Embed Size (px)
Citation preview

Ras Bodik CS 164 Lecture 24 1
Dynamic Binary Translation
Lecture 24
acknowledgement: E. Duesterwald (IBM), S. Amarasinghe (MIT)

Ras Bodik CS 164 Lecture 242
Lecture Outline
• Binary Translation: Why, What, and When.
• Why: Guarding against buffer overruns
• What, when: overview of two dynamic translators:– Dynamo-RIO by HP, MIT– CodeMorph by Transmeta
• Techniques used in dynamic translators– Path profiling

Ras Bodik CS 164 Lecture 243
Motivation: preventing buffer overruns
Recall the typical buffer overrun attack:
1. program calls a method foo()
2. foo() copies a string into an on-stack array:– string supplied by the user– user’s malicious code copied into foo’s array – foo’s return address overwritten to point to user code
3. foo() returns – unknowingly jumping to the user code

Ras Bodik CS 164 Lecture 244
Preventing buffer overrun attacks
Two general approaches:
• static (compile-time): analyze the program – find all array writes that may outside array bounds – program proven safe before you run it
• dynamic (run-time): analyze the execution– make sure no write outside an array happens– execution proven safe (enough to achieve
security)

Ras Bodik CS 164 Lecture 245
Dynamic buffer overrun prevention
the idea, again:
• prevent writes outside the intended array– as is done in Java– harder in C: must add “size” to each array
• done in CCured, a Berkeley project

Ras Bodik CS 164 Lecture 246
A different idea
perhaps less safe, but easier to implement:– goal: detect that return address was overwritten.
instrument the program so that – it keeps an extra copy of the return address:
1. store aside the return address when function called (store it in an inaccessible shadow stack)
2. when returning, check that the return address in AR matches the stored one;
3. if mismatch, terminate program

Ras Bodik CS 164 Lecture 247
Commercially interesting
• Similar idea behind the product by determina.com
• key problem: – reducing overhead of instrumentation
• what’s instrumentation, anyway?– adding statements to an existing program– in our case, to x86 executables
• Determina uses binary translation

Ras Bodik CS 164 Lecture 248
What is Binary Translation?
• Translating a program in one binary format to another, for example:
– MIPS x86 (to port programs across platforms)
• We can view “binary format” liberally:
– Java bytecode x86 (to avoid interpretation)– x86 x86 (to optimize the executable)

Ras Bodik CS 164 Lecture 249
When does the translation happen?
• Static (off-line): before the program is run– Pros: no serious translation-time constraints
• Dynamic (on-line): while the program is running– Pros:
• access to complete program (program is fully linked)• access to program state (including values of data struct’s)• can adapt to changes in program behavior
• Note: Pros(dynamic) = Cons(static)
Ras Bodik CS 164 Lecture 2410
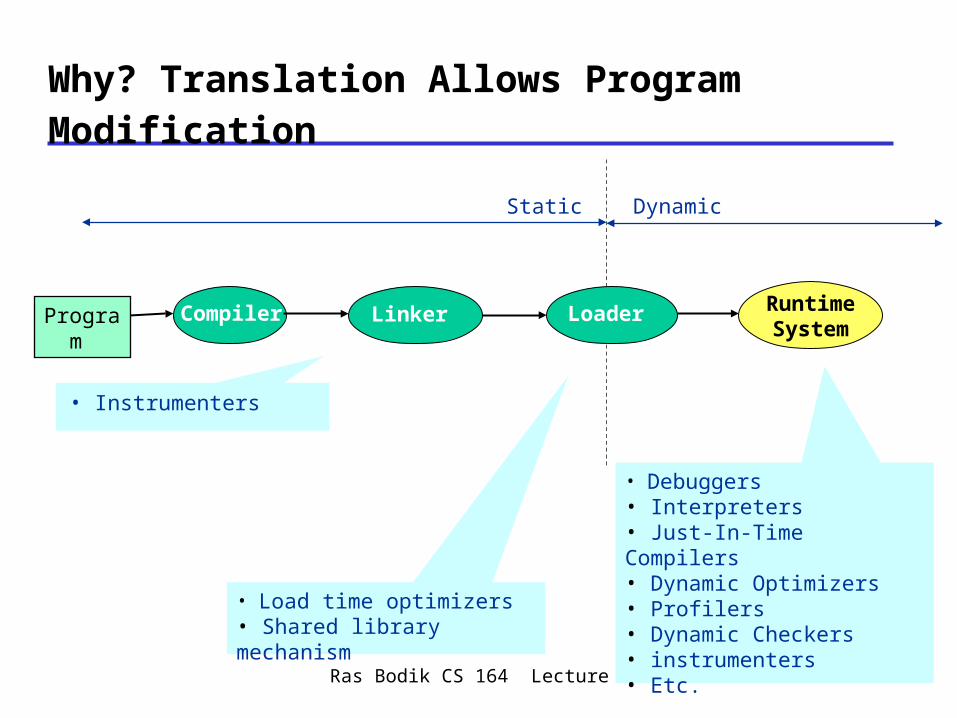
Why? Translation Allows Program Modification
Program
Compiler
Linker Loader Runtime System
Static Dynamic
• Instrumenters
• Load time optimizers • Shared library mechanism
• Debuggers• Interpreters• Just-In-Time Compilers• Dynamic Optimizers• Profilers• Dynamic Checkers• instrumenters• Etc.

Ras Bodik CS 164 Lecture 2411
Applications, in more detail
• profilers: – add instrumentation instructions to count basic
block execution counts (e.g., gprof)
• load-time optimizers:– remove caller/callee save instructions
(callers/callees known after DLLs are linked)– replace long jumps with short jumps
(code position known after linking)
• dynamic checkers– finding memory access bugs (e.g., Rational Purify)

Ras Bodik CS 164 Lecture 2412
Dynamic Program Modifiers
Running Program
Dynamic Program Modifier:Observe/Manipulate Every Instruction in the Running Program
Hardware Platform
Ras Bodik CS 164 Lecture 2413
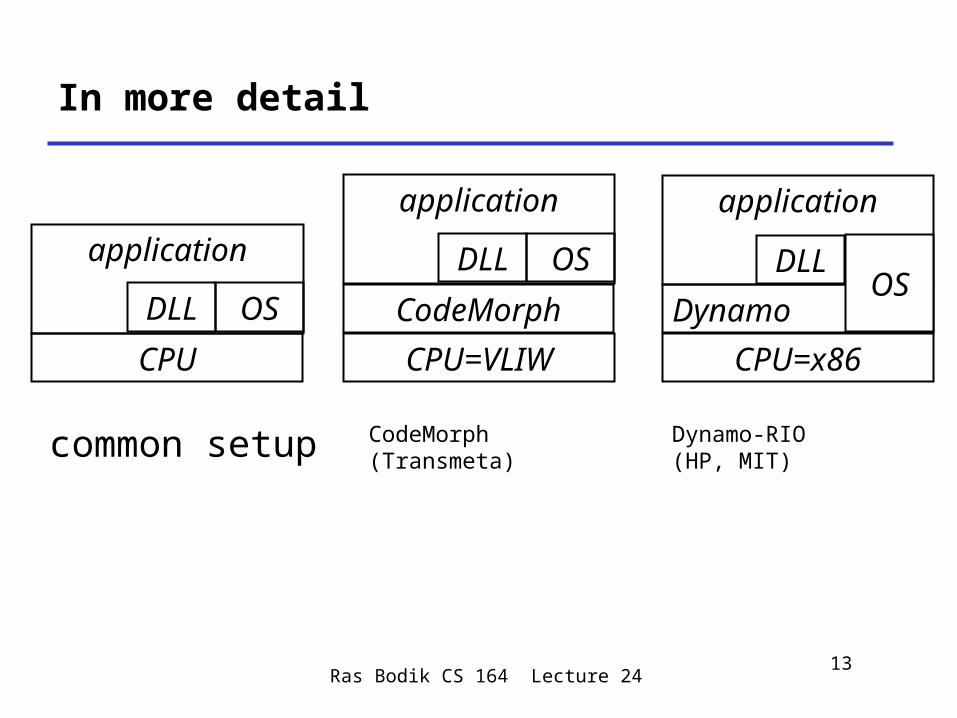
In more detail
common setup
CPU
OSDLL
application
CodeMorph
OSDLL
application
CPU=VLIW
CodeMorph(Transmeta)
Dynamo-RIO (HP, MIT)
CPU=x86
DLL
application
DynamoOS

Ras Bodik CS 164 Lecture 2414
Dynamic Program Modifiers
Requirements:: Ability to intercept execution at arbitrary points Observe executing instructions Modify executing instructions Transparency
- modified program is not specially prepared Efficiency
- amortize overhead and achieve near-native performance Robustness Maintain full control and capture all code
- sampling is not an option (there are security applications)

Ras Bodik CS 164 Lecture 2415
HP Dynamo-RIO
• Building a dynamic program modifier• Trick I: adding a code cache• Trick II: linking• Trick III: efficient indirect branch handling• Trick IV: picking traces
• Dynamo-RIO performance• Run-time trace optimizations
Ras Bodik CS 164 Lecture 2416
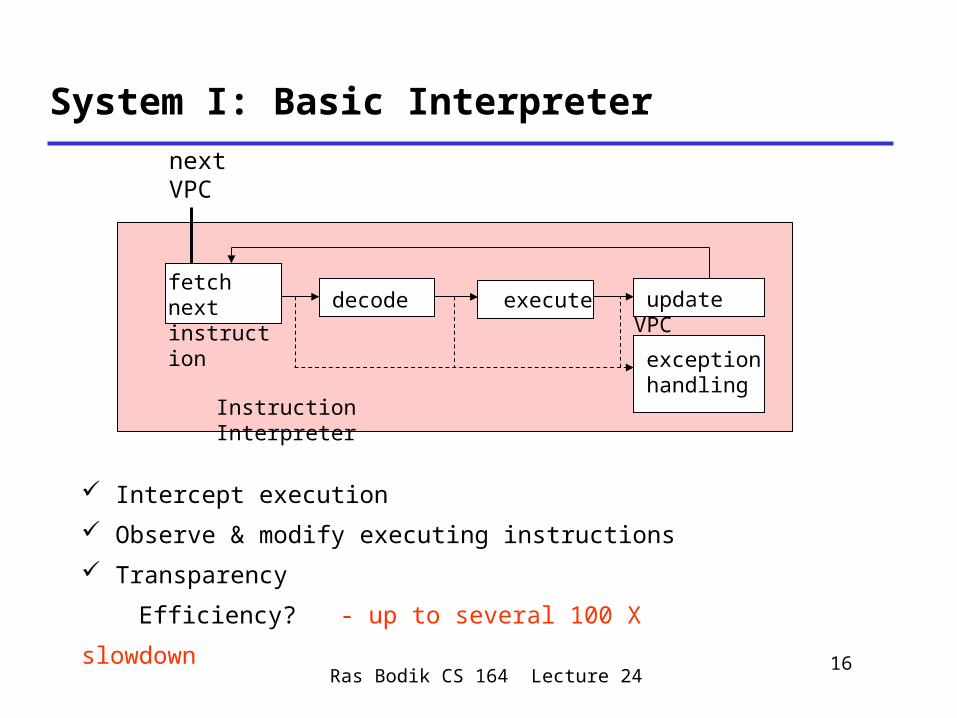
next VPC
Instruction Interpreter
System I: Basic Interpreter
decodefetch next instruction execute
exception handling
update VPC
Intercept execution
Observe & modify executing instructions
Transparency
Efficiency? - up to several 100 X slowdown
Ras Bodik CS 164 Lecture 2417
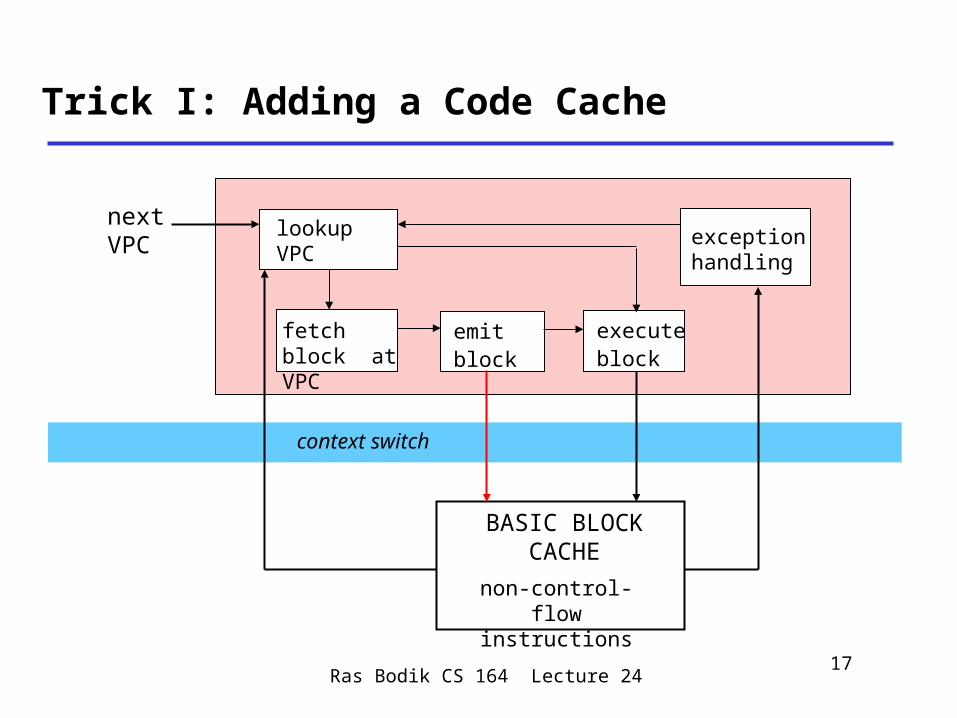
context switch
BASIC BLOCK CACHE
non-control-flow instructions
Trick I: Adding a Code Cache
next VPC
fetch block at VPC
lookup VPC
emitblock
exception handling
executeblock

Ras Bodik CS 164 Lecture 2418
add %eax, %ecx
cmp $4, %eax
jle $0x40106f
add %eax, %ecx
cmp $4, %eax
jle <stub1>
jmp <stub2>
mov %eax, eax-slot # spill eax
mov &dstub1, %eax # store ptr to stub table
jmp context_switch
mov %eax, eax-slot # spill eax
mov &dstub2, %eax # store ptr to stub table
jmp context_switch
frag7:
stub1:
stub2:
Example Basic Block Fragment
Ras Bodik CS 164 Lecture 2419
context switch
BASIC BLOCK CACHE
non-control-flow instructions
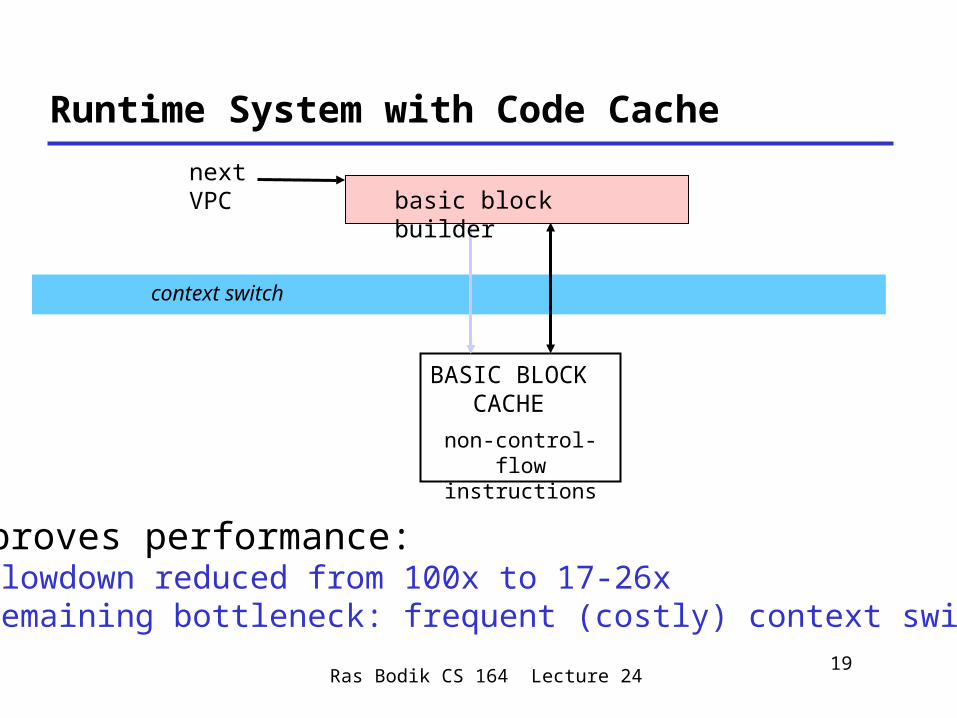
Runtime System with Code Cache
next VPC basic block builder
Improves performance:• slowdown reduced from 100x to 17-26x• remaining bottleneck: frequent (costly) context switches
Ras Bodik CS 164 Lecture 2420
add %eax, %ecx
cmp $4, %eax
jle $0x40106f
add %eax, %ecx
cmp $4, %eax
jle <frag42>
jmp <frag8>
mov %eax, eax-slot
mov &dstub1, %eax
jmp context_switch
mov %eax, eax-slot
mov &dstub2, %eax
jmp context_switch
frag7:
stub1:
stub2:
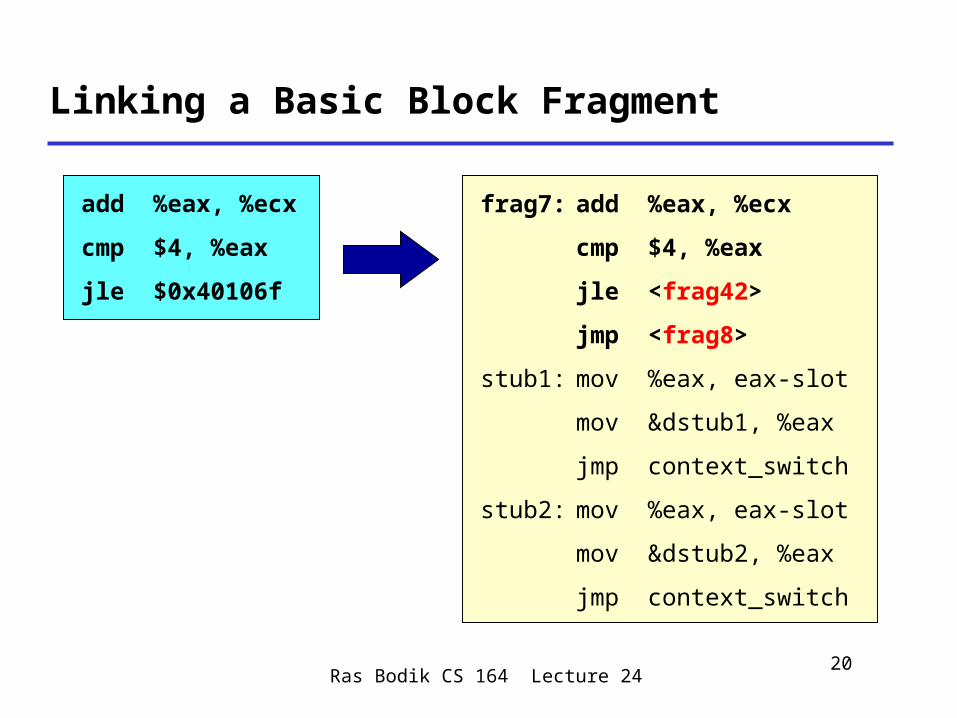
Linking a Basic Block Fragment
Ras Bodik CS 164 Lecture 2421
context switch
BASIC BLOCK CACHE
non-control-flow instructions
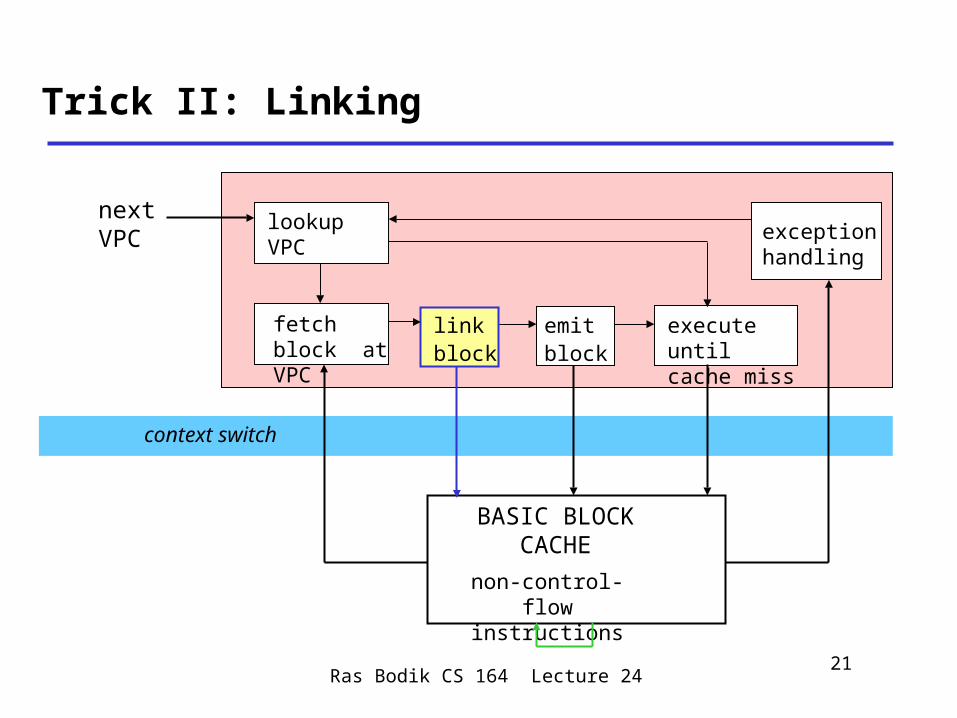
Trick II: Linking
next VPC
fetch block at VPC
lookup VPC
emitblock
exception handling
execute until cache miss
linkblock
Ras Bodik CS 164 Lecture 2422
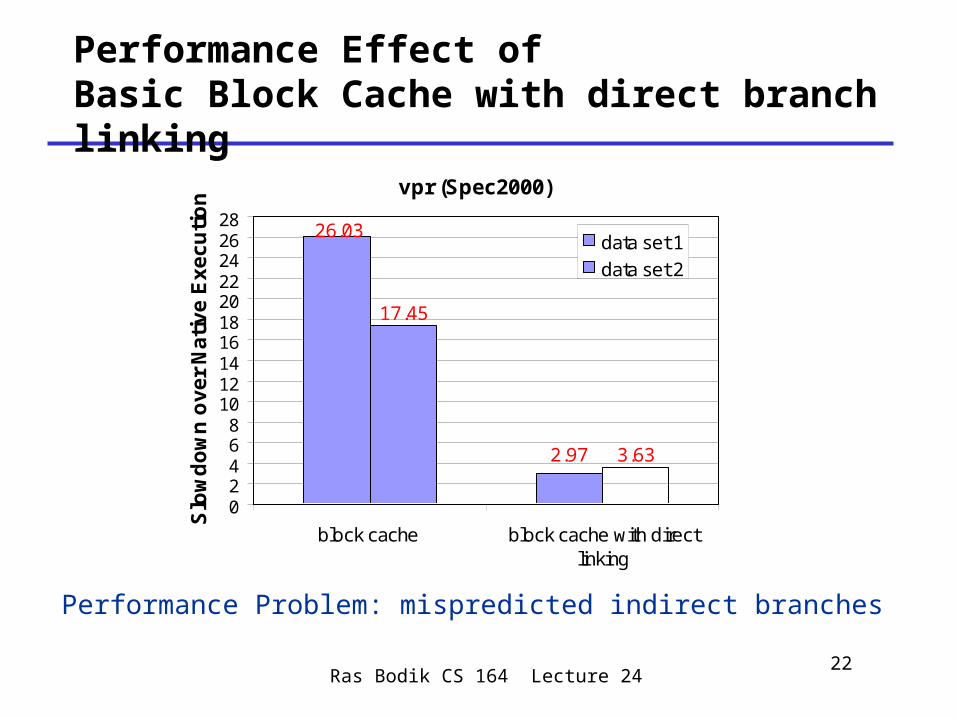
Performance Effect of Basic Block Cache with direct branch linking
Performance Problem: mispredicted indirect branches
vpr (Spec2000)
2.97
26.03
3.63
17.45
02468
10121416182022242628
block cache block cache with directlinking
Slo
wd
ow
n o
ve
r N
ati
ve
Ex
ec
uti
on
data set 1
data set 2
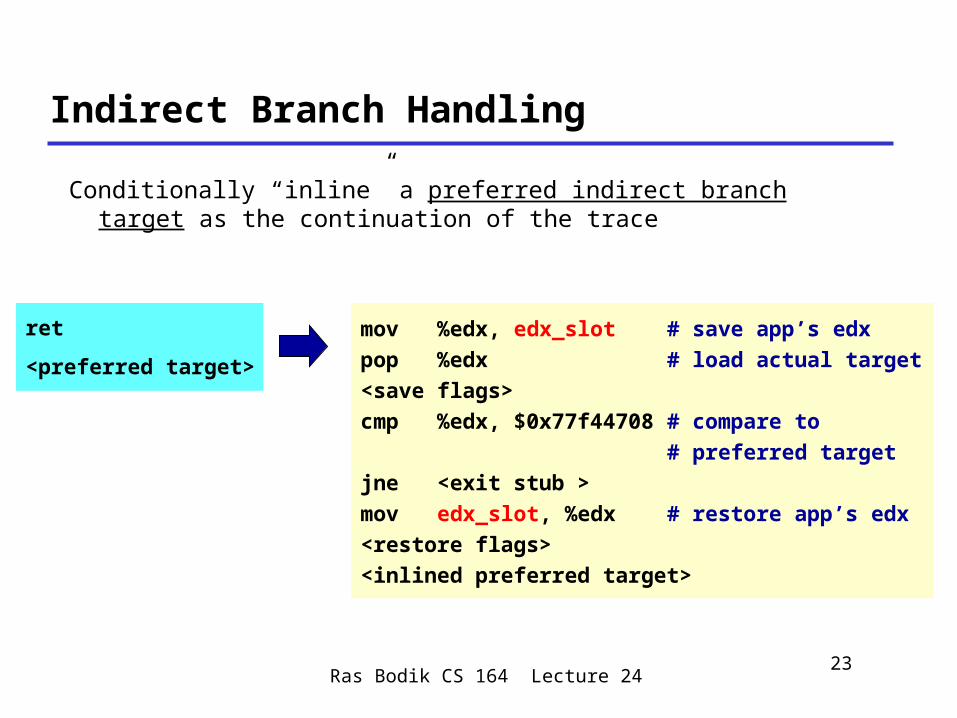
Ras Bodik CS 164 Lecture 2423
ret
<preferred target>
mov %edx, edx_slot # save app’s edx
pop %edx # load actual target
<save flags>
cmp %edx, $0x77f44708 # compare to
# preferred target
jne <exit stub >
mov edx_slot, %edx # restore app’s edx
<restore flags>
<inlined preferred target>
Conditionally “inline” a preferred indirect branch target as the continuation of the trace
Indirect Branch Handling
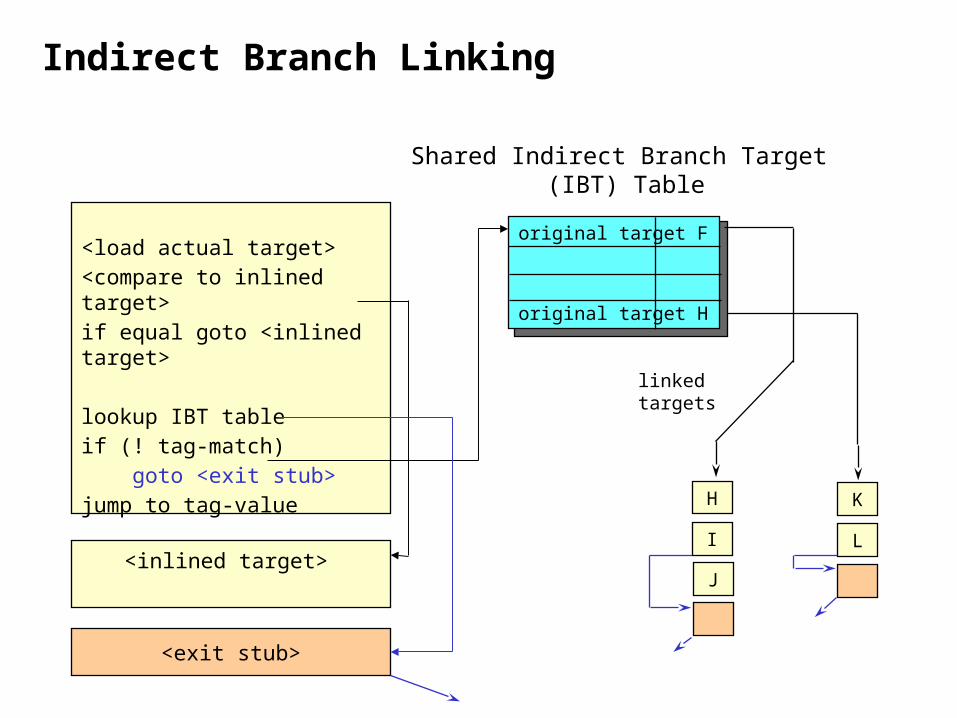
Indirect Branch Linking
H
I
K
L
J
original target F
original target H
Shared Indirect Branch Target (IBT) Table
linked targets
<load actual target><compare to inlined target>if equal goto <inlined target>
lookup IBT table if (! tag-match) goto <exit stub>jump to tag-value
<inlined target>
<exit stub>
Ras Bodik CS 164 Lecture 2425
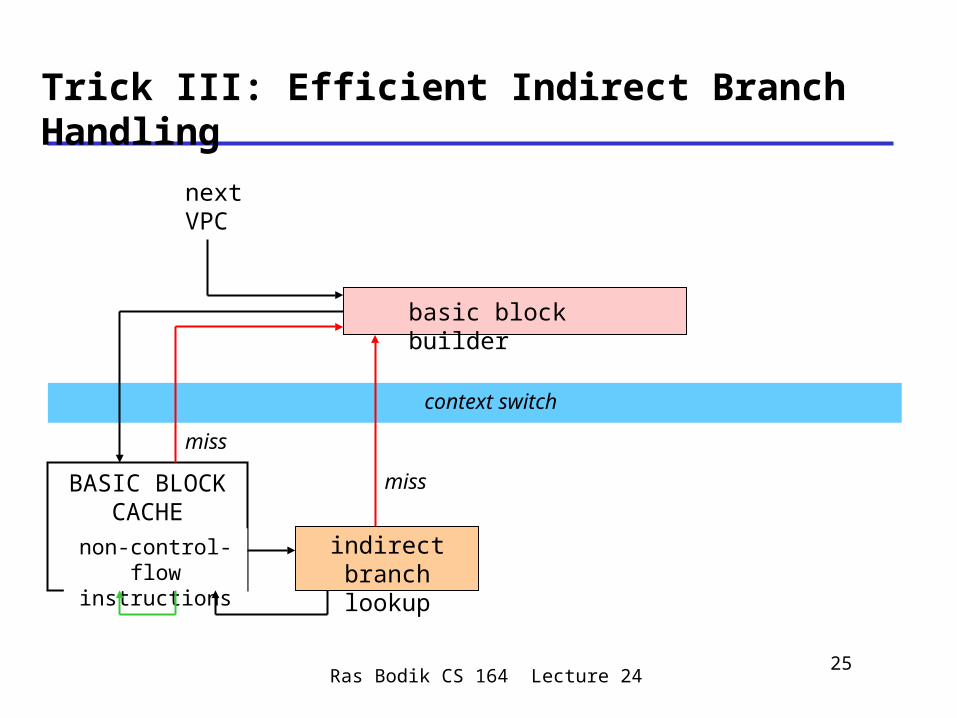
basic block builder
context switch
indirect branch lookup
BASIC BLOCK CACHE
non-control-flow
instructions
next VPC
miss
miss
Trick III: Efficient Indirect Branch Handling
Ras Bodik CS 164 Lecture 2426
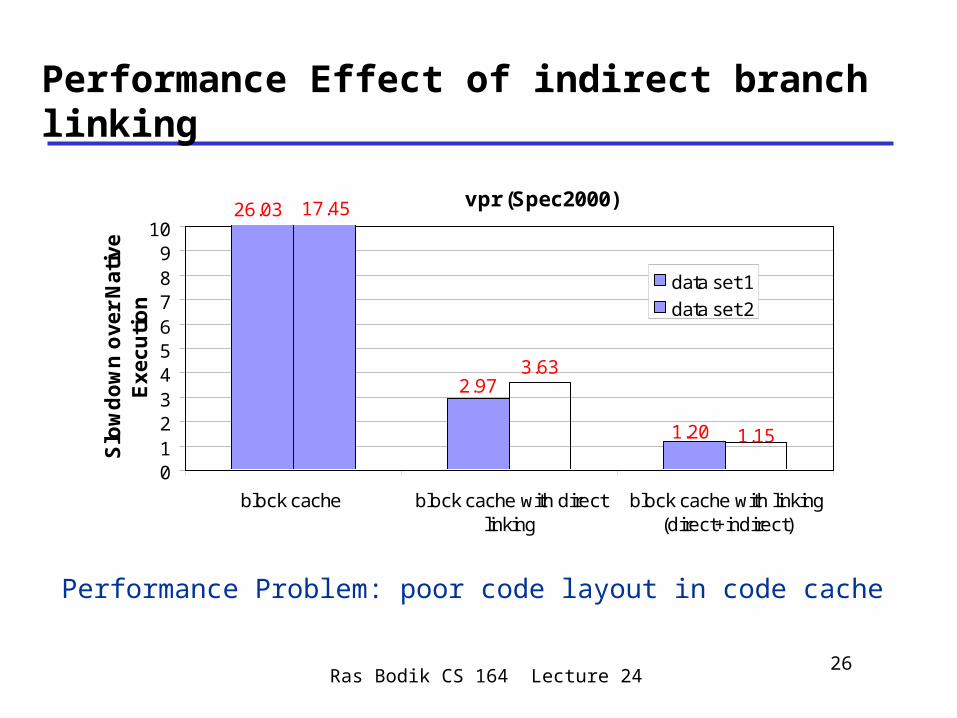
Performance Effect of indirect branch linking
Performance Problem: poor code layout in code cache
vpr (Spec2000)
3.63
1.20
2.97
26.03
1.15
17.45
0123456789
10
block cache block cache with directlinking
block cache with linking(direct+indirect)
Slo
wd
ow
n o
ve
r N
ati
ve
E
xe
cu
tio
n
data set 1
data set 2
Ras Bodik CS 164 Lecture 2427
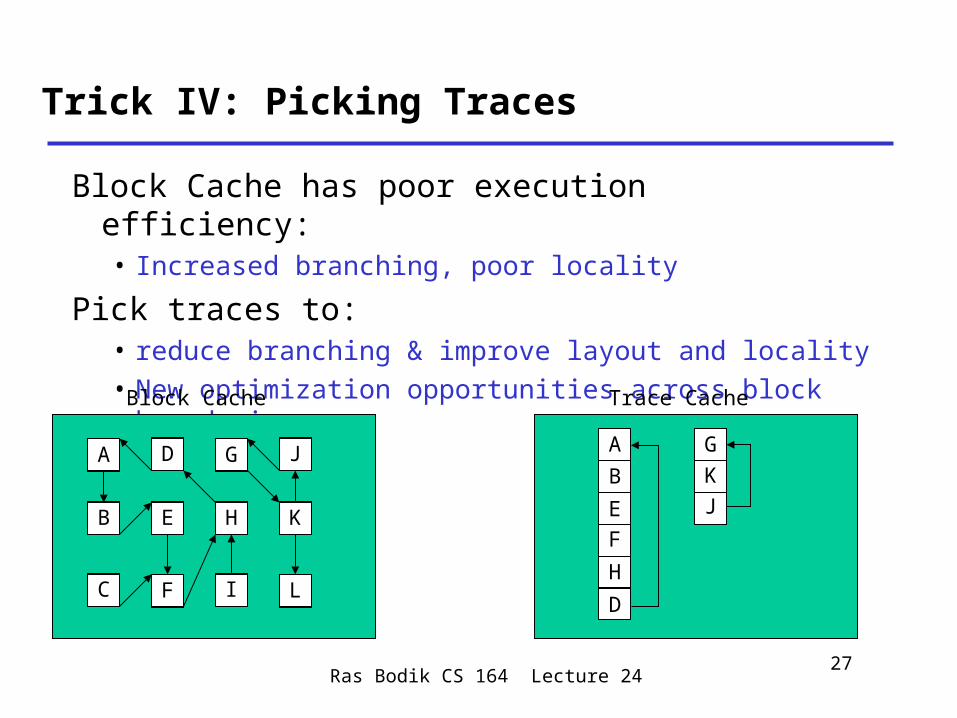
Trick IV: Picking Traces
Block Cache has poor execution efficiency:• Increased branching, poor locality
Pick traces to: • reduce branching & improve layout and locality• New optimization opportunities across block
boundaries
A
B
D G
E
C F
H
I
J
K
L
A
B
E
F
H
D
G
K
J
Block Cache Trace Cache
Ras Bodik CS 164 Lecture 2428
basic block builder
trace selectorSTART
dispatch
context switch
indirect branch lookup
BASIC BLOCK CACHE
TRACE CACHE
non-control-flow instructions
non-control-flow instructions
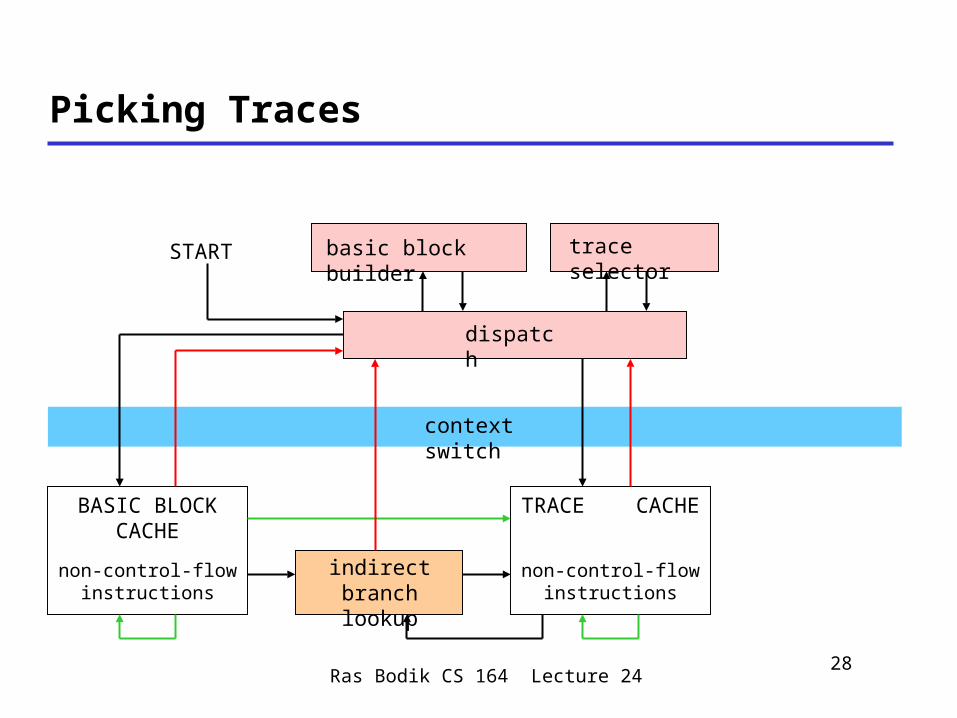
Picking Traces

Ras Bodik CS 164 Lecture 2429
Picking hot traces
• The goal: path profiling– find frequently executed control-flow paths – Connect basic blocks along these paths into
contiguous sequences, called traces.
• The problem: find a good trade-off between – profiling overhead (counting execution events),
and– accuracy of the profile.

Ras Bodik CS 164 Lecture 2430
Alternative 1: Edge profiling
The algorithm:• Edge profiling: measure frequencies of all
control-flow edges, then after a while• Trace selection: select hot traces by following
highest-frequency branch outcome.
Disadvantages:• Inaccurate: may select infeasible paths (due to
branch correlation)• Overhead: must profile all control-flow edges

Ras Bodik CS 164 Lecture 2431
Alternative 2: Bit-tracing path profiling
The algorithm:– collect path signatures and their frequencies– path signature = <start addr>.history– example: <label7>.0101101– must include addresses of indirect branches
Advantages:– accuracy
Disadvantages:– overhead: need to monitor every branch– overhead: counter storage (one counter per
path!)

Ras Bodik CS 164 Lecture 2432
Alternative 3: Next Executing Tail (NET)
This is the algorithm of Dynamo:– profiling: count only frequencies of start-of-
trace points (which are targets of original backedges)
– trace selection: when a start-of-trace point becomes sufficiently hot, select the sequence of basic blocks executed next.
– may select a rare (cold) path, but statistically selects a hot path!
Ras Bodik CS 164 Lecture 2433
NET (continued)
A
B
D G
E
C F
H
I
J
K
L
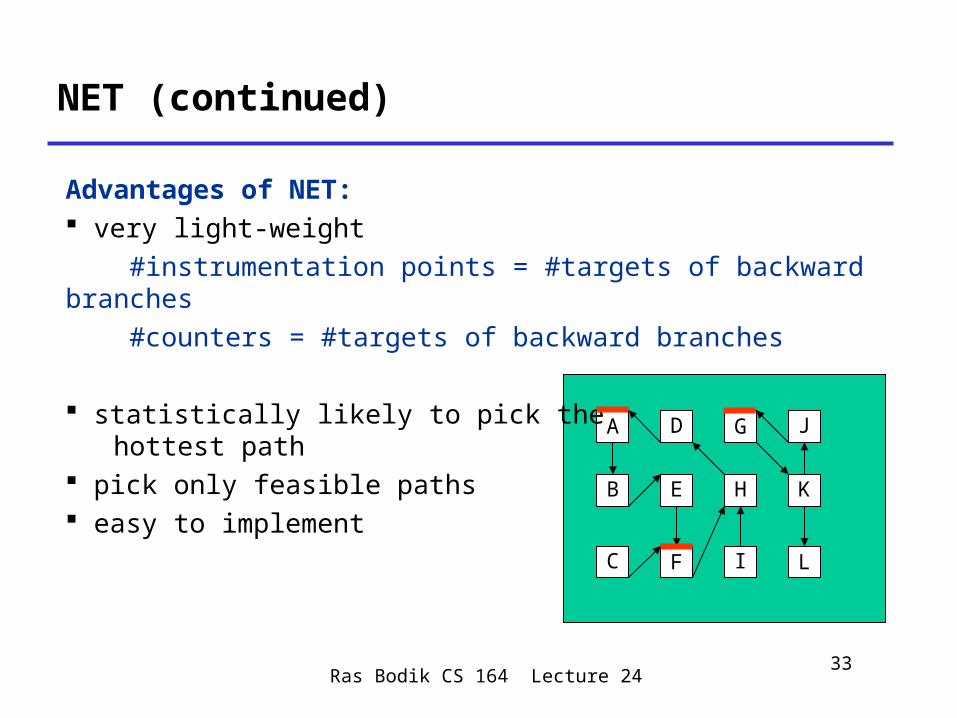
Advantages of NET: very light-weight #instrumentation points = #targets of backward branches #counters = #targets of backward branches
statistically likely to pick the hottest path pick only feasible paths easy to implement
Ras Bodik CS 164 Lecture 2434
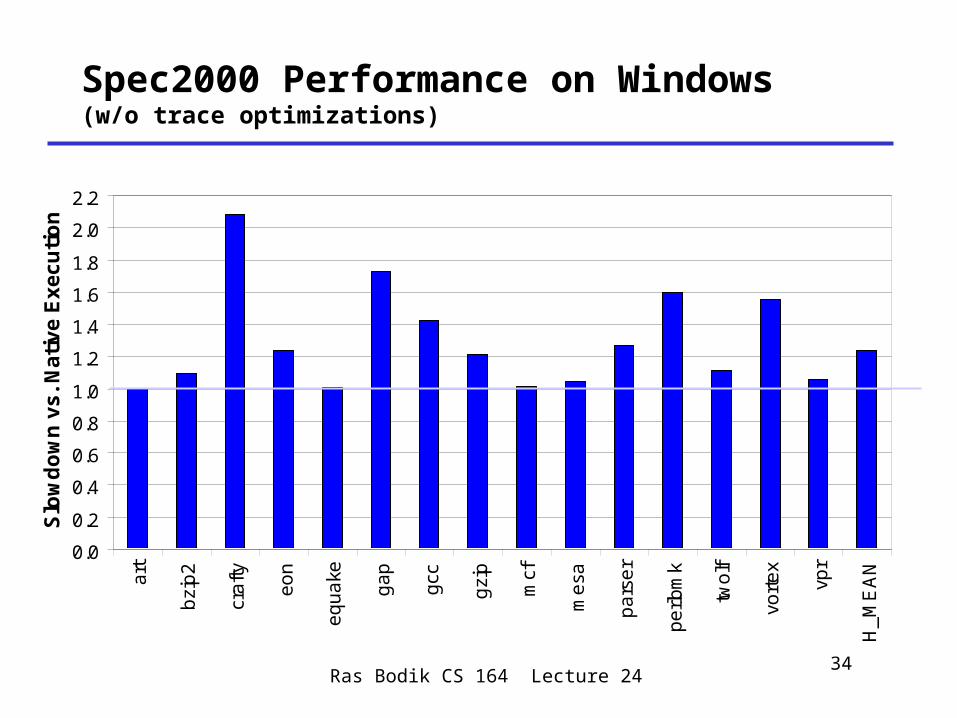
Spec2000 Performance on Windows(w/o trace optimizations)
0.0
0.2
0.4
0.6
0.8
1.0
1.2
1.4
1.6
1.8
2.0
2.2
art
bzi
p2
cra
fty
eo
n
eq
ua
ke
ga
p
gcc
gzi
p
mcf
me
sa
pa
rse
r
pe
rlbm
k
two
lf
vort
ex
vpr
H_
ME
AN
Slo
wd
ow
n v
s.
Na
tiv
e E
xe
cu
tio
n
Ras Bodik CS 164 Lecture 2435
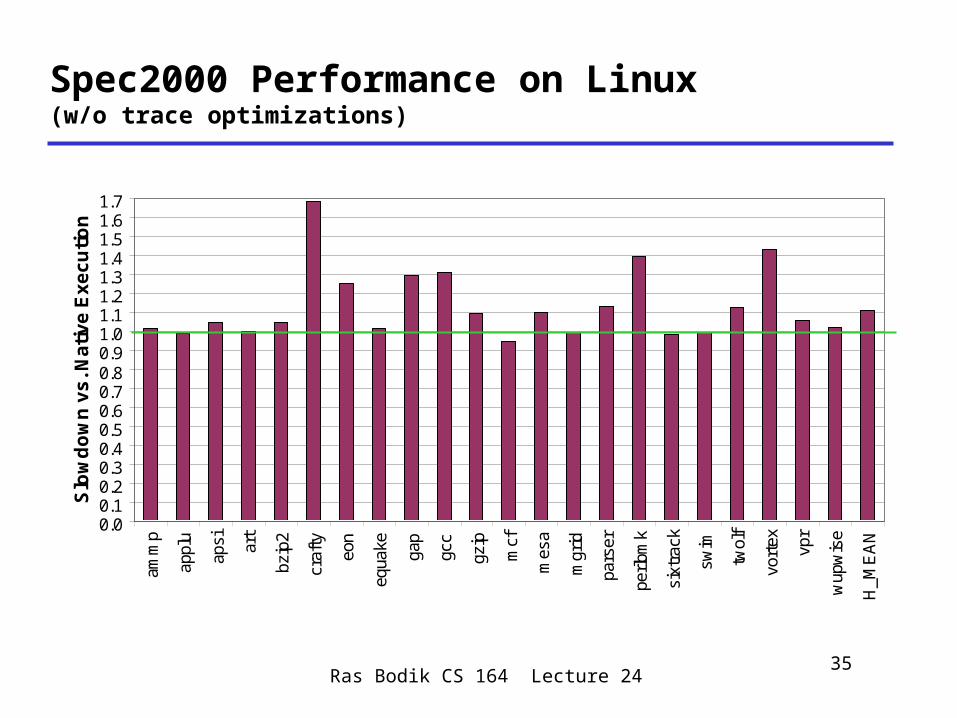
Spec2000 Performance on Linux(w/o trace optimizations)
0.00.10.20.30.40.50.60.70.80.91.01.11.21.31.41.51.61.7
amm
p
appl
u
apsi art
bzip
2
craf
ty
eon
equa
ke
gap
gcc
gzip
mcf
mes
a
mgr
id
pars
er
perl
bmk
sixt
rack
swim
twol
f
vort
ex vpr
wup
wis
e
H_M
EA
N
Slo
wd
ow
n v
s. N
ati
ve
Ex
ec
uti
on
Ras Bodik CS 164 Lecture 2436
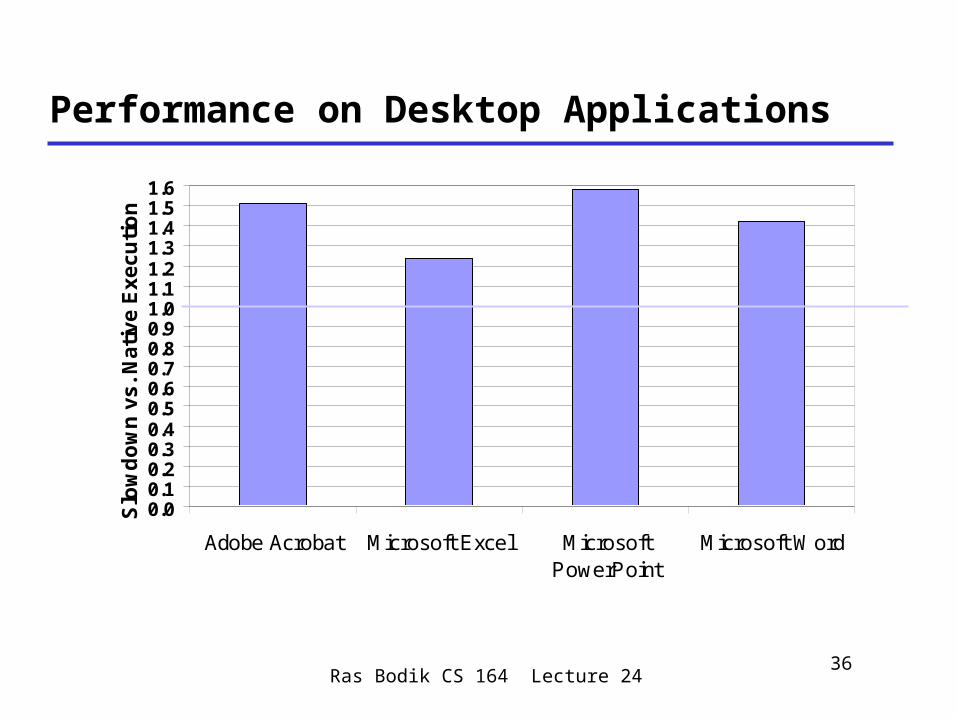
Performance on Desktop Applications
0.00.10.20.30.40.50.60.70.80.91.01.11.21.31.41.51.6
Adobe Acrobat Microsoft Excel MicrosoftPowerPoint
Microsoft Word
Slo
wd
ow
n v
s.
Na
tiv
e E
xe
cu
tio
n
Ras Bodik CS 164 Lecture 2437
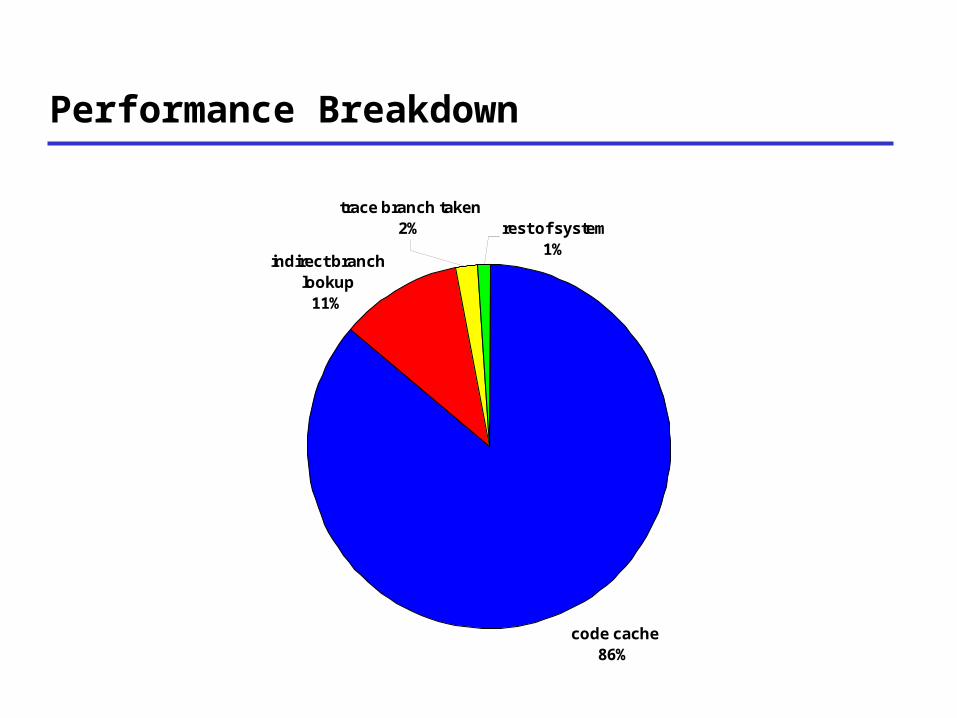
Performance Breakdown
code cache86%
indirect branch lookup
11%
trace branch taken2% rest of system
1%

Ras Bodik CS 164 Lecture 2438
Trace optimizations
• Now that we built the traces, let’s optimize them• But what’s left to optimize in a statically
optimized code? • Limitations of static compiler optimization:
– cost of call-specific interprocedural optimization– cost of path-specific optimization in presence of complex
control flow– difficulty of predicting indirect branch targets– lack of access to shared libraries– sub-optimal register allocation decisions– register allocation for individual array elements or
pointers

Ras Bodik CS 164 Lecture 2439
Maintaining Control (in the real world)
• Capture all code: execution only takes place out of the code cache
• Challenging for abnormal control flow
• System must intercept all abnormal control flow events:• Exceptions• Call backs in Windows• Asynchronous procedure calls • Setjmp/longjmp• Set thread context





























