Embed Size (px)
Citation preview

SPARSE CODINGDeep learning lab seminar
2016-02-27
Ryu Nahyeon

1 2 3 4 5
Contents
What is sparse coding?
How learning?- sparse code- dictionary
How preprocessbefore sparse coding?
How using sparse coding?
Sparse codingin brain
2

Definition
• Sparse coding is a class of unsupervised methods for learning sets of over-
complete bases to represent data efficiently. The aim of sparse coding is to find
a set of basis vectors 𝜙𝑖 such that we can represent an input vector 𝑥 as a linear
combination of these basis vectors: 𝑥 = σ𝑖=1𝑘 𝑎𝑖𝜙𝑖 (𝑥 ∈ 𝐑𝒏, 𝑘 > 𝑛)
• While techniques such PCA allow us to learn a complete set of basis vectors
efficiently, we wish to learn an over-complete set of basis vectors to represent
input vectors. Over-complete uses a redundant basis, such as the combination of
several complete bases.
• The advantage of having an over-complete basis is that our basis vectors are better able to capture
structures and patterns inherent in the input data.
3Andrew Ng, http://ufldl.stanford.edu/tutorial/unsupervised/SparseCoding/

Definition
• “a complete representation is like a small English dictionary of just a few thousand words. Any
concept can be described using the vocabulary but at the expense of long sentences. With a very
large dictionary - concept can be described with much shorter sentences, sometimes with a single
words!” (Stéphane Mallat)
• Therefore, it is possible to find sparse representations 𝐡(𝐱(𝑡)) in this large dictionary 𝐃, so that we can
reconstruct of the original input 𝐱(𝑡) efficiently.
4

Definition
• There are many terms in the dictionary and the representation of 𝐱(𝑡) is expressed compactly by
a few non-zero elements.
5

Learning Sparse Coding- Inference of sparse codes
- Dictionary update
6
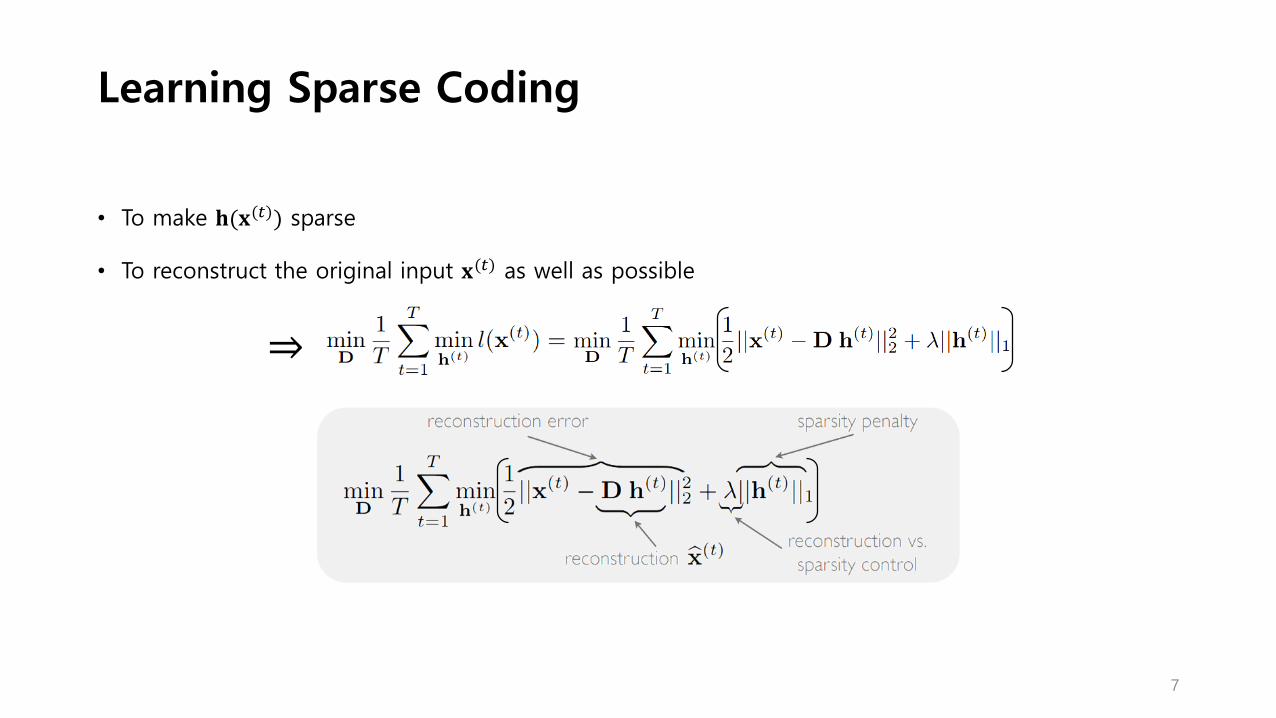
Learning Sparse Coding
• To make 𝐡(𝐱(𝑡)) sparse
• To reconstruct the original input 𝐱(𝑡) as well as possible
⇒
7

Inference of Sparse Codes
• Given D,
Using gradient descent method,
L1 norm cannot be differentiable at 0 but 𝑙(𝐱(𝑡)) can be geometrically using sign function.
8

Inference of Sparse Codes
• For a single hidden unit,
9

Iterative Shrinkage and Thresholding Algorithm
• the process of ISTA • ISTA updates all hidden units
simultaneously so this is wasteful if
many hidden units have already
converged.
• Coordinate descent algorithm
updates only the most promising
hidden unit and it has the advantage
of not requiring a learning rate.
10

Dictionary Update with Projected Gradient Descent
𝛻𝐃
11

Dictionary Update with Projected Gradient Descent
• the process of projected gradient descent
12

Dictionary Update with Block-coordinate Descent
• No need to specify a learning rate
• Solving each column 𝐃∙,𝑗
13

Dictionary Update with Block-coordinate Descent
• process of block-coordinate descent
14

Dictionary Learning Algorithm
• Process of learning algorithm
A
B
If there is a number of training inputs(𝑇 is very large), we will be spending most of our time on computing A and B performing only a single dictionary update after having visited all training inputs.
15

Online Dictionary Learning Algorithm
• Batch
▶ single update of the dictionary per pass on the training set
▶ for large datasets, we’d like to update after visiting each input
• Online learning
▶ perform inference of 𝐡(𝐱(𝑡)) for the current input
16

Online Dictionary Learning Algorithm
• Process of Online dictionary learning algorithm
17

Preprocessing before Sparse Coding
18

ZCA Preprocessing
Before running a sparse coding, it is beneficial to remove “obvious” structure from data.
▶ Mean is 0
▶ Covariance is the identity (whitening)
19
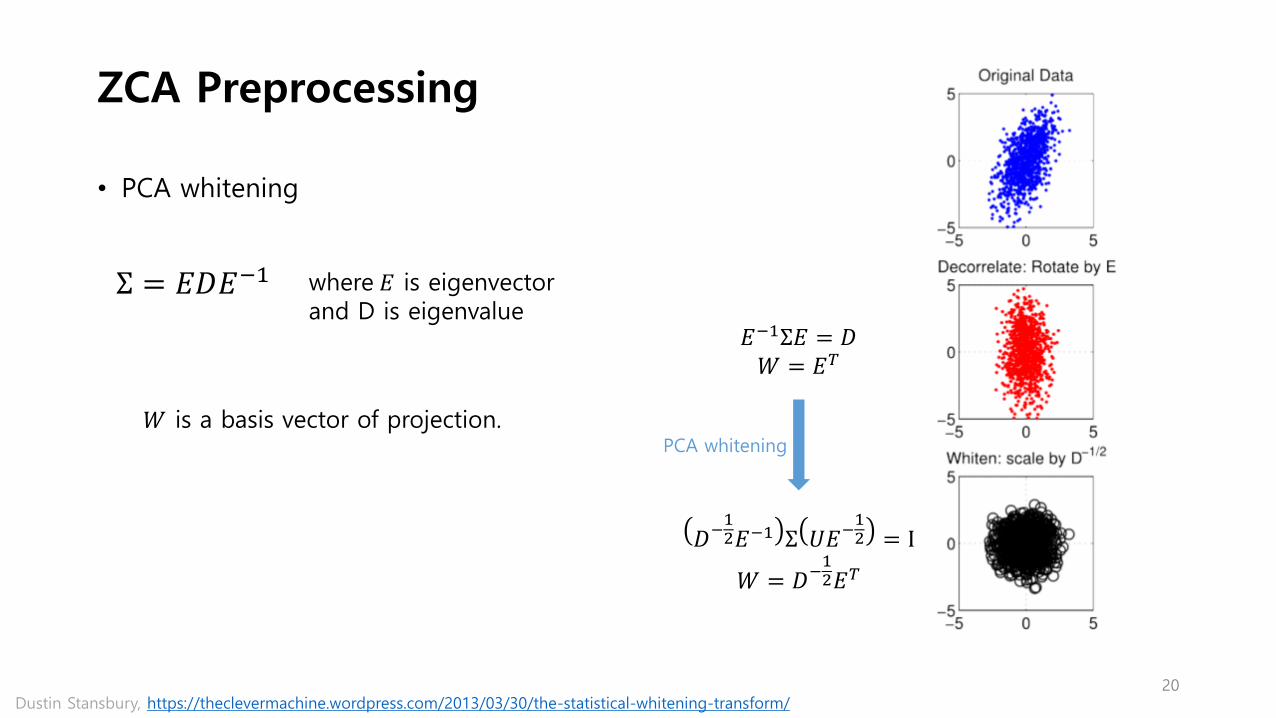
ZCA Preprocessing
• PCA whitening
Σ = 𝐸𝐷𝐸−1
𝐸−1Σ𝐸 = 𝐷𝑊 = 𝐸𝑇
𝐷−12𝐸−1 Σ 𝑈𝐸−
12 = I
𝑊 = 𝐷−12𝐸𝑇
where 𝐸 is eigenvectorand D is eigenvalue
PCA whitening
𝑊 is a basis vector of projection.
20Dustin Stansbury, https://theclevermachine.wordpress.com/2013/03/30/the-statistical-whitening-transform/
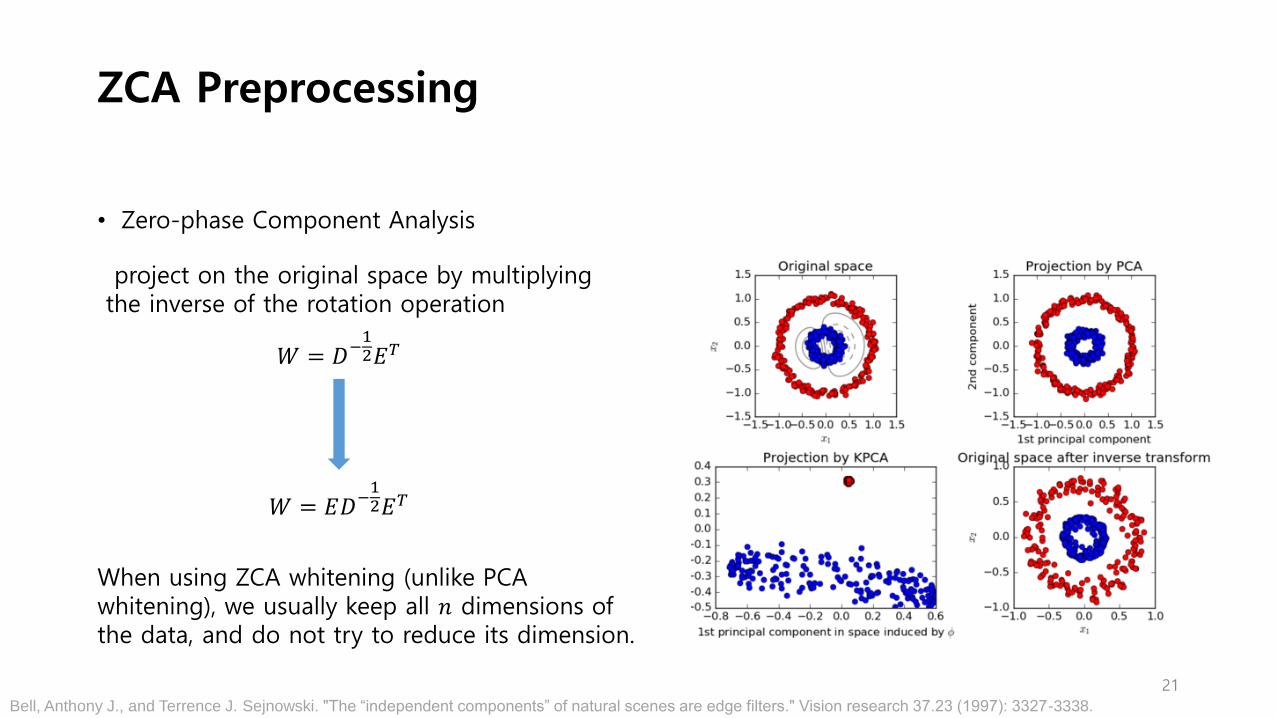
ZCA Preprocessing
• Zero-phase Component Analysis
𝑊 = 𝐸𝐷−12𝐸𝑇
𝑊 = 𝐷−12𝐸𝑇
project on the original space by multiplying the inverse of the rotation operation
When using ZCA whitening (unlike PCA whitening), we usually keep all 𝑛 dimensions of the data, and do not try to reduce its dimension.
21
Bell, Anthony J., and Terrence J. Sejnowski. "The “independent components” of natural scenes are edge filters." Vision research 37.23 (1997): 3327-3338.

Feature Extraction by Sparse Coding
22
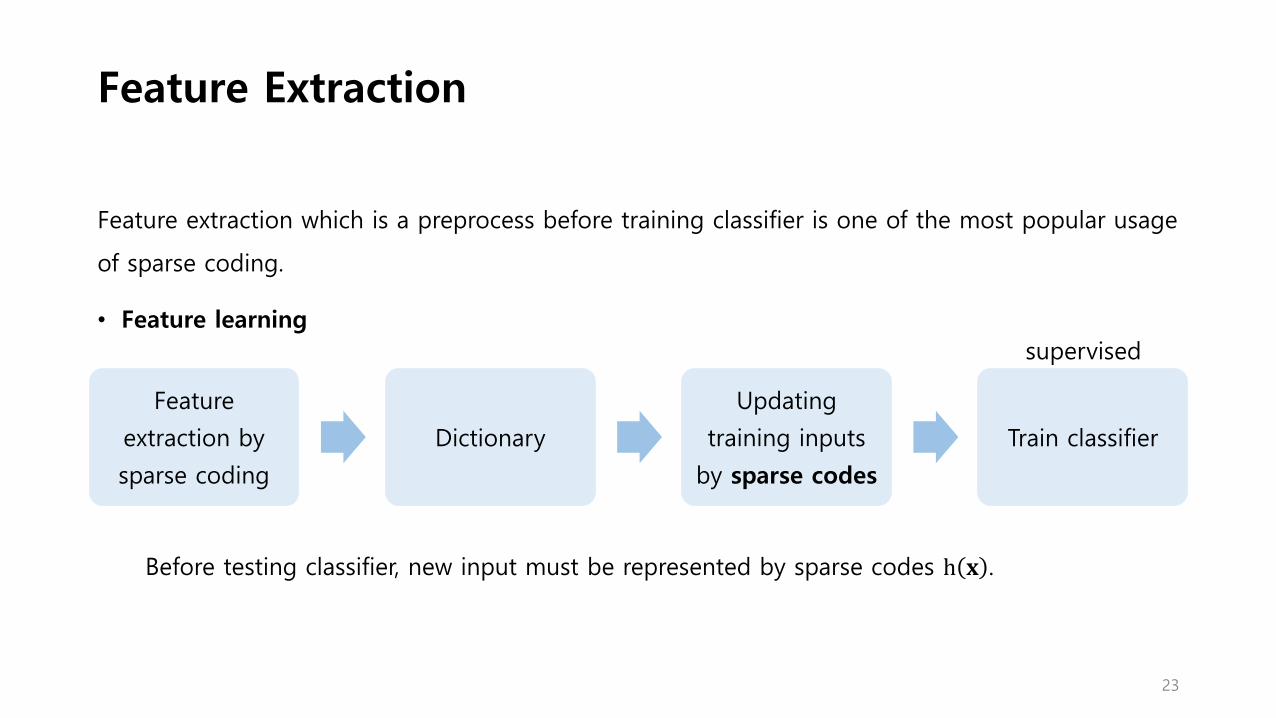
Feature Extraction
Feature extraction which is a preprocess before training classifier is one of the most popular usage
of sparse coding.
• Feature learning
Feature
extraction by
sparse coding
Dictionary
Updating
training inputs
by sparse codes
Train classifier
supervised
Before testing classifier, new input must be represented by sparse codes h 𝐱 .
23
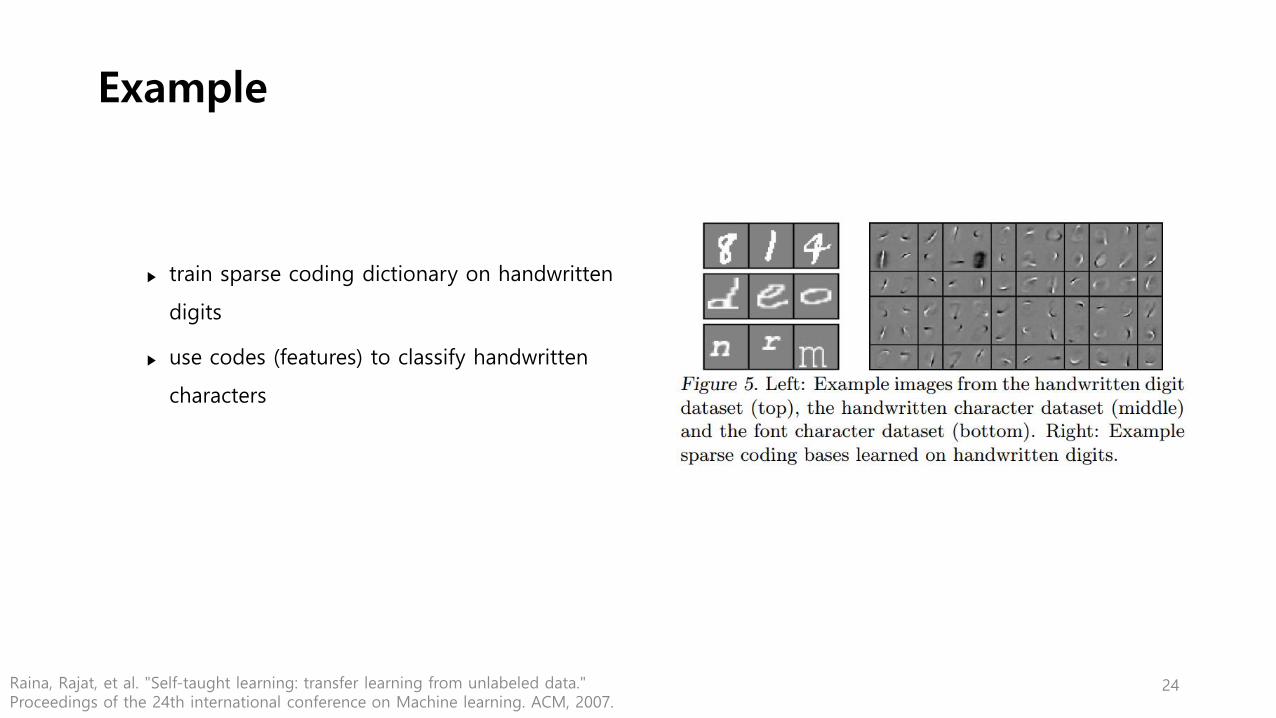
Example
▶ train sparse coding dictionary on handwritten
digits
▶ use codes (features) to classify handwritten
characters
24Raina, Rajat, et al. "Self-taught learning: transfer learning from unlabeled data." Proceedings of the 24th international conference on Machine learning. ACM, 2007.

Example - cont.
• Self-taught learning:
25Raina, Rajat, et al. "Self-taught learning: transfer learning from unlabeled data." Proceedings of the 24th international conference on Machine learning. ACM, 2007.

Sparse Coding vs V1 Neurons
26

Relationship with V1 Neurons
• V1 neuron is a region in the brain that is the part of visual cortex which is responsible for visual
process.
• V1 neurons have a similar behavior with sparse coding.
▶ Each atom(neuron) is tuned to a particular position, orientation and spatial frequency.
▶ The brain might be learning a sparse representation of visual stimulus. The brain maintains much
information but neurons do not always firing to save energy.
27
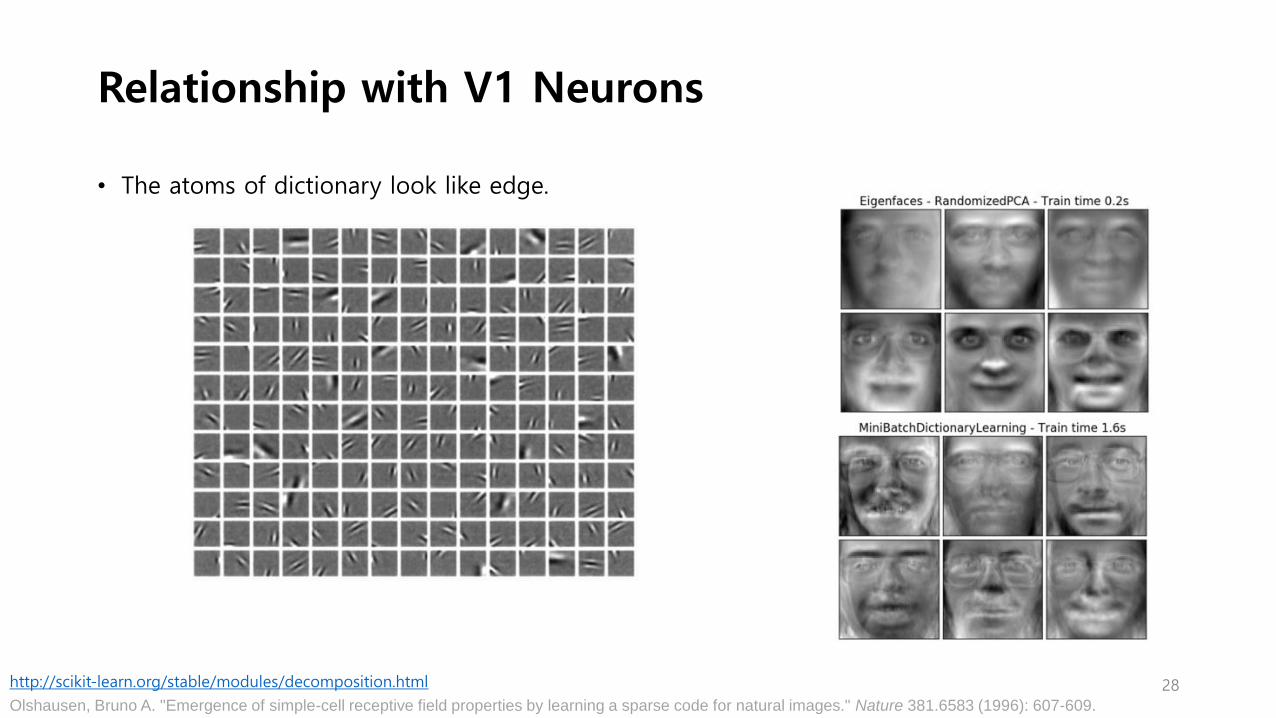
Relationship with V1 Neurons
• The atoms of dictionary look like edge.
28http://scikit-learn.org/stable/modules/decomposition.html
Olshausen, Bruno A. "Emergence of simple-cell receptive field properties by learning a sparse code for natural images." Nature 381.6583 (1996): 607-609.

Neural Networks for Unsupervised Learning
Sparse coding is one of neural networks for unsupervised learning.
▶ automatically extract meaningful features for your data
▶ leverage the availability of unlabeled data
▶ add a data-dependent regularizer to trainings
29

30





























