Embed Size (px)
Citation preview

1
GS.TSKH. LÂM QUANG THIỆP
§O L¦êNG
TRONG GI¸O DôC
Lý thuyÕt vµ øng dông
Nhµ xuÊt b¶n ®¹i häc quèc gia Hµ néi

2

3
MỤC LỤC
LỜI NÓI ĐẦU ................................................................................................................ 7
GIỚI THIỆU CẤU TRÚC VÀ CÁCH SỬ DỤNG CUỐN SÁCH ............................. 9
PHẦN I. MỘT SỐ KHÁI NIỆM BAN ĐẦU VỀ TRẮC NGHIỆM VÀ ĐO LƯỜNG
TRONG GIÁO DỤC .................................................................................................... 15
Chương 1. VỀ TRẮC NGHIỆM VÀ ĐO LƯỜNG TRONG GIÁO DỤC ............... 16 1.1. NHU CẦU ĐO LƯỜNG TRONG CUỘC SỐNG VÀ KHOA HỌC VỀ ĐO LƯỜNG
NÓI CHUNG ............................................................................................................... 16 1.2. ĐO LƯỜNG VÀ ĐÁNH GIÁ TRONG GIÁO DỤC ................................................... 17 1.3. PHÂN LOẠI CÁC MỤC TIÊU GIÁO DỤC ............................................................... 19 1.4. PHÂN LOẠI CÁC PHƯƠNG PHÁP ĐO LƯỜNG VÀ ĐÁNH GIÁ
TRONG GIÁO DỤC ................................................................................................... 23 1.5. CÁC KIỂU CÂU HỎI TRẮC NGHIỆM KHÁCH QUAN .......................................... 26 1.6. SO SÁNH CÁC PHƯƠNG PHÁP TRẮC NGHIỆM KHÁCH QUANVÀ TỰ LUẬN29
1.6.1. Các đặc điểm của phương pháp TL: ............................................................... 29 1.6.2. Các đặc điểm của phương pháp TNKQ:......................................................... 29
1.7. SỰ KẾT HỢP TRẮC NGHIỆM KHÁCH QUAN VỚI TỰ LUẬN
TRONG ĐÁNH GIÁ ................................................................................................... 37 1.8. SỬ DỤNG CÁC CÂU HỎI TRẮC NGHIỆM ĐỂ ĐÁNH GIÁ CÁC MỨC ĐỘ
NHẬN THỨC KHÁC NHAU ..................................................................................... 37 1.9. CÁCH CHẾ TÁC CÂU HỎI TRẮC NGHIỆM KHÁCH QUAN ............................... 41 1.10. QUY TRÌNH XÂY DỰNG MỘT NGÂN HÀNG CÂU HỎI HOẶC MỘT ĐỀ TRẮC
NGHIỆM TIÊU CHUẨN HÓA .................................................................................. 42 1.10.1. Mục tiêu giảng dạy, ma trận kiến thức và đề kiểm tra .................................. 42 1.10.2. Quy trình thiết kế một đề kiểm tra tiêu chuẩn hóa và một NHCH......................... 43
Chương 2. MỘT SỐ KHÁI NIỆM BAN ĐẦU VỀ THỐNG KÊ VÀ KHÁI QUÁT
VỀ TRẮC NGHIỆM CỔ ĐIỂN ............................................................. 51 2.1. MỘT SỐ KHÁI NIỆM VÀ ĐỊNH LUẬT QUAN TRỌNG
TRONG THỐNG KÊ HỌC ......................................................................................... 51 2.1.1. Xác suất .......................................................................................................... 51 2.1.2. Luật số lớn ..................................................................................................... 52 2.1.3. Tổng thể và mẫu ............................................................................................. 52 2.1.4. Phân bố .......................................................................................................... 53 2.1.5. Tương quan .................................................................................................... 57
2.2. CÁC THAM SỐ ĐẶC TRƯNG CHO MỘT CÂU HỎI TRẮC NGHIỆM VÀ MỘT
ĐỀ TRẮC NGHIỆM ................................................................................................... 59 2.2.1. Độ khó của CH ............................................................................................... 59 2.2.2. Độ phân biệt của CH ...................................................................................... 60 2.2.3. Độ tin cậy của ĐTN ....................................................................................... 62

4
2.2.4. Độ giá trị của ĐTN ......................................................................................... 64 2.3. ĐÁNH GIÁ MỘT ĐỀ TRẮC NGHIỆM ..................................................................... 66
2.3.1. Phân tích các CH trắc nghiệm ........................................................................ 66 2.3.2. Tính độ tin cậy của ĐTN ................................................................................ 68 2.3.3. Xem xét độ giá trị của ĐTN ........................................................................... 70
2.4. CÁC LOẠI ĐIỂM TRẮC NGHIỆM ........................................................................... 71 2.4.1. Điểm thô ........................................................................................................ 71 2.4.2. Điểm tiêu chuẩn tuyệt đối .............................................................................. 72 2.4.3. Các loại điểm tương đối dựa vào phân bố chuẩn ............................................ 72 2.4.4. Về các thang điểm được sử dụng ở nước ta ................................................... 75
2.5. CÁC HẠN CHẾ CỦA LÝ THUYẾT TRẮC NGHIỆM CỔ ĐIỂN
VÀ KỲ VỌNG ĐỐI VỚI MỘT LÝ THUYẾT TRẮC NGHIỆM MỚI ...................... 76
PHẦN II. TRẮC NGHIỆM HIỆN ĐẠI - LÝ THUYẾT ỨNG ĐÁP CÂU HỎI ......... 81
Chương 3. HÀM ĐẶC TRƯNG CÂU HỎI – TẾ BÀO CỦA LÝ THUYẾT ỨNG
ĐÁP CÂU HỎI ....................................................................................... 82 3.1. VỀ CÁC PHÉP ĐO LƯỜNG ...................................................................................... 82
3.1.1. Về quy trình xây dựng một phép đo lường ..................................................... 82 3.1.2. Các con số và các loại thang đo ..................................................................... 83 3.1.3. Về các phép đo lường trong tâm lý và giáo dục ............................................. 85
3.2. VỀ ĐƯỜNG CONG ĐẶC TRƯNG CÂU HỎI ........................................................... 86 3.2.1. Các mối tương tác nguyên tố và tính đơn chiều ............................................. 86 3.2.2. Xây dựng thang đo để biểu diễn các tương tác .............................................. 87 3.2.3. Ví dụ về mô hình đường cong đặc trưng câu hỏi đơn chiều, nhị phân, một
tham số (mô hình Rasch) ......................................................................................... 88
Chương 4. CÁC MÔ HÌNH ĐƯỜNG CONG ĐẶC TRƯNG
CỦA CÂU HỎI NHỊ PHÂN .................................................................. 92 4.1. BA MÔ HÌNH ĐƯỜNG CONG ĐẶC TRƯNG CỦA CÂU HỎI NHỊ PHÂN
DẠNG LOGISTIC ...................................................................................................... 92 4.1.1. Mô hình đường cong đặc trưng của câu hỏi hai tham số ................................ 92 4.1.2. Mô hình đường cong đặc trưng của câu hỏi ba tham số ................................. 94
4.2. MỘT VÀI LƯU Ý VỀ CÁC MÔ HÌNH KIỂU KHÁC VỀ ĐẶC TRƯNG
CỦA CÂU HỎI ........................................................................................................... 96 4.2.1. Mô hình đặc trưng của câu hỏi dạng đường cong tích lũy vòm chuẩn ..... 97 4.2.2. Về mô hình Rasch và vai trò của nó ............................................................... 98
Chương 5. ƯỚC LƯỢNG CÁC THAM SỐ CỦA CÂU HỎI TRẮC NGHIỆM ... 102 5.1. QUY TRÌNH ƯỚC LƯỢNG CÁC THAM SỐ CỦA CÂU HỎI ............................... 102 5.2. VỀ TÍNH BẤT BIẾN CỦA CÁC THAM SỐ CÂU HỎI
ĐỐI VỚI MẪU THÍ SINH ........................................................................................ 105
Chương 6. ĐIỂM THỰC - ĐƯỜNG CONG ĐẶC TRƯNG CỦA ĐỀ TRẮC
NGHIỆM .............................................................................................. 117 6.1. ĐIỂM THỰC VÀ ĐƯỜNG CONG ĐẶC TRƯNG CỦA ĐỀ TRẮC NGHIỆM ....... 117
6.1.1. Quan niệm về điểm thực trong CTT............................................................. 117 6.1.2. Xác định điểm thực theo IRT ....................................................................... 118 6.1.3. So sánh điểm thô, điểm thực và điểm năng lực ............................................ 122

5
6.2. MỘT SỐ PHÉP CHUYỂN ĐỔI ................................................................................ 124 6.2.1. Vài phép chuyển đổi tuyến tính .................................................................... 124 6.2.2. Vài phép chuyển đổi phi tuyến ..................................................................... 125
Chương 7. HÀM THÔNG TIN CỦA CÂU HỎI VÀ CỦA ĐỀ TRẮC NGHIỆM . 129 7.1. HÀM THÔNG TIN CỦA CÂU HỎI TRẮC NGHIỆM ............................................. 129 7.2. HÀM THÔNG TIN VÀ SAI SỐ TIÊU CHUẨN CỦA ĐỀ TRẮC NGHIỆM .................. 132
7.2.1. Hàm thông tin của đề trắc nghiệm ................................................................ 132 7.2.2. Sai số tiêu chuẩn của đề trắc nghiệm............................................................ 134 7.2.3. Hàm hiệu suất tỷ đối .................................................................................... 135
Chương 8. ƯỚC LƯỢNG NĂNG LỰC CỦA THÍ SINH
VÀ ĐỊNH CỠ ĐỀ TRẮC NGHIỆM .................................................... 137 8.1. QUY TRÌNH ƯỚC LƯỢNG GIÁ TRỊ NĂNG LỰC CỦA THÍ SINH ..................... 137
8.1.1. Các nguyên tắc chung của quy trình............................................................. 138 8.1.2. Một ví dụ đơn giản về ước lượng nhờ đồ thị ................................................ 140 8.1.3. Một ví dụ về việc sử dụng phương pháp tính lặp để tìm cực đại .................. 142 8.1.4. Về sai số ước lượng giá trị năng lực ............................................................. 145
8.2. ĐỊNH CỠ ĐỀ TRẮC NGHIỆM: ƯỚC LƯỢNG ĐỒNG THỜI THAM SỐ
CỦA CÂU HỎI VÀ NĂNG LỰC CỦA THÍ SINH .................................................. 146 8.2.1. Về việc ước lượng các tham số của câu hỏi ................................................. 146 8.2.2. Ước lượng đồng thời tham số của câu hỏi và năng lực của thí sinh:
định cỡ đề trắc nghiệm ........................................................................................... 146 8.2.3. Vấn đề metric ............................................................................................... 148
8.3. TÍNH BẤT BIẾN CỦA VIỆC ƯỚC LƯỢNG NĂNG LỰC THÍ SINH
ĐỐI VỚI CÁC ĐỀ TRẮC NGHIỆM ........................................................................ 149 8.4. VÍ DỤ VỀ ĐỊNH CỠ ĐỀ TRẮC NGHIỆM, TÍNH HÀM THÔNG TIN, HÀM ĐẶC
TRƯNG CỦA ĐỀ TRẮC NGHIỆM ......................................................................... 150
Chương 9. ĐÁNH GIÁ SỰ PHÙ HỢP GIỮA SỐ LIỆU VÀ MÔ HÌNH .............. 161 9.1. CÁC PHƯƠNG PHÁP ĐÁNH GIÁ SỰ PHÙ HỢP GIỮA SỐ LIỆU
VÀ MÔ HÌNH ........................................................................................................... 161 9.1.1. Đảm bảo tính đơn chiều ............................................................................... 162 9.1.2. Kiểm tra tính bất biến ................................................................................... 162 9.1.3. Kiểm tra các dự đoán mô hình ..................................................................... 163
9.2. VÍ DỤ VỀ ĐÁNH GIÁ SỰ PHÙ HỢP GIỮA SỐ LIỆU VÀ MÔ HÌNH .................. 164 9.2.1. Kiểm tra tính bất biến của tham số CH đối với các mẫu TS khác nhau ....... 164 9.2.2. Kiểm tra tính bất biến của năng lực TS đối với các ĐTN khác nhau ..... 166 9.2.3. Đánh giá sự phù hợp giữa số liệu thực nghiệm và mô hình
qua giá trị thặng dư tiêu chuẩn hóa ........................................................................ 168
Chương 10. THIẾT KẾ CÁC ĐỀ TRẮC NGHIỆM .............................................. 171 10.1. SO SÁNH CTT VÀ IRT TRONG VIỆC THIẾT KẾ CÁC ĐỀ TRẮC NGHIỆM ................. 171 10.2. CÁCH TIẾP CẬN CƠ BẢN ĐỂ THIẾT KẾ ĐỀ TRẮC NGHIỆM ........................ 172 10.3. MỘT SỐ LOẠI ĐỀ TRẮC NGHIỆM VÀ CÁCH THIẾT KẾ ................................ 174 10.4. ẢNH HƯỞNG CỦA MÔ HÌNH ĐƯỜNG CONG ĐTCH VÀ SỐ LƯỢNG CÂU HỎI
LÊN ĐỀ TRẮC NGHIỆM......................................................................................... 175
Chương 11. SO BẰNG CÁC ĐIỂM TRẮC NGHIỆM .......................................... 178

6
11.1. CÁC PHƯƠNG PHÁP SO BẰNG TRONG CTT ................................................... 178 11.2. CÁC PHƯƠNG PHÁP SO BẰNG – KẾT NỐI – XÁC LẬP THANG ĐO THEO IRT .... 181
11.2.1. Một số trường hợp thực hiện định cỡ và xác lập thang đo ......................... 182 11.2.2. Xác định các hằng số thiết lập thang đo ..................................................... 186
11.3. VÍ DỤ VỀ SO BẰNG – KẾT NỐI – XÁC LẬP THANG ĐO THEO IRT ............. 191
Chương 12. TRẮC NGHIỆM NHỜ MÁY TÍNH .................................................. 203 12.1. ĐẶC ĐIỂM CỦA TRẮC NGHIỆM NHỜ MÁY TÍNH
VÀ CÁC HỆ THỐNG HỖ TRỢ ............................................................................... 203 12.1.1. Một số đặc điểm của trắc nghiệm nhờ máy tính ......................................... 203 12.1.2. Đòi hỏi đối với các phầm mềm hỗ trợ trắc nghiệm nhờ máy tính .................... 204
12.2. MỘT SỐ MÔ HÌNH TRIỂN KHAI TRẮC NGHIỆM NHỜ MÁY TÍNH .............. 206 12.2.1. Các trắc nghiệm cố định nhờ máy tính ....................................................... 206 12.2.2. Các trắc nghiệm di chuyển thẳng nhờ máy tính ......................................... 207 12.2.3. Các trắc nghiệm thích ứng nhờ máy tính dựa vào câu hỏi.......................... 207 12.2.4. Các trắc nghiệm thích ứng nhờ máy tính dựa vào phân đề ......................... 210 12.2.5. Các trắc nghiệm thích ứng nhờ máy tính cấu trúc đa giai đoạn ..................... 210
12.3. VÍ DỤ VỀ TRẮC NGHIỆM THÍCH ỨNG NHỜ MÁY TÍNH ............................... 215
Chương 13. CÁC MÔ HÌNH TRẮC NGHIỆM ĐA PHÂN ................................... 219 13.1. MỘT SỐ MÔ HÌNH TRẮC NGHIỆM ĐA PHÂN ................................................. 219
13.1.1. Mô hình định giá từng phần ....................................................................... 220 13.1.2. Mô hình định giá từng phần tổng quát ....................................................... 231
13.2. CÁC VÍ DỤ VỀ ỨNG DỤNG TRẮC NGHIỆM ĐA PHÂN .................................. 232 13.2.1. Phân tích các bài kiểm tra gồm các CH tự luận
nhờ phần mềm CONQUEST.................................................................................. 232 13.2.2. Phân tích các bài kiểm tra gồm hỗn hợp các CH trắc nghiệm khách quan và
tự luận nhờ phần mềm CONQUEST...................................................................... 242 13.2.3. Phân tích các bài kiểm tra gồm hỗn hợp các CH trắc nghiệm khách quan và
tự luận nhờ phần mềm PARSCALE ...................................................................... 251
Chương 14. KHÁI NIỆM VỀ TRẮC NGHIỆM ĐA CHIỀU ................................ 256 14.1. MỘT SỐ MÔ HÌNH TRẮC NGHIỆM ĐA CHIỀU ................................................ 256
14.1.1. Mô hình trắc nghiệm đa chiều nhờ các hàm logistic tuyến tính theo
số liệu từ các CH nhị phân ..................................................................................... 256 14.1.2. Một cách tiếp cận xây dựng mô hình tổng quát cho trắc nghiệm nhị phân,
đa phân, một chiều, đa chiều .................................................................................. 262 14.1.3. Về các cách biểu hiện tính đa chiều: giữa các CH và trong từng CH ......... 265
14.2. VÀI VÍ DỤ VỀ ÁP DỤNG TRẮC NGHIỆM ĐA CHIỀU ...................................... 266 14.2.1. Phân tích bài kiểm tra gồm các CH nhị phân và đa phân đo lường 3 chiều
năng lực biểu hiện ở riêng từng CH ....................................................................... 266 14.2.2. Phân tích bài kiểm tra gồm các CH nhị phân đo lường 3 chiều năng lực
biểu hiện hỗn hợp trong mỗi CH ............................................................................ 268
Các tài liệu dẫn và tham khảo chính ........................................................................ 289

7
LỜI NÓI ĐẦU
Trong các khoa học về giáo dục có một nhánh quan trọng là khoa
học về đo lường trong tâm lý và giáo dục, thường được gọi là tâm trắc học
(psychometrics). Khoa học này ở phương Tây bắt đầu phát triển mạnh từ
cuối thế kỷ XIX và đạt được rất nhiều thành tựu vào cuối thế kỷ XX. Tuy
nhiên tại Liên Xô cũ vì gặp một số trắc trở nên khoa học này phát triển rất
chậm, điều đó cũng ảnh hưởng đến nước ta, do vậy cho đến thập niên 90
của thế kỷ XX nước ta hầu như vẫn chưa tiếp cận với khoa học này, trừ vài
ba chuyên gia ở phía Nam được đào tạo từ phương Tây trước năm 1975.
Nhìn thấy khiếm khuyết lớn nói trên trong việc xây dựng một nền
giáo dục bền vững cho đất nước, khi làm công tác quản lý ở Bộ Giáo dục
và Đào tạo vào thập niên 90 của thế kỷ trước, tác giả tập sách này đã đề
nghị Bộ Giáo dục và Đào tạo lần lượt gửi hàng mấy chục giảng viên đại
học đi học thạc sỹ và tiến sỹ về khoa học này ở các nước tiên tiến. Nhiều
người học xong đã về làm việc rải rác ở các trường đại học, cũng có người
tiếp tục làm việc ở nước ngoài. Tuy nhiên, một thực tế đáng buồn là cho
đến nay việc tiếp cận và ứng dụng khoa học này vào thực tiễn giáo dục ở
nước ta vẫn còn rất yếu kém. Trong các chương trình đào tạo giáo viên các
cấp không có một môn học thích đáng giúp sinh viên tiếp cận khoa học
này; ở các kỳ thi quan trọng cấp quốc gia, khoa học này cũng chưa thực sự
được áp dụng. Ngay trong các trường đại học lớn về sư phạm và giáo dục
hiện nay chưa có các nhóm nghiên cứu sâu về đo lường trong tâm lý và
giáo dục, cũng chưa có một cuốn giáo trình nào giới thiệu về thành tựu
hiện đại của khoa học này. Những thiếu sót nói trên chứng tỏ việc lấp lỗ
hổng về nhánh khoa học giáo dục này ở nước ta quá chậm, điều đó tất yếu
ảnh hưởng đến sự phát triển bền vững của toàn bộ hệ thống giáo dục.
Vì thấy tầm quan trọng của khoa học đo lường trong tâm lý và giáo
dục qua hoạt động thực tiễn, cũng vì vẻ đẹp bên trong của bản thân nó,
tác giả đã dành thời gian tiếp cận lý luận và áp dụng thực tiễn khoa học

8
đã nêu trong hơn mười năm qua. Cuốn sách trong tay bạn đọc nhằm đóng
góp thúc đẩy sự phát triển nhanh chóng hơn khoa học này ở nước ta.
Cuốn sách có thể sử dụng làm cơ sở ban đầu để giảng dạy trong các
chương trình đại học và sau đại học ở các trường có các ngành sư phạm
và giáo dục, đặc biệt để tạo cho các bạn giáo viên và sinh viên trẻ quan
tâm một con đường tương đối ngắn để tiếp cận khoa học này so với con
đường mà tác giả đã phải đi qua.
Từ năm 2007 đến nay, Viện Khoa học Giáo dục Việt Nam đã tạo
cơ hội cho tác giả được tham gia phân tích các kết quả trắc nghiệm khách
quan và tự luận từ việc khảo sát kết quả học tập một số môn học lớp 5,
lớp 6 và lớp 9 ở nước ta, nhờ đó tác giả có số liệu thô để minh họa về kỹ
thuật phân tích trắc nghiệm trong sách, tác giả trân trọng cảm ơn Viện về
các cơ hội nói trên. Một công cụ được dùng để phân tích kết quả trắc
nghiệm trong cuốn sách này là phần mềm phân tích trắc nghiệm
VITESTA được xây dựng đầu tiên ở nước ta theo Lý thuyết Ứng đáp
Câu hỏi. Công ty Khoa học và Công nghệ Giáo dục (EDTECH-VN) đã
cung cấp các kỹ sư giúp tác giả xây dựng thành công phần mềm nói trên,
tác giả chân thành cảm ơn Công ty về sự hỗ trợ đó. Tác giả cảm ơn
Trường Đại học Giáo dục thuộc Đại học Quốc gia Hà Nội đã hỗ trợ làm
thủ tục in cuốn sách. Cuối cùng tác giả tỏ lòng biết ơn anh Dương Quang
Minh, nghiên cứu sinh về tâm trắc học tại Viện Đại học Bang Michigan
đã đọc bản thảo cuốn sách và đóng góp nhiều ý kiến quý báu.
Một cuốn sách như thế này lẽ ra phải được các giảng viên đã có cơ
hội tiếp cận đầy đủ các chương trình đào tạo tiến sỹ ở các nước tiên tiến
viết ra, nhưng vì chờ đợi mãi hàng chục năm qua chưa thấy ai chịu khó
làm việc này nên tác giả đành phải cố gắng thực hiện. Một mảng khoa
học hiện đại rộng lớn, phát triển nhanh chóng và có nhiều ứng dụng đa
dạng, nhưng chỉ được giới thiệu thu gọn trong một cuốn sách tương đối
nhỏ như thế này thì chắc không tránh khỏi thiếu sót. Tác giả rất hoan
nghênh các ý kiến đóng góp về cuốn sách và xin bạn đọc gửi về địa chỉ
Hà Nội, tháng 10 năm 2010
TÁC GIẢ

9
GIỚI THIỆU
CẤU TRÚC VÀ CÁCH SỬ DỤNG CUỐN SÁCH
Cuốn sách gồm 2 phần lớn. Phần I có 2 chương, chương 1 giới thiệu
các khái niệm chung về trắc nghiệm và đo lường trong giáo dục; chương 2
giới thiệu khái quát về lý thuyết trắc nghiệm cổ điển. Phần II là trọng tâm
của cuốn sách, có 12 chương, tập trung vào trắc nghiệm hiện đại, đặc biệt
là Lý thuyết Ứng đáp Câu hỏi (Item Response Theory – IRT). Để bạn đọc
dễ theo dõi, đầu mỗi chương đều có nêu những vấn đề sẽ được đề cập
đến trong chương và lưu ý người đọc nên tập trung vào vấn đề gì, ở cuối
mỗi chương có các câu hỏi tự kiểm tra hoặc bài tập, hoặc cả hai.
Người đọc nếu đã quen với trắc nghiệm cổ điển qua các cuốn sách
về trắc nghiệm của GS. Dương Thiệu Tống [1] thì chỉ cần đọc lướt phần I
để nhớ lại các khái niệm sẽ được dùng đến ở phần II.
Ở phần II, IRT được trình bày theo trình tự từ các điểm xuất phát
cần thiết để xây dựng một phép đo lường trong giáo dục nói chung. Diễn
tả được bắt đầu từ khái niệm cơ bản của IRT là hàm đặc trưng câu hỏi
(biểu hiện qua đường cong đặc trưng câu hỏi), mô tả ứng đáp của một thí
sinh lên một câu hỏi, mối tương tác xảy ra trong một “tế bào” bao gồm một
cặp “thí sinh – câu hỏi”, mà tác giả gọi là “mối tương tác nguyên tố”.
Mối tương tác đó là viên gạch để xây dựng toàn bộ tòa nhà IRT, cơ sở
của khoa học đo lường hiện đại trong tâm lý và giáo dục. Chương 3 và 4
dành để giới thiệu các mô hình đường cong đặc trưng câu hỏi khác nhau,
mô hình 1, 2 và 3 tham số dạng logistic, cũng giới thiệu mối quan hệ giữa
chúng với dạng đường cong tích lũy vòm chuẩn đã được sử dụng nhiều
trong quá khứ. Vai trò của mô hình Rasch (mô hình một tham số) trong
IRT nói chung cũng được bàn đến trong chương 3. Từ chương 3 đến
chương 12 của phần II chỉ tập trung trình bày mô hình trắc nghiệm nhị
phân (dichotomous) và đơn chiều (unidimentional).

10
Sau khi giới thiệu các hàm đặc trưng câu hỏi, chương 5 mô tả định
tính về quy trình ước lượng các tham số của câu hỏi để bạn đọc hiểu thực
chất của quy trình này, rồi chương 8 trở lại giới thiệu định lượng về quy
trình ước lượng giá trị năng lực của thí sinh và ước lượng đồng thời các
tham số của câu hỏi và năng lực của thí sinh, tức là định cỡ đề trắc
nghiệm. Những bạn đọc ngại đi vào các tính toán định lượng có thể chỉ
đọc chương 5 là đủ để hình dung được khái quát cách dựa vào mô hình để
tính toán các kết quả mong đợi cuối cùng – các tham số đặc trưng câu hỏi
và giá trị năng lực của thí sinh. Bắt đầu ở chương 5 và trình bày rõ hơn ở
chương 8 một tính chất quan trọng, hòn đá tảng thể hiện ưu việt của IRT,
đó là tính bất biến của các tham số của câu hỏi và năng lực của thí sinh đối
với các phép đo bằng trắc nghiệm. Tính bất biến (invariance) này cũng
hay được diễn đạt bằng các cụm từ “không phụ thuộc vào câu hỏi” (item-
free), “không phụ thuộc vào mẫu thử” (sample-free). Các chương 6 và 7
trước hết giới thiệu thêm một công cụ quan trọng phản ánh tính chất của
câu hỏi trắc nghiệm là hàm thông tin của câu hỏi trắc nghiệm, sau đó giới
thiệu các công cụ tổng hợp mô tả tính chất của toàn bộ đề trắc nghiệm, đó
là hàm và đường cong đặc trưng đề trắc nghiệm (đường cong điểm thực)
cũng như hàm và đường cong thông tin của đề trắc nghiệm.
Chương 9 trình bày một vấn đề quan trọng, đó là cách đánh giá sự
phù hợp giữa số liệu và mô hình trong IRT. Chỉ khi mức độ phù hợp giữa
số liệu và mô hình có thể chấp nhận được thì mọi ưu điểm liên quan đến
IRT mới phát huy đầy đủ và chất lượng các phép đo lường mới đảm bảo.
Ba chương tiếp theo nêu các phương pháp ứng dụng thực tế cụ thể
của lý thuyết trắc nghiệm. Chương 10 trình bày các phương pháp thiết kế
các đề trắc nghiệm dựa vào lý thuyết trắc nghiệm cổ điển và đặc biệt là
dựa vào IRT. Chương 11 trình bày các phương pháp liên quan đến một
nhu cầu quan trọng của hoạt động đánh giá trong thực tế: làm sao so sánh
được các điểm trắc nghiệm thu được từ các đề trắc nghiệm khác nhau
cũng như so sánh được các tham số của câu hỏi trắc nghiệm thu được từ
các mẫu định cỡ khác nhau. Nhu cầu này được giải quyết bởi các phương
pháp so bằng các điểm trắc nghiệm. Chương 12 giới thiệu các mô hình
trắc nghiệm nhờ máy tính, đặc biệt là phương pháp trắc nghiệm thích ứng

11
nhờ máy tính (computational adaptive tests) một phương pháp phát triển
rất thuận lợi dựa trên cơ sở IRT.
Hai chương cuối phần II của cuốn sách trình bày các cách tiếp cận
mở rộng mô hình nhị phân đơn chiều sang các mô hình đa phân
(polytomous) và đa chiều (multidimentional). Chương 13 giới thiệu
chung các mô hình trắc nghiệm đa phân và tập trung đi sâu vào mô hình
định giá từng phần (partial credit model), một mô hình trắc nghiệm đa
chiều có tính khái quát cao. Có thể sử dụng mô hình này để phân tích kết
quả đo lường bằng các đề tự luận có cấu trúc và được quy định điểm cho
từng phần. Mô hình trắc nghiệm nhị phân được xem là một trường hợp
riêng của mô hình trắc nghiệm đa phân nói chung cũng như của mô hình
định giá từng phần. Với quan niệm đó, có thể triển khai phân tích một đề
thi kết hợp trắc nghiệm với tự luận bằng mô hình định giá từng phần.
Chương 14 trình bày mở đầu về trắc nghiệm đa chiều, giới thiệu một số
mô hình trắc nghiệm đa chiều và việc ứng dụng chúng khi phân tích ảnh
hưởng của các chiều năng lực khác nhau lên kết quả đo lường.
Phần ứng dụng lý thuyết đo lường vào thực tiễn đánh giá trong giáo
dục được trình bày qua nhiều ví dụ đan xen trong các chương. Ví dụ
được lấy phần lớn từ thực tế đánh giá ở nước ta trong mấy năm qua.
Qua các ví dụ thực tế, một vài phần mềm tính toán tiêu biểu cũng được
sử dụng, đó là phần mềm CONQUEST của ACER (Úc), phần mềm
BILOG-3M, MULTILOG, PARSCALE (Mỹ) và phần mềm VITESTA
của EDTECH-VN (Việt Nam).
Để bạn đọc dễ theo dõi, đầu cuốn sách có đưa ra bảng thống kê các từ
viết tắt được sử dụng nhiều trong sách. Hơn nữa, do thành tựu hiện đại của
khoa học đo lường trong giáo dục hầu hết gắn với các tác giả phương Tây,
cho nên có thể xem chúng ta đang nhập khẩu khoa học này từ phương
Tây. Vì vậy các thuật ngữ tiếng Việt liên quan trong sách phần lớn do tác
giả tự tạo ra, và để dễ đối chiếu khi đọc các tài liệu tiếng Anh ở cuối sách
có đưa ra một bảng thuật ngữ đối chiếu Anh – Việt.
Cuối cùng tác giả có liệt kê các tài liệu dẫn và tài liệu tham khảo
chính là các sách hoặc bài viết mà tác giả có lấy ý tưởng hoặc trích dẫn
trong cuốn sách, cũng là các tài liệu mà tác giả đã đọc và tin tưởng về

12
chất lượng. Tác giả không muốn đưa quá nhiều tài liệu tham khảo liên
quan vì không muốn giới thiệu với bạn đọc những cuốn sách mà tác giả
chưa đọc kỹ và chưa nắm chắc về chất lượng.
Tuy cố gắng giới thiệu một số kiến thức tổng quát ban đầu liên
quan đến những thành tựu hiện đại của khoa học về đo lường trong giáo
dục, nhưng cuốn sách vẫn chưa bao trùm hết các vấn đề cần thiết. Tác giả
hy vọng sẽ bổ sung trong các lần xuất bản sau.
13
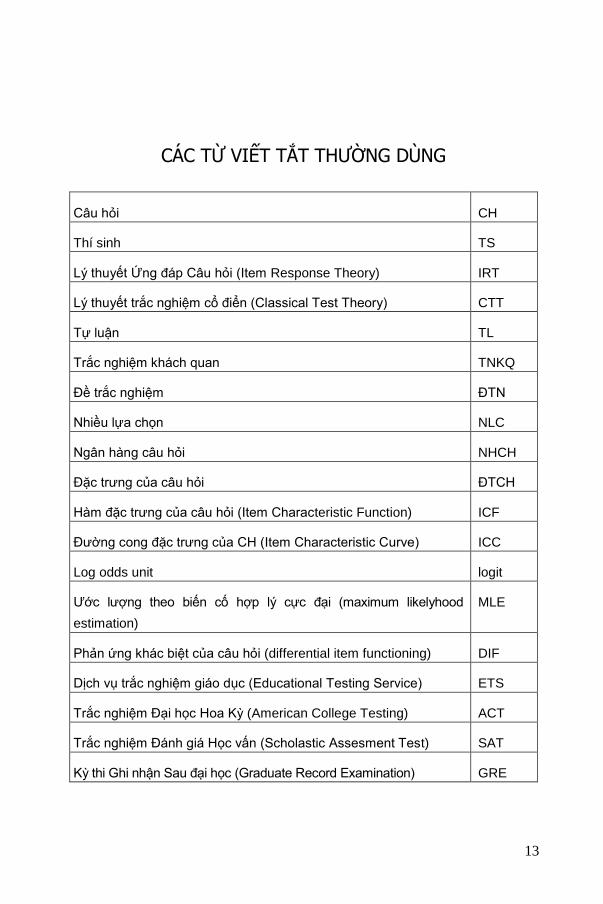
CÁC TỪ VIẾT TẮT THƯỜNG DÙNG
Câu hỏi CH
Thí sinh TS
Lý thuyết Ứng đáp Câu hỏi (Item Response Theory) IRT
Lý thuyết trắc nghiệm cổ điển (Classical Test Theory) CTT
Tự luận TL
Trắc nghiệm khách quan TNKQ
Đề trắc nghiệm ĐTN
Nhiều lựa chọn NLC
Ngân hàng câu hỏi NHCH
Đặc trưng của câu hỏi ĐTCH
Hàm đặc trưng của câu hỏi (Item Characteristic Function) ICF
Đường cong đặc trưng của CH (Item Characteristic Curve) ICC
Log odds unit logit
Ước lượng theo biến cố hợp lý cực đại (maximum likelyhood
estimation)
MLE
Phản ứng khác biệt của câu hỏi (differential item functioning) DIF
Dịch vụ trắc nghiệm giáo dục (Educational Testing Service) ETS
Trắc nghiệm Đại học Hoa Kỳ (American College Testing) ACT
Trắc nghiệm Đánh giá Học vấn (Scholastic Assesment Test) SAT
Kỳ thi Ghi nhận Sau đại học (Graduate Record Examination) GRE

14
Trắc nghiệm Tuyển sinh sau đại học ngành Quản lý (Graduate
Management Admission Test)
GMAT
Trắc nghiệm Ngoại ngữ tiếng Anh (Test of English as a Foreign Language) TOEFL
Mô hình định giá từng phần PCM
Trắc nghiệm nhờ máy tính (Computer-based test) CBT
Trắc nghiệm Thích ứng nhờ máy tính (Computational Adaptive Test) CAT
Trắc nghiệm cố định nhờ máy tính (Computerized Fixed Tests) CFT
Trắc nghiệm thích ứng nhờ máy tính cấu trúc đa giai đoạn
(Structured Computer Adaptive Multistage Test)
ca-MST
Trắc nghiệm trên giấy (paper-and-pencil test) PAP
Quá trình tạo đề tự động (automated test assembly) ATA
Trắc nghiệm di chuyển thẳng nhờ máy tính (Linear-on-the-Fly Test) LOFT

15
Phần I
MỘT SỐ KHÁI NIỆM BAN ĐẦU VỀ TRẮC NGHIỆM VÀ ĐO LƯỜNG
TRONG GIÁO DỤC

16
Chương 1
VỀ TRẮC NGHIỆM VÀ ĐO LƯỜNG TRONG GIÁO DỤC
Mở đầu chương này là các khái niệm chung về đo lường và đánh
giá trong giáo dục, các cách phân loại mục tiêu giáo dục và các cách
phân loại quan trọng đối với các phương pháp đo lường và đánh giá
trong giáo dục. Tiếp đến hai nhóm phương pháp đánh giá quan trọng là
trắc nghiệm khách quan và tự luận được trình bày, được so sánh với
nhau để dẫn đến nhận định phải tận dụng kết hợp ưu thế của từng
phương pháp phục vụ các bài toán đánh giá trong giáo dục. Một quy
trình nhằm thiết kế các đề kiểm tra tiêu chuẩn hóa và các ngân hàng câu
hỏi (NHCH) được nêu tóm tắt ở cuối chương, trong đó cho thấy ở các
khâu nào cần sử dụng lý thuyết trắc nghiệm cổ điển hay hiện đại. Làm
quen với những khái niệm mở đầu về đo lường và đánh giá trong giáo
dục ở chương này rất quan trọng để đọc tiếp các chương sau.
1.1. NHU CẦU ĐO LƯỜNG TRONG CUỘC SỐNG VÀ KHOA HỌC
VỀ ĐO LƯỜNG NÓI CHUNG
Từ buổi sơ khai của lịch sử loài người, trong quá trình lao động và
giao tiếp, con người đã phải thực hiện các phép đo lường. Đo lường là
phép so sánh một đại lượng nào đó với một vật chuẩn đã biết, và kết quả
là đưa ra các con số để đánh giá.
D. I. Menđêlêep có nói: “Ở đâu có sự đo lường thì ở đó bắt đầu có
khoa học”. Ở buổi ban đầu, con người cần đo lường để xây dựng nơi cư
trú, chế tạo quần áo, trao đổi thực phẩm, nguyên liệu… Với sự phát triển
các hoạt động của con người, các phép đo ngày càng chính xác, các đơn
vị đo ngày càng tinh tế. Chẳng hạn, để đo chiều dài người cổ đại sử dụng

17
các đơn vị đo dựa trên gang tay, để đo thời gian dùng các chu kỳ mọc và
lặn của Mặt Trời và Mặt Trăng… Người Lưỡng Hà đã biết sử dụng hệ
thập phân khi đo chiều dài, và các sử gia có biết đến đơn vị nhỏ nhất để
đo chiều dài mà người Lưỡng Hà đã sử dụng còn lưu lại ở các dấu khắc
trên ngà voi vào cỡ 1,704mm. Khi đo thời gian và góc người xưa sử dụng
cách chia vòng tròn thành 360 phần, có lẽ xuất phát từ con số 360 ngày
trong một năm.
Khi khoa học còn sơ khai thì các phép đo cũng thô thiển. Với sự
phát triển của một khoa học nào đó, độ chính xác của phép đo trong khoa
học ấy cũng ngày càng được nâng cao. Hãy lấy ví dụ về phép đo thời
gian. Thời xa xưa con người đo thời gian bằng đơn vị tính theo độ dài
ước chừng giữa thời điểm Mặt Trời mọc và Mặt Trời lặn, rồi sau đó sử
dụng đồng hồ dựa vào độ dài của chu kỳ dao động con lắc. Ngày nay
người ta phải tính đơn vị đo thời gian bằng việc xác định các bước sóng
bức xạ của dịch chuyển siêu tinh vi trong nguyên tử. Mặt khác, tùy theo
mục tiêu của mỗi phép đo mà người ta đòi hỏi độ chính xác đến đâu, tức
là chấp nhận sai số đến mức nào. Chẳng hạn, trong cuộc sống hàng ngày
người ta chỉ cần hẹn nhau chính xác đến năm ba phút. Tuy nhiên, nói
chung sự tiến bộ của khoa học giúp con người có cơ sở để thiết kế các
phép đo có độ chính xác ngày càng cao.
1.2. ĐO LƯỜNG VÀ ĐÁNH GIÁ TRONG GIÁO DỤC
Bất kỳ một quá trình giáo dục nào mà một con người tham gia cũng
nhằm tạo ra những biến đổi nhất định trong con người đó. Muốn biết
những biến đổi đó xảy ra ở mức độ nào phải đánh giá hành vi của người
đó trong một tình huống nhất định. Việc đánh giá cho phép chúng ta xác
định, một là mục tiêu giáo dục được đặt ra có phù hợp hay không và có
đạt được hay không, hai là việc giảng dạy có thành công hay không, học
viên có tiến bộ hay không.
Để việc đánh giá được đúng đắn phải triển khai đo lường: muốn so
sánh vật nào nặng hơn trong hai vật có bề ngoài không khác nhau người
ta phải đem cân chúng lên. Việc dạy và học đã xuất hiện trong lịch sử
loài người hàng nghìn năm trước đây, và để tuyển dụng người giỏi người
ta phải tạo ra các hình thức thi để so sánh các thí sinh với nhau.

18
Trong lịch sử giáo dục Việt Nam, nhằm giúp nhà vua đánh giá đúng hiền
tài để tuyển dụng vào các chức quan lại trị nước, triều đình phải tổ chức
các kỳ thi từ thấp đến cao: thi hương, thi hội, thi đình. Ở các kỳ thi này,
người ta ra đề thi cho sỹ tử làm bài, và các giám khảo đo lường năng lực
của thí sinh qua các bài thi đó dựa vào sự nhận xét chủ quan của mình.
Giám khảo giỏi và công bằng thì việc đo lường sẽ chính xác, giám khảo
kém và không công bằng thì việc đo lường thường sai lệch, như vậy việc
tuyển chọn đúng người tài cho quốc gia phụ thuộc nhiều vào độ chính
xác trong phép đo lường năng lực thí sinh của giám khảo.
Những ví dụ nêu trên cho thấy, việc đo lường và đánh giá trong
giáo dục đã phát triển từ xa xưa, tuy nhiên, có thể nói, một ngành khoa
học thật sự về đo lường trong tâm lý và giáo dục mới bắt đầu hình thành
từ cuối thế kỷ XIX. Ở châu Âu, và đặc biệt là ở Mỹ, lĩnh vực khoa học về
trắc nghiệm phát triển mạnh trong thế kỷ XX. Có thể kể những dấu mốc
quan trọng trong tiến trình phát triển, như Trắc nghiệm trí tuệ Simon-
Binet được xây dựng bởi hai nhà tâm lý học người Pháp Alfred Binet và
Theodore Simon vào khoảng năm 1905, tiếp đến được áp dụng tại Đại
học Stanford ở Mỹ bởi Lewis Terman năm 1916, sau đó nó đã được cải
tiến liên tục và được sử dụng ngày nay với tên gọi là Trắc nghiệm trí tuệ
IQ (intelligence quotient). Bộ trắc nghiệm thành quả học tập tổng hợp
đầu tiên Stanford Achievement Test ra đời vào năm 1923 ở Mỹ. Với việc
đưa vào chấm trắc nghiệm bằng máy của IBM năm 1935, việc thành lập
Hội quốc gia về Đo lường trong giáo dục (National Council on
Measurement in Education - NCME) vào thập niên 1950, sự ra đời hai tổ
chức tư nhân Educational Testing Service (ETS) năm 1947 và American
College Testing (ACT) năm 1959, hai tổ chức làm dịch vụ trắc nghiệm
lớn thứ nhất và thứ hai Hoa Kỳ, một ngành công nghiệp về trắc nghiệm
đã hình thành ở Mỹ. Từ đó đến nay khoa học về đo lường trong tâm lý và
giáo dục đã phát triển liên tục, những phê bình chỉ trích đối với khoa học
này cũng xuất hiện thường xuyên nhưng chúng không đánh đổ được nó
mà chỉ làm cho nó tự điều chỉnh và phát triển mạnh mẽ hơn. Hiện nay ở
Mỹ ước tính mỗi năm số lượt trắc nghiệm tiêu chuẩn hoá cỡ 1/4 tỷ và
trắc nghiệm do giáo viên soạn lên đến con số 5 tỷ. Tương ứng với ngành
công nghiệp trắc nghiệm đồ sộ và sự phát triển của công nghệ thông tin,

19
lý thuyết về đo lường trong tâm lý giáo dục cũng phát triển nhanh. Các
thành tựu lý luận quan trọng của khoa học về đo lường trong giáo dục đạt
được cho đến thập niên 70 của thế kỷ trước được bao gồm trong "Lý
thuyết trắc nghiệm cổ điển" (Classical Test Theory - CTT). Còn bước
phát triển về chất của nó trong khoảng 4 thập niên vừa qua bao gồm
trong “Lý thuyết trắc nghiệm hiện đại” mà cốt lõi là "Lý thuyết Ứng đáp
Câu hỏi" (Item Response Theory - IRT). IRT đã đạt được những thành
tựu quan trọng nâng cao độ chính xác của trắc nghiệm, và trên cơ sở lý
thuyết đó, công nghệ Trắc nghiệm thích ứng nhờ máy tính (Computer
Adaptive Test – CAT) ra đời. Ngoài ra, trên cơ sở những thành tựu của
IRT và ngôn ngữ học máy tính, công nghệ Criterion chấm tự động các
bài tự luận tiếng Anh nhờ máy tính của ETS đã được triển khai qua mạng
Internet trong mấy năm qua.
1.3. PHÂN LOẠI CÁC MỤC TIÊU GIÁO DỤC
Để thiết kế quá trình dạy, học và đánh giá kết quả học tập, xác định
rõ các mục tiêu của hoạt động giáo dục là rất quan trọng. Tại Hội nghị
của Hội Tâm lý học Mỹ năm 1948, B. S. Bloom đã chủ trì xây dựng một
hệ thống phân loại các mục tiêu đó. Ba lĩnh vực của các hoạt động giáo
dục đã được xác định, đó là lĩnh vực về nhận thức (cognitive domain),
lĩnh vực về cảm xúc, thái độ (affective domain) và lĩnh vực về tâm lý vận
động (kỹ năng) (psychomotor domain).
Lĩnh vực nhận thức thể hiện ở khả năng suy nghĩ, lập luận, bao
gồm việc thu thập các sự kiện, giải thích, lập luận theo kiểu diễn dịch và
quy nạp và sự đánh giá có phê phán.
Lĩnh vực cảm xúc liên quan đến những đáp ứng về mặt tình cảm,
bao hàm cả những mối quan hệ như yêu ghét, thái độ nhiệt tình, thờ ơ,
cũng như sự cam kết với một nguyên tắc và sự tiếp thu các lý tưởng.
Lĩnh vực tâm lý vận động liên quan đến những kỹ năng đòi hỏi sự
khéo léo về chân tay, sự phối hợp các cơ bắp và khả năng của thân thể từ
đơn giản đến phức tạp để điều phối động tác.
Các lĩnh vực nêu trên không hoàn toàn tách biệt hoặc loại trừ lẫn
nhau. Phần lớn việc phát triển tâm linh và tâm lý đều bao hàm cả 3 lĩnh
vực nói trên.

20
1) Lĩnh vực nhận thức
Bloom và những người cộng tác với ông ta cũng xây dựng nên các
mức độ của các mục tiêu giáo dục, thường được gọi là cách phân loại
Bloom, trong đó lĩnh vực nhận thức được chia thành các mức độ nhận
thức (hay mức độ thao tác xử lý kiến thức) từ đơn giản nhất đến phức tạp
nhất như sau [32]:
- Biết (Knowledge): được định nghĩa là sự nhớ, thuộc lòng, nhận
biết được và có thể tái hiện các dữ liệu, các sự việc đã biết hoặc đã học
được trước đây. Điều đó có nghĩa là một người có thể nhắc lại một loạt
dữ liệu, từ các sự kiện đơn giản đến các lý thuyết phức tạp, tái hiện trong
trí nhớ những thông tin cần thiết. Đây là mức độ hành vi thấp nhất đạt
được trong lĩnh vực nhận thức.
- Hiểu (Comprehention): được định nghĩa là khả năng nắm được ý
nghĩa của tài liệu. Điều đó có thể thể hiện bằng việc chuyển tài liệu từ
dạng này sang dạng khác (từ các ngôn từ sang số liệu…), bằng cách giải
thích tài liệu (giải nghĩa hoặc tóm tắt), mô tả theo ngôn từ của mình và
bằng cách ước lượng xu hướng tương lai (dự báo các hệ quả hoặc ảnh
hưởng). Hành vi ở mức độ này cao hơn so với mức độ biết, và cũng bao
gồm cả mức độ biết.
- Áp dụng (Application): được định nghĩa là khả năng sử dụng các
tài liệu đã học vào một hoàn cảnh cụ thể mới. Điều đó có thể bao gồm
việc áp dụng các quy tắc, phương pháp, khái niệm, nguyên lý, định luật
và lý thuyết. Hành vi ở mức độ này cao hơn mức độ biết và hiểu trên đây,
và cũng bao gồm cả các mức độ đó.
- Phân tích (Analysis): được định nghĩa là khả năng phân chia một
tài liệu ra thành các phần của nó sao cho có thể hiểu được các cấu trúc tổ
chức của nó. Điều đó có thể bao gồm việc chỉ ra đúng các bộ phận, phân
tích mối quan hệ giữa các bộ phận, và nhận biết được các nguyên lý tổ
chức của chúng. Hành vi ở mức độ này cao hơn so với mức độ biết, hiểu
và áp dụng, và cũng bao gồm cả các mức độ đó, vì nó đòi hỏi một sự thấu
hiểu cả nội dung và hình thái cấu trúc của tài liệu.
- Tổng hợp (Synthesis): được định nghĩa là khả năng sắp xếp các
bộ phận lại với nhau để hình thành một tổng thể mới. Điều đó có thể bao

21
gồm việc tạo ra một cuộc giao tiếp đơn nhất (chủ đề hoặc bài phát biểu),
một kế hoạch hành động (dự án nghiên cứu), hoặc một mạng lưới các
quan hệ trừu tượng (sơ đồ để phân lớp thông tin). Hành vi ở mức độ này
cao hơn so với các mức độ biết, hiểu, áp dụng, phân tích, và cũng bao
gồm cả các mức độ đó, nó nhấn mạnh các yếu tố sáng tạo, đặc biệt tập
trung vào việc hình thành các mô hình hoặc cấu trúc mới.
- Đánh giá (Evaluation): là khả năng xác định giá trị của tài liệu,
phán quyết được về những tranh luận, bất đồng ý kiến (tuyên bố, tiểu
thuyết, thơ, báo cáo nghiên cứu). Việc đánh giá dựa trên các tiêu chí nhất
định. Đó có thể là các tiêu chí bên trong (cách tổ chức) hoặc các tiêu chí
bên ngoài (phù hợp với mục đích), và người đánh giá phải tự xác định
hoặc được cung cấp các tiêu chí. Hành vi ở mức độ này cao hơn so với
tất cả các mức độ biết, hiểu, áp dụng, phân tích, tổng hợp, và cũng bao
gồm tất cả các mức độ đó.
Cách phân chia mức độ thao tác xử lý kiến thức của lĩnh vực nhận
thức trên đây do nhóm các nhà tâm lý học được chủ trì bởi B. Bloom đưa
ra từ cách đây hơn nửa thế kỷ. Vào năm 2001, các học trò cũ của Bloom là
Anderson L.W. và Krathwohl D.R. [33], sau một quá trình bàn luận với
một số nhà tâm lý học, đã đưa ra phương án điều chỉnh phân loại mục tiêu
trong lĩnh vực nhận thức của Bloom. Nội dung chính của điều chỉnh bởi
Anderson và Krathwohl là thay 2 thao tác xử lý kiến thức tổng hợp và
đánh giá ở mức độ thứ 5 và thứ 6 tương ứng bằng đánh giá và sáng tạo.
Ngoài ra, họ mô tả các thao tác xử lý kiến thức bằng các động từ thay vì
danh từ như trước đây (trong tiếng Anh), và tạo thành một ma trận phân
loại 2 chiều bằng cách, cùng với chiều đứng biểu diễn 6 thao tác xử lý kiến
thức, đưa vào thêm chiều ngang biểu diễn 4 loại kiến thức liên quan đến sự
vật (factual), khái niệm (conceptual), quy trình (procedural) và siêu nhận
thức (metacornitive). Hiện nay trong cộng đồng giáo dục thế giới sử dụng cả
hai cách phân loại cổ điển và điều chỉnh tùy theo thói quen của từng người.
2) Lĩnh vực tình cảm: lĩnh vực tình cảm được phân chia thành các
mức độ hành vi từ đơn giản nhất đến phức tạp nhất như sau:
- Tiếp nhận (Receiving): thể hiện sự tự nguyện tiếp nhận thông tin,
sự quan tâm có lựa chọn.

22
- Đáp ứng (Responding): thể hiện sự quan tâm tích cực để tiếp
nhận, sự tự nguyện đáp ứng và cảm giác thỏa mãn.
- Chấp nhận giá trị (Valuing): thể hiện niềm tin và sự chấp nhận
giá trị, sự ưa chuộng và sự cam kết.
- Tổ chức (Organization): thể hiện sự khái quát hóa các giá trị và tổ
chức thành hệ thống giá trị.
- Đặc trưng hóa (Characterization): Đây là cấp độ cao và phức tạp
nhất. Nó bao gồm hành vi liên quan tới việc tiếp nhận một tập hợp các giá
trị và sự khái quát thành đặc trưng của bản thân hay triết lý của cuộc sống.
Cách phân loại mức độ hành vi của lĩnh vực tình cảm trên đây được
đề xuất bởi nhóm nhà tâm lý học do Krathworl D.R. (1964) chủ trì.
3) Lĩnh vực kỹ năng: lĩnh vực kỹ năng được chia thành các mức độ
hành vi từ đơn giản nhất đến phức tạp nhất như sau:
- Bắt chước thụ động (Imitation): Làm theo hành vi của một người
khác một cách thụ động.
- Thao tác theo (Manipulation): Thực hiện được các thao tác theo
một sự hướng dẫn từng bước quy trình.
- Tự làm đúng (Precision): Thực hiện được một nhiệm vụ với sai
sót nhỏ và dần dần chính xác hơn mà không có nguồn hướng dẫn. Thể
hiện thao tác trơn tru, chính xác.
- Khớp nối được (Articulation): Sắp xếp được một chuỗi thao tác
bằng cách kết hợp hai hay nhiều kỹ năng, có thể cải tiến thao tác cho phù
hợp để giải quyết một vấn đề gì đó.
- Thao tác tự nhiên (Naturalisation): Chứng tỏ mức độ thực hiện
thao tác một cách tự nhiên như bản hăng (”không cần suy nghĩ”). Các kỹ
năng được kết hợp, thao tác trình tự, thực hiện nhất quán dễ dàng, tức là
mất ít năng lượng và thời gian.
Cách phân loại mức độ hành vi của lĩnh vực kỹ năng trên đây được
Dave R.H. (1970) đề xuất.
Ngoài ra còn có một số cách phân loại mục tiêu giáo dục khác,
nhưng trên đây là các cách được sử dụng phổ biến nhất.

23
1.4. PHÂN LOẠI CÁC PHƯƠNG PHÁP ĐO LƯỜNG VÀ ĐÁNH GIÁ
TRONG GIÁO DỤC
Có nhiều kiểu phân loại các phương pháp đo lường và đánh giá
trong giáo dục, tùy theo cách xem xét và mục tiêu phân loại. Chúng ta
hãy làm quen với một số kiểu phân loại sau đây.
1) Theo cách thực hiện việc đánh giá, có thể phân chia các phương
pháp đánh giá làm ba loại quan trọng: loại quan sát, loại vấn đáp và loại
viết (xem Bảng 1).
- Loại quan sát giúp đánh giá các thao tác, các hành vi, các phản ứng
vô thức, các kỹ năng thực hành và cả một số kỹ năng về nhận thức, chẳng
hạn cách giải quyết vấn đề trong một tình huống đang được nghiên cứu.
- Loại vấn đáp có tác dụng tốt để đánh giá khả năng ứng đáp các
câu hỏi được nêu một cách tự phát trong một tình huống cần kiểm tra,
cũng thường được sử dụng khi sự tương tác giữa người hỏi và người đối
thoại là quan trọng, chẳng hạn để xác định thái độ người đối thoại...
- Loại viết thường được sử dụng nhiều nhất, vì nó có các ưu điểm sau:
+ cho phép kiểm tra nhiều thí sinh cùng một lúc;
+ cho phép thí sinh cân nhắc nhiều hơn khi trả lời;
+ có thể đánh giá một số thao tác tư duy ở mức độ cao;
+ cung cấp các bản ghi trả lời của thí sinh để nghiên cứu kỹ khi
chấm điểm;
+ dễ quản lý vì người chấm không tham gia trực tiếp vào bối cảnh
kiểm tra.
Loại viết lại được chia thành hai nhóm chính:
+ Nhóm các câu hỏi (CH) trắc nghiệm tự luận (TL- essay test): Các
CH buộc thí sinh (TS) phải tự mình trình bày ý kiến trong một đoạn bài
viết để trả lời.
+ Nhóm các CH trắc nghiệm khách quan (TNKQ - objective test):
Đề thi thường bao gồm rất nhiều CH, mỗi CH nêu lên vấn đề và cho
những thông tin cần thiết để TS có thể trả lời một cách ngắn gọn.

24
Bảng 1 còn mô tả hai kiểu bài tự luận, và các loại CH TNKQ. Mục 1.5
sẽ mô tả kỹ hơn các loại CH đó. Ở nước ta nhiều người thường gọi tắt
TNKQ là “trắc nghiệm”. Thuận theo thói quen ấy, từ nay về sau nếu
trong sách này dùng từ “trắc nghiệm” mà không nói gì thêm thì ta ngầm
hiểu là TNKQ.
Bảng 1. Phân loại các phương pháp đánh giá thành quả học tập theo cách thực hiện việc đánh giá
2) Theo mục tiêu của việc đánh giá có thể phân chia các phương
pháp đánh giá làm hai nhóm: đánh giá trong tiến trình (formative) và
đánh giá tổng kết (summative).
- Đánh giá trong tiến trình được sử dụng trong quá trình dạy và học
để nhận được các phản hồi từ học viên, xem xét mức độ thành công của
việc dạy và học, chỉ ra các trở ngại và tìm cách khắc phục.
- Đánh giá tổng kết nhằm tổng kết những gì học viên đạt được, xếp
loại học viên, lựa chọn học viên thích hợp để tiếp tục đào tạo hoặc sử
dụng trong tương lai, chứng tỏ hiệu quả của khóa học cũng như việc dạy
của giảng viên, đề ra mục tiêu tương lai cho học viên.
Hai nhóm đánh giá nêu trên được tiến hành theo những cách hoàn
toàn khác nhau. Trong giảng dạy ở nhà trường, các đánh giá trong tiến trình
Cung cấp thông tin
QUAN SÁT VIẾT VẤN ĐÁP
TRẮC NGHIỆM KHÁCHQUAN (Objective tests)
TRẮC NGHIỆM TỰ LUẬN (Essay tests)
CÁC PHƯƠNG PHÁP ĐÁNH GIÁ THÀNH QUẢ HỌC TẬP
Tiểu luận
Ghép đôi
Điền khuyết
Trả lời ngắn
Đúng sai
Nhiều lựa chọn

25
thường gắn chặt với giảng viên, còn các đánh giá tổng kết thường bám sát
vào mục tiêu dạy học đã được đề ra, và có thể tách khỏi giảng viên. Khi chỉ
quan tâm đến mục tiêu của hai phương pháp đánh giá trên đây, người ta
thường diễn tả ngắn gọn hai loại phương pháp nêu trên tương ứng là đánh
giá vì việc học tập (assessment FOR learning) và đánh giá việc học tập
(assessment OF learning).
3) Theo phương hướng sử dụng kết quả đánh giá, có thể phân chia
ra đánh giá theo chuẩn (norm-referenced) và đánh giá theo tiêu chí
(criterion-referenced)
- Đánh giá theo chuẩn: là đánh giá được sử dụng để xác định mức
độ thực hiện của một cá nhân nào đó so với các cá nhân khác trong một
nhóm mà trên đó việc đánh giá được thực hiện.
- Đánh giá theo tiêu chí: là đánh giá được sử dụng để xác định mức
độ thực hiện của một cá nhân nào đó so với các tiêu chí xác định cho
trước của môn học hoặc chương trình học.
4) Theo cách chuẩn bị cuộc đánh giá, có thể phân chia đánh giá
theo hai nhóm, đánh giá tiêu chuẩn hoá và đánh giá ở lớp học.
- Đánh giá tiêu chuẩn hoá thường do các chuyên gia đánh giá thiết
kế, thử nghiệm, tu chỉnh công cụ đánh giá, soạn thảo quy trình đánh giá và
sử dụng kết quả đánh giá. Nếu đánh giá bằng TNKQ thì mỗi CH trắc
nghiệm được gắn với các chỉ số cho biết thuộc tính và chất lượng của nó
(độ khó, độ phân biệt và các tham số khác đặc trưng cho CH, nội dung và
mức độ kỹ năng gắn với CH), mỗi ĐTN phải đảm bảo có độ tin cậy và độ
giá trị xác định.
- Đánh giá ở lớp học là đánh giá chủ yếu do giáo viên tự chế tác
hoặc lựa chọn để sử dụng trong quá trình giảng dạy, có thể chưa được thử
nghiệm và tu chỉnh công phu, thường chỉ sử dụng ở lớp học hoặc trong các
kỳ kiểm tra với số lượng học sinh không lớn và không thật quan trọng.
5) Theo mức độ đảm bảo thời gian để làm đề kiểm tra, có thể phân
chia loại đánh giá theo tốc độ và đánh giá không theo tốc độ.
- Đánh giá theo tốc độ thường hạn chế thời gian, chỉ một ít TS làm
nhanh mới có thể làm hết số CH của đề kiểm tra, nhằm đánh giá khả
năng làm nhanh của TS.

26
- Đánh giá không theo tốc độ thường cung cấp đủ thời gian cho
phần lớn TS có thể kịp suy nghĩ để làm hết đề kiểm tra.
1.5. CÁC KIỂU CÂU HỎI TRẮC NGHIỆM KHÁCH QUAN
Như đã mô tả ở Bảng 1, trong nhóm TNKQ có nhiều kiểu CH
khác nhau:
- Câu ghép đôi (matching item) đòi hỏi TS phải ghép đúng từng
cặp dòng ở hai cột với nhau sao cho phù hợp về một phương diện nào đó.
Ví dụ câu trắc nghiệm về văn học:
Hãy tìm ở cột bên phải tên tác giả của hai câu thơ liệt kê ở cột
bên trái:
1. Hồ Tây cảnh đẹp hoá gò hoang
Thổn thức bên song mảnh giấy tàn
2. Rặng liễu đìu hiu đứng chịu tang
Tóc buồn buông xuống lệ ngàn hàng
3. Bóng chiều không thắm, không vàng vọt
Sao đầy hoàng hôn trong mắt trong
4. Con đường nhỏ nhỏ, gió xiêu xiêu
Lả lả cành hoang, nắng trở chiều
5. Ở ngoài kia vui sướng biết bao nhiêu
Nghe chim reo trong gió mạnh lên triều
a. Thâm Tâm
b. Xuân Diệu
c. Huy Cận
d. Nguyễn Du
e. Hàn Mặc tử
g. Tố Hữu
Đáp án: 1-d, 2-b, 3-a, 4-b, 5-g
Đối với loại CH ghép đôi, người ta thường cho số dòng ở cột bên
trái không bằng số dòng ở cột bên phải, vì rằng khi số dòng ở hai phía
bằng nhau thì hai dòng cuối cùng sẽ mặc nhiên được ghép với nhau mà
không phải lựa chọn.
- Câu điền khuyết (supply item): nêu một mệnh đề có khuyết một
bộ phận, TS phải nghĩ ra nội dung thích hợp để điền vào chỗ trống.
Ví dụ câu trắc nghiệm về lịch sử:
Ngày 2 tháng 9 năm 1945 Chủ tịch Hồ Chí Minh đã
đọc.................... khai sinh nước Việt Nam Dân chủ Cộng hòa.

27
Đáp án: Tuyên ngôn độc lập.
- Câu trả lời ngắn (short answer item): là câu trắc nghiệm chỉ đòi
hỏi trả lời bằng một từ hoặc cụm từ chỉ một khái niệm nào đó, rất ngắn.
Ví dụ câu trắc nghiệm về sinh học:
Nguyên nhân hình thành các đặc điểm thích nghi của sinh vật là gì?
Đáp án: Chọn lọc tự nhiên.
- Câu đúng sai (yes/no item): đưa ra một nhận định, TS phải lựa
chọn một trong hai phương án trả lời để khẳng định nhận định đó là đúng
hay sai. Ví dụ câu trắc nghiệm về hoá học:
Sự khử là quá trình nhường electron.
A) Đúng. B) Sai.
Đáp án: B
- Câu nhiều lựa chọn (NLC - multiple choise item) đưa ra một nhận
định và một số phương án trả lời, TS phải chọn để đánh dấu vào một
phương án đúng hoặc phương án tốt nhất. Ví dụ CH trắc nghiệm về toán:
Hãy xác định giá trị của số hạng thứ bảy trong dãy các số "tam
giác" mà 4 số hạng đầu được biểu diễn bởi các hình dưới đây:
A. 7 B. 22 C. 25 D.28
Đáp án: D
Muốn làm được câu này cần xác định quy luật hình thành mỗi số
hạng của dãy: số hạng thứ n có giá trị là 1+2+3+…+n, từ đó dễ dàng suy
ra số hạng thứ 7 là 1+2+3+4+5+6+7 = (7+1)x3+4=28.
- Câu thí sinh tự tạo đáp án (student-produced responses item) là
loại CH có đáp án bằng số mà trắc nghiệm SAT cải tiến mới đưa vào vào

28
năm 2005 để giảm bớt sự lệ thuộc của TS vào cái khung trả lời định sẵn.
TS có thể tô giá trị trả lời bằng số vào phiếu trả lời có dạng thức xác
định, do đó có thể chấm bằng máy. Ví dụ:
Tính giá trị của x thỏa mãn 2 phương trình: |4x - 7| = 5 và |3x -8| = 1.
Giải: Vì |4x - 7| = 5 nên 4x-7=±5 x= 3 hoặc x= 1/2.
Tương tự |3x -1| = x → 3x-1=±x x=1/4 hoặc x= 1/2. Như vậy
giá trị x thỏa mãn hai phương trình trên là x= 1/2. TS phải tô các ô biểu
diễn số 1/2 trên phiếu trả lời.
Trong các kiểu câu trắc nghiệm đã nêu, kiểu CH đúng-sai và kiểu
CH NLC có cách trả lời đơn giản nhất. CH đúng-sai cũng chỉ là trường
hợp riêng của CH NLC với 2 phương án trả lời.
Dễ dàng thấy rằng khi một người hoàn toàn không có hiểu biết chỉ
đánh dấu hú hoạ để trả lời một CH đúng - sai thì xác suất để người đó làm
đúng CH là 50%, cũng vậy nếu anh ta đánh dấu hú hoạ để trả lời câu trắc
nghiệm NLC với n phương án trả lời thì xác suất để làm đúng câu đó là 1/n.
Trong các kiểu CH trắc nghiệm, kiểu câu NLC được sử dụng phổ
biến hơn cả vì, một mặt, chúng có cấu trúc đơn giản, dễ xây dựng thành
các đề thi, dễ chấm điểm tự động, mặt khác, chúng cho phép đánh giá
được nhiều cấp độ nhận thức từ thấp đến cao. Vì vị trí quan trọng của
kiểu CH NLC nên sau đây chúng ta sẽ nói kỹ hơn về chúng. Loại CH
NLC thường dùng nhất là loại có 4 hoặc 5 phương án trả lời, vì số
phương án như vậy vừa đủ để giảm xác suất làm đúng do đoán mò hú
họa xuống tương ứng còn 25%, 20%, đồng thời việc chế tác chúng cũng
không quá phức tạp.
Câu trắc nghiệm NLC có hai phần, phần đầu được gọi là câu dẫn
(stem), nêu vấn đề, cung cấp thông tin cần thiết hoặc đặt một CH; phần sau
là các phương án chọn, thường được đánh dấu bằng các chữ cái A, B, C,
D,... hoặc các chữ số 1, 2, 3, 4,... Kiểu CH trắc nghiệm NLC đơn giản nhất
quy định trong các phương án chọn chỉ có một phương án đúng duy nhất
hoặc một phương án đúng nhất; các phương án khác được đưa vào có tác
dụng “gây nhiễu” (distractor) đối với TS. Nếu CH NLC được soạn tốt thì
một người không nắm vững vấn đề sẽ không thể nhận biết được trong tất

29
cả các phương án để chọn đâu là phương án đúng, đâu là phương án nhiễu.
Trong khi soạn thảo CH trắc nghiệm, người ta thường cố gắng làm cho các
phương án nhiễu đều có vẻ dường như “có lý” tựa như phương án đúng.
Về nguyên tắc, đối với người có kinh nghiệm chế tác CH, một nội
dung bất kỳ nào cần kiểm tra đều có thể được thể hiện vào một CH trắc
nghiệm theo một kiểu nào đó. Vì thế đối với tất cả các môn học người ta đều
có thể chế tác CH trắc nghiệm. Tuy nhiên, do đặc thù của từng môn học mà
việc chế tác CH trắc nghiệm cho môn này có thể khó hơn cho môn kia.
Cũng cần lưu ý rằng không phải bất cứ ai có kiến thức chuyên môn
cũng chế tác được CH trắc nghiệm có chất lượng cao cho chuyên môn
đó. Muốn chế tác CH trắc nghiệm tốt phải suy nghĩ sâu sắc về chuyên
môn, phải có những hiểu biết cơ bản về trắc nghiệm và cần tích lũy kinh
nghiệm sau một thời gian luyện tập lâu dài.
1.6. SO SÁNH CÁC PHƯƠNG PHÁP TRẮC NGHIỆM KHÁCH QUAN
VÀ TỰ LUẬN
1.6.1. Các đặc điểm của phương pháp TL
- Cho phép TS tương đối tự do trong việc lựa chọn cách bố cục,
trình bày để diễn đạt ý kiến của mình nhằm trả lời một CH sao cho chính
xác và sáng sủa.
- Trong phạm vi thời gian hạn chế (một vài giờ) đề thi chỉ có thể
hỏi vài chủ đề nào đó của môn học. Vì có quá ít chủ đề được đề cập nên
việc đánh giá không phủ kín được nội dung môn học, dễ xảy ra hiện
tượng "trúng tủ, trật tủ" tạo nên mức độ may rủi lớn trong thi cử.
- TS muốn trình bày phần kiến thức nào đó của môn học phải nhớ
lại hơn là nhận biết thông tin.
- Bài thi TL thường được người chấm đọc, đánh giá cho điểm theo
nhận định chủ quan của mình, vì vậy các điểm cho bởi những người
chấm khác nhau thường dễ không thống nhất.
1.6.2. Các đặc điểm của phương pháp TNKQ
- TS phải trả lời các CH TNKQ theo các phương án trả lời cho sẵn,
thông thường một CH chỉ có một phương án là đúng duy nhất hoặc đúng

30
nhất, phù hợp nhất. Như vậy, TS trả lời TNKQ theo một khuôn khổ định
sẵn, không thể đưa ra các ý kiến nào khác của mình.
- Vì thời gian cần thiết để trả lời một CH trắc nghiệm thường rất
ngắn nên một ĐTN KQ có thể bao gồm rất nhiều CH, có thể đánh giá bao
trùm chương trình của cả một môn học, điều này hạn chế việc học tủ và
việc "trúng tủ, trật tủ", tức là hạn chế độ may rủi trong thi cử.
- Kiến thức giúp TS lựa chọn đúng các phương án trả lời các CH
trắc nghiệm, tuy nhiên TS không có kiến thức cũng có thể "đoán mò" để
trả lời hoặc trả lời hú họa, dù rằng việc đoán mò đó cũng không dẫn "ăn
may" khi ĐTN có số CH đủ lớn (theo dõi ví dụ trình bày dưới đây).
- TS có thể nhận biết kiến thức qua các CH trắc nghiệm chứ không
cần phải nhớ lại để trình bày.
- Bài TNKQ thường được chấm điểm bằng cách so sánh xem việc
chọn phương án đúng của TS có trùng với đáp án cho sẵn hay không một
cách máy móc, do đó người chấm điểm không đưa ra quan điểm riêng để
đánh giá ĐTN mà chỉ cần đếm một cách máy móc. Từ đó TNKQ có thể
được chấm bằng máy. Chính do tính khách quan của việc chấm điểm mà
người ta gọi loại trắc nghiệm đó là trắc nghiệm khách quan.
- Việc xử lý định lượng kết quả TNKQ nhờ khoa học thống kê đã
đạt được nhiều thành tựu quan trọng. Chính vì vậy, đối với TNKQ có các
phương pháp định lượng để nâng cao chất lượng của từng CH và có quy
trình tạo các ĐTN tốt để đo chính xác năng lực của TS. Ưu thế này làm
cho TNKQ được sử dụng phổ biến trong các đánh giá tiêu chuẩn hóa.
Có một câu hỏi thường nảy sinh: trong hai phương pháp TNKQ và
TL, phương pháp nào tốt hơn? Cần phải khẳng định ngay rằng không thể
nói phương pháp nào là hoàn toàn tốt hơn, mỗi phương pháp đều có các
ưu điểm và nhược điểm nhất định. Bảng so sánh dưới đây cho thấy tuỳ
theo từng yêu cầu trong việc đánh giá, ưu thế thuộc về phương pháp nào.
Ở Bảng 2 có đưa ra bảng tóm tắt so sánh các ưu thế của phương
pháp TNKQ và TL đối với các yêu cầu khác nhau của việc đánh giá
trong giáo dục. Tuy nhiên, để làm rõ hơn một số ưu thế của TNKQ được

31
nêu trong Bảng 2, dưới đây sẽ bàn tỉ mỉ một vài vấn đề quan trọng về ưu
thế của TNKQ và TL mà nhiều bạn đọc còn nhầm lẫn.
Bảng 2. So sánh ưu thế của phương pháp trắc nghiệm khách quan và tự luận theo các yêu cầu trong việc đánh giá
Yêu cầu
Ưu thế thuộc
về phương pháp
Trắc
nghiệm
Tự luận
Ít tốn công ra đề thi
Đánh giá được khả năng diễn đạt, đặc biệt là diễn đạt
tư duy hình tượng
Thuận lợi cho việc đo lường các tư duy sáng tạo
Đề thi phủ kín nội dung môn học
Ít may rủi do trúng tủ, trật tủ
Ít tốn công chấm thi
Khách quan trong chấm thi, hạn chế tiêu cực trong
chấm thi
Giữ bí mật đề thi, hạn chế quay cóp khi thi
Có tính định lượng cao, áp dụng được công nghệ đo
lường trong việc phân tích xử lý để nâng cao chất
lượng các câu hỏi và đề thi.
Cung cấp số liệu chính xác và ổn định để sử dụng
cho các đánh giá so sánh trong giáo dục
Trước hết chúng ta hãy bàn về sự may rủi. Phương ngôn nước ta
có câu "học tài, thi phận" để nói lên sự may rủi trong thi cử. Khẳng định
đó không hoàn toàn đúng, nhưng trong cuộc sống đôi khi cũng có thể
hiện. Vậy nếu có sự may rủi trong thi cử thì phương pháp nào tạo sự
may rủi nhiều hơn, TNKQ hay TL? Với kiểu đánh dấu có vẻ giản đơn
khi làm một ĐTN, một số người tưởng rằng một TS không có chút kiến
thức nào cũng có thể làm tốt bài thi nếu “số đỏ” giúp anh ta đánh dấu
đúng vào những chỗ cần thiết. Từ suy nghĩ đó họ nhầm tưởng rằng đề

32
thi TNKQ tạo nên sự may rủi nhiều hơn đề thi TL. Thực ra hoàn toàn
ngược lại! Vì một đề thi TL thường chỉ liên quan đến một vài chủ đề
của môn học nên TS rất dễ gặp may rủi do "trúng tủ, trật tủ", còn với đề
thi TNKQ có số CH đủ lớn (ba bốn chục câu trở lên) thì sự may rủi hầu
như hoàn toàn không xảy ra. Thật vậy, như đã nói ở trên, đề thi TNKQ
bao gồm rất nhiều CH nhỏ phủ kín chương trình môn học. Nếu TS nắm
chắc nội dung môn học thì sẽ làm đúng phần lớn các CH trắc nghiệm.
Trong trường hợp TS quên hoặc không nắm vững một vài chi tiết của
môn học thì một số ít CH không làm được cũng không ảnh hưởng lớn
đến kết quả của bài thi. Ngược lại, đề thi TL thường chỉ liên quan đến
một vài chủ đề của môn học, do đó ngoài những TS học chắc thật sự,
những TS không học chắc nhưng ăn may “trúng tủ” cũng sẽ đạt kết quả
cao, còn “trật tủ” sẽ bị đánh hỏng, bất kể kiến thức của anh ta về phần
lớn nội dung còn lại của môn học như thế nào. Vậy “số đỏ” có bao giờ
đến với một TS "mít đặc" không có một hiểu biết nào mà chỉ đánh dấu
“hú họa” vào bài thi hay không? Có thể khẳng định là không bao giờ!
Thật vậy, giả sử một ĐTN gồm các CH NLC với 5 phương án trả lời,
xác suất đánh dấu “hú họa” để làm đúng một CH là 1/5. Khi số CH ít
tần suất làm đúng của TS thăng giáng rất nhiều, có thể đạt giá trị khá
lớn, giúp TS “ăn may”. Tuy nhiên, khi số CH (số phép thử) tăng lên đến
một giá trị đủ lớn, tần suất làm đúng sẽ tiến dần đến xác suất làm đúng,
tức là chỉ đạt giá trị gần với 1/5 (xem "luật số lớn" trong lý thuyết xác
suất ở mục 2.1). Nếu ĐTN có 100 CH, TS “mít đặc” sẽ chỉ làm đúng
trên dưới 20 CH. Theo cách cho điểm trắc nghiệm thông thường, người
ta thường chưa tính điểm cho một bài trắc nghiệm khi số CH trả lời
đúng nằm dưới ngưỡng làm đúng do “đoán mò” đó. Nếu tính xác suất
để một TS "mít đặc" làm đúng hoàn toàn đề trắc nghiệm nói trên thì con
số thu được còn bé hơn nữa, chỉ bằng (1/5)100. Ngoài ra, lý thuyết trắc
nghiệm hiện đại mà chúng ta sẽ làm quen ở Phần II của tập sách này
còn nâng cao độ chính xác và loại trừ khả năng "ăn may" ngay với các
ĐTN với chỉ vài chục CH.
Một quan niệm cũng thường được bàn đến là ý kiến cho rằng
phương pháp TNKQ chỉ đánh giá được khả năng ghi nhớ chứ không đo

33
được những khả năng nhận thức ở mức độ cao. Thật ra những người chế
tác CH trắc nghiệm chuyên nghiệp có khả năng chế tác các CH TNKQ
thích hợp để đánh giá tất cả 6 mức độ xử lý kiến thức trong lĩnh vực nhận
thức đã nêu trước đây. Ở mục 1.8 dưới đây chúng ta sẽ làm quen với một
số ví dụ về cách chế tác các CH để đánh giá các mức độ nhận thức như
vậy. Tất nhiên chế tác những CH để đánh giá mức độ nhận thức cao
thường khó hơn so với để đánh giá mức độ nhận thức thấp, nên những
người mới biết chế tác CH trắc nghiệm thường có thiên hướng chế tác CH
trắc nghiệm thuộc loại sau. Hiện nay trên truyền hình liên tục có những kỳ
thi sử dụng các loại CH trắc nghiệm, nhưng hầu hết các CH cho các kỳ thi
này chỉ đo lường mức độ nhận thức thấp nhất, tức là hỏi người thi có nhớ
hoặc biết một sự kiện nào đó hay không. Các chương trình truyền hình có
thể sử dụng loại CH tầm thường như vậy vì mục tiêu chủ yếu của các
chương trình đó không phải là đánh giá chính xác năng lực của những
người tham gia, mà để phổ biến các thông tin trong các CH cho đông đảo
khán giả trước màn hình. Ở đây, việc đánh giá năng lực và thứ hạng của
những người tham gia chỉ là mục tiêu phụ, để làm cho chương trình thêm
hấp dẫn. Các nhà giáo không nên nghĩ là có thể chỉ sử dụng các CH trắc
nghiệm tầm thường như ở các chương trình trên truyền hình để đánh giá
người học. Trắc nghiệm để đo lường thành quả học tập trong giáo dục đòi
hỏi đánh giá chính xác năng lực của người được trắc nghiệm, nên cần có
nhiều CH nhằm đo lường các mức độ nhận thức cấp cao, chẳng những nhớ
và hiểu mà còn áp dụng, phân tích, tổng hợp, đánh giá. Đưa ra các ý kiến
trên đây chúng tôi muốn loại bỏ quan niệm không đúng là phương pháp
TNKQ chỉ đánh giá được khả năng ghi nhớ. Tuy nhiên, phải thừa nhận là
để đánh giá khả năng sáng tạo ở mức độ rất cao thì phương pháp TNKQ bị
hạn chế hơn phương pháp TL, vì làm bài TNKQ bị giới hạn ở việc trả lời
trong những cái khung định sẵn. Do đó, trong quá trình giảng dạy rất cần
sử dụng nhiều phương pháp đo lường đánh giá khác nhau để tận dụng ưu
điểm và hạn chế nhược điểm của từng phương pháp.
Chúng ta hãy bàn thêm một chút về khả năng hạn chế nạn gian lận
quay cóp trong thời gian làm bài thi. Đối với TNKQ, với phạm vi bao
quát rộng của đề thi, TS khó có thể chuẩn bị tài liệu để "quay". Vậy liệu
họ có "cóp" bài của nhau được không? Nếu trong một phòng thi mọi

34
người đều làm một đề có hình thức như nhau thì TS rất dễ "cóp" cách tô
đáp án của nhau. Tuy nhiên một giải pháp đơn giản được thực hiện dễ
dàng hiện nay là biến một ĐTN thành nhiều phiên bản cùng nội dung
bằng cách đảo các phương án chọn trong từng CH sao cho các phương
án đúng của các ĐTN nằm ở vị trí khác nhau. Các TS ngồi gần nhau sẽ
nhận được các ĐTN hoàn toàn khác nhau về hình thức, họ sẽ phải đánh
dấu vào phiếu trả lời theo những cách hoàn toàn khác nhau, do đó họ
không thể "cóp" bài của nhau. Đây là một giải pháp chống "cóp" bài rất
hữu hiệu (tuy rằng, thực ra thay đổi vị trí các CH và các phương án trả
lời có thể làm thay đổi độ khó của CH trắc nghiệm). Như vậy đối với đề
TNKQ cả "quay" và "cóp" đều khó thực hiện hơn đối với đề TL.
Một ưu điểm nữa cũng đáng lưu ý của TNKQ so với TL là quy trình
xây dựng ĐTN đối với các kỳ thi đại trà. ĐTN có thể được xây dựng theo
một quy trình có rất nhiều người tham gia trong một thời gian đủ dài để
vận dụng "trí tuệ tập thể" nhằm tăng chất lượng và sự an toàn về nội dung,
đồng thời vẫn đảm bảo được tính bí mật, còn đề TL thì muốn đảm bảo tính
bí mật phải hạn chế tối đa số người tham gia ra đề và thời gian làm đề, sự
hạn chế này dễ dẫn đến những sơ suất trong đề thi mà một số ít người ra đề
trong một thời gian ngắn chưa phát hiện được. Thật vậy, đối với TNKQ,
có thể tổ chức cho từng cá nhân hoặc từng nhóm người tham gia soạn thảo
một số lượng rất nhỏ, khoảng 5 - 7 CH trắc nghiệm và thử nghiệm các CH
đó nhiều lần trên từng nhóm nhỏ TS thích hợp (khi thử nghiệm phải thu lại
ĐTN) để phát hiện các sai sót và tu chỉnh, các CH được thử nghiệm này
được đưa vào một NHCH trắc nghiệm đủ lớn. Sau một thời gian chuẩn bị
đủ dài, khi mọi CH trong ngân hàng đó đã đủ hoàn thiện và đảm bảo chất
lượng, người ta mới sử dụng các công nghệ và phần mềm tin học lựa chọn
các CH thích hợp để tạo lập rất nhanh các ĐTN. Quy trình nói trên vừa
đảm bảo tính bí mật vừa tăng độ an toàn cho ĐTN, nhất là các ĐTN cho
các kỳ thi đại trà cấp quốc gia.
Một khác biệt quan trọng giữa phương pháp TNKQ và TL là ở
tính khách quan. Đối với đề TL, kết quả chấm thi phụ thuộc rất nhiều
vào chủ quan của người chấm bài, do đó rất khó công bằng, chính xác.
Để hạn chế mức độ chủ quan đó, người ta có thể cải tiến việc chấm bài

35
TL bằng cách ra trước các đáp án và thang điểm rất chi tiết. Dù vậy,
việc so sánh câu trả lời của TS với đáp án chi tiết cũng tùy thuộc vào
phán xét của người chấm, thường rất khác nhau. Dù với mọi biện pháp
khắc phục tính chủ quan đó, nhiều thử nghiệm cho thấy sự thiên lệch
của kết quả chấm bài TL từ những người chấm khác nhau thường rất
lớn, thậm chí của cùng một người chấm ở những thời điểm với tâm
trạng khác nhau cũng không nhỏ. Tuy nhiên, việc ra đề TL có tính cấu
trúc với các thang điểm tỉ mỉ nếu không khéo cũng có thể dẫn đến nguy
cơ là làm giảm ưu điểm của đề TL về độ “tự do”, và biến đề TL thành
một đề TNKQ tồi.
Tính khách quan, "máy móc" của việc chấm bài TNKQ cho phép
chấm bài trắc nghiệm bằng máy. Hiện nay trên thị trường có các máy
đọc dấu hiệu quang học chuyên dụng (optical mark reader – OMR),
hoặc các máy quét ảnh thông dụng kèm thêm một phần mềm đọc dịch
có thể chấm từ hàng trăm đến hàng chục nghìn bài trong một giờ. Loại
máy quét ảnh ngày càng tốt và rẻ tiền, rất thuận lợi cho các trường học
trang bị để chấm thi trắc nghiệm.
Cuối cùng chúng tôi muốn bàn thêm về ưu thế của TNKQ liên
quan đến các công nghệ xử lý nâng cao chất lượng của từng CH trắc
nghiệm và xây dựng các ĐTN trên cơ sở các lý thuyết trắc nghiệm. Các
lý thuyết này, đặc biệt là lý thuyết trắc nghiệm hiện đại, đã đưa các
phép đo lường trong giáo dục từ loại phép đo lường dường như rất trừu
tượng, định tính và kém chính xác thành một loại phép đo có tính định
lượng cao, có thể so sánh với các phép đo trong khoa học tự nhiên và
kỹ thuật. Một trong những thành tựu quan trọng của khoa học đo lường
hiện đại trong giáo dục là khả năng thiết kế các ĐTN tương đương với
mức độ tương đương rất cao, tạo điều kiện hết sức thuận lợi cho việc
triển khai các hoạt động thi cử. Phần 2 sẽ bàn sâu hơn về khả năng này.
Qua tất cả các phân tích trên đây, chúng ta có thể đi đến một kết
luận tương đối khái quát là chất lượng của phương pháp TNKQ phụ
thuộc chủ yếu vào người làm đề và quy trình làm đề, còn chất lượng
của phương pháp TL chủ yếu phụ thuộc năng lực đánh giá và phẩm chất

36
của người chấm bài. Do đó đối với TNKQ quy trình làm ĐTN (chế tác
CH, phân tích xử lý tu chỉnh từng CH, xây dựng ĐTN theo một công
nghệ khoa học...) là hết sức quan trọng. Nếu làm ĐTN theo một quy
trình không thích hợp thì chẳng những các ưu thế của TNKQ không
được phát huy mà các nhược điểm của nó có thể được nhân lên. Do đó
có thể nói TNKQ là một con dao hai lưỡi, hiệu quả của nó phụ thuộc
nhiều vào năng lực của người dùng dao.
Như vậy cả hai phương pháp, TNKQ và TL, đều là những phương
pháp hữu hiệu để đánh giá kết quả học tập, nhưng mỗi phương pháp có
các ưu nhược điểm nhất định của mình. Cần nắm vững bản chất và công
nghệ triển khai cụ thể của từng phương pháp để có thể sử dụng mỗi
phương pháp đúng quy trình, đúng lúc, đúng chỗ.
Các chuyên gia về đánh giá cho rằng phương pháp TL nên dùng
trong những trường hợp sau:
Khi TS không quá đông;
Khi muốn khuyến khích và đánh giá cách diễn đạt;
Khi muốn tìm hiểu ý tưởng của TS hơn là khảo sát thành quả học tập;
Khi có thể tin tưởng khả năng chấm bài TL của giáo viên là chính xác;
Khi không có nhiều thời gian soạn đề nhưng có đủ thời gian để
chấm bài.
Phương pháp TNKQ nên dùng trong những trường hợp sau:
Khi số TS rất đông;
Khi muốn chấm bài nhanh;
Khi muốn có điểm số đáng tin cậy, không phụ thuộc vào người
chấm bài;
Khi phải coi trọng yếu tố công bằng, vô tư, chính xác và muốn
ngăn chặn sự gian lận khi thi;
Khi muốn đề thi có độ an toàn cao về nội dung và đảm bảo tính bí mật.
Khi muốn kiểm tra một phạm vi hiểu biết rộng, muốn ngăn ngừa
nạn học tủ, học vẹt và giảm thiểu sự may rủi.

37
1.7. SỰ KẾT HỢP TRẮC NGHIỆM KHÁCH QUAN VỚI TỰ LUẬN
TRONG ĐÁNH GIÁ
Trên đây chúng ta đã nghiên cứu tách biệt TNKQ và TL, và nêu
các ưu điểm và nhược điểm của từng phương pháp.
Tuy nhiên, với sự phát triển của khoa học về đo lường trong giáo
dục và về công nghệ TNKQ và TL, có thể thấy rằng không nên tách
biệt hoàn toàn hai phương pháp đánh giá này, xét về hai khía cạnh sau
đây. Một là, để tận dụng được ưu điểm và tránh bớt nhược điểm của
cả hai phương pháp, người ta ngày càng sử dụng nhiều đề kiểm tra có
hỗn hợp các CH TNKQ và TL. Hai là, khi phát triển các mô hình trắc
nghiệm, người ta ngày càng tìm được nhiều mô hình khái quát mà
trong đó TNKQ và TL chỉ là các trường hợp riêng, trong nhiều trường
hợp có thể kết hợp phân tích chung TNKQ và TL trong một bài kiểm
tra. Chương 13 và 14 của giáo trình này, khi xét đến các mô hình trắc
nghiệm đa phân và đa chiều sẽ có giới thiệu các ví dụ liên quan với sự
kết hợp nói trên.
1.8. SỬ DỤNG CÁC CÂU HỎI TRẮC NGHIỆM ĐỂ ĐÁNH GIÁ CÁC
MỨC ĐỘ NHẬN THỨC KHÁC NHAU
Như đã nói trên đây có thể chế tác các CH trắc nghiệm để đánh giá
các mức độ nhận thức từ thấp đến cao. Dưới đây sẽ giới thiệu ví dụ về
các CHTN được chế tác để đánh giá các mức độ nhận thức theo thang
phân chia của B. Bloom đã nêu trên đây.
1) Biết (knowledge):
Ở mức độ này người ta chỉ đòi hỏi TS nhớ lại các kiến thức đã thu
nhận được.
Ví dụ: Ai trong các nhà nghiên cứu sau đây là tác giả của tác phẩm
“Tư bản”:
A. Mannheim
B. Marx
C. Weber
D. Engels

38
E. Michels
Chú ý là các phương án chọn của CH này có sự phù hợp nội tại, vì
mọi tác gia được nêu đều là các học giả người Đức nghiên cứu về những
vấn đề xã hội. Đáp án là B.
2) Hiểu (comprehention):
Ở mức độ này kiến thức về các sự kiện, lý thuyết, quá trình v.v….
được xem là đã biết, và người ta muốn trắc nghiệm xem TS có hiểu kiến
thức đó không.
Ví dụ: Hai vật tích điện hút nhau bằng một lực xác định. Nếu điện
tích trên mỗi vật tăng gấp đôi còn khoảng cách giữa chúng giữ nguyên thì
lực tác dụng giữa chúng sẽ:
A. tăng gấp bốn.
B. tăng gấp đôi.
C. giảm một nửa.
D. tăng lên nhưng không biết tăng bao nhiêu.
Để trả lời được câu trắc nghiệm này TS phải biết định luật Culông
(Lực tương tác giữa hai điện tích tỷ lệ thuận với tích số các điện tích và
tỷ lệ nghịch với bình phương khoảng cách giữa các điện tích) và phải
hiểu mối quan hệ giữa các đại lượng trong định luật. Đáp án là A.
3) Áp dụng (application):
Đối với loại CH ở mức này phải xem là TS đã biết và hiểu các kiến
thức cần thiết làm cơ sở cho CH, cần trắc nghiệm xem họ có thể áp dụng
các điều đã biết và hiểu đó hay không. Các CH yêu cầu tính toán dựa trên
các công thức đã biết là phù hợp với mức độ này.
Ví dụ:
Giá trị nào dưới đây là xấp xỉ gần nhất của thể tích một hình cầu có
bán kính 5m?
A. 2000m3
B. 1000m3

39
C. 500m3
D. 250m3
E. 125m3
Để trả lời được CH này TS phải biết công thức để tính thể tích quả
cầu 4r3/3 (biết) và ý nghĩa của các ký hiệu khác nhau trong công thức
(hiểu), từ đó áp dụng để tính được thể tích. TS cũng không cần tính toán
chính xác đến từng chữ số thập phân, mà chỉ cần ước lượng để biết cỡ
của đáp án gần với phương án nào. Đáp án là C.
4) Phân tích, tổng hợp (analysis, synthesis):
Ví dụ:
Xem các bảng sau đây và cho biết các số liệu thống kê của nước
nào được trình bày ở các dòng 1,2 và 3:
GNP trên
đầu
người
năm 1991
(USD)
Tăng
trưởng
GNP trên
đầu người
thời kỳ
1980 - 1991
Tỷ lệ
tăng
dân số
1980 -
1991
Cơ cấu tổng thể về việc làm
thời kỳ 1980-1985 (%)
Nông
nghiệp
Công
nghiệp
Dịch
vụ
1 500 2,5% 1,5% 51 20 29
2 1570 5,8% 1,6% 74 8 8
3 25110 1,7% 0,3% 6 32 62
Hãy chọn phương án trả lời từ danh sách sau đây:
A. 1 là Hàn quốc; 2 là Kenya; 3 là Canada.
B. 1 là Sri Lanka; 2 là Đức; 3 là Thái Lan.
C. 1 là Sri Lanka; 2 là Thái Lan; 3 là Thụy Điển.
D. 1 là Namibia; 2 là Portugal; 3 là Botswana.
Để trả lời câu hỏi này TS phải nhớ các xếp hạng về kinh tế liên
quan của nhiều nước (biết) và hiểu cơ sở của sự xếp hạng đó (hiểu). Họ

40
phải áp dụng được các khái niệm đó khi được cung cấp thông tin, phải
phân tích các thông tin đã cho và tổng hợp để trả lời CH. Thật ra loại CH
này không yêu cầu TS phải nhớ các con số thống kê cụ thể, mà cần phải
xem bảng thống kê và thực hiện việc xếp hạng dựa trên các khái niệm
mà họ nắm được. Đáp án là C.
5) Đánh giá (evaluation):
Ở mức độ này TS được đòi hỏi phải đánh giá, chẳng hạn, sự nhất
quán của các tài liệu đã viết, giá trị của các quá trình thực nghiệm hoặc
việc giải thích dữ liệu.
Ví dụ : một câu hỏi về "nguyên nhân" trong đó có hai nhận định
được nối với nhau bằng từ "BỞI VÌ". TS phải đưa ra đánh giá của mình
về các sự kiện và nguyên nhân đó.
Hãy đánh giá câu in trong ngoặc sau đây theo tiêu chí được nêu
bên dưới:
"Hoa Kỳ gây cuộc Chiến tranh vùng vịnh chống Irắc năm 2003
BỞI VÌ Sađam Hussen che dấu Alqueda và chế tạo vũ khí hạt nhân"
A. Sự kiện thứ nhất và thứ hai đều đúng, và nguyên nhân là
chính xác.
B. Sự kiện thứ nhất là đúng nhưng sự kiện thứ hai không
đúng, và nguyên nhân là không đúng.
C. Sự kiện thứ nhất và thứ hai đều không đúng, và nguyên nhân
là không đúng.
D. Sự kiện thứ nhất là không đúng, sự kiện thứ hai là đúng, và
nguyên nhân là không đúng.
Đúng là Hoa Kỳ đã gây cuộc chiến tranh Vùng Vịnh chống Irắc,
nhưng không có việc Irắc che dấu Alqueda, và câu thứ hai không phải là
nguyên nhân thực chất của câu thứ nhất. Thực ra quyền lợi của các tập
đoàn dầu mỏ Hoa Kỳ đứng sau tổng thống Bush là nguyên nhân chính
xác hơn của việc Hoa Kỳ gây chiến tranh Vùng Vịnh. Để trả lời CH này
cần phải biết và hiểu tình hình chính trị của vùng Cận Đông, biết phân
tích và tổng hợp tình hình. Điều được trắc nghiệm ở đây là khả năng
đánh giá quan hệ giữa nguyên nhân và kết quả trong câu đã nêu. Đáp án
là B.

41
1.9. CÁCH CHẾ TÁC CÂU HỎI TRẮC NGHIỆM KHÁCH QUAN
Nhiều sách chuyên khảo có trình bày tỉ mỉ những điều cần lưu ý khi
chế tác các CH TNKQ. Ở đây chỉ xin nêu ngắn gọn những lưu ý chung nhất.
Yêu cầu chung:
1. Sử dụng ngôn ngữ phù hợp với TS.
2. Không hỏi quan điểm riêng của TS, chỉ hỏi sự kiện, kiến thức.
Loại nhiều lựa chọn
1. Các phương án sai phải có vẻ hợp lý.
2. Chỉ nên dùng 4 hoặc 5 phương án chọn.
3. Đảm bảo cho câu dẫn nối liền với mọi phương án chọn theo đúng
ngữ pháp.
4. Chỉ có một phương án chọn là đúng hoặc đúng nhất.
5. Tránh dùng câu phủ định, đặc biệt là phủ định hai lần.
6. Tránh lạm dụng kiểu khẳng định "Không phương án nào trên
đây đúng” hoặc “Mọi phương án trên đây đều đúng”.
7. Tránh việc làm cho phương án đúng khác biệt so với các phương
án nhiễu (dài hơn hoặc ngắn hơn, mô tả tỉ mỉ hơn...).
8. Phải sắp xếp phương án đúng và các phương án nhiễu theo thứ
tự ngẫu nhiên.
Loại đúng sai:
1. Câu phát biểu phải hoàn toàn đúng hoặc hoàn toàn sai, không có
ngoại lệ.
2. Soạn câu trả lời thật đơn giản
3. Tránh dùng câu phủ định, đặc biệt là phủ định hai lần.
Loại ghép đôi:
1. Hướng dẫn rõ về yêu cầu của việc ghép cho phù hợp
2. Đánh số ở một cột và chữ ở cột kia.
3. Các dòng trên mỗi cột phải tương đương về nội dung, hình thức,
ngữ pháp, độ dài.

42
4. Tránh các câu phủ định.
5. Số từ trên hai cột không như nhau, thường chỉ nên từ 5 đến 10 từ.
Loại điền khuyết:
1. Chỉ nên để một chỗ trống.
2. Thiết kế sao cho có thể trả lời bằng một từ đơn nhất mang tính
đặc trưng (người, vật, địa điểm, thời gian, khái niệm).
3. Cung cấp đủ thông tin để chọn từ trả lời.
4. Chỉ có một lựa chọn là đúng.
1.10. QUY TRÌNH XÂY DỰNG MỘT NGÂN HÀNG CÂU HỎI HOẶC MỘT
ĐỀ TRẮC NGHIỆM TIÊU CHUẨN HÓA
1.10.1. Mục tiêu giảng dạy, ma trận kiến thức và đề kiểm tra
Trắc nghiệm là một phép đo: dùng thước đo là đề kiểm tra để đo
một năng lực nào đó của TS. Phép đo nào cũng có mục tiêu của nó: đo
cái gì? Muốn một đề kiểm tra đo được cái cần đo, tức là đo được mức độ
đạt các mục tiêu cụ thể của môn học, cần chế tác các CH và thiết kế các
đề kiểm tra bám sát mục tiêu của môn học. Một đề kiểm tra tốt kết hợp
với việc tổ chức triển khai kỳ thi tốt sẽ giúp đạt được mục tiêu của phép
đo, tức là đo được cái cần đo, cái muốn đo.
Để đơn giản chúng ta hãy lấy ví dụ về việc xây dựng một đề kiểm
tra để đánh giá tổng kết một môn học. Nhằm giảng dạy tốt một môn học,
giảng viên cần xây dựng một danh mục chi tiết về các mục tiêu giảng
dạy, thể hiện ở năng lực hay hành vi cần đạt được của học viên qua quá
trình giảng dạy các nội dung cụ thể của môn học. Khi xây dựng một đề
kiểm tra để đánh giá môn học đó người ta phải dựa vào các mục tiêu đã
đề ra cho môn học.
Trong thực tế, các mục tiêu giảng dạy môn học không phải bao giờ
cũng có sẵn đủ chi tiết để có thể soạn thảo một đề kiểm tra. Khi đó cần
xây dựng lại chi tiết danh mục các mục tiêu. Việc xây dựng mục tiêu
thường được triển khai trong một nhóm những người cùng giảng dạy
môn học đó phối hợp với một vài chuyên gia hiểu biết về cách chế tác
các CH. Trước hết cần liệt kê các mục tiêu cụ thể liên quan đến các mức

43
độ nhận thức muốn đo đối với từng phần của môn học, sau đó tùy thuộc
tầm quan trọng của từng mục tiêu ứng với từng phần của môn học mà
quyết định là cần bao nhiêu CH.
Bảng 3. Ví dụ về sử dụng ma trận kiến thức của môn học để xác định cấu trúc của một đề kiểm tra
Mức độ nhận thức
Phần Hiểu đúng
khái niệm
Tính
toán
Lập
luận
Tổng
cộng
Giới hạn 5 3 2 10
Vi phân 3 8 3 14
Tích phân 5 8 3 16
Hàm nhiều biến 6 5 8 19
Phương trình vi phân 6 8 10 24
Phương trình đạo hàm riêng 5 6 6 17
Tổng cộng 30 38 32 100
Một công cụ thuận lợi để thiết kế cấu trúc của một đề kiểm tra là
bảng các mục tiêu giảng dạy, hoặc còn gọi là các ma trận kiến thức.
Trong bảng có chia ra các hàng ứng với các phần của môn học, và các
cột ứng với các mức độ nhận thức liên quan đến mục tiêu cụ thể. Ứng với
mỗi ô của bảng người ta ghi số CH cần xây dựng cho đề kiểm tra. Trên
Bảng 3 có trình bày ví dụ về việc thiết kế một ĐTN 100 CH cho môn
Toán ở một trường cao đẳng. Các mức độ nhận thức được lựa chọn ở đây
bao gồm 3 loại: hiểu đúng khái niệm, biết tính toán và biết lập luận trong
các trường hợp cụ thể. Tuỳ theo tầm quan trọng của từng phần nội dung
và từng mức độ nhận thức mà các giảng viên bàn nhau quy định số CH
trắc nghiệm phải chế tác: chẳng hạn ở phần về giới hạn chỉ cần 3 CH cho
kỹ năng tính toán, còn ở phần về phương trình vi phân cần đến 10 CH
cho kỹ năng lập luận.
1.10.2. Quy trình thiết kế một đề kiểm tra tiêu chuẩn hóa và một NHCH
Ở mục 1.4 đã nêu khái niệm về đánh giá tiêu chuẩn hóa. Một đề
kiểm tra tiêu chuẩn hóa thường được thiết kế bởi các CH chọn từ một
NHCH. NHCH là tập hợp một số lượng tương đối lớn các CH, trong đó
mỗi CH được mô tả gắn với các phần nội dung xác định và các tham số

44
của nó, trong trường hợp CH trắc nghiệm đó là độ khó, độ phân biệt theo
lý thuyết trắc nghiệm cổ điển, và các tham số a, b, c theo IRT. Ngoài ra,
NHCH phải được thiết kế sao cho trên đó có thể thực hiện các thao tác
loại trừ hoặc thay đổi các CH xấu, bổ sung các CH tốt để số lượng và
chất lượng các CH ngày càng tăng (xem chương 2 và chương 4).
Thiết kế một đề kiểm tra tiêu chuẩn hóa và một NHCH là khá phức
tạp. Để đơn giản chúng ta sẽ xem xét việc thiết kế một đề kiểm tra tổng
kết tiêu chuẩn hóa hoặc một NHCH cho một môn học. Có thể mô tả tóm tắt
các bước của quy trình đó như sau:
1) Xác định các nội dung chi tiết của môn học và các mức độ nhận
thức mong muốn TS đạt được liên quan đến các phần nội dung đó. Để thực
hiện bước này, một trong các cách thông dụng là xây dựng ma trận kiến
thức của môn học như ví dụ ở Bảng 3. Có thể quan niệm các con số trong
các ô của ma trận là tỷ lệ số CH cần có trong NHCH. Một đề kiểm tra tổng
kết toàn diện của môn học cũng có phân bố các CH theo tỷ lệ này. Còn các
đề kiểm tra một phần kiến thức hoặc kiểm tra giữa kỳ thì tùy theo yêu cầu
mà xây dựng cho chúng các ma trận kiến thức tương ứng.
2) Phân công cho các giáo viên, mỗi người chế tác một số CH theo
các yêu cầu gắn với các ô ma trận kiến thức, tùy theo sở trường của từng
người, sao cho tổng số CH chế tác sẽ phủ kín cả ma trận. Việc chế tác
CH trắc nghiệm của mỗi cá nhân là một quá trình lao động rất công phu,
tỉ mỉ, người chế tác phải đọc đi, đọc lại và chỉnh sửa nhiều lần.
3) Trao đổi các CH trong nhóm đồng nghiệp. Kinh nghiệm cho thấy
việc trao đổi này rất quan trọng, giúp người chế tác thấy được nhiều sai sót
mà bản thân không tự phát hiện được vì những đường mòn trong suy nghĩ.
4) Tổ chức đọc duyệt, biên tập và đưa các CH lưu vào các kho dữ
liệu trong máy tính. Phải chọn người đọc duyệt là người vừa nắm vững
chuyên môn của môn học và tương đối thành thạo trong việc chế tác CH
trắc nghiệm. Khi phát hiện các sai sót về chuyên môn hoặc về quy tắc chế
tác CH trắc nghiệm, người đọc duyệt trao đổi lại với tác giả để tác giả
chỉnh sửa. Cuối bước này sẽ thu được một tập hợp các CH trắc nghiệm đã
được chỉnh sửa công phu lưu trong máy tính. Tuy nhiên, đó chưa phải là
NHCH vì các CH chưa được thử nghiệm để xác định tham số.

45
5) Lập các đề kiểm tra thử và tổ chức trắc nghiệm thử trên các
nhóm TS đại diện cho tổng thể đối tượng sẽ được kiểm tra. Các đề kiểm
tra thử thường tương đối ngắn, cần đảm bảo thời gian đầy đủ cho TS
hoàn thành. Lưu ý thuật ngữ "trắc nghiệm thử" được sử dụng ở đây để
chỉ một khâu trung gian trong quá trình xây dựng NHCH, trong thực tế
phải tạo tình huống để các TS làm thật, vì chỉ khi họ “làm thật” hết mình
thì mới thử nghiệm được các CH.
6) Chấm và phân tích thống kê các kết quả trắc nghiệm thử để định
cỡ các CH. Việc sử dụng công nghệ trắc nghiệm nào, cổ điển hay hiện
đại, để phân tích kết quả và định cỡ CH sẽ được thể hiện ở khâu này. Quá
trình phân tích thống kê và định cỡ CH trắc nghiệm sẽ cho hai loại kết
quả: một là cung cấp các tham số của CH trắc nghiệm, hai là phát hiện
các CH có chất lượng kém.
7) Xử lý các CH chất lượng kém: hoặc là sửa đổi tu chỉnh, hoặc là
loại bỏ nếu chất lượng quá kém không thể sửa đổi được. Các CH được tu
chỉnh xong lại được đưa vào kho lưu trữ. Qua bước này một NHCH bắt
đầu hình thành. Việc tổ chức trắc nghiệm thử và chỉnh sửa các CH trắc
nghiệm có thể tổ chức rất nhiều lần, qua mỗi lần một số CH trong NHCH
được chỉnh sửa, hoàn thiện và NHCH được bổ sung. Cần lưu ý là các
tham số của mọi CH trong NHCH phải được đặt trên các thang đo chung,
điều này sẽ được trình bày rõ ở chương 11. Như vậy NHCH không phải
là một kho lưu trữ chết cứng mà nó như là một "sinh vật", có đồng hóa,
dị hóa và tăng trưởng.
8) Khi đã yên tâm về số lượng và chất lượng các CH trong NHCH
có thể thiết kế các đề kiểm tra cho các kỳ thi chính thức. Cấu trúc của
một đề kiểm tra chính thức phải được thể hiện bằng một ma trận kiến
thức tương ứng. Tính chất của một đề kiểm tra chính thức phụ thuộc vào
mục tiêu của kỳ thi: lập đề kiểm tra theo chuẩn hay theo tiêu chí, cần đo
lường chính xác dải năng lực như thế nào... Có thể thiết kế một đề kiểm
tra cung cấp kết quả đo ứng với một hàm thông tin hay một đường đặc
trưng ĐTN thích hợp (xem chương 10). Cũng như ở khâu phân tích kết
quả kiểm tra, chính khâu thiết kế đề kiểm tra này thể hiện lý thuyết trắc
nghiệm nào, CTT hay IRT, được sử dụng. Quá trình thiết kế ĐTN nói

46
trên cũng cho phép tạo ra các ĐTN tương đương chứa các tập hợp CH
trắc nghiệm khác nhau, nhưng giống nhau về cấu trúc nội dung và về các
tham số thống kê. Ở chương 2 và chương 10 sẽ trình bày rõ quan niệm về
ĐTN tương đương trong CTT và IRT, sẽ chứng tỏ rằng IRT cho phép
xây dựng các ĐTN với mức độ tương đương cao hơn nhiều so với CTT.
Sau khi quyết định chọn một ĐTN đáp ứng tốt các mục tiêu đo
lường, từ một ĐTN có thể dễ dàng sinh ra nhiều phiên bản ĐTN có cùng
nội dung nhưng hình thức khác nhau bằng cách hoán đảo thứ tự các CH
và các phương án trả lời, nhằm hạn chế TS "cóp" bài của nhau. Thủ pháp
này đơn giản nhưng việc thay đổi vị trí các CH và các phương án chọn có
thể làm thay đổi độ khó của các CH.
9) Đối với một đề kiểm tra tiêu chuẩn hóa, trước khi sử dụng đại trà
cần xây dựng một nhóm chuẩn mực và thử nghiệm đề kiểm tra trên nhóm
chuẩn mực đó. Phân tích kết quả kiểm tra và xây dựng bảng mô tả các
đặc trưng của nhóm chuẩn mực.
10) Triển khai kiểm tra chính thức. Sau khi tổ chức kiểm tra chính
thức cũng tiến hành phân tích kết quả như ở kỳ kiểm tra thử. Quá trình
này nhằm hai mục tiêu. Một là thu các kết quả của kỳ thi, các điểm đánh
giá năng lực của từng TS, mục tiêu quan trọng hàng đầu của kỳ thi. Hai
là, tiếp tục phát hiện các CH để tu chỉnh và tiếp tục đưa vào NHCH, thậm
chí nếu có một vài CH trắc nghiệm quá xấu thì có thể loại chúng ra khỏi
số liệu chấm điểm chính thức. Việc sử dụng các điểm thô (theo tổng các
CH trả lời đúng) hoặc chuyển đổi tham số năng lực sang các thang điểm
mong muốn được thực hiện theo các quy tắc của lý thuyết trắc nghiệm
tương ứng, sẽ được trình bày ở chương 2 và 11.
Một tác dụng hết sức quan trọng của các kỳ thi tiêu chuẩn hóa đại
trà là các thông tin thu được qua việc phân tích thống kê toàn bộ bài làm
của TS là những số liệu hết sức quý báu để đánh giá định lượng về tình
hình giáo dục của từng khu vực, từng cộng đồng, từng nhóm TS và đánh
giá xu thế phát triển của chất lượng giáo dục theo thời gian.
Việc sử dụng điểm thô hay các điểm chuyển đổi khác để đánh giá
năng lực của TS sẽ được bàn đến trong các chương sau.

47
Một điểm cần lưu ý nữa là vì mục đích giữ bí mật cho NHCH, các
ĐTN trong các kỳ trắc nghiệm thử phải được thu lại. Các ĐTN trong các
kỳ thi chính thức ở cấp khoa, trường được tổ chức nhiều lần trong phạm
vi hẹp cũng thường được thu lại. Tuy nhiên, trong các kỳ thi quốc gia
quy mô lớn tổ chức mỗi năm một lần trên phạm vi toàn quốc thường đề
thi và đáp án phải được công bố ngay sau khi thi xong, và quá trình chấm
thi trắc nghiệm thường được tổ chức nhanh chóng và công bố kết quả chỉ
sau một thời gian ngắn. Các ĐTN đó thường được in lại như các đề mẫu
để TS làm quen trong quá trình luyện thi.
1.10.3. Vài nét về sự phát triển của khoa học về đo lường trong giáo dục
ở nước ta
Ở nước ta, khoa học về đo lường trong giáo dục ở trong tình trạng
khá lạc hậu và phát triển rất chậm. Trước năm 1975 ở miền Nam có một
vài người được đào tạo về khoa học này từ các nước phương Tây, trong
đó có Giáo sư Dương Thiệu Tống. Vào năm 1974, một hoạt động đáng
lưu ý là kỳ thi tú tài lần đầu tiên được tổ chức ở miền Nam bằng phương
pháp TNKQ [1].
Ở miền Bắc nước ta trước đây khoa học này ít được lưu ý vì trong
hệ thống các nước xã hội chủ nghĩa cũ, kể cả Liên Xô, khoa học này rất
kém phát triển. Vào những năm sau 1975 ở phía Bắc nước ta có một số
người có nghiên cứu về khoa học đo lường trong tâm lý. Chỉ đến năm
1993 Bộ Giáo dục và Đào tạo mới mời một số chuyên gia nước ngoài
vào nước ta, xuất bản sách phổ biến về khoa học này, cũng như cử một
số cán bộ ra nước ngoài học tập. Từ đó một số trường đại học có tổ chức
các nhóm nghiên cứu áp dụng các phương pháp đo lường trong giáo dục
để thiết kế các công cụ đánh giá, soạn thảo các phần mềm hỗ trợ, mua
máy quét quang học chuyên dụng (OMR) để chấm thi. Một điểm mốc
đáng ghi nhận là kỳ thi tuyển đại học thí điểm tại trường Đại học Đà Lạt
vào tháng 7 năm 1996 bằng phương pháp TNKQ.
Từ sau năm 1997 các hoạt động đổi mới phương pháp đo lường và
đánh giá trong giáo dục ở các trường đại học lắng xuống. Cho đến mùa
thi tuyển đại học năm 2002 Bộ Giáo dục và Đào tạo mới tổ chức kỳ thi

48
tuyển đại học “3 chung”. Bộ Giáo dục và Đào tạo cũng thành lập “Cục
Khảo thí và Kiểm định chất lượng” vào năm 2003 để cải tiến việc thi cử
và đánh giá chất lượng các trường đại học, và đã dùng phương pháp trắc
nghiệm khách quan để làm đề thi tuyển đại học cho môn tiếng Anh, sau
đó là Vật lý, Hóa học, Sinh học từ mùa thi 2006. Tuy nhiên cho đến nay
(2010), những thành tựu hiện đại của khoa đo lường trong giáo dục vẫn
chưa được áp dụng và Bộ Giáo dục và Đào tạo vẫn còn lúng túng trong
việc chọn một giải pháp tuyển sinh thích hợp.
Trong khi đó một số hoạt động khảo sát kết quả học tập của học
sinh ở bậc giáo dục phổ thông có sử dụng các thành tựu của khoa học đo
lường trong giáo dục cũng được triển khai nhờ sự hỗ trợ của các dự án
giáo dục vay vốn của các ngân hàng quốc tế. Viện Khoa học Giáo dục
Việt Nam chính là đầu mối của các hoạt động này. Có thể điểm qua các
hoạt động quan trọng đầu tiên là khảo sát kết quả học tập hai môn Toán
và tiếng Việt của học sinh lớp 5 vào năm 2001 và 2007 [34], đánh giá kết
quả học tập Toán và tiếng Việt của học sinh lớp 6 và kết quả học tập
Toán, tiếng Việt, Vật lý và tiếng Anh của học sinh lớp 9 vào đầu năm
2010 kết hợp TNKQ và TL. Nước ta cũng đang chuẩn bị để tham gia
PISA quốc tế vào năm 2012.
Ngoài hoạt động của Viện Khoa học Giáo dục Việt Nam cũng có
một số cố gắng của các cơ sở ngoài nhà nước. Công ty Khoa học và Công
nghệ Giáo dục (EDTECH-VN) đã triển khai xây dựng ngân hàng câu hỏi
trắc nghiệm cho các trường cao đẳng sư phạm theo hợp đồng với Dự án
đào tạo giáo viên trung học cơ sở của Bộ Giáo dục và Đào tạo năm 2006,
thiết kế phần mềm trắc nghiệm TESTPRO phục vụ xây dựng ngân hàng
câu hỏi, làm đề thi, chấm thi trắc nghiệm và đặc biệt là phần mềm
VITESTA [19] phân tích trắc nghiệm theo lý thuyết Ứng đáp Câu hỏi
(IRT).
Đó là một số cố gắng có tác động thúc đẩy việc phát triển ứng dụng
khoa học về đo lường trong giáo dục ở nước ta.
Tuy vậy, chông gai trên con đường đổi mới giáo dục nói chung,
phát triển khoa học về đo lường trong giáo dục vẫn còn nhiều. Các
trường cao đẳng, đại học có thể đóng góp gì để thúc đẩy sự phát triển đó?

49
Chúng tôi xin đề xuất những giải pháp sau đây:
Tất cả giảng viên các trường đại học cần được bồi dưỡng những
hiểu biết sơ đẳng về khoa học đo lường trong giáo dục.
Mọi trường đại học đều nên tổ chức bộ phận nghiên cứu triển khai để
áp dụng khoa học đó vào các hoạt động kiểm tra đánh giá kết quả học tập
của học viên, hoạt động giảng dạy và phục vụ của giảng viên.
Các trường đại học và viện nghiên cứu chuyên về giáo dục cần đẩy
mạnh việc nghiên cứu về khoa học đo lường trong giáo dục để thấu hiểu
nó, từ đó hướng dẫn áp dụng nó trong toàn hệ thống giáo dục từ mẫu giáo
đến sau đại học.
Tiếp đến, cần triển khai áp dụng khoa học đo lường trong giáo dục
ra mọi hoạt động xã hội bên ngoài hệ thống giáo dục, vì rằng trong tương
lai, với sự phát triển của kinh tế xã hội, tất yếu việc áp dụng khoa học đó
sẽ trở thành một ngành công nghiệp lớn.

50
CÂU HỎI TỰ KIỂM TRA
1. Nêu các kiểu phân loại phương pháp đánh giá trong giáo dục: theo
cách thực hiện việc đánh giá, theo mục tiêu đánh giá, theo phương
hướng sử dụng kết quả đánh giá.
2. Nêu ba các lĩnh vực mục tiêu giáo dục và các mức độ hành vi trong
từng lĩnh vực.
3. Nêu hai nhóm phương pháp cấu thành loại đánh giá bằng bài viết
và các thể loại CH của TNKQ.
4. Nêu các ưu nhược điểm cơ bản của TNKQ và TL. Nên sử dụng mỗi
phương pháp trong điều kiện nào? Có nên kết hợp TNKQ với TL
trong các đề kiểm tra hay không, vì sao?
5. Nêu ví dụ về cách viết các CH TNKQ để đánh giá các mức kỹ năng
khác nhau trong lĩnh vực nhận thức.
6. Nêu các nguyên tắc cơ bản cần tuân theo khi chế tác CH trắc nghiệm.
7. Tại sao các CH và đề kiểm tra phải bám sát mục tiêu giảng dạy? Trình
bày cách sử dụng ma trận kiến thức để xây dựng một đề kiểm tra.
8. Nêu các bước cơ bản để xây dựng một đề kiểm tra tiêu chuẩn hóa
và một NHCH. Tại sao người ta ví NHCH như một vật sống?

51
Chương 2
MỘT SỐ KHÁI NIỆM BAN ĐẦU VỀ THỐNG KÊ VÀ KHÁI QUÁT
VỀ TRẮC NGHIỆM CỔ ĐIỂN
Việc học và thi trên thế giới đã diễn ra hàng nghìn năm trước đây,
nhưng một khoa học về đo lường trong giáo dục thật sự có thể xem như
bắt đầu cách đây chỉ khoảng hơn một thế kỷ. Trong thế kỷ XX, khoa học
này phát triển xuất phát từ châu Âu nhưng tăng tốc mạnh mẽ khi du nhập
vào Hoa Kỳ. Cho đến thập niên 1970 thì khoa học này phát triển tương
đối hoàn chỉnh trong khuôn khổ một lý thuyết được gọi là lý thuyết trắc
nghiệm cổ điển (classical test theory - CTT). Cuốn Trắc nghiệm và đo
lường thành quả học tập [1] của GS. Dương Thiệu Tống xuất bản ở nước
ta đã trình bày cơ sở của trắc nghiệm cổ điển. Chương này dành để trình
bày ngắn gọn các khái niệm cơ bản của của lý thuyết đó, đôi chỗ xem
như tóm tắt từ cuốn sách nói trên.
Lý thuyết trắc nghiệm được xây dựng dựa trên thống kê học, nên
trước khi đi vào lý thuyết trắc nghiệm chúng ta nhắc lại một vài khái
niệm thường sử dụng trong thống kê học.
2.1. MỘT SỐ KHÁI NIỆM VÀ ĐỊNH LUẬT QUAN TRỌNG TRONG THỐNG
KÊ HỌC
2.1.1. Xác suất
Đối với các hiện tượng ngẫu nhiên người ta không thể biết chắc
chắn một biến cố gì sẽ xảy ra, chỉ có thể nói về xác suất xảy ra một biến
cố nào đó. Ví dụ, nếu ta có một con xúc xắc được cấu tạo bằng chất liệu
hoàn toàn đồng nhất thì biến cố một mặt nào đó trong 6 mặt của con xúc

52
xắc sẽ xuất hiện sau khi gieo xúc xắc là một điều ngẫu nhiên, không thể
biết chắc trước đó. Tuy nhiên, khả năng xuất hiện mỗi một trong 6 mặt
của xúc xắc là như nhau, cho nên có thể nói xác suất xuất hiện, chẳng
hạn, mặt lục của xúc xắc, là 1/6. Xác suất là một số không âm, có giá trị
từ 0 đến 1. Xác suất bằng 0 ứng với một biến cố không thể xảy ra, xác
suất bằng 1 ứng với biến cố chắc chắn sẽ xảy ra.
Một động tác để làm xuất hiện một biến cố được gọi là một phép
thử. Chẳng hạn, việc gieo con xúc xắc là một phép thử. Chúng ta có thể
thực hiện nhiều phép thử như vậy để khảo sát việc xuất hiện mặt lục. Tỷ
số giữa số lần xuất hiện mặt lục trên tổng số phép thử được gọi là tần
suất xuất hiện mặt lục. Chẳng hạn, nếu ta gieo xúc xắc 10 lần, mặt lục
xuất hiện 2 lần, thì tần suất xuất hiện mặt lục là 2/10.
2.1.2. Luật số lớn
Có một định luật quan trọng của lý thuyết xác suất, làm cơ sở cho
mọi nghiên cứu thống kê, là luật số lớn (hoặc luật về giá trị trung bình).
Luật số lớn được chứng minh chặt chẽ trong lý thuyết xác suất. Ở
đây, chúng ta chỉ nêu nội dung bản chất của nó. Tương ứng với các ví dụ
đã nêu trên đây, với các khái niệm tần suất, xác suất và phép thử đã biết,
có thể phát biểu luật số lớn như sau:
Khi số lượng phép thử tăng lên đủ lớn, giá trị tần suất sẽ tiến dần
đến giá trị xác suất.
Điều vừa nêu trên chính là luật mạnh số lớn theo phát biểu của E. Borel.
Bạn đọc có thể kiểm tra lại luật số lớn bằng một thực nghiệm rất
đơn giản. Bạn hãy chọn một con xúc xắc và tiến hành gieo xúc xắc, đếm
số lần gieo và số lần xuất hiện mặt lục. Bạn sẽ thấy sau khi tăng số lần
gieo xúc xắc lên vài trăm, tỷ lệ số lần xuất hiện mặt lục trên tổng số lần
gieo sẽ tiến dần đến rất gần giá trị xác suất 1/6.
2.1.3. Tổng thể và mẫu
Khoa học thống kê thường xem xét các số liệu hoặc tính chất nào
đó trong một tập hợp rất lớn các đối tượng, ta sẽ gọi tập hợp đó là một

53
tổng thể (population). Chẳng hạn xem xét kết quả trắc nghiệm trong một
tổng thể gồm toàn bộ TS tham dự kỳ thi tuyển đại học ở nước ta, gồm
hàng triệu người.
Việc thực hiện nghiên cứu trên một tổng thể với một số rất lớn đối
tượng thường rất khó khăn và tốn kém. Do đó người ta thường triển khai
nghiên cứu trên một tập hợp con với số đối tượng ít hơn của tổng thể.
Tập hợp con đó được gọi là mẫu (sample) nghiên cứu. Để việc nghiên
cứu trên các mẫu thu được các kết quả thống kê gần với kết quả thu được
từ tổng thể, người ta phải chọn mẫu có tính đại diện của tổng thể. Lý
thuyết thống kê đưa ra những quy tắc xác định để chọn được các mẫu
mang tính đại diện đó.
2.1.4. Phân bố
Giả sử chúng ta tiến hành đo chiều cao của học sinh ở một trường
phổ thông trung học của một tỉnh nào đó, số đo chính xác đến cm. Ta mô
tả kết quả đo trên một đồ thị, trục hoành biểu diễn chiều cao chính xác
đến cm, trục tung biểu diễn tần suất xuất hiện một chiều cao nào đó.
Đường cong mô tả có dạng đại loại như trên Hình 2.1, được gọi là đường
cong phân bố tần suất.
Nếu chúng ta tiến hành đo chiều cao của toàn bộ học sinh trung học
của tỉnh đã nêu và mô tả trên đồ thị, ta cũng sẽ được một đường cong có
dạng giống như trên nhưng mịn màng và đều đặn hơn. Trong ví dụ nêu
trên ta có thể gọi tập hợp học sinh trung học của toàn tỉnh là một tổng
thể, và tập hợp học sinh trung học của trường đã chọn là một mẫu.
Phân bố tần suất đối với một tổng thể được gọi là phân bố xác suất.
Dạng phân bố kiểu hình chuông đối xứng như được biểu diễn trên
Hình 2.1 được gọi là phân bố chuẩn. Nhiều nghiên cứu cho thấy phân bố
tần suất của nhiều đại lượng trong tự nhiên khi xem xét trong một tổng
thể nào đó thường có dạng phân bố chuẩn, chẳng hạn phân bố tần suất
của chiều cao hoặc trọng lượng của một tập hợp người, phân bố tần suất
của một năng lực nào đó của một tập hợp TS, và do đó, phân bố điểm
trắc nghiệm đánh giá năng lực đó của tập hợp TS đã cho.

54
Hình 2.1. Phân bố chuẩn
Để xác định một phân bố tần suất cần biết hai đại lượng đặc trưng.
- Một là giá trị trung bình của các giá trị đo được trên mẫu đo (gồm n
cá thể):
x = n
x
n
1i
i (2.1)
Trong ví dụ đã cho, giá trị đó là chiều cao trung bình, được xác
định bằng cách cộng tất cả chiều cao của mọi học sinh chia cho tổng số
học sinh. Ngoài giá trị trung bình, còn có trung vị là điểm chia đôi tổng
thể, và yếu vị là điểm ứng với cực đại của đường cong phân bố. Đối với
một phân bố chuẩn đối xứng thì 3 giá trị nêu trên trùng nhau.
- Hai là độ lệch tiêu chuẩn của các giá trị đo được so với giá trị trung bình:
S =
2
1
( )
( 1)
n
i
i
x x
n
(2.2)
Lưu ý rằng ở mẫu số trong biểu thức trên là (n-1) chứ không phải n,
vì sao vậy, bạn đọc có thể tìm hiểu lý do từ lý thuyết xác suất. Tuy nhiên,

55
khi n đủ lớn thì giá trị tính theo (2.2) rất gần với căn bậc hai của trung
bình các bình phương độ lệch. Giá trị trung bình xác định vị trí của một
phân bố tần suất trên một thang đo nào đó, còn độ lệch tiêu chuẩn xác
định mức độ phân tán của các số đo của đại lượng: khi độ lệch tiêu chuẩn
bé đường cong phân bố sẽ có dạng hẹp và nhọn, còn khi độ lệch tiêu
chuẩn lớn đường cong phân bố sẽ có dạng doãn và tù.
Vài ví dụ: Các điểm thô của nhóm TS đối với một bài trắc nghiệm
được xếp từ cao đến thấp ở cột (1) trong Bảng 2.1.
Bảng 2.1.
(1) xi (2) di (3) di2
16 5,5 30,25
14 3,5 12,25
12 1,5 2,25
11 0,5 0,25
10 -0,5 0,25
10 -0,5 0,25
9 -1,5 2,25
9 -1,5 2,25
8 -2,5 6,25
6 -4,5 20,25
xi = 105 di = 0,0 2id = 76,50
Từ cột (1) có thể tính giá trị trung bình M =105/10 =10,5; độ lệch
của mỗi điểm so với giá trị trung bình d ghi ở cột (2) và bình phương của
độ lệch ghi ở cột (3). Từ đó dễ dàng tính độ lệch tiêu chuẩn S và phương sai
S2 theo công thức:
S2 = 76,5/9 = 8,5 ; S = 9/5,76 = 2,91.
Khi chọn một mẫu không đồng nhất người ta có thể thu được một
đường cong phân bố lệch. Phân bố lệch nếu có phần đuôi ở phía phải thì
là lệch dương, ngược lại nếu có phần đuôi ở phía trái thì là lệch âm (xem
Hình 2.2).

56
Phân bố đôi khi có hai yếu vị nếu trong mẫu nghiên cứu có thể
phân chia thành hai nhóm hoàn toàn khác nhau về tính chất nghiên cứu.
Chẳng hạn trong ví dụ về đo chiều cao trên đây nếu ta chọn một mẫu hỗn
hợp bao gồm học sinh lớp 6 và học sinh lớp 1 của một trường nào đó
(Hình 2.3).
Hình 2.2. Các phân bố lệch dương và lệch âm
Đối với phân bố chuẩn, lý thuyết xác suất đã xác định được biểu
thức giải tích của hàm phân bố xác suất theo các giá trị trung bình và độ
lệch tiêu chuẩn trên một tổng thể (*).
(*) Mật độ phân bố chuẩn các xác suất của các giá trị đại lượng x trên một tổng thể được
biểu diễn bởi hàm:
2
2
2σ
μ)(x
e2πσ
1p(x)
,
trong đó là trung bình của các giá trị của x đo được trên tổng thể:
n
1i
ixn
1μ ,
và là độ lệch tiêu chuẩn của các giá trị của x trên tổng thể so với giá trị trung bình,
được xác định theo biểu thức:
n2
i
2 i 1
(x μ)
σ(n 1)
.
Đại lượng 2 được gọi là phương sai của đại lượng x.

57
Hình 2.3. Phân bố có hai yếu vị
Xét từ một góc độ khác có thể phát biểu luật số lớn được nhắc đến
trên đây như sau:
Khi kích thước của mẫu được chọn càng lớn, giá trị trung bình
trên mẫu sẽ càng tiến gần đến giá trị trung bình trên tổng thể.
Chính vì vậy người ta còn gọi luật số lớn là luật về giá trị trung bình.
2.1.5. Tương quan
Trong các phép tính thống kê người ta thường gọi biến là một đại
lượng đặc trưng nào đó nhận các giá trị khác nhau từ một cá thể này đến
một cá thể khác trong một tổng thể thống kê. Ví dụ, điểm số của một
môn thi trên một tập hợp TS nào đó là một biến, mỗi TS trong tập hợp
nhận một điểm khác nhau.
Số liệu thống kê thường được sử dụng để xem xét mối quan hệ giữa
các biến khác nhau. Trong trường hợp có hai biến, mối quan hệ giữa
chúng thường được biểu diễn bằng hệ số tương quan (correlation
coefficient).
Hệ số tương quan r giữa hai biến x và y được định nghĩa như sau:
r = yx
xy
S.S
S
trong đó Sx, Sy là các độ lệch tiêu chuẩn được tính theo biểu thức
(2.2), còn xyS được gọi là hiệp biến giữa x và y, được xác định bởi
biểu thức:

58
Sxy = 1)(n
)y)(yx(x
n
1i
ii
Từ đó có thể lập được biểu thức để tính hệ số tương quan Pearson:
r =
n n n
i i i i
i=1 i=1 i=1
2n n n n
2 2 2i i i i
i=1 i=1 i=1 i=1
n x y - x y
n x -( x ) n y - y
(2.3)
Bảng 2.2.
Thí sinh (2) xi (3) yj (4) xi yj (5) x2 (6) y2
A 11 8 88 121 64
B 8 0 0 64 0
C 9 8 72 81 64
D 14 11 154 196 121
E 12 14 168 144 196
F 7 6 42 49 36
G 18 11 198 324 121
H 6 8 48 36 64
I 6 9 54 36 81
J 6 3 18 36 9
K 5 10 50 25 100
n = 11 xi = 102 yi = 88 xiyi= 892 xi2 =1112 yi
2= 856
Hệ số tương quan là một đại lượng để đo mối quan hệ tuyến tính
giữa hai biến ngẫu nhiên. Nó có giá trị trong khoảng từ -1 đến +1. Nếu
các giá trị thấp của biến x có liên hệ với các giá trị thấp của biến y, các giá
trị trung bình của biến x có liên hệ với các giá trị trung bình của biến y, các
giá trị cao của biến x có liên hệ với các giá trị cao của biến y thì hệ số
tương quan sẽ dương. Nếu các giá trị thấp của biến x có liên hệ với các
giá trị cao của biến y, các giá trị trung bình của biến x có liên hệ với các

59
giá trị trung bình của biến y, các giá trị cao của biến x có liên hệ với các
giá trị thấp của biến y thì hệ số tương quan sẽ âm. Nếu quan hệ của các
giá trị của biến x và các giá trị của biến y không tuân theo một quy luật rõ
ràng nào thì hệ số tương quan sẽ bằng 0.
Ví dụ: Một nhóm TS làm hai ĐTN ngắn và thu được hai bộ điểm số
xi và yj ghi ở cột (2) và (3) của Bảng 2.2. Hệ số tương quan giữa hai bộ
điểm số được tính theo công thức (2.3) và Bảng 2.2 như sau:
r = (11892 10288)/ 2 2[11 1112-(102) ][11 856-(88) ]
= 836/1748 = 0,478.
2.2. CÁC THAM SỐ ĐẶC TRƯNG CHO MỘT CÂU HỎI TRẮC NGHIỆM
VÀ MỘT ĐỀ TRẮC NGHIỆM
Để nghiên cứu định lượng tỉ mỉ các CH hoặc ĐTN, người ta phải
đưa vào các tham số đặc trưng. Khi soạn thảo xong một CH hoặc một
ĐTN người soạn thảo chưa biết độ lớn của các tham số đó. Chúng chỉ
được xác định bằng phương pháp thống kê từ kết quả trả lời của các TS
đối với các CH. Chúng ta hãy xem xét các tham số sau đây của các CH
và các ĐTN theo lý thuyết trắc nghiệm cổ điển.
2.2.1. Độ khó của CH
Khái niệm đầu tiên cần lưu ý là độ khó của CH trắc nghiệm. Người
ta xác định độ khó dựa vào việc thử nghiệm CH trắc nghiệm trên các đối
tượng TS phù hợp, và định nghĩa độ khó p bằng tỷ số phần trăm TS làm
đúng CH trên tổng số TS tham gia làm CH đó:
Độ khó p của CH = (2.4)
Việc sử dụng trị số p để đo độ khó như trên cho ta biết mức khó dễ
của các CH chỉ dựa vào số liệu thống kê chứ không cần xem xét nội dung
của chúng thuộc các lĩnh vực khoa học khác nhau.
Các CH của một ĐTN thường có độ khó khác nhau. Theo công
thức tính độ khó như trên, rõ ràng giá trị p càng bé CH càng khó và
ngược lại (đáng lẽ gọi p là độ dễ, nhưng thế giới đã quen dùng là độ khó -
Tổng số TS làm đúng CH
Tổng số TS tham gia làm CH

60
difficulty nên chúng tôi vẫn giữ định nghĩa này). Thông thường độ khó
của một CH có thể chấp nhận được nằm trong khoảng 0,25 - 0,75; CH có
độ khó lớn hơn 0,75 là quá dễ, có độ khó nhỏ hơn 0,25 là quá khó.
Vậy p có giá trị như thế nào thì CH có thể được xem là có độ khó
trung bình? Muốn xác định được khái niệm này cần phải lưu ý đến xác
suất làm đúng CH bằng cách chọn hú họa. Như đã biết, giả sử một CH có
5 phương án chọn thì xác suất làm đúng CH do sự lựa chọn hú hoạ của
một TS không biết gì là 20%. Vậy độ khó trung bình của CH 5 phương
án chọn phải nằm giữa 20% và 100%, tức là 60%. Như vậy, nói chung độ
khó trung bình của một CH có n phương án chọn là (100% + 1/n)/2. Độ
khó trung bình của một CH đúng-sai là 75%. Đối với các CH loại trả lời
tự do, như loại câu điền khuyết, thì độ khó trung bình là 50%.
Khi chọn lựa các câu trắc nghiệm theo độ khó người ta thường phải
loại các câu quá khó (không ai làm đúng) hoặc quá dễ (ai cũng làm
đúng). Một ĐTN tốt thường là đề có nhiều CH ở độ khó trung bình.
- Để xét độ khó của cả một ĐTN, người ta có thể đối chiếu điểm số
trung bình của ĐTN và điểm trung bình lý tưởng của nó. Điểm trung bình
lý tưởng của một ĐTN là điểm số nằm giữa điểm tối đa mà người làm
đúng toàn bộ nhận được và điểm mà người không biết gì có thể đạt do
chọn hú hoạ. Giả sử có ĐTN 50 câu, mỗi câu có 5 phương án trả lời. Điểm
thô tối đa là 50, điểm có thể đạt được do chọn hú hoạ là 0,2 50 = 10,
điểm trung bình lý tưởng là (50 + 10)/2 = 30. Nếu điểm trung bình quan
sát được trên hay dưới 30 quá xa thì ĐTN ấy sẽ là quá dễ hay quá khó.
Nói chung, nếu điểm trung bình lý tưởng nằm ở khoảng giữa phân bố các
điểm quan sát được thì ĐTN là vừa sức đối với đối tượng TS, còn khi
điểm đó nằm ở phía trên hoặc phía dưới phân bố điểm quan sát được thì
ĐTN tương ứng là khó hơn hoặc dễ hơn so với đối tượng TS.
2.2.2. Độ phân biệt của CH
Khi ra một CH hoặc một ĐTN cho một nhóm TS nào đó, người ta
thường muốn phân biệt trong nhóm TS ấy những người có năng lực khác
nhau: giỏi, trung bình, kém... Khả năng của câu trắc nghiệm thực hiện
được sự phân biệt ấy được gọi là độ phân biệt. Muốn cho CH có độ phân

61
biệt, phản ứng của nhóm TS giỏi và nhóm TS kém lên CH đó hiển nhiên
phải khác nhau. Người ta thường thống kê các phản ứng khác nhau đó để
tính độ phân biệt.
Độ phân biệt của một CH hoặc một ĐTN liên quan đến độ khó.
Thật vậy, nếu một ĐTN dễ đến mức mọi TS đều làm tốt, các điểm số đạt
được chụm ở phần điểm cao, thì độ phân biệt của nó rất kém, vì mọi TS
đều có phản ứng như nhau đối với ĐTN đó. Cũng vậy, nếu một ĐTN khó
đến mức mọi TS đều làm không được, các điểm số đạt được chụm ở
phần điểm thấp, thì độ phân biệt của nó cũng rất kém. Từ các trường hợp
giới hạn nói trên có thể suy ra rằng một ĐTN muốn có độ phân biệt tốt
thì nó phải bao gồm nhiều CH có độ khó ở mức trung bình. Khi ấy điểm số
thu được của nhóm TS sẽ có phổ trải rộng.
- Trước hết chúng ta làm quen với phương pháp cổ điển đơn giản
để tính độ phân biệt. Dựa vào tổng điểm thô của từng TS người ta tách từ
đối tượng TS ra một nhóm giỏi bao gồm 27% TS đạt điểm cao từ trên
xuống, và nhóm kém bao gồm 27% TS đạt điểm kém từ dưới lên. Gọi C
là số TS làm đúng CH thuộc nhóm giỏi, T là số TS làm đúng CH thuộc
nhóm kém, S là số lượng TS của một trong hai nhóm nói trên (27% tổng
số), ta có biểu thức tính độ phân biệt D của CH hỏi như sau:
D = S
TC (2.5)
Phương pháp vừa nêu để tính độ phân biệt rất đơn giản, có thể tính
bằng tay.
- Người ta có thể tính độ phân biệt của một CH theo một định nghĩa
khái quát hơn: đó là hệ số tương quan giữa các điểm của CH đó với tổng
điểm của cả ĐTN xét trên mọi TS làm ĐTN. Hệ số tương quan có giá trị
dương lớn (gần bằng 1) khi một TS nào đó có điểm của CH cao thì điểm
của cả ĐTN cũng cao, và ngược lại. Hệ số tương quan có giá trị âm lớn
(gần bằng -1) khi một TS nào đó có điểm của CH cao thì điểm của cả ĐTN
lại thấp, và ngược lại. Hệ số tương quan bằng không nếu điểm của CH và
điểm của cả ĐTN không có mối liên hệ chặt chẽ và ổn định nào cả. Nói
cách khác, CH có độ phân biệt tốt “khi CH và cả ĐTN đều đo lường
cùng một thứ”.

62
Như vậy, để tính độ phân biệt, người ta có thể tính hệ số tương quan
Pearson giữa điểm của CH với tổng điểm của cả ĐTN. Thông thường trị số
độ phân biệt của CH có thể chấp nhận được phải lớn hơn 0,2.
Có hai đai lượng đặc trưng khác gắn với cả ĐTN chứ không phải
gắn với từng CH, rất quan trọng để đánh giá chất lượng của ĐTN: đó là
độ tin cậy và độ giá trị của ĐTN.
2.2.3. Độ tin cậy của ĐTN
Trắc nghiệm là một phép đo: dùng thước đo là ĐTN để đo lường
một năng lực nào đó của TS. Độ tin cậy của ĐTN chính là đại lượng biểu
thị mức độ chính xác của phép đo nhờ ĐTN.
Người ta có thể tính độ tin cậy của ĐTN bằng các cách sau đây:
- Phương pháp trắc nghiệm - trắc nghiệm lại, tức là dùng một ĐTN
cho một nhóm TS làm hai lần và tính hệ số tương quan giữa hai bộ điểm.
Phương pháp này có nhược điểm: một là các ứng đáp của TS trong lần
thứ hai không độc lập so với trong lần thứ nhất, hai là năng lực của TS
trong lần thứ hai có thể đã thay đổi.
- Phương pháp các ĐTN tương đương: cho một nhóm TS làm hai
ĐTN tương đương rồi tính độ tương quan giữa hai bộ điểm. Vấn đề là
phải tốn nhiều công sức để soạn các ĐTN thực sự tương đương.
- Phương pháp phân đôi ĐTN: thực chất là tạo 2 ĐTN tương
đương, mỗi đề là một nửa của ĐTN chung. Để hai nửa ĐTN có sự tương
đương cao, người ta sắp xếp từng cặp câu chẵn và lẻ tương đương nhau
để có 2 nửa ĐTN một gồm các câu chẵn và một gồm các câu lẻ. Độ tin
cậy của nửa ĐTN bằng hệ số tương quan giữa hai bộ điểm của hai nửa
ĐTN, còn độ tin cậy của toàn ĐTN có thể thu được khi hiệu chỉnh việc
tăng độ dài gấp đôi.
Sự phụ thuộc của độ tin cậy của ĐTN vào độ dài của nó được tính
theo công thức tổng quát Spearman-Brown:
11)r(n
nrr
S
Sn
, (2.6)

63
trong đó rS là độ tin cậy của ĐTN ngắn xuất phát, rn là độ tin cậy
của của ĐTN có độ dài gấp n lần. Rõ ràng để hiệu chỉnh cho trường hợp
ĐTN có độ dài gấp đôi, ta phải dùng công thức:
1r
2rr
S
S
. (2.7)
- Phương pháp Kuder-Richardson: Việc tính độ tin cậy theo phương
pháp Kuder-Richardson dựa trên ý tưởng xem mỗi câu trong ĐTN là một
ĐTN tương đương, tức là chúng có cùng điểm trung bình và cùng phương sai.
Dựa trên giả thiết đó có thể thu được công thức Kuder-Richardson-20
như sau để tính độ tin cậy của một ĐTN:
)σ
(11k
kr
2
1
k
i
ii qp
, (2.8)
trong đó: k - số CH của ĐTN;
pi – tỷ lệ trả lời đúng đối với CH thứ i;
qi = (1 pi) – tỷ lệ trả lời sai đối với CH thứ i;
2 - phương sai của tổng điểm mọi TS đối với cả ĐTN.
Công thức K-R20 hơi khó áp dụng, vì đòi hỏi phải biết độ khó p
của từng CH.
Trong trường hợp độ khó của các CH không khác nhau nhiều,
người ta có thể biến đổi công thức K-R20 thành một công thức dễ tính
toán hơn:
2σ
)k
MM(1
11k
kr , (2.9)
trong đó M là giá trị trung bình của điểm số của cả ĐTN. Đó là
công thức Kuder-Richardson 21.
Hệ số Alpha Cronbach: Bằng các lập luận tổng quát, Cronbach L.G.
đã đưa ra một biểu thức để ước lượng độ tin cậy của một đề kiểm tra tổng

64
hợp (có thể bao gồm nhiều ĐTN con nhị phân hoặc đa phân), được sử
dụng rộng rãi trong khoa học đo lường trong tâm lý và giáo dục, có tên là
hệ số Alpha Cronbach(*). Hệ số này xác định giới hạn dưới của độ tin cậy
của một đề kiểm tra tổng hợp bao gồm k đề kiểm tra con, được biểu diễn
như sau:
k2i
i
2c
kρ 1
k 1
, (2.10)
trong đó σi2, σC
2 tương ứng là phương sai của đề kiểm tra con thứ i và
phương sai của đề kiểm tra tổng hợp. Trong trường hợp riêng đối với
một ĐTN bao gồm nhiều CH dạng nhị phân thì σi2 là phương sai của
một CH trắc nghiệm nhị phân, có thể chứng minh có giá trị bằng piqi,
khi ấy công thức của hệ số Alpha Cronbach trở về công thức K-R20
theo biểu thức (2.8).
2.2.4. Độ giá trị của ĐTN
Yêu cầu quan trọng nhất của ĐTN với tư cách là một phép đo
lường trong giáo dục là phép đo ấy đo được cái cần đo. Nói cách khác,
phép đo ấy cần phải đạt được mục tiêu đề ra cho nó. Chẳng hạn, mục tiêu
đề ra cho tuyển sinh đại học là kiểm tra xem TS có nắm chắc những kiến
thức và kỹ năng cơ bản được trang bị qua chương trình phổ thông trung
học hay không để chọn vào học đại học. Phép đo bởi ĐTN đạt được mục
tiêu đó là phép đo có giá trị. Nói cách khác, độ giá trị của ĐTN là đại
lượng biểu thị mức độ đạt được mục tiêu đề ra cho phép đo nhờ ĐTN.
Để ĐTN có độ giá trị cao, cần phải xác định tỉ mỉ mục tiêu cần đo
qua ĐTN và bám sát mục tiêu đó trong quá trình xây dựng ngân hàng CH
(*) Cronbach L.G. lần đầu tiên công bố hệ số Alpha nói trên trong một bài báo vào năm 1951
khi xem xét sự tương đương của các cách khác nhau để xác định độ tin cậy. Đây là một
bài báo nổi tiếng vào bậc nhất trong và ngoài lĩnh vực tâm trắc học. Vào thập niên 1970,
Cronbach cũng là một trong những người đầu tiên đề đưa ra lý thuyết năng lực tổng
quát (generalizability theory).

65
trắc nghiệm cũng như khi tổ chức triển khai kỳ thi. Nếu thực hiện các quá
trình nói trên không đúng thì có khả năng kết quả của phép đo sẽ phản
ánh một cái gì khác chứ không phải cái mà ta muốn đo bằng ĐTN.
Có thể xét độ giá trị của một ĐTN dưới nhiều góc độ khác nhau, và
cũng có các cách đánh giá định lượng độ giá trị. Bạn đọc có thể tìm hiểu
thêm trong các sách chuyên khảo.
Qua định nghĩa về độ tin cậy và độ giá trị, chúng ta có thể thấy rõ
mối tương quan giữa chúng. Khi ĐTN không có độ tin cậy, tức là phép
đo nhờ ĐTN rất kém chính xác, thì chúng ta không thể nói đến độ giá trị
của nó. Nói cách khác, khi ĐTN không có độ tin cậy cao thì nó cũng không
thể có độ giá trị.
Như vậy, một ĐTN có độ tin cậy cao thì có nhất thiết sẽ có độ giá
trị cao hay không? Câu trả lời là: không nhất thiết. Thật vậy, đôi khi phép
đo nhờ ĐTN có thể đo chính xác, nhưng nó đo một cái gì khác chứ không
phải cái nó cần đo, trong trường hợp đó thì ĐTN có độ tin cậy cao nhưng
độ giá trị thấp.
Ví dụ một khẩu súng chuẩn xác được người bắn nhằm vào mục tiêu
là tấm bia ngắm, các viên đạn bắn ra đều trúng chụm lân cận tâm điểm
của bia ngắm. Khẩu súng như vậy là có độ tin cậy cao, và người bắn
nhắm đúng mục tiêu nên kết quả bắn cũng đạt độ giá trị cao. Tuy nhiên
cũng khẩu súng đó nếu rơi vào tay một người ngắm nhầm mục tiêu, kết
quả là các viên đạn vẫn chụm nhưng nằm lân cận một mục tiêu khác chứ
không đúng mục tiêu đặt ra, trong trường hợp này động tác ngắm bắn vẫn
có độ tin cậy cao nhưng việc bắn súng có độ giá trị thấp.
Có thể lấy ví dụ về kỳ thi tuyển sinh đại học. Mục tiêu của kỳ thi
tuyển sinh đại học là xác định những học sinh có năng lực học tập tốt để
lựa chọn vào học chương trình đại học. Tuy nhiên, nếu ra đề thi không
thích hợp thì sẽ không đảm bảo cho kỳ thi đạt được mục tiêu đó. Chẳng
hạn, nếu trong đề thi có nhiều bài tập lắt léo đến mức một học sinh phổ
thông trung học giỏi cũng không thể làm kịp trong một thời gian ngắn,
mà chỉ những TS qua nhiều lớp luyện thi quen các dạng bài tập đó mới
làm được, thì chỉ loại “thợ làm bài tập” này có khả năng đạt điểm cao và

66
được tuyển chọn. Rút cục chúng ta sẽ chọn được những anh thợ làm bài
tập giỏi, và loại bỏ một số học sinh nắm vững chương trình phổ thông
trung học mà không có điều kiện luyện thi, đặc biệt là những học sinh từ
nông thôn. Trong lúc đó kỹ năng làm bài tập của những anh "thợ làm bài
tập" chưa chắc đã cần thiết cho quá trình học đại học. Như vậy, có thể kỳ
thi của chúng ta đo chính xác, nhưng đo một kỹ năng khác chứ không
phải năng lực mà chúng ta cần đo. Trong trường hợp này kỳ thi có thể đạt
độ tin cậy cao nhưng có độ giá trị thấp. Để đánh giá khách quan độ tin
cậy của kỳ thi tuyển sinh đại học, chúng ta có thể khảo sát xem kết quả
học đại học của học sinh có hệ số tương quan cao với kết quả thi tuyển
sinh hay không.
2.3. ĐÁNH GIÁ MỘT ĐỀ TRẮC NGHIỆM
Đánh giá một ĐTN được bắt đầu bằng phân tích các CH trong đề.
2.3.1. Phân tích các CH trắc nghiệm
Như đã nói ở chương 1, để hoàn thiện các ĐTN người ta phải triển
khai các trắc nghiệm thử. Trắc nghiệm thử là một phép đo kép: dùng
ĐTN để đo năng lực các TS, đồng thời sử dụng nhóm TS như một thước
đo để đo chất lượng các CH và bản thân ĐTN. Phép đo kép này có thể
thực hiện được nhờ hiệu quả kỳ diệu của các quy luật thống kê.
Thật vậy, tuy chưa có các tham số của ĐTN, qua nhiều bước soạn
thảo ngân hàng CH theo quy trình như nêu ở cuối chương 1, chất lượng
ĐTN cũng đã tương đối đảm bảo để có thể phân loại TS: những TS làm
đúng nhiều CH tất thuộc nhóm giỏi, những TS làm đúng ít CH tất thuộc
nhóm kém. Đưa được TS về hai đầu giỏi và kém là chúng ta đã biến
nhóm TS thành một thước đo để đo chất lượng các CH và bản thân ĐTN.
Dưới đây bạn đọc trước hết sẽ làm quen với ví dụ về việc phân tích
CH trắc nghiệm qua giá trị độ khó, độ phân biệt của chúng, khảo sát vai
trò của phương án đúng và các phương án nhiễu; sau đó sẽ tính độ tin cậy
và xem xét độ giá trị của toàn bộ ĐTN.
Để phân tích ĐTN bằng tay, người ta thường lấy ra từ tổng số TS
làm ĐTN hai nhóm con, một nhóm bao gồm 27% số người đạt điểm cao

67
nhất và một nhóm khác bao gồm 27% số người đạt điểm thấp nhất. Cách
phân chia này cho phép tính độ phân biệt bằng tay theo công thức (2.5).
Còn khi sử dụng máy tính có thể dễ dàng tính các hệ số tương quan, do
đó không cần phân chia TS thành các nhóm con như trên.
Ví dụ: Hãy xem xét số liệu qua hai trường hợp sau đây để phân tích
CH trắc nghiệm.
1) Dựa vào kết quả trắc nghiệm thử và tách ra các nhóm có điểm cao
và điểm thấp trên một ĐTN người ta đưa ra các giá trị mô tả ở Bảng 2.3
đối với một CH với 5 phương án chọn (phương án đúng là B):
Bảng 2.3.
A B* C D E Cộng
Nhóm cao (27%) 0 3 10 3 4 20
Nhóm thấp (27%) 0 6 3 5 6 20
2) Khi phân tích số liệu trả lời một ĐTN nhờ phần mềm VITESTA [19]
người ta thu được kết quả biểu diễn ở Bảng 2.4 đối với một CH có 4
phương án chọn (phương án đúng là B):
Bảng 2.4.
A B* C D
Không
trả lời
Số TS chọn 9 43 32 19 1
Tương quan giữa điểm
CH và điểm của cả ĐTN -0,34 0,35 -0,13 -0,05
Các bảng số cho phép chúng ta phân tích các CH như sau:
- Độ khó của các CH: Đối với CH ở Bảng 2.3 ta chỉ có thể tính giá
trị gần đúng của độ khó, vì không có thông tin về trả lời của các TS ngoài
hai nhóm giỏi và kém. Ở đây có 9 TS trả lời đúng trên tổng số 40 TS, do
đó độ khó gần đúng bằng: (3+6)/40 = 0,225.
Đối với CH ở Bảng 2.4 độ khó bằng 43/(9+43+32+19+1) = 0,41.

68
- Độ phân biệt của các CH:
Đối với CH ở Bảng 2.3, công thức (2.5) cho phép tính độ phân biệt
của nó: (3 - 6)/20 = -0,15.
Đối với CH ở Bảng 2.4 độ phân biệt chính là hệ số tương quan của
điểm chọn phương án đúng của CH với điểm cả ĐTN, tức là 0,35.
- Các phương án nhiễu:
Đối với CH ở Bảng 2.3, cần phải xem lại phương án B có phải là
phương án đúng hay không, vì độ phân biệt ở đây là âm. Có thể có các
khả năng: hoặc B thực sự không phải là phương án đúng nhưng người ta
đã gán nhầm đáp án vào B, hoặc do CH được diễn đạt không rõ ràng nên
đa số TS của nhóm điểm cao không chọn phương án B. Nếu cả hai khả
năng trên đều không xảy ra thì hãy xem lại trong quá trình giảng dạy
giảng viên có tạo nên sự hiểu nhầm nào liên quan đến nội dung CH hay
không. Phương án nhiễu C là rất khả nghi, vì nó có cho hệ số tương quan
dương rất lớn, giống như là phương án đúng. Phải chăng đây mới thật sự
là phương án đúng? Nếu không, cần xem lại cách diễn đạt của CH hoặc
quá trình giảng dạy đã gây hiểu nhầm. Các phương án nhiễu và D, E cho
tương quan chấp nhận được. Còn phương án A là một phương án nhiễu
tồi vì không đánh lừa được ai, cả các TS ở nhóm điểm cao và ở nhóm
điểm thấp, cần thay bằng một phương án khác.
Đối với CH ở Bảng 2.4 độ phân biệt của phương án đúng là dương
và có giá trị lớn (0,35 > 0,2), rất tốt, còn hệ số tương quan ứng với các
phương án nhiễu là âm, cũng rất phù hợp.
Qua việc phân tích độ khó, độ phân biệt của các CH nêu ở Bảng 2.3,
Bảng 2.4 và các phương án chọn của chúng, chúng ta có thể kết luận: CH
được mô tả ở Bảng 2.3 là một CH hỏi kém, cần phải sửa chữa một cách
cơ bản nếu không loại bỏ; còn CH bảng 2.4 là một CH khá tốt.
2.3.2. Tính độ tin cậy của ĐTN
Mục 2.2.3 đã trình bày các cách tính độ tin cậy của ĐTN, trong đó
có thể sử dụng phương pháp phân đôi ĐTN hoặc các công thức K-R20
và K-R21.

69
Dưới đây sẽ nêu các ví dụ về hai cách tính vừa nêu.
Dùng phương pháp phân đôi đề trắc nghiệm: Để ví dụ, ta xem
Bảng 2.2 là kết quả làm hai ĐTN ngắn, mỗi đề 11 câu, bởi một nhóm TS.
Giả sử hai ĐTN ngắn đó là hai nửa của một ĐTN dài hơn, gồm 22 câu,
ĐTN xi bao gồm các câu chẵn, ĐTN yj bao gồm các câu lẻ.
Để tính độ tin cậy của ĐTN phân đôi, trước hết ta phải tính hệ số tương
quan của hai nửa ĐTN. Việc đó đã được thực hiện ở ví dụ tại mục 2.1:
r = 0,478
Tuy nhiên, đây mới chỉ là độ tin cậy của nửa ĐTN gồm 11CH. Để
tính độ tin cậy của ĐTN xuất phát với 22 CH, cần phải hiệu chỉnh độ tin
cậy theo công thức (2.7):
r = 2rS/(rS+1) = 2 0,478/ (0,478 + 1) = 0,647.
Sử dụng các công thức K-R 20 và K-R 21:
Như đã biết, công thức K-R21 thu được từ công thức K-R20 với giả
thiết là độ khó của các CH trong ĐTN xấp xỉ bằng nhau. Để tính toán,
chúng ta hãy sử dụng ví dụ có tính giáo khoa R. Ebel đưa ra và được nêu lại
trong tài liệu tham khảo [1] về 2 ĐTN, mỗi ĐTN gồm 100 CH, với phân bố
các độ khó, điểm trung bình, độ lệch tiêu chuẩn như nêu ở Bảng 2.5.
Theo công thức K-R20 (2.8): r = [k/(k-1)](1- pq/2),
- ĐTN A: cả 100 câu đều có độ khó 0,5 thì p=0,5; q=1-p =0,5 →
pq = 0,25 → pq = 100 0,25 = 25
Từ đó: r = (100/99) (1 - 25/152) 0,898
- ĐTN B: Tích pq của mỗi CH cách đều CH nằm giữa với p=0,5 là
như nhau, do đó:
pq = 0,9 0,1 10 2 + 0,8 0,2 10 2 + 0,7 0,3 10 2 +
0,6 0,4 10 2 + 0,5 0,5 10 = 16,5
Từ đó: r = (100/99) (1 - 16,5/82) 0,750
Theo công thức K-R21 (2.9): r = [k/(k-1)][1- M(1-M/k)/2];

70
- ĐTN A:
r = (100/99) [1 - 50 (1 - 50/100)/152] 0,898
- ĐTN B:
r = (100/99) [1 - 50 (1 - 50/100)/82] 0,615
Rõ ràng hai công thức K-R.20 và K-R.21 cho kết quả như nhau đối
với ĐTN A, một ĐTN mà mọi CH đều có độ khó như nhau, và kết quả
khác nhau nhiều đối với ĐTN B, một ĐTN mà độ khó của các nhóm CH
khác nhau đáng kể, đúng như điều kiện đặt ra khi sử dụng 2 công thức đó.
Bảng 2.5.
Số CH Giá trị độ khó
(tỷ lệ trả lời đúng) ĐTN A ĐTN B
5 1
10 0,9
10 0,8
10 0,7
10 0,6
100 10 0,5
10 0,4
10 0,3
10 0,2
10 0,1
5 0,0
50 50 Điểm trung bình M
15 8 Độ lệch tiêu chuẩn
2.3.3. Xem xét độ giá trị của ĐTN
Hai đại lượng quan trọng thường được dựa vào để đánh giá một
ĐTN là độ tin cậy và độ giá trị. Khi đánh giá độ tin cậy, phải xem xét các
hệ số tin cậy và sai số tiêu chuẩn của phép đo. Còn khi đánh giá độ giá trị

71
phải coi trọng sự phân tích nội dung hơn là các số liệu thống kê. Cũng cần
lưu ý rằng đây là các đại lượng có tính tổng hợp, không những gắn liền với
chất lượng ĐTN, mà còn với toàn bộ quá trình tổ chức kỳ thi, chấm thi.
Như đã nói ở phần trước, một ĐTN muốn có độ giá trị cao tất yếu
phải có độ tin cậy cao, tuy nhiên ĐTN có độ tin cậy cao chưa hẳn đã có
độ giá trị cao. Có thể làm tăng độ tin cậy của ĐTN khi tăng mức độ thuần
nhất về nội dung của nó, nhưng để tăng mức độ thuần nhất, chẳng hạn
loại bỏ bớt các CH khó, đôi khi phải hy sinh độ giá trị. Trong những
trường hợp đó nên coi trọng độ giá trị hơn là độ tin cậy.
2.4. CÁC LOẠI ĐIỂM TRẮC NGHIỆM
Để đo năng lực của một nhóm TS về một môn học hoặc một
chương trình học nào đó, ta thường cho họ làm một đề kiểm tra. Vì phân
bố tần suất của năng lực thường có dạng chuẩn nên phân bố tần suất điểm
kiểm tra của TS (nếu điểm phản ánh đúng năng lực) cũng thường theo
dạng chuẩn.
2.4.1. Điểm thô
Một ĐTN thường bao gồm nhiều CH, mỗi CH được gán một
điểm số, chẳng hạn CH nhị phân thường là điểm 1 nếu làm đúng,
điểm 0 nếu làm sai. Sau khi chấm bài trắc nghiệm và cộng các điểm
số của từng TS ta thu được các điểm số của các TS, được gọi là điểm
thô (raw score). Đối với đề TL người ta có thể gán một điểm nào đó
cho từng ý, từng nội dung mà TS trả lời được, và sau khi chấm xong
cộng điểm của mỗi TS lại người ta cũng được một điểm thô. Cách
cho điểm TL được dùng ở Việt Nam thường ngầm định trước một
khung điểm, chẳng hạn từ 0 đến 10, và chỉ được cho điểm trong
khung đó. Điểm thô thu được như vậy tính chất có khác với điểm thô
thu được từ một ĐTN.
Để có thể so sánh các điểm số thu được của ĐTN trên một phạm vi
rộng, người ta phải biến đổi các điểm đó theo hai cách: 1) so sánh với một
tiêu chuẩn (standard) tuyệt đối đã định trước (liên quan với độ khó về nội
dung); 2) so sánh với một nhóm TS nào đó dùng làm chuẩn (norm).

72
2.4.2. Điểm tiêu chuẩn tuyệt đối
Các điểm số loại này được xác định dựa trên việc so sánh điểm thô
của một TS với điểm tối đa có thể đạt được từ ĐTN, do đó nó hoàn toàn
không bị ảnh hưởng bởi điểm số của những người khác trong nhóm khảo
sát. Một cách cho điểm thường được ưa dùng thuộc loại này là điểm phần
trăm đúng. Điểm được tính theo tỷ lệ phần trăm số CH làm đúng trên
tổng số CH của ĐTN
x = Số câu đúng
(2.11) Tổng số câu
Nhiều giáo viên thích dùng điểm phần trăm đúng này vì cách biến
đổi đơn giản. Họ còn thường quy định trước tiêu chuẩn tối thiểu mà TS
phải làm được để đạt yêu cầu, chẳng hạn làm được 50% hay 60% CH của
ĐTN. Việc quy định trước tiêu chuẩn đó là hoàn toàn tuỳ tiện, không có
tính khách quan.
2.4.3. Các loại điểm tương đối dựa vào phân bố chuẩn
Một cách biến đổi điểm khác thường dùng là dựa vào một nhóm
chuẩn mực (norm group) để xác định các thang bậc và biến đổi điểm thô
thu được theo thang bậc đó.
Giả sử điểm thô thu được từ kết quả trắc nghiệm trên một nhóm
nào đó có phân bố tần suất gần với dạng phân bố chuẩn với giá trị trung
bình là tx và độ lệch tiêu chuẩn là t. Chúng ta muốn biến đổi các điểm
thô này sang một thang điểm với giá trị trung bình đặt ở Sx và độ lệch
tiêu chuẩn là S.
Để thực hiện được phép biển đổi này chúng ta phải co dãn đường
cong phân bố chuẩn ứng với thang điểm thô sao cho độ lệch tiêu chuẩn
của đường cong đạt giá trị S, sau đó dịch chuyển đường cong thu được
sao cho điểm gốc của nó dời đến vị trí giá trị trung bình Sx trên trục số.
Phép co dãn và dịch chuyển đó được thực hiện bằng hệ thức sau:
S
SS
t
tt xxxx
, (2.12)

73
từ đó:
Stt
t
SS xxxx )(
. (2.13)
Điểm Z
Một trong các điểm tiêu chuẩn quan trọng là điểm ứng với một
phân bố chuẩn đặc biệt có giá trị trung bình được đặt tại 0 và độ lệch tiêu
chuẩn được chọn bằng 1. Điểm tiêu chuẩn đặc biệt này được gọi tên là
điểm Z. Như vậy từ biểu thức (2.12), để biến đổi một thang điểm tiêu
chuẩn bất kỳ nào đó thành thang điểm Z có thể sử dụng hệ thức sau đây:
.xx
Z
(2.14)
Hình 2.4 biểu diễn đường cong phân bố chuẩn ứng với điểm Z và
tần suất xuất hiện các trường hợp nằm trong các khoảng giữa điểm trung
bình Z = 0 và các điểm Z bằng một số nguyên lần độ lệch tiêu chuẩn. Từ
hình vẽ có thể thấy rõ ứng với một phân bố chuẩn lý thuyết khoảng
[–3,+3] bao gồm 99,8% trường hợp của phân bố, tức là trên thực tế có
thể xem là bao gồm toàn bộ các trường hợp.
Điểm Z: -3 -2 -1 0 1 2 3
Hình 2.4. Điểm Z
Một số loại điểm chuẩn khác:
Điểm Z rất thích hợp trong nghiên cứu để so sánh các bộ điểm thô
thu được từ các ĐTN khác nhau thực hiện trên cùng một nhóm TS được

74
chọn làm chuẩn. Tuy nhiên, việc sử dụng điểm Z trong thực tế không
thuận lợi vì nó có giá trị âm và các khoảng nguyên quá rộng, nên để biểu
diễn các điểm cụ thể phải dùng các số thập phân. Do đó người ta thường
sử dụng các thang điểm chuẩn khác bằng cách gán giá trị trung bình và
độ lệch tiêu chuẩn của điểm thô các giá trị lựa chọn tuỳ ý nào đó. Sau
đây là ví dụ về một số thang điểm chuẩn thường gặp.
- Các điểm trắc nghiệm tiêu chuẩn hoá của ETS: “Dịch vụ Trắc
nghiệm Giáo dục” (Educational Testing Services - ETS) là một công ty tư
nhân lớn nhất Hoa Kỳ, sản xuất các đề thi và tổ chức các kỳ thi trắc nghiệm
tiêu chuẩn hoá. Trong số các dịch vụ thi trắc nghiệm nổi tiếng của công ty
này có thể kể: Trắc nghiệm Đánh giá Học vấn (Scholastic Assesment Tets -
SAT) để phục vụ tuyển sinh đại học; Kỳ thi Ghi nhận Sau đại học (Graduate
Record Examination - GRE) bao gồm đề thi đại cương và các đề thi theo
một số môn học xác định; Trắc nghiệm Tuyển sinh Sau đại học ngành Quản
lý (Graduate Management Admission Test – GMAT) để hỗ trợ tuyển sinh
sau đại học vào các ngành quản trị kinh doanh; Trắc nghiệm Ngoại ngữ
tiếng Anh (Test of English as a Foreign Language - TOEFL)... Các trắc
nghiệm nêu trên đều sử dụng cùng một loại thang điểm với giá trị trung bình
gán ở 500, và độ lệch tiêu chuẩn được chọn bằng 100 đơn vị nguyên.
Hình 2.5. So sánh một số loại điểm tiêu chuẩn
Với cách quy định như vậy khoảng [–3,+3] ứng với khoảng
điểm [200, 800]. Trong thực tế, để dễ hiểu người ta thường giải thích là
các thang điểm ETS trải trong khoảng 200 và 800.

75
- Điểm Trắc nghiệm Đại học Hoa Kỳ (American College Testing –
ACT): ACT là một công ty phi chính phủ khác của Hoa Kỳ tổ chức kỳ
thi trắc nghiệm phục vụ tuyển sinh đại học. Trắc nghiệm ACT sử dụng
thang điểm với giá trị trung bình gán vào điểm 20, độ lệch tiêu chuẩn
được chọn bằng 5 đơn vị nguyên. Với cách quy định như vậy khoảng
[-3,+3] ứng với khoảng điểm [5, 35].
- Điểm Trắc nghiệm Trí thông minh IQ (Intelligence Quotient):
Trắc nghiệm IQ sử dụng thang điểm với giá trị trung bình gán vào điểm
100, độ lệch tiêu chuẩn được chọn bằng 15 đơn vị nguyên. Với cách quy
định như vậy khoảng [-3,+3] ứng với khoảng điểm [55, 145].
2.4.4. Về các thang điểm được sử dụng ở nước ta
Vì khoa học về đo lường và đánh giá trong giáo dục ở nước ta chưa
phát triển nên các thang điểm được sử dụng trong các trường học phần
lớn do thói quen đã có từ trước, đôi khi được du nhập từ các hệ thống
giáo dục nước ngoài.
Thang điểm đang được sử dụng phổ biến ở nước ta hiện nay là điểm
bậc 10, đó là điểm tuyệt đối được cho dựa vào sự ấn định ngầm điểm tối đa
là 10, điểm tối thiểu là 0 và điểm trung bình nằm ở khoảng 5, chứ không
phải là điểm tiêu chuẩn dựa vào phân bố chuẩn và độ lệch tiêu chuẩn.
Để phục vụ việc tuyển chọn trong các kỳ thi với nhiều môn, người
ta còn ấn định hệ số cho các môn dựa vào mức độ quan trọng của các
môn đó đối với việc học tập trong tương lai và được ấn định hoàn toàn
theo phán xét chủ quan. Hơn nữa, trong các kỳ thi tuyển nhiều môn, việc
so sánh và cộng điểm của các môn lại để lấy điểm tổng cộng nhằm xét
tuyển cũng được thực hiện khá tuỳ tiện, không có căn cứ khoa học.
Chẳng hạn, đối với TS thi vào đại học theo khối A với 3 môn Toán, Lý,
Hoá người ta xét tuyển dựa vào tổng số điểm thô của 3 môn đó, tuy rằng
trên thực tế phân bố điểm của 3 môn thường là rất khác nhau, do đó giá trị
trung bình và độ lệch tiêu chuẩn cũng hoàn toàn khác nhau.
Chúng ta có thể thiết lập các thang điểm chuẩn gần giống với thang
điểm quen dùng. Chẳng hạn, trong kỳ thi Tú tài sử dụng TNKQ lần đầu
tiên ở miền Nam nước ta vào năm 1974, thang điểm tiêu chuẩn với điểm

76
trung bình bằng 10 và độ lệch tiêu chuẩn bằng 4 đã được sử dụng, rõ ràng
theo cách quy định như vậy khoảng [-2,5, +2,5] ứng với khoảng điểm
[0, 20], gần với thang điểm trên 20 được sử dụng phổ biến ở miền Nam
lúc bấy giờ.
Tương tự như vậy, chúng ta có thể thiết lập thang điểm tiêu chuẩn
với điểm trung bình bằng 5 và độ lệch tiêu chuẩn bằng 2, khi ấy khoảng
[-2,5,+ 2,5] sẽ ứng với khoảng điểm [0, 10], gần với thang điểm trên 10
đang sử dụng phổ biến ở nước ta hiện nay.
2.5. CÁC HẠN CHẾ CỦA LÝ THUYẾT TRẮC NGHIỆM CỔ ĐIỂN
VÀ KỲ VỌNG ĐỐI VỚI MỘT LÝ THUYẾT TRẮC NGHIỆM MỚI
Phát triển từ khoảng đầu thế kỷ XX cho đến thập niên 1970, lý
thuyết trắc nghiệm cổ điển (CTT) đạt được nhiều thành tựu, tạo cơ sở
khoa học để thiết kế các phép đo tương đối chính xác. Tuy nhiên lý
thuyết đó còn bị nhiều hạn chế.
- Có lẽ một trong các hạn chế cơ bản nhất của CTT là không tách
biệt được các đặc trưng của TS độc lập với các đặc trưng của ĐTN, đặc
trưng này chỉ có thể giải thích trong mối quan hệ với đặc trưng kia.
Một đặc trưng quan trọng mà ta quan tâm là năng lực của TS.
Trong khuôn khổ CTT, năng lực được diễn tả bởi điểm của TS mà một
ĐTN cụ thể đo được. Khi ĐTN “khó”, TS sẽ thể hiện năng lực thấp, khi
ĐTN “dễ”, TS sẽ thể hiện năng lực cao. Nhưng ĐTN thế nào là “khó”
hoặc “dễ”? Độ khó của một CH được định nghĩa là “tỷ số TS làm đúng
CH trên nhóm TS tham gia”, tức là độ khó CH tuỳ thuộc năng lực của
các TS được đo. Thật quá vòng vo! Độ phân biệt của CH cũng như độ tin
cậy và độ giá trị của ĐTN cũng được xác định phụ thuộc vào một nhóm
TS cụ thể được đo. Các đặc trưng của CH và ĐTN thay đổi khi tình trạng
TS thay đổi, và các đặc trưng của TS thay đổi khi tình trạng ĐTN thay
đổi. Kết quả là rất khó so sánh các TS khi họ làm các ĐTN khác nhau
cũng như rất khó so sánh các CH khi chúng được trả lời bởi các nhóm TS
khác nhau. Cuối cùng có thể nói: về nguyên tắc không thể thực hiện các
so sánh đó. Dù các chuyên gia đo lường cố gắng tìm cách xử lý khó khăn
đã nêu như thế nào nhưng vẫn không giải quyết được vấn đề từ bản chất.

77
Trước hết chúng ta hãy xem xét hậu quả thực tiễn của việc đặc
trưng CH phụ thuộc vào nhóm TS được đưa vào để xác định chúng. Sự
phụ thuộc đó hạn chế việc ứng dụng các ĐTN cho các nhóm TS khác với
nhóm mà đã dựa vào đó để thu các đặc trưng CH. Hạn chế đó ảnh hưởng
nhiều đến việc xây dựng NHCH, công cụ quan trọng để thiết kế ĐTN.
Thật vậy, việc mở rộng một NHCH sẽ gặp khó khăn nếu các đặc trưng
của nhóm CH bổ sung thu được nhờ một nhóm TS khác với nhóm TS đã
được dựa vào để xác định các đặc trưng của NHCH cũ. Bây giờ hãy xét
đến việc năng lực xác định được của TS phụ thuộc vào ĐTN. Rõ ràng là
khi ấy rất khó so sánh điểm biểu diễn năng lực của các TS làm các ĐTN
khác nhau: các điểm đó được đặt trên các thang khác nhau và không có
một mối quan hệ hàm số nào giữa các thang điểm. Thậm chí khi các
nhóm TS được cho làm các ĐTN tương đương vấn đề vẫn tồn tại, vì khi
các nhóm TS có năng lực khác nhau (tức là ĐTN là khó hơn đối với một
nhóm TS so với nhóm TS kia), thì các điểm thu được của họ từ các ĐTN
đó có sai số khác nhau.
- Một hạn chế khác của CTT nằm ở định nghĩa của độ tin cậy. Theo
CTT, độ tin cậy là “tương quan giữa các điểm của hai ĐTN tương
đương”. Trong thực tế không thể có các ĐTN thoả mãn tiêu chí tương
đương. Liên quan với độ tin cậy là sai số tiêu chuẩn của phép đo năng lực
TS: CTT quan niệm các sai số tiêu chuẩn ấy là như nhau, trong khi thực
tế độ chính xác của phép đo năng lực là khác nhau đối với các TS có
năng lực khác nhau.
- Thêm một hạn chế nữa của CTT là lý thuyết này xem xét việc ứng
đáp ở mức độ ĐTN chứ không phải ở mức độ CH trắc nghiệm. Khái
niệm điểm thực trong trắc nghiệm cổ điển không quan tâm tới việc TS
ứng đáp một CH như thế nào. Do đó không có cơ sở để xác định xem
một TS nào đó ứng đáp tốt ra sao đối với một CH đặt ra cho anh ta. Cụ
thể hơn, CTT không cho phép dự báo về một TS hoặc một nhóm TS nào
ứng đáp một CH đã cho ra sao. CH “xác suất để một TS ứng đáp đúng
một CH xác định là bao nhiêu?” là rất quan trọng trong nhiều ứng dụng
trắc nghiệm, thì không trả lời được trong khuôn khổ CTT.
Từ những giới hạn đã nêu trên đây, có thể thấy CTT không cho
phép giải quyết tốt một số vấn đề trong thực tiễn trắc nghiệm - như thiết

78
kế ĐTN, xác định các CH gây thiên lệch, trắc nghiệm thích ứng, so bằng
các điểm trắc nghiệm.
Do các nguyên nhân nêu trên, nhiều nhà tâm trắc học cố gắng tìm
một lý thuyết mới để thay thế CTT. Lý thuyết mới này kỳ vọng sẽ đạt
được các yêu cầu sau: 1) Các đặc trưng CH không phụ thuộc nhóm TS;
2) Các điểm mô tả năng lực TS không phụ thuộc vào ĐTN cụ thể mà TS
làm; 3) Mô hình xem xét ở cấp độ CH chứ không phải cấp độ ĐTN; 4)
Mô hình không đòi hỏi các ĐTN hoàn toàn tương đương để đánh giá độ
tin cậy; và 5) Mô hình cung cấp giá trị độ chính xác khác nhau của phép
đo ở từng mức năng lực của TS.
Chúng ta sẽ thấy từ phần sau đây của cuốn sách: Lý thuyết Ứng
đáp Câu hỏi (Item Response Theory) cho phép đạt các yêu cầu kỳ vọng
nêu trên.

79
CÂU HỎI TỰ KIỂM TRA
1. Nêu các khái niệm và định luật quan trọng trong lý thuyết xác suất
thống kê: xác suất, tần suất, luật số lớn, tổng thể, mẫu, phân bố,
tương quan, giá trị trung bình, độ lệch tiêu chuẩn, phương sai.
2. Mô tả phân bố chuẩn và các loại phân bố thường gặp.
3. Cách tính độ lệch tiêu chuẩn và phương sai. Thực hành trên một ví dụ
đơn giản.
4. Cách tính hệ số tương quan Pearson. Thực hành trên một ví dụ đơn giản.
5. Định nghĩa và cách tính độ khó, độ phân biệt trong lý thuyết trắc
nghiệm cổ điển.
6. Định nghĩa độ tin cậy, độ giá trị của một ĐTN. Các phương pháp đơn
giản để tính độ tin cậy.
7. Đối với một ĐTN cụ thể khả năng nào sau đây có thể xảy ra: 1) độ tin
cậy rất cao nhưng độ giá trị rất thấp; 2) độ tin cậy rất thấp nhưng độ
giá trị rất cao?
8. Vai trò của độ tin cậy và độ giá trị của một ĐTN cụ thể và cách đánh
giá tổng quát một ĐTN.
9. Mô tả các cách đánh giá các CH trắc nghiệm theo lý thuyết trắc
nghiệm cổ điển.
10. Nêu khái niệm điểm thô và cách tính điểm tiêu chuẩn tuyệt đối dựa
vào điểm thô.
11. Trình bày cách tính Điểm Z và các thang điểm tương đối khác. Các
tham số cơ bản xác định một thang điểm tương đối.
12. Nêu các hạn chế của lý thuyết trắc nghiệm cổ điển và kỳ vọng đối với
một lý thuyết trắc nghiệm mới.

80
BÀI TẬP
Bảng 2.6 cung cấp số liệu mô tả điểm của 30 TS đối với một CH
trắc nghiệm nhị phân và điểm của họ đối với toàn bộ ĐTN. TS được chia
thành 2 nhóm có năng lực thấp và năng lực cao. Tính độ khó và độ phân
biệt (định nghĩa theo CTT) của CH đối với từng nhóm TS và nhận xét về
tính độc lập của các giá trị đó trong CTT.
Bảng 2.6.
Nhóm TS năng lực thấp Nhóm TS năng lực cao
TS số Điểm ứng
đáp CH
Điểm từ
ĐTN TS số
Điểm ứng
đáp CH
Điểm từ
ĐTN
1 0 8 16 1 33
2 0 12 17 0 28
3 0 6 18 1 29
4 0 12 19 1 30
5 0 8 20 1 29
6 0 8 21 0 28
7 0 8 22 1 33
8 0 11 23 1 32
9 1 13 24 1 32
10 0 4 25 1 33
11 1 14 26 0 34
12 1 13 27 1 35
13 0 10 28 1 34
14 0 9 29 1 38
15 0 8 30 1 37
__________________

81
Phần II
TRẮC NGHIỆM HIỆN ĐẠI - LÝ THUYẾT
ỨNG ĐÁP CÂU HỎI

82
Chương 3
HÀM ĐẶC TRƯNG CÂU HỎI – TẾ BÀO CỦA LÝ THUYẾT ỨNG ĐÁP CÂU HỎI
Chương này dành để trình bày bước xuất phát trong tiến trình xây
dựng Lý thuyết Ứng đáp Câu hỏi (Item Response Theory - IRT). Trước hết,
quy trình thiết kế một phép đo lường nói chung được mô tả, từ bước xây
dựng thang đo, tạo thước đo, định cỡ thước đo và tiến hành đo. Để xây
dựng các thang đo khác nhau các con số được sử dụng với vai trò khác
nhau. Một yêu cầu chung nhằm tăng độ chính xác của phép đo sẽ được
xác định: đó là đảm bảo cho thước đo và đối tượng đo tách biệt độc lập
với nhau, yêu cầu đó được cụ thể hóa trong các phép đo trong tâm lý và
giáo dục. Sau khi xác định yêu cầu để thiết kế một phép đo nói chung,
quy trình thiết kế phép đo trong giáo dục được bắt đầu từ một cặp tương
tác nguyên tố “thí sinh - câu hỏi”, tế bào của IRT, và mô tả từng bước
cách xây dựng hàm đặc trưng CH theo mô hình Rasch đơn giản (tức là
mô hình đơn chiều, nhị phân, một tham số).
3.1. VỀ CÁC PHÉP ĐO LƯỜNG
3.1.1. Về quy trình xây dựng một phép đo lường
Để thực hiện một phép đo trong bất kỳ lĩnh vực khoa học kỹ thuật
nào cũng cần một thước đo tác động lên đối tượng đo, từ đó rút ra các số
đo đặc trưng cho đối tượng đó. Bất kỳ một phép đo nào cũng thu được số
đo với một độ chính xác nào đó, nghĩa là phép đo nào cũng có sai số.
Khi xây dựng một phép đo, người ta thường phải tạo một thang đo,
sau đó thiết kế thước đo, và cuối cùng áp thước đo vào đối tượng cần đo

83
để so sánh nhằm đưa ra những con số giá trị đo xác định. Để có thể hình
dung quá trình đó chúng ta hãy lấy một ví dụ cụ thể đơn giản về việc
thiết kế một phép đo nhiệt độ thông thường. Đầu tiên giả sử ta lấy nhiệt
độ của nước đá đang tan và nhiệt độ của nước sôi ở áp suất thường làm
mốc, gọi tương ứng là 00C và 1000C, và khắc độ chia đều khoảng nhiệt
độ thu được: bằng cách đó ta có một thang đo. Tiếp đến ta phải thiết kế
các thước đo nhằm đo đối tượng ở một khoảng nhiệt độ nào đó, chẳng
hạn đo thân nhiệt con người. Ta sử dụng hàng loạt ống thủy tinh có chứa
thủy ngân và rút hết không khí để làm thước đo. Các ống thủy tinh muốn
trở thành thước đo phải được khắc độ, hoặc định cỡ (calibration): giả sử
đặt chúng lên hai mẫu thử (sample) có nhiệt độ chính xác và ổn định, một
mẫu ở 350, mẫu kia ở 450, đỉnh cột thuỷ ngân trong các ống thuỷ tinh
nâng lên các mức tương ứng. Từ các mức đó ta đánh dấu các vạch 350 và
450 trên các ống thủy tinh và chia khoảng ấy ra từng độ và 1/10 độ: ta đã
biến các ống thuỷ tinh thành các thước đo (nhiệt kế). Cuối cùng ta có thể
sử dụng các thước đo đã được cùng định cỡ như vậy để đo thân nhiệt của
các bệnh nhân nào đó.
Trong quy trình đo lường theo ví dụ nêu trên muốn phép đo chính
xác phải đảm bảo hai điều. Một là quá trình định cỡ (khắc độ cho thước
đo) phải đủ tin cậy, đặc biệt là các mẫu thử khác nhau không được ảnh
hưởng lên kết quả định cỡ. Hai là, dù đo bằng một thước đo nào (trong
các thước đã được cùng định cỡ) thì kết quả đo phải như nhau (trong
phạm vi sai số chấp nhận được), tức là kết quả đo không phụ thuộc vào
một thước đo cụ thể. Yêu cầu nêu trên cũng là điều kiện để đảm bảo độ
chính xác chung cho nhiều phép đo khác nhau.
3.1.2. Các con số và các loại thang đo
Nhiều nhà nghiên cứu đưa ra những định nghĩa khác nhau về đo
lường, nhìn từ các góc độ khác nhau. Chúng ta hãy lưu ý đến hai định
nghĩa sau đây.
Theo Allen, M.J. và Yen, W.M. (1979) [7]: “Đo lường là gán các
con số vào các cá thể theo một quy tắc có hệ thống để biểu diễn các đặc
tính của các cá thể đó”.

84
Benjamin Wright (1979) [10] cho rằng: “Một số đo là một vị trí
trên một đường. Đo lường là quá trình cấu trúc các đường và định vị các
cá thể trên các đường đó”.
Hai định nghĩa đều có một ý chung là đo lường là gán các con số
vào các cá thể theo một nguyên tắc nào đó, nhưng định nghĩa đầu không
nêu rõ tính chất của các con số, còn định nghĩa sau xác định rõ đó là các
con số trên một đường liên tục, tức là các số trên trục số thực. Định nghĩa
đầu rộng hơn, tuy nhiên phản ánh phép đo có tính định lượng thấp hơn,
còn định nghĩa sau phản ánh phép đo có tính định lượng cao hơn. Hai
định nghĩa đó cũng thể hiện các cách sử dụng các con số theo các cấp độ
khác nhau.
Các con số có thể được sử dụng theo 4 cách sau: làm nhãn hiệu để
phân loại, tạo thang đo theo thứ tự, thang đo theo khoảng cách và thang đo
theo giá trị.
Làm nhãn hiệu, định danh (nominal) để phân loại: Chữ số in trên
áo cầu thủ chỉ có tác dụng như một nhãn hiệu. Khi phân chia các vật và
sự vật theo các tính chất xác định có thể sử dụng các con số để đánh dấu
phân loại. Trong hai ví dụ vừa nêu không thể làm phép tính số học nào cả
trên các con số đó.
Tạo thang đo theo thứ tự (ordinal): Các con số để chỉ thứ bậc trên
một thang đo, qua con số thứ bậc có thể biết cao thấp, hơn kém. Tuy
nhiên không thể tính toán độ lớn của một tính chất gán với một thứ bậc
nào đó và so sánh các độ lớn đó với nhau. Ví dụ một học sinh được xếp
hạng ở thứ 5 không phải giỏi gấp đôi học sinh được xếp hạng ở thứ 10.
Tạo thang đo theo khoảng cách (interval): Ví dụ thang nhiệt độ C
hay F. Khoảng cách ở đây có ý nghĩa xác định, có thể so sánh các khoảng
cách với nhau và áp dụng các phép tính số học cộng trừ nhân chia. Tuy
nhiên các thang chia theo khoảng cách không có một số không tuyệt đối.
Tạo thang đo theo tỷ lệ (ratio): Thang đo này có mọi đặc điểm như
thang đo theo khoảng cách, nhưng có thêm một tính chất quan trọng: có
tồn tại một số không tuyệt đối. Ví dụ về thang đo này là độ cao, khối
lượng, số tiền… Vì có số không tuyệt đối nên có thể tính tỷ lệ giữa hai số

85
đo, chẳng hạn khi so sánh một người có 10 đồng và một người có 2 đồng
có thể nói người thứ nhất có số tiền gấp 5 lần người thứ hai.
Có thể thấy trong sự sắp xếp 4 loại thang đo trên mức độ định
lượng tăng dần từ trên xuống dưới.
Đo lường thành quả học tập trong giáo dục có thể hiểu là đo lường
năng lực tiềm ẩn nào đó của đối tượng. Chúng ta cố gắng thiết kế phép
đo sao cho có tính định lượng cao nhất, tức là không chỉ đo được các thứ
hạng của cá thể (thang đo theo thứ tự), mà còn làm cho khoảng cách giữa
các năng lực của các cá thể cũng có ý nghĩa (thang đo theo khoảng cách).
Đối với năng lực tiềm ẩn nói chung không có một số không tuyệt đối, tức
là điểm ứng với năng lực tiềm ẩn bằng không.
3.1.3. Về các phép đo lường trong tâm lý và giáo dục
Từ lâu các chuyên gia về đo lường trong tâm lý và giáo dục đã bàn
về yêu cầu của các phép đo lường này. Chẳng hạn, Thurstone từ đầu thế
kỷ này (1904) [2] đã phát biểu: các số đo phải tuyến tính và có thể ứng
dụng các phép tính số học. Wright (1982) [10] có nêu bốn đặc trưng mà
đo lường phải có là: hướng (direction), thứ tự (order), độ lớn (magnitude)
và các đơn vị có thể tái tạo (replicable units).
Khi xÐt mét phÐp ®o lêng cô thÓ trong t©m lý vµ gi¸o dôc, thíc
®o cã thÓ lµ một hoặc một tập hợp các c©u hái hoặc cái gì đó được đưa ra
để thử phản ứng của người được đo, ®èi tîng ®o lµ mét thuéc tÝnh nµo
®ã cña một người được đo, ch¼ng h¹n n¨ng lùc tiềm ẩn của người được
đo vÒ mét lÜnh vùc nµo ®ã. Để tiện trong diễn đạt, từ nay về sau ta quy
ước gọi cái được đưa ra để thử ứng đáp của người được đo (item) là câu
hỏi (CH) và đối tượng được đo nói chung là thí sinh (TS).
Cũng giống như các phép đo lường nói chung đã nêu ở 3.1.1, đối
với trắc nghiệm trong tâm lý và giáo dục, Thurstone cũng nêu ra những
đòi hỏi về phép đo lường trong giáo dục, ngụ ý rằng việc định cỡ CH
không được phụ thuộc vào mẫu TS dựng để định cỡ (sample-free) và kết
quả đo về thuộc tính của một TS nào đó cũng không được phụ thuộc vào
việc họ trả lời các CH nào (item-free). Đó là yêu cầu để đảm bảo tính
khách quan của phép đo.

86
Tuy những yêu cầu cơ bản về đo lường đã được các nhà tâm lý giáo
dục nhìn thấy từ lâu, nhưng chỉ đến những năm 60 - 70 của thế kỷ XX mới
có các công trình lý thuyết đặt nền tảng khoa học vững chắc để thỏa mãn các
yêu cầu cơ bản trên của khoa học về đo lường trong tâm lý và giáo dục.
3.2. VỀ ĐƯỜNG CONG ĐẶC TRƯNG CÂU HỎI
3.2.1. Các mối tương tác nguyên tố và tính đơn chiều
Giả sử chúng ta muốn đánh giá một loại năng lực tiềm ẩn nào đó,
chẳng hạn năng lực tiếng Anh, của 200 TS nhờ một đề trắc nghiệm có
100 CH. Trong trường hợp này ta có 200x100 = 20.000 mối tương tác
khác nhau giữa một TS và một CH trắc nghiệm. Mô hình toán về phép đo
lường trong tâm lý và giáo dục phải bắt đầu từ các mối tương tác đó giữa
TS và CH, có thể gọi là mối tương tác nguyên tố, một tế bào để xây dựng
Lý thuyết Ứng đáp Câu hỏi.
Trong tập sách này từ chương 1 đến chương 12 dành để giới thiệu
lý thuyết trắc nghiệm áp dụng để đo chỉ một loại năng lực của TS.
Khi xây dựng một mô hình toán nói chung, để đơn giản và khả thi,
bao giờ người ta cũng quan tâm đến những mối quan hệ bản chất nhất,
lược bỏ bớt những yếu tố phụ phức tạp nhưng không bản chất. Ở trường
hợp của chúng ta, để xây dựng mô hình toán phản ánh quan hệ các mối
tương tác nguyên tố TS-CH, trong đó đối với TS ta chỉ xét đến một loại
năng lực (hoặc một chiều nào đó của năng lực) được đo bởi các CH tạo nên
đề trắc nghiệm (ĐTN). Đó là giả định về tính đơn chiều (unidimensionality).
Trong thực tế thường có nhiều nhân tố ảnh hưởng lên việc làm trắc nghiệm
(động cơ, sự hồi hộp, khả năng làm nhanh, xu hướng đoán nhận, các kỹ
năng nhận thức…) ngoài năng lực chính được đo bởi ĐTN. Vậy, để đạt giả
định về tính đơn chiều cần xây dựng ĐTN sao cho khu biệt được thành
phần chính ảnh hưởng lên việc làm ĐTN. Thành phần đó được xem là
năng lực tiềm ẩn (latent trait) được đo bởi ĐTN.
Một khái niệm liên quan đến tính đơn chiều là tính độc lập địa
phương (local independent). Độc lập địa phương có nghĩa: khi giữ không
đổi năng lực tác động lên việc làm ĐTN, ứng đáp của TS đối với hai CH
nào đó là độc lập với nhau về mặt thống kê. Nói cách khác, không có

87
quan hệ giữa các ứng đáp của TS đối với các CH khác nhau. Như vậy,
năng lực được xác định bởi mô hình là yếu tố duy nhất ảnh hưởng lên
việc trả lời của TS đối với CH. Tập hợp các năng lực ấy biểu diễn một
không gian năng lực tiềm ẩn (latent trait) đầy đủ. Khi thỏa mãn tính đơn
chiều, một không gian năng lực tiềm ẩn đầy đủ chỉ chứa một năng lực.
Khi giả định về tính đơn chiều được thỏa mãn, cũng sẽ có tính độc
lập địa phương. Trên tinh thần đó hai khái niệm ấy là tương đương. Tuy
nhiên, có thể có tính độc lập địa phương ngay khi không có tính đơn
chiều, chỉ cần không gian năng lực tiềm ẩn đầy đủ được xác lập. Nếu
không gian ấy không được xác lập thì không có tính độc lập địa
phương. Chẳng hạn, các TS kiểm tra môn Toán đồng thời phải biết đọc
thạo tiếng Việt. Khi có TS không đọc thạo tiếng Việt thì năng lực tiếng
Việt sẽ ảnh hưởng đến việc làm kiểm tra Toán, và tính độc lập địa
phương sẽ không thỏa mãn. Khi mọi TS đều đọc thạo tiếng Việt thì sẽ
có tính độc lập địa phương.
Khi thỏa mãn tính đơn chiều, người ta giả định là có một Hàm đặc
trưng của câu hỏi (Hàm ĐTCH - Item Characteristic Function- ICF)
phản ánh mối quan hệ thực giữa các biến không quan sát được (năng lực
của TS) và các biến quan sát được (việc trả lời câu hỏi). Biểu diễn đồ thị
của hàm đặc trưng câu hỏi là Đường cong đặc trưng Câu hỏi (Đường
cong ĐTCH - Item Characteristic Curve – ICC). Chúng ta hãy tìm cách
xác định các đường cong ĐTCH đó.
3.2.2. Xây dựng thang đo để biểu diễn các tương tác
Trước khi xét mối tương tác nguyên tố TS - CH chúng ta cần xây
dựng một cái thang chung để biểu diễn các mối tương tác đó trên đó.
Trước hết ta giả định mỗi TS có một năng lực tiềm ẩn nào đó, và
giả thiết đây là năng lực một chiều, như đã nói ở 3.2.1. Giả sử ta có thể
biểu diễn năng lực tiềm ẩn này bằng một biến dọc theo một trục liên tục,
từ thấp đến cao, từ - đến +. Khi xét phân bố năng lực của một tập hợp
TS nào đó, ta chọn giá trị năng lực trung bình của phân bố năng lực của
tập hợp TS đó làm điểm không (0) cho thang đo năng lực, và độ lệch tiêu
chuẩn của phân bố năng lực làm đơn vị đo năng lực (=1).

88
Tiếp đến, mỗi CH có một loạt tính năng được biểu diễn bởi các
tham số xác định, như ta sẽ xem xét tiếp ở chương sau. Trong các tính
năng của CH, một tính năng quan trọng nhất là độ khó của CH. Cũng giả
thiết ta có thể biểu diễn độ khó của các CH bằng một biến dọc theo một
trục liên tục, từ thấp đến cao, từ - đến +. Khi xét phân bố độ khó của
một tập hợp CH nào đó, ta chọn giá trị độ khó trung bình của phân bố độ
khó tập hợp CH đó làm điểm không (0) cho thang đo năng lực, và độ
lệch tiêu chuẩn của phân bố độ khó CH làm đơn vị đo độ khó (=1).
Để thực hiện một phép đo bằng cách dùng một ĐTN gồm nhiều
CH nhằm đo các năng lực tiềm ẩn của từng TS trên thang đo năng lực
của tập hợp TS nói trên, ta cần làm một sự so sánh giữa năng lực của TS
và độ khó của CH. Thông thường hai đại lượng có thứ nguyên và ý nghĩa
hoàn toàn khác nhau như vậy, năng lực của TS và độ khó của CH, không
thể so sánh với nhau. Tuy nhiên như sẽ thấy ở mục sau, các biến năng lực
và độ khó sẽ được biểu diễn bằng các đại lượng tỷ đối không thứ nguyên
nên có thể so sánh chúng với nhau.
3.2.3. Ví dụ về mô hình đường cong đặc trưng câu hỏi đơn chiều, nhị
phân, một tham số (mô hình Rasch)
Để làm ví dụ, trước hết chúng tôi sẽ trình bày cách xây dựng một
đường cong ĐTCH nhị phân, một tham số. CH nhị phân là CH mà câu
trả lời chỉ có 2 mức: 0 và 1. Chúng tôi sẽ chọn cách trình bày lưu ý đến
tính logic và sư phạm nhiều hơn để bạn đọc dễ hiểu, không lưu ý đến lịch
sử của việc xây dựng các mô hình. Ở cuối chương 3, chúng ta sẽ theo dõi
lịch sử phát triển các mô hình.
IRT dựa trên hai giả thiết:
- Sự ứng đáp của một TS đối với một CH có thể được tiên đoán
bằng năng lực tiềm ẩn của TS;
- Quan hệ giữa sự ứng đáp CH của TS và năng lực tiềm ẩn làm cơ
sở cho sự đáp ứng đó có thể mô tả bằng một ICF đồng biến.
Để xây dựng một mô hình toán diễn tả một mối quan hệ phải xuất
phát từ một tiền đề nào đó. Nhµ to¸n häc Đan M¹ch, George Rasch, đã

89
xây dựng được một mô hình ICF đơn giản nhất nhưng cho đến nay cũng
được sử dụng nhiều nhất trong công nghệ trắc nghiệm. Để biểu diễn CH,
Rasch chỉ chọn một tham số: độ khó của CH. Chúng ta hãy theo dõi cách
lập luận của Rasch.
Phát biểu sau đây của Rasch có giá trị như một tiền đề làm cơ sở
cho mô hình của ông:
“Một người có năng lực cao hơn một người khác thì xác suất để
người đó trả lời đúng một câu hỏi bất kỳ phải lớn hơn xác suất của người
sau, cũng tương tự như vậy, một câu hỏi khó hơn một câu hỏi khác có
nghĩa là xác suất để một người bất kỳ trả lời đúng câu hỏi đó phải bé
hơn xác suất để trả lời đúng câu hỏi sau” (Rasch, 1960, tr. 117) [3].
Rõ ràng mô hình lý thuyết ứng đáp CH phải là một mô hình có tính
xác suất, không phải là mô hình tất định. Chúng ta có thể thấy rõ tính hợp
lý logic của tiền đề nêu trên. Với tiền đề đó, có thể đi đến kết luận: xác
xuất để một TS trả lời đúng một CH nào đó phụ thuộc vào tương quan
giữa năng lực của TS và độ khó của CH. Chúng ta sẽ chọn Θ để biểu diễn
năng lực của TS, và β để biểu diễn độ khó của CH. Tuy nhiên, để đảm
bảo khả năng so sánh năng lực và độ khó như đã nói ở mục 3.2.2, Θ và β
đều được biểu diễn dưới dạng một tỷ số (lấy giá trị trung bình của chúng
làm đơn vị). Tóm lại, với tiền đề Rasch, xác suất P để trả lời đúng CH
phụ thuộc vào tương quan giữa Θ và β, tức là ta có thể biểu diễn:
f (P) = Θ/β, (3.1)
trong đó f là một hàm nào đó của xác suất trả lời đúng.
Vấn đề là: chọn hàm f(P) như thế nào để có biểu diễn hợp lý nhất?
Trước hết, vì, mối quan hệ cộng trừ đơn giản hơn mối quan hệ nhân chia,
nên Rasch lấy logarit tự nhiên của (3.1):
ln f (P) = ln [Θ/β] = lnΘ - lnβ = θ - b (3.2)
Tiếp đến, để đơn giản, khi xét mô hình trắc nghiệm nhị phân
(dichotomous) Rasch chọn hàm f chính là [P/(1-P)], bằng biểu thức odds
(mức được thua) hoặc khả năng thực hiện đúng (likelyhood ratio), tức là
tỷ số của khả năng xảy ra sự kiện khẳng định so với khả năng xảy ra sự
kiện phủ định. Như vậy:

90
ln [P/(1-P)] = θ - b, (3.3)
ln [P/(1-P)] được gọi là logit (log odds unit).
Từ đó có thể viết:
P/(1-P) = e (θ - b)
Qua một vài biến đổi đơn giản, ta thu được:
]e[1
e)(θ P
b)(θ
bθ
(3.4)
Hàm có dạng như biểu thức (3.4) thuộc loại hàm logistic. Biểu thức
(3.4) chính là hàm đặc trưng của mô hình ứng đáp CH một tham số, hay
còn gọi là mô hình Rasch, có thể biểu diễn trên Hình 3.1 dưới đây (khi
cho b=0):
Hình 3.1. Đường cong ĐTCH một tham số
Trở lại ví dụ của chúng ta ở 3.2.1 về trường hợp 200 TS làm ĐTN
gồm 100 CH, chúng ta có 20.000 mối tương tác nguyên tố TS - CH. Từ
đó chúng ta sẽ có 20.000 giá trị xác suất trả lời đúng CH được biểu diễn
như sau:
]e[1
e)(θ P
)b(θ
bθ
jiij
ij
, (3.5)

91
trong đó, chỉ số i chạy từ 1 đến 200 đánh dấu 200 TS tham gia trắc
nghiệm, chỉ số j chạy từ 1 đến 100 đánh dấu 100 CH của ĐTN. Nếu biểu
diễn tất cả các đường cong ĐTCH trên cùng một thang với hoành độ θ thì
ta có một họ các đường cong như nhau được tịnh tiến trên trục θ, gốc của
mỗi đường cong được đặt tại hoành độ θ = bj, các đường cong không cắt
nhau. Tại gốc tọa độ của mỗi đường cong xác suất của TS thứ i trả lời
CH thứ j tương ứng là Pi = 0,5.
Hình 3.2. Họ các đường cong ĐTCH một tham số với các giá trị b khác nhau
CÂU HỎI TỰ KIỂM TRA
1) Nêu các bước cần tiến hành để xây dựng một phép đo nói chung.
Cần các điều kiện gì để có một phép đo chính xác?
2) Nêu các loại thang đo thường được sử dụng và đặc điểm của chúng.
3) Nêu các điều kiện cần thiết để đảm bảo chính xác cho phép đo bằng
đề trắc nghiệm.
4) Giải thích điều kiện đơn chiều để xây dựng mô hình Rasch.
5) Phát biểu tiền đề của Rasch.
6) Lập biểu thức hàm ĐTCH cho mô hình Rasch.

92
Chương 4
CÁC MÔ HÌNH ĐƯỜNG CONG ĐẶC TRƯNG CỦA CÂU HỎI NHỊ PHÂN
Tiếp tục mô hình đường cong ĐTCH một tham số (mô hình Rasch)
được xác định ở chương 3, chương này giới thiệu mô hình ĐTCH 2 tham
số bằng cách đưa vào thêm tham số biểu diễn độ phân biệt, và mô hình
ĐTCH 3 tham số bằng cách tiếp tục đưa vào thêm tham số mô tả hiệu
ứng đoán mò. Tính chất chung của các đường cong ĐTCH được khảo
sát. Ngoài các mô hình dựa vào hàm logistic, các đường cong ĐTCH
theo mô hình dạng đường cong tích lũy vòm chuẩn cũng được giới thiệu,
và mối quan hệ giữa chúng với các đường cong dạng hàm logistic được
xác lập. Cuối cùng, sự phát triển của mô hình Rasch trong lịch sử và các
quan điểm về việc sử dụng mô hình Rasch 1 tham số so với các mô hình
2, 3 tham số cũng được bàn đến.
4.1. BA MÔ HÌNH ĐƯỜNG CONG ĐẶC TRƯNG CỦA CÂU HỎI NHỊ
PHÂN DẠNG LOGISTIC
Chương 3 đã giới thiệu một mô hình đường cong ĐTCH đầu tiên là
mô hình Rasch. Đối với mô hình Rasch chỉ một tham số của CH được sử
dụng, đó là độ khó, nên mô hình Rasch được gọi là mô hình một tham số.
Tuy nhiên, như đã biết, trong trắc nghiệm cổ điển, người ta còn sử dụng
một tham số quan trọng thứ hai đặc trưng cho CH là độ phân biệt. Do đó
nhiều nhà tâm trắc học mong muốn đưa độ phân biệt vào mô hình đường
cong ĐTCH.
4.1.1. Mô hình đường cong đặc trưng của câu hỏi hai tham số
Từ khảo sát ở chương 3, chúng ta đã thấy các đường cong ĐTCH
một tham số có dạng như nhau, khi biểu diễn trên cùng một thang năng

93
lực θ theo hoành độ thì sẽ có một họ các đường cong hình dạng như nhau
tịnh tiến theo trục hoành, mỗi đường cong có gốc tọa độ tại điểm có θ =
bi, trong đó bi là độ khó của CH thứ i tương ứng. Chúng ta cũng thấy rõ
trong họ đường cong đã nêu độ dốc phần giữa của mọi đường cong là
như nhau, điều đó chính là do độ phân biệt là như nhau đối với mọi CH
trắc nghiệm.
Từ công thức (3.4)
θ b
(θ b)
eP (θ)
[1 e ]
(3.4)
chúng ta thấy rõ khi trục hoành biểu diễn theo logit, độ dốc phần
giữa đường cong được quyết định bởi hệ số ở số mũ của hàm e, mà ở
công thức (3.4) hệ số đó bằng 1.
Người ta có thể đưa thêm tham số a liên quan đến độ phân biệt của
CH vào hệ số ở số mũ của hàm e, kết quả sẽ có biểu thức:
a θ b
a(θ b)
eP (θ) .
[1 e ]
(4.1)
(4.1) chính là hàm ĐTCH hai tham số. Hệ số a biểu diễn độ dốc
của đường cong ĐTCH tại điểm có hoành độ θ = b và tung độ P(θ) = 0,5.
Có thể thấy rõ độ dốc của đường cong ĐTCH phản ánh độ phân
biệt của CH. Thật vậy, khi cho một biến đổi vi phân Δθ của năng lực thì
sẽ thu được một biến đổi vi phân ΔP của xác suất trả lời đúng, giá trị ΔP
này lớn hơn trên đường cong ĐTCH có độ dốc lớn so với trên đường
cong có độ dốc nhỏ. Nói cách khác, đối với CH đã cho một sự khác biệt
nhỏ về năng lực của TS cũng gây ra một độ chênh lớn về xác suất trả lời
đúng. Đó chính là ý nghĩa của độ phân biệt.
Dễ dàng xác định độ dốc của đường cong ĐTCH nhờ đạo hàm của P:
)(
2
)(1
1 ba
bae
ea
P
.
Khi = b, ∂P/∂ = a/4, đó là giá trị lớn nhất của độ dốc tại điểm
uốn của đường cong.

94
Hàm ĐTCH hai tham số trình bày trên đây và hàm ĐTCH theo mô
hình Rasch có cùng dạng thức, chỉ khác nhau ở giá trị tham số a (đối với
mô hình Rasch a=1). Như đã nói ở chương 3, các hàm có dạng như vậy
được gọi là hàm logistic, là loại hàm tạo rất nhiều thuận lợi trong nhiều
biến đổi toán học mà chúng ta sẽ xét sau này.
Trở lại ví dụ đã nêu ở mục 3.2.1 chương trước về trường hợp
200TS làm ĐTN 100 CH, chúng ta có 20.000 mối tương tác nguyên tố
TS-CH. Từ đó chúng ta cũng có 20.000 giá trị xác suất trả lời đúng CH
được biểu diễn như sau:
]e[1
e)(θ P
)b(θa
)b(θa
jiiji
iji
, (4.2)
trong đó chỉ số i chạy từ 1 đến 200 đánh dấu 200 TS tham gia trắc
nghiệm, chỉ số j chạy từ 1 đến 100 đánh dấu 100 CH của đề trắc
nhghiệm. Các đường cong ĐTCH trong họ các đường cong nói trên có độ
nghiêng khác nhau tùy theo giá trị ai tương ứng của mỗi đường cong.
Hình 4.1 biểu diễn các đường cong ĐTCH theo mô hình 2 tham số
với b=0, và a lần lượt bằng 0,5; 1,0; 1,5; 2,0; 3,0 nên độ dốc của các
đường cong ở đoạn giữa tăng dần.
Hình 4.1. Các đường cong ĐTCH hai tham số với các giá trị a khác nhau (b=0)
4.1.2. Mô hình đường cong đặc trưng của câu hỏi ba tham số
Lưu ý đến các hàm ĐTCH (3.4) và (4.1) chúng ta thấy tung độ tiệm
cận trái của chúng đều có giá trị bằng 0, điều đó có nghĩa là nếu TS có

95
năng lực rất thấp, tức Θ → 0 và θ = ln Θ → -, thì xác suất trả lời đúng CH
P(θ) cũng bằng 0.
Tuy nhiên trong thực tế triển khai trắc nghiệm chúng ta đều biết có
khi năng lực của TS rất thấp nhưng do đoán mò hoặc trả lời hú họa một
CH nên TS vẫn có một khả năng nào đó trả lời đúng CH. Trong trường
hợp đã nêu thì tung độ tiệm cận trái của đường cong không phải bằng 0
mà bằng một giá trị xác định c nào đó, với 0<c<1.
Từ thực tế nêu trên người ta có thể đưa thêm tham số c phản ánh
hiện tượng đoán mò vào hàm ĐTCH để thu được tung độ tiệm cận trái
của đường cong khác 0. Kết quả sẽ thu được biểu thức:
]e[1
ec)(1c(θθ P
bθa
bθa
, (4.3)
Rõ ràng khi θ → - hàm P(θ) → c. Trong trường hợp mô hình
đường cong ĐTCH 3 tham số khi θ = b ta có P(θ) = (c+1)/2.
Với ví dụ đã nêu ở mục 3.2.1 của chương trước về trường hợp 200
TS làm đề trắc nghiệm 100 CH, chúng ta cũng có 20.000 giá trị xác suất
trả lời đúng CH cho mô hình ba tham số ứng với 20.000 mối tương tác
nguyên tố TS - CH, biểu diễn như sau:
i j i
i j i
a θ b
i j i ia θ b
e P (θ ) c (1 c ) ,
[1 e ]
trong đó i chạy từ 1 đến 200 TS, j chạy từ 1 đến 100 CH.
Hình 4.2 biểu diễn các đường cong ĐTCH theo mô hình 3 tham số
với a=2 và các tham số c có giá trị bằng 0,1 và 0,2.
Mô hình đường cong ĐTCH 2 tham số và 3 tham số do Allan
Birnbaum (1968) [4] đề xuất đầu tiên, nên đôi khi được gọi là các mô
hình Birnbaum. Thực tế khi đưa tham số c vào, tính chất của hàm logistic
không còn nữa, tuy nhiên do thói quen có tính lịch sử người ta vẫn xếp
mô hình 3 tham số (4.3) vào loại mô hình logistic.
(4.4)

96
Hình 4.2. Các đường cong ĐTCH 3 tham số với a=2, c=0,1 và 0,2
4.2. MỘT VÀI LƯU Ý VỀ CÁC MÔ HÌNH KIỂU KHÁC VỀ ĐẶC TRƯNG
CỦA CÂU HỎI
Chúng tôi đã giới thiệu lý thuyết IRT xuất phát từ mô hình đơn
giản nhất – mô hình Rasch. Tuy nhiên trong lịch sử không phải mô hình
Rasch được đưa ra đầu tiên để xây dựng IRT.
Từ năm 1952 Lord F.M. đã đưa ra mô hình đường cong tích lũy
vòm chuẩn 2 tham số (4.5) để phân tích số liệu trắc nghiệm nhiều lựa
chọn. Sau đó vào năm 1957, Birnbaum A. [4] đã đề nghị đưa vào mô
hình logistic 2 và 3 tham số (4.1) và (4.3) dễ sử dụng hơn thay cho các
mô hình mô hình đường cong tích lũy vòm chuẩn. Tuy nhiên, cả Lord và
Birnbaum đều không quan tâm đến mô hình một tham số theo cả dạng
tích lũy vòm chuẩn cũng như dạng logistic, vì họ cho rằng mỗi CH cần ít
nhất 2 tham số mới đủ xác định mô hình, một liên quan đến độ khó và một
liên quan đến độ phân biệt, và mô hình một tham số chỉ là một trường hợp
riêng của các mô hình mà họ đề nghị. Vào năm 1960, Rasch G. [3] đã đề
nghị mô hình một tham số nhưng theo một cách tiếp cận khác hẳn so với
hai tác giả nêu trên. Nếu Lord và Birnbaum chỉ quan tâm đến việc tìm
các mô hình phù hợp với số liệu, thì Rasch muốn tìm mô hình phản ánh
được ứng đáp của TS đối với ĐTN. Rasch xuất phát từ một quan niệm
đơn giản: mức được thua (odds) của một TS khi trả lời một CH phụ thuộc
vào tích của năng lực TS và độ dễ của CH, như lập luận được trình bày ở
3.2.3. Độ phân biệt của CH không được lưu ý trong mô hình một tham số
của Rasch.

97
4.2.1. Mô hình đặc trưng của câu hỏi dạng đường cong tích lũy
vòm chuẩn
Vì phân bố chuẩn xác suất là nền tảng của lý thuyết thống kê, nên
từ lâu các nhà tâm trắc học đã dùng đường cong tích lũy vòm chuẩn
(normal ogive) làm mô hình để nghiên cứu việc trả lời CH (Muler 1904,
Urban 1910, Thomson 1919). Tính hợp lý của việc sử dụng đường cong
tích lũy vòm chuẩn làm đường cong ĐTCH được biện minh cả trên quan
điểm thực dụng lẫn lý thuyết (Lord, 1980 [5], Barker, 1992 [8]).
Biểu thức đường cong tích lũy vòm chuẩn đối với mô hình 2 tham
số có dạng:
P (θ) = 2
a(θ-b)
(-t 2)
-¥
1e dt
2π , (4.5)
và đối với mô hình 3 tham số như sau:
P (θ) = c + (1- c) dte2π
1 2)t(
b)a(θ2
. (4.6)
Biểu thức (4.5) và (4.6) cho thấy các hàm này là hàm xác suất tích
lũy tính theo mật độ xác suất của phân bố chuẩn. Đó là các hàm của biến
năng lực θ với các tham số a, b, c.
Khi khảo sát quan hệ định lượng giữa các mô hình ĐTCH có dạng
đường cong tích lũy vòm chuẩn và mô hình ĐTCH có dạng logistic,
Halley (1952) [9] đã cho biết rằng nếu nhân tham số biểu thị độ dốc a
của hàm logistic cho hệ số D=1,702 và sử dụng như ở biểu thức (4.1) thì
sự sai khác tuyệt đối giữa các xác suất biểu diễn bởi biểu thức hàm dạng
logistic (4.1) và biểu thức hàm dạng tích lũy vòm chuẩn (4.5) sẽ bé hơn
0,01 trên cả thang θ.
(nếu nhân hệ số a ở 4.1 với D=1,702 thì hai đường cong gần như
trùng nhau)
Như vậy, đối với mọi ứng dụng thực tiễn hai mô hình hàm ĐTCH
dạng logistic và dạng tích lũy vòm chuẩn là như nhau. Trong khi đó biểu

98
thức toán học của hàm logistic đơn giản hơn nhiều và tốc độ tính toán
thực tế đối với chúng giảm nhiều vì không phải tính tích phân, do đó
thậm chí có thể tính chúng trên các máy tính giản đơn. Vì lý do đó, trong
những năm gần đây người ta thiên về sử dụng mô hình các đường cong
logistic hơn là mô hình các đường cong tích lũy vòm chuẩn. Dù vậy
trong nhiều nghiên cứu lý thuyết, đặc biệt là những nghiên cứu về mối
quan hệ giữa lý CTT và IRT, người ta vẫn còn nhắc đến các mô hình hàm
tích lũy vòm chuẩn.
Hình 4.3. Các đường cong biểu diễn hàm (4.1) và (4.5)
4.2.2. Về mô hình Rasch và vai trò của nó
Chúng tôi đã chọn mô hình một tham số, mô hình Rasch, làm mô
hình trình bày đầu tiên trong các mô hình đường cong ĐTCH vì mô hình
này đơn giản nhất và phản ánh tường minh nhất mối quan hệ giữa TS và
CH. Tuy nhiên, như đã nói trên đây, trong tiến trình lịch sử hình thành
IRT không phải mô hình Rasch xuất hiện trước các mô hình khác. Nhà
toán học và tâm lý học người Đan Mạch, George Rasch, đã có ý tưởng
xây dựng "một mô hình cấu trúc cho các CH trong một ĐTN" từ thập
niên 1950, đề xuất mô hình xác suất logistic đó từ 1953, nhưng ở Mỹ
người ta biết đến công trình của ông từ khi ông công bố chính thức trong

99
một cuốn sách xuất bản năm 1960 [3]. Động cơ của Rasch muốn thể hiện
qua mô hình của mình là hạn chế việc dựa vào tổng thể TS khi phân tích
các ĐTN. Theo ông, phân tích trắc nghiệm chỉ đáng giá khi dựa vào từng
cá nhân TS, với các tham số của TS và CH được tách riêng. Để biện
minh cho quan điểm của mình, ông thường dẫn lời Skiner, người rất ghét
việc căn cứ vào thống kê dựa trên tổng thể để kết luận và thường triển
khai nghiên cứu thực nghiệm trên từng cá thể. Quan điểm của Rasch đã
đánh dấu sự chuyển tiếp từ CTT, dựa trên tổng thể với việc nhấn mạnh
đến biện pháp tiêu chuẩn hóa và ngẫu nhiên hóa, sang IRT với mô hình
xác suất tương tác giữa một CH và một TS. Sự tồn tại của các số liệu
thống kê đầy đủ của các tham số của CH trong mô hình Rasch có thể
được sử dụng vào việc điều chỉnh ước lượng các tham số năng lực theo
một cách thức đặc biệt.
Cùng trong khoảng thời gian công bố công trình của mình, Rasch
được mời sang cộng tác nghiên cứu 3 tháng tại Viện Đại học Chicago.
Tại đây, B. Wright [10] đã có rất nhiều đóng góp để nâng cao và phát
triển mô hình Rasch. Theo Wright, ý tưởng của Rasch về việc chọn mô
hình logistic với chỉ một tham số là độ khó đã giải phóng được bế tắc của
việc phát triển IRT trong nhiều thập niên, vì nhiều nhà tâm trắc học qua
các nghiên cứu của mình đã khẳng định rằng chỉ có độ khó là có thể ước
lượng được một cách ổn định và đầy đủ qua số liệu quan sát đối với loại
CH trắc nghiệm nhị phân. Do đó, hiện nay, tuy là mô hình ĐTCH đơn
giản nhất trong các mô hình IRT (và có lẽ cũng chính vì tính đơn giản
nhưng đầy đủ của nó), mô hình Rasch đã được sử dụng nhiều nhất trong
các nghiên cứu tâm lý và giáo dục. Cũng theo Wright [10], mô hình
Rasch là mô hình duy nhất thỏa mãn các yêu cầu để xây dựng các phép
đo lường khách quan trong khoa học xã hội nói chung, và Wright có ý
kiến khá cực đoan rằng không nên sử dụng các mô hình khác trong các
phép đo lường khách quan. Tuy nhiên một số nhà nghiên cứu khác cho
rằng về lý thuyết thì dạng toán học của mô hình Rasch có nhiều lợi thế,
nhưng khi nói đến mô hình toán học, tức là nói đến một sự giả định,
tiêu chuẩn để đánh giá hiệu quả của mô hình là sự phù hợp của chúng
với số liệu thực nghiệm chứ không chỉ thuần túy ở dạng toán học.
Người ta thường gọi quan điểm của Wright là quan điểm "dựa trên mô

100
hình" (model-based), còn quan điểm ngược lại là quan điểm "dựa trên
dữ liệu" (data-based).
CÂU HỎI TỰ KIỂM TRA
1) Dáng điệu của đường cong ĐTCH 2 tham số phụ thuộc tham số
a như thế nào? Tại sao tham số a đặc trưng cho độ phân biệt của câu hỏi?
2) Dáng điệu của đường cong ĐTCH 3 tham số phụ thuộc tham số
c như thế nào? Tại sao tham số c đặc trưng cho độ đoán mò của câu hỏi?
3) Ý nghĩa của hàm ĐTCH theo đường cong tích lũy vòm chuẩn.
Sự khác biệt trong thực tế của xác suất trả lời đúng CH tính toán theo các
hàm ĐTCH dạng tích lũy vòm chuẩn và dạng logistic.
4) So sánh các định nghĩa và các khoảng giá trị bằng số có thể có
của độ khó và độ phân biệt theo CTT và IRT.
5) Quan niệm của B. Wright về việc sử dụng các mô hình 1, 2, 3
tham số.
BÀI TẬP
Bảng 4.1 cho các tham số của 6 CH nhị phân.
Đối với mỗi CH hãy tính P(θ) tại θ = -3, -2, -1, 0, 1, 2 và 3. Vẽ các
đường cong ĐTCH.
CH nào dễ nhất?
CH nào có tham số độ phân biệt thấp nhất?
Một TS có năng lực θ = 0 sẽ ứng đáp đúng CH nào với xác suất cao
nhất? Xác xuất để TS ấy ứng đáp sai CH bằng bao nhiêu?

101
Bảng 4.1.
CH b a c
1 1,0 1,8 0,00
2 1,0 0,7 0,00
3 1,0 1,8 0,25
4 -0,5 1,2 0,20
5 0,5 1,2 0,00
6 0,0 0,5 0,10
Ứng đáp của 40 TS ở một mức năng lực đã cho đối với 2 CH được
cho ở Bảng 4.2. Lập một ma trận 2x2 về các ứng đáp đúng và sai đối với
2 CH nêu trên. Dùng kiểm nghiệm Chi-bình phương (χ2) về mức độ độc
lập để kiểm định tính độc lập địa phương của hai CH đó ở mức năng lực
đã cho.
Bảng 4.2.
CH Ứng đáp của các TS
1 0 0 0 0 0 1 1 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 1 1 0 0 1 1 0 1 0 1
2 0 1 1 0 0 0 0 0 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 0 0 1 1 1 1
__________________

102
Chương 5
ƯỚC LƯỢNG CÁC THAM SỐ CỦA CÂU HỎI TRẮC NGHIỆM
Chương này dành để mô tả một thao tác quan trọng trong IRT, đó
là quy trình ước lượng tham số của một CH trắc nghiệm dựa vào số liệu
thu được từ việc trả lời của các TS đối với một ĐTN. Quy trình ước
lượng được trình bày nặng về định tính để bạn đọc dễ dàng nắm được
bản chất của nó cùng với một hệ quả quan trọng của IRT là sự không phụ
thuộc của các tham số CH trắc nghiệm vào mẫu TS dùng để ước lượng
chúng, hoặc là tính bất biến của các tham số CH trắc nghiệm đối với các
phép đo lường.
5.1. QUY TRÌNH ƯỚC LƯỢNG CÁC THAM SỐ CỦA CÂU HỎI
Chương 3 và chương 4 đã trình bày các mô hình hàm ĐTCH với 1,
2 và 3 tham số. Tuy nhiên, khi xây dựng một ĐTN nào đó các tham số
của CH là chưa biết, do đó một trong các yêu cầu quan trọng để xây dựng
các ĐTN là ước lượng các tham số của các CH trắc nghiệm.
Trong các mô hình IRT, xác suất để trả lời đúng CH phụ thuộc vào
năng lực θ của TS và các tham số đặc trưng cho CH. Cả hai loại tham số,
năng lực của TS và đặc trưng của CH, đều không biết. Cái có thể biết
được là việc trả lời các CH của các TS. Vấn đề của việc ước lượng là xác
định các giá trị tham số năng lực θ của từng TS và các tham số a, b, c của
từng CH từ các kết quả ứng đáp CH. Để áp dụng IRT cho số liệu trắc
nghiệm, công việc đầu tiên và quan trọng nhất chính là ước lượng các
tham số đặc trưng cho mô hình ứng đáp CH đã chọn. Có thể nói thành
công của áp dụng IRT xoay quanh việc tạo ra được các quy trình thích
hợp để ước lượng các tham số của mô hình.

103
Để trình bày được đơn giản, trước hết chúng ta hãy xem xét việc
ước lượng các tham số đặc trưng cho CH trắc nghiệm. Khi ước lượng các
tham số đó, chúng ta giả thiết là đã biết các điểm năng lực của TS. Ở
chương 7 sẽ trình bày cách ước lượng năng lực TS và cả cách ước lượng
đồng thời tham số CH và năng lực TS.
Giả thiết chúng ta có một tập hợp gồm N TS làm một đề trắc
nghiệm có M CH. Các điểm năng lực của TS phân bố dọc theo một thang
đo năng lực. Xét một CHi xác định thứ i. Giả thiết rằng chúng ta có thể
chia tập hợp TS thành I nhóm trên thang đo năng lực, sao cho các TS
trong cùng một nhóm j nào đó có cùng một năng lực θj, cụ thể là có mj
TS trong nhóm j, với j=1,2,3,... I. Trong nhóm j có cùng điểm năng lực
xác định θj đó giả sử có rj TS trả lời đúng CHi thứ i đã cho. Như vậy, ở
mức năng lực θj, tỷ lệ trả lời đúng CHi quan sát được là pj(θj)= rj/mj, đó là
ước lượng xác suất trả lời đúng CHi ở mức năng lực đã cho. Từ đó có thể
thu được rj và tính được pj(θj) cho mỗi mức năng lực j dọc theo thang
năng lực đã cho. Có thể biểu diễn các tỷ lệ trả lời đúng đối với mỗi nhóm
năng lực như ở Hình 5.1. (xem cả ví dụ nêu ở Bảng 5.1 ở cuối chương).
Hình 5.1.
Nhiệm vụ được đặt ra là tìm một đường cong ĐTCH trùng khớp tốt
nhất với các tỷ số trả lời đúng CH quan sát được. Muốn vậy, trước hết ta
phải chọn một mô hình đường cong sao cho phù hợp. Quy trình sử dụng
để tìm đường cong trùng khớp được dựa trên thuật toán ước lượng theo

104
biến cố hợp lý cực đại (maximum likelyhood estimation). Ở chương này
sẽ mô tả định tính quy trình ước lượng đó để bạn đọc hiểu bản chất của
nó, trong chương 7 sẽ trình bày cách tiếp cận định lượng qua việc giới
thiệu dạng thức của hàm biến cố hợp lý.
Trước hết, người ta cho các giá trị tiên nghiệm (a priory) của các
tham số đường cong, chẳng hạn b=0,0 và a=1,0 đối với mô hình hàm
ĐTCH 2 tham số. Sử dụng các ước lượng đó để tính các giá trị P(θj) đối
với mọi nhóm năng lực nhờ công thức ứng với mô hình đường cong đã
chọn. Sau đó theo một thuật toán xác định như đã nêu trên người ta tìm
cách điều chỉnh các tham số ước lượng của đường cong ĐTCH sao cho
đạt được một sự trùng khớp tốt hơn giữa đường cong ĐTCH tính theo
các tham số ước lượng và các tỷ lệ trả lời đúng quan sát được. Quá trình
tính lặp để điều chỉnh như vậy sẽ tiếp tục cho đến khi sự điều chỉnh
không làm tăng mức trùng khớp một cách đáng kể. Lúc đó thì dừng
chương trình tính lặp và các giá trị a và b đạt được cuối cùng chính là giá
trị tham số của đường cong ĐTCH ước lượng được. Với các giá trị a và b
thu được ta có thể tính đường cong P(θ) theo mô hình đã chọn, đó là
đường cong trùng khớp tốt nhất với số liệu quan sát. Ví dụ trên Hình 5.2
biểu diễn đường cong ĐTCH hai tham số trùng khớp tốt nhất với số liệu
quan sát được ở Hình 5.1.
Hình 5.2.

105
Một câu hỏi quan trọng liên quan đến việc ước lượng tham số, đó là
khi nào thì có thể xem một đường cong ĐTCH cụ thể là trùng khớp với
số liệu trả lời một CH. Sự phù hợp giữa các tỷ số trả lời quan sát với các
số liệu tính toán từ đường cong ĐTCH có thể xem là trùng khớp được
đánh giá bằng chỉ số trùng khớp tốt Chi-bình phương (Chi-square
goodness-of-fit index). Chỉ số đó được xác định như sau:
))Q(θP(θ
)P(θ)p(θmχ
jj
2jj
I
1j
j2
, (5.1)
trong đó: I - số nhóm năng lực, θj - mức năng lực của nhóm thứ j,
mj - số TS có năng lực θj, p(θj) - tỷ số trả lời đúng quan sát được của
nhóm thứ j, P(θj) - xác suất trả lời đúng của nhóm thứ j theo tính toán từ
mô hình ĐTCH sử dụng để ước lượng tham số, Q(θj)= 1- P(θj).
Nếu giá trị của chỉ số thu được lớn hơn một giá trị tiêu chí quy định
nào đó thì đường cong ĐTCH được xác định bởi các giá trị đã ước lượng
của tham số CHi là không trùng khớp với số liệu quan sát. Sự không
trùng khớp này có thể do hai nguyên nhân. Thứ nhất, mô hình đường
cong ĐTCH được chọn không phù hợp. Thứ hai, các giá trị của tỷ số trả
lời đúng CHi rất phân tán nên không thể thu được sự trùng khớp tốt đối
với bất cứ mô hình đường cong ĐTCH nào. Thông thường khi phân tích
một ĐTN có một ít CH không trùng khớp do nguyên nhân thứ hai thì
người ta phải sửa chữa CH trắc nghiệm tương ứng hoặc loại bỏ nó khỏi
ĐTN. Còn nếu có rất nhiều CH cho số liệu tính toán không trùng khớp
với số liệu quan sát thì thường là do chọn mô hình đường cong ĐTCH
không phù hợp, trong trường hợp đó người ta có thể thử nghiệm chọn
một mô hình khác.
5.2. VỀ TÍNH BẤT BIẾN CỦA CÁC THAM SỐ CÂU HỎI
ĐỐI VỚI MẪU THÍ SINH
Một tính chất quan trọng của IRT là các tham số của CH ước lượng
được không phụ thuộc vào mức năng lực của các TS trả lời CH trắc
nghiệm. Từ đó có thể nói các tham số của CH là các giá trị bất biến đối
với mẫu TS trả lời. Có thể giải thích tính chất đó như sau:

106
Trước hết có thể hiểu tính bất biến đó là tính chất của mô hình hồi
quy tuyến tính. Trong mô hình hồi quy tuyến tính, đường cong hồi quy
để tiên đoán một biến Y từ một biến X thu được bằng cách nối các giá trị
trung bình của biến Y đối với mỗi giá trị của biến X. Khi mô hình hồi
quy được thỏa mãn, sẽ thu được cùng một đường hồi quy đối với bất kỳ
dãy giới hạn (một mẫu) nào của biến X. Bất kỳ một chỉ số nào rút ra từ
mô hình đó, chẳng hạn hệ số tương quan, cũng bất biến đối với mọi mẫu
con. Hiển nhiên mẫu con đó phải có tính đồng nhất.
Đối với hàm logistic ta có thể lập luận đơn giản như sau. Chẳng
hạn, một hàm ĐTCH một tham số có dạng:
i
i
θ b
i (θ b )
eP (θ ) .
[1 e ]
Từ đó, đối với CHi có độ khó bi xác định, ta có: P/(1-P) = e (θ-bi). Từ
đó trên đồ thị mối quan hệ f (θ) =ln [P/(1-P)] = θ-bi biểu diễn một đường
thẳng f(θ) cắt trục tung tại - bi. Như vậy nếu mô hình đường cong ĐTCH
đó được thỏa mãn, với mọi mẫu TS có các năng lực θj bất kỳ trong tổng
thể TS, giá trị bi thu được của CH đang xét là duy nhất. Đối với mô hình
một tham số, vì tính đối xứng của các biến -b và θ trong biểu thức, ta
cũng có thể thấy ngay là bằng lý luận tương tự có thể chứng minh tính
duy nhất của θj thu được từ các giá trị bi khác nhau, tức là tính bất biến
của năng lực đối với tập hợp các CH trắc nghiệm khác nhau. Chúng ta sẽ
quay lại tính bất biến của năng lực ở chương 7.
Để minh họa rõ hơn tính bất biến nói trên chúng ta hãy xét các ví
dụ cụ thể sau đây. Giả sử có hai mẫu TS được chọn từ một tổng thể TS
nào đó là đối tượng thiết kế của ĐTN. Nhóm thứ nhất có dải năng lực θ
khoảng từ -3 đến -1, với giá trị trung bình ở -2; nhóm thứ 2 có dải năng
lực θ khoảng từ +1 đến +3, với giá trị trung bình ở +2. Tỷ lệ trả lời
đúng một CH đã cho nào đó được tính từ số liệu quan sát cho mỗi mức
năng lực trong hai mẫu TS đã cho. Giả sử đối với mẫu thử thứ nhất ta
thu được đồ thị phân bố tỷ lệ trả lời đúng theo các nhóm năng lực biểu
diễn ở Hình 5.3.
(5.2)

107
Hình 5.3.
Quá trình ước lượng theo biến cố hợp lý cực đại được sử dụng đã
tìm được đường cong ĐTCH với các tham số a = 1,41, b = -0,76 trùng
khớp tốt với số liệu quan sát. Trên ví dụ ở Hình 5.4 có vẽ phần đường
cong ĐTCH tương ứng với dải năng lực của mẫu TS thứ nhất.
Hình 5.4.

108
Quá trình ước lượng nêu trên cũng được áp dụng đối với mẫu TS thứ
hai. Cũng như ở mẫu thử thứ nhất, ở mẫu thử thứ hai ta thu được đồ thị
phân bố tỷ lệ trả lời đúng theo các nhóm năng lực được biểu diễn ở Hình 5.5.
Việc ước lượng theo thuật toán biến cố hợp lý cực đại cho đường
cong ĐTCH với các tham số a(2) = 1,41, b(2) = -0,76 trùng khớp tốt với
số liệu quan sát. Trên Hình 5.6 có vẽ phần đường cong ĐTCH tương ứng
với dải năng lực của mẫu TS thứ hai.
Hình 5.5.
Hình 5.6.

109
Qua ví dụ tính toán trên đây có thể thấy đối với hai lần ước lượng
chúng ta thu được các tham số a và b như nhau có: a(1) = a(2); b(1) = b(2),
tức là việc ước lượng từ hai mẫu TS khác nhau cho cùng các giá trị tham
số của đường cong ĐTCH. Như vậy, tham số của CH là các bất biến đối
với mẫu TS. Kết quả dường như hơi bất ngờ này có thể dễ dàng giải thích
qua quá trình ước lượng tham số đường cong. Thật vậy, vì mẫu TS thứ
nhất có năng lực trung bình thấp (-2) nên mức năng lực bao trùm trong
mẫu TS thứ nhất sẽ chỉ liên quan phần đuôi bên trái của đường cong. Do
đó, các tỷ số trả lời đúng quan sát được sẽ trải từ các giá trị rất bé đến
trung bình. Khi làm cho đường cong trùng khớp với các số liệu đó, chỉ
phần đuôi thấp của đường cong là có liên quan. Đối với mẫu TS thứ hai,
vì chúng có năng lực trung bình cao (+2) nên các tỷ số trả lời đúng quan
sát trải từ trung bình cho đến rất gần +3. Khi làm cho đường cong trùng
khớp với các số liệu đó, chỉ phần đuôi cao của đường cong là có liên
quan. Như vậy, vì rằng cả hai mẫu TS trả lời cùng một CH nên quá trình
tìm đường cong trùng khớp liên quan đến cùng một đường cong ĐTCH.
Do đó các tham số của CH ứng với hai phép ước lượng dựa vào số liệu
của hai mẫu TS sẽ như nhau. Hình 5.2 biểu diễn kết hợp hai nhóm số liệu
quan sát của hai mẫu TS và một đường cong ĐTCH duy nhất trùng khớp
với hai nhóm số liệu.
Tính bất biến của các tham số CH đối với mẫu TS là một đặc tính
hết sức quan trọng của IRT. Tính bất biến này nói lên rằng các tham số
của CH là thuộc tính riêng của chính CH chứ không phải của mẫu TS trả
lời CH đó. Trong CTT tình trạng hoàn toàn ngược lại. Chúng ta đã biết
độ khó theo CTT được định nghĩa là tỷ lệ trả lời đúng CH trắc nghiệm
của một mẫu TS, do đó giá trị độ khó tính được sẽ phụ thuộc vào tỷ số
TS có năng lực cao trong mẫu thử. Chúng ta sẽ trở lại xem xét vấn đề này
qua ví dụ bằng số ở cuối chương.
Tính bất biến của các tham số đặc trưng cho CH và năng lực TS là
hòn đá tảng của IRT nên chúng tôi muốn trình bày để độc giả nắm vững
hơn nhờ một ví dụ bằng số có tính chất giáo khoa mượn của Hanbleton
[11], từ một kết quả của 90 TS ứng đáp một ĐTN gồm 40 CH. Kết quả
phân tích cho thấy số liệu phù hợp với mô hình ứng đáp CH hai tham số.

110
Bảng 5.1 trình bày các TS ở 9 mức năng lực j, mỗi năng lực có 10 TS,
ứng đáp đối với chỉ 1 CH của ĐTN, cùng với các tổng điểm của mỗi TS
thu được bởi ĐTN 40 CH. Hình 5.7 biểu diễn đường cong ĐTCH P().
Hình 5.7. Quan hệ giữa năng lực TS và xác suất trả lời đúng một CH
Chúng ta hãy xét 2 mẫu, mỗi mẫu gồm 30 TS, thuộc 2 nhóm năng
lực khác nhau: mẫu TS thứ nhất ở các khoảng năng lực có tâm điểm là
các giá trị = -1,716; -1,129 và -0,723; và mẫu TS thứ hai ở các khoảng
năng lực có tâm điểm là các giá trị = 0,523; 0,919 và 1,516. Trước hết,
từ Bảng 5.1 có thể tính các tham số độ khó và độ phân biệt cổ điển (theo
CTT) của CH. Độ khó được tính theo tỷ số trả lời đúng CH của hai mẫu
30 TS thứ nhất và thứ hai. Độ phân biệt được tính dựa vào hệ số tương
quan điểm nhị phân giữa điểm trả lời CH của mỗi nhóm 30 TS với điểm
tổng của các mẫu TS đó đối với toàn bộ ĐTN. Tính toán cho độ khó và
độ phân biệt tương ứng là (0,2; 0,56) đối với mẫu thứ nhất và (0,8; 0,47)
đối với mẫu thứ hai. Rõ ràng giá trị độ khó và độ phân biệt tính được
theo định nghĩa của CTT là khác nhau đối với hai mẫu TS.

111
Bây giờ chúng ta hãy tính các tham số b và a đặc trưng cho độ khó
và độ phân biệt theo IRT ứng với hai mẫu TS có các năng lực đã chọn
trên đây. Tương tự việc suy ra từ biểu thức (5.2) đối với mô hình Rasch
trên đây, từ biểu thức (4.1) đối với mô hình ứng đáp CH hai tham số
chúng ta có thể suy ra:
Pln =aθ-ab=aθ+β
1-P (5.3)
với =-ba. Hệ thức trên là biểu diễn một hàm tuyến tính của với
hai ẩn số a và (a là hệ số góc và là tung độ giao điểm của đường
thẳng với trục tung), các ẩn số đó có thể xác định chính xác nếu biết P và ở
hai điểm xác định.
Trước hết, chúng ta hãy chọn hai giá trị trên toàn bộ dải năng lực,
chẳng hạn ở đầu và cuối Bảng 5.1: =-1,716 và =1,516, và hai giá trị
tương ứng P=0,1 và P=0,9. Thay hai giá trị và P ở đầu bảng vào biểu thức
(5.3), ta có:
0,1ln =a(-1,716)+β
0,9 và 0,9
ln =a(1,516)+β0,1
,
Giải hai phương trình trên dễ dàng thu được: a = 1,36 và b = -0,1.
Bây giờ chúng ta hãy chọn hai giá trị ở mẫu năng lực thấp ở Bảng 5.1,
chẳng hạn: =-1,716 và =-0,723; và hai giá trị tương ứng P=0,1 và
P=0,3. Bằng cách tương tự như đã thực hiện trên đây chúng ta thu được
hai phương trình:
)716,1(9,0
1,0ln a và )723,0(
7,0
3,0ln a ,
Giải hai phương trình trên dễ dàng thu được: a = 1,359 và b = -0,1.
Cuối cùng, chúng ta chọn hai giá trị ở mẫu năng lực cao ở Bảng 5.1,
chẳng hạn: =0,523 và =1,516; và hai giá trị tương ứng P = 0,7 và
P=0,9. Bằng cách tương tự như đã thực hiện trên đây chúng ta thu được
hai phương trình:

112
)523,0(3,0
7,0ln a và )516,1(
1,0
9,0ln a ,
Giải hai phương trình trên dễ dàng thu được: a = 1,359 và b = -0,1.
Có thể giải thích các kết quả trên đây một cách đơn giản: là a và β
là độ dốc và tọa độ giao điểm với trục tung của đường thẳng biểu diễn
quan hệ giữa tỷ số odds (mức được thua) và . Ở bất kỳ dải năng lực nào
cũng có đường thẳng đó, và do đó có a và β (và do đó – b) như nhau.
Ví dụ trên chứng tỏ rằng khác với độ khó và độ phân biệt trong lý
thuyết trắc nghiệm cổ điển, các tham số a, b của mô hình ứng đáp CH là
bất biến đối với các mẫu TS.
Tuy nhiên chúng ta cần lưu ý vài đặc điểm của tính bất biến nói trên.
Trước hết, từ đồ thị ở Hình. 5.7 cũng như từ Bảng 5.1 ta thấy tồn
tại một mối quan hệ chính xác giữa xác suất P trả lời đúng một CH và
năng lực , điều đó có nghĩa là có sự trùng hợp tốt giữa mô hình và dữ
liệu trong cả tổng thể. Nếu không có sự trùng hợp tốt đó, hàm ln[P/(1-P)]
sẽ không chính xác là một hàm tuyến tính của , do đó sẽ không thu được
các giá trị a và b như nhau từ các mẫu TS khác nhau. Nói cách khác, tính
bất biến sẽ được tuân thủ chính xác khi có sự trùng khớp tốt của mô hình
và dữ liệu trong cả tổng thể. Cũng hoàn toàn đúng như vậy đối với sự hồi
quy tuyến tính đã nói trước đây, trong đó các hệ số hồi quy là bất biến chỉ
khi mô hình tuyến tính là trùng khớp với dữ liệu trong cả tổng thể.
Một điều rất cần lưu ý nữa là tính bất biến nói trên là tính chất của
tổng thể. Thật vậy, theo định nghĩa, đường cong ĐTCH là đường hồi quy
của xác suất trả lời CH đối với năng lực:
P= E(U|),
trong đó E là giá trị kỳ vọng, U lấy giá trị 1 nếu trả lời đúng và giá
trị 0 nếu trả lời sai của TS có năng lực . Như vậy P là giá trị trung bình
của mọi ứng đáp CH trong một mẫu con TS có năng lực xác định.
Trong các mẫu con TS năng lực thấp và năng lực cao nêu trên đây xác
suất trả lời đúng quan sát được ở mỗi giá trị chính xác bằng E(U|). Do
đó quan hệ tuyến tính giữa ln[P/(1-P)] và sẽ duy trì, nói cách khác tính

113
bất biến sẽ thể hiện. Tuy nhiên, trong một mẫu con TS khác rất khó có
khả năng giá trị trung bình của ứng đáp CH (tức xác suất trả lời đúng) sẽ
bằng E(U|) một cách chính xác. Thậm chí nếu ở một năng lực nào đó
mà P quan sát được đúng bằng E(U|) thì điều đó rất khó xảy ra ở mọi
năng lực khác. Do đó, trong các mẫu TS khác nhau rất khó tồn tại một
mối quan hệ tuyến tính chính xác giữa ln[P/(1-P)] và . Vì vậy chúng ta
không thể kỳ vọng quan sát được tính bất biến nghiêm chỉnh trong các
mẫu TS, thậm chí khi mô hình ứng đáp CH trùng khớp chính xác với số
liệu trong tổng thể mà từ đó lấy ra các mẫu. Vấn đề vi phạm tính bất biến
càng nghiêm trọng nếu có những sai số lớn khi ước lượng các tham số đặc
trưng cho TS và CH.
Việc xác định xem tính bất biến có được tuân thủ hay không là rất
quan trọng, vì mọi ứng dụng của IRT được dựa trên tính chất đó. Mặc dù
bất biến là một tính chất trong cả tổng thể và không bao giờ quan sát
được một cách tuyệt đối nghiêm chỉnh, nhưng chúng ta có thể đánh giá
"mức độ" tính chất đó được tuân thủ khi chúng ta sử dụng các mẫu số
liệu trắc nghiệm. Chẳng hạn, nếu hai mẫu TS có năng lực khác nhau
được lấy từ một tổng thể và các tham số được ước lượng trong mỗi mẫu,
thì sự phù hợp giữa hai bộ tham số ước lượng từ mỗi mẫu có thể xem
như một dấu hiệu của mức độ tuân thủ tính bất biến. Mức độ phù hợp có
thể được đánh giá bằng cách xét sự tương quan giữa hai bộ giá trị ước
lượng của mỗi tham số hoặc bằng cách nghiên cứu đồ thị phân tán. Minh
họa trên Hình 5.8 được tính toán dựa vào số liệu do Viện Khoa học Giáo
dục Việt Nam thực hiện vào năm 2007 theo một Dự án của Bộ Giáo dục
và Đào tạo [34]. Trên Hình.5.8, các giá trị tham số độ khó b của một
ĐTN thử nghiệm VIỆT1 gồm 40 CH trắc nghiệm nhị phân dùng trong
quá trình đánh giá môn tiếng Việt. Số liệu thử nghiệm thu được từ bài
làm của 535 TS lớp 5 ở 4 tỉnh/thành phố Hải Phòng, Hà Giang, Bình
Định, Hậu Giang. Số 535 TS được chia thành 2 mẫu ngẫu nhiên chọn
theo số báo danh chẵn và lẻ: mẫu 1 gồm 267 TS, mẫu 2 gồm 268 TS.
Tính toán được thực hiện nhờ phần mềm VITESTA [19]. Các điểm có
hoành độ và tung độ là độ khó b ứng với hai mẫu TS phân bố hai bên
đường thẳng phân giác, nên có thể kết luận rằng tính bất biến của các
tham số được tuân thủ tuy có sai số. Nếu trên đồ thị có mức độ phân tán

114
lớn thì điều đó chứng tỏ tính bất biến không được tuân thủ: có thể do
không có sự phù hợp giữa mô hình và số liệu, hoặc do có sai lệch lớn trong
ước lượng tham số.
Qua các phân tích trên đây cũng có thể nói tính bất biến và sự
trùng khớp của mô hình ứng đáp câu hỏi với số liệu là hai khái niệm
tương đương. Chúng ta sẽ trở lại bàn về việc đánh giá sự trùng khớp của mô
hình với số liệu trong chương 9.
Hình 5.8. Giá trị độ khó câu hỏi tính từ hai mẫu TS
trong một tổng thể
Ở ví dụ trên đây, chúng ta đã thấy rằng các tham số của CH là bất
biến đối với các mẫu TS khác nhau. Mặt khác, trong phương trình (5.3)
βaθabaθP1
Pln
ta có thể xem a, b là các biến, là tham số biểu thị độ dốc của
đường thẳng hồi quy theo biến a. Khi a thay đổi (xét các CH với độ phân
biệt khác nhau) thì độ dốc của đường thẳng hồi quy vẫn giữ nguyên độ
lớn, tức là dù với các CH nào thì năng lực cũng là bất biến.
Tính bất biến đã được minh họa đối với mô hình ứng đáp CH 2
tham số. Có thể lý luận tương tự đối với mô hình 1 và 3 tham số.

115
Bảng 5.1. Ứng đáp của 90 TS đối với một CH trắc nghiệm
và hàm ĐTCH P()
j (năng
lực chung
của các
TS trong
nhóm)
P()
Ứng đáp
và
điểm tổng
TS thứ i trong nhóm
i=1 2 3 4 5 6 7 8 9 10
-1,716 0,1
Trả lời CH 0 0 0 0 0 0 0 0 1 0
Điểm tổng 8 12 6 12 8 8 8 11 13 4
-1,129 0,2
Trả lời CH 0 1 0 0 0 0 1 0 0 0
Điểm tổng 10 14 9 8 10 11 13 12 7 7
-0,723 0,3
Trả lời CH 0 1 0 0 1 1 0 0 0 0
Điểm tổng 11 15 14 13 15 15 13 11 15 13
-0,398 0,4
Trả lời CH 0 0 1 0 1 0 1 0 0 1
Điểm tổng 13 12 18 12 17 10 16 15 12 19
-0,100 0,5
Trả lời CH 0 1 1 1 1 0 0 0 1 0
Điểm tổng 17 21 25 25 21 19 18 19 20 15
0,198 0,6
Trả lời CH 1 0 1 0 1 0 1 1 1 0
Điểm tổng 21 19 26 22 25 22 24 24 28 19
0,523 0,7
Trả lời CH 1 1 1 0 0 1 1 0 1 1
Điểm tổng 27 26 25 24 24 30 28 24 29 29
0,919 0,8
Trả lời CH 1 0 1 1 1 0 1 1 1 1
Điểm tổng 33 28 29 30 29 28 33 32 32 33
1,516 0,9
Trả lời CH 0 1 1 1 1 1 1 1 1 1
Điểm tổng 34 35 34 38 37 37 36 35 37 39
Tính bất biến của các tham số của CH và năng lực của TS là hết
sức quan trọng, đó là nền tảng của IRT, nhờ đó có thể áp dụng IRT vào
các công đoạn quan trọng sẽ xét đến sau này: so bằng (equating),
xây dựng NHCH (item banking), nghiên cứu độ lệch của CH (item bias)
và trắc nghiệm thích ứng (adaptive testing). Tuy tính bất biến của tham

116
số CH đối với các mẫu TS khác nhau là tính chất quan trọng của IRT,
nhưng đó là nguyên tắc có tính lý thuyết. Trong thực tế các tham số CH
được ước lượng nhờ thuật toán biến cố hợp lý cực đại đối với các nhóm
TS trả lời cùng các CH thường không hoàn toàn như nhau. Các trị số tính
được thường phụ thuộc vào kích thước của mẫu, cấu trúc của số liệu và
chỉ số trùng khớp tốt đối với đường cong. Nhưng dù sao các giá trị thu
được cũng "nằm trong cùng một rổ". Như vậy, trong một tình huống trắc
nghiệm thực tế, nguyên lý bất biến đối với mẫu được tuân theo, nhưng có
thể có một số biểu hiện sai khác trong việc ước lượng tham số đối với
cùng một số CH. Một điều quan trọng nữa là tính bất biến chỉ tồn tại khi
các CH được sử dụng để đo cùng một năng lực tiềm ẩn ở các mẫu TS. Và
các tham số CH cũng sẽ không duy trì tính bất biến đối với mẫu thử khi
có ảnh hưởng của các năng lực tiềm ẩn khác hoặc khi các mẫu TS không
được chọn thích hợp từ một tổng thể.
CÂU HỎI TỰ KIỂM TRA
1. Cách phân khoảng năng lực và xác định xác suất trả lời đúng
trung bình đối với một CH trong khoảng đó.
2. Giải thích tính bất biến của tham số CH ước lượng được từ các
mẫu TS khác nhau:
- Qua việc ước lượng từ các mẫu TS có năng lực khác nhau;
- Qua phương trình hồi quy tuyến tính thu được từ biến đổi hàm
ĐTCH của mô hình Rasch.
BÀI TẬP
Tính độ khó và độ phân biệt theo CTT của CH từ số liệu được mô
tả ở Bảng 5.1 khi xét hai nhóm TS, nhóm bao gồm 2 mức năng lực đầu
và nhóm bao gồm 2 mức năng lực cuối của bảng. Kết luận về sự độc lập
của các tham số đó của CH đối với các nhóm TS. So sánh với các tham
số độ khó và độ phân biệt tính theo IRT.

117
Chương 6
ĐIỂM THỰC - ĐƯỜNG CONG ĐẶC TRƯNG CỦA ĐỀ TRẮC NGHIỆM
Nếu mỗi CH trắc nghiệm ứng với một đường cong ĐTCH thì một
ĐTN, tập hợp của nhiều CH trắc nghiệm, cũng ứng với một đường cong
đặc trưng của ĐTN (còn được gọi là đường cong điểm thực). Chương này
trình bày cách tính các đường cong điểm thực của ĐTN; nêu các tính chất
của nó, so sánh điểm thực trong CTT và IRT; và nêu vài ứng dụng thực tế
của đường cong điểm thực. Cuối chương có giới thiệu một số phép chuyển
đổi phi tuyến và tuyến tính liên quan đến lý thuyết trắc nghiệm.
6.1. ĐIỂM THỰC VÀ ĐƯỜNG CONG ĐẶC TRƯNG
CỦA ĐỀ TRẮC NGHIỆM
Trắc nghiệm là một phép đo: dùng thước đo là ĐTN để đo một
năng lực nào đó của TS. Trong vật lý, để xác định chính xác giá trị được
đo và sai số của phép đo người ta thường thực hiện phép đo đó nhiều lần.
Trong trắc nghiệm, thực tế không làm được như vậy vì không thể cho TS
làm một ĐTN nào đó nhiều lần: những lần sau năng lực của TS đã biến
đổi do đã làm quen với ĐTN ở những lần trước. Tuy nhiên, về mặt hình
thức, chúng ta vẫn có thể quy ước là năng lực của TS không thay đổi sau
những lần đo để xác định khái niệm về giá trị được đo và sai số phép đo.
6.1.1. Quan niệm về điểm thực trong CTT
Theo quy ước đó chúng ta hãy định nghĩa về điểm trung bình của
một TS qua hàng loạt phép đo bằng một ĐTN. Điểm quan sát X của một
ĐTN qua hàng loạt phép đo được xem là một biến ngẫu nhiên với một
phân bố tần suất nào đó thường là không biết. Giá trị trung bình (kỳ vọng

118
toán học) của phân bố đó được gọi là điểm thực của TS. Gọi ε là sai số
của phép đo, chúng ta có thể biểu diễn quan hệ giữa điểm thực , các
điểm quan sát X và sai số ε như sau:
ε = X - . (6.1)
Điểm thực được định nghĩa trên đây theo CTT là một sự trừu tượng
toán học, không có quy trình nào để xác định. Cũng do đó sai số của
phép đo ε là một đại lượng có tính chất trung bình của phép đo nói chung
đối với toàn bộ dải năng lực của TS.
6.1.2. Xác định điểm thực theo IRT
Chúng ta hãy xét khái niệm điểm thực trong IRT. Ở các phần trước
đây chúng ta đã xét đặc trưng của từng CH trắc nghiệm và tương tác của
từng CH với từng TS, nhưng trong thực tế các CH trắc nghiệm thường
được tập hợp thành một ĐTN. Dưới đây chúng ta sẽ xét đến một ĐTN
bao gồm nhiều CH trắc nghiệm.
Giả sử CH trắc nghiệm chúng ta xét là CH nhị phân: trả lời đúng
được 1 điểm, trả lời sai được 0 điểm. Điểm thô của một TS sẽ thu được
bằng cách cộng các điểm của mọi CH trong ĐTN. Như vậy, điểm thô của
ĐTN đối với một TS thường là một số nguyên nằm giữa 0 và n, trong đó
n là số CH trong ĐTN. Giả sử một TS làm lại ĐTN (và khi làm lại người
đó không nhớ những gì đã làm những lần trước), người đó sẽ được một
điểm thô khác. Giả thiết là TS làm ĐTN nhiều lần và nhận được nhiều
điểm thô khác nhau, các điểm này phân bố quanh một giá trị trung bình
nào đó. Theo lý thuyết về đo lường, giá trị trung bình đó gần với một giá
trị được gọi là điểm thực, và định nghĩa của nó phụ thuộc vào một lý
thuyết đo lường xác định.
Chúng ta hãy tìm biểu thức của điểm thực. Có thể biểu diễn điểm
thô X tính theo số câu trả lời đúng bằng biểu thức:
n
j
j=1
X= U , (6.2)
trong đó U là vectơ ứng đáp, được biểu diễn như sau:

119
U = (U1, U2,..., Uj,...,Un), (6.3)
Trong đó Uj bằng 1 nếu trả lời đúng và bằng 0 nếu trả lời sai CH
thứ i. NÕu biÓu diÔn ®iÓm thùc lµ th× có thể tính điểm thực theo biểu
thức kỳ vọng toán học của X như sau:
)E(U)UE(E(X)τ
n
1j
j
n
1j
j
,
trong đó E là toán tử kỳ vọng toán học. V× tính chất tuyến tính của
phép tính kỳ vọng toán học nên trên đây chúng ta đã viết:
)E(U)UE(
n
1j
j
n
1j
j
.
Nếu một biến ngẫu nhiên Y lấy các giá trị y1 và y2 với các xác suất
tương ứng là P1 và P2 thì:
E(Y) = y1 P1 + y2 P2
Vì Uj có giá trị bằng 1 với xác suất Pj(θ) và giá trị bằng 0 với x¸c
suÊt Qj (θ) = [1- Pj(θ)] nªn:
))) (θP(θ0.Q(θ1.P)E(U jjjj .
Cuèi cïng ta có:
n
j
j 1
τ P (θ).
(6.4)
Tức là: điểm thực của một TS có năng lực là tổng của các xác suất
trả lời đúng của mọi CH của ĐTN tại giá trị hư vậy, đối với mọi giá
trị nếu chúng ta tiến hành cộng tất cả mọi đường cong ĐTCH trong ĐTN
chúng ta sẽ thu được đường cong đặc trưng của ĐTN, hoặc cũng gọi là
đường cong điểm thực. Đường cong đặc trưng của ĐTN là quan hệ hàm số
giữa điểm thực và thang năng lực: cho trước một mức năng lực bất kỳ có
thể tìm điểm thực tương ứng qua đường cong đặc trưng ĐTN.

120
Chúng ta hãy lấy một ví dụ minh họa có tính chất giáo khoa. Giả sử
có một ĐTN bao gồm 5 CH với các tham số cho ở Bảng 6.1.
Bảng 6.1. Các tham số của các câu hỏi trắc nghiệm
Tham số
CH số aj bj cj
1 2 -1 0,15
2 1,5 -0,5 0
3 1 0 0
4 1,5 0,5 0,1
5 2,5 1 0,2
Đồ thị 5 đường cong ĐTCH tương ứng được biểu diễn trên Hình 6.1.
Hình 6.1. 5 đường cong ĐTCH theo mô hình 3 tham số
Đường cong đặc trưng của ĐTN bao gồm 5 CH nói trên thu được
bằng cách cộng 5 đường cong ĐTCH biểu diễn trên Hình 6.2, trong đó 5
đường cong ĐTCH được vẽ lại theo một tỷ lệ xích trục tung nhỏ hơn.

121
Vì là chồng chất của các đường cong ĐTCH nên đường cong đặc
trưng ĐTN cũng có dạng một hàm đồng biến. Tiệm cận phải của đường
cong khi tiến đến + bằng điểm thực tối đa n, tức là bằng tổng số CH
trong ĐTN. Tung độ tiệm cận trái của đường cong khi tiến đến - bằng
0 đối với các mô hình 1 và 2 tham số, và bằng giá trị tổng cộng các tham
số đoán mò ci của toàn bộ n CH trong ĐTN đối với mô hình 3 tham số.
Hình 6.2. Đường cong đặc trưng của ĐTN gồm 5 CH và 5 đường cong ĐTCH tương ứng
Có thể mô tả các đặc điểm của đường cong đặc trưng ĐTN tương
tự như mô tả các đường cong ĐTCH. Đường cong đặc trưng ĐTN không
có biểu thức giải tích đơn giản nên không có các tham số đặc trưng. Độ
nghiêng của đường cong đặc trưng ĐTN cho biết điểm thực phụ thuộc
như thế nào vào năng lực, tức là liên quan đến độ phân biệt của ĐTN.
Trong một số trường hợp đường cong đặc trưng ĐTN có dạng gần đường
thẳng trong một khoảng năng lực nào đó, nhưng nói chung nó có dạng
một đường cong đồng biến. Mức năng lực ứng với trung điểm của thang
điểm thực (ứng với n/2) xác định vị trí của ĐTN trên thang năng lực.
Hoành độ của điểm đó xác định độ khó của ĐTN. Hai yếu tố độ dốc và
mức năng lực ở trung điểm thang điểm thực mô tả khá rõ đặc tính của
một ĐTN.
Giữa điểm thực và điểm năng lực có một quan hệ đơn trị, nói
cách khác điểm thực τ có thể xem là một chuyển đổi phi tuyến của . Vì
Pj () có giá trị giữa 0 và 1, nhận giá trị giữa 0 và n, do đó được biểu

122
diễn trên cùng thang đo với điểm thô nhưng có cả các giá trị không
nguyên. Để biểu diễn điểm thực dưới dạng thập phân, người ta chia
cho tổng số CH của ĐTN:
)(θPn
1
n
τπ
n
1j
j
.
Khi ở trong khoảng -∞ < < +∞ thì nằm giữa 0 và 1 (hoặc
0% và 100%). Đối với mô hình ứng đáp CH 3 tham số, giới hạn dưới của
là icn
1.
Hình 6.2 biểu diễn đường cong điểm thực qua một ví dụ có tính giáo
khoa về một ĐTN gồm 5 CH tính theo mô hình 3 tham số. Có thể xem
minh họa trên Hình 8.3 chương 8 một đường cong điểm thực của một
ĐTN thực tế - đó là ĐTN VIỆT1 đã được mô tả ở mục 5.2 chương 5.
Vì đường cong đặc trưng ĐTN là tổng của các đường cong ĐTCH
trong ĐTN nên khi mọi tham số của CH là bất biến thì các đường cong
ĐTCH sẽ bất biến, do đó các đường cong đặc trưng ĐTN cũng là bất biến,
tức là hình dạng của nó (được tính theo biểu thức 6.4) sẽ không phụ thuộc
vào phân bố tần số điểm năng lực của TS trên thang năng lực. Quan hệ
giữa điểm thô X và điểm thực τ có thể xem là quan hệ giữa quan sát trên
một mẫu với tham số của tổng thể. Ở đây cũng cần nhắc lại rằng tính bất
biến của các tham số của CH trắc nghiệm chỉ được tuân thủ khi có sự trùng
khớp cần thiết giữa mô hình IRT và số liệu thực tế, do đó tính bất biến của
dạng đường cong đặc trưng ĐTN đối với phân bố năng lực của các TS làm
trắc nghiệm cũng chỉ được tuân thủ trong điều kiện đó.
6.1.3. So sánh điểm thô, điểm thực và điểm năng lực
- Từ biểu thức điểm thô X tính theo số câu trả lời đúng đã đưa ra
trên đây:
n
j
j 1
X U
(6.5)

123
Chúng ta có thể sử dụng một số phép biến đổi để sử dụng chúng
trong việc đánh giá TS.
Phép chuyển đổi tuyến tính đơn giản nhất là chia X cho tổng số n các
CH trong ĐTN: chúng ta sẽ được điểm tỷ lệ trả lời đúng. Điểm tỷ lệ trả lời
đúng cũng có thể được sử dụng cả khi chia ĐTN ra các ĐTN con có số CH
khác nhau để đo các đối tượng khác nhau theo các mục đích khác nhau,
cách đó thường được sử dụng cho các trắc nghiệm theo tiêu chí.
Đối với trắc nghiệm theo chuẩn người ta có thể sử dụng các chuyển
đổi tuyến tính khác nhau dựa vào giá trị trung bình và độ lệch tiêu chuẩn
để thu được các điểm tiêu chuẩn như đã được mô tả ở chương 1. Ngoài
ra, khi cần so sánh các TS với nhau, điểm X có thể được chuyển đổi phi
tuyến để thu được các điểm thập phân, bách phân…
Các phép chuyển đổi nêu trên tuy làm cho việc sử dụng điểm thô
thuận lợi hơn, nhưng dù biến đổi thế nào, nhược điểm lớn của điểm thô X
vẫn tồn tại: điểm X không độc lập với số CH mà TS trả lời, và các điểm
chuyển đổi cũng không độc lập đối với nhóm TS liên quan. Ngược lại,
điểm năng lực θ có tính độc lập đó. Như đã nêu ở chương 5 và sẽ làm rõ
hơn ở chương 8, điểm năng lực của một TS độc lập với các ĐTN cụ thể
khác nhau mà TS làm và với mẫu bao gồm TS đang xét. Tính bất biến đó
là sự khác biệt cơ bản giữa điểm năng lực và điểm thô X. Vì có thể so
sánh các TS khác nhau làm các ĐTN khác nhau khi dùng điểm năng lực
nên thang điểm có thể được xem như là một thang điểm tuyệt đối liên
quan đến năng lực tiềm ẩn mà chúng ta muốn đo.
Bản chất của năng lực tiềm ẩn đó là gì? Rõ ràng đó là thuộc tính
mô tả điều mà các ĐTN đã đo. Một năng lực tiềm ẩn có thể được xác
định rất rộng, như là năng khiếu hoặc thành quả học tập, cũng có thể
được xác định rất hẹp, như khả năng thực hiện một phép tính cộng đơn
giản, hoặc nói lên đặc điểm của một cá nhân (ví dụ sự tự tin, động cơ).
Không nên hiểu năng lực tiềm ẩn là một cái gì đó bẩm sinh hoặc bất biến.
Thực ra thuật ngữ năng lực tiềm ẩn (ability hoặc trait) có thể được hiểu
không đúng là nó phản ánh một đặc trưng cố định của TS, nên một số
nhà nghiên cứu cho rằng sử dụng thuật ngữ mức độ thành thạo
(proficiency level) trong nhiều trường hợp sẽ phù hợp hơn.

124
- Ta hãy xem xét bản chất của thang điểm thô và của thang điểm
năng lực θ. Thang điểm thô X không phải là thang tỷ lệ, cũng không phải
là thang khoảng cách, mà đúng hơn hết có thể xem nó là một thang thứ
tự. Thang xác định biến năng lực cũng vậy. Tuy nhiên trong một số
trường hợp mà ta sẽ minh họa dưới đây (xem 6.2.2) có thể biến đổi thang
và giải thích như một thang tỷ lệ trong một ý nghĩa giới hạn.
- Một trong những ứng dụng quan trọng của đường cong đặc trưng
ĐTN là cung cấp phương tiện để chuyển điểm năng lực thành điểm thực.
Thang điểm năng lực có các giá trị âm dương trên trục số thực chỉ dùng
trong nghiên cứu, khó giải thích cho nhiều người hiểu. Do đó việc chuyển
đổi từ biến năng lực sang điểm thực có các tác dụng quan trọng sau: 1)
loại bỏ các giá trị âm; 2) tạo nên thang đo với các điểm từ 0 đến n (hoặc theo
tỷ lệ thập phân, bách phân…), dễ giải thích; 3) có thể xác định điểm cắt đối
với điểm thực , từ đó suy ngược lại điểm cắt trên thang ;
Một điều khá lý thú là, khi đó biết năng lực của một TS, nhờ
đường cong điểm thực của một ĐTN cụ thể có thể xác định được điểm
thực của TS đó thu được từ ĐTN đó cho mà không phải làm ĐTN. Từ đó
có thể tiên đoán điểm thực của thí sinh hoặc tình trạng đạt hay không đạt
đối với một ĐTN mới.
Cần nhấn mạnh thêm một ưu điểm của IRT là nó cho phép xác định
các sai số tiêu chuẩn của các giá trị ước lượng năng lực theo (6.1) của
mỗi TS, chứ không phải là một ước lượng sai số duy nhất cho mọi TS
như trong CTT, điều này sẽ được nói rõ hơn ở 7.2.2 chương 7.
6.2. MỘT SỐ PHÉP CHUYỂN ĐỔI
Trên đây chúng ta đã xét một phép chuyển đổi quan trọng từ thang
điểm thô sang thang điểm thực và thu được đường cong đặc trưng của
ĐTN. Dưới đây sẽ xét thêm một số phép chuyển đổi khác.
6.2.1. Vài phép chuyển đổi tuyến tính
1) Phép chuyển đổi tuyến tính đối với , b, a và tính bất định của
xác suất trả lời đúng

125
Ở chương 4 chúng ta đã thu được các biểu thức xác suất trả lời
đúng CH theo mô hình 2 và 3 tham số (4.2) và (4.3). Khi thực hiện phép
thay thế bởi * = + , b bởi b * = b + và a bởi a*= a/ trong các
biểu thức nói trên thì ta vẫn thu được:
P (*) = P (),
tức là có thể thực hiện phép chuyển đổi tuyến tính đối với , b và a
mà không làm thay đổi xác suất trả lời đúng CH. Đó là "tính bất định"
mà chúng ta sẽ thảo luận sau này. Điều đó có nghĩa là thang có thể
được chuyển đổi tuyến tính khi các tham số CH cũng được chuyển đổi
một cách tương ứng.
2) Phép chuyển đổi tuyến tính của Woodcook
Lưu ý rằng được xác định trong khoảng (-∞, ∞). Woodcook
(1978) khi tạo thang đo cho bộ công cụ trắc nghiệm tâm lý - giáo dục đã
sử dụng mô hình một tham số và thang đo:
w = 20.log9 (e) + 500 = 9,1. + 500,
(vì log9 e = 0,455). Vậy thang đo năng lực Woodcook w là một
thang tuyến tính.
Đối với độ khó cũng thực hiện biến đổi tương tự:
wb= 9,1.b + 500.
Thang w có tính chất đặc biệt là các độ chênh (w - wb) = 20; 10;
0; 10; 20 ứng với các xác suất trả lời đúng 0,90; 0,75; 0,5; 0,25; 0,1. Biến
đổi của thang trên đây là biến đổi tuyến tính.
6.2.2. Vài phép chuyển đổi phi tuyến
1) Phép chuyển đổi phi tuyến eD
Xét phép chuyển đổi biến năng lực * = eD và chuyển đổi tương
ứng của độ khó b* = eDb.
Đối với mô hình 1 tham số:

126
b)(θ
b)(θ
e1
eP(θ(
.
Qua chuyển đổi ấy xác suất trả lời đúng bằng:
**
*
DθDb
Dθ*
θb
θ
ee
e)P(θ
,
và xác suất trả lời sai bằng:
** *
* *
bQ(θ ) 1 P(θ ) .
b θ
Chúng ta hãy tính biểu thức tỷ số mức được thua O (odds):
Nếu thực hiện biến đổi này và chọn D=1,7 thì có thể chuyển đổi
cho hàm logistic gần trùng với hàm tích lũy vòm chuẩn (xem chương 3).
Nếu hai TS có năng lực *
1 và *
2 thì tỷ số mức được thua dẫn đến
thành công của họ là *1
*2
O=
O *
2
*
1
; chẳng hạn, nếu TS1 có năng lực gấp đôi
TS2 ( *
1 =2 *
2 ) thì tỷ số mức được thua trả lời đúng một CH có độ khó b*
xác định cũng gấp đôi. Từ góc độ đó, có thể xem thang là một thang tỷ
lệ (xem chương 1). Đối với CH cũng có tính chất tương tự như vậy: một
TS trả lời 2 CH có độ khó b1* và b2
* thì tỷ số mức được thua trả lời đúng
2 CH của TS là
* *1 2
* *2 1
O b=
O b; và nếu CH1 dễ hơn CH2 hai lần ( *
2b = 2 *
1b ) thì
tỷ số mức được thua trả lời đúng CH1 cũng gấp đôi CH2. Lưu ý rằng tính
chất của thang tỷ lệ nói trên của thang đo * và b*chỉ đúng với mô hình
một tham số. Đây là một trong những ưu việt của mô hình này mà chúng
ta sẽ phân tích sau này.
2) Phép chuyển đổi “log-odd”
Một chuyển đổi phi tuyến khác có ý nghĩa đối với mô hình một
tham số là chuyển đổi “log-odd”. Đối với hai TS trả lời cùng một CH thì:
*
*
*
*
) (
) (
b Q
P
O* =

127
21
2
1
*
2
*
1
2
1
ee
e
O
O
O
O
21
2
1ln O
O.
Khi năng lực khác biệt nhau 1 đơn vị thì:
1ln2
1 O
O và e
O
O
2
1
Cũng vậy nếu một TS trả lời hai CH có độ khó b1 và b2 thì:
12
2
1ln bbO
O .
Khi độ khó khác nhau 1 đơn vị thì chúng ta cũng có:
eO
O
2
1 .
Các đơn vị trên thang log-odds được gọi là logits (xem chương 3).
Các đơn vị logit có thể nhận được trực tiếp từ mô hình một tham số
như sau:
) (
) (
1 ) (
b
b
e
e P
và )(1
1)(
beQ
Từ đó:
) ( ) (
) ( b e Q
P
và do đó ln b
Q
P
)(
)(.
Đây chính là cách lập luận để thu được ICF của mô hình một tham
số ở chương 3.
Khi mô hình phù hợp với số liệu thực tế chúng ta sẽ thu được các
tham số mong muốn. Lúc đó ước lượng về năng lực của TS sẽ không phụ

128
thuộc ĐTN, và các chỉ số của CH sẽ không phụ thuộc vào mẫu thử
nghiệm. Nói cách khác: trong phạm vi sai số đo lường các giá trị ước
lượng về năng lực TS thu được từ nhiều ĐTN khác nhau sẽ như nhau,
cũng vậy, các giá trị ước lượng về tham số CH thu được từ các mẫu thử
nghiệm khác nhau cũng sẽ như nhau. Như vậy, theo IRT, các tham số của
CH và năng lực TS phải là bất biến (invariant).
Tính bất biến đó thu được bằng cách kết hợp thông tin về CH trong
quá trình ước lượng năng lực TS và bằng cách kết hợp thông tin về năng
lực TS trong quá trình ước lượng tham số của CH. Hình 5.1 có thể minh
hoạ đặc điểm đó: các TS có cùng năng lực, dù ở nhóm đánh giá 1 hay 2,
cũng có xác suất trả lời đúng CH như nhau, và cũng vậy, vì xác suất để
một TS với năng lực đã biết trả lời đúng CH được xác định bởi các tham
số của CH, nên các tham số của CH cũng phải như nhau trong 2 nhóm.
CÂU HỎI TỰ KIỂM TRA
1. Nêu quan niệm về điểm thực của một TS trong CTT.
2. Chứng minh biểu thức xác định điểm thực của một TS theo IRT.
3. Nêu các tính chất cơ bản của đường cong điểm thực và vài ứng
dụng của đường cong điểm thực.
4. Trình bày phép chuyển đổi “log-odd”.
BÀI TẬP
Giả sử năng lực θ ước lượng được của một nhóm TS nhờ một ĐTN
phân bố trong khoảng (-4, 4). Để chuyển thành thang điểm bách phân:
- Tìm một biến đổi tuyến tính thích hợp.
- Tìm một biến đổi phi tuyến thích hợp.

129
Chương 7
HÀM THÔNG TIN CỦA CÂU HỎI VÀ CỦA ĐỀ TRẮC NGHIỆM
Chương này dành để trình bày một công cụ quan trọng xác định
thông tin mà CH trắc nghiệm hoặc ĐTN cung cấp về năng lực của TS, đó
là hàm thông tin của CH trắc nghiệm và của ĐTN. Liên quan chặt chẽ
với hàm thông tin và có dáng điệu ngược với hàm thông tin là sai số tiêu
chuẩn của phép đo dùng ĐTN. Cuối chương cũng giới thiệu một công cụ
để so sánh hai ĐTN dựa trên các hàm thông tin là hàm hiệu suất tỷ đối.
7.1. HÀM THÔNG TIN CỦA CÂU HỎI TRẮC NGHIỆM
Khi nói chúng ta có thông tin về một sự vật nào đó thì có nghĩa là
chúng ta biết một điều gì đó về sự vật ấy. Trong thống kê và tâm trắc
học, thuật ngữ thông tin cũng có ý nghĩa tương tự, nhưng mang tính kỹ
thuật cao hơn. Chẳng hạn, thông tin được định nghĩa thường có quan hệ với
độ chính xác của việc ước lượng tham số.
Với quan niệm đó, từ các cách suy luận khác nhau, nhiều nhà nghiên
cứu đã đề xuất các cách tính hàm thông tin khác nhau [5]. Vì khuôn khổ
cuốn sách này chúng tôi sẽ không nhắc lại các lập luận đó, mà chỉ đưa ra
biểu thức hàm thông tin của một CH trắc nghiệm mà A. Birnbaum [4] đã
đề xuất và hiện đang được sử dụng rộng rãi nhất. Biểu thức hàm thông tin
của CH (item information function) được biểu diễn như sau:
2i
ii i
[P' (θ)]I (θ)= ,
P (θ)Q (θ)
trong đó Ii() là thông tin cung cấp bởi CH thứ i ở mức năng lực ,
các hàm Pi() và Qi() đã được định nghĩa ở các chương trước, Pi'() là
đạo hàm của Pi() theo .
(7.1)

130
Từ biểu thức (7.1) có thể suy ra các biểu thức hàm thông tin tương
ứng với các mô hình ứng đáp CH khác nhau. Đối với mô hình 3 tham số,
ta có:
2
2 i i ii i
i i
Q (θ) P (θ)-cI (θ)=a .
P (θ) 1-c
Đối với mô hình 2 tham số, khi đặt ci=0, ta có:
2
i i i iI (θ)=a P (θ)Q (θ).
Đối với mô hình Rasch 1 tham số, đặt ai=1, ta có:
i i iI (θ)=P (θ)Q (θ).
Trong các biểu thức hàm thông tin tương ứng với cả 3 mô hình đều
có chứa số hạng Pi()Qi(), tức là số hạng xuất hiện ở các biểu thức (8.8)
và (8.9) ở chương 8 trong quá trình ước lượng tham số của CH và năng
lực của TS.
Khi thay vào (7.2) biểu thức tường minh (4.4) của Pi() ứng với mô
hình ứng đáp CH logistic 3 tham số, ta được:
i i i i
2i i
i 1,7a (θ-b ) -1,7a (θ-b ) 2i
2,89a (1-c )I (θ)= ,
[c +e ][1+e ]
ở đây hệ số D=1,7 được nhân với tham số a để đưa số liệu tính nhờ
hàm dạng logistic về dạng hàm vòm chuẩn (xem mục 4.2.1 chương 4).
Từ biểu thức (7.5) có thể tính giá trị max ứng với vị trí cực đại của
hàm Ii ():
max i i
i
1θ =b + ln[0.5(1+ 1+8c )].
Da
Từ các biểu thức (7.5) và (7.6) có thể xác định được quy luật về
dáng điệu của hàm thông tin CH liên quan đến các tham số của CH như
sau. Thông tin càng cao khi: 1) giá trị b càng gần bằng ; 2) giá trị a càng
lớn; 3) giá trị c càng gần bằng 0. Nếu ci = 0 thì max= bi, còn khi ci>0 thì
(7.2)
(7.3)
(7.4)
(7.5)
(7.6)

131
thông tin mà CH cung cấp sẽ cực đại ở một mức năng lực lớn hơn độ
khó bi của CH một ít.
Để minh họa, chúng ta hãy tính các hàm thông tin của các CH có
các tham số đã được nêu ở Bảng 6.1 tại chương 6.
Bảng 6.1. Các tham số của 5 CH trắc nghiệm
Tham số
CH số aj bj cj
1 2 -1 0,15
2 1,5 -0,5 0
3 1 0 0
4 1,5 0,5 0,1
5 2,5 1 0,2
Kết quả tính toán cho phép vẽ đồ thị trên Hình 7.1.
Hình 7.1. Các đồ thị hàm thông tin của 5 CH trắc nghiệm
Các đồ thị của các hàm thông tin khẳng định các tính chất nêu trên
đây, cụ thể là:
- Hàm thông tin đạt giá trị cực đại ở vị trí i=bi khi ci=0, và ở vị trí
i lớn hơn bi một ít khi ci>0,

132
- Tham số độ phân biệt ai ảnh hưởng mạnh lên giá trị của thông tin
trong việc đánh giá năng lực mà một CH cung cấp (biên độ hàm thông tin
của CH2 với b=1,5 lớn hơn nhiều so với CH3 với b=1).
- Tham số đoán mò ci có giá trị càng lớn thì thông tin để đánh giá
năng lực càng giảm (CH2 và CH3 có giá trị ai như nhau nhưng ci của
CH4 khác 0 - bằng 0,1- nên biên độ hàm thông tin của CH4 thấp hơn
biên độ hàm thông tin của CH2).
- Tùy theo tham số của mỗi CH mà mức độ đóng góp của chúng
vào việc xác định năng lực trên thang đo năng lực sẽ khác nhau. Chẳng
hạn, CH1 và CH5 tuy cung cấp nhiều thông tin để đánh giá các phần cao
và thấp của dải năng lực, nhưng cung cấp ít thông tin để đánh giá phần
trung bình của dải năng lực, so với các CH2, CH3 và CH4.
Từ các nhận xét về dáng điệu của hàm thông tin chúng ta có thể
thấy hàm thông tin là công cụ để đánh giá sự đóng góp của từng CH trắc
nghiệm để xác định năng lực TS, dựa vào đó có thể tạo nên các ĐTN
thích hợp để đo các khoảng năng lực mong muốn. Các nhận xét cũng cho
thấy các CH ứng với mô hình 3 tham số (ci>0) có hiệu quả cung cấp
thông tin kém hơn các CH ứng với mô hình một và hai tham số. Tuy
nhiên điều cần lưu ý trước hết ở tầm quan trọng của sự phù hợp giữa mô
hình và số liệu khi chọn mô hình, vì những nhận xét trên đây chỉ đúng khi
đạt được sự trùng khớp tốt giữa mô hình và số liệu.
7.2. HÀM THÔNG TIN VÀ SAI SỐ TIÊU CHUẨN CỦA ĐỀ TRẮC NGHIỆM
7.2.1. Hàm thông tin của đề trắc nghiệm
Hàm thông tin của ĐTN (Test information Function) là tổng các
hàm thông tin của các CH có trong ĐTN:
n
i
i=1
I(θ)= I (θ)
Biểu thức trên cho thấy mọi CH đóng góp thông tin cho ĐTN để
đánh giá năng lực TS độc lập với các CH khác. Đó là điểm khác biệt của
IRT so với CTT, vì đối với CTT sự thay đổi của chỉ một CH cũng gây
(7.7)

133
ảnh hưởng lên các điểm số của bài trắc nghiệm, do đó cũng sẽ làm thay
đổi mọi chỉ số của ĐTN và CH trắc nghiệm.
Bằng cách cộng các hàm Ii() của các CH biểu diễn trên Hình 7.1
chúng ta sẽ thu được đường cong I() của ĐTN gồm 5 CH trong ví dụ có
tính chất giáo khoa trên đây. Ở Hình 7.2 đường cong nét đậm biểu diễn
hàm thông tin của ĐTN, còn các đường cong nét nhạt là các hàm thông
tin của các CH trắc nghiệm vẽ theo tỷ xích nhỏ hơn tỷ xích trên Hình 7.1.
Có thể xem minh họa trên Hình 8.4 chương 8 một đường cong hàm thông
tin và sai số tiêu chuẩn của một ĐTN thực tế - đó là ĐTN VIỆT1 đã được
mô tả ở mục 5.2 chương 5.
Hình 7.2. Các đồ thị hàm thông tin của 5 CH trắc nghiệm và của ĐTN do 5 CH đó hợp thành
Mức thông tin chung của ĐTN cao hơn nhiều so với mức thông tin
của từng CH riêng rẽ, tức là một ĐTN sẽ đo năng lực chính xác hơn
nhiều so với chỉ một CH trắc nghiệm. Từ định nghĩa hàm thông tin theo
công thức (7.7) chúng ta cũng thấy rõ: ĐTN càng có nhiều CH thì giá trị

134
của hàm thông tin càng cao, tức là một ĐTN dài thường đo năng lực
chính xác hơn một ĐTN ngắn.
Tùy theo tính chất của các CH tạo nên ĐTN mà hàm thông tin sẽ
có giá trị lớn (tức là đo chính xác) ở các khoảng năng lực xác định nào đó
và giá trị bé (tức là đo kém chính xác) ở các khoảng năng lực khác.
Do những đặc điểm nêu trên, hàm thông tin là một công cụ cực kỳ
quan trọng của IRT, nó giúp thiết kế các ĐTN cho các phép đo theo các
mục tiêu xác định. Hàm thông tin lý tưởng của một ĐTN là một đường
nằm ngang, tức là phép đo có độ chính xác như nhau ở mọi khoảng năng
lực. Tuy nhiên một ĐTN như vậy có thể không phải là tốt nhất đối với
các mục tiêu cụ thể. Chẳng hạn, nếu chúng ta muốn thiết kế một ĐTN để
cấp học bổng, hàm thông tin như vậy không phải là tối ưu. Trong trường
hợp đó cần một ĐTN đo rất chính xác trong một khoảng hẹp ở mức năng
lực là ranh giới của những TS được và không được học bổng, tức là hàm
thông tin có đỉnh cực đại ở điểm cắt (cut-off score), vì một sai số lớn
trong phép đo ở khoảng năng lực này có thể chuyển một TS từ loại được
sang loại không được học bổng hoặc ngược lại.
7.2.2. Sai số tiêu chuẩn của đề trắc nghiệm
Sai số tiêu chuẩn của việc ước lượng năng lực ở vị trí bằng:
1σ( θ)= ,
I(θ) (7.8)
Biểu thức (7.8) cho thấy hai đường cong hàm thông tin và sai số
tiêu chuẩn của một ĐTN có hình dạng đối nghịch nhau. Để hình dung
bạn đọc có thể xem đồ thị biểu diễn hai đường cong đó của ĐTN VIỆT 1
(đã được mô tả ở mục 5.2 chương 5) trên Hình 8.4 chương 8. Sự phụ
thuộc của sai số tiêu chuẩn σ vào tham số θ có một ý nghĩa quan trọng,
chỉ rõ một trong những khác biệt giữa CTT và IRT. Biểu thức (6.1) đã
nêu ở chương 6 cho thấy trong CTT sai số ε của phép đo là một đại lượng
không đổi chung cho ĐTN đối với mọi TS có năng lực khác nhau. Trong
khi đó, đối với IRT, sai số của phép đo bằng ĐTN thay đổi theo các mức
năng lực. Đây cũng là một biểu hiện của việc "cá thể hóa" phép đo lường
của IRT mà chúng ta đã đề cập khi bàn về mô hình Rasch ở chương 4.

135
Sai số tiêu chuẩn σ( θ )
của việc ước lượng năng lực ^
θ là độ lệch
tiêu chuẩn của phân bố gần chuẩn khi ước lượng giá trị năng lực theo
biến cố hợp lý cực đại ở một giá trị năng lực nào đó. Phân bố sẽ tiến
đến dạng chuẩn khi ĐTN đủ dài. Tuy nhiên, một số nghiên cứu cho thấy
rằng thậm chí các ĐTN ngắn cỡ 10 - 20 CH sự phân bố gần chuẩn cũng
thỏa mãn đối với một số mục đích.
Biên độ của sai số tiêu chuẩn nói chung phụ thuộc vào: 1) số CH
trong ĐTN (số CH càng lớn sai số tiêu chuẩn càng bé); 2) chất lượng các
CH của ĐTN (nói chung các CH càng có độ phân biệt cao và khả năng
đoán mò thấp sẽ tạo sai số tiêu chuẩn bé); 3) độ khó CH gần với giá trị
năng lực được đo (tức là ĐTN không quá khó và không quá dễ). Việc
tăng số CH trong ĐTN hoặc chọn các CH với giá trị hàm thông tin lớn sẽ
làm tăng giá trị thông tin của ĐTN và giảm sai số tiêu chuẩn, tuy nhiên
khi hàm thông tin vượt quá một giá trị nào đó thì sai số tiêu chuẩn sẽ trở
nên ổn định và sự tăng tiếp tục của hàm thông tin sẽ có tác động không
lớn lên giá trị của sai số tiêu chuẩn.
7.2.3. Hàm hiệu suất tỷ đối
Đôi khi các nhà thiết kế ĐTN muốn so sánh các hàm thông tin của
hai hoặc nhiều ĐTN khác nhau. Chẳng hạn, khi thiết kế một ĐTN cho
một kỳ thi quốc gia có thể người ta muốn so sánh các hàm thông tin của
các ĐTN được tạo bởi các CH khác nhau để chọn ĐTN nào cung cấp
thông tin nhiều nhất nhằm đo một khoảng năng lực nào đó. Tất nhiên
phải tính đến các yếu tố khác nữa khi lựa chọn một ĐTN, chẳng hạn độ
giá trị, giá thành, nội dung và độ dài của đề.
Việc so sánh hai hàm thông tin được thực hiện bằng cách tính hiệu
suất tỷ đối của một ĐTN so với một ĐTN khác:
A
B
I (θ)RE(θ)= ,
I (θ)
trong đó RE() là hiệu suất tỷ đối và IA(), IB() là các hàm thông tin
tương ứng của hai ĐTN A và B. Ví dụ tại một giá trị nào đó RE()= 1,25
thì điều đó có nghĩa là ĐTN A có tác dụng như là nó có độ dài hơn ĐTN B
25%. Như vậy cần tăng chiều dài ĐTN B thêm 25% bằng cách tăng thêm
(7.9)

136
các CH thích hợp. Ngược lại, có thể rút ngắn ĐTN A 25% mà vẫn ước
lượng được năng lực ở mức với độ chính xác như ước lượng của ĐTN B.
Kết luận trên liên quan đến việc kéo dài hay rút ngắn các ĐTN được dựa
trên giả định rằng các CH được thêm vào hoặc lược bỏ bớt là tương thích
về chất lượng thống kê đối với các CH khác trong ĐTN.
CÂU HỎI TỰ ĐÁNH GIÁ
1. Dáng điệu của hàm thông tin phụ thuộc như thế nào vào các
tham số a, b, c của hàm đặc trưng trong CH trắc nghiệm.
2. Nêu các ứng dụng của hàm thông tin của đề trắc nghiệm.
BÀI TẬP
Các tham số của CH trong một “ngân hàng” gồm 4 CH được trình
bày ở Bảng 6.2. Giả sử cần tạo ĐTN gồm 3 CH từ “ngân hàng” đó. Hãy
tính giá trị thông tin của ĐTN ở các điểm có θ bằng -2, -1, 0, 1, 2 cho
4 ĐTN có thể được tạo nên từ “ngân hàng” đó. Hãy vẽ 4 hàm thông tin
của các ĐTN. ĐTN nào nên được sử dụng cho một trắc nghiệm đo mức
đạt chuẩn với điểm cắt ở θ = 1?
CH a b c
1 1,25 -0,5 0,00
2 1,50 0,0 0,00
3 1,25 1,0 0,00
4 1,00 1,5 0,00

137
Chương 8
ƯỚC LƯỢNG NĂNG LỰC CỦA THÍ SINH VÀ ĐỊNH CỠ ĐỀ TRẮC NGHIỆM
Chương 5 đã nêu cách ước lượng các tham số của CH trắc nghiệm
dựa trên ứng đáp của TS, nhưng nặng về mô tả định tính. Chương này
được dành để trình bày vài phương pháp định lượng nhằm ước lượng giá
trị năng lực của TS, và sau đó đưa ra cách ước lượng đồng thời tham số
của các CH trắc nghiệm và giá trị năng lực của TS, tức là thực hiện thao
tác thường được gọi là định cỡ ĐTN. Tính bất biến của năng lực TS được
ước lượng bằng các CH trắc nghiệm khác nhau cũng được phân tích rõ.
Cuối chương, việc định cỡ một ĐTN nhờ phần mềm VITESTA được
trình bày tỉ mỉ như một ví dụ cụ thể từ thực tiễn bước đầu áp dụng IRT
trong hoạt động đánh giá ở nước ta.
Khi sử dụng IRT để triển khai một trắc nghiệm đối với một TS thì
mục đích quan trọng nhất là xác định được vị trí của TS đó trên thang đo
năng lực. Nếu thu được một số đo năng lực như vậy đối với mỗi TS làm
một ĐTN thì sẽ đạt hai mục tiêu: một là đánh giá được mức năng lực của
TS, hai là có thể so sánh năng lực của các TS với nhau để tuyển chọn họ
theo một tiêu chuẩn nào đó.
8.1. QUY TRÌNH ƯỚC LƯỢNG GIÁ TRỊ NĂNG LỰC CỦA THÍ SINH
Trong chương 5 khi xem xét quy trình ước lượng các tham số của
CH trắc nghiệm chúng ta giả thiết rằng đã biết giá trị tham số năng lực
của mỗi TS. Ngược lại, để ước lượng năng lực của TS chúng ta cũng giả
thiết rằng đã biết giá trị các tham số của các CH trắc nghiệm.
Chúng ta vẫn giả thiết là các ứng đáp của TS đối với mỗi CH thu
được dưới dạng nhị phân, tức là ứng đáp đúng được 1 điểm, ứng đáp sai

138
được 0 điểm. Từ đó, sau khi một TS làm một ĐTN, chúng ta sẽ thu được
một dãy các trả lời 0 hoặc 1 đối với N CH trong ĐTN, mỗi dãy đó được
gọi là một vectơ ứng đáp (các) CH của một TS. Như vậy nhiệm vụ được
đặt ra cho bài toán là sử dụng vectơ ứng đáp CH đó của TS và các tham
số CH đã biết để ước lượng tham số năng lực chưa biết của anh ta.
8.1.1. Các nguyên tắc chung của quy trình
Cũng giống như quá trình ước lượng các tham số của CH trình bày
ở chương 5, chúng ta sẽ sử dụng các quy trình biến cố hợp lý cực đại để
ước lượng năng lực của TS. Trước hết, ta gán một giá trị tiên nghiệm nào
đó cho năng lực của một TS và sử dụng các tham số đã biết của các CH
trong ĐTN để tính các xác suất ứng đáp đúng mỗi CH đối với TS đã
chọn. Sau đó sử dụng một sự điều chỉnh giá trị ước lượng năng lực để
làm tăng sự phù hợp của các xác suất ứng đáp CH tính được với vectơ
ứng đáp CH của TS. Quá trình điều chỉnh được lặp lại nhiều lần cho đến
khi có một bước điều chỉnh cho giá trị đủ bé, tức là không tạo một sự
thay đổi đáng kể của giá trị năng lực được ước lượng. Kết quả ước lượng
đó được xem là giá trị tham số năng lực của TS.
Ở mục 8.2 cuối chương này sẽ nêu quy trình ước lượng đồng thời
các giá trị năng lực của mọi TS, nhưng bước đầu này sẽ trình bày cách
ước lượng giá trị năng lực riêng rẽ của từng TS.
Giả sử một TS nào đó được chọn cách ngẫu nhiên có năng lực
ứng đáp một nhóm n CH nhị phân với kiểu ứng đáp được biểu diễn bởi
vectơ U sau đây:
U = (U1,U2,...,Uj,..., Un /),
trong đó Ui = ui =1 (ứng đáp đúng) hoặc Ui = ui = 0 (ứng đáp sai)
đối với CH thứ i. Với giả thiết về tính độc lập địa phương (tức là xác suất
trả lời đúng một CH nào đó không phụ thuộc vào các CH khác), có thể
biểu diễn xác suất ứng đáp nhóm CH của TS có năng lực đó là tích của
các xác suất trả lời từng CH:
P(U1,U2,...,Uj,..., Un|) = P(U1|). P(U2|)....P(Uj|)... P(Un|),

139
hoặc viết gọn hơn dưới dạng:
P(U|) = n
j
j=1
P(U θ) .
Vì Uj bằng 0 hoặc 1 nên có thể viết:
P(U|)= j jj j
n nU (1-U )U (1-U )
j j j j
j=1 j=1
P(U θ) [1-P(U θ)] = P Q , (8.1)
trong đó Pj = P(Uj|) và Qj = 1- P (Uj |).
Đẳng thức (8.1) biểu diễn xác suất của kiểu ứng đáp nhóm CH nói
trên. Khi kiểu ứng đáp nhóm CH đã quan sát được, tức đã có các giá trị
Uj = u j, thì sử dụng từ xác suất sẽ không thích hợp nữa, nên xác suất đó
được gọi là biến cố hợp lý (likelyhood) và được biểu diễn bởi hàm
L(u1,u2,...,uj,...,un|), trong đó uj là sự ứng đáp đối với CH thứ j, tức là:
L(u1,u2,...,uj,...,un/ ) = j j
nu (1-u )
j j
j=1
P Q . (8.2)
Vì Pj và Qj là các hàm của và các tham số của CH nên L cũng là
hàm của các tham số đó.
Việc tính toán sẽ đơn giản hơn nhiều nếu logarit hóa biểu thức
(8.2), ta được:
lnL(u|) = n
j j j j
j=1
[u lnP +(1-u )ln(1-P )] , (8.3)
trong đó u là vectơ các ứng đáp các CH của TS. Giá trị làm cho
hàm biến cố hợp lý (hoặc tương ứng, ln của hàm biến cố hợp lý) đối với
một TS đạt cực đại được định nghĩa là ước lượng của năng lực theo biến
cố hợp lý cực đại đối với TS đó.
Việc tìm giá trị cực đại của L hoặc lnL là một quá trình phức tạp
khi có nhiều TS và nhiều CH. Giá trị tạo cực đại của hàm có thể tìm
bằng quy trình "search" nhờ máy tính. Một trong các cách tìm có hiệu

140
quả là dựa vào tính chất đạo hàm bậc nhất của L hoặc lnL bằng 0 ở vị
trí cực đại. Người ta thiết lập được các phương trình từ tính chất đó và
giải giải bằng phương pháp giải tích trực tiếp hoặc phương pháp xấp
xỉ. Một trong các phương pháp xấp xỉ thường dùng là quy trình
Newton-Raphson mà bạn đọc có thể dễ dàng tìm hiểu từ các nguồn tư
liệu tương ứng, chẳng hạn từ Wikipedia(*).
Một khó khăn có thể gặp phải là đôi khi hàm L hoặc lnL không có
cực đại ở giá trị hữu hạn, hoặc TS trả lời mọi CH đều đúng hoặc đều
không đúng. Lúc đó hàm biến cố hợp lý sẽ có cực đại ở giá trị =+
hoặc = -. Đôi khi các mô hình ứng đáp dị thường có thể làm cho hàm
biến cố hợp lý không có cực đại tuyệt đối ở giá trị hữu hạn: điều này
thường xuất hiện đối với mô hình 3 tham số và ứng với trường hợp TS
trả lời đúng các CH khó nhưng trả lời sai các CH dễ. Đối với các trường
hợp mô hình trả lời dị thường hoặc trả lời mọi CH đều đúng và đều
không đúng người ta có thể khắc phục bằng quy trình ước lượng Bayes,
tuy nhiên việc mô tả quy trình đó vượt ra ngoài mục tiêu của tập sách
này. Bạn đọc quan tâm về kỹ thuật ước lượng tham số trong IRT có thể
tham khảo ở công trình [8].
8.1.2. Một ví dụ đơn giản về ước lượng nhờ đồ thị
Để minh họa cho quá trình ước lượng giá trị năng lực của TS,
chúng ta hãy theo dõi một ví dụ có tính giáo khoa sau đây. Hãy khảo
sát các ứng đáp của 4 TS đối với 5 CH trắc nghiệm xây dựng theo
mô hình 3 tham số đã được khảo sát ở chương 5 (Hình 5.1). Các
tham số của CH và vectơ ứng đáp của TS được mô tả ở Bảng 8.1.
Thực tế ở đây có hai trường hợp riêng của mô hình 3 tham số: CH3
là mô hình 1 tham số, CH4 là mô hình 2 tham số.
Hàm biến cố hợp lý đối với mỗi TS có thể xây dựng theo số liệu ở
Bảng 8.1.
(*) http: //en.wikipedia.org/wiki/Newton-Raphson.

141
Bảng 8.1. Các tham số của CH và các vectơ ứng đáp của TS
Các tham số của CH Các vectơ ứng đáp của thí sinh
Câu hỏi aj bj cj 1 2 3 4
1 2 -1 0,1 1 1 1 1
2 1,5 -0,5 0,2 0 0 1 1
3 1 0 0 0 1 0 0
4 0,5 0,5 0,00 0 0 1 1
5 4 1 0,15 0 0 0 1
Từ biểu thức (8.3) chúng ta tính được:
lnL1(u|1) = lnP1+ ln(1-P2)+ln(1-P3)+ ln(1-P4)+ln(1-P5),
lnL2(u|2) = lnP1+ ln(1-P2)+lnP3+ln(1-P4)+ln(1-P5),
lnL3(u|3) = lnP1+ lnP2+ln(1-P3)+lnP4+ln(1-P5),
lnL4(u|4) = lnP1+ lnP2+ln(1-P3)+lnP4+lnP5.
Hình 8.1. Các đường cong lnLj ứng với 4 vectơ ứng đáp CH

142
Vì các hàm Pj (và do đó Qj) là các hàm ứng đáp CH nên có thể tính
chúng khi biết các giá trị tham số của các CH đối với một giá trị xác định
cũng như với mọi giá trị của trên thang đo. Trên Hình 8.1 có vẽ riêng
từng đường cong lnLj với các tỷ xích khác nhau. Trên Hình 8.2. cả 4
đường cong lnLj được vẽ trên cùng một đồ thị với cùng một tỷ xích. Theo
các cực đại trên đường cong chúng ta có thể xác định các giá trị năng lực
j của TS.
Hình 8.2. Các đường cong lnLj vẽ trên cùng một đồ thị với cùng một tỷ xích
Minh họa trên đây với việc vẽ đồ thị theo hàm giải tích chỉ sử dụng
được khi số TS và số CH không quá lớn. Bây giờ chúng ta hãy xét
phương pháp tổng quát hơn sử dụng với ĐTN có nhiều CH và mẫu thử
nghiệm có đông TS.
8.1.3. Một ví dụ về việc sử dụng phương pháp tính lặp để tìm cực đại
Viết lại biểu thức (8.3) đối với ln của hàm biến cố hợp lý:
n
j j j j
j=1
Λ(θ)=lnL(u/θ)= [u lnP +(1-u )lnQ ]. (8.4)
Cực đại của biểu thức trên đạt được khi đạo hàm bậc nhất bằng không:
'
1 1
( ) 1 1( ) [ ] (1 )[ ]
n nj i
j jj jj i
P Qu u
P Q
= 0. (8.5)

143
Một cách tổng quát, có thể giải phương trình (8.4) bằng phương
pháp tính lặp Newton-Raphson. Đối với phương trình f(x)=0, ta có:
ss+1 s
s
f(x )x =x -
f (x ), (8.6)
trong đó )(xf là đạo hàm của f(x), s+1x là giá trị nghiệm của
phương trình ở bước lặp thứ (s+1) tính theo nghiệm của bước lặp thứ s
trước đó.
Ứng dụng vào trường hợp của hàm của phương trình (8.5), ta có:
s+1θ = sθ - s
s
Λ (θ )
Λ (θ )
, (8.7)
Trong đó Λ’ và Λ” biểu diễn các đạo hàm bậc 1 và bậc 2 của Λ đối
với . Từ biểu thức của P() đối với mô hình tổng quát của đường cong
ĐTCH 3 tham số và biểu thức (8.5) và (8.7) có thể tính được:
nj j j s j s j
jj sj=1
s+1 s s2n
j s j s j2j
jj sj-1
ˆ ˆa [u -P (θ )] [P (θ )-c ]
ˆ (1-c )P (θ )ˆ ˆ ˆθ =θ + =θ +Δθ
ˆ ˆQ (θ ) P (θ )-ca
ˆ (1-c )P (θ )
. (8.8)
Đối với mô hình ĐTCH 2 tham số, khi cj =0, ta có:
n
i i i s
i=1s+1 s sn
2i i s i s
i=1
a [u -P (θ )]
θ =θ + =θ +Δθ
ˆ ˆa P (θ )Q (θ )
. (8.9)
Quy trình tìm nghiệm theo phương pháp tính lặp có thể mô tả
như sau. Đầu tiên chọn một giá trị s nào đó cho biến số năng lực ở vế
phải. Tính trị số của các hàm Pi () đối với n CH ở giá trị s và thay vào
số hạng thứ hai ở vế phải, ta thu được một trị số điều chỉnh Δ. Cộng Δ
vào s sẽ thu được 1ˆs , và giá trị 1
ˆs này sẽ đóng vai trò s trong bước
lặp sau... Lưu ý rằng số hạng [ui - Pi( s )] là độ chênh giữa sự ứng đáp
CH của TS với xác suất trả lời đúng ở mức năng lực s . Vì ước lượng
năng lực trở nên gần hơn với năng lực thật của TS nên tổng các độ chênh

144
giữa ui và Pi( s ) sẽ trở nên nhỏ hơn. Mục đích của chúng ta là tìm được
một ước lượng năng lực tạo nên các giá trị Pi( s ) của mọi CH đồng thời
làm cực tiểu tổng số đó. Khi điều đó xảy ra, số hạng Δ sẽ trở nên càng
bé càng tốt và giá trị 1ˆs sẽ thay đổi không đáng kể sau các lần lặp. Giá
trị 1ˆs cuối cùng được dùng làm giá trị năng lực ước lượng của TS. Tùy
theo yêu cầu chúng ta có thể quy định cỡ giá trị của số gia Δ để ra lệnh
dừng quá trình tính toán.
Chúng ta hãy thử quy trình tìm nghiệm bằng phương pháp tính lặp
Newton-Raphson trên một ví dụ có tính chất giáo khoa đơn giản của một
ĐTN gồm 5 CH xây dựng theo mô hình hai tham số đối với một TS có
các ứng đáp mô tả ở Bảng 8.2. Ở bước 1 ta gán cho TS năng lực bằng
1 = 1, tính các Pj ( 1 ), Qj ( 1 ) và thay vào biểu thức Δ theo (8.9). Bước
tiếp theo lấy 2 1 + Δ và lặp lại tính toán như bước 1... Kết quả tính
toán theo các bước được mô tả ở Bảng 8.3.
Bảng 8.2. Các tham số của các CH và ứng đáp của một TS
CH
a
b
Ứng đáp của
một TS
1 1 -2 1
2 1,5 -1 1
3 1.2 0 1
4 0.8 1 0
5 2 2 1
Bảng 8.3. Kết quả của 5 bước tính lặp
Bước P1 P2 P3 P4 P5 Δ
1 1,0000 0,9526 0,9526 0,7685 0,5000 0,1192 1,7884
2 2,7884 0,9917 0,9966 0.9660 0.8070 0,8287 -0.3408
3 2,4476 0,9884 0,9944 0.9497 0,7610 0,7100 0,5007
4 2,4977 0.9890 0,9948 0,9524 0.7682 0,7302 0,0011
5 2,4988 0,9890 0.9948 0.9525 0,7684 0,7306 0,5177x10-6

145
Từ Bảng 8.3 có thể thấy với phép gán ban đầu 1 =1, chỉ sau
5 bước tính lặp ta đã xác định được giá trị năng lực của TS ứng đáp CH
theo vectơ u(1,1,1,0,1). Giá trị năng lực của TS xác định được là
=2,4988; với gia số Δ ở bước lặp thứ 5 cỡ một phần triệu.
8.1.4. Về sai số ước lượng giá trị năng lực
Cần lưu ý rằng chúng ta có thể ước lượng được năng lực đến mức
gia số ước lượng năng lực qua mỗi bước ước lượng là rất bé, tuy nhiên
chúng ta vẫn không biết được giá trị chính xác của năng lực thật. Dù sao
vẫn còn may mắn là chúng ta có thể thu được sai số tiêu chuẩn của năng
lực đã được ước lượng. Nguyên tắc cơ bản của việc ước lượng sai số là
giả thiết rằng TS có thể làm một ĐTN rất nhiều lần nhưng họ không hề
nhớ về việc làm trắc nghiệm của những lần trước. Năng lực θ có thể thu
được từ mỗi lần làm ĐTN đó. Sai số tiêu chuẩn là độ đo của sự biến thiên
các giá trị của θ xung quanh một giá trị tham số chưa biết. Khi ấy sai
số tiêu chuẩn có thể tính theo công thức như đã nêu (7.8): ^
n2j j j
j=1
1σ( θ )=
ˆ ˆa P (θ)Q (θ) (8.10)
Chú ý rằng biểu thức dưới dấu căn cũng chính là biểu thức ở mẫu
số của số gia Δ trong phương trình (8.6), do đó sai số tiêu chuẩn có thể
thu được trong quá trình ước lượng năng lực:
σ( θ ) = 9889742203,0 =0,994471830.
Như vậy ước lượng của không được chính xác cho lắm vì sai số
tiêu chuẩn rất lớn. Một trong các nguyên nhân của giá trị sai số tiêu
chuẩn lớn là do ĐTN chỉ bao gồm 5 CH.
Có hai trường hợp ứng đáp của TS không thể ước lượng được năng
lực là trường hợp ứng đáp đối với mọi CH đều đúng (giá trị năng lực
tương ứng là +) và ứng đáp đối với mọi CH đều sai (giá trị năng lực
tương ứng là -). Chương trình máy tính phải loại bỏ các trường hợp này
trước khi tính toán.

146
8.2. ĐỊNH CỠ ĐỀ TRẮC NGHIỆM: ƯỚC LƯỢNG ĐỒNG THỜI THAM SỐ
CỦA CÂU HỎI VÀ NĂNG LỰC CỦA THÍ SINH
8.2.1. Về việc ước lượng các tham số của câu hỏi
Trong chương 5 chỉ nêu khái quát một cách định tính quy trình ước
lượng các tham số của CH. Mục trên đây mô tả thuật toán thực hiện quy
trình ước lượng năng lực TS với giả thiết đã biết các tham số của CH trắc
nghiệm. Quy trình ước lượng các tham số của CH khi đã biết năng lực TS
cũng được thực hiện theo thuật toán tương tự: từ việc ứng đáp của N TS
đối với một CH chúng ta thu được hàm biến cố hợp lý cực đại có dạng:
L(u1,u2,...,uj,...,uN| ,a,b,c) =
N
j
u
j
u
jjj QP
1
)1(, (8.11)
trong đó a,b và c là các tham số của CH. Điểm khác biệt giữa hàm
biến cố hợp lý đối với một CH so với hàm đó đối với một TS là ở chỗ đối
với một CH giả định về tính độc lập địa phương không cần viện dẫn,
chúng ta chỉ cần giả định rằng các ứng đáp của N TS đối với một CH là
độc lập, một giả thiết tiêu chuẩn trong thống kê học. Khi các giá trị đã
biết, việc ước lượng các tham số CH là trực tiếp tương tự như quy trình
đã mô tả. Một khác biệt nữa là hàm biến cố hợp lý của một CH là đa
chiều, vì có 3 biến số. Do đó, để tìm biến cố hợp lý cực đại của các tham
số a, b và c chúng ta cần tìm các giá trị của a, b và c tương ứng với một
giá trị cực đại nào đó trên một mặt 3 chiều. Điều đó được thực hiện bằng
cách tìm đạo hàm bậc nhất của hàm biến cố hợp lý đối với từng tham số
a, b và c, đặt chúng bằng không và giải đồng thời các hệ phương trình phi
tuyến thu được theo 3 ẩn số (tất nhiên đối với mô hình 2 và 1 tham số thì
có tương ứng 2 và 1 ẩn số). Chúng ta lại sử dụng phương pháp Newton-
Raphson dưới dạng đa biến và giải theo phương pháp chung. Khi các giá
trị năng lực của TS đã biết, mỗi CH được xem xét độc lập. Như vậy quá
trình ước lượng có thể lặp lại n lần, mỗi lần đối với mỗi CH.
8.2.2. Ước lượng đồng thời tham số của câu hỏi và năng lực của thí sinh:
định cỡ đề trắc nghiệm
Hàm biến cố hợp lý với N TS ứng đáp n CH, khi thỏa mãn tính độc
lập địa phương, có thể viết:

147
L(u1, u2,..., uj,..., uN| , a, b, c) =
ij ij
N nu (1-u )
ij ij
i=1 j=1
P Q , (8.12)
trong đó ui là mô hình trả lời của i TS đối với n CH, là vectơ của
N tham số năng lực; a, b, c là các vectơ của các tham số CH trong một
ĐTN có n CH. Số tham số của CH là 3n, 2n và n tương ứng trong trường
hợp mô hình 3, 2 và 1 tham số. Tính độc lập địa phương phải được giả
thiết vì rằng các là chưa biết. Các tham số năng lực là N, và do đó đối
với mô hình 3 tham số tổng cộng có 3n+N tham số được ước lượng.
Kỹ thuật định cỡ một ĐTN đã được Birnbaum đưa ra năm 1968 [4]
và được áp dụng rộng rãi trong các phần mềm phân tích trắc nghiệm. Đó
là một quy trình tương tác, gồm 2 giai đoạn ước lượng biến cố hợp lý cực
đại. Giai đoạn đầu ước lượng các tham số của n CH, giai đoạn thứ hai
ước lượng các tham số năng lực của N TS. Hai giai đoạn được thực hiện
tương tác với nhau cho đến khi thu được một tập hợp ổn định các tham số
ước lượng được.
Trong giai đoạn đầu các ước lượng năng lực của mỗi TS được
xem như là đã được biểu diễn trên một thang đo với đơn vị đo thực của
năng lực tiềm ẩn. Sau đó các tham số của mỗi CH được ước lượng theo
quy trình ước lượng biến cố hợp lý cực đại như đã mô tả ở chương 5.
Quy trình được thực hiện theo từng CH một, vì đã có giả định các CH
là độc lập với nhau. Cuối cùng thu được một bộ các tham số của các CH
trong ĐTN.
Trong giai đoạn sau giả thiết rằng các giá trị tham số CH ước lượng
được ở giai đoạn trước là các giá trị thực của tham số. Sau đó năng lực
của mỗi TS được ước lượng theo quy trình ước lượng biến cố hợp lý cực
đại như đã mô tả ở đầu chương này. Vì giả định rằng các năng lực của
mọi TS là độc lập với nhau nên việc ước lượng năng lực được thực hiện
theo từng TS một.
Hai giai đoạn được lặp lại cho đến khi thỏa mãn một tiêu chí hội tụ
nào đó. Như vậy các tham số của n CH của ĐTN và các mức năng lực
của N TS được ước lượng đồng thời, tuy rằng chúng được thực hiện đối
với từng CH và TS một cách riêng biệt, vì đã có giả định là các CH và

148
các TS là độc lập với nhau. Cách tiệm cận thông minh đó làm cho một
bài toán ước lượng rất phức tạp có thể hạ xuống mức có thể giải trên một
máy tính.
Tuy nhiên trong quy trình ước lượng nói trên có một vấn đề cần
bàn đến, đó là tính bất định của quy trình ước lượng, sẽ được xét ở mục
tiếp theo.
8.2.3. Vấn đề metric
Trong hàm biến cố hợp lý nêu trên đây các tham số của CH và của
năng lực TS được xác định không đơn trị. Chẳng hạn trong hàm ứng đáp
CH 3 tham số [xem biểu thức (4.3) chương 4] nếu chúng ta thay thế
bằng *= +, b bằng b*= b+, và a bằng a*= a/ thì xác suất ứng
đáp đúng sẽ không thay đổi:
P()=P*(*).
Vì và là các hằng số bất kỳ của thang đo nên hàm biến cố hợp
lý sẽ không có một cực đại đơn trị. Bất kỳ quá trình tính toán bằng số nào
được sử dụng để tìm cực đại của hàm biến cố hợp lý cũng sẽ không đạt
kết quả vì tính bất định nói trên. Vấn đề này không được đặt ra trong hai
quá trình ước lượng tham số CH khi biết năng lực TS và ước lượng năng
lực TS khi biết tham số CH trên đây vì trong các tình huống đó không có
tính bất định.
Do tính bất định vừa nêu không thể đưa ra một metric duy nhất cho
thang đo năng lực. Theo thuật ngữ kỹ thuật có thể nói metric là duy nhất
qua một biến đổi tuyến tính. Như vậy cần phải "neo" metric lại bằng một
quy tắc tùy ý nào đó.
Có thể khử tính bất định bằng cách chọn một thang đo tùy ý cho
giá trị tham số năng lực hoặc tham số độ khó b. Cách mà nhiều người
thường dùng là đặt điểm gốc của thang đo tại một điểm nào đó và chọn
đơn vị trên thang đo bằng một giá trị nào đó. Thông thường người ta đặt
điểm gốc (điểm 0) của thang đo ở điểm trung bình của N giá trị năng lực
thu được, và khoảng đơn vị (=1) trên thang đo bằng độ lệch tiêu chuẩn
của N giá trị năng lực thu được. Một khi tính bất định bị khử, các giá trị

149
của năng lực TS và tham số CH làm cực đại hàm biến cố hợp lý có thể
xác định được.
Như vậy, metric xác định được thường phụ thuộc một nhóm TS cụ
thể làm trắc nghiệm và một tập hợp CH cụ thể trong một ĐTN. Một quá
trình ước lượng cụ thể không tạo nên một metric "thật" chung cho mọi
phép đo bằng mọi CH với mọi TS. Chúng ta sẽ xử lý vấn đề này qua quá
trình so bằng (equating) ĐTN được đề cập đến ở chương 12.
Kết quả quan trọng của quá trình định cỡ là đặt năng lực mỗi TS và
độ khó mỗi CH dọc trên một thang đo chung. Đó là một thế mạnh của
IRT. Tính chất đó cho phép người ta giải thích kết quả định cỡ một ĐTN
trong một cái khung đơn giản và cung cấp ý nghĩa cho các giá trị của các
ước lượng tham số thu được.
8.3. TÍNH BẤT BIẾN CỦA VIỆC ƯỚC LƯỢNG NĂNG LỰC THÍ SINH
ĐỐI VỚI CÁC ĐỀ TRẮC NGHIỆM
Một nguyên lý quan trọng khác của IRT là giá trị ước lượng năng
lực sẽ bất biến đối với các CH được dùng để xác định nó. Nguyên lý đó
dựa trên 2 điều kiện: 1) mọi CH đều đo cùng một năng lực tiềm ẩn; 2)
các giá trị của mọi tham số CH là ở trên một thang đo chung.
Để minh họa cho các nguyên tắc đó, chúng ta lấy ví dụ về một
TS có điểm năng lực bằng 0 được đặt ở điểm giữa của thang đo năng
lực. Trước hết ra một ĐTN gồm các CH có độ khó trung bình bằng - 2
cho TS đó làm, và kết quả ứng đáp các CH được sử dụng để ước lượng
năng lực của TS, từ đó xác định được điểm 1 của TS đối với ĐTN đã
cho. Sau đó ra một ĐTN thứ hai bao gồm các CH có độ khó trung bình
bằng +1 cũng cho TS đó làm, và kết quả ứng đáp các CH của ĐTN thứ
hai này cũng được sử dụng để ước lượng năng lực của TS, từ đó thu
được điểm 2 đối với ĐTN thứ hai. Theo nguyên lý bất biến đối các
mẫu CH thì phải có 1 = 2 , tức là hai ĐTN sẽ cho kết quả ước lượng
năng lực TS như nhau. Nguyên lý ấy đã phản ánh một sự kiện là
đường cong ĐTCH mở rộng ra toàn bộ thang đo năng lực. Nếu một
khoảng con của thang đo năng lực có thể sử dụng để ước lượng các
tham số của CH thì ngược lại, một nhóm con các đường cong ĐTCH

150
cũng có thể sử dụng để ước lượng năng lực của TS. Các CH với độ
khó trung bình cao sẽ có một điểm trên các đường cong ĐTCH của
chúng tương ứng với mức năng lực cao được quan tâm. Tương tự, các
CH với độ khó trung bình thấp cũng sẽ có một điểm trên các đường
cong ĐTCH của chúng tương ứng với mức năng lực thấp được quan
tâm. Do đó, một nhóm bất kỳ các CH nào đó cũng có thể sử dụng để
ước lượng năng lực của các TS ở điểm đã cho. Trong mỗi nhóm CH
chỉ có một phần nào đó của các đường cong ĐTCH được sử dụng,
nhưng điều đó hoàn toàn có thể chấp nhận.
Ý nghĩa thực tiễn của nguyên lý bất biến của các CH đối với việc
ước lượng năng lực TS là ở chỗ một ĐTN dù ứng với vị trí nào trên
thang đo năng lực cũng có thể dùng để ước lượng một năng lực của TS.
Chẳng hạn một TS có thể làm một ĐTN "dễ" hoặc một ĐTN "khó"
nhưng vẫn thu được một ước lượng năng lực như nhau. Đây là chỗ khác
biệt rõ rệt của IRT so với CTT, vì trong CTT, TS sẽ nhận được điểm
cao hơn khi làm một ĐTN dễ, sẽ nhận được điểm thấp hơn khi làm
ĐTN khó, và không có cách nào để biết chắc năng lực thực sự của TS.
Đối với IRT năng lực của TS là xác định và bất biến đối với các CH
được sử dụng để đo chúng. Từ "xác định" ở đây cần hiểu với ý nghĩa nó
là một giá trị riêng biệt cụ thể trong tình huống đã cho. Chẳng hạn, nếu
một TS làm một ĐTN nhiều lần và nếu có thể giả định là anh ta không
nhớ các CH hoặc cách trả lời ở các lần làm trước đây, thì năng lực của
anh ta sẽ là xác định. Tuy nhiên, nếu giữa các lần trắc nghiệm TS được
học thêm hoặc có thể rút kinh nghiệm từ các lần trắc nghiệm trước thì
năng lực của TS sẽ khác nhau ở mỗi lần trắc nghiệm. Vậy mức năng lực
của TS là bất biến trong những điều kiện đã cho, bất biến đối với phép
đo bằng các ĐTN xây dựng từ các ngân hàng CH đã được định cỡ như
nhau, nhưng không phải là cái không thể thay đổi.
8.4. VÍ DỤ VỀ ĐỊNH CỠ ĐỀ TRẮC NGHIỆM, TÍNH HÀM THÔNG TIN,
HÀM ĐẶC TRƯNG CỦA ĐỀ TRẮC NGHIỆM
Ví dụ được nêu trong phần này nhằm minh họa việc ứng dụng các
khái niệm và quy trình đã trình bày ở các chương trước và chương này
qua một bài toán cụ thể từ thực tiễn Việt Nam.

151
Số liệu phân tích cũng được mượn từ cuộc khảo sát kết quả học tập
của học sinh lớp 5 tiến hành bởi Viện Khoa học Giáo dục Việt Nam năm
2007 [34]. Ở đây sẽ định cỡ ĐTN thử môn tiếng Việt (ĐTN VIỆT1),
gồm 40 CH trắc nghiệm nhị phân, được thực hiện trên mẫu với 535 TS là
học sinh lớp 5, như đã được giới thiệu ở mục 5.2 chương 5. Công cụ tính
toán là phần mềm VITESTA [19].
Trước hết, để hình dung khái quát về ĐTN có thể xem bảng các
đường cong đặc trưng của từng CH trên Hình 8.3. Có thể nhìn thấy ngay
các CH 6, 29, 33, 35, 40 có độ dốc nhỏ, tức là tham số a bé (độ phân biệt
IRT thấp). Bảng 8.4 cho giá trị a, b của mọi CH trong ĐTN, trong đó
tham số a của các CH đã nêu đúng là có giá trị bé, thấp nhất là của
CH 33 (a=0,06749). Độ phân biệt cổ điển của các CH đó thể hiện trên
Bảng 8.5 cũng rất bé, thậm chí CH 33 có độ phân biệt âm (-0,02088248).
CH 33 và các CH tương tự phải được loại khỏi ĐTN chính thức.
Bảng các tham số của từng CH của ĐTN có giá trị sử dụng thực tế
rất cao khi phân tích sơ bộ chất lượng của từng CH và từng phương án
của CH trong ĐTN. Từ bảng trích 8.5 chẳng những chúng ta biết được
các tham số độ khó, độ phân biệt cổ điển của từng CH, mà còn biết số TS
chọn từng phương án trả lời của CH, phương án đúng cũng như phương
án nhiễu. Nếu đối với phương án đúng tương quan điểm nhị phân (chính
là độ phân biệt cổ điển) phải có giá trị dương và càng lớn càng tốt
(thường đòi hỏi cỡ >0,2), thì đối với các phương án nhiễu giá trị đó phải
âm và càng bé càng tốt. Từ các số liệu đó chúng ta có thể đánh giá chất
lượng của từng phương án chọn trong từng CH.
Cùng với bảng các đường cong đặc trưng của các CH, kết quả tính
toán cũng cho ta bảng các đường cong hàm thông tin của các CH. Để
minh họa, Hình 8.4 có biểu diễn cặp đường cong ĐTCH và hàm thông tin
của CH số 5.
Cũng như đối với từng CH, đối với toàn bộ ĐTN chúng ta cũng thu
được đường cong đặc trưng ĐTN (đường cong điểm thực) và đường cong
hàm thông tin của ĐTN. Các đường cong này được biểu diễn tương ứng
trên các Hình 8.5 và 8.6.

152
Hình 8.3. Bảng các đường cong ĐTCH của ĐTN VIỆT1 tính theo mô hình 2 tham số

153
Bảng 8.4. Các tham số a, b của các đường cong ĐTCH của ĐTN VIỆT1
+---+-----------+---------+----------|
|Câu¦ b | a | MSE |
+---+-----------+---------+----------|
¦ 1¦ -0.75829¦ 1.04830¦ 0.11392¦
¦ 2¦ -1.99097¦ 1.34161¦ 0.21798¦
¦ 3¦ -1.56526¦ 0.97956¦ 0.14154¦
¦ 4¦ -1.91935¦ 1.26318¦ 0.19878¦
¦ 5¦ -0.92946¦ 0.90974¦ 0.11292¦
¦ 6¦ 0.55030¦ 0.22657¦ 0.08847¦
¦ 7¦ 0.14565¦ 0.52787¦ 0.09383¦
¦ 8¦ 0.70154¦ 0.43199¦ 0.09401¦
¦ 9¦ -0.46461¦ 0.82219¦ 0.10265¦
¦ 10¦ 2.72380¦ 0.36628¦ 0.11822¦
¦ 11¦ 0.11510¦ 0.62417¦ 0.09613¦
¦ 12¦ -1.43655¦ 0.54562¦ 0.10720¦
¦ 13¦ -0.79394¦ 0.92599¦ 0.11052¦
¦ 14¦ -0.91405¦ 0.61333¦ 0.10138¦
¦ 15¦ -0.91320¦ 0.66784¦ 0.10338¦
¦ 16¦ -1.08248¦ 0.53193¦ 0.10055¦
¦ 17¦ 0.19373¦ 0.47343¦ 0.09268¦
¦ 18¦ 1.20518¦ 0.69869¦ 0.11319¦
¦ 19¦ -0.65378¦ 1.12469¦ 0.11426¦
¦ 20¦ -0.10064¦ 0.50456¦ 0.09308¦
¦ 21¦ -1.32392¦ 1.09650¦ 0.13596¦
¦ 22¦ -1.15269¦ 0.97690¦ 0.12240¦
¦ 23¦ -0.94972¦ 1.17745¦ 0.12375¦
¦ 24¦ -0.12999¦ 0.88086¦ 0.10261¦
¦ 25¦ -0.69608¦ 0.66428¦ 0.10034¦
¦ 26¦ -1.18279¦ 1.40695¦ 0.14395¦
¦ 27¦ -0.22323¦ 0.79100¦ 0.10038¦
¦ 28¦ -0.08077¦ 0.97647¦ 0.10524¦
¦ 29¦ 2.00720¦ 0.13027¦ 0.08908¦
¦ 30¦ -0.18945¦ 1.08015¦ 0.10826¦
¦ 31¦ 0.09852¦ 0.67260¦ 0.09733¦
¦ 32¦ -0.77120¦ 0.75519¦ 0.10428¦
¦ 33¦ 4.71609¦ 0.06749¦ 0.08977¦
¦ 34¦ -0.38175¦ 0.94010¦ 0.10531¦
¦ 35¦ 3.61823¦ 0.14436¦ 0.09550¦
¦ 36¦ 0.17917¦ 0.68336¦ 0.09791¦
¦ 37¦ 0.78273¦ 0.62917¦ 0.10175¦
¦ 38¦ 2.01173¦ 0.30128¦ 0.09955¦
¦ 39¦ 0.36695¦ 0.55641¦ 0.09545¦
¦ 40¦ 1.24440¦ 0.22300¦ 0.09023¦
|------------------------------------|

154
Bảng 8.5. Trích bảng các tham số của các CH trắc nghiệm ĐTN VIỆT1 ==============================================================================
Câu số: 1
Bỏ qua: 5
Độ phân biệt (cổ điển): 0.54026
Độ khó (cổ điển): 0.70943
Độ phân biệt IRT(a): 1.04830
Độ khó IRT(b): -0.75829
Độ phỏng đoán IRT(c): 0.00000
Các phương án: 1* 2 3 4
Số TS chọn: 376 38 68 48
Tỉ lệ TS chọn PA (%) 70.94 7.17 12.83 9.06
Tương quan điểm nhị phân: 0.54026 -0.27057 -0.22864 -0.25364
Giá trị t: 14.82210 -6.48871 -5.42213 -6.05372
Giá trị p: 0.00000 0.00000 0.00000 0.00000
==============================================================================
Câu số: 2
Bỏ qua: 1
Độ phân biệt (cổ điển): 0.36163
Độ khó (cổ điển): 0.94569
Độ phân biệt IRT(a): 1.34161
Độ khó IRT(b): -1.99097
Độ phỏng đoán IRT(c): 0.00000
Các phương án: 1 2* 3 4
Số TS chọn: 12 505 14 3
Tỉ lệ TS chọn PA (%) 2.25 94.57 2.62 0.56
Tương quan điểm nhị phân: -0.26006 0.36163 -0.21388 -0.06084
Giá trị t: -6.21778 8.95488 -5.05476 -1.40728
Giá trị p: 0.00000 0.00000 0.00000 0.07996
==============================================================================
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
==============================================================================
Câu số: 33
Bỏ qua: 4
Độ phân biệt (cổ điển): -0.02088
Độ khó (cổ điển): 0.35782
Độ phân biệt IRT(a): 0.06749
Độ khó IRT(b): 4.71609
Độ phỏng đoán IRT(c): 0.00000
Các phương án: 1 2* 3 4
Số TS chọn: 48 190 197 96
Tỉ lệ TS chọn PA (%) 9.04 35.78 37.10 18.08
Tương quan điểm nhị phân: -0.04769 -0.02088 0.02567 0.09077
Giá trị t: -1.10236 -0.48221 0.59276 2.10425
Giá trị p: 0.13540 0.31492 0.27680 0.01791
==============================================================================
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
==============================================================================
Câu số: 40
Bỏ qua: 9
Độ phân biệt (cổ điển): 0.22769
Độ khó (cổ điển): 0.39164
Độ phân biệt IRT(a): 0.22300
Độ khó IRT(b): 1.24440
Độ phỏng đoán IRT(c): 0.00000
Các phương án: 1 2 3 4*
Số TS chọn: 113 96 111 206
Tỉ lệ TS chọn PA (%) 21.48 18.25 21.10 39.16
Tương quan điểm nhị phân: 0.08209 -0.11144 -0.12559 0.22769
Giá trị t: 1.90167 -2.58886 -2.92255 5.39838
Giá trị p: 0.02888 0.00495 0.00181 0.00000
======================================================================

155
Hình 8.4. ĐTCH và hàm thông tin của CH số 5 ĐTN VIỆT1
Hình 8.5. Đường cong đặc trưng của ĐTN VIỆT1 (đường cong điểm thực)
Đường cong điểm thực là một công cụ rất tốt để xem xét sự tương
ứng giữa điểm thực (trùng với điểm thô) với điểm năng lực. Chẳng hạn,
dựa vào điểm thô người ta xác định một điểm chuẩn nào đó (thường được
gọi là điểm cắt – cut-off score), thì đường cong điểm thực cho biết giá trị
của điểm năng lực θ tương ứng với điểm cắt đã cho.

156
Hàm thông tin của ĐTN cũng là một công cụ quan trọng để đánh
giá và thiết kế ĐTN. Trước hết, từ đường cong hàm thông tin của ĐTN
VIET1 có thể thấy đề này có khả năng đo chính xác nhất khoảng năng
lực dưới trung bình một chút của mẫu thử nghiệm. Người ta có thể thiết
kế một ĐTN sao cho nó có khả năng đo chính xác nhất một khoảng năng
lực nào đó, tức là sao cho hàm thông tin ĐTN có cực đại ở khoảng năng
lực muốn đo. Điều này rất quan trọng khi chúng ta muốn từ kết quả trắc
nghiệm ra quyết định tuyển hay không tuyển TS, cấp hay không cấp học
bổng cho TS đạt điểm năng lực ở phía trên và phía dưới ngưỡng năng lực
đó. Đường biểu diễn nằm bên dưới đường cong hàm thông tin của ĐTN
phản ánh sai số tiêu chuẩn của phép đo năng lực: rõ ràng nơi nào giá trị
thông tin lớn thì sai số tiêu chuẩn của phép đo bé.
Hình 8.6. Đường cong hàm thông tin và sai số tiêu chuẩn phép đo năng lực bằng ĐTN VIỆT1
Một loại thông tin lý thú mà phần mềm VITESTA cung cấp cho
từng TS là sơ đồ bài làm của họ. Hình 8.7 có dẫn minh họa sơ đồ bài làm
của TS số 8. Biểu đồ cho thấy mức năng lực của TS này là θ= 1,89790,
tức là vào loại khá. Nửa mặt phẳng bên trái chỉ các CH mà TS làm sai,
nửa mặt phẳng bên phải chỉ các CH mà TS làm đúng, vị trí của mỗi CH
xác định độ khó của CH, tăng dần từ dưới lên theo trục thẳng đứng. Khi
có sơ đồ đó mỗi TS có thể xem xét lại kết quả học tập của mình theo các
chủ đề tri thức ứng với từng CH.

157
Thông tin quan trọng cuối cùng mà kết quả phân tích cho ta là phần
trích số liệu về năng lực của TS ở Bảng 8.6. Từ Bảng 8.6 có thể thấy
điểm thô của từng TS (tổng số CH làm đúng), ước lượng năng lực θ và
điểm quy đổi theo thang điểm 10 tính từ điểm thực. Một chi tiết cần lưu ý
là đối với mô hình 2 và 3 tham số, không có sự tương ứng một-một giữa
điểm thô và điểm năng lực, tức là có thể có 2 TS có điểm thô như nhau
nhưng điểm năng lực tương ứng của họ khác nhau, còn đối với mô hình
Rasch 1 tham số có sự tương ứng một-một giữa điểm thô và điểm thực.
Có thể nói vì tính bất biến các điểm năng lực θ nên điểm năng lực (và các
điểm thu được nhờ chuyển đổi tuyến tính từ chúng) là ước lượng chính
xác nhất năng lực của TS.
Hình 8.7. Ví dụ về sơ đồ bài làm của một TS (TS thứ 8)
Cuối cùng, biểu đồ trên Hình 8.8 cho cảm nhận về tương quan
chung giữa độ khó của ĐTN và năng lực của mẫu TS thử nghiệm: nửa
mặt phẳng trên cho thấy phân bố các CH trong ĐTN từ dễ đến khó, nửa
mặt phẳng dưới cho thấy phân bố năng lực của TS từ thấp đến cao (theo
chiều từ phải sang trái), giá trị trung bình của năng lực của TS thấp hơn
giá trị trung bình của độ khó CH (được đặt bằng không) một lượng không
đáng kể, chỉ bằng -0,001. Như vậy ĐTN VIET1 là tương đối vừa sức đối
với mẫu thử nghiệm.

158
Bảng 8.6. Bảng trích điểm thô, ước lượng năng lực θ của TS và thang điểm 10 của TS làm ĐTN VIỆT1
+----------------------------------------------------------+
¦ STT¦ SBD ¦ Năng lực ¦Sai số TC ¦Đúng/Tổng¦Điểm10¦
+-----+------------+-----------+-----------+--------+------|
¦ 1 ¦ 1030103201 ¦ 0.89404 ¦ 0.42278 ¦ 30/40 ¦ 7.51|
¦ 2 ¦ 1030103203 ¦ 2.78267 ¦ 0.61045 ¦ 38/40 ¦ 8.94|
¦ 3 ¦ 1030103205 ¦ 0.20338 ¦ 0.37424 ¦ 27/38 ¦ 6.41|
¦ 4 ¦ 1030103207 ¦ 0.22792 ¦ 0.37559 ¦ 25/39 ¦ 6.46|
¦ 5 ¦ 1030103209 ¦ 1.64722 ¦ 0.49206 ¦ 33/40 ¦ 8.28|
¦ 6 ¦ 1030103212 ¦ -0.47705 ¦ 0.35168 ¦ 20/40 ¦ 4.95|
¦ 7 ¦ 1030103214 ¦ 1.81747 ¦ 0.50918 ¦ 34/40 ¦ 8.42|
¦ 8 ¦ 1030103216 ¦ 1.89790 ¦ 0.51740 ¦ 34/40 ¦ 8.47|
¦ 9 ¦ 1030103218 ¦ 0.90688 ¦ 0.42385 ¦ 32/40 ¦ 7.52|
¦ 10 ¦ 1030103220 ¦ 0.80907 ¦ 0.41583 ¦ 30/40 ¦ 7.39|
¦ 11 ¦ 1030103222 ¦ 1.11364 ¦ 0.44166 ¦ 31/40 ¦ 7.77|
¦ 12 ¦ 1030103224 ¦ 1.18278 ¦ 0.44786 ¦ 31/40 ¦ 7.85|
¦ 13 ¦ 1030103226 ¦ 0.90424 ¦ 0.42363 ¦ 29/40 ¦ 7.52|
¦ 14 ¦ 1030103228 ¦ 0.64816 ¦ 0.40333 ¦ 30/39 ¦ 7.16|
¦ 15 ¦ 1030103230 ¦ 0.88959 ¦ 0.42241 ¦ 29/40 ¦ 7.50|
.....................................
.....................................
¦ 527 ¦ 8251703213 ¦ 0.26745 ¦ 0.37784 ¦ 25/39 ¦ 6.53|
¦ 528 ¦ 8251703215 ¦ -0.38576 ¦ 0.35285 ¦ 19/40 ¦ 5.16|
¦ 529 ¦ 8251703217 ¦ -0.74839 ¦ 0.35205 ¦ 16/40 ¦ 4.30|
¦ 530 ¦ 8251703219 ¦ -1.23353 ¦ 0.36880 ¦ 14/40 ¦ 3.15|
¦ 531 ¦ 8251703221 ¦ -0.17370 ¦ 0.35791 ¦ 24/40 ¦ 5.64|
¦ 532 ¦ 8251703223 ¦ -0.09295 ¦ 0.36065 ¦ 24/40 ¦ 5.81|
¦ 533 ¦ 8251703225 ¦ 0.26670 ¦ 0.37780 ¦ 25/40 ¦ 6.53|
¦ 534 ¦ 8251703227 ¦ -0.84373 ¦ 0.35363 ¦ 15/39 ¦ 4.06|
¦ 535 ¦ 8251703229 ¦ 0.03345 ¦ 0.36579 ¦ 25/40 ¦ 6.08|
+--------------------------------------------------------------------|
Hình 8.8. Biểu đồ tương quan giữa năng lực của TS và độ khó của ĐTN VIỆT1

159
CÂU HỎI TỰ KIỂM TRA
1. Xây dựng hàm biến cố hợp lý để ước lượng năng lực TS.
2. Trình bày phương pháp xấp xỉ giải phương trình f(x)=0 của
Newton-Raphson.
3. Mô tả một bước tính lặp để xác định giá trị năng lực .
4. Quy tắc ước lượng đồng thời năng lực TS và tham số các CH
trắc nghiệm.
5. Tính bất biến của năng lực TS đối với các CH dùng để ước lượng.
BÀI TẬP
1. Đối với ĐTN gồm 5 CH cho ở Bảng 8.1, vectơ trả lời của một
TS là (1,0,1,0,0):
Xác định hàm biến cố hợp lý ứng với TS đó. Nêu giả thiết cần tuân
theo để thiết lập được hàm đó.
Vẽ đồ thị biểu diễn hàm biến cố hợp lý cực đại lnL (có thể dùng
phần mềm tính toán, chẳng hạn, MAPLE). Dựa trên đồ thị xác định ước
lượng của θ khi hàm biến cố hợp lý đạt cực đại.
2. Các tham số của 4 CH thu được khi sử dụng mô hình 2 tham số
được cho ở Bảng 8.7. Giá trị ước lượng năng lực θ của một TS khi hàm
biến cố hợp lý đạt cực đại là 1,5.
Bảng 8.7.
CH b a
1 0,0 1,0
2 1,0 1,0
3 1,0 2,0
4 1,5 2,0
Hãy xác định sai số tiêu chuẩn của giá trị ước lượng được (lưu ý số
liệu được tính cần phù hợp với các biểu thức dạng tích lũy vòm chuẩn,
tức là a được nhân cho hệ số D – xem 4.2.1 chương 4).

160
Thiết lập khoảng tin cậy 95% đối với θ.
3. Có 3 TS với các giá trị năng lực là θ = -1, 0, 1. Ứng đáp của 3 TS
đó đối với một CH tương ứng là 0, 0, 1. Giả sử mô hình một tham số với
giá trị b (chưa biết) là phù hợp với CH.
a) Hãy lập hàm biến cố hợp lý liên quan với giá trị b chưa biết và
nêu giả thiết cần tuân theo.
b) Tính hàm biến cố hợp lý với giá trị b biến đổi từ 0 đến 1 với
bước là 0,1. Dựa trên bảng tính xác định ước lượng của b làm cho hàm
biến cố hợp lý đạt cực đại.
4. a) Đối với mô hình một tham số, hãy viết biểu thức hàm thông
tin và sai số tiêu chuẩn khi ước lượng độ khó của CH.
b) Tính sai số tiêu chuẩn của giá trị ước lượng độ khó cho số liệu cho ở
bài tập.
______________________________

161
Chương 9
ĐÁNH GIÁ SỰ PHÙ HỢP GIỮA SỐ LIỆU VÀ MÔ HÌNH
IRT là một lý thuyết có tác dụng lớn để giải quyết nhiều bài toán về
đánh giá trong giáo dục. Đặc trưng hết sức quan trọng của IRT là giải
thoát sự phụ thuộc của việc xác định tham số của CH vào mẫu thử và giải
thoát sự phụ thuộc của việc đo lường năng lực vào các ĐTN cụ thể, nói
cách khác, đối với IRT giá trị các tham số của CH và năng lực của TS là các
bất biến đối với phép đo.
Tuy nhiên chỉ riêng việc xử lý số liệu trắc nghiệm nhờ các phần
mềm xây dựng theo IRT chưa đảm bảo cho sự thành công của việc áp
dụng IRT. Tính ưu việt của IRT chỉ có thể thu được khi sự trùng khớp
giữa mô hình và số liệu trắc nghiệm được thỏa mãn. Nếu không thỏa mãn
sự trùng khớp đó thì tính bất biến của tham số CH và năng lực TS cũng
không tồn tại.
Chương này dành để trình bày một số phương pháp đánh giá sự
phù hợp giữa số liệu thu được qua trắc nghiệm và mô hình các đường
cong ĐTCH được chọn để phân tích số liệu.
9.1. CÁC PHƯƠNG PHÁP ĐÁNH GIÁ SỰ PHÙ HỢP GIỮA SỐ LIỆU VÀ
MÔ HÌNH
Có nhiều cách đánh giá sự phù hợp giữa số liệu và mô hình để chọn
mô hình IRT thích hợp. Hambleton và Swaminathan [11] đã có các đề
xuất tương đối tổng quát để thực hiện các đánh giá trên, dựa trên ba loại
chứng cứ sau đây:

162
1) Tính hiệu lực của các giả định về mô hình đối với số liệu trắc
nghiệm;
2) Mức độ đạt được các đặc tính quan trọng của mô hình (cụ thể là
tính bất biến của các tham số của CH và của năng lực);
3) Độ chính xác của mô hình dự báo so với số liệu trắc nghiệm.
9.1.1. Đảm bảo tính đơn chiều
Hai giả định chung quan trọng đối với tất cả các mô hình là tính
đơn chiều và yêu cầu trắc nghiệm không phải là trắc nghiệm tốc độ (tức
là phải đủ thời gian để TS làm trắc nghiệm). Người ta có thể chứng minh
rằng trắc nghiệm tốc độ sẽ dẫn đến tính đa chiều. Đối với mô hình hai
tham số phải chứng tỏ rằng khả năng đoán mò là không đáng kể. Còn đối
với mô hình một tham số phải đảm bảo chỉ số độ phân biệt sẽ như nhau
đối với mỗi CH. Khảo sát thống kê chi tiết về tính đơn chiều hơi phức tạp
nên sẽ không trình bày ở đây, tuy nhiên khi viết các CH trắc nghiệm phải
cố gắng đảm bảo tính chất này.
9.1.2. Kiểm tra tính bất biến
Tính bất biến của các tham số mô hình có thể đánh giá bằng các
phương pháp trực tiếp. Tính bất biến của tham số năng lực có thể nghiên
cứu bằng cách cho TS làm hai ĐTN, trong mỗi đề tham số độ khó của
các CH biến đổi trong một dải rộng. Các ĐTN được xây dựng từ một kho
CH chung mà nhờ đó năng lực TS được xác định. Người ta thường tiến
hành nghiên cứu bằng cách dùng hai ĐTN con từ một ĐTN. Với mỗi TS
một ĐTN con sẽ cho một giá trị năng lực, cặp giá trị năng lực đó được
biểu diễn trên cùng một đồ thị. Các điểm trên đồ thị ứng với tập hợp TS
sẽ xác định một đường thẳng với hệ số góc bằng 1 vì giá trị năng lực
mong đợi đối với mỗi TS không phụ thuộc vào việc chọn các CH trắc
nghiệm. Sẽ có một số điểm nằm phân tán ngoài đường thẳng vì sai số đo
lường. Khi không thu được một quan hệ tuyến tính với độ dốc bằng 1 và
điểm cắt bằng 0, hoặc khi sự phân tán vượt sai số tiêu chuẩn chờ đợi của
việc xác định năng lực thì một trong các giả định cơ bản của mô hình ứng
đáp CH có thể không được thỏa mãn.

163
9.1.3. Kiểm tra các dự đoán mô hình
Một trong các phương pháp để kiểm nghiệm mô hình dự đoán là
phương pháp thặng dư. Khi một mô hình ứng đáp CH đã được chọn, các
tham số của CH và năng lực được ước lượng, các giá trị kỳ vọng xác suất
ứng đáp đúng CH của các nhóm năng lực khác nhau được tính toán để
xem xét sự phù hợp của mô hình đã chọn. Sau đó kết quả kỳ vọng được
so sánh với kết quả thực tế.
Độ thặng dư rij là mức chênh giữa xác suất ứng đáp CH của nhóm
con TS và giá trị kỳ vọng của xác suất ứng đáp CH của nhóm TS đó:
rij = Pij - E(Pij), (9.1)
trong đó i là chỉ số của CH, j là chỉ số của nhóm con TS, Pij là tỷ lệ
ứng đáp đúng CHi của nhóm TS thứ j, còn E(Pij) là tỷ lệ kỳ vọng của ứng
đáp đúng CH thu được bằng cách dùng mô hình ứng đáp CH giả định
(xem chương 5). Các tham số của mô hình giả định được ước lượng, và
dùng các giá trị ước lượng đó để tính xác suất ứng đáp đúng CH, xác suất
đó được lấy xem như tỷ lệ trả lời đúng kỳ vọng của nhóm TS.
Trong thực tế thang năng lực thường được chia thành các khoảng
có độ rộng như nhau để tính thặng dư. Các khoảng phải đủ rộng sao cho
số lượng TS trong mỗi khoảng không quá bé để các số liệu thống kê ổn
định, đồng thời cũng phải đủ hẹp để số TS trong mỗi khoảng là đồng nhất
về năng lực. Người ta có thể lấy giá trị ở điểm giữa mỗi khoảng làm đại
diện để tính xác suất ứng đáp đúng CH và lấy giá trị đó là giá trị kỳ vọng,
hoặc tính xác suất ứng đáp đúng CH của mọi TS ở trong cùng nhóm năng
lực và lấy giá trị trung bình để làm giá trị kỳ vọng.
Một nhược điểm của độ thặng dư tính theo (9.1) là không xét đến
sai số lấy mẫu liên quan với tỷ lệ kỳ vọng của điểm ứng đáp đúng trong
một nhóm năng lực. Để khắc phục nhược điểm đó người ta sử dụng giá
trị thặng dư tiêu chuẩn hóa bằng cách chia vế phải của (9.1) với sai số tiêu
chuẩn của tỷ lệ ứng đáp đúng kỳ vọng:
ij ij
ij ij j
P -E(P ),
E(P ) 1-E(P ) /N
(9.2)
Zij =

164
trong đó Nj là số TS trong nhóm năng lực j.
Khi chọn một mô hình IRT việc nghiên cứu các giá trị thặng dư hoặc
thặng dư tiêu chuẩn hóa đối với một vài mô hình khác nhau sẽ rất có ích.
Các kiểm nghiệm Chi-bình phương (χ2) thông thường trong thống
kê cũng được sử dụng để xác định sự phù hợp của mô hình. Yen [14] đã
sử dụng một đặc trưng thống kê cải tiến từ Chi-bình phương là đặc trưng Q1
đối với CH thứ i như sau:
ij
2m
j ij
li
j=1 ij ij
N P -E(P )Q
E(P ) 1-E(P )
m
2ij
j=1
z , (9.3)
trong đó TS được chia thành m nhóm năng lực trên cơ sở ước lượng
năng lực của chúng, các ký hiệu khác tương tự như đã giải thích ở (9.1).
Q1 cũng có phân bố như Chi-bình phương với mức độ tự do bằng (m-k),
trong đó k là số tham số trong mô hình IRT. Nếu các giá trị quan sát
được vượt một giá trị tiêu chuẩn (thu được từ bảng χ2) thì giả thiết H0 về
đường cong ĐTCH phù hợp với số liệu thực nghiệm bị bác bỏ và cần phải
tìm một mô hình khác phù hợp tốt hơn.
9.2. VÍ DỤ VỀ ĐÁNH GIÁ SỰ PHÙ HỢP GIỮA SỐ LIỆU VÀ MÔ HÌNH
Để hình dung được mức độ phù hợp giữa số liệu với mô hình và
tính bất biến của tham số CH và năng lực TS, chúng ta sẽ tạm mượn ví
dụ trích từ [11] của Hambleton xét kết quả của một ĐTN 75 CH thực
hiện trên 2000 TS.
9.2.1. Kiểm tra tính bất biến của tham số CH đối với các mẫu TS
khác nhau
Trước hết ta thử nghiệm chia tổng thể TS thành 2 mẫu một cách
ngẫu nhiên, tức là 2 mẫu TS tương đương với nhau về phân bố năng lực.
Chọn hệ tọa độ có 2 trục đều chia độ theo thang logit để biểu diễn tham
số độ khó của CH. Mỗi một CH có 2 giá trị tham số độ khó b được ước
lượng bởi mẫu TS 1 và mẫu TS 2, giá trị b ước lượng theo mẫu TS 1
được biểu diễn theo trục hoành, giá trị b ước lượng theo mẫu TS 2 được
biểu diễn theo trục tung. Như vậy 2 giá trị b của mỗi CH xác định một

165
điểm trên mặt phẳng, và 75 CH cho 75 điểm trên biểu đồ. Biểu đồ thu
được trên Hình 9.1 cho thấy các điểm biểu diễn giá trị b nằm lân cận
đường phân giác của góc lập bởi trục tung và trục hoành với mức độ
phân tán thấp, điều đó chứng tỏ tính bất biến của tham số biểu diễn độ
khó b đối với hai mẫu TS đã chọn.
Tiếp đến ta thử nghiệm chia tổng thể TS thành 2 mẫu có phân bố
năng lực khác nhau, một mẫu gồm nửa số TS có năng lực thấp và một
mẫu gồm nửa số TS có năng lực cao. Lại ước lượng tham số độ khó b
theo từng mẫu, và biểu diễn tham số độ khó b được ước lượng bởi mẫu
TS năng lực cao theo trục hoành, tham số độ khó b được ước lượng bởi
mẫu TS năng lực thấp theo trục tung. Biểu đồ thu được trên Hình 9.2 cho
thấy đồ thị rải phân tán có hình như quả tạ tay: phần giữa trùng tốt với
đường phân giác nhưng hai phía ứng với giá trị độ khó cao và thấp mức
độ phân tán lớn hơn. Sự phân tán ở hai đầu có thể được giải thích như
sau: dùng mẫu TS năng lực thấp ước lượng tham số của CH có độ khó
lớn sẽ kém chính xác, và cũng như vậy khi dùng mẫu TS năng lực cao
ước lượng tham số của các CH có độ khó bé. Qua nhận xét trên có thể rút
ra kết luận là muốn ước lượng tham số CH chính xác mẫu TS phải có
phân bố năng lực rải đều từ thấp đến cao.
Hình 9.1. (vẽ lại H 5.8) Biểu đồ phân bố các điểm biểu diễn độ khó ước lượng theo hai mẫu TS có năng lực tương đương (chia mẫu ngẫu nhiên)

166
Hình 9.2 Biểu đồ phân bố các điểm biểu diễn độ khó ước lượng theo hai mẫu TS có năng lực cao và năng lực thấp
9.2.2. Kiểm tra tính bất biến của năng lực TS đối với các ĐTN khác nhau
Cũng có thể sử dụng số liệu trắc nghiệm nói trên để thử khảo sát
tính bất biến của năng lực TS được ước lượng bằng các ĐTN khác nhau.
Cách thứ nhất là chia ĐTN theo cách ngẫu nhiên thành 2 ĐTN
con có độ khó tương đương với nhau, chẳng hạn một đề gồm các câu lẻ,
đề kia gồm các câu chẵn. Dùng mỗi một trong 2 đề nói trên để ước
lượng năng lực của các TS. Chọn hệ tọa độ có 2 trục đều chia độ theo
thang logit để biểu diễn năng lực TS. Mỗi TS có 2 giá trị năng lực được
ước lượng tương ứng nhờ ĐTN1 và ĐTN2. Năng lực ước lượng theo
ĐTN1 được biểu diễn theo trục hoành, năng lực ước lượng theo ĐTN2
được biểu diễn theo trục tung, vậy mỗi TS được thể hiện bởi một điểm
trên mặt phẳng. Biểu đồ thu được trên Hình 9.3 cho thấy các điểm biểu
diễn năng lực TS nằm lân cận đường phân giác nhưng tập trung hơn ở
phần giữa và phân tán hơn ở hai đầu. Điều đó chứng tỏ việc ước lượng
năng lực sẽ chính xác hơn ở khoảng năng lực trong bình so với năng lực
cao và thấp.
Cách thứ hai là chia ĐTN thành 2 ĐTN con nhưng một đề gồm các
CH khó hơn và một đề gồm các CH dễ hơn. Một TS có 2 năng lực được
ước lượng tương ứng bằng ĐTN dễ hơn và ĐTN khó hơn, hai năng lực đó
cũng tạo thành một điểm trên mặt phẳng. Hình 9.4 cũng cho thấy các điểm

167
biểu diễn năng lực TS nằm lân cận đường phân giác nhưng tập trung hơn ở
phần giữa và phân tán hơn ở hai đầu. Điều đó cũng chứng tỏ việc ước
lượng năng lực sẽ chính xác hơn ở khoảng năng lực trung bình so với năng
lực cao và thấp, nhưng sai số ước lượng còn lớn hơn khi ước lượng năng
lực thấp bằng ĐTN khó và ước lượng năng lực cao bằng ĐTN dễ.
Hình 9.3. Biểu đồ phân bố các điểm biểu diễn năng lực θ ước lượng theo ĐTN có độ khó tương đương
Hình 9.4. Biểu đồ phân bố các điểm biểu diễn năng lực θ ước lượng theo hai ĐTN có độ khó khác nhau

168
Tóm lại, qua việc khảo sát tính bất biến của các tham số CH trắc
nghiệm đối với các mẫu TS và tính bất biến của tham số năng lực TS đối
với các ĐTN khác nhau có thể thấy rằng để tăng độ chính xác cho việc
định cỡ ĐTN cần có các ĐTN với các CH có độ khó rải đều và cần các
mẫu TS với sự phân bố năng lực theo dải rộng.
9.2.3. Đánh giá sự phù hợp giữa số liệu thực nghiệm và mô hình qua
giá trị thặng dư tiêu chuẩn hóa
Có thể sử dụng giá trị thặng dư tiêu chuẩn hóa tính theo biểu thức
(9.2) để đánh giá sự phù hợp giữa số liệu thực nghiệm và mô hình. Muốn
vậy, chia khoảng [-3, 3] logit ra làm 12 đoạn bằng nhau, mỗi đoạn chọn
điểm θ ở giữa làm điểm tựa để tính toán. Chọn một CH nào đó trong
ĐTN đã cho, chẳng hạn CH6, tính đường cong ĐTCH kỳ vọng theo mô
hình Rasch ứng với CH đó và biểu diễn giá trị trung bình của tỷ lệ ứng
đáp đúng CH lên đồ thị (Hình 9.5).
Liên quan với Hình 9.5 là các giá trị thặng dư chuẩn hóa dọc theo
đường cong ĐTCH biểu diễn trên Hình 9.6. Qua các đồ thị nêu trên có
thể thấy giữa số liệu và mô hình chưa có sự trùng khớp tốt.
Hình 9.5. Đường cong đặc trưng kỳ vọng P(θ) của CH6 và các giá trị trung bình thực nghiệm

169
Hình 9.6. Giá trị thặng dư chuẩn hóa của đường cong đặc trưng của CH6
CÂU HỎI TỰ KIỂM TRA
1. Quan hệ giữa sự trùng hợp giữa số liệu với mô hình và tính bất
biến của năng lực TS và tham số CH đối với các phép đo lường?
2. Cho vài ví dụ về sự vi phạm tính đơn chiều của CH trắc nghiệm.
3. Nêu cách xây dựng các biểu đồ trên các hình 9.1 – 9.4 và giải
thích các kết quả.
4. Nêu các điều kiện về số liệu mẫu TS và ĐTN để thu được kết
quả định cỡ ít sai lệch.
BÀI TẬP
1. Giả sử mô hình 3 tham số phù hợp với bộ dữ liệu trắc nghiệm. Giá
trị ước lượng cho một CH cụ thể là a =1,23; b = 0,76; c =0,25. Để đánh giá
sự phù hợp của mô hình đối với CH đã cho, người ta chia TS ra làm 5
nhóm năng lực dựa trên mức năng lực ước lượng được của chúng, mỗi
nhóm gồm 20 TS. Ứng đáp CH của các TS được trình bày ở Bảng 7.1.

170
a) Tính tỷ số TS trả lời đúng ở mỗi mức năng lực.
b) Tính xác suất trả lời đúng ở mỗi mức năng lực (dùng tham số
của đường cong ĐTCH ước lượng được).
c) Tính đặc trưng thống kê độ phù hợp Q1 đối với CH đó. Độ tự do
đối với kiểm nghiệm Chi-bình phương đối với trường hợp này là bao nhiêu?
d) Mô hình 3 tham số có phù hợp với số liệu của CH đã cho hay không?
Bảng 7.1.
Mức θ Các ứng đáp đối với CH
-2,0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1
-1,0 0 1 0 1 0 0 1 0 0 0 0 1 0 0 0 1 0 0 0 0
0,0 1 0 0 0 1 1 0 0 0 0 1 0 0 1 0 0 1 0 1 1
1,0 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 0 1 0 1
2,0 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 1
2. Giả sử mô hình 2 và 3 tham số cũng phù hợp với số liệu. Giá trị
ước lượng các tham số CH như sau:
a. Đối với mô hình 1 tham số: b=0,17;
b. Đối với mô hình 2 tham số: b=0,18; a=0,56.
c. Tính đặc trưng thống kê độ phù hợp Q1 để đánh giá độ phù hợp
của mô hình 1 và 2 tham số (cũng theo các năng lực như ở Bảng 7.1);
d. Mô hình 1 và 2 tham số có phù hợp với số liệu không?
e. Mô hình nào là thích hợp nhất đối với số liệu đã cho?

171
Chương 10
THIẾT KẾ CÁC ĐỀ TRẮC NGHIỆM
Thiết kế ĐTN là yêu cầu thực tiễn quan trọng hàng đầu của mọi lý
thuyết trắc nghiệm. Chương này dành để mô tả các cách tiếp cận để thiết
kế ĐTN, xuất phát từ việc so sánh CTT và IRT trong bài toán này, tiếp
đến trình bày quy trình cơ bản để thiết kế ĐTN theo IRT. Các loại ĐTN
phổ biến và cách thiết kế chúng từ các CH trong một NHCH trắc nghiệm
cũng được nêu ra.
10.1. SO SÁNH CTT VÀ IRT TRONG VIỆC THIẾT KẾ CÁC ĐỀ TRẮC NGHIỆM
Đối với CTT, để thiết kế một ĐTN thành quả học tập hoặc năng
lực, người ta chọn các CH theo nội dung và các đặc trưng của chúng - độ
khó và độ phân biệt. Độ phân biệt thường càng cao càng tốt, còn độ khó
được chọn ở mức độ thích hợp tùy theo mục tiêu của ĐTN và phân bố
năng lực dự đoán của nhóm TS là đối tượng dự định trắc nghiệm.
Tuy nhiên, như đã biết, theo CTT, các tham số CH không phải là
các bất biến đối với tổng thể TS mà người ta muốn xác định năng lực. Do
đó kết quả của kỹ thuật lựa chọn cổ điển phụ thuộc vào mức độ tương
đồng của nhóm TS được dùng để xác định các tham số của CH so với
nhóm TS mà ĐTN muốn đánh giá. Khi mức tương đồng kém thì các
tham số thu được sẽ không phù hợp với nhóm TS dự định đánh giá.
Trong thực tế đôi khi nhóm TS mà từ đó nhận được các tham số của CH
khác rất xa với nhóm TS dự định đánh giá.
Nhược điểm về sự không bất biến của các tham số CH theo CTT
gây khó khăn cho việc xây dựng một NHCH có chất lượng, vì nhiều
tham số của CH không thể so sánh với nhau. Ngoài ra, một nhược điểm

172
khác của CTT là, ngay cả khi có một NHCH tốt, không thể chọn các CH
để sinh ra được một ĐTN đáp ứng các đặc trưng cố định liên quan đến độ
chính xác của phép đo. Đóng góp của một CH của ĐTN không phụ thuộc
vào riêng biệt các đặc trưng của CH đó, mà còn phụ thuộc vào mối quan
hệ giữa nó và các CH khác trong ĐTN.
IRT cung cấp một phương pháp có hiệu quả hơn nhiều để lựa chọn
CH so với CTT. Tính bất biến của các tham số của CH xác định theo IRT
khắc phục được nhược điểm của NHCH trong CTT đã nói trên đây. Hơn
nữa, độ khó của CH và năng lực của TS được biểu diễn trên cùng một
thang đo tạo khả năng lựa chọn các CH có tác dụng tốt nhất ở các vùng
xác định của thang năng lực, chẳng hạn ở vùng điểm-cắt (cut-off score)
để phân biệt TS đạt và không đạt tiêu chuẩn lựa chọn. Ưu thế quan trọng
nhất của IRT là nó cho phép lựa chọn các CH dựa trên lượng thông tin
mà các CH đóng góp vào khối lượng thông tin tổng cộng cần thiết của
ĐTN để đáp ứng các đặc trưng của ĐTN. Vì thông tin liên quan đến độ
chính xác của phép đo nên cần chọn các CH tạo nên một ĐTN cho độ
chính xác đo lường mong muốn ở mức năng lực xác định nào đó, chẳng
hạn ở vùng điểm cắt.
10.2. CÁCH TIẾP CẬN CƠ BẢN ĐỂ THIẾT KẾ ĐỀ TRẮC NGHIỆM
Hiện nay, khi đồng thời tồn tại cả CTT và IRT, đôi khi người ta
thiết kế ĐTN dựa vào các nguyên lý của CTT, nhưng lại phân tích kết
quả theo IRT. Cách thao tác như vậy làm hạn chế sức mạnh và ưu điểm
của IRT. Để phát huy hết ưu điểm của IRT, các ĐTN nên được thiết kế
và phân tích cùng dựa trên lý thuyết đó.
Để thực hiện được điều nói trên, trước hết cần có một bộ sưu tập
CH tốt để đo một loại năng lực nào đó. Trong phạm vi của IRT, có một
hệ thống quy trình cần được sử dụng để thiết lập và bảo trì bộ sưu tập CH
đó, được gọi là quy trình xây dựng NHCH trắc nghiệm (item banking).
Mục tiêu quan trọng của quy trình này là có được một NHCH trong đó
các giá trị của các tham số CH được biểu diễn trên một thang đo năng lực
đã biết. Khi đã có ngân hàng đó, có thể chọn các CH từ ngân hàng để
thiết kế một ĐTN và xác định được các đặc trưng kỹ thuật chính của ĐTN

173
trước khi cho một nhóm TS nào đó làm ĐTN. Nếu các đặc trưng của ĐTN
không đáp ứng các mục tiêu thiết kế, có thể thay các CH đã được chọn
bằng CH khác từ NHCH cho đến khi thu được các đặc trưng của ĐTN như
mong muốn. Cách thiết kế ĐTN như vậy tiết kiệm rất nhiều thời gian và
tiền bạc vì không phải triển khai trắc nghiệm thử nhiều lần.
Để xây dựng được một NHCH trước hết phải xác định các năng lực
tiềm ẩn cần đo, chế tác các CH để đo năng lực tiềm ẩn đó, thử nghiệm
các CH nhằm loại bỏ các CH chất lượng kém. Sau một thời gian sẽ thu
được một kho lớn các CH để đo năng lực tiềm ẩn đã định. Kho CH lớn
đó sẽ được trắc nghiệm trên các mẫu TS. Một mô hình đường cong
ĐTCH được chọn, số liệu ứng đáp CH của TS được phân tích theo mô
hình Birnbaum và các ĐTN được định cỡ. Thang năng lực sinh ra từ quá
trình định cỡ đó được xem là metric cơ sở của ngân hàng CH. Theo quan
điểm thiết kế ĐTN, kết quả quá trình mô tả trên đây cho chúng ta một
kho CH đã được định cỡ sẵn, tức là một NHCH trắc nghiệm.
Vì các CH trong NHCH đã định cỡ nhằm đo một năng lực tiềm ẩn
nào đó, ĐTN được thiết kế từ ngân hàng ấy cũng nhằm đo năng lực đó.
Từ NHCH người ta lựa chọn các CH trên cơ sở nội dung và các tham số
đặc trưng để đáp ứng các mục tiêu trắc nghiệm xác định. Ưu việt của
NHCH đã được định cỡ là từ các tham số đã biết của các CH trong ngân
hàng có thể tính đường cong đặc trưng của ĐTN và hàm thông tin trước
khi thực hiện trắc nghiệm. Có thể làm như vậy vì các đường cong này
không phụ thuộc vào phân bố năng lực của TS dọc theo thang đo năng
lực, và có thể tính được chúng ngay khi biết các tham số của các CH.
Nhờ vậy người thiết kế ĐTN có thể biết trước ĐTN sẽ được làm như thế
nào trước khi trao nó cho TS thực hiện. Hơn nữa, như sẽ thấy sau này,
sau khi ĐTN được thực hiện và định cỡ, quá trình so bằng ĐTN có thể
được dùng để biểu diễn các ước lượng năng lực của nhóm TS mới trên
metric của NHCH.
Lord [5] đã đề xuất một quy trình sử dụng các hàm thông tin để
thiết kế các ĐTN đáp ứng bất kỳ yêu cầu mong muốn nào của đặc trưng
ĐTN. Quy trình dựa trên việc khai thác một NHCH sẵn có các giá trị
tham số CH được ước lượng theo một mô hình IRT đã chọn.

174
Các bước của quy trình được đề nghị như sau:
1. Quyết định về hình dáng muốn có của hàm thông tin ĐTN. Lord
gọi đó là hàm thông tin mục tiêu.
2. Chọn các CH từ ngân hàng có các hàm thông tin CH sẽ phủ kín
các vùng năng lực của hàm thông tin mục tiêu.
3. Sau khi mỗi CH được đưa vào ĐTN, tính hàm thông tin của
ĐTN bao gồm các CH đã lựa chọn.
4. Tiếp tục thay thế và lựa chọn các CH để đưa vào ĐTN cho đến
khi hàm thông tin của ĐTN tiệm cận với hàm thông tin mục tiêu ở mức
độ chấp nhận được.
Các bước trên đây thường được thực hiện dựa vào khuôn khổ các
đặc trưng nội dung của ĐTN.
10.3. MỘT SỐ LOẠI ĐỀ TRẮC NGHIỆM VÀ CÁCH THIẾT KẾ
Thông thường có thể phân chia 3 loại ĐTN như sau:
1) ĐTN để sàng lọc: Các ĐTN để sàng lọc phải có khả năng phân
tách rõ rệt giữa các TS có năng lực thấp hơn một mức nào đó và các TS
có năng lực cao hơn mức ấy. Các trắc nghiệm loại này được sử dụng để
cấp học bổng hoặc để tuyển TS vào học một chương trình nào đó.
2) ĐTN dải rộng: Các ĐTN này được sử dụng để đo năng lực trên
một dải rộng của thang năng lực. Mục đích quan trọng của loại đề này là
có thể đưa ra một tuyên bố về năng lực của TS và so sánh giữa các TS
với nhau.
3) ĐTN (mà hàm thông tin) có đỉnh hẹp: Các ĐTN loại này được
thiết kế để đo chính xác năng lực ở một vùng nào đó của thang năng lực,
nơi tập trung phần lớn năng lực của TS, và không cần đo chính xác năng
lực ở ngoài vùng ấy.
Trong 3 loại trắc nghiệm nêu trên loại ĐTN để sàng lọc có dải đo
năng lực hẹp nhất, loại ĐTN dải rộng có dải đo năng lực rộng nhất, còn
loại ĐTN đỉnh hẹp có dải đo năng lực ở mức trung bình.

175
Việc thiết kế các loại ĐTN nêu trên cần các lưu ý như sau.
- Đối với loại ĐTN để sàng lọc: Cần đặt điểm nằm giữa thang điểm
thực của đường cong đặc trưng ĐTN mong muốn ứng với mức năng lực
của điểm cắt. Đường cong hàm thông tin ĐTN cần có đỉnh cực đại nhọn
nằm trên điểm cắt. Các giá trị tham số b của các đường cong ĐTCH nên
sắp xếp ở lân cận điểm cắt mong muốn. Các CH tối ưu là CH có độ khó
nằm đúng ở điểm cắt và có độ phân biệt đủ lớn.
- Đối với loại ĐTN dải rộng: Cần đặt điểm nằm giữa thang điểm
thực của đường cong đặc trưng ĐTN mong muốn ứng với khoảng giữa
của dải năng lực muốn đo, và đường đặc trưng ĐTN trên dải năng lực đó
có dạng gần đường thẳng. Đường cong hàm thông tin ĐTN cần có dạng
mở rộng, và giá trị thông tin càng cao càng tốt. Các giá trị tham số b của
các đường cong ĐTCH nên trải rộng khắp dải năng lực.
- Đối với loại ĐTN mà hàm thông tin có đỉnh hẹp: Cần đặt điểm
nằm giữa thang điểm thực của đường cong đặc trưng ĐTN mong muốn
ứng với điểm giữa của dải năng lực muốn đo, và đường cong đặc trưng
ĐTN có độ nghiêng vừa phải ở vùng đó. Vùng cực đại của đường cong
hàm thông tin ĐTN cũng cần đặt ở vùng năng lực đó và cần có dạng
cong đều đặn. Các giá trị tham số b của các đường cong ĐTCH nên phân
bố quanh điểm giữa của dải năng lực muốn đo nhưng không quá tập
trung như trường hợp ĐTN để sàng lọc. Các CH cần có các giá trị tham
số a phân bố rộng, CH nằm trong vùng năng lực quan tâm cần có giá trị a
lớn hơn các CH nằm ở ngoài vùng đó.
10.4. ẢNH HƯỞNG CỦA MÔ HÌNH ĐƯỜNG CONG ĐTCH
VÀ SỐ LƯỢNG CÂU HỎI LÊN ĐỀ TRẮC NGHIỆM
Đối với mô hình Rasch, vì a=1 nên giá trị cực đại của hàm thông
tin CH đều bằng 0,25 và cực đại của hàm thông tin của ĐTN bằng n/4
[vì khi P=0,5 thì PQ=0,25 trong biểu thức (7.4).
- Vì có tham số đoán mò c nên mô hình 3 tham số sẽ tạo nên đường
cong đặc trưng ĐTN có dạng tuyến tính hơn và hàm thông tin ĐTN có
giá trị thấp hơn so với các đường cong tương ứng tạo thành từ tập hợp
CH có b và a như nhau: hàm thông tin của mô hình 2 tham số là hình bao

176
bên dưới của hàm thông tin của mô hình 3 tham số. Để thu được các đặc
trưng ĐTN tốt nhiều người thích chọn mô hình hai tham số hơn các mô
hình khác.
- Việc tăng số lượng CH ảnh hưởng ít lên đường cong đặc trưng
ĐTN nhưng tác động mạnh lên biên độ hàm thông tin của ĐTN. Do đó
phương án tối ưu là ĐTN có nhiều CH với các giá trị a lớn và có phân bố
giá trị b phù hợp với mục tiêu trắc nghiệm.
- Việc xem xét đồng thời các tham số liên quan đến độ khó và độ
phân biệt là rất quan trọng. Chẳng hạn, chọn một CH có độ phân biệt a
lớn nhưng độ khó b không nằm trong vùng năng lực muốn đo thì chẳng
có lợi gì cho hàm thông tin và đường cong đặc trưng của ĐTN. Do đó,
người thiết kế ĐTN cần phải xem xét cả đường cong ĐTCH và đường
cong hàm thông tin CH để khẳng định được sự đóng góp của CH đó
nhằm tăng chất lượng của các đường cong đặc trưng và đường cong hàm
thông tin của ĐTN.
CÂU HỎI TỰ KIỂM TRA
1. Phân tích các nhược điểm của CTT khi thiết kế các ĐTN.
2. Nêu các bước của quy trình Lord dùng hàm thông tin để thiết kế
một ĐTN theo IRT.
3. Mô tả tính chất của các loại ĐTN chính.
4. Cách thiết kế từng loại ĐTN theo quy trình của Lord.
5. Ảnh hưởng của mô hình đường cong ĐTCH và số lượng CH lên ĐTN.
BÀI TẬP
Bảng 10.1 biểu diễn thông tin của 6 CH tại các giá trị năng lực θ
khác nhau. Sử dụng Bảng 10.1 để giải các bài tập sau đây:
Bài tập 1
a) Tính giá trị thông tin và sai số tiêu chuẩn tại điểm θ =1,0 của
một “ĐTN” gồm các CH 2, 3 và 6.

177
b) Cần bao nhiêu CH tương tự như CH 5 để thu được sai số tiêu
chuẩn bằng 0,40 ở điểm θ =-1,0.
Bài tập 2
Có 2 ĐTN được tạo từ “ngân hàng” CH ở Bảng 10.1. ĐTN 1 bao
gồm các CH 2 và 3; ĐTN 2 bao gồm các CH 1 và 6.
a) Tính giá trị thông tin mà các ĐTN đó cung cấp ở các điểm θ = 0,0;
1,0; 2,0.
b) Tính hiệu suất tỷ đối theo (7.9) của ĐTN 1 so với ĐTN 2 ở các
điểm θ = 0,0; 1,0; 2,0. Giải thích ý nghĩa của các giá trị đó.
c) Cần thêm bao nhiêu CH tương tự CH 5 vào ĐTN 1 để ĐTN 1 và
ĐTN 2 có giá trị thông tin gần như nhau ở điểm θ = 1,0?
Bảng 10.1.
CH θ
-3 -2 -1 0 1 2 3
1 0,02 0,06 0,10 0,20 0,15 0,08 0,04
2 0,00 0,00 0,05 0,10 1,10 0,25 0,10
3 0,00 0,03 0,10 0,25 0,50 0,40 0,15
4 0,15 1,25 1,45 0,10 0,02 0,00 0,00
5 0,00 0,10 0,60 0,70 0,20 0,05 0,00
6 0,00 0,00 0,02 0,40 2,20 0,40 0,15
Bài tập 3
Giả sử người ta muốn tạo nên một ĐTN theo tiêu chí sao cho có độ
phân biệt tối ưu ở điểm θ = -1,0.
a) Nếu ĐTN bao gồm 2 CH 4 và 5 thì sai số tiêu chuẩn ở điểm
θ = -1,0 là bao nhiêu?
b) Xác suất để một TS có năng lực θ = 0,0 bị loại bằng bao nhiêu
nếu điểm cắt (cut-off score) được đặt tại θ = -1,0?

178
Chương 11
SO BẰNG CÁC ĐIỂM TRẮC NGHIỆM
Khả năng so sánh các điểm trắc nghiệm của các ĐTN khác nhau đo
cùng một năng lực là một trong những vấn đề nhận được sự quan tâm
hàng đầu của các chuyên gia đo lường. Nếu có hai TS làm hai ĐTN khác
nhau thì làm sao có thể so sánh điểm của họ với nhau? Đó là một CH đặc
biệt quan trọng khi ra các quyết định cho việc đậu rớt, cấp văn bằng,
tuyển chọn… Vấn đề là phải làm sao cho việc sử dụng kết quả thu được
từ bất cứ ĐTN nào để ra quyết định cũng như nhau.
Chương này dành để trình bày các phương pháp so bằng
(equating), trước hết theo CTT, sau đó theo IRT, và nêu việc ứng dụng
IRT để so bằng qua một ví dụ cụ thể đã triển khai ở nước ta.
Để có thể so sánh các điểm thu được bởi ĐTN X và ĐTN Y, phải
thực hiện một quá trình so bằng các điểm của hai ĐTN. Qua quá trình đó
một sự tương ứng giữa hai bộ điểm của ĐTN X và ĐTN Y được xác lập,
và điểm của ĐTN X được chuyển đổi sang thang đo và đơn vị đo của
ĐTN Y. Như vậy, một TS thu được một điểm x đối với ĐTN X sẽ có một
điểm chuyển đổi y* đối với ĐTN Y; điểm đó có thể so sánh với điểm y
của một TS làm ĐTN Y. Khi ra các quyết định cấp văn bằng, tuyển chọn,
cho đậu rớt… điểm-cắt xc đối với ĐTN X có thể chuyển đổi thành
điểm-cắt y*c đối với ĐTN Y, và điểm-cắt chuyển đổi đó có thể sử dụng để
ra các quyết định thích hợp đối với các TS làm ĐTN Y.
11.1. CÁC PHƯƠNG PHÁP SO BẰNG TRONG CTT
Nói chung các phương pháp so bằng cổ điển có hai loại: so bằng
theo phần trăm và so bằng tuyến tính.

179
- So bằng theo phần trăm được thực hiện khi xem các điểm của
ĐTN X và ĐTN Y là tương đương nếu thứ hạng phần trăm tương ứng
của chúng trong một nhóm bất kỳ nào cũng bằng nhau. Nói một cách
nghiêm khắc, để so bằng các điểm đối với hai ĐTN, các ĐTN phải được
ra cho cùng một nhóm TS. Trong thực tế, các quá trình thường được thực
hiện bằng cách ra các ĐTN cho các nhóm TS tương đương theo phân
phối ngẫu nhiên.
- Trong so bằng tuyến tính người ta giả định rằng điểm x của
ĐTN X và điểm y của ĐTN Y đều tuân theo phân bố chuẩn; x và y có
quan hệ tuyến tính với nhau, tức là
y = ax + b.
Các hệ số a và b có thể được xác định theo hệ thức:
y = ax + b
và
σy = aσx,
trong đó x, y và σx, σy tương ứng là giá trị trung bình và độ lệch
tiêu chuẩn của các điểm đối với ĐTN X và ĐTN Y. Từ đó:
a =x
y
; b = y -
x
y
x
và
y = x
y
(x-x) + y.
Nhờ biểu thức trên có thể đặt một điểm x trên metric của ĐTN Y.
Biểu thức trên chính là biểu thức biến đổi các điểm tiêu chuẩn theo các
thang đo khác nhau đã nêu ở (2.12) chương 2:
x
xx
=
y
yy
.

180
Điều giả định trong phép so bằng tuyến tính này là hai phân bố
điểm trắc nghiệm đều là phân bố chuẩn, chỉ khác nhau về giá trị trung
bình và độ lệch chuẩn. Khi giả định đó được tuân thủ thì phép so bằng
tuyến tính trở thành một trường hợp đặc biệt của phép so bằng phần trăm
tương đương, nói cách khác có thể xem nó là một tiệm cận của phép so
bằng phần trăm tương đương.
Từ bản chất của khái niệm so bằng Lord [4] đã nêu các điều kiện
hết sức nghiêm khắc sau đây:
1. Các ĐTN đo các năng lực tiềm ẩn khác nhau không thể so bằng.
2. Các điểm thô của các ĐTN có độ tin cậy khác nhau không thể so
bằng (vì nếu vậy, một điểm từ một ĐTN kém tin cậy có thể tương đương
với một điểm từ một ĐTN tin cậy).
3. Các điểm thô của các ĐTN có độ khó khác nhau không thể so bằng
(vì ĐTN sẽ không có độ tin cậy như nhau ở các mức năng lực khác nhau).
4. Các điểm trên ĐTN X và Y không thể so bằng nếu các ĐTN
không thật sự tương đương.
5. Các ĐTN có độ tin cậy hoàn hảo có thể so bằng.
• Equating is a process of deriving a function mapping score on an alternate form of a test onto the scale of the reference (anchor) form, such that after equating, any given scale score has the same meaning regardless of which test form was administered.
• So bằng là qui trình tìm một hàm nào đó để chuyển
điểm của thí sinh thu được từ một đề khảo sát nào đó
sang một thang điểm của một đề quy ước làm gốc
(reference). Xem lại .ppt của Lực.
• 5 basic “requirements” to score equating (Dorans & Holland, 2000)
– Equal Constructs
– Equal reliability
– Symmetry

181
– Equity
– Population Invariance
(Luc)
Ngoài các đòi hỏi trên để có thể so bằng, còn cần bổ sung hai điều
kiện: tính đối xứng và tính bất biến. Điều kiện đối xứng chỉ ra rằng phép
so bằng sẽ không phụ thuộc vào việc ĐTN nào được dùng làm chuẩn để
so sánh. Chẳng hạn, nếu một quy trình hồi quy được sử dụng để xác định
các hằng số trong công thức so bằng tuyến tính thì điều kiện đối xứng sẽ
không thỏa mãn nếu hệ số hồi quy để chuyển đổi từ x sang y khác với hệ
số hồi quy để chuyển đổi từ y sang x. Điều kiện bất biến chỉ ra rằng quy
trình so bằng là không phụ thuộc vào mẫu.
Các điều kiện trên đây, đặc biệt là điều kiện để so bằng, thường
không được thỏa mãn khi sử dụng các phương pháp so bằng cổ điển. Về
mặt lý thuyết thì IRT khắc phục tất cả các vấn đề đó. Nếu các mô hình
ứng đáp CH là trùng khớp với số liệu thì việc so sánh trực tiếp các tham
số năng lực của hai TS làm hai ĐTN khác nhau có thể thực hiện do tính
chất bất biến. Như vậy, về nguyên tắc nhu cầu so bằng các điểm trắc
nghiệm được xóa bỏ trong khuôn khổ IRT. Tuy nhiên, điều cần đảm bảo
là các tham số của CH và năng lực TS đối với hai ĐTN được phân bố
trên một thang đo chung (common scale). Do đó, thực ra trong khuôn
khổ IRT cần xác lập thang đo (scaling) chứ không phải cần so bằng
(equating). Tuy nhiên do thói quen người ta thường dùng hai thuật ngữ
nói trên đồng thời hoặc thay thế cho nhau.
11.2. CÁC PHƯƠNG PHÁP SO BẰNG – KẾT NỐI – XÁC LẬP THANG ĐO
THEO IRT

182
Theo IRT, tham số năng lực của một TS là bất biến đối với các
ĐTN khác nhau. Điều đó có nghĩa là, không kể sai số đo lường, các giá
trị ước lượng năng lực sẽ bất biến đối với các ĐTN khác nhau. Do đó nếu
có 2 TS làm hai ĐTN khác nhau mà trong đề đã biết các tham số của CH
thì sẽ thu được các giá trị ước lượng năng lực của họ trên cùng một thang
đo, tức là không cần xác lập thang đo hoặc so bằng gì cả.
Tuy nhiên, vấn đề sẽ khác khi chưa biết các giá trị ước lượng của
CH và năng lực TS. Khi ấy, như đã nói ở 8.2.3, có thể thay thế bằng *
= + , b bằng b* = b + và a bằng a* =a/ mà không ảnh hưởng
đến xác suất ứng đáp đúng CH (Đối với mô hình một tham số vì a=1 nên
chỉ cần thay bằng * = + , b bằng b* = b + ). Tính bất biến đó của
hàm ứng đáp CH đối với các chuyển đổi tuyến tính đưa vào một sự bất
định trong thang đo, bất định đó phải được khử trước khi ước lượng các
tham số. Một trong các cách khử sự bất định đó là tùy ý cố định thang đo
(hoặc b). Đối với mô hình 2 và 3 tham số cách thường sử dụng nhất
trong thực tế là đặt giá trị trung bình và độ lệch tiêu chuẩn của (hoặc b)
tương ứng bằng 0 và 1. Đối với mô hình 1 tham số giá trị trung bình của
(hoặc b) được đặt bằng 0. Các phần mềm tính toán thường mặc định
thực hiện điều này.
11.2.1. Một số trường hợp thực hiện định cỡ và xác lập thang đo
Chúng ta hãy xét một số trường hợp sử dụng cách định cỡ và xác
lập thang đo.
1. Trường hợp có hai nhóm thí sinh hoặc hai đề trắc nghiệm –
thực hiện so bằng
Hai nhóm TS làm một ĐTN:
Liên quan đến việc áp dụng trắc nghiệm trong thực tiễn, người ta
thường đòi hỏi một CH trắc nghiệm phải đảm bảo tính “công bằng” đối
với mọi TS, chẳng hạn hai TS một thuộc dân tộc thiểu số và một thuộc dân
tộc đa số có năng lực như nhau phải ứng đáp như nhau đối với CH đó. Để
xem xét việc đảm bảo tiêu chí đó người ta thường khảo sát chứng cứ thực
nghiệm về sự thiên lệch (bias). Một khái niệm khác có liên quan đến sự
thiên lệch là hiện tượng hai nhóm TS làm một CH trắc nghiệm nào đó có

183
sắc thái ứng đáp CH khác nhau (differential item functioning – DIF). Một
định nghĩa thường dùng về DIF là: “một CH có DIF nếu các TS có cùng
năng lực nhưng từ các nhóm khác nhau không đạt xác suất trả lời đúng CH
như nhau”. Chúng ta sẽ nghiên cứu sâu về khái niệm này sau.
Bây giờ giả sử việc ước lượng tham số CH và năng lực TS được
thực hiện riêng biệt đối với hai nhóm TS A và B. Trong quá trình ước
lượng cần cố định thang đo. Có 2 cách cố định: chuẩn hóa độ khó, tức là
cố định các giá trị trung bình và độ lệch tiêu chuẩn của độ khó (đặt chúng
tương ứng bằng 0 và 1); và chuẩn hóa các giá trị năng lực.
Trước hết xét trường hợp chuẩn hóa độ khó. Vì 2 nhóm TS cùng
làm một ĐTN nên các giá trị ước lượng tham số phải như nhau (trừ thăng
giáng do chọn mẫu) nếu mô hình trùng khớp với dữ liệu. Do đó việc xác
lập thang đo đối với các giá trị độ khó sẽ đặt các giá trị ước lượng tham
số CH và năng lực TS trên cùng một thang đo.
Trong trường hợp việc xác lập thang đo được thực hiện đối với các
giá trị năng lực, vì các giá trị trung bình và độ lệch tiêu chuẩn của năng
lực đối với hai nhóm TS thường không như nhau, việc chuẩn hóa về năng
lực sẽ làm cho các tham số CH nằm trên các thang đo khác nhau. Tuy
nhiên các tham số CH sẽ có quan hệ tuyến tính:
bA = bB + ,
aA = aB/,
trong đó bA và aA là các ước lượng tham số độ khó và độ phân biệt
trong nhóm A, và bB và aB là các giá trị tương ứng trong nhóm B. Vì và
đã được xác định, nên các ước lượng tham số CH trong nhóm B có thể
được đặt trên cùng thang đo như các ước lượng tham số CH trong nhóm A.
Đáng lưu ý hơn là việc so sánh các tham số năng lực trong nhóm A
với các tham số ấy trong nhóm B. Sử dụng các mối quan hệ như đối với
các giá trị b trên đây, mọi ước lượng năng lực B trong nhóm B có thể
được đặt trên cùng thang đo như trong nhóm A khi sử dụng mối quan hệ
tuyến tính:
*A= B+ ,

184
trong đó *A là giá trị của tham số B trên thang đo của nhóm A.
Một nhóm TS làm hai ĐTN:
Khi một nhóm TS làm hai ĐTN X và Y, vì tham số năng lực của
các TS làm hai ĐTN phải như nhau, nếu đặt giá trị trung bình và độ lệch
tiêu chuẩn của tương ứng bằng 0 và 1 thì các tham số của CH đối vơi
hai ĐTN được đặt trên cùng một thang đo. Tuy nhiên, nếu đặt giá trị
trung bình và độ lệch tiêu chuẩn của các tham số độ khó đối với mỗi
ĐTN tương ứng là 0 và 1 thì các giá trị tham số năng lực trong hai ĐTN
sẽ khác nhau và liên hệ bởi một biến đổi tuyến tính:
Y= X+ .
Các tham số của CH đối với các ĐTN X và Y được đặt trên cùng
một thang đo khi dùng mối quan hệ sau đây:
bY = bX + ,
aY = aX/.
Các ví dụ đã cho chứng tỏ rằng nếu cần so sánh các TS làm hai
ĐTN hoặc nếu cần đặt các CH từ các ĐTN khác nhau trên cùng một
thang đo thì việc định cỡ cần được thiết kế rất cẩn thận.
2. Trường hợp có nhiều nhóm thí sinh hoặc nhiều đề trắc
nghiệm - thực hiện kết nối
Bây giờ chúng ta hãy xét các trường hợp có nhiều nhóm TS làm
nhiều ĐTN khác nhau. Lúc đó không thể so bằng, mà cần các thiết kế
kết nối (linking). Trong nhiều trường hợp cần đặt các tham số CH từ hai
hay nhiều ĐTN trên cùng một thang đo chung. Điều đó là cần thiết để
có thể so sánh các mức độ khó khác nhau của các ĐTN và tạo điều kiện
để phát triển NHCH. Có 4 cách thiết kế kết nối để tạo lập thang đo các
tham số CH:
Thiết kế đơn nhóm:
Hai ĐTN cần kết nối được ra cho cùng một nhóm TS. Thiết kế này
đơn giản nhưng ít được áp dụng vì thời gian trắc nghiệm sẽ rất dài. Hơn

185
nữa, nếu hai ĐTN được cho làm nối tiếp nhau thì hiệu ứng mệt mỏi khi
làm đề sau sẽ ảnh hưởng đến tham số ước lượng và do đó ảnh hưởng đến sự
kết nối.
Thiết kế các nhóm tương đương:
Hai ĐTN cần kết nối được ra cho các nhóm tương đương (gồm các
TS được lựa chọn ngẫu nhiên) làm. Thiết kế này dễ áp dụng hơn và tránh
được hiệu ứng mệt mỏi.
Thiết kế các ĐTN có các CH neo:
Các ĐTN cần kết nối được ra cho hai nhóm TS khác nhau làm. Hai
ĐTN có một nhóm CH chung, được gọi là các CH neo. Thiết kế này có tính
khả thi cao và hay được sử dụng, và nếu chọn các CH neo thích hợp thì
tránh được các yếu điểm của thiết kế nhóm đơn hoặc nhóm tương đương.
Thiết kế có các TS chung:
Hai ĐTN cần kết nối được ra cho hai nhóm TS làm, trong đó một
nhóm con TS có mặt trong cả hai nhóm cùng làm hai ĐTN. Vì thời gian
làm bài sẽ lâu đối với nhóm chung nên thiết kế này cũng có cùng nhược
điểm như thiết kế nhóm đơn.
Trong các thiết kế nhóm đơn hoặc nhóm tương đương, khi một
nhóm TS hoặc các nhóm TS tương đương làm 2 ĐTN thì các phương
pháp được mô tả trong mục trước đây có thể được sử dụng để đặt các CH
trên cùng một thang đo. Khi xác định các hằng số thiết lập thang đo trong
thiết kế nhóm tương đương, cần các cặp giá trị năng lực tương ứng với
nhau, điều đó làm nảy sinh vấn đề, vì các nhóm khác nhau bao gồm các
TS khác nhau. Có một cách để tạo các cặp TS tương ứng là sắp xếp các
TS trong hai nhóm theo thứ tự và xem các TS có cùng thứ hạng là tương
đương với nhau.
Trong các thiết kế ĐTN có các CH neo, các tham số, và do đó các
giá trị ước lượng của chúng (không kể sai số chọn mẫu) trong hai ĐTN
sẽ có quan hệ tuyến tính, đó là
bYc = bXc + ,

186
aYc = aXc/,
trong đó bXc và bYc là các độ khó của các CH neo tương ứng trong
các ĐTN X và Y. Một khi các hằng số và đã được xác định, các giá
trị ước lượng tham số đối với mọi CH trong ĐTN X có thể được đặt trên
cùng thang đo với ĐTN Y. Các giá trị ước lượng tham số CH đối với các
CH neo trong ĐTN X và trong ĐTN Y sẽ không như nhau (vì có sai số ước
lượng), do đó sẽ được lấy trung bình.
Trong các thiết kế được mô tả trên đây, thiết kế ĐTN có các CH
neo là khả thi nhất. Do đó việc xác định các hằng số thiết lập thang đo
được bàn đến sau đây sẽ liên quan đến thiết kế có các CH neo.
11.2.2. Xác định các hằng số thiết lập thang đo
Các phương pháp xác định các hằng số thiết lập thang đo và
(hoặc chỉ hằng số đối với mô hình một tham số) sau đây thường được
sử dụng:
1. Phương pháp hồi quy;
2. Phương pháp trung bình và sigma.
3. Phương pháp trung bình và sigma mạnh.
4. Phương pháp đường cong đặc trưng.
Phương pháp hồi quy: Một khi đã thu được các giá trị ước lượng
tham số CH trong 2 nhóm, một quy trình hồi quy có thể được dùng để
xác định đường thẳng trùng khớp tốt nhất đi qua các điểm:
bYc = bXc + +e.
Số hạng e biểu thị sai số trùng khớp của đường thẳng vì không phải
mọi điểm đều nằm đúng trên đường, còn bYc và bXc là các ước lượng tham
số độ khó của CH đối với các CH neo trong ĐTN Y và X. Nếu sử dụng
các TS chung thì:
Yc = Xc + +e,

187
trong đó Yc và Xc là các ước lượng năng lực của một TS làm
tương ứng ĐTN Y và X.
Các ước lượng và của các hệ số hồi quy là
Yc
Xc
sα=r
s và Yc Xc
ˆ ˆβ=b -αb ,
trong đó r là hệ số tương quan giữa các giá trị ước lượng các tham
số độ khó đối với các CH neo, Ycb và Xcb là các giá trị trung bình, còn sYc
và sXc là các độ lệch tiêu chuẩn tương ứng. Đối với thiết kế có TS chung
thì các giá trị đó trong các biểu thức được thay thế bằng các giá trị tương
ứng đối với ước lượng năng lực.
Có một vấn đề đối với phương pháp hồi quy là nó không đáp ứng
điều kiện đối xứng. Thật vậy, vì các hệ số để tiên đoán bYc từ bXc là khác
với các hệ số để tiên đoán bXc từ bYc và không thể thu được một cách đơn
giản bằng cách chuyển đổi phương trình tiên đoán
bYc = ˆbˆXc .
Có nghĩa là không thể từ đó rút ra
bXc = Ycˆb -β
α.
Do đó cách tiếp cận hồi quy không phải là một quy trình thích hợp
để xác định các hằng số thiết lập thang đo.
Phương pháp trung bình và sigma:
Vì rằng
bYc = bXc +
nên suy ra
Yc Xcb =αb +β
và
sYc = sXc .
Do đó
= sYc /sXc

188
và
= Yc Xcb -αb .
Hơn nữa, vì rằng
bYc = bXc +
nên biến đổi từ bYc sang bXc có thể thu được theo biểu thức
bXc = Ycb -β
α.
Như vậy, phương pháp trung bình và sigma thỏa mãn đòi hỏi về
tính đối xứng (Khi sử dụng thiết kế có TS chung, các giá trị trung bình và
độ lệch tiêu chuẩn ước lượng tương ứng theo được sử dụng để xác định
và ).
Một khi và đã được xác định, các ước lượng tham số CH theo
ĐTN X được đặt trên cùng thang đo với ĐTN Y khi sử dụng các hệ thức
b*Y = bX +
a*Y = aX/,
trong đó b*Y và a*
Y là các giá trị độ khó và độ phân biệt của các CH
trong ĐTN X được đặt trên thang đo của ĐTN Y. Các ước lượng tham số
của các CH neo là các giá trị trung bình vì rằng chúng không hoàn toàn
như nhau do sai số ước lượng.
Đối với mô hình một tham số, các giá trị ước lượng độ khó của CH
đối với các CH neo liên hệ với nhau theo hệ thức
bYc = bXc +
và rằng =1. Từ đó suy ra
Yc Xcb =b +
và do đó
= Yc Xcb -b .
Như vậy, các giá trị ước lượng độ khó CH của ĐTN X được
chuyển đổi bằng cách thêm vào lượng sai khác của độ khó trung bình của
các CH neo.
Phương pháp trung bình và sigma mạnh: Trong phương pháp trung
bình và sigma mô tả trên đây không xét đến việc các tham số của CH

189
được ước lượng với độ chính xác khác nhau (tức là, một vài ước lượng
độ khó có sai số tiêu chuẩn lớn hơn các ước lượng khác). Lin (15) đã đề
nghị một phương pháp trung bình và sigma mạnh có xét đến việc các ước
lượng tham số với sai số tiêu chuẩn khác nhau. Mỗi một cặp giá trị
(bYci,bXci) đối với CH neo thứ i trong các ĐTN Y và X được gán các trọng
số bằng nghịch đảo của giá trị phương sai lớn hơn của hai ước lượng.
Cặp có phương sai lớn sẽ có trọng số bé, cặp có phương sai bé sẽ có
trọng số lớn. Phương sai của các ước lượng tham số thu được bằng cách
đảo ma trận thông tin và lấy phần tử đường chéo thích hợp. Đối với mô
hình 3 tham số ma trận thông tin có các cạnh 3x3, trong khi đối với mô
hình 1 tham số ma trận có các cạnh 1x1, tức là có một phần tử.
Các bước để tiến hành phương pháp trung bình và sigma mạnh có
thể tóm tắt như sau:
1. Đối với mỗi cặp (bYci,bXci) xác định trọng số wi theo biểu thức:
wi= [maximum{v(bYci), v(bXci)}]-1,
trong đó v(bYci) và v(bXci) là các phương sai của các ước lượng của
các CH neo.
2. Tính các trọng số:
' ii k
j
j=1
wW
w
trong đó k là số các CH neo trong ĐTN X và Y.
3. Tính các ước lượng đã được gán trọng số:
b'Yci = w'i b Yci,
b'Xci = w'i b Xci.
4. Xác định các giá trị trung bình và độ lệch tiêu chuẩn của các ước
lượng tham số CH có trọng số.
5. Xác định và nhờ các giá trị trung bình và độ lệch tiêu chuẩn
của các giá trị ước lượng có trọng số.

190
Phương pháp đường cong đặc trưng: Phương pháp trung bình và
sigma (và phiên bản sigma mạnh của nó) coi trọng mối quan hệ tồn tại
giữa các tham số độ khó và bỏ qua mối quan hệ tồn tại giữa các tham số
độ phân biệt trong việc xác định các hằng số để thiết lập thang đo.
Haebara (1980) [16] và Stoking và Lord (1983) [7] đã đề nghị phương
pháp “đường cong đặc trưng”, có tính đến thông tin có trong các tham số
về cả độ khó lẫn độ phân biệt.
Điểm thực τXa của một TS với năng lực θa ứng với k CH neo của ĐTN
X là:
τXa = ),,,(1
XciXciXci
k
i
a cabP
.
Tương tự, điểm thực τYa của một TS với cùng năng lực θa ứng với k
CH neo của ĐTN Y là:
τYa = k
a Yci Yci Yci
i=1
P(θ ,b ,a ,c ) .
Đối với bộ CH neo,
bYci = bXci +
aYci = aXci /,
và
cYci = cXci.
Các hằng số α và được chọn bằng cách cực tiểu hóa hàm F sau đây
F = N
2Xa Ya
a=1
1(τ -τ )
N
,
với N là số lượng TS. Hàm F là một hàm của và và là một chỉ
thị về sự khác biệt giữa τXa và τYa. Quy trình xác định và là một quy
trình tương tác, bạn đọc quan tâm có thể tìm hiểu ở [16] và [17].
Trong việc sử dụng cách thiết kế ĐTN có các CH neo thì số lượng
CH neo, và quan trọng hơn, các đặc trưng của chúng đóng vai trò quan
trọng đối với chất lượng của việc kết nối. Chẳng hạn, nếu các CH neo là
quá dễ đối với ĐTN này và quá khó đối với ĐTN kia thì các giá trị ước
lượng tham số thu được trong hai ĐTN sẽ không ổn định và sự kết nối sẽ
không tốt. Do đó, một điều rất quan trọng là các CH neo đều nằm ở

191
khoảng độ khó có thể chấp nhận đối với cả hai nhóm. Kinh nghiệm cho
thấy là các kết quả tốt nhất sẽ thu được nếu các CH neo là đại diện của
các CH của hai ĐTN cần liên kết. Hơn nữa, một điều quan trọng là phải
đảm bảo sao cho hai nhóm TS có phân bố năng lực tương tự, ít nhất là
đối với các CH neo. Thông thường số CH neo bằng khoảng từ 20% đến
25% của số lượng CH trong các ĐTN.
11.3. VÍ DỤ VỀ SO BẰNG – KẾT NỐI – XÁC LẬP THANG ĐO THEO IRT
Để minh họa việc áp dụng IRT trong bài toán so bằng – kết nối –
xác lập thang đo chung, dưới đây cũng sẽ mượn số liệu từ một nghiên
cứu của Việt Nam đã được giới thiệu ở mục 5.2 chương 5 [34].
Ví dụ ở phần này sẽ tập trung vào việc so bằng hai ĐTN tiếng Việt
năm 2001 (VIỆT01) và năm 2007 (VIỆT07). Đề VIỆT07 chính là đề
chính thức thu được từ việc chỉnh sửa đề thử nghiệm VIỆT1 đã giới thiệu
ở phần định cỡ ĐTN chương 8.
ĐTN VIỆT01 gồm 56 CH, triển khai trên 72.645 TS, ĐTN VIỆT07
gồm 40 CH, triển khai trên 59.405 TS. Hai ĐTN có 12 CH chung, dùng
để neo khi kết nối hai ĐTN. Bài toán so bằng được thực hiện theo trình
tự như sau: Bước 1, định cỡ và phân tích hai ĐTN riêng rẽ; bước 2, từ
các tham số của các CH neo xác định các hệ số biến đổi tuyến tính liên
kết giữa chúng với nhau, dựa vào đó để thu một bộ tham số chung cho
các CH neo; bước 3, định cỡ chung ĐTN kết nối trên toàn bộ số TS của
hai năm 2001 và 2007. Quá trình so bằng giới thiệu ở đây được thực hiện
bởi phần mềm VITESTA [19], mô hình được lựa chọn là mô hình Rasch
1 tham số. Dưới đây là một số kết quả cụ thể.
Các CH neo được sắp xếp ở cuối ĐTN VIỆT01 (CH 45-56) và
đầu ĐTN VIỆT07 (CH 1-12). Bảng 11.1a,b cho tham số độ khó b thu
được từ hai ĐTN VIỆT01 và VIỆT07 khi định cỡ riêng rẽ. Bảng 11.2
cho các tham số độ khó b của 12 CH khi định cỡ riêng rẽ bởi mẫu TS
năm 2001 và 2007 cùng độ chênh lệch giữa chúng, từ đó có thể thấy
tham số độ khó b của cùng một CH thu được từ hai ĐTN là khác nhau,
vì tính bất định nêu ở chương 3 và vì các điều kiện không đồng nhất
khác của hai mẫu TS 2001 và 2007. Hiệu của hai giá trị trung bình của

192
tham số độ khó của các CH neo tính được theo 2 mẫu TS 2001 và 2007
chính là hằng số hiệu chỉnh β thu được nhờ phương pháp trung bình và
sigma ở mục 11.2 nêu trên đây, và giá trị của chúng sau khi hiệu chỉnh
(độ khó của các CH neo vẫn còn sai khác). Để cảm nhận tường minh sự
khác nhau của việc ứng đáp các CH neo sau khi điều chỉnh của hai mẫu
TS 2001 và 2007, trên Hình 11.1 có biểu diễn các đường cong ĐTCH
của 12 CH neo. Bảng 11.3a và 11.3b cho giá trị của độ khó b tương ứng
của ĐTN VIỆT01 và VIỆT07 sau khi so bằng. Khi so bằng 2 ĐTN và
tính điểm TS, giá trị điểm trung bình năng lực của TS làm ĐTN
VIỆT01 được đặt ở giá trị 500 và độ lệch tiêu chuẩn được đặt bằng 100
(kiểu thang điểm ETS và các khảo sát quốc tế thường dùng, xem
chương 2), ta thu được giá trị điểm trung bình năng lực của TS làm
ĐTN VIỆT07 là 528, như vậy có thể thấy về trung bình trình độ tiếng
Việt của học sinh cuối lớp 5 ở nước ta sau 6 năm có tăng lên, từ 500 lên
528, độ gia tăng này có ý nghĩa vì sai số tiêu chuẩn vào cỡ 20. Bảng
trích 11.4 cho biết điểm thô, giá trị năng lực tính theo thang logit và
điểm biến đổi theo thang điểm ETS của một số trong 132.029 học sinh
lớp 5 ở nước ta. Để minh họa, trên các Hình 11.2a,b và Hình 11.3a,b có
biểu diễn tương ứng các đồ thị hàm thông tin và biểu đồ tương quan
năng lực TS và độ khó CH của hai ĐTN VIỆT01 và VIỆT07. Các hàm
thông tin của 2 ĐTN có dạng tương tự, tuy nhiên cực đại của hàm thông
tin ĐTN VIỆT01 lớn hơn của hàm thông tin ĐTN VIỆT07, vì VIỆT01
có nhiều CH hơn VIỆT07. Các biểu đồ tương quan giữa năng lực TS và
độ khó CH của 2 ĐTN cũng có hình dáng và phân bố khá giống nhau,
do đó chúng là các công cụ tốt giúp xác định và so sánh năng lực tiếng
Việt của học sinh tiểu học ở nước ta sau 6 năm.
Bảng 11.1.
a) Tham số độ khó b của ĐTN VIỆT01 theo kết quả phân tích riêng năm 2001 |-----------------------------| ¦ Câu| b | MSE | |-------+----------+----------|
¦ 1¦ -0.40680¦ 0.00871¦ ¦ 2¦ -1.25874¦ 0.01111¦ ¦ 3¦ 0.15392¦ 0.00855¦ ¦ 4¦ -0.55287¦ 0.00892¦ ¦ 5¦ -1.11822¦ 0.01049¦

193
¦ 6¦ -1.05829¦ 0.01026¦ ¦ 7¦ -0.81332¦ 0.00948¦ ¦ 8¦ -0.43235¦ 0.00874¦ ¦ 9¦ -0.31563¦ 0.00862¦ ¦ 10¦ -1.00026¦ 0.01005¦ ¦ 11¦ -1.56957¦ 0.01290¦ ¦ 12¦ -0.55967¦ 0.00893¦ ¦ 13¦ -1.14782¦ 0.01061¦ ¦ 14¦ -1.15667¦ 0.01065¦ ¦ 15¦ -1.22060¦ 0.01093¦ ¦ 16¦ 0.47833¦ 0.00890¦ ¦ 17¦ -0.21927¦ 0.00855¦ ¦ 18¦ -0.79621¦ 0.00943¦ ¦ 19¦ -1.31552¦ 0.01139¦ ¦ 20¦ -0.77621¦ 0.00938¦ ¦ 21¦ 0.66139¦ 0.00926¦ ¦ 22¦ -0.73066¦ 0.00927¦ ¦ 23¦ -0.92284¦ 0.00979¦ ¦ 24¦ -1.63503¦ 0.01336¦ ¦ 25¦ 0.21404¦ 0.00859¦ ¦ 26¦ 0.23056¦ 0.00860¦ ¦ 27¦ -1.63702¦ 0.01337¦ ¦ 28¦ -1.42598¦ 0.01199¦ ¦ 29¦ -1.25093¦ 0.01107¦ ¦ 30¦ -0.44895¦ 0.00877¦ ¦ 31¦ -0.16937¦ 0.00852¦ ¦ 32¦ 0.34421¦ 0.00872¦ ¦ 33¦ -0.23103¦ 0.00856¦ ¦ 34¦ -1.30792¦ 0.01135¦ ¦ 35¦ -0.51992¦ 0.00887¦ ¦ 36¦ -1.40554¦ 0.01188¦ ¦ 37¦ -0.38699¦ 0.00869¦ ¦ 38¦ 0.79425¦ 0.00959¦ ¦ 39¦ 0.03301¦ 0.00850¦ ¦ 40¦ -1.03777¦ 0.01018¦ ¦ 41¦ -0.02055¦ 0.00850¦ ¦ 42¦ 0.67120¦ 0.00928¦ ¦ 43¦ -0.40105¦ 0.00871¦ ¦ 44¦ -0.00491¦ 0.00850¦ ¦ 45¦ 0.40680¦ 0.00880¦ ¦ 46¦ -0.55488¦ 0.00892¦ ¦ 47¦ -0.36740¦ 0.00867¦ ¦ 48¦ -0.24192¦ 0.00856¦ ¦ 49¦ -1.42691¦ 0.01200¦ ¦ 50¦ -1.01329¦ 0.01009¦ ¦ 51¦ -0.65383¦ 0.00911¦ ¦ 52¦ -0.26461¦ 0.00858¦ ¦ 53¦ -0.59477¦ 0.00899¦ ¦ 54¦ -1.20899¦ 0.01088¦ ¦ 55¦ -0.86062¦ 0.00961¦ ¦ 56¦ -0.00325¦ 0.00850¦ |-----------------------------|
b) Tham số độ khó b của ĐTN VIỆT07 theo kết quả phân tích riêng
năm 2007 |-----------------------------|
¦ Câu | b | MSE |
|-------+----------+----------|
¦ 1¦ -0.17269¦ 0.00943¦
¦ 2¦ -1.04980¦ 0.01136¦
¦ 3¦ -0.89541¦ 0.01078¦
194
¦ 4¦ -0.67575¦ 0.01015¦
¦ 5¦ -1.33248¦ 0.01275¦
¦ 6¦ -0.94850¦ 0.01097¦
¦ 7¦ -0.90206¦ 0.01081¦
¦ 8¦ -0.39180¦ 0.00963¦
¦ 9¦ -0.47171¦ 0.00975¦
¦ 10¦ -1.01864¦ 0.01123¦
¦ 11¦ -1.03522¦ 0.01130¦
¦ 12¦ -0.37199¦ 0.00961¦
¦ 13¦ -0.17557¦ 0.00943¦
¦ 14¦ -0.52462¦ 0.00984¦
¦ 15¦ 0.33107¦ 0.00958¦
¦ 16¦ -0.70335¦ 0.01022¦
¦ 17¦ -0.08015¦ 0.00939¦
¦ 18¦ 0.45291¦ 0.00975¦
¦ 19¦ 0.43537¦ 0.00973¦
¦ 20¦ -0.15795¦ 0.00942¦
¦ 21¦ -0.80858¦ 0.01051¦
¦ 22¦ -0.67539¦ 0.01015¦
¦ 23¦ -0.01612¦ 0.00938¦
¦ 24¦ -0.68603¦ 0.01018¦
¦ 25¦ -0.54303¦ 0.00987¦
¦ 26¦ -1.14496¦ 0.01178¦
¦ 27¦ -0.50227¦ 0.00980¦
¦ 28¦ -0.20098¦ 0.00945¦
¦ 29¦ -0.22443¦ 0.00946¦
¦ 30¦ -0.93792¦ 0.01093¦
¦ 31¦ -0.89692¦ 0.01079¦
¦ 32¦ -0.73789¦ 0.01031¦
¦ 33¦ 0.35977¦ 0.00962¦
¦ 34¦ -1.15998¦ 0.01185¦
¦ 35¦ -0.99764¦ 0.01115¦
¦ 36¦ 0.03601¦ 0.00939¦
¦ 37¦ -0.82247¦ 0.01055¦
¦ 38¦ -0.27659¦ 0.00950¦
¦ 39¦ -0.75063¦ 0.01035¦
¦ 40¦ 0.28991¦ 0.00954¦
|-----------------------------|

195
Bảng 11.2. Độ khó b của các CH neo của hai ĐTN VIỆT01 và VIỆT07
tính theo ứng đáp riêng rẽ của hai mẫu TS 2001 và 2007
a) Trước khi hiệu chỉnh | Đề VIỆT01 | Đề VIỆT07
-----------------------------------------------------------------
| Câu 45 | 0.4067979 | Câu 1 | -0.1726923 |
| Câu 46 | -0.5548833 | Câu 2 | -1.049797 |
| Câu 47 | -0.3673979 | Câu 3 | -0.8954135 |
| Câu 48 | -0.2419222 | Câu 4 | -0.6757485 |
| Câu 49 | -1.426911 | Câu 5 | -1.332482 |
| Câu 50 | -1.013286 | Câu 6 | -0.9484966 |
| Câu 51 | -0.6538253 | Câu 7 | -0.9020628 |
| Câu 52 | -0.2646112 | Câu 8 | -0.391803 |
| Câu 53 | -0.5947695 | Câu 9 | -0.4717063 |
| Câu 54 | -1.208988 | Câu 10 | -1.018644 |
| Câu 55 | -0.8606218 | Câu 11 | -1.035222 |
| Câu 56 | -0.003254782 | Câu 12 | -0.3719883 |
----------------------------------------------------------------
TRUNG BINH : -0.5653061 TRUNG BINH : -0.7721714
ĐÔ LỆCH CHUÂN : 0.5177267 ĐÔ LỆCH CHUÂN : 0.3500517
SAU KHI HIỆU CHINH ĐÊ 2 THEO ĐÊ 1
HỆ SÔ CHUYÊN ĐÔI: ANFA = 1; BETA = -0.2068653
b) Sau khi hiệu chỉnh
(Độ khó b của các CH của ĐTN VIỆT07 đã được trừ cho giá trị β) -----------------------------------------------------------------
|Đề VIỆT01| b |Đề VIỆT07| b | Chênh lệch |
-----------------------------------------------------------------
| Câu 45 | 0.4067979 | Câu 1 | 0.03417304 | 0.3726249 |
| Câu 46 | -0.5548833 | Câu 2 | -0.8429314 | 0.2880481 |
| Câu 47 | -0.3673979 | Câu 3 | -0.6885482 | 0.3211503 |
| Câu 48 | -0.2419222 | Câu 4 | -0.4688832 | 0.2269610 |
| Câu 49 | -1.426911 | Câu 5 | -1.125617 | -0.3012946 |
| Câu 50 | -1.013286 | Câu 6 | -0.7416313 | -0.2716544 |
| Câu 51 | -0.6538253 | Câu 7 | -0.6951975 | 0.04137218 |
| Câu 52 | -0.2646112 | Câu 8 | -0.1849377 |-0.07967347 |
| Câu 53 | -0.5947695 | Câu 9 | -0.264841 |-0.32992850 |
| Câu 54 | -1.208988 | Câu 10| -0.8117784 |-0.39721000 |
| Câu 55 | -0.8606218 | Câu 11| -0.8283571 |-0.03226471 |
| Câu 56 | -0.00325478| Câu 12| -0.165123 | 0.1618682 |
-----------------------------------------------------------------

196
Bảng 11.3.
Độ khó các CH sau khi so bằng(*)
a) Đề VIỆT01 |--------------------------|
¦ Câu | b | MSE | |-------+----___---+----------|
¦ 1¦ -0.40680¦ 0.00871¦ ¦ 2¦ -1.25874¦ 0.01111¦ ¦ 3¦ 0.15392¦ 0.00855¦ ¦ 4¦ -0.55287¦ 0.00892¦ ¦ 5¦ -1.11822¦ 0.01049¦ ¦ 6¦ -1.05829¦ 0.01026¦ ¦ 7¦ -0.81332¦ 0.00948¦ ¦ 8¦ -0.43235¦ 0.00874¦ ¦ 9¦ -0.31563¦ 0.00862¦ ¦ 10¦ -1.00026¦ 0.01005¦ ¦ 11¦ -1.56957¦ 0.01290¦ ¦ 12¦ -0.55967¦ 0.00893¦ ¦ 13¦ -1.14782¦ 0.01061¦ ¦ 14¦ -1.15667¦ 0.01065¦ ¦ 15¦ -1.22060¦ 0.01093¦ ¦ 16¦ 0.47833¦ 0.00890¦ ¦ 17¦ -0.21927¦ 0.00855¦ ¦ 18¦ -0.79621¦ 0.00943¦ ¦ 19¦ -1.31552¦ 0.01139¦ ¦ 20¦ -0.77621¦ 0.00938¦ ¦ 21¦ 0.66139¦ 0.00926¦ ¦ 22¦ -0.73066¦ 0.00927¦ ¦ 23¦ -0.92284¦ 0.00979¦ ¦ 24¦ -1.63503¦ 0.01336¦ ¦ 25¦ 0.21404¦ 0.00859¦ ¦ 26¦ 0.23056¦ 0.00860¦ ¦ 27¦ -1.63702¦ 0.01337¦ ¦ 28¦ -1.42598¦ 0.01199¦ ¦ 29¦ -1.25093¦ 0.01107¦ ¦ 30¦ -0.44895¦ 0.00877¦ ¦ 31¦ -0.16937¦ 0.00852¦ ¦ 32¦ 0.34421¦ 0.00872¦ ¦ 33¦ -0.23103¦ 0.00856¦ ¦ 34¦ -1.30792¦ 0.01135¦ ¦ 35¦ -0.51992¦ 0.00887¦ ¦ 36¦ -1.40554¦ 0.01188¦ ¦ 37¦ -0.38699¦ 0.00869¦ ¦ 38¦ 0.79425¦ 0.00959¦ ¦ 39¦ 0.03301¦ 0.00850¦ ¦ 40¦ -1.03777¦ 0.01018¦ ¦ 41¦ -0.02055¦ 0.00850¦ ¦ 42¦ 0.67120¦ 0.00928¦ ¦ 43¦ -0.40105¦ 0.00871¦ ¦ 44¦ -0.00491¦ 0.00850¦ ¦ 45¦ 0.22049¦ 0.00880¦ ¦ 46¦ -0.69891¦ 0.00892¦ ¦ 47¦ -0.52797¦ 0.00867¦ ¦ 48¦ -0.35540¦ 0.00856¦ ¦ 49¦ -1.27626¦ 0.01200¦ ¦ 50¦ -0.87746¦ 0.01009¦ ¦ 51¦ -0.67451¦ 0.00911¦ ¦ 52¦ -0.22477¦ 0.00858¦ ¦ 53¦ -0.42981¦ 0.00899¦ ¦ 54¦ -1.01038¦ 0.01088¦ ¦ 55¦ -0.84449¦ 0.00961¦ ¦ 56¦ -0.08419¦ 0.00850¦ |--------------------------|

197
b) Đề VIỆT07 ------------------------------|
¦ Câu | b | MSE |
|-----------------------------| ¦ 1¦ 0.22049¦ 0.00943¦
¦ 2¦ -0.69891¦ 0.01136¦
¦ 3¦ -0.52797¦ 0.01078¦
¦ 4¦ -0.35540¦ 0.01015¦
¦ 5¦ -1.27626¦ 0.01275¦
¦ 6¦ -0.87746¦ 0.01097¦
¦ 7¦ -0.67451¦ 0.01081¦
¦ 8¦ -0.22477¦ 0.00963¦
¦ 9¦ -0.42981¦ 0.00975¦
¦ 10¦ -1.01038¦ 0.01123¦
¦ 11¦ -0.84449¦ 0.01130¦
¦ 12¦ -0.08419¦ 0.00961¦
¦ 13¦ 0.03129¦ 0.00943¦
¦ 14¦ -0.31775¦ 0.00984¦
¦ 15¦ 0.53794¦ 0.00958¦
¦ 16¦ -0.49649¦ 0.01022¦
¦ 17¦ 0.12671¦ 0.00939¦
¦ 18¦ 0.65977¦ 0.00975¦
¦ 19¦ 0.64223¦ 0.00973¦
¦ 20¦ 0.04891¦ 0.00942¦
¦ 21¦ -0.60171¦ 0.01051¦
¦ 22¦ -0.46852¦ 0.01015¦
¦ 23¦ 0.19074¦ 0.00938¦
¦ 24¦ -0.47916¦ 0.01018¦
¦ 25¦ -0.33616¦ 0.00987¦
¦ 26¦ -0.93809¦ 0.01178¦
¦ 27¦ -0.29541¦ 0.00980¦
¦ 28¦ 0.00588¦ 0.00945¦
¦ 29¦ -0.01757¦ 0.00946¦
¦ 30¦ -0.73105¦ 0.01093¦
¦ 31¦ -0.69005¦ 0.01079¦
¦ 32¦ -0.53103¦ 0.01031¦
¦ 33¦ 0.56664¦ 0.00962¦
¦ 34¦ -0.95311¦ 0.01185¦
¦ 35¦ -0.79077¦ 0.01115¦
¦ 36¦ 0.24288¦ 0.00939¦
¦ 37¦ -0.61560¦ 0.01055¦
¦ 38¦ -0.06972¦ 0.00950¦
¦ 39¦ -0.54377¦ 0.01035¦
¦ 40¦ 0.49677¦ 0.00954¦
|-----------------------------|
*) Các giá trị độ khó b của các CH neo bằng trung bình của các giá trị
tương ứng của ĐTN VIỆT01 và VIỆT07 khi phân tích riêng rẽ (Bảng 11.2a,b)

198
Bảng 11.4. Trích điểm thô, điểm năng lực θ, và điểm thực quy đổi theo thang điểm ETS của các ĐTN VIỆT01 và VIỆT07 được đặt trên thang điểm
chung
STT SBD Năng lực
θ
Sai số
tiêu chuẩn Đúng/Tổng
Điểm kiểu
ETS
1 10101031011 2.10463 1.02190 55/56 782.50
2 10101031021 2.53838 1.44499 56/56 840.72
3 10101031031 2.53838 1.44499 56/56 840.72
4 10101031041 2.10463 1.02190 55/56 782.50
5 10101031051 2.10463 1.02190 55/56 782.50
6 10101031061 1.21130 0.54220 52/56 662.59
7 10101031071 1.21130 0.54220 52/56 662.59
8 10101031081 2.10463 1.02190 55/56 782.50
9 10101031091 1.67089 0.73768 54/56 724.28
10 10101031101 0.60513 0.39380 47/56 581.23
……………………………………………………………………….…
59375 82515152022 -0.03739 0.34716 24/39 494.98
59376 82515152052 0.73048 0.43875 33/40 598.05
59377 82515152082 0.52353 0.40250 31/40 570.27
59378 82515152122 0.03430 0.35117 25/40 504.60
59379 82515152142 -0.51703 0.34173 17/40 430.60
59380 82515152032 0.62256 0.41862 32/40 583.57
59381 82515152062 -1.22627 0.41101 8/40 335.40
59382 82515152092 0.10784 0.35617 26/40 514.48
59383 82515152132 0.10784 0.35617 26/40 514.48
59384 82515152152 -0.03739 0.34716 24/40 494.98

199
Hình 11.1. Sự ứng đáp khác biệt đối với các CH neo từ hai mẫu TS năm 2001 và 2007

200
Hình 11.2a. Đường cong hàm thông tin của ĐTN VIỆT01
Hình 11.2b. Đường cong hàm thông tin của ĐTN VIỆT07
Hình 11.3a. Biểu đồ tương quan giữa năng lực của TS và độ khó của ĐTN VIỆT01

201
Hình 11.3b. Biểu đồ tương quan giữa năng lực của TS và độ khó của ĐTN VIỆT07
Các phương pháp so bằng theo lý thuyết trắc nghiệm cổ điển có
nhiều nhược điểm, mà quan trọng nhất là chúng không thỏa mãn các điều
kiện để so bằng. Các phương pháp IRT loại trừ sự cần thiết phải so bằng
vì tính bất biến của các năng lực TS và tham số CH. Tuy nhiên, vì việc
thiết lập thang đo là cần thiết để hạn chế tính bất định trong các mô hình
ứng đáp CH, các tham số về năng lực TS và độ khó CH sẽ chỉ bất biến
với một phép biến đổi tuyến tính, có nghĩa là các tham số của CH và
năng lực TS của cùng các CH và cùng các TS sẽ có quan hệ tuyến tính
trong hai nhóm. Một khi các quan hệ tuyến tính được xác lập, các ước
lượng của tham số CH và ước lượng của năng lực TS có thể đặt trên cùng
một thang đo chung. Quy trình đó, thường gọi là kết nối (linking) và thiết
lập thang đo (scaling), có thể thực hiện nhờ một số thiết kế. Thiết kế
quan trọng nhất là thiết kế ĐTN có các CH neo, trong đó hai ĐTN có
chứa một nhóm CH chung được ra cho hai nhóm TS khác nhau làm. Khi
sử dụng các CH chung có thể xác định các hệ số biến đổi tuyến tính liên
quan đến các tham số của CH đối với hai ĐTN bằng một phương pháp
nào đó. Sau khi biết được dạng thức biến đổi tuyến tính các ước lượng
của năng lực TS và tham số CH có thể đặt trên một thang đo chung. Bạn

202
đọc quan tâm đến các phương pháp so bằng có thể tham khảo công trình
tổng hợp của M.J. Kolen và R.Brennan (2004) [18].
______________________
CÂU HỎI TỰ KIỂM TRA
1. Tầm quan trọng của việc so bằng điểm trắc nghiệm trong thực
tiễn? Mô tả tổng quát về quá trình so bằng.
2. Mô tả phép so bằng tuyến tính trong CTT. Điều kiện mặc định
của so bằng tuyến tính là gì? Nêu vài ví dụ về so bằng tuyến tính lấy từ
chương 2.
a. Quan niệm của Lord về điều kiện để so bằng.
b. Tại sao người ta nói về nguyên tắc trong IRT không cần so bằng?
c. Nêu các cách kết nối cơ bản để tạo lập thang đo chung trong IRT.
d. Mô tả quy trình kết nối và tạo lập thang đo chung trong thiết kế
các ĐTN có các CH neo.
BÀI TẬP
Hai ĐTN A và B có 10 CH chung bắc cầu được cho hai nhóm TS
làm, và mô hình 3 tham số phù hợp với số liệu. Giá trị trung bình và độ lệch
tiêu chuẩn của các giá trị b của các CH chung được cho ở bảng sau đây:
ĐTNA ĐTNB
Trung bình 4,2 3,5
Độ lệch chuẩn 2,2 1,8
Tham số độ khó và độ phân biệt của một CH trong ĐTN B tương
ứng là 1,4 và 0,9. Hãy đặt các giá trị đó trên cùng thang đo của ĐTN A.

203
Chương 12
TRẮC NGHIỆM NHỜ MÁY TÍNH
Trắc nghiệm có thể thực hiện trên giấy (paper-and-pencil - PAP),
cũng có thể thực hiện trên máy tính và mạng máy tính. Trắc nghiệm nhờ
máy tính (computer-based testing - CBT) được thực hiện trong những
điều kiện khác biệt với trắc nghiệm trên giấy nên cần được thiết kế cho
thích hợp. Với sự phổ biến của máy tính cá nhân và mạng máy tính,
mạng Internet, CBT được sử dụng ngày càng phổ biến. Hơn nữa, sự phát
triển của IRT cũng giúp nâng cao hiệu quả của CBT, đặc biệt giúp thiết
kế các phương pháp trắc nghiệm thích ứng nhờ máy tính (computerised
adaptive testing - CAT) có hiệu quả cao.
Chương này dành để trình bày phương pháp CBT phổ biến và sau
đó có đưa ra một ví dụ có tính giáo khoa về CAT.
12.1. ĐẶC ĐIỂM CỦA TRẮC NGHIỆM NHỜ MÁY TÍNH
VÀ CÁC HỆ THỐNG HỖ TRỢ
12.1.1. Một số đặc điểm của trắc nghiệm nhờ máy tính
So với trắc nghiệm trên giấy việc triển khai CBT đòi hỏi nhiều đầu
tư phức tạp hơn để đảm bảo chất lượng, và đôi khi giá thành đắt hơn. Do
đó để tăng tính khả thi và chất lượng CBT phải đảm bảo cung cấp các
thiết bị, phương tiện với các tính năng thích hợp (máy tính, hệ thống máy
tính, sự kết nối để truyền tín hiệu, dải thông và tốc độ đường truyền...),
đồng thời phải có các phần mềm tương ứng được sử dụng cho các loại
mô hình triển khai CBT khác nhau. Khi ấy cơ sở dữ liệu bao gồm nhiều
thông tin đa phương tiện (âm thanh, hình ảnh...) cần được truyền và xử lý
trong thời gian trắc nghiệm thực, và trắc nghiệm phải đồng thời được
triển khai cho số đông TS, ứng phó với tình trạng kẹt đường truyền.

204
CBT có thể thiết kế cho các kỳ thi không có giám thị hoặc các kỳ
thi có giám thị. Khi không có giám thị, vấn đề chống quay cóp phải được
tính đến. Trắc nghiệm trực tuyến qua Internet có thể triển khai khi TS
ngồi ở bất kỳ nơi nào có máy tính nối mạng, tuy nhiên vấn đề xác định
đúng người làm trắc nghiệm hiện nay vẫn đang còn là một khó khăn. Do
đó việc sử dụng trắc nghiệm trực tuyến tại các địa điểm định sẵn có giám
thị thường được sử dụng để đối phó với khó khăn này.
Các phần giới thiệu các loại CBT dưới đây được dựa vào công
trình tổng hợp của F. Drasgow, R.M. Luecht vaf R.E. Bennett trong [13].
12.1.2. Đòi hỏi đối với các phầm mềm hỗ trợ trắc nghiệm nhờ máy tính
Một phần mềm hỗ trợ cho trắc nghiệm nhờ máy tính thường phải
thực hiện các thao tác sau đây:
Giải mã và cấu trúc lại các tệp dữ liệu nguồn;
Tiếp nhận, kiểm tra và cho phép TS thực hiện;
Chọn các CH cho TS làm (theo một dãy xác định, ngẫu nhiên hoặc
theo cách nào đó, chẳng hạn dựa vào tính thích ứng...);
Hướng dẫn và theo dõi việc di chuyển của TS xuyên qua toàn bộ ĐTN;
Trình diễn các CH của ĐTN và đưa ra các câu trả lời để bổ sung
các kích hoạt, tương tác của các CH;
Ghi nhận và lưu giữ các câu trả lời;
Tiến hành kiểm tra thời gian (ví dụ buộc kết thúc một phần) và
cung cấp chỉ thị thời gian cho TS;
Cho điểm tức thời cho các câu trả lời – việc này có thể cần đối với
trắc nghiệm thích ứng cũng như đối với việc cho điểm kết thúc, nếu điểm
đó cần thông báo cho TS;
Ghi nhận kết quả và chuyển đến nơi lưu trữ.
Các phần mềm trắc nghiệm được thiết kế khác nhau để thực hiện
các thao tác nêu trên tùy theo các thể loại trắc nghiệm khác nhau.
Thường mỗi phần mềm hỗ trợ cho một hoặc vài mô hình cung cấp CBT.

205
Các mô hình CBT thường khác nhau ở mức độ thích ứng, độ lớn và dạng
của các đơn vị ĐTN, tốc độ và các giao diện được sử dụng.
- Một đặc trưng cơ bản đầu tiên của các mô hình CBT là mức độ
thích ứng mà ĐTN tạo nên. Cơ chế cơ bản đối với một trắc nghiệm thích
ứng rất đơn giản. Từ các chương trước có thể thấy rõ là một ĐTN có thể
đo chính xác nhất năng lực của một TS nếu độ khó của ĐTN tương ứng
với năng lực TS. Do đó một ĐTN duy nhất không thể đo lường năng lực
của mọi TS với độ chính xác như nhau. Vì vậy, tốt nhất là cung cấp cho
mỗi TS một ĐTN được thiết kế riêng “thích ứng” (“may đo” – tailored)
với năng lực của TS đó.
Trong lịch sử, trắc nghiệm thích ứng đầu tiên là trắc nghiệm trí tuệ
do Binet thiết kế từ năm 1908. Nhưng các nghiên cứu bài bản được triển
khai bởi F. Lord áp dụng cho ETS vào cuối thập niên 1960 để khắc phục
tình trạng độ chính xác của phép đo giảm nhiều đối với các TS có năng
lực rất cao và rất thấp. Lord thấy rằng có thể giảm độ dài của các ĐTN
nhiều mà không ảnh hưởng đến độ chính xác của phép đo nếu ĐTN được
thiết kế cung cấp thông tin cực đại về năng lực của TS. Trắc nghiệm
thích ứng chỉ khả thi khi được các máy tính tương đối mạnh hỗ trợ lưu
trữ nhiều thông tin của các CH, sinh đề, điều khiển ứng đáp, cho điểm …
trong quá trình thi, do đó nó bắt đầu phát triển mạnh vào cuối thập niên
1970. Hơn nữa, IRT đặc biệt thích hợp với CAT vì nó cho phép thu được
các ước lượng năng lực của TS không phụ thuộc vào tập hợp các CH tạo
nên ĐTN. Tuy mỗi TS được làm một ĐTN khác nhau về độ khó nhưng
đặc điểm nêu trên cung cấp một cái thang để so sánh các năng lực ước
lượng được của TS. Theo Hambleton [11], mô hình IRT thích hợp nhất
đối với CAT là mô hình 3 tham số, vì nó phù hợp tốt nhất với dữ liệu CH
NLC so với mô hình 1 và 2 tham số.
Một trắc nghiệm thích ứng thiết kế độ khó của các CH trong ĐTN
phù hợp với năng lực biểu hiện nào đó của mỗi TS. Mục tiêu của một
trắc nghiệm thích ứng thuần túy là cực đại hóa độ tin cậy của ĐTN (độ
chính xác của điểm số) đối với từng TS, dù TS đó có năng lực ở mức độ
nào. Các CH quá dễ hoặc quá khó đối với một TS không đóng góp bao
nhiêu vào việc tăng độ tin cậy của việc đo lường năng lực, tức là việc cho

206
điểm số đánh giá TS. Bằng cách thiết kế độ khó của các CH tương ứng
với năng lực của một TS xác định, có thể làm cho độ tin cậy của các
điểm trắc nghiệm đạt giá trị cực đại.
- Đặc trưng thứ hai của mô hình CBT là các đơn vị ĐTN được sử
dụng để triển khai trắc nghiệm. Trong trường hợp thông thường đơn vị ấy
bao gồm chỉ một CH duy nhất. Tuy nhiên người ta cũng sử dụng tập hợp
một nhóm CH để triển khai trắc nghiệm, gọi là “phân đề” (testlet). TS có
thể chọn phân đề theo nhiều cách: chọn ngẫu nhiên từ một tập hợp nhiều
phân đề, chọn theo trình tự từ một danh mục, hoặc là chọn theo một thuật
toán thích ứng.
- Tốc độ cũng là một đặc trưng của mô hình CBT. Ở các trung tâm
trắc nghiệm thương mại, thời gian trắc nghiệm thường được giới hạn vì
thông thường thời gian tỷ lệ với giá thành. Tuy nhiên cung cấp đủ thời gian
để TS trả lời là một điều kiện để đảm bảo tính đơn chiều của trắc nghiệm.
- Một đặc trưng khác của CBT là cách dịch chuyển. Có hai cách
dịch chuyển: hoặc theo một thiết kế xác định, hoặc theo kết quả ứng đáp
của bước trước đó. Một số phần mềm cho phép TS xem qua mọi CH của
ĐTN, trả lời và đánh dấu các CH còn phân vân để cuối cùng quay lại sửa
đổi. Chỉ khi nào TS thỏa mãn và “giao nộp” (submit) phân đề trắc nghiệm
thì sau đó TS mới bị cấm thay đổi.
12.2. MỘT SỐ MÔ HÌNH TRIỂN KHAI TRẮC NGHIỆM NHỜ MÁY TÍNH
Có nhiều mô hình triển khai trắc nghiệm nhờ máy tính, tuy nhiên
chúng ta sẽ chỉ xem xét các mô hình thông dụng sau đây: 1) Các trắc
nghiệm cố định nhờ máy tính; 2) Các trắc nghiệm di chuyển thẳng;
3) Các trắc nghiệm thích ứng dựa vào CH; 4) Các trắc nghiệm thích ứng
dựa vào phân đề; 5) Các trắc nghiệm thích ứng có cấu trúc đa giai đoạn.
12.2.1. Các trắc nghiệm cố định nhờ máy tính
Các trắc nghiệm cố định nhờ máy tính (Computerized Fixed Tests -
CFT) là một mô hình triển khai bao gồm rất nhiều ĐTN xây dựng trước
được máy tính cung cấp. Các TS khác nhau có thể tiếp xúc với các ĐTN
khác nhau về dạng thức và trình tự CH, tuy rằng ĐTN có mọi CH như
nhau. Khi sử dụng mô hình này một vài ĐTN được cung cấp để cho từng

207
TS lựa chọn theo một kiểu ngẫu nhiên. Các ĐTN khác nhau là tương
đương (parallel), tức là đồng nhất về nội dung và như nhau về độ khó.
Các ĐTN CFT là tương tự với các ĐTN trên giấy (PAP) có các CH cố
định. Biện pháp đảo thứ tự các CH và thứ tự các phương án chọn nhằm
mục đích đề phòng TS cóp bài của nhau. Tuy nhiên, nhiều nghiên cứu
cho thấy vị trí CH trong ĐTN có thể ảnh hưởng lên độ khó của CH, do
hiệu ứng mệt mỏi và nhiều lý do khác.
12.2.2. Các trắc nghiệm di chuyển thẳng nhờ máy tính
Các trắc nghiệm di chuyển thẳng nhờ máy tính (Linear-on-the-Fly
Tests - LOFT) là một loại hình CBT gần với CFT. Tuy nhiên, khác với
CFT, LOFT kết hợp với thuật toán tạo ĐTN tại chỗ (trong thời gian thực)
xem như một chức năng của phần mềm CBT tạo nên cho mỗi TS một
ĐTN duy nhất (nhưng không phải thích ứng). CTT hoặc IRT có thể sử
dụng để tạo ra các ĐTN ngẫu nhiên tương đương cho LOFT. Có hai cách
dùng mô hình LOFT: tạo sẵn ĐTN tự động từ trước, hoặc tạo ĐTN ngay
tại chỗ. Ưu điểm của việc tạo sẵn ĐTN từ trước là các chuyên gia trắc
nghiệm có thể duyệt trước các đề.
Ưu điểm quan trọng của mô hình LOFT là nhiều ĐTN có thể xây
dựng ngay tại chỗ từ cùng một kho CH. Hơn nữa, có một phần CH trùng
lặp giữa các ĐTN cho phép xem xét quan hệ giữa các ĐTN. Khi xây
dựng ĐTN ngay tại chỗ, thuật toán xây dựng ĐTN có thể hạn chế bớt
việc một số CH xuất hiện quá nhiều lần. Mô hình LOFT cũng có các ưu
điểm như mô hình CFT, nhưng hiệu quả sử dụng kho CH cao hơn.
12.2.3. Các trắc nghiệm thích ứng nhờ máy tính dựa vào câu hỏi
Các trắc nghiệm thích ứng nhờ máy tính dựa vào CH (Item-Level
Computer Adaptive Testing - CAT) là trắc nghiệm thích ứng, hoặc trắc
nghiệm “may đo”, tạo nên các độ khó của ĐTN thích hợp với từng TS,
theo từng CH. Ý tưởng sử dụng máy tính để làm cho độ khó của một CH
phù hợp với năng lực của một TS đã được Lord đề xuất trước đây [5].
Dưới dạng sơ khai nhất của CAT, quá trình “may đo” đó được sử dụng
bằng cách theo dõi việc ứng đáp của một TS đối với một CH của ĐTN rồi
sử dụng thông tin đó để chọn CH được đưa ra tiếp theo. Mô hình CAT do
đó được phát triển tiếp nối trong thời gian thực bằng các phần mềm trắc

208
nghiệm dùng cách lựa chọn CH đơn giản theo thuật toán thử nghiệm
(heuristic). Trong CAT, tiêu chuẩn trước hết để lựa chọn CH là cực đại hóa
hàm thông tin và do đó cực tiểu hóa sai số đo lường của điểm TS.
Trên Hình 12.1 có minh họa về quá trình có hai TS giả định ứng
đáp 50 CH. Thang thẳng đứng chỉ năng lực θ từ -3 đến 3 logit. Dãy 50
CH thích ứng được chỉ trên trục nằm ngang. Giả sử cả 2 TS bắt đầu từ
giá trị ước lượng năng lực ở mức 0. Sau khi đưa ra CH đầu tiên, các điểm
năng lực ước lượng được bắt đầu tách ra. Qua quá trình trả lời 50 CH, các
điểm năng lực của hai TS được tách ra một cách có hệ thống để TS A tiệm
cận dần giá trị +1,0 và TS B tiệm cận dần giá trị -1,0. Độ khó của 50 CH
được chọn lọc đối với mỗi ứng đáp thích hợp của TS sẽ tiến dọc theo các
điểm năng lực được ước lượng: các CH cho TS A sẽ khó hơn các CH cho
TS B. Hình 12.1 cũng biểu diễn các sai số ước lượng dựa theo CAT. Độ
rộng của mỗi khoảng sai số hai bên điểm năng lực giảm dần trong tiến
trình ứng đáp: từ phía mép trái khoảng sai số khá rộng, qua gần một nửa
tiến trình CAT khoảng sai số giảm nhanh. Sau khoảng chừng 20 CH
khoảng sai số bắt đầu ổn định, có giảm nhưng chậm hơn.
Hình 12.1. Ví dụ về quy trình CAT được thực hiện bởi hai thí sinh A và B
Có một số phương pháp để dừng tiến trình CAT: 1) Có thể sử dụng
các ĐTN có độ dài cố định, việc dừng tiến trình được thực hiện mà không

209
căn cứ vào sai số xác định điểm năng lực của TS; 2) Đưa ra một độ chính
xác đòi hỏi nào đó, khi đạt được độ chính xác đó thì dừng tiến trình.
Dựa vào tình huống trắc nghiệm người ta có thể chọn một trong hai
phương pháp nêu trên để dừng tiến trình. Đối với trắc nghiệm theo
chuẩn, trong đó các tiêu chuẩn thực hiện đã được xác định cho ĐTN, tiêu
chí về sai số tiêu chuẩn cực tiểu thường được sử dụng. Khi ấy trắc
nghiệm của một TS được dừng lại khi sai số đo đối với điểm năng lực
của TS đạt thấp hơn một ngưỡng nào đó. Đối với trắc nghiệm đánh giá
mức độ thành thạo, hoặc trắc nghiệm theo tiêu chí, ví dụ trắc nghiệm để
tuyển sinh, để cấp chứng chỉ, tiến trình được dừng lại khi biết rõ năng lực
của TS cao hơn hoặc thấp hơn một điểm ngưỡng nào đó, điểm chuẩn
hoặc điểm sàn.
Hình 12.2. So sánh sai số tiêu chuẩn đạt được nhờ CAT và đạt được nhờ trắc nghiệm chọn đề ngẫu nhiên
Ưu điểm nổi bật của CAT là tăng hiệu quả trắc nghiệm, tức là tăng
độ chính xác phép đo năng lực của TS khi sử dụng ít CH hơn so với các
loại trắc nghiệm không thích ứng. Hiệu quả đó đạt được bằng cách tránh
cho TS phải trả lời nhiều CH quá khó hoặc quá dễ so với năng lực của
anh ta. Do đó ĐTN CAT thường ngắn hơn nhiều so với một ĐTN tương
ứng trên giấy. Nói chung, để đạt một độ chính xác như nhau cho một

210
phép đo năng lực, một ĐTN CAT cần khoảng một nửa số CH so với một
ĐTN không thích ứng. Hình 12.2 mô tả hiệu quả thu được khi sử dụng
CAT so với khi sử dụng một trắc nghiệm lựa chọn CH ngẫu nhiên.
Đường liền cho thấy sai số tiêu chuẩn trung bình của ước lượng năng lực
qua 50 CH theo CAT, còn đường chấm chấm là giá trị tương ứng theo
cách chọn ngẫu nhiên. Theo CAT chỉ sau 20 CH có thể đạt độ chính xác
ước lượng tương đương với cách chọn ngẫu nhiên sau 50 CH.
12.2.4. Các trắc nghiệm thích ứng nhờ máy tính dựa vào phân đề
Trắc nghiệm thích ứng dựa vào phân đề (testlet) là trắc nghiệm dựa
vào các nhóm CH tạo thành các phân đề cho một TS chứ không phải dựa
vào chỉ một CH đơn lẻ. Như vậy, phần mềm cho trắc nghiệm này phải:
1) xem phân đề là đơn vị thích ứng; 2) chấm điểm các phân đề tức khắc
(trong thời gian thực); 3) chọn các phân đề tiếp theo để trắc nghiệm;
4) kết thúc trắc nghiệm khi phân đề cuối cùng được hoàn thành hoặc khi
đạt được một tiêu chí dừng máy nào đó.
Phân đề có thể là một nhóm CH liên quan đến một đoạn bài đọc,
liên quan đến một hình ảnh hoặc một nội dung nào đó. Sau khi TS hoàn
thành xong một phân đề, máy tính ghi điểm của phân đề đó và chọn phân
đề để làm tiếp. Như vậy, dạng trắc nghiệm này là thích ứng ở cấp độ
phân đề chứ không phải ở cấp độ CH. Cách tiếp cận này cho phép kiểm
soát nội dung kỳ thi và cho phép TS bỏ qua, xem lại và thay đổi câu trả
lời trong một nhóm CH. Nó cũng cho phép kiểm tra lại nội dung và tham
số đo lường của nhóm CH trước khi cho thi.
12.2.5. Các trắc nghiệm thích ứng nhờ máy tính cấu trúc đa giai đoạn
Các trắc nghiệm thích ứng nhờ máy tính cấu trúc đa giai đoạn
(Structured Computer Adaptive Multistage Tests – ca-MST) là các trắc
nghiệm thích ứng tự thực hiện có sử dụng phân đề. Loại trắc nghiệm này
được sử dụng nhiều trong những năm gần đây.
Về tính năng, ca-MST là một mô hình phân đề thích ứng đa giai
đoạn được tạo lập trước. Mô hình sử dụng một kỹ thuật thiết kế mạnh kết
hợp được các công nghệ thích ứng đa giai đoạn và tạo đề tự động theo
một kiểu cho phép người thiết kế ĐTN đảm bảo được một sự kiểm soát
cao hơn đối với chất lượng các ĐTN và dữ liệu.

211
Đơn vị cơ bản của ca-MST là các môđun hoặc phân đề, là các
nhóm CH được tạo lập sẵn có độ lớn từ vài ba cho đến hàng trăm CH.
Các môđun có thể bao gồm các CH rời rạc hoặc các CH ứng với cùng
một đoạn văn hoặc hình ảnh. Các môđun hoặc phân đề này thường có các
đặc trưng thống kê xác định (chẳng hạn có độ khó trung bình hoặc mức
chính xác xác định), và một cụm nội dung nào đó được đưa vào trong
một cấu trúc môđun. Tiếp đến, các môđun trắc nghiệm được tập hợp vào
một “bảng” (panel) và được gán cho một giai đoạn trắc nghiệm riêng biệt
trong bảng. Cách tiếp cận ghép các CH vào các môđun và ghép các
môđun vào các bảng làm cho việc trắc nghiệm thích ứng có thể thực hiện
được trong một mô hình ca-MST và sau đó cung cấp một cách cụ thể để
kiểm tra việc đưa ra các CH và/hoặc các môđun theo thời gian, thông qua
việc sử dụng lại và các quy tắc trùng lặp liên quan với các bảng.
Từ phía TS, mô hình ca-MST thể hiện như một trắc nghiệm đa giai
đoạn theo đường thẳng. Hình 12.3 biểu diễn một ca-MST 3 giai đoạn như
là một dãy gồm 3 môđun. Sau mỗi giai đoạn, chu trình trắc nghiệm và
cho điểm lại bắt đầu. Chu trình cho điểm và trắc nghiệm có thể bao gồm
cả việc thích ứng và ra quyết định, nhưng TS không nhìn thấy các quyết
định đó.
Hình 12.3. Ví dụ các trắc nghiệm thích ứng nhờ máy tính cấu trúc đa giai đoạn.
Cần lưu ý là việc tạo lập tự động ĐTN phải đảm bảo sao cho từng phân
đề được xây dựng trước đáp ứng được mọi đặc trưng thống kê và nội dung.
Như một phần của việc tạo lập tự động các ĐTN, mỗi phân đề xây
dựng trước được đưa vào các bảng, mỗi bảng chứa 4, 7 hoặc nhiều hơn
các phân đề, tuỳ theo việc thiết kế các bảng của những người xây dựng
ĐTN. Mỗi phân đề được gắn một cách tường minh vào một giai đoạn xác
định và một tuyến xác định trên bảng (dễ, trung bình hoặc khó) dựa trên

212
độ khó trung bình của phân đề. Nhiều bảng có thể được chuẩn bị với sự
trùng lặp CH được kiểm tra xuyên qua các bảng khác nhau. Hình 12.4
biểu diễn một thiết kế bảng đa giai đoạn 1-3-3. Một phân đề (A) được
gắn với giai đoạn 1. Ba phân đề (B,C,D) được gắn với giai đoạn 2, và 3
phân đề khác (E,F,G) được gắn với giai đoạn 3. Độ khó của mỗi phân đề
được kiểm tra thông qua việc tạo lập trắc nghiệm tự động, sử dụng hàm
thông tin của ĐTN theo IRT, hướng độ khó của mỗi phân đề vào một
vùng xác định của thang điểm liên quan. Như vậy có 7 hàm thông tin
ĐTN mục tiêu làm cơ sở cho thiết kế bảng 1-3-3.
Hình 12.4. Ví dụ về các trắc nghiệm thích ứng nhờ máy tính cấu trúc đa giai đoạn với các bảng chứa các phân đề
Một mô hình nhiều bảng được biểu diễn trên hình 12.4. Các bảng
đó sẽ được xây dựng đồng thời nhờ phương pháp tạo ĐTN tự động và
được phối hợp như là các dạng ĐTN trong một tệp dữ liệu nguồn của
phần mềm. Khi một TS ngồi vào để chuẩn bị làm trắc nghiệm, TS sẽ
chọn một bảng nào đó một cách ngẫu nhiên. Sáu mũi tên liền nét trên
Hình 12.4 là các lộ trình thích ứng được phép dịch chuyển trong bảng đó
giữa các bảng. Bốn mũi tên đứt nét biểu diễn các lộ trình thứ cấp. Các lộ
trình xác định thậm chí có thể được kích hoạt để tránh cho TS khỏi nhảy
qua các lộ trình khác. Các lộ trình từ giai đoạn 1 sang giai đoạn 2 chỉ dựa

213
trên kết quả của TS ở phân đề A. TS có kết quả thấp đi theo lộ trình đến
phân đề B, TS có kết quả trung bình - đến phân đề C, TS có kết quả cao
nhất - đến phân đề D. Các lộ trình đi đến giai đoạn 3 (các phân đề E, F và
G) được chỉ dẫn dựa vào kết quả tích luỹ qua mọi phân đề trước đó.
Có 7 con đường tồn tại xuyên qua mỗi bảng 1-3-3 được mô tả trên
Hình 12.4: A+B+E, A+B+F, A+C+E, A+C+F, A+C+G, A+D+F,
A+D+G. Mỗi bảng được cấu trúc tường minh sao cho mỗi một con
đường nêu trên cung cấp một trắc nghiệm cân bằng về nội dung, đáp ứng
mọi đặc trưng liên quan ở cấp độ ĐTN. Các dãy bảng được xây dựng
trước đồng thời để thực hiện trắc nghiệm, sử dụng cách tạo lập tự động
các trắc nghiệm. Bằng cách kết hợp và ghép các phân đề xuyên qua các
bảng, hàng trăm bảng có thể được xây dựng nếu kho CH đủ lớn.
Khi đã được xây dựng, mỗi bảng sau đó trở thành một đối tượng dữ
liệu hình thức để thực hiện trắc nghiệm. Như vậy, mỗi bảng sẽ “tự biết”
phải làm sao để thực hiện trắc nghiệm thích ứng. Việc tạo nên các bảng
như là các đối tượng dữ liệu chính thức làm cho hệ thống thao tác có
nhiều ưu điểm liên quan đến bảo mật, kiểm tra chất lượng và quản lý dữ
liệu. Các hội đồng trắc nghiệm có thể xem xét trước nội dung và chất
lượng của các ĐTN trong mỗi bảng. Hơn nữa, các triển khai thử nghiệm
có thể được thực hiện để đảm bảo rằng mọi bảng đều hoạt động tốt trước
khi kích hoạt ở nơi tổ chức thi. Về mặt bảo mật, các bảng có thể được
giao cho TS theo cách ngẫu nhiên, các CH có thể hoán đổi ngẫu nhiên
giữa các phân đề, và sự chồng gối lên nhau qua các bảng có thể được
kiểm tra tường minh qua hệ thống tạo đề tự động xem như một phương
tiện để kiểm tra sự rủi ro của việc xuất hiện CH. Cuối cùng, các bảng có
liên quan cụ thể với vấn đề trắc nghiệm lại, tức là, các bảng mà TS đã
thấy trước kia sẽ được sử dụng lại do được lựa chọn khi một TS được
trắc nghiệm lại.
Trong thời gian thực, việc chấm điểm và dẫn đường cho TS có thể
đơn giản hoá rất nhiều nhờ đưa vào một sơ đồ dẫn đường chấm điểm cho
mỗi bảng. Cơ chế dẫn đường chấm điểm dựa vào điểm trả lời đúng tích
luỹ và các điểm cắt (cut-offs) xác định trước phỏng theo tiêu chuẩn thông
tin cực đại được sử dụng trong CAT. Điểm cắt theo số CH trả lời đúng có

214
thể lưu lại như một phần của dữ liệu của bảng. Chẳng hạn, thiết kế 1-3-3
mô tả ở Hình 12.4 đòi hỏi chính xác 10 giá trị của điểm dẫn đường
(A→B, A→C, A→D, A+B→E, A+B→F, A+C→E, A+C→F, A+C→G,
A+D→F và A+D→G). Thao tác này làm đơn giản hoá chức năng dẫn
đường và cho điểm khi vận hành trắc nghiệm nhờ phần mềm (tức là giảm
bớt việc xử lý số liệu phức tạp và các bước tính toán - đặc biệt trong môi
trường trắc nghiệm nhờ Web).
Cần lưu ý là thiết kế 1-3-3 trên Hình 12.4 chỉ là một ví dụ về mô
hình một bảng ca-MST. Tuỳ tình huống và yêu cầu của trắc nghiệm mà
thiết kế mô hình cho thích hợp (số giai đoạn, số mức độ khó ở mỗi giai
đoạn, độ lớn của các phân đề,… ). Ví dụ về một số thiết kế đã được đề
nghị và sử dụng: 1-3; 1-2-2; 1-3-4; 1-3-4-5; 1-3-3-3. Chú ý là việc sử
dụng nhiều giai đoạn chứa các môđun ngắn hơn có thể làm cho sự thích
ứng mềm dẻo hơn.
Thực chất mô hình ca-MST là một giải pháp thoả hiệp, nhằm cố
gắng thoả mãn yêu cầu về sự thích ứng ở mức độ nào đó, đồng thời đảm
bảo tuân theo các đặc trưng nội dung cho mọi TS và tránh được việc sử
dụng quá nhiều CH. Mô hình đó có nhiều ưu điểm:
Cho phép TS xem xét nghiên cứu các CH trong phạm vi một phân đề;
Làm nổi lên nhiều hiệu quả đo lường của CAT, đặc biệt đối với các
trắc nghiệm dài và có nhiều đòi hỏi khắt khe;
Làm đơn giản hoá nhu cầu phải xây dựng thử nghiệm và áp dụng
các hệ thống phần mềm mới đắt tiền;
Sử dụng ở mức độ cao quá trình tạo đề tự động (ATA) như là một
quá trình ngoại vi, hạn chế nhu cầu sử dụng ATA trong phần mềm triển
khai trắc nghiệm thời gian thực.
Vì các bảng có thể xây dựng sẵn nên có thể xét duyệt kiểm tra
chúng trước để đảm bảo chất lượng của mỗi ĐTN. Nếu có nơi nào đó mà
con người không thể xét duyệt tốt thì có thể thiết kế cơ chế kiểm tra chất
lượng buộc phần mềm lưu ý đến các bảng có vấn đề.

215
Ưu điểm cuối cùng có liên quan đến vấn đề quản lý dữ liệu, vì khung
các bảng ca-MST tuân theo một sơ đồ thiết kế định hướng đối tượng, tạo
phương tiện để lưu trữ, xử lý, kiểm nghiệm chất lượng các ĐTN.
12.3. VÍ DỤ VỀ TRẮC NGHIỆM THÍCH ỨNG NHỜ MÁY TÍNH
Để nêu một ví dụ về CAT dưới đây sẽ mượn một trắc nghiệm do
Reshetar chuẩn bị, được trình bày lại ở [11]. “Ngân hàng” CH cho trắc
nghiệm ở ví dụ có tính giáo khoa này chỉ gồm 13 CH với các tham số cho
ở bảng dưới đây. Đối với một trắc nghiệm CAT thực sự ngân hàng CH
phải bao gồm hàng trăm CH.
Bảng 12.1.“Ngân hàng” CH cho ví dụ về CAT
Câu hỏi Các tham số
b a c
1 0,09 1,11 0,22
2 0,47 1.21 0,24
3 -0,55 1,78 0,22
4 1.01 1,39 0,08
5 -1,88 1,22 0,07
6 -0,82 1,52 0,09
7 1,77 1,49 0,02
8 1,92 0,71 0,19
9 0,69 1,41 0,13
10 -0,28 0,98 0,01
11 1,47 1,59 0,04
12 0,23 0,72 0,02
13 1,21 0,58 0,17
Các bước của quá trình thực hiện CAT diễn ra như sau:
1. Đầu tiên, CH 3 được chọn, đó là một CH có tham số độ khó b
trung bình và tham số độ phân biệt a cao. Giả sử TS trả lời đúng CH 3.
Việc ước lượng năng lực bằng quy trình biến cố hợp lý cực đại (MLE)

216
không thể thực hiện trước khi TS trả lời một CH đúng và một CH sai (vì
các ứng đáp hoàn toàn sai và hoàn toàn đúng ứng với ước lượng giá trị θ
tương ứng bằng -∞ và +∞).
2. Một CH khác, CH 12 được chọn vì tham số độ khó b của nó lớn
hơn CH mà TS làm trước đó. Giả sử TS trả lời đúng CH 12. Ước lượng
năng lực bằng MLE cũng chưa thể thực hiện được.
3. Tiếp theo, CH 7 được chọn, CH này khó hơn CH 3 và 12. Giả sử
TS trả lời sai CH 7. Vectơ ứng đáp 3 CH của TS có thể biểu diễn là
(1,1,0). Sử dụng quy trình MLE ước lượng được năng lực của TS là
=1,03. Hàm thông tin của ĐTN gồm 3 CH ở mức năng lực đó có giá
trị I( =1,03)=0,97 và sai số tiêu chuẩn tương ứng là σ( =1,03) = 1,02.
Bảng 12.2 mô tả diễn biến của quá trình ứng đáp CH.
Bảng 12.2. Năng lực theo MLE cho một thí sinh và sai số tiêu chuẩn ở cuối mỗi bước của CAT
Bước CH số Ứng đáp CH I( ) σ( )
1 3 1 - - -
2 12 1 - - -
3 7 0 1,03 0,97 1,02
4 4 1 1,46 2,35 0,65
5 11 0 1,13 3,55 0,55
6 9 1 1,24 4,61 0,47
7 2 1 1,29 5,05 0,45
8 1 1 1,31 5,27 0,44
9 8 0 1,25 5,47 0,43
4. Sau đó thông tin của mọi CH còn lại trong “ngân hàng” tại giá trị
năng lực =1,03 được tính và biểu diễn ở Bảng 12.3. CH 4 được chọn tiếp
theo vì nó cho thông tin lớn nhất ở mức năng lực =1,03. Giả sử TS trả lời
đúng CH 4, dùng quy trình MLE ước lượng năng lực TS theo vectơ ứng đáp
4 CH là (1,1,0,1). Năng lực mới ước lượng được là =1,46.
5. Lại tính thông tin của mọi CH còn lại ở mức năng lực mới
=1,46. Quá trình mô tả trên đây được tiếp tục khi chọn một CH mới,
ước lượng năng lực, xác định các thông tin được cung cấp bởi các CH

217
chưa sử dụng, rồi chọn một CH tiếp theo cho TS ứng đáp dựa trên giá trị
thông tin của CH đó… như đã mô tả trên đây. Để tiếp tục quy trình đã nêu,
CH 11 được chọn, tiếp đến là CH 9, CH2, CH 1 và cuối cùng là CH 8. Quá
trình được ngừng lại khi sai số tiêu chuẩn của năng lực TS không tiếp tục
giảm quá một giá trị bé xác định nào đó. Ở ví dụ đã trình bày ở Bảng
12.2 giá trị bé đó là 0,01. Ở thời điểm dừng tính toán giá trị năng lực TS
ước lượng được là =1,25.
Bảng 12.3. Giá trị thông tin do các CH chưa sử dụng cung cấp
ở mỗi bước CAT
Bước Giá trị thông tin cho bởi CH
1 2 3 4 5 6 7 8 9 10 11 12 13
4 1,03 0,034 0,547 - 1,192 0,010 0,051 - 0,143 1,008 0,251 1,101 - 0,166
5 1,46 0,179 0,319 - - 0,004 0,017 - 0,205 0,579 0,136 1,683 - 0,175
6 1,13 0,292 0,494 - - 0,008 0,039 - 0,159 0,917 0,219 - - 0,170
7 1,24 0,249 0,433 - - 0,006 0,029 - 0,175 - 0,187 - - 0,173
8 1,29 0,232 - - - 0,006 0,026 - 0,182 - 0,175 - - 0,174
9 1,31 - - - - 0,005 0,024 - 0,186 - 0,168 - - 0,174
10 1,25 - - - - 0,006 0,028 - - - 0,184 - - 0,173
____________________________

218
CÂU HỎI TỰ KIỂM TRA
1. Các tính năng cần có của một phần mềm hỗ trợ cho trắc nghiệm
nhờ máy tính?
2. Các đặc trưng cơ bản của một mô hình trắc nghiệm nhờ máy tính?
3. Nêu nội dung cơ bản của các mô hình trắc nghiệm nhờ máy tính
CFT, LOFT, các mô hình CAT dựa vào CH, dựa vào phân đề.
4. Mô tả tiến trình thực hiện mô hình trắc nghiệm thích ứng nhờ
máy tính cấu trúc đa giai đoạn (ca-MST) với thiết kế theo bảng và các ưu
nhược điểm của mô hình này.
BÀI TẬP
Trong ví dụ nêu ở chương 12, giả sử một TS thực hiện các CH 3,12
và 3 7 và ứng đáp theo vectơ (1, 1, 0). CH 4 được chọn để thực hiện tiếp
và TS ứng đáp sai. Năng lực được xác định theo MLE cho θ = 0,45. Hãy
tính hàm thông tin cho các CH còn lại ở điểm θ đó. TS sẽ phải thực hiện
CH nào ở bước tiếp theo?

219
Chương 13
CÁC MÔ HÌNH TRẮC NGHIỆM ĐA PHÂN
Cho đến nay chúng ta chỉ làm quen với IRT trong phạm vi rất hẹp,
đó là mô hình đối với trường hợp các CH có kiểu ứng đáp nhị phân
(dichotomous), tương ứng với hai mức điểm 0 và 1, để đo lường chỉ một
năng lực tiềm ẩn, hoặc nói cách khác, đo lường năng lực tiềm ẩn đơn
chiều (unidimentional).
Chương này sẽ giới thiệu việc đo lường năng lực tiềm ẩn đơn
chiều, nhưng bằng các CH với kiểu ứng đáp đa phân (polytomous), tức là
TS có thể ứng đáp không chỉ theo hai mức điểm 0 và 1, mà theo nhiều
mức điểm khác nhau. Trong các mô hình trắc nghiệm đa phân, mô hình
định giá từng phần (partial credit model - PCM) được đặc biệt chú ý vì
tính tổng quát và khả năng ứng dụng rộng rãi của nó. Trong phần ứng
dụng trắc nghiệm đa phân, các ví dụ về phân tích các đề TL được cho
điểm từng phần và phân tích các đề kết hợp TNKQ và TL được minh
họa, đồng thời các phần mềm phổ biến CONQUEST và PARSCALE
được kết hợp giới thiệu.
13.1. MỘT SỐ MÔ HÌNH TRẮC NGHIỆM ĐA PHÂN
Trong thập niên 1970, các nghiên cứu về trắc nghiệm chủ yếu tập
trung vào việc triển khai ứng dụng mô hình nhị phân. Các số liệu liên quan
đến tính đa phân được nhị phân hóa để phân tích. Tuy nhiên một số nhà
nghiên cứu cũng đã lưu ý đến mô hình trắc nghiệm đa phân từ cuối thập
niên 1960 và tập trung mạnh mẽ từ đầu thập niên 1980. Nhà nghiên cứu
quan tâm đến mô hình đa phân sớm nhất có lẽ là Samejima, F.[21], người
đầu tiên đã đưa vào mô hình ứng đáp đa cấp (graded response model).

220
Ở nước ta, trong nhiều cuộc điều tra để tìm hiểu phản ứng của
người được hỏi về một vấn đề nào đó các bảng hỏi (questionnaire) với
kiểu trả lời theo thang Likert: rất không đồng ý, không đồng ý, đồng ý,
rất đồng ý được sử dụng rất phổ biến. Loại bảng hỏi tương tự liên quan
đến mô hình thang đánh giá (rating scale model) của Anderrson E.B,
Andrich D. [23],[24]. Tiếp theo hàng loạt mô hình trắc nghiệm đa phân
được đề xuất: mô hình định giá từng phần của Master G.N. [25], mô hình
định giá từng phần hai tham số hoặc mô hình định giá từng phần tổng
quát (generalised partial credit model) của Yen W.M [29] và Muraki E.
[26]. Các mô hình trên phản ánh sự thực hiện của TS đối với các nhiệm
vụ đa phân theo thứ tự (ordered polytomous tasks), hoặc nói cách khác,
được áp dụng cho các số liệu có phân hạng theo thứ tự (ordered
categorical data).
Vài mô hình đa phân khác, mô hình phân loại theo định danh
(nominal categories model) của Bock R.D.[27] và mô hình ứng đáp (đầy
đủ) cho các CH NLC (response model for multiplechoice items) của
Thissen, D. và Steinberg, L.[28] được đề xuất để áp dụng cho số liệu
không có phân hạng theo thứ tự (unordered data) như là m phương án lựa
chọn cho một CH nhiều lựa chọn. Các mô hình này cho phép thu được
nhiều thông tin hơn về một mức năng lực của TS từ một CH so với điều
chỉ biết TS trả lời đúng hay không.
Các mô hình nêu trên khác nhau chủ yếu ở cách tạo mô hình số liệu
đa phân và số tham số trong mỗi mô hình. Một số mô hình khác nhau sử
dụng cho số liệu cụ thể có thể cho kết quả tương tự. Dưới đây chúng tôi
sẽ chỉ giới thiệu vài mô hình IRT đa phân được sử dụng rộng rãi nhất và
dễ dàng chuyển biến thành các mô hình gần gũi tương tự.
13.1.1. Mô hình định giá từng phần
1) Thiết lập biểu thức:
Để thiết lập mô hình định giá từng phần (partial credit model-
PCM) Masters xét CH có nhiều hạng (category) điểm để TS đạt được, và
giả định rằng xác suất để TS đạt hai hạng điểm kế tiếp nhau tuân theo
quy luật của mô hình Rasch nhị phân.

221
Do vậy, trước hết chúng ta hãy nhớ lại biểu thức (3.4) của mô hình
Rasch đơn giản nhất cho trường hợp CH nhị phân:
θ-b
(θ-b)
eP (θ)=
[1+e ] , (3.4)
hay có thể viết lại:
θ-δ
(θ-δ)
ePr (X=1)=
[1+e ] , (13.1b)
Ở đây, chúng ta hiểu hàm ĐTCH chính là hàm xác suất để đạt hạng
điểm 1 của một CH nhị phân có hai hạng điểm 0 và 1. Chúng ta cũng
thay ký hiệu độ khó bi của CH thứ i bằng ký hiệu δi cho thống nhất với
cách ký hiệu của nhiều sách nước ngoài khi mô tả trắc nghiệm đa phân.
Tương tự, xác suất để đạt hạng điểm 0 của CH nhị phân với hai
hạng điểm 0 và 1 chính là:
(θ-δ)
1Pr (X=0)=
[1+e ] . (13.1a)
Hoặc chúng ta biểu diễn (11.1) và (11.2) dưới dạng tường minh hơn:
1(θ -δ )
Pr(X=0) 1Pr(X=0/X=0 or X=1)= =
Pr(X=0)+Pr(X=1) 1+ e, (13.2a)
đó là xác suất để TS đạt hạng điểm 0 của CH trong điều kiện CH có
hai hạng điểm 0 và 1, và: .
1
1
(θ -δ )
(θ -δ )
Pr(X=1) ePr(X=1/X=0 or X=1)= =
Pr(X=0)+Pr(X=1) 1+e. (13.2b)
đó là xác suất để TS đạt hạng điểm 1 của CH trong điều kiện CH có
hai hạng điểm 0 và 1.
Tương tự, nếu CH nhị phân có 2 hạng điểm 1 và 2 thì chúng ta có
xác suất để TS đạt được hạng điểm 1 và 2 tương ứng là:

222
2
Pr(X=1) 1Pr(X=1/X=1orX=2)= =
Pr(X=1)+Pr(X=2) 1+exp(θ-δ ) , (13.3a)
2
2
exp(θ-δ )Pr(X=2)Pr(X=1/X=1orX=2)= =
Pr(X=1)+Pr(X=2) 1+exp(θ-δ ). (13.3b)
Bây giờ chúng ta hãy xét trường hợp đối với CH đa phân, chẳng
hạn CH có 3 hạng điểm 0,1 và 2. Xác suất để TS đạt được các hạng điểm
tương ứng 0,1,2 xét trong điều kiện CH có 3 hạng điểm tương ứng là:
1 1 2
Pr(X=0)Pr(X=0/X=0,X=1orX=2)= =
Pr(X=0)+Pr(X=1)+Pr(X=2)
1,
1+exp(θ-δ )+exp(2θ-(δ +δ ))
13.4a)
1
1 1 2
Pr(X=1)Pr(X=1/X=0,X=1 or X=2)=
Pr(X=0)+Pr(X=1)+Pr(X=2)
exp( - )==
1 + exp ( - ) + exp (2 -( + ))
(13.4b)
1 2
1 1 2
Pr(X=1)Pr(X=2/X=0,X=1 or X=2)=
Pr(X=0)+Pr(X=1)+Pr(X=2)
exp (2 -( + ))=
1 + exp ( - ) + exp (2 -( + ))
(13.4c)
Trong các biểu thức (13.4) trên đây có thể lưu ý là hệ số đứng trước
θ biểu diễn giá trị hạng điểm của CH đa phân.
Từ đó, tổng quát hơn, khi CH thứ i là đa phân với các hạng điểm
0,1,2,...,mi thì xác suất để TS n đạt điểm x của CH thứ i sẽ là:
i
x
n ik
k=0ni m h
n ik
h=0 k=0
exp (θ -δ )
Pr(X =x)=
exp (θ -δ )
, (13.5)

223
trong đó, để tiện trong việc ký hiệu, chúng ta quy định
1)(exp0
0
ik
k
n . Có thể thử kiểm tra khi CH chỉ có 2 hạng điểm (0,1)
thì (13.5) giản lược thành biểu thức của mô hình Rasch (3.4).
2) Một số lưu ý:
- Mô hình Rasch nhị phân là một trường hợp riêng của PCM. Do
đó các phần mềm tính toán cho PCM có thể sử dụng cho trường hợp nhị
phân mà không phải thực hiện một biến đổi đặc biệt nào, và các CH nhị
phân và CH PCM có thể trộn lẫn khi phân tích.
- Các hạng điểm của PCM là có thứ tự (ordered): Các hạng điểm
0,1,2,..., m của một CH PCM phải tăng theo thứ tự để phản ánh sự tăng dần
của một nămg lực tiềm ẩn nào đó. PCM giả định rằng các TS có năng lực
cao hơn sẽ có khả năng nhiều hơn để đạt các hạng điểm cao hơn của CH.
- Tuy nhiên, PCM không phải là mô hình có các bước tuần tự: Việc
xây dựng PCM chỉ xác định xác suất có điều kiện của hai hạng điểm kế
tiếp nhau. PCM không có đòi hỏi nào về việc phải có một quá trình tuần
tự theo các bước để đạt được các hạng điểm. Điều đó có nghĩa là PCM
không buộc TS phải làm được mọi nhiệm vụ với hạng điểm thấp hơn thì
mới làm được các nhiệm vụ với hạng điểm cao hơn. Điều lưu ý này rất
quan trọng khi giải thích các tham số δk của CH. Chẳng hạn, trong ví dụ
CH có 3 hạng điểm trên đây tham số δ2 không phản ánh độ khó của CH
đối với “bước” thứ 2 như là một bước độc lập.
3) Các đường cong đặc trưng câu hỏi theo PCM và ý nghĩa của δk:
Vì việc thiết lập PCM dựa vào mô hình Rasch nhị phân đối với
2 hạng điểm kế tiếp nhau nên thường gây hiểu nhầm rằng δk là độ khó của
bước thứ k khi bước thứ k được xem như một CH độc lập. Việc giải thích δk
sẽ được làm rõ sau này qua các đồ thị biểu diễn các đường cong ĐTCH.
Các đường cong ĐTCH theo PCM là đồ thị biểu diễn các xác suất
đạt được mỗi hạng điểm phụ thuộc vào năng lực θ.

224
Hình 13.1. Các đường cong ĐTCH trắc nghiệm nhị phân ứng với xác suất trả lời sai P(X=0) và xác suất trả lời đúng P(X=1)
Hình 13.2. Các đường cong ĐTCH của một CH PCM có 3 hạng điểm (với δ1 < δ2)
Đối với mô hình Rasch nhị phân, người ta ít quan tâm đến đường
cong biểu diễn xác suất đạt hạng điểm 0, vì xác suất đó đơn giản bằng [1-
P(θ)], và đường biểu diễn của nó chính là đường cong đối xứng với

225
đường P(θ) qua trục thẳng đứng đi qua điểm có hoành độ θ khi
P(θ) =0,5 (Hình 13.1). Các biểu thức (13.1a) và (13.1b) cho thấy hai
đường cong P(θ) và [1-P(θ)] cắt nhau khi θ=δ, và khi ấy P(θ) =0,5.
Hình 13.3. Các đường cong ĐTCH đối với một CH PCM có 3 hạng điểm (với δ1> δ2)
Hình 13.2 biểu diễn các đường cong ĐTCH lý thuyết của một CH
PCM với 3 hạng điểm 0, 1 và 2. Từ các biểu thức 13.4a, 13.4b và 13.4c
có thể thấy khi θ=δ1 thì P(X=0) = P(X=1), và khi θ=δ2 thì P(X=1) =
P(X=2), và các giá trị xác suất tương ứng bé hơn 0,5 vì các mẫu số lớn
hơn 2. Từ Hình 13.2 có thể thấy 2 giá trị δ1 và δ2 chia dải năng lực ra làm
3 vùng. Khi TS có năng lực nằm trong vùng từ -∞ đến δ1 thì xác suất đạt
được hạng điểm 0 là lớn nhất, khi TS có năng lực nằm trong vùng từ δ1
đến δ2 thì xác suất đạt được hạng điểm 1 là lớn nhất, khi TS có năng lực
nằm trong vùng từ δ2 đến +∞ thì xác suất đạt được hạng điểm 2 là lớn
nhất. Trong các khẳng định trên đây lưu ý là xác suất đạt được hạng điểm
tương ứng là lớn nhất so với riêng rẽ xác suất đạt các hạng điểm khác,
nhưng có thể bé hơn xác suất tổng hợp để đạt được các hạng điểm khác.

226
Chẳng hạn ở Hình 13.2 trong vùng từ δ1 đến δ2 thì xác suất tổng hợp để
đạt được hạng điểm 0 và 2 cao hơn xác suất đạt được hạng điểm 1. Từ
các nhận xét trên, nếu dùng tham số δ làm chỉ thị về ”độ khó của CH” thì
có thể nói rằng, chẳng hạn, δ1 là điểm mà bắt đầu từ đó xác suất đạt được
hạng điểm 1 cao hơn xác suất đạt được hạng điểm 0, và cũng tương tự, δ2
là điểm mà bắt đầu từ đó xác suất đạt được hạng điểm 2 cao hơn xác suất
đạt được hạng điểm 1.
Cần lưu ý là có một vấn đề đối với PCM khi giải thích tham số δ.
Đối với một số CH, giá trị của tham số δk có thể không diễn biến theo
“thứ tự”. Chẳng hạn, xét ví dụ một CH PCM 3 hạng điểm được biểu diễn
trên Hình 13.3. Trong vùng ứng với hạng điểm 1 ở giữa đường cong xác
suất có giá trị rất thấp, tức là rất ít TS đạt hạng điểm 1, hoặc hạng điểm 1
là hạng điểm không thật phổ biến. Trường hợp này làm cho việc giải
thích các đường cong ĐTCH gặp khó khăn: không có mức năng lực nào
của TS mà xác suất đạt được hạng điểm 1 cao nhất, và giá trị các tham số
δ1 và δ2 diễn biến không theo thứ tự (trường hợp này δ1 > δ2). Chính đây
là một nhược điểm khi dùng δ để giải thích việc trả lời CH liên quan đến
năng lực. Tuy nhiên, Masters [25] cho rằng tính không tăng theo thứ tự
giá trị tham số δ không nhất thiết chứng tỏ là CH l có vấn đề, vì khi thiết
lập PCM người ta đã không đòi hỏi nghiêm khắc rằng giá trị của δ phải
tăng theo thứ tự. Điều quan trọng được đòi hỏi khi xây dựng PCM là lúc
xem xét một TS ứng đáp CH có các hạng điểm (k-1) và k thì xác suất đạt
hạng điểm k phải tuân theo mô hình Rasch. Nếu CH chỉ có 2 hạng điểm
(k-1) và k thì có một xác suất bằng nhau để đạt hạng điểm (k-1) hoặc k,
xác suất đó là 0,5. Khi CH có nhiều hạng điểm hơn, như ở trường hợp
Hình 13.3, tham số δ vẫn là vị trí ứng với năng lực mà xác suất để đạt
2 hạng điểm tiếp giáp nhau là bằng nhau, tuy nhiên xác suất ở giao điểm
đó không còn bằng 0,5, vì còn có các xác suất để đạt các hạng điểm khác
với (k-1) và k. Ở Hình 13.3 xác suất để đạt hạng điểm 1 là rất bé trong
suốt cả dải rộng năng lực (có thể do hạng điểm 2 quá dễ đạt) cho nên
hoành độ giao điểm giữa các đường cong xác suất đạt hạng điểm 0 và 1
có giá trị lớn hơn các hoành độ giao điểm giữa các đường cong xác suất
đạt hạng điểm 1 và 2; 0 và 2. Khi áp dụng PCM cho các CH mà các hạng
điểm ứng với các bước tuần tự để giải các bài toán, hiện tượng giá trị δ

227
tăng không tuần tự rất dễ xảy ra. Ví dụ, một bài toán đòi hỏi bước 1 phải
thiết lập biểu thức nghiệm của bài toán, bước 2 là tính toán bằng số để có
nghiệm cụ thể, cho điểm 2 nếu làm được trọn vẹn, còn điểm 1 nếu tìm
được đúng biểu thức nhưng tính toán sai. Số TS đạt hạng điểm 0 và điểm
2 có thể nhiều, nhưng số TS đạt hạng điểm 1 có thể rất ít, kết quả ứng
đáp sẽ tương tự như CH được biểu diễn ở Hình 13.3.
4) Một vài tham số khác được sử dụng trong PCM
Từ các tham số chính δ của CH PCM nhiều tác giả đề nghị sử dụng
các dạng thức biến đổi khác của tham số để dễ giải thích kết quả hơn.
- Giá trị trung bình δ• của các δk: được tính theo công thức sau đây
và được biểu diễn bằng δ• (delta chấm):
m
• k
k=1
1δ = δ ,
m . (13.6)
trong đó m là số hạng điểm của CH.
- Khoảng cách τk từ các δk đến giá trị trung bình δ•:
τk = δ• - δk (13.7)
Có thể minh họa về các tham số δ• và τk nhờ Hình 13.4 biểu diễn
các đường cong của CH theo PCM với 5 hạng điểm, trên đó có vẽ vị trí
của δ• và các khoảng cách τk. Từ Hình 13.4 có thể giải thích các tham số
vừa nêu như sau: 1) δ• là giá trị độ khó trung bình của các CH theo PCM,
có thể sử dụng chỉ một độ khó trung bình đó cho toàn bộ CH PCM nếu
không muốn xét từng độ khó δk của từng hạng điểm riêng biệt. 2) Các
tham số τk được gọi là các ”tham số bước”, nó chỉ khoảng cách từ giá trị
độ khó trung bình đến các hạng điểm của đường đặc trưng PCM. Tham
số τk cũng phải chịu các vấn đề về tính không biến đổi tuần tự như tham
số δk..
Về toán học, δ• chính là hoành độ giao điểm của hai đường biểu
diễn xác suất ứng với hạng điểm đầu và hạng điểm cuối, chẳng hạn Pr(0)
và Pr(4) trên Hình 13.4. Đối với CH PCM 3 hạng điểm, hai đường cong

228
Pr(0) và Pr(2) đối xứng với nhau qua đường thẳng θ = δ•, còn đường
cong Pr(1) cũng có trục đối xứng là đường thẳng đó. Các tính chất trên
không được duy trì khi số hạng điểm lớn hơn 3.
Hình13.4. Ý nghĩa của các tham số δk. và k liên quan đến các đường cong ĐTCH theo mô hình PCM
5) Các đường cong xác suất tích lũy và các tham số ngưỡng
Thurstone γ:
Như đã nói trước đây, trong PCM, các tham số δ không phản ánh
độ khó để đạt các hạng điểm. Đối với các CH PCM, để đạt được hạng
điểm 2 nói chung TS cần thực hiện được nhiều nhiệm vụ hơn so với đạt
hạng điểm 1. Để phản ánh thành tựu tích lũy đó đôi khi người ta sử dụng
các ngưỡng Thurstone để chỉ “độ khó” của các mức điểm.
Ngưỡng Thurstone đối với một hạng điểm được xác định như là
năng lực để từ đó xác suất để có được hạng điểm đó hoặc cao hơn đạt giá
trị 0,5.
Từ đồ thị các đường cong xác suất để TS đạt các hạng điểm của
một CH PCM, chẳng hạn có 5 hạng điểm, có thể vẽ các đường cong xác
suất tích lũy. Ví dụ, đường cong xác suất tích lũy Pr (≥1) để TS đạt hạng
điểm 1 và cao hơn thu được bằng cách cộng Pr(1) + Pr(2) +...+ Pr(5),

229
đường cong xác suất tích lũy Pr(≥2) để TS đạt hạng điểm 2 và cao hơn
thu được bằng cách cộng Pr(2) + Pr(3) +...+ Pr(5),... Hình 13.4 biểu diễn
đồ thị các đường cong xác suất tích lũy nêu trên. Đường thẳng Pr(θ)=0,5
cắt các đường cong xác suất tích lũy lần lượt tại các điểm có hoành độ γ1,
γ2, γ3, γ4, các giá trị đó được gọi là các ngưỡng Thurstone.
Hình13.5. Các đường cong xác suất tích lũy và các tham số ngưỡng
Thurstone k của một CH theo mô hình PCM với 5 hạng điểm
Từ đồ thị Hình 13.5 có thể giải thích ý nghĩa của các ngưỡng
Thurstone nói trên. Khi năng lực TS dịch chuyển theo trục nằm ngang từ
-∞ đến γ1 thì xác suất đạt điểm 0 là lớn hơn 0,5; trong khi xác suất để đạt
được điểm ≥ 1 bé hơn 0,5; do đó có thể gọi khoảng -∞ đến γ1 là “vùng
điểm 0”. Khi năng lực tăng từ γ1 đến γ2 xác suất để đạt được điểm ≥ 1 là
lớn hơn 0,5; trong khi xác suất để đạt được điểm ≥ 2 là bé hơn 0,5; do đó
có thể gọi khoảng γ1 đến γ2 là “vùng điểm 1”. Bằng cách lập luận tương
tự chúng ta có các “vùng điểm 2”, “vùng điểm 3”, “vùng điểm 4”. Từ
quan điểm đó, có thể xem các ngưỡng Thurstone là các điểm cắt để chia
dải năng lực thành các “vùng điểm”. Đối chiếu với trường hợp CH nhị
phân thì đường cong tích lũy Pr(≥1) trên đây trùng với đường cong
ĐTCH của mô hình Rasch nhị phân, và độ khó b chính là hoành độ ứng
với điểm mà xác suất trả lời đúng CH bằng 0,5; tức là b trùng với γ1, như
vậy độ khó của CH trong trường hợp nhị phân cũng chính là điểm

230
ngưỡng, nó chia dải năng lực thành 2 vùng: “vùng điểm 0” và “vùng
điểm 1”, và độ khó b của CH ứng với điểm bắt đầu của “vùng điểm 1”.
Như vậy có thể xem γ1 là số đo độ khó ứng với hạng điểm 1, γ2 là số đo độ
khó ứng với hạng điểm 2,... Chẳng hạn, nếu các ngưỡng Thurstone của
một CH PCM 3 hạng điểm là -1,2 và 2,3 logit, thì điều đó có nghĩa là
tương đối dễ đạt điểm 1 nhưng rất khó đạt điểm 2, vì “vùng điểm 1” quá
rộng và “vùng điểm 2” ứng với năng lực quá cao.
Hình 13.6. Đường cong điểm kỳ vọng của một CH PCM với 3 hạng điểm
Chúng ta hãy tính điểm kỳ vọng của một CH xem như một hàm của
năng lực. Hãy giả thiết CH có 3 hạng điểm, xác suất để một TS đạt được
điểm 0, điểm 1 và điểm 2 được biểu diễn bởi các hệ thức (13.4a, b, c).
Điểm kỳ vọng E đối với CH đó xem như một hàm của θ với các tham số
δ1 và δ2 là:
E= 0 . Pr(X=0) + 1 . Pr(X=1) + 2 . Pr(X=2). (13.8)
Khi tính E như một hàm của θ ta có thể biểu diễn đường cong điểm
kỳ vọng, tương tự như đường cong ĐTCH. Ví dụ minh họa được biểu
diễn ở Hình 13.6. Từ hình vẽ có thể xác định E1 là hoành độ ứng với
điểm kỳ vọng 0,5; nằm giữa hạng điểm 0 và 1, E2 là hoành độ ứng với
điểm kỳ vọng 1,5; nằm giữa hạng điểm 1 và 2. Có thể xem vùng nằm
giữa E1 và E2 là “vùng điểm 1”, vùng nằm trước E1 là “vùng điểm 0”,
vùng nằm sau E2 là “vùng điểm 2”. Như vậy, có thể xem E1 là tham số độ
khó của CH đối với điểm 1, E2 là tham số độ khó của CH đối với điểm 2.
Cách biểu diễn này dễ hiểu hơn đối với những người không chuyên.

231
13.1.2. Mô hình định giá từng phần tổng quát
Việc lập luận để đưa ra mô hình PCM hoàn toàn xuất phát từ mô
hình Rasch cho CH nhị phân, tức là chỉ quan tâm đến độ khó của CH,
không xét đến độ phân biệt. Một số tác giả mong muốn xây dựng mô
hình đa phân có sử dụng cả độ phân biệt của CH. Yen, W.M. [29] và
Muraki, E. [26] đã đưa ra mô hình định giá toàn phần tổng quát, trong đó
ngoài tham số phản ánh độ khó của CH còn sử dụng cả tham số phản ánh
độ phân biệt. Biểu thức tổng quát về xác suất ứng đáp CH đa phân cho
mô hình định giá từng phần tổng quát (GPCM) có dạng như sau:
i
h
ik
k-1th m l
ik
l-1 k-1
exp Z (θ)
P (θ)= ,
exp Z (θ)
(13.8)
trong đó mi là số lượng hạng điểm của CH GPCM thứ i; Zik= aik(θ -
δi + γik), với ai đặc trưng cho độ phân biệt, được gọi là tham số độ dốc
(slope parameter), δi được gọi là tham số định vị CH (item location), còn
γik được gọi là tham số ngưỡng của hạng điểm (category threshold).
Hình 13.7. Các đường cong ĐTCH theo mô hình GPCM với các tham số a khác nhau

232
Khi sử dụng cả đặc trưng độ phân biệt, các đường cong ĐTCH
GPCM với các giá trị a khác nhau sẽ có độ dốc khác nhau. Hình 13.7
trích từ công trình [13] biểu diễn minh họa các hàm Pih (θ) ứng với một
CH GPCM với 3 hạng điểm, các đường P1h(θ) ứng với a1 = 1,0; b11=0,0;
b12=-1,5; các đường P2h(θ) ứng với b12=-0,5; a2 < a1 còn các tham số khác
giữ nguyên. Hình vẽ cho thấy độ dốc của các đường cong P2(θ) giảm so
với các đường cong P1(θ), giao điểm của các đường cong P11 (θ) và
P12(θ) có hoành độ bằng b12=-1,5; giao điểm của các đường cong P21 (θ)
và P22(θ) có hoành độ bằng b12=-0,5.
13.2. CÁC VÍ DỤ VỀ ỨNG DỤNG TRẮC NGHIỆM ĐA PHÂN
13.2.1. Phân tích các bài kiểm tra gồm các CH tự luận
nhờ phần mềm CONQUEST
Để minh họa việc áp dụng trắc nghiệm đa phân vào thực tiễn đánh
giá trong giáo dục ở nước ta, chúng tôi xin mượn số liệu khảo sát kết quả
học tập của học sinh lớp 6 vào năm 2009 do Viện Khoa học Giáo dục
Việt Nam thực hiện theo một Dự án của Bộ Giáo dục và Đào tạo. Khảo
sát được triển khai trên cơ sở đánh giá kết quả học tập 2 môn Toán và
Ngữ văn, thực hiện trên các mẫu đại diện của học sinh lớp 6 từ 250
trường trung học cơ sở thuộc 25 tỉnh/thành phố, đại diện cho 8 vùng
miền trên cả nước. Ở đây chúng tôi chỉ lấy số liệu để nêu ví dụ về kỹ
thuật phân tích, còn việc công bố các kết quả đánh giá cụ thể thuộc thẩm
quyền của các cơ quan quản lý giáo dục.
Các đề kiểm tra Ngữ văn có hai phần: TNKQ và TL. Phần
TNKQ bao gồm các CH nhị phân, mỗi câu có 2 mức điểm 1 và 0,
được chấm tự động. Phần TL được chia thành nhiều câu, mỗi câu có
một số phần, điểm tối đa của mỗi phần được quy định. Ở đây phần TL
sẽ được tách ra phân tích như một đề độc lập. Chúng ta sẽ quy ước ký
hiệu 4 CH của phần TL là VTL1 – VTL4. Các CH VTL1 – VTL3 là
các CH mở, trả lời ngắn. CH VTL4 là một bài viết dài hơn, được cho
điểm theo các ý theo 3 phần về nội dung, 2 phần về hình thức và 1
phần dành cho các ý có sáng tạo. Mỗi phần được xem như một CH con
có số điểm tối đa được mô tả ở Bảng 13.1.

233
Bảng 13.1. Điểm tối đa cho các phần con trong các CH TL Ngữ văn
Phần a Phần b Phần c
VTL1 1a: 2 1b: 3
VTL2 2a: 2 2b: 3
VTL3 5
VTL4 nd-a: 3 nd-b: 5 nd-c: 2
ht-a: 4 ht-b: 4 st: 2
Như vậy phần TL của đề Ngữ văn có thể xem là một đề bao gồm
các CH con kiểu PCM như sau: CH1 (VTL1a và VTL1b); CH2 (VTL2a
và VTL2b); CH3; CH4 (VTL4nd-a, VTL4nd-b, VTL4nd-c; VTL 4 ht-a,
VTL 4 ht-b; VTL 4 st). Tổng cộng phần TL có 11 CH con, với tổng điểm
tối đa là 35 điểm.
Bài kiểm tra được triển khai trên mẫu gồm 9844 TS là học sinh lớp 6.
Phần TL được một số giáo viên chấm theo thang điểm tối đa phân bố như
ở Bảng 13.1 trên đây, điểm do giáo viên chấm có thể xem là điểm thô của
các CH con thuộc phần TL, dùng làm số liệu đầu vào để phân tích.
Chúng ta sẽ sử dụng phần mềm CONQUEST [31] (của Australian
Council of Educational Research – ACER, do Margaret L. Wu, Raymond
J. Adams viết) để phân tích phần TL đề Ngữ văn. CONQUEST là phần
mềm được xây dựng theo IRT với mô hình Rasch đa chiều tổng quát
(generalised multidimentional Rasch Item Response model). Trong
trường hợp một chiều CONQUEST cho phép phân tích cả mô hình Rasch
đơn giản và mô hình PCM, trong đó mô hình trước là một trường hợp
riêng của mô hình sau.
Dưới đây sẽ dẫn một số kết quả phân tích.
Trước hết, Bảng 13.2 cho kết quả ước lượng các tham số độ khó
trung bình δ• (ESTIMATE) của các CH con và các tham số biểu thị độ
phù hợp giữa số liệu và mô hình. MNSQ là bình phương trung bình của
số thống kê phản ánh độ phù hợp (giá trị kỳ vọng bằng 1), CI là khoảng
tin cậy (confident interval), T là giá trị t-test (giá trị càng bé càng tốt,
nhưng giá trị tăng khi cỡ mẫu tăng).

234
Bảng 13.2. Độ khó trung bình δ• của các CH con
==============================================================================
ConQuest: Generalised Item Response Modelling Software Sat Jan 09 13:47 2010
TABLES OF RESPONSE MODEL PARAMETER ESTIMATES
==============================================================================
VARIABLES UNWEIGHTED FIT WEIGHTED FIT
--------------- ----------------------- ---------------------
item ESTIMATE ERROR^ MNSQ CI T MNSQ CI T
------------------------------------------------------------------------------
1 VTL1a -0.539 0.012 1.20 (0.97, 1.03) 13.3 1.09 (0.97, 1.03) 7.0
2 VTL1b -1.541 0.012 1.47 (0.97, 1.03) 28.6 1.19 (0.96, 1.04) 7.7
3 VTL2a -0.439 0.011 1.18 (0.97, 1.03) 11.7 1.15 (0.97, 1.03) 10.3
4 VTL2b -0.314 0.010 1.09 (0.97, 1.03) 6.3 1.08 (0.97, 1.03) 5.7
5 VTL3 0.435 0.008 1.37 (0.97, 1.03) 23.5 1.34 (0.97, 1.03) 21.7
6 VTL4nda -0.160 0.012 1.14 (0.97, 1.03) 9.4 1.09 (0.97, 1.03) 6.5
7 VTL4ndb 0.014 0.010 0.75 (0.97, 1.03)-19.0 0.75 (0.97, 1.03) -18.8
8 VTL4ndc 0.611 0.012 1.08 (0.97, 1.03) 5.5 1.08 (0.98, 1.02) 6.1
9 VTL4hta -0.124 0.011 0.76 (0.97, 1.03)-18.2 0.77 (0.97, 1.03) -17.4
10 VTL4htb 0.430 0.011 0.78 (0.97, 1.03)-16.3 0.79 (0.97, 1.03) -16.3
11 VTL4st 1.627* 0.035 0.84 (0.97, 1.03)-11.8 0.87 (0.97, 1.03) -9.5
------------------------------------------------------------------------------
An asterisk next to a parameter estimate indicates that it is constrained
Separation Reliability = 1.000
Chi-square test of parameter equality = 27038.85, df = 10, Sig Level = 0.000
^ Quyck standard errors have been used
==============================================================================
Bảng 13.3 cho ví dụ minh họa về ước lượng các tham số bước (τk= δk- δ0)
ứng với các hạng điểm của các CH con do CH3 và CH4 sinh ra và các sai số
tiêu chuẩn cũng như các tham số biểu thị độ phù hợp giữa số liệu và mô hình.
Bảng 13.3. Ví dụ về tham số bước τk(tau) ứng với các hạng điểm của các CH con
=========================================================================== VARIABLES UNWEIGHTED FIT WEIGHTED FIT
---------------- ----------------------- -------------
item step ESTIMATE ERROR^ MNSQ CI T MNSQ CI T
---------------------------------------------------------------------------
...........................................................................
3 VTL2a 0 1.17 (0.97, 1.03) 11.3 1.16 (0.97, 1.03) 10.9
3 VTL2a 1 1.442 0.039 1.00 (0.97, 1.03) 0.1 1.00 (0.94, 1.06) 0.1
3 VTL2a 2 -1.442* 1.15 (0.97, 1.03) 10.3 1.10 (0.98, 1.02) 7.9
4 VTL2b 0 1.34 (0.97, 1.03) 21.8 1.06 (0.97, 1.03) 3.6
4 VTL2b 1 -0.308 0.022 0.99 (0.97, 1.03) -0.9 1.01 (0.97, 1.03) 0.5
4 VTL2b 2 0.605 0.029 1.08 (0.97, 1.03) 5.5 1.01 (0.96, 1.04) 0.6
4 VTL2b 3 -0.296* 1.06 (0.97, 1.03) 4.2 1.00 (0.98, 1.02) -0.4
....................................................................
========================================================================
Hình 13.8 là biểu đồ tương quan giữa năng lực θ của TS và độ khó
trung bình δ• của các CH con đặt theo trục thẳng đứng theo thang logit,
hướng dương từ dưới lên, mức 0 của thang được xác định theo giá trị của ==================================================================
ConQuest: Generalised Item Response Modelling Software. Sat Jan 09 12:47 2010

235
MAP OF LATENT DISTRIBUTIONS AND RESPONSE MODEL PARAMETER ESTIMATES
==================================================================
Terms in the Model (excl Step terms) +item
------------------------------------------------------------------
3 | |
| |
| |
X| |
X| |
X| |
XX| |
2 X| |
XX| |
XX| |
XXXX|11 |
XXXX| |
XXXXX| |
XXXXXX| |
1 XXXXX| |
XXXXXX| |
XXXXXX| |
XXXXXXXX|8 |
XXXXXXXX|5 |
XXXXXXXXXX|10 |
XXXXXXXX| |
XXXXXXXXX| |
0 XXXXXXXX|7 |
XXXXXXXXX|6 9 |
XXXXXXXXX|4 |
XXXXXXXX|3 |
XXXXXXX|1 |
XXXXXXX| |
XXXX| |
-1 XXXX| |
XXXX| |
XXX| |
XX| |
XX|2 |
XX| |
X| |
-2 X| |
X| |
X| |
| |
| |
| |
| |
-3 | |
====================================================
Each 'X' represents 60.7 cases
====================================================
Hình 13.8. Biểu đồ tương quan giữa năng lực TS và độ khó trung bình của các CH con
ConQuest: Generalised Item Response Modelling Software Sat Jan 09 12:47 2010
MAP OF LATENT DISTRIBUTIONS AND THRESHOLDS
==================================================================
Generalised-Item Thresholds
------------------------------------------------------------------

236
|10.4
4 |
|
|
|
|
|7.5
|
3 |
|9.4
|11.2
X|
X|
X|
XX|
2 X|
XX|6.3
XX|5.5
XXXX|
XXXX|8.2
XXXXX|7.4
XXXXXX|
1 XXXXX|5.4 10.3
XXXXXX|
XXXXXX|
XXXXXXXX|
XXXXXXXX|5.3 11.1
XXXXXXXXXX|9.3
XXXXXXXX|4.3
XXXXXXXXX|
0 XXXXXXXX|5.2
XXXXXXXXX|1.2 4.2
XXXXXXXXX|3.2 7.3 8.1
XXXXXXXX|
XXXXXXX|3.1 6.2
XXXXXXX|
XXXX|1.1
-1 XXXX|2.3 4.1 10.2
XXXX|5.1
XXX|9.2
XX|
XX|
XX|2.2 7.2
X|6.1
-2 X|2.1
X|
X|
|9.1 10.1
|7.1
==================================================================
Each 'X' represents 60.7 cases
The labels for thresholds show the levels ofitem, and step, respectively
==================================================================
Hình 13.9. Biểu đồ tương quan giữa năng lực TS và các giá trị ngưỡng γk của các hạng điểm trong các CH con
độ khó. Hình 13.9 là biểu đồ tương tự về tương quan giữa năng lực θ của
TS và các giá trị ngưỡng Thurstone γk ứng với các hạng điểm của các CH
con, các con số trên biểu đồ, ví dụ như 6.3, thì chữ số đầu biểu diễn số
hiệu CH, chữ số thứ hai biểu diễn hạng điểm.

237
Ngoài các tham số được ước lượng trên đây, CONQUEST còn cung
cấp các đặc trưng liên quan đến từng CH con. Bảng 13.4 giới thiệu các
thông tin liên quan đến hai CH con VTL2a và VTL2b, đó là các giá trị độ
phân biệt (discrimination), các giá trị ngưỡng (thresholds) Thurstone γk, các
giá trị độ khó δk ứng với các hạng điểm cũng như sai số tiêu chuẩn và các
tham số thể hiện độ phù hợp của số liệu với mô hình.
Bảng 13.4. Ví dụ về thông tin liên quan đến các CH con VTL2a và VTL2b. ==========================================================================
..........................................................................
item:3 (VTL2a)
Cases for this item 9844 Discrimination 0.58
Item Threshold(s): -0.56 -0.32 Weighted MNSQ 1.15
Item Delta(s): 1.00 -1.88
--------------------------------------------------------------------------
Label Score Count % of tot Pt Bis t (p) PV1Avg:1 PV1 SD:1
--------------------------------------------------------------------------
0 0.00 2948 29.95 -0.54 -64.41(.000) -0.63 0.84
1 1.00 727 7.39 -0.10 -10.34(.000) -0.22 0.83
2 2.00 6168 62.66 0.57 69.20(.000) 0.58 0.90
9 0.00 1 0.01 -0.02 -2.11(.035) -1.42 0.00
==========================================================================
item:4 (VTL2b)
Cases for this item 9844 Discrimination 0.70
Item Threshold(s): -1.00 -0.16 0.28 Weighted MNSQ 1.08
Item Delta(s): -0.62 0.29 -0.61
--------------------------------------------------------------------------
Label Score Count % of tot Pt Bis t (p) PV1Avg:1 PV1 SD:1
--------------------------------------------------------------------------
0 0.00 1967 19.98 -0.53 -62.57(.000) -0.84 0.86
1 1.00 2020 20.52 -0.23 -23.59(.000) -0.29 0.71
2 2.00 1440 14.63 -0.02 -1.80(.073) 0.08 0.76
3 3.00 4416 44.86 0.63 80.48(.000) 0.83 0.82
9 0.00 1 0.01 -0.02 -2.11(.035) -1.42 0.00
==========================================================================
..........................................................................
CONQUEST cũng cho phép vẽ đồ thị của các loại hàm khác nhau
mô tả tính chất của các CH và của đề kiểm tra. Dưới đây sẽ lần lượt giới
thiệu các ví dụ minh họa.
Hình 13.10 nêu ví dụ về các đường cong đặc trưng của CH con
VTL2b với 4 hạng điểm 0,1,2,3. Dưới đồ thị có ghi các giá trị của δk ứng
với 3 hạng điểm, các giá trị này trùng hợp với các giá trị ở Bảng 13.4. Có
thể thấy các giá trị này ứng với hoành độ giao điểm của các đường cong
xác suất đạt được các hạng điểm của CH con, và các giá trị δk không tăng
tuần tự, như đã lưu ý ở 13.1.1, vì xác suất để đạt hạng điểm 2 quá bé.
Hình 13.11 nêu ví dụ về các đường cong xác suất tích lũy của CH
con VTL2b ứng với 3 hạng điểm 1,2,3. Dưới đồ thị có ghi các giá trị

238
ngưỡng Thurstone γk ứng với các 3 hạng điểm 1,2,3. Có thể thấy các giá
trị này ứng với hoành độ giao điểm của các đường đó với đường thẳng
song song với trục hoành đi có tung độ bằng 0,5. Hoành độ của các giao
điểm nói trên chia trục năng lực θ lần lượt thành các vùng điểm 0, 1, 2, 3.
Hình 13.10. Các đường cong đặc trưng của CH con VTL2b
với 4 hạng điểm
Hình 13.11. Các đường cong xác suất tích lũy của CH con VTL2b
ứng với 3 hạng điểm
Hình 13.12 nêu ví dụ về các đường cong điểm kỳ vọng của CH con
VTL2b. Đây là một đường cong đồng biến biểu diễn sự tăng xác suất đạt
các hạng điểm cao hơn khi tăng năng lực θ, và điểm kỳ vọng lớn nhất là
hạng điểm 3.

239
Hình 13.12. Đường cong điểm kỳ vọng của CH con VTL2b
Hình 13.13 nêu ví dụ về các đường cong hàm thông tin của CH con
VTL2b. Đường cong chứng tỏ CH đang xét cung cấp thông tin để đo chính
xác khoảng năng lực ở mức trung bình, thông tin cực đại ở giá trị θ ≈ 0.
Hình 13.13. Đường cong hàm thông tin của CH con VTL2b
Cuối cùng là các đồ thị mô tả các đặc trưng của toàn bộ đề kiểm tra
gồm 3 CH TL (bao gồm 11 CH con). Hình 13.14 biểu diễn đường cong
hàm thông tin tổng thể của đề kiểm tra. Hàm thông tin chứng tỏ đề kiểm
tra cung cấp thông tin để đo chính xác khoảng năng lực trung bình của TS.
Hình 13.15 biểu diễn đường cong đặc trưng của đề kiểm tra (đường cong
điểm thực). Đây là một đường cong đồng biến với năng lực θ, nhánh phải
tiệm cận với giá trị điểm cực đại của đề kiểm tra (35 điểm).

240
Cuối cùng, Bảng 13.5 trích giới thiệu các giá trị năng lực tiềm ẩn
của TS, các sai số tiêu chuẩn của ước lượng và điểm thô tương ứng của
TS. Từ ước lượng năng lực có thể xác định điểm thực của từng TS nhờ
quan hệ giữa năng lực θ và điểm thực τ theo công thức (6.4) ở chương 6
và thể hiện trên đường cong điểm thực vừa mô tả.
Hình 13.14. Đường cong hàm thông tin tổng thể của
đề kiểm tra tự luận môn Ngữ văn
Hình 13.15. Đường cong đặc trưng tổng thể (đường cong điểm thực)
của đề kiểm tra tự luận môn Ngữ văn

241

242
Bảng 13.5. Trích các giá trị năng lực tiềm ẩn và điểm thô tương ứng của TS
Thí sinh Điểm thô Điểm thô
tối đa Năng lực θ
Sai số tiêu chuẩn
1
2
3
4
5
6
7
8
9
10
............
9835
9836
9837
9838
9839
9840
9841
9842
9843
9844
29.00
29.00
29.00
29.00
28.00
23.00
21.00
31.00
27.00
26.00
...........
11.00
20.00
21.00
8.00
21.00
13.00
8.00
11.00
17.00
29.00
35.00
35.00
35.00
35.00
35.00
35.00
35.00
35.00
35.00
35.00
...........
35.00
35.00
35.00
35.00
35.00
35.00
35.00
35.00
35.00
35.00
1.92331
1.92331
1.92331
1.92331
1.64703
0.63957
0.32447
2.62205
1.40487
1.18843
...........
-1.09265
0.17624
0.32447
-1.55648
0.32447
-0.80292
-1.55648
-1.09265
-0.24699
1.92331
0.54413
0.54413
0.54413
0.54413
0.50415
0.40659
0.38795
0.64275
0.47617
0.45299
...........
0.38482
0.38178
0.38795
0.40454
0.38795
0.37725
0.40454
0.38482
0.37158
0.54413
Trên đây chúng tôi chỉ trình bày các kết quả chính mà CONQUEST
cung cấp. Bạn đọc muốn tìm hiểu kỹ hơn về phần mềm này có thể tham
khảo ở tài liệu [31] và trang web [30].
13.2.2. Phân tích các bài kiểm tra gồm hỗn hợp các CH trắc nghiệm
khách quan và tự luận nhờ phần mềm CONQUEST

243
Như đã thảo luận ở chương 1, TNKQ và TL có những ưu nhược
điểm khác nhau, và trong một đề kiểm tra nếu kết hợp được cả các CH
TNKQ và TL thì chúng ta có thể sử dụng được ưu điểm của hai loại.
Phân tích đề kiểm tra hỗn hợp TNKQ và TL có thể thực hiện được
nếu sử dụng các mô hình IRT đơn chiều kết hợp, chẳng hạn mô hình Rasch
nhị phân và PCM, hoặc mô hình IRT nhị phân 2, 3 tham số với GPCM.
Để minh họa, dưới đây chúng tôi sẽ giới thiệu một đề kiểm tra môn
Vật lý sử dụng cho kỳ khảo sát kết quả học tập của học sinh lớp 9 cũng
do Viện Khoa học Giáo dục Việt Nam triển khai năm 2009.
Đề kiểm tra Vật lý gồm 2 phần:
- Phần TNKQ gồm 30 CH theo kiểu NLC có 4 phương án trả lời,
chúng ta sẽ quy ước ghi nhãn các CH TNKQ theo thứ tự từ L1 đến L30.
Mỗi CH TNKQ trả lời đúng được tính 1 điểm, như vậy phần TNKQ của
đề Vật lý được tối đa 30 điểm.
- Phần TL gồm 3 CH, mỗi CH TL được chia thành các phần con
với mức điểm tối đa được quy định.
Có thể mô tả phân bố điểm của đề kiểm tra hỗn hợp môn Vật lý
nhờ Bảng 13.6.
Bảng 13.6. Điểm tối đa cho các phần của CH hỗn hợp TNKQ và TL môn Vật lý
Phần a Phần b Phần c Phần d
L1 1
L2 1
L30 1
LTL31 31a: 1 31b: 4
LTL32 32a: 1 32b: 2 32c: 1 32d: 1
LTL33 33a: 2 33b: 2 33c: 1
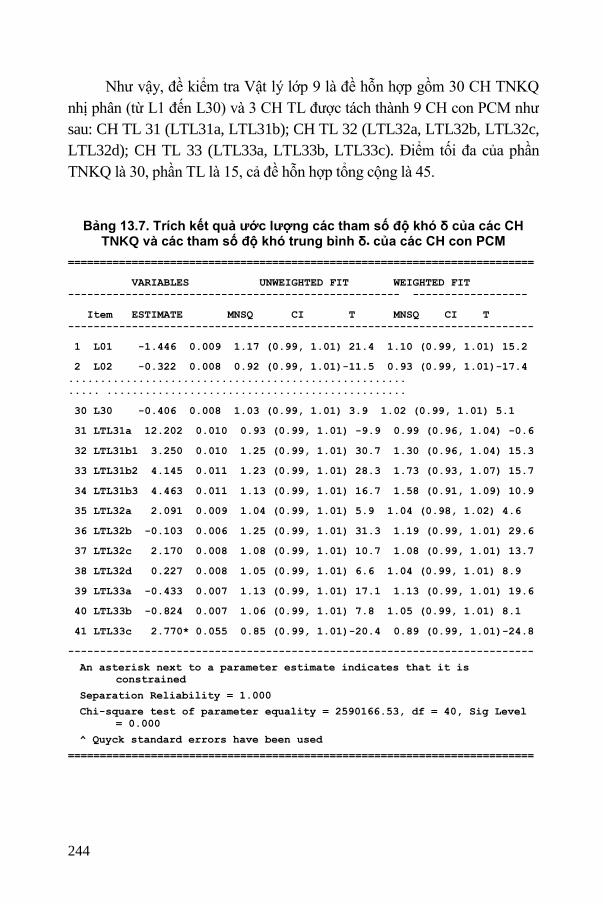
244
Như vậy, đề kiểm tra Vật lý lớp 9 là đề hỗn hợp gồm 30 CH TNKQ
nhị phân (từ L1 đến L30) và 3 CH TL được tách thành 9 CH con PCM như
sau: CH TL 31 (LTL31a, LTL31b); CH TL 32 (LTL32a, LTL32b, LTL32c,
LTL32d); CH TL 33 (LTL33a, LTL33b, LTL33c). Điểm tối đa của phần
TNKQ là 30, phần TL là 15, cả đề hỗn hợp tổng cộng là 45.
Bảng 13.7. Trích kết quả ước lượng các tham số độ khó δ của các CH TNKQ và các tham số độ khó trung bình δ• của các CH con PCM
=========================================================================
VARIABLES UNWEIGHTED FIT WEIGHTED FIT
---------------------------------------------------- ------------------
Item ESTIMATE MNSQ CI T MNSQ CI T
-------------------------------------------------------------------------
1 L01 -1.446 0.009 1.17 (0.99, 1.01) 21.4 1.10 (0.99, 1.01) 15.2
2 L02 -0.322 0.008 0.92 (0.99, 1.01)-11.5 0.93 (0.99, 1.01)-17.4
.....................................................
..... ...............................................
30 L30 -0.406 0.008 1.03 (0.99, 1.01) 3.9 1.02 (0.99, 1.01) 5.1
31 LTL31a 12.202 0.010 0.93 (0.99, 1.01) -9.9 0.99 (0.96, 1.04) -0.6
32 LTL31b1 3.250 0.010 1.25 (0.99, 1.01) 30.7 1.30 (0.96, 1.04) 15.3
33 LTL31b2 4.145 0.011 1.23 (0.99, 1.01) 28.3 1.73 (0.93, 1.07) 15.7
34 LTL31b3 4.463 0.011 1.13 (0.99, 1.01) 16.7 1.58 (0.91, 1.09) 10.9
35 LTL32a 2.091 0.009 1.04 (0.99, 1.01) 5.9 1.04 (0.98, 1.02) 4.6
36 LTL32b -0.103 0.006 1.25 (0.99, 1.01) 31.3 1.19 (0.99, 1.01) 29.6
37 LTL32c 2.170 0.008 1.08 (0.99, 1.01) 10.7 1.08 (0.99, 1.01) 13.7
38 LTL32d 0.227 0.008 1.05 (0.99, 1.01) 6.6 1.04 (0.99, 1.01) 8.9
39 LTL33a -0.433 0.007 1.13 (0.99, 1.01) 17.1 1.13 (0.99, 1.01) 19.6
40 LTL33b -0.824 0.007 1.06 (0.99, 1.01) 7.8 1.05 (0.99, 1.01) 8.1
41 LTL33c 2.770* 0.055 0.85 (0.99, 1.01)-20.4 0.89 (0.99, 1.01)-24.8
-------------------------------------------------------------------------
An asterisk next to a parameter estimate indicates that it is
constrained
Separation Reliability = 1.000
Chi-square test of parameter equality = 2590166.53, df = 40, Sig Level
= 0.000
^ Quyck standard errors have been used
=========================================================================

245
Bài kiểm tra được triển khai trên các mẫu gồm 35.579 TS là học
sinh lớp 9 nước ta trên 63 tỉnh/thành phố ở 8 vùng miền trong cả nước,
sau đó phần TNKQ được chấm điểm tự động, còn phần các CH TL được
một số giáo viên chấm theo các thang điểm phân bố như đã nêu ở bảng
trên đây. Các điểm thô thu được qua quá trình chấm nói trên được đưa
phân tích bằng phần mềm CONQUEST để ước lượng các tham số của 30
CH TNKQ nhị phân và 9 CH con PCM, trong đó các CH TNKQ nhị
phân là trường hợp riêng của CH PCM. Dưới đây sẽ dẫn một số kết quả
tính toán để minh họa, chủ yếu lưu ý nhiều đến các phần phản ánh sự
phối hợp của các CH TNKQ và TL.
Trước hết, ở Bảng 13.7 trích kết quả ước lượng các tham số độ khó
trung bình δ (ESTIMATE) của các CH TNKQ nhị phân và các tham số δ•
của các CH con PCM được tách từ các CH TL và các tham số biểu thị độ
phù hợp của số liệu với mô hình.
Bảng 13.8 trích kết quả ước lượng tham số bước (step parameter) τk
(= δ• - δk) đối với các hạng điểm của các CH con PCM đa phân và các độ
phù hợp của từng hạng điểm của mỗi CH con đối với mô hình.
Hình 13.16 là biểu đồ về tương quan giữa năng lực θ của TS và các
giá trị ngưỡng Thurstone γk ứng với các hạng điểm của các CH con, đặt
theo trục thẳng đứng hướng từ dưới lên, đo bằng logit, mức 0 của thang
được xác định theo giá trị của ngưỡng. Các con số trên biểu đồ, ví dụ 32.1,
thì chữ số đầu biểu diễn số hiệu CH, chữ số thứ hai biểu diễn hạng điểm.
Đối với các CH TNKQ nhị phân thì giá trị ngưỡng γ cũng trùng với giá
trị độ khó δ và được biểu diễn bởi chỉ một chữ số.

246
Bảng 13.8. Trích kết quả ước lượng tham số bước τk
đối với các hạng điểm của các CH con PCM đa phân
=========================================================================
VARIABLES UNWEIGHTED FIT WEIGHTED FIT
------------------- ----------------------- -----------------
item step ESTIMATE ERROR^ MNSQ CI T MNSQ CI T
------------------------------------------------------------------------------------
31 LTL31a 0 0.93 (0.99, 1.01)-10.2 0.99 (0.96, 1.04) -0.6
31 LTL31a 1 -15.677 0.023 0.93 (0.99, 1.01) -9.9 0.99 (0.96, 1.04) -0.6
31 LTL31a 2 15.677* _BIG_ (0.99, 1.01)_BIG_ _BIG_(0.00,_BIG_)_BIG_
------------------------------------------------------------------------------------
----------------------------------------------------------------------------------
40 LTL33b 0 1.05 (0.99, 1.01) 6.7 1.01 (0.99, 1.01) 1.0
40 LTL33b 1 -0.286 0.012 1.01 (0.99, 1.01) 1.4 1.01 (0.99, 1.01) 1.6
40 LTL33b 2 0.286* 1.08 (0.99, 1.01) 10.8 1.06 (0.99, 1.01) 11.8
41 LTL33c 0 0.87 (0.99, 1.01)-17.5 0.91 (0.99, 1.01)-22.4
41 LTL33c 1 -2.728 0.012 0.87 (0.99, 1.01)-17.9 0.90 (0.99, 1.01)-23.2
41 LTL33c 2 2.728* 0.03 (0.99, 1.01)_BIG_ 0.04 (0.81, 1.19)-20.0
------------------------------------------------------------------------------------
An asterisk next to a parameter estimate indicates that it is constrained
^ Quyck standard errors have been used
===================================================================================

247
=================================================================
MAP OF LATENT DISTRIBUTIONS AND THRESHOLDS -Fri Oct 30 16:09 2009
| Các ngưỡng γk của các CH con |31.2 32.2 33 34 35.2 37.2 41.2
|
|
3 |
|
|
|
|32.1
|
|
2 |
X|
X|
XX|
XX|
XX|
XX|15
XX|
1 XXXX|
XXXX|11
XXXXX|
XXXXXXX|13
XXXXXX|39.2
XXXXXX|36.2
XXXXXXX|
XXXXXXXX|38
0 XXXXXXXXX|41.1
XXXXXXXXXX|29
XXXXXXXX|40.2
XXXXXXXXX|2
XXXXXXXX|30
XXXXXXXX|12 19 36.1
XXXXXXXXX|4 7 10 18
XXXXXXXX|22
-1 XXXXXXX|
XXXXXXX|3
XXXXX|17 21 23 28 37.1
XXXXX|9 39.1
XXXXXX|1 6 40.1
XXXX|5 24
XXX|26
XXX|14 27 35.1
-2 XX|8 16
X|20 25
X|
X|
X|
|
|
-3 |
|
|31.1
==================================================
Each 'X' represents 204.5 cases. The labels for thresholds show the
levels of item, and step, respectively
Hình 13.16. Tương quan giữa năng lực θ của TS và các giá trị ngưỡng γk

248
Về các thông tin quan trọng đối với từng CH, Bảng 13.9 chỉ trích
giới thiệu 2 CH đại diện: CH L12 là TNKQ nhị phân, và CHTL33b là
CH con PCM với 3 hạng điểm. Các bảng con ở Bảng 13.9 có trình bày
các thông tin liên quan, đó là các giá trị độ phân biệt (discrimination), các
giá trị ngưỡng (thresholds) Thurstone γk và độ khó δk ứng với các hạng
điểm, cũng như sai số tiêu chuẩn và các tham số thể hiện độ phù hợp của
số liệu với mô hình. Trường hợp của CH TNKQ thì giá trị ngưỡng γ và
độ khó δ trùng nhau.
Bảng 13.9. Trích thông tin về các CH đại diện (trắc nghiệm khách quan nhị phân và PCM đa phân)
=========================================================================
GENERALISED ITEM ANALYSIS- Fri Oct 30 16:24 2009
=========================================================================
item:12 (L12)
Cases for this item 35560 Discrimination 0.48
Item Threshold(s): -0.53 Weighted MNSQ 0.95
Item Delta(s): -0.53
-------------------------------------------------------------------------
Label Score Count % of tot Pt Bis t (p) PV1Avg:1 PV1 SD:1
-------------------------------------------------------------------------
1 0.00 4188 11.78 -0.25 -48.80(.000) -0.88 0.79
2 1.00 19772 55.60 0.48 103.31(.000) 0.09 0.87
3 0.00 4059 11.41 -0.17 -32.27(.000) -0.69 0.88
4 0.00 7248 20.38 -0.24 -47.53(.000) -0.71 0.82
9 0.00 293 0.82 -0.07 -12.30(.000) -0.91 0.80
=========================================================================
-------------------------------------------------------------------------
-------------------------------------------------------------------------
item:40 (LTL33b)
Cases for this item 35579 Discrimination 0.55
Item Threshold(s): -1.45 -0.20 Weighted MNSQ 1.05
Item Delta(s): -1.11 -0.54
-------------------------------------------------------------------------
Label Score Count % of tot Pt Bis t (p) PV1Avg:1 PV1 SD:1
-------------------------------------------------------------------------
0 0.00 7658 21.52 -0.48 _BIG_ (.000) -1.07 0.79
1 1.00 11067 31.11 -0.08 -15.08(.000) -0.40 0.79
2 2.00 16659 46.82 0.47 101.10(.000) 0.16 0.84
9 0.00 195 0.55 -0.04 -7.72(.000) -0.79 0.77
=========================================================================
Đối với các đồ thị biểu diễn từng CH chúng ta cũng chỉ giơí thiệu các
đường cong đặc trưng của hai CH đại diện tương ứng nêu ở Bảng 13.9 trên
các Hình 13.17 và Hình 13.18. Cuối cùng là các đường cong gắn với tổng
thể đề kiểm tra Vật lý: hàm thông tin và hàm đặc trưng của đề kiểm tra.
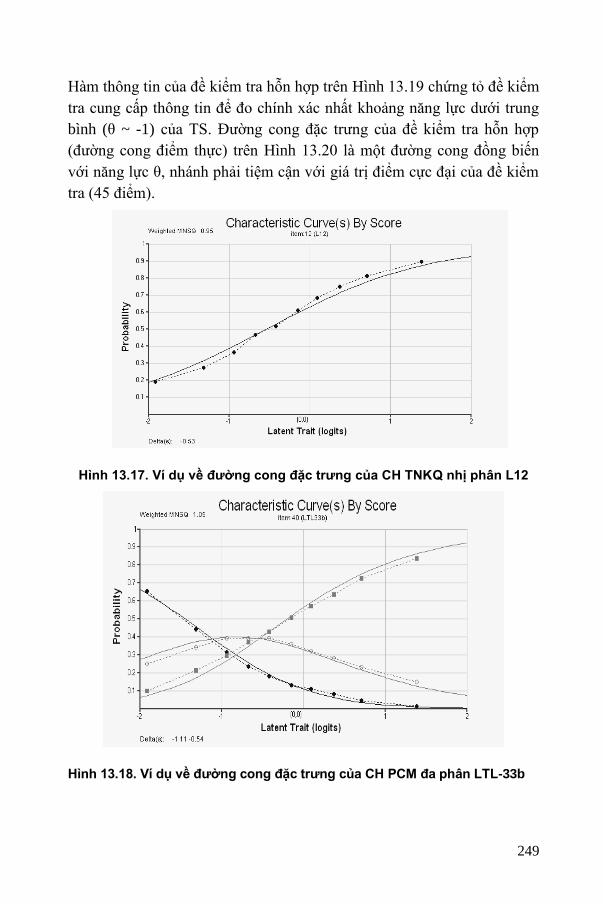
249
Hàm thông tin của đề kiểm tra hỗn hợp trên Hình 13.19 chứng tỏ đề kiểm
tra cung cấp thông tin để đo chính xác nhất khoảng năng lực dưới trung
bình (θ ~ -1) của TS. Đường cong đặc trưng của đề kiểm tra hỗn hợp
(đường cong điểm thực) trên Hình 13.20 là một đường cong đồng biến
với năng lực θ, nhánh phải tiệm cận với giá trị điểm cực đại của đề kiểm
tra (45 điểm).
Hình 13.17. Ví dụ về đường cong đặc trưng của CH TNKQ nhị phân L12
Hình 13.18. Ví dụ về đường cong đặc trưng của CH PCM đa phân LTL-33b

250
Hình 13.19. Đường cong hàm thông tin của đề Vật lý lớp 9 (trắc nghiệm khách quan và tự luận)
Hình 13.20. Đường cong điểm thực của đề Vật lý lớp 9 (hỗn hợp trắc nghiệm khách quan và tự luận)

251
13.2.3. Phân tích các bài kiểm tra gồm hỗn hợp các CH trắc nghiệm
khách quan và tự luận nhờ phần mềm PARSCALE
Hai phần mềm cho các mô hình IRT đa phân được sử dụng phổ
biến ở Hoa Kỳ là MULTILOG và PARSCALE. MULTILOG do Thissen
xây dựng, áp dụng cho cả các trắc nghiệm với các hạng điểm nhị phân và
đa phân như mô hình ứng đáp đa cấp (graded response) của Samejima,
mô hình ứng đáp định danh (nominal responses – non-ordered) của
Bock, mô hình các CH NLC của Thissen và Steinberg. Các số liệu trắc
nghiệm ứng đáp nhị phân cũng được sử dụng như một trường hợp riêng
của trắc nghiệm đa phân. Phần mềm PARSCALE do Muraki và Bock
xây dựng, cũng áp dụng được cho hàng loạt mô hình như mô hình ứng
đáp đa cấp của Samejima, mô hình thang đánh giá (rating scale) của
Anderson, mô hình định giá từng phần tổng quát (generalised partial
credit) của Muraki. Phần mềm PARSCALE có thể áp dụng để giải quyết
các bài toán phức tạp như phân tích các bài kiểm tra hỗn hợp gồm nhiều
CH đa phân và nhị phân 2, 3 tham số; giúp khảo sát để điều chỉnh sự
thiên lệch do nhiều người khác nhau chấm điểm bài kiểm tra …
Dưới đây chúng ta sẽ làm quen với một trong hai phần mềm nói
trên, cụ thể là phần mềm PARSCALE, qua ví dụ phân tích một bài kiểm
tra tiếng Anh lớp 9 Trung học phổ thông cũng được Viện Khoa học Giáo
dục Việt Nam thực hiện vào năm 2009 theo một Dự án của Bộ Giáo dục
và Đào tạo.
Đề tiếng Anh lớp 9 (ký hiệu ANH9) có 20 CH trắc nghiệm nhị
phân và 5 CH TL ngắn. Mỗi CH trắc nghiệm nhị phân trả lời đúng được
1 điểm, trả lời sai 0 điểm; mỗi CH TL ngắn được cho theo 3 mức điểm
0,1,2. Như vậy tổng điểm của phần trắc nghiệm nhị phân là 20, của phần
TL là 10, của toàn bộ đề hỗn hợp ANH9 là 30.
Khi phân tích bằng phần mềm PARSCALE ta sẽ sử dụng mô hình
định giá từng phần tổng quát (GPCM) trong đó các CH TL có tham số
độ dốc a và các CH nhị phân có 3 tham số. Sau đây là một số kết quả
phân tích.

252
Bảng 13.10. Tham số của các CH theo IRT
+------+---------+-------+---------+--------+---------+--------+
| ITEM | SLOPE | S.E. |LOCATION | S.E. |GUESSING | S.E. |
|Câuhỏi| Độdốc a |Ssốchuẩn|Độ khó δ|Ssốchuẩn|TSđoánmò c|Ssốchuẩn|
+======+=========+========+========+========+========+========+
| 0001 | 1.290 | 0.052 | 0.222 | 0.029 | 0.504 | 0.009 |
+------+--------+--------+--------+--------+--------+--------+
| 0002 | 0.999 | 0.041 | 0.797 | 0.025 | 0.306 | 0.009 |
+------+--------+--------+--------+--------+--------+--------+
| 0003 | 1.192 | 0.046 | 0.246 | 0.029 | 0.426 | 0.010 |
+------+--------+--------+--------+--------+--------+--------+
| 0004 | 0.771 | 0.041 | -0.547 | 0.107 | 0.528 | 0.027 |
+------+--------+--------+--------+--------+--------+--------+
| 0005 | 0.649 | 0.046 | -1.271 | 0.246 | 0.661 | 0.045 |
+------+--------+--------+--------+--------+--------+--------+
| 0006 | 1.443 | 0.056 | 1.186 | 0.016 | 0.246 | 0.004 |
+------+--------+--------+--------+--------+--------+--------+
| 0007 | 0.812 | 0.031 | -0.792 | 0.082 | 0.289 | 0.033 |
+------+--------+--------+--------+--------+--------+--------+
| 0008 | 1.048 | 0.032 | 0.785 | 0.016 | 0.133 | 0.006 |
+------+--------+--------+--------+--------+--------+--------+
| 0009 | 0.980 | 0.030 | -0.036 | 0.032 | 0.211 | 0.013 |
+------+--------+--------+--------+--------+--------+--------+
| 0010 | 0.923 | 0.044 | 1.022 | 0.026 | 0.372 | 0.008 |
+------+--------+--------+--------+--------+--------+--------+
| 0011 | 1.088 | 0.035 | -0.058 | 0.031 | 0.313 | 0.012 |
+------+--------+--------+--------+--------+--------+--------+
| 0012 | 1.075 | 0.028 | -0.599 | 0.036 | 0.108 | 0.020 |
+------+--------+--------+--------+--------+--------+--------+
| 0013 | 0.833 | 0.024 | 0.022 | 0.032 | 0.094 | 0.014 |
+------+--------+--------+--------+--------+--------+--------+
| 0014 | 0.964 | 0.032 | 0.040 | 0.034 | 0.298 | 0.013 |
+------+--------+--------+--------+--------+--------+--------+
| 0015 | 1.092 | 0.033 | 0.231 | 0.024 | 0.248 | 0.010 |
+------+--------+--------+--------+--------+--------+--------+
| 0016 | 0.794 | 0.036 | 1.316 | 0.025 | 0.199 | 0.007 |
+------+--------+--------+--------+--------+--------+--------+
| 0017 | 1.105 | 0.028 | -0.665 | 0.036 | 0.107 | 0.020 |
+------+--------+--------+--------+--------+--------+--------+
| 0018 | 0.987 | 0.023 | -0.129 | 0.024 | 0.053 | 0.011 |
+------+--------+--------+--------+--------+--------+--------+
| 0019 | 1.296 | 0.043 | 0.005 | 0.026 | 0.395 | 0.010 |
+------+--------+--------+--------+--------+--------+--------+
| 0020 | 0.802 | 0.023 | 0.520 | 0.023 | 0.078 | 0.009 |
+------+--------+--------+--------+--------+--------+--------+
| 0021 | 0.917 | 0.009 | 0.265 | 0.008 | 0.000 | 0.000 |
+------+--------+--------+--------+--------+--------+--------+
| 0022 | 1.051 | 0.011 | 0.449 | 0.008 | 0.000 | 0.000 |
+------+--------+--------+--------+--------+--------+--------+
| 0023 | 0.983 | 0.013 | 0.488 | 0.009 | 0.000 | 0.000 |
+------+--------+--------+--------+--------+--------+--------+
| 0024 | 0.727 | 0.006 | 0.154 | 0.009 | 0.000 | 0.000 |
+------+--------+--------+--------+--------+--------+--------+
| 0025 | 0.990 | 0.011 | 1.331 | 0.010 | 0.000 | 0.000 |
+------+--------+--------+--------+--------+--------+--------+

253
Bảng 13.11. Trích ước lượng năng lực θ của thí sinh
IDENTIFICATION ABILITY S.E. (Mã thí sinh) (Năng lực θ)(Saisốtiêuchuẩn)
---------------------------------------------
1010010101 | -0.1562 0.3258
--------------------------------------------
1010010104 -1.5611 0.5529
--------------------------------------------
1010010106 -1.3682 0.5726
--------------------------------------------
1010010110 -0.5506 0.3541
--------------------------------------------
1010010113 0.2857 0.2983
--------------------------------------------
1010010116 -0.1677 0.3699
--------------------------------------------
.............................................
............................................
--------------------------------------------
8969710802 | -0.5973 0.3952
--------------------------------------------
8969710803 | -0.1066 0.2914
--------------------------------------------
8969710806 | 1.0381 0.3212
--------------------------------------------
8969710809 | 0.5810 0.2833
--------------------------------------------
8969710812 | 0.2195 0.2762
--------------------------------------------
8969710818 | -0.2513 0.3173
--------------------------------------------
8969710823 | -1.6395 0.5755
---------------------------------------------
Bảng 13.10 cho kết quả ước lượng các tham số của từng CH và các
sai số tiêu chuẩn kèm theo. Đối với các CH trắc nghiệm nhị phân 1-20:
slope chính là giá trị độ dốc a, location chính là độ khó δ, guessing chính
là tham số đoán mò. Bảng 13.11 trích kết quả ước lượng năng lực θ của
từng TS và sai số tiêu chuẩn kèm theo.
Ngoài các bảng số, PARSCALE còn cho các biểu đồ. Hình 13.21
biểu diễn bảng các đường cong ĐTCH của mọi CH trong đề kiểm tra. 20
CH trắc nghiệm nhị phân được tính theo mô hình 3 tham số, các đường
cong thể hiện các độ dốc và các tung độ tiệm cận trái khác nhau. 5 CH
TL ngắn được phân tích theo mô hình GPCM, mỗi CH cho 3 đường cong

254
diễn tả xác suất ứng đáp của 3 hạng điểm, từ các đường cong đó chúng ta
có thể có các ý niệm khái quát về các vùng năng lực và xác suất ứng đáp
từng hạng điểm: chẳng hạn CH PCM25 thể hiện hạng điểm 1 ở giữa có
nhiều TS ứng đáp đúng hơn các CH khác, nhưng năng lực để ứng đáp các
hạng điểm 1 và 2 là khá cao. Hình 13.22 giới thiệu biểu đồ hàm thông tin
và sai số tiêu chuẩn của đề hỗn hợp ANH9: đề cho thông tin để đo
khoảng năng lực trên trung bình chính xác hơn, sai số tiêu chuẩn của
phép đo ở vùng đó bé hơn.
Hình 13.21. Bảng các đường cong ĐTCH của
đề kiểm tra ANH9
Hình 13.22. Biểu đồ hàm thông tin và sai số tiêu chuẩn
của đề kiểm tra ANH9

255
CÂU HỎI TỰ KIỂM TRA
1. Khác biệt giữa mô hình thang đánh giá (rating scale model) và
mô hình định giá từng phần (PCM).
2. Nêu giả thiết cơ bản để xây dựng PCM. Quan hệ giữa PCM và
trắc nghiệm nhị phân.
3. Ý nghĩa của các tham số δk δ•, τk, γk và quan hệ giữa chúng với
giá trị độ khó b trong trắc nghiệm nhị phân.
4. Mô tả các đường cong ĐTCH theo hạng điểm, đường cong xác
suất tích lũy, đường cong điểm kỳ vọng trong trường hợp trắc nghiệm đa
phân và trường hợp riêng của chúng trong mô hình trắc nghiệm nhị phân.
5. Mô tả mô hình PCM tổng quát (GPCM).
6. Nêu những điểm cần lưu ý khi kết hợp phân tích trắc nghiệm nhị
phân với trắc nghiệm đa phân, phân tích số liệu TNKQ với TL.
________________________

256
Chương 14
KHÁI NIỆM VỀ TRẮC NGHIỆM ĐA CHIỀU
Khi xây dựng các mô hình ứng đáp CH ở chương 3, để đơn giản
hóa chúng ta đã đặt điều kiện về tính đơn chiều (unidimentionality) của
CH, tức là CH chỉ đo một thứ năng lực tiềm ẩn, hoặc chỉ đo một chiều
(dimension) của năng lực tiềm ẩn đa chiều (multidimentionality). Tuy
nhiên, trong thực tế, để thực hiện một ứng đáp nào đó TS thường phải có
các chiều khác nhau của năng lực, chẳng hạn để giải một bài toán TS cần
cả kỹ năng đọc hiểu đề toán và các kỹ năng toán học. Nhiều nghiên cứu
cũng khẳng định rằng đôi khi việc định cỡ các CH theo mô hình đơn chiều
cho thấy có biểu hiện ứng đáp CH khác biệt (differential item functioning)
là do các năng lực ứng đáp CH của mẫu TS là đa chiều.
Lord, F.M. & Novick [6], McDonald R.P [20] và Sanejima, F.[21]
là trong số những người đầu tiên nghiên cứu các mô hình IRT đa chiều.
Nhưng đến khoảng thập niên 1990 các nhà nghiên cứu mới phát triển các
mô hình đa chiều cùng với các phần mềm ước lượng các tham số.
Chương này sẽ chỉ giới thiệu một số mô hình IRT đa chiều tiêu
biểu với các cách mở rộng từ mô hình một chiều không quá phức tạp đối
với mục đích giáo khoa.
14.1. MỘT SỐ MÔ HÌNH TRẮC NGHIỆM ĐA CHIỀU
14.1.1. Mô hình trắc nghiệm đa chiều nhờ các hàm logistic tuyến tính
theo số liệu từ các CH nhị phân
Reskase, M.D. đã mở rộng mô hình đơn chiều logistic tuyến tính ra
mô hình đa chiều bằng các lập luận như sau. Các TS sử dụng nhiều năng
lực tri thức để ứng đáp trắc nghiệm, nhưng có một số năng lực liên quan

257
đến nhiệm vụ trắc nghiệm, và một số năng lực không liên quan. Hơn nữa,
một số nhiệm vụ của đề trắc nghiệm nhạy cảm với các năng lực nào đó,
một số nhiệm vụ khác thì không. Số chiều của năng lực cần cho mô hình
phân tích một dữ liệu phụ thuộc cả vào số chiều và mức độ năng lực của
các TS cũng như số chiều nhận thức mà đề kiểm tra thể hiện sự nhạy cảm
với chúng.
Mô hình của Reskase M. D. (xem trong [12]) dựa vào trắc nghiệm
nhị phân (0,1) với dữ liệu của mô hình được chứa trong ma trận có N
dòng biểu hiện TS và n cột biểu hiện CH hoặc nhiệm vụ phải thực hiện.
Reskase nêu các giả định về dữ liệu như sau: 1) Xác suất trả lời đúng CH
đồng biến với năng lực của TS; 2) Hàm xác suất theo năng lực là trơn
(khả vi); 3) Xác suất của tổng hợp các ứng đáp bằng tích các xác suất
riêng biệt (giả thiết về tính độc lập địa phương, xem 8.1.1).
1. Công thức của mô hình
Công thức cơ bản của mô hình được khái quát hóa từ công thức
ứng với mô hình logistic ba chiều nhị phân (4.4):
ij j i
a θ +dij j i
a θ +d
i ij i i i j i i
e P (U =1/a ,d ,c ,θ )=c +(1-c )
[1+e ] , (14.1)
trong đó:
P(Uij= 1/ai, di, ci, θj) là xác suất ứng đáp đúng (đạt điểm 1) của TSj
đối với CH i;
Uij là ứng đáp của TSj đối với CHi;
ai là vectơ của các tham số liên quan đến độ phân biệt của CH (tốc
độ tăng xác suất ứng đáp đúng CH so với sự tăng năng lực của TS);
di là tham số liên quan đến độ khó của CH;
ci là xác suất ứng đáp đúng CH khi các năng lực ứng đáp CH rất thấp
(→ - ∞) (đối với trường hợp nhị phân thường gọi là tham số đoán mò);
θj là vectơ năng lực của TSj.

258
Các khái niệm nêu trên sẽ được giải thích rõ hơn dưới đây.
2. Đồ thị biểu diễn mô hình
Công thức của mô hình xác định một mặt cong cho biết xác suất
ứng đáp đúng CH phụ thuộc vào vị trí của TS trong không gian năng lực
được xác định bởi vectơ θ. Các thành phần của vectơ là các chiều của
năng lực tiềm ẩn của TS. Khi chỉ tồn tại hai chiều thì có thể biểu diễn
công thức xác suất bằng đồ thị 3 chiều. Hình 14.1a biểu diễn mặt xác suất
của CH với a1 =0,8; a2 =1,4; d= -2,0; c=0,2. Có thể thấy tính chất đồng
biến của mặt xác suất theo θ1 và θ2, và thấy mặt tiệm cận nằm ngang ở
các giá trị θ thấp. Hình 14.1b biểu diễn hình chiếu của các đường đồng
mức xác suất ứng đáp đúng CH: đó là các đường thẳng, vì logarit của
hàm mũ trong công thức mô hình có dạng tuyến tính.
3. Ý nghĩa của các tham số của mô hình
Công thức biểu diễn mô hình chứa các tham số của cả TS và CH.
- Các tham số năng lực của TS: Các tham số năng lực của TS là các
thành phần θj. Nhiều nghiên cứu chứng tỏ xác định quá nhiều hoặc quá ít
số chiều của năng lực cũng không tốt. Tất nhiên số chiều được sử dụng
phụ thuộc vào mục đích của việc phân tích. Không có đòi hỏi nào buộc
phải biểu diễn các chiều thẳng góc với nhau.
- Độ phân biệt của CH: Các tham số độ phân biệt của mô hình
được xác định bởi các thành phần của vectơ a, cũng có thể được giải
thích tương tự như tham số a trong mô hình nhị phân (mục 4.1.1). Một
thành phần nào đó của vectơ a liên quan đến độ dốc của mặt xác suất
ứng đáp đúng theo hướng tương ứng với trục θ. Nếu hướng ta quan
tâm song song với mặt xác suất thì độ dốc sẽ bằng 0 và CH không có
độ phân biệt. Người ta đưa vào độ phân biệt tổng hợp của CH được
xác định như sau:

259
(a)
(b)
Hình 14.1. Mặt ĐTCH với 2 chiều năng lực θ1, θ2 (a) và hình chiếu các đường đồng mức xuống mặt phẳng (θ1,θ2) (b)

260
MDISCi = p
2ik
k=1
a , (14.2)
trong đó p là số chiều trong không gian năng lực θ, aik là các thành
phần của vectơ ai.
- Độ khó của CH: Tham số di của mô hình liên quan đến độ khó của
CH. Tuy nhiên d không giống b trong mô hình nhị phân, vì d ở (14.1)
đóng vai trò –b trong (4.4). Giá trị tương đương với b là độ khó đa chiều
được xác định bởi:
MDIFFi = i
i
-d
MDISC , (14.3)
Giá trị MDIFFi cho biết khoảng cách từ gốc của không gian năng
lực θ đến điểm có độ dốc lớn nhất theo hướng đi từ gốc. Hướng có độ
dốc lớn nhất tính từ gốc tọa độ được xác định bởi công thức:
αik = arccos ik
i
a
MDISC , (14.4)
trong đó αik là góc hợp giữa đường thẳng vẽ từ gốc tọa độ đến điểm
có độ dốc lớn nhất với trục tọa độ thứ k của CH thứ i.
- Tiệm cận thấp: là mặt phẳng xác định bởi tham số Ci, tương tự
như tham số ci trong biểu thức (4.4).
4. Hàm đặc trưng của đề trắc nghiệm và hàm thông tin của câu hỏi
Hàm đặc trưng (hàm điểm thực) và hàm thông tin của đề trắc
nghiệm ứng với mô hình nhị phân đa chiều cũng có thể khái quát từ các
biểu thức tương ứng (6.4) và (7.7) của mô hình nhị phân đơn chiều. Hàm
điểm thực được biểu diễn bởi:
τ (θ) =n
i
i=1
1P (θ)
n , (14.5)
trong đó τ (θ) là giá trị điểm kỳ vọng của TS có năng lực θ, còn
Pi(θ) là xác suất trả lời đúng CHi.

261
Hàm thông tin của CH được biểu diễn bởi:
Iiα (θ) =
2
α i
i i
P (θ)
P (θ) 1-P (θ)
, (14.6)
trong đó Iiα (θ) là thông tin mà CHi cung cấp theo hướng α của
không gian năng lực và α là toán tử xác định đạo hàm theo hướng α.
Mặt thông tin của đề trắc nghiệm thu được bằng cách cộng các mặt thông
tin của các CH trong đề tính theo cùng hướng.
5. Ước lượng tham số:
Các tham số của mô hình được ước lượng nhờ quy trình biến cố
hợp lý cực đại tương tự như quy trình được mô tả ở mục 8.1. Mục tiêu
của quy trình là tìm bộ tham số CH và TS làm cực đại biến cố hợp lý của
các ứng đáp CH quan sát được. Công thức cơ bản của phương trình biến
cố hợp lý:
L = N n
ij i i i j
j=1 i=1
P(u /a ,d ,c ,θ ) , (14.7)
trong đó u ij là ứng đáp đối với CHi của TSj (0 hoặc 1). Tìm cực đại
của hàm L nhờ phương pháp Newton-Raphson, trước hết cho cố định
tham số CH và ước lượng tham số TS, sau đó cố định tham số TS và ước
lượng tham số CH, tương tự quy trình đã mô tả ở (8.2.2).
6. Độ trùng khớp tốt (goodness of fit)
Mục tiêu của mô hình là giải thích chính xác sự tương tác giữa TS
và CH. Tùy theo mức độ đạt được mục tiêu ấy mà mô hình sẽ có ích
trong các ứng dụng cụ thể. Vì mọi mô hình đều phải đơn giản hóa các
mối tương tác giữa TS và CH nên các mô hình đều bị phủ định khi mẫu
quá lớn. Cho nên không thể đặt vấn đề mô hình có phù hợp với số liệu
hay không, mà chỉ có thể đặt vấn đề mức độ phù hợp của mô hình có đủ
để áp dụng hay không.
Một trong các cách tiếp cận được đề nghị ở đây là xem xét cẩn thận
ma trận hiệp biến thặng dư (residual covariance matrix) giữa các CH để

262
xác định chứng cứ có thể hay không thể sử dụng mô hình. Các số hạng
của ma trận nxn yếu tố được tính theo công thức:
covik =
N
ij i j kj k j
j=1
(u -P (θ ))(u -P (θ ))
N
, i, k=1,2…,n;
trong đó i và k biểu diễn các CH trong đề trắc nghiệm. Giá trị thặng
dư lớn có thể cho thấy quy trình ước lượng không hội tụ, số chiều xác
định còn quá ít hoặc mô hình không phù hợp. Đánh giá các giá trị thặng
dư này là quá trình khá công phu, đòi hỏi nhiều kinh nghiệm.
14.1.2. Một cách tiếp cận xây dựng mô hình tổng quát cho trắc
nghiệm nhị phân, đa phân, đơn chiều, đa chiều
Wu, M.L. và Adams, R.J. [31] tại Cơ quan Nghiên cứu Giáo dục
Úc (Australian Council for Educational Reseach – ACER) đã đề xuất một
cách tiếp cận tổng quát để xây dựng chương trình CONQUEST dựa trên
mô hình Rasch mở rộng cho trắc nghiệm nhị phân, đa phân, đơn chiều,
đa chiều. Chương trình CONQUEST được sử dụng rộng rãi ở Úc cho
một số chương trình khảo sát giáo dục quốc tế lớn, đặc biệt là PISA
(Programme for International Student Assessment). Vào những năm gần
đây CONQUEST được mở rộng cho mô hình nhiều tham số chứ không
chỉ mô hình Rasch.
Dưới đây sẽ mô tả tổng quát cách tiếp cận nói trên.
Các tác giả xét hai thành phần của mô hình: mô hình ứng đáp CH
và mô hình tổng thể TS. Mô hình ứng đáp CH là mô hình Rasch đa chiều
tổng quát, cho phép áp dụng cho hàng loạt mô hình liên quan. Việc kết
hợp mô hình ứng đáp CH với mô hình tổng thể TS cho phép sử dụng
CONQUEST cho phép hồi quy tiềm ẩn [31].
1) Mô hình logistic nhị phân và đa phân đơn chiều
- Giả sử có I CH (i=1,...,I) mỗi CH có Ki +1 phương án trả lời
(k=0,1,...,Ki). Dùng biến vectơ ngẫu nhiên Xi = (Xi1,..., XiKi), trong đó:
1 nếu ứng đáp CHi ở hạng điểm j
0 đối với các trường hợp khác (14.8) Xij =

263
Ứng đáp ở hạng điểm 0 được ký hiệu bởi vectơ có mọi thành phần
bằng 0.
Để thiết kế tổng quát cho hàng loạt mô hình Rasch nhị phân trong công
trình [31] đã dùng thủ thuật đưa vào các vecst[ và ma trận. trước hết, các CH
được mô hình hóa qua vectơ ξ = (ξ1,..., ξp) của P tham số. Một vectơ thiết kế aik
với (i=1,...,I; k=0,1,...,Ki) có độ dài P được đưa vào để kết nối mỗi hạng điểm trả
lời CH với các thành phần của ξ. Chẳng hạn, aik = (1,0,1,0,0,...,0) thì aikξ = ξ1+ ξ3,
tức là aikξ là tổ hợp tuyến tính của các thành phần của ξ ứng với một hạng điểm ứng
đáp CH nhất định. Có thể tập hợp aik trong một ma trận thiết kế
1 210 11 12 1 20 21 22 2 0 1 2, , , ... , , , , ... , ..., , , , ...
IK K I I I IKA a a a a a a a a a a a a có P cột, và có số
hàng bằng tổng mọi hạng điểm của mọi CH.
Ngoài ra, mỗi hạng điểm có một điểm hoặc giá trị trọng số xác
định. Gọi bik là điểm của hạng k của CH i. Thiết lập một vectơ điểm:
1 210 11 12 1 20 21 22 2 0 1 2, , , ..., , , , , ..., , ..., , , , ...,
IK K I I I IKb b b b b b b b b b b b b , (14.9)
và quy ước như thường lệ hạng ứng đáp 0 có điểm 0 đối với mọi
CH, tức là b10=b20=…=bI0=0.
Với tất cả các định nghĩa trên đây, gọi năng lực tiềm ẩn là θ, có thể
biểu diễn xác suất ứng đáp một CH như sau:
i
ij i
ik K
ik ij
j=0
exp b θ+a ξPr X =1;A,b,ξ/θ =
exp b θ+a ξ
, (14.10)
trong đó tổng ở mẫu số được thực hiện trên mọi hạng điểm của CH
thứ i.
Có thể xét một vài trường hợp riêng. Nếu chọn:
0 0 0 0 ... 0
1 0 0 0 ... 0
A= 0 0 0 0 ... 0
0 1 0 0 ... 0
... ... ... ... ... ...
,
0
1
= 0
0
...
b
, 1 2ξ= ξ ξ ... ...

264
thì biểu thức (14.10) trở thành:
i
i1
i
exp θ+ξPr X =1;A,b,ξ/θ =
1+exp θ+ξ,
Tức là mô hình Rasch nhị phân đơn giản.
Đối với PCM 3 hạng điểm 0,1,2 có thể xác định ma trận A và vectơ b
như sau:
0 0 0 0 ... 0
1 0 0 0 ... 0
A= 1 1 0 0 ... 0
0 0 0 0 ... 0
... ... ... ... ... ...
,
0
1
b= 2
0
...
, 1 2ξ= ξ ξ ... ... ,
khi ấy:
1 1 2
1Pr hang 0;A,b,ξ/θ =
1+exp θ+ξ +exp 2θ+ξ +ξ, (14.11a)
1
1 1 2
exp θ+ξPr hang1;A,b,ξ/θ =
1+exp θ+ξ +exp 2θ+ξ +ξ, (14.11b)
1 2
1 1 2
exp 2θ+ξ +ξPr hang2;A,b,ξ/θ =
1+exp θ+ξ +exp 2θ+ξ +ξ. (14.11c)
Rõ ràng các biểu thức (14) trùng với các biểu thức (13) của chương 13
đối với PCM (ở đây đã sử dụng ξ thay cho -δ).
2) Mô hình logistic nhị phân và đa phân đa chiều
Từ mô hình logistic nhị phân và đa phân đơn chiều trên đây có thể
mở rộng thành mô hình đa chiều bằng cách thay thế đại lượng vô hướng
θ biểu diễn năng lực bằng vectơ năng lực D ,..., 21θ với D chiều
năng lực. Khi ấy mô hình ứng đáp CH trở thành:

265
i
ik ij
ik K
ik ij
j=0
exp b θ+a ξPr X =1;A,b,ξ/θ =
exp b θ+a ξ
. (14.12)
Lưu ý rằng trong biểu thức (14.12) không chỉ thay thế biến vô
hướng θ bằng biến vectơ θ, mà còn thay thế hàm điểm bik bằng vectơ bik,
tức là đối với mỗi hạng ứng đáp có một điểm hoặc trọng số cho một
chiều năng lực. Chẳng hạn, đối với một CH nhị phân i xác suất ứng đáp
đúng của năng lực 2 chiều sẽ là:
1 2 i
i1
1 2 i
exp 2θ +θ +ξPr X =1;A,b,ξ/θ =
1+exp 2θ +θ +ξ
Biểu thức trên cho thấy năng lực để ứng đáp CH là hàm tuyến tính
của hai năng lực tiềm ẩn, và năng lực thứ nhất cần nhiều hơn năng lực
thứ hai vì có trọng số 2.
14.1.3. Về các cách biểu hiện tính đa chiều: giữa các CH và
trong từng CH
Hình 14.2. Hai kiểu biểu hiện tính đa chiều của các CH trắc nghiệm

266
Nhiều nhà nghiên cứu đưa vào khái niệm tính đa chiều giữa các
CH và trong từng CH. Một bài trắc nghiệm là đa chiều giữa các CH nếu
nó bao gồm nhiều bài trắc nghiệm con đơn chiều. Một bài trắc nghiệm là
đa chiều trong từng CH nếu mỗi CH đòi hỏi nhiều chiều năng lực tiềm ẩn
để trả lời. Hai kiểu đa chiều của bài trắc nghiệm được minh họa ở Hình
14.2. Ở nửa bên trái Hình 14.2 mô tả bài trắc nghiệm 3 chiều gồm 9 CH
theo kiểu đa chiều giữa các CH, mỗi chiều được đánh giá riêng biệt bởi 3
CH. Nửa bên phải của Hình 14 mô tả bài trắc nghiệm 3 chiều gồm 9 CH
với cả 2 kiểu đa chiều giữa các CH và đa chiều trong từng CH, trong đó
4 CH 1, 5, 8, 9 chỉ đo một chiều năng lực, còn các CH khác đo đồng thời
2 hoặc 3 chiều năng lực.
14.2. VÀI VÍ DỤ VỀ ÁP DỤNG TRẮC NGHIỆM ĐA CHIỀU
14.2.1. Phân tích bài kiểm tra gồm các CH nhị phân và đa phân
đo lường 3 chiều năng lực biểu hiện ở riêng từng CH
Để minh họa việc áp dụng IRT trong việc phân tích số liệu trắc
nghiệm bao gồm cả các CH nhị phân và đa phân đo nhiều chiều năng lực,
chúng ta sẽ phân tích một bài kiểm tra Toán lớp 6 Trung học phổ thông
cũng được Viện Khoa học Giáo dục Việt Nam thực hiện vào năm 2009
theo một Dự án của Bộ Giáo dục và Đào tạo.
Bảng 14.1. Điểm tối đa cho các phần của CH hỗn hợp TNKQ và TL môn Toán
Điểm tối đa
T1 1
T2 1
T30 1
T31 3
T32 32a: 4 32b: 2 32c: 2
T33 6
T34 6
T35 7

267
Đề kiểm tra Toán lớp 6 (ký hiệu TOAN6) có 2 loại CH: 30 CH
TNKQ nhị phân, 5 CH TL đa phân. Điểm tối đa của các CH hoặc thành
phần của chúng được biểu diễn ở Bảng 14.1. Trong các CH TL chỉ có
CH TL 32 chia thành 3 CH con. Đề TOÁN6 kiểm tra 3 lĩnh vực nội
dung: số tự nhiên, số nguyên và đoạn thẳng, Bảng 14.2 cho biết phân bố
của các CH TNKQ và TL theo các nội dung nêu trên.
Bảng 14.2. Bảng phân bố các CH theo 3 lĩnh vực nội dung của Đề Toán 6 hỗn hợp TNKQ và TL
Số tự nhiên Số nguyên Đoạn thẳng
TNKQ 1-5; 7-13; 21-23 6, 15-20, 24,25 26-30
TL 32a, 32b, 32c,34 31,33 35
Đề kiểm tra được thực hiện trên 9.846 học sinh lớp 6 từ 25 tỉnh/thành
phố trong cả nước như đã trình bày ở mục 13.2.1. Ở ví dụ này chúng ta tạm
quan niệm 3 lĩnh vực nội dung mà đề kiểm tra muốn đo như 3 chiều năng
lực và phân tích bài toán đa phân, đa chiều bằng phần mềm CONQUEST.
Bảng 14.2 cho thấy mỗi CH được chế tác để đo một năng lực xác định, nên
theo mô tả ở phía trái Hình 14.2 đây là bài toán đa chiều giữa các CH.
Sau đây là một vài kết quả phân tích.
Bảng 14.3 là ma trận tương quan và hiệp biến cho các hệ số tương
quan giữa các chiều của năng lực. Hình 14.3 trình bày các biểu đồ cho
thấy mối quan hệ giữa các mức năng lực của TS ứng với 3 chiều năng lực
và giá trị độ khó của các CH (hoặc độ khó trung bình của các CH con).
Hình 14.4 trình bày các biểu đồ biểu hiện quan hệ giữa các mức năng lực
của TS ứng với 3 chiều năng lực và giá trị ngưỡng γk của các hạng điểm
của các CH con.

268
Bảng 14.3. Ma trận các giá trị tương quan và hiệp biến
giữa 3 chiều năng lực =================================================
COVARIANCE/CORRELATION MATRIX
--------------------------------------------------------------------------------------
Dimension 1 2 3
Dimension 1 0.958 0.614
Dimension 2 0.948 0.547
Dimension 3 0.936 0.924
--------------------------------------------------------------------------------------
Variance 1.118 (0.016) 0.913 (0.013) 0.385 (0.005)
==================================================
14.2.2. Phân tích bài kiểm tra gồm các CH nhị phân đo lường 3 chiều
năng lực biểu hiện hỗn hợp trong mỗi CH
Ví dụ này được mượn từ một minh họa trình bày trong Cẩm nang
giới thiệu phần mềm CONQUEST [31]. Các tác giả đã sử dụng số liệu
mô phỏng ứng đáp của 2.000 TS đối với một đề trắc nghiệm gồm 9 CH
nhị phân. Các CH được giả định đánh giá 3 chiều năng lực, trong đó các
CH và các chiều năng lực có mối tương quan như phần bên phải của
Hình 14.2 (đa chiều trong từng CH). Các giá trị trung bình của mỗi chiều
năng lực tiềm ẩn bằng 0, còn các giá trị hiệp biến giữa các chiều năng lực
được biểu diễn bởi ma trận dưới đây:
100 0 00 058
0 00 100 058
058 058 100
. . .
. . .
. . .
Các tham số độ khó được xác định bằng -0,5 đối với các CH 1, 4
và 7; bằng 0,0 đối với các CH 2,5 và 8; bằng 0,5 đối với các CH 3,6 và 9.
Dùng phần mềm CONQUEST phân tích với điều kiện hội tụ là 0,0001,
chương trình tính lặp 345 lần. Kết quả được trình bày ở các Bảng 14.4 và
14.5. Ước lượng ở Bảng 14.4. chứng tỏ số liệu mô phỏng phù hợp tốt với
mô hình (các độ khó ước lượng của các CH gần với các giá trị mô phỏng
nêu trên đây; bình phương trung bình của số thống kê phản ánh độ phù

269
========================================================================
ConQuest: Generalised Item Response Modelling Software Fri Feb 26
10:23 2010
MAP OF LATENT DISTRIBUTIONS AND RESPONSE MODEL PARAMETER ESTIMATES
========================================================================
Dimension Terms in the Model (excl Step terms)
------------------------------------------------------------
Dimension1 Dimension2 Dimension3 +item
------------------------------------------------------------------------
| | | |
3 | | | |
| | | |
| X| | |
X| X| | |
X| X| | |
X| XX| | |
X| XX| | |
2 X| XX| | |
XX| XXX| | |
XX| XXX| | |
XX| XXXX| | |
XX| XXXX| | |
XXX| XXXXX| X|14 |
XXX| XXXXXX| X|23 34 |
1 XXXX| XXXX| XX|33 |
XXXX| XXXXXX| XXX|13 |
XXXXX| XXXXXX| XXXX|21 27 28 36 |
XXXXX| XXXXXX| XXXX|16 30 31 35 |
XXXXX| XXXXXX| XXXXXX| |
XXXXX| XXXXXXX| XXXXXXX|11 32 |
XXXXXX| XXXXX| XXXXXXXX| |
0 XXXXX| XXXXX| XXXXXXXX|6 7 18 19 37 |
XXXXX| XXXXXXXXXXXXXX|25 |
XXXX| XXXX|XXXXXXXXX|15 20 |
XXXXX| XXX| XXXXXXXX| |
XXXX| XX| XXXXXXX|1 10 12 22 24 |
XXXX| XX| XXXXXX|4 9 17 |
XXXX| XX| XXXX|2 |
-1 XXX| XX| XXXX|8 26 |
XXX| X| XX|5 29 |
XXX| X| X| |
XX| | X|3 |
X| | | |
X| | | |
X| | | |
-2 | | | |
X| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
-3 | | | |
========================================================================
Hình 14.3. Biểu đồ tương quan giữa năng lực TS ở 3 chiều năng lực và các giá trị độ khó của CH hoặc độ khó trung bình của các CH con
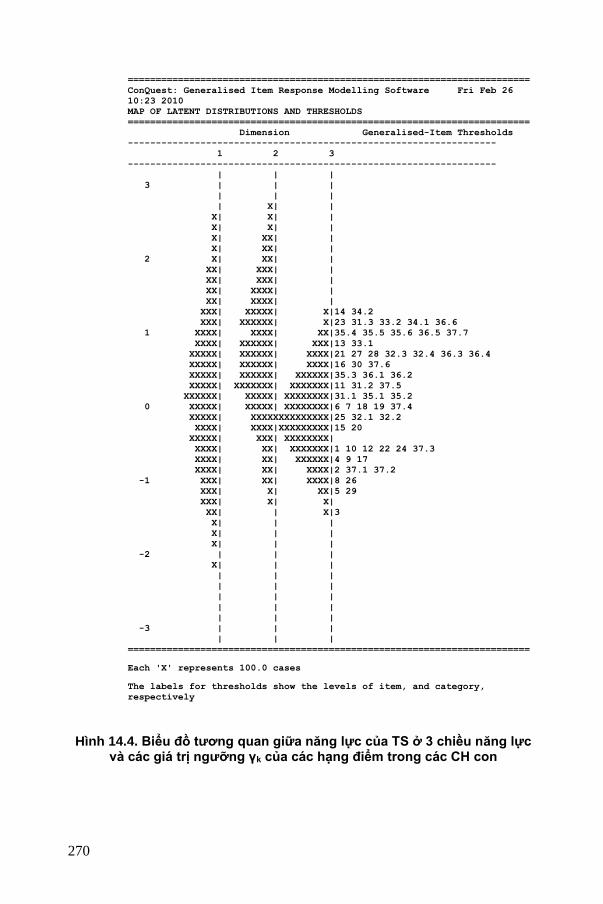
270
========================================================================
ConQuest: Generalised Item Response Modelling Software Fri Feb 26
10:23 2010
MAP OF LATENT DISTRIBUTIONS AND THRESHOLDS
========================================================================
Dimension Generalised-Item Thresholds
------------------------------------------------------------------
1 2 3
------------------------------------------------------------------
| | |
3 | | |
| | |
| X| |
X| X| |
X| X| |
X| XX| |
X| XX| |
2 X| XX| |
XX| XXX| |
XX| XXX| |
XX| XXXX| |
XX| XXXX| |
XXX| XXXXX| X|14 34.2
XXX| XXXXXX| X|23 31.3 33.2 34.1 36.6
1 XXXX| XXXX| XX|35.4 35.5 35.6 36.5 37.7
XXXX| XXXXXX| XXX|13 33.1
XXXXX| XXXXXX| XXXX|21 27 28 32.3 32.4 36.3 36.4
XXXXX| XXXXXX| XXXX|16 30 37.6
XXXXX| XXXXXX| XXXXXX|35.3 36.1 36.2
XXXXX| XXXXXXX| XXXXXXX|11 31.2 37.5
XXXXXX| XXXXX| XXXXXXXX|31.1 35.1 35.2
0 XXXXX| XXXXX| XXXXXXXX|6 7 18 19 37.4
XXXXX| XXXXXXXXXXXXXX|25 32.1 32.2
XXXX| XXXX|XXXXXXXXX|15 20
XXXXX| XXX| XXXXXXXX|
XXXX| XX| XXXXXXX|1 10 12 22 24 37.3
XXXX| XX| XXXXXX|4 9 17
XXXX| XX| XXXX|2 37.1 37.2
-1 XXX| XX| XXXX|8 26
XXX| X| XX|5 29
XXX| X| X|
XX| | X|3
X| | |
X| | |
X| | |
-2 | | |
X| | |
| | |
| | |
| | |
| | |
| | |
-3 | | |
| | |
========================================================================
Each 'X' represents 100.0 cases
The labels for thresholds show the levels of item, and category,
respectively
Hình 14.4. Biểu đồ tương quan giữa năng lực của TS ở 3 chiều năng lực và các giá trị ngưỡng γk của các hạng điểm trong các CH con

271
Bảng 14.4: Độ khó ước lượng δ (hoặc b) của các CH và các giá trị thống kê phản ánh độ phù hợp giữa số liệu và mô hình
====================================================================================
ConQuest: Generalised Item Response Modelling Software Tue Mar 02 18:12 2010
TABLES OF RESPONSE MODEL PARAMETER ESTIMATES
====================================================================================
TERM 1: items
------------------------------------------------------------------------------------
VARIABLES UNWEIGHTED FIT WEIGHTED FIT
--------------- ----------------------- ---------------------------
item ESTIMATE ERROR^ MNSQ CI T MNSQ CI T
---------------------------------------------------------------------------------
1 1 -0.380 0.049 0.99 (0.94, 1.06) -0.2 1.00 (0.96, 1.04) -0.2
2 2 -0.009 0.026 1.04 (0.94, 1.06) 1.2 1.02 (0.95, 1.05) 0.9
3 3 0.496 0.029 1.03 (0.94, 1.06) 1.0 1.03 (0.95, 1.05) 1.0
4 4 -0.529 0.028 1.01 (0.94, 1.06) 0.2 1.01 (0.94, 1.06) 0.4
5 5 0.028 0.049 1.00 (0.94, 1.06) -0.0 1.00 (0.96, 1.04) -0.0
6 6 0.402 0.050 1.00 (0.94, 1.06) 0.1 1.00 (0.96, 1.04) -0.0
7 7 -0.510 0.022 1.03 (0.94, 1.06) 0.9 1.00 (0.93, 1.07) 0.1
8 8 0.085 0.049 1.01 (0.94, 1.06) 0.2 1.00 (0.96, 1.04) 0.3
9 9 0.528 0.050 1.02 (0.94, 1.06) 0.5 1.01 (0.96, 1.04) 0.4
-----------------------------------------------------------------------------------
An asterisk next to a parameter estimate indicates that it is constrained
Separation Reliability = 0.990
Chi-square test of parameter equality = 1435.26, df = 9, Sig Level = 0.000
^ Quyck standard errors have been used
====================================================================================
hợp gần bằng giá trị kỳ vọng (1,0), giá trị t-test T gần bằng 0). Bảng 14.5
cho các giá trị hiệp biến ước lượng cũng gần với giá trị mô phỏng (0 và
0,58), giá trị phương sai ước lượng cũng vậy (~1,0).
=========================================================================
COVARIANCE/CORRELATION MATRIX
Dimension
----------------------------------------------------
Dimension 1 2 3
Dimension 1 0.098 0.642
Dimension 2 0.100 0.580
Dimension 3 0.667 0.550
-------------------------------------------------------------------------
Variance 0.897 (0.028) 1.077 (0.034) 1.033 (0.033)
-------------------------------------------------------------------------
An asterisk next to a parameter estimate indicates that it is constrained
Values below the diagonal are correlations and values above are
covariances
=========================================================================
Bảng 14.5. Ma trận các giá trị tương quan và hiệp biến giữa 3 chiều năng lực
Các hình 14.5a, 14.5b,14.5c là các biểu đồ thể hiện quan hệ giữa các
mức năng lực ứng với từng chiều năng lực của TS và các giá trị độ khó
của CH. Qua các biểu đồ có thể thấy rõ một số CH tham gia đo đồng thời

272
==============================================================
ConQuest: Generalised Item Response Modelling Software
Tue Mar 02 18:12 2010
MAP OF LATENT DISTRIBUTIONS AND RESPONSE MODEL PARAMETER ESTIMATES
=============================================================
Dimension 1 +items
------------------------------------------------------------
3 | |
| |
| |
| |
X| |
X| |
X| |
2 | |
X| |
XX| |
XXX| |
XXX| |
XXXXX| |
XXXXXX| |
1 XXXXXXX| |
XXXXXXXXX| |
XXXXXXX| |
XXXXXXXXXXX| |
XXXXXXXXXXX|3 |
XXXXXXXXXXXX| |
XXXXXXXXXXX| |
XXXXXXXXXXXX| |
0 XXXXXXXXXXX|2 |
XXXXXXXXXXX| |
XXXXXXXXXXX|1 |
XXXXXXXXX|4 7 |
XXXXXXXXXX| |
XXXXXXXXXX| |
XXXXXXX| |
-1 XXXXXX| |
XXX| |
XXXX| |
XXXXX| |
XXX| |
XX| |
XX| |
-2 X| |
X| |
X| |
X| |
| |
X| |
| |
-3 | |
============================================================
Each 'X' represents 9.8 cases
============================================================
Hình 14.5a. Biểu đồ tương quan giữa chiều thứ 1 của năng lực TS và các giá trị độ khó của CH

273
============================================================
Dimension 2 +items
------------------------------------------------------------
| |
X| |
| |
3 | |
| |
X| |
| |
X| |
X| |
XX| |
2 XXX| |
X| |
XX| |
XX| |
XXXXX| |
XXXXXX| |
XXXXXX| |
1 XXXXX| |
XXXXXXX| |
XXXXXXX| |
XXXXXXXXX| |
XXXXXXXXXXXX| |
XXXXXXXXXXX|6 |
XXXXXXXXX| |
XXXXXXXXXXXX|5 |
0 XXXXXXXXXXX|2 |
XXXXXXXXXX| |
XXXXXXXXX| |
XXXXXXXXXXX|4 7 |
XXXXXXXXXXX| |
XXXXXXX| |
XXXXXXX| |
-1 XXXXXX| |
XXXXX| |
XXXX| |
XXXX| |
XXXX| |
XXX| |
XX| |
-2 XX| |
XX| |
X| |
X| |
| |
| |
| |
-3 | |
| |
============================================================
Each 'X' represents 9.8 cases
Hình 14.5b. Biểu đồ tương quan giữa chiều thứ 2 của năng lực TS và các giá trị độ khó của CH

274
============================================================
Dimension 3 +items
------------------------------------------------------------
3 | |
| |
| |
X| |
X| |
X| |
X| |
2 XX| |
XX| |
XXX| |
XXX| |
XXX| |
XXXXX| |
XXXXX| |
1 XXXXXX| |
XXXXXXXX| |
XXXXXXXX| |
XXXXXXXXX| |
XXXXXXXXX|3 9 |
XXXXXXXXXXXX| |
XXXXXXXXXX| |
XXXXXXXXXX|8 |
0 XXXXXXXXXXX| |
XXXXXXXXXX| |
XXXXXXXXXXXXX| |
XXXXXXXXXX|7 |
XXXXXXXXX| |
XXXXXXXX| |
XXXXXXX| |
-1 XXXXXXX| |
XXXXX| |
XXXXX| |
XXX| |
XXXX| |
XXXX| |
XX| |
-2 XX| |
X| |
X| |
X| |
X| |
| |
| |
-3 | |
| |
============================================================
Each 'X' represents 9.8 cases
============================================================
Hình 14.5c. Biểu đồ tương quan giữa chiều thứ 3 của năng lực TS và các giá trị độ khó của CH

275
=================================================================
ConQuest: Generalised Item Response Modelling Software Tue Mar
02 18:12 2010
MAP OF LATENT DISTRIBUTIONS AND RESPONSE MODEL PARAMETER ESTIMATES
=================================================================
Dimension 1 Dimension 2 Dimension 3
+items
------------------------------------------------------------------
| X| |
| | |
3 | | |
| | |
| X| |
| | X|
X| X| X|
X| X| X|
X| XX| X|
2 | XXX| XX|
X| X| XX|
XX| XX| XXX|
XXX| XX| XXX|
XXX| XXXXX| XXX|
XXXXX| XXXXXX| XXXXX|
XXXXXX| XXXXXX| XXXXX|
1 XXXXXXX| XXXXX| XXXXXX|
XXXXXXXXX| XXXXXXX| XXXXXXXX|
XXXXXXX| XXXXXXX| XXXXXXXX|
XXXXXXXXXXX| XXXXXXXXX| XXXXXXXXX|
XXXXXXXXXXX|XXXXXXXXXXXX| XXXXXXXXX|3 9
XXXXXXXXXXXX| XXXXXXXXXXX|XXXXXXXXXXXX|6
XXXXXXXXXXX| XXXXXXXXX| XXXXXXXXXX|
XXXXXXXXXXXX|XXXXXXXXXXXX| XXXXXXXXXX|5 8
0 XXXXXXXXXXX| XXXXXXXXXXX| XXXXXXXXXXX|2
XXXXXXXXXXX| XXXXXXXXXX| XXXXXXXXXX|
XXXXXXXXXXX| XXXXXXXXXXXXXXXXXXXXXX|1
XXXXXXXXX| XXXXXXXXXXX| XXXXXXXXXX|4 7
XXXXXXXXXX| XXXXXXXXXXX| XXXXXXXXX|
XXXXXXXXXX| XXXXXXX| XXXXXXXX|
XXXXXXX| XXXXXXX| XXXXXXX|
-1 XXXXXX| XXXXXX| XXXXXXX|
XXX| XXXXX| XXXXX|
XXXX| XXXX| XXXXX|
XXXXX| XXXX| XXX|
XXX| XXXX| XXXX|
XX| XXX| XXXX|
XX| XX| XX|
-2 X| XX| XX|
X| XX| X|
X| X| X|
X| X| X|
| | X|
X| | |
| | |
-3 | | |
==================================================================
Each 'X' represents 9.8 cases
==================================================================
Hình 14.6. Biểu đồ tổng hợp tương quan giữa 3 chiều năng lực TS và các giá trị độ khó của CH

276
hai chiều năng lực, như các CH2 và CH4 đo đồng thời 2 chiều năng lực 1
và 2; CH3 đo đồng thời 2 chiều năng lực 1 và 3; riêng CH7 tham gia đo
đồng thời 3 chiều năng lực 1, 2, 3. Hình 14.6 là biểu đồ tổng hợp biểu
hiện tương quan giữa 3 chiều năng lực TS và các giá trị độ khó của CH.
________________________
CÂU HỎI TỰ KIỂM TRA
1. Mô tả mô hình trắc nghiệm đa chiều logistic tuyến tính với số
liệu trắc nghiệm nhị phân của Reskase.
2. Mô tả cách tiếp cận xây dựng mô hình tổng quát cho trắc nghiệm
nhị phân, đa phân, một chiều, đa chiều của Wu và Adams.
3. Trình bày khái niệm về tính đa chiều giữa các CH và trong từng
CH trong trắc nghiệm đa chiều.
4. Cách sử dụng các phần mềm CONQUEST và PARSCALE để
phân tích các trắc nghiệm đa chiều.

277
TRẢ LỜI BÀI TẬP
(Một số bài tập trong tập sách này được trích từ tài liệu tham khảo [11])
Chương 2
Bài tập:
Độ khó theo CTT: đối với nhóm TS năng lực thấp p=3/15=0,20;
đối với nhóm TS năng lực cao p=12/15= 0,8.
Độ phân biệt theo CTT (có thể tính theo Exel các hệ số tương quan
giữa 2 vectơ “điểm ứng đáp CH” và “điểm từ ĐTN”): đối với nhóm TS
năng lực thấp r=0,68; đối với nhóm TS năng lực cao r=0,39.
Qua các kết quả tính toán rõ ràng các tham số tính được phụ thuộc
rất mạnh vào mẫu TS.
Chương 4
Bài tập 1:
Theo các giá trị a, b, c cho ở Bảng 4.1 có thể tính các giá trị P(θ)
của 6 CH tại các giá trị θ đã cho. Kết quả được trình bày ở Bảng 1:
Bảng 1.
θ
CH
-3 -2 -1 0 1 2 3
1 0,000 0,000 0,002 0,045 0,500 0,955 0,998
2 0,008 0,027 0,085 0,233 0,500 0,767 0,915
3 0,250 0,250 0,252 0,284 0,625 0,966 0,998
4 0,205 0,236 0,412 0,788 0,964 0,995 0,999
5 0,000 0,006 0,045 0,265 0,735 0,955 0,994
6 0,165 0,239 0,369 0,550 0,731 0,861 0,935

278
CH4 dễ nhất vì từ mức θ = -1,0 trở đi xác suất ứng đáp đúng đều
cao hơn các CH khác.
CH6 có độ phân biệt thấp nhất và các giá trị P(θ) tăng chậm theo θ.
TS với năng lực θ =0 có xác suất ứng đáp đúng CH 4 cao nhất là
0,788; và xác suất ứng đáp sai là 1-P(θ)=1-0,788=0,212.
Bài tập 2:
Ma trận 2x2 về các ứng đáp đúng và sai đối với 2 CH đã cho có
dạng ở Bảng 2:
Bảng 2.
CH 2
CH1
Sai
Đúng
Sai Đúng
28
12
40
8(A) 20(B)
8(C) 4(D)
16 24
Để kiểm nghiệm về tính độc lập của 2 CH, từ bảng trên có thể tính
tham số thống kê χ2 :
χ2 = N(AD-BC)2 / (A+B)(B+D)(D+C)(C+A)= 40(8.4 – 20.8)2
/(8+20)(20+4)(4+8)(8+8)=5,08.
Đối chiếu với giá trị χ2 từ bảng: khi độ tự do bằng 2-1=1, mức ý
nghĩa α=0,5 thì χ2=3,843. Như vậy giá trị χ2 tính được lớn lơn giá trị cho
ở bảng, do đó có thể phủ định giả thiết về sự độc lập của 2 CH với mức ý
nghĩa 0,05. Kết luận là số liệu không phù hợp với mô hình đơn chiều.
Chương 5
Bài tập:
Độ khó cổ điển của CH tính theo mẫu TS gồm 2 dòng đầu Bảng 5.1
chương 5 là p=3/20=0,15; theo mẫu TS gồm 2 dòng cuối bảng là
p = 17/20=0,85. Độ phân biệt cổ điển (tính theo Exel) của CH tính theo
mẫu TS gồm 2 dòng đầu là r= 0,612; theo mẫu TS gồm 2 dòng cuối là
r= 0,44.

279
Tính b và a theo IRT dựa vào biểu thức (5.3):
Từ mẫu TS gồm 2 dòng đầu lập được 2 phương trình ứng với điểm đầu và điểm
cuối: ln(0,1/0,9) = a(-1,716) - ab và ln (0,2/0,8) = a(-1,129) - ab, chúng
cho các nghiệm a= 1,381 và b=-0,126; Từ mẫu TS gồm 2 dòng cuối lập
được 2 phương trình ứng với điểm đầu và điểm cuối: ln(0,8/0,2)=a(0,919)-ab
và ln(0,9/0,1)=a(1,1516)-ab, chúng cho các nghiệm a=1,358 và b= -
0,102.
Rõ ràng các tham số độ khó độ phân biệt cổ điển phụ thuộc mạnh
vào mẫu TS, còn các tham số b và a theo IRT ít biến đổi (tuy các mẫu
thử để tính rất nhỏ).
Chương 6
Bài tập:
Các giá trị θ trong khoảng (-4,4) có thể chuyển đổi thành thang
bách phân, chẳng hạn:
tuyến tính: y=100(4+θ).
phi tuyến:
n
i
iPn
y1
)(100
.
Chương 7
Bài tập:
Dựa vào biểu thức (7.4) và (7.7) ở chương 7 có thể tính các giá trị
hàm thông tin của các ĐTN gồm 3 CH, trình bày ở Bảng 3:
Bảng 3.
θ ĐTN(1,2,3) ĐTN(1,2,4) ĐTN(1,3,4) ĐTN(2,3,4)
-2 0,219 0,219 0,187 0,054
-1 1,361 1,339 0,965 0,540
0 2,918 2,681 1,486 2,250
1 1,738 1,215 1,907 2,172
2 0,492 0,667 1,059 1,076

280
Từ các giá trị thông tin của các ĐTN cho ở Bảng 3 có thể thấy ở
khoảng năng lực θ=1,0 ĐTN gồm các CH 2,3 và 4 cho giá trị thông tin
lớn nhất, do đó nó là ĐTN tốt nhất để đo mức đạt chuẩn ở điểm chuẩn
θ=1,0.
Chương 8:
Bài tập 1:
Hàm biến cố hợp lý cực đại đối với TS có vectơ ứng đáp
(1,0,1,0,0) là L(u|)= P1 Q 2 P3 Q 4Q5,
hoặc dưới dạng logarit:
lnL(u|) = LnP1+ ln(1-P2)+lnP3+ln(1-P4)+ln(1-P5).
Để xác định được các biểu thức trên, các CH phải tuân theo giả
thiết độc lập địa phương.
Đồ thị biểu diễn hàm lnL có dạng được vẽ ở Hình 1:
Hình 1.
Hàm lnL đạt cực đại tại giá trị bằng cỡ -0,65, vậy đó là giá trị ước
lượng của θ theo biến cố hợp lý cực đại.
Bài tập 2:

281
a) )()( 22
iiQPaDI , trong đó D2 = 1,72 = 2,89. Theo các giá trị
b và a của 4 CH cho ở Bảng 8.4, có thể tính được giá trị I tại θ= 1,5: I
(θ= 1,5) = 5,19. Từ đó: 19,5
1)5,1( =0,44.
b) Khoảng tin cậy 95% của giá trị θ:
θ= 1,5 ± 1,96*0,44 = 1,5 ± 0,86 = (0,64, 2,36).
Bài tập 3:
Giả thiết ứng đáp của 3 TS với năng lực θ1, θ2, θ3 là độc lập với nhau,
khi ấy:
P(U1, U2, U3 / θ1, θ2, θ3) = P(U1/ θ1)P(U2/ θ2)P(U3/ θ3).
Từ đó có thể lập hàm biến cố hợp lý khi ứng đáp của 3 TS là (0,0,1):
L= Q1 Q2P3 =
)1(7,1
)1(7,1
)0(7,1)1(7,1 11
1
1
1b
b
bb e
e
ee
Từ đó có thể tính L theo các giá trị của b, kết quả được trình bày ở
Bảng 4 dưới đây:
Bảng 4.
b 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
L 0,357 0,386 0,411 0,432 0,447 0,455 0,458 0,454 0,444 0,429 0,409
Theo Bảng 4, giá trị hàm L cực đại ở khoảng b~0,6, đó là ước
lượng của b theo biến cố hợp lý cực đại.
Bài tập 4:
a) Với mô hình 1 tham số, a=1, khi ước lượng giá trị độ khó b, hàm
thông tin và sai số tiêu chuẩn có thể viết như sau:
2i iI(b)=D P(θ )Q(θ ) và
1σ(b)=
I(b).
b) Với các giá trị θ và b ở bài tập 3, ta tính được:
I(b) = 2,89(0,062.0,938 + 0,265.0,735 + 0,644.0,336) = 1,376.

282
σ(b) = 0,85.
Chương 9:
Bài tập 1:
Độ khó cổ điển ở các mức năng lực:
θ=-2: p=0,20; θ=-1: p=0,25; θ=0: p=0,40; θ=1: p=0,75; θ=2:
p=0,90.
Xác suất trả lời đúng ở các mức năng lực:
P(θ=-2)=0,25; P(θ=-1)=0,27; P(θ=0)=0,38; P(θ=1)=0,72; P(θ=2)=0,95.
Hàm đặc trưng thống kê cải tiến:
2m
j j j
1
j=1 j j
N P -E(P )Q =
E(P ) 1-E(P )
=220(0,20-0,25)
0,25 . 0,75+
220(0,25-0,27)
0,27 . 0,73+
220(0,40-0,38)
0,38 . 0,62
+ 220(0,75-0,72)
0,72 . 0,28+
220(0,90-0,95)
0,95 . 0,05= 1,48;
Mức độ tự do là m-k=5-3=2.
χ 22;0,5 (ở độ tự do 2 và mức ý nghĩa 5%) = 5,99 (từ bảng χ 2). Vì giá
trị tính toán không vượt quá giá trị tương ứng ở bảng, có thể kết luận
rằng mô hình 3 tham số là phù hợp với số liệu đối với CH này.
Bài tập 2:
a)
2m
j j j
1
j=1 j j
N P -E(P )Q =
E(P ) 1-E(P )
- Đối với mô hình 1 tham số:
1=
220(0,20-0,02)
0,02 . 0,98 +
220(0,25-0,12)
0,12 . 0,88 +
220(0,40-0,43)
0,43 . 0,57 +
220(0,75-0,80)
0,80 . 0,20 +
220(0,90-0,96)
0,96 . 0,04= 38,52;
Mức độ tự do là m-k=5-1=4.

283
- Đối với mô hình 2 tham số:
Q1=
220(0,20-0,11)
0,11. 0,89+
220(0,25-0,25)
0,25. 0,75+
220(0,40-0,46)
0,46. 0,54+
220(0,75-0,69)
0,69. 0,31
+220(0,90-0,85)
0,85. 0,15= 2,67;
Mức độ tự do là m-2=5-1=3.
Đối chiếu với số liệu ở Bảng χ 2 ta có: đối với mô hình 1 tham số
χ 24;0,5= 9,488; đối với mô hình 2 tham số χ 2
3;0,5= 7,815. Như vậy
mô hình 1 tham số không phù hợp với số liệu, còn mô hình 2 tham số
phù hợp với số liệu.
Trong 3 mô hình, mô hình 3 tham số phù hợp với số liệu tốt nhất,
mô hình 2 tham số cũng phù hợp khá, còn mô hình 1 tham số không phù
hợp. Trong trường hợp này, xét đến các mặt tiện lợi khác, chọn mô hình
2 tham số có lẽ là thích hợp nhất.
Chương 10:
Bài tập 1:
Giá trị thông tin của “ĐTN” gồm 3 CH tại năng lực θ=1,0:
I(θ=1,0) =1,10+0,50+2,20 =3,8; Từ đó σ(θ=1,0) = 8,3
1=0,51.
Khi σ(θ=-1,0)=0,40 thì sẽ có I(θ=-1,0) ~ 6,25. Muốn có giá trị hàm
thông tin như vậy ở điểm θ=-1,0 cần (6,25/0,6) ~11 CH cho giá trị thông tin ở
điểm θ=-1,0 giống như CH5.
Bài tập 2:
Các giá trị thông tin của 2 “ĐTN” 1 và 2 tại 3 vị trí θ được tính và
trình bày ở Bảng 5 dưới đây:
Bảng 5. Giá trị thông tin của 2 “ĐTN”
“ĐTN”
θ
0,0 1,0 2,0
1 (CH2, CH3) 0,35 1,6 0,65
2 (CH1, CH6) 0,6 2,35 0,48

284
b) Hiệu suất tỷ đối của “ĐTN1” so với “ĐTN2” ở 3 mức năng lực
đã cho được trình bày ở Bảng 6:
Bảng 6. Hiệu suất tỷ đối
θ
0,0 1,0 2,0
Hiệu suất tỷ đối
RE(θ)=I1(θ)/ I2(θ)
0,58
0,68
1,35
“ĐTN1” có hiệu suất thấp hơn “ĐTN2” ở các mức năng lực
θ=0,0 và θ=1,0 (hiệu suất tỷ đối RE(θ) tương ứng là cỡ 0,58 và 0,68);
nhưng có hiệu suất cao hơn ở mức năng lực θ = 2,0 (hiệu suất tỷ đối
RE(θ) = 1,35).
Khi σ(θ=-1,0)=0,40 thì sẽ có I(θ=-1,0) ~ 6,25. Muốn đạt giá trị hàm
thông tin như vậy ở điểm θ=-1,0 cần (6,25/0,6) ~11 CH cho giá trị thông tin ở
điểm θ=-1,0 giống như CH5.
Ở mức năng lực θ=1,0 “ĐTN2” cho giá trị thông tin cao hơn
“ĐTN1” một lượng bằng (2,35-1,60 = 0,75), do đó cần thêm vào
“ĐTN1” một số CH cho thông tin tương tự như CH5 bằng (0,75/0,2) ~ 4.
Bài tập 3:
Đối với “ĐTN” gồm 2 CH 4 và 5 ta có:
I(θ=-1,0) = 1,45+0,60 = 2,05; do đó σ(θ=-1,0)~0,70.
Chương 11:
Bài tập: Theo bài tập, chúng ta có 2 ĐTN, giữa 2 ĐTN có một số
CH chung bắc cầu, gọi ĐTN A là Xc và ĐTN B là Yc. Cho mỗi nhóm TS
làm một ĐTN và quá trình xác định tham số độ khó b nhờ Xc và Yc cho
các giá trị trung bình tương ứng là MX =4,2; MY=3,5 và độ lệch chuẩn
tương ứng là sX =2,2 và sY=1,8. Theo phương pháp trung bình và sigma
có thể tính các hằng số chuyển thang đo:
α = sY/sX=1,8/2,2= 0,82; β = MY - α MX= 3,5 – 0,82.4,2 = 0,06.
Từ đó các giá trị b và a trên thang của Y có thể chuyển về thang X:
b*= 0,82.(-1,4) + 0,06 = -1,09; a*= 0,9/0,82=1,1.

285
Chương 12:
Bài tập: Theo bài tập, TS đã ứng đáp 3 CH 3, 12, 7 (theo Bảng
12.l) với vectơ ứng đáp tương ứng (1, 1, 0). Sau đó CH 4 được chọn để
ứng đáp tiếp theo, và TS ứng đáp sai, khi ấy năng lực ước lượng được là
θ=0,45. Có thể tính các giá trị hàm thông tin của các CH còn lại ở mức
năng lực θ đó, biểu diễn ở Bảng 7.
Bảng 7.
CH 1 2 5 6 8 9 10 11 13
I(θ=0,45) 0,50 0,66 0,03 0,19 0,18 1,06 0,48 0,45 0,16
CH cho giá trị thông tin lớn nhất ở mức θ=0,45 là CH 9, do đó nó
sẽ được chọn cho bước ứng đáp kế tiếp.
_______________

286
BẢNG ĐỐI CHIẾU MỘT SỐ THUẬT NGỮ ANH VIỆT
Affective domain Lĩnh vực cảm xúc, thái độ
Automatic Test Asembly - ATA Tạo đề tự động
Calibration Định cỡ
Chi-square goodness-of-fit index Chỉ số trùng khớp tốt Chi-bình phương
Classical Test Theory - CTT Lý thuyết trắc nghiệm cổ điển
Cognitive domain Lĩnh vực nhận thức
Computer Adaptive Test – CAT Trăc nghiệm thích ứng nhờ máy tính
Computer-based-testing - CBT Trắc nghiệm nhờ máy tính
Computerized Fixed Tests - CFT Các trắc nghiệm cố định nhờ máy tính
Criterion-referenced Đánh giá theo tiêu chí
Dichotomous Nhị phân
Differential item functioning - DIF Ứng đáp câu hỏi khác biệt
Difficuilty Độ khó
Dimension Chiều
Discrimination Độ phân biệt
Equating So bằng
Essay test Trắc nghiệm tự luận
Formative assessement Đánh giá trong tiến trình
Generalised partial credit model -GPCM Mô hình định giá từng phần tổng quát
Invariant Tính bất biến
Item banking Xây dựng ngân hàng CH
Item Characteristic Curve - ICC Đường cong đặc trưng của câu hỏi

287
Item Characteristic Function - ICF Hàm đặc trưng của câu hỏi
Item information function Hàm thông tin của câu hỏi
Item-free Không phụ thuộc vào câu hỏi
Item Response Theory - IRT Lý thuyết Ứng đáp Câu hỏi
Linear-on-the-Fly Test - LOFT Trắc nghiệm di chuyển thẳng nhờ
máy tính
Linking Kết nối
Local independent Độc lập địa phương
Matching item Câu ghép đôi
Maximum likelyhood estimation - MLE Ước lượng theo biến cố hợp lý cực đại
Multidimentionality Đa chiều
Multiple choise question- MCQ Câu nhiều lựa chọn
Norm-referenced Đánh giá theo chuẩn
Objective test Trắc nghiệm khách quan
Paper-and-pencil test - PAP Trắc nghiệm trên giấy
Partial credit model - PCM Mô hình định giá từng phần
Polytomous Đa phân
Psychomotor domain Lĩnh vực tâm lý vận động (kỹ năng)
Questionnaire Bảng hỏi
Rating scale model Mô hình thang đánh giá
Raw score Điểm thô
Sample-free Không phụ thuộc vào mẫu
Scaling Xác lập thang đo
Short answer item Câu trả lời ngắn
Student-produced response Thí sinh tự tạo ứng đáp

288
Summative assessment Đánh giá tổng kết
Supply item Câu điền khuyết
Structured Computer Adaptive
Multistage Tests
Trắc nghiệm thích ứng nhờ máy tính
cấu trúc đa giai đoạn
Test information function Hàm thông tin của đề trắc nghiệm
Testlet Phân đề
True score Điểm thực
Unidimentionality, unidimentional Đơn chiều, tính đơn chiều
Yes/no question Câu đúng sai

289
CÁC TÀI LIỆU DẪN VÀ THAM KHẢO CHÍNH
1. Dương Thiệu Tống. Trắc nghiệm và đo lường thành quả học tập
(phương pháp thực hành). Nhà xuất bản Khoa học Xã hội, 2005.
2. Thurstone, L.L. A method of scaling psychological and
educational tests. Journal of Educational Psychology, 16(7), 1925.
3. Rasch, G. Probablistic Models for Some Intelligence and
Attainment Tests. Copenhagen, Denmark: Danish Institute for
Educational Research, 1960.
4. Birnbaum, A. Some latent trade models and their use in inferring
an examinee's ability. Trong F.M. Lord and M.R. Novick (Eds),
Statistical Theories of Mental Test Scores. Reading, M.A: Addison-
Wesley, 1968.
5. Lord, F.M. Applications of Item Response Theory to Practical
Testing Problems. Lawrence Erbaum Associates, Publishers, 1980.
6. Lord, F.M.; Novick, M.R. Statistical Theories of mental test
scores. Reading, MA: Addison-Wesley, 1968.
7. Allen, M. J.; Yen, W. M. Introduction to Measurement Theory.
Monterey, California: Brooks/Cole Publishing Company, 1979.
8. Barker, F.B. Item Response Theory - Parameter Estimation
Techniques, Marcel Dekker, Inc, 1992.
9. Haley, D.C. Estimation of the dosage mortality relationship when
the dose is subject to error, (Technical Report N0 15). Stanford,
C.A: Stanford Univerrsity, Applied Mathematics and Statistics
Labolatory, 1952.
10. Wright, B. D.; Mark H.S. Best Test Design, University of
Chicago, MESA PRESS, 1979.

290
11. Hambleton, R.K.; Swaminathan, H.; Jane Roges, H.. Fundamentals
of Item Response Theoty. SAGE Publications, 1991.
12. Van der Linden, W. J.; Hambleton, R.K. (editors). Handbook of
Modern Item Response Theory. Springer, 1997.
13. Brenman, R. L. Educational Measurement, 4th edition,
ACE/PRAEGER series on Higher Education, 2006.
14. Yen, M.W. Using simulation results to choose latent trait model.
Applied Psychological Measurement, 5, 1981.
15. Linn R.L.; Harnisch D.L. Interactions betweem item content and group
membership on achievement test items. Journal of Educational
Measurement, 18. 1981.
16. Haebara, T. Equating logistic ability scales by weighted least
squares method. Japanese Psychological Research, 22, 1980.
17. Stocking M.L.; Lord, F.M. Developing a common metric in item
response theory, Applied Psychological Measurement, 7, 1983
18. Kolen, M.J.; Brennan, L. (editors). Test Equating, Scaling and Linking,
Spinger, 2004.
19. Lâm Quang Thiệp, Lâm Ngọc Minh, Lê Mạnh Tấn, Vũ Đình Bổng -
Phần mềm VITESTA và việc phân tích số liệu trắc nghiệm. Tạp chí Giáo dục,
số 176, 11/2007.
20. McDonald, R.P. Non-linear factor analysis. Psychometric Monograph,
No 15, 1967.
21. Samejima, F. Estimation of latent ability using response pattern of
graded scores. Psychometric Monograph, No 17, 1969.
22. Samejima, F. Normal ogive model on the continious response level
in the multidimentional latent space. Psychometrika 39, 1974.
23. Andersen, E. B. Sufficient statistics and latent trait models. Psychometrica
42, 1977.
24. Andrich, D. A rating formulation for ordered response categories.
Psychometrica 43, 1978.

291
25. Master, G.N. A Rasch model for partial credit scoring. Psychometrica
47, 1982.
26. Muraki, E. A generalised partial credit model: Application of an
EM algorithm. Psychometrica 16, 1992.
27. Bock, R.D. Estimating item parameters and latent ability when
responses are scored in two or more nominal categories.
Psychometrika 37, 1972.
28. Thissen D.;Steinberg L. A response model for multiple choice
items. Psychometrica 49, 1984.
29. Yen, W.M. Scaling performance assessment: Strategies for
managing local item dependence. Journal of Educational
Measurement, 30(3), 1993.
30. http://assess.com/xcart/product.php?productid=220&cat=1&page=1
31. Wu, M.L.; Adams, R. J., Wilson, M. R.; Handane, S A.. “ACER
CONQUEST, Version 2.0”, ACER Press, 2007.
32. Bloom, B.S. and Krathwohl, D. R. (1956) “Taxonomy of Educational
Objectives”: The Classification of Educational Goals, by a
committee of college and university examiners. Handbook I:
Cognitive Domain. NY, NY: Longmans, Green.
33. Anderson, L. W. and Krathwohl, D.R. (Eds.) “A Taxonomy for
Learning, Teaching, and Assessing: A Revision of Bloom's
Taxonomy of Educational Objectives”. Allyn & Bacon. Boston,
MA (Pearson Education Group), 2001
34. Bộ Giáo dục và Đào tạo. “Báo cáo khảo sát kết quả học tập môn
Toán và tiếng Việt của học sinh lớp 5 năm học 2006 - 2007”.
















![Bé GI¸O DôC VμO T¹O Bé QUèC PHßNG HäC VIÖN CHÝNH TRÞ [ ] filebé gi¸o dôc vμ §μo t¹o bé quèc phßng häc viÖn chÝnh trÞ [ ] §inh xu¢n khu£ quan hÖ gi÷a](https://img.pdfslide.net/doc/110x75/5e1d0defeeab96343d580822/b-gio-dc-vo-to-b-quc-phng-hc-vin-chnh-tr-gio-dc.jpg)












