Embed Size (px)
Citation preview

Music Processing Algorithms
David MeredithDepartment of Media Technology
Aalborg University

Recent projects
Musical pattern matching and discovery
•Finding occurrences of a query pattern in a work
•Finding works that are similar to a query work
•Discovering themes in a work
Pitch spelling•Predicting the pitch names (e.g.,
) of notes in a “piano-roll” representation (e.g., MIDI)
•Essential for transcription from MIDI (or audio) to notation

Algorithms for pattern matching and pattern discovery in music

Uses of musical pattern discovery algorithms In content-based music retrieval
• Creating an index of memorable patterns to enable faster retrieval
For music analysts, performers and listeners
• A motivic/thematic analysis can assist understanding and appreciation
In transcription• Helps with inferring beat and metrical structure
• similar patterns have similar metrical structure• Helps with inferring grouping and phrasing
• “parallellism” (Lerdahl and Jackendoff, 1983) most important factor in grouping
In composition and improvisation• Cure composer’s block by suggesting new material based on patterns discovered in music already written
• Automatically create new music that develops themes discovered in music already played
• Use analysed thematic structure as a template for a new work

Importance of repeated patterns in music analysis and cognition Schenker (1954. p.5):
•repetition “is the basis of music as an art”
Bent and Drabkin (1987, p.5):•“the central act” in all forms of music analysis is “the test for identity”
Lerdahl and Jackendoff (1983, p.52):
•“the importance of parallelism [i.e., repetition] in musical structure cannot be overestimated. The more parallelism one can detect, the more internally coherent an analysis becomes, and the less independent information must be processed and retained in hearing or remembering a piece”

Most musical repetitions are neither perceived nor intended
Rachmaninoff, Prelude in C sharp minor, Op.3, No.2, bars 1-6

Interesting musical repetitions are structurally diverse Want to discover all and only interesting repeated patterns
•i.e., themes and motives
Class of interesting repeated patterns is structurally diverse because
•patterns vary widely in structural characteristics
•many ways of transforming a musical pattern to give another pattern that is perceived to be a version of it• e.g., we can transpose it, embellish it, change tempo harmony, accompaniment, instrumentation, etc.

Example of repeated motive
Barber, Sonata for Piano, Op.26, 1st mvt, bars 1-4

Example of thematic transformation
J.S.Bach, Contrapunctus VI from Die Kunst der Fuge, bars 1-5

String-based algorithms for discovering musical patterns Most previous approaches assume music represented as strings
•each string represents a voice or part
•each symbol represents a note or an interval between two consecutive notes in a voice
Similarity between two patterns measured in terms of edit distance calculated using dynamic programming
•see, e.g., Lemstrom (2000), Hsu et al. (1998), Rolland (1999)

Problems with the string-based approach - Edit distance
B is an embellished version of A
If both patterns represented as strings each symbol represents pitch of note
then edit distance between A and B is 9
If allow pattern with 9 differences to count as a match, then get many spurious hits

Problems with string-based approach - Polyphony
If searching polyphonic music and• do not know voice to which each note belongs (e.g., MIDI format 0 file); or
• interested in patterns containing notes from 2 or more voices
then• combinatorial explosion in number of possible string representations
• if don’t use all possible representations then may not find all interesting patterns
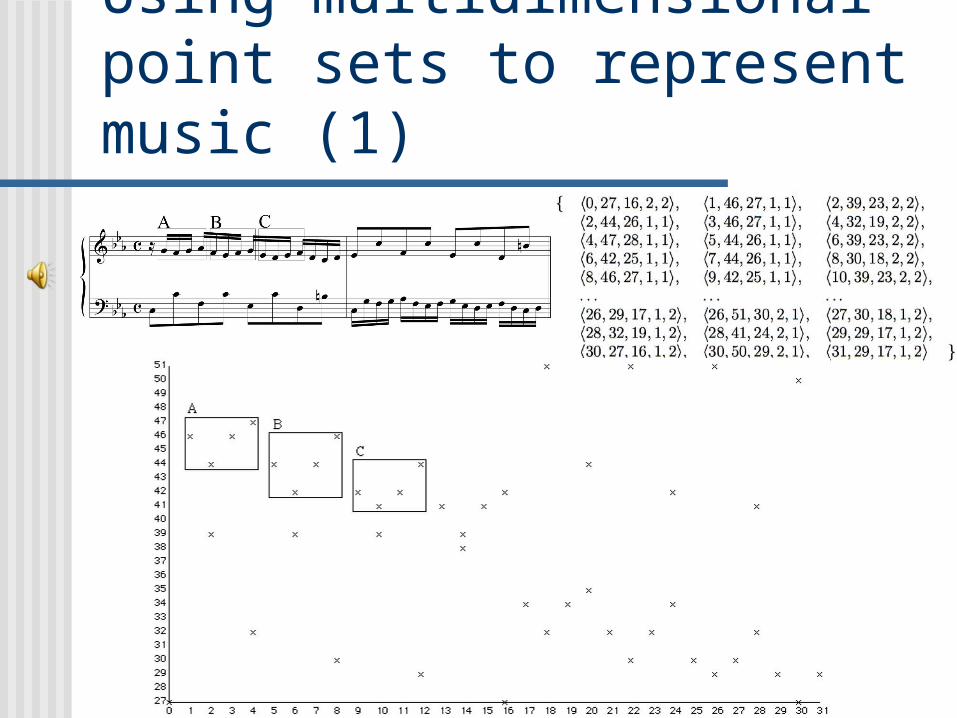
Using multidimensional point sets to represent music (1)
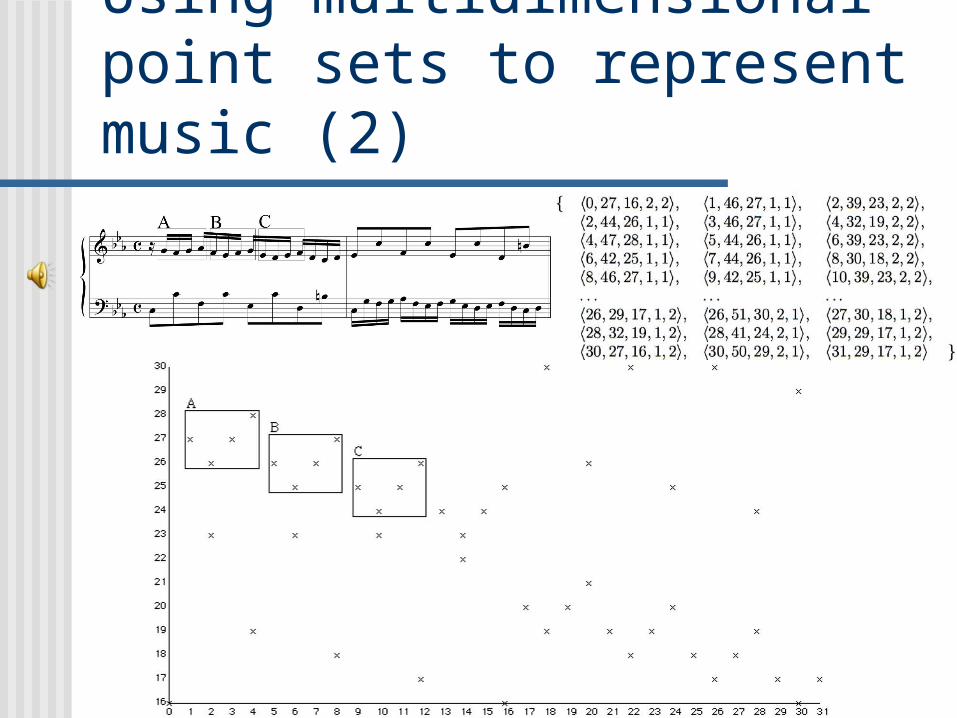
Using multidimensional point sets to represent music (2)

SIA - Discovering all maximal translatable patterns (MTPs)
Pattern is translatable by vector v in dataset if it can be translated by v to give another pattern in the dataset
MTP for a vector v contains all points mapped by v onto other points in the dataset
O(kn2 log n) time, O(kn2) spacewhere k is no. of dimensions & n is no. of points
O(kn2) average time with hashing

SIATEC - Discovering all occurrences of all MTPs
Translational Equivalence Class (TEC) is set of all translationally invariant occurrences of a pattern
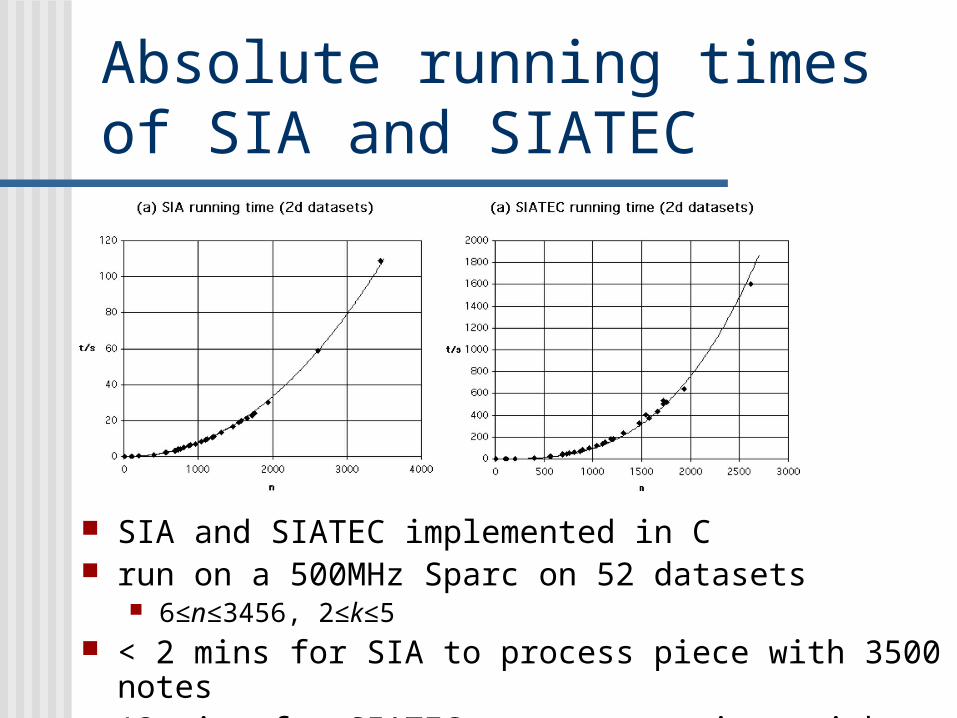
Absolute running times of SIA and SIATEC
SIA and SIATEC implemented in C run on a 500MHz Sparc on 52 datasets
6≤n≤3456, 2≤k≤5 < 2 mins for SIA to process piece with 3500 notes
13 mins for SIATEC to process piece with 2000 notes

Need for heuristics to isolate interesting MTPs 2n patterns in a dataset of size n SIA generates < n2/2 patterns
• => SIA generates small fraction of all patterns in a dataset
Many interesting patterns derivable from patterns found by SIA
BUT many of the patterns found by SIA are NOT interesting
• 70,000 patterns found by SIA in Rachmaninoff’s Prelude in C# minor
• probably about 100 are interesting
=> Need heuristics for isolating interesting patterns in output of SIA and SIATEC

Heuristics for isolating musical themes and motives
Cov=6CR=6/5
Cov=9CR=9/5
Comp = 1/3 Comp = 2/5 Comp = 2/3
Coverage Number of points covered by occurrences of the pattern
Compactness = Number of points in pattern
Number of points in region spanned by pattern
Compression ratio Coverage
Number of points in pattern + Freq. of occurrence of pattern -1
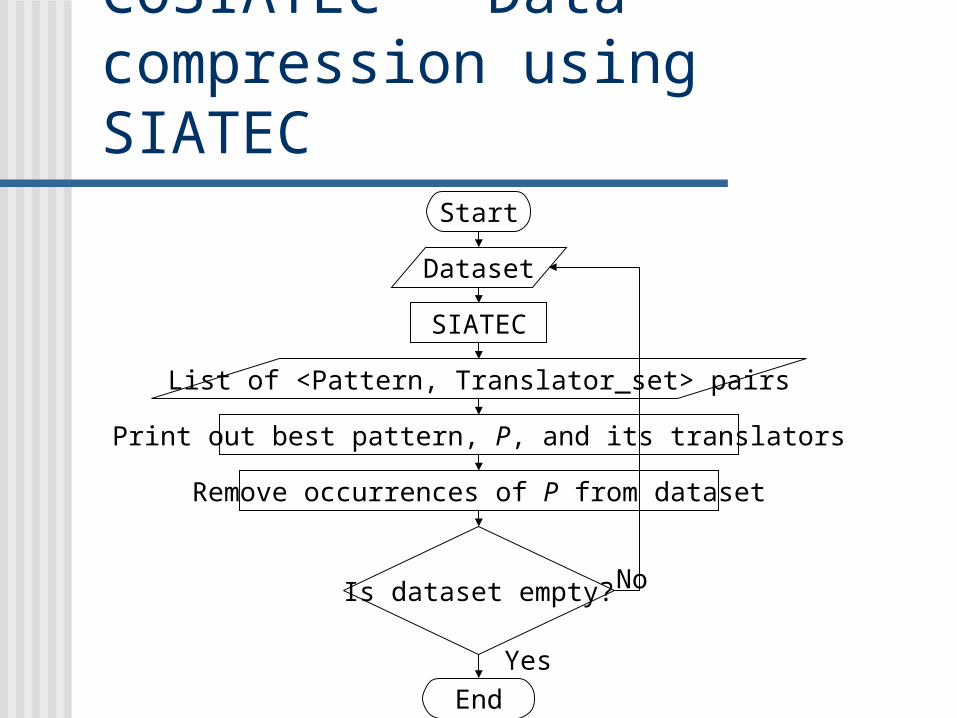
COSIATEC - Data compression using SIATEC
Start
Dataset
SIATEC
List of <Pattern, Translator_set> pairs
Print out best pattern, P, and its translators
Remove occurrences of P from dataset
Is dataset empty?
End
No
Yes

Using COSIATEC for finding themes and motives in music
First iteration Second iteration

SIAM - Pattern matching using SIA
k dimensions n points in dataset m points in query O(knm log(nm)) time O(knm) space O(knm) average time with hashing
Query pattern
Dataset

Improving SIAM - Ukkonen, Lemström & Mäkinen (2003) Use sweepline-like scanning of the dataset (Bentley and Ottmann, 1979)
Generalized to approximate matching of sets of horizontal line-segments
However, restricted to 2-dimensional representations (unlike SIA-family)
Improved complexity to O(mn log m + n log n + m log m) running time (without hashing)
O(m) working space Implemented as algorithm P2 on C-BRAHMS demo web site
• <http://www.cs.helsinki.fi/group/cbrahms/demoengine/>

Improving SIAM - MSM(Clifford et al., 2006) Finding size of maximal match is 3SUM hard (i.e., O(n2) )
Reduce problem of multi-dimensional point-set matching to 1d binary wildcard matching Random projection to 1D Length reduction by universal hashing Binary wildcard matching using FFTs Find best match and check in O(m) time exactly how many points match at the location that can be inferred from this match
Reduces time complexity to O(n log n)
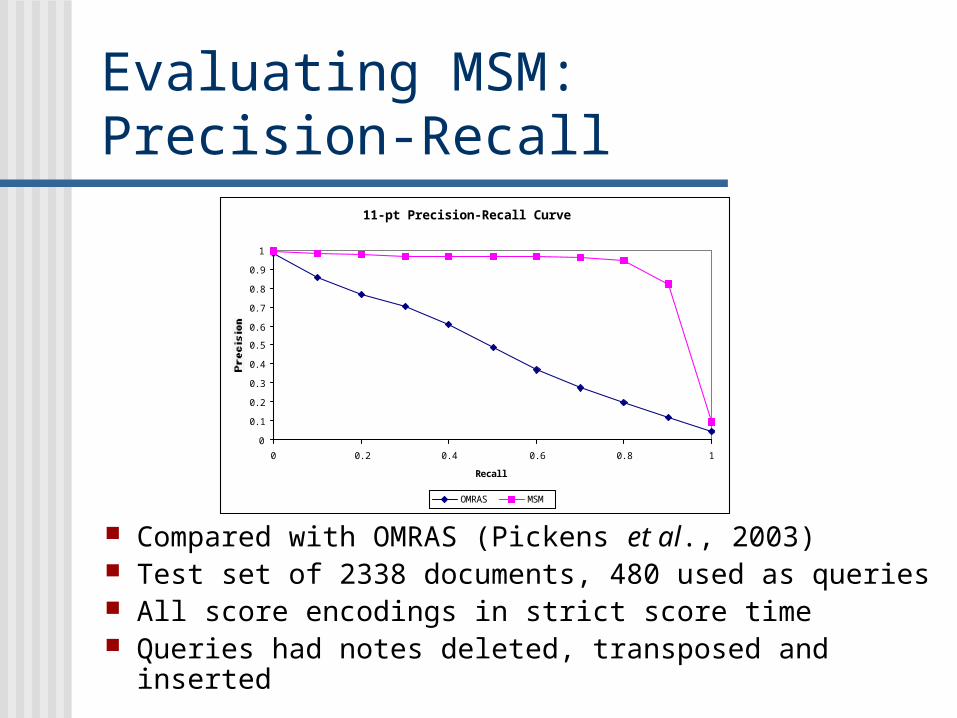
Evaluating MSM: Precision-Recall
Compared with OMRAS (Pickens et al., 2003) Test set of 2338 documents, 480 used as queries All score encodings in strict score time Queries had notes deleted, transposed and inserted
11-pt Precision-Recall Curve
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
Recall
OMRAS MSM

Evaluating MSM:Running time
Run on prefixes of various sizes of first movement of Beethoven’s 3rd Symphony
Each prefix matched against itself Compared with largest common subset algorithm of Ukkonen, Lemström and Mäkinen (2003) MSM nearly 2 orders of magnitude faster (log scale)

Pitch spelling algorithms

A pitch spelling algorithmtakes this...
Chr
omat
ic p
itch
Time

...and computes thisD
iato
nic
pitc
h
Time

Why are pitch spelling algorithms useful? In transcription, for generating a correctly notated score from a MIDI or audio file
In content-based music retrieval For representing better the perceived tonal relationships between notes
Allows us to find occurrences that sound like the query but contain different chromatic intervals
For better understanding the cognitive processes that underlie the perception of tonal music

Why is the same sound spelt differently in different contexts?
1
2
3
4

Comparative analysis of pitch spelling algorithms Algorithms analysed, evaluated and (in some cases) improved
•Longuet-Higgins (1976, 1987, 1993)•Cambouropoulos (1996,1998, 2001, 2003)
•Temperley (2001)•Chew and Chen (2003, 2005)•Meredith (2003, 2005, 2006)
Test corpus•195972 notes, 216 movements, 8 baroque and classical composers
•almost exactly equal number of notes (24500) for each composer

The PS13s1 algorithm
MID
I Not
e nu
mbe
r
Time
Tonic chroma and pitch name class
Fre
q
Ebb Bbb Fb Cb Gb Db Ab Eb Bb F C G D A E B F# C# G# D# A#
2 9 4 11 6 1 8 3 10 5 0 7 2 9 4 11 6 1 8 3 10
1 T
T1
T 1
2 T
T 1
1 T
Initial pitch name class

The PS13s1 algorithm
MID
I Not
e nu
mbe
r
Time
Tonic chroma and pitch name class
Fre
q
Ebb Bbb Fb Cb Gb Db Ab Eb Bb F C G D A E B F# C# G# D# A#
2 9 4 11 6 1 8 3 10 5 0 7 2 9 4 11 6 1 8 3 10
T1
T 1
T 1
T 1
T 1
T 2
Initial pitch name class

Evaluation criteria and performance metrics Evaluation criteria
• Spelling accuracy - how well an algorithm predicts the pitch names
• Style dependence - how much spelling accuracy depends on style
Performance metrics• Note error rate - proportion of notes in corpus spelt incorrectly
• Style dependence - standard deviation of note error rates over 8 composers
Robustness to temporal deviations• Best versions of algorithms also run on version of test corpus in which onsets and durations were randomly adjusted
• To evaluate how well algorithms would work on files generated directly from performances
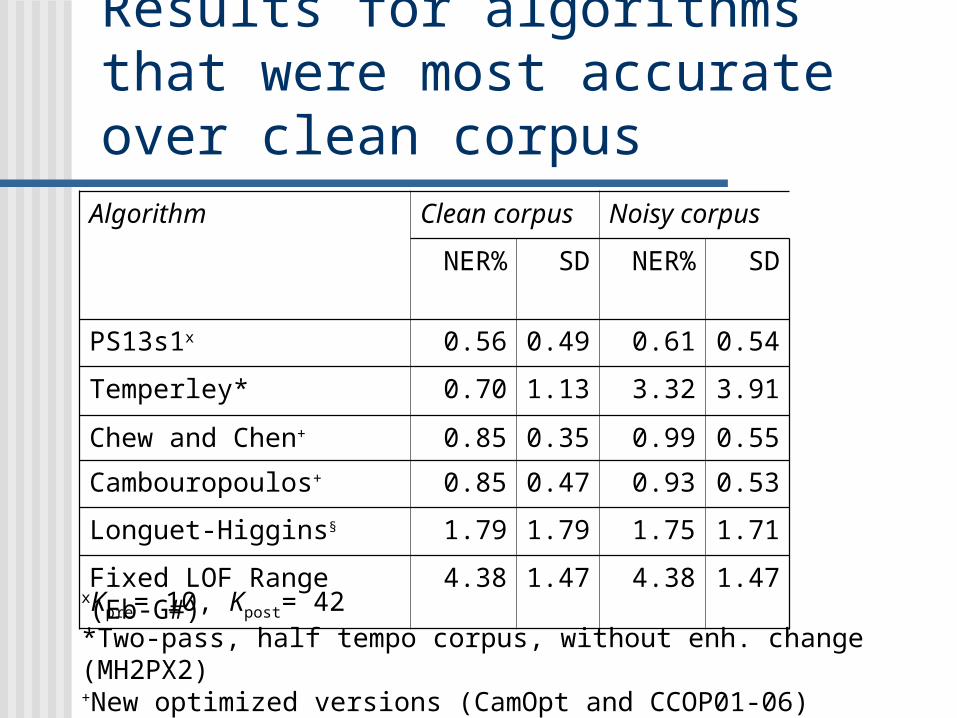
Results for algorithms that were most accurate over clean corpusAlgorithm Clean
corpusNoisy corpus
NER% SD NER% SD
PS13s1x 0.56 0.49
0.61 0.54
Temperley* 0.70 1.13
3.32 3.91
Chew and Chen+ 0.85 0.35
0.99 0.55
Cambouropoulos+ 0.85 0.47
0.93 0.53
Longuet-Higgins§ 1.79 1.79
1.75 1.71
Fixed LOF Range (Eb-G#)
4.38 1.47
4.38 1.47
xKpre= 10, Kpost= 42*Two-pass, half tempo corpus, without enh. change (MH2PX2)+New optimized versions (CamOpt and CCOP01-06)§Only when music processed a voice at a time (LH1V)

Some perceptual and cognitive implications PS13s1 performs best when it uses a substantial “post-context”
containing 23-42 notes None of the other algorithms use a post-context larger than about 3 or 4
notes Suggests that whether or not a pitch class is perceived to be the
tonic at a point depends to some extent on notes that immediately follow it in the music
PS13s1 with only a relatively small local context including a post-context performed better than Chew and Chen’s algorithm which uses all the music preceding the note to be spelt
Suggests that perceived tonic is much more dependent on local context than global context
In agreement with a “concatenationist view of music perception” (Tillmann and Bigand, 2004; Gurney, 1966; Levinson, 1997)
Best context sizes for PS13s1 contained from 50 to 58 notes With music at a “natural” tempo, this corresponds to an average
duration of 5.03 – 5.81 seconds Corresponds well with estimates of the duration of the perceptual
present• Fraisse: around 5 s; Clarke: 3-8 s
Events within perceptual present are “directly perceived” Can therefore be particularly easily re-interpreted in the light of events
that occur later in the perceptual present Therefore feasible that notes occurring up to 4 seconds after the one to
be spelt may influence it’s interpretation and therefore its spelling

Future work

Further development of SIA family of algorithms Compare SIA algorithms with methods developed in other more mature fields (e.g., computer vision, graph matching)
Improve time complexity of SIA algorithms with techniques such as ones used in MSM
Adapt algorithms for approximate matching and scaling (matching at different tempi)
Adapt SIA and SIATEC for early pruning of uninteresting patterns

Further work on PS13s1 Incorporate PS13s1 into complete MIDI-to-notation transcription system
Incorporate PS13s1 into Sibelius notation software
Use PS13s1 for key-tracking and harmonic analysis
Use PS13s1 for feature extraction on audio data

References On pattern-matching and pattern-discovery
Meredith, D., Lemström, K. and Wiggins, G. A. (2002) "Algorithms for discovering repeated patterns in multidimensional representations of polyphonic music". Journal of New Music Research, 31(4), 321-345.http://taylorandfrancis.metapress.com/link.asp?id=yql23xw0177lt4jd
Meredith, D. (2006) "Point-set algorithms for pattern discovery and pattern matching in music". In Content-Based Retrieval, Dagstuhl Seminar Proceedings, 06171.http://drops.dagstuhl.de/opus/volltexte/2006/652
On pitch-spelling algorithms Meredith, D. (2006) “The ps13 Pitch Spelling Algorithm”. Journal of New Music Research, 35(2), 121-159.http://taylorandfrancis.metapress.com/link.asp?id=q679l61r31m18460
Meredith, D. (2007) “Computing Pitch Names in Tonal Music: A Comparative Analysis of Pitch Spelling Algorithms”, DPhil dissertation, University of Oxford.http://www.titanmusic.com/papers/public/meredith-dphil-final.pdf

The end
Thanks!





























