Embed Size (px)
Citation preview

Tesina de Grado El algoritmo ADIOS:
Detalles e Implementación
Director: Dr. Gabriel InfanteLopez Grupo de Procesamiento de Lenguaje Natural Facultad de Matemática, Astronomía y Física Universidad Nacional de Córdoba
Alumno: Esteban Ruiz Lic. en Cs. de la Computación Fac. de Cs. Exactas, Ing. y Agrim Univ. Nacional de Rosario

Contenido
● El algoritmo ADIOS– Ideas generales
– Sobre este trabajo
– Conceptos útiles, esquema del algoritmo
● Problemas encontrados● El algoritmo reespecificado● Implementación● Conclusiones

¿Qué es el algoritmo ADIOS?El problema:
Inferir reglas subyacentes en corpus no anotados.
ADIOS: Automatic Distillation of StructureZ. Solan, D. Horn, E. Ruppin, S. Edelman (TAU)

Ventajas y característicasVentajas y características● No supervisado● Corpus no estructurado● Combina probabilidades y reglas
Desventajas
● Infiere sólo gramáticas limitadas

Sobre este trabajo
● Estudio del algoritmo● Problemas● El algoritmo ADIOS
reespecificado● Diseño o implementación
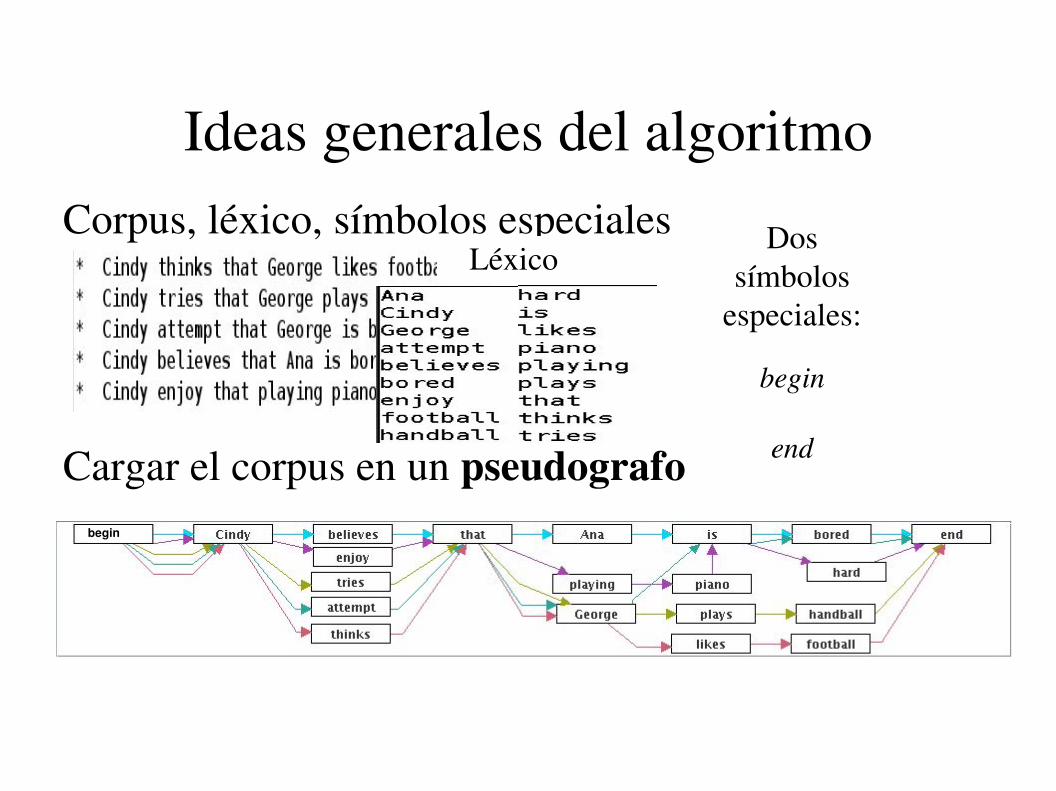
Ideas generales del algoritmoCorpus, léxico, símbolos especiales
Cargar el corpus en un pseudografo
LéxicoDos
símbolos especiales:
begin
end
begin
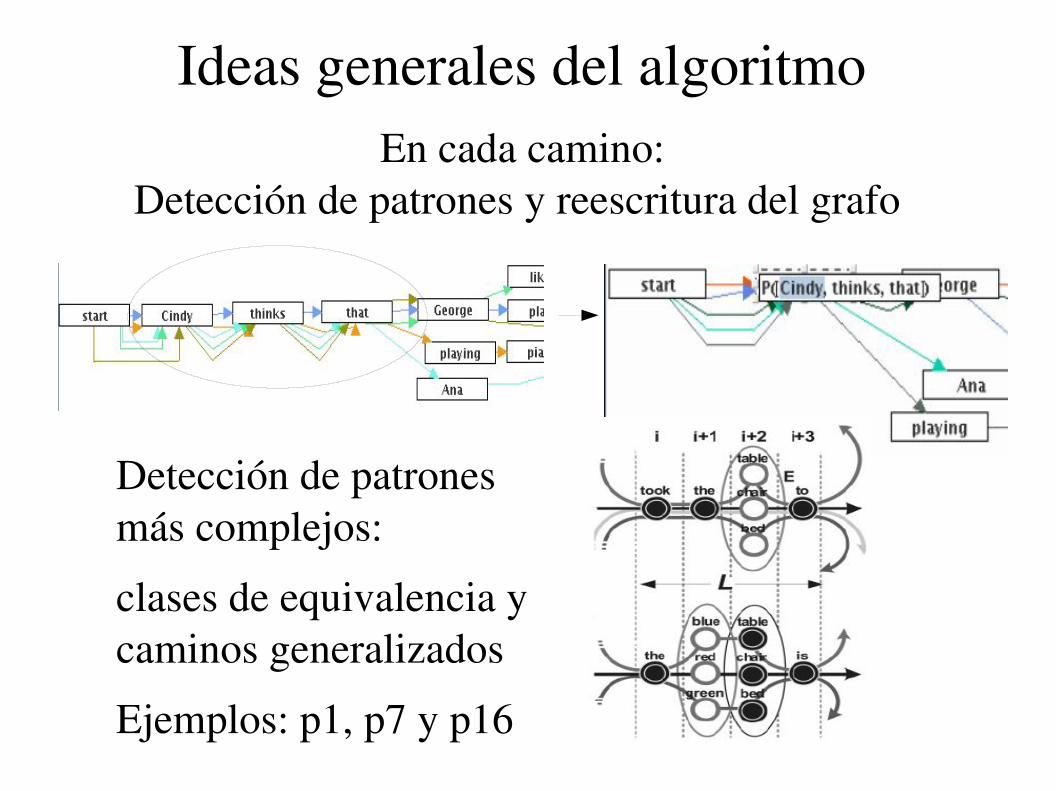
Ideas generales del algoritmoEn cada camino:
Detección de patrones y reescritura del grafo
Detección de patrones más complejos:
clases de equivalencia y caminos generalizados
Ejemplos: p1, p7 y p16
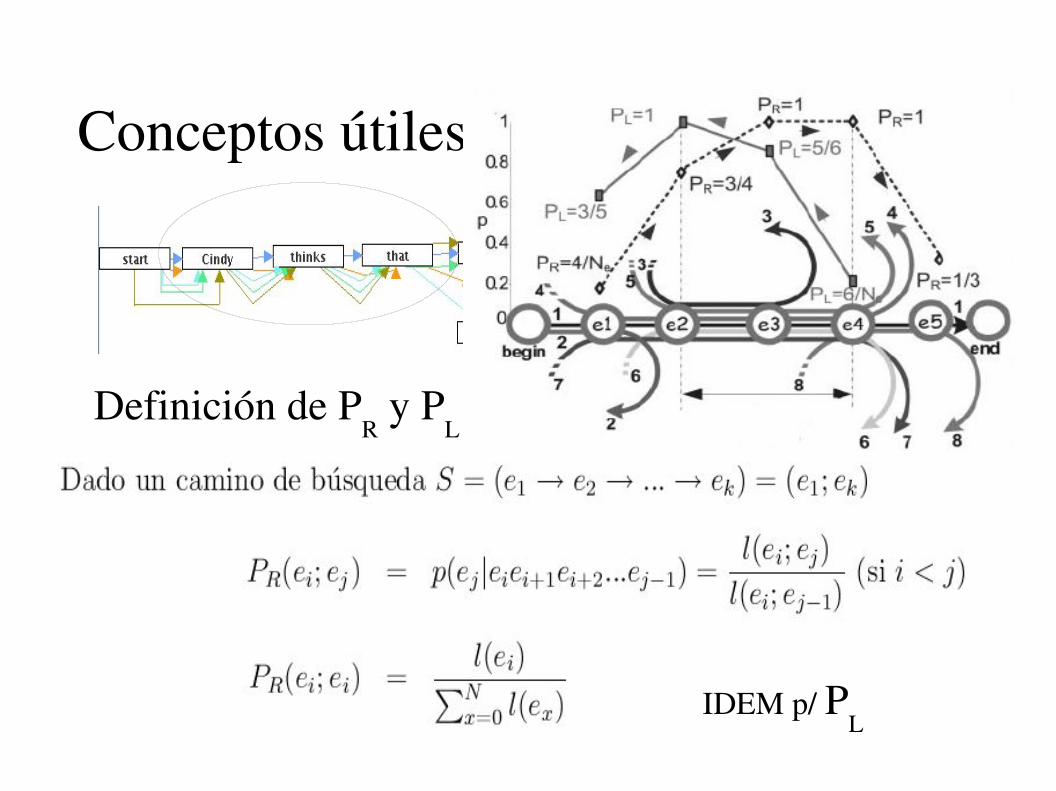
Conceptos útiles
Definición de PR y P
L
IDEM p/ PL

Más conceptos útiles● Matriz M
● DR y D
L (Relaciones de decrecimiento)
● Prueba de significación
DR(e1;e5) = 1/3

El procedimiento MEX (simplificado)

Esquema del algoritmo:Inicializacion:Repetir hasta el
fin del archivo:
● Leer el archivo hasta encontrar el final de una secuencia
● Cargar los símbolos encontrados como un nuevo camino en el pseudografo
Destilación de patronesCon cada camino:
● Ejecutar MEX en ese camino
● Si se obtuvo un patrón reescribir (rewire) el grafo
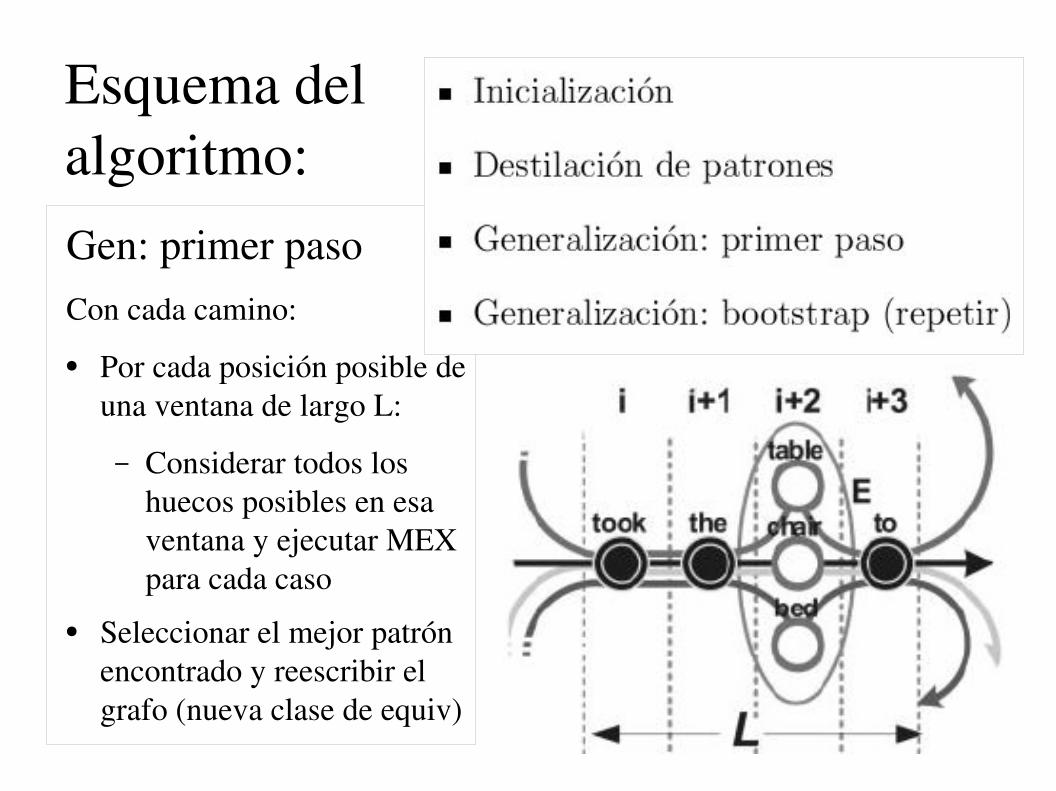
Esquema del algoritmo:Gen: primer pasoCon cada camino:
● Por cada posición posible de una ventana de largo L:
– Considerar todos los huecos posibles en esa ventana y ejecutar MEX para cada caso
● Seleccionar el mejor patrón encontrado y reescribir el grafo (nueva clase de equiv)
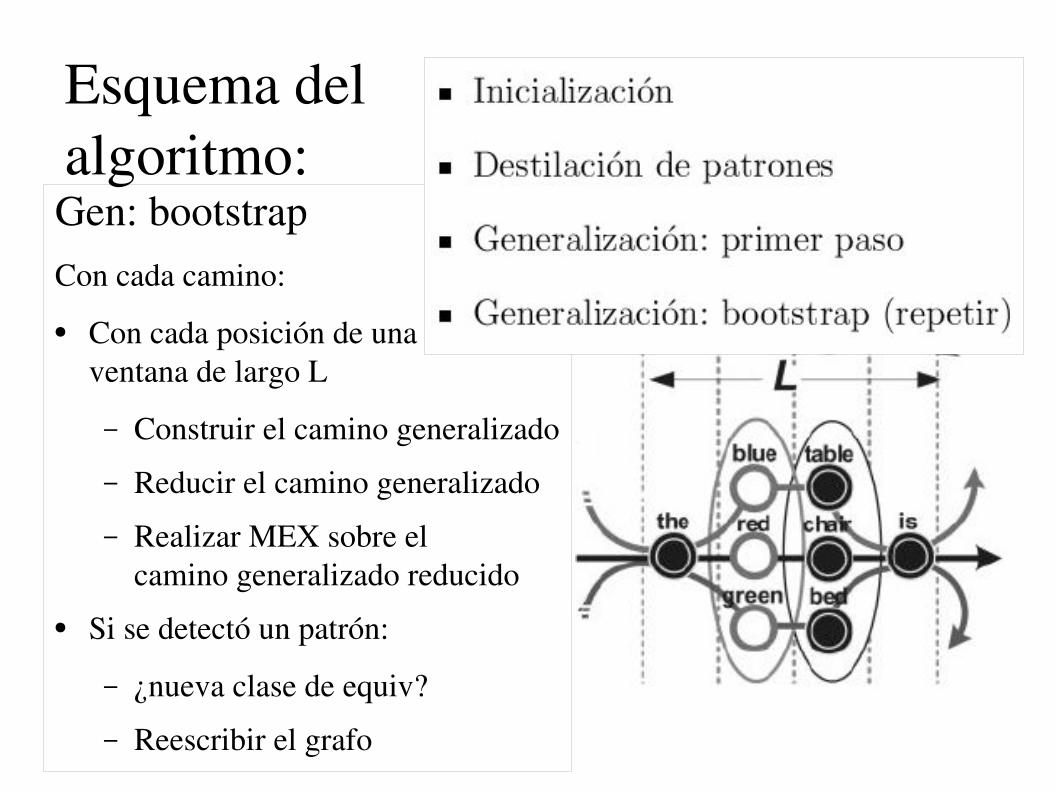
Esquema del algoritmo:Gen: bootstrapCon cada camino:
● Con cada posición de una ventana de largo L
– Construir el camino generalizado
– Reducir el camino generalizado
– Realizar MEX sobre elcamino generalizado reducido
● Si se detectó un patrón:
– ¿nueva clase de equiv?
– Reescribir el grafo

Dificultades● Superposición ● Cálculo de P en caminos generalizados ● Orden y repetición de pasos del algoritmo● Determinación de la significación● Problemas de borde● Comienzo y fin de patrones● Diferencias con ADIOSLite● Referencias e índices incorrectos

Superposición
Medidas de similitud de conjuntos
Jaccard:
Overlap:
¡Overlap no sirve!
una de
le
les
mes
X Y
J(X,Y) = 2/5 O(X,Y)=2/3
de
le
les
mes
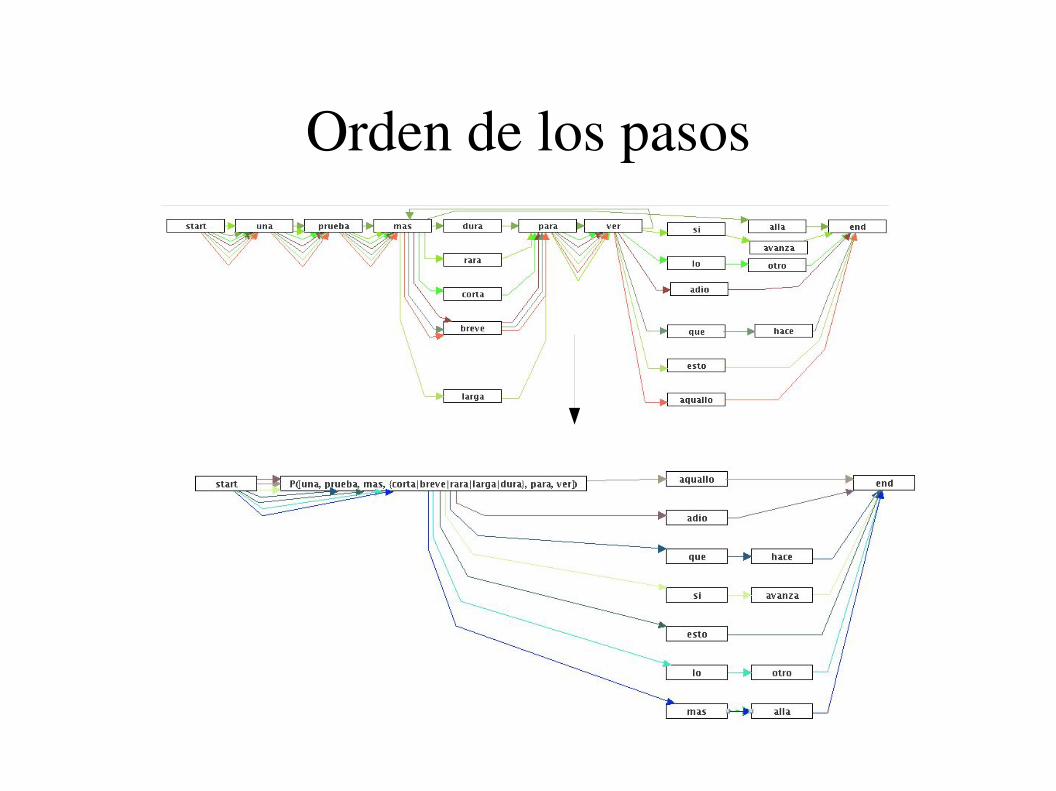
Orden de los pasos
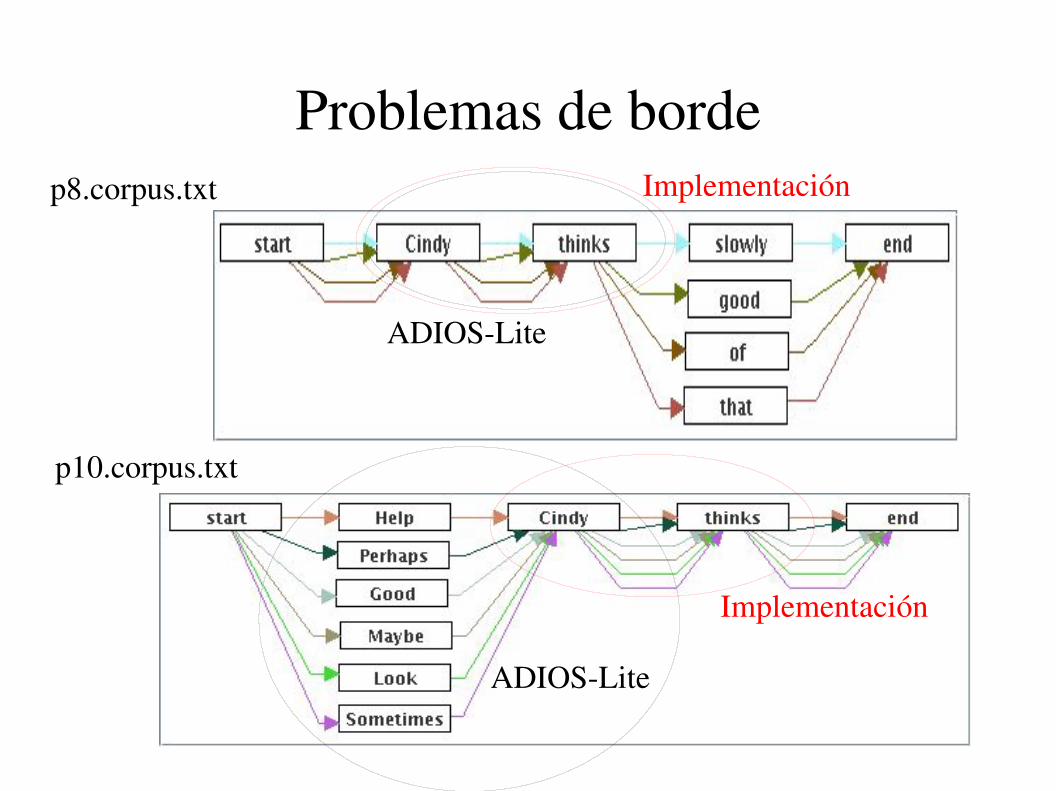
Problemas de bordep8.corpus.txt
p10.corpus.txt
ADIOSLite
ADIOSLite
Implementación
Implementación

Diferencias con ADIOSLite
p25.corpus.txt

Software utilizado
● cvs● eclipse● JDK 6● Libreria graph2 de apache y Jgraph● ArgoUML
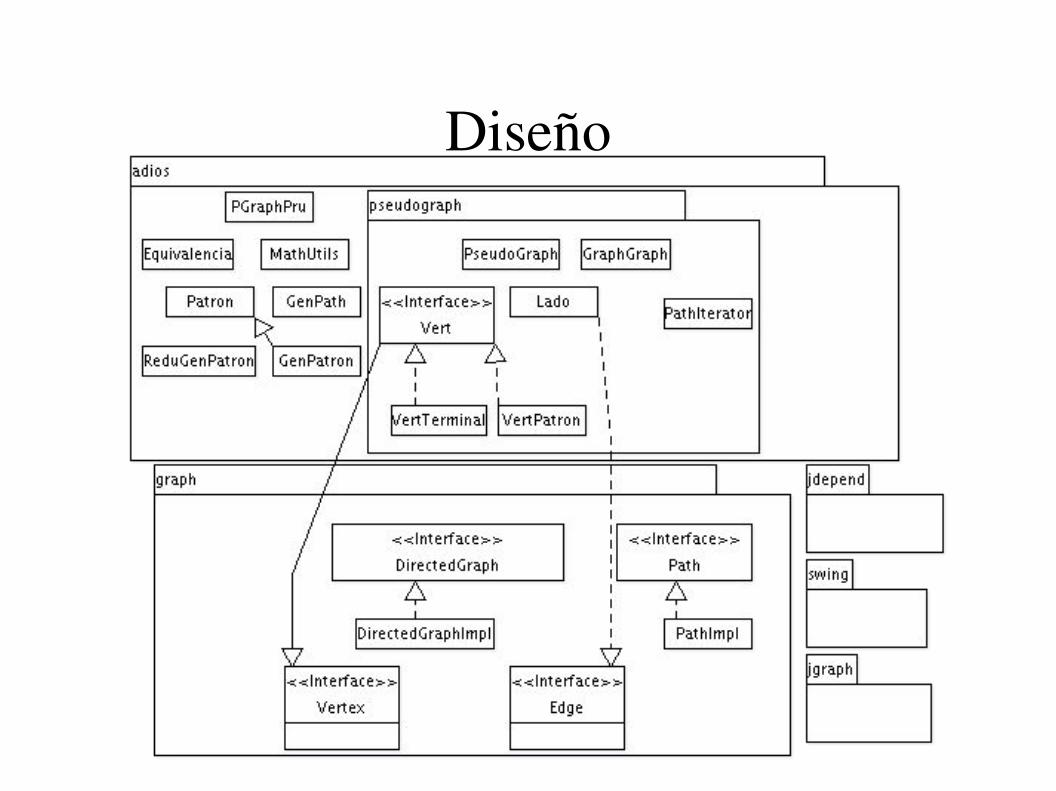
Diseño
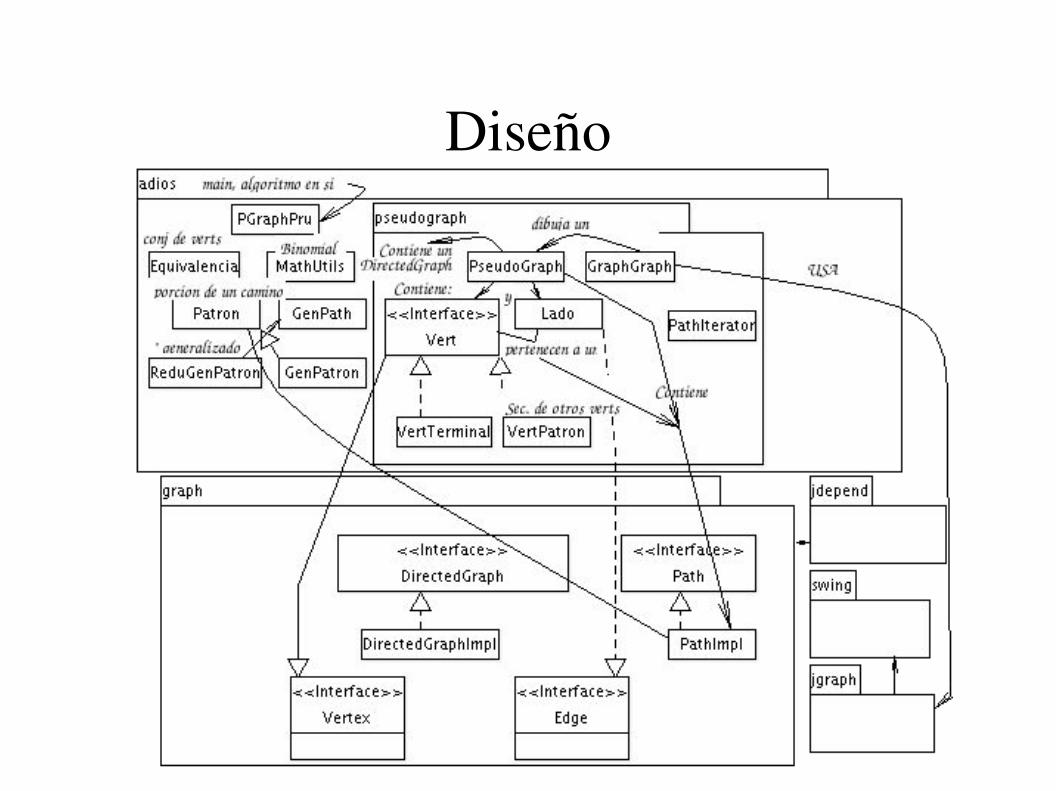
Diseño

Experiencias de la implementación
● Cálculo de números combinatorios y significación
● Testing● Problemas con la especificación
¡de 33 segundos a 4 mili!

Conclusiones
● Distancia entre explicación original e implementación efectiva
● Diseño orientado a objetos y tiempo de ejecución

Trabajo futuro
● Optimización● Contacto con Z. Solan● Adios en acción● Variaciones del algoritmo

BibliografíaZ. Solan, D. Horn, E. Ruppin and S. Edelman, Unsupervised learning of
natural languages. Editado por James L. McClelland, Carnegie Mellon University, Pittsburgh, PA, y aprobado June 14, 2005.
D. S. Moore, Estadística aplicada básica, Antoni Bosch editor, 1995.
M. Triola, Estadística elemental, Addison Wesley Longman, 7ma. ed., 2000.
D. K. Hildebrand, L. Ott, Estadística aplicada a la administración y a la economía, Addison Wesley Longman, 3ra. ed, 1998.
J. Makkonen, H. AhonenMyka and Marko Salmenkivi, Applying Semantic Classes in Event Detection and Tracking.
J. Weeds, D. Weir and D. McCarthy, Characterising Measures of Lexical Distributional Similarity.

BibliografíaJ. Brookshear, Lenguajes formales, autómatas y complejidad. Addison
Wesley Iberoamericana.
L. A. Ballesteros, Resolving ambiguity for crosslanguage information retrieval: A dictionary approach, Univ. of Massachusetts, 2001.
N. K. Bosa, P. Liang, Neural Network Fundamentals with Graphs, Algorithms, and Applications.
P. G. Hoel, S. C. Port, C. J. Stone, Introduction to Stochastic Proceses, Waveland Press, 1987.
C. M. Grinstead, J. L. Snell, Introduction to Probability, AMS, second revised edition, 1997.
G. Infante Lopez, Two level grammars for natural language parsing, Soluciones Gráficas, 2005.

Preguntas

Agradecimientos

ADIOS





























