Embed Size (px)
Citation preview

REPÚBLICA BOLIVARIANA DE VENEZUELA UNIVERSIDAD DEL ZULIA
FACULTAD DE CIENCIAS ECONÓMICAS Y SOCIALES DIVISIÓN DE ESTUDIOS PARA GRADUADOS
PROGRAMA ESPECIALIZACIÓN EN GERENCIA DE EMPRESAS TURÍSTICAS MENCIÓN: SERVICIOS DE HOSPITALIDAD
PREDICCIÓN DE RESERVACIONES DE
HABITACIONES EN HOTELES
Trabajo especial de grado presentado para optar al grado académico de Especialista en Gerencia de Empresas Turísticas. Mención Servicios de
Hospitalidad
Autor: Ing. Eduardo Emiro Rios.M.Sc C.I.: V- 2.865.274
Tutor: Econ. Ramón Emilio Pérez Salas. MSc C.I.: V-3.463.162
Maracaibo, Octubre 2012

DEDICATORIA
En memoria de mi esposa Rebeca María.
Con todo cariño a mis hijos: Juan Eduardo, Jeny, Maria Inés, Alexander, José Eduardo, Flor María, Maria Isabel, Hildemaro, María Virginia, Maria Alcira, Aura Elena y Cesar David.
A mis nietos: Andrea Virginia, Hildemaro Andrés, Andrés Eduardo, Luis Fernando, Juan Diego, Sarah Elizabeth.
A mis compañeros de estudio.

AGRADECIMIENTO El autor quiere expresar su agradecimiento a los profesores tutores MSc
Ramón Emilio Pérez Salas y Dra. Yanyn Aurora Rincón Quintero por las
sugerencias dadas para el mejor desarrollo de la tesis.
También quiero agradecer a la Profesora Silvia Calvani, quien sugirió el tema
de investigación en cuestión, por sus recomendaciones iniciales.
Al profesor Luís Carrillo, por sus atenciones durante el desarrollo de este
post grado.
Al joven Ricardo Nuñez y a Doña Flor de Colina que me ayudaron con el
modelo Delphi.

CONSTANCIA DE APROBACIÓN DEL TUTOR
En el carácter de tutor del Trabajo especial de Grado “PREDICCIÓN DE RESERVACIONES DE HABITACIONES EN HOTELES” presentado por el ciudadano Ing Eduardo Emiro Rios, Cédula de Identidad No 2865274, para optar al título de Especialista en Gerencia de Empresa Mención Servicios de Hospitalidad, considero que dicho trabajo reúne los requisitos y meritos suficientes para ser sometido a consideración, presentación pública y evaluación por parte del jurado examinador que se designe.
En la ciudad de Maracaibo, al primer día del mes de Octubre de 2012.
_________________________________ MSc. Ramón Emilio Pérez Salas
C.I. V-3463162

INDICE GENERAL FRONTISPICIO DEDICATORIA AGRADECIMIENTO ÍNDICE DE CONTENIDO LISTA DE TABLAS LISTA DE GRÁFICOS RESUMEN ABSTRACT INTRODUCCIÓN 1 CAPÍTULO I: ANÁLISIS SITUACIONAL 3 1. Descripción de la realidad 3 1.1. Identificación de la realidad 3 1.2. Sistematización de la realidad 4 2.Objetivos de la investigación 6 2.1. Objetivo general 6 2.2. Objetivos Específicos 6 3.Justificación de la investigación 7 4. Delimitación de la Investigación 7 CAPÍTULO II: MARCO TEÓRICO
8
1. Antecedentes de la investigación 8 2. Bases Teóricas 11 2.1.Introducción a los Análisis de Pronósticos 12 2.1.1. Importancia de Pronosticar 13 2.1.2. Tipos de Pronósticos 13 2.1.3. Selección del Método 13 2.1.4. Pasos a seguir 14 2.1.5 Administración del Proceso de Pronóstico 14 2.2. Conceptos esenciales de Estadística 14 2.3 Modos de coleccionar datos 14 2.4 Concepto de Extrapolación 15 2.5. Definiciones en la investigación 16 2.6. Estimación de la tendencia 18 2.7. Estacionalidad 21 2.8. Métodos de Predicción 22 2.8.1. Métodos Cualitativos 24 2.8.1.1 El Método Delphi 24 2.8.1.2 Análisis de Escenarios 26 2.8.1.3. Método de Redes neuronales artificiales 27 2.8.1.4. Método Difuso 31 2.8.2. Métodos de Predicción Cuantitativa 34 2.8.2.1.Precisión de las predicciones 34 2.8.2.2. Promedios móviles 35 Promedios móviles sencillos 36

Promedio móvil acumulados 37 Promedio móvil ponderado 38 Promedio móvil exponencial 39 Promedio móvil modificado 42 Suavizamiento Exponencial 43 Suavizamiento doble exponencial 44 Mediana móvil 45 2.8.2.3. Modelos de promedio autoregresivo de
media móvil (ARMA) 45
Modelo autoregresivo AR 46 Modelo de promedio móvil MA 46 Modelo del Promedio autoregresivo móvil 46 2.8.2.4. Predicción con los modelos ARIMA 47 2.8.2.5. Método espectral 48 2.8.2. 6. Métodos Probabilísticos 49 Método de Monte Carlo 49 3. Sistema de Variables 52 3.1. Definición conceptual 52 3.2.Definición operacional 52 Tabla de Variables 53 CAPÍTULO III: MARCO METODOLÓGICO
54
1. Tipo de investigación 54 2. Diseño de la Investigación 54 3. Fuentes de la información 55 4. Instrumentos de la investigación 55 5. Procedimiento de la investigación 55 CAPÍTULO IV: ANÁLISIS DE RESULTADOS
1. Introducción 56 2. Análisis de la Tendencia 60 3. Análisis de la aleatoriedad 64 4. Análisis de la Estacionalidad 65 5. Obtención de las ecuaciones de predicción. 70 5.1. Modelos del promedios móviles (MA) 70 5.2. Modelo autoregresivo 72 5.3. Modelo de promedio autoregresivo de media móvil
(ARMA) 72
5.3.1. Modelos de regresión estudiados 74 5.4. Predicción por el método de Monte Carlo 77 5.5. Predicción por el Método Delphi 78 5.6. Predicción por el Método Espectral 79 6. Comparación de resultados 80 7. Recomendación de Metodología 80

CONCLUSIONES 86
RECOMENDACIONES 87 REFERENCIAS BIBLIOGRÁFICAS 88 ANEXOS A .Conceptos Básicos de Estadística B. Predicción con los modelos generados con Eviews ® por el
método móvil autoregresivo
C. Predicción por el método de Monte Carlo D Predicción por el método Delphi aplicado al Hotel E. Predicción por el método espectral

LISTA DE TABLAS
Tabla Página
1 Tabla de Variables 53
2 Habitaciones ocupadas en el Hotel Granada desde 1984 hasta 2004
57
3 Habitaciones ocupadas en el Hotel Granada: estadísticas 58
4 Estadísticas del Hotel Granada. Muestra de Ene 1984 a Dic. 1999 60
5 Hotel Granada: valores de la serie de tiempo después de quitarle la tendencia
64
6 Correlograma sobre los datos originales del Hotel Granada 65
7 Hotel Granada: Datos después de quitarle la tendencia incorporando los promedios anuales y mensuales
67
8 Hotel Granada: estadísticos después de quitarle tendencia 67
9 Promedio móviles simples de doce términos de la tabla 6 68
10 Hotel Granada: promedios móviles corregidos por estacionalidad 68
11 Hotel Granada: Índices estacionales de habitabilidad 69
12 Estacionalidad del Hotel Granada 69
13 Hotel Granada: Modelo de predicción tipo MA(12) 71
14 Hotel Granada: modelos sencillos de modelos autoregresivos y móviles
73
15 Hotel Granada: modelos sencillos de modelos autoregresivos y móviles arreglados
73
16 Hotel Granada: Modelo autoregresivo AR(12) 74
17 Comparación de los resultados de los modelos de predicción 75
18 Resultados del EVIEWS® para el modelo 7 76
19 Pronóstico y Predicción para el modelo 7 77

20 Resultados de la Predicción para el año 2000 del Hotel Granada 78
21 Resultados del Método Delphi 79
22 Resultados del Método Espectral para la ecuación trisenoidal 80
23 Comparación de Resultados 80
LISTA DE GRÁFICOS
2 Esquema de un sistema difuso 32
3 Habitaciones ocupadas en el Hotel Granada desde 1984 hasta 2004 57
4 Habitaciones ocupadas en el Hotel Granada: todos los años
dibujados superpuestos desde Enero a Diciembre
58
5 Hotel Granada: resultado del análisis de tendencia 62
6 Hotel Granada: serie de tiempo después de quitarle la tendencia 63 7 Hotel Granada: Gráfico de cotejamiento con el modelo MA(12) 71

8 Hotel Granada: Cotejo del Modelo 7 72

RIOS, EDUARDO EMIRO. PREDICCIÓN DE RESERVACIONES DE HABITACIONES EN HOTELES”. Universidad del Zulia. Especialización en Gerencia de Empresas Turísticas, Mención Servicios de Hospitalidad. Maracaibo, 2012
RESUMEN
Se ha efectuado un análisis de los métodos para obtener la predicción de las reservaciones de habitaciones en hoteles, tanto en forma teórica como práctica. Se han estudiado los métodos cualitativos como el método Delphi y cuantitativos como los métodos de Monte Carlo, modelos autoregresivos ARMA y el método espectral. Para su desarrollo se utilizaron los programas de computadora EVIEWS® y EXCEL® para obtener los mejores resultados. Como resultado para el hotel investigado se demostró que la mejor predicción se hizo con el método espectral, suponiendo una ecuación lineal sinusoidal que toma en cuenta la tendencia y la estacionalidad a través de tres elementos de ondas senoidales, ponderado por factores relativos de los meses. Se encontró, además, el mejor modelo autoregresivo y se hizo un ensayo utilizando el método de Monte Carlo. Se recomendó utilizar el método Delphi rutinariamente y los otros métodos ocasionalmente para analizar las estadísticas y adquirir experiencia. Palabras Clave: predicción, hoteles, recepción, modelos, espectro, autoregresivo Correo Electrónico: [email protected]

RIOS, EDUARDO EMIRO. PREDICCIÓN DE RESERVACIONES DE HABITACIONES EN HOTELES”. Universidad del Zulia. Especialización en Gerencia de Empresas Turísticas, Mención servicios de Hospitalidad. Maracaibo, 2012
ABSTRACT An analysis of methods for predicting the reservations of rooms in hotels was made, both in theory and practice. They have been studied qualitative methods such as Delphi and quantitative method such as Monte Carlo, autoregressive ARMA and the spectral methods. The computer programs EViews ® and Excel ® were used for best results. The result showed for the hotel investigated that the best prediction was found with the spectral method, assuming a sinusoidal linear equation that takes into account the trend and seasonality through three sine-wave components, weighted by factors related to the months. It further found the best autoregressive model and it was made test using the Monte Carlo method. It was recommended using the Delphi method routinely the other methods occasionally to analyze the statistics and to obtain experience. Keywords: forecast, hotels, reception, models, spectrum, autoregressive Email : [email protected]

1
INTRODUCCIÓN
Hacer una predicción es hacer propuestas acerca de eventos para obtener los
posibles resultados reales a partir de la historia observada. Es palabra sinónima de
estimación. Ambas palabras se refieren al uso y aplicación de métodos estadísticos que
emplean series de tiempo con datos provenientes de eventos tales como los que se
refiere esta investigación sobre la recepción de huéspedes en un hotel.
Los términos riesgo e incertidumbre están asociados a los términos predicción y
estimación; en virtud de que la predicción se acompaña con el grado asociado de
incertidumbre. El proceso está asociado también a la planificación. La predicción dirá
como lucirá el futuro, mientras que la planificación dirá como el futuro debería lucir.
No existe un método único para efectuar la predicción: la selección del método a
utilizar debe estar basado en sus objetivos, las condiciones de los datos y de la decisión
que se desea encontrar y de los costos involucrados en la investigación. Una buena
manera de encontrar un método apropiado es construyendo antes un árbol de decisión
que consiste en: (a) exhibir la anatomía del problema en términos de árbol de flujo–
decisión,( b) evaluar las consecuencias,(c) asignar probabilidades a las ramificaciones y
d) determinar la estrategia optima de acuerdo al aspecto económico. (Raiffa,1970)
Esta investigación comprende los siguientes cuatro capítulos:
El capítulo I se plantea la situación actual de la predicción de habitaciones en un
hotel, además de realizar la justificación teórica, metodológica y práctica.
El capítulo II describe el marco referencial, en el cual se muestran una serie de
antecedentes que han representado un aporte a la investigación del problema, la
descripción detallada de cada uno de los métodos de predicción, con las bases teóricas
donde se indican las diferentes técnicas, el análisis del sistema de variables y los
indicadores.
El capítulo III detalla el tipo de investigación, la manera como ha sido diseñada, las
técnicas de investigación que se utilizarán y las diferentes fases o procedimientos para
llevar a cabo la investigación.
El capítulo IV comprende el análisis de los resultados obtenidos con las
investigaciones efectuadas.

2
Por último se plantearán las conclusiones y recomendaciones.
Como resultado de la investigación se conocerán los métodos de predicción para
habitaciones que pueden aplicar los hoteles, escogiendo al que conduzca al mínimo
error, con las implicaciones de costo y tiempo y usándolos en un caso particular con los
datos de un hotel tomado de la literatura publicada.

3
CAPÍTULO I
ANÁLISIS SITUACIONAL
1. DESCRIPCIÓN DE LA REALIDAD
Venezuela se encuentra en una región importante que puede ser desarrollada
como zona turística principal para todo el norte de la América del Sur y el Caribe. Para
tener una clara idea de las potencialidades del país en materia de turismo se analizará
brevemente los aspectos clave que influyen en la economía venezolana.
Venezuela pasó de ser un país pastoril a un país potencialmente rico debido al
descubrimiento del petróleo, ocurrida en 1922. Desde entonces, Venezuela ha sido un
país exportador de petróleo. El petróleo es utilizado para actuaciones estratégicas,
inclusive conflictivas en el escenario internacional y materia indispensable del
desenvolvimiento económico mundial. Por esta razón la cuestión petrolera siempre es
de permanente interés y de perfiles novedosos.
Pero en Venezuela, es necesario hacerse una pregunta fundamental: ¿Cuánto
depende nuestro desarrollo de la dinámica del petróleo?
Según Maza Zabala (2010):
“Estamos obsesionados por los múltiples problemas que estamos teniendo en el país dada la carga de inquietudes, riesgos y angustias que agobia el común de los venezolanos. Pero como se dice debemos preocuparnos por las acciones que se están realizando en la economía venezolana que influirán sobre los venezolanos de las generaciones futuras que vivirán, lucharán y sufrirán con dificultades, dependiendo de las condiciones que dejen los gobiernos de turno.”
Según la Organización Mundial del Turismo (OMT,2008), se estima que la
proporción de la población mundial que realiza turismo internacional es 3,5% y se
calcula que se duplicará para el año 2020, del cual el 14% vendrá de Europa, 10% de
Asia y Oceanía y 8 % de América. Para el año 2008, según el Banco Central de
Venezuela (2009), la participación del turismo en la economía nacional se ubicó en
3,6%, notándose un incremento de 0,05% anual, es decir habrá un incremento de 0,5%
en diez años, si no se hace un esfuerzo para aumentarlo. Lo anterior conlleva a que se

4
debe incrementar todas las acciones para mejorar la cantidad de turismo que venga a
Venezuela que incluye aumento de la divulgación de los sitios turísticos que coloquen a
Venezuela como preferencial en los países de Europa, Asia y América.
1.1. IDENTIFICACIÓN DE LA REALIDAD
Debido a la incertidumbre reinante, uno de los factores que rigen la gerencia de la
utilidad en los hoteles es la escasa información de cuantas personas ocuparán el hotel
a una fecha determinada, por lo que el objetivo primordial de esta investigación es
conocer los métodos para predecir la ocupación; por lo que descrita esta situación
problemática, la pregunta clave es: ¿Cuál es el método de predicción con menor error
de reservación en hoteles tres estrellas, representado en este caso por el Hotel
Granada tomado de la literatura?
1.2. SISTEMATIZACIÓN DE LA REALIDAD
No existe un método único para efectuar la predicción: la selección del método a
utilizar debe estar basado en sus objetivos, las condiciones de los datos, de la decisión
que se desea encontrar, del tiempo y de los costos involucrados en la investigación.
Una buena manera de encontrar un método apropiado es construyendo antes un árbol
de decisión que consiste en: (a) exhibir la anatomía del problema en términos de árbol
de flujo–decisión, (b) evaluar las consecuencias, (c) asignar probabilidades a las
ramificaciones y (d) determinar la estrategia óptima de acuerdo al aspecto económico.
(Raiffa, 1970)
En esta investigación se considerará el problema de la predicción diaria de
habitaciones en un hotel porque en la gran cantidad de hoteles que están sujetos a los
efectos de la oferta y la demanda, cualquier mejoramiento en la tecnología de la
predicción de las reservaciones de habitaciones y su ocupación diaria impactará
significantemente en el sistema de gerencia de ganancias debido a que la predicción
del número de habitaciones a rentar, es el principal mecanismo en las decisiones sobre
precios y habitaciones.
La consideración que debe prevalecer es lograr el método que ayude a la
administración a tomar las decisiones precisas. Por esa razón, se debe medir la

5
necesidad que tiene la gerencia para tomar decisiones. Algunos hoteles de acuerdo a
su tamaño no requerirán de un pronóstico muy preciso, mientras que los grandes con
gran cantidad de habitaciones si lo requieren. En esta investigación se tratarán los
métodos más conocidos y la manera de decidir cuál es el más conveniente a
determinado hotel, a través del análisis de datos tomados de un hotel tomado de la
literatura.
La exposición de las partes anteriores tiene como objetivo subrayar la creencia de
que la capacidad administrativa y el sentido común deben formar parte del proceso
porque quien hace la predicción es un asesor de la dirección y no un monitor
automático de la toma de decisiones.
Poll (1987), citado en el artículo de Zhacary et al (2009) estimó que un 20% de
mejoramiento en el error de cálculo de la predicción aumentaría en un 1% las
ganancias generadas en el sistema de administración. Esto impactará posiblemente las
ganancias netas debido a los márgenes pequeños de ganancias que existen en la
industria hotelera.
La presente investigación está enmarcada en la línea de investigación de gerencia
proactiva del turismo y estará enfocada a responder la pregunta: ¿Cómo se identifica el
método para predecir las reservaciones de los hoteles con menor error?
La variable de investigación es el método de predicción de reservaciones de
habitaciones de hoteles. Las preguntas a resolver son las siguientes:
• ¿Cuál es el método para la predicción de la tendencia de las reservaciones de
habitaciones de los hoteles?
• ¿Cuál es el método para el establecimiento de los períodos estacionales para la
evaluación de las reservaciones de habitaciones en hoteles?
• ¿Cuál es el método para la predicción de reservaciones de habitaciones en
hoteles?
• ¿Cuáles serán los lineamientos para la predicción de habitaciones en hoteles?
Para resolver las anteriores preguntas se debe identificar como se ejecuta el
proceso de reservación de habitaciones. En los hoteles es importante conocer de

6
antemano el número de habitaciones a ser ocupadas en un día determinado. Este
número depende de las reservaciones y las cancelaciones efectuadas. Además en el
momento de hacer las reservaciones se determina el número de días que estará
ocupada la habitación. En algunos momentos se pueden hacer reservaciones en
grupos y por supuesto también es viable las cancelaciones de la asistencia de estos
grupos.
Para analizar la situación se halla la tendencia de los datos de las reservaciones,
se analizan las diversas estaciones de tiempo que pueden ocurrir en un año en los
hoteles y se construyen métodos de predicción matemáticos o no. El mejor método
desde el punto de vista de esta investigación, es aquel que genera menos error en el
número predictivo tomando en cuenta las implicaciones de costos y tiempos. El método
puede cambiar de un hotel a otro y se requiere tomar en cuenta el tiempo y el costo de
la investigación, antes de tomar una decisión gerencial.
2. OBJETIVOS DE LA INVESTIGACIÓN
2.1. Objetivo General Identificar el método de predicción con menor error de reservaciones de
habitaciones en el hotel Granada.
2.2. Objetivos Específicos a. Identificar el método para la predicción de la tendencia de datos de las reservaciones
de habitaciones en el hotel Granada.
b. Determinar el método para el establecimiento de los períodos estacionales para la
evaluación de reservaciones de habitaciones en el hotel Granada.
c. Establecer el método para la predicción de reservaciones de habitaciones en el hotel
Granada.
d. Establecer los lineamientos para la predicción de reservaciones de habitaciones en
hoteles (Caso Hotel Granada).

7
3. JUSTIFICACIÓN DE LA INVESTIGACIÓN
Autores como Zakhary (2009), han demostrado que la predicción de reservaciones
es importante para fijar los precios de las habitaciones y para aumentar las ganancias
del negocio.
La elaboración de este análisis permitirá a las universidades, escuelas de turismo,
organizaciones de sitios de hospitalidad turística como a cualquier interesado en la
temática del turismo y la hospitalidad sobre cómo aplicar un análisis para hacer la
predicción en cada uno de sus eventos, permitir deducir la bondad de cada uno de los
métodos y comprobar la posibilidad de uso en los hoteles del país.
Conocer el número de habitaciones que serán ocupadas podría incidir en el
sistema de ahorro de energía, contratación de personal, nuevas inversiones para el
mejoramiento de la rentabilidad del hotel y también de la comunidad al recuperar
mayores impuestos.
El trabajo es importante porque aunque se tienen varias empresas que han hecho
sistemas para el control de entrada y salida de huéspedes y por consiguiente su
disponibilidad, pocos tienen un sistema de análisis de predicción de reservaciones. En
Venezuela, hasta el presente, la mayoría de los hoteles hacen predicción basadas en la
experiencia gerencial.
4. DELIMITACIÓN DE LA INVESTIGACIÓN
La línea de investigación es en la rama de gerencia proactiva del turismo. Está
limitada al área hotelera, específicamente al Hotel Granada, de España con la
información tomada de la literatura y se desarrollará en el marco del Programa
Especialización Gerencia de Empresas Turísticas, mención: Servicios de Hospitalidad,
que imparte la División de Estudios para Graduados de la Facultad de Ciencias
Económicas y Sociales de la Universidad del Zulia.
No se pudo hacer a hoteles situados en Venezuela debido a la confidencialidad de
los datos de reservaciones de las empresas en el área.
La investigación se llevó a cabo desde Septiembre 2011 hasta Mayo 2012.

8
CAPÍTULO II
MARCO TEÓRICO
1. ANTECEDENTES DE LA INVESTIGACIÓN
Existen métodos estadísticos para intentar predecir la presencia de reservaciones,
llegadas y cancelaciones. El problema ha sido analizado por Lee (1990) para el sistema
de aerolíneas. Lo hizo basado en modelos estocásticos que analizan una similitud con
la dinámica de nacimientos y muertes en una población. Para los casos de hoteles una
reservación se considera como un “nacimiento” y una cancelación se considera una
“muerte”. A continuación se resumirán algunos trabajos de investigación que han
servido como guías a este trabajo de investigación.
Martínez de Pisón et al (2001) escribieron un artículo sobre la aplicación de las
técnicas de computación para un sistema de soportes de decisión de un hotel (An
application of Soft Computing Techniques for a Hotel Decisión Support System). En él
analiza que debido a la proliferación de portales Web especializados en reservas en
línea de habitaciones de hotel, muchos clientes esperan hasta el último momento para
realizar sus reservas y obtener mejores precios. Como consecuencia de esto, para los
gerentes de hotel es un reto poder maximar los beneficios mediante el ajuste continuo
de los precios de habitaciones de forma que estos sean más atractivos para los clientes
frente a los hoteles de la competencia.
Se usa la computadora para desarrollar modelos capaces de predecir las futuras
reservaciones de cada día del año para un hotel cualquiera a partir de la base de datos
históricos. Los modelos desarrollados forman parte de un software de apoyo a la toma
de decisiones para la gestión de hoteles. Esta metodología ha sido utilizada en este
trabajo para efectuar programas de computadoras para deducir métodos de análisis del
problema.

9
Schwartz y Cohen (2008) presentaron un trabajo sobre los estimados subjetivos de
la incertidumbre de la predicción de ocupación por los gerentes de hoteles (Subjetive
Estimates of Occupancy Forecast Uncertainty by Hotel Revenue Managers). Un
resumen de la investigación es el siguiente:
Cincuenta y siete gerentes de hoteles participaron en un estudio relacionado con el
uso de paquetes de computadoras para la simulación de la predicción en hoteles.
Examinaron los datos de ocupación como los anotaron originalmente y los usaron para
predecir simulando en los programas su propio estimado de ocupación diaria. El
estudio subrayó la naturaleza subjetiva de la incertidumbre de la predicción,
demostrando que dependen de los años individuales de experiencia y del género.
Como aporte a esta investigación, el anterior escrito sugiere que existe una gran
incertidumbre en la obtención de la predicción, por ello es necesario estimar también los
errores y enseñar a los gerentes a la interpretación de ellos. A medida que el gerente
tenga más experiencia, los resultados serán mejores.
Rajopadhye et al (2008) escribieron un artículo sobre la incertidumbre de la
predicción en la demanda de cuartos de hotel (Forecasting Uncertain Room Demand)
que se resume a continuación:
En este trabajo se evalúa la incertidumbre en las dinámicas del hotel y el efecto de
las decisiones que pueden ser costosas en términos financieros. Se hace la predicción
de la incertidumbre en ciertas variables económicas dentro de las actividades de la
organización. La predicción que se discute en este artículo se basa en modelos
cuantitativos y no incorpora experticia gerencial. Sin embargo, los resultados se
encuentran que son satisfactorios para ciertos días, pero para otros no. Se cree que el
juicio humano es importante cuando se trata de eventos externos que puedan afectar
las variables predichas. Se usaron datos reales de un hotel para ilustrar el mecanismo
de predicción. Como aporte a la investigación, se llega a la conclusión que la experticia
gerencial es importante para la obtención de un buen resultado en una predicción. Y
que a pesar de la importancia del cálculo matemático y estadístico, debe ser pesado
siempre con las habilidades del gerente.

10
Zakhary et al (2009) han presentado un artículo para predecir el arribo y ocupación
al hotel usando simulaciones con el método de Monte Carlo (Forecasting Hotel Arrival
and Occupancy Using Monte Carlo Simulation). Un resumen se dará a continuación:
En este artículo se propuso una simulación con el método de Monte Carlo para el
problema de llegada y ocupación de las habitaciones de los hoteles. Se simula el
proceso de reservaciones contra tiempo y al establecer los patrones se hace la
predicción. Un punto importante para la predicción precisa es que se conozcan los
parámetros involucrados y se propone encontrar estos parámetros a partir de los datos
históricos. Se consideró un caso de estudio del problema de predicción para el Plaza
Hotel, Alexandria, Egipto. El modelo propuesto da mejores resultados comparado a las
aproximaciones anteriores. Como parte de esta investigación se elaboró el trabajo de
predicción usando el Método de Monte Carlo para el hotel investigado.
En el mismo trabajo de Zakhary y otros (2009) aparece un recuento de los
modelos de Weatherford y Kimes (2003), Zahkary et al (2008), Yuksel (2007) todos para
aplicar varios métodos de suavización exponencial. Mientras que Ben Ghalia y Wang
(2000) desarrollaron un sistema de predicción usando modelaje de matemática difusa
(fuzzy mathematical). Pfeifer y Bodily (1990) consideraron los modelos de ARMA para el
problema de llegada a los hoteles mientras que Andrew et al (1990) aplicaron la
aproximación de Box-Jenkins y la suavización exponencial mensual en el hotel.
También Chow et al. (1998) usaron ARIMA para estudiar la ocupación del hotel. De los
anteriores métodos solo se utilizará el método ARIMA debido a los buenos resultados
que aporta para datos con estacionalidad. Rajopadhye et al. (2001) junto con Zakhary
et al (2009) han sido uno de los pocos que han utilizados métodos probabilísticos
mediante una aproximación de Monte Carlo para hacer predicción de reservaciones y
ocupación de habitaciones de hoteles.
Haensel y Koole (2010) presentaron un artículo sobre predicción de la
habitaciones rentadas mediante actualización dinámica: un caso de estudio con los
datos de reservaciones del hotel (Booking, Horizon Forecasting with Dynamic Updating:
A Case Study on Hotel Reservation Data). Un resumen se da a continuación.

11
En el análisis se determina que la demanda altamente precisa es fundamental
para el éxito de cada modelo de gerencia. A menudo en la práctica y en la teoría, se
necesita predecir la curva de reservaciones así como también el número de
reservaciones esperadas para cada día en el horizonte de reservaciones. Para predecir
se ajustaron dinámicamente a las primeras observaciones usando mínimos cuadrados
con pesos y entre instancias de productos sucesivos. La respuesta fue probada con
datos de reservaciones reales de hoteles y se demostró una mejora en las cifras
predichas. Los métodos utilizados por Haensel y Koole (2010) fueron utilizados en esta
investigación principalmente para predecir las tendencias de los datos.
Todos los trabajos anteriormente citados serán utilizados como base para efectuar
esta investigación.
2. BASES TEÓRICAS
A continuación se presentan las bases teóricas de esta investigación. Primero se
hablará en forma general para estudiar el análisis de pronósticos, para luego estudiar
los métodos.
La mayoría de los métodos de pronosticación fueron deducidos, durante el siglo
XIX basado en el análisis de regresión. Es más recientemente que han surgido nuevas
y distintas técnicas de predicción. La predicción de la cantidad de habitaciones
ocupadas en los hoteles y en los hospitales es de análisis muy reciente y no va más allá
de 1970. Actualmente se han desarrollado técnicas más precisas de pronóstico y ahora
todos los administradores tienen herramientas de análisis más complejas.
La práctica común es hacer las predicciones basadas en la intuición de la
gerencia. Sin embargo, sin pretender descartar sus decisiones, es importante encontrar
un método que pueda mejorar la precisión de la predicción. Algunos de los métodos
que se describirán están asociados al pensamiento subjetivo que tiene la gerencia del
proceso, basado en la creencia intuitiva.
Los métodos de predicción se dividen en métodos cualitativos que se basan en el
juicio humano y en la intuición, muchas veces sin datos históricos y métodos
cuantitativos que requieren utilizar suficientes datos históricos. Estos últimos métodos

12
se clasifican a la vez en determinísticos y probabilísticos. Los métodos determinísticos
comprenden la identificación de las relaciones entre la variable a pronosticar y otras
variables de influencia. Su objetivo es desarrollar una fórmula empírica para obtener el
valor que se desea predecir con la historia reciente. Los métodos probabilísticos utilizan
las teorías de la probabilidad y los números aleatorios para efectuar la predicción.
En este capítulo se detallarán primero los métodos cuantitativos determinísticos,
luego los métodos cuantitativos probabilísticos y por último los métodos cualitativos,
describiendo las filosofías y modelos más utilizados. En cada uno de ellos se darán sus
bondades y sus defectos.
Ha habido pocos escritos sobre la predicción de la llegada de huéspedes a un
hotel. La mayoría de los trabajos que tienen relación se han desarrollado para la
predicción de reservaciones en las líneas aéreas. La reservación de pasajeros de las
líneas aéreas tiene muchas similitudes, como por ejemplo el cálculo de las
reservaciones y cancelaciones. Pero, existen situaciones en las reservaciones de
habitaciones en hoteles que son diferentes, como el número de días de estadía, que es
una variable muy importante en la gerencia de hoteles y que no existe en la predicción
de los pasajes de aviación. El problema se ha desarrollado en dos vertientes: modelos
sencillos y modelos avanzados.
Los modelos sencillos aplican el análisis de series y aplican modelos de series de
tiempo. En cambio, en los modelos avanzados se toman en cuenta las reservaciones y
se basan en el concepto de “calculo al futuro”. Esto significa que si se tiene en este
momento K reservaciones para el día T, se puede esperar N reservaciones más hasta
ese día. La predicción será entonces K+N huéspedes. Por supuesto tomando en cuenta
también las predicciones de las cancelaciones.
2.1. Introducción a los Análisis de Pronósticos
La mayoría de los métodos de pronosticación fueron deducidos durante el siglo
XIX, tales como el análisis de regresión. Fue más recientemente que han surgido
nuevas técnicas de predicción. La predicción de la cantidad de habitaciones ocupadas
en los hoteles y en los hospitales es de análisis muy reciente y no va más allá de 1970.

13
Especialmente técnicas como las de Box-Jenkins son muy recientes. Con el
advenimiento de las computadoras, se han desarrollado técnicas más precisas de
pronóstico. Ahora, todos los administradores tienen herramientas de análisis más
complejas y precisas.
2.1.1. Importancia de pronosticar La pregunta que en este momento se tiene es ¿Por qué es tan importante
pronosticar? La práctica común es hacer las predicciones basadas en la intuición de la
gerencia. Sin embargo, sin pretender descartar sus decisiones, es mucho mejor si se
encuentra un método que pueda mejorar la precisión de la predicción. Algunos de los
métodos que se describirán están asociados al pensamiento subjetivo real que tiene la
gerencia del proceso basado en la creencia intuitiva.
2.1.2. Tipos de pronósticos Desde el punto de vista de la longitud del banco de datos que se tenga para la
predicción, estas se dividen en predicciones a corto plazo y predicciones a largo plazo.
Las predicciones son largas o cortas de acuerdo al tamaño de la base de datos. Las
predicciones cortas son usadas por las gerencias medias para los análisis de estrategia
inmediatos. Las predicciones a largo plazo se utilizan para definir el curso de operación
de la totalidad de la empresa.
Por otra parte, los pronósticos pueden ser cualitativos o cuantitativos. Los
pronósticos cualitativos no necesitan de un gran banco de datos, se basan en el buen
juicio de la gerencia. Por el contrario los pronósticos cuantitativos requieren un banco
de datos y no requieren el juicio de la gerencia, pues se basan en la matemática y la
estadística y sus técnicas mecánicas de análisis.
2.1.3. Selección del Método La consideración que debe prevalecer es lograr el método que ayude a la
administración a tomar las decisiones precisas. Por esa razón, se debe medir la
necesidad que tiene la gerencia para tomar decisiones. Algunos hoteles de acuerdo a
su tamaño no requerirán de un pronóstico muy preciso, mientras que los grandes con
gran cantidad de habitaciones requieren un pronóstico mejor. En esta investigación se

14
tratarán los métodos más usados y la manera de decidir cuál es el más conveniente a
determinado hotel.
2.1.4. Pasos a seguir Según Hanke y Reitsh (1996) todos los procesos formales de decisión y el cálculo
de los pronósticos de ellos, requieren los siguientes pasos:
• Recopilación de datos.
• Reducción, condensación o promediación de los datos.
• Construcción del modelo.
• Extrapolación del cálculo del modelo (que es el pronóstico en sí).
El primer paso sugiere la importancia de obtener datos adecuados y asegurarse
que son correctos. Esto requiere tener en la gerencia un validador del dato. El segundo
paso es importante porque se manifiesta la frecuencia necesaria de suavización de los
datos, principalmente si se tiene una gran cantidad de datos y cuando se tenga
estacionalidad o dependan del tiempo. El tercer paso, la construcción del modelo,
implica ajustar los datos reunidos en un trabajo que sea adecuado para minimizar el
error en el pronóstico utilizando el modelo más sencillo posible, pues ello implica la
aceptación por los administradores de la empresa. El cuarto paso es el pronóstico en sí.
2.1.5 Administración del Proceso de Pronóstico
La exposición de las partes anteriores tuvo como objetivo subrayar la creencia de
que la capacidad administrativa y el sentido común deben formar parte del proceso
administrativo. Quien hace la predicción es un asesor de la dirección y no un monitor
automático de la toma de decisiones, por lo que el involucramiento gerencial es
imprescindible.
2.2. Conceptos Esenciales de Estadística El proceso de predicción requiere entender algunos conceptos estadísticos, por
ello para la comprensión de los conceptos se remite el lector al Anexo A. Si el lector es
diestro con los conceptos básicos de estadística no requiere leer este anexo.
2.3. Modos de coleccionar datos La llegada de clientes a ocupar las habitaciones de un hotel puede estar influida
por varios parámetros como sexo, edad, profesión, por lo que es necesario efectuar

15
rutinariamente encuestas para determinar la influencia de estos parámetros en la
predicción. Hay varias maneras de administrar encuestas. La escogencia de la manera
de coleccionar los datos está determinada por varios factores: (a) Costos, (b)
Cubrimiento de la población objetivo, (c) Flexibilidad de las preguntas, (d) Deseo de los
respondientes a participar y (e) exactitud de la respuesta. Métodos diferentes crean
efectos de modo que cambian como se respondan las preguntas.
2.4. Concepto de Extrapolación Extrapolación es un proceso de construcción de nuevos puntos fuera del rango
conocido. Es similar al proceso de interpolación que construye nuevos puntos entre los
puntos conocidos, pero los resultados de extrapolaciones son a menudo menos
precisos y están sujetos a mayores incertidumbres.
La extrapolación lineal significa crear una línea tangente al final de los datos
conocidos y extendiéndolas más allá de los límites. La extrapolación dará mayor
incertidumbre mientras más se extienda fuera de los datos conocidos. Para definir la
extrapolación se requieren dos puntos de la tangente para calcular la ecuación de la
línea de extrapolación. Si se conocen dos puntos xk,yk y xk-1, yk-1 , la ecuación de
extrapolación par el punto (x*.y*) viene dada por
que es idéntica a la interpolación lineal. Es posible incluir más de dos puntos,
promediando la pendiente de la interpolación lineal, mediante técnicas de regresión.
La más común de las representaciones de las predicciones lineales es:
es el valor predicho, x(n-i), son los valores observados, ai son los coeficientes
predictores y p es el número de términos de la ecuación. El error generado por los
estimados es:
La mejor manera de la estimación de los coeficientes es través del método de los
mínimos cuadrados.

16
La extrapolación polinómica se puede hacer usando todos los datos anteriores.
Generalmente la extrapolación con polinomios se hace utilizando la interpolación de
Lagrange o usando el método de Newton de diferencias finitas para crear series de
Newton que cotejen los datos. El polinomio se usa después para la extrapolación de los
datos. Existen otros métodos como el cónico o el método francés pero salen del
alcance de este trabajo. Todos los detalles de la extrapolación se ejecutan por medio
de análisis de regresión.
2.5. Definiciones en la investigación La llegada de huéspedes a los hoteles se maneja mediante dos procesos de
efectos opuestos: las reservaciones y las cancelaciones. Un hotel típico hace
reservaciones pocos días o semanas antes del día de ocupación. Generalmente las
reservaciones aumentan significativamente a medida que se acerca el día determinado.
Una reservación negada es aquella que es rechazada por el hotel debido a la falta de
disponibilidad para todo o parte del período involucrado. Las reservaciones pueden ser
canceladas en cualquier momento antes de la fecha determinada. La tasa de
cancelaciones también aumenta a medida que se acerca la fecha determinada. Está
influida por la política de cancelaciones que tenga el hotel (que algunas veces incluye
algunos pagos).
El total de registros de huéspedes (total booking) para cualquier tiempo τ antes
del día determinado t es el total de reservaciones menos el total de las cancelaciones
efectuadas al tiempo τ. La curva de registros (booking curve) es el gráfico del total de
registros de huéspedes en función del tiempo hasta el arribo (es decir, t-τ). Las llegadas
representan el número neto de huéspedes que se chequean (check-in) en un día
particular t. Muchas veces se representa como un porcentaje de la capacidad
disponible del hotel. La ocupación es el número de cuartos ocupados en un día
determinado t. También puede medirse en porcentaje de la capacidad disponible del
hotel. Este último es la variable objetivo a ser medida y predicha en un estudio como el
que se realiza en esta investigación.
Existen clientes que se chequean el mismo día sin reservaciones, se llaman
huéspedes walk-in. Estos datos también son analizados de la misma manera que las
reservaciones, las cancelaciones y las llegadas. Algunas veces, algunos huéspedes

17
potenciales que habían reservado una habitación, no llegan el día determinado y por lo
tanto perdiendo su pago o parte de su pago. Estos clientes se llaman no-show y
también son parte de estudio.
Cada habitación se reserva por número de noches. Este parámetro se llama
longitud de estadía (length of stay) o LOS. Algunas veces los clientes se retiran antes
de la culminación de su estadía, conduciendo a un proceso de baja en la estadía
(understay). También puede ser lo contrario, en donde un huésped trata de
permanecer varios días más allá de su estadía. Este proceso se llama procesos en
alza (overstay).
La mayoría de las empresas hoteleras trabajan segmentando los clientes en
categorías, y dinámicamente aplicar tarifas a un número determinado de habitaciones;
especificando los precios para cada categoría de acuerdo a las demandas esperadas,
de modo de maximar las ganancias del hotel (Vinod, 2004).
Otro aspecto de gestión de ganancias es la implantación de la estrategia de
ofrecer más habitaciones que las disponibles (overbooking). Esto significa que el hotel
permite que se reserven habitaciones a huéspedes, excediendo la capacidad del hotel,
suponiendo que un grupo de habitaciones reservadas serán canceladas. Sin embargo,
si el número de huéspedes con reservación válida, que llegan en un día, sobrepasa la
capacidad del hotel, éste sufrirá una falta de creencia por el cliente y adicionalmente
tendrá algunos costos extras al tratar de colocar el cliente en otro hotel cercano.
La necesidad de hacer predicciones acertadas en las predicciones de
reservaciones y ocupaciones es un problema de optimización de datos y se debe a los
siguientes aspectos:
• El número óptimo de habitaciones en cada categoría de habitaciones que
maximice las ganancias está principalmente influenciado por la demanda para
los próximos días.
• El precio de cada categoría se debería fijar de acuerdo a la demanda futura.
Esto proviene de la conocida relación oferta-demanda. Estas cifras y la del
párrafo anterior se determinan en el marco de problemas de optimización ya
dicho.

18
• La óptima estrategia de sobre reservación también puede ser determinada. De
hecho los modelos propuestos permiten obtener predicciones en la presencia de
cualquier estrategia de sobre reservación.
Para los efectos de esta investigación los problemas de optimización no serán
analizados.
Como se mencionó anteriormente existen dos parámetros principales en esta
investigación. En la primera fase se investiga todos los parámetros del proceso de
reservaciones. En la segunda fase se simula el proceso de reservaciones hacia
adelante para obtener la predicción (usando los estimados obtenidos en la primera
fase). La estimación de parámetros comienza con las encuestas estadísticas.
Las encuestas estadísticas son un método usado para coleccionar de una manera
sistemática, información de una muestra de hechos. Aunque la mayoría de las personas
están familiarizadas con los registros de opinión pública que se reportan en la prensa, la
mayoría de las encuestas no son públicas (como es el caso de las encuestas de
hoteles). Las encuestas proveen información importante para toda clase de
investigación. La encuesta puede enfocar varios diferentes tópicos tales como
preferencias, comportamiento, etc. dependiendo de su propósito. Puesto que la
investigación por encuesta está siempre basada en una muestra de la población, el
éxito de la investigación es dependiente de la representatividad de la muestra.
2.6. Estimación de la Tendencia
Antes de aplicar y hallar las estaciones que puedan estar ocurriendo en los datos
es imprescindible encontrar si estos datos tienen alguna tendencia. Es decir si los datos
siguen un patrón matemático durante el tiempo, determinar este patrón y luego aplicar
los conceptos de estacionalidad. Esto permite aplicar la tendencia futura del negocio de
reservaciones de habitaciones, sin tomar en cuenta la estacionalidad.
Se debe mencionar aquí, que la demanda de habitaciones en un hotel tendrá una
tendencia que es consecuencia del cambio en las condiciones internas y también de las
condiciones externas, como demandas turísticas y cambios en los negocios del área.
También es posible que cuando se hagan los análisis se reflejen hechos que son
eventuales, como por ejemplo un congreso técnico que posteriormente no se volverá a

19
tener, sino en un largo plazo y que por lo tanto sale del cálculo y debe ser analizado en
forma ocasional.
Según Arellano (2001), existen tres modelos de series de tiempos, que
generalmente se aceptan como buenas aproximaciones a las verdaderas relaciones,
entre los componentes de los datos observados. Estos son:
a) Aditivo: X(t)=T(t) + E(t) + A(t)
b) Multiplicativo: X(t) = T(t). E(t). A(t)
c) Mixto: X(t) = T(t).E(t) + A(t)
donde:
X(t) es el resultado predicho
T(t) es el componente de la tendencia.
E(t) es el componente estacional.
A(t) es un componente aleatorio (accidental y desconocido de su causa).
La suposición más común es que A(t) sea un componente aleatorio o ruido
blanco con media cero y varianza constante.
Un modelo aditivo es adecuado, por ejemplo, cuando el componente estacional
E(t) no depende de otros componentes. Si por el contrario la estacionalidad varía con la
tendencia, el modelo más adecuado es el multiplicativo. Por supuesto, el modelo
multiplicativo puede ser transformado en aditivo, haciendo un cambio al tomar
logaritmos. Lo importante del asunto es modelar adecuadamente los componentes de la
serie.
Para hacer la estimación de la tendencia se supone que no existe la componente
estacional E(t) y se aplica el modelo aditivo:
X(t) = T(t) + A(t) donde A(t) es el ruido.
Hay varios métodos para hallar T(t). Los más utilizados son:
a) Ajustar una función de tiempo, como un polinomio, una exponencial u
otra función suave de t.
b) Suavizar (o filtrar) los valores de la serie.
c) Utilizar diferencias.

20
Las curvas de tendencias deben cubrir un periodo relativamente largo para ser
una buena representación de la tendencia a largo plazo. La tendencia rectilínea y la
exponencial se pueden aplicar a corto plazo, puesto que una curva S a largo plazo
puede parecer una recta en un período restringido de tiempo. El gráfico 1 ilustra las
ecuaciones y gráficas de las formas de curvas más comunes. En particular, pueden ser
útiles para determinar si las medidas exhiben una tendencia de aumento o disminución
que estadísticamente se distinga de un comportamiento aleatorio. En la llegada de
huéspedes se puede determinar la relación que ocurre con las fechas en el año.
Generalmente, las tendencias son determinadas por el método de mínimos
cuadrados. Es decir, el modelo genera valores que hacen mínima las diferencias entre
los valores observados y los predichos de acuerdo a la siguiente relación:
Mínimo
Aquí at+b es la línea de tendencia, de modo que la sumatoria de las
desviaciones de la línea de tendencia es lo que va a ser minimizada. Este caso siempre
puede hacerse porque es un caso particular de la regresión lineal simple. Para el resto
de esta investigación, “tendencia” significará la pendiente de la línea de mínimos
cuadrados, porque así se llama convencionalmente.
Un punto interesante que debe ser estudiado y aprendido es la tendencia que
producen los datos aleatorios. Si una serie se analiza para conocer si es aleatoria y se
trata de calcular una tendencia a través de los datos, ésta será cero o cercana al cero si
los datos son aleatorios, es decir no hay una explicación física para ellos.
Para analizar una serie (de tiempo) de datos, se supone que se puede representar
con una tendencia más un ruido:
donde a y b son constantes desconocidas y las e son errores distribuidos
aleatoriamente.
Una vez elaborado el modelo lineal anterior se puede hacer la hipótesis nula de
que la tendencia a es significantemente igual a cero. Se puede demostrar si la
tendencia es cero o no, basado en un grado porcentual de significación. Una de las
críticas que se le hace al razonamiento es tratar de darle linealidad a los datos, debido

21
a los supuestos que hay otros factores que son importantes para efectuar la predicción.
Si se desea analizar varios factores se deberá hacer lo que se llama en estadística un análisis factorial.
Ecuación Grafica
T(t)= a+bt (lineal)
T(t) = aebt (Exponencial)
T(t) = a+bect (Exponencial modificada)
T(t) = β0+β1t+……..+
(Polinomial)
Gráfico 1. Tipos de Ecuaciones y Gráficos de Tendencias (Arellano,2001)
2.7. Estacionalidad La estacionalidad es el principal factor que afecta considerablemente el nivel de
demanda de los hoteles. Al estudiar los períodos de alta y baja demanda se puede
deducir los precios de las habitaciones para obtener las máximas ganancias. En los
negocios de los hoteles, los días se categorizan en dos partes: alta y baja estación. Sin
embargo, del estudio de la afluencia de algún hotel, se puede deducir que puedan que
existan tres estaciones y en ese caso las llamaríamos alta, media y baja estación.

22
La mayoría de los hoteles deciden la clasificación de los días del año, de acuerdo
a las consultas que se le hacen a la gerencia, empleando un método conocido, como el
Delphi, por ejemplo. Sin embargo, para el efecto de esta investigación se pretenderá
dividir en dos grupos las ocupaciones de las habitaciones probando si entre ellas existe
una diferencia en las medias estadísticas.
Una buena técnica (Bogo,1975) es desestacionalizar las series de tiempo hallando
índices equivalentes para cada dato dentro de cada estación, haciendo las
predicciones, posterior a quitar los efectos de la tendencia. La desestacionalización se
hace por medio de dividir cada dato entre el promedio de los valores históricos. Para
ellos se escoge el promedio para cada estación por medio de la siguiente ecuación:
donde SA es el promedio de la estación, s(t) son los N valores que se desean
desestacionalizar y sA es el promedio encontrado. Los valores desestacionalizados
sdes se calculan dividiendo cada término por el promedio encontrado mediante la
siguiente ecuación:
El subtérmino des significa que el valor está desestacionalizado.
Hasta este momento se ha hablado de la estacionalidad en el período de un año,
sin embargo, existe también estacionalidad en los días de la semana. Algunos hoteles
tienen su mayor cantidad de clientes en los días lunes a viernes, mientras otros basan
su negociación en los fines de semana. Para los hoteles tipo resort, los períodos de
mayor ocupación son los fines de semana. El resto de los días tienen un patrón distinto
de comportamiento.
Para tomar en cuenta la estacionalidad en la semana, se considera la serie
desestacionalizada obtenida en el análisis previo (es decir sdes) y se le aplican los
algoritmos para desestacionalización semanal. Siguiendo a Bogo(1975) el
procedimiento es el siguiente:

23
• Para cada serie de tiempo, ya desestacionalizada, se calcula el
promedio para el período de tiempo (Prom-sem) de todos los
tiempos.
• Se calcula la serie de tiempo relativa o normalizada, dividiendo
cada valor entre el promedio. Esto se hace para captar los saltos de
efectos debido a los cambios de condiciones.
• El promedio estacionario para determinado período de tiempo está
dado por la mediana de la serie promedias.
Se vuelve a hacer énfasis que después de obtener estos resultados se debe
consultar la opinión de la gerencia, pues ellos tienen mayores conocimientos de los
eventos futuros como convenciones o eventos deportivos o políticos.
2.8. Métodos de Predicción
En la literatura sobre el tema existe suficiente teoría sobre los métodos de
predicción. Los conceptos que se emitirán a continuación han sido tomado de las
referencias de Bogo(1975), Hanke y otros (1996). Según ellos, los métodos de
predicción se dividen en cualitativos y cuantitativos. A su vez los métodos cuantitativos
pueden ser determinísticos o probabilísticos. En esta sección se explicarán cada uno de
estos métodos de la siguiente manera:
Métodos Cualitativos.
Método de Delphi.
Análisis de Escenarios.
Método de Redes neuronales.
Método difuso.
Métodos Cuantitativos Determinísticos.
Métodos de Series de tiempos.
Método Espectral.
Métodos Cuantitativos Probabilísticos.
Simulación de eventos: Método de Monte Carlo.

24
2.8.1. Métodos Cualitativos Los métodos cualitativos comprenden: el método Delphi, el análisis de escenarios,
el método de las redes neuronales y el método difuso. Los analizaremos en este orden.
2.8.1.1. El Método Delphi
Este es un método descrito ampliamente en la literatura y en las páginas de
internet, ejemplo Antigarraga (2011) de la Universidad de Deuste y otras referencias.
Es una técnica de comunicación estructurada, desarrollada originalmente como un
método de predicción interactiva y sistemática que se ejecuta con un panel de expertos.
En la versión normal, los expertos responden a cuestionarios en dos o más vueltas.
Después de cada vuelta, un facilitador provee un sumario anónimo de las predicciones
de los expertos resultado de la vuelta anterior así como las razones para sus juicios.
Así, los expertos son emplazados a revisar sus anteriores respuestas a la luz de
las replicas de los otros miembros del panel. Se cree que durante este proceso el rango
de las respuestas disminuirá y el grupo convergerá hacia la respuesta “correcta”.
Finalmente, el proceso se detiene después de un criterio de parada predefinido (por
ejemplo, número de vueltas, encuentran un consenso, estabilidad de los resultados,
etc.) y el promedio o la mediana de los resultados de las vueltas finales determinan los
resultados.
Otras versiones, como la Política Delphi, han sido diseñadas para uso normativo y
explorativo, particularmente en el área de la política social y la salud pública.
El método Delphi se basa en el principio de las predicciones (y por ende las
decisiones) de un grupo estructurado de individuos es más preciso que los de los
grupos no estructurados. La técnica también se puede adaptar a las reuniones cara a
cara y entonces recibe el nombre de mini-Delphi. Delphi se ha usado para predecir
negocios y tiene ciertas ventajas sobre otras predicciones estructuras.
El nombre “Delphi” deriva del “Oráculo de Delphi”. Los autores del método no
están felices con el nombre porque implica adivinar el futuro. El método fue desarrollado
en la armada americana al comienzo de la Guerra Fría, para predecir el impacto de la
tecnología sobre la guerra. Fue desarrollado por el proyecto RAND durante la década
1950-1960 por Olaf Helmer, Norman Dalkey y Nocholas Rescher, y desde entonces ha
sido utilizado con muy pocas modificaciones.

25
Características Clave del Método Delphi
Las siguientes características del método Delphi, tomadas de Astigarraga (2011)
ayudan a los participantes a enfocarse sobre los asuntos a mano.
Las contribuciones iniciales de los expertos se coleccionan en la forma de
respuestas a los cuestionarios y sus comentarios a estas preguntas. El panel director
controla las interacciones entre los participantes procesando la información y filtrando
completamente el contenido irrelevante. Esto evita los efectos negativos de las
discusiones cara a cara y resuelve los problemas usuales de las dinámicas de grupo.
Los participantes hacen retroflujo comentando sus propias predicciones, las
respuestas de los otros y el progreso del panel como un todo. En cualquier momento
pueden revisar sus propuestas anteriores. Mientas en grupos de reuniones de
participantes tienden a detenerse en un determinado punto, el método Delphi evita esto
tratando de obtener una respuesta mejor.
Generalmente los participantes permanecen anónimos. Sus identidades no se
revelan, aún después de la completación del reporte final. Esto previene la autoridad,
personalidad o reputación de algunos participantes para dominar a otros durante el
proceso. Adicionalmente, libera a los participantes de sus defectos, minimiza el “efecto
de halo”, permite expresiones libre de opiniones, se tiene crítica abierta y la facilidad de
admitir de errores cuando se revisan los juicios anteriores.
La persona que coordina el método Delphi se conoce como facilitador y como tal
dirige las respuestas del panel de expertos, que son seleccionados por alguna razón,
por ejemplo, por conocimiento, opinión o visión. El facilitador envía cuestionarios,
encuestas, etc. y si el panel de expertos acepta, siguen las instrucciones. Las
respuestas son coleccionadas y analizadas, para que los puntos comunes y en conflicto
sean identificados. Si el consenso no se alcanza, el proceso continúa a través de tesis y
antítesis, hasta que gradualmente se resuelven los conflictos y se alcanzan el
consenso.
No siempre el Método Delphi da resultados positivos. Se han dados casos donde
el método ha sido débil, debido principalmente a que a veces la predicción no siempre
obedece al consenso de los expertos.

26
2.8.1.2. Análisis de Escenarios Similar al método Delphi, el análisis de escenarios es el proceso de estudiar los
posibles futuros eventos considerando las alternativas. Así, el análisis de escenarios,
que es el principal método de proyecciones, no trata de mostrar una figura exacta del
futuro, sino que presenta consecuentemente varias alternativas de los futuros
desarrollos.[Firmenich (2011)]
Por consiguiente, se observa una relación de los posibles eventos. No son
solamente eventos observables, también desarrolla los caminos que conducen a esos
desarrollos. Contrario a la prognosis, el análisis de escenarios no usa la extrapolación
del pasado. Y no espera que los datos recogidos en el pasado sean todos validos en el
futuro. Trata de considerar los desarrollos posibles y los puntos de cambios, que están
conectados con el pasado en algunos puntos. Algunas veces, se demuestran varios
escenarios dentro del análisis para conseguir distintos resultados. Es útil generar
escenarios optimistas y pesimistas y el escenario que es más probable. Ha sido
discutido ampliamente y la experiencia demuestra que con estos tres escenarios se
hace un mejor análisis. El análisis se diseña para permitir mejorar la toma de decisiones
al permitir los diferentes escenarios y sus implicaciones.
Los análisis de escenarios se pueden usar para recordar puntos escondidos. Por
ejemplo que suceda una inundación en la ciudad donde colapsen los sitios dormitorios,
que requeriría hacer un trabajo extraordinario para alojar las personas. Aunque la
probabilidad de que ocurra es pequeña, los efectos son tan grandes que se requiere
considerarlo como un escenario posible. Pero, generalmente, la posibilidad es
despreciada por las organizaciones que hacen escenarios porque sobrecargan de
trabajo a las personas que los ejecutan.
Para analizar las implicaciones financieras, las entidades generan tres escenarios
de crecimiento (crecimiento rápido, crecimiento moderado y crecimiento lento) haciendo
las predicciones financieras respectivas. A estos escenarios se le determinan
correlaciones y se le aplican probabilidades de ocurrencia. Al final se puede calcular el
escenario probabilístico ponderado incluyendo el grado de atractividad.
Dependiendo de la complejidad del escenario problema se puede demandar un
ejercicio adicional para tratar de prever cómo se mantendrá el futuro. Para ellos se le

27
calcula probabilidad a cada evento y se hace un ejercicio con el método de Monte Carlo
como se verá más adelante. Las salidas se modelan estadística y matemáticamente
para tomar en cuenta la variabilidad dentro de los escenarios sencillos y de sus
relaciones.
Aunque es un instrumento muy valioso a veces falla debido a que no tiene
parámetros como promedios, desviaciones y límites de confianza que los hacen
distintos a los sistemas de predicción corrientes. Los análisis de escenario no sustituyen
a los métodos tradicionales y tampoco están exentos de errores. Se refiere al lector a la
bibliografía para obtener más detalles de cómo se ejecutan los cálculos de escenarios.
2.8.1.3. Método de Redes Neuronales Artificiales Una Red Neuronal Artificial (RNA) es un paradigma de procesamiento de la
información que se inspira en la forma biológica del sistema nervioso y como procesa la
información. El elemento clave de este paradigma es la nueva estructura del sistema de
procesamiento de la información. Se compone de un gran número de elementos de
procesamiento altamente interconectados (neuronas) que trabajan al unísono para
resolver problemas específicos. Las RNA, como las personas, aprenden con el ejemplo.
La información que sigue ha sido tomado libremente del escrito de Stergiuo y Dinitro
(2011) aparecida en la red internet. Una RNA está configurada para una aplicación
específica, como la clasificación de patrones de reconocimiento o de datos, a través de
un proceso de aprendizaje. El aprendizaje en los sistemas biológicos implica ajustes
para las conexiones sinápticas que existen entre las neuronas. Esto se aplica también
en el análisis de antecedentes históricos.
Las simulaciones de redes neuronales parecen ser un fenómeno reciente. Sin
embargo, este campo se estableció antes de la llegada de las computadoras y ha
sobrevivido por mucho tiempo. En la actualidad, el campo de redes neuronales disfruta
de un resurgimiento del interés y el correspondiente aumento de financiamiento.
La pregunta es ¿Por qué utilizar redes neuronales? Las redes neuronales, con su
notable capacidad para entender el significado de datos complejos o imprecisos, se
puede utilizar para extraer patrones y detectar tendencias que son demasiados
complejas para ser vistas por los seres humanos o las técnicas de otros productos
informáticos. Una red neuronal entrenada puede ser considerada como un "experto" en

28
la categoría de información que se ha dado a analizar. Este experto se puede utilizar
para proporcionar proyecciones, dadas las nuevas situaciones de interés y responder a
"qué pasa si".
Además otras ventajas son: a) Aprendizaje adaptativo: La capacidad de aprender
a hacer las tareas basadas en los datos proporcionados para la formación o la
experiencia inicial. b) Auto-organización: Una RNA puede crear su propia organización
o representación de la información que recibe durante el tiempo de aprendizaje. c)
Operación en tiempo real: los cálculos de la RNA pueden llevarse a cabo de forma
paralela, y los dispositivos especiales que existen están diseñados y fabricados para
aprovechar esta capacidad. d) Tolerancia a fallos a través de codificación de la
información redundante: la destrucción parcial de una red da lugar a la correspondiente
degradación de rendimiento. Sin embargo, algunas capacidades de la red pueden ser
retenidas, incluso con daños en la red principal.
Las redes neuronales adoptan un enfoque diferente para la solución de problemas
a las computadoras. Las computadoras convencionales utilizan un enfoque algorítmico
es decir, el equipo sigue una serie de instrucciones con el fin de resolver un problema.
El proceso de información neural de redes trabaja de una manera similar al cerebro
humano. La red se compone de un gran número de elementos de procesamiento
altamente interconectados (neuronas) que trabajan en paralelo para resolver un
problema específico. Las redes neuronales aprenden con el ejemplo. No pueden ser
programadas para realizar una tarea específica. Los aprendizajes deben ser
seleccionados cuidadosamente para que sean útiles. La desventaja es que debido a
que la red usa toda la información para resolver el problema por sí mismo, su
funcionamiento puede ser impredecible.
Las redes neuronales y los algoritmos convencionales de las computadoras no
están en competencia, sino que se complementan entre sí. Hay tareas que se adaptan
mejor a un enfoque algorítmico, como las operaciones aritméticas y otras que se
adaptan mejor a las redes neuronales. Aún más, un gran número de tareas, requieren
de sistemas que utilizan una combinación de los dos enfoques (normalmente una
computadora convencional se utiliza para supervisar la red neuronal para llevar a cabo

29
la tarea con la máxima eficacia). Las redes neuronales no hacen milagros. Pero si se
usa con sensatez pueden producir resultados asombrosos.
El punto clave aquí es como el cerebro humano aprende. Queda mucho por
descubrir acerca de cómo el cerebro se entrena para procesar la información, por lo que
abundan las teorías. En el cerebro humano, una neurona típica recoge señales de los
otros por medio de una serie de estructuras finas llamadas dendritas. La neurona envía
los picos de actividad eléctrica por medio de una posición larga y delgada llamada
axón, que se divide en miles de sucursales. Al final de cada rama, una estructura
llamada sinapsis convierte la actividad de los axones en los efectos eléctricos que
inhiben o excitan la actividad de los axones en las neuronas conectadas. Cuando una
neurona recibe una entrada de excitación que es lo suficientemente grande con
respecto a su entrada inhibitoria, envía un repunte de la actividad eléctrica por su axón.
El aprendizaje se produce mediante el cambio de la eficacia de las sinapsis para que
cambie la influencia de una neurona a otra.
Para llevar a cabo estas redes neuronales, se debe tratar de las características
esenciales de las neuronas y sus interconexiones. A continuación, por lo general se
tiene un programa de computadora para simular estas características. Sin embargo,
debido al poco conocimiento del trabajo de las neuronas y a que la capacidad de
computación es limitada, los modelos son idealizaciones de las verdaderas redes de
neuronas.
Una neurona artificial es un dispositivo con varias entradas y una salida. La
neurona tiene dos modos de funcionamiento, el modo de entrenamiento y el modo de
uso. En el modo de entrenamiento, la neurona puede ser entrenada para el juego (o
no), con una entrada particular. En el modo de uso, cuando un patrón de entrada que
se enseñó se detecta en la entrada, su salida asociada se convierte en la corriente de
salida. La regla de disparo es un concepto importante en las redes neuronales y es
responsable de su alta flexibilidad. Una regla de disparo determina cómo se calcula si
una neurona debe dar juego para cualquier patrón de entrada. Se relaciona con todos
los patrones de entrada, no sólo aquellos en los que se formó el nodo.

30
El proceso se implementa utilizando la técnica de la distancia de Hamming
(Stergiou C et al, 2011). La regla es la siguiente: Se tiene una colección de patrones de
entrenamiento para un nodo, algunos de los cuales hacer el juego (generalmente
llamados conjuntos 1 y otros que le impiden hacerlo, llamados conjuntos 0). Basado en
la información que se la ha suplido el modelo decide cual es “la más cercana
respuesta”. Si hay un empate, entre pros y contras, entonces el patrón permanece en
el estado indefinido.
Una aplicación importante de redes neuronales es el reconocimiento de patrones.
El reconocimiento de patrones se puede implantar mediante el uso de proceso de
alimentación de la red neuronal que ha sido entrenada. Durante el entrenamiento, la red
se entrena a los productos asociados con los patrones de entrada. Cuando se utilice la
red, el patrón de entrada trata de hallar la salida del patrón asociada. Todos los
métodos de aprendizaje utilizados para la adaptación de redes neuronales tienen un
supervisor que incorpora un instructor externo de manera que cada unidad de
producción se le dice cuál es su respuesta deseada a las señales de entrada. Durante
el proceso de aprendizaje se puede requerir la información global.
Teniendo en cuenta esta breve descripción de las redes neuronales y cómo
funcionan, se pregunta cómo se puede aplicar este método al manejo de las
recepciones de habitaciones en los hoteles. Dado que las redes neuronales son los
mejores en la identificación de patrones o tendencias de los datos, están bien
adaptadas para las necesidades de predicción o pronóstico, incluyendo, las que se
analizan en esta investigación.
Las redes neuronales se pueden utilizar de forma experimental para modelar la
recepción de pedidos de habitaciones en los hoteles. El diagnóstico se puede lograr
mediante la construcción de un modelo del sistema de un hotel y su comparación con
las mediciones en tiempo tomadas en el hotel. Si esta rutina se lleva a cabo con
regularidad, el potencial de las condiciones que ocurren en el hotel puede detectarse en
una etapa temprana y por lo tanto hacer que el proceso de recepción sea mucho más
fácil. Un modelo del sistema habitacional debe imitar la relación entre las variables
concurrentes a las distintas estaciones.

31
Si un modelo es una adaptación a un hotel en particular, entonces se convierte en
un modelo de la condición total de recepción de ese hotel. El simulador tiene que ser
capaz de adaptarse a las características de ese hotel no importa el tipo, sin la
supervisión de un experto. En esta investigación no se profundizará sobre los modelos
neuronales pero si el lector desea hacerlo se le aconseja leer el trabajo de Stergiou y
Suganos (2011). Si se desea ejecutar y armar una red neuronal se recomienda entrar
en www.netl.doe.gov y bajar los programas libres de computadora llamados neuro3 y redes Neurales 1.0. 2.8.1.4. Método Difuso
La lógica difusa o heurística se basa en lo relativo de lo observado como posición
diferencial. Este tipo de lógica toma dos valores aleatorios, pero contextualizados y
referidos entre sí. Así, por ejemplo, una persona que mida 2 metros es claramente una
persona alta, si previamente se ha tomado el valor tipo de la persona baja y se ha
establecido en un metro. Ambos valores están contextualizados a personas y referidos
a una medida métrica lineal.
A continuación se da una introducción al método difuso tomado de la referencia de
Hoekstra (2010) en donde aplica la técnica difusa para predecir las reservaciones en
hoteles.
La lógica difusa se adapta mejor al mundo real en el que vivimos, e incluso puede
comprender y funcionar con nuestras expresiones, del tipo "hace mucho calor", "no es
muy alto", "el ritmo del corazón está un poco acelerado", etc. La clave de esta
adaptación al lenguaje, se basa en comprender los cuantificadores de nuestro lenguaje
(en los ejemplos de arriba "mucho", "muy" y "un poco"). En la teoría de conjuntos
difusos se definen también las operaciones de unión, intersección, diferencia, negación
o complemento y otras operaciones sobre conjuntos, en los que se basa esta lógica. Si
el lector no está familiarizado con estos términos se le recomienda leerlos en el Anexo
A.
Para cada conjunto difuso, existe asociada una función de pertenencia para sus
elementos, que indican en qué medida el elemento forma parte de ese conjunto difuso.
Las formas de las funciones de pertenencia más típicas son trapezoidales, lineales y

32
curvas. Se basa en reglas heurísticas de la forma SI (antecedente) ENTONCES
(consecuente), donde el antecedente y el consecuente son también conjuntos difusos,
ya sea puros o resultado de operación con ellos. Sirvan los siguientes ejemplos de regla
heurística para esta lógica (nótese la importancia de las palabras "muchísimo",
"drásticamente", "un poco" y "levemente" para la lógica difusa):
SI hace muchísimo calor ENTONCES aumentó drásticamente la
temperatura.
SI voy a llegar un poco tarde ENTONCES aumento levemente la
velocidad.
Los métodos de inferencia para esta base de reglas deben ser simples, veloces y
eficaces. Los resultados de dichos métodos son un área final, fruto de un conjunto de
áreas solapadas entre sí (cada área es resultado de una regla de inferencia). Para
escoger una salida concreta a partir de tanta premisa difusa, el método más usado es el
del centroide, en el que la salida final será el centro de gravedad del área total
resultante. Las reglas de las que dispone el motor de inferencia de un sistema difuso
pueden ser formuladas por expertos, o bien aprendidas por el propio sistema, haciendo
uso en este caso de redes neuronales para fortalecer las futuras tomas de decisiones.
Los datos de entrada suelen ser recogidos por sensores, que miden las variables
de entrada de un sistema. El motor de inferencias se basa en valores difusos, que están
aumentando exponencialmente su capacidad de procesamiento de reglas a medida que
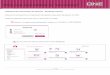
aumentan los datos. Un esquema de funcionamiento típico para un sistema difuso
podría ser de la siguiente manera:
Gráfico 2. Esquema de un Sistema Difuso (Hoekstra,2010)

33
En el gráfico, el sistema de control hace los cálculos con base a sus reglas
heurísticas, comentadas anteriormente. La salida final actuaría sobre el entorno físico, y
los valores de las nuevas entradas anteriormente modificados por la salida del sistema
de control, serían tomados por sensores del sistema.
Por ejemplo, imaginando que nuestro sistema difuso fuese la recepción de pedido
de habitaciones en un hotel que se autorregula según las necesidades: Los elementos
difusos del modelo están en los datos de entrada, que en este caso bien podrían ser los
días faltantes para el día determinado, los costos de las habitaciones, etc. Estos datos
se someten a las reglas del motor de inferencia (como se ha comentado antes, de la
forma SI... ENTONCES... ), resultando un área de resultados. De esa área se escogerá
el centro de gravedad, proporcionándola como salida. Dependiendo del resultado, la
gerencia de recepción del hotel podría aumentar el mercadeo o disminuir los costos.
La lógica difusa se utiliza cuando la complejidad del proceso en cuestión es muy
alta y no existen modelos matemáticos precisos, para procesos altamente no lineales y
cuando se envuelven definiciones y conocimientos no estrictamente definidos
(impreciso o subjetivo). En cambio, no es una buena idea usarla cuando algún modelo
matemático ya soluciona eficientemente el problema, cuando los problemas son
lineales o cuando no tienen solución.
En la inteligencia artificial, la lógica difusa, se utiliza para la resolución de una
variedad de problemas, principalmente los relacionados con control de procesos
industriales complejos y sistemas de decisión en general, la resolución la compresión
de datos, etc. Los sistemas de lógica difusa están también muy extendidos en la
tecnología cotidiana, por ejemplo en cámaras digitales, sistemas de aire acondicionado,
lavarropas, etc. Los sistemas basados en lógica difusa imitan la forma en que toman
decisiones los humanos, con la ventaja de ser mucho más rápidos, son generalmente
robustos y tolerantes a imprecisiones y ruidos en los datos de entrada.
Como principal ventaja, se suele destacar los excelentes resultados que brinda un
sistema de control basado en lógica difusa: ofrece salidas de una forma veloz y precisa,
disminuyendo así las transiciones de estados fundamentales en el entorno físico que

34
controle. También está la indecisión de auxiliarse bien por los expertos o por la
tecnología (principalmente mediante redes neuronales) para reforzar las reglas
heurísticas iniciales de cualquier sistema de control basado en este tipo de lógica. En
esta investigación no se profundizara sobre este método por salirse del alcance. Buena
información se encuentra en la red internet.
2.8.2. Métodos de Predicción Cuantitativa Los métodos de series de tiempo, como los que se tienen en las recepciones de
huéspedes, usan datos históricos como base para la estimación de los procesos
futuros. Se clasifican en:
(a) Promedios móviles.
(b) Promedio móviles ponderados.
(c) Suavizamiento Exponencial.
(d) Promedio Autoregresivo de media móvil (ARMA).
(e) Promedio Autoregresivo integrado de media móvil (ARIMA).
(f) Método Espectral
La anterior clasificación ha sido tomada del libro de Hanke (1996) con la excepción
del Método espectral que fue tomado del libro de Bogo(1975) y de algunas referencias
de internet que se muestran en la bibliografía.
Los métodos de predicción causales o econométricos usan la suposición de que
es posible identificar los factores infradyacentes que pueden influir la variable que está
siendo predicha. Por ejemplo, la información acerca de las condiciones del clima puede
mejorar la habilidad de un modelo de predecir la venta de paraguas. Y en la industria de
hotelería, los datos de los huéspedes como sexo, edad, estado civil, etc. pueden influir
en la predicción de su llegada al hotel. La mayoría de las soluciones terminan utilizando
análisis de regresión que incluye un gran grupo de métodos que se pueden usar para
predecir los valores futuros de las variables usando la información de otras variables.
2.8.2.1. Precisión de las predicciones. El error de la predicción es la diferencia entre el valor real y el valor predicho para
el periodo correspondiente

35
donde Et es el error predicho, Yt es el valor real y Ft es la predicción para el periodo t.
En la precisión de la predicción se utilizan varias ecuaciones a través de todos los
métodos. Estos parámetros y ecuaciones son:
Error Medio Absoluto
Error Porcentual Absoluto Medio .
Desviación Absoluta Media Porcentual ….
Error Medio Cuadrático
Habilidad Prediccional
Para los efectos de esta investigación se usará el Error Medio Cuadrático, aunque
cualquiera de los anteriores da la misma respuesta lógica.
2.8.2.2. Promedios Móviles En estadística, el promedio móvil, llamado en inglés moving average, rolling
average, rolling mean o running average, es un tipo de filtro de respuestas de impulso
finito usado para analizar un conjunto de datos al crear una serie de promedios de
diferentes subconjuntos del conjunto total de datos.
Dados una serie de números y un tamaño de subconjunto fijo, el promedio móvil
se puede obtener tomando el promedio del primer subconjunto. Luego, el tamaño del
subconjunto se mueve hacia adelante, creando un nuevo conjunto de números que se
promedia. Este proceso se repite sobre el conjunto total de datos. El grafico de conectar
todos los promedios se llama promedio móvil. Un promedio móvil es un conjunto de
números, cada uno de los cuales es el promedio del subconjunto correspondiente de un
conjunto grande de puntos. Un promedio móvil se puede usar también con pesos no

36
iguales para cada valor de dato en el subconjunto enfatizando valores particulares en el
subconjunto. En este caso se llama promedio móvil ponderado.
Los promedios móviles se utilizan para suavizar los datos de series de tiempos
que tienen fluctuaciones cortas con el fin de resaltar tendencias altas o ciclos. La
separación entre los términos largos y cortos depende de la aplicación, del
pronosticador colocando los valores de los promedios móviles acordes con cada caso.
Los promedios móviles se pueden usar, por ejemplo, con las entradas diarias, creando
subconjuntos de siete días, para determinar los días críticos de la semana.
Los promedios móviles se pueden clasificar en:
a) Promedios móviles sencillos.
b) Promedios móviles acumulados.
c) Promedios móviles ponderados.
d) Promedios móviles exponenciales.
e) Medianas móviles.
Promedio móviles sencillos En las aplicaciones financieras un promedio móvil sencillo (en inglés, simple
moving average, SMA) es un promedio no ponderado de los n puntos de datos
anteriores. Sin embargo, en la matemática natural el promedio se toma con el número
de puntos a ambos lados del valor central. Esto asegura que esas variaciones en la
media están alineadas con las variaciones en los datos y no que tengan saltos en el
tiempo. Un ejemplo de un promedio móvil sencillo no ponderado para una muestra de
10 días de los huéspedes que llegan a un hotel, es la media de los huéspedes que
ocurrieron en los anteriores 10 días. Si las cantidades de estos huéspedes son HM, HM-
1, … HM-9, entonces la fórmula es:
Cuando se calculan valores sucesivos, se obtiene un nuevo valor en la suma y se quita
el valor más viejo, obteniendo una suma completa cada vez. Se puede utilizar la
siguiente ecuación:

37
La selección del tamaño del período depende del tipo de movimiento de interés,
tan corto, intermedio o largo como se desee. En términos de hospitalidad, los niveles de
promedio móvil se pueden interpretar como una caída o una subida de mercado.
Si los datos usados no están centrados alrededor de la media, un promedio móvil
sencillo falla con los datos, si no se ponderan los datos. Un SMA puede estar también
desproporcionalmente debido a puntos viejos en decadencia o nuevos datos que estén
en aumento. Una de las características del SMA es que los datos tienen una fluctuación
siempre en un ciclo completo aunque se encuentra raramente un ciclo regular perfecto.
Para el caso de hospitalidad es ventajoso evitar el salto inducido usando
solamente los datos ponderados. Entonces, se puede calcular un promedio móvil central, usando datos igualmente espaciados a los lados con cualquier cantidad de
puntos en las series donde el promedio se calcula y extrapolando esta serie
promediada.
La manera más sencilla de suavizar una serie de tiempo es calcular el promedio
móvil simple o no ponderado. La estadística suavizada St es entonces exactamente la
media de las k observaciones:
donde la escogencia de k es un entero k>1 arbitrario. Un valor pequeño de k tendrá
menos efecto de suavizamiento y será más responsable a cambios recientes, mientras
que un k grande tendrá un efecto suavizador mayor y produce un pronunciado vacío en
la secuencia suavizada. Una desventaja de esta técnica es que no puede usarse en los
primeros k-1 términos de la serie de tiempos.
Promedio móvil acumulado
En un promedio móvil acumulado, los datos llegan en una forma ordenada y las
estadísticas obtienen los promedios de todos los datos hasta el punto actual. Un
gerente de hotel pudiera querer utilizar un promedio de todos los últimos puntos hasta

38
el punto de hoy usando los promedios móviles acumulados. Si no se usan pesos en los
datos se puede calcular este promedio utilizando la siguiente ecuación:
El método para calcularlo, llamado también de la fuerza bruta, sería almacenar
todos los datos, sumarlos y dividir por el número de puntos cada vez que un nuevo
dato llega. Sin embargo, es posible simplemente actualizar el promedio móvil
acumulado cuando un nuevo valor xi+1 se hace disponible, usando la fórmula:
Donde CA0 se puede tomar igual a cero.
Así los promedios móviles acumulados actuales para un nuevo dato son igual al
anterior promedio móvil acumulado más la diferencia entre el último dato y el anterior
divido por el número de puntos recibidos y así sucesivamente. Cuando todos los puntos
datos se encuentran (i=N), el promedio móvil acumulado será igual al promedio final.
La derivación de la fórmula del promedio móvil acumulado es fácil. Usando
y similarmente para i+1 se ve que:
Resolviendo esta ecuación para CAi+1 resulta en:
Promedio Móvil Ponderado Un promedio ponderado es cualquier promedio que tiene factores multiplicadores
para dar diferentes pesos en los datos a las diferentes posiciones en la muestra.
Matemáticamente, el promedio ponderado es la convolución de los datos con una
función de peso fijada. En el análisis técnico de datos, un promedio móvil ponderado
tiene el significado específico de los pesos que decrecen en progresión aritmética en n
días donde en el último día tiene un peso de n, en el anterior día n-1 y así de manera
regresiva hasta uno.

39
El denominador es un número triangular igual a n(n+1)/2. En la forma más general
será siempre la suma de los pesos individuales.
Cuando se calcula el WMA a lo largo de valores sucesivos, se puede notar que la
diferencia entre los numeradores de WMAM+1 y WMAM es npM+1- pM … -pM-n+1.
Denotando la suma pM +pM+1…+…+pM-n+1 por TOTALM, entonces
Los pesos decrecen desde el más alto hasta el más reciente dato que se coloca
en uno. Es importante comparar con los promedios móviles exponenciales que se
detallarán a continuación.
Un método ligeramente más complicado para suavizar una serie de tiempo {xt} es
calcular un promedio móvil ponderado escogiendo primero un conjunto de factores
ponderantes {w1, w2, …wk} tal que y luego utilizar estos factores para
calcular las estadísticas suavizadas {st}:
En la práctica los factores ponderantes se escogen para dar más peso a los
términos más recientes en las series de tiempo y menos peso a los más viejos. Nótese
que esta técnica tiene la misma desventaja que la técnica de móvil simple (es decir, no
se puede usar hasta que se tengan k observaciones). Además es más complicado su
cálculo. Si no se tienen los datos de cada etapa es difícil, para no decir imposible,
reconstruir una nueva señal debido a que las muestras viejas pueden tener otros pesos.
Por su puesto esto se puede evitar guardando los datos originales.
Promedio Móvil Exponencial

40
También conocido como promedio móvil exponencialmente ponderado (EMA) es
un tipo de filtro de respuesta que aplica factores ponderantes que decrecen
exponencialmente. El peso de cada punto más viejo decrece exponencialmente nunca
alcanzando cero. El promedio móvil exponencial para una serie Y se puede calcular
recursivamente así:
Para t>1, donde:
• El coeficiente α representa el grado de decrecimiento del peso, un factor
constante de suavización entre 0 y 1. Un valor alto de α descuenta las
observaciones más viejas mucho más rápido. Alternativamente α se puede
expresar en términos de N periodos de tiempo, donde α = 2/(N+1). Por ejemplo,
para N=19 es equivalente a α=0,1. La vida media de los pesos (el intervalo sobre
el cual, los pesos decrecen por un factor de 2) es aproximadamente N/2,8854
(dentro del 1% si N>5)
• Yt es la observación en el período de tiempo t.
• St es el valor de la EMA a cualquier período de t.
S1 está indefinido. S2 se puede inicializar de diferentes maneras, pero es más
común colocando S2 a Y1, aunque existen otras técnicas, tales como colocar S2 igual al
promedio de las primeras 4 o 5 observaciones. La buena obtención de S2 es importante
porque afecta el promedio móvil resultante y depende básicamente de α; los valores de
α pequeños hacen que la escogencia de S2 sea relativamente más importante que para
valores de α altos, puesto que valores altos de α descuenta las observaciones viejas
más rápido.
Esta formulación está de acuerdo a Hunter (1986). Repitiendo la aplicación de
esta fórmula para diferentes tiempos, se puede eventualmente escribir St como una
suma ponderada de puntos Yt como:

41
Para cualquier valor de k=0,1,2 El peso para cualquier punto en general Yt-i es
α(1-α)i-1.Una aproximación alterna fue dada por Roberts (1959) usando Yt en vez de Yt-1
Esta fórmula se puede expresar en términos de análisis como sigue mostrando los
pesos del EMA hacia los últimos datos:
Expandiendo EMAayer cada vez resulta en una serie de potencias que muestran
como los factores ponderantes del punto de dato p1, p2, etc. decrecen
exponencialmente:
Esta es una suma infinita con términos decrecientes.
Los N períodos en EMA de N días, solamente especifican el factor α. N es un
punto de parada para los cálculos del día en la manera como es en una SMA. Para
valores suficientemente altos, los primeros N puntos en una EMA representan cerca del
86% de los pesos totales de los cálculos como se demuestra a continuación:
y el límite
La fórmula de potencias que se muestra arriba da un valor de comienzo para un
día particular, después del cual se puede aplicar la fórmula de los días sucesivos
mostrada anteriormente. La pregunta de cuánto se debe retroceder para un valor inicial,

42
depende, en el peor de los casos, de los otros datos. Grandes valores en los datos
viejos afectarán en el total aún si sus pesos son muy pequeños. Si los precios de las
habitaciones tienen variaciones pequeñas entonces se deben considerar los pesos. El
peso omitido para detener después de k términos es:
lo cual es
Es decir, la fracción
fuera del peso total.
Por ejemplo, para tener un 99,9% del peso total, se coloca la relación, arriba igual
a 0,1% y se resuelve para k:
donde k es el número de términos a usarse. Puesto que log (1-α) se aproxima a
(-2)/(N+1) a medida que aumenta N, la ecuación se simplifica a
para este ejemplo (99,9% de peso). Es decir si N vale 19, entonces el número de
términos k es igual 69.
Promedio Móvil Modificado
Un promedio móvil modificado (MMA), llamado también promedio móvil suavizado
se define como:

43
En otras palabras, este es el promedio móvil exponencial, con α=1/N.
Suavizamiento Exponencial
El Suavizamiento Exponencial es una técnica que se puede aplicar a los datos en
series de tiempo, bien sea para producir datos suavizados o para hacer predicción. Las
series de tiempo son en sí mismo una secuencia de observaciones. El fenómeno
observado puede ser un proceso esencialmente aleatorio o puede estar ordenado, pero
con ruidos. Donde se presente el promedio móvil simple, las observaciones anteriores
están igualmente ponderadas asignando pesos decrecientes exponencialmente en el
tiempo.
El suavizamiento exponencial se aplica comúnmente en datos económicos y
financieros, pero se puede usar con cualquier conjunto discreto de medidas repetidas.
La secuencia de datos es a menudo representada por [xt], y la salida del algoritmo de
suavizamiento exponencial se escribe comúnmente como [st], que se refiere como el
mejor estimado de lo que será el próximo valor de x. Cuando la secuencia de
observaciones comienza al tiempo t =0, la forma más simple de suavizamiento
exponencial se da por las fórmulas:
Para t>1 y donde α es el factor suavizante, con 0<α<1.
En otras palabras, el estadístico de suavizamiento st es un promedio simple
ponderado de las xt-1 observaciones previas y el estadístico previo st-1. El término factor
suavizante aplicado a α es aquí un inverso, es decir a medida que α aumenta,
disminuye el nivel de suavizamiento. En el caso límite de α=1, la serie de salida es igual
a la serie original. El suavizamiento exponencial simple es fácil de aplicar, y produce
una estadística suave tan pronto como se tienen dos observaciones.
Los valores de α, cuando están cercanos a 1 tienen menos efecto de
suavizamiento y dan más peso a los eventos más recientes, mientras que cuando se

44
acerca a cero, dan más suavizamiento y menos peso a los eventos recientes. No hay
una manera única de escoger α. El juicio del dueño del negocio (hotel) se usa para
hacer esta escogencia. Un método alternativo y matemático es emplear el método de
los mínimos cuadrados para determinar α, tal que haga mínima la suma cuadrática
(sn-1 –xn-1)2.
Al contrario de otros métodos, esta técnica no requiere un número de
observaciones alto antes de comenzar a ser aplicada para producir resultados. En la
práctica, sin embargo “un buen promedio” no se alcanzará hasta que se tengan varias
muestras. Para reconstruir la señal original sin pérdida de información, se debe
disponer de todos los cálculos anteriores, porque se requieren para hacer la nueva
etapa de cálculo. La forma más simple de suavizamiento exponencial es también
conocida como promedio móvil ponderado exponencial (PMPE). Técnicamente, se
puede clasificar como un modelo de promedio autoregresivo integral de media móvil
(ARIMA).
Suavizamiento Doble Exponencial El suavizamiento exponencial simple no trabaja bien cuando existe una tendencia
única en los datos. En tales situaciones se prefiere usar el suavizamiento doble
exponencial.
Otra vez, aquí, los datos crudos de la secuencia se representan por {xt},
comenzando al tiempo t=0. Se usa {st} para representar el valor suavizado para el
tiempo t. y {bt} es el mejor estimado para la tendencia del tiempo t. La salida del
algoritmo se escribe ahora como Ft+m , un estimado del valor de x al tiempo t+m, m>0
basado en los datos originales hasta el tiempo t. El suavizamiento doble exponencial
está dado por las fórmulas:

45
Donde α es el factor suavizante de los datos, 0<α<1, β es el factor de suavización
de la tendencia, 0<β<1 y bo se toma como (xn-1-x0)/(n-1) para todo n<1. Nótese que Fo
está indefinido (no existe estimación para t=0), y de acuerdo a la definición F1=s0+b0,
está bien definido.
Mediana Móvil. Desde el punto de vista de la estadística, los promedios móviles, cuando se
utilizan para estimar tendencias en series de tiempo, son susceptibles a enrarecer los
eventos con anomalías. Un estimado más robusto de la tendencia es la mediana móvil simple sobre n puntos de tiempos.
donde la mediana se encuentra, por ejemplo, arreglando los valores entre paréntesis y
encontrando el punto que se ubica en la mitad.
Estadísticamente, el promedio móvil es óptimo para obtener la tendencia de las
series de tiempo cuando las fluctuaciones acerca de la tendencia están distribuidas
normalmente. Sin embargo, la distribución normal no describe cuando se tienen altas
desviaciones de la tendencia, porque no explica porque esas desviaciones tienen gran
efecto sobre los estimados. Se puede demostrar que si las desviaciones se suponen
distribuidas laplacianamente, entonces el movimiento de la mediana es
estadísticamente óptimo. Para una variación dada, la distribución de Laplace coloca las
más altas probabilidades en eventos extraños mejor que la distribución normal, lo cual
explica porque la mediana en movimiento tolera altibajos mejor que la media en
movimiento.
2.8.2.3. Modelos de Promedio Autoregresivo de Media Móvil (ARMA) Estos modelos son llamados algunas veces Modelos de Box-Jenkins
(Hanke,1996), debido a que utilizan esta metodología para hacer las estimaciones y se
aplican generalmente a datos en series de tiempo auto correlacionadas. Dada una serie
de tiempo Xt, los modelos ARMA son una herramienta para entender y quizás predecir
los valores futuros de las series. El modelo consiste de dos partes, una parte
autoregresiva AR y una parte de un promedio móvil MA. El modelo es referido entonces

46
como ARMA(p,q) donde p es el orden de la autoregresión y q es el orden del promedio
móvil (como se definirá abajo).
Modelo autoregresivo (AR)
La notación AR(p) se refiere al modelo autoregresivo de orden p. El modelo se
escribe así:
Donde φ1, ……φp , son los parámetros del modelo, c es una constante y ξt es la
constante del error o ruido blanco. La constante c es a veces omitida por simplicidad.
Se hace necesario colocar algunas restricciones en los valores de los parámetros de
este modelo para que el modelo permanezca estacionario.
Modelo del Promedio Móvil (MA) La notación MA(q) se refiere al modelo del promedio móvil de orden q.
Donde las θ1, …..θq son los parámetros del modelo, µ es el valor esperado de Xt (a
menudo supuesto igual cero), y los ξ son otra vez, términos del error o ruido blanco.
Modelo del Promedio Autoregresivo Móvil (ARMA) La notación ARMA (p,q) se refiere al modelo con p términos autoregresivos y q
términos de promedios móviles. El modelo contiene los modelos AR(p) y MA(q).
En algunos textos los modelos se especificarán en términos de un operador de
salto L. En estos términos entonces el modelo AR(p) está dado por:
donde φ representa el polinomio

47
El modelo MA(q) está dado por
donde θ representa el polinomio
Finalmente, la combinación ARMA(p,q) está dada por
Los modelos ARMA en general pueden, después de escoger p y q, utilizar
regresión por mínimos cuadrados para encontrar los valores de los parámetros que
minimizan el término de error. Se considera generalmente buena práctica encontrar los
valores más pequeños de p y q que provea un aceptable cotejo a los datos. Algunos
paquetes de computadora como MATLAB, IMLS numerical libraries, incluyen rutinas
para determinar los factores p y q, programadas en C, Java o Fortran.
Predicción con los modelos ARIMA Los modelos ARIMA se utilizan para procesos no estacionarios Xt que tienen una
tendencia confiable:
(a) Una tendencia constante (es decir con promedio cero) se modela con d=0
(una constante que se definirá más adelante).
(b) Una tendencia lineal (es decir comportamiento lineal) se modela con una
d=1.
(c) Una tendencia cuadrática (es decir comportamiento creciente) se modela
por d=2.

48
En estos casos, el modelo ARIMA se puede visualizar como una “cascada” de
dos modelos. El primero es no estacionario:
Mientras el segundo es estacionario de amplio sentido:
Ahora las técnicas de predicción estándar se pueden formular por el proceso de
Yt, y entonces (teniendo unas suficientes condiciones iniciales), Xt se puede predecir
con oportunos pasos de integración.
2.8.2.5. Método Espectral
Basado en los puntos anteriores y tomando en cuenta el aspecto estacional de los
datos, se puede analizar los datos tomando en cuenta las fluctuaciones de las series de
tiempo, un enfoque estadístico que parte de la idea de que dichas oscilaciones se
deben a funciones periódicas inherentes. Según se describe en Bogo(1975), se cree
que las series de tiempo se pueden adaptar a términos sinusoidales. Es decir, se
supone que el modelo que ajusta los datos es:
Donde ξ tiene media cero y varianza constante. Este método se conoce como método
espectral. θj es una variable que depende del tiempo. aj y bj son constantes parciales.
Para el caso de esta investigación, la ecuación se le ha agregado el efecto de la �
tendencia y el efecto mensual, convirtiendo la ecuación anterior en la siguiente:

49
A0 es el intercepto y b es la pendiente de la tendencia. El multiplicador Fm varía en
forma diferente para cada mes, es decir F1 es el multiplicador para el mes de enero, F2
para el mes de febrero, etc. Otras explicaciones se darán en el capítulo IV.
2.8.2.6. Métodos Probabilísticos Los métodos probabilísticos se basan en el uso de números aleatorios y
funciones estadísticas para generar las predicciones. De ellos desarrollaremos
solamente el Método de Monte Carlo.
El método de Monte Carlo En esta sección se describirá el método numérico probabilístico que se conoce
como Método de Monte Carlo. Comienza con una descripción básica de los principios y
luego se discutirá el método en sí. Al final se discutirá las ventajas y desventajas del
método. Hay una gran cantidad de libros e informaciones en internet para la descripción
del método pero la información aquí descrita está tomada parcialmente de Pengelly
J.(2002) y Doner A.(2010).
El método Monte Carlo provee soluciones aproximadas a una gran variedad de
problemas al ejecutar muestreos de experimentos estadísticos. Se define en sí como
una metodología que utiliza simulaciones estadísticas utilizando secuencias de
números aleatorios. El método se hace simulando muchas veces un fenómeno
utilizando números aleatorios y cálculos de probabilidad para obtener una aproximación
al resultado del problema.
Su nombre deriva de que Monte Carlo, la capital de Mónaco, tiene muchos
casinos que son buenos ejemplos de generación de números aleatorios. La técnica
existe desde 1940, cuando se utilizó su aplicación en la investigación de la fusión
nuclear. Sin embargo, la técnica se comenzó a utilizar en profundidad cuando se
tuvieron computadoras de gran velocidad y capacidad de memoria. Al tenerlas se
pudieron efectuar millares de simulaciones en poco tiempo, haciendo su uso rentable.
El análisis del error que se tiene cuando se utiliza el método es la clave para
decidir su uso. Es por ello, que existen varias maneras de enfocar el método. Sin
embargo, en esta investigación solo se nombrará el más sencillo de ellos. El método se
entiende mejor si se explica en forma práctica, aunque en esta investigación solo se
hizo con la historia mensual de habitaciones.

50
Para los efectos de la gerencia de reservaciones de habitaciones en los hoteles se
procede de la siguiente manera. Una vez que se han estimado los promedios
estacionales y la curva de reservaciones, como se detalló en la pasada sección,
entonces se puede efectuar el proceso de predicción. Se desarrolla simulando el
proceso de reservaciones, cancelaciones, llegadas, etc., exactamente como sucede en
el hotel y con el modelo que se ha desarrollado. Se usan todos los valores de los
parámetros obtenidos en el paso de estimación anterior. Debido al aspecto aleatorio del
proceso de reservaciones, un solo ensayo no es suficiente. Se requieren generar
muchos caminos en el comportamiento aleatorio de Monte Carlo, y luego tomar la
media de estos caminos para cualquier instante futuro en la predicción. Este ensayo se
puede aplicar para cualquier tiempo dentro de la predicción y también para las
reservaciones, cancelaciones y llegadas y otros parámetros del hotel en forma aislada.
Cuando se desea predecir un día particular se requiere establecer un horizonte
haciendo uso de la información que se ha recopilado. Este es el punto de comienzo de
cómo se construirán las predicciones. Por ejemplo, si se encuentra en el tiempo t, se
puede desear predecir las llegadas para el tiempo t+5. Supóngase que el hotel tiene ya
20 reservaciones para la fecha futura. El número resultante se le añade a estas 20
reservaciones. Igualmente, se procede para las cancelaciones y los otros eventos. El
fenómeno está críticamente influenciado por las variables de predicción, con el efecto
de ir disminuyendo la exactitud a medida que se aleje más la fecha de predicción. A
continuación se detalla el algoritmo:
1. Supóngase que el inicio es el tiempo t y se desea predecir el intervalo (t+1
: t+T). De los registros del hotel se sabe que se tienen R(i,t´)
reservaciones para las llegadas t´=t+1, ……t+T, donde i t´-t.
2. Se conoce que la variable s(t´) para todos los tiempos anteriores t´ t está
definida por la ecuación:
Se hace la predicción de s(t´) para el horizonte considerado mediante la
metodología descrita anteriormente en el párrafo sobre reservaciones y
cancelaciones y para todos los tiempos de predicción de la siguiente manera:

51
Para τ=t+1 hasta t+T ejecútese lo siguiente:
(a) Cancelaciones: Genere las cancelaciones a partir de una distribución
binomial, como sigue. Para cada día de llegada t´ , t´=τ ,….., t+T, las
reservaciones al momento son H(t´-τ+1,t´). La fracción de las
cancelaciones es c(t´-τ) donde c es la función que ya ha sido estimada
de los datos históricos en la fase de estimación de parámetros. Se
genera un ensayo de Bernoulli para cada reservación con probabilidad
p=c(t´-τ) que ocurra una cancelación para la reservación. Reste la
reservación cancelada y actualice la nueva matriz de reservaciones
H(t´-τ+1,t´).
(b) Reservaciones: genere nuevas reservaciones para cada tiempo de
llegada como sigue. Para cada día de llegada t´, t´=τ,…..,t+T. La curva
de reservaciones para algún tiempo t´ será una de las formas
normalizadas, según la estación correspondiente multiplicada por el
nivel de predicción s(t´). Genere las reservaciones usando la
distribución binomial correspondiente con el número de ensayos N y
probabilidad p determinada de acuerdo al método anteriormente
explicado.
(c) Reservaciones de Grupos: para cada reservación generada
determine el tamaño del grupo generando un número por reservación
de acuerdo a la distribución del tamaño del grupo. Nótese que si el
número generado es igual a 1 significa que es una reservación
individual, que por supuesto es el más alto valor de probabilidad.
(d) Longitud de la estadía: Para cada reservación genere una longitud de
la estadía para la estación especificada de acuerdo a la distribución
estadística de la estadía.
(e) Para reservación generada en los puntos (b) –(d) se determina si la
reservación puede ser aceptada o negada de acuerdo al máximo
permitido por el hotel. Un intento de reservación es negada, si en los
días que se pretende ubicar una habitación están todas las del hotel
ocupadas. En caso de que el hotel esté trabajando con la política de

52
sobre disponibilidad, la reservación se coloca como tentativa. Nótese
que todas reservaciones tienen que trabajarse una a la vez.
3. Repita los pasos (3) para K veces-caminos de Monte Carlo para futuras
reservaciones. Una vez terminada se genera la media o la mediana que
será utilizada como valor resultado predicho.
En el caso particular de esta investigación se utilizó el método de Monte Carlo
para predecir el número de huéspedes promedio diario.
3. SISTEMA DE VARIABLES
3.1. DEFINICIÓN CONCEPTUAL La predicción de reservaciones de habitaciones en hotelería es la estimación en el
futuro del número de habitaciones que serán ocupadas para un determinado día o lapso
(Zakhary et al, 2009).
3.2. DEFINICIÓN OPERACIONAL La predicción de reservaciones de habitaciones se hace operacionalmente a
través del uso de modelos matemáticos y de decisión para obtener un resultado lo más
cercano posible a la realidad.
La razón principal por la cual se planteó esta investigación fue proporcionar
esquemas para la comprensión y uso de métodos de predicción de reservaciones de
habitaciones y de su ocupación para la industria hotelera nacional. La tabla 1 muestra el
resumen de la tabla de variables.

53
Tabla 1
TABLA DE VARIABLES FORMULACIÓN DEL PROBLEMA: ¿Cómo se identifica el método estadístico para predecir las reservaciones de los hoteles con menor error? OBJETIVO GENERAL : Identificar el método de predicción con menor error de reservaciones de habitaciones en el Hotel Granada OBJETIVOS ESPECÍFICOS
VARIABLE
DIMENSIONES
INDICADORES
Identificar el método para la predicción de la tendencia de datos de las reservaciones de habitaciones en el Hotel Granada
Pendiente de la tendencia Error en la predicción
Porcentaje de error en la predicción de la tendencia
Determinar el método para el establecimiento de los períodos estacionales para la evaluación de reservaciones de habitaciones en el Hotel Granada
Número de estaciones en el año Error en la predicción
Porcentaje de error en la predicción de los períodos estacionales
Establecer el método para la predicción de reservaciones de habitaciones en el Hotel Granada.
Método de Predicción
Predicciones del número de habitaciones a reservar Tiempo de estadía. Error en la predicción
Porcentaje de error en la predicción de reservaciones y en el tiempo de estadía
Establecer los lineamientos para la predicción de reservaciones de habitaciones en hoteles
Pasos para la predicción del número reservaciones de habitaciones en hoteles (Caso Hotel Granada)

54
CAPÍTULO III
MARCO METODOLÓGICO
En este capitulo se enfocará en establecer la metodología mediante la cual se
pretendió lograr los objetivos propuestos tales como tipo y diseño de la investigación
además del procedimiento que se llevó a cabo.
1. TIPO DE INVESTIGACIÓN El tipo de esta investigación es descriptiva porque se detallan los datos sobre las
reservaciones de habitaciones de hoteles, específicamente sobre un hotel Granada,
tomado de la literaturatura. Las técnicas utilizadas para resolver el problema serán, en
algunos casos, cuantitativas y en otros casos cualitativas. Es cuantitativa pues se
utilizan métodos matemáticos estadísticos para hacer la predicción de las reservaciones
y las ocupaciones de habitaciones que ocurren en un hotel a través de los pasos de
búsqueda de la tendencia de datos, de la estacionalidad, de la predicción de los
tiempos de estadía y por último de las reservaciones. En ellos se medirán los
fenómenos utilizando estadísticas para establecer patrones de comportamiento.
Por otra parte, ciertos métodos, como el Delphi, se declaran cualitativos pues se
enmarcan dentro de la percepción de las personas, sin utilizar estadísticas, basados en
el conocimiento que tienen los gerentes de la realidad del negocio hotelero. Ambos
métodos resumen la información de manera cuidadosa y luego analizan
minuciosamente los resultados, a fin de extraer generalizaciones significativas sobre el
fenómeno estudiado.
2. DISEÑO DE LA INVESTIGACIÓN El diseño de la investigación fue experimental siguiendo el siguiente
procedimiento: (a) Se desarrollaron las técnicas cuantitativas, (b) luego las técnicas
cualitativas, tal como se describirán más adelante en este mismo capítulo.

55
3. FUENTES DE LA INFORMACIÓN Los datos para la investigación fueron tomados de trabajos publicados
anteriormente y de algunos recopilados de fuentes confiables. Se obtuvo la información
de textos, Internet y personas involucradas con el turismo. El plan que se diseñó podrá
ser empleado en otras investigaciones posteriores relacionadas con el tema para hacer
análisis similares en las otras áreas del turismo.
4. INSTRUMENTOS DE LA INVESTIGACIÓN Para efectuar la investigación se procedió a utilizar paquetes de computadora de
uso común. En este caso se utilizarán los paquetes EXCEL® perteneciente a Microsoft
Corporation y el paquete EVIEWS® perteneciente a Quantitative Micro Software
(QMS). De acuerdo con el aspecto metodológico la investigación usará los instrumentos
estadísticos, matemáticos y de juicio para obtener los resultados deseados.
5. PROCEDIMIENTO DE LA INVESTIGACIÓN
Los pasos a seguir fueron los siguientes:
(a) Se desarrolló el cálculo de la tendencia de los datos aportados usando el
método de regresión, con el fin de diagnosticar si existe una pendiente de
incremento o decremento en la tendencia, con el fin de normalizarlos para el
siguiente paso.
(b) Con los datos generados en el paso anterior, se desarrolló la búsqueda de
estaciones de tiempos en el año usando el método de comparación de
medias de promedios en movimiento.
(c) Desarrollado el paso anterior se elaboró el hallazgo del método apropiado de
predicción por comparación del error generado entre los datos reales y los
calculados. El que tenga menor error es el más apropiado para las
predicciones. Se desarrolló el ejercicio de predicción con los métodos
autoregresivos, Monte Carlo, Delphi y Espectral.
(d) Se hizo un resumen de la metodología para hacer evaluaciones similares de
predicción.

56
CAPITULO IV
ANÁLISIS DE RESULTADOS
Los métodos explicados en esta investigación se aplicarán en datos tomados de la
literatura sobre recepción de huéspedes en hoteles, específicamente el Hotel Granada
de España (Aguilera,1997) . Los años de las estadísticas han sido modificados aunque
se ha conservado los datos originales para el efecto de discutir la metodología. El
orden de la investigación tendrá los siguientes pasos: a) Análisis de los datos históricos;
b) Cálculo de la media; c) Cálculo de la tendencia; d) Cálculo de la estacionalidad; d)
búsqueda de los modelos estadísticos y e) predicción.
Los datos a utilizar son los que aparecen en la tabla 2 y la Gráfica 3 después de
convertir los porcentajes de recepción del trabajo original, a número de habitaciones
suponiendo que el número de habitaciones del hotel es 150, con el fin de hacer los
ejercicios de predicción.
Se han estudiado medidas mensuales por 20 años. De los gráficos se deduce lo
siguiente:
a) una distinguida estacionalidad se observa en la gráfica. Se nota un
decrecimiento al final de cada año y un aumento de los meses intermedios.
b) Aparentemente hay una pequeña tendencia en los datos hacia el crecimiento,
que se identificará en la sección correspondiente.
c) Existió en 1989 un aumento sobre los límites que puede ser debido a un evento
extraordinario que ocurrió en el hotel.
d) Parece ser que durante el año 2003-2004 hubo una recesión en el número de
habitaciones ocupadas en el hotel.
e) El gráfico muestra la tendencia de los valores a través de los años.

57
Tabla 2. Habitaciones ocupadas en el Hotel Granada desde 1984 hasta 2004
Ene. Feb. Mar. Abr. May Jun. Jul. Ago. Sep. Oct. Nov. Dic. 1984 44 42 53 64 58 51 70 87 67 50 39 381985 41 46 50 56 59 51 68 81 62 46 36 361986 34 36 40 55 47 41 55 70 53 40 33 311987 35 48 55 73 54 52 76 90 70 57 49 401988 49 54 73 76 77 64 87 105 78 67 53 441989 50 53 63 83 69 60 72 90 65 66 51 441990 45 50 55 82 66 60 59 88 64 61 45 521991 43 43 52 69 70 52 59 87 66 60 45 411992 46 48 54 78 66 48 50 83 67 57 45 431993 38 48 63 67 60 54 63 85 69 59 45 431994 48 48 52 74 66 63 66 94 74 67 51 441995 41 50 62 75 69 61 67 86 76 66 47 381996 48 50 66 71 76 56 60 82 76 61 48 451997 43 50 60 83 74 61 58 79 71 69 50 511998 45 56 69 70 69 58 58 80 73 67 54 461999 53 58 78 77 78 60 57 82 70 70 57 552000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50(Aguilera,1997,modificada por Ríos,2012).
Grafico 3: Habitaciones ocupadas en el Hotel Granada desde 1984 hasta 2004.(Ríos,2012)

58
Grafico 4: Habitaciones ocupadas en el Hotel Granada: Todos los años dibujados superpuestos desde Enero hasta Diciembre (Ríos, 2012)
(Ríos,2012)
La tabla 3 muestra las estadísticas ocurridas en el hotel durante los 20 años de
análisis. En ella se nota que la mediana y la media están muy cercanas, pudiéndose
tomar que la recepción promedia diaria del hotel es de 60 huéspedes. El mínimo se
Tabla 3: Habitaciones ocupadas en el Hotel Granada Estadísticos
Media 59,9708 Error típico 0,876279 Mediana 59 Moda 50 Desviación estándar 13,57526606 Varianza de la muestra 184,2878487 Curtosis -0,319353759 Coeficiente de asimetría 0,303726834 Rango 74 Mínimo 31 Máximo 105 Suma 14393 Cuenta 240

59 situó en 31 y el máximo en 105. El intervalo de confianza se calculó mediante la
ecuación mostrada en el anexo A, utilizando EXCEL® en 1,72 con una probabilidad de
95% (α=0,05), por lo que los valores mínimo y máximo de confianza son 59 y 61
huéspedes respectivamente. Otros datos estadísticos se encuentran en la tabla 3.
Los valores de la tabla representan los datos actualmente conocidos, sin embargo
para los efectos de obtener un modelo confiable, se hará el análisis tomando solamente
desde Enero de 1984 hasta Diciembre de 1999. Es decir, 192 observaciones. Hay que
mencionar que una muestra adecuada tiene por lo menos cuarenta datos (T>40), lo que
ocurre en esta investigación. Para cada modelo se evaluará la predicción para el
período desde Enero de 2000 hasta Diciembre de 2004. En el resto del análisis se
utilizará el programa EVIEWS®, por lo que algunas de las ilustraciones pueden estar en
inglés. Un análisis de las series de tiempo comprende el intento de identificar los
factores que ejercen sobre cada uno de los valores periódicos de una serie. Este
procedimiento de identificación se denomina descomposición. Cada componente se
identifica por separado de tal manera que la serie histórica pueda proyectarse al futuro
y utilizarse en pronósticos tanto en corto como a largo plazo. Los cuatro componentes
más comunes son: tendencias, variaciones cíclicas, variaciones estacionales y
fluctuaciones irregulares.
a) La tendencia es el componente de largo plazo que constituye la base de
crecimiento (o declinación) de una serie histórica. Los efectos básicos que afectan la
tendencia de una serie son: cambios en el comportamiento de la población, inflación,
cambio tecnológico y cambios en la calidad del producto. En el caso investigado se nota
una ligera tendencia al aumento.
b) Variación cíclica: Es el comportamiento de fluctuaciones en forma de ondas o
ciclos, de más de un año de duración producido por cambios en las condiciones
económicas. En el caso investigado no se nota este fenómeno.
c) Variación estacional: los movimientos estacionales se encuentran en los casos
tipificados como trimestral, mensual, semanal o diario. La estacionalidad se refiere al
patrón de cambio regular recurrente a través del tiempo. El fenómeno se completa

60 dentro de un año y se repite año tras año. En esta investigación se nota estacionalidad
que se analizará en las próximas secciones.
d) Fluctuaciones irregulares: Este comportamiento es producido por sucesos
impredecibles o no periódicos. Pueden ser producidos por cambio en el clima poco
usual, huelgas y en el caso de hoteles por congresos, elecciones, etc.
Para los efectos de esta investigación se seguirán tres pasos: a) Análisis de la
tendencia. b) Análisis de los procesos cíclicos. c) Predicción
2. Análisis de la tendencia.
La tendencia es un movimiento extenso y continuo de toda la serie de tiempo que
puede depender de una cantidad de factores. Si ocurriesen factores externos se
debería utilizar una técnica de factorización, tal como el análisis factorial, antes de
trabajar con las series en tiempo. Una forma de representar la tendencia es mediante el
ajuste de la serie por un polinomio de variable independiente tiempo. Este método
presenta inconvenientes cuando el polinomio que se necesita es elevado, ya que
exagera las oscilaciones finales de la curva. En la práctica el ajuste más utilizado es el
lineal, en aquellos casos donde los valores históricos pueden representarse así. Existen
también ajustes exponenciales, logarítmicos, logísticos, etc.
Para el cálculo de la tendencia de los datos sobre ocupación de habitaciones de la
Tabla 2, se utilizó EVIEW®, suponiendo una tendencia en forma lineal con una
ecuación Y=α+βX+ξ, donde α es el coeficiente independiente, β es la pendiente y ξ es
el error de la medida. Los resultados se muestran en la tabla 4.
Tabla 4: Estadísticas del Hotel Granada. Muestra de Ene 1984 a Dic 1999
(Ríos,2012)

61
La tabla 4 muestra los resultados en ella se nota que el coeficiente de
determinación, R2 es muy bajo (R2=0,046). El R cuadrado: es el coeficiente de
determinación donde 0 . La raíz positiva de R2 es el coeficiente de correlación
entre la variable independiente y la variable dependiente.
La variación de los datos se visualiza al calcular el coeficiente de variación a partir
de la tabla 3 con V=desviación estándar / media = 13,94 / 59,52 = 0,23, que a pesar de
la poca correlación existe una variación moderada. La variación es menor mientras más
se acerca a cero y es baja en la práctica por debajo de 0,3. Valores pequeños de R2 no
es un indicativo tácito que no existe buena correlación. El valor de la pendiente es igual
a 0,65757 huéspedes/mes. Este valor se utilizará para normalizar los datos originales al
quitarles la tendencia. La ecuación de la tendencia es:
donde años es la fracción de años medida desde el 01-01-1984. Hab es el número de
habitaciones predichas en la línea de tendencia.
Algunas de otras informaciones que aparecen en la tabla 4 son:
El R cuadrado ajustado nunca debe ser mayor que el R2. No tiene mucha
importancia para una regresión entre dos variables, pero decrece a medida que se
agregan otras variables.
El estadístico F es el estadístico que se construye para contrastar si los
parámetros asociados a las variables explicativas (sin tomar en cuenta el término
independiente) son conjuntamente iguales a cero, es decir permite contrastar la
capacidad explicativa conjunta de las variables introducidas en el modelo. Dado que el
estadístico puede expresarse en términos de R2, el contraste puede considerarse como
un modo de determinar si el coeficiente de determinación del modelo es
suficientemente elevado estadísticamente como para decir la capacidad explicativa del
modelo. Mientras más alto, mejor explica la ecuación.

62
Estadístico t de Student: se calcula como el cociente entre el estimador y su error
estándar y permite contrastar la hipótesis de que el coeficiente es igual cero y por lo
tanto la variable en cuestión no es individualmente significativa para explicar el
comportamiento de la variable dependiente.
La probabilidad proporciona dos veces el área que el valor absoluto del estadístico
t deja a su derecha e indica la probabilidad de cometer el error de rechazar la hipótesis
nula siendo cierta (error tipo I). Estos valores están calculados de la distribución t de
Student con T-K-1 grados de libertad, siendo K+1 el número de coeficientes de
regresión incluyendo el término constante.
La probabilidad (Estadítico F de Snedecor): al igual que con el estadístico t, este
valor mide la probabilidad de cometer el error de tipo I, es decir, de rechazar la hipótesis
nula siendo cierta.
La grafica 5 muestra el resultado de investigación con la tendencia. En la parte
superior los datos reales con su tendencia encontrada. En la parte inferior se muestran
los residuos. Nótese que en la gráfica de los residuos se les han dibujado las dos
desviaciones estándar de los residuos.
Gráfica 5: Hotel Granada: resultado del análisis de la tendencia.(Ríos,2012)

63
Un método sencillo que también da el resultado de la tendencia es el conocido
como medias móviles. El resultado es que se puede hallar los valores de la tendencia
utilizando un promedio de 2N+1 términos consecutivos de la serie de tiempo con el fin
de suavizarla. Cuando se procedió tomando N igual a 3 (7 puntos) y efectuando
nuevamente la regresión se obtuvo un valor de la pendiente de 0,6377, el cual es muy
cercano al anterior valor, por lo que tomaremos aquel como tendencia para nuestra
investigación.
En resumen los valores de la primera regresión muestran una ligera tendencia a
aumentar a razón de 0,65757 huéspedes por año. Este efecto puede ser despreciado
antes de efectuar el análisis de estacionalidad, sin embargo para los efectos de la
investigación será tomada en cuenta.
Gráfico 6: Hotel Granada serie de tiempo después de habérsele quitado la tendencia (Ríos, 2012)

64
En la Tabla 5, se muestran los datos de habitaciones después de habérsele
quitado la tendencia. El grafico 6 muestra los mismos resultados.
Tabla 5: Hotel Granada: Valores de la serie de tiempo después de quitarle la tendencia.
(Ríos,2012) 3. Análisis de la Aleatoriedad
Uno de los problemas principales en el análisis de las series de tiempo es probar
la hipótesis de aleatoriedad. Para ello, existen numerosas pruebas estadísticas, con
características, ventajas y desventajas según el uso que se vaya a hacer de ellas. Estas
pruebas tratan de responder a la pregunta: ¿Cuál es la probabilidad de que en una
serie de tiempo el ordenamiento de unos datos se deba al azar? Para series no
aleatorias es probable que existan dependencias de algún tipo entre términos
sucesivos. Una medida útil de dichas dependencias es la denominada correlación serial
o autocorrelación.
Si los elementos de la serie se miden con respecto a la media de todo el conjunto
de términos, el coeficiente de autocorrelación de orden k es
Donde ν son los valores residuos con respecto la media correspondiente; n es el
número de valores y k es el rezago.

65
Si la serie es aleatoria, el valor teórico de rk es cero para cualquier valor de k
distinto de cero. En general, para valores grandes de n la varianza de rk en una serie
aleatoria es aproximadamente rk= 1/(n-k). Con este valor se puede comparar el valor
original obtenido para saber si la serie es aleatoria o no .
Si con los datos de la tabla 2 se efectúa un ajuste por medio de las medias
móviles, se obtienen unos residuos entre la serie original y la ajustada. Efectuando este
trabajo en el Eview®, se obtiene la tabla 6.
Tabla 6: Correlograma sobre los datos originales del Hotel Granada
(Ríos,2012)
La tabla muestra que el coeficiente de autocorrelación con rezago 12 es igual a
0,810. El desvió estándar de la serie aleatoria es igual a . El resultado
revela que la serie residual de habitabilidad no es aleatoria.
4. Análisis de la Estacionalidad
El análisis de la tendencia tiene implicaciones en la planificación a largo plazo. El
análisis del componente estacional de una serie histórica tiene implicaciones más
inmediatas de corto plazo y es de gran importancia para los niveles medio e inferior de
la administración. Hay una relación tácita entre las estaciones, el alquiler de
habitaciones y los gastos de comida, útiles de los cuartos y personal utilizado. La

66 identificación del comportamiento estacional en una serie histórica difiere del análisis de
la tendencia en por lo menos dos formas:
a) Mientras que la tendencia se determina en forma directa a partir de los datos
disponibles, el componente estacional se determina eliminando los otros componentes,
de modo que al final solo queda el estacional.
b) Mientras que la tendencia se determina mediante una ecuación o líneas de
mejor ajuste, se debe calcular un valor estacional por separado para cada estación o
mes, mediante un número índice. Al igual que en el análisis de tendencia, se han
desarrollado diversos métodos para medir la variación estacional, la mayoría de los
cálculos de índice estacional que ahora se emplea, son variaciones del método de la
proporción al promedio móvil.
El componente estacional en una serie histórica se mide en la forma de un número
índice. Su cálculo, que representa el grado de influencia estacional para un segmento
del año en particular, comprende la comparación de los valores medios o esperados
para este segmento (mes) con el promedio de todos los segmentos del año.
Estas series generadas a partir de la original por eliminación de la tendencia se
denominan “series de residuos” y deberán contener predominantemente fluctuaciones
estacionales. Para estimar la estacionalidad se requiere haber decidido el modelo a
utilizar (aditivo o mixto), lamentablemente esto no es siempre claro. En esta situación se
debe calcular ambas series residuales y elegir aquella cuyos valores correspondientes
a una estación dada oscilen menos en torno al promedio. Pero para efectos de esta
investigación se hará el trabajo usando el modelo aditivo.
Habiendo ya eliminado la tendencia, se trabajará con la serie de residuos que
consiste en restar a la serie original los efectos de la tendencia, quedando los valores
de la tabla 7 a los que se ha agregado los promedios anuales y por mes.
La tabla 8 muestra los principales estadísticos de habitabilidad del Hotel Granada
que incluyen los promedios, desviación estándar, la mediana, el coeficiente de
variación, la varianza, la curtosis, el primer y tercer cuartil y los intervalos de confianza.
Usando la metodología descrita en Bogo(1975) los valores de la tabla 8 se
calculan así: el promedio mensual de habitaciones del año 1984 fue de 54,9
habitaciones y este valor corresponde en promedio al mes de julio de 1984. Se toma el

67 promedio correspondiente al mes de Julio de la tabla 9 y se promedia con el valor anual
para obtener el valor estacional como aparece en la tabla 10.
Los demás valores se calculan de la misma manera, restando y sumando el
primero y último término de cada serie local de doce meses. En cada tabla se efectúan
los promedios para cada uno de los meses en el período correspondiente. Nótese que
no aparecen los términos Enero-Junio para 1984 y los meses Julio-Diciembre de 1999
debido a que en los promedios móviles de valor 12, toma los valores de 6 meses antes
y 6 valores después.
TABLA 7: Hotel Granada: Datos después de quitarle la tendencia
incorporando los promedios anuales y mensuales PROM
ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC ANUAL
1984 43,9 41,9 52,8 63,8 57,7 50,7 69,6 86,6 66,5 49,5 38,4 37,3 54,9 1985 40,3 45,2 49,2 55,1 58,1 50,0 67,0 79,9 60,8 44,8 34,7 34,7 51,7 1986 32,6 34,6 38,5 53,5 45,4 39,4 53,3 68,2 51,2 38,1 31,1 29,0 42,9 1987 33,0 45,9 52,9 70,8 51,8 49,7 73,6 87,6 67,5 54,5 46,4 37,4 55,9 1988 46,3 51,3 70,2 73,2 74,1 61,0 84,0 86,9 74,9 63,8 49,8 40,7 64,7 1989 46,7 49,6 59,5 79,5 65,4 56,4 68,3 86,3 61,2 62,2 47,1 40,1 60,2 1990 41,0 45,9 50,9 77,8 61,8 55,7 54,7 83,6 59,6 56,5 40,5 47,4 56,3 1991 38,3 38,3 47,2 64,2 65,1 47,1 54,0 82,0 60,9 54,8 39,8 35,7 52,3 1992 40,7 42,6 48,6 72,5 60,5 42,4 44,4 77,3 61,2 51,2 39,1 37,1 51,5 1993 32,0 42,0 56,9 60,9 53,8 47,8 56,7 78,6 62,6 52,5 38,5 36,4 51,6 1994 41,4 41,3 45,3 67,2 59,1 56,1 59,0 87,0 66,9 59,9 43,8 36,8 55,3 1995 33,7 42,7 54,6 67,5 61,5 53,4 59,4 78,3 68,3 58,2 39,2 30,1 53,9 1996 40,1 42,0 57,9 62,9 67,8 47,8 51,7 73,7 67,6 52,6 39,5 36,5 53,3 1997 34,4 41,3 51,3 74,2 65,2 52,1 49,1 70,0 62,0 59,9 40,8 41,8 53,5 1998 35,7 46,7 59,6 60,6 59,5 48,5 48,4 70,4 63,3 57,2 44,2 36,1 52,5 1999 43,1 48,0 68,0 66,9 67,9 49,8 46,8 71,7 59,6 59,6 46,5 44,5 56,0 Prom 38,95 43,71 53,97 66,91 60,92 50,49 58,75 79,25 63,39 54,71 41,22 37,60
(Ríos,2012) Tabla 8: Hotel Granada: Estadísticos después
de quitarle la tendencia ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC
Promedio 38,95 43,71 53,97 66,91 60,92 50,49 58,75 79,25 63,39 54,71 41,22 37,60Desv. Estandar 4,86 4,22 8,08 7,52 6,96 5,40 10,99 6,82 5,26 6,64 4,85 4,65Mediana 40,17 42,64 52,85 67,06 60,98 49,91 55,68 79,27 62,27 55,68 40,12 36,92Coef‐ Variación 0,12 0,10 0,15 0,11 0,11 0,11 0,19 0,09 0,08 0,12 0,12 0,12Varianza 23,61 17,81 65,26 56,48 48,38 29,17 120,70 46,45 27,68 44,03 23,54 21,61
(Ríos,2012)

68
Tabla 9: Promedios móviles simples de doce términos a partir de la tabla 7
ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 1984 54,89 54,74 54,88 54,73 54,37 54,381985 52,65 52,37 52,14 51,94 51,79 51,68 51,36 50,92 50,47 50,40 49,88 49,431986 44,49 44,01 43,60 43,33 43,18 42,94 42,95 43,43 44,02 44,75 45,01 45,441987 52,79 53,60 54,28 54,96 55,60 55,95 56,50 56,73 57,45 57,55 58,48 58,951988 63,76 63,73 64,04 64,43 64,57 64,71 64,72 64,65 64,21 64,47 64,11 63,921989 61,02 60,99 60,42 60,35 60,24 60,22 59,98 59,83 59,47 59,40 59,25 59,221990 56,70 56,59 56,52 56,28 56,00 56,31 56,20 55,88 55,73 55,16 55,30 54,941991 52,91 52,84 52,90 52,83 52,80 52,32 52,42 52,60 52,65 53,00 52,81 52,611992 51,80 51,60 51,62 51,47 51,44 51,49 51,13 51,11 51,45 50,97 50,69 50,911993 51,47 51,53 51,59 51,64 51,61 51,59 51,98 51,95 51,46 51,73 51,95 52,301994 54,27 54,62 54,80 55,11 55,33 55,35 55,03 55,08 55,47 55,49 55,58 55,471995 54,78 54,42 54,48 54,41 54,22 53,94 54,20 54,17 54,31 54,12 54,38 54,151996 53,54 53,35 53,32 53,08 53,10 53,36 53,13 53,10 52,82 53,30 53,18 53,371997 53,34 53,19 52,95 53,26 53,32 53,54 53,60 53,82 54,17 53,60 53,36 53,211998 52,69 52,70 52,76 52,64 52,78 52,55 52,85 52,91 53,26 53,52 53,87 53,931999 55,61 55,67 55,51 55,61 55,71 56,06
(Ríos,2012) Tabla 10: Hotel Granada: promedios móviles corregidos por estacionalidad (Ríos,2012).
(Ríos,2012).
ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 1984 54,89 54,74 54,88 54,73 54,37 54,381985 52,65 52,37 52,14 51,94 51,79 51,68 51,36 50,92 50,47 50,40 49,88 49,431986 44,49 44,01 43,60 43,33 43,18 42,94 42,95 43,43 44,02 44,75 45,01 45,441987 52,79 53,60 54,28 54,96 55,60 55,95 56,50 56,73 57,45 57,55 58,48 58,951988 63,76 63,73 64,04 64,43 64,57 64,71 64,72 64,65 64,21 64,47 64,11 63,921989 61,02 60,99 60,42 60,35 60,24 60,22 59,98 59,83 59,47 59,40 59,25 59,221990 56,70 56,59 56,52 56,28 56,00 56,31 56,20 55,88 55,73 55,16 55,30 54,941991 52,91 52,84 52,90 52,83 52,80 52,32 52,42 52,60 52,65 53,00 52,81 52,611992 51,80 51,60 51,62 51,47 51,44 51,49 51,13 51,11 51,45 50,97 50,69 50,911993 51,47 51,53 51,59 51,64 51,61 51,59 51,98 51,95 51,46 51,73 51,95 52,301994 54,27 54,62 54,80 55,11 55,33 55,35 55,03 55,08 55,47 55,49 55,58 55,471995 54,78 54,42 54,48 54,41 54,22 53,94 54,20 54,17 54,31 54,12 54,38 54,151996 53,54 53,35 53,32 53,08 53,10 53,36 53,13 53,10 52,82 53,30 53,18 53,371997 53,34 53,19 52,95 53,26 53,32 53,54 53,60 53,82 54,17 53,60 53,36 53,211998 52,69 52,70 52,76 52,64 52,78 52,55 52,85 52,91 53,26 53,52 53,87 53,931999 55,61 55,67 55,51 55,61 55,71 56,06
PROMEDIOS 54,12 54,08 54,06 54,09 54,11 54,13 54,06 54,06 54,12 54,14 54,15 54,15

69
Tabla 11: Hotel Granada: Índices Estacionales de Habitabilidad
(Ríos,2012) Si ahora se comparan los promedios por mes de habitaciones con los ajustados
estacionalmente, se obtienen los valores indicados en la tabla 11.
Visualmente existen tres estaciones. Para escoger el comienzo y fin de cada
estación se dividen el rango de valores entre 3.
Rango de Valores=146,46 – 69,37=77,09. El intervalo de cada estación es: 25,67.
Luego las estaciones son:
Tabla 12: Estacionalidad del Hotel Granada
Ene Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic
Estación 1 1 2 2 2 1 2 3 2 2 1 1 Estación Corregida
1 1 2 2 2 2 3 3 3 3 1 1
(Ríos,2012)
El anterior cálculo determina que se deben tener en cuenta tres estaciones:
• Primera Estación: Noviembre-Febrero.
• Segunda Estación Marzo hasta Junio.
• Tercera Estación: Julio-Octubre.
Es importante tomar en cuenta, en este momento, la movilidad de algunas fechas
como el Carnaval, Semana Santa y la ocurrencia de fechas feriadas en los días viernes
o lunes que influyen en los resultados. Su efecto solo podría hallarse haciendo unas
estadísticas en donde se tomen en cuenta estos factores.
1 2 3 4 5 6 7 8 9 10 11 12
ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC
Promedio Tabla 8 38,9 43,7 53,9 66,9 60,9 50,4 58,7 79,2 63,3 54,7 41,2 37,6
Promedio Tabla 9 54,1 54,0 54,0 54,0 54,1 54,1 54,0 54,0 54,1 54,1 54,1 54,1
Índice 71,9 80,8 99,8 123,7 112,5 93,2 108,6 146,6 117,1 101,0 76,1 69,4 100,1
Índice Ajustado 71,90 80,74 99,73 123,59 112,47 93,18 108,56 146,46 117,01 100,94 76,04 69,37 100,00

70 5. Obtención de las Ecuaciones de Predicción
Para el análisis y obtención de las ecuaciones de predicción se utilizó el método
estadístico de regresión por etapas, conocido en inglés como Stepwise regression.
Consiste en obtener las ecuaciones sencillas de predicción utilizando una variable a la
vez. Obtener los factores de correlación R cuadrado para cada una de ellas. Arreglarlas
en orden decreciente de acuerdo al factor de R cuadrado y luego comenzando las
regresiones progresivas con aquella que tiene mayor R cuadrado e irle agregando el
resto de las variables hasta la última mas significante como veremos más adelante. Se
puede predecir que la mejor ecuación es aquella que tiene mayor factor F, sin embargo,
en esta investigación se generarán todas las ecuaciones significativas y con ellas se
harán las predicciones. Luego se cotejará cada predicción contra los valores y se
calculará el error medio cuadrático para escoger el mejor modelo y en ese momento se
escoge la mejor ecuación. Para tener clara la explicación dada en el capítulo II (página
44) se repite brevemente la explicación.
5.1 Modelo del promedios móviles (MA).
La notación MA(q) se refiere al modelo del promedio móvil de orden q.
Donde las θ1, …..θq son los parámetros del modelo, µ es el valor esperado de Xt (a menudo
supuesto igual cero), y los ξ son los términos del error o ruido blanco.
Utilizando el programa de computación EVIEWS® se obtuvieron todos los
modelos MA desde MA(1) hasta M(12). Como ejemplo se muestra la salida de los
resultados para el modelo MA(12) en la tabla 12. El gráfico 7 muestra la comparación
de los valores originales (que aquí tienen disminuido el efecto de tendencia) con los
valores calculados y los residuos generados.
Por ahora se van a resaltar los elementos más importantes de esta regresión.
Como puede verse la variable dependiente es HAB2 (valor de las habitaciones
rentadas, después de restar la tendencia), la constante toma el valor 54,59003 y ante
un incremento del promedio de HAB2t-12 {correspondiente a MA(12)} de una unidad, el
valor de HAB2 incrementada es 0.841160 de la diferencia entre el valor medido y el

71 promedio. La medidas de bondad de ajuste: R2 = 0.729542 y el estadístico t de la
variable HAB2t-12 (MA(12)) es 21,91214, lo que da una probabilidad de 0.0000 de que
dicha variable sea no significativa. Como puede verse, todas las variables tiene el signo
esperado y son significativas al 0,05% (valor escogido para hacer el cálculo). En este
caso no es tan es importante tomar en cuenta el R2 ajustado, sin embargo este
indicador es de mucha importancia en regresiones multivariadas, ya que se pueden
estar incluyendo algunas variables que no son relevantes y por lo tanto se pierden
grados de libertad. El test t nos indica que la variable es significativa con un 95% de
confianza.
Tabla 13. Hotel Granada. Modelo de Predicción tipo MA(12).
(Ríos,2012)
Grafico 7. Hotel Granada. Gráfico de Cotejamiento con el modelo MA(12). Ríos(2012)
5.2. Modelo autoregresivo (AR).

72
La notación AR(p) se refiere al modelo autoregresivo de orden p. El modelo se escribe
así:
Donde φ1, ……φp , son los parámetros del modelo, c es una constante y ξt es la constante del
error o ruido blanco. También se han construido los modelos autoregresivos AR, desde AR(1)
hasta el AR(12), pero no se muestran por ahorro de espacio, excepto la ecuación resultante .
Tanto los modelos de promedio móviles MA(p), para p=1 hasta 12 y los modelos
autoregresivos AR(q) para q=1 hasta 12, se muestran en la tabla 14. Al arreglar la tabla 14 en
orden de mayor a menor por la variable R cuadrado, se obtiene la tabla 15 que servirá para
decidir sobre la construcción de los modelos del Promedio Móvil Autoregresivo (ARMA). La
tabla 14 muestra los 24 modelos calculados junto con los parámetros de decisión. Cada modelo
se interpreta así, por ejemplo para el primer modelo AR(1). La ecuación es
Donde HAB2 significa el valor del número de habitaciones después de quitar la tendencia.
Las últimas tres columnas de la tabla 14, señalan el valor del estadístico t de la variable, el
estadístico F de la ecuación y la probabilidad de que la ecuación sea no significativa. Como se
ve en la tabla 14, solo 6 modelos sencillos se pueden utilizar como modelos de predicción.
5.3 Modelo del Promedio Autoregresivo de Media Móvil (ARMA).
La notación ARMA (p,q) se refiere al modelo con p términos autoregresivos y q términos
de promedios en movimiento. El modelo contiene los modelos AR(p) y MA(q).
Como se dijo anteriormente, se utilizará el análisis de regresión estadística por
etapas (Stepwise regression analysis) en donde se analiza desde el modelo más
sencillo con mas alto R cuadrado y se le van agregando las otras variables que le
siguen en otros valores de R cuadrado.

73
Tabla 14: Hotel Granada. Modelos sencillos de modelos autoregresivos y móviles Variable Intercepto Coeficiente R cuadrado Estadístico T Estadístico F Probabilidad AR(1) 54,29052 0,575051 0,337239 9,665309 93,41820 0.0 AR(2) 54,35561 0,117442 0,013832 1,623850 2,636889 0,106083 AR(3) 54,35345 ‐0,115791 0,013437 ‐1,595887 2,546856 0,112203 AR(4) 54,30492 ‐0,136269 0,018640 ‐1,879617 3,532961 0,061724 AR(5) 54,27152 ‐0,208820 0,043422 ‐2,897888 8,397756 0,004211 AR(6) 54,29333 ‐0,227067 0,051283 ‐3,153747 9,946123 0,001883 AR(7) 54,23027 ‐0,220430 0,048616 ‐3,0558004 9,351391 0,002562 AR(8) 54,06744 ‐0,151862 0,023641 ‐2,099230 4,406767 0,0372 AR(9) 53,99684 ‐0,124653 0,015926 ‐1,711533 2,929345 0,088696 AR(10) 54,00867 0,0078507 0,006287 1,067154 1,138817 0,287332 AR(11) 54,13961 0,501368 0,257957 7,888332 62,22577 0,0 AR(12) 54,59003 0,841160 0,729542 21,91214 480,1420 0.0 MA(1) 54,22206 0,552996 0,331250 9,129160 94,11210 0,0 MA(2) 54,202260 0,150529 0,018211 2,093808 3,524186 0,062012 MA(3) 54,26627 ‐0,2022695 0,024958 ‐2,850867 4,863405 0,028632 MA(4) 54,24259 ‐0,139573 0,020880 ‐1,938928 4,051872 0,045534 MA(5) 54,21777 ‐0,043617 0,043617 ‐3,162817 8,665145 0,003648 MA(6) 54,23705 ‐0,089038 0,019775 ‐1,221052 3,832976 0,051718 MA(7) 54,24031 ‐0,282672 0,055459 ‐4,029472 11,15589 0,001008 MA(8) 54,19484 ‐0,194718 0,033458 ‐2,724444 6,577028 0,011103 MA(9) 54,18841 ‐0,435245 0,068905 ‐6,700003 14,06076 0,000235 MA(10) 54,28622 0,134482 0,010904 1,840982 2,094630 0,149465 MA(11) 54,37496 0,644869 0,343340 11,50442 99,34322 0,0 MA(12) 54,38683 0,888958 0,570957 4580,337 252,8460 0,0
(Ríos,2012)
Tabla 15: Hotel Granada. Modelos sencillos de modelos autoregresivos y móviles arreglados por R cuadrado.
Variable Intercepto Coeficiente R cuadrado Estadístico T Estadístico F Probabilidad AR(12) 54,59003 0,841160 0,729542 21,91214 480,1420 0.0 MA(12) 54,38683 0,888958 0,570957 4580,337 252,8460 0,0 MA(11) 54,37496 0,644869 0,343340 11,50442 99,34322 0,0 AR(1) 54,29052 0,575051 0,337239 9,665309 93,41820 0.0 MA(1) 54,22206 0,552996 0,331250 9,129160 94,11210 0,0 AR(11) 54,13961 0,501368 0,257957 7,888332 62,22577 0,0 MA(9) 54,18841 ‐0,435245 0,068905 ‐6,700003 14,06076 0,000235 MA(7) 54,24031 ‐0,282672 0,055459 ‐4,029472 11,15589 0,001008 AR(6) 54,29333 ‐0,227067 0,051283 ‐3,153747 9,946123 0,001883 AR(7) 54,23027 ‐0,220430 0,048616 ‐3,0558004 9,351391 0,002562 MA(5) 54,21777 ‐0,043617 0,043617 ‐3,162817 8,665145 0,003648 AR(5) 54,27152 ‐0,208820 0,043422 ‐2,897888 8,397756 0,004211 MA(8) 54,19484 ‐0,194718 0,033458 ‐2,724444 6,577028 0,011103 MA(3) 54,26627 ‐0,2022695 0,024958 ‐2,850867 4,863405 0,028632 AR(8) 54,06744 ‐0,151862 0,023641 ‐2,099230 4,406767 0,0372 MA(4) 54,24259 ‐0,139573 0,020880 ‐1,938928 4,051872 0,045534 MA(6) 54,23705 ‐0,089038 0,019775 ‐1,221052 3,832976 0,051718 AR(4) 54,30492 ‐0,136269 0,018640 ‐1,879617 3,532961 0,061724 MA(2) 54,202260 0,150529 0,018211 2,093808 3,524186 0,062012 AR(9) 53,99684 ‐0,124653 0,015926 ‐1,711533 2,929345 0,088696 AR(2) 54,35561 0,117442 0,013832 1,623850 2,636889 0,106083 AR(3) 54,35345 ‐0,115791 0,013437 ‐1,595887 2,546856 0,112203 MA(10) 54,28622 0,134482 0,010904 1,840982 2,094630 0,149465 AR(10) 54,00867 0,0078507 0,006287 1,067154 1,138817 0,287332
(Ríos,2012) 5.3.1 Modelos de regresión estudiados.
Para encontrar cual es el modelo que mejor predice el comportamiento de la
habitabilidad del hotel se analizaron seis modelos deducidos a partir de la tabla 14 mas

74 tres modelos adicionales que fueron agregados después de analizar los resultados de
los primeros seis. Los resultados se encuentran en el ANEXO B, donde se muestra el
resultado de la regresión efectuada con el programa EVIEWS® y el gráfico
acompañante que muestra la predicción. Se muestran también para estos modelos el
análisis de comparación con los datos reales para el período Enero de 2000 hasta
Diciembre de 2004 usando EXCEL®. Al final de la comparación se muestra el cálculo
del error medio cuadrático para cada uno de los modelos, mediante la ecuación
Como ilustración se muestra aquí el primer modelo de regresión tomado de la
tabla 14 para AR(12). Los resultados se muestran en la tabla 16.
Nótese el alto valor de R cuadrado y del estadístico F. También el estadístico t y la
probabilidad cero de que este modelo no explique el problema. El modelo resultante es
Tabla 16. Hotel Granada. Modelo autoregresivo AR(12),
(Ríos,2012)
Para hacer la predicción se utilizó nuevamente la opción forescast de EVIEWS®
obteniendo los resultados que fueron grabados en un archivo especial para ello. Los
resultados se muestran en el ANEXO B. Utilizando la ecuación del error medio

75 cuadrático mostrada anteriormente se hizo el cálculo para efectos de comparación. Es
importante hacer notar que la herramienta EVIEWS® es útil, pues hacer el trabajo con
EXCEL® o a mano tendría mucho trabajo.
Para el resto de los modelos se procedió igual. Los resultados se muestran en la
tabla 17.
Tabla 17: Comparación de los resultados de los modelos de predicción. No Variables R2 Estadístico F Error Cuadrático 1 AR(12) 0,729 480,1 7,26 2 AR(12),MA(12) 0,759 278,5 8,37 3 AR(12), MA(12),MA(11) 0,753 179,3 6,80 4 AR(12), AR(1),MA(12), MA(11) 0,775 151,3 7,65 5 AR(12), AR(1),MA(12),MA(11),MA(1) 0,80 142,2 6,22 6 AR(12), AR(1), AR(11), MA(12),
MA(11), MA(1) 0,81 121,8 6,47
7 AR(12), MA(1), MA(11) 0,80 236,8 6,43 8 AR(12),MA(11) 0,75 269,3 7,06 9 AR(12),AR(1),MA(11) 0,77 201,6 7,26 (Ríos,2012)
Nótese que después del modelo 2, todos los modelos no incrementan
holgadamente el valor de R cuadrado. Comenzando con el modelo 1, se nota por el
valor del estadístico F que la variable AR(12) debe ser retenida en la ecuación
resultante, pues ningún otro modelo tiene valor más alto que el modelo 1. Al analizar los
primeros 6 modelos, se desecharon en cada uno de los modelos las variables en donde
la probabilidad de t fuera mayor que cero, surgiendo los modelos 7,8 y 9. De ellos se
escoge el modelo 7 debido a que produce menos error cuadrático con un buen valor de
F apropiado y es el menos complicado, por lo que se aconseja tomarlo como modelo
predictor.
En resumen el modelo predictor que se aconseja es el modelo 7, es decir el que
utiliza AR(12), MA(1), MA(11). La salida del modelo dada por el EVIEWS® se presenta
en la tabla 18, el gráfico de cotejo se muestra en la gráfica 8 y los pronósticos se dan
en la tabla 19.
Tabla 18. Resultados de EVIEWS® para el modelo 7

76
(Ríos,2012)
Gráfico 8: Hotel Granada : Cotejo del Modelo 7 (Ríos,2012)
Tabla 19. Pronósticos y Predicción para el Modelo 7

77
DATOS PRONOSTICADOS
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 49,0 58,9 71,7 73,3 69,7 53,6 54,1 72,4 65,6 64,3 53,6 50,32001 50,8 59,6 71,0 72,5 69,2 54,9 55,4 71,7 65,6 64,5 55,0 52,12002 52,5 60,4 70,5 71,8 68,9 56,2 56,6 71,1 65,7 64,7 56,3 53,72003 54,1 61,1 70,1 71,2 68,7 57,4 57,8 70,6 65,9 65,0 57,5 55,22004 55,6 61,8 69,8 70,8 68,6 58,5 58,9 70,3 66,1 65,3 58,7 56,6
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50 ERROR CUADRATICO: 6,43
(Ríos,2012)
La ecuación resultante es
HAB2(T) = C + C12 *AR(12) + B1*MA(1) + B11*MA(11))
donde AR(12), MA(1), MA(11) son los valores correspondientes de habitación
restándole el valor promedio 54,18881. Sin embargo, se debe tener en cuenta que
cuando se trabaja directamente con EVIEWS®, el programa coteja y predice
directamente.
5.4. Predicción con el Método Monte Carlo El método Monte Carlo es una técnica muy usada en la industria para hacer
predicciones. Existen una gran cantidad de paquetes para hacer uso de la técnica, de
los cuales los más nombrados son el Cristal Ball y el Risk. El Cristal Ball es un
programa de computadora sofisticado de predicción basado en una tabla EXCEL®,
mientras que el RISK es un programa construido por el Departamento de Energía de
Estados Unidos de América y puede ser bajado de la internet de la página de
www.netl.doe.gov . Sin embargo aunque el primero se adapta a la predicción deseada
en esta investigación, para su uso debe pagarse una cuota y no estuvo disponible en

78 este momento. Por otra parte el RISK es muy sencillo y solo permitiría hacer predecir
mes a mes y no en conjunto para un año como se desea aquí.
En vista de lo explicado en el párrafo anterior se decidió construir un modelo de
Monte Carlo en EXCEL® para los datos que se tenían. Así se copiaron los datos en
originales de historia en una página y a partir de ella se dedujeron la pendiente de los
datos y los valores de promedio y desviación estándar para cada mes. Una vez
obtenidos los anteriores datos se supuso que podrían tratarse como una serie de
distribución normal con media y desviación estándar a las encontradas. Se predijo por
el método de Monte Carlo para 50 casos y a partir de ellos se dedujeron los valores
máximo, mínimo y más probable de la predicción para los meses de Enero a Diciembre
del año siguiente a los datos (año 2000). Se hicieron dos grandes ejercicios, uno
primero suponiendo toda la historia y uno segundo suponiendo los últimos cinco años.
Como es lógico, donde existe una gran variación con el tiempo, el segundo caso tuvo
una predicción mejor con menos error medio cuadrático.
A continuación se presenta un resumen de los resultados de la predicción. En el
ANEXO C se presenta el trabajo EXCEL® efectuado.
Tabla 20: Resultados de la predicción para el año 2000 del Hotel Granada
ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC
Mínimo 38 46 57 72 71 57 62 84 76 63 47 37Máximo 41 49 65 85 77 63 65 85 78 67 50 46Mas Probable 50 59 79 80 79 60 53 79 70 72 61 59
Datos Reales 2000 53 61 69 80 72 62 52 70 68 72 62 55
DIFERENCIA -3 -2 10 0 7 -2 1 9 2 0 -1 4 Error Medio Cuadrático = 6,77
(Ríos,2012) 5.5. Predicción con el Método Delphi
El método Delphi es el más sencillo de elaborar y el menos costoso. Como se
explicó en el capítulo II, para efectuarlo se hace una reunión con las personas
involucradas, se les reparte los datos históricos tal como aparece en el ANEXO D y se
les pide que hagan una predicción de acuerdo a sus datos y a su criterio y experiencia.
Una vez recogida la información se comprueba que no haya incongruencias y se les

79 devuelve para empezar a analizar para obtener un consenso. Los resultados totales se
muestran en el Anexo D y el resumen en la tabla 21, sin embargo es muy importante el
uso posterior que se da a la información hallada y por ello daremos aquí algunos
detalles adicionales.
Tabla 21: Resultados del Método Delphi
(Ríos,2012)
El error cuadrático fue de 5,67, que fue menor que cualquiera de los otros dos
métodos. Los cinco gerentes empleados para hacer la predicción tenían distinta
experiencia y por lo tanto sus errores medios cuadráticos fueron: 11,10; 6,32; 5,77; 7,87
y 10,59. El análisis posterior de las predicciones parciales permite deducir cuales son
los meses difíciles de predicción y si la gerencia general del hotel lo considera
conveniente, cuáles son los gerentes que estuvieron mejores en sus predicciones, de
modo de pesar en las opiniones futuras de acuerdo a la experiencia ganada. Una última
cosa, el error medio cuadrático del consenso 5,67 fue menor que cualquiera de los
errores parciales de los gerentes, lo que indica la importancia de las reuniones
gerenciales para obtener estos resultados.
5.6. Método Espectral
En el anexo E se muestra en detalle los pasos para obtener la predicción
utilizando el método espectral. Se elaboró el ejercicio en EXCEL®, dando como
resultado un error medio cuadrático de 5,26. Sin embargo un segundo ejercicio se
efectuó utilizando la información de los últimos cinco años, resultando un error medio
cuadrático de 5,00
De la ecuación base mostrada a continuación
Con- sen- so
Ene
Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic
45 57 65 75 69 60 55 75 72 65 50 52 2000 Ene
Feb Mar Abr May Jun Jul Ago Sep Oct Nov Dic
53 61 69 80 72 62 52 70 68 72 62 55

80 HAB= [a + b T + c* sen (d+eT) + f*sen(g+hT) + j*sen(k+lT)]*F(I) Se dedujeron los valores en la tabla 21 Tabla 22: Resultados del Método Espectral para la Ecuación trisenoidal
a=52,8183 b=0,0585 c=0,9363 d=0,9565 e=0,4892 f=7,8444 g=-1,5307 h=0,5306 j=-4,5876 k=-0,7583 l=0,0889
f1=0,7919 f2= 0,8233 f3= 0,9465 f4= 1,1135 f5=1,0175 f6= 0,8798 f7=1,0627 f8=1,5120 f9=1,2912 f10=1,1761 f11= 0,9126 f12= 0,8089
(Ríos,2012) Esta ecuación muestra que los meses más difíciles de predecir para este hotel en
particular son Agosto (f8=1,5120) y Septiembre (f9=1,2912).
6. Comparación de los Resultados A continuación se presenta un resumen de los resultados:
Tabla 23: Comparación de los resultados de los Métodos de Predicción Método Error Medio Cuadrático Tiempo aproximado de
Análisis(días) Autoregresivo AR(12), MA(1), MA(11). 6,43 3-4 días
Método Monte Carlo 6,77 2 días
Método Delphi 5,67 1 día
Método Espectral 5.26 2 días
Como se nota el método que dio menos error cuadrático fue el método Espectral,
seguido por el Delphi. El autoregresivo con un error medio cuadrático de 6,43 puede
mejorar su predicción, si se le ponderan sus datos con valores altos en fechas
recientes. El método espectral puede hacerse en menos tiempo y como en el caso
mencionado de tomar la información más reciente se obtiene la predicción con menos
error medio cuadrático. En cuanto a los tiempos el método que consume menos tiempo
es el Delphi que lo hace el más práctico.

81 7. Lineamientos para efectuar el Análisis de Predicción.
En resumen, el procedimiento para efectuar la predicción depende del tiempo que
se dispone para hacerlo. Se recomienda efectuar el análisis Delphi rutinariamente a
discreción de la Gerencia General, llevando control de las opiniones de los gerentes
para después establecer pesos de acuerdo a su certeza y así obtener mejores
resultados. Los análisis Monte Carlo, Autoregresivo y Espectral se pueden hacer cada
mes, mostrándolo a los gerentes involucrados para que estos adquieran más
experiencia. El personal del departamento de recepción del hotel debe ser diestro en el
análisis de datos y estar pendiente de los siguientes procesos (Antunez, 2012):
Visualizar el tipo de serie que se le presenta.
Una muestra adecuada tiene por lo menos cuarenta datos (T>40). ¿Luce la serie
como una estacionaria débil que tanto la media y la varianza de los datos analizados
sea constante en el tiempo? Si no se está seguro proceda a hacer un análisis de
estacionalidad.
identifique la estacionalidad.
Una de las formas de identificar la estacionalidad es mediante el grafico de barras,
líneas apiladas, líneas separadas y correlograma.
a) Gráficos de Barras: En esta parte del análisis se deben observar los picos de la
serie, que son descritas por la grafica y si estos picos se repiten en los meses o años
posteriores podemos decir que existen pruebas de estacionalidad.
b) Líneas Apiladas (Seasonal Stacked Line): Ahora interesa examinar el
comportamiento trimestral, bimestral, semestral o mensual según sea el caso, para lo
cual se hace uso de histogramas, este debe presentar un comportamiento diferente en
los siguientes periodos para que se diga que existe estacionalidad en la serie.
c) Líneas Separadas: Ahora interesa observar el comportamiento de cada mes,
trimestre o bimestre según sea el caso. Si dicho comportamiento en la variable es
diferente podemos decir que existe estacionalidad en dicha serie.
d) Correlograma: La función de autocorrelación es dar una medida de la correlación
que existe entre las observaciones continuas.

82 e) Función de Autocorrelación Simple (AC): Estos coeficientes presentan una
medida entre observaciones de series separadas por k períodos en el tiempo. En la
práctica solo se tienen muestras por lo que solo se puede calcular la función de
autocorrelación muestral (pk).
f) Función de Autocorrelación Parcial(PAC): Esta función mide la correlación que
existe entre Xt y Xt-k quitando los efectos Xt_x, Xt-2, ...Xt-k-1 que son las observaciones
intermedias entre los períodos de separación. Un correlograma está formado por dos
columnas, una de ellas está referida a la autocorrelación simple y la otra a la
autocorrelación parcial.
Ajuste Estacional
EViews® tiene incorporado relacionales y factores estacionales, en los siguientes
puntos.
a) Generate by Equation(Generar por ecuación): Aun que este no es un filtro de
estacionalidad, se dirá que esta opción pide una serie para usar en la
actualización de las series seleccionadas.
b) Seasonal Adjustment (Ajuste estacional): Esta opción crea una serie de ajuste
estacional. Usa cuatro métodos que son: La razón con el promedio móvil y
diferencia del promedio móvil, el método multiplicativo X-11, el método aditivo X-
11 y el Census X-12.
c) Exponential Smoothing (Suavizacion Exponencial): Este Filtro crea una seria
que ha sido suavizada. En EViews® se puede encontrar formas simple y dobles de
suavización exponencial.
Promedio Movil La relación de promedio móvil se calcula anual (12 meses), Semestral (6 meses), o
Trimestral (3 meses). Para el cálculo del índice de estacionalidad, se calcula entre el
promedio del ratio móvil para meses, trimestre o semestres.
Descomposición de la serie de tiempo.
Toda serie de tiempo se puede descomponer en, al menos, 3 elementos:
Estacionalidad, Tendencia y Ciclo.

83 a) Estacionalidad: Es un componente que se repite siempre en intervalos de tiempo
similares. Como mencionan muchos autores la estacionalidad se debe a razones
estacionales (invierno, verano, otoño y primavera), factores institucionales o legales
(gratificación de julio y diciembre), costumbres, etc. Por lo general esta estacionalidad
no puede ir más allá de los 12 meses del año, sin embargo hay caso donde el período
es mayor.
b) Tendencia: Es un componente que refleja el comportamiento de mediano y largo
plazo de la variable. Los factores que explican la tendencia de la serie de tiempo son
aquellas variables importantes y relevantes que inciden de manera significativa en la
serie de tiempo. Existen dos tipos de tendencia: estocástica y determinística. La
tendencia es aleatoria o estocástica cuando la pendiente de la misma cambia en el
tiempo. Y será determinística cuando la pendiente de la serie no varía.
c) Ciclo: El ciclo muestra el comportamiento de corto plazo de la serie de
tiempo, lo que dependerá de los factores no estructurales que se pueden presentar en
el mercado. En la práctica existen dos tipos de ciclo:
• Regular cuyo comportamiento es uniforme y moderado, por lo que se
puede predecir.
• Irregular cuyo comportamiento es totalmente errático e impredecible, por
lo que es difícil de estimarlo.
Modelo ARMA(p,q)
El proceso ARMA combina las propiedades de los procesos autorregresivos y los
de media móvil, por lo que se espera que este proceso sea muy flexible y que puedan
representar un gran número de series temporales.
Siguiendo con la metodología Box-Jenkins, se debe estimar el modelo, que tiene
como objetivo hallar un vector de parámetros de autoregresivos y el vector de
parámetros de media móvil, que minimice la suma de cuadrados de los errores del
modelo.
Validación del Modelo: Si el modelo supera las dos primeras etapas, se pasa a analizar
la validación y si ésta es superada entonces se está en condiciones de predecir los
valores futuros.

84 Análisis de Estabilidad
Un punto muy importante es el análisis de los coeficientes, para examinar si se
cumple las condiciones de estacionalidad.
Otro punto a tener en cuenta es la significancia de los coeficientes del modelo
ARMA, la matriz de correlaciones para evitar problemas de correlación y el análisis de
estabilidad para analizar la estabilidad de los coeficientes.
Significancia de los coeficientes
En esta sección se analizan los coeficientes del modelo ARMA para muestras
grandes, basándose en la prueba t-Student. Se analizan cada coeficiente para ver si es
relevante para el modelo.
Matriz de correlaciones Se analiza la matriz de correlaciones, con el objetivo de detectar si existe
problema de multicolinealidad. Si la correlación entre dos coeficientes es muy próxima a
0.9 o mayor al R-cuadrado entonces se tiene indicio que existe un problema de
multicolinealidad y si esto ocurre, los coeficientes son muy inestables.
Para evitar este problema serie conveniente eliminar algunos coeficientes no
significativos, para conseguir estabilidad en los parámetros aun a costa de un grado de
ajuste mejor.
Predicción del Modelo
Si el modelo supera las dos primeras etapas, se pasa a efectuar la validación
y si esta es superada entonces se puede efectuar la predicción. Los pronósticos
pueden ser de dos formas; puntuales o por intervalos. Para el primer caso se hace uso
de un modelo ajustado en forma explícita, mientras que para el segundo paso se
agrega un valor t para la significancia estadística (grado de confianza) al cual se quiere
trabajar. Y se recomienda graficar los datos reales como los datos proyectados, para de
esta manera observar el grado de ajuste de las proyecciones realizadas. Para el AR (p)
esto implica utilizar el pronóstico puntual anterior y para la parte MA (q) la esperanza
matemática de los errores.

85 Criterios para evaluar la predicción|
Raíz del error cuadrático medio (RECM) La pérdida asociada con un error aumenta en proporción con el cuadrado del
error. Mientras menor sea el error cuadrático medio mejor es el modelo de
predicción.

86
CONCLUSIONES
Con base a la investigación efectuada se concluye lo siguiente:
1. Se identificaron cuatro métodos de predicción de la tendencia: la lineal, la
exponencial, la exponencial modificada y la polinomial. Para los datos del hotel en
investigación se encontró que la tendencia lineal era la que mas se adaptaba.
2. Se identificó la metodología para analizar la estacionalidad de la llegada de
huéspedes a un hotel. Para el hotel en estudio se identificaron tres estaciones
(Noviembre-Febrero), (Marzo-Junio)(Julio-Octubre).
3. se identificaron varios métodos para la predicción de llegada de huéspedes a un
hotel. Para el hotel en referencia se analizaron los datos con cuatro métodos:
autoregresivo, Monte Carlo, Delphi y Espectral.
3. En el hotel utilizado en esta investigación, los resultados obtenidos fueron:
Método Error Medio Cuadrático Modelo autoregresivo AR(12), MA(1), MA(11). 6,43
Método Monte Carlo 6.77
Método Delphi 5.67
Método Espectral 5,26
Obteniendo el modelo espectral el menor error medio cuadrático. Sin embargo es
muy posible que si se ponderan los datos en tiempo se pueda obtener una mejor
predicción en todos los métodos.
4. El método más rápido de ejecutar y el que más se adapta a una gerencia de
hotel es el Delphi. Sin embargo, su precisión depende de la experiencia de las
personas involucradas en su uso.
5. El método Espectral demuestra que el mes de mas incertidumbre y difícil de
predecir en el hotel en estudio es Agosto.

87
6. Es factible hacer una predicción razonable de la llegada de huéspedes a un
hotel basado en la información histórica que se tenga, siempre que esta sea
suficiente en tamaño de acuerdo al método que se utilice. En general los datos
deben ser más de 32.
7. Se cuentan con herramientas para efectuar las predicciones a un costo y tiempo
razonable.
8. El paquete de computadora Eviews® es una herramienta muy buena para
efectuar predicciones de eventos que dependen del tiempo y de otros procesos
estadísticos.

86
CONCLUSIONES
Con base a la investigación efectuada se concluye lo siguiente:
1. Se identificaron cuatro métodos de predicción de la tendencia: la lineal, la
exponencial, la exponencial modificada y la polinomial. Para los datos del hotel en
investigación se encontró que la tendencia lineal era la que mas se adaptaba.
2. Se identificó la metodología para analizar la estacionalidad de la llegada de
huéspedes a un hotel. Para el hotel en estudio se identificaron tres estaciones
(Noviembre-Febrero), (Marzo-Junio)(Julio-Octubre).
3. se identificaron varios métodos para la predicción de llegada de huéspedes a un
hotel. Para el hotel en referencia se analizaron los datos con cuatro métodos:
autoregresivo, Monte Carlo, Delphi y Espectral.
3. En el hotel utilizado en esta investigación, los resultados obtenidos fueron:
Método Error Medio Cuadrático Modelo autoregresivo AR(12), MA(1), MA(11). 6,43
Método Monte Carlo 6.77
Método Delphi 5.67
Método Espectral 5,26
Obteniendo el modelo espectral el menor error medio cuadrático. Sin embargo es
muy posible que si se ponderan los datos en tiempo se pueda obtener una mejor
predicción en todos los métodos.
4. El método más rápido de ejecutar y el que más se adapta a una gerencia de
hotel es el Delphi. Sin embargo, su precisión depende de la experiencia de las
personas involucradas en su uso.
5. El método Espectral demuestra que el mes de mas incertidumbre y difícil de
predecir en el hotel en estudio es Agosto.

87
6. Es factible hacer una predicción razonable de la llegada de huéspedes a un
hotel basado en la información histórica que se tenga, siempre que esta sea
suficiente en tamaño de acuerdo al método que se utilice. En general los datos
deben ser más de 32.
7. Se cuentan con herramientas para efectuar las predicciones a un costo y tiempo
razonable.
8. El paquete de computadora Eviews® es una herramienta muy buena para
efectuar predicciones de eventos que dependen del tiempo y de otros procesos
estadísticos.

89
REFERENCIAS BIBLIOGRÁFICAS
Andrew W., Cranage, D., Lee C: “Forecasting Hotel occupancy rates with times series models: an empirical analysis”. Hospitality Research Journal. 14, 173-181. (1990) Antunez, César: “Análisis de Series de Tiempo”. Bajado de internet el dia 05-02-12. Astigarraga, E. : “El Método Delphi”, Universidad de Deusto. Bajado de internet el 05-02-2012. Banco Central de Venezuela (2009): “Informe para el año 2008” Ben Ghalia, M, Wang P, “Intelligent system to support judgment business forecasting. The case of estimating hotel room demand” IEEE transaction on fuzzy system. August 2000. Bogo, H: “Planeamiento, Mercados y Precios”. Ediciones Macchi Lòpez. 1975 Box G.E.P y Jenkins G M : “Time series Analysis, Forecasting and Control”. Holden-Day, San Francisco, Rev Ed. 1976 Carrillo L; Rincón Y; Iazzetta E; Batlle F:“Referentes Metodológicos para la Elaboración del Trabajo Especial de Grado”, (2011) FACES, Universidad del Zulia. Chow W.S., Shyu, J.C., Wang,K.C. : “Developing a forecast system for hotel occupancy rate using integrated ARIMA models”. Journal of International Hospitality, Leisure Tourism Management 1, 50-80. (1998) Constitución de la República Bolivariana de Venezuela. Gaceta Oficial Extraordinaria de la República Bolivariana de Venezuela. Número 5.453. Caracas, 24 de marzo de 2000. Decreto con Rango, Valor y Fuerza de Ley Orgánica de Turismo. Gaceta Oficial Extraordinaria de la República Bolivariana de Venezuela Número 5.889. Caracas, 31 de julio de 2008.

90
Decreto con Fuerza de Ley Orgánica de Planificación. Gaceta Oficial Extraordinaria de la República Bolivariana de Venezuela. Número 5.554. Caracas, 13 de noviembre 2001. Firmenich, Ernesto : “Metodología para la construcción de escenarios”. Bajado de internet el día 05-12-2011. Gray William y Liguori: “Hoteles y Moteles administración y funcionamiento”, (2007) Editorial Trillas, Reimpresión. Hanke, Jhon y Reitsh Arthur: “Pronósticos en los Negocios”, (1996) Prentice Hall Hispanoamérica. Haensel D y Koole G.: “Booking Horizon Forecasting with Dinamic Updating: A Case Study in Hotel Reservation Data”, 2010 (Bajado de internet el 20-10-11) Hoekstra M.: “Hotel Booking by means of Fuzzy Logic prediction”, BMI paper. September 2010. Holt Charles C (1957): Referido en “Forecasting trends and seasonal by exponential weghted averages”, International Journal of Forecasting 20 (1) Marzo 2004. Hunter (1986): referido por NIST/SEMATECH e-Handbook of Statistical methods. National Institute of Standard and Technology, 2004 Marrero, Gustavo: “Breve introducción al manejo del Eviews”. Universidad Complutense de Madrid. Bajado de internet el día 8-02-2012. Maza Zabala D. (2010): Artículos en la Revista Zeta, Revista Venezolana. Martinez-de-Pisón F.J., Escribano R., Fernández R., Pérez José: “An application of soft computing for a hotel decision support system“, Universidad de la Rioja, España, (2009) Morillas Raya, A. (2006) Introducción al análisis de datos difusos. Edición electrónica. Texto completo en Referencia del escrito sobre métodos difusos (decirlo en la tesis) www.eumed.net/libros/2006b/amr/ Organización Mundial del Turismo (2008), Compendio Estadístico de la Organización Mundial del Turismo (OMT). Informe Anual.

91
Organización Mundial de Turismo (OMT). (1999). TURISMO: PANORAMA 2020. Madrid, España. Ostle Bernard: “Estadística Aplicada”, Editorial Limusa-Wiley, 1968 Pfeifer, P Bodily S., “A test of Soacetime ARMA modeling and forecasting of hotel data. Journal of Forecasting 9, 255-272, (1990) Plan Estratégico Nacional de Turismo (PENT) 2009-2013. (2008) Ministerio del Poder Popular para el Turismo. Polt, S : “Forecasting is difficult, especially if it is refers to the future”. In presentation at the Reservation and Yield management Study Group Annual Meeting,(1987) Melbourne, Australia. Proyecto Nacional Simón Bolívar Primer Plan Socialista -PPS- 2007- 2013. Raiffa H.: “Decision Analysis Introductory Lectures on Choices under Uncertainty”. Addison Wesley Series, Segunda Impresión, Julio 1970; pag 239 Rajopadhye, M, Ben Ghalia, M, Wang P.P., Baker, T., Eister C.V. : “Forecasting uncertain hotel room demand”. Information Sciences 132, 1-11 (2001) Reglamento Orgánico del Ministerio del Poder Popular para el Turismo. Gaceta Oficial de la República Bolivariana de Venezuela. Número 38.481. Caracas, 18 de julio de 2006. Rios, Eduardo E: “Curso de Estadística Aplicada”, 1997, CIED. Roberts S (1959): referido por NIST/SEMATECH e-Handbook of Statistical Methods. National Institute of Standard y Technology (2004) Sabino Carlos A: “Como hacer una tesis”, Editorial Panapo, 1994. Schwartz Z. y Cohen E: “Subjective Estimates of Occupancy Forecast Uncertainty by Hotel Revenue Managers”, Journal of Travel and Tourism Marketing”, (2008),pag 59-66,

92
Stergiou Ch y Dimitro S: “Neural Network”, encontrado el 12-10-11 en GOOGLE. Weatherford, L.R., Kimes, S.E.: “A comparison of forecasting methods for hotel revenue management”. International Journal of Forecasting 99(19), 401-415. January 2003 Yuksel, S: “An integrated forecasting approach to hotel demand”. Mathematical and Computing Model (2007) Zhakary A; Atiya A, El Shishiny H; Gayar N: Forecasting Hotel Arrival Using Monte Carlo Simulation”-(2009) Cairo University, Giza, Egypt. Zhahary A, El Gayar N., Atiya A.F.: “A comparative study of the pick up method and its variations using a simulated hotel reservation data “. ICGST International Journal of Artificial Intelligence and Machine Learning 8, 15-21 (2008)

ANEXO A CONCEPTOS BÁSICOS DE ESTADÍSTICA
Este anexo presenta los conceptos básicos estadísticos que se utilizarán en esta
investigación. La estadística como ciencia permite abordar los estudios de fenómenos
que ocurren bajo las leyes de la incertidumbre o azar. El azar induce al comportamiento
caprichoso imposibilitando la predicción con exactitud de los resultados de la siguiente
prueba u observación del fenómeno en estudio. La característica predominante en los
hechos estudiados por la estadística es la variación entre las mediciones recopiladas
que se puede deber a causas asignables o a causas aleatorias.
La discriminación de la variabilidad es una de las grandes aplicaciones de la
estadística, cuyo objetivo es determinar el efecto que pueden tener los valores
estudiados por el investigador. La reducción de la dispersión en los valores, producida
por las causas asignables hace posible obtener mediciones con alto grado de
uniformidad, con mayor calidad y con una mayor probabilidad de predecir los siguientes
resultados.
1. Concepto de Estadística. Es la ciencia que utiliza los métodos científicos para recolectar, organizar, resumir,
analizar y presentar datos numéricos relativos a un conjunto de observaciones
efectuadas a individuos o cosas con el fin de extraer conclusiones válidas para efectuar
decisiones lógicas.
Los métodos estadísticos se agrupan en dos categorías: la estadística descriptiva
que es aquella que se utiliza para la recolección, organización, interpretación y
representación gráfica de la información, mientras que la estadística inductiva es la que
se utiliza para inferir el comportamiento de un fenómeno en la población, a partir de la
información contenida en una muestra extraída de esa población.
2. Elementos Estadísticos Importantes. Los elementos estadísticos más importantes son: la población, la muestra, la
muestra aleatoria, la medición, la distribución.
2.1. Población (N). Una población representa la totalidad de datos de un conjunto, finito o infinito, que
resultan al observar o realizar un experimento o fenómeno.

2.2. Muestra (n). Es un subconjunto de la población, extraída con el fin de investigar las
propiedades o características de la población de donde procede.
2.3. Muestra Aleatoria. Una muestra aleatoria es aquella obtenida de tal forma que cada observación en
la población tiene igual probabilidad de ser seleccionada para pasar a formar parte de la
muestra.
2.4 Medición. Se entiende por medición el proceso de asignación de valores a elementos u
objetos para representar o cuantificar una o más propiedades del objeto. Se distinguen
cuatro tipos de mediciones: a escala nominal, a escala ordinal, a escala de intervalo y a
escala de razón:
2.4.1. Escala Nominal Consiste en la asignación arbitraria de números o símbolos a cada una de las
diferentes categorías en las cuales puede dividirse la variable o factor en estudio.
Ejemplo: Los números que se le colocan a las habitaciones en los hoteles.
2.4.2. Escala Ordinal. Además de la asignación de números es posible establecer un orden que puede
ser mayor que, menor que. Ejemplo: número de habitaciones ocupadas en un hotel.
2.4.3. Escala de Intervalo. Además de las características de la escala ordinal, la asignación numérica se
realiza dentro de un intervalo. El valor cero es arbitrario y no refleja ausencia de la
variable. Permite comparar las diferencias entre pares de elementos u observaciones.
Ejemplos: Temperatura, coeficiente de inteligencia.
2.4.4. Escala de Razón. Es la escala en donde no existe un cero único. Es decir, el valor cero representa
ausencia de la magnitud que se está midiendo.
2.5. Distribución de Frecuencias. Cuando se dispone de una gran cantidad de mediciones es conveniente
clasificarlas en porciones llamadas clases con sus correspondientes frecuencias. En la
distribución de frecuencias se reconocen varios componentes.

2.5.1. Clases. Intervalos en los cuales queda dividida la máxima amplitud encontrada en las
observaciones. La amplitud de clase cuando es la misma para todos se denota por I.
2.5.2. Frecuencia Absoluta. Número de observaciones incluida en cada clase. Se denota por fi
2.5.3. Marcas de clase. Es el promedio de los límites de cada clase. Se denota por mi.
2.5.4. Frecuencia Relativa. Es la proporción de observaciones que se incluyen en cada clase. Se denota por
fr.
2.5.5. Frecuencia Acumulada. Representa la suma de las frecuencias absolutas hasta la clase considerada. Se
denota por Fa.
2.5.6. Frecuencia Relativa Acumulada. Es la suma de las frecuencias relativas hasta la clase considerada. Se denota por
Fra.
2.6. Representación Gráfica de las distribuciones. La distribución de las observaciones se visualiza mejor mediante la representación
gráfica. Los tipos de representaciones gráficas más utilizadas son: histogramas,
polígonos y ojivas.
2.6.1. Histogramas. Es un diagrama en el que las frecuencias se representan con el área de un
rectángulo. La base del rectángulo es la amplitud de cada clase y se coloca sobre el eje
de las abscisas. La altura representa la frecuencia absoluta o la frecuencia relativa y se
coloca sobre el eje de las ordenadas.
2.6.2. Polígono Es un gráfico que se obtiene al unir mediante una poligonal las ordenadas de las
marcas de clase en el diagrama de frecuencias
2.6.3. Ojiva: Se obtiene al unir en el plano cartesiano los puntos que generan el par ordenado
cuyo primer componente es el límite inferior de cada clase y de segundo componente la
frecuencia acumulada hasta dicha clase.

3. Medidas de Tendencia Central: El análisis de los datos se efectúa estableciendo la distribución estadística que
explica mejor el comportamiento de los datos. Para ello un primer paso es establecer la
tendencia central que estos datos tienen cuya descripción se efectúa a través del
cálculo de los promedios. Los promedios calculados pueden ser matemáticos (media
aritmética, geométrica y armónica) o no matemáticos (mediana, moda y cuartiles).
3.1. Promedios Matemáticos 3.1.1. Media Aritmética.
Es el número que resulta de dividir la suma de los valores de la variable entre el
número de ellos. Para datos no agrupados la fórmula es:
n
xx
n
ii∑
= =−
1
dónde xi son las n mediciones de la variable en estudio.
Para datos agrupados, la fórmula es:
∑
∑=
=
=−
n
ii
n
iii
f
xfx
1
1
dónde fi , xi representan la frecuencia absoluta y el valor de los diversos elementos,
respectivamente, y n el número de datos agrupados.
3.1.2. Media Geométrica. La media geométrica es la raíz enésima del producto de n observaciones. Se
denota con la letra G. La media geométrica no puede obtenerse si alguna de las
observaciones es igual a cero.
Pata datos agrupados, se utiliza la fórmula:
nnxxxxG ...... 321=
dónde las xi son las observaciones de la variable en estudio.
En forma logarítmica:

∑= ixn
G log1 log
3.1.3. Media Armónica. La media armónica de una serie de mediciones es el recíproco de la media
aritmética de sus recíprocos. Se denota con la letra H.
Para datos agrupados se utiliza la fórmula:
n
xH
n
i∑ ⎥
⎦
⎤⎢⎣
⎡
= 1
1
1
3.2. Promedios no Matemáticos. Algunas veces no es conveniente reportar los promedios matemáticos por ser
inapropiados, como por ejemplo, cuando su valor no se encuentra entre los datos
observados. En estos casos es mejor utilizar los promedios no matemáticos, tales como
la mediana o la moda.
3.2.1. Mediana. La mediana es el valor que ocupa la posición intermedia en las observaciones
cuando estas están ordenadas. Es decir, es el valor de la observación en donde existe
el mismo número de observaciones por encima y por debajo de ella. Se denota por Md.
Si existe un número impar de datos el valor de la observación que ocupa la
posición (n+1)/2 es la mediana, mientras que si existe un número par de observaciones,
la mediana se calcula tomando el promedio de los valores que ocupan las posiciones
n/2 y n/2+1.
3.2.2. Moda. La moda es el valor de la serie que más se repite. Se denota con Mo.
3.3. Medidas de Dispersión. Adicional a las medidas de tendencia central, es necesario describir la posición de
los diversos valores con respecto al punto central. Tal descripción se hace por medio de
los parámetros estadísticos de dispersión tales como el rango, la desviación media, la
varianza y la desviación típica.

3.3.1. Rango. Es la diferencia entre el mayor y el menor valor de las observaciones. El rango es
igual a
R = Vmáximo - Vmínimo
Tiene la desventaja de que en su cálculo solo intervienen dos observaciones. Si
tales valores constituyen valores extremos, el rango reflejaría una dispersión engañosa.
3.3.2. Desviación Media. Es el promedio de los valores absolutos de las desviaciones de las observaciones
con respecto a una medida de posición (por lo general, la mediana). Se utiliza cuando
se tienen un número reducido de datos. 3.3.3. Varianza.
La varianza de un conjunto de datos o mediciones xi se define como la suma de
los cuadrados de las observaciones como respecto a la media, dividida por (n-1). Se
denota por S2.
Se calcula por la fórmula:
1
)( 2
12
−
−
=∑=
−
n
xxS
n
ii
3.3.4. Desviación Típica. La desviación típica es la raíz cuadrada de la varianza. Se denota por la letra S.
2SS =
3.3.5. Coeficiente de Variación. Este coeficiente es una medida de dispersión relativa, que permite presentar la
desviación típica como un porcentaje de la media de la distribución. Se denota por la
letra V y se calcula por la fórmula.
−=x
SV
Puede notarse que el coeficiente de variación es adimensional, es decir no posee
unidades de medidas y por lo tanto se puede emplear en la comparación de series de
diferentes unidades.

3.3.6. Asimetría. El coeficiente de asimetría de una distribución de datos. Es la medida utilizada
para describir la forma en que se hallan repartidas las frecuencias correspondientes.
Una distribución es simétrica, si existe un valor central que la divide en dos porciones
iguales y en el cual coinciden los demás promedios.
Una distribución asimétrica puede ser negativa o positiva dependiendo si la
mayoría de las observaciones están a la izquierda o derecha del punto central.
4. Experimentos. La obtención de resultados de experimentos está asociada a la posibilidad de que
determinado hecho ocurra o no. Esta posibilidad se analiza mediante los conceptos de
probabilidad y de sus conceptos asociados de experimento aleatorio, espacio muestral,
evento o suceso y sus propiedades.
4.1. Experimento Aleatorio. Se dice que un experimento es aleatorio cuando manteniendo las mismas
condiciones, es imposible predecir con certeza sus resultados.
4.2. Espacio Muestral. Es el conjunto formado por todos los resultados obtenidos al realizar un
experimento aleatorio. Se representa por la letra S.
4.3. Evento o Suceso. Es cualquier subconjunto del espacio muestral. Puede ser simple o compuesto. El
evento simple no admite descomposición en otros eventos. Se representa por la letra E.
4.4. Eventos Mutuamente Excluyentes. Se dice que dos eventos son mutuamente excluyentes en un experimento
aleatorio cuando no pueden ocurrir simultáneamente.
4.5. Evento Unión.
Dados los eventos E1 y E2, el evento unión denotado por E1 ∪ E2, es el conjunto que
incluye los eventos elementales de E1 y E2 incluyendo los eventos elementales
comunes de ambos.

4.6. Evento Intersección.
Dados los eventos E1 y E2, el evento intersección, denotado por (E1 ∩ E2) es el
conjunto que incluye los sucesos elementales comunes a E1 y E2.
4.7. Eventos Complementarios. Los eventos E1 y E2 son complementarios en el espacio muestral S, si uno
contiene los elementos que le faltan al segundo para ser igual a S. La intersección de
E1 y E2 es nula y por lo tanto son mutuamente excluyentes.
5. Probabilidad. La probabilidad de un evento E asociado a un espacio muestral S, denotado por
P(E) es el cociente entre el número de casos favorables (m) y el número de casos
posibles (n) del experimento, siempre y cuando todos los eventos elementales tengan
igual oportunidad de ocurrir.
P(E) = m/n
La probabilidad real del evento se obtiene cuando n tiende a infinito. Existen
varios tipos de probabilidad.
5.1. Probabilidad Conjunta. Dados dos eventos de S, que no son mutuamente excluyentes, la probabilidad
conjunta es la medida de la probabilidad de ocurrencia simultánea de dichos eventos.
Se denota por:
P(E1∩ E2)
5.2. Probabilidad Condicional. Dados dos eventos de S, E1 y E2, la probabilidad condicional de E1 dado que ya
sucedió E2 está dada por:
( ))(
)(/2
2121 EP
EEPEEP ∩=
Sí P(E2) >0.
5.3. Ocurrencia Simultánea. Dado dos eventos de S, E1 y E2, la probabilidad de que ocurran simultáneamente
es igual a la multiplicación de la probabilidad de ocurrencia de uno de los eventos por la

probabilidad de ocurrencia condicional del segundo evento dado que el primer suceso
ya ocurrió. Se escribe así:
( ) ( ) ( )12121 /. EEPEPEEP =∩
5.4. Eventos Independientes. Dos eventos son independientes si la ocurrencia de uno de ellos no influye en la
ocurrencia del otro. Cuando esto ocurre, entonces:
.. ( ) ( ) ( )2121 * EPEPEEP =∩
6. Distribuciones y Funciones Se ha dicho que la población está formada por todos los elementos acerca de los
cuales se van a obtener conclusiones. Frecuentemente es imposible o al menos
impráctico, tomar medidas de toda la población. En tales casos, se toman las medidas a
una muestra escogida de la población al azar para obtener conclusiones de toda la
población.
Para obtener una buena generalización de la población, se selecciona una
muestra al azar, esto es, la muestra se escoge de manera que cada individuo en la
población tiene igual oportunidad de ser seleccionado en la muestra.
Para representar matemáticamente el fenómeno estudiado, las observaciones son
analizados por medios de expresiones llamadas distribuciones y funciones. Las
distribuciones y funciones están basadas en las características de las variables
involucradas.
6.1. Variable Aleatoria Dado un experimento aleatorio con su correspondiente espacio muestral S, se
llama variable aleatoria a la función que asigna a los eventos de S un número real. Las
variables aleatorias se designan con las últimas letras latinas X, Y, Z. Los valores de las
variables aleatorias se designan con las mismas letras pero en minúscula. (x, y, z). Las
variables aleatorias pueden ser discretas o continuas.
6.2. Variable Aleatoria Discreta. Las variables aleatorias son discretas cuando los valores de los experimentos se
expresan por valores enteros. Ejemplo: El número de huéspedes que llegan a un hotel.

6.3. Variable Aleatoria Continua. Cuando los valores pueden tener un valor cualquiera en un intervalo determinado.
Ejemplos: Valores de los índices de fluidez de un líquido.
6.4. Distribución de Probabilidad. Dada una variable aleatoria discreta X asociada a una probabilidad de ocurrencia
P(X=x), la distribución de x muestra las frecuencias relativas de la manera como todos
los valores de x pueden ocurrir. La distribución de probabilidad puede ser visualizada
en términos de una curva f(x), la cual puede ser aproximada por la curva de un
histograma de frecuencia relativa, hecha con rectángulos que tienen un ancho de una
unidad.
Las dos características principales de la distribución de probabilidad:
1. P(X=x) >=0 2. Σ P(X=x)=1
Ejemplo: en el experimento relativo de lanzar un dado no cargado, la probabilidad
de obtener un cuatro es P(X=4) = 1/6.
6.5. Función de Densidad
Dada una variable aleatoria continua se dice que la función f(x) es de densidad
sí:
Ejemplo: El tiempo de llegadas de los huéspedes se distribuyen según una función de
densidad a determinar.
6.6. Función de Distribución Acumulada. La función distribución acumulada F(x) es una función cuyo valor en cada punto c
es la probabilidad que una observación x sea menor o igual que el valor c. Así, en cada
punto c la altura de F(c) es igual al área bajo f(x) desde -∞ hasta c. Generalmente es la
∫
∫
=≤≤
=
=+
− b
a
dxxfbxaP
dxxf
xf
).()(
1).(
>0)( 00
00

función de distribución acumulada la que es tabulada y permite obtener la probabilidad
sobre cualquier intervalo, simplemente, restando un área de la otra.
La figura 1 representa esta expresión matemática:
Figura 1: Expresión Matemática de la definición de la probabilidad
Puesto que una observación aleatoria x debe tener un valor, el área total bajo la
curva de f(x) es la unidad.
También, la función de distribución acumulada se aproxima a 1 cuando x se hace
muy grande: F(+∞)=1. Se recuerda que F(-∞)=0. También, la función de densidad f(3),
por ejemplo, no es en sí misma la probabilidad de obtener un número particular pues en
una observación aleatoria el valor es cero; es decir, para cualquier número a, el área en
a es:
7. Prueba de una Hipótesis estadística.
A menudo se obtiene y analiza una muestra con el propósito de probar una
hipótesis inicial, llamada la hipótesis nula, acerca de la población. Por ejemplo,
supongamos que establecemos que la hipótesis nula es que la varianza σ2 de la
población es 15. Se puede demostrar que la función (n-1)s2/σ2 tiene una cierta
distribución muestral que puede ser obtenida en las tablas. Por ejemplo, si σ2 es en
verdad 15 y la población tiene un cierto tipo de distribución (en este caso normal),
∫ ∫− −
−=−=≤≤b
oo
a
oo
aFbFdxxfdxxfbxaP )()()().()(
∫+
−
=oo
oo
dxxf 1)(
∫ =a
a
dxxf 0)(

entonces el estadístico (n-1)s2/15 calculado de las muestras de tamaño 11 tiene una
distribución muestral como se ve en la figura 2
Figura 2: Distribución muestral
La distribución así graficada muestra que la probabilidad del estadístico 10s2/15
cae por debajo de 3,25 o por encima de 20,5 (esto es el área bajo estas porciones de la
curva de densidad de probabilidad) es solamente 5%, si σ2 es realmente 15.
Para ejecutar la prueba, se calcula 10s2/15 de la muestra. Si cae fuera del
intervalo 3,25 a 20,5 se rechaza la hipótesis nula de que σ2 es 15 bajo la suposición de
que si σ2 fuera 15, un valor grande o pequeño de 10s2/15 sería improbable.
En este ejemplo se ha rechazado la hipótesis si 10s2/15 era demasiado grande o
demasiado pequeña, usando lo que llamamos prueba de dos colas, con 2,5% en cada
extremo del área bajo la curva de distribución incluida en la región rechazada. Si se
está interesa solamente si la varianza fuera mayor que 15, se usaría la prueba de una cola con una región de rechazo de 10s2/15 > 18,3.
Si no se rechaza la hipótesis nula, entonces se concluye categóricamente que la
hipótesis es verdad. Sencillamente reconocemos que la muestra es compatible con la
clase de población descrita en la hipótesis nula. Esto es, que el estadístico calculado
no puede ser considerado extremo si se mantiene la hipótesis.
7.1. Niveles de Significación y Tipos de Error En el ejemplo que se describe en la parte superior, se rechaza la hipótesis nula si
el cálculo de 15s2/15 cae en una región de valores extremos a la cual la hipótesis nula

asigna probabilidades de solamente 0,05. Aquí, el 5% se llama nivel de significación
de la prueba y se denota por α. Hay un 5 % de riesgo de error, para que aún si la
hipótesis nula es verdadera, hay un 5% de probabilidad de que se rechace. Este tipo de
error, el rechazo de la hipótesis nula cuando es verdadera, se llama error tipo I. El
riesgo del error tipo I es α, el nivel de significación. Este nivel es arbitrario, y debe
escogerse al momento del diseño del experimento. Algunas veces, cuando es
importante evitar los errores tipo I, como en la prueba de productos costosos, se utiliza
un nivel de error α de 1% o 0,1%.
La falla de rechazar una falsa hipótesis se llama Error Tipo II. El riesgo de un
error tipo II se denota con β. En el ejemplo anterior, suponga que la varianza no es
igual a 15, pero tiene un valor alternativo, digamos 25. Es posible que el estadístico
10s2/15 caiga entre 3,25 y 20,5. Conduciendo a aceptar (falla de rechazar) la hipótesis
que σ2 es 15, aunque realmente es 25. La probabilidad de hacer un error tipo II
depende del valor alternativo; por ejemplo. Sería menos deseable aceptar la hipótesis
nula cuando σ2 es igual a 25 que cuando sea igual a 16.
7.2. Intervalos de Confianza.
Al estimar la media de la población μ, por medio de una medida, digamos la
media de la muestra ⎯x, no se puede estar conforme con decir que μ tiene un valor
cercano a ⎯x. Realmente, se hace uso de una distribución de muestreo de ⎯x para
construir un intervalo alrededor de ⎯x y, con una confianza especificada, establecer que
μ permanece en el intervalo. Para un 95% de intervalo de confianza, la proposición
será 95% correcto del tiempo, en el sentido de que si se obtienen muchas muestras y
se calcula ⎯x y el correspondiente intervalo de confianza para cada una de ellas, en
alrededor de 95 casos de cada 100, los intervalos de confianza contendrán a μ.
Los puntos extremos de los intervalos de confianza se llaman límites de
confianza, y la frecuencia relativa con la cual los intervalos contendrán μ (en el sentido
citado arriba) se llama coeficiente de confianza. El coeficiente de confianza se escoge
frecuentemente como 0,95 o 0,99. Al especificar la longitud del intervalo de confianza, a
menudo determinamos el tamaño de la muestra.

Si el error estándar de un estadístico se conoce o puede ser estimado, el intervalo
de confianza de 95% se puede construir fácilmente usando como límites de confianza el
estadístico más o menos dos veces su error estándar. Por ejemplo, para la media, estos
límites de confianza son: ⎯x ± 1,98σ⎯x = ⎯x ± 1,98σ/√n, donde σ es la desviación
estándar de las observaciones individuales. Si σ es conocida, se puede usar la longitud
del intervalo de confianza 4σ/√n para determinar el tamaño de n. Por ejemplo, si σ es 10
y se quiere mantener μ en un intervalo de longitud 5, se tendrá 4(10)/ √n = 5, es decir
n=64.
7.3. Intervalos de Tolerancia. Los límites de confianza incluyen algún parámetro de la población (como por
ejemplo la media μ). Los intervalos de tolerancia se construyen de datos experimentales
para incluir P% o más de la población con la confianza de 1-α. Esto es, si los intervalos
de tolerancia se construyen para muchas muestras de acuerdo a las reglas
especificadas, entonces en 100(1-α) % de los casos incluirán por lo menos P% de la
población. El porcentaje P se llama Cobertura de la población. Los intervalos de
tolerancia se calculan de la muestra para determinar dónde cae la mayoría de
población. Se obtienen de los datos dados en las especificaciones.
7.4. Grados de Libertad. En física, un punto que se mueve libremente en un espacio tridimensional tiene
tres grados de libertad. Las tres variables x, y, z pueden tomar diferentes valores
independientemente. Si se supone que los puntos se mantienen en un plano, entonces
tendrán dos grados de libertad. Este hecho se obtiene de la ecuación del plano:
ax+by+cz=d. Al determinar dos de las coordenadas, la tercera queda automáticamente
determinada.
Un concepto similar se utiliza en el lenguaje estadístico. La suma de los n
cuadrados de desviación de la media de la muestra:
donde

∑=
−
=n
iix
nx
1
1
Se dice que tiene n-1 grados de libertad, pues una vez que se fija ⎯x, solamente
n-1 de las x se pueden escoger independientemente y la enésima está entonces
determinada. Las distribuciones de muestras de algunos estadísticos dependen del
número del grado de libertad. Los estadísticos más utilizados son la t de Student, Chi
cuadrado (χ2) y F.
8. Distribuciones Particulares Las llegadas de las reservaciones a los hoteles se puede manejar con alguno de
las siguientes tres tipos de distribuciones: Normal, Binomial y Poisson.
8.1. Distribución Normal: La distribución normal es aquella que tiene la función de densidad de
probabilidad:
22/2)(.21)( σμ
σπ−−= xexf
con media μ y desviación estándar σ, es de particular interés tanto en la estadística
aplicada como en la teórica. Ocurre frecuentemente en problemas prácticos y es fácil de
usar debido a que sus propiedades han sido ampliamente estudiadas. La distribución
normal se ilustra en la siguiente figura.
Figura 3: Función de densidad de la Distribución Normal
Frecuentemente, sobre los valores de las medidas se ejecutan cambios para
obtener una distribución normal equivalente haciendo z=(x - μ)/σ que tiene media igual

a cero y desviación estándar igual a uno. La curva es simétrica, con una moda y su
mediana coincide con la media. La importancia de esta transformación es que cualquier
distribución puede cambiarse a esta distribución normal equivalente lo que permite
utilizar una sola tabla de valores para todas las distribuciones.
Si cada una de las variables independientes xi tiene una distribución normal con
media μi y variancia σi2 , entonces la suma y= Σ cixi donde las ci son constantes, tendrá
una distribución normal con media Σciμi y varianza Σci2σi
2.
La función acumulada de la distribución normal es
∫−
−−=x
oo
xexF 22/2)(
21)( σμ
σπ
Una curva típica de este tipo se da a continuación. Note que la altura de la curva
F(x) en un punto c es igual al área debajo de la curva f(x) a la izquierda de c.
Figura 4. Función de Distribución Acumulada de la Distribución Normal.
En cualquier libro de estadística se encuentran los valores de la función
acumulativa de la distribución normal, los valores de z y las características de la
distribución normal
8.2. Distribución Binomial. Supóngase que en un experimento, cada miembro de la muestra se va a juzgar
bajo el criterio de sí o no, como es el caso de aceptar o fallar, producto bueno o malo,
cara o sello. Supóngase además, que un suceso aleatorio tiene una probabilidad p de

aceptar y una probabilidad q de fallar. Por lo tanto p + q = 1. La distribución binomial se
define por
xnxn
xn qpCxP −= .)( Para x=0,1,2,3,......n.
donde :
Pn(x) = probabilidad de obtener exactamente x aciertos en n intentos.
Cxn = número de combinaciones de n cosas tomadas x a la vez. Se denota también por
C(n,x) con 0! = 1 y C el número de combinaciones de acuerdo a la siguiente
ecuación
))......(3)(2((1()1)......(2)(1(
)!(!!
xxnnnn
xnxnC n
x
+−−−=
−=
La probabilidad de obtener al menos r aciertos en n intentos es
∑=
n
rxn xP )(
La media y la varianza de x, el número de aciertos en n intentos está dado por
μ=np y σ2=npq.
Algunas de los usos de la función de distribución binomial son los siguientes:
a) Como una distribución discreta para cotejar un conjunto de
datos los cuales se clasifican en dos grupos
b) Como una distribución básica en el muestreo de atributos.
Ejemplo:
Si la probabilidad que un hotel esté ocupado a un 80% es 0,25. ¿Cuáles son las
probabilidades de que entre los próximos 10 días (a) A lo máximo dos días alcancen el
80%?. (b) al menos cuatro días alcancen el 80%?

Solución: Ecuación Binomial para n= 10 y p=0,25
Número de Fallas
Probabilidad Binomial Función Binomial Acumulada
0 0,0563 0,0563 1 0,1877 0,2440 2 0,2816 0,5226 3 0,2503 0,7759 4 0,1460 0,9219 5 0,0584 0,9803 6 0,0162 0,9965 7 0,0031 0,9996 8 0,0004 1,0000 9 0,0000 1,0000 10 0,0000 1,0000
De la tabla anterior, la segunda columna da la probabilidad de alcanzar
exactamente en número de veces que se especifica en la primera columna. La tercera
columna da el acumulado de obtener n logros en los 10 días. Luego las respuestas son:
(a) 0,5226 = 52,26 %
(b) 1-0,7759 = 0,2241 = 22,41 %
8.3. Distribución de Poisson: La distribución de Poisson es una aproximación de la distribución normal cuando n
es grande y p es pequeña.
La ecuación de la distribución de Poisson es
!.)(xemxP
mx −
=
para X=0,1,2........
donde m = np de la distribución binomial aproximada y e=2,71828, la base de los
logaritmos naturales. Nótese que 0! = 1 y que m0 = 1. La media y la varianza de la
distribución de Poisson son iguales μ = m y σ2 = m, Las tablas de Poisson están
disponibles en cualquier manual de estadística.
La distribución de Poisson se aplica en algunos casos por ser más fácil de utilizar
que la distribución binomial. Por ejemplo, supóngase que en el proceso de recepción
de pedidos de habitaciones, el número de recepciones en un día ocurre de una manera
aleatoria, no afectada por el momento en que ocurra otro número de recepciones.
Supóngase, además, que la probabilidad que d recepciones que se producirán en un
intervalo dado de tiempo, no estarán afectados por el número de recepciones en otro

intervalo de tiempo, Entonces, si el número promedio de recepciones es m, la función
de distribución de Poisson será
!)(
xemxP
mx −
=
para x=0,1,2,3,... que da la probabilidad de obtener x recepciones en un día. Si las
cifras de producción no están de acuerdo con las frecuencias predichas, se puede
decidir que las recepciones no están ocurriendo aleatoriamente y que están siendo
afectadas por alguna elemento extraño.
Ejemplo: Supóngase que se tienen los siguientes cálculos de un proceso de recepción
tal como se muestra en la tabla. Siguiendo el método que se describe abajo se puede
decir que los valores teóricos y prácticos son bastantes cercanos y por lo tanto se
puede deducir que no hay ninguna sospecha de que haya elementos extraños en la
predicción.
Encuentro de número de cancelaciones utilizando la Distribución de Poisson
Número de Retiros de
los reservados,
x
Número de
Ocurrencias de x retiros
en 1 día
Frecuencia relativa de
ocurrencia de x retiros en 1 día
Frecuencia de ocurrencias
predichas por la Distribución de
Poisson
0 102 0,5075 0,4741 1 59 0,2935 0,3538 2 31 0,1542 0,1320 3 8 0,0398 0,0328 4 0 0.0000 0,0061 5 1 0.0050 0,0009 6 0 0,0000 0,0001
7 o más 0 0,0000 0,0000 Total 201 1,0000 0,9998
Note que el número total de retiros es 150 (=1x59+2x31+3x8+5x1); el número total
días donde se hicieron observaciones fueron 201. La media estimada del número de
defectos es m=150/201 = 0,74627.
9. Pruebas e Intervalos de Confianza para Medias En este enciso se estudian las pruebas y los intervalos de confianza para las
medias de las poblaciones basadas en muestras aleatorias tomadas de las
poblaciones. En este enciso cuando se diga prueba se referirá a prueba de hipótesis,

estableciendo de antemano antes del experimento que la media de la población tiene
un valor numérico específico. La prueba concluirá que los datos son o no son
consistentes con la hipótesis.
El método de la prueba depende si la desviación estándar de la población es
conocida o desconocida. En la experimentación, el caso de tener poblaciones con
desviaciones estándar desconocida, es lo más usual. En trabajos repetitivos, tales
como control de calidad de la población y pruebas estándar, la desviación estándar
puede algunas veces ser calculada a partir de la cantidad de datos de la muestra.
Todas las pruebas estadísticas y los intervalos de confianza están basados en la
suposición de que las muestras son aleatorias y la mayoría de ellas en la suposición de
que las poblaciones tienen distribuciones normales. Muchos experimentos físicos y
químicos muestran sus variables con una tendencia a ser distribuciones normales
basadas en los datos recopilados anteriormente. Los resultados de los análisis
estadísticos son generalmente números desconocidos y normalmente se requieren
establecer intervalos de confianza alrededor del cálculo del parámetro deducido con las
muestras.
Supongamos que deseamos saber el número habitaciones ocupadas por día en
un mes. Como los valores diarios son diferentes en vez de un promedio único. De modo
que una manera de describir la población es dando una media y un intervalo de
confianza alrededor de esa media. Por lo tanto es deseable obtener métodos para
obtener estos parámetros estadísticos.
9.1 Prueba de la media μ cuando la Desviación Estándar es conocida.
Para hacer esta prueba se supone que (a) la muestra es aleatoria y (b) que la
población esta normalmente distribuida con desviación estándar σ conocida o que el
tamaño de la muestra es grande (n > 30). En donde el valor de s se puede sustituir por
σ.
9.1.1. Prueba Normal
Dada una muestra de tamaño n, la prueba para un grado de significación α,
suponiendo que la media de la población μ tiene un valor hipotético a, se calcula el
estadístico

n
axz σ
...
_
−=
La distribución de z es normal con desviación estándar unitaria, donde σ/√n es la
desviación estándar de media ⎯x.
Para una prueba que incluya ambos extremos de la hipótesis nula suponiendo que
μ = a. Se rechaza la hipótesis, si z cae en la región de rechazo ⎥ z⎥ > zα/2 donde ⎥ z⎥ es
el valor absoluto de z. El valor de zα/2 es aquel que es excedido con probabilidad de α/2
por la variable normal z, si la hipótesis nula se mantiene.
Para una prueba que incluya un solo lado de la hipótesis nula que μ = a. contra la
alternativa que μ > a, se rechaza la hipótesis sí z > zα.
Para una prueba que incluya un solo lado de la hipótesis nula de que μ = a. contra
la alternativa de que μ < a, se rechaza la hipótesis sí z < - zα.
Para un nivel de significación de 5 % estas regiones de rechazo son:
⏐z ⏐ > 1,960 para la prueba de dos extremos de μ= a.
z > 1,645 para la prueba de un extremo para μ = a contra la alternativa de
μ > a.
z < - 1,645 para la prueba de un extremo para μ = a contra la alternativa de
μ < a.
Si z cae en la región de rechazo para la prueba que está elaborándose, se
rechaza la hipótesis nula de que la media de la población μ es igual a a bajo la
suposición que tal valor de z (grande o pequeño) ocurriría con probabilidad de
solamente 5 % si la hipótesis nula se mantiene,
Si la población es finita de tamaño N más que infinita, remplace el cálculo de z por
Nótese que además de la hipótesis nula. Hay varias suposiciones adicionales:
1
_
−−
−=
NnN
n
axz
σ

• que σ es conocida,
• que el estadístico z tiene una distribución normal y
• que la muestra es aleatoria.
El rechazo de la hipótesis nula no significa necesariamente que la hipótesis por sí
misma es falsa; sino que algunas de las suposiciones en la construcción del modelo
matemático de trabajo no han sido satisfechas.
Por otra parte, la falla de rechazar la hipótesis nula no es siempre una evidencia
de que sea cierta. Si la muestra es pequeña, solamente cuando existe una gran
separación de la hipótesis nula sería lo que adjudicaría significación. Por lo tanto, es
importante planificar los experimentos de suficiente tamaño para mantener los riesgos
de error a bajos niveles aceptables.
Ejemplo: El Número de reservaciones medio de un hotel es 200 y la desviación
estándar es de 12. Tomando 40 días de muestreo para una temporada determinada
(una estación) se tuvo una media de alcance de 186,3 habitaciones. Pruebe con 5 % de
nivel de significación si la temporada especial cambió la media de alcance,
Solución: Calculamos
22,740/122003,186
/
_
−=−
=−
=n
axzσ
Para un nivel de significación de 5 %, la región de rechazo de dos extremos es
⏐z⏐> 1,96. Puesto que –7,22 es menor que –1,96, cae en la región de rechazo, y se
rechaza la hipótesis nula que la media μ es igual a 200 habitaciones. Se concluye que
la temporada en estudio cambió el comportamiento de recepción del hotel. Se utilizó
una región de rechazo de dos extremos porque antes del experimento se estaba
interesado en saber si había sucedido cambio en ambas direcciones. Si se hubiera
estado interesado en una sola dirección (disminuir, por ejemplo) se hubiera usado la
región de rechazo de un solo extremo z < -1,645.
9.1.2. Determinación del Tamaño de la Muestra: Cuando un experimento va a ser ejecutado y los resultados se analizarán por el
método de esta sección, se debe hacer una decisión acerca del tamaño de la muestra
que se va a usar. Supóngase que se desea eliminar la posibilidad de no rechazar la

hipótesis nula de μ=a, si μ realmente tiene un valor alternativo particular b. Existe un
riesgo específico β de hacer tal error (llamado error tipo II). Se adopta el nivel de
significación α (el riesgo de rechazar la hipótesis nula cuando la media es realmente a;
esto es, la probabilidad de un error tipo I). En el ejemplo dado aquí, el nivel α se tomó
como 0,05.
Usando μ = b, tendremos que
( )2y ab
znbn
za−
==+σσ
Usando este tamaño se asegura que el experimento permitirá aceptar la hipótesis
nula que μ = a o la hipótesis alterna μ = b con pequeños riesgos satisfactorios de
estar errados en cualquier caso.
9.1.3. Intervalos de Confianza:
Los límites de confianza 100(1-α) % de la media de la población μ son:
Donde σ es la conocida desviación estándar y zα/2 es el valor en la distribución
normal estándar tal que la probabilidad de una desviación aleatoria que numéricamente
sea mayor que zα/2 es α.
9.2. Prueba para la media μ cuando σ es desconocida.
La prueba llamada t se utiliza a menudo para analizar estos casos y puede ser usada
cualquiera que sea el tamaño de la muestra. Para ello se calcula el estadístico
donde s es la desviación estándar y n es el tamaño de la muestra. Para pruebas de
dos extremos, compare el valor calculado con el valor de tα/2, n-1 con la condición de que
N. tamañode finitas spoblacione para 1
.
infinitas spoblacione para
2/
_
2/
−−
±
±
NnN
nzx
nzx
σ
σ
α
α

P(t)= α/2 en las tablas correspondientes que aparecen en cualquier libro de estadística.
El suscrito n-1 representa el número de grados de libertad f. Si I t I > tα/2, n-1 se
rechaza la hipótesis nula de que μ = a.
Para pruebas de un solo extremo de la hipótesis nula μ = a, contra la alternativa
de que μ > a, se usa la región de rechazo de t > ta, n-1.
9.2.1. Intervalos de Confianza.
Los límites de confianza para la media μ con coeficiente de 100(1-α) % son
nstx n 1,2/
_
−± α
donde tα/2,n-1 es otra vez la t para n-1 grados de libertad, la probabilidad de exceder con
P(t) = α/2.
10. Análisis de Regresión
A menudo deseamos predecir el valor de una variable y para varios valores de
una o más variables xi. Algunas veces una ley física conecta las variables de modo que
una de ellas se puede expresar en función de otras xi. Por ejemplo la ecuación
y=1/2gx2 permite predecir la distancia recorrida por un cuerpo que cae en un tiempo x.
Sin embargo, todas las relaciones entre dos o más variables no son siempre conocidas
y es necesario hacer un ajuste por medio de una ecuación obtenida por técnicas
estadísticas.
El análisis de regresión es una técnica para encontrar por medios matemáticos
la relación que existe entre dos o más variables con sus límites de confianza de modo
que se pueda decir si los datos son consistentes con la hipótesis.
El análisis de varianza permite determinar si ciertos valores escogidos de cada
una de las variables xi ( para i=1 hasta k) difieren en sus efectos sobre la variable
dependiente y. Las xj no son necesariamente variables continuas, y sus efectos no
necesitan tener una forma funcional dada. Por análisis de regresión se puede
determinar el efecto funcional de las variables continuas xi.
Un tercer método, el análisis de covarianza, es especialmente importante cuando
alguna condición del experimento no puede ser mantenida constante. Con este método,

se puede describir, y si se desea remover, el efecto de la condición cambiante, y probar
el efecto de las otras variables sobre la variación remanente de y. La ecuación de la curva de regresión de y sobre x da para cada x la media de la
correspondiente distribución y. Esta curva obtenida como resultado del análisis de los
datos es una aproximación a la curva de regresión verdadera y se puede usar para
predecir los valores de y. En los casos lineales, la curva se llama regresión lineal. El
análisis de regresión se puede aplicar de datos recolectados de dos maneras: a) De datos experimentales, en donde se desee medir el efecto de las variables x
sobre la variable y.
b) Cuando los puntos (x,y) se puedan escoger en forma aleatoria de una
distribución normal de puntos en el plano xy.
10.1 Método de Mínimos Cuadrados. El método general usado para estimar la curva de regresión de una población a
partir de datos de una muestra se llama método de mínimos cuadrados. La curva de
regresión de la muestra, de y sobre x, para un grado dado es la curva entre todas
aquellas de ese grado que minimiza la suma de los cuadrados de las desviaciones
verticales (y) de los puntos observados de la curva.
10.2. Regresión Lineal. La ecuación de una línea de regresión de y sobre x es
bxay +=´
donde los coeficientes de regresión son la pendiente de la línea de regresión b y el
intercepto a
.
La ecuación general se puede escribir como :
( )222_
__
∑∑∑ ∑ ∑
∑
∑−
−=
⎟⎠⎞
⎜⎝⎛ −
⎟⎠⎞
⎜⎝⎛ −⎟⎠⎞
⎜⎝⎛ −
=xxn
yxxyn
xx
yyxxb
ny
xbya ∑ ∑=−=xb -
. __
⎟⎠⎞
⎜⎝⎛ −=−
__´´ xxbyy

que muestra que la línea pasa por el centro de gravedad de los puntos observados. El
valor y¨ distingue el valor calculado de los valores observados.
10.3. Variaciones alrededor de la Línea de Regresión.
El gráfico, en la dirección vertical (y), de los puntos observados alrededor de la
línea de regresión se mide por medio de la desviación estándar sy.x. donde
( ) ( ) ( )22222
2
2, 1
21
21
2rs
nnsbs
nn
nýy
s yxyii
xy −−−
=−−−
=−
−= ∑
Las dos últimas formas se pueden usar para efectuar los cálculos. El valor de r se
llama coeficiente de correlación y se definirá más adelante. El valor de sy,x suele
llamarse error estándar de la estimación.
La suma de los cuadrados de las desviaciones de los yi de sus medias totales
puede dividirse en dos partes: esto es, el total de la suma de los cuadrados es igual a
la suma de los cuadrados de las desviaciones de la línea de regresión mas la suma de
los cuadrados de las desviaciones de los valores de regresión de ⎯y.
10.4. Coeficiente de Correlación. Se define como coeficiente de correlación de una muestra al valor r resultante de
la siguiente relación:
Esta relación permanece siempre entre –1 y +1. Si y solamente si todos los
puntos se encuentran en la línea, entonces r=±1. Si r=0, la regresión no explica ninguna
variación de y y la línea de regresión es horizontal ( y´=⎯y).
( ) ( )∑ ∑ ∑ ⎟⎠⎞
⎜⎝⎛ −+−=−
2_!2!2 yyyyyy iiii
[ ][ ]∑ ∑∑∑∑ ∑∑∑
−−
−=
−
−−=
2222,
_
)()()1())((
yynxxn
yxxynsn
yyyxr
yx

10.5 Regresión Lineal Múltiple.
Si la variable y depende de varios factores, es mejor usar una fórmula que tenga
a todas ellas para hacer la predicción. Las variables x1, x2, x3,,,,,, xk se evaluarán contra
la variable resultante y a través de todos los valores que adquieran cada una de las
variables independientes. Los valores tomados por las variables son x11,x12,x13,...x21,
x22, etc.
La discusión que se efectuó para explicar la regresión lineal se aplica también
para la regresión múltiple. Si las curvas de regresión tienen una forma distinta a la linear
se ejecuta una transformación de variables para llevarla a la forma lineal.
10.6. Regresiones No Lineales Para el análisis de variables que no guardan una linealidad, se hacen transformaciones
que las conduzcan a ecuaciones lineales. La siguiente es una de ellas
Ecuación Transformación
nXaY .= XnaY logloglog +=

Anexo B
Predicciones con los Modelos Generados por EVIEWS®
Para el método móvil autoregresivo
Nota: Las variables M(q) y A(p) deben restárseles los valores de la media de la variable dependiente antes de utilizarlos para cálculos manuales. Si se efectúan
utilizando EVIEWS®, el mismo programa hace los cálculos para cotejo y predicción.

PREDICCIONES CON LOS MODELOS
MODELO 1: Ecuación: HAB2(T) = C + C12 *HAB2(T-12)

PREDICCIONES DE LOS MODELOS

MODELO 1: Ecuación : HAB2(T) = C + C12 *HAB2(T-12)
PREDICCIONES DE LOS MODELOS
MODELO 1: Ecuación : HAB2(T) = C + C12 *HAB2(T-12)

DATOS PRONOSTICADOS AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 48,0 57,7 71,6 74,0 70,9 55,6 55,5 69,7 66,1 64,8 55,8 51,12001 49,9 57,0 68,8 72,7 71,1 59,3 57,1 67,3 65,5 58,5 53,62002 51,9 56,9 66,7 71,4 71,1 62,2 58,9 65,9 66,7 66,0 60,6 56,02003 53,8 57,2 65,2 70,2 70,9 64,3 60,6 65,3 66,7 66,4 62,3 58,12004 55,7 57,8 64,2 69,2 70,6 65,9 62,3 65,1 66,7 66,8 63,8 60,0
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO 7,262

PREDICCIONES DE LOS MODELOS
MODELO 2: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B12*MA(12)

PREDICCIONES DE LOS MODELOS
MODELO 2: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B12*MA(12)

PREDICCIONES DE LOS MODELOS
MODELO 2: Ecuación : HAB2(T) = C + C12 *HAB2(T-12) + B12*MA(12)
DATOS PRONOSTICADOS AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 45,4 49,8 59,6 69,4 65,2 55,5 60,4 79,3 66,6 60,2 48,4 45,42001 46,3 50,7 60,3 69,9 65,8 56,3 61,0 79,5 67,2 60,9 49,3 46,42002 47,3 51,6 60,9 70,3 66,3 57,0 61,7 79,8 67,7 61,6 50,3 47,32003 48,3 52,5 61,6 70,8 66,9 57,8 62,3 80,0 68,2 62,2 51,2 48,32004 49,3 53,3 62,3 71,2 67,4 58,5 63,0 80,3 68,7 62,9 52,1 49,3
DATOS ORIGINALES AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO : 8,370

PREDICCIONES DE LOS MODELOS
MODELO 3: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B12*MA(12) + B11*MA(11)

PREDICCIONES DE LOS MODELOS
MODELO 3: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B12*MA(12) + B11*MA(11)

PREDICCIONES DE LOS MODELOS
MODELO 3: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B12*MA(12) + B11*MA(11)

DATOS PRONOSTICADOS AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 48,3 59,2 71,6 71,9 69,1 53,0 54,8 71,9 65,0 64,3 53,4 50,22001 50,6 59,8 70,3 70,6 68,2 54,7 56,2 70,6 64,8 64,2 55,0 52,32002 52,7 60,4 69,3 69,6 67,5 56,1 57,4 69,6 64,7 64,2 56,5 54,22003 54,5 61,1 68,6 68,8 67,1 57,5 58,6 68,9 64,7 64,4 57,8 55,92004 56,2 61,7 68,1 68,3 66,8 58,7 59,6 68,4 64,9 64,6 59,1 57,5
DATOS ORIGINALES AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO : 6,800
PREDICCIONES DE LOS MODELOS
MODELO 4: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1)+B12*MA(12) + B11*MA(11)

PREDICCIONES DE LOS MODELOS
MODELO 4: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1) +B12*MA(12) + B11*MA(11)

PREDICCIONES DE LOS MODELOS
MODELO 4: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1)+ B12*MA(12) + B11*MA(11)

DATOS PRONOSTICADOS
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 48,2 58,3 73,7 75,9 72,1 55,8 55,6 69,7 66,1 65,5 57,1 52,32001 50,7 57,4 69,6 73,8 72,0 60,2 57,5 66,9 66,3 65,8 59,8 55,22002 53,0 57,3 66,8 71,8 71,6 63,3 59,6 65,4 66,3 66,1 61,8 57,72003 55,3 57,7 65,0 70,0 71,0 65,4 61,6 64,8 66,1 66,3 63,4 59,82004 57,4 58,6 63,9 68,6 70,3 66,8 63,3 64,9 66,1 66,5 64,5 61,6
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO 7,650

PREDICCIONES DE LOS MODELOS
MODELO 5: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1) +B12*MA(12) + B11*MA(11)+ B1*MA(1)

PREDICCIONES DE LOS MODELOS
MODELO 5: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1) +B12*MA(12) + B11*MA(11)+ B1*MA(1)

PREDICCIONES DE LOS MODELOS
MODELO 5: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1) +B12*MA(12) + B11*MA(11)+ B1*MA(1)

DATOS PRONOSTICADOS
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 48,3 56,8 69,0 72,8 68,8 54,1 53,2 73,0 65,9 63,4 52,6 49,02001 49,7 57,7 69,0 72,5 68,8 55,0 54,3 72,8 66,0 63,7 53,7 50,42002 51,1 58,6 69,1 72,3 68,8 56,0 55,4 72,7 66,2 64,1 54,7 51,82003 52,5 59,4 69,3 72,2 68,8 56,8 56,4 72,7 66,4 64,5 55,8 53,12004 53,7 60,3 69,4 72,1 68,9 57,7 57,4 72,7 66,7 65,0 56,8 54,3
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO : 6,22

PREDICCIONES DE LOS MODELOS
MODELO 6: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1)+ AR(11)+ B12*MA(12) + B11*MA(11)+ B1*MA(1)

PREDICCIONES DE LOS MODELOS
MODELO 6: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1)+ AR(11) +B12*MA(12) + B11*MA(11)+ B1*MA(1)

PREDICCIONES DE LOS MODELOS
MODELO 6: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + AR(1)+ AR(11) +B12*MA(12) + B11*MA(11)+ B1*MA(1)

DATOS PRONOSTICADOS
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 47,8 56,1 66,9 72,0 68,5 55,9 51,3 72,4 65,6 63,9 53,2 49,32001 49,1 56,2 66,1 71,3 68,9 57,3 51,3 71,8 65,7 64,7 54,8 51,12002 50,4 56,4 65,5 70,6 69,3 58,7 51,5 71,2 65,7 65,5 56,4 52,92003 51,7 56,7 65,0 70,1 69,6 60,1 51,9 70,8 65,8 66,2 57,8 54,52004 53,0 57,2 64,7 69,6 69,8 61,5 52,3 70,4 65,8 66,8 59,1 56,0
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO 6,470
PREDICCIONES DE LOS MODELOS
MODELO 7: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B1*MA(1) + B11*MA(11))

PREDICCIONES DE LOS MODELOS
MODELO 7: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B1*MA(1) + B11*MA(11))

PREDICCIONES DE LOS MODELOS
MODELO 7: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B1*MA(1) + B11*MA(11))

DATOS PRONOSTICADOS
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 49,0 58,9 71,7 73,3 69,7 53,6 54,1 72,4 65,6 64,3 53,6 50,32001 50,8 59,6 71,0 72,5 69,2 54,9 55,4 71,7 65,6 64,5 55,0 52,12002 52,5 60,4 70,5 71,8 68,9 56,2 56,6 71,1 65,7 64,7 56,3 53,72003 54,1 61,1 70,1 71,2 68,7 57,4 57,8 70,6 65,9 65,0 57,5 55,22004 55,6 61,8 69,8 70,8 68,6 58,5 58,9 70,3 66,1 65,3 58,7 56,6
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO: 6,43
PREDICCIONES DE LOS MODELOS
MODELO 8: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B11*MA(11))

PREDICCIONES DE LOS MODELOS
MODELO 8: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B11*MA(11))

PREDICCIONES DE LOS MODELOS
MODELO 8: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) + B11*MA(11))

DATOS PRONOSTICADOS
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 48,5 60,4 74,5 73,7 69,8 52,8 55,0 71,9 64,9 65,1 54,7 51,22001 51,3 60,8 72,1 71,5 68,4 54,8 56,5 70,1 64,5 64,7 56,4 53,62002 53,7 61,3 70,3 69,9 67,4 56,5 57,9 68,8 64,3 64,4 57,8 55,62003 55,7 61,8 69,0 68,7 66,7 58,0 59,2 67,9 64,3 64,4 59,1 57,42004 57,4 62,3 68,1 67,8 66,3 59,3 60,3 67,2 64,4 64,5 60,3 58,9
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO: 7,06
PREDICCIONES DE LOS MODELOS
MODELO 9: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) +AR(1) + B11*MA(11))

PREDICCIONES DE LOS MODELOS
MODELO 9: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) +AR(1) + B11*MA(11))

PREDICCIONES DE LOS MODELOS
MODELO 9: Ecuación: HAB2(T) = C + C12 *HAB2(T-12) +AR(1) + B11*MA(11))

DATOS PRONOSTICADOS
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 48,0 57,7 71,6 74,0 70,9 55,6 55,5 69,7 66,1 64,8 55,8 51,12001 49,9 57,0 68,8 72,7 71,1 59,3 57,1 67,3 66,6 65,5 58,5 53,62002 51,9 56,9 66,7 71,4 71,1 62,2 58,9 65,9 66,7 66,0 60,6 56,02003 53,8 57,2 65,2 70,2 70,9 64,3 60,6 65,3 66,7 66,4 62,3 58,12004 55,7 57,8 64,2 69,2 70,6 65,9 62,3 65,1 66,7 66,8 63,8 60,0
DATOS ORIGINALES
AÑO ENE FEB MAR ABR MAY JUN JUL AGO SEP OCT NOV DIC 2000 53 61 69 80 72 62 52 70 68 72 62 552001 48 54 75 71 69 58 55 72 71 66 54 512002 56 64 76 80 76 62 49 70 82 69 50 432003 39 56 58 65 65 51 47 63 61 64 45 542004 48 64 76 73 76 61 60 70 78 72 48 50
ERROR CUADRATICO : 7,26