β3 X32 +···+ βk Xk2 + u2
M M M M M M
Yi = β1 + β2 X2i + β3 X3i +···+ βk Xki + ui
M M M M M M
Yn = β1 + β2 X2n + β3 X3n +···+ βk Xkn + un
On Yi és el valor de la variable dependent per a l’individu i i Xji és el valor de la variable Xj per a l’observació i.
Per facilitar la feina, aquest sistema d’equacions se sol expressar utilitzant la notació matricial de la manera següent:
1
2
1
1
2
1
32
23222
13121
1
2
1
1
11
××××⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
+
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
⋅
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
nnkkknknnn
k
k
nn u
uu
XXX
XXXXXX
Y
YY
M
M
M
M
M
M
LL
MMMM
MMMM
MMMM
LL
LL
M
M
M
β
ββ
de manera compacta:
111 ×××× +⋅= nkknn UBXY
El vector Y conté les observacions de la variable dependent per a les n observacions.
A la matriu X les columnes representen el valor de la variable explicativa corresponent per a cada una de les n observacions. La primera columna és la que correspon al terme constant, i tots els seus valors són 1.
B és un vector que conté els k paràmetres del model de regressió, els quals representen l’efecte marginal individual de la corresponent variable explicativa sobre la variable dependent:
[ ]j
jX|E β=
∂∂ XY
I el vector U conté els n termes de pertorbació corresponents a cada observació.

Introducció a l’Anàlisi de Regressió Lineal
65
3.1.1. Hipòtesis bàsiques del model de regressió clàssic amb més d’una variable explicativa
Les hipòtesis bàsiques del model de regressió clàssic, que s’han explicat a l’apartat 2.2.1 en el marc del model de regressió simple, a continuació s’exposaran en el context de l’anàlisi de regressió múltiple.
Aquestes hipòtesis són les següents:
El model de regressió és lineal (o linealitzable) en les variables i en els paràmetres.
El nombre d’observacions ha de ser més gran que el nombre de paràmetres que s’hagin d’explicar.
No hi ha cap relació lineal exacta entre les variables explicatives del model. En aquesta situació es diu que hi ha absència de multicolinealitat perfecta entre les variables explicatives.
Les variables explicatives es consideren no estocàstiques, de manera que l’únic factor aleatori del model és el terme de pertorbació.
Totes les variables rellevants per explicar el comportament de la variable dependent s’han inclòs al model i no s’hi han inclòs variables irrellevants.
Hi ha variabilitat en els valors de les variables explicatives.
Hipòtesis sobre el terme de pertorbació (en notació matricial):
- E[U] = 0
És a dir,
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
nu
uu
M2
1
U i [ ]⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
0
00
MUE
Els factors continguts dins el terme de pertorbació no afecten sistemàticament el valor esperat de la variable dependent.
- E[U·U´] = σ2I
On I és la matriu identitat.
Si es té:

M. Cladera; A. Matas
66
=′⋅ ×× nn 11 UU
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
221
22221
12121
nnn
n
n
uuuuu
uuuuuuuuuu
L
MOMM
L
L
llavors, aplicant esperances,
[ ] =′⋅ ×× nnE 11 UU
( ) ( ) ( )( ) ( ) ( )
( ) ( ) ( ) ⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
221
22221
12121
nnn
n
n
uEuuEuuE
uuEuEuuEuuEuuEuE
L
MOMM
L
L
I2
2
2
2
00
0000
σ
σ
σσ
=
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
L
MOMM
L
L
La matriu E[U·U´] és la matriu de variàncies i covariàncies de U, de manera que la diagonal conté les variàncies dels termes de pertorbació i fora de la diagonal hi figuren les covariàncies. Si aquesta matriu és igual a σ2I, es compleixen les hipòtesis d’homoscedasticitat i no autocorrelació.
- E[X´·U] = 0
Aquesta hipòtesi se satisfà si es dóna el supòsit que les variables explicatives siguin no estocàstiques.
- U ∼ N [0n×1, σ2In×n]
La pertorbació aleatòria es distribueix normalment i, per tant, també ho fa la variable dependent.
Les conseqüències de les hipòtesis referents al terme de pertorbació sobre la distribució de la variable dependent es poden resumir de la manera següent:
Y ∼ N [XB, σ2I]
3.2. Estimació dels paràmetres per MQO Utilitzant la notació matricial, el model de regressió múltiple s’ha especificat de la manera següent:

Introducció a l’Anàlisi de Regressió Lineal
67
111 ×××× +⋅= nkknn UBXY
Si es compleixen les hipòtesis bàsiques del model clàssic, els estimadors de MQO dels coeficients de regressió són estimadors lineals òptims. Com s’ha explicat en el cas del model de regressió simple, el mètode de MQO consisteix a minimitzar la suma dels quadrats de la diferència entre els valors observats i els ajustats de la variable dependent, és a dir, la SQR.
D’acord amb l’especificació matricial utilitzada, els valors ajustats s’expressen com a:
11 ××× ⋅= kknnˆˆ BXY
On 1×nY és el vector dels valors ajustats de la variable dependent per a cada observació mostral i B és un vector que conté els coeficients de regressió estimats.
D’aquesta manera els residus de l’estimació són:
111 ××× = nnnˆ-YYe
11 ××× ⋅= kknnˆ- BXY
El vector e conté els residus corresponents a cada una de les observacions mostrals:
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
⋅
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
−
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=
kknnn
k
k
nn ˆ
ˆˆ
XXX
XXXXXX
Y
YY
e
ee
β
ββ
M
M
M
LL
MMMM
MMMM
MMMM
LL
LL
M
M
M
M
M
M2
1
32
23222
13121
2
1
2
1
1
11
e
Amb la notació matricial la SQR s’expressa com a e´·e:
[ ] ∑=
×
× =+++=
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
⋅=⋅n
iin
nn
nn eeee
e
ee
eee'1
2222
21
1
2
1
121 L
M
MLLee
Substituint el vector e per la seva expressió es té:

M. Cladera; A. Matas
68
( ) ( ) B XX B XYB B XY Y YBX YBX Yee ˆˆˆ-ˆ-ˆ-ˆ- ′′+′′′=′
=⋅′
Notem que Y X BB XY ′′=′ ˆˆ , pel fet que ( ) Y X BB XY ′′=′′ ˆˆ ,3 i a més, com
que Y X B ′′ˆ és una matriu 1 × 1,4 transposada i original són la mateixa.
Per tant, e´·e es pot escriure com a:
B XXBY X B2Y Yee ˆˆˆ ′′+′′′=⋅′ -
Per obtenir els estimadors de MQO dels coeficients de regressió s’ha de minimitzar aquesta expressió respecte a B :
B XX BYX B2Y YB
ˆˆˆˆ
Min ′′+′′′ -
Derivant respecte de B i igualant a zero s’obté:
[ ] 0=∂
⋅′∂
B
eeˆ
0B XX2Y X2- =′+′ ˆ
Y XB XX ′=′ ˆ
A partir d’aquí, el vector d’estimadors de MQO de cada un dels coeficients de regressió es calcula com a:
( ) Y X XXB ′′= − 1ˆ
Aquesta expressió és formada per dues parts. En primer lloc, la matriu X´X és la matriu de moments encreuats de les variables explicatives:
knknn
k
k
nkknkk
n
XX
XXXX
XXX
XXX
××⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=′
LL
MMM
MMM
LL
LL
LL
MMM
MMM
LL
LL
2
222
121
21
22221
1
11111
XX
3 A i B són dues matrius de manera que AB està definit, llavors (AB)´= B´A´, és a dir, la transposada del producte de dues matrius és el producte de les seves transposades en ordre contrari. Això es pot generalitzar a més de dues matrius. 4 111nnkk1 ×××× =′′ AYXB .

Introducció a l’Anàlisi de Regressió Lineal
69
kkkiikiiki
kiiiii
kiiiii
kiii
ki
i
i
XXXXXX
XXXXXXXXXXXX
XXXn
×
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
∑∑∑∑
∑∑∑∑∑∑∑∑∑∑∑
232
32
323
2322
2
32
3
2
L
MMMM
L
L
L
Per altra banda, la matriu X´Y és la matriu de moments encreuats entre les variables explicatives i la variable dependent:
1
3
2
1
2
1
21
22221
111
×××
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=′
∑
∑∑∑
kiki
ii
ii
i
nnnkknkk
n
YX
YXYX
Y
Y
YY
XXX
XXX
MM
M
M
LL
MMM
MMM
LL
LL
Y X
Igual que s’ha dit per al model de regressió simple, en el cas del model múltiple, si es compleixen les hipòtesis bàsiques del model de regressió clàssic,5 els estimadors de MQO dels paràmetres del model són estimadors lineals, centrats, de variància mínima, consistents i tenen distribució normal.
Exemple 3.1. Estimació de la relació entre el preu de l’habitatge i algunes de les seves característiques
Amb la finalitat d’estimar la relació entre el preu dels habitatges en una determinada ciutat, Y, els metres quadrats d’aquestes, X2, i el nombre d’habitacions, X3, s’especifica el model de regressió següent:
Yi = β1 + β2 X2i + β3 X3i + ui
On ui és un terme de pertorbació que compleix les hipòtesis bàsiques del models de regressió clàssic.
Per estimar aquest model es disposa d’una mostra de 12 habitatges, amb dades dels seus preus (en milers d’euros), els metres quadrats i el nombre d’habitacions.
5 Vegeu l’apartat 2.2.1.

M. Cladera; A. Matas
70
Y X2 X3 117 100 2 187 180 4 232 240 4 133 160 3 115 140 2 213 220 4 175 180 2 154 190 3 151 140 3 182 220 3 134 160 2 185 230 4
Per facilitar els càlculs de l’estimació dels paràmetres es proporcionen els sumatoris següents:
9781.Yi =∑ 16022 .X i =∑ 363 =∑ iX
60040822 .X i =∑ 2103712 .YX ii =∑ 770632 .XX ii =∑
21063 .YX ii =∑ 11623 =∑ iX
A partir d’aquestes dades es poden estimar els paràmetres del model per MQO:
( ) Y X XXB ′′= − 1ˆ
=′ XX⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
1167706367706600408160236160212
....
. i =′ YX
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
2106210371
9781
..
.
Per invertir la matriu X´X és necessari calcular-ne el determinant:
600891.=′ XX
i la matriu d’adjunts:
( )⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−
−−=′
60023748034008648039684064008684067005641
...
..
....Adj XX

Introducció a l’Anàlisi de Regressió Lineal
71
Obtenint la matriu inversa:
( )⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−
−−=′ −
60023748034008648039684064008684067005641
60089111
...
..
....
. XX
Llavors, el vector dels estimadors dels coeficients de regressió és:
1333 21062103719781
60023748034008648039684064008684067005641
6008911
××⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡⋅
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−
−−=
.
.
.
...
..
....
.B
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
0007861284049520035619
6008911
..
.
..
.
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
34014556070921
,,,
Per tant, el model estimat és:
iii X,X,,Y 32 34014556070921 ++=
Els resultats obtinguts indiquen que si la resta de factors es mantenen constants, l’efecte d’un metre quadrat més sobre el preu de l’habitatge és de 556 euros, i el d’una habitació més, de 14.340 euros.
3.3. Bondat d’ajust. Coeficient de determinació i coeficient de determinació corregit
En el cas del model de regressió simple s’ha vist que el coeficient de determinació R2 és una mesura de la bondat d’ajust de la recta de regressió que indica el percentatge de la variació total de la variable dependent Y explicada per les variacions de la variable explicativa X. La utilització d’aquesta mesura es pot estendre al cas del model de regressió múltiple, on el que interessa és conèixer la proporció de la variació total de Y explicada per les variables explicatives X2, X3,...,Xk.
El procediment que es pot seguir per obtenir el R2 en el context del model múltiple és el mateix que l’utilitzat en el cas del model simple. A l’apartat 2.4

M. Cladera; A. Matas
72
s’ha mostrat com la variació total de la variable dependent es pot descompondre en variació explicada i variació no explicada pel model, i s’obtenia l’expressió següent:
( ) ( ) ∑∑∑===
+−=−n
ii
n
ii
n
ii eYYYY
1
2
1
2
1
2
on aquests tres sumatoris representaven la variació total, la variació explicada i la variació residual, respectivament.
Utilitzant la notació matricial, aquestes variacions es poden escriure de la manera següent:
2
1
2 YnYVTn
ii −= ∑
=
2Yn−′= Y Y
2
1
2 YnYVEn
ii −= ∑
=
2Ynˆˆ −′= Y Y
2Ynˆˆ −′′= B XX B
Com que ( ) Y X XXB ′′= − 1ˆ , llavors YXBXX ′=′ ˆ , de manera que es té:
2YnˆVE −′′= Y XB
Y XBYY ′′−′=−= ˆVEVTVR
Per tant, el coeficient de determinació R2, que és el quocient entre la VE i la VT, es pot escriure de la forma següent:
2
22
Yn
YnˆR
−′
−′′=
Y Y
Y XB
Com ja s’ha comentat en el seu moment, el R2 està entre 0 i 1, i indica que hi ha un bon ajust si és a prop d’1 i un mal ajust si és a prop de 0.

Introducció a l’Anàlisi de Regressió Lineal
73
Exemple 3.2. Càlcul del coeficient de determinació
Per avaluar la bondat d’ajust del model de regressió estimat a l’Exemple 3.1, es calcula el coeficient de determinació:
2123411
2 .Yn
ii =∑
=
833164,Y =
9851721583316412212341 22 ,.,.YnVT =⋅−=−′= Y Y
2YnˆVE −′′= Y XB
[ ] 2833164122106210371
978134014556070921 ,
..
.,,, ⋅−
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡⋅=
=12.345,547
VR = VT – VE = 15.172,985 – 12.345,547 = 2.827,438
8136098517215547345122 ,,.,.
VTVER ===
El valor del R2 indica que un 81,36% de les variacions mostrals del preu de l’habitatge s’expliquen per les variacions en els metres quadrats i en el nombre d’habitacions.
Una característica important del R2 és que és una funció no decreixent del nombre de variables explicatives, de manera que si s’afegeix una nova variable explicativa al model el R2 no disminuirà sinó que segurament augmentarà.
Per veure que això és així se suposa el model següent:
Yi = β1 + β2 X2i + β3 X3i + ui
Les variables explicatives X2 i X3 expliquen conjuntament una determinada proporció de la variació de la variable dependent Y. Si s’inclou una tercera variable explicativa X4, la proporció de la variació de la variable dependent que expliquin conjuntament les variables X2, X3 i X4 serà com a mínim igual a la que explicaven X2 i X3, i a la pràctica sol ser més gran. Per tant, quan s’inclou una nova variable explicativa al model augmenta el R2.

M. Cladera; A. Matas
74
Aquesta propietat té importants implicacions a l’hora de comparar models alternatius per a la mateixa variable dependent però amb distint nombre de variables explicatives. Si per a la comparació s’utilitza el R2, la conclusió serà sempre la mateixa: el millor model és el que té més variables explicatives.
Per evitar aquest efecte s’ha de tenir en compte el nombre de variables a l’hora de calcular la mesura de bondat d’ajust que s’utilitzi per a la comparació. Això pot fer-se si s’utilitza el coeficient de determinació corregit o ajustat 2R :
112
−−
−=nVT
knVRR
on cada una de les sumes de quadrats considerades s’ha corregit pels seus graus de llibertat.
És fàcil derivar que alternativament el 2R es pot calcular a partir del R2:
( )22 111 Rkn
nR −⎟⎠⎞
⎜⎝⎛
−−
−=
Ja s’ha comentat que quan s’introdueix una nova variable explicativa s’incrementa la VE, però això té un cost estadístic, que és la pèrdua de graus de llibertat, la qual cosa, com es veurà a l’apartat següent, implica una pèrdua d’eficiència en les estimacions. En utilitzar el R2 per comparar els models no es té en compte aquest cost, que sí que s’incorpora en el càlcul del 2R .
Exemple 3.3. Comparació de dos models amb distint nombre de variables explicatives
Amb dades sobre les vendes d’automòbils, V, la renda per càpita, R, el preu mitjà dels automòbils, Pa, i el preu mitjà de la benzina, Pb, en 20 províncies espanyoles s’ha estimat els següent model de regressió:
iiii PbˆPaˆRˆˆV 4321 ββββ +++= 21R = 0,830
Alternativament s’ha estimat un altre model en el qual no s’inclou la variable Pb com a explicativa:
iii PaˆRˆˆV 321 ααα ++= 22R = 0,826
Per comparar ambdós models es calculen els 2R :

Introducció a l’Anàlisi de Regressió Lineal
75
( ) 79808300142012012
1 ,,R =−⎟⎠⎞
⎜⎝⎛
−−
−=
( ) 80508260132012012
2 ,,R =−⎟⎠⎞
⎜⎝⎛
−−
−=
Per tant, es pot observar com, encara que el R2 del primer model és més elevat, el 2R és més baix. Per tant, si s’ha d’elegir un dels dos models, en funció del 2R se seleccionaria el segon.
Cal dir que per comparar dos models mitjançant el 2R és necessari que la variable dependent sigui la mateixa i que la mida mostral també sigui la mateixa.
Per altra banda, quan es volen comparar models distints per a la mateixa variable dependent, la mateixa mida mostral i el mateix nombre de variables explicatives, el R2 sí que és vàlid.
3.4. Inferència en el model de regressió lineal múltiple Per construir intervals de confiança per als paràmetres del model de regressió i contrastar hipòtesis sobre el seu valor és necessari conèixer la distribució de mostreig dels seus estimadors.
A continuació s’exposarà la distribució de mostreig dels estimadors de MQO dels paràmetres del model i la seva utilització per fer inferència.
3.4.1. Distribució de mostreig dels estimadors de MQO
A l’apartat 3.2 s’ha demostrat que el vector dels estimadors de MQO dels paràmetres del model es pot calcular de la manera següent:
( ) Y X XXB ′′= − 1ˆ
Es pot definir la matriu C com la part no aleatòria d’aquesta expressió aplicant la hipòtesi de no aleatorietat de les variables explicatives:
Ck×n = (X´X)-1k×kX´k×n
Per tant, el vector B es pot escriure com a:

M. Cladera; A. Matas
76
1
2
1
1
2
1
1
2
1
21
22221
11211
×××× ⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⋅
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
∑
∑∑
kkkiki
ii
ii
nnnkknkk
n
n
ˆ
ˆˆ
YC
YCYC
Y
YY
CCC
CCCCCC
ˆ
β
ββ
MMM
L
MMM
L
L
B
Llavors es té que cada jβ és igual a ∑=
n
iijiYC
1
. Per tant, els estimadors de
MQO dels paràmetres del model de regressió lineal múltiple són estimadors lineals. A més, com que Y és una variable normal, si es compleixen les hipòtesis del model clàssic, cada jβ és una combinació lineal de variables
aleatòries normals i, per tant, té distribució normal.
Quant a l’esperança dels estimadors de MQO,
( ) YXXXB 1 ′⋅′= −ˆ
Substituint Y per la seva expressió i simplificant,
( ) ( )UXBXXXB 1 +′⋅′= −ˆ
( ) ( ) UXXXXBXXX 11 ′′+′′= −−
( ) UXXXB 1 ′′+= −
Aplicant esperances i sota el supòsit que les variables explicatives són no estocàstiques:
( ) ( ) ( )UXXXBB 1 EˆE ⋅′⋅′+= −
Pel fet que E(U) = 0, es té:
( ) BB =ˆE
Per tant, els estimadors de MQO dels paràmetres del model són estimadors centrats.
Pel que fa a la variància d’aquests estimadors, s’ha demostrat que el vector B es pot escriure com a:
( ) UX XXBB 1 ′′+= −ˆ
i per tant,
=− BB ( ) UXXX 1 ′′ −

Introducció a l’Anàlisi de Regressió Lineal
77
A partir d’aquesta expressió es pot obtenir la matriu de variàncies i covariàncies dels estimadors de MQO:
( ) ( )( ) ⎥⎦⎤
⎢⎣⎡ ′
−−= BBBBB ˆˆEˆVC
( ) ( )[ ]11 −− ′′′′= XX XUU X XXE
Com que se suposa que les variables explicatives són no estocàstiques:
( ) ( ) [ ] ( ) 1−− ⋅′′′′= XXXUUXXXB 1 EˆVC
Si es compleixen les hipòtesis d’homoscedasticitat i no autocorrelació, la matriu de variàncies i covariàncies de U és igual a σ2I. Per tant,
( ) ( ) ( ) 121 −− ′′′= XX XIX XXB σˆVC
i simplificant es té:
( ) ( ) 12 −′= XXB σˆVC
La matriu ( )BVC és la matriu de variàncies i covariàncies dels estimadors de MQO dels paràmetres del model de regressió.
A la diagonal d’aquesta matriu s’hi troben les variàncies dels estimadors, i fora de la diagonal les seves variàncies:
( )
( )( )
( )( ) mjjm
kkkkkkk
k
k
aσβ,βcov
aσβvar
aσβvaraσβvar
aaa
aaaaaa
2
2
222
2
112
1
21
22221
11211
12 =
=
==
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=′ −
M
L
MMM
L
L
XXσ
Per tant, si es compleixen les hipòtesis del model clàssic, el vector dels estimadors de MQO dels coeficients de regressió té la distribució següent:
( )( )12 −′∼ XXBB σ,Nˆ
i cada un dels jβ :
( )jjjj a,Nˆ 2σββ ∼ , j = 1,...,k.
Llavors, estandarditzant aquesta distribució s’obté l’estadístic:

M. Cladera; A. Matas
78
( )1 02
,Na
ˆ
jj
jj ∼−
σ
ββ
que permetrà contrastar hipòtesis sobre el valor de βj i construir intervals de confiança.
El problema és que la variància del terme de pertorbació és desconeguda i caldrà estimar-la abans de poder fer inferència sobre els paràmetres del model.
Estimació de σ2
Igual que en el cas del model simple, l’estimador no esbiaixat de la variància del terme de pertorbació és la variància residual:
kn
eS
n
ii
R −=
∑=1
2
2
L’única diferència entre aquest estimador i l’utilitzat en el context del model de regressió simple és el denominador. En aquest cas els graus de llibertat són n – k, ja que abans de calcular la SQR és necessari estimar els k paràmetres del model. En el model simple únicament hi ha dos paràmetres i, per tant, els graus de llibertat són n – 2.
L’arrel de la variància residual és, com ja s’ha indicat, l’error estàndard de la regressió.
De l’expressió de la variància residual es dedueix que la reducció del nombre de graus de llibertat redueix l’eficiència de l’estimació pel fet que augmenta la variància residual i, per tant, l’error estàndard de la regressió.
L’estadístic 21
2
σ
∑=
n
iie
té distribució χ2 amb n – k graus de llibertat. Llavors, la
variància residual té la distribució següent:
22
2
)( knR knS −−
∼ χσ
Coneixent quin és l’estimador de la variància del terme de pertorbació i quina és la seva distribució, es pot utilitzar l’estadístic

Introducció a l’Anàlisi de Regressió Lineal
79
kn
jjR
jj taS
ˆ−∼
−
2
ββ
del qual es poden derivar fàcilment els intervals de confiança i els estadístics que s’utilitzaran per contrastar hipòtesis sobre els paràmetres del model.
El denominador d’aquest estadístic és l’error estàndard de jβ :
( ) jjRj aSˆes 2=β
i habitualment l’estadístic s’expressa com a:
( ) knj
jj tˆes
ˆ−∼
−
β
ββ
3.4.2. Contrastació de la significació individual de les variables explicatives
Una vegada estimat el model i per poder contrastar la significació de les variables explicatives introduïdes en l’especificació del model, es pot procedir de manera anàloga al cas del model de regressió simple.
Si la variable Xj és significativa per explicar el comportament de la variable dependent Y, llavors el paràmetre βj serà distint de zero. Per tant, per contrastar la significació de la variable Xj es planteja el següent contrast d’hipòtesis:
H0: βj = 0
HA: βj ≠ 0
Si es rebutja la H0, la variable Xj és significativa, mentre que si la H0 no es pot rebutjar la conclusió serà que Xj no és significativa.
L’estadístic de contrast és l’estadístic t:
( ) kn
certaHj
j tˆes
ˆt −∼=
0β
β
Les variables explicatives que resultin no significatives s’han d’eliminar de l’especificació del model i aquest s’ha de tornar a estimar. Si no es fa així s’estimen paràmetres innecessàriament i cada paràmetre que s’ha d’estimar implica la pèrdua d’un grau de llibertat. Si es redueixen els graus de llibertat,

M. Cladera; A. Matas
80
augmenta l’error estàndard de la regressió i per tant es perd eficiència en les estimacions dels paràmetres del model.
Exemple 3.4. Contrastació de la significació individual de les variables del model estimat per al preu de l’habitatge
A l’Exemple 3.1 s’ha estimat el següent model per analitzar el comportament dels preus de l’habitatge en una ciutat determinada:
iii X,X,,Y 32 34014556070921 ++=
Per contrastar la significació del nombre d’habitacions, X2, i els metres quadrats, X3, és necessari realitzar una sèrie de càlculs previs.
kn
ˆ
knVEVT
kn
eS
n
ii
R −′′−′
=−−
=−
=∑
= YXBYY1
2
2
1593149
4388272312
562384338212341 ,,.,..==
−−
=
i l’error estàndard de la regressió és 17,724.
( )⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−
−−=′ −
60023748034008648039684064008684067005641
60089111
...
..
....
. XX
( ) 1840600891
961593142 ,.
,ˆes =⋅=β
( ) 14996008916002371593143 ,
.
.,ˆes =⋅=β
Ara ja es poden calcular els estadístics t corresponents a cada un dels coeficients de regressió:
( ) 021318405560
2
22
,,,
ˆes
ˆt ===
ββ
β
( ) 5671149934014
3
33
,,,
ˆes
ˆt ===
ββ
β

Introducció a l’Anàlisi de Regressió Lineal
81
En aquest cas, l’estadístic t, sota H0 certa, es distribueix com una t amb 9 graus de llibertat. Per tant, el valor crític del contrast, utilitzant un nivell de significació del 5%, és t9 = 2,262.
Llavors es pot dir que en aquest model el nombre d’habitacions és significatiu, però no ho són els metres quadrats.
3.4.3. Contrastació de la significació conjunta de les variables explicatives
A l’apartat anterior s’ha fet referència a la contrastació de la significació individual de cada una de les variables explicatives incloses en el model de forma separada.
Ara es considerarà la contrastació de la significació conjunta de totes les variables explicatives del model. En aquest cas la hipòtesi nul·la que s’ha de contrastar és:
H0: β2 = β3 = ··· = βk = 0
I la hipòtesi alternativa:
HA: algun βj és distint de 0.
Si es rebutja la H0 es considerarà que l’evidència empírica indica que el model és conjuntament significatiu, és a dir, que almenys un dels paràmetres del model és significativament distint de zero.
Si la H0 no es pot rebutjar, es considerarà que l’evidència empírica permet afirmar que el model no és conjuntament significatiu.
L’estadístic de contrast que s’ha d’utilitzar és el següent:
knVRkVEF
−−
=1
La distribució d’aquest estadístic es pot derivar de la manera que s’exposa a continuació.
Ja s’ha vist que la variació total de la variable dependent es pot descompondre en variació explicada i variació residual, de manera que:
( )∑=
−=n
ii YYVT
1
2 ( )∑=
−=n
ii YYVE
1
2 ∑
=
=n
iieVR
1
2

M. Cladera; A. Matas
82
A l’apartat 3.4.1 ja s’ha indicat que l’estadístic 21
2
σ
∑=
n
iie
té una distribució χ2
amb n – k graus de llibertat.
Per altra banda, els graus de llibertat de la VT són n – 1, ja que abans de
calcular-la s’ha d’estimar la mitjana mostral. Així, l’estadístic ( )
21
2
σ
∑=
−n
ii YY
té
distribució χ2 amb n – 1 graus de llibertat.
A més, com que es compleix que
VT=VE+VR
i, per tant,
222 σσσVRVEVT
+=
llavors l’estadístic ( )
21
2
σ
∑=
−n
ii YY
té distribució χ2 amb k – 1 graus de llibertat,
ja que
221
21
222
knkn
VRVEVT
−−− +=
+=
χχχσσσ
Per tant, sota H0 certa l’estadístic de contrast es distribueix segons una distribució F amb k – 1 graus de llibertat al numerador i n – k graus de llibertat al denominador:6
( )kn,kcertaH
FknVR
kVEF −−∼−−
= 1 0
1
6 Si 2
νχ i 2ωχ són dues variables aleatòries amb distribució 2χ independents i amb
graus de llibertat ν i ω, respectivament, llavors es té:
( )ωνω
ν
ωχνχ
,F∼2
2

Introducció a l’Anàlisi de Regressió Lineal
83
Relació entre l’estadístic de contrast de significació conjunta i el R2
L’estadístic F que s’ha d’utilitzar per a la contrastació de la significació conjunta del model es pot expressar alternativament com a:
( ) knRkRF
−−−
= 2
2
11
Per tant, si el R2 és elevat, l’estadístic F també ho serà i conduirà a rebutjar la H0.
Taula d’anàlisi de la variància
La informació utilitzada per a la contrastació de la significació conjunta s’acostuma a presentar en forma d’una taula que es coneix amb el nom de taula d’anàlisi de la variància i té l’estructura següent:
Font de variació Graus de llibertat
Suma de quadrats
Mitjana de quadrats
Estadístic F
Regressió k – 1 VE VE/(k – 1) F
Error o residual n – k VR VR/(n – k)
Total n – 1 VT VT/(n – 1)
Exemple 3.5. Contrastació de la significació conjunta
De l’Exemple 3.2 es té que les variacions corresponents al model estimat per al preu de l’habitatge són:
VE = 12.345,547
VR = 2.827,438
VT = 15.172,985
Es vol contrastar la significació conjunta de les variables del model, és a dir, la H0: β2 = β3 = 0.
L’estadístic de contrast és:
64819943882722547345121 ,
,.,.
knVRkVEF ==
−−
=
Al nivell de significació del 5% el valor crític és F(2,9) = 4,26. Per tant, es rebutja la H0 i es pot dir que, segons l’evidència mostral de què es disposa, el model és conjuntament significatiu.

M. Cladera; A. Matas
84
La taula d’anàlisi de la variància és:
Font de variació G. de l. SQ MQ F
Regressió 2 12.345,547 6.172,773 19,648
Error o residual 9 2.827,438 314,159
Total 11 15.172,985 1.379,362
3.4.4. Contrastació de restriccions lineals entre els paràmetres
En aquest apartat s’analitzarà la contrastació d’un tipus d’hipòtesis sobre els paràmetres del model molt habitual dins l’anàlisi de regressió lineal: la contrastació de restriccions lineals entre els paràmetres del model.
Una vegada que s’ha estimat un model de regressió, s’ha avaluat la bondat de l’ajust i s’han contrastat les hipòtesis sobre la significació individual i conjunta dels paràmetres del model, es pot estar interessat a contrastar alguns supòsits de la teoria econòmica que es manifesten en restriccions lineals sobre els paràmetres del model.
Les restriccions lineals que es tractaran en aquest text impliquen que una determinada combinació lineal dels paràmetres del model és igual a una constant:
a2β2 + a3β3 +···+ akβk = a
Les restriccions lineals en forma de desigualtat requereixen la utilització de procediments distints dels que s’exposaran a continuació.
Exemple 3.6. Exemple de restricció lineal en els paràmetres del model
S’especifica un model per a la producció de les empreses d’un determinat sector a partir de la funció de Cobb-Douglas:
iuKlnLlnAlnYln +++= 32 ββ
Es vol contrastar l’existència en el sector de rendiments constants a escala. Aquest supòsit implica que els paràmetres del model han de complir la restricció següent:
β2 + β3 = 1
El procediment per a la contrastació de restriccions lineals entre els paràmetres del model és el següent:

Introducció a l’Anàlisi de Regressió Lineal
85
1) Plantejament de les hipòtesis. La hipòtesi nul·la suposa que la restricció que s’ha de contrastar és certa, i la hipòtesi alternativa, que els paràmetres del model no satisfan la restricció.
H0: a2β2 + a3β3 +···+ akβk = a
HA: la restricció no és certa.
Per contrastar més d’una restricció simultàniament, la hipòtesi nul·la suposa que totes són certes.
2) Estimació del model no restringit i del model restringit.
El model restringit és el model especificat de tal manera que s’incorpora la restricció que es vol contrastar, mentre que el model no restringit és el model general, que no incorpora la restricció.
Per obtenir el model restringit se substitueix la restricció o les restriccions que es pretenen contrastar dins l’equació del model general. Amb la imposició de les restriccions el model pot perdre algunes variables explicatives, o donar lloc al fet que algunes explicatives del model restringit siguin combinació lineal de les del model general.
El model restringit s’estimarà per MQO, de la mateixa manera que s’ha fet amb el model general. Aquest procediment es coneix com a mínims quadrats restringits (MQR).
3) L’estadístic de contrast que s’ha d’utilitzar es basa en la comparació de la VR del model restringit, VRR, i la del model no restringit, VRNR:
( )( ) ( )kn,r
certaHNR
NRR)R( F
kn/VRr/VRVRF −∼
−−
= 0
on r és el nombre de restriccions que es volen contrastar i k és el nombre de paràmetres del model no restringit.
La VR del model no restringit té n – k graus de llibertat i la del model restringit en té n – (k – r), ja que s’han d’estimar r paràmetres menys. Per exemple, es té el model
Yi = β1 + β2X2i + β3X3i + ui
I es vol contrastar la restricció β2 – β3 = 0, és a dir, β2 = β3.
Llavors, el model restringit, incorporant la restricció que s’ha de contrastar, és:

M. Cladera; A. Matas
86
Yi = β1 + β2(X2i + X3i) + ui
Els graus de llibertat de la VR d’aquest model són n – (k – 1), ja que en lloc de tres paràmetres se n’han d’estimar únicament dos.
4) Si es rebutja la hipòtesi nul·la, significa que les restriccions lineals no són certes i que, per tant, el model adequat per representar el comportament de la variable dependent és el model no restringit.
Si no es pot rebutjar la hipòtesi nul·la, significa que les restriccions són certes i que per representar el comportament de la variable dependent és millor el model restringit.
Exemple 3.7. Especificació dels models restringit i no restringit
Per a la contrastació de la restricció lineal plantejada a l’Exemple 3.6, el model no restringit és:
iuKlnLlnYln +++= 321 βββ
i el model restringit:
( ) iuKlnLlnYln +−++= 221 1 βββ
( ) iuKlnLlnKlnYln +−+=− 21 ββ
i*i
*i uXY ++= 21 ββ
on *iY és igual a KlnYln − i *
iX és igual a KlnLln − .
Exemple 3.8. Contrastació d’una restricció lineal
S’ha especificat el següent model de regressió lineal:
Yi = β1 + β2X2i + β3X3i + ui
De l’estimació de MQO amb dades d’una mostra de 10 observacions s’obté que la SQR és 3.306.
Es vol contrastar la hipòtesi que existeix la següent relació lineal entre els paràmetres del model:
β2 = 2β3

Introducció a l’Anàlisi de Regressió Lineal
87
Per tant:
H0: β2 = 2β3
HA: β2 ≠ 2β3
Si la restricció s’incorpora a l’especificació del model, s’obté el model restringit:
Yi = β1 + β3(2X2i + X3i) + ui
Yi = β1 + β3*iX + ui
on *iX és igual a (2X2i + X3i).
De l’estimació de MQO d’aquest model s’obté que la SQR és 3.379.
L’estadístic de contrast és:
( )( )
( )( ) 1540
3103063130633793 ,
/./..
kn/VRr/VRVRF
NR
NRR)R( =
−−
=−
−=
Al nivell de significació del 5% el valor crític és F(1,7) = 5,59. Per tant, no es pot rebutjar la hipòtesi nul·la, cosa que significa que la restricció és certa.
Procediment de contrastació de restriccions lineals utilitzant la notació matricial
Per expressar les restriccions lineals que s’han de contrastar en forma matricial es construeix una matriu R en la qual les files són els coeficients de la combinació lineal entre els paràmetres del model per a cada restricció. Si hi ha més d’una restricció, cada fila es correspon amb una:
R = ⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
MMM
L
L
k
k
bbbaaa
21
21
També es defineix un vector r on cada element és el valor al qual ha de ser igual la combinació lineal dels paràmetres:
r=⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
M
ba
Llavors les restriccions s’expressen com a:

M. Cladera; A. Matas
88
RB = r
És a dir,
RB = ⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
MMM
L
L
k
k
bbbaaa
21
21
·
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
kβ
ββ
M2
1
=⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
M
ba
= r
De manera que es té:
a2β2 + a3β3 +···+ akβk = a
b2β2 + b3β3 +···+ bkβk = b
M M M M
La hipòtesi nul·la s’escriu com a:
H0: RB = r
Exemple 3.9. Especificació d’una restricció lineal en els paràmetres del model utilitzant la notació matricial
A partir de la situació plantejada a l’Exemple 3.6, el model no restringit és:
iuKlnLlnAlnYln +++= 32 ββ
La restricció lineal que es pretén contrastar és:
β2 + β3 = 1
Per expressar aquesta restricció amb notació matricial es defineixen els vectors següents:
R = ( )110 r = 1 B´ = ( )321 βββ
De manera que la restricció es pot escriure:
RB = r → β2 + β3 = 1

Introducció a l’Anàlisi de Regressió Lineal
89
Exemple 3.10. Contrastació de diverses restriccions lineals simultànies
Es té el següent model de regressió:
Yi = β1 + β2X2i + β3X3i + β4X4i + ui
Es volen contrastar les restriccions següents:
β2 + β3 = 1
β4 = 0
Per expressar aquestes restriccions matricialment, es defineixen la matriu i els vectors següents:
R = ⎟⎟⎠
⎞⎜⎜⎝
⎛10000110
r = ⎟⎟⎠
⎞⎜⎜⎝
⎛01
B´ = ( )4321 ββββ
Llavors les restriccions es poden escriure com a:
RB = r
El model restringit que s’obté incorporant ambdues restriccions és:
Yi – X2i = β1 + β3 (X3i – X2i) + ui
i*i
*i uXY ++= 21 ββ
On *iY és igual a Yi – X2i i *
iX és igual a X3i – X2i.
3.4.5. Contrastació de la nul·litat d’un subconjunt de paràmetres
Un altre tipus de contrast que habitualment és útil és la contrastació de la nul·litat d’un subconjunt de paràmetres. El plantejament del contrast és similar al de l’apartat anterior.
El model no restringit és:
iqiqikkkikiii uXXXXXY ++++++++= ++ ββββββ LL 1133221
Es vol contrastar si les variables Xk+1, Xk+2,...,Xq, són significatives conjuntament per explicar el comportament de la variable dependent. Si aquestes variables no fossin significatives, els paràmetres βk+1, βk+2,...,βq, serien igual a zero. Per tant, la hipòtesi nul·la que s’ha de contrastar és:

M. Cladera; A. Matas
90
H0: βk+1 = βk+2 =···= βq
HA: algun βj que és distint de zero.
En aquest cas el model restringit conté les variables X2, X3,...,Xk i s’han d’estimar k paràmetres. El model general conté totes les variables explicatives i, per tant, s’han d’estimar q paràmetres.
L’estadístic de contrast és:
( ) ( )( ) ( )qn,kq
certaHNR
NRR)R( F
qn/VRkq/VRVRF −−∼
−−−
= 0
3.5. Predicció en el model de regressió lineal múltiple Tal com s’ha explicat a l’apartat 2.7, una vegada que s’ha estimat i validat el model de regressió, es pot utilitzar per fer predicció dels valors de la variable dependent en funció del valor de les variables explicatives.
També s’ha comentat que es pot distingir la predicció d’un valor individual de la predicció de la mitjana. Aquesta distinció no dóna lloc a diferències en les prediccions puntuals però sí en les prediccions per intervals.
En aquest apartat, seguint un procediment anàleg a l’utilitzat en el cas del model de regressió simple, s’exposarà la forma de calcular prediccions, puntuals i per intervals, per a un valor individual i per a la mitjana de la variable dependent.
3.5.1. Predicció de la mitjana
Per a uns valors determinats de les variables explicatives, X20, X30, ...,Xk0, es vol predir el valor esperat de la variable dependent:
E(Y0| X20, X30, ...,Xk0) = β1 + β2 X20 + β3 X30 +···+ βk Xk0
Es pot definir un vector X0 que contingui els valors de les variables explicatives per als quals es vol predir la mitjana de la variable dependent:
X0 =
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
0
20
1
kX
XM
Llavors l’expressió anterior es pot escriure com a:

Introducció a l’Anàlisi de Regressió Lineal
91
E(Y0|X0) = BX0′
La predicció d’aquesta esperança s’obté substituint els paràmetres poblacionals desconeguts pels seus estimadors. Per tant, la predicció puntual és el valor ajustat pel model quan les variables explicatives tenen els valors X0:
( ) ΒY|YE 00 XX ′== 00
Amb notació escalar:
020210 kk XˆXˆˆY βββ +++= L
Per obtenir estimacions per intervals és necessari conèixer l’error estàndard de
0Y .
La variància de 0Y és:
( ) ( )ΒvarYvar 0X′=0
( ) 00 XX Βvar′=
( ) 0-12
0 X XXX ′′= σ
( ) 0-1
02 X XXX ′′= σ
Substituint la variància del terme de pertorbació pel seu estimador, la variància residual, es té que l’error estàndard de 0Y és:
( ) ( ) 0-1
02R X XXX ′′= SYes ˆ
0
Per tant, l’expressió de l’interval de confiança del (1 – α)100% de nivell de confiança per a E(Y0|X0) és:
( )[ ]( ) ( )[ ]02
010010 YestY|YEIC kn%α
α −− ±=0X
3.5.2. Predicció d’un valor individual
En aquest cas es pretén predir el valor de la variable dependent per a uns determinats valors de les variables explicatives, continguts a X0:
Y0 = X0´B
La predicció puntual d’aquest valor coincideix amb la de l’apartat anterior, i és el valor ajustat pel model per als valors de les explicatives a X0:

M. Cladera; A. Matas
92
BX0ˆ
0 ′=Y
Amb notació escalar:
020210 kk XˆXˆˆY βββ +++= L
L’error d’estimació, és a dir, la diferència entre el valor predit i l’observat, és:
uBXBX 00 +′′ −=− ˆˆ00 YY
L’esperança d’aquest error és zero, ja que B és un estimador no esbiaixat de B i l’esperança de u és 0.
Per obtenir estimacions per intervals és necessari conèixer l’error estàndard de l’error de predicció.
La variància de 00 YY − és:
( ) ( ) ( ) 00 XBXu ˆvarvarYYvar ′+=− 00
( ) 0-12
02 X XXX ′′+= σσ
( )( )0-1
02 X XXX ′′+= 1σ
Substituint la variància del terme de pertorbació pel seu estimador, la variància residual, es té que l’error estàndard de 00 YY − és:
( ) ( )( )01-
02R X XXX1 ′′+=− SYYes ˆˆ
00
Per tant, es pot derivar fàcilment que l’expressió de l’interval de confiança del (1 – α)100% de nivell de confiança per a Y0 és:
( )( ) ( )[ ]002
010010 YYestYYIC kn% −±= −−α
α

4. Problemes amb la informació mostral


Introducció a l’Anàlisi de Regressió Lineal
95
Fins ara s’ha presentat el model de regressió lineal múltiple suposant que es complien determinades hipòtesis sobre els distints component del model. En aquest apartat s’explicaran alguns del problemes que sorgeixen al model de regressió lineal quan la mostra de què es disposa per dur a terme l’anàlisi de regressió presenta algun tipus de problema. En concret es tractarà el cas en què les variables explicatives estan correlacionades entres si, i el cas en què la mostra contingui observacions atípiques.
4.1. Problemes amb la mostra Quan s’utilitzen dades reals per fer una anàlisi de regressió s’ha de ser conscient que poden aparèixer diversos problemes o deficiències en aquestes dades. Alguns d’aquests problemes són els que s’enumeren a continuació:
Poques observacions mostrals.
Poca variabilitat de les variables explicatives.
La conseqüència d’aquests dos problemes és l’obtenció d’estimacions poc eficients.
En el model de regressió simple, per exemple,
( )( ) ( )Xvarn
XX
ˆvar n
ii
×=
−=
∑=
2
1
2
2
1σσβ
Si el nombre d’observacions mostrals és massa petit o la variància de les variables explicatives és massa petita, llavors la variància dels jβ pot ser
massa gran. Això implica poca precisió de les estimacions dels coeficients de regressió.
Correlació entre les variables explicatives del model:
En el model de regressió múltiple amb dues variables, per exemple, les variàncies dels estimadors dels coeficients de regressió són:
( ) 222
2 aˆvar σβ = ( ) 332
3 aˆvar σβ =
on a22 i a33 són els coeficients de la diagonal de la matriu (X´X)-1 corresponents.
Amb notació escalar es té:

M. Cladera; A. Matas
96
( )( ) ( )2
1
222
2
2
321 xx
n
ii rXX
ˆvar−−
=
∑=
σβ i ( )( ) ( )2
1
233
2
3
321 xx
n
ii rXX
ˆvar−−
=
∑=
σβ
En aquestes expressions es pot observar que com més gran sigui la correlació entre les dues variables explicatives més gran és la variància dels estimadors i, per tant, menys precises són les estimacions dels coeficients de regressió.
En el model de regressió múltiple es pot tenir el problema de la multicolinealitat. Amb aquest concepte es fa referència a la situació en què, com a conseqüència d’una forta correlació entre les variables explicatives, és difícil distingir els efectes que cada variable té, de forma individual, sobre la variable dependent (que és el que es pretén fer estimant els jβ ).
Ja s’ha comentat que un dels supòsits del model de regressió clàssic és la no existència de relació lineal exacta entre les variables explicatives. Amb notació matricial aquest supòsit implica que el rang de la matriu X, d’ordre n × k, tingui rang complet, és a dir, que el rang de la matriu X sigui igual a k. Quan el rang d’aquesta matriu és més petit que k, indica que alguna variable explicativa es pot obtenir com a combinació lineal de les altres. En aquesta situació s’està en presència de multicolinealitat perfecta, que no és una situació gaire freqüent. Una situació més habitual és aquella en la qual les variables presenten colinealitat, encara que no perfecta.
Presència d’observacions atípiques.
Una observació atípica és una observació molt allunyada de la resta que no pareix que segueixi el mateix patró de comportament que segueixen les altres observacions. Quan s’utilitza el mètode de MQO aquesta observació pot tenir una influència important sobre l’equació de regressió estimada.
En aquest capítol l’explicació se centrarà en dos dels problemes enumerats: la multicolinealitat i les observacions atípiques.
4.2. Multicolinealitat A l’apartat 3.1.1 s’ha vist que un dels supòsits del model clàssic de regressió lineal consisteix en la no existència de relació lineal exacta entre les variables explicatives, és a dir, la no existència de multicolinealitat perfecta. En aquest apartat es comentaran quines són les conseqüències de l’existència de

Introducció a l’Anàlisi de Regressió Lineal
97
multicolinealitat sobre els resultats de l’anàlisi de regressió, les mesures estadístiques per a la detecció de la multicolinealitat i algunes alternatives per combatre-la.
4.2.1. Definició i conseqüències de la multicolinealitat
Com ja s’ha indicat, la multicolinealitat fa referència a aquella situació en la qual, com a conseqüència d’una forta correlació entre les variables explicatives, no és possible conèixer l’efecte individual de cada variable explicativa sobre la variable dependent, és a dir, els coeficients de regressió estimats no reflecteixen correctament aquests efectes.
Si existeix multicolinealitat perfecta el rang de la matriu X és més petit que k, és a dir, alguna variable explicativa es pot obtenir com a combinació lineal de les altres. En aquest cas no es pot obtenir la matriu (X´X)-1 i, per tant, no es pot calcular el vector dels estimadors de MQO dels coeficients de regressió, que és igual a (X´X)-1X´Y.
Aquesta situació no és la més freqüent, sinó que és més habitual el cas en què existeix un cert grau de multicolinealitat encara que no perfecta. En aquest cas, encara que es poden obtenir les estimacions dels paràmetres de model, l’existència d’una elevada correlació lineal entre les variables explicatives té les conseqüències que es descriuen a continuació sobre les estimacions de MQO.
1) Dificultat per separar els efectes individuals de les variables explicatives
Si les variables explicatives estan correlacionades és pràcticament impossible separar els efectes individuals de les diferents variables que presenten un grau elevat de correlació lineal. Les estimacions dels efectes de les variables correlacionades poden contenir errors importants pel fet que el paràmetre que representa l’efecte d’una variable pot absorbir la influència de les altres variables amb les quals aquesta està correlacionada.
2) Variàncies i covariàncies dels estimadors de MQO elevades
Les variàncies i les covariàncies dels estimadors MQO són molt elevades, és a dir, les estimacions són poc precises.
La matriu de variàncies i covariàncies del vector B és:
( ) ( ) ( ) XX
XX XXB′
′=′= − AdjˆVC 212 σσ

M. Cladera; A. Matas
98
Si la multicolinealitat és perfecta, la matriu X no té rang complet i el determinant |X´X| és zero. Si la multicolinealitat no és perfecta, el determinant no és zero però els seu valor és petit i, per tant, les variàncies i covariàncies dels estimadors són elevades.
3) Els estadístics t no són fiables
El fet que les variàncies i, per tant, els errors estàndards dels coeficients estimats puguin ser molt grans, pot dur a no poder rebutjar hipòtesis nul·les indegudament i negligir determinades variables com a explicatives quan sí que ho són. En aquests casos els contrasts de significació individual i els de significació conjunta poden donar conclusions contradictòries.
( )j
j
ˆes
ˆt
β
β=
Si l’error estàndard de l’estimador és elevat, l’estadístic t serà petit, proper a zero, i probablement no sobrepassarà el valor crític que permetria rebutjar la hipòtesi nul·la que el coeficient és igual a zero. És a dir, l’existència de multicolinealitat pot dur a no rebutjar la hipòtesi que la variable és no significativa quan realment és falsa.
4) El model és poc robust
Els resultats de les estimacions de MQO són molt sensibles a petits canvis en les dades. Per exemple, si el model s’estima amb una determinada mostra i després es reestima amb una observació menys, les estimacions dels coeficients de regressió poden ser molt distintes.
5) Signes no esperats en els coeficients estimats
Com a conseqüència de l’elevada variància dels estimadors es poden obtenir signes no esperats en les estimacions dels paràmetres del model, signes contraris a la lògica econòmica.
A pesar de la gravetat del problema de la multicolinealitat, si la finalitat del model és purament predictiva i no descriptiva, pot emprar-se amb el mateix grau de fiabilitat (perquè el model estimat sí que recull l’efecte conjunt de totes les variables explicatives) sempre que en els períodes per als quals es fa predicció se segueixi complint l’estructura entre les variables recollides en el model estimat.

Introducció a l’Anàlisi de Regressió Lineal
99
Per altra banda, en presència d’un cert grau de multicolinealitat els estimadors de MQO conserven les seves propietats. És a dir, són estimadors lineals, centrats, de variància mínima, consistents i normals.
Exemple 4.1. Efectes de la multicolinealitat sobre els resultats de l’estimació del model
S’ha estimat un model que relaciona els dividends que paga una empresa als seus accionistes, D, amb el preu, P, i les unitats venudes, V, del seu producte. Els resultats de l’estimació per MQO són els següents:
iii P,V,,D 0150 01508600 ++−= R2 = 0,945 F=25,804 > ( )05032,,F = 9,55
20512
,t =β i 27613
,t =β . El valor crític és 02503
,t = 3,182.
Es pot observar que el R2 indica que l’ajust és bo, i el contrast de significació conjunta mostra que les variables conjuntament són significatives. Malgrat això, els contrasts de significació individual indiquen que individualment les dues variables explicatives són no significatives.
Aquestes contradiccions fan pensar en l’existència de correlació entre les variables explicatives. El coeficient de correlació lineal entre aquestes variables confirma la sospita: P,Vr = 0,94.
4.2.2. Detecció de la multicolinealitat
Per detectar si existeix un problema de multicolinealitat s’han proposat diferents mesures, entre les quals es troben les següents:
Si en un model es rebutja la hipòtesi 0210 ==== k:H βββ L mitjançant l’estadístic F i algunes, o totes, les variables del model, individualment considerades, es rebutgen com a explicatives amb l’estadístic t, això dóna indicis d’un possible problema de multicolinealitat.
L’obtenció de signes no esperats en les estimacions dels paràmetres del model pot ser conseqüència de l’elevada variància dels estimadors deguda a la presència de multicolinealitat.
En un model amb dues variables explicatives es pot calcular el coeficient de correlació per detectar l’existència de multicolinealitat:

M. Cladera; A. Matas
100
( )( )
( ) ( )∑∑
∑
==
=
−−
−−=
n
ii
n
ii
n
iii
xx
XXXX
XXXXr
1
233
1
222
13322
32
Si 32xxr és elevat, la mostra pot generar problemes de multicolinealitat.
Si el nombre de variables explicatives és més gran que dos, les correlacions simples poden ser totes baixes i, malgrat això, existir un greu problema de multicolinealitat perquè es produeixin combinacions entre elles.
Per tant, si hi ha més de dues variables explicatives, examinar tots els possibles coeficients simples de tots els regressors dos a dos pot no ser suficient, ja que l’elevada correlació lineal pot ser múltiple i implicar més de dos regressors.
Què es pot fer per detectar l’existència d’elevades correlacions múltiples? Una possibilitat és computar el coeficient de determinació múltiple de cada regressor amb la resta.
Si s’ha especificat el següent model de regressió:
Yi = β1 + β2·X2i + β3·X3i +···+ βk·Xki + ui
per detectar l’existència de multicolinealitat es pot calcular el coeficient de determinació múltiple de la regressió de cada variable explicativa amb la resta:
232 kX,...,X|XR , del model kikii XˆXˆˆX γγγ +++= L3312
2,....,| 23 kXXXR , del model kikii XˆXˆˆX γγγ +++= L2213
M 2
12 −kk X,...,X|XR , del model ikkiki XˆXˆˆX 112321 −−+++= γγγ L
Si la variable Xj està correlacionada amb altres variables explicatives, el R2 de la regressió de Xj amb la resta d’explicatives serà elevat. Si no existeix correlació, el R2 serà baix.
En el model de regressió lineal múltiple es por demostrar que la variància dels estimadors de MQO dels coeficients de regressió es pot escriure com a:

Introducció a l’Anàlisi de Regressió Lineal
101
( )( ) ( )2
1
2
2
1jX
n
ijji
j
RXX
ˆvar−−
=
∑=
σβ
Si la variable Xj està correlacionada amb altres variables explicatives del model, 2
jXR serà elevat i la variància de jβ també. Per tant, l’estimador
jβ serà poc precís.
Una mesura utilitzada per a la detecció de la multicolinealitat i derivada dels 2
jxR són els factors d’inflació de la variància (FIV) dels coeficients
de regressió. El FIV és una mesura estadística que permet saber si la variància d’un estimador està inflada per la presència de multicolinealitat en el model respecte al cas ideal en què hi hagués absència total de multicolinealitat.
( )( ) ( )
( )∑
∑
=
=
−
−−==
n
ijji
X
n
ijji
j
XX
RXX
esexplicativd' resta laamb ióincorrelac total
de ideal cas el en tindria que Variància
efectivaestimadorl' de Variància
ˆFIVj
1
2
2
2
1
2
2
1
σ
σ
β
Simplificant, s’obté:
( )21
1
jX
jR
ˆFIV−
=β
Com més gran és el ( )jˆFIV β més gran és el grau de correlació de la
variable Xj amb la resta d’explicatives.
Els FIV es poden calcular alternativament de la manera que es descriu a continuació.
La matriu RX és la matriu de correlacions entre les variables explicatives:

M. Cladera; A. Matas
102
RX =
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
1
11
32
332
232
L
MOMM
L
L
kk
k
k
XXXX
XXXX
XXXX
rr
rrrr
Si s’inverteix aquesta matriu es té:
RX-1=
( )( )
( )⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
kˆFIV
ˆFIV
ˆFIV
β
ββ
O3
2
Cada un dels elements de la diagonal d’aquesta matriu és el FIV de l’estimador corresponent.
El problema del FIV és que no existeix un valor límit a partir del qual es pugui afirmar que hi ha un problema greu de multicolinealitat. Malgrat això, uns valors del FIV superiors a 5 s’associen amb 2
jXR superior a 0,8,
que ja es poden considerar bastant elevats per generar conseqüències considerables sobre el model. Els problemes són més greus si el FIV és més gran que 10, valor que s’associa amb 2
jXR més gran que 0,9.
El valor del determinant de la matriu RX també s’utilitza per detectar la presència de multicolinealitat en el model. El valor d’aquest determinant pot estar entre 0 i 1. Si hi ha multicolinealitat perfecta, el valor del determinant és 0, i si hi ha absència total de multicolinealitat el determinant és 1. Llavors, com més baix sigui el valor del determinant, més alt és el grau de multicolinealitat que presenta el model.
Una altra possibilitat per detectar l’existència de correlació entre una variable Xj i algunes de les altres variables explicatives és fer el següent. Primer, estimar el model complet amb Y com a variable dependent en funció de totes les variables explicatives. Després, eliminar una de les variables explicatives, per exemple la que té una correlació simple més elevada amb l’explicativa que es considera, Xj, i reestimar el model. Llavors, en el model reestimat, l’error estàndard estimat de jβ s’hauria
d’haver reduït considerablement, si hi ha un elevat grau de multicolinealitat en el model complet. Com més gran és aquesta reducció, més gran és la correlació entre Xj i la variable explicativa eliminada. Llavors, en general, una comparació entre els errors estàndards estimats

Introducció a l’Anàlisi de Regressió Lineal
103
per a un coeficient determinat entre dues regressions, una que contingui k – 1 variables explicatives i l’altra k – 2, proporciona informació sobre l’extensió de la multicolinealitat en el model complet deguda a la variable explicativa eliminada.
Exemple 4.2. Càlcul dels FIV
Igual que a l’Exemple 4.1, s’ha estimat un model que relaciona els dividends que paga una empresa als seus accionistes, D, amb el preu, P, i les unitats venudes, V, del seu producte, i a més s’ha inclòs com a explicativa el preu del producte de la competència, Pc. Els resultats de l’estimació per MQO són els següents:
iiii Pc,P,V,,D 0010 0200 00705460 +++−= , R2 = 0,967
F=19,915 > ( )05022
,,F =19
52902
,t =β , 71213
,t =β i 18014
,t =β . El valor crític és 02502
,t = 4,303.
El R2 indica que l’ajust és bo i el contrast F que les variables conjuntament són significatives. Però els contrasts de significació individual indiquen que individualment les tres variables explicatives són no significatives.
Aquestes contradiccions fan pensar en l’existència de correlació entre les variables explicatives. Per confirmar-ho es calculen els FIV.
La diagonal de la inversa de la matriu de correlacions entre les variables explicatives és:
RX-1 =
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
422123310
44311
,,
,
Per tant, els FIV de 2β i 3β són més grans que 10 i molt superiors al de 4β , cosa que indica que les variables V i P estan correlacionades.
El contrast t indica que el preu de la competència no és significatiu. Aquesta conclusió no és deguda a la multicolinealitat, ja que aquesta variable no està correlacionada amb les altres dues. Llavors es pot dir que el preu de la competència no és una variable significativa per explicar el comportament dels dividends de l’empresa.
4.2.3. Mesures per combatre la multicolinealitat

M. Cladera; A. Matas
104
Quan es detecta la presència de multicolinealitat, es pot tractar d’aplicar alguna de les diferents solucions que s’han anat proposant, encara que cap d’elles no sol resultar plenament satisfactòria i, de vegades, no és possible dur-les a la pràctica.
Cal dir que el tractament que es faci del problema de la multicolinealitat depèn de la finalitat de l’anàlisi de regressió que es realitzi. Així, si l’objectiu és fer prediccions, com que la multicolinealitat no afecta l’ajust del model, i si se suposa que la correlació existent entre les variables explicatives es manté en el període de predicció, les prediccions generades per un model amb multicolinealitat poden ser adequades. Per altra banda, si l’objectiu és fer una anàlisi estructural, conèixer els efectes de les variables explicatives sobre la dependent i contrastar hipòtesis sobre els paràmetres, serà necessari prendre mesures davant el problema de la multicolinealitat.
Algunes de les mesures que poden considerar-se davant la presència de multicolinealitat són les següents:
Augmentar la mida de la mostra. Aquesta és una solució que sovint se sol suggerir però que moltes vegades no és factible, ja que per a l’estimació del model segurament s’han considerat totes les observacions disponibles, i ja que pot no conduir a una eliminació o reducció del problema si en afegir-hi noves observacions, s’hi segueix complint el mateix patró de multicolinealitat.
Utilitzar informació externa per a l’estimació provinent d’estudis previs o altres mètodes.
La informació externa pot consistir, per exemple, en el coneixement del compliment d’alguna restricció sobre els paràmetres del model o el coneixement del valor d’algun paràmetre a partir d’estudis previs o estimacions complementàries.
Per exemple, es vol estimar el següent model i es detecta l’existència de multicolinealitat entre X1 i X2:
iiii uXXY +++= 33221 βββ ,

Introducció a l’Anàlisi de Regressió Lineal
105
però es té informació del valor de 3β per un estudi realitzat anteriorment.
Es podria fer la següent transformació del model:
iiii uXXY ++=− 22133 βββ ,
i estimar sense problemes.
Per aplicar aquest tipus de solucions s’ha d’analitzar la fiabilitat de la informació externa i la seva adequació al model que es vol estimar.
Prescindir d’una de les dues variables explicatives correlacionades. El problema de la multicolinealitat es redueix, de forma essencial, a una falta d’informació suficient a la mostra que permeti estimar de forma més o menys correcta els paràmetres individuals. De vegades es pot estar interessat en el valor d’uns paràmetres més que en altres, i si existeix un elevat grau de multicolinealitat entre les variables que formen part de la regressió es pot tractar d’excloure’n una, la que tingui menys interès, i estimar els paràmetres corresponents a la resta.
El problema és que aquesta mesura por donar lloc a un altre tipus de problemes: especificació incorrecta del model per omissió de variables rellevants, que conduiria a l’obtenció d’estimadors esbiaixats i inconsistents.
Per decidir en quins casos convé eliminar una determinada variable del model i en quins no, s’ha proposat el criteri següent, en termes de l’error quadràtic mitjà (EQM):
- Si l’estadístic del contrast de significació individual de l’estimador βj és inferior a 1, en termes de l’EQM és millor eliminar la variable explicativa Xj de l’especificació del model.
- Si l’estadístic del contrast de significació individual de l’estimador βj és superior a 1, en termes de l’EQM és millor mantenir la variable explicativa Xj a l’especificació del model.
Transformació de les dades. Sol fer-se a l’anàlisi de dades temporals. La transformació més habitual consisteix a utilitzar les dades transformades en diferències. Si dues variables estan molt relacionades entre si, les seves diferències no tenen per què estar-ho. Altres transformacions també utilitzades són fer feina amb taxes de creixement en lloc de valors absoluts; expressar les variables en proporcions; utilitzar la transformació logarítmica de les variables, etc.

M. Cladera; A. Matas
106
El problema d’aquestes transformacions és que poden donar lloc a l’incompliment d’algun dels supòsits del model clàssic, com ara el d’homoscedasticitat i el de no autocorrelació.
Estimació de Ridge. El mètode de Ridge és un mètode d’estimació alternatiu que tracta d’evitar els problemes que sorgeixen a l’estimació per MQO quan hi ha multicolinealitat a causa del valor baix del determinant |X´X|. L’estimació de Ridge proposa la suma d’una determinada quantitat als elements de la diagonal de la matriu X´X. L’estimador de Ridge és un estimador esbiaixat, encara que pot permetre la reducció de la variància dels estimadors.
4.3. Observacions influents i observacions atípiques A l’apartat anterior s’ha comentat un dels problemes que hi pot haver a les dades de la mostra utilitzada per estimar un model de regressió i que tenen conseqüències negatives sobre els resultats de l’anàlisi: la presència de multicolinealitat.
En aquest apartat es farà referència a un altre d’aquests problemes, el que consisteix en la presència a la mostra d’observacions estranyes que poden influir de manera important en els resultats de l’estimació dels paràmetres del model.
Exemple 4.3. Influència d’una observació estranya en les estimacions dels paràmetres del model
Per analitzar la relació entre les despeses en publicitat, X, i les vendes de les empreses d’un determinat sector, Y, es disposa d’una mostra d’onze empreses que han proporcionat informació sobre els valors de les variables d’interès el darrer any.
Al gràfic següent es pot observar que hi ha una empresa que té un comportament molt diferent del de la resta, i que si s’inclou en el conjunt de dades utilitzades per a l’estimació influeix notablement sobre la recta de regressió mostral que s’obté. Si s’omet aquesta observació, la recta obtinguda és bastant distinta.

Introducció a l’Anàlisi de Regressió Lineal
107
0
200
400
600
800
1.000
1.200
1.400
1.600
1.800
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Y
X
− − − − recta de regressió estimada sense l’observació atípica ⎯⎯⎯ recta de regressió estimada amb totes les observacions mostrals
Com s’ha dit, una observació estranya, que presenti valors bastant diferents dels de la resta d’observacions, pot influir en els resultats de l’estimació del model, però no sempre és així. De fet, es pot distingir influència a priori i influència a posteriori.
Es parla d’influència a priori quan es té una observació que presenta valors de la variable dependent i/o de les variables explicatives bastant diferents dels de la resta d’observacions i que, per tant, s’espera que podrà influir en els resultats de l’estimació del model. Si es comprova que efectivament aquesta observació influeix en els resultats, es diu que també és influent a posteriori, però si encara que presenti valors estranys no influeix sobre els resultats de l’estimació, té influència a priori però no a posteriori.
Exemple 4.4. Observació influent a priori però no influent a posteriori
Al gràfic de l’Exemple 4.3 es té una observació que és influent a priori, ja que té un valor de la variable explicativa superior al de la resta, i també ho és a posteriori, ja que la seva inclusió a la mostra fa que s’obtingui una recta de regressió bastant diferent de la que s’obté si no s’hi inclou.

M. Cladera; A. Matas
108
Y
X
− − − − recta de regressió estimada sense l’observació atípica ⎯⎯⎯ recta de regressió estimada amb totes les observacions mostrals
En aquest gràfic, en canvi, es té una observació que és influent a priori, ja que té valors de la variable dependent i la variable explicativa més grans que la resta, però que no té influència a posteriori, ja que la recta de regressió mostral no varia substancialment amb la seva inclusió.
Alguns dels efectes que poden tenir les observacions influents consisteixen en variacions importants en els valors de les estimacions dels paràmetres del model, errors estàndards dels estimadors elevats, increment de la SQR i, per tant, reducció del valor del R2 i increment del valor de la variància residual, i fins i tot poden provocar l’incompliment d’alguna de les hipòtesis del model clàssic, com la hipòtesi de linealitat o la de normalitat.
Per tant, és important analitzar la possible existència d’observacions influents a la mostra. A l’apartat 4.3.1 s’analitzaran les mesures utilitzades més sovint per a la detecció d’observacions estranyes i per a l’avaluació de la seva influència sobre els resultats de l’estimació del model.
No totes les observacions estranyes tenen les mateixes característiques ni la mateixa influència sobre els resultats del model, sinó que es pot fer la classificació següent:

Introducció a l’Anàlisi de Regressió Lineal
109
- Observacions que presenten valors atípics per a les variables explicatives.
- Observacions que presenten valors atípics per a la variable dependent.
- Observacions que presenten valors atípics per a les variables explicatives i per a la variable dependent.
- En cada una de les situacions anteriors les observacions poden tenir o no influència sobre els resultats de l’estimació del model.
Les mesures que es presenten a continuació permeten conèixer si hi ha observacions estranyes a la mostra, així com saber de quin tipus són i quina és la seva influència en l’estimació del model.
4.3.1. Mesures per a l’anàlisi d’observacions estranyes
La teoria economètrica ha proposat diverses mesures per detectar les observacions que presenten valors estranys dels de la resta i per avaluar la influència d’aquestes observacions sobre els resultats de l’estimació del model. En aquest apartat s’explicaran algunes de les utilitzades amb més freqüència.
1) Mesura per identificar les observacions amb valors estranys per a les variables explicatives. El palanquejament (leverage)
Aquesta mesura serveix per conèixer si els valors que presenta una observació determinada per a les variables explicatives són molt distints dels de la resta d’observacions.
Cada una de les observacions de la mostra té associat un lever, hii, que és l’element i-èsim de la diagonal de la matriu
X´ X(X´X) H -1=
Els levers estan acotats entre dos valors,
≤N1 hii ≤ 1
i com més diferent sigui una observació de la resta d’observacions, més gran serà el seu lever.
El criteri que s’utilitza per decidir si es pot considerar o no que una observació presenta valors de les variables explicatives substancialment diferents dels de la resta d’observacions es basa en la comparació del seu lever amb la mitjana de tots els levers, i és el següent:

M. Cladera; A. Matas
110
- Si hii ≥ 2 h , l’observació i-èsima és una observació substancialment distinta de la resta pel que fa als valors de les variables explicatives.
- Si hii < 2 h , l’observació i-èsima no és una observació substancialment distinta de la resta pel que fa als valors de les variables explicatives.
Si una observació té un lever elevat, la variància del valor ajustat pel model per a aquesta observació és gran i, per tant, aquest valor ajustat és poc precís.
2) Mesures per identificar les observacions amb valors atípics per a la variable dependent. Anàlisi dels residus
Una observació atípica o outlier és una observació que té associat un residu d’estimació molt superior al de la resta, de manera que no pareix que segueixi el mateix patró de comportament que segueixen les altres observacions. Quan s’utilitza el mètode de MQO per estimar els paràmetres del model, aquesta observació pot tenir una influència important sobre l’equació de regressió estimada.
Es poden considerar distints criteris per detectar si una observació es pot considerar o no un outlier, basats en l’anàlisi dels residus de l’estimació:
Els outliers tenen associat un residu d’estimació més gran que el de la resta d’observacions. En aquest sentit, la comparació del residu d’una observació amb els de la resta pot servir per decidir si una observació és o no un outlier.
- Si |ei| ≥ 2n
|e|n
ii∑
=1 , l’observació i-èsima pot ser considerada un outlier.
- Si |ei| < 2n
|e|n
ii∑
=1 , l’observació i-èsima no pot ser considerada un
outlier.
En lloc del residu es pot considerar el residu estandarditzat:
( ) ( )iiR
i
i
i
hS
eees
e
−=
12
Aquest estadístic té distribució t de Student amb n – k graus de llibertat, de manera que el criteri de decisió és:

Introducció a l’Anàlisi de Regressió Lineal
111
- Si ( )iiR
i
hS
e
−12≥ 2α
knt − , l’observació i-èsima pot ser considerada un
outlier.
- Si ( )iiR
i
hS
e
−12< 2α
knt − , l’observació i-èsima no pot ser considerada un
outlier.
Una tercera opció consisteix en la utilització dels residus estudentitzats amb eliminació, ri, que es calculen de la manera que es descriu a continuació.
En primer lloc es reestima el model sense l’observació objecte de l’anàlisi, l’observació i-èsima, i s’obté el vector de paràmetres estimats:
( )iB = ( ) ( )( ) ( ) ( )iiii YXXX ′′ −1
on el subíndex (i) indica que les estimacions s’han realitzat sense l’observació i-èsima. Utilitzant aquestes estimacions es pot obtenir el residu associat a l’observació i-èsima:
( ) ( ) iiiiiii YYYe X−=−= ( )iB
on Xi és un vector d’ordre 1 × k que conté els valors de les variables explicatives per a l’observació i-èsima.
La variància de ( )iie és:
( )( ) =iievar ( ) ( )( )( )iiii XXXX ′′+ −12 1σ
i l’error estàndard:
( )( ) =iiees ( ) ( ) ( )( )( )iiiiiRS XXXX ′′+ −12 1
El residu estudentitzat té l’expressió següent:
( )
( ) ( ) ( )( )( )iiiiiR
iii
S
er
XXXX ′′+=
−12 1
L’estadístic ri té una distribució t de Student amb n – 1 – k graus de llibertat, de manera que:
- Si ri ≥ 21
αknt −− , l’observació i-èsima pot ser considerada un outlier.

M. Cladera; A. Matas
112
- Si ri < 21
αknt −− , l’observació i-èsima no pot ser considerada un
outlier.
3) Mesures per analitzar la influència d’una observació. Distància de Cook, DFFITS, DFBETAS i COVRATIO
Una vegada que s’han identificat les observacions amb valors estranys, per a les explicatives o per a la dependent, la següent passa és determinar si són observacions influents. Es diu que una observació és influent si es produeixen canvis importants en el model quan l’observació s’exclou de l’estimació. Les mesures que es presentaran per determinar la influència d’una observació són distància de Cook, DFFITS, DFBETAS i COVRATIO.
Distància de Cook:
La distància de Cook és una mesura per detectar les observacions que tenen una influència més gran en l’ajust del model que la resta i que poden fer variar els valors estimats per als paràmetres del model de manera substancial. Concretament, aquesta mesura avalua la influència de l’observació i-èsima sobre els n valors ajustats.
La distància de Cook per a l’observació i-èsima es defineix com a:
( )( ) ( )( )2R
iii Sk
ˆˆˆˆDC
YYYY −′
−=
on ( )iY és el vector de valors ajustats utilitzant l’estimació dels paràmetres
obtinguda en estimar el model sense l’observació i-èsima. En el vector ( )iY
s’inclou el valor ajustat per a aquesta observació, encara que no s’hagi utilitzat per a l’estimació del model.
La distància de Cook segueix una distribució F amb k graus de llibertat al numerador i n – k al denominador, de manera que:
- Si DCi ≥ ( )α
kn,kF − , l’observació i-èsima té una influència més gran
que la resta en el model.
- Si DCi < ( )α
kn,kF − , l’observació i-èsima no té una influència més
gran que la resta en el model.
DFFITS:

Introducció a l’Anàlisi de Regressió Lineal
113
Aquest estadístic mesura la influència de l’observació i-èsima en el seu valor ajustat, iY :
( )
( ) iiiR
iiii
hS
YYDFFITS
2
−=
L’observació i-èsima es pot considerar influent si:
n
kDFFITSi 2>
DFBETAS:
DFBETAS mesura la influència de la i-èsima observació sobre els coeficients de regressió individuals:
( )
( ) jjiR
ijji,j
aS
ˆˆDFBETAS
2
ββ −=
on ajj és l’element j-èsim de la matriu (X´X)–1.
DFBETASj,i mesura la influència de l’observació i-èsima sobre l’estimació de βj. Com més gran sigui el valor absolut d’aquesta mesura, més gran és l’efecte de l’observació sobre l’estimació del paràmetre. Es pot considerar que l’observació i-èsima és influent si:
nDFBETAS i,j
2>
COVRATIO:
Aquest estadístic mesura el canvi en el determinant de la matriu de variàncies i covariàncies dels estimadors a causa de l’eliminació de l’observació i-èsima:
( ) ( ) ( )( )( )( )( )12
12
−
−
′
′=
XX
XX
R
iiiRi
Sdet
SdetCOVRATIO
L’observació i-èsima es pot considerar influent si:
n
kCOVRATIOi31 >−

M. Cladera; A. Matas
114
Les mesures anteriors tracten de detectar tres tipus de situacions que no tenen per què donar-se aïlladament, sinó que algunes o totes elles poden ser simultànies. Així, una observació pot tenir valors estranys per a les variables explicatives, ser un outlier i tenir una influència elevada sobre l’ajust del model. També es pot donar el cas que un outlier o una observació amb valors estranys de les variables explicatives no sigui una observació influent.
Exemple 4.5. Avaluació de la influència d’observacions estranyes
Es disposa d’una mostra de 13 observacions per estimar la relació entre les variables Y i X. Es realitzen quatre estimacions, utilitzant per a cada una l’esmentada mostra i afegint una observació addicional, diferent en cada estimació. Els resultats de les quatre estimacions es presenten als gràfics següents:
(1)
Y = 26,7 + 2,48XR2 = 0,71
Y = 27,3 + 2,15XR2 = 0,16
24
26
28
30
32
34
0 0,5 1 1,5 2 2,5 3
(2)
Y = 26,7 + 2,48XR2 = 0,71
Y = 27,3 + 1,26XR2 = 0,62
24
26
28
30
32
34
0 0,5 1 1,5 2 2,5 3
(3)
Y = 26,7 + 2,48XR2 = 0,71
Y = 28,1 - 0,45XR2 = 0,03
24
26
28
30
32
34
0 0,5 1 1,5 2 2,5 3
(4)
Y = 26,7 + 2,48XR2 = 0,71
Y = 26,9 + 2,09XR2 = 0,81
24
26
28
30
32
34
0 0,5 1 1,5 2 2,5 3
_ observacions de la mostra original ♦ observacions addicionals

Introducció a l’Anàlisi de Regressió Lineal
115
Al gràfic (1) l’observació afegida és un outlier, que presenta un residu d’estimació molt superior a la resta d’observacions, però malgrat això no és una observació influent, en el sentit que amb la seva inclusió no varia substancialment la recta de regressió mostral obtinguda. On sí que hi ha variació és en la SQR, i en conseqüència es produeix una reducció del R2 i un increment de la 2
RS i dels errors estàndards dels estimadors.
En la situació corresponent al gràfic (2) es té una observació que presenta valors de la variable explicativa més elevats que la resta d’observacions i que a més té una influència considerable sobre els resultats de l’estimació del model.
Al gràfic (3) l’observació estranya és un outlier i a més presenta valors de la variable explicativa superiors als de la resta. Es pot observar que la seva influència sobre les estimacions dels paràmetres és molt important, fins al punt que el pendent de la recta de regressió té signe negatiu quan abans era positiu.
A l’últim, al gràfic (4) s’observa que l’observació afegida té un valor de l’explicativa diferent dels de la resta d’observacions però no és una observació influent, ja que no afecta substancialment els resultats de l’estimació del model.
Les possibles causes de la presència d’observacions estranyes són diverses i determinen les solucions que s’han d’aplicar:
- Errors a les dades. En aquest cas, una vegada detectada l’observació s’hauran de corregir els errors.
- Omissió de factors rellevants al model. Les observacions atípiques absorbeixen la influència d’aquests factors. Per resoldre el problema s’hauran d’especificar al model els factors omesos com a variables explicatives.
- Períodes atípics a les sèries temporals. Si en una sèrie temporal es té un conjunt d’observacions atípiques consecutives, pot indicar que es tracta d’un període excepcional. En aquest cas, si es poden justificar les raons d’aquesta excepcionalitat, el model continua sent aplicable. Una altra solució consisteix a no utilitzar les dades corresponents a aquest període atípic.

M. Cladera; A. Matas
116
De manera general, davant la presència d’observacions atípiques, si són poques, i sobretot si són influents, la solució pot ser la seva exclusió de l’estimació del model. Però si el nombre d’observacions atípiques és important i no se’n pot justificar la presència, s’haurà de posar en dubte la validesa del model especificat.

Aplicació


Introducció a l’Anàlisi de Regressió Lineal
119
Un grup d’investigadors estan interessats a analitzar els factors explicatius de la variabilitat de la despesa farmacèutica de les unitats de prestació de serveis d’atenció primària de salut. Com a factors potencialment explicatius d’aquesta despesa es consideren els següents:
La mida de la població adscrita a cada unitat. Aquesta variable pot reflectir el tipus de població que atén la unitat, si és urbana o rural, i condiciona tant l’oferta com la demanda de serveis d’atenció primària.
El pes de les persones més grans de 65 anys en el total de la població adscrita. És ben sabut que les persones de més edat demanen una major quantitat de serveis sanitaris d’atenció primària i consumeixen més medicaments que les persones de menys edat.
El pes dels homes i de les dones sobre el total de la població adscrita, ja que alguns estudis donen com a resultat que les dones fan un ús més gran de serveis sanitaris d’atenció primària.
Per tant, si se suposa que aquests factors poden influir sobre el cost de farmàcia associat a les unitats d’atenció primària, l’especificació general de la relació que es vol analitzar és la següent:
C = f(P, E, H)
On C és el cost en farmàcia de cada unitat, P és la població total adscrita a cada unitat, E representa el grau d’envelliment de la població adscrita i H és el percentatge d’homes sobre el total de la població adscrita.
Per tal d’analitzar aquesta relació, s’especifica un model de regressió lineal clàssic d’acord amb l’expressió següent:
Ci = β1 + β2Pi + β3Ei + β4Hi + ui
Per estimar aquest model es disposa d’una mostra de 25 unitats d’atenció primària de les quals es coneix el cost en farmàcia per habitant durant l’any 2000, el total de persones adscrites a la unitat durant el mateix període de temps i el percentatge de més grans de 65 anys i el d’homes sobre el total de la població adscrita a cada unitat. Aquestes dades es recullen a la taula següent:

M. Cladera; A. Matas
120
Obs. C P E H Obs. C P E H
1 101,38 26.289 13,90 48,49 14 130,82 12.187 18,53 49,73 2 84,50 26.733 8,64 50,08 15 114,29 23.385 17,45 47,79 3 97,22 23.590 14,16 49,43 16 99,33 20.324 10,59 49,77 4 154,23 9.014 21,91 49,85 17 136,92 12.069 24,01 50,18 5 104,48 18.367 13,94 49,03 18 129,06 17.284 17,77 47,31 6 126,79 17.339 13,80 49,09 19 106,86 6.992 39,00 49,29 7 118,89 17.448 18,54 47,90 20 103,57 11.081 15,04 50,34 8 145,88 13.793 20,46 49,41 21 121,29 8.817 15,58 49,71 9 110,41 28.220 17,35 49,14 22 110,60 18.469 15,90 49,57
10 144,96 13.284 22,40 48,85 23 105,53 18.594 12,66 49,92 11 114,17 23.704 14,22 49,88 24 139,83 6.844 18,31 49,67 12 124,73 11.648 18,87 49,16 25 136,35 12.548 15,74 49,90 13 139,89 20.602 18,44 48,15
Els resultats de l’estimació d’aquest model per MQO són els que es presenten a continuació:
βj es(βj) tj Sig. FIVj
Constant 488,584 216,797 2,254 0,035P –0,002 0,001 –2,996 0,007 1,803E –0,068 0,681 –0,100 0,921 1,678H –6,802 4,208 –1,616 0,121 1,235
Taula d'anàlisi de la variància SQ G. de l. MQ F Sig.
Regressió 3.196,493 3 1.065,498 4,892 0,010Residual 4.573,523 21 217,787Total 7.770,015 24 R2 0,411
Pot observar-se que de les tres variables explicatives introduïdes, només una, la població adscrita, és significativa. El percentatge de més grans de 65 anys i el percentatge d’homes no resulten significatius al nivell de significació del 5%, tal com es dedueix del fet que el p-valor del contrast de significació individual (Sig. a la taula de resultats) és superior a 0,05 (0,92 i 0,12, respectivament).
Per altra banda, el contrast de significació conjunta indica que les variables explicatives considerades són significatives conjuntament, ja que el p-valor d’aquest contrast és 0,010, inferior al 0,05.
Abans de prendre alguna decisió sobre la reespecificació del model eliminant les dues variables que pareix que no són significatives, s’analitzaran les dades

Introducció a l’Anàlisi de Regressió Lineal
121
mostrals per tal de detectar la possible existència d’alguna anomalia que pogués haver influït sobre els resultats del model.
1) Anàlisi de la multicolinealitat
En els resultats de l’estimació es presenten els FIV de cada un dels coeficients de regressió. Com es pot apreciar, el seu valor no és gaire superior a la unitat i, per tant, podríem dir que no hi ha problemes de colinealitat entre les variables explicatives incloses al model.
2) Anàlisi del palanquejament
Per detectar l’existència d’observacions amb valors estranys de les variables explicatives es calculen els levers de cada una de les observacions (vegeu taula de la pàgina següent). El criteri per decidir si el lever d’una observació és suficientment gran per dir que presenta palanquejament consisteix en la seva comparació amb el doble de la mitjana de tots els levers: 2 h = 0,24.
Dos dels levers superen el valor crític:
h1818 = 0,30
h1919 = 0,64
Per tant, les observacions 18 i 19 presenten palanquejament, és a dir, tenen valors per a alguna o algunes de les variables explicatives molt allunyats dels de la resta d’observacions.
3) Anàlisi dels outliers
Per estudiar la possible existència d’outliers s’han calculat els residus estudentitzats (vegeu taula de la pàgina següent). Per poder decidir si els residus estudentitzats són suficientment grans, es comparen amb el valor
21
αknt −− . Utilitzant un α de l’1% es té:
00504125
,t −− = 2,845
L’observació 19 té un residu estudentitzat igual a –5,73 i, per tant, superior al valor crític. Llavors, es pot considerar que l’observació 19 és un outlier.
4) Anàlisi de la influència de les observacions
S’ha obtingut que les observacions 18 i 19 presenten valors estranys, però falta saber si influeixen o no en els resultats de l’estimació del model. Per avaluar la influència de les observacions s’ha calculat la distància de Cook (vegeu taula de la pàgina següent). El valor amb què es compara aquest

M. Cladera; A. Matas
122
estadístic per tal de decidir si una observació pot considerar-se o no influent és α
kn,kF − . Utilitzant un α del 5% es té:
050214,
,F = 2,84
La distància de Cook per a l’observació 19 és 6,84, superior al valor crític, cosa que permet dir que és una observació influent. L’observació 18, en canvi, encara que presenti palanquejament no es pot considerar una observació influent segons aquest criteri.
Llavors, la mostra conté una observació, la 19, que presenta valors estranys per a alguna o algunes variables explicatives, és un outlier i, a més, té una influència considerable sobre els resultats del model.
Obs. hii ri DC Obs. hii ri DC 1 0,11 –0,42 0,01 14 0,03 0,36 0,00 2 0,21 –0,89 0,07 15 0,16 –0,23 0,00 3 0,06 –0,62 0,01 16 0,07 –0,78 0,02 4 0,07 1,78 0,09 17 0,13 1,08 0,06 5 0,03 –1,00 0,02 18 0,30 –0,27 0,01 6 0,03 0,44 0,00 19 0,64 –5,73 6,84 7 0,13 –0,66 0,02 20 0,11 –1,54 0,10 8 0,01 1,53 0,03 21 0,14 –0,82 0,04 9 0,23 0,91 0,08 22 0,01 –0,29 0,00
10 0,04 1,12 0,03 23 0,05 –0,48 0,01 11 0,11 0,84 0,03 24 0,14 0,26 0,00 12 0,04 –0,40 0,00 25 0,05 0,88 0,02 13 0,09 1,47 0,07
En els gràfics parcials de cada una de les variables explicatives amb la variable dependent l’observació 19 es representa per una creu. Es pot veure que per a aquesta observació el percentatge de més grans de 65 anys és superior que per a la resta.

Introducció a l’Anàlisi de Regressió Lineal
123
0
50
100
150
200
0 10.000 20.000 30.000
P
C
0
50
100
150
200
0 20 40 60
E
C
0
50
100
150
200
47 48 49 50 51
H
C
Se suposa que aquest valor atípic és un error en la transcripció de les dades i, per tant, es decideix estimar el model eliminant aquesta observació. Els resultats del model estimat amb les 24 observacions restants són els que es mostren a continuació:
βj es(βj) tj Sig.
Constant 199,562 145,614 1,370 0,186 P –0,001 0,000 –2,536 0,020 E 3,081 0,697 4,421 0,000 H –2,261 2,768 –0,817 0,424
Taula d'anàlisi de la variància SQ G de l. MQ F Sig.
Regressió 5.858,375 3 1.952,792 22,581 0,000 Residual 1.729,591 20 86,480 Total 7.587,966 23 R2 0,772
Amb l’exclusió de l’outlier s’han produït alguns canvis en els resultats del model:

M. Cladera; A. Matas
124
Les estimacions dels paràmetres han variat substancialment.
La VR s’ha reduït dràsticament.
S’ha produït un increment important del R2 i del valor de l’estadístic F de significació conjunta.
S’han reduït considerablement els errors estàndards de les estimacions dels paràmetres del model.
La variable E ha passat a ser significativa.
Per altra banda, la variable H continua sense ser significativa, per tant, es reestima el model eliminant aquesta variable. Els resultats són aquests:
βj es(βj) tj Sig. ICI ICs
Constant 81,254 14,946 5.437 0,000 50,172 112,336 P -
0,00092 0,0004 –2.463 0,023 –0,002 0,00014
E 3,325 0,624 5.325 0,000 2,026 4,624 Taula d'anàlisi de la variància
SQ G de l. MQ F Sig. Regressió 5.800,672 2 2.900,336 34,078 0,000 Residual 1.787,295 21 85,109 Total 7.587,966 23 R2 0,764
En aquest cas totes les variables són significatives individualment i conjuntament, i la bondat d’ajust és considerable.
Les estimacions dels coeficients de regressió indiquen que les poblacions grans presenten un cost per habitant més baix que les petites, com ho indica el signe negatiu del coeficient corresponent a la variable P. El percentatge de més grans de 65 anys, en canvi, té un efecte positiu sobre els costs de farmàcia, tal com s’esperava.
A la taula de resultats d’aquesta darrera estimació es mostren també els intervals de confiança al nivell de confiança del 95% per als paràmetres del model.
Utilitzant el model estimat es vol predir quin seria el cost en farmàcia per habitant per a una nova unitat a la qual s’adscriuran 20.250 persones, de les quals el 15,2% són més grans de 65 anys.
La predicció puntual d’aquest cost és el valor ajustat pel model:
0C = 81,254 – 0,00092·20.250 + 3,325·15,2 = 113,165 euros/habitant.

Introducció a l’Anàlisi de Regressió Lineal
125
Per tant, s’espera que el cost de farmàcia d’aquesta nova unitat d’atenció primària serà de 113,165 euros per habitant.
Per calcular un interval de confiança del 95% per a aquesta predicció se segueix el procediment següent:
( ) ( )( )01
02
00 XXXX1 −′′+=− RSCCes
( )05330110985 ,, +×=
468,9=
( ) ( )[ ]002
0950 CCestCCIC kn% −±= −α
[ ]4689165113 025021 ,t, , ⋅±=
[ ]858132 47193 ,,,=
Per tant, amb un nivell de confiança del 95%, s’espera que el cost en farmàcia per habitant de la nova unitat tindrà un valor que estigui entre 93,471 i 132,858 euros.


Exercicis resolts


Introducció a l’Anàlisi de Regressió Lineal
129
Exercici 1
S’ha estimat el següent model per conèixer la relació entre el consum (C) i l’ingrés (I), utilitzant una mostra de 12 observacions de periodicitat anual:
( ) t,
t I,,C02207190650231 +−= R2 = 0,99 i =2
RS 995,038
a) Es pot afirmar, a un nivell de significació del 5%, que la propensió marginal a consumir és significativament distinta de zero?
b) Entre quins dos valors es pot afirmar, a un nivell de confiança del 90%, que es troba la propensió marginal a consumir?
c) Contrastau, a un nivell de significació del 10%, la hipòtesi que la propensió marginal a consumir no és superior a la unitat.
d) Calculau l’interval de confiança del 95% per al consum agregat mitjà que es produiria en un període d’anys en què l’ingrés mantingués un valor de 4.500.
Nota: la mitjana mostral de l’ingrés és 4.326,175.
e) Calculau l’interval de confiança del 95% per al consum en un any concret en què l’ingrés tingués un valor de 4.500. Comparau aquest resultat amb el de l’apartat d).
Solució:
a) La hipòtesi que s’ha de contrastar és:
H0: β1 = 0
HA: β1 ≠ 0
Per contrastar aquesta hipòtesi s’utilitza el contrast t de significació individual:
( )68232
0220
7190
1
11
,,
,ˆes
ˆt ===
β
ββ
El valor de l’estadístic t és superior al valor crític 2282025010 ,t , = i, per tant,
es rebutja la H0, de manera que es pot dir, al nivell de significació del 5%, que la propensió marginal a consumir és significativament distinta de zero.

M. Cladera; A. Matas
130
b) L’expressió de l’interval de confiança del 90% per la propensió marginal a consumir és:
( ) ( )[ ] [ ] [ ]7590 679002208121719012
1901 ,,,,,,ˆestˆIC kn% =⋅±=±= − βββ α
c) La hipòtesi que s’ha de contrastar és:
H0: β1 ≤ 1
HA: β1 > 1
Per contrastar aquesta hipòtesi s’utilitza l’estadístic t:
( )77312
0220
171901
1
11
,,
,ˆes
ˆt −=
−=
−=
β
ββ
El valor de l’estadístic t és inferior al valor crític 37211010 ,t , = i, per tant, no
es pot rebutjar la H0, de manera que no es pot dir, al nivell de significació del 10%, que la propensió marginal a consumir és superior a 1.
d) La predicció puntual del consum és:
850033500471906502310 ,..,,C =⋅+−=
L’interval de confiança que es demana és el següent:
( )( ) ( )[ ]02
0950 CestCCEIC kn%α
−±=
on
( ) ( )( ) ⎟⎟
⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−
−+=
∑ 2
202
01
II
IIn
SCesi
R
( )⎟⎟⎠
⎞⎜⎜⎝
⎛ −+=
636863055217532645004
121038995
2
,..,..,
= 9,876
i ( )∑ −2IIi s’ha obtingut de
( )( )( )∑ −
=2
221
II
Sˆesi
Rβ → ( ) ( )( ) 221
22
0220038995
,,
ˆes
SII Ri ==−∑
β
= 2.055.863,636

Introducció a l’Anàlisi de Regressió Lineal
131
Per tant, l’interval de confiança del 95% per al consum agregat mitjà que es produiria en un període d’anys en què l’ingrés mantingués un valor de 4.500 és:
( )( ) [ ] [ ]8540253 846981287692282850033950 ,.,,.,,,.CEIC % =⋅±=
e) La predicció puntual del consum és la mateixa que a l’apartat anterior:
850033500471906502310 ,..,,C =⋅+−=
L’interval de confiança en aquest cas és:
( ) ( )[ ]002
0950 CCestCCIC kn% −±= −α
on
( ) ( )( ) ⎟⎟
⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−
−++=−
∑ 2
202
0011
II
IIn
SCCesi
R
( )⎟⎟⎠
⎞⎜⎜⎝
⎛ −++=
636863055217532645004
1211038995
2
,..,..,
= 33,054
Per tant, l’interval de confiança del 95% per al consum en un any concret en què l’ingrés tingués un valor de 4.500 és:
( ) [ ] [ ]077,4943 2069302054332282850033950 .,,.,,,.CIC % =⋅±=
En aquest cas l’interval de confiança de la predicció és més ample a causa de l’efecte del terme de pertorbació, que en la predicció de la mitjana no influeix. Per tant, en la predicció d’un valor individual es té menys precisió que en la predicció de la mitjana.
Exercici 2
Un investigador ha realitzat una anàlisi de la relació entre el PIB, l’estoc de capital (K) i l’ocupació (L) en l’economia d’un determinat país durant el període 1991-2000.
El model que ha especificat per dur a terme aquesta anàlisi és el següent:
lnPIBt = β1 + β2lnKt + β3lnLt + ut

M. Cladera; A. Matas
132
on ut és una pertorbació aleatòria que compleix les hipòtesis clàssiques del model de regressió lineal.
Els resultats de l’estimació de MQO d’aquest model són els següents:
( ) ( ) t,
t,
t^
Lln,Kln,,-PIBln04600700419049901150 ++= R2 = 0,961 i EER=0,028
a) Com s’interpreten econòmicament els paràmetres β2 i β3 del model?
b) Construïu la taula d’anàlisi de la variància.
c) Contrastau la significació individual i conjunta de les variables explicatives.
d) Plantejau com contrastaríeu la hipòtesi que les elasticitats del PIB respecte al capital i al treball sumen 1.
Solució:
a) β2 i β3 representen l’elasticitat del PIB respecte al capital i al treball respectivament.
b) Per construir la taula d’anàlisi de la variància s’han de fer alguns càlculs previs:
n = 10, k = 3
(EER)2 = 0,0282
kn
VR
−= →VR = 0,0282·7 = 0,005
R2 = 0,961 = VT
VR−1 → 1280
96101
0050 ,,
,VT =−
=
VE = VT – VR = 0,123
Font de variació G. de l. SQ MQ F
Regressió 2 0,123 0,0615 87,857
Error o residual 7 0,005 0,0007
Total 9 0,128 0,014
c) A la taula d’anàlisi de la variància de l’apartat anterior es té el valor de l’estadístic F del contrast de significació conjunta:

Introducció a l’Anàlisi de Regressió Lineal
133
F = 87,857 > ( ) 74405072 ,F ,, = , i per tant, es pot dir que les variables
explicatives són conjuntament significatives.
En relació amb la significació individual, els estadístics de contrast són:
12870700
4990 ,,
,tK == i 10890460
4190 ,,
,tL ==
Ambdós superen el valor crític 365202507 ,t , = i, per tant, les dues variables
són significatives individualment.
d) La hipòtesi que es vol contrastar és la següent:
H0: β2 + β3 = 1
HA: β2 + β3 ≠ 1
Per realitzar el contrast s’ha d’estimar el model restringit, l’especificació del qual és:
lnPIBt = β1 + (1-β3)lnKt + β3lnLt + ut
lnPIBt – lnKt = β1 + β3(lnLt – lnKt) + ut
t*t
*t uXY ++= 31 ββ
On *tY és igual a lnPIBt – lnKt i *
tX és igual a lnLt – lnKt.
Per estimar aquest model s’haurien de calcular primer les noves variables dependent, *
tY , i explicativa, *tX , com a combinació de les originals. Una
vegada estimat el model restringit es calcularia l’estadístic de contrast:
( )( ) ( )kn,r
certaHNR
NRR)R( F
kn/VRr/VRVRF −∼
−−
= 0
Si el valor de l’estadístic F(R) sobrepassa el valor crític ( )α
kn,rF
−, es rebutja
la hipòtesi nul·la i, per tant, la restricció és falsa. Si el valor de F(R) no permet rebutjar la hipòtesi nul·la, no es pot dir que la restricció sigui falsa.
Exercici 3
Un grup d’investigadors fan un estudi sobre la despesa sanitària pública a Espanya, amb l’objectiu principal de conèixer quins són els determinants de les variacions de l’esmentada despesa. Per aconseguir aquest objectiu han

M. Cladera; A. Matas
134
recopilat dades sobre el percentatge de variació anual, per al període 1981-1995, de les variables següents:
DESPESA: Despesa sanitària pública. COBERT: Taxa de cobertura sanitària: percentatge de població protegida. MENOR65: Població de menys de 65 anys. MAJOR65: Població de més de 65 anys. IPS: Índex de preus sanitaris. PREST: Prestació sanitària real mitjana per persona.
Els investigadors estimen diversos models per després decidir quin és el més adequat per assolir el seu objectiu:
MODEL 1
ttt
ttt
PRESTIPSMAJORMENORCOBERTESAPDES
108,1059,165232,0 6556,002,122,0ˆ
+++++−=
Error estàndard de la regressió (EER) = 0,218 F = 2.028,147
MODEL 2
tttt PREST,IPS,COBERT,,ESAPDES 1131100101810440 +++=
99802 ,R =
MODEL 3
Eliminen del MODEL 1 les variables MENOR65 i MAJOR65 i hi introdueixen una nova variable, FACDEM (factor demogràfic), que tracta d’agrupar en un sol regressor l’efecte de la població. Aquesta nova variable es defineix com a:
ttt MAJOR,MENORFACDEM 653365 ⋅+=
El model que estimen és:
t
tttt
PRESTIPSFACDEMCOBERTESAPDES
110,1 065,1946,0039,1493,0ˆ
++++−=
=2RS 0,062
a) Al MODEL 1, contrastau la hipòtesi nul·la que la població és irrellevant en la determinació de les variacions de la despesa sanitària pública.

Introducció a l’Anàlisi de Regressió Lineal
135
b) Un dels investigadors sosté que l’efecte marginal de la població de més de 65 anys sobre la despesa sanitària pública és 3,3 vegades el de la població de menys de 65 anys. És suficient l’evidència mostral per afirmar que l’investigador està equivocat?
c) En funció dels resultats dels apartats anteriors, quin creieu que seria el model més adequat per explicar l’evolució de les variacions de la despesa sanitària?
Solució:
a) El plantejament de les hipòtesis en termes dels paràmetres del model és:
H0: βMENOR65 = βMAJOR65 = 0
HA: Algun dels paràmetres és distint de zero.
El model restringit es correspon amb el MODEL 2, mentre que el model no restringit és el MODEL 1.
L’estadístic de contrast que s’ha d’utilitzar per a la contrastació de la hipòtesi és el següent:
( ) ( )( ) ( )qn,kq
certaHNR
NRR)R( F
qn/VRkq/VRVRF −−∼
−−−
= 0
Les VR dels dos models es poden obtenir a partir de les dades de què es disposa a l’enunciat:
MODEL 1
EERkn
VR
−= → ( ) ( ) 42806152180 22 ,,knEERVR =−⋅=−⋅=
knVR
kVEF−
−=
1→ ( ) ( )16218,0147,028.21 22 −⋅=−⋅= kEERFVE
928481,=
VT = VE + VR = 482,356

M. Cladera; A. Matas
136
MODEL 2
VT
VRR −= 12 → ( ) ( ) 9650356482998011 2 ,,,VTRVR =−=−=
Llavors el valor de l’estadístic de contrast és:
( )( ) 6465
6154280242809650 ,
/,/,,F )R( =
−−
=
El valor de l’estadístic supera el valor crític, que és 26405092 ,F ,, = , i per
tant, es rebutja la hipòtesi nul·la, de manera que es pot dir que la restricció no és certa.
b) El plantejament de les hipòtesis en termes dels paràmetres del model és:
H0: βMAJOR65 = 3,3βMENOR65
HA: βMAJOR65 ≠ 3,3βMENOR65
El model restringit es correspon amb el MODEL 3, mentre que el model no restringit és el MODEL 1.
L’estadístic de contrast que s’ha d’utilitzar per a la contrastació de la hipòtesi és el següent:
( )( ) ( )kn,r
certaHNR
NRR)R( F
kn/VRr/VRVRF −∼
−−
= 0
La variació residual del MODEL 3 es pot obtenir de la manera següent:
kn
VRSR−
=2 → ( ) ( ) 62051506202 ,,knSVR R =−=−=
Per tant, el valor de l’estadístic de contrast és:
( )( )
03746154280
14280620 ,/,
/,,F )R( =−
−=
El valor de l’estadístic no supera el valor crític, que és 12505091 ,F ,, = , i per
tant, no es pot rebutjar la hipòtesi nul·la, fet que indica que es pot donar la restricció per vàlida.
c) El MODEL 2 implica una restricció sobre els paràmetres del model que no és vàlida, i per tant, el rebutjam.

Introducció a l’Anàlisi de Regressió Lineal
137
La diferència entre el MODEL 1 i el MODEL 3 consisteix en una restricció que s’ha donat com a vàlida amb l’evidència empírica disponible. Per tant, per obtenir estimacions més eficients se seleccionaria el model restringit: el MODEL 3.
Exercici 4
Per tal d’analitzar el comportament del consum a l’economia espanyola, un investigador decideix especificar i estimar el model següent, representatiu de la relació existent entre el consum ( )tC i l’ingrés ( )tY : ttt uYC ++= 10 ββ , on
tu és una pertorbació aleatòria que compleix les hipòtesis clàssiques d’un model de regressió lineal.
Per estimar aquesta relació disposa de dades, en cents d’euros, relatives a consum privat per càpita a preus constants i renda personal disponible, també a preus constants, per a l’economia espanyola en el període 1974-1990, en el qual la mitjana del consum va ser 55,23 i la mitjana de la renda 60,78, i les variàncies 162,43 i 206,31 respectivament.
Els resultats de l’estimació d’aquest model són els següents:
( ) ( ) t,,
t Y,,C01509360880421 += ESR = 0,888
Una altra de les múltiples versions de la funció de consum és la següent:
tttt uCYC +++= −1321 βββ
En aquesta versió es complementa la versió simple del model: s’hi incorpora una nova variable explicativa (consum retardat), que tracta de recollir el fet que part del consum efectuat és degut als hàbits de consum que persisteixen any rere any.
Els resultats de l’estimació d’aquest segon model són els següents:
( ) ( ) ( ) 1086007208340280640640 −++= t
,t
,,t C,Y,,C ESR = 0,700
Digau si aquest model és més apte que el model simple per explicar el comportament dels consumidors espanyols.
Solució:
Si es contrasta la significació individual de la nova variable explicativa, s’observa que és significativa:

M. Cladera; A. Matas
138
145255630860280 0250
141,t,
,,t ,
Ct=>==
−
A més, es pot comparar l’error estàndard de la regressió dels dos models, observant que el del segon és inferior:
EER1 = 0,888 > EER2 = 0,700
Per tant, les mesures estadístiques utilitzades indiquen que la segona especificació és més adequada per representar el comportament dels consumidors espanyols durant el període de temps considerat.
Exercici 5
Es vol estimar un model explicatiu del comportament de la demanda d’un determinat producte (Q). Com a variables explicatives es consideren la renda dels consumidors (R), el preu del producte (P) i el preu d’un producte complementari (Pc). S’han recopilat dades d’una família que ha donat informació sobre la seva renda i les unitats demanades del producte durant 10 mesos. També s’han recollit dades sobre els preus del producte i del seu complementari durant el mateix període de temps.
La matriu de correlacions de les variables explicatives és aquesta:
R P Pc R 1,000 0,296 0,294 P 0,296 1,000 0,998 Pc 0,294 0,998 1,000
a) S’ha estimat un primer model en el qual la variable dependent és la quantitat demanada i les variables explicatives són la renda de la família, el preu del producte i el preu del complementari. Els resultats que s’han obtingut són els següents:
βj es(βj) t Sig. Constant 97,979 62,953 1,556 0,171 R 0,100 0,030 3,337 0,016 P 0,848 0,780 1,087 0,319 Pc –2,097 1,596 –1,313 0,237
Creieu que aquests resultats estan d’acord amb la lògica econòmica?

Introducció a l’Anàlisi de Regressió Lineal
139
b) S’ha pogut obtenir informació sobre cinc períodes addicionals que s’han incorporat a la mostra per reestimar el model, i s’han obtingut els resultats següents:
βj es(βj) t Sig. Constant 17,614 6,546 2,691 0,021 R 0,104 0,023 4,470 0,001 P –0,156 0,066 –2,372 0,037 Pc –0,047 0,135 –0,352 0,732
La matriu de correlacions de les variables explicatives amb les noves observacions és la següent:
R P Pc R 1,000 –0,205 0,629P –0,205 1,000 0,463Pc 0,629 0,463 1,000
Comentau les diferències entre aquests resultats i els de l’apartat anterior.
Solució:
a) Els resultats de l’estimació del model no pareix que siguin coherents amb els postulats de la teoria econòmica, ja que el coeficient corresponent al preu del producte és positiu i no significatiu. Aquests resultats poden ser deguts a algun problema a les dades utilitzades per a l’estimació, com la colinealitat entre algunes de les variables explicatives.
A partir de la matriu de correlacions de les variables explicatives es poden obtenir els FIV de cada coeficient, calculant-ne la inversa:
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛=
386250710250
09611-
,,
,
XR
Com es pot observar, els FIV corresponents als coeficients dels preus dels dos productes són molt elevats, cosa que indica l’existència d’un problema de multicolinealitat entre aquestes dues variables explicatives.
b) Una de les solucions al problema de la multicolinealitat consisteix a augmentar la informació mostral, sempre que es rompi el patró de colinealitat.
En aquest cas els resultats de l’estimació del model pareix que indiquen que els problemes almenys s’han reduït. Si es calculen els FIV es té:

M. Cladera; A. Matas
140
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛=
19146442
43731-
,,
,
XR
Els FIV no són excessivament elevats, per tant s’ha aconseguit reduir la correlació entre els preus dels dos productes a un nivell acceptable.
El preu del producte complementari no és significatiu i, per tant, s’hauria de reestimar el model eliminant aquesta variable.
Exercici 6
Per estimar la relació existent entre la producció d’una empresa, Y, i els factors capital, K, i treball, L, utilitzats, s’especifica el model següent:
iiii uKLY +++= 321 βββ
Per realitzar l’estimació per MQO es disposa d’una mostra de 18 empreses a partir de la qual s’han calculat els sumatoris següents:
1503.Ki =∑ 570=∑ iL 5006362 .Ki =∑ 100222 .Li =∑
400117.LK ii =∑
Utilitzant aquestes dades s’obtenen els resultats següents:
(1) ( ) ( ) ( ) i
,i
,,i K,L,,Y
180741046326500470025897 +−= R2 = 0,81
L’investigador aconsegueix dades referents a 7 empreses més i decideix incorporar-les a l’anàlisi. D’aquesta manera estima de nou el model amb les 25 observacions i obté els resultats següents:
(2) ( ) ( ) ( ) i
,i
,,i K,L,,Y
03012095617250385047975 ++= R2 = 0,824
Comparau aquests resultats amb els que es presenten a l’equació (1) i comentau les diferències explicant a què creieu que són degudes i calculant, si és necessari, les mesures estadístiques adients per corroborar les vostres afirmacions.
Solució:
Al model (1) s’observa que el factor treball resulta no significatiu i el seu coeficient té signe negatiu:

Introducció a l’Anàlisi de Regressió Lineal
141
⇒=<=−
= 13122707414700 0250
15 ,t,,,t ,
L L no significatiu.
⇒=>== 13126131806500 0250
15 ,t,,
,t ,K K significatiu.
Al model (2) s’ha incrementat la mostra utilitzada per fer les estimacions, i s’obté que les dues variables explicatives, treball i capital, són significatives i els coeficients que les acompanyen són positius:
⇒=>== 0742231203850 0250
22 ,t,,
,t ,L L significatiu.
⇒=>== 07421624030
7250 025022 ,t,
,,t ,
K K significatiu.
En el model (1) el coeficient de la variable treball té un signe que no és l’esperat. A més, la variable treball és no significativa, quan la lògica econòmica diu que ho hauria de ser. Això fa sospitar de l’existència de multicolinealitat, que provoca que els errors estàndards dels coeficients estimats estiguin inflats i, en el cas del treball, això doni lloc al fet que el valor del t-ràtio no ens permeti rebutjar la 020 =β:H , quan realment és falsa. Per comprovar si efectivament existeix un problema de multicolinealitat, es calcula el coeficient de correlació entre les dues variables explicatives:
( )( )( ) ( )
95022
,LLKK
LLKKr
ii
iiKL =
−−
−−=
∑∑
A la mostra utilitzada per a la primera estimació la relació entre les dues variables explicatives és molt elevada i és la causant de les anomalies detectades a les estimacions.
Exercici 7
Un investigador es proposa explicar el nivell d’importacions d’un país, Y, mitjançant les variables explicatives PIB, X2, i formació bruta de capital, X3. Per fer-ho disposa d’una mostra corresponent a un període d’11 anys d’observacions anuals de les esmentades variables. Les dades mostrals són les següents:
Obs. Y X2 X3

M. Cladera; A. Matas
142
1 15,9 149,3 4,2 2 16,4 161,2 4,1 3 19,0 171,5 3,1 4 19,1 175,5 3,1 5 18,8 180,8 1,1 6 20,4 190,7 2,2 7 22,7 202,1 2,1 8 26,5 212,4 5,6 9 28,1 226,1 5,0
10 27,6 231,9 5,1 11 18,3 239,0 0,7
Amb aquestes dades s’ha estimat aquest model de regressió:
( ) ( ) 34170
20230
406110508553 X,X,,Y,,
t ++−= R2 = 0,805
S’ha calculat el palanquejament per a cada observació, els residus estudentitzats i la distància de Cook. Aquestes mesures es presenten a la taula següent:
Observació Palanquejament Residu estudentitzat
Distància de Cook
1 0,26214 –1,02444 0,18973
2 0,15031 –1,32006 0,16897
3 0,06027 0,25131 0,00425
4 0,04160 0,10025 0,00058
5 0,19603 1,21979 0,18811
6 0,04575 0,56366 0,01833
7 0,06019 1,26067 0,08782
8 0,22560 0,12340 0,00268
9 0,21111 0,66128 0,06784
10 0,26695 –0,00113 0,00000
11 0,48005 –8,80431 3,25486
Creieu que hi ha alguna observació que es pugui considerar influent? Si és així, estimau el model sense aquesta observació i comparau els resultats amb els del model estimat amb el total de les observacions.
Solució:

Introducció a l’Anàlisi de Regressió Lineal
143
Quant al palanquejament, destaca el valor associat a l’observació 11, que és molt superior als valors que presenten la resta d’observacions. De fet, la mitjana dels levers és igual a 0,182, i l’única observació que té un lever superior al doble d’aquesta mitjana és l’11. Per tant, es pot considerar que aquesta observació presenta palanquejament.
Quant a l’anàlisi dels residus, l’observació 11 és la que té associat un major residu estudentitzat. El valor crític per decidir si aquest residu és suficientment elevat perquè aquesta observació sigui considerada un outlier és
21
αknt −− , que en aquest cas és 0050
7,t = –3,499. Com es pot observar, el valor
corresponent a l’observació 11 és l’únic que sobrepassa el valor límit. Per tant, aquesta observació pot considerar-se un outlier.
Queda saber si l’observació 11, que s’ha vist que pot considerar-se atípica, també és una observació influent. Per això s’analitza la distància de Cook. Es pot apreciar que l’observació amb un valor superior, amb diferència, per a aquest estadístic és l’11. El valor crític per decidir si es pot considerar o no una observació influent és α
kn,kF − . Amb un α del 5% es té 05083,
,F = 4,07, valor que és lleugerament superior al de la distància de Cook per a l’observació considerada. Però amb un α del 10% es té 100
83,
,F = 2,92, valor que permet dir que l’observació és influent.
L’estimació del model sense l’observació 11 es realitza a continuació:
( )⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡−=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
−=′′= −
525015000099
02079554088841500214
0590001002000010000200280020002804005
1
,,,
,,.,
,,,,,,,,,
ˆ YXXXB
VT = Y´Y yn− = 185,065
YXB ′′= ˆVE yn− = 181,932
VR = VT – VE = 3,133
Per tant, els errors estàndards dels coeficients de regressió estimats són:
( ) 009000020310
1333222 ,,,a
kn
VRˆes =−
=−
=β
( ) 16200590310
1333333 ,,,a
kn
VRˆes =−
=−
=β

M. Cladera; A. Matas
144
I el coeficient de determinació:
9830065185
9321812 ,,
,
VT
VER ===
Els resultats de l’estimació del model sense l’observació 11 es resumeixen de la manera següent:
( ) ( ) 31620
20090
525015000099 X,X,,Y,,
t ++−= R2 = 0,983
Poden observar-se diferències considerables respecte als resultats obtinguts amb tota la mostra:
- Les estimacions dels paràmetres del model són bastant distintes.
- Els errors estàndards dels coeficients estimats s’han reduït.
- Ha augmentat substancialment el coeficient de determinació.

Introducció a l’Anàlisi de Regressió Lineal
145
Bibliografia recomanada
ARTÍS, M. ET AL. (1999). Introducció a l’Econometria, Col·lecció Manuals 18, Edicions de la Universitat Oberta de Catalunya i Edicions de la Universitat de Barcelona, Barcelona.
GUISÀN, M. C. (1997). Econometría, McGraw-Hill, España.
GUJARATI, D. N. (1997). Econometría, McGraw-Hill, Colombia.
MADDALA, G. S. (1996). Introducción a la Econometría, Prentice-Hall, México.
MARTÍN, G.; LABEAGA, J. M.; MOCHÓN, F. (1997). Introducción a la Econometría, Prentice-Hall, España.
NOVALES, A. (1993). Econometría, McGraw-Hill, España.
NOVALES, A. (1996). Estadística y Econometría, McGraw-Hill, España.
URIEL, E. ET AL. (1990). Econometría. El modelo lineal, AC, España.





























