Embed Size (px)
Citation preview

Knowledge RepresentationKnowledge Representation
MeetsMeets
Stochastic PlanningStochastic Planning
Bob Givan
Joint work w/ Alan Fern and SungWook Yoon
Electrical and Computer Engineering
Purdue University

Bob Givan Electrical and Computer Engineering Purdue University
2Dagstuhl, May 12-16, 2003
Overview We present a form of approximate policy iteration
specifically designed for large relational MDPs.
We describe a novel application viewing entire planning domains as MDPs we automatically induce domain-specific planners
Induced planners are state-of-the-art on: deterministic planning benchmarks stochastic variants of planning benchmarks
Bob Givan Electrical and Computer Engineering Purdue University
3Dagstuhl, May 12-16, 2003
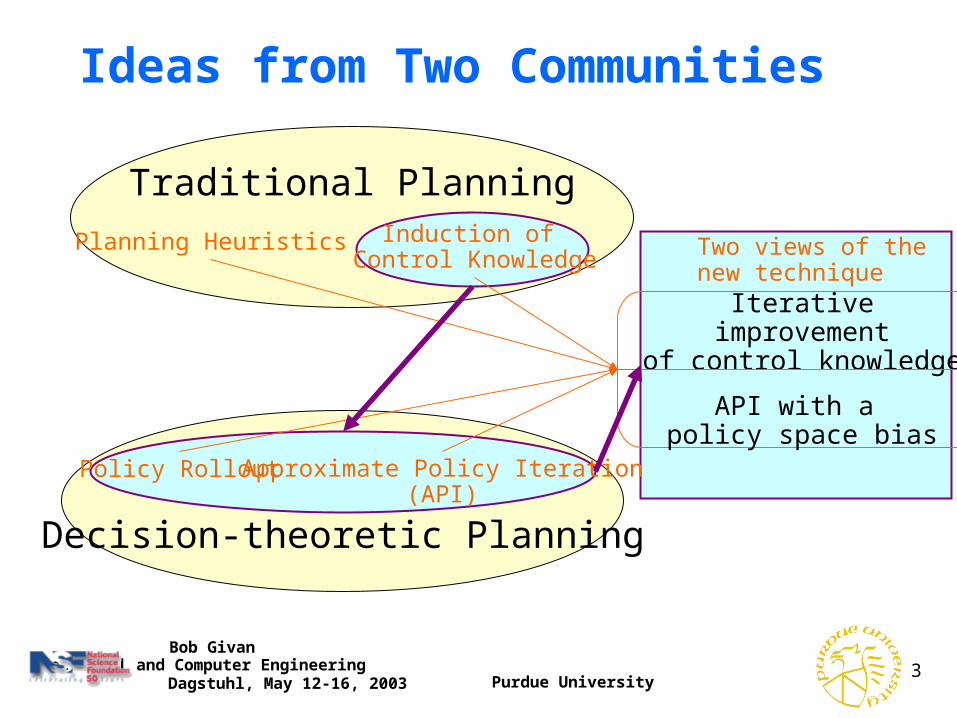
Decision-theoretic Planning
Traditional Planning
Ideas from Two Communities
Induction of Control Knowledge
Planning Heuristics
Policy Rollout Approximate Policy Iteration(API)
Two views of the new technique
Iterative improvementof control knowledge
API with a policy space bias

Bob Givan Electrical and Computer Engineering Purdue University
4Dagstuhl, May 12-16, 2003
Planning Problems
?
Current State Goal State/Region
States: First-order Interpretations of a particular language
A planning problem gives: a current state a goal state a list of actions and their semantics (may be stochastic)
Available actions:
Pickup(x) PutDown(y)

Bob Givan Electrical and Computer Engineering Purdue University
5Dagstuhl, May 12-16, 2003
Distributions over problems sharing one set of actions (but with different domains and sizes)
Planning Domains
Blocks World Domain
??
? ?
Available actions:
Pickup(x) PutDown(y)

Bob Givan Electrical and Computer Engineering Purdue University
6Dagstuhl, May 12-16, 2003
Traditional planners solve problems, not domains. little or no generalization between problems in a domain
Planning domains “solved” by control knowledge pruning some actions, typically eliminating search
Control Knowledge
?
?
?X
e.g. “don’t pick up a solved block”
X
X

Bob Givan Electrical and Computer Engineering Purdue University
7Dagstuhl, May 12-16, 2003
Recent Control Knowledge Research Human-written c. k. often eliminates search
[Bacchus & Kabanza, 1996] TL-Plan
Helpful c. k. can be learned from “small problems”[Khardon, 1996 & 1999] Learning Horn clause
action strategies
[Huang, Selman & Kautz, 2000] Learning action selection & action rejection rules
[Martin & Geffner, 2000] Learning generalized policies in concept languages
[Yoon, Fern & Givan, 2002] Inductive policy selection forstochastic planning domains

Bob Givan Electrical and Computer Engineering Purdue University
8Dagstuhl, May 12-16, 2003
Unsolved Problems
Finding control knowledge without immediate access to small problems Can we learn directly in a large domain?
Improving buggy control knowledge All previous techniques produce unreliable control
knowledge…with occasional fatal flaws.
Our approach: view control knowledge as an MDP policy and apply policy improvement
A policy is a choice of action for each MDP state

Bob Givan Electrical and Computer Engineering Purdue University
9Dagstuhl, May 12-16, 2003
View domain as one big statespace, each state a planning problem
This view facilitates generalization between problems.
Planning Domains as MDPs
Blocks World Domain
??
? ?
Available actions:
Pickup(x) PutDown(y)
Pickup(Purple)

Bob Givan Electrical and Computer Engineering Purdue University
10Dagstuhl, May 12-16, 2003
Decision-theoretic Planning
Traditional Planning
Ideas from Two Communities
Induction of Control Knowledge
Planning Heuristics
Policy Rollout Approximate Policy Iteration(API)
Two views of the new technique
Iterative improvementof control knowledge
API with a policy space bias

Bob Givan Electrical and Computer Engineering Purdue University
11Dagstuhl, May 12-16, 2003
Given a policy and a state s, can we improve (s)?
If V(s) < Q(s,b), then (s) can be improved to blue.
Can make such improvements at all states at once:
Policy Iteration
sRo
Rb
…
tn
s1
sk
t1…
V(s) = Q(s,o) = Ro + Es’{s1…sk} V(s’)
Q(s,b) = Rb + Es’{t1…tn} V(s’)
(s)
Policy Improvement
base policy improved policy

Bob Givan Electrical and Computer Engineering Purdue University
12Dagstuhl, May 12-16, 2003
Flowchart View of Policy Iteration
Current Policy
Choose best actionat each state
Compute Q
for each actionat all states
Compute V
at all states
Improved Policy ’
V
Q
Problem: too many states
Bob Givan Electrical and Computer Engineering Purdue University
13Dagstuhl, May 12-16, 2003
Compute V
at all statesat all states
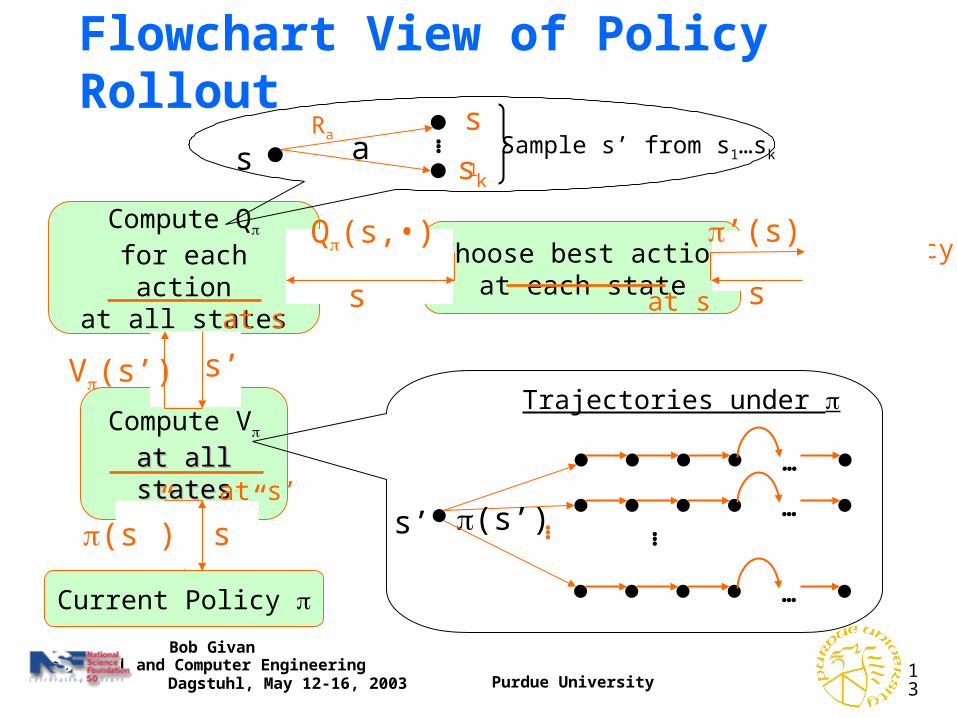
Flowchart View of Policy Rollout
Improved Policy
V
Q Choose best actionat each state
Compute Q
for each actionat all states
Current Policy
s”(s”) s’ …(s’)
…
…
…
…Trajectories under
s’V(s’)
at s’
sRa … s1
sk
a Sample s’ from s1…sk
s
Q(s,•)
at ss
’(s)
at s

Bob Givan Electrical and Computer Engineering Purdue University
14Dagstuhl, May 12-16, 2003
Approximate Policy Iteration
Compute Q
for each action
at state ss
Q(s,•)
Compute V
at state s’at state s’
Choose best actionat state s
Current Policy
s”(s”)
s’V(s’)
s
’(s)draw a training set of pairs (s,’(s)) learn a policyrepeat
Idea: use machine learning to control the number of samples needed
Refinement: use pairs (s,Q(s,•)) to define mis- classification costs

Bob Givan Electrical and Computer Engineering Purdue University
15Dagstuhl, May 12-16, 2003
Challenge Problem
Consider the following stochastic blocks world problem:
Goal: Clear(A)Assume: Block color affects pickup() success
Optimal policy is compact, but value function is not – state value depends on set of colors above A
A A
?

Bob Givan Electrical and Computer Engineering Purdue University
16Dagstuhl, May 12-16, 2003
Policy for Example Problem
A compact policy for this problem: 1. If holding a block, put it down on the table,
else… 2. Pick up a clear block above A.
How can we formalize this policy?
A A
?1.
A
?A
2.

Bob Givan Electrical and Computer Engineering Purdue University
17Dagstuhl, May 12-16, 2003
Action Selection Rules [Martin&Geffner, KR2000]
Pickup a clear block above block A…
Action selection rules based on classes of objects Apply action a to an object in class C (if possible). abbreviated C : a
How can we describe the object classes?
A A
?
A
?A

Bob Givan Electrical and Computer Engineering Purdue University
18Dagstuhl, May 12-16, 2003
A
?A
Formal Policy for Example Problem
English Decision List Taxonomic Syntax
1.“blocks being held” : putdown
2.“clear blocks above block A” : pickup
1. holding : putdown
2. clear (on* A) : pickup
A A
?1. 2.
We find this policy with a heuristic search
guided by the training data

Bob Givan Electrical and Computer Engineering Purdue University
19Dagstuhl, May 12-16, 2003
Decision-theoretic Planning
Traditional Planning
Ideas from Two Communities
Induction of Control Knowledge
Planning Heuristics
Policy Rollout Approximate Policy Iteration(API)
Two views of the new technique
Iterative improvementof control knowledge
API with a policy space bias

Bob Givan Electrical and Computer Engineering Purdue University
20Dagstuhl, May 12-16, 2003
API with a Policy Language Bias
Compute Q
for each action
at state ss
Q(s,•)
Compute V
at state s’at state s’
Choose best actionat state s
Current Policy
s”(s”)
s’V(s’)
s
’(s) Train a new policy ’
’

Bob Givan Electrical and Computer Engineering Purdue University
21Dagstuhl, May 12-16, 2003
Incorporating Value Estimates What happens if the policy can’t find reward?
For learning control knowledge, we use the FF-plan plangraph heuristic
s’ …(s’)
…
…
…
…
Trajectories under Use a value estimate at these states

Bob Givan Electrical and Computer Engineering Purdue University
22Dagstuhl, May 12-16, 2003
Initial Policy Choice
Policy iteration requires an initial base policy
Options include: random policy greedy policy with respect to a planning heuristic policy learned from small problems

Bob Givan Electrical and Computer Engineering Purdue University
23Dagstuhl, May 12-16, 2003
Experimental Domains
(Stochastic)Blocks World
(Stochastic)Painted Blocks
World
(Stochastic)Logistics World
SBW(n) SPW(n) SLW(t,p,c)

Bob Givan Electrical and Computer Engineering Purdue University
24Dagstuhl, May 12-16, 2003
API Results
Starting with flawed policies learned from small problems
Su
cce
ss R
ate
Su
cce
ss R
ate

Bob Givan Electrical and Computer Engineering Purdue University
25Dagstuhl, May 12-16, 2003
API Results
We used the heuristic of FF-plan (Hoffman and Nebel ’02 JAIR)
Starting with a policy greedy with respect to adomain independent heuristic

Bob Givan Electrical and Computer Engineering Purdue University
26Dagstuhl, May 12-16, 2003
How Good is the Induced Planner?
SuccessRate
Average Plan Length
RunningTime(s)
FF API FF API FF API
BW(10) 1 0.99 33 25 0.1 0.5
BW(15) 0.96 0.99 53 39 4.8 0.9
BW(20) 0.72 0.98 74 55 35.2 1.4
BW(30) 0.11 0.99 112 86 176.1 2.4
LW(4,6,4) 1 1 16 16 0.0 0.5
LW(5,14,20) 1 1 73 74 0.7 3.4

Bob Givan Electrical and Computer Engineering Purdue University
27Dagstuhl, May 12-16, 2003
Conclusions Using a policy space bias, we can learn good
policies for extremely large structured MDPs.
We can automatically learn domain-specific planners that compete favorably with the state-of-the-art domain-independent planners.

Bob Givan Electrical and Computer Engineering Purdue University
28Dagstuhl, May 12-16, 2003
Approximate Policy Iteration
Sample states s, and compute Q values at each:
Form a training set of tuples (s,b,Q,b(s)).
Learn a new policy from this training set.
sRo
Rb
…
tn
s1
skt1…
Estimate Rb + Es’{t1…tn} V(s’) by
Sampling states ti from t1…tn
Drawing trajectories under from ti to estimate V
Computing Q,b(s):

Bob Givan Electrical and Computer Engineering Purdue University
29Dagstuhl, May 12-16, 2003
Markov Decision Process (MDP) Ingredients:
System state x in state space X Control action a in A(x) Reward R(x,a) State-transition probability P(x,y,a)
Find control policy to maximize objective fun

Bob Givan Electrical and Computer Engineering Purdue University
30Dagstuhl, May 12-16, 2003
Control Knowledge vs. Policy Perhaps the biggest difference in communities:
deterministic planning works with action sequences decision-theoretic planning works with policies
Policies are needed because uncertainty may carry you to any state. compare: control knowledge also handles every state
Good c.k. eliminates search defines a policy over the possible state/goal pairs





























